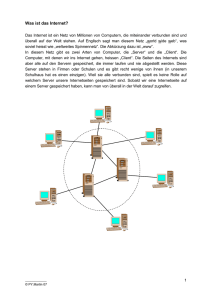
Internet-Protokolle - Technische Fakultät
Werbung

Internet-Protokolle Grundstudiums-Seminar im Wintersemester 2001/2002 Herausgeber: Jörn Clausen Technische Fakultät Universität Bielefeld 31. Mai 2002 ii Inhaltsverzeichnis 1 Netzwerk-(Ge)Schichten 1.1 Vernetzte Rechner . 1.2 Rechnernetze . . . . 1.3 Datenpakete . . . . . 1.4 Netzwerk-Schichten . 1.5 Datenkapselung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2 4 6 6 9 2 Organisationen im Internet 11 3 Request for Comments 3.1 Was RFCs sind . . . . . . . . . . . . 3.2 Entstehungsgeschichte . . . . . . . . 3.3 RFC-Nebensereien . . . . . . . . . . 3.3.1 STD-Serie . . . . . . . . . . . 3.3.2 Best Current Practice (BCP) 3.3.3 For Your Information (FYI) . 3.4 Der Internet Standard Track . . . . 3.4.1 Maturity Levels . . . . . . . . 3.4.2 Internet Standards Process . 3.5 RFC-Formate . . . . . . . . . . . . . 3.5.1 Keywords . . . . . . . . . . . 3.6 Interessante RFCs . . . . . . . . . . 3.7 Jon Postel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 17 18 20 20 21 21 22 22 23 26 26 26 27 4 Link-Layer, Ethernet 4.1 Zeitliche Einordnung des Link-Layers . . . . . . . . . . . . . . . . . . . . . . 4.2 Gremien die interessant sind . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3 Das ISO-OSI-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 29 29 30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii Inhaltsverzeichnis 4.4 4.5 4.6 4.7 Der Link-Layer . . . . . . . . . . . . . . . . . Ethernet . . . . . . . . . . . . . . . . . . . . . 4.5.1 Die zeitliche Entwicklung des Ethernet 4.5.2 Erfolg mal anders. . . . . . . . . . . . 4.5.3 Arbeitsweise des CSMA/CD . . . . . 4.5.4 Der Backoff-Algortihmus . . . . . . . . Versionsunterschiede . . . . . . . . . . . . . . Andere Protokollarten kurz angeschnitten . . 5 Internet Protocol (IP) 5.1 IP Header . . . . . 5.2 Der Befehl ifconfig 5.3 Der Befehl netstat 5.4 Die Zukunft des IP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 Address Resolution Protocol (ARP) 6.1 ARP (Address Resolution Protocol) . . . . . 6.1.1 Funktionsprinzip des ARPs . . . . . . 6.1.2 ARP-Cache . . . . . . . . . . . . . . . 6.1.3 ARP-Format . . . . . . . . . . . . . . 6.2 RARP (Reverse Address Resolution Protocol) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 33 33 33 34 35 36 36 . . . . 39 40 44 45 45 . . . . . . . . . . . . . . . . . . . . 47 47 47 48 49 51 7 Prüfsummen im Internet Protocol – Internet Checksum 7.1 Prüfsummen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7.2 Prüfsummen im IP (Internet Protocol) . . . . . . . . . . . . . . . . . . 7.3 Ermittlung und Kontrolle der Prüfsumme . . . . . . . . . . . . . . . . 7.3.1 Prüfsummenberechnung beim Sender eines Datenpaketes . . . 7.3.2 Kontrolle der Prüfsumme beim Empfänger eines Datenpaketes 7.4 Eigenschaften des Prüfsummen-Operators . . . . . . . . . . . . . . . . 7.5 1er-Komplement-Addition . . . . . . . . . . . . . . . . . . . . . . . . . 7.5.1 Addition mit Übertrag . . . . . . . . . . . . . . . . . . . . . . . 7.5.2 Addition ohne Übertrag . . . . . . . . . . . . . . . . . . . . . . 7.5.3 Komplement-Addition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 53 53 54 54 54 54 55 56 56 57 . . . . . . . . . . . . 59 59 59 60 61 62 71 71 72 75 75 75 75 . . . . . . . . . . . . . . . 8 Internet Control Message Proctocol (ICMP) 8.1 Internet Control Message Protocol . . . . . . . . . 8.1.1 Einleitung . . . . . . . . . . . . . . . . . . . 8.1.2 ICMP-Prinzipien . . . . . . . . . . . . . . . 8.1.3 ICMP-Spezifikationen - Nachrichtenformat 8.1.4 ICMP-Spezifikationen - Typen . . . . . . . 8.1.5 Typenbetrachtung . . . . . . . . . . . . . . 8.1.6 Zusammenfassung . . . . . . . . . . . . . . 8.2 ICMP auf Anwendungsebene: ping . . . . . . . . . 8.3 ICMP-Schwachstellen . . . . . . . . . . . . . . . . 8.3.1 Denial of Service . . . . . . . . . . . . . . . 8.3.2 Ping of Death . . . . . . . . . . . . . . . . . 8.3.3 Redirect - Umleiten von Daten . . . . . . . iv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Inhaltsverzeichnis 8.3.4 Abhilfe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 9 IP Routing 9.1 IP-Routing . . . . . . . . . . 9.1.1 Statisches Routing . . 9.1.2 Traceroute . . . . . . 9.1.3 Dynamisches Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77 77 77 81 83 10 User Datagram Protocol (UDP) 10.1 Ein kurzer Überblick . . . . 10.2 Aufbau . . . . . . . . . . . 10.3 Checksum . . . . . . . . . . 10.4 Ports . . . . . . . . . . . . . 10.5 UDP & ICMP . . . . . . . 10.6 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85 85 86 86 87 87 87 11 IP Fragmentation 11.1 Überblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Der IP-Header . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Aufteilung in Fragmente . . . . . . . . . . . . . . . . . . . . 11.4 Fragmentation und ICMP . . . . . . . . . . . . . . . . . . . 11.4.1 Type 3, Code 4 - Fragmentation needed, but DF set. 11.4.2 Type 11, Code 1 - Reassembly time exceeded. . . . . 11.5 RFC 1812: Anforderungen an Router . . . . . . . . . . . . . 11.6 MTU Path Discovery . . . . . . . . . . . . . . . . . . . . . . 11.7 Probleme durch Fragmentation . . . . . . . . . . . . . . . . 11.8 Fragmentation und Angriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89 89 89 91 92 92 92 92 93 94 94 12 Domain Name System (DNS) 12.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . 12.2 Die Theorie des DNS . . . . . . . . . . . . . . . . . . . 12.2.1 Alternative zu DNS: die host-Datei . . . . . . . 12.2.2 Die Geschichte des DNS . . . . . . . . . . . . . 12.2.3 Die Organisation des DNS . . . . . . . . . . . . 12.2.4 Der Begriff der Zone . . . . . . . . . . . . . . . 12.2.5 Verschiedene Arten von Nameservern . . . . . 12.3 Die Namensauflösung . . . . . . . . . . . . . . . . . . . 12.3.1 Der Resolver . . . . . . . . . . . . . . . . . . . 12.3.2 Rekursive DNS-Queries . . . . . . . . . . . . . 12.3.3 Iterative DNS-Queries . . . . . . . . . . . . . . 12.4 Die Resource Records . . . . . . . . . . . . . . . . . . 12.5 Das DNS-Protokoll . . . . . . . . . . . . . . . . . . . . 12.5.1 Codierung des Domainnamens . . . . . . . . . 12.5.2 DNS-Header . . . . . . . . . . . . . . . . . . . 12.5.3 DNS-Question . . . . . . . . . . . . . . . . . . 12.5.4 DNS-Answer, DNS-Authority, DNS-Additional 12.6 nslookup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95 95 95 96 96 97 98 99 100 100 100 101 101 103 103 104 105 106 107 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v Inhaltsverzeichnis 13 Transmission Control Protocol (TCP) 109 14 TCP Flow Control und Congestion Avoidance 14.1 Silly Windows Syndrome . . . . . . . . . . . . . . . . . 14.1.1 Heuristiken gegen das Silly Window Syndrome 14.2 Timer . . . . . . . . . . . . . . . . . . . . . . . . . . . 14.2.1 Retransmission Timer . . . . . . . . . . . . . . 14.2.2 TCP Persist Timer . . . . . . . . . . . . . . . . 14.2.3 Keepalive Timer . . . . . . . . . . . . . . . . . 14.3 Congestion . . . . . . . . . . . . . . . . . . . . . . . . 14.3.1 Congestion Collapse . . . . . . . . . . . . . . . 14.4 End-to-End Congestion Control . . . . . . . . . . . . . 14.4.1 Slow-Start . . . . . . . . . . . . . . . . . . . . . 14.4.2 Congestion Avoidance . . . . . . . . . . . . . . 14.4.3 Fast Retransmit/Fast Recovery Algorithmus . 14.4.4 Beispiel . . . . . . . . . . . . . . . . . . . . . . 14.5 Network-Assisted Congestion Control . . . . . . . . . 14.5.1 Random Early Discard (RED) . . . . . . . . . 14.5.2 Explicit Congestion Notification (ECN) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111 111 112 112 112 116 116 117 118 118 118 119 119 121 123 124 124 15 Telnet und rlogin 15.1 Einleitung . . . . . . . . . . . . 15.2 Telnet-Protokoll . . . . . . . . 15.2.1 Client-Server-Modell . . 15.2.2 NVT ASCII . . . . . . . 15.2.3 Telnet-Kommandos . . . 15.2.4 Option Negotiation . . . 15.2.5 Übertragungsmodi . . . 15.2.6 Beispiel-Session . . . . . 15.3 Rlogin-Protokoll . . . . . . . . 15.3.1 Aufbau der Verbindung 15.3.2 Rlogin-Kommandos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125 125 125 126 127 127 127 128 129 132 133 133 16 File Transfer Protocol (FTP) 16.1 Einführung . . . . . . . . . . . 16.2 FTP Protocol . . . . . . . . . . 16.2.1 The control connection . 16.2.2 The data connection . . 16.3 Data Representation . . . . . . 16.4 FTP Commands . . . . . . . . 16.5 FTP Replies . . . . . . . . . . . 16.6 Connection Management . . . . 16.7 Anonymes FTP . . . . . . . . . 16.8 Ephemeral Data Port . . . . . 16.9 Default Data Port . . . . . . . 16.10FTP Beispiel . . . . . . . . . . 16.11Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135 135 135 136 136 137 138 138 139 140 140 140 142 146 vi Inhaltsverzeichnis 17 Simple Mail Transfer Protocol (SMTP) 17.1 Einleitung . . . . . . . . . . . . . . . . . . . 17.2 E-Mail-Systeme . . . . . . . . . . . . . . . . 17.3 Entwicklung . . . . . . . . . . . . . . . . . . 17.4 Simple Mail Transfer Protocol . . . . . . . . 17.4.1 Nachrichtenformat (RFC 822) . . . . 17.4.2 Das Protokoll (RFC 821) . . . . . . 17.4.3 SMTP-Befehle . . . . . . . . . . . . 17.4.4 Reply codes . . . . . . . . . . . . . . 17.4.5 Relay . . . . . . . . . . . . . . . . . 17.4.6 MX-Records . . . . . . . . . . . . . 17.5 Weiterentwicklung . . . . . . . . . . . . . . 17.5.1 ESMTP - SMTP Service Extensions 17.5.2 MIME . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147 147 147 149 150 150 151 152 153 156 157 158 158 159 18 Hypertext Transfer Protocol (HTTP) 18.1 HTTP . . . . . . . . . . . . . . . . 18.1.1 Allgemeiner Aufbau . . . . 18.2 URL . . . . . . . . . . . . . . . . . 18.3 Client Request . . . . . . . . . . . 18.3.1 Aufbau . . . . . . . . . . . 18.3.2 Methoden . . . . . . . . . . 18.4 Server Response . . . . . . . . . . 18.4.1 Aufbau . . . . . . . . . . . 18.4.2 Status Codes . . . . . . . . 18.5 Header Einträge . . . . . . . . . . 18.6 Beispiele . . . . . . . . . . . . . . . 18.7 Keep-Alive . . . . . . . . . . . . . 18.8 Proxy . . . . . . . . . . . . . . . . 18.8.1 Proxy-Caching . . . . . . . 18.9 HTTP 1.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161 161 162 162 162 163 163 164 164 164 165 166 168 169 169 170 . . . . . . . anfangen? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171 171 171 172 173 173 173 175 175 176 176 177 181 181 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 Internet Relay Chat (IRC) 19.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . 19.1.1 Was ist das IRC und was kann man damit 19.1.2 Die Entstehung des IRC . . . . . . . . . . 19.2 Die Technische Struktur des IRC . . . . . . . . . 19.2.1 Netzaufbau . . . . . . . . . . . . . . . . . 19.2.2 Das IRC-Protokoll . . . . . . . . . . . . . 19.2.3 Nachrichtenformat . . . . . . . . . . . . . 19.2.4 Sendemöglichkeiten . . . . . . . . . . . . . 19.3 Verwendung . . . . . . . . . . . . . . . . . . . . . 19.3.1 Netzübersicht . . . . . . . . . . . . . . . . 19.3.2 Strukturen im IRC . . . . . . . . . . . . . 19.4 Probleme und Risiken des IRC . . . . . . . . . . 19.4.1 Aktuelle Probleme . . . . . . . . . . . . . vii Inhaltsverzeichnis viii KAPITEL 1 Netzwerk-(Ge)Schichten Jörn Clausen Liebe LeserInnen, liebe Studierende, liebe Angehörige! Im Herbst 2001 schrieb ich im kommentierten Vorlesungsverzeichnis zu diesem Seminar: Das Internet ist inzwischen aus dem Alltag vieler Leute nicht mehr wegzudenken. Medien wie EMail oder das WWW werden ebenso selbstverständlich benutzt wie Telefon oder Fax. Und ebenso wie bei diesen klassischen Kommunikationsformen nimmt das Wissen um ihre Funktionsweise und die zugrundeliegenden Techniken ab. Diese Situation ist für den reinen Konsumenten“ dieser ” Medien sicherlich akzeptabel, aber Personen, die unmittelbar mit den neuen Medien arbeiten, können typischerweise von einem Blick unter die Motorhaube“ ” profitieren. Ich konnte ich nicht ahnen, daß das Thema Internet-Protokolle“ ein derart großes Interes” se finden würde. Die Teilnehmerzahl war geradezu überwältigend, und trotz des üblichen Schwunds im Laufe des Semesters konnten auch noch die letzten Vortragenden vor einem beachtlichen Publikum sprechen. Allen Teilnehmern, Vortragenden wie Zuhörenden, Aktiven wie Passiven, sei an dieser Stelle gedankt. Mit diesem Reader (der leider mit etwas Verspätung erscheint) liegt nun endlich auch eine schriftliche Zusammenfassung des Seminars vor. 1 1 Netzwerk-(Ge)Schichten 1.1 Vernetzte Rechner Wie im kVV-Kommentar erwähnt, hat das Internet inzwischen den Weg in unseren Alltag gefunden. Seit etwa Mitte der 90er Jahre des letzten Jahrhunderts haben wir uns allmählich daran gewöhnt, an allen möglichen und unmöglichen Stellen EMail- oder Web-Adressen zu finden. Wir wissen (hoffentlich), was die Netiquette ist, und wir glauben auch nicht mehr, das jemand auf der Tastatur ausgerutscht ist, wenn wir ein :-) sehen. Und dennoch ist das Internet nicht erst zum oben genannten Zeitpunkt entstanden. Und es wurde auch nicht erschaffen, um bunte Bilder, sinnfreie Webseiten und geklaute Musik zu transportieren. Die Geschichte des Internets ist sehr viel älter, und es war ursprünglich zu weit weniger spannenden Zwecken gedacht. Eine ausführliche Beschreibung der Ereignisse kann in [12] nachgelesen werden. Das Internet basiert auf Technologien, die zunächst wenige Rechner über große Strecken miteinander verbinden sollten. Angestoßen wurde die Entwicklung von einem Mitarbeiter des DoD (Department of Defense), dem US-amerikanischen Verteidigungsministerium. Dieser ärgerte sich darüber, daß in seinem Büro vier einzelne Terminals standen, jedes mit einem anderen Großrechner in einem der nationalen Rechenzentren verbunden. Die berechtigte Frage dieses Mitarbeiters war: Reicht denn nicht ein Terminal, mit dem ich mich mit ” jedem der vier Rechner verbinden kann?“ Damit war bereits die erste grundlegende Anwendung in einem Rechnernetzwerk formuliert: Das Arbeiten auf einem entfernten Rechner, das remote login. Einige Jahre später. . . Das DoD hatte inzwischen per Forschungsauftrag das ARPANet entwickeln lassen. Dieses verband zunächst Rechner in den Universitäten, die an seiner Entwicklung beteiligt waren. Im Laufe der Zeit kamen immer mehr Computer an neuen Standorten hinzu, und mehr und mehr Leute waren an der Entwicklung des Netzes beteiligt oder wurden zu seinen Nutzern. Und die Leute entdeckten, daß man mit diesem Netz nicht nur auf den Großrechnern am anderen Ende des Kontinents Forschung betreiben konnte. Schnell entwickelten sich Anwendungen, um Dateien auszutauschen, Nachrichten zu verschicken, oder mit anderen Nutzern zu diskutieren. Im Laufe der Zeit wurden immer mehr Anwendungen entwickelt oder entdeckt“, die man ” in einem Rechnernetz einsetzen kann. Hier nur eine (unvollständige) Auswahl der Möglichkeiten: verteiltes Arbeiten Das oben bereits erwähnte remote login ist einer der grundlegendsten Dienste. Im einfachsten Fall wird dem Benutzer ein virtuelles Terminal zur Verfügung gestellt, mit dem er sich auf einem Computer einloggen kann, als säße er an einem Terminal, das direkt mit diesem verbunden ist. Das X-Window System erlaubt es, eine graphische Arbeitsoberfläche ganz oder teilweise (d.h. einzelne Applikationen) auf einem entfernten Rechner laufen zu lassen. Kommunikation Im Laufe der Zeit haben sich verschiedene Arten der netzbasierten Kommunikation entwickelt, die in den meisten Fällen aber lediglich bereits bestehenden 2 1.1 Vernetzte Rechner Kommunikationsformen nachempfunden wurden. EMail ist das Versenden von elektronischer Post, und inzwischen haben wir auch unter dem Äquivalent zur Werbung per Postwurfsendung zu leiden: Spam. Andere Arten der Kommunikation sind Diskussionen zwischen mehreren Personen, die entweder per EMail (auf Mailing-Listen), in Newsgroups, im IRC oder in Chatrooms ablaufen können. Datentransfer Daten aller Art lassen sich über ein Netzwerk verteilen. Dabei kann es sich um Software, wissenschaftliche Ergebnisse, Literatur und viele andere Dinge handeln. Durch das WWW ist die Bedeutung von FTP und vor allem von anonymous FTP zurückgegangen, trotzdem handelt es sich in vielen Fällen (immer) noch um eine adäquate Technik, um bestimmte Daten allgemein zur Verfügung zu stellen. verteilte Ressourcen Viele Ressourcen, die zum Betrieb eines Computers benötigt werden, besitzen einerseits einen gewissen Anschaffungswiderstand, andererseits ist ihr Betrieb mit administrativer Arbeit verbunden. So kosten Plattenplatz (und vor allem ein dazugehöriges Backup-System), Drucker, Scanner und andere Geräte Geld in der Anschaffung, aber vor allem Geld und Zeit in der Einrichtung und Unterhaltung. In vielen Fällen rentiert es sich daher doppelt, bestimmte Peripherie lediglich einmal anzuschaffen und von mehreren Rechnern nutzen zu lassen. Ein weiterer Vorteil ist eine homogene Arbeitsumgebung: Egal an welchem Rechner man arbeitet, man hat immer die gleichen Daten und kann auf die gleiche Peripherie zugreifen. verteiltes Rechnen Viele aktuelle wissenschaftliche Probleme erfordern einen hohen Rechenaufwand. Massiv Parallele Rechner, die über eine Vielzahl von Prozessoren verfügen, sind in der Regel deutlich teurer, als die gleiche Anzahl Prozessoren in Einzelrechnern. Ausserdem lassen sich Netzwerke von Rechnern besser skalieren und leichter modernisieren. Durch geeignete Software läßt sich ein derartiges Rechnernetz als ein homogenes Rechner-Reservoir“ benutzen. Der Benutzer kann eine Berechnung an” stoßen, hat aber keine Kontrolle darüber, auf welchem (oder welchen) Knoten des Netzwerks die Berechnung ausgeführt wird. Projekte wie SETI haben die Möglichkeiten und Grenzen einer Skalierung solcher Rechnerverbünde auf globaler Ebene gezeigt. Informationssysteme Wie bereits eingangs erwähnt, ist das World Wide Web vor einigen Jahren zu der Killer-Applikation“ geworden, durch die die Allgemeinheit auf das ” Internet aufmerksam wurde. Ein negativer Seiteneffekt dieser Entwicklung ist leider, daß die Begriffe Internet“ und World Wide Web“ häufig synonym verwendet werden. ” ” So ist häufig von Internet-Adressen“ die Rede, wenn eigentlich Web-Adressen (oder ” noch genauer: Uniform Resource Locators, URLs) gemeint sind. Vermutlich muß das Web nicht näher vorgestellt werden: Alle und jeder können im WWW über nahezu beliebige Dinge berichten. Große und kleine Firmen, öffentliche Einrichtungen, Vereine und Interessengruppen aller Art, und viele Privatpersonen betreiben ihre eigenen Websites, auf denen sie die Informationen verbreiten, die sie verbreiten wollen. Jegliche Schätzungen über die Anzahl der existierenden Webseiten dürften mit Unsicherheiten verbunden sein, deren absolute Werte im Bereich von Millionen von Seiten liegen. Und dennoch sind Angebote dieser Art nicht erst mit dem WWW entstanden. Bereits einige Jahre zuvor gab es Gopher, ein rein textbasiertes, hierarchischen System. 3 1 Netzwerk-(Ge)Schichten (a) Bus (b) Ring (c) Stern Abbildung 1.1: Verschiedene Netz-Topologien. Diverse Einrichtungen verbreiteten bereits auf diese Weise Informationen, darunter viele Universitäten, aber z.B. auch die Vereinten Nationen. Und auch ganz andere Protokolle wurden für Informationssysteme mißbraucht“: So konnte man lange Jah” re aktuelle Wetterinformationen erhalten, indem man XXX@YYY anfingerte, und ein telnet auf Port 451 von McKusick.COM lieferte über mehrere Jahre den Zustand des Weinkellers von Marshall Kirk McKusick. Unterhaltung/Spiele Und zu guter Letzt kann man natürlich auch seine Freizeit in Rechnernetzen bzw. im Internet verbringen. Bereits 1978 enstand das erste Multi-User Dungeon. MUDs sind vergleichbar mit textbasierte Adventures. Der entscheidende Unterschied ist, daß man andere, reale Mitspieler treffen kann, die ebenfalls auf der Suche nach einem Schatz, einem Drachen oder Dem Einen Ring sind. Inzwischen hat auch die Spiele-Industrie den Nutzen des Internets erkannt. Der aktuelle Trend sind MPOGs, multiplayer online games, bei denen die Teilnehmer rund um den Globus mit- oder gegeneinander spielen können. Das Bemerkenswerte ist, daß alle diese Anwendungen die gleichen Basis-Technologien verwenden, die Internet-Protokolle. Und auch wenn einige dieser Protokolle allmählich an ihre Grenzen stoßen, die Tatsache, die sie teilweise mehr als 30 Jahre gehalten“ haben, sollte ” Beachtung finden. Jegliche Erweiterung, Erneuerung und jeder Ersatz muß sich an diesem Erfolg messen lassen. 1.2 Rechnernetze Damit Rechner untereinander Daten austauschen können, müssen sie miteinander verbunden sein. Wenn mehrere Rechner gemeinsam miteinander verbunden sind, spricht man von einem Rechnernetz. Im Laufe der Zeit wurden verschiedene Vernetzungsverfahren entwickelt, die unterschiedliche Netz-Topologien verwenden (siehe Abb. 1.1): 4 1.2 Rechnernetze Abbildung 1.2: Zwei Bus-förmige Netze, die durch einen Router miteinander verbunden sind. Bus Bei der in Abb. 1.1(a) gezeigten Struktur sind alle Rechner über eine gemeinsame Datenleitung miteinander verbunden. Jeder Rechner kann mit jedem anderen Rechner kommunizieren. Allerdings können im gesamten Netz immer nur jeweils zwei Rechner gleichzeitig Daten austauschen. Wenn gerade zwei Rechner miteinander reden“ und ” ein dritter Rechner versucht, Daten zu versenden, kommt es zu einer Kollision. Ring In ringförmigen Netzen (siehe Abb. 1.1(b)) wandern die Daten auf der geschlossenen Datenleitung im Kreis. Die angeschlossenen Rechner können zu bestimmten Zeitpunkten Daten in den Ring schicken bzw. für sie bestimmte Daten auslesen. Die Daten bewegen sich immer in der gleichen Richtung durch den Ring. Eine unmittelbare Kommunikation wie im Bus findet daher nicht statt. Stern Bei einer Sternverknüpfung (Abb. 1.1(c)) sind alle Rechner über eine eigene Datenleitung mit einer zentralen Netzwerkkomponente, einem Switch, verbunden. Wenn ein Rechner Daten sendet, stellt der Switch eine temporäre Verbindung mit dem Zielrechner her. Der Switch kann mehrere solcher Verbindungen gleichzeitig verwalten, so daß mehrere unabhängige Paare von Rechnern zur selben Zeit miteinander Daten austauschen können. Die Rechnernetze, die sich mit diesen Technologien aufbauen lassen, sind in ihrer Größe beschränkt. Mit derartigen Netzen lassen sich maximal einige hundert Rechner verbinden, die räumlich nicht allzu weit voneinander getrennt sein dürfen, maximal einige hundert Meter. Um eine größere Anzahl Rechner zu vernetzen, oder um größere Entfernungen zwischen Netzen überbrücken zu können, müssen einzelne Rechnernetze miteinander verbunden werden. Dies geschieht, wie in Abb. 1.2 angedeutet, mit Hilfe eines Routers. Wenn ein Rechner im oberen Netz Daten mit einem Rechner im unteren Netz austauschen will, sorgt der Router für den Transfer der Daten zwischen den beiden Netzen. Andere Daten, die zwischen zwei Rechnern eines Teilnetzes ausgetauscht werden, werden nicht in das jeweils andere Netz übertragen. Durch die Verknüpfung mehrerer Netze können auf diese Weise Verbünde von Netzwerken geschaffen werden, sogenannte internets. Als Internet (mit großem I“) bezeichnet man ” 5 1 Netzwerk-(Ge)Schichten das globale Netz, das durch die Verknüpfung vieler einzelner Teilnetze weltweit entstanden ist. Gemeinsames Merkmal aller Teilnetze ist, daß in ihnen die Internet-Protokolle zur Kommunikation eingesetzt werden. 1.3 Datenpakete Die Kommunikation zwischen zwei Rechnern kann prinzipiell auf zwei Arten erfolgen: Verbindungsorientiert und verbindungslos. Bei der verbindungsorientierten Kommunikation erfolgt der Austausch der Daten über eine dedizierte Verbindung, die speziell für diese Kommunikation bereitgestellt wird. Dies ist vergleichbar mit dem Telefonsystem, bei dem zunächst eine Verbindung aufgebaut werden muß, bevor Sprache oder Daten übertragen werden können. Im Gegensatz dazu wird bei einer verbindungslosen Kommunikation keine direkte Verbindung aufgebaut. Die Daten werden über Zwischenstationen (üblicherweise Router) vom Absender zum Empfänger transportiert. Dabei versucht jeder Router, einen günstigen nächsten Empfänger der Daten auszuwählen, um die Daten zum Ziel zu bringen. In aller Regel kann der Absender den genauen Weg der Daten nicht bestimmen oder ermitteln. Vor der Übertragung werden die Daten in Pakete zerteilt. Jedes Paket wird einzeln und unabhängig von anderen Paketen an den Empfänger geschickt. Dort müssen die einzelnen Fragmente wieder zusammengesetzt werden, um die Ausgangsdaten zu erhalten. Dabei hat der Empfänger zu beachten, daß die Pakete in einer anderen Reihenfolge eintreffen können, als sie beim Absender abgeschickt wurden. Außerdem können einzelne Pakete verloren gegangen sein, oder es können Pakete dupliziert worden sein. Sender und Empfänger versuchen, solche Fehlerzustände festzustellen, was aber nicht immer möglich ist. Alle Kommunikationsteilnehmer versuchen, die Daten so weiterzuleiten, daß sie den gewünschten Empfänger erreichen. Es kann aber nicht garantiert werden, daß dies auch tatsächlich gelingt. Dieses Vorgehen wird als best effort“ bezeichnet. ” 1.4 Netzwerk-Schichten Um die Kommunikation in einem Rechnernetz zu ermöglichen, existieren verschiedene Protokolle, die jeweils unterschiedliche Aspekte des Datentransports behandeln. Die Protokolle sind in Schichten angeordnet, wie in Abb. 1.3 gezeigt. Die Internet-Protokolle werden typischerweise in die folgenden vier Schichten unterteilt: link layer Die Verbindungsschicht beschreibt die physikalische Verbindung eines Rechners mit einem Netzwerk. Durch die Beschaffenheit des Übertragungsmediusm werden in dieser Schicht üblicherweise Eigenschaften wie Übertragungsgeschwindigkeiten oder 6 1.4 Netzwerk-Schichten application DNS, telnet, SMTP, HTTP transport TCP, UDP network IP, ICMP link Ethernet, ARP/RARP Abbildung 1.3: Netzwerk-Schichten minimale und maximale Paketgrößen festgelegt. In dieser Schicht sind Protokolle wie Ethernet oder PPP angesiedelt. network layer Die Netzwerkschicht sorgt für den Transport von Datenpaketen im Netzwerk. Wenn sich zwei Kommunikationspartner in unterschiedlichen Teilnetzen befinden, sorgen die Protokolle der Netzwerkschicht dafür, daß die Daten zum Empfänger geroutet werden. In dieser Schicht befindet sich u.a. das Internet Protocol (IP). transport layer Die Transportschicht ermöglicht den Austausch von Daten zwischen zwei Rechnern. Einige Protokolle dieser Schicht abstrahieren von der Paket-orientierten Kommunikation der Netzwerkschicht. Sie ermöglichen einen scheinbar konstanten und fehlerfreien Datenstrom zwischen zwei vernetzten Rechnern. Ein derartiges Protokoll ist das Transport Control Protocol (TCP). application layer In der Anwendungsschicht befinden sich die Protokolle verschiedener Dienste. Dies sind Protokolle wie telnet oder HTTP. Jede Schicht baut auf den Protokollen der darunterliegenden Schicht auf. So verwenden die Protokolle des application layer die Protokolle des transport layer. Diese Anordnung der Protokolle in Schichten hat vor allem zwei Gründe: • Eine Applikation (bzw. ihr Programmierer) muß sich nicht um Dinge wie Routing oder die physikalischen Eigenschaften eines Übertragungsmediums kümmern. Der transport layer abstrahiert von diesen Problemen, und stellt einheitliche Mechanismen zur Verfügung, Daten von einem Rechner zu einem anderen zu transportieren. Der Programmierer muß nicht für jede Anwendung das Rad neu erfinden“. ” • Durch die klare Trennung in Schichten lassen sich leichter Änderungen vornehmen, z.B. neue Protokolle etablieren. Wenn ein neues Protokoll in der Verbindungsschicht eingeführt wird, muß in der Netzwerkschicht eine Anpassung daran vorgenommen werden. Die Protokolle der Transport- oder Applikationsschicht sollten von dieser Änderung aber nicht betroffen sein, bestehende Applikationen sollten also weiterhin funktionieren. 7 1 Netzwerk-(Ge)Schichten ftp-Protokoll application transport network link ftp ftp TCP-Protokoll TCP IP-Protokoll IP Ethernet Ethernet-Protokoll Rechner 1 TCP IP Ethernet Rechner 2 Abbildung 1.4: Kommunikation zwischen den Schichten ftp ftp TCP TCP IP Ethernet Rechner 1 IP IP Ethernet Ethernet Router Ethernet Rechner 2 Abbildung 1.5: Routing in der Netzwerkschicht In Abb. 1.4 ist schematisch dargestellt, wie zwei Rechner Daten per ftp austauschen. Die Daten fließen vom ftp-Client auf dem einen Rechner durch dessen Transport-, Netzwerkund Verbindungsschicht, um auf dieser letzten Ebene zum zweiten Rechner übertragen zu werden. Dort fließen die Daten wieder durch die Protokollschichten nach oben, bis sie im ftpServer verarbeitet werden können. Die scheinbare Sicht für jede Protokoll-Ebene wird durch die horizontalen Pfeile angedeutet: Für den ftp-Client sieht es so aus, als würde er direkt mit dem ftp-Server kommunizieren. Ebenso scheinen sich die beiden TCP-Implementierungen auf den beiden Rechnern direkt“ miteinandern zu verständigen. ” Wenn sich der Zielrechner nicht im gleichen Netz befindet wie der Quellrechner, sondern in einem Netz, das über einen Router erreicht werden kann, stellt sich die Situation wie in Abb. 1.5 dar. Die Daten müssen innerhalb des Routers von einem Netzwerk-Interface zu einem anderen weitergereicht werden. Dazu besitzt der Router intern eine Implementierung eines Netzwerkschicht-Protokolls, in diesem Fall IP. In der Transport- und der Anwendungs- 8 1.5 Datenkapselung user data Eth. header app. header user data TCP header app. header user data IP header TCP header app. header user data IP header TCP header app. header user data Eth. trailer Abbildung 1.6: Kapselung der Daten beim Transport schicht treten gegenüber Abb. 1.4 keine Unterschiede auf. Diese Schichten bemerken“ den ” Router garnicht. Aus der Sicht des ftp-Clients ist es vollkommen unerheblich, ob sich der Zielrechner im gleichen Netz befindet, oder in einem anderen Netzwerk. Neben dem hier gezeigten Modell mit vier Schichten gibt es andere Netzwerk-Modelle. Das ISO-OSI-Modell verwendet sieben Netzwerk-Schichten, in die sich die einzelnen Protokolle einordnen lassen. Einige der Schichten besitzen eine Entsprechung im gezeigten Vier-Schichten-Modell, andere kommen neu hinzu. So existiert unterhalb des link layers eine physikalische Schicht, die z.B. Signal-Pegel beschreibt, also deutlich hardware-näher ist als der link layer. 1.5 Datenkapselung Das Ziel der ftp-Verbindung im vorherigen Abschnitt ist der Transport von Daten von einem Rechner zum anderen. Tatsächlich werden aber viel mehr Informationen übertragen, als die eigentlichen Nutzdaten. Jedes Protokoll, das beim Durchlaufen der Schichten verwendet wird, erweitert das zu transportierende Datenpaket um einen header, manche Protokolle hängen zusätzlich noch einen trailer an (siehe Abb. 1.6). Der header beschreibt die Daten, und wie sie weiterzuverarbeiten sind. Header enthalten typischerweise Zieladressen, Längeninformationen oder Prüfsummen. Damit können die Daten dem richtigen Empfänger zugestellt werden, der sie dann extrahieren und auf ihre Korrektheit überprüfen kann. Das Datenpaket durchläuft auf dem Zielrechner die Protokoll-Schichten in umgekehrter Reihenfolge, und jede Schicht schält“ die enthaltene Nutzlast heraus, um sie an die nächsthöhere ” Schicht weiterzureichen. 9 1 Netzwerk-(Ge)Schichten 10 KAPITEL 2 Organisationen im Internet Anja Durigo, Christina Partzsch Organisationen im Internet Internet Society (ISOC) http://www.isoc.org Die Internet Society wurde im Juni 1992 gegründet und ist eine internationale Non-ProfitOrganisation für akademische, forschungs- und lehrebezogene sowie gemeinnützige Belange. Die ISOC befasst sich mit dem Wachstum und der Entwicklung des weltweiten Internet und der Art, wie das Internet benutzt wird. Neben sozialen, politischen und technischen Fragen im Zusammenhang mit dem Internet beschäftigt sich die Internet Society vornehmlich mit PR-Arbeiten. Die ISOC ernennt die Mitarbeiter des Internet Architecture Boards, welche der Nominierungs-Ausschuss des Internet Engineering Task Force vorschlägt. Internet Architectur Board (IAB) http://www.iab.org 11 2 Organisationen im Internet Zu den Aufgaben des Internet Architectur Board zählt die Beratung der Internet Society. Sie ernennt des weiteren den Vorsitzenden der Internet Engineering Steeling Group. Das Internet Architecture Board setzt Maßstäbe für Entwicklung und Dokumentation, insbesondere der Request For Comment Serien. Internet Engineering Task Force (IETF) http://www.ietf.org Die Internet Engineering Task Force ist ein Teil des Internet Architecture Board (IAB) und kann als eine offene, internationale Gemeinschaft angesehen werden. Eine Aufgabe der IETF ist es, technische Standards im Internet vorzuschlagen. Weiter ist sie zuständig für das Internet Protokoll Engineering und die anschliessend notwendige Standardisierung. Die IETF ist in folgende acht Gebiete aufgeteilt: 1. Anwendungen (Applications) 2. Internet 3. IP: Next Generation 4. Netzwerkmanagement (Network Management) 5. Betriebliche Anforderungen (Operational Requirements) 6. Routing 7. Sicherheit (Security) 8. Transport- und Anwenderdienste (Transport and User Services) Jedes Gebiet hat ein oder zwei Gebiet-Direktoren. Die Gebiet-Direktoren, zusammen mit dem IETF/IESG Vorsitzenden, bilden die IESG. Jedes Gebiet hat mehrere Working Groups (Arbeitsgruppen), die, sobald eine Arbeitsgruppe ihr Ziel erreicht hat, wieder aufgelöst wird. Als Teil des Internet Architectur Board befasst sichder IETF mit der Entwicklung des Internet und dessen reibungslosen Funktionieren. Hierfür sorgen viele internationale Designer, Forscher, sowie Betreiber und Anbieter von Netzwerken. Da es sich um eine offene Gemeinschaft handelt, kann jeder Interessent Mitglied werden. Internet Engineering Steering Group (IESG) Jedes Gebiet der IETF hat zwei Gebiet-Direktoren. Die Gebiet-Direktoren, zusammen mit dem IETF-Vorsitzenden, bilden die IESG. 12 Jedes Gebiet hat mehrere Arbeitsgruppen, eine Working Group, die auf ein ganz bestimmtes Ziel hinarbeitet. Das Ziel kann ein informatives Dokument, die Schöpfung einer ProtokollSpezifizierung, oder der Entschluss von Problemen im Internet sein. Die meisten Arbeitsgruppen haben eine endliche Lebenszeit. Das heisst, sobald eine Arbeitsgruppe ihr Ziel erreicht hat, wird sie aufgelöst. Ein Mitglied einer Arbeitsgruppe ist jemand, der die Mailingliste der Arbeitsgruppe abonniert hat. Es ist jedermann erlaubt eine Arbeitsgruppensitzung zu besuchen. Gebiete können auch Birds of a Feather (BOF) sessions haben (das sind spontane Arbeitsgruppensitzungen), diese haben die gleichen Ziele wie Arbeitsgruppen allgemein, ausgenommen, dass sie keine spezielles Ziel haben und nur ein oder zwei mal zusammenkommen. BOFs werden oft gehalten, um zu entscheiden, ob genug Interesse zum Bilden einer Arbeitsgruppe vorhanden ist. Die Internet Engineering Steering Group (IESG) ist verantwortlich für das technische Management der IETF Aktivitäten und für die Internet Standards. Aufgabe der IESG ist es, den Prozess der Entwicklung zu verwalten. Weiter ist sie direkt verantwortlich für die Handlungen, die mit Eintragung in und Ausführung der Internet Standards verbunden werden. Internet Research Steering Group (IRSG) Die Internet Research Steering Group (IRSG) steuert und koordiniert die Arbeiten der IRTF. Die IRSG besteht aus dem Vorsitzenden des IRTF, den Vorsitzenden der verschiedenen Forschungsgruppen und weiteren Personen der Forschungsgemeinschaft. Internet Research Task Force (IRTF) Das Ziel der Internet Research Task Force ist die Förderung der Forschung im Hinblick auf das Wachstum und die Zukunft des Internets. Um das zu erreichen ist die Zusammensetzung der IRTF so organisiert, das sie aus kleineren Forschungsgruppen zusammengesetzt ist. Folgende Forschungsgruppen sind derzeit gebildet: • End-to-End • Information Infrastructure Architecture • Privacy and Security 13 2 Organisationen im Internet • Internet Resource Discovery • Routing • Services Management • Reliable Multicast Internet Assigned Numbers Authority (IANA) http://www.iana.org Die Internet Assigned Numbers Authority war die zentrale Koordinationsstelle für InternetProtokolle. Diese wurde durch die Regierung der USA unterstützt. Die IANA war zuständig für die Vergabe von IP-Adressen und Domain-Namen. Die USA hatte dann keine weiteren Geldmittel bereitgestellt, da das Internet zu einem Forschungsnetz von Hochschulen und der Allgemeinheit geworden ist. Somit musste eine neue Form dieser Organisation gefunden werden. Demnach ist die IANA in der ICANN aufgegangen. Réseaux IP Européens (RIPE) http://www.ripe.net Die Reseaux IP Europeens ist ein Zusammenschluß europäischer Netze. Das RIPE Network Coordination Centre ist zuständig für Verwaltung und Registrierung von IP-Adressen. Deutsches Forschungsnetz (DFN) http://www.dfn.de Der DFN wurde 1984 vom Bundesministerium für Forschung und Technologie gegründet und ist Betreiber des Wissenschaftsnetzes WIN. Ziele des DFN sind wissenschaftliche Daten auszutauschenund deren Forschungsergebnisse im Internet zu publizieren. Der DFN will desweiteren Lösungen zu Sicherheits- oder allgemeinen Netzproblemen zu finden. Der Verein ist ein Zusammenschluß deutscher Hochschulen, Forschungseinrichtungen und privater Wirtschaftsunternehmen und wurde ins Leben gerufen, um zum einen wissenschaftliche Daten auszutauschen und Forschungsergebnisse im Internet zu publizieren und zum anderen, um Lösungen zu Sicherheits- oder allgemeinen Netzproblemen zu finden. 14 International Network Information Center (InterNIC) http://www.internic.net Die InterNIC ist eine internationale Vergabestelle für Domain-Namen und wurde 1993 gegründet. Die InterNIC Registration Service (NIC = Network Information Center) ist die ausführende Organisation, welche die Verwaltung der Internet-Adressen und Domainnamen im Auftrag der IANA organisiert. Die InterNIC beinhaltet drei Organisationen: • dem Information-Services (von General Atomics betrieben)- diese stellt Informationen zur Verfügung (z.B. alle RFCs, Materialien der ISOC und IETF) • Directory-Services (AT&T)- diese führt Listen von Hilfsquellen, wie z.B. FTPAdressen, Listen von Servern, Kataloge von Bibliotheken und Datenarchiven • Registry-Services (Network Solutions Inc.) - diese weist Domain-Namen und IPAdressen zu Um den Informationsdurst der Internet-Anwender zu stillen, wird von der NSF das Internet Network Information Center gegründet, welches eigentlich aus drei Organisationen besteht. Zum einen gibt es die Information-Services, die eine Vielzahl von Dokumenten, z.B. alle RFCs, Materialien der ISOC und IETF und andere Dokumente zur Verfügung stellt und von General Atomics betrieben wird. Der zweite Dienst sind die sogenannten DirectoryServices, welche Listen von Hilfsquellen, z.B. FTP-Adressen, Listen von Servern, Kataloge von Bibliotheken und Datenarchiven bereitgestellt. Die Aufgaben des Directory-Services die Domain-Namen und IP-Adressen des Internet zugewiesen. Diese Aufgabe wird von Network Solutions INc. ausgeführt. Im Januar 2001 wurden die Rechte der InterNIC an die ICANN übertragen. Internet Corporation for Assigned Names and Numbers (ICANN) http://www.icann.org Die Internet Corporation for Assigned Names and Numbers ist eine 1998 gegründete NonProfit-Organisation mit Sitz in Kalifornien. Sie hat Teilaufgaben der IANA übernommen. Die ICANN regelt die Vergabe und Verwaltung von Domain-Namen und sorgt für einheitliche technische Grundlagen und Standards im Netz. Weiter beschließt sie die Zulassung von Top-Level-Domains (7 neue im Nov. 2000) und betreibt den A-Root-Server. Die ICANN besteht aus einem internationalen Verwaltungsrat, dieser ist zusammengesetzt aus Repräsentanten einer Wählerschaft und weiteren internationalen Repräsentanten. 15 2 Organisationen im Internet Deutsches Network Information Center (DE-NIC) http://www.denic.de Die Denic ist der NIC untergeordnet. Sie wurde 1994 am Rechenzentrum der Universität Karlsruhe gegründet. Zu ihren Aufgaben gehört die Verwaltung der Vergabe der Namensräume innerhalb Deutschlands und Koorfination der Verteilung der Internetnummern. Desweitern betreibt die DE-NIC den Primary Nameserver für die Bundesrepublik. Die Verwaltung der deutschen Internet Funktionsweise des Internet basiert auf einer eindeutigen Vergabe von Rechnernummern. Dafür ist in jedem Land eine bestimmte Organisation, das Network Information Center, verantwortlich. Für Deutschladn wird diese Aufgabe vom DE-NIC übernommen. Die DE-NIC arbeitet eng mit den Internetanbietern zusammen, ist jedoch völlig unabhängig von ihnen. Der sogenannte Primary Nameserver hat die Aufgabe, dass über diese Maschine alle am Internet angeschlossenen Rechner Auskunft über die Adressen sämtlicher Rechner im deutschen Teil des Internet erhalten. W3-Konsortium http://www.w3.org 1994 gegründete Organisation, die speziell die Weiterentwicklung technischer Standards des World Wide Web koordiniert (z.B. HTML oder das HTTP-Protokoll). Drei Institute gehen im W3C auf: Das Massachusetts Institute of Technology Laboratory for Computer Science [MIT/LCS] in den USA, das Institut National de Recherche en Informatique et en Automatique [INRIA] in Europa und die Keio University Shonan Fujisawa Campus in Japan. Das W3C liefert Informationen über das WWW und Standards, entwickelt Referenzcode und -Implementationen und liefert verschiedene Prototypen und Beispiel-Anwendungen. Direktor des W3C ist Tim Berners-Lee, Erfinder des World Wide Web. Das W3C wird durch seine Mitgliedorganisationen unterstützt, ist aber unabhängig von ihnen. Mit der WebGemeinschaft zusammen werden Produktspezifikationen und Software erarbeitet, welche dann weltweit frei zur Verfügung gestellt werden. 16 KAPITEL 3 Request for Comments Sven Kanies, Stefan Vitz 3.1 Was RFCs sind RFCs (Request of Comments) sind technische Dokumente, auf denen das Internet aufbaut. Ihr Ziel ist es, eine bestimmte Position oder einen Vorschlag öffentlich zur Diskussion zu bringen, damit ihn andere Personen kommentieren können. Ohne diese Dokumente wäre ein funktionierender Betrieb des Internets praktisch unmöglich. RFCs werden meist als Standards für das Internet“ bezeichnet, was teilweise richtig, aber auch teilweise falsch ” ist. Alle sogenannten Internet Standards sind zwar als RFCs veröffentlicht, aber nur ein (kleiner) Teil von ihnen sind echte Standards, was in den meisten RFCs auch immer wieder gerne ausdrücklich betont wird. Neben ihrer Funktion als Standardisierungsmedium sind die RFCs noch der offizielle Veröffentlichungskanal solch wichtiger Organisationen wie der IESG, IAB und der Internet Society. Sie decken zusätzlich zu den Internet Standards einen weiten Bereich an Themen ab, von frühen Diskussionen neuer Forschungskonzepte bis hin zu Zustandsbeschreibungen des Internets. RFCs sind eine Reihe von durchnummerierten Dokumenten, die verschiedene Gewohnheiten (tatsächliche und vorgeschlagene) beschreiben, die einen Bezug zum Internet haben und von der IETF herausgegeben werden. Sie werden aber auch von anderen Institutionen wie Firmen, Universitäten und sogar von Privatleuten genutzt, um zum Beispiel Vorschläge für neue Standards oder Bewertungen bereits bestehender oder sich im Standardisierungsprozess befindender Protokolle der breiten Öffentlichkeit zugänglich zu machen. Grundsätzlich kann jeder ein Dokument einreichen, welches als RFC gedacht ist. 17 3 Request for Comments Es müssen nur einige grundsätzliche Regeln beachtet werden, die unter anderem ausführlich in RFC 2223 Instructions to RFC Authors“ erläutert werden. Die Dokumente werden ” von einer Arbeitsgruppe der IETF und/oder dem RFC-Editor geprüft. Dabei durchläuft das Dokument verschiedene Stufen, die Stufen der Entwicklung, Testung und Akzeptanz. Die Stufen bilden den sogenannten Standardisierungsprozess. Die Stufen werden formal als maturity levels“ (Reifestufen) bezeichnet. (Mehr dazu in Kapitel 3.4 - Der Internet ” ” Standard Track“ dieser Ausarbeitung). Der größte Teil der RFCs behandelt technische Festsetzungen und Übereinkommen, die sogenannten Protokolle. Protokolle sind für die Zusammenarbeit der Systeme unentbehrlich; Programme, die untereinander Daten austauschen, müssen auf einigen Übereinstimmungen hinsichtlich des Datenformates und verwandten Themen beruhen. Während einige RFCs Standards festlegen sind andere rein informativer Natur. Von diversen Scherz-RFCs, bevorzugt am 1.4. eines Jahres veröffentlicht, soll hier abgesehen werden, sie sollen auch im Folgenden wenig Beachtung finden. Als Herausgeber der RFCs kann man den RFC-Editor ansehen. Dieser kann durch eine Person oder auch durch eine Gruppe verkörpert werden und ist Teil des IAB. Früher hatte Jon Postel diese Stellung inne, doch inzwischen ging das Amt an die Networking Division des USC Information Sciences Institute (ISI) in Marina del Rey (CA.) über, deren Direktor Jon Postel lange Zeit war. Eine Besonderheit der RFCs ist, dass sie, einmal veröffentlicht, nie verändert oder aktualisiert werden können. Man kann nur ein neues RFC herausbringen, welches das alte ersetzt. Bei einer Ersetzung wird das alte RFC mit der Bezeichnung Obsoleted by ” RFC xxx“ gekennzeichnet, das neue RFC beinhaltet einen Hinweis Obsolets RFC xxx“ ” auf das alte RFC. Korrekturen an einem RFC werden durch Updates RFC xxx“ und ” Updated by RFC xxx“ gekennzeichnet. ” Auf der Homepage des RFC-Editors (http://www.rfc-editor.org) findet man kostenlos zugänglich alle bisher veröffentlichten RFCs und hat die Möglichkeit, die einzelnen RFCs einzusehen und herunterzuladen. So dienen RFCs z.B. Systembetreuern und Programmierern als qualitativ hochwertige Informationsquelle. 3.2 Entstehungsgeschichte Am 7.4.1969 verfasste der Student Steve Crocker einen Artikel Host Software“. Am UCLA ” (University of California, Los Angeles) sollte der erste IMP des ARPANET aufgestellt werden und eine kleine Gruppe von Informatikern hatte sich zur Aufgabe gemacht, die notwendigen Protokolle zu entwerfen, die für die Kommunikation der Groß-Rechner untereinander und mit dem IMP notwendig waren. Steve Crocker war damals Mitarbeiter an der UCLA und Teil dieser Gruppe. Sein Artikel war die Zusammenfassung eines Treffens der NWG (Network Working Group). Steve Crocker hatte erkannt, dass viele der Mitarbeiter noch Studenten waren und eine übergeordnete Autorität fehlte. Er suchte einen Weg, den Fortgang der Arbeiten zu dokumentieren und machte mit seinem Artikel den Anfang. Um keinen offiziellen Anspruch zu erheben und um zur öffentlichen Diskussion seines Vorschlages aufzurufen, nannte 18 3.2 Entstehungsgeschichte er die Dokumentation einfach Request for Comments“ (zu Deutsch etwa sinngemäß: ” Kommentare erwünscht“). Er schuf damit eine bis dahin nicht gekannte Plattform ” wissenschaftlichen Meinungsaustausches. Seinem Beitrag folgten Diskussionen verschiedenster Protokollvorschläge für Netzwerke, die anfangs gemäß ihres Erscheinungsdatums nummeriert wurden. Abbildung 3.1: RFC-Veröffentlichungen pro Jahr seit 1969 Die Bedeutung, die die RFCs in den Folgejahren erlangt haben, sei nur am Beispiel des im ARPANET verwendeten Protokolls aufgezeigt werden: Im Februar des Jahres 1970 wurde im RFC 33 New HOST-HOST Protocol“ erstmals über ein neues Protokoll berichtet, ” welches von den Knotenrechnern im ARPANET benutzt werden sollte. Die Diskussion über das neue Network Control Protocol“ (NCP) zog sich über 6 Monate hin und wurde ” noch in etlichen anderen RFCs (36, 39, 44, 45, 46, 47, 53, 54, 55 und 57) diskutiert. Letztendlich ging aus dieser Diskussion im Juli das Simplified NCP“ hervor und wurde als ” Standardprotokoll für das ARPANET übernommen. Dieses Beispiel soll verdeutlichen, welche Wichtigkeit die RFCs auch in den ersten Jahren des Entstehens des ARPANET hatten. Erst 1983 schuf man im Internet Activities Board (IAB) die Stelle eines RFC Editors“, ” die die eingehenden Diskussionsbeiträge erst nach einer eingehenden Begutachtung zur Veröffentlichung als RFC freigab. Diese Stelle nahm in den Anfangsjahren bis zu seinem Tod Jon Postel ein. So beugte er viele Jahre der wachsenden Flut an halbherzigen“ ” Ausarbeitungen vor. Die Bedeutung der RFCs wird durch die Fülle der standardisierten Protokolle verdeutlicht, die im Laufe der Zeit aus ihnen hervor gegangen sind. Im Oktober 1994 wurde das erste Internet Standard RFC (STD 1) veröffentlicht. Im August 1995 folgte das erste Best Current Practices RFC (BCP 1). Diese Nebenserien werden im nächsten Kapitel das Ausarbeitung ausführlich vorgestellt. 19 3 Request for Comments Abbildung 3.2: Die sogenannten Internetpioniere“ Jon Postel, Steve Crocker und Vint ” Cerf bei ihrer Arbeit am ARPAnet. 3.3 RFC-Nebensereien 3.3.1 STD-Serie Hier sind alle RFCs enthalten, die einen gültigen Standard beschreiben. Wird ein neuer Standard angenommen, bekommt er zusätzlich zu seiner RFC-Nummer noch eine Nummer der Nebenserie in der Form STD xxx. Wenn einmal einem Standard eine STD-Nummer zugewiesen wurde, so bleibt diese gleich. Allerdings kann das Referenz-RFC, in dem der Standard beschrieben ist, durch ein neues ersetzt werden. Technical Standart (TS) In solchen Dokumenten werden u. a. Protokolle, Services und Prozeduren beschrieben. Es wird nur auf die technische Seite wie z.B. Befehle und Aufbau des Protokolls Wert gelegt. Allerdings wird meistens noch eine Bemerkung über den Einsatzbereich und den Zweck der Spezifikation angefügt. Appliciability Statement (AS) Beinhaltet ein oder mehrere TS und legt fest, wie sie angewendet werden (u. a. auch die Bedingungen der Implementierung) · Anmerkung: Ein AS darf keinen höheren MaturityLevel haben als die TS, auf die es sich bezieht. Außerdem weist das AS den bezogenen TS einen Requirement Level“ zu: ” 20 3.3 RFC-Nebensereien required Das TS ist unbedingt erforderlich (IP ICMP in TCP/IP) recommened Es empfiehlt sich, das TS zu implementieren, da die Erfahrung es zeigt und/oder allgemein akzeptiertes technische Wissen es Nahe legt. Herstellern wird es stark empfohlen die Protokolle der empfohlenen TSs in ihre Produkte zu integrieren. Ausnahmen sollten durch einen speziellen Umstand gerechtfertigt sein. (z.B. sollte das telnet Protokoll durch alle Systeme eingeführt werden, die vom Remote access“ ” profitieren würden) elective Die Implementierung des entsprechenden TS ist, innerhalb des Gebietes der Anwendbarkeit des AS, optional. Es liegt im Ermessen des Herstellers sie einzuführen bzw. des Benutzers sie als notwendig, für die eigenen Zwecke einzustufen. Für TS, die aus dem Standardisierungsprozess ausgeschieden sind, gibt es zusätzlich 2 Requirement Level: Limited Use Es rät sich an, das Benutzungsumfeld genau zu definieren und die Benutzung darauf zu zu beschränken. Not Recommened Betrifft TS, die nicht für nützlich genug befunden wurden, oder deren Benutzung zwecklos ist, weil sie z.B. historischer Natur sind Zwar sind TS und AS getrennt voneinander definiert, dennoch sind häufig ein AS sowie ein oder mehrere TS in einem Dokument vereinigt. Dies ist vor allem dann sinnvoll, wenn sich das AS auf die TS bezieht und die TS keinen Bezug von außerhalb“ haben. Sollte dies der ” Fall sein, werden sie dann häufig einzeln veröffentlicht. 3.3.2 Best Current Practice (BCP) In den BCPs werden die Vorgehensweisen, Praktiken und Strukturen der IETF festgelegt. Sie durchlaufen meist einen verkürzten Standardisierungsprozess. Alle Dokumente werden in der übergeordneten Serie RFC veröffentlicht. Sie werden von der IESG vor der Veröffentlichung geprüft. 3.3.3 For Your Information (FYI) Diese RFCs beschreiben keinen Standard, sie dienen einfach nur zur genaueren Information über einen Standard oder stellen einen Entwurf vor, der noch weiterer Entwicklung und Ausarbeitung bedarf. Sie werden dann mit dem Zusatz Experimental“ versehen. ” 21 3 Request for Comments 3.4 Der Internet Standard Track Ein Protokoll, eine Policy oder etwas vergleichbares, was ein im ganzen Internet anerkannter Standard werden soll, muss den sog. Internet Standard Track“ durchlaufen. In diesem ” Prozess wird der Vorschlag auf mehreren Stufen , den sog. Maturity Level“, diskutiert ” und praktisch erprobt, bevor er schlussendlich zum Internet Standard wird oder ob er nochmal überarbeitet oder gar abgelehnt wird. Die Entscheidungen, ob ein Vorschlag in den Internet Standard Track aufgenommen wird, wann er hoch- oder umgestuft wird, werden zwar von der IESG getroffen, allerdings hat die gesamte Internet Community Möglichkeiten zur Einflussnahme durch Kommentieren. 3.4.1 Maturity Levels Es gibt insgesamt 3 Maturity Levels, die zum Internet Standard Track gehören: Proposed Standard Ist der Einstiegslevel in den Internet Standard Track. Um in den Internet Standard Track aufgenommen zu werden, muss eine Spezifikation als technisch ausgereift und stabil, als sinnvoll und nützlich angesehen und auch von der Community akzeptiert werden. Erst dann trifft die IESG die Entscheidung, sie zum Proposed Standard zu machen und sie auf den Standard Track zu setzen. Draft Standard Um zum Draft Standard zu werden, muss die Spezifikation mindestens zweimal erfolgreich interoperable (zwischen zwei verschiedenen Codebasen) implementiert worden sein. Dazu kommt die Notwendigkeit ausreichend praktischer Erfahrung. Dabei ist bei der Implementierung darauf zu achten, dass man alle Features und Optionen der Spezifikation eingebaut hat. Ansonsten müssen solche Optionen und Features, auf die dies nicht zutrifft, aus dem Standard entfernt werden. Eine der Entscheidungshilfen, um ein Proposed Standard zum Draft Standard gemacht wird, ist die Dokumentation des verantwortlichen Working Group Chair. Er muss die Implementierungen und die Beobachtungen und Erfahrungen mit der Spezifikation beschreiben. Internet Standard Hat man sie dann mehrmals implementiert und dadurch praktische Erfahrung gewonnen, kann die Spezifikation dann zum Internet Standard werden. Auf diesem Level ist sie technisch ausgereift, fehlerfrei und stabil. Sie bekommt nun eine Nummer in der STD-Reihe zugewiesen. Zu diesen 3 Standard Track Maturity Levels kommen dann noch 3 andere sog. Off-Track ” Maturity Levels“ hinzu. Diese Levels kennzeichnen z.B. veraltete Spezifikationen oder welche, die technisch noch nicht ausgereift sind. Experimental Typischerweise trifft dies auf Spezifikationen zu, die Teil von Forschungen oder Entwicklungen sind. Sie dienen als allgemeine Information für die technische 22 3.4 Der Internet Standard Track Internetgemeinschaft und als Beweis von geleisteter Forschungsarbeit (z.B. einer Arbeitsgruppe der IETF oder einer IRTF Forschungsgruppe) Informational RFCs mit diesem Level dienen nur der allgemeinen Information der Internet Community und sonst nichts. Sie haben keinerlei Platz im Standardisierungsprozess. Spezifikationen, die in solchen Dokumenten beschrieben werden, sind rein informativer Natur. Dies ist wichtig, da häufiger versucht wurde, den Internet Standards Track auf diesem Wege zu umgehen. Auch werden Spezifikationen, die nicht von einer Working Group erarbeitet wurden, sondern Entwicklungen einer Firma sind, häufig als Informational RFCs veröffentlicht, solange der Entwickler und der RFC-Editor zustimmen. Da es einige Versuche gab, den Internet Standard Track über die Ausnutzung des Experimental/Informational Status auszuhebeln, hat man den Weg, wie ein RFC diesen Status erhält, angepasst. Generell ist es so, dass alle Dokumente, die nicht Ergebnis einer Arbeit einer Working Group sind, direkt beim RFC Editor eingereicht werden müssen. Dieser veröffentlicht sie dann für 2 Wochen als Internet Drafts und wartet auf Kommentare der Internet Community. Nach Ablauf der Zeit wird das Dokument dann als RFC mit dem entsprechenden Status veröffentlicht, wenn der RFC die Anforderungen an die RFCs bezüglich editorieller und informativer Gesichtspunkte für erfüllt hält (sprich: Das Ding liest sich gut und das Thema hat etwas mit dem Internet zu tun). Der Schutzmechanismus besteht jetzt einfach darin, dass der RFC-Editor jedes Dokument, das seiner Meinung nach den Arbeitsbereich der IETF berührt, der IESG anzeigt. Nun setzt sich die IESG mit dem Dokument auseinander und entscheidet, ob es wie vorgesehen mit dem beantragten Status veröffentlicht wird, oder ob es in den Internet Standard Track eingehen soll. Nun kann es auch sein, dass der Autor nicht will dass es in den Internet Standard Track eingeht, dass das Thema mit der Arbeit des IETF in Konflikt steht oder bereits Forschungsobjekt einer bestehenden Working Group ist. In einem solchen Falle ist eine Veröffentlichung als Informational/Experimental RFC dennoch möglich. Allerdings wird dann im Disclaimer oder im Status of this Memo“ des RFCs auf die Umstände der Veröffentlichung hingewiesen. ” Historic Als letzten Off-Track Maturiy Level erfüllt dieser genau das, was der Name bereits andeutet: Er kennzeichnet RFCs, die veraltet sind, entweder weil eine neue Version vom Standard bereits veröffentlicht wurde und den Internet Standard Track durchlaufen hat oder weil die technische Entwicklung den Standard überflüssig gemacht hat. 3.4.2 Internet Standards Process Der Prozess ist in mehrere Actions“ unterteilt, wie das Aufnehmen einer Spezifikation in ” den Internet Standard Track, das Hochstufen oder das Auschliessen von z.B. veralteten Standards. Jede der Actions wird durch einer Empfehlung des Working Group Verantwortlichen gegenüber seines Area Direktors veranlasst und muss durch die IESG bestätigt 23 3 Request for Comments werden. Falls die Spezifikation nicht durch eine Workgroup ausgearbeitet wurde, wird die Action durch eine Empfehlung eines Einzelnen gegenüber der IESG ausgelöst. Initiation of Action Damit eine Spezifikation in den Internet Standard Track aufgenommen wird oder eine Stufe aufsteigt, wird zunächst ein Internet Draft veröffentlicht, es sei denn, die Spezifikation wurde seit ihrer Veröffentlichung als RFC nicht mehr verändert. Sie bleibt für mindestens 2 Wochen Internet Draft, bevor eine Empfehlung abgegeben werden kann. Die IESG entscheidet, nun ob eine Action bestätigt wird, indem sie einmal feststellt, ob alle Kriterien für die vorgesehene neue Stufe zufriedenstellend erfüllt sind, und ob die Spezifikation den erforderlichen Standard für technische Dokumente einhält. Wenn zu erwarten ist, dass die Spezifikation eine sehr grosse Wirkung auf das Internet haben wird, kann die IESG eine unabhängige Kommission beauftragen, ein Gutachten über die möglichen Auswirkungen zu erstellen. Sobald eine Entscheidung ansteht, wird die IETF von der IESG benachrichtigt und löst einen sog. Last Call“ aus. Dies geschieht, um der Internet Community die Möglichkeit zu ” geben, auf die Entscheidung der IESG durch Kommentare Einfluss zu nehmen. Für gewöhnlich dauert die Last-Call Phase 2 Wochen, bei Spezifikationen, die nicht durch eine Workgroup der IETF entwickelt wurden, sogar 4 Wochen. Für beide: Ist es nach Meinung der IESG für das Interesse der Internet Community wichtig, kann sie auch auf eine längere Zeitdauer beschließen, oder eine bestehende verlängern. Wichtig ist auch, dass die IESG nicht daran gebunden ist, welche Action empfohlen wurde. Je nach ihrer Entscheidung und der Antwort auf einen Last Call, kann die IESG der Spezifikation eine andere Kategorie zuordnen. Sollte sie aber die Absicht haben, der Spezifikation eine andere Stufe als beantragt zu geben noch bevor der Last Call veröffentlicht wurde, muss es im Last Call angemerkt sein. Einige Zeit nach Ablauf des Last Call wird die IESG dann die Entscheidung treffen und sie über die IETF Mailing Liste bekannt geben. Weiterhin wichtig ist, dass die IESG die Bildung einer neuen Workinggroup vorschlagen kann wenn ein Last Call grosse Kontroversen ausgelöst hat. Sobald die Action von der IESG bestätigt worden ist, wird der RFC Editor benachrichtigt. Dieser bringt dann ein neues RFC heraus, das alte Internet Draft wird dann gelöscht. Advancing in the Standard Tracks Die zuvor beschriebene Prozedur wird jedes mal neu durchlaufen, wenn eine Spezifikation in den Internet Standards Track aufgenommen oder eine Stufe aufsteigen soll. Die erste Stufe ist der Proposed Standard. Dieser Status wird für mindestens 6 Monate beibehalten, bevor der Draft Standard erreicht werden kann. Auf dieser Stufe verbleibt die Spezifkation mindestens 4 Monate oder bis zum nächsten IESG Treffen, je nachdem welche Frist später 24 3.4 Der Internet Standard Track abläuft. Generell beginnen die Fristen jeweils ab der Veröffentlichung als RFC oder der Bekanntgabe einer IESG Entscheidung. Da eine Spezifikation sehr wahrscheinlich geändert wird, um erkannte Fehler und Probleme zu beseitigen, kann es bei größeren Modifikationen möglich sein, dass die Zeiträume, die eine Spezifikation im aktuellen Standard verbringt, ausgedehnt werden. Bei noch größeren Änderungen wird eventuell nach einer Empfehlung der IESG eine neue Spezifikation erstellt, die den ganzen Weg nochmal von vorne durchlaufen muss. Ändert sich der Status einer Spezifikation, wird für gewöhnlich auch ein neues RFC veröffentlicht. Dies trifft nur dann nicht zu, wenn es zu keinerlei Änderung seit dem letzten RFC kam. Es wird jedoch nicht bei jedem kleinen Fehler ein neues RFC erstellt. Stattdessen werden die Änderungen gesammelt und fließen dann ins neue RFC ein. Sollte es aber einen wesentlichen Fehler geben, so geht ein Antrag an den RFC-Editor oder die IESG, das RFC neu zu veröffentlichen (mit neuer Nummer), wobei die Zeitrechnung für das aktuelle Stadium nicht neu beginnt. Wenn eine Spezifikation 24 Monate auf dem gleichen Level (außer dem Internet Standard Level) verbleibt, so soll die IESG darüber befinden, ob es sich lohnt, die Spezifikation weiter auf dem Standard Track zu behalten. Gesichtspunkte dabei sind einmal der technische Aufwand und der Sinn bzw. die Nützlichkeit der Spezifikation. Wenn die IESG sich dazu entschließt, die Spezifikation zu verwerfen, bekommt sie einen historischen Status. Sonst wird sie weiter entwickelt (ggf. auf einem anderen Maturity Level). Revising a Standard Eine neue Version eines neuen Standards muss den ganzen Internet Standard Track erneut durchlaufen. Sobald sie zum Internet Standard erhoben wurde, ersetzt sie den alten Standard, der von nun an als Historic gekennzeichnet wird. Die STD-Nummer bleibt gleich. In einige Fällen kann es dazu kommen, dass beide Standards nebeneinander existieren, aufgrund der Verbreitung des alten Standards. Dabei muss die Beziehung beider Versionen zueinander in einem passendem Dokument geregelt werden (evtl. in einem Applicability Statement). Retiring a Standard Sobald ein Standard durch die Weiterentwicklung der Technologie überflüssig geworden ist, oder er einfach durch einen neuen, besseren Standard ersetzt wurde, kann z.B. eine Working Group oder ein Area Direktor eine Anfrage an die IESG stellen, dem alten Standard den Status Historic zu verpassen. Auch hier finden die Regeln für Standard Actions (u.a. Last Call) ihre Anwendung. 25 3 Request for Comments 3.5 RFC-Formate Grundsätzlich werden RFCs in Englisch geschrieben. Sie dürfen zwar in andere Sprachen übersetzt werden, aber im Zweifelsfalle gilt immer die englische Version (z. B. bei Übersetzungsfehlern). Das offizielle Format von RFCs ist das normale Textformat (ASCII-Textformat). Einige RFCs, nicht alle, sind jedoch auch in anderen Formaten wie z.B. HTML oder Postscript verfügbar. Die Verfügbarkeit in anderen Formaten wie Postscript bedeutet gleichzeitig, dass die Dateien mehrere Megabyte groß sein können, wobei jedoch auch eine bessere Qualität erreicht werden kann. Beispielsweise wurden in einigen älteren RFCs Bilder und Skizzen nur mit dem reinen ASCII-Zeichensatz kreiert“. ” Das Layout eines RFC Dokumentes ist generell sehr streng festgelegt (Kopfzeile auf jeder Seite, Anzahl der maximalen Zeichen pro Zeile und Zeilen pro Seite). Das RFC 2223 behandelt ausführlich die Struktur von RFCs 3.5.1 Keywords Im Zusammenhang mit den RFCs gibt es nun mehrere Keywords. Diese Keywords wurden festgelegt, um sicher zu wissen, was der Autor der Spezifikation fordert und was nicht. Sie sind genauer im RFC 2119 beschrieben. • MUST (Required, Shall): Diese Option muss unbedingt eingebaut werden. • MUST NOT (Shall Not): Diese Eigenschaft darf unter keine Umständen enthalten sein. • SHOULD (Recommended): Unter bestimmten Umständen kann es sinnvoll sein, die Option (Beispiel) zu vernachlässigen, man muss sich aber um die Konsequenzen bewusst sein und sie abwägen. • SHOULD NOT : Da es einige Umstände und Situationen geben kann wo eine Option sinnvoll ist, kann sie eingesetzt werden. Im allgemeinen aber ist davon abzuraten. • MAY (Optional): Hier ist es abhängig vom jeweiligen Programmierer, ob er eine Option nutzt oder nicht. Es muss aber sichergestellt sein, dass die Implementierung mit anderen zusammenarbeiten, die die Option nicht unterstützen (bzw. unterstützen). 3.6 Interessante RFCs Aufgrund der vielen bislang veröffentlichten RFCs (Stand März 2002: ungefähr 3200) kann hier nur eine sehr kleine Auswahl von wichtigen und interessanten RFCs gegeben werden. Für eine Liste, die sämtliche Internet Standards, Draft Standards, Proposed 26 3.7 Jon Postel Standards sowie Experimental, Historical und Informational RFCs enthält, ist das STD 1 zu empfehlen. Viele RFCs, deren Nummer durch 100 teilbar sind, sind das STD 1, wobei ein neu erscheinendes RFC jeweils die vorhergehende obsolete macht. Ähnlich dazu enthalten viele 99er RFCs eine Auflistung aller veröffentlichten RFCs seit dem vorhergehenden 00er RFC. Einige Standards und das zugehörige RFC: Standard IP ICMP TCP TELNET SMTP Bezeichnung Internet Protocol Internet Control Message Protocol Transmission Control Protocol Telnet Protocol Specification Simple Mail Transfer Protocol STD 5 5 7 8 10 RFC 791 792 793 854 821 Daneben sind noch folgende RFCs interessant: RFC 1 2026 2028 2223 2360 2468 2555 Thema Host Software The Internet Standards Process – Revision The Organizations Involved in the IETF Standards Process Instructions to Authors Guide for Internet Standards Writers I remember IANA 30 Years of RFCs 3.7 Jon Postel Jon Postel (6. August 1943 - 16. Oktober 1998) wird als einer der Internet-Pioniere bezeichnet. Zusammen mit Stephen Crocker arbeitete er an den Grundlagen des ARPANET. Er entwickelte das Internet Adress Sytem und war 30 Jahre lang IANA Direktor. Daneben war er knapp 30 Jahre lang RFC-Editor. Knapp 2500 RFCs gingen durch seine Hände, wobei er nicht auf staubtrockene und todernste RFCs bestand (1. April RFCs). Er hat (in RFC 1122) den Fundamentalsatz im Bereich Protokoll-Design und -Implementierung geprägt: Be liberal in what you accept, and conservative in what you send“ ” 27 3 Request for Comments 28 KAPITEL 4 Link-Layer, Ethernet Dennis Sinder, Marc Kammer 4.1 Zeitliche Einordnung des Link-Layers Der Link-Layer ist zeitlich nicht ganz so leicht einzuzordnen, da er kein in sich eigener Standard ist. Er ist Teil des ISO-OSI-Modells dessen Entwicklung im Jahre 1974 begann und im Jahre 1978 erstmals der Öffentlichkeit vorgestellt wurde. Die heutige Version des ISO-OSI-Modells, wurde jedoch erst im Jahre 1984 veröffentlicht, nachdem sich die ISO und das CCITT in einigen Streitfragen des Modells geeinigt hatten. 4.2 Gremien die interessant sind Internationale Normen werden von der ISO (International Standards Organization) ausgegeben, einer freiwilligen, nicht per Staatsvertrag geregelten Organisazion, die 1946 gegründet wurde. Ihre Mitglieder sind die nationalen Normungsinstitute der 89 beteiligten Staaten. Dazu gehören ANSI (USA), BSI (Großbritanien), AFNOR (Frankreich), DIN (Deutschland), und 85 weitere. IEEE Das IEEE (Institute of Electrical and Electronics Engineers) oder auch eye - triple ” 29 4 Link-Layer, Ethernet E“ genannt wurde ebnfalls im Jahre 1946 gegründet. Es ist ein amerikanischer Zusammenschluß von Ingenieure und Techniker, das u.a. Standards inbesondere im Bereich der Datenkommunikation bearbeitet und veröffentlich. DIX Das DIX ist eine Unternehmensgruppe bestehend aus DEC, Intel und Xerox 4.3 Das ISO-OSI-Modell Um den Data Link Layer einordnen zu können, nehmen wir als Beispiel das wohl bekannteste Modell, das bereits angesprochene OSI-Modell. Das OSI-Modell besteht aus sieben Schichten, für die jeweils bestimmte Aufgaben definiert sind. Diese Aufgaben können dann individuell durch die passenden Protokolle erledigt werden. Die unterste Schicht des OSI-Models ist die Bitübertragungsschicht (Physical Layer), die sich um die Übertragung der rohen Bits über einen Kommunikationskanal kümmert. Die zweite Schicht, auf die wir nachher noch genauer eingehen werden, ist die Sicherungsschicht (Data Link Layer). Ihre Aufgabe besteht darin die Übertragungseinrichtung in eine Leitung zu verwandeln, die sich der dritten Schicht frei von unerkannten Übertragungsfehlern darstellt. Die dritte Schicht, die sogenannte Vermittlungsschicht (Network Layer), hat die Aufgaben das Routing von Ursprungs- zum Besimmungsort durchzuführen, Paketmassen im Netz zu steuern, so dass es zu keinen Staus kommt, Bits für die Kostenberechnung zu zählen und sich an verschiedene andere Teilnetze anzupassen. Die vierte Schicht, die Transportschicht (Transport Layer) hat die Aufgabe, die Daten die ihr von der über ihr liegenden Schicht übergeben werden, bei Bedarf in kleinere Einheiten zu zerkleinern und danach an die Vermittlungsschicht weiterzugeben. Sie sorgt dafür, dass die so enstandenen Teile richtig beim Empfänger ankommen. Die fünfte Schicht, die Sitzungsschicht (Session Layer) ermöglicht es, Benutzern an verschieden Maschinen, Sitzungen untereinander aufzubauen. Eine Sitzung emöglicht den gewöhnlichen Datentransport, wie die Transportschicht auch, bietet aber zusätzlich erweiterte Dinste, die für bestimmte Anwendungen nützlich sind.Ein Benutzer kann sich z.B. in einer Sitzung an einem entfernten System anmelden oder Dateien zwischen zwei Maschinen übertragen. 30 4.4 Der Link-Layer Die sechste Schicht ist die Darstellungschicht (Presentation Layer). Sie führt bestimmte Funktionen aus, die durch ihre häufige Verwendung eine allgemeine Lösung rechtfertigen, anstatt es jedem Benutzer zu überlassen, die damit verbundenen Aufgaben zu lösen. Anders als die anderen Schichten, die nur daran interessiert sind, Bits zuverlassig von hier nach da zu befördern, hat die Darstellungsschicht die Besonderheit, dass sie sich auch um Syntax und Semantik der übertragen Informationen kümmert. Die siebte und letzte Schicht ist die Verarbeitungsschicht (Application Layer), die letztendlich eine Menge anderer Aufgaben hat. Wie z.B. E-Mail, Remote Job spezielle Einrichtungen. 4.4 Der Link-Layer Wie schon erwähnt nutzt der Link Layer, auch Verbindungssicherungsschicht genannt, die Übertragungsleistung der Bitübertragungsschicht, um die Dateien fehlerüberprüft von einer Station auf einer Leitung zu einer anderen Station zu übertragen. Er unterteilt sich hierbei in zwei Bereiche, den LLC (Logical Link Control) und die MAC-Teilschicht (Media Access Control), wobei jeweils folgende Spezialfunktionen auszuführen sind. Der LLC stellt eine genau festgelegte Dienstschnittstelle zur Vermittlungsschicht dar. Die MAC-Teilschicht dagegen legt fest, wie die Bits der Bitübertragungsschicht zu Rahmen zusammengestellt werden. Sie kümmert sich um Fehler bei der Datenübertragung. Sie regelt den Rahmenfluß, so dass langsame Empfänger nicht von schnellen Sendern mit Daten überschüttet werden und Sie verwaltet Verbindungen Die Aufgabe des LLC, welches unabhängig von den Zugriffsmethoden ist, liegt darin, die Daten aus der Vermittlungsschicht der Senders sicher zur Vermittlungsschicht des Empfängers zu transportieren. Dabei werden drei verschiedene Dienste angeboten. Unbestätigte verbindungslose Dienste laufen so ab, dass der Quellrechner unabhängige Rahmen (Data Frames) an den Empfänger schickt, ohne dass dieser den Empfang bestätigen muß. Weder vorher noch nachher wird eine Verbindung aufgebaut. Wenn aufgrund von Störungen ein Rahmen in der Leitung verlorengeht, wird in der Sicherungsschicht nicht versucht, die Daten wiederherzustellen. Bestätigte verbindungslose Dienste sind hinsichtlich der Zuverlässigkeit der nächste Schritt. Kommt dieser Dienst zum Einsatz, werden zwar immer noch keine Verbindungen benutzt, aber der Empfang jedes abgeschickten Rahmens wird einzeln durch einen Bestätigungsrahmen (Acknowlege Frame) bestätigt. So weiß jeder Sender, ob sein Rahmen sicher angekommen ist. Kommt der Rahmen nicht innerhalb eines festgelegten Zeitraums an, kann er noch einmal abgeschickt werden. Verbindungsorientierte Dienste sind die hochwertigsten Dienste, die der Vermittlungsschicht von der Sicherungsschicht geboten werden können. Kommen verbindungsorientierte Dienste zum Einsatz, bauen Quell- und Zielrechner vor jeder Datenübertragung eine Verbindung zueinander auf. Jeder über diese Verbindung geschickter Rahmen ist numeriert, 31 4 Link-Layer, Ethernet und die Sicherungsschicht sorgt dafür, dass jeder abgeschickte Rahmen auch ankommt. Die MAC-Teilschicht ist im Gegensatz zum LLC abhängig vom LAN-Typ definiert. In der MAC-Schicht wird der Zugriff auf das Übertragungsmedium geregelt und die Netzadressen der einzelnen Stationen ausgewertet. Durch die Dienste der MAC-Schicht stellt sich das gesamte LAN für zwei Partnerinstanzen der LLC-Schicht wie ein Draht zwischen den beiden Stationen dar. Desweiteren wird dort auch die schon genannte Rahmenerstellung, Fehlerüberwachung und Flusssteuerung behandelt. Zur Vorbeugung von Fehlern unterteilt die Sicherungsschicht einen Bitstrom in diskrete Rahmen und rechnet eine Prüfsumme für jeden Rahmen aus. Sobald ein Rahmen seinen Bestimmungsort erreicht, wird die Prüfsumme neu errechnet. Wenn die neu berrechnete Prüfsumme nicht mit der im Rahmen angegebenen übereinstimmt, weiss die Sicherungsschicht, dass ein Fehler aufgetreten sein muß, und unternimmt die zur Behebung nötigen Schritte (z.B. Verwerfen des fehlerhaften Rahmens und Zurücksenden einer Fehlermeldung). Eine Unterteilung des Bitstroms in Rahmen ist schwierig, daher wurden einige Methoden entwickelt wobei sich eine Kombination aus Zeichenzählung, der Prüfsumme und dem Bitstopfen durchgesetzt hat. Bei der ersten Methode zur Rahmenerstellung wird ein Feld im Header des Rahmens eingefügt, das die Anzahl der Zeichen im Rahmen angibt. Sobald die Sicherungsschicht auf der Empfängerseite dieses Feld liest, weiß sie, wie viele Zeichen ankommen und wo folglich das Ende des Rahmens sein wird. Beim Bitstopfen wird am Anfang und am Ende ein Bitmuster (Flag) gesetz, damit man den Anfang und das Ende eines Rahmens identifizieren kann. Kommt jedoch dieses Bitmuster in den zu versendenden Daten vor, wird es gekennzeichnet indem ein Bitmuster in die Daten einfügt, dass von der Sicherungsschicht des Empfängers wieder enfernt wird. Die Fehlerüberwachung geschieht, wenn möglich, über die schon angesprochen Bestätigungsrahmen, so das der Empfänger eine positive oder negative Nachricht zurück schickt. Um dem Verlust von Daten zu erkennen setzt der Sender einen Timer, so dass er wenn er nach abgelaufener Zeit keine Nachricht erhält den Rahmen nochmal schickt. Um Duplikaten vorzubeugen werden die Rahmen Nummeriert, so dass Originale von Wiederholungen unterschieden werden können. Es ist auch eine Flußsteuerung (Flow Control) vorhanden, damit der Sender die Rahmen nicht schneller abschickt als der Empfänger sie verarbeiten kann. Das Protokoll enthält genau definierte Regeln, wann ein Sender den nächsten Rahmen abschicken darf. Diese Regeln verbieten es dem Sender, Rahmen ohne ausdrückliche oder allgemeine Erlaubnis des Empfängers abzuschicken. Es gibt ein Verfahren namens Huckepacktransport (Piggybacking) welches zur Netzentlastung führen soll. Wenn ein Datenrahmen ankommt, verzögert der Empfänger die Übertagung der Bestätigungsrahmens so lange, bis die Vermittlungsschicht das nächste Packet übermittelt. Die Betätigung wird an den ausgehenden Datenrahmen angehängt. 32 4.5 Ethernet 4.5 Ethernet 4.5.1 Die zeitliche Entwicklung des Ethernet 1972 wurde bei Xerox an einer Netzwerktechnologie gearbeitet. Dies waren die ersten experimentellen Schritte in Richtung Ethernet. Das erste funktionstüchtige Local Area Network, kurz LAN, auf Ethernet-Basis wurde unter der Schirmherrschaft von Robert Metcalfe von der Firma Xerox entwickelt und 1975 im Xerox-Palo Alto Research Center (PARC), implementiert. Es verband auf einer Kabellänge von 1 km 100 Stationen mit einer Übertragungsrate von 2,94 Mbps. Das Xerox Ethernet war so erfolgreich, das Xerox, DEC, und Intel einen Standard für ein 10-Mbps-Ethernet ausarbeiteten. Dieser, und nicht die ursprüngliche Version des Ethernets, ist die Basis für das Regelwerk 802.3 vom IEEE. Der ursprüngliche Standard definiert die Parameter für 10-Mbps-Basisband, wofür ein Koaxiakabel mit 50 Ohm benutzt wird. Aufbauend auf die 1979 festgelegte 10 Mbps Technik des DIX-Ethernets, verabschiedete das IEEE 1983 den Standard 802.3. Als Weiterentwicklung wurde 1995 mit dem Standard 802.3u das Fast-Ethernet vorgestellt. Die letze Entwicklung auf Ethernetbasis dürfte der Standard 802.3z (Gigabit-Ethernet) sein. Noch etwas kurioses zur Namensgebung.Das System Ethernet, erhielt seinen Namen durch den sogenannten Lichtäther“, von dem einmal angenommen wurde, daß sich in ihm ” elektromagnetische Strahlung fortpflanzt. Dies lässt sich auf James Clerk Maxwell im 19. Jahrhundert zurückführen, welcher entdeckte das sich elektromagnetische Strahlung durch eine Wellengleichung beschreiben läßt. Fortan nahmen die Wissenschaftler allgemein an, dass der Weltraum mit einer ätherischen Substanz“ gefüllt sein muss in dem sich die ” Strahlung fortpflanzen kann. Erst nach dem berühmten Experiment von Michelson-Morley 1887 entdeckten die Physiker, dass sich elektromagnetische Strahlung im Vakuum fortpflanzen kann, der Äther also nicht existiert. 4.5.2 Erfolg mal anders. Es sollte erwähnt werden dass das Ethernet eine unglaubliche Erfolgsgeschichte“ be” schrieben hat. So gab man der Entwicklung des Ethernets zu seiner Entstehungszeit nur kurz- bis mittelfristige Überlebenschancen. Oft wurde auf den Branchenriesen Big ” Blue“ IBM verwiesen welcher damals eigenbrötlerisch ein eigenes Netzwerkverfahren entwickelte. Auch gab es noch andere Standards, welche sich praxistauglicher und in vielen 33 4 Link-Layer, Ethernet Situationen als besser erwiesen als das Ethernet. Trotz dieser Schwierigkeiten und nicht zu verleugnender technischer Mängel (gerade bei hoher Netzlast), sollte sich das Ethernet zu der Netzwerktechnologie schlechthin entwicklen. Der Erfolg hat jedoch mehrere Gründe. Einer ist sicherlich dass Xerox die Lizenzen zum Bau von Ethernetprodukten sehr günstig verkaufte. So war es für andere Unternehmen attraktiv Hardware für dieses System zu bauen. Auch dass Ethernet später von dem IEEE als Standard anerkannt wurde trug zum Erfolg bei. Durch die günstige Lizenzvergabe und den anerkannten Standard des Ethernets entwickelte sich schnell eine hohe Produktvielfalt, welche in Relation gesehen auch noch günstig angeboten werden konnte. Eine letzte Tatsache, welche bei der erfolgreichen Verbreitung des Ethernets weiterhin eine tragende Rolle gespielt hat, war mit Sicherheit, dass die Unternehmen, welche hinter Ethernet standen, eine nicht zu unterschätzende Marktmacht hatten. Ethernet ist also der Namensgeber für eine Reihe verschiedener Netzwerkübertragungsstandards, welche sich primär durch die Datenübertragungsgeschwindigkeit unterscheiden. Wobei wir uns hauptsächlich mit dem Ethernet befassen, welches später unter der IEEE Norm 802.3 bekannt wurde. 4.5.3 Arbeitsweise des CSMA/CD Was alle Versionen des Ethernets gemeinsam haben ist das Carrier Sense Multiple Acess with Collision Detection, kurz CSMA/CD, Zugangs- bzw. Übertragungsverfahren. CSMA/CD ist der Name für die Art und Weise, wie Ethernet funktioniert bzw. kommuniziert. Im Ethernet werden die Daten über einen gemeinsamen Übertragungskanal transportiert. Den Zugriff auf diesen Übetragungskanal regelt CSMA/CD. Jede Station (Rechner) die Daten zu senden hat, versucht, auf den gemeinsamen Übertragungskanal zuzugreifen, wenn sie ihn zuvor als frei erkannt hat. Greifen zwei Stationen gleichzeitig auf das Medium zu, kommt es zu einer Kollision. Das CSMA/CD-Verfahren regelt diese Kollisionen. Durch das Verfahren wird die Buskollision erkannt, beide Stationen beenden die Übertragung und senden ein spezielles Kollisionssignal (Jam-Signal). Jede Station versucht die Aussendung ihrer Daten nach einer vorgegebenen Zeit wieder (siehe: 4.5.4). Die Zeit ist für jede Station unterschiedlich. Hat sich eine Station durchgesetzt, kann sie ein vollständiges Datenpaket senden. 34 4.5 Ethernet 4.5.4 Der Backoff-Algortihmus Bei einer einer Kollision des CSMA/CD Verfahrens werden bestimmte Zeitintervall abgewartet bevor eine erneute Datenübertragung versucht wird. Nach der ersten Kollision wird entweder 0 oder 1 Zeitintervall abgewartet. Nach der zweiten Kollision wird zwischen 0 und 22−1 Zeitintervallen entschieden und nach der n-ten Kollision wird zwischen 0 und 2 n−1 Zeitintervallen entschieden. Somit veringert sich die Warscheinlichkeit exponentiell, dass eine weitere Kollision entsteht. Nach 10 Kollisionen ist das Maximum an Zeitintervallen bei 0 bis 1023 erreicht und nach der sechzehnten Kollision wird ein Fehler angezeigt. Die Daten welche von Ethernet versendet werden, werden in sogennannte Frames“ un” terteilt. Das grösste Datenpaket in Ethernet die sogenannte Maximum Transmission Unit, kurz MTU, beträgt 1500 bytes, der Frame an sich kann aber maximal 1526 bytes Grösse annehmen. Die Grösse des Datenpaketes ist von unterschiedlichen Faktoren abhängig. Die elementarste ist natürlich der Anteil von Daten im Frame an sich, hinzu kommen noch 26 andere mögliche Bytes welche sich, wie in der nächsten Abbildung dargestellt, wie folgt: Abbildung 4.1: Frame Format nach dem IEEE 802.3 Standard. Wobei man darauf hinweisen muss, dass es sich um das Frameformat vom IEEE Standard 802.3 handelt. Ein interessantes Feld ist die Zieladresse“ (destination address) sowie die Quelladresse“ ” ” (source address). Dort wird die Hardwareadresse jeder einzelnen Netzwerkkarte angegeben. Und bei 48-2=46 verfügbaren Bits gibt es etwa 7 x 1013 globale Adressen. Damit wird beabsichtigt, dass jede Station genau durch die richtige 48-Bit-Nummer adressiert werden kann. Ziel des ganzen war es, eine weltweit eindeutige Zuordnung vorzunehmen. In der Praxis kommt es leider vor, dass die Idealvorstellung einer weltweit einzigartigen Addresse nicht eingehalten wird. Die Vermittlungsschicht muss feststellen, wo sich das Ziel befindet. Weiterhin wichtig ist, dass die Norm 802.3 eine minimale Grösse jedes Frames festlegt. Dies dient dazu, Datenmüll“ von tatsächlichen Paketen zu unterscheiden. Die Länge muss ” von der Zieladresse bis zur Prfüsumme mindestens 64 Byte betragen. Falls der Datenteil des Frames kleiner als 46 Byte ist, füllt das Pad-Feld den Frame bis zum Minimum auf. 35 4 Link-Layer, Ethernet Die Festlegung einer minimalen Frame-Länge hat noch einen wichtigeren Grund. Damit soll verhindert werden, dass eine Station die Übertragung eines kurzen Frames beendet, bevor sein erstes Bit überhaupt das andere Ende des Kabels erreicht hat, wo er dann eventuell mit einem anderen Frame kollidiert. 4.6 Versionsunterschiede Wie bereits erwähnt gibt es unterschiedliche Versionen von Ethernet. So die ursprüngliche von Xerox und die IEEE-Norm 802.3. Die entscheidenden Unterschiede sind dann auch mehr im Detail zu finden, dies kommt unter anderem auch daher, weil beide Versionen weiterhin auf dem CSMA/CD Zugangsverfahren als Übetragungsmethode beruhen. Jedoch sind die Unterschiede nicht zu vernachlässigen. Ein Unterschied ist zum Beispiel im Frame-Format zu finden. So weist der Frame vom Standard-Ethernet“ kein Länge des ” ” Datenfeldes“ (length) Feld auf wie dies beim IEEE 802.3 der Fall ist und aus Abbildung 4.1 hervorgeht. Stattdessen ist dort ein type“ Feld angegeben, welches die Art von Daten ” welche folgen beschreiben soll. Weitere Unterschiede sind, dass beide Ethernetspezifikationen unterschiedliche Signalpegel definieren und für einige Baugruppen andere Verzögerungsanforderungen. Ethernet- und IEEE 802.3-Systeme können auf dem selben Koiaxkabel arbeiten. Ein Datenaustausch zwischen Ethernet- und IEEE 802.3-Stationen ist aber nicht möglich. 4.7 Andere Protokollarten kurz angeschnitten SLIP: SLIP (Serial Line IP) ist ein sehr einfaches Protokoll, um IP-Datagramme über serielle Point-to-Point Verbindungen zu schicken. Es packt die Daten einfach in einen Umschlag“ ” (Frame) und verschickt sie. Im Unterschied zu PPP kann SLIP IP-Pakete n solche Frames einkapseln, enthält aber keine Fehlererkennung oder Fehlerkorrektur. PPP: Die Verbesserung des SLIP, das PPP (Point-to-Point Protokoll) wurde als offizieller Internet-Standard übernommen. Es unterstüzt Fehlererkennung, mehrere Protokolle, die Vergabe von IP-Adressen zum Zeitpunkt des Verbindungsaufbaus, Authentifikation und viele andere Verbesserungen gegenüber SLIP. Die drei wichtigsten Merkmale von PPP sind: Erstens die übliche Rahmenerstellungsmethode mit Fehlerekennung. Zweitens ein Verbin- 36 4.7 Andere Protokollarten kurz angeschnitten dungsprotokoll zum Testen von Leitungen, Anschalten und Beenden von Verbindungen, welches sich Link Control Protokoll nennt. Und drittens das Network Control Protokoll, was die Optionen auf der Vermittlungsschicht aushandelt. Bei Verbindungsaufbau verden LCP Rahmen versendet, nach eingegangener Antwort folgen NCP-Pakete und daraufhin wird die IP-Adresse zugewiesen. Bei Verbindungsabbau wird NCP benutzt, um die Verbindung zur Vermittlungsschicht abzubauen, die IP-Adresse wird freigegeben und zum Schluß wird das LCP benutzt, um die Verbindung auf der Sicherungsschicht zu beenden. Folgende Internetquellen wurden benutzt: • http://www.heise.de • http://www.cavebear.com/CaveBear/Ethernet/ • http://www.yale.edu/pclt/COMM/ETHER.HTM • http://www.webopedia.com/TERM/E/Ethernet.html 37 4 Link-Layer, Ethernet 38 KAPITEL 5 Internet Protocol (IP) Corina Fietz Das Internet kann man als eine Sammlung von Teilnetzen oder autonomen Systemen ” betrachten, die miteinander verbunden sind“[39]. Ein Netz aus Leitungen mit hoher Band” breite und schnellen Routern“[39] bezeichnet man als Backbone. An die Backbones werden ” regionale Netze und an diese LANs von Universitäten, Unternehmen und Internet-ServiceProvidern angeschlossen“[39]. Ein Protokoll legt die Form einer Kommunikation fest, d.h. es müssen bestimmte Regeln bzw. einheitliche Codes festgelegt werden, damit jeder weiß, was gemeint ist. Beim Internet Protocol wird dies durch den IP-Header erreicht. Das IP wird spezifiziert im RFC 791 vom September 1981. Es stellt einen Datenübertragungsservice zur Verfügung. Seine Aufgabe ist es, nach bestem Bemühen“ (best effort) Daten von ” ” der Quelle zum Ziel zu befördern, unabhängig davon, ob sich diese Maschinen im gleichen Netz befinden oder ob andere Netze dazwischenliegen“[39]. IP enthält allerdings keinen Mechanismus, der Garantie dafür bietet, daß die gesendeten Daten ihren Bestimmungsort erreichen. Schlägt die Übertragung fehl, d.h. werden bei der Übertragung Fehler im Header festgestellt, verwirft IP die zu versendenden Daten und versucht, eine diesbezügliche Nachricht an den Absender zu schicken. Jegliche erforderliche Zuverlässigkeit muß durch die Protokolle der höheren Schichten, wie z.B. TCP gewährleistet werden. Datenfragmente können verloren gehen, dupliziert werden oder in falscher Reihenfolge ankommen. IP ist ein verbindungsloses Protokoll. Das bedeutet, es besteht keine direkte Verbindung zum Kommunikationspartner. IP vermittelt zwischen dem TransportLayer und dem Link-Layer. 39 5 Internet Protocol (IP) 5.1 IP Header Bytes Bits 1 1 2 4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 32 Version Length Type of service Prec. 2 3 TOS Total Length 0 Flags Identification Fragment Offset 0 DFMF 3 Time to live Protocol Header Checksum 4 Source Address 5 Destination Address Options Words 1-5 Padding Data hhhh hhhhhhhhh hhhh hhhh hhhh hhhh hhhh hhhh hhhh h hhh hhhh hh h hhhh hhhh hhhh h hhh Prec.: Precedence Zur Datenübertragung erstellt IP ein sogenanntes Datengramm. Als Synonyme für Datengramm werden in der Literatur auch die Begriffe Datenpaket oder einfach Paket, datagram oder packet verwendet. Ein IP-Datengramm besteht aus einem Header und den zu versendenden Daten“[13]. Der ” ” 40 5.1 IP Header IP-Header hat einen festen 20 Byte großen Teil“, d.h. 5 mal 32-Bit-Wörter, und einen op” tionalen Teil mit variabler Länge“[39] (max. 40 Byte). Der IP-Header besteht aus folgenden Feldern: Version: Das Feld Version besteht aus 4 Bits. Die derzeitige Version ist Nr. 4 beichnet mit IPv4. Length: Das Feld Length besteht aus 4 Bits. Es gibt die Anzahl der 32-Bit-Wörter einschließlich dem optionalen Teil an. Der Mindestwert ist 5 Wörter, wenn keine Optionen vorhanden sind. Da dieses Feld aus 4 Bits besteht (1111=15), d.h. maximal der Wert 15 angegebenwerden kann, wird die Länge des Headers auf maximal 60 Bytes (15 × 4 Bytes pro Wort) beschränkt. Das bedeutet, für das Optionenfeld verbleiben maximal 40 Bytes (abzüglich 20 Bytes für die ersten 5 Wörter). Diese Länge ist für manche Optionen viel zu klein, z.B. wenn die Route eines Pakets aufgezeichnet werden soll. Type of service: Das Feld Type of service besteht aus 8 Bits. Es enthält zunächst das Feld Precedence, das aus 3 Bits besteht. Hier kann eine Priorität von 0 bis 7 (111=7) angegegeben werden. Es folgen 4 TOS-Bits und ein nicht genutztes Bit, das 0 sein muß. Bei den 4 TOS-Bits wird durch eine 1 angegeben, auf welche Funktion Wert gelegt wird und zwar bedeutet eine 1 bei dem 1. TOS-Bit: Verzögerungsminimierung 2. TOS-Bit: Durchsatzmaximierung 3. TOS-Bit: Zuverlässigkeitsmaximierung 4. TOS-Bit: Kostenminimierung Sind alle 4 TOS-Bits auf 0, bedeutet das normalen Service. In der Praxis wird das ” Feld Type of Service von den heute eingesetzten Routern gänzlich ignoriert“[39]. Type-of-Service-Belegungen Anwendungsbeispiele Telnet, FTP control FTP data any IGP, SNMP NNTP BOOTP, ICMP Minimierung der Verzögerung (delay) 1 0 0 0 0 Maximierung des Durchsatzes (throughout) 0 1 0 0 0 Maximierung der Zuverlässigkeit (reliability) 0 0 1 0 0 Minimierung der Kosten (monetary cost) 0 0 0 1 0 Belegung: 1: auf diese Funktion wird besonderen Wert gelegt 41 5 Internet Protocol (IP) 0: normale Funktion Begriffe: IGP: Interior Gateway Protocol SNMP: Simple Network Management Protocol NNTP: Network News Transfer Protocol BOOTP: Bootstrap Protocol Total Length: Das Feld Total Length besteht aus 16 Bits. Es gibt die Länge des IPDatengramms, also Header und Daten in Bytes an (maximal 1111 1111 1111 1111 = 65 535 Bytes). Auch wenn es möglich ist, ein 65535Byte großes IP-Datengramm zu senden, wird es von den meisten Linklayern aufgeteilt. Davon abgesehen gibt es ein deutlich geringeres Mindestmaß für die Größe von Datenpaketen, die ein Host in der Lage sein muß zu empfangen: nur 576 Bytes. Identification: Das Feld Identification besteht aus 16 Bits. Es identifiziert jedes Datengramm eindeutig. Das ist erforderlich, wenn ein größeres Datenpaket in mehrere Datengramme aufgeteilt wird. So kann der Zielhost feststellen (...), zu welchem Daten” gramm ein neu ankommendes Fragment gehört. Alle Fragmente eines Datengramms enthalten den gleichen Identification-Wert.“[39] Flags: Das Feld Flags besteht aus 3 Bits. Die Flags geben an, ob es erlaubt ist, ein größeres Datenpaket in mehrere kleinere zu zerlegen und wenn ja, ob noch mehr Fragmente folgen. Ist ein Datenpaket zu groß, um es als Ganzes zu übertragen, aber Fragmentieren nicht erlaubt, so wird es nicht übertragen. Aus jedem Fragment wird ein Datengramm mit eigenem Header erstellt. Die Belegung sieht folgendermaßen aus: das erste Bit muß 0 sein, beim zweiten Bit bedeutet: 0: Fragmentieren möglich 1: nicht Fragmentieren (DF=Don’t fragment) beim dritten Bit bedeutet: 0: letztes Fragment 1: es kommen noch mehr Fragmente (MF=More fragments) (vgl. [27]) Fragment Offset: Das Feld Fragment Offset besteht aus 13 Bits. Es teilt dem Empfänger die Position eines Fragments im ursprünglichen Datengramm mit. Beim ersten Fragment, oder wenn überhaupt nicht fragmentiert wurde, stehen alle Bits auf 0. Time to live = TTL = Hop Count: Das Feld Time to live besteht aus 8 Bits. Es legt eine Zeitgrenze fest, bis zu der ein Datengramm auf dem Weg zum Empfänger im Internet verbleiben darf. Dabei wird der Wert, in der Regel auf 32 oder 64 Sekunden voreingestellt. Bei jedem durchlaufenen Router verringert sich der Wert um mindestens 42 5.1 IP Header 1, auch wenn der Router schneller durchlaufen wird. Steht der Wert auf 0, so wird das Datengramm vernichtet und der Absender benachrichtigt, daß die Übertragung fehlgeschlagen ist. Das Feld Time to Live verhindert folglich, daß sich durch falsch konfigurierte Router Endlosschleifen bilden. (vgl. [33, 27]) Protocol: Das Feld Protocol besteht aus 8 Bits. Es gibt an, welches Transportprotokoll (z.B. TCP, UDP u.a.) verwendet werden soll. Die Transportprotokolle werden durch eine einheitliche Nummerierung identifiziert, die durch die Organisation IANA festgelegt wird. Header checksum: Das Feld Header checksum besteht aus 16 Bits. Es ist eine Prüfsumme zur Erkennung von Fehlern, die bei der Übertragung von Router zu Router auftreten können. Es wird nur der Header geprüft, nicht die Daten. Die Header-Prüfsumme ” muß bei jeder Teilstrecke“, d.h. bei jedem Durchlauf eines Routers neu berechnet ” werden, da sich mindestens ein Feld immer ändert (Time to live)“[39]. Sie wird durch einen Algorithmus berechnet, bei der der Header in 16-Bit-Halbworte aufgeteilt und deren Summe ermittelt wird. Wenn das Datengramm empfangen wird, wird erneut die Summe berechnet und mit dem Wert im checksum field verglichen. Stimmen die Werte nicht überein, wird das Datengramm vernichtet (checksum error). Durch die Kontrollfunktion der Header checksum bietet IP ein hohes Maß an Korrektheit, Fehler sind unwahrscheinlich, aber möglich, wenn z.B. eine Vertauschung von 2 gleichen Bits zwischen zwei 16-Bit-Halbworten auftritt. Source Address: Das Feld Source Address besteht aus 32 Bits. Es ist die IP-Adresse des Senders. Destination Address: Das Feld Destination Address besteht aus 32 Bits. Es ist die IPAdresse des Empfängers. Options: Das Feld Options besteht aus maximal 40 Bytes. In diesem Feld können bei Bedarf zusätzliche Informationen definiert werden. Dabei ist es erforderlich, eine im RFC 791 festgelegte Form einzuhalten. Um zu funktionieren, müssen diese Optionen von jedem Router unterstützt werden bzw. freigegeben sein. Es ist auch möglich, bestimmte Optionen abzuschalten, um Mißbrauch zu vermeiden. So ist z.B. an der Universität Bielefeld die Option Strict Source Routing (Erklärung unten) abgeschaltet. Ansonsten wäre die Authenzität des Absenders in Frage gestellt. Beispiele definierter Optionen: • Sicherheit (Security): Die Option Sicherheit bezeichnet, wie geheim das Datengramm ist, z.B. war es ursprünglich gedacht, daß ein Router in einer militärischen Anwendung diese ” Option benutzt, um festzulegen, daß die Übertragung nicht durch bestimmte Länder fließen soll“[39]. In der Praxis wird diese Option von den meisten Routern nicht unterstützt und wahrscheinlich nicht mehr benutzt. Durch Nutzung dieser Option würde man ja gerade brisante Daten markieren und es so möglichen Gegnern erleichtern, an geheime Informationen zu kommen. 43 5 Internet Protocol (IP) • Striktes Source-Routing (Strict Source Routing): Hier wird durch Angabe jeder einzelnen IP-Adresse der zu durchlaufenden Router von der Quelle bis zum Ziel der komplette Pfad des Datengramms festgelegt. Diese Option ist in der Universität Bielefeld abgeschaltet, um Mißbrauch zu vermeiden. Es könnte beispielsweise sonst geschehen, daß Datengramme mit entsprechendem Inhalt über andere Adressen geroutet werden und so den Anschein erwecken, einen anderen Absender zu haben, als in der Realität. • Loses Source-Routing (Loose Source Routing): Hier wird eine Liste von Routern festgehalten, die in der angegebenen Reihenfolge durchlaufen werden müssen. Anders als beim strikten Source-Routing können zusätzlich auch andere Router gewählt werden. • Routenaufzeichnung (Record Route): Bei der Routenaufzeichnung hängt jeder durchlaufene Router seine IP-Adresse an das Optionenfeld an. Dadurch können Systemmanager Fehler in den ” Routing-Algorithmen verfolgen“[39]. • Zeitstempel (Time Stamp): Die Option Zeitstempel entspricht der Option Routenaufzeichnung mit zusätzlicher Zeiterfassung. Padding: Padding heißt übersetzt Polsterung/Füllmaterial. Da Optionen auch aus weniger als 32 Bit bestehen können, wird Padding benutzt, um sicherzustellen, daß der Header auf einer 32-Bit -Grenze endet, d.h. es wird mit Null-Bits aufgefüllt (vgl. [27]). 5.2 Der Befehl ifconfig Der Befehl ifconfig dient der Konfiguration der Netzwerkschnittstellen für die Benutzung von TCP/IP. Der Befehl wird normalerweise beim Booten gestartet, um jede Schnittstelle eines Hosts zu konfigurieren. Die MTU (Maximum Transmission Unit) zeigt den maximalen Durchsatzwert der Schnittstelle in Bytes an, d.h. wie groß ein Datengramm maximal sein darf, um die Schnittstelle passieren zu können. Es gibt zahlreiche Optionen für ifconfig, auf die hier nicht näher eingegangen wird. Um den Befehl an der Universität Bielefeld auf den studentischen Rechnern in der Technischen Fakultät auszuprobieren, muß beim Prompt /usr/sbin/ifconfig -a eingegeben werden. Dabei werden durch die Eingabe von -a alle Schnittstellen angezeigt. Beispiel: cfietz@antipasto /usr/sbin/ifconfig -a lo0: flags=1000849<UP,LOOPBACK,RUNNING,MULTICAST,IPv4> mtu 8232 index 1 inet 127.0.0.1 netmask ff000000 ge0: flags=1000863<UP,BROADCAST,NOTRAILERS,RUNNING,MULTICAST,IPv4> mtu 1500 index 2 inet 192.168.133.3 netmask ffffff00 broadcast 192.168.133.255 hme0: flags=1000863<UP,BROADCAST,NOTRAILERS,RUNNING,MULTICAST,IPv4> mtu 1500 index 3 inet 129.70.133.113 netmask ffffff00 broadcast 129.70.133.255 44 5.3 Der Befehl netstat lo0: flags=2000849<UP,LOOPBACK,RUNNING,MULTICAST,IPv6> mtu 8252 index 1 inet6 ::1/128 hme0: flags=2000841<UP,RUNNING,MULTICAST,IPv6> mtu 1500 index 3 inet6 fe80::a00:20ff:fefc:c670/10 5.3 Der Befehl netstat Der Befehl netstat stellt Informationen über die Schnittstellen eines Systems, die MTU jeder einzelnen Schnittstelle die Anzahl ein-und ausgehender Datenpakete, ein- und ausgehender Errormeldungen und Kollisionen und die übliche Größe der ausgehenden Schlange zur Verfügung. Bei einer Eingabe von netstat -n werden IP-Adressen anstelle von Namen, wie z.B. antipasto.TechFak.Uni-Bielefeld.DE angegeben. Eine Eingabe von -i liefert Schnittstelleninformationen. Beispiel: cfietz@antipasto netstat Name Mtu Net/Dest lo0 8232 127.0.0.0 ge0 1500 192.168.133.0 hme0 1500 129.70.133.0 Name lo0 hme0 Ipkts Ierrs Opkts Oerrs Collis Queue 24724619 0 24724619 0 0 0 507268466 0 1502855215 0 0 0 240730951 0 246679105 0 0 0 Mtu Net/Dest Address 8252 ::1 ::1 1500 fe80::a00:20ff:fefc:c670/10 fe80::a00:20ff:fefc:c670 cfietz@antipasto netstat Name Mtu Net/Dest lo0 8232 loopback ge0 1500 SunRay-ge0 hme0 1500 cip-ether Name lo0 hme0 -ni Address 127.0.0.1 192.168.133.3 129.70.133.113 Ipkts Ierrs Opkts Oerrs Collis 24724619 0 24724619 0 0 240730951 0 246679105 0 0 -i Address Ipkts Ierrs Opkts Oerrs Collis Queue localhost 24724640 0 24724640 0 0 0 3.133.168.192.in-addr.arpa 507282117 0 1502904778 0 0 antipasto.TechFak.Uni-Bielefeld.DE 240735054 0 246683474 0 Mtu Net/Dest Address 8252 localhost localhost 1500 fe80::a00:20ff:fefc:c670/10 fe80::a00:20ff:fefc:c670 0 0 0 Ipkts Ierrs Opkts Oerrs Collis 24724640 0 24724640 0 0 240735055 0 246683475 0 0 5.4 Die Zukunft des IP Aufgrund des phenomenalen Wachstums des Internets in den letzten Jahren und der ineffizienten Ausnutzung der vorhandenen Adressen, werden die IP-Adressen knapp. Deshalb werden die 32-Bit-Adressen zukünftig zu klein sein. Es steigt aber nicht nur die Anzahl der Benutzer, sondern auch die Datenmenge. Das Internet dient zunehmend als Unterhaltungs- und Kommunikationsmedium. Den höheren Anforderungen, die Grafiken, ganze Videos und Telekommunikationsprogramme stellen, ist IPv4 zunehmend nicht mehr gewachsen. 45 5 Internet Protocol (IP) Nachfolger von IPv4 ist IPv6. Dabei handelt es sich nicht um ein grundsätzlich anderes Protokoll, sondern es basiert auf IPv4 mit einigen Veränderungen. IPv6 begegnet dem Problem der Adressenknappheit mit größeren Adressen. Statt 32-BitAdressen, werden 128-Bit-Adressen verwendet, die zweckmäßigerweise im Hexadezimalsystem notiert werden. Das entspricht umgerechnet der gigantischen Zahl von 1024 IPAdressen pro m2 Erdoberfläche. Außerdem wird die anzuhängende Kontrollinformation effizienter gestaltet. Statt einem Header gibt es einen Basisheader mit weniger Feldern und Zusatzheader nach Bedarf. Das Time-to-Live-Feld wird durch das Hop-Limit-Feld abgelöst, das nur noch die tatsächlichen Routerdurchläufe mißt, statt eine Mischung aus Routerdurchläufen und Zeit. IPv6 bietet End-To-End Fragmentation, das bedeutet, in Routern findet keine Fragmentation mehr statt. Ist das Datenpaket zu groß, wird es nicht übertragen. Es ist Aufgabe des Quellrechners, große Datenpakete ggf. zu fragmentieren. In diesem Fall wird ein Fragment Extension Header angefügt. Auch der Optionenteil ist verbessert worden. So gibt es z.B. eine Option zur ” Echtzeitübertragung“[13], die u.a. für Telekommunikationsprogramme erforderlich ist. Alles in allem wird ein schnelleres Routing erreicht. IPv6 beinhaltet nun im Protokoll selbst Mechanismen zur sicheren Datenübertragung“[13], ” wie z.B. authentification (Echtheit des Absenders bzw. Empfängers) und data integrity (Datenintegrität, unveränderter Inhalt der Daten). Für isolierte Netzwerke stellt IPv6 die Möglichkeit zur Verfügung, eigene Adressen festzulegen und miteinander zu kommunizieren, ohne von einem Router abhängig zu sein. IPv6 ist außerdem erweiterungsfähig für zukünftige Verbesserungen. Statt wie IPv4 alle Details festzulegen, erlaubt IPv6 zusätzliche Merkmale für zukünftige Anwendungen aufzunehmen. 46 KAPITEL 6 Address Resolution Protocol (ARP) Sabrina Kögler 6.1 ARP (Address Resolution Protocol) Von jedem Übertragungsnetz (z.B. Ethernet, Token Ring) wird eine eigene Übertragungsmethode benutzt. Die hierbei benutzen Adressen werden Hardware-Adressen genannt. Für jedes Netz muß ein Verfahren gefunden werden, das zum Beispiel die Internet-Adressen in passende Hardware-Adressen umsetzt. Diese Umsetzung wird Adressenauflösung (address resolution) genannt. Hierfür existiert ein spezifisches Protokoll, das Address Resolution Protocol (ARP) 6.1.1 Funktionsprinzip des ARPs Ein Rechner, der die Hardware-Adresse seines Zielrechners nicht kennt, schickt eine sogenannte ARP-Anforderung als Broadcast-Datagramm ab. Diese ARP-Anforderung enthält die Internet- und die Hardware-Adresse des Senders und die Internet-Adresse des Zielrechners. Wenn die Netzwerkschicht die Anforderung erhält, ein Datagramm an eine andere IPAdresse zu senden, sucht es zuerst im ARP-Cache nach der korrespondierenden HardwareAdresse. Falls im ARP-Cache kein Eintrag gefunden wird, wird vom Initiator mit Hilfe von ARP die Hardware-Adresse der fraglichen IP-Adresse zu ermitteln versucht. In der Hoffnung, diese Frage wenigstens temporär aus der Welt zu schaffen, sendet ARP in diesem 47 6 Address Resolution Protocol (ARP) Fall, die sogenannte ARP-Anforderung an alle Rechner mittels der Hardware-BroadcastAdresse. In dieser Anforderung setzte ARP seinen eigenen Ethernet-Typ (0X08086) ein. Jetzt überprüfen alle Rechner, ob sie mit der Anfrage gemeint sind. Nur der Rechner, der das Ziel der Anforderung war beantwortet das Paket mit einer ARP-Bestätigung. Der Zielrechner schickt die ARP-Bestätigung dann direkt an den anfragenden Rechner. Diese Bestätigung enthält seine Hardware-Adresse, die der anfragende Rechner zur Übertragung der Nutzerdaten verwenden kann . Dieses Verfahren wäre jedoch sehr kostenintensiv, in Hinsicht auf hohe Netzlast und hohe Belastung nicht beteiligter Rechner, wenn die ARP-Anforderung jeden Datenaustausch einleiten würde. Aus diesem Grund wurde der ARP-Cache eingeführt. 6.1.2 ARP-Cache Das ARP-Cache ist eine Tabelle von IP-Adressen und dazugehörigen Hardware-Adressen, die jeder Rechner führt. Hier werden die eingehende Antwort vermerkt und stehen für eine weitere und vor allem schnellere bzw. effizientere Nutzung bereit. Wenn innerhalb eines definierten Timeouts keine Antwort auf die Broadcast-Anfrage eingeht, wird die Anforderung erneut gestellt. Der Cache wird aktualisiert, sobald eine ARP-Anfrage oder ARP-Bestätigung eintrifft. Alle Rechner die sich im LAN befinden, können die Broadcast versandten ARP-Anfragen nutzen, um ihren eigenen ARP-Cache auf dem aktuellen Stand zu halten. Das ARP-Cache wird meistens für ihre Informationen solange gehalten, bis die Geräteeinheit zurückgesetzt oder ausgeschaltet wird. Jedoch gibt es in einigen TCP/IPImplementierungen ein zeitliches Limit. Dieses Limit beträgt zwischen 10 und 20 Minuten. Wird ein Eintrag innerhalb dieses Zeitraums nicht verwendet, erfolgt die Löschung dieser Einträge. Ansonsten wäre eine einmal getroffene Zuordnung von IP-Adressen zu der Hardware-Adresse von unbeschränkter Dauer. Der Austausch einer defekten Netzwerkkarte würde in diesem Fall dazu führen, daß der Rechner nicht mehr im Netz erreichbar ist. Ein Standby-Server könnte die Arbeit des ausgefallenen Hauptservers nicht mit der gleichen IP-Adresse fortsetzen und eine doppelt vergebene IP-Adresse brächte das Netz durcheinander. Demnach dürfen in einem gut verwalteten Netzwerk keine Duplikate von IP-Adressen entstehen. Jedoch wie oben schon erwähnt, existiert nicht immer ein zeitliches Limit. Andere Systeme arbeiten mit einer zeitgesteuerten Aktualisierungsfunktion. Hierbei wird etwa alle 15 Minuten eine ARP-Anforderung abgesetzt, um sicherzustellen, daß die vorhandenen Einträge noch immer in den Eigenschaften der aktuellen Umgebung entsprechen. Der Befehl “arp” gibt den Inhalt der ARP-Tabelle aus. Um sich der Einsicht in die gesamte ARP-Tabelle zu verschaffen, benutzt man die Option -a. Beispiel einer ARP-Tabelle: Net to Device -----hme0 hme0 ge0 hme0 ge0 ge0 48 Media Table: IPv4 IP Address Mask Flags Phys Addr -------------------- --------------- ----- --------------pasta.TechFak.Uni-Bielefeld.DE 255.255.255.255 08:00:20:86:57:0f V01Router.TechFak.Uni-Bielefeld.DE 255.255.255.255 00:d0:d3:a5:5c:d9 224.101.101.101 255.255.255.255 01:00:5e:65:65:65 224.101.101.101 255.255.255.255 01:00:5e:65:65:65 73.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f8:03:91 72.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f7:fc:6f 6.1 ARP (Address Resolution Protocol) ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 ge0 hme0 ge0 hme0 ge0 75.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f7:f8:c1 74.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f8:31:5b 69.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f8:33:91 68.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f8:a4:89 71.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f8:86:99 70.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f8:ed:dd 65.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:95:46 64.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:7d:8c 44.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:98:d4 46.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:70:13 43.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:8b:ef 37.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f2:86:64 32.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:94:40 61.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:fb:00 57.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:98:bb 59.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:8f:f6 58.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:7d:92 52.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:fa:ed 51.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:fa:ec 50.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:93:af 3.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:fc:c6:70 29.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:89:22 28.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f5:34:9c 31.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f2:84:a0 25.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:9c:41 27.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:8f:fd 20.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:9a:da 16.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f0:fa:b4 18.133.168.192.in-addr.arpa 255.255.255.255 08:00:20:f5:1e:3e vino.TechFak.Uni-Bielefeld.DE 255.255.255.255 SP 08:00:20:e6:f8:f4 2.133.168.192.in-addr.arpa 255.255.255.255 SP 08:00:20:e6:f8:f4 BASE-ADDRESS.MCAST.NET 240.0.0.0 SM 01:00:5e:00:00:00 BASE-ADDRESS.MCAST.NET 240.0.0.0 SM 01:00:5e:00:00:00 6.1.3 ARP-Format Die Struktur eines ARP-Datagramms wurde als einfaches Standardformat für den Einsatz beliebiger Netzwerktypen entworfen. ARP operiert direkt in der Datensicherungsschicht und wird daher in deren Rahmen codiert. Die ARP-Datagramme erhalten folgende Felder: Hardware: In diesem Feld werden Netzwerktypen definiert. Zuläßig sind nur folgende Typen: 1. Ethernet 2. Experimentelles Ethernet 3. Amateurfunk AX.25 4. Proteon ProNET Token-Ring 5. Chaos 49 6 Address Resolution Protocol (ARP) 6. IEEE.802 7. ARCNET 8. Hyperchannel 9. Lanstar 10. Autonet short adress 11. LocalTalk 12. LocalNet (IBM PCNet oder Syntec Inc.LocalNet) Protokoll: Hier wird angegeben, von welchem Protokoll die Operation angefordert wurde. Es werden die gleichen Werte wie im Ethernet-Typenfeld eines Rahmens verwendet. Beispiel:Dem Internet Protocol wird der Wert 0x0800 zugeschrieben. vHLEN: Hier wird die Länge der Hardware-Adresse in Oktetten angegeben Beispiel: Die IEEE-LAN-Hardware-Adresse hat den HLEN-Wert 6 PLEN: Hier wird die Länge der Vermittlungsschicht-Adresse in Oktetten dokumentiert. Beispiel:Ipv4 hat den PLEN-Wert 4 Operation: Hier stehen für das ARP zwei Operationen zur Verfügung und noch zwei weitere für das RARP. 1. Der Wert 1 wird für die ARP-Anforderung benutzt. 2. Der Wert 2 wird für die ARP-Antwort genommen. 3. Der Wert 3 wird für die RARP-Anforderung benutzt. 4. Der Wert 4 wird für die RARP-Anwort benutzt. Adressen: Hier werden die Hardware-Adressen sowie die IP-Adressen des Absenders und das gleichnamige Paar des Empfängers vermerkt. 0 7 8 15 16 HARDWARE TYPE HLEN PLEN 31 PROTOCOL TYPE OPERATION SENDER HA(octets 0-3) SENDER HA(octets 4-5) SENDER IP(octets 0-1) SENDER IP(octets 2-3) TARGET HA(octets 0-1) TARGET HA(octets 2-5) TARGET IP(octets 0-3) 50 6.2 RARP (Reverse Address Resolution Protocol) 6.2 RARP (Reverse Address Resolution Protocol) Geräte ohne eigenen Massenspeicher, die am Netz angeschlossen werden, wissen nach dem Einschalten noch nicht ihre Internetadresse. Aus diesem Grund gibt es ein umgekehrtes ARP, das Reverse Address Resolution Protocol. Das RARP ist dem ARP sehr ähnlich. Der Unterschied besteht lediglich darin, daß in diesem Fall die physikalische Adresse (Hardware-Adresse) bekannt ist und die logische Adresse (IP-Adresse) unbekannt ist. Soll ein Rechner ohne eigene IP-Adresse eine TCP/IP Verbindung herstellen, ist die Zuweisung einer IP-Adresse durch einen RARP-Server notwendig. Der Rechner sendet eine RARPAnfrage als Broadcast-Datagramm an das Netz. Diese RARP-Anfrage beinhaltet nur die eigene Hardware-Adresse Der RARP-Server wandelt die Hardware-Adresse mit Hilfe seiner Referenz-Tabelle in eine IP-Adresse um und sendet daraufhin diese Information mit einer RARP-Bestätigung zurück. Das Paket-Format von RARP ist mit dem Paket-Format von ARP identisch, nur werden im Operationsfeld die Werte 3 für Anforderung und 4 für Antwort verwendet. Die Zuverlässigkeit dieses Verfahrens kann gesteigert werden, indem man mehrere RARP-Server einsetzt. Einer wird dazu als Hauptserver (Primary RARP Server) eingerichtet, der seine Antwort sofort nach Eintreffen der Anfrage schickt. Die übrigen Server antworten entweder erst nach einer zufällig gewählten Pause oder nur dann, wenn eine RARP-Anfrage gleichen Inhalts kurz hintereinander zweimal verschickt wurde. Da das RARP für weitere Einstellungen wie zum Beispiel Subnetz-Adressen nicht geeignet ist, sind aus diesem Grund zwei weitere Protokolle entstanden, die leistungsstärker sind. Zum einen das BOOTP (Bootstrap Protocol), das mit Brücken und Routern kompatibel ist und mehr Informationen übermitteln kann. Und das zweite Protokoll ist das DHCP (Dynamic Host Configuration Protocol). 51 6 Address Resolution Protocol (ARP) 52 KAPITEL 7 Prüfsummen im Internet Protocol – Internet Checksum Jessica Butz 7.1 Prüfsummen Viele Netzwerkprotokolle bilden bei der Erstellung ihrer Datenframes eine Prüfsumme. Bei manchen Protokollen wird sie über ein ganzes Datenpaket gebildet, bei anderen nur über einen Teil davon. Das Internet Protocol (IP) bildet seine Prüfsumme nur über die Daten im Header des Datenpaketes. Die eigentlich verschickten Daten werden nicht in die Berechnung einbezogen und können daher von IP auch nicht auf Korrektheit überprüft werden. Dies übernehmen Protokolle höherer Schichten wie zum Beispiel TCP oder UDP. Bei diesen Protokollen beinhaltet die Prüfsummenberechnung auch die Nutzdaten, so daß dadurch eine fehlerfreie Transmission gewährleistet ist. Welcher Algorithmus in IP implementiert ist und wie eine Prüfsummenberechnung und -überprüfung durchgeführt wird, wird in den nachfolgenden Abschnitten erklärt. 7.2 Prüfsummen im IP (Internet Protocol) Die Berechnung der Prüfsumme im IP, oft auch als “Internet Checksum” bezeichnet, wird in den RFCs 1071, 1141 und 1624 beschrieben. Hier werden bestimmte Eigenschaften genannt, die der zur Berechnung verwendete Operator haben sollte, sowie ausgeführt, wie die Berechnung abläuft. 53 7 Prüfsummen im Internet Protocol – Internet Checksum Die im Internet Protocol implementierte Art der Prüfsummenberechnung verwendet das 1er-Komplement, eine Art der binären Addition (siehe Abschnitt 7.5). Diese Rechenoperation erfüllt alle vorgegebenen Anforderungen. Wie damit die Prüfsumme für ein Datenpaket ermittelt wird, erläutert der folgende Abschnitt. 7.3 Ermittlung und Kontrolle der Prüfsumme 7.3.1 Prüfsummenberechnung beim Sender eines Datenpaketes Wenn ein IP-Datenpaket erstellt wird, werden den eigentlich zu versendenden Daten bestimmte protokollspezifische Daten, der sogenannte Header, hinzugefügt. Dieser beinhaltet unter anderem auch ein Feld, in dem die Prüfsumme abgelegt wird. Um diese zu berechnen und einzufügen sind mehrere Schritte nötig. Zuerst setzt der Sender das Prüfsummenfeld auf 0. Dann wird der Header, der aus 5 Worten à 32 Bit besteht, in 16-Bit-Stücke zerteilt. Diese werden zusammenaddiert. Über die gesamte Summe wird nach der im Folgenden beschriebenen Methode das Komplement gebildet. Das Komplement wird in das dafür vorgesehene Feld im Header geschrieben. Dann wird das Datenpaket verschickt. 7.3.2 Kontrolle der Prüfsumme beim Empfänger eines Datenpaketes Der Empfänger des Datenpaketes bildet die Summe über den gesamten Header des Datenpaketes. Da das Prüfsummenfeld im Header das Komplement der Summe der Headerfelder beinhaltet, ist das Ergebnis der Addition bei einem gültigen Datenpaket immer 0. Ist das Ergebnis der Addition allerdings verschieden von 0, so ist ein Übertragungsfehler aufgetreten. Das Paket ist ungültig, und es wird vernichtet. IP kümmert sich nicht darum, daß das Datenpaket erneut angefordert wird, wenn es defekt war. Dies wird durch Protokolle höherer Schichten, wie z.B. TCP, übernommen. 7.4 Eigenschaften des Prüfsummen-Operators • Der Operator sollte kommutativ sein. Dadurch ist die Reihenfolge, in der addiert wird, beliebig. Die binäre Addition ist (wie die normale Addition auch) kommutativ, da 1+0 = 0+1 = 1 ist. • Ein neutrales Element muß vorhanden sein. Das neutrale Element wird vom Datensender ins Püfsummenfeld eingetragen, bevor die Summer errechnet wird. Es darf sozusagen nicht mitgezählt werden. In der 1er- 54 7.5 1er-Komplement-Addition Komplement-Addition, wie auch in der normalen Addition, ist das neutrale Element die 0. • Es muß ein inverses Element geben. Das inverse Element ist hier das Komplement einer Bitfolge; addiert man Inverses und Original-Bitfolge, so ist das Ergebnis gleich dem neutralen Element, also 0. • Der Operator sollte assoziativ sein. • Die Operation soll auf verschiedensten Maschinen schnell auszuführen sein. Diese Eigenschaft ist sehr wichtig, da das Berechnen der Prüfsumme neben dem Kopieren der Daten zu den zeitaufwendigsten Prozessen bei der Erstellung von Datenpaketen gehört. Der zur Zeit verwendete Algorithmus erfüllt diese Voraussetzung, da er lediglich Negation und Addition verwendet. Beide Berechnungen sind schnell durchführbar. • Der Operator sollte systematisch sein. Der Begriff “systematisch” bedeutet hier, daß durch das Hinzufügen der Prüfsumme zum Header die Information der Datenbytes nicht verändert wird. • Die Prüfsumme sollte inkrementell veränderbar sein. Da beim Routing bestimmte Felder im Header, so zum Beispiel der TTL-Wert (time to live) verändert werden, muß die Prüfsumme, die dieses Feld ja beinhaltet, dementsprechend angepaßt werden. Würde man sie bei jedem Routerdurchlauf komplett neu berechnen, so würde die Datenübertragung viel zu lange dauern. Daher wird sie inkrementell verändert. Wird der TTL-Wert bei einem Routerdurchlauf um 1 erniedrigt, so muß man den Wert im Prüfsummenfeld lediglich um 1 erhöhen, damit er wieder dem Komplement der Gesamtsumme entspricht. Um die Prüfsumme zu aktualisieren, addiert man also die Differenz aus dem alten und dem neuen Wert eines Header-Feldes. Daß man die Differenz addieren muß und nicht abziehen darf, wird an folgendem Beispiel mit Dezimalzahlen deutlich: Angenommen, der Wert des TTL beträgt vor dem Routerdurchlauf 6, danach also 5. Das Komplement der Prüfsumme betrage -214. Die Differenz zwischen 6 und 5 beträgt 1, also addiert man 1 zum Komplement hinzu. Im Prüfsummenfeld steht demnach jetzt -213. Wird diese Zahl rekomplementiert, so ergibt sich 213, das heißt, die Gesamtsumme der Headerfelder wurde um 1 vermindert, was der Verminderung des TTL-Wertes entspricht. 7.5 1er-Komplement-Addition Die 1er-Komplement-Addition ist eine Art des binären Rechnens. Sie wird zum Beispiel bei der binären Subtraktion verwendet, die auf eine Addition zurückgeführt wird. Vom Subtrahenden wird hierzu das Komplement gebildet und dann zum Minuenden hinzuaddiert. Dies 55 7 Prüfsummen im Internet Protocol – Internet Checksum entpricht dem Abziehen der Zahl. Entsteht bei der Addition ein Übertrag, so wird dieser zum niedrigstwertigen Bit hinzuaddiert (engl. “add with end-around carry”). Es gibt zwei Darstellungen der Zahl 0, nämlich die positive Null (+0), repräsentiert durch die Bitfolge 000...0, und die negative Null (-0), welche durch 111...1 dargestellt wird. Ansonsten gelten die üblichen Regeln für die binäre Addition, welche wie folgt lauten: A 0 0 1 1 B 0 1 0 1 A+B 0 1 1 0 Übertrag 1 Um eine Binärzahl zu komplementieren, werden die Bits invertiert, d.h. aus 1 wird 0 und umgekehrt. Dies ist einfach und schnell zu berechnen, da die Bitfolge nur durch einen Inverter geschickt werden muß. 7.5.1 Addition mit Übertrag Entsteht bei der Addition nach den oben genannten Regeln ein Übertrag, so bedeutet dies, daß das Ergebnis eine positive Zahl ist. Der Übertrag wird zum niedrigstwertigen Bit hinzuaddiert; die dann entstehende Zahl ist das Gesamtergebnis. - 12 7 = 5 1 0 1 1 0 1 0 1 → Komplement + 1 1 1 0 1 0 1 0 0 0 0 1 0 0 0 0 1 1 7.5.2 Addition ohne Übertrag Wenn bei der Addition kein Übertrag entsteht, dieser also 0 ist, so bedeutet dies, daß das Ergebnis eine negative Zahl ist. Die Bitfolge muß nun noch rekomplementiert und negiert werden, um das Endergebnis zu erhalten. 56 - 5 7 = -2 0 0 1 1 0 1 1 1 → Komplement → rekomplementieren/negieren + 0 1 1 0 1 0 1 0 0 0 0 1 1 0 1 0 7.5 1er-Komplement-Addition 7.5.3 Komplement-Addition Addiert man zu einer Zahl ihr Komplement (also das inverse Element), so beträgt das Ergebnis immer 111...1. Da es keinen Übertrag gibt, muß das Ergebnis rekomplementiert und negiert werden; es wird also zu -000...0. Genau diese Berechnung wird beim Empfänger eines Datenpaketes mit dem durch den Sender mitgeschickten Komplement und der errechneten Prüfsumme durchgeführt. - 12 12 = -0 1 1 1 1 0 0 0 0 → Komplement → rekomplementieren/negieren + 1 0 1 0 1 0 1 0 0 1 1 0 0 1 1 0 57 7 Prüfsummen im Internet Protocol – Internet Checksum 58 KAPITEL 8 Internet Control Message Proctocol (ICMP) René D. Obermüller, Daniel Kleinehagenbrock 8.1 Internet Control Message Protocol 8.1.1 Einleitung Das ICMP (Internet Control Message Protocol ) ist ein Hilfsprotokoll, welches zusammen mit dem Internet-Protokoll (IP ) auf der Netzwerkschicht implementiert ist. Da ICMP das IP -Protokoll als Basis verwendet, macht es den Anschein, als wäre ICMP zusammen mit TCP und UDP auf der Transportebene angesiedelt. Dem ist jedoch nicht so. ICMP muss neben dem Internet-Protokoll in TCP/IP implementiert werden. Erstmalig taucht ICMP als Standard April 1981 im RFC 777 auf. Im September 1981 gab es dann ein Update durch RFC 792, welche zusätzlich zu den bisherigen ICMP Typen noch eine Netzwerkinformationsnachricht enthält. Dieser RFC enthält alle auch heute noch gültigen Spezifikationen. Stark erweitert wurde das Protokoll dann 1991 im RFC 1256. Hier wurde ICMP um einen Aspekt erweitert, nämlich um spezielle Routernachrichten (ICMP Typ 9 und 10), die vorher nicht vorhanden waren. Der Hintergrund für die Entwicklung von ICMP ist die weitgehend fehlende Kontrolle 59 8 Internet Control Message Proctocol (ICMP) darüber, was mit via Internet-Protokoll verschickten Paketen passiert. Wie bereits aus der Veranstaltungsübersicht bekannt, können Pakete abgesehen davon, dass sie ordnungsgemäß ankommen, auch verloren gehen, dupliziert werden oder in falscher Reihenfolge am Ziel ankommen. Darüberhinaus kann es passieren, dass ihre Lebensdauer“ (Time-To-Live) ” abläuft. Wenn man sich die Verbindungsschicht (Link Layer ) ansieht, können noch weitere Fehler einer ordnungsgemäßen Kommunikation im Wege stehen. So kann es zum Beispiel vorkommen, dass ein routendes System (also ein Rechner, der zwei oder mehrere Netzwerke miteinander verbindet) ausgefallen, überlastet, oder eventuell falsch konfiguriert ist. An dieser Stelle setzt das Internet Control Message Protocol an. Mit ICMP lassen sich Fehlermeldungen und auch Routinginformationen versenden. Fehler allerdings können auch mit ICMP nicht behoben werden, im besten Falle lediglich aufgedeckt. ICMP -Fehlermeldungen können nur an den Sender des Paketes, welches die Fehlermeldung ausgelöst hat, gesendet werden, nicht jedoch zwangsläufig an das routende System, welches den Fehler verursacht hat. Sinnvoll ist es jedoch trotzdem, da im Internet-Protokoll an sich die Möglichkeit, solche Fehlermeldungen zu senden, nicht vorhanden sind. So kann immerhin ein Teil der Fehler aufgeklärt werden, wenn auch nicht alle - beispielsweise wenn der Empfänger oder Router eines fehlerhaften Paketes den Absender nicht mehr erreicht, kommt selbstverständlich auch keine Fehlermeldung an. Ursprünglich war ICMP nur für die Kommunikation zwischen routenden Systemen gedacht, das hat sich jedoch geändert: Alle Rechner im Netzwerk können ICMP -Anfragen, ICMP -Informationen und ICMP -Fehlermeldungen versenden bzw. verwerten. 8.1.2 ICMP-Prinzipien Um die Netzwerke nicht mit zu vielen ICMP -Nachrichten zu belasten, folgt ICMP gewissen Prinzipien. • ICMP -Fehlermeldungen werden höchstens einmal pro Fehler verschickt • Es gibt nie ICMP -Fehlermeldungen als Antwort auf ICMP -Fehlermeldungen, damit sich die ICMP -Nachrichten nicht aufschaukeln – ICMP -Fehlermeldungen auf ICMP Informationsmeldungen oder ICMP -Anforderungen sind allerdings möglich • ICMP -Nachrichten werden nicht versandt, wenn das Bezugspaket keinen eindeutigen Empfänger hatte – also zum Beispiel, wenn das Bezugspaket an eine Multicast- oder Broadcastadresse ging • ICMP -Fehlermeldungen werden nur als Antwort auf das erste Fragment eines Datagrams, nie auf die folgenden Fragmente versandt. 60 8.1 Internet Control Message Protocol 8.1.3 ICMP-Spezifikationen - Nachrichtenformat ICMP nutzt – wie bereits erwähnt – das Internet-Protokoll als Basis. Somit besteht ein ICMP -Paket komplett betrachtet aus einem Ethernet-Rahmen-Header, einem EthernetRahmen-Datenteil, der einen IP -Header und einen IP -Datenteil beinhaltet; in den letzteren bettet sich dann der ICMP -Header zusammen mit dem ICMP -Datenteil ein. Frame-Daten Frame-Header IP-Daten IP-Header ICMP -Header ICMP -Daten Das ICMP -Paket selbst sieht folgendermassen aus: 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme o Header Je nach Typ verschiedene Inhalte hhhh h hhhhhhhhh hhhh hhhh hhhh hhhh hhhh hhhh hhh h hhhh hhhh hh hh h hhhh h hh 61 8 Internet Control Message Proctocol (ICMP) 8.1.4 ICMP-Spezifikationen - Typen Destination Unreachable - Ziel nicht erreichbar (Typ 3) Kann aus irgendeinem Grund ein Router ein Ziel nicht erreichen, oder ein Dienst oder Port auf dem Zielrechner ist nicht erreichbar, wird diese Nachricht verwendet. Die einzelnen Möglichkeiten werden in Zusammenhang mit den Codes deutlich. 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme unbenutzt IP-Datagram-Header und die ersten 64 Bits des Originalpaketes Typ: 3 Code: 0 = net unreachable – Zielnetzwerk nicht erreichbar (z.B. fehlerhafte Routingtabellen, oder Entfernung“ laut Routingtabelle unendlich groß) ” 1 = host unreachable – Zielrechner nicht erreichbar (der Router im Zielnetzwerk kann den Zielrechner nicht erreichen) 2 = protocol unreachable – Der angegebene Dienst auf diesem Rechner kann nicht erreicht werden. 3 = port unreachable – Der Port für dieses Paket kann nicht erreicht werden (z.B. wenn der Port vom Zielrechner ignoriert oder blockiert wird) 4 = fragmentation needed and DF set – Das Paket ist für den Router zu groß, er darf es jedoch nicht in Fragmente zerlegen, da DF (Don’t Fragment – nicht fragmentieren) im IP-Datagram-Header gesetzt ist 5 = source route failed – Source Routes sind im Paket gesetzt, aber die Durchführung scheitert an Routereinstellungen Code 0,1,4 und 5 werden normalerweise von routenden Systemen versendet, 2 und 3 vom Zielrechner. Time Exceeded Message - Zeitüberschreitung (Typ 11) Jedes IP-Paket erhält eine sogenannte Lebensdauer (Time-To-Live). Diese wird pro routendem System, über das das Paket verläuft mindestens um eine Sekunde (falls die Verweil“dauer auf dem Router kleiner oder gleich einer Sekunde ist) oder um die ” 62 8.1 Internet Control Message Protocol tatsächlich auf dem Router gewartete“ Zeit verringert. Sollte es passieren, dass der Wert ” unter 0 fällt, muss das Paket vernichtet werden. Das System, welches das Paket vernichtet, schickt gleichzeitig an den Sender eine ICMP Code 11 Nachricht, um zu signalisieren, dass genau dieser Fall eingetreten ist. Aufbau des Paketes: 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme unbenutzt IP-Datagram-Header und die ersten 64 Bits des Originalpaketes Typ: 11 Code: 0 = time to live exceeded in transit – Lebenszeit des Paketes beim Transport überschritten 1 = fragment reassembly time exceeded – Die Zeit ist beim Zusammensetzen der Fragmente am Zielsystem überschritten worden Code 0 wird im Regelfall von einem routenden System gesendet, Code 1 im Regelfall vom Zielsystem. Parameter Problem Message (Typ 12) Wenn ein Router oder das Zielsystem ein IP-Datagram verwerfen muss, weil sich die Einstellungen des Datagrams nicht mit den lokalen IP-Einstellungen vereinbaren lassen, so kann das System, an dem das Datagram verworfen wird, an den Absender eine ICMP Typ 12 Nachricht senden, um dieses Problem mitzuteilen. Aufbau des Typ 12 ICMP Paketes: 63 8 Internet Control Message Proctocol (ICMP) 0 7 8 ICMP Typ 15 16 31 Prüfsumme ICMP Code Pointer unbenutzt IP-Datagram-Header und die ersten 64 Bits des Originalpaketes Typ: 12 Code: 0 – Das Feld “Pointer“ im ICMP -Header ist aktiv. Im Feld Pointer“ ist ein Zeiger enthalten, der angibt welches Byte (Oktett) des IP” Datagram-Headers zum Parameterproblem geführt hat. Kann sowohl von Routern als auch von Zielsystemen verschickt werden. Source Quench - Quelle dämpfen (Typ 4) Dieser ICMP Typ wird verwendet, um die Rate der Pakete pro Zeit je nach Auslastung des routenden Systems zu optimieren. 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme unbenutzt IP-Datagram-Header und die ersten 64 Bits des Originalpaketes Typ: 4 Code: 0 Wenn ein routendes System (z.B. aufgrund mangelnder Ausgangsbandbreite oder temporärer Überlastung) keinen Platz mehr für weitere Pakete hat, kann das System an den Absender eine sogenannte Source Quench Nachricht verschicken. Diese soll dem Sender signalisieren, dass die Rate der Pakete, die in einer gewissen Zeit verschickt werden, verringert werden soll, da Pakete bereits verworfen wurden aufgrund übergelaufenem Zwischenspeicher oder da der Speicher überzulaufen droht. Der Router wird dann für jedes Paket das verworfen wird, oder aber für jedes Paket, das eingeht, sobald der Speicher eine gewisse Auslastung erreicht hat, eine solche Nachricht an den Absender schicken. Der 64 8.1 Internet Control Message Protocol Absender kann dann die Rate verringern, so lange bis er keine Source Quench Nachricht mehr erhält. Dann kann die Rate wieder langsam angehoben werden, und gedrosselt, falls wieder Source Quench Nachrichten gesendet werden. Dies ist in gewisser Weise sinnvoll, da die Paketrate - sofern der Sender die Bandbreite besitzt - immer an der oberen Grenze gehalten werden kann. Ausserdem hilft diese Nachricht, übermässige Netzbelastung zu vermeiden, denn die Anzahl der durch Überlauf verlorenen bzw. verworfenen Pakete wird so möglichst gering gehalten. Letztendlich muss man aber sagen, dass diese Idee sich nicht durchsetzen konnte, da die Angelegenheit doch etwas komplizierter ist. Wenn das Netzwerk bzw. die Verbindung tatsächlich schon überlastet ist, dann ist es fraglich, ob es sinnvoll ist, zusätzliche Nachrichten – wie diese ICMP-Nachricht – zu verschicken. TCP bietet für diese Problematik weitaus bessere Möglichkeiten. Diese Nachricht kann von Routern wie von Zielsystemen verschickt werden. Redirect Message - Umleitung (Typ 5) Entdeckt ein routendes System eine kürzere Verbindung vom Absender zu sich selbst oder zum designierten Empfänger, so kann diese Nachricht versendet werden, damit der Sender künftig die andere, kürzere Route benutzt. Dies spielt z.B. eine Rolle, wenn Rechner Standardgateways benutzen - in dem Fall kann vielleicht ein anderer Gateway günstiger in der Topologie angeordnet sein. Aufbau: 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme Gateway Internet Address IP-Datagram-Header und die ersten 64 Bits des Originalpaketes Typ: 5 Code: 0 = Redirect datagrams for the Network – Alle Pakete für das Zielnetzwerk sollen die angegebene Routeradresse nutzen 1 = Redirect datagrams for the Host – Alle Pakete für dieses Zielsystem sollen die angegebene Routeradresse nutzen 65 8 Internet Control Message Proctocol (ICMP) 2 = Redirect datagrams for the Type of Service and Network – Alle Pakete für dieses Zielnetzwerk, die diese Anwendung verwenden, sollen die angegebene Routeradresse nutzen 3 = Redirect datagrams for the Type of Service and Host – Alle Pakete für dieses Zielsystem, die diese Anwendung verwenden, sollen die angegebene Routeradresse nutzen Gateway Internet Address: Dieses Feld liefert die neue Gatewayadresse, über die die Pakete, die im Code eingegrenzt sind, laufen sollen Diese Nachricht wird nur von routenden Systemen verschickt. Echo Request / Echo Reply (Typ 0 und Typ 8) Dieses Nachrichtenpaar ist dazu da, um die Geschwindigkeit, Zuverlässigkeit und das Bestehen einer Verbindung zu prüfen. Das System, welches eine Verbindung prüfen möchte, sendet eine bestimmte Datensequenz, und wartet darauf, ob diese Sequenz wieder zurückkommt. Falls das passiert, lässt sich die Verzögerung messen mittels der Zeit, bis das Paket wieder zurückkommt sowie die Zuverlässigkeit zum einen durch Prüfen, ob das Antwortpaket die gleiche Datensequenz enthält wie das Anfragepaket, zum anderen durch die Anzahl der verschickten Pakete, die dann auch wirklich zurückkommen. Aufbau: 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme Sequence Number Identifier Data hhhh h hhhhhhhhh h hhh hhhh hhhh hhhh hhhh hhhh hhhh hhhh hhhh hhhh h hhhh h hh Typ: 0 für Echo Reply (Antwort) 8 für Echo Request (Anfrage) 66 8.1 Internet Control Message Protocol Code: 0 Identifier und Sequence Number sind für die Identifizierung des jeweiligen Paketes gedacht, da meist mehrere Pakete auf einmal versendet werden. Diese beiden Nachrichten werden sowohl von routenden Systemen als auch von Hosts verwendet. Timestamp Request / Timestamp Reply (Typ 13 und 14) Typ 13 und 14 können verwendet werden, um Zeiten zu vergleichen (und evtl. Uhren zu stellen.). Aufbau: 0 7 8 ICMP Typ 15 16 31 Prüfsumme ICMP Code Identifier Sequence Number Originate Timestamp Recieve Timestamp Transmit Timestamp Typ: 13 für Timestamp Request 14 für Timestamp Reply Code: 0 Identifier und Sequence Number sind für die Identifizierung des jeweiligen Paketes gedacht, da meist mehrere dieser Pakete versendet werden, um einen Abweichungsdurchschnitt zu ermitteln. Der Absender der Timestamp Anfrage trägt im Feld Originate Timestamp“ den ” 67 8 Internet Control Message Proctocol (ICMP) Zeitpunkt der Absendung ein. Das Zielsystem trägt dann, bevor das Paket als Typ 14 wieder zurückgeschickt wird, im Feld Recieve Timestamp“ den Empfangszeitpunkt ein, ” und im Feld Transmit Timestamp“ den Zeitpunkt, an dem das Paket wieder zurückgesen” det wird. Die Darstellung des Timestamps sind Sekunden seit Mitternacht nach Universal Time (London). Diese beiden Typen können von routenden Systemen wie von Hosts verwendet werden. Information Request / Reply (Typ 15 und 16) Diese Nachricht kann verwendet werden, um die Adresse des eigenen Netzwerkes herauszufinden. Aufbau: 0 7 8 ICMP Typ 15 16 ICMP Code Identifier 31 Prüfsumme Sequence Number Typ: 13 für Information Request 14 für Information Reply Code: 0 Das sendende System sendet diese Nachricht mit der eigenen Adresse an die Zieladresse 0.0.0.0, was so viel bedeutet wie: eigenes Netzwerk. Ein antwortendes System setzt dann in der Antwort die Adresse des Anfragesenders in das Zielfeld und seine eigene Adresse in das Absenderfeld. Somit kann der Anfragesender bei Erhalten des Antwortspaketes die richtige Netzwerk-id erhalten. Verwendet von Routern wie Hosts. 68 8.1 Internet Control Message Protocol Routernachrichten - Router Discovery Messages (Typ 9 und 10) Dieser ICMP -Typ ist dafür gedacht, um den Datenverkehr zu automatisieren. Wie man sich sicherlich vorstellen kann, ist das manuelle Administrieren von Routinglisten mit Eintragen von Gateways auf allen Rechnern in großen Netzwerken recht aufwändig. Mittels der Router Advertisement Message verkünden“ die Routenden Systeme von Zeit zu Zeit ihre ” eigenen zum jeweiligen Netzwerk-Interface gehörenden Adressen in das Netzwerk, damit die Rechner, ohne dass ein manueller Eingriff nötig wird, die Gateway-Adressen verwenden können. Die Router Discovery Messages werden in der RFC 1256 erwähnt. Eine Router Advertisement Message sieht folgendermassen aus: 0 7 8 15 16 31 ICMP Typ ICMP Code Prüfsumme Num Addrs A. Entry Size Lifetime Router Address 1 Preference Level 1 .. . Router Address N Preference Level N Typ: 9 Code: 0 Num Addrs: Anzahl der mitgelieferten Adressen Lifetime: Gültigkeitsdauer Addr Entry Size: Anzahl der 32-Bit-Wörter, die für jeweils eine Adressinformation dienen Router Address x ist die x-te mitgelieferte Routeradresse und das zugehörige Preference Level x beschreibt seinen Rang, oder seine Wertigkeit. Systeme die diese Nachricht erhalten, verwenden den Router mit dem höchsten Rang als erstes, ist dieser nicht erreichbar, wird der Router mit der zweithöchsten Wertigkeit verwendet. Wenn man einen Rechner mit dem Netzwerk verbindet, sind diesem Rechner möglicherweise keine Router bekannt. Zu diesem Zweck kann dieser Rechner eine Router Advertisement Message anfordern, indem der Rechner eine Router Solicitation Message abschickt. Die Router Solicitation Message hat folgenden Aufbau: 0 7 8 ICMP Typ 15 16 ICMP Code 31 Prüfsumme Reserved 69 8 Internet Control Message Proctocol (ICMP) Typ: 10 Code: 0 Reserved: enthält den Wert 0 - dieses Feld wird bei Empfang des Paketes ignoriert. Diese beiden ICMP Typen sind übrigens Beispiele für sogenannte Multicast Messages, Nachrichten, die an das gesamte Netzwerk gesendet werden. Für das Versenden von Router Advertisement Messages gibt es auf routen Systemen Einstellungen, die vorhanden sein müssen. Im einzelnen sind das: • Einstellungen pro Netzwerkinterface: – AdvertisementAddress – Zieladresse für Advertisements. Entweder Multicast an alle Systeme im Netzwerk, oder eine (begrenzte) Broadcast-Adresse. – MaxAdvertisementInterval – Die maximal erlaubte Zeit zwischen zwei MulticastAdvertisements an diesem Netzwerkinterface. Der Wert muss zwischen 4 und 1800 Sekunden liegen, Standardeinstellung: 600 Sekunden. – MinAdvertisementInterval – Die minimal erforderliche Zeit zwischen zwei Multicast-Advertisements an diesem Netzwerkinterface. Der Wert muss zwischen 3 und MaxAdvertisementInterval liegen, Standardeinstellung: 0.75 * MaxAdvertisementInterval – Advertisementlifetime – Enthält die Lebensdauer, die im IP-Header bei Advertisement eingetragen wird. Darf nicht unter MaxAdvertisementInterval und nicht über 9000 Sekunden liegen. Standardwert ist 3 * MaxAdvertisementInterval • Einstellungen für jede IP -Adresse: – Advertise – Legt fest, ob die jeweilige Adresse in der Advertisement Message angekündigt wird. Standard: TRUE – PreferenceLevel – Legt die Wertigkeit dieser Adresse als Standardrouteradresse fest wie in der Advertisement Nachricht verwendet. Ein 32-Bit-Wert wird dazu gebildet in Relation zur Wertigkeit anderer Router. 70 8.1 Internet Control Message Protocol 8.1.5 Typenbetrachtung rdo@Corvus:~$ netstat --statistics [...] Icmp: 31 ICMP messages received 0 input ICMP message failed. ICMP input histogram: destination unreachable: 29 echo requests: 2 6 ICMP messages sent 0 ICMP messages failed ICMP output histogram: destination unreachable: 4 echo replies: 2 [...] rdo@Corvus:~$ ping 141.1.1.1 [...] rdo@Corvus:~$ netstat --statistics Icmp: 35 ICMP messages received 0 input ICMP message failed. ICMP input histogram: destination unreachable: 30 echo requests: 2 echo replies: 3 6 ICMP messages sent 0 ICMP messages failed ICMP output histogram: destination unreachable: 4 echo replies: 2 Es handelt sich hierbei um zwei ICMP-Statistiken, einmal vor und einmal nach einem ping-Befehl. Der Rechner ist ein Router nach etwa 3 Stunden Betrieb. Wie man deutlich sehen kann, spielt in erster Linie der ICMP-Typ 3, destination unreachable, eine Rolle. Die anderen Typen tauchen praktisch gar nicht auf. 8.1.6 Zusammenfassung Es lässt sich abschliessend nach Betrachtung der Spezifikationen sagen, dass ICMP ein Mechanismus ist, der unter Umständen zur Fehlerermittlung beitragen kann, aber auch informativen Zwecken dienlich ist. 71 8 Internet Control Message Proctocol (ICMP) 8.2 ICMP auf Anwendungsebene: ping Das Programm ping bedient sich des ICMP -Protokolls auf Anwendungsebene. Dazu werden ICMP Messages Typ 8 und Typ 0 verwendet. Mit Typ 8 (Echo Request) können Anfragen gestellt werden, und mit der Ankunft von Typ 0 Nachrichten (Echo Replies) kann ping Auswertungen vornehmen. ping gibt es für jedes System, auf dem es auch eine Portierung von TCP/IP gibt. ping wird in erster Linie verwendet, um zu prüfen, ob eine Netzwerkverbindung überhaupt besteht, bzw. ob ein bestimmter oder beliebiger Zielrechner erreicht werden kann. Früher galt die Aussage, dass wenn ein Rechner nicht angepingt werden kann, auch anderer TCP/IP-Netzwerkverkehr zu dem Rechner nicht möglich ist. Dies hat ein wenig an Gültigkeit verloren, da es heutzutage nicht ganz unüblich ist, ICMP-Datagramme, die nicht mit einer bestehenden Verbindung korrespondieren, aus Sicherheitsgründen zu ignorieren. So kann es also sehr wohl sein, dass das anpingen“ eines Rechners nicht möglich ” ist, aber z.B. durchaus der Webserver auf dem Rechner erreicht werden kann. Desweiteren liefert ping Informationen darüber, wie lange es gedauert hat, bis die Antwort eingegangen ist. Diese Zeit nennt man beispielsweise Ping Reply Time, Lag oder Verzögerung. Es folgen einige typische ping-Ausgaben. 72 8.2 ICMP auf Anwendungsebene: ping robermue@vino /usr/sbin/ping -s -R -v barbaresco.TechFak.Uni-Bielefeld.DE 56 5 64 bytes from barbaresco.TechFak.Uni-Bielefeld.DE (129.70.133.60): icmp_seq=0. time=0. ms IP options: <record route> barbaresco.TechFak.Uni-Bielefeld.DE (129.70.133.60), vino.TechFak.Uni-Bielefeld.DE (129.70.133.112), (End of record) robermue@vino /usr/sbin/ping -s -R -v www.Uni-Bielefeld.DE 56 7 64 bytes from pan1.hrz.uni-bielefeld.de (129.70.4.66): icmp_seq=7. time=1. ms IP options: <record route> V01Router.TechFak.Uni-Bielefeld.DE (129.70.188.18), v01-cat6500-1-msfc.hrz.uni-bielefeld.de (129.70.188.34), v0-cat6500-1-msfc.hrz.uni-bielefeld.de (129.70.4.251), pan1.hrz.uni-bielefeld.de (129.70.4.66), v0-cat6500-1-msfc.hrz.uni-bielefeld.de (129.70.188.33), v01-cat6500-1-msfc.hrz.uni-bielefeld.de (129.70.188.17), V01Router.TechFak.Uni-Bielefeld.DE (129.70.133.1), vino.TechFak.Uni-Bielefeld.DE (129.70.133.112), (End of record) rdo@Colossus:~$ ping www.linux.org PING www.linux.org (198.182.196.56): 56 data bytes 64 bytes from 198.182.196.56: icmp_seq=0 ttl=234 time=233.0 64 bytes from 198.182.196.56: icmp_seq=1 ttl=234 time=334.0 64 bytes from 198.182.196.56: icmp_seq=2 ttl=234 time=265.6 64 bytes from 198.182.196.56: icmp_seq=3 ttl=234 time=244.5 64 bytes from 198.182.196.56: icmp_seq=4 ttl=234 time=221.0 ms ms ms ms ms --- www.linux.org ping statistics --5 packets transmitted, 5 packets received, 0% packet loss round-trip min/avg/max = 221.0/259.6/334.0 ms PING wird ausgefuehrt fuer www.techfak.uni-bielefeld.de [129.70.136.200] mit 32 Bytes Daten: Antwort von 129.70.136.200: Bytes=32 Zeit=102ms TTL=245 Zeitueberschreitung der Anforderung. Antwort von 129.70.136.200: Bytes=32 Zeit=98ms TTL=245 Antwort von 129.70.136.200: Bytes=32 Zeit=99ms TTL=245 Ping-Statistik fuer 129.70.136.200: Pakete: Gesendet = 4, Empfangen = 3, Verloren = 1 (25% Verlust), Ca. Zeitangaben in Millisek.: Minimum = 98ms, Maximum = 102ms, Mittelwert = 74ms 73 8 Internet Control Message Proctocol (ICMP) Sehr interessant ist der letzte ping, vollzogen mit ping aus einer Microsoft-Implementierung. Man beachte den Mittelwert im Verhältnis zum Minimum und Maximum. 74 8.3 ICMP-Schwachstellen 8.3 ICMP-Schwachstellen 8.3.1 Denial of Service Da ICMP -Nachrichten einen erheblichen Einfluss haben auf die Art und weise, ob und wie zwischen verschiedenen Rechnern kommuniziert wird, erscheint es logisch, dass man damit auch eine Menge Schaden anrichten kann. Einige TCP/IP -Implementierungen nutzen ICMP nicht ganz aus. Fehlermeldungen beinhalten zwar laut RFC -Spezifikation den IP-Header sowie die ersten 64 Bit des Paketes, welches den Fehler ausgelöst hat, jedoch wird diese Zusatzinformation bei einigen Implementationen nicht beachtet. So kann im Grunde jeder, der von einem Rechner eine Verbindung kennt, mittels einer Fehlermeldung die Verbindung unterbrechen. Eine lange Tradition“ hat diese Methode im IRC, um Leute einfach aus dem Chat ” zu entfernen. Die Leichtigkeit in diesem Fall besteht darin, dass man per IRC whois nachschauen kann, welchen Server der IRC Client verwendet, und welche Adresse der Chatter verwendet. Man kann dann einfach, entweder mit gefälschter IP des Clients eine Fehlermeldung an den Server - was aber geringere Aussichten hat, da die meisten IRC-Server auf Unix-kompatiblen Systemen laufen und somit die besseren TCP/IPImplementierungen haben -, oder mit gefälschter IP des Servers eine Fehlermeldung an den Client senden. Dabei braucht man lediglich den Verbindungsport des Clients zu raten - im Regelfall liegt dieser zwischen 1024 und 4000, und der des Servers ist im Regelfall bekannt. 8.3.2 Ping of Death Diese Schwachstelle nutzt einen Fehler in manchen Versionen des Internet-Protokolls. Es werden ICMP -Pakete verschickt, die eine Übergröße besitzen. Manche Rechner werden dann beim Wiederzusammensetzen der Pakete abstürzen. Das Problem beim Zusammensetzen übergroßer Pakete betrifft allerdings TCP/IP generell. Ähnlich wie beim ferngesteuerten Auflegen des Modems – eine recht beliebte Angriffsmethode, auf die aber nicht weiter eingegangen wird, weil sie mit ICMP an sich nicht viel zu tun hat – wird ICMP bzw. ping auf der Anwendungsebene eingesetzt, weil es einfacher ist, als würde man ein neues Programm zu diesem Zweck schreiben. 8.3.3 Redirect - Umleiten von Daten Diese Methode bedient sich der ICMP Redirect Message, mit der dem Sender signalisiert wird, eine andere Route zu verwenden. Somit kann man unter bestimmten Gegebenheiten den Netzwerkverkehr eines Systems auf das eigene System umleiten. Glücklicherweise 75 8 Internet Control Message Proctocol (ICMP) funktioniert dies aber nur, wenn Angreifer und Angegriffener sich im gleichen Netzwerk befinden. Dieser Angriff wird häufig kombiniert mit gefälschten Ethernet-Hardware-Adressen, was auch wiederum nur lokal funktioniert. 8.3.4 Abhilfe Da alle drei hier erwähnten Schwachstellen darauf beruhen, dass die TCP/IP Implementationen Fehler beeinhalten, nämlich dass • in manchen Implementationen das ICMP Paket nicht vollständig ausgewertet wird, • übergroße Pakete nicht als solche erkannt werden, bietet eigentlich nur eine sichere TCP/IP -Implementation Abhilfe. 76 KAPITEL 9 IP Routing Jan-Gerrit Drexhage, Garvin Gripp 9.1 IP-Routing Wo immer 2 oder mehr logische Netze miteinander kommunizieren müssen kommt IPRouting ins Spiel. IP-Routing ist ein Mechanismus der auf Layer 3 des OSI-Schichtenmodells arbeitet. Ohne Routing wäre das Internet in seiner heutigen Form nicht vorstellbar, schliesslich ist die Dezentralität ein vielzitiertes Merkmal des Internets. Dies wird nur durch die dynamische Konfiguration der Internet-Router möglich. Ein Router ist ein Gerät mit mindestens 2 Interfaces. Interfaces können sowohl physikalisch als auch logisch sein, physikalische Interfaces sind z.B. Ethernet-Karten, ISDN-Karten, ein IPSec-Tunnel ist hingegen ein logisches Interface, da der IPSec-Datenverkehr letztendlich wieder über die Netzwerkkarte geht. Um entscheiden zu können an welche Interfaces der eingehende Datenverkehr weitergeleitet werden soll verwaltet jeder Router eine Routingtabelle, in der verschiedene Routen bereitgehalten werden. Anhand der Zieladresse in den IP-Headern der Datenpackete werden diese an das entsprechende Interface geleitet. 9.1.1 Statisches Routing Für kleine Netzwerke, die unter einer zentralen Administration stehen bietet sich die grundlegendste Form von Routing an, das statische Routing. Hierbei werden Routen jeweils 77 9 IP Routing Internet 192.168.6.2 192.168.5.1 192.168.6.1 eth0 eth1 212.15.194.33 ippp0 eth0 eth1 Router1 192.168.7.1 Router2 192.168.7.0/24 192.168.5.0/24 Abbildung 9.1: Beispielnetz manuell festgelegt. Sollte es zu Umstrukturierungen im Netzwerk kommen, muss für die betroffenen Segmente ein neues Routing implementiert werden. Im Gegensatz zum dynamischen Routing wird auf einen Ausfall einer Leitung oder eines Routers nicht reagiert, in einem solchen Fall ist der Zielrechner oder das Zielnetz dann nicht erreichbar. Bedeutung von statischen Routen In Abbildung 9.1 ist ein Netzwerk schematisiert, welches sich aufgrund der geringen Grösse nicht für den Einsatz eines dynamischen Routings eignet. Es sind 2 Rechnerpools und 2 Router im Einsatz, wobei “Router2” eine ISDN-Einwahl ins Internet hat. Auch wenn man Workstations mit nur einer Netzwerkkarte normalerweise nicht als Router bezeichnet, wird auch hier eine Art Routing betrieben. Jeder Rechner muss entscheiden, ob ein Packet was über die Netzwerkkarte hereinkommt für ihn bestimmt ist. Das gleiche passiert mit ausgehenden Paketen, wenn diese nicht für den Rechner selber bestimmt sind werden sie anhand einer “Default Route” an einen Gateway-Rechner weitergeleitet, in diesem Fall ist das “Router1”. Die Routingtabelle eines Client-Rechners könnte so aussehen: Destination 192.168.5.0 0.0.0.0 78 Gateway 0.0.0.0 192.168.5.1 Genmask 255.255.255.0 0.0.0.0 Flags Metric Ref U 0 0 UG 0 0 Use Iface 0 eth0 0 eth0 9.1 IP-Routing Die erste Route bezeichnet das lokale Pool-Netz. Ein Paket was für einen Rechner aus dem Netz 192.168.5.0/255.255.255.0 bestimmt ist wird direkt an das Interface eth0 weitergeleitet, also an die erste und einzige Netzwerkkarte. Die zweite Route ist eine “Default Route”, existiert keine andere spezifischere Route für ein gegebenen IP-Packet wird das Packet an das Gateway “192.168.5.1” weitergeleitet. In diesem Fall bedeutet das dass alles, was nicht an einen benachbarten Poolrechner adressiert ist an das Gateway weitergeleitet wird. Interessant ist noch das Feld “Flags”. Die wichtigsten 3 sind folgende: • U Die Route ist aktiv (Up) • H Das Ziel ist ein Host und kein Netzwerk . • G Das Ziel ist über einen Gateway zu erreichen und ist nicht direkt Angebunden. Die Routingtabelle von Router1 besteht nur aus einer Route mehr: router1:/home/juser$ route -n Kernel IP routing table Destination Gateway Genmask 192.168.5.0 0.0.0.0 255.255.255.0 192.168.6.0 0.0.0.0 255.255.255.0 0.0.0.0 192.168.6.2 0.0.0.0 Flags U U UG Metric 0 0 0 Ref 0 0 0 Use 0 0 0 Iface eth0 eth1 eth1 Die erste Route ist die Netzroute ins linke Poolnetz und zeigt wieder auf die erste Netzwerkkarte. Die zweite Route beschreibt das Netz zwischen “Router1” und “Router2”. Die dritte Route ist wieder eine Defaultroute, diesmal zu “Router2” Schliesslich noch die Routingtabelle auf “Router2”: router2:/home/juser$ route -n Kernel IP routing table Destination Gateway Genmask 192.168.5.0 192.168.6.1 255.255.255.0 192.168.6.0 0.0.0.0 255.255.255.0 192.168.7.0 0.0.0.0 255.255.255.0 0.0.0.0 0.0.0.0 0.0.0.0 Flags UG U U U Metric 0 0 0 0 Ref 0 0 0 0 Use 0 0 0 0 Iface eth0 eth0 eth1 ippp0 Hier beschreibt die erste Route eine Gateway-Route zu dem linken Poolnetz, die zweite ist für das Transfernetz zwischen den Routern zuständig. Die dritte Route zeigt auf das rechte Poolnetz, während die vierte Route eine Defaultroute für das ISDN Interface ist. Jeglicher Traffic der nicht an eins der drei lokalen Netze gerichtet ist wird als “extern” betrachtet und wird über die ISDN-Leitung nach draussen geroutet. 79 9 IP Routing IP-Packet Ja Packet entgegennehmen Router ist das Ziel? Nein Ja Packet auf das Interface leiten Connected Route? Nein Ja Sonstige Route? An Gateway schicken Nein Ja Defaultroute? An Defaultgateway schicken Nein Packet verwerfen Abbildung 9.2: Funktionsdiagramm eines Routers Funktionsweise eines Routers Die Arbeitsweise eines Routers ist in Abbildung 9.2 skizziert. Diese Funktionsweise trifft grundlegend für jeden Rechner zu, jedes TCP/IP-fähiges Betriebssystem sieht die Konfiguration eines Lokalen Netzwerks und eines Default-Gateways vor, was in den oben beschriebenen zwei Routen für einen Poolrechner resultiert. Normalerweise bezeichnet man jedoch Clients nicht als Router, erst wenn ein Rechner tatsächlich als Gateway fungiert ist hiervon die Rede. Je nach Anwendungsgebiet gibt es Router in den unterschiedlichsten Grössen, Ausstattungen und Preislagen. Mit einer zweiten Netzwerkkarte, einem Modem oder einer ISDN-Karte kann jeder PC als Router eingesetzt werden, man spricht hier meistens von Software-Routern, da die Hardware nicht speziell für die Routertätigkeit entwickelt wurde. Hardware-Router sind in ihren kleinsten Ausführungen kaum grösser als ihre zugehörigen Handbücher und sind nur für ein eng begrenztes Aufgabengebiet geeignet, z.B. als ISDN-Router. In den grossen Versionen stehen manche Router den aktuellen PCs weder in Prozessortakt noch in der Grösse des RAM-Speichers nach. Solche Geräte bringen neben hochspezialisierter Hardware auch eine umfangreiche Software mit, die den Einsatz als Backbone-Router noch um viele weitere Funktionen ergänzen. 80 9.1 IP-Routing 9.1.2 Traceroute traceroute ist ein Programm, welches benutzt wird um Probleme beim Routen festzustellen, die zwischen Quelle und Ziel auftreten. traceroute dient als eine Art Ersatz für das “record-route” Flag im TCP-Header, da “record-route” vorraussetzt, das es vom Router unterstützt wird. Das “record-route” Flag benutzt den TCP-Header um die IPs, durch die das Packet geroutet wird, aufzuzeichnen. Da ein TCP-Header aber nur eine festgelegte maximale Größe hat, kann record-route maximal 8 IPs aufzeichnen. Für damalige Verhältnisse war dies ausreichend. Im rasant wachsendem Internet heutzutage sind 8 Hops, die maximal “record-routed” werden können, nicht ausreichend um an das gewünschte Ziel zu kommen. traceroute hingegen funktioniert anders, und basiert auf den Protokollen ICMP und UDP. traceroute ist weitaus flexibler als das Flag “record-route”, da traceroute erst bei mehr als 255 Hops die Grenze erreicht. Gleichzeitig ist die Grenze von traceroute die Grenze der Internetprotokolle, die es heutzutage gibt (IPv6 eingeschlossen). Da das heutige Internet engmaschig geroutet wird, ist ein Hopcount von über 255 sehr unwahrscheinlich. Prinzip traceroute benutzt das TTL-Field (time to live) des UDP-Protokolls um die Route “sichtbar” zu machen. traceroute schickt UDP-Packets die mit einer TTL von 1 beginnen und mit einer zufällig gewählten ungewöhnlich hohen Portadresse beginnt, die mit jedem Packet inkrementiert wird, bei jedem dritten Packet wird dann das TTL-field inkrementiert, da für jeden Hop drei Probes gemacht werden. Damit wird erreicht, das jeder Router eine ICMP Message “Time exceeded.” für das jeweilige Packet an den Sender zurückschickt. Diese fängt traceroute wieder auf und stellt sie dar mit Routernamen und latency-Zeiten der drei Packets pro Router. Dies wird solange fortgeführt bis das Ziel erreicht wird. Das letzte Stück der Route (zwischen letzten Router und Zielrechner) kann man nicht mit dem ICMP-Error “Time exceeded” visualisieren, da ja die Packets nun das Ziel erreicht haben. Hier werden die hohen Portadressen ausgenutzt um die ICMP-Errormessage “Port unreachable” zu provozieren, welcher dann durch traceroute wieder ausgegeben wird wie bei den anderen Routern in Form von Rechnername und latency-Zeiten. Damit wäre dann der Arbeitsablauf von traceroute abgeschlossen. Funktionsweise im Detail Ein Beispielnetz sei mit Abbildung 9.1 gegeben. Der Quellrechner sei der Rechner mit der IP 192.168.5.0/24, und der Zielrechner hat die IP 192.168.7.0/24. Der Benutzer am Quellrechner führt traceroute aus und gibt die IP des Zielrechners als Parameter an. traceroute schickt drei UDP-Packets mit hoher Portnummer und einer TTL von 1 los und wartet bis die erwarteten ICMP Errormessages von router1 wieder ankommen. Die Portnummer wird pro gesendetes Packet inkrementiert um den Ablauf unstörbar durch gleichzeitiges Ausführen von traceroute zu machen. Dies läßt sich nur mit Hilfe von tcpdump visualisieren und wird durch traceroute nicht dargestellt. Die ICMP Errormessages werden dann 81 9 IP Routing wie im Beispiel ausgegeben. Danach werden wieder drei Packets geschickt, diesmal mit inkrementierter TTL, also mit einer TTL von 2. Nun wartet traceroute wieder maximal 15 Sekunden (das ist die Timeoutzeit von 5 Sekunden * 3 Packets) auf die ICMP Errormessages von router2. Diese werden dann wieder wie im Beispiel von traceroute dargestellt. Nun schickt traceroute wieder 3 Packets, welche ihr Ziel erreichen. Nun bekommt traceroute anstelle vom ICMP-Errormessage “Time exceeded” die ICMP-Errormessage “Port unreachable”, da das Programm während des ganzen Verlaufs mit einer sehr hohen Portadresse anfängt Packets zu versenden und diese mit jedem gesendetem Packet inkrementiert. Und damit hat traceroute seine Ausführung beendet. Die folgende Ausgabe eines traceroute Aufrufes zeigt den Weg den der Traffic zwischen zwei Punkten zurücklegt, die physikalisch nur durch wenige hundert Meter Luftlinie getrennt werden. Wie man sieht werden hier bereits mehr als 10 Hops benötigt, also mehr als man mit dem “record-route” Flag aufzeichnen könnte. Auf der anderen Seite benötigt man zu weit entfernten Rechnern z.B. in Australien selten mehr als 20-25 Hops, auf den interkontinentalen Leitungen liegen mehrere tausend Kilometer zwischen zwei Routern. stoffel@voyager:~$ /usr/sbin/traceroute www.devcon.net traceroute to www.devcon.net (212.15.193.33), 30 hops max, 38 byte packets 1 enterprise (192.168.42.1) 0 ms 0 ms 3 ms 2 access4.bitel.net (212.100.40.37) 20 ms 19 ms 19 ms 3 eth1.router1.bitel.net (212.100.40.46) 24 ms 25 ms 24 ms 4 bb-gw.bicos.net (212.100.32.85) 20 ms 20 ms 20 ms 5 Bielefeld.de.alter.net (139.4.31.49) 21 ms 21 ms 21 ms 6 POS8-0-0.gw1.Bielefeld2.de.alter.net (149.227.30.165) 64 ms 55 ms 89 ms 7 BiCIX.Bielefeld2.de.alter.net (139.4.244.186) 22 ms 21 ms 26 ms 8 fxp0.aragon.bi-cix.de (193.41.212.253) 21 ms 22 ms 21 ms 9 devconsult.bi-cix.de (193.41.212.27) 22 ms 21 ms 21 ms 10 sec-01.bi.devcon.net (212.15.192.30) 25 ms 22 ms 22 ms 11 vhost.devcon.net (212.15.193.33) 24 ms 23 ms 23 ms Schwächen von traceroute Neben den Stärken und Nutzen von traceroute gibt es auch einige Nachteile. Die wiedergegebene Route ist nicht verbindlich, da während des traceroute-Vorgangs Veränderungen der Routen vorkommen können. Somit können zum Beispiel die latency-Zeiten verfälscht werden, wenn die ICMP-Errormessages einen anderen Weg zurück nehmen als die UDPPackets hin. Es kann auch vorkommen, das man eine “flappende” Route hat, die ihren Weg ständig schnell ändert. Dies führt dazu das die gesendeten Packets voneinander getrennt werden und dadurch traceroute eine Route darstellt die in Wirklichkeit gar nicht existieren kann, wenn zum Beispiel zwei von traceroute benachbart dargestellte Router physikalisch gar nicht miteinander verbunden sind. Es gibt noch zwei weitere Modi von Routern, die die effektive Benutzung von traceroute erschweren. Ein Modus ist das nicht-dekrementieren von 82 9.1 IP-Routing IP-Packets. Demzufolge wird auch keine TTL-Überprüfung vorgenommen, und somit auch keine ICMP-Messages erstellt, die traceroute zum Darstellen der Route benötigt. (“Stealth”Mode) Auch sind implementierte Packetfilter, die ICMP-Packets filtern, ein Problem für traceroute, da traceroute anhand der ICMP-Packets die Route darstellt. 9.1.3 Dynamisches Routing Wie bereits erwähnt eignet sich das manuelle eintragen von Routen für kleine Netzwerke, wenn alle beteiligten Netze unter einer Administration stehen. Doch bereits wenn das eigene Firmennetz eine bestimmte Grösse erreicht und spätestens wenn man als Internet Provider auftreten will ist der Einsatz von dynamischen Routing Protokollen unabdingbar. Das Prinzip das dahinter steht ist immer das gleiche, auf dem betreffenden Router läuft ein Programm was mittels eines Routing Protokolls mit anderen Routern kommuniziert und bei bedarf Einträge in der Routingtabelle einträgt, ändert oder entfernt. Es wird zwischen verschiedenen Routing Protokollen unterschieden. • Interior Gateway Protocols (IGP) sind für den Einsatz unterhalb einer einheitlichen Routing Policy gedacht, also z.B. für den Einsatz innerhalb eines Firmennetzes. • Exterior Gateway Protocols (EGP)sind für die Kommunikation zwischen Routern verschiedener Systeme gedacht. Im Zusammenhang mit BGP spricht man hier auch von “Autonomen Systemen”, kurz “AS”. • Distance Vector Protocols bezeichnen Protokolle, bei denen durch regelmässig stattfindende “Announcements” jeder beteiligte Router seinem jeweiligen Nachbarn mitteilt, welche Netze er erreichen kann. Announct ein Router eine Route, die er von einem anderen bereits gelernt hat, vermerkt er dies durch die Erhöhung eines Hopcounters. So kann jeder Router für jedes Ziel errechnen, welche Route günstiger ist. Distance Vector Protocols zeichnen sich durch eine niedrige Ressourcenbelastung der Router aus, dafür dauert es etwas länger bis der Ausfall einer Leitung bei allen Routern zu einer entsprechenden Anpassung der Routingtabellen führt. • Link State Protocols propagieren nicht die Netze, die sie erreichen könne, sondern die Verbindungen (Links). Jeder Router errechnet dann für sich wie das Netz aussieht und wie der optimale Weg für ein gegebenes Packet lautet. Ändert ein Link seinen Status (z.B. von “Up” nach “Down”) wird diese Information sofort an alle beteiligten Router verteilt und alle berrechnen eine neue Map ihrer Umgebung. Die Resourcenbelastung ist bei Link State Protokollen deutlich höher, da der Router für jede Leitungsänderung wieder neue optimale Routen errechnen muss. Dafür sorgt das “flooding” von LinkÄnderungen zu einer schnellen Reaktion aller Router auf den Ausfall, so dass das gesamte Netzwerk besser vo Ausfällen geschützt ist. OSPF (Open shortest path first) und BGP (Border Gateway Protocol) haben sich als die wichtigsten Routingprotokolle herausgestellt. OSPF ist ein Interior Gateway Protocol was nach dem “Link State” Prinzip arbeitet, BGP in der aktuellen Version 4 ist der de 83 9 IP Routing facto Standard für das Routing zwischen Internet-Providern weltweit. BGP ist ein Distance Vector Protokoll, bei ca. 30.000 Routen momentan ist die Resourcenbelastung für die Router schon so gross genug, ein Link State Protocol wäre hier sicherlich fehl am Platz. 84 KAPITEL 10 User Datagram Protocol (UDP) Matthias Donner Das UDP-Protokoll wird, genauso wie TCP, in die Transport-Schicht des Schichtenmodells eingeordnet. UDP ist die Abkürzung für User Datagram Protocol“ und wie man aus ” Datagram bereits schließen kann, handelt es sich um ein paketorientiertes Protokoll. 10.1 Ein kurzer Überblick UDP ist im RFC 768 vom August 1980 spezifiziert. Es ist ein sogenanntes verbindungsloses Protokoll. Dies bedeutet, dass kein expliziter Verbindungskanal zwischen Sender und Empfänger aufgebaut wird. Es hat den Nachteil, dass abgeschickte Datenpakete verloren gehen, dupliziert werden oder in einer anderen Reihenfolge beim Empfänger ankommen, als sie vom Sender abgeschickt wurden. Um all diese Probleme“ muss sich die auf UDP aufbau” ende Applikation kümmern. Auf der anderen Seite ist UDP ein recht schlankes Protokoll, dass über einen geringen Protokoll-Overhead verfügt und somit auch wenig Verwaltungsaufwand fordert. Bei ankommenden Paketen kann die Integrität durch eine Prüfsumme gewährleistet werde. UDP wird zum Beispiel für Broadcast Dienste verwendet, bei denen Nachrichten von einem Rechner aus an mehrere Empfänger verteilt werden. Zudem wird es auch für gewisse Echtzeitanwendungen, wie die Übertragung vom Sprache oder Video genutzt. Hierbei wird die Priorität auf einen hohen Datendurchsatz gelegt und der mögliche Verlust von Daten in Kauf genommen. UDP wird auch von DNS und SNMP benutzt. 85 10 User Datagram Protocol (UDP) 10.2 Aufbau UDP Header: 0 15 16 31 Source Port Destination Port Length Checksum UDP-Pakete werden mit Hilfe von IP verschickt, somit befinden sich diese Pakete im Datenbereich des IP-Pakets. Jedes UDP-Paket beginnt mit dem Header. Er besteht aus vier 16 Bit großen Feldern. Source Port, Destination Port, Length und Checksum. Das Feld Source Port ist optional und sollte Null enthalten, sofern diese Funktion nicht benötigt wird (siehe Ports). Das Feld Length gibt die Länge des UDP Pakets inklusive Header an. Im Feld Checksum steht diese, die wie folgt berechnet wird. 10.3 Checksum UDP Pseudo Header: 0 15 16 31 Source Address Destination Address Zero Protocol UDP Length Zur Berechnung der Prüfsumme wird zunächst ein sogenannter Pseudo-Header“ erzeugt. Er ” besteht aus der 32 Bit langen IP-Adresse des Senders, der ebenfalls 32 Bit langen IP-Adresse des Empfängers, gefolgt von einem Nullbyte (für spätere Erweiterungen) dann ein Byte, dass das Protokoll identifiziert (17 bei UDP) und schließlich noch die Länge des gesamten UDP Pakets in einem 16 Bit großen Feld. Teile dieser Informationen werden aus dem IP-Header bezogen. Somit lässt sich nicht nur die Integrität der Daten überprüfen, sondern es kann auch festgestellt werden ob das Paket bei der richtigen IP-Adresse angekommen ist. Nun wird die Prüfsumme über diesen Pseudo-Header, den UDP-Header und auch über die UDP Daten – im Gegensatz zu IP – berechnet. Dazu werden die Daten in 16 Bit Wörter unterteilt. Falls dies nicht glatt aufgeht wird der Rest mit Nullen aufgefüllt (“Padding“). Dann werden diese Wörter aufaddiert und von der Summe das Einerkomplement gebildet. Dieser Wert wird nun in dem Header Feld Checksum eingetragen, in dem während der Berechnung Null stand. Der Pseudo-Header wird, genauso wie die zum Auffüllen verwendeten Nullen, nicht mit versand und fließt auch nicht in den Wert der Länge des Pakets mit ein. Wird nun ein Paket empfangen das fehlerhaft ist, so wird dieses verworfen und es wird keine ICMPNachricht verschickt. Es ist zudem möglich, die Checksum zu deaktivieren, indem man alle 86 10.4 Ports Bits auf Null setzt. Falls die Berechnung der Checksum Null ergeben sollte, werden alle Bits auf Eins gesetzt. Dies ist möglich, da es im Einerkomplement zwei Darstellungen der Null gibt. Jedoch wird vom Deaktivieren der Checksum abgeraten, da es auch in vermeintlich sicheren lokalen Netzwerken versteckte Fehlerquellen geben kann und so die Gefahr entsteht, unbemerkt mit falschen Daten zu arbeiten. 10.4 Ports Die Verwendung von Ports ist der wichtigste Unterschied zu IP. Somit ist es möglich, dass mehrere Prozesse gleichzeitig über UDP kommunizieren. Dies wird Multiplexing genannt. Jedem Prozess wird ein Port zugewiesen, an dem für ihn eintreffende Daten weitergeleitet werden. Einige Portnummern sind für bestimmte Anwendungen reserviert. Die von UDP verwendeten Portnummern sind unabhängig von den TCP-Portnummern, wobei es meistens so ist, dass eine Applikation immer die gleiche Portnummer benutzt, egal ob über UDP oder TCP. 10.5 UDP & ICMP Folgende ICMP Nachrichten können in Zusammenhang mit UDP verschickt werden: • Destination Unreachable (= Network, Host, Protokol oder Port nicht errreichbar) • Time Exceeded (= Time To Live abgelaufen) • Parameter Problem (= IP Parameter ungültig) • Source Quench Letzteres bedeutet, dass der Sender Daten zu schnell sendet und der Empfänger oder ein Router diese nicht so schnell verarbeiten oder zwischenspeichern kann. Der Sender wird durch diese Nachricht aufgefordert, die Daten langsamer zu senden. Jedoch wird von der Versendung dieser Nachricht abgeraten, da Router diese nicht unbedingt weiterleiten müssen und da der sendende Prozess schon terminiert sein kann bevor die Source Quench“ ” Nachricht eintrifft. Ausserdem erhöhen diese Nachrichten zusätzlich die Netzlast, was in diesem Fall kontraproduktiv ist. 10.6 Zusammenfassung UDP ist ein schlankes verbindungsloses Protokoll, dass die Integrität der Daten durch eine Prüfsumme gewährleistet. Es bietet einen im Vergleich zu TCP hohen Datendurchsatz 87 10 User Datagram Protocol (UDP) und durch die Verwendung von Ports können mehrere Prozesse gleichzeitig über UDP kommunizieren. 88 KAPITEL 11 IP Fragmentation Christian Biere 11.1 Überblick Das Internet Protocol (IP) erlaubt die sogenannte Fragmentation. Dies bedeutet, dass ein IP-Paket in mehrere kleine IP-Pakete zerteilt – fragmentiert“ – wird. Fragmentation wird ” dann benötigt, wenn in einem Netzwerk ein IP-Paket gesendet werden soll, das größer ist, als die maximale Paketgröße in diesem Netzwerk. Beispielsweise darf ein Ethernet-Paket nicht größer als 1500 Bytes sein, ein IP-Paket kann aber bis zu 64 Kilobyte groß sein. 11.2 Der IP-Header Abbildung 11.1 zeigt ein Beispiel für zwei Fragmente. Welche Fragmente zusammengehören erkennt der Empfänger an den Feldern Version, Identification, Protocol, Source Address und Destination Address, da diese bei allen Fragmenten eines Pakets übereinstimmen müssen. Das erste Fragment nennt man auch Fragment Zero. Der Name erklärt sich so, dass hier der Fragment Offset auf Null, also Zero, gesetzt ist. Bei allen Fragmenten ausser dem letzten ist das More Fragment-Flag gesetzt (MF). Daran sieht der Empfänger, dass das Paket fragmentiert ist. Erhält der Empfänger das letzte Fragment, dann kann er die Fragmente zu dem kompletten Paket zusammenfügen. Total Length gibt die Größe des jeweiligen Fragments 89 11 IP Fragmentation Erstes Fragment 0 15 16 Version IHL=5 Total Length = 568 ToS Fragment Offset = 0 Flags Identification = 111 TTL = 64 31 Protocol = 17 Header Checksum Source Address Destination Address UDP Header UDP Data Zweites Fragment 0 15 16 Version IHL=5 Total Length = 472 ToS Fragment Offset = 69 Flags Identification = 111 TTL = 64 31 Protocol = 17 Header Checksum Source Address Destination Address UDP Data Abbildung 11.1: Ein Beispiel für zwei Fragmente. 90 11.3 Aufteilung in Fragmente an. Fragment Offset gibt an, an welche Stelle das Fragment in das gesamte Paket gehört. Allerdings muss Fragment Offset mit acht multipliziert werden. Dies ergibt sich einfach dadurch, dass Fragment Offset nur 13 Bits lang ist, während ein IP Paket 65536 Bytes groß sein darf, also 2 hoch 16. Die Differenz von 3 Bits ergibt 2 hoch 3, also 8. Der IP-Header ist allerdings mindestens 20 Bytes groß, also muss jedes Fragment minimal 28 Bytes groß sein. Ein Restfragment darf 21 Bytes nicht unterschreiten. Die Größe des gesamten Pakets weiss der Empfänger erst, wenn er das letzte Fragment ohne MF-Flag erhalten hat, indem zum Fragment Offset multipliziert mit acht die Total Length hinzuaddiert wird. Die IP Header Checksum muss natürlich für jedes Fragment angepasst werden. Die restlichen Felder bleiben unverändert. Die Type-Of-Service-Flags (ToS) und das Don’t FragmentFlag (DF) können zwar für jedes Fragment unterschiedlich gesetzt sein. Dies wird man aber vermeiden wollen, damit alle Fragmente unter den gleichen (guten) Bedingungen ihr Ziel erreichen. Man sieht auch, dass sich ein Protokoll, das auf IP aufbaut, wie UDP in diesem Beispiel, nicht um die Fragmentation kümmern muss. So wird der UDP-Header weiterhin nur einmal und im Anschluss die UDP-Daten geschickt. 11.3 Aufteilung in Fragmente Es gibt grundsätzlich vier Methoden, um ein Paket in einzelne Fragmente zu zerlegen. Bei der ersten Methode geht man so vor, dass man für die Größe des ersten Fragments die PathMTU wählt. Für die restlichen Pakete ermittelt man dann eine durchschnittliche Größe. So erreicht man, dass das wichtige erste Fragment den Zielhost erreicht, ohne dass es Probleme mit der Fragmentation an sich gibt. Ausserdem benötigt der Transfer der restlichen Pakete jeweils in etwa die gleiche Zeit, da sie ungefähr die gleiche Größe haben, so dass sich ein gleichmäßigerer Fluss ergibt. Bei der zweiten Methode wählt man für die Größe jedes Fragment die Path-MTU und schickt eventuell ein Restfragment hinterher. Dadurch erreicht man, dass alle Fragmente ihr Ziel erreichen können, ohne weiter fragmentiert werden zu müssen, solange sich die Route und die Path-MTU nicht zwischenzeitlich ändern. Das letzte Fragment benötigt jedoch weniger Zeit, da es kleiner ist als die voherigen Fragmente. Dies ist eventuell bei bestimmten Anwendungen nicht erwünscht. Die nächste Methode macht sich zunutze, dass jeder Router eine MTU von mindestens 576 Bytes hat und wählt daher für jedes Fragment eine durchschnittliche Größe, die 576 Bytes nicht überschreitet. Im letzten Fall macht man nur noch den Unterschied, dass man für jedes Fragment, ausser einem letzten Restfragment, genau 576 Bytes wählt. Die beiden letzten Methoden haben jedoch den Nachteil, dass sie die Path-MTU nicht opti- 91 11 IP Fragmentation mal ausnutzen, wenn diese 576 Bytes überschreitet. Sie werden standardmäßig verwendet, wenn man die Path-MTU nicht ermitteln kann oder möchte. 11.4 Fragmentation und ICMP ICMP-Meldungen werden nur für das Fragment Zero generiert. Für die restlichen Fragmente wird keine Fehlermeldung per ICMP verschickt. Erreicht das Fragment Zero den Zielhost nicht, so ist unklar, woran der Transfer gescheitert ist. Es gibt zwei ICMP-Codes, die für Fragmentation genutzt werden: 11.4.1 Type 3, Code 4 - Fragmentation needed, but DF set. Dies bedeutet, dass ein Router ein Paket erhalten hat, das zu groß ist, um es weiterleiten zu können. Da das DF-Flag gesetzt ist, darf es aber nicht fragmentiert werden und der Router sendet diese Fehlermeldung an den Sender zurück. 11.4.2 Type 11, Code 1 - Reassembly time exceeded. Der Empfänger hat nicht alle Fragmente erhalten, um das Paket zusammenfügen zu können. Nach einer gewissen Zeit verwirft er deshalb alle Fragmente die zu diesem Paket gehören und schickt dem Sender diese ICMP-Meldung. 11.5 RFC 1812: Anforderungen an Router Router sollten die Anzahl der Fragmente so minimal wie möglich halten, da kleine Fragmente zu ineffizienter Nutzung des Netzwerks führen. Zum einen benötigt jedes Fragment zusätzlich mindestens 20 Bytes für den Header, wodurch zusätzliche Bandbreite verbraucht wird. Zum anderen müssen die Header auch erzeugt und vom Empfänger überprüft werden, was zu erhöhtem Rechen- und Verwaltungsaufwand führt. Weiterhin dürfen Router die Fragmente nicht zusammenfügen, sondern müssen sie einzeln weiterleiten. Da die Fragmente über unterschiedliche Routen verschickt werden können, wäre es möglich, dass der Router vergeblich auf die restlichen Fragmente wartet und so die Zustellung des Pakets verhindert wird, obwohl kein Fragment verloren gegangen ist. Ausserdem würde es auch die Speicherressourcen des Routers unnötig belasten, weil er alle Fragmente im Speicher halten müsste, bevor er sie weiterleiten kann. Eine Ausnahme ergibt sich, wenn das Paket für das Netzwerk des Routers bestimmt ist. Dann darf er, muss aber nicht, die Fragmente zusammenfügen. Ein Beispiel hierfür wäre ein Router, 92 11.6 MTU Path Discovery der ressourcenschwache Hosts, wie z.B. Handies oder PDAs, bedient, denen man diesen Aufwand nicht zumuten kann oder möchte. Ein Router darf Fragmente gesondert behandeln, indem er davon ausgeht, dass, falls er ein Fragment verwirft, das gesamte Paket noch einmal geschickt wird. Dies würde also zu zusätzlicher Netzlast führen. Allerdings könnte man dieses Verhalten auch ausnutzen, indem man viele Fragmente schickt, so dass der Router alle anderen Pakete verwirft. Bei dieser Implementierung muss man also vorsichtig vorgehen. Letztlich wird noch gefordert, dass Router eine Maximum Transfer Unit (MTU), von 576 Bytes unterstützen müssen. Das heisst, erhält ein Router ein Paket dieser Größe muss er es unfragmentiert an einen anderen Router weiterleiten können. Für Hosts gilt dies übrigens nicht, diese müssen nur eine minimale MTU von 68 Bytes unterstützen. 11.6 MTU Path Discovery Um die Path-MTU zu ermitteln, gibt es ebenfalls vier gängige Methoden. Die ersten drei machen sich ICMP zu nutze; die Letzte nutzt IP Options. Im ersten Fall schickt der Sender nur ein Fragment Zero und wartet auf die ICMP-Meldung Reassembly time exceed“. Da die ICMP-Meldung den IP-Header enthält, kann der Sender ” an dem Total Length-Field ablesen, ob das Paket zwischendurch fragmentiert wurde und Total Length als Path-MTU annehmen. Im zweiten Fall setzt der Sender das DF-Flag, wählt eine für ihn optimale Paketgröße und wartet auf die ICMP-Meldung Fragmentation needed, but DF set“. Der Sender verringert ” dann die Größe, indem er sich mittels binärer Suche an die Path-MTU herantastet, oder gebräuchliche Werte wie z.B. 1492 (Ethernet), 576 (Analog-Modems) ausprobiert. Die ersten beiden Methoden haben den Nachteil, dass man irgendein Paket schicken muss, dadurch aber weitere Fehler provoziert, wie z.B. dass ein Protokoll nicht unterstützt wird oder irrtümlich einem laufenden Prozess zugeordnet wird. Die nächste Methode ist relativ neu und führt einen neuen ICMP-Typ Probe Path“ ein. ” Hierbei schickt der Sender ein solches ICMP-Paket, die Router und der Host passen dann die Werte in diesem an und schicken das Paket mit den korrigierten Werten zurück. Da diese Methode relativ neu ist, wird sie jedoch nur von wenigen Hosts und Routern unterstützt. Die letzte Methode hat den Vorteil, dass sie sowohl auf ICMP verzichtet als auch während des Transfers durchgeführt werden kann, auch piggy-backing genannt. Zunächst setzt der Sender die IP Option Probe MTU“. Die Router passen den Wert für die Path-MTU an und ” der Empfänger antwortet schliesslich, indem er in einem Paket die IP Option MTU Reply“ ” setzt. Es sind also keine zusätzlichen Pakete nötig, wenn der Transfer sowieso bi-direktional abläuft, wie z.B. bei TCP. Leider ist auch diese Methode nicht von Anfang an spezifiziert 93 11 IP Fragmentation und wird nicht von allen Routern und Hosts unterstützt. Schlagen alle Methoden fehl, wird eine Path-MTU von 576 angenommen. 11.7 Probleme durch Fragmentation Wie schon erwähnt, leidet die Performance eines Netzwerks durch Fragmentation und belastet die Ressourcen der beteiligten Router und Hosts zusätzlich. Zudem wird Fragmentation in einigen Netzwerken nicht unterstützt, da Fragmente beispielsweise durch einen Paketfilter verworfen werden, wenn der Administrator dies für sinnvoll hält. Leider haben manche TCP/IP-Implementierungen und sogar Firewalls Probleme mit ungewöhnlichen Fragmenten, was zu Sicherheitsproblemen führen kann. Auch ICMP wird des öfteren von Administratoren deaktiviert, da einige ICMP-Typen gewissen Sicherheitsprobleme mit sich bringen. Anstatt nur diese Typen zu filtern, wird ICMP oft komplett deaktiviert, so dass die für Fragmentation spezifischen ICMP-Meldungen nicht zum Sender gelangen. Dies wiederum führt dazu, dass der Sender erst nach einem Timeout die Pakete erneut sendet und nicht erfährt, woran der Transfer gescheitert ist. Dadurch ergeben sich unnötige zeitliche Verzögerungen. 11.8 Fragmentation und Angriffe Wie schon erwähnt, haben manche Implementierungen Probleme mit Fragmentation. So gab es z.B. Probleme mit Firewalls, die unter bestimmten Umständen Fragmente fälschlicherweise weitergeleitet haben, die sie hätten filtern sollen. Dies ergibt sich dadurch, dass sich Fragmente überlappen können. Ein schlechter Paketfilter prüft eventuell nur einmal das Fragment Zero, da dieses z.B. den Header und somit die genutzen Ports enthält. Wird das Fragment nun nochmal mit anderen Ports geschickt, überschreibt es das erste Fragment. So erreicht es letztlich auch einen gesperrten Port. Ebenfalls Probleme mit sich überlappenden Offsets haben die TCP/IP-Stacks von Windows 95 und Windows NT 4.0, die sogar zu einem Absturz oder dem berühmten Blue-Screen-Of-Death führen können. Teilweise wird auch nur das lokale Netzwerk lahmgelegt. Auch FreeBSD 3.0 hatte Probleme mit ungültigen UDP Fragmenten, was zu einer Kernel Panic, also einem Systemabsturz führte. Es muss beispielweise geprüft werden, dass das IP Paket nicht größer als 64 Kilobyte ist, da Fragment Offset multipliziert mit acht plus Total Length 65536 um fast das doppelte überschreiten kann. Schreibt der TCP/IP-Stack beim Zusammenfügen der Pakete diese ohne Prüfung in einen zu kleinen Puffer, führt dies unweigerlich zu Problemen. Die genannten Probleme zeigen, dass es sich um keinen Fehler der Spezifikation sondern der Implementierung handelt. Es zeigt aber auch, dass Fragmentation mit Vorsicht zu genießen ist. 94 KAPITEL 12 Domain Name System (DNS) Alexander Hosfeld, Carsten Herkenhoff 12.1 Einleitung Ohne das Domain Name System hätte das Internet vermutlich nicht die Bedeutung erlangt, die es jetzt hat. Denn auch wenn es wohl vielen Internetbenutzern nicht bewusst ist, dass sie die Dienste des Domain Name Systems in Anspruch nehmen, so könnte ohne DNS keine email verschickt, keine Seite angesurft werden (jedenfalls nicht im üblichen Sinne) und auch ein netzbasierter Zugriff wäre nur unter Schwierigkeiten möglich. Denn erst das DNS verbindet die IP-Adressen, die von den Rechnern verstanden werden, mit den Domainnamen, die man sich besser einprägen kann. Unter Zuhilfenahme einer riesigen verteilten Datenbank, in der sämtliche Domainnamen und IP–Adressen hinterlegt sind, können einzelne DNS-Server miteinander kommunizieren, um eine nicht bekannte IP-Adresse anzufragen. Inwieweit diese Kommunikation abläuft, soll die vorliegende Hausarbeit, die im Rahmen des Seminars Internetprotokolle“ an der Universität Bielefeld verfasst wurde, klären. ” 12.2 Die Theorie des DNS Das vorliegende Kapitel will die Entwicklung des DNS aufzeigen. Anhand einer Alternative zu einem DNS-System möchte ich dessen Nachteile aufzeigen und darstellen, wie es überhaupt zu der Notwendigkeit kam, DNS zu entwickeln. 95 12 Domain Name System (DNS) 12.2.1 Alternative zu DNS: die host-Datei Um zu einer funktionierenden Namensauflösung zu kommen, muss man nicht zwingend das DNS bemühen. Es existieren durchaus Alternativen, die unter Umständen einfacher einzurichten und zu administrieren sind als ein komplettes DNS-System. Gerade in kleineren Netzwerken ist der Einsatz einer host-Datei und deren netzwerkweite Verteilung einfacher zu bewerkstelligen als das Aufsetzen zweier DNS-Server. Die host-Datei ist eine reine textbasierte Datei und könnte für ein kleineres Netzwerk folgendermaßen aufgebaut sein: # /etc/hosts # loopback: 127.0.0.1 localhost # IP #------------192.168.1.1 192.168.1.2 192.168.1.3 129.70.136.200 FQDN --------------------------gateway.foo.bar user.foo.bar joe.foo.bar www.TechFak.Uni-Bielefeld.DE host -----gw user joe techfak Diese host-Datei wird — wie man sich leicht vorstellen kann — mit zunehmender Netzwerkgröße schnell unübersichtlich. Und wenn man bedenkt, dass diese Datei auf jeden host im Netzwerk verteilt werden muss, so darf man den damit verbundenen Traffic nicht unterschätzen. Zudem kann man nicht gewährleisten, dass die Hostdaten konsistent sind: Wenn sich während der Verteilung der host-Datei ein Hostname geändert hat, kann dieser nicht gleich angesprochen werden, weil die host-Datei eventuell noch nicht auf allen Rechnern aktuell ist. Außerdem muss man die Möglichkeit in Betracht ziehen, dass ein hostname mehrfach vergeben wird, wenn es keine zentrale Instanz gibt, die die Namensvergabe überwacht. 12.2.2 Die Geschichte des DNS Die oben beschriebene host-Datei kam in der frühen Geschichte des Internets, dem sog. ARPAnet tatsächlich zur Anwendung. Da das ARPAnet damals aus nur rund 100 Knoten bestand, war die HOSTS.TXT eine einfache Möglichkeit, die Namensauflösung zu realisieren. Als aber mit der Umstellung des Netzwerkprotokolls auf TCP/IP die Anzahl der Rechner im ARPAnet förmlich explodierte, wurde diese Art der Namensauflösung ineffizient, so dass man nach einer Alternative suchte, die die gerade beschriebenen Nachteile der host-Datei beseitigt. Paul Mockapetris veröffentlichte 1984 zwei RFCs (882 und 883), in denen er eine Alternative zu der HOSTS.TXT vorstellte. Die Grundlagen für das uns heute bekannte DNS wurden gelegt[1]. 96 12.2 Die Theorie des DNS 12.2.3 Die Organisation des DNS Das Domain Name System ist in einer weltweit verteilten, umgekehrt baumstrukturierten Datenbank organisiert: Ausgehend von der root-Domain, zweigen die einzelnen sog. TopLevel -Domains (TLDs) ab, die dann in bis zu 126 Ebenen weiter unterteilt werden können. Die einzelnen Ebenen werden durch Punkte abgetrennt. Ein Name wie porta.TechFak.Uni-Bielefeld.DE. ist also wie folgt zu lesen: der Rechner mit dem Namen porta“ ist der Top-Level-Domain DE zugehörig, ist also wahrscheinlich in ” Deutschland zu finden. Er gehört der Universität Bielefeld, genauer gesagt: der Technischen Fakultät, an[21]. Neben den internationalen Top-Level-Domains, wie z.B. de für Deutschland, fr für Frankreich oder auch das eher unbekannte us für United States1 , gibt es eine Handvoll Domains, die keiner geographischen Zugehörigkeit zuzuordnen sind[21]: • com: Kommerzielle Organisation • net: Organisationen, die mit Netzwerken zu tun haben • org: (nichtkommerzielle) Organisationen • mil: Militärische Einrichtungen • edu: (vornehmlich US-amerikanische) Universitäten und Bildungseinrichtungen • int: Internationale Organisationen • gov: US-amerikanische Regierungsinstitutionen Aufgrund der Verknappung aussagekräftiger Domainnamen wurde gegen Ende 2000 von der ICANN sieben neue Top Level Domains eingeführt: • biz: Businesses • info: Allgemeine Informationen • name: Private Personen • pro: Buchhalter, Juristen, Ärzte, (...) • museum: Museen • aero: Fluggesellschaften, Flughäfen und Reiseveranstalter • coop: Genossenschaftliche Unternehmen und Organisationen 1 Eine vollständige Auflistung nach ISO 3166 kann man unter ftp://ftp.ripe.net beziehen. 97 12 Domain Name System (DNS) Die Domain in-addr.arpa Der Domain in-addr.arpa kommt eine besondere Bedeutung zu: sie wurde zur Auflösung von IP-Adressen auf Domainnamen eingeführt. in-addr.arpa enthält insgesamt vier Ebenen mit jeweils 255 Subdomains, so dass jede IP-Adresse in die Domain aufgenommen werden kann. porta.TechFak.Uni-Bielefeld.DE ist mit der IP-Adresse 129.70.136.108 also mit 108.136.70.129.in-addr.arpa“ in der in-addr.arpa-Domain zu finden. Dass die IP-Adresse ” im Domainname rückwärts erscheint, ist plausibel wenn man bedenkt, dass einzelne Bereiche der in-addr.arpa-Domain delegiert werden: die Zone 70.129.in-addr.arpa ist an die Universität Bielefeld delegiert, da für sie das Klasse B-Netz 129.70.0.0/16 reserviert wurde. Würde man die IP-Adresse nicht umdrehen“, so würde die Domain 70.129.in-addr.arpa ” alle Hosts beinhalten, deren IP-Adresse auf .70.129 endet. Eine solche Domain wäre fast unmöglich zu administrieren[1]. Die in-addr.arpa-Domain spielt auch bei der Authentifizierung eine Rolle. Bei den r-Utilities z.B. werden die IP-Adressen mit den Host-Namen, die in .rhosts oder hosts.equiv stehen, verglichen, um den Zugang zu erlauben oder abzulehnen[19]. Die Hesiod-Klasse Der Aufbau des DNS bietet die Möglichkeit, statische Informationen aufeinander abzubilden. Hesiod ist eine Erweiterung des DNS, die diese Möglichkeit ausnutzt, um ein verteiltes Datenbanksystem zu erschaffen. Hierzu wurde bind dahingehend gepatcht, eine neue Klasse verwalten zu können: die Hesiod-Klasse. Informationen der Hesiod-Klasse liegen tabellarisch vor und werden durch bind organisiert. Die Hesiod-Klasse wurde offiziell in bind integriert, so dass dieser eine Hesiodanfrage eines Resolvers ohne weiteres durchführen kann. Obwohl es prinzipiell möglich wäre, allgemeine statische Daten unter Hesiod zu mappen, so findet Hesiod vor allem in der Benutzerverwaltung in Verbindung mit NIS Verwendung. Die TechFak z.B. setzt Hesiod für den Automounter und in Verbindung mit dem rcinfo-System ein. Mit hesinfo HesiodName HesiodNameType steht ein benutzerfreundliches Frontend zur Verfügung, mit dem man die Hesioddatenbank abfragen kann. 12.2.4 Der Begriff der Zone Neben dem Begriff der Domain (oder auch Domäne), existiert der Begriff der Zone. Eine Zone bezeichnet einen Teil einer Domain, für den ein Nameserver die Verantwortung (Authorität, oder auch authority) trägt. Rechner, die von einem Nameserver einer untergeordneten Domain (Subdomain) verwaltet werden, gehören nicht zu der Zone des übergeordneten Nameservers, obwohl die Subdomain zur Domain gehört. Es ist leicht ersichtlicht, dass nicht nur ein Nameserver alle Domains der Welt verwalten kann. Von daher muss eine Möglichkeit existieren, einen Teil einer Domain an andere Nameserver zu delegieren. Den delegierten Teil der Domain nennt man Zone. Eine delegierte Zone hat die Freiheit, diese Zone in weitere Subdomains oder weitere Zonen zu unterteilen[31]. Im Falle der Top-Level-Domain DE, sieht das folgendermaßen aus: alle Rechner, deren 98 12.2 Die Theorie des DNS hostname auf .DE endet, gehören zur Domain DE. Aber zur Zone DE gehören nur diejenigen Rechner an, die vom DENIC, der zentralen Registrierungsstelle für die DE-Domain, selbst verwaltet werden, also wahrscheinlich nur eine Handvoll von Rechnern. Die Domain Uni-Bielefeld.de wurde vom DENIC an die Universität Bielefeld delegiert, die damit die Authorität über die Zone Uni-Bielefeld.de erhält, und damit die Möglichkeit hat, weitere Subdomains (wie z.B. TechFak.Uni-Bielefeld) einzurichten und eventuell auch zu delegieren. Da eine Domain u.U. wesentlich mehr Information enthält als ein Nameserver benötigt (man denke nur an die root-Domain), arbeiten diese grundsätzlich mit Zonen und nicht mit Domains[1]. 12.2.5 Verschiedene Arten von Nameservern Aus administrativen Gründen ist es ratsam mehrere Nameserver zu haben. Zum einen verteilt man den DNS-Traffic auf mehrere Nameserver und sorgt gleichzeitig für eine Redundanz. Aus administrativen Gründen ist aber auch davon abzuraten, mehrere Nameserver für eine Zone zu authorisieren, da man Änderungen im DNS dann auf mehreren Nameservern gleichzeitig durchführen müsste. Aus diesem Grund existieren mehrere Arten von Nameservern: 1. Master oder primäre Nameserver 2. Slave oder sekundäre Nameserver 3. Forwarder 4. Caching-only Nameserver Master Nameserver (auch primäre Nameserver gennant) sind die Nameserver, die die Authorität über eine Zone haben. Die Konfiguration der authorisierten Zone erfolgt über Datenbankdateien. Diese Dateien liegen in einem textorientierten Format vor und folgen den Resource Records, die in Kapitel 12.4 erläutert werden. Slave Nameserver (oder auch sekundäre Nameserver) besitzen zwar auch die Authorität über die Zone, beziehen die Zonendaten aber in regelmäßigen Abständen2 vom Master Nameserver. Diesen Vorgang nennt man Zonentransfer. Der Zonentransfer kann auch manuell durch named-xfer angestoßen werden. Forwarder sind Nameserver, die von anderen Nameservern rekursive Anfragen erhalten. Sie dienen sozusagen als DNS-Proxy für andere Nameserver. Forwarder können in Netzen eingesetzt werden, in denen die Nameserver selbst über keinen Netzanschluss verfügen. Sie laufen also vorzugsweise auf Gateways. Caching-only Nameserver haben keine Authorität über eine Zone, sondern dienen lediglich dazu einen DNS-Cache aufzubauen, um lokale Anfragen möglichst schnell und ohne WAN-Traffic beantworten zu können. Sie greifen ausschließlich auf Forwarder zu[31]. 2 Die Zeitspanne kann durch die Refresh-Direktive beeinflusst werden 99 12 Domain Name System (DNS) 12.3 Die Namensauflösung Nachdem geklärt wurde, wie der DNS-Namensraum aufgebaut ist, möchte ich auf die Namensauflösung zu Sprechen kommen. Wie läuft eine Namensauflösung im Detail ab, wenn man z.B. mit telnet (ssh ist ja leider nicht möglich) auf porta.TechFak.Uni-Bielefeld.DE zugreift? 12.3.1 Der Resolver Dasjenige Programm, das die Namensauflösung anfordert (im obigen Fall also telnet), greift auf den Resolver zu. Der Resolver ist eine in den Nameserver integrierte Bibliothek, die die Kommunikation mit dem Nameserver übernimmt und dessen Antwort wieder an das aufrufende Programm zurückgibt. Er bildet sozusagen den clientbasierenden Teil des DNS und wird über die Datei /etc/resolv.conf konfiguriert. Auf porta.TechFak könnte sie folgendermaßen aussehen: Die /etc/resolv.conf domain TechFak.Uni-Bielefeld.DE nameserver 129.70.5.16 Die Defaultdomain wird normalerweise über den FQDN3 selbst ermittelt: es ist der Teil des FQDN, der hinter dem ersten Punkt steht. Wenn im FQDN kein Punkt auftaucht, ist die Defaultdomain die root“-Domain, was aber zwangsläufig falsch sein muss, da die ” root“-Domain keine hosts hat, sondern nur delegiert. ” Der Resolver geht standardmäßig davon aus, dass auf dem lokalen Rechner ein Nameserver läuft. Wenn dem nicht so ist, kann bzw. können über die nameserver -Direktive ein oder mehrere alternative Nameserver angegeben werden. Da die Seitenanzahl dieser Hausarbeit leider beschränkt ist, muss ich die weiteren Konfigurationsmöglichkeiten des Resolvers außer Acht lassen. Auch eine weitere Resolver-Konfigurationsdatei, die /etc/host.conf bleibt nichtbeachtet.4 12.3.2 Rekursive DNS-Queries Wenn ein Programm auf die Funktionen des Resolvers zugreift5, so richtet der Resolver eine rekursive DNS-Abfrage an den spezifizierten Nameserver. Rekursiv bedeutet in diesem Zusammenhang, dass alle Arbeit dem DNS-Server überlassen wird: Alle Schritte, die zur 3 FQDN steht für Full Qualified Domain Name und stellt den vollen Domainnamen dar, der auf UnixBetriebssystemen mit hostname -f oder uname -n ermittelt werden kann. 4 Bei Interesse können die jeweiligen man-pages weiterhelfen: host.conf(5), resolv+(8), resolver(3), resolver(5) 5 C-Programme includen /usr/include/netdb.h und für Perl existiert hier das Net::DNS-Modul, das aus dem CPAN bezogen werden kann. 100 12.4 Die Resource Records Namensauflösung notwendig sind, werden von dem angefragten Nameserver durchgeführt und bei Beendigung des Prozesses wird die Antwort an den Resolver (und damit an das aufrufende Programm) zurückgegeben[22]. 12.3.3 Iterative DNS-Queries Die Arbeit des Nameservers gestaltet sich folgendermaßen: Erreicht ihn eine rekursive Anfrage des Resolvers nach einem Host, z.B. foo.bar.domain.org“, so fragt er iterativ ” (auch als nichtrekursiv bezeichnet) bei dem nächstliegenden Nameserver nach. Erhält ein Nameserver iterative Anfragen, gibt er die ihm bestmögliche Antwort zurück, d.h. er überprüft, ob er für den angefragten Host die Zonenauthorität besitzt oder ob in seinem Cache bereits Informationen über den Host vorliegen. Ist beides nicht der Fall, gibt er die Adresse desjenigen Nameservers zurück, der am nächsten beim angeforderten Hostnamen liegt. Bei der Anfrage nach foo.bar.domain.org“, wird der angesprochene Nameserver also ” bei dem root“-Nameserver anfragen (wenn er selbst keine genaueren Informationen ” über foo.bar.domain.org“ hat), worauf dieser ihn wahrscheinlich an den Nameserver der ” ORG-Domain verweisen wird. Wenn diesem der host foo.bar.domain.org“ auch nicht ” bekannt ist, gibt er ebenfalls den nächstliegenden Nameserver zurück, also wahrscheinlich den von domain.ORG. Diese Art der Abfrage wird so lange fortgesetzt, bis ein Nameserver gefragt wird, der für foo.bar.domain.org“ die Authorität besitzt (dies sollte der Name” server von bar.domain.org sein) und letztendlich die IP-Adresse von foo.bar.domain.org“ ” zurückgibt[22]. 12.4 Die Resource Records Aufgrund der hierachischen und dezentralisierten Struktur des DNS sind für eine Zone verschiedene Angaben notwendig. So muss z.B. spezifiziert werden, • welcher Rechner für die Namensauflösung der Zone zuständig ist. item unter welcher IP-Adresse ein Rechner innerhalb der Zone zu finden ist. • zu welchem Rechner die Mail für die Domain zugestellt werden soll. Diese Konfiguration erfolgt über Resources, die — sowie die host-Datei — in einem textorientieren Format beim Nameserver vorliegen. Jeder Zone lassen sich unbegrenzt viele Resources zuordnen. Eine Resource-Information bezeichnet man auch als Resource Record oder kurz RR. 101 12 Domain Name System (DNS) Kürzel SOA Resource Record Start of Authority NS A NameServer Address MX CNAME Mail Exchanger Canonical hostname PTR Pointer Bedeutung Einleitung für die RRs der spezifizierten Zone Nameserver der Zone Zuordnung des FQDN zu einer IPAdresse Angabe zum Mailserver der Zone Setzt einen Link auf einen bestehenden A-Record Ordnet in der in-addr.arpa-Domain den hostname auf eine IP-Adresse zu weniger gebräuchliche RRs: TXT HINFO Text Host Info Kommentar zum host Nähere Angaben zur Hardware und Betriebssystem Eine auf die TechFak bezogene db-Datei könnte also so aussehen6 ; db.techfak: TechFak.Uni-Bielefeld.DE. IN SOA dns.TechFak.Uni-Bielefeld.DE pk.TechFak.Uni-Bielefeld.DE. ( ; mailto 1810200001 ; Serial-Nr. 10800 ; Refresh (3 Std.) 3600 ; Retry (1. Std.) 604800 ; Expire (1 Woche) 86400 ) ; TTL (1 Tag) IN IN IN IN spaghetti IN (...) popocatepetl IN porta IN 6 NS NS MX MX techfac.TechFak.Uni-Bielefeld.DE noc.HRZ.Uni-Bielefeld.DE 100 gemma.techfak.uni-bielefeld.de 300 mail1.RRZ.Uni-Koeln.DE A 129.70.133.49 A 129.70.136.108 CNAME popocatepetl.TechFak.Uni-Bielefeld.DE Das Format der einzelnen Resource Records ist programmabhängig, also nicht DNS-spezifisch. Die nachfolgenden Beispiele beziehen sich auf BIND. 102 12.5 Das DNS-Protokoll 12.5 Das DNS-Protokoll Aufgrund des geringeren Overheads und der höhren Geschwindigkeit basieren DNSAbfragen auf UDP. Lediglich bei einem Zonentransfer zwischen zwei Nameservern wird auf TCP zurückgegriffen, um die Konsistenz der Daten zu gewährleisten. Zur Kommunikation dient sowohl bei UDP als auch bei TCP der Port 53[33]. Die DNS-Kommunikation erfolgt über 16bit-Messages, deren Aufbau immer gleich ist: 0 7 8 15 Header o Der Header mit einer Größe von 12 Byte Question o Die an den Nameserver gerichtete Frage Answer o RRs, die die Frage beantworten Authority o auf authoritative Server zeigende NS-RRs Additional o Zusätzliche Resource Records Bis auf den Header sind alle Felder optional. Im Header wird angegeben, welche der vier möglichen Felder vorhanden sind[22]. 12.5.1 Codierung des Domainnamens In einer DNS-Message werden die Domainnamen nicht durch Strings repräsentiert, sondern folgen einem bestimmten Codierungsverfahren: Die Länge der Abschnitte (Labels), die normalerweise durch einen Punkt im Domainnamen abgetrennt sind, werden jeweils vor die betreffenden Labels - also an die Stelle des Punktes - gestellt. Den Abschluss bildet der Zero-String. Für porta.TechFak.Uni-Bielefeld.DE sähe das z.B. folgendermaßen aus: 0 1 5 porta 5 6 7 13 14 15 7 1 3 TechFak 27 28 29 30 31 Uni-Bielefeld 2 DE \ 0 Da in einer DNS-Message häufig die abschließenden Labels – also der Domainname – mehrfach auftreten, besteht die Möglichkeit diese Redundanz zu beseitigen, indem man beim erneuten Auftreten des Labels einen Zeiger auf das bereits vorhanden Label setzt. Da ein Label maximal 63 Bytes groß sein darf, reichen für die Längenangabe 6 Bit aus, um die Länge des nachfolgenden Labels zu codieren. Die ersten beiden MSBs sind demzufolge 103 12 Domain Name System (DNS) immer 0. Folgt allerdings ein Zeiger auf ein bestehendes Label werden diese MSBs auf 1 gesetzt. Die verbleibenden 6 Bit des Bytes und die 8 Bit des nächsten Bytes bestimmen den Offset des Labels vom Beginn der DNS-Message[1]. 0 1 9 9 10 spaghetti 17 18 25 6 0xC0 12.5.2 DNS-Header Der DNS-Header ist folgendermaßen aufgebaut: 0 15 ID Q R Opcode A T R R A C D A Z RCODE QDCOUNT ANCOUNT NSCOUNT ARCOUNT ID QR OPCODE AA TC RD RA Z 104 Eine 16-bit Zahl, die bei einer Anfrage und deren Antwort gleich ist, um die Zusammengehörigkeit sicherzustellen. Bei einer Anfrage auf 0 und bei einer Antwort auf 1 gesetzt. Spezifiziert die Art der Anfrage: 0 Standard-Query 1 Inverse Query 2 Abfrage des Serverstatus 3-15 Reserviert für zukünftige Nutzung Authoritative Answer – bei einer authoritativen Antwort gesetzt. Trunctation – Wird die bei UDP maximale Paketgröße von 512Byte überschritten und die DNS-Nachricht gekürzt, ist dieses bit gesetzt. Recursion Desired – weist in einer Query zu einer rekursiven Anfrage an. Recursion Available – wird vom angefragten Server gesetzt oder gelöscht - je nachdem ob dieser rekursive Anfragen zulässt. Reserviert für zukünftige Nutzung und muss auf 0 gesetzt sein. 12.5 Das DNS-Protokoll RCODE QDCOUNT ANCOUNT NSCOUNT ARCOUNT Response Code – Der Rückgabecode wird bei einer Antwort gesetzt: 0 Keine Fehler 1 Format error : die Anfrage konnte nicht interpretiert werden. 2 Server error : die Anfrage konnte aufgrund eines Serverfehlers nicht beantwortet werden. 3 Name error : Der abgefragte Domainname existiert nicht. 4 Not implemented – Diese Art der Abfrage wird vom Nameserver nicht unterstützt (z.B. bei einer Hesiod-Abfrage bei einer früher Version von bind). 5 Refused : Anfrage wurde aus Sicherheitsgründen abgelehnt. 6-15 Reserviert für zukünftige Nutzung. Anzahl der Queries im Questionteil. Anzahl der Resource Records im Answer-Teil Anzahl der Resource Records im Authority-Teil Anzahl der Resource Records im Additional-Teil 12.5.3 DNS-Question Die Question-Section enthält die anzufragenden Informationen. Obwohl im Header durch den QDCOUNT-Eintrag die Möglichkeit besteht, innerhalb einer DNS-Message mehrere Queries zu haben, wird dies von den meisten Nameservern nicht unterstützt. Die Question-Section besteht im einzelnen aus folgenden Teilabschnitten[22]: 0 7 8 15 QNAME hhhh h hhhhhhhhh hhhh hhhh hhhh hh h hhh QTYPE QCLASS 105 12 Domain Name System (DNS) QNAME QTYPE QCLASS Der abzufragende Domainname. Die Codierung erfolgt wie in Kapitel 12.5.1 beschrieben. Die Binärrepräsentation des Resource Record. Z.B.: 1 A-RR 2 NS-RR 5 CNAME 6 SOA 12 PTR-RR 15 MX-RR 252 Zonentransfer 255 ANY Die abzufragende Klasse: 1 IN – Internet class 2 CS – CSNET class 3 CH – CHAOS class 4 HS – Hesiod class 255 ANY – beliebige Klasse 12.5.4 DNS-Answer, DNS-Authority, DNS-Additional Die Answer-, Authority und Additionalsection folgenden dem gleichen Aufbau: 0 15 NAME TYPE CLASS TTL RDLENGTH RDATA hhhh h hhhhhhhhh h hhh hhhh hhhh hh h hhh 106 12.6 nslookup NAME TYPE CLASS TTL RDLENGTH RDATA Der Domainname des spezifizierten Resource Records. Die Art des im RDATA spezifizierten Resource Records (s.o.). Die Klasse des Resource Records (s.o.). Der Time-to-live-Wert, nach dem der Resource Record aus dem Cache gelöscht werden sollte. Die Anzahl der Bytes im RDATA-Feld. Die Resource Records. 12.6 nslookup Zur Interaktion zwischen Nameserver und Benutzer stehen zahlreiche Kommandos zur Verfügung. Utilities wie nslookup, host oder auch dig dienen der Formulierung von NameserverQueries, sind also sozusagen Frontends für den Resolver. nslookup kann in einem interaktiven Modus oder per Kommandozeilenargumente betrieben werden. Eine Sitzung in der Daten über die TechFak abgefragt werden, könnte beispielsweise folgendermaßen aussehen: rechner:~\$ nslookup > server 129.70.5.16 Default server: 129.70.5.16 Address: 129.70.5.16#53 > set type=NS > TechFak.Uni-Bielefeld.DE Server: 129.70.5.16 Address: 129.70.5.16#53 TechFak.Uni-Bielefeld.DE TechFak.Uni-Bielefeld.DE TechFak.Uni-Bielefeld.DE TechFak.Uni-Bielefeld.DE TechFak.Uni-Bielefeld.DE nameserver=techfac.TechFak.Uni-Bielefeld.DE. nameserver=noc.rrz.Uni-Koeln.DE. nameserver=waldorf.Informatik.Uni-Dortmund.DE. nameserver=noc.BelWue.DE. nameserver=noc.HRZ.Uni-Bielefeld.DE. Durch den set type“-Befehl kann die Abfrage auf die in Kapitel 12.5.3 beschriebenen QTY” PEs gesetzt werden[32]. host lässt sich ausschließlich durch Kommandozeilenparameter steuern. Ein interaktiver Modus existiert hier nicht[32]. rechner:~\$ host -t NS TechFak.Uni-Bielefeld.DE 129.70.5.16 TechFak.Uni-Bielefeld.DE NS techfac.TechFak.Uni-Bielefeld.DE TechFak.Uni-Bielefeld.DE NS noc.rrz.Uni-Koeln.DE TechFak.Uni-Bielefeld.DE NS waldorf.Informatik.Uni-Dortmund.DE TechFak.Uni-Bielefeld.DE NS noc.BelWue.DE TechFak.Uni-Bielefeld.DE NS noc.HRZ.Uni-Bielefeld.DE 107 12 Domain Name System (DNS) 108 KAPITEL 13 Transmission Control Protocol (TCP) Ronny Gärtner, Sonja Hunscha, Jörg Sprügel Der Vortrag Transmission Control Protocol“ wurde von Ronny Gärtner gehalten. Anstatt ” einer herkömmlichen Ausarbeitung hat er gemeinsam mit mit Sonja Hunscha und Jörg Sprügel, Studenten des Faches Mediengestaltung, eine Web-Seite erstellt, die u.a. eine animierte Darstellung der Funktionsweise von TCP enthält. Das Ergebnis ihrer Arbeit ist unter der Adresse http://tcp.joerg-spruegel.de zu finden. Zur anzeige der Animation wird ein Web-Browser mit Flash-Plugin benötigt. 109 13 Transmission Control Protocol (TCP) 110 KAPITEL 14 TCP Flow Control und Congestion Avoidance Jonas Rosenfeldt, Florian Schäfer 14.1 Silly Windows Syndrome Eine Erscheinung, die bei fensterbasierten Kontrollmechanismen auftreten kann, stellt das silly window syndrome (Syndrom unsinniger Fenster) dar. Es handelt sich hierbei um ein Performance Problem, das auftreten würde, wenn die sendende und die empfangende Applikation mit unterschiedlichen Geschwindigkeiten arbeiten. TCP buffert (speichert) die eingehenden Daten und die Empfänger Applikation verarbeitet sie dann. Wenn nun diese Applikation nur ein Oktet (das kleinst mögliche Datensegment) zur Zeit verarbeitet und die sendende Applikation die Daten schnell genug generiert, wird der Buffer(Speicher) des Empfängers unter Umständen aufgefüllt und der Sender wird ein Acknoledgement (Bestätigung) bekommen, das spezifiziert, das das Fenster (Window → sliding Window) gefüllt wurde. Da die Applikation im weiteren Verlauf Daten verarbeitet, wird in diesem Fall ein Oktet des Buffers frei. Das TCP der Empfängerseite generiert nun eine Bestätigung und teilt mit, das ein Oktet des Speichers (Buffers) frei ist. Der Sender würde nun ein einzelnes Oktet Window an Daten schicken, was zu einer Serie von schmalen Datensegmenten führen würde, die die Bandbreite des Netzwerkes unnötig belasten würden. Außerdem würde jedes einzelne Datensegment mit Header zusätzliche Verarbeitungszeit kosten. Auf dem sendenden Computer müsste die IP Software das Segment in ein Datagramm einbauen, die Header Checksum müsste generiert werden, das Datagramm müsste geroutet werden und zum zuständigen Network Interface übertragen werden. Auf dem empfangenen Computer würde die IP Software die IP Checksum verifizieren und das Segment zu TCP übermitteln. TCP 111 14 TCP Flow Control und Congestion Avoidance müsste die Segment Checksum abgleichen, die Sequenz Nummer untersuchen, die Daten extrahieren und sie im Buffer platzieren. 14.1.1 Heuristiken gegen das Silly Window Syndrome Empfänger Seite: Wenn sich der Buffer gefüllt hat, sendet der Receiver ein Acknoledgement, das eine zero Window Anweisung beinhaltet. Anstatt jedoch gleich eine Window Anweisung zuschicken, wenn im Buffer Platz freigeworden ist, wartet TCP und sendet erst wenn der Buffer zur Hälfte seiner totalen Größe frei ist. Sender Seite: Wenn auf der Sender Seite schmale Pakete durch die Applikation generiert werden ( Beispiel Oktet ) schickt TCP das erste Oktet. Während TCP auf das Acknoledgement wartet wird TCP aber zusätzliche Oktets in den Buffer laden und diese zusammen verschicken, wenn das Acknoledgement eintrifft. Diese relativ einfachen Maßnahmen verhindern eine Verminderung der Bandbreite und die Verschwendung an Rechenleistung. 14.2 Timer 14.2.1 Retransmission Timer Da TCP für die Internet Umgebung bestimmt ist, muß es die zeitlichen Unterschiede verschiedene Ziele (Destinations) zu erreichen und durch Conguestion(Netzlast) resultierende Verzögerungen ausgleichen können. Segmente müssen bei der Annahme ihres Verlustes neu versendet werden, deshalb braucht TCP bestimmte Regeln, um möglichst schnell festzustellen, das ein Verlust vorliegt. Eine Frist muß festgesetzt werden, bei deren Überschreitung TCP einen Verlust annimmt. Diese bezieht sich auf das älteste unbestätigte Segment, das in diesem Fall wiederholt gesendet wird. Round Trip Timer(RTT) Da der Datendurchsatz und damit die Übertragungszeit im Internet stark schwanken kann muß die Frist im Lauf der Verbindung angepaßt werden. Dieses geschieht mit Hilfe der Round Trip Time (Umlaufzeit). Einerseits muß die RTT groß genug sein um eventuell verzögert eintreffende Segmente zu berücksichtigen, andererseits muß sie hinreichend klein sein um einen Verlust möglichst schnell festzustellen. 112 14.2 Timer Abbildung 14.1: ambiguous Acknoledgements Dabei wurden im Laufe der Zeit verschiedene Berechnungsmethoden der RTT in TCP integriert, um den Datendurchsatz optimal zuhalten. • Beispiel : 1.(0 ≤ α < 1) RT T = α ∗ OldRT T ) + ((1 − α) ∗ (N ewRoundT ripSample) • Beispiel2 : 1 : α = 0.9, OldRT T = 1500ms, N ewRoundT ripSample = 1700(0.9 ∗ 1500ms) + (0.1 ∗ 1700ms) = 1520ms • Beispiel2 : α = 0.1, OldRT T = 1500ms, N ewRoundT ripSample = 1700(0.1 ∗ 1500ms) + (0.9 ∗ 1700ms) = 1680ms Je näher α an 1 liegt, desto unempfindlicher wird die RTT gegenüber Änderungen innerhalb einer kurzen Zeitspanne ( z.B. ein einzelnes Segment, das länger braucht ). Je näher α an 0 liegt, desto eher reagiert die RTT mit einer entsprechenden Veränderung. Timeout Wenn ein Packet gesendet wird, generiert TCP den Timeout als eine Funktion von der aktuellen RTT. Frühere Implementationen benutzten β(β > 1) als einen konstanten Faktor und machten den Timeout größer als die RTT. • T imeout = β ∗ RT T β wurde dabei als 2 gesetzt. 113 14 TCP Flow Control und Congestion Avoidance Karn‘s Algorithmus und Timer Backof Karn‘s Algorithmus verhindert das Problem der ambiguous Acknoledgements (nicht eindeutige Bestätigungen). Da TCP bei einem nochmals gesendeten Segment keine neue Numerierung durchführt, könnte es passieren, daß für ein verloren gegangenes Segment ein Acknoledgement doch noch eintrifft und TCP annimmt es würde sich hierbei um das Acknoledgement für das soeben übermittelte handeln. In diesem Falle würde eine sehr viel niedrigere RTT angesetzt werden. Um dieses zu verhindern wurde TCP mit einem zusätzlichen Algorithmus versehn. Dabei lässt der Algorithmus die Zeiten der Retransmissions außer acht und verbindet die Timeouts mit einer Timer Backoff Strategie. Jedesmal wenn TCP ein Retransmit losschicken muß, wird der Timeout erhöht. • N ewT imeout = γ ∗ T imeout Typischerweise wird γ = 2 gesetzt Dieses läuft solange, bis erfolgreich ein Segment ohne Retransmission gesandt werden konnte. Responding to High Variance in Delay Da die Netzlast sehr stark schwanken kann, muß TCP schnell darauf reagieren können, um den Durchsatz möglichst optimal zuhalten. Da das vorgestellte Timeout Modell nur bei einer Belastung von 30% des Internets einen guten Durchsatz erzielt, wurden 1989 weitergehende Implementationen vorgenommen. Dadurch konnte TCP größere zeitliche Verzögerungen ( RTT Differenzen ) besser managen und so den Durchsatz verbessern. • DIF F = SAM P LE − OldRT T • SmoothedRT T = OldRT T + δ ∗ DIF F • DEV = OldDEV + ρ(| DIF F | −OldDEV ) • T imeout = SmoothedRT T + η ∗ DEV DEV = estimated mean deviation ( veranschlagte mittlere Abweichung ) Smoothed RTT = gerundete RTT δ = Bruch zwischen 0 und 1 der bestimmt wie schnell die neue Sample den Durchschnitt (RTT) beeinflusst. 114 14.2 Timer Abbildung 14.2: 200 zufällig generierte RTTs als Punkte dargestellt und der Retransmission Timer als Linie ρ = Bruch zwischen 0 und 1 der bestimmt wie schnell die neue Sample die mittlere Abweichung beeinflusst. η = ist ein Factor, der kontrolliert wie stark die Abweichung in den neuen Timeout einfließt. Erfahrungen haben gute Ergebnisse mit den Werten δ = undη = 3 gezeigt. 1 23 , ρ = 1 22 • OldD EV = 0.2sgesetzt • SAM P LE − OldRT T = DIF F → 3.2682s − 2.8012s = 0.4670s • OldR T T + δ ∗ DIF F = SmoothedRT T → 2.8012s + 0.058375s = 2.8596s • OldDEV + ρ → 0.2s + 1 22 (0.4670 − 1 23 ∗ 0.4670s =→ 2.8012s + 0.2s) =→ 0.2s + 0.06675s = 0.26675s • SmoothedRT T + η ∗ DEV = T imeout → 2.8596s + 3 ∗ 0.26675s = 3.65985s Im Vergleich: Nach den vorherigen Methoden würden der Timout zwischen 5.5978s und 6.5364s liegen. 115 14 TCP Flow Control und Congestion Avoidance 14.2.2 TCP Persist Timer Segmente 1-13 zeigen den normalen Daten Transfer vom Client zum Server. In Segment 13 acknolegded der Server die vorangegangenen Datensegmente, setzt aber das Window auf 0. Das hält den Client davon ab noch mehr Daten zuschicken und dieser setzt seinen Persist Timer. Wenn der Client kein Window Update bekommt und der Timer abläuft, versucht er mit einem zero Window herauszufinden, ob das Update verlorenging (→Zeiten der Anfrage: 1,5s, 3s, 6, 12s, 24s, 48s, 60s, 60s,...). 14.2.3 Keepalive Timer Ablauf: • Eine Verbindung wurde aufgebaut. • Ein Datenaustausch erfolgte, es werden keine weiteren Daten gesendet, die Verbindung bleibt bestehen. • Jede zwei Stunden wird ein Keepalive Packet gesendet, wird es von der anderen Seite acknoledged, wird der Keepalive Timer wieder auf zwei Stunden gesetzt. • Ist die Verbindung unterbrochen, werden 10 Keepalive Proben im Abstand von 75s gesendet. Wird eine davon acknoledged, wird der keepalive Timer wieder auf zwei Stunden gesetzt. • Wird nicht acknoledged, wird die Verbindung für tot erklärt. 116 14.3 Congestion Abbildung 14.3: Persist Timer 14.3 Congestion In Netzwerken kann bei hoher Belastung an bestimmten Knotenpunkten (Routern) die sogenannte congestion (deutsch: Stau, Verstopfung) auftreten. Bei diesem Phänomen füllt sich der Puffer eines Routers schneller als dieser die Daten verarbeiten und weiterreichen kann, und neu ankommende Datenpakete müssen verworfen werden. Eine solche Überlastung eines Routers entsteht wenn Daten von einem schnelleren (z.B. Ethernet LAN) in ein langsameres Netzwerk (z.B. WAN) übertragen werden, oder wenn ein Router weniger Output-Kapazität hat als die Summe seiner Inputs. 117 14 TCP Flow Control und Congestion Avoidance 14.3.1 Congestion Collapse Der Sender der jeweiligen Verbindung, von der ein oder mehrere Pakete verworfen werden mussten, schickt nun die verlorenen Pakete erneut (retransmission) und erhöht damit wiederum die Belastung für das Netzwerk. Dadurch können auch andere Verbindungen zur retransmission gezwungen werden, was die Belastung weiter steigert. Dadurch kann es passieren, dass ein stabiler Status (der sog. congestion collapse) erreicht wird, in dem jedes Paket erst nach mehrmaliger retransmission beim Empfänger ankommt, die Durchsatzrate also extrem schlecht ist. Dies kann auch ohne ’echte’ Congestion - also den Verlust von Paketen - entstehen, wenn die Belastung plötzlich auftritt (z.B. durch Datei-Transfers). Da viele Daten in den Puffern der Router zwischengespeichert werden müssen, dauert es länger bis sie weitergeleitet werden können. Dadurch steigt die Round-Trip-Time (RTT) schneller an als der Sender berechnet hat und der RTT-Timer läuft ab (sog. Timeout) bevor das Paket bestätigt werden kann. Dann werden unnötige Retransmissions gesendet, was wieder eine Erhöhung der Belastung zur Folge hat. Um dem entgegenzuwirken wurden verschiedene Algorithmen zur Congestion Control entwickelt. 14.4 End-to-End Congestion Control Bei der end-to-end congestion control sind nur die beiden Endpunkte der Verbindung, also Sender und Empfänger, beteiligt. Da die Wahrscheinlichkeit eines Paketverlustes durch Beschädigung (o.ä.) weit unter 1 % liegt, wird hier der Paketverlust als Anzeichen für einen Stau angesehen. 14.4.1 Slow-Start Der slow-start Algorithmus führt zunächst eine neue Variable ein. Zu dem vom slidingwindow Prinzip bekannten receiver window kommt ein weiteres, das congestion window (CongWin). Dabei wird jeweils das Minimum dieser beiden Fenster, das sog. allowed window, gesendet. Beim Start wird • CongW in = 1 · M SS also auf eine maximale Segmentgröße (oder Paketgröße) gesetzt, daher der Name slowstart. Damit wird die Wahrscheinlichkeit von unnötigen retransmissions durch zu plötzlich einsetzende Datenströme verringert. 118 14.4 End-to-End Congestion Control Für jedes bestätigte Segment wird dann das congestion window um eine MSS erhöht, also nach einer RTT um 1 MSS, nach 2 RTT’s um 2 MSS, nach 3 RTT’s um 4 MSS, usw. Das bedeutet das congestion window wächst exponentiell bis entweder ein bestimmter Schwellwert (siehe Abschnitt 14.4.2 und Abbildung 14.4) oder die Größe des receiver windows überschritten wird. 14.4.2 Congestion Avoidance Bei Überschreiten des Schwellwertes (Threshold) tritt der congestion avoidance Algorithmus in Kraft. Das congestion window wird jetzt nur noch um höchstens 1 MSS pro RTT erhöht. Die genaue Formel für die Berechnung des neuen Werts für CongWin lautet: • CongW in = CongW in + (Segmentgröße)2 CongW in + Segmentgröße 8 In Abbildung 14.4 sieht man wie das congestion window nach Erreichen des Schwellwertes nur noch additiv vergrößert wird. Wenn in der congestion avoidance oder slow-start Phase ein Timeout (RTT-Timer läuft ab) auftritt, also ein Paket verloren gegangen ist, wird der • Schwellwert = CongW in 2 , und dann das • CongW in = 1 · M SS gesetzt. Dann setzt der slow-start Algorithmus ein, da das congestion window wieder unterhalb des Schwellwertes liegt. Zu Beginn einer TCP-Verbindung wird der Schwellwert = 64kbytes gesetzt. Dieser Wert ist so groß, daß bei den meisten Verbindungen die Größe des receiver windows kleiner als der Schwellwert ist. Wenn kein Timeout auftritt vergrößert sich das congestion window dann sehr schnell (exponentiell) bis zur maximalen Größe. 14.4.3 Fast Retransmit/Fast Recovery Algorithmus Damit ein Paketverlust schon vor Ablaufen des RTT-Timers erkannt werden kann und nicht nach jedem Paketverlust die slow-start Phase von Anfang an durchlaufen werden muss, wurde 1990 dieser Algorithmus von Van Jacobson entwickelt. 119 14 TCP Flow Control und Congestion Avoidance Abbildung 14.4: Entwicklung der Größe des congestion windows 120 14.4 End-to-End Congestion Control Er macht sich zunutze, daß TCP nach Erhalt eines (Daten-) Segments außerhalb der Reihenfolge sofort ein acknowledgement (ACK) mit der Sequenznummer des letzten in Reihenfolge erhaltenen Segments schickt. Sobald ein ACK beim Sender doppelt ankommt verändert dieser die Variablen CongWin und Schwellwert nicht mehr. Nachdem drei solcher Duplikat-ACKs beim Sender angekommen sind, geht dieser davon aus, daß ein Paket nicht nur verspätet beim Empfänger eintrifft, sondern tatsächlich verlorengegangen ist. Das ist meist vor dem Ablaufen des RTT-Timers der Fall, trotzdem wird sofort eine retransmission geschickt (darum: fast retransmit). Die Variablen werden nun wie folgt geändert: • Schwellwert = allowed window 2 • CongW in = Schwellwert + 3 · M SS Wenn weiterhin Duplikate ankommen wird jedes mal das congestion window um 1 MSS erhöht und ein neues Segment verschickt, sofern die neue window Größe dies zulässt. Es ist zulässig neue Segmente trotz des verlorenen Pakets zu schicken, weil das Ankommen neuer Duplikat-ACKs beim Sender bedeutet, daß Segmente, die nach dem verlorenen geschickt wurden, beim Empfänger angekommen sind. Darum wird auch nach Erhalt der 3 Duplikat ACKs das congestion window halbiert (zur Stauvermeidung), um dann wieder um 3 MSS vergrößert zu werden (weil nach dem verlorenen wieder drei Segmente angekommen sind). Sobald das erste ACK beim Sender ankommt, daß neue Daten bestätigt (eine höhere Sequenznummer hat als die Duplikate) wird • CongW in = Schwellwert gesetzt und normal mit congestion avoidance weitergesendet (darum: fast recovery). 14.4.4 Beispiel Am Beispiel in Abbildung 14.5 kann man die Funktionsweise der oben beschriebenen Algorithmen nachvollziehen. Alle Angaben in diesem Abschnitt sind in bytes (Abbildung und Text). Das Segment 45 geht verloren. Der Empfänger merkt das daran, daß zwischen den Segmenten 43 und 46 eine Lücke in den Sequenznummern vorhanden ist. Nach dem Empfang von Segment 46 schickt der Empfänger sofort ein Duplikat-ACK (Segment 60) zurück. Genauso verfährt er immer wenn ein Segment ankommt, daß die Lücke nicht schließt. Der Sender verändert die Variablen (CongWin und Schwellwert) nicht mehr, nachdem er Segment 60 empfangen hat (siehe Tabelle unten in Abbildung 14.5). Erst nachdem er Seg- 121 14 TCP Flow Control und Congestion Avoidance Abbildung 14.5: Congestion Avoidance - Beispielgrafik 122 14.5 Network-Assisted Congestion Control ment 62, das dritte Duplikat-ACK, empfangen hat, setzt er Schwellwert = 1024 und CongW in = 1792; wegen: • Schwellwert = allowed2window = von MSS (hier 256) 2426 2 = 1024 (Abgerundet auf das nächste Vielfache • CongW in = Schwellwert + 3 · M SS = 1024 + 3 · 256 = 1792 und sendet eine retransmission des Segments, das auf die Sequenznummer der DuplikatACKs folgt. Die nächsten empfangenen Duplikat-ACKs (Segmente 64-66, 68, 70) bewirken jeweils eine Erhöhung des congestion windows um eine MSS (256). Mit Segment 72 wird das erste ACK empfangen, das neue Daten bestätigt (Sequenznummer höher als Duplikat-ACKs). Jetzt wird CongW in = Schwellwert gesetzt und weil CongW in ≤ Schwellwert nach dem slow-start Algorithmus eine MSS addiert, was einen Wert von 1280 ergibt. Nach Empfang des nächsten ACKs (nicht mehr in Abbildung 14.5 enthalten) wird der congestion avoidance Algorithmus benutzt, also bleibt der Schwellwert auf 1024 und das congestion window berechnet sich wie folgt: • CongW in = CongW in + • CongW in = 1280 + (256)2 1280 (Segmentgröße)2 CongW in + 256 8 + Segmentgröße 8 = 1363 (gerundet) 14.5 Network-Assisted Congestion Control Bei der network-assisted congestion control sind nur die Router des Netzwerkes zwischen Sender und Empfänger beteiligt. Hier gibt es verschiedene Möglichkeiten congestion zu vermeiden. 1. Router können eine ICMP Source Quench Message direkt an den Sender schicken, wenn ein Paket wegen überlaufen der Queue (=Puffer des Routers) verworfen werden musste. Der Sender einer TCP-Verbindung reagiert auf eine solche ICMP Message indem er • CongW in = 1 · M SS setzt und • mit unverändertem Schwellwert in die slow-start Phase übergeht 2. Mit Hilfe von Active Queue Management (AQM) können Staus erkannt werden, bevor die Queue wirklich voll ist und Pakete nach dem tail-drop Verfahren verworfen werden müssen. AQM berechnet dazu die durchschnittliche Queue-Länge, lässt also kurzzeitige Fluktuationen zu. Füllt sich die Queue jedoch längerfristig und droht 123 14 TCP Flow Control und Congestion Avoidance überzulaufen, gibt es verschiedene Methoden den Empfänger (im Gegensatz zur ICMP Source Quench Message, wo der Sender benachrichtigt wird) einer TCP-Verbindung davon in Kenntnis zu setzen: RED, ECN. Router, die AQM nicht unterstützen und nur das tail-drop Verfahren anwenden (also immer die letzten, nicht mehr in die Queue passenden Pakete verwerfen), haben den Nachteil verschiedene TCP-Verbindungen zu synchronisieren. Das passiert wenn mehrere Pakete verschiedener Verbindungen nicht mehr in die Queue passen, also gleichzeitig verworfen werden. Dann werden auch die retransmissions für diese Pakete fast gleichzeitig geschickt. Daraus ergibt sich dann, daß verschiedene Verbindungen immer zur gleichen Zeit senden und sich im Leerlauf befinden, was eine schlechte Ausnutzung der vorhandenen Kapazität des Netzwerkes bedeutet. 14.5.1 Random Early Discard (RED) Bei diesem Verfahren werden zwei Schwellwerte für die Länge der Queue eines Routers eingeführt: Tmin und Tmax . Ist die Queue Länge • unterhalb von Tmin , werden keine Pakete verworfen • oberhalb von Tmax , werden alle neu ankommenden Pakete verworfen (die beiden Werte werden so gewählt, daß dieser Zustand möglichst nie eintritt, da er wieder dem Tail-Drop Verfahren entspricht) • zwischen Tmin und Tmax , werden neu ankommende Pakete mit einer bestimmten Wahrscheinlichkeit verworfen, die höher wird je näher die Queue-Länge an Tmax herankommt und je größer das Paket ist. 14.5.2 Explicit Congestion Notification (ECN) Das ECN Verfahren nutzt die bisher nicht benötigten Bits 6 und 7 im IP ToS(Type of Service)-Feld. Am Anfang einer Verbindung handeln Sender und Empfänger ihre ECNFähigkeit aus. Sind beide ECN-fähig, setzt der Sender jeweils das Bit 6 um den Routern die ECN-Fähigkeit der Verbindung anzuzeigen. Sobald eine Queue droht überzulaufen, setzt der Router das sog. congestion experienced (CE) Bit 7 um dem Empfänger den Stau anzuzeigen. Dieser kann dann sein congestion window entsprechend verkleinern. Dieses Verfahren ist besonders effektiv, da nicht auf Paketverlust und damit auf Ablaufen eines Timers oder 3 Duplikat-ACKs gewartet werden muss. 124 KAPITEL 15 Telnet und rlogin Thomas Bekel 15.1 Einleitung Applikationen, die dem Benutzer die Möglichkeit bieten, sich über eine TCP/IP-Verbindung auf Rechnern einzuloggen, werden allgemein als remote login applications bezeichnet.[33] Die beiden am häufigsten verwendeten sollen hier vorgestellt werden: telnet und rlogin. Telnet ist eine der ältesten Internet Applikationen überhaupt, erste Implementierungen fanden sich bereits 1969 (im ARPANET). Inzwischen ist telnet als Standardapplikation in nahezu jeder TCP/IP-Implementierung zu finden. Der Name ist eine Abkürzung für telecommunications network protocol“. ” Rlogin stammt aus dem Berkeley Unix. Es war ursprünglich nur für die Verwendung auf Unix-Systemen vorgesehen, ist aber inzwischen auch auf andere Betriebssysteme portiert worden. 15.2 Telnet-Protokoll Das Telnet-Protokoll entspricht in seinem Aufbau dem typischen TCI/IP-Client-ServerModell. Der Telnet Client baut eine (einzige) TCP-Verbindung zum Server auf. Die Tasta- 125 15 Telnet und rlogin Telnet client Telnet server login shell pseudo− terminal TCP/IP driver TCP/IP terminal driver kernel kernel TCP connection user at a terminal Abbildung 15.1: Client-Server-Modell tureingaben am Client werden direkt an den Server übertragen.[7] Die resultierende Bildschirmausgabe wird über die selbe TCP-Verbindung zum Client übermittelt. Mittels eines einfachen Terminal Standards, dem NVT ASCII, geschieht die Datenübertragung zwischen Client und Server. Hierbei können vier verschiedene Übertragungsmodi verwendet werden, die mittels option negotiation eingestellt werden und verschiedene Telnet-Kommandos verwenden. 15.2.1 Client-Server-Modell Das in Abbildung 15.1 schematisch dargestellte Client-Server-Modell besteht aus mehreren Komponenten: Der Telnet-Client auf der linken Seite der Abbildung ist ein Programm, das über zwei Verbindungen mit Elementen des Kernels im Client-System verbunden ist. Eine Verbindung besteht über den Terminal-Treiber des Betriebssystems hin zum Benutzer. Die andere Verbindung wird über den TCP/IP Stack des Kernels und eine TCPVerbindung zum Server-System aufgebaut. Dort wird der Telnet-Server über den TCP/IPTreiber im Kernel angesprochen. Der Telnet-Server bietet die Benutzer-Schnittstelle zum Server-System – die login shell – über einen Pseudo-Terminal-Treiber an. Deutlich sieht man in der Abbildung, daß sowohl der Telnet-Client als auch der Telnet-Server Programme außerhalb des System Kernels sind, also auf Applikationsebene (im sogenannten user space) laufen. Aufgrund dieses modularen Aufbaus können einzelne Komponenten leicht dynamisch ausgetauscht werden. Der Server kann z. B. andere Programme anstelle von telnet und login shell starten. Telnet Verbindungen auf verschiedene Ports des Server-Systems entsprechen verschiedenen Programmen auf dem Telnet-Server, sogenannten Systemdiensten oder services 1. Die Plazierung des Telnet-Servers auf Applikationsebene hat auch Nachteile: So ist es z. B. offensichtlich ineffizient, daß jede Tastatureingabe des Benutzers zwischen den einzelnen Elementen des Modells übertragen werden muss. Insbesondere bei den Über1 Die entsprechenden Zuordnungen zwischen Ports und Diensten werden bei Unix-Systemen in der Regel in der Datei /etc/services festgelegt. 126 15.2 Telnet-Protokoll gängen zwischen kernel- und user-space sind zahlreiche process context switches notwendig. Diese sind unter anderem für die begrenzte Geschwindigkeit von Telnet-Applikationen verantwortlich. 15.2.2 NVT ASCII Beim Telnet Protokoll kommunizieren Client und Server mit Hilfe eines einfachen Standards, dem Network Virtual Terminal, oder NVT ASCII. Dieser besteht aus einem 7-Bit U.S.-Zeichensatz, wobei jedes 7-Bit Zeichen 8-bittig übertragen wird. Das high-order Bit ist – sofern keine protokollspezifischen Kommandos eingeleitet werden sollen – auf Null gesetzt. Das Telnet Programm auf der Clientseite sollte die 7-Bit Zeichen entsprechend des (lokal) verwendeten Zeichensatzes umsetzen, um sie auf dem Bildschirm darzustellen. Außerdem sind die Tastatureingaben auf den NVT ASCII Standard umzusetzen. Ein Zeilenende wird als carriage return gefolgt von linefeed übertragen, ein normaler Wagenrücklauf“ als car” riage return und einem anschließenden Null-Byte. NVT ASCII wird auch bei vielen anderen Protokollen und Applikationen verwendet, z. B. FTP, SMTP, Finger oder Whois. 15.2.3 Telnet-Kommandos Protokollspezifische Kommandos werden – da nur eine TCP-Verbindung vorhanden ist – innerhalb der normalen Kommunikation übertragen. Jedes Kommando wird durch ein 0xFFByte eingeleitet. Das zu übertragende Kommando wird anschließend (als Byte kodiert) übermittelt. Dieses Verfahren wird als in-band signaling bezeichnet, das 0xFF-Byte wird IAC (interpret as command) genannt. Eine Übersicht der Komanndos zeigt Tabelle 15.1. 15.2.4 Option Negotiation Das Telnet-Protokoll bietet Client und Server die Möglichkeit der option negotiation, also die Möglichkeit, Optionen auszuhandeln. Beide Seiten dürfen hierbei gleichermaßen – symmetrisch – einzelne Parameter anbieten, fordern, akzeptieren oder ablehnen. Hierzu werden die Kommandos 240 und 250-254 verwendet. Tabelle 15.2 soll den Prozeß des Aushandelns verdeutlichen. Wie man in Tabelle 15.2 sieht, existieren insgesamt sechs Szenarien der option negotiation: Die Aktivierung einer Option kann sowohl positiv als auch negativ beantwortet werden, so daß hierbei vier Möglichkeiten entstehen. Das Deaktivieren einer Option muß immer bestätigt werden, woraus die beiden letzten Szenarien in der Tabelle resultieren. Inzwischen sieht das Telnet-Protokoll mehr als 40 Optionen vor, die mittels option negotiation ausgehandelt werden können. Einige, wie z. B. der Terminal Typ, die Terminal Geschwindigkeit, die Fenstergröße oder Umgebungsvariablen, benötigen mehr Parameter als das reine Ein- oder Ausschalten. Diese sogenannten suboptions werden nach positiver 127 15 Telnet und rlogin Aushandlung mittels begin suboption (Kommando 240) und end suboption (Kommando 250) eingeleitet bzw. beendet. 15.2.5 Übertragungsmodi Für die Datenübertragung zwischen Telnet-Client und -Server gibt es vier verschiedene Modi. Diese unterscheiden sich in der Kombination verschiedener protokollspezifischer Optionen, die mittels option negotiation eingestellt werden. Half-duplex Dieser Übertragungsmodus ist der einfachst mögliche und somit in jedem Telnet Programm implementiert. Charakteristisch ist, daß Tastatureingaben vom Client nur nach Aufforderung durch den Server möglich sind. Hierzu wird das Telnet-Kommando GO AHEAD verwendet. Zeichenweise Übertragung – character at a time“ ” Code dez. hex. Name EOF SUSP ABORT EOR SE NOP DM BRK IP AO AYT EC EL GA SB WILL WONT DO DONT IAC 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 0xEC 0xED 0xEE 0xEF 0xF0 0xF1 0xF2 0xF3 0xF4 0xF5 0xF6 0xF7 0xF8 0xF9 0xFA 0xFB 0xFC 0xFD 0xFE 0xFF Beschreibung end-of-file suspent current process abort process end of record suboption end no operation data mark break interrupt process abort output are you there? escape character erase line go ahead suboption begin option negotiation option negotiation option negotiation option negotiation interpret as command Tabelle 15.1: Telnet-Kommandos 128 15.2 Telnet-Protokoll Die zeichenweise Datenübertragung wird durch Aktivierung der Optionen SUPPRESS GO AHEAD und ECHO erreicht. Jedes Zeichen, das vom Client zum Server übertragen wird, wird mittels echo quittiert. Obwohl hierbei offensichtlich Überschneidungen zwischen Daten beider Richtungen auftreten, ist dies der Standardübertragungsmodus. ‘Improvisierte’ zeilenweise Übertragung – line at a time“ ” Dieser Modus, auch kludge line mode genannt, wird verwendet, wenn keine der beiden für den zeichenweisen Übertragungsmodus notwendigen Optionen aktiviert wurde. ‘Echte’ zeilenweise Übertragung – linemode“ ” Neuere Telnet-Implementierungen unterstützen diesen Modus, der als solcher mittels option negotiation ausgehandelt wird. Alle Mängel der anderen zeilenweisen Übertragung treten hier nicht auf. 15.2.6 Beispiel-Session Abbildung 15.2 auf Seite 130 zeigt das Protokoll einer Telnet-Session. Zur besseren Übersicht sind die Zeilen numeriert worden. Die Befehle, sowie (Tastatur-)Ein- und (Bildschirm)Ausgaben werden im folgenden ausführlich erläutert: Sender WILL WILL DO DO WONT DONT Empfänger Beschreibung → ← DO Sender will eine Option aktivieren Empfänger stimmt zu → ← DONT Sender will eine Option aktivieren Empfänger lehnt ab → ← WILL Sender bittet Empfänger, eine Option zu aktivieren Empfänger stimmt zu → ← WONT Sender bittet Empfänger, eine Option zu aktivieren Empfänger lehnt ab → ← DONT Sender will eine Option deaktivieren Empfänger muß zustimmen → ← WONT Sender bittet Empfänger, eine Option zu deaktivieren Empfänger muß zustimmen Tabelle 15.2: Sechs Szenarien der Option Negotiation 129 15 Telnet und rlogin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 jake:~>telnet telnet> toggle options Will show option processing. telnet> open localhost echo Trying 127.0.0.1... Connected to localhost. Escape character is ’^]’. abcdef abcdef ^] telnet> mode character SENT DO SUPPRESS GO AHEAD SENT DO ECHO RCVD DO SUPPRESS GO AHEAD SENT WILL SUPPRESS GO AHEAD RCVD DO ECHO SENT WONT ECHO RCVD WILL SUPPRESS GO AHEAD RCVD WONT ECHO aabbccddeeff^] telnet> mode line SENT DONT SUPPRESS GO AHEAD SENT WILL LINEMODE RCVD DONT SUPPRESS GO AHEAD SENT WONT SUPPRESS GO AHEAD RCVD WILL LINEMODE SENT DONT LINEMODE RCVD WONT SUPPRESS GO AHEAD RCVD DONT LINEMODE abcdef abcdef ^] telnet> close Connection closed. telnet> quit jake:~> Abbildung 15.2: Protokoll einer Telnet-Session 130 15.2 Telnet-Protokoll Zeile 1: Der Aufruf des Telnet-Programms erfolgt am Unix-Prompt (jake:~>) mit dem Befehl telnet. Zeile 2: An der Eingabe-Aufforderung, dem Telnet-Prompt (telnet>) wird der Befehl toggle options eingegeben. Dies bewirkt, daß die Befehle und Antworten der option negotiation ausführlich ausgegeben werden. Zeile 3: Hier wird der letzte Befehl bestätigt. Zeile 4: Am folgenden Prompt wird der Befehl open localhost echo eingegeben. Damit wird eine Verbindung zum Systemdienst echo auf dem Rechner localhost initiiert. Der Systemdienst (oder service) echo beantwortet jegliche Eingabe mit der selben Ausgabe, also mit einem exakten Echo. Zeilen 5–7: Die Ausgaben des Verbindungsaufbaus werden angezeigt. Wichtig ist hier die Angabe des escape characters (^]), der zum Erreichen des Telnet-Prompts in der laufenden Session eingegeben werden muss. Zeile 8: Die Zeichenkette abcdef (gefolgt von carriage return) wird eingegeben. Zeile 9: Der service echo des Telnet-Servers beantwortet diese Eingabe durch Ausgabe der selben Zeichenkette. Zeile 10: Als nächstes wird der escape character ^] eingegeben. Zeile 11: Am Telnet-Prompt wird der Befehl mode character eingegeben, um vom zeilenweisen in den zeichenweisen Übertragungsmodus zu wechseln. Dies geschieht mittels option negotiation, wie man in den folgenden Zeilen der Ausgabe sehen kann. Zeilen 12+13: Der Telnet-Server wurde aufgefordert, die Optionen SUPPRESS GO AHEAD und ECHO zu aktivieren. Zeilen 14+15: Der Telnet-Server hat den Client ebenfalls aufgefordert, die Option SUPPRESS GO AHEAD zu aktivieren. Dies wird vom Client sofort positiv beantwortet. Zeilen 16+17: Der Client wird aufgefordert, die Option ECHO zu aktivieren. Der Client lehnt dies jedoch ab. Zeilen 18+19: Der Telnet-Server beantwortet die Optionen (der Zeilen 12+13): SUPPRESS GO AHEAD wird bestätigt, ECHO jedoch abgelehnt. Zeile 20: Erneut wird die Zeichenkette abcdef eingegeben. Aufgrund des zeichenweisen Übertragungsmodus wird nun jedes einzelne Zeichen direkt nach der Eingabe (von echo) wiederholt. Die Eingabe wird mit dem escape character ^] beendet, um erneut zum Telnet-Prompt zu gelangen. Zeile 21: Mittels mode line soll zurück zur zeilenweisen Übertragung gewechselt werden. Der resultierende Vorgang der option negotiation kann in den folgenden 8 Zeilen beobachtet werden. Zeile 22+23: Der Telnet-Server wird vom Client aufgefordert, SUPPRESS GO AHEAD aus- und LINEMODE einzuschalten. 131 15 Telnet und rlogin Zeilen 24+25: Der Telnet-Client wird vom Server aufgefordert, die Option SUPPRESS GO AHEAD auszuschalten. Der Client bestätigt dies. Zeilen 26+27: Der Telnet-Server fordert vom Client, LINEMODE zu aktivieren. Dies wird abgelehnt, obwohl der Client seinerseits in Zeile 23 diese Option angeboten hat. Zeilen 28+29: Hier werden die beiden Optionen beantwortet, die der Client in den Zeilen 22+23 gefordert hat: beide (SUPPRESS GO AHEAD und LINEMODE ) werden negativ beantwortet. Die erstgenannte sollte deaktiviert werden, was der Server bestätigt hat. Die Forderung, LINEMODE zu aktivieren wurde vom Server abgelehnt. Auch hier fällt der oben genannte Widerspruch auf: Die Option LINEMODE wird abgelehnt, obwohl die Gegenseite die Aktivierung dieser Option selbst gefordert hat. Zeilen 30+31: Die Eingabe der Zeichenkette abcdef wird erneut zeilenweise mittels echo wiedergegeben. Also erfolgte eine Umschaltung zurück zum ersten (zeilenweisen) Übertragungsmodus. Zeilen 32-36: Mit Hilfe des escape characters wird zum Telnet-Prompt gewechselt. An diesem wird der Befehl close eingegeben, so daß die Verbindung beendet wird. Der folgende quit-Befehl beendet schließlich die Telnet-Session, und man gelangt zurück zum Unix-Prompt. Zusammenfassung der Beispiel-Session Am oben erläuterten Beispiel einer Telnet-Session lassen sich unterschiedliche Übertragungsmodi und deren Aushandlung per option negotiation beobachten. Der zeichenweise Übertragungsmodus, der in der Session mittels mode character eingestellt wird, entspricht dem bereits erläuterten character at a time Modus. Die Optionen SUPPRESS GO AHEAD und ECHO werden hierzu verwendet. Mittels mode line wird der kludge line Modus ausgehandelt, der auf Seite 129 erklärt wird. Warum kein echter“ Linemode ausgehandelt wird, ” ist unklar. Client und Server bieten sich die entsprechende Option gegenseitig an, lehnen sie jedoch anschließend wieder ab. Wie bereits gesagt, unterstützen nur neuere TelnetImplementierungen linemode, so daß der mode line Befehl auf anderen (neueren) UnixSystemen zu einem anderen Modus führen kann als in der oben protokollierten Session. 15.3 Rlogin-Protokoll Rlogin wurde zuerst mit 4.2 BSD Unix vorgestellt und war zunächst nur als remote login application zwischen Unix Systemen vorgesehen. Deshalb kommt es mit einem einfacheren Protokoll als telnet aus, da z. B. keine option negotiation notwendig ist, wenn die Betriebssysteme auf Client- und Serverseite im voraus bekannt sind. Inzwischen sind auch rlogin Implementierungen für nicht-Unix Systeme vorhanden. 132 15.3 Rlogin-Protokoll 15.3.1 Aufbau der Verbindung Rlogin benutzt eine einzige TCP-Verbindung zwischen Client und Server. Nachdem die normale TCP-Verbindung aufgebaut ist, findet gemäß Rlogin Protokoll folgende Kommunikation statt: 1. Der Client sendet vier Zeichen(folgen) zum Server: ein zero-Byte, den Benutzernamen auf dem Clientsystem gefolgt von einem zero-Byte, den Benutzernamen auf dem Serversystem gefolgt von einem zero-Byte, sowie den Namen des Terminaltyps gefolgt von einem /“, der Terminalgeschwindigkeit und schließlich noch einem zero-Byte. ” 2. Der Server antwortet mit einem zero-Byte. 3. Der Server kann bei Bedarf nach dem Passwort des Benutzers fragen. Dieses wird anschließend innerhalb der normalen Datenübertragung – also im Klartext – gesendet. Inzwischen gibt es rlogin Implementierungen, die die Passwortübertragung mittels Kerberos ermöglichen. 4. Der Server sendet normalerweise noch eine Anfrage bzgl. der Fenstergröße des ClientTerminals. 15.3.2 Rlogin-Kommandos Wie bei telnet existieren auch hier protokollspezifische Kommandos, die innerhalb der normalen Datenübertragung gesendet werden. Man unterscheidet server to client und client to server Kommandos. Aufgrund des recht einfachen Protokolls existieren nur wenige Kommandos. Diese werden mittels urgent mode übertragen, einem TCP-spezifischen Übertragungsmodus. Server to client“ Kommandos ” Sobald der Server ein Kommando zum Client schickt, wird dieses als letztes Byte der urgent data gesendet. Der Client reagiert entsprechend des Protokolls auf das Kommando. Tabelle 15.3 zeigt eine Liste dieser Kommandos. Client to server“ Kommandos ” Derzeit ist nur ein einziges client to server Kommando definiert, die Übertragung der aktuellen Fenstergröße. Dies geschieht, wie bereits erwähnt, nach Aufforderung durch den Server oder bei Änderung der Fenstergröße. Sendet der Client ein Kommando zum Server, wird dies mittels in-band signaling angekündigt. Dabei wird das Kommando durch 0xFF eingeleitet. Serverseitig muß daher das gesamte Datenaufkommen nach diesen Bytes untersucht werden. Clientseitig ist eine derartige Kontrolle nicht notwendig, da Komman- 133 15 Telnet und rlogin Byte Beschreibung 0x02 flush output“, der Client wird aufgefordert, alle Daten bis zum ” Kommando-Byte zu verwerfen. Außerdem verwirft der Client alle noch gepufferten Terminal Ausgabe Daten. Dieses Kommando sendet der Server, wenn der interrupt key vom Client empfangen wird. 0x10 stop flow control“, der Client unterbricht die Steuerung der Da” tenübertragung (flow control ). 0x20 resume flow control“, der Client nimmt die Steuerung der Daten” übertragung wieder auf. 0x80 send window size“, der Client wird aufgefordert, die aktuelle Fen” stergröße anzugeben. Außerdem sollen zukünftige Änderungen der Fenstergröße dem Server mitgeteilt werden. Dieses Kommando wird normalerweise immer nach erfolgreichem Verbindungsaufbau und erfolgter Anmeldung des Benutzers gesendet. Tabelle 15.3: Server to client“ Kommandos ” dos vom Server mittels out-of-band signaling angekündigt werden, also mit Hilfe des TCP urgent modes. 134 KAPITEL 16 File Transfer Protocol (FTP) Zaruhi Aydinyan 16.1 Einführung Der Transport von Daten aller Art erfolgt im Internet mit dem Programm FTP. Während Telnet nach dem Aufbau der Verbindung zwischen Client und Server lediglich das interactive Ausführen von Programmen auf dem Zielsystem ermöglicht, können mit dem FTP Dateien zwischen den Systemen kopiert werden. Der komplette Vorgang der Dateiübertragung wird dabei von der Client-Seite gesteuert. Voraussetzung für eine erfolgreiche Übertragung ist eine Zugangsberechtigung für das Zielsystem, die im Rahmen des Verbindungsaufbaues mit FTP mittels User-Identifikation und Passwort überprüft wird. 16.2 FTP Protocol FTP unterscheidet sich von den anderen Applikationen, weil es dabei zwei TCP Verbindungen benutzt, um Dateien zu übertragen: control connection und data connection: 135 16 File Transfer Protocol (FTP) Abbildung 16.1: client user at a terminal user interface server user control connection protocol interpreter (FTP commands) (FTP replies) user file system data transfer function data connection server protocol interpreter server data transfer file system function 16.2.1 The control connection Server macht ein ”passive open” auf dem Port für FTP (21) und erwartet die Verbindung von der Client-Seite. Client macht ein ”active open” für TCP vom Port (21) um control connection zu bestätigen. Die control connection bleibt offen für die Zeit der Kommunikation zwischen Client und Server. Dieser Typ der Verbindung wird für die Übertragung von den Befehlen vom Client zum Server und für die Replies vom Server benutzt. 16.2.2 The data connection Eine data connection wird jedes mal aufgebaut, wenn eine Dateiübertragung zwischen Client und Server stattfindet. Die Figure 16.1 stellt Aufbau von Client und Server und die beiden obengenannten Verbindungen dar. Diese Zeichnung zeigt, dass interaktiver User normalerweise sich nicht mit den Befehlen und Antworten beschäftigt, die über control connection ausgetauscht werden. Damit beschäftigen sich die beiden protocol interpreters. User interface präsentiert, welche Art von interface für den interaktiven User wünschenswert ist, und verwandelt es in FTP commands, die über control connection gesendet werden. Ebenso replies, die vom Server über control connection kommen, können in jedes gewünschte Format verwandelt werden. Also, 136 16.3 Data Representation es gibt zwei protocol interpreters, die zwei Dateiübertragungsfunktionen steuern. 16.3 Data Representation Um die Weise von der Dateiübertragung und Dateiaufbewahrung zu steuern gibt es in FTP verschiedene Optionen: 1. File Typ • ASCII File Typ (Default) • EBCDIC File Typ • Image File Typ oder Binär • Local File Typ 2. Format Control • Nonprint (Default) • Telnet Format Control • Fortran Carriage Control 3. Struktur • File Struktur (Default) • Record Struktur • Page Struktur 4. Transmission Mode • Stream Mode (Default) • Block Mode • Compressed Mode Aber zur Zeit sind viele Optionen schon veraltet und werden nicht mehr benutzt, deshalb kann man viele Optionen einfach ignorieren. Normalerweise benutzt man folgende Optionen: 1. File Typ - ASCII oder Binär. Im ersten Fall wird Textdatei über data connection in NVT ASCII gesendet. Im zweiten Fall wird Datei als einen kontinuerlichen Fluss von bits gesendet.(Diese Möglichkeit wird normalerweise verwendet um die binären Dateien zu übertragen). 2. Format Control - Nonprint (Default). 137 16 File Transfer Protocol (FTP) 3. Struktur - File Struktur. Die Datei wird als einen kontinuerlichen Fluss von bytes gesehen. Es gibt keine innere Struktur. 4. Transmission Mode - Stream Mode (Default). Die Datei wird als einen Fluss von bytes gesendet. Und wenn der Sender data connection beendet bedeutet es dann end-of-file. 16.4 FTP Commands Die Befehle und Antworten, die über control connection zwischen Client und Server gesendet werden, sind in NVT ASCII. Die Befehle sind alle 3 oder 4 bytes lang, und bestehen aus ASCII Grossbuchstabensymbolen, einige Befehle haben sogar Optionen. Es gibt mehr als 30 verschiedene FTP-Befehle, die vom Client zum Server gesendet werden können. Die folgende Tabelle stellt einige Befehle dar, die am häufigsten benutzt werden. Befehl Beschreibung ABOR Die Unterbrechung von dem vorhergehenden FTP Befehl und von der Dateiübertragung LIST filelist Listing files (directories) PASS password Passwort auf dem Server PORT n1, n2, n3, n4, n5, n6 Client IP Adresse (n1-n4) und Port (n5x256+n6) QUIT Logoff vom Server RETR filename Verschaffen von file STOR filename Speichern von file SYST Der Server gibt den Typ vom System zurück TYPE type Bestimmen vom Typ von file: A für ASCII, I für Image USER username Benutzername auf dem Server 16.5 FTP Replies FTP Replies sind 3-stellige Nummern in ASCII, mit einer Mitteilung danach. Software braucht hier nur diese Zahlen zu lesen, um Replies zu verstehen und User kann einfach die Mitteilung lesen und braucht nicht mehr sich an die Bedeutung jeder Zahl zu erinnern. Jede von den drei Positionen der Zahlen hat ihre eigene Bedeutung. Die nächste Tabelle zeigt die Bedeutungen der Zahlen von den ersten zwei Positionen. Die dritte Position gibt die Bedeutung für error message zurück. 138 16.6 Connection Management Reply 1yz 2yz 3yz 4yz 5yz x0z x1z x2z x3z x4z x5z Beschreibung Positive vorläufige Antwort (Positive preliminary reply). Die Handlung beginnt, aber es wird eine weitere Antwort erwartet vor dem Abschicken eines Befehles. Positive volle Antwort (Positive completion reply). Ein neuer Befehl kann gesendet werden. Positive zwischenzeitliche Antwort(Positive intermediate reply). Der Befehl wurde angenommen, aber es muss ein anderer Befehl gesendet werden. Vorübergehende negative volle Antwort (Transient negative completion reply). Die gefragte Handlung hat nicht stattgefunden, aber der Zustand des Fehlers ist vorübergehend, deshalb kann dieser Befehl später wiederholt werden. Ständige negative volle Antwort (Permanent negative completion reply) Der Befehl wurde nicht angenommen und soll nicht wiederholt werden. Syntax Fehler Information Verbindungen. Antworten bezogen auf Kontrolle von data connection. Authentifikation. Die Antworten für Login oder Account-Befehle. Nicht spezifiziert. Filesystem Status 16.6 Connection Management Es gibt 3 Möglichkeiten von data connection: 1. File wird vom Client zum Server gesendet 2. File wird vom Server zum Clientr gesendet 3. Liste von den Dateien wird vom Server zum Client gesendet Wir wissen schon, dass control connection bleibt offen für die Zeit der Kommunikation zwischen Client und Server, data connection dagegen findet nur statt, wenn es danach verlangt wird. Jetzt ist die Frage: Wie werden die Port-Nummern für die data connection gewählt und wer macht ”passive open” und wer macht ”active open”? Wir haben schon gesehen, dass gewöhnliche Transmission Mode ist Stream Mode (bei UNIX ist es sogar die einzige Möglichkeit), und in diesem Fall end-of-file bedeutet auch das Ende von data connection. Dies heisst, dass für jede Dateiübertragung soll eine neue Verbindung gebaut werden. Normalerweise wird das alles in 4 Schritten gemacht: 1. Der Aufbau von data connection ist unter Kontrolle vom Client, weil der kann Befehle senden, die nach data connection verlangen. 139 16 File Transfer Protocol (FTP) 2. Vom Client wird normalerweise ephemeral Port-Nummer für seine Seite von data connection gewählt. Client macht ”passive open” vom diesen Port. 3. Client sendet die Port-Nummer zum Server über control connection mit der Hilfe vom PORT-Befehl. 4. Server bekommt die Port-Nummer über control connection und macht ”active open” für diesen Port auf dem Clienthost. Die Seite vom Server benutzt für data connection immer Port 20. Die erste Zeichnung von Figure 16.2 zeigt die Zustände von connections während des dritten Schrittes. Ephemeral port vom Client für control connection ist 1173, und Ephemeral port vom Client für data connection ist 1174. Der Befehl, der vom Client gesendet wurde ist PORT Befehl und hat sechs dezimal Nummern in ASCII, die mit den Kommatan getrennt wurden. Die ersten vier Nummern spezifizieren IP Adresse vom Client, die Server benutzen soll für ”active open”, und die nächste zwei sind 16-bit Port-Nummern. Die zweite Zeichnung von Figure 16.2 zeigt die Zustände von connections, wenn Server ”active open” zur Client-Seite von data connection macht. Das Port vom Server ist Port 20. Server macht immer ”active open” für data connection. Normalerweise macht Server auch ”active close” von data connection. Ausnahme ist der Fall, wenn Client eine Datei zum Server in Stream Mode sendet. In diesem Fall wird connection von der Client-Seite beendet. 16.7 Anonymes FTP Wir wissen schon, dass um mittels FTP auf ein Fremdsystem zugreifen zu können, ist im Normalfall eine Zugangsberechtigung notwendig. Dies dient natürlich dem Schutz jener Daten, die nicht für den internetweiten Gebrauch vorgesehen sind. Für alle anderen Daten, die diesen Schutz nicht benötigen und die für alle Internetbenutzer zugängig sein sollen, gibt es eine besondere Form von FTP, die den Zugriff auf Daten ohne Passwort ermöglicht und zwar: anonymes FTP. Über das gesamte Internet verteilt gibt es FTP File Server, die anonymen Zugriff auf ihre Dateiarchive ermöglichen. Die dazu notwendige Benutzeridentifikation ist immer ”anonymous” und als Passwort genügt die Eingabe der eigenen e-mail Adresse. 16.8 Ephemeral Data Port Wir wissen schon, dass normalerweise vom Client für seine Seite von data connection ephemeral Port-Nummer gewählt wird, die danach mit dem PORT-Befehl bestätigt sein soll. Was passiert, wenn Client keinen PORT-Befehl zum Server sendet, um die Port-Nummer zu bestätigen? 16.9 Default Data Port In dem Fall, wenn Client keinen PORT Befehl zum Server sendet, um die PortNummer von der Client-Seite zu bestätigen, benutzt Server automatisch die gleiche 140 16.9 Default Data Port Abbildung 16.2: FTP server FTP client (control connection) port 1173 PORT 140,252,13,34,4,150\ r\ n -> port 21 port 1174 (passive open) IP addr 140.252.13.34 FTP client FTP server (control connection) port 1173 port 1174 (passive open) port 21 SYN to 140.252.13.34, port20 port 1174 (active open) IP addr 140.252.13.34 141 16 File Transfer Protocol (FTP) Port-Nummer für data connection, die für control connection früher benutzt wurde. Und dies kann viele Probleme verursachen für Client, der in Stream Mode arbeitet. 16.10 FTP Beispiel Wir werden jetzt eine FTP Session mit ftp.uni-bielefeld.de betrachten. Alle Zeilen, die mit ---> anfangen, sind die Befehle vom Client zum Server und die Zeilen, die mit 3 Ziffern beginnen, sind Replies vom Server. Normalerweise generiert jeder FTPBefehl one-line Reply, aber wenn es multiline Reply gebraucht wird, dann enthält die erste Zeile Strich anstatt Leerzeichen und die letzte Zeile enthält dann die gleichen 3-stellige Ziffern und danach Leerzeichen. cab:~>ftp ftp.uni-bielefeld.de Connected to share.hrz.uni-bielefeld.de. 220 share.hrz.uni-bielefeld.de FTP server (Version wu-2.6.1(1) Fri Jul 27 11:41:07 METDST 2001) ready. Name (ftp.uni-bielefeld.de:tbekel): anonymous 331 Guest login ok, send your complete e-mail address as password. Password: 230-Welcome to 230FTP.Uni-Bielefeld.DE 230-------------------230230Local time: Fri Jan 18 14:09:43 2002 230Current working dir: / 230Remote Host Name: cab.Genetik.Uni-Bielefeld.DE 230Maximum Number of Users: 30 230Current Number of Users: 1 230Administrator’s Email Address: [email protected] 230230-This server supports on-the-fly tar and compression of directories and 230-files. To download a directory, simply request directoryname.tar.gz! 230-Be carefull with links, cause tar doesn’t follow links! 230230-ATTENTION: Due to the illegal distribution of stolen software, the 230incoming directory of this site is CLOSED for DOWNLOADS. 230If you want to UPLOAD something which should be downloadable, 230contact the administrator (see above for address)! 230230 Guest login ok, access restrictions apply. ftp> debug Debugging on (debug=1). ftp> dir ---> PORT 129,70,160,44,215,2 200 PORT command successful. ---> LIST 142 16.10 FTP Beispiel 150 Opening ASCII mode data connection for /bin/ls. total 167956 drwxr-xr-x 15 root root 1024 Dec 20 14:39 . drwxr-xr-x 15 root root 1024 Dec 20 14:39 .. drwxr-xr-x 11 root sys 1024 Jul 16 2001 .mnt0 drwxrwxr-x 9 root mathematik 8192 Jun 14 2000 .mnt1 drwxrwsr-x 12 root techfak 512 Jun 11 1997 .mnt2 drwxr-xr-x 2 root sys 96 Jul 12 1999 .mnt3 drwxr-xr-x 2 root sys 96 Jul 12 1999 .mnt4 drwxr-xr-x 2 root sys 96 Jul 12 1999 .mnt5 ---------1 root sys 0 Sep 1 1999 .notar d--x--x--x 2 root sys 96 Jul 12 1999 bin drwxr-xr-x 2 root sys 96 Dec 20 14:39 dev d--x--x--x 3 root sys 96 Jul 12 1999 etc lrwxr-xr-x 1 root sys 5 Aug 2 1999 ftp.hrz -> .mnt0 drwxrwxrwt 33 ftpincom rest 5120 Jan 17 22:01 incoming drwxr-xr-x 2 root root 96 Jun 28 1999 lost+found -rw-r--r-1 root sys 76446235 Jan 18 00:47 ls-lR -rw-r--r-1 root sys 9435207 Jan 18 00:50 ls-lR.gz dr-xr-xr-x 5 root sys 1024 Jul 16 2001 pub -rw-r--r-1 root sys 352256 Jan 12 23:26 quotas d--x--x--x 4 root sys 96 Aug 31 1999 usr 226 Transfer complete. 1322 bytes received in 0.037 seconds (34.53 Kbytes/s) ftp> cd pub ---> CWD pub 250 CWD command successful. ftp> dir ---> PORT 129,70,160,44,215,14 200 PORT command successful. ---> LIST 150 Opening ASCII mode data connection for /bin/ls. total 8 dr-xr-xr-x 5 root sys 1024 Jul 16 2001 . drwxr-xr-x 15 root root 1024 Dec 20 14:39 .. lrwxr-xr-x 1 root sys 13 Feb 21 2000 CPAN -> ../.mnt0/CPAN lrwxr-xr-x 1 root sys 12 Jul 30 1999 X11 -> ../.mnt2/X11 lrwxr-xr-x 1 root sys 19 Jul 30 1999 benchmarks -> ../.mnt0/benchma lrwxr-xr-x 1 root sys 15 Aug 16 1999 crypto -> ../.mnt0/crypto lrwxr-xr-x 1 root sys 15 Jul 30 1999 dialin -> ../.mnt0/dialin lrwxr-xr-x 1 root sys 13 Jul 16 2001 elsa -> ../.mnt0/elsa lrwxr-xr-x 1 root sys 12 Jul 30 1999 gnu -> ../.mnt2/gnu lrwxr-xr-x 1 root sys 17 Jul 30 1999 graphics -> ../.mnt2/graphics lrwxr-xr-x 1 root sys 20 Jul 30 1999 infosystems -> ../.mnt2/infosy lrwxr-xr-x 1 root sys 17 Jul 30 1999 math -> ../.mnt1/pub/math lrwxr-xr-x 1 root sys 17 Jul 30 1999 netscape -> ../.mnt0/netscape lrwxr-xr-x 1 root sys 19 Jul 30 1999 networking -> ../.mnt2/network 143 16 File Transfer Protocol (FTP) dr-xr-xr-x 2 root sys 1024 Jul 30 1999 papers lrwxr-xr-x 1 root sys 20 Jul 30 1999 programming -> ../.mnt2/p dr-xr-xr-x 2 root sys 96 Jul 30 1999 projects lrwxr-xr-x 1 root sys 15 Jul 30 1999 sysadm -> ../.mnt2/sysadm dr-xr-xr-x 2 root sys 1024 Feb 11 2000 systems lrwxr-xr-x 1 root sys 16 Jul 30 1999 tex -> ../.mnt1/pub/tex lrwxr-xr-x 1 root sys 19 Aug 4 1999 y2kpatches -> ../.mnt0/y2 226 Transfer complete. 1723 bytes received in 0.079 seconds (21.36 Kbytes/s) ftp> cd tex ---> CWD tex 250-Please read the file README.archive-features 250- it was last modified on Mon Oct 7 00:00:00 1996 - 1927 days ago 250-Please read the file README.mirrors 250- it was last modified on Thu Jan 3 16:16:00 2002 - 15 days ago 250-Please read the file README.site-commands 250- it was last modified on Fri Apr 8 00:00:00 1994 - 2840 days ago 250-Please read the file README.structure 250- it was last modified on Tue May 11 11:58:00 1999 - 982 days ago 250-Please read the file README.uploads 250- it was last modified on Thu Dec 30 11:00:00 1999 - 749 days ago 250 CWD command successful. ftp> dir ---> PORT 129,70,160,44,215,44 200 PORT command successful. ---> LIST 150 Opening ASCII mode data connection for /bin/ls. total 480 drwxrwxr-x 20 862 mathematik 8192 Jan 18 00:31 . drwxrwxr-x 7 root mathematik 8192 Oct 25 09:16 .. -rw-rw-r-1 862 mathematik 394 Oct 2 1998 .index.cgi -rw-rw-r-1 862 mathematik 356 Mar 9 1995 CTAN-search.html -rw-rw-r-1 862 mathematik 5552 Jan 3 16:16 CTAN.sites -rw-rw-r-1 862 mathematik 4574586 Jan 17 01:21 FILES.bydate -rw-rw-r-1 862 mathematik 4574586 Jan 17 01:21 FILES.byname -rw-rw-r-1 862 mathematik 4574586 Jan 17 01:21 FILES.bysize -rw-rw-r-1 862 mathematik 4953 Jan 17 01:21 FILES.last07days -rw-rw-r-1 862 mathematik 3372 Oct 7 1996 README.archive-features lrwxrwxrwx 1 862 mathematik 10 Jan 5 2000 README.mirrors -> CTAN.si -rw-rw-r-1 862 mathematik 1012 Apr 8 1994 README.site-commands -rw-rw-r-1 862 mathematik 3531 May 11 1999 README.structure -rw-rw-r-1 862 mathematik 4133 Dec 30 1999 README.uploads lrwxr-xr-x 1 root mathematik 5 Sep 22 1999 archive-tools -> tools drwxrwxr-x 4 862 mathematik 8192 Sep 22 1999 biblio lrwxr-xr-x 1 root mathematik 6 Sep 22 1999 bibliography -> biblio lrwxr-xr-x 1 root mathematik 14 Sep 22 1999 dante -> usergrps/dante drwxrwxr-x 14 862 mathematik 8192 Sep 24 1999 digests 144 16.10 FTP Beispiel lrwxr-xr-x 1 root mathematik 4 Sep 22 1999 documentation -> info drwxrwxr-x 57 862 mathematik 8192 May 30 2001 dviware drwxrwxr-x 147 862 mathematik 8192 Nov 3 00:20 fonts drwxrwxr-x 37 862 mathematik 8192 Aug 9 00:22 graphics drwxrwxr-x 9 862 mathematik 8192 Jan 14 00:32 help -rw-rw-r-1 862 mathematik 6868 Dec 15 20:22 index.html drwxrwxr-x 6 862 mathematik 8192 Sep 22 1999 indexing drwxrwxr-x 45 862 mathematik 8192 Nov 3 00:20 info drwxrwxr-x 50 862 mathematik 8192 Jan 9 00:32 language lrwxr-xr-x 1 root mathematik 8 Sep 22 1999 languages -> language drwxrwxr-x 33 862 mathematik 8192 May 17 2001 macros drwxrwxr-x 9 862 mathematik 8192 Sep 22 00:25 nonfree drwxrwxr-x 11 862 mathematik 8192 Nov 29 00:21 obsolete drwxrwxr-x 220 862 mathematik 8192 Jan 15 00:31 support drwxrwxr-x 21 862 mathematik 8192 Nov 13 00:24 systems drwxrwxr-x 5 862 mathematik 8192 Sep 24 1999 tds drwxrwxr-x 38 862 mathematik 8192 Apr 4 2001 tools -rw-rw-r-1 862 mathematik 5209 Nov 26 2000 upload.html drwxrwxr-x 10 862 mathematik 8192 Nov 10 00:19 usergrps drwxrwxr-x 32 862 mathematik 8192 Jun 16 2001 web 226 Transfer complete. 2786 bytes received in 0.15 seconds (18.05 Kbytes/s) ftp> type Using ascii mode to transfer files. ftp> type binary ---> TYPE I 200 Type set to I. ftp> get index.html ---> PORT 129,70,160,44,215,81 200 PORT command successful. ---> RETR index.html 150 Opening BINARY mode data connection for index.html (6868 bytes). 226 Transfer complete. local: index.html remote: index.html 6868 bytes received in 0.028 seconds (237.09 Kbytes/s) ftp> type ascii ---> TYPE A 200 Type set to A. ftp> get index.html ---> PORT 129,70,160,44,215,134 200 PORT command successful. ---> RETR index.html 150 Opening ASCII mode data connection for index.html (6868 bytes). 226 Transfer complete. local: index.html remote: index.html 7053 bytes received in 0.019 seconds (366.23 Kbytes/s) ftp> quit 145 16 File Transfer Protocol (FTP) ---> QUIT 221-You have transferred 13921 bytes in 2 files. 221-Total traffic for this session was 22955 bytes in 6 transfers. 221-Thank you for using the FTP service on share.hrz.uni-bielefeld.de. 221 Goodbye. cab:~> 16.11 Zusammenfassung FTP wird für die Dateiübertragungen benutzt. Der Unterschied zwischen FTP und anderen Applikationen besteht darin, dass FTP zwei TCP Verbindungen zwischen Client und Server benutzt: control connection für den Austausch von Befehlen und Antworten und data connection für die Dateiübertragungen. FTP benutzt NVT ASCII für alle Befehle und Antworten. Die Form von FTP, die am meisten benutzt wird, ist anonymes FTP. 146 KAPITEL 17 Simple Mail Transfer Protocol (SMTP) Christoph Liersch, Marc Eßmeier 17.1 Einleitung Das Simple Mail Transfer Protocol (SMTP) ist das verbreitetste und meistgenutzte Protokoll für den Versand von electronic mail ( E-Mail“) im Internet. Diese Ausarbeitung ” versucht zunächst einen allgemeinen Überblick über die Funktionen eines E-Mail-Systems zu geben, und geht im Anschluß darauf konkret auf SMTP ein. Dies beinhaltet einen kurzen Rückblick auf die Entstehung von SMTP in Form der für den Standard relevanten RFCs 821 und 822, welche auch anhand von einigen Beispielen erläutert werden. Der Hauptteil befaßt sich vor allem mit der Struktur und dem Ablauf des Protokolls sowie einigen technischen Besonderheiten, den Abschluß bildet ein Überblick über die seit der ursprünglichen Veröffentlichung entstandenen Weiterentwicklungen des SMTP. 17.2 E-Mail-Systeme E-Mail-Systeme bestehen prinzipiell aus zwei Subsystemen: den Benutzeragenten“, (User ” Agents, UA) sowie den Nachrichtentransferagenten“ (Message Transfer Agents, MTA). Bei ” den Benutzeragenten handelt es sich in der Regel um lokale Programme, die dem Benutzer das Empfangen, Bearbeiten und Versenden von Nachrichten ermöglichen, während die Nachrichtentransferagenten normalerweise als Systemdienste im Hintergrund laufen und für 147 17 Simple Mail Transfer Protocol (SMTP) den Transport der Nachricht zum Empfänger zuständig sind. Die Grundfunktionen eines E-Mail-Systems sind wie folgt definiert: • Composition steht generell für das Erstellen einer Nachricht, was je nach System auf der Kommandozeile, mit einem einfachen Texteditor oder innerhalb einer ausgewachsenen graphischen Oberfläche erfolgen kann. Das E-Mail-System kann auch die z.B. in den Header-Feldern vorhandenen Informationen zur Unterstützung des Benutzers verwenden, in dem es beispielsweise bei der Beantwortung einer E-Mail automatisch die Adresse des Absenders als neuen Empfänger übernimmt. • Transfer steht für den Transport der Nachricht vom Absender zum Empfänger. Dies soll automatisch und ohne Interaktion des Absenders geschehen, weshalb das E-MailSystem auch Vorgehensweisen für Sonderfälle wie z.B. einem Datenstau“ auf dem ” Datenhighway vorsehen muß, damit keine Nachrichten verloren gehen. Die E-Mail könnte dann einen anderen Weg nehmen oder in eine Warteschleife gesetzt werden. • Reporting hat die Aufgabe, den Absender über den Status seiner abgeschickten Nachricht zu informieren. Er könnte so z.B. vom E-Mail-System darüber informiert werden, ob seine Nachricht überhaupt beim Empfänger angekommen ist (Eingangsbestätigung) bzw. bereits gelesen wurde (Lesebestätigung), oder ob sie umgeleitet oder zwischengespeichert wurde. • Displaying zeigt dem Benutzer eingegangene Nachrichten an. Gegebenenfalls konvertiert es diese in ein anderes Format oder ruft externe Programme auf, die zur Darstellung des Nachrichteninhalts benötigt werden. • Disposition bestimmt, was mit der angekommenen Nachricht geschieht. Der Benutzer hat hier die Möglichkeit, die Nachrichten zu speichern, zu löschen oder auf andere Art und Weise weiterzuverarbeiten. Bereits vorhandene, gespeicherte Nachrichten sollen natürlich wieder aufruf- und auch beantwort- oder weiterleitbar sein. Die fünf Funktionen Composition, Transfer, Reporting, Displaying und Disposition stellen die absoluten Grundfunktionen eines E-Mail-Systems dar. Neben diesen gibt es natürlich bei verschiedenen Systemen eine große Anzahl weiterer Funktionen, um E-Mail vielseitiger verwendbar zu machen. Diese sind in der heutigen Zeit oft mit dem Ziel einfacher Bedienbarkeit in bunte Oberflächen“ eingebunden, so dass sich der Benutzer um die einzelnen ” Funktionen keine Gedanken mehr machen muss. Abbildung 17.1 enthält eine graphische Darstellung der grundliegenden Funktionsweise eines E-Mail-Systems. Der Benutzeragent stellt dem Benutzer über das user interface“ die ” Funktionen des Systems zur Verfügung, damit dieser z.B. Nachrichten empfangen, lesen und verschicken kann. Ausgehende E-Mails werden zunächst zwischengespeichert, bis sie erfolgreich an den Nachrichtentransferagenten (nachfolgend nur noch MTA genannt) übertragen worden sind. Dementsprechend werden eingehende Nachrichten von einem MTA in der Mailbox des Benutzers abgelegt, wo dieser auf sie (wieder mit Hilfe des Benutzeragenten) zugreifen kann. 148 17.3 Entwicklung Abbildung 17.1: Funktionsweise eines E-Mail-Systems 17.3 Entwicklung Mit der Einführung des Internets gab es die Möglichkeit, mit anderen zu kommunizieren, ohne dass man telefonieren oder sie besuchen mußte, denn beides ist ziemlich zeitaufwendig und kann sich, wenn die andere Person gerade nicht da ist, auch als ziemlich zwecklos erweisen. Da kam vielen Firmen als weitere Alternative zum Brief, der ja nicht gerade der schnellste Weg ist, die E-Mail gerade recht. Sie ist schnell, relativ zuverlässig und wenn die Person gerade unterwegs ist, kann sie die Mail unter gegebenen Umständen auch vom Urlaubsort abrufen. Der einzige Nachteil war, dass es keinen wirklichen Standard gab (aus der Sicht des gerade frisch eingeführten Internets) und so das Schreiben einer E-Mail sicherlich sehr umständlich gewesen sein muss. 1982 dachte sich deswegen eine Gruppe von Studenten, dass man das wohl ändern sollte und entwickelte das in RFC 821 beschriebene Simple Mail Transfer Protocol, welches einen Standard für den Austausch von Nachrichten zwischen verschiedenen Rechnersystemen festlegte. Das dazugehörige Nachrichtenformat wurde in RFC 822 festgelegt. Aber anscheinend dachten sich einige große Firmen, dass sie es besser könnten und veröffentlichten 1984 ein Protokoll, das nach ihren Plänen alles besser können sollte als die Entwicklung der Studenten. Was die CCITT bei ihrer X.400-Empfehlung nicht bedachte war, dass das Protokoll auch benutzerfreundlich implementiert werden muss, oder wenigstens nicht so umfangreich und kompliziert sein darf, dass man keinen Unterschied zu dem ursprünglichen, protokolllosen Zustand feststellen kann. In den Jahren darauf kämpften somit zwei unterschiedliche Möglichkeiten gegeneinander, um sich als Standard durchzusetzten. Das eine Protokoll, entwickelt und genutzt von großen Firmen und Regierungen, konnte sich aber letztendlich nicht gegen die von Studenten entwickelte Lösung durchsetzen. SMTP war zwar einfach, aber es funktionierte, während X.400 aufgrund seiner Komplexität kaum zufriedenstellend implementiert werden konnte. 149 17 Simple Mail Transfer Protocol (SMTP) 17.4 Simple Mail Transfer Protocol 17.4.1 Nachrichtenformat (RFC 822) RFC 822 legt fest, dass eine E-Mail aus zwei Teilen bestehen muss, um die angestrebte Automatisierung zu erreichen, nämlich aus den Header-Feldern und dem Body. Typische Header-Felder sind Date“ für das Absendedatum, From“ für die Absenderadres” ” se, Subject“ als moderne Betreffzeile und natürlich To“ als Empfängeradresse. Die Auto” ” matisierung wird erreicht, da der MTA aus diesen und anderen noch vorhandenen Informationen eine Verpackung, Envelope (mit einem Umschlag eines Briefes vergleichbar, definiert in RFC 821), erstellt und so alle relevanten Informationen den MTAs auf dem Weg zum Ziel zu präsentieren. Desweiteren schreiben die einzelnen MTAs, die die Mail weiterleiten, ihre Daten als jeweils neuen Header auf den Envelope“ bzw. hängen die Informationen an ” die ursprüngliche Mail an, ohne deren Inhalt zu verändern. Im Envelope ist der eigentliche Inhalt der E-Mail, der sogenannte Body, verpackt. RFC 822 legt desweiteren fest, dass die E-Mail nur NVT-ASCII-Zeichen enthalten darf, was zur heutigen Zeit eine Einschränkung darstellt (aber dazu später mehr). Abbildung 17.2: Vergleich des Aufbaus von Brief und E-Mail In dem Schaubild Vergleich des Aufbaus von Brief und E-Mail“ kann man die Gemeinsam” keiten einer E-Mail mit einem Brief erkennen. Wie man sieht sind es mehr als man auf den ersten Eindruck annehmen möchte. Das ist auch im folgenden Beispiel, der Klartextdarstellung einer empfangenen E-Mail mitsamt Headern, erkennbar. 150 17.4 Simple Mail Transfer Protocol Received: from [172.20.1.104] (helo=mailgate6.cinetic.de) by mx06.web.de with esmtp (Exim 4.11 #37) id 16Y7Jb-0005z9-00 for [email protected]; Tue, 05 Feb 2002 16:15:23 +0100 Received: from mail.uni-bielefeld.de (mail2.uni-bielefeld.de [129.70.4.90]) by mailgate6.cinetic.de (8.11.2/8.11.2/ WEBDE Linux 8.11.0-0.2) with ESMTP id g15FFNF23760 for <[email protected]>; Tue, 5 Feb 2002 16:15:23 +0100 Received: from uni-bielefeld.de (offhnwlu.uni-bielefeld.de [129.70.6.65]) by mail.uni-bielefeld.de (Sun Internet Mail Server sims.4.0.2000.10.12.16.25.p8) with ESMTP id <[email protected]> for [email protected]; Tue, 5 Feb 2002 16:14:40 +0100 (MET) Date: Tue, 05 Feb 2002 16:14:29 +0100 From: Christoph Liersch <[email protected]> Subject: Das ist die Betreffzeile To: [email protected] Message-id: <[email protected]> MIME-version: 1.0 Content-type: text/plain; charset=us-ascii Content-transfer-encoding: 7BIT X-Mailer: Mozilla 4.77 [en] (Win98; U) Hier steht der eigentliche Nachrichtentext. 17.4.2 Das Protokoll (RFC 821) SMTP, ursprünglich festgelegt in RFC 821, definiert einen Standard für den Austausch von E-Mail zwischen zwei MTAs (Message Transfer Agents). Aufgrund zahlreicher Weiterentwicklungen stellt SMTP auch heute trotz seines Alters noch einen de-facto-Standard dar, in diesem Abschnitt soll aber zunächst nur die Funktionsweise der ursprünglichen Version erläutert werden. Der Versand von E-Mail erfolgt im Normalfall transparent für den Benutzer, d.h. dieser arbeitet mit einem Programm zum Empfangen, Lesen und Versenden von E-Mail (User Agent bzw. Benutzeragent), der eigentliche Transport der Nachricht zum Empfänger findet automatisch und ohne Zutun des Benutzers statt. Das Schaubild E-Mail mit SMTP“ zeigt eine schematische Darstellung des Nachrichten” transports. Die Nachricht wird mit einem User Agent erstellt und an einen Message Tranfer Agent übertragen. Dieser hat nun die Aufgabe, die Nachricht über das Internet an den MTA des Empfängers weiterzuleiten, was abhängig von den beteiligten Systemen auf mehr oder minder direktem Wege geschehen kann. Dieses Verfahren ist textbasiert, die Kommunikation zwischen zwei MTAs ist also auch für Menschen direkt lesbar“. Wie auch in der eigentlichen Nachricht wird NVT-ASCII ver” wendet. Zunächst wird vom MTA des Absenders (nachfolgend Client“ genannt) eine TCP” 151 17 Simple Mail Transfer Protocol (SMTP) Abbildung 17.3: E-Mail mit SMTP Verbindung zu Port 25 des Empfänger-MTAs ( Server“) aufgebaut. Der Client kann dann ” Befehle an den Server senden, worauf dieser jeweils mit einem dreistelligen Reply code“ ” und einem optionalen Textstring antwortet. Im Gegensatz zu anderen Internet-Protokollen ist die Menge der Befehle bei SMTP eher gering - RFC 821 fordert für eine gültige Implementation des Protokolls nur acht Befehle: HELO, MAIL, RCPT, DATA, QUIT, RSET, VRFY und NOOP. 17.4.3 SMTP-Befehle Der minimale SMTP-Befehlssatz enthält folgenden Kommandos: • HELO <Hostname> – Eine Art Begrüßung ( Hello“), in welcher der Client dem Server ” seine Identität in Form des FQDN (fully qualified domain name) mitteilt • MAIL FROM: <Adresse> – Einleitung der Übertragung einer Nachricht, enthält die Adresse des Absenders als Parameter • RCPT TO: <Adresse> – Festlegung der Empfänger-Adresse(n) • DATA – Einleitung der Übertragung des eigentlichen Nachrichteninhalts • RSET – Zurücksetzung der Verbindung, bereits eingegebene Daten werden verworfen (Reset) • VRFY <Adresse> – Überprüft ob eine bestimmte Adresse dem Server als gültiger Empfänger bekannt ist (Verify) • NOOP – Löst nur eine kurze Antwort des Servers aus, keine weitere Wirkung (No Operation) • QUIT – Beendet die Verbindung 152 17.4 Simple Mail Transfer Protocol Folgende Befehle sind optional und daher nicht zwingend in jeder SMTP-Implementation vorhanden: • EXPN <Adresse> – Auflösung einer Mailing-Liste • HELP <Befehl> – Ruft Informationen zu dem als Parameter angegebenen Befehl auf • TURN – Vertauschung der Client-Server-Rollen: Ermöglicht Versand von Nachrichten in die andere Richtung ohne erneuten Verbindungsaufbau • SEND FROM: <Adresse>, SOML FROM: <Adresse>, SAML FROM: <Adresse> – sind Relikte aus den Anfängen der E-Mail, wo es noch eine Rolle spielte, ob der Empfänger direkt am Terminal saß oder nicht 17.4.4 Reply codes Auf die vom Client gesendeten Befehle reagiert der Server mit einem sogenannten Reply code, einer dreistelligen Zahl, und einem für den Menschen lesbaren Textstring (optional). Die Reply codes sind in verschiedene Kategorien und Unterkategorien eingeteilt. Als Beipiel sei hier der Code 220“ angeführt: Die erste Zahl (2) signalisiert dem Client, dass der Befehl ” fehlerlos ausgeführt wurde, die zweite (2), dass die Verbindung hergestellt ist und die Null zeigt dem Client, dass alles in Ordnung ist und er weiter Befehle abschicken kann. Diese Codeklassen sind typisch und werden auch bei anderen Server-Client-Protokollen, wie z.B. FTP, eingesetzt. Übersetzungstabelle Reply codes 1yz 2yz 3yz 4yz 5yz x0z x1z x2z x3z x4z x5z xyz Positiver Beginn eines Befehls. Weitere Eingabe erforderlich Positive Beendigung eines Befehls. Weitere Befehle möglich Positiver Zwischenzustand. Weitere Eingaben müssen folgen Transientes Problem. Befehl nicht ausgeführt. Eingabe wiederholen Definitives Problem. Befehl nicht wiederholen Syntax eines Befehls Allgemeine Information Verbindungszustand Nicht spezifiziert Nicht spezifiziert Statusmeldung z = Weitere Unterteilung/Nummerierung der Meldung Einige Beispiele für Reply codes mit dem jeweils zugehörigen Textstring: • 501 Syntax error in parameters or arguments 153 17 Simple Mail Transfer Protocol (SMTP) • 502 Command not implemented • 503 Bad sequence of commands • 504 Command parameter not implemented • 211 System status, or system help reply • 214 Help message • 220 “domain” Service ready • 221 “domain” Service closing • 250 Requested mail action okay, completed • 251 User not local; will forward to “forward-path” • 450 Requested mail action not taken: mailbox unavailable • 550 Requested action not taken: mailbox unavailable • 451 Requested action aborted: error in processing • 551 User not local; please try “forward-path” • 452 Requested action not taken: insufficient system storage • 552 Requested mail action aborted: exceeded storage allocation • 553 Requested action not taken: mailbox name not allowed • 354 Start mail input; end with “CRLF”.“CRLF” • 554 Transaction failed Ein einfaches Beispiel eines Mail-Versands mit dem SMTP. Hinweis: Die den Zeilen vorgestellten Kürzel für Server bzw. Client und die zusätzlichen Leerzeilen zwischen den einzelnen Befehlen wurden nur zum besseren Verständnis des Vorgangs eingefügt. (S: Server, C: Client) S: 220 Beta.GOV Simple Mail Transfer Service Ready C: HELO Alpha.EDU S: 220 Beta.GOV C: MAIL FROM:<[email protected]> S: 250 OK C: RCPT TO:<[email protected]> S: 250 OK C: RCPT TO:<[email protected]> S: 550 No such user here C: RCPT TO:<[email protected]> S: 250 OK C: DATA S: 354 Start mail input; end with <CR><LF>.<CR><LF> 154 17.4 Simple Mail Transfer Protocol C: C: C: S: ...sends body of mail message... ...continues for as many lines as message contains... <CR><LF>.<CR><LF> 250 OK C: QUIT S: 221 Beta.GOV Service closing transmission channel Erläuterung: In diesem Beispiel sendet Benutzer Smith vom Host Alpha.EDU eine Mail an drei Empfänger Jones, Green und Brown am Host Beta.GOV. Dazu baut der SMTP-Client von Alpha.EDU zunächst eine TCP-Verbindung zu Port 25 von Beta.GOV auf. Der Server liefert zunächst eine Statusmeldung in der er sich identifiziert und seine Bereitschaft zur Annahme von E-Mails bestätigt, der Client identifiziert sich ebenfalls. Der Client leitet nun mit dem MAIL-Befehl die Übergabe der Nachricht ein, übermittelt Sender und Empfänger sowie den eigentlichen Nachrichteninhalt und beendet schließlich die Verbindung. Bei der Angabe des Empfängers [email protected] reagiert der Server mit einer Fehlermeldung, erkennbar an dem Reply code 550 und der Meldung No such user ” here“: Dem System ist kein Benutzer mit diesem Namen bekannt, dementsprechend wird die Annahme verweigert. Das Protokoll legt nicht fest, wie der Client auf solche Fehlermeldungen zu reagieren hat. Die sinnvollste und auch übliche Methode ist es aber, wie hier im Beispiel den Vorgang nicht vollständig abzubrechen sondern mit den anderen gültigen Empfängern fortzufahren. Nun ein echtes“, unverändertes Beispiel für eine SMTP-Session: ” >telnet gemma.techfak.uni-bielefeld.de 25 220 gemma.TechFak.Uni-Bielefeld.DE ESMTP Sendmail 8.9.1/8.9.1 /TechFak/pk+ro20010720; Wed, 23 Jan 2002 11:05:54 +0100 (MET) HELO localhost 250 gemma.TechFak.Uni-Bielefeld.DE Hello pD9E0437A.dip.t-dialin.net [217.224.67.122], pleased to meet you MAIL FROM:<[email protected]> 250 <[email protected]>... Sender ok RCPT TO:<[email protected]> 250 <[email protected]>... Recipient ok DATA 354 Enter mail, end with "." on a line by itself Subject: Das ist die Betreffzeile Hier der eigentlich Text der Nachricht, beendet durch einen einzelnen Punkt in einer Zeile . 250 LAA11554 Message accepted for delivery QUIT 221 gemma.TechFak.Uni-Bielefeld.DE closing connection Zunächst wird wieder eine Verbindung zu dem SMTP-Server hergestellt. Dieser meldet sich mit dem Reply code 220 und identifiziert sich im dazugehörigen Textstring. Es folgt die Begrüßung“ bzw. ” 155 17 Simple Mail Transfer Protocol (SMTP) Identifizierung des Clients, woraufhin der Server erneut mit einer Statusmeldung antwort, und es wird analog zum vorherigen Beispiel eine E-Mail versandt. Die folgende Ausgabe verdeutlicht die Funktion einiger Befehl, die nicht direkt zum Versand einer Nachricht notwendig sind. Es wird mit zunächst mit VRFY ein Benutzername überprüft (welcher dem System auch bekannt ist), dann mit dem EXPN-Befehl eine Mailingliste aufgelöst und schließlich mittels HELP eine Liste der verfügbaren Hilfethemen angezeigt. >telnet gemma.techfak.uni-bielefeld.de 25 220 gemma.TechFak.Uni-Bielefeld.DE ESMTP Sendmail 8.9.1/8.9.1 /TechFak/pk+ro2001720; Wed, 23 Jan 2002 11:28:01 +0100 (MET) HELO localhost 250 gemma.TechFak.Uni-Bielefeld.DE Hello pD9E045BE.dip.t-dialin.net [217.224.69.190], pleased to meet you VRFY juser 250 Joe User <[email protected]> EXPN webmaster 250-Rainer Orth <[email protected]> 250-Peter Koch <[email protected]> 250-Jennifer Rinne <[email protected]> 250-Arne Hauenschild <[email protected]> 250 Anke Weinberger <[email protected]> HELP 214-This is Sendmail version 8.9.1 214-Topics: 214HELO EHLO MAIL RCPT DATA 214RSET NOOP QUIT HELP VRFY 214EXPN VERB ETRN DSN 214-For more info use "HELP <topic>". 214-To report bugs in the implementation send email to [email protected]. 214-For local information send email to Postmaster 214-at your site. 214 End of HELP info QUIT 221 gemma.TechFak.Uni-Bielefeld.DE closing connection 17.4.5 Relay Relay oder Relaying bezeichnet allgemein die Zwischenspeicherung von E-Mails auf einem Server, der nicht selbst der Empfänger-MTA ist, sondern die Nachricht an diesen weiterleitet. Dieses Konzept bietet einige Vorteile, wie z.B. eine erhöhte Ausfallsicherheit: so gehen Nachrichten nicht verloren, wenn der Empfangs-MTA nicht erreichbar ist. Auch läßt sich mit Relay-Systemen ein vor allem in Bezug auf Sicherheitsaspekte besserer Netzwerkaufbau verwirklichen, wenn z.B. private Netze mit dem Internet verbunden werden sollen. Ursprünglich galt im Internet ein gewisses Je” der hilft jedem“-Prinzip, MTAs nahmen also in der Regel auch E-Mails von ihnen unbekannten Absendern an ihnen unbekannte Empfänger an. Mit zunehmenden Nutzerzahlen des Internets entstanden aber immer öfter Probleme, wenn dieses Verhalten z.B. zum massenhaften Versand von 156 17.4 Simple Mail Transfer Protocol Abbildung 17.4: Schema eines Relay-Systems Werbe-Mails (Spam) mißbraucht wurde. Heutzutage ist das Relay in der Regel stark eingeschränkt, um solchen Mißbrauch zu verhindern. Viele Systeme nehmen nur E-Mails an, wenn der Empfänger ein lokaler, bekannter Benutzer ist. Oft wird auch der Mailversand auf bestimmte IP-Adressräume eingeschränkt und die Adressen bekannter Spammer gesperrt. 17.4.6 MX-Records Bisher sind wir davon ausgegangen, dass der Empfänger-MTA direkt mit dem Internet verbunden ist und sein Domainname mit dem Domainteil der E-Mail-Adressen übereinstimmmt. Der MX-Record (Mail Exchange Record) ist ein spezieller DNS-Eintrag, der die Konfiguration von E-Mail-Systemen vereinfacht, indem dem Domain-Teil einer E-Mail-Adresse ein bestimmter Mail-Server zugewiesen wird. Dies ermöglicht den Versand von Nachrichten an Systeme ohne direkte Internet-Anbindung, oder auch die Festlegung von alternativen Servern für den Fall, dass der normale Empfangs-MTA nicht zur Verfügung steht. Beispiel: Abfrage des MX-Records von techfak.uni-bielefeld.de %nslookup Default Server: router.domain.de Address: 192.168.100.100 > set q=mx 157 17 Simple Mail Transfer Protocol (SMTP) > techfak.uni-bielefeld.de Server: router.domain.de Address: 192.168.100.100 Non-authoritative answer: techfak.uni-bielefeld.de MX preference = 100, mail exchanger = gemma.techfak.uni-bielefeld.de techfak.uni-bielefeld.de MX preference = 300, mail exchanger = mail1.RRZ.Uni-Koeln.de techfak.uni-bielefeld.de nameserver = TECHFAC.techfak.uni-bielefeld.de techfak.uni-bielefeld.de nameserver = noc.RRZ.Uni-Koeln.de techfak.uni-bielefeld.de nameserver = waldorf.Informatik.Uni-Dortmund.de techfak.uni-bielefeld.de nameserver = noc.BelWue.de techfak.uni-bielefeld.de nameserver = noc.HRZ.uni-bielefeld.de gemma.techfak.uni-bielefeld.de internet address = 129.70.136.103 mail1.RRZ.Uni-Koeln.de internet address = 134.95.100.208 TECHFAC.techfak.uni-bielefeld.de internet address =129.70.132.100 noc.RRZ.Uni-Koeln.de internet address = 134.95.100.209 waldorf.Informatik.Uni-Dortmund.de internet address = 129.217.4.42 noc.BelWue.de internet address = 129.143.2.1 noc.HRZ.uni-bielefeld.de internet address = 129.70.5.16 Von Interesse sind hier die zwei Zeilen mit den MX preference“-Einträgen: Hier wird fest” gelegt, welche Rechner für die Annahme von E-Mails an Adressaten innerhalb der Domain techfak.uni-bielefeld.de zuständig sind. Die Einträge besitzen zwei Werte: Mail exchanger“ ” gibt den zu verwendenden Rechner an; Preference“ ist eine Prioritätsangabe: sendende MTAs ” versuchen zunächst immer die Nachrichten dem MTA mit dem niedrigsten Wert zu übergeben, erst wenn dieser nicht erreichbar ist wird der Rechner mit dem nächsthöheren Wert benutzt. Im Normalfall sollen E-Mails von gemma.techfak.uni-bielefeld.de entgegengenommen werden (preference = 100), bei Nichterreichbarkeit ist mail1.RRZ.Uni-Koeln.de zuständig (preference = 300). 17.5 Weiterentwicklung 17.5.1 ESMTP - SMTP Service Extensions Das Protokoll wurde in seiner ursprünglichen Form bereits 1982 veröffentlicht, und wurde seitdem ständig weiterentwickelt. Die Erweiterungen werden als SMTP Service Extensions“ bezeichnet, ” man spricht auch von ESMTP (Extended SMTP). Die jeweiligen Erweiterungen werden wie das ursprüngliche Protokoll selbst in RFCs beschrieben und bei der IANA (Internet Assigned Numbers Authority) registriert. Eine Besonderheit ist, dass alle Erweiterungen abwärtskompatibel sind und so bestehende Implementationen nicht beeinflußt werden. In der Praxis verhält sich ESMTP daher analog zu SMTP, es werden jedoch weitere Funktionen unterstützt. Wie im nachfolgenden Beispiel sichtbar, macht der Server die Unterstützung von ESMTP zu Anfang der Session bekannt. Der Client begrüßt den Server nun mit einem EHLO”(für Extended Hello“), woraufhin dieser eine mehrzeilige Antwort zur ” ” Bekanntmachung der verfügbaren Funktionen liefert. 220 gemma.TechFak.Uni-Bielefeld.DE ESMTP Sendmail 8.9.1/8.9.1/ TechFak/pk+ro20010720; Wed, 23 Jan 2002 12:23:45 +0100 (MET) EHLO localhost 250-gemma.TechFak.Uni-Bielefeld.DE Hello pD9E04337.dip.t-dialin.net [217.224.67.55], pleased to meet you 250-EXPN 158 17.5 Weiterentwicklung 250-VERB 250-8BITMIME 250-SIZE 8388608 250-DSN 250-ONEX 250-ETRN 250-XUSR 250 HELP Die einzelnen Zeilen beginnen mit dem Reply code 250, darauf folgt ein Keyword (mit optionalem Parameter) zur Beschreibung der Funktion. EXPN steht so z.B. für die Unterstützung des ExpandBefehls zur Auflösung von Mailing-Listen, DSN für Eingangsbestätigungen und SIZE 8388608 gibt die maximale erlaubte Größe anzunehmender E-Mails an (hier ist die Dateigröße in Byte der Parameter). Neben dem Protokoll selbst wurde aber auch das Nachrichtenformat weiterentwickelt, da es in seiner ursprünglichen Form wie in RFC 822 beschrieben einige Einschränkungen enthält. So werden nur Textnachrichten unterstützt, es ist nur ein Zeichensatz definiert (7-Bit US-ASCII) und die Zeilen sind auf maximal 1000 Zeichen beschränkt. 17.5.2 MIME Die grundliegenden Ziele der Weiterentwicklung des Nachrichtenformats waren die Unterstützung anderer Zeichensätze (sowohl in der Nachricht selbst als auch in den Header-Feldern), andere Formate für den Body der Nachricht (z.B. Audio-/Videodokumente) bzw. mehrere Formate innerhalb einer E-Mail. Realisiert wurden diese Eigenschaften durch den MIME-Standard (Multipurpose Internet Mail Extensions, RFCs 2045-2049). Eine detaillierte Beschreibung der Funktionsweise würde den Umfang dieser Ausarbeitung sprengen, allgemein werden zusätzliche Header-Felder für die Speicherung der benötigten MIME-Informationen benutzt, während die jeweiligen Inhalte in eine ASCIIDarstellung umgerechnet werden. Diese können dann vom Empfänger wieder in die ursprüngliche Form zurückgewandelt werden. Der Umweg über die ASCII-Darstellung vergrößert den Umfang der Nachricht zwar etwas, dafür wird die Kompatibilität mit älteren Implementationen des Protokolls gewahrt und nur die Benutzeragenten müssen an die Veränderungen angepasst werden. 159 17 Simple Mail Transfer Protocol (SMTP) 160 KAPITEL 18 Hypertext Transfer Protocol (HTTP) Florian Schäfer, Matthias Behnisch 18.1 HTTP HTTP – Hypertext Transfer Protokoll – dient zur Kommunikation zwischen Web-Clients und -Servern. Die erste Version wurde 1990 von Tim Berners Lee, dem “Vater” des WWW, am CERN geschrieben. Zusammen mit dem Adressierungsschema URI (Uniform Resource Identifier) und der Sprache für Web-Dokumente, HTML (Hypertext Markup Language), bildet HTTP sozusagen das Grundgerüst des WWW. Hiermit verwirklichte Tim Berners Lee seine Idee eines computerübergreifenden Systems von miteinander durch Hypertext verlinkten Objekten, ab 1990 wurde es “WWW” genannt. HTTP ist das Standardtransferprotokoll im WWW. Da TCP/IP im Internet benutzt wird, eignet es sich gut als Transportprotokoll für HTTP. Vom Standard wird dies allerdings nicht explizit gefordert. HTTP ist ein ASCII-Protokoll, d.h.eine einfache Telnet-Verbindung reicht aus, um direkt mit einem Web-Server zu kommunizieren. Hierbei werden eine Reihe von Befehlen, sog. Methoden, benutzt, die es ermöglichen, entweder Daten vom Server anzufordern oder zu ihm zu übertragen. Da HTTP “stateless” ist, werden alle Datenpakete voneinander unabhängig behandelt. Es muß keine feste Reihenfolge eingehalten werden und es gibt keine Information über vorherige Operationen. Alle HTTP-Versionen sind abwärtskompatibel. 161 18 Hypertext Transfer Protocol (HTTP) 18.1.1 Allgemeiner Aufbau HTTP läßt sich in zwei grundlegende Elemente aufteilen: Anfragen vom Client an den Server und Antworten vom Server an den Client. Alle neueren Versionen unterstützen zwei Arten von Anfragen, einfache und volle. Bei der einfachen Anfrage wird vom Client keine Protokollversion festgelegt. Dieses Feature ermöglicht eine weitgehende Abwärtskompatibilität, da die Antwort beispielsweise im Falle einer Web-Page die rohe Page ohne Header und andere versionsabhängige Eigenschaften wie MIME-Typisierung oder Kodierung wäre. Die volle Anfrage enthält die HTTP-Protokollversion, Informationen über die MIME-Version, den Content-Type etc. Auf jede Anfrage folgt eine Antwort, bestehend aus einer Statuszeile und möglicherweise weiteren Informationen (z.B eine Web-Page oder eine beliebige andere Datei, vollständig oder teilweise). In der Statuszeile stehen die Status-Codes. 18.2 URL URL – Uniform Resource Locator – stellt ein Adressierungsschema dar, welches es erlaubt, jedem Objekt im WWW eine weltweit eindeutige Adresse zuzuordnen. Eine solche Adresse besteht aus drei Teilen: • Das verwendete Schema • Der DNS-Name der Maschine, auf der sich das Zielobjekt befindet • Der lokale Name des Objektes (normalerweise der Dateiname) Aufbau: <Schema>:<DNS-Name><Objekt-Name> Beispiel einer URL: http://www.uni-bielefeld.de/index.html Mit Hilfe der URLs ist fast der gesamte Internet-Zugang über den anwenderfreundlichen Browser möglich. 18.3 Client Request Der Client Request wird vom Client zum Server gesendet. Ein Client ist z.B. ein Web-Browser und der Server ist ein HTTP-Server wie z.B. Apache. Im Request fordert der Client einen Bestandteil einer WWW-Seite an und macht Angaben über die angeforderten Daten und über sich selbst. 162 18.3 Client Request 18.3.1 Aufbau <Methode> <URI> <HTTP Version> Request Header leere Zeile (enthält nur CRLF) Daten In der ersten Zeile teilt der Client mit, welche Methode er benutzen möchte. Danach folgt die Adresse sowie die benutze HTTP Version. Sonstige Angaben folgen im Request Header, der mit einer leeren Zeile abgeschlossen wird. Falls im Request Daten an den Server gesendet werden, folgen sie dem Header. 18.3.2 Methoden Mit der Methode spezifiziert der Client, was er vom Server möchte. Er kann entweder Daten anfordern oder an den Server übertragen. GET HEAD POST PUT DELETE TRACE OPTIONS Daten einer Adresse anfordern wie GET, aber nur der Header der Antwort wird übermittelt Daten an den Server senden z.B. Eingaben in einem Formular wie POST, die Daten werden an der angegebenen URL gespeichert die angegebene URL wird gelöscht der Request wird unverändert vom Server zurückgesendet liefert zusätztliche Informationen über den Server Die am häufigsten benutzte Methode ist GET. Sie dient dazu, eine Datei vom Server zum Client zu übertragen. Dabei wird für jeden Bestandteil einer Seite ein eigener GET-Request mit dazugehöriger URL versendet. HEAD macht prinzipiell das gleiche, nur wird die angeforderte Datei nicht gesendet. Da nur der zu der Datei gehörende Header vom Server kommt, kann der Client durch die HEAD Methode genaueres über die Datei herausfinden und so entscheiden, ob er die Datei wirklich anfordern will. Die letzte Methode mit praktischer Bedeutung ist POST, die dann Verwendung finden kann, wenn der Server Daten vom Client benötigt. Dies ist z.B. der Fall bei Suchmaschinen, in denen der User Begriffe eingeben kann und diese dann durch POST zum Server gelangen. 163 18 Hypertext Transfer Protocol (HTTP) 18.4 Server Response Die Server Response ist die Antwort des Servers auf einen vorhergehenden Request des Clients. In ihr teilt der Server den Erfolg (oder Misserfolg) der gewünschten Operation mit und sendet gegebenenfalls die angeforderte Datei. 18.4.1 Aufbau <HTTP Ver.> <Status Code> <Beschreibung> Response Header leere Zeile (enthält nur CRLF) Daten In der ersten Zeile steht zunächst die benutzte Version von HTTP. Danach folgt der Status der geforderten Operation, zuerst durch eine Zahl, den sogenannten Status Code, ausgedrückt. Nach dem Code folgt noch eine nähere Beschreibung, die für den User verständlicher ist als eine nackte Zahl. Es folgen die verschiedenen Response-Header-Einträge, die wie beim Request durch eine leere Zeile abgeschlossen werden. Diese Header-Einträge liefern Informationen über den Server und die übermittelten Daten, die wie beim Request direkt nach dem Header folgen. 18.4.2 Status Codes Die Status Codes sind dreistellige Zahlen, deren erste Ziffer die Untergruppe des Codes angibt. Die folgende Liste enthält einige wichtige Codes. 164 18.5 Header Einträge 1xx 100 Informational Continue Request erhalten, Verarbeitung läuft 2xx 200 201 202 Successfull OK Created Accepted Operation konnte ausgeführt werden 3xx 301 304 Redirection Moved Not Modified besondere Funktionen 4xx 400 401 403 404 Client Error Bad Request Unauthorized Forbidden Not Found Request ist falsch oder nicht ausführbar 5xx 500 503 Server Error Internal Server Error Service Unavailable Server kann einen gültigen Request nicht ausführen Mit Hilfe der Codes erfährt der Client, ob sein Request ausgeführt werden konnte. So sendet der Server bei Erfolg einen Code der Gruppe 2xx, bei einem erfolgreichen GET lautet die Antwort 200, also OK. Falls der Client eine nicht mehr gültige URL anfordert, erhält er eine “404 Not Found” Nachricht. Die Codes der Gruppe 3xx ermöglichen zusätzliche Funktionen des Clients bzw. des Servers. Wenn z.B. eine URL nicht mehr aktuell ist, der Server aber die neue Adresse kennt, dann sendet er einen “301 Moved” Code und die neue URL im Response Header. Der Client kann dann eine Anfrage an die neue Adresse richten. 18.5 Header Einträge Die Einträge im Header lassen sich einteilen in Request, Response und solche, die in beiden vorkommen. Sie sind jedoch nicht unbedingt zwingend erforderlich und verschiedene Client- und Server-Software unterscheidet sich zum Teil erheblich in deren Verwendung. Hier nun einige Header-Felder: 165 18 Hypertext Transfer Protocol (HTTP) Request Header Accept: Accept-Language: Accept-Encoding: Host: If-Modified-Since: If-None-Match: Referer: User-Agent: aktzeptierte Medien-Typen bevorzugte Sprachen unterstützte Kodierungen (gzip usw.) an welche Domain Request gerichtet ist nur wenn Datei seit bestimmten Zeitpunkt verändert nur wenn der ETag nicht übereinstimmt Adresse, von der der Link ausgeht welche Client Applikation (Browser) Response Header Location: Server: neue URL, falls die Anfrage weitergeleitet wird welche Server-Software in beiden Connection: Date: Art der Verbindung Zeitpunkt des Sendens Einige dieser Einträge werde ich bei den folgenden Beispielen noch näher erläutern. Nach dem Request- bzw. Response-Header folgen die Daten. Auch wenn der Server mit einem Fehler-Code (siehe Status-Codes) antwortet, kann er zusätzliche Daten hinzufügen, die den Fehler für den User genauer erläutern. Falls Daten enthalten sind, beziehen sich folgende Header Einträge auf diese: ETag: Content-Type: Content-Encoding: Content-Language: Content-Length: Expires: Last-Modified: eindeutiger Code zur Identifizierung der Datei Art der Daten (text/html usw.) Kodierung der Daten (gzip usw.) Sprache Länge der Daten in Bytes wann die Daten ungültig werden wann die Daten das letzte Mal verändert wurden 18.6 Beispiele Zum besseren Verständnis jetzt erstmal zwei Beispiele. Der erste Block ist dabei der Request und der nachfolgende die zugehörige Response. GET / HTTP/1.1 User-Agent: Opera/5.0 (Linux 2.2.18 i686; U) [en] Host: www.techfak.uni-bielefeld.de Accept: text/html, image/png, image/jpeg, image/gif, image/x-xbitmap, */* Accept-Encoding: deflate, gzip, x-gzip, identity, *;q=0 Connection: Keep-Alive ------------------------------------------------------------------------- 166 18.6 Beispiele HTTP/1.1 200 OK Date: Tue, 05 Feb 2002 16:41:19 GMT Server: Apache/1.3.12 (Unix) Last-Modified: Fri, 01 Feb 2002 07:25:55 GMT Content-Length: 8096 Keep-Alive: timeout=15 Connection: Keep-Alive Content-Type: text/html <!DOCTYPE ...................... Diesen Request erstellt Opera wenn man die Seite http://www.techfak.uni-bielefeld.de aufruft. In der ersten Zeile steht “GET /”, d.h. die Startseite wird angefordert. Wenn auf einem Server mehrere virtuelle Hosts existieren (Virtual Hosting) werden diese durch das “Host:” Feld unterschieden. Der Browser unterstützt mehrere Medien-Typen, die er im “Accept:” Feld angibt. “*/*” bedeutet, daß er notfalls auch alle anderen Typen bekommen möchte. Auch die unterstützten Datenkodierungen gibt er durch “Accept-Encoding:” an. Die Antwort des Servers beginnt mit dem Code “200 OK”, damit teilt er mit, daß der Request erfolgreich bearbeitet werden konnte. Er liefert auch noch Informationen über die gesendete Datei, und zwar deren Typ “Content-Type:”, Größe “Content-Length:” und das Datum, an dem die Datei das letzte Mal verändert wurde “Last-Modified:”. Nach der leeren Zeile ist der Response Header beendet und es folgt die Datei. HEAD http://www.techfak.uni-bielefeld.de If-Modified-Since: Sat, 02 Feb 2002 08:00:00 GMT User-Agent: lwp-request/1.39 -----------------------------------------------304 Not Modified Connection: close Date: Tue, 05 Feb 2002 17:29:48 GMT Server: Apache/1.3.12 (Unix) ETag: "5ffe8-1fa0-3c5a4303" Client-Date: Tue, 05 Feb 2002 17:28:16 GMT Client-Peer: 129.70.136.200:80 Dieses Beispiel demonstriert die Methode HEAD. Es wird wieder die gleiche Seite angefordert, nur diesmal gibt der Client durch “If-Modified-Since:” im Request Header an, daß er die Datei nur haben möchte, falls sie seit dem gegebenen Datum verändert wurde. So könnte ein Browser vorgehen, wenn die Seite schon besucht wurde und im lokalen Cache vorhanden ist. Die Antwort des Servers beginnt mit dem Code “304 Not Modified”, d.h. die Seite wurde nicht verändert. Zusätzlich gibt der Server noch einen Code zur Identifizierung der Datei durch “ETag:” an, mit dem der Client verifizieren kann, daß er die Datei wirklich schon hat. Da die Methode HEAD 167 18 Hypertext Transfer Protocol (HTTP) benutzt wurde, folgen dem Response Header keine Daten. Aber selbst wenn anstatt dessen GET benutzt würde folgten in diesem Fall keine, da durch den “If-Modified-Since” Eintrag die Datei nur bei einem späteren Datum übertragen worden wäre. 18.7 Keep-Alive Für jede Datei die übertragen werden soll, werden 4 Schritte ausgeführt: Aufbau der Verbindung, Request, Response, Ende der Verbindung. Jedoch wurden die WWW-Seiten mit der Zeit immer umfangreicher und die meisten Sites bestehen aus vielen Dateien (mehrere Frames, Bilder, Animationen usw.). Es ist eigentlich unnötig für jede Datei eine neue Verbindung aufzubauen und wieder zu schließen, da die Dateien ja sowieso vom gleichen Server kommen. Dieses Vorgehen führt nur zu einer stärkeren Netzwerkbelastung und verschlechtert die Übertragunsgeschwindigkeit durch das unnütze Öffnen und Schließen von Verbindungen. Darum wurde ab der Version HTTP/1.1 die Keep-Alive Verbindung eingeführt, die auch schon vorher experimentell Anwendung fand. Die Idee dahinter ist, daß die Verbindung zwischen Server und Client bestehen bleibt, bis alle Dateien übertragen wurden. Nach dem Verbindungsaufbau werden also Request und Response mehrfach durch die selbe Verbindung ausgeführt. Dieses Vorgehen ist ab HTTP/1.1 Standard, muß also nicht extra durch ein “Connection: keep-alive” Header Eintrag angegeben werden. Aber wie verständigen sich Client und Server über das Ende der Verbindung? Beide können jederzeit durch ein “Connection: close” die Verbindung beenden, wobei dies meistens durch den Server geschieht, nachdem alle Dateien übertragen wurden. Damit der Server die Verbindung nicht zu lange offen hält, falls der Client unerwartet abbricht, gibt es eine Timeout Zeit. Nach deren Ablauf trennt der Server die Verbindung, falls kein neuer Request eintrifft. Ein weiterer Vorteil dieses Verfahrens ist das sogenannte “Pipelining”. Das bedeutet, daß der Client nicht mit einem neuen Request warten muß bis die Response des Servers auf den vorhergehenden Request eintrifft. Er kann stattdessen viele Anfragen nacheinander abschicken und wartet dann auf die Antworten des Servers, die jedoch in der gleichen Reihenfolge eintreffen müssen. Wie man mit Hilfe der Abbildung erkennen kann, führt das zu einer höheren Übertragungsgeschwindigkeit von umfangreichen Web-Seiten. 168 18.8 Proxy 18.8 Proxy Über HTTP können beliebige Daten übermittelt werden. Viele Daten, die auf ftp- und gopherServern etc. liegen, können nicht direkt mit HTTP angefordert werden. Eine Lösung wäre, daß der Browser alle möglichen Protokolle unterstützt. Da diese Möglichkeit aber zusätzlichen Speicherplatz kostet und der Browser zu umfangreich werden würde, bedient man sich eines Proxy-Servers. Ein Proxy-Server ist eine Art Gateway, das HTTP mit dem Browser und verschiedene andere Protokolle mit den Servern spricht. So muß der Browser nur HTTP können, den Rest erledigt der Proxy. Gleichzeitig ist es möglich, die Daten, die über den Proxy laufen, zu cachen. Der nächste Abschnitt behandelt diese Möglichkeit. Der Proxy-Server kann auf einer beliebigen Maschine laufen, die Zugang zum internen und externen (Internet) Netz hat. Das heißt, es ist auch möglich, daß der Proxy auf derselben Maschine läuft wie der Browser. ftp HTTP WWW−Browser Proxy ftp−Server go ph er Cache ws ne gopher−Server news−Server 18.8.1 Proxy-Caching Der Proxy-Server leitet einfach jede Anfrage weiter, auch wenn die gleiche Anfrage erst kurz vorher gestellt wurde, was sehr ineffizient ist und unnötige Netzlast verursacht. Die Lösung für dieses Problem ist der Cache. Bei jeder Anfrage vom Browser befragt der Proxy erst den Cache, ob sich das angeforderte Objekt schon darin befindet. Ist das so, wird das Objekt aus dem Cache an den Browser übermittelt. Wenn das Objekt nicht im Cache ist, wird die Anfrage an den Server weitergeleitet. Die Daten, die der Server als Antwort schickt, werden in den Cache geladen und gleichzeitig an den Browser weitergeleitet. Von nun an ist das Objekt im Cache vorhanden und kann bei der nächsten Anfrage direkt aus dem Cache an den Browser übertragen werden. Natürlich ist Caching auch ohne Proxy möglich, in diesem Fall erledigt dies der Client selbst, was 169 18 Hypertext Transfer Protocol (HTTP) aber ein paar Nachteile hat, zumindest wenn mehrere Clients den Proxy-Server benutzen. Dann spart Proxy-Caching Plattenplatz, da nur eine Kopie des Objektes gecached wird. Ausserdem können “Look ahead” und andere vorausschauende Algorithmen effizienter genutzt werden, da die Anzahl der Clients und damit auch die Grundlage der Statistik, die für die Cache-Verwaltung benutzt wird, viel aussagekräftiger ist. Die Aktualität der Objekte wird unter anderem durch das Header-Feld “if modified since” gewährleistet, durch das der Client herausfinden kann, ob die Datei, die angefordert wird, seit einem bestimmten Zeitpunkt aktualisiert worden ist. Weitere allgemeine Vorteile des Caching sind: • Zugriff auf Daten, die auf dem ursprünglichen Server gerade nicht verfügbar sind • schnellere Erreichbarkeit der Daten von Orten aus, die keine oder eine nur sehr langsame Verbindung zu den Servern mit den Originaldaten haben Natürlich gibt es auch Nachteile: • wenn nur wenige Clients häufig auf wechselnde Dateien zugreifen, wird Caching nutzlos • wenn die Caching-Strategie fehlschlägt wird möglicherweise ein veraltetes Objekt an den Client zurückgeschickt 18.9 HTTP 1.1 Die Version 1.1 ist zum Draft Standard geworden (RFC 2616), das W3C hat die Arbeit an HTTP/1.1 fast komplett eingestellt, da es dabei um einen stabilen Standard handelt. Nur eine kleine Gruppe von Mitarbeitern verfolgt die weitere Entwicklung von HTTP, z.B. experimentelle Implementierungen von neuen Features. In Version 1.1 sind einige Eigenschaften verbessert worden. Beispielsweise ermöglicht HTTP/1.1 im Vergleich zu älteren Versionen ein efizientes Caching. In den älteren Versionen war oft nicht klar definiert, wann Objekte überhaupt gecached werden dürfen, oder wie lange diese im Cache bleiben sollen. 170 KAPITEL 19 Internet Relay Chat (IRC) Lars Molske, Damian Nowak 19.1 Einleitung 19.1.1 Was ist das IRC und was kann man damit anfangen? Der IRC, oder Internet Relay Chat, ist wohl einer der interaktivsten Dienste die das Internet bieten kann. Er stellt ein grosses Mehrbenutzer-Kommunikationssystem dar, das man sich grob als Internet-CB-Funk vorstellen kann. Ein Vorteil zum CB-Funk ist jedoch, dass nicht nur Menschen aus der eigenen Region, sondern Menschen aus der ganzen Welt kostenlos daran teilnehmen können. Tausenden Menschen wird so die Möglichkeit geboten sich via Internet in verschiedenen Chaträumen, den so genannten Channels, zu treffen und gleichzeitig in Echtzeit zu unterhalten. Diese Unterhaltungen laufen in Textzeilen auf dem Bildschirm ab. Channels gibt es deshalb, weil sonst mit Sicherheit ein heilloses Chaos entstehen würde, wenn Tausende Menschen aufeinander einreden/tippen würden. Die Themen der einzelnen Channels sind so verschieden wie die Benutzer. Man kann zu wirklich jedem Thema oder Interessengebiet den passenden Channel finden. Ist dem nicht so, hat jedermann die Möglichkeit, einen eigenen Channel zu eröffnen und Leute einzuladen oder zu warten, bis ihn jemand in der Channel-Liste findet und ihn betritt. So nutzen viele Menschen das IRC als regelmäßigen Treffpunkt mit Freunden und Bekannten um Spass zu haben, Informationen auszutauschen, Hilfe zu Softwareprogrammen zu bekommen o.ä.. So gesehen ist auch der oft gehörte Ruf des Internet Relay Chat als rein unseriöses Spass-Medium nicht begründet. Der Sinn und die Verwendung liegt allein beim jeweiligen Benutzer. Jarkko Oikarinen (der Ur-Vater des IRC) sagte einmal über das IRC: 171 19 Internet Relay Chat (IRC) People get to meet each other around the world, by first meeting each other on ” IRC, and then later in real life. I also know many people who met first through IRC and then got married and are living happily. I myself have met lots of nice people from many countries through IRC, people I definitely would not have had a chance of meeting otherwise. I have attended some IRC meetings, and have always found it very interesting to meet the people typing on the other terminals, and I have learned that the impression you get through the keyboard is often very different from the one in real life. Which one is the right one is, of course, a matter of opinion...“1 Ein ganz besonderer Aspekt sollte noch erwähnt werden: Immer dann wenn auf der Welt etwas interessantes passiert, bildet sich der Channel #report. Gerade in Krisenzeiten, zum Beispiel zur Zeit des Golf-Krieges, hat das IRC seine Vorteile unter Beweis stellen können und so stark an Popularität zugenommen. Brandaktuelle Neuigkeiten bekam man aus dem IRC: Als sich Anfang 1991 der Golfkrieg verschärfte, trafen sich hunderte von IRCern auf ” diesem Kanal und lauschten den Berichten. Schneller als CNN, aus erster Hand und zum Teil sehr dramatisch: Z. B. berichtete damals ein IRCer aus Israel, wie 100 Meter neben ihm eine Scud-Rakete eingeschlagen ist, und ihm durch die Erschütterung die Teetasse vom Tisch gefallen ist. Die Logfiles von damals sind heute noch auf FTP-Servern archiviert. Weitere Anlässe für einen #report-Kanal waren z. B. der Putschversuch in Moskau (1992) und das 94er Erdbeben in Kalifornien.“2 Wem das Internet zu anonym ist, oder wer sich fragt Wo sind all die Millionen Internet Nutzer ” eigentlich?“, sollte einmal in einem der IRC-Netze vorbeischauen. Dort kann man Tausende von ihnen treffen. 19.1.2 Die Entstehung des IRC Die Entstehung des IRCs kann man bis ins Jahr 1988 zurückverfolgen. Der Vater des IRC, ein Student namens Jarkko Oikarinen, arbeitete damals an der University of Oulu in Finnland als Administrator eines Sun-Serversystems. Auf diesem lief die OuluBox, ein öffentliches Bulletin Board System (BBS). Damals hatte er nicht viel zu tun, und so entwickelte er das Ur-System des IRC – jedoch nicht mit der Intention, ein weltumspannendes Chat-Netzwerk zu schaffen. Alles was er wollte, war ein “Mehr-Personen-Schwatz-Programm“.3 So I started doing a communications program, which was meant to make OuluBox ” (a Public Access BBS running on host tolsun.oulu.fi, administered by me) a little more usable.“4 Als das IRC zu wachsen begann, verabschiedete er sich langsam von seiner eigentlichen Idee, das BBS aufzuwerten, und steuerte auf ein eigenständiges Chat-System hin. Da Finnland zu diesem Zeitpunkt jedoch noch nicht an das Internet angeschlossen war, verbreitete sich das IRC zunächst nur langsam 1 aus: http://www.filetrading.net/html/irc/intro.htm aus der Veröffentlichungsreihe der Abteilung “ Organisation und Technikgenese“ des Forschungsschwerpunkts Technik-Arbeit-Umwelt am Wissenschaftszentrum Berlin für Sozialforschung GmbH 3 aus “Eine kurze Geschichte des IRCs“ http://oswald.pages.de/chat/rps/#109 4 aus einer persönlichen E-Mail Oikarinens an Kai Seidler 2 172 19.2 Die Technische Struktur des IRC und nur in Finnland. Seine eigentliche Verbreitung begann erst langsam mit der Internetverbindung Finnland-Amerika, der Siegeszug des IRC begann, und das ältere “Talk“-Protokoll (erlaubte direktes Messaging von 2 Usern nach dem Client-to-Client Prinzip) wurde vom IRC Protokoll verdrängt. Jedoch war die Netzstruktur noch lange Zeit schlecht, so dass internationale Verbindungen nur selten zustande kamen. Die IRCer der einzelnen Länder waren also einige Zeit noch meist unter sich. Heute hat sich das IRC jedoch in Dimensionen entwickelt, die nie geplant waren. Es war für maximal 100 User gedacht, heute gibt es mehrere unabhängige IRC Netze mit jeweiligen Benutzerzahlen im hohen zweistelligen Tausender-Bereich. So kann man sich auch leicht vorstellen, dass es heute zu mehr und mehr Problemen kommt. Doch dazu später mehr. 19.2 Die Technische Struktur des IRC 19.2.1 Netzaufbau Das IRC funktioniert nach dem Client-Server Prinzip. Das bedeutet im Klartext, dass sich ein User an einem zentralen Rechner, dem IRC-Server, anmeldet. Dazu benutzt er einen Client, welcher die Vermittlerfunktion zwischen Benutzer und Server einnimmt. Die eigentliche Arbeit wird vom Server erledigt, deshalb reicht zum IRCen auch schon ein relativ schwacher Rechner. Doch genau diese Struktur führt bei den heutigen Ausmassen der IRC Netze zu Problemen: If the existing networks have been able to keep growing at an incredible pace, we ” must thank hardware manufacturers for giving us ever more powerful systems.“ 5 Die IRC-Server der verschiedenen Netze sind im Normalfall azyklisch untereinander verbunden (siehe Abb. Baumstruktur, Seite 174). Das führt dazu, dass die Server sich ständig untereinander synchronisieren müssen, um immer die aktuellen Zustandsinformationen aller anderen Server zu haben. Diese Synchronisation funktioniert aufgrund des zu übertragenden Datenvolumens nicht immer wie sie soll, doch dazu mehr in 19.4.1. So kann Client 1 an Server 4 auch mit Client 4 an Server 2 kommunizieren, ohne dass sie am gleichen Server hängen. Dazu sollte man erwähnen, dass sich bis zum heutigen Tage mehrere unabhängige IRC-Netze entwickelt haben, die zwar weitgehend nach dem gleichen Prinzip funktionieren, aber untereinander nicht verbunden sind. Nur netzinterne Server sind miteinander verbunden, die Netze sind es nicht! 19.2.2 Das IRC-Protokoll Durch das IRC-Protokoll wird der generelle Austausch von Nachrichten und Daten im IRC beschrieben. Es ist aufgrund seiner finnischen Herkunft ein 8-bit Protokoll (da der finnische Zeichensatz nicht in 7 Bit passt), jedoch wurden die Schlüsselwörter und -zeichen so gewählt, dass es US-ASCII und Telnet kompatibel ist. Das Protokoll muss natürlich nicht nur die eigentlichen Daten der Nachrichten an sich beinhalten, sondern auch Daten, die zur Verwaltung der Kommunikation im IRC benötigt werden. Das IRC-Protokoll verwaltet nicht nur die Kommunikation zwischen Client und Server, sondern auch zwischen den Servern untereinander. Natürlich sind die Rechte der ClientVerbindungen im Gegensatz zu den Server-Verbindungen einschränkt. Das in RFC 2813 beschrie5 aus RFC2810 173 19 Internet Relay Chat (IRC) Abbildung 19.1: Beispiel: Dynamische Verbindungen des IRCNet in der BRD Abbildung 19.2: Client-Server Baumstruktur 174 19.2 Die Technische Struktur des IRC bene Server-Protokoll hat sich jedoch zugunsten der Skalierbarkeit weiter, vom Client Protokoll weg entwickelt. Grosse Netze wie sie heute vorkommen wären wohl sonst nur noch schwerer möglich. Als Transportprotokoll für das IRC wurde das Transmission Control Protocol (TCP) gewählt, das eine relativ verlässliche Kommunikation zwischen den Teilnehmern verspricht. TCP garantiert durch seine Struktur, dass die Daten fehlerfrei, ohne Verlust oder Duplizierung und in der richtigen Reihenfolge beim Empfänger eintreffen. Es wären auch andere Protokolle als Basis denkbar (z.B. Multicast-IP), jedoch sprechen die guten Eigenschaften von TCP natürlich für seine Verwendung um einen verlässlichen Kommunikationsdienst aufzubauen. Neben dem IRC-Protokoll kommt im IRC auch noch das DCC- und das CTCP-Protokoll zu Einsatz, auf die im Verlauf noch näher eingegangen wird. Sowohl das IRC-Protokoll, als auch DCC und CTCP werden im RFC 1459 6 beschrieben. In den RFCs 2810-28137 wurden notwendige Aktualisierungen und Erweiterungen definiert. 19.2.3 Nachrichtenformat Jede IRC-Nachricht besteht aus einem optionalen Präfix, dem eigentlichen Kommando und den Kommandoparametern. Diese drei Teile werden durch ASCII-Leerzeichen getrennt, das Ende einer Nachricht wird durch das so genannte <CR>-<LF> (Carriage-Return - Line Feed) codiert. Die Länge einer Nachricht darf 512 Zeichen nicht überschreiten. Das Präfix wird durch ein führendes ’:’ erkannt. Gesendete Elemente, die nicht diesen Aufbau haben oder deren Absender bei fehlendem Präfix nicht ermittelt werden können, werden vom Server schlicht ignoriert. Im Präfix wird der Absender angegeben. Also entweder ein Servername oder eine UserAbsenderadresse. Bei einem User namens Hans Meier mit dem Nickname Hansi würde das Präfix so aussehen: “[email protected]“ wenn sein Host Rechner1 an der Uni-Bielefeld wäre. Das Präfix ist jedoch optional, da der empfangene Server bei fehlendem Präfix den Absender durch die Herkunft der Nachricht ermittelt. Das Kommando beinhaltet entweder ein gültiges IRC-Kommando (wie z.B. join, msg, squit...) oder eine ASCII-Zahl (daher dreistellig). Im Präfix sind dann für das Kommando spezifische Angaben enthalten, bei join z.B. der ChannelName. Server haben darüber hinaus die Möglichkeit des “Numeric Replies“. Um den Datenverkehr zu verringern sendet der Server nur eine 3-stellige Zahl, die in bestimmten Liste (z.B Error-Replies oder Command-Responses) eine bestimmte Nachricht codiert. So zum Beispiel wenn beim JoinBefehl im Parameter ein ungültiger oder nicht existenter Channel angegeben ist. Dann wird der Fehlercode 403 (ERR NOSUCHCHANNEL) gesendet. 19.2.4 Sendemöglichkeiten Grundsätzlich kann man die IRC-Kommunikation in drei Kategorien Unterteilen: • One-To-One (Unicast): Es wird der direkteste Weg gewählt. Dies geschieht nicht zuletzt auch aus Sicherheitsgründen. Je weniger Knotenpunkte die Nachricht passiert, desto weniger Abhörmöglichkeiten bestehen. One-To-One Kommunikation erfolgt in den allermeisten Fällen nur durch Clients, da Server sich nur selten “etwas zu sagen haben“. 6 7 http://www.ietf.org/rfc/rfc1459.txt http://www.ietf.org/rfc/rfc2810.txt bzw. http://www.ietf.org/rfc/rfc2811.txt. . . 175 19 Internet Relay Chat (IRC) • One-To-Many: Um mehrere Ziele effizient anzusprechen, gibt es mehrere Möglichkeiten: – To-A-List: Vom Client wird eine Liste mit Empfängeradressen (Usern) angegeben. Da dies jedoch ganz offensichtlich relativ umständlich ist, kommt diese Möglichkeit zu senden nur selten zum Einsatz. – To-A-Group (Multicast): Häufigste Sendeart, so kommt sie z.B. beim Client-ToChannel-Messaging zum Einsatz. Ein Channel ist also eine dynamische Liste von Usern, an die eine Nachricht versendet wird. Die Nachricht wird nur an die Server weitergeleitet, an denen User aus dem betreffenden Channel angemeldet sind. Egal wie viele User aus einem Channel an einem Server angemeldet sind, die Nachricht wird vom sendenden Server (also dem Server an dem der Absender-Client angemeldet ist) nur einmal an den Empfänger-Server gesendet, dort dupliziert und anschliessend an die betreffenden User weitergeleitet. – To-A-Host (auch Local): Es wird nur an User oder Server mit einer bestimmten HostMask gesendet. Diese Sendemöglichkeit kann also z.B. von Operatoren verwendet werden, um eine Mitteilung an alle User zu schicken, die sich an einem bestimmten Server angemeldet haben oder die gleiche Host-Mask haben. Local-Nachrichten werden nur an den Server geschickt, an dem man selbst angemeldet ist. • One-To-All (Broadcast): Eine Nachricht wird an alle Server oder Clients des Netzes oder sogar beide geschickt. Dies kommt z.B. bei dem Informationsaustausch zwischen den Servern (Server-to-Server) zum Einsatz, damit alle Server die gleichen Informationen über bestehende Channels oder Nicknames o.ä. haben. Es gibt jedoch keinen Client-Befehl der durch eine einzige Nachricht an alle Clients gesendet wird. Wie man sich denken kann, wird durch eine Broadcast-Nachricht erheblicher Traffic erzeugt. 19.3 Verwendung 19.3.1 Netzübersicht Zu Beginn der Entwicklung des mittlerweile weltumspannenden Netzes gab es nur das EFNet 8 . 1996 änderte sich die Situation und das EFNet spaltete sich in das EFNet und das IRCNet9 auf. Während das EFNet seitdem vor allem die U.S. Amerikanischen Server umfasst, bot das IRCNet für die Europäischen Nutzer den IRC-Service. Das EFNet hat im Durchschnitt mehr User, jedoch umfasst das IRCNet mehr Länder. In den letzten Jahren haben sich noch eine handvoll alternative Netze entwickelt, zum Beispiel das bei Online-Gamer beliebte Quakenet10 oder das zur Zeit größte Alternativnetz Undernet11 . Die neuen Netze sind vor allem entstanden, weil die großen Netze zu groß, langsam und fehleranfällig geworden sind. Aktuell sind auf den Servern Benutzerzahlen von 50000 Usern oder mehr keine Seltenheit mehr. 8 http://www.efnet.net http://www.ircnet.net 10 http://www.quakenet.eu.org 11 http://www.undernet.org 9 176 19.3 Verwendung 19.3.2 Strukturen im IRC Der Nick Nachdem ein User sich mit einem IRC-Server verbunden hat, muss er einen eindeutigen Nickname auswählen. Es ist nicht möglich, dass innerhalb eines IRC-Netzes mehrerer User den gleichen Nickname haben. Dies hat Vorteile, aber auch Nachteile. Ein Vorteil ist, dass ein User immer eindeutig anhand seines Nicknames zu identifizieren ist, ein Nachteil besteht jedoch darin, dass es teilweise zu regelrechten “Nick Wars“ kommt, wenn sich zwei User um einen Nickname streiten. Zum Beispiel versucht die eine Person möglichst immer vor der anderen das IRC zu betreten, um so seinen Nick für sich zu belegen. Oder sie versucht möglichst immer im IRC zu bleiben, auch wenn sie in Wirklichkeit gar nicht anwesend ist. Ein weiteres Problem besteht auch darin, dass zwar jeder Nickname nur einmal im IRC existieren kann. Doch selbst durch einen auf den User ausgeführten Whois-Befehl kann nicht garantiert werden, dass man sich mit dem gleichen User wie am letzten Tag unterhält. Eine Zeit lang gab es Überlegungen, ob es sinnvoll und machbar wäre, Nicknames zu registrieren und zu schützen. Dabei sollte eine Ident-Abfrage beim Connect auf den Server den Benutzer identifizieren und somit sicherstellen, dass auch nur er den entsprechenden Nicknamen wählen kann. Dazu müsste aber auch jeder Server in dem entsprechenden IRC-Netz die Informationen über die Nutzer immer verfügbar haben, um den Ident-Lookup erfolgreich auszuführen und mit den Daten zu vergleichen. Da jedoch der Aufwand nicht dem Nutzen gerecht wird, bieten die meisten Netze diese Funktion nicht an. Client-to-Channel Messaging Wie oben schon kurz erwähnt, dienen innerhalb eines IRC-Netzes Chaträume, genannt Channels, zum Austausch der Nachrichten zwischen den IRC-Teilnehmern. Eine Nachricht, die ein User in einen Channel sendet ist für jeden anderen User, der sich auch gerade in dem betreffenden Channel aufhält, lesbar. Jeder User hat die Möglichkeit, einem Channel beizutreten12 oder auch einen neuen Channel zu formen13 . Natürlich ist es möglich (und durchaus üblich) sich in mehreren Channels gleichzeitig aufzuhalten. Das IRCNet hat zum Beispiel mehr als 40000 offene Channels im Durchschnitt. Es gibt fast zu jedem Thema einen oder meist mehrere Channels. Der Name eines Channels muss immer eine Zeichenkette sein. Er darf keine Leerzeichen oder manche Sonderzeichen enthalten. Vor dem Channel-Namen muss grundsätzlich entweder eine # oder ein & stehen. Mit # beginnende Channel sind von allen Servern erreichbar. Ein mit einem & beginnender Channel ist nur von dem Server aus erreichbar, auf dem er geöffnet wurde. 12 13 /join [<channel>] /join [<noch nicht existierender Channel>] 177 19 Internet Relay Chat (IRC) Beispiel: /server irc.fu-berlin.de Verbindet den Client mit dem Server /join #newTestChan Erstellt den Channel #newTestChan auf dem Server irc.fu-berlin.de. Jeder User im gesamten IRCNet kann jetzt mit dem gleichen Kommando dem Channel beitreten, somit auch User, die mit dem Server irc.freenet.de verbunden sind. /join &newTestChan Erstellt den Channel &newTestChan auf dem Server irc.fu-berlin.de. Nur User die auch direkt auf irc.fu-berlin.de angemeldet sind, können diesem Channel beitreten. Für andere ist er nicht erreichbar. Wenn sie das Kommando eingeben würden, würde der gleiche Channel auf ihrem Server geöffnet. Der Operator-Status Wenn jemand einen neuen Channel eröffnet, bekommt er den “OP-Status“, und ist damit “Owner“ des Channels. Damit ist dieser der Channel-Operator. Der Operator ist durch ein @ vor dem Nickname gekennzeichnet. Der Operator kann zum Beispiel mit dem mode-Befehl bestimmte Attribute für seinen Channel setzen oder anderen Clients in diesem Channel den OP-Status verleihen. Er kann den Channel auch mit einem Passwort versehen, ihn unsichtbar machen oder ihn moderieren – das bedeutet nur User, denen er Voice (ein + vor dem Nick) erteilt hat, können in diesem Channel Nachrichten senden. Zudem kann ein Channel-OP User aus dem Channel werfen oder sogar bannen. Der Channel-OP genießt in seinem Channel eine gewisse Allmacht. Missbraucht er diese, hat man die Möglichkeit, sich bei einem Server-Admin zu beschweren. Die Server-Admins sind die sogenannten IRC-OPs. Sie stellen die höchste Machtinstanz im IRC da und haben alle Rechte, so können sie auch Channel-OPs, die ihre “Macht“ missbrauchen, den Operator-Status entziehen. Bei manchen Usern hat sich mittlerweile eine Art Sport daraus entwickelt, in möglichst vielen Channels den OP-Status zu bekommen, sozusagen als IRC-Statussymbol. Dies führt oft zu Problemen. So zum Beispiel im Falle der Channel-takeover-Versuche oder zu ängstlich reagierenden Channel-OPs. Es kann durchaus vorkommen, dass diese beim geringsten Verdacht mit einem Kickban reagieren, um ihren Channel zu schützen. Das bedeutet, das ein User aus dem Channel geworfen wird, und unmittelbar aus diesem Channel für eine bestimmte Zeitspanne verbannt wird. Das bedeutet, dass er keine Möglichkeit mehr hat, den Channel nach dem kick zu betreten, bis der Ban aufgehoben wird. Client-to-Client Messaging Wie im Kapitel “Sendemöglichkeiten“ auf Seite 175 beschrieben, bietet das IRC neben der Möglichkeit eine Nachricht an alle User im Channel zu senden, auch die Möglichkeit, Nachrichten an nur 178 19.3 Verwendung einen oder oder mehrere User zu senden. Den gebräuchlichsten Weg stellen die Befehle /msg und /query dar. Der Befehl /msg sendet eine Nachricht zu dem angegebenen User, oder auch durch “,“ getrennt an eine Liste von Usern. Im Gegensatz zu dem Befehl /msg ist es mit /query nicht möglich, an eine Liste von User zu senden, sondern nur genau an einen anderen User. /query öffnet ein neues Message-Fenster, in welchem der gesamte Nachrichtenaustausch stattfindet. Normalerweise tauschen sich zwei User per /query aus, der Befehl /msg wird in der Regel zum Senden einer kurzen Nachricht oder eines Befehls an ein Script oder an einen Bot genutzt. DCC - Direct Client Connect Eine weitere Möglichkeit die das IRC bietet, ist der DCC (Direct Client Connect). Mit Hilfe des DCC-Protokolls können zwei User eine direkte Peer-to-Peer Verbindung zum “sicheren“ chatten oder Datentransfer ohne Einbindung des Servers öffnen. Sendet ein User eine DCC-Anfrage an einen anderen User, leitet der Server die Verbindung ein, indem er die IP-Adresse des anderen Users weitergibt und der DCC dann über eine direkte Peerto-Peer Verbindung aufgebaut wird. Der angefragte User bekommt in diesem Fall (bei den meisten Client-Programmen) eine Warnmeldung, dass eine direkte Verbindung aufgebaut wird, die nicht mehr über den IRC-Server verfolgt und kontrolliert werden kann. Somit ergibt sich die Gefahr, schädliche Daten zu empfangen. Ein User sollte sich immer genau vergewissern, wer ihm eine DCC-Anfrage sendet, um diese Gefahr zu minimieren, denn auf diesem Wege werden viele Viren, Trojaner und schädliche Scripte verteilt. Der DCC ist hauptsächlich sehr beliebt, weil er es ermöglicht Daten zu versenden, die kein bestimmtes Format haben müssen. Durch den DCC ist es im IRC also auch möglich nicht nur zu kommunizieren, sondern auch Dateien zwischen Usern zu transferieren. Der zweite große Vorteile des DCCs liegt darin, das er nicht über Server geroutet wird. Dadurch müssen weniger Stationen überbrückt werden – das “Lag“ wird minimiert und die Datenpakete können wesentlich schwerer verändert oder angezapft werden. CTCP - Client-To-Client Protocol Der DCC stand am Anfang seiner Entwicklung in direkter Konkurenz zu dem CTCP (Client-ToClient Protocol). Dieses Protokoll wurde ursprünglich entwickelt, um Dateien über das IRC zu übertragen, konnte sich aber nicht gegen den DCC durchsetzten. Heute wird das CTCP ausschließlich zum Senden einfacher Anfragen an einen anderen Client benutzt. CTCP wird z.B. eingesetzt, um bei einem anderen Client die lokale Zeit, die benutzte Version und Implementierung abzufragen. Eine der wohl bekanntesten CTCP Funktionen ist das Kommando /ping. Ein Pingliefert einem User eine Information darüber zurück, wie lange eine Message von einem Client zum anderen braucht. Der /ping-Befehl sendet einfach nur ein Signal, auf das ein Client automatisch mit einem Pong! antwortet. Genauso wie bei dem DCC läuft eine CTCP-Verbindung nicht über einen IRC-Server, sondern wird 179 19 Internet Relay Chat (IRC) nur durch ihn vermittelt. Alle weiteren Übertragungen erfolgen auf direktem Wege von Client zu Client. Deshalb sind seine Eigenschaften analog zu denen des DCC. Kommando und Funktionsübersicht Alle IRC-Clientprogramme benutzen dieselben Kommandos, die an den Server weitergegeben und nicht lokal verarbeitet werden. In diesem Abschnitt werden die wichtigsten Kommandos aufgelistet. • /server [<servername>] broadcast Mit diesem Befehl verbindet sich der Client mit dem angegebenen Server. • /list [-<options>] [<channel>] local Der list-Befehl gibt eine Liste sämtlicher Channels zurück, die im jeweiligen IRC-Netz existieren. Dabei besteht die Möglichkeit, die Liste zu filtern. Mögliche Optionen sind: – min <n> - listet alle Channels mit minimal n Benutzern. – max <n> - listet alle Channels mit maximal n Benutzern. – public - listet alle öffentliche Channels. – private - listet alle private Channels. – topic - listet Channels, die ein Topic gesetzt haben. – wide - stellt die Liste in einer kompakteren Form dar. Zusätzliche kann man die Channels mit weiteren Optionen (-name oder -users) nach Channelnamen oder Benutzerzahl sortieren lassen. • /lusers [<server>] local /lusers gibt an, wieviele User, Operatoren, Server und Channel es zur Zeit im IRC gibt. Dabei ist es möglich, diesen Befehl nur für einen bestimmten Server auszuführen oder alle Server anzufragen. • /motd [<server>] local oder unicast Dieser Befehl fragt die message of the day des angegebenen Servers ab. In dieser stehen wichtige Verhaltensregeln und wichtige Broadcast-Nachrichten. • /admin [<server>] local oder unicast Durch /admin wird die Liste aller momentan auf einem Server anwesenden IRC-Operatoren angezeigt. • /ping [<nick/channel>] unicast oder multicast Der Ping-Befehl misst die Antwortzeit eines Signals, das an einen anderen IRC-Clients oder Server gesendet wird. Er wird eingesetzt um zu überprüfen, ob überhaupt eine Verbindung zu einem anderen Client/Server besteht und wie lange die Nachrichtenübermittlung benötigt. Er funktioniert also genau so wie der vom Betriebssystem her bekannte Ping-Befehl. Wird ein Channelname angegeben, verhält sich der Befehl, als ob man jeden User in diesem Channel einzeln anpingt. • /join [<channel>] broadcast Dieser Befehl dient dazu, einem Channel beizutreten. • /part [<channel>] broadcast Mit /part verlässt man den Channel wieder. 180 19.4 Probleme und Risiken des IRC • /nick [<nick>] broadcast Der Befehl /nick dient dazu, seinen Usernamen zu ändern. Da viele User oft ihren Nick wechseln, wird dadurch eine hohe Netzlast erzeugt. Unter Umständen kann es somit durchaus einige Zeit dauern, bis der Befehl ausgeführt wird. • /msg [<nick>] [<Nachricht>] unicast Ein /msg schickt die betreffende Nachricht nur an den User, dessen Nick angegeben ist. • /query [<nick>] unicast Ein Query stellt eine Verbindung mit einem anderen User her – man könnte ihn also als eine Art privaten Chatraum beschreiben. Er ist die Erweiterung des /msg-Befehls. Der Query wird anders als der DCC-chat14 über einen oder mehrere Server verwaltet. • /whois [<nick>] local Der Whois-Befehl bietet Informationen über den betreffenden User. Er liefert den Namen des Users (falls angegeben), die Host-Mask (Einwahlmaske), in welchen Channels der User sich aufhält und wie lange der User inaktiv (idle) ist. Er ist die Erweiterung des /who-Befehls, der genauso funktioniert. Jedoch liefert /who nur den Namen. Ergänzend dazu gibt es auch noch den /whowas-Befehl, welcher für kurze Zeit nachdem ein User das IRC verlassen hat dieselben Informationen bereitstellt. • /dns [<nick>] unicast Mit /dns kann man sich die IP-Adresse des angegebenen Users anzeigen lassen. • /kick [<nick>] broadcast Dieser Befehl ist den Channel- oder IRC-Operatoren vorbehalten und entfernt den betreffenden User aus dem Channel oder von dem Server. Zumeist wird dieser Befehl aufgrund unangemessenen Verhaltens angewandt. Bei groben Vergehen auch gefolgt oder verbunden mit einem /ban. Dies bedeutet die Verbannung vom Server/Channel und die IP-Adresse des gebannten Users wird gesperrt bis der Ban aufgehoben wird. • /dcc [<command>] [<arguments>] unicast Der DCC-chat stellt eine Besonderheit im IRC-Netz dar, weil die Verbindung direkt zwischen den Clients (Peer-to-Peer) aufgebaut wird und ohne Server funktioniert. Sie ist somit am “sichersten“. Zudem gibt es wie schon erwähnt mit den Kommandos send und get die Möglichkeit, Dateien zu senden und zu empfangen. Es existieren noch wesentlich mehr Befehle, jeden hier aufzunehmen würde den Rahmen sprengen und ist nicht Ziel dieser Ausarbeitung. Beispielsweise kann man noch die Kommandos /topic, /mode, /lastlog, /ignore, etc. nennen. Die hier beschriebenen Befehle reichen aber vollkommen aus, um sich im IRC einigermaßen gut zurecht zu finden. 19.4 Probleme und Risiken des IRC 19.4.1 Aktuelle Probleme Das IRC hat mit einigen wesentlich Problemen unterschiedlicher Art zu kämpfen: 14 siehe DCC, Seite 179 181 19 Internet Relay Chat (IRC) Überlastung Das wohl größte Problem des IRC-Netzes besteht darin, dass sich das Protokoll mittlerweile als nicht leistungsfähig genug erweist, um den großen Benutzeransturm stand zu halten und es zu einer regelrechten Überlastung des Netzes kommt. 1991 waren im Durchschnitt nur 250 User im IRC gleichzeitig aktiv. Schon 1994 waren es dann um die 5000 und schließlich mittlerweile über 80000. So kann es in den wirklich großen Netzen passieren, dass eine Nachricht 20 Sekunden bis hin zu über einer Minute braucht, bis sie von einem Client bis zum anderen gelangt. Netsplit Bedingt durch die Überlastung einzelner Server kommt es immer wieder und besonders zu Spitzenzeiten vermehrt zu sogenannten Netsplits. Das bedeutet, dass ein Server ausfällt oder die Verbindung zu einem anderen Server verliert. Die Verbindung muss dann entweder neu geroutet werden oder die eine Seite ist solange von der anderen abgeschnitten, bis der Server wieder verfügbar ist. Daraus resultiert natürlich, dass ein User 1, der mit dem Server 1 verbunden ist, die Verbindung zu User 2 und 3 verliert, wenn diese sich auf einem anderen Server (Server 2) befinden und Server 1 und 2 die Verbindung verlieren. Jedoch können sich User 2 und 3 weiterhin verständigen.(Siehe Grafik 19.2) Hohe Netzlast Für den einzelnen User ist die vom IRC verursachte Netzlast (genannt Traffic) verschwindend gering, jedoch haben die Server, vor allem die hoch frequentierten und zentralen, ein sehr hohes TrafficAufkommen. Das liegt zum einen an der Tatsache, dass das IRC kostenlos ist und zum anderen an der Fehlkonzipierung des Protokolls für solche Benutzerzahlen. So manchen Netzbetreibern wurde der durch den IRC-Service erzeugte Traffic zu hoch, was unter anderem auch zur Abspaltung des IRCNets vom EFNets führte. Langsam entspannt sich die Lage wieder, da sich mittlerweile mehrere kleine Netze erfolgreich etablieren konnten und sich so die Last nicht auf ein Netz alleine stützt. Nach und nach implementieren die Netze auch Verbesserungen im Protokoll und führten strengere Regeln für das Aufhalten im IRC ein. So sind z.B. in manchen Netzen automatisierte Scripte und Bots nicht erlaubt oder User werden nach einer gewissen Zeit der Inaktivität vom Server getrennt. Ebenso ist auf fast allen Servern so genanntes Flooding verboten, oder zumindest nicht gern gesehen. Tausch von illegalen Materialien Ein weiteres Problem stellt sich für das IRC in rechtlicher Hinsicht, da es bekannterweise rege zum Tausch von illegalem Material eingesetzt wird. Viele große Warez-Groups 15 betreiben IRCChannel, in denen im großen Stil Daten gehandelt werden. Im IRC ist das Nachvollziehen solcher Datentransfere noch schwerer als es bei den bekannten Tauschbörsen á la Napster oder dem Gnutella15 Tauschringe für raubkopierte Software, Filme und Musik 182 19.4 Probleme und Risiken des IRC Netzwerk ist. Dies ist um so ärgerlicher, da durch die großen Dateien erheblich der Traffic damit die Probleme erhöht werden. 16 und Sicherheit Ein weiteres zentrales Problem der IRC-Netze ist die Sicherheit. Da dem IRC-Protokoll das TCP/IPProtokoll zu Grunde liegt, hat es fast die gleichen Probleme. Für Geübte stellt es kein Problem dar, Nachrichten mitzulesen, zu verändern oder über das IRC in einem Rechner einzubrechen, wenn auf diesem keine besonderen Vorsichtsmaßnahmen getroffen worden sind. Im folgenden Abschnitt sind die häufigsten Risiken aufgelistet. Für genauere Beschreibungen und Lösungsvorschläge (Schutzmaßnahmen und ähnliches) bietet sich die FAQ von IRChelp.org17 an. • Trojaner Trojaner/trojanische Pferde sind in soweit eine Gefahr, wenn der IRC-User nichts ahnend alle ihm zugesandten Dateien speichert und bestenfalls noch ausführt. Die schädigende Wirkung dürfte eigentlich allgemein bekannt sein. Doch sogar in beliebten Scriptsammlungen finden sich ab und zu Trojaner. • Denial of Service Attacks Solche sogenannten Nukes stellen in den seltensten Fällen eine wahre Gefahr für den User da, zumal es kaum vorkommt, dass ein solcher Angriff auf einen kleinen Heimcomputer verübt wird. • Backdoors In manchen Clients (jedoch vornehmlich in öffentlich verbreiteten Scripten) sind Backdoors eingebaut, die dem Angreifer ermöglichen, in den Client oder gar in das System seines Opfers einzubrechen. Auch hier gilt jedoch, dass ein vorsichtiger Umgang mit Scripten dieses Risiko minimiert – wenn nicht sogar ganz ausschließt. Auf allen guten Script-Seiten und auch auf IRChelp.org befinden sich Listen mit solchen “unsicheren“ Scripten und Clients. 16 17 siehe 19.4.1 http://www.irchelp.org/irchelp/security/ 183 19 Internet Relay Chat (IRC) 184 Literaturverzeichnis [1] Paul Albitz und Cricket Liu. DNS and BIND. O’Reilly & Associates, Inc., 4. Auflage (2001). [2] Fred Baker. Requirements for IP Version 4 Routers. Request for Comments 1812, Internet Engineering Task Force (1995). [3] R. Braden, D. Borman und C. Partridge. Computing the Internet checksum. Request for Comments 1071, Internet Engineering Task Force (1988). [4] Robert Braden. Requirements for Internet Hosts - Communication Layers. Request for Comments 1122, Internet Engineering Task Force (1989). [5] Scott Bradner. Key words for use in RFCs to Indicate Requirement Levels. Request for Comments 2119, Internet Engineering Task Force (1997). [6] Scott O. Bradner. The Internet Standards Process. Request for Comments 2026, Internet Engineering Task Force (1996). [7] Douglas Comer und David L. Stevens. Internetworking with TCP/IP, Band 1. Prentice Hall, 4. Auflage (2000). [8] Stephen E. Deering. ICMP Router Discovery Messages. Request for Comments 1256, Internet Engineering Task Force (1991). [9] Roy T. Fielding, James Gettys, Jeffrey C. Mogul, Henrik Frystyk Nielsen, Larry Masinter, Paul J. Leach und Tim Berners-Lee. Hypertext Transfer Protocol – HTTP/1.1. Request for Comments 2616, Internet Engineering Task Force (1999). [10] Ross Finlayson, Timothy Mann, Jeffrey Mogul und Marvin Theimer. A Reverse Address Resolution Protocol. Request for Comments 903, Internet Engineering Task Force (1984). [11] Ian S. Graham. The HTML Sourcebook. John Wiley & Sons (1996). [12] Katie Hafner und Matthew Lyons. Where Wizards Stay Up Late – The origins of the Internet. Simon & Schuster (1996). [13] Heiko Holtkamp. Einführung in TCP/IP (1997). URL http://www.rvs.uni-bielefeld.de/~heiko/tcpip/ 185 Literaturverzeichnis [14] Christophe Kalt. Internet Relay Chat: Architecture. Request for Comments 2810, Internet Engineering Task Force (2000). [15] Christophe Kalt. Internet Relay Chat: Channel Management. Request for Comments 2811, Internet Engineering Task Force (2000). [16] Christophe Kalt. Internet Relay Chat: Client Protocol. Request for Comments 2812, Internet Engineering Task Force (2000). [17] Christophe Kalt. Internet Relay Chat: Server Protocol. Request for Comments 2813, Internet Engineering Task Force (2000). [18] Christopher A. Kent und Jeffrey C. Mogul. Fragmentation Considered Harmful. In Proc. SIGCOMM ’87, Band 17. ACM (1987). [19] Tobias Klein. Linux Sicherheit. Security mit Open-Source-Software – Grundlagen und Praxis. dpunkt-Verlag, 1. Auflage (2001). [20] Tracy Mallory und A. Kullberg. Incremental updating of the Internet checksum. Request for Comments 1141, Internet Engineering Task Force (1990). [21] Paul Mockapetris. Domain Names – Concepts and Facilities. Request for Comments 1034, Internet Engineering Task Force (1987). [22] Paul Mockapetris. Domain Names – Implementation and Specification. Request for Comments 1035, Internet Engineering Task Force (1987). [23] U.S. Department of Energy. Domain Name Service Vulnerabilities (1996). URL http://ciac.llnl.gov/ciac/bulletins/g-14.shtml [24] David C. Plummer. An Ethernet Address Resolution Protocol. Request for Comments 826, Internet Engineering Task Force (1982). [25] Jon Postel. User Datagram Protocol. Request for Comments 768, Internet Engineering Task Force (1980). [26] Jon Postel. Internet Control Message Protocol. Request for Comments 792, Internet Engineering Task Force (1981). [27] Jon Postel. Internet Protocol. Request for Comments 791, Internet Engineering Task Force (1981). [28] Jon Postel, Yakov Rekhter und Tony Li. Best Current Practices. Request for Comments 1818, Internet Engineering Task Force (1995). [29] Jon Postel und Joyce K. Reynolds. Instructions to RFC Authors. Request for Comments 2223, Internet Engineering Task Force (1997). [30] Anil Rijsinghani. Computation of the Internet Checksum via Incremental Update. Request for Comments 1624, Internet Engineering Task Force (1994). [31] Bernhard Röhrig. Linux im Netz – Das Standardwerk zu LAN und WAN. C & L Computeru. Literaturverlag, 2. Auflage (1999). [32] Ellen Siever. Linux in a Nutshell. O’Reilly Verlag, 2. Auflage (1999). [33] Richard W. Stevens. TCP/IP Illustrated, Band 1. Addison-Wesley (2000). [34] Richard W. Stevens. TCP/IP Illustrated, Band 2. Addison-Wesley (2000). [35] Richard W. Stevens. TCP/IP Illustrated, Band 3. Addison-Wesley (2000). [36] Gerhard Stummer. Adaptionsmechanismen verteilter Multimedia-Internetanwendungen. Diplomarbeit, Johannes Kepler Universität Linz (2001). 186 Literaturverzeichnis [37] Jürgen Suppan-Borowka. Ethernet-Handbuch. DATACOM-Buchverlag (1987). [38] Andrew S. Tanenbaum. Computer Networks. Prentice Hall (1996). [39] Andrew S. Tanenbaum. Computernetzwerke. Pearson (2000). 187