Entwicklung einer relationalen Datenbank
Werbung

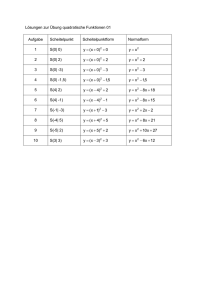
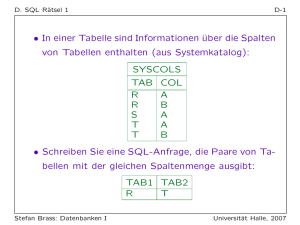
Entwicklung einer relationalen Datenbank RELATIONALE DATENBANK ist eine Sammlung von großen Mengen an Informationen in Tabellen, die in Beziehung zueinander stehen. Vorgehensweise zur Entwicklung einer relationalen Datenbank in vier Schritten Die Entwicklung einer relationalen Datenbank, z. B. in einem Unternehmen, erfolgt in einer strukturierten Reihenfolge. Diese sinnvolle Reihenfolge erfolgt in vier Schritten. 1. SCHRITT: ANALYSE Bei der Analyse werden die gesammelten Daten einer Tabelle genau betrachtet. Redundante (= mehrfach gespeicherte, also überflüssige) Daten und inkonsistente (= unkorrekte/unstimmige) Daten müssen zerlegt werden. 2. SCHRITT: ENTWURF Beim Entwurf werden die Daten der zerlegten Tabellen vereinfacht dargestellt. Diese Datenmodellierung findet in der Informatik mit Hilfe des sogenannten ER-Modells statt. Das Entity Relationship-Modell (=Objektmengen-Beziehungsmodell) ist ein in der Informatik genormtes Datenbankmodell. Es dient der vereinfachten Darstellung von Klassen und Attributen, die in Beziehung zueinander stehen. 3. SCHRITT: IMPLEMENTIERUNG Bei der Implementierung werden die Klassen und die Attribute der einzelnen Tabellen mit Hilfe eines Datenbankmanagementsystems (=Datenbanksoftware, wie z. B. Access) erstellt. Auf der Grundlage des erarbeiteten Entity-Relationship-Modells werden die Tabellen mit dem Kombinationsschlüssel in Beziehung zueinander gesetzt. 4. SCHRITT: REALISIERUNG Bei der Realisierung werden die Attributwerte in die Tabellen eingegeben. Zur einfachen Eingabe dienen dem Benutzer sogenannte Formulare. Zur Auswertung der Daten muss der Benutzer sogenannte Abfragen erstellen. Zum Ausdrucken der selektierten Daten einer Abfrage verwendet der Benutzer sogenannte Berichte. 1. SCHRITT: ANALYSE Bei der Analyse werden die gesammelten Daten einer Tabelle genau betrachtet. Redundante (= mehrfach gespeicherte, also überflüssige) Daten und inkonsistente (= unkorrekte/unstimmige) Daten müssen zerlegt werden. Mehrfache Speicherung der gleichen Information = Redundanz Unstimmigkeit zwischen gespeicherten Informationen oder auch zwischen verschiedenen Relationen (Tabellen) = Inkonsistenz Diesen Vorgang nennst du in der Fachsprache „Normalisierung“. Du unterscheidest drei Normalformen. Bei der 1. NORMALFORM treten keine Mehrfachmerkmale bei den Datensätzen mehr auf. Oder anders ausgedrückt: In eine Zelle einer Tabelle steht nur ein Attributwert. 2. NORMALFORM Voraussetzung: Die Tabelle befindet sich in der 1. Normalform Mehrfach gespeicherte (=redundante Daten) werden vermieden. Die Haupttabelle wird dabei in mehrere Tabellen zerlegt. Jede Tabelle beinhaltet sinnvoll zueinander passende Attribute, z. B. Vorname und Nachname Jede entstandene Tabelle enthält ein mögliches Schlüsselattribut, z. B. ID_Nr Diese Attribute nennst du Schlüssel. Der Schlüssel dient zur eindeutigen Identifizierung eines Objekts zur Sortierung, zum Suchen und Auffinden von Datensätzen in Datenbanken Enthält eine Tabelle kein geeignetes Attribut, so müssen selbstdefinierte Attribute, wie z. B. Kundennummer, hinzugefügt werden. Eine neue Tabelle muss erzeugt werden, wo alle Schlüssel in Beziehung zueinander gebracht werden. Diese Tabelle nennst du „Kombinationsschlüssel“. Du sprichst von der 2. Normalform wenn die 1. Normalform gegeben ist und jeder Datensatz durch den Schlüssel einer Tabelle vom Kombinationsschlüssel abhängig ist. 3. NORMALFORM Die zerlegten Tabellen werden nochmals überprüft. Tabellen mit redundanten (=mehrfach gespeicherten) Daten werden nochmals zerlegt. Daten, die in funktionaler Abhängigkeit stehen, wie z. B. PLZ und Ort, bleiben in einer Tabelle. Du sprichst von der 3. Normalform wenn die 2. Normalform gegeben ist und mit Ausnahme der Schlüssel(attribute) alle Attribute eines Datensatzes voneinander unabhängig sind.