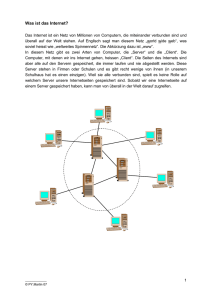
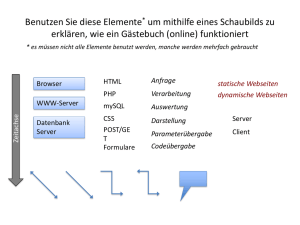
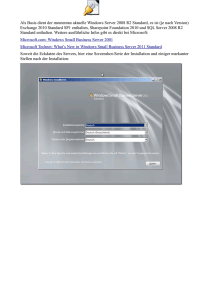
State-of-the-Art von Verschlüsselungstechniken für
Werbung

Institut für Wirtschaftsinformatik Prof. Dr. Gottfried Vossen State-of-the-Art von Verschlüsselungstechniken für Database-as-a-Service Bachelor Arbeit Betreuer: Vorgelegt von: Dr. Jens Lechtenbörger Guido Hirth [email protected] Abgabetermin: 2011-10-10 -I- Inhaltsverzeichnis 1 Einleitung ...........................................................................................................................1 2 Grundlagen.........................................................................................................................2 2.1 Database-as-a-Service.................................................................................................2 2.1.1 Definition ...........................................................................................................2 2.1.2 Vertrauensmodell ...............................................................................................3 2.1.3 Anforderungen...................................................................................................5 2.2 Kryptographie .............................................................................................................5 2.2.1 AES – Ein symmetrisches Kryptosystem..........................................................5 2.2.2 RSA – Ein asymmetrische Kryptosystem .........................................................7 2.2.3 Homomorphismen .............................................................................................8 2.3 Kryptoanalyse ...........................................................................................................13 2.4 Structured Query Language ......................................................................................16 3 Verschlüsselungsschemata zur sicheren Abfrage externer Daten ....................................19 3.1 Index-Verfahren.........................................................................................................19 3.1.1 Hashbasierendes Verfahren..............................................................................21 3.1.2 B+ -Bäume........................................................................................................25 3.1.3 Partitionierende Verfahren ...............................................................................28 3.2 Selektive Verschlüsselung .........................................................................................30 3.3 Homomorphe Verschlüsselung .................................................................................33 3.4 Kryptographische Hardware .....................................................................................34 4 Verschlüsselungskonzepte mit Proxy-Unterstützung .......................................................36 4.1 Abfrage angepasste Verschlüsselung ........................................................................36 4.2 Mehr-Benutzer Szenario ...........................................................................................37 5 Analyse der vorgestellten Verfahren ................................................................................42 6 Proof-of-Concept Implementierungen .............................................................................46 6.1 CryptDB ....................................................................................................................46 6.2 TrustedDB .................................................................................................................47 7 Zusammenfassung und Ausblick .....................................................................................50 Literaturverzeichnis ...............................................................................................................II Verzeichnis von Web-Adressen ........................................................................................... IX -1- 1 Einleitung Datenbanksysteme sind ein immer wichtiger werdendes Werkzeug in Organisationen. Ihre Bedeutung wird durch die zunehmende weltweite Vernetzung noch stärker wachsen. Gleichzeitig wird der systematische Einsatz von Datenbanksystemen wegen der zunehmenden Informationsmenge, der steigenden Komplexität der Anwendungen und der erhöhten Leistungsanforderungen immer schwieriger. Viele Organisationen setzten deshalb vermehrt serviceorientierte Architekturen ein bzw. lagern die komplette technische Infrastruktur aus. Sie kaufen sich diese Leistungen bei Dienstleistungsanbietern ein und erwerben eine Databaseas-a-Service, lassen also das Datenbanksystem oder Teilfunktionen davon von einem Dritten extern betreiben. Das Paradigma des Database-as-a-Service geht auf [HIM02] zurück. Die Autoren beschreiben im Jahr 2002 schon wegweisend: “The technological aspects of developing database as a service lead to new research challenges. First and foremost is the issue of data privacy.” [HIM02, S. 30] Es existieren mittlerweile zahlreiche Forschungsrichtungen zu dem Thema Database-as-aService, die beispielsweise die Geschwindigkeit und die Skalierbarkeit betrachten. Ein fundamentales Problem in diesem Kontext ist jedoch vor allem die Sicherheit der Daten. So sollen beispielsweise sensible und geschäftsrelevante Daten bei einem Anbieter hinterlegt werden, ohne vollkommene Sicherheit über die Vertrauenswürdigkeit des Anbieter zu haben. Neben den Datendiebstahl durch Dritte ist auch der unautorisierte Zugriff durch Administratoren der Anbieter (vgl. [7]) ein kritisches Hemmnis. Die Daten müssen also nicht nur vor den üblichen Angriffen durch nicht autorisierte Instanzen geschützt werden, sondern vielmehr auch vor dem Dienstleistungsanbieter selbst. Dies geschieht durch adäquate Sicherheitsmaßnahmen, insbesondere durch den Einsatz von Verschlüsselungstechniken, deren aktueller Stand und Funktionsweisen in dieser Arbeit vorgestellt werden soll. In Kapitel 2 werden für diese Arbeit notwendige Grundlagen erläutert. Dabei wird zunächst das Paradigma Database-as-a-Service erläutert, dann wichtige kryptographische Grundlagen ausgeführt und anschließend die Abfragesprache SQL weiter beleuchtet. In Kapitel 3 und 4 werden unterschiedliche Verschlüsselungsverfahren vorgestellt, wobei Kapitel 4 das Szenario um eine weitere Instanz, den Proxy, erweitert. Im folgenden Kapitel 5 werden die Verfahren analysiert. In Kapitel 6 werden dann zwei Proof-of-Concept Implementierungen präsentiert, die einen Teil der vorgestellten Verschlüsselungsschemata einbetten. Die Arbeit endet mit einem Fazit und Ausblick. -2- 2 Grundlagen 2.1 Database-as-a-Service 2.1.1 Definition Das Paradigma des Database-as-a-Service wurde geprägt von [HIM02], die das Prinzip der serviceorientierten Architektur auf Datenbanksysteme übertrugen. Die Ideen des ursprünglichen Application-Service-Provider-Modells (ASP) sind in dem heutigen Begriff des CloudComputing aufgegangen. Ein Anwender lagert dabei seine IT bzw. Teile von dieser an einen Dienstleister aus, um so Kosten zu sparen. Er spart dabei insbesondere die Wartungs- und Entwicklungskosten für die Rechenzentren und kann spontan benötigte Ressourcen in der Regel beliebig und dynamisch hinzufügen. Er zahlt dabei nur die im Endeffekt benötigten Ressourcen (Pay-per-Use). Der Anbieter hingegen versucht seinen Gewinn über entsprechende Skaleneffekte zu erzielen. Eine Cloud-Dienstleistung ist dabei folgendermaßen charakterisiert (vgl. [HV10]): • Gemeinsame Nutzung physischer Ressourcen Verschiedene Nutzer/Mandanten nutzen die gleichen Ressourcen (Multi-Tenancy). • Unverzügliche Anpassbarkeit an den Ressourcenbedarf Der Cloud-Anbieter passt die für den Nutzer aktiven Ressourcen dynamisch entsprechend der Auslastung an. • Selbstbedienung nach Bedarf Der Nutzer kann benötigte Ressourcen jederzeit beliebig selbstständig aktivieren. • Umfassender Netzwerkzugriff Die Bandbreite des Anbieters muss groß genug sein, um die Dienste sinnvoll nutzen zu können. • Messung der Servicenutzung Die tatsächliche Ressourcennutzung muss genau berechnet werden können, dies ist für die nutzungsbezogene Bezahlung nötig. Es existieren zahlreiche verschiedene Dienstleistungen in der Cloud, die unter dem Begriff Anything-as-a-Service (XaaS), gemäß eines passenden Suffixes zusammengefasst werden. Nach der Definition des National Institute of Standards and Technology (NIST) [8] lassen sich die folgenden drei Hauptbegriffe herausstellen: -3- • Software-as-a-Service (SaaS) • Platform-as-a-Service (PaaS) • Infrastructure-as-a-Service (IaaS) SaaS-Anbieter stellen Software zur Verfügung, die ein Nutzer sofort und in der Regel über einen Webbrowser benutzen kann. Anbieter von PaaS erlauben es dem Nutzer eigene Software auf einer bereitgestellten Platform ausführen zu können. Im Gegensatz dazu stellen IaaS nur grundlegende Funktionen, wie Back-Ups etc. sowie eigentliche Rechenleistung zur Verfügung, die dann vom Nutzer selber weiter verwaltet werden muss. Das in dieser Arbeit fokussierte Paradigma des Database-as-a-Service kann nicht ausschließlich einer der Kategorien zugeordnet werden, sondern erstreckt sich vielmehr über die verschiedenen Ebenen und lässt sich nur bei konkreten Implementierungen einzeln einordnen. Der Begriff Database-as-a-Service wird in dieser Arbeit als DaaS abgekürzt. In der Literatur wird vielfach auch die Abkürzung DAS verwenden, was jedoch nicht dem sonst in der Cloud-Umgebung üblichem XaaS-Schema entspricht. Auch die Abkürzung DBaaS ist öfter aufzufinden, da das Kurzwort DaaS auch im Bereich der reinen Datenspeicherung für Dataas-a-Service verwendet wird. Die Bezeichnung ODB(S) für outsourced database (system) hat sich nicht durchgesetzt. DaaS ist ein duales Konzept, da es sowohl wirtschaftliche Konzepte sowie technische Konzepte berücksichtigt (vgl. [Lan09]). Aus wirtschaftlicher Sicht erhält der Nutzer eine genaue leistungsbezogene Abrechnung, die Möglichkeit Dienstgütevereinbarungen abzuschließen und die Dienste beliebig und berechenbar zu skalieren. Aus technischer Sicht erhält der Nutzer Datenbankfunktionalitäten. Dies können einzelne Teilfunktionalitäten oder Gesamtkonzepte sein. Es muss insbesondere möglich sein, ein Datenmodell vorgeben zu können und über eine Abfragesprache, meist SQL (vgl. Kapitel 2.4), auf hinterlegte Daten zuzugreifen. 2.1.2 Vertrauensmodell In dem DaaS-Szenario treten folgende verschiedene Akteure auf: • Dateninhaber: Der Dateninhaber ist die Person, die im Besitz der Daten ist, diese zur Nutzung freigibt und evtl. Berechtigungen für die Datenzugriffe bestimmt (Lese-, Schreibrechte). -4- • Nutzer: Der Nutzer stellt die Abfragen an die Datenbank.1 • Server/Anbieter: Der Anbieter stellt einen Server zur Verfügung, über den er Datenbankfunktionalität anbietet. Der Dateninhaber und die Nutzer sind in diesem Zusammenhang Vertrauenswürdigkeit zu unterstellen, denn sie sind der Auftraggeber und autorisierte Nutznießer. Der Server hingegen ist nicht vollkommen vertrauenswürdig. In dem DaaS Kontext führt er zwar alle Anweisungen des Nutzers und Dateninhabers korrekt aus, indem er die richtigen Tupel entsprechend einer Anfrage zurück gibt ohne diese zu verändern und indem er sich um die ordentliche Speicherung der Daten etc. kümmert. Er gilt jedoch als honest-but-curious. Denkbar ist beispielsweise, dass der Server sensible Daten für persönliche Zwecke sammelt und auswertet, um diese an Dritte weiter zu verkaufen. Dem Server wird also die Ausführung von passiven Attacken vorgeworfen. In Kapitel 4 wird darüber hinaus noch eine weitere Instanz eingeführt, nämlich ein ProxyServer. • Proxy: Ein Proxy-Server vermittelt zwischen dem Nutzer und dem Server. Der Proxy-Server wird entweder auch von einem dritten Dienstleistungsanbieter betrieben oder vom Nutzer selbst, gilt jedoch in beiden Fällen als vertrauenswürdig. Im Unterschied zu einem DaaS-Anbieter kann einem Proxy-Anbieter eher vertraut werden, weil nur sehr kleine Datenmengen geschützt werden müssen, sodass keine umfangreiche DatenbanksystemFunktionalität angeboten werden muss. Zudem ist dem Anbieter eines Proxys nicht unbedingt bewusst, was auf dem Server ausgeführt wird, wohingegen ein DaaS-Anbieter schon deutlich zweckspezifischer ist (vgl. [DRD11]). Alle anderen Randbedingungen werden hier als sicher unterstellt und nicht weiter betrachtet. Zum Beispiel wird die Verbindung zwischen den unterschiedlichen Akteuren als sicher angesehen (Ende-zu-Ende). Es wird darüber hinausgehend nicht weiter auf das Forschungsfeld des Private Information Retrieval (PIR) eingegangen, das u.a. Abfrageschemata komplett verbirgt.2 1 2 Wenn der Begriff “Nutzer“ nicht im Kontext einer Abfrage an eine Datenbank fällt, ist der Nutzer der Vertragspartner für den Anbieter, also auch synonym zu Dateninhaber. Für einen Einstieg sei auf [CKGS98] und [OS07] verwiesen. -5- 2.1.3 Anforderungen Trotz der beschriebenen Vorteile durch den Einsatz von DaaS-Konzepten, darf das Augenmerk auf die Datensicherheit nicht verloren gehen (vgl. [WAF11]), insbesondere wenn es sich um geschäftskritische Daten handelt. Ein Nutzer kann zwar davon ausgehen, dass der Anbieter alle Anweisungen korrekt ausführt. Er kann jedoch entweder den Implementierungen von Sicherheitsmaßnahmen seitens des Anbieters nicht vertrauen oder dem Anbieter böswillige Absichten unterstellen. Um einen sicheren Einsatz zu gewährleisten, müssen deshalb folgende Kriterien von der Dienstleistung des Anbieters erfüllt werden (vgl. [KL10]): • Vertraulichkeit: Der Anbieter erhält keine Informationen über die Daten. • Integrität: Daten müssen in unveränderter Form vorliegen. Jeder nicht autorisierte Zugang zu den Daten wird erkannt. • Authentizität: Die Integrität und Herkunft der Daten muss beweisbar sein. Jeder Zugriff auf die Daten wird protokolliert. • Verfügbarkeit: Ein berechtigter Nutzer kann zu jeder Zeit auf die Daten zugreifen. • Zuverlässigkeit: Die Daten werden zuverlässig gesichert (back-up). • Effizienz: Der Zugriff muss in vergleichbarer Zeit wie in herkömmlichen selbst betriebenen Datenbanken erfolgen. Der Schwerpunkt dieser Arbeit liegt auf der Vertraulichkeit der in Kapitel 2.1.1 beschriebenen grundlegenden Konzepte, nämlich die verschlüsselte Hinterlegung der Daten und deren Abfrage. Dabei sollen zu jeder Zeit möglichst viele der Berechnungen bzw. Abfragen beim Anbieter bearbeitet werden. Die weiteren Anforderungen sind nicht Bestandteil dieser Arbeit, auch wenn insbesondere die Effizienz stark von dem gewählten Verfahren abhängig ist (vgl. Kapitel 5). 2.2 Kryptographie 2.2.1 AES – Ein symmetrisches Kryptosystem Die Abkürzung AES steht für Advanced Encryption Standard und ist ein Vertreter der symmetrischen Kryptosysteme. Symmetrische Verschlüsselungen sind dadurch gekennzeichnet, dass beide Teilnehmer den gleichen Schlüssel verwenden. Klartexte besitzen in der Regel -6- unterschiedliche Längen, jedoch erwarten Verschlüsselungsverfahren in der Regel feste Eingabegrößen. Klartexte werden deshalb in entsprechende Einheiten (Blöcke oder Zeichen) gruppiert. Man teilt die symmetrischen Verfahren deshalb weiter in Blockchiffren-basierte Verfahren und Stromchiffren (Zeichen für Zeichen) auf (vgl. hier und im Folgenden [Eck09] und [Ert07]). AES ist seit dem Jahr 2000 der direkte Nachfolger des Data Encryption Standard (DES), ist eine symmetrische Blockchiffre mit fester Blocklänge von 128 Bit und hat eine Schlüssel k mit der Länge von wahlweise 128, 192 oder 256 Bit. Jeder Block wird in eine interne Darstellung als Form einer 4x4-Matrix umgewandelt, wobei jeder Eintrag der Matrix 8 Bit groß ist (4 ∗ 4 ∗ 8 = 128). Diese Matrix wird als state bezeichnet. Jeder Block wird mehrfach wiederholend (mehrere Runden) mit derselben Abfolge von Funktionen bearbeitet. Für jede Runde wird aus dem symmetrischen Schlüssel ein sogenannter Rundenschlüssel abgeleitet (Schlüsselexpansion), der dann vor und nach jeder Runde über ein exklusives Oder mit dem Block verknüpft wird. Jede Runde kann dann grob folgendermaßen beschrieben werden: • Substitution: Jedes Byte aus der Matrix wird mit Hilfe einer Substitutionschiffre ersetzt. Eine solche Chiffre ersetzt jedes Zeichen eines Alphabets in ein dazu entsprechendes Zeichen aus einem anderen Alphabet. Ein Byte kann 28 = 256 Ausprägungen annehmen, die dazugehörige Transformationen lassen sich also effizient in einer Look-Up Tabelle speichern, der s.g. S-Box. • Permutation: Die Einträge einer Zeile der Matrix werden nach links verschoben. Dabei wird jede Zeile i ∈ {0,1,2,3} um i Stellen verschoben. Dieser Vorgang wird als ShiftRow-Transformation bezeichnet. • Diffusion: Nach der Zeilentransformation erfolgt nun die Spaltentransformation der Matrix, die s.g. MixColumn-Transformation. Dies erfolgt durch eine Multiplikation der Matrix mit einem Vektor, der Polynome enthält und so die Einträge der Spalten der Matrix in Wechselwirkung treten lässt. Jedes Bit ist somit von dem Schlüssel abhängig, die Substitution ist stark resistent und durch die Transformationen erfolgt eine sehr gute Durchmischung. Für eine AES-Verschlüsselung mit einer Schlüssellänge von 128 Bit werden zum Zeitpunkt dieser Arbeit 16 Runden empfohlen [1]. Da alle Schritte/Transformationen invertierbar sind, erfolgt die Entschlüsselung durch Anwendung der entsprechenden Inversen in umgekehrter Reihenfolge. Die einfachste Art Blockchiffren zu verwenden, besteht darin, die einzelnen Blöcke jeweils für sich nach obigem Schema zu verschlüsseln. Dieser Stil wird electronic codebook (ECBModus) genannt, da eine Art Tabelle mit Klartext-Chiffre-Paaren erstellt werden kann. Ein -7- Angreifer kann allerdings in bestimmten Szenarien Teile der Chiffre durch Ersetzen von Blöcken manipulieren. Bei einer Banküberweisung mit immer gleichen Sender und Empfänger könnte ein Angreifer beispielsweise den Block mit dem sich nur ändernden Betrag versuchen zu manipulieren. Die einzelnen Blöcke werden deshalb in der Regel vorher miteinander verknüpft, z.B. durch das cipher block chaining (CBC-Modus). Jeder Block wird dabei erst mit dem Chiffretext seines Vorgängers verkettet und dann erst verschlüsselt: ci = Enck (ci−1 ⊕ mi ) Die Verschlüsselung des ersten Blocks erfolgt unter einem vereinbarten Startwert c0 , der als Initialisierungsvektor (IV) bezeichnet wird. Es existieren zahlreiche weitere Betriebsmodi für Blockchiffren. 2.2.2 RSA – Ein asymmetrische Kryptosystem Das RSA-Verfahren ist benannt nach seinen Erfindern Rivest, Shamir und Adleman und ist ein Vertreter der asymmetrischen Verfahren. Die zentrale Idee eines asymmetrischen Verfahren ist die Einführung eines Schlüsselpaares für jeden Nutzer. Jedem Nutzer wird ein geheimer Schlüssel sk (Private-Key) und ein öffentlicher pk (Public-Key) zugewiesen, wobei der öffentliche Schlüssel allen anderen Nutzern bekannt ist. Klartexte werden vom Sender mit dem öffentlichen Schlüssel des Empfängers verschlüsselt. Nur dieser kann dann den Chiffretext unter Verwendung seines geheimen Schlüssels entschlüsseln. Ein Nutzer muss also in Abgrenzung zur symmetrischen Verschlüsselung nicht unterschiedliche Schlüssel für jeden anderen Nutzer zur verschlüsselten Kommunikation vorhalten. Asymmetrische Verfahren bestehen in der Regel aus zwei elementaren Teilen: der Schlüsselerzeugung und dem eigentlichen Verschlüsselungsalgorithmus (vgl. hier und im Folgenden [Eck09] und [Ert07]). Schlüsselerzeugung: Der private und öffentliche Schlüssel müssen von einander abhängen. Zur Berechnung der Schlüssel werden sogenannte Einweg-Funktionen verwendet, damit vom öffentlichen Schlüssel keine Rückschlüsse auf den privaten Schlüssel gezogen werden können. Eine Einweg-Funktionen f : X −→ Y ist dadurch gekennzeichnet, dass für alle x ∈ X der Funktionswert f (x) effizient berechenbar ist und es umgekehrt kein effizientes Verfahren gibt, dass aus dem Bild y = f (x) das Urbild x berechnen kann. Das RSA-Verfahren benutzt das Faktorisierungsproblem als Einwegfunktion: Die Berechnung einer Multiplikation von zwei sehr großen Primzahlen p und q kann effizient erfolgen, allerdings ist für die Primfaktorzerlegung großer Zahle – also des Ergebnisses – kein effizientes Verfahren bekannt. Da laufend neue Verfahren entwickelt werden, die solche Zerlegungen für immer größere Zahlen immer schneller erledigen, wird aktuell eine Länge des entstehenden Produkts von > 2048 Bit empfohlen [BBB+ 11]. Der Ablauf für die Schlüsselgenerierung kann nun folgendermaßen beschrieben werden: -8- • Wähle zwei zufällige Werte für p und q mit den oben genannten Eigenschaften und berechne pq = n. • Wähle eine natürliche Zahl d ∈ [0, n − 1], sodass gilt ggT (ϕ(n), d) = 1, wobei ϕ(n) = (p − 1)(q − 1). Empfohlen wird dabei max(p,q) < d < ϕ(n) − 1. • Berechne e als Lösung der Gleichung ed mod ϕ(n) = 1. e entspricht also der multiplikative Inverse modulo ϕ(n) zu d. • Gib das Zahlenpaar pk = (e,n) als öffentlichen Schlüssel bekannt und halte sk = (d,n) als privaten Schlüssel geheim. Verschlüsselungsalgorithmus: Die Verschlüsselung eines Klartextes m erfolgt durch die Berechnung c = mei mod n, wobei ei der öffentliche Schlüssel des Empfängers i ist. Der Empfänger kann nun wiederum durch die Berechnung cdi mod n = m den Klartext rekonstruieren. Für einen anderen Nutzer ist die Entschlüsselung des Chiffretextes c nicht möglich aufgrund des Problems des diskreten Logarithmus. Für eine Funktion ax mod n = y ist kein effizientes Verfahren bekannt, das zu gegebenen y mit dem diskreten Logarithmus x = loga y mod n bestimmen kann. 2.2.3 Homomorphismen Eine homomorphe Verschlüsselung erlaubt es einem Nutzer aus zwei (oder mehreren) Chiffretexten einen neuen Chiffretext zu gewinnen, der dem chiffrierten Ergebnis einer algebraischen Funktion über den Klartexten der Chiffretexte entspricht. Dabei werden weder die Klartextdaten noch die verwendeten Schlüssel sichtbar. Seien (A,◦g ) und (B, ◦h ) zwei Gruppen, so wird eine Abbildung f : A −→ B Homomorphismus genannt (vgl. [BSMM08]), wenn für alle x,y ∈ A gilt: f (x ◦g y) = f (x) ◦h f (y) Für eine additive homomorphe Verschlüsselung (beispielsweise [Pai99]) gilt: Dec( f (Enc(x),Enc(y))) = x + y Eine multiplikative homomorphe Verschlüsselung ist z.B. die RSA Verschlüsselung aus Kapitel 2.2.2. -9- Eine besondere Familie der homomorphen Verschlüsselungen stellen die vollhomomorphen Verschlüsselungsschemata dar (Fully Homomorphic Encryption – FHE). Bei diesen Homomorphismen sind die Operationen nicht auf eine einzelne Funktion (entweder Addition oder Multiplikation) beschränkt, wie dies in Abgrenzung dazu bei den partiellhomomorphen Verschlüsselungen (Somewhat Homomorphic Encryption – SHE) der Fall ist. Die vollhomomorphen Verschlüsselungen erlauben vielmehr die Ausführung einer beliebigen Funktion auf die Chiffredaten. Ein homomorphes Verschlüsselungsschema ε besteht aus den vier Algorithmen KeyGenε , Encryptε , Decryptε und Evaluateε . In einem asymmetrischen Verschlüsselungsschema generiert KeyGenε in Abhängigkeit von λ (wobei λ ein Sicherheitsparameter ist, der die BitLänge der Schlüssel angibt) einen privaten Schlüssel sk und einen öffentlichen Schlüssel pk.3 Dem Evaluateε Algorithmus ist eine Menge erlaubter Funktionen Fε zugeordnet. Für eine Funktion f ∈ Fε und einem Chiffretext ci = Encrypt(pk, mi ) erstellt dieser einen neuen Chiffretext c = Evaluate(pk , f , c1 , . . . ,ct ), sodass gilt: Decrypt(sk, c) = f (m1 ,...,mt ). Ziel eines homomorphen Verschlüsselungsschemas in einem DaaS-Szenario ist es, Berechnungen (Evaluateε ) auszulagern und diese von einem Dritten durchführen zu lassen. Es gelten deshalb folgende Anforderungen: • Alle Algorithmen müssen effizient im Sinne einer polynomiellen Laufzeit poly(λ ) sein; auch Evaluateε soll effizient im Sinne einer polynomiellen Laufzeit für den ServiceAnbieter sein. • Die Entschlüsselung von ci = Encrypt(·) und c = Evaluate(·) muss die gleiche Rechenkapazität benötigen (wird vom Client durchgeführt). • Die Chiffretextlänge von c und ci muss identisch sein (compact ciphertexts). c muss also unabhängig von f immer die gleiche Chiffretext-Größe und EntschlüsselungsKomplexität haben. Die Komplexität von Evaluateε ist ersichtlicherweise auch abhängig von f . f wird in homomorphen Verschlüsselungen als Schaltkreis dargestellt. Insbesondere Angaben wie a = b ? c : d für boolsche Zuweisungen können nicht ausgewertet werden, da die Werte verschlüsselt sind. Man nutzt deshalb die bitweise Binäroperationen, die dann als Schaltkreis dargestellt werden. Das Beispiel würde dann in a = (b AND c) OR ((NOT b) AND d) entsprechend umgeschrieben werden. Die Darstellung der Funk3 Es sind auch symmetrische homomorphe Verschlüsselungsschemata möglich. - 10 - tion als Schaltkreis hat zudem den Vorteil, dass es für eine homomorphe Verschlüsselung ausreicht, die elementaren Funktionen Addition, Subtraktion und Multiplikation zu beherrschen.4 Für die Berechnung der Komplexität von f wird die Anzahl der Gatter der Schaltkreisfunktion bestimmt. Dabei gilt Evaluateε als effizient, wenn ein polynomielles g(λ ) existiert, sodass die Komplexität in O(S f ∗ g(λ )) liegt, wobei S f die Anzahl der AND-, OR- und NOT-Gatter von f entspricht. [RAD78] waren die Ersten, die vollhomomorphe Schemata für die nahe Zukunft voraussagten. Erst [Gen09] stellt allerdings einen Entwurf für eine vollhomomorphe Verschlüsselung vor. Im Folgenden soll ein davon abgeleitetes Schema (vgl. [DGHV10] und [Gen10]), das allerdings nur Berechnungen von ganzen Zahlen ermöglicht, skizzenhaft vorgestellt werden. Zur Vereinfachung wird an dieser Stelle mit einer symmetrischen Variante begonnen. Eine Umwandlung eines symmetrischen in ein asymmetrisches Verfahren und umgekehrt ist nach [Rot11] immer möglich. In Abhängigkeit von dem Sicherheitsparameter λ gilt: N = λ , P = λ 2 , Q = λ 5 . • KeyGenε (λ ): generiert einen zufälligen P-bit langen Schlüssel p, der ungerade ist. • Encryptε (p,mi ): verschlüsselt ein Bit mi ∈ {0,1} mit ci = p ∗ q + (2r + mi ), wobei q eine Q-bit lange Zufallszahl und r eine Zufallszahl ist, sodass (2r + mi ) N-bit lang ist. (2r + mi ) wird dabei als Rauschen (noise) bezeichnet, welches nachfolgend näher beschrieben wird. • Homomorphe Grundoperationen: Addε (c1 ,c2 ) → c = c1 +c2 , Subε (c1 ,c2 ) → c = c1 −c2 , Mulε (c1 ,c2 ) → c = c1 ∗ c2 • Evaluate( f ,c1 ,..,ct ): wandelt die als Schaltkreis dargestellte Funktion f in eine Funktion f˜ um, indem alle Gatter aus f mit den entsprechenden homomorphen Grundoperationen vertauscht werden. Sie erzeugt dann den Chiffretext c = f˜(c1 ,...,ct ) • Decryptε (p,c): berechnet das Klartext-Bit m = (c mod p) mod 2. Die Berechnung der Funktion kann vereinfacht werden durch die äquivalente Funktion m = LSB(c) ⊕ LSB(bc/pe), weil p ungerade ist, wobei b·e die Rundung zur nächsten ganzzahligen Zahl darstellt und LSB(·) das niedrigstwertige Bit (least significant bit) ist. Das Rauschen ist also die Differenz zum nächsten Vielfachen von p. Es muss gelten, dass dieses Rauschen kleiner als p ist, da sonst das Ergebnis durch die Verschlüsselung verfälscht wird (c mod p). Bei jeder Operation innerhalb von Evaluateε erhöht sich das Rauschen allerdings. Im schlimmsten Fall erhöht sich das Rauschen quadratisch durch Anwendung von Multε ; bei der Verwendung von Addε verdoppelt es sich. Operationen sind also nur möglich, 4 AND(x,y) = xy, OR(x,y) = 1 − (1 − x)(1 − y), NOT (x) = 1 − x - 11 - solange das Rauschen kleiner als p/2 ist. Für c1 ∗ c2 gilt beispielsweise c = (. . .) ∗ p + (2r1 r2 + r1 m2 + m1 r2 ) ∗ 2 + m1 m2 Mit Decryptε (p,c) −→ (c mod p) mod 2 ergibt sich daher m = m1 ∗ m2 Dieses Verschlüsselungsschema kann bereits Polynome bis zum Grad d mit t Variablen berechnen, für die gilt: (︀ )︀ 2N∗d dt < p/2 Dies gilt ungefähr, wenn d < P/(N log(t)). 5 Das Schema wird als sicher angesehen, da es auf dem NP-schweren Problem des approximate gcd (vgl. [Sch85]) basiert, welches nicht in polynomieller Laufzeit gelöst werden kann. Die oben gewählten Parameter N, P und Q stellen dies sicher. Bootstrapping Bei dem bisher vorgestellten Verfahren handelt es sich um ein partiellhomomorphes Verschlüsselungsschema, da das Rauschen nach einiger Zeit zu groß wird. [Gen09] führt deshalb den Begriff und das Verfahren des Bootstrapping ein. Dies wird zunächst im allgemeinen erläutert und anschließend auf das eben vorgestellte Verschlüsselungsschema ε angewandt. Ziel des Bootstrapping ist es, das Rauschen zu reduzieren, um weitere Operationen ausführen zu können. Die einzige Funktion, die das Rauschen vermindert und das aktuelle Ergebnis erhält ist genau eine Decrypt-Funktion. Ein Schema ist also bootstrapable, wenn Decrypt ∈ F. Eine Evaluate Methode kann somit auch Decrypt verarbeiten. Das Verschlüsselungsschema ist folglich selbstreferenzierend in dem Sinne, dass es auch die eigenen Funktionen des entsprechenden Verschlüsselungsschemas ausführen kann. Dies ermöglicht es, das Rauschen wieder auf das Anfangsrauschen einer Encryptε Funktion zu reduzieren. Die Ent- und Wiederverschlüsselung muss allerdings so geschehen, dass zu keiner Zeit irgendjemand Zugriff auf die Klartextdaten erhält. Für die folgende konzeptionelle Erklärung wird an dieser Stelle ein asymmetrisches Verfahren verwendet. ̂︁i = Encrypt(pki+1 ,ski ) ist der private Schlüssel ski verschlüsselt unter pki+1 , dabei ist i die sk entsprechende Ebene der Schaltkreisfunktion, wenn die Gatter topologisch geordnet sind. Die eigentliche Funktion, die das Umverschlüsseln vornimmt, also das Rauschen entfernt, ̂︁i , ci ) ist: Recrypt(pki+1 ,Decrypt,sk Diese erstellt zunächst eine weitere Verschlüsselung über das schon bereits verschlüsselte ci : ĉ︀i = Encrypt(pki+1 , ci ). ̂︁i ,̂︀ Recrypt ruft dann in einem zweiten Schritt die Methode Evaluate(pki+1 , Decrypt, sk ci ) auf. Diese berechnet zunächst den Schlüssel ski , mit dem ci verschlüsselt ist. Sie benutzt dann diesen Schlüssel dazu, ci in m umzuwandeln. Das geschieht homomorph innerhalb der 5 Die Bitfolge (bn−1 , . . . , b0 ) wird dabei interpretiert als die Koeffizienten des Polynoms Poly(x) vom Grad n − 1: Poly(x) = bn−1 ∗ xn−1 + ... + b0 ∗ x0 (Beispiel: 11001 ≡ x4 + x3 + 1) Es handelt sich hier mathematisch um einen Ring der Polynome x über dem Körper (0,1) (vgl. [Kow06]). - 12 - darüber liegenden Verschlüsselung ĉ︀i . Die innere Verschlüsselung ist damit aufgehoben, der Klartext nur noch unter der äußeren Schicht verschlüsselt und das Rauschen entfernt. Die Enschlüsselungsfunktion wird also auf der inneren Schicht aufgerufen – es wird dabei zu jeder Zeit auf verschlüsselten Daten gearbeitet. Der Chiffretext soll allerdings nicht nur neu umverschlüsselt werden, sondern es sollen vielmehr Operationen darauf ausgeführt werden. Deshalb wird die Decrypt Funktion in soweit zu einem D erweitert, dass diese auch zusätzlich noch eine kleine Berechnung ausführt. So wird die Berechnung sukzessiv über die Schaltkreisfunktion ausgeführt. Das oben vorgestellte Verfahren ist bisher noch nicht bootstrappable, da die Berechnung von Decryptε noch zu komplex ist mit m = LSB(c) ⊕ LSB(bc/pe). Die LSB(·) Funktion und der XOR Operator sind trivale Funktionen, allerdings stellt sich die Berechnung von bc/pe als zu kompliziert dar. Es handelt sich in diesem Fall um die Multiplikation von den Zahlen c und 1/p, die beide P-bit lang sind. Dabei kann das neu erhaltende Polynom bis zu P Grade haben. Wie oben angemerkt, kann das Schema allerdings nur Polynome vom Grade d < P/(N log(t) berechnen. Die Funktion Decryptε wird deshalb insoweit geändert, dass sie nicht mehr zwei große Zahlen, sondern nur eine Menge kleiner Zahlen multipliziert und diese dann aufsummiert. Diese Summe entspricht dann dem Ergebnis bc/pe. Es ergibt sich somit das folgende finale Schema Z, das hier vereinfachend auf die Funktionen des obigen Schemas ε zurückgreift: • KeyGenZ (λ ): erzeugt über KeyGenε (λ ) die Schlüssel (pkε ,skε ). Erzeugt dann eine Menge ~y = (y1 , . . . ,yβ ), wobei yi ∈ [0,2), sodass für eine Teilmenge S ⊆ {1, . . . ,l} gilt: ∑︀ i∈S yi ≈ 1/p mod 2. Erzeuge nun skZ , wobei dies eine Verschlüsselung von S in Form eines Vektors ~s ∈ {0,1}β ist, und pkZ als das Paar (pkε ,~y). • EncryptZ (pkZ , m): extrahiert pkε und ~y aus pkZ . Erzeugt dann ci mit Encryptε (pkε ,m) und berechnet eine Menge~x = (x1 , . . . ,xβ ), wobei xk = ci ∗ yk , ∀yk ∈~y. Die Funktion gibt nun den Chiffretext c als (ci , x) zurück. • EvaluateZ : entspricht Evaluateε . • DecryptZ (skZ , c): extrahiert S aus skZ , sowie ci und x aus c. Berechnet nun ∑︀ ∑︀ ∑︀ m = LSB(c) ⊕ LSB(b i si ∗ xi e). Dies gilt, da: i si ∗ xi = i c ∗ si ∗ yi = c ∗ 1/p mod 2. Hervorzuheben ist, dass in der Encrypt Funktion schon ein Teil der Berechnung von Decrypt vorweggenommen wird und so eine Art Zwei-Phasen-Verschlüsselung entsteht. Das hier beschriebene Schema Z ist nun vollhomomorph: Die DecryptZ Funktion ist von der Komplexität so gering, sodass die EvaluateZ Methode diese auch verwerten kann (Bootstrapping) und so das Rauschen zu jeder Zeit verringern kann. Das Vorgehen, die Berechnung der Entschlüs- - 13 - selungsfunktion nach obigen Prinzip zu vereinfachen, wird in der Literatur als Squashing the Decryption Circuit bezeichnet. Das Schema gilt als sicheres Verschlüsselungsschema, obwohl pkZ bereits Hinweise auf skZ enthält, da die Aufteilung auf dem NP-schweren Untermengensummen-Problem (sparse subset sum) basiert (vgl. [CLRS10]). 2.3 Kryptoanalyse Dieser Abschnitt soll einen Überblick über die Sicherheit von Verschlüsselungsverfahren bieten. Nach dem Kerckhoffschen Prinzip [Ker83] sollte die Stärke eines Verfahrens nur auf der Geheimhaltung des Schlüssels liegen und nicht auf der Geheimhaltung des Algorithmus. Da die Algorithmen deshalb in der Regel von ihren Autoren veröffentlicht werden, ist es das oberste Ziel der Angreifer, hieraus Rückschlüsse auf den verwendeten Schlüssel zu erlangen. Die Sicherheit eines Verschlüsselungsschema lässt sich in der Regel durch zwei Merkmale bestimmen: welche Angriffsszenarien werden durchgeführt und welche Informationen gelangen dabei an den Angreifer (vgl. hier und im Folgenden [BNS10]). Grundsätzlich unterscheidet man folgende Angriffsszenarien: • COA - ciphertext only attack: Der Angreifer erhält verschiedene Chiffretexte, die alle mit demselben Schlüssel verschlüsselt sind. • KPA - known plaintext attack: Der Angreifer kennt über die verschiedenen Chiffretexte hinaus auch noch eine Menge zugehöriger Klartexte. • CPA - chosen plaintext attack: Der Angreifer hat in diesem Szenario die Möglichkeit, einen beliebigen Klartext in einen Chiffretext verschlüsseln zu lassen (dies geschieht durch eine dritte Partei, der Angreifer hat keinen Zugriff auf den Schlüssel). • CCA - chosen ciphertext attack: Der Angreifer erhält zu einer von ihm vorgeschlagenen Menge an Chiffretexten die dazugehörigen Klartexte. Die vorgestellten Angriffsszenarien können weiter untergliedert werden in direkte und adaptive Angriffe. Führt der Angreifer seinen Angriff aus, erkennt er erst dann eines der oben beschriebenen Szenarien und agiert entsprechend, dann handelt es sich um einen direkten Angriff. Kennt der Angreifer allerdings schon bereits im Vorhinein die Angriffsmöglichkeit und kann er den Angriff entsprechend anpassen, handelt es sich um einen adaptiven Angriff. Sicher im Sinne der Ununterscheidbarkeit ist ein Schema, wenn ein Angreifer zwei Nachrichten m1 und m2 verschlüsseln lässt, er nur einen der beiden Chiffretexte zurückerhält und - 14 - er durch seinen Angriff keine weiteren Informationen erlangen konnte, die eine Zuordnung von einem der beiden Klartexte zu dem Chiffretext ermöglichen. Dieses Problem ist auch als Ciphertext Indistinguishability (IND) bekannt. Ein Kryptosystem gilt als sicher, wenn es unter einem adaptiven CCA ununterscheidbar ist (IND-CCA); in diesem Szenario darf der Angreifer allerdings nicht den erhaltenden Chiffretext entschlüsseln lassen, sondern nur andere Chiffrate. Die Trefferwahrscheinlichkeit, das richtige mi zu wählen, beträgt dann für einen Algorithmus A des Angreifers: Pr[A(m0 , m1 , c) = m | c = Enck (m), m ∈ {m0 , m1 }] = 0,5 Die Wahrscheinlichkeit, die richtige Wahl nach einem Angriff (a posteriori) zu treffen, ist also genauso so hoch wie vor dem Angriff (a priori). Da eine solche perfekte Sicherheit für einen Datensatz der Länge n allerdings auch einen Schlüssel der Länge n benötigt, ist der Sicherheitsbegriff nicht für die Praxis geeignet. Es wurde deshalb das Konzept der praktischen Sicherheit eingeführt. Ein Verfahren wird als praktisch sicher bezeichnet, wenn „der Aufwand zur Durchführung der Kryptoanalyse die Möglichkeiten eines jeden denkbaren Analsysten übersteigt und die erforderlichen Kosten den erwarteten Gewinn bei weitem übertreffen“ [Eck09, S. 299]. Ein Analysealgorithmus gilt als effizient, wenn er ein Problem in polynomieller Laufzeit berechnen kann. Umgekehrt gilt natürlich, dass ein sicheres Verschlüsselungsverfahren auf einem NP-schweren Problem basieren muss, damit gerade kein entsprechend effizienter Analysealgorithmus existiert.6 Ein Verfahren, das praktisch sicher ist, sollte zudem folgende Konstruktionsprinzipien verfolgen (vgl. [Eck09]): • Partitionierung: Der Schlüsselraum eines Schemas darf nicht partitionierbar sein. Würde sich der Schlüsselraum z.B. bei jedem Analyseschritt halbieren, reduziert sich der Suchaufwand bei n Schlüsseln auf log(n). • Diffusion: Jedes Chiffrezeichen sollte von möglichst vielen Klartextzeichen, sowie dem gesamten Schlüssel abhängen, damit die statistischen Besonderheiten des Klartextes ausgeglichen werden. • Konfusion: Der Zusammenhang zwischen dem Klartext, dem Schlüssel und dem Chiffretext sollte so komplex wie möglich gehalten werden. • Klartextangriffe: Ein Verschlüsselungsschema sollte IND-CCA sicher sein. Zwei Konzepte dienen zur Definition der praktischen Sicherheit: polynomielle Ununterscheidbarkeit und semantische Sicherheit. 6 Aufgrund der Worst-Case Vorgehensweise fällt ein Algorithmus bereits dann in die Klasse NP, wenn seine Berechnung für eine Eingabe einen nicht-polynomiellen Aufwand erfordert. Ist aber der Aufwand für andere Eingaben polynomiell, so kann das zugrunde liegende Verschlüsselungsschema gebrochen werden. - 15 - Ein Chiffriersystem ist polynomiell ununterscheidbar, wenn ein Angreifer zwei Nachrichten wie oben generiert und deren Chiffrate in polynomieller Zeit nicht unterscheiden kann. Sicher im Sinne einer polynomiellen Ununterscheidbarkeit ist ein Schema, wenn der Angreifer bei der obigen Berechnung eine Wahrscheinlichkeit von 0,5 + ν(λ ) erhält, wobei für einen wachsenden Sicherheitsparameter λ (λ entspricht der Länge des Schlüssels) der Ausdruck ν(λ ) gegen 0 konvergiert und somit vernachlässigbar ist. Je größer die Schlüssellänge demnach ist, desto näher liegt die Erfolgswahrscheinlichkeit an der Ratewahrscheinlichkeit. Das Konzept der semantischen Sicherheit ähnelt dem der perfekten Sicherheit. Die semantische Sicherheit wird zur Definition der Public-Key Sicherheit verwendet. Ob ein Klartext m eine bestimmte Eigenschaft aufweist, sei durch die Funktion h(m) −→ {0,1} erklärt. Es gilt dann für zwei verschieden Angreifer mit den Algorithmen A und B: Pr[A(λ , c, PK) = h(m)] ≤ Pr[B(λ ,PK) = h(m)] + ν(λ ) Jeder Angreifer A kann also nur unwesentlich bessere Aussagen über den Klartext machen, als ein Angreifer B, der keinen Chiffretext kennt. Die beiden Konzepte stehen in einer engen Beziehung. Ein Public-Key Schema ist polynomiell ununterscheidbar, wenn es semantisch sicher ist (vgl. [MRS88]). Damit ein Verfahren polynomiell sicher ist, muss es die Verschlüsselung durch Hinzufügen von Zufallsrauschen oder die entsprechende Auswahl eines Initialisierungsvektors bei einer Blockchiffre zufällig gestalten. Die Funktionen sind dann probabilistisch und erzeugen entsprechende Verteilungen über die Chiffretexte. Der Informationsgehalt einer Nachricht wird nach [Sha01] durch die so genannte Entropie beschrieben. Der Informationsgehalt und der dazugehörige Entropiewert stehen dabei in einem umgekehrten Verhältnis zueinander. Die Entropie einer Nachricht ist also maximal, wenn die Chiffretext-Werte gleichverteilt sind. Die Entropie beträgt dann Hmax = log(n). Je mehr eine Quelle von der maximalen Entropie abweicht, desto günstiger stehen die Chancen, dass aus einer Menge von Klartexten derjenigen, welcher am wahrscheinlichsten ist, tatsächlich zum beobachteten Chiffretext passt. Je mehr Informationen über die Chiffre- und Klartexte bekannt sind, desto unsicherer ist ein Verschlüsselungsschema. Ein Beispiel für eine Caesar-Verschlüsselung soll dies verdeutlichen: Ein solches Schema verschiebt ein Alphabet um eine bestimmte Anzahl von Stellen. Der in der deutschen Sprache am häufigsten verwendete Buchstabe ist das E. Angenommen, in dem chiffrierten Text würde der Buchstabe G am häufigsten vorkommen. Das G ist der siebte Buchstabe im Alphabet und E ist der fünfte Buchstabe im Alphabet. Es erscheint also als sehr wahrscheinlich, dass der verwendete Schlüssel 2 ist, also alle Buchstaben um zwei Buchstaben nach rechts verschoben wurden. Generell probiert ein Brute-Force Angreifer alle möglichen Schlüssel nach absteigender Wahrscheinlichkeit nacheinander aus und versucht so, den passenden Schlüssel für das Verfahren zu finden. Bei langen Schlüsseln und einem damit verbundenen großen Suchraum wird das Verfahren allerdings schnell sehr ineffizient. Angreifer bedienen sich deshalb einer Vielzahl anderer Methoden. Bekannte Vertreter sind u.a. die lineare und die differenzielle - 16 - Kryptoanalyse. Die lineare Kryptoanalyse basiert auf der linearen Annäherung an den wahrscheinlichsten Schlüssel, die differenzielle Analyse untersucht die Auswirkungen von Differenzen in Klartextblöcken auf die Differenzen in den Chiffretextblöcken. Einen Einstieg für verschiedene Kryptoanalyse-Methoden bietet [SL07]. 2.4 Structured Query Language Die Structured Query Language (SQL) ist eine Datenbanksprache zur Definition, Abfrage und Manipulation von Daten in relationalen Datenbanken. SQL ist von ANSI und ISO standardisiert und wird von gängigen Datenbanksystemen unterstützt. Der Sprachumfang von SQL beinhaltet vier Kategorien (vgl. [MKF+ 03]): • Data Definition Language (DDL) beschreibt, wie Datenbanktabellen angelegt, geändert oder gelöscht werden (CREATE, ALTER, DROP). • Data Manipulation Language (DML) beschreibt, wie schreibende und manipulierende Zugriffe auf eine Datenbanktabelle wirken (INSTERT, UPDATE, DELETE). • Data Query Language (DQL) wird oftmals auch mit der DML zusammengefasst. Die DQL beschreibt nur die reinen lesenden Zugriffe auf eine oder mehrere Datenbanktabellen (SELECT). • Data Control Language (DCL) beschreibt, wie z.B. Zugriffsrechte in einer Datenbanktabelle vergeben oder entzogen werden können (GRANT, REVOKE) und ist u.a. auch für die referentielle Integrität der Daten verantwortlich. Im Folgenden soll ein kurzer Überblick über die Bestandteile der DQL gegeben werden, die insbesondere im Hinblick auf die Abfrage verschlüsselter, externer Daten interessant sind. Die Funktionalitäten einer lesenden Abfrage können unterteilt werden in Filterung, Aggregation und Verbund der Daten. Filterung: Eine Tabelle kann bezüglich der Werte ihrer Attribute gefiltert werden. Es werden nur die Daten angezeigt, deren Wert dem Suchbegriff entsprechen. Die Werte lassen sich dabei mit den folgenden Operatoren vergleichen: {= , < , > , ≤ , ≥, <>}. Der LIKE Operator untersucht ein Attribut auf ein bestimmtes Muster. Durch die Verwendung von boolschen Ausdrücken (AND, OR, NOT) kann die Filterung über die Attribute dabei beliebig kombiniert werden. Es existieren weitere vereinfachende Abfragen, beispielsweise die Bereichsabfragen (BETWEEN Operator), die Kombinationen aus den vorherigen Operatoren sind. Das folgende SQL-Beispiel demonstriert den Einsatz von Filtern: - 17 - SELECT * FROM ‘Person‘ WHERE Person.Stadt LIKE ‘%ster‘ AND Person.PLZ > 48147 AND Person.Hausnummer BETWEEN 50 AND 100; In dem Beispiel werden aus der Datenbankrelation Person all die Datensätze zurückgegeben, die den entsprechenden Bedingungen der Abfrage genügen: Die Person wohnt in einer Stadt, die den Wortteil “ster“ enthält, die Postleitzahl ist nummerisch größer als 48147 und die Hausnummer der Person liegt zwischen den Werten 50 und 100. Über ein ORDER BY Statement können die Daten entsprechend eines Attributs sortiert werden. Aggregation: Werden die Daten durch Operationen verdichtet, spricht man von einer Aggregation der Daten. Die wichtigsten Operatoren sind die Summe der ausgewählten Daten (SUM), die Anzahl der ausgewählten Tupel (COUNT) und der Durchschnittswert (AVG = SUM/COUNT). Hinzu kommen die Maximumsfunktion (MAX) und die Minimumsfunktion (MIN). Über das GROUP BY Statement können die Ausgaben entsprechend den Daten gruppiert werden. SELECT Person.Name, COUNT(Person.Name) FROM ‘Person‘ WHERE Person.Hausnummer BETWEEN 50 AND 100 GROUP BY Person.Name; In diesem Beispiel werden zunächst alle Personen betrachtet, deren Hausnummer zwischen den Werten 50 und 100 liegen. Für jeden Namen in dieser Datenbank wird nun eben dieser und die Häufigkeit des Auftretens zurückgegeben; es mögen beispielsweise 15 Personen mit dem Name Müller die Bedingung erfüllen, dann ist einer der Rückgabewerte Müller, 15. Verbund: Ein Verbund (JOIN) verknüpft zwei verschiedene Relationen miteinander. Ein wichtiges Differenzierungsmerkmal ist die Unterscheidung zwischen equi- und non-equiJoins. Die equi-Joins verbinden zwei Relationen über gleiche Werte (=). Ein non-equi-Join arbeitet über andere Vergleichsoperatoren (< , >). Die equi-Joins werden weiter unterschieden zwischen dem Inner- und dem Outer-Join. Der Inner-Join verknüpft Zeilen aus zwei Tabellen, wenn die zu verknüpfenden Werte in beiden Tabellen vorkommen. Ein Outer-Join verknüpft Zeilen aus zwei Tabellen, auch wenn die zu verknüpfenden Werte nur in einer Tabelle vorkommen.7 Ein SQL-Beispiel kann beispielhaft folgendermaßen aussehen: SELECT * FROM ‘Person‘ INNER JOIN ‘Abrechnung‘ ON Person.Name = Abrechnung.Name; 7 Über die relationale Algebra hinaus gibt es in SQL noch weitere Join-Typen. Eine Übersicht findet sich unter [2]. - 18 - Die Abfrage gibt eine neue Relation zurück, die die Attribute beider Tabellen von Person und Abrechnung enthält; sofern das Datenfeld Name beidseitig übereinstimmt, werden die entsprechenden Datensätze aus den Tabellen zeilenweise verbunden. Die bisher vorgestellten Funktionen werden zu den Begrifflichkeiten in Tabelle 2.1 zusammengeführt. Tabelle 2.1: SQL-Funktion Begriffsdefinition Operationen Begriff Vergleiche Identität Verhältnis/Bereich Suche = , <> <, ≤, >, ≥, BETWEEN LIKE Beschränkung Anzahl Summe Durchschnitt MAX, MIN COUNT SUM AVG Gleichheit Ungleichheit equi-JOIN non-equi-JOIN Aggregate Verknüpfung Auf den ersten Blick implizieren einige Funktionen andere, dies ist aber nicht unbedingt wahr, weshalb die Funktionen einzeln aufgelistet werden. Wird die Identitätsfunkion unterstützt, wird nicht zwangsweise eine Verknüpfung per Gleichheit zwischen zwei Tabellen unterstützt. Die Relationen können nämlich mit unterschiedlichen Schlüsseln verschlüsselt werden, weshalb gleiche Klartextwerte unterschiedliche Chiffrewerte in verschiedenen Tabellen aufweisen. Da selbst Datensätze innerhalb einer Tabelle mit unterschiedlichen Schlüsseln verschlüsselt werden können, wird auch COUNT nicht zwingend unterstützt, wenn die Identitätsfunkionen unterstützt wird. Die Durchschnittsfunktion AVG kann zwar durch SUM/COUNT berechnet werden, wird hier aber der Vollständigkeit halber auch aufgelistet. - 19 - 3 Verschlüsselungsschemata zur sicheren Abfrage externer Daten 3.1 Index-Verfahren Die Hinterlegung der Daten auf dem Server unter Verschlüsselung der gesamten Tabelle ist nicht zweckmäßig, da zumindest ein Teil der Abfrageverarbeitung auf dem Server stattfinden soll. Wird eine Tabelle als ganzes verschlüsselt, wird sie also durch einen einzigen Chiffretext dargestellt, muss der Server diesen Chiffretext immer komplett an den Client schicken, da er selber keine Informationen aus dem Chiffrat ziehen können darf. So kann der Server keine Abfragen selber über die Daten durchführen und müsste die komplette verschlüsselte Tabelle an den Client schicken, der dann selber die Abfrage durchführen würde. Bei den Indexverfahren wird deshalb eine Verschlüsselung auf Tupelebene empfohlen (vgl. [HIM02], [DVJ+ 03] und[YGJK10]). Erfolgt die Verschlüsselung der Daten allerdings auf Tupelebene, sind weitere Informationen nötig, um die Daten entsprechend einer Abfrage zu lokalisieren. Dies erfolgt intuitiv über die Einführung von so genannten Index-Sets für die einzelnen verschlüsselten Tupel, über die der Server Abfragen auswerten kann. Diese Indizes sind für die Namensgebung dieses Ansatzes verantwortlich. Für jedes relevante Attribut A, über das später Abfragen ausgewertet werden können soll, muss ein entsprechender Index diesem Set hinzugefügt werden. Jedes ursprüngliche Tupel t(A1 , . . . , An ) wird also bei der Hinterlegung auf den Server auf t 0 (Tk , I1 , . . . ,Im ), m ≤ n abgebildet, wobei t 0 [Tk ] den Verschlüsselungswert des kompletten Tupels t(·) (durch eine invertierbare Verschlüsselungsfunktion mit dem Schlüssel k) und Ii die Verschlüsselungswerte der einzelnen relevanten Attributausprägungen Ai darstellen, siehe dazu skizzenhaft die Tabellen 3.1 und 3.2. Tabelle 3.1: Klartext Tabelle 3.2: Verschlüsselt Gutschrift Kontonummer Betrag Enc_ Gutschrift ID Tk 27933 32846 69473 93457 1 2 3 4 awu9hak6 aba5kof3 oto1hok5 ado9nal8 350 400 100000 2500 I1 α β γ δ I2 ε ϑ κ λ Im Folgenden sollen die zugrunde gelegten Strukturannahmen für die Index-Verfahren beschrieben werden. Diese gehen auf [HIM02] zurück, die als erste die Abfrage verschlüsselter Daten in dem heutigen Database-as-a-Service-Szenario betrachteten. Auf Architekturebene wird hinsichtlich der Client-Seite weiter differenziert zwischen dem eigentlichen Nutzer, dem Inhaber der Daten und einer vertrauenswürdigen Zwischenschicht (trusted frontend). Die vertrauenswürdige Zwischenschicht nimmt dabei die Anfragen des Nutzers entgegen, - 20 - schreibt diese entsprechend um, leitet sie an den Server weiter und das Ergebnis dann später wieder an den Nutzer zurück. Der Nutzer muss sich daher nicht weiter um spezielle Abfragen für die verschlüsselten Daten kümmern. Der Prozess kann folgendermaßen skizziert werden (vgl. [For10]): 1. Der Nutzer sendet seine Abfrage Q im eigentlichen Klartext an die Zwischenschicht. 2. Die Zwischenschicht teilt die Abfrage Q in zwei Unterabfragen Qs und Qc auf. Dabei beinhaltet Qs alle Abfragen über die verschlüsselten Daten und Qc weitere Berechnungen darüber. Die Zwischenschicht sendet Qs nun an den Server. 3. Der Server bearbeitet Qs nun auf der verschlüsselten Datenbank und sendet die entsprechenden Tupel in ihrer verschlüsselten Form an die Zwischenschicht. 4. Die Zwischenschicht entschlüsselt zunächst die erhaltenden Tupel, führt nun Qc auf ihnen aus und sendet letztendlich das Ergebnis von Q als Klartext zum Nutzer. Die wichtigsten Schritte werden in Abbildung 3.1 dargestellt. Abbildung 3.1: Ablauf Indexverfahren Ziel der in diesem Unterkapitel vorgestellten Verfahren ist es, die in Qs hinterlegten Abfragen zu maximieren und die von Qc zu minimieren, um möglichst große Teile der Berechnungen zum Server zu verlagern (vgl. Kapitel 2.1.3). Damit die Zwischenschicht die Abfrage Q entsprechend umschreiben kann, muss diese entsprechende Metadaten über die Index-Set-Zuordnung vorbehalten. Die im Folgenden vorgestellten Verfahren unterscheiden sich insbesondere in der Erstellung der Indizes Ii . Am Ende jedes Unterkapitels werden für die verschiedenen Index-Verfahren jeweils exemplarisch gezeigt, wie die Tabelle 3.1 entsprechend in verschlüsselter Form auf dem Server - 21 - hinterlegt wird. Zudem wird beschrieben, wie die, von der vertrauenswürdigen Zwischenschicht umgeschriebene, neue Form der folgenden Abfrage an den Server lautet: SELECT Gutschrift.Kontonummer FROM ‘Gutschrift‘ WHERE Gutschrift.Betrag = 100000; Diese beispielhaften Darstellungen sollen dem Leser zum Verständnis der Index-Verfahren helfen. 3.1.1 Hashbasierendes Verfahren Ein intuitiver Ansatz ist es, die Indizes Ii jeweils mit einer deterministischen Einweg-Hashfunktion über die normalen Attribute Ai zu berechnen: t[Ii ] = h(Ai ), h : Di −→ Bi , wobei Di der Definitionsbereich von Ai und Bi derjenige von Ii ist. Eine Abfrage wird dann folglich so umgeschrieben, dass Ai mit Ii ersetzt wird. Dieser triviale Ansatz reduziert jedoch zum einen das Handlungsspektrum des Service-Anbieters auf elementare Identitätsfunkionen und enthüllt andererseits die Kardinalität der Ai , was weitere Angriffsszenarien erlaubt (vgl. [DVJ+ 03]). Es gibt zahlreiche Forschungsarbeiten, die deshalb versuchen, die Hashfunktionen so zu konstruieren, dass weitere Funktionalität auf dem Server ausgeführt werden kann. Diese Konzepte werden in diesem Unterabschnitt vorgestellt. Sie können weiter unterteilt werden in Suchverfahren und ordnungserhaltende Verfahren. Suchverfahren Der Ansatz von [SWP00] umgeht u.a. das Problem der Kardinalität, indem gleiche Attributsausprägungen durch das Hinzufügen von Zufallszahlen nicht den gleichen Hashwert haben. Das vorgestellte Verschlüsselungsschema besteht aus drei Phasen: der initialen Verschlüsselung, dem Suchen und der Entschlüsselung. Der Inhaber der Daten verschlüsselt den Index, bzw. den Klartext m zunächst mit einem herkömmlichen deterministischen Verschlüsselungsalgorithmus E(Ai ). Dieser Kern-Chiffretext hat eine Bitfolge der Länge M (für die genaue Parameterwahl sei auf [SWP00] verwiesen). Der Inhaber generiert außerdem eine Pseudozufallszahl Si mit Länge von N Bits, wobei N frei gewählt werden kann, sodass 0 < N < M. Sei Fk (x) eine Pseudo-Random Funktion (PRF) (vgl. [Gol07]) mit dem Startwert (random seed) k, dann erzeugt diese eine Folge von pseudo-zufälligen Zahlen mit der jeweiligen Bitlänge von M − N. Der Inhaber berechnet nun Fb (Si ), wobei der Startwert bi = fc (Ai ) durch eine weitere PRF f berechnet wird, die aber unabhängig von F ist. Das zu einem Attribut zugehörige bi ist also Teil einer für einen Dritten nicht reproduzierbare Folge. Für einen Nutzer, der im Besitz des Startwertes c ist, ist sie das allerdings schon. Anschließend konkateniert der Inhaber Si kFbi (Si ), dessen Verbund die - 22 - Länge M besitzt und berechnet durch bitweise Anwendung des exklusiven Oders Ci = E(Ai ) ⊕ (Si ||Fbi (Si )) und speichert dieses Ergebnis auf dem Server. Für eine Suche nach Einträgen mit dem Attribut Ai sendet der Nutzer nun E(Ai ) und das entsprechende bi an den Server. Der Server berechnet für jeden Eintrag j in der Datenbank T j = E(Ai ) ⊕C j . Stößt der Server nun auf einen passenden Eintrag, müsste dieser gerade (Si ||Fbi (Si )) entsprechen.8 Der Server kennt allerdings weder Si noch Fbi (Si ). Da er den ursprünglichen Schlüssel bi für die PFR F übergeben bekommen hat, kann er jedoch überprüfen, ob die beiden Werte korrekt entsprechend zusammenpassen. Wenn gilt, dass (M−N+1),M 1,(M−N) Fbi (T j ) = Tj ist ein der Suche entsprechender Eintrag j gefunden. Dabei bezeichnen T X,Y die Bitstellen X bis Y von T . Der Server gibt dann das zu dem Eintrag zugehörigen verschlüsselte Tupel zurück. Eine erweiterte Variante dieses Verfahren erlaubt es die einzelnen verschlüsselten Ci für jedes Attribut eines Tupels, ähnlich einer Blockchiffre im beispielsweise CBC-Modus (vgl. Kapitel 2.2.1), zusammen mit dem eigentlichen Chiffretext des Tupels zu einem großen Chiffrat zu verbinden. Dies ermöglicht es einem Nutzer, einen Chiffretext direkt auf Schlagwörter zu untersuchen. Für eine detaillierte Erläuterung, auf die an dieser Stelle nicht weiter eingegangen wird, wird auf [SWP00] verwiesen. Das hier vorgestellte Verfahren leidet allerdings unter erheblichen Performance-Problemen, sowohl in der Speicher-, sowie in der CPU-Auslastung (vlg. [Uca05] und [EAAA11]). [Goh03] und [BC04] stellen daher ein Schema vor, das auf Bloom-Filtern basiert. Dies ermöglicht eine wesentlich effizientere Speicherauslastung und eine Suche in O(1). Bloom-Filter berechnen für jede Attributsausprägung Ai aus der Menge A = {A1 ,..,An } einer Relation verschiedene Hashfunktionen h1 , . . . ,hr , wobei hi : {0,1} −→ [1,m], ∀i ∈ [1,r]. m ist dabei ein wählbarer Parameter, der von n abhängt (für Details vgl. [Blo70]). Für jeden Datensatz existiert nun ein Array BF mit m Bits. Alle Einträge von BF sind mit 0 initialisiert. Für jedes Ergebnis der hi wird der entsprechende Index des Arrays, der aus Ergebniswert resultiert, auf 1 gesetzt. Bei der Suche muss der Nutzer für die gesuchte Attributsausprägung die Hashwerte berechnen und dem Server dann das entsprechende Bloom-Filter-Muster übergeben. Dieser überprüft dann seine Bloom-Filter-Indexstruktur darauf. Die oben genannten Ansätze kombinieren auch hier die Bloom-Filter mit PRF, um entsprechende statistische Auswertungen zu verhindern. Beispielabfrage Das folgende Beispiel soll die Erstellung der Indizes nach dem Verfahren von [SWP00] 8 Das Schema macht sich hier X ⊕Y = Z ⇐⇒ X ⊕ Z = Y zunutze. - 23 - stellvertretend für die Suchverfahren weiter verdeutlichen. Betrachten wir an dieser Stelle den Klartextwert 100000 und den dazugehörigen Indexwert 11100000 (vgl. Tabelle 3.3 und 3.4). Sei E(100000) = 10111001, dann beträgt also M = 8. Sei N = 5 gewählt, S für 100000 sei S = 01011 und Fb (S) = 001 (b ist hier nicht näher betrachtet), dann entspricht E(100000) ⊕ (S||Fk (S)) = 10111001 ⊕ 01011001 = 11100000 gerade dem beschriebenen Indexwert. Für eine Suche schreibt die Zwischenschicht des Nutzers die Abfrage (s.o.) nun in die Serverabfrage Qs , die den entsprechenden Datensatz ermittelt, und die Clientabfrage Qc um, die dann das relevante Attribut Kontonummer aus diesem extrahiert. Der Nutzer schickt zunächst Qs mit E(100000) = 10111001 und b an den Server: SELECT Enc_Gutschrift.T_k FROM ‘Enc_Gutschrift‘ WHERE Enc_Gutschrift.I2 = 10111001 KEY = b; Der Server berechnet zunächst T j = E(100000) ⊕C j für jeden Eintrag j. Sei die Iteration über die Datensätze momentan bei dem richtigen Indexwert angelangt, dann berechnet er in diesem Fall T = 10111001 ⊕ 11100000 = 01011001. Der Server überprüft nun ob Fb (T 1,5 ) = T 6,8 , also ob Fb (01011) = 001. Da dies offenbar der Fall ist, ist das gesuchte Tupel gefunden und wird vom Server in seiner verschlüsselten Form (oto1hok5) zurückgeschickt. Der Nutzer entschlüsselt dann den Datensatz und extrahiert die Kontonummer. Tabelle 3.3: Klartext Tabelle 3.4: [SWP00] verschlüsselt Enc_ Gutschrift Gutschrift Kontonummer Betrag ID Tk I1 I2 27933 32846 69473 93457 1 2 3 4 awu9hak6 aba5kof3 oto1hok5 ado9nal8 01100000 10100000 01011110 11111100 11000110 10110100 11100000 11001010 350 400 100000 2500 Ordnungserhaltende Verfahren Die bisher vorgestellten Verfahren bieten – wie oben schon angemerkt – nur grundlegende I/O Funktionen für die Daten auf dem Server. Ein Ansatz auch Vergleichs- und Bereichsabfragen vom Server auf den verschlüsselten Daten durchführen zu lassen, ist die Einführung von ordnungserhaltenden Indizes. Ordnungserhaltende Indizes nutzen eine Zuordnungsfunktion, die die ursprüngliche Ordnung des Definitionsbereichs auf den Wertebereich beibehält - 24 - (order-preserving encryption). Das erste Verfahren, das sich mit ordnungserhaltenden Indizes im DaaS-Umfeld beschäftigt, geht auf [AKSX04] zurück. Das größte Problem bei dieser Art von Indizes ist das Generieren von Informationen aus den Abständen zwischen den Werten. Es gilt beispielsweise eine proportionale Zuordnung der Werte zu verhindern. Der vorgestellte Ansatz nimmt eine auf dem Definitionsbereich beliebig verteilte Eingabe von Werten als Input und transformiert diese in eine gewünschte Verteilung um. Somit ist diese proportionale Zuordnung nicht mehr nachvollziehbar. Unterschiedlich verteilte Eingabewerte sind nach der Transformation nicht mehr voneinander zu unterscheiden, wie beispielsweise in den Abbildungen 3.2a und 3.2b. Die Eingabewerte von Abbildung 3.2a sind gleichverteilt, wohingegen die von 3.2b normalverteilt sind. Transformiert in die Zeta-Verteilung sind die beiden Datensätze nicht mehr voneinander zu unterscheiden. (a) Gleichverteilte Eingabewerte (b) Normalverteilte Eingabewerte Quelle: [DVF+ 07] Abbildung 3.2: Transformation der Datenwertverteilung in die Zeta-Verteilung Der Algorithmus modelliert zunächst eine Verteilung der Klartextwerte durch Einführung von linearen Splines und unterteilt diese dann zunächst in kleine Abschnitte. Anschließend transformiert er diese Abschnitte und die Werte innerhalb der Abschnitte zu gleichverteilten Werten (Inter- und Intrapartitionstransformation). Die gleichverteilten Werte werden anschließend in die Zielverteilung transformiert. Die Parameter werden in einer Datenstruktur beim Nutzer gehalten, die es erlaubt, die Werte wieder zurück zu entschlüsseln. Für diesen Ansatz müssen alle später möglichen Klartext-Eingabemöglichkeiten bekannt sein, da der ganze Verschlüsselungsprozess sonst erneut durchgeführt werden muss, weil die Abstände sonst nicht mehr entsprechend verteilt wären. Erst [BCLO09] untersuchen den Ansatz erneut und ermöglichen das dynamische Einfügen neuer Werte. Auch hier geschieht dies durch die Einführung von PRF. Die von den Autoren vorgeschlagene Funktion ersetzen - 25 - sie in [BCO11] und stellen ein Berechnungsmodell für die Erfolgswahrscheinlichkeit von Angriffen auf, die die Distanzen ermitteln können. Beispielabfrage Die ordnungserhaltenden Indizes ermöglichen dem Server in jedem Szenario, die Ordnungsinformationen über die Daten zu ermitteln. Dies zeigt auch das entsprechende Beispiel für ordnungserhaltende Verfahren (vgl. Tabelle 3.6). Die Chiffrewerte haben innerhalb der beiden Attributen die gleiche Ordnung, wie die dazugehörigen Klartexte. Die hier beispielhaften verschlüsselten Werte sind an dieser Stelle sehr nahe an den Klartextwerten, was normalerweise nicht der Fall sein sollte, um Zuordnungen zu vermeiden. An dieser Stelle sind die Chiffretext allerdings zur Veranschaulichung für die Verteilung so gewählt worden. Der Abfrageablauf ist nun genau der gleiche, wie bei den Suchverfahren, nur die Serverabfrage Qs lautet in diesem Fall: SELECT Enc_Gutschrift.T_k FROM ‘Enc_Gutschrift‘ WHERE Enc_Gutschrift.I2 = 3600; Der Nutzer muss dann wie bei bereits oben beschrieben in der Zwischenschicht das Attribut Kontonummer extrahieren. 3.1.2 Tabelle 3.5: Klartext Tabelle 3.6: [AKSX04] verschlüsselt Gutschrift Kontonummer Betrag Enc_ Gutschrift ID Tk I1 I2 27933 32846 69473 93457 1 2 3 4 awu9hak6 aba5kof3 oto1hok5 ado9nal8 20000 40000 60000 80000 900 1800 3600 2700 350 400 100000 2500 B+ -Bäume Für die effiziente Nutzung von Vergleichs- und Bereichsabfragen werden in Datenbanksystemen in der Regel Indizes basierend auf B+ -Bäumen verwendet (vgl. hierzu und im Folgenden [WV02]). [DVJ+ 03] schlagen deshalb ein Verfahren vor, das die beim Server hinterlegte Indexstruktur der Ii ebenfalls auf B+ -Bäumen basieren lässt. Dieses Verfahren verbirgt jedoch die Ordnungsstruktur der Indizes im Gegensatz zu den zuvor beschriebenen Ansätzen. Ein B+ -Baum ist ein balancierter Suchbaum, bestehend aus einer Wurzel, einer Menge von inneren Knoten, einer Menge von Blättern und einer Menge von Kanten. Er ist hauptsächlich bestimmt durch seinen sogenannten fan-out n. Bei einem B+ -Baum unterscheiden sich die Strukturen der inneren Knoten von denen der Blättern. Während die Blätter Zeiger auf die - 26 - eigentlichen Daten enthalten, enthalten die inneren Knoten nur Zeiger auf folgende Knoten. Bis auf den Wurzelknoten hat jeder Knoten n Zeiger P1 , . . . , Pn auf Kindknoten. Jedes Blatt enthält neben den Verweisen auf die Daten einen Zeiger auf seinen Blattnachfolger. Jeder Knoten kann bis zu n − 1 Suchschlüssel enthalten, mindestens aber d(n − 1)/2e. Die Schlüssel K1 , . . . ,Kn eines Knotens sind in aufsteigender Reihenfolge sortiert: Ki < K j , ∀i < j. Diese Schlüssel bestimmen durch die Zeiger den Wertebereich der Unterbäume. Für jeden Schlüssel ci j , der in dem Unterbaum liegt, der durch die Schlüssel Ki und K j bestimmt wird, gilt: Ki < ci j ≤ K j . Die Traversierung des Baumes bei einer Suche des Schlüssels x erfolgt grob nach folgendem Schema: wähle Zeiger Pj , für Ki < x ≤ K j im aktuellen Knoten. Wiederhole diesen Schritt für jeden Knoten, bis ein Blatt erreicht ist. Ist der Schlüssel x dort nicht vorhanden, existiert für diesen kein Eintrag in dem Baum. Der Aufwand der Suche ist also abhängig von der Höhe des Baumes, die wiederum durch den fan-out bestimmt ist. Die obere Schranke für die Kn ). Höhe eines B+ -Baumes beträgt log f +1 ( 2∗ f Das Verfahren von [DVJ+ 03] verschlüsselt zunächst die Relation R auf Tupelebene (Zeilenebene). Die neuen Tupel t 0 (·) werden in der externen Datenbank gespeichert. Der Client erstellt initial einen temporären B+ -Baum mit den Klartextdaten und speichert dann eine verschlüsselte Version von diesem auf dem Server.9 Diese verschlüsselte Version wird später für das Suchverfahren benutzt. Die Verschlüsselung des Baumes erfolgt dabei nicht auf Schlüssel-Ebene, sondern die Knoten werden als ganzes komplett verschlüsselt abgespeichert. Dies ist notwendig, da der Server sonst selber Informationen über die Reihenfolge der Indizes erhält. Die Speicherung des Baumes auf dem Server erfolgt in Form einer Tabelle mit zwei Attributen: einer Knoten ID und dem verschlüsselten Wert des Knotens. Bei einer Bereichsabfrage muss die Zwischenschicht des Clients nun selbstständig durch eine Serie von Abfragen über den beim Server hinterlegten Baum traversieren, da diese in diesem Szenario keine weitere Informationen über den Baum hat. Er geht dabei nach dem oben beschriebenen Schema vor. Diesmal muss er allerdings zuerst den Inhalt des Knoten entschlüsseln, kann daraufhin die nötige nächste Knoten-ID bestimmen und sendet dann erneut eine Anfrage mit der entsprechend Knoten-ID an den Server. Für die Abfrage nach einem einzelnen Tupel müssen also in der Regel Abfragen entsprechend der Höhe des Baumes durchgeführt werden. Da diese logarithmisch zu der Anzahl der Datenbankeinträge ist, müssen im Gegensatz zu etwaigen anderen Verfahren, nicht alle Datensätze linear überprüft werden. Allerdings verbleibt durch dieses Verschlüsselungsverfahren ein Großteil der Berechnungen bei dem Nutzer. Bereichsabfragen sind durch das Verschlüsselungsverfahren auch möglich, benötigen allerdings eine deutlich höhere Abfolge von Abfragen, da mindestens zwei Werte bestimmt werden müssen. 9 Der optimale fan-out wird dabei nach [DVJ+ 03] ermittelt. - 27 - Bei dieser Art von Abfrage gelangen jedoch trotz der Verschlüsselung des Inhaltes Informationen über die Strukturierung der Daten an den Server, da dieser immerhin die Abfragereihenfolge des Clients verfolgen kann. [LC05] erweitern deshalb den bisher beschriebenen Ansatz um Techniken, die die Struktur der Indizes verbergen. Sie setzten dabei hauptsächlich drei Konzepte ein: (1) Die Abfrage wird mit weiteren, zufällig ausgewählten Knoten angereichert. (2) Die verschlüsselten Knoten werden regelmäßig vertauscht. (3) Die Daten werden dabei jedes Mal so neu verschlüsselt, sodass der Verschlüsselungswert nicht dem des ursprünglichen gleicht. [VFP+ 11b] stellen eine modifizierte Variante vor, die nun auch die Reproduktion von Abfragemustern verhindert. Dabei haben die Autoren insbesondere das Vertauschen der Knoten verbessert. Ihr Ansatz basiert auch weiterhin auf B+ -Bäumen. Die bisher vorgestellten Arbeiten konzentrieren sich auf die Suche in den Bäumen. [Dan05] zeigt, wie auf Strukturen der obigen Ansätze das Einfügen, Löschen und Modifizieren von Daten funktioniert. Beispielabfrage Aus Platzgründen wird bei diesem Beispiel nur das Attribut Betrag als B+ –Baum dargestellt. Der Dateninhaber erstellt zunächst lokal den B+ –Baum (vgl. Abbildung 3.3 – die Darstellung des Baumes orientiert sich an [DVJ+ 03]) und erzeugt dann eine tabellarische Form davon (vgl. Tabelle 3.8). Dort entsprechen die Ki -Einträge den Zeigern auf den nächsten Knoten und die Di -Einträge entsprechen den eigentlichen Datenverweisen (in der Baum-Abbildung nicht dargestellt). Die tabellarische Form des Baumes verschlüsselt er nun (vgl. Tabelle 3.9) und speichert diese zusammen mit den, bereits aus den vorherigen Beispielen bekannten, verschlüsselten Daten (vgl. Tabelle 3.7) auf dem Server ab. Ein Nutzer muss für die Beispielabfrage sukzessiv durch den Baum iterieren, indem er mit dem Wurzelknoten beginnt: SELECT Enc_Knoten.Enc_Knoteninhalt FROM ‘Enc_Knoten‘ WHERE Enc_Knoten.Knoten-ID = 1; Er entschlüsselt das Ergebnis Dec(2EXvvvR0) = (K2, 2500, K3), bestimmt so die nächste notwendige Knoten-ID K3 (da 100000 > 2500, den rechten Eintrag wählen) und stellt entsprechend eine neue Abfrage: SELECT Enc_Knoten.Enc_Knoteninhalt FROM ‘Enc_Knoten‘ WHERE Enc_Knoten.Knoten-ID = 3; Dies führt der Nutzer solange durch, bis er den Datenverweis D3 erhält. Er führt dann eine letzte Abfrage durch: SELECT Enc_Gutschrift.T_k FROM ‘Enc_Gutschrift‘ WHERE Enc_Gutschrift.ID = 3; - 28 - Letztendlich muss der Nutzer noch analog zu den bisherigen Beispielen in der Zwischenschicht das Attribut Kontonummer extrahieren. Abbildung 3.3: B+ –Baum Tabelle 3.7: Verschlüsselt Enc_ Gutschrift ID Tk 2500 400 350 400 2500 100000 Tabelle 3.8: Tabellarische Form 3.1.3 1 2 3 4 100000 awu9hak6 aba5kof3 oto1hok5 ado9nal8 Tabelle 3.9: Verschlüsselte Form Knoten Knoten-ID Knoteninhalt Enc_ Knoten Knoten-ID Enc_ Knoteninhalt 1 2 3 4 5 6 7 1 2 3 4 5 6 7 (K2, 2500, K3) (K4, 400, K5) (K6, 100000, K7) (D1, 350, K5) (D2, 400, K6) (D4, 2500, K7) (D3, 100000, −) 2EXvvvR0 09idXPap WqdGhO3o nNK4SAOT sWiU45Np v84oanif X7uxHwa8 Partitionierende Verfahren Ein weiterer Ansatz, der das Ausführen von Funktionalität auf dem Server erlaubt, besteht darin, die Attributsausprägungen Ai in Partitionen aufzuteilen. Dies ermöglicht das Verstecken der Kardinalitäten von Ai . Das erstmals von [HIM02] beschriebene Verfahren teilt die Ausprägungen Ai zunächst in Intervalle, die so genannten Buckets P = {p1 , . . . ,pk } ein. Jedem p j wird dabei eine ID über eine kollisionsfreie Hashfunktion hi : P −→ N zugewiesen. Diese ID entspricht dem später auf dem Server hinterlegten Index I j = h(p j ). Ein ordnungserhaltender Index Ii ist an dieser Stelle nicht nötig, kann aber auch eingesetzt werden, bringt dann allerdings die in Kapitel 3.1.1 beschriebenen Vor- und Nachteile mit. Die Bucketabschnitte werden zusammen mit ihren IDs in der Client-Zwischenschicht als Meta-Daten hinterlegt. Dieses Verfahren ermöglicht es dem Server, zunächst nur einfache Identitätsabfragen durch zu führen. Es sind auch Bereichsabfragen möglich. Dies erfordert aber ein ähnliches Vorgehen wie in Kapitel 3.1.2, nämlich durch das Senden einer Abfolge von Anfragen über - 29 - die einzelnen Buckets. [MT06] stellen eine Möglichkeit vor, den Server auch Aggregationsfunktionen zurückgeben zu lassen. Sie ermöglichen dies, indem sie bei der Hinterlegung der Daten auf dem Server direkt beim Nutzer die Anzahl der Ai (COUNT) und die Summe der Ai (SUM) für jedes p j bestimmen und diese in verschlüsselter Form hinterlegen. Bei einer Abfrage schickt der Server die vorher berechneten Ergebnisse zurück. Dies hat zur Folge, dass bei einer Modifikation der Daten auch die jeweiligen Aggregationsdaten des Bucket neu berechnet werden müssen. Da der Wert der einzelnen Ii mehreren Klartextwerten zugeordnet ist, erhält die Zwischenschicht des Clients in den Verfahren dieses Kapitels durch die Abfrage in der Regel mehrere Tupel, die nicht der eigentlichen Abfrage des Nutzers entsprechen. Die Abfragen müssen also noch einmal in der Zwischenschicht um die falschen Tupel bereinigt werden. Entscheidend für die Sicherheit der Daten ist die Abschnittsgröße der Buckets. Eine beispielsweise geringe Anzahl von Buckets erhöht die Anzahl der falschen Tupel, da nun jeweils mehr verschiedene Ai in den einzelnen p j vorkommen. Sie erhöht allerdings auch die Datensicherheit, da die Unterscheidung der Ai in ihrer verschlüsselten Form schwerer fällt. Es ist zudem wichtig, die Anzahl der Ai in den Abschnitten möglichst gleichverteilt zu lassen, um keine Rekonstruktion der Relation der Klartextdaten zuzulassen. Mit der Abwägung zwischen Datensicherheit und einem genauerem Abfrageergebnis beschäftigen sich [HMT04]. Die Autoren stellen ein Framework vor, das zu gegebenem Grad zulässiger Privatsphäre die entsprechende Abstandsgröße der Buckets berechnet. [WD08] erweitern das Verfahren der Partitionierung, indem sie die strikten Grenzen der Abschnitte auflösen, so dass diese nun überlappend sein können, was eine Zuordnung der Klartextdaten zu den Indizes weiter erschwert. Die hier vorgestellten Verfahren ermöglichen kein dynamisches Einfügen neuer Werte, da sonst die Bucketabschnitte nicht mehr den eben genannten Anforderungen entsprechen. Beim Hinzufügen neuer Werte in die Abschnitte müssen alle Buckets und Indizes neu berechnet werden. Beispielabfrage In dem folgenden Beispiel sind die Attributsausprägungen Kontonummer und Betrag beide in Intervalle aufgeteilt (vgl. 3.11). Für den Server lassen sich so beispielsweise die Datensatzpaare (1,2) und (3,4) bis auf Tk nicht weiter unterscheiden. Damit die Zwischenschicht des Nutzers die Beispielabfrage entsprechend aufteilen und umschreiben kann, muss diese Metadaten über die Zuordnung von Werten zu den entsprechenden Intervallen vorhalten. Der Nutzer schickt dann letztendlich die folgende Anfrage Qs an den Server: SELECT Enc_Gutschrift.T_k FROM ‘Enc_Gutschrift‘ WHERE Enc_Gutschrift.I2 = 75; - 30 - Der Server gibt dem Nutzer in diesem Fall zwei Werte zurück, nämlich die Datensätze mit der ID 3 und 4. Der Nutzer muss das Ergebnis also noch um das falsch-positiven Tupel 4 bereinigen und kann dann erneut die Kontonummer extrahieren. 3.2 Tabelle 3.10: Klartext Tabelle 3.11: [HIM02] verschlüsselt Gutschrift Kontonummer Betrag Enc_ Gutschrift ID Tk I1 I2 27933 32846 69473 93457 1 2 3 4 awu9hak6 aba5kof3 oto1hok5 ado9nal8 500 500 600 600 53 53 75 75 350 400 100000 2500 Selektive Verschlüsselung In der Literatur wird in der Regel klar zwischen Zugriffskontrolle und Datenverschlüsselung nach dem Prinzip der Trennung von Strategie und Mechanismus (vgl. [Tan09]) unterschieden. In diesem Unterabschnitt wird allerdings ein Ansatz beschrieben, der diese beiden Konzepte miteinander kombiniert. Da dieser Ansatz starken Einfluss auf das Verschlüsselungsschema hat, sei er an dieser Stelle näher ausgeführt. Die Überwachung und Verwaltung der Zugriffskontrolle soll auch in diesem Szenario an den Server ausgelagert werden. Die Umgehung des oben genannten Prinzips ist auf Grund der Anforderungen durchaus vertretbar (vgl. [MS03]). Ein intuitiver Ansatz ist es, jeden Datensatz mit einem entsprechenden symmetrischen Verfahren vielfach mit unterschiedlichen Schlüsseln zu verschlüsseln und die Schlüssel an die jeweiligen Nutzer zu verteilen. Die Anzahl zu verwaltender Schlüssel bei den einzelnen Nutzern steigt dann allerdings für jeden verfügbaren Dateisatz linear an. Erfolgt die Verschlüsselung nach einem asymmetrischen Verfahren, können viele Nutzer Daten verschlüsseln und hochladen. Nur ein Nutzer, der im Besitz des entsprechenden privaten Schlüssels ist, kann allerdings diese Daten durchsuchen und entschlüsseln. Das von [VFJ+ 10] beschriebene Verfahren hat deshalb das Ziel, die Anzahl der Schlüssel bei den Nutzern auf genau einen zu minimieren und trotzdem jeden Datensatz nur einmal verschlüsseln zu müssen. Die Autoren gehen in ihrem Szenario davon aus, dass die Nutzer nur lesend auf die Daten zugreifen müssen und Schreibvorgänge durch den Dateninhaber durchgeführt werden. Sie benutzten zur Erreichung des einzelnen Schlüssels ein so genanntes Schlüsselableitungsverfahren (key derivation). Durch solche Verfahren lassen sich Schlüssel hierarchisch von einander ableiten. Die Autoren greifen dabei auf das von [ABFF09] beschriebene Verfahren zur Schlüsselableitung zurück, weil es dynamische Modifikationen erlaubt und dabei den Aufwand für die Wiederverschlüsselung und das Einfügen neuer Schlüssel minimiert. Das Ableitungsverfahren basiert auf den öffentlich zugänglichen Mengen der Token T und - 31 - den Labeln L, sowie der geheimen Menge an Schlüsseln K. Bei zwei gegebenen Schlüssel ka und kb ist ein Token definiert als ta,b = kb ⊕ h(ka , lb ), wobei h(·) eine deterministische Hashfunktion ist und das öffentliche Label lb von kb abhängig ist. Durch gegebenes ka lässt sich also über die öffentlich verfügbaren ta,b und lb der entsprechend nächste Schlüssel kb berechnen. So kann ein beliebiges Netz von Schlüsselabfolgen durch Token (z.B. (ta,b , lb ) → (tb,c , lc ) → (tc,d , ld )) realisiert werden. Dieses Netz lässt sich auch als Zugriffsgraph darstellen. Abbildung 3.4 stellt einen solchen Graph beispielhaft dar. Quelle: [VFJ+ 10] Abbildung 3.4: Zugriffsgraph Die in der Abbildung 3.4 dargestellten durchgezogenen Linien entsprechen den Token und die gestrichelten Linien den zugewiesenen Schlüsseln. Für die Benutzers {A,B,C,D} sind die diese Schlüssel die jeweiligen Eintritts-Schlüssel für die Ableitung. Für die Daten R = {r1 , · · · ,r9 } ist ri der entsprechende Schlüssel zum Entschlüsseln der Daten i. Wie der Graph veranschaulicht, erlaubt diese Hierarchie sogar schon die Bildung von Nutzergruppen. Der Knoten v15 stellt beispielsweise eine solche Gruppe von Nutzern dar, da er von Nutzer A,B,C und D erreichbar ist und auf einen Datensatz zeigt; durch Entfernen des Schlüssels kann so auf einmal der gesamten Gruppe der Zugriff verwehrt werden. Die Autoren aus [VFJ+ 10] zeigen, dass eine Modifikation dieses Zugriffsgraphen bei Änderungen der Zugriffsrechte durch das Hinzufügen/Entfernen von Knoten und Kanten beliebig erfolgen kann, was bei einer Änderung der Nutzerrechte zwingend Bedingung ist. Bisher ist es nötig, dass die Zugriffsrechte und Verschlüsselungen bereits im Vorhinein berechnet und auf den Server geladen werden. Bei einer Modifikation muss der Inhaber diese erneut berechnen und hochladen. Die Autoren führen deshalb eine so genannte Zwei- - 32 - Schichten-Verschlüsselung ein (Two-layer encryption). Der Inhaber erstellt wie schon zuvor die Verschlüsselung (Base Encryption Layer - BEL). Der Server verschlüsselt diese Daten nach demselben Prinzip darüber noch ein zweites Mal (Surface Encryption Layer - SEL). Dabei weist er jedem Nutzern einen weiteren Schlüssel zi zu, der sich allerdings von dem ursprünglich von Inhaber zugewiesenem Schlüssel ableiten lässt.10 Der vom Inhaber erstellte und der vom Server generierte Zugriffsgraph sind zu diesem Zeitpunkt isomorph. Werden nun die Zugangsrechte angepasst, fügt der Dateninhaber zunächst Token für die neuen entsprechenden Pfade des Zugriffsgraphen auf der BEL-Ebene hinzu bzw. entfernt welche; er muss an dieser Stelle allerdings nicht die Verschlüsselung neu berechnen. Anschließend weist er den Server an, die entsprechenden Änderungen auf der eigenen SEL-Ebene auszuführen. Möchte ein Nutzer auf die Daten zugreifen, muss er sich zunächst durch die SEL Ebene vorarbeiten. Hat er alle entsprechenden Rechte bekommen und kann die entsprechenden Schlüssel ableiten, muss er sich in einem zweiten Schritt durch die Token-angepasste BEL-Ebene durcharbeiten und erhält schließlich die entsprechenden Daten. Ein sehr ähnlicher Ansatz existiert von [WLOB09], die ein etwas anderes Schlüsselableitungsverfahren benutzen. Dieses umgeht die komplexe Graphen-Struktur des Ansatzes von [VFJ+ 10], die nach mehrfachen Änderungen der Zugriffsrechte entstehen kann. Allerdings muss bei diesem Verfahren mehr als eine verschlüsselte Version der Daten hinterlegt werden, was zu einem höheren Speicheraufkommen führt. Das bis zu dieser Stelle beschriebene Vorgehen entspricht dem grundlegenden Konzept der selektiven Verschlüsselung. Es kann mit vielen anderen Verfahren kombiniert werden, allerdings sind die im folgenden beschriebenen Aspekte zu beachten. In [VFP+ 11a] kombinieren die Autoren das Konzept der selektiven Verschlüsselung mit einem indexbasierten Ansatz zur Abfrage der Daten. Wird das Verfahren der selektiven Verschlüsselung auch auf die Indizes angewendet, dann könnte ein Nutzer in einigen Szenarien auch Informationen über Tupel erhalten, für die er eigentlich keinen Zugang hat. Haben beispielsweise zwei Datensätze einen gleichen Index, ein Nutzer A hat Leserechte für beide Datensätze, ein Nutzer B allerdings nur einen der beiden, dann könnte Nutzer B trotzdem auch den anderen Datensatz abfragen, da die gleiche Schlüsselableitung möglich wäre. Nutzer B könnte zwar nicht den eigentlichen Datensatz entschlüsseln, jedoch wüßte er zumindest, dass diesem der entsprechende Index zugeordnet ist. Das vorgestellte Verfahren teilt die Nutzer deshalb so in weitere Gruppen auf, dass gleiche Indizes innerhalb der Gruppen überschneidungsfrei sind. Dann wird für jede Gruppe ein eigener Indexwert für jede Attributsausprägung hinterlegt. Der Speicherplatz erhöht sich bei einer großen Anzahl von Nutzern also enorm, wenn viele Nutzer auf gleiche Attribute zugreifen. Bei einem Indexverfahren muss dann der Nutzer seine Abfrage in einer Zwischenschicht 10 Dies ist nötig, damit der Nutzer weiterhin nur einen einzigen Schlüssel verwalten muss. zi kann dabei vom Inhaber bereitgestellt werden. - 33 - so umschreiben, dass er den ihm entsprechenden Index zu der Attributsausprägung wählt. In diesem Fall sind nur Identitätsabfragen möglich. 3.3 Homomorphe Verschlüsselung Das in Kapitel 2.2.3 vorgestellte Verfahren der homomorphen Verschlüsselung eignet sich konzeptionell sehr gut für die sichere Abfrage verschlüsselter Daten. Wie oben bereits erwähnt wurde, wurde erst 2009 ein entsprechendes vollhomomorphes Verschlüsselungsschema vorgestellt. Doch bereits vorher beschäftigt sich [HIM04] mit homomorphen Verschlüsselungen im Database-as-a-Service Umfeld. Die Autoren führen das homomorphe Konzept ein, um Aggregationsabfragen auf verschlüsselten Daten durchführen zu können. Der dort verwendete Mechanismus basiert jedoch auf einem eigens entwickelten partiellhomomorphen Schema und unterstützt nur Additionen. Dies ermöglicht die Aufsummierung von Zahlwerten (SUM), die Zählung der Zellen (COUNT) und die Bildung von Durchschnitten (AVG). Das dort vorgestellte Schema ist allerdings sehr anfällig u.a. gegenüber ciphertext-only Angriffen (vgl. [MT06]). Die Autoren schlagen deshalb ein anderes SHE vor, dass das unsichere Schema ersetzten soll. Für das neue Schema formulieren sie deshalb neben den in Kapitel 2.3 vorgestellten Anforderungen an eine Verschlüsselung folgende weitere Kriterien, die im Kontext einer praktischen Umsetzung in einem DaaS-Szenario nötig sind: die Größe des Ciphertext, die nötigen Berechnungen und die zu übertragenden Datenmengen sollen minimal sein. Die Verfahren von [OU98] oder auch von [Pai99] erscheinen dabei als passend für eine additive homomorphe Verschlüsselung. Während die Funktionen der SHE Schemata für einige Anwendungen ausreichend sind (z.B. additive Homomorphismen für die Berechnung von Durchschnittswerten etc.), ist es durch die vollhomomorphe Verschlüsselung möglich, beliebige Funktionalität auf den verschlüsselten Daten auszuführen. Die bisherigen Schemata, die auf dem ersten Schema von [Gen09] basieren, gelten durch eine kleine Modifikation als IND-CCA sicher (vgl. [LMSV10]). Unterstützt das Schema die homomorphe Evaluation von Addition und die Multiplikation, so sind bei einer Schaltkreisdarstellung der Funktion alle Grundelemente (AND, OR, NOT) berechenbar. Für eine Einführung in die Erstellung logischer Schaltungen sei auf [OV06] verwiesen. Erste Implementierungen von dem vollhomomorphen Schema von [Gen09] gelten jedoch als sehr ineffizient (vgl. [DJ10]).11 Es gibt seitdem zwei identifizierbare Hauptrichtungen, in denen intensiv geforscht wird: zu einem wird das ursprüngliche Schema weiterentwickelt und zum anderen werden Schemata entwickelt, die sich nur auf arithmetische Funktionen für Zahlen konzentrieren. 11 Spezialfälle der SHE gelten allerdings als sehr effizient in ihrem Funktionsumfang, wie beispielsweise das schon erwähnte Kryptosystem von [Pai99]. - 34 - Momentan werden eine Vielzahl von neuen Ergebnissen vorgestellt. Einen aktuell sehr guten Überblick bietet [Sch11]. Obwohl große Fortschritte gemacht worden sind, erscheinen die aktuell vorgestellten Verschlüsselungsschemata allerdings als noch nicht praktisch einsetzbar (vgl. [LNV11] und [SV11]). Die Laufzeiten einer aktuellen Implementierung (vgl. [CNT11]) verdeutlichen dies beispielhaft (vgl. Tabelle 3.12). Die Laufzeiten sind abhängig von dem gewählten Sicherheitsparameter λ (vgl. Kapitel 2.2.3). Insbesondere die Schlüsselgenerierung Tabelle 3.12: Laufzeiten der Implementierung von [CNT11] λ pk Größe KeyGen Encrypt Decrypt Recrypt 42 52 62 72 46 KB 229 KB 1074 KB 4,6 MB 4,4 s 37 s 5 min 10 s 43 min 0,05 s 0,81 s 11 s 2 min 54 s 0,04 s 0,04 s 0,09 s 0,24 s 1,9 s 10 s 1 min 18 s 14 min 9 s dauert für die Sicherheitsanforderungen sehr lange, aber auch die Recrypt-Methode für das Bootstrapping, die pro Funktion mehrfach aufgerufen wird, um das Rauschen gering zu halten, hat eine Dauer, die für die Praxis in der Regel nicht praktikabel ist. Diese Ergebnisse stehen im Einklang mit [GGEK11]; für eine Multiplikation von zwei 16-bit Zahlen braucht deren Implementierung 23 Minuten. Für ein einfaches SELECT-Statement über 10 Datenbankeinträge mussten durch das Bootstrapping insgesamt 600000 Additionen und Multiplikationen ausgeführt werden. Momentan werden kontinuierlich neue Verbesserungen bezüglich der Praxistauglichkeit erzielt. Unter gleichen Bedingungen, wie bei den Ergebnisse aus Tabelle 3.12, benötigte ein kurz davor veröffentlichtes Verfahren von [GH11] für einen Sicherheitsparameter λ = 72 noch eine pk Größe von 2,25 GB pro Schlüssel und die dazugehörige Schlüsselerzeugung KeyGen benötigte 2,2 Stunden. 3.4 Kryptographische Hardware Eine weitere Möglichkeit, den Server entsprechende Berechnungen über verschlüsselte Daten durchführen zu lassen, ist die Installation von zusätzlicher, vertrauenswürdiger Hardware beim Service-Anbieter. Diese Hardware wird als so genannter secure-coprocessors (SC) bezeichnet (vgl. [MT05]). SC sind eigenständige, für sich geschlossene Computer-Systeme, auf denen ein Nutzer beliebige Funktionalität programmieren und ausführen kann. Diese Zusatz-Computer werden über beispielsweise eine PCI-Schnittstelle an die Server angeschlossen (vgl. [DLP+ 01]). Die SC-Einheiten sind durch entsprechende Sensoren vor einem physischen Zugriff durch den Service-Anbieter geschützt, sodass dieser keine entsprechenden Hardwarezugriffe vornehmen kann. Sollten die Sensoren ausgelöst werden, löscht der SC den momentanen Zustand und fährt sich herunter. Durch diese Sicherheitsmaßnahmen und der kleine verfüg- - 35 - bare Platz ist die Leistung dieser Geräte jedoch sehr begrenzt und der Preis relativ hoch. Der momentan erhältliche, aktuelle IBM 4764 PCI-X Cryptographic Coprocessor mit einer Prozessorgeschwindigkeit von nur ca. 233MHz kostet beispielsweise 8500 US-Dollar [3]. Die SC bieten allerdings in einigen Bereichen speziell ausgerichtete Hardwareunterstützung für der Berechnung von kryptographischen Funktionen, sodass solche Berechnungen beschleunigt durchgeführt werden können. Die von [KC05] und [MT05] vorgestellten Ansätze verfolgt ein dem Kapitel 3.1 sehr ähnliches Verfahren, wollen den Nutzer aber weiter entlasten. Zunächst verschlüsselt der Client die Datenbank mit einem symmetrischen Verfahren. Der hier benutzte Schlüssel wird an die SC-Einheit übermittelt. Der Schlüsselaustausch erfolgt dabei über ein asymmetrisches Verschlüsselungsverfahren. Der Nutzer benutzt dazu den öffentlichen Schlüssel des SC. Der SC ist also nun auch in der Lage, die Datenbank zu entschlüsseln. Wie bei den bereits vorgestellten Verfahren, teilt eine vertrauenswürdige Zwischenschicht des Clients die Abfrage Q in Qs und Qc auf. An dieser Stelle wird Qc allerdings nicht vom Client berechnet, sondern wird an die SC-Einheit ausgelagert. Diese nimmt dann die Ergebnisse von Qs entgegen, führt die entsprechenden Berechnungen Qc aus und leitet das Ergebnis in verschlüsselter Form über den Server wieder zurück an den Client. Der Engpass dieses Ansatzes ist allerdings die geringe Leistungsfähigkeit des SC. Neben der begrenzten Rechenkapazität der SC ist auch der begrenzte Speicher ein Problem, insbesondere bei größeren Datenbanken. Die Autoren haben deshalb ein Verfahren entwickelt, dass dem des virtuellen Speichers sehr ähnlich ist (vgl. [Tan09]), wobei die Pages allerdings in verschlüsselter Form auf dem Server ausgelagert werden. Um entsprechende Zuordnungen der Pages zu den vom Server ersichtlichen Abfragen Qc zu verhindern, werden weitere zufällige Seitenanfragen von der SC-Einheit hinzugefügt. Ein ähnlicher Ansatz wurde mit Hilfe der Techniken der Trusted Computing Group (TCG) [5] vorgestellt (vgl. [SGR09]). Hier muss der Server ein trusted-platform-module (TPM) integrieren. Es handelt sich bei dem TPM im Gegensatz zum SC nur um einen passiven Chip, der Befehle entgegen nimmt, diese bearbeitet und ein Ergebnis zurückliefert. Die Funktionsmöglichkeiten sind also nicht wie bei einem SC gegeben. Für eine Darstellung der Funktionsweise sei auf [Eck09] verwiesen. Zusammengefasst hasht der TPM-Chip das BIOS, den Bootloader und die Software an sich und verhindert so entsprechende Änderungen des Systems. Zur Ausführung kann so über hier nicht näher definierte Prozeduren sichergestellt werden, dass nichts vom Server auf technischer Ebene manipuliert wurde. Durch gesicherte virtuelle Maschinen lässt sich eine vertrauenswürdige Umgebung in dieser Form schaffen (vgl. [NHP11]). Allerdings gelten die TPM nicht unbedingt als sicher, da viele Attacken darauf erfolgreich ausgeführt werden konnten (vgl. [PMP10]), beispielsweise gelang es [6] die Daten wie die Kryptoschlüssel auszulesen. Ersichtlicherweise kann dieses Verfahren mit den anderen aus diesem Kapitel kombiniert werden. - 36 - 4 Verschlüsselungskonzepte mit Proxy-Unterstützung 4.1 Abfrage angepasste Verschlüsselung Das Konzept der Abfrage angepassten Verschlüsselung erscheint erstmals in [PRZB11]. Die Autoren benutzen eine ganze Reihe bereits bekannter Verfahren, die in einer Art Bibliothek für die Verschlüsselung der Daten auf dem Server hinterlegt sind. Einige dieser Verschlüsselungsverfahren enthüllen mehr Informationen über die enthaltenden Daten als andere, unterscheiden sich allerdings auch in ihrem Funktionsumfang, der auf den verschlüsselten Daten ausgeführt werden kann. In der Regel gilt: Je sicherer ein Verfahren ist, desto weniger Informationen enthüllt es über die Daten und kann deshalb einen geringeren Funktionsumfang anbieten, als schwächere Verfahren. Es erfolgt deshalb die Einführung einer so genannten Schichten-Verschlüsselung (onion encryption). Alle Datensätze werden initial mit dem Verfahren der höchsten Sicherheitsstufe verschlüsselt. Muss nun eine Abfrage auf dem Server durchgeführt werden, die das aktuelle Verschlüsselungsschema nicht erlaubt, werden die Daten der Relation auf jenes entsprechende niedrigere Verschlüsselungslevel umverschlüsselt, welches die in der Abfrage geforderten Funktionalität noch ausführen kann. Ein Proxy ist dafür verantwortlich, das entsprechende Level der Verschlüsselung zu wahren. Die Sicherheitsstufen können auch wieder erhöht werden. Ziel ist es, das sicherste Verschlüsselungsverfahren für die benötigte Funktonalität zu verwenden und dies dynamisch anzupassen. Der Proxy nimmt zunächst die Abfragen der Nutzer entgegen. Er überprüft nun, ob die auf dem Server hinterlegten Daten das adäquate Verschlüsselungslevel aufweisen, um die gewünschte Funktionalität durchführen zu können. Ist dies nicht der Fall, weist der Proxy den Server an, die Daten auf das entsprechend nötige Niveau um zu verschlüsseln. Der Server hat dabei zu keiner Zeit Zugriff auf die Klartextdaten. Das aktuelle Verschlüsselungslevel hält der Proxy lokal in einem eigenen Schema vor, sodass er das aktuelle Schema jederzeit bestimmen kann. Die Umverschlüsselung der Daten in ein anderes (in der Regel schwächeres Schema) auf dem Server geschieht über dort bereits durch den Nutzer hinterlegte user defined functions (UDF). Dies sind bereits vorher vom Nutzer definierte Prozeduren, die den Funktionsumfang des DBMS erweitern und auf die der Server keinen Einfluss nehmen kann. Der Proxy ruft dazu die UDF Decrypt(K,lold ) auf, wobei K ein entsprechend speziell generierter Schlüssel ist, mit K = PRP(table t, column c, onion o, layer l) und PRP(·) einem Generator für eine Pseudozufallpermutation entspricht. Decrypt bezeichnet eine Funktion, die nicht auf den Klartext entschlüsselt, sondern auf die nächst niedrigere Sicherheitsstufe. Eine minimale Verschlüsselung wird immer behalten und nicht weiter entschlüsselt, sodass der Server niemals die Klartexte erhält. Der Nutzer kann in dem dargestellten Ansatz auch minimale Verschlüsselungsschichten an- - 37 - geben, muss also nicht unbedingt in Kauf nehmen, dass bei einer entsprechenden Abfrage mehr Informationen enthüllt werden, sondern kann die Abfrage somit als ungültig zurückweisen. Kommen über die Zeit einige Abfragen nur selten vor, die das Verschlüsselungslevel allerdings dauerhaft senken, kann der Proxy den Server anweisen, das Verschlüsselungslevel wieder anzuheben. Die Umverschlüsselung kann also bidirektional durchgeführt werden. Der Vorteil einer Abfrage angepassten Verschlüsselung ist, dass so in der Regel das maximale Verschlüsselungslevel gehalten wird, das noch praktikabel ist. Im Folgenden sollen die von den Autoren beispielhaft vorgeschlagenen Sicherheitsklassen von Verschlüsselungsverfahren kurz vorgestellt werden. Es können allerdings noch beliebig weitere Zwischenschichten eingeführt werden, soweit dies zweckmäßig ist. Die Klassen sind nach ihrer Sicherheit absteigend geordnet. In der Tabelle 4.1 sind die Klassen mit entsprechenden Operationen verknüpft, die die Autoren den unterschiedlichen Verfahren aus den Klassen zugeordnet haben. Tabelle 4.1: Schichtenverschlüsselung Verschlüsselungsklasse Probabilistisch (P) Deterministisch (D) Ordnungserhaltend (O) Suchbar (S) Partiellhomomorph (PH) SQL-Funktionen {= , <>} (für ein bestimmtes Tupel) {= , <>, COUNT, GROUP BY, equi-JOIN} ∪ (P) {BETWEEN, MAX, MIN, ORDER BY, non-equi-JOIN} ∪ (D) { LIKE} ∪ (D) {SUM, AVG} Die probabilistischen Verfahren können nur einzelne Werte vergleichen, nicht aber Werte einer ganzen Tabelle, da der gleiche Klartext nicht in gleiche Chiffretexte resultiert. Die deterministischen hingegen können eine verschlüsselte Relation auf das entsprechend häufigere Auftreten eines Tupels überprüfen. Die unterschiedlichen Join-Verfahren aus (D) und (O) können nur unterstützt werden, solange gleiche Schlüssel für unterschiedliche Relationen und Tupel verwendet werden, andernfalls können die Funktionen nicht ausgeführt werden. 4.2 Mehr-Benutzer Szenario Die meisten der bisher vorgestellten Verfahren eignen sich schlecht für die Nutzung mit unterschiedlichen Teilnehmern (vgl. Kapitel 3.2). Der hier vorgestellte Ansatz von [DRD11] erlaubt im Gegensatz zur selektiven Verschlüsselung auch das Bearbeiten und die Modifikation der Datensätze. Die Autoren nutzen das in [BBS98] erstmals vorgestellte Verfahren der Proxy-Verschlüsselung. In einem solchen Verschlüsselungsschema besitzt jeder Nutzer einen Schlüssel. Ein unter einem bestimmten Schlüssel verschlüsselter Chiffretext kann mit einer Proxy-Verschlüsselungsfunktion so in einen anderen Chiffretext umgewandelt werden, dass dieser von einem anderen Nutzer mit einem anderen Schlüssel in den Klartext umgewandelt - 38 - werden kann, wenn dieser die entsprechenden Rechte besitzt (s.u.). Dabei sind weder Informationen über den Verschlüsselungsschlüssel noch über die Klartextdaten nötig. Die ProxyVerschlüsselung baut dabei auf anderen bekannten Verschlüsselungsverfahren auf. Das hier vorgestellte Verfahren ist RSA-basiert. Das Verschlüsselungsschema ε wird im folgenden beschrieben. • IGenε (λ ) ist für die Generierung der Parameter (p,q,N,ϕ(N), e, d) für den standard RSA Algorithmus in Abhängigkeit von dem Sicherheitsparameter λ verantwortlich. Dabei sind p und q zwei große Primzahlen, N = p ∗ q , ϕ(·) entspricht der eulerschen Funktion (Anzahl teilerfremden Zahlen), e ist ein öffentlicher Schlüssel im Sinne des RSAVerfahrens und d ist der dazugehörige private Schlüssel. Alle Parameter mit Ausnahme von N und ϕ(N) werden geheim gehalten (auch der “öffentliche“ RSA-Schlüssel e). • UGenε (e,d): Der Inhaber der Daten, bzw. eine andere Instanz, die für die Rechteverwaltung zuständig ist, generiert ein Schlüsselpaar zwischen einem Nutzer i und dem Proxy, das jeweils aus einem öffentlichen und einen privaten Schlüssel besteht: (Ue,i , Ud,i ) für den Nutzer und (Pe,i , Pd,i ) für den Server. Die Schlüssel werden so gewählt, das gilt: Ue,i ∗ Pe,i ≡ e mod ϕ(N) und Ud,i ∗ Pd,i ≡ d mod ϕ(N). • UEncε (m) ist der Verschlüsselungsalgorithmus für einen Nutzer i, um die Nachricht m zu chiffrieren. Der Nutzer nutzt dazu seinen öffentlichen Schlüssel Ue,i und erstellt den Chiffretext c = mUe,i mod N. • PEncε (c) nutzt der Server, um den Chiffretext mit seinem öffentlichen Schlüssel Pe,i entsprechend umzuverschlüsseln: ĉ = cPe,i mod N = (mUe,i mod N)Pe,i mod N = mUe,i Pe,i mod N = me mod N Die Nachricht ist jetzt also mit dem ursprünglichen öffentlichen Schlüssel e des RSA Verfahrens verschlüsselt und nicht mehr von dem Schlüssel des Nutzers i abhängig. • PDecε (ĉ) ist die Funktion, die der Server nutzt, um ĉ in den entsprechenden Chiffretext ct mit dem für einen anderen Nutzer t zugewiesenen Schlüssel Pd,t umzuwandeln, so dass Nutzer t diesen dann später entschlüsseln kann: ct = ĉPd,t mod N. • UDecε (ct ) ermöglicht es dem Nutzer mit Hilfe seines privaten Schlüssels Ud,t , den Chiffretext ct entsprechend den Klartext m zu bestimmen: - 39 Ud,t ct mod N = (ĉPd,t mod N)Ud,t mod N = ĉPd,t Ud,t mod N = ĉd mod N =m Die Nachricht wurde an dieser Stelle also nach dem ursprünglichen RSA-Verfahren entschlüsselt. Für Ue,i ∗ Pe,i ≡ e mod ϕ(N) gilt, dass die andere Partei nicht das entsprechende Gegenstück berechnen kann, also unter Kenntnis von Ue,i sich Pe,i nicht bestimmen lässt. Der “Proxy“ aus dem Proxy-Verschlüsselungsschema ist in dem Database-as-a-Service-Szenario der Server des Anbieters. Der Proxy im Sinne dieses Kapitelabschnittes ist ein so genannter Key Management Server (KMS). Dieser übernimmt die Verwaltung sämtlicher Schlüssel und ist insbesondere die einzige Instanz, die IGenε (λ ) und UGenε (e,d) ausführen kann. Die entsprechend generierten Schlüsselpaare leitet er an den Nutzer (Ue,i , Ud,i ) und den Server (Pe,i , Pd,i ) weiter. Sollen einem Nutzer die entsprechenden Rechte entzogen werden, weist die KMS-Einheit den Server an, den entsprechenden Schlüssel serverseitig zu löschen. Einem Nutzer ist es dann nicht mehr möglich, entsprechende Suchanfragen durchzuführen (s.u.) und die Daten zu entschlüsseln. Jeder Datensatz/Tupel t(·) wird in verschlüsselter Form nach dem Schema ε hinterlegt. Entsprechende Indizes (vgl. Kapitel 3.1) sind für eine Suche über die Daten hinzuzufügen. Für die Verschlüsselung dieser Indizes muss allerdings ein anderes Verschlüsselungsschema verwendet werden, da das oben beschriebene Verschlüsselungsschema ε deterministisch ist. Gleiche Indizes hätten dann deshalb den gleichen Chiffretext. Die Autoren stellen infolgedessen ein Verschlüsselungsverfahren χ vor, das Zufallsrauschen enthält, um entsprechende Attacken zu verhindern (dieses Schema ist nur für die suchbaren Indizes anzuwenden, die eigentlichen Daten werden weiterhin mit dem Schema ε verschlüsselt): • IGenχ (λ ) geniert unter Einfluss des Sicherheitsparameters λ die für das Schema nötigen Parameter. Diese sind {p,q,g,x,h,k,gk ∗ hk }, wobei p und q zwei große Primzahlen sind. g, x und k sind gleichverteilte Zufallszahlen und h = gx mod p. {p,q,g,h,gk ∗ hk } sind öffentlich zugängliche Parameter. {x,k} sind geheim. • UGenχ erzeugt ein Schlüsselpaar für zwischen dem Nutzer t und dem Server, nämlich Ut für den Nutzer und Pt für den Server. Dabei soll gelten: Ut ∗ Pt = k mod p. • UEncχ (t(·)) verschlüsselt die dem Tupel t(·) zugeordneten Indizes {I1 , . . . , In }. Dazu hasht der Nutzer die Indizes zunächst mit einer Hashfunktion h: σi = h(Ii ). Im Folgenden - 40 - erzeugt er dann eine Zufallszahl rt und berechnet: ci,1 = (grt +σi ∗ hrt )Ut mod p und ci,2 = h((gk ∗ hk )rt mod p), ∀i ∈ {1, . . . ,n} Der Nutzer sendet nun die Paare c = {(c1,1 ,c1,2 ), . . . ,(cn,1 ,cn,2 )} an den Server. • PEncχ (c) benutzt der Server, um die in c enthaltene Paare umzuverschlüsseln in ĉi,1 = cPi,1t mod p = ((grt +σi ∗ hrt )Ut mod p)tP mod p = (grt +σi ∗ hrt )k mod p ĉi,2 = ci,2 Das so neue erhaltene ĉ speichert der Server in seiner Datenbank zu den entsprechenden Datensätzen. • U − Searchχ (I) erzeugt die Abfrage Qs vom Nutzer s , die an den Server gesendet wird. Dazu bildet die Funktion zuerst das entsprechende σ = h(I) und dann die eigentliche Abfrage Qs = g−σ Us mod p. • P − Searchχ (Qs ) dient zur konkreten Ausführung der Suche auf dem Server. Dazu formuliert der Server zunächst die Abfrage Qs um: Q̂s = QPs s mod p = (g−σ Us mod p)Ps mod p = g−σ k mod p Bei der nun folgenden Suche iteriert der Server über die Datensätze und berechnet für jedes Paar (ĉi,1 , ĉi,2 ) in ĉ: y1 = ĉi,1 ∗ Q̂s = (grt +σi ∗ hrt )k mod p) ∗ (g−σ k mod p) = (gk∗rt +k∗σi ∗ hk∗rt ) ∗ g−σ k mod p = (gk∗rt +k∗(σi −σ ) ∗ hk∗rt ) mod p y2 = h(y1 ). Wenn das entsprechende Ii zu dem gewünschten I gefunden ist, gilt offenbar (σi −σ ) = 0 und damit: y2 = h((gk∗rt ∗ hk∗rt ) mod p) = h((gk ∗ hk )rt mod p) = ci,2 So ist das Durchsuchen der verschlüsselten Indizes nach einem konkreten Index I durch den Nutzer s möglich, obwohl eine anderer Nutzer t vorher unabhängig ein Zufallsrauschen hin- - 41 - zugefügt hat. Die beschriebene Schemata-Kombination von χ und ε gilt als semantisch sicher, unterbindet allerdings nicht die Offenlegung des Suchmusters. Allerdings ist es dem Server bei einer Collusion-Attacke, also in Kooperation mit einem Nutzer, möglich, die geheimen Schlüssel der Schemata zu rekonstruieren und so beliebig auf die Daten zu greifen zu können. Dies ist ein Problem der Proxy-Verschlüsselung an sich. Entsprechende neue Verfahren unter Verwendung von bilinearen Abbildungen schaffen es, dies zu vermeiden (vgl. [BBS98, LV11]). - 42 - 5 Analyse der vorgestellten Verfahren Die in Kapitel 3 und 4 vorgestellte Verfahren sollen in diesem Abschnitt verglichen werden. Insbesondere unterscheiden sich die Verfahren im Hinblick auf die Unterstützung der in Kapitel 2.4 vorgestellten Funktionalitäten. Die hashbasierten Indexverfahren können weiter eingeteilt werden in die durchsuchbaren und die ordnungserhaltenden Schemata. Es handelt sich bei beiden Klassen um deterministische Verfahren mit unterschiedlicher, über eine einfache deterministische Hashfunktion hinaus gehender Funktionalität. Durch die deterministische Eigenschaft ist es mit beiden Verfahren möglich, sowohl Identitätsabfragen als auch die Anzahl der vorhandenen identischen Tupel abzufragen. Durch die Identitätseigenschaft können beide Verfahren darüber hinaus Verknüpfungen mit anderen Tabellen über Gleichheitsbedingungen erstellen, solange die zu verknüpfenden Relationen mit dem gleichen Schlüssel verschlüsselt worden sind. Ist dies nicht der Fall, resultieren gleiche Klartexte nicht in gleiche Chiffretexte in den Tabellen. Die Suchverfahren ermöglichen es ferner, die Chiffretexte nach bestimmten Schlüsselwörtern zu durchsuchen, wenn die einzelnen Schlagwörter entsprechend dem in Kapitel 3.1.1 vorgestellten Verfahren verknüpft worden sind. Ist ein hashbasiertes Verschlüsselungsschema ordnungserhaltend, dann ermöglichst dies eine Menge neuer Funktionalitäten. Durch die ordnungserhaltende Struktur sind sämtliche Bereichs- und Vergleichsabfragen möglich. Das minimale und maximale Tupel sind auch feststellbar. Da gleiche Werte im Klartext auch in gleiche Werte des Chiffretextes resultieren, um die Ordnung abzubilden, ist die Anzahl gleicher Tupel feststellbar. Ein (non-equi) Join ist auch hier nur möglich, solange die Relationen mit den gleichen Schlüsseln verschlüsselt wurden. Durch die zusätzliche Einführung einer Abbildung der Relation in Form eines B+ -Baumes können Vergleichsabfragen effizient durchgeführt werden. Es müssen nicht mehr mit linearen Aufwand alle n Tupel überprüft werden, sondern nur noch ca. log(n). Auch die Beschränkungen der Werte können sehr schnell ermittelt werden, allerdings sind Bereichsabfragen sehr ineffizient durch die dabei nötige Vielzahl von Abfragen. Die Funktionalität erscheint also eher beschränkt und nur für sehr spezielle Anwendungen effizient zu sein, zumal das Einfügen neuer Werte sehr aufwändig ist. Die Partitionierungsverfahren ermöglichen keine neue Funktionalität, sondern dienen eher dazu, die statistischen Eigenschaften der Chiffretexte im Sinne der Datensicherheit weiter zu verbessern. Identitätsabfragen und Abfragen über die Anzahl der Tupel sind nur begrenzt möglich, in dem Sinne, dass die Abfrage ungenau ist und Tupel enthält, die nicht der eigentlichen Abfrage entsprechen. Diese falschen Datensätze entstehen dadurch, dass die Werte nun in Bereiche/Partitionen aufgeteilt werden. Die Abfragen müssen also in einem zweiten Schritt durch eine vertrauenswürdige Instanz, wie der vertrauenswürdigen Zwischenschicht beim Nutzer, weiter bereinigt werden. Die Gruppe der partiellhomomorphen Verschlüsselungsschemata unterscheiden sich stark in - 43 - ihrem Funktionsumfang. [HIM04] beschreibt ein sehr funktionsreiches Schema, allerdings gilt dies als sehr unsicher und wird deshalb an dieser Stelle nicht weiter betrachtet. Die als sicher geltenden Schemata unterstützen in der Regel nur die Addition oder Multiplikation, können also nur eine begrenzte Anzahl von Operationen (in diesem Fall die additiven) durchführen. Sie sind in der Regel probabilistisch und können deshalb keine Identitätsabfragen o.ä. bearbeiten. Nur die Bildung von Summen und Durchschnitten über verschiedene Tupel ermöglichen diese additiven partiellhomomorphen Schemata. Eine Übersicht der bisher analysierten Verfahren findet sich in Tabelle 5.1. Tabelle 5.1: Übersicht Funktionsumfang der vorgestellten Verschlüsselungsschemata Begriff Vergleiche Aggregate Verknüpfung Identität Verhältnis/Bereich Suche Beschränkung Anzahl Summe Durchschnitt Gleichheit Ungleichheit S O B P 4 4 4 4 4 • 4 4 4 PH 4 4 • 4 4 • • • Legende: 4 B P PH wird unterstützt B+ -Baum Partitionierung Partiellhomomorph • S O wird teilweise unterstützt }︂ Suchbar Hashbasierend Ordnungserhaltend Die vollhomomorphen Verschlüsselungsverfahren und der Einsatz kryptographischer Hardware ermöglichen die Bearbeitung sämtlicher Funktionalität. Die Abfrage-angepasste Verschlüsselung tut dies auch, realisiert dies aber durch die Kombination der unterschiedlichen Verfahren. Die Konzepte der selektiven Verschlüsselung und die der Mehr-Benutzer im Proxy-Szenario erweitern bestehende Verschlüsselungsverfahren um die Fähigkeit einer kleinen Zugriffskontrolle. Bei der selektiven Verschlüsselung können zwar mehrere Nutzer durch das Lesen der Daten partizipieren, allerdings kann nur ein Nutzer die Daten bearbeiten und erstellen. In dem proxybasierten Ansatz können alle Benutzer lesen sowie Schreibvorgänge durchführen. Nicht herangezogen in diesem Vergleich werden die Effizienz und die Kosten der einzelnen Verfahren. Die meisten der vorgestellten Verfahren stellen nur Konzepte dar und wurden, wenn überhaupt, unter völlig verschiedenen Bedingungen und unterschiedlichen Gesichtspunkten implementiert und getestet. Auch Komplexitätsangaben sind in der Regel nicht vor- - 44 - handen. Ein Vergleich an Hand der technischen und ökonomischen Effizienz erscheint daher nicht vollends möglich. Anzumerken ist, dass B+ -Bäume einen Großteil der Arbeit an den Nutzer auslagern, die vollhomomorphen Verschlüsselungen sehr ineffizient sind und die kryptographische Hardware bis vor kurzem als viel zu kostenintensiv galten (vgl. Kapitel 6.2). Die Bewertung der Verfahren anhand ihrer Sicherheit erfolgt unter dem Hinweis, dass z.T. sehr heterogene Sicherheitsvorstellungen existieren. Informationen, die in dem einen Kontext sensibel sind, mögen es für einen anderen nicht sein. So ist beispielsweise im Bankenwesen die Ordnung von Überweisungsbeträgen sensibel, da bei einem Angriff der Chiffretext des Betrages einer Überweisung durch einen höheren ausgetauscht werden könnte. Die Ordnung von den zugewiesenen Kontonummern von Banken erscheinen dahingegen eher unkritisch. In diesem Kontext findet im Folgenden eine Generierung von verschiedenen Klassifikationen von Verschlüsselungsverfahren statt. Die Einordnung der Verschlüsselungsschemata in die Klassen erfolgt hinsichtlich ihrer Entropie. Die unterschiedlichen Klassen sind hinsichtlich ihres Sicherheitslevels in absteigender Reihenfolge sortiert (vgl. [PZB11]): Probabilistisch: Die sichersten Schemata haben ein starkes Zufallsrauschen. Zwei gleiche Klartextwerte haben unterschiedliche Chiffretexte, wobei keine Verbindung zwischen diesen beiden hergestellt werden kann. Homomorph: Bei diesen Schemata handelt es sich auch um probabilistische Verschlüsselungen, allerdings erlauben diese eine gewisse Funktionalität. Deterministisch: Diese Verfahren verwandeln gleiche Werte in auch immer gleiche Chiffretexte um. Suchbar: Diese Schemata erlauben es einem Nutzer, Texte auf bestimmte Schlüsselwörter hin zu durchsuchen. Es handelt sich in der Regel um deterministische Verfahren, die etwas mehr Funktionalität erlauben. Ordnungserhaltend: Die schwächsten Verfahren behalten die ursprüngliche Ordnung des Definitionsbereichs auf den Wertebereich bei und geben so Informationen über die Ordnung der Klartexte indirekt über die Chiffretexte preis. Die in dieser Arbeit vorgestellten homomorphen Verfahren sind am sichersten, dabei sogar sicher im Sinne der semantischen Sicherheit und der in Kapitel 2.3 vorgestellen Definitionen (vgl. [LMSV10]). Rein probabilistische Verfahren werden hier nicht weiter behandelt, da kein solches Verfahren existiert, das die Ausführung von Funktionalität im Sinne dieser Arbeit zulässt. Die B+ -Bäume fallen in die Kategorie der deterministischen Verfahren und stellen dort die wohl sichersten Schemata dar. Gleiche Ausgangswerte resultieren dabei nur zu einem späteren Zeitpunkt in gleiche Chiffrewerte, solange die Struktur des Baumes gleich - 45 - bleibt, da innerhalb der verschlüsselten Tupel auch die Zeiger auf den nächsten Eintrag des Baumes enthalten sind. Gleiche Werte innerhalb eines aktuellen Baumes haben sogar unterschiedliche Werte durch ihre Zeiger. Die nächst sicheren Verfahren stellen die partitionierenden Schemata dar. Hier werden mehrere Klartextwerte auf einen Chiffretext abgebildet, ohne weitere Informationen zu veröffentlichen, da die Werte innerhalb und außerhalb der Intervalle gleichverteilt sind. Über die Kardinalitäten der einzelnen Attributsausprägungen lassen sich also, im Vergleich zu sonstigen deterministischen Verfahren, kaum Aussagen treffen, was die Kryptoanalyse erschwert. Die hier vorgestellten suchbaren Verfahren sind deterministisch, konkatinieren allerdings wiederum deterministisch verschlüsselte Schlagwörter mit dem Chiffretext. Ein Angreifer kann so immerhin die verschlüsselten Tupel identifizieren, die einem ihm bekannten (verschlüsselten) Schlagwort entsprechen. Kennt ein Angreifer beispielsweise die verschlüsselte Version des Schlagwortes “Passwort“, so kann er alle verschlüsselten Tupel, die das Wort “Passwort“ enthalten, identifizieren. Die wohl schwächste Gruppe stellen die ordnungserhaltenden Verfahren dar. Neben dem kurz skizzierten obigen Szenario, lassen sich auch insbesondere nummerische Differenzen zwischen verschiedenen Chiffretexten wesentlich effizienter und exakter berechnen (vgl. [BCO11]), was wesentlich für die differentiale Kryptoanalyse ist. Sicherheitseinordnungen der Mehr-Benutzer-Verfahren sind auf Grund von mangelnden Analysen und Angaben nicht weiter möglich. Der Einsatz von kryptographischer Hardware gängiger Secure-Coprocessors gilt als sicher (vgl. [PPM11]). Hier ist allerdings zu beachten, dass in erster Linie die Umgebung gesichert ist, die Daten allerdings trotzdem entsprechend durch ein probabilistisches Verfahren gesichert werden müssen. - 46 - 6 Proof-of-Concept Implementierungen 6.1 CryptDB CryptDB (vgl. hier und im Folgenden [PRZB11]) ist eine vom Massachusetts Institute of Technology (MIT) entwickelte Software, die insbesondere das in Kapitel 4.1 vorgestellte Konzept der an die Abfrage-angepassten Verschlüsselung implementiert. Bei CryptDB handelt sich um ein eigenständiges Programm, das auf einem Application-Server laufen muss und zwischen einer MySQL-Datenbank und deren Nutzer geschaltet wird. Bei dem Nutzer sind in der Regel nur sehr wenige Änderungen vorzunehmen. Hier müssen im Grunde nur die Einstellungen für die (direkte) Verbindung zur Datenbank umgeschrieben werden zu einer Verbindung zu CryptDB. Auf dem MySQL-Server müssen auch keine weiteren Änderungen von Einstellungen getätigt werden. Lediglich die UDF’s und die Relationen müssen hier in verschlüsselter Form neu hinterlegt werden. CryptDB bietet neben der Abfrage-angepassten Verschlüsselung auch einen Modus für den mehrere Benutzer an. In dem Mehrbenutzermodus verschlüsselt ein Nutzer bei der Chiffrierung des Klartextes diesen mit seinem eigenen Schlüssel. Datensätze innerhalb einer Relation werden also in der Regel mit unterschiedlichen Schlüssel verschlüsselt: cm = EnckA (m). Der Schlüssel kA ist einem bestimmten Nutzer A zugeordnet. Der Mehrbenutzermodus wird durch die Einführung von verketteten Schlüsseln nach dem speak-for-Prinzip von [WABL94] realisiert. Dabei wird ein Schlüssel kA in chiffrierter Form durch einen anderen Schlüssel kB in einer weiteren Relation auf dem Server hinterlegt: ckA = EnckB (kA ) Diese Verkettung kann beliebig erweitert werden. Ein Nutzer B kann nun den Schlüssel kA und dann dadurch m berechnen. Dieses Verfahren ermöglicht es, den Datensatz in nur einer verschlüsselten Form zu hinterlegen und gleichzeitig mehreren Nutzern den Zugang zu ermöglichen. Der Mehrbenutzermodus schränkt die Funktionalität der ausführbaren Operationen allerdings erheblich dadurch ein, dass für jeden Datensatz ein anderer Schlüssel verwendet wird. So können im Grunde keine Funktionen mehr durchgeführt werden. Dieser Ansatz von CryptDB (Mehrbenutzer) wird deshalb an dieser Stelle nicht weiter beachtet. CryptDB kann in dem von uns nun betrachteten normalen Modus (Abfrage-angepasst) umfangreiche Operationen durchführen. Durch Observation eines großen shared SQL-Servers sind die Autoren der Implementierung an 126 Millionen unabhängige SQL-Abfragen und den zugrundeliegende Daten gelangt. Nur 500 von diesen Abfragen konnte CryptDB nicht verarbeiten, dies entspricht einer Erfolgsquote von ca. 99,5%. Insbesondere der Textvergleich auf Klein- und Großschreibung und komplexe mathematische Transformationen konnten nicht durchgeführt werden. - 47 - Im Folgenden sollen kurz die Ergebnisse von durchgeführten Tests bezüglich der Effizienz von CryptDB im Abfrage-angepassten Modus vorgestellt werden. Die Ergebnisse basieren auf dem TPC-C Benchmark [4]. • Die Netzwerkauslastung steigt um ca. 26%. • Das Speicheraufkommen auf dem Server erhöht sich ca. um den Faktor 3,7. Dies liegt insbesondere daran, dass die Chiffretexte mehr Bits benötigen als die dazugehörigen Klartexte. • Der eigentliche MySQL-Server braucht im Schnitt 20% länger, um die gestellten Abfragen zu beantworten. • CryptDB benötigt für eine Abfrage durchschnittlich 0,6 ms zur Zwischenbearbeitung der Abfragen. Die 0,6 von CryptDB extra benötigten Millisekunden lassen sich weiter anteilig differenzieren. Ungefähr 25% der Zeit werden für generelle, grundlegende Proxy-Funktionalitäten benötigt, ca. 25% für die Ver- und Entschlüsselung der erhaltenen Daten und ca. 50% für die Analysen der Abfragen und die entsprechende Umschreibung. Die Umverschlüsselung der Daten ist in der Regel nicht weiter relevant, da diese nur sehr punktuell durchgeführt wird (vgl. Kapitel 4.1). Zu der Geschwindigkeit der Umverschlüsselung wurden keine näheren Angaben gemacht. Zum Vergleich: Eine beispielhaft ausgewählte SELECT Abfrage mit einer darin enthaltenen Summen-Aggregation dauert in dem normalen Szenario mit direkter Anbindung an die Datenbank 0,11 ms. Bei der Zwischenschaltung von CryptDB erhöht sich die Gesamtzeit der Abfrage um den Faktor neun auf 0,99 ms. 6.2 TrustedDB TrustedDB (vgl. hier und im Folgenden [BS11]) stellt eine Proof-of-Concept Implementierung für den praktikablen Einsatz von kryptographischer Hardware (vgl. Kapitel 3.4) dar. Diese kann eine gute Alternative zu vollhomomorphen Verschlüsselungsschemata verkörpern, da sie im Grunde auch beliebige Funktionalität ausführen kann und perfekt sicher ist. Die Datenbank wird dabei einfach mit einem entsprechenden sicheren, symmetrischen Verfahren verschlüsselt. Die Autoren gehen neben der eigentlichen Implementierung auch insbesondere auf den Kostenaspekt der verwendeten Hardware ein und vergleichen diesen mit dem von traditioneller Hardware beim Nutzer und dem von normalen Cloud Compu- - 48 - ting Anbietern. Der Einsatz kryptographischer Hardware gilt nämlich als sehr teuer (vgl. [ZCL09]). Die Architektur und die Abfrageverarbeitung werden grob im Folgenden beschrieben. Die Attribute der Relationen sind eingeteilt in öffentliche und private/sensible Daten. Die privaten Attribute sind in verschlüsselter Form und die öffentlichen als Klartext auf dem Server hinterlegt. Auf dem Server ist ein secure-coprocessor (SC) eingebaut. Dieser hat einen Public-Key, sodass die Verschlüsselungen entsprechend erfolgen können. Der Verlauf einer Abfrage vollzieht sich dabei grob nach folgendem Schema: 1. Der Nutzer sendet seine Abfrage Q in verschlüsselter Form unter dem Public-Key des Servers an diesen. 2. Der Server-Anbieter kann die Abfrage nicht verstehen und leitet diese deshalb an den SC weiter. Die Abfrage wird dort von einem Abfrage-Steuerungseinheit (request handler) entgegengenommen. 3. Die Abfrage-Steuerungseinheit entschlüsselt Q und leitet die Abfrage an eine AbfrageAnalyseeinheit (query parser) weiter. Diese analysiert die Abfrage und schreibt sie so in entsprechende Unterabfragen um, dass die Abfragen bzgl. öffentlicher Attribute auf dem Server und Abfragen über private Attribute auf dem SC ausgeführt werden können. 4. Die Abfrage-Verwaltungseinheit (query dispatcher) regelt nun die Handhabung der neuen Unterabfragen, leitet diese an die Ausführungseinheiten (engine) des Servers und des SC weiter und verwaltet die entsprechenden Beziehungen der Abfragen. 5. Die Ausführungseinheit ist auch für die Zusammenführung der erhaltenen Ergebnisse aus den Unterabfragen zuständig und leitet diese wieder in verschlüsselter Form über den Server an den Nutzer zurück. Die Abfrage-Steuerungseinheit, -Analyseeinheit, -Verwaltungseinheit und die Ausführungseinheit der SC befinden sich in der gesicherten Umgebung des secure-coprocessors. Die Performancebewertung von TrustedDB erfolgt nur sehr grobgranular. Sie wurde durch ausgewählte Abfragen aus dem TCP-H Benchmark12 bestimmt. Die gesamte Bearbeitungszeit erhöht sich bei dieser Implementierung ca. um den Faktor acht. Hier ist jedoch zu beachten, dass die gesamte Bearbeitungszeit stark mit der Anzahl von privaten und öffentlichen Attributen, die in der Abfrage enthalten sind, korreliert. Die Autoren von TrustedDB haben großes Augenmerk auf die Kostenanalyse ihres Ansatzes 12 Es handelt sich hier um einen anderen Benchmark der TCP Gruppe als dem aus Kapitel 6.2 - 49 - gelegt. Sie erweitern dabei die Arbeit von [CS11], die die Kosten im Bereich Cloud Computing auf einzelne CPU-Zyklen herunterbricht und so vergleichbar mit normaler Hardware macht. Darüber hinaus beziehen sie auch die Kosten für die Netzwerkverbindungen, die eigentliche Hardware, die Serverstandorte, die Energiekosten und die Personalkosten mit ein. Es ergeben sich dabei die ungefähren Kosten aus Tabelle 6.1. Kryptographische Hardware ist gegenüber der normalen Cloud also wesentlich teurer pro Tabelle 6.1: Kosten pro CPU-Zyklus im Vergleich Szenario Pikocent/CPU-Zyklus TN 25 CC 0,5 KH 50 Legende: TN KH Traditionelle Hardware beim Nutzer Kryptographische Hardware in der Cloud CC Pikocent Cloud Computing 10−14 US-Dollar Quelle: [BS11] CPU-Zyklus, entspricht aber ca. dem Kostenniveau von traditionellen in-house Lösungen. Bei der Arbeit über verschlüsselte Inhalte sind allerdings deutlich mehr CPU-Zyklen auszuführen, als auf den Klartextdaten. [BS11] haben beispielhaft das bereits oben erwähnte additive SHE Schema aus [Pai99] genauer analysiert und kommen zu dem Ergebnis, dass bei einer Verwendung dieses Schemas auf einem normalen DaaS-Anbieter pro Addition (bei z.B. einer Summen-Aggregation) das 30000-fache an Operationen nötig sind, als wenn die Berechnung im Klartext innerhalb der SC erfolgt. Die Autoren kommen zu dem Schluss, dass es kostentechnisch deutlich vorteilhafter ist, kryptographische Hardware einzusetzten, anstatt die in dieser Arbeit vorgestellten Verfahren zu verwenden. - 50 - 7 Zusammenfassung und Ausblick Zusammenfassend ist festzuhalten, dass mittlerweile eine Vielzahl von Verschlüsselungstechniken für Daten in einem DaaS Kontext existieren. Die unterschiedlichen Verfahren wurden in Kapitel 3 und 4 vorgestellt und in Kapitel 5 weiter analysiert. In Kapitel 6 wurden zwei Proof-of-Concept Implementierungen präsentiert. Eine Vergleichbarkeit der Verfahren ist nur schwer zu erlangen. Die Arbeit hat ihren Fokus insbesondere auf den Funktionsumfang der Verfahren. Während dieser zum Teil schwer zu bestimmen ist, scheitert ein Vergleich aus der bisherigen Literatur im Hinblick zu sonst üblichen Datenbankbenchmarks. Es existiert kein einheitliches zu Grunde gelegtes Schema. Selbst Ergebnisse, die auf den ersten Blick vergleichbar erscheinen, unterscheiden sich bei genauerer Untersuchung hinsichtlich der verwendeten Hardware, den Datenabfragen, den dazu zu Grunde gelegten Datensätzen etc., die die Benchmarks maßgeblich beeinflussen. Es werden keine Angaben darüber gemacht, in wie weit die Verfahren gut parallel auf dem Server laufen können und wie skalierbar sie somit eigentlich sind; erst in [CJP+ 11] werden diese Probleme ansatzweise betrachtet. Darüber hinaus weisen auch die meisten Sicherheitsanalysen, sofern sie existieren, einen hohen Mangel an Homogenität auf. Viele der vor allem früh vorgestellten Verfahren sind eher ad-hoc Natur (vgl. [HMT04]). Zudem mangelt es an einem einheitlichen Sicherheitsbegriff, da dieser oft anwendungsspezifisch ist. Ein Effizienzvergleich der unterschiedlichen Verfahren unter diesem Gesichtspunkt ist für die Zukunft wünschenswert und zeigt eine Forschungslücke auf. Eine eindeutige Empfehlung für ein Verfahren kann an dieser Stelle nicht ausgesprochen werden. Auch wenn die momentanen Implementierungen von vollhomomorphen Verfahren bisher noch sehr ineffizient sind, stellen sie allerdings ein sehr vielversprechendes Konzept dar. Es handelt sich dabei um ein sehr junges Forschungsfeld bzw. um ein Forschungsfeld, das erst kürzlich einen bahnbrechenden Fortschritt erfahren hat. Die Forschungstätigkeit ist momentan sehr hoch auf diesem Gebiet und es werden zahlreiche Verbesserungen veröffentlicht. Solange die Verfahren allerdings weiter eine so schlechte Performance haben, ist der neu aufgerollte Ansatz mit kryptographischer Hardware vorzuziehen. Da das DaaS-Szenario immer populärer wird, wird auch insbesondere die eng verknüpfte Datensicherheit weiter an Bedeutung gewinnen. Die Wahl für ein Verschlüsselungsverfahren muss momentan allerdings noch anwendungsbezogen erfolgen und lässt sich nicht generalisieren. - II - Literaturverzeichnis [ABFF09] ATALLAH, M.J. ; B LANTON, M. ; FAZIO, N. ; F RIKKEN, K.B.: Dynamic and Efficient Key Management for Access Hierarchies. In: ACM Transactions on Information and System Security (TISSEC) 12 (2009), Nr. 3, S. 181–193 [AKSX04] AGRAWAL, R. ; K IERNAN, J. ; S RIKANT, R. ; X U, Y.: Order preserving encryption for numeric data. In: Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data (SIGMOD’04), 2004, S. 563–574 [BBB+ 11] BARKER, E. ; BARKER, W. ; B URR, W. ; P OLK, W. ; S MID, M.: Recommendation for key management - part 1: General (revised). NIST Special Publication SP 800-57. 2011. – Forschungsbericht [BBS98] B LAZE, M. ; B LEUMER, G. ; S TRAUSS, M.: Divertible Protocols and Atomic Proxy Cryptography. In: Proceedings of Advances in Cryptology International Conference on the Theory and Application of Cryptographic Techniques (EUROCRYPT’98), 1998, S. 127–144 [BC04] B ELLOVIN, S.M. ; C HESWICK, W.R.: Privacy-Enhanced Searches Using Encrypted Bloom Filters. Cryptology ePrint Archive, Report 2004/022, 2004. – http://eprint.iacr.org/ [BCLO09] B OLDYREVA, A. ; C HENETTE, N. ; L EE, Y. ; O’N EILL, A.: Order-Preserving Symmetric Encryption. In: Proceedings of the 28th international conference on Theory and application of cryptographic techniques (EUROCRYPT’09), 2009, S. 224–241 [BCO11] B OLDYREVA, A. ; C HENETTE, N. ; O’N EILL, A.: Order-Preserving Encryption Revisited: Improved Security Analysis and Alternative Solutions. In: Proceedings of the 31st Annual Conference on Advances in Cryptology (CRYPTO’11), 2011, S. 578–595 [Blo70] B LOOM, B.H.: Space/time trade-offs in hash coding with allowable errors. In: Communications of the ACM 13 (1970), S. 422–426 [BNS10] B EUTELSPACHER, A. ; N EUMANN, H. ; S CHWARZPAUL, T.: Kryptografie in Theorie und Praxis: Mathematische Grundlagen. 2. Auflage. Vieweg+Teubner Verlag, 2010 - III - [BS11] BAJAJ, S. ; S ION, R.: TrustedDB: a trusted hardware based database with privacy and data confidentiality. In: SIGMOD Conference, 2011, S. 205–216 [BSMM08] B RONSTEIN, I.N. ; S EMENDJAJEW, K.A. ; M USIOL, G. ; M UEHLIG, H.: Taschenbuch der Mathematik. 7. Auflage. Wissenschaftlicher Verlag Harri Deutsch GmbH, 2008 [CJP+ 11] C URINO, C. ; J ONES, E. ; P OPA, R.A. ; M ALVIYA, N. ; W U, E. ; M ADDEN, S. ; BALAKRISHNAN, H. ; Z ELDOVICH, N.: Relational Cloud: A Database Service for the Cloud. In: Proceedings of the 5th Conference on Innovative Data Systems Research (CIDR’11), 2011, S. 235–240 [CKGS98] C HOR, B. ; K USHILEVITZ, E. ; G OLDREICH, O. ; S UDAN, M.: Private information retrieval. In: Journal of the ACM 45 (1998), Nr. 6, S. 965–981 [CLRS10] C ORMEN, T.H. ; L EISERSON, C.E. ; R IVEST, R.L. ; S TEIN, C.: Algorithmen eine Einfuehrung. 3. Auflage. Oldenbourg Wissenschaftsverlag, 2010 [CNT11] C ORON, J.S. ; NACCACHE, D. ; T IBOUCHI, M.: Optimization of Fully Homomorphic Encryption. Cryptology ePrint Archive, Report 2011/440, 2011. – http://eprint.iacr.org/ [CS11] C HEN, Y. ; S ION, R.: To Cloud Or Not To Cloud? Musings On Costs and Viability. In: Proceedings of the 2nd ACM Symposium on Cloud Computing (SOCC11), 2011. – in Erscheinung [Dan05] DANG, T.K.: Oblivious Search and Updates for Outsourced Tree-Structured Data on Untrusted Servers. In: International Journal of Computer Science and Applications (IJCSA) 2 (2005), Nr. 2, S. 67–84 [DGHV10] D IJK, M. van ; G ENTRY, C. ; H ALEVI, S. ; VAIKUNTANATHAN, V.: Fully Homomorphic Encryption over the Integers. In: Proceedings of the 29th international conference on Theory and application of cryptographic techniques (EUROCRYPT’10), 2010, S. 24–43 [DJ10] D IJK, M. van ; J UELS, A.: On the impossibility of cryptography alone for privacy-preserving cloud computing. In: Proceedings of the 5th USENIX conference on Hot Topics in Security (HotSec’10), 2010, S. 1–8 [DLP+ 01] DYER, J.G. ; L INDEMANN, M. ; P EREZ, R. ; S AILER, R. ; D OORN, L. van ; - IV - S MITH, S.W. ; W EINGART, S.: Building the IBM 4758 Secure Coprocessor. In: Computer 34 (2001), Nr. 10, S. 57–66 [DRD11] D ONG, C. ; RUSSELLO, G. ; D ULAY, N.: Shared and searchable encrypted data for untrusted servers. In: Journal of Computer Security 19 (2011), Nr. 3, S. 367–397 [DVF+ 07] DAMIANI, E. ; V IMERCATI, S. ; F ORESTI, S. ; JAJODIA, S. ; PARABOSCHI, S. ; S AMARATI, P.: Selective Data Encryption in Outsourced Dynamic Environments. In: Journal Electronic Notes in Theoretical Computer Science (ENTCS) 168 (2007), S. 127–142 [DVJ+ 03] DAMIANI, E. ; V IMERCATI, S. ; JAJODIA, S. ; PARABOSCHI, S. ; S AMARATI, P.: Balancing confidentiality and efficiency in untrusted relational DBMSs. In: Proceedings of the 10th ACM Conference on Computer and Communications Security (CCS’03), 2003, S. 93–102 [EAAA11] E ARN, J. ; A LSAQOUR, R. ; A BDELHAQ, M. ; A BDULLAH, T.: Searchable Symmetric Encryption: Review and Evaluation. In: Journal of Theoretical and Applied Information Technology 30 (2011), Nr. 1, S. 48–54 [Eck09] E CKERT, C.: IT-Sicherheit: Konzepte - Verfahren - Protokolle. 6. Auflage. Oldenbourg Wissenschaftsverlag, 2009 [Ert07] E RTEL, W.: Angewandte Kryptographie. 3. Auflage. Hanser Fachbuchverlag, 2007 [For10] F ORESTI, S.: Preserving Privacy in Data Outsourcing. 1. Auflage. Springer New York, 2010 [Gen09] G ENTRY, C.: Fully homomorphic encryption using ideal lattices. In: Proceedings of the 41st annual ACM Symposium on Theory of Computing (STOC’09), 2009, S. 169–178 [Gen10] G ENTRY, C.: Computing arbitrary functions of encrypted data. In: Communications of the ACM 53 (2010), Nr. 3, S. 97–105 [GGEK11] G AHI, Y. ; G UENNOUN, M. ; E L -K HATIB, K.: A Secure Database System using Homomorphic Encryption Schemes. In: Proceedings of the 3rd International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA’11), 2011, S. 54–58 -V- [GH11] G ENTRY, C. ; H ALEVI, S.: Implementing Gentry’s fully-homomorphic encryption scheme. In: Proceedings of the 30th International Conference on Theory and Application of Cryptographic Techniques (EUROCRYPT’11), 2011, S. 129–148 [Goh03] G OH, E.J.: Secure Indexes. Cryptology ePrint Archive, Report 2003/216, 2003. – http://eprint.iacr.org/ [Gol07] G OLDREICH, O.: Foundations of Cryptography: Basic Tools. 1. Auflage. Cambridge University Press, 2007 [HIM02] H ACIGUMUS, H. ; I YER, B. ; M EHROTRA, S.: Providing Database as a Service. In: Proceedings of the 18th International Conference on Data Engineering, 2002, S. 29–38 [HIM04] H ACIGUMUS, H. ; I YER, B.R. ; M EHROTRA, S.: Efficient Execution of Aggregation Queries over Encrypted Relational Databases. In: 9th International Conference on Database Systems for Advances Applications (DASFAA’04), 2004, S. 125–136 [HMT04] H ORE, B. ; M EHROTRA, S. ; T SUDIK, G.: A privacy-preserving index for range queries. In: Proceedings of the 30th International Conference on Very Large Data Bases (VLDB’04), 2004, S. 720–731 [HV10] H ASELMANN, T. ; VOSSEN, G.: Database-as-a-Service für kleine und mittlere Unternehmen. Arbeitsbericht Nr. 3 des Instituts für angewandte Informatik an der WWU. 2010. – Forschungsbericht [KC05] K ANTARCIOGLU, M. ; C LIFTON, C.: Security Issues in Querying Encrypted Data. In: Proceedings of the 19th Annual Working Conference on Data and Applications Security (DBSec’05), 2005, S. 325–337 [Ker83] K ERCKHOFFS, A.: La cryptographie militaire. In: Journal des sciences militaires 9 (1883), S. 5–83 [KL10] K AMARA, S. ; L AUTER, K.: Cryptographic cloud storage. In: Proceedings of the 14th International Conference on Financial Cryptograpy and Data Security (FC’10), 2010, S. 136–149 [Kow06] KOWALK, W: CRC Cyclic Redundancy Check - Analyseverfahren mit Bitfiltern. Universitaet Oldenburg. 2006. – Forschungsbericht - VI - [Lan09] L ANSING, J.: Database-as-a-Service: Charakterisierung und Modellentwurf. DaaS-Workshop, Universitaet Muenster. 2009. – Forschungsbericht [LC05] L IN, P. ; C ANDAN, K.S.: Hiding Tree Structured Data and Queries from Untrusted Data Stores. In: Information Systems Security 14 (2005), Nr. 4, S. 10–26 [LMSV10] L OFTUS, J. ; M AY, A. ; S MART, N.P. ; V ERCAUTEREN, F.: On CCA-Secure Fully Homomorphic Encryption. Cryptology ePrint Archive, Report 2010/560, 2010. – http://eprint.iacr.org/ [LNV11] L AUTER, K. ; NAEHRIG, M. ; VAIKUNTANATHAN, V.: Can Homomorphic Encryption be Practical? Cryptology ePrint Archive, Report 2011/405, 2011. – http://eprint.iacr.org/ [LV11] L IBERT, B. ; V ERGNAUD, D.: Unidirectional Chosen-Ciphertext Secure Proxy Re-Encryption. In: IEEE Transactions on Information Theory 57 (2011), Nr. 3, S. 1786–1802 [MKF+ 03] M ICHELS, J. ; K ULKARNI, G. ; FARRAR, C. ; E ISENBERG, A. ; M ATTOS, N.M. ; DARWEN, H.: The SQL Standard. In: it - Information Technology 45 (2003), Nr. 1, S. 30–38 [MRS88] M ICALI, S. ; R ACKOFF, C. ; S LOAN, B.: The notion of security for probabilistic cryptosystems. In: SIAM Journal on Computing 17 (1988), Nr. 2, S. 412–426 [MS03] M IKLAU, G. ; S UCIU, D.: Controlling access to published data using cryptography. In: Proceedings of the 29th International Conference on Very Large Databases (VLDB’03), 2003, S. 898–909 [MT05] M YKLETUN, E. ; T SUDIK, G.: Incorporating a Secure Coprocessor in the Database-as-a-Service Model. In: Proceedings of the 2005 Innovative Architecture on Future Generation High-Performance Processors and Systems (IWIA’05), 2005, S. 38–44 [MT06] M YKLETUN, E. ; T SUDIK, G.: Aggregation Queries in the Database-As-aService Model. In: DAMIANI, Ernesto (Hrsg.) ; L IU, Peng (Hrsg.): Data and Applications Security XX. Springer Heidelberg, 2006, S. 89–103 [NHP11] N EISSE, R. ; H OLLING, D. ; P RETSCHNER, A.: Implementing Trust in Cloud Infrastructures. In: Proceedings of the 11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID’11), 2011, S. 524–533 - VII - [OS07] O STROVSKY, R. ; S KEITH, W.: A survey of single-database private information retrieval: techniques and applications. In: Proceedings of the 10th International Conference on Practice and Theory in Public-Key Cryptography (PKC’07), 2007, S. 393–411 [OU98] O KAMOTO, T. ; U CHIYAMA, S.: A New Public-Key Cryptosystem as Secure as Factoring. In: Proceedings of the 16th International Conference on Theory and Application of Cryptographic Techniques (EUROCRYPT’98), 1998, S. 308–318 [OV06] O BERSCHELP, W. ; VOSSEN, G.: Rechneraufbau und Rechnerstrukturen. 10. Auflage. Oldenburg Wissenschaftsverlag, 2006 [Pai99] PAILLIER, P.: Public-key cryptosystems based on composite degree residuosity classes. In: Proceedings of the 17th international conference on Theory and application of cryptographic techniques (EUROCRYPT’99), 1999, S. 223–238 [PMP10] PARNO, B. ; M C C UNE, J.M. ; P ERRIG, A.: Bootstrapping Trust in Commodity Computers. In: Proceedings of the 2010 IEEE Symposium on Security and Privacy (SP’10), 2010, S. 414–429 [PPM11] PARNO, B. ; P ERRIG, A. ; M C C UNE, J.M.: Bootstrapping Trust in Modern Computers. 1. Auflage. Springer New York, 2011 [PRZB11] P OPA, R. ; R EDFIELD, C. ; Z ELDOVICH, N. ; BALAKRISHNAN, H.: CryptDB: Protecting Confidentiality with Encrypted Query Processing. In: Proceedings of the 23rd ACM Symposium on Operating Systems Principles (SOSP’11), 2011. – in Erscheinung [PZB11] P OPA, R. ; Z ELDOVICH, N. ; BALAKRISHNAN, H.: CryptDB: A Practical Encrypted Relational DBMS. Computer Science and Artificial Intelligence Laboratory MIT-CSAIL-TR-2011-005. 2011. – Forschungsbericht [RAD78] R IVEST, R.L. ; A DLEMAN, L. ; D ERTOUZOS, M.L.: On Data Banks and Privacy Homomorphisms. In: Foundations of Secure Computation (1978), S. 169–179 [Rot11] ROTHBLUM, R.: Homomorphic Encryption: From Private-Key to Public-Key. In: Proceedings of the 8th Theory of Cryptography Conference (TCC’11), 2011, S. 219–234 [Sch85] S CHÖNHAGE, A.: Quasi-GCD computations. In: Journal of Complexity 1 (1985), Nr. 1, S. 118–137 - VIII - [Sch11] S CHMIDT, P.: Fully Homomorphic Encryption: Overview and Cryptanalysis, TU Darmstadt, Diploma Thesis, 2011 [SGR09] S ANTOS, N. ; G UMMADI, K.P. ; RODRIGUES, R.: Towards trusted cloud computing. In: Proceedings of the 2009 Conference on Hot Topics in Cloud Computing (HotCloud’09), 2009 [Sha01] S HANNON, C. E.: A mathematical theory of communication. In: ACM SIGMOBILE Mobile Computing and Communications Review 5 (2001), Nr. 1, S. 3–55 [SL07] S TAMP, M. ; L OW, R.M.: Applied cryptanalysis: breaking ciphers in the real world. 1. Auflage. Wiley-IEEE Press, 2007 [SV11] S MART, N.P. ; V ERCAUTEREN, F.: Fully Homomorphic SIMD Operations. Cryptology ePrint Archive, Report 2011/133, 2011. – http://eprint.iacr.org/ [SWP00] S ONG, D.X. ; WAGNER, D. ; P ERRIG, A.: Practical Techniques for Searches on Encrypted Data. In: Proceedings of the 2000 IEEE Symposium on Security and Privacy, 2000, S. 44–55 [Tan09] TANENBAUM, A.S.: Moderne Betriebssysteme. 3. Auflage. Pearson Studium, 2009 [Uca05] U CAL, M: Searching in encrypted data. University of Maryland. 2005. – Forschungsbericht [VFJ+ 10] V IMERCATI, S. ; F ORESTI, S ; JAJODIA, S ; PARABOSCHI, S. ; S AMARATI, P.: Encryption policies for regulating access to outsourced data. In: ACM Transactions on Database Systems (TODS) 35 (2010), Nr. 2, S. 121–146 [VFP+ 11a] V IMERCATI, S. ; F ORESTI, S. ; PARABOSCHI, S. ; JAJODIA, S. ; S AMARATI, P.: Private Data Indexes for Selective Access to Outsourced Data. In: Proceedings of the 10th Workshop on Privacy in the Electronic Society (WPES 2011), 2011. – in Erscheinung [VFP+ 11b] V IMERCATI, S. ; F ORESTI, S. ; PARABOSCHI, S. ; P ELOSI, G. ; S AMARATI, P.: Efficient and Private Access to Outsourced Data. In: Proceedings of the 31st International Conference on Distributed Computing Systems (ICDCS’11), 2011, S. 710–719 - IX - [WABL94] W OBBER, E. ; A BADI, M. ; B URROWS, M. ; L AMPSON, B.: Authentication in the Taos operating system. In: ACM Transactions on Computer Systems (TOCS) 12 (1994), Nr. 1, S. 3–32 [WAF11] W EIS, J. ; A LVES -F OSS, J.: Securing Database-as-a-Service: Issues and Compromises. In: IEEE Security and Privacy 99 (2011). – in Erscheinung [WD08] WANG, J. ; D U, X.: LOB: Bucket Based Index for Range Queries. In: Proceedings of the 9th International Conference on Web-Age Information Management (WAIM’08), 2008, S. 86–92 [WLOB09] WANG, W. ; L I, Z. ; OWENS, R. ; B HARGAVA, B.: Secure and efficient access to outsourced data. In: Proceedings of the 2009 ACM Workshop on Cloud Computing Security (CCSW’09), 2009, S. 55–66 [WV02] W EIKUM, G. ; VOSSEN, G.: Transactional information systems: theory, algorithms, and the practice of concurrency control and recovery. 1. Auflage. Morgan Kaufmann Publishers, 2002 [YGJK10] Y IU, N.L. ; G HINITA, G. ; J ENSEN, C.S. ; K ALNIS, P: Enabling search services on outsourced private spatial data. In: The VLDB Journal 19 (2010), Nr. 3, S. 363–384 [ZCL09] Z HANG, J. ; C HAPMAN, A. ; L EFEVRE, K.: Do You Know Where Your Data’s Been? Tamper-Evident Database Provenance. In: Proceedings of the 6th VLDB Workshop on Secure Data Management, 2009, S. 17–32 Verzeichnis von Web-Adressen [1] Bruce Schneier on Security - New Attack on AES. http://www.schneier.com/blog/ archives/2011/08/new_attack_on_a_1.html. – Last accessed: 2011/10/09 [2] Datenbank Online Lexikon, FH Köln. http://wikis.gm.fh-koeln.de/wiki_db/ Datenbanken/Join-Typ-SQL. – Last accessed: 2011/10/09 [3] IBM 4764 PCI-X Cryptographic Coprocessor. http://www-03.ibm.com/security/ cryptocards/pcixcc/order4764.shtml. – Last accessed: 2011/10/09 [4] Transaction Processing Performance Council. http://www.tpc.org. – Last accessed: 2011/10/09 -X- [5] Trusted Computing Group. http://www.trustedcomputinggroup.org/. – Last accessed: 2011/10/09 [6] heise Security - Hacker liest Kryptoschlüssel aus TPM-Chip aus. -926883. – Last accessed: 2011/10/09 http://heise.de/ [7] LAG Köln - Ein Missbrauch von Zugriffsrechten durch einen EDVAdministrator. http://www.justiz.nrw.de/nrwe/arbgs/koeln/lag_koeln/j2010/4_Sa_ 1257_09urteil20100514.html. – Last accessed: 2011/10/09 [8] National Institute of Standards and Technology - Cloud-Computing. http://collaborate. nist.gov/twiki-cloud-computing/bin/view/CloudComputing/Documents. – Last accessed: 2011/10/09 Abschließende Erklärung Ich versichere hiermit, dass ich meine Bachelor Arbeit „State-of-the-Art von Verschlüsselungstechniken für Database-as-a-Service“ selbständig und ohne fremde Hilfe angefertigt habe, und dass ich alle von anderen Autoren wörtlich übernommenen Stellen wie auch die sich an die Gedankengänge anderer Autoren eng anlehnenden Ausführungen meiner Arbeit besonders gekennzeichnet und die Quellen zitiert habe. Münster, den 10. Oktober 2011