Deskriptive Statistik Deskriptive Statistik Deskriptive Statistik
Werbung

AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Grundlagen der Biometrie
Beschreibende und schließende Statistik in
klinischen Studien
“Jede mathematische Formel
reduziert die Anzahl der Zuhörer
um 50%”
PD Dr. Thomas Sudhop & Dr. med. Dipl. chem. Michael Reber
Abteilung für Klinische Pharmakologie
Wie viele Formeln werden benötigt,
um den Saal zu leeren?
Universität Bonn
“Statistik“
Deskriptive Statistik
Lehre von den Verteilungen
Deskriptive Statistik = empirische
Verteilungen von Merkmalen
Aufgabe:
Strukturierung der Rohdaten
Induktive/Analytische Statistik =
Schließen von einer Stichprobe auf
die Grundgesamtheit
Wahrscheinlichkeitstheorie =
Verteilungen von Zufallsvariablen
Deskriptive Statistik
Deskriptive Statistik
Tabellen / Graphische Darstellung
Patient
Placebo
Arznei
alpha
Arznei
beta
Tabellen / Graphische Darstellung
Patient
200
Placebo
Medisan
alpha
Medisan
beta
Blutdrucksenker im Vergleich
1
161
150
135
250
161
150
135
2
158
150
133
190
2
158
150
133
200
3
222
206
196
185
3
222
206
196
150
4
225
223
201
180
4
225
223
201
18
228
226
204
19
162
150
139
172
20
196
180
172
188,4 174,75
Mittelwerte
198,95
….
195
175
….
170
18
228
226
204
19
162
150
139
20
196
Mittelwerte
198,95
180
165
160
Placebo
Arznei alpha
Arznei beta
Placebo
RR
1
Arznei alpha
100
Arznei beta
50
0
0
5
10
15
20
Proband
188,4 174,75
1
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Deskriptive Statistik
Was?
Strukturierung der Rohdaten
Population
Population (Grundgesamtheit)
Die Grundgesamtheit sind alle Individuen, für
welche Schlussfolgerungen gezogen werden sollen.
Wie?
Verwendung mathematischer Methoden zur
standardisierten Erfassung bestimmter
Merkmale der erhobenen Daten
Warum?
Hervorheben wesentlicher Zusammenhänge
durch Datenreduktion und graphische
Darstellung um anderen Personen ohne
Kenntnisse der Einzeldaten die erhobenen
Beobachtungen vermitteln zu können
Stichprobe
Stichprobe
-
Alle Einwohner eines Bundeslandes
-
Alle Autos in Deutschland
-
Alle Typ II Diabetiker (Zielpopulation)
Populationen weisen einen großen Umfang
(=Menge der Elemente) auf und können daher
nicht vollständig untersucht werden.
Repräsentative Stichprobe
Stichprobe sollte Elemente aus allen
Bereichen der Population umfassen
Eine Stichprobe aus einer Population stellt
die Anzahl von Individuen dar, welche
tatsächlich beobachtet werden.
9 Alle PKW, welche an einem Stichtag zugelassen
wurden
Der Stichprobenumfang (Elemente der
Stichprobe = Fallzahl) muss ausreichend
groß sein
8 Alle roten PKW in Berlin sind nicht repräsentativ
für alle PKW
Stichproben sollten repräsentativ für
die Population sein
Univariante deskriptive Statistik
Kurze und prägnante Charakterisierung
der Daten einer Stichprobe
Lagemaße
- Mittelwerte
-
Arithmetisches Mittel
-
Geometrisches Mittel
Lagemaße
-
Harmonisches Mittel
Streumaße
-
Getrimmtes Mittel
Statistische Kennwerte
Graphische Darstellung
- Median
2
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Lagemaße
Arithmetisches Mittel
Der Mittelwert beschreibt das Verhalten der
Daten „im Mittel“ (Σ = Summe)
? Wo liegt das Zentrum der
Daten
Er ist der durchschnittliche Wert aller
Elemente einer Menge
? Was ist ein typischer mittlerer
Wert
Nachteil: empfindlich gegenüber Extremen
Berechnung:
Mittelwert = Summe aller Element : Anzahl aller Elemente
x=
Geometrisches Mittel
x1 + x2 + x3 + L + xn
n
Log - Transformation
Findet häufig Anwendung in der Pharmakokinetik
⊕ Weniger empfindlich gegen Extremwerte
Berechnung erfordert log.-Transformation
Berechnung:
statistische Verfahren beruhen auf der
Annahme, dass Versuchsdaten sich der
Normalverteilung annähern
x = n x1 ⋅ x2 ⋅ x3 ⋅ K ⋅ xn
15
16
Log - Transformation
Harmonisches Mittel
• Anpassung der Transformation durch Auswahl des Logarithmus
Es dient als Lagemaß, wenn die Beobachtungswerte
Verhältniszahlen sind (z.B. zur Berechnung einer
durchschnittlichen Geschwindigkeit oder
Überlebenszeit). Bsp.: Ohmsches Gesetz
• Anwendung bei rechtschiefer Verteilung (Es liegen mehr
Werte rechts vom Mittelwert)
Berechnung:
x = n x1 ⋅ x2 ⋅ x3 ⋅ K ⋅ xn
ln( x1) + ln( x 2) + ... + ln( xn)
n
= Geometrisches Mittel
ln( x) =
e ln( x )
17
18
3
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Getrimmtes Mittel
Median
Entspricht einem Arithmetischen Mittel
Der Median beschreibt den mittleren
Wert in einer sortierten Stichprobe
Vor der Berechnung werden an beiden Enden der
Verteilung die Extremwerte gekappt (grau unterlegt)
0
100
200
300
400
500
Berechnung:
Stichprobe aufsteigend sortieren
Bei ungeradem Stichprobenumfang
Bei geradem Stichprobenumfang
⇒ Mittleres Element ist der Median
600
⇒ Median ist der Mittelwert aus den beiden mittleren
Elementen
19
20
Median Beispiel
Mittelwert versus Median
Bestimmung des Alters-Medians von 6 Patienten
Der Mittelwert ist derjenige Wert, der die Daten auf einer
Waage ausbalanciert. Entfernte Werte besitzen eine große
Hebelkraft.
Alter der Patienten: 48, 50, 46, 52, 47, 48
1. Schritt: aufsteigend sortieren
0
100
200
300
400
500
600
46, 47, 48, 48, 50, 52
Beim Median spielt der Abstand der Beobachtung keine Rolle.
Der Median ist robust gegen Ausreißer.
2. Schritt: Mittelwert der beiden mittleren Werte bilden
46, 47, 48, 48, 50, 52
( 48 + 48 ) ÷ 2 = 48
Der Alters-Median der Patienten beträgt 48 Jahre
21
22
Mittelwert versus Median
Praktisches Beispiel Lagemaße
Die Wahl zwischen Mittelwert und Median ist:
Klinische Studie mit ACE-Hemmern
- Abhängig davon, ob ein typischer oder ein
mittlerer Wert gesucht wird
360 Probanden
Randomisiert auf drei Behandlungsarme
- Abhängig von der Verteilung (Normal, Schief
oder „Gibt es Ausreißer?“)
- Abhängig davon, ob Präzision oder Robustheit
im Vordergrund steht
23
24
4
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Streumaße
Streumaße - Übersicht
Streumaße liefern Informationen zur
Zusammensetzung (Streuung) von Stichproben
Range
Standardabweichung
Stichprobe A: { 2, 2, 3, 3, 4, 4, 4, 5, 5, 6 }
Varianz
Stichprobe B: { 2, 2, 2, 5, 6, 9, 9, 19, 19, 21 }
Standardfehler
Quantile / Perzentile
25
26
Range (Spannweite)
Range / Median
Definition: Differenz aus größtem und kleinstem Element
einer Stichprobe
Median und Range beschreiben Stichprobe
Stichprobe A: { 2, 2, 3, 3, 4, 4, 4, 5, 5, 6 }
Stichprobe A: { 2, 2, 3, 3, 4, 4, 4, 5, 5, 6 }
Median: 4
Range: 4
Range: 6 - 2 = 4
0
2
4
6
8 10 12 14 16 18 20 22
Stichprobe B: { 2, 2, 2, 4, 5, 6, 9, 19, 19, 21 }
Stichprobe B: { 2, 2, 2, 5, 6, 9, 9, 19, 19, 21 }
Median: 5,5
Range: 19
Range: 21 - 2 = 19
0
2
4
6
8 10 12 14 16 18 20 22
27
Streumaße - Übersicht
28
Standardabweichung
Range
Standardabweichung (engl. Standard deviation, SD) wird
meist in Verbindung mit dem Mittelwert angegeben
Standardabweichung
Varianz
Mittelwert ± Standardabweichung (Mean ± SD)
Sie stellt ein Maß für die Streuung um den Mittelwert dar.
Standardfehler
Grobe Vorstellung: gibt den „durchschnittlich“ Abstand
des Einzelwertes vom Mittelwert an.
Quantile / Perzentile
29
30
5
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Standardabweichung
Standardabweichung
3
3
2
2
Arithmetisches Mittel
Arithmetisches Mittel
-1
-1
-2
-2
-2
SD =
-2
( x − x1 ) + ( x − x2 ) + ( x − x3 ) + ... + ( x − xn ) 2
n −1
2
2
2
31
Standardabweichung
32
Standardabweichung
Proband
Stichprobe A: { 2, 2, 3, 3, 4, 4, 4, 5, 5, 6 }
Mittelwert: 3.8 ± 1.3
0
2
4
6
8 10 12 14 16 18 20 22
Stichprobe B: { 2, 2, 2, 5, 6, 9, 9, 19, 19, 21 }
Mittelwert: 9.4 ± 7.6
0
2
4
6
Blutdruck (syst.)
Tablette A
Tablette B
1
140
150
2
125
141
3
120
110
4
130
107
5
135
152
6
115
105
127,5
127,5
9,4
22,5
8 10 12 14 16 18 20 22
Mittelwert
SD
33
34
Streumaße - Übersicht
Varianz
Range
Varianz = Standardabweichung²
Standardabweichung
„Mittleres Abstandsquadrat“ der
Elemente vom Mittelwert der Stichprobe
Varianz
Standardfehler
Berechnung:
Quantile / Perzentile
Varianz =
( x − x1 ) 2 + ( x − x2 ) 2 + ( x − x3 ) 2 + ... + ( x − xn ) 2
n −1
35
36
6
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Standardabweichung / Varianz
Streumaße - Übersicht
Standardabweichung ist das meistgebrauchte
Streuungsmaß
Range
Vorteil der Standardabweichung - gleiche
Einheit wie die ursprünglichen Messwerte.
Standardabweichung
Varianz
Standardfehler
Quantile / Perzentile
37
38
Standardfehler des Mittelwerts (SEM)
Standardfehler des Mittelwerts (SEM)
Standardfehler
standard error of the mean = SEM
Der Standardfehler beschreibt nicht die Daten.
SEM gibt die Genauigkeit des Mittelwertes als
Schätzwert an.
Abgeleitet aus Standardabweichung
(SD) und Stichprobenumfang (n)
CAVE: Häufig wird SEM anstelle des StandardAbweichung verwandt. Die kleinere Maßzahl für
SEM soll eine bessere Wirkung suggerieren.
Immer kleiner als Standardabweichung
SEM =
SD
n
Nährung 95%-KI des Mittelwert:
Mittelwert +/- 2 SEM
39
SD Ù SEM
40
SD > SEM
SD =
-3S
-2S
-1S
1S
2S
Alter von 9 Kindern
Mittelwert +/- 2 SEM
( x − x1 ) 2 + ( x − x2 ) 2 + ( x − x3 ) 2 + ... + ( x − xn ) 2
n −1
SEM =
SD
n
3S
Mean ± SD
(11,4 ± 9,0)
Mittelwert +/- Standardabweichung
Mean ± SEM
(11,4 ± 3,0)
41
42
7
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Streumaße - Übersicht
Rang
Meßwert
57
77
80
82
90
90
91
115
116
116
121
124
130
132
135
136
140
143
145
148
Definition
Range
Standardabweichung
Position innerhalb
der aufsteigend
sortierten
(Rang-)Liste einer
Stichprobe
Beispiel
Varianz
Standardfehler
Platzierungen im
Sport
Berechnung
Quantile / Perzentile
Elemente
aufsteigend
sortieren
Beginnend bei „1“
nummerieren
Rang
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
43
Perzentile
Als x%-Perzentile
wird derjenige
Wert einer
Stichprobe
bezeichnet, der
kleiner oder
gleich x% aller
Werte ist
Meßwert
57
77
80
82
90
90
91
115
116
116
121
124
130
132
135
136
140
143
145
148
Rangplatz
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
44
Perzentile - BMI
Perzentile
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
45
Quartile
Bezeichnen die
25%, 50%, 75%
und 100% Perzentile
Meßwert
57
77
80
82
90
90
91
115
116
116
121
124
130
132
135
136
140
143
145
148
Rangplatz
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Perzentile
46
Inter-Quartil-Spannweite
Quartil
„interquartile
range“
25%
1. Quartil
50%
2. Quartil
75%
3. Quartil
100%
4. Quartil
Bezeichnet die
Differenz aus 3.
und 1. Quartil
50% aller Werte
einer Stichprobe
liegen innerhalb
dieses Bereichs
Meßwert
57
77
80
82
90
90
91
115
116
116
121
124
130
132
135
136
140
143
145
148
Rangplatz
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Perzentile
Quartil
25%
1. Quartil
50%
2. Quartil
75%
3. Quartil
100%
4. Quartil
47
48
8
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Grafik - Histogramm
3
Graphische Darstellung
2
1
0
1
2
3
4
5
6
7
Stichprobe A: { 2, 2, 3, 3, 4, 4, 4, 5, 5, 6 }
49
Quartile
50
Grafik - Boxplots
*
„Box“ – Bereich von der
25. zur 75. Perzentile
*
*
größte normale Beobachtung
Stäbe (whiskers) sind
nicht einheitlich definiert
A
oberes Quartil
Minimum / Maximum
(SPSS)
Mittelwert (grau Vertrauensintervall)
Median
unteres Quartil
10% / 90% Perzentile
B
kleinste normale Beobachtung
51
Boxplots – Bsp. ACE-Hemmer
140
52
Es werden Lagemaße (Mittelwert, Median, 95%Perzentile) von Streumaßen
(Standardabweichung, Varianz, SEM, range,
interquartile range) unterschieden.
120
29
100
11
Anhand dieser Parameter können Untersuchungsergebnisse standardisiert berichtet werden, so
dass es anderen gelingt, die Ergebnisse einer
Untersuchung nachzuvollziehen, ohne alle
Einzeldaten zu kennen.
80
WEIGHT
niedriger Ausreißer
Die deskriptive Statistik beschreibt
mathematische Eigenschaften des erhobene
Datenmaterials anhand von Stichproben
24
60
40
N=
*
Zusammenfassung
180
160
größter Ausreißer
10
20
1
2
GENDER
53
54
9
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Wahrscheinlichkeit
Verhältnis „Anzahl aller günstigen Ereignisse“
zu „Anzahl aller möglichen Ereignisse“
Grundlagen der Biometrie
Anzahl aller günstigen Ereignisse
Anzahl aller möglichen Ereignisse
p=
Beschreibende und schließende Statistik in
klinischen Studien
Wahrscheinlichkeit, mit einem Würfel im
nächsten Wurf eine „6“ zu werfen:
p=
PD Dr. med. Thomas Sudhop & Dr. med. Dipl. chem. Michael Reber
{6}
1
= = 0.166666 ≅ 16,7%
{1,2,3,4,5,6} 6
Abteilung für Klinische Pharmakologie
Universität Bonn
p liegt immer im Intervall [0; 1] (0-100%)
56
Chance (Odd)
Absolute und relative Häufigkeit
Verhältnis „Anzahl aller günstigen Ereignisse“
zu „Anzahl aller ungünstigen Ereignisse“
p=
Anzahl aller günstigen Ereignisse
Anzahl aller ungünstigen Ereignisse
Chance, mit einem Würfel im nächsten Wurf
eine „6“ zu werfen:
Absolute Häufigkeit
Relative Häufigkeit
Angabe, wie oft ein
bestimmter Datenwert in
der Stichprobe enthalten
ist
Angabe, wie oft ein
bestimmter Datenwert in
der Stichprobe relativ
zum Stichprobenumfang
enthalten ist
20
40%
n=50
n=50
16
{6}
1
p=
= = 0,2 ≅ 20%
{1,2,3,4,5} 5
32%
15
30%
12
10
5
24%
20%
8
16%
7
5
10%
14%
10%
2
0
Zufallsvariable
(Random variable)
Alter
systolischer Blutdruck
....
Zielgröße in einer Studie
2
3
4
5
6
Mathematiknoten einer Jahrgangsstufe
1
2
3
4
5
Mathematiknoten einer Jahrgangsstufe
6
58
Skalen für Zufallsvariablen
Variable in einer Studie, die auf einer
Zufallsstichprobe basiert
4%
0%
1
57
diskret / kategorial
Nominalskaliert: keine lineare Ordnung
Ordinalskaliert: Ausprägung kann geordnet werden
Beispiel: Farben, ja/nein
Beispiel: Schulnoten
stetig / kontinuierlich
Zufallsvariable unterliegt einer bestimmten
Verteilung
intervallskaliert: Differenzen sind einheitlich
interpretierbar
Beispiel: Temperatur in Grad Celsius
verhältnisskaliert: Verhältnisse sind einheitlich
interpretierbar
Beispiel: Luftdruck, etc.
59
60
10
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Normalverteilung
Standard-Normalverteilung (z)
Histogramm -> Verteilung
Ν(µ, σ²)
µ = 120
σ = 10
Ν(0,1)
µ=0
σ=1
0,40
0,35
0,30
f ( z) =
0,25
0,20
34,1% 34,1%
0,10
160
150
140
130
120
110
100
90
80
160
155
150
145
140
135
130
125
120
115
110
105
100
95
90
85
80
0,15
0,05
0,00
2,2%
0,15%
-4
2,2%
13,6%
-3
-2
0,15%
13,6%
-1
0
1
2
3
4
z=
61
Z-Verteilung
„Kritische Werte“
( x − µ )2
2σ 2
1 − 12 z 2
e
2π
x−µ
σ
62
Z-Transformation
„Kritische Werte“
µ=0
σ=1
< 5% der Werte sind >1,645
X = zσ + µ
0,05 = 5%
0,975 = 97,5%
-4
−
1
e
σ 2π
160
150
140
130
120
110
90
0,45
100
80
160-164
155-159
150-154
145-149
140-144
135-139
130-134
125-129
120-124
115-119
110-114
95-99
105-109
90-94
100-104
85-89
80-84
160-169
150-159
140-149
130-139
120-129
110-119
90-99
100-109
80-89
f ( x) =
-3
-2
-1
0
1
2
3
4
-4
-3
-2
-1
0
1
2
3
4
1,645
1,96
Durch Transformation können die kritischen
Werte der z-Verteilung auf jede
Normalverteilung angepasst werden
µ=0
σ=1
0,025 = 2.5%
-4
-3
-2
-1
0
1
2
1,96
3
4
< 5% der Werte sind
>1,96 bzw.
bzw. < -1,96
krit. Grenze (z97,5%) = 1,96*10+120 = 139,6 mmHg
64
„Central Limit Theorem“
12
Der Mittelwert der Stichproben-Mittelwerte
entspricht dem Mittelwert der Population
18
16
8
RR in der Normalbevölkerung: µ=120, σ=10
63
Central limit Theorem
10
14
12
6
5
5
5
5
5
5
10
8
4
Ist die Population normal verteilt, so ist auch
der Mittelwert der Stichproben-Mittelwerte
normal verteilt
6
4
2
2
0
0
1
2
3
4
5
6
Verteilung der
Einzelwerte:
Uniform
2.5
2.6 2.7 2.8
2.9 3.0 3.1 3.2 3.3 3.4
3.5 3.6 3.7
3.8 3.9 4.0 4.1 4.2 4.3
4.4 4.5 4.6 4.7
Ist die Population nicht normal verteilt, so ist
der Mittelwert der Stichproben-Mittelwerte
dennoch annähernd normal verteilt*
Verteilung der
Stichprobenmittelwerte: Normal
65
*für große Stichproben
66
11
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Standardabweichung und
Standardfehler
Der x%-Vertrauensbereich eines Mittelwerts
einer Stichprobe (x) bezeichnet das Intervall,
das mit x%iger Wahrscheinlichkeit den
Mittelwert der Population (µ) enthält
Standardfehler
Standardabweichung
SD ist die Standardabweichung der
Einzelwerte
Konfidenzintervall /
Vertrauensbereich des Mittelwerts
SEM entspricht der
Standardabweichung
der Mittelwerte
SEM =
SD σ
=
n
n
SEM =
2
Beispiel: x=122 mmHg, 95%-CI [118; 124]
2 Konstellationen sind zu unterscheiden
σ2
Varianz/SD der Population ist bekannt
Varianz/SD der Population ist unbekannt
n
67
68
Vertrauenbereich für z-Verteilung
N(µ,σ²) = N(0, 1)
0,45
Systolischer Blutdruck der Normalpopulation
(SD=10 mmHg)
µ=0
σ=1
0,40
0,35
0,30
Beispiel:
95%-CI bei bekannter SD der Population
Stichprobe mit n=25 liefert einen Mittelwert
von 122 mmHg
X = zσ + µ
0,25
0,20
100%
-∞... +∞
0,15
0,10
[ x − z2 ,5% ⋅ σ ; x + z97 ,5% ⋅ σ ]
0,05
0,00
-4
-3
-2
-1
0
1
2
3
4
[ x − z2 ,5% ⋅
σ
n
; x + z97,5% ⋅
σ]
95%CI = x ± 1,96 ⋅
n
µ=0
σ=1
0,45
0,40
0,35
0,30
95%CI = 122 ± 1,96 ⋅ 2 = 122 ± 3,92
0,25
0,20
2.5%
< -1,96
0,15
0,10
[ x − 1,96 ⋅ SEM ; x + 1,96 ⋅ SEM ]
97,5%
> +1,96
0,05
[ x − 1,96 ⋅
0,00
-4
-3
-2
-1
0
1
2
3
4
σ
n
; x + 1,96 ⋅
σ
n
10
25
]
95%CI = [ 118,078 ; 125,92 ]
69
70
Irrtumswahrscheinlichkeit α
95%-Konfidenzintervall
95% aller Stichproben
beinhalten mit ihrem
95%-CI den Populationsmittelwert µ
µ=0
σ=1
0,45
0,40
0,35
0,30
α = 5%
0,25
0,20
2.5%
< -1,96
0,15
0,10
zα / 2 = −1,96
97,5%
> +1,96
z1−α / 2 = +1,96
0,05
0,00
Nur 5% aller Stichproben
beinhalten mit ihrem
95%-Vertrauensintervall
nicht den Populationsmittelwert µ
-4
-3
-2
-1
0
1
2
3
4
µ=0
σ=1
0,45
0,40
0,35
0,30
α = 1%
0,25
0,20
0,5%
< -2,576
0,15
0,10
zα / 2 = −2,576
99,5%
> +2,576
z1−α / 2 = +2,576
0,05
0,00
-4
µ
71
-3
-2
-1
0
1
2
3
4
72
12
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
95%-Vertrauensbereich bei
unbekannter SD
Konfidenzintervall bei bekannter SD
σ
CI1−α = [ x − z1−α / 2 ⋅
n
; x + z1−α / 2 ⋅
σ
n
Bei unbekanntem Populations-SD müssen
anstelle von z1-α/2 die entsprechenden Werte
der t-Verteilung eingesetzt werden
]
95%CI = x ± 1,96 ⋅ SEM
95%CI = x ± z0,975 ⋅ SEM
α = Irrtumswahrscheinlichkeit
σ = Standardabw. der Population
x = Mittelwert der Stichprobe
CI1−α = [ x − tn −1,1−α / 2 ⋅
n = Umfang der Stichprobe
σ
n
; x + tn −1,1−α / 2 ⋅
σ
n
]
73
Konfidenzintervall in der
analytischen Statistik
t-Verteilung (Student-t)
df=20
74
df
tdf;0,975
z0,975
4
9
29
60
2,776
2,262
2,045
2,000
1,96
1,96
1,96
1,96
Klinische Studie
df=9
Df = Degree of Freedom
(Freiheitsgrade)
Patienten mit Grenzwerthypertonie (n=15)
Zielgröße: systolischer Blutdruck
Design: 1-armig, intraindividueller Vergleich
df=4
Systolischer Blutdruck vor Therapie (RRt=0) und nach
4 Wochen (RRt=28) kontinuierlicher Intervention
Fragestellung: Ist durch die Intervention eine
Blutdruckänderung nachweisbar?
Zufallsvariable: RRt=28 - RRt=0
-3
-2
-1
0
1
2
3
75
Beispiel
Zufallsvariable: RRt=28 - RRt=0
x
SD
SEM
Vorher
140
135
141
140
140
135
141
140
144
143
140
138
120
124
137
137.20
6.70
1.73
Nachher
136
132
134
139
133
127
136
136
146
137
132
130
119
118
135
132.80
7.22
1.86
Differenz
-4
-3
-7
-1
-7
-8
-5
-4
2
-6
-8
-8
-1
-6
-2
-4.40
2.99
0.77
Konfidenzintervalle t 14,1-α /2 Linke Grenze Rechte Grenze
95%
2.14
-6.06
-2.75
97%
2.41
-6.26
-2.54
99%
2.98
-6.70
-2.11
99.90%
4.14
-7.59
-1.21
99.95%
4.50
-7.87
-0.93
99.99%
5.36
-8.54
-0.27
76
Konfidenzintervall für Differenzen
Beinhaltet ein 1-α
Konfidenzintervall für
eine Differenz die „0“, so
kann keine „signifikante
Differenz“ angenommen
werden.
p
0.05
0.03
0.01
0.001
0.0005
0.0001
Ist die „0“ nicht im 1-α
Konfidenzintervall für eine
Differenz enthalten, so
kann von einem
signifikanten Unterschied
ausgegangen werden
Die Differenz ist mit einer
Irrtumswahrscheinlichkeit
von α von „0“ verschieden
Da das 95%-Konfidenzintervall nicht die „0“ umfasst, ist die
Behandlungsdifferenz von „0“ verschieden
Simplifiziert: Es liegt ein signifikanter Behandlungseffekt mit
Irrtumswahrscheinlichkeit von α = 0,05 vor
-3
77
-2
-1
0
1
2
3
78
13
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
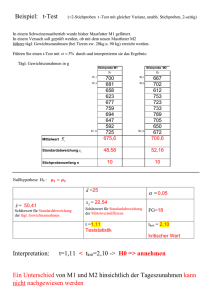
Statistischer Test
Hypothesen
Aufbau der Hypothesen
Einfluss der Intervention
H0: hat keinen Einfluss
H1: hat einen Einfluss
Die Null-Hypothese (H0) geht von keinem
systematischen Unterschied aus. Gefundene
Unterschiede sind zufällig und nicht systematisch
Die Alternativ-Hypothese (H1 / HA) ist die logische
Umkehrung der Null-Hypothese, d.h. es existiert ein
systematischer Unterschied. Gefundene Unterschiede
sind nicht zufällig, sondern systematisch
Bezogen auf gemessene Differenz der
Stichprobe
H0: Differenz ist nicht „0“ verschieden
H1: Differenz ist von „0“ verschieden
Null- und Alternativ-Hypothesen müssen sich
gegenseitig ausschließen und alle Möglichkeiten
abdecken.
79
H0: RRt=28 - RRt=0 = 0
H1: RRt=28 - RRt=0 ≠ 0
Zweiseitiger Test
0,35
4 Möglichkeiten, wie Testergebnis und
Wirklichkeit zusammentreffen können
0,30
0,25
0,20
2,5%
0,15
97,5%
0,10
0,05
-3
-2
-1
0
1
2
3
H0 wird akzeptiert, H1 ist in Wirklichkeit wahr
H0 wird abgelehnt, H1 ist in Wirklichkeit wahr
H0 wird abgelehnt, H0 ist in Wirklichkeit wahr
0,35
0,30
0,25
0,20
H0: RRt=28 - RRt=0 = 0
Einseitiger Test
H0 wird akzeptiert, H0 ist in Wirklichkeit wahr
4
0,40
H1: RRt=28 - RRt=0 < 0
0,00
Gerichteter Effekt
5%
0,15
0,10
0,05
0,00
-4
-3
-2
-1
0
1
2
3
4
81
Statische Fehler
Fehler I. Art und II. Art
Testentscheidung
Differenz=0
(H0 beibehalten)
α-Fehler
Differenz<>0
(H1ist wahr)
Differenz=0
(H0 ist wahr)
Richtig
positiv
(Power = 1-β)
Falsch
positiv
(Fehler I. Art
α-Fehler)
Falsch
negativ
(Fehler II. Art
β-Fehler)
82
Testergebnis und Wirklichkeit
Statistische Fehler
Wirklichkeit
Differenz<>0
(H0 ablehnen)
80
0,40
0,45
Wenn H0 wahr ist, muss H1 falsch sein
0,45
-4
Wenn H0 falsch ist, muss H1 wahr sein
Testergebnis und Wirklichkeit
Statistische Fehler
Ein- und zweiseitige Fragestellung
Ungerichteter Effekt
H0 wird abgelehnt, obwohl H0 in Wirklichkeit wahr ist
Ein Effekt wird angenommen, wo keiner ist
β-Fehler
Richtig
negativ
H0 wird akzeptiert, obwohl H1 in Wirklichkeit wahr ist
Ein vorhandener Effekt wird nicht erkannt
Welcher Fehler ist „schlimmer“ und daher eher
zu vermeiden?
83
84
14
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Signifikanz-Niveau
Gepaarter t-Test
Konsequenzen eines falsch-positiven Tests
Testet, ob eine Differenz
uneffektive Behandlung
Risiko ohne Nutzen („Nihil nocere“)
Kosten ohne Nutzen
Verteilung der Differenz
entspricht einer t-Statistik
der Form:
Fazit
Das Risiko eines falsch positiven Tests sollte bekannt
sein und durch vorherige Festlegung eines α-Niveaus
kontrolliert werden
t=
Übliche Werte für α
Vorher
140
135
141
140
140
135
141
140
144
143
140
138
120
124
137
zwischen unabhängigen
Beobachtungspaaren von
„0“ verschieden ist
d
SEd
Nachher
138
131
135
136
134
136
138
134
140
141
142
140
121
117
131
mit n-1 Freiheitsgraden
0,05 (5%), 0,01 (1%), 0,001 (0,1%) ...
Das Signifikanz-Niveau muss vor Testbeginn
festgelegt werden
d
SDd
Differenz
-2
-4
-6
-4
-6
1
-3
-6
-4
-2
2
2
1
-7
-6
-2,93
3,09
SEd
t
t krit; 14; 2,5%
0,80
-3,68
-2,14
tkrit; 14; 97,5%
2,14
85
86
Gepaarter t-Test
„Kritische Werte“
Gepaarter t-Test
Beispiel
H 0 ist abzulehnen , wenn t > tkrit ,n −1,1−α / 2
Akzeptanzbereich (95%)
d
t=
SEd
-4
-3
-2
-1
0
1
2
3
t=
4
-4
-2,14
− 2,93
d
=
= −3,68
0,8
SEd
-3
-2
-1
0
1
2
3
4
2,14
-2,14
Ist der gefundene t-Wert kleiner als der untere kritische
Wert oder größer als der obere kritische Wert, muss die
Nullhypothese H0 auf dem α-Signifikanzniveau abgelehnt
werden
2,14
Da |t|=3,43 größer als der kritische Wert für
die t-Verteilung bei 14 Freiheitsgraden und
dem 0,975-Quantil ist (2,14), muss die H0Hypothese auf dem Signifikanz-Niveau α=0,05
verworfen werden
Einfacher: Ist der Betrag des gefundenen t-Wertes
größer als der positive (obere) kritische Wert, muss H0
abgelehnt werden: t > tkrit ,n −1,1−α / 2
87
Gepaarter t-Test
Bedeutung des p-Wertes
α
0,05
0,02
0,01
0,005
0,004
0,003
0,0025
0,0024
1-α/2
0,9750
0,9900
0,9950
0,9975
0,9980
0,9985
0,9988
0,9988
tkrit,14,1-α/2
2,14
2,62
2,98
3,33
3,44
3,58
3,67
3,70
-4
-3
-2
88
P-Wert eines statistischen Tests
-1
0
1
2
3
Vorher
140
135
141
140
140
135
141
140
144
143
140
138
120
124
137
4
− 2,93
d
=
= −3,68
t=
0,8
SEd
P-Wert
89
Nachher
138
131
135
136
134
136
138
134
140
141
142
140
121
117
131
d
SDd
Differenz
-2
-4
-6
-4
-6
1
-3
-6
-4
-2
2
2
1
-7
-6
-2,93
3,09
SEd
t
tkrit; 14; 97,5%
p
0,80
-3,68
2,14
0,0025
P bezeichnet die
Wahrscheinlichkeit eine
solche Differenz oder noch
extremere wie die
gefundene zu erhalten,
wenn die Null-Hypothese
wahr wäre
Alternativ: Die
Wahrscheinlichkeit, dass
eine solche Differenz
zufällig beobachtet wird
(ohne das ein signifikanter
Unterschied vorhanden
wäre)
Wenn p<α, muss die H0Hypothese abgelehnt
werden
90
15
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Klinische Studie
Clinical Trial Example
“Z99” wurde zur Behandlung der systoloischen
Hypertonie etwickelt
H0: Eine 7-tägige Behandlung mit Z99 beeinflusst den
systolischen Blutdruck im Vergleich zu Placebo nicht
“Z99 a new compound lowering BP”
Hypotheses
xZ99 = xPBO
Phase II Studie über 7 Tage an 50 Therapie-naiven
milden Hypertonikern (130 < RRsys. < 160 mmHg)
H1: Eine 7-tägige Behandlung mit Z99 beeinflusst den
systolischen Blutdruck im Vergleich zu Placebo
xZ99 ≠ xPBO
Design
Randomisiert
Doppel-blind
Placebo-kontrolliert
2-armige Parallelgruppenstudie (1:1)
Wenn H0 wahr ist, muss H1 falsch sein
UND
Wenn H0 falsch ist, muss H1 wahr sein
91
92
Klinische Studie
Statistischer Plan
Klinische Studie
Ergebnisse
Voraussetzung
n = 2 x 25 Patienten
Beide Behandlungsgruppen weisen bedingt durch
vorherige Randomisierung vergleichbare
Ausgangswerte auf
Ausgangswerte
Statistischer Test
xPBO: 142 ± 15 mmHg (MW ± SD)
xZ99: 142 ± 16 mmHg
Nach 7 Tagen
Vergleich der beiden Gruppenmittelwerte nach 7
Tagen Behandlung mittels t-test für unabhängige
Stichproben
xPBO: 142 ± 15 mmHg
xZ99: 129 ± 17 mmHg
t-test: p = 0.0078
Signifikanz-Niveau wird auf α = 0,05 gesetzt
Mean
SD
p
PBO
150
160
145
133
166
120
157
158
120
120
145
132
122
145
120
143
120
140
150
145
148
171
151
140
145
142
15
93
17
Durchführung eines statistischen
Tests
3
“Operating the Black Box”
Festlegung von H0 und H1
H
0
25
94
Intervallskalierte Daten
Normalverteilung der Gruppen
Test
Black Box
Varianzhomogenität der Gruppen
In Abhängigkeit vom
Testergebnis (p)
H0 ablehnen: H1 ist wahr oder
H0 beibehalten: H0 ist “wahr“
0,0078
Voraussetzungen für t-Test
H1
Wahl des Signifikanz-Niveaus α
Testdurchführung
Z99
120
130
110
133
115
140
157
120
100
155
145
132
122
145
120
150
110
100
110
130
148
130
151
130
130
129
17
kann verletzt werden, wenn n1=n2
wenn n1<>n2 und Varianzhomogenität nicht
gegeben, spezielle Anpassung der Freiheitsgrade
möglich
Reject H0
95
96
16
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Test auf Normalverteilung
Test auf Varianzhomogenität
Verfahren in SPSS (explorative Datenanalyse)
Verfahren in SPSS (t-Test für unverbundene
Stichproben)
Kolmogorov-Smirnov Test
H0: Stichprobe ist normalverteilt
H1: Stichprobe ist nicht normalverteilt
Levene‘s Test (F-Test auf Varianzhomogenität)
2
2
H0: σ 1 = σ 2
2
2
H1: σ ≠ σ
1
2
Shapiro-Wilk Test
H0: Stichprobe ist normalverteilt
H1: Stichprobe ist nicht normalverteilt
Wenn H1 wahr, spezieller heteroskedastischer t-Test
mit Anpassung der Freiheitsgrade
97
Nichtparametrischer Test:
2 unabhängige Stichproben
98
Nichtparametrischer Test:
2 verbundene Stichproben
Mann-Whitney U-Test
aka Wilcoxon Rank-Sum Test
aka Mann-Whitney-Wilcoxon Rank-Sum Test
Wilcoxon signed-ranks
Bildet aus den Werten Ränge und berechnet
modifizierte t-Statistik für die Ränge (robuster
gegen Ausreißer)
Sortiert Differenzen nach absolutem Betrag und
bildet entsprechende Ränge
Modifizierte t-Statistik für Ränge
Trennschärfer als t-Test, wenn
Voraussetzungen für t-Test verletzt sind
99
100
Einfluss der Fallzahl
2-Stichproben-Tests
“Weniger ist mehr?”
Gleiche Studie aber nur die ersten n = 2 x
13 Patienten werden ausgewertet
Parametrisch
Verbundene
Daten (gepaart)
Gepaarter
t-Test
unverbundene
Daten
t-Test für
unverbundene
Daten
Nichtparametrisch
Ausgangswerte
Wilcoxon
signedsigned-ranks Test
xPBO: 142 ± 15 mmHg
xZ99: 142 ± 16 mmHg
Ergebnis nach 7 Tagen Behandlung
Mann-Whitney U
Test
xPBO: 141 ± 17 mmHg
xZ99: 129 ± 17 mmHg
t-test: p = 0.0987
da p > α (0.05) kann H0 nicht verworfen werden
“Z99” hat keinen Einfluss auf den systolischen
Blutdruck
101
Mean
SD
p
PBO
150
160
145
133
166
120
157
158
120
120
145
132
122
145
120
143
120
140
150
145
148
171
151
140
145
141
17
Z99
120
130
110
133
115
140
157
120
100
155
145
132
122
145
120
150
110
100
110
130
148
130
151
130
130
129
17
0,0987
102
17
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
β Fehler und statistische Power
Einfluss der Fallzahl
β Fehler
Eine zu geringe Fallzahl kann falsch negative
Ergebnisse bewirken (Fehler II. Art/β-Fehler)
Experimente müssen die notwendige
statistische Power aufweisen, um signifikante
Ergebnisse liefern zu können
Definition: Wahrscheinlichkeit H0 nicht zu verwerfen,
obwohl H0 falsch ist
z.B.: Obwohl µPBO ≠ µZ99 liefert der Test xPBO = xZ99
(falsch negatives Ergebnis)
Statistische Power (1-β)
Fazit: Beim Design eines Experiments ist eine
Fallzahlabschätzung notwendig!
Definition: Wahrscheinlichkeit H0 zu verwerfen, wenn H0
falsch ist, d.h. die Wahrscheinlichkeit eine “reale” Differenz
auch als solche zu entdecken
Vereinfacht: Wahrscheinlichkeit ein signifikantes
Testergebnis zu erhalten (wenn ein signifikanter
Unterschied besteht)
103
Vermeidung von β Fehlern:
Power-Schätzung/Berechnung
104
Power & Fallzahl
Vergleich der beiden “Z99”-Experimente
1. Experiment: n = 2x25 ⇒ Power ~ 80%
2. Experiment: n = 2x13 ⇒ Power ~ 38%
Power-Schätzung
Wenn die stat. Power eines Studiendesigns nur 50%
beträgt, wird jede 2. Studie mit diesen Parametern
keine signifikanten Unterschiede anzeigen
Konfirmatorische Studien: Power ≥ 80%
Große Phase III Studien: 85-95%
105
Faktoren, die die Fallzahl beeinflussen
1. Festlegung von α und gewünschter Power
n
Je niedriger das angestrebte α, um so höher die
erforderliche Fallzahl
2. Schätzung der nachzuweisenden Differenz
n
Je größer die gewünschte Power, um so höher die
erforderliche Fallzahl
Power
n
Je kleiner die nachzuweisende Differenz, um so höher
die erforderliche Fallzahl
Ist die Schätzung klinisch relevant?
3. Schätzung der erwarteten Varianz/Standardabweichung
Geschätzte Differenz
z.B. α = 0.05 (5%), power = 80%
α
Power (1-β)
106
Fallzahlberechnung
Signifikanz-Niveau (α)
GPOWER - Version 2.0 Franz Faul & Edgar Erdfelder
Möglichst realistische Werte aus vorangegangenen Experimenten
oder der Literatur verwenden
xPBO - xZ99
Je größer die Standardabweichung, um so höher die
erforderliche Fallzahl
n
4. Fallzahlberechnung durchführen (oder durchführen lassen!)
Geschätzte Standardabweichung
SD
107
Ist die geschätzte Fallzahl klinisch realisierbar?
Ist die geschätzte Fallzahl adäquat zum klinischen Problem?
Anpassung der Fallzahl an die geschätzte Drop-Out-Rate
108
18
AGAH Annual Meeting 2004, Berlin
T. Sudhop und M. Reber: Workshop Biometrie - Beschreibende und schließende Statistik in Klinischen Studien
Anpassung der Fallzahlschätzung
„Drop out“ Rate
Praktische Fallzahlschätzung
1. Beispiel
α = 5%
Faktoren, die die “Drop out” Rate beeinflussen
Power = 80%
Studiendauer
Krankheitsbezogene Verschlechterung
Studienbedingte Unannehmlichkeiten, Adverse Events ...
Geschätzte Differenz & SD
Die Fallzahlschätzung sollte immer auch die antizipierte
Drop out Rate beinhalten
xPBO - xZ99 ~ 13 mmHg
SDpooled ~ 16
Fallzahlberechnung
n = 50 & antizipierte “drop out” Rate 11% ⇒ n = 56
2 x n = 50
Antizipierte Drop out Rate: 0%
GPOWER - Version 2.0 Franz Faul & Edgar Erdfelder
25 Patienten pro Gruppe
benötigt
109
Tipps & Tricks
Power: A priori & Post-hoc
“A priori” Power
“Post-hoc” Power
Schätzung, basierend auf
Berechnung, basierend auf
geschätzte Differenz
beobachteter Differenz
geschätzte SD
beobachteter SD
kalkulierte Fallzahl
echter Fallzahl
110
“Oder, warum Studien scheitern?”
Frühzeitige Einbindung des Statistikers in die
Studienplanung
Verwendung realistischer Schätzer für die erwartete
Differenz und Varianz/SD
Strikte Protokolleinhaltung
Exakte Messung
“Post-hoc Power” kann größer aber auch kleiner als die “a priori Power” sein!
sein!
Vermeidung von Drop outs
111
112
Literatur
Bücher
Rossner B. Fundamentals of Biostatistics. Duxberry Press
Dawson-Saunders B. & Trapp R.G. Basics and Clinical
Biostatistics. Prentice Hall International Inc.
Motulsky, H. Intuitive Biostatistics, Oxford University Press
Software
SPSS - www.spss.com
SAS - www.sas.com
Buchner A., Faul F., Erdfelder E. GPOWER 2.0 - Computer
program for power- and sample size calculation,
http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/
(Freeware) [MS-DOS/Windows and Macintosh]
113
19