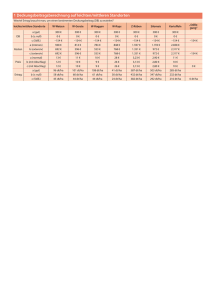
Nutzerverwaltung und datenbasierte Rechtevergabe für mobile
Werbung

Nutzerverwaltung und datenbasierte Rechtevergabe für mobile Datenbankanwendungen - Studienarbeit David Wiese [email protected] Betreuer Dipl.-Inf. Christoph Gollmick Prof. Dr. Klaus Küspert Friedrich-Schiller-Universität Jena Fakultät für Mathematik und Informatik Institut für Informatik Lehrstuhl für Datenbanken und Informationssysteme Ernst-Abbe-Platz 1-4 07743 Jena Mai 2004 Kurzfassung Mit der zunehmenden Verbreitung mobiler Technik und dem damit einhergehenden Anstieg der Nutzung und Entwicklung mobiler Datenbanksysteme ist ein interessanter Trend in der Anwendungsentwicklung zu beobachten. Die wichtigste Anforderung heißt nun: Anytime, Anywhere Computing. Rechner, Benutzer und Daten sind nicht mehr nur auf einen Ort fixiert, sondern können sich beinahe unabhängig voneinander bewegen. Bei der Vielzahl solcher auf den kommerziellen Einsatz ausgerichteten Anwendungen steht die Anzahl und Vertrauenswürdigkeit der auf gemeinsame Datenbestände zugreifenden Nutzer nicht von Beginn fest. In der vorliegenden Arbeit wird daher zunächst das Konzept einer flexiblen, dynamischen Nutzerverwaltung und eines inhaltsorientierten Rechtekonzepts für das interaktive Reiseinformationssystem HERMES zusammen mit den erforderlichen Grundlagen vorgestellt und im weiteren ausführlich auf die Integration in die Infrastruktur der nutzerdefinierten Replikation eingegangen. Abschließend wird das Zusammenspiel zwischen den Komponenten der zu Grunde gelegenen Architektur und die Korrektheit der beschriebenen Mechanismen an einfachen nachvollziehbaren Testszenarien zum tieferen Verständnis demonstriert. Inhaltsverzeichnis 1. Einleitung ........................................................................................................................................................................5 2. Grundlagen......................................................................................................................................................................6 2.1. HERMES - Das interaktive Reiseinformationssystem................................................................................................6 2.1.1. Nutzerdefinierte Replikation .............................................................................................................................6 2.1.2. Drei-Stufen-Architektur ....................................................................................................................................7 2.1.3. Details der nutzerdefinierten Replikation..........................................................................................................8 2.1.4. Fragmentkonzept...............................................................................................................................................9 2.1.5. Integration von HERMES in die 3-Stufen-Architektur .......................................................................................9 2.2. Grundlegende Sicherheitsfunktionen .....................................................................................................................11 2.2.1. Authentifizierung ............................................................................................................................................11 2.2.2. Autorisierung...................................................................................................................................................11 2.2.3. Authentifizierung, Autorisierung unter DB2 UDB .........................................................................................11 2.2.4. Auditing ..........................................................................................................................................................12 2.2.5. Übertragungssicherung....................................................................................................................................12 2.3. Zugriffskontrollansätze ..........................................................................................................................................13 2.3.1. Benutzerbestimmte Zugriffskontrolle .............................................................................................................13 2.3.1.1. Fähigkeitslisten ........................................................................................................................................14 2.3.1.2. Zugriffskontrolllisten ...............................................................................................................................14 2.3.1.3. Weitergabe von Rechten ..........................................................................................................................15 2.3.2. Systembestimmte Zugriffskontrolle ................................................................................................................16 2.3.3. Rollenbasierte Zugriffskontrolle .....................................................................................................................16 2.4. Anforderungen an die Zugriffskontrolle von HERMES ...........................................................................................17 2.5. Zugriffskontrolle in Datenbanksystemen ...............................................................................................................18 2.5.1. Nutzerverwaltung und Authentifizierung........................................................................................................18 2.5.2. Schemabasierte Rechtevergabe .......................................................................................................................18 2.5.3. Zugriffskontrolle durch Programmlogik .........................................................................................................18 2.5.4. Physische Separation durch Nutzung mehrerer Datenbanken.........................................................................19 2.5.5. Einsatz von Sichten .........................................................................................................................................19 2.5.6. Trigger.............................................................................................................................................................20 2.5.7. Routinen (Prozeduren, Funktionen) ................................................................................................................20 2.5.8. Proprietäre Ansätze .........................................................................................................................................21 2.6. Oracle Label Security.............................................................................................................................................21 2.6.1. Einführung ......................................................................................................................................................21 2.6.2. Analyse und Implementierung ........................................................................................................................24 2.6.3. Bewertung .......................................................................................................................................................25 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur...........................................................................26 3.1. Sicherheitsarchitektur des RPS ..............................................................................................................................26 3.2. Das Nutzermanagement des RPS ...........................................................................................................................27 3.2.1. Dienste des RPS ..............................................................................................................................................27 3.2.2. Rollenbasierte Zugriffskontrolle .....................................................................................................................28 3.2.3. Implementierung .............................................................................................................................................29 3.2.4. Nutzerpflege durch CREATE/ALTER/DELETE USER ................................................................................30 3.3. Rechtekonzept und Nutzermanagement von HERMES............................................................................................31 3.3.1. Nutzerverwaltung ............................................................................................................................................31 3.3.2. Rechtekonzept .................................................................................................................................................33 3.3.3. Referential Constraints....................................................................................................................................36 Einführung ............................................................................................................................................................36 Fremdschlüsselproblematik im tupelbasierten Rechtekonzept von HERMES ........................................................37 3.4. Anwendungsspezifische Autorisierungs- und Authentifizierungs-Routinen auf dem RPS....................................40 3.4.1. Autorisierung für CREATE REPLICATION VIEW ......................................................................................41 3.4.2. Autorisierung für ALTER REPLICATION VIEW.........................................................................................43 3.4.3. Autorisierung für SYNCHRONIZE ................................................................................................................44 3.5. Lokale Autorisierungsmechanismen auf dem Client..............................................................................................48 3.6. Private Bereiche in herkömmlichen Anwendungen ...............................................................................................51 3.6.1. Parametrisierte Sichten....................................................................................................................................51 3.6.2. Fremdschlüsselbeziehungen von und zu privaten Daten.................................................................................53 3.7. Private Bereiche in HERMES ...................................................................................................................................54 iii 3.7.1. Ermitteln der synchronisierenden Nutzer ........................................................................................................54 3.7.2. Integration in die RPS-Architektur..................................................................................................................55 4. Testszenarien.................................................................................................................................................................58 4.1. Autorisierung auf dem Client .................................................................................................................................58 4.1.1. INSERT...........................................................................................................................................................60 4.1.2. DELETE..........................................................................................................................................................60 4.1.3. UPDATE.........................................................................................................................................................61 4.2. Autorisierung auf dem RPS....................................................................................................................................61 4.2.1. CRISP-Tool.....................................................................................................................................................62 4.2.2. CSSP-Tool ......................................................................................................................................................63 4.2.3. INSERT...........................................................................................................................................................65 4.2.4. DELETE..........................................................................................................................................................66 4.2.5. UPDATE.........................................................................................................................................................67 5. Zusammenfassung und Ausblick ..................................................................................................................................69 5.1. Zusammenfassung..................................................................................................................................................69 5.2. Ausblick .................................................................................................................................................................69 Anhang..............................................................................................................................................................................71 A Java-Skript CRISP.java.............................................................................................................................................71 B Java-Skript CSSP.java...............................................................................................................................................73 Literaturverzeichnis ..........................................................................................................................................................76 Abbildungsverzeichnis......................................................................................................................................................77 iv 1. Einleitung Technische Weiterentwicklungen und die unaufhaltsam fortschreitende Miniaturisierung ermöglichen kompaktere, leistungsstärkere mobile Endgeräte (Notebooks, Personal Digital Assistants, Mobiltelefone). Dies wiederum eröffnet die Perspektive für eine Vielzahl neuartiger Anwendungen unter dem Einsatz mobiler Datenbank- und Informationssysteme. Ein Ziel besteht in der Erschließung von Anwendungsbereichen mit explizitem Orts- und Situationsbezug, die dem Nutzer über die reine Informationsbeschaffung hinaus auf seinen Aufenthaltsort und aktuelle Tätigkeit angepasste Daten lokal für die Informationsverarbeitung bereitstellen. Beispiele hierfür lassen sich im Gesundheitswesen, Verkehr, Vertrieb und auch in interaktiven Reiseinformationssystemen finden. Bedingt durch begrenzte Speicher- und Stromressourcen sowie niederfrequente Netzwerkverbindungen mit vergleichsweise geringen Bandbreiten wird ein Dienst zur nutzerdefinierten Replikation [Gol03] benötigt, der auf einer vorhandenen mobilen Client/Server-Datenbankumgebung aufsetzt und den mobilen Nutzern die benötigten Daten als auch entsprechende unverbundene Manipulationsmöglichkeiten jederzeit kostengünstig zur Verfügung stellt. Die neuartigen Anwendungsbereiche zeichnen sich durch eine potentiell unbegrenzte variable Nutzerzahl aus, die eine effiziente Verwaltung der Nutzer und die Kontrolle derer Zugriffe auf die gemeinsamen Daten erforderlich macht. Die vorliegende Arbeit setzt sich daher den Entwurf eines inhaltsorientierten, feingranularen Rechtekonzepts und einer damit verbundenen flexiblen Nutzerverwaltung zum Ziel. Im Mittelpunkt aller Betrachtungen soll das am Lehrstuhl konzipierte, interaktive, mobile Reiseinformationssystem HERMES [Bau03] stehen. Obwohl spezielle Datenbank-Addons erworben werden können, wie beispielsweise Oracle Label Security (siehe Abschnitt 2.6.), gibt es doch keine optimale Lösung. Daher wird ein prototypisches Konzept für HERMES entwickelt, aufbauend auf einigen Aspekten der Dateiverwaltung unter Unix [Fri03] und gängigen Internetforen. Vorgestellte Prinzipien lassen sich aber auch problemlos auf alternative Anwendungen übertragen. Im Kapitel 2 erfolgt zunächst eine allgemeine Beschreibung des HERMES, der nutzerdefinierten Replikation und der dafür nötigen Architektur. Weiterhin werden die grundlegende Begriffe und Mechanismen zur Realisierung einer Zu-griffskontrollpolitik sowie die Anforderungen an HERMES in Bezug auf die Rechte- und NutzerVerwaltung dargelegt. Kapitel 3 beinhaltet die Spezifikationen der Nutzer- und Rechteverwaltung auf Serverund Client-Seite und geht dabei auf Besonderheiten der Replikation ein. Verschiedene Testszenarien zeigen im Kapitel 4 die Funktionalität der beschriebenen Techniken und sollen dem vertiefenden Verständnis dienen. In Kapitel 5 werden schließlich die wichtigsten Inhalte der Arbeit noch einmal zusammengefasst und Ausblicke auf weiterführende Arbeiten gegeben. Im Anhang finden sich die im Verlauf des Textes angesprochenen JavaSkripte zur Unterstützung einer zukünftigen Implementierung. 5 2. Grundlagen Ziel dieses Kapitels ist es, die für das Verständnis der Arbeit relevanten Grundlagen umfassend zu erklären. Nachdem im Abschnitt 2.1. HERMES und die zu Grunde liegende Architektur eingeführt werden, beschreibt Abschnitt 2.2. die für Informationssysteme grundsätzlichen Sicherheitsfunktionen. Die darauf aufbauenden Zugriffskontrollansätze finden sich in den Kapiteln 2.3. Es schließt sich ein Anforderungskatalog von HERMES an und im Abschnitt 2.5. werden die Möglichkeiten zur Realisierung von Rechteverwaltungen in Datenbanksystemen ausführlich vorgestellt. Den Schluss dieses Kapitels bildet der Abschnitt 2.6., welcher einen Einblick in das von Oracle angebotene Produkt Oracle Label Security gewährt und dessen Tauglichkeit für das HERMESSzenario analysiert. 2.1. HERMES - Das interaktive Reiseinformationssystem HERMES hat die Aufgabe, seine Nutzer zum einen bei der Reiseplanung (z.B. Bestimmung von Reiserouten, Suche nach Ortschaften) wunschgemäß zu unterstützen und zum anderen als elektronischer Reisebegleiter, ortsabhängige Informationen bereitzustellen. Zusätzlich soll die HERMES-Anwendung über sogenannte private Bereiche verfügen, in denen ein Anwender vollkommen isoliert und ohne Kenntnis der Präsenz von Daten anderer Nutzer persönliche und vertrauliche Informationen (Reiseberichte, Notizen, Aufzeichnungen) ablegen kann, auf die nur er (lesend und/oder schreibend) zugreifen kann. Der Großteil der Daten, wie Informationen (Öffnungszeiten, Preise, Erfahrungen, Bewertungen, Reiseberichte) über Orte, Sehenswürdigkeiten, Gebäude, Hotels oder Restaurants wird, im Gegensatz zu klassischen Touristenführern, von den mobilen Nutzern selbst und in der Regel vor Ort erstellt und aktualisiert. Nur der kleinere Teil der Information (die sogenannten Basisdaten), wie etwa demographische Fakten (Fläche, Einwohnerzahl) über Orte, wird zentral bereitgestellt und ist durch den Nutzer in der Regel nicht änderbar. Demnach sind vorwiegend die potentiell über die ganze Welt verteilten Nutzer von HERMES am Aufbau und der Pflege des Datenbestandes beteiligt. Sie sammeln die Informationen vor Ort, können diese auf ihren mobilen Geräten zwischenspeichern, manipulieren und letztlich einem zentralen Server zur Verfügung stellen. 2.1.1. Nutzerdefinierte Replikation Offensichtlich kann eine Auswahl der Daten für die Replikation, aufgrund der Zeit-, Ort- und Situationsabhängigkeit, nicht durch eine zentrale Instanz vorgegeben werden, vielmehr bedarf es einer nutzer- oder anwendungsgesteuerten Replikat-Anforderung zur Laufzeit. Aufgrund der mangelnden Unterstützung der dynamischen Replikatauswahl sowie anschließender unverbundener Verfügbarkeit und Manipulationsmöglichkeit aktueller mobiler Datenbanklösungen, wurde für HERMES und verwandte Anwendungen ein Dienst zur nutzerdefinierten Replikation (NR) entwickelt, der auf einer vorhandenen mobilen Client/Server-Datenbank-Umgebung aufsetzt [Gol00]. Der zyklische Arbeitsablauf (siehe Abbildung 1) der nutzerdefinierten Replikation beginnt zunächst mit der einmaligen Auswahl des für die Replikation freigegebenen Datenbankausschnittes (Replikationsschema), erweitert um Konfliktbehandlungsmethoden, durch den Replikationsadministrator. Anschließend, in der Phase der Replikatdefinition, spezifizieren die Clients bzw. die darauf laufenden Anwendungen im verbundenen Zustand die Schema- und Datenelemente, die für eine spätere unverbundene Phase lokal verfügbar sein sollen sowie deren Verwendungsabsicht, durch das Anfordern von entsprechenden Änderbarkeitszusicherungen (nur lesend, exklusiv oder optimistisch). In der nun notwendigen Synchronisation werden zunächst bereits lokal vorgenommene Änderungen mit dem Serverdatenbestand abgeglichen (Reintegration1), wenn nötig mit einer entsprechenden 1 Bei der ersten Synchronisation bzw. bei unveränderten Client-Daten ist keine Reintegration nötig. 6 Kapitel 2. Grundlagen Konfliktbehandlung, gefolgt von der Rückübertragung der entsprechenden (geänderten) Daten zum Client (DBMS). Anschließend können die replizierten Daten in der als Normalzustand angenommenen, unverbundenen Phase unabhängig von anderen Nutzern, mit den Mitteln des Client-DBMS gelesen und/oder modifiziert (Ergänzung neuer bzw. Änderung bestehender Daten) werden und die Ergebnisse der lokalen Transaktionen zu gegebener Zeit erneut mit dem zentralen Datenbestand synchronisiert werden. Der angesprochene Zyklus entsteht dadurch entweder durch die Re- bzw. Neu-Definition von Replikaten und/oder der Reintegration geänderter Daten. (Re-)Definition der Replikate Reintegration Synchronisation unverbundene Arbeit mit Replikaten Rückübertragung Abbildung 1: Prinzipieller Arbeitszyklus der nutzerdefinierten Replikation Die in der mobilen Kommunikation auftretenden Empfangs- oder Sendeprobleme wie eine temporäre NichtErreichbarkeit, mangelnde Energieversorgung oder das Ausschalten des Geräts durch den Nutzer selbst während einer notwendigen aktiven Verbindungsphase sind kein Bestandteil der Betrachtungen und die Mechanismen zu deren Behandlung werden als gegeben vorausgesetzt. 2.1.2. Drei-Stufen-Architektur Zur Unterstützung der nutzerdefinierten Replikation und neuerlichen mobilen Anwendungen wie HERMES, in denen Aktivitäten ausschließlich vom Client ausgehen, wird eine Erweiterung des Client-Server-Modells [Gol00] zu einer 3-Stufen-Architektur vorgenommen. Letztere besteht nunmehr aus mehreren mobilen Clients, dem zentralen Quellserver und einem zwischengeschalteten Replication Proxy Server (RPS). Auf dem als gegeben angenommenen Quellserver ist das gesamte Informationsangebot, in Form von Quelldatenbanken, verschiedener bereits betriebener Datenbankanwendungen gespeichert. Trotz der Integration mobiler Clients soll die unveränderte Weiternutzung dieser Anwendungen möglich bleiben. Der RPS speichert alle durch den (die) Replikationsadministrator(en) zur Replikation (durch die mobilen Clients) freigegebenen Quellserverdaten nochmals. Der RPS stellt den Anwendungen alle Dienste bereit, um das vom Quellserver "geerbte" Datenbankschema mobiltauglich zu machen. Dazu gehören die: Abwicklung der drahtlosen Kommunikation mit den mobilen Clients Verarbeitung von Replikations- und Synchronisationsanfragen der Clients automatisierte Behandlung von Änderungskonflikten (Key-Pool-, SLOT-, Escrow-Verfahren) Replikatverwaltung Dabei sollten Änderungen am RPS immer rückabbildbar bleiben, d.h. es dürfen durch den RPS keine über seine "Mobilisierungstätigkeit" hinausgehende Änderungen vorgenommen werden. Zudem ist ein fortlaufender bidirektionaler Datenabgleich zwischen dem RPS und der Quelle nötig, da Datenänderungen auf jeder Seite möglich 7 Kapitel 2. Grundlagen sind. Die redundante Datenspeicherung und der beiderseitige Datenaustausch sind jedoch nicht unbegründet und bieten eine Reihe von Vorteilen, beispielsweise die ausbleibende Notwendigkeit der Erweiterung der bestehenden Quellserverfunktionalität, die Entkopplung und Entlastung des Quellservers sowie die Optimierbarkeit der physischen Speicherstruktur auf dem RPS [Mül03]. Die beim Datenabgleich möglicherweise entstehenden Änderungskonflikte werden durch die Strategie "server wins" aufgelöst, d.h. die Änderungen an der Quelle setzen sich durch. Als DBMS des RPS und der Quelle wird DB2 UDB von IBM eingesetzt. Der Datenabgleich mit dem Quellserver erfolgt mit dem DB2 DataPropagator. Um auch Handheld-Geräte zu unterstützen, führt die Wahl des Client-DBMS unweigerlich zu Adaptive Server Anywhere, das von Sybase (bzw. iAnywhere) als Bestandteil des SQL Anywhere Studio angeboten wird. Die Realisierung der Synchronisation zwischen dem RPS und den mobilen Clients wird durch das von Sybase bzw. iAnywhere angebotene Softwareprodukt MobiLink ermöglicht. Auf die genauen Gründe der konkreten Produktwahl soll hier nicht näher eingegangen werden, da sie in [Mül03] nachgelesen werden können. 2.1.3. Details der nutzerdefinierten Replikation Die Dienste des RPS können durch eine deskriptive, an SQL angelehnte Sprachschnittstelle genutzt werden. Durch das Anlegen bzw. Registrieren einer, für jede zur Replikation freigegebenen Quelldatenbank, korrespondierenden konsolidierten Datenbank (REGISTER CONSOLIDATED DATABASE) mit entsprechenden konsolidierten Tabellen (CREATE CONSOLIDATED TABLE) spezifiziert ein Replikationsadministrator die den mobilen Clients zur Replikation angebotenen änderbaren oder nicht-änderbaren Daten sowie die zu verwendende Konfliktbehandlung im Falle änderbarer Tabellen. Für jede konsolidierte Datenbank bzw. Tabelle des RPS besitzt der Client wiederum eine separate Replikatdatenbank bzw. Replikattabelle. Demnach liegt jeder ClientReplikatdatenbank genau eine konsolidierte RPS- und damit genau eine Quell-Datenbank zu Grunde. Das konsolidierte und das Replikatschema sollten bis auf Datenbanksystemunterschiede gleich sein. Integritätsbedingungen (Fremdschlüsselbeziehungen, Schlüssel, Check-Bedingungen, Trigger) der Quelle werden weitestgehend automatisch und in Spezialfällen manuell auf das Client- und RPS-DBMS übertragen, um eine frühzeitigen Erkennung von Integritätsverletzungen zu ermöglichen. Jede Anwendung nutzt mindestens eine Quelldatenbank (und damit auch die entsprechende konsolidierte bzw. replizierte Datenbank), kann die Daten aber auch, beispielsweise aus Sicherheitsgründen, auf mehrere Datenbanken verteilen. Es ist zudem nicht ausgeschlossen, dass mehrere Anwendungen eine gemeinsame Datenbank benutzen, obwohl die Praxisrelevanz eines solchen Falles als äußerst gering eingeschätzt werden kann. Für das Anlegen der Replikatdatenbanken sind die mobilen Anwendungen bzw. ein für den Client zuständiger Administrator nötig. Die gezielte Auswahl der zur unverbundenen Arbeit benötigten Daten, kann hingegen dynamisch zur Laufzeit, durch das Anlegen von, auf den konsolidierten Tabellen beruhenden, Replikationssichten (CREATE REPLICATION VIEW) erfolgen. Optional können dabei Änderbarkeitszusicherungen für eine unverbundene lokale Manipulation der Daten angefordert und die Parametrisierung von Konfliktbehandlungsmethoden vorgenommen werden. Durch das logische Konstrukt der Replikationssichten wird die Unterscheidung zwischen den geforderten Daten und den tatsächlich replizierten Daten möglich. Die Menge der durch den Client definierten Replikationssichten bildet ein Fenster, durch das ein bestimmter Ausschnitt der Quelldatenbank sichtbar ist. Der RPS sorgt automatisch dafür, dass alle hierzu benötigten Daten (u.U. mehr als die geforderten) auf den Client übertragen und in den entsprechenden Replikattabellen gespeichert werden. Damit wird die sogenannte "replica unawareness" unterstützt, d.h. die Clients arbeiten auf den lokalen Daten so, als ob sie direkt mit der Server-Datenbank kommunizieren würden. Erzeugt wird dann eine, den Gegebenheiten des Client-DBMS entsprechende, lokale Sicht, welche genau die tatsächlich geforderten Daten, der ihr zu Grunde liegenden (Replikat-) Tabellen selektiert. Änderungen auf der für eine Replikationssicht angelegten lokalen änderbaren Sicht, führen folglich zu Änderungen an den zu Grunde liegenden Replikattabellen. Die Forderungen der lokalen Änderbarkeit von Daten wird als Anforderung einer Änderbarkeitszusicherung bezeichnet. Unterschieden werden optimistische und exklusive Änderbarkeitsanforderungen. Besitzt ein Client eine nicht-exklusive (optimistische) Änderbarkeitszusicherung für die angeforderten Daten, so können auch andere mobile Clients Änderungen an den Daten vornehmen. Die bei der späteren Synchronisation eventuell 8 Kapitel 2. Grundlagen auftretenden Konflikte müssen dann den, bei der Erzeugung der Replikationssicht, spezifizierten Konfliktbehandlungsmethoden unterzogen werden. Exklusive Änderbarkeitszusicherungen sichern das alleinige Änderungsrecht an den Daten, schränken aber zugleich die Verfügbarkeit derer erheblich ein. Aus diesem Grund sollten Zusicherungen dieser Art nur vereinzelt und einem kleinen ausgewählten Nutzerkreis eingeräumt werden. Um die Verfügbarkeit nicht komplett zu restringieren, können exklusive Änderbarkeitszusicherungen noch auf INSERT beschränkt werden. Eine Unterteilung in DELETE- und UPDATE-Zusicherungen (auf einzelne Spalten) wie in [Mül03] vorgeschlagen, erfolgt jedoch in der aktuellen Implementierung des RPS aus Komplexitäts- und Performancegründen nicht [Pfe04]. Einem mobilen Client kann eine Änderbarkeitszusicherung nur dann gewährt werden, wenn die anderen Clients gewährten dem nicht entgegen stehen (z.B. nicht zweimal exklusives INSERT für dieselben Daten). Die genaue theoretische Klassifizierung und Kompatibilitäten der Änderbarkeitszusicherungen untereinander können den Arbeiten [Mül03] und [Pfe04] entnommen werden. 2.1.4. Fragmentkonzept Die Realisierung der nutzerdefinierten Replikation zur anwendungsgesteuerten dynamischen Auswahl relationaler Datenbankinhalte erfordert eine effiziente Verwaltung von Replikatanforderungen tausender mobiler Clients. Das in [GR03] vorgestellte Fragmentkonzept nimmt sich dieses Problems an und stellt eine Lösung vor, die auf der automatischen Gruppierung von semantisch und nach Auswertung der Zugriffsprofile mobiler Nutzer zusammengehörenden Daten zu logischen Verwaltungseinheiten, kurz Fragmenten, basiert. Ein Fragment ist dabei eine Menge horizontaler, vertikaler oder kombinierter Tabellenpartitionen aus einer oder mehreren Tabellen, angereichert mit Zusatzinformationen (z.B. Beziehungen zu anderen Fragmenten) [GR03]. Die nutzerdefinierte Replikation, die sich den Einsatz von Fragmenten als Verwaltungs- und Übertragungsgranulat zu Nutze macht, übernimmt dabei folgende Aufgaben: Vollständige Zerlegung (Fragmentierung) der zur Replikation freigegebenen Daten Angefragte Daten sollten nur einmal auf den Client repliziert werden, egal von wie vielen Replikationssichten sie benutzt werden Für die Integritätssicherung erforderliche Daten (z.B. Tupel aus Fremdschlüsselbeziehungen) gilt es ebenfalls auf den Client zu übertragen Für jeden mobilen Client sind nur die von ihm referenzierten Fragmente abzuspeichern Automatisches Sammeln aller einen Client betreffenden Datenänderungen im unverbundenen Zustand, die dann bei der Synchronisation sofort übertragen werden können Der Anfangszustand der Fragmente wird im laufenden Betrieb automatisch und inkrementell durch die Zugriffsstatistiken der mobilen Nutzer angepasst Eine geeignete Sperrverwaltung der durch die Client-Anwendung spezifizierbaren Änderbarkeits-Modi der Replikation (exklusiv, optimistisch) durch den Einsatz von Granulatsperren auf eine feste Menge vorgegebener Prädikate (Fragmente) Die eigentliche Fragmentbildung verläuft in zwei Schritten. Bei der Schemafragmentbildung werden alle Tabellen zu einem Schemafragment zusammengefasst, die in Beziehung stehen (z.B. durch Fremdschlüsseldefinitionen) und die bei der Replikation immer zusammen übertragen werden sollen. In einem zweiten Schritt, der Datenfragmentbildung wird jedes Schemaframent in einzelne Datenfragmente zerlegt, die jeweils Tupel mit gemeinsamen Merkmalen (Ortsattribute, Integritätsbedingungen, nutzer- oder gruppenbezogene Daten, nur-lese Daten) zusammenfassen. Inwieweit sich das Fragmentkonzept auf die angestrebte Nutzer- und Rechte-Verwaltung vorteilhaft auswirkt, wird im Abschnitt 3.3.2. erläutert. 2.1.5. Integration von HERMES in die 3-Stufen-Architektur HERMES nutzt eine (Quell-)Datenbank und wurde speziell für die mobile Anwendung konzipiert. Es ist daher nicht zweckmäßig, Zugriffe von auf der Quelldatenbank arbeitenden HERMES-Nutzern zu erlauben. Die Quellanwendung von HERMES weiß demnach auch von der Existenz des RPS und nutzt die angebotenen Befehle zur Interaktion mit den Client-Nutzern. 9 Kapitel 2. Grundlagen Die anwendungsspezifischen, zur Replikation freigegebenen Quelldaten liegen, wie bereits beschrieben, auf dem RPS als Kopie vor. In der unverbundenen Phase geänderte Daten können bei der Synchronisation nicht einfach in das konsolidierte Schema übernommen werden, da die Arbeit auf dem Client nicht überwacht werden kann und die darauf gespeicherten Daten prinzipiell beliebig manipulierbar sind. Infolgedessen stellt HERMES eine Menge von Prozeduren und Funktionen bereit, die der Identifikation des Nutzers und seiner Rechte bei der Replikation bzw. Synchronisation dienen. Die Parameter und Namen der Routinen sind vom RPS vorgegeben und werden in dem Abschnitt 3.4. näher erläutert. Optional besteht für den RPS nutzende Anwendungen die Möglichkeit des Einsatzes separater RPS-Applikationen. Letztere dienen, ähnlich den Routinen, der Einhaltung von geforderten Sicherheitsrichtlinien und kommunizieren dazu mit den entsprechenden Quell- bzw. ClientApplikationen. Eine Kombination der Mechanismen ist auch möglich und sollte selbst den komplexesten Anforderungen genügen. Es folgt ein Überblick der wichtigsten Funktionen der HERMES-Anwendung seitens Quelle und Client. Eine detaillierte Beschreibung kann [Bau03] und den weiteren Abschnitten entnommen werden. Haupt-Funktionen der HERMES-Client-Anwendung: Übersicht über im System bzw. lokal vorhandene Daten Auswahl von Daten für die Replikation Aktualisierung replizierter Daten (initiiert durch den Nutzer) Reintegration lokal geänderter Daten mit dem zentralen Datenbestand sowie adäquate Benachrichtigung des Nutzers in Konfliktfällen mit evtl. Lösungsvorschlägen Registrieren neuer HERMES-Nutzer und Senden der zu prüfenden Informationen an die HERMESSERVER-Anwendung Speichern sämtlicher Informationen des einen lokalen HERMES-Nutzers Haupt-Funktionen der HERMES-SERVER-Anwendung (auf der Quelle): Auslösen der Registrierung des Clients beim RPS (Account-Generierung) Speichern und Verwalten der Informationen aller HERMES-Nutzer Abbildung 2 stellt die verwendete Architektur und die Integration von HERMES anschaulich dar, wobei vereinfachend davon ausgegangen wird, dass der Client alle angebotenen Quellanwendungen und zugehörige Datenbanken nutzt und aus diesem Grund alle korrespondierenden Replikatdatenbanken besitzt. Nicht alle QuellserverAnwendungen nutzen die Möglichkeit eigene Prozeduren oder Funktionen auf dem RPS für ihre Sicherheitspolitik zu implementieren. Vielmehr nutzen sie eigens implementierte RPS-Applikationen (Appl. c-h) für ihre Zwecke. Abbildung 2: Architektur zur Unterstützung neuartiger mobiler Anwendungen 10 Kapitel 2. Grundlagen 2.2. Grundlegende Sicherheitsfunktionen Im Folgenden werden die in Informationssystemen notwendigen Grundfunktionen Authentifizierung, Autorisierung, Beweissicherung und Übertragungssicherung beschrieben. Es soll auch auf die für DB2 spezifischen Besonderheiten eingegangen werden. 2.2.1. Authentifizierung Unter Authentifizierung ist die Verifikation einer vorgegebenen Identität zu verstehen. Grundsätzlich lassen sich drei verschiedene Authentifizierungsansätze unterscheiden [Rup02]: Überprüfung eines Wissensmerkmals ("something you know"): Eine Entität wird aufgrund ihres vorhandenen faktischen Wissens authentifiziert. Die in der Praxis am häufigsten verwendete Variante ist die Abfrage von Wissen, wie z.B. Passwörter oder persönliche Identifikationsnummern. Überprüfung eines Besitzmerkmals ("something you have"): Der Benutzer authentifiziert sich mit Hilfe eines möglichst einfach überprüfbaren und fälschungssicheren Identifikationsausweis (z.B. Magnet- oder Chipkarten) Überprüfung eines Seinsmerkmals ("something you are"): Die Überprüfung der Echtheit einer Identität erfolgt anhand individueller biometrischer Merkmale. Derartige Verfahren wie z.B. die Messung von Fingerabdrücken, Handflächen, der Iris oder auch des individuellen Schreibstils haben sich bisher aufgrund zu hoher Fehleranfälligkeit und Kosten noch nicht durchsetzen können. In mobilen Datenbankanwendungen authentifizieren sich vertrauenswürdige (trusted) Nutzer lediglich auf dem Client (auf Ebene des Betriebssystems durch Login+Passwort oder eines Besitz- bzw. Seinsmerkmals), andernfalls (untrusted) auch auf dem von ihnen angesprochenen Server (Server-Login+Passwort). 2.2.2. Autorisierung Unter Autorisierung oder Zugriffskontrolle versteht man die Spezifikation von Regeln, wer welche Art von Zugang unter welchen Bedingungen zu welchen Informationen oder Objekten hat. Bei der Autorisierung wird grundsätzlich zwischen Zugriffsrechteverwaltung und –überprüfung unterschieden [Rup02]. Die Verwaltung umfasst das Erteilen, Entziehen und Pflegen von Zugriffsrechten. Vor Ausführung eines Zugriffs muss dann überprüft werden, ob dieser gemäß Rechteverwaltung zulässig ist oder gegen etwaige Bedingungen verstößt. Ein Zugriffsrecht lässt sich dabei vereinfacht als Tripel bestehend aus Subjekt, Objekt und zugehöriger Zugriffsaktion beschreiben und bildet die Beziehungen der Komponenten untereinander ab. 2.2.3. Authentifizierung, Autorisierung unter DB2 UDB DB2 UDB Version 8.1 besitzt im Gegensatz zu anderen Datenbanksystemen (z.B. Oracle) kein eigenes Nutzerkonzept, sondern verwendet zur Authentifizierung die vom Betriebssystem (oder von einem separaten Produkt wie Kerberos) bereitgestellten Nutzer und Nutzergruppen. Die Autorisierung und Rechtevergabe für die datenbank-spezifische Funktionalität erfolgt dann durch DB2 selbst mittels Privileges (Zugriffsrechte) und Authority level (auch Authorities, dt. Berechtigungsstufen). Diese zwei Mechanismen dienen zur Steuerung des Zugriffs auf den Datenbankmanager und seine Datenbankobjekte. Benutzer können nur auf solche Objekte (z.B. Tabellen, Sichten) zugreifen, für die sie berechtigt sind, d.h. für die sie über das erforderliche Zugriffsrecht oder die erforderliche Berechtigungsstufe verfügen. Privileges erlauben es Nutzern, Datenbankressourcen zu erstellen oder auf sie zuzugreifen. Dabei werden zwei Kategorien von Zugriffsrechten unterschieden, solche, die Aktionen für die Datenbank als Ganzes umfassen (Bsp.: CONNECT-Recht) und Zugriffsrechte, die sich auf einzelne Objekte innerhalb der Datenbank beziehen (z.B. SELECT-Recht auf eine Tabelle). 11 Kapitel 2. Grundlagen Authorities gruppieren Zugriffsrechte zur Realisierung eines Rollenkonzepts. DB2 bietet 5 Authority level: SYSADM (Systemadministrator), SYSCTRL (system resource administrator), SYSMAINT (system maintenance administrator), DBADM (Datenbankadministrator) und LOAD, welche jeweils die Zugriffsrechte zusammenfassen, die für die angedachten Aufgaben notwendig sind. Die Rechte der SYS...-Autoritäten werden durch die Mitgliedschaft in spezifischen Betriebssystem-Gruppen erworben. Abbildung 3 ([IBM02a]) veranschaulicht die Hierarchie der Authorities und Privileges noch einmal. SYSADM DBADM SYSCTRL SYSMAINT Database Users with Privileges Abbildung 3: Authorities und Privileges in DB2 Zugriffsrechte werden in der Regel automatisch vergeben (z.B. beim Erstellen eines Datenbankobjekts an den Erzeuger) oder von berechtigten Nutzern mit den SQL-Anweisungen GRANT und REVOKE an einzelne Nutzer oder eine Gruppe von Nutzern explizit erteilt bzw. entzogen. Eine weitere Möglichkeit der Rechtevergabe ist die Zugehörigkeit zu einer der vom Datenbanksystem verwalteten symbolischen Gruppen SYSADM, SYSCTRL, SYSMAINT oder PUBLIC (umfasst alle Nutzer). Eine Übersicht und die Details des Rechtekonzepts können in der entsprechende Dokumentation [IBM02b] nachgelesen werden. 2.2.4. Auditing Die Beweissicherung (Auditing) trägt zur Erhöhung der Nachvollziehbarkeit, Verbindlichkeit und Integrität bei. Sie dokumentiert alle Informationen über Zugriffe und Zugriffsversuche sämtlicher Subjekte. Die aufgezeichneten Protokolle müssen in regelmäßigen Zeitabständen auf Unregelmäßigkeiten und Regelverstöße überprüft werden. Mit ihrer Hilfe lassen sich die für eine Operation verantwortlichen Subjekte identifizieren und geeignete Maßnahmen und Konsequenzen ableiten [Rup02]. DB2 unterstützt das Auditing über die sogenannte Audit Facility. Letztere erlaubt das Verwalten und die Generierung eines Audit Trails für eine Menge vordefinierter Datenbank-Ereignisse und speichert die Aufzeichnungen in einem Audit-Log-File (siehe [IBM02b]). 2.2.5. Übertragungssicherung Daten und Informationen müssen nicht nur innerhalb eines Systems sicher sein, sondern auch bei der Übertragung zwischen den Systemkomponenten und zum Benutzer bzw. Client. Implementierungen der Übertragungssicherung basieren häufig auf kryptographishen Verfahren sowie normierten Kommunikationsprotokollen (z.B. TCP/IP). Für jeglichen Datenstrom vom oder zum Server soll in unserem Fall eine SSL (Secure Socket Layer)-Verbindung genutzt werden, bzw. ein vergleichbares Verfahren vorausgesetzt werden. 12 Kapitel 2. Grundlagen 2.3. Zugriffskontrollansätze Zugriffskontrolle regelt den lesenden, ändernden und löschenden Zugriff auf Daten und schützt somit deren Geheimhaltung und Authentizität vor ungewollten (accidental) oder beabsichtigten (malicious) Bedrohungen [Rup02]. Die Aufgabe von Zugriffskontrollmechanismen besteht demnach darin, nur solche direkten Zugriffe auf Daten zuzulassen, die autorisiert worden sind. In der Literatur lassen sich grundsätzlich drei verschiedene Klassen von Zugriffskontrollansätzen unterscheiden: Benutzerbestimmte Zugriffskontrolle (Discretionary Access Control, DAC) Systembestimmte Zugriffskontrolle (Mandatory Access Control, MAC) Rollenbasierte Zugriffskontrolle (Role-based Access Control, RBAC) 2.3.1. Benutzerbestimmte Zugriffskontrolle Die benutzerbestimmte Zugriffskontrolle ist eine Maßnahme zur Beschränkung des Zugriffs auf Objekte basierend auf der Identität der Subjekte und/oder Gruppen, denen sie angehören [Kaß95]. Sämtliche Objekte haben einen Eigentümer (Eigentümer-Paradigma), der alle Rechte an dem Objekt besitzt und verwaltet. Er kann sie an weitere Subjekte ohne vorherige Vermittlung und Genehmigung einer zentralen Instanz (zum Beispiel den System- oder Sicherheitsadministrator) weitergeben und auch widerrufen. Die Verwaltung der Rechte und der durch sie beeinflusste Informationsfluss unterliegt somit der Diskretion des einzelnen Benutzers, was dem Zugriffsmodell auch den Namen gab. Mit benutzerbestimmbaren Strategien können objektbezogene Sicherheitseigenschaften nicht von vornherein festgelegt werden. Eine Sicherheitsstrategie kann deshalb nur durch das Zusammenspiel mehrerer Objekte realisiert werden. Zugriffsregeln von DAC-Modellen werden üblicherweise in Zugriffskontrollmatrizen gespeichert (siehe Abbildung 4). Hierbei werden die Subjekte in den Zeilen 1 bis i und die Objekte in den Spalten 1 bis j abgetragen. Der Eintrag in Zeile i und Spalte j enthält die Menge der Zugriffsrechte R ij , die ein Subjekt S i auf ein Objekt O j hat. Mögliche Zugriffsrechte sind Lesen, Schreiben, Löschen oder Anlegen. Die Granularität der Objekte und Subjekte ist ein sehr wichtiger Parameter bei der Konzeption eines diskreten Zugriffskontrollmodells mit weitreichenden Auswirkungen auf den späteren Betrieb. Werden zum Beispiel nur komplette Tabellen eines RDBMS als Objekte identifiziert, so ist es später nicht möglich den Zugriff auf Datensätze innerhalb einer Tabelle einzuschränken. Objekte Subjekte ... O1 O2 Oj S1 R11 R12 R1 j S2 R21 R22 R2 j ... Si Ri1 Ri 2 Rij Abbildung 4: Zugriffskontrollmatrix Ein Beispiel für einen nicht autorisierten Informationsfluss soll folgende Problematik verdeutlichen: Subjekt S1 ist Besitzer einer vertraulichen Tabelle O1 und gewährt nur Subjekt S 2 Leserechte für diese Tabelle. Subjekt S 2 könnte nun eine neue Tabelle O 2 anlegen, die entsprechenden Rechte dafür vorausgesetzt, und den Inhalt von O1 hineinkopieren. Danach könnte S 2 als Erzeuger und Eigentümer der Tabelle O 2 einem Dritten Leserechte auf O2 erteilen und so die vertraulichen Inhalte veröffentlichen obwohl S1 dies eigentlich nicht zulassen wollte. Solches Fehlverhalten von Subjekten kann somit nur im Nachhinein durch Auditing-Maßnahmen erkannt werden. 13 Kapitel 2. Grundlagen DAC Mechanismen sind für starke Systemsicherheit wenig oder nur sehr eingeschränkt geeignet, denn Zugriffsentscheidungen werden nur aufgrund von Identität und Eigentumsrechten getroffen und ignorieren dabei andere sicherheitsrelevante Informationen, so wie etwa die Rolle des Benutzers oder die Schutzbedürftigkeit eines Objekts. 2.3.1.1. Fähigkeitslisten Zugriffskontrollmatrizen eignen sich zwar sehr gut für eine übersichtliche, logische Darstellung, sind in der Praxis aufgrund ihrer Unflexibilität und schnell wachsenden Größe allerdings ungeeignet. Durch das zeilenweise Zerlegen der Zugriffskontrollmatrix entstehen Fähigkeitslisten (capability list, CL), die jedem Subjekt die erlaubten Zugriffsrechte bezüglich der einzelnen Objekte zuordnen und diese direkt beim Subjekt speichern. Subjekt 1 Objekt 1 Objekt 5 R11 R15 Objekt 3 Subjekt 2 R23 Objekt 5 Subjekt 3 R35 ... Objekt 1 Subjekt n Objekt 2 Rn1 Objekt 4 Rn 2 Rn 4 Abbildung 5: Fähigkeitsliste Vorteilhaft an dieser Art der Rechteverwaltung ist, dass nur noch relevante (nicht leere) Einträge gespeichert werden und dass die Frage, welche Rechte ein bestimmtes Subjekt hat, schnell entscheidbar ist. Nachteilhaft dagegen wirkt sich aus, dass es zu einer unkontrollierten Propagierung von Rechten (und daher auch zu Problemen beim Entzug (Revokation) dieser Rechte) kommen kann. Des weiteren können die einzelnen Fähigkeitslisten sehr lang werden, wenn die Zahl der Objekte in einem System die Zahl der Subjekte bei weitem übersteigt. Letztlich kann die Frage, wer auf ein bestimmtes Objekt zugreifen darf, aufgrund der gewählten Speicherungsstruktur für die administrierten Rechte nicht direkt beantwortet werden. Hierzu ist eine exhaustive Suche über die Fähigkeitslisten aller im System vorhandenen Subjekte erforderlich [Kaß95]. 2.3.1.2. Zugriffskontrolllisten Die alternative Darstellung ist die Zugriffskontrollliste (access control list, ACL). Hierbei erfolgt die Partitionierung der Zugriffskontrollmatrix spaltenweise. Jedes Element der Liste spezifiziert für ein Objekt, welche Subjekte welche Art von Zugriff haben. Objekt 1 Subjekt 1 Subjekt 4 Subjekt 2 R11 R41 R21 Subjekt 9 Objekt 2 R92 ... Objekt n Subjekt 4 Subjekt 9 R4 n R9 n Abbildung 6: Zugriffskontrollliste 14 Kapitel 2. Grundlagen Ein Vorteil von Zugriffskontrolllisten besteht darin, dass die zu verwaltenden Listen recht kurz sind, sofern die Zahl der Subjekte in einem System kleiner als die Zahl der Objekte ist. Der Verwaltungsaufwand lässt sich sogar noch weiter reduzieren, wenn Subjekte in Gruppen angeordnet werden. Darüber hinaus lassen sich die für ein bestimmtes Objekt zugriffsberechtigten Subjekte schnell bestimmen, und es werden nur relevante Einträge verwaltet. Die gewählte Speicherungsstruktur wirkt sich insofern nachteilig aus, als dass die Fähigkeiten eines Subjektes nur durch die Traversierung der Zugriffskontrolllisten aller Objekte bestimmt werden können. Für benutzerbestimmbare Zugriffskontrolle ist es essentiell, dass bei der Erzeugung eines Objektes mindestens ein Subjekt in die Zugriffskontrollliste eingetragen wird (meist das erzeugende Subjekt). Im mobilen Datenbankszenario, so auch bei HERMES, ist die Anzahl der Subjekte häufig bedeutend größer als die Anzahl der Objekte, so dass der Einsatz einer Zugriffskontrollliste die günstigere Alternative darstellt, sofern man die Subjekte zusätzlich gruppiert. Für HERMES soll jedoch aus Gründen der Effizienz zu jedem Objekt keine Liste zugriffsberechtigter Subjekte (bzw. Gruppen) gespeichert werden, sondern nur ein Eintrag. Dies hat den Vorteil, dass die Zugriffsberechtigungen direkt am Objekt gespeichert werden können und keine aufwendige Traversierung durchgeführt werden muss. Die zugreifenden Subjekte sowie Art der Objekte, deren Granularität und die genaue Umsetzung finden sich im Abschnitt 3.3. 2.3.1.3. Weitergabe von Rechten Eine charakteristische Eigenschaft benutzerbestimmbarer Zugriffskontrolle in Abgrenzung zu regelbasierter Zugriffskontrolle (vergleiche Abschnitt 2.3.3.) ist die Möglichkeit der Subjekte, Rechte für den Zugriff auf eigene Objekte weiterzupropagieren oder erteilte Rechte zu entziehen. Grundsätzlich sind zwei Arten von Rechtepropagierungen zu unterscheiden [Kaß95]: Wird ein Recht mit Kopiererlaubnis (grant option) an ein Subjekt weiterpropagiert, so wird der Empfänger ermächtigt, dieses Recht seinerseits anderen Subjekten zu erteilen. Erfolgt die Delegierung ohne Kopiererlaubnis, so kann der Empfänger zwar die dadurch autorisierten Operationen auf Objekten durchführen, die Weitergabe dieser Rechte ist ihm jedoch untersagt. Ziel eines wohldefinierten Autorisierungssystems muss es sein, die Historie der Weitergaben genau zu verfolgen, um unkontrolliertes Propagieren zu vermeiden. Auf diese Weise soll erreicht werden, dass der Systemzustand nach dem Entzug eines Rechtes so ist, als ob dieses Recht nie erteilt worden wäre. Dabei können zwei Probleme auftreten [Kaß95]: i. ii. Ein Subjekt (Empfänger) kann dasselbe Recht von verschiedenen anderen Subjekten (Absendern) erhalten haben. Ruft einer der Absender dieses Recht zurück, so darf dies nicht zu einer Entziehung der durch andere Subjekte gewährten Rechte führen. Da das Empfängersubjekt nach dem Erhalt eines Rechtes mit Kopiererlaubnis berechtigt ist, dieses Recht seinerseits weiterzupropagieren, muss diese Möglichkeit der Weitergabe beim Rückruf eines Rechtes ebenfalls Berücksichtigung finden. Wurde dasselbe Recht auch von anderen Absendern erhalten (siehe i), so können, je nach zeitlicher Reihenfolge, die Weitergaben von Rechten an Dritte trotz des Rückrufs eines Absenders unbeeinflusst bleiben. Ein Propagierungs- und Revokationsalgorithmus, der diese Probleme löst und sich durchgesetzt hat, wird erstmals in System R [GW76] vorgestellt und soll hier nicht näher betrachtet werden. Gängige DBMSe (Oracle, DB2) machen sich die Prinzipien des Algorithmus zu Nutze und speichern in internen Tabellen (Systemtabellen) das folgende 4-Tupel (A,P,O,B) ab. Nutzer A (grantor) hat Privileg P (select, delete, update, insert) auf Objekt O (Tabelle, Sicht) an den Nutzer B (grantee) gewährt. Die SQL-Norm bietet für die Zugriffskontrolle und Rechtedelegierung GRANT und REVOKE an: GRANT privilege [, ...] ON object [ ( column [, ...] ) ] [, ...] TO { PUBLIC | username [, ...] } [ WITH GRANT OPTION ] 15 Kapitel 2. Grundlagen erlaubt das Erteilen von Zugriffsrechten (Privileges) bis auf einzelne Spalten einer Tabelle und die Möglichkeit die eigenen Rechte an Dritte weiterzugeben (WITH GRANT OPTION). Objekte sind unter anderem Basisrelationen und Sichten. GRANT REVOKE [ GRANT OPTION FOR ] { SELECT | INSERT | UPDATE | DELETE | REFERENCES } ON object [ ( column [, ...] ) ] FROM { PUBLIC | username [, ...] } { RESTRICT | CASCADE } REVOKE, als inverse Operation zu GRANT, dient dem Entziehen von Zugriffsrechten. Dies wird dadurch kompliziert, dass ein Benutzer dasselbe Recht über unterschiedliche GRANT-Anweisungen erhalten haben kann (siehe Punkt i). Der die REVOKE-Operation auslösende Benutzer muss derjenige gewesen sein, der diese Rechte auch gewährt hat. Die optionale Angabe GRANT OPTION FOR in der REVOKE-Anweisung bedeutet, dass der Benutzer nicht versucht, die angegebenen Rechte per se zu löschen, sondern nur für diese Rechte die Berechtigung zur Rechtevergabe zu widerrufen. Bekommt Nutzer B ein spezielles Recht mit grant-Option von Nutzer A und gibt es seinerseits weiter an Nutzer C, dann kann Nutzer A das Recht kaskadierend entziehen, mittels dem CASCADE-Schlüsselwort. Wenn hingegen RESTRICT spezifiziert wurde, kann Nutzer A das Recht nicht entziehen, wenn es Nutzer B bereits an andere Nutzer gewährt hat. 2.3.2. Systembestimmte Zugriffskontrolle Die Zugriffskontrolle in benutzerbestimmten Zugriffskontrollsystemen zeichnet sich durch ein hohes Maß an Flexibilität aus, da jeder Besitzer von Daten prinzipiell in der Lage ist, jedem Subjekt Zugriff auf diese Daten zu gewähren. Häufig fordert die Anwendungssemantik, insbesondere im militärischen Bereich, jedoch eine restriktivere Einschränkung des Zugriffs durch fest definierte Anwendungsregeln, die den Kreis der möglichen zugreifenden Objekte beschränkt. Die sachgerechte Benutzung diskreter Zugriffskontrolle allein reicht nicht aus, um diese Regeln einzuhalten, da nicht erzwungen werden kann, dass jedes Subjekt sie befolgt [Rup02]. Dies motiviert die Einführung systembestimmter oder mandatorischer Zugriffskontrolle, die den Gedanken verfolgt, im System einheitlich vorgegebene Sicherheitsrichtlinien (Policies) durchzusetzen. Die Policy wird dabei durch einen Administrator systemweit und fest vorgegeben, wobei Benutzern nicht erlaubt wird, diese zu ändern bzw. weiterzugeben. Die so festgelegten systemglobalen Eigenschaften dominieren über die benutzerspezische Rechtevergabe, das heißt, ein Zugriff auf ein Objekt wird auch dann verweigert, wenn es zwar eine explizite Benutzerfreigabe gibt, diese jedoch im Gegensatz zur durchzusetzenden systemweiten Vorgabe steht. Hieraus folgt insbesondere (im Gegensatz zu benutzerbestimmten Zugriffskontrolle), dass der Besitzer eines Objektes unter Umständen überhaupt keinen Zugriff mehr auf seine eigenen Objekte hat. Die Zugriffsentscheidung wird schließlich anhand von Attributen getroffen, welche den Objekten zugeordnet sind und eine Reihe von sicherheitsrelevanten Informationen beinhalten. Als nachteilig kann die Starrheit der anfangs festgelegten Richtlinien gesehen werden, die während der Laufzeit nicht änder- bzw. anpassbar sind und eine entsprechende vorausdenkende Anfangsimplementierung bedingen. Die häufigste Form dieser Art von Sicherheitspolicies stellt das Multilevel Security Konzept dar. Hierbei wird jeder Entität (Subjekt als auch Objekt) ein bestimmtes Sicherheitslevel mit dementsprechenden Rechten zugeordnet. Die detailliertere Beschreibung einer Umsetzung namens "Oracle Label Security", erfolgt im Abschnitt 2.6. 2.3.3. Rollenbasierte Zugriffskontrolle Neben dem traditionellen DAC und MAC kann die Vergabe von Zugriffsrechten auch rollenbasiert erfolgen (role-based access control, RBAC). Hierbei stehen nicht die Subjekte sondern die durch sie durchzuführenden Aufgaben im Vordergrund. Benutzer, die aufgrund ihrer Aufgaben und Verantwortlichkeiten, über die gleichen Rechte verfügen sollen, werden dann einer bestimmten Rolle (benannte Zusammenfassung von Rechten) zuge16 Kapitel 2. Grundlagen ordnet. Rollen sind eine Weiterentwicklung des Gruppenkonzeptes, bei dem lediglich Mengen von Benutzern nach verschiedenen Kriterien zusammengefasst werden. Zwischen Rollen und Benutzern sowie Rollen und Zugriffsrechten auf Objekte existiert eine n:m-Beziehung. Ein Subjekt kann mehreren Rollen zugeordnet sein und eine Rolle kann viele Subjekte als Mitglieder besitzen. Ebenso kann eine Rolle die Zugriffsrechte auf mehrere Objekte repräsentieren und ein Objekt darf von mehreren Rollen bearbeitet werden [Rup02]. Rollen können durchaus hierarchisch strukturiert sein. Dabei muss darauf geachtet werden, dass keine Zyklen bei der Zuweisung entstehen. Subjekte Rolle 1 ... Rolle 2 Rolle n Rolle 3 Objekte Abbildung 7: Hierarchie einer rollenbasierten Zugriffskontrolle 2.4. Anforderungen an die Zugriffskontrolle von HERMES Das lokale Einfügen, Ändern und Löschen auf replizierten Daten ist eine wesentliche Forderung von HERMES, da, im Unterschied zu herkömmlichen Touristenführern, die mobilen Nutzer weitgehend selbst die Daten für das System erstellen und pflegen (Nutzeradministratoren) sollen. Dazu gehören Informationen über Hotels, Restaurants (z.B. Speisekarten) und Reiseberichte. Zur Realisierung dieser Funktionalität wird eine adäquate Nutzerverwaltung und Rechtevergabe benötigt. Die klassischen schemaorientierten Techniken in Datenbanksystemen sind in einer Umgebung mit vielen Tausend und wechselnden Nutzern, die vorwiegend Daten in dieselben wenigen Tabellen einfügen bzw. deren Inhalte modifizieren, nicht ausreichend. Vielmehr werden datenabhängige Verfahren und erweiterte Zugriffsmodi mit folgenden Zusicherungen benötigt: Jedes Objekt hat einen Besitzer (Eigentümer-Paradigma). Der Besitzer kann anderen Nutzern Rechte auf seine Objekte vergeben. Die Rechtevergabe auf Subjekte muss variierbar sein: Es müssen sowohl einzelne Subjekte als auch Gruppen von Subjekten autorisiert werden können. Der lesende Zugriff ist mit Ausnahme der privaten Bereiche uneingeschränkt möglich. Nutzer können nur auf autorisierte Objekte schreibend zugreifen Die Existenz von sogenannten Nutzeradministratoren, die als Datenkontrolleure mit erweiterten Rechten die von anderen Nutzern eingebrachte Daten prüfen (auf Korrektheit, Verstöße, usw.) und gegebenenfalls aktualisieren. Die Objekte von HERMES sind häufig langlebig. Zugriffsbeschränkungen auf diese Objekte können sich daher im Laufe der Zeit ändern. Die Durchführung dieser Änderungen oder die Vergabe neuer Zugriffsrechte muss somit dynamisch, das heißt im laufenden System, erfolgen können. Keineswegs sollte die Spezifikation neuer Autorisierungen nur am "stehenden" System vorgenommen werden können. Zugriffskontrollmechanismen sollen einen möglichst geringen Einfluss auf das Laufzeitverhalten und den Speicherplatzbedarf haben. Das Autorisierungssystem muss zu jedem Zeitpunkt logisch konsistent sein. Es hat die verfolgte Sicherheitspolitik korrekt abzubilden. Das System soll einfach handhabbar und auch unabhängig von einer RPS-Umgebung einsetzbar sein. 17 Kapitel 2. Grundlagen Das Ziel besteht deshalb darin, ein System zum Differenzieren und Verwalten der Objekte und der darauf basierenden Rechte zu schaffen. Die Granularität des Kontrollbereichs sollte grundsätzlich möglichst fein (idealerweise stellen die Objekte einzelne Tupel dar) sein, um auf die heterogenen Anforderungen im HERMES-Umfeld individuell reagieren zu können. Einschränkungen sind jedoch im Hinblick auf die Performance zu beachten. Je feiner die autorisierbaren Granularitäten für die Subjekt-, Objekt- und Zugriffstyp-Domänen sind, desto höhere Kosten fallen für die Evaluierung von Sicherheitsanfragen und die Administration von Rechten an. 2.5. Zugriffskontrolle in Datenbanksystemen Dieser Abschnitt beschäftigt sich mit den zur Verfügung stehenden Möglichkeiten der Zugriffskontrolle in relationalen Datenbanksystemen. Detaillierte produktspezifische Syntax-Betrachtungen werden nicht angestellt, vielmehr soll die Gesamtanalyse im Mittelpunkt stehen, die durch Einhaltung der SQL-Norm seitens der DatebankProdukte ermöglicht wird. So bieten DBM-Systeme alle durchweg Mechanismen wie Sichten, Trigger, Prozeduren und die Umsetzung der benutzerbestimmten Zugriffskontrolle. Hauptaugenmerk wird auf die Verwirklichung feingranularer Zugriffsbeschränkung im Hinblick auf die Entwicklung eines Zugriffkontrollsystems für HERMES gelegt. 2.5.1. Nutzerverwaltung und Authentifizierung Grundsätzlich verfügt jedes Datenbanksystem über Nutzer und Gruppen, die auf die Datenbankobjekte zugreifen wollen. Ein einzelner Nutzer kann dabei mehreren Gruppen angehören und jede Gruppe kann beliebig viele Mitglieder besitzen. Oracle-Datenbanken unterstützen zudem das in Abschnitt 2.3.3. beschriebene Rollenkonzept. Die Nutzer und Gruppen können entweder durch das Datenbanksystem selbst (z.B. Sybase Adaptive Server Enterprise oder Oracle9i) oder implizit durch das zugrundeliegende Betriebssystems (z.B. DB2) definiert werden. Die Authentifizierung der Nutzer kann im DBMS selbst (Oracle9i, Sybase ASE), durch das Betriebssystem (DB2, Oracle9i, Sybase ASE) oder durch separate externe Produkte (z.B. Kerberos) erfolgen. Die grundlegende Autorisierung der Zugriffe auf Objektebene erfolgt in jedem Fall innerhalb des DBMS. 2.5.2. Schemabasierte Rechtevergabe Allen relationalen Datenbanksystemen ist die Rechtevergabe auf einzelne Objekte (z.B. Tabellen, Sichten) eines Schemas oder auf das Schema selbst gemein. Die Rechte lassen sich grundsätzlich in Objekt- und System-Rechte (sog. Authorities bei DB2, system privileges bei Oracle) einteilen. System-Rechte stellen eine Zusammenfassung von Rechten auf einer höheren als die Schema- bzw. Objekt-Ebene dar (bei DB2 z.B. Rechte auf Instanzenebene). Die Rechte auf einzelne Objekte realisieren die Umsetzung der DAC-Funktionalität. Jedes Objekt hat einen Besitzer (vornehmlich der Erzeuger desselben), der sämtliche Rechte auf dieses innehält und die Weitergabe (mittels GRANT) bzw. den Entzug (mittels REVOKE) von Rechten auf dieses Objekt an andere Nutzer bzw. Gruppen nach eigenem Ermessen regulieren kann. Bei Interaktion eines Nutzers mit den Objekten der Datenbank werden seine Rechte geprüft und bei nicht vorhandener Autorisierung entsprechende Fehler erzeugt. Diese elementare grobgranulare Rechtevergabe, sollte geschickt mit anderen Mechanismen kombiniert werden, um eine spezialisierte (werte- bzw. zeilenbasierte) Zugriffskontrolle zu ermöglichen. 2.5.3. Zugriffskontrolle durch Programmlogik Wird die Zugriffskontrolle in die Applikationslogik eingebettet, so autorisiert selbige an die Datenbank gerichtete SQL-Anfragen. Durch den zusätzlichen Anwendungscode kann der Zugriff auf einzelne Datensätze eingeschränkt und überwacht werden, dennoch kann diese zusätzliche Sicherheitsvorkehrung umgangen werden, indem ein Nutzer außerhalb der Anwendung, beispielsweise durch andere Anwendungen, Tools oder durch Di18 Kapitel 2. Grundlagen rektzugriff, auf die Datenbank zugreift. Will die Anwendung den Zugriff auf die Daten anhand deren Sensibilität2 vornehmen, so sind in der Regel viele zusätzliche (Hilfs-)Tabellen nötig. 2.5.4. Physische Separation durch Nutzung mehrerer Datenbanken Eine alternative Methode, die Daten anhand ihrer Sensibilität zu trennen und nur befugten Subjekten Zugang zu gewähren, stellt die Verwendung eine separaten Datenbank für jede Sensibilitätsstufe dar. So erhält man beispielsweise eine extra Datenbank für alle streng vertraulichen Daten, eine weitere für geheime und eine letzte für allen zugängliche Informationen. Dieser Ansatz ist in der Praxis völlig unakzeptabel. Der Overhead in punkto Ressourcenverbrauch (Arbeitsspeicher, Plattenplatz) und die Kosten der Verwaltung bzw. Administration einer Datenbank multiplizieren sich mit der Anzahl der neuen Datenbanken. Weiterhin bedarf das Auslesen von Daten aus verschiedenen Datenbanken sogenannten Distributed Queries und spezieller Anwendungslogik. 2.5.5. Einsatz von Sichten Generell ist es vorteilhafter die Autorisierungslogik so nahe als möglich bei den Daten zu implementieren, so dass eine Umgehung unmöglich ist. Sichten realisieren die Vereinfachung komplexer Datenbankschemata auf konkret benötigte Teildaten (sogar auf feingranulare Tupel- und Spaltenebene) und liefern logische Datenunabhängigkeit, d.h. Anwendungen, die auf die Sichten zugreifen bleiben stabil gegenüber Schemaänderungen. Indem einzelnen Nutzern oder Gruppen die Rechte auf die zu Grunde liegenden Basistabellen entzogen werden und die entsprechende Zuordnung zu den einzelnen Sichten mit passenden Objekt-Rechten (INSERT, UPDATE, DELETE, SELECT) vorgenommen wird, erlaubt man den Subjekten bzw. Anwendungen den Zugriff auf schutzbedürftigen Daten ausschließlich über die Sichten. Auf diese Weise ist es möglich, sensible Tupel aus Datenschutzgründen zu verbergen bzw. auch um Daten in neuer Form zu präsentieren. Die optionale Spezifikation von WITH CHECK OPTION bei der Sichtenerzeugung respektiert die angestrebte Zugriffskotrolle insofern, als dass keine INSERT- oder UPDATE-Operationen erlaubt sind, die zum Verletzen der Sichtdefinition führen würden. In Verbindung mit dem Spezialwert USER (vorhanden in DB2, Oracle, ASE) und der Verwendung der Gruppe (gefordert von der SQL-Norm) bei der Rechtevergabe können benutzerspezifische, parametrisierte Sichten erzeugt werden, die für jeden Nutzer anders aussehen. USER liefert den aktuellen Nutzernamen, der einer Datenbanksession zugeordnet ist. PUBLIC ist eine symbolische Gruppe, der jeder Datenbanknutzer implizit angehört. Es folgt eine Veranschaulichung des Prinzips: PUBLIC create view EigeneAuftraege as select * from Auftraege where Name = USER with check option; revoke all privileges on Auftraege from PUBLIC; grant select, insert on EigeneAuftraege to PUBLIC; Durch die Erzeugung der Sicht, dem Entziehen sämtlicher Rechte auf die Basistabelle und anschließender Rechtezuweisung an sämtliche Nutzer kann jeder Benutzer (nur) seine persönlichen Aufträge (vorausgesetzt die Tupel verfügen über die Spalte "Name") sehen und neue einfügen, aber nicht löschen. Um Sichten zur Klassifikation von Tupeln nach Sensibilität zu ermöglichen, ist schon mehr Aufwand nötig: create view sensitive_employee as select * from employee where sensitivity='Sensitive' or sensitivity = 'Confidential' or sensitivity = 'Public' create view confidential_employee as select * from employee where sensitivity = 'Confidential' or sensitivity = 'Public' 2 Schutzwürdigkeit 19 Kapitel 2. Grundlagen create view public_employee as select * from employee where sensitivity = 'Public' Wie an dem Beispiel deutlich wird, muss für jedes Sicherheitslevel eine separate Sicht und in den Basistabellen eine zusätzliche Spalte für die Klassifizierung der Tupel definiert werden. Im obigen Beispiel befähigt ein höheres Sicherheitslevel auch zum Zugriff auf weniger hoch eingestufte Tupel. Obige Technik ist nur für eine kleine Anzahl an Nutzern ratsam, da die vielen Sichten verwaltet und sämtlichen Nutzern adäquate Rechte zugewiesen werden müssen. Oft ist dieser Ansatz auch zu starr, wenn sich die zu Grunde gelegene Sicherheitspolitik ändert (z.B. bei Einführung neuer Sicherheitslevel). Nachteilig gestaltet sich die schlechte Performance bei der Definition großer Sichten (z.B. Mehrfachjoin von Tabellen mit vielen Tupeln), da Anfragen an die Sicht immer erst in entsprechende Anfragen an die Basistabellen umgewandelt werden müssen. Ebenfalls problematisch ist die eingeschränkte Update-Fähigkeit von Sichten. Unterschiedliche DBMS-Produkte haben zudem andere Bedingungen zur Gewährung des schreibenden Zugriff auf die Sicht (generell müssen die Attribute eindeutig den Basistabellen zugeordnet werden können). 2.5.6. Trigger Ein Trigger ist ein Block von (PL)SQL-Anweisungen, die mit einer Tabelle oder einer Sicht assoziiert und für ein ereignisbedingtes Auslösen von Aktionen zuständig ist. Beim Entwurf von Triggern werden ein Ereignis (INSERT, DELETE, UPDATE (auch auf einzelne Spalten)), eine Bedingung (BEFORE, AFTER, INSTEAD OF) für die Aktivierung desselben spezifiziert und die Aktion(en) zur Ausführung, wenn der Trigger aktiviert wurde. Durch die normkonforme Angabe von for each row bzw. for each statement wird der Trigger für jede Einzeländerungen einer mengenwertigen Änderung bzw. nur einmal für die gesamte Änderung "gefeuert". Somit können Schreibrechte einzelner Tupel (in Verbindung mit dem Wert des aktuellen Nutzers, z.B. durch die USERVariable) autorisiert werden. Wenn Anweisungen den Sicherheitsanforderungen der Triggerdefinition nicht genügen, kann ein Fehler signalisiert werden, um eine entsprechende Änderung an den Daten der Basistabelle zu verhindern. Trigger werden zwar auf eine Basistabelle (oder Sicht) definiert, können aber durchaus Aktionen auf anderen Tabellen derselben Datenbank ausführen, um so tabellenübergreifende Zugriffsrechte zu prüfen. Die sogenannten INSTEAD-OF-Trigger, die lediglich auf Sichten definiert werden können, ersetzen die den Trigger auslösende Operation komplett durch die Anweisungen im Rumpf und können so eigene Prüfungen oder Semantiken implementieren. Sogenannte INSTEAD-OF-VIEWS (Sichten mit INSTEAD-OF-Triggern) erlauben dann beispielsweise einem gewissen Personenkreis ein update auf mehrere Tabellen durch die Sicht, auf die sie normalerweise nur lesenden Zugriff hätten, sei es durch gewollte Schreibbeschränkungen oder durch die nicht mögliche Änderbarkeit der Sicht augrund der Einschränkungen des DBMS. Leserechte (SELECT) können durch Trigger jedoch nicht geprüft werden. Daher ist die Kombination von Triggern mit anderen in diesem Abschnitt. beschriebenen Techniken für eine vollständige Sicherheitspolitik notwendig. Trigger können zudem durch ihre Aktionen auch wieder (ungewollt) andere Trigger auslösen. Nicht nur muss man evtl. Kaskadierungen im Überblick behalten um Zyklen zu vermeiden, die Performance kann dadurch auch nachteilig beeinflusst werden. 2.5.7. Routinen (Prozeduren, Funktionen) Routinen können vielseitig programmiert (extern mit einer Hochsprache, Parameterübergabe, verschiedene Rückgabetypen, Zugriff auf externe Dateien, Verwendung von dynamischem SQL) und dementsprechend breitgefächert angewendet werden. Sie können den Code für die Zugriffsregeln beinhalten und sollten eingesetzt werden, wenn eine Kombination von Sichten zusammen mit den normalen DAC-Rechten auf Schemaobjekte unzureichend für die angestrebten Zwecke ist. So kann eine Prozedur oder Funktion von Triggern oder von der Applikation aufgerufen werden, um beispielsweise vor einem INSERT gegen eine Tabelle eine Reihe von RechtePrüfungen vorzunehmen. Der Nachteil wird dabei auch deutlich. Man muss "Hintertüren" zu den Rohdaten vermeiden, so dass z.B. kein Einfügen gegen die Basistablle mehr möglich ist. Des weiteren können Routinen alleine nicht wirksam werden. Es bedarf immer einer aufrufenden Komponente (Applikation, Trigger, oder andere Routinen). 20 Kapitel 2. Grundlagen 2.5.8. Proprietäre Ansätze Unter proprietären Ansätzen versteht man urheberrechtlich geschützte Implementierungen der jeweiligen DBMS-Hersteller. Solche Verfahren können von Anwendungsentwicklern bzw. Administratoren meist leichter implementiert und für komplexere, sicherheitsrelevante Umgebungen genutzt werden als bisher beschriebene Mechanismen. Zudem können die DBMS-internen Ansätze aufgrund ihrer Datennähe nicht durch "Hintertüren" umgangen werden. Allerdings sollten diese Verfahren nur im Falle von hohen Sicherheitsanforderungen zum Einsatz kommen, da der Datenzugriff immens beschränkt werden kann und es einer genauen Analyse der Subjekte, Objekte und den angestrebten Interaktionen bedarf. Im folgenden Abschnitt soll auf die derzeit einzig dokumentierte Lösung von Oracle eingegangen werden. 2.6. Oracle Label Security Wie bereits angedeutet, bedarf es in HERMES und ähnlichen mobilen Szenarien datenabhängiger (also tupelabhängiger) Mechanismen zur Autorisierung der Zugriffe. Zum jetzigen Zeitpunkt bieten nur Oracle9i (,Oracle10i) und Adaptive Server Enterprise 12.5 von Sybase zeilenbasierte Zugriffsmodelle. Momentan in Entwicklung befindliche Versionen von IBM DB2 UDB für z/OS und Microsoft SQL Server versprechen ebenfalls derart feingranulare Implementierungen. Im folgenden soll nun genauer auf die von Oracle angebotene "Label Security" eingegangen werden. 2.6.1. Einführung Die Oracle9i Enterprise Edition beinhaltet die hauseigene Datenbankoption Oracle Label Security (OLS) zur Zugriffskontrolle unternehmenskritischer Daten. Oracle Label Security wurde ursprünglich für die U.S.Regierung zum Schutz streng vertraulicher Informationen entwickelt. Nunmehr ist die Lösung auch auf dem freien Markt für Unternehmen erhältlich. Damit können Informationen in Unternehmen gemeinsam genutzt und trotzdem an entsprechender Stelle die Anforderungen an den Datenschutz oder die vertrauliche Behandlung von Daten erfüllt werden. Mit Hilfe von Oracle Label Security können Anwender ohne zusätzliche Programmierung anhand von selbst definierbaren Klassifizierungsmerkmalen unternehmenskritische Daten (z.B. interne Schwachstellen einer Firma, medizinische Berichte oder Dokumente anstehender Kriminalermittlungen) zusätzlich auf Datensatz- (Row Level) statt nur auf Tabellen-Ebene absichern, egal, ob die Daten im eigenen Unternehmen oder bei einem Online Service Provider lagern. Die zeilenbasierte Zugriffskontrolle wird dabei nicht durch eine fehleranfällige und umgehbare Applikationslogik, sondern direkt durch das DBMS (mit eine Menge an Prozeduren und Constraints) gesteuert. Dies reduziert zum einen die Größe und Komplexität der Anwendungen, vermeidet eigene Software-Entwicklung und Wartung und garantiert die Autorisierung so nahe wie möglich an den zu schützenden Daten. Oracle Label Security setzt hierzu auf die Oracle-interne VPD-Technologie (Virtual Private Database) auf. VPD ermöglicht den Zugriff auf gleiche Daten durch verschiedene Benutzergruppen, so dass die Subjekte nur die für sie relevanten Daten sehen (Need-to-Know-Prinzip). So liefert dieselbe Anfrage eines Kunden (sieht nur seine Aufträge) und des Vertriebs (sieht die Aufträge seiner Kunden) unterschiedliche Ergebnistupel. Obwohl VPD für mehrere Nutzergruppen zuständig ist, erfolgt keine redundante Speicherung der Daten und im Gegensatz zur Implementierung durch eine separate außenstehende Anwendung, kann die Zugriffskontrolle nicht umgangen werden. Jedem Subjekt und Objekt (einzelnes Tupel) wird eine Sicherheitsmarke (engl. sensitivity label) zugewiesen, welche bei den Subjekten als Ermächtigung (clearance) und bei den Objekte als Klassifikation (classification) bezeichnet wird. Diese Sicherheitsmarke beschreibt die Vertrauenswürdigkeit des Subjekts bzw. die Sensibilität des Objekts. Die Klassifikation der zu schützenden Information reflektiert dabei den potentiellen Schaden, der durch eine nicht autorisierte Enthüllung (disclosure) der Information entstehen könnte. Sicherheitsmarken bestehen aus mindestens einer und maximal drei Komponenten. Sie können aus einzelnen Hierarchieleveln (sensitivity level) oder einer Kombination mit Abteilungen (compartments) und/oder Gruppen (sensitivity groups) bestehen. 21 Kapitel 2. Grundlagen Ein Hierarchielevel reflektiert die ansteigende Empfindlichkeit bzw. Schutzbedürftigkeit der Daten. Beispielhafte Hierarchielevel sind in absteigender Rangfolge geheim, streng vertraulich, vertraulich, öffentlich. Die Anzahl der Hierarchielevel kann selbst definiert werden, in den meisten Anwendungen ist ein Level jedoch ausreichend Die Abteilung ist eine nicht hierarchische Komponente zur Klassifizierung der Daten nach (Funktions-) Bereichen (areas) wie z.B. Finanzen, Marketing, Produktion oder Forschung. Abteilungen werden hauptsächlich in Regierungs- und Militär-Umgebungen genutzt, da den meisten kommerziellen Anwendungen die Verwendung von Gruppen ausreicht. Gruppen identifizieren unter anderem Organisationen (Filiale Nord, Süd), Regionen (US, UK) oder die Besitzerhierarchie der Daten (Manager, einfaches Personal) und können im Unterschied zu Abteilungen hierarchisch genutzt werden. Wird einem Nutzer eine Gruppe in einer Hierarchie zugeordnet, so hat er Zugriffsrechte auf alle Subgruppen. Nachfolgende Abbildungen 8 und 9 [Ora02] zeigen den Zusammenhang der möglichen Label-Komponenten (dargestellt als Dimensionen) und beispielhafte Belegungen. Abbildung 8: Dimensionale Beziehungen der Label-Komponenten Es gilt zu beachten, dass nur die Sensitivity Level hierarchisch geordnet sind, d.h. mit Level 3 assoziierte Tupel sind sicherheitsbedürftiger als jene mit Level 2. Ein für Level 3 autorisiertes Subjekt hat für gewöhnlich auch Zugriff auf Objekte mit Level 2. Abbildung 9: Typische Label-Komponenten-Ausprägungen 22 Kapitel 2. Grundlagen Jedem Oracle Label Security Nutzer wird eine Menge von autorisierten Komponenten durch den Administrator zugeordnet: User Max Level: Das höchste Level, auf das der Nutzer während Lese- und Schreiboperationen Zugriff hat User Min Level: Das minimale Level, auf das der Nutzer bei Schreiboperationen Zugriff hat. Das User Max Level muss größer oder gleich dem User Min Level sein. Der Nutzer kann weder Daten mit einem Level kleiner als das eigene Minimum aktualisieren oder löschen, noch kann er ein Tupel mit einem geringeren Level einfügen. User Default Level: Das Default-Level beim Verbinden mit der Datenbank User Default Row Level: Das beim Einfügen von Tupeln genutzte Default-Level die Menge der autorisierten Abteilungen die Menge der autorisierten Gruppen ein nur-lesender Zugriff oder Lese/Schreib-Zugriff für jede Gruppe und jede Abteilung Das Nutzer- bzw. Session-Label ist nun eine bestimmte Kombination aus Level, Abteilungen und Gruppen, mit welcher der Nutzer zum aktuellen Zeitpunkt arbeitet. Der Nutzer ist in der Lage sein eigenes Session Label auf jede beliebige Kombination seiner autorisierten Komponenten zu setzen. Die eigentliche Zugriffskontrolle basiert auf dem Vergleich des aktuellen Datenlabels mit dem Label des Nutzers (session label). Die Komponenten eines Labels sind durch Doppelpunkte getrennt und haben folgende Struktur: level : compartment : group Die Rechte für die einzelnen Daten-Label werden nochmals aufgeteilt in Lese- und Schreib-Erlaubnis. Der lesende Zugriff ist erlaubt, wenn das Nutzer-Label-Level gleich- oder höher-rangig als das Level des DatenLabels ist und der Nutzer Lese-Erlaubnis auf mindestens eine, der durch das Daten-Label spezifizierten Gruppen und auf alle zum Objekt gehörenden Abteilungen besitzt. Abbildung 10 [Ora02] illustriert beschriebenes Verfahren in einem einfachen Kontrollflussdiagramm. In dem Falle, dass die Tests erfolgreich sind und der Zugriff gewährt werden kann, "dominiert" das Label des Nutzers das Daten-Label. Abbildung 10: Kontrollfluss der lesenden OLS-Autorisierung Der Algorithmus zur Prüfung des Schreibzugriffs (siehe Abbildung 11 [Ora02]) ist ein wenig komplizierter. Zunächst wird wieder geprüft, ob das maximale Nutzer-Session-Label-Level gleich- oder höher-rangig als das Level des Daten-Labels ist. Anschließend wird geprüft, ob das Daten-Level gleich oder höher als das Minimum Level des Nutzers ist. Zuletzt prüft das System, analog zum Lesezugriff ob der Nutzer Schreibzugriff auf mindestens eine, der durch das Daten-Label identifizierten Gruppen und auf alle Abteilungen besitzt. Schlägt einer dieser Tests fehl, wird dem Nutzer der Zugriff auf das Objekt verwehrt. 23 Kapitel 2. Grundlagen Abbildung 11: Kontrollfluss der schreibenden OLS-Autorisierung Es gilt zu beachten, dass der Nutzer keinen Schreibzugriff auf Daten unter seinem Minimum Level und über seinem aktuellen Session Level hat. Jedoch kann er immer Daten unterhalb seines Minimum-Levels lesen (sog. read down). Bsp.: Data Label = Internal User Label = Sensitive : Alpha, Beta : US, UK : Alpha, Beta : UK Sämtliche Bedingungen zum genehmigbaren lesenden Tupelzugriff sind in dem Beispiel erfüllt. Der Nutzer kann sogar eine höhere Ermächtigung ("sensitive") vorweisen, als die Klassifizierung des Tupels ("Internal") vorschreibt. Der schreibende Zugriff auf sämtliche derart klassifizierte Tupel ist jedoch nur erlaubt, wenn das User Minimum Level auf "Internal" (oder noch geringer) gesetzt ist. 2.6.2. Analyse und Implementierung Bevor die zeilenbasierte Zugriffskontrolle implementiert werden kann, sollte eine ausführliche Analyse der Notwendigkeit und der Struktur des zu Grunde liegenden Systems vollzogen werden. Die Planungsphase besteht im wesentlichen aus fünf Schritten: 1. Schritt: In Zusammenarbeit mit einem Administrator oder einem um die Struktur wissenden Anwendungsentwickler werden die Tabellen bestimmt, die eine Oracle Label Security-Sicherheitspolitik benötigen. Oft handelt es sich dabei um eine geringe Anzahl an Kandidaten. 2. Schritt: Nachdem die Tabellenkandidaten ermittelt wurden, können die erforderlichen Hierarchielevel der Daten identifiziert werden. Dazu ist eine Aufstellung bzw. Bewertung aller aktuellen und zukünftigen Tabelleninhalte erforderlich. Assistieren sollte ein Mitarbeiter der Firma (z.B. ein Manager), dem die geschäftlichen Tätigkeiten und Arbeitsabläufe weitreichend bekannt sind. 3. Schritt: Es folgt das optionale Bestimmen der Gruppen mithilfe eines in den Ablauf der Unternehmensprozesse eingeweihten Mitarbeiters. 4. Schritt: Folgend die optionale Analyse der Abteilungen. Dabei sollte beachtet werden, dass ein Nutzer, im Unterschied zur Gruppe, Teil aller Abteilungen eines Labels sein muss. Kommerziellen Anwendungen reicht die Gruppenfunktionalität oft aus. 24 Kapitel 2. Grundlagen 5. Schritt: Abschließend wird die Aufstellung der zugreifenden Subjekte vorgenommen. Die Nutzer werden in einzelne Typen (regular, highly privileged, administrative) separiert, denen die bereits klassifizierten User-Label zugeordnet werden. Die eigentliche Einrichtung, Administration und Konfiguration der Berechtigungen kann über die GUI des Oracle Policy Manager oder anhand der Oracle Label Security API vollzogen werden und beginnt mit dem Erzeugen einer Oracle Label Security Policy. Im Anschluss werden die einzelnen, in der Analysephase ermittelten Daten-Label-Komponenten (level, compartments, groups) definiert und die Daten-Label an sich erzeugt. Schließlich können den Nutzern die entsprechenden Label zugewiesen werden. Letztlich wird die Policy unter Angabe zusätzlicher Optionen auf die Tabelle bzw. das ganze Schema angewandt, so dass die Tabelle um eine zusätzliche (nicht sichtbare) benannte, das Label der Tupel tragende, Spalte erweitert wird (bereits existente Tupel müssen separat gelabelt werden). Dabei kann die Anwendung der Policy auf einzelne Operationen (select, insert, update, delete) beschränkt werden. Des weiteren besteht die Möglichkeit der Definition einer zusätzlichen WHERE-Bedingung (SQL-Prädikat) zu bestehenden Policies, um spezifischeren lesenden Datenzugriff über die Label hinaus zu ermöglichen (z.B. kann man so den Zugriff auf eine Tabelle auf die Monate Februar bis Juli einschränken). Die zeilenbasierte Zugriffskontrolle erlaubt jedoch nur die Kontrolle des Zugriffs auf individuelle Zeilen, wenn dem Nutzer zusätzlich entsprechende Rechte (Privileges) auf der Tabelle gewährt wurden. Somit bleibt die schemaorientierte (DAC-)Zugriffskontrolle weiterhin erforderlich. Zudem ist es möglich spezielle Rechte für die Daten-Label zu definieren: Das WRITEDOWN Recht erlaubt dem Nutzer das Herabsetzen des Daten-Levels, ohne Beeinflussung der Abteilungen oder Gruppen. Das neue Daten-Level muss geringer als das aktuelle, aber auch gleichzeitig größer oder gleich des Nutzers Minimum Level sein. Analog zum WRITEDOWN Recht existiert das WRITEUP Recht, dass einem Nutzer das Heraufsetzen des Daten-Levels auf einen Wert kleiner oder gleich seines Maximum Level ermöglicht, ohne Änderung der Abteilungen und Gruppen des Tupels. Zusätzlich gibt es das sogenannte WRITEACROSS Recht. Damit kann der Nutzer, bei gleichbleibendem Daten-Level, die Abteilungen und Gruppen des Tupels auf jeden beliebigen in der Policy existenten Wert ändern. Ein Nutzer mit Leserecht auf eine (oder mehrere) Gruppen kann z.B. die Gruppen-Komponente auf eine Gruppe ändern, auf die er oder sie nicht explizit Zugriff hat. 2.6.3. Bewertung Das vorgestellte Produkt Oracle Label Security implementiert die zeilenbasierte Zugriffskontrolle auf Basis der Sensibilität der Daten und den Ermächtigungen der zugreifenden Nutzer. Sicherheitsrelevante Anwendungen, die Daten vor unberechtigten Zugriffen schützen wollen und dabei eine Rangfolge von Vertraulichkeitsstufen implizieren, sind damit sicherlich gut bedient. Für das im Vordergrund der Arbeit stehende HERMES scheinen die Mechanismen allerdings weniger geeignet und zu komplex. Zum einen ist eine derart restriktive Einteilung der Daten nicht zweckdienend und zum anderen sind weder die Anzahl noch die Absichten der Nutzer von vornherein bekannt. HERMES zeichnet sich durch eine potentiell unbegrenzte, über den Globus verteilte, schwankende Nutzerzahl aus. Diese tausende Nutzer greifen orts- und situationsbedingt auf Tabellentupel zu und können nicht zu Beginn oder zur Laufzeit adäquaten Labeln zugeordnet werden. Selbst wenn dies möglich wäre, unter Zuhilfenahme von zusätzlichen HERMES-Administratoren, so würde ein erheblicher, inakzeptabler Administrations- und Verwaltungsaufwand entstehen. Die Nutzer sollen zudem die Möglichkeit besitzen den Zugriff Anderer auf die eigenen Daten flexibel und eigenmächtig festzulegen und bei Bedarf wieder zu entziehen. Eine mandatorische Zugriffskontrollpolitik, die auf von Administratoren festgelegten system-globalen Regeln basiert, ist daher offensichtlich ungeeignet für ein interaktives mobiles Reiseinformationssystem. Aus diesem Grund wird in den folgenden Abschnitten eine eigene, an das mobile Szenario angepasste Rechteverwaltung entwickelt. 25 3. Authentifizierung und Autorisierung in der 3-SchichtenArchitektur Zunächst werden in den Abschnitten 3.1. und 3.2 die "Bedrohungen" gegen die Daten des RPS, die dadurch erforderliche Nutzerverwaltung und die einfache rollenbasierte Rechtevergabe beschrieben. Gegenstand des Abschnitts 3.3. sind die Einführung und die prototypische Umsetzung des HERMES-Rechtekonzept und der HERMES-Nutzerverwaltung auf dem Quellserver. Die folgenden Abschnitte erläutern die Unterschiede der Anwendungs-Authentifizierung bzw. -Autorisierung auf dem RPS und auf dem Client. Einen Vorschlag der Implementierung und Integration privater Bereiche in die NR soll in den letzten Abschnitten 3.6. und 3.7. erläutert werden. 3.1. Sicherheitsarchitektur des RPS Um ein Informationssystem vor Gefahren und Risiken zu schützen, müssen die Bedrohungen analysiert und daraufhin geeignete Gegenmaßnahmen ergriffen werden. Unter Bedrohungen versteht man Gefahren aus dem Umfeld des Systems, die direkt oder indirekt zum Schaden führen können. Bedrohungen durch Menschen richten sich meist gegen die drei Ziele Vertraulichkeit, Integrität und Verfügbarkeit. Ohne Sicherstellung dieser Sicherheitsanforderungen verlieren Informationen ihren eigentlichen Wert [Rup02]. Vertraulichkeit: Es muss gewährleistet werden, dass nur berechtigten Entitäten (Personen, Anwendungen) die, für die Erfüllung ihrer Aufgaben, nötigen Informationen zugänglich sind (Need-to-know-Prinzip). Integrität: Integrität strebt die Richtigkeit der Daten an. Über den gesamten Lebenszyklus hinweg, von der Erzeugung über die Verarbeitung, Auswertung, Darstellung, bis hin zur Archivierung muss sichergestellt sein, dass nur erlaubte und beabsichtigte Veränderungen an den Daten vorgenommen werden. Die Identität des Datenmanipulators bzw. –nutzers muss zu jederzeit eindeutig bekannt und zuordenbar sein. Verfügbarkeit: Darunter versteht man die Möglichkeit, Ressourcen in definierter Form, innerhalb einer nützlichen und angemessenen Zeit zu nutzen. Ressourcen und Informationen, die zwar existieren, auf die aber aus irgendeinem Grund nicht zugegriffen werden kann, sind zu jenem Zeitpunkt wertlos. Eine aufzustellende Sicherheitspolitik soll diese drei Sicherheitsanforderungen gewährleisten. Hierzu gehören die einzusetzenden Maßnahmen, aber auch die Analyse der schutzbedürftigen Objekte und der bedrohenden Subjekte sowie die formelle Beschreibung der Autorisation von Subjekten auf Objekte (Zugriffskontrollpolitik). Sicherheit für eine private Applikation wie HERMES erfordert andere, im Allgemeinen geringere Maßnahmen als für ein geschäftliches oder gar militärisches Informationssystem, da sowohl die Bedrohungen als auch die Sensibilität bzw. der Wert der Schutzobjekte weit geringer sind. Generell stehen in den folgenden Betrachtungen die Gefahren durch den Client als potentiellen Schadensverursacher im Mittelpunkt. Folgende Schutzbedarfskategorien können dabei unterschieden werden: (I) Schutz vor normalen DBMS-Aktivitäten, dazu gehören z.B. alle Änderungen unter Umgehung der Replikationssichten auf dem Client. (I.1) Schutz vor unbefugter Manipulation durch berechtigte Nutzer – vorsätzlich oder durch Bedienfehler (I.2) Schutz vor unbefugter Manipulation durch nicht berechtigte Nutzer (II) Schutz vor Hacker-Aktivitäten, dazu gehören geänderte Skripte, manipulierte Log-Einträge und Client-Software 26 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Da jede Anwendung auf dem RPS über unterschiedlich sicherheitsrelevante Daten verfügt, muss sie sich selbst um die Autorisierung der Subjektzugriffe kümmern. Der RPS kann dabei lediglich unterstützen, indem er die Identität der Clients prüft und ob auch nur die tatsächlich zur Manipulation angeforderten Daten im Rahmen der gewährten Änderbarkeitszusicherung lokal bearbeitet wurden. Insbesondere das bewusste und vorsätzliche Ausnutzen von Sicherheitslücken durch externe und interne Angreifer (II) stellt eine zunehmende Gefahr dar, deren Erkennung sowie das Ergreifen von Gegenmaßnahmen sind allerdings nicht Gegenstand dieser Arbeit. Bei der Umsetzung der Sicherheitsarchitektur muss ein optimistischer Ansatz verwendet werden, d.h. es wird im Anschluss (bei der Synchronisation) der lokalen unverbundenen Arbeit geprüft, ob die Änderungen auch autorisiert werden können. Die Ursache liegt darin, dass dem Client selbst nicht vertraut werden kann. Die eigentliche lokale unverbundene Ausführung hat man nicht unter Kontrolle. Der Client-Nutzer ist Root-Administrator auf seiner Maschine und kann damit beinahe alles manipulieren (z.B. Umgehung der Replikationssichten, Löschen von Integritätstriggern, Manipulation des RPS-Account, Ändern von Primärschlüsselattributen ...). Deshalb muss die endgültige Entscheidung, ob eine Operation erlaubt ist, durch den als "sicher" angenommenen RPS-Server bei der Reintegration der Daten erfolgen. Es folgt ein Beispiel: Nutzer A hat Daten für den Ort Jena optimistisch änderbar repliziert, Nutzer B die Daten von Weimar exklusiv. Beide Anforderungen können problemlos gewährt werden, da die entsprechenden Tupel unterschiedlichen Fragmenten entstammen. Fordert Nutzer A anschließend doch noch Daten aus Weimar zur unverbundenen Modifikation (weil er beispielsweise auf einer Durchreise ist), so schlägt die Forderung fehl. Aber Nutzer A kann jetzt unter Umgehung seiner lokalen Sichten einen Datensatz von Ort = Jena auf Ort = Weimar setzen. einen Datensatz mit Ort = Weimar einfügen durch Änderung des Logs das Update eines Datensatzes mit Ort = Weimar vortäuschen (z.B. auf Ort = Jena) und synchronisieren. Das würde die Exklusivitätsbedingung von B verletzen. Um diesem Problem zu begegnen, verwendet der RPS die Informationen der Tupel pro Tabelle, die beim Download an den Client geschickt wurden und prüft bei der Reintegration (d.h. beim synchronize) alle vom Client übermittelten Datensätze. Nur wenn diese Tupel dem Filter der Download-Skripte genügen, dürfen sie von dem RPS aus in die konsolidierten Tabellen eingebracht werden. Das sichert, dass Änderungen im eigenen Sichtfenster (Definitionsbereich der lokalen Replikationssichten) bleiben. Die genaue Umsetzung ist ein wenig komplexer und kann in [Pfe04] nachgelesen werden. Die sich anschliessende Authentifizierung beim RPS und die Autorisierung der Aktionen im zulässigen Replikations-Sichtfenster durch die Anwendungen wird anhand der folgenden Abschnitte deutlich gemacht. 3.2. Das Nutzermanagement des RPS Der RPS implementiert für seine Zwecke ein eigenes Nutzermanagement und verwaltet die Rechte der seine Dienste nutzenden Entitäten. Es soll im folgenden kurz auf die Authentifizierung und Autorisierung der RPSNutzer eingegangen werden. 3.2.1. Dienste des RPS Der RPS stellt als Dienstleister den ihn nutzenden Subjekten, bzw. Anwendungen eine Menge von Befehlen zur Verfügung. Man unterscheidet folgende zwei disjunkte, strikt zu trennende Dienstgruppen: (I) Dienste für Replikationsadministratoren - register/cancel consolidated DB create/drop consolidated table start/stop replication create/alter/delete user 27 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur (II) Dienste für die mobilen Clients (ausschließlich im verbundenen Zustand): - register/cancel replica DB create/drop replication view group create/alter/drop replication view synchronize Auf die einzelnen Befehle soll hier nicht näher eingegangen werden. Nachzulesen ist deren Syntax und Semantik in der Arbeit von [Pfe04]. Lediglich der Zusammenhang zum Nutzer- und Rechtekonzept soll verdeutlicht werden. Der RPS muss sicherstellen, dass nur ihm bekannte Subjekte bzw. Anwendungen seine Dienste in Anspruch nehmen und zudem die erforderlichen Rechte vorweisen können. Dies motiviert die Einführung einer eigenen Nutzerverwaltung und einer rollenbasierten Zugriffskontrolle. 3.2.2. Rollenbasierte Zugriffskontrolle Der RPS verfügt über ein eigenes Nutzermanagement, wobei jedem Nutzer ein eindeutiges RPS-Login sowie gewisse Rechte auf RPS-Ebene (zusammengefasst zu Rollen) zugeordnet wird. Auf dem RPS gibt es nur zwei Nutzertypen, die durch den RPS-Account identifiziert werden. Administratoren für die Erzeugung und Wartung der konsolidierten Tabellen und Fragmente, sowie mobile Clients, welche alle die Dienste der Replikation in Anspruch nehmen dürfen. In Folge dessen werden zwei Basisrollen unterschieden: die REMOTE-CLIENT-ROLE und die RPS-ADMIN-ROLE. Beide unterteilen sich in weitere spezifischere Rollen, so dass eine simple Hierarchie entsteht. In dieser Hierarchie stellen die vom RPS angebotenen Befehle die untersten (unteilbaren) ElementarRechte dar. REMOTE-CLIENT-ROLE Diese Rolle umfasst ausschließlich Rechte für den Remote-Zugriff durch mobile Clients auf den RPS bzw. auf die vom RPS angebotenen Client-Dienste. Nur über einen gültigen RPS-Account ist es einem Client überhaupt erst möglich, Befehlsanforderungen an den RPS zu senden. CLIENT: Die CLIENT-Rolle ermöglicht den Clients, grundsätzlich alle Befehle der Gruppe (II) ausführen zu dürfen, ausgenommen das Feature der exklusiven Replizierbarkeit EXCL_CLNT: Als Obermenge der CLIENT-Rolle enthält diese Rolle alle deren Rechte inkl. der Möglichkeit der Forderung von exklusiven Änderbarkeitszusicherungen. Hierbei ist allerdings im Fall von HERMES (oder ähnlichen Anwendungen) durch die Anwendungen selbst auf die Übereinstimmung der Rechte auf Anwendungs- und RPS-Ebene zu achten. Bei HERMES dürfen lediglich die SuperUser (siehe Abschnitt 3.3.1.) Daten exklusiv replizieren, d.h. der Client-Nutzer muss über die EXCL_CLNT-Rolle auf RPS-Seite und über die SuperUser-Autorität seitens der HERMES-Anwendung verfügen. Nur eine geringe Anzahl an Clients sollten diese Rolle zugeordnet bekommen, da sich durch die exklusive Replikation die Verfügbarkeit der Daten erheblich einschränken lässt. RPS-ADMIN-ROLE Diese Rolle ist für Administratoren des RPS gedacht, die lokal, mittels einer eigenen Anwendung, auf den Daten des RPS arbeiten. RPS_ROOT_ADM: Ausschließlich für Administratoren des RPS, die damit das Recht erlangen, alle Befehle der Gruppe (I) uneingeschränkt auszuführen. Somit erhalten sie auch das Recht selbst neue RPS-Administratoren anzulegen, Rechte bestehender Administratoren oder Clients zu ändern oder auch gänzlich zu löschen. Per Default existiert auf dem RPS ein solcher ROOT-Admin, der im übrigen nicht gelöscht werden kann. Er kann sich dann neue Gleichberechtigte zur Unterstützung seiner Aufgaben auf dem RPS kreieren. 28 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur RPS_ADM: Nutzer dieser Rolle haben alle Rechte der RPS_ROOT_ADM-Rolle, bis auf die Möglichkeit die Befehle CREATE/ALTER/DELETE USER aufzurufen. RPS_CTRL_ADM: Inhaber dieser Rolle sind nur für START/STOP REPLICATION zuständig, d.h. ohne Direktzugriff auf die Daten. Damit die Administratoren die RPS-Befehle ausführen können, sind bestimmte Rechte seitens des zugrunde liegenden DBMS notwendig. Wie bereits erwähnt, kommt auf dem RPS IBM DB2 zum Einsatz. Zu den Aufgaben eines Administrators zählen neben der Erzeugung von konsolidierten Datenbanken, dem Durchführen von Backup- und Restore-Operationen, auch das Tuning von Performance-Einstellungen an der DBM- oder den DB-Konfigurationsdateien und die Überwachung der Ressourcenauslastung mittels Monitoring. Daraus folgt, dass neben dem SYSADM-Account des RPS selbst, ein weiterer für die Menge der Administratoren existieren muss. Prinzipiell müssen die Administratoren nicht der Betriebssystemnutzergruppe, welche über SYSADM-Autorität verfügt, angehören. Vielmehr existiert eine Anwendung auf dem RPS, die sich mittels eines solchen Accounts den Zugang zu den Daten verschafft, die nötigen Rechte bereitstellt und dafür sorgt, dass nur beim RPS authentifizierte Administratoren Befehle ihrer zugeordneten RPS-Rolle ausführen dürfen. Natürlich kann man gewissen Administratoren den Account (+Passwort) auch bekannt machen, so dass sie unter Umgehung der Anwendung direkt an den Daten arbeiten können. Eine solche Personengruppe braucht nicht über die RPS-Nutzerverwaltung authentifiziert zu werden, da ihren Mitgliedern vertraut werden kann. Den Anwendungen bleibt es selbst überlassen, ob sie das vom RPS angebotene Nutzerkonzept für ihre eigenen Zwecke verwenden oder zusätzlich ein weitergehendes implementieren, so der Fall bei HERMES. Die Klärung, was welcher Nutzer konkret darf, liegt dann bei der Anwendung selbst. Es besteht die Möglichkeit beim RPS Stored Procedures zu registrieren, welche den Zugriff auf eine bestimmte Ressource unabhängig vom RPSAccount freischalten oder blockieren können. Näheres dazu siehe Abschnitt 3.4.3. Der RPS weiß von dem gewählten Nutzermanagement seiner Anwendungen nichts, bietet seine Dienste an und wird von ihnen gesteuert. Allerdings müssen die Anwendungen notwendigerweise über die RPS-Nutzer und demnach auch über das RPSNutzermanagement Bescheid wissen. 3.2.3. Implementierung Der RPS verwaltet eine nicht replizierbare und nur in der Hilfsdatenbank des RPS existierende Tabelle der registrierten RPS-Nutzer. Wie bereits beschrieben, wird jedem (eindeutigen) Login ein Passwort und genau eine Rolle zugeordnet. create table RPS_User ( login varchar(128) not null primary key, pass varchar(128) not null, role varchar(12) not null check (role in ('CLIENT', 'EXCL_CLNT', 'RPS_ROOT_ADM', 'RPS_ADM', 'RPS_CTRL_ADM')) ) Bei jeder Befehlsanfrage der Clients werden deren Identität und die Rechte auf die RPS-Daten verifiziert. Analog verhält es sich für die RPS-Administratoren, die lediglich über eine Applikation die Befehle des RPS aufrufen. Durch das RPS-Passwort ist gewährleistet, dass der einfache Trial-And-Error-Versuch sich als anderer Client (Schutzbedarfskategorie I.2) oder Administrator mit höheren Rechten auszugeben, fehlschlägt. Für HERMES und verwandte Anwendungen muss sich der Client-Nutzer lediglich seine Anwendungs-Kennung und zugehöriges Passwort merken. Die seinen Client eindeutig identifizierende RPS-Login+Passwort-Kombination wird von der Server-Anwendung automatisch generiert (durch den Aufruf von CREATE USER) und auf dem Client (etwa in einer CFG-Datei der Anwendung oder einer lokalen Tabelle) gespeichert. Theoretisch ist es möglich, praktisch wohl weniger sinnvoll, dass beliebig viele Nutzer ein Client-Gerät und damit genau eine RPS-ID benutzen. Da es auch Anwendungen geben kann, die lediglich auf das vom RPS implementierte Nutzermanagement zurückgreifen, wird in der aktuellen Implementierung [Pfe04] genau ein Anwender 29 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur pro mobilem Endgerät gefordert. Weitaus sinnvoller erscheint die Möglichkeit eines Anwendungsnutzers, die Replikatdaten durch Nutzung mehrerer Client-Geräte und damit mehrerer RPS-Logins entsprechend zu verteilen. Eine Unterscheidung und Zuordnung der eigentlichen Nutzer ist deshalb nur durch ein eigenes Nutzermanagement der Anwendung möglich. Solange sich der Nutzer authentifizieren kann, spielt es für die Anwendung keine Rolle von welchem physischen Gerät neue Anforderungen oder Reintegrationen stammen. In jedem Fall können auf einem Client mehrere Anwendungen mit Kontakt zum RPS laufen. Bei der Synchronisation ist durchweg klar, welche Anwendung angesprochen werden soll, da den für die Synchronisation spezifizierten Replikat-Tabellen entsprechende konsolidierte Tabellen auf dem RPS zugeordnet sind. Somit kann die Anwendung anhand der ihr zugehörigen konsolidierten Datenbanken identifiziert werden (vorausgesetzt zwei Anwendungen nutzen unterschiedliche Datenbanken). 3.2.4. Nutzerpflege durch CREATE/ALTER/DELETE USER CREATE USER: Der Befehl dient dem Anlegen neuer RPS-Nutzer und kann von RPS_ROOT_ADM-Rolleninhabern und von Server-Anwendungen, die einen neuen Client-(Nutzer) beim RPS registrieren wollen, aufgerufen werden. >>--CREATE USER--rps-id--PASS--password--WITH ROLE-----+--CLIENT---------+-->< +--EXCL_CLNT------+ +--RPS_ROOT_ADM---+ +--RPS_ADM--------+ `--RPS_CTRL_ADM---´ Der Befehl liefert den Returncode 0 im Falle des Erfolgs und 1 zusammen mit einer Fehlernachricht, wenn der RPS-Account nicht erstellt werden kann (z.B. wenn bereits ein RPS-Nutzer mit dem übergebenen Login existiert). Bei Erfolg werden die erzeugten Daten in die RPS_User Tabelle eingetragen. Fortan wird dieser RPSAccount bei jeder Befehlsanforderung zur Authentifizierung (die natürlich auf dem RPS erfolgt) des Clients bzw. des Administrators beim RPS verwendet. Letzlich muss der neu erzeugte RPS-Account durch die Anwendung an den Client geschickt und die In-formationen beispielsweise in einer CFG-Datei abgespeichert werden. Es bleibt jedoch der (Server-) Anwendung überlassen, ob sie diese neuen Daten ebenfalls abspeichert und evtl. den eigenen Nutzern zuordnet. ALTER USER Mit dieser Instruktion ist es möglich, die Rolle und das Passwort eines RPS-Nutzers zu ändern. Nur Server-Anwendungen und Administratoren mit den erforderlichen Rechten ist es erlaubt diesen Befehl aufzurufen. >>--ALTER USER--rps-id--+--------------------------------------+-----> `--NEW ROLE-----+--CLIENT---------+----´ +--EXCL_CLNT------+ +--RPS_ROOT_ADM---+ +--RPS_ADM--------+ `--RPS_CTRL_ADM---´ >-------+--------------------------------------------+-------------->< `--OLD PASS--password--NEW PASS--password----´ Der einen Fehler signalisierende Return-Code 1 wird zurückgeliefert, wenn dass spezifizierte Passwort inkorrekt ist oder die Rolle nicht zu dem bisherigen Typ passt. Einem Client-RPS-Login dürfen keine RPS-AdministratorRollen und den Administratoren dürfen keine Client-Rechte zugeordnet werden. So kann in dem HERMES-Szenario ein normaler Client-Nutzer, der zu einem SuperUser "befördert" wurde auch mit der entsprechenden RPS-Rolle abgeglichen werden (durch die HERMES-SERVER-Anwendung) oder ein RPS-Root-Administrator kann die Rollen anderer RPS-Administratoren anpassen bzw. sein Passwort ändern. Eine Eigen-Herabstufung in Bezug auf die Rechte wird, im Gegensatz zu gängigen DBMS-Varianten (wie z.B. DB2), nicht zugelassen, andernfalls könnte sich ein RPS_ROOT_ADM selbst die RPS_CTRL_ADM-Rolle zuweisen (aus welchen Gründen auch immer) und sich somit sämtlichen bisherigen Rechten entledigen. 30 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur DELETE USER Dabei handelt es sich um den komplementären Befehl zu CREATE USER, zum Löschen eines bestehenden RPSAccounts. >>--DELETE USER--rps-id--->< Das Löschen ist nur berechtigten Autoritäten möglich und liefert in allen anderen Fällen einen Fehler. 3.3. Rechtekonzept und Nutzermanagement von HERMES Die Anforderungsanalyse im Abschnitt 2.4. und die Betrachtungen der Realisierungsmöglichkeiten in Datenbanksystemen haben gezeigt, dass eine eigene Implementierung eines Zugriffskontrollsystems und der damit verbundenen Nutzerverwaltung unumgänglich ist. HERMES verwendet nun konkret ein tupelbasiertes Rechtekonzept, welches nicht auf den herkömmlichen Betriebssystem- und Datenbanknutzern beruht. Die Authentifizierung bzw. Autorisierung seiner Nutzer auf Basis eines "physischen" DBMS-Nutzer-Accounts regelt HERMES selbst. Letzteres muss sogar durch die Anwendung geschehen, da die herkömmlichen Datenbank-Autorisierungsmethoden (System- und Objektrechte für einzelne Nutzer, Verwendung des SQL GRANT/REVOKE) nicht mehr angewendet werden können. 3.3.1. Nutzerverwaltung Die HERMES-Anwendung verwaltet auf dem Quellserver drei Tabellen mit jeweils unterschiedlichen Aufgaben und Sichtbarkeiten zur Realisierung des Nutzerkonzepts. Die folgende sogenannte Stammdatentabelle mit den persönlichen Daten (angelehnt an Newsgroups) aller HERMES-Nutzer ist zur lesenden Replikation durch die Clients freigegeben. Dies hat den Vorteil, dass alle, den, für die unverbundene Arbeit, replizierten Daten zugeordneten Besitzer identifiziert und deren persönliche Informationen (E-Mail, Homepage, Vor- und Nachname) dem Client bereitgestellt werden können. create table User_Info ( HID integer not null primary key, nickname varchar(128) not null UNIQUE, name varchar(128), birthday DATE, email varchar(128), homepage varchar(128), member_since DATE not null with default CURRENT DATE, is_SuperUser CHAR(1) not null check (is_SuperUser IN ('Y','N')) ) Die Nutzer von HERMES werden durch eine eindeutige Ziffer, dem sogenannten HERMES Identifier (HID), identifiziert. Sie legen diesen Identifikator weder selbst fest, noch sind sie sich dessen bewusst. Die Eindeutigkeit des Nickname stellt sicher, dass andere Nutzer den Erzeuger von Daten immer identifizieren und keine Verwechslungen auftreten können. Angelehnt an Internetforen wird die Menge der HERMES-Nutzer unterteilt in normale Nutzer und Administratoren (SuperUser). Die Aufgaben der SuperUser sind Administration und Prüfung der (durch andere Nutzer eingebrachten) HERMES-Daten. Dazu verfügen sie über erweiterte Rechte, wodurch sie generell alle (nicht exklusiv gesperrten) Daten bearbeiten können. Sie können dabei als "Datenkontrolleure" gezielt Änderungen (z.B. aus rechtlichen Gründen) am Datenbestand vornehmen. Zur Unterstützung dieses Nutzertyps wurden auf RPSEbene exklusive Änderungszusicherungen eingeführt, die dem mobilen Client das alleinige Änderungsrecht für die angeforderten Daten garantieren. Es wird unterstellt, dass diese Nutzer nur in begründeten Fällen auf diese Möglichkeit zurückgreifen. 31 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Auswahlkriterien aus dem Kreis der Nutzer sind beispielsweise die Aktivität eines Nutzers, die Qualität und Quantität der eingebrachten Daten, aber auch die regionale Zugehörigkeit3 spielt eine Rolle. So macht es z.B. wenig Sinn, einen Berliner mit der Pflege der Daten aus München zu beauftragen und umgekehrt. Dabei müssen auch die SuperUser nicht zwangsläufig Kenntnisse im Datenbank-Bereich besitzen, da auch sie die Oberfläche der Client-Anwendung einsetzen. Die Tabelle Auth_Info enthält alle zur Authentifizierung notwendigen Informationen (Kennungen und verschlüsselte Passwörter der Nutzer), die den Clients verborgen bleiben sollen und nicht repliziert werden können: CREATE TABLE Auth_Info ( HID INTEGER not null primary key, Pass VARCHAR(128) not null, Foreign Key (HID) references User_Info ON DELETE CASCADE ) Das Passwort (Pass) und ein eindeutiger, für andere Nutzer sichtbarer Nickname werden von jedem neuen Nutzer anfänglich selbst gewählt, gedanklich vermerkt oder verschlüsselt abgespeichert, und dienen der zukünftigen Anmeldung an HERMES. Zur Authentifizierung wird die HID zum entsprechenden Login bestimmt, das angegebene Passwort verschlüsselt und mit in der Authentifizierungstabelle gespeicherten Wert verglichen. Die letzte der notwendigen Nutzertabellen bildet die Zuordnung der Nutzer-IDs auf die RPS-Kennungen ab. Ähnlich wie die Authentifizierungstabelle braucht diese den Clients nicht zur Replikation zur Verfügung gestellt werden. CREATE TABLE RPS_HID_Mapping ( HID integer not null, RPS_login varchar(128) not null UNIQUE, Primary Key (HID, RPS_login), Foreign Key (HID) references User_Info ON DELETE CASCADE ) Die Wahl des zweiattributigen Primärschlüssels und die zusätzliche Forderung der Eindeutigkeit des RPS-Logins in der Menge aller Tupel, realisieren die bisher genannten Forderungen. Pro Client-Gerät wird nur ein HERMESNutzer erlaubt, welcher jedoch die Möglichkeit hat, seine Replikatdaten auf mehrere verschiedene Clients zu verteilen. Für die Praxis ist es sicherlich irrelevant, mehrere Nutzer für einen mobilen Client zu unterstützen. So wurden die mobilen Geräte, im Gegensatz zu Workstations oder stationären PCs, gerade für den Gebrauch eines einzelnen mobilen Nutzers konzipiert. Falls es dennoch Anwendungen geben sollte, die pro Client-Gerät mehrere Nutzer erlauben, so muss auch jedem eine separate RPS-ID zugeordnet werden. Um Redundanzen zu vermeiden, braucht lediglich das RPS-Login gespeichert werden. Das RPS-Passwort oder die zugeordnete Rolle sind nicht nötig, da die Authentifizierung vom RPS selbst vorgenommen wird. Allerdings sollte man sich der möglichen Inkonsistenzen bewusst sein, die bei Löschungen bzw. Änderungen von RPSLogins entstehen können. Da aufgrund unterschiedlicher Datenbanken keine Fremdschlüsselbeziehung von RPS_HID_Mapping.RPS_login auf RPS_User.login definiert werden kann, müssen die Administratoren oder die Applikationen bei Änderungen der RPS-Accounts in der Hilfsdatenbank des RPS, Folgeänderungen in den entsprechenden Zuordnungstabellen der Anwendungen berücksichtigen und eigenständig aktualisieren. Das Löschen eines HERMES-Nutzers aus der Stammdatentabelle (User_Info), beispielsweise durch einen Administrator oder durch den Nutzer selbst, führt aufgrund der Fremdschlüsselbeziehungen zum propagierten Löschen der entsprechenden Tupel in den Tabellen Auth_Info sowie RPS_HID_Mapping. Die entsprechenden konsolidierten Tabellen werden auf dem RPS durch einen Replikationsadministrator folgendermaßen erzeugt (Syntax gemäß Abschnitt 3.7.2. oder [Pfe04]): CREATE CONSOLIDATED TABLE User_Info AS SELECT * FROM User_Info FOR CONSOLIDATED DATABASE HERMES READ ONLY 3 Die regionale Zugehörigkeit spielt für die folgenden Betrachtungen keine Rolle und wurde demnach beabsichtigt ausser Acht gelassen. 32 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur CREATE CONSOLIDATED TABLE Auth_Info AS SELECT * FROM Auth_Info FOR CONSOLIDATED DATABASE HERMES NO CLIENT REPLICATION CREATE CONSOLIDATED TABLE RPS_HID_Mapping AS SELECT * FROM RPS_HID_Mapping FOR CONSOLIDATED DATABASE HERMES NO CLIENT REPLICATION Konfliktbehandlungsmethoden sind für die durch Clients unveränderbaren Tabellen nicht erforderlich. Erstanmeldung und Authentifizierung Neue HERMES-Nutzer müssen sich einmalig im verbundenen Zustand bei der HERMES-Server-Anwendung registrieren. Die spezifizierten persönlichen Informationen sowie das Login (Nickname) und Passwort werden in die Quelltabellen User_Info4 und Auth_Info eingetragen, sofern das Login nicht bereits durch einen anderen Nutzer Verwendung findet. In letzterem Falle wird dem Nutzer eine Fehlermeldung zurücksignalisiert und er muss das Login neu wählen, solange bis schlussendlich ein nicht verwendetes gefunden wurde. Eventuell ist es sinnvoll dem Nutzer dabei eine Reihe von ungenutzten ähnlichen Nickname-Vorschlägen zu unterbreiten, um den Registrierungsprozess nicht unnötig zu verlängern. Nun kann die Server-Anwendung das Client-Gerät des Nutzers beim RPS durch den Aufruf von CREATE USER unter Angabe eigens generierter, adäquater Werte (Login, Passwort, Rolle) registrieren, die entsprechenden Informationen in der Tabelle RPS_HID_Mapping speichern und dem Client die RPS-Account-Informationen schicken. Bei jedem folgenden Befehlsaufruf des Clients wird der dort gespeicherte RPS-Account und der vom Anwender zu spezifizierende Anwendungsaccount an den RPS geschickt. Nur bei erfolgreicher Authentifizierung übergibt der RPS letzteren an die optional zu registrierende Autorisierungs-Schnittstelle (Stored Procedures) der Anwendung, welche dann für die anwendungsspezifische Authentifizierung und Autorisierung zuständig ist (siehe Abschnitt 3.4.). Ein böswilliger Nutzer kann versuchen, das RPS-Login und Passwort seines Client-Gerätes zu ändern (Client Nutzer können prinzipiell alles). Durch die erforderliche Passwort-Authentifizierung ist allerdings nahezu sichergestellt, dass er sich nicht als anderer Client ausgeben kann. Dazu sollten die Passwörter nicht leicht zu erraten sein und angemessen verschlüsselt werden. Bei der Änderung des RPS-Accounts macht der Nutzer somit lediglich die Identifizierung seines Clients beim RPS ungültig und kann nicht mehr authentifiziert werden. Wird das Client-Gerät gestohlen, verfügt der Dieb lediglich über den RPS-Account, aber nicht über das HERMES-Passwort (sofern der bestohlene Nutzer intelligent genug war, sein HERMES-Passwort nicht unverschlüsselt auf dem Client-Gerät abzulegen). Demnach kann der fremde Nutzer nur auf nicht anwendungsbezogene RPS-Dienste zugreifen. Ohne die HERMES-Authentifizierung kommt er nicht an die Inhalte der konsolidierten Datenbank. Wenn er jedoch einen HERMES-Account besitzt und dennoch versucht, von dem gestohlenen Gerät an die konsolidierten Daten heranzukommen, so wird bei der Anwendungsauthentifizierung das Nichtübereinstimmen von HERMES-ID und zugeordneter RPS-ID registriert und der Zugriff verwehrt. 3.3.2. Rechtekonzept Auf dem beschriebenen Nutzerkonzept baut die Rechteverwaltung und -vergabe auf. Hierbei handelt es sich um eine zeilenbasierte Zugriffskontrolle (Row-Level-Access) wie sie in ähnlicher aber restriktiverer Art und Weise von Oracle implementiert wird (siehe Abschnitt 2.6.). Die schützenswerten Objekte stellen einzelne Datensätze dar. Eine noch feinere Unterteilung auf einzelne Spalten ist im Hinblick auf die Performance und die angestrebte Semantik nicht sinnvoll. Dabei verlangt HERMES folgende Daten-Kategorien: (A) 4 Private Daten: Lese- und Schreibrecht nur für den Besitzer (beispielsweise sinnvoll für private Reiseberichte, Notizen, persönliche Aufzeichnungen) Die HID kann dabei mittels einer generischen Sequenz erzeugt werden 33 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur (B) (C) (D) (E) (F) Basis-Daten: unveränderliche HERMES-Basisdaten (z.B. demographische Ortschafts-, Regions-Informationen) Public-Daten: von HERMES bereits vorgegebene, durch alle Nutzer modifizierbare Basisdaten (z.B. Historie von Ortschaften) Nutzerdaten mit Leserecht für alle, aber Schreibrecht nur für den Tupel-Besitzer (z.B. Reiseberichte) Nutzerdaten mit Lese- und Schreibrecht für alle (z.B. Reiserouten) Nutzerdaten mit Lese- und Schreibrecht für eine Gruppe von HERMES-Nutzern Bis auf die Daten der Kategorie (A) können alle Tupel von jedem registrierten Nutzer uneingeschränkt gelesen werden. Die ausführliche Beschreibung solcher privaten Tupel bzw. Tabellen erfolgt in den Abschnitten 3.6. und 3.7. Neue Tupel können durch jeden authentifizierten Nutzer eingefügt werden. Die Verwaltung der Schreibrechte bestehender Datensätze (UPDATE bestimmter Spalten, DELETE des Tupels) ist im wesentlichen der nutzerbestimmten Zugriffskontrolle (siehe Abschnitt 2.3.1.) angelehnt. Nur der Eigentümer eines Objekts, sprich der Erzeuger eines Datensatzes, verwaltet dessen Zugriffsrechte. Für alle Tabellen, die Daten der Kategorien (C) bis (F) beinhalten sollen, sind zur Umsetzung des Schreibzugriffs zwei zusätzliche Spalten erforderlich. Damit kann für ein beliebiges Tupel festgestellt und gespeichert werden, welcher Nutzer es eingefügt hat (d.h. wem es gehört) und welche Rechte vergeben wurden. Ein Administrator der Anwendung bestimmt zum Zeitpunkt der Erzeugung des Quellschemas, welche Tabellen mit dieser tupelorientierten Rechteverwaltung versehen werden: CREATE TABLE <tabname> ( ... Owner integer not null WITH DEFAULT 0 REFERENCES User_Info(HID) ON DELETE SET DEFAULT, WriteAccess integer REFERENCES BuddyGroups(group_ID) ON DELETE SET NULL ) Das Attribut Owner identifiziert die HID des Erzeugers eines jeden Tupels. Im Gegensatz zu der Verwendung des Nickname (Varchar(128)) bietet die Referenz auf die HERMES-ID (Integer) eine Menge von Vorteilen. Jedes Tupel belegt sparsame 4 Byte, statt 128 Byte beim Einsatz eines Strings. Wenn ein Nutzer nun mittels Server-Anwendung seinen Nick ändern will, braucht lediglich ein UPDATE auf den entsprechenden Datensatz in der Stammdatentabelle auf der Quelle erfolgen. Würde der Nickname zur Besitzer-Identifizierung der Tupel eingesetzt werden, so müssten bei einer angestrebten Namensänderung alle Tabellen des Schemas durchsucht und jedes Tupel dieses Nutzers aktualisiert werden. Vorteilhaft wirkt sich auch die Fremdschlüsselbeziehung in Zusammenhang mit der Datenübertragung aus. Durch das Fragmentkonzept werden nicht nur die vom Nutzer explizit angeforderten Tupel einer Tabelle an den Client übertragen, sondern auch der Ausschnitt der Stammdatentabelle, der die Informationen der Besitzer jener Tupel bereitstellt5. Die Nutzer haben dadurch die Möglichkeit, lokal und unverbunden beispielsweise die aussagekräftigen Nicknamen zu den Daten oder die E-Mail-Adresse zur Kontaktaufnahme einzusehen. Eine Änderung der Besitzerspalte ist dem Besitzer selbst und allen anderen Nutzern (inkl. SuperUser) verboten, da keine Tupel an andere verschenkt werden sollen. Des weiteren sollten die Werte dieses Attributs automatisiert durch die HERMES-Client-Anwendungslogik eingetragen werden, da man dem Nutzer nicht die Kenntnis seiner HID voraussetzen kann. Der Besitzer hat automatisch volles Lese- und Schreibrecht auf seine erzeugten Datensätze. Die Spalte WriteAcess erlaubt ihm zudem die Einschränkung der zugriffsberechtigten Subjekte durch die Angabe einer Gruppen-ID: NULL: Der Besitzer des Tupels hat den Zugriff nicht freigegeben (Kategorie (D)) 0: Der Datensatz steht allen HERMES-Nutzern zur Modifikation frei (Kategorie (E)) Jede andere gültige Gruppen-ID: Der Besitzer erlaubt nur den Mitgliedern einer von ihm erzeugten Gruppe (Buddyliste) den Schreibzugriff auf das Tupel (Kategorie (F)) 5 Genauer gesagt erhält der Nutzer die Daten automatisch, kann aber erst darauf zugreifen, wenn er sie explizit anfordert. 34 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Das Recht zur Weitergabe (Entzug) von Zugriffsrechten an einzelne Nutzer (zusammengefasst zu einer Gruppe) ist demnach nur dem Besitzer der Daten erlaubt und nicht wie beim ähnlichen SQL GRANT auch weiteren ermächtigten Subjekten (durch WITH GRANT OPTION). Sogar die HERMES-SuperUser dürfen den Zugriffsmodus nicht ändern. Unabhängig von dem aktuellen Wert der Zugriffsmodus-Spalte können die HERMES-SuperUser auf alle Daten, außer denen der Kategorien (A) und (B) modifizierend zugreifen. Die Einfüge-Operation ist für alle authentifizierten Nutzer möglich, es sei denn, ein anderer Client hat eine exklusive INSERT-Änderbarkeitszusicherung angefordert und erhalten. Eine besondere Stellung nehmen die Kategorien (B) und (C) ein, welche die sogenannten HERMES-Basisdaten klassifizieren. Diese werden nicht von den mobilen Nutzern, sondern durch den HERMES-ROOT-Administrator (HID = 0, nickname = 'ROOT') nach der Schemadefinition und im laufenden Betrieb, exklusiv auf der Quelle eingefügt. Für Tabellen, die ausschließlich unveränderliche Basisdaten enthalten, ist es möglich die beiden MetaSpalten aus Gründen der Speicherökonomie nicht zu definieren und sämtlichen Nutzern Schreibzugriffe zu entziehen (REVOKE INSERT, UPDATE, DELETE ON <tabname> FROM PUBLIC) und nur lesenden Zugriff zu gewähren (GRANT SELECT ON <tabname> TO PUBLIC). Alternativ könnte man sich die Mechanismen des RPS zu Nutzen machen und solche konsolidierte Tabellen als READ ONLY definieren. Zur Unterstützung des Gruppenkonzepts müssen, neben den drei Tabellen für die Nutzerverwaltung, in der Quelldatenbank bzw. konsolidierten HERMES-Datenbank folgende Tabellen existieren: CREATE TABLE BuddyGroups ( group_ID integer not null primary key, group_name varchar(128) not null, group_owner integer not null REFERENCES User_Info(HID) ON DELETE CASCADE, UNIQUE (group_name, group_owner) ) CREATE TABLE GroupMembers ( group_ID integer not null REFERENCES BuddyGroups ON DELETE CASCADE ON UPDATE RESTRICT, group_member integer not null REFERENCES User_Info(HID) ON DELETE CASCADE, primary key (group_ID, group_member) ) Ein HERMES-Nutzer kann sich über die Client-Anwendung eine Menge von Freundes-Gruppen mit beliebig vielen Mitgliedern definieren, denen er dann Schreibzugriff auf seine Daten gewähren kann (Eintragung einer bestimmten group_ID in die WriteAccess-Spalte). Dies muss im verbundenen Zustand geschehen, da man dem Nutzer kein externes, über seine lokalen "Fenster" hinausgehendes Wissen abverlangen und nur registrierte HERMES-Mitglieder eintragen will. Eine besondere Stellung nimmt die Gruppe mit der ID = 0 und dem Namen PUB ein, die keine Mitglieder beinhaltet und die Gesamtheit aller registrierten HERMES-Nutzer symbolisiert. Da jeder Gruppe ein eindeutiger Gruppenbesitzer zugeordnet werden muss, verwendet man hierfür einfach den HERMES-ROOT-Nutzer (HID = 0), der für die Einbringung der Basisdaten verantwortlich ist. Die Tabelle BuddyGroups enthält die Namen (group_name) und Besitzer (group_owner) aller definierten Gruppen. Es wird ein künstlicher Schlüssel (group_ID) verwendet, damit der Gruppenname nicht global eindeutig sein muss. Es wird hingegen verlangt, dass die Namen der Gruppen eines HERMES-Nutzers eindeutig sind (sichergestellt durch die UNIQUE-Constraint-Definition). Die einer Gruppe angehörigen HERMES-Nutzer (group_member) sind in der Tabelle GroupMembers abgebildet. Die entsprechenden konsolidierten, nur lesbar replizierbaren Tabellen werden auf dem RPS folgendermaßen erzeugt: CREATE CONSOLIDATED TABLE BuddyGroups AS SELECT * FROM BuddyGroups FOR CONSOLIDATED DATABASE HERMES READ ONLY CREATE CONSOLIDATED TABLE GroupMembers AS SELECT * FROM GroupMembers FOR CONSOLIDATED DATABASE HERMES READ ONLY 35 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Die Tabellen sollen auf dem Client nur lesbar sein, da die Änderung an Gruppen anderer Nutzer verboten ist und die Definition eigener Gruppen sowie Änderungen an den bestehenden aus den bereits genannten Gründen nur im verbundenen Zustand erfolgen darf. Wird ein Nutzer X (bzw. der ihm zugeordnete Datensatz) aus der Stammdatentabelle gelöscht, so sollen alle seine erzeugten Tupel dem HERMES-ROOT-Nutzer (HID = 0) "gutgeschrieben" werden und somit den restlichen Nutzern zumindest lesend weiterhin zur Verfügung stehen. War ein Tupel von X für alle zum Schreiben freigegeben (WriteAccess = 0) oder lediglich für den Erzeuger selbst (WriteAccess = NULL), so soll das auch im folgenden der Fall sein, d.h. der Wert der Spalte WriteAccess bleibt unverändert. Hat der Nutzer X jedoch den Schreibzugriff eines Tupels einer bestimmten Gruppe erlaubt, so muss das Tupel zukünftig nur lesend bleiben (WriteAccess = NULL), da das Löschen von X, aufgrund der Fremdschlüsselbeziehung der Tabelle BuddyGroups, auch das Löschen aller von ihm definierten Gruppen zur Folge hat. Die genannten Forderungen werden in den Schema-Tabellen mit integrierter Rechteverwaltung durch den Default-Wert der Spalte Owner und die referentiellen Integritätsregeln ON DELETE SET DEFAULT sowie ON DELETE SET NULL implementiert. 3.3.3. Referential Constraints In diesem Abschnitt wird auf Besonderheiten von Fremdschlüsselbeziehungen im Einsatz des zeilenorientierten Rechtemanagements und der Integration in die nutzerdefinierte Replikation sowie Möglichkeiten der Auflösung der dabei entstehenden Probleme eingegangen. Einführung Referentielle Integritätsbedingungen entstehen aus dem Zusammenhang zwischen Primär- und Fremdschlüsseln. Eine referentielle Integritätsbedingung FOREIGN KEY (<attr-list>) REFERENCES <table'> (<attr-list'>) definiert eine Inklusionsabhängigkeit: Zu jedem Fremdschlüsselwert der Attribute (<attr-list>) der referenzierenden Tabelle (Kind-Tabelle) muss ein entsprechender Schlüsselwert von (<attr-list'>) in der referenzierten Tabelle <table'> (Vater-Tabelle) existieren. Dabei muss (<attr-list'>) ein Schlüsselkandidat (UNIQUE-KEY) der referenzierten Tabelle sein. Die Klauseln ON DELETE und ON UPDATE geben an, welche Aktionen bzgl. der Kind-Tabelle bei einem DELETE bzw. UPDATE auf die referenzierte Tabelle ausgeführt werden sollen, um die referentielle Integrität der Datenbank zu gewährleisten. Ist dies nicht möglich, so werden die gewünschten DELETE/UPDATE-Operationen nicht ausgeführt, bzw. zurückgesetzt. Hierbei sind die folgenden Optionen zu unterscheiden: NO ACTION: Die DELETE- oder UPDATE-Operation wird auf der Vater-Tabelle zunächst ausgeführt. Danach wird geprüft, ob "dangling references" (Verweise auf Objekte, die nicht mehr existieren) in der Kind-Tabelle entstanden sind. Falls ja, war die Operation verboten und wird zurückgenommen. In DB2 muss man genauer differenzieren. ON UPDATE NO ACTION garantiert für jede Aktualisierung in der Vater- oder der Kind-Tabelle die Existenz eines zum Fremdschlüsselwert des Kind-Tupels gehörenden Wert in der Vater-Tabelle. Dabei muss der Wert nach dem UPDATE nicht der gleiche wie zuvor sein. Durch ON DELETE NO ACTION wird sichergestellt, dass nach dem Löschen jeder Fremdschlüsselwert in der Kind-Tabelle einen korrespondierenden in der Vater-Tabelle hat (NACHDEM alle anderen referentiellen Integritätsregeln angewandt wurden). RESTRICT: Die DELETE/UPDATE-Operation auf der Vater-Tabelle wird nur dann ausgeführt, wenn keine "dangling references " in der Kind-Tabelle entstehen können. In DB2 fordert ON UPDATE RESTRICT, dass nach dem UPDATE jeder Fremdschlüsselwert noch auf den selben Vater-Wert zeigt. ON DELETE RESTRICT unterscheidet sich lediglich in der Priorität von ON DELETE NO ACTION. Es muss nämlich VOR der Prüfung weiterer Integritätsregeln, die obige Bedingung gelten. 36 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur CASCADE: Die DELETE/UPDATE-Operation auf der Vater-Tabelle wird ausgeführt. Die referenzierenden Tupel in der Kind-Tabelle werden ebenfalls mittels DELTE entfernt, bzw. mittels UPDATE geändert. Ist die KindTabelle selbst Vater-Tabelle bzgl. einer anderen Bedingung, so wird das DELETE/UPDATE bzgl. der dort festgelegten Lösch/Änderungs-Regel weiter behandelt. SET DEFAULT: Die DELETE/UPDATE-Operation auf der Vater-Tabelle wird ausgeführt und bei den referenzierenden Tupel in der Kind-Tabelle wird der entsprechende Fremdschlüsselwert auf die für die betroffenen Spalten festgelegten DEFAULT-Werte gesetzt. Dafür muss dann wiederum ein entsprechendes Tupel in der referenzierten Relation existieren. SET NULL: Die DELETE/UPDATE-Operation auf der Vater-Tabelle wird ausgeführt. In der Kind-Tabelle wird der entsprechende Fremdschlüsselwert durch NULL ersetzt, vorausgesetzt NULLs sind zulässig. Fremdschlüsselproblematik im tupelbasierten Rechtekonzept von HERMES Prinzipiell können Tupel in HERMES beliebig per Fremdschlüssel referenziert werden, da allen nicht privaten Tabellen das Leserecht durch sämtliche Nutzer gemein ist. Zudem findet das von DB2-implementierte Tabellenrecht REFERENCES (erlaubt einem Nutzer die Tabelle als Vatertabelle zu referenzieren) aufgrund der gewählten Implementierung von HERMES (ein physischer DB-Account und viele tausend logische Nutzer) keine Anwendung. Für weitergehende Rechtekonzepte, bei denen auch Lesesperren auf Tupelebene erteilt werden können (wie z.B. bei Oracle Label Security), muss als Voraussetzung einer Referenzbildung das Leserecht auf die referenzierte Vater-Zeile existieren. Probleme treten erst im Zusammenhang mit den von DB2 implementierten, durch die Kinder-Tabellen zu definierenden referentiellen Integritätsregeln für die DELETE-Operationen (ON DELETE CASCADE / SET NULL / RESTRICT / NO ACTION) im Zusammenhang mit den Schreibrechten auf die Kinder-Tupel auf. Die von DB2 implementierten Update-Integritätsregeln (ON UPDATE RESTRICT / NO ACTION) erlauben keine propagierte Änderung an den Kind-Tupeln bei einer Änderung des referenzierten Vater-Tupels und sind daher als unproblematisch anzusehen. Wenn man, im Zusammenhang mit dem tupelbasierten Rechtekonzept, ein Vater-Tupel (in einer Fremdschlüsselbeziehung) löschen will, dann muss man auch über das entsprechende Schreibrecht auf die Kinder-Tupel verfügen, sofern deren referentielle Integritätsregeln ON DELETE CASCADE oder SET NULL lauten. Im schlimmsten Fall heißt das also, dass der Nutzer sein eigens eingefügtes Tupel nicht mehr löschen kann, sobald jenes mindestens einem anderen, nicht modifizierbaren Tupel in einer Fremdschlüsselbeziehung als Vater dient. Dieser Gefahr muss sich allerdings der Nutzer bewusst sein, der ein Tupel in eine Vatertabelle einfügt ! In dem Produkt Oracle Label Security darf kein Vater-Tupel gelöscht werden, wenn noch referenzierende Kinder existieren. Dafür müssen erst explizit alle entsprechenden Kinder-Datensätze gelöscht werden. Es sei angenommen, dass das Vater-Tupel gelöscht werden kann, d.h. der Nutzer über die nötigen Schreibrechte verfügt. Wie bereits erwähnt, treten die Probleme lediglich bei den Lösch-Modi CASCADE und SET NULL auf. Bei NO ACTION/RESTRICT erfolgen keine Änderungen an Datensätzen der Kind-Tabelle. Im Falle von SET NULL werden die Fremdschlüssel-Attribute der Zeilen des Kindes auf NULL gesetzt, deren Werte auf die Primärschlüssel- oder die entsprechenden Unique-Werte des zu löschenden Vater-Tupels zeigen. Dieses Aktualisieren (auf NULL-Setzen) setzt natürlich das Schreibrecht des, das Vater-Tupel löschenden, HERMES-Nutzers auf ALLE davon betroffenen Kinder-Tupel voraus. Das UPDATE (auf den Wert NULL) der entsprechenden Spalte kann keine weiteren abhängigen Relationen beeinflussen, da deren vermeintliche Fremdschlüssel lediglich auf mit NOT NULL deklarierte Unique- oder Primärschlüssel-Attribute verweisen dürfen. Bei mit CASCADE definierten Fremdschlüsselbeziehungen werden alle Kinder-Tupel gelöscht, die auf das zu löschende Vater-Tupel zeigen. Das Löschen der Kinder wiederum kann zu einem kaskadierendem Propagieren der Löschoperationen zu weiteren abhängigen Relationen führen. Eine Prüfung der Schreibrechte auf alle transitiv abhängigen Kinder-Tupel soll, ähnlich wie in ORACLE Label Security, nicht erfolgen, da die Zeit für das Auffinden und Prüfen aller in der Fremdschlüsselhierarchie enthaltenen Tupel den Rahmen des Zumutbaren leicht sprengen könnte, wie folgendes Beispiel anschaulich demonstriert. 37 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Die in Abbildung 12 dargestellten Tabellen entsprechen im wesentlichen der Schemadefinition von [Bau03]. Eine Beschreibung der Funktion und Inhalte der einzelnen Tabellen wird nicht vorgenommen, da hierbei lediglich die Veranschaulichung der möglichen Komplexität von Fremdschlüsselhierarchien im Vordergrund steht. Fremdschlüsselbeziehungen werden durch gerichtete Kanten und Tabellen als Knoten dargestellt, wobei der Endpunkt die Vatertabelle bezeichnen soll. An den Kanten stehen die Namen der Fremdschlüsselattribute der Kindtabelle, die auf den Primärschlüssel des Vaters (Attributnamen unten rechts in den Knoten) zeigen. Alle Fremdschlüsselbeziehungen seien mit ON DELETE CASCADE definiert. Das Löschen des Tupels x in Ortschaft, kann beispielsweise zum Löschen von 100 Tupeln der Tabelle Route_Innerorts führen. Jedes dieser Tupel kann wiederum zum Löschen von 100 weiteren Tupeln in der Tabelle Route_IO_Inhalt führen. Analoges gelte für die Tabelle Gebäude und dessen Kind Route_IO_Inhalt sowie für die Kinder Ortschaft_Statistik, Ortschaft_Historie und Route_Ortschaften. Demnach würden schlimmstenfalls insgesamt 100*100 + 100*100 + 100 + 100 + 100 = 2300 Tupel in Folge gelöscht werden, für die alle eine explizite Rechteprüfung vorgenommen werden müsste. Mit einer realistischen Anzahl an Tupeln (mehrere Hunderttausend) und steigender Fremdschlüsselhierarchietiefe ist ein explizites Prüfen von exponentiell vielen Tupeln bei akzeptabler Performance ausgeschlossen, gerade im hierbei betrachteten mobilen Datenbankszenario. Gebäude GebNr GebNr RNr ONr ONr Ortschaft_Statistik ONr Route_InnerOrts RNr Route RNr RNr ONr Ortschaft ONr Ortschaft_Historie ONr Route_IO_Inhalt RNr, Position ONr Route_Ortschaften RNr, Position RNr ONr Abbildung 12: HERMES-Testschema für referentielle Integritätsregeln Daher erfolgt vor dem Löschen des Vater-Tupels, mittels einer für jede Tabelle anzulegenden Stored Procedure, eine Prüfung der direkten Kind-Tabellen. Im CASCADE-Fall dürfen keine, das Vater-Tupel referenzierende, Kinder-Tupel existieren und im SET NULL-Fall muss der Löschende auch autorisiert sein, die entsprechenden Spalten des Kindes auf NULL zu setzen. Die folgende tabellenspezifische Stored Procedure muss vor dem beabsichtigten Löschen eines Tupels aufgerufen werden und erhält als Eingabeparameter die HERMES-ID des Nutzers, der das durch die, an die Prozedur zu übergebenden, Primärschlüsselwerte (Anzahl und Typ der Attribute abhängig von der spezifizierten Tabelle) eindeutig identifizierte Tupel zu löschen beabsichtigt. Als Output-Parameter liefert die Prozedur das Vorhandensein (authorized='Y') oder Fehlen (authorized='N') der Berechtigung für die geplante Aktion, zusammen mit einer entsprechenden Fehlermeldung. Zur Erzeugung der Prozedur wird lediglich vorausgesetzt, dass der spezifizierte HERMES-Nutzer bereits authentifiziert wurde und dass im angegebenen Schema die Funktionen is_SuperUser() und is_group_Member() wie in Abschnitt 3.4. spezifiziert, existieren. CREATE PROCEDURE <schemaname>.RISP_<tabname> (IN HID integer, IN <primkeycol_1> <datatype_1>, ... IN <primkeycol_n> <datatype_n>, OUT authorized CHAR(1), OUT msg varchar(300)) Das automatisierte Erzeugen dieser Prozeduren wird durch das Java-Tool "CRISP" (Create Referential Integrity Stored Procedure) unterstützt. Durch den Aufruf: java CRISP <databasename> <schemaname> <tabname> wird das DDL-Skript "CRISP_<tabname>.sql" erzeugt, dass mittels "db2 -td@ +c -fCRISP_<tabname>.sql" durch einen Replikationsadministrator aufgerufen werden kann. Das Tool bestimmt unter anderem alle unmittelbaren Kinder der spezifizierten Vater-Tabelle und berücksichtigt dabei auch die Möglichkeit eines Kindes, beliebig viele 38 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Fremdschlüsselbeziehungen auf den Primärschlüssel oder auf beliebig viele Unique-Schlüssel der Vatertabelle zu besitzen. Beispielsweise liefert der folgende Aufruf die Prozedur für die Tabelle Ortschaft (alle Fremdschlüssel darauf sind mit ON DELETE CASCADE definiert): $ java CRISP hermes_DB hermes ortschaft CONNECT TO HERMES_DB@ CREATE PROCEDURE HERMES.RISP_ORTSCHAFT (IN HID integer, IN V_ONR INTEGER, OUT authorized CHAR(1), OUT msg varchar(300)) READS SQL DATA LANGUAGE SQL BEGIN IF (V_ONR) IN (SELECT ONR FROM HERMES.GEBAEUDE) THEN SET authorized = 'N'; SET msg = 'Unable to delete from ORTSCHAFT. Delete the referencing rows in GEBAEUDE first'; return 1; END IF; IF (V_ONR) IN (SELECT ONR FROM HERMES.ORTSCHAFT_HISTORIE) THEN SET authorized = 'N'; SET msg = 'Unable to delete from ORTSCHAFT. Delete the referencing rows in ORTSCHAFT_HISTORIE first'; return 1; END IF; IF (V_ONR) IN (SELECT ONR FROM HERMES.ORTSCHAFT_STATISTIK) THEN SET authorized = 'N'; SET msg = 'Unable to delete from ORTSCHAFT. Delete the referencing rows in ORTSCHAFT_STATISTIK first'; return 1; END IF; IF (V_ONR) IN (SELECT ONR FROM HERMES.ROUTE_INNERORTS) THEN SET authorized = 'N'; SET msg = 'Unable to delete from ORTSCHAFT. Delete the referencing rows in ROUTE_INNERORTS first'; return 1; END IF; IF (V_ONR) IN (SELECT ONR FROM HERMES.ROUTE_ORTSCHAFTEN) THEN SET authorized = 'N'; SET msg = 'Unable to delete from ORTSCHAFT. Delete the referencing rows in ROUTE_ORTSCHAFTEN first'; return 1; END IF; SET authorized = 'Y'; END@ SET msg = 'Deleting Row possible'; COMMIT@ Vor dem Einbringen der Client-Daten auf den RPS muss ein Aufruf einer solchen Prozedur stets erfolgen (innerhalb der Synchronize-Autorisierungs-Prozedur, siehe Abschnitt 3.4.3.), um mutwilligen unberechtigten Manipulationen von Client-Nutzern vorzubeugen. Für Anwender, die sich strikt an die Anwendung halten und keine eigenmächtigen Manipulationen an der Struktur ihres lokalen Datenbankschemas vornehmen, reichen die auf den Client-Tabellen definierten Rechte-Trigger (siehe Abschnitt 3.5.), die automatisch VOR jeder Operation auf die Tupel in den Replikattabellen aufgerufen werden und die Zugriffsrechte des HERMES-Client-Nutzers verifizieren. Hierbei ist es durch automatisch hervorgerufene, kaskadierte Trigger-Aktivierungen möglich, entsprechende Rechte vorausgesetzt, Kinder-Tupel der gesamten Fremdschlüsselhierarchie zu löschen. Doch das Fehlen auch nur eines Rechtes, löst das Rollback der gesamten Transaktion aus (d.h. das Vater-Tupel kann letztendlich doch nicht gelöscht werden). Ein weiteres Problem entsteht lediglich im Zusammenhang mit der Synchronisation. Angenommen ein Nutzer habe Schreibrechte auf alle Kinder-Tupel und es sei ON DELETE CASCADE auf RPS- und Client-Seite definiert wurden. Der lokale Client-Nutzer löscht nun ein Tupel, das zur Löschung von weiteren Tupeln in der KinderTabelle führt. Da die Änderungen bei der späteren Synchronisation als Einzelaktionen an den RPS geschickt werden, entsteht ein Scheinkonflikt. Das Löschen des Vater-Tupels auf dem RPS triggert auch die Löschung der Kinder-Tupel auf den entsprechenden konsolidierten Tabellen. Wenn nun im folgenden die automatisch gelöschten Tupel der Client-Kinder-Tabellen auch auf dem RPS gelöscht werden sollen, existieren diese auf dem RPS gar nicht mehr. Das ist allerdings insofern nicht weiter problematisch, als dass der Versuch ein nicht vorhandenes Tupel zu löschen lediglich eine Warnung und keinen Fehler liefert. Auch die Reihenfolge der Einbringung der Änderungen an den Daten auf den RPS spielt keine Rolle. Wenn die Kinder-Tupel zuerst gelöscht werden, referenzieren diese ja ohnehin nicht mehr das im nachhinein zu löschende Vater-Tupel. Zu guter letzt bietet MobiLink auch die Möglichkeit getriggerte Änderungen durch die Synchronisation zu deaktivieren. Wenn sich der böswillige Client-Nutzer nun aber der lokalen Rechte-Trigger entledigt, schlägt das kaskadierende Löschen nicht fehl und er löscht möglicherweise Tupel, auf denen er keinerlei Schreibrechte besitzt. Zwar werden unbefugte Aktionen bei der Synchronisation zurückgewiesen, dennoch wird das Löschen des Vater-Tupels 39 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur als erfolgreich in die konsolidierten Tabellen eingebracht und triggert so das kaskadierende Löschen aller Tupel (auch derer, die der synchronisierende Nutzer nicht löschen kann). Hier könnte MobiLink durch Deaktivierung getriggerte Aktionen aushelfen, jedoch soll das Konzept auch für andere eingesetzte Synchronisationsprodukte dienlich sein. Deshalb muss die RISP-Prozedur beim Synchronisieren aufgerufen werden. So könnten dann auf dem RPS evtl. Kinder-Tupel gelöscht werden (natürlich nur solche, auf die der Nutzer auch Schreibrechte besitzt), ohne dass das Vater-Tupel entfernt wird. Das ist allerdings unproblematisch, da der Nutzer ohnehin das Recht hat diese Kinder-Tupel zu löschen, und führt zum Inkonsistentmachen der lokalen Datenbank des synchronisierenden Nutzers. Auch wenn ein böswilliger Client-Nutzer die lokalen UPDATE- und DELETE-Regeln der Fremdschlüsselbeziehungen ändert (geht nur, wenn die Tabelle keine Daten enthält, aber er kann die Daten exportieren, die Kind-Tabellen neu anlegen und anschließend wieder importieren), können dabei nur lokale Inkonsistenzen entstehen. 3.4. Anwendungsspezifische Autorisierungs- und AuthentifizierungsRoutinen auf dem RPS Der RPS weiß von dem Nutzermanagement und der Rechteverwaltung seiner Anwendungen nichts. Nachdem er die Identität des Clients und die damit verbundenen Rechte bei einer Befehlsanfrage verifiziert hat, übergibt er eine festgelegte Menge von Informationen an eine genormte Schnittstelle. Dabei handelt es sich um Stored Procedures mit vom RPS festgelegter Syntax (Anzahl und Datentypen der Parameter), die von den Anwendungen implementiert, in den entsprechenden konsolidierten Datenbanken gespeichert werden und der Authentifizierung bzw. Autorisierung der Anwendungsnutzer dienen. Dabei werden die Daten nicht verändert, es erfolgt lediglich eine Menge fallweiser Prüfungen. Der RPS stellt für jeden Anwendungsdaten manipulierenden ClientRPS-Befehl leere Default-Procedures bereit (liefern immer Erfolg zurück), die von den Anwendungen mit eigenem Nutzer- und Rechtemanagement dann (ähnlich objektorientierter Programmiersprachenkonzepte) überladen werden können. Die Stored Procedures sollten nach Möglichkeit in reinem statischen SQL (die Statements werden bereits zur Compilierzeit verarbeitet) gehalten werden, um Performance verringernde Übersetzungen und Optimierungen zur Laufzeit zu vermeiden. Das gewählte DBMS des RPS, sprich IBM DB2 UDB, speichert die voroptimierten Statements in Form von sogenannten Packages in der Datenbank, die dann zur Laufzeit durch den EXECUTE-Befehl ausgeführt werden. Aber auch die Verwendung von dynamischen SQL hat Vorteile (Automatisieren repetierender Anweisungen; Code der für jede Datenbank, Tabelle genutzt werden kann; Code, der sich selbst ändernden Gegebenheiten anpasst). Die Anwendungsentwickler bzw. -administratoren sollten daher gründlich die Möglichkeiten gegeneinander abwiegen. Zur Authentifizierung der übergebenen HERMES-ID (inkl. verschlüsseltem Passwort) bei Aufruf von RPS-Befehlen dient eine einfache SQL-basierte, in der zur Anwendung gehörenden konsolidierten Datenbank liegende, Funktion namens AUTH_CHECK(). Der skalare Rückgabewert signalisiert die erfolgreiche Authentifizierung (1) oder den Mißerfolg (0). Die HERMES-ID wird von der Client-Software automatisch zum entsprechenden Login des Nutzers bestimmt. CREATE FUNCTION AUTH_CHECK (auth_ID integer, auth_pass varchar(128)) RETURNS SMALLINT BEGIN ATOMIC IF auth_pass = (select pass from Auth_Info where HID = auth_ID) THEN return 1; ELSE return 0; END IF; END Die Funktion MAP_CHECK() dient der Prüfung der Abbildung (mapping) des HERMES-Login auf den RPSLogin. Auch hier entspricht der Rückgabewert 1 einer korrekten Abbildung (d.h. wie in der Nutzertabelle gespeichert) und 0 signalisiert einen Fehler. CREATE FUNCTION MAP_CHECK (rps_ID varchar(128), auth_ID integer) RETURNS SMALLINT BEGIN ATOMIC IF (rps_ID, auth_ID) IN (select RPS_login, HID from RPS_HID_Mapping) THEN return 1; ELSE return 0; END IF; END 40 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Die Funktion Is_SuperUser() prüft lediglich für einen übergebenen HERMES-Nutzernamen, ob es sich um einen SuperUser handelt (Rückgabewert 1) oder nicht (Rückgabewert 0). CREATE FUNCTION Is_SuperUser (auth_ID integer) RETURNS SMALLINT BEGIN ATOMIC IF 'Y' = (select is_SuperUser from User_Info where HID = auth_ID) THEN RETURN 1; ELSE RETURN 0; END IF; END Die diversen Stored Procedures nutzen allesamt diese Funktionen für ihre Zwecke und prüfen somit vor der eigentlichen Autorisierung die korrekte Identität des HERMES-Nutzers bzw. dessen zugeordnetes RPS-Login. Wie bereits erwähnt, ist die anwendungsspezifische Autorisierung nur bei RPS-Befehlen sinnvoll, die auch Anwendungsdaten beeinflussen. Im folgenden werden demnach die HERMES-Implementierungen für die Befehle CREATE/ALTER REPLICATION VIEW und SYNCHRONIZE präsentiert. Da die Änderungen beim SYNCHRONIZE tabellenweise reintegriert werden, ist eine solche Stored Procedure für jede Tabelle des Anwendungsschemas anzulegen. Die Synchronize-Prozeduren verwenden des weiteren eine zusätzliche Hilfsfunktion, mit der ermittelt wird, ob eine übergebene HERMES-ID (auth_id) als Mitglied in der spezifizierten Gruppe (grp_ID) enthalten ist: CREATE FUNCTION Is_GroupMember (auth_ID integer, grp_ID integer) RETURNS SMALLINT BEGIN ATOMIC IF grp_ID = 0 OR auth_ID IN (select group_member from GroupMembers where group_ID = grp_ID) THEN RETURN 1; ELSE RETURN 0; END IF; END Jede Prozedur verfügt mindestens über vier Eingabe- und zwei Ausgabeparameter. Essentielle Inputwerte sind der RPS-Login und die RPS-Rolle sowie die Anwendungskennung (HID) und Passwort. Da die Prozeduren ohnehin nur vom RPS nach dem Parsen des RPS-Befehls und der erfolgten Authentifizierung des Client aufgerufen werden, braucht das RPS-Kennwort nicht übergeben werden und die Prüfung der Korrektheit aller Eingabeparameter kann entfallen. Alle Prozeduren liefern als Rückgabewerte (in Form von Ausgabeparametern) die Antwort 'Y' (Nutzer ist autorisiert) oder 'N' (Nutzer nicht autorisiert) zusammen mit einer Nachricht, welche die Ursache des Misserfolgs oder den Erfolg signalisiert. Für den Aufruf einer Stored Procedure muss die Verbindung mit der entsprechenden konsolidierten Datenbank hergestellt werden, welche die Prozedur beinhaltet. 3.4.1. Autorisierung für CREATE REPLICATION VIEW Die Anweisung CREATE REPLICATION VIEW dient zum Anlegen einer Replikationssicht. Für jede der Replikationssicht zu Grunde liegende konsolidierte Tabelle (bzw. Sicht) wird in der Replikatdatenbank eine leere korrespondierende Replikattabelle angelegt (sofern diese noch nicht existiert), anschließend wird eine lokale Sicht erzeugt, die auf den Replikattabellen basiert, den Namen der Replikationssicht trägt und deren Sichtdefinition der, bei der Definition der Replikationssicht, spezifizierten Selektionsanweisung entspricht. >>--CREATE REPLICATION VIEW-rv-name-+-----------------+-> `-| column-list |-´ >---AS--restricted-select-statement---------------------> >---FOR--| requested actions |--------------------------> .--WITH CHECK OPTION--. >---+---------------------+-----------------------------> `---NO CHECK OPTION---´ 41 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur >---+----------------------------------------------+----> `--INTO REPLICATION VIEW GROUP--rv-group-name--´ >---+------------------------------------+------------->< `--| conflict handling parameters |--´ requested actions |---OFFLINE--+--READ--------------------+---------------| +--OPTIMISTIC READ INSERT--+ +--OPTIMISTIC ALL----------+ +--EXCLUSIVE READ INSERT---+ `--EXCLUSIVE ALL-----------´ Die genaue Beschreibung der einzelnen Elemente des Syntaxdiagramms kann [Pfe04] entnommen werden. Für die angestrebte Betrachtung sind lediglich die Abschnitte restricted-select-statement und requested-actions von Bedeutung. Ersteres dient der Auswahl derjenigen Daten aus der konsolidierten Datenbank, die durch die Replikationssicht auf dem Client zur unverbundenen Arbeit bereitgestellt werden sollen. Hierbei sind alle Selektionsanweisungen zugelassen, die entsprechend dem Client-DBMS zur Definition einer Sicht in der Replikatdatenbank erlaubt sind. Sollen beim späteren unverbundenen Arbeiten jedoch Änderungsoperationen (INSERT, DELETE, UPDATE) auf der Replikationssicht ausgeführt werden, so muss dies spezifiziert werden durch FOR OFFLINE: READ (DEFAULT): Angeforderte Daten sind lokal nicht änderbar OPTIMISTIC READ INSERT: Gibt an, dass auf den angeforderten Daten lokal Lese- und Einfügeoperationen optimistisch durchgeführt werden können OPTIMISTIC ALL: Gibt an, dass auf den angeforderten Daten lokal Lese-, Einfüge-, Änderungs- und Löschoperationen optimistisch durchgeführt werden können EXCLUSIVE READ INSERT: Gibt an, dass auf den angeforderten Daten lokal Lese- und Einfügeoperationen exklusiv durchgeführt werden können. Die Daten sind in der konsolidierten Datenbank für alle anderen Benutzer gesperrt und können von ihnen während der Dauer der exklusiven Sperre nicht synchronisiert werden. EXCLUSIVE ALL: Gibt an, dass auf den angeforderten Daten lokal Lese-, Einfüge-, Änderungs- und Löschoperationen exklusiv durchgeführt werden können. Die Daten sind in der konsolidierten Datenbank für alle anderen Benutzer gesperrt und können von ihnen während der Dauer der exklusiven Sperre nicht synchronisiert werden. Die angeforderte Änderbarkeitszusicherung kann nur gewährt werden, wenn folgende drei Bedingungen erfüllt sind: 1. Die Replikationssicht basiert ausschließlich auf änderbaren konsolidierten Tabellen 2. Die für die Replikationssicht anzulegende lokale Sicht ist (entsprechend der Sichtenänderbarkeitskriterien des Client-DBMS) änderbar. 3. Die anderen mobilen Clients gewährten Änderbarkeitszusicherungen konfligieren nicht mit der angeforderten. Die Prüfung der Bedinungen (und evtl. Scheitern der Definition) erfolgt durch den RPS bzw. durch das Fragmentierer-Modul. Es besteht also die Möglichkeit, Daten aus konsolidierten Tabellen im RPS exklusiv oder optimistisch änderbar anzufordern. Ob das für einen Nutzer bzw. Client erlaubt ist, entscheidet zunächst der RPS anhand seiner Client-Nutzer-Aufstellung (Nur RPS-Logins mit der EXCL_CLNT-Rolle dürfen exklusiv selektieren und synchronisieren). Anschließend "fragt" der RPS über die Stored Procedure bei der Server-Anwendung nach, was der konkrete Nutzer darf. Im Fall von HERMES dürfen nur die authentifizierten SuperUser exklusive Änderbarkeitszusicherungen anfordern. CREATE PROCEDURE CRT_RV_AUTHORITY_CHECK (IN RPS_ID VARCHAR(128), IN RPS_Role VARCHAR(12), IN select_stmt VARCHAR(4096), IN requested_action VARCHAR(22), IN auth_ID integer, IN auth_pass VARCHAR(128), OUT authorized CHAR(1), OUT msg varchar(300)) MODIFIES SQL DATA LANGUAGE SQL BEGIN 42 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur -- pruefe Authentifizierung IF AUTH_CHECK(auth_ID, auth_pass) = 1 THEN IF MAP_CHECK(RPS_ID, auth_ID) = 1 THEN -- nur HERMES-SuperUser duerfen exklusiv replizieren IF substr(requested_action,1,9)='EXCLUSIVE' AND Is_SuperUser(auth_ID) = 0 THEN SET authorized = 'N'; SET msg = 'SuperUser authority required for exclusive replication'; return 1; ELSE -- erfolgreiche Autorisierung signalisieren SET authorized = 'Y'; SET msg = 'Authorization successful'; END IF; ELSE SET authorized = 'N'; SET msg = 'Invalid RPS-HERMES ID Mapping'; return 1; END IF; ELSE SET authorized = 'N'; return 1; END IF; SET msg = 'Authentication failed'; END Die Prozedur authentifiziert den HERMES-Nutzer und prüft dessen zugeordneten RPS-Login auf Übereinstimmung anhand der entsprechenden HERMES-Nutzertabelle. Werden Daten zur exklusiven Modifikation gefordert, so muss es sich um einen SuperUser handeln dessen Client bzw. RPS-ID die EXCL_CLNT-Rolle zugeordnet ist. Die letzte Forderung wird vom RPS selbst geprüft, wenn FOR OFFLINE EXLUSIVE ... spezifiziert wurde. Die RETURN-Anweisungen dienen lediglich dem vorzeitigem Abbruch der Prüfungen. Sobald ein Test nicht erfolgreich ist, kann die ganze Abarbeitung unterbrochen und zum Aufrufenden zurückgekehrt werden. Die hier nicht benötigte Select-Anweisung der Sichtendefinition wird übergeben, da andere Anwendungen möglicherweise die der Sicht zu Grunde gelegenen Tabellen per dynamisches SQL herausfiltern oder sonstige Rechteprüfungen vornehmen wollen. 3.4.2. Autorisierung für ALTER REPLICATION VIEW Die Anweisung ALTER REPLICATION VIEW dient zum Ändern bestimmter Eigenschaften einer Replikationssicht, wie z.B. die Zuordnung zu einer anderen Replikationssichtengruppe, Zurücknehmen bzw. Ändern bestehender Änderbarkeitszusicherungen oder auch die Anpassung der Parametrisierung von Konfliktbehandlungsmethoden. >>--ALTER REPLICATION VIEW--RV-NAME---------------------> >---+------------------------------------------------+--> `--SET REPLICATION VIEW GROUP TO--RV-GROUP-NAME--´ >---+-----------------------------------------------+---> `--SET MODIFIABILITY TO--| REQUESTED ACTIONS |--´ >---+------------------------------------------+------->< `--| ALTER CONFLICT HANDLING PARAMETERS |--´ Die requested actions sind analog zu CREATE REPLICATION VIEW definiert, alle anderen Spezifizierungen sollen hier nicht betrachtet werden. Analog zu der Prozedur für die CREATE REPLICATION VIEW-Anweisung, muss auch hier neben der Authentifizierung und der RPS-HERMES-Abbildungsprüfung lediglich die SuperUser-Identität geprüft werden, falls eine bisherige Anforderung in eine exklusive Änderbarkeitsanforderung geändert wurde. Die RPS-Rolle braucht nicht geprüft zu werden, da der RPS selbst diese Prüfung vor Ausführung der Prozedur übernimmt. Die der Replikationssicht zu Grunde liegenden Replikattabellen könnten bei Bedarf (weitergehende Rechteprüfung alternativer Anwendungen) aus den Hilfstabellen RPS.REPLICATIONVIEWS und RPS.USED_TABLES der RPS-Hilfsdatenbank entnommen werden (siehe [Mül03]). 43 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur CREATE PROCEDURE ALTER_RV_AUTHORITY_CHECK (IN RPS_ID VARCHAR(128), IN RPS_Role VARCHAR(12), IN new_requested_action VARCHAR(22), IN auth_ID integer, IN auth_pass VARCHAR(128), OUT authorized CHAR(1), OUT msg varchar(300)) MODIFIES SQL DATA LANGUAGE SQL BEGIN -- pruefe Authentifizierung IF AUTH_CHECK(auth_ID, auth_pass) = 1 THEN IF MAP_CHECK(RPS_ID, auth_ID) = 1 THEN -- nur HERMES-SuperUser duerfen exklusiv replizieren IF substr(new_requested_action,1,9)='EXCLUSIVE' AND Is_SuperUser(auth_ID) = 0 THEN SET authorized = 'N'; SET msg = 'SuperUser authority required for exclusive replication'; return 1; ELSE -- erfolgreiche Autorisierung signalisieren SET authorized = 'Y'; SET msg = 'Authorization successful'; END IF; ELSE SET authorized = 'N'; SET msg = 'Invalid RPS-HERMES ID Mapping'; return 1; END IF; ELSE SET authorized = 'N'; return 1; END IF; SET msg = 'Authentication failed'; END 3.4.3. Autorisierung für SYNCHRONIZE Die Anweisung SYNCHRONIZE dient zum Veranlassen einer gemeinsamen Synchronisation einer Menge von Replikationssichten, die zu sogenannten Replikationssichtengruppen (Menge von Replikationssichten auf deren Daten die mobile Anwendung innerhalb der gleichen Transaktion zugreifen will) zusammengefasst und einer Replikatdatenbank zugeordnet sind. >>--SYNCHRONIZE--+--ALL-------------------------------------+---> | .-,---------. | | V | | `--REPLICATION VIEW GROUP-----rvg-name--+--' >--OF REPLICA DATABASE--replica-db-name-------------------------> .--NONCASCADING--. >---+----------------+---+--------------------+-----------------> `---CASCADING----´ `--ONLY IF REQUIRED--' >---+-------------------------------+-------------------------->< `--| alter-conflict-handling |--´ Durch die Spezifikation von ALL wird das gemeinsame Synchronisieren aller in der entsprechenden Replikatdatenbank enthaltenen Relpikationssichtengruppen veranlasst. Mittels der Option REPLICATION VIEW GROUP rvgname, ... kann spezifiziert werden, welche Replikationssichtengruppen gemeinsam synchronisiert werden sollen. Weiterführende Details können der Arbeit [Pfe04] entnommen werden. Die Synchronisation einer Replikattabelle kann als ein transaktionsorientierter Datenabgleich mit der ihr zu Grunde liegenden konsolidierten Tabelle verstanden werden [Mül03]. In einer ersten Phase werden die Änderungen an der Replikattabelle seit der letzten Synchronisation übertragen, einer Konfliktbehandlung unterzogen und wenn möglich in die entsprechende konsolidierte Tabelle eingebracht. Danach werden Änderungen an der konsolidierten Tabelle zum Client übertragen um die Inhalte abzugleichen. In der gewählten Implementierung der RPS-Architektur wird MobiLink als Synchronisationskomponente eingesetzt. MobiLink besteht aus zwei wesentliche Komponenten, dem MobiLink synchronization client und -server. Die Steuerung des Synchronisationsverlaufs erfolgt durch drei Synchronisationsskripte für jede Tabelle und die eigentliche Durchführung der Synchronisation durch den Zugriff des synchronization server auf diese Skripte [Mül03]. 44 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Eine wesentliche Forderung von kommerziellen Synchronisationsprodukten und somit auch von MobiLink ist die eindeutige Identifikation der Tupel, um die getätigten lokalen Änderungen zu erfassen. Dazu muss ein Primärschlüssel auf jede Tabelle existieren und darüber hinaus dürfen dessen Struktur und Werte vom Client nicht geändert werden. Bei der sich aus zwei Transaktionen zusammensetzenden Synchronisation überträgt der MobiLink synchronization client zunächst Informationen über all diejenigen Tupel zum MobiLink synchronization server, die auf der Client-Datenbank seit der letzten erfolgreichen Synchronisation geändert, eingefügt oder gelöscht wurden. Die entsprechenden Änderungen werden dann vom MobiLink synchronization server auf der zentralen konsolidierten Datenbank innerhalb einer Transaktion nachvollzogen. Anschließend generiert der MobiLink synchronization server eine Liste aller in der entsprechenden Client-Datenbank zu löschenden, zu ändernden bzw. einzufügenden Tupel. Diese Liste wird zum MobiLink synchronization client übertragen, welcher dann die entsprechenden Änderungen an den Daten der Client-Datenbank, innerhalb einer einzigen Transaktion, vornimmt. MobiLink verwendet eine ODBC-Verbindung pro parallel stattfindender Synchronisation, wobei sogenannte Synchronisationsnutzer die Clients (bzw. die Replikatdatenbanken) identifizieren [Mül03]. Daher ist es zweckmäßig für den Wert des Synchronisationsnutzers die RPS-ID des Clients zu verwenden. Inwiefern diese Zuordnung noch von Nutzen sein kann, wird im Abschnitt 3.7. zu den privaten Bereichen demonstriert. Die Datenänderungen auf dem mobilen Client werden in den lokalen Transaktions-Logdateien protokolliert. Mit deren Hilfe kann MobiLink feststellen, welche Tupel unangetastet, geändert, neu eingefügt oder gelöscht wurden. Auf dem RPS existieren zu jeder konsolidierten Tabelle zwei zusätzliche sogenannte Image-Tabellen. Diese sind leer, wenn kein mobiler Client eine Synchronisation initiiert oder laufen hat. Das Before Image6 enthält alle Tupel der entsprechenden Tabelle zum Zeitpunkt der Replikation bzw. nach Abschluss der vorangegangenen Synchronisation der Clients. Das After Image enthält die Tupel aller synchronisierenden Clients, sprich den Zustand nach dem unverbundenen lokalen Arbeiten unmittelbar vor der Reintegration. Die eigentliche konsolidierte Tabelle X, auf der auch Änderungen durch Quellserveranwendungen vorgenommen werden können, bezeichnet man als Current Image. Die Before und After Image Tabellen sind strukturgleich der zugehörigen konsolidierten Tabelle und enthalten zusätzlich eine Spalte mit der RPS-ID, die zum Primärschlüssel hinzugenommen werden muss, da die Images prinzipiell Tupel verschiedener synchronisierender Clients enthalten können. RPS Before Image von X Client Konsolidierte Tabelle X Replikattabelle X unverbundene Manipulation lokales TransaktionsLOG After Image von X Abbildung 13: Image-Tabellen für die Reintegration Abbildung 13 stellt dies vereinfacht dar. Eigentlich arbeitet der mobile Nutzer nicht direkt auf den Replikattabellen, sondern mittels der Client-Anwendung auf den Replikationssichten. Die Tupel des synchronisierenden 6 Die Before-Images werden auch den Logdateien der synchronisierten Clients entnommen 45 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Clients werden statt direkt in die konsolidierte Tabelle vorerst in die Images gespeichert und können einer Konfliktbehandlung und der Anwendungsautorisierung unterzogen werden. Sind alle einzubringenden Tupel des Client konfliktfrei und autorisiert manipuliert wurden, so werden sie aus den Image-Tabellen gelöscht und in die eigentliche konsolidierte Tabelle eingebracht. In jedem anderen Fall bricht die Synchronisation ab und informiert den Client über die ursächlichen Tupel und die Art des Fehlers. Alternativ gibt es eine Konfliktbehandlung, bei der nicht mittendrin abgebrochen wird und die dem Nutzer am Ende alle Fehler mitteilt. Um dieses beschriebene Vorgehen zu unterstützen, kann die Anwendung Synchronisations-Prozeduren implementieren, die auf die Daten der Before- bzw. After-Image-Tabellen zugreifen und alle vom Client-Nutzer angefassten Tupel der Zugriffskontrolle unterziehen. Dabei wird nach dem All-or-Nothing-Prinzip verfahren, d.h. wenn auch nur ein unautorisierbares Tupel existiert, wird das Fehlschlagen der Autorisierung und damit der gesamten Reintegrationstransaktion zurückgeliefert. Dies ist notwendig, da jede Anwendung über ein eigenes oder auch kein Rechtemanagement verfügen kann und prinzipiell die Möglichkeit besteht, dass jede Tabelle andere Autorisierungsmaßnahmen verlangt. Die Schnittstelle einer solchen, pro konsolidierter Tabelle, anzulegenden Prozedur sieht folgendermaßen aus: CREATE PROCEDURE SACC_<tabname> (IN RPS_ID VARCHAR(128), IN RPS_Role VARCHAR(12), IN auth_ID integer, IN auth_pass varchar(128), OUT authorized CHAR(1), OUT msg varchar(300)) SACC steht für Synchronize Access Control Check und <tabname> ist durch den Namen der konsolidierten Tabelle zu ersetzen, für die die Prozedur die Autorisierung vornehmen soll. Die Bezeichnung der Before (<tabname>_B) und After Image (<tabname>_A) Tabellen ist festgelegt und muss nicht als Parameter übergeben werden. Generell werden nur die veränderten Tupel des an die Prozedur zu übergebenden RPS-Nutzers für eine weitere Untersuchung ausgewählt. Bei einem Insert wird das After Image, bei einem Delete wird das Before Image und bei einem Update werden beide Images betrachtet. Unabhängig von dem Wert der Spalte WriteAccess darf der Besitzer des Tupels zu jeder Zeit schreibend darauf zugreifen (abgesehen von exklusiven Änderbarkeitsanforderungen anderer SuperUser). Hat die Spalte WriteAccess den Wert NULL, darf nur der Besitzer und ein SuperUser schreibend zugreifen. Eine Ausnahme bilden nur lesbare Tupel des HERMES-Nutzers ROOT (HID = 0), die lediglich von ROOT selbst modifiziert werden dürfen. Der Zugriffsmodus für die Gruppe PUB (group_id = 0) erlaubt jedem HERMES-Nutzer den Schreibzugriff. In jedem anderen Fall enthält die Spalte des Zugriffsmodus eine durch den Besitzer selbst definierte Gruppen-ID und es wird geprüft, ob das zugreifende Subjekt Mitglied der Gruppe ist. Sobald das Löschen eines Tupels erfolgreich autorisiert wurde, kann die in Abschnitt 3.3.3. beschriebene Prozedur zur Prüfung auf abhängige referenzierende Kinder-Tupel aufgerufen werden. Das automatisierte Erzeugen dieser schemaspezifischen Prozeduren für HERMES wird durch das Java-Tool "CSSP" (Create Synchronize Stored Procedure) unterstützt. Durch den Aufruf java CSSP <databasename> <schemaname> <tabname> wird das DDL-Skript "CSSP_<tabname>.sql" erzeugt und kann von dem Replikationsadministrator ausgeführt werden durch die Anweisung db2 -td@ +c -fCSSP_<tabname>.sql. Eine funktionierende Beispielprozedur findet sich in Abschnitt 4.2.2. CREATE PROCEDURE SACC_<tabname> (IN RPS_ID VARCHAR(128), IN RPS_Role VARCHAR(12), IN auth_ID integer, IN auth_pass varchar(128), OUT authorized CHAR(1), OUT msg varchar(300)) MODIFIES SQL DATA LANGUAGE SQL BEGIN -- Deklarationsteil -- Typ abhaengig von der Definition des primaryKey-Attributs DECLARE BF_Prim1 INTEGER; DECLARE AF_Prim1 INTEGER; DECLARE BF_PRIM2 ... ... DECLARE AF_PRIMn ... 46 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur DECLARE DECLARE DECLARE DECLARE BF_Owner integer; AF_Owner integer; BF_Access integer; AF_Access integer; DECLARE at_end SMALLINT DEFAULT 0; -- bestimme von den veraenderten Tupeln alle Primarykey-Attribute und beide -- Metaspalten, der full-outer join umfasst ebenfalls alle PrimaryKey-Attribute DECLARE c1 CURSOR FOR select BF.<prim_attr_1>, ..., BF.<prim_attr_n>, BF.owner, BF.writeaccess, AF.<prim_attr_1>, ..., AF.<prim_attr_n>, AF.owner, AF.writeaccess from (select * from <tabname>_A EXCEPT (select * from <tabname>_A INTERSECT select * from <tabname>_B)) as AF FULL OUTER JOIN (select * from <tabname>_B EXCEPT (select * from <tabname>_A INTERSECT select * from <tabname>_B)) as BF ON (BF.<prim_attr_1>, ..., BF.<prim_attr_n>) = (AF.<prim_attr_1>, ..., AF.<prim_attr_n>) WHERE (BF.rps_login is NULL AND AF.rps_login = RPS_ID) OR (AF.rps_login is NULL AND BF.rps_login = RPS_ID) OR (BF.rps_login = AF.rps_login AND BF.rps_login = RPS_ID); DECLARE CONTINUE HANDLER for NOT FOUND SET at_end = 1; -- pruefe Authentifizierung IF AUTH_CHECK(auth_ID, auth_pass) = 1 THEN BEGIN -- pruefe Zuordnung des Client zum HERMES-Nutzer IF MAP_CHECK(RPS_ID, auth_ID) = 0 THEN SET authorized = 'N'; SET msg = 'Invalid RPS-HERMES ID Mapping'; return 1; END IF; OPEN c1; floop: LOOP fetch c1 into BF_PRIM1,..., BF_PRIMn, BF_Owner, BF_Access, AF_PRIM1,..., AF_PRIMn, AF_Owner, AF_Access; IF at_end = 1 THEN LEAVE floop; END IF; -- zur Bestimmung der getaetigten Operation reicht das erste PrimaryKey-Attribut -- neu eingefügtes Tupel IF BF_PRIM1 is NULL THEN IF NOT( AF_Owner = auth_ID ) THEN SET authorized = 'N'; SET msg = 'Insertion failed (wrong owner)'; return 1; END IF; IF AF_ACCESS is not null AND AF_ACCESS <> 0 AND NOT( auth_ID = COALESCE((select group_owner from BuddyGroups where AF_ACCESS = group_ID),0)) THEN SET authorized = 'N'; SET msg = 'Insertion failed (unauthorized Group ID)'; return 1; END IF; END IF; -- geloeschtes Tupel IF AF_PRIM1 is NULL THEN IF NOT( BF_Owner = auth_ID OR (BF_Access IS NOT NULL AND Is_GroupMember(auth_ID, BF_Access) = 1) OR ( is_SuperUser(auth_ID) = 1 AND BF_Owner <> 0)) THEN SET authorized = 'N'; SET msg = 'Unauthorized Delete Access'; return 1; ELSE -- darf das Tupel geloescht werden, -- so pruefe referentielle Integritaeten 47 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur call RISP_<tabname>_B(auth_ID, BF_PRIM1,...BF_PRIMn, RPS_ID, authorized, msg); IF authorized = 'N' THEN return 1; END IF; END IF; END IF; -- update-Tupel IF AF_PRIM1 is NOT NULL AND BF_PRIM1 is NOT NULL THEN IF BF_Owner <> AF_Owner THEN SET authorized = 'N'; SET msg = 'Owner column must not be updated'; return 1; END IF; IF ( (AF_Access is NULL AND BF_Access IS NOT NULL) OR (BF_Access is NULL AND AF_Access is NOT NULL) OR AF_Access <> BF_Access) AND auth_ID <> BF_Owner THEN SET authorized = 'N'; SET msg = 'Accessmode only updatable by owner'; return 1; END IF; IF NOT( BF_Owner = auth_ID OR (BF_Access IS NOT NULL AND Is_GroupMember(auth_ID, BF_Access) = 1) OR ( is_SuperUser(auth_ID) = 1 AND BF_Owner <> 0)) THEN SET authorized = 'N'; SET msg = 'Update of row prohibited'; return 1; END IF; END IF; END LOOP floop; close c1; -- erfolgreiche Autorisierung signalisieren SET authorized = 'Y'; SET msg = 'Authorization successful'; END; ELSE SET authorized = 'N'; SET msg = 'Authentication failed'; return 1; END IF; END 3.5. Lokale Autorisierungsmechanismen auf dem Client HERMES stellt Trigger und Routinen zur Verfügung, so dass das tupelorientierte Rechtekonzept bereits lokal auf dem Client erzwungen wird. Diese Autorisierungskomponenten dienen der Fehlervermeidung korrekt arbeitender Client-Nutzer, d.h. solchen die lediglich auf die durch die Replikationssicht definierten Daten über die ClientAnwendung zugreifen. Auf dem Client haben die Replikattabellen mit integriertem Nutzermanagement die folgende, ihren konsolidierten Pendants gleichende Form: CREATE TABLE <tabname> ( ... Owner integer not null WITH DEFAULT 0 REFERENCES User_Info(HID) ON DELETE SET DEFAULT, WriteAccess integer REFERENCES BuddyGroups(group_ID) ON DELETE SET NULL ) Zudem existieren für jede Replikatdatenbank die Stammdatentabelle User_Info und die beiden Gruppentabellen BuddyGroups sowie GroupMembers mit der gleichen Struktur wie die zugeordneten konsolidierten Tabellen. Dabei enthalten sie nicht die Informationen aller registrierten HERMES -Nutzer bzw. aller definierten (Buddy-) Gruppen, wie das auf dem RPS der Fall ist, sondern lediglich den mit Hilfe des Fragmentkonzepts automatisch bestimmten Ausschnitt der von den lokalen Tabellen (über die OWNER- und WriteAccess-Spalte) referenzierten Nutzer- bzw. Gruppen-Kennungen. Der Nutzer erhält somit automatisch zu seinen angeforderten Tupeln die Informationen derer Besitzer und die Mitglieder der spezifizierten Gruppen zum reinen lesenden Zugriff. Sofern sich die Informationen der Nutzer auf der Quelle, bzw. dem RPS ändern, werden sie bei der nächsten Synchronisation automatisch an den Client repliziert. Aus Gründen des Datenschutzes ist es möglich, durch die ClientAnwendung alle Mitglieder, bis auf den lokalen Nutzer selbst, der vorhandenen Gruppen zu löschen, so dass 48 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur diese am Ende maximal einen Eintrag (die HID des Client-Nutzers) vorweisen oder leer sind. Die entsprechende dafür benötigte Anweisung auf dem Client könnte folgendermaßen lauten (das ? steht für den einzusetzende HID des lokalen HERMES-Nutzer): DELETE FROM GroupMembers WHERE group_member <> ? Dies ist erforderlich, weil in den im folgenden beschriebenen Autoritätsprüfungskomponenten bei schreibenden Zugriff lediglich geprüft wird, ob der lokale Nutzer in der durch das Tupel spezifizierten Gruppe enthalten ist. Des weiteren kann es nützlich sein, dass die lokale User_Info-Tabelle nicht nur die Nutzer der replizierten Tupel enthält, sondern auch die Informationen des Client-Inhabers. Zudem enthalten alle lokalen BuddyGroup-Tabellen immer die symbolische Gruppe PUB (mit group_ID = 0) zur Identifikation der Gesamtheit aller HERMES-Nutzer. Diese beiden erforderlichen Tupel werden bei der Erstanmeldung automatisch durch die Client-Anwendung eingetragen. Wenn der Nutzer (in dem Fall, dass er es nicht von Anfang an ist) zum SuperUser gewählt wird oder mittels der Server-Anwendung seine persönlichen Daten ändert und die Änderung in der Tabelle User_Info auf dem Quellserver (bzw. auf der auf dem RPS liegenden Kopie) aktualisiert wurde, werden die geänderten Informationen bei der nächsten Synchronisation automatisch an den Client repliziert. Wie bereits in Abschnitt 3.3.2. erwähnt, kann die Erzeugung oder das Löschen eigener Gruppen nur über die Client-Anwendung und im verbundenen Zustand mit dem RPS (bzw. der Quelle) erfolgen. Die Gruppendefinitionen werden dann in die entsprechenden Tabellen der Quelle bzw. des RPS übernommen und dem Client geschickt. Um die Fremdschlüsselintegrität nicht zu verletzen, müssen zuvor die Stammdateninformationen neuer auf dem Client noch nicht existierender HERMES-Nutzer in die lokale Tabelle User_Info eingetragen werden. Für die Implementierung der lokalen unverbundenen Autorisierung werden auf dem Client (pro Replikatdatenbank) zwei zusätzliche Tabellen benötigt, die bei der Synchronisation nicht an den RPS übertragen werden. Eine für die Anwendungskennung (HID) des Client-Nutzers und die andere Tabelle für den RPS-Login sowie zugehöriges Passwort. Beide Tabellen werden bei der Erstanmeldung eines neuen Nutzers (und damit auch der ersten Befehlsanforderung des Client an den RPS) durch die Anwendung in jeder entsprechenden Replikatdatenbank einmalig angelegt (mit den übersandten Informationen der Server-Anwendung gefüllt). CREATE TABLE CLIENT_Appl_User ( HID integer not null REFERENCES User_Info (HID) ) Aus Sicherheitsgründen wird das HERMES-Passwort nicht lokal gespeichert. Lediglich der HERMES-Nutzer selbst muss sich jenes merken und (durch die Client-Anwendung) in verschlüsselter Form bei Anfragen an die konsolidierten Daten angeben. Seine eigenen Informationen kann der Client-Nutzer mithilfe der in dieser Hilfstabelle gespeicherten HID nun jederzeit aus der Stammdatentabelle entnehmen. CREATE TABLE CLIENT_RPS_User ( login varchar(128) not null, pass varchar(128) not null ) Für Applikationen mit alternativen Sicherheitspolitiken und Zugriffskontrollmechanismen kann die Struktur der Tabellen durchaus anders aussehen. Es ist auch denkbar, diese Informationen in einer eigens vorgesehenen Konfigurationsdatei der Client-Anwendung abzulegen. Das Auslesen der Werte zur Bereitstellung an die Trigger erfordert allerdings mehr Aufwand (dynamisches SQL) und wird hier nicht betrachtet. Die Tabellen enthalten jeweils nur eine Zeile, die einerseits den aktiven HERMES-Nutzer und andererseits sein mobiles Arbeitsgerät identifizieren. Da unkontrollierte Änderungen an den obigen Tabellen unvermeidbar sind, werden die (HERMES, RPS) Identität und die damit verbundenen Rechte, wie bereits beschrieben, bei jeder Befehlsanfrage des Client an den RPS authentifiziert und autorisiert. Die nachfolgende Funktion liefert die HID des den Client besitzenden Nutzers und kann von anderen Funktionen oder Triggern aufgerufen werden: 49 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur CREATE FUNCTION GET_AUTH_ID() RETURNS integer RETURN select HID from CLIENT_Appl_User Auch auf dem Client existieren, ähnlich wie auf dem RPS und der Quelle, die Hilfsfunktionen, mit denen geprüft wird, ob der Client-Nutzer Mitglied einer Gruppe ist, bzw. ob es sich um einen SuperUser handelt: CREATE FUNCTION Is_GroupMember (grp_ID integer) RETURNS SMALLINT BEGIN ATOMIC IF grp_ID = 0 OR GET_AUTH_ID() IN (select group_member from GroupMembers where group_ID = grp_ID) THEN RETURN 1; ELSE RETURN 0; END IF; END CREATE FUNCTION Is_SuperUser () RETURNS SMALLINT BEGIN ATOMIC IF 'Y' = (select is_SuperUser from User_Info where HID = GET_AUTH_ID()) THEN RETURN 1; ELSE RETURN 0; END IF; END Drei Before-Trigger auf jeder lokalen änderbaren Replikattabelle (d.h. die zugeordnete konsolidierte Tabelle darf nicht als nur lesbar definiert worden sein) dienen der Einhaltung der Rechte des Client-Nutzers. Die durchgeführten Prüfungen sind denen der Synchronisation nachempfunden und weitestgehend selbsterklärend. create trigger <tabname>_INS BEFORE INSERT on <tabname> referencing new as n for each row mode db2sql BEGIN ATOMIC IF (n.Owner <> Get_Auth_ID()) THEN SIGNAL SQLSTATE 'Z0001' ('Insertion failed (wrong owner)'); END IF; IF n.WriteAccess > 0 AND n.WriteAccess IS NOT NULL AND NOT ( Get_Auth_ID()= COALESCE((select group_owner from BuddyGroups where group_id=n.WriteAccess), 0) THEN SIGNAL SQLSTATE 'Z0002' ('Insertion failed (unauthorized Group ID)'); END IF; END create trigger <tabname>_DEL BEFORE DELETE on <tabname> referencing old as o for each row mode db2sql BEGIN ATOMIC IF NOT (o.Owner = CLIENT.Get_Auth_ID() OR (o.WriteAccess IS NOT NULL AND CLIENT.Is_GroupMember(o.WriteAccess) = 1) OR (CLIENT.is_SuperUser() = 1 AND o.Owner <> 0)) THEN SIGNAL SQLSTATE 'Z0003' ('Unauthorized Delete Access'); END IF; END create trigger <tabname>_UPD BEFORE UPDATE on <tabname> referencing new as n old as o for each row mode db2sql BEGIN ATOMIC IF o.Owner <> n.Owner THEN SIGNAL SQLSTATE 'Z0004' ('Owner column must not be updated'); END IF; 50 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur IF ( (n.WriteAccess IS NULL AND o.WriteAccess IS NOT NULL) OR (o.WriteAccess is NULL AND n.WriteAccess IS NOT NULL) OR n.WriteAccess <> o.WriteAccess) AND o.Owner <> GET_AUTH_ID() THEN SIGNAL SQLSTATE 'Z0005' ('Accessmode only updatable by owner'); END IF; IF NOT (o.Owner = CLIENT.Get_Auth_ID() OR (o.WriteAccess IS NOT NULL AND CLIENT.Is_GroupMember(o.WriteAccess) = 1) OR (CLIENT.is_SuperUser() = 1 AND o.Owner <> 0)) THEN SIGNAL SQLSTATE 'Z0006' ('Update of row prohibited'); END IF; END Wie bereits im Abschnitt 3.3.3. zur Problematik mit Fremdschlüsselbeziehungen erläutert, ist auf dem Client keine explizite Prüfung der Rechte von Kinder-Tupeln bei Löschung eines Vater-Tupels nötig. Die Trigger werden automatisch vom DBMS vor der Änderung eines jeden Tupels aufgerufen und prüfen die Rechte der beabsichtigten Aktion. Sobald in einer kaskadierten Folgeänderungsoperation ein Trigger einen Fehler liefert, führt dies zum Rollback der ganzen Transaktion, so dass das Löschen des Vater-Tupels scheitert. 3.6. Private Bereiche in herkömmlichen Anwendungen HERMES hat nicht nur die Speicherung, Bereitstellung und Verwaltung durch alle Nutzer ortsabhängig änderbarer Daten zur Aufgabe. Zusätzlich soll die Anwendung über sogenannte private Bereiche verfügen, in denen ein Anwender vollkommen isoliert und ohne Kenntnis der Präsenz von Daten anderer Nutzer persönliche und vertrauliche Informationen (Reiseberichte, Notizen, Aufzeichnungen, Tagebucheinträge) ablegen kann, auf die nur er (lesend und/oder schreibend) zugreifen kann. Dieses Konzept ist weder neu, noch stellt es etwas mobilspezifisches dar. Im folgenden wird daher zunächst die geeignete Implementierung von privaten Bereichen in Anwendungen betrachtet, deren Nutzerzahl entweder von vornherein bekannt oder nach oben hin abschätzbar ist und die aufgrund dessen für jeden Nutzer einen eigenen DBMS-Nutzeraccount verwenden. 3.6.1. Parametrisierte Sichten Selbstredend ist es verschwenderisch und aufwendig einem jeden Nutzer separate Tabellen für seine privaten Daten zuzuweisen und die Rechteverwaltung auf diese Tabellen einem Administrator zu überlassen. Das Prinzip wird indes realisiert mittels sogenannter parametrisierter, dynamischer Sichten auf einen gemeinsamen globalen Schemaausschnitt. Der von solch einer pro Tabelle anzulegenden Sicht zurückgelieferte Ausschnitt ist erst zur Laufzeit, abhängig von der Identität des zugreifenden Nutzers, bekannt. Hierzu verwendet man die in allen gängigen DBMS vorhandene und von der SQL-Norm spezifizierte Variable USER, wie bereits im Abschnitt 2.5.5. beschrieben, die den Namen des aktuellen Datenbanknutzers liefert. Dies macht eine zusätzliche den Besitzer eines Tupels identifizierende Spalte für jede private Tabelle erforderlich, die in der Sicht ausgeblendet und somit dem Nutzer nicht zugänglich gemacht werden soll. Zudem werden Datenbanknutzern sämtliche Rechte auf den Basistabellen entzogen und entsprechende Rechte auf die Sichten erteilt, so dass es den Nutzern nur noch möglich ist über die Sicht ihre Daten zu sehen (Abbildung 14) T3 T1 T2 S3 S1 S2 DB-Nutzer DB-Nutzer DB-Nutzer Abbildung 14: Konzept der Privatisierung 51 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Durch die Verwendung von Sichten sind keine zusätzlichen Trigger oder Routinen auf den Basistabellen erforderlich, die prüfen, ob sich der Nutzer in seinem privaten Bereich bewegt. Angenommen es existiere eine Tabelle Auftraege mit den Aufträgen sämtlicher Mitarbeiter eines Betriebs: CREATE TABLE Auftraege ( ANr integer not null, ... Owner varchar(128) not null DEFAULT USER, primary key (ANr, Owner) ) Auf die möglichen Spalten zur Charakterisierung der Aufträge (angedeutet durch ...) wird wegen mangelnder Relevanz bezüglich der angestrebten Betrachtungen nicht eingegangen. Die zusätzliche Spalte Owner identifiziert den Erzeuger bzw. Besitzer eines Datensatzes. Wichtig ist weiterhin die notwendige Wahl des Primärschlüssels einer jeden privaten Tabelle, welcher zusätzlich noch die Owner-Spalte beinhalten muss, um die Daten der einzelnen Nutzer unabhängig von anderen zu machen. Somit können zwei verschiedene Nutzer Aufträge mit der gleichen Auftragsnummer (ANr) in ihre privaten Bereiche einfügen, ohne sich der globalen Zusammenhänge bewusst sein zu müssen. Da es sich um ein transparentes Verfahren der Datenkapselung handelt, dürfen die Nutzer privater Bereiche weder wissen, dass es Daten anderer Nutzer gibt, noch dürfen jene die Arbeit des eigenen Nutzers beeinflussen (beispielsweise durch konfligierende Operationen). Deshalb ist es wichtig, dass die zu definierende Sicht alle Spalten der Tabelle, bis auf die Besitzerspalte selektiert. Der Wert der Besitzerspalte wird lediglich in der WHERE-Klausel der Sichtdefinition verwendet, um ausschließlich die Tupel des aktuellen7 Nutzers zu selektieren: CREATE VIEW EigeneAuftraege AS SELECT ANr,... from Auftraege WHERE Owner = USER; Der Basistabelle werden sämtliche Rechte entzogen. Daraufhin werden der Sicht die entsprechenden Rechte gewährt: revoke all privileges on Auftraege from PUBLIC; grant select, insert, update on EigeneAuftraege to PUBLIC; Ein Mitarbeiter der Firma, welcher lesende Anfragen an die Sicht stellt, sieht nun nur seine eigens eingefügten Daten. Auftraege select * from EigeneAuftraege ANr 1 1 3 4 ... 3 ... Gustav select * from EigeneAuftraege ... ... ... ... ... ... ... ... ... ... Owner Hugo Gustav Bernd Hugo ... ... Gustav Hugo Abbildung 15: Beispiel der Tupelauswahl in privaten Tabellen Die Nutzer können ihre eigenen Daten (die sie selbst eingefügt haben) nach Belieben manipulieren, löschen oder selektieren. Zu diesem Zweck sehen sie alle Spalten, außer der Owner-Spalte und modifizieren die Daten nach dem Glauben, die ANr sei der künstliche Primärschlüssel. Bei der Einfügung neuer Daten wird ihr Datenbanknutzername automatisch durch den DEFAULT-Wert in der Basistabellendefinition hinzugefügt. In der Abbildung 15 wird deutlich, dass sowohl Nutzer "Bernd" als auch "Gustav" jeweils einen Datensatz mit gleicher ANr in die 7 aktuell meint hier den Nutzer, der zur Laufzeit auf die Sicht zugreift 52 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Basistabelle eingefügt haben, sich dessen aber nicht bewusst waren, da sie die Tupel anderer Nutzer nicht sehen oder manipulieren können. Es gilt jedoch, sich einiger Einschränkungen im Zusammenhang mit privaten Tabellen und tupelübergreifenden (oder sogar tabellenübergreifenden) Integritätssicherungen im Klaren zu sein. UNIQUE-Constraints (UNIQUE KEY, UNIQUE INDEX) müssen analog dem Primärschlüssel die Owner-Spalte beinhalten, so dass diese nicht über die Grenzen des privaten Bereiches eines Nutzers hinaus gelten. Wird die Eindeutigkeit eines Attributes (oder einer Kombination) über alle Tupel der gesamten Tabelle, statt über den einen privaten Teilbereich verlangt, so kann es bei Modifikationen dieser Attributes durch einen Nutzer zur Fehlermeldung (Attributwert existiert schon durch einen anderen Nutzer) kommen, deren Ursache und Auflösung der Nutzer anhand seiner Sicht nicht bestimmen kann. In ähnlicher Art und Weise muss bei (tupelübergreifenden) Check-Bedingungen und Triggern darauf geachtet werden, dass diese nicht nutzerübergreifend sind. 3.6.2. Fremdschlüsselbeziehungen von und zu privaten Daten Bei der Definition von Fremdschlüsselbeziehungen zwischen privaten Tabellen sind nur Referenzen auf Schlüsselkandidaten (UNIQUE, PRIMARY KEY) erlaubt, sprich auf Attributkombinationen die notwendigerweise das Attribut Owner enthalten. Ein Nutzer darf und kann somit nur Attributwerte seiner eigenen Tupel in anderen privaten Tabellen referenzieren. Fremdschlüssel von "normalen" Tabellen auf private sind nicht erlaubt, da dies der Definition und Intention privater Bereiche entgegenstehen würde. Auf die normalen Tabellen haben alle Nutzer Zugriff und sehen dieselbe Datenmenge, während die Menge der Datensätze in privaten Tabellen für jeden Nutzer unterschiedlich ist. Da lediglich Fremdschlüssel auf UNIQUE-Attributkombinationen erlaubt sind und diese bei privaten Tabellen in jedem Fall die Owner-Spalte enthalten, so muss auch ein Owner-Attribut in der "normalen" (Kind-)Tabelle existieren. Dies ist aber nicht zwingend notwendig und oft auch unerwünscht, wenn es sich um globale Tabellen handelt. Für Fremdschlüsseldefinitionen von privaten Tabellen auf Attribute normaler Tabellen sind die (in den privaten Kind-Tabellen zu definierenden) referentiellen Integritätsregeln für die UPDATE- und DELETE-Operationen genauer zu betrachten. Datensätze aus den normalen Tabellen können, sofern keine zusätzlichen Zugriffskontrollmechanismen implementiert wurden, uneingeschränkt von allen Datenbanknutzern gelöscht oder aktualisiert werden. Die Regel ON DELETE/UPDATE CASCADE kann in den privaten Kinder-Tabellen nicht definiert werden, da der ein Vater-Tupel löschende/aktualisierende Nutzer unter Umständen gar nicht von der Existenz eines abhängigen Kind-Tupels weiß und somit auch keine Rechte hat, dieses zu löschen bzw. aktualisieren. Die Regeln ON DELETE/UPDATE NO RESRICT/ACTION helfen auch nicht weiter. In diesem Fall kann ein Nutzer unter Umständen ein Tupel nicht mehr löschen bzw. aktualisieren, wenn noch für ihn nicht sichtbare, referenzierende Kinder-Tupel existieren. Die Regeln ON DELETE/UPDATE SET NULL müssen daher für alle solche Fremdschlüsselbeziehungen gefordert werden, so dass nach dem Aktualisieren oder Löschen eines Vater-Tupels einfach der entsprechende Verweis in der Kind-Tabelle "entfernt" wird (zeigt ins Leere). Sind NULLs für die Attribute des Fremdschlüssels nicht erlaubt, so wird gefordert, dass die Vater-Tabelle als READ ONLY (nur lesbar), bzw. INSERT ONLY 8 (es dürfen lediglich Tupel hinzugefügt und bestehende selektiert werden) definiert ist und somit keine Modifikationen (UPDATE, DELETE) an möglicherweise referenzierten Attributen vorgenommen werden können. Abbildung 16 stellt den Zusammenhang in Form eines gerichteten Graphen dar. Die Knoten repräsentieren Tabellen, die gerichteten Kanten die Fremdschlüsselbeziehungen zwischen ihnen. Eine Kante (B,A) symbolisiert beispielsweise, dass in der (Kind-)Tabelle B mindestens ein auf die (Vater-)Tabelle A verweisender Fremdschlüssel definiert wurde. Die Kanten innerhalb der Menge der privaten Tabellen (privater Schema-Bereich) sind ungerichtet dargestellt, da deren Orientierung für die Betrachtungen keine Rolle spielt. 8 Die Forderung nach INSERT ONLY kann erreicht werden, indem man Nutzern der Tabelle nur die Rechte SELECT und INSERT mittels eines GRANT gewährt 53 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur privater SchemaBereich C B A I L on delete set NULL on update set NULL Abbildung 16: Fremdschlüsselbeziehungen von und zu privaten Tabellen Durch das Fehlen der ON UPDATE SET NULL-Regel in dem Produkt IBM DB2 UDB, muss verlangt werden, dass Tabellen der Form L (Vater-Tabellen für private Kind-Tabellen) für die Datenbanknutzer grundsätzlich READ ONLY bzw. INSERT ONLY sind. Dadurch entstehen keinerlei Integritätsverletzungen zwischen Kind und Vater und die Kontrolle der Werte der Fremdschlüsselattribute in den Kind-Tupeln liegt bei dem Besitzer selbst. 3.7. Private Bereiche in HERMES Die in Abschnitt 3.6. beschriebenen allgemeingültigen Konzepte sollen nun für das mobile Szenario angewendet werden. Im Zusammenhang mit der nutzerdefinierten Replikation sind einige Einschränkungen hinzunehmen. Auf dem RPS wird lediglich ein DBMS-Nutzeraccount für alle mobilen Nutzer verwendet. In Folge dessen regelt die HERMES-Anwendung die Nutzerverwaltung und -authentifizierung mit eigenen Hilfstabellen. Damit kann die Variable USER nicht weiter verwendet werden. Durch die Replikation ergeben sich jedoch andere Möglichkeiten zur Umsetzung privater Bereiche. Grundsätzlich gilt, dass für "privatisierte" Tabellen das tupelorientierte Rechtekonzept nicht im vollen Umfang benötigt wird. So kann die Hilfsspalte mit dem Zugriffsmodus entfallen, da nur die Besitzer der einzelnen Tupel Lese- und Schreibzugriff haben. Die Spalte Owner zur Identifikation des Besitzers ist nach wie vor unerlässlicher Bestandteil solcher Tabellen und aller auf ihnen definierten Schlüsselkandidaten (analog zu Abschnitt 3.6.), wird jedoch durch einen Integer-Wert (der HID) repräsentiert. Weiterhin macht es für solche Tabellen keinen Sinn exklusive Änderbarkeitszusicherungen anzufordern oder Konfliktprüfungen durchzuführen, da konfligierende Operationen nur bei gemeinsam genutzten und manipulierbaren Daten auftreten können. 3.7.1. Ermitteln der synchronisierenden Nutzer Jede Verbindung zu einer Datenbank wird in DB2 (und einigen anderen relationalen Datenbank-Produkten) durch die sogenannte eindeutige Application-ID identifiziert, die mit der eigens zu erzeugenden, externen Funktion application_id() ermittelt werden kann. Der Code zur Erstellung der Funktion kann in [Pfe04] nachgelesen werden. Die aktuell synchronisierenden Nutzer (MobiLink Synchronization User) werden zusammen mit der Application-ID ihrer Verbindung in einer Tabelle der RPS Hilfsdatenbank gespeichert. CREATE TABLE connected_ml_users ( app_id VARCHAR(128) NOT NULL, ml_s_user VARCHAR(128) NOT NULL, PRIMARY KEY (app_id) ) Wie bereits im Abschnitt 3.4.3. erwähnt, setzt man den Namen des MobiLink-Synchronisationsnutzers auf die RPS-ID des synchronisierenden Clients. 54 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Mittels der Funktion cur_sync_RPSID() wird der aktuelle RPS-Nutzer zurückgeliefert, sofern der Client über MobiLink eine Verbindung mit der entsprechenden konsolidierten Datenbank, zwecks Synchronisation aufgebaut hat und damit in der Tabelle connected_ml_users steht. CREATE FUNCTION cur_sync_RPSID() RETURNS VARCHAR(128) BEGIN ATOMIC RETURN SELECT ml_s_user FROM connected_ml_users WHERE app_id = application_id(); END Durch die Abbildung von HERMES-ID auf RPS-ID kann leicht der zum synchronisierenden Client gehörende HERMES-Nutzer ermittelt werden: CREATE FUNCTION cur_sync_HID() RETURNS INTEGER BEGIN ATOMIC RETURN SELECT HID FROM RPS_HID_Mapping WHERE RPS_login = cur_sync_RPSID(); END Alle Funktionen und die Tabelle connected_ml_users müssen in derselben RPS-Datenbank liegen. 3.7.2. Integration in die RPS-Architektur Seitens HERMES sind Tabellen entweder "privatisiert" oder für alle Subjekte im Rahmen der implementierten Rechtepolitik zu nutzen. Die privaten Bereiche stellen somit ein Feature der HERMES Anwendung dar. Der RPS soll die Benutzung auf mobiler Seite nur ermöglichen und unterstützen. Es soll hier lediglich die Implementierung in Verbindung mit der nutzerdefinierten Replikation gezeigt werden, da bei HERMES keine Nutzer auf der Quelle arbeiten. Dabei hat der RPS die Aufgabe den gültigen Bestand der privaten Daten aller Nutzer persistent zu speichern und zu verwalten. Auf dem Client befinden sich hingegen ausschließlich die Daten des einen, das Gerät nutzenden HERMES-Anwenders. Im Falle des Verlustes oder einer Beschädigung des Client-Gerätes sind die persönlichen Daten nicht gänzlich verloren und können gegebenenfalls (solange sich der Nutzer weiterhin bei HERMES authentifizieren kann) rückübertragen werden. Eine konsolidierte private Tabelle ist ein Replikat der Basistabelle des Quellserver mit allen Spalten. Auf der Client-Seite sind tatsächlich nur die Tupel des einen Nutzers vorhanden, wodurch die dortige Existenz der Owner-Spalte unnütz wird. Die hat zur Folge, dass sich neben der Spaltenanzahl auch die Primär- und Fremdschlüssel (auf private Tabellen) auf dem Client und dem RPS um diese, den Tupel-Besitzer identifizierende, Spalte unterscheiden. Bei der Replikation ist also sicherzustellen, dass nur die Daten des aktuell synchronisierenden Clients aus den privaten Tabellen übertragen werden. Entsprechend müssen die in die konsolidierten Tabellen zu reintegrierenden Datensätze um die zusätzliche Spalte Owner mit der ID des aktuell synchronisierenden HERMES-Nutzers erweitert werden. Mit den herkömmlichen Methoden der nutzerdefinierten Replikation und den existierenden Befehlen auf dem RPS ist ein solches automatisches Vorgehen nicht möglich. Die Definition des Befehls CREATE CONSOLIDATED TABLE wird daher um eine zusätzliche parametrisierte Option SUBSTITUTE COLUMN erweitert: >>--CREATE CONSOLIDATED TABLE--cons-table-name------------------> .-,--------------------. V | >---AS SELECT--+-----source-column-name--+--+-------------------> `-------------*--------------´ >---FROM--+------------------------+-source-table-name----------> `-source-table-schema--.-´ >---+------------------------------+----------------------------> `--WHERE--simple-where-clause--' 55 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur >---FOR CONSOLIDATED DATABASE--cons-db-name---------------------> >---+------------------------------------------------+----------> `--TABLESPACES--| part-table-space-assignment |--' >---+----------------------------------------------------+------> +--| conflict handling methods |---------------------+ +--SUBSTITUTE COLUMN--col_name--WITH |subst_value|---+ +--READ ONLY-----------------------------------------+ `--NO CLIENT REPLICATION-----------------------------' >---+--------------------------+------------------------------->< `--EXPIRY IN--expiry-days--´ subst_value |------+--constant--+------| `--function--´ Die Syntax und Semantik aller anderen Parameter und Definitionen kann in [Pfe04] nachgelesen werden. Angenommen es existiere auf der Quelle eine private Tabelle namens "source-table-name" mit den n+1 Attributen (attr_1, ..., attr_n, col_name). Durch SUBSTITUTE COLUMN wird der RPS angewiesen, zusätzlich eine auf die konsolidierte Tabelle aufbauende Sicht mit dem Namen cons-table-name_V anzulegen, die alle Spalten ausgenommen der mit Namen col_name projeziert: CREATE VIEW cons-table-name_V AS SELECT attr_1, ..., attr_n FROM cons-table-name WHERE col_name = subst_value Durch die WHERE-Klausel selektiert die Sicht für die Replikation nur diejenigen Tupel aus der konsolidierten privaten Tabelle, deren Spalte col_name den Wert subst_value hat. Neben der Sicht wird auch ein INSTEADOF-INSERT-Trigger auf selbige erzeugt, der beim Einfügen neuer Daten in die Sicht durch die Reintegration, jedes Tupel automatisch um die Spalte col_name mit dem Wert von subst_value erweitert in die Tabelle constable-name einfügt: CREATE TRIGGER cons-table-name_T INSTEAD OF INSERT ON cons-table-name_V REFERENCING NEW as new FOR EACH ROW MODE DB2SQL BEGIN ATOMIC insert into cons-table-name values (new.attr_1, ..., new.attr_n, subst_value); END Änderungen an den privaten Daten in Form von Löschungen oder Aktualisierungen durch den Besitzer werden "direkt" an der Sicht und ohne zusätzliche Trigger vorgenommen. Es folgt eine Demonstration der Umsetzung. Auf der Quelle existiere folgende Tabelle der privaten Reiseberichte [Bau03]: CREATE TABLE RBNr Titel Datum Freitext OWNER_ID priv_Reisebericht ( INTEGER NOT NULL, VARCHAR(30) NOT NULL, DATE, VARCHAR(1000) NOT NULL, integer not null references User_Info ON DELETE CASCADE, PRIMARY KEY (RBNr, OWNER_ID) ) Das Anlegen der entsprechenden gleichnamigen konsolidierten Tabelle auf dem RPS mit der gleichen Anzahl an Spalten erfolgt durch die Anweisung: CREATE CONSOLIDATED TABLE priv_Reisebericht AS SELECT * FROM priv_Reisebericht FOR CONSOLIDATED DATABASE HERMES SUBSTITUTE COLUMN OWNER_ID WITH cur_sync_HID() 56 Kapitel 3. Authentifizierung und Autorisierung in der 3-Schichten-Architektur Die mit diesem Befehl implizit angelegte Sicht und der Trigger haben die Form: CREATE VIEW priv_Reisebericht _V AS SELECT RBNr, Titel, Datum, Freitext FROM priv_Reisebericht WHERE OWNER_ID = cur_sync_HID() CREATE TRIGGER priv_Reisebericht_T INSTEAD OF INSERT ON priv_Reisebericht_V REFERENCING NEW as new FOR EACH ROW MODE DB2SQL BEGIN ATOMIC insert into priv_Reisebericht values (new.RBNr, new.Titel, new.Datum, new.Freitext, cur_sync_HID()); END Auf dem Client ist die gewohnte Anweisung zum Erzeugen der Replikationssicht anzuwenden: CREATE REPLICATION VIEW Mein_privater_Reisebericht AS SELECT * FROM priv_Reisebericht_V FOR OFFLINE OPTIMISTIC ALL Bei der Synchronisation werden die Daten aus der Sicht an den Client (an die der Replikationssicht zu Grunde gelegenen Replikattabelle) geschickt und bei Reintegration wieder dort eingefügt. Durch den INSTEAD-OFTrigger wird das in die Sicht einzufügende Tupel um die HERMES-ID des Nutzers des synchronisierenden Clients erweitert und in die eigentliche konsolidierte Tabelle eingefügt. 57 4. Testszenarien In diesem Kapitel wird die Nutzung der Trigger und Routinen aus Sicht des Anwenders beschrieben. Die angeführten Beispiele wurden für diesen Zweck konstruiert und bilden keine realen Sachverhalte ab. Zunächst soll auf die Autoritätsprüfung von INSERT-, DELETE- und UPDATE-Operationen auf dem Client (Abschnitt 4.1.) und anschließend auf die der Synchronisation (Abschnitt 4.2.) eingegangen werden. Dabei werden die in Abschnitt 3.3.3. und 3.4.3. beschriebenen Tools CRISP und CSSP kurz anhand von Beispielaufrufen vorgestellt. 4.1. Autorisierung auf dem Client Der Nutzer des Clients mit der HID = 1 und dem nick wieda möge Daten von folgenden HERMES-Nutzern auf seinen Client repliziert haben: User_Info: HID ----------0 1 2 3 4 NICK -------ROOT wieda hugo ernst whity NAME ----------------Klaus Küspert David Wiese Hugo Hugenott Ernst H. Whity Weismann BIRTHDAY ---------09/13/1981 11/11/1911 05/03/1976 01/01/1990 MAIL [email protected] [email protected] [email protected] [email protected] [email protected] HOMEPAGE ----------------------minet.uni-jena.de/dbis/ www.ewto.de www.hugos-welt.com - MEMBER_SINCE -----------01/01/2000 03/31/2004 03/31/2004 03/31/2004 03/31/2004 IS_SUPERUSER -----------Y Y N N N Zur Identifikation des Client-Nutzers und der RPS-Daten des mobilen Geräts dienen nachfolgende Tabellen: CLIENT_Appl_User: CLIENT_RPS_User: HID ------1 login pass ------------- ------------------User1 9302oqp92rgsf<<sf Die Tabellen der Gruppen-Informationen sind wie folgt gefüllt: GroupMembers: BuddyGroups: GROUP_ID ------------0 1 7 GROUP_NAME ------------PUB Friends Buddies GROUP_OWNER ------------0 1 3 GROUP_ID GROUP_MEMBER ------------- --------------1 2 1 4 7 1 7 4 Zusammengefasst: GROUP_ID ----------0 1 1 7 7 GROUP_NAME ---------PUB Friends Friends Buddies Buddies OWNER ---------ROOT wieda wieda ernst ernst MEMBER --------hugo whity wieda whity Die Betrachtungen beziehen sich auf die durch Fremdschlüsselbeziehungen abhängigen Tabellen Ortschaft, Ge- baeude, Oeffnungszeiten: CREATE TABLE Ortschaft ( ONr INTEGER NOT NULL PRIMARY KEY, PLZ CHAR(5) NOT NULL, Name VARCHAR(50) NOT NULL, Owner integer not null WITH DEFAULT 0 REFERENCES User_Info(HID) ON DELETE SET DEFAULT, WriteAccess integer REFERENCES BuddyGroups(group_ID) ON DELETE SET NULL ) 58 Kapitel 4. Testszenarien CREATE TABLE Gebaeude ( GebNr INTEGER NOT NULL PRIMARY KEY, ONr INTEGER NOT NULL REFERENCES Ortschaft ON DELETE CASCADE, Strasse VARCHAR(50), HausNr VARCHAR(10), TelefonNr VARCHAR(20), Owner integer not null WITH DEFAULT 0 REFERENCES User_Info(HID) ON DELETE SET DEFAULT, WriteAccess integer REFERENCES BuddyGroups(group_ID) ON DELETE SET NULL ) CREATE TABLE Oeffnungszeiten ( GebNr INTEGER NOT NULL REFERENCES Gebaeude ON DELETE CASCADE, Tag CHAR(7) NOT NULL, von_a VARCHAR(5) NOT NULL, bis_a VARCHAR(5) NOT NULL, von_b VARCHAR(5), bis_b VARCHAR(5), Owner integer not null WITH DEFAULT 0 REFERENCES User_Info(HID) ON DELETE SET DEFAULT, WriteAccess integer REFERENCES BuddyGroups(group_ID) ON DELETE SET NULL, PRIMARY KEY(GebNr, Tag) ) Die Struktur dieses Teilschemas ist der Arbeit von [Bau03] entnommen. Erklärungen, Entwurfsentscheidungen und das komplette HERMES-Schema können dort nachgelesen werden. Der Nutzer wieda hat hierbei folgende Tupel zur unverbundenen Arbeit lokal zur Verfügung: Ortschaft: ONR ----------1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 PLZ ----70173 80331 10115 14469 28195 20095 65183 19053 30159 40210 55116 66111 01067 39104 24103 99084 83512 83022 83435 NAME -------------------Stuttgart Muenchen Berlin Potsdam Bremen Hamburg Wiesbaden Schwerin Hannover Duesseldorf Mainz Saarbruecken Dresden Magdeburg Kiel Erfurt Wasserburg am Inn Rosenheim Bad Reichenhall OWNER ---------ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT WRITEACESS_FOR --------------ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT ROOT Bei der Tabelle Ortschaft handelt es sich um eine Basisdatentabelle, welche die Information lediglich zum lesen zur Verfügung stellt. Gebaeude: GEBNR ONR ----------- ----------1 17 2 17 3 17 4 17 5 17 10 18 11 18 12 19 13 19 14 19 15 17 16 17 17 17 18 17 19 17 STRASSE --------------------------Stadtzentrum Marienplatz Stadtzentrum Kuestergasse Herrengasse Josephpassage Ludwigsplatz Stadtzentrum Wittelsbacher Strasse Salinenstrasse Teststrasse Nochnestrasse Schonwiedernestrasse Markt Neuhausstrasse 59 HAUSNR ---------15 26 15 111 2 231 3 23 TELEFON ---------086513003 08072490 - OWNER ---------wieda wieda wieda hugo hugo wieda wieda wieda wieda wieda wieda ROOT ROOT wieda wieda WRITEACESS_FOR --------------PUB PUB PUB hugo hugo PUB PUB PUB PUB PUB PUB ROOT PUB PUB Friends Kapitel 4. Testszenarien Oeffnungszeiten: GEBNR ----------3 4 5 11 13 14 TAG ------1101100 1111100 0000011 0111110 1111100 1111111 VON_A ----9.00 10.00 11.00 9.00 8.00 10.00 BIS_A ----14.00 21.00 15.00 13.00 12.00 12.00 VON_B ----11.30 14.00 14.00 14.00 BIS_B ----16.00 17.00 16.00 16.00 OWNER ---------wieda hugo wieda wieda wieda wieda WRITEACESS_FOR --------------PUB hugo wieda PUB PUB PUB 4.1.1. INSERT Für die Autorisierung sind die auf jede der 3 Tabellen anzulegenden, im Abschnitt 3.5. beschriebenen, Trigger verantwortlich. Obwohl als Client-DBMS das Produkt Adpative Server Anywhere von Sybase eingesetzt werden soll, wurden die nachfolgenden Beispielanweisungen mit IBM DB2 getestet. Da beide Systeme die gleichen erforderlichen Konstrukte mit geringfügiger syntaktischer Abweichung beinhalten, stellt eine Konvertierung keine Probleme da. Der Client-Nutzer versucht zunächst ein neues Tupel in die Tabelle Gebaeude einzufügen: insert into Gebaeude values (26, 15, 'Kreuzgasse', NULL, NULL, 1, NULL) DB20000I The SQL command completed successfully. Dabei sind keine Probleme aufgetreten. Der nächste Versuch, ein Tupel unter falschen Nutzernamen (bzw. Nutzer-ID) einzufügen (durch Umgehung der lokalen HERMES-Client-Software), scheitert jedoch korrekterweise mit der entsprechenden Fehlermeldung des INSERT-Triggers der Tabelle Gebaeude: insert into Gebaeude values (27, 15, 'Kreuzgasse', NULL, NULL, 2, NULL) Application raised error with diagnostic text: "Insertion failed SQLSTATE=Z0001 (wrong owner)". Auch der Versuch der Angabe einer nicht existierenden Gruppe(n-ID) führt zur Fehlersignalisierung des Triggers. Denselben Fehler liefert auch die Angabe einer Gruppe, die der Client-Nutzer nicht selbst erzeugt hat. Eine Ausnahme bildet die Gruppe PUB (ID = 0), die von allen HERMES-Nutzern spezifiziert werden darf. insert into Gebaeude values (28, 16, 'Eselsbruecke', NULL, NULL, 1, 4) Application raised error with diagnostic text: "Insertion failed (unauthorized Group ID)". SQLSTATE=Z0002 insert into Gebaeude values (29, 15, 'Dorfgraben', NULL, NULL, 1, 0) DB20000I The SQL command completed successfully. 4.1.2. DELETE Die unveränderbaren Daten in der Tabelle Ortschaft dürfen nicht einmal durch einen SuperUser (wie z.B. wieda) modifiziert, bzw. gelöscht werden: delete from ortschaft where Onr = 11 Application raised error with diagnostic text: "Unauthorized Delete Access". SQLSTATE=Z0003 In den "normalen" Tabellen hingegen, darf ein SuperUser selbst Tupel löschen, die der Besitzer nicht zum öffentlichen Schreibzugriff freigegeben hat. delete from gebaeude where Gebnr = 4 DB20000I The SQL command completed successfully. 60 Kapitel 4. Testszenarien Es gilt zu beachten, dass das abhängige Kind-Tupel in der Tabelle Oeffnungszeiten kaskadiert mit gelöscht wurde (nachdem der Trigger auf Oeffnungszeiten keinen Fehler lieferte). Angenommen Nutzer Hugo (HID = 2) versucht ein derart referenziertes Tupel zu löschen: delete from gebaeude where Gebnr = 5 Application raised error with diagnostic text: "Unauthorized Delete Access". SQLSTATE=Z0003 Der zurückgelieferte Fehler und das Scheitern des Löschvorgangs liegt in dem referenzierenden Tupel in der Tabelle Oeffnungszeiten begründet, auf welches der Nutzer hugo keinen Schreib-Zugriff hat. 4.1.3. UPDATE Änderungen an der Owner-Spalte sind weder SuperUsern (und damit erst recht nicht "normalen" HERMES-Nutzern) noch den Besitzern der Tupel selbst erlaubt: update gebaeude set owner=2 where gebNr = 1 Application raised error with diagnostic text: "Owner column must not be updated". SQLSTATE=Z0004 Der Zugriffsmodus WriteAccess hingegen darf ausschließlich vom Besitzer des Tupels beliebig modifiziert werden. So liefert der Versuch des SuperUsers wieda den Zugriffsmodus eines Tupels des Nutzers hugo zu ändern einen entsprechenden Fehler: update gebaeude set writeaccess = 0 where gebnr = 5 Application raised error with diagnostic text: "Accessmode only updatable by owner". SQLSTATE=Z0005 Das gleiche Statement durch den Nutzer hugo (dem Besitzer des Tupels) verläuft erfolgreich: update gebaeude set writeaccess = 0 where gebnr = 5 DB20000I The SQL command completed successfully. Das Rechtekonzept von HERMES erlaubt die Definition von Gruppen von Nutzern, denen der Schreibzugriff auf bestimmte Tupel gewährt wird. In der folgenden Anweisung ändert der Nutzer hugo ein Tupel des Nutzers wieda, der jenes der Gruppe Friends zum schreibenden Zugriff zur Verfügung stellt: update gebaeude set telefonnr = '33443' where gebnr = 19 DB20000I The SQL command completed successfully. Da hugo Mitglied der Gruppe Friends ist, darf er das Attribut telefonNr verändern. 4.2. Autorisierung auf dem RPS Auf dem RPS erfolgt die Autorisierung bei der Synchronisation durch die bereits im Abschnitt 3.4.3. beschriebenen Routinen. Die auf dem RPS zusätzlich notwendigen Tabellen sollen folgendermaßen gefüllt sein: Auth_Info: HID PASSWORD -------- -----------------0 oaösdblasdfow.7 1 asnlafnklasdnas 2 mnxyb,xcyhja<<j 3 laKNFPÖDNCL NFN 4 AOJaslasödsadnn .... 61 Kapitel 4. Testszenarien RPS_User: LOGIN ---------ROOT Admin1 User0 User1 User2 User3 User4 ... ENCRYPTED_PASS -------------------asldklsadhfsaj3o0 pwfo095p4rjpdsdwt laflncxncHHDKJKNX 9302oqp92rgsf<<sf 0q43jpaiwrnüuawej 342048208h(/&ßfjs x,cn,vlwepipwesaf ROLE -----------RPS_ROOT_ADM RPS_ADM EXCL_CLNT EXCL_CLNT CLIENT CLIENT CLIENT RPS_HID_Mapping: HID RPS_LOGIN ------ ----------0 User0 1 User1 2 User2 3 User3 4 User4 ... Neben den eigentlichen Tabellen des HERMES-Schemas existieren auf dem RPS zusätzlich die sog. Image-Tabellen, die wie folgt aussehen: CREATE TABLE Gebaeude_A ( GebNr INTEGER NOT NULL, ONr INTEGER NOT NULL, Strasse VARCHAR(50), HausNr VARCHAR(10), TelefonNr VARCHAR(20), Owner integer not null WITH DEFAULT 0 REFERENCES HERMES.User_Info(HID) ON DELETE SET DEFAULT, WriteAccess integer REFERENCES HERMES.BuddyGroups(group_ID) ON DELETE SET NULL, RPS_LOGIN varchar(128) not null, primary key (GebNr, RPS_LOGIN), foreign key (ONR, RPS_LOGIN) references Ortschaft_A ) ... (analog Gebaeude_B, Ortschaft_B, Ortschaft_A, Oeffnungszeiten_B, Oeffnungszeiten_A) Dabei gibt die zusätzliche Spalte RPS_LOGIN nicht den Besitzer des Tupels an, sondern identifiziert den synchronisierenden Client. 4.2.1. CRISP-Tool Das Java-Tool "CRISP" dient dem Erzeugen einer Stored Procedure zur Prüfung auf abhängige Kind-Tabellen und muss aufgerufen werden, bevor die Prozedur "SACC_<tabname>" angelegt werden kann. Beispiel eines Aufrufs (CRISP <dbname> <schemaname> <tabname>): > java CRISP hermes_db hermes gebaeude_B erzeugt die folgende Datei: _______ CRISP_GEBAEUDE_B.sql ______________________________________________________________________ CONNECT TO HERMES_DB@ CREATE PROCEDURE RISP_GEBAEUDE_B (IN HID integer, IN V_GEBNR INTEGER, IN V_RPS_LOGIN VARCHAR(128), OUT authorized CHAR(1), OUT msg varchar(300)) READS SQL DATA LANGUAGE SQL BEGIN IF (V_GEBNR, V_RPS_LOGIN) IN (SELECT GEBNR,RPS_LOGIN FROM OEFFNUNGSZEITEN_B) THEN SET authorized = 'N'; SET msg = 'Unable to delete from GEBAEUDE_B. Delete the referencing rows in OEFFNUNGSZEITEN_B first'; 62 Kapitel 4. Testszenarien return 1; END IF; SET authorized = 'Y'; END@ SET msg = 'Deleting Row possible'; COMMIT WORK@ ___________________________________________________________________________________________________ HERMES-Nutzer hugo (HID=2) versucht in der Tabelle Gebaeude das Tupel mit der GebNr=4 zu löschen (d.h. es existiert nur im Image Gebaeude_B und nicht auch in Gebaeude_A). Dieses wird jedoch durch ein abhängiges Kind-Tupel der Tabelle Oeffnungszeiten referenziert. Demnach kann das Vater-Tupel nicht gelöscht werden und die entpsrechende RISP-Prozedur liefert einen Fehler zurück. call RISP_GEBAEUDE_B (2, 4, 'User2', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Unable to delete from GEBAEUDE. Delete the referencing rows in OEFFNUNGSZEITEN first Return Status = 1 Das beabsichtigte Löschen des Tupels mit der GebNr=2 ist uneingeschränkt möglich, da weder ein referenzierendes Kind-Tupel noch eine Einschränkung des Schreibzugriffs besteht: call RISP_GEBAEUDE_B (1, 2, 'User1', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : Y Parameter Name : MSG Parameter Value : Deleting Row possible Return Status = 0 4.2.2. CSSP-Tool Durch das CSSP-Tool kann die eigentliche Routine zur Rechteprüfung für die Synchronisation erstellt werden. > java CSSP hermes_db hermes gebaeude _______CSSP_GEBAEUDE.sql __________________________________________________________________________ CONNECT TO hermes_db@ CREATE PROCEDURE SACC_GEBAEUDE (IN RPS_ID VARCHAR(128), IN RPS_Role VARCHAR(12), IN auth_ID integer, IN auth_pass varchar(128), OUT authorized CHAR(1), OUT msg varchar(300)) MODIFIES SQL DATA LANGUAGE SQL BEGIN -- Deklarationsteil DECLARE BF_Prim1 INTEGER; DECLARE AF_Prim1 INTEGER; DECLARE DECLARE DECLARE DECLARE BF_Owner integer; AF_Owner integer; BF_Access integer; AF_Access integer; DECLARE at_end SMALLINT DEFAULT 0; DECLARE c1 CURSOR FOR select BF.gebnr, BF.owner, BF.writeaccess, (select * from gebaeude_A 63 AF.gebnr, AF.owner, AF.writeaccess from Kapitel 4. Testszenarien EXCEPT (select * from gebaeude_A INTERSECT select * from gebaeude_B)) as AF FULL OUTER JOIN (select * from gebaeude_B EXCEPT (select * from gebaeude_A INTERSECT select * from gebaeude_B)) as BF ON (AF.gebnr) = (BF.gebnr) WHERE (BF.rps_login is NULL AND AF.rps_login = RPS_ID) OR (AF.rps_login is NULL AND BF.rps_login = RPS_ID) OR (BF.rps_login = AF.rps_login AND BF.rps_login = RPS_ID); DECLARE CONTINUE HANDLER for NOT FOUND SET at_end IF AUTH_CHECK(auth_ID, auth_pass) = 1 BEGIN = 1; THEN IF MAP_CHECK(RPS_ID, auth_ID) = 0 THEN SET authorized = 'N'; SET msg = 'Invalid RPS-HERMES ID Mapping'; return 1; END IF; OPEN c1; floop: LOOP fetch c1 into BF_PRIM1, BF_Owner, BF_Access, AF_PRIM1, AF_Owner, AF_Access; IF at_end = 1 THEN LEAVE floop; END IF; -- insert IF BF_PRIM1 is NULL THEN IF AF_Owner <> auth_ID THEN SET authorized = 'N'; SET msg = 'Insertion failed (wrong owner)'; return 1; END IF; IF AF_ACCESS is not null AND AF_ACCESS <> 0 AND NOT( auth_ID = COALESCE((select group_owner from BuddyGroups where AF_ACCESS = group_ID),0)) THEN SET authorized = 'N'; SET msg = 'Insertion failed (unauthorized Group ID)'; return 1; END IF; END IF; --delete IF AF_PRIM1 is NULL THEN IF NOT( BF_Owner = auth_ID OR (BF_Access IS NOT NULL AND Is_GroupMember(auth_ID, BF_Access) = 1) OR ( is_SuperUser(auth_ID) = 1 AND BF_Owner <> 0)) THEN SET authorized = 'N'; SET msg = 'Unauthorized Delete Access'; return 1; ELSE call RISP_Gebaeude_B(auth_ID,BF_PRIM1, RPS_ID,authorized, msg); IF authorized = 'N' THEN return 1; END IF; END IF; END IF; --update IF AF_PRIM1 is NOT NULL AND BF_PRIM1 is NOT NULL THEN IF BF_Owner <> AF_Owner THEN SET authorized = 'N'; SET msg = 'Owner column must not be updated'; return 1; END IF; IF ( (AF_Access is NULL AND BF_Access IS NOT NULL) OR (BF_Access is NULL AND AF_Access is NOT NULL) OR AF_Access <> BF_Access) AND auth_ID <> BF_Owner THEN SET authorized = 'N'; SET msg = 'Accessmode only updatable by owner'; 64 Kapitel 4. Testszenarien return 1; END IF; IF NOT( BF_Owner = auth_ID OR (BF_Access IS NOT NULL AND Is_GroupMember(auth_ID, BF_Access) = 1) OR ( is_SuperUser(auth_ID) = 1 AND BF_Owner <> 0)) THEN SET authorized = 'N'; SET msg = 'Update of row prohibited'; return 1; END IF; END IF; END LOOP floop; close c1; SET authorized = 'Y'; SET msg = 'Authorization successful'; END; ELSE SET authorized = 'N'; SET msg = 'Authentication failed'; return 1; END IF; END@ COMMIT WORK@ ___________________________________________________________________________________________________ Zunächst wird versucht die Prozedur mit einer nicht übereinstimmenden RPS-HID-Zuordnung aufzurufen und im Anschluß liegt ein inkorrektes Anwendungs-Passwort vor: call SACC_gebaeude ('User0', 'EXCL_CLIENT', 1, 'asnlafnklasdnas', ?, ?)@ Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Invalid RPS-HERMES ID Mapping Return Status = 1 call SACC_gebaeude ('User1', 'EXCL_CLIENT', 1, 'test', ?, ?)@ Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Authentication failed Return Status = 1 4.2.3. INSERT Der Client mit der RPS-ID User2, d.h. der HERMES-Nutzer mit der HID=2 versucht ein Tupel unter Angabe eines fälschlichen Nutzernamens einzufügen: GEBAEUDE_A: (1, 17, 'Stadtzentrum', NULL, NULL, 1, 0, 'User2') call SACC_gebaeude ('User2', 'CLIENT', 2, 'mnxyb,xcyhja<<j', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N 65 Kapitel 4. Testszenarien Parameter Name : MSG Parameter Value : Insertion failed (wrong owner) Return Status = 1 Jetzt versucht Nutzer hugo eine nicht ihm gehörende Gruppe einem seiner Tupel zuzuordnen: GEBAEUDE_A: (2, 18, 'Kirchstrasse', NULL, NULL, 2, 7, 'User2') call SACC_gebaeude ('User2', 'CLIENT', 2, 'mnxyb,xcyhja<<j', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Insertion failed (unauthorized Group ID) Return Status = 1 Eine nicht existente Gruppe kann aufgrund des fehlenden Vater-Tupels nicht angegeben werden: GEBAEUDE_A: (2, 18, 'Kirchstrasse', NULL, NULL, 2, 9, 'User2') SQL0530N The insert or update value of the FOREIGN KEY "HERMES.GEBAEUDE_A.SQL040402195552101" is not equal to any value of the parent key of the parent table. SQLSTATE=23503 4.2.4. DELETE Der SuperUser wieda versucht nun erfolglos ein unveränderliches Basis-Tupel zu löschen: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 0, NULL, 'User1') call SACC_gebaeude ('User1', 'EXCL_CLIENT', 1, 'asnlafnklasdnas', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Unauthorized Delete Access Return Status = 1 Die Tupel (auch wenn der Nutzer diese nicht für einen Fremd-Schreibzugriff freigegeben hat) jedes beliebigen anderen Nutzers können durch einen SuperUser gelöscht werden: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, NULL, 'User1') call SACC_gebaeude ('User1', 'EXCL_CLIENT', 1, 'asnlafnklasdnas', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : Y Parameter Name : MSG Parameter Value : Authorization successful Return Status = 0 Wenn noch abhängige Tupel in den Kind-Tabellen existieren, kann das Vater-Tupel nicht gelöscht werden: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, NULL, 'User2') Oeffnungszeiten_B: (2, '1101100', '9.00', '14.00', '11.30', '16.00', 1, NULL, 'User2') 66 Kapitel 4. Testszenarien call SACC_gebaeude ('User2', 'CLIENT', 2, 'mnxyb,xcyhja<<j', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Unable to delete from GEBAEUDE. Delete the referencing rows in OEFFNUNGSZEITEN first Return Status = 1 4.2.5. UPDATE Ähnlich wie auf dem Cient ist das Ändern der Besitzerspalte verboten und der Zugriffsmodus lediglich durch den Tupelbesitzer selbst erlaubt: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, NULL, 'User2') GEBAEUDE_A: (2, 18, 'Kirchstrasse', NULL, NULL, 1, NULL, 'User2') call SACC_gebaeude ('User2', 'CLIENT', 2, 'mnxyb,xcyhja<<j', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Owner column must not be updated Return Status = 1 GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 1, NULL, 'User2') GEBAEUDE_A: (2, 18, 'Kirchstrasse', NULL, NULL, 1, 7, 'User2') call SACC_gebaeude ('User2', 'CLIENT', 2, 'mnxyb,xcyhja<<j', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Accessmode only updatable by owner Return Status = 1 Nachfolgendes Update durch einen SuperUser (wieda) verläuft ohne Probleme: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, NULL, 'User1') GEBAEUDE_A: (2, 18, 'Kirchstrasse', NULL, '0496677', 2, NULL, 'User1') call SACC_gebaeude ('User1', 'EXCL_CLIENT', 1, 'asnlafnklasdnas', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : Y Parameter Name : MSG Parameter Value : Authorization successful Return Status = 0 67 Kapitel 4. Testszenarien Der Besitzer selbst kann natürlich immer uneingeschränkt schreibend auf seine Tupel zugreifen: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, NULL, 'User2') GEBAEUDE_A (2, 18, 'Kirchstrasse', '17', '0496677', 2, NULL, 'User2') call SACC_gebaeude ('User2', 'CLIENT', 2, 'mnxyb,xcyhja<<j', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : Y Parameter Name : MSG Parameter Value : Authorization successful Return Status = 0 Obiges Tupel ist nicht für den schreibenden Zugriff anderer (normaler) HERMES-Nutzer freigegeben: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, NULL, 'User3') GEBAEUDE_A: (2, 18, 'Kirchstrasse', '17', '0496677', 2, NULL, 'User3') call SACC_gebaeude ('User3', 'CLIENT', 3, 'laKNFPÖDNCL NFN', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : N Parameter Name : MSG Parameter Value : Update of row prohibited Return Status = 1 Anders sieht die Sache jedoch aus, wenn der Besitzer eine Gruppe vertrauenswürdiger Zugriffsberechtigter angegeben hat: GEBAEUDE_B: (2, 18, 'Kirchstrasse', NULL, NULL, 2, 7, 'User3') GEBAEUDE_A: (2, 18, 'Kirchstrasse', '17', '0496677', 2, 7, 'User3') call SACC_gebaeude ('User3', 'CLIENT', 3, 'laKNFPÖDNCL NFN', ?, ?) Value of output parameters -------------------------Parameter Name : AUTHORIZED Parameter Value : Y Parameter Name : MSG Parameter Value : Authorization successful Return Status = 0 68 5. Zusammenfassung und Ausblick 5.1. Zusammenfassung Das Ziel der Arbeit bestand in dem Beschreiben erster Konzepte der durch neuartige mobile Datenbankanwendungen, wie das mobile Reiseinformationssystem HERMES, notwendigen flexiblen Nutzerverwaltung und datenbasierte Rechteverwaltung, bzw. -vergabe. Einen Aspekt bildete dabei die Vorstellung und Erläuterung von HERMES sowie der zu Grunde gelegenen Architektur. Der Abschnitt wurde beabsichtigt kurz gehalten, da sich bereits eine Reihe vorangegangener und laufender Arbeiten mit der Theorie und Implementierung dieser Infrastruktur beschäftigen. Nach einer Einführung in die für Zugriffskontrollmechanismen notwendigen Begriffe und Techniken, wurde betrachtet, inwieweit die herkömmlichen, schemaorientierten Techniken zur Realisierung des Vorhabens geeignet sind. Darüber hinaus erfolgte die Vorstellung des von Oracle angebotenen Produkts Oracle Label Security, wodurch eine systembestimmte, zeilengranulare Zugriffskontrolle auf Basis von Nutzer- und Datenklassifikationen durchgesetzt werden kann. Die dadurch entstehenden Möglichkeiten reichen einerseits für unsere Zwecke nicht aus und sind stellenweise zu restriktiv. Dies motivierte die Einführung und ausführliche Beschreibung einer eigenen Nutzer- und Rechteverwaltung, welche die Realisierung der verschiedenen Nutzerprofile (Besitzer von Daten, Nutzer, Administratoren), die Zugriffskontrolle sowie die Rechtevergabe an andere Nutzer erlauben. Ein weiterer zentraler Punkt der Arbeit war die Integration der Zugriffskontrollmechanismen in die 3-SchichtenArchitektur der nutzerdefinierten Replikation sowie das Aufzeigen und Lösen auftretender Probleme. Anschließend wurde auf ein spezielles Feature der HERMES-Anwendung eingegangen, welches die Unterstützung des RPS erforderlich macht und wodurch es möglich wird, verschiedenen Nutzern eigene private Bereiche auf denselben Schema-Ausschnitt einzuräumen. Letztlich konnten die beschriebenen Verfahrensweisen und deren Möglichkeiten ausführlich anhand beispielhafter Testfälle der Nutzung und Anwendung im HERMES-Universum verdeutlicht werden. 5.2. Ausblick Die vorgestellten Konzepte sind aufgrund der prototypischen Natur des mobilen Reiseinformationssystems HERMES und der verwendeten Architektur für den kommerziellen Einsatz unzureichend und auf den experimentellen Einsatz beschränkt. Auch wurden einige stillschweigende Annahmen getroffen, die es noch zu analysieren bzw. konkretisieren gilt. Es wurde beispielsweise vorausgesetzt, dass es sich bei den durch Zugriffskotrollmechanismen zu schützenden Objekten um einzelne Datensätze handelt. Für die praktische Verwendung könnte jedoch erwogen werden, komplexere Objekte zu konzipieren, die sich etwa auf Tupeln bzw. einzelne Spalten über mehrere logisch zusammengehörende Tabellen erstrecken. So könnte man einem Nutzer das Recht erteilen, ein neues Hotel einzufügen. Hierfür sollten nicht nur die statistischen Informationen des Gebäudes selbst eingefügt werden, sondern auch einzelne in der Objekthierarchie tiefer gelegene Objekte, wie Gästezimmer, Lobby, Restaurants oder umliegende sanitäre Einrichtungen, die sich abermals in kleinere Komponenten aufteilen lassen, müssen in der Rechtevergabe Berücksichtigung finden. Somit reicht es nicht aus, ein einzelnes Tupel in eine Tabelle einzufügen und dieses mit Zugriffsrechten zu versehen. Die Rechte auf einzelne Objekte müssen automatisiert auf mehrere interne Tabellen und Tupel abgebildet werden. Dazu reichen zwei simple Meta-Spalten pro Tabelle natürlich nicht aus. Eventuell könnte man die Objekte, Subjekte und Rechte auf dem Prinzip der Fähigkeits- bzw. Zugriffskontrolllisten in relationaler angepasster Form verwalten. Zusätzlich kann man erwägen, das Schreibrecht aufzuteilen in einzelne Einfüge-, Lösch- und Änderungs-Rechte, die unabhängig voneinander gewährt bzw. entzogen werden können. 69 Kapitel 5. Zusammenfassung und Ausblick In weiterführenden zukünftigen Arbeiten sollten auch die bisher nur informell beschriebenen HERMES-Client bzw. HEMES-Server Anwendungen genauestens charakterisiert, formalisiert und implementiert werden. Außerdem könnte man eine automatisierte Transformation der Rechte- und Nutzerverwaltung, in Verbindung mit den Möglichkeiten des RPS, von Anwendungen evaluieren, die bisher nur auf der Quelle laufen und mobilfähig gemacht werden sollen. So bietet beispielsweise die Adaption von schemabasierten Rechtekonzepten auf Datenbanksystem-Nutzern, in die Umgebung des RPS interessante Möglichkeiten. 70 Anhang A Java-Skript CRISP.java // CRISP.java // Autor: David Wiese // Erstellt am 29.2.04 // CRISP - Create Referential Integrity Stored Procedure // uebergeben werden: Datenbankname, Schemaname, Tabellenname // erzeugt eine SP für die uebergebene Tabelle für das HERMES-Rechtekonzept zum Prüfen, // ob ein referenziertes Tupel geloescht werden kann // - es gibt max. einen Primaerschluessel, aber potentiell beliebig viele Unique-Schluessel, // die referenziert werden können // - die Menge der Unique-Key-Attribute und die der Primaerschluesselattribute können nicht disjunkt sein, // sind aber in keinem Fall gleich // funktioniert nur mit DB2 built in types, nicht für distinct, datalink, ref oder structured type import java.sql.*; import java.lang.*; import java.io.*; import java.util.*; public class CRISP { // Funktion ersetzt im String s alle Vorkommen von alt durch neu public static String replace( String s, String alt, String neu ) { // indexOf findet den Index des ersten Vorkommens von alt, Strings beginnen in Java bei 0 // indexOf liefert -1, wenn der gesuchte String nicht mehr gefunden wird int pos = s.indexOf(alt); while (pos != -1) { //substring(start, end) liefert den Teil des Strings von Index start bis end-1 s = s.substring(0,pos) + neu + s.substring(pos + alt.length()); pos += neu.length(); pos = s.indexOf(alt, pos); } return s; } public static void main (String[] args) { // JDBC-Treiber fuer DB2 try { Class.forName("COM.ibm.db2.jdbc.app.DB2Driver"); } catch (Exception e) { e.printStackTrace(); } try { if (args.length != 3) { System.out.println("Usage: CRISP <dbname> <schemaname> <tabname>"); return; } String databasename = args[0].toUpperCase(); String schemaname = args[1].toUpperCase(); String tabname = args[2].toUpperCase(); File f = new File("CRISP_"+tabname+".sql"); BufferedWriter buf = new BufferedWriter(new FileWriter(f)); buf.write("CONNECT TO "+databasename+"@\n\n"); // Verbindung zur DB herstellen Connection con = DriverManager.getConnection("jdbc:db2:"+databasename); // AutoCommit setzen con.setAutoCommit(false); // Statements vorbereiten -> Statementobjekte erzeugen Statement stmt = con.createStatement(); //stmt2,3,4 benötigt, da verschachtelte DB-Anfragen sonst nicht möglich sind Statement stmt2 = con.createStatement(); Statement stmt3 = con.createStatement(); ResultSet rs, rs2, rs3; // bestimme den Namen und Typ der Primaerschluesselattribute geordnet nach keyseq rs=stmt.executeQuery("select colname, typename, length, scale from syscat.columns where tabschema = '"+ schemaname+"' AND tabname = '"+tabname+"' AND keyseq > 0 order by keyseq"); String prim = ""; String prim_vals = ""; //Namen der Variablen der PrimKey-Werte fuer die SP int c = 0; while (rs.next()) { String colname = rs.getString(1); prim_vals += ((c>0) ? ", V_" : "V_") + colname; String typename = rs.getString(2); prim += "IN V_" + colname +" "+ typename; int scale = rs.getInt(4); // BLOB, CLOB, DBCLOB als Primaerschluessel-Attribute werden nicht betrachtet if (typename.equals("CHARACTER") || typename.equals("VARCHAR") || typename.equals("DECIMAL") 71 Anhang || typename.equals("GRAPHIC") || typename.equals("VARGRAPHIC") || typename.equals("FLOAT")) { prim += "("+rs.getInt(3); if (scale != 0) prim += ","+scale; prim += ")"; } prim += ", "; c++; } buf.write("CREATE PROCEDURE "+schemaname+".RISP_"+tabname+"\n(IN HID integer, "+prim); buf.write("OUT authorized CHAR(1), OUT msg varchar(300)) \nREADS SQL DATA LANGUAGE SQL\nBEGIN\n"); // bestimme alle Namen der Kinder-Tabellen, die ihre RICs mit ON DELETE CASCADE oder // ON DELETE SET NULL definiert haben rs = stmt.executeQuery("select distinct tabname from syscat.references where reftabname = '"+ tabname+"' AND reftabschema = '"+schemaname+"' AND deleterule in ('C','N')"); while (rs.next()) { String child_tabname = rs.getString(1); // bestimme alle constraints mit diesem child_tab // jedes constraint hat eine Delrule aus ('C', 'N') rs2=stmt2.executeQuery("select distinct constname, refkeyname, deleterule from syscat.references "+ "where tabschema = '"+ schemaname+"' AND reftabname = '"+tabname+"' AND tabname = '"+child_tabname+"'"); while (rs2.next()) { String child_constname = rs2.getString(1); String parent_constname = rs2.getString(2); String delrule = rs2.getString(3); // auslesen der matchenden (anhand der colseq) Spaltennamen rs3 = stmt3.executeQuery("select child.colname, parent.colname from " + "syscat.keycoluse child JOIN syscat.keycoluse parent ON (child.colseq) = (parent.colseq) " + "where child.constname = '" + child_constname + "' AND parent.constname = '"+parent_constname+"'"); String parent_cols = "", child_cols = ""; int count = 0; while (rs3.next()) { parent_cols += ((count>0) ? "," : "") + rs3.getString(2); child_cols += ((count>0) ? "," : "") + rs3.getString(1); count++; }//while rs3 // pruefe jetzt, ob die parent_col_names zu einem unique oder primary key gehoeren // da unique-Attribute (echte) Teilmenge des primary key sein koennen // prim-key und unique-key muessen getrennt behandelt werden, da der SP die Prim-Key-Werte // uebergeben werden // Primary-Key-Attribut hat keyseq > 0, d.h. wenn mind. 1 Attribut mit // keyse =Null oder keyseq=0 gefunden wurde, dann handelt es sich um einen Unique-Key rs3 = stmt3.executeQuery("select count(*) from syscat.columns where tabname = '"+tabname+ "' AND tabschema = '"+schemaname+"' AND colname IN ('"+ ((String)replace(parent_cols, ",", "','"))+"') AND (keyseq IS NULL OR keyseq = 0)"); rs3.next(); boolean unique_parent = (rs3.getInt(1) > 0) ? true : false; // wenn Kind mit ON DELETE CASCADE definiert if (delrule.equals("C")) { // Referenz auf den Prim-KEy if (!unique_parent) { // pruefe, ob es noch den PrimKey referenzierende Kindertupel gibt buf.write("\tIF (" + prim_vals + ") IN (SELECT " + child_cols + " FROM " + schemaname +"."+ child_tabname+") THEN\n"); buf.write("\t\tSET authorized = 'N';\n\t\tSET msg = 'Unable to delete from "+tabname+ ". Delete the referencing rows in "+child_tabname+" first';\n"); buf.write("\t\treturn 1;\n"); buf.write("\tEND IF;\n\n"); } else { // Referenz auf einen Unique-Key // pruefe, ob es noch den UniqueKey referenzierende Kindertupel gibt // dazu muessen die Werte der Unique-Key-Attribute zunaechst bestimmt werden buf.write("\tIF (SELECT COUNT(*) from (select "+child_cols+" FROM "+schemaname +"."+ child_tabname+ " INTERSECT \n\t"); buf.write(" SELECT "+parent_cols+" FROM "+schemaname +"."+tabname+" WHERE ("+ ((String)replace(prim_vals,"V_", ""))+") = ("+prim_vals+")) as a) > 0 THEN\n"); buf.write("\t\tSET authorized = 'N';\n\t\tSET msg = 'Unable to delete from "+tabname+ ". Delete the referencing rows in "+child_tabname+" first';\n"); buf.write("\t\treturn 1;\n"); buf.write("\tEND IF;\n\n"); } } else { // Kind mit ON DELETE SET NULL definiert // Referenz auf den Prim-KEy if (!unique_parent) { // gibt es den PrimKey referenzierende Kinder-tupel, auf die "login" // keine Schreibrechte besitzt, dann Fehler buf.write("\tIF (SELECT COUNT(*) FROM "+schemaname+"."+child_tabname+" WHERE ("+ child_cols+")=("+prim_vals+") AND \n"); buf.write("\t NOT (Owner = HID OR (WriteAccess is not null AND "+ schemaname +"."+"Is_GroupMember(HID, WriteAccess) = 1) OR " + "("+schemaname+".is_superUser(HID)=1 AND Owner <> 0))) > 0 THEN\n"); buf.write("\t\tSET authorized = 'N';\n\t\tSET msg = 'Unable to delete from "+tabname+ ". Write Access not permitted to all referencing rows in "+child_tabname+"';\n"); buf.write("\t\treturn 1;\n"); buf.write("\tEND IF;\n\n"); } else { // Referenz auf einen Unique-Key // gibt es den Unique-KEy referenzierende Kinder-tupel, auf die "login" // keine Schreibrechte besitzt, dann Fehler buf.write("\tIF (SELECT COUNT(*) FROM "+schemaname +"."+child_tabname+ " WHERE ("+ child_cols+") IN \n\t"); buf.write(" (SELECT "+parent_cols+" FROM "+schemaname +"."+tabname+" WHERE ("+ (String)replace(prim_vals,"V_", "")+") = ("+prim_vals+")) AND \n"); 72 Anhang buf.write("\t NOT (Owner = HID OR (WriteAccess is not null AND "+ schemaname +"."+"Is_GroupMember(HID, WriteAccess) = 1) OR " + "("+schemaname+".is_superUser(HID)=1 AND Owner <> 0))) > 0 THEN\n"); buf.write("\t\tSET authorized = 'N';\n\t\tSET msg = 'Unable to delete from "+tabname+ ". Write Access not permitted to all referencing rows in "+child_tabname+"';\n"); buf.write("\t\treturn 1;\n"); buf.write("\tEND IF;\n\n"); } } } //while rs2 } //while rs con.commit(); stmt.close(); con.close(); buf.write("\tSET authorized = 'Y'; SET msg = 'Deleting Row possible'; \nEND@\n\nCOMMIT@"); //sicherstellen, dass alles geschrieben wurde buf.flush(); buf.close(); } //try // Fehlerbehandlung catch (Exception e) { e.printStackTrace(); } } //main } //class B Java-Skript CSSP.java // CSSP.java // Autor: David Wiese // Erstellt am 04.04.04 // CSSP - Create Synchronize Stored Procedure // uebergeben werden: Datenbankname, Schemaname, Tabellenname // erzeugt eine SP für die uebergebene Tabelle zur Autorisierung bei der Synchronisation // Voraussetzungen: // in dem uebergebenen Schema existieren die Funktionen Auth_Check, Map_check, // is_GroupMember, is_SuperUser sowie die BEFORE (<tabname>_B) und die AFTER (<tabname>_A)-Tabellen // die Prozedur RISP_<tabname>_B und die Tabellen BuddyGroups // funktioniert nur mit DB2 built in types, nicht für distinct, datalink, ref oder structured type import java.sql.*; import java.lang.*; import java.io.*; import java.util.*; public class CSSP { // Funktion ersetzt im String s alle Vorkommen von alt durch neu public static String replace( String s, String alt, String neu ) { // indexOf findet den Index des ersten Vorkommens von alt, Strings beginnen in Java bei 0 // indexOf liefert -1, wenn der gesuchte String nicht mehr gefunden wird int pos = s.indexOf(alt); while (pos != -1) { //substring(start, end) liefert den Teil des Strings von Index start bis end-1 s = s.substring(0,pos) + neu + s.substring(pos + alt.length()); pos += neu.length(); pos = s.indexOf(alt, pos); } return s; } public static void main (String[] args) { // JDBC-Treiber fuer DB2 try { Class.forName("COM.ibm.db2.jdbc.app.DB2Driver"); } catch (Exception e) { e.printStackTrace(); } try { if (args.length != 3) { System.out.println("Usage: CSSP <dbname> <schemaname> <tabname>"); return; } String databasename = args[0].toUpperCase(); String schemaname = args[1].toUpperCase(); String tabname = args[2].toUpperCase(); File f = new File("CSSP_"+tabname+".sql"); BufferedWriter buf = new BufferedWriter(new FileWriter(f)); buf.write("CONNECT TO "+databasename+"@\n\n"); buf.write("CREATE PROCEDURE "+ schemaname + ".SACC_"+tabname+"\n"); buf.write("(IN RPS_ID VARCHAR(128), IN RPS_Role VARCHAR(12),\n IN auth_ID integer, "+ "IN auth_pass varchar(128),\n OUT authorized CHAR(1), OUT msg varchar(300))\n"); buf.write("MODIFIES SQL DATA LANGUAGE SQL\nBEGIN\n\t-- Deklarationsteil\n"); 73 Anhang // Verbindung zur DB herstellen Connection con = DriverManager.getConnection("jdbc:db2:"+databasename); // AutoCommit setzen con.setAutoCommit(false); // Statements vorbereiten -> Statementobjekte erzeugen Statement stmt = con.createStatement(); ResultSet rs; // bestimme den Namen und Typ der Primaerschluesselattribute geordnet nach keyseq rs=stmt.executeQuery("select colname, typename, length, scale from syscat.columns where tabschema = '"+ schemaname+"' AND tabname = '"+tabname+"' AND keyseq > 0 order by keyseq"); String primkey = ""; String BF_key = ""; int c = 1; while (rs.next()) { String colname = rs.getString(1); primkey += ((c>1) ? ", BF." : "BF.") + colname; String typename = rs.getString(2); int scale = rs.getInt(4); // BLOB, CLOB, DBCLOB als Primaerschluessel-Attribute werden nicht betrachtet if (typename.equals("CHARACTER") || typename.equals("VARCHAR") || typename.equals("DECIMAL") || typename.equals("GRAPHIC") || typename.equals("VARGRAPHIC") || typename.equals("FLOAT")) { typename += "("+rs.getInt(3); if (scale != 0) typename += ","+scale; typename += ")"; } buf.write("\tDECLARE BF_PRIM" + c + " " + typename + ";\n"); buf.write("\tDECLARE AF_PRIM" + c + " " + typename + ";\n"); BF_key += ((c>1) ? "," : "") + "BF_PRIM"+c; c++; } //while rs buf.write("\n\tDECLARE BF_Owner integer;\n\tDECLARE AF_Owner integer;"+ "\n\tDECLARE BF_Access integer;\n\tDECLARE AF_Access integer;\n"+ "\n\tDECLARE at_end SMALLINT DEFAULT 0;\n\n"); buf.write("\tDECLARE c1 CURSOR FOR\n\tselect " + primkey + ", BF.owner, BF.writeaccess, "+ replace(primkey, "BF", "AF") + ", AF.owner, AF.writeaccess from\n\t\t"+ "(select * from " + schemaname+"."+tabname+"_A\n\t\t\tEXCEPT\n\t\t"+ "(select * from " + schemaname+"."+tabname+"_A INTERSECT select * from " + schemaname+"."+tabname+ "_B)) as AF\n\tFULL OUTER JOIN\n\t\t"+ "(select * from " + schemaname+"."+tabname+"_B\n\t\t\tEXCEPT\n\t\t"+ "(select * from " + schemaname+"."+tabname+"_A INTERSECT select * from " + schemaname+"."+tabname+ "_B)) as BF\n\tON ("+primkey+") = ("+ replace(primkey, "BF", "AF") + ")\n\tWHERE\t(BF.rps_login is NULL AND AF.rps_login = RPS_ID) OR\n\t\t"+ "(AF.rps_login is NULL AND BF.rps_login = RPS_ID) OR\n\t\t"+ "(BF.rps_login = AF.rps_login AND BF.rps_login = RPS_ID);\n\n"); buf.write("\tDECLARE CONTINUE HANDLER for NOT FOUND SET at_end = 1;\n\n"); buf.write("\tIF "+schemaname+".AUTH_CHECK(auth_ID, auth_pass) = 1 THEN\n\tBEGIN\n\t\t"+ "IF "+schemaname+".MAP_CHECK(RPS_ID, auth_ID) = 0 THEN\n\t\t\tSET authorized = 'N';\n\t\t\t"+ "SET msg = 'Invalid RPS-HERMES ID Mapping';\n\t\t\treturn 1;\n\t\tEND IF;\n\n\t\tOPEN c1;"+ "\n\n\t\tfloop:\n\t\tLOOP\n\t\t\tfetch c1 into "+BF_key+", BF_Owner, BF_Access, "+ replace(BF_key, "BF", "AF") + ", AF_Owner, AF_Access;\n\t\t\t"+ "IF at_end = 1 THEN LEAVE floop; END IF;\n\n"); buf.write("\t\t\t-- insert\n\t\t\tIF BF_PRIM1 is NULL THEN\n\t\t\t\t"+ "IF AF_Owner <> auth_ID THEN\n\t\t\t\t\tSET authorized = 'N';\n\t\t\t\t\t"+ "SET msg = 'Insertion failed (wrong owner)';\n\t\t\t\t\treturn 1;\n\t\t\t\tEND IF;\n\n"+ "\t\t\t\tIF AF_ACCESS is not null AND AF_ACCESS <> 0 AND\n\t\t\t\t\t"+ "NOT( auth_ID = COALESCE((select group_owner from "+schemaname+".BuddyGroups where "+ "AF_ACCESS = group_ID),0))\n\t\t\t\tTHEN\n\t\t\t\t\tSET authorized = 'N'; \n\t\t\t\t\t"+ "SET msg = 'Insertion failed (unauthorized Group ID)';\n\t\t\t\t\treturn 1;\n\t\t\t\tEND IF;"+ "\n\t\t\tEND IF;\n\n"); buf.write("\t\t\t--delete\n\t\t\tIF AF_PRIM1 is NULL THEN\n\t\t\t\t"+ "IF NOT( BF_Owner = auth_ID OR (BF_Access IS NOT NULL AND\n\t\t\t\t\t"+ schemaname+".Is_GroupMember(auth_ID, BF_Access) = 1)\n\t\t\t\t\t"+ "OR ("+schemaname+ ".is_SuperUser(auth_ID) = 1 AND BF_Owner <> 0))\n\t\t\t\t THEN\n\t\t\t\t\t"+ "SET authorized = 'N'; SET msg = 'Unauthorized Delete Access';\n\t\t\t\t\treturn 1;"+ "\n\t\t\t\tELSE\n\t\t\t\t\tcall "+schemaname+".RISP_"+tabname+"_B(auth_ID,"+BF_key+", RPS_ID,"+ "authorized, msg);\n\t\t\t\t\tIF authorized = 'N' THEN return 1; END IF;\n\t\t\t\tEND IF;"+ "\n\t\t\tEND IF;\n\n"); buf.write("\t\t\t--update\n\t\t\tIF AF_PRIM1 is NOT NULL AND BF_PRIM1 is NOT NULL\n\t\t\tTHEN"+ "\n\t\t\t\tIF BF_Owner <> AF_Owner THEN\n\t\t\t\t SET authorized = 'N';\n\t\t\t\t\t"+ "SET msg = 'Owner column must not be updated';\n\t\t\t\t\treturn 1;\n\t\t\t\tEND IF;\n\n\t\t\t\t"+ "IF (\t(AF_Access is NULL AND BF_Access IS NOT NULL) OR\n\t\t\t\t\t"+ "(BF_Access is NULL AND AF_Access is NOT NULL) OR\n\t\t\t\t\t"+ "AF_Access <> BF_Access) AND auth_ID <> BF_Owner\n\t\t\t\tTHEN\n\t\t\t\t\t"+ "SET authorized = 'N';\n\t\t\t\t\tSET msg = 'Accessmode only updatable by owner';\n\t\t\t\t\t"+ "return 1;\n\t\t\t END IF;\n\n\t\t\t\tIF NOT( BF_Owner = auth_ID OR (BF_Access IS NOT NULL AND"+ "\n\t\t\t\t\t"+schemaname+".Is_GroupMember(auth_ID, BF_Access) = 1) OR\n\t\t\t\t\t"+ "( "+schemaname+".is_SuperUser(auth_ID) = 1 AND BF_Owner <> 0))\n\t\t\t\tTHEN\n\t\t\t\t\t"+ "SET authorized = 'N'; SET msg = 'Update of row prohibited';\n\t\t\t\t\treturn 1;\n\t\t\t\t"+ "END IF;\n\t\t\tEND IF;\n\n\t\tEND LOOP floop;\n\t\tclose c1;\n\t\t"+ "SET authorized = 'Y'; SET msg = 'Authorization successful';\n\tEND;\n\tELSE\n\t\t"+ "SET authorized = 'N'; SET msg = 'Authentication failed';\n\t\treturn 1;\n\tEND IF;"+ "\nEND@\n\nCOMMIT@"); con.commit(); 74 Anhang stmt.close(); con.close(); //sicherstellen, dass alles geschrieben wurde buf.flush(); buf.close(); } //try // Fehlerbehandlung catch (Exception e) { e.printStackTrace(); } } //main } //class 75 Literaturverzeichnis [Bau03] K. Baumgarten. Konzeption und Schemaentwurf eines interaktiven mobilen Reiseinformationssystems. Studienarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, Juli 2003. [Fri03] Aeleen Frisch. Unix System-Administration kurz & gut, O'Reilly, April 2003. [Gol00] C. Gollmick. Anwendungsklassen und Architektur Mobiler Datenbanksyste-me. In Tagungsband des 12. Workshop "Grundlagen von Datenbanken", Plön, Deutschland, Bericht Nr. 2005, Seiten 36–40, ChristianAlbrechts-Universität Kiel, Juni 2000. [Gol03] C.Gollmick. Nutzerdefinierte Replikation zur Realisierung neuer mobiler Datenbankanwendungen. In Tagungsband der 10. GI-Fachtagung Datenbanksysteme für Business, Technology und Web (BTW), Leipzig, Band P-26 aus Lecture Notes in Informatics (LNI), Seiten 453-462, Februar 2003. [GR03] C. Gollmick und G. Rabinovitch. Fragmentbildung zur Unterstützung der nutzerdefinierten Replikation. In Post-Proceedings of the Workshop Scalability, Persistence, Transactions - Database Mechanisms for Mobile Applications, Karlsruhe, Band P-43 aus Lecture Notes in Informatics (LNI), Seiten 79-93, April 2003. [GW76] P. P. Griffith und B. W. Wade. An Authorization Mechanism for a Relationale Database System. In ACM Transactions on Database Systems, Band 1(3), Seiten 242–255, September 1976. [IBM02a] IBM. DB2 UDB SQL Reference (Version 8), 2002. [IBM02b] IBM. DB2 UDB Administration Guide: Implementation (Version 8), 2002. [Kaß95] T. Kaß. Anwendungsspezifische Autorisierungsstrategien in polymorphen persistenten Programmierumgebungen: Ein Bibliotheksansatz. Diplomarbeit, Fachbereich für Informatik, Universität Hamburg, Dezember 1995. [Lie03] M. Liebisch. Synchronisationskonflikte beim mobilen Datenbankzugriff: Vermeidung,Erkennung und Behandlung. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, Februar 2003. [Mül03] T. Müller. Architektur und Realisierung eines Replication Proxy Server zur Unterstützung neuartiger mobiler Datenbankanwendungen. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, April 2003. [Ora02] Oracle. Oracle Label Security Administrator's Guide (Release 9.2), März 2002. [Pfe04] R. Pfender. Entwurf und Implementierung eines Replication Proxy Server zur Unterstützung nutzerdefinierter Replikation in mobilen Datenbankszenarien. Diplomarbeit, Institut für Informatik, Friedrich-Schiller-Universität Jena, April 2004. [Rup02] J. Rupprecht. Datensicherheit im Data Warehousing - Grundlagen, Zugriffskontrolle, Fallbeispiele. Beitrag, Institut für Wirtschaftsinformatik, Universität St. Gallen, September 2002. 76 Abbildungsverzeichnis Abbildung 1: Prinzipieller Arbeitszyklus der nutzerdefinierten Replikation ......................................................................7 Abbildung 2: Architektur zur Unterstützung neuartiger mobiler Anwendungen ..............................................................10 Abbildung 3: Authorities und Privileges in DB2 ..............................................................................................................12 Abbildung 4: Zugriffskontrollmatrix ................................................................................................................................13 Abbildung 5: Fähigkeitsliste .............................................................................................................................................14 Abbildung 6: Zugriffskontrollliste ....................................................................................................................................14 Abbildung 7: Hierarchie einer rollenbasierten Zugriffskontrolle......................................................................................17 Abbildung 8: Dimensionale Beziehungen der Label-Komponenten.................................................................................22 Abbildung 9: Typische Label-Komponenten-Ausprägungen............................................................................................22 Abbildung 10: Kontrollfluss der lesenden OLS-Autorisierung.........................................................................................23 Abbildung 11: Kontrollfluss der schreibenden OLS-Autorisierung..................................................................................24 Abbildung 12: HERMES-Testschema für referentielle Integritätsregeln ............................................................................38 Abbildung 13: Image-Tabellen für die Reintegration .......................................................................................................45 Abbildung 14: Konzept der Privatisierung........................................................................................................................51 Abbildung 15: Beispiel der Tupelauswahl in privaten Tabellen .......................................................................................52 Abbildung 16: Fremdschlüsselbeziehungen von und zu privaten Tabellen ......................................................................54 77