RN1 V55.fm - Informatik an der TU Clausthal
Werbung

Vorlesung Rechnernetze I
Prof. Dr. Harald Richter
Die Vervielfältigung oder Weitergabe des Skripts ist nur mit Genehmigung des Verfassers gestattet.
Alle Rechte liegen beim Verfasser.
1
1 Entwicklung der Kommunikationstechnik
Ursprünge:
Informationstyp:
Transportmedium:
Übertragungstechnik:
Fortschritt:
Protokoll:
Zukunft:
TV (Fernsehen)
Telex (Fernschreiber =
Vorläufer zu FAX)
Video
Funkwellen:
terrestrisch/
Satellit + Koaxkabel
Antennen:
Parabol,
Stab, ...
Analog-TV
-> Digital
TV
Zeichen/Daten
Koax- und
verdrilltes
Kupferkabel
LANs:
Ethernet,
TokenRing, ...
1G-> 40G
Ethernet
Sprache
Glasfaser
MANs:
FDDI,
DQDB,
...
Telefon
verdrilltes
Kupferkabel +
Glasfaser
WAN:
SONET/
SDH
S-ISDN
B-ISDN
DVB-T/DAB
IP
ATM-Protokoll
IBCN (Integrated Broadband Communication Network):
weltweites Mobil-/Festnetz + Internet + Multimedia + TV
2
2 Ziele von Rechnernetzen
Datenverbund
• = Zugriff auf entfernte Dateien über Middleware wie z.B. das Network File System (NFS)
Funktionsverbund
• = Zugriff auf besondere Rechner wie z.B. Web-Server, Video-Server, Datenbank-Server, ...
Lastverbund
• = Gleichmäßige Verteilung der Rechnerlast über Middleware wie z.B. beim Grid/Cloud
Computing
Verfügbarkeitsverbund
• = Fehlertoleranz
Speziell für das Internet gilt zusätzlich:
• Informationsverbund = riesiges Lexikon weltweit verteilter Informationen
• Kommunikationsverbund = soziale Medien (Facebook, Twitter,...)
• Infrastruktur für Handel und Dienstleistungen = eCommerce
3
Klassifikation von Netzen nach der Distanz
keine
Rechnernetze
GrößenordProzessororte
nungen der
Entfernungen
(ca.-Werte)
Bezeichnung
0,1 m-10 m
Multiprocessor, Multicomputer, Parallelrechner
Platine
Rechnersystem
10 m-10 km
Raum
Gebäude
Local Area Network (LAN), Beispiel
Ethernet
Campus, Fabrik
Rechnernetze
10 km-100km Stadt, Region
Metropolitan Area Network (MAN), Beispiel FDDI
100 km100000 km
Wide Area Network (WAN), Beispiel
Internet
Land
Kontinent
Planet
Man unterscheidet zwischen lokalen Netzen (LAN = Local Area Network), Stadtnetzen
(Metropolitan Area Network) und Weitverkehrsnetzen (WAN = Wide Area Network)
4
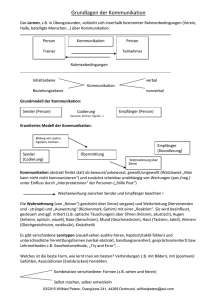
3 Standardmodell der Kommunikation:
Das ISO-7-Schichtenmodell für Offene Systeme
Wurde Anfang 1970er Jahre von der OSI entworfen. OSI = OPEN SYSTEMS INTERCONNECTION = Untergruppe der ISO
Einführung von neuen Grundbegriffen (= Terminologie)
Einführung eines verbindlichen Modells für geschichtete Kommunikation
Das ISO-7-Schichten-Modell schlägt sieben Schichten und deren Funktionalität vor.
Jede Schicht hat bei der Datenübertragung einen eigenen Satz von Aufgaben zu übernehmen.
Datenaustausch ist nur zwischen benachbarten Schichten möglich, nicht kreuz und
quer
Im Internet wurden vom ISO-7-Schichten-Modell nur Schicht 1-4 und Schicht 7 implementiert
5
3.1
Blockschaltbild der Kommunikation im ISO-7-Schichtenmodell
Rechnersystem i
Anwendungs
Prozess X1
===
Rechnersystem j
Anwendungs
Prozess Xn
Anwendungs
Prozess Y
Bsp.: BSDSocket Schnittstelle
Bsp.: WinSocket Schnittstelle
Kommunikationssystem nach
OSI-Standard
Kommunikationssystem nach
OSI-Standard
physikalisches
Medium
Verbundene Systeme
6
3.2
Grober Aufbau des ISO-7-Schichtenmodells
Schicht 1 - 4
• Bit-und Nachrichtentransfer durch Datenrahmen (frames) bzw. Pakete (packets); keine höheren Funktionen
• Inhalt der Daten ist ohne Bedeutung für die transportorientierten Schichten. Kein Bezug auf die Kooperationsbeziehung der Teilnehmer.
Schicht 5 - 7
Transportorientierte Schichten = Schichten 1-4: Technische Erbringung von Übertragungen durch:
Anwendungsorientierte Schichten = Schichten 5-7: Anwendungsbezogene Kommunikationsdienstleistungen
Kooperation der Teilnehmer wird berücksichtigt durch:
•
•
•
•
•
Steuerung des Ablaufs (Sitzungssteuerung)
Informationsdarstellung (verschiedene Zeichensätze und Datenformate)
Kompensation von Fehlverhalten (Neustart eines Downloads bei Fehler)
Datenverschlüsselung (Kryptographie)
Datenkompression (JPEG, MPEG, MP3)
7
3.3
Feiner Aufbau des ISO-7-Schichtenmodells
ist anders aufgebaut
als System A
heterogenes Rechnernetz
Endsystem A
beliebige räumliche Entfernung
Teil des Betriebssystems in
Form von Bibliotheken
Teil der Rechner-Hardware
3.4
Endsystem B
Anwendungsschicht
Anwendungsspezifische Programme
7
Darstellungsschicht
Datenformatierung und -darstellung
6
Sitzungsschicht
Dialogsteuerung
5
Transportschicht
Ende-zu-Ende-Datenaustausch
4
Vermittlungsschicht
Ende-zu-Ende-Vermittlung
3
Sicherungsschicht
Nur zwischen benachbarten Rechnern
2
Physikalische Schicht
Physikalische Übertragung
1
Aufgaben der Schichten des ISO-Modells
1.) Die Bitübertragungsschicht ermöglicht die transparente Übertragung eines Stroms
8
binärer Informationen über ein Kabel aus Kupfer oder Glasfaser oder über Funk (=
ungesicherter Bitstrom + mech. u. el. Spezifikation der Strecke)
2.) Die Sicherungsschicht regelt den Zugang zur Schicht 1, entdeckt Übertragungsfehler
und bremst zu schnelle Sender (= gesicherte Bits + Zugang + Flusssteuerung) jeweils
zwischen benachbarten Rechner
3.) Die Vermittlungsschicht wählt eine Netz-Route von Rechner zu Rechner über Zwischenknoten aus (= Wegewahl)
4.) Die Transportschicht übermittelt die Daten von Sendeprozess zu Empfangsprozess,
d.h. von Ende-zu-Ende. Sie entlastet den Benutzer von den Details der Datenübertragung, z.B. durch Sicherstellung der Paketreihenfolge.
5.) Die Kommunikationssteuerungsschicht vereinfacht die Zusammenarbeit zwischen
den kommunizierenden Anwendungsprozessen z.B. durch Wiederanlauf (Neustart,
recovery); legt full-/halfduplex Übertragungsmodus fest.
6.) Die Darstellungsschicht transformiert u.a. die Daten in eine Form, die von beiden
Anwendungsprozessen verstanden wird und komprimiert und verschlüsselt optional
(= Datenformate + Kompression + Verschlüsselung)
7.) Die Anwendungsschicht enthält Benutzeranwendungen. Sie ist sehr groß (Bsp.: >106
apps)
9
3.5
Terminologie und grundlegende Prinzipien im ISO-Modell
Offenes System für die Kommunikationsteilnehmer
• jedes Rechnersystem aus Hardware, Software und Peripherie, das sich an die OSI-Standards hält, kann kommunizieren.
N-Schicht (1N 7):
• wird aus sämtlichen Programmen der Schicht N in allen offenen Systemen gebildet.
Analogie: dieselben Stockwerke Nr. N aller Gebäude der Welt bilden die N-Schicht.
N-Instanz (N-Entity):
• Ganz bestimmte Implementierung einer Funktion der Schicht N auf einem System
• Es kann auf demselben Rechner mehrere N-Instanzen geben, die unterschiedliche Protokolle implementieren; Bsp. TCP u. UDP
Partnerinstanzen (Peer-Entities):
• Instanzen derselben Schicht auf verschiedenen Rechnern. Peer-Entities erfüllen die Funktionen einer Schicht durch Datenaustausch von peer zu peer
Hinweis: peer = Gleichgestellter, d. h. einer, der der gleichen (Adels)schicht angehört
3.6
Was macht eine Schicht im ISO-Modell?
Hauptaufgabe jeder Schicht ist es, der darüber liegenden Schicht Dienste (= Funktionen) anzubieten. Diese Dienste setzen sich zusammen aus:
• Dienstleistungen, die innerhalb dieser Schicht erbracht werden und
10
• der Summe der Dienstleistungen aller darunter liegenden Schichten
Schichten sind über Dienste miteinander verknüpft. Sie bilden die Schnittstelle zwischen den Schichten. In der Software-Entwicklung heißt diese Schnittstelle application
programming interface, API
Dienste bestehen wiederum aus Dienstelementen (= Unterprogrammaufrufen)
Da Schichten jeweils aufeinander aufbauen, ergibt sich eine Hierarchie von Diensten,
deren Umfang mit der Schichthöhe zunimmt
11
3.7
Hierarchie von Diensten im ISO-Modell
Benutzer A
Benutzer B
Anwendungsdienste
Darstellungsdienste
Kommunikationssteuerung
Transportdienste
Wegewahldienst
Gesicherte Bit-Ströme
Kabel, Stecker, Spannungspegel
Übertragungsleitung
Jede Schicht benutzt die Funktionen (= Dienste) der darunter liegenden Schicht
Daten werden physikalisch nur auf der untersten Ebene zwischen den Rechnern übertragen, d. h. der Übertragungsstrecke
Auf allen n-Schichten mit n>1 werden Daten nur innerhalb desselben Rechners „hin
und her geschoben“ (im Form von Aufrufparameter und Resultatwerten)
12
3.8
Indirekte Kommunikation im ISO-Modell (Partnerprotokolle)
Partnerprotokoll
= peer protocol
indirekte (virtuelle)
Kommunikation
Application
direkte
Kommunikation
Presentation
Session
Transport
Network
Data Link
Physical
Physikalisches Übertragungsmedium
• Daten werden innerhalb eines Rechners von Schicht zu Schicht transportiert
• Zwischen 2 Rechnern können Daten nur auf der Schicht 1 transportiert werden
• Kommunikation zwischen Instanzen höher als Schicht 1 werden indirekt (virtuell) abgewikkelt
13
• Indirekte Kommunikation wird mittels eines Protokolls zwischen Partnerinstanzen so
durchgeführt, dass beide Partnerinstanzen „sich verstehen“ (Protokoll = gemeinsame
„Sprache“)
3.8.1
Direkte und indirekte Kommunikation
Dienstelement
obere Schnittstelle
N-Schicht
untere Schnittstelle
c
c
d
Instanz
a
Protokoll
= indirekt
c
c
Instanz
a
a = gleichgestellte N-Instanzen
(Peer Entities)
b = Dienst besteht aus einer
Menge von Dienstelementen
c = Dienstelement
(Service Primitives)
d = Protokoll zwischen Gleichgestellten (Peer Protocol)
} b Dienst
c
c
Rechner A
= direkt
= direkt
c
c
Rechner B
Direkter Datenaustausch erfolgt mit Hilfe von Dienstelementen (= Unterprogrammaufrufen) eines Dienstes (= einer API) zwischen benachbarten Schichten desselben Rechners
14
Indirekter Datenaustausch erfolgt mit Hilfe eines Protokolls zwischen Partnerinstanzen
auf verschiedenen Rechnern
Eine direkte Kommunikation der Schicht N (1<N<7) erfolgt nur mit den Schichten (N+1)
und (N-1)
Indirekte Kommunikation (Protokoll) mit Partnerinstanzen (Peer Entities)
3.8.1.1
Schicht
7
Implementierung der direkten und indirekten Kommunikation im Internet
Quelle
Layer 7-Protokoll
M
M
Ziel
Anwendung
Layer 4-Protokoll
H4
H4 M
4
Segmentierung
H3 H4 M1
3
2
Fragmentierung
Layer 3 Protokoll
H3 H4 M2
Reassemblierung
H3 H4 M2
...
...
Layer 2-Protokoll
H2 H3 H4 M1 T2 H‘2 H‘3 H‘4 M‘2 T‘2
M
H3 H4 M1
Network
Reassemblierung
H2 H3 H4 M1 T2 H‘2 H‘3 H‘4 M‘1 T‘2
1
Transport
Data Link
Physical
physikalische Verbindung
Hinweis: M = Message (Nachricht), H = Header (Vorspann = Nachrichtenkopf), T = Trailer (Nachspann)
15
Nachricht M wird von „oben nach unten“ und dann von „unten nach oben“ durchgereicht = direkte Kommunikation
Beim Durchreichen nach unten wird M in zwei Schritten zerkleinert: zuerst „segmentiert“ dann „fragmentiert“
M wird bei jedem Übergang zwischen 2 Schichten um jeweils einen neuen Vorspann
(Header) und ggf. auch um einen Nachspann (Trailer) verlängert
Am Ziel werden Trailer und Header schrittweise wieder entfernt und die Nachricht zusammengebaut (= Reassemblierung in 2 Schritten)
Die Header sind notwendig, um zum Ziel zu finden
Die Trailer sind notwendig, um eine sog. Prüfsumme (CRC) zu speichern
Zwischen Schicht 4 und Schicht 3 findet eine „Segmentierung“ zur Zerkleinerung der
Pakete statt
Zwischen Schicht 3 und Schicht 2 findet eine „Fragmentierung“ zur Zerkleinerung der
Pakete statt
Hinweis: Protokoll = Menge der Regeln für den indirekten Datenaustausch zwischen Entities derselben
Schicht (peer-to-peer communication
16
3.8.2
Definition Dienst, Dienstzugangspunkt, Dienstelemente )
Rechner A
Anwendungsprozess A
Protocol Stack
Dienstelement
Rechner B
Datenaustausch
Anwendungsprozess B
Dienst
Dienstzugangspunkt
entity A
entity B
Peer Entity
der Schicht
(N)
physikalisches Medium
Die Schichten werden in ihrer Implementierung auch als Protocol Stack bezeichnet
Def.: N-Schnittstelle: Menge von Dienstelementen (Unterprogrammaufrufen) der Schicht
N. Dienstzugangspunkt: Name des Unterprogrammaufrufs mit Art und Typ der Übergabe- und Resultatparameter (= Signatur der Prozedur).
17
3.9
Die 4 Arten von ISO-Dienstelementen
Rechner A
Rechner B
Prozess a
1.
Request
Prozess b
4.
Confirmation
3.
Response
2.
Indication
Datenübertragung
Es gibt für jeden Dienst einer Schicht i (1<i<7) 4 Dienstelemente, die gemeinsam den
Dienst in Form eines 4-Phasen Handshakes bilden:
1.) Anforderung (Request) = Aktivieren eines Dienstes der Schicht durch den Dienstnehmer
2.) Anzeige (Indication) = Dem Diensterbringer anzeigen, dass vom Dienstnehmer ein
Dienst angefordert wurde
3.) Antwort (Response) = Quittieren einer vorherigen Anzeige oder Erbringung des angeforderten Dienstes durch den Diensterbringer
18
4.) Bestätigung (Confirmation) = Quittieren einer vorherigen Anforderung beim Dienstnehmer
3.10
Die 3 Phasen der ISO-Kommunikation
Darüberhinaus heißt jede Kommunikation, die in folgenden 3 Phasen abläuft, verbindungsorientierte Kommunikation:
• Verbindungsaufbau (Connect), Datentransfer (Data Transfer) und Verbindungsabbau (Disconnect)
Für jede der 3 Phasen gibt es einen Dienst, der diese Phase implementiert
Eine verbindungsorientierte Kommunikation steht im Gegensatz zur sog. verbindungslosen Kommunikation, bei der sofort gesendet werden kann (kein Verbindungsaufbauund -abbau)
Request, Indication, Response und Confirmation sind die 4 Typen von Dienstelementen, die es bei jedem verbindungsorientierten Protokoll im Prinzip jedenfalls in jeder
Schicht i (1 < i < 7) gibt
Die Zahl der Kombination aus Dienste, Dienstelemente und Phasen einer Schicht berechnet sich zu: dN Dienste der Schicht N * 4 Dienstelemente pro Dienst * 3 Phasen =
dN*12 Kombination (im Prinzip)
19
3.10.1
Beispiel: Presentation.Connect = Verbindungsaufbaudienst der Schicht 6
Rechner B
Rechner A
Schicht 6
ConnectDienst der
Schicht 6
5 darunterliegende
Schichten
Presentation Layer B
Presentation Layer A
1.) Presentation. Connect.
Request-Dienstelement
4.) Presentation. Connect.
ConfirmationDienstelement
3.) Presentation. Connect.
ResponseDienstelement
2.) Presentation.
Connect. Indication-Dienstelement
Protocol Stack
Protocol Stack
20
3.11
Zusammenfassung ISO-7-Schichten-Modell
1.) Die ISO-Bitübertragungsschicht ermöglicht die Übertragung von Informationen über
ein Kabel aus Kupfer oder Glasfaser oder per Funk = ungesicherter Bitstrom +
mechanische + elektrische + funktionale + prozedurale Spezifikation der Strecke
2.) Die ISO-Sicherungsschicht regelt den Zugang zum Übertragungsmedium, entdeckt
Übertragungsfehler jeweils zwischen benachbarten Rechnern, macht ggf. eine Rahmenwiederholung und bremst zu schnelle Sender durch Flusssteuerung =Zugang +
gesicherte Bits + Flusssteuerung
3.) Die ISO-Vermittlungsschicht macht einen Verbindungsaufbau und -abbau, wählt
einen Weg vom Quellrechner zum Zielrechner durch das Netz. Im Allgemeinfall verläuft dieser über mehrere Zwischenknoten. Sie zerkleinert zu große Schicht 3-Pakete
in kleinere Schicht 3-Pakete (=“Fragmente“), die anschließend von Schicht 2 übertragen werden können, und setzt diese beim Empfänger wieder in der richtigen Reihenfolge zu einem Paket zusammen = Fragmentierung und Reassemblierung. Sie
erkennt, welches Schicht 3-Fragment zu welchem Schicht 3-Paket gehört.
4.) Die ISO-Transportschicht macht ebenfalls einen Verbindungsaufbau und -abbau,
übermittelt die Daten gesichert von Sendeprozess zu Empfangsprozess, d.h. von
Ende-zu-Ende. Sie stellt die Paketreihenfolge sicher, löscht Duplikate und macht im
Fehlerfall eine Ende-zu-Ende Paketwiederholung. Sie erlaubt eine Pufferverwaltung
21
bei Sender und Empfänger und stellt Prioritäten bei der Übertragung zur Verfügung.
Sie sorgt schließlich dafür, dass das Netz nicht überlastet wird = idealer Kanal
5.) Die ISO-Kommunikationssteuerungsschicht vereinfacht die Zusammenarbeit zwischen den kommunizierenden Anwendungsprozessen z.B. durch Rücksetzen und
Wiederanlauf einer unterbrochenen Verbindung (recovery). Sie legt full-/halfduplex
fest und erlaubt das Multiplexen mehrerer logischer Kanäle auf einen physikalischen
Kanal = Dialogsteuerung, Recovery, Multiplexen
6.) Die ISO-Darstellungsschicht transformiert die Daten in eine Form, die von beiden
Anwendungsprozessen verstanden wird und komprimiert und verschlüsselt optional
(= Datenformate + Kompression + Verschlüsselung).
7.) Die Anwendungsschicht enthält Middleware und Benutzeranwendungen = Millionen
von Diensten, Anwendungen und Apps
Das Internet implementiert den größten Teil der ersten vier Schichten des ISO-Modells
22
Anwendung
Dateitransfer (ftp, Port 20, 21), Telnet (Port 23), E-Mail (smtp, Port 25),
DNS (Port 53), NFS, www (http, Port 80), ...
Transport
Transmission Control Protocol TCP, User Datagram Protocol UDP
Vermittlung
Sicherung 2b (Logical Link
Control
Sicherung 2a (Medienzugangssteuerung)
Bitübertragung
Internet Protokolle IPv4, IPv6
Internet Control Message Protocol ICMP
speziell für
SONET
/SDH
SONET
/SDH
speziell
für E1/
T1
speziell für
FDDI
speziell für
DQDB
ISO
Logical
Link
Control
(theoretisch)
Speziell
für
WLAN
Point
to
Point
Protocol
(PPP)
E1/T1
FDDI
DQDB
Ethernet
WLAN
DSL
4 Bitübertragungsschicht (ISO-Schicht 1)
ISO-Definition: „Die Bitübertragungsschicht definiert die mechanischen, elektrischen,
funktionalen und prozeduralen Eigenschaften, um physikalische Verbindungen zwischen Datenendeinrichtungen und Datenübertragungseinrichtungen aufzubauen, aufrecht zu erhalten und abzubauen.“
23
Die Bitübertragungsschicht sorgt für die Übertragung eines transparenten Bitstroms
zwischen Sicherungsschicht-Instanzen über physikalische Verbindungen
Eine physikalische Verbindung realisiert die Übertragung eines Bitstroms im Vollduplex- oder im Halbduplex-Modus
Vollduplex = gleichzeitiger bidirektionaler Datenaustausch
Halbduplex (=Simplex) = zu einer Zeit nur in einer Richtung, dann wird die Richtung gewechselt u.s.w. (= unidirektionaler Datenaustausch mit wechselnden Kommunikationsrichtungen)
4.1
Es werden in der Bitübertragungsschicht mechanische, elektrische, funktionale und
prozedurale Schnittstellen und Regeln definiert, die von Sender und Empfänger eingehalten werden müssen, damit Daten ausgetauscht werden können
4.1.1
Mechanische Schnittstellen
Hier geht es im die Abmessungen der Stecker, die Anordnung der Pins im Stecker etc.
4.1.2
Spezifikationen in der Bitübertragungsschicht
Elektrische Schnittstellen auf den Leitungen
Hier werden die Signalpegel (Spannungs- oder Stromwerte) für High- und Low-Bits, sowie die Art der Erdung und Schirmung der Kabel festgelegt
24
4.1.3
Funktionale Schnittstellen
Hier wird festgelegt, welcher Pin welche grundsätzliche Funktion hat und wie deren
Zeitverhalten, das sog. Timing ist
Hier wird auch die Bitrate der Bitübertragung und die Art der verwendeten Codierung
festgelegt
Beispiel: V.24/RS-232 mit den Datenleitungen TX, RX und den optionalen Steuerleitungen Request to Send, Clear to Send, Data Set Ready und Data Terminal Ready, sowie
GND
4.1.4
Prozedurale Regeln
Hier wird festgelegt, wie die Pins des Steckers im Kontext zu den anderen Pins sich verhalten müssen, d.h., hier geht es um das logische Zusammenspiel der einzelnen
Schnittstellenleitungen
Wichtig für die Benutzung der Schnittstellenleitungen
Beispiel: bei V.24/RS-232 darf das Clear to Send-Signal des Modems erst dann aktiv
werden (High), wenn zuvor Data Set Ready des Modems und wenn Request to Send des
Computers aktiv wurde, der an das Modem angeschlossen ist
25
4.1.5
Beispiele für mechanische Spezifikationen: USB
USB 3.0-Stecker, Standard Typ A (10 Pins)
USB 3.0-Stecker, Micro Typ B (10 Pins)
USB 3.1-Stecker, Typ C (24 Pins)
Beispiel für eine elektrische Spezifikation: V.24 EIA RS-232
Driver
Sender
Interconnecting Cable Terminator
Empfänger
Kabel
12 V
D
Interface
4.1.6
Signal Ground
26
T
In der kleinsten V24/RS-232-Version sind nur 2 verdrillte Kabeladern + Masse (GND) nötig
Keine Abschirmung der Adern, nur Verdrillung (= Telefonkabel) => sehr preisgünstig
4.2
Asynchron heißt: kein Taktsignal zwischen Sender und Empfänger, Bsp.: V.24/RS-232
Synchron heißt: Taktinformation wird zeitgleich mit den Nutzbits übertragen, Bsp. USB
Für synchrone Übertragung wird eine Codierung, verwendet die auf der Datenleitung
den Takt mitüberträgt (preisgünstig, da keine separate Taktleitung nötig)
Da der Empfänger den Sendetakt erhält, wird dieser zur Abtastung der Bitsignale benutzt = Synchronisation der Bitsignale mit dem Taktsignal => stabile Erkennung der
Bits selbst bei hohen Datenraten
4.2.1
Asynchrone und synchrone Übertragung
Asynchrone Übertragung
Sender und Empfänger haben voneinander unabhängige, i.e. lokale Taktgeber
Beispiel: V.24/RS-232
„Freie Leitung“ (= Leitung ohne Daten) entspricht einem kontinuierlich gesendeten
High-Bit Problem der Unterscheidung zwischen freier Leitung und High-Pegel.
Das Start-Bit setzt die Leitung auf Low und startet so den Taktgeber beim Empfänger
Ein Übertragungsrahmen enthält 5 bis 8 Nutzbits (= 1 Zeichen)
27
Das Stop-Bit setzt die Leitung wieder auf High. Dieses Signal muss 1, 1.5 oder 2 BitIntervalle andauern; entspricht 1, 1.5 oder 2 Stop-Bits
Ein Paritätsbit dient zur Überprüfung der Nutzbits beim Empfänger
4.2.1.1
Vorteile der asynchronen Übertragung
Es wird keine Synchronisierung des Empfänger-Taktgebers mit dem Sender-Taktsignal benötigt, da kein Takt übertragen wird
Hardware-mäßig leicht zu implementieren
4.2.1.2
Nachteile der asynchronen Übertragung
Die Taktgeber weichen im Laufe der Zeit voneinander ab, da sich kleine Zeitunterschied
akkumulieren
Erhebliche Einschränkungen bzgl. Datenraten und Rahmenlängen
Beispiel: V.24/RS-232
Die „Nutzlast“ des Rahmens ist sehr kurz (nur 1 Zeichen; entspricht 5-8 Bits)
Es sind nur niedrige Datenraten und kurze Längen möglich
Die Start- und Stop-Bits bedeuten einen Mehraufwand, und die Effizienz sinkt
28
Beispiel: 1 Start-Bit + 7-Bit ASCII-Zeichen + 1 Paritätsbit + 1 Stop-Bit => d.h., insgesamt
10 Bit pro Rahmen für 7 Nutzbits => 30% Overhead. Nur 70% der Leitungsbandbreite stehen für Benutzerdaten zur Verfügung.
Bitrate begrenzt auf 100 kbit/s bei einer Entfernung von 15 m
Aufgrund der geringen Komplexität, des geringen Preises und der kleinen Polzahl immer im Vergleich zu USB noch in Verwendung
4.2.1.3
Timing-Diagramm einer asynchronen Übertragung (V24/RS-232)
In den beiden nachfolgenden Timing-Diagrammen wird der Signalverlauf über der Zeit
bei der Übertragung eines Zeichens und bei einer Zeichenfolge gezeigt
29
4.2.1.4
Leitungscode für ein Zeichen
Signalhöhe
Stopbit (Pegel wie im Ruhezustand)
Lange Eins = Ruhezustand
5 bis 8 Datenbits
Signalwert = 1
Signalwert = 0
Zeit
Startbit
1
Paritybit
(Odd, Even)
1,5
2
4.2.1.5
Leitungscode für eine Zeichenfolge
Beliebig lange Ruhepause zwischen Rahmen
Ruhezustand
Startbit
Stop
bit
Start
bit
Stop
bit
))
))
))
1 1 1 1 0 0 0 1
Stop
bit
Start
bit
0 0 1 0 1 1 0 0
= 1. Zeichen+ odd Parity
= 2. Zeichen+odd Parity
30
1 00
1
0 1
0
= 3. Zeichen+odd Parity
4.2.1.6
Effekt der auseinander laufenden Uhren bei asynchroner Übertragung
Senderate f1
Abtastrate f2 > f1
start
1
2
3
4
5
6
7
8 stop
Fehlabtastung!
4.2.2
Synchrone Übertragung
Sende- und Empfangstakt laufen beliebig lange im Gleichtakt, d.h. synchron
=> Eine Neusynchronisation der Takte über ein Startbit vor jedem Zeichen ist nicht erforderlich
Taktsignal wird entweder auf einer separaten Leitung übertragen (= zu teuer) oder aus
dem Code des Datensignals regeneriert (= Regelfall)
Taktregenerierung aus dem Datensignal erfordert eine spezielle Codierung der Daten
z. B. mittels Manchester-Code, um Daten und Takt gemeinsam auf derselben Leitung
übermitteln zu können
31
4.2.2.1
Timing-Diagramm einer synchronen Übertragung
Bit = Bit = Bit = Bit =
Zelle Zelle Zelle Zelle
1
0
1
1
0
0
1
0
0
1
0
0
Daten
Clock
(Takt)
Abtastzeitpunkte liegen stets in der Mitte der Bitzelle
Im Beispiel erfolgt das Auslesen der Datenbits bei abfallender Flanke des Taktsignals
4.2.2.2
Beispiel für synchrone Übertragung: der Universal Serial Bus (USB)
Dient zur Anbindung von Peripherie an Rechner, Tablets und Smartphones über Kupferkabel
Die neueste Version USB 3.1 mit Typ C Stecker/Buchse überträgt Daten mit 10 Gb/s
Erlaubt zusätzlich 100 W Leistung bei +5 V zu übertragen, um die Peripherie zu versorgen
32
4.2.3
USB bietet deutlich mehr Funktionen als RS232:
• Datensignale können über USB-Hubs auf der ISO-Schicht 1 an mehrere periphere Geräte sternförmig verteilt werden
• Es sind auch Hub-Kaskaden möglich, die eine baumförmige Verteilung erlauben
• USB-Geräte werden in „Klassen“ unterteilt
· Klassen unterscheiden sich u.a. bzgl. der Datenmenge pro Rahmen und den zeitlichen Abstände zwischen den Rahmen
· Die jeweilige Geräteklasse wird automatisch erkannt, was ein komplexes Protokoll
beim Einstecken eines neuen USB-Geräts erfordert
· Für jede Geräteklasse ist ein anderer USB-Gerätetreiber erforderlich
• Daten werden in Form von „Transaktionen“ übertragen
4.2.3.1
Vergleich synchrone/asynchrone Übertragung am Beispiel USB
Nachteile von USB-Geräten
Es gibt eine Vielzahl von USB-Versionen, -Kabeln, -Steckern und -Buchsen
• Der Host hat stets einen andere Buchse und damit auch einen anderen Stecker als die Peripherie
• Die einzelnen Versionen sind nur manchmal abwärts-kompatibel zueinander
Entfernung ist bei USB 3.1 mit Typ C-Stecker auf ca. 2 m Länge beschränkt => kein LAN
sondern Bus
33
USB 3.1 mit Typ C-Stecker benötigt 24-polige Kabel und Stecker/Buchsen
USB ist insgesamt komplex und damit rel. teuer
USB ist ein Sicherheitsrisiko:
• Es gibt die Möglichkeit des „Device Firmware Upgrades“, bei dem harmlose USB-Geräte
durch Hacker umprogrammiert werden können
• Es gibt in den USB-Gerätetreibern gängiger Betriebssysteme keine Firewall
4.3
Physikalische Medien zur Datenübertragung
1.) Verdrilltes Adernpaar („twisted pair“) zur Verminderung von Übersprechen auf parallel geführte, sonstige Kabel, sowie zur Elimination von Einstreuungen von diesen
Kabeln
• Dies ist die klassische Telefonverkabelung. Sie wird auch für DSL-Übertragung zur Ortsvermittlungsstelle eingesetzt
• Braucht wenig Platz, hat enge Biegeradien, ist sehr preiswert
• Datenrate bis ca. 50 Mbit/s bei VDSL
2.) Abgeschirmtes und verdrilltes Adernpaar, „shielded twisted pair“, STP
• Unempfindlich gegen Störstrahlung von außen
• Sendet auch keine Störstrahlung nach außen
• Der Schirm erlaubt einen definierten Wellenwiderstand zwischen Signalleitungen und Masse => Datenraten bis ca. 3 Gbit/s sind damit auf einer einzigen Doppelader von ca. 5 m Länge möglich
34
• Ist teurer als twisted pair
3.) Koaxialkabel: Noch störsicherer, ermöglicht noch höhere Datenraten bis ca. 100 Gbit/s
über viele Kilometer, noch teurer, in Kupferkabel-basierten Weitverkehrsnetzen verbreitet
4.) Lichtwellenleiter (Glasfaser): sehr hohe Übertragungsraten bis ca. 1 Tbit/s, geringe
Dämpfung und völlig ohne Störungsein- und -auskopplungen, aufwendige Steckverbinder, am teuersten. Die Basis aller Weitverkehrsnetze ab ca. 1985.
35
4.3.1
Aufbau eines STP-Kabels, Beispiel USB 3.0
4.3.2
Aufbau eines Koaxialkabels
50 Ohm-Koaxialkabel heißt: Wellenwiderstand zwischen Innenleiter und Schirm ist 50
Ohm
Sender u. Empfänger müssen die gleiche Impedanz wie das Kabel haben, damit es zu
keinen Reflektionen kommt und damit die LAN-Transceiver die hohe Spannung eines
Wellenbergs erhalten
36
Kupferkern (Innenleiter)
mit Leitfähigkeit >> 1
Isolierschicht (Dielektrikum) mit relativer Dielektrizitätskonstante r > 1
4.3.3
geflochtener, elektrisch leitender
Außenleiter mit Leitfähigkeit >> 1
Plastikschutzschicht
Glasfaserkabel
Theoretisches Limit: ca. 300 TeraBit/s = ungefähr die Frequenz des Lichts
Als Transmitter und Receiver werden Halbleiterbauelemente verwendet:
• Laserdiode oder Leuchtdiode als Sender, Photodiode als Empfänger
Beschränkende Faktoren für die Datenrate: Absorption und Dispersion in der Faser
37
4.3.3.1
Absorption in der Faser
Eingangssignal
4.3.3.2
Ausgangssignal
Dispersion in der Faser
Eingangssignal
Ausgangssignal
Zeit
Zeit
Die optische Kopplung zwischen zwei Fasern ist mechanisch aufwendig, da der Kern
der Faser, der das Licht leitet, nur ca. 1 m - 50 m dünn ist (Präzisionsstecker!)
4.3.4
Technologien bei Glasfasern
Es gibt Stufenindex-, Gradientenindex- und Monomode-Fasern
38
4.3.4.1
Stufenindex-Faser
Radius r
Kern
Brechungsindex n
Zeit
Mantel
Output
Signal ist
schwach und
breit
Zeit
Totalreflektionen
Der Brechungsindex springt zwischen Kern und Mantel bei ca. 50 m Innendurchmesser
4.3.4.2
Gradientenindex-Faser
Radius r
Faser
Input
Kern
Brechungsindex n
Faser
Input
Mantel
„Kontinuierliche“
Reflektionen
Zeit
Output
geringere
Dämpfung
und Verzerrung
Zeit
Der Brechungsindex des Kerns geht im Intervall 0 bis 50 m kontinuierlich in den des
Mantels über
39
4.3.4.3
Monomode-Faser
Radius r
Input
Kern
Brechungsindex n
Faser
Mantel
Output
Signal ist
am besten
Zeit
= Wellenleiter: Faserdurchmesser ist
in der Größenordnung der Wellenlänge
Zeit
Die Faser ist so dünn (ca. 1 m), dass sie in der Größenordnung der Wellenlänge liegt
Das Licht wird nur von der Faser über quantenmechanische Effekte gelenkt
40
4.3.5
Vergleich der Glasfasertechnologien
104
Übertragbare Informationsmenge (M Bit/s)
Gr
103
565
140
102
34
101
Mo
no
mo
Systemparameter:
max. Regeneratorabstand aufgrund der
Dämpfung
de
ad
fas
ie n
er
t en
in d
ex
f as
er
Si
gn
a lw
Gr
e ll
ad
en
ie n
lä n
t en
ge
in d
13
ex
00
fas
3
nm
er
(fe
85
rn
0n
es
m
In f
(n
ah
ra
ro
es
t)
In f
ra
ro
t)
2
1
0
2
6 10
20
30
40
100
200
Verstärkerabstand in km
41
600
1000
1
Gradientenfaser, LED
als Sender, 850nm
Wellenlänge
2
Gradientenfaser, Laser
als Sender, 1300nm
Wellenlänge
3
Monomodefaser, Monomode-Laser als Sender, 1300nm Wellenlänge
4.4
Modulation von Signalen
Modulation: Aufprägung von digitalen Daten oder analogen Signalen auf hochfrequente analoge Signale (=elektromagnetische Wellen)
Modem (= Modulator + Demodulator): dient zur Modulation digitaler Daten (Modulator
zum Senden; Demodulator zum Empfangen)
Es gibt 3 Modulationsarten für elektromagnetische Wellen
1.) Amplitudenmodulation (AM) => Amplitude Shift Keying (ASK) für Binärdaten
2.) Frequenzmodulation (FM) => Frequency Shift Keying (FSK) für Binärdaten
3.) Phasenmodulation (PM) => Phase Shift Keying (PSK) für Binärdaten
Signalstärke
Amplitude
Sinusschwingung
{
Zeit
Phase
Frequenz / Wellenlänge
42
4.4.1
Beispiele zu Modulationsverfahren
0
1
0
1
1
0
0
1
0
0
1
0
(a)
(b)
große/kleine
Amplitude
(c)
große/kleine
Frequenz
(d)
High = kleine
Phase = Sinus;
Low = große
Phase = Cosinus
(a) binäres Datensignal, das eine Welle moduliert
(b) Extremfall der amplitudenmodulierten Welle, Amplitude 1 ist >0, Amplitude 2 = 0
(c) Frequenzmodulierte Welle (Frequenz springt zwischen 2 Frequenzen hin und her)
(d) Phasenmodulierte Welle (Phase springt zwischen 2 Phasen hin und her)
43
4.5
Codierung von Signalen
Die analogen Signale werden in der Zeit und in der Signalhöhe diskretisiert (= quantisiert) und dann durch einen Code repräsentiert. Anstelle des Analogsignals wird der
Codewert übertragen. Dies wird als Analog/Digital-Umsetzung bezeichnet.
Im einfachsten Fall wird der Binärcode zur Darstellung des Signals verwendet; bei
Rechnernetzen wird der Binärcode allerdings nicht eingesetzt, da ungeeignet
Zur Analog/Digital-Umsetzung gibt es auch die inverse Operation, die D/A-Wandlung
(Rückkonvertierung). Ein elektronischer Baustein (Chip) kann beides. Er wird als
CODEC (Codierer/Decodierer) bezeichnet und ist in Handys und ISDN-Telefonen eingebaut.
Analogsignale
4.5.1
CODEC
Digitale PCM-Signale
CODEC
Analogsignale
Non Return to Zero Codes (NRZ-Codes)
Die NRZ-Codes bilden eine ganze Familie von Codes
Das gemeinsame Kennzeichen der NRZ-Codes ist, dass ein fester Pegel während eines
Bitintervalls herrscht. Pegelwechsel erfolgen nur an den Intervallgrenzen.
44
Non return to zero soll daran erinnern, dass der Signalpegel für die Übertragung der
„1“ innerhalb des Bitintervalls nicht auf 0 Volt zurückkehrt, sondern beim High-Pegel
bleibt
NRZ Codes sind einfach zu implementieren
4.5.1.1
NRZ-L-Code (L= Level)
Der NRZ-L-Code ist der bekannte Binärcode, wie er in jedem Rechner verwendet wird
• d.h.,: „1“ = hoher Pegel, „0“ = niedriger Pegel
4.5.1.2
NRZ-M-Code und NRZ-S-Code (M = Mark, S = Space)
NRZ-M und NRZ-S sind sog. differenzielle Codierungen
D.h., es wird nicht der absolute Spannungswert (hoher Pegel bzw. niedriger Pegel) zur
Codierung von „0“ und „1“ verwendet, sondern ein Spannungswechsel vom augenblicklichen Wert in den komplementären Wert (z.B. von hoch nach niedrig oder von
niedrig nach hoch).
NRZ-M heißt:
• zur Darstellung der „1“ wird ein Spannungswechsel vorgenommen
• Zur Darstellung der „0“ wird kein Signalwechsel vorgenommen
NRZ-S heißt:
• zur Darstellung der „0“ wird ein Spannungswechsel vorgenommen
• Zur Darstellung der „1“ wird kein Signalwechsel vorgenommen
45
Vorteile von NRZ-M und NRZ-S gegenüber NRZ-L:
• Unter Einfluss von Störungen wie z.B. Rauschen sind Signalwechsel leichter zu detektieren als absolute Signalpegel, da Wechsel nur kurz dauern, während Pegel im Wert einbrechen können
• D.h. Pegel schwanken bei Störungen, müssen aber mit einem festen Schwellwert verglichen werden, um zwischen „0“ und „1“ zu unterscheiden, was dann zu Fehlinterpretationen führt
Nachteile aller NRZ-Codes:
1.) eine stets vorhandene Gleichstromkomponente => keine Trafo- oder Kondensatorkopplung möglich => sog. „Erdschleifen“ und Störungen sind wahrscheinlich
2.) Es gibt Synchronisierungsprobleme zwischen Sender und Empfänger bei langen „0“Folgen bei NRZ-M, bzw. bei langen „1“-Folgen bei NRZ-S, da sich nichts auf der Leitung ändert
4.5.2
Biphase-Codes = Zweite Gruppe von Codes
Das Kennzeichen aller Biphase-Codes ist, dass es zwei zeitliche Abschnitte (Phasen)
in jeder Bitzelle gibt => höhere Bandbreite erforderlich
Alle Biphase-Codes haben mindestens einen und höchstens zwei Spannungswechsel
pro Bitzelle
46
4.5.2.1
Biphase-L (= Manchester-Code)
Die erste Hälfte der Bitzelle enthält die Binärdarstellung, d.h. eine hohe Spannung bei
„1“, eine niedrige Spannung bei „0“
In der 2. Hälfte der Bitzelle wechselt der Spannungswert zum Komplement
Immer ein Signalwechsel in der Mitte des Intervalls; Je nach Bitfolge ggf. auch Signalwechsel am Ende des Intervalls
Der Signalwechsel in der Mitte wird vom Empfänger als Taktsignal für eine synchrone
Übertragung genutzt
Vor- und Nachteile von Manchester:
• Nachteil: Doppelte Baudrate bei unveränderter Bitrate gegenüber reinem Binärcode (doppelt so häufige Spannungswechsel)
• Vorteil: Takt und Daten können gleichzeitig auf demselben Kabel übertragen werden = taktsynchrone Übertragung
Wird für Ethernet verwendet
4.5.2.2
Differential Manchester-Code
Immer ein Signalwechsel in der Intervallmitte (= wie bei Manchester, die Bits werden
aber nicht explizit in der ersten Hälfte der Bitzelle kodiert)
Bei „0“ zusätzlicher Signalwechsel am Intervallbeginn. Bei „1“ passiert nichts.
Wird für Token Ring verwendet, da störungsicherer als Manchester
47
4.5.2.3
Immer ein Signalwechsel am Intervallbeginn
Bei „1“ zusätzlicher Signalwechsel in der Intervallmitte. Bei „0“ passiert nichts.
4.5.2.4
Biphase-S
Immer ein Signalwechsel am Intervallbeginn (wie Biphase-M)
bei „0“ zusätzlicher Signalwechsel in der Intervallmitte (komplementär zu Biphase-M)
4.5.2.5
Biphase-M (= Miller-Code oder FM-Code)
Modified Miller-Code (= Modified Delay „Modulation“, MFM-Code)
Signalwechsel am Ende des Intervalls, wenn nach einer Null wieder eine „0“ folgt
Bei „1“ zusätzlicher Signalwechsel in der Intervallmitte
Vorteile:
• Bandbreitebedarf ist geringer als bei Manchester oder Biphase-M
• Störsicherheit ist größer als bei Manchester, da differentieller Code
Wird für die Datenaufzeichnung bei magnetischen Medien (Festplatten, Bänder) verwendet. Bits können damit auf der Festplatte dichter gepackt werden.
4.5.2.6
Bipolar-Code (= Alternate Mark Inversion)
Verwendet drei Signalwerte: positive Spannung, Null und negative Spannung
48
„1“ wird im Wechsel durch einen positiven bzw. negativen Impuls in der 1. Hälfte des
Bitintervalls dargestellt
„1“ ist abwechselnd eine positive Spannung und eine negative Spannung
In der 2. Hälfte kehrt die Spannung jeweils auf Null zurück
Nachteil: doppelte Baudrate
Vorteil: keine Gleichstromkomponente => Trafo- oder Kondensatorkopplung ist möglich
Wird bei ISDN verwendet
4.5.2.7
Vorteile der Biphase-Codes
Leichte Taktsynchronisierung zwischen Sender und Empfänger, weil mindestens ein
Spannungswechsel pro Bitintervall stattfindet = taktsynchrone Übertragung, d.h. Takt
kann zusammen mit den Daten in demselben Signal übertragen werden
Spannungswechsel dienen als Impulsflanke zum Triggern des Empfänger-Flipflops
Fehlererkennung ist bereits auf Ebene 1 des ISO-7-Schichten-Modells anhand des Ausbleibens eines Spannungswechsels in einer Bitzelle möglich
49
4.5.3
Graphische Beispiele bei Leitungscodes
1
0
1
1
0
0
0
1
1
0
1
NRZ-L
NRZ-L = non return to
zero-level
NRZ-M = non return to
zero-mark
NRZ-S = non return to
zero-space
NRZ-M
NRZ-S
Biphase-L
(Manchester)
Biphase-M
Biphase-S
DifferentialManchester
Modified Miller
Bipolar
50
4.6
Multiplexen von Signalen
Definition: Übertragungsweg
• physikalisch-technisches Transportsystem für Signale (z. B. Kabel)
Definition: Übertragungskanal
• Verwaltungsgröße innerhalb eines Übertragungsweges zur Übertragung des Signalstroms
einer einzigen Quelle
Auf einem Übertragungsweg können mehrere Übertragungskanäle parallel betrieben
werden
Die Aufspaltung der gesamten Übertragungskapazität eines Übertragungsweges auf
verschiedene Übertragungskanäle ist möglich und effizient
Definition: Multiplexing
• Die Aufspaltung eines Übertragungswegs in mehrere Übertragungskanäle heißt Multiplexing
• Durch Multiplexing wird es möglich, einen Übertragungsweg mehrfach zu nutzen => Effizienzsteigerung
Übertragungswege können sowohl in der Zeit als auch in der Bandbreite mehrfach genutzt werden => Frequenzmultiplex + Zeitmultiplex
51
4.6.1
Frequenzmultiplexen
a)
b)
Amplituden
Modulation
Input
Basisband
Kanal 1
c)
Output
(a) Spektren dreier Telefongespräche (3
Basisbänder)
(b) Im Spektrum verschobene Basisbänder (Breitband)
(c) Spektrum der Signale auf dem Übertragungsweg (Kabel)
verschobenes Basisband (Breitband)
1
f
0
Spektrum
f
60
64
68
72
Spektrum
Kanal 1
Kanal 2
Kanal 2
1
f
0
f
60
64
68
0
f
60
72
64
Kanal 3
1
f
300
3100
Kanal 3
0
f
60
64
68
72
52
68
72
4.6.1.1
Grundidee des Frequenzmultiplexens
Breitbandige Übertragungswege ermöglichen die Unterbringung vieler Übertragungskanäle in unterschiedlichen Frequenzbereichen (Frequenzbändern), d. h., man teilt die
verfügbare Bandbreite in eine Reihe von - nicht notwendigerweise gleich breiten - Frequenzbändern auf und ordnet jedem Frequenzband einen Übertragungskanal zu.
Frequenz
Bandbreite des
Übertragungskanals
Kanal 1
Kanal 2
Bandbreite des
Übertragungsweges
...
Kanal n
Zeit
Es gilt: Summe über alle Kanalbandbreiten Bandbreite des Übertragungsweges
53
4.6.1.2
Prinzipielle Realisierung von Frequenzmultiplexen
Amplituden-Modulatoren
Bits
BST = Bitstrom
BST1
Amplituden-Demodulatoren
Filter f1
Träger f1
BST1
BST2
Frequenzgemisch
BST2
Bits
Filter f2
Träger f2
3 AM-modulierte
Träger f1, f2, f3 auf
einem Kabel
BST3
BST3
Träger f3
Filter f3
Hinweis: BST i = Bitstrom i, entspricht Kanal i; Träger = Sinusschwingung, die moduliert wird
54
4.6.2
Zeitmultiplexen tritt in Form des synchronen und des asynchronen Zeitmultiplexens
auf (synchronous/asynchronous Time Division Multiplexing)
4.6.3
Zeitmultiplexen
Synchrones Zeitmultiplexen
Beim synchronen Zeitmultiplexen wird die Zeit in sog. Zeitscheiben gleicher Länge eingeteilt, die auf Sender und Empfängerseite zum selben Zeitpunkt beginnen und enden
Die gesamte verfügbare Bandbreite wird für eine feste Zeit ts, der sog. Zeitscheibe, jedem Kanal zur Verfügung gestellt
Nach einer Umschaltzeit wird die Bandbreite zum nächsten Kanal weitergereicht
Nach einer Periodendauer T>ts wiederholt sich das Schema
Pro Periode erhält jeder Kanal eine Zeitscheibe (time slot) => time sharing
Zeitmultiplex ist aufgrund der notwendigen Pufferung nur für zeitdiskrete Signale einsetzbar (bevorzugt zeit- und wertdiskrete Signale, d.h. Digitalsignale)
55
4.6.3.1
Beispiel: Telefonvermittlung- und übertragung
Frequenz
Es gilt: Summe über alle Zeitscheiben
Periodendauer des Übertragungswegs
Bandbreite des
Übertragungswegs
Umschaltzeiten
ZeitscheiZeitscheibe K5
be K1
K1
K2
K3
K4
Periodendauer
56
K5
Zeit
4.6.3.2
Prinzipielle Realisierung von synchronem Zeitmultiplexen
Rotierender Abtaster
Bits
BST = Bitstrom
BST1
BST2
BST3
Puffer 1
Puffer 2
Puffer 3
Rotierender Verteiler
Bits
t1
t1
t2
TS1
TS3
TS2
t2
TS4
t3
t3
Puffer 1
Puffer 2
Puffer 3
BST1
BST2
BST3
• Jeder Sender i hat innerhalb einer Umlaufperiode des Abtasters eine feste Zeitscheibe (time slot) TSi. Abtaster und Verteiler rotieren im gleichen Takt und mit gleicher Phase
Synchrones Zeitmultiplexing
• Die Zeittakt-Stabilität (Jitter) zwischen Abtaster und Verteiler ist wichtig, sonst erfolgt eine
falsche Zuordnung des Bitstroms beim Empfänger
57
4.6.4
Asynchrones Zeitmultiplexen
Hierbei wird der Übertragungsweg dem Sender nicht fest über eine Zeitscheibe, sondern nach Bedarf zugeteilt
Anforderungsbasierter Medienzugang, Beispiel Ethernet
Asynchrones Zeitmultiplex wird auch als statistisches Zeitmultiplexing (STDM = statistical time division multiplexing) bezeichnet, weil a priori nicht klar ist, wer wann senden will
Der Empfänger kann aus der Zeitlage der Zeitscheiben nicht mehr die Herkunft der Daten erkennen
Es ist für jeden Datenrahmen eine Verwaltungszusatzinformation in Form eines sog.
Vorspanns (Headers) bestehend aus Zieladresse, Kanalkennzahl u.s.w. erforderlich
Man spricht nicht mehr von Zeitscheiben sondern von (Daten)rahmen
4.6.4.1
Aufbau der Datenrahmen bei asynchronem Zeitmultiplex
Zeit
Header
Inhalt
1. Datenblock (Rahmen)
...
...
Header
Inhalt
i. Datenblock
58
Header
Inhalt
(i+1). Datenblock
4.6.5
Vergleich zwischen synchronem und asynchronem Zeitmultiplexen
A2
synchrones Zeit-Multiplexing
A1
2
3
1
Bitströme 1 - 3
C2 B1 leer C1 leer A2 leer leer A1
B1
Multiplexer
C2
Ausgang
C1
C2 B1 C1
asynchrones Zeit-Multiplexing
= effizienter
Eintreffende Datenrahmen
A2 A1
Beim synchronen Zeitmultiplex ist die Zeitscheibe eines Kanals, auf dem nicht gesendet wird, verloren!
Vorteil von asynchrones Zeitmultiplexing: nützt den Übertragungsweg effizienter
Nachteil von asynchronem Zeitmultiplexing: Wenn sehr viele gleichzeitig senden,
kommt ein Sender möglicherweise nie zum Senden => für Echtzeit ungeeignet
Synchrones Zeitmultiplexing: für Echtzeit geeignet
Asynchrones Zeitmultiplexing wird häufig bei LANs eingesetzt, u.a. auch im Ethernet
59
4.6.6
Mobilfunknetz als Beispiel für gleichzeitiges Zeit- und Frequenzmultiplexen
GSM = Global System for Mobile Communication, UMTS = Universal Mobile Telephone
system, LTE = Long Term Evolution
Bei GSM/UMTS/LTE wird gleichzeitig synchrones Zeit- und Frequenzmultiplex eingesetzt, um für eine a priori nicht bekannte Zahl von Mobiltelefonen die niedrige Bandbreite des Funk-Übertragungsweges effizienter zu nutzen
Beispiel GSM: Der zur Verfügung stehende Frequenzbereich ist 890,2-914,8 MHz für die
uplink-Kommunikation (vom Mobiltelefon zur Basisstation) und 935,2-959,8 MHz für die
downlink-Kommunikation (von der Basisstation zum Mobiltelefon)
Damit werden pro Basisstation 124 Kanäle für up- und downlink durch Frequenzmultiplex realisiert => Die Bandbreite eines Kanals beträgt 200 KHz
Gleichzeitig wird jeder Kanal in 8 Zeitscheiben zu je 577 s unterteilt
im Prinzip könnten von jeder Basisstation bis zu 124*8 = 992 Mobiltelefone simultan
bedient werden
Hinzu kommt: jede Basisstation muss auf anderen Frequenzen innerhalb des zur Verfügung stehende Frequenzbereichs senden als die Nachbarbasisstation, damit Störungen zwischen den Basisstationen vermieden werden
=> Aufteilung der Frequenzbereiche in räumliche Bezirke („Zellen“), in deren Mitte
jeweils eine Basisstation steht, so dass sich keine Frequenzen zwischen benachbarten Basisstationen überlappen
60
Da sich die Funkwellen kugelförmig ausbreiten, ist das Verbreitungsgebiet einer Zelle
auf dem Boden ein Kreis
Der Kreis wird mittels eines regelmäßigen Sechsecks approximiert
Bienenwabenstruktur der Funkzellen
B
G
a) homogene Zellgröße auf
dem flachen Land (gleiche
Buchstaben bezeichnen gleiche Frequenzen)
b) kleinere Zellen für Städte in
der Mitte
C
A
F
B
G
A
D
E
C
F
B
G
D
E
C
A
a)
F
D
b)
E
5 Sicherungsschicht (ISO-Schicht 2)
Im ISO-Modell ist die Sicherungsschicht zwischen je zwei benachbarten Rechnern relevant
Sie leistet mehr als nur die Daten zu sichern
61
5.1
Verdeckung (= Unsichtbarmachung) von Übertragungsfehlern zwischen direkt benachbarten Rechnern (keine Zwischenknoten), bestehend aus den Teilschritten Erkennung
und Behebung
Flusssteuerung (flow control) des Datenverkehrs zum Nachbarrechner
Bei LANs mit mehreren Sendern auf einem Übertragungsmedium: Steuerung des Zugangs zum gemeinsam genutzten Medium (= Medium Access Control, MAC)
5.2
Aufgaben der Sicherungsschicht
Ursachen von Übertragungsfehlern
Fehler werden häufig durch andere elektrische und elektronische Geräte verursacht
Diese Störungen haben physikalische Gründe:
1.) „Weißes Rauschen“ = thermisches Rauschen von Leitungen und Bauteilen aufgrund
der Brownschen Molekularbewegung
• hohe Temperatur, z.B. aufgrund der Abwärme von Geräten => starkes Rauschen
• Entscheidend für die Signalgüte ist das Verhältnis von Signalspannung/Rauschspannung
2.) Dämpfung des Nutzsignals
• Ist abhängig von der Frequenz des Nutzsignals: hohe Frequenz => hohe Dämpfung
3.) Verzerrung des Nutzsignals
62
• Ist abhängig von der Frequenz und von der Amplitude des Nutzsignals: hohe Frequenz
oder hohe Amplitude => hohe Verzerrung
4.) Übersprechen auf Leitungen
• verursacht durch Induktion, kapazitive Kopplung und elektromagnetische Wellen
• Induktion (Magnetfelder): schnelle Feldänderungen => hohe Störspannung
• Kapazitive Kopplung (elektrische Felder): lange, parallele Leitungen => hohe Störspannung
• Elektromagnetische Wellen => hohe Frequenz => hohe Störspannung
5.) Potentialunterschiede in der Masseleitung zwischen Sender und Empfänger
• Verursacht z.B. aufgrund von sog. Erdschleifen
• Eine Erdschleife kommt über die sog. „Erdung“ ins Spiel, d.h. über die Schutzerde an metallischen Gerätesteckern, die der VDE vorschreibt.
• Die Erdschleife wird geschlossen, wenn an den Gerätesteckern von Sender und Empfänger aus Unkenntnis die Signalerden mit Schutzerde verbunden werden
• Durch das Verbinden von Signal- mit Schutzerde entsteht parallel zur Masseleitung des Signals eine zweite Masseleitung über die Schutzerde, und die Erdschleife ist geschlossen
• Über die geschlossene Erdschleife können erhebliche Ströme (sog. Ausgleichsströme)
fliessen, die wiederum einen Potentialunterschied zwischen der Signalerde von Sender
und Empfänger bewirken. Dieser Potentialunterschied verursacht Störungen.
• Es ist deshalb verboten, Signalerde mit Schutzerde zu verbinden!
63
5.3
Fehlercharakteristik bei Übertragungsfehlern
Fehler kommen oft nach einer langen Pause und dann kurz aufeinander folgend: sog.
Bursts auch Fehlerbündel genannt
Beispiel: bei einem Burst von 10 ms und einem 1,5 Mbit/s-DSL-Modem entspricht dies
15 000 falschen Bits
Vorteil von Bursts: Nur wenige Blöcke enthalten Fehler
Nachteil: Schwer zu korrigieren, da i.d.R. viele Fehler auf einmal auftreten
Wiederholung eines ganzen Datenrahmens wegen Burst-artigem Fehlerverhalten
5.4
Fehlererkennung
Zur Fehlererkennung wird die Nutzinformation durch Zusatzinformation ergänzt
Diese wird als Prüfbit oder als Prüfsumme zusammen mit den Nutzdaten übertragen
Je nach Umfang der Redundanz und verwendetem Code kann eine gewisse Anzahl an
Fehlern sogar korrigiert werden
Fehlerkorrektur wird bei Rechnernetzen allerdings nicht eingesetzt, statt dessen wird
die Datenübertragung wiederholt
Der Zusammenhang zwischen der Fehlerhäufigkeit der Übertragungsstrecke und der
gewünschten Wahrscheinlichkeit der Entdeckung bzw. Korrektur eines Fehlers wird in
der Nachrichtentechnik, einem Teilgebiet der Elektrotechnik, behandelt
64
Die Nachrichtentechnik kann erklären, wie groß bei n Nutzbits der Umfang der notwendigen Redundanz sein muss, um i Bitfehler erkennen und j<i korrigieren zu können
5.4.1
Fehlererkennung durch Paritätsbit
Bsp. 1
ein
ASCIIZeichen
Bsp. 2
Bsp. 3
Bit 1
0
1
1
Bit 2
1
0
1
Bit 3
0
0
0
Bit 4
0
1
0
Bit 5
0
0
0
Bit 6
0
1
0
Bit 7
1
1
1
0
0
1
Paritätsbit
gerade
Parität
1
1
65
0
ungerade
Das Paritätsbit ergänzt die Anzahl der Einsen im Zeichen (= „Quersumme“), so dass sie
gerade/ungerade wird (gerade Parität = gerade Zahl von Einsen)
Berechnung erfolgt so, dass die gesamten Quersumme inkl. Parity gerade oder ungerade wird
Bei einer asynchronen Übertragung (V.24) wird für jedes einzelne Zeichen ein Prüfbit
verwendet
Nachteil: Es kann nur ein Fehler erkannt und keiner korrigiert werden
Genauer: es kann eine ungerade Zahl von Bitfehlern erkannt werden
Auskunft, wie viele falsche Bits erkannt bzw. wie viele korrigiert werden können, gibt
die sog. Hamming-Distanz H
Zwei Binärworte A, B derselben Länge haben die Hamming-Distanz H, wenn sie sich in
H Bits unterscheiden
Die Hamming-Distanz definiert eine Metrik in einem diskreten n-dimensionalen Punktraum, in dem jedes Binärwort der Länge n einen Punkt darstellt
Wird im Punktraum um jedes Nutzwort A ein Sicherheitsabstand H bis zu einem beliebigen Nachbarn B geschaffen, können H-1 falsche Bits erkannt und H/2 korrigiert werden
Alle Bitkombinationen innerhalb des Sicherheitsabstandes H sind bis auf das Wort A
selbst verboten
Erkennt der Empfänger eine verbotene Bitkombination, dann weiß er, dass ein Fehler
vorliegt
66
Erkennt der Empfänger die erlaubte Bitkombination A, dann liegt mit hoher Wahrscheinlichkeit kein Fehler vor
Eine Methode zur Erzielung einer Hamming-Distanz H zwischen zwei Worten A, B ist
der Cyclic Redundancy Check (CRC)
5.4.2
Fehlererkennung durch Prüfsumme (Cycling Redundancy Check, CRC)
Das Prinzip für Cycling Redundancy Check lautet:
1.) Betrachte einen Bitstring als die Kurzdarstellung eines Polynoms vom Grad n in der
Variablen x, bei dem nur die Koeffizienten 0 und 1 aufgeschrieben werden
• Beispiel: 11001 sei ein Polynom in x vom Grad 4 gemäß: x4 + x3 + x0
2.) Wähle ein sog. Generatorpolynom G(x) vom Grad g in Form eines zweiten Bitstrings
• Einige Generatorpolynome sind bereits fertig und normiert, so dass die Wahl leicht fällt
3.) Hänge an die Nachricht M(x) eine CRC-Prüfsumme so geschickt an, dass das daraus
entstehende neue Polynom T(x) aus Nachricht plus Prüfsumme durch G(x) teilbar ist.
4.) Übertrage T(x) und prüfe beim Empfänger das empfangene T(x) auf Teilbarkeit durch
G(x)
5.) Die Nachricht ist mit hoher Wahrscheinlichkeit dann korrekt übertragen, wenn die
Teilbarkeit gegeben ist
67
5.4.2.1
Algorithmus für die CRC-Berechnung
1.) Es sei die Nachricht M und das Generatorpolynom G(x) vom Grad g gegeben. Dann
hänge man g Nullen an M an, erzeuge also M(x)00...0
2.) Teile M(x)00...0 durch G(x) gemäß Division modulo 2, d.h. ohne Borgen, ohne Übertrag. (Diese spezielle Arithmetik ist Teil der sog. Galouis-Feldtheorie)
• Bei der Division kann ein Rest R entstehen. Falls R>0, dann Schritt 3.) sonst Schritt 4.)
3.) Subtrahiere den Rest von M(x)00...0 gemäß modulo 2 (= ohne Borgen, ohne Übertrag)
4.) Das Ergebnis ist T(x), d.h. die zu transferierende Nachricht samt Prüfsumme
• Die g least significand bits von T(x) sind die CRC-Prüfsumme
• T(x) ist garantiert durch G(x) teilbar, da ein etwaiger Rest vorher subtrahiert wurde.
5.) Der Empfänger teilt das empfangene T(x) durch G(x)
6.) Gibt es keinen Rest (R=0), ist T(x) mit hoher Wahrscheinlichkeit fehlerfrei übertragen
worden
68
5.4.2.2
Erstes Beispiel für CRC-Berechnung
Rahmen: 1 1 0 1 0 1 1 0 1 1 Generator: 1 0 0 1 1 => Grad g = 4
Nachrichten nach dem Anhängen von 4 Nullbits: 1 1 0 1 0 1 1 0 1 1 0 0 0 0, dann teilen:
1 1
-1 0
’’ 1
-1
’’
0
0
0
0
0
-0
’’
1
1
0
0
0
0
0
-0
’’
0 1 1 0 1 1 0 0 0 0 : 1 0 0 1 1 = 1 1 0 0 0 0 1 0 1 0 mit Rest 1 1 1 0
1
kein Borgen!
1 1
Daraus:
1 1
11010110110000-1110=11010110111110
0 0 1
0 0 0
gesendeter Rahmen
0 0 1 0
Nutzdaten
CRC-Prüfsumme
0 0 0 0
0 0 1 0 1
-0 0 0 0 0
Wichtig:
’’0 1 0 1 1
1.) Addition ohne Übertrag ist hier wie Subtraktion ohne
-0 0 0 0 0
Borgen d.h. diese spezielle Addition ist mit dieser spezi’’ 1 0 1 1 0
ellen Subtraktion identisch! Beides wiederum ist mit der
-1 0 0 1 1
bitweisen EXOR-Operation identisch (gemäß algebrai’’ 0 1 0 1 0
scher Feldtheorie von Galois)
-0 0 0 0 0
’’1 0 1 0 0
2.) Subtraktion von Dividend und Divisior erfolgt bereits
- 1 0 0 1 1
dann, wenn Dividend und Divisor gleich viele Stellen ha’’ 0 1 1 1 0
ben, nicht erst wenn Dividend größer oder gleich Divisor
-0 0 0 0 0
ist, wie sonst üblich. Eine Null als MSB zählt dabei nicht
Rest:
’’ 1 1 1 0
als Stelle!
69
5.4.2.3
Zweites Beispiel für CRC-Berechnung
Rahmen: 1 0 0 1 1 0 0 1
1 0 0 1
-1 0 1 0
’’ 0 1 1
-0 0 0
’’ 1 1
- 1 0
’’ 1
- 1
’’
Rest:
1
1
0
0
0
1
1
0
1
-1
’’
Generator: 1 0 1 0 1 => g=4, also: 1 0 0 1 1 0 0 1 0 0 0 0
0 0 1 0 0 0 0 : 1 0 1 0 1 = 1 0 1 1 1 1 0 1 mit Rest 1001
0
0
0 0
0 1
0 1
1 0
1 1
0 1
1 0
-1 0
’’ 0
-0
’’
gesendeter Rahmen: 1 0 0 1 1 0 0 1 0 0 0 0 - 1 0 0 1 =
1 0 0 1 1 0 0 1 1 0 0 1
1
1
0
0
0
1
1
0
1
-1
’’
0
1
1
0
1
0
1
0
1
0
1
1
0
1
1
0
0
0
0 0
0 1
0 1
Der Empfänger
1 0 0 1 1 0 0
-1 0 1 0 1
’’ 0 1 1 0 0
-0 0 0 0 0
’’ 1 1 0 0 0
- 1 0 1 0 1
’’ 1 1 0 1
-1 0 1 0
’’ 1 1 1
-1 0 1
’’ 1 0
-1 0
’’ 0
-0
’’
Rest:
70
berechnet nach der Übertragung:
1 1 0 0 1 : 1 0 1 0 1 = 1 0 1 1 1 1 0 1
1
1
0
0
0
1
1
0
1
-1
’’
1
1
0
0
0
0
0
0
0
0
1
1
0
1
1
0
0
0
0 1
0 1
0 0 = O.K.
5.4.2.4
Beispiele für CRC-Generatorpolynome
CRC-16 =x16 + x15 + x2 + 1 (ISO)
CRC-CCITT =x16 + x12 + x5 + 1
Beide werden für Datenübertragung benutzt, die Regel sind aber heutzutage 32 Bit
5.4.2.5
Erkannt werden:
•
•
•
•
alle einfachen und zweifachen Bitfehler
alle Fehler mit einer ungeraden Bitzahl
alle Fehler, die direkt hintereinander auftreten (= Bursts), aber nur mit einer Länge < 16 Bit
99,998% aller längeren Bursts mit > 16 fehlerhaften Bit direkt hintereinander
5.4.2.6
Implementierung der CRC-Berechnung
CRC lässt sich sehr einfach in Hardware mit Hilfe eines Schieberegisters und der bitweisen XOR-Funktion implementieren
5.5
Potential der Fehlererkennung durch CRC-16- und CRC-CCITT-Polynome
Bit Stuffing und Rahmenbegrenzer
Zur Anwendung von fehlererkennenden und fehlerkorrigierenden Codes muss der Datenstrom in einzelne Abschnitte unterteilt werden => „Rahmen“ (frames) bzw. Pakete
ab ISO Schicht 3
71
Problem: Wie kann man den Rahmenanfang im Bitstrom erkennen, wenn jedes beliebige Bitmuster in den Nutzdaten vorkommen kann?
Bit Stuffing (Bitstopfen) zur Kennzeichnung des Rahmenanfangs
Als Kennzeichnung wählt man z.B. 01111110 (= 6 Einsen hintereinander). Der Sender
fügt nach fünf Einsen im Nutzdatenstrom eine 0 ein.
Er fügt keine 0 ein, wenn es sich um den Rahmenanfang handelt.
Wenn der Empfänger nach fünf Einsen eine Null sieht, entfernt er diese aus dem Datenstrom.
Wenn er keine 0 sieht, weiß er, dass es sich um einen Rahmenanfang und nicht um
Nutzdaten handelt.
5.5.1
Beispiel für Nutzdatentransfer mit 6 Einsen am Stück
Sender
Leitung
Empfänger
011111
0111110
011111
101011111
1010111110
101011111
72
0101
0101
0101
5.5.2
Weitere Beispiele für Bit Stuffing
0
1
2
3
4
5
6
7
Kennzeichnung des Rahmenanfangs
Übertragung von 6 Einsen im
Nutzdatenstrom:
1
eingeschoben
Übertragung von 5 Einsen einer Null und einer Eins:
0
1
0
0
eingeschoben
Übertragung von 5 Einsen
und zwei Nullen:
eingeschoben
Sechs Einsen hintereinander kann es auf der Leitung nur am Rahmenanfang geben
73
5.5.3
Realisierung des Bitstopfens
Empfangen von Nutzdaten
Senden von Nutzdaten
(Kein Rahmenanfang)
(Ereignis: eintreffendes Bit)
Sender hat 6 Zustände
Empfänger hat 8 Zustände (inkl. Fehlerzustand)
0/0
Start
A
0/0
0/0
0/0
Drei Einsen
gekommen
1/1
0/0
Vier Einsen
gekommen
E
1/1
Fünf Einsen 1/1
gekommen
und 0 eingefügt
Notation: e/a
e = Eingabe
a = Ausgabe
1/1
1/10
F
Realisierung über endliche Automaten für Sender und Empfänger
D
1/1
E
1/1
C
1/1
0/0
1/1
0/0
Zwei Einsen
gekommen
D
Start
B
1/1
0/0
Ersetze die 5.
Eins durch 10
0/0
Eine Eins
gekommen
C
1/1
A
1/1
B
0/0
0/0
F
0/0
eingefügte G
0 wurde entfernt
0/
1/1
Ersetze 10 durch
1, wenn 4 Einsen
vorausgegangen
sind.
H Fehlerzustand: Rahmenanfang in den Nutzdaten
74
5.6
Typisches Rahmenformat der Schicht 2
Zeit
Flag, z.B.:
01111110
Target
Address
Source
Address
Control
(Steuerung)
0,1, 2,...Data
Bytes
Checksum
(CRC)
Rahmen-Kennzeichner
Rahmen-Kennzeichner (frame delimiter)
Flag = „Flagge“ = Rahmenkennzeichnung mittels Bit Stuffing
Rahmenbegrenzer am Paketende kann entfallen, wenn die Rahmenlänge bekannt ist,
oder wenn nächster Rahmen unmittelbar nachfolgt
5.6.1
Flag
01111110
Sprachregelung bei Schicht 1, 2 und 3
Auf der Schicht 1 spricht man von Bitstrom
Auf der Schicht 2 spricht man von Rahmen
Auf allen Schichten 3 spricht man von Paket
5.6.2
Das Steuerfeld eines ISO-Schicht 2-Rahmens („Control“)
Hinweis: to control: steuern; to check: kontrollieren; feed-back control: regeln
75
Im Steuerfeld eines ISO-Schicht 2-Rahmens steht die Rahmenlänge, sowie ggf. eine
sog. Empfangsbestätigung (Acknowledge) oder eine Rahmen-Sequenznummer
Hinweis: Acknowledgement = Anerkennung, Bestätigung, Quittung
Im Falle von Ethernet steht im Steuerfeld die Rahmenlänge aber kein Acknowledge,
bzw. keine Sequenznummer
Im Internet wird deshalb die Funktion von Acknowledges bzw. Sequenznummern
durch weitere Steuerfelder in Paketen der Schichten 3 und 4 nachgeahmt
D.h., im Internet tauchen Acknowledges bzw. Sequenznummern erst auf den Schichten
3 bzw. 4 auf und haben dort dieselbe Funktion wie in ISO-Schicht 2-Rahmen
Die Rahmenlänge wird bei variabel langen Rahmen vom Empfänger der Schicht 2 stets
benötigt, um zu wissen, wo die Prüfsumme anfängt bzw. der Rahmen endet
Schicht 2-Acknowledges, sofern vorhanden, werden vom Empfänger zur Quittierung
korrekt erhaltener Rahmen, sowie zur Flusssteuerung (flow control) zwischen benachbarten Rechnern benutzt
Hinweis: Flusssteuerung heißt: Sind die letzten Blöcke zu schnell gekommen? Falls ja, bremst der
Empfänger den Sender.
Schicht 2-Sequenznummern, sofern vorhanden, werden benutzt zur:
1.) Erkennung doppelt bzw. mehrfach gesendeter Datenrahmen
2.) Zur Sicherstellung der korrekten Rahmenreihenfolge, sowie ebenfalls zur Flusssteuerung
76
5.7
Bestätigungen (Acknowledges)
Für jedes Datenpaket vom Sender zum Empfänger wird eine Bestätigung in Gegenrichtung geschickt, sofern das Datenpaket unversehrt empfangen wurde
Wird das Paket nicht empfangen oder fehlerhaft empfangen, erhält der Sender keine
Bestätigung => der Sender merkt dies anhand einer Zeitschranke (time out)
Zwei Fälle müssen dabei unterschieden werden: a) wenn das Paket nicht empfangen
wurde b) wenn die Bestätigung verloren ging
5.7.1
Zwei Fälle von Datenverlust
Sender
Empfänger
Sender
Empfänger
AC
Paketverlust
Hinrichtung
K
Paketverlust
Rückrichtung
1. Verlust eines Datenblocks:
2. Verlust einer Quittung:
- Senke wartet auf Daten
- Quelle wartet auf Bestätigung
- Quelle wartet auf Bestätigung - Senke wartet auf neue Daten
77
Problem mit Acknowledges: Ohne Überwachung einer Zeitobergrenze würde der Sender in beiden Fällen beliebig lange auf das Acknowledge warten
Lösung: Einführung einer Zeitschranke (Timeout) beim Sender
Neues Problem: welchen Wert soll die Zeitschranke haben?
Für den Time Out-Wert gibt es keine generelle Lösung!
5.7.2
Bestätigung mit Zeitschranke (timeout) auf der Senderseite
Sender
Empfänger
Zeitüberwachung
Bl
oc
Time- benötigte
Zeit
outZeit
k
K
AC
Sender
Empfänger
Zeitüberen
wachung B
tw
l oc
ed
k
er
TimeoutZeit
Aktivierung
des Timouts
er
od
K
AC
(1) Beispiel für eine fehlerfreie Übertragung
(2) Beispiel für das Erkennen eines
Nachrichtenverlustes durch Ablauf
der Zeitschranke
de
Bl rsel
oc be
k
(1)
K
AC
(2)
rechtzeitig
Weiteres Problem: Der Rahmen i wird 2x fehlerfrei übertragen
78
Gibt der Empfänger den Block i an die nächst höhere Schicht 2x weiter?
Daraus entstünde ein Duplikat, das zu einem Fehler führen würde
Lösung: Einführung von Sequenznummern
5.7.3
Bestätigung mit Zeitschranke und Sequenznummern auf der Sender- und Empfängerseite
Aufgaben von Sequenznummern:
1.) Erkennung von Duplikaten
• bei einer unerwünschten Verdopplung des Rahmens bleibt die Sequenznummer gleich
2.) Quittieren von mehreren Rahmen auf ein Mal (Sammelquittung)
3.) Zur Flusssteuerung zwischen benachbarten Rechnern
Im Internet wird eine Flusssteuerung nur von TCP vorgenommen
Dazu benützt TCP keinen eigenen Mechanismus
Vielmehr werden Sequenznummern zweckentfremdet, indem das Absenden etwas verzögert wird (delayed acknowledge)
Sequenznummern werden sowohl zur Fehlerkontrolle als auch zur Flusssteuerung
verwendet
79
5.7.3.1
Beispiel für das Erkennen von Duplikaten
Sender
Empfänger
Bl
oc
ki
-1
verarbeiten
Zurückgeschickte Sequenznummern, i-1, i, i+1, ... dienen zugleich
als Bestätigung.
K
AC
Zeitüberwachung
Bl
oc
i-1
ki
K
AC
timeout
Bl
oc
= weiterleiten zur Schicht 3
(Vermittlungsschicht)
i
verarbeiten
= weiterleiten zur Schicht 3
(Vermittlungsschicht)
ki
wegwerfen,
K
AC
80
i
weil schon einmal empfangen
5.7.3.2
Beispiel für eine Sammelquittung
Quelle
(Sender)
0
I(0)
1
verarbeiten
I(1)
2
I(2)
I(3)
3
4
)
B( 1
verarbeiten
t
ou
e
tim 2
3
4
5
wegwerfen,
weil I(3) fehlt
wegwerfen,
weil I(3) fehlt
wegwerfen,
weil I(2) schon da
I(5)
I(2)
I(3)
Situation: I(2) wird zu
spät bestätigt und I(3)
geht verloren. Deshalb
wird I(2), I(3), I(4) und I(5)
zwei Mal gesendet => ineffizient im Fehlerfall
verarbeiten
I(4)
)
B(2 I(
5)
)
B(4
verarbeiten
verarbeiten
)
B(5
verarbeiten
I(4)
5
Zeitüberwachung
Senke
(Empfänger)
I = Informationsblock
B = Bestätigung
Zurückgeschickte Sequenznummer B (1) dient als Bestätigung für die Blöcke 0 und 1
81
5.8
Nachdem ein Übertragungsfehler durch CRC-Prüfung oder Timeout erkannt wurde,
sollte der betreffende Rahmen neu geschickt werden, sofern nicht Echtzeitbedingungen herrschen (z.B. aufgrund von Video-Streaming in web TV)
Für die Rahmenwiederholung gibt es verschiedene Strategien:
5.8.1
Fehlererbehebung durch Rahmenwiederholung
Fehlerbehebung mit „go-back-n“ und ohne Pufferung beim Empfänger
Im Falle eines Fehlers (CRC falsch) bleibt das Ack aus
Nach Ablauf des Timers überträgt der Sender sämtliche Rahmen ab dem unbestätigten
Rahmen neu.
alle Rahmen ab dem Fehler
noch einmal übertragen
Timeout-Intervall
Sender 0
1
2
3
4
5
6
7
8
2
3
4
0
1
F
6
7
8
9
10
5
6
2
4
3
k ck ck ck ck
c
A
A
A
A
A
1
0
k ck
c
A
A
Empfänger
5
V
V
V
V
V
V
2
3
4
5
Fehler
Von der Sicherungsschicht
verworfene Rahmen
82
Zeit
6
7
8
Fehler werden empfängerseitig anhand eines falschen CRCs festgestellt und senderseitig anhand des Timeouts
Jeder Rahmen muss einzeln quittiert werden
Keine Sammelquittung möglich, da keine Pufferung
Vorteil: Einsparen von Pufferplatz. Ist heutzutage nicht mehr wichtig.
Nachteil: Ineffizient im Fehlerfall, da alle Rahmen des Timeout-Intervalls neu übertragen werden müssen. Ist auch heute noch ein Nachteil.
83
5.8.2
Fehlerbehebung mit „go-back-n“ und mit Pufferung beim Empfänger
Für Rahmen 6 kommt Ack 8 zu spät, aber
Rahmen 7 und 8 werden nicht zweimal
übertragen
Timeout-Intervall
Sender 0
1
2
3
4
5
6
7
8
2
3
4
1
0
k ck
c
A
A
Empfänger
0
1
F
k
Ac
3
4
5
6
7
8
2
Fehler
Zeit
5
Von der Sicherungsschicht
gepuffert (gespeichert)
V
6
9
10 11 12
8
k
Ac
V
V
V
9
9
10
Nachricht 2-8 an die
Vermittlungsschicht
übergeben
Im Falle eines Fehlers bleibt das Ack aus
Der Empfänger puffert alle danach korrekt erhaltenen Rahmen
Nach Ablauf des Timers beginnt der Sender, alle Rahmen ab dem Unbestätigten neu zu
übertragen, bis er eine Sammelquittung vom Empfänger erhält
Der Sender fährt danach mit dem ersten noch nicht übertragenen Rahmen fort
Die erneute Übertragung von 7 und 8 wird durch Sammelacknowledge vermieden
Sammelquittungen haben den Vorteil höherer Ausnutzung der Bandbreite
Anwendung: TCP
84
5.8.3
Fehlerbehebung durch „selective repeat“
Timeout-Intervall
Sender 0
1
2
3
A
Empfänger
0
ck
1
4
0
A
ck
F
Fehler
5
6
1
A
3
ck
4
3
7
2
9
10 11 12 13 14
2
9
10 11
4
5
6
7
8
k
k
k
k
k
k
k
k
k
Ac Ac Ac Ac Ac Ac Ac Ac Ac
5
6
7
8
2
Von der Sicherungsschicht
gepuffert
Zeit
8
9
10 11 12
Rahmen 2-8 werden an die
Vermittlungsschicht
übergeben => Latenz durch Fehlerkorrektur
Der Empfänger bestätigt jeden korrekt erhaltenen Rahmen sofort (keine Sammelquittung)
Er puffert alle korrekt erhaltenen Rahmen, auch nach einem fehlerhaften Rahmen
Bei Ablauf des Timers überträgt der Sender nur den nicht bestätigten Rahmen neu
Jedes fehlerfreie Paket wird bestätigt
Nachteil: viele Bestätigungen => schlechte Ausnutzung der Bandbreite in Gegenrichtung
Vorteil: keine unnötige Wiederholung korrekt empfangener Pakete => gute Ausnutzung
der Bandbreite zwischen Sender und Empfänger
Da Acknowledges viel kürzer als Nutzdaten sind, lohnt sich dieses Verfahren
85
Allen Verfahren gemeinsam ist eine erhöhte Latenz bei der Datenübergabe im Fehlerfall
5.8.4
Aktive Fehlerkontrolle
Bisher: passive Fehlerkontrolle
Passiv heißt nicht-Senden von (positiven) Acknowledges
Nachteile der passiven Fehlerkontrolle:
• Keine Unterscheidung zwischen fehlenden und fehlerhaften Blöcken
• Zeitverzögerung bis zur Wiederholung des Sendevorgangs = unnötige Wartezeit beim Sender im Fehlerfall
Milderung des Latenzproblems durch aktive Fehlerüberwachung
Aktive Fehlerüberwachung geschieht durch Versenden von negativen Quittungen
(NACKs)
86
S
E
Info
rm
atio
n
Paketempfang ohne Übertragungsfehler
Senden von ACK
ung
g
i
t
ä
t
Bes CK
A
S
Info
r
on mati-
K
NAC
(Wi
ede
rh o
lung
)
E
Paket wird mit Übertragungsfehler empfangen
Senden von NACK
Datum wird vor Ablauf
des Timeout noch einmal
gesendet = schneller
Wenn ein Rahmen unterwegs verloren geht, enthält der Sender weder ACK noch NACK
Timeout des Senders wird aktiv
87
5.9
Die Flusssteuerung soll verhindern, dass der Sender den Empfänger mit Daten überschwemmt, d. h. zu schnell sendet => der Datenfluss wird gebremst (=gesteuert)
Für die Flusssteuerung wird oft kein eigener Mechanismus eingesetzt
Vielmehr wird die Fehlererkennung über Acknowledges ocer über Sequenznummern
„zweckentfremdet“
Acknowledges bzw. Sequenznummern dienen dann zur Datensicherung und zur Flusssteuerung
5.9.1
Flusssteuerung
Stop & Wait-Protokoll
Zur Flusssteuerung kann der Empfänger sein Acknowledge beim Empfang jedes Rahmens etwas verzögern
Dadurch sinkt der Datendurchsatz insgesamt
Die Verögerung heißt Delayed Acknowledge und das daraus resultierende Protokoll
„Stop & Wait-Protokoll“
Der Wert der Verögerung darf den Time Out-Wert des Senders für die Ankunft des Acknowledge nicht überschreiten
Andernfalls wiederholt der Sender den Datenrahmen und der Empfänger erhält noch
mehr Daten (=gegenteiliger Effekt)
88
5.9.2
Wenn Sequenznummern als Ersatz für Acknowledges verwendet werden, dann kann
der Empfänger zur Flusssteuerung das Absenden einer Sequenznummer etwas verzögern
Der Effekt und die Konsequenzen sind dieselben wie beim Stop & Wait-Protokoll
5.9.3
Flusssteuerung im Internet
Im Internet wird eine Flusssteuerung nur von TCP vorgenommen, aber nicht auf der Sicherungsschicht
Dazu benützt TCP keinen eigenen Mechanismus, vielmehr werden Sequenznummern
zweckentfremdet, indem deren Absenden etwas verzögert wird (delayed acknowledge)
D.h., bei TCP erfolgt die Nachbildung eines Stop & Wait-Protokoll im TCP-Schiebefenster-Protokoll unter Beachtung dessen, was die senderseitige Time Out-Überwachung
erlaubt
5.9.4
Sequenznummern als Ersatz für Acknowledges
Stop-and-Wait-Protokoll zur Flusssteuerung zwischen benachbarten Rechnern
Vorbedingungen für Stop-and-Wait-Protokoll:
1.) Überwiegend fehlerfreie Übertragung zwischen Sender und Empfänger
2.) Beschränkte Anzahl von Puffern (z.B. genau ein Puffer bei Sender und Empfänger)
89
3.) Verarbeitungsgeschwindigkeiten unterscheiden sich (z. B. schneller Großrechner
und langsames Handy)
4.) Timeout steht auf ausreichend hohem Wert
Positives Acknowledges kann als einfache Flusssteuerung verwendet werden
Nachteil: es kann nie mehr als ein Datenrahmen (ab L3 Datenpaket )unterwegs sein
Der Sender muss auf das Acknowledge warten = Stop & Wait-Protokoll = sehr langsame Datenübertragung
5.9.5
Flusssteuerung mit Schiebefenster
Schiebefenster-Protokoll (Sliding Window) vermeidet Nachteile der vorangegangenen
Protokolle und ist gleichzeitig effizient bei der Bandbreiteausnutzung
Sliding Window ist Stand der Technik und wird bei TCP eingesetzt
Bei Ethernet gibt es allerdings kein Schiebefenster, deshalb gilt das unten gesagte
beim Internet nur für Schicht 4 mit TCP als Protokoll
Sliding Window beruht bei Sender und Empfänger auf je einem Ringpuffer, d.h., es sind
immer zwei Ringpuffer nötig, einer zum Senden und einer zum Empfangen
Ein Ringpuffer wird über einen Zeiger implementiert, der modulo-mäßig inkrementiert
wird
90
Beim Erreichen der Obergrenze fängt der Pointer wieder von unten an zu zählen =
„Ring“
Der Speicherbereich zwischen größtem und kleinsten Wert des Pointers ist der Ringpuffer
Die Größe des Ringpuffers sei r
Wird in den Ringpuffer geschrieben, wird der Pointer modulo-mäßig inkrementiert
Wird aus dem Ringpuffer gelesen, wird der Pointer modulo-mäßig dekrementiert
Der Ringpuffer wird zum Sliding Window, wenn noch ein zweiter Pointer verwendet
wird
FP + BP definieren einen aktiven Bereich innerhalb des Ringpuffers r
Dieser aktive Bereich heißt „Sliding Window“ (Schiebefenster)
Sliding Window = Frontpointer FP + Backpointer BP
Außerdem gilt: FP + BP werden beim Sliding Window nur modulo-mäßig inkrementiert
aber nie dekrementiert
Die maximale Größe des Sliding Window im Ringpuffer sei w (w r)
w heißt auch window size (Fenstergröße)
5.9.5.1
Ablauf beim Schiebefenster
Für den Ablauf gelten folgende Regeln:
91
1.) Beim Verbindungsaufbau vereinbaren Sender und Empfänger die Größe r der Ringpuffer und die Fenstergröße w (Nebenbedingung: w r Zahl n der Sequenznummern)
2.) Nach dem Verbindungsaufbau besitzt der Sender das Recht, bis zu w Rahmen bzw.
Pakete zu senden, ohne ein Acknowledge zu empfangen
3.) Spätestens nach w Rahmen bzw. Pakete muss beim Sender ein Acknowledge eintreffen, sonst stoppt der Sender => „Schließen“ des Fensters beim Sender
4.) Der Empfänger kann schon vor dem Schließen des Fensters beim Sender Acknowledges an den Sender senden => „Öffnen“ des Fensters beim Sender
5.9.5.2
Verhalten von Frontpointer und Backpointer bei Sender und Empfänger
1.) Beim Sender inkrementieren gesendete Daten den Backpointer BPSender
2.) Beim Sender inkrementieren empfangene ACKs den Frontpointer FPSender
3.) Beim Empfänger inkrementieren empfangene Daten den Backpointer BPEmpfänger
4.) Beim Empfänger inkrementieren gesendete ACKs den Frontpointer FPEmpfänger
Für Sender und Empfänger gilt, dass der Abstand zwischen FP und BP maximal = w
sein kann
92
Der Sender weiß, dass ein empfangenes ACK bedeutet, dass die Daten beim Empfänger angekommen sind und an dessen Sicherungsschicht weitergeleitet wurden d.h.,
dass alles O.K. ist
Beispiel: bei Sender und Empfänger sei r = 8 und die Fenstergröße w sei 3.
Sender darf bis zu 3 Pakete ohne Bestätigung schicken
Back Pointer
7
0
6
1
5
2
4
3
93
Sender kann aus seinem Sendepuffer die
Rahmen mit der Nr. 0, 1
und 2 abschicken
Front Pointer
5.9.5.3
Beispielablauf für ein Schiebefensterprotokoll mit r=8 und w=3
0
Sender
0
Empfänger
Empfänger kann
Rahmen 0,1 und
2 empfangen
2
frei
1
1
Sender kann
Rahmen 0,1
und 2 schicken
2
belegt
Sender will
noch Rahmen
2 schicken
2
Bl
oc
k(
0)
Blo
ck
(1)
Bl
oc
k
Empfänger kann
Rahmen 1 und
2 empfangen
)
Ack (0
(2)
)
Ack (2
0
0
Sender will
Rahmen 3
schicken
1
2
Blo
ck
1
(3)
4
3
Sender will
Rahmen 4 und
5 schicken
5
2
5
3
Empfänger kann
Rahmen 4 und
5 empfangen
5
4
Empfänger kann
Rahmen 3,4 und
5 empfangen
4
94
Sender
Empfänger
Blo
ck
(4)
Bl
oc
k(
5)
Sender will
momentan
nichts schicken
)
Ack (5
7
6
Sender will
Rahmen 6, 7
und 0 schicken
5.9.5.4
Empfänger hat
keinen Puffer
frei
0
7
0
6
Empfänger kann
Rahmen 6,7 und
0 empfangen
Wahl von Fenstergröße w und Puffergröße r beim Empfänger
Es sind verschiedene Fälle zu unterscheiden:
1.) langsamer PC sendet mit kleiner Latenz an schnelle Workstation, und es soll das stop
& wait-Protokoll verwendet werden => r = w = 1 ist ausreichend
95
schnell
Acknowledge
wird sofort geschickt
langsam
senden
empfangen
2.) schnelle Workstation sendet mit kleiner Latenz an langsamen PC, und es soll das
stop & wait-Protokoll verwendet werden => r = w = 1 ist ausreichend
schnell
senden
langsam
empfangen
lange Pause bis
zum Acknowledge
(sollte kürzer als
der timeout sein
Bei ungleichmäßig schnellen Kommunikationspartnern und kleiner Latenz und stop
& wait-Protokoll ist r=w=1 ausreichend
96
3.) Beide Rechner sind gleich schnell, und es gibt eine kurze Latenz zwischen den Rechnern, und es soll eine hohe Bandbreite erreicht werden
Es sind w>1 Puffer erforderlich
Ein ununterbrochener Strom von Daten entsteht dann, wenn w so groß ist, dass das
erste Acknowledge beim Sender eintrifft, bevor sein Sliding Window schließt
Beispiel: Kommunikation zwischen zwei Servern => z.B.: 2 w 7
4.) Beide Rechner sind gleich schnell, und es gibt eine lange Latenz zwischen den Rechnern, und es soll eine hohe Bandbreite erreicht werden
Es sind w>>1 Puffer erforderlich
Begründung:
• eine Strecke mit großer Latenz wirkt wie eine langes Rohr (sog. Pipeline) durch das Rahmen/Pakete wandern müssen
• Es ist ein großes w nötig, um zu Beginn der Übertragung die lange Übertragungsstrecke
(Pipeline) mit Rahmen füllen zu können
• Je größer die Verzögerung bei der Übertragung, desto größer muss w gewählt werden
• Hinzu kommt: Nach dem Füllen der Pipeline muss die Pipeline möglichst ständig gefüllt
bleiben, um eine hohe Bandbreite zu erzielen
Auch hier muss das erste Acknowledge beim Sender eintreffen, bevor sein Sliding
Window schließt
97
Beispiel: Kommunikation zwischen zwei Servern mit Übertragung über einen geostationären Nachrichtensatelliten => z.B.: 16 w 127
lange Verzögerung, da
mehr als 2x36 000 km
Wegstrecke
6 Lokale Netze (LANs)
6.1
Ein LAN (Local Area Network) ist ein Netzwerk für die bitserielle Übertragung zwischen
Rechnern auf demselben Grundstück
Ein LAN befindet sich rechtlich unter der Kontrolle des Benutzers und muss deshalb
auf den Bereich innerhalb dessen Grundstückgrenzen beschränkt bleiben
6.2
Was ist ein LAN?
Merkmale eines lokalen Netzes
Hohe Geschwindigkeit (100 MBit/s - 10 GBit/s)
98
Einfacher, kostengünstiger Anschluss (meistens Ethernet oder Industrial Ethernet)
Keine Telekom-Gesetzgebung, da alles auf eigenem Grundstück
Anschluss aller Arten von Geräten möglich, wie:
• PCs, Workstations, Großrechner, Drucker und andere periphere Geräte
• Geräte und Apparate der Kosumelektronik und der Automatisierungstechnik
Übergang auf Weitverkehrsnetz (WANs) wie z.B. das Internet erfolgt mittels Gateway
Position von lokalen Netzen im ISO-Modell
Schicht 3
Vermittlungsschicht
Schicht 2b
LLC = Logical Link
Control
Schicht 2a
Schicht 1
Sicherungsschicht
MAC = Medium Access Control
Übertragungsschicht
99
LAN
= phys. Medium für
LANs (Kabel oder Funk)
6.3
Die Sicherungsschicht im LAN nach IEEE 802
802.1
Sicherungsschicht
data link
layer
LLC-Teilschicht 2 b
MAC-Teilschicht 2a
MAC
Bitübertragungsschicht
physical
layer
MAC
MAC
802.3
802.4
802.5
CSMA/CD Token Bus Token Ring
MAC
802.6
DQDB
...
MAC
MAC
802.11
WLAN
802.15
Bluetooth
Physikalisches Medium (Kabel, Funk)
Standardisierung von LANs erfolgt in ISO-Schicht 1 und 2
• 802.1 = übergeordnete 802-Standards
• 802.2 = mittlerer Teil der Sicherungsschicht = Logical Link Control (LLC)
• 802.x = unterer Teil der Sicherungsschicht = Medium Access Control (MAC)
Mittlerweile gibt es ca. 22 IEEE 802.X-Normen, von denen einige sehr wichtig sind, wie
z.B. Ethernet und WLAN
100
6.4
Es gibt ein prinzipielles Problem beim Schreiben auf einen gemeinsam genutzten, physikalischen Übertragungsweg wie zum Beispiel Funk
Grund: Funk ist ein sog. Broadcast-Medium und voneinander unabhängige Stationen
könnten gleichzeitig anfangen zu senden Sendekollisionen
Die Medienzugangsschicht 2a sorgt deshalb für einen geordneten Ablauf beim Medienzugang
Bei Punkt-zu-Punkt-Verbindungen bestehend aus nur einem Sender und einem Empfänger ist die Schicht 2a ohne Funktion (Beispiel: Switched Ethernet)
6.4.1
Der Medienzugang bei LANs durch Schicht 2a (MAC Layer)
Wie werden Kollisionen geregelt?
Es gibt zwei grundsätzliche Verfahren, die auf ganz unterschiedlichen Prinzipien beruhen:
1.) Kollisionsentdeckung
• Prinzip 1: „Lasse Kollisionen stattfinden, entdecke sie, und wiederhole die Übertragung zu
einem zufällig ausgewählten, späteren Zeitpunkt in der Hoffnung, dass es dadurch besser
wird“
· so verfahren sog. CSMA/CD-Systeme (CSMA/CD=Carrier Sense for Multiple Access with
Collision Detection). Ethernet ohne Switch gehört dazu.
2.) Kollisionsverhinderung
101
• Prinzip 2: „Verwende eine im Kreis zirkulierende Marke („Token“) als Sendeberechtigungserlaubnis, um den Zugriff auf das Medium zu steuern. Nur wer die Marke hat darf senden.“
· so verfährt FDDI: Das Token, ist ein spezieller Rahmen der Schicht 2a, der den Zugriff
auf das gemeinsame Medium derjenigen Station erlaubt, bei der sich das Token gerade
befindet
• Prinzip 3: „Ein Sender darf nur dann senden, wenn er von einem Master („Host“) dazu aufgefordert wird“. Zu jedem Zeitpunkt wird maximal ein Sender vom Master zum Senden aufgefordert.
· so verfährt USB
• Prinzip 4: „Alle Sender dürfen gleichzeitig Daten an einen Switch senden. Dieser priorisiert
diejenigen Datenrahmen, die gleichzeitig auf denselben Ausgang wollen, so, dass in geordneter Weise ein Rahmen nach dem anderen den Ausgang verlässt. Die Rahmen mit
niedrigerer Priorität werden vom Switch gepuffert, während ein hochpriorer Rahmen gesendet wird.
· so verfährt switched Ethernet
6.4.2
Beispiele für gemeinsam genutzte Übertragungsmedien
Beispiele für LANs und periphere Busse mit gemeinsam genutzten Übertragungsmedium sind:
1.) Mobilfunktelefonie
·
Das gemeinsam genutzte Medium sind Funkkanäle derselben Frequenz
2.) WLAN
102
·
Das gemeinsam genutzte Medium sind Funkkanäle derselben Frequenz
3.) Bluetooth
·
Das gemeinsam genutzte Medium sind Funkkanäle derselben Frequenz
4.) IRDA Infrarot-Schnittstellen
·
Das gemeinsam genutzte Medium ist infrarotes Licht im Raum mit derselben Wellenlänge
5.) USB
• Das gemeinsam genutzte Medium ist der USB Hub
• Der USB Hub arbeitet auf ISO-Schicht 1 und verteilt jeden Rahmen des Rechners an alle
Ports des Hubs und damit an alle Peripherigeräte
6.) Switched Ethernet
• Das gemeinsam genutzte Medium ist der Ethernet Switch
• Ein Ethernet Switch puffert und serialisiert Datenrahmen, die gleichzeitig auf denselben
Ausgang wollen. Er arbeitet auf Schicht 2 und macht eine Wegewahl anhand der MAC-Zieladresse, so dass ein Rahmen den Switch auf dem richtigen Port verläßt.
6.4.3
Gemeinsames Übertragungsmedium mit Kollisionsentdeckung (CSMA/CD)
CSMA/CD bedeutet:
• Ein gemeinsam genutztes Medium wie z.B. Funk oder gemeinsames Kabel wird von allen
potentiellen Sendern abgehört, um festzustellen, ob gerade gesendet wird oder nicht
103
• Wenn gerade gesendet wird, darf niemand sonst senden
• Wenn gerade nicht gesendet wird, darf jeder sendewillige Rechner senden
Kollisionen sind zu diesem Zeitpunkt möglich
• Ein potentieller gleichzeitiger Mehrfachzugriff von 2 oder mehr Sendern wird durch Kollisionserkennung + zufällig langes Abwarten bei jedem Senders geregelt
• Kollsisionserkennung heißt, jeder Sender lauscht, ob seine Sendung unverfälscht auf dem
gemeinsamen Medium zu hören ist oder nicht
• Wenn ja, ist alles O.K., wenn nein, gibt es eine Kollision
• Zufällig langes Abwarten bedeutet, dass jeder Sender auswürfelt, wie lange er nach einer
erkannten Kollision mit einem erneuten Sendeversuch wartet
• Dazu wird ein Pseudozufallszahlengenerator verwendet
6.4.4
Gemeinsames Übertragungsmedium mit Kollisisionsverhinderung
6.4.4.1
Beispiel Ethernet
Ethernet hat im Prinzip eine Kollisisionsverhinderung, denn für einen gewisse Zeit erfolgt keine Kollision von zwei Rahmen, die zum selben Ausgangsport wollen, weil jeder
Rahmen im Switch gepuffert wird bis der Ausgang frei ist
Der gewünschte Ausgang muss allerdings frei werden, bevor der Switch-Puffer voll ist
Sobald der Puffer des Switches voll ist, gehen bei Switched Ethernet unbemerkt Rahmen verloren, da Ethernet keine Schicht 2b mit Flusssteuerung und Acknowledge hat
104
6.4.4.2
USB-Peripheriegeräte werden durch USB-Adressen individuell von einem Rechner
(„Host“) angesprochen und dürfen nur senden, wenn sie vom Host dazu aufgefordert
werden
Der Host spricht zu einer Zeit nur ein peripheres USB-Gerät an
Dadurch wird gleichzeitiges Senden mehrerer Geräte ausgeschlossen
Dies wird als Transaktionskonzept bezeichnet und realisiert eine Kollisisionsverhinderung
Eine Pufferung von Datenrahmen findet nicht statt, da ein Hub ein ISO-Schicht 1-Gerät
ist
6.5
Beispiel USB
Die Datensicherung bei LANs durch Schicht 2b (Logical Link Control)
Die ISO-Schicht 2b macht die Datensicherung zwischen räumlich benachbarten Rechnern
Gemäß IEEE gibt es drei verschiedene Datensicherungsarten: LLC Typ 1, 2 und 3
LLC1 ist das einfachste und LLC 2 das komplexeste Verfahren, LLC 3 ist in der Mitte.
Beispiel: Ethernet unterstützt LLC Typ 1
6.5.1
LLC Typ 1: Unbestätigter und verbindungsloser Dienst
Unbestätigte Übertragung (=keine Acknowledges für Datenrahmen)
105
kein Verbindungsaufbau notwendig
Höhere Schichten >2 sind für die Erhaltung der Reihenfolge der Rahmen, für die Fehlerbehebung und für Flusssteuerung verantwortlich (im Internet macht dies TCP)
So verfährt Ethernet
Ethernet hat aber zumindest 32 Bit-CRC im Rahmentrailer
6.5.2
LLC Typ 2 implementiert sog. verbindungsorientierten Dienst
Verbindungsorientierter Dienst heißt: es gibt 3 Phasen: Aufbau, Transfer und Abbau
LLC Typ 2 implementiert alle drei Phasen
Datentransfer erfolgt mit Bestätigung (ACK)
LLC Typ 2 garantiert die Ablieferung des Pakets beim Empfänger und die richtige Reihenfolge der Rahmen und macht auch Flusssteuerung
Wird im Internet erst auf Schicht 4 durch TCP umgesetzt
6.5.3
LLC Typ 2: Bestätigter Verbindungsorientierter Dienst
LLC Typ 3: Bestätigter verbindungsloser Dienst
LLC Typ 3 implementiert sog. bestätigten aber verbindungslosen Dienst (Datagramme)
Bestätigter verbindungsloser Dienst heißt: es keinen Verbindungsaufbau und -abbau
und keine Garantie der korrekten Reihenfolge der Datagramme, aber für jeden Rahmen
erfolgt eine Bestätigung
106
Wird bei Token Ring oder Token Bus Bus eingesetzt, z.B. für die Steuerung von Bearbeitungsmaschinen an einem Fließband zur Automobilproduktion
6.5.4
Weitere Beispiele von Schicht 2b-Protokollen (nicht ISO und nicht IEEE)
• PPP = point-to-point protocol
• SLIP = subscriber line interface protocol
• PPP und SLIP dienen zur gesicherten Datenübertragung, wenn Modems (DSL!) als Schicht
1 und 2a verwendet werden
• PPPoE = PPP over Ethernet: PPP-Variante zur gesicherten Datenübertragung, falls Ethernet als Schicht 1 und 2a eingesetzt wird
6.6
Beispiele für Schicht 2-Rahmenformate sind USB, CSMA/CD sowie Ethernet als ursprüngliches CSMA/CD-LAN
6.6.1
Beispiele für Schicht 2-Rahmenformate
USB-Rahmenformat für Datenpakete
USB unterscheidet zwischen 16 verschiedenen Rahmentypen
107
Der Rahmentyp, der Daten überträgt, hat das folgende Format:
Idle
Sync
32 bits
PID
8 bits
Data
0-1024
x 8 bits
CRC
16 bits
EOP
Idle
1.) Idle: zeigt dem Empfänger, dass der Host momentan keine Daten sendet
2.) Sync: erlaubt dem Empfänger, auf das Datensignal zu synchronisieren, d.h., den Takt
im Signal zu erkennen und von den Daten zu separieren
3.) PID (Packet Identifier): zeigt in diesem Fall an, dass ein Datenrahmen folgt
4.) Data: Nutzdatenfeld
5.) CRC: Prüfsumme
6.) EOP (End of Packet): zeigt das Rahmenende an
Bei einem anderen Rahmentyp namens „Token“ wird ein 7 Bit-Adressfeld übertragen,
das bis zu 127 Geräte an einer USB Hub-Kaskade ansprechen kann
Das Addressfeld ist das Gegenstück zur CSMA/CD-MAC-Adresse (siehe unten)
USB-Geräteadressen werden allerdings im Gegensatz CSMA/CD-MAC-Adressen jedesmal neu beim Einstecken eines USB-Geräts vergeben
108
6.6.2
CSMA/CD-Rahmenformat
Bei IEEE 802.x gibt es 2 Adressformate für die Herkunfts- und die Zieladresse: sog.
MAC-Adressen (MAC = Medium Access Control)
1.) 6 Byte MAC-Adressen (48-Bit) = üblich, z.B. bei Ethernet und WLAN
I/G
U/L
46 Bits Adresse
2.) 2 Byte-MAC-Adressen (16 Bit) = sehr selten und nur für lokales Netz ohne Verbindung
nach außen
I/G
15 Bits Adresse
Bei 6 Byte MAC-Adressen stehen 2 Steuerbits (I/G und U/L) zur Verfügung, bei 2 Byte
MAC-Adressen nur eins (I/G)
Bei 6 Byte-Adressen sind 46 Adressbit nutzbar = ca. 7*1013 Adressen
Bedeutung der MAC-Steuerbits bei 6-Byte Adressen:
• I/G= 0: Stationsadresse für eine Punkt-zu-Punkt-Verbindung = üblich
• I/G= 1: Broadcast-Verbindung
109
·
·
Die Broadcast-Verbindung ist rel. selten, wird aber beim Address Resolution Protocol
ARP verwendet
Wenn I/G=1, dann müssen alle anderen Bits ebenfalls auf 1 sein
Broadcast-Adresse = FF-FF-FF-FF-FF-FF
• U/L= 0: Weltweit eindeutige MAC-Adresse = häufig
• U/L= 1: Local verwaltete MAC-Adresse ohne Verbindung nach aussen = seltener
Bei U/L = 1 darf kein Gateway im selben LAN existieren
Bei U/L = 1 kann die MAC-Adresse durch den Benutzer frei gewählt werden
U/L = 1 wird z.B. bei Cloud Computing für die sog. Compute Nodes verwendet
Bei U/L = 0 gibt es einen LAN Gateway, der u.a. für die Abbildung IP-Adresse->MACAdresse zuständig ist
6.6.2.1
Schicksal der weltweit eindeutigen MAC-Adressen
6 Byte MAC-Adressen mit U/L = 0 waren ursprünglich weltweit eindeutig, denn jede
Ethernetkarte hatte eine fest verdrahtete MAC-Adresse
Wurde mittlerweile geändert, es gibt per Software-definierbare MAC-Adressen, was es
Hackern leider erleichtert zu betrügen
110
6.6.3
1 Gb/s-Ethernet-Rahmenformat gemäß IEEE 802.3
7 Byte
1
2/6
2/6
2
0-1500
x
Präambel
SD
DA
SA
Control
Data
Pad
4
FCS
Präambel: 7 Byte: 7 x 10101010 = maximal viele Bitwechsel zur Empfängersynchronisation
• Die Präambel dient zur Synchronisation des Empfängertaktes mit dem Sendetakt
SD: Starting Delimiter (1 Byte: 10101011)
Der Starting Delimiter dient zur genauen Kennzeichnung, wann ein Paket anfängt.
DA: Destination Address (i.d.R. 6 Byte MAC-Adresse)
Die Zieladresse dient zur Klärung, wohin ein Paket geschickt werden soll
SA: Source Address (i.d.R. 6 Byte MAC-Adresse)
Die Herkunftsadresse sagt, wer den Rahmen gesendet hat
Control: enthält die Länge n der Daten (2 Byte)
• Achtung: Werte ab 2048 (0x0800) kennzeichnen nicht mehr die Länge, sondern kodieren
zusätzliche Steuerungsfunktionen, den sog. EtherType
Datenfeld aus n Bytes, 0 n 1500
111
Pad: Füllbytes zur Erreichung der Mindestrahmenlänge von 64 Byte, falls Nutzdaten <
46 Byte
Achtung: Die Präambel und der SD werden bei der Rahmenlänge nicht gezählt
Nutzdaten sollten mindestens 46 Byte lang sein, sonst wird ein Pad eingefügt
Mindestlänge eines 1Gb/s-Rahmens ohne Präambel und SD muss 64 Byte betragen,
um Kollisionen auf die maximal erlaubte Entfernung erkennen zu können
Der Ethernetrahmen-Overhead ohne Pad beträgt 26 Byte
FCS (Frame Check Sequence) = 4 Byte CRC
Neben dem Standard-Ethernet gibt es noch zahlreiche Varianten, die z.T. auch standardisiert sind
Ethernet ist mehr ein Markenname als eine ganz bestimmte Technologie
Werte ab 0x0800 im Control-Feld kodieren folgende Ethertypes:
• Spezialtypen wie z.B. Echtzeit-Ethernet (PROFINET, EtherCAT, POWERLINK, SERCOS III)
• die verwendeten Protokolle auf Schicht 2 oder 3 (PPPoE, IPv4, IPv6, arp, rarp)
• die Existenz eines virtuellen LANs (VLAN) durch den Wert = 0x8100
6.6.3.1
Varianten von 1 Gb/s-/10 Gb/s-Ethernet mit Switch
Es gibt diverse Varianten von 1 Gb/s- und 10 Gb/s-Ethernet mit Switch
Hinweis: die nachfolgenden Ethernat-Varianten haben nichts mit den Ethertypes zu tun. Beides existiert
gleichzeitig und getrennt.
112
1.) 1000BASE-T: hat 4 verdrillte Doppeladern in ungeschirmtem Cat-5e-Kupferkabel als
DTE-Anschlusskabel; bis 100 m = kurzes LAN; dies ist ein weit verbreitete Standard.
2.) 1000BASE-CX: hat 2 verdrillte Doppeladern in geschirmtem Cat-7-Kupferkabel; nur
mit Switch, bis 25 m = sehr kurzes LAN; wenig verbreitet.
3.) 1000BASE-LX: hat 2 Glasfaserkabel für bidirektionalen Transfer; entweder nur Punktzu-Punkt oder mit Switch und elektrisch/optisch-Wandlern; bis 5 Km = gutes LAN;
wenig verbreitet.
4.) 10GBaseT: hat 4 verdrillte Doppeladern in geschirmtem Cat-7-Kupferkabel; nur mit
Switch; bis 100 m bei Beachten spezieller Verlegevorschriften = kurzes LAN; wenig
verbreitet.
5.) 10GBASE-LR: hat 2 Glasfaserkabel für bidirektionalen Transfer; entweder nur Punktzu-Punkt oder mit Switch und elektrisch/optisch-Wandlern; bis 10 km = kurzes MAN;
wenig verbreitet.
6.7
VLANs
Virtuelle LANs („VLANs“) erlauben eine Kopplung zwischen mehreren realen LANs, die
am selben Switch angeschlossen sind, sowie eine Wegewahl zum richtigen Ziel-LAN
Hinweis: Die Wegewahl erfolgt auf der ISO-Schicht 2 nicht auf der Schicht 3, was der ISO-Einteilung
widerspricht.
113
VLANS erlauben außerdem innerhalb eines realen LANs mehrere virtuelle Sub-LANs
aufzubauen, die aus Benutzersicht voneinander getrennt sind
Die Trennung bewirkt, dass das eine VLAN das andere nicht erreichen kann, obwohl
beide real durch dasselbe physikalische LAN implementiert werden
Dazu wird der Header im Datenrahmen um ein VLAN-Adressfeld erweitert
Beispiel: Bei Ethernet-basierten VLANs verlängert sich der Rahmen um 4 Byte für die
VLAN-Adresse
Der Ethernet-Rahmen-Overhead ohne Pad beträgt somit bei VLAN 30 Byte
Dementsprechend verkürzen sich die minimalen Ethernet-Nutzdaten ohne Pad auf 42
Byte
6.8
Repeater, Bridge, Switch, Gateway, Router, Hub und Firewall
Repeater = elektrischer Verstärker auf der ISO-Schicht 1 innerhalb eines LAN-Segments oder zwischen zwei Segmenten desselben LANs
Bridge = Kopplung auf der ISO-Schicht 2a von genau zwei verschiedenen LANs
• macht eine elektrische Trennung der Signale (Potentialtrennung)
• macht keine Rahmenspeicherung
• macht keine Kollisionserkennung oder Kollisionsvermeidung
Hub = wie Bridge, aber für die Kopplung von mehr als zwei LANs
114
Switch = wie Hub, d.h. sternförmige Verbindung auf der ISO-Schicht 2a zur Kopplung
von >1 LANs, inkl. der Wegewahl zwischen den LANs
• Zusätzlich erfolgt für einen gewisse Zeit keine Kollision an den Switch-Ausgängen, denn
im Switch werden solange Rahmen gepuffert, bis der gewünschte Ausgang frei ist, oder
bis der Puffer voll ist
Gateway = Verbindung auf ISO-Schicht 3 zwischen einem LAN und mindestens einem
MAN oder WAN
• Paketpufferung findet statt
• Im Falle mehrerer MANs oder WANs, die an den Gateway angeschlossen sind, gibt es auch
eine Wegewahl
Router = Verbindung auf ISO-Schicht 3 zwischen mehreren WANs
• Paketpufferung und Wegewahl findet stets statt
Firewall = Gateway auf Schicht 4 zwischen einem WAN und dem privaten MAN/LAN einer Firma
• kontrolliert, ob auf Schicht 7 http oder email als Protokoll verwendet wird, d.h. prüft die
Schicht 7-Nutzlast
• i.d.R. dürfen aus Sicherheitsgründen nur email- und http-Pakete die Firewall passieren
sehr viele verteilte Anwendungen und viele Middleware verwenden http als ein Transportprotokoll auf der Schicht 7 ohne irgendetwas mit dem www zu tun zu haben
115
6.9
Adressauflösung = Abbildung der Internet-Adresse (IP-Adresse) eines Rechners auf
die physikalische Adresse (MAC-Adresse)
LAN Gateway hat eine Abbildungstabelle und benützt das Address Resolution Protocol
ARP. Dieser Fall ist bei Ethernet LANs fast immer gegeben.
6.9.1
Adressauflösung im LAN
Address Resolution Protocol ARP
Das ARP-Protokoll im LAN Gateway läuft folgendermaßen ab:
1.) LAN Gateway sendet mittels MAC-Broadcast ein ARP-Request-Paket, welches die
eigene MAC- und IP-Adresse sowie die IP-Adresse des gesuchten Empfängers enthält
2.) LAN Gateway wartet auf die Antwort des Empfängers in Form eines ARP-Reply-Paket,
welches dessen MAC-Adresse enthält
116
phys. Adresse des
Host B gesucht
ARP-Request Broadcast-Paket
R
Gateway
X
B
Y
Host
Host
Host
B antwortet
ARP-Reply-Paket
R
X
B
Y
Gateway
Optimierung: ARP-Cache im Gateway hält frühere (IP, MAC)-Adresspaare für die
schnelle Beantwortung späterer Anfragen vor
Optional: Jede Station speichert lokal (IP, MAC)-Paare, um ARP requests zu vermeiden
ARP wird z.B von den Befehlen ipconfig in Windows bzw. ifconfig in Unix benützt
ARP-Cache kann durch die Befehle arp bzw. arping angezeigt werden
117
6.9.2
Reverse ARP
Reverse ARP (RARP-Protokoll) bildet MAC-Adressen auf IP-Adressen ab
118
6.10
Verdrahtung lokaler Netze
Endgeräte (Rechner)
kein Switch
Switch
Ethernet
(1 Gb/s)
kein
Switch
Stern
Token
Ring
Ring
teilweise vermaschtes Netz
kein Switch
Switches
nicht für
LANs
Endgeräte
Baum
vollständig vermaschtes Netz
119
gemeinsam genutztes
Übertragungsmedium
(Funk, Koaxialkabel)
7 Echtzeitzugang ins Internet
Ein Echtzeitzugang ins Internet wird für z.B. für Multimedia-Anwendungen benötigt und
muss zuerst auf Schicht 1 und 2 bereitgestellt werden
Def.: Multimediale Datenübertragung heißt: mindestens ein zeitdiskretes und ein zeitkontinuierliches Medium wird gleichzeitig für die Übertragung von Information benutzt, und
beide Medien sind zeitlich miteinander synchronisiert.
Zeitdiskret sind: Text, Folien, Diagramme, Tabellen, Bilder. Zeitkontinuierlich sind: Audio, Video
Beispiel: für Multimediale Datenübertragung: Audio + Diagramme, Video + Folien,
Audio + Video + Text + Diagramme
Zahl der gleichzeitig verwendeten Medien verschiedener Kategorien ist 2
Durch die Kombination von 2 Medien verschiedener Kategorien entsteht eine neue
Art der Präsentation von Information: Multimedia
Eine multimediale Präsentation ist interessanter, detaillierter und leichter nachvollziehbar
Erzeugung von Multimediadaten mit Hilfe spezieller Software wie z.B. dem Adobe Director
120
7.1
Multimedia-Anforderungen
Die Kombination von zeitdiskreten mit zeitkontinuierlichen Medien setzt die zeitliche
Synchronisation beider Medienarten voraus
Übertragung von Audio-, Video- und multimedialen Daten erfordert deshalb:
1.) Bewahrung der zeitlichen Synchronisation zwischen Bild-, Ton-, Text- und Graphikdaten
2.) Wiedergabe der Daten in Echtzeit
Datenübertragung muss mit Zeitbezügen untereinander und zur Realzeit erfolgen
(=Echtzeitübertragung und Echtzeitdarstellung)
Eine Ethernet-LAN-Technik mit gemeinsam genutzen Medium (Kabel oder Switch) ist
ungeeignet, da indeterministisch (Zugang zum gemeinsamen Kabel ist vom Zufall
abhängig bzw. davon, ob ein Ausgangsport im Switch gerade frei ist oder nicht)
Geeignet sind nur Netztechniken mit garantierter Zustellzeit
alle Punkt-zu-Punkt-Netze sind prinzipiell geeignet
alle Broadcast-Netze mit „deterministischem Zeitmultiplex“ sind geeignet
Beispiel für Punkt-zu-Punkt-Netze: Telefonsysteme
Beispiele deterministischer Zeitmultiplexnetze: Token Ring (LAN), FDDI (MAN), Telefon-PCM-Systeme (WAN), Telefon-S-ISDN (WAN), B-ISDN (WAN) = SONET/SDH
121
Hinweis: S-ISDN = „Small Band Integrated Services Digital Network“ = Schmalbandiges Netz für Telefonund Datendienste
Hinweis: B-ISDN = „Broad Band Integrated Services Digital Network“ = Breitbandiges Netz für Telefon- und
Datendienste
Beispiel eines zeitdeterministischen Protokolls: ATM (=Asynchronous Transfer Mode).
TCP/IP hingegen ist nicht zeitdeterministisch, d.h. nicht echtzeitfähig, was für Multimedia-Anwendungen ein Problem darstellt
7.2
Internet-Anwendungen mit und ohne Echtzeit
•
•
•
•
•
E-Commerce über das www
E-Learning über Internet-basierte, interaktive Lernmanagementsysteme (Moodle, Ilias, ...)
Videokonferenzen über z.B. Netmeeting oder DFNVC Webkonferenz
Bildtelefonie über z.B Skype, VoIP, Tango, Viber, ...
Web-TV über das www, IP-TV über das Internet, Web-Radio über das www, d.h. Audio on
Demand statt CDs und Video-on-Demand statt Video-DVDs
• Teleworking (Heimarbeitsplätze)
• Home Office-Anwendungen über Cloud Computing. Anwender-Software im Netz verfügbar
statt auf lokaler Festplatte gespeichert; Bsp. Google Docs.
• Überwachungsdienste über Web-Kameras (es gibt >>104 Kameras in Deutschland)
122
7.3
Echtzeitzugang über das Telefonnetz
Das Telefonnetz überträgt Daten und Gespräche mittels digitaler PCM-Technik in Echtzeit
Zugang zum Internet von der Ortsvermittlungsstelle bis zum Wohnzimmer kann dagegen sowohl analog als auch digital sein
Analoger Zugang erfolgt über einfaches Modem (bis 56 Kb/s), DSL-Modem (derzeit bis
ca. 50 Mb/s) oder Videokabel (bis ca. 110 Mb/s)
• DSL = Digital Subscriber Line = digitaler Teilnehmeranschluß
• DSL ist eine sehr schnelle Technik für analoge Datenübertragung
• DSL funktioniert mit analogem Telefonanschluss, aber auch über S-ISDN, d.h. über einen
digitalen Teilnehmeranschluss, da auf dem Kabel unterschiedliche Frequenzen benutzt
werden
Digitaler Zugang erfolgt über S-ISDN oder Glasfaser
123
Konfiguration bei (DSL)-Modem-Zugang
Telefonortsvermittlungsstelle
Kunde
(DSL)-Modem
kurzes Kabel (Ethernet
oder USB) oder WLAN
Fernvermittlungsstelle
(DSL)-Modems
max. 10 km verdrillte
Telefonleitung
Gateway
Sonet/SDH WAN
Fernvermittlungsstelle
Kunde
Internet Provider
(DSL)-Modem
Gateway
Sonet/SDH oder MAN
7.4
Alternative Echtzeitzugangstechnologien
Es gibt Alternativen zum Internet-Echtzeitzugang per DSL-Modem:
124
Sonet/SDH WAN
7.3.1
•
•
•
•
•
•
•
•
Über Richtfunkstrecken (z.B. zum Anschluss von Dörfern ans Internet)
Über tieffliegende Satelliten (= LEOs, Low Earth Orbiters)
Über funkbasierte LANs (IEEE 802.11x)
Über GSM, UMTS oder LTE-Mobilfunknetze mittels EDGE, HSDPA, ...
Über Datenübertragung durch das Stromnetz (= Powerline-Technik)
Über neu zu verlegende Glasfasern und Kupferkabel (= FTTC, Fiber to the Curb)
Über neu zu verlegende Glasfasern zum Endkunden (= FTTH, Fiber to the Home)
Über neu zu verlegende Glasfasern und Fernseh-Koaxkabel (= HFC, Hybrid Fiber Coax)
Powerline-Technik wurde von den Stromherstellern angeboten, war aber bislang nur in
Nischenanwendungen erfolgreich
Satelliten, Funk-LANs, Handys, DSL, FTTC und FTTH werden von den Telecoms betrieben
HFC wird von den Kabelfernsehanbietern angeboten
7.4.1
HFC (Hybrid Fiber Coax)
Über ein einziges Koaxialkabel beim Kunden werden sowohl digitales Fernsehen, als
auch breitbandiger Internet-Zugang und Telefonie betrieben = „Triple Play“
Die Koaxialkabel werden vom Kabelnetzbetreiber mit hoher Bandbreite über Glasfaser
mit Fernsehprogrammen, mit digitalen Audio- und Videostreams und mit Internet versorgt
Verteilung beim Endkunden über gemeinsam genutztes Medium (Koaxialkabel)
125
Notwendige Voraussetzungen: existierende Koaxialkabel für Kabelfernsehen mit ca.
450 MHz Bandbreite werden durch Kabel höherer Bandbreite (z.B. 750 MHz) ersetzt
300 MHz zusätzliche Bandbreite
Zusätzliche Bandbreite entspricht 50 6-MHz-Fernsehkanälen und wird zur Übertragung
von Multimediadaten verwendet (unidirektional)
Um einen Rückkanal vom Kunden zum Provider zu ermöglichen, werden die unidirektionalen Verstärker der Kabelsignale durch bidirektionale ersetzt werden (teuer!)
Die extra 50 6-MHz-Kanäle verwenden die effiziente Quadrature Amplituden Modulation
(QAM) oder die noch bessere Discrete Multitone Modulation (DMT)
pro Kanal sind bei QAM ca. 40 Mb/s Echtzeitdatenrate möglich, bei DMT bis ca. 100
Mb/s!
Alle 50 Kanäle werden per Broadcast an die Haushalte verteilt
Zur gezielten Adressierung jedes Haushalts sind die Daten individuell verschlüsselt
Ziele: Wahrung der Privatsphäre trotz Broadcast + Zugang nur für zahlende Kunden.
Analoges Vorbild: Pay TV
Multimediadaten sind MPEG1/2/4-kodierte Videofilme für Video-on-Demand mit zusätzlichen zeitdiskreten Informationen
126
Fernseh-Koaxkabel
Kabel TVAnbieter
Glas=
faser
(Headend)
Glas=
faser
Kopfstation
Fernseh-Koaxkabel
Kopfstation
Jedes Headend versorgt einige tausend Haushalte d.h. ganze Wohngebiete mit TV, Video-on-Demand, Internet und Telefonie
7.4.2
FTTC (Fiber to the Curb)
Hinweis: Curb = Randstein
Glasfasern sind bis in die einzelnen Straßen verlegt. Von dort geht es über Telefonkabel (= verdrillte Kupferkabel) in die Häuser (= “last mile”)
2-stufige Hierarchie eines Verteilnetzes
127
Datentransfer ist im Gegensatz zu HFC Punkt-zu-Punkt (kein Broadcast)
Kupferkabel der “letzten Meile” sind kurz => sehr gut für DSL geeignet
genug Bandbreite für MPEG1/2/4 ohne teure Koaxkabel, incl. Telefonanschluss
Nutzung der bereits zahlreich vorhandenen Telefonkabel-Infrastruktur
Betreiber sind die Telekomanbieter
Ortsvermittlungsstelle
Glas=
faser
ONU
curb
Glas=
faser
Telefonkabel
ONU
Telefonkabel
Hinweis: ONU = Optical Network Unit = el./opt. Konverter
128
Jede ONU versorgt ca. 16 Haushalte über 16 verdrillte Kupferkabel mit Daten in beiden
Richtungen (bidirektional)
Nachteil zu HFC: viel mehr ONUs als Headends notwendig
7.4.3
FTTH (Fiber to the Home)
Jeder Haushalt erhält einen SONET/SDH-Anschluss mit z.B. 155 Mb/s (OC3)
ultimative Lösung der Zukunft, zum Teil schon realisiert (Bsp.: neue Bundesländer,
Stadtstaaten wie Singapur)
Nachteil: immense Kosten, >50% der Investitionen des Telefonsystems liegen in den
Kupferkabeln zum Endkunden => last mile ist ein Kostenproblem
7.5
Echtzeitzugang über xDSL (Digital Subscriber Line)
xDSL ist die Technologie der “Supermodems” für Telefonanschlüsse (=verdrillte Zweidrahtleitungen). x steht für A, H, V, S, U, I oder {}
xDSL betreibt analogeTelefonleitungen mit wesentlich höherer Bandbreite (>> 3 KHz)
als 56-Kb/s-Modems
Nutzt die Tatsache, dass ab der Ortsvermittlungsstelle die Datenübertragung digital ist
und sehr hohe Bandbreiten aufweist (= SONET/SDH-Hierarchie auf ISO-Schicht 1)
129
Nutzt Fortschritte der digitalen Signalverarbeitung (Signalprozessoren, effiziente Modulationsverfahren) zur Beseitigung von Echos, Übersprechen, Rauschen und sonstigen Störungen
Theoretische Grundlage für xDSL ist das sog. Shannon-Theorem
7.5.1
Shannon-Theorem
Das Shannon-Theorem berechnet die Übertragungsgeschwindigkeit eines rauschbehafteten Kanals unter Vernachlässigung von Dämpfung und Dispersion
Das Shannon-Theorem ist deshalb eine Obergrenze dessen, was möglich ist
Dämpfung bewirkt, dass das Nutzsignal abgeschwächt wird
Dispersion bewirkt, dass das Nutzsignal verbreitert wird
Unter diesen Voraussetzungen gilt:
• K = B*log2[1+10**(S/10N)] => K ~ B
• K = Übertragungsgeschwindigkeit (= Kanalkapazität), wird in Baud = 1/s gemessen
• B = Bandbreite des Kanals, wird in Hertz = 1/s gemessen (semantischer Unterschied zw.
Hertz und Baud!)
• S/N = Signal- zu Rauschleistung, wird in dB (dezibel) gemessen
Beispiel:
• 3 KHz Telefonbandbreite erlaubt bei 35 dB Signal-/Rauschverhältnis ca. 30 Kb/s Datenrate
• 8 Mb/s Datenrate erfordern ca. 800 KHz an Kanalbandbreite
130
Neben dem Shannon-Theorem wird die Übertragungsgeschwindigkeit eines rauschbehafteten Kanals wesentlich durch Dämpfung und Dispersion des Übertragungsmediums bestimmt
Beides ist bei Kupferkabeln abhängig von Leitungslänge und Leitungsquerschnitt
In Deutschland gilt:
• Leitungslänge zwischen Telefon und Telefonvermittlung ist 10 km
• Typische Länge ist 2-4 km
• Leitungsquerschnitt des Kupferkabels ist 0,4 oder 0,6 mm (2 Kabelsorten)
• Fast nie gibt es Verstärker zwischen Kunde und Ortsvermittlungsstelle
Nur die Übertragungsbandbreite B des Kupferkabels muss für K berücksichtigt werden
Wohnt der Kunde nahe genug an einer Ortsvermittlungsstelle (<< 1 km), sind über DSL
sehr hohe Datenraten möglich (bis ca. 50 Mbit/s über VDSL, theoretisch bis 100 Mb/s)
DSL-Datenraten sind in der Praxis oft niedriger als der Nominalwert, für den man bezahlt, da die Leitungslängen vielerorts nicht mehr ermöglichen
131
7.5.1.1
Kanalkapazität K als Funktion der Leitungslänge eines Kupferkabels
K
[MBaud]
100
90
80
70
Theoretische
Grenze
60
Derzeitige praktische Grenze
bei VDSL
50
40
30
20
10
0
0,75
1,5
2,25
3,0
3,75 4,5
l [km]
Existierende Telefonkabel erlauben auf kurze Entfernungen sehr hohe Datenraten
7.5.2
Warum ist die XDSL-Technik wirtschaftlich interessant?
Über 700 Millionen installierte Festnetz-Telefonanschlüsse weltweit
96% davon sind Kupferkabel-basierend
132
>50% der gesamten Investitionen der Telecoms liegen in der Verkabelung
Komplett flächendeckende Glasfaserkabel bis ins Haus werden noch viele Jahre dauern (hohe Installationskosten; weniger für das Kabel als für die Verlegung)
Flächendeckende Glasfaserverkabelung in den neuen Bundesländern ist vorhanden,
wird aber nicht genutzt, bis DSL flächendeckend eingeführt ist
xDSL ist eine sehr kosteneffektive Lösung, da bereits installierte Kupferleitungen
genutzt werden
7.5.3
Aufbau eines xDSL-Zugangs
xDSL-Übertragung
Telefonkabel
Kunde
Orts=
Vermittlung
SONET/
SDH
xDSL-Übertragung
Kupfer-/Glasfaserkabel
Orts=
Vermittlung
Internet Provider
Beispiel: ADSL, VDSL
• Kunde hat Zugriff auf Telefonnetz und Internet über dieselbe Telefonleitung
133
• Leitung wird über Frequenzweiche (sog. splitter) im Frequenzmultiplex betrieben
• Datenrate vom Kunden (upstream) bis ca. 5 Mb/s bei VDSL
• Datenrate zum Kunden (downstream) bis ca. 50 Mb/s bei VDSL
7.5.4
Die verschiedenen Typen von xDSL
xDSL: Sammelbezeichnung für alle DSL-Arten
IDSL: das heutige ISDN
ADSL: Asymmetric Digital Subscriber Line (derzeit der Standard bei der Dt. Telekom)
UDSL: Universal Digital Subscriber Line (=ADSL-light)
HDSL: High Data Rate Digital Subscriber Line
SDSL (entspricht HDSL2): Single Line Digital Subscriber Line
VDSL (Nachfolger von ADSL): Very High Rate Digital Subscriber Line
134
7.5.5
Leistungsparameter der xDSL-Techniken
Internet-Dienste und Anwendungen
Datenrate und
Preis
~ 50
Mbps
~ 16
Mbps
~ 6 Mbps
~2
Mbps
~ 144
kbps
~ 56
kbps
VDSL
ADSL
ADSL
Teleworking, Teleteaching Telemedizin,
Video-On-Demand
über IPTV und Web-TV
3.)
Standard bei Firmenund Privatkunden
2.)
Einfache Anwendungen
1.)
SDSL
ISDN
Sprachband-Modem
Zahl potentieller Nutzer
135
7.5.6
Internet-Zugang über Sprachband-Modem oder ISDN
Sprachband-Modem oder ISDN
Sprachband-Modem oder ISDN
Vermittelte Telefonverbindung über SONET/SDH
Server eines InternetProviders
136
Internet-Zugang über ADSL mit Splitter
1
2-Draht-Leitung
7.5.7
2
1
1
2
2
DSLModem
Vermittlungseinrichtung
DSLModem
Frequenzweichen
(Splitter)
Server/Gateway eines
Internet-Providers
Der Splitter ist eine Frequenzweiche und dient zur Aufteilung der Frequenzbereiche
zwischen Telefon und ADSL
Auf der Zweidrahtleitung werden verschiedene Frequenzbereiche verwendet, um unterschiedliche Informationsströme (Telefon, Fax und Daten) gleichzeitig zu übertragen
Informationströme, die nicht im Basisband übertragen werden, verwenden effiziente
Modulationsarten, um der Shannon-Obergrenze möglichst nahe zu kommen:
137
Diese sind Quadrature Amplitude Modulation (QAM), Carrierless Amplitude/Phase-Modulation (CAP) und Discrete Multitone Modulation (DMT), wovon DMT die beste ist
7.5.8
Aufteilung der Übertragungsfrequenzen bei CAP-Modulation
Signalstärke
auf
dem
Kabel
in [dB]
ISDN
0
analoges
Telefon
0,3
3,4
DSL
Downstream
zum Kunden
DSL
Upstream
zum Provider
80 94
Splitter-Abzweig 1
106 120
Splitter-Abzweig 2
138
550
Frequenz in
[kHz]
7.5.9
ADSL-Übertragungskette
Kunde
Ortsvermittlungsstelle
Downstream
bis 16 Mb/s
A
D
S
L
bis 10 km
Upstream
bis 1,5 Mb/s
A
D
S
L
SONET/
SDH
Kernnetz
Multimedia
Server
Internet
Service
Provider
Voll-Duplexübertragung mit asymmetrischen Datenraten über eine Kupfer-Zweidrahtleitung
Die erreichbaren Übertragungsraten sind von der Entfernung und von der Leitungsqualität abhängig
Das DSL-Modem adaptiert sich automatisch an die verfügbare Leitungsqualität
Adaption erfolgt nach jedem Einschalten des Modems oder nach dem Rücksetzen desselben von der Ortsvermittlungsstelle aus
Die analoge Datenübertragung basiert bei ADSL auf der DMT-Modulation
Die DMT-Modulation ist die Nachfolgerin der CAP, die wiederum die Nachfolgerin von
QAM ist
139
Hinweis: QAM: Quadrature Amplitude Modulation
Hinweis: CAP: Carrierless Amplitude/Phase Modulation
Hinweis: DMT: Discrete Multitone Modulation
Telefon/Fax und DSL sind bei ADSL aufgrund unterschiedlicher Frequenzen simultan
möglich (stören sich nicht)
Typische Anwendungen für ADSL:
• schneller Internet-Zugang für Firmen und Privathaushalte
• Multimedia-Zugang, Video-on-Demand, ...
• und ganz normales telefonieren oder faxen
7.5.10
Warum hat ADSL asymmetrische Datenraten?
Die Upstream-Signale laufen auf dem Weg zur Ortsvermittlungsstelle in großer Zahl auf
engem Raum in einem Kabelkanal zusammen
Übersprechen entsteht, wenn Kabel über längere Strecken parallel und eng beieinander geführt werden
Viele parallele Kabelbündel verstärken nochmal das Übersprechen
Hinzu kommt, dass die Nutzsignale vor der Ortsvermittlungsstelle aufgrund ihres Weges schon stark gedämpft sind
Die Upstream-Signale sind vor der Ortsvermittlungsstelle klein und werden stark
gestört. Nur niedrige Datenraten sind möglich.
140
Der Grund ist das Übersprechens zwischen Leitungen unterschiedlicher DSL-Modems
Andererseits laufen die Downstream-Signale zu getrennten Teilnehmer-Modems weiträumig auseinander
Das Übersprechen wirkt sich hier wesentlich weniger aus, da die Nutzsignale genau
dann hoch sind, wenn sie eng beieinander verlaufen
Deshalb kann man in der downstream-Richtung höhere Bitraten realisieren
Dieses Verhalten passt zum Kundenverhalten: Browsen im Internet, Video-on-Demand
usw. sind von der Nutzung her ebenfalls asymmetrisch, da viel mehr download als upload erfolgt
7.5.11
QAM-Modulation
Quadrature Amplitude Modulation war die erste Modulationstechnik für DSL-Modems
QAM ist eine Kombination von Amplituden- und Phasenmodulation
QAM heißt:
• Es gibt eine konstante Frequenz, die sog. Trägerschwingung, die das Modem aussendet
und die amplituden- und phasenmoduliert ist
• Die erlaubten Amplituden- und Phasenwerte sind diskret und aus einer vorab festge-
legten Menge von 8, 16 oder 32 Werten
Beispiel: Bei 8-fach QAM gibt es 8 Kombinationen aus 2 verschiedenen Amplitudenund 4 verschiedenen Phasenwerten.
141
Es gibt ein mathematisches Kalkül, das auf Zeigern mit Phasen- und Amplitudenwinkeln beruht: die komplexen Zahlen in der Gausssche-Zahlenebene
Zur Kennzeichnung der erlaubten Kombinationen aus Amplituden- und Phasenwerte
werden komplexe Zahlen, bestehend aus Phasenwinkeln und Amplituden, in die
Gausssche-Zahlenebene eingezeichnet
Anhand der Gaussschen-Zahlenebene ist allerdings nicht erkennbar, welche Frequenz
die Trägerschwingung hat
Würde man diese Information hinzufügen, müsste die ganze Gausssche-Zahlenebene
mit der Frequenz der Trägerschwingung rotieren
142
Beispiel: Die 8-fach- und 16-fach-QAM in der Gaussschen -Zahlenebene
j Im
{Signal}
j Im
{Signal}
Re
{Sig-
Re
{Signal}
8-fach QAM
Die roten Punkte
stellen die zulässigen Amplituden/PhasenKombinationen
dar
16-fach QAM
Jeder Punkt im Diagramm (= komplexe Zahlenebene) entspricht einer erlaubten Kombination aus Amplitude und Phase und kodiert eine Bitkombination aus drei bzw. 4 Bit
8-fach QAM: 2 Amplituden + 8 Phasensprungwinkel, aber nur jeder 2. Punkt belegt =>
8 Datenpunkte, also 3 Bits pro Baud => in einer Sinusschwingung können 3 Bit übertragen werden
143
16-fach QAM: 4 Amplituden+ 8 Phasensprungwinkel + nur jeder 2. Punkt belegt => 16
Datenpunkte, also 4 Bits/Baud => in einer Sinusschwingung können 4 Bit übertragen
werden
Problem: je dichter die Gauss-Zahlenebene mit erlaubten Kombinationen belegt wird,
desto schwieriger wird die Unterscheidung der einzelnen Phasen und Amplituden beim
Empfänger
7.5.11.1 Vectoring
Die erlaubten Kombinationen werden in der Gauss-Zahlenebene etwas verschoben,
und zwar in der Art, dass sie am Ende der Übertragungsstrecke aufgrund der Störungen an der Stelle sind, wo sie ohne Störungen hätten sein sollen (=“Vorverzerrung“)
7.5.12
CAP-Modulation
CAP ist eine verbesserte Version von QAM und benützt höhere Frequenzen
Die Trägerfrequenz („Carrier“), deren Amplitude und Phase moduliert wird, wird nach
der Modulation herausgefiltert wird (= „Carrierless“)
Telefondienst und ISDN liegen unterhalb des CAP-Frequenzspektrums, stören also
nicht
CAP ist aufwärtskompatibel zum Telefondienst und zu Fax
144
7.5.13
DMT-Modulation
DMT ist ein nochmals verbessertes QAM bzw. ein verbessertes CAP
Die Verbesserung liegt darin, dass nicht nur ein Träger fester Frequenz verwendet wird,
sonden viele
Üblich sind 256 verschiedene Trägerfrequenzen, die alle separat QAM-moduliert werden
Die 256 Trägerfrequenzen werden als Subbänder bezeichnet
Daraus resultiert eine 256-fache Datenrate
Damit sich die einzelnen Trägerfrequenzen möglichst wenig gegenseitig stören, werden sie gleichmäßig auf den zur Verfügung stehenden Frequenzbereich verteilt
Zusätzlich wird der zur Verfügung stehende Frequenzbereich des zweiadrigen, verdrillten Telefonkabels gegenüber CAP deutlich vergrößert
Dies geht auf Kosten der maximal möglichen Kabellänge, da nur kurze Kabel solche
hohen Frequenzen nicht zu stark dämpfen
Bei VDSL wird das Kabel mit der maximal möglichen Bandbreite betrieben, die angepasst ist an Kabellänge, Kabeldurchmesser und äußeren Störungen
145
Frequenzaufteilung bei DMT:
Signalstärke
[dB]
Telefon/ISDN
DSL
256 Subbänder
Analoges Telefon
und Fax im untersten Band
3,4 26
138
1104
f
[kHz]
Die unteren Subbänder bis 138 KHz werden vom analogen Telefon, Fax und ISDN belegt, stehen also für das DSL-Modem nicht zur Verfügung
Schließlich wird bei DMT das Übertragungsverhalten jedes einzelnen Subbands individuell berücksichtigt
Manche Subbänder sind schneller als andere, da auf deren Trägerfrequenzen weniger
Störungen auftreten
Dort können mehr Bits pro Sekunde bei gleicher Fehlerrate übertragen werden => Bitratenadaption
Jedes Subband ist ca. 4 kHz breit. Es wird auch als „Kanal“ bezeichnet.
146
Jeder Kanal überträgt bis ca. 60 kbit/s, falls ein gutes Signal-/Rauschverhältnis vorhanden ist (nach Shannon besser als 30 dB)
Bei starken Störungen in einigen Subbändern werden diese nicht verwendet
Die Datenrate bei DMT liegt pro Kanal zwischen 60 Kbit/s und 0 Kbit/s
In der Summe über alle Kanäle sind im günstigsten Fall ohne Störungen ca. 16 Mbit/s
über ADSL, bei VDSL bis ca. 50 Mbit/s möglich
Der Telefondienst/Fax liegt wie bei CAP unterhalb der DMT-Frequenzen für Datendienste und wird, falls erforderlich, separat geführt (Splitter an beiden Enden der Leitung
notwendig)
DMT ist amerikanischer ANSI- (T1.413) und europäischer ETSI-Standard
7.5.13.1 Automatische Bitraten-Adaption bei DMT
Wichtiges Prinzip der DMT: „DMT adapts to every line condition“
Damit werden Störungen umgangen bzw. ausgeblendet
147
7.5.13.2 Übertragungsverhalten von Telefonkabeln ohne Störungen
Sendesignal [Bit/s]
Kabeldurchlass
= 1/Dämpfung
[dB]
Empfangssignal [Bit/s]
Frequenz
Frequenz
Frequenz
Sender
Kabel
Empfänger
Das Telefonkabel wirkt wie ein sog. Tiefpass, d.h., es läßt tiefe Frequenzen gut durch
und hohe schlecht => die Dämpfung ist eine Funktion der Frequenz
Hinzu kommt: die Dispersion (Verzerrung) ist ebenfalls eine Funktion der Frequenz
Zusätzlich zu Rauschen, Dämpfung und Dispersion kommen Störungen von außen, die
die schnelle Datenübertragung erschweren
Eine Bitratenadaption jedes Kanals an diese Effekte ist deshalb sinnvoll
148
7.5.13.3 Übertragungsverhalten von Telefonkabeln mit Störungen
Sendesignal [Bit/s]
Sender
Empfangssignal [Bit/s]
Kabel
Empfänger
Funkstörung
Reflektion
Frequenz
Frequenz
Übersprechen
Frequenz
Bei der DMT-Modulation messen die DSL-Modems automatisch nach jedem Einschalten die Übertragungsgüte jedes einzelnen Kanals und adaptieren die Bitrate kanalweise gemäß der jeweiligen Übertragungseigenschaften
Dieser Vorgang dauert einige Minuten und findet jede Nacht statt
Dazu wird die DSL-Verbindung - auch bei einer Flat Rate - unterbrochen
Typische Störungen bei der DSL-Übertragung sind:
• Thermisches Rauschen von Leitungen und Bauteilen aufgrund der Brownschen Molekularbewegung
• Dämpfung des Nutzsignals
149
•
•
•
•
Verzerrung des Nutzsignals
Kabelabzweigung mit daraus resultierender Reflexion des Signals (Echo)
hochfrequente Einstreuung von außen (z.B. durch Radio oder Handy)
Übersprechen, verursacht durch parallel geführte Kabelbündel von Telefonleitungen
7.5.14
HDSL - „High“ Data Rate Digital Subscriber Line
Kunde
T1: 1.544 Mbps : 2
Paare
H E1: 2.048 Mbps : 3
D Paare
S
bis ca. 4 km
L
Vermittlungseinrichtungen
H Optisches
D Netz der TeS lekom-FirL
H
D
S
L
Kunde
H
D
S
L
SONET/SDH
Ältere Technik mit symmetrischen Bitraten über verdrillte Kupferdrähte (Kabelpaare)
Entstanden als kostengünstige Technik der Telecoms zur Realisierung von T1 oder E1
(=1,5 Mbit/s oder 2 Mbit/s-Leitungen) über zwei bis drei parallele Telefonkabelpaare
Basiert auf QAM mit 2 Bits pro 1 Baud oder CAP-Modulation (= viel weniger effektiv als
DMT)
Kein simultaner Telefondienst auf dem Kabel möglich
150
Typische Anwendungen: Für ältere Gebäude, die keinen Glasfaseranschluss haben
Beachte: Glasfaseranschlüsse ins Internet kosten bei der Dt. Telekom je nach Geschwindigkeit ca. € 5000-60 000 pro Monat!
7.5.15
SDSL - Symmetric Digital Subscriber Line
Vermittlungseinrichtungen
Kunde
S
D
S
L
1.544/2.048 Mbps
bis ca. 3 km
S
D
S
L
CORE
NE
WORK
„optical“
S
D
S
L
Kunde
1,5 / 2
Mb/s
S
D
S
L
SONET/SDH
„Single Line“-Version von HDSL (nur eine Zweidrahtleitung => kostensparend)
Symmetrische Bitraten für Firmen, die Content z.B. für eCommerce ins Netz stellen
Basiert auf QAM, CAP oder DMT-Modulation
Telefondienst und T1/E1 simultan möglich
Typische Anwendungen: wie HDSL aber ebenfalls veraltet
151
7.5.16
VDSL - Very High Data Rate Digital Subscriber Line
remote
side
V
D
S
L
Downstream
bis 50 Mb/s
bis 1 km
bis 10 Mb/s
Upstream
CO side
V
D
S
L
CORE
NETWORK
Multimedia
Service
Provider für Video-on-Demand
Internet
Service
Provider
CO = Central Office
Voll-Duplexübertragung über eine Zweidrahtleitung
Höhere Datenraten als ADSL, aber viel kürzere Kabellängen
Telefondienst, ISDN und Datenübertragung simultan
Typische Anwendungen: nächste Generation von xDSL
VDSL-Netz zur Zeit im Aufbau, u.a. für Video-on-Demand in HDTV-Qualität
152
7.5.17
Die xDSL-Familie im Überblick
symmetrische Datenraten
asymmetrische Datenraten
HDSL
SDSL
ADSL
VDSL
High Data
Rate DSL
Single Line
DSL
Asymmetric
DSL
Very High
Data Rate
DSL
Downstream
1,544 oder
2,048 Mb/s
1,544 oder
2,048 Mb/s
bis ca. 16
Mb/s
bis ca. 50
Mb/s
Upstream
1,544 oder
2,048 Mb/s
1,544 oder
2,048 Mb/s
bis ca. 2
Mb/s
bis ca. 10
Mb/s
max. Leitungslänge
ca. 3 bis 4
km
ca. 2 bis 3
km
bis ca. 10 km
bis ca. 1
km
Adernpaare
2 bei 1,544
Mb/s, 3 bei
2,048 Mb/s
1
1
1
analoges
Telefon/Fax
nein
ja
ja
ja
ISDN
nein
ja
ja
ja
Bezeichnung
Bedeutung
153
Bezeichnung
HDSL
SDSL
ADSL
VDSL
benutzte
Bandbreite
bis 240 kHz
bis 240 kHz
bis 1,1 MHz
bis 30 MHz
Modulationsverfahren
CAP
CAP
DMT
DMT, DWMT
T1/E1Dienste, alte
WAN und
Serverzugänge
T1/E1Dienste, alte
WAN- und
ServerZugänge
Internetzugang, WebTV
HDTV Videoon-Demand
Anfang 90er
Mitte 90er
Mitte/Ende
90er
seit Anfang
2006
Einsatzbereiche
Verfügbarkeit seit
154
7.6
Point-to-Point Echtzeit-Protokoll (PPP) der ISO-Schicht 2b
PVC
PPP
CO
xDSL
xDSL als
Schicht 1
und 2a
ATM
RAS
WAN/
MAN
SONET/SDH = Digitales
Telefon/Datennetz als
Schicht 1 und 2a = WAN
Für den Kunden wird TCP und IP über PPP und DSL transportiert
Im digitalen Telefon-/Datennetz (WAN) wird TCP und IP über ATM und SONET/SDH
transportiert oder TCP/IP betreiben die Glasfaser direkt ohne ATM
Hinweis: CO = Central Office = Telefon-Ortsvermittlungsstelle
Hinweis: RAS = Remote Access Server des Internet Providers
Hinweis: PVC = Permanent Virtual Circuit in ATM = Emulation einer Standleitung in einem virtuellen ATMNetz
PPP ist das Schicht 2b-Protokoll für DSL-Modems
155
Ab der Ortsvermittlungsstelle (CO) geht es dann über das optische „Kernnetz“ einer
Telekommunikations-Firma mit IP über ATM oder purem IP als Protokoll weiter
Der Zugang zum Internet erfolgt über über das optische Kernnetz zu einem Remote Access Server (RAS) des Internet Providers
Der Internet Provider (z.B. 1&1) mietet dazu mehrere sog. PVCs vom Betreiber eines realen oder virtuellen ATM-Netzes
PPP kann bis zum RAS des Internet Providers ausgedehnt werden, PPP wird dann
als „Nutzlast“ (payload) von ATM übertragen
ATM wiederum dient in den Kernnetzen (WANs) als Schicht 2-4-Protokoll und verwendet SONET/SDH als Schicht 1 (Bitübertragungsschicht)
Auf ATM sitzt manchmal, aber nicht immer IP als Nutzlast auf, gefolgt von TCP oder
UDP
7.6.1
Funktion von PPP
PPP stellt eine Schicht 2b-Punkt-zu-Punkt-Verbindung zwischen 2 DSL-Modems her
PPP ist echtzeitfähig und stellt über eine Prüfsumme am Rahmenende fest, ob ein
Übertragungsfehler vorliegt
PPP macht keine Rahmenwiederholung im Fehlerfall, da Rahmenwiederholungen echtzeitschädlich sein können, weil sie Übertragungszeit kosten
PPP nimmt auch keine Authorisierung oder Authentifizierung vor, die sog. AA
AA wird mit extra Protokoll realisiert, z.B. mit Password Authentication Protocol (PAP)
156
7.6.2
Protokollphasen von PPP
1.) Verbindungsaufbau und Konfigurationsaushandlung: ein PPP-Knoten (=DSL-Modem)
sendet spezielle Datenrahmen zum Aufbau der Datenverbindung und zur Konfiguration in der Schicht 2.
2.) Prüfen der Verbindungsqualität: die Leitung wird ausgemessen (eigentlich optional,
wird aber bei DSL-Modems standardmäßig eingesetzt)
3.) Konfiguration des Schicht 3-Protokolls (z.B. IP). Der PPP-Knoten sendet optional spezielle Rahmen zur Konfiguration der Schicht 3. Bei DSL-Modems nicht notwendig, da
nur Punkt-zu-Punkt-Strecke ohne Routing. Diese Funktionalität ist zudem außerhalb
der ISO-7-Schichten-Regeln, da Schicht 2 und Schicht 3 vermischt werden.
4.) Datenübertragung
5.) Verbindungsabbau
8
Echtzeit-Übertragung im Internet
Bei DSL, PCM- oder Sonet/SDH- als Schicht 1 ist Echtzeitübertragung problemlos möglich
Bei ATM-Protokollen (= Schicht 2,3 und 4) sind die Echtzeitbedingungen ebenfalls erfüllt
157
Bei IP Version 4 sind die Echtzeitbedingungen nicht erfüllt
Bei IP Version 6 ist Echtzeit mit Einschränkungen möglich
Schicht 7-Protokolle versuchen, trotz IPv4 näherungsweise Echtzeit zu implementieren
Beispiele für solche Anwendungen: Voice over IP (= telefonieren über das Internet mit
Hilfe eines IP-Telefonapparats oder eines Rechners) mittels Skype, Viber, Tango, ...
Verbesserung der Situation nur durch Übergang auf IPv6 möglich
8.1
PCM-Verfahren zur Echtzeit-Übertragung
PCM = Pulscode-“Modulation“ (schlechte Terminologie, da PCM eine Codierung und
keine Modulation ist)
Dient für die Echtzeitübertragung von Daten auf der ISO-Schicht 1 zwischen TelefonOrtsvermittlungsstellen
Verwendet synchrones Zeitmultiplex:
• Verschiedene Datenquellen werden reihum nacheinander übertragen
• Jeder Quelle wird periodisch eine Zeitscheibe (time slot) zugeteilt
• Multiplexer und Demultiplexer laufen zeitsynchron, d.h gleich schnell und phasenstarr
158
Prinzip:
...
Multiplexer
Bitstrom 2
...
Bitstrom n
Demultiplexer
Bitstrom n
8.1.1
Zeitscheibe 2
Zeitscheibe 1
Bitstrom 2
Bitstrom 1
Zeitscheibe 2
Zeitscheibe 1
bis Zeitscheibe n
Bitstrom 1
bis Zeitscheibe n
Systemparameter von PCM-Zeitmultiplexsystemen
Jedes PCM-Zeitmultiplex-System hat bestimmte Systemparameter, wie z.B.:
• Die kleinste Übertragungseinheit pro Zeitabschnitt (Time Slots): 1 Bit, 1 Byte, n-Bit-Wort
oder Block von n-Bit-Wort Worten
• Die Dauer jedes Zeitabschnitts. Time Slots sind stets äquidistant.
• Die Anzahl der Time Slots in jeder Umlaufperiode
• Die Häufigkeit der Zeitscheibenzuteilung pro Übertragungskanal (1 Mal oder mehrere Male
pro Umlaufperiode)
• Vorhandene Synchronisierhilfen zwischen Multiplexer und Demultiplexer, wie z.B. gemeinsamer Takt für beide Geräte
159
• Sog. Melde- und Signalisierungsdaten für: Rufnummernwahl, Klingeln, Anrufumleitung,
Anrufweiterschaltung, Rufnummernanzeige, Gebührenzählung etc.
8.1.2
Aufbau eines typischen T1-PCM-Rahmens
Kleinste Übertragungseinheit pro Zeitabschnitt: 8 Bit
Dauer jedes Zeitabschnitts: ca. 3,9 µs, Dauer der Umlaufperiode: 125 µs (8000 Hz)
160
Anzahl der Zeitabschnitte pro Periode: 24 Kanäle bei T1-PCM
8.1.3
T1-PCM-System (USA und Japan)
24 Kanäle zu je 8 Bit pro Wiederholungsperiode => 64 000 bit/s pro Kanal
Hinweis: 64 000 bit/s sind nicht gleich mit 64 Kbit/s
Datenmenge pro Periode heißt „Rahmen“. Bruttodatenrate des Rahmens ist 1,544 Mb/s
Das 8. Bit jedes übertragenen Wortes dient als Melde und Signalisierungsbit
Es werden nur 7 Bit pro Kanal als Abtastwerte vom Mikrofon des Telefons übertragen
Sprachqualität ist im Vergleich zu Europa eingeschränkt
8.1.4
E1-PCM-System (Welt ohne USA und Japan)
Periodendauer = 125 s, bei 32 Kanälen zu je 64 000 bit/s
alle 125 s kommen 32 Zeitscheiben zu je 8 Bit => Bruttodatenrate 2,048 Mb/s
30 Zeitscheiben sind für Nutzdaten, 2 Zeitscheiben für Verwaltungsinformation
161
8.1.4.1
Aufbau der Datenrahmen bei E1
Gesamte Rahmenlänge
125 µs
0
PCM-codierte
Kanäle
1 bis 15
Kennzeichnungs-Time
Slot
1
15 16
2
PCM-codierte
Kanäle
16 bis 31
30
17
1 Zeitscheibe
X
0
0 1
1
0
1
31
8
Bit
1
In den Rahmen Nr. 1, 3, 5,... wird am Rahmenanfang ein frame delimiter übertragen
Y
In den Rahmen Nr. 2, 4, 6,... wird am Rahmenanfang ein „Meldewort“ übertragen. Es enthält Verwaltungsinformationen: D Meldebit für dringenden Alarm; N Meldebit für nicht dringenden Alarm,
X für internationale Verwendung; Y für nationale Verwendung;
3,9 µs
X
1
D N
Y
Y
Y
0,49 µs pro Bit
162
Zeitabschnitte (= Zeitscheiben) sind mit 0 bis 31 nummeriert
Ein Abschnitt ist ca. 3,9 µs lang. Die gesamte Rahmendauer ist auf 125 Mikrosekunden
genormt
Im Zeitabschnitt 0 werden abwechselnd Rahmenkennworte (u. a. zur Rahmenidentifizierung, Synchronisierung) und Meldeworte, u. a. zur Überwachung der Leitung übertragen
Der Kennzeichen-Zeitschlitz dient zur Übertragung vermittlungstechnischer Daten zur
Rufnummerübertragung, zum Verbindungsauf- und abbau und zur Gebührenzählung
Die 30 übrigen Zeitabschnitte transportieren jeweils 8 Bit lange Abtastwerte eines digitalen Fernsprechkanals mit einer Rate von 64 000 b/s pro Kanal
Anstelle von Fernsprechsignalen werden auch beliebige andere digitalisierte Daten
aus dem Internet und anderen Rechnernetzen in Echtzeit übertragen
8.1.5
Sowohl E1- als auch T1-PCM-Systeme erlauben, mehrere Rahmen zu „Trägern“ höherer Baudraten zu multiplexen
Beim Multiplexen werden mehrere vollständige Träger niederer Datenrate incl. deren
Verwaltungsinformation zu einem Träger höherer Datenrate zusammengefasst
8.1.5.1
PCM-Hierarchien
T1-Hierarchie
Multiplexen erfolgt bitweise nicht byteweise
163
Achtung: die Bitrate bei Ti+1 ist ein nicht ganzzahliges Vielfaches der Übertragungs-Bitraten von Ti, für alle i
8.1.5.2
E1-Hierarchie
Bei E1-Systemen erfolgt das Multiplexen von E1-Rahmen im Gegensatz zu T1 in festen
Schritten von 4 Inputs pro Output, und es gilt stets: En+1 = 4 En => klareres Konzept
E1- bzw. T1-Systeme sind untereinander inkompatibel => Datenaustausch nur über
Konverter möglich
PCM 30 = 2,048 Mbit/s (= E1)
• x 4 liefert PCM 120 = 8,448 Mbit/s (= E2)
• x 4 liefert PCM 480 = 34,368 Mbit/s (= E3)
164
• x 4 liefert PCM 1920=139,294 Mbit/s (= E4)
• x 4 liefert PCM 7680 =564,992 Mbit/s (= E5) und so weiter
Multiplexhierarchie ist nach oben offen: derzeit bis 40 Gb/s in Europa und bis 160 Gb/
s in USA
erlaubt die Aufwärtskompatibilität bestehender Systeme zu Systemen mit höherer
Datenrate
8.2
SONET = „Synchronous Optical Network“ (= Entwicklung der USA)
SDH = „Synchronous Digital Hierarchy“ (= Entwicklung der Europäer)
SDH ist praktisch identisch zu SONET => weltweite Kompatibilität ist garantiert
SONET/SDH ist ein Wide Area Network (WAN)
8.2.1
Sonet/SDH zur Echtzeit-Übertragung
Warum gibt es SONET/SDH?
E1- und T1-PCM-Systeme beruhen noch auf Kupferkabeln
Moderne PCM-Systeme sind jedoch Glasfaser-basiert
SONET/SDH ist das von der ITU standardisierte Glasfaser-basierte PCM-System
Marktanteil von SONET/SDH bei Glasfaser-PCM-Systemen ist sehr hoch
165
8.2.2
Ziele von SONET/SDH
1.) Weltweit einheitlicher Rahmenaufbau für alle Netzbetreiber
Weltweite Kompatibilität aller Glasfaser-PCM-Systeme
2.) Kompatibilität zu den alten Kupferkabel-basierten PCM-Systemen E1 und T1
Unterstützung von Hierarchien aus Multiplex-Rahmen
• Transportiert T1-, T2-, T3-,..., und E1-, E2-, E3- ,..., Träger
• Transportiert auch ATM- und IP-Datenrahmen (ATM = Echtzeitprotokoll für SONET/SDH)
3.) Unterstützung von automatisierter Verwaltung und Wartung aller Netzkomponenten,
sog. „Operation, Administration and Management (OAM)“, so dass menschliche
Interventionen minimiert werden (Kostengründe)
8.2.3
Eigenschaften von SONET/SDH
Synchrones Zeitmultiplexsystem (PCM) mit max. 1 ns Phasendifferenz zwischen Multiplexer und Demultiplexer (= „Jitter“)
Besteht aus Vermittlern, Multiplexern und Repeatern, die über Glasfaser verbunden
sind
Repeater: dienen zum Verstärken des Datensignals
Multiplexer: fassen mehrere Teilbitströme zu einem „höheren Träger“ zusammen, z.B.
4*E1 zu E2 => Multiplexhierarchie
166
Vermittler:
• dienen zur Wegewahl
• sind Bestandteil von Quell-/Zielmultiplexern und allen Multiplexern dazwischen
SONET/SDH implementiert Punkt-zu-Punkt-Verbindungen (sog. SONET-Pfade)
Mehrere Punkt-zu-Punkt-Verbindungen ergeben allgemeinen Graphen als Verbindungstopologie
Aus Redundanzgründen werden je 2 parallele Punkt-zu-Punkt-Verbindungen zu einem
Doppelring ähnlich wie bei FDDI zusammengeschaltet => Fehlertoleranz
167
8.2.4
Aufbau eines SONET/SDH-Pfades
Repeater
Multiplexer
Repeater
Destination
Multiplexer
Empfänger
(Ziel)
Sender (Quelle)
Source
Multiplexer
Section
(Abschnitt)
Leitung
Section
Section
Section
Line
Path
(Pfad)
Abschnitt (section) = Glasfaserstrecke zwischen 2 Geräten (Multiplexer oder Repeater)
Leitung (line) = Faserstrecke zwischen 2 Multiplexern
Pfad (path) = Faserstrecke zwischen Quell- und Zielmultiplexer
8.2.5
SONET/SDH als ISO-Schicht 1 und 2
SONET/SDH ist die ISO-Schicht 1 und 2 für Telefon, Fax und Internet
SONET/SDH ist in 4 Subschichten unterteilt:
168
• Photonteilschicht, Abschnittsteilschicht, Leitungsteilschicht und Pfadteilschicht
8.2.6
Subschichten von SONET/SDH
Sublayers:
Path
Line
Line
Line
Section
Section
Section
Section
Photonic
Photonic
Photonic
Photonic
Multiplexer
Destination
Source
Repeater
Section
Section
Line
Teilschichten
ISO Schicht 1
Path
Section
Line
Path
Photonteilschicht:
• Spezifikation der Glasfaser und der Wellenlänge (meist Infrarot wg. geringer Dämpfung)
• Wandlung zwischen optischem und elektrischem Signal für Empfang und Verstärkung
Abschnittsteilschicht:
• Erkennen von Rahmenanfang und -ende
169
• Erstellen, Einspeisen, Übertragen und Entnehmen von SONET-Rahmen aus der Faser
Leitungsteilschicht:
• Multiplexen/Demultiplexen gemäß Multiplexhierachie
Pfadteilschicht:
• Unterstützt den Ende-zu-Ende-Transport von Daten zwischen Quell- und Zielmultiplexer
Hinweis: die Schicht 1 bei SONET/SDH übernimmt Aufgaben der Datensicherung, die eigentlich erst in
ISO-Schicht 2 relevant werden. Sie leistet außerdem wesentliche Beiträge zu Aufgaben, die erst in der
Wegewahlschicht und der Transportschicht anfallen. Dies ist nicht im Sinne des ISO-7-Schichten-Modells.
Das Routing wird von ATM oder IP gemacht. Die Protokolle benützen dabei SONET/
SDH-Vermittler-Hardware in den Multiplexern der Schicht 1.
8.2.7
SONET/SDH-Rahmenaufbau
Der wichtigste SONET/SDH ist der sog. Basisrahmen
Der Basisrahmen ist ein Block von 810 Byte Länge. Dieser wird ununterbrochen alle
125 s gesendet, auch wenn nicht so viele Nutzdaten zu transferieren sind.
Bitrate des Basisrahmens ist 51,84 Mb/s, Wiederholungsrate der Basisrahmen ist
8000 Rahmen/s
Basisrahmen heißt auch „STS-1“
Der Nutzdatenanteil ist 774 Byte bei 810 Byte => Nutzdatenrate: 49,536 Mbit/s => 96%
Effizienz
170
Jedes Byte des Blocks wird bitweise über eine Glasfaser übertragen (ein Byte nach
dem anderen und jeder Rahmen nach seinem Vorgängerrahmen)
Datenrate von 8000 Rahmen/s passt zu alten PCM-Systemen
Aufwärtskompatibilität zu kupferkabelbasierten Systemen
Aufgrund des ununterbrochenen Sendes von Blöcken ergibt sich eine vorhersagbare
Datenrate und eine deterministische Zustellzeit (Latenz) der Rahmen
SONET/SDH ist echtzeitfähig
Jeder Block von 810 Byte wird gedanklich als 2-dim. Tabelle (= 2 dimensionale Datenstruktur) interpretiert
0 µs
...
Zeit
125 µs
Die gedachte Tabelle hat 90 Spalten und 9 Zeilen (=9*90 Byteblock)
3+1 Spalten der gedachten Tabelle sind für Transportzusatzinformation reserviert
171
8.2.7.1
Feinstruktur des SONET/SDH-Rahmenaufbaus
90 Spalten
Transport-Zusatzinformation
3 Spalten
1 Spalte
0 µs
Zeit
AbschnittsZusatzinformation
3 Zeilen
LeitungsZusatzinformation
6 Zeilen
PfadZusatzinformation
9 Zeilen
125
µs
Transportzusatzinformation dient dem automatisierten Betrieb und dem Management
der SONET/SDH-Geräte (OAM); Wichtig, da Geräte und Glasfaser im Boden vergraben
sind!
172
Die ersten 3 Zeilen der ersten 3 Spalten enthalten Transportzusatzinformation zur SONET/SDH-Abschnittsverwaltung
Die restlichen 6 Zeilen der ersten 3 Spalten enthalten Transportzusatzinformation zur
SONET/SDH-Leitungsverwaltung
Zusätzlich gibt es eine Spalte mit Transportzusatzinformation zur SONET/SDH-Pfadverwaltung
Die Transportzusatzinformation definiert den Beginn einer weiteren gedachten Struktur, den sog. Synchronous Payload Envelope (SPE)
Der SPE dient zum flexiblen Transport von Nutzdaten verschiedener Länge
Der SPE kann mitten im Byteblock beginnen
Sein Beginn wird durch einen Zeiger in der Leitungsverwaltung gekennzeichnet
Der SPE reicht bis zum Beginn des nächsten SPE im nachfolgenden Byteblock
173
8.2.7.2
Lage des SPE zwischen zwei aufeinanderfolgenden Rahmen
174
Sektions- und
Leitungszusatzinformation (3 Spalten)
PfadZusatzinformation (1 Spalte)
gedankliches
Anhängen der
Positionen 4-5,
9-10, ... an die
Positionen 3,8, ...
H1 H2
J1
Rahmen N
(9 Reihen)
Anfang von
SPE 1
Fortset9 Reizung 1 hen
Fortsetzung 2
H1 H2
Rahmen
N+1
(9 Reihen)
3 Spalten
J1’
Anfang von
SPE 2
87 Spalten
2 Byte (H1 und H2) bilden einen Zeiger auf die zwischen den Bytefeldern J1 und J1’ liegenden Nutzdatenbyte des SPE => Durch H1 und H2 ist direkter Zugriff auf den SPE gegeben
175
Durch einen weiteren Zeiger namens C1 wird die Position eines gemultiplexten STS-1Rahmens in der Multiplexhierarchie eines STS-N-Rahmens adressiert
Durch C1 ist ein direkter Zugriff auf einzelne STS-1-Rahmen d.h. auf einzelne Kanäle
in der Multiplexhierachie gegeben
Hinweis: Für die Begriffe „STS-1“ und „STS-N“ siehe nachfolgende Kapitel
8.2.7.3
Diese 3 Felder werden gebraucht für:
•
•
•
•
•
•
Abschnitts-, Leitungs- und Pfadinformation
Rahmenerkennung
Datensicherung
Fehlerüberwachung der Übertragungsstrecken und Geräte im Erdboden
Übertragung von Takt und Synchronisation zwischen Multiplexern
Prüfinformationen für OAM
Sprachkanäle für OAM
Die Infos der Abschnittsverwaltung werden am Ende jedes Abschnitts ausgewertet
und dann für den nachfolgenden Abschnitt wieder neu erzeugt
Die Infos der Leitungsverwaltung werden am Ende jeder Leitung ausgewertet und für
die nachfolgende Leitung wieder neu erzeugt
Die Infos der Pfadverwaltung werden nur einmal erzeugt (am Anfang des Pfades) und
ausgewertet (am Ende des Pfades)
176
8.2.8
SONET/SDH-Multiplexen
Beim Multiplexen werden mehrere vollständige Byteblöcke niederer Datenrate inkl. deren Verwaltungsinformation zu einem Byteblock höherer Datenrate zusammengefasst
Der Byteblock höherer Datenrate wird als Träger bezeichnet
Multiplexen der Byteblöcke erfolgt auf Bytebasis
Der neue Byteblock hat die n-fache Größe der Eingangsblöcke (bei n Eingangsströmen)
Seine Wiederholrate ist ebenfalls 125 s
Datenrate ist n-fach höher
SONET verwendet ganzzahlige Vielfache der STS-Grundrate für die Bitraten höherer
Träger
STS-N = Synchronous Transfer Signal Number N; STS-Grundrate ist STS-1 = 51.84 Mb/s
Mehrere Multiplexer hintereinander definieren eine Multiplexhierarchie wie bei E1/T1Systemen
Es ergibt sich eine Hierarchie von Datenraten: STS-1, STS-2,..., allerdings gibt es keinen festen Faktor 4 mehr beim nächst höheren Träger wie bei E1, E2=4*E1, E3=4*E2
etc.
177
8.2.9
Aufbau eines STS-N-Rahmens
N*90 Spalten
TransportZusatzinformation
N*3 Spalten
Container
N*86 Spalten
0
9 Reihen
N Spalten
Pfad-Zusatzinformation
125
µs
Die Daten werden byteweise in den STS-N-Rahmen gemultiplext
Die Felder für Sektions-, Leitungs- und Pfad-Zusatzinformationen sind jeweils N-mal
vorhanden
über die Zusatzinformationen ist ein direkter Zugriff auf die Nutzdaten möglich
178
8.2.10
Beispiel für eine Multiplexhierarchie bei SONET/SDH
Das gewandelte optische Signal bildet eine Hierarchie: OC-1, OC-2,...,OC-48,...OC-N
Hinweis: OC = Optical Carrier = opt. Trägersignal
OC-x ist bis auf eine zusätzliche Datenverschlüsselung (Scrambling) das optische Pendent zum elektrischen STS-x-Signal
179
Scrambling sorgt für Datensicherheit und verhindert außerdem lange 0000...- oder
1111...-Folgen (= besser für die Empfängerelektronik)
8.2.11
Multiplexraten bei SONET/SDH
155 Mb/s, 622 Mb/s und 2488 Mb/s sind gebräuchliche Datenraten für ATM, wenn ATM
über SONET/SDH transportiert wird
100 Gb/s ist derzeit die maximale Datenrate des in Deutschland existierenden DFN-Wissenschafts-Netzes X-WIN
8.2.11.1 Höhere Datenraten für einen einzigen Sender
Hohe Übertragungsraten (>>STS1 bzw. >>STM1) für eine einzige Datenquelle können
dadurch erzielt werden, dass man mehrere Basisrahmen dieser Quelle multiplext
In diesem Fall wird nicht byteweise gemultiplext sondern spaltenweise
Dabei werden korrespondierende Spalten mehrerer Byteblöcke derselben Quelle konkateniert
Der neue Byteblock hat eine entsprechend größere Spaltenzahl
Der neue Byteblock hat die n-fache Größe der Eingangsblöcke und wird ebenfalls in
125s übertragen => es folgen mehr Spalten schneller hintereinander
180
9 Stadtnetze (Metropolitan Area Networks, MANs)
Stadtnetze erstrecken sich nicht nur über eine Stadt, sondern auch eine Region oder
auch über ein größeres Firmengelände oder einen Universitätscampus
9.1
Beispiele für ein MAN: FDDI und DQDB
FDDI = Fibre distributed Data Interface
• = glasfaserbasiertes MAN mit 100 Mb/s mit bis 200 km Länge
DQDB = Distributed Queue Dual Bus
• = MAN mit 34 Mb/s = Standard für die ersten Glasfaserleitungen
9.2
FDDI (Fiber Distributed Data Interface)
Durch ANSI und ISO standardisierter Nachfolger von Token Ring als MAN
Große räumliche Ausdehnung (200 km)
Große Anzahl an Stationen (bis 1.000), die angeschlossen werden können
Topologie ist aus Fehlertoleranzgründen ein Doppelring mit gegenläufigen Rahmen
Glasfaserbasierend (Gradientenfaser oder Monomode-Faser) mit 1.300 nm Wellenlänge = fernes Infrarot
Preisgünstige Leuchtdioden als Sender (keine teuren Laserdioden)
181
Zugangssteuerung (Medium Access Control) über kreisende Sendeberechtigungsmarke (Token) mit zahlreichen Überwachungen (Checks) der Funktion, wie z.B. time-outÜberwachung der periodischen Wiederkehr des Tokens an jeder Station etc.
Erhöhung der Bandbreite durch multiples Senden zur selben Zeit auf demselben Ring
durch Anhängen mehrerer Senderahmen zu einem ganzen Zug von Rahmen
Kreisendes Token resultiert in deterministischen Sendezeiten (sog. time slots) für jede
Station => Echtzeitdatenübertragung ist möglich = „synchrone Betriebsweise“
Bandbreite kann auch anderweitig genutzt werden („asynchrone Betriebsweise“)
Durch Time Sharing des Rings ist im schnellen Wechsel synchrone und asynchrone
Betriebsweise möglich
182
Beispiel für eine FDDI-Topologie
Klasse B
Klasse A
Station
1
Station 4
Klasse C
Klasse A
Station 5
Klasse B
Station
2
Klasse B
Station
3
„Single Attachement Station“ = Klasse B
„Dual Attachment Station“ = Klasse A
Konzentrator
„Single and Dual Attachement Station“ = Klasse C
9.2.1
Station 6
Klasse A
single attachment: 1 FDDI-Anschluss
dual attachment:
2 FDDI-Anschlüsse
attachment:
Anhang, Zusatz
183
9.2.2
FDDI als Backbone
PCs oder
Workstations
Weitverkehrsnetz
Host
Konzentrator
Gateway
FDDI-Ring
IEEE 802.3
Ethernet Bridge
IEEE 802.4
Token Bus Bridge
IEEE 802.5
Token Ring Bridge
diverse lokale Netze
Hinweis: Backbone: Rückgrat
9.3
Vergleich Ethernet und FDDI
9.3.1
Ethernet (mit Switch und ohne Zugangssteuerung)
Einfaches Protokoll, leicht implementierbar, kein Netzwerk-Monitor notwendig
Topologische Einschränkungen (bei Switch nur Sterntopologie möglich)
184
Keine Rahmen-Prioritäten, zudem Problem des „bubbling idiots“
Keine zeitliche Obergrenze bei der Rahmenzustellung garantierbar
für Echtzeit selbst mit Switch nur bedingt geeignet, aber preisgünstig und weit verbreitet
9.3.2
FDDI (Token-Zugangssteuerung)
hohe Zuverlässigkeit u.a. dank Glasfaser und Fehlerbehebung bei Token-Verlust
(=„Token Recovery“) durch Netzwerk-Monitor
Hohe Systemausnutzung, überträgt viel Verkehr effizient
Unterstützt unterschiedliche Rahmenprioritäten
Feste Zustellzeit bei der Rahmenübertragung garantierbar (außer beim Auftreten von
Fehlern) deterministisch, für Echtzeit geeignet
Übertragung von zeitsynchronem Echtzeitverkehr zusammen mit Nicht-Echtzeitverkehr (asynchron) auf demselben Kabel
Eine Weiterentwicklung von FDDI ist CarRing
10 Weitverkehrsnetze (Wide Area Networks, WANs)
Weitverkehrsnetze verbinden Stadtnetze (MANs) miteinander, in Einzelfällen auch
LANs
185
10.1
Unterschied zwischen LANs, MANs und WANs
LANs und MANs bestehen aus einem gemeinsamen Übertragungsmedium (Kabel oder
Switch oder Funkkanal) und den daran angeschlossenen Rechnern (sog. Hosts)
LANs und MANs sind Broadcast-Netze auf der Schicht 1. Eine Wegewahl (Routing) ist
nicht erforderlich, da jede Nachricht im Prinzip bei allen Hosts vorbeikommt.
WANs bestehen aus mind. 1 Weitverkehrsstrecke sowie aus einem oder mehreren
LANs und/oder MANs am Anfang und Ende der Weitverkehrsstrecke als Zubringer
Es gilt: alle Weitverkehrsstrecken sind Punkt-zu-Punkt-Verbindungen.
Beispiel: SONET/SDH ist eine Punkt-zu-Punkt-Verbindung zwischen zwei benachbarten
Multiplexern.
An den Endpunkten einer Weitverkehrsstrecke sitzen spezielle Hosts, sog. Router
Im Falle von SONET/SDH wird die Wegewahl von Multiplexern vorgenommen.
Jeweils zwei benachbarte Router sind miteinander verbunden
Router dienen zur Kopplung von MANs und WANs
Es gilt: jeder Router ist mit einem Nachbar-Router über eine Punkt-zu-Punkt-Verbindung gekoppelt. Diese Strecke kann ein LAN, MAN oder eine Weitverkehrsstrecke sein.
Bei WANs ist ein sendender Host i. A. nicht im selben LAN oder MAN wie der empfangende Host.
186
Auf seinem Weg durchläuft ein Paket i. A. mehrere Netze (LANs, MANs, WANs)
Bei der Kopplung von WANs ist eine Wegewahl (Routing) erforderlich
Multicast -und Broadcast-Funktionen auf Schicht 3 würden eine Vervielfältigung eines
eintreffenden Pakets im Router erfordern
Dies wird bei IPv4 nicht gemacht, statt dessen werden auf Schicht 4 viele einzelne
Punkt-zu-Punkt-Verbindungen aufgebaut.
Beispiel: Bei web TV können das Zehntausende simulaner TCP-Verbindungen sein.
Beispiel: für eine Weitverkehrsstrecke mit Protokoll: ATM über SONET/SDH.
ATM entspricht ungefähr den ISO-Schichten 2-4
SONET/SDH entspricht ungefähr der ISO-Schicht 1
187
11 Vermittlungsschicht (ISO-Schicht 3)
Die Vermittlungsschicht transportiert ein Datenpaket, das von einem Host erzeugt
wird, über eine Folge von Routern zum empfangenen Host
Die Folge von Routern heißt Weg, Pfad, Route oder Leitweg durch das Netz
Das Routing erfolgt mit Methoden der Graphentheorie
Dabei wird das Netz als Graph dargestellt
Knoten des Graphen sind die Router
Kanten des Graphen sind LANs, MANs und Weitverkehrsstrecken
188
11.1
Position der Router im ISO-Modell
Schichten
Anwendung
Endsystem
Zwischenknoten als
Vermittlungsschicht
Endsystem
Darstellung
Sitzung
Transport
Vermittlung
Sicherung
Bitübertragung
physikalische Medien
In den Routern existieren nur die Schichten 1-3 des Protokollstapels, denn Vermittler
interessieren sich nicht für den Inhalt der Datenpakete
Pakete müssen im Stack nur bis Schicht 3, in den Endsystemen hingegen in allen
Schichten verarbeitet werden
189
11.2
Aufgaben der ISO-Vermittlungsschicht
Ziel der ISO-Schicht 3: eine möglichst große Vielfalt von Netzen und Technologien soll
unterstützt werden
Dies wird im Internet sowohl bei IPv4 als auch bei v6 erreicht
Die ISO-Vermittlungsschicht ist für die Wegewahl, sowie für einen Verbindungsaufund -abbau und auch für Multiplexen und Demultiplexen mehrerer Pakete zuständig
Hinweis: beim Time Division Multiplex dient eine Leitung oder ein Funkkanal nacheinander der
Übertragung mehrerer Pakete unterschiedlicher Herkunft und Ziele.
Die ISO-Vermittlungsschicht zerkleinert außerdem beim Sender zu lange Pakete in kürzere Fragmente und vereinigt diese wieder zum Originalpaket beim Empfänger (Fragmentation and Reassembly)
Sie macht Fehlererkennung/Fehlerbehebung zwischen Sender und Empfänger (Endezu-Ende)
Sie sorgt für die Sicherstellung der korrekten Paketreihenfolge beim Empfänger durch
Sequenznummern
Sie verhindert die Überflutung des Empfängers durch zu viel Daten in zu kurzer Zeit
durch eine sog. Flow Control
Sie verhindert eine Überlastung der an die Router angeschlossenen Teilnetze durch
eine sog. Congestion Control
190
Von diesen vielen Aufgaben ist bei IPv4 nicht viel übrig geblieben (nur Wegewahl, sowie Fragmentation and Reassembly, sowie etwas Fehlererkennung), IPv6 ist besser
11.2.1
Zwei Arten der Datenübertragung in der ISO-Schicht 3
Es gibt zwei Arten der Datenübertragung: „virtuelle Verbindungen“ und „Datagramme“
Beispiel: IP = Datagramm, ATM = virtuelle Verbindung.
Def.: Virtuelle Verbindung:
• Eine virtuelle Verbindung zwischen zwei Endsystemen (Hosts) ahmt eine direkte physikalische Verbindung wie z.B. ein Stück Draht zwischen zwei Hosts nach
• Da es eine solche direkte Verbindung i.a. aufgrund der (vielen) Router dazwischen nicht
gibt, spricht man von einer virtuellen Verbindung
Def.: Datagramm:
• Jedes Datagramm umfasst genau ein Paket
• Das Paket wird als isolierte Einheit betrachtet, die geroutet werden muss
11.2.1.1 Eigenschaften von ISO-Schicht-3-virtuellen Verbindungen
Der Weg durch das Netz wird vor dem ersten Datentransfer in einer Verbindungsaufbauphase vollständig festgelegt
In jedem Zwischenknoten findet nur in der Verbindungsaufbauphase eine Wegewahlentscheidung statt
191
Der Verkehr nimmt nach der Verbindungsaufbauphase stets denselben Weg
Die Pakete brauchen deshalb keine Herkunfts- und Zieladresse im Header
Am Ende des Datentransfer folgt eine sog. „Verbindungsabbauphase“
Jede virtuellen Verbindung hat insgesamt drei Phasen
• Verbindungsaufbau, Datenübertragung und Verbindungsabbau
Vorteile von virtuellen Verbindungen
• Kein Aufwand für die Wegewahl während der Datenübertragung nötig
Nachteile von virtuellen Verbindungen
• Rel. unflexibel bei sich schnell ändernden Netztopologien oder Routerausfällen
• Aufwand für den Verbindungsauf- und abbau nötig
• Verbindungsauf- und abbau lohnen sich nur bei längeren Übertragungen
11.2.1.2 Eigenschaften von ISO-Schicht-3-Datagrammen
Jedes Paket enthält eine Herkunfts- und Zieladresse
Die Zieladresse bestimmt in jedem Router die richtige vom Router abgehende Leitung
Für jedes Datagramm wird in jedem Router spontan eine Wegewahlentscheidung getroffen
Die Wegewahlentscheidung hängt vom Ziel des Pakets, von dem momentanen Zustand
der an den Router angeschlossenen Subnetze und vom derzeitigen Füllgrad der Router-Sendepuffer ab
192
Pakete, die zur selben Nachricht gehören, können unterschiedliche Wege gehen
Pakete,die später abgeschickt wurden, können früher ankommen
Vorteile von Datagrammen:
• Simpler als virtuelle Verbindungen, daher einfacher zu implementieren
• Kein Verbindungsauf- und -abbau nötig, deshalb niedriger Overhead, was gut für kurze Datentransfers ist
• Flexibler und zuverlässiger bei Router-Ausfällen, da mehr als ein Weg zum Ziel führt
• Datagramme sind besser geeignet für heterogene Teilnetze, die miteinander gekoppelt
sind, da virtuelle Verbindungen für heterogene Teilnetze technisch aufwendig sind
Nachteile von Datagrammen:
• Zieladresse und Herkunftsadresse sind in jedem einzelnen Datagramm notwendig
• Pakete können in permutierter Reihenfolge beim Empfänger eintreffen
• Schicht-3-Datagramme haben keine gute Fehlerüberwachung und implementieren keine
Flusssteuerung und keine Überlastungssteuerung
11.2.2
Virtuelle Verbindungen und Datagramme auf den ISO-Schichten 3 und 4
Virtuelle Verbindungen und Datagramme kann es sowohl auf ISO-Schicht 3 als auch
auf Schicht 4 geben
Virtuelle Verbindungen auf Schicht 3 unterscheiden sich jedoch von Schicht-4-Verbindungen:
193
Def.: Eine ISO-Schicht-3-Verbindung bezieht sich darauf, dass die Wegewahl nur einmal
während der Verbindungsaufbauphase erfolgt. Der Datentransfer erfolgt über einen sog.
„perfekten Kanal“ (siehe unten).
Def.: Eine ISO-Schicht-4-Verbindung bezieht sich darauf, dass es einen Zustand
„Schicht-4-Verbindung aufgebaut“ gibt, der in einem endlichen Automaten bei Sender
und bei Empfänger registriert wird. Auch hier erfolgt der Datentransfer über einen perfekten Kanal.
D.h., Schicht-3-Verbindungen haben nichts mit Schicht-4-Verbindungen zu tun, vielmehr kann man z.B. eine Schicht-4-Verbindung mit einem Schicht-3-Datagramm kombinieren
Beispiel: IP und UDP sind Datagramme, TCP macht virtuelle Verbindungen. Es kann
sowohl TCP mit IP als auch UDP mit IP kombiniert werden.
11.2.3
Perfekte Kanäle bei virtuellen Verbindungen
Eine virtuelle Verbindung ist ein perfekter Kanal durch das Netz
Perfekte Kanäle erbringen folgende Dienstleistungen:
•
•
•
•
Sicherstellung der Paketreihenfolge beim Empfang (kein Überholen)
Erkennung von Übertragungsfehlern und Korrektur durch Paketwiederholung
Verlorene und duplizierte Pakete werden erkannt und wiederholt bzw. beseitigt
Flusssteuerung wird von Ende-zu-Ende durchgeführt
194
11.2.3.1 Aufbau einer virtuellen Verbindung in einem Beispiel-WAN
Der Verbindungsaufbau erfolgt schrittweise auf jeder Teilstrecke
R
LAN
R
WAN
1. Connect
Request
H
2. Connect
Request
G/R
Beispiel
WAN
G/R
H
H
G/R
H
WAN
MAN
R
R
H = Endsystem (Host)
R = Router, G = Gateway
R
R
3.+4. Connect
Request
H
G/R
G/R
G/R
Connect
Confirmations
H
H
Connect
Confirmations
G/R
G/R
R
R
195
H
11.2.3.2 Verwaltung virtueller Verbindungen in einem Beispiel-WAN
H
B
H
Hosts
H
C
H
D
A
LANs
F
E
H
LANs
MANs
oder WANs
Router/Gateways
H
In jedem Router werden Tabellen mit Zustandsinformationen über durchlaufende virtuelle Verbindungen verwaltet.
Beispiel: Ausgehend von A und B sollen acht neue virtuelle Verbindungen durch das
obige WAN gelegt werden.
Ausgehend von A
Ausgehend von B
lfd. Nr.
Pfad
lfd. Nr.
Pfad
0
ABCD
1
BCD
0
AEFD
0
BAE
196
1
ABFD
1
BF
2
AEC
-
-
3
AECDFB
-
-
In jedem Router gibt es eine Tabelle zur Verwaltung der virtuellen Verbindungen
Jede im Router ankommende und abgehende virtuelle Verbindung erhält eine Nummer
Beispiel: Zustandsinformation in den Routern aufgrund alter und neuer Pfade:
H
Zum Host-Empfänger
H
Vom
Host =
sender
A
H0 B0
H1 E 0
B0 E 1
H2 B1
H3 E 2
H4 E 3
Tabelle
B
A0
H0
H1
A1
H2
F0
E
A0
A1
A2
A3
C0
C1
A0
F0
F1
H0
F0
H0
C0
C1
197
C
B0
B1
E0
E1
F
E0
B0
B1
D0
D0
D1
H0
D2
D0
D1
H0
B0
D
C0
C1
F0
F1
C2
H0
H1
H2
H3
F0
Beispiel: H 4 E 3 in Router A heißt: Vom Host H kommt eine Verbindung bei Router A
an, die dort unter der Nr. 4 verbucht wird. Diese Verbindung wird unter der Nr. 3 an den
Router E weitergereicht und dort ebenfalls unter der Nr. 3 verbucht.
Eine virtuelle Verbindung hat beim Nachbar-Router dieselbe Nummer, wenn sie den
Nachbar-Router betritt und i.d.R. eine andere Nummer wenn sie den Nachbar-Router
wieder verlässt
Beispiel: Verbindung HAECDFBH
Verbindungsnummer
H to A
4
A to E
4 3
E to C
3 1
C to D
1 2
D to F
2 0
F to B
0 0
B to H
0 0
H
A
E
C
D
F
B
0
H
Der Vorteil unterschiedlicher Verwaltungsnummern für dieselbe ankommende und abgehende Verbindung ist, dass jeder Router seine Routing-Tabelle selbständig verwalten kann, ohne dass netzweit eindeutige Verbindungsnummern vergeben werden müssen, was unmöglich wäre
198
Nur zwischen benachbarten Routern muss für dieselbe Verbindung dieselbe Nummer
verwendet werden, aber nicht innerhalb eines Routers
11.3
Routing-Algorithmen für virtuelle Verbindungen und Datagramme
Sowohl virtuelle Verbindungen als auch Datagramme benötigen Routing-Algorithmen
Allerdings ist der Aufwand bei einer einmal hergestellten virtuellen Verbindung erheblich kleiner als bei Datagrammen, da die Wegewahlentscheidung bereits getroffen ist
11.3.1
Aufgabe von Routing-Algorithmen
Def.: Die Aufgabe von Routing-Algorithmen ist die Wegewahl für Pakete vom Quellsystem zum Zielsystem (Ende-zu-Ende)
Der Wegewahlalgorithmus eines Routers entscheidet, auf welcher Ausgangsleitung eines Routers ein eingegangenes Paket weitergeleitet wird
Wünschenswerte Eigenschaften eines Wegewahlalgorithmus sind:
•
•
•
•
•
•
Korrekt: Paket findet immer zum Ziel
Einfach: schnell auszuführen
Robust gegen Rechner- oder Leitungsausfälle
Stabil: liefert deterministische Ergebnisse
Fair: kein Paket wird benachteiligt
Optimal: findet den schnellsten oder den kürzesten Weg
199
11.3.2
Eigenschaften von Routing-Algorithmen
Zwei Optimierungskriterien, die ein Routing-Algorithmus verfolgen sollte:
• Entweder Minimierung der durchschnittlichen Paketverzögerung (Netzlatenz) oder
• Maximierung des Gesamtdurchsatzes des Netzes (Netzbandbreite)
Dies sind sich widersprechende Optimierungen, daher gilt oft folgende Heuristik:
• Nur Minimierung der Latenz, indem die Verzögerungen auf den einzelnen Teilstrecken
(hops) minimiert wird (= Kompromiss)
Vorteil der Latenzminimierung auf den Teilstrecken:
• Reduziert meist auch die Ende-zu-Ende Latenz (aber nicht in allen Fällen)
• Vermindert benötigte Bandbreite
• Steigert Durchsatz, allerdings i. A. nicht bis zum Maximum
In einem Netz können Latenz und Durchsatz nicht gleichzeitig optimiert werden, weil
hoher Durchsatz gemäß Warteschlangentheorie (Queueing Theory) nur durch eine
hohe Latenz erreichbar ist.
Beispiel: Wartezimmer beim Arzt ist meistens voll, da Ärzte ihren Patienten-Durchsatz
optimieren wollen, aber nicht deren Wartezeit.
11.3.3
Klassifikation von Routing-Algorithmen
1. Statische (nicht adaptive) Verfahren
• Keine Berücksichtigung des aktuellen Netzzustandes
200
• Gehen von Mittelwerten im Netz aus, nicht von lokalen Informationen, die sich ändern
• Pfad zwischen Knoten i und j wird für alle (i, j) vor der Inbetriebnahme des Netzes berechnet
• Keine Änderung während des Betriebs => statisches Routing
2. Adaptive Verfahren
• Entscheidungen basieren auf aktuellem Netzzustand
• Messungen/Schätzungen der Topologie und des Verkehrsaufkommens sind Basis für die
Wegewahlentscheidung
Feinere Unterteilung der adaptiven Verfahren erfolgt gemäß:
• Zentralisierte Verfahren
• Lokale Verfahren
• Verteilte Verfahren
11.3.4
Statisches Routing
Beim statischen Routing ist die gesamte Topologie des Netzes einer zentralen Stelle
bekannt
Sie berechnet die optimalen Pfade für jedes Paar (i, j) von Knoten, erstellt daraus die
Routing-Tabelle für die einzelnen Knoten und versendet diese an alle (= Routing über
statische Tabellen)
Nur sinnvoll, wenn das Netz klein und statisch ist
201
Eigenschaften von statischem Routing:
• Optimale Pfade (i, j) für alle i, j sind i.d.R. kürzeste Pfade oder schnellste Pfade
• Kürzeste Pfade werden zentral über den Graphenalgorithmus „Spannbaum“ bestimmt
bzw. über „minimalen Spannbaum“
• Das bekannteste Verfahren zur Berechnung eines minimalen Spannbaums ist das von Dijkstra
• Definition Spannbaum:
Gegeben sei Graph G = (V, E). Dann ist G’= (V, E’) ein Spannbaum von G, wenn G’ = Baum
E’ erreicht alle Knoten von G gilt.
11.3.4.1 Zusammenfassung statisches Routing
Eigenschaften
• Tabellen werden zentral erstellt
• Tabellen werden vor Inbetriebnahme des Netzes in die Knoten geladen und dann nicht
mehr verändert
Vorteile
• Einfach zu implementieren
• Gute Ergebnisse bei relativ konstanter Topologie und konstantem Verkehr
Nachteile
• Schlecht bei stark variierendem Verkehrsaufkommen und bei Topologieänderungen
• Schlecht bei großen Netzen (skaliert nicht)
202
11.3.5
Optimierungen von Routing-Algorithmen
Sowohl bei statischem als auch bei dynamischem (= adaptivem) Routing können zwei
Optimierungen erfolgen:
• Mehrfachpfade: dienen zum Finden alternativer Wege durch das Netz
• Hierarchische Wegewahl: dient zur Vereinfachung der Routing-Algorithmen
11.3.5.1 Mehrfachpfade (Multipath Routing)
Prinzip: Benutzung alternativer Wege zwischen jedem Knotenpaar (i, j) ist erlaubt
Vorteile:
• Alternative Wege können gemäß ihrer „Güte“ ausgewählt werden: „gute“ Wege häufiger,
„schlechte“ seltener
· guter Weg := schnellster/kürzester/geringste Warteschlange/höchste Bandbreite/höchste Zuverlässigkeit => Metrik
• Höherer Durchsatz durch Verteilung des Datenverkehrs auf mehrere Pfade erreichbar
• Höhere Zuverlässigkeit, da der Ausfall eines Links nicht so schnell zur Unerreichbarkeit
von Knoten führt
203
11.3.5.2 Realisierung von Mehrfachpfaden
Jeder Knoten enthält Routing-Tabelle mit je einer Zeile für jeden möglichen Zielknoten
eine Zeile
Zielknoten
A1
G1
A2
G2
...
Ai: i-beste Ausgangsleitung des jeweiligen Zwischenknotens
Gi: Gewicht für Ai (drückt die Güte der Leitung aus)
An
Gn
• Gi bestimmt die Wahrscheinlichkeit, mit der Ai benutzt wird
• Die Summe aller Gewichte Gi muss 1 ergeben
• Die Gewichte Gi der Ausgangsleitungen werden gemäß der jeweils gewählten Metrik
(schnellster Weg, kürzester Weg,...) bestimmt
204
Beispiel: gegeben sei eine Paketquelle J und ein Ziel B und mit G1(A) = 0,46; G2(H) =
0,31; G3(I) = 0,23
A
B
I
J
H
L
K
Gewichte werden auf dem Zahlenstrahl von 0 bis 1 aufgereiht (z. B. links das höchste,
rechts das niedrigste; genaue Reihenfolge ist jedoch ohne Belang)
über H
über A
0
D
G
F
3 Alternativen
E
C
Gewicht G1
0,46
Gewicht G2
über I
0,77 Gewicht G3 1
Dann erfolgt eine Zufallsauswahl der alternativen Ausgangsleitung gemäß ihres Gewichts (= Güte):
• Generieren einer Zufallszahl z (0 z 1)
205
• Wähle A, falls 0 zG1, wähle H falls G1z< G1+G2, wähle I falls G1+G2 z < G1+G2+G3
Jeder Weg wird im Mittel entsprechend der Länge seiner Güte mit der gewünschten
Häufigkeit benutzt
11.3.5.3 Hierarchische Wegewahl
Ausgangssituation: die Größe der Routing-Tabellen ist ohne hierarchische Leitwegbestimmung proportional zur Größe des Netzwerks:
Nachteile dieser Methode:
• Großer Speicherbedarf + viel CPU-Zeit zum Durchsuchen der Tabellen
• Viel Bandbreite zum Austausch von Informationen zwischen den Routern
Ab einer bestimmten Netzgröße ist hierarchische Leitwegbestimmung notwendig
Hierarchische Wegewahl heißt, dass die Menge der Router in Regionen unterteilt wird
Üblicherweise wird eine zweistufige Hierarchie verwendet, bestehend aus Regionen
und Knoten innnerhalb jeder Region
Jeder Knoten kennt dabei:
• Alle Routing-Details in seiner Region + die Wege zu allen anderen Regionen
Er kennt nicht die Wege innerhalb anderer Regionen
Er weiß nur, in welcher Region der Zielknoten liegt und routet zu dieser Region
Nachteil: nicht immer sind optimale Entscheidungen möglich
206
11.3.5.4 Beispiel einer zweistufigen Hierarchie
Region 1
1B
2A
1C
1A
Volle Tabelle für 1A
2B
Region 2
2D
2C
Region 4
4B
Region 3
3A
5B
5A
3B
4A
4C
5C
Region 5
5D
5E
Hierarchische Tabelle für 1A
Ziel
Leitung
Teilstrecken
1A
-
-
hierarchische Tabelle ist
viel kürzer
Ziel
Leitung
Teilstrekken
1A
-
-
1B
1B
1
1C
1C
1
2A
1B
2
2B
1B
3
2C
1B
3
2D
1B
4
3A
1C
3
3B
1C
2
4A
1C
4
4B
1C
3
4C
1C
4
1B
1B
1
1C
1C
1
5A
1C
4
2
1B
2
5B
1C
5
3
1C
2
5C
1B
5
4
1C
3
5D
1C
6
5
1C
4
5E
1C
5
207
11.3.6
Adaptives Routing
Man unterscheidet drei Gruppen von adaptiven Verfahren:
1.) Zentrale Verfahren
2.) Lokale Verfahren
3.) Verteilte Verfahren
Zentral heißt:
• Einer führt offline oder online den Wegewahl-Algorithmus aus (= zentrale Instanz)
Lokal heißt:
• Alle Router führen den Algorithmus aus, aber ohne Kommunikation miteinander (= isoliert)
Verteilt heißt:
• Alle Router führen den Algorithmus mit Kommunikation aus, d. h. unter Austausch von Information untereinander
11.3.7
Adaptives und verteiltes Routing
Folgende Methoden wurden bzw. werden im Internet angewandt:
1.) „Distanz“vektor-Verfahren (ganz alt)
2.) Link-Zustandsverfahren (mittelalt)
208
3.) OSPF-Verfahren (derzeit aktuell)
Aus Kompatibilitätsgründen müssen neue Router alle 3 Verfahren unterstützen
11.3.7.1 Das „Distanz“vektor-Verfahren
Prinzip: Die Knoten tauschen mit ihren nächsten Nachbarn Routing-Informationen aus
Jeder Knoten X sendet dazu periodisch an seinen direkten Nachbarn Y (für alle Y) eine
Liste mit seinen gemessenen/geschätzten Güten für jedes Ziel im Subnetz
Umgekehrt empfängt X eine analoge Liste vom Nachbarn Y
Jeder Knoten kennt nach dem Austausch die „Distanz“ (=Gütemaß) zu jedem direkten
und indirekten Nachbarn hinsichtlich:
• der Anzahl der Teilstrecken, die bis zum Nachbarn nötig ist
• der Verzögerungszeit (Latenz) zum Nachbarn. Diese wird über sog. Echopakete ähnlich
wie bei ping gemessen.
• der Warteschlangenlängen in den Sende- und Empfangspuffern der Nachbarn
Dann wird für die gewählte Metrik das Transitivgesetz angewandt:
• Sei e der eigene Wert der Metrik für das Paar (X, Y), sowie Z ein beliebiger Ziekknoten und
E(Z) der Nachbarwert für das Paar (Y, Z) , dann gilt:
· Der Wert der Metrik für das Paar (X, Z) über Y als Zwischenknoten lautet:
· Distanz(X, Z)=E(Z) + e,
· E wird dabei aus der Liste von Y an X entnommen
209
Mit dieser Methode erstellt sich jeder Router im Subnetz nach und nach eine eigene,
vollständige Routing-Tabelle
Nach jeder Periode konvergiert die Tabelle näher zur Wahrheit (=iteratives Verfahren)
Problem: Der Ausfall eines Routers wird nur langsam erkannt (= count-to-infinity-Problem), da die Ausbreitung dieser Information im Netz viele Iterationen erfordert
11.3.7.2 Beispiel für das „Distanz“vektor-Verfahren
A
C
B
G
F
E
D
H
8 12
I
10
J
6
K
L
betrachteter Knoten J
J misst die Latenz zu seinen Nachbarn A, I, K, und H und erhält:
• JA-Verzögerung = 8, JI-Verzögerung = 10, JH-Verzögerung = 12, JK-Verzögerung = 6
J empfängt seinerseits von seinen Nachbarn A, I, K, und H die Latenzen zu allen anderen Knoten (vom jeweiligen Nachbarknoten aus gesehen)
210
Aus beiden Informationen baut J mit Hilfe der Transitivität der Latenz-Metrik eine lokale
Latenztabelle auf
Im dritten Schritt verteilt J seine lokale Tabelle an seine direkte Nachbarn A, I, K, und H
Vorgang wird periodisch von allen Knoten wiederholt
Es bildet sich i.A. nach einigen Iterationen ein eingeschwungener Zustand aller Werte
in den Routingtabellen aus
Der eingeschwungener Zustand bleibt solange bestehen, bis das Netz seine Übertragungseigenschaften oder seine Topologie ändert
Der eingeschwungener Zustand kommt nicht zustande, wenn das count-to-infinity-Problem auftritt
In diesem Fall oszillieren die Werte in den Tabellen hin und her
Dieses Phänomen ist der Grund, warum das Distanzvektorverfahren abgelöst wurde
211
Beispiel: gegeben seien beim Distanzvektorverfahren folgende Tabellen, die J empfängt:
Ziel
von A
von I
von H
von K
A
0
24
20
21
B
12
36
31
28
C
25
18
19
36
D
40
27
8
24
E
14
7
30
22
F
23
20
19
40
G
18
31
6
31
H
17
20
0
19
I
21
0
14
22
J
9
11
7
10
K
24
22
22
0
L
29
33
9
9
Eigene Messungen zu den Nachbarn seien: JA = 8, JI = 10, JH = 12, JK = 6
Hinweis: die Latenzen AJ, IJ, HJ und KJ, die die Nachbarknoten sehen, sind i.a. anders, als die, die J sieht,
d.h. es gilt: AJ JA=> Latenzen sind in Rechnernetzen i.a. nicht symmetrisch.
212
J wählt dann aus den eigenen Messungen und den empfangenen Latenzen den besten
Weg aus
Ergebnis: Tabelle in J nach dem Austausch von J mit seinen direkten Nachbarn:
Ziel
Latenz
über
Ziel
Latenz
über
A
8
A
G
18
H
B
20
A
H
12
H
C
28
I
I
10
I
D
20
H
J
0
-
E
17
I
K
6
K
F
30
I
L
15
K
11.3.7.3 Das Link-Zustandsverfahren
Ist Nachfolger des Distanzvektorverfahrens
Mittlerweile auch schon veraltet
Prinzip:
• Jeder Router in einem Subnetz (Routing Region) ist im Vollbesitz aller „Güte“-Werte eines
Subnetzes
213
• Dazu sendet jeder Router sog. ICMP-Pakete an alle anderen Router im Subnetz, nicht nur
an seine direkte Nachbarn
Hinweis: ICMP= Internet Control Message Protocol = wichtiges Steuerungsprotokoll im Internet
• Entsprechend empfängt jeder Router ICMP-Pakete von allen anderen Routern im Subnetz
• Dadurch kann jeder Router für sich die Topologie des ganzen Subnetzes rekonstruieren
• Als Gütewerte werden die üblichen Metriken, d.h. schnellster Weg, kürzester Weg, u.s.w.
verwendet
• Mit Hilfe der Topologie und der Güte jeder Verbindung kann jeder Router für sich einen minimalen Spannbaum des Subnetzgraphen aufbauen
Problem: Das Link-Zustandsverfahren ist nicht flexibel und nicht sicher genug gegen
Hacker-Angriffe
11.3.7.4 Das OSPF-Verfahren
OSPF = open „shortest path first“
Ist der Nachfolger des Link-Zustandsverfahrens und Stand der Technik
Prinzip: Wie das Link-Zustandsverfahren, aber mit einer Reihe von Erweiterungen:
1.) Ist wegen der Verwendung einer Datenbank anstelle einer Tabelle Hacker-sicherer
2.) Unterstützt mehrere Metriken (kürzeste, schnellste Wege etc.)
3.) Berücksichtigt alternative Wege
214
4.) Unterstützt hierarchisches Routing mit 2 Stufen durch ein Link-Zustandsverfahren in
jeder Region
• Vorgehensweise:
· von jedem Knoten in der Region wird gem. Dijkstra ein min. Spannbaum seines Subnetzes berechnet
· Topologie des Spannbaums und Güte jeder Wegstrecke werden in jedem Router in einer
Datenbank gehalten, nicht in einer Tabelle
11.4
Vermittlungsschicht des Internet (IP)
Die Vermittlungsschicht des Internet (IPv4 oder IPv6 implementiert einige aber nicht
alle Eigenschaften einer ISO-Vermittlungsschicht
Insbesonders ist IP kein perfekter Kanal
Bei Weitverkehrsnetzen hat IP nur dann eine Routingfunktiong, wenn IP auf SONET/
SDH ohne ATM übertragen wird
IP macht im Internet die Wegewahl, sofern es nicht als Nutzlast von ATM transportiert
wird
11.4.1
IPv4 und V6
IPv4 und V6 sind Protokolle für die Ende-zu-Ende-Kommunikation zwischen Sender
und Empfänger mit folgenden Haupt-Eigenschaften:
• Macht die Wegewahl (1P) im Internet, sofern es nicht als Nutzlast von ATM transportiert
215
wird
• Ist ein verbindungsloser Dienst, d.h. ein Datagramm-Protokoll
• Fragmentiert beim Übergang in ein Subnetz mit kleinerer maximaler Rahmenlänge ein großes Paket in mehrere kleinere Rahmen
• Reassembliert Fragmente, d.h. Rahmen wieder zum Original IP-Paket, sobald die maximale
Rahmenlänge dies zulässt)
Beispiel: Von SONET/SDH nach Ethernet = Übergang in ein Subnetz mit kleinerer maximaler Rahmenlänge (MTU)
Hinweis: MTU = Maximum Transport Unit auf der Schicht 2
Nachteile von IP:
• Maximale IP-Paketlänge ist 64 KB, davon entfallen mindestens 20 Byte auf den Header
Ist für kleine Datenmengen (<20 Byte) ineffizient, da großer Header
• Schützt nicht vor Paketverlusten oder von Verlusten von Teilen eines Pakets, den Schicht
3-Fragmenten, da es keine automatische Paket- bzw. Fragmentwiederholung im Fehlerfall
gibt
• Nur IPv6 unterstützt Quality of Service (QoS) bei der Übertragung, mit IPv4 sind Garantiern
für Echtzeitdatenübertragung nicht möglich
IPv4 hat eine hohe praktische Bedeutung, da weit verbreitet
Bedeutung von IP wird nach flächendeckender Einführung von IPv6 noch steigen
216
11.4.2
Aufbau eines IPv4-Pakets (IP Header)
0
4
8
VERS LEN
16
TYPE OF SERVICE
PROTO
24
31
TOTAL LENGTH
FLAGS
IDENT
TIME
19
FRAGMENT OFFSET
HEADER CHECKSUM
HEADER
SOURCE IP ADDRESS
DESTINATION IP ADDRESS
PADDING
OPTIONS
DATA
NUTZDATEN
...
11.4.2.1 Die Header-Felder von IPv4
VERS
4b
LEN
TYPE OF SERVICE (Bedeutung siehe
unten)
4b
8b
Protokollversion von IP, z. Z. IPv4
oder IPv6
Länge des Headers (in 32 Bit-Wörtern)
Bits 0-5: DSCP (Differentiated Services Code Point) siehe unten
Bits 6-7: ECN (Explicit Congestion
Notification = IP-Flusssteuerung) s.u.
217
TOTAL LENGTH
16b
IDENT
16b
FLAGS
3b
FRAGMENT
OFFSET
13b
TIME
8b
PROTO
8b
HEADER
CHECKSUM
SOURCE
ADDRESS
DESTINATION
ADDRESS
16b
Länge incl. Nutzdaten in Bytes =>
Maximale IP-Paketlänge = 64 KB
Information, zu welchem Datagramm
dieses Paket nach einer Fragmentierung gehört (siehe unten)
nicht fragmentieren bzw. letztes Fragment (DF/LF)
Position dieses Pakets (=Fragment)
innerhalb des Datagramms mit der
Nummer IDENT [in 8-Byte-Einheiten]
Lebensdauer in Sekunden („time to
live“) 255 s. Oft werden statt Sekunden die Zahl der Zwischenknoten
(Router Hops) gezählt.
Ist inzwischen veraltet bzw. wird teilweise anders verwendet
Typ des darüberliegenden höheren
Protokolls = UPD oder TCP
EXOR-Verknüpfung der Header-Wörter als Prüfsumme für den Header
32b
IP Adresse des Quell-Hosts
32b
IP-Adresse des Ziel-Hosts
218
OPTIONS
PADDING
DATA
max. 40
Für Router-Management, WegelogByte lang buch und ähnliches (siehe unten)
Auffüller, so dass stets Wortgrenzen
erreicht werden
Nutzdatenfeld (Payload)
11.4.2.2 DSCP (Differentiated Services Code Point)
Enthalten Informationen, wie das Paket an der Grenze zwischen zwei Subnetzen weitergeleitet werden soll
Dazu kann das Paket in eine von 64 Klassen eingeteilt werden
Beispiel: 1.) Es gibt eine sog. Expedited Forwarding-Klasse für Pakete, die eine geringe
Latenz benötigen. 2.) Es gibt 12 sog. Assured Forwarding-Klassen = Einteilung der
Pakete in vier Klassen zu je drei Prioritäten.
Funktioniert in der Praxis bei IPv4 nur selten
11.4.2.3 ECN (Explicit Congestion Notification)
Dient zur Mitteilung eines Routers an seinen Vorgängerrouter, dass bei ihm Überlastung droht
Theoretisch breitet sich diese Information rückwärts bis zur Datenquelle aus, worauf
diese die Datenrate reduziert
Funktioniert in der Praxis bei IPv4 nur selten
219
11.4.2.4 Ident und Fragment Offset
Ein IP-Fragment ist ein vollständiges IP-Paket mit komplettem Header, bei dem die Felder Ident und Fragment Offset belegt sind
Fragmentation + Reassembly sind notwendig, wenn die darunterliegende Schicht 2 keine 64 KB Datenrahmen übertragen kann, sondern nur kleinere Rahmen
Trifft immer bei Ethernet als Schicht 1+2a zu, da es dort nur Datenrahmen mit max. 1500
Byte gibt
11.4.2.5 Beispiele für IPv4-Optionen
1.) „Strict Source Routing“: enthält eine Liste von Router-IP-Adressen, auf denen das
Paket zum Ziel gelangt. Nur diese Route darf verwendet werden.
2.) „Record Route“: weist alle Router an, ihre IP-Adresse in das Optionenfeld einzutragen, damit der Weg des Pakets vom Empfänger zurückverfolgt werden kann (Wegelogbuch)
• Problem hierbei: 40 Byte im Optionsfeld reichen nicht aus, wenn viele Zwischenstufen
durchlaufen werden, was heutzutage oft der Fall ist.
3.) „Time Stamp“: weist alle Router an, eine 32-Bit-Zeitangabe in das Optionenfeld einzutragen
Die letzen beiden Optionen sind für Testzwecke
220
Hinweis: Die vollständige Liste aller möglichen Optionen steht unter www.iana.org/assignments/ipparameters
11.4.3
Aufbau eines IPv6-Pakets
Minimale Header-Länge ist 40 Byte (ohne Erweiterungs-Header), also noch mehr als bei
IPv4
Optional kann ein Erweiterungs-Header variabler Länge dazukommen
Maximale IPv6-Paketlänge ist 64 K-1+40 Byte (mit Erweiterung-Header und Nutzdaten,
aber ohne sog. Jumbograms)
Die ersten 40 Header-Bytes:
0
0
1
Minimum
Header:
10x32
Bit-Worte
2
3
4
5
6
7
8
9
Version
4
8
12
16
Traffic Class
20
24
28
Flow Label
Payload Length
Next Header
16 Byte Source Address
16 Byte Destination Address
221
Hop Limit
31
11.4.3.1 Bedeutung der ersten 40 Header-Bytes
Feldname
Länge Bedeutung
Version
4 Bit
Traffic Class
Flow Label
Payload Length
Next Header
Hop Limit
Source Address
Destination
Address
11.4.4
6 = IPv6
Für Quality of Service (QoS). Ist wie bei IPv4 definiert, d.h. besteht aus:
8 Bit
Bits 0-5: DSCP (Differentiated Services Code Point)
Bits 6-7: ECN (Explicit Congestion Notification = IP-Flusssteuerung)
20 Bit Zur Attributierung des Pakets wegen QoS und Echtzeitdatenübertragung
Länge des Pakets ohne Minimum Header aber mit Erweiterungs-Header in
16 Bit
Byte. D.h., der Minimum Header wird bei der Paketlänge nicht mitgezählt.
Typ des Erweiterungs-Headers (wenn Erweiterungs-Header da, bzw. auch
8 Bit
für Erweiterungen von Schichten höher als 3)
Maximale Anzahl an Routern, die ein Paket zurücklegen darf. Wird beim
8 Bit
Durchlaufen eines Routers („Hop“) um eins verringert. Pakete mit Wert null
werden gelöscht. Verhindert ewig kreisende Pakete.
128 Bit IP Adresse des Quell-Hosts
128 Bit IP Adresse des Ziel-Hosts
Quality of Service (QoS) in IPv6
Bei IPv6 funktioniert QoS dann, wenn alle beteiligten Akteure IPv6 unterstützen, d.h.
wenn Quell- und Zielrechner, sowie alle Router dazwischen IPv6-fähig sind
Dies ist derzeit meist nicht der Fall
222
11.4.4.1 Traffic Class
Ist wie bei IPv4 definiert
11.4.4.2 Flow Label
IPv6 erlaubt zustandslose und zustandsbehaftete Datenübertragung
Bei zustandsloser Datenübertragung kann das Paket durch Zusatzinformation attributiert werden
Die Zusatzinformation ist das sog. Flow Label
Beispiel: Es gibt einen Flow Label-Wert für das Zusammenfassung von IPv6-Paketen zu
einer ganzen Gruppe mit dem Ziel einer besseren Lastverteilung zwischen Routern.
Bei zustandsbehafteter Datenübertragung ist eine sog. Signalisierung zwischen Quellund Zielrechner und Routern möglich, die Zustände ausdrückt
Die Signalisierung erfolgt ebenfalls über das Flow Label-Feld
Beispiel: Es gibt es einen Flow Label-Wert für die Signalisierung durch RSVP oder
durch das sog. General Internet-Signaling Transport-Protokoll (GIST).
11.4.5
Adressierung in IPv4
Das Internet besteht aus einer riesigen Zahl von Netzen (>>105), die durch IP adressiert
werden, sofern IP nicht ATM-Nutzlast ist, d.h. getunnelt wird
223
Hinweis: Tunneling = Verfahren, um IP-Pakete durch inkompatible Netze zu routen wie z.B. ATM. IP-Paket
hat im Netz, durch das getunnelt wird, keine Funktion sondern wird als Nutzlast der Schicht 7 transportiert
Beispielkonfiguration für Teilnetze im Internet
11.4.5.1 32 Bit IPv4-Adressen
Es werden für die Adressierung je 32 Bit für Quelle und Ziel verwendet, was heutzutage
zu wenig ist
224
IP-Adressen wurden über lange Zeit bestimmten Adressklassen zugeordnet und in festen Portionsgrössen vergeben, sog. Classful Addressing
Nach einigen Jahrzehnten gingen langsam die Adressen aus und man begann, die letzten noch übrig gebliebenen Adressen ohne Klasseneinteilung und in beliebigen Portionen zu vergeben (= Classless Interdomain Routing, CIDR)
Des weiteren begann man, Adressen nur kurzzeitig, d.h. dynamisch zu vergeben (über
das sog. DHCP) oder mehrfach zu verwenden, z.B. global 1 Mal und lokal mehrfach
(über das sog. Network Address Translation, NAT), um der drohenden Adressknappheit zu entgehen
Traditionell wurden Internet-Adressklassen vom einem sog. Network Information Center (NIC) bzw. seinen Unterorganisationen in den einzelnen Ländern zugeteilt (http://
www.nic.com)
Die Unterorganisation des NIC in Deutschland ist das denic (http://www.denic.de)
Das denic hat die klassenbasierten Adressen an Endkunden vermietet
Heutzutage werden klassenlose Adressbereiche in frei wählbaren Portionsgrößen gegen Gebühr von der Internet Assign Number Authority (IANA) vergeben (http://www.iana.org)
Die IANA ist eine Unterorganisation der ICANN, die die Standards des Internet festlegt
Die IANA hat 5 Unterorganisationen, die für die 5 Regionen der Welt zuständig sind
Für Europa ist die Unterorganisation RIPE zuständig (http://www.ripe.net)
225
Dort kann jeder Privatmann, jede Firma, Behörde oder Behörde IP-Adressen kostenpflichtig und meist für ein Jahr beziehen
Da fast alle IP-Adressen klassenbasiert sind, wird im weiteren diese Adressierung erläutert
11.4.5.2 Klassenbasierte IPv4-Adressen
Die klassenbasierte IPv4-Adresse ist eine hierarchische Adresse aus Netz- und HostAdresse (netid und hostid)
Es gibt drei Formate für Subnetze unterschiedlicher Größe sowie ein Format für Multicast
Gebräuchliche Schreibweise für alle IPv4-Adressen sind 4 Zahlen 255 mit Punkten dazwischen
Beispiele:
• 10.0.0.0 für Arpanet (class A)
• 128.10.0.0 für ein großes LAN (class B)
• 192.5.48.0 für ein kleines LAN (class C)
226
11.4.5.3 Aufbau klassenbasierter IPv4-Adressen
für Multi- 3 Formate
cast
Typ Netzadr.
123...7 8
netid
16
hostid
24
31
7 Bit netid, 24 Bit hostid
31
01 23...
15 16
CLASS B 10
hostid
netid
31
012
23 24
34...
netid
hostid
CLASS C 110
31
45...
0123
group address
CLASS D 1110
14 Bit netid, 16 Bit hostid
21 Bit netid, 8 Bit hostid
Es gibt folgende Adressklassen:
•
•
•
•
•
0
CLASS A 0
Hostadresse
Klasse-A-Netze: 1.0.0.0 bis 127.255.255.255
Klasse-B-Netze: 128.0.0.0 bis 191.255.255.255
Klasse-C-Netze: 192.0.0.0 bis 223.255.255.255
Klasse-D-Netze: 224.0.0.0 bis 239.255.255.255 (nur für Multicast)
reserviert: 240.0.0.0 bis 255.255.255.255
Bei den IPV4-Adressen gibt es ganze Adressbereiche mit spezieller Bedeutung
für Broadcast, für das eigene Netz, für den eigenen Host und für loop back
Hinweis: Loopback = Host sendet an sich selber
227
Durch diese speziellen Adressbereiche gehen einige Mio. Adressen verloren
IPv6 hingegen stellt praktisch unbegrenzt viele Adressen zur Verfügung (128 Bit =>
2128 Adressen)
11.5
IP-Subnetze
Beim Internet gibt es die Möglichkeit, einen Teil der Hostadresse lokal als Subnetzadresse zu vergeben, wodurch eine 3-stufige (= hierarchische) IP-Adressvergabe entsteht
Beispiel:
• Die TUC hat von der NIC bzw. IANA ein Klasse-B-Netz mit 139.174.0.0 als Netzadresse (sog.
address domain) gemietet, das vom RZ verwaltet wird
• Die 16 Bit Hostadressen dieser Domäne können lokal beliebig aufgeteilt werden, z.B. in 8
Bit-Subnetzadresse und 8 Bit Host-Adresse
• Jedem TUC-Institut wurde vom RZ-Netzwerkadministrator eine 8 Bit-Subnetzadresse zugewiesen
• Das Institut für Informatik beispielsweise hat als Subnetzadresse 100, so dass dort alle IPAdressen 139.174.100.x lauten
• Im IfI wiederum weist der IfI-Netzwerkadministrator jedem Rechner eine Host-Adresse innerhalb obiger Subnetzadresse zu
Einführung einer dreistufigen Adresshierarchie aus Netzklasse, Netzadresse und
Subnetz
228
• Der Standard-Gateway im IfI hat beispielsweise die IP-Adresse 139.174.100.254
Hinweis: Bemerkung: Ein IP-Subnetz hat nichts mit einem Subnetz der Schicht 1 und 2 zu tun.
Verschiedene LANs können ein gemeinsames IP-Subnetz bilden.
Die Adressierung der Subnetze geschieht über Subnetzmasken, die lokal mit der IP-Adresse UND-verknüpft werden
Beispiel: 139.174.100.x AND 255.255.255.0 liefert das Informatik-Subnetz 139.174.100.0
(255.255.255.0 ist die Subnetzmaske)
11.5.1
Vorteile von Subnetzen
Router müssen an ihren Ausgangs-Ports nicht eine große Zahl von Hosts (bis zu 16M2) verwalten, sondern nur wissen, über welche Leitung man zum jeweiligen Subnetz gelangt
Erhebliche Einsparungen in den Routing-Tabellen
Subnetze sind von außen nicht erkennbar, deshalb kann die Unterteilung in Subnetze
ohne die NIC bzw. IANA, d.h. dezentral (= vor Ort) gemacht werden
Die Wegewahl erfolgt hierarchisch, was einfacher ist
229
12 Transportschicht (ISO-Schicht 4)
Im ISO-Modell ist die Schicht 4 sowohl in Form von virtuellen Verbindungen als auch
in Form von Datagrammen möglich
12.1
Im Internet ist beides, virtuelle Verbindungen und Datagramme, realisiert
Es gibt das Transmission Control Protocoll (TCP) für virtuelle Verbindungen und das
Universal Datagram Protocol (UDP) für Datagramme
TCP hat fast alle Eigenschaften der ISO-Transportschicht sowie zusätzliche Optimierungs-Funktionen, die es bei ISO nicht gibt, wie z.B. einen adaptiven Time-out
UDP realisiert nur sehr wenige Funktionen der ISO-Transportschicht
12.2
Die ISO-Transportschicht
Die ISO-Transportschicht beinhaltet die Spezifikation und eine Beispielimplementierung und ist verbindungsorientiert
12.2.1
Die Internet-Transportschicht
Aufgaben der ISO-Transportschicht
Aufbau- und Abbau einer Verbindung zwischen Sender und Empfänger
Bereitstellen von QoS
230
Hinweis: QoS = Quality of Service. QoS ist bei der ISO-Transportschicht höher als bei TCP.
Beispiel: Bietet priorisierte Datenübertragung („expedited data“)
Vollduplex-Datenübertragung
Sichere Datenübertragung über einen perfekten Kanal bestehend aus: 1.) Einhalten der
Paketreihenfolge 2.) automatische Paketwiederholung bei Übertragungsfehlern 3.) automatisches Löschen von mehrfach übertragenen Paketen
FIFO-Reihenfolge wird bei der Übertragung bewahrt
Teilnehmer B
Teilnehmer A
Warteschlange von A nach B
Datenpakete
Warteschlange von B nach A
Transportsystem
12.2.2
Weitere Eigenschaften der ISO-Transportschicht
Ausnahme bei der FIFO-Reihenfolge sind Expedited Data = Daten hoher Priorität
231
• Expedited Data halten untereinander ebenfalls ihre Reihenfolge ein, werden aber zwischen
normale Pakete („Daten-PDUs“) eingestreut (=“verschränkte Übertragung“)
• Eine separate Warteschlange für Expedited Data kann bei Sender und Empfänger existieren, muss aber nicht
Datenpakete erleiden durch die Ausführung der Dienste der Transportschicht eine
Verzögerung (Latenz), da ggf. Pakete in der Reihenfolge umgeordnet werden müssen
(packet reorder), oder weil Pakete nochmal übertragen werden müssen (packet retry)
Der Anwendungsprozess greift auf die Transportschicht über einen sog. Transportschicht-Dienstzugangspunkt (TSAP, Transport Layer Service Access Point) zu
Die Transportschicht wiederum spricht die Vermittlungsschicht über einen Vermittlungsschicht-Dienstzugangspunkt (NSAP, Network Layer Service Access Point) an
Die TSAPs werden bei TCP durch „Ports“, d.h. spezielle Adressen im Betriebssystem
des Empfängers realisiert
Die Transportschicht erlaubt über Ports die direkte Kommunikation mit Prozessen auf
einem anderen Rechner
Die beschriebenen Eigenschaften der ISO-Transportschicht wurden in TCP implementiert, zusammen mit einigen Optimierungen zur Verbesserung des Datendurchsatzes
und des Time Out-Verhaltens (=Optimierungsfunktionen)
232
12.2.3
Funktionsaufrufe (API) der ISO-Transportschicht
12.3
Transportprotokolle im Internet (TCP, UDP)
TCP ist das wichtigste Transportprotokoll im Internet, denn in vielen LANs wie z.B.
Ethernet ist die ISO-Schicht 2b nicht vollständig implementiert
Dieses Versäumnis wird von TCP auf Schicht 4 behoben
Das komplette TCP-Paket wird im Datenfeld eines IP-Pakets als Nutzlast transportiert
Neben TCP gibt es noch UDP, das allerdings nur Datagramm-basiert ist, d.h. keine sichere Übertragung bietet
TCP Ist hinsichtlich des Datenaustauschs effizient für große Datenmengen, aber nicht
echtzeitfähig
233
Die TCP-Transportschicht verbessert die QoS des Internets beträchtlich, allerdings
nicht in Richtung Echtzeit
12.3.1
Datensicherung durch TCP
TCP sichert die Nutzdaten auf dem Weg von Sendeprozess zu Empfangsprozess, d.h.
von Ende zu Ende über einen perfekten Kanal
Arbeitsumgebung der Transportschicht ist das ganze Internet
Arbeitsumgebung der Sicherungsschicht ist nur das Kabel bis zum nächsten Rechner
Hinweis: Die Sicherungsschicht arbeitet nur zwischen benachbarten Rechnern. Prozesse gibt es nicht und
deshalb existieren auch keine Port-Adressen und keine Interprozesskommunikation.
12.3.2
Von TCP erbrachte Dienste
Stellt die sichere Kommunikation von Prozess-zu-Prozess in 3 Phasen bereit:
• Verbindungsaufbau
• Datenübertragung
• Verbindungsabbau
Fasst mehrere kurze TCP-Daten derselben Verbindung zu einem langen Paket zusammen
Effizienter bzgl. der erreichbaren Bandbreiteausnutzung, da der Header-Anteil im
Paket im Vergleich zur Nutzlast weniger ins Gewicht fällt
234
Zerteilt (segmentiert) lange Nachrichten der darüberliegenden Anwendungsschicht in
64 K-Pakete und vergibt eine Sequenznummer für jedes TCP-Teilpaket
Baut segmentierte Nachrichten anhand der Sequenznummer wieder zusammen (reassembly)
Hinweis: Auf Schicht 3 gibt es bei IP den Vorgang „Fragmentation and Reassembly“. Dieser hat nichts mit
„Segmentation and Reassembly“ bei TCP auf Schicht 4 zu tun. Beide Vorgänge laufen parallel und
unabhängig voneinander ab. Fragmentation auf Schicht 3 zerteilt zu lange IP-Pakete in kürzere IP-Pakete,
die von Schicht 2 übertragen werden können. Segmentation auf Schicht 4 zerteilt zu lange Nachrichten in
kürzere TCP-Pakete.
Verbessert die Fehlertoleranz durch Rücksetzen einer existierenden Verbindung (reset)
Leistet Ende-zu-Ende-Flusssteuerung durch Bestätigungen (Acknowledges)
Stellt die richtige Paketreihenfolge beim Empfänger durch Sequenznummern sicher
Hinweis: Sequenznummern erkennen auch das Fehlen oder Verdoppeln von Paketen und implementieren
Acknowledges.
235
12.3.3
Aufbau eines TCP-Pakets (TCP Header)
16-Bit
16-Bit
Herkunfts-Port
Ziel-Port
Sequenznummer des Pakets
Huckepack-Acknowledge für ein zuvor von der Gegenseite gesendetes Paket
HeaderLänge
unbelegt
C E U A P R S F
W C R C S S Y I
R E G K H T N N
Prüfsumme von Header inkl. Nutzdaten
Fenstergröße
Zeiger auf hochpriore Daten im Datenfeld
Optionen (0 bis 10x 32-Bit-Worte)
Datenfeld, 0 bis 64K-40 Byte, (-40, wenn Optionenfelder der IP- und TCP-Header = 0 sind)
Herkunfts-Port und Ziel-Port:
• 16-Bit-Adressen zur Spezifikation von Herkunfts- und Zielprozess über Ports
236
• Liste der reservierten Port-Adressen steht unter: www.iana.org
Sequenznummer (32 Bit) des nachfolgenden Datenfeldes:
• Jedes TCP-Segment ist ein TCP-Paket, das Teil einer größeren Nachricht sein kann, die
mehr als ein Paket umfasst
• Ist die Nachricht kleiner als ca. 64KB, dann gibt es keine multiplen Segmente, sondern nur
eine einziges TCP-Paket, in dessen Nutzlast sie übertragen wird
• Die Sequenznummer dient
· zur Mitteilung einer initialen Sequenznummer zum Verbindungsaufbau an den Empfänger
· Zur Abwicklung des Schiebefensterprotokolls, inkl. Acknowledge und Flusssteuerung
· zum Paketlöschen, falls ein Paket mehrfach empfangen wurde
· zur Sortierung der TCP-Pakete in der richtigen Reihenfolge beim Empfänger (packet reorder)
· zum korrekten Einsortierten eines Pakets in eine Nachricht, das wegen eines Übertragungsfehlers wiederholt wurde
· zum korrekten Einsortierten eines Pakets in eine Nachricht, das nicht ankam und deshalb wiederholt wurde
„Huckepack“-Acknowledge-Nummer (32 Bit) vom Empfänger zum Sender:
• wird doppelt verwendet: a) für Verbindungsauf- und abbau b) sorgt während der Datenübertragung für die Quittierung von zuvor empfangenen Paketen nach dem HuckepackVerfahren.
237
Def.: Huckepack-Verfahren heißt, dass das Acknowledge in einem ganz normalen Datenpaket vom Empfänger zurück zum Sender mitgeschickt wird, sofern es ein solches Paket
überhaupt gibt. Das Huckepack-Verfahren bedeutet, dass das Absenden eines Pakets
zusätzlich dazu verwendet wird, um das Acknowledge für den Empfang eines vorgegangenen Paktes demselben Sender zu quittieren. An beiden Paketen, d.h. am aktuellen und
am vorangegangenen sind die gleichen Rechner beteiligt. Gibt es das Paket nicht, wird
ein extra Acknowledge-Paket vom Empfänger zum Sender geschickt, das nur das Acknowledge und keine Daten enthält.
Header-Länge (4 Bit) = Zahl der 32-Bit-Worte im Header incl. des Optionenfeldes
(kleinster Wert ist 5, größter Wert ist 15)
max. zehn 32-Bit-Worte im Optionenfeld möglich
CWR = Congestion Window Reduced und ECE = Explicit Congestion Notification Enabled (ECE)
• Dienen zur Steuerung des Datenverkehrs, wenn das Netz überlastet ist, die sog. Stausteuerung, in der Weise, dass keine Pakete verloren gehen
• Die beiden Header Bits CWR und ECE von TCP sowie die 2 Bits der Explicit Congestion
Notification ECN von IP gehören funktional zusammen und werden alle vier für die Stausteuerung benötigt
URG (1 Bit, urgent): Gesetzt, wenn der Zeiger auf hochpriore Daten im Header gültig ist
ACK (1 Bit): Gesetzt, wenn die Acknowledge-Nummer gültig ist
238
PSH (1 Bit, push): Gesetzt, wenn Daten im Datenfeld beim Sender nicht gepuffert werden dürfen, sondern sofort gesendet werden müssen
Verhindert senderseitig das Zusammenfassen mehrerer kleiner Pakete zu einem großen
Verbessert das Echtzeitverhalten bei der Datenübertragung auf Kosten der Effizienz
RST (1 Bit, reset): dient dem Rücksetzen der TCP-Verbindung
SYN (1 Bit, synchronize): dient zusammen mit ACK und dem Huckepack-Acknowledge
dem Verbindungsaufbau
FIN (1 Bit, final): kennzeichnet das letzte Paket beim Verbindungsabbau
Die Funktionen von SYN, ACK und FIN sind mit Hilfe komplexer endlicher Automaten
definiert
Hinweis: Es gibt auf Sender- und Empfängerseite je einen komplexen endlichen Automaten für
Verbindungsauf- bzw. -abbau. Die Automaten für Verbindungsaufbau registrieren die Phase, in der sich
die virtuelle Verbindung befindet (Verbindung im Aufbau oder aufgebaut). Die Automaten für
Verbindungsabbau registrieren ebenfalls die Phase, in der sich die virtuelle Verbindung befindet
(Verbindung teilweise oder ganz abgebaut).
Fenstergrösse (16 Bit) vom Empfänger zum Sender: dient zur Flusssteuerung durch
das Schiebefensterprotokoll
• Gibt an, wie viele Byte ab dem zuletzt bestätigten Byte gesendet werden dürfen
Prüfsumme (16 Bit): sichert das gesamte TCP-Paket incl. Header und Daten
239
• Da dieses Feld Teil des Headers ist, wird nur ein sog. Pseudo-Header ohne das Prüfsummenfeld geprüft
Zeiger auf hochpriore Daten (16 Bit):
• Gibt den Abstand in Byte zur aktuellen Sequenznummer an, ab dem im Datenfeld hochpriore Daten stehen, falls vorhanden
Optionen (0 bis max. 10x 32-Bit-Worte):
• Wird z.B. verwendet, um dem Sender anzuzeigen, wie viele Daten der Empfänger maximal
pro Paket puffern kann
Hinweis: Die vollständige Liste aller möglichen Optionen steht unter www.iana.org/assignments/tcpparameters
Datenfeld von 0 bis ca. 64K Byte
12.3.3.1 Unterschiede zwischen Push Flag und URG Flag
Push-Pakete sind mit dem PSH-Flag gekennzeichnete Pakete
PSH=TRUE bewirkt, dass das Paket nicht aus Effizienzgründen zwischengespeichert
werden darf, bis es mit anderen kleineren Paketen derselben Verbindung vereinigt werden kann
Pakete mit PSH=TRUE müssen vom Sender sofort abgeschickt werden
Sind bereits mehrere, kleinere TCP-Pakete derselben Verbindung zwischengespeichert, werden diese mit dem Push-Paket vereinigt und das Gesamtpaket wird sofort abgeschickt
240
keine zusätzliche Latenz auf der Senderseite
URG=TRUE-Pakete werden senderseitig wie Push=TRUE-Pakete behandelt. d.h. sie
sind senderseitig dasselbe wie PSH=TRUE-Pakete
URG-Pakete werden jedoch beim Empfänger sofort bearbeitet, PSH-Pakete nicht
keine zusätzliche Latenz beim Empfänger bei URG=TRUE
Hochpriore Übertragungen erlauben es u.a., fehlerhafte Übertragungen oder falsch laufende Programme beim Empfänger über das Netz vorzeitig durch den Sender abzubrechen
12.3.4
Optimierung der Datenübertragung durch TCP
TCP ist bandbreiteeffizient, d.h. es schont die zur Verfügung stehende Bandbreite
Die Gründe für die Effizienz liegen in:
1.) der Zusammenfassung mehrerer kleiner Pakete zu einem großen beim Sender
2.) der Verwendung eines adaptiven Schiebefensters zur Flusssteuerung zwischen Sender und Empfänger (flow control)
• Durch die Adaptivität im Schiebefenster wird ständig die mutmaßlich beste Größe jedes
Pakets ermittelt
• die Flusssteuerung vermeidet einen Pufferüberlauf beim Empfänger durch zu große und
zu viele Pakete
241
3.) der Verwendung einer adaptiven Stausteuerung (congestion control)
• die Stausteuerung vermeidet Staus im Netz durch zu viele Pakete in den Routern
4.) der Verwendung eines adaptiven Time-Outs
• durch die Adaptivität des Time Outs werden unnötige Wartezeiten bei Paketverlust so gut
es geht vermieden. Ganz vermeiden lassen sie sich jedoch nie.
12.3.5
Flusssteuerung und Stausteuerung (congestion control) bei TCP
Um Überlastungen des Internet zu vermeiden, versucht jede einzelne TCP-Verbindung,
nur soviel Daten zu senden, wie der jeweilige Empfänger und das Netz zwischen Sender und Empfänger verkraften kann
Das besondere Problem dabei ist, dass sich die verkraftbare Menge sowohl beim Empfänger als auch beim Internet ständig ändert
Einige der Gründe für die Schwankungen im Netz sind:
• vorübergehende Überlastung eines Routers durch zu viele eintreffende Pakete (= Hot
Spots)
• mehrere, zufällig gleichzeitige Übertragungen von Sendern zum selben Empfänger über
denselben Router
• Routerausfälle und -abschaltungen
Wird ein Router überlastet, wirft er Pakete weg
Dies bemerkt der Sender durch einen Time Out
242
Änderungen in der verkraftbaren Datenmenge beim Empfänger werden durch die
Flusssteuerung erkannt und vom Sender behandelt
Schwankungen im Netz werden durch die Stausteuerung erkannt und ebenfalls vom
Sender behandelt
adaptive Flusssteuerung und adaptive Stausteuerung bei TCP
Dazu wird vom Sender ständig die größtmögliche Sendepuffergröße sowohl für das
Netz als auch für den Empfänger berechnet
Die momentan größtmögliche Sendepuffergröße für das Netz heißt Überlastungsfenster (congestion window)
Die momentan größtmögliche Sendepuffergröße für den Empfänger heißt EmpfängerSchiebefenster (sliding window)
Aus beiden Größen nimmt der Sender das Minimum als tatsächliche Sendepuffergröße
und schickt diese Menge an Daten ab
Zusätzlich versuchen IPv4 und V6 bei der Stausteuerung zu helfen, was bei IPv6 besser
gelingt als be IPv4
12.3.6
Slow Start
Def.: Slow Start ist ein Algorithmus zur Berechnung der tatsächlichen Sendepuffergröße
beim Sender und läuft folgendermaßen ab (= slow start ohne fast recovery):
243
1.) Beim Aufbau der TCP-Verbindung initialisiert der Sender die Größe des Überlastungsfenster (congestion window) des Netzes auf einen niedrigen Anfangswert von
z.B. 1 KB
• Danach teilt der Empfänger dem Sender im TCP-Optionenfeld die Größe des EmpfängerSchiebefensters (sliding window) in seiner Acknowledge-Antwort mit
• Außerdem wird vom Sender beim Verbindungsaufbau ein sog. Schwellwert auf 64 KB festgelegt
• Dann wird ein Paket gesendet, das dem Minimum aus initialem Überlastungsfenster und
initialem Empfänger-Schiebefenster entspricht (= Start der Datenübertragung)
2.) Danach werden mit jeder neuen Iteration alle drei Werte (Überlastungsfenster, Empfänger-Schiebefenster und Schwellwert) aktualisiert
3.) Für jedes erhaltene Acknowledge verdoppelt der Sender die Größe des Überlastungsfenster des Netzes
• Dies erfolgt, indem TCP zu einem gesendeten TCP-Segment ein zweites Segment derselben Länge hinzufügt (sofern vorhanden)
• Es ist die Phase des exponentiellen Wachstums
• Das Verdoppeln wird solange wiederholt, bis entweder kein Acknowledge mehr zurückkommt, oder bis das Empfänger-Schiebefenster droht überzulaufen, oder bis der Schwellwert droht, überschritten zu werden
· Ein fehlendes Acknowledge entdeckt der Sender durch einen Time Out
· Eine drohende Überlastung des Empfängers entdeckt der Sender anhand der Übermitt244
·
lung der Empfänger-Schiebefenstergröße, die zusammen mit dem Sammelacknowledge vom Empfänger zurück zum Sender gesendet wird
Eine drohende Überschreitung des Schwellwerts erkennt der Sender selber
4.) Droht der Schwellwert überschritten zu werden, erhöht der Sender sein Überlastungsfenster mit jedem Acknowledge nur noch linear
• Dies ist die Phase des linearen Wachstums, die sich der momentan möglichen Grenze von
Netz und Empfänger behutsam annähert
• Droht das Empfänger-Schiebefenster überzulaufen, sendet der Sender nur noch so viel,
wie in das Empfänger-Schiebefenster passt
• Kommt kein Acknowledge mehr zurück, wird vom Sender ein neuer Schwellwert festgelegt, der der Hälfte des momentan erreichten Überlastungsfensters entspricht
Der Schwellwert speichert den halben maximalen Wert, den das Überlastungsfenster
jeweils eine Iteration vorher erreicht hatte
• Außerdem wird die Größe des Überlastungsfensters des Netzes auf den initialen Wert zurückgesetzt
5.) Die Schritte 2-4 werden solange wiederholt bis alles gesendet wurde
Der Vorteil dieses Verfahrens ist, dass es sich durch die exponentielle Steigerung am
Anfang der größtmöglichen Sendemenge schnell annähert und dieser durch die lineare Steigerung am Ende sehr nahe kommt
245
12.3.6.1 Beispiel für den zeitlichen Verlauf des Überlastungsfenster des Netzes (Slow Start)
Anfangsgröße des Überlastungsfenster des Netzes sei 1 KB, Anfangsschwellwert sei
32 K, Anfangsgröße des Empfänger-Schiebefensters sei 64 K
Der Sender kann nicht mit der Größe des Empfänger-Schiebefensters beginnen, sondern nur mit der wesentlich kleineren Größe des Überlastungsfensters
Zusätzlich wurden in der Zeichnung zwei weitere Dinge angenommen:
1.) Die Größe des Überlastungsfenster des Netzes sei zu Beginn des 2. Iterationszyklus
genauso groß wie am Anfang, d.h. 1 KB
• Dies ist in der Praxis aber i.A. nicht der Fall, vielmehr ändert sich das Überlastungsfenster
2.) In der 2. Iteration werde nach 4 Verdopplungen der neue Schwellwert von 20 KB exakt
erreicht wird (wobei 20 zudem auch keine Zweierpotenz ist)
• In der Praxis werden aber Schwellwerte i.d.R. nicht exakt erreicht, sondern der Sender
schaltet auf linearen Zuwachs um, bevor die nächste Verdopplung den Schwellwert überschreiten würde, oder er begrenzt den Wert der nächsten Verdopplung auf den Wert des
Schwellwerts
12.3.7
Beispiel für den zeitlichen Verlauf des Empfänger-Schiebefensters
Für dieses Beispiel wird vereinfachend angenommen, dass das Netz zwischen Sender
und Empfänger stets schnell genug ist
246
Einfluss des Überlastfensters des Netzes wird im Bsp. nicht berücksichtigt
Des weiteren wird angenommen, dass die TCP-Instanz des Empfängers die Weitergabe
des empfangenen Segments solange verzögern darf, bis das Empfänger-Schiebefenster voll ist
247
URG-Bit im Header des Segments sei im Bsp. nicht gesetzt
Im TCP-Optionenfeld teilt der Empfänger dem Sender beim Senden des Acknowledge
mit, wieviel Empfangspuffer der Empfänger noch frei hat (Bsp.: WINDOWSIZE = 2048)
248
2K
Ändert sich die Größe des Empfänger-Schiebefensters, wird dies dem Sender über ein
zweites Acknowledge mit derselben Sequenznummer mitgeteilt
249
Im zweiten Acknowledge wird vom Empfänger das Feld WINDOWSIZE auf den Wert gesetzt, den der Empfänger verkraften kann
12.3.8
Adaptiver TCP-Time Out
Es wird beim Abschicken jedes Paket beim Sender gemessen, wie lange es bis zum zugehörigen Acknowledge dauert
• Die gemessene Zeit sei gleich M, M steht für Messwert
Durch die gemessene Zeit M wird die „Entfernung“ zum Empfänger bestimmt
Def.: Als Round Trip Time (RTT) wird hier die Zeit bezeichnet, die entsteht, wenn M über
mehrere Messungen hinweg geglättet wird.
Zur Glättung werden Messungen aus der unmittelbaren Vergangenheit berücksichtigt
RTT berechnet sich iterativ zu: RTTneu := RTTalt + (1-)M
Dies entspricht einer Glättung;a ist der 1. Glättungsfaktor der Berechnung
Der berechnete Wert von RTT ist in der Praxis selten optimal. Deshalb wird eine zweite
Rechnung nachgeschaltet.
Dazu wird die Differenz zwischen dem aktuellen Messwert M und der Round Trip Time
RTT berechnet und mit D bezeichnet (D steht für Differenz)
D wird in analoger Weise wie zuvor RTT geglättet:
Dneu := Dalt + (1-) abs(M - RTTneu), b ist der 2. Glättungsfaktor der Berechnung
250
und werden von der jeweiligen TCP-Instanz (= Implementierung) festgelegt und sind
nicht normiert
Dann wird ähnlich zur 1. und 2. Glättung der jeweils aktuelle Time-Out-Wert berechnet
Time Out = 4Dneu + RTTneu; der Faktor 4 ist der 3. Glättungsfaktor und konstant
Der Algorithmus stellt insgesamt eine hohe Glättung der Messwerte M dar und vermeidet dadurch starke Schwankungen beim Time Out, selbst wenn die Messwerte stark
schwanken
Stellt sich der so berechnete Timeout-Wert als zu niedrig heraus (= kein Acknowledge,
dafür ständig Time Outs), wird als „Rettungsmaßnahme“ der zuletzt verwendete Wert
Timeout-Wert verdoppelt (= pragmatische Lösung)
Zusammenfassung:
• Aus adaptivem Schiebefenster +adaptivem Überlastungsfenster + adaptivem Time
Out + Sammeln von Bytes bis zur Schiebefenstergröße (= blockweise Pufferung) ergibt sich bei TCP eine hohe Effizienz bei der Übertragung großer Datenmengen
• Umgekehrt ist TCP sehr ineffizient bei kleinen Datenmengen
Beispiel: 1 Byte Tastaturinformation wird bei rlogin über das Internet mittels 40 Byte
TCP/IP-Overhead übertragen => 2,4% Effizienz
12.4
Berkeley Sockets/WinSockets als die Schnittstelle zu TCP und UDP
Sind die konkrete Umsetzung eines Transportschicht-Dienstzugangspunkts
251
Sind die Programmierschnittstelle zur Kommunikation mit der Transportschicht im Internet
Existieren auf nahezu allen Platten-Betriebssystemen (bei Windows als WinSockets)
Unterscheiden sich von der ISO-Spezifikation beim Aufruf z.B. darin, ob der Aufruf blockierend ist oder nicht
Wurden in einer POSIX-Spezifikation erweitert
Erlauben die Kommunikation über TCP- oder UDP-Protokolle
Verwenden IP- und Port-Adressen zur netzweit eindeutigen Adressierung von Prozessen auf Rechnern, z.B. bei der Nutzung von Server-Diensten
Die TCP/UDP Socket API ruft ihrerseits die sog. Raw Socket API von IP auf
12.4.1
Die Berkeley/WinSocket Socket-API
Die Socket-API besteht im wesentlichen aus 8 verschiedenen Aufrufen: socket, bind,
listen, accept, connect, send, receive und close
Es wird zwischen Client und Server unterschieden
12.4.1.1 Ablauf der Kommunikation zwischen Client und Server
Client-seitig:
• Socket ohne Inhalt für die Kommunikation mit dem Server erstellen durch socket()
Hinweis: Socket: Anschlussdose, Steckdose. Dient für die Interprozesskommunikation zwischen Client
und Server.
252
• Erstellten leeren Socket mit der Socket-Adresse des Servers laden, sowie eigene SocketAdresse an den Server übermitteln durch connect()
• Senden von Daten an den Server und empfangen von Daten vom Server: send(), receive()
• Socket schließen durch close()
Server-seitig:
• Leeren Socket zum späteren Anmelden von Clients beim Server erstellen: socket()
• Laden des Anmelde-Sockets mit der Socket-Adresse des Servers, über die der Server Client-Anfragen akzeptiert: bind()
• Auf eine Client-Anfrage warten: listen()
• Client-Anfrage akzeptieren und dann einen zweiten Socket für die Kommunikation mit diesem Client erstellen: accept()
• Senden und empfangen von Daten auf dem zweiten Socket für diesen Client: send(), receive()
• Zweiten Socket für diesen Client schließen: close(), ggf. auch ersten Socket für das Anmelden eines Client schließen
12.4.1.2 int socket(int domain, int type, int protocol);
Diese Funktion wird sowohl vom Server als auch vom Client aufgerufen
Die Funktion erzeugt eine sog. Socket-Verbindung
Diese Socket-Verbindung erlaubt es Client und Server, anschließend über send() und
recv() durch Datenaustausch miteinander zu kommunizieren
253
Die Socket-Verbindung enthält u.a. eine sog. Socket-Adresse
Def.: Eine Socket-Adresse ist eine Datenstruktur aus IP-Adresse und Portnummer. Mit
diesen beiden Angaben kann weltweit eindeutig jeder Prozess in einem Rechner adressiert werden, um mit ihm zu kommunizieren.
socket() gibt einen sog. socket file descriptor „sockfd“ zurück, d.h. socket() returniert
sockfd
Def.: Ein socket file descriptor ist eine logische Gerätenummer, wie sie bereits vom
Lesen und Schreiben auf Dateien bekannt ist, und dient zur Kommunikation mit einem
anderen Rechner. D.h., der socket file descriptor ist eine Nummer, die es erlaubt, auf
einen anderen Rechner lesend und schreibend zuzugreifen
Die Socket-Adresse sockaddr ist eine lokale Datenstruktur für weltweite Prozessadressierung, die logische Gerätenummer sockfd ist eine lokale Integer-Zahl als Abkürzung
für sockaddr
Überhaupt ähnelt die Socket-Kommunikation dem Lesen und Schreiben einer Datei
Sowohl vom Server als auch vom Client werden logische Gerätenummern (=sockfds)
als Abkürzung für den Zugriff auf die Socket-Verbindung verwendet
sockfds dienen dem lokalen Betriebssystem als Index in einer Tabelle, in der Datenstrukturen stehen, die ähnlich wie die Dateisystem-Steuerblöcke aufgebaut sind (sog.
File Handles)
254
Zwei solcher File Handle-Datenstrukturen werden für die Kommunikation mit dem jeweils anderen Rechner benötigt
Der Server benötigt seine logische Gerätenummer sockfd1,Server für seine nachfolgenden Funktionen bind(), listen() und accept() als Aufrufparameter
Der Client benötigt seine logische Gerätenummer sockfdClient für seine nachfolgenden
Funktionen connect(), send(), recv() und close() als Aufrufparameter
Für die Funktionen send(), recv() und close() des Servers benötigt dieser zusätzlich
eine zweite logische Gerätenummer sockfd2,Server als Aufrufparameter, die über accept() bereitgestellt wird
Die Beschreibung der Parameter des Socket-Aufrufs int socket(int domain, int type, int
protocol) ist:
• Eingabeparameter domain: gibt das Routingprotokoll an
· Definiert sind als Integer-Konstanten u.a. die Werte
· PF_INET für das Routingprotokoll IPV4
· PF_INET6 für das Routingprotokoll IPV6
• Eingabeparameter type: gibt die sog. Dienstart an
· Definiert sind als Integer-Konstanten u.a. die Werte
· SOCK_STREAM für die zuverlässige Übertragung einer unendlichen Folge von Bytes
· SOCK_SEQPACKET für die zuverlässige Übertragung einer endlichen Folge von Datenpaketen
• Eingabeparameter protocol: gibt das Transportprotokoll an
255
· Definiert sind als Integer-Konstanten u.a. die Werte
· IPPROTO_TCP für TCP
· IPPROTO_UDP für UDP
• Return Value: sockfd: socket file descriptor = Integer-Zahl als logische Gerätenr.
12.4.1.3 int bind(int sockfd1,Server, const struct sockaddr *my_addr, socklen_t addrlen);
Die Funktion wird nur vom Server aufgerufen und kommt nach dessen socket()-Aufruf
Sie verknüpft die erste logische Gerätenummer, d.h. den Server socket file descriptor
sockfd1,Server mit der Server-lokalen Datenstruktur my_addr, die die Socket-Adresse
des Servers enthält
D.h., hinter der logischen Gerätenummer sockfd1,Server des Servers steht nach dem
Aufruf von bind dessen eigene Socket-Adresse
Bind() returniert 0, falls O.K. und -1, falls nicht O.K
Die Beschreibung der Parameter ist:
• Eingabeparameter sockfd: socket file descriptor von socket() des Servers, d.h.
sockfd1,Server
• Eingabeparameter my_addr: lokale Datenstruktur. my_addr besteht aus der IP-Adresse
des Servers und aus einer lokalen Portnummer des Servers. Beide sind vom Typ integer.
• Eingabeparameter addrlen: Länge von my_addr in Bytes
• Return Value: status: Statusinformation über den Erfolg der Prozedur
256
12.4.1.4 int listen(int sockfd1,Server, int backlog);
Wird nur vom Server aufgerufen und kommt nach dessen bind()
Wartet darauf, dass durch ein nachfolgendes connect() des Clients eine Verbindung
hergestellt wird
Falls nacheinander mehrere connect-Anforderungen beim Server eintreffen, werden
alle bis zur Obergrenze „backlog“ von listen() in einer Warteschlange zwischengespeichert
Hinweis: backlog = Rückstand, Nachholbedarf
listen() returniert 0, falls alles O.K. ist und -1, falls nicht O.K.
Die Beschreibung der Parameter ist:
• Eingabeparameter sockfd: socket file descriptor von socket() des Servers, d.h.
sockfd1,Server
• Eingabeparameter backlog: Anzahl von connect-Anforderungen, die in einer listen-Warteschlange maximal gespeichert werden können.
• Return Value: status: Statusinformation über den Erfolg der Prozedur
12.4.1.5 int connect(int sockfdClient, const struct sockaddr *serv_addr, socklen_t addrlen);
Wird nur vom Client aufgerufen und kommt nach dessen socket()-Aufruf
Connect() verbindet den Client mit dem Server
257
Dazu muss der Client wissen, zu welchem Server-Prozess er sich verbinden möchte,
d.h. er muss serv_addr kennen
Connect() schreibt außerdem in die Datenstruktur cliaddr des Servers seine eigene Clientadresse hinein, sobald dieser den Aufruf accept() durchführt, so dass dieser weiß,
wo sein Client im Internet zu finden ist
Connect() returniert 0, falls O.K. und -1, falls nicht O.K.
Die Beschreibung der Parameter ist:
• Eingabeparameter sockfd: socket file descriptor von socket() des Client, d.h. sockfdClient
• Eingabeparameter serv_addr: Client-lokale Datenstruktur, in der die Socket-Adresse des
Servers steht, zu dem eine Verbindung aufgebaut werden soll
• addrlen: Länge von serv_addr in Bytes
• Return Value status: Statusinformation über den Erfolg der Prozedur
12.4.1.6 int accept(int sockfd1,Server, struct sockaddr *cliaddr, socklen_t *addrlen);
Wird nur vom Server aufgerufen und kommt nach listen()
Accept() verbindet den Server mit dem Client und bearbeitet den Client connect()-Aufruf
accept() entfernt dazu die vorderste Client Connect-Anforderung aus der Warteschlange von listen() und bearbeitet diese Client Connect-Anforderung
accept() erzeugt für die Bearbeitung der Client Connect-Anforderung eine zweite Socket-Verbindung namens sockfd2,Server
258
Hinweis: In diesem Moment sind Server-seitig gleichzeitig die beiden Socket Descriptoren sockfd1,Server
und sockfd2,Server aktiv, allerdings ist bislang nur sockfd1,Server initialisiert. Hinter sockfd1,Server des
Servers steht die IP-Adresse und Portnr. des Servers, hinter sockfd2,Server wird nach dem Aufruf von
accept die Socket-Adresse des Clients stehen.
accept() verknüpft den zweiten socket file descriptor sockfd2,Server mit der zweiten Socket-Adresse cliaddr
accept() gibt den zweiten socket file descriptor sockfd2,Server und die zweite Socket-Adresse cliaddr als Ergebnis zurück
D.h., hinter der logischen Gerätenummer sockfd2,Server des Servers steht nach dem
Aufruf von accept die Client Socket-Adresse cliaddr
Damit weiß der Server, wo sein Client im Internet zu finden ist
sockfd2,Server dient als Abkürzung für cliaddr und damit als Abkürzung zum Client
Danach kann der Server über sockfd2,Server auf die zweite Socket-Adresse (=cliaddr)
zugreifen und so die IP-Adresse und die Portnr. des Client feststellen, um send(), receive() und close() aufzurufen
Die Beschreibung der Parameter ist:
• Eingabeparameter
d.h.sockfd1,Server
sockfd:
socket
file
descriptor
von
socket()
des
Servers,
• Ausgabeparameter cliaddr: zweite Socket-Adresse
· cliaddr = Server-lokale Datenstruktur, in der die IP-Adresse des entfernten Client-Computers und dessen Portnummer stehen, sobald dieser connect() aufgerufen hat
259
· Über cliaddr kann der Client angesprochen werden
• Eingabe-/Ausgabeparameter addrlen: Länge von cliaddr in Bytes
• Return Value: sockfd2,Server = zweiter socket descriptor = zweite logische Gerätenr. des
Servers als Abkürzung zum Client
12.4.1.7 int send(int {entweder sockfdClient für Client oder sockfd2,Server für Server}, const void
*buffer, size_t length, int flags);
Wird von Server und Client aufgerufen und kann beim Server nach accept() und beim
Client nach connect() kommen
Sendet Daten vom Server zum Client bzw. vom Client zum Server, sofern der Empfänger ein receive() ausführt
Returniert die Zahl der gesendeten Bytes, falls O.K. und -1, falls nicht O.K.
Die Beschreibung der Parameter ist:
• Eingabeparameter sockfdClient des Client bzw. sockfd2,Server des Servers
•
•
•
•
Eingabeparameter buf: string, der die zu sendenden Daten als Bytes enthält
Eingabeparameter length: gibt die Länge von buf an
Eingabeparameter flags: spezifiziert die Art des Sendens genauer
Return Value: SentBytesOrStatus = entweder Länge der gesendeten Bytes oder -1 bei Fehler
260
12.4.1.8 int recv(int {entweder sockfdClient für Client oder sockfd2,Server für Server}, void *buffer, size_t length, int flags);
Wird von Server und Client aufgerufen und kann beim Server nach accept() und beim
Client nach connect() kommen
Empfängt Daten vom Client oder vom Server
Returniert die Zahl der empfangenen Bytes, falls O.K. und -1, falls nicht O.K.
Die Beschreibung der Parameter ist:
• Eingabeparameter sockfdClient bzw. sockfd2,Server: socket file descriptor von socket() des
Clients bzw. von accept() des Servers
• Ausgabeparameter buf: string, der die empfangenen Daten als Bytes enthält
• Eingabeparameter length: gibt die Länge von buf an
• Eingabeparameter flags: spezifiziert die Art des Sendens genauer
• Return Value: ReceivedBytesOrStatus = entweder Länge der empfangenen Bytes oder -1
bei Fehler
12.4.1.9 int close(int {entweder sockfdClient für Client oder sockfd2,Server für Server});
Wird von Server und Client als letztes aufgerufen
Schließt eine bestehende Socket-Verbindung
Der Vorgang entspricht dem Schließen einer zuvor geöffneten Datei
261
Allerdings muss die Socket-Verbindung sowohl vom Client als auch vom Server geschlossen werden
Returniert 0, falls O.K. und -1, falls nicht O.K.
Die Beschreibung der Parameter ist:
• Eingabeparameter sockfdClient von socket() des Clients bzw. sockfd2,Server von accept()
des Servers
• Return Value: status: Statusinformation über den Erfolg der Prozedur
12.4.1.10Zusammenfassung Berkeley-Sockets
Die Berkeley-Sockets und ihre Varianten sind nicht besonders übersichtlich in der
Handhabung
Ohne sie ist aber kein Aufruf von TCP oder UDP möglich. d.h., sie sind sehr wichtig
Viel Erfolg!
262