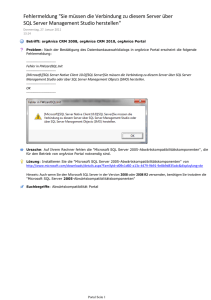
Schutzebenen von SQL Server AlwaysOn. Eine
Werbung

Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung Autor: LeRoy Tuttle, Jr. (Microsoft). Mitwirkende: Cephas Lin (Microsoft), Justin Erickson (Microsoft), Lindsey Allen (Microsoft), Min He (Microsoft), Sanjay Mishra (Microsoft). Bearbeiter: Alexei Khalyako (Microsoft), Allan Hirt (SQLHA), Ayad Shammout (Caregroup), Benjamin Wright-Jones (Microsoft), Charles Matthews (Microsoft), David P. Smith (ServiceU), Juergen Thomas (Microsoft), Kevin Farlee (Microsoft), Shahryar G. Hashemi (Motricity), Wolfgang Kutschera (Bwin Party). Veröffentlicht: Januar 2012 Betrifft: SQL Server 2012 Zusammenfassung: Thema dieses Whitepapers: Reduzieren geplanter und ungeplanter Downtime, Maximieren der Anwendungsverfügbarkeit und Gewährleisten von Datenschutz durch den Einsatz einer HA- und DR-Lösung mit SQL Server 2012 AlwaysOn-Technologie. Ein wichtiges Ziel dieses Whitepapers ist es, eine gemeinsame Grundlage für den fachlichen Austausch zwischen Unternehmern, technischen Entscheidern, Systemarchitekten, Infrastrukturentwicklern und Datenbankadministratoren zu schaffen. Der Inhalt gliedert sich in zwei Hauptbereiche: Konzepte für hohe Verfügbarkeit und Notfallwiederherstellung. Eine kurze Erläuterung der geschäftlichen Einflussfaktoren und Herausforderungen, die bei der Planung, Verwaltung und Evaluierung einer hochverfügbaren Datenbankumgebung eine Rolle spielen. Es folgt eine kurze Übersicht über die HA (High Availability)- und DR (Disaster Recovery)-Funktionen der SQL Server 2012 AlwaysOn- und Windows Server-Lösungen. Schutzebenen von SQL Server AlwaysOn. Eine ausführlichere Erörterung des Funktionsumfangs, des Grundprinzips sowie der Abhängigkeiten zwischen den Schutzebenen einer SQL Server AlwaysOnLösung. Beschreibt die Verfügbarkeit der Infrastruktur, den Schutz auf SQL Server-Instanzebene und Datenbankebene sowie die Funktionalität von Datenebenenanwendungen. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung i Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung ii Copyright Die Informationen werden in ihrem derzeitigen Zustand zur Verfügung gestellt. Die in diesem Dokument enthaltenen Angaben und Ansichten, einschließlich URLs und anderer Verweise auf Internetwebsites, können ohne vorherige Ankündigung geändert werden. Ihnen obliegt das Risiko der Verwendung. Einige der hier dargestellten Beispiele werden nur zu Illustrationszwecken bereitgestellt und sind fiktiv. Ähnlichkeiten mit realen Gegebenheiten sind weder beabsichtigt noch erwünscht. Mit diesem Dokument erwerben Sie keine Rechte an geistigem Eigentum in Microsoft-Produkten. Sie können dieses Dokument zu internen Zwecken und als Referenz kopieren und verwenden. © 2012 Microsoft. Alle Rechte vorbehalten. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung iii Inhalt Konzepte für hohe Verfügbarkeit und Notfallwiederherstellung ........................ 1 Was ist Hochverfügbarkeit? ...................................................................................................................... 1 Geplante und ungeplante Downtime ..................................................................................................................................... 1 Herabgesetzte Verfügbarkeit .................................................................................................................................................. 2 Quantifizieren der Downtime ................................................................................................................... 2 Ziele der Wiederherstellung ................................................................................................................................................... 3 Anpassung der ROI- oder Opportunitätskosten ...................................................................................................................... 3 Überwachen des Verfügbarkeitszustands .............................................................................................................................. 4 Planen der Notfallwiederherstellung ...................................................................................................................................... 4 Übersicht: Hochverfügbarkeit mit Microsoft SQL Server 2012 ................................................................ 5 SQL Server AlwaysOn .............................................................................................................................................................. 5 Deutliche Verkürzung geplanter Downtime ........................................................................................................................... 5 Verzicht auf inaktive Hardware und Verbesserung der Kosteneffizienz und Leistung ........................................................... 6 Einfache Bereitstellung und Verwaltung ................................................................................................................................ 6 Gegenüberstellung von RPO und RTO .................................................................................................................................... 6 Schutzebenen von SQL Server AlwaysOn ........................................................... 7 Infrastrukturverfügbarkeit ........................................................................................................................ 8 Windows-Betriebssystem ....................................................................................................................................................... 8 Windows Server Failover Clustering ....................................................................................................................................... 9 WSFC-Clustervalidierungs-Assistent ..................................................................................................................................... 11 WSFC-Quorummodi und Abstimmungskonfiguration .......................................................................................................... 12 WSFC-Notfallwiederherstellung durch erzwungenes Quorum ............................................................................................. 15 Schutz auf SQL Server-Instanzebene ...................................................................................................... 17 Verbesserte Verfügbarkeit – SQL Server-Instanzen .............................................................................................................. 17 AlwaysOn-Failoverclusterinstanzen ...................................................................................................................................... 18 Datenbankverfügbarkeit ......................................................................................................................... 21 AlwaysOn-Verfügbarkeitsgruppen ........................................................................................................................................ 21 Failover von Verfügbarkeitsgruppen .................................................................................................................................... 22 Verfügbarkeitsgruppenlistener ............................................................................................................................................. 24 Optimierte Datenbankverfügbarkeit .................................................................................................................................... 26 Empfehlungen zur Clientkonnektivität ................................................................................................... 27 Schlussfolgerung ...............................................................................................28 Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung iv Konzepte für hohe Verfügbarkeit und Notfallwiederherstellung Die Wahl der richtigen Datenbanktechnologie für eine HA- und DR-Lösung wird erleichtert, wenn alle Beteiligten den gleichen Wissenstand über geschäftliche Einflussfaktoren, Herausforderungen, Planungsziele, Verwaltung und Beurteilung der RTO- und RPO-Ziele haben. Leser, denen diese Konzepte bereits geläufig sind, können mit dem Abschnitt Übersicht: Hochverfügbarkeit mit Microsoft SQL Server 2012 dieses Dokuments fortfahren. Was ist Hochverfügbarkeit? Bei einer Softwareanwendung bzw. einem Dienst wird Hochverfügbarkeit im Hinblick auf die Nutzererfahrung und die Erwartungen des Endanwenders gemessen. Die geschäftsschädigende Wirkung von Downtime lässt sich konkret in Informationsverlust, Sachbeschädigung, Produktivitätsverlust, Opportunitätskosten, Vertragsschäden oder dem Verlust des Firmenwerts ausdrücken. Das Ziel einer Hochverfügbarkeitslösung besteht grundsätzlich darin, die Auswirkungen von Downtime zu minimieren oder abzuschwächen. Eine tragfähige Strategie muss ein optimales Gleichgewicht zwischen Geschäftsprozessen und SLAs (Vereinbarungen zum Servicelevel) einerseits sowie technischen Voraussetzungen und Infrastrukturkosten andererseits schaffen. Vertragliche Vereinbarungen und die Erwartungen von Kunden und anderen Beteiligten entscheiden darüber, ob eine Plattform als hoch verfügbar eingestuft wird. Die Verfügbarkeit eines Systems kann wie folgt berechnet werden: 𝐴𝑐𝑡𝑢𝑎𝑙 𝑢𝑝𝑡𝑖𝑚𝑒 × 100% 𝐸𝑥𝑝𝑒𝑐𝑡𝑒𝑑 𝑢𝑝𝑡𝑖𝑚𝑒 Der resultierende Wert wird in der Branche häufig als die "Anzahl der 9nen" ausgedrückt, die die Lösung erzielt. Der Wert vermittelt die jährliche mögliche Uptime bzw. umgekehrt die Downtime in Minuten. Anzahl der 9nen 2 3 4 5 Prozentuale Verfügbarkeit 99% 99,9% 99,99% 99,999% Gesamte Downtime/Jahr 3 Tage, 15 Stunden 8 Stunden, 45 Minuten 52 Minuten, 34 Sekunden 5 Minuten, 15 Sekunden Geplante und ungeplante Downtime Systemausfälle sind entweder vorauskalkuliert und geplant oder das Ergebnis eines ungeplanten Ausfalls. Sofern geeignete Vorkehrungen getroffen wurden, müssen Ausfallzeiten nicht als negativ angesehen werden. Es gibt zwei Hauptkategorien vorhersehbarer Downtimes: Geplante Wartung. Für geplante Wartungsaufgaben wie Softwarepatches, Hardwareupgrades, Kennwortupdates, Offline-Reindizierung, Datenladevorgänge oder die Erprobung von Wiederherstellungsprozeduren wird ein vorangekündigtes Zeitfenster eingeplant. Mit einem zweckmäßigen, gut organisierten Betriebsablauf sollten sich Ausfallzeiten minimieren und Datenverluste verhindern lassen. Geplante Wartungen sollten als Präventionsmaßnahme zur Abwehr schwerwiegenderer Ausfallszenarien verstanden werden, die nicht planbar sind. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 1 Ungeplanter Ausfall. Es sind System-, Infrastruktur- oder Prozessausfälle denkbar, die ungeplant oder unkontrolliert auftreten. Wieder andere sind zwar vorhersehbar, werden aber als zu unwahrscheinlich eingestuft oder haben tolerierbare Auswirkungen auf die Geschäftsabläufe. Eine robuste Hochverfügbarkeitslösung erkennt diese Ausfälle und sorgt für eine automatische Wiederherstellung des Systems und der Fehlertoleranz. Bei der Festlegung von SLAs für hohe Verfügbarkeit sollten getrennte Leistungskennzahlen (KPIs) für geplante Wartungen und ungeplante Downtime berechnet werden. Auf diese Weise können Sie die Kosten geplanter Wartungsaktivitäten und den Nutzen, den die Vermeidung ungeplanter Ausfallzeiten mit sich bringt, gegenüberstellen. Herabgesetzte Verfügbarkeit Hohe Verfügbarkeit folgt nicht dem Alles-oder-Nichts-Prinzip. Als Alternative zu einem Komplettausfall ist es für den Endbenutzer häufig akzeptabel, dass ein System nur teilweise bzw. mit eingeschränkter Funktionalität oder Leistung verfügbar ist. Die unterschiedlichen Verfügbarkeitsgrade sind: Schreibgeschützter und verzögerter Betrieb. Während eines Wartungsfensters oder einer stufenweisen Notfallwiederherstellung können weiterhin Daten abgerufen werden, neue Workflows und im Hintergrund laufende Prozesse werden jedoch vorübergehend angehalten oder in die Warteschlange gestellt. Datenlatenz und verminderte Reaktionszeiten von Anwendungen. Hohe Auslastung, Verarbeitungsbacklogs oder ein partieller Plattformausfall können dazu führen, dass eingeschränkte Hardwareressourcen nicht ausreichen oder überlastet sind. Obwohl die Benutzererfahrung beeinträchtigt wird, kann die Arbeit mit Produktivitätseinbußen fortgesetzt werden. Partieller, kurzzeitiger oder bevorstehender Ausfall. Ist die Anwendungslogik bzw. der Hardwarestack robust genug, dann kann der Prozess nach einem Fehler wiederholt oder selbsttätig korrigiert werden. Derartige Probleme werden vom Endbenutzer in Form von Datenlatenz oder langsam reagierenden Anwendungen wahrgenommen. Partieller End-to-End-Ausfall. Innerhalb der vertikalen Schichten des Stacks (Infrastruktur, Plattform und Anwendung) oder horizontal zwischen verschiedenen Funktionseinheiten können geplante oder ungeplante Ausfälle geordnet ablaufen. Je nach den betroffenen Funktionen oder Komponenten bemerken Benutzer die Leistungsminderung u. U. nur teilweise oder gar nicht. Jedes dieser suboptimalen Szenarien ist nur ein Teil des Spektrums, das in seiner Gesamtheit zu einem Totalausfall führen würde. Sie können genauso als Zwischenschritt in einer stufenweisen Notfallwiederherstellung betrachtet werden. Quantifizieren der Downtime Bei einem geplanten oder ungeplanten Ausfall besteht das primäre Unternehmensziel darin, das System wieder online zu schalten und Datenverluste so gering wie möglich zu halten. Jede Minute Downtime verursacht direkte und indirekte Kosten. Bei einer ungeplanten Downtime müssen Zeit und Aufwand für die Suche nach der Fehlerursache, die Feststellung des aktuellen Systemzustands und die Ermittlung der erforderlichen Wiederherstellungsschritte im Gleichgewicht sein. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 2 Bei jedem Ausfall sollte zu einem festgelegten Zeitpunkt die Entscheidung getroffen werden, die Suche nach der Ausfallursache oder weitere Wartungstasks einzustellen, das System wieder online zu schalten und ggf. die Fehlertoleranz wiederherzustellen. Ziele der Wiederherstellung Datenredundanz ist einer der wichtigsten Aspekte einer HA-Datenbanklösung. Transaktionsaktivitäten auf der primären SQL Server-Instanz werden synchron oder asynchron auf eine oder mehrere sekundäre Instanzen repliziert. Bei einem Ausfall kann für laufende Transaktionen ein Rollback ausgeführt werden; andernfalls gehen sie aufgrund der verzögerten Datenweitergabe auf den sekundären Instanzen verloren. Sie können sowohl die Auswirkungen messen als auch die Wiederherstellungsziele festlegen, indem Sie die Wiederanlaufdauer und die Latenz der zuletzt wiederhergestellten Transaktion auswerten: RTO (Recovery Time Objective, Wiederanlaufdauer). Entspricht der Dauer des Ausfalls. Das anfängliche Ziel besteht darin, das System zumindest im schreibgeschützten Modus wieder online zu bringen, damit die Fehlerursache erforscht werden kann. Das primäre Ziel ist jedoch die vollständige Wiederherstellung bis zu dem Punkt, an dem neue Transaktionen möglich sind. RPO (Recovery Point Objective, Wiederanlaufzeitpunkt). Wird häufig als Maß für tolerierbaren Datenverlust bezeichnet und entspricht dem zeitlichen Abstand oder der Latenz zwischen der letzten festgeschriebenen Datentransaktion vor dem Ausfall und den ersten wiederhergestellten Daten nach dem Fehler. Der tatsächliche Datenverlust kann je nach Systemauslastung zum Zeitpunkt des Ausfalls sowie nach dem Fehlertyp und der verwendeten Hochverfügbarkeitslösung variieren. RTO- und RPO-Werte sollten als Zielvorgaben für die vom Unternehmen tolerierbare Downtime sowie für akzeptablen Datenverlust verwendet werden. Außerdem können sie als Metriken zur Überwachung des Verfügbarkeitszustands eingesetzt werden. Anpassung der ROI- oder Opportunitätskosten Die Kosten einer Downtime können sich für ein Unternehmen entweder finanziell oder in einer schwindenden Kundenzufriedenheit niederschlagen. Entweder sie laufen über einen längeren Zeitraum auf oder entstehen an einem bestimmten Punkt im Ausfallzeitfenster. Sie können nicht nur die Kosten eines Ausfalls mit einer bestimmten Wiederherstellungszeit und einem Datenwiederherstellungspunkt prognostizieren, sondern auch die Geschäftsprozess- und Infrastrukturinvestitionen kalkulieren, die zur Erreichung der RTO- und RPO-Vorgaben bzw. zur vollständigen Vermeidung des Ausfalls erforderlich wären. Investitionen kommen in folgenden Bereichen infrage: Vermeiden von Downtime. Ohne Ausfälle entstehen erst gar keine Wiederherstellungskosten. Die Investitionen umfassen fehlertolerante und redundante Hardware bzw. Infrastrukturen, die Workload-Verteilung auf isolierte POFs (Points of Failure, Fehlerpunkte) sowie die Planung von Ausfallzeiten für vorbeugende Wartungsmaßnahmen. Automatisierte Wiederherstellung. Die Auswirkung eines Systemausfalls auf die Benutzererfahrung lässt sich in hohem Maße durch eine automatische und transparente Wiederherstellung abfedern. Ressourcennutzung. Sekundäre oder Standby-Infrastrukturkomponenten bleiben bis zum Auftreten eines Fehlers oft ungenutzt. Sie können aber auch für Leseoperationen oder zur Verbesserung der Gesamtsystemleistung genutzt werden, indem Arbeitslasten auf die gesamte verfügbare Hardware verteilt werden. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 3 Die für bestimmte RTO- und RPO-Vorgaben erforderlichen Investitionen in Verfügbarkeits- und Wiederherstellungsmechanismen können in Kombination mit den prognostizierten Downtimekosten als Zeitfunktion ausgedrückt und angepasst werden. Bei einem tatsächlichen Ausfall können kostenrelevante Entscheidungen auf Grundlage der verstrichenen Downtime gefällt werden. Überwachen des Verfügbarkeitszustands Aus praktischer Sicht sollten Sie während eines Ausfalls nicht versuchen, die ROI- oder Opportunitätskosten unter Berücksichtigung aller relevanten Variablen in Echtzeit zu berechnen. Stattdessen sollten Sie die Datenlatenz auf den Standbyinstanzen stellvertretend für den erwarteten RPO überwachen. Verwenden Sie bei einem Ausfall zunächst nicht zu viel Zeit für die Fehlersuche, sondern konzentrieren Sie sich darauf, dass Ihre Wiederherstellungsumgebung ordnungsgemäß arbeitet, und ziehen Sie zur späteren technischen Fehleranalyse ausführliche Systemprotokolle und sekundäre Datenkopien heran. Planen der Notfallwiederherstellung Während es bei hoher Verfügbarkeit darum geht, einen Ausfall zu vermeiden, muss bei der Notfallwiederherstellung dafür gesorgt werden, dass das System wieder hoch verfügbar wird. Notfallwiederherstellungsmaßnahmen und Zuständigkeiten sollten soweit wie möglich vor einem tatsächlichen Ausfall festgelegt werden. Die Entscheidung, automatisierte oder manuelle Failover zu initiieren, sowie der Wiederherstellungsplan sollten durch aktive Überwachungs- und Warnmechanismen gestützt werden und an vordefinierte RTO- und RPO-Schwellenwerte gekoppelt sein. Ein ausgereifter Notfallwiederherstellungsplan sollte Folgendes abdecken: Granularität der Ausfall- und Wiederherstellungsebenen. Je nachdem, wo der Ausfall auftritt und welchen Fehler er verursacht, können Korrekturmaßnahmen auf verschiedenen Ebenen ergriffen werden: Rechenzentrum, Infrastruktur, Plattform, Anwendung oder Workload. Aussagekräftige Fehlerinformationen. Der allgemeine Überwachungsverlauf sowie letzte Ergebnisse, Systemwarnungen, Ereignisprotokolle und Diagnoseabfragen sollten den Verantwortlichen problemlos zugänglich sein. Koordination der Abhängigkeiten. Welche System- und Geschäftsabhängigkeiten bestehen innerhalb des Anwendungsstacks und übergreifend für alle Beteiligten? Entscheidungsbaum. Ein vordefinierter, reproduzierbarer, validierter Entscheidungsbaum, der Rollenverantwortlichkeiten, Fehlertriage, Failoverkriterien in Form von RPO- und RTO-Vorgaben sowie vorgeschriebene Wiederherstellungsschritte beinhaltet. Validierung. Welche Schritte müssen im Anschluss an die Systemwiederherstellung nach einem Ausfall unternommen werden, um sicherzustellen, dass der normale Betrieb wieder aufgenommen wurde? Dokumentation. Alle oben genannten Punkte sollten ausführlich und verständlich dokumentiert werden, damit der Wiederherstellungsplan auch von anderen Teams möglichst ohne Unterstützung ausgeführt werden kann. Diese Art der Dokumentation wird häufig auch als "Run Book" bezeichnet. Probewiederherstellung. Der Notfallwiederherstellungsplan sollte regelmäßig ausgeführt werden, um erwartete RTO-Baselinewerte festzulegen. Dabei sollte auch die regelmäßige Rotation zwischen dem Standort mit dem primären Replikat und den einzelnen DR-Replikaten einkalkuliert werden. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 4 Übersicht: Hochverfügbarkeit mit Microsoft SQL Server 2012 Die Einhaltung der notwendigen RPO- und RTO-Vorgaben erfordert die kontinuierliche Verfügbarkeit (Uptime) wichtiger Anwendungen sowie den Schutz kritischer Daten vor geplanter und ungeplanter Downtime. SQL Server bietet eine Reihe von Funktionen, mit denen sich diese Ziele ohne einen hohen Kosten- und Zeitaufwand umsetzen lassen. Leser, die die neue AlwaysOn-Funktionalität bereits kennen, können zum Abschnitt Schutzebenen von SQL Server AlwaysOn übergehen, in dem das Thema eingehender behandelt wird. SQL Server AlwaysOn AlwaysOn ist eine neue integrierte, flexible und kosteneffiziente Lösung für Hochverfügbarkeit und Notfallwiederherstellung. Sie bietet Daten- und Hardwareredundanz innerhalb eines bzw. mehrerer Rechenzentren und verbessert die Failoverzeit von Anwendungen, um die Verfügbarkeit unternehmenswichtiger Anwendungen zu verbessern. AlwaysOn ist flexibel konfigurierbar und ermöglicht die Einbeziehung der vorhandenen Hardware. Zur Konfiguration der Verfügbarkeit auf Datenbank- und Instanzebene können AlwaysOn-Lösungen zwei zentrale Eigenschaften von SQL Server 2012 nutzen: AlwaysOn-Verfügbarkeitsgruppen sind neu in SQL Server 2012. Sie erweitern die Funktionalität der Datenbankspiegelung, verbessern die Verfügbarkeit von Anwendungsdatenbanken und ermöglichen protokollbasierte und verlustfreie Datenumlagerungen zum Schutz der Daten, wenn kein freigegebener Speicher verwendet wird. Verfügbarkeitsgruppen verfügen über eine Reihe integrierter Optionen: das automatische und manuelle Failover einer logischen Datenbankgruppe, Unterstützung von bis zu vier sekundären Replikaten sowie schnelles Anwendungsfailover und automatische Seitenreparatur. AlwaysOn-Failoverclusterinstanzen (FCIs) verbessern das SQL Server-Failoverclustering und unterstützen standortübergreifende Cluster in mehreren Subnetzen, wodurch ein Failover von SQL Server-Instanzen über mehrere Rechenzentren möglich wird. Ein weiterer Vorteil sind schnellere und besser vorhersagbare Instanzfailover, die die schnellere Anwendungswiederherstellung ermöglichen. Deutliche Verkürzung geplanter Downtime Die Hauptursache für Anwendungsausfälle in einem Unternehmen sind geplante Downtimes, die durch Betriebssystempatches, Hardwarewartungen usw. verursacht werden. Auf diese geplanten Aufgaben können bis zu 80 Prozent der Ausfälle in einer IT-Umgebung zurückgeführt werden. Mit SQL Server 2012 können geplante Downtimes deutlich reduziert werden, indem weniger Patches installiert und mehr Wartungstasks online ausgeführt werden: Windows Server Core. SQL Server 2012 unterstützt Bereitstellungen unter Windows Server Core, einer schlanken, optimierten Bereitstellungsoption für Windows Server 2008 und Windows Server 2008 R2. Mit dieser Konfiguration lassen sich geplante Downtimes mit Windows Server Core dank reduzierter Betriebssystempatches um bis zu 60 Prozent verringern. Onlinevorgänge. Die verbesserte Unterstützung von Onlinevorgängen, z. B. für die LOB-Reindizierung und die Verwendung von Spalten mit Standardwerten, tragen zu kürzeren Ausfallzeiten während der Datenbankwartung bei. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 5 Rolling Upgrades und Patches. AlwaysOn-Funktionen unterstützen Rolling Upgrades und Instanzpatches, was die Anwendungsdowntime deutlich verringert. SQL Server auf Hyper-V. In der Hyper-V-Umgebung gehostete SQL Server-Instanzen bieten den zusätzlichen Nutzen der Livemigration, bei der virtuelle Computer völlig ohne Downtime zwischen Hosts migriert werden können. Administratoren führen Wartungsaufgaben auf dem Host ohne Beeinträchtigung der Anwendungen aus. Verzicht auf inaktive Hardware und Verbesserung der Kosteneffizienz und Leistung In einer typischen Hochverfügbarkeitslösung kommen teure Server zum Einsatz, die redundant und passiv sind. Mit AlwaysOn-Verfügbarkeitsgruppen können Sie sekundäre Datenbankreplikate auf ansonsten passiven oder unausgelasteten Servern für Leseoperationen wie Berichtsabfragen oder Backups von SQL Server Reporting Services nutzen. Durch die Fähigkeit, das primäre und sekundäre Datenbankreplikat gleichzeitig zu nutzen, verbessert sich die Leistung aller Workloads, weil die Ressourcenlast besser auf die Serverhardware verteilt werden kann. Einfache Bereitstellung und Verwaltung Funktionen wie der Konfigurations-Assistent, die Unterstützung der Windows PowerShellBefehlszeilenschnittstelle, Dashboards, dynamische Verwaltungssichten (DMVs), die richtlinienbasierte Verwaltung und die System Center-Integration vereinfachen die Bereitstellung und Verwaltung von Verfügbarkeitsgruppen. Gegenüberstellung von RPO und RTO Die unternehmensweiten RPO- und RTO-Ziele sollten die Hauptfaktoren bei der Wahl einer SQL ServerTechnologie für Ihre HA- und DR-Lösung sein. Diese Tabelle bietet einen groben Vergleich zwischen den mit den unterschiedlichen Lösungen erzielten Ergebnissen: SQL Server-Lösung für Hochverfügbarkeit und Notfallwiederherstellung AlwaysOn-Verfügbarkeitsgruppe – synchrones Commit AlwaysOn-Verfügbarkeitsgruppe – asynchrones Commit AlwaysOn-Failoverclusterinstanz Datenbankspiegelung(2) – hohe Sicherheit (synchron + Zeuge) Datenbankspiegelung(2) – hohe Leistung (asynchron) Protokollversand Sichern, Kopieren, Wiederherstellen(3) Potenzieller Datenverlust (RPO) Potenzielle Wiederherstellungszeit (RTO) Automatisches Failover Lesbare sekundäre Replikate(1) Null Sekunden Ja(4) 0-2 Sekunden Minuten Nein 0-4 NV(5) Sekunden bis Minuten Sekunden Ja NV Ja NV Minuten(6) Minuten bis Stunden(6) Stunden bis Tage(6) Nein Nein NV Nicht während einer Wiederherstellung Nicht während einer Wiederherstellung Null Sekunden(6) Minuten(6) Stunden(6) Nein (1) Eine AlwaysOn-Verfügbarkeitsgruppe darf unabhängig vom Typ maximal vier sekundäre Replikate enthalten. Funktion wird in zukünftigen Versionen von Microsoft SQL Server nicht mehr bereitgestellt. Verwenden Sie stattdessen AlwaysOnVerfügbarkeitsgruppen. (3) Sichern, Kopieren und Wiederherstellen ist für die Notfallwiederherstellung, nicht aber für hohe Verfügbarkeit geeignet. (4) Das automatische Failover einer Verfügbarkeitsgruppe auf oder von einer Failoverclusterinstanz wird nicht unterstützt. (5) Die FCI selbst bietet keinen Datenschutz. Ob es zu einem Datenverlust kommt, hängt vom implementierten Speichersystem ab. (6) Hängt stark von der Arbeitslast, dem Datenvolumen und den Failoverprozeduren ab. (2) Diese Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 6 Schutzebenen von SQL Server AlwaysOn SQL Server AlwaysOn-Lösungen unterstützten Fehlertoleranz und Notfallwiederherstellung über mehrere logische und physische Infrastruktur- und Anwendungsebenen hinweg. Ursprünglich wurden die Pflichten und Verantwortlichkeiten der verschiedenen Beteiligten und Rollen häufig getrennt gehalten, sodass jeder vorwiegend nur für einen Teil des Ganzen zuständig war. In diesem Abschnitt des Whitepapers wird ausführlicher auf die einzelnen Ebenen und deren Grundfunktionen eingegangen. Zusätzlich erhalten Sie Orientierungshilfen für Ihre Entwurfs- und Implementierungsentscheidungen. Eine erfolgreiche SQL Server AlwaysOn-Lösung setzt voraus, dass Sie die Aufgaben der einzelnen Ebenen kennen und dass diese reibungslos interagieren können: Infrastrukturebene. Zur Gewährleistung von Fehlertoleranz auf Serverebene und für die knoteninterne Netzwerkkommunikation werden Windows Server Failover Clustering (WSFC)Funktionen für die Systemüberwachung und Failoverkoordination genutzt. SQL Server-Instanzebene. Eine SQL Server AlwaysOn-Failoverclusterinstanz (FCI) ist eine SQL ServerInstanz, die sich auf mehrere Serverknoten erstreckt und ein Failover auf die Serverknoten in einem WSFC-Cluster ausführen kann. Die Knoten zum Hosten der FCI sind an einen robusten SAN- oder SMB-Speicher (symmetrisch und freigegeben) angeschlossen. Datenbankebene. Eine Verfügbarkeitsgruppe ist eine Gruppe von Benutzerdatenbanken, die zusammen ein Failover ausführen. Eine Verfügbarkeitsgruppe besteht aus einem primären Replikat und einem bis vier sekundären Replikaten. Jedes Replikat wird von einer SQL Server-Instanz (FCI oder Nicht-FCI) auf einem anderen Knoten des WSFC-Clusters gehostet. Clientkonnektivität. Datenbankclientanwendungen können eine Verbindung direkt mit dem Netzwerknamen einer SQL Server-Instanz oder mit einem virtuellen Netzwerknamen (VNN) herstellen, der an einen Verfügbarkeitsgruppenlistener gebunden ist. Der VNN abstrahiert die Topologie des WSFC-Clusters und der Verfügbarkeitsgruppe und leitet Verbindungsanforderungen basierend auf einer Logik an die geeignete SQL Server-Instanz und das entsprechende Datenbankreplikat um. Das folgende Diagramm veranschaulicht die logische Topologie einer typischen AlwaysOn-Lösung: Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 7 Infrastrukturverfügbarkeit Sowohl AlwaysOn-Verfügbarkeitsgruppen als auch AlwaysOn-Failoverclusterinstanzen nutzen das Betriebssystem Windows Server und WSFC als Plattformtechnologie. Mehr als je zuvor sind Microsoft SQL Server-Datenbankadministratoren auf fundierte Kenntnisse dieser Technologien angewiesen. Windows-Betriebssystem Zur Bereitstellung der grundlegenden Infrastruktur und allgemeiner Netzwerk-, Speicher-, Sicherheits-, Patching- und Überwachungsdienste nutzt SQL Server die Windows-Plattform. Die verschiedenen Editionen von SQL Server 2012 bauen schrittweise auf den weiterentwickelten Funktionen äquivalenter Editionen des Windows Server 2008 R2-Betriebssystems auf, darunter auch die Betriebssysteme Windows Server 2008 R2 Standard, Windows Server 2008 R2 Enterprise und Windows Server 2008 R2 Datacenter. Weitere Informationen finden Sie unter: Hardware- und Softwareanforderungen für die Installation von SQL Server 2012 (http://msdn.microsoft.com/de-de/library/ms143506(SQL.110).aspx). Installationsoption Windows Server Core SQL Server 2012 unterstützt als wichtige Hochverfügbarkeitsfunktion die Bereitstellung der Server CoreInstallationsoption unter Windows Server 2008 oder höher. Die Server Core-Installationsoption bietet eine minimal ausgestattete Umgebung zur Ausführung spezifischer Serverrollen mit eingeschränkter Funktionalität und sehr reduzierter GUI-Unterstützung. Standardmäßig sind nur die nötigen Dienste und eine Eingabeaufforderungsumgebung aktiviert. Da das Betriebssystem in diesem Modus weniger angreifbar und einfacher zu verwalten ist, werden die laufende Wartung und das Patching deutlich reduziert. Eine wichtige Überlegung bei der Bereitstellung von SQL Server 2012 unter Windows Server Core besteht darin, dass die gesamte Bereitstellung, Konfiguration, Administration und Wartung von SQL Server und Betriebssystem in einer Skriptumgebung wie Windows PowerShell oder mithilfe von Befehlszeilen- oder Remotetools erfolgen muss. Optimieren von SQL Server für die private Cloud Hohe Verfügbarkeit und Notfallwiederherstellung gewinnen besonders in privaten Cloudumgebungen immer mehr an Bedeutung. Implementieren Sie SQL Server in Ihrer privaten Cloud, um die Computer-, Netzwerk- und Speicherressourcen effizient zu nutzen und deren physische Komplexität sowie Investitions- und Betriebskosten gering zu halten. SQL Server hilft, Bereitstellungen zu konsolidieren, Ressourcen effizient zu skalieren und bedarfsgesteuert bereitzustellen, ohne die Kontrolle aus der Hand zu geben. SQL Server bietet neben Windows Server Failover Clustering-Support für Hyper-V-Host- und Gastsysteme auch Unterstützung für die Livemigration, mit der virtuelle Computer ohne wahrnehmbare Ausfallzeiten zwischen Hosts umgelagert werden können. Die Livemigration kann auch mit dem Gastclustering kombiniert werden. Weitere Informationen finden Sie unter Private Cloud Computing - Optimieren von SQL Server für die private Cloud (http://www.microsoft.com/SqlServerPrivateCloud). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 8 Windows Server Failover Clustering Windows Server Failover Clustering (WSFC) bietet Infrastrukturfunktionen zur Unterstützung von HA- und DR-Szenarien bei gehosteten Serveranwendungen wie Microsoft SQL Server. Wenn ein WSFC-Clusterknoten oder -dienst ausfällt, können die auf diesem Knoten gehosteten Dienste oder Ressourcen automatisch oder manuell auf einen anderen verfügbaren Knoten übertragen werden. Dieser Vorgang wird als Failover bezeichnet. Bei AlwaysOn-Lösungen werden Failover von FCIs und Verfügbarkeitsgruppen unterstützt. Diese Funktionen werden von den Knoten im WSFC-Cluster kollektiv zur Verfügung gestellt: Verteilte Metadaten und Benachrichtigungen. Metadaten des WSFC-Diensts und gehosteter Anwendungen sind in jedem Knoten im Cluster enthalten. Die Metadaten umfassen WSFCKonfiguration und -Status sowie Einstellungen der gehosteten Anwendung. Änderungen an den Metadaten oder am Status eines Knotens werden automatisch an die anderen Knoten im Cluster weitergegeben. Ressourcenverwaltung. Einzelne Knoten im Cluster stellen u. U. physische Ressourcen bereit, z. B. direkt angeschlossene Speichermedien (DAS), Netzwerkschnittstellen sowie den Zugriff auf freigegebenen Festplattenspeicher. Gehostete Anwendungen, wie SQL Server, registrieren sich als Clusterressource und können Start- und Integritätsabhängigkeiten von anderen Ressourcen konfigurieren. Systemüberwachung. Die Integrität zwischen den Knoten und die des primären Knotens wird durch eine Kombination aus getakteter Netzwerkkommunikation und Ressourcenüberwachung ermittelt. Die allgemeine Integrität des Clusters wird anhand der Stimmen eines Knotenquorums im Cluster bestimmt. Failoverkoordination. Jede Ressource wird zum Hosten auf einem primären Knoten konfiguriert und kann automatisch oder manuell an mindestens einen sekundären Knoten übertragen werden. Eine integritätsbasierte Failoverrichtlinie steuert die automatische Übertragung des Ressourcenbesitzes zwischen Knoten. Knoten und gehostete Anwendungen werden im Falle eines Failovers benachrichtigt, damit sie entsprechend reagieren können. Weitere Informationen finden Sie unter Windows Server | Failoverclustering und Lastenausgleich zwischen Knoten (http://www.microsoft.com/windowsserver2008/de/de/failover-clustering-main.aspx). Hinweis: Es ist mittlerweile unverzichtbar, dass sich Datenbankadministratoren mit den internen Abläufen in WSFC-Clustern und der Quorumverwaltung auskennen. Alle AlwaysOn-Abläufe sind von der Systemüberwachung über die Verwaltung bis hin zur Wiederherstellung untrennbar mit der WSFCKonfiguration verknüpft. WSFC-Speicherkonfigurationen Windows Server Failover Clustering setzt voraus, dass jeder im Cluster enthaltene Knoten die angeschlossenen Speichermedien, Datenträgervolumes und das Dateisystem selbst verwaltet. Außerdem wird beim WSFC davon ausgegangen, dass das Speichersubsystem sehr stabil läuft und daher der Clusterknoten als fehlerhaft eingestuft wird, wenn das an einen Knoten angeschlossene Speichermedium nicht verfügbar ist. Bei schreibbasierten Vorgängen wird ein Datenträgervolume mit einer SCSI-3 PR (Persistent Reservation) jeweils an einen einzelnen Clusterknoten logisch angeschlossen. Je nach Funktionalität und Konfiguration des Speichersubsystems kann der logische Besitz des Datenträgervolumes bei einem Knotenausfall auf einen anderen Knoten im Cluster übergehen. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 9 Die SQL Server AlwaysOn-Technologie nutzt die folgenden kombinierten WSFC-Speicherkonfigurationen und ist gleichzeitig darauf beschränkt: Direkt angeschlossener oder Remotespeicher. Speichermedien sind direkt physisch an den Server angeschlossen oder werden über ein Netzwerk oder einen Hostbusadapter (HBA) durch ein Remotegerät dargestellt. Zu den Remotespeichertechniken gehören Storage Area Network (SAN)basierte Lösungen, wie iSCSI oder Fibre Channel, sowie auf Server Messaging Block (SMB)Dateifreigaben basierende Lösungen. Symmetrischer oder asymmetrischer Speicher. Speichermedien gelten als symmetrisch, wenn auf jedem Knoten im Cluster genau dieselbe Konfiguration und dieselben Dateipfade wie auf dem logischen Datenträgervolume abgebildet sind. Die physische Implementierung und Kapazität der zugrunde liegenden Datenträgervolumes kann variieren. Dedizierter oder freigegebener Speicher. Dedizierter Speicher wird für einen einzelnen Knoten im Cluster reserviert und zugewiesen. Auf freigegebenen Speicher können mehrerer Knoten im Cluster zugreifen. Die Steuerung und der Besitz kompatibler, freigegebener Speichermedien kann unter Verwendung von SCSI-3-Protokollen von einem Knoten auf einen anderen übertragen werden. WSFC unterstützt Dateifreigaben durch das gleichzeitige Hosting freigegebener Clustervolumes auf mehreren Knoten. SQL Server unterstützt jedoch keinen Mehrknotenzugriff auf freigegebene Volumes. Hinweis: Für SQL Server-FCIs ist es weiterhin erforderlich, dass alle möglichen Knotenbesitzer der Instanz auf symmetrischen freigegebenen Speicher zugreifen können. Dank der Einführung von AlwaysOn-Verfügbarkeitsgruppen ist es jetzt jedoch möglich, unterschiedliche Nicht-FCI-Instanzen von SQL Server in einem WSFC-Cluster bereitzustellen, die alle über eigenen, dedizierten lokalen oder Remotespeicher verfügen können. Integrität von WSFC-Ressourcen und Failover Jede Ressource in einem WSFC-Clusterknoten kann in regelmäßigen Abständen oder bedarfsgesteuert Status- und Integritätsdaten melden. Verschiedene Umstände können zum Ausfall einer Clusterressource führen: Stromausfall, Festplatten- oder Arbeitsspeicherfehler, Netzwerkkommunikationsfehler, fehlerhafte Konfiguration oder nicht reagierende Dienste. Sie können zwischen WSFC-Clusterressourcen wie Netzwerken, Speichern oder Diensten Abhängigkeiten konfigurieren. Die kumulierte Integrität einer Ressource wird ermittelt, indem sukzessiv Rollups des eigenen Integritätsstatus gefolgt von dem Integritätsstatus aller Ressourcenabhängigkeiten ausgeführt werden. Für AlwaysOn-Verfügbarkeitsgruppen werden die Verfügbarkeitsgruppe und der Verfügbarkeitsgruppenlistener als WSFC-Clusterressourcen registriert. Für AlwaysOnFailoverclusterinstanzen werden der SQL Server-Dienst und der SQL Server-Agent-Dienst als WSFCClusterressourcen registriert und von der VNN (Virtual Network Name)-Ressource der Instanz abhängig gemacht. Wenn eine WSFC-Clusterressource innerhalb eines bestimmten Zeitraums eine festgelegte Anzahl von Fehlern registriert, führt der Clusterdienst aufgrund der konfigurierten Failoverrichtlinie einen der folgenden Schritte aus: Die Ressource wird auf dem aktuellen Knoten neu gestartet. Die Ressource wird offline geschaltet. Für die Ressource und deren Abhängigkeiten wird ein automatisches Failover auf einen anderen Knoten initiiert. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 10 Hinweis: Die Integrität von WSFC-Clusterressourcen steht in keiner direkten Verbindung mit der Integrität des einzelnen Knotens bzw. des gesamten Clusters. WSFC-Clustervalidierungs-Assistent Der Clustervalidierungs-Assistent ist Bestandteil des Failoverclusterings von Windows Server 2008 und Windows Server 2008 R2. Mit diesem hilfreichen Tool kann der Datenbankadministrator vor der Bereitstellung einer SQL Server AlwaysOn-Lösung sicherstellen, dass die WSFC-Umgebung fehlerfrei und stabil läuft. Der Clustervalidierungs-Assistent führt eine Reihe gezielter Tests für eine Reihe von Servern, die als Knoten in einen Cluster eingebunden werden sollen, oder für einen vorhandenen Cluster aus. Dabei wird die zugrunde liegende Hardware und Software eingehend darauf getestet, wie gut ein WSFC-Cluster in einer bestimmten Konfiguration unterstützt werden kann. Bei der Validierung werden für jeden Knoten in folgenden Kategorien spezifische Tests ausgeführt und Daten gesammelt: System. Informationen zu BIOS-Versionen, Umgebungen, Hostbusadaptern, RAM, Betriebssystemversionen, Geräten, Diensten, Treibern usw. Netzwerk. Informationen zur NIC-Bindungsreihenfolge, Netzwerkkommunikation, IP-Konfiguration und Firewallkonfiguration. Überprüft die Knotenkommunikation auf allen NICs. Speicher. Informationen zu Festplatten, Laufwerkkapazität, Zugriffslatenz, Dateisystemen usw. Überprüft SCSI-Befehle, Failoverfunktionalität sowie symmetrische und asymmetrische Speicherkonfigurationen. Systemkonfiguration. Überprüft die Active Directory-Konfiguration, die Signatur von Treibern, Speicherdumpeinstellungen, erforderliche Betriebssystemfunktionen und -dienste, kompatible Prozessorarchitekturen sowie Updatelevels von Service Packs und Windows-Software. Die Tests dienen dazu, eine Clusterkonfiguration zu optimieren, Konfigurationsänderungen nachzuverfolgen und eine problematische Clusterkonfiguration zu identifizieren, bevor Ausfälle auftreten. Die Testergebnisse können zu Referenzzwecken als HTML-Dokument gespeichert werden. Die Tests sollten vor und nach einer Änderung der WSFC-Konfiguration, vor der Installation von SQL Server und im Zuge einer Notfallwiederherstellung ausgeführt werden. Microsoft Customer Support Services (CSS) benötigen einen Clustervalidierungsbericht, um Support für die jeweilige WSFCClusterkonfiguration leisten zu können. Weitere Informationen finden Sie unter Schrittweise Anleitung für Failovercluster: Prüfen der Hardware für einen Failovercluster (http://technet.microsoft.com/de-de/library/cc732035(WS.10).aspx). Hinweis: Wenn die Clusterkonfiguration asymmetrischen Speicher nutzt, wie bei hardwarebasierten geografisch verteilten Clusterspeicherlösungen oder AlwaysOn-Verfügbarkeitsgruppen, müssen u. U. eine Reihe von Hotfixes angewendet werden, damit der Clustervalidierungs-Assistent die Speichervalidierung erfolgreich abschließen kann. Weitere Informationen finden Sie unter Voraussetzungen, Einschränkungen und Empfehlungen für AlwaysOn-Verfügbarkeitsgruppen (http://msdn.microsoft.com/dede/library/ff878487(SQL.110).aspx#SystemReqsForAOAG). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 11 WSFC-Quorummodi und Abstimmungskonfiguration WSFC verwendet einen quorumbasierten Ansatz zur Überwachung der Clusterintegrität und Maximierung der Fehlertoleranz auf Knotenebene. Ein fundiertes Verständnis der WSFC-Quorummodi und Knotenabstimmungskonfiguration sind eine Voraussetzung für die Entwicklung, Ausführung und Problembehandlung einer HA- und DR-Lösung mit AlwaysOn-Technologie. Ermitteln des Clusterzustands per Quorum Jeder Knoten in einem WSFC-Cluster kommuniziert seinen Integritätsstatus regelmäßig an andere Knoten. Bei nicht reagierenden Knoten wird der Status als fehlerhaft betrachtet. Eine Quorumknotengruppe wird aus der Mehrheit der Abstimmungsknoten und -zeugen im WSFCCluster gebildet. Die allgemeine Integrität und der Status eines WSFC-Clusters werden mithilfe einer regelmäßigen Quorumabstimmung ermittelt. Das Vorhandensein eines Quorums bedeutet, dass der Cluster fehlerfrei ist und Fehlertoleranz auf Knotenebene gewährleisten kann. Kommt kein Quorum zustande, ist der Cluster nicht fehlerfrei. Die Integrität des gesamten WSFCClusters muss überwacht werden, um sicherzustellen, dass fehlerfreie sekundäre Knoten für das Failover von Primärknoten verfügbar sind. Fällt die Quorumabstimmung negativ aus, wird der gesamte WSFCCluster vorsichtshalber offline geschaltet. Gleichzeitig werden auch alle beim Cluster registrierten SQL Server-Instanzen angehalten. Hinweis: Wenn ein WSFC-Cluster aufgrund eines Quorumfehlers offline geschaltet wird, kann er lediglich durch einen manuellen Eingriff wieder online geschaltet werden. Weitere Informationen finden Sie im Abschnitt WSFC-Notfallwiederherstellung durch erzwungenes Quorum weiter unten in diesen Ausführungen. Quorummodi Ein Quorummodus wird auf WSFC-Clusterebene konfiguriert, um die für die Quorumabstimmung verwendeten Methoden festzulegen. Das Failovercluster-Manager-Hilfsprogramm empfiehlt basierend auf der Anzahl von Clusterknoten einen Quorummodus. Anhand der folgenden Quorummodi wird erläutert, wie ein Stimmenquorum zustande kommt: Knotenmehrheit: Mehr als die Hälfte der stimmberechtigten Knoten im Cluster müssen positiv abstimmen, damit der Cluster als fehlerfrei eingestuft wird. Knoten- und Dateifreigabemehrheit: Dies ist mit dem Quorummodus "Knotenmehrheit" vergleichbar, mit der Ausnahme, dass eine Remotedateifreigabe ebenfalls als Abstimmungszeuge konfiguriert ist und die Verbindung von Knoten mit dieser Freigabe auch als positive Stimme gezählt wird. Mehr als die Hälfte der möglichen Stimmen muss positiv ausfallen, damit der Cluster als fehlerfrei angesehen wird. Als bewährte Methode sollte sich die Zeugendateifreigabe nicht auf einem Knoten im Cluster befinden und für alle Knoten im Cluster sichtbar sein. Knoten- und Datenträgermehrheit: Ähnelt dem Quorummodus "Knotenmehrheit", mit der Ausnahme, dass eine Clusterressource für einen freigegebenen Datenträger ebenfalls als Abstimmungszeuge festgelegt ist und die Verbindung von Knoten mit diesem freigegebenen Datenträger auch als positive Stimme gezählt wird. Mehr als die Hälfte der möglichen Stimmen muss positiv ausfallen, damit der Cluster als fehlerfrei angesehen wird. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 12 Nur Datenträger. Eine Clusterressource für einen freigegebenen Datenträger ist als Zeuge festgelegt, und die Verbindung von Knoten mit diesem freigegebenen Datenträger wird als positive Stimme gezählt. Weitere Informationen finden Sie unter Schrittweise Anleitung für Failovercluster: Konfigurieren des Quorums in einem Cluster (http://technet.microsoft.com/de-de/library/cc770620(WS.10).aspx). Hinweis: Sofern nicht jeder Knoten im Cluster für die Verwendung desselben Quorumzeugen (freigegebener Speicher) konfiguriert ist, sollten Sie grundsätzlich den Quorummodus "Knotenmehrheit" verwenden, wenn die Anzahl stimmberechtigter Knoten ungerade ist, und den Quorummodus "Knotenund Dateifreigabemehrheit", wenn die Anzahl stimmberechtigter Knoten gerade ist. Stimmberechtigte und nicht stimmberechtigte Knoten Jeder Knoten im WSFC-Cluster ist standardmäßig Mitglied des Clusterquorums. Jeder Knoten, Dateifreigabezeuge und Datenträgerzeuge verfügt bei der Ermittlung der Integrität des gesamten Clusters über eine Stimme. Bisher wurden die WSFC-Clusterknoten, die zur Bestimmung der Clusterintegrität herangezogen werden, in dieser Quorumdefinition als stimmberechtigte Knoten bezeichnet. Vielleicht möchten Sie in bestimmten Situationen verhindern, dass jeder Knoten eine Stimme besitzt. Jeder Knoten in einem WSFC-Cluster versucht ständig, ein Quorum herzustellen. Dabei kann kein einzelner Knoten im Cluster definitiv ermitteln, ob der Cluster als Ganzes fehlerfrei oder nicht fehlerfrei ist. Aus Sicht der einzelnen Knoten können einige andere Knoten jederzeit offline sein, sich in einem Failoverprozess befinden oder aufgrund eines Netzwerkkommunikationsfehlers nicht reagieren. Mit der Quorumabstimmung soll beispielsweise festgestellt werden, ob der scheinbare Zustand der einzelnen Knoten im WSFC-Cluster dem tatsächlichen Zustand der Knoten entspricht. Bei allen Quorummodellen mit Ausnahme von "Nur Datenträger" hängt die Wirksamkeit einer Quorumabstimmung von der Kommunikation zwischen den stimmberechtigten Knoten im Cluster ab. Wenn sich alle Knoten im selben physischen Subnetz befinden, sollte die Quorumabstimmung als zuverlässig betrachtet werden. Wenn ein Knoten in einem anderen Subnetz allerdings nicht auf eine Quorumabstimmung reagiert, obwohl er online und auch sonst fehlerfrei ist, liegt dies in den meisten Fällen an einem Netzwerkkommunikationsfehler zwischen Subnetzen. Je nach Clustertopologie, Quorummodus und Konfiguration der Failoverrichtlinien kann durch den Netzwerkkommunikationsfehler ggf. mehr als eine Gruppe (oder eine Teilmenge) stimmberechtigter Knoten entstehen. Wenn mehr als eine Teilmenge stimmberechtigter Knoten selbständig ein Quorum erzielen kann, wird dies als Split-Brain-Szenario bezeichnet. Bei einem solchen Szenario kann es vorkommen, dass sich die Knoten in den einzelnen Quoren unterschiedlich verhalten und Konflikte verursachen. Hinweis: Das Split-Brain-Szenario ist nur in folgenden Fällen möglich: Ein Systemadministrator erzwingt manuell ein Quorum, oder (sehr selten) ein erzwungenes manuelles Failover führt zur expliziten Unterteilung der Quorumknoten. Weitere Informationen finden Sie im Abschnitt WSFCNotfallwiederherstellung durch erzwungenes Quorum weiter unten in diesen Ausführungen. Um die Quorumkonfiguration zu vereinfachen und Uptime zu verlängern, ist es ratsam, die NodeWeightEinstellung (mit dem Wert 0 der 1) der einzelnen Knoten anzupassen, damit kein Quorumverlust entsteht. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 13 Empfohlene Anpassungen der Quorumabstimmung Befolgen Sie die nachstehenden Richtlinien in der angegebenen Reihenfolge, um die empfohlene Quorumabstimmungskonfiguration für den Cluster zu ermitteln: 1. Standardmäßig keine Stimme. Kein Knoten ohne explizite Berechtigung ist stimmberechtigt. 2. Alle Primärknoten. Jeder Knoten, der das primäre Replikat einer AlwaysOn-Verfügbarkeitsgruppe hostet oder bevorzugter Besitzer der AlwaysOn-Failoverclusterinstanz ist, sollte über eine Stimme verfügen. 3. Schließen Sie mögliche Besitzer von automatischen Failovern ein. Jeder Knoten, der nach einem automatischen Failover zu einem Host eines primären Replikats oder einer FCI werden kann, sollte über eine Stimme verfügen. 4. Schließen Sie Knoten des sekundären Standorts aus. Generell sollten Sie Knoten, die sich an einem sekundären Standort für die Notfallwiederherstellung befinden, keine Stimme geben. Es ist nicht wünschenswert, dass Knoten am sekundären Standort an einer Entscheidung beteiligt sind, bei der es um das Versetzen des Clusters in den Offlinezustand geht, wenn für den primären Standort kein Fehler vorliegt. 5. Ungerade Anzahl von Stimmen. Fügen Sie dem Cluster bei Bedarf eine Zeugendateifreigabe, einen Zeugenknoten (mit oder ohne SQL Server-Instanz) oder einen Zeugendatenträger hinzu, und passen Sie den Quorummodus an, um mögliche Gleichstände bei der Quorumabstimmung zu verhindern. 6. Stimmberechtigungen nach einem Failover neu bewerten. Es ist nicht wünschenswert, ein Failover auf eine Clusterkonfiguration auszuführen, die kein fehlerfreies Quorum unterstützt. Weitere Informationen zur Anpassung der Stimmberechtigung von Knoten finden Sie unter Konfigurieren der Clusterquorum-NodeWeight-Einstellungen (http://msdn.microsoft.com/dede/library/hh270281(SQL.110).aspx). Die Stimmberechtigung eines Dateifreigabezeugen kann nicht angepasst werden. Stattdessen müssen Sie einen anderen Quorummodus auswählen, um die Stimme ein- oder auszuschließen. Hinweis: SQL Server verfügt über mehrere dynamische Verwaltungssichten (DMVs), mit denen Sie die WSFC-Clusterkonfiguration und Quorumknotenstimmen verwalten können. Weitere Informationen finden Sie unter Überwachen von Verfügbarkeitsgruppen (http://msdn.microsoft.com/de-de/library/ff878305(SQL.110).aspx). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 14 WSFC-Notfallwiederherstellung durch erzwungenes Quorum Quorumfehler werden normalerweise durch einen schwerwiegenden Fehler oder einen dauerhaften Kommunikationsfehler verursacht, der mehrere Knoten im WSFC-Cluster betrifft. Vergessen Sie nicht, dass bei einem Quorumfehler alle Clusterdienste, SQL Server-Instanzen und Verfügbarkeitsgruppen im WSFC-Cluster offline geschaltet werden, da der Cluster keine Fehlertoleranz auf Knotenebene gewährleisten kann. Ein Quorumfehler bedeutet, dass fehlerfreie Abstimmungsknoten im WSFC-Cluster nicht mehr dem Quorummodell entsprechen. Einige Knoten sind möglicherweise völlig ausgefallen, und andere haben den WSFC-Dienst möglicherweise nur heruntergefahren und sind, abgesehen vom Verlust der Fähigkeit, mit einem Quorum zu kommunizieren, u. U. fehlerfrei. Um den WSFC-Cluster wieder online zu schalten, müssen Sie die Ursache für den Quorumfehler in der vorhandenen Konfiguration auf mindestens einem Knoten beheben. In einem Notfallszenario müssen Sie eventuell alternative Hardware beschaffen oder neu konfigurieren. Unter Umständen empfiehlt es sich auch, die übrigen Knoten im WSFC-Cluster gemäß der erhalten gebliebenen Clustertopologie neu zu konfigurieren. Sie können ein erzwungenes Quorum für einen WSFC-Clusterknoten verwenden, um die Sicherheitskontrollen, durch die der Cluster offline geschaltet wurde, außer Kraft zu setzen. Damit wird der Cluster im Endeffekt angewiesen, die Quorumsstimmenprüfungen anzuhalten, und Sie erhalten damit die Möglichkeit, die WSFC-Clusterressourcen und SQL Server auf beliebigen Knoten im Cluster wieder online zu schalten. Diese Art der Notfallwiederherstellung sollte die folgenden Schritte umfassen: 1) Bestimmen des Fehlerumfangs. Stellen Sie fest, welche Verfügbarkeitsgruppen oder SQL ServerInstanzen nicht mehr reagieren, welche Clusterknoten online und nach dem Ausfall erreichbar sind, und überprüfen Sie die Windows-Ereignisprotokolle und SQL Server-Systemprotokolle. Wo praktikabel, sollten Sie forensische Daten und Systemprotokolle für spätere Analysen beibehalten. 2) Starten des WSFC-Clusters mit erzwungenem Quorum auf einem einzelnen Knoten. Schalten Sie den Cluster von einem ansonsten fehlerfreien Knoten aus online, indem Sie ein Quorum erzwingen. Um potenzielle Datenverluste zu minimieren, wählen Sie einen Knoten aus, der zuletzt ein primäres Replikat der Verfügbarkeitsgruppe gehostet hat. Weitere Informationen finden Sie unter Erzwingen des Starts eines Clusters ohne Quorum (http://msdn.microsoft.com/de-de/library/hh270275(v=SQL.110).aspx). Hinweis: Ein erzwungenes Quorum bewirkt, dass Quorumüberprüfungen im gesamten Cluster blockiert werden, bis der WSFC-Cluster eine Stimmenmehrheit erreicht und automatisch in einen regulären Quorumbetriebsmodus übergeht. 3) Normales Starten des WSFC-Diensts auf jedem einzelnen ansonsten fehlerfreien Knoten. Sie müssen die Option für das erzwungene Quorum nicht angeben, wenn Sie den Clusterdienst auf den anderen Knoten starten. Sobald der WSFC-Dienst auf den einzelnen Knoten wieder online ist, verhandelt er mit den anderen fehlerfreien Knoten, um den neuen Clusterkonfigurationszustand zu synchronisieren. Denken Sie daran, diesen Schritt für jeden Knoten getrennt auszuführen, um einen möglichen "Wettlauf" beim Auflösen des letzten bekannten Clusterstatus zu verhindern. Hinweis: Stellen Sie sicher, dass jeder gestartete Knoten mit den anderen neu online geschalteten Knoten kommunizieren kann. Andernfalls besteht das Risiko, dass mehrere Quorumknotengruppen entstehen, die zu einem Split-Brain-Szenario führen. Wenn Sie unter Schritt 1 die richtigen Informationen ermittelt haben, sollte dieser Fall nicht eintreten. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 15 4) Anwenden des neuen Quorummodus und der neuen Knotenstimmenkonfiguration. Wenn durch das Erzwingen des Quorums alle Knoten im Cluster erfolgreich neu gestartet wurden und die Ursache für den Quorumfehler korrigiert wurde, sind keine Änderungen am ursprünglichen Quorummodus und der Knotenstimmenkonfiguration erforderlich. Andernfalls sollten Sie den neu wiederhergestellten Clusterknoten und die Topologie der Verfügbarkeitsreplikate überprüfen und den Quorummodus und die Stimmenverteilungen für die einzelnen Knoten ggf. ändern. Schalten Sie den WSFC-Clusterdienst auf nicht wiederhergestellten Knoten offline, oder setzen Sie die Stimme auf 0. Hinweis: An diesem Punkt ist es möglich, dass die Knoten und SQL Server-Instanzen im Cluster wieder normal zu arbeiten scheinen, obwohl immer noch kein fehlerfreies Quorum besteht. Vergewissern Sie sich mithilfe des Failovercluster-Managers oder des AlwaysOn-Dashboards in SQL Server Management Studio oder der entsprechenden DMVs, dass das Quorum wieder fehlerfrei ist. 5) Wiederherstellen der Datenbankreplikate der Verfügbarkeitsgruppen nach Bedarf. Einige Datenbanken können sich im Rahmen des regulären SQL Server-Startprozesses selbsttätig wiederherstellen und online schalten. Andere Datenbanken müssen u. U. manuell wiederhergestellt werden. Sie können potenzielle Datenverluste verringern und Zeit sparen, indem Sie die Verfügbarkeitsgruppenreplikate in der folgenden Reihenfolge wieder online schalten: primäres Replikat, synchrone sekundäre Replikate, asynchrone sekundäre Replikate. 6) Reparieren oder Austauschen fehlerhafter Komponenten und erneute Überprüfung des Clusters. Nachdem Sie das System nach dem anfänglichen schwerwiegenden Fehler und Quorumfehler wiederhergestellt haben, sollten Sie die fehlerhaften Knoten reparieren oder austauschen und die zugehörigen WSFC- und AlwaysOn-Konfigurationen entsprechend anpassen. Hierzu kann es erforderlich sein, Verfügbarkeitsgruppenreplikate zu löschen, Knoten aus dem Cluster zu entfernen oder die Software eines Knotens zu vereinfachen oder neu zu installieren. Hinweis: Sie müssen alle fehlerhaften Verfügbarkeitsreplikate reparieren oder entfernen. Das Transaktionsprotokoll von SQL Server 2012 wird am letzten bekannten Punkt des Verfügbarkeitsreplikats mit den am weitesten zurückliegenden Daten nicht abgeschnitten. Wenn ein fehlerhaftes Replikat nicht repariert oder aus der Verfügbarkeitsgruppe entfernt wird, wachsen die Transaktionsprotokolle an, und es besteht das Risiko, dass nicht mehr ausreichend Speicherplatz für die Transaktionsprotokolle der anderen Replikate verfügbar ist. 7) Wiederholen von Schritt 4 (nach Bedarf). Das Ziel besteht darin, die für einen fehlerfreien Betrieb angemessene Fehlertoleranz und Hochverfügbarkeit wiederherzustellen. 8) Ausführen einer RPO/RTO-Analyse. Sie sollten SQL Server-Systemprotokolle, Datenbanktimestamps und Windows-Ereignisprotokolle analysieren, um die Fehlerursache zu bestimmen und die tatsächlichen Wiederherstellungspunkt- und Wiederherstellungszeitdaten zu dokumentieren. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 16 Schutz auf SQL Server-Instanzebene Die nächste Schutzebene in einer AlwaysOn-Lösung ist die Datenplattform selbst, d. h., die Funktionalität, die durch Microsoft SQL Server 2012 und die Integration mit Windows Server-Infrastrukturkomponenten verfügbar gemacht wird. Verbesserte Verfügbarkeit – SQL Server-Instanzen SQL Server 2012 bietet neue Instanzfunktionen, die die Verfügbarkeit von AlwaysOn-Failoverclusterinstanzen und eigenständigen Instanzen verbessern, die AlwaysOn-Verfügbarkeitsgruppen hosten. Diese Verbesserungen erleichtern die Verwaltung und Problembehandlung bei Failovern: Flexible Failoverrichtlinie. Die neue gespeicherte sp_server_diagnostics-Systemprozedur gibt den Schweregrad von Fehlern, die sich auf die SQL Server-Instanz auswirken, unter Verwendung der FailureConditionLevel-Eigenschaft zurück. Eine WSFC-Failoverrichtlinie bestimmt, inwieweit sich dieser Wert auf die SQL Server-Instanz auswirkt. Das Spektrum reicht von relativer Fehlertoleranz bis hin zu einer Warnung für jeden internen SQL Server-Komponentenfehler. Failover können bei beliebigen Fehlergraden ausgelöst werden: Serverausfall, keine Serverreaktion, schwerwiegender Fehler, mittelschwerer Fehler oder anderer definierter Fehlerzustand. Die FailureConditionLevel-Eigenschaft kann für Failoverrichtlinien von FCIs oder Verfügbarkeitsgruppen verwendet werden. Da die Fehlergrade für die Failoversteuerung vor SQL Server 2012 nicht abgestuft waren, wurde bei jedem Fehler auf Dienstebene ein Failover ausgelöst. Weitere Informationen finden Sie unter Failoverrichtlinie für Failoverclusterinstanzen (http://msdn.microsoft.com/de-de/library/ff878664(SQL.110).aspx). Verbesserte Instrumentierung und Protokollierung. Mithilfe zahlreicher AlwaysOn-spezifischer Systemkonfigurationssichten, DMVs, Leistungsindikatoren sowie einer Extended EventsSystemintegritätssitzung können Informationen zur Problembehandlung, Optimierung und Überwachung einer AlwaysOn-Bereitstellung erfasst und gesichert werden. Viele davon sind über neue Facets und Richtlinien der SQL Server-Richtlinienverwaltung zugänglich. Weitere Informationen finden Sie unter Dynamische Verwaltungssichten und -funktionen für AlwaysOn-Verfügbarkeitsgruppen (http://msdn.microsoft.com/dede/library/ff877943(SQL.110).aspx) und sys.dm_os_cluster_nodes (http://msdn.microsoft.com/dede/library/ms187341(SQL.110).aspx). Unterstützung von SMB-Dateifreigaben. Da Datenbankdateien für eigenständige und Failoverclusterinstanzen auf einer Remotedateifreigabe unter Windows Server 2008 oder höher gespeichert werden können, benötigt nicht jede FCI einen eigenen Laufwerkbuchstaben. Diese Option empfiehlt sich zur Speicherkonsolidierung, oder um Datenbankdateispeicher auf einem physischen Server für das Gastbetriebssystem eines virtuellen Computers zu hosten. Mit der richtigen Konfiguration lässt sich annähernd die E/A-Leistung eines direkt angeschlossenen Speichermediums erzielen. Weitere Informationen finden Sie unter SQL-Datenbanken auf Dateifreigaben – Zeit zum Umdenken (http://blogs.msdn.com/b/sqlserverstorageengine/archive/2011/10/18/sql-databases-on-fileshares-it-s-time-to-reconsider-the-scenario.aspx). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 17 Hinweis: In einem WSFC-Cluster können Sie der SQL Server-Ressourcengruppe keine Ressourcenabhängigkeit für eine SMB-Dateifreigabe hinzufügen; die Verfügbarkeit der Dateifreigabe muss auf andere Weise sichergestellt werden. Wenn eine Dateifreigabe nicht mehr erreichbar ist, löst SQL Server eine E/A-Ausnahme aus und wird offline geschaltet. WSFC-Interoperabilität mit DNS. Der VNN (Virtual Network Name) einer FCI oder eines Verfügbarkeitsgruppenlisteners wird nur während der VNN-Erstellung oder bei Konfigurationsänderungen beim DNS registriert. Alle virtuellen IP-Adressen – ob online oder offline – werden unter dem gleichen VNN beim DNS registriert. Bei einem Clientaufruf zum Auflösen des VNNs im DNS werden alle registrierten IP-Adressen in alternierender Roundrobin-Reihenfolge zurückgegeben. AlwaysOn-Failoverclusterinstanzen Der Hauptzweck einer AlwaysOn SQL Server-Failoverclusterinstanz (FCI) besteht darin, die Verfügbarkeit einer SQL Server-Instanz, die auf dem lokalen Server gehostet wird, und der Speicherhardware innerhalb eines einzelnen Rechenzentrums zu verbessern. Eine FCI ist eine einzelne logische SQL Server-Instanz, die zwar auf mehreren Knoten in einem WSFC (Windows Server Failover Clustering)-Cluster installiert, aber jeweils nur auf einem Knoten aktiv ist. Clientanwendungen stellen eine Verbindung mit einem VNN und einer virtuellen IP-Adresse her, die im Besitz des aktiven Clusterknotens sind. Alle installierten Knoten verfügen über eine identische Konfiguration und identische SQL ServerBinärdateien. Der WSFC-Clusterdienst repliziert auch relevante Änderungen, die in den WindowsRegistrierungseinstellungen der aktiven Instanz vorgenommen wurden, auf die einzelnen installierten Knoten. Jeder Knoten, auf dem die FCI installiert ist, wird innerhalb einer bevorzugten Failoverabfolge als möglicher Besitzer der Instanz und ihrer Ressourcen angesehen. Datenbankdateien werden auf freigegebenen symmetrischen Speichervolumes gespeichert und als Ressource beim WSFC-Cluster registriert und befinden sich im Besitz des Knotens, der gerade die FCI hostet. Weitere Informationen finden Sie unter AlwaysOn-Failoverclusterinstanzen (http://msdn.microsoft.com/de-de/library/ms189134(SQL.110).aspx). FCI-Failoverprozess Beim Ausfall einer abhängigen Clusterressource interagiert eine AlwaysOn-Failoverclusterinstanz über den folgenden übergeordneten Failoverprozess mit dem WSFC-Clusterdienst: 1) Ein Neustart ist indiziert. Eine regelmäßige Überprüfung des WSFC-Clusters oder der SQL ServerFailoverrichtlinienkonfiguration ergibt einen Fehlerstatus. Vor einem Failover auf einen anderen Knoten wird standardmäßig versucht, den Dienst neu zu starten. Ein Timeout beim Neustart weist auf einen Ressourcenfehler hin. 2) Ein Failover ist indiziert. Die Überprüfung einer Failoverrichtlinie ergibt, dass ein Knotenfailover erforderlich ist. 3) Der SQL Server-Dienst wurde angehalten. Wenn der SQL Server-Dienst aktuell ausgeführt wird, wird versucht, ihn ordnungsgemäß zu beenden. 4) Die WSFC-Clusterressource wird übertragen. Das Besitzrecht an der SQL ServerClusterressourcengruppe und deren abhängigen Ressourcen für das Netzwerk und den freigegebenen Speicher werden auf den als nächstes definierten Knotenbesitzer der FCI übertragen. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 18 5) SQL Server wird auf dem neuen Knoten gestartet. Die SQL Server-Instanz durchläuft die normale Startprozedur. Wenn die Instanz nicht innerhalb eines bestimmten Timeoutzeitraums wieder online ist, versetzt der Clusterdienst die Ressource auf dem neuen Knoten in einen fehlerhaften Zustand. 6) Benutzerdatenbanken werden auf dem neuen Knoten wiederhergestellt. Während REDO-Befehle für das Transaktionsprotokoll und ein Rollback für nicht festgeschriebene Transaktionen ausgeführt werden, ist für jede Benutzerdatenbank der Wiederherstellungsmodus aktiviert. FCI-Verbesserungen Frühere SQL Server-Versionen verfügten über eine FCI-Installationsoption. Mit SQL Server 2012 wurden mehrere Funktionserweiterungen eingeführt, die die Stabilität und Benutzerfreundlichkeit der Verfügbarkeitsfunktionen verbessern: Multisubnetz-Cluster. SQL Server 2012 unterstützt WSFC-Clusterknoten, die sich über mehrere Subnetze erstrecken. Eine auf einem WSFC-Clusterknoten installierte SQL Server-Instanz kann gestartet werden, wenn eine Netzwerkschnittstelle verfügbar ist. Dieser Vorgang wird als "OR"Clusterressourcenabhängigkeit bezeichnet. Bei früheren SQL Server-Versionen mussten alle Netzwerkschnittstellen funktionsfähig sein, damit der SQL Server-Dienst gestartet bzw. ein Failover ausgeführt werden konnte. Außerdem mussten sich alle Schnittstellen im selben Subnetz oder VLAN befinden. Hinweis: Die Replikation auf Speicherebene zwischen Clusterknoten ist bei Multisubnetz-Clustern nicht implizit aktiviert. Eine Multisubnetz-FCI-Lösung muss eine SAN-basierte Drittanbieterlösung nutzen, um Daten zu replizieren und das Speicherfailover zwischen Clusterknoten zu koordinieren. Weitere Informationen finden Sie unter SQL Server 2012 AlwaysOn: Standortübergreifende Failoverclusterinstanz (http://sqlcat.com/sqlcat/b/whitepapers/archive/2011/12/22/sql-server2012-alwayson_3a00_-multisite-failover-cluster-instance.aspx). Zuverlässige Ausfallerkennung. Der WSFC-Clusterdienst unterhält eine dedizierte Administratorverbindung mit jeder SQL Server 2012-FCI auf dem Knoten. Über diese Verbindung wird regelmäßig die gespeicherte Systemprozedur sp_server_diagnostics aufgerufen, die umfassende Informationen zum Systemstatus zurückgibt. Vor SQL Server 2012 wurde der Status einer FCI vorwiegend über einen unilateralen Abrufmechanismus ermittelt. Dabei wurde vom WSFC-Clusterdienst regelmäßig eine neue SQL-Clientverbindung mit der Instanz hergestellt, der Servername abgefragt und die Verbindung anschließend wieder getrennt. Schon bei Ereignissen wie einem Verbindungsfehler, einem Abfragetimeout o. ä. wurde ein Failover ausgelöst, ohne dass aussagekräftige Diagnoseinformationen verfügbar waren. Weitere Informationen finden Sie unter sql_server_diagnostics (http://msdn.microsoft.com/dede/library/ff878233(SQL.110).aspx). Die Unterstützung für FCI-Speicherszenarien wurde erweitert: Bessere Unterstützung für Bereitstellungspunkte. SQL Server-Setup erkennt jetzt die Einstellungen der Clusterdatenträger-Bereitstellungspunkte. Die angegebenen Clusterdatenträger und alle verbundenen Datenträger werden der SQL Server-Ressourcenabhängigkeit während des Setups automatisch hinzugefügt. Lokal gespeicherte "tempdb". Für tempdb-Datenbanken nutzen FCIs jetzt lokalen, nicht freigegebenen Speicher. Das können lokale Solid-State-Laufwerke sein, auf die ressourcenintensive E/A-Aktivitäten eines freigegebenen SANs ausgelagert werden. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 19 Vor SQL Server 2012 erforderten FCIs, dass die tempdb auf einem symmetrischen freigegebenen Speichervolume gespeichert ist, das bei einem Failover zusammen mit anderen Systemdatenbanken repliziert wurde. Hinweis: Die tempdb-Datenbank wird in der master-Datenbank angelegt, die beim Failover zwischen Knoten verschoben wird. Das setzt einen gültigen symmetrischen Dateipfad (Laufwerk, Ordner und Berechtigungen) für alle potenziellen Knotenbesitzer voraus, da der SQL Server-Dienst andernfalls auf einigen Knoten ggf. nicht gestartet wird. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 20 Datenbankverfügbarkeit Die von der Infrastruktur bereitgestellten HA-Funktionen und die SQL Server-Komponenten auf Instanzebene wirken zusammen, um gehostete Datenbanken implizit zu schützen. Eine AlwaysOnLösung bietet zusätzliche Optionen für den expliziten Schutz von Datenbankdaten und Datenebenenanwendungen. AlwaysOn-Verfügbarkeitsgruppen Eine Verfügbarkeitsgruppe umfasst eine Gruppe von Benutzerdatenbanken, die bei einem Failover zusammen von einer SQL Server-Instanz auf eine andere Instanz innerhalb desselben WSFC-Clusters repliziert werden. Clientanwendungen können über einen WSFC-VNN (Virtual Network Name) – d. h. Verfügbarkeitsgruppenlistener – eine Verbindung mit den Datenbanken der Verfügbarkeitsgruppe herstellen. Die zugrunde liegenden SQL Server-Instanzen werden bei diesem Vorgang abstrahiert. AlwaysOn-Verfügbarkeitsgruppen überlassen Aufgaben wie Systemüberwachung, Failoverkoordination und Serverkonnektivität den WSFC (Windows Server Failover Clustering)-Diensten. Die AlwaysOnUnterstützung muss für jede SQL Server-Instanz aktiviert werden, die auf einem WSFC-Clusterknoten installiert ist. Die Instanzen müssen jedoch keine FCI-Instanz sein und erfordern keinen symmetrischen freigegebenen Speicher. Weitere Informationen finden Sie unter Übersicht über AlwaysOn-Verfügbarkeitsgruppen (http://msdn.microsoft.com/de-de/library/ff877884(SQL.110).aspx). Verfügbarkeitsreplikate und -rollen Jede SQL Server-Instanz in der Verfügbarkeitsgruppe hostet ein Verfügbarkeitsreplikat, das eine Kopie der Benutzerdatenbanken in der Verfügbarkeitsgruppe enthält. Eine SQL Server-Instanz kann nur ein Verfügbarkeitsreplikat aus einer bestimmten Verfügbarkeitsgruppe hosten, während dieselbe Instanz jedoch mehrere Verfügbarkeitsgruppen enthalten kann. Die SQL Server-Instanz muss über dedizierte (nicht freigegebene) Speichervolumes verfügen. Eines der Verfügbarkeitsreplikate übernimmt die Rolle des primären Replikats. Es wird als Masterkopie der Verfügbarkeitsgruppendatenbanken festgelegt und für Lese-/Schreibvorgänge aktiviert. Eine Verfügbarkeitsgruppe kann ein bis vier zusätzliche lesbare Verfügbarkeitsreplikate aufnehmen, die jeweils die Rolle eines sekundären Replikats übernehmen. Synchronisierung von Verfügbarkeitsreplikaten Der Inhalt jeder Datenbank in einer Verfügbarkeitsgruppe wird zwischen dem primären Replikat und den einzelnen sekundären Replikaten synchronisiert, indem Daten auf der Basis eines SQL ServerProtokolls verschoben werden. Daher muss für alle Datenbanken in der Verfügbarkeitsgruppe das Wiederherstellungsmodell FULL festgelegt werden. Sekundäre Replikate werden mit einer vollständigen Sicherung und Wiederherstellung der Datenbanken und Transaktionsprotokolle des primären Replikats initialisiert. Sobald neue Transaktionen auf dem primären Replikat festgeschrieben werden (Commit), wird der entsprechende Abschnitt des Transaktionsprotokolls zwischengespeichert, in eine Warteschlange gestellt und über das Netzwerk an einen Datenbankspiegelungs-Endpunkt auf den einzelnen sekundären Replikatknoten gesendet. Auf diese Weise werden neue Einträge aus dem Transaktionsprotokoll des primären Replikats an die Transaktionsprotokolle der einzelnen sekundären Replikate angehängt. Jedes sekundäre Replikat übermittelt regelmäßig eine Protokollfolgenummer (LSN) zurück an das primäre Replikat. Dabei handelt es sich um ein digitales Wasserzeichen, das angibt, wie viel Prozent des Transaktionsprotokolls festgeschrieben und auf den Remotedatenträger geschrieben wurden. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 21 Hinweis: Jedes Verfügbarkeitsreplikat verfügt über eigene unabhängige Transaktionsprotokoll-REDOThreads, die nicht unter die Synchronisierung von Verfügbarkeitsreplikaten fallen. Verzögerungen bei REDO-Vorgängen werden auf den sekundären Replikaten als Datenlatenz wahrgenommen. Zusätzlich zur Rolle als primäres oder sekundäres Replikat verfügt jedes Verfügbarkeitsreplikat auch über einen Verfügbarkeitsmodus, der das Festschreiben der Transaktionsprotokolle während einer COMMIT TRAN-Anweisung regelt: Synchroner Commitmodus. Das primäre Replikat schreibt eine Transaktion erst fest, nachdem alle sekundären Replikate mit synchronem Commit bestätigt haben, dass die auf die Transaktions-LSN folgenden Transaktionsprotokolle vollständig festgeschrieben wurden. Eine Verfügbarkeitsgruppe kann bis zu 2 sekundäre Replikate mit synchronem Commit enthalten. Der synchrone Commitmodus verursacht in den Datenbanken des primären Replikats zwar Transaktionslatenz, stellt jedoch auch sicher, dass die auf den sekundären Replikaten festgeschriebenen Transaktionen keine Datenverluste aufweisen. Asynchroner Commitmodus. Das primäre Replikat führt Transaktionscommits aus, nachdem das lokale Transaktionsprotokoll festgeschrieben wurde. Es wartet jedoch nicht, bis ein sekundäres Replikat mit asynchronem Commit das Festschreiben seines Transaktionsprotokolls bestätigt hat. Eine Verfügbarkeitsgruppe kann bis zu 4 sekundäre Replikate mit asynchronem Commit enthalten. Dabei sind maximal 4 sekundäre Replikate eines beliebigen Typs zulässig. Im asynchronen Commitmodus wird die Transaktionslatenz in den primären Replikatdatenbanken zwar minimiert, aber die Transaktionsprotokolle des sekundären Replikats können hinter dem primären Replikat zurückliegen, was Datenverluste zur Folge haben kann. Weitere Informationen finden Sie unter Verfügbarkeitsmodi (http://msdn.microsoft.com/dede/library/ff877931(SQL.110).aspx). Der Gesamtstatus des Datenflusses zwischen den Verfügbarkeitsreplikaten wird durch den Synchronisierungsstatus jedes Replikats angegeben. Wenn der Synchronisierungsstatus beim Failover auf ein sekundäres Replikat nicht "Synchronisiert" oder "Wird synchronisiert" lautet, treten höchstwahrscheinlich Datenverluste auf. In den Synchronisierungsdaten jedes sekundären Replikats ist eine Sitzungstimeout-Eigenschaft enthalten. Wenn ein sekundäres Replikat, das für den Verfügbarkeitsmodus mit synchronem Commit konfiguriert wurde, das Sitzungstimeout überschreitet, wird es intern vorübergehend als "asynchron" gekennzeichnet. So wird sichergestellt, dass sich der Ausfall des sekundären Replikats nicht auf das Commit des Transaktionsprotokolls auf dem primären Replikat auswirkt. Nachdem das sekundäre Replikat wieder fehlerfrei ist und das primäre Replikat eingeholt hat, wird automatisch der synchrone Commitmodus wiederhergestellt. Failover von Verfügbarkeitsgruppen Die Verfügbarkeitsgruppe und ein entsprechender VNN werden als Ressourcen im WSFC-Cluster registriert. Failover für Verfügbarkeitsgruppen werden auf der Ebene eines Verfügbarkeitsreplikats ausgeführt und unterliegen den Integritäts- und Failoverrichtlinien des primären Replikats. Eine Failoverrichtlinie für Verfügbarkeitsgruppen verwendet die FailureConditionLevel-Eigenschaft, um die Toleranzschwelle für Ausfälle anzugeben, die sich auf die Verfügbarkeitsgruppe auswirken, zusammen mit der gespeicherten Systemprozedur sp_server_diagnostics. Dieser Mechanismus wird auch für FCI-Failoverrichtlinien verwendet. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 22 Anstatt den Besitz von freigegebenen physischen Ressourcen bei einem Failover auf einen anderen Knoten zu übertragen, wird WSFC dazu genutzt, ein sekundäres Replikat auf einer anderen SQL ServerInstanz neu zu konfigurieren, sodass es zum primären Replikat wird. Die VNN-Ressource der Verfügbarkeitsgruppe wird dann auf diese Instanz übertragen. Alle Clientverbindungen der betroffenen Verfügbarkeitsreplikate werden zurückgesetzt. Der aktuelle Status, Synchronisierungszustand und Verfügbarkeitsmodus der Replikate bestimmen zusammen die Failoverbereitschaft eines jeden Replikats. Dies ist ein Indikator für die Wahrscheinlichkeit eines Datenverlusts. Diese Informationen zum Replikatstatus werden im AlwaysOn-Dashboard oder in der sys.dm_hadr_availability_replica_states-Systemsicht angezeigt. Jedes Verfügbarkeitsreplikat verfügt außerdem über einen konfigurierten Failovermodus, der das Replikatverhalten bei einem indizierten Failover steuert. Automatisches Failover (ohne Datenverlust). Dieser Modus ermöglicht das schnellstmögliche Failover aller AlwaysOn-Konfigurationen, weil das Transaktionsprotokoll des sekundären Replikats bereits festgeschrieben und synchronisiert wurde. Für offene Transaktionen auf dem primären Replikat wird ein Rollback ausgeführt, und die Rolle des primären Replikats wird ohne Benutzereingriff auf ein sekundäres Replikat übertragen. Für die primären und sekundären Replikate müssen der automatische Failovermodus und der Verfügbarkeitsmodus für synchrone Commits festgelegt werden. Der Synchronisierungsstatus zwischen den Replikaten muss "Synchronisiert" lauten. Darüber hinaus muss der WSFC-Cluster über ein fehlerfreies Quorum verfügen. Automatische Failover werden nicht unterstützt, wenn sich das primäre oder das sekundäre Replikat auf einer FCI befindet. Diese Funktion ist blockiert, um einen "Wettlauf" zwischen Verfügbarkeitsgruppen- und FCI-Failovern zu unterbinden. Manuelles Failover. Bei diesem Modus kann der Administrator den Status des primären Replikats bewerten und ein Failover auf ein sekundäres Replikat einleiten oder nicht. Je nach Verfügbarkeitsmodus und Synchronisierungsstatus stehen folgende Optionen zur Verfügung: o Geplantes manuelles Failover (ohne Datenverlust). Dieser Failovertyp wird nur unterstützt, wenn sowohl das primäre als auch das sekundäre Replikat fehlerfrei sind und den Status "Synchronisiert" aufweisen. Dieser Typ ist funktional vergleichbar mit einem automatischen Failover. o Erzwungenes manuelles Failover (Datenverlust möglich). Dies ist der einzig mögliche Failovertyp, wenn für das sekundäre Zielreplikat der Verfügbarkeitsmodus für asynchrone Commits eingestellt ist bzw. das Zielreplikat nicht mit dem primären Replikat synchronisiert ist. Warnung: Diese Failoveroption ist ausschließlich für die Notfallwiederherstellung konzipiert. Wenn das primäre Replikat fehlerfrei und verfügbar ist, sollten Sie den Verfügbarkeitsmodus der beteiligten Replikate in den synchronen Commitmodus ändern und ein geplantes manuelles Failover ausführen. Weitere Informationen finden Sie unter Ausführen eines erzwungenen manuellen Failovers einer Verfügbarkeitsgruppe (http://msdn.microsoft.com/de-de/library/ff877957(SQL.110).aspx). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 23 Sie müssen ein manuelles Failover ausführen, wenn eine der folgenden Bedingungen auf das primäre Replikat oder das sekundäre Failoverreplikat zutrifft: Der Failovermodus lautet "Manuell". Der Verfügbarkeitsmodus lautet "Asynchroner Commit". Das Replikat befindet sich auf einer FCI. Weitere Informationen finden Sie unter Failovermodi (AlwaysOn-Verfügbarkeitsgruppen) (http://msdn.microsoft.com/de-de/library/hh213151(SQL.110).aspx). Hinweis: Wenn für das neue primäre Replikat nicht der synchrone Commitmodus festgelegt wurde, weisen die sekundären Replikate nach einem Failover den Synchronisierungsstatus "Angehalten" auf. Es werden so lange keine Daten an die sekundären Replikate gesendet, bis das primäre Replikat den synchronen Commitmodus aufweist. Verfügbarkeitsgruppenlistener Ein Verfügbarkeitsgruppenlistener ist ein virtueller WSFC-Netzwerkname (VNN), über den Clients auf eine Datenbank in der Verfügbarkeitsgruppe zugreifen. Die VNN-Clusterressource ist im Besitz der SQL Server-Instanz, auf der das primäre Replikat gehostet wird. Der VNN wird nur während der Erstellung des Verfügbarkeitsgruppenlisteners oder im Verlauf von Konfigurationsänderungen beim DNS registriert. Alle virtuellen IP-Adressen, die im Verfügbarkeitsgruppenlistener definiert sind, werden unter demselben VNN beim DNS registriert. Damit der Verfügbarkeitsgruppenlistener verwendet werden kann, muss der VNN in einer Verbindungsanforderung des Clients als Server angegeben und der Name einer Datenbank verwendet werden, die in der Verfügbarkeitsgruppe enthalten ist. Im Normalfall würde so eine Verbindung mit der SQL Server-Instanz hergestellt, die das primäre Replikat hostet. Zur Laufzeit verwendet der Client einen lokalen DNS-Resolver, um eine Liste der IP-Adressen und TCPPorts abzurufen, die dem VNN zugeordnet sind. Der Client versucht dann, eine Verbindung mit jeder der IP-Adressen herzustellen, bis die Verbindung erfolgreich ist oder das Verbindungstimeout überschritten wurde. Wenn der Parameter MultiSubnetFailover auf TRUE festgelegt ist, versucht der Client, die Verbindungsversuche parallel auszuführen, was die Ausführung eines Clientfailovers wesentlich beschleunigt. Bei einem Failover werden alle Clientverbindungen auf dem Server zurückgesetzt, die Besitzrechte für den Verfügbarkeitsgruppenlistener gehen mit der primären Replikatrolle auf eine neue SQL ServerInstanz über, und der VNN-Endpunkt wird an die virtuellen IP-Adressen und TCP-Ports der neuen Instanz gebunden. Weitere Informationen finden Sie unter Verfügbarkeitsgruppenlistener, Clientkonnektivität und Anwendungsfailover (http://msdn.microsoft.com/de-de/library/hh213417(SQL.110).aspx). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 24 Filtern nach Anwendungsabsicht Beim Herstellen der Verbindung über den Verfügbarkeitsgruppenlistener kann die Anwendung angeben, ob sowohl Lese- als auch Schreibzugriffe oder ausschließlich Lesezugriffe ausgeführt werden. Falls keine Anwendungsabsicht angegeben wird, werden Lese-/Schreibzugriffe für den Client angenommen. Für die primäre und sekundäre Rolle jedes Verfügbarkeitsreplikats können Sie eine VerbindungszugriffEigenschaft angeben, die als verbindungsspezifischer Filter für die Anwendungsabsicht des Clients verwendet wird. Bei einer unzulässigen Kombination von Anwendungsabsicht und Verbindungszugriff wird die Verbindung automatisch abgelehnt. SQL Server sollte die Clientverbindungsanforderungen mithilfe der folgenden Regeln herausfiltern. Das Verfügbarkeitsreplikat befindet sich in der primären Rolle und der Verbindungszugriff entspricht: Jede beliebige Anwendungsabsicht zulassen. Clientverbindungen nicht nach Anwendungsabsicht filtern. Nur explizite Lese-/Schreibabsicht zulassen. Verbindung zurückweisen, wenn der Client Lesezugriffe angibt. Das Verfügbarkeitsreplikat befindet sich in der sekundären Rolle und der Verbindungszugriff entspricht: Keine Verbindungen sind zulässig. Alle Verbindungen ablehnen; das Replikat wird nur für die Notfallwiederherstellung verwendet. Jede beliebige Anwendungsabsicht zulassen. Clientverbindungen nicht nach Anwendungsabsicht filtern. Anwendungsabsicht "Lesezugriff". Verbindung ablehnen, wenn der Client keine Lesezugriffe angibt. Weitere Informationen finden Sie unter Konfigurieren des schreibgeschützten Zugriffs auf ein Verfügbarkeitsreplikat (http://msdn.microsoft.com/de-de/library/hh213002(SQL.110).aspx). Anwendungsabsicht: Routing von Leseoperationen Ein Alleinstellungsmerkmal für AlwaysOn-Verfügbarkeitsgruppen ist deren Fähigkeit, die StandbyHardwareinfrastruktur für andere Zwecke als die Notfallwiederherstellung zu nutzen. Indem Sie eines oder mehrere der sekundären Replikate für den Lesezugriff konfigurieren, können Sie die Arbeitslast primärer Replikate zu einem beträchtlichen Teil auslagern. Die folgenden Arbeitslasten können auf lesbare sekundäre Replikate ausgelagert werden: Reporting, Datenbanksicherungen, Datenbank-Konsistenzprüfungen, Indexfragmentierungsanalyse, DatenpipelineExtraktion, operative Unterstützung und Ad-hoc-Abfragen. Für jedes Verfügbarkeitsreplikat können Sie optional eine sequenzielle Routingliste mit Endpunkten der SQL Server-Instanz konfigurieren. Diese gilt, solange sich das Replikat in der primären Rolle befindet. Falls vorhanden, werden Clientverbindungsanforderungen, für die die Anwendungsabsicht "Lesezugriff" festgelegt wurde, anhand der Liste zum ersten verfügbaren sekundären Replikat in der Liste umgeleitet, das die oben beschriebenen Filterbedingungen erfüllt. Hinweis: Das Routing von Lesezugriffen wird von dem Verfügbarkeitsgruppenlistener ausgeführt, der an das primäre Replikat gebunden ist. Die Clientumleitung funktioniert nicht, wenn das primäre Replikat offline ist. Weitere Informationen finden Sie unter Konfigurieren des schreibgeschützten Routings für eine Verfügbarkeitsgruppe (SQL Server) (http://msdn.microsoft.com/de-de/library/hh653924(SQL.110).aspx) Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 25 Optimierte Datenbankverfügbarkeit SQL Server 2012 bietet mehrere Funktionserweiterungen für die Datenbankkonfiguration und verwandte Aufgaben. Die folgende Erweiterung reduziert die Wiederherstellungszeit: Vorhersagbare Wiederherstellungszeit. Sie können ein Zielwiederherstellungszeit-Intervall pro Datenbank festlegen, über das die zeitgesteuerte Ausführung eines im Hintergrund ausgeführten CHECKPOINT-Befehls gesteuert wird. Dieser indirekte Prüfpunkt tritt regelmäßig auf und basiert auf der Zeit, die die Wiederherstellung des Transaktionsprotokolls bei einem Neustart oder Failover schätzungsweise dauert. Dadurch werden E/A-Aktivitäten für die einzelnen Prüfpunkte in etwa gleich große Segmente unterteilt und die Vorhersagbarkeit der Wiederanlaufdauer (RTO) verbessert. Vor SQL Server 2012 wurden CHECKPOINT-Befehle – unabhängig vom Transaktionsvolumen und der Transaktionslast – in festgelegten Intervallen ausgeführt, was die Vorhersagbarkeit der Wiederherstellungszeit erschwert hat. Weitere Informationen finden Sie unter Datenbankprüfpunkte (http://msdn.microsoft.com/dede/library/ms189573(SQL.110).aspx). Die folgenden Verbesserungen helfen, geplante Downtimes zu minimieren: Onlineindizierung für LOB-Spalten. Indizes, die Spalten vom Datentyp varbinary(max), varchar(max), nvarchar(max) bzw. XML-Datentypen enthalten, können jetzt online neu erstellt oder reorganisiert werden. Onlineschemaänderung für neue NOT NULL-Spalten. Wenn einer SQL Server 2012-Datenbanktabelle eine neue NOT NULL-Spalte mit einem Standardwert hinzugefügt wird, ist zur Aktualisierung der Systemmetadaten nur eine Schemasperre erforderlich. Beim Ausführen der ALTER TABLE-Anweisung müssen nicht alle Zeilen mit Daten aufgefüllt werden. Der Standardspaltenwert wird von SQL Server nur physisch gespeichert, wenn eine Zeile tatsächlich geändert oder neu indiziert wird. Abfragen geben den Standardwert aus den Metadaten zurück, solange kein tatsächlicher Spaltenwert vorhanden ist. Beispiel für die optimierte Unterstützung von Speicherszenarien: Automatische Seitenreparatur. Bestimmte Fehler in Speichersubsystemen können zur Beschädigung einer Datenseite führen und sie unlesbar machen. AlwaysOn-Verfügbarkeitsgruppen sind in der Lage, diese Fehlertypen zu erkennen und automatisch zu reparieren, indem asynchron eine neue Kopie der betroffenen Datenseiten von einem anderen Verfügbarkeitsreplikat angefordert und repliziert wird. Eine ähnliche Funktionalität war bereits vor SQL Server 2012 für die Datenbankspiegelung verfügbar. Diese wurde jetzt auf die Unterstützung mehrerer Replikate ausgeweitet. Weitere Informationen finden Sie unter Automatische Seitenreparatur (http://msdn.microsoft.com/de-de/library/bb677167(SQL.110).aspx). Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 26 Empfehlungen zur Clientkonnektivität Beachten Sie die folgenden Hinweise, damit Clientanwendungen die Vorteile der Microsoft SQL Server 2012 AlwaysOn-Technologien in vollem Umfang nutzen können: AlwaysOn-fähige Clientbibliothek. Verwenden Sie eine Clientbibliothek, die die TDS (Tabular Data Stream)-Protokollversion 7.4 oder höher unterstützt. Das sollte die Unterstützung der AlwaysOnFunktionalität von Clientseite gewährleisten. Beispiele für Clientbibliotheken sind der .NET Framework 4.02-Datenanbieter für SQL Server und SQL Native Client 11.0. ConnectionProvider-Eigenschaft: MultiSubnetFailover = True. Verwenden Sie dieses Schlüsselwort in den Verbindungszeichenfolgen, um Clientbibliotheken die parallele Verbindung mit allen IPAdressen zu ermöglichen, die für den Verfügbarkeitsgruppenlistener oder die FCI mit IP-Adressen in mehreren Subnetzen registriert sind. ConnectionProvider-Eigenschaft: ApplicationIntent = ReadOnly. Lagern Sie Leseoperationen nach Möglichkeit vom primären Replikat auf sekundäre Replikate aus. Timeout älterer Clientverbindungen. Ältere Clientbibliotheken unterstützen keine parallelen Verbindungsversuche. Bei mehreren IP-Adressen versuchen sie deshalb, nacheinander eine Verbindung mit jeder IP-Adresse herzustellen, bis ein TCP-Timeout eintritt oder der Verbindungsversuch erfolgreich ist. Sie sollten das Verbindungstimeout für ältere Clients anpassen, um die Timeouts und wiederholten Verbindungsversuche bei mehreren IP-Adressen zu reduzieren. Stellen Sie einen Wert von mindestens 15 Sekunden + 21 Sekunden für jedes sekundäre Replikat ein. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 27 Schlussfolgerung Dieses Whitepaper dient als Richtschnur, um geplante und ungeplante Downtimes zu reduzieren, die Anwendungsverfügbarkeit zu erhöhen und Daten durch den Einsatz einer HA- und DR-Lösung mit SQL Server 2012 AlwaysOn-Technologie effizient zu schützen. Viele Faktoren und Herausforderungen bei der Planung, Verwaltung und Überwachung einer hochverfügbaren Datenbankumgebung sind unter Verweis auf den Wiederanlaufzeitpunkt (RPO) und die Wiederanlaufdauer (RTO) messbar. SQL Server 2012 AlwaysOn bietet Funktionen auf Infrastruktur-, Datenplattform- und Datenbankebene, die Ihrem Unternehmen helfen, gängige HA- und DR-Lösungen in Übereinstimmung mit den festgelegten RPO- und RTO-Zielen umzusetzen. Weitere Informationen: http://www.microsoft.com/sqlserver/: SQL Server-Website http://technet.microsoft.com/de-de/sqlserver/: SQL Server TechCenter http://msdn.microsoft.com/de-de/sqlserver/: SQL Server DevCenter War dieses Dokument hilfreich? Geben Sie uns Ihr Feedback. Bewerten Sie dieses Dokument auf einer Skala von 1 (schlecht) bis 5 (ausgezeichnet), und begründen Sie Ihre Bewertung. Beispiel: Bewerten Sie es hoch aufgrund guter Beispiele, ausgezeichneter Screenshots, klarer Formulierungen oder aus einem anderen Grund? Bewerten Sie es niedrig aufgrund schlechter Beispiele, ungenauer Screenshots oder unklarer Formulierungen? Dieses Feedback hilft uns, die Qualität von veröffentlichten Whitepapers zu verbessern. Feedback senden ◊ Version 1.1, 21. Februar 2012. Microsoft SQL Server AlwaysOn-Lösungen für Hochverfügbarkeit und Notfallwiederherstellung 28