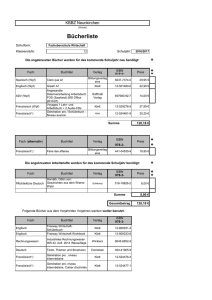
7 Datenmodellierung und Datenbanken
Werbung

Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
7 Datenmodellierung und Datenbanken
berall dort, wo es um die Aufbewahrung oder Verarbeitung von großen Datenmengen geht,
sind Datenbanksysteme im Spiel. Diese „Informations-Massenlager“ sind darauf spezialisiert,
den Umgang mit großen Datenmengen zu vereinfachen. Daf r wird meist eine standardisierte
Schnittstelle zur Verf gung gestellt.
Der Umgang mit einem Datenbanksystem ist relativ unproblematisch, falls die
zugrundeliegende Datenstruktur gut an das Problem angepaßt ist und einige
Randbedingungen erf llt. Zur die Entwicklung solcher Datenstrukturen gibt es einige
bew hrte Techniken, die wir nun kennenlernen wollen.
Den gesamten Entwicklungsprozeß wollen wir anhand speziellen Beispiels aus dem
Bibliotheksbereich veranschaulichen. Allerdings verzichten wir dabei auf eine vollst ndige
Behandlung des gesamten Systeme und besprechen jeweils nur Ausschnitte daraus.
7.1 Informelle Beschreibung des Systems
Anfangs veranstalten wir eine Art „Brainstorming“, indem wir den gesamten f r uns
relevanten Wirklichkeitsausschnitt genau ansehen. Dazu holen wir alle n tigen Informationen
ber die Anforderungen ein, informieren uns ber Randbedingungen, auf deren Gestaltung
wir keinen Einfluß haben, bestimmen die Grenzen des Systems und seine geplante
Funktionalit t. Die sp teren Nutzer werden ausf hrlich nach ihren W schen und
Vorstellungen befragt.
In unserem Beispiel soll eine kleine Bibliothek elektronisch verwaltet werden. Dazu m ssen
Informationen zu Buchtiteln, Exemplaren, Autoren und Bibliothekskunden gespeichert und
verarbeitet werden k nnen.
Die Bibliothek verf gt ber einen Internet-Anschluß, weshalb das Frontend des Systems ber
einen Webbrowser bedient werden soll.
7.2 Datenmodellierung
Nach der “weichen“ informellen Beschreibung ist es nun Zeit, das System „hart“ zu
beschreiben, also formal zu beschreiben. Daf r gibt es eine Reihe von Techniken, die je nach
den Eigenheiten des Systems Vor- und Nachteile haben. Im Datenbankbereich ist die EntityRelationship Modellierung die mit Abstand h ufigste und erfolgreichste Technik.
7.2.1 Entity-Relationship Modell
Nun entwerfen wir ein solches Entity-Relationship Modell f r unser System. Es besteht aus
einer Menge von Entit tsklassen und Beziehungen zwischen diesen Entit tsklassen. Solange
wir nicht (mathematisch) exakt die Bedeutung der einzelnen Symbole von ER-Modellen
festgelegt haben, haben wir es allerdings genau genommen immer noch mit einer informellen
(intuitiven) Modellierungstechnik zu tun.
Entit ten
Der erste Schritt besteht in der Identifizierung der Entit ten. Hierbei handelt es sich um
individuelle und identifizierbare Elemente, Objekte, Individuen, Sachen, Begriffen, Ereignisse
o. . innerhalb des Systems. Diese Entit ten werden durch ihre Eigenschaften (Attribute)
beschrieben:
Seite 1
Peter Hubwieser
Didaktik der Informatik I
Titel:
Autor:
Verlag:
Ort:
Jahr
ISBN
Preis
Exemplare
Zustand
Standort
Fr ulein Smillas Gesp r f r Schnee
Peter Høeg
Carl Hanser
M nchen
1994
3-499-13599-x
19,90
3
gut, sehr gut, gut
Zimmer 3, Regal 5, Fach 7,7 und 8, Platz 3, 15,12
Name
Vorname
Land
andere Buchtitel
Høeg
Peter
D nemark
„Der Plan von der Abschaffung des Dunkels“
Name
Vorname
Geburtsdatum
Straße
PLZ
Ort
Telefon
Sperre
Meier
Peter
24.4.1966
Tegtm llerweg 9
80089
M nchen
(089) 383 245 12
keine
WS 1998/99
Entit tsklassen
Entit ten mit gleichen Eigenschaften werden dann unter einem Oberbegriff zu Entit tsklassen
zusammengefaßt. In unserem Fall stellen wir fest, daß die M glichkeit, mehrere Exemplare je
Buch zu verwalten, bei der Klassifizierung Probleme macht. Wir f hren also eine eigene
Entit t f r die Exemplare ein. Bei den Personen stellen wir Unterschiede bei den Attributen
von Autoren und Ausleihern fest. Damit erhalten wir vorerst die folgenden Entit tsklassen
(mit den Attributen in Klammern):
•
•
•
•
•
Buchtitel (Titel, Autor, Verlag, Ort, Jahr, ISBN, Preis)
Exemplar (Bezeichnung, Zustand, Aufnahmedatum)
Standort (Zimmer, Regal, Fach, Platz)
Autor (Name, Vorname, Land, andere)
Kunde (Name, Vorname, Geburtsdatum, Straße, PLZ, Ort, Telefon, Sperre)
Allerdings haben wir immer noch einige Probleme:
• Wie sollen die Zuordnungen von Buchtiteln zu Autoren, Exemplaren und Kunden geregelt
werden ?
• Wie soll man mit der Liste weiterer Ver ffentlichungen (andere) bei den Autoren
umgehen?
Beziehungen
Die L sung wird durch das Konzept der Beziehungen (relationships) zwischen Entit tsklassen
geliefert. Buchtitel und Autor werden durch die Beziehung verfasst_von verbunden. Damit
er brigt sich gleichzeitig die Verwaltung von „weiteren Exemplaren“. Buchtitel und
Seite 2
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Exemplar k nnen durch die Beziehung ist_vorhanden verkn pft werden, Exemplar und
Kunde durch die Beziehung ausgeliehen_von, Exemplar und Standort durch steht_in.
Ein genauer Blick auf die Situation zeigt uns, daß auch die Beziehungen Eigenschaften
(Attribute) haben k nnen. So ist es etwa sinnvoll, unsere Beziehung ausgeliehen_von mit den
Attributen Datum und Bearbeiter zu versehen.
ER-Diagramme
Um die bersicht zu bewahren, stellt man ER-Modelle meist graphisch in speziellen ERDiagrammen dar. Seine Elemente sind Entit tsklassen (Rechtecke), Beziehungen zwischen
diesen Entit tsklassen (Rauten) und Eigenschaften (Attribute) der Entit tsklassen und
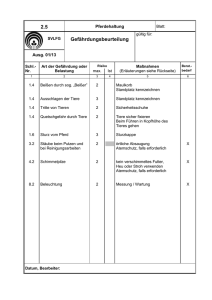
Beziehungen, symbolisiert durch Ellipsen. In unserem Fall erhalten wir das ER-Diagramm
aus Abbildung 1.
Verlag
Ort
Jahr
Preis
ISBN
Name
Vorname
Land
Autor
Titel
Buchtitel
verfasst_von
Autor
Name
ist_
vorhanden
Vorname
Platz
Geb.Dat.
Fach
Kunde
Straße
Exemplar
steht_in
Standort
Regal
PLZ
Ort
ausgeliehen
_von
Datum
Tel.
Bearbeiter
Sperre
Zimmer
Bez.
Zustand
Aufn.Dat.
Abbildung 1: ER-Diagramm der Bibliothek
In umfangreicheren ER-Diagrammen l ßt man die Attribute zugunsten der bersichtlichkeit
meist weg. Diese m ssen dann allerdings getrennt in eigenen Tabellen notiert werden.
Zur Umsetzung des Entwurfs in ein reales Datenbanksystem ist es von großer Bedeutung,
wieviele Entit ten der einen Seite durch eine bestimmte Beziehung mit Entit ten der anderen
Seite verbunden werden k nnen. Dies Eigenschaft heißt Kardinalit t der Beziehung. In einem
groben Ansatz gibt es daf r drei M glichkeiten:
• Kardinalit t 1:1
Einer Entit t der einen Seite wird genau eine Entit t der anderen Seite zugeordnet und
umgekehrt.
Exemplar
102201
steht_in
Standort
Zimmer 2, Regal 2, Fach 12, Platz 14
Seite 3
Peter Hubwieser
Didaktik der Informatik I
12110
23311
WS 1998/99
Zimmer 3, Regal 3, Fach 1, Platz 12
Zimmer 1, Regal 12, Fach 12, Platz 2
1
ber die Problematik der Identifikation von Entit ten ber spezielle Schl sselattribute
werden wir uns sp ter Gedanken machen
• Kardinalit t 1:n
Einer Entit t der einen Seite k nnen mehrere Entit ten der anderen Seite zugeordnet werden,
umgekehrt aber h chstens eine Entit t
Buchtitel
Fr ulein Smillas ..
Fr ulein Smillas ..
Fr ulein Smillas ..
ist_vorhanden
Exemplar
10223
10224
10225
• Kardinalit t n:m
Einer Entit t der einen Seite k nnen mehrere Entit ten der anderen Seite zugeordnet werden
und umgekehrt. Dieser Fall kann immer in zwei Beziehungen mit den Kardinalit ten 1:m
bzw. n:1 aufgel st werden.
Buchtitel
Physik, Jahrgangsstufe 8
Physik, Jahrgangsstufe 8
Physik, Jahrgangsstufe 8
Fr ulein Smillas Gesp r f r Schnee
Der Plan von der Abschaffung des Dunkels
verfaßt_von
Diese n:m-Beziehung k nnte man aufl sen in
verfaßt_u.a._von (1:n)
und
Autor
Herbert Knauth
Siegfried K hnel
Hubert Schafbauer
Peter Høeg
Peter Høeg
hat_verfaßt (m:1)
Im ER-Diagramm notieren wir die Kardinalit ten mit Hilfe der entsprechenden Zahlen am
linken und rechten Ankn pfungspunkt der Beziehungen.
Buchtitel
n
verfaßt_von
m
Autor
Abbildung 2: Notation der Kardinalit t im ER-Diagramm
7.2.2 Relationale Modellierung
Parallel zum ER-Modell k nnte man auch gleich von Beginn an ein relationales Modell
aufbauen, mit dem man bereits auf der Ebene der Implementierung in einer relationalen
Datenbank (siehe unten) angekommen w re. Die Einhaltung von Normalformen sorgt bei
diesem Vorgehen daf r, daß am Ende eine brauchbare Datenstruktur entsteht. In der Regel ist
das Ergebnis dieser Strategie identisch mit dem Produkt, das man durch Umformung eines
guten ER-Modells in ein relationales Modell erh lt. Diese Umformung wird im n chsten
Kapitel beschrieben.
Seite 4
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Relationen
Der Name des Modells stammt vom mathematischen Begriff der Relation ab. Eine
mathematische Relation R ist eine Menge von Tupeln r = (r1, .. ,rn), deren Komponenten ri
jeweils aus einer bestimmten Grundmenge Ri stammen. Dann ist die Menge aller Tupel genau
das Kartesische Mengenprodukt R1 x R2 x .. x Rn. Eine Relation R ist eine Teilmenge dieses
Produktes:
R = {r | r = (r1, .. ,rn)
r1
R1 , .. , rn
Rn }
R1 x .. x Rn
Ein entscheidendes Merkmal einer Relation ist ihre (feste) Stelligkeit, d.h. die Anzahl der
Elemente ihrer Tupel. In der Informatik verwendet man als Grundmengen anstelle der inder
Mathematik blichen Zahlenmengen oft selbstdefinierte Mengen von Bezeichnern (Namen),
sogenannte Sorten oder Typen, wie etwa Ort = {Bad Aibling, Kolbermoor¸ M nchen,
Rosenheim, Großkarolinenfeld, ...} oder M nner = {Ernst Huber, Franx Muxeneder, Hanno
Buckmann, ...}
Beispiele f r Relationen:
1. Wir betrachten die Mengen A = {2, 3, 4} und B = { 5, 6, 8} sowie die Relation R1 = {(a,
b) A x B | a teilt b}. Dann besteht das kartesische Produkt A x B aus den allen Paaren
(2-Tupeln), die man durch Kombination eines Elementes aus A und eines Elementes aus
B bilden kann, also aus 3 * 3 = 9 Paaren :
A x B = {(2, 5), (2, 6,), (2, 8), (3, 5), (3, 6), (3, 8), (4, 5), (4, 6), (4, 8)}
R1 enth lt dagegen nur die Paare (a, b)
teilt b“ erf llt ist:
A x B, f r welche die Relationsbedingung „a
R1 = {(2, 6), (2, 8), (3, 6), (4, 8)}.
2. Die Relation R2 = ist_verheiratet_mit ist eine Teilmenge des 2-stelligen
Mengenproduktes M nner x Frauen:
(Anna M ller, Ernst Huber) R2
Anna M ller ist_verheiratet_mit Ernst Huber
3. Die 3-stellige Relation R3 = Adresse ist ein Teil des Mengenproduktes Straße x PLZ x
Ort. Dazu k nnten die folgenden 3-Tupeln geh ren:
(Sudetenstr. 16, 83059, Kolbermoor), (Westendstr. 4a, 83043 Bad Aibling)
Je h her die Stelligkeit einer Relation ist, desto bersichtlicher wird es, sie in Tabellenform
zuschreiben. Unser letzes Beispiel k nnte dann etwa so aussehen:
Sudetenstr. 16
Westendstr. 4a
R merstr. 11
83059
83043
80333
Kolbermoor
Bad Aibling
M nchen
Relationales Modell
Ein relationales Modell besteht aus einer Menge von Tabellen (T1, .. , Tn), die jeweils aus
einer (grunds tzliche unbeschr nkten) Menge von Datens tzen (Tupeln) mit gleicher Struktur
Seite 5
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
bestehen: Ti = {d1, ..., dk}. Ein Datensatz di enth lt eine Reihe von Daten, die als Werte der
Attribute aufgefaßt werden k nnen. dk = (xk1, .., xkm). Die Struktur einer Tabelle wird durch
eine Liste von Attributnamen (a1, .. am) festgelegt.
T1 = Autor
a1
a2
a3
Name Vorname Land
Høeg
Peter
D nemark
d1
Knauth Herbert
Deutschland d2
K hnel Siegfried
Deutschland d3
T2 = Buchtitel
a1
Titel
Physik,
Jahrgangsstufe 8
Fr ulein Smillas
Gesp r f r
Schnee
Der Plan von der
Abschaffung des
Dunkels
a2
Verlag
Oldenbou
rg
Hanser
a3
a4
Ort
Jahr
M nchen 1994
Hanser
M nchen 1996
M nchen 1991
Wertemengen
Jedes Attribut ai kann Werte aus einer bestimmten Wertemenge (Sorte oder Typ) Si
annehmen. Zum Beispiel in der Tabelle T2:
S1 = Text,
S2 = Verlagsname
S3 = Ortsbezeichung,
S4 = Jahresangabe
(Standardsorte)
= {Springer, Hanser, Oldenbourg, O’Reilly, ... }
= {M nchen, Wien, Z rich, New York, .. }
= {1500, 1501, 1502, ... 9999}
Die Festlegung dieser Mengen (im Datenbankjargon auch Dom nen genannt) erlaubt
zumindest prinzipiell eine gewisse Kontrolle der G ltigkeit (Validit t) von Benutzereingaben.
Oft wird dann jedoch bei der Implementierung aus Effizienzgr nden darauf verzichtet und
eine Standardsorte verwendet.
Schema
Die Struktur der Tabelle wird in kompakter Weise durch das sogenannte Schema festgelegt:
Tk (a1:S1, .. ,am:Sm),
etwa Buchtitel(Titel: Text, Verlag: Verlagsname, Ort: Verlagsort, Jahr: Jahresangabe).
Mathematisch gesehen handelt es sich bei einer Tabelle mit dem Schema S = (a1:S1, .. ,am:Sm)
um eine Relation:
R S1 x .. x Sm
•
Punktnotation
Falls man es mit mehreren Tabellen zu tun hat, wird zur Vermeidung von Unklarheiten die
Tabelle, zu der das Attribut geh rt, (durch einen Punkt getrennt) dem Attributnamen
vorangestellt:
Tk.ai
bezeichnet somit den Namen des i-ten Attributs der Tabelle Tk. Beispiele daf r sind
Seite 6
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Autor.Name, Buchtitel.Verlag.
Schl ssel
Wenn wir annehmen, daß es in unserer Tabelle Autoren zwei (verschiedene) deutsche
Autoren mit dem Namen Hans Meier gibt, bekommen wir Probleme, da diese Datens tze
nicht unterscheidbar sind. Will man beispielsweise die Anzahl der Buchtitel eines der beiden
Autoren feststellen, so werden automatisch auch die B cher des anderen Hans Meier
mitgez hlt.
Jede Tabelle (Relation) muß also ein Attribut oder eine Kombination von Attributen
enthalten, die sicherstellen, daß auf jeden einzelnen Datensatz zugegriffen werden kann. Ein
solches Attribut bzw. eine solche Kombination von Attributen heißt Schl ssel der Tabelle T
bzw. der Relation R.
Mathematisch ausgedr ckt gilt (im Fall eines einzelnen Attributs):
ai heißt Schl ssel einer Relation R
f r zwei Tupel r, s R mit r = (r1, .. , rm) und s = (s1, .., sm) gilt: ri = si
r = s.
Zumindest die Kombination aller Attribute sollte auf jeden Fall ein Schl ssel der Tabelle sein.
Andernfalls enth lt die Tabelle identische Datens tze. In unserer Autorentabelle m ssen wir
also mindestens ein neues Attribut einf hren, um einen Schl ssel zu erhalten. Mit großer
Wahrscheinlichkeit w re dann die Kombination aller Attribute ein brauchbarer Schl ssel. Da
jedoch auch diese Eindeutigkeit nicht absolut sicher ist, greift man in der Datenbanktechnik
meist auf k nstliche Schl sselattribute (Indentifikationsnummern) zur ck, die per
definitionem eindeutig sind. Wir ndern also das Schema unserer Autoren:
Autor (Autor_nr: Integer, Name: Text, Vorname: Text, Land: L ndername).
Damit haben wir den k nstlichen Schl ssel Autor_nr eingef hrt. In der tabellarischen
Darstellung von Relationen unterstreichen wir ab jetzt die Schl sselattribute.
7.2.3 Optimierung des relationalen Modells
Bei Verzicht auf ER-Modellierung sind die ersten Entw rfe des relationalen Modells meist in
mehrfacher Hinsicht nicht optimal. Um diese Schwachstellen zu beseitigen, gibt es eine Reieh
von Normalformen, die sicherstellen, daß der Entwurf datentechnisch zumindest. brauchbar
ist.
Erste Normalform (1NF)
Eine Tabelle ist in erster Normalform, falls alle Attribute nur atomare Werte annehmen
k nnen. Es d rfen also Mengen, Aufz hlungstypen oder Wiederholungsgruppen als Werte
der Attribute auftreten.
Nicht in erster Normalform w re die folgende Tabelle:
Kunde
Name
Vorname
Adresse
M ller
Anna
Sudetenstr. 18, 83222, Rosenheim
Huber
Karl
Knallerweg 19, 86321, Ganselham
Seite 7
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Die erkennt man bereits am Schema
Kunde(Name: Text, Vorname: Text, Adresse: Text x PLZ x Ortsname)
Eine berf hrung in die erste Normalisierung m ßte das Attribut Adresse in drei Attribute
mit atomaren Wertebereichen aufteilen:
Kunde
Name
Vorname
Straße
PLZ
Ort
M ller
Anna
Sudetenstr. 18
83222
Rosenheim
Huber
Karl
Knallerweg 19
86321
Ganselham
Zweite Normalform (2NF)
Beim Entwurf eines Bibliothekssystems (ohne ER-Modell!) k nnte ein Entwickler auf die
folgende Tabelle kommen:
B cher
Titel_Nr Titel
Autor
Exemplar_nr Zimmer Regal
Fach
Platz
1222
Fr ulein
Smilla...
Peter Høeg 01
2
3
12
3
1222
Fr ulein
Smilla
Peter Høeg 02
2
3
12
4
1222
Fr ulein
Smilla
Peter Høeg 03
2
3
12
5
1333
Das Parf m
Patrick
S ßkind
01
2
3
13
1
1333
Das Parf m
Patrick
S ßkind
02
2
3
13
2
1333
Das Parf m
Patrick
S ßkind
03
2
3
13
3
Bei der Arbeit mit dieser Tabelle treten u.a. die folgenden Probleme auf:
Datenredundanz: F r jedes Exemplar werden Titel und Autor erneut eingetragen, obwohl
die n tige Information bereits durch das erste Exemplar vorhanden ist.
Ungewollter Datenverlust: Sind vor bergehend, etwa wegen Besch digung, keine
Exemplare eines Buches mehr vorhanden, so gehen die Informationen ber Titel und
Autor verloren. Bei der Neuanschaffung m ssen diese Informationen wieder besorgt
werden.
M gliche Inkonsistenz: Falls bei der Eintragung eines neuen Exemplars von „Das
Parf m“ die Datentypistin beispielsweise aus Versehen den Autor Edgar Wallace eintr gt,
gibt es den Titel „Das Parfum“ jetzt von zwei verschiedenen Autoren.
Seite 8
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Das Problem geht offensichtlich darauf zur ck, daß f r die gesamte Tabelle mindestens die
Attributkombination Titel_nr und Exemplar_nr als Schl ssel gebraucht wird, w hrend f r
einige Attribute wie Titel und Autor bereits Titel_nr als Schl ssel ausreicht.
•
Funktionale Abh ngigkeit
Um dieses Problem kompakter und exakter beschreiben zu k nnen, f hren wir den Begriff der
Funktionalen Abh ngigkeit ein:
Ein Attribut ai einer Relation R heißt funktional abh ngig von einem Attribut ak, falls f r alle
Tupel r, s R gilt:
rk = sk
Wir schreiben dann kurz: ak
ri = si .
ai.
Falls ein Attribut ai ist von einem Attribut ak funktional abh ngig ist, k nnen zwei Tupel also
nur dann verschiedene Werte von ai aufweisen, wenn sich auch die Werte von ak
unterscheiden.
F r die Funktionale Abh ngigkeit von einer Kombination zweier Attribute gilt dann
entsprechend:
akam
ai
r, s R : rk = sk
rm = sm
ri = si.
In unserem Beispiel sind die Attribute Autor, Titel von Titel_nr funktional abh ngig.
Dagegen h ngen Zimmer, Regal, Fach und Platz funktional von Titel_nr und
Exemplar_nr. ab:
Titel_nr Titel
Titel_nr Autor
Titel_nr, Exemplar_nr
Titel_nr, Exemplar_nr
Titel_nr, Exemplar_nr
Titel_nr, Exemplar_nr
Zimmer
Regal
Fach
Platz.
Zwei Datens tze mit verschiedenen Autoren m ssen sich also auch in der Titel_nr
unterscheiden. Falls die Regale oder die Pl tze unterschiedlich sind, d rfen die
Kombinationen der Titel_nr und der Exemplar-nr nicht identisch sein.
Als Schl ssel ist in unserer Tabelle ist daher nur die Kombination aus Titel_nr und
Exemplar_nr brauchbar. Das Problem liegt darin, daß einige Attribute bereits von einem Teil
der Schl sselkombination funktional abh ngig sind. Genau diese Abh ngigkeit wird durch die
2. Normalform ausgeschlossen.
•
2. Normalform
Eine Tabelle ist in zweiter Normalform, wenn sie in erster Normalform ist und wenn jedes
Attribut, das zu keiner Schl sselkombination geh rt,
nur von der gesamten
Schl sselkombination, nicht jedoch bereits von einem Teil davon funktional abh ngig ist.
Die Umformung in die zweite Normalform bringt daher eine Abspaltung neuer Tabellen mit
den kritischen Attributen mit sich, wobei jeweils der Teilschl ssel, von dem die
problematische Abh ngigkeit vorlag, als neuer Schl ssel verwendet wird. Die anderen Teile
Seite 9
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
des urspr nglichen Schl ssels verbleiben dennoch in der Ausgangstabelle, um die
urspr nglichen Zuordnungen zu erhalten.
In unserem Beispiel wird eine Tabelle Buchtitel mit den Attributen Titel_nr, Titel und
Autor abgespalten. Die Tabelle B cher wird sinnvollerweise in Exemplare umbenannt Die
Schl sseln von Exemplar bleibt weiterhin die Kombination aus Exemplar_nr und
Buchtitel_nr.
Buchtitel
Exemplare
Titel_ Titel
nr
Autor
Exempla Titel_nr
r_nr
Zimmer Regal
Fach
Platz
1222
Fr ulein Smillas..
Peter Høeg
01
1222
2
3
12
3
1333
Das Parf m
Patrick
S ßkind
02
1222
2
3
12
4
03
1222
2
3
12
5
01
1333
2
3
13
1
02
1333
2
3
13
2
03
1333
2
3
13
3
Dritte Normalform (3NF)
Trotz Vorliegens der 2. Normalform kann es noch zu Datenredundanzen kommen. Wir
betrachten unsere obige Kundentabelle, die wir noch um einen k nstlichen Schl ssel
Kunde_nr erg nzt haben.
Kunde
Kunde_nr
Name
Vorname
Straße
PLZ
Ort
00012
M ller
Anna
Sudetenstr. 18
83222
Rosenheim
00013
Huber
Karl
Knallerweg 19
86321
Ganselham
00014
Meier
Amelie
K rberweg 18
83222
Rosenheim
00015
Hanser
Kurt
K stnerstr. 10 A
83222
Rosenheim
Wegen des atomaren Schl ssels ist die Tabelle in 2. Normalform. Das Attribut Ort enth lt
jedoch redundante Daten, da bereits das Attribut PLZ die Werte von Ort eindeutig festlegt.
Aus der Sicht funktionaler Abh ngigkeit gilt hier:
Kunde_nr
PLZ
Ort
Eine solche Kette funktionaler Abh ngigkeiten heißt transitive funktionale Abh ngigkeit.
Genau diese Eigenschaft der Tabelle verursacht die Datenredundanzen. Wir fordern also f r
die dritte Normalform:
Eine Tabelle ist in dritter Normalform, wenn sie sich in zweiter Normalform befindet und
wenn kein Nichtschl sselattribut transitiv abh ngig von irgendeinem Schl sselattribut ist.
Seite 10
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Die Umformung in die dritte Normalform zwingt zu einer erneuten Aufspaltung, wobei aus
dem „mittleren“ Schl ssel in der Kette der Abh ngigkeiten zusammen mit den davon
abh ngigen Attributen eine neue Tabelle gebildet wird. Das neue Schl sselattribut verbleibt
aber auch in der urspr nglichen Tabelle, um Informationsverluste auszugleichen. Die davon
anh ngigen Attribute verschwinden jedoch. In unserem Beispiel:
T1: Kunde
T2: PLZ
Kunde_nr
Name
Vorname
PLZ
Straße
PLZ
Ort
00012
M ller
Anna
83222
Sudetenstr. 18
83222
Rosenheim
00013
Huber
Karl
86321
Knallerweg 19
86321
Ganselham
00014
Meier
Amelie
83222
K rberweg 18
00015
Hanser
Kurt
83222
K stnerstr. 10 A
7.2.4 Umsetzung von ER-Modellen in Relationale Modelle
Von einem gut durchdachten ER-Modell ausgehend kann man in der Regel schnell und
einfach ein sauberes relationales Modell erstellen. Die Umwandlung erfolgt mit Hilfe relativ
einfacher Regeln, f r die nur relativ selten Ausnahmen zu beachten sind.
Entit ten
Entit ten werden zu Tabellen, Attribute zu Spalten. In jeder Tabelle wird ein
Schl sselattribut (oder eine Kombination von Attributen als Schl ssel) definiert.
Wir erhalten aus unserem ER-Modell der Bibliothek f r die Entit ten die folgenden
Tabellenschamata:
Buchtitel (Buchtitel_nr, Titel, Autor, Verlag, Ort, Jahr, ISBN, Preis)
Exemplar (Exemplar_nr, Bezeichnung, Zustand, Aufnahmedatum)
Standort (Standort_nr, Zimmer, Regal, Fach, Platz)
Autor (Autor_nr, Name, Vorname, Land, andere)
Kunde (Kunde_nr, Name, Vorname, Geburtsdatum, Straße, PLZ, O
Beziehungen
• Kardinalit t 1:1
Beziehungen der Kardinalit t 1:1 k nnen in eine der beiden Tabellen der beteiligten Entit ten
eingebaut werden, indem man das Schl sselattribut der anderen Tabelle aufnimmt. Dieses
Attribut heißt dort Fremdschl ssel.
Die 1:1-Beziehung steht_in wird durch den Fremdschl ssel Standort_nr in die Tabelle
Exemplar aufgenommen. Ebensogut k nnte man die Tabellen Exemplar und Standort zu einer
einzigen vereinigen, falls man keine anderweitigen Beziehungen der beiden Entit ten findet.
Exemplar (Exemplar_nr, Bezeichnung, Zustand, Aufnahmedatum, Standort_nr)
Seite 11
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
• Kardinalit t 1:n
Beziehungen mit der Kardinalit t 1:n werden umgewandelt, indem man das Schl sselattribut
der 1-Seite als zus tzliches Attribut in der Tabelle der n-Seite aufnimmt.
Unsere 1:n-Relation ist_vorhanden wird durch den Fremdschl ssel Buchtitel_nr in der
Tabelle Exemplare realisiert:
Exemplar (Exemplar_nr, Bezeichnung, Zustand, Aufnahmedatum, Buchtitel_nr)
• Kardinalit t m:n
Beziehungen mit der Kardinalit t m:n werden als eigene Tabelle, die mindestens die
Schl sselfelder der beiden beteiligten Entit tentabellen enth lt, umgesetzt.
So wird aus unserer Beziehung verfaßt_von nun die Tabelle
Verfaßt_von (Buchtitel_nr, Autor_nr)
• Ausnahme
Falls eine Relation eigene Attribute hat, die auch anderweitig von Belang sind, ist es
entgegen dieser Regeln meist g nstiger, eine eigene Tabelle f r die Relation zu definieren.
Die 1:n-Relation ausgeliehen_von zwischen Kunde und Exemplar k nnte man mitsamt den
beiden Attributen Ausleihedatum und Bearbeiter in die Tabelle Exemplar einbauen.
Sp testens, wenn die Verwaltung einer Entit t Bearbeiter f r die Personalangeh rigen in
Betracht kommt, wird jedoch auch daf r eine eigene Tabelle sinnvoll:
Ausgeliehen_von (Kunde_nr, Exemplar_nr, Ausleihedatum, Bearbeiter_nr).
7.3
Abfragen und Berichte
7.3.1 Relationenalgebra
F r das Verst ndnis von Abfragesprachen wie SQL ist es sehr g nstig einige mathematische
Grundlagen mit Hilfe des relationalen Modells zu legen. Wir f hren dazu die folgenden
Operationen auf Relationen (Tabellen) ein.
• Projektion
P(a1, .., ak) (R) = {(x1, .., xk) | r R r.ai = xi }
Mit Hilfe der Projektion P(a1, .., ak) kann man die Attribute (Spalten) a1, .., ak aus der Tabelle
extrahieren. r.ai = xi steht dabei f r die Aussage, daß das Attributes ai im Tupel r den Wert xi
annimmt.
P(Titel, Autor) (Buchtitel) =
{(Fr ulein Smillas.. , Peter Høeg), (Das Parf m, Patrick S ßkind) ... }
• Auswahl
W(P) (R) = {r | r R P(r) = wahr}
Mit dieser sehr m chtigen Operation kann eine Teilmenge der Tupel ausgesucht werden, die
eine bestimmte Aussageform erf llen.
Mit P = [Ort = Rosenheim] wird dann
W(P) (Kunde) = {
(00012, M ller, Anna, ..),
Seite 12
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
(00014, Meier, Amelie, ..),
(00015, Hanser, Kurt, ..)}
• Kreuzprodukt R x S = {(r1, .. ,rn, s1, .. ,sm) | (r1, .. ,rn) R (s1, .. ,sm) S}
Das Kreuzprodukt kombiniert jedes Tupel aus R mit allen Tupeln aus S, wobei die Schemata
vereinigt werden. Es ist vor allem als Grundmenge f r Join-Operationen (s.unten) sehr
wichtig.
Wir betrachten das ganze am Beispiel zweier Tabellen Konto und Kunde aus dem
Bankbereich.
Kunde
Name
Meier
M ller
Huber
Vorname
Hans
Anna
Karl
Konto
Konto_nr
364 234
23 244
123 444
Konto_nr
364 234
23 244
123 444
Saldo
+1298
+13455
-1099
Kreditrahmen
12000
12000
6000
Kunde x Konto ergibt dann die folgende auf den ersten Blick ziemlich sinnlose
Kombination:
Kunde.
Kunde.
Kunde.
Konto.
Konto. Konto.
Name
Vorname
Konto_nr
Konto_nr
Saldo
Kreditrahmen
Meier
Hans
364 234
364 234
+1298
12000
Meier
Hans
364 234
23 244
+13455 12000
Meier
Hans
364 234
123 444
-1099
6000
M ller
Anna
23 244
364 234
+1298
12000
M ller
Anna
23 244
23 244
+13455 12000
M ller
Anna
23 244
123 444
-1099
6000
Huber
Karl
123 444
364 234
+1298
12000
Huber
Karl
123 444
23 244
+13455 12000
Huber
Karl
123 444
123 444
-1099
6000
Hier haben wir die Schreibweise T.a f r ein Attribut a aus der Tabelle T verwendet, um die
Zugeh rigkeit der Attribute deutlich zu machen.
•
Equi-Join
R
S = a1 ,.., a n , b1 ,.., b m R.a i = S.b k
R.a i =S.b k
Der Equi-Join liefert die Menge aller Tupel aus R S, bei denen die Werte der angegebenen
Attribute identisch sind. Es kann eine beliebige Anzahl von Gleichheitsforderungen
angegeben werden.
Kunde
Konto ergibt die folgende Tabelle:
Kunde.Konto_nr = Konto.Konto_ nr
Kunde.
Name
Meier
M ller
Huber
Kunde.
Vorname
Hans
Anna
Karl
Kunde.
Konto_nr
364 234
23 244
123 444
Konto.
Konto_nr
364 234
23 244
123 444
Konto.
Saldo
+1298
+13455
-1099
Konto.
Kreditrahmen
12000
12000
6000
Eine Verallgemeinerung des Equi-Join ist der Theta-Join, bei dem man anstatt einer
Gleichheitsforderung eine beliebige Vergleichsoperation wie , < etc. zul ßt.
Seite 13
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
• Natural Join
R S
Die Ergebnismenge des Natural Join der beiden Relationen R und S besteht aus allen Tupeln
aus R x S, bei denen diejenigen Attribute, die in R und in S vorkommen, den gleichen Wert
haben. Der Natural Join ist ein Equi-Join, der alle gemeinsamen Attribute zweier Tabellen
erfasst, ohne dass man diese explizit angeben muss. Er liefert die Kombination zweier
Tabellen, die man am h ufigsten ben tigt. Die gemeinsamen Attribute werden
sinnvollerweise nur noch einmal in der Tabelle aufgef hrt.
In unserem Bankbeispiel ergibt Kunde Konto die folgende Tabelle, wobei das redundante
Attribut Konto.Konto_nr weggelassen wird.
Kunde.
Kunde.
Kunde.
Konto. Konto.
Name
Vorname
Konto_nr
Saldo
Kreditrahmen
Meier
Hans
364 234
+1298
12000
M ller
Anna
23 244
+13455 12000
Huber
Karl
123 444
-1099
6000
Eine gewisse Problematik liegt in der Bestimmung der gemeinsamen Attribute, falls diese
nicht v llig identische Namen haben. Man denke etwa an das folgende Tabellensystem:
Buchtitel (Buchtitel_nr, Titel, Autor, Verlag, Ort, Jahr, ISBN, Preis)
Autor (Autor_nr, Name, Vorname, Land, andere)
In Buchtitel Autor ist nicht unbedingt klar, daß die Attribute Buchtitel.Autor und
Autor.Name als identisch zu betrachten sind. Im Zweifelsfall sollte man daher auf einen
entsprechenden Equi-Join zur ckgreifen.
Die folgenden Operationen Vereinigung, Durchschnitt und Differenz liefern nur dann wieder
eine Relation, wenn man sich beim Ergebnis auf den Durchschnitt der Schemata von R und S,
also auf die gemeinsamen Attribute, beschr nkt. Der Einfachheit halber vereinbaren wir,
diese drei Operationen nur auf Relationen mit identischen Schemata anzuwenden. In unserem
Beispiel reduzieren wir dazu die Tabellen Kunde und Autor auf die gemeinsamen Attribute
Name und Vorname.
• Vereinigung
R S={r|r R r S}
Die Vereinigungsmenge besteht aus allen Tupeln, die entweder der einen Relation oder der
anderen Relation angeh ren.
Kunde
Autor = {(Meier, Hans), (M ller, Emil), ...
(Høeg, Peter,),(S ßkind, Patrick), ... }
• Durchschnitt
R S={r|r R r S}
Der Durchschnitt besteht aus allen Tupeln, die sowohl der einen Relation als auch der anderen
Relation angeh ren.
In unserem Beispiel liefert Kunde Autor Name und Vorname aller Personen, die sowohl
als Autor wie auch als Kunde registriert sind.
• Differenz
R – S = {r R r S}
Die Differenz von R und S ist die Menge aller Tupel, die R , aber nicht S angeh ren.
Seite 14
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
Kunde - Autor ergibt die Namen und Vornamen aller Personen, die Kunde, aber nicht Autor
sind.
7.3.2 Die Abfragespache SQL
Zur Durchf hrung von Abfragen in realen Datenbanksystemen verwendet man nicht den oben
beschriebenen mathematischen Relationenkalk l, sondern spezielle Abfragesprachen. Am
meisten Verbreitung hat dabei die Abfragesprache SQL (Structured Query Language)
gewonnen, die sich aus der von IBM f r das Datenbanksystem R entwickelten
Vorl ufersprache SEQUEL entwickelt hat.
1) Abfragen aus einer Tabelle
• Die SELECT-Anweisung
Die Hauptkomponente einer SQL-Abfrage ist die SELECT-Anweisung. Ihre Syntax lautet
SELECT
<Attributliste>
FROM
<Tabellenliste>
WHERE
<Bedingungsliste>
Eine Abfrage nach den Titeln und dem Erscheinungsjahr aller B cher, die von Peter Høeg
nach 1990 erschienen sind, sieht in SQL so aus:
SELECT
FROM
WHERE
Titel, Jahr
Buchtitel
Autor = ´Peter Høeg´ AND Jahr > 1990
• SELECT und Projektion
Der Vergleich mit dem Relationenkalk l liefert die exakte Bedeutung der SELECTAnweisung:
SELECT
a, b
FROM
T
ist offensichtlich gleichbedeutend mit der Projektion P(a,b)(T): Die Anweisung liefert die
Spalten (Attribute) a, b aus der Tabelle T. Ein * gibt an, daß man alle Attribute der Tabelle
haben will.
• WHERE und Auswahl
Die Anweisung
SELECT
*
FROM
T
WHERE
P
bewirkt eine Auswahl W(P) (T). Wir erhalten alle Datens tze, f r welche die Aussage P wahr
ist.
2) Verkn pfung mehrerer Tabellen
• kartesisches Produkt
Die Angabe mehrerer Tabellen nach FROM ohne einschr nkende WHERE-Klausel (s.unten)
liefert das kartesische Produkt der angegeben Tabellen
SELECT *
Seite 15
Peter Hubwieser
Didaktik der Informatik I
WS 1998/99
FROM S, T
ist quivalent mit S T. Zur Projektion von Spalten aus dem Produkt kann die Punktnotation
verwendet werden:
SELECT Buchtitel.Titel, Buchtitel.Jahr, Autor.*
FROM Buchtitel, Autor
• Equi-Join
Der Equi-Join wird einfacherweise durch die Angabe der Vergleichsbedingung hinter
WHERE realisiert:
SELECT *
FROM R, S
WHERE R.a = S.b
ist gleichbedeutend mit R
S.
R.a i =S.b k
7.4
Literatur
Korth Henry F., Silberschatz Abraham: Database System Concepts. Mac Graw - Hill, New
York 1991.
Horn C., Kerner I.O.(Hrsg.): Lehr- und
Informatik. Fachbuchverlag Leipzig, 1997.
bungsbuch Informatik. Band 3: Praktische
Schwinn H.: Relationale Datenbanksysteme. Carl Hanser Verlag, M nchen, Wien, 1992.
Zentralstelle f r Computer im Unterricht [Hrsg.]: Datenbank. Arbeitskreis „Datenbanken im
Unterricht“. Augsburg 1997.
Seite 16