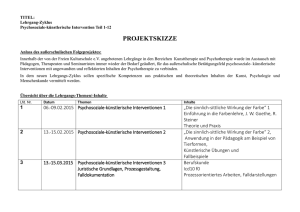
Wahlpflichtfach im Klinischen Studienabschnitt zum Thema „Schmerz“
Werbung

1 Wahlpflichtfach im Klinischen Studienabschnitt zum Thema „Schmerz“ WS 2007/08 Anmeldung: Sekretariat des Instituts für Medizinische Psychologie, Bunsenstr. 3, 35037 Marburg Tel. 28-66250, Fax 28-64881, e-mail: [email protected] Leistungsnachweis: Der Leistungsnachweis erfolgt über eine Hausarbeit in einem Fachgebiet nach Wahl. 1. Akutschmerz und postoperative Schmerztherapie(0,5 SWS) 1.1. Einführung – Bedarf, Nutzen, Risiken der postoperativen Schmerztherapie 1.2. Patienteninformation und –aufklärung 1.3. Schmerzmessung und Dokumentation 1.4. Differenzialdiagnose von postoperativen Schmerzen 1.5. Systemische Schmerztherapie (Opioide, Nicht-Opioide, Ko-Analgetika und Applikationswege) 1.6. Regionalanästhesie (Rückenmarksnahe Verfahren und periphere Nervenblockaden) 1.7. Organisation des Akut-Schmerzdienstes Der Kurs gliedert sich in ein Seminar und eine Hospitation beim postoperativen Akutschmerzdienst. Im Seminar wird die Bedeutung und Problematik des Akutschmerzes erarbeitet und das perioperative Schmerztherapie-Konzept der Klinik für Anästhesie vorgestellt. Verfahren der Regionalanästhesie werden multimedial erläutert und die ultraschallgestützte Lokalisation von peripheren Nerven durch die Studierenden selbst ist möglich. Die Hospitation beim Akutschmerzdienst bedeutet Teilnahme an der klinischen Visite bei den postoperativen Patienten des Klinikums, die mit Regionalanästhesieverfahren behandelt werden. Lehrender: Dr. G. Dinges , Klinik für Anästhesie und Intensivtherapie (e-mail: [email protected]) Termin: Vorbesprechung und Terminfestlegung am 22.10.2007, 16.30 h im Besprechungsraum Anästhesie (Nullebene/Raum 0/2126). 2. Biologische Mechanismen der Chronifizierung (0,5 SWS) 2.1. Neurobiologische Grundlagen des Schmerzes 2.2. Das Hinterhorn des Rückenmarks 2.3. Neurotransmitter-und Neuromodulatorsysteme 2.4. Mechanismen der strukturellen und funktionellen Plastizität Lehrender: Prof. Dr. E. Weihe, Institut für Anatomie und Zellbiologie ([email protected]) Termine: Termin erfragen unter Tel. 28-66247 Ort: Seminarraum 1 des Instituts für Anatomie und Zellbiologie 3. Schmerzdiagnostik und psycho-soziale Mechanismen der Chronifizierung mit Fallvorstellung (0,5 SWS) 3.1. Das bio-psycho-soziale Schmerzmodell 3.2. Differenzierung akuter-chronischer Schmerz (ICIDH- und ICF-Konzept der WHO) 3.3. Schmerzmessung (VRS, NRS, VAS) und psychometrische Verfahren 3.4. Lebensaltersbezogene Probleme der Diagnostik und Therapie chronischer Schmerzen 3.5. Diagnostik der Chronifizierung (Stadienkonzepte) 3.6. Lerntheoretische Modelle der Chronifizierung (Modelllernen, operantes und respondentes Modell) 3.7. Komplexe und syndrom-spezifische Modelle (Diathese-Stress, Fear-Avoidance, yellow flags, etc.) 3.8. Psychologische Therapieverfahren und Schmerzmanagement 3.9. Medikamentenabhängigkeit und Entzug 3.10. Interdisziplinäre Kooperation Lehrender: Prof. Dr. Dr. H.D. Basler, Institut für Medizinische Psychologie Termin: Samstag, den 10.11., 2007, 9:00 Uhr – 16:00 Uhr, Unterrichtsraum des Instituts für Medizinische Psychologie, Bunsenstr. 3, III. Etage 4. Diagnostik und Therapie chronischer Rücken- und muskuloskelettaler Schmerzsyndrome mit Fallvorstellungen und praktischen Übungen (0,5 SWS) 3.1. Besonderheiten der Pathophysiologie und Ätiopathogenese 3.2. Symptomatik und Differenzialdiagnostik radikulärer und nichtradikulärer Schmerzen) 3.3. qualitätsgesicherte Schmerztherapie des chronischen Rückenschmerzes -Interdisziplinärer Kooperation 3.4. entzündliche rheumatische Erkrankungen 3.5. degenerative Gelenkerkrankungen 3.6. weichteilrheumatische Erkrankungen 3.7. myofaszialer Schmerz 1 2 Lehrender: PD Dr. H. Konder, Schmerzklinik des Katholischen Krankenhauses Hagen Termin: Samstag, den 19. Januar, 2008, Unterrichtsraum des Instituts für Medizinische Psychologie, Bunsenstr. 3, III. Etage (bitte Sportkleidung mitbringen wg. der praktischen Übungen) 5. Diagnostik und Therapie chronischer Kopf- und Gesichtschmerzsyndrome sowie neuropathischer Schmerzsyndrome mit Fallvorstellungen (0,5 SWS) 3.8. Migräne 3.9. Kopfschmerz vom Spannungstyp 3.10. Clusterkopfschmerz 3.11. Medikamenten-induzierter Kopfschmerz 3.12. Trigeminusneuralgie 3.13. Mono- und Polyneuropathien 3.14. zentraler Schmerz 3.15. Komplexes regionales Schmerzsyndrom 3.16. Interdisziplinäre Kooperation Lehrende: Dr. M. Teepker (verantwortlich), PD Dr. K. Schepelmann, Prof. Dr. Braune Termin: Vier Termine freitags innerhalb des Semesters, 17:00 bis 18:30 Uhr, jeweils nach der Schmerzkonferenz in der dritten Woche des Monats, Konferenzraum des Zentrums für Nervenheilkunde 6. Neurochirurgische Verfahren in der Schmerztherapie mit Fallvorstellungen (0,5 SWS) a. Indikationsbereich neurochirurgischer Verfahren b. Läsionsverfahren c. Elektrostimulationsverfahren d. Dekomprimierende Verfahren e. Interdisziplinäre Kooperation Lehrender: Prof. Dr. Dieter Hellwig, Klinik für Neurochirurgie Termin: Drei Termine Mittwoch, 16:00 Uhr bis 18:00 Uhr (oder nach Vereinbarung). Die Veranstaltung findet statt im Raum No. 3130 Ebene + 1 (Seminarraum NCH) am Klinikum. 7. Tumorschmerz und Palliativmedizin mit Fallvorstellungen (0,5 SWS) a. Schmerzursachen und Symptomatik b. Therapie einschließlich WHO-Stufenschema c. Ziele und Inhalte der Palliativmedizin d. Organisation palliativmedizinischer Versorgung Lehrender: Prof. Dr. Andreas Lübbe, Cecilien-Klinik, Bad Lippspringe Termin: Dienstag, den 6. November, 9:00 – 12:30 Uhr und Dienstag, den 4. Dezember, 9:00 – 12:30 Uhr, Bibliothek der Informatik, Bunsenstr. 3, 1. Stock 8. Somatoforme Schmerzstörung: Wie kann man Somatisierung verstehen – wie erhebt man die Anamnese? Mit Fallbesprechungen (0,5 SWS) 8.1. Was sind somatoforme (Schmerz-)Störungen? 8.2 Wie kann man ihre Entstehung konzeptuell fassen? 8.3. Was sind mögliche auslösende Faktoren? 8.4. Wie erhebt man die Anamnese und wie gestaltet man die Beziehung? Lehrender: Dr. G. Bolm, Institut für Medizinische Psychologie Termin: Samstag, den 17. November, 2007, 10 – 13 h, 14:30-17:30 h, Institut für Medizinische Psychologie, Unterrichtsraum 9. Interdisziplinäre Schmerzkonferenz (0,5 SWS) Für die Teilnahme an vier Schmerzkonferenzen werden 0,5 SWS angerechnet. Die Schmerzkonferenz findet an jedem 3. Freitag im Monat in der Zeit von 15:00 Uhr bis 17:00 Uhr im Unterrichtsraum in der ersten Etage des Zentrums für Nervenheilkunde, Rudolf-Bultmann-Straße 8, statt. 2 3 Leistungsnachweis im Wahlpflichtfach „Schmerz“ Der Leistungsnachweis erfolgt über eine Hausarbeit. Die Studierenden können wählen, in welchem Teilgebiet sie eine Hausarbeit schreiben wollen. Das Thema muss mit dem für das Teilgebiet zuständigen Dozenten abgesprochen werden. Kriterien für die Ausgabe und Benotung der Hausarbeit (1) Das Thema soll den angebotenen Lehrstoff vertiefen. (2) Das Thema soll durch eine Datenbank gestützte Literatursuche zu bearbeiten sein. In Frage kommen sowohl Originalarbeiten als auch Review-Artikel oder Meta-Analysen. Eine ausschließliche Wiedergabe des Inhalts von Lehrbüchern ist nicht zu akzeptieren. (3) Der Umfang der Hausarbeit soll die Länge eines Originalartikels nicht überschreiten. Als Richtwert gilt ein Seitenumfang von 10 - 15 Manuskriptseiten einschließlich Zusammenfassung und Literaturverzeichnis, Schriftgröße 12, 1 ½ zeilig geschrieben. (4) Folgende Kriterien werden der Benotung zu Grunde gelegt: a) Qualität der vorausgestellten Zusammenfassung b) Darlegung der Fragestellung c) Methodik der Datenbank-Recherche, Auswahlkriterien für die in der Hausarbeit dargestellten Artikel d) Darstellung der Ergebnisse unter inhaltlichen und methodischen Gesichtspunkten (zur Methodik siehe das Skript zu „Evidence Based Medicine“ auf den Folgeseiten) e) Kommentierung, in welchem Ausmaß die Ausgangsfrage durch das Literaturstudium beantwortet werden konnte f) Formale Gestaltung (Quellenangaben, Zitate, Gliederung, etc.) 3 4 Einführung in die Evidenz Basierte Medizin (EBM) Prof. Dr. Dr. H.D. Basler, Institut für Medizinische Psychologie 1. Was ist Evidenz Basierte Medizin? Meine Studenten fühlen sich unbehaglich, wenn ich ihnen sage: „Die Hälfte dessen, was Ihnen als Medizinstudenten beigebracht wird, wird sich in 10 Jahren als falsch erweisen. Und das Problem besteht darin, dass keiner Ihrer Lehrer Ihnen derzeit sagen kann, was zu dieser Hälfte gehört.“ (Dr. Sydney Burwell, ehemaliger Dekan der Harvard Medical School, zit. nach Sackett et al., 2000). Diese Aussage Dr. Burwells liegt fast 50 Jahre zurück. Die Halbwertszeit des medizinischen Wissens hat sich inzwischen weiterhin verkürzt. Es ist abzusehen, dass nur noch die Hälfte dessen, was Studierende zu Beginn ihrer klinischen Ausbildung lernen, auch am Ende dieser Ausbildung Gültigkeit haben wird. Aus dieser Erkenntnis wurde folgende Schlussfolgerung gezogen: Wichtiger als Gegenstandskataloge einzelner Fachgebiete zu lernen ist es für angehende Ärzte, sich mit den Methoden vertraut zu machen, die ihnen helfen, sich in kurzer Zeit auf den neuesten Stand des medizinischen Wissens zu bringen und diesen bei der klinischen Entscheidungsfindung zu berücksichtigen. Genau dieses ist das Ziel der Evidenz Basierten Medizin (EBM=evidence based medicine), wobei unter Evidenz Belege und rationale Begründungen für Entscheidungen verstanden werden. Nach Sackett et al. (1996) ist EBM „der gewissenhafte, ausdrückliche und vernünftige Gebrauch der gegenwärtig besten externen, wissenschaftlichen Belege (evidence) für Entscheidungen in der medizinischen Versorgung individueller Patienten“. EBM impliziert somit eine strenge Ausrichtung klinischer Entscheidungen an den neuesten Ergebnissen klinischer medizinischer Forschung. Erst wenn solche Ergebnisse nicht vorliegen, soll auf das Erfahrungswissen des einzelnen Arztes zurück gegriffen werden. Obwohl das Bemühen um eine wissenschaftliche Fundierung klinischer Entscheidungen in der Medizin nicht neu ist, gab es bis vor wenigen Jahren massive Barrieren sowohl für die Verbreitung als auch für die Umsetzung klinisch relevanter Forschungsergebnisse in der Versorgungspraxis. Das führte zu einer häufig jahrelangen Verzögerung von wissenschaftlich begründeten Veränderungen in der Patientenversorgung. Heute ermöglichen die modernen elektronischen Kommunikationsmedien jedem Arzt, sich über die nach neuestem Wissen beste Versorgung seiner Patienten zu informieren. Der Begriff EBM wurde erst 1992 an der McMaster University in Kanada geprägt. Trotz dieser kurzen Geschichte kann sich heute kein klinisch tätiger Arzt der Diskussion um EBM entziehen, und sei es aufgrund der Forderung, die Therapie bestimmter Krankheiten nach Evidenz basierten Leitlinien durchzuführen. Die von der Bundesregierung favorisierten Disease Management Programme (z.B. für Diabetes, Asthma und Brustkrebs) fordern von den beteiligten Ärzten, sich in der Patientenversorgung an Leitlinien zu orientieren, die auf der Basis von EBM erstellt wurden. Nach Sackett et al. (2000) umfasst das Evidenz basierte Vorgehen des in der Patientenversorgung tätigen Arztes fünf Schritte, die hier jedoch nicht alle ausführlich erklärt werden: Schritt 1: Formulierung einer beantwortbaren Frage, die sich auf die beste Lösung für ein Problem bezieht, das von einem Patienten präsentiert wird. Hierbei kann es sich um Fragen der Prävention, der Diagnose, der Prognose, der Therapie oder der Ursache für eine Erkrankung handeln. 4 5 Schritt 2: Suche nach der besten Evidenz, um diese Frage zu beantworten. Hierbei kommen je nach Fragestellung und vorhandenem Wissen verschiedene Informationsquellen in Betracht: eigene klinische Erfahrung, die Meinung von medizinischen Autoritäten, Lehrbücher oder die Ergebnisse der in Datenbanken gespeicherten wissenschaftlichen Untersuchungen. Schritt 3: Kritische Bewertung der vorhandenen Evidenz. Die Bewertung soll sich darauf beziehen, wie nahe die Evidenz der Wahrheit kommt (wie valide sie ist), wie stark sie ausgeprägt ist (Effektstärke = size of the effect) und in welchem Ausmaße das erzielte Ergebnis in der eigenen klinischen Praxis anwendbar ist. Schritt 4: Abgleichung der durch die bisherigen Schritte gefundenen Evidenz mit den uns aufgrund unserer Ressourcen und der speziellen Individualität des Patienten gegebenen Möglichkeiten Schritt 5: Kritische Evaluation unserer eigenen Kompetenz in der Durchführung Evidenz basierter Analysen und deren Umsetzung in die Praxis mit der Zielsetzung einer ständigen Qualitätsverbesserung Dieses Skript konzentriert sich auf den dritten Schritt, insbesondere auf die kritische Bewertung der vorhandenen Evidenz. Die Bewertungskriterien der Evidenz richten sich nach dem Inhalt der klinischen Forschungsgebiete: Ursachenforschung, Therapieforschung und Diagnoseforschung. 2. Forschungsgebiete in der klinischen Medizin Ursachenforschung Ursachenstudien in der klinischen Medizin untersuchen, ob eine bestimmte Erkrankung auf eine zeitlich vorausgehende Bedingung zurückzuführen ist1. Bei dieser Bedingung kann es sich um eine möglicherweise schädliche Substanz (z.B. ein Umweltgift bei einer Krebserkrankung), um ein Verhalten (z.B. Rauchen bei Lungenkrebs), um eine genetische Disposition (z.B. Trisomie 21 bei Down-Syndrom) oder um eine physiologische (Dys-) Regulation (z.B. essentielle Hypertonie bei Herzinfarkt) handeln. Bevorzugte Studiendesigns bestehen in Kohortenstudien oder Fall-Kontroll-Studien. Therapieforschung In Therapiestudien geht es darum, die Wirksamkeit therapeutischer Interventionen zu erforschen. Hierbei kann es sich um medikamentöse Therapien, chirurgische Interventionen, Patientenschulungen, Psychotherapie oder alternative Heilverfahren handeln. Das bevorzugte Studiendesign ist die randomisierte kontrollierte Studie. 1 Kritisch muss angemerkt werden, dass die Forschung in der klinischen Medizin zwar zu Erkenntnissen über Krankheitsursachen beitragen, Beweise für ursächliche Zusammenhänge allerdings nicht erbringen kann. Ursachenforschung ist die Domäne des Experiments. Experimente mit Menschen sind aus ethischen Gründen nicht durchführbar. Statt von „Ursache“ sollte daher besser von „Assoziation“ gesprochen werden. Klinische Forschung kann feststellen, dass bestimmte Erkrankungen mit bestimmten Bedingungen assoziiert sind. Es ist zutreffender, diese Bedingungen als „Risikofaktor für die Erkrankung“, nicht aber als deren Ursache zu bezeichnen. In Laborexperimenten kann anschließend, z.B. im Rahmen von Tierversuchen, überprüft werden, ob die beobachtete Assoziation tatsächlich kausal zu interpretieren ist. In der Ursachenforschung sind klinische und laborexperimentelle Forschung wechselseitig voneinander abhängig. 5 6 Diagnoseforschung In Diagnosestudien geht es darum, die Objektivität, Zuverlässigkeit (Reliabilität) und Gültigkeit (Validität) diagnostischer Tests zu untersuchen. Zur Überprüfung der Validität ist ein Außenkriterium erforderlich, das den „Goldstandard“ darstellt. Diagnostische Tests sind dann nützlich, wenn sie ökonomischer anzuwenden sind als der Goldstandard. Der Goldstandard zur Diagnostik eines Tumors im Bauchraum ist z.B. die Computertomografie (CT). Nachteil dieser Methode sind die hohen hierdurch verursachten Kosten und die hohe Strahlenbelastung. Billiger ist es, eine Ultraschalluntersuchung durchzuführen. Die Diagnostik mit dem Ultraschall-Gerät ist nur so weit valide, wie die hierdurch erzielten Ergebnisse mit denen des CT übereinstimmen. Die Ergebnisse des diagnostischen Tests (Ultraschall) und des Goldstandards (CT) werden zeitgleich erhoben und miteinander verglichen. Bevorzugtes Design ist daher die Querschnittsstudie (cross sectional study)2. 3. Hierarchie der Evidenzkriterien bei Ursachen- und Therapiestudien Wenn Ärzte danach streben, die beste wissenschaftliche Evidenz zu berücksichtigen, müssen ihnen Kriterien an die Hand gegeben werden, diese zu beurteilen. EBM stellt für diesen Zweck eine Hierarchie von Kriterien auf, die sich an der Aussagekraft wissenschaftlicher Erkenntnismethoden orientieren. Die Evidenzhierarchie systematische Reviews und Meta-Analysen randomisiert-kontrollierte Studien Kohortenstudien Fall-Kontroll-Studien Querschnittsstudien Fallberichte Expertenurteil klinische Erfahrung Klinische Erfahrung, Expertenurteil und Fallberichte stehen deshalb an unterster Stufe, weil hierbei die Wahrscheinlichkeit systematischer Fehler („bias“, s.u.) am höchsten ist. Das erworbene Wissen beruht in diesen Fällen nicht auf einem kontrollierten methodischen Vorgehen, sondern auf bei verschiedenen Ärzten häufig unterschiedlichen persönlichen Erfahrungen. Diese können auch auf falsche Interpretationen von Sachverhalten zurück zu führen sein. Wenn z.B. ein Patient nach einer Therapie nicht wieder in die Sprechstunde kommt, so kann das daran liegen, dass er geheilt ist, aber auch daran, dass er aus Enttäuschung über die wirkungslose Behandlung einen anderen Arzt 2 Eine Sonderform der Diagnosestudie ist die Screeningstudie. Screenings dienen zum Nachweis von Erkrankungen in einem präsymptomatischen Stadium und richten sich auf die Bevölkerung. Bekannt ist z.B. das Diabetes-Screening durch einen Urinzucker-Teststreifen. Der Goldstandard in der Diabetesdiagnostik ist der Glukose-Toleranztest. Der Einsatz des Teststreifens ist zu rechtfertigen, wenn dessen Ergebnisse mit denen des Goldstandards übereinstimmen. Der Teststreifen- soll möglichst alle Personen erfassen, die auch durch den Glukose-Toleranztest als Fälle identifiziert worden wären (das ist eine Frage der Sensitivität des Screening-Tests) und - er soll möglichst alle Personen ausschließen, die gesund sind (das ist eine Frage der Spezifität des Screening-Tests). Die Validitätsparameter Sensitivität und Spezifität bestimmen neben der Messgenauigkeit (Reliabilität) die Güte eines diagnostischen Tests. 6 7 aufgesucht hat. Selbst wenn sicher gestellt werden kann, dass die Behandlung erfolgreich war, kann der Erfolg nicht direkt auf die Therapie zurückgeführt werden. Der Behandlungserfolg kann eingetreten sein, weil der Patient sich z.B. zusätzlich mit Hausmitteln therapiert hat, oder es kann sich um eine Spontanheilung gehandelt haben. Möglicherweise wären zudem andere Behandlungsmethoden bei diesem Patienten wirksamer gewesen. 4. Studiendesigns klinischer Studien Der Fallbericht Fallberichte beschreiben die medizinische Geschichte eines einzelnen Patienten in narrativer Form. Sie werden häufig als Fallserien publiziert, in denen die Patientengeschichten dazu dienen, Vermutungen zu besonderen Aspekten einer Krankheit, einer Behandlung oder - das findet man heute am häufigsten - einer Nebenwirkung zu veranschaulichen. Besonders in der letztgenannten Form können sie große Bedeutung erlangen. Es soll in diesem Zusammenhang in die Publikation von McBride aus dem Jahre 1961 in der Zeitschrift Lancet erinnert werden. Der Arzt hatte bemerkt, dass zwei Neugeborenen in seiner Klinik die Gliedmaßen fehlten. Die Anamnese hatte ergeben, dass beide Mütter während der Frühschwangerschaft ein neues Medikament gegen Schlafstörungen (Thalidomid, Handelsname in Deutschland: Contergan) eingenommen hatten. Er wollte nun so schnell wie möglich seine Kollegen auf die von ihm vermuteten Nebenwirkungen des Medikaments durch die Publikation aufmerksam machen. Aus diesem Beispiel wird deutlich, dass durch aktuelle, anschauliche Fallberichte Hypothesen generiert werden können, die nachfolgend durch systematische Studien überprüfbar werden. Sie können das Anfangsglied einer Kette von Studien darstellen, die eine zunehmende Evidenz ermöglichen. Die Querschnittsstudie zur Überprüfung der Assoziation von Variablen In Querschnittstudien werden mindestens zwei Variablen zum gleichen Zeitpunkt erhoben. Sie dienen dazu, eine vermutete Assoziation zwischen diesen Variablen zu überprüfen. Es gibt zahlreiche klinische Fragestellungen, bei denen der Arzt an der Assoziation von Variablen interessiert ist. Beispielsweise kann es von Bedeutung sein, Körpergröße und Lebensalter von Kindern in der Bevölkerung zu erheben, um Nomogramme zu erstellen, mit deren Hilfe der Wachstumsverlauf eines individuellen Kindes beurteilt werden kann. Oder es wird der Frage nachgegangen, ob sich körperlich aktive Diabetiker gesünder fühlen als nicht-aktive, indem eine Stichprobe von Personen mit dieser Diagnose gleichzeitig nach ihrem Bewegungsverhalten und nach der Einschätzung ihres Gesundheitszustands befragt wird. Die Vermutung, dass Diabetes in der Bevölkerung unterdiagnostiziert ist, könnte mit einer Untersuchung überprüft werden, in der jede Person aus einer Bevölkerung einem Glukose-Toleranztest unterzogen wird und das Ergebnis dieses Tests mit der Aussage verglichen wird, ob dieses Ergebnis der Person schon vorher bekannt war oder nicht. Durch reine Querschnittsstudien kann der Forscher Ursachen oder Therapieeffekte nicht ermitteln. Nehmen wir an, ein Doktorand hätte die Vermutung, dass chronische Schmerzen zu depressiven Verstimmungen führen. Er lässt alle Patienten, die die Schmerzambulanz des Klinikums besuchen, einen Depressionstest ausfüllen und entnimmt aus den Krankenakten Angaben zu dem Ausmaß der Chronizität. Er stellt fest, dass erwartungsgemäß die am stärksten chronifizierten Patienten die höchsten Werte im Depressionstest haben. Ist damit die Vermutung bestätigt worden? Nein, denn die beobachteten Assoziationen dürfen niemals kausal interpretiert werden. Die Ergebnisse könnten nämlich auch darauf hinweisen, dass nicht etwa chronischer Schmerz die Ursache depressiver Verstimmungen ist, sondern dass 7 8 umgekehrt depressive Verstimmungen die Chronifizierung des Schmerzes fördern. Es sind allerdings Zweifel nicht nur an der möglichen Interpretation der Ergebnisse angebracht, darüber hinaus könnten die Ergebnisse bereits durch die Auswahl der Probanden verfälscht worden sein. Möglicherweise suchen die Schmerzambulanz vorzugsweise solche Patienten mit stark chronifizierten Schmerzen auf, die gleichzeitig eine depressive Verstimmung aufweisen. Nicht depressive Patienten könnten mit der Therapie durch den Primärarzt eher zufrieden sein und daher keinen Anlass sehen, sich einer Spezialambulanz anzuvertrauen. Ein „Selektionsbias“ könnte daher die Ergebnisse verzerrt haben. Dieser Selektionsbias kann durch das Design nicht kontrolliert werden. Ein weiterer Doktorand möchte die Wirksamkeit einer für die Patienten kostenlosen Patientenbroschüre über gesunde Ernährung für Diabetiker überprüfen. Er hat beobachtet, dass einige Patienten diese Broschüre nach der Diagnostik der Erkrankung in der Klinik mit nach Hause genommen haben, andere nicht. Er hat die Idee, mit allen Patienten bei der nächsten Konsultation einen Wissenstest durchzuführen und sie gleichzeitig zu fragen, ob sie die Broschüre gelesen haben. Er stellt fest, dass der Test häufiger von Patienten bestanden wird, die angeben, die Broschüre gelesen zu haben. Somit kann eine Assoziation zwischen dem Lesen der Broschüre und dem Wissen aufgezeigt werden. Bitte erläutern Sie dem Doktoranden, warum er durch das Design der Querschnittstudie die Wirksamkeit der Intervention nicht überprüfen kann. Ein Problem besteht darin, dass der Wissensstand der beiden Gruppen vor dem Mitnehmen der Broschüre nicht bekannt ist. Möglicherweise wusste die Gruppe, welche die Broschüre eingesteckt hat, bereits zu diesem Zeitpunkt mehr über Ernährung als die andere Gruppe. Zum anderen kann es sein, dass sich die beiden Gruppen nicht nur in ihrem Vorwissen unterscheiden, sondern auch in anderen Variablen, die Einfluss auf das Ergebnis des Tests nehmen können. Hierzu könnte z.B. die Schulbildung gehören oder die Bereitschaft zur Mitarbeit in der Therapie (Compliance). Schulbildung und Compliance könnten sogar zu der Entscheidung beigetragen haben, die Broschüre zu lesen. Dann wäre der entscheidende Wirkfaktor nicht das Lesen der Broschüre, sondern eine dritte oder vierte Bedingung, die unkontrolliert in das Ergebnis einginge. Solche dritten Bedingungen werden als konfundierende Variablen (confounder) bezeichnet. Wenn sie zu Beginn einer Studie nicht bekannt sind, können sie nur durch eine randomisierte Zuweisung der Patienten auf eine Versuchs- und eine Kontrollgruppe in ihren Auswirkungen auf die Zielgröße oder den Endpunkt der Studie (auch „abhängige Variable“ genannt, in diesem Fall das Wissen) in Schach gehalten werden. Damit ist allerdings der Rahmen einer Querschnittstudie gesprengt. Die Fall-Kontroll-Studie als Studie mit retrospektivem Design In einer Fall-Kontroll-Studie werden Patienten mit einer bestimmten Erkrankung (Fälle) identifiziert und diese je nach Fragestellung entweder mit Patienten einer anderen Erkrankung, mit gesunden Personen aus der Bevölkerung oder mit Verwandten (Kontrollen) hinsichtlich eines oder mehrerer Merkmale retrospektiv (rückschauend) verglichen. Das Verfahren, nach dem die Versuchsgruppe (die Fälle) und die Kontrollgruppe (die Nicht-Fälle) zusammen gestellt werden, nennt man Matching. Fall-Kontroll-Studien werden im Regelfall im Kontext der Ursachenforschung durchgeführt. Sie eignen sich insbesondere für die Erforschung der Ätiologie seltener Erkrankungen. Wenn ich z.B. daran interessiert bin, ob Säuglinge, die in Bauchlage schlafen, häufiger einen plötzlichen Kindestod erleiden, werde ich alle Fälle von plötzlichem Kindestod in einer Versuchsgruppe sammeln und für jeden Fall eine lebende Vergleichsperson suchen. Ich werde mich bei den Eltern beider Gruppen nach der Schlafposition der Säuglinge erkundigen und die Häufigkeit der Bauchlagen in beiden Gruppen miteinander vergleichen. 8 9 Das große Problem der Fall-Kontroll-Studien besteht darin, adäquate Kontrollpersonen zu finden, da das Ergebnis wesentlich durch die Auswahl der Kontrollen bestimmt wird. Ich muss sehr sorgfältig überlegen, welche Variablen außer der Schlafposition Einfluss auf den Kindestod nehmen und damit als Confounder wirken könnten. Das könnten z.B. das Geschlecht sein, das Lebensalter, die Anzahl der Geschwister oder bestimmte Vorerkrankungen. Den Einfluss dieser Confounder versuche ich durch das Matching zu kontrollieren, indem ich die Bedingungen, die als Confounder wirken könnten, in Versuchs- und Kontrollgruppe konstant halte. Wer aber garantiert mir, dass ich nicht zu Beginn der Studie mögliche Confounder übersehe, die dann unkontrolliert Einfluss auf meinen Studienendpunkt3 (den Kindestod) nehmen? Ein weiteres Problem besteht in der eindeutigen Zuordnung dessen, was als Fall bezeichnet wird. Das, was unter plötzlichem Kindestod verstanden werden soll, muss eindeutig definiert sein und eine Abgrenzung von anderen frühkindlichen Todesursachen ermöglichen. Für Fälle müssen klare Ein- und Ausschlusskriterien definiert sein. Ein drittes Problem schließlich entsteht durch die rückwirkende Erhebung der Daten, wobei Verzerrungen der Erinnerung selten auszuschließen sind. Werden die Eltern im obigen Beispiel wirklich in der Lage sein, zuverlässig Auskunft über die Schlafpositionen ihrer Kinder zu geben? Dieses Problem stellt sich umso mehr, je länger das zu beobachtende Ereignis zurück liegt. Die Kohortenstudie In einer Kohortenstudie werden zwei (oder mehrere) Personengruppen ausgewählt, die sich in ihrer Exposition gegenüber einer kritischen Variablen unterscheiden. Im Gegensatz zur Fall-KontrollStudie handelt es sich im Regelfall (aber nicht ausschließlich) um ein prospektives Design. Das heißt beide Personengruppen werden über einen zuvor definierten Zeitraum darauf hin beobachtet, ob sich in der exponierten Gruppe häufiger eine Erkrankung oder eine andere interessierende Veränderung zeigt als in der nicht exponierten Gruppe. Die kritische Variable kann z.B. eine Noxe sein, ein Verhalten oder (patho-) physiologischer Zustand. Wie Fall-Kontroll-Studien gehen Kohortenstudien im Regelfall ätiologischen Fragestellungen nach. Eine der bekanntesten Kohortenstudien ist die von Hill, Doll und Peto im Jahre 1951 begonnene Studie an 40 000 britischen Ärzten mit einer Nachbeobachtungszeit von 40 Jahren. Die Ärzte wurden zu Beginn der Studie in folgende vier Kohorten eingeteilt: Nichtraucher, leichte, mittlere und starke Raucher. Als Endpunkte der Studie wurden Gesamtmortalität (alle Todesfälle) und ursachenspezifische Mortalität (Tod infolge einer bestimmten Erkrankung) untersucht. Die Ergebnisse zeigten einen erheblichen Anstieg der durch Lungenkrebs bedingten Todesfälle wie auch der Todesfälle insgesamt bei den Rauchern, wobei eine Dosis-Wirkungs-Beziehung beobachtet wurde: Je mehr geraucht wurde, desto wahrscheinlicher war es, an einem Bronchialkarzinom zu erkranken. Gegenüber Fall-Kontroll-Studien haben Kohortenstudien mit einem prospektiven Design den Vorteil, dass Erinnerungsverfälschungen keine Relevanz besitzen. Wie bei den Fall-KontrollStudien gehört allerdings auch bei diesem Studientyp die Auswahl einer zum Vergleich geeigneten Kontrollgruppe zu den schwierigsten Aufgaben des Forschers. Welche Confounder könnten neben der kritischen Variablen Einfluss auf den interessierenden Endpunkt nehmen? Gelingt es wirklich, alle möglichen Confounder so zu kontrollieren, dass sie in Versuchs- und Kontrollgruppe gleich verteilt sind? Andere Bezeichnungen für „Studienendpunkt“ sind „Erfolgskriterium“ oder „abhängige Variable“. Es handelt sich um die Variable, an welcher der Erfolg einer Intervention gemessen wird. 9 3 10 Um diese Probleme zu demonstrieren, sollen die Ergebnisse von Kohortenstudien zu Alkoholkonsum und Mortalität geschildert werden, nach denen eine J-förmige Beziehung zwischen den beiden Variablen besteht. Das beste Ergebnis (in Bezug auf die Vermeidung eines frühzeitigen Todes) erzielte die Gruppe der moderaten Trinker. Konsequente Abstinenzler hingegen, so scheint es, sterben signifikant häufiger in jungen Jahren. Würden Sie aufgrund dieser Studienergebnisse Abstinenzlern raten, regelmäßig täglich ein Glas Rotwein zu trinken? Könnten diese Ergebnisse möglicherweise durch den nicht kontrollierten Einfluss eines Confounders zu erklären sein? Was könnte das für ein Confounder sein? Mit hoher Wahrscheinlichkeit ist dieses Ergebnis dadurch zu erklären, dass der Gesundheitszustand als möglicher Confounder nicht kontrolliert wurde. Abstinenzler sind häufig nicht aus Überzeugung, sondern aus Notwendigkeit abstinent - dann nämlich, wenn bei ihnen eine (chronische) Krankheit vorliegt, die von ihnen den Alkoholverzicht fordert, gleichzeitig aber das Mortalitäsrisiko erhöht. Weiterhin könnte auch ein Zusammenhang zwischen religiösen Überzeugungen und Mortalität bestehen. Die Trinkgewohnheiten von Moslems oder anderen ethnischen Gruppen könnten in diesem Fall zu einer Verzerrung des Studienendpunktes beigetragen haben.4 Die randomisiert-kontrollierte Studie als klinisches Äquivalent des Laborexperimentes In einer randomisiert-kontrollierten Studie (RCT= randomized controlled trial) werden die Teilnehmer nach dem Zufallsprinzip einer Interventionsgruppe und einer Kontrollgruppe zugeordnet. Entscheidend ist, dass jede Person vor Beginn der Intervention die gleiche Wahrscheinlichkeit besitzt, der einen oder der anderen Gruppe zugewiesen zu werden. Prototyp eines solchen Zufallsverfahrens ist der Münzwurf. Beide Gruppen werden über einen zu Beginn der Studie festgelegten Zeitraum und in Hinblick auf zu Beginn der Studie festgelegte Endpunkte analysiert, wobei angenommen wird, dass die Intervention den Ausprägungsgrad der Endpunkte beeinflusst. Die randomisiert-kontrollierte Studie stellt das klinische Äquivalent des Laborexperimentes dar. Sie erlaubt es, die Ausprägung der Endpunkte ursächlich auf die durchgeführte Intervention zurück zu führen. RCT-Designs erheben den Anspruch, Confounder vollständig kontrollieren zu können. Voraussetzung ist, dass jede mögliche Confounder-Variable zu Beginn der Studie in gleicher Ausprägung in Versuchs- und Kontrollgruppe vorhanden ist. Dieses zu gewährleisten, ist der eigentliche Zweck der Randomisierung. Bei einer genügend großen Anzahl von Probanden ist davon auszugehen, dass die bei dem einzelnen Probanden vorliegenden Kombinationen von Confoundern durch das Ergebnis des Münzwurfs in gleicher Weise den beiden Gruppen zugewiesen werden. In diesem Fall unterscheiden sich die beiden Gruppen ausschließlich durch die Intervention, so dass Unterschiede zwischen den untersuchten Endpunkten eindeutig als Wirkung der Intervention interpretiert werden können.5 4 Trotz dieser Überlegungen gilt die Hypothese von der J-förmigen Beziehung zwischen Alkoholkonsum und Mortalität nicht als widerlegt. 5 Wenn bereits bei der Studienplanung bekannt ist, welche Confounder Einfluss auf die Endpunkte nehmen könnten, wird empfohlen, bei der Randomisierung eine gleiche Verteilung der Confounder auf Versuchsund Kontrollgruppe vorzunehmen. Dieses Verfahren bezeichnet man als „Stratifizierung“. Man schließt dadurch aus, dass die Confounder durch Zufall in Versuchs- und Kontrollgruppe ungleich verteilt sein könnten. Z.B. ist bekannt, dass Patienten mit langer Krankheitsdauer und hohem Ausmaß an Chronifizierung auf jede Art von Therapie schlechter ansprechen als erst vor kurzem erkrankte Patienten. Man würde bei der Studienplanung in diesem Fall darauf achten, dass sich gleich viele Personen mit langer wie mit kurzer Krankheitsdauer in den Studiengruppen befinden. 10 11 Mögliche Confounder sind nicht nur zu Beginn einer Studie bei der Zusammenstellung der Gruppen, sondern auch während der Durchführung der Studie zu kontrollieren. Confounder können zu verschiedenen Zeitpunkten der Durchführung einer Studie wirksam werden und die Studienergebnisse verfälschen. In diesem Fall wird von einem Bias gesprochen. Nach Greenhalgh (2003) sind verschiedene Formen des Bias zu unterscheiden: der Selektionsbias, der PerformanceBias, der Attrition-Bias und der Detektionsbias. Es ist für die Interpretation einer RCT bedeutsam, die möglichen Auswirkungen der unterschiedlichen Formen eines Bias zu erkennen. Mögliche Biasquellen in randomisiert-kontrollierten Studien Zielpopulation der Studie Selektionsbias Performance-Bias Randomisierung auf Interventionsgruppe Randomisierung auf Kontrollgruppe Interventionsbehandlung Kontrollbehandlung Nachbeobachtung Nachbeobachtung Messung der Endpunkte Messung der Endpunkte Attrition-Bias Detektionsbias Der Selektionsbias entsteht, wenn eine Randomisierung nicht wirklich nach dem Zufallsprinzip erfolgt, sondern wenn eine Methode angewendet wird, welche dem Arzt im voraus verrät, welcher Gruppe ein Patient zugeteilt wird. Es hat sich nämlich gezeigt, dass in einem solchen Fall der Arzt dazu neigt, einen Patienten eher in die Studie aufzunehmen, wenn er glaubt, dass dieser eine Verum-Behandlung erhält. Insbesondere könnten Patienten mit einer schwereren Erkrankung unbewusst vom Placeboarm der Studie ferngehalten werden. Zu den nicht akzeptablen Methoden gehören die Randomisierung nach der letzten Ziffer des Gebutsdatums (ungerade Zahlen in Gruppe A, gerade in Gruppe B), nach dem Münzwurf des behandelnden Arztes, eine sequentielle Zuordnung (Patient A in Gruppe 1, Patient B in Gruppe 2, etc.) und nach dem Datum des Klinikbesuchs (alle Patienten der einen Woche in Gruppe 1, alle der zweiten Woche in Gruppe 2, etc.). In all diesen Fällen steigt die Wahrscheinlichkeit einer ungleichen Verteilung von Confounder-Variablen. Das Zufallsprinzip ist hingegen gewährleistet, wenn durchgehend nummerierte verschlossene Umschläge innen eine vom Computer zufällig ausgewählte Zahl für die Gruppenzuweisung enthalten und hierdurch die Patienten nach Einschluss in die Studie einer Gruppe zugewiesen werden. In diesem Fall spricht man von einem „concealed assignment“. Der Performance-Bias bezieht sich auf die Zeit der Behandlung. Idealerweise muss die Intensität der Behandlung der Patienten in Versuchs- und Kontrollgruppe identisch sein mit dem einzigen Unterschied der Art der Intervention. Die Erfahrung zeigt, dass behandelnde Ärzte, wenn sie nicht verblindet hinsichtlich der Gruppenzuordnung sind, den Patienten der Versuchsgruppe mehr Aufmerksamkeit (längere Kontaktzeiten, anderes non-verbales Verhalten, stärkere Zuwendung) schenken als denen der Kontrollgruppe. In einem solchen Fall könnte ein beobachteter Unterschied in der Ausprägung des Endpunktes nicht mehr allein auf die Intervention, sondern er müsste auch auf die unterschiedliche Zuwendung zurück geführt werden. Der Attrition-Bias bezieht sich auf die Zeit der Nachbeobachtung nach der Intervention und hier insbesondere auf die Studienabbrecher (drop outs). Eine hohe Zahl von Studienabbrechern kann es unmöglich machen, aus den nur bei den verbliebenen Patienten beobachteten Endpunkten auf die 11 12 Wirksamkeit der Intervention zu schließen. Es hat sich nämlich gezeigt, dass Studienabbrecher sich von den Nicht-Abbrechern in deren Ausprägung des Endpunktes der Studie unterscheiden. Abbrecher sind z.B. weniger compliant in Bezug auf die Einhaltung der Intervention (z.B. die Einnahme der Medikamente oder die Durchführung einer Übungsbehandlung) als Nicht-Abbrecher. Sie klagen häufiger über unerwünschte Wirkungen der Intervention, versäumen häufiger Kontrolltermine und sind unzufriedener. Wird jeder Teilnehmer, der eine Studie vorzeitig beendet, bei der Auswertung der Ergebnisse einfach ignoriert, führt dies zu einer systematischen Verzerrung der Ergebnisse - fast immer zugunsten der Intervention. Aus diesem Grund gelten Studien mit einer geringen Nachbeobachtungsrate (z.B. < 70 %) oder mit deutlich unterschiedlichen Nachbeobachtungsraten in Versuchs- und Kontrollgruppe nicht als beweiskräftig. Um den Attrition-Bias zu kontrollieren, gehört es inzwischen zum Standard, die Ergebnisse von Vergleichsstudien auf einer Intention-to-treat Basis zu analysieren. Hierbei werden die Daten sämtlicher Patienten, unabhängig davon, ob sie die Studie beendet haben oder nicht, in die Auswertung einbezogen. Da von den Abbrechern zum Zeitpunkt der Nachbeobachtung (Follow-up) keine Daten mehr vorliegen, werden häufig Daten dieser Personen aus vorhergehenden Messungen verwendet. Der härteste Test besteht darin, anzunehmen, dass alle Abbrecher Behandlungsmisserfolge sind. In diesem Fall wäre es am sinnvollsten, den bei Eingang in der Studie gemessenen Wert des Endpunkts in der Follow-up-Analyse zu verwenden (initial value carried forward). Wenn selbst unter diesen Bedingungen sich weiterhin eine Überlegenheit der Interventionsgruppe über die Kontrollgruppe zeigt, kann der Gültigkeit der erhaltenen Ergebnisse Vertrauen geschenkt werden. Der Detektionsbias bezieht sich auf mögliche systematische Unterschiede in der Bewertung der Endpunkte bei Personen der Versuchsgruppe und der Kontrollgruppe. Wenn Ärzte, die den Behandlungserfolg zu beurteilen haben, wissen, welche Personen die Verum- und welche die Kontrollintervention bekommen haben, so lassen sie ihr Urteil durch dieses Wissen (unbewusst) beeinflussen. Von Sackett et al. (1991) wurde der Beweis erbracht, dass die Beurteilung klinischer Symptome und die Auswertung diagnostischer Tests (z.B. eines Röntgenbildes oder eines EKG) auch bei erfahrenen Ärzten alles andere als objektiv ist und durch Erwartungen der Ärzte über das Ergebnis bestimmt wird. Wenn ein Arzt z.B. weiß, dass ein Patient in eine Gruppe randomisiert wurde, die blutdrucksenkende Medikamente erhielt, könnte er geneigt sein, die Blutdruckmessung zu wiederholen, wenn die erste Messung unerwartet hoch ausgefallen ist. Möglicherweise ist nun die zweite Messung niedriger und der Patient wird nicht mehr als Fall (Hypertoniker) entdeckt (detected). Der Detektionsbias ist ebenso wie der Performance-Bias durch eine Verblindung zu kontrollieren. Der Arzt, der die Follow-up-Untersuchung durchführt, darf nicht über die Gruppenzuordnung des Patienten informiert sein. Das Bundesgesundheitsamt fordert als Wirksamkeitsnachweis vor der Zulassung von Medikamenten die Durchführung einer RCT. Hierbei wird der Versuchsgruppe ein Verum-Präparat verabreicht, der Kontrollgruppe ein Placebo. Da bekannt ist, dass Erwartungen über die Wirksamkeit einer Intervention sowohl auf Seiten des Arztes als auch des Patienten die tatsächliche Wirksamkeit beeinflussen (und somit Confounder sind, vgl. Rosenthal-Effekt), darf weder Arzt noch Patient wissen, welcher Intervention ein Patient zugewiesen wurde. Ist diese Bedingung realisiert, spricht man von einer Doppel-Blind-Studie. Das systematische Review und die Meta-Analyse Die bisher geschilderte Methodik bezieht sich ausschließlich auf Primär- oder Originalarbeiten. Systematische Reviews und Meta-Analysen als Sekundärarbeiten haben das Ziel, Primärstudien zu 12 13 gleichen Fragestellungen zusammen zu fassen. Sie bedienen sich dabei einer explizit in der jeweiligen Publikation aufgeführten und reproduzierbaren Methodik, die den Vergleich verschiedener Originalarbeiten ermöglicht. Eine Meta-Analyse geht insofern über ein sytematisches Review der Literatur hinaus als hier eine statistische Synthese der nummerischen Ergebnisse mehrerer Studien zur gleichen Thematik vorgenommen wird. Die Wirksamkeit einer Intervention kann mit einer statistischen Maßzahl beschrieben werden, der, da sie sich auf die Ergebnisse mehrerer Studien bezieht, eine größere Sicherheit zukommt als der jeder einzelnen Studie. Dies ist der Grund, warum Meta-Analysen auf der höchsten Stufe der Evidenzleiter angesiedelt sind. Für den in der Versorgung tätigen Arzt haben systematische Reviews und Meta-Analysen verschiedene Vorteile im Vergleich zu Originalarbeiten: 1. Ärzte können die große Informationsflut anhand von systematischen Reviews besser als durch das Studium von vielen Einzelarbeiten bewältigen. 2. Festgelegte Anleitungen für die Reviewer zur Auswahl der analysierten Originalarbeiten verringern systematische Fehler in Bezug auf den Einschluss und Ausschluss von Studien. Die Anleitungen beziehen sich z.B. explizit auf die Quellen, die berücksichtigt werden sollen (z.B. nicht nur in medizinischen Datenbanken enthaltene Literatur, sondern auch „graue“ Literatur zur Kontrolle des Publikationsbias6). 3. Die Resultate verschiedener Studien können miteinander verglichen werden, und auf diese Weise werden Aussagen über die Konsistenz oder Heterogenität der Ergebnisse möglich. Die Schlussfolgerungen sind daher zuverlässiger und genauer als bei Einzelstudien. 4. Quantitative systematische Reviews (Meta-Analysen) erhöhen die Präzision der Gesamtergebnisse. Die Qualität eines systematischen Reviews oder einer Meta-Analyse hängt davon ab, ob die zuvor in diesem Text beschriebenen Kriterien zur Beurteilung der methodischen Qualität von Originalarbeiten rigoros angewendet werden. Die Arbeit, die der sich mit der Originalliteratur auseinander setzende Arzt in die Beurteilung der methodischen Güte der Einzelarbeiten investieren muss, wird ihm von den Reviewern bereits abgenommen. So findet sich in den Reviews neben der Auflistung der einbezogenen Studien auch eine Beurteilung der methodischen Qualität der Studien. Die in den Studien erzielten Ergebnisse werden anschließend auf dem Hintergrund der Güte der Methodik bewertet. 5. Fragen zur Beurteilung der methodischen Qualität von Studien Entscheiden Sie zunächst, ob es sich um eine Primärstudie (Originalarbeit) oder um eine Sekundärstudie (systematisches Review, Meta-Analyse) handelt. Bei Sekundärstudien stellen Sie folgende Fragen: 1. Wie haben die Autoren sicher gestellt, dass tatsächlich alle relevanten Originalarbeiten in die Untersuchung aufgenommen wurden? Welche Quellen wurden außer medizinischen Datenbanken berücksichtigt? 2. Wie wurde die methodische Qualität der Originalarbeiten beurteilt, und wurden die Studien angemessen hinsichtlich ihrer methodischen Qualität gewichtet? 3. Wurden die erzielten Ergebnisse angemessen interpretiert? Können Sie die Schlussfolgerungen nachvollziehen? 6 Der Publikationsbias besteht darin, dass nachgewiesenermaßen Studien, die erwartungswidrige Ergebnisse zeigen, seltener publiziert werden als solche mit erwartungskonformen Ergebnissen. Diese Tatsache führt dazu, dass die Wirksamkeit von Interventionen überschätzt wird, wenn nur auf publizierte Studien zurück gegriffen wird. 13 14 4. Bei Meta-Analysen sollte auch die eingesetzte statistische Methodik beurteilt werden. Hierfür sind allerdings Spezialkenntnisse erforderlich. Handelt es sich um eine Originalarbeit, konzentrieren Sie sich zunächst auf das Design, ordnen Sie dieses einem der o.g. Studien-Typen zu und fragen Sie sich, ob das Design der Fragestellung angemessen ist. Um welchen Forschungsbereich geht es? Ursachenstudien verwenden im Regelfall ein Fall-Kontroll-Design oder ein Kohorten-Design. Therapiestudien verwenden ein randomisiert-kontrolliertes Design. Bei einem Querschnitts-Design stellen Sie die folgenden Fragen: 1. Ist die gewählte Stichprobe geeignet, die vermutete Assoziation zwischen zwei Variablen zu überprüfen? Oder gibt es Hinweise darauf, dass beobachtete oder nicht auffindbare Assoziationen sich als Stichproben abhängig erweisen könnten? 2. Wird in der Arbeit diskutiert, durch welche Drittvariablen (Confounder) die gefundene oder nicht gefundene Assoziation erklärt werden könnte? 3. In welcher Weise werden gefundene Assoziationen interpretiert? Werden kausale Interpretationen ausgeschlossen? Bei einem Fall-Kontroll-Design stellen Sie die folgenden Fragen: 1. Hat ein Matching statt gefunden? 2. Welche Variablen wurden in das Matching einbezogen? Sind alle möglichen Counfounder kontrolliert worden? Welche nicht kontrollierten Confounder könnten die Ergebnisse beeinflusst haben? Wird hierauf in der Diskussion der Ergebnisse eingegangen? 3. Sind die Kriterien für die Definition eines Falles deutlich durch Ein- und Ausschlusskriterien beschrieben worden? Wurde sicher gestellt, dass diese Kriterien befolgt wurden? 4. Ist die retrospektive Erhebung der Daten zuverlässig? Wie wurde kontrolliert, ob z.B. Erinnerungsverfälschungen die Datenerhebung beeinflusst haben? Bei einem Kohorten-Design stellen Sie folgende Fragen: 1. Welche Begründung geben die Autoren für die Wahl der Vergleichsgruppe? 2. Welche möglichen Confounder berücksichtigen die Autoren? 3. Gibt es möglicherweise noch weitere, nicht kontrollierte Confounder? Gehen die Autoren in der Diskussion hierauf ein? 4. Welche Bias-Quellen, die im Zusammenhang mit randomisiert-kontrollierten Studien besprochen worden sind, wurden von den Autoren kontrolliert? Bei einem randomisiert-kontrollierten Design stellen Sie die folgenden Fragen: 1. Sind die Ein- und Ausschlusskriterien deutlich dargestellt worden? Ist damit klar, was als „Fall“ zu definieren ist, um den es in dieser Studie geht? 2. Nach welcher Methode erfolgte die Randomisierung? Wird hierdurch sicher gestellt, dass die Gruppenzuweisung ausschließlich nach Zufallsprinzipien erfolgt, oder konnte jemand möglicherweise Einfluss auf die Zuweisung nehmen? 3. War die Person, welche die Probanden einschloss, zu diesem Zeitpunkt blind gegenüber der Gruppenzuweisung der Probanden? Oder ist ein Selektionsbias nicht auszuschließen? 4. Wird über mögliche Confounder-Variablen berichtet? Falls ja, wie wird mit diesen in der Studie umgegangen? 5. Haben die Probanden beider Gruppen außer der unterschiedlichen Intervention ansonsten eine völlig gleiche Behandlung erfahren? War sicher gestellt, dass das Wissen um die Gruppenzuweisung nicht Einfluss nehmen konnte auf die Behandlung selbst? Ist somit der Performance-Bias kontrolliert worden? 14 15 6. Wie viele drop-outs gab es in Versuchs- und Kontrollgruppe? Gibt es Aussagen über die Ursachen des drop-outs? 7. Ist die Anzahl der drop-outs akzeptabel? Wie wurde mit der Tatsache von drop-outs umgegangen? Gab es z.B. eine „Intention-to-treat“-Analyse? 8. Wie wird der Erfolg der Intervention gemessen? Was ist der primäre Endpunkt der Studie? 9. Ist sicher gestellt, dass der Erfolg der Intervention objektiv überprüft wurde? Wie weit sind die Endpunkte abhängig von den Meinungen und Erwartungen derjenigen, welche die Endpunkte gemessen haben? Konnte deren Erwartungshaltung in das Ergebnis eingehen? Oder waren die Untersucher blind gegenüber der Gruppenzuweisung der Probanden? Abschließende Bemerkung Evidenz Basierte Medizin bezieht sich auf die jeweils beste verfügbare Evidenz zur Lösung eines durch einen Patienten präsentierten Problems. Auch wenn randomisiert-kontrollierten Studien die größte Beweiskraft zugeschrieben wird, sehen wir uns in der Versorgungspraxis jedoch häufig mit dem Problem konfrontiert, dass Studien mit hohem methodischen Niveau als Informationsquellen nicht zur Verfügung stehen. Trotzdem muss für und mit dem Patienten eine Entscheidung getroffen werden. Auch in diesem Fall ist nach der besten Evidenz zu suchen. Sie kann sich aus der Konsultation des nächsten erreichbaren Experten ergeben oder, wenn auch dieses nicht möglich ist, auf die eigene klinische Erfahrung stützen. Auch in diesen Fällen handelt der Arzt Evidenz basiert, vorausgesetzt er hat zuvor vergeblich nach methodisch höherwertigen Informationsquellen gesucht. Empfohlene Literatur Zur Einführung geeignet: Greenhalgh, T. (2003). Einführung in die Evidence-based Medicine. Kritische Beurteilung klinischer Studien als Basis einer rationalen Medizin. Verlag Hans Huber, Bern. Sackett, D.L., Strauss, S.E., Richardson, W.S., Rosenberg, W., Haynes, R.B. (2000). EvidenceBased Medicine - How to practice and teach EBM. Churchill Livingstone, Edinburgh. Weitere zitierte Literatur: Sackett, D.L., Haynes, R.B., Guyatt, G.H., et al. (1991). Clinical epidemiology - a basic science for clinical medicine. Little Brown, London. Sackett, D.L., Rosenberg, W., Gray, J.A. et al. (1996). Evidence based medicine: What it is and what it isn’t. British Medical Journal, 312, 71-72. 15