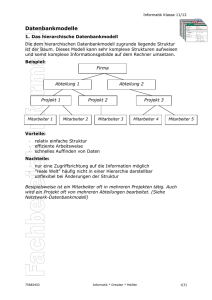
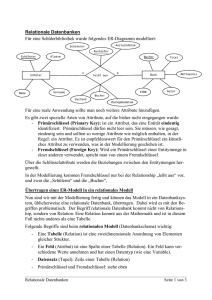
11_8335_201-Datenmodelle in der Praxis - Offene
Werbung

Das diesem Dokument zugrundeliegende Vorhaben wurde mit Mitteln des Bundesministeriums für Bildung und Forschung unter dem Förderkennzeichen 16OH21005 gefördert. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt beim Autor/bei der Autorin. 1 In diesem Abschnitt wollen wir uns genauer mit der Frage beschäftigen: Wie gehe ich bei der Erstellung eines Datenmodells vor? Hierbei gehen wir davon aus, dass es sich um das physikalische Modell handelt, da diese in der Praxis am meisten verwendet werden und auch direkt gepflegt werden. Begriffliche und logische Datenmodelle werden in der Praxis nur bei einem TopDown Ansatz erstellt. In der Praxis werden oft physikalische Modelle direkt gepflegt. 2 Die wichtigsten Schritte bei der Erstellung eines Datenmodells sind in der Abbildung dargestellt. 1. Schritt: Identifizieren von Entity-Typen 2. Schritt: Finden der notwendigen Attribute 3. Schritt: Festlegen der Datentype zu den jeweiligen Attributen 4. Schritt: Festlegen eines Primärschlüssels 5. Schritt: Identifizieren von Beziehungen 6. Schritt: Festlegen der Kardinalitäten einer Beziehung Erst ganz am Ende schauen wir uns das Modell aus Sicht der Normalisierung an. Was es mit Normalisierung auf sich hat, finden Sie in einem eigenen Abschnitt, in dem wir uns diesem Thema besonders widmen. Hier wollen wir uns zunächst Schritte 1 bis 6 näher ansehen. 3 Ausganspunkt bei allen Datenmodellen sind meist • Text Dokumente • Mündliche Informationen in einem Meeting • Kurze Notiz in einer E-Mail. • Interviewtechniken Der erste Schritt ist dabei immer das Finden von Entity-Typen. Für die Identifikation von Entity-Typen gehen Sie wie folgt vor: • Welche Artefakte aus der realen Welt spielen eine Rolle? Diese sind potentielle Kandidaten • Welche Substantive werden verwendet? • Wie häufig kommen bestimmte Substantive bei der Beschreibung der Aufgabenstellung vor? Haben wir einen Entity-Typ Kandidaten gefunden, so stellt sich die Frage nach der Namenswahl. Bei der Namenswahl haben sich in der Praxis folgende Regeln als sehr nützlich herausgestellt (Best Practices): • Entity-Namen sind immer Substantive 4 • Substantive immer im Singular oder immer im Plural verwenden ( Also entweder „Produkt“, „Kunde“ oder „Produkte“, „Kunden2 ). Aber niemals mischen. Sonst können umfangreichere Datenmodelle mit mehrere Entity-Typen schnell unübersichtlich werden. • Wenn Sie nicht sicher sind, ob es sich einen Begriff als Entity-Type oder als Attribut modellieren sollen, entscheiden Sie sich notfalls für einen Entity-Typen. Der Wechsel von Entity-Type zu Attribut ist in einem Modell einfacher durchzuführen, als die Umstellung von Attribut auf einen-Entity Typen. Beispiel hierfür wäre die Farbe eines Autos. Hinweis: • Eine Empfehlung von Oracle bezüglich Konventionen für Entity-Typen = TabellenNamen finden Sie unter https://docs.oracle.com/cd/E18727_01/doc.121/e12897/T302934T458266.htm 4 Bei der Identifikation von Attributnamen achten wir auch wieder auf die Beschreibung der Aufgabenstellung. Hierbei wenden Sie folgende Regeln an. • Achten Sie auf Adjektive (Eigenschaftswörter) wie Größe, Gewicht, Länge, Nummer, Preis, • Achten Sie auf Zeitangaben • Achten Sie auf Ortsangaben • Achten Sie auf Angaben, wodurch sich Entitys unterscheiden All diese Informationsdetails liefern uns Hinweise auf mögliche Attribute. Ob eine Eigenschaft aus der Aufgabenstellung wirklich ein Attribut wird, hängt davon ab, ob diese Attributwerte in irgendeiner Form später benötigt werden oder nicht. 5 Nachdem wir die Attribute identifiziert haben, müssen wir uns für einen Datentypen entscheiden. Da die Datentypen zum Teil herstellerspezifisch sind, müssen wir zunächst folgende Entscheidung treffen. Verwenden wir einen Datentyp, der von allen Datenbankherstellern unterstützt wird oder verwenden wir einen Datenbankhersteller spezifischen Datentypen. Um diese Entscheidung treffen zu können , wenden wir folgende Regel an ( Best Practices): • Wir verwenden nur herstellerspezifische Datentypen, wenn keines der Standarddatentypen die notwenigen Anforderungen abdeckt. Beispiel: Um Zeichenketten abzulegen, gibt es den Standard Datentype VARCHAR. Dies führt aber bei den meisten Datenbanken zu Problemen, wenn wir zum Beispiel Chinesische oder Japanische Zeichen ablegen wollen. Hierfür gibt es zum Beispiel in Oracle den Datentyp VARCHAR2. Bei SQL Server gibt es hierzu den Datentype NVARCHAR 6 ORACLE siehe : https://docs.oracle.com/cd/B28359_01/server.111/b28318/datatype.htm#CDEFDGFE MS SQL Server siehe : https://msdn.microsoft.com/de-de/library/ms186939.aspx 6 In dieser Abbildung sehen Sie die Standarddatentypen von SQL, die zum Beispiel von dem Tool DBDesigner unterstützt werden. Diese sind die Datentypen, die am meisten in Datenmodellen verwendet werden. 7 Schlüsselattribute identifizieren eine Entity eindeutig. Sofern ein Entity-Type eine entsprechende Beziehung zu einem realen Artefakt/Gegenstand hat, wie zum Beispiel einem „Auto“, so verwenden wir die Informationen als Primärschlüssel, die wir auch in der realen Welt verwenden, um eine Sache eindeutig zu identifizieren. Sofern dies nicht möglich ist, definieren wir einen künstlichen Schlüssel als Primärschlüssel. Beispiel aus der realen Welt um Dinge/Sachen eindeutig zu identifizieren: • Autos Kennzeichen, Fahrgestellnummer • Personen Personalausweisnummer, Sozialversicherungsnummer • Farben RAL Nummer • Häuser Nummer im Grundbuch, GPS Daten • Rechnungen Rechnungsnummer • Bestellungen Bestellnummer • Produkte Produktnummer • Serververbindungen Session Nummer 8 • Nachrichten MessageID Schwieriger ist es, wenn man einen Computer eindeutig identifizieren will. Schauen Sie sich hierzu einmal die Übung: Datenmodellierung PK für Entity-Computer Beispiele: Zusammengesetzte Primärschlüssel • SoftwareProdukt ( SWProdktName, SWVersion) Hinweis: • Da ein Primärschlüssel eine Entity eindeutig identifiziert , muss ein Primärschlüssel beim Erzeugen eines Eintrages (SQL: INSERT INTO ..) immer angegeben werden und darf niemals NULL sein. Bedeutung von NULL siehe im Abschnitt „Best Practices“ • Als Datentyp für einen Primärschlüssel empfiehlt aus Performancegründen der Datentype „INTEGER“ • Nachträglich sollte der Wert eines Primärschlüssels nicht geändert werden. Weil dies eine sehr zeitaufwendige Operation bei vielen Datensätzen sein kann da das DBMS : • eine Überprüfung aller Einträge vornehmen muss, um doppelte Einträge auszuschließen • Der Zugriffsindex für den Zugriff neu aufgebaut werden muss. • Sofern der Primärschlüssel in anderen Tabellen verwendet wird, müssen auch alle Einträge geändert werden, bei den der Primärschlüssel als Fremdschlüssel eingetragen ist. Zum Nachschlagen: • Sieh auch : http://sqlmag.com/business-intelligence/what-makes-good-primary-key 8 Im nun folgenden Schritt geht es um das Identifizieren von Beziehungen. Also das Finden von Beziehungen. Die Kardinalitäten stehen erst im nächsten Schritt im Mittelpunkt. Im Fokus stehen hier folgende Fragestellungen: • Zwischen welchen Entity-Typ gibt es eine Beziehung? • Wie stelle ich fest, ob es überhaupt eine Beziehung gibt? In der Praxis gehen Sie wie folgt vor: • Analysieren Sie die Aufgabenstellung und achten sie dabei auf Aussagen, die auf folgende Punkte hinweisen: a) Wird eine Funktion gefordert, die auf eine Abfrage hinweist bei der Informationen von mehr als einem Entity-Type sind? b) Wird in der Aufgabenstellung eine Aussage gemacht, die auf eine Regel bzw. Vorschrift hinweist Beispiel zu Fall a) Ein gutes Beispiel sehen Sie in der Abbildung. In dem Datenmodell sind die Entity-Typen „Auto“ und „Fahrer“ zu finden. In der Aufgabenstellung wird 9 explizit gefordert, dass eine Funktion gefordert wird, um herauszufinden, welcher Fahrer gerade mit einem Auto unterwegs ist. Diese bedeutet also, dass wir im Datenmodell Informationen hinterlegen müssen, sobald ein Fahrer ein Auto benutzt. In der Abbildung ist somit zu sehen, dass es eine Beziehung gibt zwischen Auto und Fahrer. Wie diese Beziehung genau modelliert wird, sehen wir, wenn wir uns mit den Kardinalitäten beschäftigen. Beispiel zu Fall b) Bei der Aufgaben für die Erstellung eines Datenmodells für einen Online-Shop könnte folgende Aussage/Forderung stehen: „Ein Bestellung kann es eine oder mehrere Lieferungen geben. Dies ist immer der Fall, wenn ein oder mehrere Artikel sofort lieferbar sind und ein oder mehrere Artikel erst später lieferbar sind“ In diesem Fall wäre es sinnvoll zwischen den Entity-Typen „Bestellung“ und „Lieferung“ eine 1-N Beziehung zu verwalten. 9 Im letzten Schritt identifizieren wir, welche Kardinalitäten sich aus der Aufgabenstellung ergeben. Um die Kardinalitäten zu bestimmen, hinterfragen wir die Anzahl der Entitys, die beteiligt sein müssen bzw. sein können sofern eine Beziehung besteht. In dem Beispiel aus der Abbildung ergibt sich, dass folgende Fälle auftreten können a) Es gibt Fahrer, die aktuell kein Auto fahren b) Es gibt Autos die aktuell nicht gefahren werden c) Ein Fahrer kann nur ein Auto fahren. d) Ein Auto kann nur genau von einem Fahrer gefahren werden In den Fällen a) und b) besteht keine Beziehung zwischen den Entitys Aus den Fällen c) und d) entnehmen wir, dass es sich um eine EINS-ZU-EINS Beziehung handeln muss. Aus der Abbildung entnehmen wir, dass aus diesem Grund folgende Designentscheidung getroffen wurde. • Der Primärschlüssel aus „Fahrer“ wird als Fremdschlüssel Attribut in „Auto „eingetragen. 10 Alternativ wäre natürlich auch möglich, den Primärschlüssel von „Auto“ als Fremdschlüsselattribute in „Fahrer“ einzutragen. Aus Modellierungssicht ist beides korrekt. In der Praxis werden aber noch zusätzliche Überlegungen angestellt. Um den Fokus nicht zu verlieren wird an dieser Stelle nur beispielhaft eine Überlegung vorgestellt, die sinnvoll ist bei der Vergabe von Fremdschlüsseln. Annahme das Datenmodell ist für eine Mittelständige Firma mit Dienstfahrzeugen gedacht, • Frage 1) Wie viele Einträge/Entitys erwarten wir bei „Auto“ in der Praxis vermutlich ca. 100 bis max. 200 Autos • Frage 2) Wie viele Einträge/Entitys erwarten wir für „Fahrern“ in der Praxis vermutlich max. Anzahl Mitarbeiter z.B. 1000..5000 Mitarbeiter Hinterlegt man den Fremdschlüssel bei „Fahrer“, so sind, wenn alle Autos unterwegs sind, nur 200 Attribute bei dem Fremdschlüsseln besetzt. Dies würde nicht nur Plattenplatz belegen, der selten benutzt wird. Hinterlegt man den Fremdschlüssel bei „Auto“ , so sind, wenn alle Autos unterwegs sind, alle Fremdschlüsselattribute besetzt. Auf Beziehungen gehen wir später nochmals näher ein, wenn wir und näher mit Beziehungen in der Praxis beschäftigen wollen. 10 Wie Sie sicherlich vermuten, müssen die Tabellennamen innerhalb eines Datenmodells eindeutig sein. Bei der Verwendung von Datenmodellierungswerkzeugen, wird diese Regel meist von den Werkzeugen selbst überwacht. Somit kann man schon bei der Erstellung eines Modells die Eindeutigkeit der Tabellennamen = Entity-Namen gewährleisten. Die Frage ist jedoch: Was ist, wenn zwei oder mehrere Teams, unabhängig voneinander, Datenmodelle entwickeln und als Datenbankschema in einer gemeinsamen Datenbank abgelegt werden sollen. Beispiel: • Team A erstellt ein Datenmodell für die Abteilung „Einkauf“ und definiert hierzu einen Entity-Type „Bestellung“ Dieser Entity-Typ wird verwendet, um Bestellungen bei externen Firmen zu verwalten. Sie dient also dazu, um festzuhalten, was alles bereits bestellt wurde. • Team B erstellt ein Datenmodell für den Vertrieb und definiert hierzu ebenfalls einen Entity-Typ „Bestellung“. Dieser Entity-Typ wird verwendet für die Bestellungen, die von Kunden kommen. Um diese Problem zu lösen, bieten die Hersteller unterschiedliche Lösungen an. 11 Oracle unterstützt hierzu ein Konzept, mit dem man für ein Datenbankschema ein „Paket“ definieren kann. Dann müssen die Namen nur innerhalb des Paketes eindeutig sein. Das dies sehr SQL spezifisch ist, wollen wir das Thema an dieser Stelle nicht weiter vertiefen. Wichtig ist nur, dass Sie sich bewusst werden, • das Entity-Namen innerhalb ihres Datenmodells eindeutig sind • Sie sollten die Namen sorgsam auswählen. Sie sollten nicht zu allgemein sein (z.B. Person). 11 In der Praxis kommt es sehr oft vor, dass Attribute immer einen Wert haben müssen. Damit das Datenbanksystem dies überprüfen kann, kann man bei der Definition von Attributen angeben, dass Werte angegeben werden müssen. Jedoch kommt es auch oft vor, dass Attribute nicht immer einen Wert haben müssen. Damit man unterscheiden kann, ob ein Attribut einen Wert besitzt oder nicht, gibt es die Definition von NULL. NULL ist ein ganz spezieller Wert der anzeigt, dass KEIN WERT vorhanden ist. Bei dem Anlegen eines Attributes für eine Tabelle kann man daher folgende Vorgaben machen • NOT NULL – dies bedeutet, dass NULL Werte nicht erlaubt sind. Eine Anwendung muss daher immer einen Wert angeben. Bei den meisten Datenbanken sind standardmäßig immer NULL Werte erlaubt und nur in den Fällen, bei denen keine NULL Wert erlaubt ist, kann man beim Anlegen die Bedingung „NOT NULL“ angeben. 12 In dieser Abbildung sind die wichtigsten Aussagen zur Verwendung von NULLWerten nochmals aufgeführt. 13 Wie aus der Abbildung ersichtlich ist, stellen Beziehungen einen Zusammenhang dar zwischen Entitys. Um diese entdecken, ist es manchmal notwendig, Fragen zu stellen, die aus unterschiedlichen Blickrichtungen kommen. Genauer gesagt man muss von unterschiedlichen Entity-Typen eine Beziehung betrachten. Betrachten wir hierzu das untere Beispiel in der Abbildung und stellen uns vor wir sollen ein Datenmodell für eine Art Bücherei erstellen. Hierbei haben wir es mit natürlich mit Büchern und mit Personen zu tun. Hierbei bieten sich folgende Fragestellungen an, um heraus zu finden, ob Beziehungen in dem Model hinterlegt werden müssen oder nicht: a) Ist es wichtig zu wissen, welche Bücher ein Kunde gekauft hat? b) Ist es wichtig zu wissen, welche Bücher, von welchen Kunden gekauft wurden? Wie Sie erkennen können, wird in Frage a) sprachlich der AKTIV –Fall verwendet, während in Frage b) der PASSIV- Fall verwendet wird. Merke: 14 In der Praxis immer aktive/passiv Fall-Fragen stellen, um Beziehungen zu entdecken. 14 Hier sehen wir ein Beispiel wie am 1-1 Beziehungen abbilden kann. Wobei in dem Beispiel davon ausgegangen wurde, dass Besitzer und Fahrer unabhängig voneinander existieren können. Wir kommen später noch einmal darauf zurück, wenn wir uns näher beschäftigen mit dem Thema „Identifying UND non-Identifying“ Relationships. Wie auf der Abbildung zu erkennen ist, wurde der Primärschlüssel von der Tabelle AUTO als Fremdschlüssel in die Tabelle BESITZER übernommen. Um nun auszuschließen, dass die Kombination ( b_id, a_id) nur ein einziges mal vorkommt, können wir via SQL einen sogenannten UNIQUE-INDEX für die Spalten (b_id , a_id) definieren. Dadurch haben wir definiert, dass es sich nur um eine 1-1 Beziehung handeln kann, sofern die Beziehung besteht. Genau genommen handelt es sich bei dieser Art der Umsetzung um eine 0..1 zu 0-1 Beziehung. Ein Beispiel für eine echte 11 Beziehung lernen wir kennen, wenn wir uns Identifying-Relationships im Detail ansehen. 15 Hier sehen Sie zwei Möglichkeiten wie man einen 1-N Beziehung abbilden kann. In dem Beispiel sehen sie zwei Tabellen In der Tabelle AUTO sind Informationen über Autos hinterlegt, wobei der Primärschlüssel das Attribut „a_id“ ist. In der Tabelle BESITZER sind Informationen über Besitzer hinterlegt. Weiterhin wird davon ausgegangen, dass es Personen geben kann, die aktuell kein Auto besitzen können. Oder umgekehrt, dass es Autos geben kann, die aktuell keine Besitzer haben. Aber ein Auto kann nur einen Besitzer haben und ein Besitzer kann nur ein Auto besitzen . Genau genommen ist es also eine 0..1 – zu 0-1 Beziehung !! In einem solchen Fall bieten sich zwei Optionen der Modellierung an: Option 1: Bei Option 1 hat man sich entschieden, den Primärschlüssel von AUTO als Fremdschlüssel in die Tabelle BESITZER einzutragen. 16 Option 2: Bei Option 2 hat man sich entschieden, den Primärschlüssel von BESITZER in die Tabelle AUTO als Fremdschlüssel einzutragen. Für beide Optionen gilt, dann: Ist der Fremdschlüssel NOT NULL, dann existiert eine Beziehung. Ist der Wert des Fremdschlüssels NULL , so gibt es keine Beziehung. Die Frage ist nun: Für welche der beiden Optionen, soll ich mich in der Praxis entscheiden. Nun diese hängt davon ab, wie viele Einträge in den jeweiligen Tabellen zu erwarten sind und wieviel der Eintrage eventuell einen NULL Value als Fremdschlüssel haben. Gibt es sehr viele Besitzer und wenige Autos und fast jedes Auto hat einen Besitzer, dann ist Option 2 günstiger, da in der Tabelle AUTO fast jeder Fremdschlüssel NOT NULL ist. Tipp zum Vertiefen: Überlegen Sie sich die Verhältnisse , wenn es sehr viele Autos gibt und einige Besitzer. Welche Option wäre dann besser? Versuchen Sie Ihre Entscheidung schriftlich festzuhalten. 16 In dieser Abbildung ist dargestellt, wie eine M-N Beziehung in Tabellen abgebildet wird. Hierzu benötigen wir eine extra Tabelle mit dem Namen FAHRERLAUBNIS. In dieser Tabelle sind zwei Spalten vorhanden, in denen der jeweilige Primärschlüssel der Partnertabellen (AUTO, FAHRER) hinterlegt sind. Somit lassen sich durch das Eintragen der Schlüsselkombinationen beliebige Beziehungen erzeugen. Durch das Löschen eines Eintrages wird eine Beziehung dann auch wieder gelöscht. 17 Hier sehen sie ein weiteres Beispiel für eine M-N Beziehung. 18 Nun wollen wir uns dem Thema „Identifying“ und „Non-Identifying“ Relationships zuwenden. Hierbei geht es um die Frage: Kann ein Eintrag in einer Tabelle nur existieren ( im Sinne ist erlaubt), wenn in einer anderen Tabelle ein spezieller Eintrag besteht. Besteht die Anforderung, dass ein Eintrag in einer Tabelle nur existieren darf, wenn in einer anderen Tabelle ein spezieller Eintrag vorhanden ist, dann benötigen wir eine „Identifying-Relationship“. Andernfalls implementieren wir eine „Non-Identifying“ Relationship. Wie das im einzelnen geht schauen wir uns als nächstes anhand von einem Beispiel an. 19 Schauen wir uns zunächst „Identifying“ Relationships an. Wie Sie in dem Beispiel sehen, gibt es eine Tabelle BESTELLUNG und ein Tabelle LIEFERUNG. Der Primärschlüssel in der Tabelle BESTELLUNG ist bestnr. Für die Tabelle LIEFERIUNG definieren wir eine Spalte (Attribute) liefer_nr, welches eindeutig sein muss/soll. Dieses Attribut wird benötigt, da es zu einer Bestellung ja mehrere Lieferungen geben kann. Dadurch wird jede Lieferung eindeutig identifiziertWenn wir nun davon ausgehen, dass es keine Lieferung geben darf, dann übernehmen wir den Primärschlüssel aus der Tabelle BESTELLUNG als Fremdschlüssel in die Tabelle LIEFERUNG. Für die Tabelle LIEFERUNG definieren wir nun einen Primärschlüssel, der sich aus dem Tupel (bestnr, liefer_nr) zusammensetzt. Hiermit erreichen wir, dass es keine Lieferung gibt ohne eine Bestellung. Es kann aber zu einer Bestellung mehrere Lieferungen geben. 20 In der englisch sprachigen Literatur werden die Begriffe Parent-Table und Child-Table verwendet. Dabei bezeichnet die Child-Tabelle, die Tabelle, deren Einträge von einem Eintrag /Existenz in der Parent-Tabelle abhängen. Die andere Tabelle wird dementsprechend als Parent Tabelle bezeichnet. 20 Nun wollen wir uns ein Beispiel für eine „Non-Identifying“ Relationship ansehen. In dem Beispiel ist zu sehen, dass ein Buch und ein Besitzer unabhängig voneinander existieren können. Daher haben beide Tabelle eigene Primärschlüssel. Um eine Beziehung z.B. 1-N herzustellen, können wir die Verfahren anwenden, die wir bisher schon kennengelernt haben. Als kleine Übung zum Vertiefen stellen Sie folgende Überlegungen an. Um welche Art von Verbindung handelt es sich , wenn man eine Extra-Tabelle anlegen würde, welche als Attribute jeweils die Primärschlüssel der beiden Tabellen BOOK und OWNER hätten und beide Attribute als Primärschlüssel für diese neue Tabelle definieren. Mit anderen Worten: Der Primärschlüssel der extra Tabelle setzt sich aus den beiden Fremdschlüsseln zusammen. 21 22