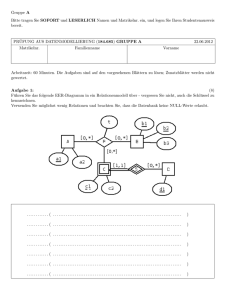
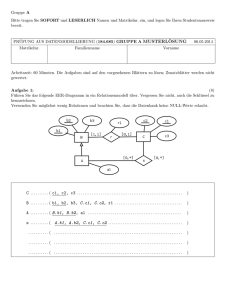
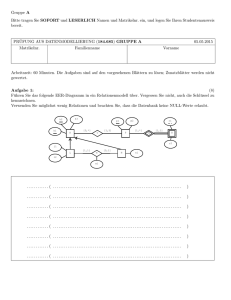
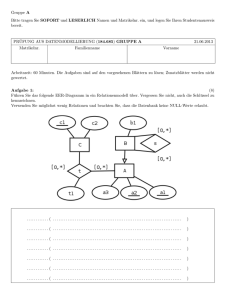
Datenbanksysteme I - Praktische Informatik
Werbung

Udo Kelter Datenbanksysteme I Datenbanksysteme I Udo Kelter 2013-12 Inhaltsverzeichnis Vorwort 6 Lehrmodul 1: Datenverwaltungssysteme 1.1 1.2 1.3 1.4 1.5 Einleitung und Übersicht . . . . . . . . . . . . . . . . Grundbegriffe . . . . . . . . . . . . . . . . . . . . . . . 1.2.1 Daten – Wissen – Information . . . . . . . . . 1.2.2 Informationssysteme . . . . . . . . . . . . . . . 1.2.3 Externe Darstellung von Daten . . . . . . . . . 1.2.4 Datenverwaltungssysteme . . . . . . . . . . . . Datenverwaltungsprobleme . . . . . . . . . . . . . . . 1.3.1 Anwendungsnahe Datenmodellierungskonzepte 1.3.2 Korrekheitsüberwachung . . . . . . . . . . . . . 1.3.3 Such- und Auswertungsfunktionen . . . . . . . 1.3.4 Backup und Versionierung . . . . . . . . . . . . 1.3.5 Datenschäden durch Systemabstürze . . . . . . 1.3.6 Mehrbenutzerfähigkeit und Zugriffskontrollen . 1.3.7 Entfernter Zugriff . . . . . . . . . . . . . . . . . 1.3.8 Paralleler Zugriff . . . . . . . . . . . . . . . . . 1.3.9 Datenintegration und Sichten . . . . . . . . . . 1.3.10 Evolution der Datenbestände . . . . . . . . . . Dateisysteme . . . . . . . . . . . . . . . . . . . . . . . 1.4.1 Arten von Dateisystemen . . . . . . . . . . . . 1.4.2 Verwaltung formatierter Daten in Dateien . . . 1.4.2.1 Codierungen . . . . . . . . . . . . . . 1.4.2.2 Such- und Auswertungsfunktionen . . OLTP-Datenbankmanagementsysteme . . . . . . . . . 1.5.1 Datenbankmodelle . . . . . . . . . . . . . . . . 5 13 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 14 14 16 17 18 22 23 24 25 27 28 29 30 31 32 33 33 34 35 35 37 37 38 6 1.5.2 Datenintegration, Datenunabhängigkeit Ebenen-Schema-Architektur . . . . . . . 1.5.3 Transaktionsverarbeitung . . . . . . . . 1.6 Information-Retrieval-Systeme . . . . . . . . . 1.7 Ein- und Ausgabeschnittstellen . . . . . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . und die . . . . . . . . . . . . . . . . . . . . . . . . . 3. . . . . . . . . . Lehrmodul 2: B-Bäume 49 2.1 2.2 Historischer Hintergrund . . . . . . . . . . . . . . . . . Verzeichnisse . . . . . . . . . . . . . . . . . . . . . . . 2.2.1 Generische ADT . . . . . . . . . . . . . . . . . 2.2.2 Der generische ADT directory [S,I] . . . . 2.3 B-Bäume . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.1 Grundlegende Implementierungsentscheidungen 2.3.2 Vielweg-Suchbäume . . . . . . . . . . . . . . . 2.3.3 Merkmale von B-Bäumen . . . . . . . . . . . . 2.3.4 Primärschlüssel . . . . . . . . . . . . . . . . . . 2.4 Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . 2.4.1 Suche . . . . . . . . . . . . . . . . . . . . . . . 2.4.2 Einfügung . . . . . . . . . . . . . . . . . . . . . 2.4.3 Löschung . . . . . . . . . . . . . . . . . . . . . 2.4.4 Beispiel . . . . . . . . . . . . . . . . . . . . . . 2.5 B*-Bäume . . . . . . . . . . . . . . . . . . . . . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Lehrmodul 3: Architektur von DBMS 3.1 3.2 3.3 3.4 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . Produkt vs. Laufzeitkern . . . . . . . . . . . . . . . Prozeßarchitektur von Informationssystemen . . . . Eine Abstraktionshierarchie von Datenbankobjekten 3.4.1 Übersicht . . . . . . . . . . . . . . . . . . . . 3.4.2 Ebene 0: physische Blöcke . . . . . . . . . . . 3.4.3 Ebene 1: DB-Segmente und DB-Seiten . . . . 3.4.4 Ebene 2: Zugriffsmethode für Sätze . . . . . 3.4.4.1 Zugriffsstrukturen . . . . . . . . . . 3.4.4.2 Realisierung von Sätzen auf Seiten . 3.4.4.3 Indexe . . . . . . . . . . . . . . . . . 3.4.5 Ebene 3: Einzelobjekt-Operationen . . . . . . 39 41 42 45 47 50 50 50 52 53 53 54 56 57 58 58 58 60 62 63 65 66 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 67 68 72 72 74 74 75 76 79 80 81 (gen: 2013-12-9-600) 7 3.4.6 Ebene 4: Mengen-Schnittstelle . . . . . . . . . . . . . 3.4.7 Beziehung zur 3-Ebenen-Schema-Architektur . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Lehrmodul 4: Das relationale Datenbankmodell 84 4.1 4.2 Datenbankmodelle vs. reale Datenbanksprachen . . . . . Die Struktur relationaler Datenbanken . . . . . . . . . . 4.2.1 Tabellen . . . . . . . . . . . . . . . . . . . . . . . 4.2.2 Relationen . . . . . . . . . . . . . . . . . . . . . 4.2.3 Integritätsbedingungen . . . . . . . . . . . . . . . 4.3 Die relationale Algebra . . . . . . . . . . . . . . . . . . . 4.3.1 Die Selektion . . . . . . . . . . . . . . . . . . . . 4.3.2 Die Projektion . . . . . . . . . . . . . . . . . . . 4.3.3 Die Mengenoperationen . . . . . . . . . . . . . . 4.3.4 Die Umbenennung . . . . . . . . . . . . . . . . . 4.3.5 Das Kreuzprodukt . . . . . . . . . . . . . . . . . 4.3.6 Verbundoperationen . . . . . . . . . . . . . . . . 4.3.6.1 Beispiel . . . . . . . . . . . . . . . . . . 4.3.6.2 Der natürliche Verbund . . . . . . . . . 4.3.6.3 Der Theta-Verbund . . . . . . . . . . . 4.3.6.4 Äußere Verbunde . . . . . . . . . . . . 4.3.7 Die Division . . . . . . . . . . . . . . . . . . . . . 4.3.8 Relationale Vollständigkeit . . . . . . . . . . . . 4.3.9 Ausdrücke in der relationalen Algebra . . . . . . 4.4 Schlüssel . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4.1 Superschlüssel und Identifizierungsschlüssel . . . 4.4.2 Primärschlüssel . . . . . . . . . . . . . . . . . . . 4.4.3 Fremdschlüssel . . . . . . . . . . . . . . . . . . . 4.4.4 Kriterien für die Festlegung von IdentifizierungsPrimärschlüsseln . . . . . . . . . . . . . . . . . . 4.4.5 Weitere Schlüsselbegriffe . . . . . . . . . . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . und . . . . . . . . . Lehrmodul 5: Der relationale Tupel-Kalkül 5.1 5.2 Die relationalen Kalküle . . . Der relationale Tupel-Kalkül 5.2.1 Beispiel 1 (Selektion) . 5.2.2 Beispiel 2 (Projektion) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82 82 83 85 86 86 88 90 91 91 93 94 95 96 98 98 100 102 103 103 107 108 109 109 112 113 114 115 117 119 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120 121 121 122 8 5.2.3 Beispiel 3 (Mengenoperationen) . 5.2.4 Beispiel 4 (natürlicher Verbund) 5.2.5 Beispiel 5 (Division) . . . . . . . 5.3 Syntax von Ausdrücken im RTK . . . . 5.4 Sichere RTK-Ausdrücke . . . . . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Lehrmodul 6: Einführung in SQL 123 123 124 124 125 128 129 6.1 6.2 Einführung . . . . . . . . . . . . . . . . . . . . . . . . . . . . Abfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.2.1 Grundform . . . . . . . . . . . . . . . . . . . . . . . . 6.2.2 Nachbildung der Operationen der relationalen Algebra in SQL . . . . . . . . . . . . . . . . . . . . . . . . . . 6.2.3 Gruppierungen und Aggregationen . . . . . . . . . . . 6.3 Änderungsoperationen . . . . . . . . . . . . . . . . . . . . . . 6.3.1 Erzeugen von Tupeln . . . . . . . . . . . . . . . . . . . 6.3.2 Löschen von Tupeln . . . . . . . . . . . . . . . . . . . 6.3.3 Ändern von Tupeln . . . . . . . . . . . . . . . . . . . . 6.4 Nullwerte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.5 Schema-Operationen . . . . . . . . . . . . . . . . . . . . . . . 6.5.1 Definition von Relationen . . . . . . . . . . . . . . . . 6.5.1.1 Attributdefinitionen . . . . . . . . . . . . . . 6.5.1.2 Definition von Integritätsbedingungen . . . . 6.5.2 Änderung der Definition einer Relation . . . . . . . . 6.5.3 Sichten . . . . . . . . . . . . . . . . . . . . . . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130 131 131 133 137 141 141 142 144 144 146 147 147 148 151 152 152 Lehrmodul 7: Implementierung relationaler Operationen 154 7.1 7.2 7.3 Einleitung . . . . . . . . . . . . . . . . . Triviale Implementierungen . . . . . . . Exkurs: Indexstrukturen . . . . . . . . . 7.3.1 Primärindexe . . . . . . . . . . . 7.3.2 Sekundärindexe . . . . . . . . . . 7.4 Optimierungen der Selektion . . . . . . 7.5 Optimierungen der Projektion . . . . . . 7.6 Optimierungen der Verbundberechnung Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155 155 157 157 159 160 163 163 167 (gen: 2013-12-9-600) 9 Lehrmodul 8: Abfrageverarbeitung und Optimierung169 8.1 Motivation . . . . . . . . . . . . . . . . . . . 8.1.1 Grobablauf einer Abfrageverarbeitung 8.1.2 Optimierungsansätze . . . . . . . . . . 8.2 Optimierungskriterien . . . . . . . . . . . . . 8.3 Algebraische Optimierung . . . . . . . . . . . 8.3.1 Äquivalente algebraische Ausdrücke . 8.3.2 Optimierungsheuristiken . . . . . . . . 8.3.3 Optimierungsalgorithmen . . . . . . . 8.4 Kostenschätzung . . . . . . . . . . . . . . . . Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Lehrmodul 9: Metadaten 9.1 9.2 9.3 9.4 9.5 Einordnung und Motivation . . . . . . . . . . . . . . . . . . . 9.1.1 Metadaten in Datenbanken . . . . . . . . . . . . . . . 9.1.2 Metadaten in der Dokumentverwaltung . . . . . . . . 9.1.3 Metadaten vs. Nutzdaten . . . . . . . . . . . . . . . . 9.1.4 Selbstreferentialität . . . . . . . . . . . . . . . . . . . 9.1.5 Sprachebenen in der Linguistik . . . . . . . . . . . . . Arten von Metadaten . . . . . . . . . . . . . . . . . . . . . . 9.2.1 Typbezogene vs. entitätsbezogene Metadaten . . . . . 9.2.2 Instantiierbare Metadaten . . . . . . . . . . . . . . . . Selbstreferentialität in relationalen Datenbanken . . . . . . . 9.3.1 Repräsentation relationaler Schemata durch Tabellen . 9.3.2 Zugriff auf selbstreferentiell repräsentierte Schemata . 9.3.3 Metatypen und Meta-Metadaten . . . . . . . . . . . . 9.3.4 Übersicht über die semantischen Ebenen . . . . . . . . 9.3.5 Meta-Ebenen vs. Implementierungsebenen von Datenbankobjekten . . . . . . . . . . . . . . . . . . . . . . . Selbstreferentialität in XML . . . . . . . . . . . . . . . . . . . 9.4.1 Aufbau von XML-Dateien . . . . . . . . . . . . . . . . 9.4.2 Typ-Annotationen . . . . . . . . . . . . . . . . . . . . 9.4.2.1 Typ-Annotationen in schwach strukturierten Daten . . . . . . . . . . . . . . . . . . . . . . 9.4.2.2 Typ-Annotationen in strikt typisierten Nutzdaten . . . . . . . . . . . . . . . . . . . . . . Metadaten in der UML-Begriffswelt . . . . . . . . . . . . . . 9.5.1 Bedeutungsebenen von UML-Modellen . . . . . . . . . 9.5.2 “ist-Instanz-von”-Beziehungen . . . . . . . . . . . . . 170 170 171 174 175 175 179 181 183 187 188 189 190 191 192 193 194 195 195 196 199 199 201 202 204 206 208 208 209 209 210 212 212 216 10 9.5.2.1 Interpretation der UML-Modelle der Ebene M1217 9.5.2.2 Interpretation der UML-Modelle der Ebene M2218 Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219 Lehrmodul 10: Entwurf redundanzfreier Datenbankschemata 220 10.1 Einleitung und Einordnung . . . . . . . . . . . . . . . . . . . 221 10.2 Fehler beim Entwurf relationaler Datenbankschemata . . . . 222 10.2.1 Zu viele Attribute in einem Relationentyp . . . . . . . 222 10.2.2 Zu “kleine” Relationentypen . . . . . . . . . . . . . . 224 10.2.3 Verlustfreie Zerlegungen . . . . . . . . . . . . . . . . . 226 10.3 Funktionale Abhängigkeiten . . . . . . . . . . . . . . . . . . . 227 10.3.1 Beispiel und Definition . . . . . . . . . . . . . . . . . . 227 10.3.1.1 Beispiel für die Analyse einer Tabelle . . . . 229 10.3.1.2 Identifizierungs- und Superschlüssel . . . . . 230 10.3.2 Funktionale Abhängigkeiten als Integritätsbedingungen 230 10.3.3 Verlustfreie Zerlegungen . . . . . . . . . . . . . . . . . 231 10.3.4 Die Armstrong-Axiome . . . . . . . . . . . . . . . . . 232 10.3.5 Die transitive Hülle einer Menge funktionaler Abhängigkeiten . . . . . . . . . . . . . . . . . . . . . . 235 10.3.6 Kanonische Überdeckung von funktionalen Abhängigkeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . 237 10.4 Das Boyce-Codd-Kriterium . . . . . . . . . . . . . . . . . . . 241 10.4.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . 241 10.4.2 Boyce-Codd-Zerlegungen . . . . . . . . . . . . . . . . 243 10.5 Lokale Überwachbarkeit . . . . . . . . . . . . . . . . . . . . . 246 10.5.1 Motivation und Definition . . . . . . . . . . . . . . . . 246 10.5.2 Beispiel: Postleitzahlenbuch . . . . . . . . . . . . . . . 247 10.6 Die dritte Normalform . . . . . . . . . . . . . . . . . . . . . . 251 10.6.1 Motivation und Definition . . . . . . . . . . . . . . . . 251 10.6.2 Konstruktion einer Zerlegung in dritter Normalform . 252 10.7 Überwachung funktionaler Abhängigkeiten . . . . . . . . . . . 257 10.8 Weitere Normalformen . . . . . . . . . . . . . . . . . . . . . . 258 10.8.1 Die erste Normalform . . . . . . . . . . . . . . . . . . 258 10.8.2 Die zweite Normalform . . . . . . . . . . . . . . . . . 261 10.8.3 Mehrwertige Abhängigkeiten und die vierte Normalform 261 Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267 Literatur 269 (gen: 2013-12-9-600) Index 11 270 Vorwort Dieses Buch ist im Kontext verschiedener Vorlesungen über Informations- bzw. Datenbanksysteme entstanden, die ich in den letzten Jahren am Fachbereich Elektrotechnik und Informatik der Universität Siegen angeboten habe. Die Vorlesungen sind Komponenten der Studiengänge Technische Informatik, Wirtschaftsinformatik, Angewandte Informatik sowie diverser Nebenfachinformatiken. Bei diesen Studiengängen handelt es sich meist um integrierte Studiengänge, die sowohl einen Abschluß nach 7 Semestern (vergleichbar mit dem Bachelor) als auch nach 9 Semestern ermöglichen. In den letzten Jahren wurden die Studiengänge erheblich umstrukturiert oder neu entworfen. Die frühere Vorlesung “Informationssysteme”, die einen Umfang von 4 SWS zzgl. Übungen hatte, die Teil des Hauptstudiums war und die in dieser Form auch in vielen anderen Informatik-Studiengängen anzutreffen ist, wurde abgeschafft. Sie wurde ersetzt durch 1. das Kernfach “Datenbanksysteme I”, das von fast allen InformatikStudenten besucht wird, und 2. darauf aufbauende speziellere, aus Katalogen wählbare Vorlesungen, die von wesentlich weniger Studenten besucht werden. Kernfächer haben einen Umfang von 2 SWS zzgl. 1 SWS Übungen und decken zentrale, praxisrelevante Bereiche vor allem der praktischen Informatik in einer einführenden, kompakten Darstellung ab [Ke00]. Das vorliegende Buch ist am Denkmodell des Kernfachs orientiert und unterscheidet sich in zwei Merkmalen deutlich von üblichen Lehrbüchern Stand: 01.12.2013 c 2013 Udo Kelter Vorwort 13 über Datenbanksysteme (DBS), die sich am Denkmodell der 4-SWSVorlesung im Hauptstudium orientieren: Stoffumfang: Mit rund 270 Seiten ist es wesentlich weniger umfangreich als übliche DBS-Lehrbücher, die meist zwischen 600 und 1000 Seiten Umfang und teilweise enzyklopädischen Charakter haben. Derartige Lehrbücher sind für Kernfächer wenig geeignet: das Herausfiltern der Teilmenge des Stoffs, der als prüfungsrelevant definiert wird, ist nicht trivial, denn jedes einzelne Thema wird in solchen umfangreichen Werken von vorneherein vertiefter angelegt und behandelt werden als in einer kompakten Darstellung. Während bei umfangreichen Werken - wenn überhaupt - die Möglichkeit besteht, Teilmengen zu bilden, verfolgt das vorliegende Buch genau den umgekehrten Ansatz: es definiert eine Stoffmenge, die der Autor als grundlegend ansieht. Dieser Kern kann dann flexibel um Ergänzungsbände bzw. noch feingranularer um einzelne Lehrmodule erweitert werden; Details hierzu s. unten. Phase des Studiums: Während konventionelle DBS-Lehrbücher eher für das Hauptstudium konzipiert sind, geht das vorliegende Buch von der Annahme aus, daß das Kernfach “Datenbanksysteme I” im 3. Semester besucht wird. Die theoretischen Vorkenntnisse und praktischen Erfahrungen der Hörer sind somit signifikant schlechter als bei Hörern im Hauptstudium. Daher werden in diesem Buch formale Darstellungsformen und Themen, die entsprechende Erfahrung erfordern, ausgespart, soweit dies dem präzisen Verständnis nicht abträglich ist. Stoffumfangsbegrenzung. Unterstellt wird, wie schon erwähnt, eine Vorlesung im Umfang von 2 SWS Vorlesung, die im Wintersemester stattfindet. Der Stoffumfang ist daher auf 15 Vorlesungstermine eingestellt. Das Thema Datenbanksysteme ist sehr umfangreich. Das Problem ist nicht, für eine Vorlesung genügend Stoff zu finden, sondern im Gegenteil den prüfungsrelevanten Stoff auf ein realistisches Maß einzugrenzen. Als Richtschnur dient hier die Stoffmenge, die man 14 Vorwort bei einem klassischen Vortrag mit stichpunktartigen Tafelanschrieben schafft. Alle in diesem Buch vorliegenden Texte sind schriftliche Varianten solcher Vorträge, es wurde natürlich anders formuliert, es wurden aber keine Ergänzungen oder sonstiger Stoff hinzugefügt, der letztlich zusätzlich zu lernen ist. Unter diesen Bedingungen ergibt sich mit relativ hoher Genauigkeit ein Text von etwa 3300 Worten für einen Vorlesungstermin von 90 Minuten (eine “Vorlesungsdoppelstunde”), bei kniffligen Themen etwas weniger Text, bei einfachen etwas mehr. Die 3300 Worte entsprechen bei der vorliegenden Formatierung etwa 16 Seiten. In diesem Sinne ist das Buch “umfangskontrolliert”. Frühere Umfragen haben ergeben, daß man für eine erste Lektüre, bei der man sich Notizen macht oder kleinere Selbsttests durchführt, ca. 60 - 90 Minuten Zeit für 16 Seiten Text benötigt, für das Nachlesen nach dem Vortrag etwa die Hälfte davon. Stoffauswahl. Allgemeines Ziel der Vorlesung ist, die wesentlichsten konzeptionellen und technologischen Grundlagen zu vermitteln, die für die Realisierung von datenbankbasierten Informationssystemen benötigt werden, wobei der Schwerpunkt auf Abfragesprachen und den Schemaentwurf gelegt wird. Der Inhalt dieses Buchs kann dementsprechend in folgende Blöcke eingeteilt werden: 1. eine allgemeine und einführende Darstellung der Probleme bei der persistenten Verwaltung von Daten und eine Übersicht über die wichtigsten Klassen von Datenverwaltungssystemen 2. eine Einführung in die Architektur von Datenbankmanagementsystemen (incl. der Vorstellung von B-Bäumen) 3. das relationale Datenbankmodell: seine Grundlagen und mehrere Abfragesprachen (relationale Algebra, relationaler Tupelkalkül, SQL); vorgestellt wird nur die Kernfunktionalität der Sprachen, wobei ein Überblick über die verschiedenen Sprachstile gewonnen werden soll 4. Grundbegriffe der Optimierung 5. Entwurf von Datenbankschemata: die wichtigsten Normalformen Vorwort 15 6. Grundbegriffe im Bereich Transaktionen, Concurrency Control und Recovery Kein Lernziel dieses Buchs sind die Installation, Administration oder Tuning von konkreten DVS-Produkten, eine komplette Behandlung der Sprache SQL, die Modellierung von Daten mit ER- oder Klassendiagrammen; viele dieser Themen werden in aufbauenden Veranstaltungen bzw. Lehrmodulen behandelt werden (s.u.). Zur Struktur dieses Buchs. Dieses Buch besteht im Gegensatz zu anderen Bücher nicht aus Kapiteln, sondern aus Lehrmodulen. Jedes Lehrmodul ist auch als selbständiger Text im WWW ausgehend von http://pi.informatik.uni-siegen.de oder http://www.kltr.de erreichbar. Motiviert wurde seinerzeit das Konzept der Lehrmodule dadurch, daß immer wieder Teile des Lehrstoffs gezielt benötigt wurden (z.B. zur kurzfristigen Einarbeitung von Studentischen Hilfskräften oder Diplomanden) und daß bei spezielleren Themen häufig zusätzliche Texte oder neue Versionen der Texte verfügbar waren. Im Unterschied zu den Kapiteln eines Buchs sind Lehrmodule möglichst autark gestaltet. Durchgehende Beispiele oder häufige Verweise auf andere Kapitel, auf die man in “normalen” Büchern besonders stolz ist, werden hier ganz bewußt vermieden, weil sie Abhängigkeiten erzeugen und das separate Lesen einzelner Kapitel erschweren. Wenn ohne allzuviel Redundanz möglich, wird statt eines Verweises auf andere Stellen der Lerngegenstand, auf den Bezug genommen wird, direkt dargestellt, ggf. in skizzenhafter Form. Während ein Buch fast immer sequentiell gelesen wird, ist die Lesereihenfolge der Lehrmodule wesentlich freier. Der Graph in Bild 1 zeigt die relativ wenigen noch vorhandenen Reihenfolgerestriktionen. Ein gepunkteter Pfeil stellt nur eine Empfehlung dar. Die Abkürzungen bedeuten folgendes: DVS DBIF DBSA BB Datenverwaltungssysteme Schnittstellen zu Datenbankinhalten Architektur von DBMS B-Bäume 16 Vorwort DVS DBIF DBSA BB RDBM RTK IRO TID SQL1 ERS AVO Abbildung 1: Lesereihenfolge der Lehrmodule RDBM RTK SQL1 IRO AVO ERS TID Das relationale Datenbankmodell Der relationale Tupel-Kalkül Einführung in SQL Implementierung relationaler Operationen Abfrageverarbeitung und Optimierung Entwurf redundanzfreier Datenbankschemata Transaktionen und die Integrität von Datenbanken Ergänzendes Material. In einigen Fällen ist zu den Lehrmodulen ergänzendes Material erhältlich, z.B. Formulare, Software etc. Das Material ist unter den o.g. URLs im WWW frei verfügbar. Vortragsfolien. Für die meisten Lehrmodule sind Vortragsfolien in Form von PostScript-Dateien auf Anfrage für Lehrende frei verfügbar. Die Folien sind nicht über die WWW-Seiten abrufbar. Begleitende Übungen. Es wird dringend empfohlen, den zunächst im Buch und/oder in der Vorlesung erlernten Stoff in Übungsaufgaben anzuwenden und so zu festigen. Dies gilt ganz besonders für die hier vorgestellten Datenbankabfragesprachen (insb. SQL). Übungsaufgaben und eine SQL-Übungsdatenbank sind ebenfalls im WWW ausgehend von den o.g. Adressen erreichbar. Vorwort 17 Dank. Danken möchte ich den Lesern früherer Versionen dieser Texte für die vielen Hinweise auf Fehler und Verbesserungsmöglichkeiten. Kommentare und Fehlermeldungen. Kein langer Text ist fehlerfrei, so auch dieser. Hinzu kommt, daß sich manche Gebiete der Informatik immer noch so rasch weiterentwickeln, daß auch Lehrtexte schnell eine störende “Patina” bekommen können. Daher sind Hinweise auf Fehler und Verbesserungsmöglichkeiten sowie Kommentare aller Art sehr willkommen (am besten elektronisch an [email protected]). Aufbauende und ergänzende Lehrmaterialien. Auf die Vorlesung Datenbanksysteme I bauen die Vorlesungen Datenbanksysteme II und weitere Spezialvorlesungen auf. Themenschwerpunkte darin sind: – objektorientierte Datenbanken – XML und XML-basierte Datenbanken bzw. Abfragesprachen – WWW-Schnittstellen zu Datenbanken und die dahinterstehenden Server-Architekturen, inkl. Applikationsserver – Transaktionen, Concurrency Control und Recovery Zu allen vorstehenden Themen sind Lehrmodule im WWW ausgehend von den o.g. Adressen erhältlich. Nicht behandelt in der Vorlesung Datenbanksysteme I und den vorstehend genannten aufbauenden Vorlesungen wird die datenorientierte Anforderungsanalyse anhand von Entity-Relationship- oder Klassendiagrammen. Dieses Themengebiet wurde aufgrund mehrerer Gründe komplett der parallel angebotenen Vorlesung Softwaretechnik I bzw. den dazu gehörigen Buch zugeordnet: – Die Anforderungsanalyse umfaßt viele Aspekte – Daten, Funktionen, Zustände, Bedienschnittstellen usw. –, und diese sind integriert zu betrachten. – Die Datenmodellierung ist unabhängig davon sinnvoll und einsetzbar, ob es sich um Daten in einem Datenbanksystem, Dateisystem, 18 Vorwort irgendeinem anderen Datenverwaltungssystem oder sogar um transiente, also nur im Hauptspeicher vorhandene Daten handelt. – Thema der Vorlesung sind Datenbanksysteme und nicht Informationssysteme. Datenbank[management]systeme sind eine Komponente in der Gesamtarchitektur eines Informationssystems, die Standardoperationen zum Speichern und Durchsuchen von Daten anbietet. Datenmodellierungssprachen für die Anforderungsanalyse (insb. die ER-Notationen oder UML-Notationen für Analyseklassendiagramme) haben zwar viele begriffliche Berührungspunkte mit Datenbankmodellen, sind aber prinzipiell etwas anderes, denn sie beinhalten überhaupt keine operationalen Schnittstellen (also Standardoperationen). Von derartigen Details soll während der Anforderungsanalyse gerade abstrahiert werden. Umgekehrt sind die Standardoperationen und deren exakte Semantik der wichtigste Aspekt eines Datenbankmodells. Für ein und dieselbe Datenmodellierungssprache können die Details zugehöriger Standardoperationen kraß verschieden ausgestaltet werden. Illustrieren kann man dies daran, daß z.B. auf Basis der Grundkonzepte der ER-Modellierung sowohl navigierende Datenbankmodelle als auch mengenorientierte Datenbankmodelle (ähnlich wie das relationale Modell) definiert wurden. Nichtsdestotrotz sind gute Kenntnisse in der Datenmodellierung für jeden, der Informationssysteme entwickelt, absolut unerläßlich. Sofern also nicht ohnehin irgendeine komplette Vorlesung über Softwaretechnik (z.B. das parallel angebotene Kernfach Softwaretechnik I) besucht wird, sollten wenigstens Grundkenntnisse in der Datenmodellierung erworben werden. Hierfür sind die Lehrmodule [SASM], [DMER] und [TAE] aus der Vorlesung Softwaretechnik I geeignet. Lehrmodul 1: Datenverwaltungssysteme Zusammenfassung dieses Lehrmoduls Drei wichtige Arten von Datenverwaltungssystemen sind Dateisysteme, Datenbankmanagementsysteme zur Transaktionsverarbeitung (OLTP-Systeme) und Information-Retrieval-Systeme. Dieses Lehrmodul listet die wichtigsten Datenverarbeitungsaufgaben auf und vergleicht die Fähigkeiten der einzelnen Systeme in den jeweiligen Aufgabenbereichen. Einleitend werden grundlegende Begriffe wie Information, Wissen und Daten definiert. Abschließend gehen wir noch auf die softwaretechnische Frage ein, inwieweit die Datenverwaltungssysteme die Konstruktion von Ein- und Ausgabeschnittstellen unterstützen. Vorausgesetzte Lehrmodule: keine Stoffumfang in Vorlesungsdoppelstunden: c 2005 Udo Kelter 2.2 Stand: 17.10.2005 20 1.1 Datenverwaltungssysteme Einleitung und Übersicht Dieses Lehrmodul betrachtet das Problem der Datenverwaltung aus einer sehr allgemeinen Perspektive. Ziel ist es, eine Übersicht über die wesentlichen Alternativen, wie Daten persistent gespeichert werden können, zu geben und die Vor- und Nachteile dieser Alternativen zu vergleichen. Aus Platzgründen können nur die wichtigsten Klassen von Datenverwaltungssystemen (DVS) skizziert werden. Wir beschreiben in Abschnitt 1.3 zunächst eine Reihe von Einzelproblemen, die bei der Verwaltung von Daten auftreten und die für die Bewertung und Einschätzung einzelner DVS heranzuziehen sind. In den folgenden Abschnitten 1.4 bis 1.6 werden die wichtigsten Datenverwaltungssysteme skizziert. Einleitend werden in Abschnitt 1.2 die zentralen Begriffe Daten, Wissen und Information eingeführt. 1.2 1.2.1 Grundbegriffe Daten – Wissen – Information Information ist der zentrale Begriff der Informatik – dementsprechend vielschichtig ist er, und deshalb wird er meist nicht exakt definiert. Die unterschiedlichen Definitionen sind nicht alle konsistent zueinander. Da wir hier die Themen “Informations”systeme und “Daten”banken behandeln wollen, kommen wir aber nicht umhin, diese Begriffe wenigstens für diesen Kontext festzulegen; wir brauchen daher auch nicht den Anspruch aufzustellen, alle Aspekte z.B. des Begriffs Information abzudecken. Wir beginnen mit dem Begriff Daten. Die folgende Zeichenfolge ist ein Beispiel eines Datums: 2000 Dargestellt ist hier offensichtlich eine Zahl, nämlich 2000. Genauer gesagt sieht man hier auf dem Bildschirm oder einem Blatt Papier die externe Darstellung einer Zahl. Intern in einem Rechner könnte unsere Zahl binär in einem Speicherwort gespeichert sein oder als Text Datenverwaltungssysteme 21 oder vielleicht auf noch andere Weise; diese Aspekte werden durch die “Syntax”, der unser Datum unterliegt, festgelegt. Unter Syntax versteht man Regeln, die für ein zugrundeliegendes Alphabet bestimmen, welche Zeichenfolgen, also Texte, als korrekt geformt anzusehen sind. Wir verallgemeinern den Begriff Syntax dahingehend, daß wir nicht nur Zeichen eines Alphabets, sondern genereller Inhalte von Speicherzellen irgendeines Speichermediums zulassen. Unsere Zahl 2000 ist zwar syntaktisch korrekt, aber sie sagt als solche nichts aus. Es könnte eine Jahreszahl sein oder eine Gewichtsangabe oder eine Benutzernummer. Offensichtlich benötigen wir immer einen Kontext, um ein Datum zu interpretieren, also seine Bedeutung erkennen zu können. Neben der Syntax benötigen wir somit eine Semantik, die bestimmt, wie (syntaktisch korrekte) Texte zu interpretieren sind. Durch die Semantik wird aus einem Datum (Fakten-) Wissen. In unserem Beispiel könnte uns das Datum 2000 zu dem Wissen verhelfen, daß Speichermodule des Typs X eine Kapazität von 2000 MB haben. Kompliziertere Sachverhalte müssen durch mehrere Daten repräsentiert werden, die dann gemeinsam zu interpretieren sind. Die nächste Frage ist, ob uns das Wissen über bestimmte Sachverhalte überhaupt interessiert bzw. uns etwas nützt. Vielleicht ist es mir völlig egal, daß Platten des Typs X eine Kapazität von 2000 MB haben, weil ich schon ausreichend große Platten in meinem Rechner habe und jetzt keine Platten mehr kaufe. Für jemand anders könnte dieses Wissen hingegen eine wichtige Information sein, weil ein anderer Rechner umkonfiguriert werden soll. Umgangssprachlich1 versteht man unter Information Wissen (oder einen Zugewinn an Wissen), das nutzbar ist und ggf. einen Effekt hat, z.B. dahingehend, daß jemand seine politische Meinung ändert oder sich neue Speichermodule kauft oder nach Südfrankreich verreist. Ob ein bestimmtes Wissen auch Information ist, ist offenbar nur subjektiv entscheidbar. Wir haben bisher den Weg vom Datum über das Wissen zur Infor1 Beispielsweise in Sätzen wie “Ich brauche Informationen über die Firma XY” oder “Er ist gut informiert”. 22 Datenverwaltungssysteme mation beschrieben. Daten entstehen auf dem umgekehrten Weg: Man hat Informationen in einem bestimmten Interessengebiet. Für dieses Interessengebiet (auch als Weltausschnitt oder universe of discourse bezeichnet) muß zunächst im Rahmen einer semantischen Modellierung eine geeignete Syntax und Semantik entwickelt werden, so daß anschließend Wissen in diesem Weltausschnitt durch Daten repräsentiert werden kann. Wie Informationen durch Faktenwissen zu repräsentieren sind, ist oft ganz offensichtlich. Die Kapazität einer Festplatte kann man hinreichend gut durch eine einzige Zahl ausdrücken. Schwieriger ist es, eine Syntax und Semantik zu finden, in der man ausdrücken kann, daß sich die Festplatte mit diesem oder jenem Plattencontroller nicht verträgt, vor allem, wenn noch ein CD-ROM am gleichen Bus angeschlossen ist, und dies speziell dann, wenn die Gehäuse-Innentemperatur über 34 Grad Celsius liegt. Bei solchen komplexen Sachverhalten ist das Ergebnis einer semantischen Modellierung keineswegs eindeutig, und je nach der gewählten Syntax und Semantik kann es sein, daß bestimmte Details der Ausgangsinformation gar nicht mehr oder nur mit viel Aufwand aus den vorhandenen Daten rekonstruierbar sind. Dies gilt ganz besonders dann, wenn freier umgangssprachlicher Text verwendet wird. 1.2.2 Informationssysteme Wir haben Daten bisher verstanden als interne Speicherstrukturen. Damit ein Benutzer die Daten kennenlernen, also zu Wissen umformen kann, müssen sie auf einem Bildschirm angezeigt oder auf Papier gedruckt oder in eine sonstige geeignete externe Darstellung überführt werden; vorher muß man natürlich Daten eingeben können. Unter einem Informationssystem verstehen wir ganz allgemein ein (Software-) System, durch das Daten erfaßt, angezeigt, weitergegeben, durchsucht und ausgewertet werden können. Typischerweise handelt es sich um umfangreiche Datenbestände. Für Informationssysteme ist die in Bild 1.1 gezeigte 3-SchichtenArchitektur als Grobarchitektur zu empfehlen. Diese reflektiert die Datenverwaltungssysteme 23 (G)UI-Schicht Batch-Applikationen Fachkonzeptschicht Datenhaltungsschicht Abbildung 1.1: 3-Schichten-Architektur von Informationssystemen drei Hauptaufgaben, die ein Informationssystem bewältigt: – Speicherung von Daten – anwendungsbezogene Verarbeitungsfunktionen – Interaktion mit den Benutzern über graphische oder textuelle Schnittstellen oder alternativ nichtinteraktive Stapeljobs. 1.2.3 Externe Darstellung von Daten Ein bestimmtes Datum, das in der Datenhaltungsschicht existiert, kann i.a. auf dem Bildschirm oder auf Papier unterschiedlich dargestellt werden. Eine ganze Zahl kann bspw. als Dual-, Oktal-, Dezimaloder Hexadezimalzahl dargestellt werden. Eine Fließkommazahl könnte gerundet dargestellt sein. Nicht nur elementare Datenelemente, auch komplette Strukturen können alternative Darstellungen besitzen. Als Beispiel betrachten wir einen Familienstammbaum. Dieser enthält Daten über Eltern-KindBeziehungen von mehreren Personen. Diese Daten kann man in einer Tabelle darstellen, die zu jeder Person die Mutter und den Vater angibt. Alternativ könnte man die Daten als Graph darstellen, wobei die Personen die Knoten des Graphen bilden. Wir nehmen jetzt einmal an, daß die Anordnung der Knoten auf einer Fläche (also die Koordinaten) vom Benutzer bestimmbar sind. Dann stellen diese Koordinaten ebenfalls Daten dar, die allerdings keine inhaltliche Bedeutung haben: 24 Datenverwaltungssysteme die graphische Anordnung der Knoten mag zwar die Übersichtlichkeit erhöhen, “inhaltlich” ändert sich dadurch aber nichts. Die Koordinaten und ähnliche Daten nennt man auch Layout-Daten. Manchmal gibt es nur eine naheliegende externe Darstellung. Diese Darstellung kann ggf. dynamisch geändert werden: beispielsweise könnte es möglich sein, bei der Anzeige von Fließkommazahlen zu wählen zwischen einer Darstellung mit 8 Stellen hinter dem Komma oder einer gerundeten Darstellung als ganze Zahl und zwischen einer Darstellung als Oktal-, Dezimal- oder Hexadezimalzahl. Derartige Darstellungsvarianten werden typischerweise durch Steuerparameter des Anzeigewerkzeugs gesteuert; diese Steuerparameter werden nicht als Teil der eigentlichen Daten angesehen. 1.2.4 Datenverwaltungssysteme Die bisherigen Überlegungen waren unabhängig davon, wie umfangreich die Datenmengen sind und welche Lebensdauer die Daten haben. Bei fast allen Anwendungsprogrammen müssen größere Datenmengen langfristig gespeichert werden. Wenn die Datenmengen größer werden, reicht irgendwann der Hauptspeicher nicht mehr aus, und es muß auf externe Medien, heute praktisch immer Magnetplatten, ausgewichen werden. Die langfristige Speicherung erfordert den Einsatz persistenter Speichermedien, was ebenfalls auf Magnetplatten oder sog. tertiäre Speichermedien hinausläuft. Durch den Einsatz persistenter Speichermedien entstehen andere Randbedingungen als bei einer Speicherung im Hauptspeicher, ferner entstehen durch die Merkmale der persistenten Speichermedien eigene neue Probleme. Daher ist es sinnvoll, eigene Systeme zu schaffen, mit deren Hilfe große Datenbestände persistent gespeichert werden können; solche Systemen nennen wir Datenverwaltungssysteme (DVS). DVS bestehen überwiegend aus Komponenten, die in der 3Schichten-Architektur, die in Bild 1.1 gezeigt ist, der Datenhaltungsschicht zuzuordnen sind. Es gibt sehr unterschiedliche Arten von Datenverwaltungssyste- Datenverwaltungssysteme 25 men. Die bekanntesten Datenverwaltungssysteme sind Dateisysteme. Sie sind praktisch auf jedem Rechner vorhanden, weil bereits das Betriebssystem selbst für den Eigenbedarf Daten persistent speichern muß. Welches DVS in einer gegebenen Problemstellung eingesetzt werden soll, ist in der softwaretechnischen Denkwelt des Phasenmodells eine Frage, die in der Analyse- oder Entwurfsphase zu entscheiden ist. Für die Auswahl eines DVS sind die relevanten Anforderungen festzustellen, und die verfügbaren DVS sind anhand dieser Anforderungen zu bewerten. Ziel dieses Lehrmoduls ist es daher, eine Übersicht über die wichtigsten Arten von Datenverwaltungssystemen zu geben und ihre Fähigkeiten und Einsatzbereiche zu beschreiben. Konkret werden wir drei Arten von Systemen etwas näher betrachten: – Dateisysteme – OLTP- (on-line transaction processing) Datenbankmanagementsysteme (DBMS)2 ; hierunter fallen objektorientierte und konventionelle, insb. relationale DBMS. OLTP-Systeme dienen dazu, die betrieblichen Daten von Unternehmen, z.B. Konten, Verkäufe, Buchungen usw., zu verwalten. Diese Daten werden durch Transaktionen ständig ergänzt oder modifiziert. OLTP-Systeme müssen sehr hohe Anforderungen hinsichtlich Verfügbarkeit, Datensicherung, Performanz, parallelem Zugriff, Zugriffskontrollen u.a. erfüllen. – IR- (information retrieval) Systeme; typische Beispiele hierfür sind Auskunftssysteme für Bibliotheksbestände, Fahrpläne, Produktkataloge usw. IR-Systeme haben oft einen statischen Datenbestand (z.B. auf einer CD-ROM gespeichert). Die Abgrenzung zwischen OLTP-Systemen und IR-Systemen ist nicht scharf, ferner gibt es viele Unterarten von OLTP-Systemen und IR-Systemen, u.a. – XML-DBMS, 2 Diese Systeme werden oft einfach als DBMS bezeichnet; wie wir gleich sehen werden, gibt es andere DBMS, die nicht zur Transaktionsverarbeitung gedacht oder geeignet sind. 26 – – – – – – Datenverwaltungssysteme Geo-DBMS, deduktive DBMS, Entwurfsdatenbanken, Projektdatenbanken, Repositories, OLAP-Systeme, Decision-Support-Systeme, Dokumentarchivierungssysteme Multimedia-DBMS usw. Diese Systeme unterscheiden sich oft hinsichtlich ihrer Leistungsmerkmale und internen Architektur erheblich von OLTP-DBMS, so daß man sie als selbständige Typen von DVS ansehen kann. Die originäre Kernaufgabe eines DVS besteht darin, Daten abzulegen und wiederaufzufinden; viele der genannten Systeme bieten Funktionen an, die man eher als Auswertung und Aufbereitung bezeichnen könnte und die man daher intuitiv eher der Fachkonzeptschicht (vgl. Bild 1.1) oberhalb der reinen Datenverwaltung zuordnen würde. Eine solche Trennung ist aber oft aus Performance-Gründen nicht praktikabel. Bei den obengenannten Systemen sind daher für konkrete Anwendungsgebiete Teile des Fachkonzepts in der Datenhaltung integriert. Noch einen Schritt weiter gehen sogenannte erweiterbare DBMS, bei denen über entsprechende Schnittstellen Teile der Applikation3 in den Datenbankkern integriert werden können. Für eine erste Begriffsbildung, die das Ziel dieses Lehrmoduls ist, ist aber die Beschränkung auf die drei o.g. DVS-Typen sinnvoll. Um begrifflich sauber zu bleiben, muß man eigentlich trennen zwischen dem Datenbestand und der Software, die den Datenbestand einkapselt (s. auch Bild 1.2). Unter einem DBMS versteht man das Softwaresystem, unter einer Datenbank den Datenbestand, unter einem Datenbanksystem (DBS) das DBMS zusammen mit der Datenbank. Bei Dateisystemen wird hingegen nicht sauber zwischen beiden Begriffen getrennt. Die Bezeichnung Dateisystem wird sowohl für 3 Hinweis: In der Datenbankliteratur versteht man unter einer “Applikation” ein Anwendungsprogramm, das ein DBMS benutzt. Dieser Begriff hat nichts zu tun mit dem Begriff application (als Gegensatz zu applet) aus der Denkwelt von Java. (Datenbank-) Applikationen sind häufig in COBOL, C und C++ geschrieben; erst seit kurzem werden auch vermehrt Applikationen in Java geschrieben. Datenverwaltungssysteme 27 “Dateiverwaltungssystem” verwendet als auch für den verwalteten Datenbestand, also z.B. den Inhalt einer Magnetplatte. Aus dem Kontext wird meist klar, was gemeint ist. Exkurs: Persistente Speichermedien. Zur persistenten Speicherung eines Datenbestands sind persistente Speichermedien erforderlich. Die gängigsten Beispiele hierfür sind Magnetplatten, CD-ROMs und Disketten. Im Gegensatz zum Arbeitsspeicher eines Rechners geht der Inhalt persistenter Speichermedien beim Ausschalten des Systems nicht verloren. Durch die zu einem Speichermedium gehörige Hardware werden zunächst sehr elementare Möglichkeiten vorgegeben, wie das Speichermedium formatiert werden kann und wie Daten auf das Speichermedium geschrieben (bei schreibbaren Medien) und gelesen werden können. Typischerweise werden immer ganze Datenblöcke von z.B. 1 kB Größe zwischen dem Medium und dem Arbeitsspeicher übertragen. Anwendungsprogramm Datenverwaltungssystem Daten Abbildung 1.2: Kapselung von Daten auf Speichermedien Diese hardwarenahen Schnittstellen werden aber aus diversen Gründen nicht für normale Anwendungsprogramme zugänglich gemacht, sondern analog zum information hiding bei Datenobjekten durch ein DVS eingekapselt (s. Bild 1.2). Das DVS bietet somit bestimmte Datenverwaltungsdienste an. Technisch kann dies in Form eines API oder einer graphischen Bedienschnittstelle oder auf noch andere Art realisiert sein; diese Unterschiede sind hier nicht relevant. Entscheidend ist vielmehr, welche Funktionen das DVS letztlich anbie- 28 Datenverwaltungssysteme tet; hier liegen die wesentlichen Unterschiede zwischen den verschiedenen DVS. Im Sinne der Einkapselung ist es auch unerheblich, ob ein DVS A auf ein anderes DVS B aufbaut. Beispielsweise bauen viele DBMS auf einem Dateisystem auf, während andere direkt auf die Hardwareschnittstellen aufsetzen, das Betriebssystem also umgehen. Größere DBMS bieten sogar beide Optionen an. Laufzeitkern und Dienstprogramme. Der Laufzeitkern eines DVS realisiert die Schnittstelle, auf die die Anwendungen aufsetzen. Technisch gesehen kann der Laufzeitkern z.B. aus einer Bindemodulbibliothek bestehen. Neben dem Laufzeitkern gehören zu einem DVS immer auch Administrations- und Dienstprogramme, die eigene Bedienschnittstellen haben und insofern neben den Anwendungen stehen (s. Bild 1.3). Beispiele sind Programme zur Benutzerverwaltung, Systeminstallation, Systemüberwachung, Unterstützung der Anwendungsentwicklung und Performance-Optimierung. Anwendungsprogramm Dienstprogramme Laufzeitkern Daten Abbildung 1.3: Laufzeitkern und Dienstprogramme eines DVS 1.3 Datenverwaltungsprobleme Wie schon oben erwähnt kann die Auswahl eines DVS nur auf Anforderungen im Zusammenhang mit der Verwaltung von Daten basieren. In diesem Abschnitt analysieren wir daher aus einer sehr allgemeinen Datenverwaltungssysteme 29 Anschauung heraus derartige Anforderungen und bewerten die drei oben genannten DVS-Typen schon einmal grob hinsichtlich dieser Anforderungen. 1.3.1 Anwendungsnahe Datenmodellierungskonzepte Natürlich muß es möglich sein, die Daten einer Anwendung überhaupt in das DVS und zurück zu übertragen. Diese Anforderung ist allerdings recht unspezifisch, denn irgendwie kann man fast alle Daten in jedes gegebene DVS übertragen. Beispielsweise könnte man den Text eines Buchs zeilenweise mithilfe eines relationalen DBMS in einer Relation speichern. Dies ist aber wenig sinnvoll, weil die Struktur des Buchs so weitgehend verlorengeht. Bei einer derartigen Diskrepanz zwischen der Struktur der Daten aus Anwendungssicht und der Struktur der Daten im DVS spricht man auch von einer Fehlanpassung (impedance mismatch). Beispiele für eine solche Diskrepanzen sind Arrays und Zeiger, die z.B. in relationalen Datenbanken nicht unterstützt werden. Ein n-dimensionales Array muß i.w. durch eine Tabelle mit n Spalten für die Indexwerte und eine Spalte für den Wert des Array-Elements nachgebildet werden. Wenn also a[4,5,6] = 999 ist, dann würde die Tabelle das Tupel (4,5,6,999) enthalten. Eine Fehlanpassung kann nicht nur aufgrund ungeeigneter Datenmodellierungskonzepte, sondern auch aufgrund ungünstig gestalteter Programmschnittstellen auftreten. Eine Fehlanpassung führt dazu, daß in den Applikationsprogrammen aufwendige Konversionen realisiert werden müssen, die zwischen der Darstellung der Daten im Hauptspeicher und im DVS konvertieren. Zu fordern ist also, daß das DVS eine möglichst einfache und direkte Nachbildung der Strukturen der konkreten Anwendung ermöglicht. Dateisysteme sind in dieser Hinsicht oft ideal, weil man in allen gängigen Programmiersprachen (insb. deren EinAusgabebibliotheken) Laufzeitobjekte direkt auf Dateien schreiben bzw. von dort zurückladen kann4 . Problematisch ist nur die Rekon4 Besonders unterstützt wird dieser Ansatz durch das sogenannte MMIO (memory-mapped IO), das von allen modernen Betriebssystemen angeboten wird und 30 Datenverwaltungssysteme struktion von Zeigern zwischen Datenobjekten. Weitere Probleme werden unten diskutiert werden. Objektorientierte OLTP-Systeme unterstützen ebenfalls persistente Laufzeitobjekte und verhalten sich damit ähnlich günstig wie Dateisysteme. OLTP-Systeme mit klassischen Datenbankmodellen (insb. relationale Systeme) sind für übliche betriebliche Anwendungen, in denen große Mengen gleichförmig strukturierter Daten anfallen, gut geeignet, nicht gut hingegen bspw. für technische Anwendungen, in denen sehr komplexe Datenstrukturen auftreten. IR-Systeme sind hier wie relationale OLTP-Systeme anzusehen. Eine Fehlanpassung ist kaum vermeidbar, wenn auf den gleichen Daten mehrere Anwendungsprogramme arbeiten sollen, die in verschiedenen Sprachen geschrieben sind, und wenn diese Sprachen signifikant verschiedene Typbildungskonzepte haben. 1.3.2 Korrekheitsüberwachung Die grundlegenden Möglichkeiten eines DVS zur Datenmodellierung geben zunächst nur einen Rahmen vor. Dieser erzwingt immerhin ein Mindestmaß an Korrektheit der Daten. Oft sind aber über einen rein syntaktischen Rahmen hinausgehende Korrektheitskriterien einzuhalten. Beispielsweise sollte das Alter einer Person nicht irgendeine Zahl sein, sondern eine Zahl zwischen 1 und ca. 100, für die Namensschreibweise kann eine Codiervorschrift vorliegen, daß der erste Vorname ausgeschrieben und alle folgenden durch ihre Initialen abgekürzt werden, und in der Adresse sollte die Postleitzahl zum Ort passen. Wenn in einer Personendatenbank ein Attribut Personennummer vorhanden ist, wird man fordern, daß die Personennummern eindeutig sind, daß also zu jeder Personennummer höchstens eine Person eingetragen ist. Das Attribut Personennummer ist somit geeignet, einzelne Datenelemente zu identifizieren, und wird daher als Identifizierungsschlüssel bezeichnet. Die Schlüsseleigenschaft ist immer dann bei dem Dateiinhalte direkt in den (virtuellen) Hauptspeicher eines ausgeführten Programms eingeblendet werden. Das MMIO wird typischerweise in Vorlesungen über Betriebssysteme behandelt. Datenverwaltungssysteme 31 gefährdet, wenn eine neue Person mit einer bestimmten Nummer eingetragen werden soll; es muß dann geprüft werden, ob diese Nummer schon benutzt ist. Die vorstehenden Korrektheitskriterien sind insofern statisch, als sie jederzeit gelten sollen. Zusätzlich sind dynamische Kriterien denkbar. Beispielsweise kann eine Person vom Zustand verheiratet in den Zustand geschieden oder verwitwet übergehen, nicht hingegen in den Zustand ledig. Dateisysteme unterstützen die Korrekheitsüberwachung überhaupt nicht, IR-Systeme meist ebenfalls nicht. Nur OLTP-Systeme bieten üblicherweise eine nennenswerte Unterstützung der Korrekheitsüberwachung. Komplexe Korrektheitskriterien müssen aber auch dort durch die Applikation überwacht werden. 1.3.3 Such- und Auswertungsfunktionen Unter Suchfunktionen verstehen wir Funktionen, die anhand bestimmter Kriterien einzelne Elemente des Datenbestands auffinden. Hierbei muß klar getrennt werden zwischen zwei Arten, wie Suchkriterien zu verstehen sind: – Bei der exakten Suche wird die Menge der Datenelemente, die die Suchkriterien exakt erfüllen, gewünscht. Wenn z.B. die Kunden mit einem Jahresumsatz von über 100.000 DM einen Sonderrabatt von 1 % bekommen sollen, dann werden exakt diese Kunden gesucht, sonst keine. – Bei der vagen Suche weiß der Frager nicht genau, wonach er sucht; man sucht z.B. nach irgendeinem Kunden, der in Bonn oder Umkreis wohnt und ca. 100.000 DM Umsatz gemacht hat. Ein Kunde in Bonn mit 50.000 DM Umsatz wäre besser als einer in Köln mit 90.000 DM Umsatz. Während die Treffermenge bei der exakten Suche keine relevante Sortierung hat, erwartet man bei der vagen Suche für jeden Treffer eine Schätzung der Relevanz, also der Wahrscheinlichkeit, ein passendes Element zu sein, und eine Sortierung der Treffermenge anhand 32 Datenverwaltungssysteme dieser Wahrscheinlichkeiten. Bei der vagen Suche wird man Elemente, die knapp neben dem angegebenen Selektionskriterium liegen (z.B. wenn sich die Schreibweise eines Namens nur geringfügig unterscheidet), trotzdem in die Treffermenge aufnehmen. IR-Systeme enthalten meist sehr ausgefeilte Verfahren, mit denen “knapp danebenliegende” Treffer gefunden und Treffer bewertet werden können. Unter Auswertungsfunktionen – im Gegensatz zu Suchfunktionen – verstehen wir Funktionen, die aus den originären Daten abgeleitete Daten liefern, von einfachen Zählungen und Aggregationen bis hin zu anspruchsvollen mathematischen Analysen, Hochrechnungen und ähnlichem. OLTP-DBMS bieten primär die exakte Suche an, ferner einfache Auswertungen. IR-Systeme unterstützen primär die vage Suche und bieten keine Auswertungsfunktionen an. Dateisysteme bieten als solche überhaupt keine Such- oder Auswertungsfunktionen an; allerdings können derartige Aufgaben oft durch Dienstprogramme, die zum Standardumfang des Betriebssystems gehören, gelöst werden (s.u. im Abschnitt 1.4). Bei den Such- und Auswertungsfunktionen interessiert insbesondere, wieweit sie skalieren. Man sagt, daß eine Funktion skaliert, wenn sie auf große Datenbestände anwendbar ist und dabei Laufzeiten und sonstiger Ressourcenbedarf nicht überproportional ansteigen. Wir unterscheiden hierzu ganz grob drei Größenklassen von Datenbeständen: klein: ca. 1 MB mittel: ca. 1 GB groß: ca. 1 TB (= 1024 GB) Bei mittleren bis großen Datenbeständen lassen sich akzeptable Antwortzeiten der Suchfunktionen und mancher Auswertungsfunktionen nur durch den Einsatz von Indexen erreichen. Indexe werden durch OLTP-DBMS und IR-Systeme unterstützt, nicht hingegen durch Dateisysteme. Datenverwaltungssysteme 1.3.4 33 Backup und Versionierung Auch bei “persistenten” Speichermedien besteht die Gefahr von Datenverlusten. Ursachen können Gerätedefekte, Verlust oder Beschädigung von Datenträgern, absichtliche oder versehentliche Löschung von Daten usw. sein. Im Falle eines solchen Datenverlusts muß versucht werden, möglichst rasch einen akzeptablen Zustand der Daten wiederherzustellen. Die Randbedingungen und Konzepte der einzelnen DVS-Typen unterscheiden sich hier erheblich. Backup-Programme für Dateisysteme arbeiten i.d.R. mit “Archiven”, die Kopien von Dateien – ggf. in komprimierter Form – enthalten und die auf sequentiell les- bzw. schreibbaren Medien, insb. Magnetbändern, gespeichert werden können. Ein Beispiel eines solchen Systems für UNIX-Rechner ist tar (tape archive). Eine Datei kann zu verschiedenen Zeiten in Archive kopiert werden und existiert dann in mehreren Versionen; hierdurch wird implizit eine rudimentäre Versionsverwaltung unterstützt. Im Falle eines Defektes können einzelne Dateien wieder von einem Archiv in das Dateisystem zurückkopiert werden. Dies kann bewußt dazu eingesetzt werden, einen früheren Zustand einer Datei wiederherzustellen. Archive eignen sich auch gut dazu, Daten von einem Rechner zu einem anderen zu transportieren. In OLTP-Systemen können normalerweise nicht ohne weiteres Teile des Datenbestands in ein Archiv kopiert und später, nachdem sich die Datenbank verändert hat, wieder dorthin zurückkopiert werden. Im schlimmsten Fall sind die Datenbankschemata verändert worden, das Wiedereinspielen scheitert dann sozusagen schon syntaktisch. Selbst bei unveränderten Schemata könnten durch die eingespielten Daten Konsistenzkriterien verletzt werden. Ein partielles Zurücksetzen der Datenbank auf einen früheren Zustand ist aber auch bei den typischen Anwendungen von OLTP-Systemen nicht sinnvoll: die DB muß jeweils einen aktuell gültigen Inhalt haben, nicht irgendeinen früheren veralteten. Daher stellen die Backup-Konzepte für OLTP-Systeme nur auf den Fall von Medienfehlern ab mit dem Ziel, durch weitere Maßnahmen möglichst rasch wieder den aktuell gültigen Inhalt der Datenbank zu rekonstruieren. Will man mit OLTP-Systemen auch 34 Datenverwaltungssysteme früher gültige Daten verwalten, muß dies in den Datenbankschemata explizit berücksichtigt werden; zu jedem Datenwert muß dann zusätzlich die Gültigkeitsdauer gespeichert werden, was die Formulierung von Abfragen verkompliziert und zu Performance-Problemen führen kann. Bei IR-Systemen, die aus anderen, “originären” Datenbeständen generiert werden, muß im Fall einer Beschädigung nur die Generierung wiederholt werden. Eine Rücksetzung auf eine frühere Version des Systems ist hier ebenfalls aus Anwendungssicht nicht sinnvoll. 1.3.5 Datenschäden durch Systemabstürze Ein weiteres Gefahrenpotential für Datenbestände sind Systemabstürze, entweder des Betriebssystems oder der Anwendungsprogramme. Bei Abstürzen der Anwendungsprogramme können infolge von unvollständig durchgeführten Änderungen inkonsistente Zuständen hinterlassen werden, bei Betriebssystemabstürzen können auch interne Strukturen des Dateisystems oder der Speichermedien beschädigt werden. In jedem Fall können beliebig große Teile des Datenbestands betroffen und unbrauchbar geworden sein; im Extremfall liegt ein Totalschaden wie bei einem Medienfehler vor. Welche und wie aufwendige Maßnahmen zur Vorbeugung bzw. Schadensbehebung vorgesehen werden, hängt stark vom Wert der Daten und der tolerierbaren Stillstandszeit der Anwendungen ab. Bei einem Absturz des Systems oder Anwendungsprogramms ist der Zustand von Dateien, in denen geschrieben worden ist, i.a. unvorhersehbar; es können weitreichende Schäden bis zum völligen Datenverlust auftreten. Bei einem Systemabsturz können auch schon zurückliegende, scheinbar abgeschlossene Schreibzugriffe verloren sein, da die Änderungen u.U. zunächst nur in Puffern erfolgen. OLTP-Systemen beinhalten sehr umfangreiche Schutzmaßnahmen gegen Datenschäden infolge von Systemabstürzen. Konventionelle Dateisysteme bieten nur einen sehr schlechten Schutz: es sind praktisch keine vorbeugenden Maßnahmen vorhanden, nach einem Systemabsturz muß das gesamte Dateisystem auf Defekte durchsucht werden. Dies kann bei großen Systemen selbst bei schnellen Datenverwaltungssysteme 35 Rechnern 10 - 30 Minuten dauern, was oft zu lang ist. Modernere, sogenannte journaling Dateisysteme beinhalten präventive Maßnahmen, durch die die Auswirkungen von Systemabstürzen stark reduziert werden und nur noch in extremen Ausnahmefällen umfangreiche Schäden eintreten können, d.h. in der Regel ist ein sofortiger Neustart des Systems möglich. Bei IR-Systemen werden typischerweise keine Änderungen on-line ausgeführt; daher entsteht das Problem von Schäden durch Systemabstürze hier nicht. 1.3.6 Mehrbenutzerfähigkeit und Zugriffskontrollen Datenbestände müssen oft von verschiedenen Benutzern benutzt werden; oft haben diese Benutzer unterschiedliche Rechte. Fast alle DVS beinhalten daher Zugriffskontrollen. Basis hierfür ist stets eine Benutzerverwaltung, mit der die Benutzer erfaßt werden, die überhaupt Zugang zu dem System haben sollen. Ferner ist es fast immer möglich, Benutzer zu Gruppen zusammenzufassen und den Gruppen Rechte einzuräumen. Bei Dateisystemen ist die Benutzer- bzw. Gruppenverwaltung naheliegenderweise die des Betriebssystems5 ; DBMS haben oft eine eigene Benutzerverwaltung. Die Administration von Rechten an Datenelementen ist bei Dateisystemen wesentlich anders als bei DBMS bzw. IR-Systemen. In Dateisystemen kann im Prinzip für jede einzelne Datei bestimmt werden, wer sie lesen bzw. schreiben darf. In DBMS bzw. IR-Systemen wäre dies wegen der vielen kleinen Datengranulate viel zu aufwendig. Stattdessen werden Rechte für Mengen von Objekten vergeben, die durch Selektionsbedingungen beschrieben werden. An neu erzeugten Objekten, die in eine so beschriebene Menge fallen, gelten dadurch automatisch die entsprechenden Rechte; eine explizite Vergabe von Rechten ist nicht notwendig. Die mengenorientierte Rechtevergabe ist dem Bedarf in typischen betrieblichen Anwendungen angepaßt, die objektorientierte Vergabe von Rechten in Dateisystemen eher dem Bedarf bei 5 PC-Betriebssysteme, die keine Benutzerverwaltung beinhalten, betrachten wir nicht, da sie offensichtlich keine sinnvolle Basis für wertvolle Datenbestände sind. 36 Datenverwaltungssysteme der Dokumentverarbeitung. In DBMS können Zugriffe von Benutzern außerdem nicht nur auf Basis der Instanzen, sondern auch auf Basis von Typen eingeschränkt werden. Beispielsweise könnten bei einer Mitarbeiterdatenbank die Telephonnummern u.ä. vom Pförtner lesbar sein, Gehaltsdaten könnten nur von entsprechenden Mitarbeitern der Verwaltung gelesen und geschrieben werden. Allgemein können einzelne Attribute der Objekte eines bestimmten Typs für einen bestimmten Benutzer nicht lesoder schreibbar sein. Derartige typbasierte Zugriffskontrollen sind in Dateisystemen prinzipiell nicht möglich. 1.3.7 Entfernter Zugriff Bei vielen parallelen Benutzern muß von verschiedenen Rechnern aus auf den gemeinsamen Datenbestand zugegriffen werden. Häufig will man die Datenanzeige und Kommunikation mit dem Bediener auf einem PC abwickeln, während das DBMS auf einem zentralen Rechner läuft. In der Schichtenarchitektur aus Bild 1.1 laufen somit die GUISchicht und die Datenhaltungsschicht in separaten Programmen auf verschiedenen Rechnern. Die mittlere, für die Fachlogik zuständige Schicht kann ebenfalls auf einem eigenen Rechner ausgeführt werden (der “Applikationsserver”). Operationsaufrufe von einer höheren Schicht auf eine untere werden so zu entfernten Aufrufen. Entfernte Aufrufe sind wesentlich aufwendiger als lokale. Dies fällt vor allem dann ins Gewicht, wenn sehr viele Einzelaufrufe auftreten oder große Datenvolumina übertragen werden müssen. Dies betrifft vor allem die Kommunikation zwischen der Fachkonzeptschicht und der Datenhaltungsschicht. Auf Details der Verteilungsarchitekturen können wir hier aus Platzgründen nicht eingehen. Festzuhalten bleibt jedenfalls, daß ein DVS bei bestimmten Verteilungsarchitekturen Schnittstellen anbieten muß, die einen entfernten Zugriff auf die Datenbestände ermöglichen und daß ggf. die Entwicklung verteilter Applikationen unterstützt werden sollte. Im Zusammenhang mit der Verteilung tritt oft zusätzlich das Pro- Datenverwaltungssysteme 37 blem der Heterogenität auf. Ganz elementar können auf den verschiedenen Arbeitsplatzrechnern verschiedene Prozessoren vorliegen, die z.B. verschiedene Zahlendarstellungen benutzen. Dementsprechend müssen alle Datentypen bei der Übertragung zwischen Applikation und DVS zwischen dem internen Format des DVS und einem plattformspezifischen Format konvertiert werden. Ein ähnliches (allerdings nicht durch die Verteilung verursachtes) Problem entsteht, wenn die Applikationen in unterschiedlichen Sprachen geschrieben sind. 1.3.8 Paralleler Zugriff Sofern auf gleiche Datenbestände von verschiedenen Benutzern parallel zugegriffen wird, können Parallelitätsanomalien entstehen. Sofern alle Benutzer nur lesen, treten keine Probleme auf, insofern entstehen bei IR-Systemen keine diesbezüglichen Probleme. Bei Dateisystemen und OLTP-Systemen sind aber (natürlich) auch schreibende Zugriffe möglich. Zur Lösung der Probleme gibt es verschiedene Concurrency-Control-Verfahren; das bekannteste ist der wechselseitige Ausschluß (bzw. allgemeiner das 2-Phasen-Sperrprotokoll), der mithilfe von Sperrungen realisiert wird. Sperren werden inzwischen in vielen Betriebssystemen angeboten; Gegenstand einer Sperre ist immer eine komplette Datei. Sofern man viele Daten in einer Datei speichert, muß also die gesamte Datei gesperrt werden, auch wenn nur für ein einziges darin enthaltenes Datenelement eine Sperre benötigt wird. Dies führt zu sachlich unnötigen Serialisierungen von Zugriffen und zu einem sehr geringen Parallelitätsgrad. Teilt man den Datenbestand auf sehr viele kleine Dateien auf, behebt man zwar das Granularitätsproblem der Sperren, bekommt aber ein erhebliches Performance-Problem wegen des ständigen Lokalisierens, Öffnens und Schließens der Dateien. Leistungsfähige OLTP-DBMS bieten sehr ausgefeilte Sperrverfahren an, durch die relativ kleine Sperreinheiten (einzelne Tupel oder Sätze) gesperrt und die große Mengen von Sperren verwaltet werden können. Nur mit derartigen OLTP-DBMS kann man Systeme bauen, 38 Datenverwaltungssysteme die von sehr vielen Benutzern parallel genutzt werden können. Bei IR-Systemen entfällt die gesamte Problematik, weil auf IRSysteme nur lesend zugegriffen wird. 1.3.9 Datenintegration und Sichten Von mittleren bis großen Applikationen, insb. betrieblichen Informationssystemen, müssen verschiedene Arten von Benutzern (“Rollen”) gleichzeitig bedient werden. Unterschiedliche Rollen haben unterschiedliche Informationsbedürfnisse; neben Daten, die von allgemeinem Interesse sind, treten auch rollenspezifische Daten auf. In einer Bank könnten z.B. folgende Arbeitsgebiete mit jeweils eigenen Daten vorhanden sein: – Privat-Girokonten – Firmen-Girokonten – Wertpapierhandel – Hypotheken Bestimmte Daten, z.B. Kundenadressen, werden natürlich ganz oder teilweise in mehreren Arbeitsgebieten benötigt. Es wäre nun sehr ungeschickt, diese Daten mehrfach, also redundant zu speichern; stattdessen sollten diese Daten nur einmal im DVS gespeichert, unsere Kundenadressen z.B in einem einzigen zentralen Adreßverzeichnis. Die Daten, die eine Applikation benötigt, müssen für diese nun wieder geeignet zusammengesetzt werden. Eine redundanzfreie Modellierung und Speicherung ist im Prinzip bei allen DVS möglich6 . Das entscheidende Problem ist das Wiederzusammensetzen von zerlegten Datenbeständen: die meisten DVS unterstützen diesen Vorgang überhaupt nicht, eine nennenswerte Unterstützung bieten nur relationale DBMS durch den Sichtenmechanismus. 6 Wie Datenbestände zerlegt werden müssen, damit Redundanzen vermieden werden, ist im Kontext von relationalen Datenbanken unter dem Begriff “Normalform” zuerst erforscht worden. Normalformen sind aber völlig unabhängig davon anwendbar, welches DVS eingesetzt wird. Auch dann, wenn “tabellarische” Daten in Dateien gespeichert werden (z.B. wie in Abschnitt 1.4 beschrieben), können die Typstrukturen normalisiert werden. Datenverwaltungssysteme 1.3.10 39 Evolution der Datenbestände Viele Informationssysteme existieren über sehr lange Zeiträume. Im Lauf der Zeit müssen die Datenbestände und Anwendungen aufgrund neuer Anforderungen immer wieder ergänzt werden. In einfachen Fällen werden nur Daten ergänzt, z.B. kommen neue Attribute bei vorhandenen Datenelementen hinzu. In komplizierteren Fällen müssen die vorhandenen Daten umstrukturiert werden, z.B. um Redundanzen zu vermeiden (s. voriger Abschnitt). Die Frage ist nun, wie stark die vorhandenen Applikationen - bei großen Informationssystemen können dies Tausende von Programmen sein - von einer Änderung der Struktur der Datenbestände betroffen sind. Verwendet man Dateisysteme zur Datenverwaltung, müssen selbst bei trivialen Modifikationen der Dateiformate, z.B. beim Anfügen eines neuen Felds am Ende der Sätze, alle Applikationen angepaßt werden. D.h. die Quelltexte der Applikationen müssen vorliegen und vom vorhandenen Compiler übersetzbar sein; bei sehr alten Programmen ist das oft nicht der Fall. Weiter müssen alle betroffenen Programmteile gesucht und korrigiert werden, das Programm muß nach der Änderung getestet werden; dies kann signifikante Aufwände verursachen. Ideal wäre es daher, wenn die vorhandenen Applikationen als Binärprogramme unverändert weiterbenutzt werden könnten oder allenfalls neu compiliert werden müßten; dies bezeichnet man als Datenunabhängigkeit der Applikationen. DBMS leisten dies zumindest bei “einfachen” Änderungen. Bei relationalen DBMS können die Applikationen durch den Sichtenmechanismus auch vor etwas komplexeren Änderungen der Datenstrukturen geschützt werden. 1.4 Dateisysteme Datei(management)systeme sind mit Abstand die verbreitetsten DVS. In diesem Abschnitt stellen wir einige speziellere Arten von Dateisystemen vor und behandeln die Frage, ob und wie durch Dienstprogramme auch formatierte Daten in Dateien verwaltet werden können. Wir gehen auf einige wesentliche Aspekte von Dateisystemen nicht 40 Datenverwaltungssysteme ein, insb. nicht auf den Aufbau und die Struktur von Verzeichnissen, Blockverwaltung auf den Medien u.ä. Themen, die üblicherweise in Vorlesungen über Betriebssysteme behandelt werden. Stattdessen konzentrieren wir uns auf Merkmale einzelner Dateien, insb. auf die Frage, wie Daten in einer Datei strukturiert abgespeichert werden können. 1.4.1 Arten von Dateisystemen Man unterscheidet zeichen- und satzorientierte Dateisysteme. Zeichen bzw. Sätze sind die elementaren Einheiten, aus denen eine Datei besteht, und können nur als Ganze gelesen oder geschrieben werden. Bei den satzorientierten Dateisystemen unterscheidet man zusätzlich solche mit fester bzw. variabler Satzlänge. Für die Menge der Elemente (Zeichen bzw. Sätze) einer Datei existieren folgende Strukturen, die auch die Zugriffsmöglichkeiten festlegen: – sequentielle Struktur: alle Elemente bilden eine Sequenz, die nur in dieser Reihenfolge durchlaufen werden kann. – Arraystruktur: auf jedes Element kann direkt anhand seiner Nummer zugegriffen werden. Die für einen Zugriff benötigte Zeit ist bei allen Elementen in etwa gleich. – Verzeichnisstruktur (nur bei satzorientierten Systemen): Jedes Element bekommt bei seiner Erzeugung einen Schlüsselwert (meist ein Text fester Länge), der in der Datei eindeutig sein muß. Mit Hilfe dieses Schlüsselwerts kann später direkt auf den Satz zugegriffen werden. Die für einen Zugriff benötigte Zeit ist auch hier bei allen Elementen in etwa gleich. Bei einer Arraystruktur bzw. einer Verzeichnisstruktur ist meist zusätzlich eine sequentielle Struktur verfügbar. Eine kombinierte Verzeichnis- / sequentielle Struktur wird auch indexsequentiell (ISAM; index sequential access method) genannt. Datenverwaltungssysteme 1.4.2 1.4.2.1 41 Verwaltung formatierter Daten in Dateien Codierungen Übliche Dateisysteme unterstützen applikationsspezifische Datentypen bzw. formatierte Daten nicht. Applikationsspezifische Datenstrukturen können nur als “Syntax” einer Datei realisiert werden. So könnte z.B. in einem UNIX-System die Datei /etc/passwd folgende Textzeilen enthalten: root:x:0:0:root:/root:/bin/tcsh bin:x:1:1:bin:/bin:/bin/bash daemon:x:2:2:daemon:/sbin:/bin/bash lp:x:4:7:lp daemon:/var/spool/lpd:/bin/bash man:x:13:2::/var/catman:/bin/bash at:x:25:25::/var/spool/atjobs:/bin/bash wwwrun:x:30:65534:Daemon user for apache:/tmp:/bin/bash Jede Zeile enthält Angaben zu einem Systembenutzer, und zwar den Namen, verschlüsseltes Paßwort, interne Benutzernummer, Gruppennummer, Beschreibung, home-Verzeichnis und Login-Shell. Die Felder sind durch einen Doppelpunkt getrennt, dürfen also selbst keinen Doppelpunkt enthalten. In einigen Feldern darf nur die textuelle Darstellung einer Zahl, deren Größe begrenzt ist, stehen. Das Dateisystem kennt derartige syntaktische Restriktionen nicht und überwacht sie daher auch nicht; die Restriktionen müssen allein durch die Programme, die die Daten verändern, sichergestellt werden. Ein offensichtlicher Nachteil des Dateiformats im letzten Beispiel ist die schlechte Erkennbarkeit, wo die einzelnen Felder liegen, so daß das Editieren solcher Dateien mit einem normalen Texteditor sehr fehleranfällig ist. Dieses Problem wird bei Dateiformaten reduziert, in denen textuelle Bezeichner für die Felder verwendet werden, etwa wie im folgenden Beispiel: 42 Datenverwaltungssysteme #begin{user} { USERNAME=root PASSWD=x USERID=0 GROUPID=0 DESCRIPTION=root HOMEDIR=/root SHELL=/bin/tcsh } In solchen Formaten können die Felder in beliebiger Reihenfolge angegeben werden und fehlen, dann wird ein Vorgabewert verwendet. Zu derartigen Formaten gehören Parser bzw. Unparser, die eine Datei in eine Menge von Laufzeitobjekten konvertieren und umgekehrt. Ein ähnliche Idee liegt dem XML-Ansatz zugrunde. Allerdings werden bei der XML sogenannte tags benutzt, um Datenelemente zu klammern, bspw.: <USERNAME>root</USERNAME> <USERID>0</USERID> <SHELL>/bin/tcsh</SHELL> Ein tag besteht u.a. aus den Sonderzeichen < und > und einem Schlüsselwort, das das tag identifiziert. Ein einleitendes tag (sozusagen die öffnende Klammer) kann zusätzlich Steueranweisungen hinter dem Tag-Namen haben, ein schließendes tag hat einen / vor dem tagNamen. Eine Besonderheit des XML-Ansatzes besteht darin, daß eine Datei nicht nur die eigentlichen Nutzdaten enthält, sondern auch das Schema für diese Daten enthalten kann. Statt von Schema spricht man hier von einer Dokumenttypdefinition (DTD). Der eigentliche Nutzen der DTD liegt darin, daß man sie als Spezifikation für einen Parser ansehen kann, der einen Dateiinhalt in eine Hauptspeicherdarstellung konvertiert, oder für einen Editor, der Instanzen des Dokumenttyps bearbeiten kann. Mit einem einzigen “generischen” Parser oder Editor können daher beliebige XML-Dateien bearbeitet werden. Datenverwaltungssysteme 1.4.2.2 43 Such- und Auswertungsfunktionen Dateisysteme bieten direkt keine Such- oder Auswertungsfunktionen an. Allerdings sind in fast allen Betriebssystemen Textprozessoren vorhanden, durch die (direkt oder mit Hilfe von Shell-Skripten) in formatierten Dateien gesucht werden kann. So sind in UNIX-Systemen die Programme sed , cut , awk , perl usw. hierfür einsetzbar, ferner diverse in die Kommandointerpreter eingebaute Funktionen. Mit diesen Programmen kann man u.a. aus einer Datei diejenigen Zeilen selektieren, in denen ein bestimmtes Textmuster auftritt, einzelne Felder ausschneiden, diese Daten mit anderen Daten mischen und für Ausgaben aufbereiten. Diese Programme und Funktionen haben allerdings zwei gravierende Nachteile: – Sie skalieren nicht. Bei mittleren Datenbeständen sind die Antwortzeiten i.a. nicht mehr akzeptabel. Bei kleinen Datenbeständen sind die Antwortzeiten dagegen gut oder sogar sehr gut, Textprozessoren können unter dieser Annahme eine durchaus vorteilhafte Implementierungstechnologie sein. Durch Indexierungssysteme wie z.B. glimpse lassen sich zwar auch für umfangreiche Datenbestände in Dateien Indexe aufbauen, die die Suche stark beschleunigen können, allerdings gilt dies nur mit diversen signifikanten Einschränkungen. – Entwickler solcher Anwendungen müssen mehrere Skript- und Textprozessorsprachen und deren Kombination beherrschen, und es müssen komplizierte Algorithmen realisiert werden. Dies ist für gelegentliche Benutzer nicht zumutbar. 1.5 OLTP-Datenbankmanagementsysteme OLTP ist die Abkürzung von on-line transaction processing. Diverse Merkmale von OLTP-Systemen sind schon in den vorstehenden Abschnitten erläutert worden, insb. Funktionen für die exakte Suche, Recovery, Mehrbenutzerfähigkeit, Datenintegration und Datenunabhängigkeit. Wir gehen in diesem Abschnitt auf einige Punkte detaillierter ein. 44 Datenverwaltungssysteme 1.5.1 Datenbankmodelle Daten werden in einem OLTP-DBMS strukturiert gespeichert, d.h. das OLTP-DBMS kennt die Struktur der Daten. Dies ist die entscheidende Basis dafür, bei Abfragen Strukturelemente der gesuchten Daten benennen zu können oder Daten für einzelne Applikationen zusammenstellen zu können, um deren Datenunabhängigkeit zu erreichen. Wie die Daten strukturiert werden können, legt das Datenbankmodell des OLTP-DBMS fest. Vereinfacht gesagt definiert ein Datenbankmodell die Struktur einer Datenbank und die Operationen auf dieser Struktur. Man teilt die bekannten Datenbankmodelle in konventionelle und nichtkonventionelle ein: – Zu den konventionellen Datenbankmodellen zählen das relationale, das Netzwerk- und das hierarchische Datenbankmodell. – Zu den nichtkonventionellen Datenbankmodellen zählen u.a. objektorientierte, Geo-, deduktive und Multimedia-Datenbankmodelle. Darüber hinaus gibt es Mischformen, z.B. objekt-relationale Systeme. Etwas konkreter gesagt ist ein Datenbankmodell bestimmt durch: 1. Eine “Denkwelt”, in der anwendungsspezifische Datentypen (z.B. ein Objekttyp Person mit den Attributen Name, Vorname usw.) definiert werden können. Notiert werden derartige Definitionen üblicherweise in einer Datendefinitionssprache (data definition language, DDL)7 Diese ist analog zu sehen zu den Teilen einer Programmiersprache, die in Typdefinitionen benutzt wird. 2. Operationen auf dem Inhalt einer Datenbank, insb. Operationen, die einzelne Datenelemente erzeugen, schreiben, lesen, selektieren oder löschen. Diese Operationen werden meist in Form einer 7 Eigentlich müßte es Datentypdefinitionssprache heißen; wir schließen uns hier aber dem allgemeinen Sprachgebrauch an. Datenverwaltungssysteme 45 Abfrage- bzw. Datenmanipulationssprache (data manipulation language, DML) angeboten. Sie sind in dem Sinne generisch, daß sie mit beliebigen anwendungsspezifischen Datentypen arbeiten. Der gewünschte Datentyp muß oft als Parameter explizit angegeben werden, z.B. muß in der Operation, die ein neues Objekt erzeugt, der gewünschte Typ (z.B. Person) angegeben werden. Die Operationen des Datenbankmodells stellen gemäß dem Prinzip der Datenkapselung die Schnittstelle dar, über die auf die Datenbank, die hier die Rolle des “schwarzen Kastens” spielt, zugegriffen wird, ohne daß interne Realisierungsdetails nach außen bekanntgegeben werden. 3. ggf. Integritätsbedingungen, typischerweise Einschränkungen der zulässigen Datenbankinhalte. Als Beispiel geben wir einige Merkmale des relationalen Datenbankmodells an: 1. Man kann Tabellen mit beliebigen “Spaltenköpfen” definieren; 2. Man kann z.B. Tupel in einer Relation selektieren oder zwei Relationen anhand gleicher Attributwerte “verbinden”; 3. Man kann als Integritätsbedingung festlegen, daß bestimmte Attribute bzw. Attributmengen Identifizierungsschlüssel sein sollen. 1.5.2 Datenintegration, Datenunabhängigkeit und die 3-Ebenen-Schema-Architektur Eine zentrale Leistung von DBMS besteht darin, Daten auf drei verschiedenen “Ebenen” betrachten und in Form von “Schemata” Eigenschaften der Daten definieren zu können. Veranschaulicht wird dies in der 3-Ebenen-Schema-Architektur, die in Bild 1.4 gezeigt ist. Um Mißverständnissen vorzubeugen sei darauf hingewiesen, daß es sich hier nicht um eine Software-Architektur, also um eine Zerlegung des Systems in Komponenten handelt, wie sie z.B. in Bild 1.1 gezeigt ist. Die 3-Ebenen-Schema-Architektur beschreibt ausschließlich Eigenschaften der Datenhaltungsschicht. 46 Datenverwaltungssysteme Sicht 1 ........ Sicht n konzeptuelles Schema internes Schema Abbildung 1.4: Schema-Architektur von DBMS Das konzeptuelle Schema in der Mitte dieser Architektur definiert die logische Gesamtstruktur aller Daten, d.h. hier werden alle Applikationen, die innerhalb eines Unternehmens benötigt werden, aus einer Gesamtsicht heraus betrachtet, und es werden alle einzelnen Datenelemente, die in irgendeiner der Applikationen benötigt werden, hierin vereinigt. Ferner werden hier Beziehungen der Daten untereinander festgelegt, und es werden solche Integritätsbedingungen formuliert, die systemweit gelten sollen. Nicht berücksichtigt werden hierin Implementierungsaspekte oder Optimierungen (zumindest in der Theorie; in der Praxis muß man oft von dieser Regel abweichen). Das interne Schema gibt an, wie die Strukturen, die auf der konzeptuellen Ebene definiert worden sind, auf physische Strukturen abzubilden sind. Unter physischen Strukturen verstehen wir hier Festlegungen, wie die Daten auf Platten bzw. in Dateien angeordnet, sortiert und formatiert werden. Ebenfalls geregelt wird auf dieser Ebene, welche Indexe, d.h. welche Hilfsstrukturen zur Beschleunigung von Zugriffen, angelegt werden sollen. Hier wird die Sortierreihenfolge von Sätzen innerhalb von Dateien bestimmt, und es können noch diverse andere Optimierungen, je nach dem Datenmodell und nach dem DBMS, eingebaut werden. Ein einzelnes Anwendungsprogramm benötigt i.a. nur einen kleinen Teil der vielen Typdefinitionen, die im konzeptuellen Schema enthalten Datenverwaltungssysteme 47 sind. Die komplette Datenbank muß also sozusagen “gefiltert” und auf den Bedarf dieser Anwendung reduziert werden. Genau dieses leistet der Sichtenmechanismus eines DBMS. Ein externes Schema, auch Sicht (view) genannt, spezifiziert eine solche eingeschränkte Sicht auf die Datenbank. Im Vergleich zum konzeptuellen Schema werden nur ein Teil der Daten oder abgeleitete Daten sichtbar gemacht. Entsprechend dieser Schema-Architektur unterscheidet man zwei Arten der Datenunabhängigkeit: Physische Datenunabhängigkeit bedeutet, daß die konzeptionellen Strukturen der Daten unabhängig von den physischen Strukturen sind und daß somit die physischen Strukturen geändert werden können, ohne daß dies einen Einfluß auf die konzeptionellen Strukturen hat. Datenbankmanagementsysteme unterstützen also die Trennung zwischen physischer und logischer Organisation der Daten. Logische Datenunabhängigkeit bedeutet, daß die Sichten, auf denen die Applikationen arbeiten, von [gewissen] Änderungen des konzeptuellen Schemas nicht betroffen sind, in diesem Sinne also unabhängig vom konzeptuellen Schema sind. 1.5.3 Transaktionsverarbeitung Die eigentliche Besonderheit von OLTP-DBMS liegt darin, daß sie Transaktionen unterstützen und hohe Anforderungen an die Sicherheit der Daten und an die Systemverfügbarkeit erfüllen8 . Diese Sicherheitseigenschaften sind weitestgehend unabhängig vom Datenbankmodell und in der Praxis oft viel wichtiger als technische Finessen des Datenbankmodells. Transaktionen adressieren mehrere Bedrohungen der Integrität des Datenbestands. Datenschäden durch parallelen Zugriff (vgl. Abschnitt 1.3.8) werden durch Concurrency-Control-Verfahren verhindert. CC-Verfahren in OLTP-Systemen gehen davon aus, daß Transaktionen kurz sind, 8 Letzteres gilt natürlich nur für jahrelang in der Praxis bewährte Produkte. 48 Datenverwaltungssysteme also nur wenige Datengranulate betreffen und Ausführungszeiten im Sekundenbereich haben. Datenschäden können ferner durch Systemabstürze (s. Abschnitt 1.3.5) und natürlich durch Medienfehler verursacht werden; Defekte an Magnetplatten sind zwar selten, aber keineswegs unmöglich. Für fast alle Unternehmen ist eine Zerstörung oder wesentliche Beschädigung des Datenbestands eine Katastrophe. Die heute verwalteten Datenbestände sind so umfangreich, daß sie bei einem Verlust der Datenbank in “endlicher” Zeit nicht mehr von Hand rekonstruiert werden können, es kommen also ausschließlich automatische RecoveryVerfahren in Betracht. Selbst ein kurzer Systemausfall führt bei den heute üblichen on-line-Zugriffen praktisch zu einem sofortigen Stillstand aller geschäftlichen Aktivitäten und entsprechend hohen Verlusten, die Recovery-Verfahren müssen daher sehr effizient arbeiten. 1.6 Information-Retrieval-Systeme Das klassische Beispiel eines Information-Retrieval- (IR-) Systems ist eine Literaturdatenbank. Neuere und vielleicht sogar bald wichtigere Beispiele sind Warenkataloge, Wirtschaftsauskünfte oder Büroinformationssysteme. Im Gegensatz zu anderen DVS versteht man ein IR-System immer als komplettes Informationssystem incl. einer interaktiven Bedienschnittstelle. Äußerlich betrachtet erscheint ein IR-System bzgl. der Datenverwaltung i.w. als ein relativ einfaches relationales System, denn der Datenbestand entspricht i.w. einer einzigen Tabelle, die z.B. Buchbeschreibungen enthält. Daß diese Tabelle recht groß (105 bis 107 Einträge) und längere Texte enthält (z.B. die Zusammenfassung eines Buchs), ist dabei sekundär. Dieser äußerliche Eindruck täuscht allerdings. IR-Systeme unterscheiden sich in vielen Aspekten ganz wesentlich von OLTP-Systemen. Auf die andere Interpretation von Suchanfragen wurde schon in Abschnitt 1.3.3 hingewiesen. Der Benutzer erwartet für jeden Treffer eine Einschätzung von dessen Relevanz. Um die Treffer besser bewer- Datenverwaltungssysteme 49 ten zu können, ist es in IR-Systemen sinnvoll, in einem Suchauftrag Gewichtungen für die einzelnen Selektionskriterien anzugeben. Negierte Kriterien (“nicht von der Firma X”) sollten nicht zum Ausschluß von Elementen aus der Treffermenge führen, sondern nur als Minuspunkte bei der Bewertung behandelt werden. Nicht nur die Suchaufträge sind vage zu interpretieren, auch die vorhandenen Daten können eine gewisse Unschärfe aufweisen. So beschreibt weder der Titel noch die Inhaltsangabe eines Buches den Inhalt des Buchs exakt. Manchmal fehlen auch Daten (z.B. das Erscheinungsjahr des Buches ist unbekannt). Auch mit unscharfen oder unvollständigen Daten muß vernünftig umgegangen werden. IR-Systeme sind praktisch immer interaktiv. Die Interaktion eines Benutzer mit einem IR-System unterscheidet sich erheblich von der mit einem OLTP-System. Wenn bei der Inventur eines Buchladens die Liste der Bücher in der Abteilung “Gartenbau” gefragt ist, muß die komplette Liste dieser Bücher erscheinen, bspw. 250 Stück. Wenn eine Kundin ein Buch über Gartenbau sucht, will sie 1 Buch kaufen, keine 250. Erst nachdem sie weiß, daß insg. 250 Bücher zum Thema Gartenbau zur Auswahl stehen, ist klar, daß der Suchraum weiter eingeschränkt werden muß. Die Suche in einem IR-System hat daher typischerweise 2 Phasen: in der ersten Phase werden einzelne oder kombinierte Selektionskriterien ausprobiert und das System zeigt nur die Zahl der Treffer an, sozusagen als eine extrem kompakte Darstellung der Treffermenge, etwa wie im folgenden Beispiel: Nr. Treffer Selektionskriterium 1 250 Gartenbau 2 83 Rosen 3 44 Obstbaeume 4 31 Hecken 5 75 #1 & #2 6 17 #1 & #2 & #3 7 0 #1 & #2 & #3 & #4 Sobald die Treffermenge klein genug ist (ca. 10 - 20 Treffer), läßt 50 Datenverwaltungssysteme sich unsere Kundin eine detailliertere Beschreibung der Treffer anzeigen. Wenn nichts Passendes dabei ist, werden ggf. neue Selektionskriterien ausprobiert. Letzteres sollte auch so möglich sein, daß bisher vorhandene Treffer als irrelevant oder besonders relevant markiert werden können und bei der nächsten Suche nach ähnlichen bzw. unähnlichen Elementen gesucht wird. Letztlich liegt also ein iterativer Prozeß vor, das IR-System muß derartige Dialoge unterstützen. Benutzer von IR-Systemen suchen i.a. Information (im Sinne des Abschnitts 1.2.1), die wegen ihrer Komplexität keine eindeutige Repräsentation hat. Wird bei der Suche eine andere Repräsentation unterstellt als bei der Speicherung, werden Informationen bei einer reinen Faktensuche, insb. auch bei einer Stichwortsuche anhand von Textmustern (pattern matching), nicht gefunden. Hierzu ein Beispiel: Unsere Kundin sucht Bücher über Obstbäume, also sucht sie nach dem Stichwort Obstbaeume ; ein Buch, das im Titel Obstbaum , Steinobstbaeume , Birnbaeume oder Frisches Obst von eigenen Baeumen enthält, würde bei einer reinen Faktensuche nicht gefunden. Das IR-System sollte erkennen können, daß die vorstehenden Terme Ähnlichkeiten aufweisen. Unähnlichkeiten entstehen u.a. durch Flexionen, unterschiedliche Wortstellungen und Verwendung allgemeinerer, speziellerer oder synonymer Begriffe. Nur in einfachen Fällen kann man diese ähnlichen Terme durch Textmuster finden, i.a. sind wesentlich komplexere Verfahren notwendig. Die Fachgruppe Information Retrieval innerhalb der Gesellschaft für Informatik definiert Information Retrieval wie folgt (s. [Fu05]): “Im Information Retrieval (IR) werden Informationssysteme in bezug auf ihre Rolle im Prozeß des Wissenstransfers vom menschlichen Wissensproduzenten zum Informations-Nachfragenden betrachtet. Die Fachgruppe “Information Retrieval” in der Gesellschaft für Informatik beschäftigt sich dabei schwerpunktmäßig mit jenen Fragestellungen, die im Zusammenhang mit vagen Anfragen und unsicherem Wissen entstehen. Vage Anfragen sind dadurch gekennzeichnet, daß die Antwort a priori nicht eindeutig definiert ist. Hierzu zählen neben Fragen mit unscharfen Kriterien insbesondere auch sol- Datenverwaltungssysteme 51 che, die nur im Dialog iterativ durch Reformulierung (in Abhängigkeit von den bisherigen Systemantworten) beantwortet werden können; häufig müssen zudem mehrere Datenbasen zur Beantwortung einer einzelnen Anfrage durchsucht werden. Die Darstellungsform des in einem IR-System gespeicherten Wissens ist im Prinzip nicht beschränkt (z.B. Texte, multimediale Dokumente, Fakten, Regeln, semantische Netze). Die Unsicherheit (oder die Unvollständigkeit) dieses Wissens resultiert meist aus der begrenzten Repräsentation von dessen Semantik (z.B. bei Texten oder multimedialen Dokumenten); darüber hinaus werden auch solche Anwendungen betrachtet, bei denen die gespeicherten Daten selbst unsicher oder unvollständig sind (wie z.B. bei vielen technisch-wissenschaftlichen Datensammlungen). Aus dieser Problematik ergibt sich die Notwendigkeit zur Bewertung der Qualität der Antworten eines Informationssystems, wobei in einem weiteren Sinne die Effektivität des Systems in bezug auf die Unterstützung des Benutzers bei der Lösung seines Anwendungsproblems beurteilt werden sollte. ” 1.7 Ein- und Ausgabeschnittstellen Wir haben Datenverwaltungssysteme bisher vor allem hinsichtlich ihrer Datenmodellierungs-, Analyse- und Suchfunktionen betrachtet, also Funktionen, die man der Datenhaltungsschicht in Bild 1.1 zuordnet und die im Laufzeitkern des DVS (s. Bild 1.3) realisiert werden. Für die Auswahl eines DVS ist ein weiterer wichtiger Aspekt, ob und wie die Konstruktion der erforderlichen Benutzerschnittstellen zur Ein- und Ausgabe der Daten unterstützt wird. Der Aufwand zur Realisierung dieser Schnittstellen (s. GUI-Schicht in Bild 1.3) kann ganz erheblich sein. Vereinfacht werden kann die Realisierung dieser Schnittstellen durch fertige Standardapplikationen und/oder durch Applikations-Frameworks. Bei Dateisystemen sind immer Texteditoren wie z.B. emacs verfügbar. Unter einem Texteditor verstehen wir hier einen Editor, der normalerweise jedes einzelne darstellbare Byte einer Datei als Zeichen anzeigt, wobei eine Zeichencodierung wie ISO 8859-1 (Latin-1) benutzt wird. Nicht gemeint sind hier Editoren für formatierten Text, 52 Datenverwaltungssysteme die Fettschrift, mehrere Schriftgrößen und -Arten und das Seitenlayout anzeigen können und die üblicherweise in Büropaketen enthalten sind. Mit derartigen Texteditoren können beliebige Dateiinhalte ediert werden, insb. natürlich auch Dateiformate wie in Abschnitt 1.4.2.1 beschrieben. Auf die Realisierung von speziellen Eingabeschnittstellen kann daher völlig verzichtet werden. Bei OLTP-DBMS sind formularartige Schnittstellen zur Eingabe und Änderung einzelner Datenelemente üblich, ferner tabellarische Darstellungen von Mengen von Datenelementen. In betrieblichen Anwendungen treten viele Datentypen (Größenordnung 100 bis 1000) auf, für jeden Datentyp ist eine eigene Schnittstelle erforderlich. Aufgrund der großen Anzahl verursacht eine “manuelle” Konstruktion all dieser Schnittstellen einen unvertretbar hohen Aufwand. Eine erste Lösung dieses Problems besteht in “generischen” Editoren, die formularartige oder tabellenförmige Darstellungen benutzen. Derartige Werkzeuge arbeiten für beliebige Datenbankschemata und sind praktisch ohne Anpassungsaufwand einsetzbar. In den Formularen bzw. Tabellen werden üblicherweise z.B. Namen von Attributen, die im Schema definiert sind, direkt als Spaltenköpfe eingesetzt, d.h. lesbarere Bezeichnungen, Sprachvarianten oder an den konkrete Anwendung angepaßte Hilfefunktionen sind nicht möglich. Systembedingt können die Standardschnittstellen daher keine höheren Ansprüche an die Gestaltung der Schnittstellen erfüllen. Höhere Ansprüche können nur von individuell gestalteten Schnittstellen erfüllt werden. Viele DBMS unterstützen die Entwicklung derartiger Schnittstellen durch Listengeneratoren oder AnwendungsFrameworks. Listengeneratoren interpretieren Spezifikationen von Schnittstellen, ihre Flexibilität ist daher begrenzt durch vorgegebene Optionen und beschränkter als die von Anwendungs-Frameworks, die beliebig durch Individualsoftware ergänzt werden können. Bei allen Varianten muß wegen der Komplexität der Systeme mit einem signifikanten Einarbeitungsaufwand gerechnet werden. Der gesamte Problemkomplex ist ein eigenes Themengebiet der Softwaretechnik und kann hier nicht vertieft behandelt werden. Datenverwaltungssysteme 53 In IR-Systemen gibt es normalerweise nur einen oder nur wenige Dokumenttypen; das bei betrieblichen Anwendungen auftretende Mengenproblem stellt sich hier also nicht. Hinzu kommt, daß Ähnlichkeitsbegriffe und Relevanzbewertungen oft dokumenttypspezifisch sind. Daher werden i.d.R. individuelle Schnittstellen realisiert. Wenn die Generierung von Indexen sehr aufwendig ist und nur in längeren Intervallen erfolgt, kann es sinnvoll sein, die Abfrageschnittstelle und die Dateneingabe völlig verschieden zu gestalten. Glossar 3-Ebenen-Schema-Architektur: Strukturmodell eines DBS, das eine externe, eine konzeptuelle und eine interne Ebene unterscheidet, in denen Typen definiert und andere Festlegungen zu den Typen gemacht werden können 3-Schichten-Architektur: eines Informationssystems: Grobarchitektur mit Schichten für die Datenhaltung, Funktionslogik und Benutzerinteraktion Dateisystem: a) Software: Komponente eines Betriebssystems, die Dateien, Verzeichnisse und weitere damit zusammenhängende Konzepte auf einer Platte oder ähnlichen Datenspeichern realisiert; b) Daten: Inhalt einer Platte eines ähnlichen Datenspeichers, die von einer Dateisystem-Software verwaltet wird Dateisystem, satzorientiertes: Dateisystem-Software, Sätze elementare Speichereinheiten sind bei der ganze Concurrency Control: Steuerung der parallelen Ausführung von Transaktionen, so daß eine gegenseitige Beeinflussung vermieden wird Datenbankmanagementsystem (DBMS): Software, die eine Datenbank verwaltet und einkapselt Datenbankmodell: konzeptuelle Basis eines DBMS; definiert u.a. eine Denkwelt zur Definition applikationsspezifischer Schemata und eine allgemeine Abfragesprache Datenbankmodell, Netzwerk-: “konventionelles” Datenbankmodell; die Datenbank hat die Struktur eines Netzwerks Datenbankmodell, hierarchisches: “konventionelles” Datenbankmodell; die Datenbank hat die Struktur einer Menge von Bäumen 54 Datenverwaltungssysteme Datendefinitionssprache (data definition language): Sprache, in der für ein DBMS (oder allgemeiner DVS) Typdefinitionen notiert werden können Datenintegration: Behandlung des bei größeren Informationssystemen auftretenden Problems, daß verschiedene Nutzertypen überlappende Datenbestände nutzen Datenverwaltungssystem (DVS): System, das Daten persistent verwalten kann und das Suchfunktionen und andere Dienste anbietet Normalform: Korrektheits- bzw. Qualitätskriterium für Schemata; Beispiele: 1., 2. und 3. Normalform und Boyce-Codd-Normalform OLTP-System (on-line transaction processing system): DBMS, das eine größere Anzahl von Transaktionen, die i.d.R. nur auf kleine Teile der Datenbank zugreifen, parallel ausführen kann und das umfangreiche Schutzvorrichtungen gegen Applikationsfehler und sonstige Störungen bietet Recovery: Schutzvorrichtungen im DBMS gegen Applikationsfehler, Medienfehler, Systemabstürze und sonstige Störungen, die zu Datenverlusten führen könnten Schema: Typdefinitionen in einer Datenbank Transaktion: Folge von Zugriffen auf eine Datenbank, die einen konsistenten Datenbankzustand in einen neuen konsistenten Datenbankzustand überführt und die vom DBMS “atomar” ausgeführt wird, also ganz oder gar nicht wirksam wird und nicht mit parallelen Transaktionen interferiert Lehrmodul 2: B-Bäume Zusammenfassung dieses Lehrmoduls B-Bäume bzw. B*-Bäume sind eine der wichtigsten Erfindungen der Informatik. Sie implementieren den generischen abstrakten Datentyp “Verzeichnis”. Im Gegensatz zu den hauptspeicherorientierten binären Bäumen sind B-Bäume plattenorientiert. Weiterhin weisen sie die Besonderheit auf, nicht zu degenerieren und Suchzeiten in der Größenordnung von log(n) zu garantieren. B*-Bäume verbessern die Suchgeschwindigkeit weiter, indem die Nutzdaten nur noch in den Blättern des Suchbaums gespeichert werden, wodurch die Indexknoten einen höheren Verzweigungsgrad haben können. Vorausgesetzte Lehrmodule: keine Stoffumfang in Vorlesungsdoppelstunden: c 2005 Udo Kelter 1.0 Stand: 22.10.2005 56 2.1 B-Bäume Historischer Hintergrund B-Bäume sind eine der wichtigsten Erfindungen der Informatik. BBäume entstanden im Kontext der Entwicklung relationaler Datenbanken [BaM72]; ohne B-Bäume wären die heute allgegenwärtigen relationalen Datenbanksysteme nicht denkbar. In der Architektur von DBMS realisieren sie eine Direktzugriffsmethode für Speichersätze. B-Bäume sind Suchbäume, sie gehören zu den grundlegenden Datenstrukturen, sie werden daher oft in Informatik-Grundvorlesungen vorgestellt. Im Gegensatz zu den hauptspeicherorientierten binären Bäumen sind B-Bäume plattenorientiert. Weiterhin weisen sie (ähnlich wie AVL-Bäume) die Besonderheit auf, nicht zu degenerieren; es ist garantiert, daß die Höhe eines B-Baums logarithmisch von der Zahl der enthaltenen Elemente abhängt. B-Bäume können im Detail recht unterschiedlich implementiert sein, sogar die Schnittstellen können viele fallspezifische Besonderheiten aufweisen. Um von diesen Besonderheiten zu abstrahieren, führen wir zunächst den Begriff generischer abstrakter Datentyp (gADT) ein und beschreiben einen B-Baum als einen gADT. Dieser gADT beinhaltet natürlich eine Operation, die in einem Datenbestand nach einzelnen Elementen sucht, daneben aber auch Operationen zum Einfügen und Löschen von Datenelementen. Das entscheidende Problem ist hierbei, die Balancierung des Suchbaums zu erhalten. In diesem Lehrmodul beschreiben wir die Techniken, die dieses Ziel erreichen. Abschließend gehen wir noch kurz auf B*-Bäume ein; diese optimieren die Suchgeschwindigkeit durch Trennung der Indexstrukturen von den Datenblöcken weiter. 2.2 2.2.1 Verzeichnisse Generische ADT B-Bäume realisieren eine Zugriffsstruktur, die man Verzeichnis nennt. “Verzeichnis” ist wiederum ein wichtiger generischer abstrakter Da- B-Bäume 57 tentyp. Ein generischer abstrakter Datentyp (gADT, auch Typkonstruktor genannt) ist ein abstrakter Datentyp, in dessen Schnittstelle, insb. bei den Parametern der Operationen, ein bestimmter Basisdatentyp (ggf. auch mehrere) offenbleiben; durch Einsetzen eines konkreten Basisdatentyps wird der generische abstrakte Datentyp zu einem einfachen abstrakten Datentyp, von dem Instanzen gebildet werden können. gADT kommen versteckt schon in der Informatik-Grundausbildung vor: dort werden z.B. Listen, Stapel, Suchbäume usw. als Datenstrukturen eingeführt, i.d.R. aber für einen bestimmten Typ von darin enthaltenen Datenelementen, z.B. ganze Zahlen oder Zeichenketten; diesen Typ nennt man auch den Basisdatentyp. Man macht sich leicht klar, daß der Basisdatentyp für die Funktionsweise einer “abstrakten” Liste oder eines Stapels völlig unerheblich ist. Aus einer Implementierung einer Liste von ganzen Zahlen kann man leicht eine Implementierung einer Liste von Zeichenketten machen, indem man überall dort, wo der Basisdatentyp auftritt, den passenden neuen Typ einsetzt9 . Der gADT Liste abstrahiert gerade von den Differenzen dieser Listenarten und könnte Liste[B] genannt werden, um auszudrücken, daß ein formaler Typ-Parameter B vorhanden ist. Der Begriff gADT bezieht sich nur auf die Syntax und Semantik der Schnittstelle, also die exportierten Typen und Operationen, und die Wirkung der Operationen, nicht hingegen auf die Implementierung. Man kann in manchen Programmiersprachen generische Implementierungen realisieren, die Details sind unterschiedlich und hier irrelevant. Man kann jedenfalls wie üblich bei abstrakten Datentypen verschiedene Implementierungen derselben Schnittstelle realisieren. Arrays lassen sich ebenfalls als gADT auffassen; daß man ihre Implementierung nicht sieht, weil sie als Teil der Programmiersprache implementiert sind, ist dabei unerheblich. Arrays haben zwei formale Typ-Parameter: (a) den Indexbereich N, der immer ein endliches In9 Ferner können typspezifische Kopieroperationen auftreten und andere Details anzupassen sein, diese Details spielen im weiteren aber keine Rolle. 58 B-Bäume tervall der ganzen Zahlen ist, und (b) der Typ der Arrayelemente B. Man könnte also vom gADT array [N,B] reden. 2.2.2 Der generische ADT directory [S,I] Ein Verzeichnis (directory) ist eine Datenstruktur, die Elemente (“Sätze”) enthält, die aus einem Schlüsselwert und zugeordneten Daten (dem “Inhalt”) bestehen. Ein Beispiel für ein solches Element ist eine Personenbeschreibung, wobei die Personalnummer der Schlüsselwert ist und diverse Angaben zur Person die zugeordneten Daten. Der gADT directory [S,I] hat also zwei Basisdatentypen, für die folgendes gilt: – S ist der Typ der Schlüsselwerte; er muß eine Operation größer als(S,S), die zwei Schlüsselwerte vergleicht, anbieten. Implementierungen von Directories haben meist zusätzliche implementierungsspezifische Restriktionen für diesen Typ, z.B. könnten nur ganze Zahlen oder Strings der Länge 8 zulässig sein. – I ist der Typ des Inhalts eines Eintrags. I hat keinen Einfluß auf die Funktionslogik eines directory. Auch hier kann es implementierungsspezifische Restriktionen geben. Der gADT directory [S,I] bietet folgende Operationen auf Verzeichnissen an (die Kleinbuchstaben v, s und i bezeichnen den übergebenen Wert bzw. die übergebene Referenz; hinter dem Doppelpunkt steht ggf. der Typ des Rückgabewerts): create(): V Anlegen eines leeren Verzeichnisses dispose(V) Löschen des Verzeichnisses v insert(V,S,I) Einfügen bzw. Überschreiben des Satzes mit dem Schlüsselwert s in v; der neue Inhalt ist i delete(V,S) Löschen des Satzes mit Schlüsselwert s in v read(V,S): I Lesen des Satzes mit Schlüsselwert s in v; zurückgegeben wird der Satzinhalt. read liefert einen Fehler, wenn kein Satz mit Schlüsselwert s in Verzeichnis v vorhanden ist. B-Bäume 59 Die vorstehenden Operationen stellen einen Minimalumfang dar. Darüberhinaus bieten manche Implementierungen des gADT Verzeichnis zusätzliche Operationen an: next key(V,S) liefert den nächstgrößeren Schlüsselwert nach s in v. Diese Operation ermöglicht es, alle Einträge des Verzeichnisses v sequentiell zu durchlaufen. read interval(V,S,S): liste[I] liest alle Sätze mit einem Schlüsselwert zwischen den beiden übergebenen Schlüsselwerten in Verzeichnis v. Diese Operation kann im Prinzip auch unter Benutzung von next key realisiert werden, allerdings kann sie effizienter implementiert werden als die sonst notwendigen Einzelzugriffe. Ein B-Baum ist eine effiziente, plattenorientierte Implementierung des gADT directory, incl. sequentiellem Durchlauf und Intervallabfrage. 2.3 2.3.1 B-Bäume Grundlegende Implementierungsentscheidungen Zwei Optimierungsziele stehen hier im Vordergrund: – Bei der Suche nach dem Satz mit dem Schlüsselwert s sollen möglichst wenige Seiten besucht (also Blöcke übertragen) werden. Der bei hauptspeicherorientierten Suchstrukturen im Vordergrund stehende Rechenaufwand spielt hier keine Rolle, da ein Plattenzugriff in der Größenordnung von 10 Millisekunden dauert, also ca. 106 bis 107 mal mehr als ein Rechenschritt der CPU. – Der Platz auf der Platte soll möglichst gut ausgenutzt werden. Das Verhältnis von den Nutzdaten zu dem Brutto-Platzbedarf sollte über 50 % liegen. Unter Nutzdaten verstehen wir hier die Schlüsselwerte und die zugehörigen Satzinhalte, die ja auf jeden Fall gespeichert werden müssen. Hinzu kommen Zeigerstrukturen und 60 B-Bäume sonstige Hilfsdaten und insb. Speicherbereiche, die aus technischen Gründen reserviert werden müssen. Der Brutto-Platzbedarf ist die Gesamtgröße der letztlich auf der Platte für das Verzeichnis benutzten Sektoren. 2.3.2 Vielweg-Suchbäume Binäre Suchbäume sind in ihrer Grundform hauptspeicherorientiert, d.h. man unterstellt eine Speicherverwaltung, bei der einzelne Knoten in Abschnitten des Hauptspeichers liegen, die direkt adressierbar sind. Eine sehr simple Methode, die Struktur eines binären Suchbaums auf der Platte zu realisieren, besteht darin, einfach jeden Knoten des Suchbaums in einen eigenen Block zu schreiben. Im Vergleich zu einer Hauptspeicherimplementierung wären die Verweise auf die Unterbäume, die in jedem Knoten stehen, keine Hauptspeicheradressen mehr, sondern Nummern von Blöcken auf der Platte (“Medienadressen”). Die grundlegenden Algorithmen zum Suchen, Einfügen und Löschen in Bäumen können ansonsten unverändert bleiben. Dieser simple Ansatz hat indes den gravierenden Nachteil, i.a. den Platz auf der Platte schlecht auszunutzen. Bei einem binären Suchbaum enthält ein Knoten folgenden Daten: – die Zeiger auf linken und rechten Unterbaum – den Schlüsselwert – den Inhalt mit Nutzdaten, von dem wir annehmen, daß er in einem Bytefeld fester Länge gespeichert werden kann Knoten im Baum s linker Unterbaum Nutzdaten rechter Unterbaum Nehmen wir z.B. folgende Größen an: B-Bäume b t k i 61 Blockgröße in Bytes Platzbedarf für eine Medienadresse (Verweis auf Teilbaum) Platzbedarf für einen Schlüsselwert Platzbedarf für Satzinhalt z.B. b = 2048 z.B. t = 8 z.B. k = 8 z.B. i = 110 Jeder Block wäre in unserem Beispiel also nur zu 134/2028 oder ca. 6.6 % gefüllt. Dies entspricht nicht unseren obigen Optimierungszielen. Um den Füllungsgrad der Blöcke zu verbessern, müssen mehrere Sätze und Verweise auf Unterbäume in einem Block gepackt werden. Wir sprechen dann von einem Vielweg-Suchbaum. Um die Funktion eines Vielweg-Suchbaums zu verstehen, betrachten wir noch einmal die Struktur eines Knotens in einem binären Suchbaum. Der in einem Knoten enthaltene Schlüsselwert s teilt den Schlüsselwertbereich in zwei Intervalle. Alle Schlüsselwerte, die im linken bzw. rechten Unterbaum vorkommen, liegen im unteren bzw. oberen Intervall. Ein Vielweg-Suchbaum verallgemeinert nun die Idee des binären Suchbaums dahingehend, nicht nur zwei Intervalle des Schlüsselwertbereichs und zugehörige Unterbäume zu haben, sondern n > 2. Für einen Vielweg-Suchbaum gilt daher: – Ein Knoten besteht aus – n Verweisen auf Teilbäume T1 , ..., Tn und – n − 1 Schlüsselwerten s1 , ..., sn−1 und zugehörigen Inhalten. s1 T1 s2 T2 s3 T3 s4 T4 T5 – Die Schlüsselwerte s1 , ..., sn−1 teilen den gesamten Schlüsselwertbereich in n Intervalle auf. Deshalb bezeichnen wir sie oft als Trennschlüsselwerte. Sei Ki die Menge der im Teilbaum Ti auftretenden Schlüsselwerte. Alle x ∈ Ki liegen im i-ten Intervall, also: 62 B-Bäume – ∀x ∈ K1 : x < s1 – ∀x ∈ Ki , 1 < i < n : si−1 < x < si – ∀x ∈ Kn : sn−1 < x Der Platzbedarf für einen Knoten eines Vielweg-Suchbaums steigt linear mit n an. Bei gegebener Blockgröße und gegebenem Platzbedarf für eine Medienadresse, einen Schlüsselwert und einen Satzinhalt (s.o.) kann man die Zahl der Schlüsselwerte, die maximal in einen Block passen, mit folgender Formel berechnen: ⌊(b − t)/(k + i + t)⌋ In unserem obigen Beispiel (b=2048; t=8; k=8; i=110) ergibt sich n=16. 2.3.3 Merkmale von B-Bäumen B-Bäume sind spezielle Vielweg-Suchbäume. Ihre besonderen Eigenschaften sind: 1. Alle Knoten mit Ausnahme der Wurzel sind wenigstens zur Hälfte gefüllt. Man spricht von einem B-Baum der Ordnung m, wenn in jedem Knoten (mit Ausnahme der Wurzel) mindestens m und maximal 2m Schlüsselwerte auftreten. Für die Wurzel gilt: entweder ist sie ein Blatt (d.h. der Baum hat ≤ 2m Knoten), oder sie hat wenigstens 2 Unterbäume. 2. Alle Pfade von der Wurzel zu einem Blatt sind gleich lang. 3. Ein innerer Knoten mit n Schlüsselwerten hat n+1 nichtleere Unterbäume, d.h. innere Knoten haben keine leeren Unterbäume. Bild 2.1 zeigt einen B-Baum der Ordnung 2. Abschätzung der Suchgeschwindigkeit: B-Bäume sind sehr effiziente Datenstrukturen, die Zeit zum Auffinden eines Datenelements anhand seines Schlüsselwerts hängt nur logarithmisch ab von der Zahl der Datenelementen in dem B-Baum. Um dies zu zeigen, untersuchen B-Bäume 63 12 2 5 34 17 19 76 42 50 59 70 83 102 Abbildung 2.1: B-Baum der Ordnung 2 wir zunächst, wieviele Schlüsselwerte bzw. Sätze ein Baum der Höhe h und Ordnung m mindestens enthält. Ebene wenigstens 2 Teilbäume 0 1 Sei h die Höhe des B-Baums (also die Zahl der Ebenen ohne Wurzelebene). Dann ist die Zahl der Knoten eines Teilbaums der Ebene 1 2 jeweils > m Teilbäme h = = 1 + (m + 1) + (m + 1)2 + .... + (m + 1)h−1 (m+1)h −1 (m+1)−1 Die Zahlh der in einem Teilbaum der Ebene 1 enthaltenen Schlüssel −1 h ist m∗ (m+1) (m+1)−1 = (m + 1) − 1. Da mindestens 2 Teilbäume der Ebene 1 vorhanden sind, enthält der gesamte Baum n > 2 ∗ ((m + 1)h − 1) + 1 Schlüssel. Wenn wir diese Formel nach h auflösen, erhalten wir: h ≤ logm+1 n+1 2 Beispiel: Für n = 1.000.000 Sätze und m = 8 ergibt sich 1000000+1 h ≤ log9 ≈ 5.97 bzw. aufgerundet h < 6. Für das Durch2 laufen des Baumes von der Wurzel bis zu einem Blatt werden also maximal 7 Seitenzugriffe benötigt. 2.3.4 Primärschlüssel Bei einem B-Baum bilden die Daten zur Realisierung der Baumstruktur und die Nutzdaten eine untrennbare Einheit. Anders gesehen sind 64 B-Bäume die Indexstrukturen in Primärdaten eingebettet. Man spricht deshalb hier von einem Primärindex. Der durch den Primärindex unterstützte Suchschlüssel wird Primärschlüssel genannt. Da die Einträge im B-Baum in aufsteigender Reihenfolge gemäß dem Primärschlüssel sortiert sind, ist für einen Datenbestand nur ein Primärindex möglich. 2.4 Algorithmen Im folgenden beschreiben wir die Algorithmen, mit denen die Verzeichnis-Operationen in einem B-Baum realisiert werden. Bei Bäumen als Suchstrukturen steht man immer von dem Problem, daß der Suchbaum degenerieren kann, wenn z.B. Elemente in sortierter Reihenfolge eingefügt werden. Die Suchzeiten können dadurch sehr schlecht werden. B-Bäume adressieren dieses Problem dadurch, daß der Baum balanciert wird. 2.4.1 Suche Der Suchalgorithmus ist eine direkte Verallgemeinerung des Suchalgorithmus für binäre Bäume: bei binären Bäumen durchläuft man den Baum von der Wurzel aus und wandert bei einem Knoten, der den Schlüsselwert s enthält, in den linken bzw. rechten Teilbaum, wenn der gesuchte Eintrag einen Schlüsselwert < s bzw. > s ist. Die Teilbäume stehen für die Schlüsselbereichsintervalle [0,s) und (s,∞]. Anders gesagt wandert man in dasjenige Intervall, in dem der gesuchte Eintrag liegen muß. Analog geht man bei Vielweg-Suchbäumen vor, nur daß hier mehrere (disjunkte) Intervalle zur Auswahl stehen. 2.4.2 Einfügung Die grundlegende Vorgehensweise bei insert(v,s,i) ist: – Knoten suchen, in dem Satz mit Schlüsselwert s sein müßte – Satz mit Schlüsselwert s und Inhalt i dort einfügen B-Bäume 65 – wenn 2m+1 Sätze in der Seite, dann Überlaufbehandlung Das eigentliche Problem - insb. hinsichtlich der Balancierung des Baums - ist also die Überlaufbehandlung. Bäume wachsen normalerweise nach unten10 . Der geniale Einfall bei B-Bäumen besteht darin, den Baum zunächst in die Breite und ggf. oben an der Wurzel wachsen zu lassen. Im einzelnen wird ein Überlauf wie folgt behandelt: – Wir fügen den Satz gedanklich an der richtigen Stelle im Knoten ein (in Wirklichkeit geht das nicht, weil der Knoten nur 2m Einträge aufnehmen kann), so daß jetzt 2m+1 Sätze vorhanden sind. – den übergelaufenen Knoten teilen wir in zwei neue, minimal gefüllte Knoten mit jeweils m Sätzen auf; der eine enthält die Sätze 1 bis m, der andere die Sätze m+2 bis 2m+1 (s. Bild 2.2) ..... x s 1 ..... s m s m+1 übergelaufener Knoten y ..... s m+2 ..... s 2m+1 ..... x s 1 ..... s m s m+1 y ..... s m+2 ..... s 2m+1 Abbildung 2.2: Überlaufbehandlung – Im Elternknoten des übergelaufenen Knotens wird der bisher vorhandene Verweis auf den übergelaufenen Knoten ersetzt durch (a) zwei Verweise auf die beiden neuen Knoten und (b) den mittleren (m+1.) Satz, der den Trennschlüssel für die beiden neuen Teilbäume enthält. Im Elternknoten ist danach die Zahl der Sätze um 1 erhöht. 10 Dies gilt natürlich nur in der Informatik, wo Bäume unnatürlicherweise die Wurzel “oben” haben. 66 B-Bäume – Falls auch der Knoten in der nächsthöheren Ebene überläuft, wird auch dieser Überlauf nach dem gleichen Schema behandelt. Der Überlauf kann sich so nach oben bis zur Wurzel fortsetzen. Im Extremfall läuft die bisherige Wurzel über, und der Baum wächst um eine Ebene. Er wächst also an der Wurzel! 2.4.3 Löschung Die grundlegende Vorgehensweise in delete(v,s) ist: – Knoten N suchen, in dem der Satz mit Schlüsselwert s enthalten ist (Fehler, falls nicht vorhanden) – sofern N ein Blatt ist, den Satz dort löschen. Andernfalls, also wenn N ein innerer Knoten ist, den zu löschenden Satz dort mit dem nächsten Satz überschreiben (der nächste Satz hat den nächstgrößeren nach s auftretenden Schlüsselwert; er steht im “rechts folgenden” Unterbaum im Blatt “unten links”); anschließend diesen nächsten Satz löschen und Knoten N – nunmehr ein Blatt – entsprechend neu festlegen. – sofern N nur noch m-1 Sätze enthält und nicht die Wurzel ist, Unterlaufbehandlung durchführen. Das entscheidende Problem bei Löschungen ist natürlich, ein Degenerieren des Baums zu verhindern. Analog zur Überlaufbehandlung gehen wir hier so vor, daß wir zunächst die Breite des Baumes reduzieren und ggf. sogar die Höhe. Ein Unterlauf wird nach folgendem Verfahren behandelt: – sofern es einen Nachbarknoten von N mit k + m, k ≥ 1, Sätzen gibt (oBdA sei dies der rechte Nachbar; wir bezeichnen ihn i.f. mit R), Ausgleich zwischen N und R durchführen – andernfalls Verschmelzen von N und R B-Bäume 67 Ausgleich zwischen N und R: Die naheliegende Idee ist hier, den untergelaufenen Knoten aufzufüllen mit Sätzen, die einer der Nachbarn entbehren kann11 . Konkret gehen wir wie folgt vor (s. Bild 2.3): x N ... m−1 ... y ... s ... R ... m ... N .. m−1 .. x .. s1 .. R .. s2 .. ... m ... .. s1 .. y .. s2 .. Abbildung 2.3: Unterlaufbehandlung – Der Satz (mit Schlüsselwert x) im Elternknoten von N, der Verweise auf N und R abgrenzt, wird nach N verschoben. – Wenn R insg. k+m Sätze enthält, dann (k-1)/2 (ab- oder aufgerundet) Sätze aus R an das Ende in N verschieben – nächsten Satz aus R im Elternknoten als neuen Trennsatz zwischen N und R eintragen Verschmelzen von N und R: In diesem Fall enthalten N und R m-1 bzw. m Sätze. Zusammen mit dem Satz im Elternknoten, der die Einträge für N und R trennt, haben wir genau 2m Sätze. Diese Sätze bilden einen neuen Knoten, der die bisherigen Knoten N und R ersetzt. Im Elternknoten reduziert sich die Zahl der Einträge hierdurch um 1. Sofern im Elternknoten ebenfalls ein Unterlauf eintritt, wird dieser nach dem gleichen Schema wie der ursprüngliche Unterlauf behandelt. Dies kann sich rekursiv bis zur Wurzel fortsetzen. Im Extremfall wird die Wurzel gelöscht und die Höhe des Baums sinkt um eine Ebene. 11 Die Idee des Ausgleichs liegt auch beim Einfügen nahe, d.h. man könnte einen übergelaufenen Knoten zunächst mit einem schlecht gefüllten Nachbarknoten ausgleichen. Dies führt aber zu vielen fast vollen Blöcken und macht Blocküberläufe häufiger, speziell unter der meist zutreffenden Annahme, daß ein Datenbestand tendenziell wächst. Blocküberläufe sind jedoch unerwünscht, da statt einem Block mit einem Blattknoten zwei geschrieben werden müssen (sowohl beim Ausgleich als auch bei einer Teilung); zusätzlich ist wenigstens ein innerer Knoten zu behandeln. 68 B-Bäume x N ... m−1 ... R ... m ... N .. m−1 .. x ... m ... R (freigeben) Abbildung 2.4: Verschmelzung 2.4.4 Beispiel Als Beispiel betrachten wir einen B-Baum mit Ordnung 2. Ausgehend von einem leeren Baum fügen wir wie folgt Sätze ein (angegeben sind immer nur deren Schlüsselwerte). – Einfügen von Sätzen mit den Schlüsselwerten 50, 102, 34, 19 und 5. Bei der letzten Einfügung läuft der bisher einzige Knoten über (im folgenden Bild ist links der zu große Knoten gezeigt) und muß geteilt werden. Die Mitte bildet der Schlüsselwert 34; dieser wandert in die neu zu bildende Wurzel, die linke und rechte Hälfte bilden jeweils neue Knoten. 34 [5] 19 34 50 102 5 19 50 102 – Nach dem Einfügen von Sätzen mit den Schlüsselwerten 76, 42, 2 und 83 tritt erneut ein Überlauf ein. 34 2 5 19 34 42 50 76 [83] 102 2 5 19 76 42 50 83 102 – Nach dem Einfügen von Sätzen mit den Schlüsselwerten 59, 70, 12 und 17 tritt erneut ein Überlauf ein. B-Bäume 69 34 76 2 5 12 [17] 19 12 83 102 42 50 59 70 2 5 34 76 42 50 59 70 17 19 83 102 – Wenn nun der Satz mit Schlüsselwert 83 gelöscht wird, kann der betroffene Knoten mit seinem linken Nachbarn ausgeglichen werden. 12 2 5 34 76 12 42 50 59 70 17 19 83 102 34 2 5 70 42 50 59 17 19 76 102 – Wenn der Satz mit Schlüsselwert 2 gelöscht wird, muß der betroffene Knoten mit seinem rechten Nachbarn verschmolzen werden 12 2 5 34 70 42 50 59 17 19 2.5 34 76 102 70 42 50 59 5 12 17 19 76 102 B*-Bäume Bei der Suche nach einem Satz müssen alle Ebenen eines B-Baums durchlaufen werden. Für jede Ebene ist je ein Block zu übertragen. Wie schon früher erwähnt ist die Reduktion der Zahl der Blockübertragungen das wichtigste Optimierungsziel. Die Höhe des Baums können wir nur reduzieren, wenn wir den Verzweigungsgrad (bzw. die Ordnung m) erhöhen. In B*-Bäumen 70 B-Bäume erreicht man dies – unter Inkaufnahme eines geringen Ausmaßes an Redundanz – dadurch, daß in den inneren Knoten der Baumstruktur nur die Schlüsselwerte gespeichert, der Satzinhalt also weggelassen wird. Komplette Sätze (Schlüsselwert und Inhalt) stehen stehen nur noch in den Blättern der Baumstruktur, also der untersten Ebene. Alle Nicht-Blattknoten sind reine Indexknoten. Der Satz, der zu einem Schlüsselwert gehört, der in einem NichtBlattknoten auftritt, kann z.B. jeweils im “rechts” anschließenden Unterbaum untergebracht werden. Der Unterbaum zwischen zwei Trennschlüsseln s1 und s2 enthält also alle auftretenden Schlüsselwerte im halboffenen Intervall [s1,s2). Wenn bei der Suche ein Schlüsselwert in einem Nicht-Blattknoten gefunden wird, muß dementsprechend im “rechts” anschließenden Unterbaum weitergesucht werden. Die Schlüsselwerte in den inneren Knoten werden in den Blättern noch einmal gespeichert. Es liegt somit in geringem Ausmaß Redundanz vor (Schlüsselwerte sind i.a. kurz). Der entscheidende Vorteil von B*-Bäumen liegt darin, daß wesentlich mehr Einträge in einen Block passen. Hierzu betrachten wir erneut unser früheres Beispiel in Abschnitt 2.3.2. Mit i=0 (wegen des fehlenden Satzinhalts) und den unveränderten Werten b=2048, t=8 und k=8 und ergeben sich (b-t)/(k+i+t) = 127 Einträge pro Block. Für die Höhe des Suchbaums aus in Abschnitt 2.3.3 dem Beispiel 1000000+1 ≈ 2.8, d.h. wir sparen ergibt sich bei nunmehr h ≤ log128 2 rund die Hälfte der Blockübertragungen ein. Bei B*-Bäumen wird ferner im Vergleich zu B-Bäumen die Zahl der Nicht-Blattknoten erheblich reduziert, im vorstehenden Beispiel ca. um den Faktor 8. Hierdurch ist es fast immer möglich, alle inneren Knoten im Hauptspeicher zu puffern, d.h. bei einer Suche brauchen keine Indexblöcke übertragen zu werden, sondern nur noch ein einziger (Daten-) Block! Dieser Wert kann nicht weiter verbessert werden. Ein weiterer Vorteil von B*-Bäumen besteht darin, daß Sätze variabler Länge leicht handhabbar sind. Aufgrund der diversen Vorteile werden in der Praxis nur B*-Bäume eingesetzt. B-Bäume 71 Glossar B-Baum: entweder abstrakte Implementierung des generischen abstrakten Datentyps Verzeichnis oder konkrete Implementierung für konkrete Basisdatentypen B*-Baum: Variante des B-Baums, bei der Nutzdaten nur auf der untersten Baumebene gespeichert werden und alle oberen Ebenen reine Indexknoten enthalten generischer abstrakter Datentyp: abstrakter Datentyp, in dessen Schnittstelle, insb. bei den Parametern der Operationen, ein Basisdatentyp (ggf. auch mehrere) offenbleibt; durch Einsetzen eines konkreten Basisdatentyps wird der generische abstrakte Datentyp zu einem einfachen abstrakten Datentyp, von dem Instanzen gebildet werden können Ordnung (eines B-Baums): Minimalzahl der Trennschlüssel in einem Knoten; die Maximalzahl ist genau doppelt so hoch Überlauf (beim Einfügen in einen B-Baum): Überschreiten der Maximalzahl an Einträgen in einem Knoten eines B-Baums Unterlauf (beim Löschen in einem B-Baum): Unterschreiten der Minimalzahl an Einträgen in einem Knoten eines B-Baums Verzeichnis (directory): generischer abstrakter Datentyp mit zwei Basisdatentypen, die den Schlüsselwertebereich bzw. den Inhalt eines Eintrags definieren; grundlegende Operationen sind das Einfügen, Löschen und Auslesen von Einträgen; optional sind Operationen für ein sequentielles Durchlaufen bzw. Auslesen mehrerer Einträge Vielweg-Suchbaum: Suchbaum, der den binären Suchbaum insofern verallgemeinert, daß jeder Knoten nicht nur einen, sondern n Einträge bzw. (Trenn-) Schlüsselwerte enthält, und nicht 2, sondern n+1 Unterbäume hat; die n+1 Unterbäume enthalten Einträge mit solchen Schlüsselwerten, die vor dem ersten, zwischen dem i-ten und i+1-ten bzw. nach dem letzten Trennschlüsselwert liegen Lehrmodul 3: Architektur von DBMS Zusammenfassung dieses Lehrmoduls Dieses Lehrmodul gibt eine erste Einführung in die Architektur von DBMS. Einleitend betrachten wir ein DBMS aus einer Gesamtsicht und konzentrieren uns dann auf zwei wichtige Aspekte des DBMS-Kerns: (a) wir zeigen, daß i.d.R. der Datenbankkern als eigener Hintergrundprozeß ausgeführt werden muß, und wir diskutieren die Konsequenzen hinsichtlich der Performanceoptimierung. (b) Wir skizzieren, in welchen Stufen die Datenobjekte, mit denen das Datenbankmodell operiert, auf Datenstrukturen im Hauptspeicher und letztlich auf Magnetplatten oder anderen persistenten Speichermedien abgebildet werden. Vorausgesetzte Lehrmodule: obligatorisch: empfohlen: – Datenverwaltungssysteme – Schnittstellen zu Datenbankinhalten Stoffumfang in Vorlesungsdoppelstunden: Stand: 21.10.2005 1.0 c 2005 Udo Kelter Architektur von DBMS 3.1 73 Einleitung Dieses Lehrmodul gibt einen ersten Einblick in den Aufbau und die Struktur eines DBMS. Der Begriff Architektur ist mehrdeutig (eine allgemeinere Diskussion dieses Begriffs findet sich in [SAR]); wir werden hier primär die Software-Komponenten betrachten, aus denen ein DBMS besteht. Hierbei kann es sich sowohl um selbständig lauffähige Programme als auch um Schichten innerhalb von Programmen, insb. dem Laufzeitkern, handeln. Wir werden hier ebenfalls auf die Prozeßarchitektur, also die Struktur der Prozesse zur Laufzeit, eingehen. Es gibt keine Einheitsarchitektur, die bei allen DBMS gleichartig anzutreffen wäre, noch nicht einmal bei einer vergröberten Betrachtung. Die Architektur eines DBMS hängt ganz erheblich von mehreren Faktoren ab: – natürlich vom Datenbankmodell, hier insb. davon, ob ein navigierendes oder ein mengenorientiertes Datenbankmodell vorliegt – von der Art, wie Applikationen an das DBMS angebunden werden (s. Lehrmodul ??) – von den ggf. vorhandenen Verteilungskonzepten – von der “Größenklasse” und damit zusammenhängend den Optimierungszielen. 3.2 Produkt vs. Laufzeitkern Wenn man ein DBMS-Produkt kauft, wird man auf der InstallationsCD eine (erschreckend) hohe Zahl von Programmen finden, die man wie folgt gruppieren kann: – Laufzeitkern: diese Programme und Programmteile (Bibliotheken) werden während der “produktiven” Nutzung des DBMS ausgeführt. – Administrations- und Dienstprogramme (s. auch Bild 1.3) für diverse Zwecke: – Installation 74 Architektur von DBMS – Überwachung des laufenden Betriebs und Gewinnung von statistischen Daten – Performance-Tuning – Sicherheitsüberwachung – Backup der Datenbank, Verwaltung von Tertiärspeichermedien, Prüfen und ggf. Reparieren der Datenbank – Benutzeradministration – Verwaltung registrierter Anwendungen – Accounting – Programme, die Entwicklung von Applikationen unterstützen; man kann diese als eine angepaßte Software-Entwicklungsumgebung ansehen. Beispiele sind Präprozessoren, die in Quelltexte eingebettete Anweisungen vorübersetzen, oder Editoren, mit denen man die Datenbankschemata spezifizieren und dokumentieren kann. Die Abgrenzung zwischen den Dienstprogrammen und den Entwicklungswerkzeugen ist nicht ganz scharf. Wenn separate Entwicklungs- und “Produktions”rechner benutzt werden, sind die Entwicklungswerkzeuge typischerweise nur auf dem Entwicklungsrechner installiert. Dienstprogramme und Entwicklungswerkzeuge sind zwar für die praktische Nutzung von DBMS sehr wichtig, auf sie wird aber in Vorlesungen und Lehrbüchern über Datenbanken fast nicht eingegangen – so auch hier. Allgemeine Kenntnisse über Datenmodelle und Kenntnisse über die Laufzeitkerne haben insofern höhere Priorität, als sie bei der Behandlung der Dienstprogramme und Entwicklungswerkzeuge stets vorausgesetzt werden müssen. 3.3 Prozeßarchitektur von Informationssystemen Informationssysteme kann man i.d.R. in 3 Softwareschichten strukturieren (s. Bild 1.1): Architektur von DBMS 75 – GUI / Benutzerinteraktion – Realisierung der Fachkonzepte, Applikationssemantik – Datenverwaltung Im einfachsten Fall kann man die zugehörigen Module zu einem einzigen Programm zusammenbinden, d.h. diese Module würden in den virtuellen Hauptspeicher eines Betriebssystemprozesses geladen und dort gemeinsam ausgeführt. Hinsichtlich der Ziele, die durch den Einsatz von DBMS angestrebt werden, hätte eine solche 1-ProzeßArchitektur aber gravierende Nachteile: – Das DBMS kann aus Performancegründen nicht nur auf den persistenten Medien (also Platten) arbeiten, sondern muß große Teile der Datenbank in Puffer in den Hauptspeicher laden und primär auf diesen Pufferinhalten arbeiten. Nun war es ein Ziel von DBMS, vielen Benutzern und Applikationen gleichzeitig Zugriff auf die Datenbank zu ermöglichen. Dies würde bei einer 1-Prozeß-Architektur bedeuten, daß jede Applikation eigene Puffer hätte und daß dort Teile der Datenbank lägen, die ggf. schon gegenüber dem Zustand auf der Platte verändert worden sind. Wollte eine andere Applikation jetzt auf diese Teile der Datenbank zugreifen, müßte sie herausfinden, ob eine und ggf. welche andere Applikation diese Teile der Datenbank gerade puffert und sich an diese Applikation wenden. Jedes Applikationsprogramm müßte also gleichzeitig als Server für die zufällig gerade in seinen Puffern befindlichen Teile der Datenbank arbeiten. Dies ist völlig inpraktikabel. – Ein weiteres Ziel von DBMS bestand darin, Zugriffskontrollen zu realisieren, d.h. nicht autorisierten Benutzern den Zugang auf bestimmte Daten zu verwehren. Bei einer 1-Prozeß-Architektur können solche Dienste aber nicht sicher implementiert werden (zumindest bei allgemein verfügbaren Programmiersprachen und Betriebssystemen). In fast allen gängigen höheren Programmiersprachen und erst recht in maschinennahen Sprachen können Zeiger manipuliert werden, und es kann im Prinzip auf beliebige Adressen im (virtuellen) Hauptspeicher zugegriffen werden. Dies bedeutet, daß die Applikation auch direkt auf die Inhalte der Datenbankpuffer 76 Architektur von DBMS zugreifen und dort Daten auslesen und verändern könnte, d.h. die Zugriffskontrollmechanismen sind umgehbar. – Unkontrollierte Zugriffe des Applikationsprogramms könnten darüber hinaus interne Datenstrukturen des DBMS zerstören und so zu Programmabstürzen führen. Die einzige praktikable Alternative, das DBMS und die Datenbankpuffer vor direkten Zugriffen durch die Applikation zu schützen, besteht darin, diese Programme bzw. Daten in einen separaten Betriebssystemprozeß zu laden, s. Bild 3.1. Aus der Sicht von Applikationen ist diese Verlagerung des DBMS-Laufzeitkerns in einen anderen Prozeß i.w. nicht sichtbar, denn das API zum DBMS bleibt völlig unverändert. “Hinter dem API” liegt aber jetzt keine Implementierung mehr, sondern eine Bibliothek oder ein RPC- (remote procedure call) Mechanismus, der die Operationsaufrufe i.w. unverarbeitet an den Serverprozeß sendet, welcher die eigentliche Operation ausführt und die Ergebnisse zurücksendet. [G]UI der Applikations- DBMS- Applikation Server Server Appl-API Bibliothek DBMS-API Bibliothek Datenbank Abbildung 3.1: Prozeßarchitektur von Informationssystemen Aus Performance-Gründen kann es sinnvoll sein, auch das GUI und die Applikationssemantik verschiedenen Prozessen zuzuordnen; es ergibt sich dann die in Bild 3.1 gezeigte Struktur mit 3 Prozessen. Für die technische Realisierung eines solchen entfernten Operationsaufrufs gibt es diverse Alternativen, die nicht hier, sondern im Architektur von DBMS 77 Rahmen von Vorlesungen über Rechnernetze behandelt werden. Die Merkmale dieser Mechanismen sind für unsere Diskussion weitgehend irrelevant bis auf die beiden folgenden Punkte: – Wenn ein Applikationsprogramm gestartet wird, muß es herausfinden können, ob schon ein Serverprozeß für die Datenbank läuft und wie es Kontakt zu diesem Serverprozeß aufnehmen kann. Hierzu müssen Hilfssysteme verfügbar sein, die entsprechende Auskünfte geben können und den Verbindungsaufbau teilweise automatisieren. Die Struktur dieser Hilfssysteme hängt stark von der Kommunikationstechnologie ab, die eingesetzt wird. Insgesamt ist die Installation und Benutzung eines DBMS im Vergleich zu Dateien dadurch wesentlich komplizierter und erfordert Kenntnisse in der gewählten Kommunikationstechnologie. – Ein entfernter Operationsaufruf ist deutlich ineffizienter als ein lokaler. Ein lokaler Operationsaufruf innerhalb eines Programms verursacht einen Aufwand, der je nach Umfang der Parameter in der Größenordnung von einigen Dutzend oder hundert Maschineninstruktionen, bei heutigen Prozessoren also in der Größenordnung von Mikrosekunden liegt. Bei einem entfernten Operationsaufruf sind zwei Fälle zu unterscheiden: 1. Der Serverprozeß läuft auf dem gleichen Rechner: in diesem Fall werden zuerst die Parameter geeignet codiert, der aufrufende Prozeß wird stillgelegt, der wartende Serverprozeß wird aktiviert, er entpackt die Parameter und führt die gewünschte Operation aus. Nach Beendigung der Operationsausführung werden umgekehrt die Ergebnisse an den aufrufenden Prozeß zurücktransferiert. Die beiden Prozeßwechsel und die beiden Datenübertragungen kosten typischerweise Rechenzeit in der Größenordnung von 0.1 Millisekunden. 2. Der Serverprozeß läuft auf einem anderen Rechner. In diesem Fall kommt bei beiden Kommunikationen der Kommunikationsaufwand hinzu; hier muß mit einem Mindestaufwand in der Größenordnung von 1 Millisekunde (bei langsamen Netzen auch mehr) gerechnet werden, ferner ist die Übertragungsbandbreite 78 Architektur von DBMS signifikant kleiner. Hieraus folgt bereits, daß ein entfernter Aufruf bedeutend teurer (Faktor: ca. 1000 bis 10000) ist als ein lokaler und daß man sich in interaktiven Systemen, die gute Antwortzeiten haben sollen, nur wenige (Größenordnung 10 bis 100) Datenbankzugriffe pro Interaktion leisten kann. Sofern die Menge der als Eingabeparameter oder Rückgabewerte übertragenen Daten in der Größenordnung von einigen kB liegt, hat sie auf diese Zeiten praktisch keinen Einfluß, erst bei deutlich größeren Datenmengen oder sehr langsamen Netzwerken beeinflußt sie die Gesamtzeit proportional zum Übertragungsvolumen. Hieraus folgt als weitere Erkenntnis, daß es performanter ist, wenige umfangreichere Operationen aufzurufen als viele kleine. 3.4 3.4.1 Eine Abstraktionshierarchie von Datenbankobjekten Übersicht Jedes DBMS muß letztlich die Datenstrukturen seines Datenbankmodells auf Basis des unterliegenden Dateisystems oder, bei direktem Zugriff auf die Hardware, der Platten realisieren. Die Diskrepanz dieser beiden Denkwelten ist erheblich, daher wird diese Realisierung typischerweise in mehrere Schritte eingeteilt, bei denen - von unten nach oben gesehen - jeweils ein neuer Typ von internen Speichereinheiten realisiert wird. Man kann sich diese Schichtung durch mehrere aufeinander aufbauende Pakete veranschaulichen (s. Bild 3.2)12 . Wir skizzieren i.f. ein derartiges Schichtenmodell für interne Speichereinheiten bzw. Datenbankobjekte und gehen anschließend im Detail auf die Schichten ein: – Die unterste Ebene operiert mit Blöcken, die über Medienadressen 12 Reale DBMS-Kerne sind deutlich komplizierter, insofern ist dieses Bild keine exakte, sondern allenfalls eine partielle und vereinfachende Darstellung der Architektur eines DBMS-Kerns. Architektur von DBMS 79 Ebene 4: n-Tupel/Objekte Ebene 3: 1-Tupel/Objekt Ebene 2: Speichersätze Ebene 1: Segmente/Seiten Ebene 0: physische Blöcke Abbildung 3.2: Abstraktionshierarchie von Datenbankobjekten identifiziert werden und die zwischen den permanenten Medien und dem Arbeitsspeicher übertragen werden. – Auf Ebene 1 wird die durch die Hardware vorgegebene Menge der Blöcke zu Segmenten gruppiert. Segmente ähneln insofern Dateien, als sie angelegt und gelöscht werden können und ihre Größe (also die Menge zu zugeordneten Blöcke) wachsen oder schrumpfen kann. – In Ebene 2 wird der Inhalt einzelner Segmente, der sich auf Ebene 1 noch als Folge von Seiten darstellt, feinkörniger strukturiert, typischerweise als Folge oder Verzeichnis von (Speicher-) Sätzen. Integriert hierin sind (primäre) Indexe, z.B. B*-Bäume. – In Ebene 3 wird der Inhalt einzelner Sätze, der sich auf Ebene 2 noch als unstrukturiertes Bytefeld darstellt, in Felder strukturiert, die den Attributen von Tupeln oder Objekten entsprechen. Auf dieser Ebene werden die konzeptuellen Schemata in konkrete Speicherstrukturen umgesetzt. – Während Ebene 3 Operationen realisiert, die mit einzelnen Tupeln oder Objekten arbeiten, realisiert Ebene 4 Operationen mit Mengen von Objekten. Dieser Ebene ist u.a. der Problemkomplex der Optimierung zuzuordnen. 80 Architektur von DBMS Wir betrachten i.f. die Ebenen detaillierter und beginnen bei der Hardware als unterster Ebene. 3.4.2 Ebene 0: physische Blöcke Ein physischer Block ist ein Datenbereich auf einem Permanentspeicher wie Magnetplatte, optische Platte, Band usw., dessen (Netto-) Inhalt von der Hardware und den zugehörigen Treibern zwischen dem Speichermedium und dem Hauptspeicher transportiert werden kann. Normalerweise werden physische Blöcke nur durch das Dateimanagementsystem des Betriebssystems verwaltet, d.h. Anwendungsprogramme können überhaupt nicht direkt damit arbeiten, sondern arbeiten nur mit Dateien, die bereits eine eigene Abstraktionsschicht oberhalb der physischen Blöcke darstellen. Die von Betriebssystemen realisierten Dateisysteme sind allerdings nicht optimal angepaßt an den Bedarf von DBMS, daher umgehen manche DBMS das Betriebssystem und greifen “direkt” auf die Platte zu. Für uns sind nur zwei Operationen mit physischen Blöcken relevant, nämlich den Transport vom Medium in einen Hauptspeicherbereich und umgekehrt. Für die Speicherung einer Datenbank eignen sich nur solche Medien, bei denen man direkt, also schnell, auf jeden vorhandenen physischen Block zugreifen kann. Hierzu hat jeder Block, der auf dem Medium vorhanden ist, eine eindeutige Medienadresse. Die Gesamtmenge der Blöcke auf einem Medium hängt von dessen Hardware-Eigenschaften und ggf. von Parametern bei der Formatierung des Mediums ab. 3.4.3 Ebene 1: DB-Segmente und DB-Seiten Aus Sicht der höheren Schichten besteht der auf Ebene 1 realisierte persistente Speicher aus mehreren Segmenten. Jedes Segment besteht aus einer Folge von Seiten. Man kann Segmente anlegen und löschen. Typischerweise wird z.B. beim Erzeugen einer Relation oder eines Index ein Segment angelegt, das die zugehörigen Daten aufnimmt. Die Seiten haben eine feste Größe, z.B. 2 kB, diese Größe kann ggf. beim Anlegen des Segments gewählt werden. Im einfachsten Fall Architektur von DBMS 81 entspricht eine Seite einem Block, eine Seite kann aber auch mehrere Blöcke groß sein. Innerhalb eines Segments wird eine Seite durch eine laufende Nummer identifiziert (Medienadressen sind hier nicht mehr sichtbar). Segmente können “hinten” seitenweise wachsen oder gekürzt werden. über die Seitenummer zusammen mit dem Segmentidentifizierer kann direkt auf die Seite zugegriffen werden. Hierzu müssen die Blöcke, die der Seite entsprechen, vorher geladen, d.h. in den Arbeitsspeicher übertragen werden. Ein Segment ähnelt einer Datei, wobei ganze Seiten statt einzelner Bytes oder Sätze Übertragungseinheiten sind. Im Gegensatz zu Dateisystemen kann aber die Identifizierung in einem DBMS weitaus einfacher gestaltet werden, d.h. wir benötigen hier keine Dateiverzeichnisse oder Zugriffskontrollen. Zu jedem Segment verwaltet das DBMS einen Segmentdeskriptor, der alle relevanten Administrationsdaten enthält. Innerhalb der derselben wird vermerkt, wie Seitennummern und Medienadressen einander zugeordnet sind; diese Zuordnung kann sich dynamisch ändern. Ferner werden die freien Blöcke auf den Medien verwaltet. Für die höheren Schichten ist nicht mehr erkennbar, an welcher konkreten Medienadresse eine Seite steht. Die vorstehend beschriebene Struktur nennt man auch Zugriffsmethode für Seiten13 . 3.4.4 Ebene 2: Zugriffsmethode für Sätze Diese Schicht simuliert sozusagen die Speichereinheit Satz bzw. Zeichen auf der Speichereinheit Seite. Eine Seite enthält i.a. mehrere Sätze. Sätze sind als Speichereinheit in DBMS deutlich wichtiger als Zeichen (bei Zugriffsmethoden in Betriebssystemen ist es umgekehrt). 13 In manchen Betriebssystemen wird eine solche Zugriffsmethode direkt für Anwendungen nutzbar angeboten, in anderen Betriebssystemen existiert sie nur intern, während auf ihrer Basis für Anwendungen Zugriffsmethoden für Zeichen oder Sätze angeboten werden. 82 Architektur von DBMS Aus Sicht der höheren Schichten besteht ein Segment nunmehr aus einer Menge von Sätzen bzw. Zeichen und einer Zugriffsstruktur. 3.4.4.1 Zugriffsstrukturen Eine Zugriffsstruktur bestimmt, wie einzelne Speichereinheiten identifiziert und lokalisiert werden können und wie die Menge der Speichereinheiten des Segments verändert werden kann. Eine Zugriffsstruktur sollte man als generischen abstrakten Datentyp (ähnlich wie Liste, Array, Baum, Hash-Tabelle usw.) ansehen. Eine konkrete Zugriffsmethode ist also ein abstrakter Datentyp, der aus einer generischen Zugriffsstruktur durch Wahl einer bestimmten Speichereinheit entsteht. Unter einer Speichereinheit verstehen wir i.f. einen Satz oder ein Zeichen. Zugriffsstrukturen verstehen wir hier nur als Spezifikationen; für eine bestimmte Spezifikation kann es unterschiedliche Implementierungen geben. Die Literatur enthält eine unübersehbare Vielfalt konkreter Datenstrukturen und Algorithmen, die einzelne Zugriffsstrukturen implementieren. Aus Platzgründen können wir hier nur Beispiele skizzieren. Sequentielle Zugriffsstruktur: Diese Zugriffsstruktur entspricht einer einfach verketteten Liste von Speichereinheiten. Sie ist auch auf sequentiellen Medien (Bändern, Bandkassetten) realisierbar. Nur eine einzige Speichereinheit des Segments ist “aktuell lokalisiert” und damit direkt les- oder schreibbar. Von dort aus kann nur schrittweise zum nächsten (und ggf. vorigen) Element navigiert werden. Der (effiziente) Direktzugriff zum n-ten Satz ist nicht möglich. Nur die erste Speichereinheit kann direkt lokalisiert werden, manchmal auch das Ende, also die Position hinter der letzten Speichereinheit. Die Folge der Speichereinheiten kann nur am Ende verlängert oder gekürzt werden, Einfügen oder Löschen in der Mitte ist nicht möglich. Die wesentlichen Operationen sind somit: – beim Schreiben eines Segments: – Überschreiben der aktuell lokalisierten Speichereinheit Architektur von DBMS 83 – Anhängen einer Speichereinheit am Ende – beim Lesen eines Segments: – Abfrage, ob Segmentende erreicht – Kopieren der lokalisierten Speichereinheit in einen Puffer Direktzugriffsstrukturen: Bei Direktzugriffsstrukturen können einzelne Speichereinheiten durch eine Nummer oder einen Schlüsselwert identifiziert werden und “direkt”, d.h. für beliebige Sätze in ungefähr gleicher Zeit, lokalisiert und dann gelesen oder überschrieben werden, ferner ggf. erzeugt oder gelöscht werden. Neben dem direkten Zugriff muß natürlich immer auch ein effizienter sequentieller Zugriff durch alle Sätze möglich sein, bei dem jede Seite nur einmal übertragen werden muß; hier interessiert, ob hierbei die Sätze in der Reihenfolge geliefert werden, die der aufsteigenden Reihenfolge ihrer Schlüsselwerte entspricht. Es gibt i.w. zwei Formen von Direktzugriffsstrukturen: die arrayartige Direktzugriffsstruktur und die Verzeichnisstruktur. Arrayartige Direktzugriffsstruktur: Diese Zugriffsstruktur entspricht einem hinten dynamisch erweiterbaren Array. Speichereinheiten werden durch laufende Nummern identifiziert. Es gibt Operationen, mit denen man die aktuelle Länge des Arrays abfragen und diese herauf- oder heruntersetzen kann. Nicht möglich ist das Einfügen einer Speichereinheit zwischen zwei vorhandenen Speichereinheiten. Da laufende Nummern natürlicherweise sortiert sind, kann man zusätzlich sehr leicht eine sequentielle Zugriffsstruktur anbieten. Effizient realisiert werden kann eine arrayartige Direktzugriffsstruktur in Zugriffsmethoden für Zeichen oder Sätze fester Länge, bei variabler Satzlänge treten Probleme auf. Zugriffsmethoden für Seiten realisieren übrigens ebenfalls eine arrayartige Direktzugriffsstruktur. Verzeichnisstruktur: Diese Zugriffsstruktur tritt nur bei Sätzen als Speichereinheit auf. Jeder Satz hat hier einen zugeordneten 84 Architektur von DBMS Schlüsselwert14 . Die Schlüsselwerte stammen aus einem Schlüsselwertbereich. Beispiele für Schlüsselwertbereiche sind die ganzen Zahlen von 0 bis 232 -1 oder alle Texte von 8 Zeichen Länge über einem gegebenen Alphabet. Der Schlüsselwertbereich ist i.a. in der Schnittstelle und in der Implementierung der Zugriffsmethode “hart verdrahtet”; die Schlüsselwerte müssen ja in diversen Operationen als Parameter übergeben werden. Die Verzeichnisstruktur wirkt auf den ersten Blick sehr ähnlich wie die arrayartige Direktzugriffsstruktur, dieser Eindruck täuscht aber. Der entscheidende Unterschied besteht darin, – daß immer der gesamte, sehr große Schlüsselwertbereich verfügbar ist, es gibt also keine variable Obergrenze für die gültigen Schlüsselwerte, und – daß es sein kann, daß zu einem Schlüsselwert aktuell kein Satz vorhanden ist. I.a. ist sogar nur für einen winzigen Bruchteil der zulässigen Schlüsselwerte ein Satz vorhanden. Ein Schlüsselwert identifiziert entweder keinen oder genau einen Satz in einem Segment. Während bei einer arrayartigen Direktzugriffsstruktur die Nummern der aktuell vorhandenen Speichereinheiten ein geschlossenes Intervall bilden, können die Schlüsselwerte der aktuell vorhandenen Sätze bei einer Verzeichnisstruktur beliebig verstreut im Schlüsselwertbereich liegen. Daher kommen für Verzeichnisstrukturen keine Implementierungen in Frage, bei denen sich der Schlüsselwert implizit durch die Position des Satzes im Segment ergibt, sondern nur solche Implementierungen, bei denen der Schlüsselwert jedes Satzes explizit gespeichert wird. Binäre Suchbäume und Hash-Tabellen sind bekannte Beispiele für derartige Datenstrukturen im Hauptspeicher. Von diesen grundlegenden Datenstrukturen gibt es diverse angepaßte und erweiterte Varianten, die auf die Besonderheiten einer seitenorientierten Speicherung abgestimmt sind, z.B. B-Bäume oder B*-Bäume. Da B-Bäume auch ein effizientes sequentielles Durchlaufen aller Sätze in aufsteigender Reihenfolge der vorhandenen Schlüsselwerte er14 Oft wird die Bezeichnung “Schlüssel” als Synonym zu Schlüsselwert benutzt; dies vermeiden wir hier ganz bewußt. Architektur von DBMS 85 lauben, spricht man hier auch von einer indexsequentiellen Zugriffsmethode (ISAM; index sequential access method). Verzeichnisstruktur mit Intervallabfrage: Hier ist im Vergleich zur normalen Verzeichnisstruktur eine zusätzliche (effizient realisierte) Operation vorhanden, die alle Speichereinheiten liefert, deren Schlüsselwert zwischen einer unteren und einer oberen Schranke liegt. 3.4.4.2 Realisierung von Sätzen auf Seiten Wir betrachten hier beispielhaft einige einfache Verfahren, wie die sequentielle Zugriffsstruktur und die arrayartige Direktzugriffsstruktur auf Seiten effizient realisiert werden kann. Die Verzeichnisstruktur erfordert komplizierte Verfahren, auf die wir hier nicht eingehen. Die Varianten der Zugriffsmethoden für Sätze unterscheiden sich darin, ob alle Sätze des Segments gleiche bzw. unterschiedliche Länge haben. Die zugehörigen Angaben, z.B. die feste Satzlänge oder die maximale Satzlänge bei variabler Satzlänge, werden innerhalb des Segmentdeskriptors gespeichert. Anordnung von Sätzen fester Länge. Bei fester Satzlänge braucht die Länge eines Satzes nicht bei jedem Satz gespeichert zu werden. Die Speicherabschnitte für je einen Satz können einfach hintereinandergelegt werden. Bild 3.3 zeigt zwei prinzipielle Alternativen: Seite 1 Satz 1 Satz 2 Seite 2 Satz 3 Satz 4 Seite 1 Satz 1 Satz 2 Seite 3 Satz 5 Satz 6 Seite 2 Satz 3 Satz 4 Seite 3 Satz 5 Satz 6 Abbildung 3.3: Anordnung von Sätzen fester Länge auf Seiten 86 Architektur von DBMS 1. Man bildet gedanklich aus den Inhalten der Seiten einen durchgehenden Adreßraum und legt die Sätze dicht in diesen Adreßraum (s. Bild 3.3 oben). Nachteilig ist hier, daß ein Satz ggf. nicht komplett in einer Seite liegt und daß, um einen solchen Satz zu lesen oder zu schreiben, zwei Blöcke übertragen werden müssen, sofern eine Seite einem Block entspricht. 2. Man legt nur so viele Sätze in eine Seite, wie ganz hineinpassen. Nachteil ist hier der ungenutzte Verschnitt am Ende der Seite. Der Nachteil der doppelten Blockübertragung ist in den meisten Fällen gravierender als der des Verschnitts. Satzanordnung bei variabler Satzlänge. Bei allen Zugriffsmethoden für variable Satzlänge steht man (unabhängig von der Zugriffsstruktur) vor dem Problem, daß die Länge jedes einzelnen Satzes in irgendeiner Form erkennbar sein muß. Am einfachsten ist ein Längenfeld vor dem Satz: Die ersten 2 oder 4 Bytes eines Satzes enthalten dessen Länge als Binärzahl. Die tatsächliche Länge des Satzes wird i.d.R. noch auf ein ganzes Vielfaches von 4 oder 8 aufgerundet. Die Sätze können z.B. analog zu Sätzen fester Länge hintereinander in der Seite stehen (s. Bild 3.3 unten). Bei variabler Satzlänge entsteht prinzipiell das Problem, daß – der noch freie Platz innerhalb der Seite verwaltet werden muß – wenn Sätze verlängert oder neu eingefügt werden, eine Seite überlaufen kann – wenn Sätze verkürzt oder gelöscht werden, der Füllungsgrad der Seite schlecht werden kann – die Zahl der Sätze pro Seite variabel ist und daher die Seite, in der sich der i-te Satz eines Segments befindet, nicht berechnet werden kann. 3.4.4.3 Indexe Indexe sind generell Datenstrukturen, die einen effizienten Zugriff zu Daten ermöglichen, die durch einen gegebenen Attributwert identifiziert werden. Bei manchen Zugriffsmethoden sind Indexe in die Architektur von DBMS 87 Primärdaten integriert; einen solchen Index bezeichnet man auch als Primärindex. Primärindexe sind also integraler Bestandteil einer Zugriffsmethode für Sätze. Indexe können auch unabhängig von den Primärdaten existieren und heißen dann Sekundärindex. Ein Sekundärindex ist ein Verzeichnis, das zu jedem auftretenden Wert eines Attributs eine Liste von Referenzen auf die Tupel bzw. Objekte, bei denen dieser Attributwert auftritt, enthält. Während pro Segment nur ein Primärindex vorhanden sein kann, können beliebig viele Sekundärindexe angelegt werden. Naheliegend ist es, für einen Sekundärindex ein eigenes Segment mit einer Direktzugriffsstruktur anzulegen. Für jeden auftretenden Attributwert wird ein Satz angelegt, – dessen Schlüsselwert der Attributwert ist (problematisch können hier Text-Attribute sein, bei denen die Länge stark variiert) und – dessen Inhalt die Liste der Referenzen auf die primären Daten ist. Als Referenzen kommen Primärschlüsselwerte, Surrogate von Objekten oder sogenannte Tupel-Identifizierer in Frage. Wenn man Sekundärindexe auf diese Weise realisiert, bauen sie auf Primärindexen auf, können also als eigene (Zwischen-) Schicht betrachtet werden. 3.4.5 Ebene 3: Einzelobjekt-Operationen Diese Ebene exportiert Operationen, die mit einzelnen Tupeln oder Objekten arbeiten. Ein Tupel oder Objekt wird i.d.R. als Inhalt eines Satzes gespeichert, die Menge der Tupel einer Relation in den Sätzen eines Segments. Die Details (mögliche Attributtypen usw.) hängen vom Datenbankmodell ab. In navigierenden Datenbankmodellen wird insb. die Navigation zwischen Objekten auf dieser Ebene realisiert, in relationalen Systemen die Behandlung von Cursors. 88 3.4.6 Architektur von DBMS Ebene 4: Mengen-Schnittstelle Diese Ebene entfällt weitgehend bei rein navigierenden Datenbankmodellen. Bei textuellen Schnittstellen muß hier zunächst die textuelle Formulierung einer Anweisung in eine interne Darstellung übersetzt werden. Dies beinhaltet diverse Prüfungen, u.a. der Syntax, des Vorhandenseins von referenzierten Relationen oder Typen, der Zugriffsrechte usw. Im Erfolgsfall wird danach im Rahmen der Optimierung ein möglichst effizient ausführbarer Plan erstellt, der den Auftrag realisiert; entgegen der Bezeichnung “Optimierung” wird allerdings aus Aufwandsgründen nicht versucht, wirklich einen optimalen Ausführungsplan zu finden, sondern nur anhand von Heuristiken einen wahrscheinlich recht guten. Der erstellte Plan wird schließlich ausgeführt. Nach Abarbeitung müssen die Ergebnisse entweder in geeigneten Datenstrukturen bereitgestellt werden (bei einem API) oder für eine externe Darstellung aufbereitet werden. 3.4.7 Beziehung zur 3-Ebenen-Schema-Architektur In Abschnitt 1.5.2 wurde die 3-Ebenen-Schema-Architektur für DBMS eingeführt. Diese korreliert lose mit der hier in Abschnitt 3.4 eingeführten Abstraktionshierarchie von Datenbankobjekten. Bei der Abstraktionshierarchie von Datenbankobjekten hatten wir unterstellt, daß es sich primär um Nutzdaten handelt. Schemadaten müssen natürlich auch persistent verwaltet werden, und die Speicherungsoperationen können hierfür im Prinzip auch ausgenutzt werden (z.B. auf der Ebene von Speichersätzen); auf dieses Thema wollen wir aber hier nicht eingehen. Vereinfachend kann man den Zusammenhang zwischen den Hierarchien wie folgt ausdrücken: – Die beiden oberen Schichten der Schema-Architektur (Sichten und konzeptionelles Schema) beeinflussen die Arbeitsweise der oberen Schichten der Datenbankobjekt-Hierarchie (1- und n-TupelSchicht). Architektur von DBMS 89 – Das interne Schema beeinflußt die Arbeitsweise der drei unteren Schichten der Datenbankobjekt-Hierarchie. In der 1- bzw. n-Tupel-Schicht finden z.B. Prüfungen statt, ob angegebene Typnamen (z.B. Attribute oder Relationentypen) bekannt sind; hierzu werden das externe und das konzeptuelle Schema herangezogen. Auf der Speichersatzebene muß z.B. eine gewünschte Sortierung eingehalten werden, und es müssen Indexstrukturen bei Änderungen an den indexierten Daten gewartet werden. Glossar Index: Datenstruktur, die einen effizienten Zugriff zu Speichereinheiten ermöglicht, die durch einen Attributwert identifiziert werden Laufzeitkern: Teil eines DVS, das als geladenes Programm die Funktionen des API ausführt Primärindex: in die Nutzdaten integrierter Index Seite (Kontext: interne Architektur eines DBMS-Laufzeitkerns): Speichereinheit der Seitenebene Sekundärindex: Verzeichnis, das zu einzelnen Werten eine Liste von Referenzen auf die Speichereinheiten enthält, in denen dieser Attributwert auftritt Speichersatz: Speichereinheit der Speichersatzebene in der internen Architektur eines DBMS-Laufzeitkerns Serverprozeß: im Betriebssystem selbständig oder sogar auf einem separaten Rechner laufender Prozeß, der die Funktionen einer Schicht eines Informationssystems (z.B. Datenhaltungsschicht) ausführt Zugriffsmethode (access method ): wird in Begriffen wie indexsequentielle Zugriffsmethode (ISAM; index sequential access method) verwendet; bezeichnet eine Methode, wie die Speichereinheiten (Sätze bzw. Seiten) einer bestimmten Ebene intern auf Basis der nächstieferen Ebene organisiert werden und wie einzelne Einheiten lokalisiert und bearbeitet werden können; beinhaltet sowohl die (abstrakten) Schnittstellen als auch die Hauptmerkmale der Implementierung Zugriffsstruktur: abstrakte Schnittstelle, über die eine Menge von Speichereinheiten (i.d.R. Sätze) verwaltet wird Lehrmodul 4: Das relationale Datenbankmodell Zusammenfassung dieses Lehrmoduls Das relationale Datenbankmodell besteht im Kern aus Operationen wie der Selektion, der Projektion und diversen Verbundoperationen. Diese werden in der relationalen Algebra zusammengefaßt. Dieses Lehrmodul stellt diese Operationen vor. Vorab wird die statische Struktur einer relationalen Datenbank definiert. Aus der Vielzahl denkbarer Integritätsbedingungen werden hier nur Schlüsselbegriffe behandelt; wir unterscheiden u.a. Identifikations-, Super-, Fremd-, Primär- und Sekundärschlüssel. Vorausgesetzte Lehrmodule: obligatorisch: – Datenverwaltungssysteme Stoffumfang in Vorlesungsdoppelstunden: Stand: 09.12.2002 2.0 c 2002 Udo Kelter Das relationale Datenbankmodell 91 Das relationale Datenbankmodell ist eines der drei “konventionellen” Datenbankmodelle und, gemessen am Entwicklungstempo der Informatik, schon uralt. Es geht auf Arbeiten von E.F. Codd am IBM San Jose Research Laboratory [Co70] zurück. Seine Entwicklung wurde maßgeblich von mehreren Prototypen relationaler DBMS beeinflußt, namentlich dem System R am IBM San Jose Research Laboratory, Ingres an der University of California at Berkeley und Query-by-Example am IBM T.J. Watson Research Center. Im Laufe der Jahre wurden sehr umfangreiche formale Grundlagen des relationalen Datenbankmodells entwickelt, ferner wurden vielfältige Erweiterungen der ursprünglichen Konzepte vorgeschlagen. In der Praxis ist das relationale Datenbankmodell heute dominierend. Eine Vielzahl kommerzieller oder kostenloser relationaler DBMS ist verfügbar. 4.1 Datenbankmodelle vs. reale Datenbanksprachen Das relationale Datenbankmodell legt zunächst nur zentrale, grundlegende Konzepte fest (s. Begriff Datenbankmodell in Lehrmodul 1), nämlich die Struktur einer Datenbank und lesende Operationen auf dieser Struktur. Ein praktisch benutzbares System muß zusätzlich viele technische Details festlegen, angefangen bei der Syntax entsprechender Sprachen und Bedienschnittstellen. Zum Vergleich: das Konzept einer while-Schleife wird von allen normalen imperativen Programmiersprachen unterstützt, die konkrete Syntax und technische Details können ganz erheblich differieren (for (..,..,..) { .. } in C; WHILE ... BEGIN ... END in Modula-2). Neben den Abfragen und Datenänderungen müssen außerdem Funktionen bzw. Sprachkonstrukte zur Definition konzeptueller und interner Schemata, Rechteverwaltung, Administration usw. angeboten werden; das relationale Datenbankmodell legt diese Bereiche nicht fest. Ähnlich wie Programmiersprachen sind daher die konkreten Abfragesprachen für relationale Systeme äußerlich sehr verschieden und differieren auch außerhalb der 92 Das relationale Datenbankmodell grundlegenden Konzepte in vielen technischen Details. Für die Darstellung der grundlegenden Konzepte braucht man natürlich dennoch Notationen, also eine Sprache. Die relationale Algebra und die relationalen Kalküle kann man in diesem Sinne als Sprachen ansehen, die nur den Kern des relationalen Datenbankmodells abdecken und von jeglichem störenden Ballast befreit sind. 4.2 4.2.1 Die Struktur relationaler Datenbanken Tabellen Die statische Struktur einer relationalen Datenbank kann man informell wie folgt definieren (eine präzisere Definition folgt später): 1. Eine relationale Datenbank besteht aus mehreren Tabellen. Jede Tabelle hat einen eindeutigen Namen. 2. Eine Tabelle hat eine Menge von Spalten. 3. Eine Spalte hat einen eindeutigen Namen, der im Tabellenkopf steht, und einen zugeordneten Wertebereich. Statt von einer Spalte reden wir auch von einem Attribut. 4. Der Rumpf (oder “Inhalt”) einer Tabelle enthält beliebig viele Zeilen; jede Zeile enthält in jeder Spalte einen Wert entsprechend dem Wertebereich der Spalte. Tabelle: kunden Kundennummer Kundenname 177177 Meier, Anne 177180 Büdenbender, Christa 185432 Stötzel, Gyula 167425 Schneider, Peter 171876 Litt, Michael Wohnort Weidenau Siegen Siegen Netphen Siegen Abbildung 4.1: Beispieltabelle Kreditlimit 2000.00 9000.00 4000.00 14000.00 0.00 Das relationale Datenbankmodell 93 Als Beispiel betrachten wir eine Tabelle kunden , in der Daten über die Kunden eines Unternehmens verwaltet sein mögen (s. Bild 4.1). Die Spalte Kreditlimit gibt an, wieviele Waren dem Kunden auf Kredit geliefert werden. Der Sinn der restlichen Spalten ist offensichtlich. Die Wertebereiche der Spalten sind (von links nach rechts): 1. ganze Zahl, 2. Text, 3. Text, 4. reelle Zahl. Über Längenbeschränkungen der Texte oder die Genauigkeit der Zahlen machen wir uns an dieser Stelle keine Gedanken. Eine Zeile repräsentiert oft eine Entität in der realen Welt, in unserem Beispiel repräsentiert jede Zeile einen Kunden. Wenn die Tabelle zwei völlig gleiche Zeilen enthalten würde, wäre der gleiche Sachverhalt doppelt repräsentiert; dies wäre sinnlos, Duplikate von Zeilen werden daher nicht erlaubt. Die Spalten enthalten die Beschreibungsmerkmale der repräsentierten Entität. Interessant ist hier die Beobachtung, daß die Reihenfolge der Spalten unwesentlich ist, die folgende Tabelle ist zu der vorstehenden offenbar äquivalent: Tabelle: kunden Wohnort Kundennummer Weidenau 177177 Siegen 177180 ... ... Kundenname Meier, Anne Büdenbender, Christa ... Kreditlimit 2000.00 9000.00 ... Eine Zeile können wir daher auch als eine Menge von Attributzuweisungen auffassen, z.B. die erste Zeile als: Kundennummer = 177177; Wohnort = Weidenau; Kundenname = ”Meier, Anne”; Kreditlimit = 2000.00 Während die Reihenfolge der Attribute aus einer konzeptuellen Sichtweise irrelevant ist, ist sie für die physische Speicherung i.a. relevant. Beide Sichtweisen müssen aber strikt getrennt werden; Datenbankmodelle definieren nur konzeptuelle Aspekte, die physische Speicherung bleibt hier völlig außer Betracht. 94 Das relationale Datenbankmodell 4.2.2 Relationen Die Bezeichnung “relational” stammt von mathematischen Begriff einer Relation ab. Eine Relation ist in der Mathematik bekanntlich definiert als Teilmenge des Kreuzprodukts mehrerer Mengen, i.a.: R ⊆ D1 × D2 × . . . × Dn Ein Element einer Relation nennt man Tupel. Den Inhalt der letzten Tabelle könnte man offenbar als folgende Relation ansehen: kunden ⊆ string × integer × string × real Tabellen werden oft als Relationen bezeichnet und umgekehrt, es gibt aber einen signifikanten Unterschied: Relationen haben kein Äquivalent zum Tabellenkopf. Die “Spalten” einer Relation haben keinen Namen, sie sind nur anhand ihrer Position benennbar, und ihre Bedeutung muß durch eine separate Definition angegeben werden. Letzteres leistet ein Relationentyp. Ein Relationentyp (auch als Relationenschema oder Relationenformat bezeichnet) besteht aus: – einem Namen, der innerhalb einer Datenbank eindeutig ist – einer Folge von Attributdefinitionen Notieren werden wir Relationentypen nach folgendem Muster: Relationentypname = ( . . . , Attributname, . . . ) wenn die Wertebereiche der Attribute schon anderweitig bekannt sind oder im Moment nicht interessieren, und als Relationentypname = ( . . . , Attributname: Wertebereich; . . . ) wenn die Wertebereiche angegeben werden sollen. Als Wertebereiche der Attribute sind nur elementare Datentypen wie integer, real, date, string usw. zugelassen, nicht hingegen strukturierte Datentypen wie Arrays, Tupel, Mengen usw. oder gar Relationen15 . Unsere erste Version der Kundentabelle führt also zu folgendem Relationentyp: 15 In erweiterten relationalen Modellen, die wir hier nicht behandeln, können Attribute dagegen strukturierte Typen haben. Das relationale Datenbankmodell 95 Kunden = ( Kundennummer: integer; Kundenname: string; Wohnort: string; Kreditlimit: real ) Wir werden einen Relationentyp oft vereinfachend als Menge (und nicht Folge) von Attributen ansehen und die Schreibweisen A ∈ R bzw. R1 ⊆ R2 benutzen, um darzustellen, daß das Attribut A im Relationentyp R vorkommt bzw. daß im Relationentyp R1 nur Attribute aus dem Relationentyp R2 vorkommen. Da wir hier den Begriff Typ gebrauchen, sei ein Vergleich mit den Typen in Programmiersprachen gestattet: ein Relationentyp entspricht in etwa einem Datentyp, der als Menge von Objekten (oder Records) mit den Attributen gemäß dem Relationentyp definiert ist. Eine Relation kann man in der Denkwelt von Programmiersprachen als Variable dieses Typs ansehen. In Datenbanken ist die strikte Trennung zwischen Typ und Variable wenig sinnvoll, weil es zu jedem Relationentyp immer nur eine Relation gibt. Daher werden dort immer gleich Relationen definiert, ihr Typ wird nur implizit mitdefiniert und hat keinen Namen. Für die Erklärung des relationalen Datenbankmodells werden wir allerdings wiederholt Relationentypen benötigen, so daß wir auf diesen Begriff nicht verzichten können. Bzgl. der Schreibweisen werden wir die Konvention einhalten, – Namen von Relationen klein zu schreiben – Namen von Relationentypen und Attributmengen groß zu schreiben Wenn wir festlegen, daß eine Relation r von Relationentyp R sein soll, ist wegen des Rückgriffs auf den mathematischen Relationsbegriff implizit klar, – daß alle Tupel von r insofern korrekt sind, daß die Werte der einzelnen Attribute aus den passenden Wertebereichen stammen, und 96 Das relationale Datenbankmodell – daß keine Tupel in r doppelt vorhanden sind (eine Relation ist eine Menge und keine Multimenge)16 . Wir werden i.f. Tabellen als Darstellung von Relationen benutzen und die beiden Begriffe in diesem Sinne synonym verwenden. 4.2.3 Integritätsbedingungen Es gibt sehr viele Arten, Integritätsbedingungen in relationalen Datenbanken zu formulieren; es ist ein bißchen Geschmackssache, wieviele davon man zum “Kern” des relationalen Datenbankmodells zählt. Man kann die Integritätsbedingungen grob wie folgt einteilen: – Dynamische Integritätsbedingungen schränken die erlaubten Zustandsübergänge bei Änderungen der Daten ein. Beispielsweise könnte bei einem Attribut Familienstand der Übergang von verheiratet nach ledig verboten sein. Dynamische Integritätsbedingungen werden wir nicht weiter betrachten. – Statische Integritätsbedingungen schränken den erlaubten Zustand einer Datenbank weiter ein. Das bekannteste Beispiel sind (Identifizierungs-) Schlüssel. Integritätsbedingungen können allenfalls bei Änderungen an den Daten verletzt werden. Ein DBMS muß daher bei allen ändernden Operationen entsprechende Prüfungen durchführen und die Operation ggf. mit einem Fehlercode zurückweisen. Lesende Operationen sind dagegen überhaupt nicht von Integritätsbedingungen betroffen: diese Operationen arbeiten auf beliebigen Datenbankinhalten, also erst recht auf der Teilmenge der “korrekten” Datenbankinhalte. Aus diesem Grunde sind Integritätsbedingungen für die nachfolgende Diskussion der relationalen Algebra nicht erforderlich. 16 Technisch wäre es kein Problem, auch Multimengen zuzulassen. In der Praxis erspart man sich aus Performancegründen oft die Eliminierung von Duplikaten. Wie schon erwähnt sind aber Duplikate von Tupeln i.a. nicht sinnvoll. Das relationale Datenbankmodell 4.3 97 Die relationale Algebra Der Begriff Algebra stammt aus der Mathematik. Eine Algebra ist definiert durch eine Wertemenge17 und i.a. mehrere Funktionen, die mit Werten dieser Menge arbeiten. Beispiele für Algebren sind die reellen Zahlen oder Matrizen zusammen mit den diversen Rechenoperationen. Die Funktionen können beliebig viele Argumente haben und liefern stets einen Wert aus der Wertemenge zurück. Daher kann man Funktionsaufrufe schachteln und Ausdrücke konstruieren. Die relationale Algebra ist eine ganz normale Algebra im vorstehenden Sinn. Als Werte benutzen wir beliebige Relationen. Daß die entstehende Wertemenge recht groß ist und ganze Relationen als Argumente oder Resultate etwas schwergewichtig erscheinen mögen, braucht uns nicht weiter zu stören. Die relationale Algebra enthält keine Operationen, mit denen man Relationen erzeugen bzw. löschen und in einer Relation Tupel einfügen, löschen oder verändern kann. Derartige Operationen müssen in realen Sprachen natürlich vorhanden sein; die relationale Algebra konzentriert sich ausschließlich auf die “lesenden” Operationen und die Frage, welche Daten man aus einer vorhandenen Datenbank extrahieren kann. Es wird vorausgesetzt, daß die Relationen der Datenbank schon irgendwie existieren und mit Tupeln gefüllt worden sind. Analog gilt dies für die Relationentypen, also das konzeptuelle Schema der Datenbank. Die Operationen der relationalen Algebra entsprechen nicht unzufällig den typischen Aufgaben, die beim Umgang mit Datenbanken in der Praxis auftreten. Wir stellen sie anschließend einzeln vor. 4.3.1 Die Selektion Die Selektion erlaubt es, aus einer vorhandenen Relation r bestimmte Tupel zu selektieren. Zurückgeliefert wird eine neue Relation, die nur 17 Dies gilt für eine einsortige Algebra. Mehrsortige Algebren arbeiten mit mehreren Wertemengen, die hier als Sorten bezeichnet werden. 98 Das relationale Datenbankmodell die Tupel enthält, die das Selektionskriterium erfüllen. Notiert wird die Selektion üblicherweise in der Form σBedingung ( r ) Der griechische Buchstabe sigma (σ) erinnert an das S im Wort Selektion. Das Ergebnis einer Selektion hat den gleichen Relationentyp wie die Argumentrelation. Als Beispiel betrachten wir die Menge der Kunden aus der Relation kunden in Bild 4.1, deren Kreditlimit größer als 5000 DM ist. Folgender Ausdruck liefert eine Relation mit genau diesen Kunden: σKreditlimit>5000.00 ( kunden ) Die entstehende Tabelle ist Tabelle: σKreditlimit>5000.00 ( kunden ) Kundennummer Kundenname 177180 Büdenbender, Christa 167425 Schneider, Peter Wohnort Siegen Netphen Kreditlimit 9000.00 14000.00 Im vorstehenden Beispiel trat nur eine sehr einfache Selektionsbedingung auf, die den Wert eines Attributs mit einer Konstanten verglich. Neben > sind auch die Vergleichsoperatoren <, ≤, ≥, = und 6= möglich. Ferner können so geformte elementare Bedingungen mit den Booleschen Operatoren (∧, ∨, ¬) und Klammern zu Ausdrücken zusammengesetzt werden. Die Bedingungen dürfen sich natürlich nur auf solche Attribute beziehen, die im Typ der Argumentrelation vorkommen. Übungsaufgabe: Zeigen Sie, daß die und-Verküpfung von zwei Bedingungen durch eine Hintereinanderschaltung von zwei Selektionen mit den einzelnen Bedingungen ersetzt werden kann, daß also für eine beliebige Relation r und Bedingungen B1 und B2 gilt: σB1∧B2 ( r ) = σB1 (σB2 ( r )) = σB2 (σB1 ( r )) Das relationale Datenbankmodell 4.3.2 99 Die Projektion Die Projektion löst das Problem, überflüssige Attribute in den Tupeln einer Relation zu entfernen. Man projiziert eine Relation auf die Attribute, die man noch beibehalten möchte. Notiert wird die Projektion üblicherweise in der Form πAttributmenge ( r ) Der griechische Buchstabe pi (π) erinnert an das Wort Projektion. Als Beispiel betrachten wir wieder die Relation kunden in Bild 4.1. Wir möchten jetzt nur noch Kundenname und Wohnort haben, die beiden anderen Attribute bzw. Spalten sollen “wegprojiziert” werden. Dies erreichen wir mit folgender Ausdruck: πKundenname,Wohnort ( kunden ) Die entstehende Tabelle ist: Tabelle: πKundenname,Wohnort ( kunden ) Kundenname Wohnort Meier, Anne Weidenau Büdenbender, Christa Siegen Stötzel, Gyula Siegen Schneider, Peter Netphen Litt, Michael Siegen Das Ergebnis einer Projektion hat i.a. nicht den gleichen Relationentyp wie die Argumentrelation18 . Der Typ der Ergebnisrelation hat genau die in der Projektion angegebenen Attribute. Für die formale Definition der Projektion benötigen wir folgende neue Notation: Sei r eine Relation mit Relationentyp R , t ein Tupel in r , also t ∈ r , A ⊆ R eine nichtleere Teilmenge der Attribute in R . Dann bezeichnet t[A] das Tupel, das die Attributwerte für die Attribute in A gemäß t enthält. Mit dieser Notation können wir das Ergebnis einer Projektion wie folgt definieren: 18 Eine Ausnahme ist lediglich der wenig sinnvolle Sonderfall, daß man auf alle Attribute der Argumentrelation projiziert. 100 Das relationale Datenbankmodell πA (r) = { t[A] | t ∈ r } Im vorigen Beispiel hat die Ergebnisrelation genausoviele Tupel wie die Argumentrelation. Dies ist nicht immer der Fall, wie folgendes Beispiel zeigt: πWohnort ( kunden ) Die entstehende Tabelle ist: Tabelle: πWohnort ( kunden ) Wohnort Weidenau Siegen Netphen Sie hat nur noch 3 Tupel, denn in der Spalte Wohnort treten nur 3 verschiedene Werte auf. Man betrachte noch einmal die obige Definition der Projektion: πA (r) ist als Menge, nicht als Multimenge definiert. Zwei verschiedene Tupel t1 , t2 ∈ R , t1 6= t2 , können nach der Projektion gleich sein und führen daher nur zu einem einzigen Tupel in der Ergebnisrelation. Übungsaufgabe: Seien P , Q und R Relationentypen, r eine Relation vom Typ R . Zeigen Sie, daß folgendes gilt: P ⊆ Q ⊆ R 4.3.3 ⇒ π P (π Q ( r )) = π P ( r ) Die Mengenoperationen Da Relationen als Mengen von Tupeln definiert sind, sind automatisch alle Mengenoperationen auf Relationen anwendbar. Voraussetzung ist natürlich, daß die beteiligten Relationen den gleichen Relationentyp haben. Wenn also r1 und r2 Relation vom Typ R sind, dann ist r1 ∪ r2 die Vereinigung r1 ∩ r2 der Schnitt r1 − r2 die Differenz von r1 und r2 . Das Ergebnis hat wieder den Relationentyp R . Das relationale Datenbankmodell 101 Als Beispiel betrachten wir wieder die Relation kunden in Bild 4.1. Wir suchen jetzt die Kunden, die in Weidenau wohnen oder ein Kreditlimit > 10000 haben. Hierzu definieren wir die Relation k1 wie folgt: k1 = σWohnort=“W eidenau′′ ( kunden ) ∪ σKreditlimit=10000 ( kunden ) Das Ergebnis ist: Tabelle: k1 Kundennummer 177177 167425 Kundenname Meier, Anne Schneider, Peter Wohnort Weidenau Netphen Kreditlimit 2000.00 14000.00 Wir hätten dieses Ergebnis natürlich auch mit der folgenden Definition erzielen können; k1 = σWohnort=“W eidenau′′ ∨ Kreditlimit=10000 ( kunden ) Übungsaufgabe: Zeigen Sie, daß die oder-Verküpfung von zwei Bedingungen durch eine Vereinigung von zwei Selektionen mit den einzelnen Bedingungen ersetzt werden kann, daß also für eine beliebige Relation r und Bedingungen B1 und B2 gilt: σB1∨B2 ( r ) = σB1 ( r ) ∪ σB2 ( r ) 4.3.4 Die Umbenennung Aus technischen Gründen benötigen wir für die folgenden Operationen eine Hilfsoperation, mit der man Attribute umbenennen kann. Sei r eine Relation vom Typ R und A ∈ R , B ∈ / R . Dann ist ρA →B (r ) eine Relation mit dem gleichen “Inhalt” wie r , aber einem Typ, bei den das Attribut A in B umbenannt worden ist19 . Der Buchstabe rho 19 Diese Definition ist formal nicht sauber, sollte aber dennoch präzise verständlich sein. Eine formal saubere Definition bedingt einen wesentlich höheren notationellen Aufwand; Tupel müssen dann als Abbildungen von Mengen von Attributnamen in Mengen von Wertemengen definiert werden (wie z.B. in [Vo99]). Da dieser nota- 102 Das relationale Datenbankmodell (ρ) erinnert an rename. Der Typ der Ergebnisrelation ist, als Attributmenge aufgefaßt, gleich ( R − { A }) ∪ { B }. Wir wenden die Umbenennungsoperation auch auf Relationennamen an. Sei r eine Relation vom Typ R , s ein Name, der bisher keine Relation benennt, dann ist ρs (r ) eine Relation namens s mit Typ R und dem gleichen Inhalt wie r . 4.3.5 Das Kreuzprodukt Eine sehr häufige praktische Aufgabe besteht darin, Tupel aus verschiedenen Relationen zu neuen Tupeln zu “verbinden”; Beispiele werden wir erst später besprechen. Das Verbinden von Einzelelementen zu einem Tupel ist durch das mathematische Kreuzprodukt hinlänglich bekannt und wurde bereits beim Relationsbegriff ausgenutzt. Es liegt nahe, statt einzelner Wertebereiche auch ganze Relationen durch das mathematische Kreuzprodukt zu verbinden. Seien also r1 , . . . , rn Relationen, dann können wir folgendes mathematische Kreuzprodukt bilden: r1 × ... × rn Dies ist aber leider keine Relation im Sinne der relationalen Algebra: Ein Tupel in diesem Kreuzprodukt hat die Form (t1 , . . . , tn ) wobei ti ein Tupel aus Ri ist; als Elemente relationaler Tupel sind aber nur elementare Datentypen zugelassen. Wir hätten auch ein Problem, den Relationentyp dieses Kreuzprodukts zu benennen. Ein Lösungsansatz besteht darin, die Tupel ti , ..., tn zu “konkatenieren”, also ein einziges neues Tupel zu bilden. Diese Idee funktioniert aber nur dann, wenn keine Attributnamen doppelt auftreten, also wenn die Typen der beteiligten Relationen paarweise disjunkt sind. tionelle Aufwand keinen signifikanten Gewinn an Präzision bringt, andererseits der intuitiven Verständlichkeit abträglich ist, wird er hier vermieden. Das relationale Datenbankmodell 103 Unter dieser Annahme können wir das relationale Kreuzprodukt folgendermaßen definieren: r 1 × . . . × r n = { < t1 | . . . | tn > | t i ∈ r i } Darin ist < t1 | . . . | tn > die Konkatenation der einzelnen Tupel. Der Typ des Kreuzprodukts ist die Vereinigung der Ri , 1 ≤ i ≤ n. Die Bildung eines Kreuzprodukts veranschaulicht Bild 4.2 am Beispiel zweier Relationen, die 3 bzw. 2 Tupel enthalten; der Aufbau der Tupel interessiert hier nicht, der Inhalt ist mit “aa”, “bb” usw. nur angedeutet. aa bb cc X xx yy = aa aa bb bb cc cc xx yy xx yy xx yy Abbildung 4.2: Beispiel eines Kreuzprodukts Da jedes Tupel der ersten Relation mit jedem Tupel der zweiten kombiniert wird, gilt folgende Formel: | r×s |=| r | ∗| s | worin | r | die Anzahl ihrer Tupel einer Relation r bezeichnet. Die “Länge” der Ergebnistupel (gemessen in der Zahl der Attribute) ist gleich der Summe der Längen der Argumenttupel. Bei der Kreuzproduktbildung entstehen also sehr viele und lange Tupel20 . Wir hatten unser relationales Kreuzprodukt bisher nur unter der Annahme definieren können, daß die Typen der beteiligten Relationen paarweise disjunkt sind; diese Annahme ist natürlich nicht immer 20 Deshalb wird das Kreuzprodukt in der Praxis auch fast nie wirklich berechnet. Im Rahmen der Optimierung werden Kreuzprodukte, die in einer vorgegebenen Abfrage auftreten, praktisch immer zu Verbundoperationen umgeformt; letztere lassen sich meist effizient berechnen. Mit relationalen Abfragesprachen kann man (bzw. sollte man oft sogar) Abfragen formulieren, die auf den ersten Blick extrem ineffizient aussehen. Wir gehen hierauf in Abschnitt 4.3.9 noch näher ein. 104 Das relationale Datenbankmodell erfüllt. Die Lösung besteht darin, die Attribute, die in mehr als einer Relation auftreten, umzubenennen. Sei A ein solches Attribut; dann wird A in jeder Relation ri , in deren Typ A vorkommt, zu ri . A umbenannt, d.h. wir führen vor der eigentlichen Bildung des Kreuzprodukts die Umbenennung ρ A → r i. A ( r i) durch. Unter der Annahme, daß die Namen aller ri verschieden sind, sind anschließend alle Attributnamen eindeutig. Wenn die vorstehende automatische Umbenennung von Attributen im Einzelfall unpassend ist, können natürlich die betroffenen Attribute auch explizit vor der Bildung des Kreuzprodukts umbenannt werden. Gelegentlich will man auch das Kreuzprodukt einer Relation mit sich selbst bilden. Dies verbieten wir hier und verlangen, daß in solchen Fällen zunächst explizit eine der Relationen umbenannt wird, so daß letztlich alle involvierten Relationen eindeutige Namen bekommen. 4.3.6 4.3.6.1 Verbundoperationen Beispiel Wir betrachten nun das schon angekündigte Beispiel, bei dem Daten zu einer Entität, die in verschiedenen Relationen stehen, zusammenzuführen sind. Wir führen hierzu eine weitere Relation lieferungen ein, die folgenden Relationentyp hat: Lieferungen = ( Datum: date; Wert: real; Lager: integer; Kundennummer: string; Lieferadresse: string ) Ein Tupel dieses Typs zeigt an, daß an den durch die Kundennummer identifizierten Kunden am angegebenen Datum Waren im angegebenen Gesamtwert geliefert worden sind, und zwar vom angegebenen Lager aus an die angegebene Lieferadresse. Der Inhalt der Relation lieferungen sei wie in Bild 4.3 angegeben. Das relationale Datenbankmodell Tabelle: lieferungen Datum Wert Kundennummer 00-08-12 2730.00 167425 00-08-14 427.50 167425 00-08-02 1233.00 171876 105 Lager Mitte Nord West Lieferadresse Bahnhofstr. 5 Luisenstr. 13 Bergstr. 33 Abbildung 4.3: Beispieltabelle für Lieferungen Nehmen wir nun an, wir wollten eine Relation erzeugen (und anzeigen oder ausdrucken), in der für alle Lieferungen Datum, Wert und der Name des Kunden angezeigt werden. Den Namen der Kunden mit einer gegebenen Kundennummer können wir anhand der Relation kunden herausfinden. Wir können das gesuchte Resultat in mehreren Schritten wie folgt konstruieren: 1. Wir bilden das Kreuzprodukt von lieferungen und kunden : r1 = lieferungen × kunden Die beiden Relationen haben das Attribut Kundennummer gemeinsam. Nach unseren früheren Festlegungen ist das Attribut in lieferungen.Kundennummer bzw. kunden.Kundennummer umbenannt worden. 2. In r1 ist jedes Lieferungstupel mit jedem Kundentupel kombiniert worden. Die meisten dieser Kombinationen sind für unseren Zweck unsinnig und daher überflüssig; wir interessieren uns nur für die Kombinationen, bei denen lieferungen.Kundennummer und kunden.Kundennummer den gleichen Wert haben, denn nur hier sind die richtigen Kundendaten und Lieferungsdaten kombiniert. Wir bilden also r2 = σ lieferungen.Kundennummer = kunden.Kundennummer ( r1 ) 3. In r2 sind die Spalten lieferungen.Kundennummer und kunden.Kundennummer identisch: dies war gerade die Selektionsbedingung. Eine der beiden Spalten ist offensichtlich entbehrlich und kann entfernt werden. Der lange Attributname der verbliebenen 106 Das relationale Datenbankmodell Spalte ist dann nicht mehr notwendig, wir können einfacher wieder den ursprünglichen Namen verwenden. Wir gehen nun so vor, daß wir zuerst eine der Spalten in den ursprünglichen Namen umbenennen: r3 = ρlieferungen.Kundennummer→Kundennummer ( r2 ) 4. Die überflüssige Spalte mit dem langen Namen können wir nun entfernen, indem wir einfach auf die Vereinigung der beiden Relationentypen projizieren: r4 = πLieferungen ∪ Kunden ( r3 ) 5. Zum Schluß entfernen wir noch die nicht benötigten Attribute; gefragt war nur nach dem Datum, Wert und Kundennamen: r5 = πDatum,Wert,Kundenname ( r4 ) Unser Endresultat sieht folgendermaßen aus: Tabelle: r5 Datum Wert 00-08-12 2730.00 00-08-14 427.50 00-08-02 1233.00 4.3.6.2 Kundenname Schneider, Peter Schneider, Peter Litt, Michael Der natürliche Verbund Das vorige Beispiel weist eine sehr häufig auftretende Struktur auf: die Werte in der Spalte Kundennummer in der Relation lieferungen kann man als “Referenzen” auf Tupel in der Relation kunden ansehen. Wir unterstellen jetzt einmal, daß die Kundennummern eindeutig sind, daß also eine Kundennummer höchstens einmal in der Spalte Kundennummer in der Relation kunden auftritt. Unsere Absicht war es, zu jedem Tupel in lieferungen die dort stehende Referenz auf ein Kundentupel zu verfolgen und Daten aus diesem Kundentupel hinten an das Lieferungstupel anzuhängen - so hätte man es auch von Hand gemacht (s. auch Bild 4.4). Letztlich verbinden wir solche Paare von Lieferungstupel und Kundentupel, die Das relationale Datenbankmodell 107 im gemeinsamen Attribut Kundennummer den gleichen Wert haben. Solche Paare von Tupeln bilden Verbundpartner voneinander. ..... 177180 ..... ..... 177180 ..... 177180 11111 00000 00000 11111 1111 0000 0000 1111 Abbildung 4.4: Auflösung einer “Referenz” Der natürliche Verbund (natural join) verallgemeinert diesen Vorgang; er faßt die obigen Schritte 1 bis 4 zu einer einzigen Operation, die mit dem Zeichen 1 notiert wird, zusammen. Gegeben seien zwei Relationen r und s mit den Relationentypen R bzw. S . Sei V = R ∩ S . Dann ist 1 wie folgt definiert: r 1 s = π R ∪ S (ρ r.V → V (σ r.V=s.V ( r × s ))) Die Attribute in V nennt man auch die Verbundattribute. In den meisten Fällen hat man genau ein Verbundattribut, es kann i.a. beliebig viele Verbundattribute geben, also V = {v1 ,...,vn }. Die Schreibweise ρ r.V → V (...) ist eine Kurzform für ρr.v1 →v1 (. . . (ρr.vn →vn (...)) . . .) Die Schreibweise σ r.V=s.V ist eine Kurzform von σr.v1 =s.v1 ∧ ... ∧ r.vn =s.vn Es werden also nur solche Tupel verbunden, die in allen Verbundattributen übereinstimmen. In dem Sonderfall, daß R und S disjunkt sind, also V die leere Menge ist, ist auch die Selektionsbedingung leer, d.h. die selektierten Tupel müssen keine Bedingung erfüllen, es wird also nichts weggefiltert. Bei V = ∅ bilden auch die Projektion und die Umbenennung ihre Argumente identisch ab, der natürliche Verbund verhält sich dann also wie das Kreuzprodukt. Mit Hilfe des natürlichen Verbunds können wir das Beispiel in Abschnitt 4.3.6.1 wesentlich einfacher lösen, und zwar in der Form 108 Das relationale Datenbankmodell πDatum,Wert,Kundenname ( lieferungen 1 kunden ) Übungsaufgabe: Zeigen Sie, daß im Sonderfall R = S der Verbund den Durchschnitt der beiden Relationen bildet, also: R = S ⇒ r 1 s = r∩s Übungsaufgabe: Zeigen Sie, daß der natürliche Verbund eine assoziative Operation ist, d.h. für beliebige Relationen r , s und t gilt: (r 1 s ) 1 t = r 1 (s 1 t ) 4.3.6.3 Der Theta-Verbund Beim natürlichen Verbund wurden bei der Prüfung, ob ein Paar von Tupeln verbunden werden soll, – der Vergleichsoperator = benutzt, und – es wurde jeweils das gleiche Attribut in beiden Tupeln für den Vergleich herangezogen. Dies wird beim Θ- (Theta-) Verbund dahingehend verallgemeinert, – daß irgendein Vergleichsoperator Θ ∈ {=, 6=, <, ≤, >, ≥} benutzt wird und – daß unterschiedliche Attribute in beiden Tupeln für den Vergleich herangezogen werden. Wenn r und s Relationen vom Typ R bzw. S sind und A ∈ R und B ∈ S Attribute mit gleichen Wertebereich, dann ist ein Theta-Verbund wie folgt definiert: r 1r.A Θ s.B s := σr.A Θ s.B ( r × s ) Man kann geteilter Meinung darüber sein, ob der Theta-Verbund viel einbringt; eine wesentliche Ersparnis an Schreibarbeit und ein dementsprechender Gewinn an Übersichtlichkeit der Ausdrücke – die ein großer Vorteil des natürlichen Verbundes sind – tritt hier jedenfalls nicht ein. Das relationale Datenbankmodell 109 Ein Gleichheitsverbund (equi-join) ist ein Theta-Verbund mit dem Vergleichsoperator =. 4.3.6.4 Äußere Verbunde Wir betrachten noch einmal das Beispiel in Abschnitt 4.3.6.1 und nehmen an, in der Relation kunden sei das Tupel mit der Kundennummer 167425 gelöscht worden. Wenn wir jetzt wieder den Verbund lieferungen 1 kunden bilden, würden die beiden ersten Tupel in der Relation lieferungen (s. Bild 4.3) keinen Verbundpartner mehr finden und dementsprechend herausfallen. Dies ist aber oft nicht erwünscht. Wenn der Kundenname nicht ermittelt werden kann, sollte der Sachverhalt, daß der Wert unbekannt ist, angezeigt werden, etwa in folgender Form: Datum Wert 00-08-12 00-08-14 00-08-02 2730.00 427.50 1233.00 Kundennummer 167425 167425 171876 Lieferadresse Kundenname Bahnhofstr. 5 Luisenstr. 13 Bergstr. 33 NULL NULL Litt, Michael Der Text NULL soll einen Nullwert darstellen; dieser drückt aus, daß der tatsächliche Attributwert unbekannt ist. In der vorstehende Tabelle haben wir bei den Tupeln aus lieferungen (also dem linken Verbundargument), die keinen Verbundpartner gefunden haben, einen künstlichen Verbundpartner benutzt. Diese Art von Verbund nennt man linken äußeren Verbund. Analog wird beim rechten äußeren Verbund für Tupel des rechten Verbundarguments ggf. ein künstlicher Verbundpartner benutzt. Der äußere Verbund ist die Vereinigung von linkem und rechtem äußeren Verbund. 4.3.7 Die Division Das Kreuzprodukt ist in gewisser Weise vergleichbar mit einer Multiplikation; im Kreuzprodukt r × s wird jedes Tupel aus r mit jedem 110 Das relationale Datenbankmodell Tupel aus s kombiniert (s. auch Bild 4.2). Die relationale Division kann man sich als eine Art inverse Operation zum Kreuzprodukt vorstellen. Hierzu betrachten wir das Beispiel in Bild 4.2 noch einmal genauer. Jedes der Tupel “aa”, “bb” und “cc” der linken Relation führt zu einem eigenen Abschnitt im Ergebnis (in Bild 4.2 jeweils durch einen kleinen Zwischenraum abgesetzt): die linken Hälften der Tupel eines Abschnitts enthalten alle das gleiche, z.B. “aa”, die schattiert dargestellten rechten Hälften bilden eine Kopie der rechten Argumentrelation. Diese rechte Hälfte eines Abschnitts wiederholt sich wie ein Stempelabdruck immer wieder. Bei der Umkehrung der Kreuzproduktbildung suchen wir sozusagen nach Stempelabdrücken (s. Bild 4.5): aa aa bb bb cc cc cc dd xx yy xx zz xx yy zz xx : xx yy = aa cc Abbildung 4.5: relationale Division – Dividend ist eine Relation x vom Typ X ; – Divisor ist eine Tupelmenge in einer Teilmenge der Spalten, aufgefaßt als Relation s vom Typ S (der “Stempel”) – im Quotienten enthalten sind solche Tupel aus den restlichen Spalten von x , die mit allen Tupeln des Divisors kombiniert auftreten Im Beispiel in Bild 4.5 ist für “aa” ein kompletter Stempelabdruck vorhanden, für “bb” und “dd” nur ein unvollständiger, “bb” und “dd” sind daher nicht im Ergebnis enthalten. Die Tupel “bb/xx” und “dd/xx” tragen somit nicht zum Ergebnis bei, ebenfalls nicht das Tupel “bb/zz”, da “zz” nicht im Divisor auftritt. Die relationale Division ähnelt insofern der ganzzahligen Division ohne Rest. Wegen Das relationale Datenbankmodell 111 dieses Rests erhält man, wenn man den Quotienten wieder mit dem Divisor multipliziert, i.a. nur noch eine Teilmenge des ursprünglichen Dividenden: (x ÷ s ) × s ⊆ x Formal definiert ist die Division wie folgt: Gegeben sei – eine Relation x vom Typ X (der Dividend) – eine Relation s vom Typ S (der Divisor), wobei ∅ = 6 S und S ⊂ X sein muß. Sei R = X − S . Dann ist x ÷ s = { t | t ∈ π R ( x ) ∧ {t} × s ⊆ x } Das Ergebnis ist eine Relation vom Typ R . Ein Tupel t ist genau dann im Ergebnis enthalten, wenn {t} × s ⊆ x , also wenn für alle t’ ∈ s gilt: < t | t′ > ∈ x . Bildlich gesprochen enthält das Ergebnis diejenigen “linken Hälften” von Tupeln aus x , die mit allen “rechten Hälften” aus s kombiniert in x auftreten. Anwendungsbeispiel. Als Anwendungsbeispiel für die Division betrachten wir eine Relation konten , die Angaben zu den Konten einer Bank enthält und die folgenden Relationentyp hat: Konten = ( Kontonummer: integer; Kundennummer: integer; Filialenname: string ) Der Filialenname gibt den Namen der Filiale an, bei der das Konto geführt wird. Ein Kunde kann bei jeder Filiale eine oder mehrere Konten haben. Gesucht sind nun die Kunden, die bei allen Filialen wenigstens ein Konto haben. Für die Lösung unserer Aufgabe bilden wir zunächst die Relation kundeFiliale = πKundennummer,Filialenname ( konten ) Diese enthält genau dann ein Tupel < k, f >, wenn der Kunde k wenigstens ein Konto in der Filiale f hat. Die Liste aller Filialen erhalten wir als eine 1-spaltige Tabelle mittels: filialen = πFilialenname ( kundeFiliale ) 112 Das relationale Datenbankmodell Die Kunden, die in jeder Filiale ein Konto haben, erhalten wir nunmehr durch: kundeFiliale ÷ filialen Das Typische an unserem Anwendungsbeispiel war, daß ein allQuantor bei der Beschreibung der gesuchten Daten benutzt wurde (... Kunden, die bei allen Filialen ein Konto haben). Für derart spezifizierte Suchergebnisse kann man generell die Division einsetzen. In den Selektionsbedingungen einer Selektion ist ein all-Quantor nicht erlaubt; die Division bietet daher einen Ersatz. Ein Ersatz für den Existenz-Quantor ist nicht notwendig, denn dieser wird implizit durch die Selektion realisiert. Berechnung von x ÷ s : x ÷ s kann direkt durch Ausnutzung der Definition berechnet werden: – Man bildet π R ( x ) als die Menge der Kandidaten, die im Ergebnis enthalten sein könnten – Für jedes t ∈ π R ( x ) prüft man, ob {t} × s ⊆ x . Die Division ist aber auch, was man spontan vielleicht nicht erwarten würde, zurückführbar auf die früher definierten Operationen. Zu berechnen sei also x ÷ s . Sei R = X − S und r = πR (x ) r enthält i.a. eine Obermenge von x ÷ s , r kann Tupel enthalten, für die {t} × s ⊆ x nicht gilt. Um diese Tupel zu finden, benutzen wir einen Trick: Wir bilden zunächst die Relation r × s . Sei nun inv = ( r × s ) − x inv ist die Invertierung von x in r × s . Wir betrachten den Inhalt von inv an einem Auszug unseres Beispiels aus Bild 4.5. inv enthält kein Tupel der Form “aa/...”, weil alle derartigen Tupel in r × s auch in x vorhanden sind und somit abgezogen wurden. Für Tupel der Form “bb/...” gilt dies nicht: es bleibt eines übrig. Beide Fälle sind in Bild 4.6 veranschaulicht. Das relationale Datenbankmodell (r x s) aa aa bb bb xx yy xx yy 113 x (r x s) − x aa aa bb xx yy xx bb zz bb yy Abbildung 4.6: relationale Division Die Tupel in π R ( inv ) sind somit gerade diejenigen, die in r zuviel sind. Unser Endresultat ist also x ÷ s = r − π R ( inv ) bzw. 4.3.8 x ÷ s = π R ( x ) − π R ((π R ( x ) × s ) − x ) Relationale Vollständigkeit Wir haben inzwischen eine Reihe von Operationen mit Relationen kennengelernt und schon bei den relativ komplizierten Verbundoperationen und der Division bemerkt, daß wir sie auf die einfacheren Operationen σ, π, ρ, ∪, −, × zurückführen konnten. Die Verbundoperationen und die Division mögen zwar die Formulierung mancher Abfragen erleichtern, sie erweitern die Fähigkeiten der relationalen Algebra aber nicht wirklich, d.h. es gibt kein Suchproblem, das nur mit ihrer Hilfe lösbar wäre. Dieser Effekt ist auch bei diversen weiteren Operationen, die man sich noch ausdenken kann, zu beobachten. Hieraus schlußfolgert man, daß die Ausdruckskraft, die durch die vorstehende Operationenmenge erreicht wird, einerseits ausreichend für eine große Klasse von Problemen, andererseits ein Minimum an Ausdruckskraft ist, das von jeder Abfragesprache für relationale Datenbanken erreicht werden sollte; solche Sprachen nennt man daher 114 Das relationale Datenbankmodell relational vollständig21 . Die Operationenmenge {σ, π, ρ, ∪, −, ×} ist übrigens minimal in dem Sinne, daß keine der Operationen auf die anderen zurückführbar ist, jede echte Teilmenge wäre nicht mehr relational vollständig. Wir hätten alternativ statt des Kreuzprodukts zuerst den natürlichen Verbund einführen können und hätten dann das Kreuzprodukt auf den natürlichen Verbund zurückgeführt; die Operationenmenge {σ, π, ρ, ∪, −, 1} ist also eine andere minimale, relational vollständige Operationenmenge. 4.3.9 Ausdrücke in der relationalen Algebra Wie schon einleitend erwähnt setzen wir bei der relationalen Algebra eine existierende Datenbank, also ein konzeptuelles Schema und dazu passende existierende Relationen, voraus. Hierdurch ist eine Menge von Namen von Relationen und Attributen vorgegeben. Diese Namen können wir nun an passender Stelle in den Operationen der relationalen Algebra einsetzen. Überall dort, wo eine relationale Operation eine Relation als Argument benötigt, kann natürlich wiederum ein relationaler Ausdruck eingesetzt werden. Syntaktisch korrekte Ausdrücke sind analog zu arithmetischen Ausdrücken in gängigen Programmiersprachen definiert. Details der Syntaxdefinition und -prüfung und Übersetzung interessieren uns an dieser Stelle nicht, und wir setzen i.f. syntaktisch korrekte Ausdrücke voraus. Ausdrücke werden klassischerweise von innen nach außen ausgewertet. Die entstehenden Zwischenresultate müssen gepuffert werden. Diese Zwischenresultate können, wenn Verbunde oder Kreuzprodukte auftreten, extrem groß werden, d.h. man kann erhebliche PerformanceProbleme bekommen, wenn man einen relationalen Ausdruck in kanonischer Weise auswertet. Man kann das Ergebnis eines relationalen Ausdrucks oft effizienter 21 Diese Bezeichnung ist insofern irreführend, als eine praxisgerechte Sprache viele über die zentralen Abfrageoperationen hinausgehende Funktionen anbieten muß, s. Abschnitt 4.1. So gesehen sind die Operationen der relationalen Algebra ziemlich unvollständig. Das relationale Datenbankmodell 115 berechnen als durch eine kanonische Auszuwertung; die Bestimmung eines effizienteren Rechenverfahrens bezeichnet man als Optimierung. Durch die Optimierung ist es vielfach möglich, auch äußerlich “ineffiziente” Ausdrücke recht effizient auszuwerten. Die entscheidende Konsequenz hieraus ist, daß man bei der Formulierung relationaler Abfragen zunächst keine Rücksicht auf Ineffizienz bei der kanonischen Auswertung nehmen sollte und sich stattdessen besser auf die inhaltliche Korrektkeit des Ausdrucks konzentieren sollte. Lösungen, die klar und korrekt, aber “ineffizient” sind, sind vielfach kompakter und deswegen leichter für Optimierer behandelbar als “effiziente” komplizierte (und schlimmstenfalls inkorrekte) Lösungen. Wenn der Optimierer der Datenbank wider Erwarten doch keine effiziente Ausführung findet – Wunder wirken können Optimierer nicht, und nicht jedes DBMS hat einen guten Optimierer – , kann man in einem zweiten Schritt immer noch versuchen, durch Umformung der Anfrage die eigentliche Arbeit des Optimierers doch selbst von Hand zu erledigen. 4.4 Schlüssel Wir hatten schon in Abschnitt 4.2.3 Identifizierungsschlüssel als eine typische Integritätsbedingung erwähnt; nachdem wir nun die Operationen der relationalen Algebra kennen, können wir einige Schlüsselbegriffe leichter exakt definieren. 4.4.1 Superschlüssel und Identifizierungsschlüssel Wir betrachten noch einmal die Relation kunden in Bild 4.1. Von dem Attribut Kundennummer verlangten wir schon früher, daß es “eindeutig” sein sollte, m.a.W. daß zu jeder Kundennummer höchstens ein Tupel vorhanden sein sollte. Eine Kundennummer identifiziert also, sofern vorhanden, genau ein Tupel. Formal läßt sich dies so ausdrücken: kn ∈ πKundennummer (kunden) ⇒ | σKundennummer=kn (kunden) | = 1 116 Das relationale Datenbankmodell Die vorstehende Bedingung ist äquivalent zu der folgenden kompakteren Bedingung (Beweis: Übungsaufgabe): | πKundennummer (kunden) | = | kunden | Das Attribut Wohnort hat diese Eigenschaft offensichtlich nicht. Es könnte aber sein, daß die beiden Attribute Wohnort und Kundenname zusammen die Identifizierungseigenschaft haben. Genereller kann eine beliebige Menge von Attributen zur Identifikation von Tupeln verwendet werden. Eine derartige Menge von Attributen nennen wir einen Superschlüssel. Die formale Definition lautet: Sei R ein Relationentyp, K ⊆ R eine Attributmenge. Wenn K ein Superschlüssel für R ist, dann gilt für jede korrekte Relation r mit dem Relationentyp R stets folgendes: | πK (r) | = | r | Die Attribute in K nennen wir auch Schlüsselattribute. Bildlich gesprochen gehen beim Projizieren auf einen Superschlüssel keine Tupel verloren, weil eben keine Kombination der Werte der Schlüsselattribute doppelt auftritt. Der seltsam klingende Name Superschlüssel rührt daher, daß die Attributmenge gemäß der vorstehenden Definition auch “überflüssige” Attribute enthalten kann, die für die Identifikation eigentlich nicht gebraucht werden. Ein extremes Beispiel ist die Attributmenge R; R ist immer ein Superschlüssel für R , sofern die Relation eine Menge ist (also keine Duplikate erlaubt sind). Ein Identifizierungsschlüssel ist eine minimale Menge von Attributen, die Superschlüssel ist. Für unsere Relation kunden sind {Kundennummer} und {Kundenname, Wohnort} Identifizierungsschlüssel. Wenn zusätzlich die Personalausweisnummer zu jedem Kunden vorhanden wäre, wäre {Personalausweisnummer} ein weiterer Identifizierungsschlüssel. Dieses Beispiel zeigt, daß es für einen Relationentyp mehrere Identifizierungsschlüssel geben kann. Die Bezeichnung Schlüssel wird meist als Synonym zu Identifizierungsschlüssel verstanden. Unter einem Schlüsselwert bei einem Das relationale Datenbankmodell 117 Tupel t verstehen wir die Menge der Attributwerte von t bei den Attributen des Identifizierungsschlüssels. Es sei noch einmal daran erinnert, daß Schlüsseleigenschaften Integritätsbedingungen, also vom Anwender definierte Anforderungen sind. Zu der Erkenntnis, daß eine Attributmenge K ein Identifizierungsschlüssel ist, kommt man nicht etwa dadurch, daß man den Zustand der Datenbank eine Zeitlang beobachtet und währenddessen dauernd kontrolliert, ob die Identifizierungseigenschaft erfüllt ist. Es ist genau umgekehrt: die Identifizierungseigenschaft wird vorgegeben, und das DBMS hat dafür zu sorgen, daß unerwünschte Zustände verhindert werden. Das DBMS muß bei jedem Einfügen eines neuen Tupels oder Ändern eines vorhandenen Tupels für jeden Identifizierungsschlüssel prüfen, ob der neue Schlüsselwert schon in der Relation auftritt. Diese Prüfung kann so implementiert werden, daß die ganze Relation linear durchsucht wird. Dies ist i.a. (außer bei kleinen Relationen) zu ineffizient, daher muß praktisch immer für einen Identifizierungsschlüssel ein Verzeichnis angelegt werden, in dem die aktuell vorhandenen Schlüsselwerte verzeichnet sind und das effizient durchsuchbar ist (z.B. als Baumstruktur oder Hash-Tabelle)22 . Dieses Verzeichnis muß bei allen Datenänderungen entsprechend aktualisiert werden. Sofern eine Relation mehrere Identifizierungsschlüssel hat, muß für jeden ein eigenes Verzeichnis der vorhandenen Schlüsselwerte angelegt werden. Viele DBMS erlauben es, Relationen zu definieren, die keinen einzigen Identifizierungsschlüssel haben. Eine derartige Relation kann Tupelduplikate enthalten. Auch die Gesamtmenge aller Attribute bildet hier keinen Schlüssel, denn dann wären keine Duplikate erlaubt. 22 Eine effiziente Suche wird z.B. auch durch die sortierte Speicherung nach dem Identifizierungsschlüssel ermöglicht; allerdings machen hier Einfügungen und Löschungen Probleme. Derartige Implementierungstechniken sind kein Thema dieses Lehrmoduls. 118 4.4.2 Das relationale Datenbankmodell Primärschlüssel Die Verzeichnisse für die Identifizierungsschlüssel kosten Platz und Rechenzeit, man würde sie daher lieber vermeiden. Dies ist in der Tat bei vielen internen Speicherstrukturen möglich. Bei den folgenden Annahmen und Implementierungsentscheidungen: 1. jedes Tupel wird in einem Speichersatz gespeichert (vgl. Lehrmodul 3), 2. die Relation wird in einem B*-Baum gespeichert, 3. der Identifizierungsschlüssel ist einelementig (enthält also nur ein Attribut), 4. man verwendet die Schlüsselwerte der Tupel als Schlüsselwerte im B*-Baum bekommt man die Eindeutigkeitsprüfung praktisch gratis! Diese sehr effiziente Prüfung der Schlüsseleigenschaft ist aber nur bei einem einzigen Identifizierungsschlüssel möglich; wenn man mehrere Identifizierungsschlüssel hat, muß man für die übrigen nach wie vor separate Verzeichnisse anlegen. Als Primärschlüssel bezeichnet man denjenigen Identifizierungsschlüssel, für den die Möglichkeit der sehr effizienten Prüfung der Schlüsseleigenschaft ausgenutzt werden soll. Welche Implementierungstechniken hierzu verwendet werden, bleibt eine Entscheidung des DBMS-Herstellers. Neben der Prüfung der Schlüsseleigenschaft ist natürlich bei einem Primärschlüssel auch die Suche nach dem Tupel, das einen bestimmten Wert bei diesem Attribut hat, besonders effizient möglich. Derartige Suchvorgänge sind z.B. bei der Verbundbildung nötig; s. das Beispiel in Abschnitt 4.3.6.1. Daher wird man, sofern mehrere Identifizierungsschlüssel vorhanden sind, denjenigen als Primärschlüssel auswählen, mit dem häufig Verbunde gebildet werden. In den meisten Fällen hat man aber ohnehin nur einen einzigen Identifizierungsschlüssel, der dann automatisch als Primärschlüssel zu wählen ist. Die vorstehenden Beobachtungen zeigen, daß die Festlegung des Primärschlüssels eine Implementierungsentscheidung ist, die für die Das relationale Datenbankmodell 119 konzeptionelle Struktur der Datenbank unerheblich ist. Im Sinne der 3-Ebenen-Schema-Architektur (s. Abschnitt 1.5.2) gehört die Festlegung des Primärschlüssels also zum internen Schema. Im Gegensatz dazu gehören Identifizierungsschlüssel zum konzeptuellen Schema. Leider wird zwischen den Ebenen oft nicht sauber getrennt. Die Bezeichnung Schlüssel wird vielfach auch als Synonym zu Primärschlüssel verstanden. Eine wesentliche Ursache für diese Vermischung von Begriffen liegt darin, daß man beim Entwurf der konzeptuellen Schemata durchaus Rücksicht auf deren Implementierung nehmen muß; dies steht etwas im Widerspruch zu der Idealvorstellung, wonach die konzeptuellen und implementierungsbezogenen Aspekte völlig getrennt voneinander auf den beiden unteren Ebenen der 3-Ebenen-Schema-Architektur behandelt werden können. Betrachten wir hierzu wieder das Beispiel in Bild 4.1. Einer der Identifizierungsschlüssel war {Kundenname, Wohnort}. Dieser Identifizierungsschlüssel ist i.a. als Primärschlüssel ungeeignet, weil hier die internen Schlüsselwerte als Konkatenation der beiden Attributwerte gebildeten werden müßten und weil diese Zeichenketten relativ lang werden können. Aus Effizienzgründen erlauben Implementierungen von B*-Bäumen und ähnlichen internen Strukturen ggf. nur relativ kurze Schlüsselwerte fester Länge, z.B. ganze Zahlen mit 4 oder 8 Bytes Länge oder Zeichenketten mit 8 Zeichen. Sofern die “natürlichen” Identifizierungsschlüssel alle als Primärschlüssel ungeeignet sind, muß man ein künstliches Schlüsselattribut erfinden; hierauf gehen wir in Abschnitt 4.4.4 ausführlicher ein. 4.4.3 Fremdschlüssel Identifizierungsschlüssel einer Relation werden oft von einer anderen Relation aus “referenziert”. In unserer Relation lieferungen kam z.B. das Attribut Kundennummer vor, das Identifizierungsschlüssel in kunden ist. Es sollte offensichtlich keine Lieferung geben, bei der die Kundennummer “ins Leere zeigt”, weil sie in kunden nicht auftritt. Die Abwesenheit solcher Datenfehler bezeichnet man auch als referentielle Integrität. Formal formuliert fordern wir folgende Men- 120 Das relationale Datenbankmodell geninklusion: πKundennummer (lieferungen) ⊆ πKundennummer (kunden) Kundennummer bezeichnen wir als Fremdschlüssel in der Relation lieferungen. Alle Werte, die im Attribut Kundennummer in lieferungen auftreten, müssen auch im Attribut Kundennummer in kunden auftreten. Die allgemeine Definition ist: sei K eine Attributmenge, r eine Relation mit dem Relationentyp R, K ⊆ R, s eine andere Relation mit dem Relationentyp S und K der Primärschlüssel in S. Wenn K Fremdschlüssel in r (mit Bezug auf s) ist, dann gilt stets πK (r) ⊆ πK (s) Das DBMS muß hier verhindern, 1. daß Tupel in s, auf die noch Referenzen in r existieren, gelöscht werden, und 2. daß Tupel in r erzeugt werden, bei denen der Wert der Fremdschlüsselattribute kein Tupel in s referenziert. Nullwerte sollten in Fremdschlüsseln vermieden werden. Wenn man sie zuläßt, bedeutet ein Nullwert, daß unbekannt ist, welches andere Tupel referenziert wird. 4.4.4 Kriterien für die Festlegung von Identifizierungsund Primärschlüsseln Identifizierungsschlüssel werden häufig als Fremdschlüssel in anderen Relationen benutzt; hieraus ergeben sich mehrere Kriterien, die bei der Festlegung von Identifizierungsschlüsseln beachtet werden sollten: – Können die Werte beim Eintragen immer sofort bestimmt werden? Man kann theoretisch auch Nullwerte bei Schlüsselattributen zulassen, praktisch stört dies aber sehr. U.a. können keine Fremdschlüssel-Referenzen auf dieses Tupel in anderen erzeugt werden. – Sind die Werte kurz und schreibbar? Dies betrifft wieder den Fall, daß in anderen Relationen Fremdschlüssel-Referenzen von Hand eingetragen werden müssen. Das relationale Datenbankmodell 121 – Sind die Werte “sprechend”, d.h. ist den Systembenutzern intuitiv verständlich, welche reale Entität durch ein Tupel dargestellt wird? Diese Anforderung steht oft im Widerspruch zu den beiden ersten. Ein weiteres Kriterium betrifft die zeitliche Entwicklung des Datenbankinhalts. Die aktuell in einem Identifizierungsschlüssel auftretenden Werte müssen natürlich eindeutig sein; zusätzlich kann es sinnvoll sein, die Eindeutigkeit über die Zeit hinweg zu verlangen. Beispielsweise könnte Kundenname ein Identifizierungsschlüssel sein und derzeit eine Kundin “Meier, Anna” vorhanden sein. Diese wird irgendwann gelöscht, und ein Jahr später wird eine andere, neue Kundin eingetragen, die zufällig genauso heißt. Wenn man derartiges vermeiden will, dürfen einmal benutzte Identifizierungsschlüsselwerte nicht wiederverwendet werden. Hierzu müßte ein Verzeichnis aller jemals verwendeten Identifizierungsschlüsselwerte geführt werden, was sehr aufwendig und platzraubend sein kann. Die vorstehenden Anforderungen werden oft von “natürlichen” Identifizierungsschlüsseln, die sich aus einer von Implementationsaspekten unbeeinflußten Datenmodellierung ergeben, nicht erfüllt. Beispielsweise sind textuelle Namen zwar oft gut verständlich, aber zu lang und wiederverwendbar. Im Endergebnis entscheidet man sich daher oft dazu, ein künstliches Schlüsselattribut, meist eine laufende Nummer, zu erfinden. Das Attribut Kundennummer ist ein Beispiel hierfür, denn “von Natur aus” haben Kunden keine Nummer. 4.4.5 Weitere Schlüsselbegriffe Sofern mehrere Identifizierungsschlüssel vorhanden sind, werden sie oft auch als Schlüsselkandidaten bezeichnet. Jeder Identifizierungsschlüssel ist ein Kandidat dafür, Primärschlüssel zu werden, nur einer schafft es. Diese Bezeichnung vermengt die konzeptuelle und interne Begriffs- und Denkwelt besonders stark, weshalb wir sie weitgehend vermeiden werden. Ein Sortierschlüssel (sort key) bestimmt die Reihenfolge, in der 122 Das relationale Datenbankmodell die Speichersätze in einem DB-Segment gespeichert werden. Hierdurch kann die Verarbeitung kompletter Relationen beschleunigt werden. Ein Sortierschlüssel muß nicht unbedingt identifizierend sein. Ein Sekundärschlüssel (secondary key) ist eine Menge von Attributen, für die ein Sekundärindex vorhanden ist. Ein Sekundärschlüssel ist i.a. nicht identifizierend. Der Sekundärindex ist eine Datenstruktur, die jedem Sekundärschlüsselwert eine Liste der Sätze bzw. Tupel zuordnet, bei denen die entsprechenden Attributwerte auftreten. Beispielsweise könnte es sinnvoll sein, bei der Relation konten einen Sekundärindex für das Attribut Kundenname einzurichten; dies beschleunigt die Suche nach den Kunden mit einem bestimmten Namen erheblich. Die folgende Tabelle stellt noch einmal alle Schlüsselbegriffe zusammen und gibt jeweils an, ob es sich um einen Begriff der konzeptuellen oder internen Ebene in der 3-Ebenen-Schema-Architektur handelt und ob die Attribute identifizierend sind. Begriff Identifizierungsschlüssel Superschlüssel Schlüsselkandidat Fremdschlüssel Primärschlüssel Sekundärschlüssel Sortierschlüssel Ebene logisch logisch logisch logisch intern intern intern identifizierend ja ja ja nein meist nein nein Implementierungen für Primärschlüssel sind meist so gestaltet, daß die Eindeutigkeit der Schlüsselwerte erzwungen wird. Man kann aber auch leicht Varianten dieser Implementierungen bilden, bei denen mehrere Sätze mit dem gleichen Primärschlüsselwert vorhanden sein dürfen, die dann beim Lesen als Gruppe behandelt werden. Bei solchen Implementierungen ist ein Primärschlüssel nicht automatisch auch Identifizierungsschlüssel. Das relationale Datenbankmodell 123 Glossar Division: Operation der relationalen Algebra, die in gewisser Weise invers zum Kreuzprodukt ist und mit der Suchaufgaben gelöst werden können, die All-Quantoren enthalten Fremdschlüssel: (Kontext: Attributmenge F in Relation R1 ist Fremdschlüssel auf eine Relation R2) Menge von Attributen, die Tupel in einer anderen Relation identifizieren sollen; ist eine Integritätsbedingung, wonach die Projektion von R1 auf F komplett in der Projektion von R2 auf F enthalten ist Identifizierungsschlüssel: minimale Menge von Attributen, die ein Superschlüssel ist Primärschlüssel: Attribut (-kombination), terstützt die der Primärindex un- Projektion: Operation der relationalen Algebra, mit der in den Tupeln einer Eingaberelation Attribute entfernt werden können; entstehende Duplikate werden eliminiert relationale Algebra: Algebra mit den Kernfunktionen relationaler Datenbanksysteme im Bereich der Abfragedienste, insb. Selektion, Projektion, Mengenoperationen, Kreuzprodukt, natürlicher bzw. ThetaVerbund und Division Relationenschema: Namen und Typen der Attribute einer Relation; Synonyme: Relationentyp, Relationenformat Schlüssel: Oberbegriff für mehrere spezielle Schlüsselbegriffe; oft als Synonym für Identifizierungsschlüssel benutzt Schlüsselkandidat: Synonym für Identifizierungsschlüssel Sekundärschlüssel: Attribut (-kombination), für die ein Sekundärindex vorhanden ist Selektion: Operation der relationalen Algebra, mit der Tupel einer Eingaberelation anhand einer Bedingung selektiert werden können Sortierschlüssel: Attribut (-kombination), nach der intern sortiert gespeichert wird Spalte (column): einer Tabelle; Synonym: Attribut Superschlüssel: Menge von Attributen, deren Werte die Tupel einer Relation eindeutig identifizieren 124 Das relationale Datenbankmodell Tabelle (table): Hauptbestandteile einer relationalen Datenbank; wird oft als Synonym zu Relation benutzt Verbund: Operation der relationalen Algebra, mit der die Tupel zweier Eingaberelationen paarweise verbunden werden, sofern Sie eine Verbundbedingung erfüllen; beim Theta-Verbund wird die Verbundbedingung explizit vorgegeben, beim Gleichheitsverbund werden Attribute der zu verbindenden Tupel auf Gleichheit getestet, beim natürlichen Verbund werden nur Tupel verbunden, die in allen Attributen, die beiden Relationen gemeinsam sind, jeweils die gleichen Werte haben Verbund, äußerer: der linke (rechte) äußere Verbund ist eine Variante der normalen Verbunde, bei denen Tupel der linken (rechten) Eingaberelation, die keinen Verbundpartner in der rechten (linken) Eingaberelation finden, ergänzt um Nullwerte bei den fehlenden Attributen, zum Ergebnis hinzugenommen werden; der beidseitige äußere Verbund liefert die Vereinigung des rechten und linken äußeren Verbunds Zeile (row ): einer Tabelle; Synonym: Tupel Lehrmodul 5: Der relationale Tupel-Kalkül Zusammenfassung dieses Lehrmoduls Die relationalen Kalküle sind neben der relationalen Algebra ein alternativer Formalismus, mit dem sich die grundlegenden Möglichkeiten zur Abfrage von Daten in relationalen Datenbanken definieren lassen. Dieses Lehrmodul stellt den relationalen Tupel-Kalkül an Beispielen vor. In der Grundform des Tupel-Kalküls sind Abfragen möglich, die zu “unendlich” großen Ergebnissen führen. Daher erlaubt man nur sogenannte sichere Abfragen. Wir diskutieren abschließend die relationale Vollständigkeit der Kalküle. Vorausgesetzte Lehrmodule: obligatorisch: – Datenverwaltungssysteme – Das relationale Datenbankmodell Stoffumfang in Vorlesungsdoppelstunden: c 2001 Udo Kelter 0.5 Stand: 24.11.2001 126 5.1 Der relationale Tupel-Kalkül Die relationalen Kalküle Wenn ein Benutzer bestimmte Daten aus einer relationalen Datenbank extrahieren will, muß er, wenn er die relationale Algebra (s. Lehrmodul 4) verwendet, einen Ausdruck finden, der die gesuchte Menge konstruiert. Der Benutzer muß also zu seinem Suchproblem eine konstruktive, prozedurale Lösung finden. Schöner wäre es, wenn man dem DBMS nur die gesuchten Daten beschreiben müßte und wenn dann das DBMS selbst einen Weg fände, das Suchergebnis zu konstruieren. Dies ist gerade die Grundidee der relationalen Kalküle. Die Frage ist nun, wie der Benutzer dem DBMS die gesuchten Daten beschreibt. Der grundlegende Ansatz besteht darin, hierbei elementare Vergleichsbedingungen zu verwenden - wie wir sie schon bei der relationalen Algebra kennengelernt haben -, und auf dieser Basis aussagenlogische Ausdrücke zu bilden. Man verwendet hier den Prädikatenkalkül 1. Ordnung mit Quantoren. Letztlich bildet man also ein Prädikat, das die gesuchten Daten beschreibt. Es gibt nun zwei grundlegende Alternativen, wie man die Parameter für das Prädikat gestaltet: – Tupelvariablen: Eine Abfrage hat hier folgende Grundform: { t | P (t) } Das Prädikat P(t) entscheidet für ein Tupel t, ob es zu den gesuchten Daten gehört. Man spricht hier vom relationalen Tupel-Kalkül (RTK). – Bereichsvariablen: Eine Abfrage hat hier folgende Grundform: { < x1 , x2 , ..., xn > | P (x1 , x2 , ..., xn ) } Jedes der xi stellt einen Attributwert dar. Das Prädikat P (x1 , x2 , ..., xn ) entscheidet für eine Kombination von Attributwerten, ob sie ein Tupel bilden, das zu den gesuchten Daten gehört. Man spricht hier vom relationalen Bereichskalkül. Die beiden Varianten sind für unsere Zwecke gleichwertig; wir werden i.f. nur den relationalen Tupel-Kalkül vorstellen. Der relationale Tupel-Kalkül 5.2 127 Der relationale Tupel-Kalkül Wir illustrieren den relationalen Tupel-Kalkül an den gleichen BeispielRelationen wie in Lehrmodul 4, s. Bild 5.1. Tabelle: kunden Kundennummer Kundenname 177177 Meier, Anne 177180 Büdenbender, Christa 185432 Stötzel, Gyula 167425 Schneider, Peter 171876 Litt, Michael Tabelle: lieferungen Datum Wert Kundennummer 00-08-12 2730.00 167425 00-08-14 427.50 167425 00-08-02 1233.00 171876 Wohnort Weidenau Siegen Siegen Netphen Siegen Lager Mitte Nord West Kreditlimit 2000.00 9000.00 4000.00 14000.00 0.00 Lieferadresse Bahnhofstr. 5 Luisenstr. 13 Bergstr. 33 Abbildung 5.1: Beispieltabellen Wir werden i.f. folgende Schreibweise benutzen: Wenn A ein Attribut ist und t ein Tupel, dann ist t[A] der Wert des Attributs A in t (auch als die Projektion des Tupels t auf A bezeichnet). Hierbei unterstellen wir natürlich A ∈ R, wobei R der Relationentyp von t ist. 5.2.1 Beispiel 1 (Selektion) Wir suchen hier Kundennummer, Kundenname, Wohnort und Kreditlimit derjenigen Kunden, deren Kreditlimit über 10000 DM liegt. Dies liefert uns die folgendermaßen definierte Menge: { t | t ∈ kunden ∧ t[Kreditlimit] > 10000 } Die Bedingung t[Kreditlimit] > 10000 stellt hier eine Selektionsbedingung dar. Statt der hier vorliegenden elementaren Bedingung 128 Der relationale Tupel-Kalkül sind i.a. natürlich auch komplexe Ausdrücke möglich. Das Beispiel zeigt, daß Selektionen in den relationalen Kalkülen sehr einfach formulierbar sind. In der relationalen Algebra sieht die Selektion wie folgt aus: σKreditlimit>10000 (Kunden) Im folgenden gehen wir die wichtigsten Operatoren der relationalen Algebra durch und zeigen beispielhaft, daß auch sie durch entsprechende aussagenlogische Konstrukte nachbildbar sind. 5.2.2 Beispiel 2 (Projektion) Wir ändern unser voriges Beispiel dahingehend ab, daß wir nur noch die Namen der Kunden haben wollen. In der relationalen Algebra würden wir auf dieses Attribut projizieren: πKundenname (σKreditlimit>10000 (Kunden)) Die Projektion können wir in den aussagenlogischen Ausdrücken nicht direkt nachbilden. Wir müssen hier die Definition der Projektion direkt einsetzen. Die Projektion einer Relation r auf eine Attributmenge A ist wie folgt definiert: t ∈ πA (r) ⇔ ∃s ∈ r ∧ s[A] = t[A] Die vorstehende Definition einer Projektion integrieren wir nun in den Ausdruck, der unsere gesuchte Menge definiert: { t | ∃s ∈ kunden ∧ s[Kreditlimit] > 10000 ∧ s[Kundenname] = t[Kundenname] } Der Typ des Ergebnisses ist in diesem Beispiel nur implizit definiert. (In Beispiel 1 war er durch die Bedingung t ∈ Kunden explizit definiert.) Dadurch, daß der aussagenlogische Ausdruck den Term t[Kundenname] enthält, ist implizit festgelegt, daß die Ergebnistupel ein Attribut namens Kundenname haben. Der Ergebnistyp enthält genau alle so vorgegebenen Attribute. Der relationale Tupel-Kalkül 5.2.3 129 Beispiel 3 (Mengenoperationen) Gesucht sind nun die Nummern aller Kunden, deren Kreditlimit über 10000 DM liegt und die eine Lieferung im Wert von über 1000 DM bekommen haben. Den hier auftretenden Mengendurchschnitt bilden wir direkt auf die und-Verknüpfung ab: { t | (∃s ∈ kunden ∧ s[Kreditlimit] > 10000 ∧ s[Kundennummer] = t[Kundennummer] ) ∧ (∃u ∈ lieferungen ∧ u[Wert] > 1000 ∧ u[Kundennummer] = t[Kundennummer] ) } Analog können wir die Mengenvereinigung durch die oder-Verknüpfung nachbilden und die Mengendifferenz durch eine “und-nicht”Verknüpfung. 5.2.4 Beispiel 4 (natürlicher Verbund) Gesucht sind nun die Lieferungen im Wert von über 1000 DM, anzugeben ist der Wert und der Name des Kunden. Bei Verwendung der relationale Algebra würden wir hier einen Verbund bilden: πKundenname,Wert (σWert>1000 (lieferungen) 1 kunden) Den Verbund simulieren wir, indem wir in einem aussagenlogischen Ausdruck die Gleichheit der Werte der Verbundattribute verlangen: { t | ∃u ∈ lieferungen ∧ u[Wert] > 1000 ∧ t[Wert] = u[Wert] ∧ (∃s ∈ kunden ∧ s[Kundennummer] = u[Kundennummer] ∧ t[Kundenname] = s[Kundenname] ) } Der eigentliche Test auf Gleichheit der Verbundattribute ist in dem Teilausdruck s[Kundennummer] = u[Kundennummer] enthalten. 130 5.2.5 Der relationale Tupel-Kalkül Beispiel 5 (Division) Wir suchen jetzt die Kundennummern derjenigen Kunden, die schon von allen Lagern Lieferungen bekommen haben. In der relationalen Algebra sieht die Lösung wie folgt aus: πKundennummer,Lager (lieferungen) ÷ πLager (lieferungen) In den relationalen Kalkülen können wir den all-Quantor direkt einsetzen, ein Umweg über eine Operation wie die Division ist nicht mehr nötig. Informell ausgedrückt hat die gesuchte Menge folgende Spezifikation: { t | ∀ Lager l gilt : ∃ Lief erung f ür Kunde t von Lager l aus } Konkret ist die Lösung wie folgt: { t | ∀ l ( l ∈ lieferungen ⇒ ∃ lf ( lf ∈ lieferungen ∧ l[Lager] = lf [Lager] ∧ t[Kundennummer] = lf [Kundennummer] ) ) } Die Ergebnistupel haben den Typ {Kundennummer}. Die allquantifizierte Variable l durchläuft die ganze Relation lieferungen und projiziert diese, da wir im Rest des Ausdrucks nur l[Lager] benutzen, praktisch auf das Attribut Lager. Eine Kundennummer t ist nur dann im Ergebnis, wenn für alle Lager ein Lieferungstupel lf vorhanden ist, das die Kundennummer t und das Lager l aufweist. 5.3 Syntax von Ausdrücken im RTK Wie schon erwähnt ist { t | P (t) } die Grundform einer Abfrage im RTK. Für das darin enthaltene Prädikat gelten die folgenden syntaktischen Regeln: Erlaubte atomare Ausdrücke sind: 1. s ∈ r falls s eine Tupelvariable und r eine Relation ist Der relationale Tupel-Kalkül 131 2. s[A] Θ u[B] falls – s und u Tupelvariable sind – A und B Attribute gleichen Typs, die bei s bzw. u definiert sind – Θ ein Vergleichsoperator ist 3. s[A] Θ c falls – s eine Tupelvariable ist – A ein Attribut, das bei s definiert ist – Θ ein Vergleichsoperator ist – c eine Konstante aus dem Wertebereich von A ist RTK-Ausdrücke sind generell wie folgt aufgebaut: 1. Atomare Ausdrücke sind RTK-Ausdrücke. 2. Ist P ein RTK-Ausdruck, so sind auch ¬P und (P ) RTK-Ausdrücke. 3. Sind P und Q RTK-Ausdrücke, so sind auch P ∧ Q und P ∨ Q RTK-Ausdrücke. 4. Ist P (s) ein RTK-Ausdruck mit der freien Tupelvariablen s, so sind auch ∃s (P (s)) und ∀s (P (s)) RTK-Ausdrücke. Eine Variable v in einem Ausdruck P heißt frei, wenn P keinen Quantor über v enthält. 5.4 Sichere RTK-Ausdrücke Wir hatten bisher noch völlig offengelassen, wie ein DBMS zu einem gegebenen RTK-Ausdruck die Lösung dieser Suchaufgabe findet. Ein einfaches Auswertungsverfahren besteht darin, alle involvierten Relationen zu durchlaufen und das Prädikat auszuwerten. Dummerweise sind auch RTK-Ausdrücke folgender Form möglich: { t | ¬(t ∈ kunden)} Wir verstehen diese Abfrage so, daß die enthaltenen Tupel den Typ Kunden haben. Verlangt wären hier alle denkbaren Tupel außer denen, die sich gerade in der Datenbank befinden. Die Anzahl dieser Tupel ist extrem groß, das Ergebnis kann in der Praxis nicht konstruiert 132 Der relationale Tupel-Kalkül werden. Derartige “unendliche” Mengen23 sind auch innerhalb von verschachtelten RTK-Ausdrücken möglich. Generell können RTK-Ausdrücke, die unendliche Zwischen- oder Endergebnisse enthalten, nicht ausgewertet werden. RTK-Ausdrücke, bei denen dieses Problem nicht auftritt, bei denen also beim Arbeiten auf beliebigen Datenbankinhalten nur “endliche” Resultate auftreten, bezeichnen wir als sicher. Ein DBMS würde also dann, wenn der Benutzer einen unsicheren Ausdruck auswerten lassen will, dies ablehnen. Dazu muß vor Auswertung des Ausdrucks entschieden werden, ob er nun sicher ist oder nicht. Diese Entscheidung ist nicht immer einfach, weshalb man zwei Arten von Sicherheit unterscheidet: – semantische Sicherheit: Dies ist die Sicherheit im allgemeinen Sinn. Leider ist sie i.a. nicht entscheidbar, d.h. dieser Begriff nützt uns in der Praxis nichts. – syntaktische Sicherheit: Hier werden syntaktische Restriktionen definiert, die hinreichend, aber nicht unbedingt notwendig für die semantische Sicherheit sind. Die Grundidee besteht hier darin zu verlangen, daß jede freie Variable t überall durch Teilausdrücke wie t[A] = c oder t ∈ r an endliche Wertebereiche gebunden wird, die dann “gefahrlos” durchlaufen werden können. Auf Details wollen wir hier nicht eingehen. In der Praxis kann man nur mit der syntaktischen Sicherheit arbeiten, d.h. das DBMS wird bestimmte Ausdrücke als unsicher ablehnen, obwohl sie es inhaltlich nicht sind. Die Menge der sicheren RTK-Ausdrücke bezeichnen wir mit SRTK. Relationale Vollständigkeit. Wir hatten oben bereits beispielhaft gezeigt, daß man alle Operationen der relationalen Algebra durch 23 Wegen der Endlichkeit der Wertebereiche der Attribute ist natürlich auch die Zahl der damit konstruierbaren Tupel endlich; praktisch sind die Mengen dennoch viel zu groß, um mit Rechnern verarbeitet werden zu können. Der relationale Tupel-Kalkül 133 RTK-Ausdrücke nachbilden kann. Die Frage ist, ob auch die Umkehrung gilt. Für die allgemeinen RTK-Ausdrücke gilt sie nicht. Dies macht man sich leicht klar, weil es in der relationalen Algebra kein Äquivalent zu den unsicheren Ausdrücken gibt: Eine Menge wie { t | ¬(t ∈ kunden)} kann in der relationalen Algebra nicht konstruiert werden; hierzu bräuchte man einen “Konstruktor”, der alle Tupel zu einem Relationentyp liefert; von dieser “unendlichen” Menge wäre dann die vorhandene Relation abzuziehen. Anders verhält es sich beim sicheren RTK: Man kann zeigen, daß man zu jedem SRTK-Ausdruck einen Ausdruck in der relationalen Algebra finden kann, der das gleiche Ergebnis berechnet. Die relationale Algebra und der SRTK sind daher gleichmächtig; insb. ist somit auch der SRTK relational vollständig. Vergleich von (S)RTK und relationaler Algebra. Nachdem sich der SRTK und die relationale Algebra bzgl. ihrer Ausdrucksfähigkeit nicht unterscheiden, liegt die Frage nahe, für welche der beiden Denkwelten man sich entscheiden sollte. – Wie die obigen Beispiele zeigen, sind viele einfache Beispiele mit dem RTK umständlicher zu formulieren als mit der relationalen Algebra. – Denk- und Schreibweisen mit Quantoren sind für mathematisch ungeübte Benutzer nicht geeignet. – Der RTK ist leichter als die relationale Algebra um Ausgabeanweisungen und Standardfunktionen (Summe, Maximalwert etc.) erweiterbar. In der Praxis benutzte Sprachen enthalten stets eine Mischung aus beiden Denkwelten, also sowohl prozedurale als auch deskriptive Sprachelemente. 134 Der relationale Tupel-Kalkül Glossar relationaler Bereichskalkül: auf Prädikaten basierende Abfragesprache für relationale Datenbanken, in der einzelne Attribute als Variable benutzt werden relationaler Tupel-Kalkül (RTK): auf Prädikaten basierende Abfragesprache für relationale Datenbanken, in der ganze Tupel als Variable benutzt werden Sicherheit (von RTK-Ausdrücken): ein RTK-Ausdruck ist sicher, wenn er ausgewertet werden kann, ohne daß dabei unbeschränkt große Zwischen- oder Endergebnisse auftreten Lehrmodul 6: Einführung in SQL Zusammenfassung dieses Lehrmoduls Dieses Lehrmodul führt in die elementaren Kommandos von SQL ein. Ein Schwerpunkt liegt auf den Möglichkeiten zur Formulierung von Abfragen. Weiter werden Möglichkeiten zur Definition und Änderung von Schema gezeigt. Einleitend wird ein Abriß der historischen Entwicklung und der wichtigsten Varianten von SQL gegeben. Vorausgesetzte Lehrmodule: obligatorisch: – Datenverwaltungssysteme – Das relationale Datenbankmodell Stoffumfang in Vorlesungsdoppelstunden: c 2005 Udo Kelter 1.3 Stand: 16.10.2005 136 6.1 Einführung in SQL Einführung SQL ist die mit Abstand wichtigste Sprache für relationale Systeme. SQL umfaßt Kommandos zur Abfrage und Manipulation von Daten und Schemata, ferner diverse Administrationsfunktionen. Im Laufe der Zeit ist der Funktionsumfang von SQL ganz erheblich angewachsen, und es existieren mehrere Varianten der Standards. Historie. Der Ursprung von SQL geht auf das System/R zurück. System/R war ein Prototyp eines relationalen DBMS, das im Zeitraum von 1971 - 1981 bei der IBM für deren Mainframes entwickelt wurde. Der Name der Sprache war seinerzeit noch SEQUEL (“Structured English Query Language”). Später wurde sie umgetauft in “Structured Query Language”, heute liest man die Abkürzung SQL meist als “Standard Query Language”. 1981 war eine erste kommerzielle Implementierung von SQL durch die IBM verfügbar (SQL/Data System). Später folgten weitere Implementierungen, einerseits durch die IBM (DB2, QMF), andererseits durch mehrere konkurrierende Unternehmen, u.a. Oracle, Informix und Sybase. Aus Sicht von Anwendern ist eine Standardisierung der Sprache sehr wünschenswert, denn nur dann, wenn unterschiedliche Hersteller Implementierungen der gleichen Sprachdefinition anbieten, ist ein Wechsel zwischen konkurrierenden Produkten möglich und kann ein offener Markt entstehen. Dementsprechend wurden zunächst durch das ANSI bzw. später die ISO mehrere Versionen von SQL standardisiert. Die erste Version wurde unter den Namen SQL1 bzw. SQL86 im Jahre 1986 verabschiedet. 1989 folgte ein sogenanntes Addendum-1; der neue Standard wird auch als SQL89 bezeichnet. 1992 folgte die Version SQL2 bzw. SQL92. Die ersten Standards deckten nur einen Kern an Funktionen ab; Folge hiervon war, daß in der Praxis viele implementierungsspezifische Erweiterungen notwendig waren, so daß die unterschiedlichen Implementierungen doch nicht wirklich kompatibel bzw. austauschbar waren. Erst SQL92 hatte einen relativ vollständigen Funktionsumfang, dieser wurde allerdings von praktisch keinem Produkt exakt implementiert. Einführung in SQL 137 Ende der 90er Jahre ist eine neue Version namens SQL3 durch die ISO publiziert worden. Der Funktionsumfang von SQL3 kann in erster Näherung als unendlich bezeichnet werden, möglicherweise gibt es keine einzelne Person, die die Spezifikationen komplett gelesen hat. In diesem einführenden Lehrmodul beschränken wir uns natürlich auf die wichtigsten Funktionalitäten. Daß SQL sich als wichtigste relationale Sprache durchgesetzt hat, liegt übrigens weniger an seinen sprachlichen bzw. technischen Qualitäten, sondern eher an der Macht seiner Anbieter. In der Tat wurde SQL wegen diverser Mängel von bekannten Datenbankforschern heftig kritisiert. Dies hat jedoch nichts am Erfolg von SQL ändern können. SQL definiert sowohl eine “interaktive” Sprache (durch Kommandos wie CREATE TABLE oder SELECT ) als auch ein Programm-API (durch Kommandos wie DECLARE CURSOR , OPEN , FETCH usw.) Wir gehen in diesem Lehrmodul nur auf die interaktive Sprache ein. Bei den folgenden Beispielen verwenden wir Großbuchstaben für die Schlüsselworte (Kleinbuchstaben sind auch zulässig). 6.2 6.2.1 Abfragen Grundform Eine Abfrage in SQL hat folgende Grundstruktur: SELECT A1, ...., An FROM r1, ...., rm WHERE P Man fängt beim Lesen am besten mit der 2. Klausel, der FROM -Klausel an. Dort ist angegeben, welche Relationen die Grundlage der Abfrage bilden. In der Begriffswelt der relationalen Algebra bedeutet die Angabe mehrerer Relationen, daß deren Kreuzprodukt gebildet wird. Als nächstes sollte man die WHERE -Klausel lesen, sofern sie vorhanden ist (sie ist optional). Sie enthält ein Prädikat, das sich auf die Relationen beziehen muß, die in der FROM -Klausel angegeben sind. In der Begriffswelt der relationalen Algebra spezifiziert die WHERE -Klausel 138 Einführung in SQL eine Selektion. Wenn die WHERE -Klausel fehlt, wird nicht selektiert, der Vorgabewert für P ist sozusagen true . Die SELECT -Klausel sollte man zum Schluß lesen. Angegeben ist dort eine Liste von Attributen, die im Resultat auftreten. Die SELECT Klausel gibt also den Relationentyp des Ergebnisses an. Sie entspricht einer Projektion auf die angegebenen Attribute; entgegen ihrem Namen stellt sie keine Selektion dar24 . Durch Angabe von * werden alle Attribute der angegebenen Relationen ausgegeben, d.h. es findet keine echte Projektion statt. Übersetzt man die obige Grundform einer SQL-Abfrage also in die relationale Algebra, ergibt sich folgender Ausdruck: π A1,....,An (σP ( r1 × . . . × rm )) Mit anderen Worten kombiniert die Grundform einer SQL-Abfrage ein Kreuzprodukt, eine Selektion und eine Projektion. Duplikateliminierung. Der vorstehende Ausdruck in der relationalen Algebra ist in einem Punkt allerdings nicht äquivalent zur SQLAbfrage: bei der SQL-Abfrage werden Duplikate normalerweise nicht eliminiert. In der relationalen Algebra findet wegen des Rückgriffs auf die Mengenlehre immer implizit eine Duplikateliminierung statt. Wenn eine Duplikateliminierung gewünscht wird, muß zusätzlich das Schlüsselwort DISTINCT in der SELECT -Klausel angegeben werden. Die Duplikate werden nach der Projektion eliminiert. Wir verwenden i.f. die schon aus Lehrmodul 4 bekannten Tabellen kunden und lieferungen (s. Bild 6.1). Die Abfrage SELECT DISTINCT Wohnort FROM kunden gibt dann drei Tupel aus, und zwar gerade die drei verschiedenen auftretenden Ortsnamen. Ohne DISTINCT würden 5 Tupel ausgegeben. Es gibt gute Gründe, Duplikate nicht automatisch zu eliminieren. Die Eliminierung erfordert praktisch eine Sortierung, also eine 24 Die bisher erwähnten erheblichen linguistischen Mängel sollten schon ein gewisses Maß an Evidenz für die erwähnte massive Kritik an SQL liefern. Einführung in SQL 139 bei großen Datenmengen sehr aufwendige Operation. Ferner werden durch die Duplikateliminierung bestimmte Zähl- und Aggregationsoperatoren beeinflußt. Tabelle: kunden Kundennummer Kundenname 177177 Meier, Anne 177180 Büdenbender, Christa 185432 Stötzel, Gyula 167425 Schneider, Peter 171876 Litt, Michael Tabelle: lieferungen Datum Wert Kundennummer 00-08-12 2730.00 167425 00-08-14 427.50 167425 00-08-02 1233.00 171876 Wohnort Weidenau Siegen Siegen Netphen Siegen Lager Mitte Nord West Kreditlimit 2000.00 9000.00 4000.00 14000.00 0.00 Lieferadresse Bahnhofstr. 5 Luisenstr. 13 Bergstr. 33 Abbildung 6.1: Beispieltabellen 6.2.2 Nachbildung der Operationen der relationalen Algebra in SQL Wie wir oben schon gesehen haben, stellt die Grundform einer Abfrage in SQL eine Kombination mehrerer Operationen der relationalen Algebra dar. Umgekehrt können alle Operationen der relationalen Algebra wie in Tabelle 6.2 angegeben in SQL nachgebildet werden. Zu Tabelle 6.2 ist anzumerken: In der Selektion können die einfachen Vergleichsoperatoren = , <> (ungleich), < , > , <= und >= sowie diverse andere Vergleichsoperatoren verwendet werden. Bei den Vergleichen mit numerischen Werten können auch arithmetische Ausdrücke gebildet werden, bei Zeichenketten können in Konstanten folgende Sonderzeichen benutzt werden: für ein beliebiges Zeichen 140 Einführung in SQL σA=a (r) σA=B (r) πA1 ,...,An (r) r∪s r∩s r−s r×s r1s r[AΘB]s SELECT DISTINCT SELECT DISTINCT SELECT DISTINCT SELECT DISTINCT UNION SELECT DISTINCT SELECT DISTINCT INTERSECT SELECT DISTINCT SELECT DISTINCT EXCEPT SELECT DISTINCT SELECT DISTINCT SELECT DISTINCT SELECT DISTINCT * FROM r WHERE A = a * FROM r WHERE A = B A1 , ..., An FROM r * FROM r * FROM s * FROM r * FROM s * FROM r * * * * FROM FROM FROM FROM s r, s r NATURAL JOIN s r, s WHERE r.A Θ s.B oder SELECT DISTINCT * FROM r JOIN s ON r.A Θ s.B Abbildung 6.2: Umsetzung von Operationen der relationalen Algebra in SQL % für mehrere beliebige Zeichen Als Vergleichsoperator ist dabei LIKE bzw. NOT LIKE zu benutzen. Elementare Vergleiche können mit den Booleschen Operatoren AND , OR und NOT verknüpft werden. Bei den Mengenoperatoren ist bei der in der Tabelle angegebenen Form Voraussetzung, daß beide Relationen die gleiche Zahl von Attributen haben und die Folge der Wertebereiche der Attribute gleich ist (die Namen der Attribute spielen dagegen keine Rolle). Es gibt Varianten der Mengenoperationen, bei denen die Felder nicht anhand ihrer Position, sondern ihres Namens verglichen werden. Anzugeben ist hier eine Sequenz von Attributnamen; beide Relationen werden dann zuerst auf diesen Relationentyp projiziert, danach wird die Mengenoperation ausgeführt. Einführung in SQL 141 Bei der Vereinigung werden Duplikate eliminiert; will man dies verhindern, muß man den Operator UNION ALL verwenden. Der Operator NATURAL JOIN für den natürlichen Verbund ist erst seit SQL2 verfügbar. Ansonsten kann der natürliche Verbund natürlich auch “von Hand” wie folgt nachgebildet werden: SELECT DISTINCT r.A1, .., r.Ak, B1, .., Bm, C1, .., Cn FROM r, s WHERE r.A1=s.A1 AND ... AND r.Ak=s.Ak wenn r die Attribute A1, ..., Ak, B1, ..., Bm und s die Attribute A1, ..., Ak, C1, ..., Cn hat. In der WHERE -Klausel werden die gemeinsamen Attribute durch lange Attributnamen identifiziert. Auch in der SELECT -Klausel müssen die langen Namen verwendet werden, obwohl die Werte in beiden Relationen gleich sind. Äußere Verbunde. Der linke, rechte bzw. beidseitige äußere Verbund kann in den folgenden Notationen aufgerufen werden: SELECT * FROM r LEFT JOIN s ON verbundbedingung SELECT * FROM r RIGHT JOIN s ON verbundbedingung SELECT * FROM r FULL JOIN s ON verbundbedingung Tupelvariablen. Schon bei der relationalen Algebra haben wir das Problem identifiziert, daß bei Abfragen, die ein Kreuzprodukt einer Relation mit sich selbst erfordern, die Attribute einer der Relationen oder diese Relation insgesamt umbenannt werden muß. SQL bietet als entsprechendes Konstrukt Tupelvariablen an. Als Beispiel betrachten wir die Suche nach denjenigen Kunden, die ein größeres Kreditlimit als der Kunde mit Nummer 185432 haben. Die Lösung ist: SELECT T.Kundenname FROM kunden S, kunden T WHERE S.Kundennummer = 185432 AND T.Kreditlimit > S.Kreditlimit 142 Einführung in SQL Umbenennung von ausgegebenen Attributen. In der SELECT Klausel kann jedes ausgegebene Attribut umbenannt werden. Beispiel: SELECT Kundenname AS Name, Wohnort AS Ort FROM kunden Genutzt werden kann diese Möglichkeit z.B. dazu, die Anzeige von Tabellen durch Standardanzeigewerkzeuge zu beeinflussen oder um ähnliche Tabellen in Mengenoperationen verarbeiten zu können. Aggregierte Werte (s.u.), die zunächst keinen Namen haben, können so benannt werden. Geschachtelte Abfragen. Die Abarbeitung einer SQL-Abfrage kann man sich so vorstellen, daß für jede Kombination der Tupel in den Eingaberelationen die Bedingung in der WHERE -Klausel geprüft wird; falls die Kombination der Eingabetupel die Bedingung erfüllt, werden die in der SELECT -Klausel angegebenen Attribute ausgegeben. Für eine bestimmte Kombination der Eingabetupel kann auch eine innere Abfrage gebildet werden wie im folgenden Beispiel: SELECT * FROM kunden WHERE Kreditlimit > 10000 AND Kundennummer IN (SELECT Kundennummer FROM lieferungen WHERE Betrag > 2000) Es werden hier diejenigen Kunden angezeigt, deren Kreditlimit größer als 10000 ist und die schon einmal eine Lieferung im Wert von über 2000 Euro bekommen haben. Der Operator IN prüft dabei, ob ein angegebenes Tupel in der angegebenen Relation enthalten ist. Das Attribut Kundennummer steht dabei für ein Tupel mit einem Attribut. Der Operator NOT IN steht für den Test auf Nicht-Enthaltensein. Es sind auch längere Tupel möglich, dann sind die Attribute in spitzen Klammern durch Komma getrennt aufzulisten, wie in folgendem Schema: Einführung in SQL 143 WHERE < A1, A2, ... > IN (SELECT A1, A2, .... FROM .... WHERE .... ) SOME- und ALL-Operatoren. Ein allgemeinere Version des Enthaltenseinstests stellen die SOME-Operatoren dar. Der Operator > SOME testet, ob der angegebene Wert größer als irgendein Tupel in der angegebenen Relation ist. Analog arbeiten weitere SOME-Operatoren für ≥, <, ≤, =, 6=. Analog zu den SOME-Operatoren gibt es entsprechende ALL-Operatoren, bei denen geprüft wird, ob alle Werte in der angegebenen Relation größer, kleiner usw. als der Vergleichswert sind. Sortierung der Ausgabetabelle. Mithilfe der ORDER BY -Klausel kann die Ausgabetabelle nach einem oder mehreren Attributen sortiert werden. Pro Attribut kann eine aufsteigende (Schlüsselwort ASC ; Vorgabe) oder fallende (Schlüsselwort DESC ) Sortierreihenfolge gewählt werden. Beispiel: SELECT * FROM lieferungen ORDER BY Kundennummer ASC, Datum DESC Die Attribute, nach denen sortiert wird, müssen ausgegebene Attribute gemäß der SELECT -Klausel sein. 6.2.3 Gruppierungen und Aggregationen Vielfach will man die Tupel einer Relation anhand bestimmter Attributwerte gruppieren und die so entstehenden Gruppen zählen oder bestimmte Attributewerte innerhalb der Gruppe aufsummieren. Hierzu ein Beispiel: wir möchten für unsere Beispieldatenbank für jeden Kunden folgendes wissen: – die Anzahl der Lieferungen, die an ihn gegangen sind, und – den Gesamtwert der Lieferungen Gesucht ist also eine Abfrage, die eine Relation mit drei Spalten liefert: dem Kundennamen (oder die Nummer) und die beiden vorstehenden Angaben. 144 Einführung in SQL Die Zahl der Lieferungen an einen bestimmten Kunden ist gerade die Zahl der lieferungen-Tupel, die sich auf diesen Kunden beziehen. Wenn X die Kundennummer eines Kunden ist, dann könnten wir diese Tupelmenge mit der Abfrage SELECT * FROM lieferungen WHERE Kundennummer = X bestimmen. Man könnte nun auf die Idee kommen, irgendwie in einer Schleife alle auftretenden Kundennummern zu durchlaufen, jedesmal diese Abfrage zu starten und die Ergebnismenge zu zählen bzw. die Werte im Attribut Betrag aufzusummieren und die Ergebnistabelle zeilenweisen irgendwie zusammenzusetzen. Das ist eine typische prodedurale Denkweise; würden die Daten als Java-Laufzeitobjekte vorliegen und müßten wir ein imperatives Programm schreiben, das die gewünschten Angaben berechnet, wäre diese Denkweise durchaus in Ordnung. In relationalen Sprachen ist diese Denkweise ein typischer Anfängerfehler und zum Scheitern verurteilt: relationale Sprachen sind nichtprozedural, Schleifen sind nicht vorgesehen und werden sinngemäß durch andere Konstrukte ersetzt. In der Tat können die oben erwähnten Zählungen und Summierungen überhaupt nicht mit den Mitteln der relationalen Algebra oder äquivalenter Sprachkonstrukte in SQL realisiert werden. SQL bietet aber mit der GROUP BY-Klausel und weiteren Sprachkonstrukten eine Lösungsmöglichkeit. Unsere Aufgabe können wir in SQL wie folgt lösen: SELECT Kundennummer, COUNT(*), SUM(Betrag) FROM lieferungen GROUP BY Kundennummer Die GROUP BY-Klausel verändert die Bedeutung der SELECTAnweisung wie folgt: 1. Zunächst werden wie üblich Kreuzprodukte bzw. Verbunde gebildet, sofern mehrere Relationen in der FROM-Klausel angegeben sind, und die resultierenden Tupel gemäß der WHERE-Klausel, sofern vorhanden, selektiert. 2. Die verbleibenden Tupel werden in Gruppen eingeteilt. Das Attribut, das in der GROUP BY-Klausel angegeben wird, wird i.f. Grup- Einführung in SQL 145 pierungsattribut genannt. Für jeden Wert X, der im Gruppierungsattribut auftritt, wird eine Gruppe gebildet. Zu dieser Gruppe gehören alle Tupel, die den Wert X im Gruppierungsattribut haben. In unserem Beispiel wird also für jede auftretende Kundennummer eine Gruppe gebildet, die gerade die Lieferungstupel mit dieser Kundennummer enthält. Wenn mehrere Gruppierungsattribute angegeben werden, wird analog zu jeder Kombination von Werten in den Gruppierungsattributen eine Gruppe gebildet. 3. Für jede Gruppe (und nicht etwa für jedes Eingabetupel!) wird genau ein Tupel ausgegeben. Als Ausgabeattribute bzw. -Werte sind erlaubt: – Gruppierungsattribute - deren Wert ist nach Konstruktion bei allen Tupeln in der Gruppe gleich; Attribute, die keine Gruppierungsattribute sind, sind dagegen nicht zulässig, denn deren Wert kann in der Gruppe verschieden sein, d.h. es ist unklar, welcher der auftretenden Werte ausgegeben werden soll; – Aggregationsoperatoren Die Liste der Aggregationsoperatoren ist: COUNT: Anzahl AVG: Durchschnitt MIN: Minimum MAX: Maximum SUM: Summe Bei den numerischen Aggregationsoperatoren (alle außer COUNT) ist als Argument ein numerisches Attribut anzugeben. In die angegebene Operation werden alle Attributwerte einbezogen, die nicht NULL sind. Der Operator COUNT zählt die Tupel; als Argument muß entweder ein Attribut angegeben werden, dann zählt COUNT die Tupel, bei denen dieses Attribut nicht NULL ist, oder * , dann zählt COUNT alle Tupel. In unserer obigen Musterlösung erzeugt also COUNT (*) die Zahl der Lieferungen eines Kunden und SUM(Betrag) den Gesamtwert aller Lieferungen. 146 Einführung in SQL Sofern die GROUP BY -Klausel fehlt und trotzdem in der SELECTKlausel ein Aggregationsoperator benutzt wird, bildet die ganze Relation eine einzige Gruppe. So kann man z.B. durch die Abfrage SELECT count(*) FROM r die Zahl der Tupel der Relation r gezählt werden. Da pro Gruppe nur ein Tupel ausgegeben wird, wird hier nur eine einzige Zahl ausgegeben. Aggregation und Verbunde. Wenn wir im obigen Beispiel nicht nur die Kundennummer, sondern auch die Kundennamen ausgeben wollen, müssen wir einen Verbund mit der Relation kunden bilden und die Lösung wie folgt modifizieren: SELECT lieferungen.Kundennummer, Kundenname, COUNT(*), SUM(Betrag) FROM lieferungen NATURAL JOIN kunden GROUP BY lieferungen.Kundennummer, Kundenname Zunächst unmotiviert wirkt hier, daß auch das Attribut Kundenname als Gruppierungsattribut angegeben wird. Die Gruppen werden durch dieses zusätzliche Attribut nicht kleiner, weil innerhalb jeder Gruppe der Kundenname gleich ist. Dieses Wissen fehlt dem SQL-Prozessor aber im allgemeinen Fall, daher müssen alle auszugebenden Attribute in der GROUP BY -Klausel angegeben werden. Es sei noch darauf hingewiesen, daß die obige Musterlösung für diejenigen Kunden, die noch keine Lieferung bekommen haben, gar kein Tupel enthält, also auch kein Tupel, das in der 3. und 4. Spalte eine Null enthält. Sind derartige Aufgabetupel für die “leeren Gruppen” gewünscht, muß der natürliche Verbund durch einen äußeren Verbund (im vorliegenden Fall reicht der rechte äußere Verbund) ersetzt werden, ferner COUNT(*) durch COUNT(Kundenname) , damit die Tupel, die durch den äußeren Verbund mit Nullerwerten erzeugt werden, nicht mitgezählt werden. Bedingungen mit aggregierten Werten. Angenommen, wir suchen die Kunden, die schon im Wert von über 10.000 Euro gekauft haben. Die Summe der bisherigen Käufe können wird zwar in Einführung in SQL 147 der SELECT -Klausel mit SUM(Betrag) ausgeben, nicht hingegen in der WHERE -Klausel für Selektionsbedingungen ausnutzen. Wie schon erwähnt wird die WHERE -Klausel vor der Gruppierung ausgewertet; Aggregationsoperatoren können daher in der WHERE -Klausel nie auftreten. Um die ausgegebenen Tupel, die jeweils einer Gruppe entsprechen, zu selektieren (und nicht etwa die Eingabetupel), bietet SQL die HAVING -Klausel an: SELECT Kundennummer, SUM(Betrag) FROM lieferungen GROUP BY Kundennummer HAVING SUM(Betrag) > 10000 Schachtelungen von Aggregationsoperatoren. Diese sind nicht erlaubt, stattdessen muß auf eine Ersatzkonstruktion ausgewichen werden. Wenn wir z.B. den oder die Kunden mit dem maximalen Gesamtumsatz suchen, können wir nicht HAVING SUM(Betrag) = MAX(SUM(Betrag)) als Bedingung angeben. Stattdessen muß eine eingeschachtelte Abfrage benutzt werden: SELECT Kundennummer, SUM(Betrag) FROM lieferungen GROUP BY Kundennummer HAVING SUM(Betrag) >= ALL (SELECT SUM(Betrag) FROM lieferungen GROUP BY Kundennummer) 6.3 6.3.1 Änderungsoperationen Erzeugen von Tupeln Tupel können mit dem INSERT-Kommando erzeugt werden, z.B.: INSERT INTO kunden VALUES (131415, "Groll, Renate", "Bamberg", 12000) 148 Einführung in SQL In der VALUES-Klausel müssen die Attributwerte des zu erzeugenden Tupels in der Reihenfolge gemäß der Definition des Relationentyps angeordnet sein. Alternativ kann die Reihenfolge der Attribute auch explizit bestimmt werden: INSERT INTO kunden (Kundenname, Wohnort, Kundennummer, Kreditlimit) VALUES ("Groll, Renate", "Bamberg", 131415, 12000 ) Es ist auch möglich, nur eine Teilmenge der Attribute anzugeben. Für die fehlenden Attribute werden Nullwerte oder Vorgabewerte eingesetzt; dies kann bei der Definition des Relationentyps festgelegt werden. Eine Variante des INSERT-Kommandos ermöglicht es, Tupel, die aus anderen Relationen als Ergebnis einer Abfrage bestimmt worden sind, einzufügen, also zu kopieren. Beispiel: INSERT INTO lieferungen (Kundennummer, Lieferadresse, Betrag, Datum) SELECT Kundennummer, Wohnort, 100, 24.12.2000 FROM kunden WHERE Kreditlimit > 10000 Dieses Kommando fügt in die Relation lieferungen für alle Kunden, die ein Kreditlimit von über 10000 Euro haben, eine Weihnachtslieferung im Wert von 100 Euro ein. 6.3.2 Löschen von Tupeln Die Grundform des Löschkommandos ist DELETE FROM r WHERE B Dabei ist B eine Bedingung wie bei der SELECT-Anweisung. Der Effekt der Anweisung besteht darin, daß die Tupel, die die Bedingung B erfüllen, in der Relation r gelöscht werden. Wenn die WHERE-Klausel fehlt, werden alle Tupel gelöscht, die anschließend leere Relation besteht weiter. In der FROM-Klausel kann immer nur eine Relation ange- Einführung in SQL 149 geben werden. Wenn man in mehreren Relationen Tupel löschen will, muß man pro Relation ein eigenes Löschkommando abgeben. Einige Beispiele: – Löschen des Kunden mit Kundennummer 131415: DELETE FROM kunden WHERE Kundennummer = 131415 – Löschen aller Lieferungen an den Kunden mit Kundennummer 131415 DELETE FROM lieferungen WHERE Kundennummer = 131415 – Löschen aller Kunden, die noch keine Lieferung bekommen haben DELETE FROM kunden WHERE 0 = (SELECT COUNT (*) FROM lieferungen WHERE kunden.Kundennummer = lieferungen.Kundennummer ) Probleme können bei eingeschachtelten SELECT-Anweisungen auftreten. Betrachten wir hierzu folgendes Beispiel: DELETE FROM kunden WHERE Kreditlimit < (SELECT AVG(Kreditlimit) FROM kunden ) Dieses Kommando soll diejenigen Kunden löschen, deren Kreditlimit unter dem durchschnittlichen Kreditlimit liegt. Wenn man nun alle Tupel der Relation der Reihe nach durchläuft und jedesmal die innere SELECT-Anweisung neu berechnet, werden zu viele Tupel gelöscht: wenn die ersten Tupel mit kleinem Kreditlimit gelöscht worden sind, steigt das durchschnittliche Kreditlimit an, so daß bei späteren Auswertungen der Löschbedingung ein höherer Vergleichswert benutzt wird. Eine Lösung des Problems kann darin bestehen, Tupel während der Abarbeitung des DELETE-Kommandos nicht wirklich zu löschen, 150 Einführung in SQL sondern nur als zu löschend zu markieren und die tatsächliche Löschung erst am Ende, also nach Auswertung aller inneren SELECTAnweisungen, vorzunehmen. Eine andere, einfachere Lösung besteht darin, solche Löschkommandos gar nicht zuzulassen. 6.3.3 Ändern von Tupeln Mit Hilfe des UPDATE-Kommandos kann man einzelne Attributwerte ändern. Die restlichen Attribute der betroffenen Tupel bleiben unverändert. Als Beispiel betrachten wir die Erhöhung der Kreditlimits aller Siegener Kunden um 50 %: UPDATE kunden SET Kreditlimit = Kreditlimit * 1.5 WHERE Wohnort = "Siegen" In der WHERE-Klausel sind eingeschachtelte SELECT-Anweisungen erlaubt, allerdings dürfen sich diese nicht auf die geändert werdende Relation beziehen. 6.4 Nullwerte Wenn man beim Einfügen von Tupeln nur eine Teilmenge aller Attribute angibt und bei den übrigen Attributen keine Vorgabewerte definiert sind, erhalten diese als Wert den Nullwert. Das gleiche passiert, wenn Tupel über Sichten, die als Projektion definiert sind (s. Abschnitt 6.5.3), eingefügt werden. Neben diesen technischen Gründen ist eine weitere Ursache für Nullwerte, daß die tatsächlichen Werte (noch) nicht bekannt oder anwendbar sind. Betrachten wir hierzu das Attribut Kreditlimit der Relation kunden: – Manche unserer Kunden sind Laufkundschaft; sie bezahlen immer bar. Das Attribut Kreditlimit ist für sie sinnlos. – Für Kunden, die beantragen, bei uns auf Kredit kaufen zu können, holen wir zuerst eine Bankauskunft ein. Solange die Bankauskunft nicht vorliegt, kann das Kreditlimit nicht festgelegt werden. Angenommen, wir hätten ein weiteres Attribut DatumBankauskunft, Einführung in SQL 151 das das Datum der Bankauskunft enthält. Solange hier kein Datum steht, wäre das Attribut Kreditlimit nicht anwendbar. – Selbst nach Vorliegen der (positiven) Bankauskunft muß erst der Chef das Kreditlimit konkret festlegen; solange er dies nicht getan hat, ist der Kunde zwar kreditwürdig, aber sein Kreditlimit noch unbekannt. Man könnte in allen vorstehenden Fällen den Wert des Attributs Kreditlimit auf 0,00 setzen, allerdings wären die drei vorstehenden Fälle und der vierte Fall, daß bei dem Kunden trotz positiver Bankauskunft das Kreditlimit vorerst auf 0,00 gesetzt wird, nicht unterscheidbar. Um die vorstehenden Fälle sauber unterscheiden zu können, bräuchte man eigentlich drei verschiedene Nullwerte. Eigentlich müßte man eher von Nichtanwendbarkeits- oder Unbekannt-Werten (oder -Anzeigen) reden, dies sind keine wirklichen Werte aus den Wertebereich der Attribute. SQL unterstützt genau einen Nullwert. Man muß somit alle eigentlich unterschiedlichen Nichtanwendbarkeits- oder Unbekannt-Werte auf diesen einen Nullwert abbilden, verliert also Information. Nullwerte sind daher und aus anderen Gründen problematisch. Der Nullwert kann mit dem Schlüsselwort NULL explizit gesetzt werden. Beispiel: INSERT INTO kunden VALUES (131415, "Groll, Renate", "Bamberg", NULL) Wenn zwei Tupel in einem Attribut beide den Wert NULL haben, bedeutet das nicht, daß beide den gleichen Wert in diesem Attribut haben. Der Wert ist in diesem Fall schlicht unbekannt, mit sehr hoher Wahrscheinlichkeit aber verschieden. Das gleiche gilt bei einem Vergleich mit einer Konstanten. Das Resultat eines Vergleichs mit einem Nullwert wird daher so definiert, daß immer ein negatives Ergebnis geliefert wird. Eigentlich ist das falsch, eigentlich kann man das Resultat gar nicht exakt bestimmen, weil man den oder die Vergleichswerte gar nicht kennt. Die negativen Vergleichsresultate führen zu unerwarteten Effekten. Bei der folgenden Abfrage 152 Einführung in SQL SELECT * FROM r WHERE A > 0 OR A =< 0 ist die Bedingung in der WHERE-Klausel mathematisch gesehen eine Tautologie, und man könnte glauben, es würde somit die gesamte Relation r zurückgeliefert. Dies trifft nicht zu, die Tupel, bei denen der Wert von A NULL ist, fehlen im Ergebnis. Ob der Nullwert vorliegt, kann wie folgt getestet werden: SELECT * FROM r WHERE A IS NULL Analog testet IS NOT NULL , ob kein Nullwert vorliegt. Bei den Aggregationsoperatoren außer COUNT zählen Tupel, die bei dem relevanten Attribut den Wert NULL haben, überhaupt nicht mit, d.h. der aggregierte Wert wird auf Basis der übrigen Tupel gebildet. Der wirkliche aggregierte Wert ist natürlich unbekannt, der angegebene ist wahrscheinlich der richtige oder er liegt nahe beim richtigen Wert. Wenn man sich dieses Sachverhalts oder der Anwesenheit der Nullwerte nicht bewußt ist, können die ausgegebenen Zahlen falsch interpretiert werden. 6.5 Schema-Operationen Ein Schema in SQL umfaßt Angaben aus mehreren Bereichen, neben der Definition von Relationen und Sichten z.B. auch Angaben zur Autorisierung. Wir gehen hier nur auf die Definition von Relationen und Sichten ein. Eine Relation wird in SQL als Tabelle (table) bezeichnet, ein Attribut als (Tabellen-) Spalte (column) und ein Tupel als Zeile (row). In einer Datenbank kann es mehrere Schemata geben; diese werden im Katalog verwaltet. Bestimmte Teile der Schemata, z.B. Bereichsdefinitionen, können in mehreren Schemata eines Katalogs wiederverwendet werden. Bei den folgenden Syntaxdefinitionen verwenden wir Großbuchstaben für die Schlüsselworte (Kleinschreibung ist auch zulässig) und Kleinbuchstaben für die nichtterminalen Bezeichner. Einführung in SQL 6.5.1 153 Definition von Relationen Tabellen werden mit dem Kommando CREATE TABLE erzeugt. Vereinfacht (ohne Berücksichtigung diverser Optionen) hat es folgenden Aufbau: CREATE TABLE table-name ( list-of-table-elements ) Als Beispiel betrachten wir die Definition unserer Relation kunden: CREATE TABLE kunden ( Kundennummer DECIMAL(6) NOT NULL, Kundenname CHAR(20), Wohnort CHAR(15), Kreditlimit DECIMAL(9,2), PRIMARY KEY (Kundennummer) ) Ein Element der Tabellendefinition ist eine Attributdefinition oder eine Integritätsbedingung. Die Definition unserer Relation kunden enthält vier Attributdefinitionen und eine Integritätsbedingung. Die einzelnen Elemente werden durch ein Komma voneinander getrennt. 6.5.1.1 Attributdefinitionen Im obigen Beispiel ist zu jedem Attributnamen ein Wertebereich angegeben. Die Denkwelt für diese Wertebereichs- bzw. Typangaben orientiert sich eher an Programmiersprachen wie COBOL als an Pascal oder C. Dies ist kein Zufall, da diese Sprachen bei betrieblichen Anwendungen als Gastsprachen nach wie vor dominieren. Als Datentypen stehen u.a. zur Verfügung: CHAR(l ) oder CHARACTER (l ): Zeichenkette mit der festen Länge l VARCHAR(l ) oder CHARACTER VARYING (l ): Zeichenkette mit einer variablen Länge, maximal aber l Zeichen DEC(l,m) oder DECIMAL (l,m): Dezimalzahlen mit l Stellen vor dem Komma und m Stellen hinter dem Komma 154 Einführung in SQL INT oder INTEGER, SMALLINT FLOAT, REAL, DOUBLE PRECISION: diverse Fließkomma-Formate DATE, TIME, INTERVAL u.a.: diverse Formate für Datum und Uhrzeit Die Angabe NOT NULL schließt Nullwerte bei diesem Attribut aus. Durch eine Angabe DEFAULT wert kann ein Vorgabewert spezifiziert werden. Als Vorgabewert kann auch NULL spezifiziert werden. Ein einzelner Wertebereich kann auch explizit mit einem Namen versehen werden und dann in verschiedenen Relationen benutzt werden. Als Beispiel führen wir dies für das Attribut Kundennummer durch: CREATE DOMAIN Kundennummertyp AS DECIMAL(6) NOT NULL; CREATE TABLE kunden ( Kundennummer Kundennummertyp, ..... ) Die Definition eines Attributs innerhalb der Definition einer Tabelle hat insg. folgende Struktur: column-name { data-type | domain } [ DEFAULT { wert | NULL } ] [ list-of-column-constraints ] 6.5.1.2 Definition von Integritätsbedingungen SQL bietet sehr umfangreiche Konzepte zur Integritätssicherung. Wir stellen hier nur Möglichkeiten zur Definition von Schlüsseln vor. Identifizierungsschlüssel. gabe Eine Attributmenge kann durch die An- UNIQUE ( list-of-column-names ) als Identifizierungsschlüssel definiert werden. Sofern diese Attributmenge einelementig ist, kann die Schlüsseleigenschaft auch direkt bei Einführung in SQL 155 der Attributdefinition durch das Schlüsselwort UNIQUE angegeben werden. Sofern ein Identifizierungsschlüssel angegeben ist, muß auch ein Primärschlüssel angegeben werden. Nullwerte sind in Identifizierungsschlüsseln erlaubt. Es kann sogar mehrere Tupel geben, die den Wert NULL in einem oder mehreren Attributen des Identifizierungsschlüssels haben. Es wird hier unterstellt, daß die wirklichen Werte alle verschieden sind. Primärschlüssel. Eine Attributmenge kann durch die Angabe PRIMARY KEY ( list-of-column-names ) als Primärschlüssel definiert werden; implizit wird die Attributmenge damit gleichzeitig als Identifizierungsschlüssel definiert. Es kann mehrere Identifizierungsschlüssel, aber nur einen Primärschlüssel geben (vgl. Lehrmodul 4). Wie schon erwähnt ist die Spezifikation eines Primärschlüssels eine Frage, die in der 3-Ebenen-Schema-Architektur dem internen Schema zuzuordnen ist. M.a.W. werden hier Angaben zum konzeptuellen und zum internen Schema der Datenbank vermengt. In den Attributen eines Primärschlüssels sind Nullwerte nicht erlaubt. Fremdschlüssel. Ein Fremdschlüssel wird wie folgt angegeben: FOREIGN KEY ( list-of-column-names ) REFERENCES table-name [ ( list-of-column-names ) ] In unserer Relation lieferungen war z.B. das Attribut Kundennummer ein Fremdschlüssel für das Attribut Kundennummer in der Relation kunden. In SQL wird dies wie folgt notiert: CREATE TABLE lieferungen ( Kundennummer Kundennummertyp, ..... FOREIGN KEY ( Kundennummer ) REFERENCES kunden; ); 156 Einführung in SQL Die Liste der Attributnamen hinter dem Schlüsselwort REFERENCES braucht nur dann angegeben zu werden, wenn dort Attribute mit anderen Namen referenziert werden sollen. Bei einer einelementigen Attributmenge kann die Fremdschlüsseleigenschaft auch innerhalb der Attributdefinition angegeben werden, z.B.: CREATE TABLE lieferungen ( Kundennummer Kundennummertyp REFERENCES kunden, ..... ); Nach dem Einrichten eines Fremdschlüssels verhindert das DBMS “defekte Referenzen”, also Wertekombinationen in den Fremdschlüsselattributen in der referenzierenden Relation, die in der referenzierten Relation nicht auftreten. Eine Einfüge- oder Änderungsoperation in der referenzierenden Relation, die zu einer defekten Referenz führen würde, wird vom DBMS mit einer Fehlermeldung abgebrochen. Defekte Referenzen können auch durch Löschungen oder Änderungen in der referenzierten Relation entstehen; hier sind verschiedene Reaktionen sinnvoll und durch zusätzliche Optionen in der FOREIGN KEY-Klausel wählbar. Bei einer Löschung gibt es folgende Optionen: 1. NO ACTION: Der Löschversuch wird abgelehnt, das Tupel nicht gelöscht. Dies ist die Voreinstellung. Bei allen folgenden Alternativen wird das zu löschende Tupel tatsächlich gelöscht. 2. CASCADE: Alle Tupel in der referenzierenden Tabelle, die das gelöschte Tupel referenzieren, werden ebenfalls gelöscht. Würde man also in der Relation kunden ein Kundentupel löschen, würden implizit auch alle Lieferungstupel für diesen Kunden in der Relation lieferungen gelöscht. Die implizit gelöschten Tupel könnten ihrerseits Ziel von Referenzen aus einer dritten Relation sein. Beispielsweise könnten wir eine weitere Relation haben, die zu jeder Lieferung die einzelnen gelieferten Posten angibt und die einen Fremdschlüssel auf ein zusätzliches Attribut Lieferscheinnummer in lieferungen enthält. Wenn dieser Fremdschlüssel ebenfalls mit der Option CASCADE an- Einführung in SQL 157 gegeben wäre, würden beim Löschen eines Kunden auch alle Lieferposten aller seiner Lieferungen gelöscht werden. 3. SET NULL: In der referenzierenden Tabelle werden die entstehenden defekten Referenzen auf NULL gesetzt. Diese Option ist nur zulässig, wenn die Attribute des Fremdschlüssels nicht als NOT NULL definiert sind. 4. SET DEFAULT: In der referenzierenden Tabelle werden die Attribute in den entstehenden defekten Referenzen auf ihren jeweiligen Vorgabewert gesetzt. Diese Option ist nur zulässig, wenn für diese Attribute Vorgabewerte definiert worden sind. Mit dem Schlüsselwort ON DELETE kann das gewünschte Verhalten bei Löschungen angegeben werden. Beispiel: CREATE TABLE lieferungen ( Kundennummer Kundennummertyp, ..... FOREIGN KEY ( Kundennummer ) REFERENCES kunden ON DELETE CASCADE ); Das Verhalten bei Änderungen muß separat angegeben werden, und zwar mit dem Schlüsselwort ON UPDATE. Die wählbaren Alternativen sind die gleichen wie bei Löschungen, allerdings bekommt CASCADE eine andere Bedeutung: Alle Tupel in der referenzierenden Tabelle, die das geänderte Tupel referenzieren, werden passend mitgeändert, so daß die damit ausgedrückte Beziehung erhalten bleibt. 6.5.2 Änderung der Definition einer Relation Nachdem eine Relation einmal erzeugt und mit Daten gefüllt worden ist, können auch noch nachträglich Details der Definition geändert werden. Hierzu dient das ALTER -Kommando: ALTER TABLE table-name { ADD [column] column-name data-type | ALTER [column] column-name { DROP DEFAULT | SET default-definition } 158 Einführung in SQL | ADD [CONSTRAINT constraint-name] { UNIQUE ( list-of-column-names ) | PRIMARY KEY ( list-of-column-names ) | FOREIGN KEY ( list-of-column-names ) REFERENCES table-name [ ( .... ) ] | ..... } | DROP CONSTRAINT constraint-name } Mit dem DROP -Kommando können Domänen, Tabellen, Sichten und ganze Schemata gelöscht werden. 6.5.3 Sichten Eine Sicht (view) (s. Lehrmodul 1) ist eine virtuelle Tabelle, die aus anderen Tabellen abgeleitet ist. Tabellen, die keine Sichten sind, nennen wir auch Basistabellen. Im Gegensatz zu einer Basistabelle ist eine Sicht nicht physisch gespeichert, sondern wird bei jeder Benutzung dynamisch berechnet. Definiert wird eine Sicht mit dem CREATE VIEW -Kommando: CREATE VIEW view-name [ ( list-of-column-names ) ] AS select-expression Die Sicht wird hauptsächlich durch eine Abfrage (die SELECT-expression ) bestimmt. In dieser Abfrage können wiederum Sichten in der FROM-Klausel benutzt werden. Glossar Aggregation (im Kontext von SQL): Ausgabe auf Basis von Gruppen von Tupeln; je eine Gruppe bilden die Tupel, die in den sog. Gruppierungsattributen gleiche Werte haben; ausgegeben wird pro Gruppe nur ein Tupel, dessen Attribute können sein: a. Gruppierungsattribute, b. über die Gruppe aggregierte Werte, insb. Zählungen und für ein bestimmtes Attribut Summe, Minimum, Maximum und Durchschnitt der Werte, die in der Gruppe auftreten Einführung in SQL 159 Katalog: Teil der Datenbank, in dem die Schemata repräsentiert werden Nullwert: spezieller Wert eines Attributs, der ausdrückt, daß der Wert nicht angegeben werden kann, z.B. weil der wirkliche Wert (noch) nicht bekannt ist, das Attribut bei diesem Tupel nicht sinnvoll anwendbar ist oder sonstige Gründe vorliegen Sicht (im Kontext von SQL) (view ): virtuelle Tabelle, die mittels einer Abfrage definiert wird SQL: von der ISO und anderen Standardisierungsinstitutionen in mehreren Varianten definierte Sprache für relationale Datenbanken Lehrmodul 7: Implementierung relationaler Operationen Zusammenfassung dieses Lehrmoduls Aus der formalen Definition der relationalen Operationen ergeben sich unmittelbar triviale Implementierungen. Diese sind in vielen Fällen sehr ineffizient, besonders bei Selektionen und Verbunden. Dieses Lehrmodul stellt effizientere Implementierungen vor; meist werden hierbei Primär- oder Sekundärindexe ausgenutzt. Vorausgesetzte Lehrmodule: obligatorisch: – Das relationale Datenbankmodell Stoffumfang in Vorlesungsdoppelstunden: Stand: 30.11.2002 0.8 c 2002 Udo Kelter Implementierung relationaler Operationen 7.1 161 Einleitung Die Bedeutung der relationalen Operationen kann in sehr präziser, aber dennoch abstrakter Weise unter Benutzung mathematischer Begriffe (insb. der Mengenlehre) definiert werden, s. Lehrmodul 4. Diese Definitionen kann man auch direkt in triviale Implementierungen umsetzen. Man erkennt aber leicht, daß diese trivialen Implementierungen teilweise extrem ineffizient und daher inpraktikabel sind. In diesem Lehrmodul betrachten wir effizientere Implementierungen; diese beruhen teilweise auf Indexen. Wir betrachten hier nur die Implementierung einzelner relationaler Operationen; die Abarbeitung komplexer algebraischer Ausdrücke wird in einem separaten Lehrmodul behandelt Lehrmodul 8. Ferner betrachten wir nur die wichtigsten Operationen der relationalen Algebra, wir konzentrieren uns auf Selektionen und Verbunde. Dieses Lehrmodul erhebt nicht den Anspruch, die enorme Vielfalt an Optimierungsmöglichkeiten und Indexstrukturen auch nur annähernd zu repräsentieren. Ziel ist es vielmehr, anhand der simplen Optimierungstechniken zu zeigen, welche Größenordnung des Rechenaufwands für die relationalen Operationen erreichbar ist. 7.2 Triviale Implementierungen Die mathematischen Definitionen der relationalen Operationen können unmittelbar in die folgenden “trivialen” Implementierungen umgesetzt werden. Wir bestimmen noch jeweils den Aufwand unter der Annahme, daß die betroffenen Relationen n bzw. m Tupel enthalten. Selektion: Man durchläuft alle Tupel einer Relation, wertet jedesmal das Selektionsprädikat aus und gibt ggf. das Tupel aus. Der Aufwand hat die Größenordnung O(n). Wenn A Identifikationsschlüssel ist, muß bei einer Selektionsbedingung der Form σA=x im Durchschnitt die halbe Relation durchlaufen werden, bis das gesuchte Tupel gefunden ist, sofern alle vorhandenen Schlüsselwerte gleichhäufig gesucht werden. Bei großen Relationen ist 162 Implementierung relationaler Operationen dies sehr ineffizient. Projektion: Man durchläuft alle Tupel einer Relation und gibt die gewünschten Attribute aus. Der Aufwand hierfür ist exakt n, die Relation muß komplett durchlaufen werden. Wenn zusätzlich eine Duplikateliminierung verlangt ist, muß die Ergebnismenge sortiert werden (zusätzlicher, insg. dominierender Aufwand in der Größenordnung O(n*log(n))). Wenn die Projektionsattribute einen Identifizierungsschlüssel enthalten, können natürlich keine Duplikate auftreten, und eine Duplikateliminierung ist überflüssig. Mengenoperationen: Die Algorithmen für die Mengenoperationen sind ebenfalls trivial. Sofern die Mengen schon geeignet sortiert sind, ist der Aufwand linear, ansonsten kommt der Aufwand für die Sortierung hinzu. Kreuzprodukt: Man durchläuft geschachtelt beide Relationen und gibt jeweils die Konkatenation der beiden aktuellen Tupel aus. Der Aufwand hat die Größenordnung O(n*m), wenn n bzw. m die Zahl der Tupel in den beiden Relationen ist. Verbunde: Man kann den Verbund auf ein Kreuzprodukt, gefolgt von einer Selektion und einer Projektion zurückführen (s. Abschnitt 4.3.6.2). Den größten Aufwand darin wird i.a. das Kreuzprodukt verursachen. Diese trivialen Implementierungen sind, wie die vorstehenden Größenordnungsangaben für den Aufwand zeigen, oft sehr ineffizient. Dies gilt vor allem für die Verbundbildung. I.f. besprechen wir daher diverse Optimierungsmaßnahmen für die einzelnen Operationen. Optimierungsziele. Vorrangiges Optimierungsziel bei der Implementierung der elementaren Operationen ist eine möglichst geringe Zahl von Plattenzugriffen. Die CPU-Belastung spielt nur eine sekundäre Rolle. Implementierung relationaler Operationen 7.3 163 Exkurs: Indexstrukturen Indexe spielen für effiziente Implementierungen der Selektion und des Verbunds eine große Rolle. Die Optimierungsmöglichkeiten hängen dabei stark von den Strukturen innerhalb der Indexe ab; wir geben daher vorab einen Überblick über die wichtigsten Indexstrukturen und deren Eigenschaften. 7.3.1 Primärindexe Primärindexe sind Datenstrukturen, die in die “Nutzdaten” eingebettet sind und die Primärschlüssel realisieren. Bis auf wenige Ausnahmen kann ein Datenbestand nur einen Primärindex haben. B*-Bäume. B- bzw. B*-Bäume sind bekanntlicherweise Baumstrukturen, die auf die Besonderheiten einer blockorientierten Speicherung adaptiert sind. Ihre wesentlichen Eigenschaften sind: – Die Struktur der Indexblöcke hat einen sehr hohen Verzweigungsgrad (typischerweise >10), d.h. die Zahl der Indexblöcke ist signifikant kleiner als die Zahl der Primärdatenblöcke. Die Baumstruktur hat meist nur 3 - 4 Ebenen. – Bei der Suche nach einem Satz mit gegebenem Primärschlüsselwert müssen zunächst die Indexblöcke durchlaufen werden. Wegen der geringen Anzahl können aber meist die oberen Ebenen der Struktur im Hauptspeicher gepuffert werden, d.h. hierdurch werden nur sehr wenige oder keine Blockübertragungen verursacht. – B*-Bäume ermöglichen effiziente Implementierungen von Intervallabfragen und von sequentiellen Durchläufen in steigender oder fallender Reihenfolge der Primärschlüsselwerte. – Verarbeitet man eine Menge von Sätzen in steigender oder fallender Reihenfolge ihrer Primärschlüsselwerte, so wird jeder Index- oder Primärdatenblock nur einmal von der Platte gelesen. 164 Implementierung relationaler Operationen Hash-Verfahren. Die Grundidee des Hash-Verfahrens, die zu speichernden Einheiten in einem Array zu verwalten, läßt sich direkt auf die Verhältnisse bei eine Speicherung auf Platte adaptieren: Als Array-Elemente wählt man Blöcke (bzw. Seiten), die ja ebenfalls direkt adressierbar sind. In der Regel passen mehrere Sätze in einen Block; man benötigt also noch interne Verwaltungsstrukturen innerhalb eines Blocks. Die grundlegenden Hash-Verfahren sehen bei einem Tabellenüberlauf ein komplettes Rehashing vor; im Hauptspeicher und bei kleinen Datenbeständen mag das gehen, bei großen Datenbeständen auf Platte ist dieses Vorgehen völlig unrealistisch. Beim offenen Hashing können sehr lange Überlaufketten entstehen, was ebenfalls unattraktiv ist. Eine praktikable Lösung dieses Problems besteht darin, in zwei Schritten über eine Blockadreßtabelle auf Blöcke zuzugreifen: Schlüsselwert k Hashfunktion hash(k) Blockadreßtabelle Seiten/Blöcke Abbildung 7.1: Erweiterbares Hashing 1. Schritt: Berechnung einer Position in der Blockadreßtabelle 2. Schritt: Zugriff auf den Datenblock und Durchsuchen desselben Die Blockadreßtabelle sollte ca. 100 bis 1000 Mal kleiner als die Datenbank gewählt werden und möglichst im Hauptspeicher gehalten werden. Verschiedene Einträge in der Blockadreßtabelle können auf den gleichen Datenblock verweisen, d.h. in einem Block befinden sich Sätze mit unterschiedlichem Hash-Wert. Schlecht gefüllt Datenblöcke können so vermieden werden. Die Blockadreßtabelle kann mit vertretbarem Aufwand reorganisiert werden, ohne alle Datenblöcke zu kopieren; daher nennt man dieses Verfahren auch erweiterbares Ha- Implementierung relationaler Operationen 165 shing. Auf die möglichen Varianten von Reorganisationen und die Behandlung von Blocküberläufe gehen wir hier nicht weiter ein. Der prinzipielle Vorteil von Hash-Verfahren gegenüber Suchbäumen, daß keine Indexknoten durchlaufen werden müssen, bleibt erhalten: Im Idealfall wird über den Hashwert eines vorgegebenen Primärschlüsselwerts sofort der Block gefunden, der den zugehörigen Satz enthält. Je nach der Überlaufbehandlung und der Änderungshäufigkeit im Datenbestand geht dieser Vorteil aber teilweise wieder verloren; auf Details gehen wir hier nicht ein. Hash-Verfahren unterstützen keine Intervallabfragen. 7.3.2 Sekundärindexe Sekundärindexe existieren separat vom Primärdatenbestand und unterstützen insb. auch die Suche nach nicht-identifizierenden Attributen und Attributkombinationen. Ein Sekundärindex unterstützt die Suche für eine Attributmenge A (meist ist A einelementig); A wird auch als zugehöriger Suchschlüssel bezeichnet. Konzeptuell ist der Sekundärindex eine Datenstruktur, die für jede Wertekombination der Attribute aus A eine Trefferliste liefert. Die Trefferliste enthält in irgendeiner Form Referenzen auf die Sätze, bei denen die Wertekombination der Attribute auftritt. Beispielsweise könnte es zu der Relation lieferungen einen Sekundärindex für das Attribut Kundennummer geben; der Sekundärindex würde dann die Suche nach den Lieferungen an einen Kunden unterstützen. Sekundärindexe stellen die Originaldaten in gewisser Weise umgekehrt (invertiert) dar; ein normales Tupel t enthält die Information, daß ein Attribut A den Wert x hat, ein Index zum Attribut A enthält die Information, daß der Wert x u.a. im Tupel t auftritt. Datenbestände mit Index werden daher auch invertiert genannt. Eine naheliegende Wahl für die Referenzen in den Trefferlisten sind Primärschlüsselwerte. Die Trefferliste ist dann zu durchlaufen, und für jeden Eintrag kann über den Primärindex auf den entsprechenden Satz zugegriffen werden. 166 Implementierung relationaler Operationen Aktualisierung von Sekundärindexen. Wie schon erwähnt enthalten Sekundärindexe im Prinzip redundante Daten; werden die Primärdaten geändert, müssen die Sekundärindexe entsprechend angepaßt werden. Wird z.B. beim Tupel t der Wert des Attributs A von x1 nach x2 geändert, muß im Sekundärindex für den Suchschlüssel A im Eintrag für x1 die Referenz auf t gelöscht und im Eintrag für x2 die Referenz auf t eingefügt werden. Wenn die beiden Einträge nicht zufällig in der gleichen Seite liegen, müssen also wenigstens 2 Seiten geschrieben25 und, falls sie nicht schon gepuffert waren, vorher gelesen werden. Änderungsoperationen werden also durch Sekundärindexe deutlich teurer. Bei einer hinreichend hohen Änderungshäufigkeit können sich (zu viele) Sekundärindexe daher insgesamt negativ auf die Systemleistung auswirken. 7.4 Optimierungen der Selektion Bei der Selektion können Indexe unter bestimmten Umständen vorteilhaft ausgenutzt werden. Wir müssen hierzu verschiedene Formen von Selektionsbedingungen unterscheiden: Selektionsbedingung der Form σA=x . Wenn das Attribut A der Primärschlüssel ist, kann sehr effizient mit konstantem Aufwand (also O(1)) auf den einen Treffer zugegriffen werden. Sofern ein Sekundärindex für das Attribut A vorliegt, hängt es von bestimmten Umständen ab, ob es sich lohnt, den Index auszunutzen. Der Einsatz lohnt nicht bei einer geringen Selektivität des Attributs. Um dies präziser zu fassen, benötigen wir einige Größen; sei sr der durchschnittliche Speicherplatzbedarf eines Tupels (incl. Hilfsdaten) der Relation r 25 Das Schreiben kann eine Zeitlang aufgeschoben werden, da die Indexdaten aus den Primärdaten rekonstruiert werden können. Hier bestehen komplexe Zusammenhänge mit der Transaktionsverarbeitung, auf die wir hier nicht eingehen können. Implementierung relationaler Operationen 167 b die Größe eines Blocks bf = ⌊b / sr ⌋ der Blockungsfaktor, also die Zahl der Sätze, die in einen Block passen Beispiel: mit b=4096 Bytes und sr =200 ist bf=20. |r| die Zahl der Tupel in der Relation r V(A,r) die Zahl der verschiedenen Werte, die Attribut A in Relation r annimmt Wenn man vereinfachend annimmt, daß jeder Wert des Attributs A gleichhäufig auftritt, dann liefert eine Selektion der Form σA=x ungefähr | r | / V(A,r) Tupel zurück, oder anders gesagt den V(A,r)-ten Teil der Relation r. Diesen “Verkleinerungsfaktor” bezeichnet man auch als die Selektivität des Attributs A. Wenn nun V(A,r) ≤ bf ist, die Selektivität also kleinergleich dem Blockungsfaktor ist, ist unter der Annahme, daß die Treffertupel gleichmäßig über die Blöcke verstreut liegen, in jedem Block wenigstens ein Treffertupel vorhanden, d.h. praktisch alle Blöcke müssen übertragen werden. Durch den Einsatz des Sekundärindex können dann also keine Blockübertragungen eingespart werden. Im Gegenteil führt die Benutzung des Sekundärindex zu zusätzlichen Blockübertragungen für Blöcke des Sekundärindex. Hieraus folgt - insb. wenn man zusätzlich den Änderungsaufwand für den Sekundärindex berücksichtigt -, daß Sekundärindexe für Attribute mit geringer Selektivität nicht sinnvoll sind. Selektionsbedingung der Form σA>x ∧ A<y (Intervallabfrage zum Attribut A). Sofern die internen Zugriffsmethoden auch Intervallabfragen unterstützen (z.B. bei B-Bäumen), können auch diese effizient bearbeitet werden, wobei hier der Aufwand linear von der Größe der Treffermenge abhängt. Entscheidend ist hier die kompakte (clusternde) Speicherung von Sätzen bzw. Tupeln mit aufeinanderfolgenden Schlüsselwerten innerhalb eines Blocks. Hierdurch braucht für jeweils bf Sätze nur ein Block übertragen zu werden (mit Ausnahme der “Randblöcke”). 168 Implementierung relationaler Operationen Selektionsbedingung der Form σA>x . Bei Selektionskriterien, in denen Vergleichsoperatoren wie > verwendet werden, wird unter bestimmten Gleichverteilungsannahmen im Schnitt die halbe Relation zurückgeliefert, d.h. im Sinne der vorstehenden Bemerkungen liegt eine extrem schlechte Selektivität vor. Eine wesentliche Aufwandsreduktion gegenüber dem sequentiellen Durchsuchen der Relation ist also bei >-Vergleichen durch Indexe nicht möglich. Selektionsbedingung mit mehreren Attributen und einem Index. Wenn das Selektionskriterium die Form σA=x ∧X hat und für A ein Primär- oder Sekundärindex vorhanden ist, kann die undVerknüpfung in der Selektion konzeptionell auf die Schachtelung σX (σA=x (...)) zurückgeführt werden, d.h. unter Ausnutzung des Index werden nur relativ wenige Tupel von der Platte gelesen; für diese Tupel werden dann die weiteren Bedingungen direkt überprüft. Vorteilhaft ist es in diesem Zusammenhang, wenn Tupel, die im gleichen Block liegen, hintereinander verarbeitet werden und so letztlich jeder Block nur einmal übertragen werden muß. Werden die Tupel in einem B*-Baum gespeichert, so kann man dies erreichen, indem man die Tupel nach ihren Primärschlüsselwerten sortiert verarbeitet. Selektionsbedingung mit mehreren Attributen und mehreren Indexen. Sind mehrere elementare Bedingungen vorhanden, bei denen jeweils ein Sekundärindex für das auftretende Attribut vorhanden ist, so können ggf. zunächst, bevor auf die eigentlichen Daten zugegriffen wird, Trefferlisten für die einzelnen Elementarbedingungen erstellt und die logischen Verknüpfungen zwischen den Elementarbedingungen durch entsprechende Mengenoperationen realisiert werden. Speziell bei und-Verknüpfungen kann es sein, daß die Treffermenge auf diese Weise deutlich verkleinert wird und weniger Blöcke übertragen werden müssen Implementierung relationaler Operationen 7.5 169 Optimierungen der Projektion Bei der Projektion läßt sich der Aufwand, die komplette Eingaberelation zu verarbeiten und ggf. Duplikate zu eliminieren, im Prinzip nicht reduzieren. Der Aufwand für das Lesen der Eingaberelation kann allerdings komplett vermieden werden, wenn es sich bei der Eingaberelation um ein Zwischenergebnis einer vorherigen Operation handelt, z.B. einer Selektion oder einem Verbund, indem man die Projektion in die vorgeschaltete Operation integriert und gleich bei der Generierung des Zwischenergebnisses berücksichtigt. Konzeptionell handelt es sich dann um neue, kombinierte Operationen. Die Annahme, daß eine Projektion nach einer anderen Operation erfolgt, ist sehr häufig schon bei der Formulierung einer Abfrage erfüllt und kann oft vom Optimierer durch Umstellung der Anfrage erreicht werden. 7.6 Optimierungen der Verbundberechnung Verbunde sind häufig, da infolge der Normalisierung vielfach Daten, die für eine Anwendung benötigt werden, auf mehrere Relationen verteilt werden. Die Ineffizienz des Grundalgorithmus für den Verbund ist daher äußerst nachteilig, und es sind diverse Varianten und Optimierungsmaßnahmen entwickelt worden. Einfaches Iterieren. Die oben skizzierte Implementierung wird auch als Einfaches Iterieren oder nested loop join bezeichnet und ist in Varianten für den natürlichen Verbund, den Θ-Verbund, die äußeren Verbunde und das Kreuzprodukt anwendbar. In vereinfachter Form handelt es sich um folgende geschachtelte Schleife: for each tuple t1 in r1 for each tuple t2 in r2 pruefe, ob <t1|t2> in Ergebnismenge kommt 170 Implementierung relationaler Operationen Wenn z.B. | r1 | = 10.000 und | r2 | = 200 ist, dann wird die innere Anweisung 2.000.000 Mal durchlaufen. Eine wichtige Frage ist, ob die Relation r2 immer wieder neu von der Platte gelesen werden muß und somit Blockübertragungen notwendig werden. Bei den heute üblichen Hauptspeichergrößen kann man erhebliche Datenmengen im Hauptspeicher puffern. Wenn wir wenigstens eine Relation (also die kleinere) komplett im Hauptspeicher puffern können, tun wir das und brauchen somit beide Relationen nur einmal zu lesen. Relationen können aber trotzdem zu groß sein, um komplett gepuffert werden zu können. Die folgenden Überlegungen gehen zur Vereinfachung davon aus, daß immer nur ein Block gepuffert werden kann. Sofern die Tupel der Relation r2 in zufälliger Reihenfolge, also gestreut im entsprechenden DB-Segment, verarbeitet werden, muß i.a. für jedes Tupel ein Block übertragen werden. Dies ist extrem ungünstig, in unserem obigen Beispiel kommen wir auf 2.000.000 Blockübertragungen. Eine offensichtliche Verbesserung liegt darin, die Relation r2 geblockt zu speichern - falls sie es nicht sowieso ist, lohnt es sich, eine temporäre Kopie anzulegen - und sie bei jedem Durchlauf in physischer Reihenfolge zu lesen. Die Zahl der Blockübertragungen reduziert sich dann um den Blockungsfaktor. In unserem Beispiel würde r2 bei einem Blockungsfaktor 20 nur 10 Blöcke belegen, bei 10.000 Schleifendurchläufen wären 100.000 Blockübertragungen nötig. Blockorientiertes Iterieren. Eine weitere deutliche Verbesserungsmöglichkeit ergibt sich, wenn auch r1 einen hohen Blockungsfaktor hat. Anstatt nun für jedes Tupel in r1 jeweils die ganze Relation r2 zu lesen, lesen wir immer einen Block in r1 und r2 und verarbeiten alle darin enthaltenen Paare von Tupeln: for each block B1 in r1 for each block B2 in r2 for each tuple t1 in B1 Implementierung relationaler Operationen 171 for each tuple t2 in B2 pruefe, ob <t1|t2> in Ergebnismenge kommt Die Zahl der Blockübertragungen reduziert sich dann noch einmal um den Blockungsfaktor. Wenn in unserem Beispiel auch r1 einen Blockungsfaktor 20 hat, also 500 Blöcke belegt, sind nur noch 5.000 Blockübertragungen erforderlich. Wir haben bisher unterstellt, daß pro Relation genau ein Block gepuffert werden kann, was ziemlich unrealistisch ist. Sind insgesamt n Blöcke für die Pufferung verfügbar, so bilden wir in beiden Relationen jeweils Abschnitte von n/2 Blöcken und behandeln jeweils einen Abschnitt wie einen Block im obigen Algorithmus. Verbundberechnung mit Index. Beim einfachen und blockorientierten Iterieren wird die zweite Relation im Prinzip immer wieder sequentiell nach Verbundpartnern für das aktuell betrachtete Tupel der ersten Relation durchsucht. Die lineare Suche ist das ineffizienteste Suchverfahren. Sofern für die zweite Relation ein Primär- oder Sekundärindex für das Verbundattribut (bzw. die Verbundattribute) vorliegt, ist mit dessen Hilfe eine wesentlich effizientere Suche möglich (s. Bild 7.2). U.U. lohnt es sich, einen Index temporär aufzubauen. r1 A Index für r2 r2 A Abbildung 7.2: Verbundberechnung mit Index Diese Verbundberechnung mit Index ist im sehr häufigen Fall anwendbar, daß der Verbund über einen Fremdschlüssel gebildet wird; der Fremdschlüssel ist dann in der anderen Relation Primärschlüssel. Ein 172 Implementierung relationaler Operationen Beispiel hierfür ist der schon früher betrachtete Verbund lieferungen 1 kunden. Wie schon früher erwähnt lohnt der Einsatz von Indexen nicht, wenn das unterstützte Attribut eine schlechte Selektivität hat. Bei großen, nicht pufferbaren Relationen und geringer Selektivität des Verbundattributs entstehen allerdings immens große Resultate, die mit hoher Wahrscheinlichkeit die verfügbaren Ressourcen überlasten, so daß derartige Abfragen ohnehin unrealistisch sind. Misch-Verbund (Merge Join). Sofern bei einem Verbund r1s das Attribut A Verbundattribut ist und sowohl r als auch s nach A sortiert gespeichert sind, kann der Verbund unter gewissen Bedingungen wie beim Misch-Algorithmus in einem einzigen parallelen Durchlauf durch die beiden Relationen konstruiert werden. r1 A r2 A x x x x x Abbildung 7.3: Misch-Verbund Hierzu wird in einer Schleife der jeweils nächstgrößere, in beiden Relationen auftretende Wert des Verbundattributs bestimmt26 . In beiden Relationen bilden die Tupel, bei denen dieser Wert auftritt, jeweils ein “Abschnitt”. Alle Tupel in den beiden Abschnitten müssen paarweise kombiniert und ausgegeben bzw. weiterverarbeitet werden. Sofern das Verbundattribut eine hohe Selektivität hat, sind diese Abschnitte kurz und können wahrscheinlich komplett gepuffert werden. Andernfalls werden diese Abschnitte entsprechend lang - im Extremfall kann die ganze Relation einen einzigen Abschnitt bilden -, d.h. 26 Werte, die nur in einer der Relationen auftreten, müssen nur bei äußeren Verbunden betrachtet werden. Implementierung relationaler Operationen 173 wir stehen hier wieder vor dem Problem, einen Abschnitt puffern zu müssen. Allerdings sind, wie schon oben erwähnt, Verbundattribute mit geringer Selektivität ohnehin eher unrealistisch. 3-Wege-Verbund. Ein Verbund zwischen drei Relationen r1 1 r2 1 r3 kann im Prinzip auf die Hintereinanderschaltung zweier binärer Verbunde (entweder (r11r2) 1 r3 oder r1 1 (r21r3) ) zurückgeführt werden. Anzustreben ist in diesem Fall ein möglichst kleines Zwischenergebnis. Alternativ kann der 3-stellige Verbund auch direkt, also ohne die ggf. aufwendige Erzeugung eines Zwischenergebnisses, erzeugt werden. Als Grundidee verwenden wir die Verbundberechnung mit Index. Wir durchlaufen die mittlere Relation tupelweise (s. Bild 7.4) und suchen jeweils “links” (in r1) und “rechts” (in r3) mit Unterstützung je eines Index nach Verbundpartnern. r1 A r2 A B r3 B Abbildung 7.4: 3-Wege-Verbund Dieses Verfahren ist besonders vorteilhaft anwendbar, wenn r2 eine Verbindungstabelle zwischen r1 und r3 ist. Glossar 3-Wege-Verbund: Verfahren zur Berechnung von zwei Verbunden mit 3 Eingaberelationen einfaches Iterieren: Verfahren zur Verbundberechnung, bei dem die beiden Eingaberelationen in zwei geschachtelten Schleifen durchlaufen werden 174 Implementierung relationaler Operationen erweiterbares Hashing: Variante des Hashings, bei dem die Hashtabelle über eine Umsetztabelle indirekt adressiert wird und die einzelnen Felder der Hashtabelle gestreut auf der Platte gespeichert werden können invertierter Datenbestand: Datenbestand, zu dem ein oder mehrere Sekundärindexe vorhanden sind Misch-Verbund (merge join): Verfahren zur Verbundberechnung, bei dem die beiden Eingaberelationen zunächst nach den Verbundattributen sortiert werden und dann für jeden auftretende Wertekombination der Verbundattribute eine “lokaler” Verbund berechnet wird Sekundärindex: Verzeichnis, das zu einzelnen Werten eine Liste von Referenzen auf die Speichereinheiten enthält, in denen dieser Attributwert auftritt Selektivität (eines Attributs einer Relation): Zahl der verschiedenen Werte des Attributs in seiner Relation; der entsprechende Bruchteil der Relation wird im Durchschnitt geliefert, wenn nach einen auftretenden Wert des Attributs selektiert wird Lehrmodul 8: Abfrageverarbeitung und Optimierung Zusammenfassung dieses Lehrmoduls Ein wesentlicher Vorteil relationaler Datenbanken liegt darin, daß die Abarbeitung von Abfragen automatisch optimiert werden kann. Zunächst wird im Rahmen der algebraischen Optimierung die Abfrage anhand von Heuristiken in eine äquivalente, aber effizienter ausführbare Form umgewandelt. In der anschließenden internen Optimierung wird zwischen ggf. verfügbaren Implementierungen der Elementaroperationen entschieden und damit zusammenhängend über die Ausnutzung von Indexen. Die alternativen Ausführungspläne werden hierzu anhand ihrer geschätzten Ausführungskosten bewertet. Vorausgesetzte Lehrmodule: obligatorisch: – Das relationale Datenbankmodell – Implementierung relationaler Operationen empfohlen: – Architektur von DBMS Stoffumfang in Vorlesungsdoppelstunden: c 2003 Udo Kelter 1.2 Stand: 12.10.2003 176 Abfrageverarbeitung und Optimierung 8.1 Motivation Praktisch benutzte Abfragesprachen und selbst die relationale Algebra sind Hochsprachen im gleichen Sinne wie “höhere” Programmiersprachen: sie entlasten den Nutzer von vielen systemnahen, lästigen Details der Datenverwaltung und erlauben es, Probleme in der Denkwelt abstrakterer Konzepte zu lösen, im Falle von Abfragesprachen in der Denkwelt des Datenbankmodells. Die Operationen des Datenbankmodells müssen auf systemnahe Funktionen zurückgeführt werden, insb. müssen die Datenobjekte, mit denen die Operationen des Datenbankmodells arbeiten (einzelne Tupel bzw. Tupelmengen) letztlich auf Strukturen der Speichermedien (i.d.R. Magnetplatten) abgebildet werden. Diese Abbildung stellt man sich softwaretechnisch am besten als eine Schichtenarchitektur vor. Die oberste Schicht exportiert Operationen mit Tupelmengen und basiert auf der darunterliegenden Schicht, die Operationen mit einzelnen Tupeln exportiert27 . Wir beziehen uns hier begrifflich auf relationale Systeme, bei objektorientierten Systemen gelten diese Betrachtungen analog für Objekte. Navigierende Datenmodelle haben i.d.R. keine mengenwertigen Operationen, so daß die oberste Schicht entfällt. Wir konzentrieren uns in diesem Lehrmodul auf die Frage, wie Operationen mit Tupelmengen, insb. also Abfragen, auf Operationen mit einzelnen Tupeln zurückgeführt werden können. 8.1.1 Grobablauf einer Abfrageverarbeitung Den Ablauf der Bearbeitung einer Abfrage kann man wie folgt grob gliedern: 1. Umformung der textuellen Darstellung der Abfrage in eine interne Darstellung (analog zum Parser in einem Compiler) und Korrektheitsüberprüfung 2. Erstellung und Vergleich möglicher Ausführungspläne 27 Lehrmodul 3 beschreibt die Schichten detaillierter. Abfrageverarbeitung und Optimierung 177 3. Ausführung des “optimalen” Plans Die Korrektheitsüberprüfung im ersten Schritt betrifft – die Syntax und – die verwendeten Ressourcen; mit Hilfe des Systemkatalogs wird festgestellt, ob die angegebenen Relationen und Attribute überhaupt existieren und ob entsprechende Zugriffsrechte gegeben sind. Weiter werden in diesem Schritt virtuelle Relationen durch ihre definierende Abfrage ersetzt (view resolution). Im Endeffekt wird die Abfrage in eine interne Baumdarstellung umgeformt, die einen Ausdruck in der relationalen Algebra oder einer Erweiterung derselben repräsentiert. Der zweite Schritt, die Optimierung, ist dadurch motiviert, daß es meist zu einer Abfrage mehrere Ausführungsvarianten gibt, die alle das gleiche Resultat liefern, aber verschiedene Kosten verursachen. 8.1.2 Optimierungsansätze Die Frage, wo und wie die Abarbeitung einer Abfrage optimiert werden kann, kann offensichtlich nicht ohne Bezug auf die Abfragesprache diskutiert werden. Wir beschränken uns hier auf die relationale Algebra (s. Lehrmodul 4), da sie einerseits die wichtigsten mengenwertigen Abfrageoperationen umfaßt, andererseits syntaktisch sehr einfach strukturiert ist. Bei komplexeren Sprachen steigt vor allem die Zahl der Abfrageoperationen an, die prinzipielle Vorgehensweise bleibt aber gleich. Die Abarbeitung einer Abfrage können wir für unsere aktuelle Fragestellung in zwei Themenkomplexe gliedern: – die Implementierung der Operationen der relationalen Algebra – die Verarbeitung geschachtelter Ausdrücke. Die beiden Themenkomplexe sind nicht ganz unabhängig voneinander, aber hilfreich für die Gliederung möglicher Optimierungsmaßnahmen. 178 Abfrageverarbeitung und Optimierung Optimierung der Elementaroperationen. Wie schon in Abschnitt 4.3.9 erwähnt, haben Ausdrücke in der relationalen Algebra eine intuitive operationale Semantik, nämlich die Auswertung von innen nach außen. Dies unterstellt, daß für jede Operation der relationalen Algebra genau eine Implementierung vorhanden ist und daß bei der Abarbeitung des Ausdrucks diese Implementierung mit den passenden Zwischenresultaten ausgeführt wird. Diese Annahme trifft aber in doppelter Hinsicht nicht zu: – Für eine Operation kann es mehrere Implementierungen geben, die verschieden effizient sind und von denen eine auszuwählen ist, ggf. abhängig von den benutzten Datenstrukturen. – Es kann Implementierungen kompletter Teilausdrücke geben. Als Beispiel betrachten wir eine Selektion gefolgt von einer Projektion (πA (σB (...))): bei der intuitiven Abarbeitung würde man bei der Selektion ganze Tupel in eine temporäre Relation schreiben und diese dann projizieren. Stattdessen erzeugt man besser gleich die projizierten Tupel und spart so den Platz und Aufwand für die temporäre Relation komplett ein. Alternative Implementierungen einzelner Operationen und Implementierungen kompletter Teilausdrücke zählen wir hier zu den Optimierungsmaßnahmen im Bereich der Implementierung von Operationen. Optimierung der Abarbeitung von Ausdrücken. Die Optimierung der Abarbeitung von geschachtelten Ausdrücken sei durch folgendes Beispiel motiviert: wir unterstellen wieder die Relationen kunden und lieferungen und suchen die Namen der Kunden, die am 24.12.2000 eine Lieferung bekommen haben. Diese Frage können wir auf zwei verschiedene Arten beantworten: πKundenname (σDatum=24.12.2000 ( lieferungen 1 kunden )) und πKundenname (σDatum=24.12.2000 ( lieferungen ) 1 kunden ) Abfrageverarbeitung und Optimierung 179 Beide Ausdrücke sind äquivalent, berechnen also das gleiche Ergebnis, der zweite ist aber effizienter, weil der Verbund mit einer kleineren Menge gebildet wird. Hierbei unterstellen wir wieder die intuitive operationale Semantik von Ausdrücken; wenn wir von einem effizienteren Ausdruck reden, sehen wir den Ausdruck als einen (vereinfachten, abstrakten) Ausführungsplan an. Daß es zu einer Aufgabe mehrere verschiedene, aber äquivalente Lösungen gibt, trifft generell auf alle Hochsprachen zu und auf SQL sogar in deutlich stärkerem Ausmaß als auf die relationale Algebra. Ein Gegenstand der Optimierung ist somit die Auswahl einer möglichst kostengünstigen Lösung. Hierbei wird in zwei Schritten vorgegangen: 1. Bei der algebraischen Optimierung werden zu dem vom Nutzer vorgegebenen Ausdruck ein oder mehrere äquivalente Ausdrücke gebildet, die aufgrund von Heuristiken effizienter ausführbar erscheinen. Ein Beispiel hierfür wurde oben gegeben. Die algebraische Optimierung ist im Gegensatz zu den weiteren Maßnahmen unabhängig vom aktuellen Inhalt der Datenbank. 2. Bei der anschließenden internen Optimierung werden für jeden Ausdruck mehrere alternative Ausführungspläne gebildet. In einem Ausführungsplan wird über die reine Operationsschachtelung hinaus festgelegt, – welche der alternativ verfügbaren Implementierungen einer Operation gewählt wird; da für manche Implementierungen ein Index vorhanden sein muß, wird auch entschieden, ob Indexe ausgenutzt werden; – welche Zwischenergebnisse auf Platte oder im Hauptspeicher angelegt werden. Für jeden Ausführungsplan werden die Ausführungskosten geschätzt. Bei dieser Schätzung spielen eine Rolle: – Merkmale des aktuellen Datenbestands, insb. die Größe von Relationen und die Verteilung von Attributwerten 180 Abfrageverarbeitung und Optimierung – interne Speicherungsstrukturen, z.B. vorhandene Indexe oder Sortierungen Ferner werden gemeinsame Unterausdrücke berücksichtigt, die nur einmal berechnet werden müssen. Anzumerken ist noch, daß die Bezeichnung Optimierung insofern mißverständlich (oder gar falsch) ist, als i.d.R. nicht etwa eine optimale, also minimal aufwendige Bearbeitung der Abfrage gesucht wird, sondern nur eine möglichst gute bzw. bessere als die intuitiv naheliegende. Zum einen muß natürlich der Aufwand für die Optimierung kleiner bleiben als der Gewinn durch die bessere Ausführungsvariante. Bei sehr kleinen Datenbanken lohnt sich deshalb die Optimierung oft nicht. Sodann gibt es i.a. zu viele Ausführungsvarianten, um alle einzeln betrachten zu können, und man kann i.a. die Kosten einer Variante nicht exakt prognostizieren, man muß also mit Heuristiken arbeiten. 8.2 Optimierungskriterien Bisher haben wir die Frage offengelassen, anhand welcher Kriterien wir bestimmen, ob eine Abfrageverarbeitung gut oder weniger gut ist. Im Endeffekt geht es um Performance-Maße wie Antwortzeit oder Durchsatz, die aus Benutzersicht erkennbar sind. Diese Größen können als solche aber nicht direkt geschätzt werden, man muß also auf andere Meßgrößen bzw. Optimierungskriterien zurückgreifen. Aufwand entsteht insb. in folgender Hinsicht: – Plattenzugriffe zum Lesen der Ausgangsdaten und Schreiben und Lesen von Zwischenergebnissen – Plattenplatzbedarf für Zwischenergebnisse – Hauptspeicherbedarf – bei verteilten Systemen: Anzahl der Kommunikationen, Datenübertragungsvolumen – Rechenaufwand (CPU-Belastung) Abfrageverarbeitung und Optimierung 181 Ferner gibt es speziellere, ggf. sogar anwendungsspezifische Aufwandskriterien. Das wichtigste Kriterium ist in der Regel die Zahl der Plattenzugriffe. Daher stellen viele Optimierungsverfahren vor allem auf die Reduktion der Plattenzugriffe ab. Die CPU-Belastung ist aber auch keineswegs unwichtig; bei den heute üblichen großen Hauptspeichern können oft alle relevanten Daten gepuffert werden, so daß nach dem unvermeidlichen initialen Lesen und ggf. Schreiben der Endergebnisse keine weiteren Plattenzugriffe anfallen. Es liegt daher nahe, mehrere dieser Meßgrößen mit geeigneten Faktoren zu gewichten und daraus ein Kostenmaß für Abfrageverarbeitungen zu bilden. In diesem Zusammenhang spricht man auch von kostenbasierter Optimierung. 8.3 8.3.1 Algebraische Optimierung Äquivalente algebraische Ausdrücke Ziel der algebraischen Optimierung ist es, zu einem vorgegebenen Ausdruck einen äquivalenten Ausdruck zu finden, der effizienter ausführbar ist. Zwei relationale Ausdrücke A1 und A2 sind äquivalent, wenn bei einem beliebigen Datenbankinhalt beide Ausdrücke das gleiche Ergebnis liefern. Für die algebraische Optimierung ist daher der Begriff Äquivalenz von zentraler Bedeutung. Im folgenden listen wir eine Reihe von Äquivalenzen auf, die mehr oder minder unmittelbar durch Einsetzen der Definitionen beweisbar sind und die auch als Gesetze bezeichnet werden. r, s und t sind i.f. beliebige Relationen; bei den Mengenoperationen müssen die beteiligten Relationen den gleichen Typ haben. B, B1 und B2 sind Selektionsbedingungen, die syntaktisch zu den Typen der Argumentrelationen passen, Q, Q1 und Q2 sind Verbundbedingungen. Kommutativgesetze. Vereinigung, Schnitt, Verbund und Kreuzprodukt sind kommutativ: 182 Abfrageverarbeitung und Optimierung r∪s=s∪r r∩s=s∩r r1s=s1r r 1Q s = s 1Q r r×s=s×r Assoziativgesetze. dukt sind assoziativ: Vereinigung, Schnitt, Verbund und Kreuzpro- r ∪ (s ∪ t) = (r ∪ s) ∪ t r ∩ (s ∩ t) = (r ∩ s) ∩ t r 1 (s 1 t) = (r 1 s) 1 t r 1Q1 (s 1Q2 t) = (r 1Q1 s) 1Q2 t r × (s × t) = (r × s) × t Auflösung komplexer Selektionsbedingungen. Die Booleschen Operatoren ∧ und ∨ zwischen Bedingungen B1 und B2 können wie folgt in Schachtelungen von Selektionen oder Mengenoperationen umgeformt werden: σB1∧B2 (r) = σB1 (σB2 (r)) σB1∧B2 (r) = σB2 (σB1 (r)) σB1∧B2 (r) = σB1 (r) ∩ σB2 (r) σB1∨B2 (r) = σB1 (r) ∪ σB2 (r) Distributivgesetze zwischen Selektion und Mengenoperatoren. σB (r ∪ s) = σB (r) ∪ σB (s) σB (r ∩ s) = σB (r) ∩ σB (s) σB (r − s) = σB (r) − σB (s) = σB (r) − s Gesetze für die Projektion. Seien U, V ⊆ R. Dann gilt πU (πV (r)) = πU ∩V (r). Eine Projektion kann mit einer Selektion vertauscht werden, wenn die Selektionsbedingung B nur Attribute aus V (die Menge der Attribute, auf die projiziert wird) enthält: Abfrageverarbeitung und Optimierung 183 σB (πV (r)) = πV (σB (r)) Eine Projektion kann mit dem Vereinigungsoperator vertauscht werden28 : πY (r ∪ s) = πY (r) ∪ πY (s) Verbund und Selektion. Seien r1 bzw. r2 Relationen des Typs R1 bzw. R2, B eine Selektionsbedingung, die nur Attribute aus R1 beinhaltet, Q eine Verbundbedingung. Dann gilt: σB (r1 1 r2) = σB (r1) 1 r2 σB (r1 1Q r2) = σB (r1) 1Q r2 Als Erläuterung hierzu betrachten wir folgende Beispiele; sei R1 = { A, B, C, D }, R2 = { C, D, E, F }: σA=B (r1 1 r2) σA=E (r1 1 r2) σA=a (r1 1A=F r2) σA=F (r1 1B=E r2) = 6 = = 6 = σA=B (r1) 1 r2 σA=E (r1) 1 r2 σA=a (r1) 1A=F r2 σA=F (r1) 1B=E r2 Wenn die Attribute, die in einer Selektionsbedingung sel auftreten, in beiden Relationenschemata enthalten sind, dann gilt: σsel (r1 1 r2) = σsel (r1) 1 σsel (r2) Kreuzprodukt und Selektion. Seien r1 bzw. r2 Relationen des Typs R1 bzw. R2, B eine Selektionsbedingung, die nur Attribute aus R1 beinhaltet. Dann gilt: σB (r1 × r2) = σB (r1) × r2 Ist B eine Verbundbedingung, so gilt: σB (r1 × r2) = r1 1B r2 28 Für den Durchschnitt und die Differenz gilt dies nicht. Übungsaufgabe: Finden Sie ein Gegenbeispiel. 184 Abfrageverarbeitung und Optimierung Verbund und Projektion. Nach einem Verbund wird meist sofort oder später (z.B. nach einer Selektion) projiziert, d.h. manche der zunächst aufwendig erzeugten Attribute werden später unbenutzt gelöscht. Die Frage ist, ob man dies nicht vermeiden kann und ob man vorher projizieren kann. Wie das nächste Beispiel (R1 und R2 seien wie vorstehend definiert) zeigt, ist die Vertauschung aber i.a. nicht zulässig: πA (r1 1 r2) 6= (πA (r1)) 1 r2 Der Fehler liegt darin, daß {C, D} = R1 ∩ R2 die Verbundattribute von r1 und r2 sind und daß diese Verbundattribute im rechten Teil der Formel bei r1 wegprojiziert worden sind, der dortige Verbund also zum Kreuzprodukt degeneriert; auf der rechten Seite werden also i.a. mehr Tupel entstehen. Wenn bei der Projektion die Verbundattribute erhalten bleiben, kann das Problem nicht auftreten. Anders gesagt müssen dann, wenn man eine Projektion an einem Verbund vorbei nach innen ziehen will, die Verbundattribute innen erhalten bleiben. Nach dem Verbund müssen sie dann separat entfernt werden. Diese Vorüberlegungen motivieren die folgende Äquivalenz. Seien r1 bzw. r2 Relationen des Typs R1 bzw. R2, U ⊆ R1 ∪ R2, Q eine Verbundbedingung, V die in Q auftretenden Verbundattribute. Seien U1 = (U ∩ R1) ∪ V und U2 = (U ∩ R2) ∪ V. Dann ist πU (r1 1Q r2) = πU (πU1 (r1) 1Q πU2 (r2)) Beim natürlichen Verbund ist analog V = R1 ∩ R2. Man kann also vor der Verbundbildung alle Attribute entfernen, die nicht für die Verbundbildung oder die außenstehende Projektion benötigt werden. Anzumerken ist hier, daß, sofern r1 und r2 nicht im Hauptspeicher gepuffert werden können, der längere Ausdruck effizienter ausführbar sein wird, obwohl er mehr Operationen enthält. Kreuzprodukt und Projektion. Das Kreuzprodukt können wir hier als Sonderfall des Verbunds mit leerer Verbundbedingung behandeln; die Menge der Verbundattribute ist somit leer und die allgemeine Formel für den Verbund vereinfacht sich zu: Abfrageverarbeitung und Optimierung 185 πU (r1 × r2) = πU (πR1∩U (r1) × πR2∩U (r2)) = πR1∩U (r1) × πR2∩U (r2) 8.3.2 Optimierungsheuristiken Im vorigen Abschnitt ist eine größere Anzahl Äquivalenzen vorgestellt worden. Im Rahmen der algebraischen Optimierung können diese jetzt ausgenutzt werden, um zu einem vorgegebenen Ausdruck einen äquivalenten, aber effizienter ausführbaren zu finden. Bei einem gegebenen Ausdruck werden normalerweise mehrere der Äquivalenzen anwendbar sein. Nach einem Umformungsschritt wird dies erneut der Fall sein, wir erhalten somit i.a. viele denkbare Sequenzen von Umformungsschritten. Selbst dann, wenn wir unsinnige Sequenzen - z.B. solche, in denen direkt nach einer Umformung die inverse Umformung auftritt - aussortieren, bleibt die Zahl der Sequenzen i.a. viel zu hoch, um alle parallel verfolgen zu können. Die nachfolgenden, als Regeln formulierten Optimierungsheuristiken beschreiben solche Umformungsschritte, die mit sehr hoher Wahrscheinlichkeit und meist auch in intuitiv unmittelbar einsichtiger Weise die Effizienz verbessern. Dabei wird zum einen die “Richtung”, in der die Äquivalenzen ausgenutzt werden sollten, vorgegeben, ferner werden teilweise Bedingungen für einen Umformungsschritt angegeben. Regel 1: Selektionen sollten so früh wie möglich ausgeführt werden. Selektionen werden also möglichst weit nach innen in geschachtelte Ausdrücke verschoben. Hierdurch werden Zwischenergebnisse kleiner. Selbst wenn diese nicht gespeichert werden, sinkt immer noch der Verarbeitungsaufwand. Regel 2: Eine äußere Selektion, deren Bedingung eine Konjunktion ist, sollte in eine Schachtelung von Selektionen aufgebrochen werden. Der Sinn dieser Regel liegt darin, daß die Regel 1 dann öfter anwendbar ist und möglichst viele elementare Selektionen unmittelbar bei den Basisrelationen angewandt werden. 186 Abfrageverarbeitung und Optimierung Sofern mehrere Einzelselektionen in der Form σB1 (σB2 (X)) unmittelbar aufeinanderfolgen, sollte die Selektion mit der höheren Selektivität nach innen verschoben werden. Sofern X bereits eine Basisrelation ist, sollten vorhandene Indexe ausgenutzt werden (vgl. Abschnitt 7.4). In beiden Fällen beziehen wir uns auf Merkmale der aktuellen Datenbank, derartige Entscheidungen gehören also nicht mehr strikt zur algebraischen Optimierung, sondern schon zur internen Optimierung. Regel 3: Selektionen und Kreuzprodukte sollten zu Verbunden zusammengefaßt werden, d.h. Tupel, die die Verbundbedingung nicht erfüllen, werden gar nicht erst erzeugt. Regel 4: Bei einem Verbund von 3 und mehr Relationen sollten Verbunde zuerst berechnet werden, die voraussichtlich kleine Ergebnisse erzeugen. Kleine Ergebnisse sind wahrscheinlich, wenn – die Verbundattribute Identifizierungsschlüssel in einer der beteiligten Relationen sind – mehrere Verbundattribute statt nur einem vorhanden sind – die beteiligten Relationen klein sind29 Regel 5: Sofern sinnvoll (z.B. wenn Verbundergebnisse zwischengespeichert werden müssen) sollten zusätzliche Projektionen eingefügt werden. Die neuen Projektionen sollten natürlich mit einer ggf. vorhandenen vorhergehenden (also inneren) Operation zusammengefaßt werden; vgl. generelle Bemerkungen zu Projektionen in Abschnitt 7.6. Regel 6: Sofern an irgendeiner Stelle im Syntaxbaum Zwischenergebnisse gespeichert werden müssen, sollten alle äußeren Projektionen, soweit möglich, bis an diese Stelle verschoben werden. 29 Auch dieses Argument basiert auf Merkmalen der aktuellen Datenbank, gehört also nicht mehr strikt zur algebraischen, sondern zur internen Optimierung. Abfrageverarbeitung und Optimierung 8.3.3 187 Optimierungsalgorithmen Die vorstehenden Heuristiken sind noch kein Algorithmus - sie geben immerhin an, in welcher “Richtung” die Äquivalenzen aus Abschnitt 8.3.1 ausgenutzt werden sollten. Nach wie vor können in einer bestimmten Situation mehrere Äquivalenzen anwendbar sein. Ein Optimierungsalgorithmus legt fest, – welche Äquivalenz an welcher Stelle als nächstes ausgenutzt werden soll; – wann das Verfahren abgebrochen wird; hierbei ist natürlich die algebraische und interne Optimierung insgesamt zu betrachten. Der zusätzliche Grenznutzen weiterer Optimierungsmaßnahmen kann nach den ersten, offensichtlichen Maßnahmen unsicher sein. Wegen der kombinatorischen Explosion der möglichen Einzelmaßnahmen kann der Aufwand für die Optimierung selbst ausufern; auch hier müssen Heuristiken eingesetzt werden, um die Untersuchung weniger aussichtsreicher Maßnahmen früh abbrechen zu können. Ein einfacher Optimierungsalgorithmus könnte folgendermaßen vorgehen: 1. zerlegen von Selektionen, deren Bedingung eine Konjunktion ist, in geschachtelte Selektionen (Regel 2) 2. verschieben aller Selektionen so weit wie möglich nach innen (Regel 1) 3. zusammenfassen von Selektionen und Kreuzprodukten zu Verbunden (Regel 3) 4. vertauschen der Reihenfolge von Verbunden gem. Größe der Relationen (Regel 4) 5. ggf. einfügen von zusätzlichen Projektionen bei Verbunden (Regel 5) 6. verkleinern von zu puffernden Zwischenergebnissen, indem Projektionen nach innen verschoben werden (Regel 6) 188 Abfrageverarbeitung und Optimierung Wenn eine Regel an mehreren Stellen innerhalb des Ausdrucks anwendbar ist, wird sie jeweils an der ersten gefundenen Stelle zuerst angewandt. Beispiel für eine Optimierung. Als Beispiel betrachten wir folgende SQL-Abfrage und ihre Optimierung: SELECT DISTINCT r.A, s.B FROM R r, S s, T t WHERE r.C = t.C AND s.D = t.D AND r.E = e Nach der obligaten Syntaxprüfung wird diese Abfrage nach dem Standardschema zunächst in folgenden Ausdruck übersetzt: πr.A,s.B (σr.C=t.C∧s.D=t.D∧r.E=e (r × (s × t))) Nach Schritt 1 (Anwendung von Regel 2) erhalten wir: πr.A,s.B (σr.C=t.C (σs.D=t.D (σr.E=e (r × (s × t))))) Unter Anwendung von Regel 1 verschieben wir die Selektionen σr.E=e und σs.D=t.D nach innen in das Kreuzprodukt: πr.A,s.B (σr.C=t.C (σs.D=t.D (σr.E=e (r) × (s × t)))) πr.A,s.B (σr.C=t.C (σr.E=e (r) × σs.D=t.D (s × t))) Unter Anwendung von Regel 3 bilden wir jeweils aus einer Selektion und einem Kreuzprodukt einen Verbund: πr.A,s.B (σr.E=e (r) 1r.C=t.C (σs.D=t.D (s × t))) πr.A,s.B (σr.E=e (r) 1r.C=t.C (s 1s.D=t.D t)) Als nächstes stellt sich die Frage, in welcher Reihenfolge die beiden Verbunde ausgeführt werden sollen30 . Sofern keine weitere Information über die Größe der Relationen verfügbar ist, können wir wegen der Selektion davon ausgehen, daß die Eingaberelation σr.E=e (r) die kleinste ist; daher sollte zunächst mit ihr ein Verbund berechnet werden. Da sich die Verbundbedingung, in der r vorkommt, auf t als zweite 30 Dies unter der Annahme, daß kein 3-Wege-Verbund gewählt wird, was hier vermutlich die effizienteste Lösung wäre, aber um des Beispiels willen hier nicht weiter verfolgt wird. Abfrageverarbeitung und Optimierung 189 Relation bezieht, sollte der erste Verbund zwischen r und t gebildet werden. Wir stellen unseren Ausdruck also wie folgt um: πr.A,s.B ((σr.E=e (r) 1r.C=t.C t) 1s.D=t.D s) Zum Schluß fügen wir noch Projektionen ein, um nicht im Endergebnis benötigte Attribute vor den Verbundbildungen zu entfernen: πr.A,s.B ( πr.A,t.D (σr.E=e (r) 1r.C=t.C t) 1s.D=t.D πs.B,s.D (s) ) und πr.A,s.B ( πr.A,t.D ( πr.A,r.C (σr.E=e (r)) 1r.C=t.C πt.D,t.C (t) ) 1s.D=t.D πs.B,s.D (s) ) 8.4 Kostenschätzung Wir hatten schon bei der algebraischen Optimierung z.B. bei der Berechnung mehrerer Verbunde bemerkt, daß man ggf. Informationen über die Größe der Relationen braucht, um entscheiden zu können, welche Alternative die wahrscheinlich günstigere ist. Die Kosten einer Abfrage (z.B. die reale Antwortzeit, s. Abschnitt 8.2) können nicht exakt prognostiziert werden, sondern allenfalls später bei der Ausführung gemessen werden31 . Die absoluten Kosten sind auch insofern unwichtig, als es primär um den Vergleich verschiedener Ausführungspläne geht, also relative Kostenangaben ausreichen. Anzustreben ist daher allenfalls eine ungefähre Prognose, ferner müssen die Ausgangsdaten leicht beschaffbar sein und die Berechnungsfunktionen dürfen nicht zu aufwendig sein. Als hinreichend exakter Maßstab hat sich die Zahl der in Zwischenergebnissen oder im Endergebnis erzeugten Tupel bewährt. Um diese 31 Wobei sich herausstellen wird, daß die Kosten nicht exakt reproduzibel sind, insofern eine exakte Prognose weitere Einflußfaktoren berücksichtigen müßte. 190 Abfrageverarbeitung und Optimierung zu berechnen oder abzuschätzen, werden folgende Ausgangsdaten (vgl. Abschnitt 7.4) verwendet: sr der durchschnittliche Speicherplatzbedarf eines Tupels (incl. Hilfsdaten) der Relation r |r| die Zahl der Tupel in der Relation r V(A,r) die Zahl der verschiedenen Werte, die Attribut A in Relation r annimmt Diese (und ggf. weitere) Daten über den Datenbestand können i.a. nicht ständig exakt vorgehalten werden; es reicht aber aus, diese Daten z.B. einmal täglich zu betriebsschwachen Zeiten zu aktualisieren. Die laufenden Änderungen in der Datenbank haben auf diese statistischen Werte i.a. nur marginalen Einfluß, d.h. die leicht veralteten statistischen Daten sind weiterhin brauchbar. Schätzung der Kosten einer Selektion. In einigen Sonderfällen kann die Größe des Ergebnisses recht genau vorhergesagt werden: – Hat die Selektionsbedingung die Form A=a und ist A Identifizierungsschlüssel, so gilt | σA=a (...) | ≤ 1. Analog gilt dies für Identifizierungsschlüssel mit mehreren Attributen. – Hat die Selektionsbedingung die Form A=a und existiert ein Sekundärindex für A, so kann die Zahl der Treffer durch Auslesen eines einzigen Satzes im Sekundärindex bestimmt werden. Sofern diese Sonderfälle nicht zutreffen, kann mit Hilfe der Zahl V(A,r) wie folgt geschätzt werden: | σA=a (r) | = |r| V (A,r) Diese Schätzung unterstellt, daß jeder Wert des Attributs A in etwa gleichhäufig auftritt, die Varianz der Häufigkeitsverteilung also vernachlässigbar ist. Schätzung der Kosten einer Projektion. Bei Projektionen ohne Duplikateliminierung hat die Ausgabe gleichviele Tupel wie die Eingaberelation. Mißt man die Größe der Relationen in Tupeln, so gilt Abfrageverarbeitung und Optimierung 191 | π...(r) |=| (r) |. Für eine detailliertere Analyse des Platzbedarfs des Ergebnisses kann man den Platzbedarf der projizierten Tupel zusätzlich betrachten. Bei Projektionen mit Duplikateliminierung gilt das Vorstehende ebenfalls, sofern die Menge der Attribute, auf die projiziert wird, einen Identifizierungsschlüssel enthält. Kosten eines Kreuzprodukts. akte Formel: Hier gilt ausnahmsweise eine ex- | r×s|=|r| ∗|s| Schätzung der Kosten eines Verbunds. Seien r1 bzw. r2 Relationen des Typs R1 bzw. R2 und V = R1 ∩ R2 die Verbundattribute. Wenn die beiden Relationen keine gemeinsamen Attribute haben, also V = ∅, ist der Verbund ein Kreuzprodukt und die vorstehende Formel ist anwendbar. Sofern V einen Identifizierungsschlüssel für R2 enthält, ist für jedes Tupel aus r1 höchstens ein Verbundpartner vorhanden, also: | r1 1 r2 | ≤ | r1 | Sofern zusätzlich V in r1 als Fremdschlüssel auf r2 deklariert ist, also sichergestellt ist, daß immer ein Verbundpartner vorhanden ist, gilt | r1 1 r2 | = | r1 |. Sofern die vorstehenden Voraussetzungen nicht zutreffen, kann es zu einem Tupel von r1 mehrere Verbundpartner in r2 geben. Die Größe des Ergebnisses kann dann analog wie bei der Selektion abgeschätzt werden. Hierzu nehmen wir vereinfachend an: – V = {A}, also nur ein Verbundattribut – Gleichverteilung der Werte von A in r2 Für ein Tupel t in r1 ist die Menge der Verbundpartner in r2 gerade σA=t[A] (r2). Zur Schätzung der Größe dieser Menge setzen wir die bei der Selektion entwickelte Formel ein und erhalten: 192 Abfrageverarbeitung und Optimierung |r2| = | r1 1 r2 | = | r1 | ∗ V (A,r2) |r1|∗|r2| V (A,r2) In den vorstehenden Überlegungen können wir natürlich die Rollen von r1 und r2 vertauschen und erhalten | r2 1 r1 | = |r2|∗|r1| V (A,r1) Wir haben nun zwei unterschiedliche Schätzungen für | r2 1 r1 |, denn V(A,r1) und V(A,r2) können signifikant verschieden sein. Wenn bspw. V(A,r1) kleiner als V(A,r2) ist, bedeutet das, daß in r2 mehr unterschiedliche Werte im Attribut A auftreten als in r1. Offensichtlich können dann nicht alle Tupel in r2 einen Verbundpartner finden, die nur in einer Relation auftretenden Werte sind “hängende Referenzen”. Als Beispiel betrachten wir in Bild 8.1 zwei Relationen r1 und r2 mit Verbundattribut A und V(A,r1)=3 und V(A,r2)=8. Zur Vereinfachung treten die Zahlen 1, 2, 3 usw. als Werte in A auf, ferner nehmen wir an, daß beide Relationen nach A sortiert sind. Wenn wir nun r1 durchlaufen, finden wir zu jedem Tupel in r1 |r2| 8 Tupel in r2 als Ver|r1|∗|r2| Tupel. bundpartner. Insgesamt entstehen also 8 A r1 1 2 3 V(A,r1)=3 A 1 2 3 4 . . . r2 V(A,r1)=8 Abbildung 8.1: Größenschätzung eines Verbunds Wenn wir stattdessen r2 durchlaufen, finden wir nur für | r2 | ∗ 83 Tupel überhaupt einen Verbundpartner in r1. Für jedes dieser Tupel 3 |r1| finden wir |r1| 3 Verbundpartner. Insgesamt entstehen also | r2 | ∗ 8 ∗ 3 = |r1|∗|r2| Tupel. 8 Generell gilt also: bei der unterstellten Gleichverteilung der Attributwerte und bei der (optimistischen) Annahme, daß alle in r2 auf- Abfrageverarbeitung und Optimierung 193 tretenden Werte auch in r1 auftreten, also πA (r2) ⊂ πA (r1), müssen wir die höhere Selektivität bzw. den kleineren Schätzwert verwenden. Unsere obige Annahme πA (r2) ⊂ πA (r1) kann falsch sein. Sofern in beiden Relationen nur wenige Werte in A gemeinsam auftreten, wird das Ergebnis kleiner werden. Im Extremfall πA (r1) ∩ πA (r2) = ∅ ist das Ergebnis sogar leer. Sofern man die Zahl der in beiden Relationen in A auftretenden Werte bestimmt (was in der Praxis aus Aufwandsgründen i.a. nicht möglich sein wird), kann hiermit ein weiterer Korrekturfaktor gebildet werden. Allerdings wird die Schätzung immer unzuverlässiger; an dieser Stelle sei daran erinnert, daß auch die Annahme der Gleichverteilung der Attributwerte i.a. die Realität stark vereinfacht. Glossar Äquivalenz relationaler Ausdrücke: zwei relationale Ausdrücke sind äquivalent, wenn bei einem beliebigen Datenbankinhalt beide Ausdrücke das gleiche Ergebnis liefern Ausführungsplan: konkreter Algorithmus, der zu einer gegebenen Abfrage das Ergebnis berechnet Optimierung: Kollektion von Maßnahmen, die zu einer möglichst effizienten Berechnung eines Abfrageergebnisses führen Optimierung, algebraische: Umformung einer gegebenen Abfrage in eine äquivalente, effizienter ausführbare; unabhängig vom Datenbankinhalt Optimierung, interne: Optimierungsmaßnahmen, bei denen Merkmale des Datenbestands, Indexe, Sortierungen und sonstige interne Merkmale ausgenutzt werden, um einen möglichst guten Ausführungsplan zu konstruieren bzw. auszuwählen Sichtenauflösung: Ersetzung einer virtuellen Relation durch die sie definierende Abfrage bei der Abfrageverarbeitung Lehrmodul 9: Metadaten Zusammenfassung dieses Lehrmoduls Metadaten sind Daten über (Nutz-) Daten. Metadaten treten in Datenbanken, in der Dokumentverwaltung, bei der Software-Modellierung und in vielen weiteren Kontexten auf. Entitätsbezogene Metadaten sind einzelnen Nutzdatengranulaten, typbezogene Metadaten hingegen dem Typ von Nutzdatengranulaten zugeordnet. Systeme, die Metadaten im gleichen Datenbankmodell wie die Nutzdaten repräsentieren, nennt man selbstreferentiell. Typbezogene Metadaten (Schemata) sind instantiierbar, wenn ein DVS verfügbar ist, das die Instantiierung durchführt. Die auftretenden Metadaten, deren selbstreferentielle Darstellung und die entstehende Metadaten-Hierarchie untersuchen wir für relationale Datenbanken, XML-Dateien und die Metamodell-Hierarchie der UML. Vorausgesetzte Lehrmodule: obligatorisch: – Datenverwaltungssysteme – Architektur von DBMS – Einführung in SQL Stoffumfang in Vorlesungsdoppelstunden: Stand: 25.06.2007 2.0 c 2007 Udo Kelter Metadaten 9.1 195 Einordnung und Motivation Informell definiert man Metadaten als “Daten über Daten”, also Daten, die andere (Nutz-) Daten beschreiben oder einordnen, sie besser verständlich machen, ihre Struktur darstellen usw. Diese Definition unterstellt, daß es andere Daten gibt (oder gab oder geben wird, der Zeitpunkt ist unerheblich) und daß die Metadaten einen vorhandenen Informationsbedarf stillen. Der Begriff Metadaten ist alt, er wird immer wieder in neuen Kontexten und in neuen Variationen benutzt. Er ist ferner mit weiteren komplexen Begriffen wie Metaschema, Metamodell und Meta-CASE verbunden. Schließlich ist die Trennung zwischen Daten und Metadaten nicht immer eindeutig. Dies alles erklärt die regelmäßig auftretenden Konfusionen um diese Begriffe. Für Metadaten wichtige Kontexte waren und sind: – Dokumentverwaltung: Nutzdaten sind hier Bücher und andere elektronische Dokumente, Metadaten sind Angaben über Autor, Publikationsjahr, Verleger, ggf. persönliche Anmerkungen usw. Die wichtigste Dokumentsammlung ist inzwischen sicherlich das WWW; die Bezeichnung Metadaten wird seit einigen Jahren zunehmend mit diesem Kontext verbunden. – Datenbanken: hier treten neben den Nutzdaten diverse Arten von Metadaten auf, die wichtigsten sind die konzeptuellen Schemata. – Programmierung: in objektorientierten Sprachen ist das Prinzip der Reflexion (reflection) bzw. Introspektion verbreitet; bei Bedarf können hier Metadaten dynamisch erzeugt werden, die Informationen über die Typstruktur von Objekten darstellen. – System-Modellierung: man kann die Struktur von Modellen mittels Metamodellen spezifizieren; die UML benutzt diesen Ansatz durchgängig In den folgenden Abschnitten analysieren wir die vorstehenden Fälle detaillierter, um Gemeinsamkeiten und Unterschiede herauszuarbeiten. 196 9.1.1 Metadaten Metadaten in Datenbanken Beim Stichwort Datenbankinhalt denkt man oft nur an die eigentlichen Nutzdaten, z.B. bei einer Adreßdatenbank an die Tupel, die jeweils eine Adresse darstellen. Auch wenn von Datenbankabfragen bzw. Datenmanipulationsoperationen die Rede ist, sind i.d.R. diese Nutzdaten gemeint. Neben den Nutzdaten gibt es aber noch weitere Daten, die ebenfalls mehr oder weniger notwendiger Inhalt einer Datenbank sind und die i.d.R. eigene Zugriffsschnittstellen haben: 1. die Datenbankschemata, also insb. die Definitionen der applikationsspezifischen Typen 2. Daten über die zugelassenen Benutzer und deren Rechte 3. Daten über die physische Organisation der Datenbank (z.B. Aufteilung auf Dateien oder logische Plattenlaufwerke, Datenträger, Archive u.ä.) und ggf. interne Schemata 4. ggf. Daten über integrierte Applikationen und speziell bei objektorientierten DBMS Daten über die Operationen einzelner Objekttypen 5. Angaben zur Herkunft der Daten: z.B. kann zu jedem Datum interessieren, wann und von welchem Benutzer es um letzten Mal geändert wurde An Rande erwähnenswert sind transiente Hilfsdaten, z.B. über die angemeldeten Anwendungsprozesse und die von ihnen gehaltenen Sperren. Bei manchen DBMS kann man diese Daten abfragen und so spezielle Informationsbedürfnisse befriedigen. Transiente Metadaten betrachten wir i.f. nicht weiter. Die im Kontext von DBMS auftretenden Arten von persistenten Metadaten können wir danach gruppieren, wer ggf. diese Daten lesen oder ändern möchte und welche Schnittstellen dafür benötigt werden: 1. Eine erste Gruppe persistenter Metadaten dient primär dazu, die logische Struktur der Daten zu beschreiben und das Verständnis von Sinn und Zweck der Daten zu unterstützen; man kann hier von semantischen Metadaten reden. Hierzu zählen die externen und Metadaten 197 konzeptuellen Schemata, Angaben zur Herkunft der Daten und Angaben zu den Applikationen, in denen die Daten verwendet werden. Für diese Metadaten muß es Schnittstellen geben, durch die die Daten von Applikationen abgefragt und ggf. auch geändert werden können. Ferner sind entsprechende Standard-Dienstprogramme wünschenswert; benutzt werden sie von Applikationsentwicklern beim Entwickeln und Testen der Applikationen und teilweise auch von Endnutzern. 2. Eine zweite Gruppe von persistenten Metadaten dient vor allem administrativen Zwecken. Hierzu zählen die internen Schemata, Zugriffsrechte, Verwaltung der Datenträger usw. Diese Metadaten spielen normalerweise (zum Glück) keine Rolle für die Applikationslogik oder den Endbenutzer, sie werden typischerweise nur vom Datenbank- bzw. Systemadministrator benutzt. Für die administrativen Metadaten muß es i.w. die gleichen Schnittstellen für Abfragen und Änderungen geben wie für die semantischen. Die Trennlinie zwischen semantischen und administrativen Metadaten ist nicht scharf, sie hängt von den individuellen Informationsbedürfnissen ab. Häufig besteht an den administrativen Metadaten kein Interesse, daher sie werden nicht als Metadaten wahrgenommen. 9.1.2 Metadaten in der Dokumentverwaltung Klassische Fälle von Dokumentsammlungen sind elektronische Bibliotheken und Büroinformationssysteme. Während diese Sammlungen noch halbwegs strukturiert sind, ist das WWW als “Dokumentsammlung” extrem heterogen und unstrukturiert. Dementsprechend schwierig ist es, in solchen nicht oder nur schwach strukturierten Datenbeständen zu suchen und Metadaten zu systematisieren. Metadaten sind hier vor allem dazu gedacht, die Suche nach Dokumenten zu unterstützen. Eine wichtige Methode, die Strukturen von Nutzdaten besser erkennbar zu machen, besteht darin, zu trennen zwischen 198 Metadaten – inhaltlich relevanten Daten, die in XML-Dateien gespeichert werden, und – Formatierungsangaben bzw. Layout-Daten, die z.B. in Style-Sheets verwaltet werden. Formatierungsangaben sind oft nicht wirklich Teil der Nutzdaten, weil sie abhängig von Benutzerpräferenzen oder Anzeigekontexten geändert werden. Die Struktur von XML-Dateien kann durch Dokumenttypdefinitionen (oder XML-Schemata) beschrieben werden; diese sind konzeptuell vergleichbar mit Datenbankschemata. 9.1.3 Metadaten vs. Nutzdaten Bei vielen Metadaten stellt sich die Frage, wieso man sie nicht als Nutzdaten ansieht, vor allem wenn auch der Endnutzer darauf zugreift, und ob hier nicht die konzeptionelle Trennung zwischen Nutzdaten und Metadaten zerstört wird. Die Antwort ist: 1. Daten sind dann Metadaten, wenn es einen Nutzdatenbestand gibt (oder gab oder geben wird), den die Metadaten beschreiben, und wenn die Metadaten zur Interpretation dieser Nutzdaten tatsächlich genutzt werden. Metadaten beziehen sich immer auf einen Nutzdatenbestand, ohne diesen sind sie keine Metadaten. Die tatsächliche Nutzung ist eine Frage des Standpunkts oder der Systemgrenzen, kann also subjektiv unterschiedlich beurteilt werden. Ein Beispiel sind Analyse-Datenmodelle (ER-Diagramme oder Analyse-Klassendiagramme): diese sind Metadaten für eine Person, die sie gebraucht, um entsprechende Nutzdaten zu verstehen oder zu dokumentieren, und nur Nutzdaten für einen ER- oder UML-Diagrammeditor. 2. Die Speicherungsform spielt keine Rolle dafür, ob Daten Metadaten sind oder nicht. Man kann z.B. die DB-Schemata als Text repräsentieren oder durch Tabelleninhalte. Unabhängig von der Speicherungsform sind die Schemata immer Metadaten. Metadaten 199 3. Wer bzw. welches System die Metadaten ausnutzt, um die Nutzdaten zu interpretieren, ist ebenfalls unerheblich; entscheidend ist, daß die Metadaten überhaupt für diesen Zweck genutzt werden. In manchen Fällen werden Metadaten in der Bedienschnittstelle eines Informationssystems angezeigt, damit Anwender die Nutzdaten verstehen und einordnen können; ein Anwender nutzt die Metadaten mental aus, um die Nutzdaten richtig zu interpretieren. Metadaten werden oft auch ausgenutzt, um die Nutzdaten maschinell zu interpretieren oder zu verarbeiten. Hauptbeispiel sind die konzeptuellen Schemata; im DBMS-Kern werden sie dazu benutzt, um Schnittstellen zu den Nutzdaten zu realisieren, in Browsern oder ähnlichen Applikationen dazu, Standard-Darstellungen der Nutzdaten zu erzeugen. 9.1.4 Selbstreferentialität Eine ähnliche Frage wie die nach dem Unterschied zwischen Nutzdaten und Metadaten ist die Frage, ob man die Metadaten wie normale Nutzdaten, also im gleichen Datenbankmodell mittels eines passenden Schemas modellieren soll. Die Antwort ist: Für die Speicherungsform und technische Handhabung der Metadaten stehen im Prinzip alle Optionen offen, also auch die Modellierung im gleichen Datenbankmodell wie die Nutzdaten oder sogar die Speicherung in der gleichen Installation. Details hängen natürlich vom Datenbankmodell ab. Weiter unten werden wir am Beispiel von relationalen Datenbanken zeigen, wie man relationale Schemata durch Tabellen repräsentieren kann. Sofern Datenbankschemata oder vergleichbare Typdefinitionen eines Datenverwaltungssystem (DVS) als Nutzdaten repräsentiert werden, bezeichnet man dies auch als Selbstreferentialität32 . Die 32 Der Begriff Selbstreferentialität ist nicht optimal, aber es gibt keinen völlig überzeugenden. Nicht gemeint ist hier Rekursion oder eine Referenz eines Objekts auf sich selbst. Selbstreferenzierung ist eigentlich ein linguistischer Begriff und bezeichnet das Phänomen, daß ein Text direkt oder indirekt Aussagen über sich selbst macht (“Jede Regel hat Ausnahmen.”). Es treten mehrere Sprachebenen auf, die Aussagen über den Text liegen auf einer Meta-Sprachebene. 200 Metadaten selbstreferentielle Verwaltung bzw. Repräsentation von Metadaten ändert natürlich nichts an dem inhaltlichen Charakter der Metadaten, Metadaten werden nicht zu Nutzdaten, nur weil sie technisch genauso wie die Nutzdaten verwaltet werden. Die Selbstreferentialität liegt insofern nahe, als die Datenbankschemata und andere DB-Metadaten sowieso innerhalb der Datenbank-Installation benötigt werden und irgendwie verwaltet werden müssen. Vorteilhaft ist ferner, daß man die Standardschnittstellen und Standardeditoren des Systems verwenden kann, um die Metadaten zumindest auszulesen. Veränderungen an den Metadaten dagegen verursachen erhebliche Probleme, die wir später diskutieren werden. 9.1.5 Sprachebenen in der Linguistik Metadaten weisen viele Parallelen zum Konzept der Metasprachen auf, das aus der Linguistik stammt. Eine zentrale Erkenntnis der Linguistik ist, daß sprachliche Aussagen auf verschiedenen semantischen Sprachebenen (anders gesagt Bedeutungsebenen) stehen können: Die Basis bilden Aussagen in der sogenannten Objektsprache (“Hans Maier wohnt in Essen.”). Nicht mehr zur Objektsprache, sondern zur Metasprache erster Stufe gehören Aussagen über Aussagen der Objektsprache, z.B.: “Nachnamen fangen mit einem Großbuchstaben an.” “Eine Postleitzahl hat 5 Ziffern.” “Deutsche Sätze haben meist ein Subjekt und ein Prädikat.” Die vorstehenden Beispiele machen Aussagen zur Wortbildung und Syntax der Objektsprache. Darüber hinaus könnnen auch Aussagen zur Bedeutung und zum Wahrheitsgehalt von Aussagen gemacht werden: “Seine Behauptung ist eine Unverschämtheit.” “Dieses Buch enthält viele Fehler.” “Kinder und Betrunkene lügen nicht.” “Wenn A und B Aussagen sind, wenn eine Aussage der Form ‘aus A folgt B’ gilt und wenn A zutrifft, dann trifft auch B zu.” Metadaten 201 Das letzte Beispiel zeigt, daß die mathematische Aussagenlogik Aussagen in der Metasprache enthält. Die Metasprache zweiter Stufe enthält Aussagen über Aussagen der Metasprache erster Stufe. Der vorige Abschnitt enthält viele derartige Aussagen. Die Parallele zwischen Metadatenebenen und Sprachebenen ergibt sich daraus, daß Daten ebenfalls Aussagen sind, nur nicht in der Syntax einer Umgangssprache, sondern etwas kryptischer und platzsparender codiert. Nutzdaten entsprechen daher Aussagen in der Objektsprache, Metadaten Aussagen in der Metasprache. Wie wir später sehen werden, muß man analog zu Metasprachebenen auch Metadatenebenen unterscheiden. Ein großes Problem entsteht für die Linguistik dadurch, daß die Umgangssprache alle Sprachebenen zugleich beinhaltet und daß eine einzige Aussage Begriffe und Bedeutungen auf mehreren Ebenen haben kann (“Dieser Satz hat fünf Worte.”). Wenn eine Aussage auf der Metaebene auf sich selbst Bezug nimmt und dabei etwas über ihre eigene Wahrheit oder Falschheit aussagt, kann ein Paradoxon entstehen (“Dieser Satz ist falsch.” “Keine Regel ohne Ausnahme.”). Bei Daten und Metadaten existieren normalerweise keine analogen Probleme, weil diese durch den Anwendungskontext genau einer Bedeutungsebene zugeordnet sind. Von der Linguistik kann die Informatik lernen, daß man sich massive Probleme einhandelt, wenn man Bedeutungsebenen nicht voneinander strikt trennt. 9.2 9.2.1 Arten von Metadaten Typbezogene vs. entitätsbezogene Metadaten Sowohl bei Datenbanken wie auch in der Dokumentverwaltung kann man zwei Arten von Metadaten unterscheiden: – entitätsbezogene Metadaten: diese sind einzelnen Nutzdatengranulaten bzw. den dadurch dargestellten realen Entitäten zugeord- 202 Metadaten net. Beispiel: Publikationsdatum oder Seitenzahl eines Buchs. Entitätsbezogene Metadaten müssen für jedes Nutzdatengranulat individuell verwaltet und wie normale Attribute der Nutzdaten modelliert werden. Sie können integriert mit den Nutzdaten oder separat verwaltet werden. – typbezogene Metadaten: XML-Dokumenttypdefinitionen, Datenbankschemata, Data Dictionary-Einträge usw. sind Metadaten, die einheitlich für eine Sammlung von Dokumenten, Tupeln, Datensätzen usw. eines bestimmten Typs gelten. Jedes einzelne Nutzdatengranulat muß einen eindeutigen Typ haben, über den Typ werden ihm die typbezogenen Metadaten indirekt zugeordnet. Entitätsbezogene Metadaten werden in diesem Lehrmodul nicht weiter betrachtet. 9.2.2 Instantiierbare Metadaten Oben wurden Datenbankschemata als Beispiele von typbezogenen Metadaten genannt – daß ein Nutzer ein Datenbankschema zum Verständnis der Datenbank benutzt, mag durchaus vorkommen, viel häufiger werden Datenbankschemata aber benutzt, um die Datenbank zu “konfigurieren” und die Aufnahme von Nutzdaten überhaupt erst zu ermöglichen. Typbezogene Metadaten, die von einem Datenverwaltungssystem (DVS) instantiiert werden können, bezeichnen wir als instantiierbare Metadaten oder Schemata für dieses DVS. Metadaten sind nicht von sich aus instantiierbar, sondern nur, wenn ein DVS vorhanden ist, das die Instantiierung im Detail bestimmt. Charakteristisch für den Umgang des DVS mit den instantiierbaren Metadaten ist: – Das DVS wird durch Schemata konfiguriert. D.h. dieses DVS realisiert eine Funktion, mit der ein Schema in das DVS übernommen werden kann (Beispiel: CREATE TABLE ...); danach können Daten gemäß diesem Schema (“Instanzen”) in einer Installation des DVS erzeugt, geändert, gelöscht und durchsucht werden (durch Funktio- Metadaten 203 nen analog zu INSERT, UPDATE, DELETE und SELECT in relationalen DBMS). – Alle vorgenannten Funktionen sind insofern generisch, als sie mit beliebigen Basistypen, die in einem Schema definiert sind, arbeiten können, und wenigstens einen Typ-Parameter haben, in denen ein zu benutzender Basistyp explizit angeben wird (z.B. INSERT INTO relationR ..., SELECT attributeA FROM relationR ...). – Die Grundzüge der generischen Funktionen werden durch das zugrundeliegende Datenbankmodell definiert. Wie diese Funktionen im Detail arbeiten und ob es ggf. weitere ergänzende Funktionen gibt, wird erst durch das konkrete DVS bestimmt. Beispielsweise könnten verschiedene relationale DBMS mit signifikant verschiedenem Funktionsumfang durch die exakt gleichen Schemata konfigurierbar sein. Was es also konkret bedeutet, daß eine Instanz von instantiierbaren Metadaten gebildet wird und in welcher Form eine Instanz danach existiert, hängt in groben Zügen vom Datenbankmodell und im Detail von dem konkreten DVS ab, wird jedenfalls nicht allein durch die Schemata (egal in welcher Darstellung) spezifiziert. Für sich alleine genommen sagen die Schemata insb. nichts darüber aus, – welche enthaltenen Typen einzeln instantiierbar sind (i.d.R. sind z.B. Attribute nicht einzeln instantiierbar) und – welche generischen Funktionen vorhanden sind, welche Parameter sie haben, ob sie mit einzelnen Instanzen oder mit Mengen von Instanzen arbeiten und wie sie im Detail arbeiten. Typbezogene vs. instantiierbare Metadaten. Instantiierbare Metadaten sind definitionsgemäß typbezogenen, aber nicht alle typbezogenen Metadaten sind instantiierbar. Ein Beispiel für typbezogene, nicht instantiierbare Metadaten sind Angaben zu einem Datenfeld, warum und auf wessen Wunsch es eingeführt wurde und wie es pragmatisch zu benutzen ist. Metadaten sind nur dann instantiierbare Me- 204 Metadaten tadaten, wenn sie die generischen Funktionen des unterstellten DVS beeinflussen. Instantiierbare Metadaten haben einen wesentlich anderen Charakter als “normale” Metadaten: – Statt die Nutzdaten nur deskriptiv zu ergänzen oder unscharf zu beschreiben, sind instantiierbare Metadaten Vorschriften, wie die Nutzdaten strukturiert sein müssen. – Während normale Metadaten frei gestaltet werden können, müssen instantiierbare Metadaten völlig konsistent mit den Konzepten des unterstellten DVS und dessen Datenbankmodell sein. Wie instantiierbare Metadaten aussehen können, wird sehr genau durch das unterstellte DVS vorgegeben, der eventuelle Informationsbedarf von Nutzern spielt keine Rolle. Instantiierbare Metadaten sind daher letztlich als eine von mehreren denkbaren Repräsentationen der Schemata des unterstellten DVS anzusehen. – Die Schemata müssen auf jeden Fall innerhalb des Datenbankkerns verwaltet werden, während alle anderen Metadaten außerhalb des Datenbankkerns, also wie normale Nutzdaten verwaltet werden. Instanz-von-Beziehungen. Sofern das DVS die instantiierbaren Metadaten (und ggf. weitere typbezogene Metadaten) selbstreferentiell darstellt, liegt es nahe, die Nutzdaten mit ihren Typdefinitionen zu verbinden. Technisch kann dies auf unterschiedliche Weise geschehen, z.B. durch Instanz-von-Beziehungen von den Nutzdaten zu den selbstreferentiellen Schema-Darstellungen. Im Endeffekt können Applikationen, die mit den Nutzdaten arbeiten, die zugehörigen selbstreferentiell repräsentierten Metadaten lokalisieren, auslesen und bei der Verarbeitung der Nutzdaten ausnutzen. Oft werden in der Applikation selbst gemäß dem Analysemuster Exemplartyp (s. [AMU]) Beschreibungen von Typen und deren Instanzen verwaltet und durch Instanz-von-Beziehungen verbunden. Wie die Instanzen erzeugt und verwaltet werden, kann bei der Gestaltung der Applikation völlig frei entschieden werden. Die durch die Applikation Metadaten 205 bzw. das DBMS realisierten Instanz-von-Beziehungen haben daher eine völlig andere Bedeutung und dürfen trotz ähnlich klingender Namen nicht gleichgesetzt werden. 9.3 Selbstreferentialität in relationalen Datenbanken 9.3.1 Repräsentation relationaler Schemata durch Tabellen In relationalen Systemen werden Schemata üblicherweise selbstreferentiell repräsentiert. Der ANSI/ISO SQL-Standard von 2003 definiert eine Datenbank INFORMATION SCHEMA, die diverse Metadaten zu allen Relationen in allen Datenbanken einer Installation bereitstellt. Die Schemata werden durch rund 20 Tabellen repräsentiert, darunter die Tabellen SCHEMATA, TABLES, COLUMNS und TABLE CONSTRAINTS. Die Datenbank INFORMATION SCHEMA ist mit SELECT lesbar; verändert werden kann sie nur durch Kommandos wie CREATE TABLE, nicht hingegen durch die Elementaroperationen INSERT, DELETE und UPDATE. I.f. stellen wir eine stark vereinfachte Version der Inhalte dieser Datenbank vor. Angaben über die vorhandenen Tabellen und deren Attribute kann man selbstreferentiell bereitstellen mittels einer Tabelle tabellenattribute, die für jedes Attribut jeder Tabelle den Namen, Typ usw. angibt33 . Die benutzerdefinierte Relation kunden mit den Spalten Kundennummer, Kundenname, Wohnort und Kreditlimit würde innerhalb dieser Tabelle wie folgt repräsentiert: 33 Die hier definierte Tabellen tabellenattribute und idschluessel sind stark vereinfachte Versionen der Tabellen COLUMNS und TABLE CONSTRAINTS. Wir gehen hier vereinfachend davon aus, daß nur ein einziges Datenbankschema verwaltet werden muß und man sich implizit hierauf bezieht. 206 Metadaten Tabelle: tabellenattribute Tabellenname Attributname ... ... kunden Kundennummer kunden Kundenname kunden Wohnort kunden Kreditlimit ... ... Attributtyp ... integer char(40) char(25) decimal(5,0) ... Vorgabewert ... – – – 0,0 ... Die vorhandenen Identifizierungsschlüssel könnte man durch die folgende Tabelle (idschluessel) darstellen. Eine Tabelle kann mehrere Identifizierungsschlüssel haben, diese werden durch das Attribut IdSchlNr durchnumeriert. Jeder einzelne Identifizierungsschlüssel besteht aus einer Menge von Attributen, pro Attribut wird ein Tupel in der Tabelle eingetragen. Tabelle: idschluessel Tabellenname IdSchlNr ... ... kunden 1 ... ... Attributname ... Kundennummer ... Letztlich kann man alle Angaben über Tabellen, Domänen, Sichten, Primärschlüssel, Fremdschlüssel usw., die in den SQL-Kommandos zur Schemaverwaltung ( CREATE TABLE usw.) textuell dargestellt werden, auch in tabellarischer Form repräsentieren. Allerdings deutet bereits das vorstehende Beispiel darauf hin, daß die tabellarische Darstellung aller Details eines Schemas nicht besonders übersichtlich ist und die textuelle Darstellung deutlich lesbarer ist. Die Komplexität der Schemata kann reduziert werden, wenn man für Detailstrukturen eine textuelle Darstellung wählt. In unserem Beispiel haben wir dies für die Attributtypen so gemacht: Texte wie “decimal(5,0)” beinhalten mehrere Angaben, für die bei einer komplett relationalen Modellierung eigene Spalten vorhanden sein müßten. Das Prinzip der Selbstreferentialität ist nicht nur bei den Schemata, sondern bei allen Arten von Metadaten anwendbar, z.B. administrati- Metadaten 207 ve Metadaten, insb. sofern der Bedarf besteht, diese Metadaten ohne zusätzliche Schnittstellen abfragen oder sogar verändern zu können. Das Prinzip der Selbstreferentialität ist im Prinzip bei allen Datenbankmodellen anwendbar, nicht nur beim relationalen. Schemata und die viele andere Arten von Metadaten haben indessen eine komplexe Struktur, die spannende Frage ist, ob es die Modellierungsfähigkeiten des Datenbankmodells erlauben, diese Strukturen bequem zu modellieren. Das obige Beispiel zeigte bereits, daß das relationale Modell nur bedingt geeignet ist, relationale Schemata zu modellieren. 9.3.2 Zugriff auf selbstreferentiell repräsentierte Schemata Der offensichtliche praktische Nutzen der Selbstreferentialität ist, daß man die Standardschnittstellen des Systems verwenden kann, um die Schemata auszulesen. Man braucht keine eigene Schnittstelle im DBMS-Kern zu realisieren; eine ggf. gewünschte andere Darstellung - z.B. textuell - kann durch eine Applikation außerhalb des Datenbankkerns realisiert werden. Ob man die Schemata auch nach der gleichen Methode verändern kann, ist hingegen fraglich: 1. Wenn wir wieder auf das Beispiel der Tabelle tabellenattribute zurückkommen, dann müßte das Löschen eines Tupels zur Folge haben, daß in der betroffenen Tabelle ein Attribut entfernt und ggf. Teile der Datenbank konvertiert werden. Dies ist aber u.U. überhaupt nicht möglich oder nicht im Normalbetrieb; der Versuch, das Tupel zu löschen, müßte dann mit einer speziellen Fehlermeldung abgelehnt werden. Dies bedeutet, daß sich die Semantik von Standardoperationen ändert, wenn man sie auf Metadaten anwendet, und zwar durch eine Vielzahl von Nebeneffekten und zusätzliche Fehlerfälle. Dies ist umständlicher und schlechter verstehbar als eigene Operationen. 2. Die Struktur der Metadaten ist oft relativ komplex und kann komplizierte Integritätsbedingungen aufweisen. Da das zugrundeliegende Datenbankmodell normalerweise recht elementare Operationen 208 Metadaten aufweist, braucht man mehrere elementare Operationen, um eine korrekte Typdefinition zu konstruieren oder abzuändern (z.B. bei einer Objekttypdefinition wird zuerst der Typ erzeugt und dann werden ‘Eltern’-Beziehungen zu den Supertypen erzeugt, dann die Attribute zugeordnet). Die einzelnen Änderungen dürfen zunächst keine Auswirkungen auf die Metadaten haben, erst wenn die gesamte Sequenz von Operationen ausgeführt ist, können die Metadaten tatsächlich geändert werden. Da das DBMS von sich aus den Abschluß der Änderung nicht erkennen kann, benötigt man zusätzlich eine Operation, die den Abschluß signalisiert; das DBMS muß dann herausfinden, welche Detailänderungen vorgenommen wurden, und prüfen, ob der neue Zustand korrekt ist. Die Vorstellung, daß durch normale Datenmanipulationsoperationen implizit auch die Metadaten verändert werden, kann hier praktisch nicht mehr aufrechterhalten werden. Aufgrund der vorstehenden Probleme eignet sich der selbstreferentielle Ansatz i.a. nur für das Auslesen, nicht aber für das Ändern von Metadaten. Daher werden im ANSI/ISO SQL-Standard alle Tabellen mit Metadaten als schreibgeschützt definiert. 9.3.3 Metatypen und Meta-Metadaten Die Metadaten haben natürlich auch Typen; diese Typen bezeichnet man als Metatypen, entsprechende Schemata als Metaschemata. Ein Beispiel für ein Metaschema ist das Schema unserer oben erwähnten Tabelle tabellenattribute. Die Metatypen kann man wiederum selbstreferentiell repräsentieren; diese Daten sind Daten über Metadaten, also Meta-Metadaten. Die folgende Tabelle zeigt dies für die Metatypen aus den Tabellen tabellenattribute und idschluessel. Man beachte, daß die Spaltenköpfe der beiden genannten Tabellen hier zu Datenwerten in der Spalte Attributname werden. Metadaten Tabelle: datenbankmodellKonzepte Tabellenname Attributname Attributtyp tabellenattribute Tabellenname char(200) tabellenattribute Attributname char(200) tabellenattribute Attributtyp char(200) tabellenattribute Vorgabewert char(1000) idschluessel Tabellenname char(200) idschluessel IdSchlNr integer idschluessel Attributname char(200) 209 Vorgabewert – – – – – – – Die Tabelle wurde datenbankmodellKonzepte genannt, weil die Metatypen den Konzepten aus dem Datenbankmodell entsprechen. Es war relativ leicht, die Tabelle datenbankmodellKonzepte hinzuschreiben und den Begriff Meta-Metadaten zu bilden. Bei genauem Hinsehen ist aber nicht klar, ob das überhaupt sinnvoll ist, was wir da gemacht haben: 1. Meta-Metadaten stillen eigentlich keinen Informationsbedarf, der bei der Interpretation oder Verarbeitung der Metadaten entstehen würde. Entwickler von Applikationen und Datenbank-Nutzer wissen sowieso, daß Attribute einen Namen, Typ und Vorgabewert haben, dahingehend besteht kein Informationsbedarf. Wenn diese Kenntnisse über das Datenmodell nicht vorhanden wären, könnte man außerdem die Meta-Metadaten, die ja als Nutzdaten repräsentiert werden, gar nicht abfragen, denn um die Abfrage formulieren zu können, muß man dieses Wissen schon haben. Allenfalls sind Abfragen sinnvoll, wie lang z.B. der Name einer Tabelle maximal sein darf; dies sind aber technische Details, die man eher als Konfigurationsparameter der generischen Funktionen des DBMS-Kerns auffassen wird. Der DBMS-Kern konsultiert auch nicht die Meta-Metadaten, bevor er auf die Metadaten zugreift, um herauszufinden, ob er diese Metadaten als Schemata von relationalen Tabellen oder als Dokumenttypdefinitionen von XML-Dateien oder Konfiguration einer 210 Metadaten Suchmaschine interpretieren soll – die generischen Funktionen, die der Laufzeitkern eines relationalen DBMS realisiert, können nur mit relationalen Tabellen arbeiten, mit sonst nichts. 2. Die Meta-Metadaten können nicht ohne weiteres (signifikant) geändert werden, ohne zugleich den DBMS-Kern umzuprogrammieren. Ändert man das Metaschema ab, so ist deswegen alleine überhaupt nicht klar, wie der DBMS-Kern mit diesen neuen Strukturen umgehen soll. Wir könnten z.B. in der Tabelle datenbankmodellKonzepte ein neues Tupel (’tabellenattribute’, ’Geheimhaltungsstufe’, ’char(200)’, ’’ ) eintragen. Was das bedeuten soll, ist völlig unklar. Man müßte zunächst klären, wie das Konzept einer Geheimhaltungsstufe zu verstehen ist, dazu passend müßte ggf. die Syntax des CREATE TABLE-Kommandos erweitert werden, und die Wirkung der generischen Funktionen müßte geeignet modifiziert werden. Außerdem müßte natürlich die Metadaten-Tabelle tabellenattribute eine weitere Spalte Geheimhaltungsstufe bekommen. Im Endeffekt müssen wesentliche Teile des DBMS-Kerns umgestaltet werden. Ferner müßten ggf. sogar alle Nutzdaten entsprechend angepaßt werden. Als Konsequenz aus den vorstehenden Überlegungen sind das Metaschemata eines DBMS und dessen selbstreferentielle Repräsentation durch Meta-Metadaten, also hier die Tabelle datenbankmodellKonzepte, immer komplett statisch. Selbstreferentiell repräsentierte Metaschemata sind daher (in üblichen DBMS) in der Praxis weitgehend sinnlos! Man kann diese Metadaten nicht ändern, und um diese Daten abzufragen, muß man viele Konzepte schon vorher kennen, weil sie in der Abfrage verwendet werden. 9.3.4 Übersicht über die semantischen Ebenen Man kann die auftretenden Daten bzw. selbstreferentiellen Schemarepräsentationen je nach ihrer Bedeutung in mehrere Ebenen einteilen, diese Ebenen sind in der Tabelle in Bild 9.1 zusammengefaßt. Lesehinweise zu dieser Tabelle: Auf Ebene 0 werden Nutzdaten Metadaten Nr. Bedeutungsebene (Daten repräsentieren...) 2 1 0 Meta-Metadaten: Repräsentationen von Metaschemata / Metatypen Metadaten: Repräsentationen von Schemata / Typen Nutzdaten: Repräsentationen von Realwelt-Entitäten 211 Beispiel einer dargestellten Entität Begriff “Tabelle” Tabellenschema “Adressen” eine Adresse Syntax und Semantik der Daten wird bestimmt durch ... MetaMetaschema veränderbar Metaschema + Datenbankmodell + DBMS Schema + Dokumentation ja nein ja Abbildung 9.1: Hierarchie der Bedeutungsebenen von Daten in einer Datenbank verwaltet. Die “syntaktische” Struktur der Nutzdaten wird durch ein Schema vorgegeben, das allerdings komplexere Konsistenzbedingungen i.d.R. nicht beinhaltet; letztere können z.B. in einem Data Dictionary verbal dokumentiert sein, insofern wird noch nicht einmal die syntaktische Struktur der Daten durch das Schema vollständig dargestellt. Überhaupt nicht dargestellt wird die Bedeutung der Daten. Schemata werden auf Ebene 0 nur genutzt, aber nicht in irgendeiner Form als Daten repräsentiert oder verwaltet. Auf Ebene 1 werden Repräsentationen von Schemata verwaltet. Daß dies in der syntaktischen Form von Tabellen geschieht, ist willkürlich, man könnte genausogut eine textuelle Darstellung verwenden34 . Entscheidend ist, daß Schemata dargestellt werden. Für das Metaschema gelten die gleichen prinzipiellen Bemerkungen wie für das Schema: es stellt nur die syntaktische Struktur der Schemata weitgehend dar, 34 Die textuelle Darstellung wäre durch eine Grammatik bzw. Sprachdefinition strukturiert! Man kann übrigens die Daten auf alle Ebenen textuell darstellen und erhält dann eine Hierarchie von Sprachebenen. In der Tabelle muß dazu überall “Schema” durch “Grammatik” ersetzt werden. 212 Metadaten aber nicht vollständig, und die Bedeutung der Schemata überhaupt nicht. Die letzte Spalte gibt an, ob diese Daten innerhalb eines DBMS durch die Nutzer veränderbar sind. Man kann diese Daten- und Schemahierarchie beliebig nach oben fortsetzen, es bringt aber nichts ein. Schon auf Ebene Metadaten stößt das Prinzip der Selbstreferentialität an Grenzen, denn ändernde Standard-Operationen sind nicht mehr erlaubt35 . Die selbstreferentielle Repräsentation der Metatypen ist sinnlos, weil die Metatypen eines DBMS komplett statisch sind. 9.3.5 Meta-Ebenen vs. Implementierungsebenen von Datenbankobjekten Die semantischen Meta-Ebenen in Bild 9.1 werden leicht verwechselt mit den Ebenen der Abstraktionshierarchie für Datenbankobjekte, die in Abschnitt 3.4 vorgestellt wird. Prinzipiell haben diese beiden Hierarchien nichts miteinander zu tun, sie sind völlig orthogonal zueinander. Nutzdaten, Metadaten und ggf. Meta-Metadaten existieren alle nebeneinander und gleichzeitig als persistente Daten, sie müssen in irgendeiner Form auf den persistenten Medien gespeichert und beim Lesen von dort in mehreren Schritten an die Schnittstellen gebracht werden. Ein extern sichtbares Tupel, das z.B. eine Adresse darstellt, existiert intern in absteigender Reihenfolge der Ebenen als Pufferbereich, als Inhalt eines Speichersatzes, als Teil eines Blocks und letztlich als magnetische Struktur auf einer Platte – in allen Fällen sind dies semantisch gesehen die gleichen Nutzdaten, nur die Implementierungsebene unterscheidet sich. In der nachfolgenden Tabelle sind Nutzdaten in Spalte 2 skizziert und jeweils mit “Std.” für Standardverfahren mar35 Zur Klarstellung sei daran erinnert: wir diskutieren hier nur instantiierbare Metadaten, also Repräsentationen von Schemata. Andere Metadaten können natürlich mit Standard-Operationen geändert werden, da sie keine operationale Bedeutung haben. Obwohl es sich semantisch um Metadaten handelt, können sie technisch wie Nutzdaten behandelt werden. Metadaten 213 kiert. Implementierungsebene Nutzdaten n-Tupel-Ebene 1-Tupel-Ebene Speichersatzebene Std. Std. Std. Metadaten (Schemata) nur lesen nur lesen Std. Segmentebene Std. Std. Metametadaten (Metaschemata) geeignet?? geeignet?? nur teilw. sinnv. nur teilw. sinnv. Analog wie Nutzdaten müssen auch die Metadaten über die komplette Implementierungshierarchie hinweg realisiert werden. In der vorstehenden Tabelle sind Metadaten in Spalte 3 skizziert, die parallelen Spalten für Nutzdaten und Metadaten sollen andeuten daß beide Arten von Daten gleichzeitig nebeneinander existieren. Auf den beiden unteren Ebenen kann man die Metadaten wie normale Daten verwalten, man kann aber ebensogut abweichende Implementierungen verwenden, weil auf Metadaten anders als auf Nutzdaten zugegriffen wird. Auf der 1-Tupel-Ebene kann man immerhin noch für lesende Zugriffe die Standardschnittstellen und Implementierungsverfahren anbieten, für schreibende Zugriffe sind andere Schnittstellen sinnvoller. Auch dann, wenn Standardverfahren zum Einsatz kommen, und unabhängig von der Implementierungsebene sind die Daten, die z.B. ein Schema darstellen, immer Metadaten. Metametadaten, also speziell das Metaschemata, kann man theoretisch ebenfalls selbstreferentiell repräsentieren; diese Daten existieren dann parallel zu den Nutzdaten und Metadaten ebenfalls über alle Implementierungsebenen. Wie aber schon früher diskutiert können aus diversen praktischen Gründen Metametadaten nur mit sehr starken Einschränkungen selbstreferentiell repräsentiert werden. Weil es auch wenig Vorteile einbringt, liegt es nahe, komplett darauf zu verzichten. 214 9.4 9.4.1 Metadaten Selbstreferentialität in XML Aufbau von XML-Dateien XML-Dateien enthaltenen i.w. zwei Teile: – einen Nutzdatenbestand, dessen Struktur ein Baum ist. Der Baum wird textuell dargestellt. Ein Teilbaum, auch Element genannt, wird in einem Textabschnitt dargestellt, der mit einem öffnenden tag beginnt, z.B. <Adresse>, und einem schließenden tag endet, z.B. </Adresse>. Jeder Knoten des Baums hat einen Typ, der Name des Typs steht in beiden tags. Im öffnenden tag können ferner Attributwertzuweisungen stehen, z.B. <Adresse AdrID=’A112’>. Hier ein Beispiel eines Teils der Nutzdaten: <Adresse AdrID=’A112’ > <Name>Frank</Name> <Vorname>Ulrich</Vorname> <Straße>Hauptstr.</Straße> <Hausnummer>5</Hausnummer> <Ort PLZ=’57076’>Siegen</Ort> </Adresse> <Adresse> .... </Adresse> – einer optionalen Dokumenttypdefinition (DTD), in der die Schachtelungsstruktur der tags definiert wird. Bei der DTD handelt es sich im Prinzip um eine kontextfreie Grammatik, die die Syntax und die inhaltliche Struktur des Textes, der die Nutzdaten darstellt, definiert. Hier können wir folgenden sehr interessanten Sachverhalt feststellen: Die Bedeutungsebenen von Daten, Metadaten usw. in Datenbanken (s. Tabelle 9.3.4) gelten analog für Texte, Grammatiken, Meta-Grammatiken usw. Das Prinzip der Selbstreferentialität wird somit (mit hier nicht interessierenden Ausnahmen) auch in XML-Dateien in Form von DTDs Metadaten 215 oder XML-Schemata angewandt. Auf Details gehen spätere Lehrmodule über Transportdateien und die XML [TRD] ein. 9.4.2 Typ-Annotationen Eine spezielle, oft irreführende Form von Metadaten stellen die Typangaben in den Tags in XML-Dateien dar. Derartige Angaben zum Typ der Daten, die direkt in die Nutzdaten eingebettet sind, bezeichnen wir als Typ-Annotationen. Typ-Annotationen treten auch in Bibtex-Dateien und vielen anderen Transportdateiformaten auf. Als Beispiel betrachten wir wieder den obigen Ausschnitt aus einer XML-Datei, die in den Nutzdaten eine Adreßliste enthält. Die eigentlichen Adreßdaten sind offensichtlich Nutzdaten. Die Frage ist, ob die Namen der Elementtypen und Attribute Metadaten sind und welche Art von Metadaten hier vorliegt. Diese Namen kann man ohne weiteres gemäß der allgemeinen Definition, wonach Metadaten die Interpretation der Nutzdaten ermöglichen bzw. unterstützen, als entitätsbezogene Metadaten ansehen; dies ist abhängig von der subjektiven Verwendung dieser Daten. Unklar ist hingegen, ob diese Namen auch typbezogene Metadaten in dem Sinne sind, daß sie implizit ein Schema der Nutzdaten darstellen (ggf. redundant bei jeder Instanz). 9.4.2.1 Typ-Annotationen in schwach strukturierten Daten An dieser Stelle muß man sich bewußt machen, daß XML eigentlich für schwach strukturierte Daten gedacht ist, das sind Daten, deren Struktur extrem variantenreich ist und/oder sich ständig unvorhersehbar ändert. Das Fehlen von eindeutigen Typdefinitionen ist gerade das Wesensmerkmal schwach strukturierter Daten. In Datenbanken und in vielen Programmiersprachen haben Typen die zentrale Eigenschaft, für alle Instanzen des Typs eine einheitliche Struktur sicherzustellen; genau diese Eigenschaft ist unerwünscht bei schwach strukturierten Daten. Weil es für derartige Daten keine Schemata im Sinne von Datenbanken gibt, ist die Selbstreferentialität hier prinzipiell nicht sinnvoll. 216 Metadaten Wenn man, obwohl es kein Schema gibt, trotzdem etwas über die Struktur aller Instanzen eines Elementtyps wissen will, kann man bestenfalls die Kindelementtypen und Attribute, die bei den vorhandenen Instanzen dieses Elementtyps auftretenden, aufsammeln. Man findet aber mit dieser Methode viele Strukturmerkmale nicht sicher heraus: die zulässige Häufigkeit einzelner Kindelemente, Reihenfolgerestriktionen, bei Attributen wie z.B. AdrID die Art des Attributs36 . Ferner könnte die vollständige Typdefinition einer Adresse eine optionale Angabe der Anrede und des Landes beinhalten, die zufällig in den vorhandenen Nutzdaten nirgendwo auftritt. Die implizit durch die Typ-Annotationen gegebenen Typdefinitionen sind also i.a. vage und unvollständig. 9.4.2.2 Typ-Annotationen in strikt typisierten Nutzdaten Sofern die Daten strikt typisiert sind, also eine DTD (oder ein XMLSchema) vorhanden ist und nur gemäß der DTD gültige XML-Dateien betrachtet werden, interessiert die Frage nicht mehr, ob die tags implizit eine Typdefinition darstellen. Die Typnamen in den tags sind nunmehr als Referenzen auf die Typdefinitionen in der DTD zu verstehen, also als unidirektional implementierte “ist-Instanz-von”Beziehungen37 . Wenn man Typ-Annotationen als Referenzen auf Typdefinitionen versteht, ist es wenig sinnvoll, sie als entitätsbezogene Metadaten anzusehen, weil sie ja nur Referenzen auf etwas anderes sind und selbst nichts aussagen. Dies wird besonders offensichtlich, wenn die Typnamen keine intuitive Semantik vermitteln, sondern nur “sinnlose”, generierte Nummern sind: ..... <TypId117543>Frank</TypId117543> <TypId117544>Ulrich</TypId117544> 36 Möglich wäre ein ID-, IDREF-, IDREFS- oder CDATA-Attribut. Es kommt hier nicht darauf an, daß die Typdefinitionen tatsächlich technisch in einem XML-Format vorliegen, sondern daß sie im Anwendungskontext (z.B. innerhalb von Applikationen) als Referenzen auf Typdefinitionen interpretiert und benutzt werden. 37 Metadaten 217 ..... Der entscheidende Punkt ist hier, daß man (meist unbewußt) zu einem anderen Datenbankmodell übergegangen ist, nämlich zu einem Datenbankmodell mit streng typisierten Datengranulaten. In einem solchen Datenbankmodell hat jedes Datengranulat einen eindeutigen Typ, und für jeden Typ liegt eine vollständige Definition vor. Das relationale Datenbankmodell ist ein Beispiel hierfür. Bei einem streng typisierten Datenbankmodell müssen die internen Implementierungsstrukturen so gestaltet werden, daß zu jedem Datengranulat sein Typ festgestellt werden kann. Im relationalen Datenbankmodell wird dies i.d.R. dadurch realisiert, daß alle Tupel gleichen Typs in einem Container (einer Tabelle) verwaltet werden und die Typdefinition der Tabelle zugeordnet ist. Man kann aber auch die Datengranulate gemischt speichern, muß dann aber an jedem Datengranulat explizit eine Typangabe speichern. Ob man hierfür ausdrucksstarke Namen oder sinnlose Nummern verwendet, ist eine Implementierungsentscheidung. Konzeptuell wird in allen Fällen eine Referenz auf die volle Typdefinition realisiert. Eine XML-Datei entspricht bzgl. des Implementierungsniveaus einem B*-Baum in der Implementierungshierarchie für Datenbankobjekte38 . Die XML-Datei implementiert einen getypten Baum; man sieht (leider) die Implementierungsdetails komplett. Unsere Ausgangsfrage, ob bei strikt typisierten Nutzdaten die Typ-Annotationen Metadaten sind, ist letztlich nur Folge eines falsch gewählten Betrachtungsstandpunkts; hier werden Meta-Ebenen und Implementierungsebenen verwechselt (vgl. Abschnitt 9.3.5). 38 Man beachte die Analogie zwischen den Begriffen “physische Konsistenz” einer Datenbank und “Wohlgeformtheit / Validität” einer XML-Datei. Wenn eine Datenbank physisch inkonsistent ist, ist der intern sichtbare Inhalt nicht mehr korrekt gemäß den Schemata interpretierbar. Wenn eine XML-Datei infolge eines falsch geschriebenen Typnamens oder Fehlers in einem Tag nicht mehr valide bzgl. einer DTD bzw. wohlgeformt ist, wird ihr Inhalt nicht mehr von einem validierenden XML-Prozessor akzeptiert, sie kann nicht mehr verarbeitet werden. 218 Metadaten 9.5 9.5.1 Metadaten in der UML-Begriffswelt Bedeutungsebenen von UML-Modellen Die UML-Definition nutzt ebenfalls intensiv das Prinzip der Selbstreferentialität und setzt eine Hierarchie semantischer Ebenen ein, die auf den ersten Blick identisch zu der Hierarchie in Bild 9.1 erscheint, bei genauer Betrachtung aber erhebliche Unterschiede aufweist. Diese versteckten Begriffsdifferenzen führen notorisch zu Kommunikationsproblemen, zumal beide Begriffswelten in vielen Fällen parallel verwendet werden müssen. Der wichtigste derartige Fall ist die Transformation von Analyseklassendiagrammen in Datenbankschemata, die suggeriert, daß Analyseklassendiagramme und Datenbankschemata einander entsprechen; eben dies trifft, wie wir sehen werden, gerade nicht zu. Kürzel für die MetaEbene M3 M2 M1 M0 dieser Ebene zugeordnete Daten oder Realweltentitäten Beispiel einer Instanz Daten werden modelliert durch Repräsentation der “Sprache”, in der Typdefinitionen definiert werden (MetaMetaschema) Definitionen von Typen von Modellen bzw. Modellelementen (Meta-Metadaten) Struktur- und Verhaltensmodelle (Metadaten) Meta Object Facility (MOF) Meta-MetaMetamodell die UML MetaMetamodell Zustandsautomat “MobilTel” GUI eines Mobiltelefons Metamodell beliebige Realweltentitäten bzw. Daten, die Realweltausschnitte repräsentieren Modell Abbildung 9.2: Hierarchie der Bedeutungsebenen von Daten (Modellen) der UML Die in [UML-IS06] und anderen Quellen benutzte Hierarchie semantischer Ebenen ist in Bild 9.2 wiedergegeben. Die UML-Daten- Metadaten 219 bzw. Bedeutungsebenen M1 bis M3 (M0 bildet eine Ausnahme) haben in mehrerer Hinsicht bis auf Äußerlichkeiten gleiche Strukturen (vgl. Bilder 9.1 und 9.2) wie die Bedeutungsebenen von Nutzdaten bzw. Schemarepräsentationen in Datenbanken: – Die Daten auf allen Bedeutungsebenen sind strikt typisiert und entsprechen einem Schema bzw. einem Modell. – Der Ebene M(i+1) sind Daten zugeordnet, die das Schema bzw. das Modell der Ebene Mi selbstreferentiell repräsentieren. – Das Verhalten der Objekte auf Ebene Mi wird abgesehen von einer Ausnahme (die beiden untersten Ebenen der UML-Hierarchie) nicht auf Ebene M(i+1) spezifiziert. Eine nur scheinbare Gemeinsamkeit der Datenbank- und der UMLBegriffswelt besteht darin, daß der untersten Ebene unter anderem (!) Daten zugeordnet sind, die im Anwendungskontext relevante Entitäten der realen Welt repräsentieren. Ebene M0. Die UML-Spezifikationen betonen an vielen Stellen, daß die Daten der Ebene M0 kein Gegenstand der UML sind. Die UML ist definitionsgemäß eine Sprache, in der man Dokumente wie Klassendiagramme, Anwendungsfalldiagramme usw. formulieren kann, also Dokumente, die durch Daten repräsentiert werden, die der Ebene M1 zuzuordnen sind. Die Ebene M0 wird nur gebraucht, um punktuell erklären zu können, wie “Instanzen der Modelle” aussehen können und wie Modelle gebildet werden sollten, um einen Realweltausschnitt korrekt wiederzugeben. Ebene M1. Die Rolle der Modelle wird klar, wenn man danach fragt, welche Art von Systemen die UML bzw. ein Datenbankmodell spezifizieren und was darin die Nutzdaten sind. Der Sinn und Zweck der UML besteht darin, zu spezifizieren, wie Editoren und andere Entwicklungswerkzeuge für UML-Dokumente Modelle verarbeiten sollen. Die Nutzdaten solcher Werkzeuge bzw. Systeme sind die Modelle bzw. Diagramme, also Daten der Ebene M1! 220 Metadaten Die Frage, ob überhaupt und ggf. in welchem Sinne die UMLModelle Metadaten sind, werden wir anschließend im Detail diskutieren. An dieser Stelle sei jedenfalls betont, daß die UML nicht nur Klassendiagramme definiert, sondern auch Sequenzdiagramme und diverse andere Diagrammtypen, die Verhaltenseigenschaften modellieren. Verhaltenseigenschaften werden z.B. im Programmcode des modellierten Systems realisiert und sind i.a. innerhalb des modellierten Systems (oder wo auch immer) überhaupt nicht durch Daten repräsentiert. Daher sind Sequenzdiagramme und andere Verhaltensmodelle gar keine Metadaten: es gibt keinen Datenbestand, der mit ihrer Hilfe strukturiert oder interpretiert wird! Ebene M2. Die Daten der UML-Ebene M2 enthält Metamodelle; wie schon erwähnt werden hier ausschließlich Klassendiagramme in Sinne reiner Datenmodelle eingesetzt. Diese Modelle modellieren ausschließlich die statischen Datenstrukturen, durch die die Struktur- und Verhaltensmodelle der Ebene M1 repräsentiert werden können. Verhalten der Modelle der Ebene M1 wird nicht modelliert. Bei allen Modelltypen könnte man theoretisch z.B. Editieroperationen, durch die die Struktur- und Verhaltensmodelle aufgebaut und editiert werden, durch Aktivitätsdiagramme modellieren. Mit bestimmten Einschränkungen könnte man auch Simulatoren für Aktivitätsdiagramme spezifizieren. Offensichtlich wäre dies extrem aufwendig und im Sinne eines Standards auch überflüssig, weil dies gerade Werkzeugfunktionen sind, in denen sich die Produktanbieter unterscheiden wollen. Betont werden muß jedenfalls, daß die Metamodelle die Modelle nur sehr lückenhaft repräsentieren, weitaus unvollständiger jedenfalls, als man mit diversen Modellen der Ebene M1 den Realweltausschnitt modelliert. Daß die UML-Begriffshierarchie unterschiedslos aussagt, die nächsthöhere Stufe sei ein “Modell” der darunterliegenden, verschleiert diesen wichtigen Qualitätsunterschied und ist die Ursache vieler Mißverständnisse. Metadaten 221 Vergleich der Datenbank- und UML-Metadatenebenen. Jede Metadatenhierarchie bezieht sich explizit oder implizit auf eine bestimmte Art von Systemen39 , die Metadaten nutzen, um Nutzdaten zu interpretieren. Zentraler Bezugspunkt sind die Daten, die in der jeweiligen Systemklasse als Nutzdaten anzusehen sind. In der Datenbankbegriffswelt sind die Daten der Ebene M0 die Nutzdaten, in der UML-Begriffswelt hingegen die Daten der Ebene M1. Diese beiden Ebenen entsprechen einander daher. Alle höheren Ebenen korrespondieren dementsprechend jeweils um einen Zähler verschoben. Dieser und weitere Unterschiede bzw. Korrespondenzen sind in Bild 9.3 zusammengefaßt. Vergleichsaspekt spezifizierte Systemklasse DBMS DBMS Ebene der Nutzdaten der spezifizierten Systemklasse Ebene der Schemata / Steuerdaten der spezifizierten Systemklasse implizite Mengenverwaltung der Nutzdaten, generische Suchfunktionen Schemata / Steuerdaten dürfen sich während der Lebenszeit von Nutzdaten ändern Sichtenmechanismus für Nutzdaten M0 M1 UML CASEWerkzeuge M1 ja M2 (MetaCASE) nein ja nein ja nein Abbildung 9.3: Korrespondierende Konzepte von UML und DBMS Dem ersten, aber falschen Anschein nach entsprechen die Modelle der UML-Hierarchie – zumindest Klassendiagramme ohne Operationen – den Schemata. Bestärkt wird dieser Anschein im speziellen Fall von Analyseklassendiagrammen dadurch, daß diese fast automatisch in Schemata übersetzt werden können. Die Frage ist noch offen, welche Art von Systemen durch die Me39 oder eine Personengruppe, diesen Fall betrachtet wir hier nicht. 222 Metadaten tamodelle der UML analog zu den Schemata in einer Datenbank konfiguriert bzw. gesteuert wird. In erster Linie zu nennen sind hier sogenannte Meta-CASE-Werkzeuge, die wir unten diskutieren werden. 9.5.2 “ist-Instanz-von”-Beziehungen Die UML-Begriffswelt postuliert, daß die Objekte der Ebene Mi als Instanzen der Objekte der Ebene M(i+1) aufzufassen sind, s. z.B. Bild 7.8 in [UML-IS06] und die << instanceOf >>-Beziehungen zwischen den Objekten verschiedener Ebenen. Dies ist leider eine sehr unsaubere Begrifflichkeit, die automatisch zu Komplikationen führt. Die “ist-Instanz-von”-Beziehungen, die zwischen den verschiedenen Ebenen auftreten, sind nämlich nicht immer einheitlich interpretierbar. Ferner haben “ist-Instanz-von”-Beziehungen zwischen den korrespondierenden Ebenen bei DBMS und bei der UML teilweise verschiedene Bedeutungen. Grundsätzlich kann man “ist-Instanz-von”Beziehungen auf zwei Arten interpretieren: 1. “von unten nach oben”: Ausgangspunkt ist das reale System, das Modell ist ein vereinfachtes, unvollständiges Abbild. Aus dem Modell kann das modellierte System nicht komplett rekonstruiert werden. 2. “von oben nach unten”: Ausgangspunkt ist das Modell, es wird als Konfigurationsparameter eines “generischen” Softwaresystems benutzt und konfiguriert letzteres so, daß Instanzen des Modells verarbeitet werden können. Das System auf der unteren Ebene, das die Instanzen bearbeiten bzw. verwalten kann, entsteht durch Übersetzen oder Interpretieren des Modells. Man kann den Unterschied auch so auf den Punkt bringen, daß Modelle entweder vage oder präzise Spezifikationen des modellierten Systems sind. In der Datenbank-Begriffswelt sind insb. die instantiierbaren Metadaten, also die Schema, als präzise Spezifikation der Schicht aufzufassen, in der die Nutzdaten verwaltet werden. Metadaten 223 In der UML-Begriffswelt wird die Frage, ob Modelle als vage oder präzise Spezifikationen zu verstehen sind, oft ambivalent beantwortet und differiert auf den verschiedenen Ebenen. 9.5.2.1 Interpretation der UML-Modelle der Ebene M1 UML-Modelle der Ebene M1 werden normalerweise als vage oder unvollständige Spezifikationen verstanden. Diese Möglichkeit ist völlig unverzichtbar. Von irrelevanten Details eines Systems zu abstrahieren ist gerade das Grundprinzip der Modellierung. Bei Diagrammtypen, die Verhalten modellieren, kann man meist nicht sinnvoll oder nur mit erheblichen begrifflichen Verrenkungen definieren, was überhaupt eine Instanz des Modells sein soll und in welchen Laufzeitobjekten bzw. Realweltausschnitt sich dieses Modell manifestiert. Die Instanzbildung funktioniert bei jedem Modelltyp völlig anders, ist weitgehend undefiniert und hängt vor allem vom Phantasiereichtum des Betrachters ab. Da nach eigenem Bekunden die Ebene M0 kein Gegenstand der UML ist, liegt es nahe, die Frage nach der Bedeutung der Modelle der Ebene M1 und der “ist-Instanz-von”-Beziehungen von Ebene M0 nach M1 als eigentlich gegenstandslos anzusehen. UML-Modelle der Ebene M1 werden jedoch in manchen Kontexten als Systemspezifikationen eingesetzt, z.B. zur schnellen Bereitstellung von Wegwerf-Prototypen bei der Systemanalyse, zur Generierung von Programmrahmen aus den Modellen oder sogar zur kompletten Realisierung des Systems (insb. beim MDA-Ansatz); die UML mutiert dann von einer Modellierungssprache zu einer graphischen Programmiersprache. Entscheidend ist hier die Beobachtung, daß man heimlich zu einem anderen Systemtyp gewechselt hat. Ein GUI-Generator hat GUIs als Nutzdaten und kann durch ein Klassendiagramm konfiguriert werden. Ein GUI-Generator ist kein Klassendiagramm-Editor und erst recht kein Meta-CASE-Werkzeug im obigen Sinne. Selbst wenn man einen Klassendiagramm-Editor und einen GUI-Generator technisch in einer Arbeitsumgebung integriert, bleiben es Werkzeuge, die ihre Nutzdaten 224 Metadaten auf verschiedenen semantischen Ebenen haben. 9.5.2.2 Interpretation der UML-Modelle der Ebene M2 UML-Modelle der Ebene M2 sind bzgl. der Präzisionsfrage ebenfalls ambivalent. Die Menge der UML-Produkte, die die Conformance-Klauseln der UML erfüllen, soll möglichst groß gehalten werden. Daher werden viele Aspekte von UML-Werkzeugen (externe Darstellung der Dokumente, Dokumentverwaltung, Prüffunktionen, Speicherformat usw.) überhaupt nicht modelliert oder durch “presentation options”, “variation points” für die Semantik von Modellen und die Verwendung natürlicher Sprache zur Erklärung von Optionen sehr offen gehalten40 . Aus dieser Motivation heraus sind die UML-Spezifikationen (und damit die Modelle der Ebene M2) oft unpräzise bzw. unvollständig, im Prinzip also vage Spezifikationen. Andererseits werden die Modelle in manchen Systemen als präzise Spezifikationen benutzt. Solche Werkzeuge werden allgemein als Meta-CASE-Werkzeuge bezeichnet. Am bekanntesten sind hierunter graphische Editoren für netzwerkartige Modelltypen. Der Kerngedanke besteht darin, die erheblichen Gemeinsamkeiten, die Editoren für netzwerkartige Modelltypen aufweisen, in einem generischen Kern zu implementieren41 und diesen Kern mit einem konzeptuellen Modell der jeweiligen Modelltypen, also deren Metamodell, zu konfigurieren. Über die Modellkonzepte hin40 Die Conformance Level der UML verkomplizieren die Thematik hier zusätzlich. Die Conformance Level ermöglichen es, nur eine Teilmenge aller Dokumenttypen in einem standardkonformen Produkt zu unterstützen und unterschiedlich gute architektonische Merkmale (Konfigurier- bzw. Erweiterbarkeit) anzubieten. Für die hier diskutierten Fragen sind die Conformance Level irrelevant, denn die Frage nach der Bedeutung der Spezifikationen ist weitgehend unabhängig davon, ob der komplette Standard oder nur eine Teilmenge abgedeckt wird. 41 Hierbei wird man i.d.R. die gemäß dem Standard zulässige Vielfalt der Implementierungen substantiell einschränken, bei Wahlmöglichkeiten also entweder eine konkrete Wahl treffen und diese hart im generischen Kern der Werkzeuge verdrahten oder mehrere Wahlmöglichkeiten realisieren und durch werkzeugspezifische Konfigurationsparameter wählbar machen. Metadaten 225 aus müssen indessen auch Darstellungsformen von Diagrammelementen abhängig vom jeweiligen Modelltyp konfiguriert werden können; dies macht die Konfigurierung von Meta-CASE-Werkzeugen deutlich komplizierter als die “Konfiguration” eines DBMS mittels eines Schemas. Weitere Meta-CASE-Werkzeuge sind Transformatoren, die Modelle in andere Modelle, Programmrahmen o.ä umformen, Prüfwerkzeuge, Differenzbildungs- und Mischwerkzeuge, Export- oder Importwerkzeuge u.a.m. Auch für diese gilt analog zu Editoren, daß das Metamodell eines Modelltyps i.a. nicht ausreicht, um den generischen Kern des Meta-CASE-Werkzeugs zu konfigurieren, sondern daß zusätzliche dokumenttypspezifische Konfigurationsdaten benötigt werden. Glossar Metadaten (meta data): Daten über Daten; im Kontext von DBS vor allem Schemata bzw. Typdefinitionen Meta-Metadaten (meta meta data): Daten über Metadaten; insb. eine selbstreferentielle Repräsentation des Metaschemas Metaschema (meta schema): Schema, das zur Speicherung von Metadaten (insb. Schemata und Typdefinitionen) benutzt wird Nutzdaten: die in einem System verwalteten “primären” Daten (ohne die Metadaten) Selbstreferentialität: Ansatz, die Metadaten in einem DVS wie Nutzdaten darzustellen Typ-Annotationen: in die Nutzdaten eingebettete Angaben zum Typ der Daten, Beispiel: tags in XML Lehrmodul 10: Entwurf redundanzfreier Datenbankschemata Zusammenfassung dieses Lehrmoduls Beim Entwurf von Schemata für relationale Datenbanken können bestimmte Fehler gemacht werden, die entweder zu Redundanz oder zu einer inkorrekten Wiedergabe der Realität führen. Wir analysieren diese Entwurfsfehler genauer und definieren bestimmte Kriterien, die derartige Entwurfsfehler ausschließen. Diese Kriterien werden auch als Normalformen bezeichnet. Ein zentraler Begriff bei der Definition der Kriterien ist der der funktionalen Abhängigkeit, der den Begriff Identifizierungsschlüssel verallgemeinert. Vorausgesetzte Lehrmodule: obligatorisch: – Das relationale Datenbankmodell Stoffumfang in Vorlesungsdoppelstunden: Stand: 20.10.2005 3.0 c 2005 Udo Kelter Entwurf redundanzfreier Datenbankschemata 10.1 227 Einleitung und Einordnung Der Entwurf relationaler Datenbankschemata ist eine Tätigkeit, die man im Rahmen der Entwicklung eines Informationssystems am ehesten zur Entwurfsphase zählen kann (wenn wir das Phasenmodell unterstellen). Ausgangsbasis ist somit ein Datenmodell, das in der Analysephase gewonnen wurde, z.B. in Form eines ER- oder OOA-Modells. Das zu erstellende Datenbankschema kann man als wichtige persistente Datenstruktur innerhalb der Gesamtarchitektur des Informationssystems ansehen; häufig findet sich auch programmseitig eine äquivalente oder ähnliche Datenstruktur bzw. ein entsprechendes Modul (vgl. [TAE]). Für die Transformation von Datenmodellen in Tabellen gibt es Vorgehensweisen, die trotz punktueller Entscheidungsfreiräume insg. doch relativ schematisch ablaufen (s. Abschnitt 2 in [TAE]). Die Frage drängt sich auf, wo denn überhaupt noch ein Problem ist, das ein umfangreiches Lehrmodul rechtfertigt. Die Antwort ist, daß man die Schemata falsch entwerfen kann; Effekte dieser Fehler können sein: – redundant gespeicherte Daten42 – Datenverluste und falsche Abbildung der Realität in der Datenbank Man kann nun argumentieren, daß ein solcher Fehler in einem Datenbankschema (a) vermutlich schon in dem zugrundeliegenden Datenmodell vorlag, also nicht erst bei der Transformation des Datenmodells in das Schema verursacht worden ist, und daß man (b) den Fehler doch lieber gleich im Datenmodell vermeiden sollte. Die Antwort auf (a) ist: völlig richtig. Zu (b): Im Prinzip richtig, aber dieser Vorschlag kann in der Praxis problematisch sein. Die Feststellung, ob ein Fehler vorliegt, erfordert ein gewisses Maß an mathematischem Denkvermögen, 42 Unter Datenbänklern ist es ein fester Glaubensgrundsatz, daß redundante Datenspeicherung (in einer nichtverteilten Datenbank) etwas ganz Schlimmes sei. Dieser Glaube stammt aus einer Zeit, als die Kapazität von Platten nach heutigen Maßstäben winzig und die Preise pro MB Plattenplatz astronomisch waren, man also sehr gute Gründe hatte, keinen Platz zu verschwenden. Heute ist dieses Argument außer bei sehr großen Datenmengen nicht mehr gravierend. Aber auch ohne dieses Argument ist eine redundante Speicherung grundsätzlich unmotiviert, und wir werden später noch konkrete Nachteile identifizieren. 228 Entwurf redundanzfreier Datenbankschemata und die Behebung des Fehlers kann die Datenmodelle unanschaulicher machen. Da Datenmodelle vor allem für Anwender intuitiv verständlich sein sollen, kann insb. der zweite Punkt ein Nachteil sein. Die gute Nachricht an dieser Stelle ist, daß solche Fehler eigentlich selten sind, weil man mit etwas “Erfahrung” die Datenmodelle intuitiv richtig entwirft. Ziel dieses Lehrmoduls ist es daher, diese Erfahrung zu vermitteln und Definitionen und Algorithmen zu präsentieren, mit denen man das Vorliegen von Fehlern tatsächlich entdecken und diese durch Umbau der Schemata beseitigen kann. Historisch gesehen sind “Korrektheitsbegriffe” für Schemata im Kontext von Datenbanken entstanden, und zwar unter der wenig anschaulichen Bezeichnung “Normalformen”. Es ist eine sehr umfangreiche Theorie der Normalformen entstanden. Man kann diese Theorie im Prinzip problemlos auf die Datenmodelle der Analysephase übertragen, was aber nicht üblich ist43 . 10.2 Fehler beim Entwurf relationaler Datenbankschemata Wir beschreiben zunächst typische Fehler, die in relationalen Datenbankschemata auftreten können, und deren Konsequenzen. Als Beispiel benutzen wir die beiden Relationen kunden und lieferungen aus Lehrmodul 4 bzw. Varianten dieser Relationen. 10.2.1 Zu viele Attribute in einem Relationentyp Als Beispiel betrachten wir eine Relation kundenlieferungen, die folgenden Relationentyp hat: Kundenlieferungen = ( Datum: date; Wert: real; Kundennummer: string; 43 Über die Ursachen kann man nur spekulieren. Gründe sind sicher nicht alleine ausschlaggebend. Die o.g. anwenderseitigen Entwurf redundanzfreier Datenbankschemata 229 Kundenname: string; Wohnort: string; Kreditlimit: real; Lager: integer; Lieferadresse: string; ) Tabelle: kundenlieferungen Datum Wert Kunden- Kundenname nummer 00-08-12 2730.00 167425 Schneider, P... 00-08-14 427.50 167425 Schneider, P... 00-08-02 1233.00 171876 Litt, Michael Wohnort Netphen Netphen Siegen Kreditlimit 14000.00 14000.00 0.00 Abbildung 10.1: Beispieltabelle für Lieferungen an Kunden Bild 10.1 zeigt die zugehörige Relation kundenlieferungen mit einigen Beispieltupeln. Die Relation kundenlieferungen soll die beiden Relationen kunden und lieferungen ersetzen. In der Relation lieferungen ist das Attribut Kundennummer ergänzt worden durch die drei Attribute Kundenname, Wohnort und Kreditlimit. Ein Tupel in der Relation kundenlieferungen faßt alle Angaben zu einer Lieferung und dem belieferten Kunden zusammen, was u.U. als ganz praktisch erscheint. Dieser Relationentyp führt allerdings zu erheblichen Problemen: – Die Angaben über den Kunden müssen bei jeder Lieferung erneut gespeichert werden. Hieraus ergeben sich folgende Probleme: 1. redundante Datenspeicherung 2. Gefahr von Inkonsistenzen: bei jeder erneuten Lieferung an einen schon vorhandenen Kunden müssen erneut dessen Daten eingegeben werden; aus Versehen können aber abweichende Daten eingegeben werden, so daß dann die Daten zu diesem Kunden nicht konsistent sind. 3. die “Änderungsanomalie”: Wenn wir z.B. das Kreditlimit eines Kunden verändern, muß das entsprechende Attribut in al- ... ... ... ... 230 Entwurf redundanzfreier Datenbankschemata len Tupeln dieses Kunden modifiziert werden. M.a.W. führt die Änderung eines einzigen Sachverhalts dazu, daß an n > 1 Tupeln Änderungen vorgenommen werden müssen. – Wenn wir einen neuen Kunden erfassen wollen, der aber noch nichts geliefert bekommen hat, haben wir ein Problem (die “Einfügeanomalie”): Wenn wir ein Tupel mit den Kundendaten erzeugen wollen, müssen wir für die eigentlichen Lieferungsdaten Nullwerte einsetzen. Nullwerte sind in vieler Hinsicht sehr störend (s. Lehrmodul 6). – Wenn umgekehrt das letzte Lieferungstupel zu einem Kunden gelöscht wird, gehen auch die Daten über den Kunden selbst verloren. Hier liegt eine “Löschanomalie” vor. Insgesamt muß man hier feststellen, daß beim Relationentyp Kundenlieferungen zu viele Attribute zusammengefaßt worden sind – dieser Relationentyp ist sozusagen zu “groß” – und daß dies zu Redundanz, Nullwerten, Informationsverlusten und Anomalien beim Einfügen, Ändern und Löschen von Tupeln führt. 10.2.2 Zu “kleine” Relationentypen Ausgehend vom Problem zu großer Relationentypen könnte man im Umkehrschluß zur Meinung kommen, daß man lieber nur sehr kleine Gruppen von Attributen zu Relationen zusammenfaßt. Wir verwenden wieder die Attribute aus dem Relationentyp Lieferungen und bilden nunmehr zwei kleinere Relationentypen: Lieferungen1 = ( Datum: date; Wert: real; Kundennummer: string; ) Lieferungen2 = ( Kundennummer: string; Lager: integer; Lieferadresse: string; ) Die entsprechenden Relationen Lieferungen1 und Lieferungen2 bilden wir, indem wir Lieferungen auf die jeweiligen Attributmengen Entwurf redundanzfreier Datenbankschemata 231 projizieren: lieferungen1 = πDatum,Wert,Kundennummer (lieferungen) lieferungen2 = πKundennummer,Lager,Lieferadresse (lieferungen) Die Ergebnisse dieser Projektionen sehen folgendermaßen aus: Tabelle: lieferungen1 Datum Wert Kundennummer 00-08-12 2730.00 167425 00-08-14 427.50 167425 00-08-02 1233.00 171876 Tabelle: lieferungen2 Kunden- Lager Lieferadresse nummer 167425 Mitte Bahnhofstr. 5 167425 Nord Luisenstr. 13 171876 West Bergstr. 33 Wenn wir nun unsere Daten nur noch in den Tabellen lieferungen1 und lieferungen2 speichern, so sollten wir dennoch in der Lage sein, die ursprüngliche Tabelle lieferungen wieder zu rekonstruieren, naheliegenderweise als Verbund lieferungen1 1 lieferungen2. Das Ergebnis dieser Verbundbildung ist: Tabelle: lieferungen1 1 lieferungen2 Datum Wert Kundennummer Lager 00-08-12 2730.00 167425 Mitte 00-08-14 427.50 167425 Nord 00-08-12 2730.00 167425 Nord 00-08-14 427.50 167425 Mitte 00-08-02 1233.00 171876 West Lieferadresse Bahnhofstr. 5 Luisenstr. 13 Luisenstr. 13 Bahnhofstr. 5 Bergstr. 33 Dies ist nicht mehr die ursprüngliche Relation lieferungen! Das 3. und 4. Tupel sind neu hinzugekommen. Diese wundersame Tupelvermehrung wird dadurch verursacht, daß der Verbund über das Verbundattribut Kundennummer gebildet wird, bei diesem Attribut der Wert 167425 in zwei Tupeln auftritt und die “linke” und “rechte Hälfte” der beiden ursprünglichen Tupel beliebig miteinander kombiniert werden. Angenommen, die beiden neuen Tupel wären doch in der ursprünglichen Datenbank enthalten, dann hätte dies auf beiden Relationen 232 Entwurf redundanzfreier Datenbankschemata lieferungen1 und lieferungen2 keinerlei Einfluß, diese Unterschiede in lieferungen gehen beim Projizieren verloren. Die korrekte Relation lieferungen ist deshalb i.a. aus dem Inhalt der Datenbank nicht mehr rekonstruierbar, die Datenbank gibt also die Realität nicht mehr korrekt wieder. Die obige Zerlegung des Relationentyps Lieferungen und der zugehörigen Relation lieferungen führt also zum Verlust der Korrektheit der Datenbank und wird daher als verlustbehaftet bezeichnet. Irritierenderweise gehen bei einer verlustbehafteten Zerlegung keine Tupel verloren, sondern es kommen allenfalls welche hinzu (“Datenmüll”); leider weiß man nicht, welche. 10.2.3 Verlustfreie Zerlegungen Eine nicht verlustbehaftete Zerlegung nennen wir verlustfrei. Ein Beispiel für eine verlustfreie Zerlegung ist die Zerlegung unseres früheren Relationentyps Kundenlieferungen in die Relationentypen Kunden und Lieferungen. Allgemein ist die Verlustfreiheit von Zerlegungen wie folgt definiert: Definition: Sei R ein Relationentyp, Ri , 1 ≤ i ≤ n, Attributmengen. S {R1 , ..., Rn } heißt Zerlegung von R, falls R = ni=1 Ri Definition: Sei {R1 , ..., Rn } Zerlegung von R. Die Zerlegung ist verlustfrei ⇐⇒ für jede “korrekte” Relation44 r gilt: r = 1ni=1 πRi (r) Zerlegungen beziehen sich im Prinzip auf Relationentypen; wir werden den Begriff aber oft auch auf eine Relation r anwenden und meinen dann die Projektionen πRi (r). Da bei einer Zerlegung einer Relation und anschließendem Verbund der Projektionen πRi (r) keine der ursprünglichen Tupel verlorengehen, gilt folgender Satz: 44 Korrekte Relation soll hier bedeuten, daß die Relation den Konsistenzkriterien der Anwendung genügt. Später werden wir den Begriff Korrektheit noch präziser fassen. Entwurf redundanzfreier Datenbankschemata 233 Satz: Sei {R1 , ..., Rn } Zerlegung von R, r eine Relation mit Relationentyp R. Dann gilt: r ⊆ 1ni=1 πRi (r) Zum Beweis dieser Behauptung nehme man ein Tupel t ∈ r an. t wird durch die Zerlegung in mehrere, möglicherweise überlappende Teile t[Ri ] zerlegt. Bei der Bildung des Verbunds werden diese Teile wieder zu dem ursprünglichen Tupel t zusammengesetzt. 10.3 Funktionale Abhängigkeiten 10.3.1 Beispiel und Definition Wir kommen noch einmal auf unser Beispiel für eine verlustfreie Zerlegung zurück, die Zerlegung des Relationentyps Kundenlieferungen in die Relationentypen Kunden und Lieferungen. Daß diese Zerlegung verlustfrei ist, liegt an folgendem Merkmal der Relation kundenlieferungen: Wenn man irgendeinen Wert des Attributs Kundennummer wählt, z.B. 167425, dann kann es mehrere Tupel geben, die diesen Wert aufweisen. Diese Tupel haben bei allen anderen Attributen, die Kunden beschreiben (Kundenname usw.) immer den gleichen Wert! Hieraus folgt: Die Projektion πKunden (kundenlieferungen) enthält für jeden auftretenden Wert von Kundennummer genau ein Tupel, und {Kundennummer} ist Identifizierungsschlüssel in πKunden (kundenlieferungen). Anders gesehen liegt hier eine (partielle) Funktion im mathematischen Sinne vor, die jedem Wert von Kundennummer die Werte der anderen Kundenattribute eindeutig zuordnet. Die anderen Kundenattribute werden daher als funktional abhängig von Kundennummer bezeichnet. Wenn wir nun den Verbund πLieferungen (kundenlieferungen) 1 πKunden (kundenlieferungen) bilden, dann ist darin das Attribut Kundennummer Verbundattribut und jedes Tupel aus πLieferungen (kundenlieferungen) wird mit ge- 234 Entwurf redundanzfreier Datenbankschemata nau einem Tupel aus πKunden (kundenlieferungen) kombiniert. Die störende Tupelvermehrung unterbleibt also. Im vorigen Beispiel war jedes Kundenattribut funktional abhängig von Kundennummer. Ein Attribut kann auch von einer Menge von Attributen funktional abhängig sein. Die allgemeine Definition von funktionaler Abhängigkeit ist: Definition: Sei R ein Relationentyp und seien A, B ⊆ R zwei Attributmengen. B ist funktional abhängig von A (notiert als A → B) ⇐⇒ ∀ Relation r mit dem Relationentyp R ∀ t1, t2 ∈ r: t1[A] = t2[A] ⇒ t1[B] = t2[B] Übungsaufgabe: Beweisen Sie: A ⊇ B ⇒ A → B Funktionale Abhängigkeiten, bei denen A ⊇ B gilt, nennt man auch trivial, denn sie sagen nichts über den Datenbestand aus. Graphische Darstellung funktionaler Abhängigkeiten. Es ist manchmal hilfreich, sich funktionale Abhängigkeiten graphisch zu veranschaulichen, indem man die Attribute auf einer Zeichenfläche geeignet plaziert, die beiden beteiligten Attributmengen durch eine geschlossene Linie eingrenzt und den Abhängigkeitspfeil zwischen diesen Grenzlinien anbringt. Als Beispiel zeigt Bild 10.2 die Abhängigkeit Kundennummer→{Kundenname, Wohnort, Kreditlimit}. Kundenname Kundennummer Wohnort Kreditlimit Abbildung 10.2: Beispiel für die graphische Darstellung Entwurf redundanzfreier Datenbankschemata 10.3.1.1 235 Beispiel für die Analyse einer Tabelle Als Beispiel für die Analyse existierender Daten untersuchen wir die folgende sehr kleine Relation mit den Attributen A, B, C und D daraufhin, welche Abhängigkeiten in ihr auftreten: Tupel t1 t2 t3 t4 A a a b b B c d e e C f g g h D i j k l Bei der Analyse suchen wir zunächst nach Abhängigkeiten zwischen einzelnen Attributen, die also die Form X → Y haben (wir benutzen die Schreibweise X für die Menge {X}). Bei 4 Attributen ergeben sich im Prinzip 16 Möglichkeiten, von denen 4 trivial sind (X → X). Die Ergebnisse sind in der folgenden Tabelle angegeben. Ein + bedeutet, daß das zur Spalte gehörende Attribut funktional von dem zur Zeile gehörenden Attribut abhängt. Ein - bedeutet das Gegenteil, wobei dann noch ein Paar von Tupeln angegeben ist, das der funktionalen Abhängigkeit widerspricht. Bei trivialen Abhängigkeiten steht ein *. → A B C D A * + - (t2,t3) + B - (t1,t2) * - (t2,t3) + C - (t1,t2) - (t3,t4) * + D - (t1,t2) - (t3,t4) - (t2,t3) * Als nächstes untersuchen wir Abhängigkeiten von 2 Attributen, die also die Form XY → Z haben (wir benutzen die Schreibweise XY für die Menge {X, Y}). Einige Abhängigkeiten werden impliziert durch Abhängigkeiten von einem Attribut; dies ist dann in Klammern hinter dem + vermerkt. Wir erkennen, daß nur AC→B, AC→D und BC→D wirklich neue Abhängigkeiten sind. 236 Entwurf redundanzfreier Datenbankschemata → AB AC AD BC BD CD A * * * + (B→A) + (B→A) + (D→A) B * + + (D→B) * * + (D→B) C - (t3,t4) * + (D→C) * + (D→C) * D - (t3,t4) + * + * * Zum Schluß untersuchen wir noch Abhängigkeiten der Form XYZ → U; hier sind keine Abhängigkeiten wirklich neu: → ABC ABD ACD BCD 10.3.1.2 A * * * + (D→A) B * * + (D→B) * C * + (D→C) * * D + (AC→D) * * * Identifizierungs- und Superschlüssel Die mit Abstand häufigste Form funktionaler Abhängigkeiten sind Schlüssel. Wenn K ⊆ R ein Identifizierungs- oder Superschlüssel ist, dann gilt offensichtlich K→R Identifizierungs- und Superschlüssel sind also spezielle funktionale Abhängigkeiten, der Begriff funktionale Abhängigkeit ist eine Verallgemeinerung des Begriffs Superschlüssel. Die inhaltliche Nähe beider Begriffe zeigt sich auch in folgendem: A → B impliziert, daß in der Relation πA∪B (r) die Attributmenge A Superschlüssel ist. 10.3.2 Funktionale Abhängigkeiten als Integritätsbedingungen Bisher noch offen ist die Frage, wie man funktionale Abhängigkeiten erkennt und wieso sie überhaupt auftreten. Daß in unserer Beispielrelation kundenlieferungen die funktionale Abhängigkeit Kundennummer Entwurf redundanzfreier Datenbankschemata 237 → Kunden auftrat, ist offenbar kein Zufall. Daß jeder Kundennummer eindeutige Kundendaten zugeordnet werden, wollen wir so, dies ist in unserem Beispiel eine Anforderung, die sich aus der Analyse der Anwendung ergibt, und nicht eine temporäre Erscheinung, die zufällig gerade im aktuellen Inhalt der Relation auftritt und durch Einfügen weiterer Tupel wieder verlorengehen kann. Funktionale Abhängigkeiten sind somit Integritätsbedingungen, die im Rahmen der Systemanalyse festgestellt werden, noch bevor überhaupt die Relation angelegt und mit Tupeln gefüllt worden ist. Trotzdem kann es im Einzelfall durchaus sinnvoll sein, vorhandene Datenbestände oder verfügbare Beispieldaten daraufhin zu analysieren, ob funktionale Abhängigkeiten auftreten, und bei den gefundenen Abhängigkeiten zu fragen, ob sie Zufall sind oder nicht. Funktionale Abhängigkeiten sind daher als Teil des Datenbankschemas anzusehen. Wenn wir diesen Sachverhalt betonen wollen, werden wir für Relationentypen die alternative Notation (R, F ) benutzen. Darin ist R wie bisher die Menge der Attribute; F ist die Menge der funktionalen Abhängigkeiten. Festzuhalten bleibt, daß es Aufgabe eines Informationssystems ist, sicherzustellen, daß der aktuelle Datenbestand die Integritätsbedingungen stets einhält, also in diesem Sinne korrekt ist. Gefährdet sind funktionale Abhängigkeiten nur beim Einfügen neuer Tupel, Löschungen von Tupeln können keinen Schaden anrichten; eine Änderung betrachten wir hier als eine Abfolge von Löschung und Einfügung. Immer dann, wenn ein neues Tupel eingefügt werden soll, muß geprüft werden, ob hierdurch eine funktionale Abhängigkeit verletzt werden würde. Diese Prüfung muß innerhalb eines Informationssystems entweder von der Applikation oder vom DBMS übernommen werden. Auf diese Frage kommen wir später wieder zurück. 10.3.3 Verlustfreie Zerlegungen Wir kommen an dieser Stelle noch einmal auf den Begriff verlustfreie Zerlegung zurück. Wir hatten diesen Begriff schon in Abschnitt 10.2.3 definiert, allerdings unter Verwendung des nur informell definierten Be- 238 Entwurf redundanzfreier Datenbankschemata griffs “korrekte Relation” (s.o.). Eine Relation können wir nun präziser als korrekt definieren, wenn in ihr die funktionalen Abhängigkeiten eingehalten werden. In diesem Fall können wir die Verlustfreiheit einer Zerlegung wie folgt definieren: Definition: Sei {R1 , R2 } Zerlegung von R, F die Menge der für R gültigen funktionalen Abhängigkeiten. Die Zerlegung ist verlustfrei ⇐⇒ F impliziert R1 ∩R2 →R1 oder R1 ∩R2 →R2 Die Bedingung besagt, daß R1 ∩R2 Superschlüssel von R1 oder R2 sein muß. R1 ∩R2 sind gerade die Verbundattribute, über die Projektionen πR1 (r) und πR2 (r) einer Relation r wieder verbunden werden können. Für jede einzelne Wertekombination dieser Verbundattribute kann wegen der Superschlüsseleigenschaft in πR1 (r) oder πR2 (r) nur ein passendes Tupel, das als Verbundpartner dienen kann, vorhanden sein. Neue Tupel können daher durch Zerlegung und anschließenden Verbund nicht entstehen, die Zerlegung ist somit verlustfrei. Als Beispiel für eine verlustfreie Zerlegung sei wieder auf Abschnitt 10.3.1 verwiesen. Dort war das Attribut Kundennummer sogar Identifizierungsschlüssel in πKunden (kundenlieferungen). 10.3.4 Die Armstrong-Axiome Aus dem Beispiel in Abschnitt 10.3.1.1 läßt sich die Erkenntnis gewinnen, daß die Gesamtzahl der funktionalen Abhängigkeiten groß werden kann, daß aber die meisten entweder trivial sind oder aus anderen Abhängigkeiten folgen. Wir haben oben ohne weiteren Beweis behauptet, daß z.B. aus A→B auch AC→B folgt. Diese Behauptung können wir aber durch Einsetzen der Definitionen schnell beweisen. (Übung!) Derartige Beweise immer im Einzelfall zu führen ist aber zu aufwendig. Stattdessen kann man direkt die folgenden sogenannten Armstrong-Axiome benutzen, die eine kalkülartige Ableitung von neuen funktionalen Abhängigkeiten aus vorhandenen ermöglichen. X, Y und Z sind i.f. beliebige Attributmengen eines Relationentyps R. Entwurf redundanzfreier Datenbankschemata 239 Reflexivitätsregel: X ⊇ Y ⇒ X→Y Erweiterungsregel: X→Y ⇒ X ∪ Z→Y ∪ Z Transitivitätsregel: X→Y ∧ Y→Z ⇒ X→Z Bild 10.3 veranschaulicht die Armstrong-Axiome in einer graphischen Darstellung. Zur Vereinfachung wurde bei der Erweiterungsregel und der Transitivitätsregel angenommen, daß die beteiligten Attributmengen disjunkt sind. Die Regeln gelten natürlich auch ohne diese Annahme. Reflexivitätsregel X Y Erweiterungsregel X Z Z X Y Y Transitivitätsregel X Y Z X Z Abbildung 10.3: Graphische Darstellung der Armstrong-Axiome Ein Beispiel für den Einsatz der Regeln findet sich im letzten Abschnitt: dort haben wir u.a. behauptet, daß die Abhängigkeit ACD→B aus der Abhängigkeit A→B folgt. Beweisen können wir diese Behauptung nun wie folgt: 1. ACD→BCD 2. BCD→B (folgt aus A→B mittels Erweiterungsregel mit Z = CD) (wegen Reflexivitätsregel) 240 3. ACD→B Entwurf redundanzfreier Datenbankschemata (folgt aus 1. und 2. wegen Transitivitätsregel) Die Reflexivitätsregel ist nur eine andere Formulierung unserer früheren Behauptung, daß triviale Abhängigkeiten immer gelten. Die Erweiterungsregel und die Transitivitätsregel können ebenfalls durch Einsetzen der Definitionen leicht bewiesen werden. Dies zeigt die Korrektheit der Axiome. Die vorstehende Menge an Axiomen ist außerdem vollständig in dem Sinne, daß alle ableitbaren Abhängigkeiten durch Verwendung der Axiome herleitbar sind. Die folgenden drei zusätzlichen Axiome sind aus den vorstehenden ableitbar, bringen also qualitativ nichts Neues, vereinfachen aber oft die Ableitungen (s. auch Bild 10.4): Vereinigungsregel X Y Y X X Z Z Zerlegungsregel Y X Y Z X Z X Pseudotransitivitätsregel W W Z Z X Y X Abbildung 10.4: Zusätzliche Axiome Vereinigungsregel: X→Y ∧ X→Z ⇒ X→Y ∪ Z Entwurf redundanzfreier Datenbankschemata 241 Zerlegungsregel: X→Y ∪ Z ⇒ X→Y ∧ X→Z Pseudotransitivitätsregel: W ∪ Y→Z ∧ X→Y ⇒ W ∪ X→Z Die Pseudotransitivitätsregel bedeutet bildlich gesprochen, daß man in einer vorhandenen Abhängigkeit Voraussetzungen (die Attribute Y) durch stärkere Voraussetzungen (die Attribute X) ersetzen kann. 10.3.5 Die transitive Hülle einer Menge funktionaler Abhängigkeiten Bei der Systemanalyse steht man im Prinzip vor dem Problem, alle funktionalen Abhängigkeiten zu erfassen; später sind geeignete Maßnahmen zur Überwachung der Abhängigkeiten zu installieren, die natürlich möglichst wenig Aufwand verursachen sollen. Bei der Erfassung der funktionalen Abhängigkeiten einer Applikation stehen wir vor dem Problem, daß i.a. nur eine vom Zufall abhängige Teilmenge aller Abhängigkeiten notiert werden wird; einige der implizierten Abhängigkeiten werden fehlen. Jemand anders, der die gleiche Anwendung analysiert, käme vielleicht auf eine etwas anders zusammengesetzte Menge von Abhängigkeiten, die aber dennoch “äquivalent” zu der ursprünglichen wäre. Bzgl. der Überwachung der Abhängigkeiten besteht eine entscheidende Beobachtung darin, daß man abgeleitete Abhängigkeiten nicht mehr zu überwachen braucht, wenn man die vorausgesetzten Abhängigkeiten überwacht! Offensichtlich läßt sich der Gesamtaufwand für die Überwachung aller Abhängigkeiten minimieren, indem man nur eine minimale Menge von nicht mehr ableitbaren Abhängigkeiten überwacht, die die restlichen impliziert. Eine solche minimale Menge ist äquivalent zur Ausgangsmenge. Wichtig ist in beiden Fällen der Begriff der Äquivalenz zweier Mengen von Abhängigkeiten. Definitionstechnisch gehen wir so vor, daß wir zunächst zu einer gegebenen Menge von Abhängigkeiten die sog. transitive Hülle, die alle ableitbaren Abhängigkeiten enthält, definieren. 242 Entwurf redundanzfreier Datenbankschemata Definition: Sei F eine Menge funktionaler Abhängigkeiten. Die transitive Hülle F + (closure) von F ist die Menge aller ableitbaren funktionalen Abhängigkeiten (incl. F ). Definition: Seien F und G zwei Mengen funktionaler Abhängigkeiten. F und G sind äquivalent (G ≈ F ), wenn G+ = F + ist. Definition: Sei X ⊆ R eine Attributmenge und F eine Menge funktionaler Abhängigkeiten. X+ ist die Menge der Attribute, die bei F direkt oder indirekt abhängig von X sind. M.a.W. ist X→X+ ∈ F + . Die Mengen X+ sind sehr nützlich. Z.B. kann man mit ihnen feststellen, ob eine Attributmenge ein Superschlüssel ist. X ist genau dann ein Superschlüssel, wenn X+ = R. Die Berechnung von X+ betrachten wir zunächst an einem Beispiel. Sei R = {A, B, C, D, E}, F = {A→B, BC→D, E→D}. Gesucht ist AC+ . Wir gehen wie folgt vor: Sei Z die Menge der Attribute, von denen wir schon wissen, daß sie von AC abhängen. 1. Initial sei Z = AC. Hier nutzen wir die Reflexivitätsregel aus. 2. Wir untersuchen nun, ob eine der funktionalen Abhängigkeiten anwendbar ist, um Z zu vergrößern. Dies ist bei solchen Abhängigkeiten X→Y der Fall, für die X ⊆ Z gilt. BC→D und E→D sind derzeit nicht anwendbar. A→B ist anwendbar, wir können also B in Z aufnehmen, also Z = ABC. 3. Dadurch, daß Z größer geworden ist, können bisher nicht anwendbare Abhängigkeiten anwendbar geworden sein. Wir untersuchen daher die bisher noch nicht angewandten Abhängigkeiten, ob sie nunmehr angewandt werden können. E→D ist immer noch nicht anwendbar. BC→D ist jetzt anwendbar geworden, da BC ⊆ Z. Wir nehmen also D in Z auf, somit Z = ABCD. Entwurf redundanzfreier Datenbankschemata 243 4. Weil Z wieder größer geworden ist, untersuchen wir erneut die noch nicht angewandten Abhängigkeiten. E→D ist weiterhin nicht anwendbar. Da wir keine neuen anwendbaren Abhängigkeiten gefunden haben, sind wir fertig. AC+ = ABCD ist das Endergebnis. Allgemein kann X+ mit folgendem Algorithmus berechnet werden. Gegeben sind X und F . Z und Z1 sind temporäre Variablen, die eine Attributmenge enthalten. Z := X; Z1 := ∅; WHILE Z1 6= Z DO Z1 := Z; FOREACH X→Y ∈ F DO IF X ⊆ Z THEN Z := Z ∪ Y; X+ := Z; 10.3.6 Kanonische Überdeckung von funktionalen Abhängigkeiten Wie schon erwähnt möchte man aus Aufwandsgründen nicht alle funktionalen Abhängigkeiten kontrollieren, sondern nur eine minimale Menge, die keine ableitbaren Abhängigkeiten mehr enthält. Zu einer gegebenen Menge von funktionalen Abhängigkeiten F suchen wir daher eine Menge Fc mit folgenden Eigenschaften. 1. F ≈ Fc 2. Fc ist linksminimal: Die Abhängigkeiten in Fc enthalten auf der linken Seite keine überflüssigen Attribute, d.h. wenn man in einer Abhängigkeit auf der linken Seite ein Attribut entfernt, ist die neue Menge nicht mehr äquivalent zu F : ∀ X→Y ∈ Fc , A ∈ X : (Fc − {X→Y} ∪ {X-{A}→Y})+ 6= F + 3. Fc ist rechtsminimal: auch die rechten Seiten der Abhängigkeiten dürfen keine überflüssigen Attribute enthalten: ∀ X→Y ∈ Fc , A ∈ Y : (Fc − {X→Y} ∪ {X→Y-{A}})+ 6= F + 244 Entwurf redundanzfreier Datenbankschemata Wenn Fc diese Eigenschaften hat, ist es eine kanonische Überdeckung von F . Aus der Rechtsminimalität ergibt sich, daß Fc keine überflüssigen Abhängigkeiten enthält, d.h. für jede Abhängigkeit X→Y ∈ Fc gilt: (Fc − {X→Y})+ 6= F + . Beim Umgang mit kanonischen Überdeckungen sind zwei normierte Darstellungen für Mengen von Abhängigkeiten nützlich: 1. Einelementige rechte Seiten der Abhängigkeiten: Hier müssen alle Abhängigkeiten die Form X→A, A ∈ R, haben. Mittels der Zerlegungsregel können wir eine anders geformte Abhängigkeit X→{A1 ,..,An} in einzelne Abhängigkeiten X→Ai zerlegen. F = {A→BC} würde also in {A→B, A→C} umgeformt werden. 2. Eindeutige linke Seiten: Hier fassen wir unter Ausnutzung der Vereinigungsregel alle Abhängigkeiten mit gleicher linker Seite zu einer einzigen zusammen. Formal erhalten wir durch die Umformungen, die für eine normierte Darstellung erforderlich sind, natürlich eine andere Menge von Abhängigkeiten; inhaltlich sind diese Umformungen aber unerheblich, weswegen wir vereinfachend von einer anderen Darstellung der gleichen Menge sprechen. Der Begriff kanonische Überdeckung wird manchmal so definiert, daß neben der Minimalität auch eine der beiden normierten Darstellungsformen verlangt wird. Um nun zu einer vorgegebenen Menge F eine kanonische Überdeckung zu berechnen, prüfen wir wiederholt die obigen Bedingungen 2 und 3 und entfernen ggf. überflüssige Abhängigkeiten oder Attribute. Hierzu müßten wir nach der obigen Definition jeweils die transitive Hülle von F und der veränderten Menge von Abhängigkeiten bilden und vergleichen, was unnötig aufwendig ist, es reicht ein einfacherer Test, der von der Seite abhängt, auf der wir das Attribut entfernen: – Wenn wir auf der linken Seite einer Abhängigkeit X→Y ein Attribut A weglassen, ist die neue Abhängigkeit X-{A}→Y eine “stärkere” Entwurf redundanzfreier Datenbankschemata 245 Aussage, denn wir können aus X-{A}→Y wieder X→Y ableiten. Es gilt also automatisch (F − {X→Y} ∪ {X-{A}→Y})+ ⊇ F + Die umgekehrte Mengeninklusion gilt nicht automatisch, d.h. wir müssen explizit zeigen, daß die neue Abhängigkeit X-{A}→Y aus F abgeleitet werden kann. – Wenn wir auf der rechten Seite einer Abhängigkeit X→Y ein Attribut A weglassen, fällt diese Abhängigkeit komplett weg, falls Y = {A}. Wenn wir die normierte Darstellung mit einelementigen Mengen auf den rechten Seiten unterstellen, brauchen wir nur diesen Fall zu betrachten. Wir müssen also nur noch (F − {X→Y})+ = F + zeigen. Die Mengeninklusion “⊆” ist offensichtlich, zu zeigen bleibt die Inklusion “⊇” bzw. X→Y ∈ (Fc − {X→Y})+ . Mit anderen Worten muß die ursprüngliche Abhängigkeit X→Y aus den restlichen Abhängigkeiten folgen. Als Beispiel für die Berechnung einer kanonischen Überdeckung behandeln wir die Menge F , die in der ersten Spalte der folgenden Tabelle angegeben ist: F AB→BC A→BC B→A B→AC BC→AC C→AB Fc1 AB→B AB→C A→B A→C B→A B→C BC→A BC→C C→A C→B A→B A→C B→A B→C C→A C→B Fc2 A→B A→C B→C B→A B→C C→A C→B C→B 246 Entwurf redundanzfreier Datenbankschemata Als erstes formen wir die Menge um in ihre normierte Darstellung mit einelementigen rechten Seiten (s. Spalte 2). Duplikate, hier z.B. B→A, werden dabei eliminiert. Als zweites entfernen wir alle trivialen Abhängigkeiten, hier AB→B und BC→C. Dann suchen wir Abhängigkeiten mit gleicher rechter Seite. Wir finden hier z.B. AB→C und A→C. AB ist eine Obermenge von A. Aus A→C ist AB→C ableitbar, wir können daher AB→C entfernen. Analog verfahren wir mit BC→A und C→A. Es verbleiben nun noch die Abhängigkeiten in der 3. Spalte der obigen Tabelle. Wir suchen nunmehr nach transitiven Abhängigkeiten. A→B wird durch A→C und C→B impliziert, wird also entfernt. B→A wird durch B→C und C→A impliziert, wird also ebenfalls entfernt. Es verbleiben die Abhängigkeiten gemäß der Spalte Fc1 der Tabelle; von diesen ist keine mehr überflüssig. Wenn wir allerdings die Abhängigkeiten in einer anderen Reihenfolge untersucht hätten, hätten wir statt A→B und B→A z.B. A→C und C→A entfernen können und die Abhängigkeiten gemäß der Spalte Fc2 übrigbehalten. Dieses Beispiel zeigt, daß die kanonische Überdeckung von F nicht eindeutig bestimmt ist. Da es mehrere kanonische Überdeckungen gibt, stellt sich die Frage, welche der kanonischen Überdeckungen minimal ist bzw. ob man sich die Mühe machen soll, nach einer minimalen Überdeckung zu suchen. Die Minimalität kann sich z.B. auf die Anzahl der Abhängigkeiten, also einen Kostenfaktor, beziehen. Die Suche nach einer minimalen Überdeckung ist leider ein NP-vollständiges Problem, d.h. alle bekannten Lösungen haben eine exponentielle Laufzeit, und es ist unwahrscheinlich, daß schnellere Algorithmen existieren. Abhängigkeitsmengen mit vielen kanonischen Überdeckungen sind allerdings recht komplex und selten, d.h. die praktische Relevanz dieses Problems ist gering. Entwurf redundanzfreier Datenbankschemata 10.4 247 Das Boyce-Codd-Kriterium Eine zentrale Frage in diesem Lehrmodul war, wie “richtige” oder “gute” Relationentypen gebildet sein müssen. In Abschnitt 10.2 haben wir Mängel von Relationentypen aufgelistet; wir benötigen aber umgekehrt positive Qualitätskriterien, die angeben, wann ein Relationentyp “richtig” geformt ist. Für derartige Qualitätskriterien wird in der klassischen DatenbankLiteratur der Begriff Normalform verwendet. Ein Relationentyp ist in einer der Normalformen, wenn er das zugehörige Qualitätskriterium erfüllt. Diese Begriffsbildung ist wenig intuitiv oder sogar irreführend, denn der Begriff Normalform wird häufig anders verstanden (nämlich als normierte Darstellung), und ist allenfalls historisch erklärbar. 10.4.1 Definition Das in diesem Abschnitt vorgestellte Kriterium ist nach den Autoren Boyce und Codd benannt und besagt, daß zu große Relationentypen im Sinne von Abschnitt 10.2.1 nicht auftreten dürfen. Somit werden keine abhängigen Daten redundant gespeichert. Formal ist das BoyceCodd-Kriterium wie folgt definiert: Definition: Sei R ein Relationentyp, F die Menge der für R gültigen funktionalen Abhängigkeiten in der normierten Darstellung mit eindeutigen linken Seiten. F erfüllt das Boyce-Codd-Kriterium (bzw. ist in Boyce-Codd-Normalform, abgekürzt BCNF) ⇐⇒ ∀ X→Y ∈ F gilt: – X→Y ist trivial, also Y ⊆ X oder – X→R, d.h. X ist Superschlüssel von R Inhaltlich besagt das Boyce-Codd-Kriterium somit, daß außer den trivialen Abhängigkeiten, die ja nichts aussagen, nur Schlüsselabhängigkeiten vorhanden sein dürfen. Schlüsselabhängigkeiten sind ebenfalls unvermeidlich, denn sie sind eine Konsequenz der Schlüsseleigenschaft, und Identifizierungsschlüssel sind ja per definitionem vom Ent- 248 Entwurf redundanzfreier Datenbankschemata wickler gewünscht. Erlaubt sind also nur “unvermeidliche” Abhängigkeiten, sonst keine! Insofern ist das Boyce-Codd-Kriterium intuitiv naheliegend, ferner ist die Struktur seiner Definition sehr einfach45 . Das Boyce-Codd-Kriterium verbietet alle nichttrivialen Abhängigkeiten, die die Form X→Y haben, worin X kein Superschlüssel von R ist. Wenn K ein Identifizierungsschlüssel von X ist, dann ist in solchen Fällen Y auch indirekt von K abhängig: K→X→Y Eine derartige Abhängigkeit X→Y wird daher auch als transitive Abhängigkeit bezeichnet. Wenn man noch einmal den zu großen Relationentyp in Abschnitt 10.2.1 betrachtet, dann sollte klar werden, daß transitive Abhängigkeiten gerade die Redundanz und die Anomalien verursachen. Relationen, die das Boyce-Codd-Kriterium erfüllen, sind in diesem Sinne völlig frei von Redundanzen. Von unseren früheren Beispielen erfüllen die Relationentypen Kunden und Lieferungen das Boyce-Codd-Kriterium: – Kunden hat nur {Kundennummer} als Identifizierungsschlüssel und sonst keine funktionalen Abhängigkeiten. – Bei Lieferungen können wir {Datum, Kundennummer} als Identifizierungsschlüssel annehmen46 . Außer {Datum, Kundennummer}→ Lieferungen sind keine hiervon nicht ableitbaren nichttrivialen funktionalen Abhängigkeiten vorhanden. Der Relationentyp Kundenlieferungen erfüllt das Boyce-CoddKriterium hingegen nicht: Auch hier können wir {Datum, Kundennummer} als Identifizierungsschlüssel annehmen. Es liegt hier aber 45 Zumindest, wenn man die Definition wie hier anlegt. In manchen Lehrbüchern wird die Boyce-Codd-Normalform als Erweiterung der 3. Normalform definiert. Diese Definitionen sind technisch komplex und verbergen den intuitiv naheliegenden Sinn des Kriteriums weitgehend. Historisch ist diese Definitionsmethode dadurch erklärbar, daß die 3. Normalform zuerst gefunden wurde. 46 Um des Beispiels willen erlauben wir nur eine Lieferung pro Tag an einen Kunden. Entwurf redundanzfreier Datenbankschemata 249 die Abhängigkeit der Kundendaten von der Kundennummer vor, also Kundennummer→{Kundenname, Wohnort, Kreditlimit}. Diese Abhängigkeit verletzt das Boyce-Codd-Kriterium, denn sie ist nicht trivial und {Kundennummer} ist kein Identifizierungsschlüssel. 10.4.2 Boyce-Codd-Zerlegungen Sofern ein Relationentyp das Boyce-Codd-Kriterium nicht erfüllt, kann man ihn verlustfrei so zerlegen, daß die entstehenden Relationentypen die Boyce-Codd-Eigenschaft haben. Diese nennen wir Boyce-CoddZerlegung des Relationentyps. Das Verfahren ist sehr einfach und intuitiv naheliegend. Als Beispiel betrachten wir zunächst ein Adreßverzeichnis, eine Relation mit dem Typ Adressen = ( Name: string; Vorname: string; PLZ: integer; Wohnort: string; Telnr: string; ) Einige Beispieltupel der zugehörigen Relation adressen sind in der folgenden Tabelle angegeben: Tabelle: adressen Name Vorname Büdenbender Hanna Litt Michael Müller Markus Schmidt Karl Schneider Peter PLZ 57250 57078 57072 57078 57250 Wohnort Netphen Siegen Siegen Siegen Netphen Telnr ... ... ... ... ... Wir unterstellen, daß {Name, Vorname} der (einzige) Identifizierungsschlüssel ist. Wenn man die Beispieltabelle betrachtet, sollte einem die redundante Angabe des Ortsnamens zu den Postleitzahlen auffallen; hier liegt die Abhängigkeit PLZ→Wohnort vor. Diese Abhängigkeit verletzt natürlich das Boyce-Codd-Kriterium. 250 Entwurf redundanzfreier Datenbankschemata Die naheliegende Lösung des Problems liegt darin, die Zuordnung zwischen Postleitzahl und Ortsname in einer separaten Tabelle zu verwalten und in der Relation adressen nur noch die Postleitzahl zu speichern, den Ortsnamen dagegen zu entfernen. Wir erhalten hier folgende Relationen und zugehörige Relationentypen: Tabelle: adressen2 Name Vorname Büdenbender Hanna Litt Michael Müller Markus Schmidt Karl Schneider Peter PLZ 57250 57078 57072 57078 57250 ... ... ... ... ... ... Tabelle: plzort PLZ Wohnort 57072 Siegen 57078 Siegen 57250 Netphen Im allgemeinen gehen wir wie folgt vor: Sei R der Relationentyp und X→Y ∈ F die unzulässige Abhängigkeit, X, Y ⊆ R. Wir unterstellen, daß F in Form einer kanonischen Überdeckung vorliegt, die Abhängigkeiten also keine trivialen Anteile enthalten (somit X ∩ Y = ∅). Dann zerlegen wir (R, F ) in folgende Relationentypen: 1. (R – Y, F – {X→Y}) 2. (X ∪ Y, {X→Y}) Der erste Relationentyp hat die gleichen Identifizierungsschlüssel wie R und entsteht, indem man in R die Attribute aus Y entfernt; gerade diese Attribute entsprechen ja den redundant gespeicherten Daten. Die unzulässige Abhängigkeit entfällt. Der zweite Relationentyp hat den Identifizierungsschlüssel X und sonst keine Abhängigkeiten, erfüllt also das Boyce-Codd-Kriterium. Übung: Zeigen Sie, daß die vorstehende Zerlegung verlustfrei ist. Sofern mehrere unzulässige Abhängigkeiten in (R, F ) vorhanden sind, muß für jede einzelne unzulässige Abhängigkeit nach dem oben Entwurf redundanzfreier Datenbankschemata 251 beschriebenen Verfahren eine Zerlegung durchgeführt werden. Am Ende ist keine unzulässige Abhängigkeit mehr vorhanden und das BoyceCodd-Kriterium erfüllt. Durch die Zerlegungen erreichen wir unser Ziel, redundante Daten zu vermeiden. Es sei aber nicht verschwiegen, daß Zerlegungen auch einen Nachteil haben, der in Einzelfällen gravierend sein kann: Sofern die Daten in Form der ursprünglichen, “zu großen” Relation benötigt werden, muß diese aus den kleineren Relationen wieder rekonstruiert werden. Hierzu müssen Verbunde gebildet werden, was sehr aufwendig sein kann. Manchmal verzichtet man besser auf die Zerlegung, muß dann aber durch gezielte Maßnahmen die in Abschnitt 10.2 beschriebenen Anomalien behandeln und individuelle Maßnahmen zur Konsistenzsicherung ergreifen. Zum vorstehenden Zerlegungsverfahren ist noch nachzutragen, daß wir uns heimlich eine gewisse Unsauberkeit erlaubt haben: F kann außer X→Y noch weitere Abhängigkeiten enthalten, die Attribute aus Y und R - X beinhalten, z.B. Z→Y, Z ∩ X = ∅, s. Bild 10.5. Nachdem die R R X Z X Z Y X vor der Zerlegung Y nach der Zerlegung Abbildung 10.5: Entstehen nichtlokaler Abhängigkeiten Attribute aus Y in R entfernt worden sind, wirkt eine solche Abhängigkeit bei R etwas deplaziert, denn sie betrifft Attribute, die in R gar nicht mehr enthalten sind. Sofern alle Attribute einer Abhängigkeit zu dem zweiten Relationentyp gehören, kann man sie dem 2. Re- 252 Entwurf redundanzfreier Datenbankschemata lationentyp zuordnen, wobei dann zu prüfen wäre, ob er dann noch das Boyce-Codd-Kriterium erfüllt. Es kann aber immer noch relationsübergreifende Abhängigkeiten geben, die “quer” zu den beiden entstandenen Relationentypen liegen, d.h. die, wenn sie z.B. vom ersten auf den zweiten Relationentyp gerichtet sind, die Form U→V mit U ⊆ R-(X∪Y) und V ⊆ Y haben. 10.5 Lokale Überwachbarkeit 10.5.1 Motivation und Definition Wir sind bisher ausgegangen von der Problematik, daß ein Relationentyp R zu viele Attribute enthält und somit zerlegt werden sollte, z.B. in die Relationentypen R1 und R2 . Abhängigkeiten von R, die Attribute aus R1 – R2 und R2 – R1 enthalten, können weder R1 noch R2 gut zugeordnet werden. Man müßte solche relationsübergreifenden Abhängigkeiten47 an anderer Stelle notieren. Das Notationsproblem ist hier allerdings zweitrangig. Viel gravierender ist das Problem, daß man nun einen Verbund (zumindest partiell) berechnen muß, um die Einhaltung der Abhängigkeiten zu kontrollieren. Dies kann sehr unangenehm sein, denn die Kontrolle ist bei jeder Erzeugung oder Änderung eines Tupels erforderlich und die Berechnung von Verbunden ist i.a. aufwendig. Man möchte relationsübergreifende Abhängigkeiten daher möglichst vermeiden und nur Abhängigkeiten haben, bei denen alle involvierten Attribute zu einem Relationentyp gehören, so daß die Abhängigkeit in der zugehörigen Relation ohne Verbundbildung lokal überwachbar ist. Dies ist meist mit Hilfe von Indexen sehr effizient möglich. Nicht stören würden relationsübergreifende Abhängigkeiten, die von lokal überwachbaren ableitbar sind, denn ableitbare Abhängigkeiten brauchen ja nicht überwacht zu werden. Diese Beobachtung führt 47 Diese relationsübergreifenden Abhängigkeiten dürfen nicht mit Fremdschlüsseln verwechselt werden. Fremdschlüssel sind keine funktionalen Abhängigkeiten, sondern Inklusionsabhängigkeiten: Alle auftretenden Fremdschlüsselwerte müssen auch in der referierten Tabelle auftreten. Entwurf redundanzfreier Datenbankschemata 253 zum Begriff einer unabhängigen Zerlegung: bei einer solchen sind alle Abhängigkeiten, die durch die Zerlegung relationsübergreifend werden, ableitbar. Definition: Sei (R,F ) ein Relationentyp, {R1 , ..., Rn } eine Zerlegung von R. Für 1 ≤ i ≤ n sei Fi = { X→Y ∈ F + | X, Y ⊆ Ri } Die Zerlegung {R1 , ..., Rn } heißt unabhängig (dependency preserving) S bzgl. F , wenn ( ni=1 Fi )+ = F + . Jede der Mengen Fi enthält die Abhängigkeiten, die lokal in πRi (r) überwachbar sind. Ein Beispiel für eine unabhängige Zerlegung ist die Zerlegung von Kundenlieferungen in Kunden und Lieferungen. 10.5.2 Beispiel: Postleitzahlenbuch In diesem Abschnitt stellen wir ein Beispiel einer nicht unabhängigen Zerlegung vor. Es handelt sich hier um eine vereinfachte Variante des Postleitzahlenbuchs. Dieses gibt zu einer Stadt und einer Straße die Postleitzahl an, ferner nehmen wir an, daß ein PLZ-Gebiet immer ganz in einer Stadt liegt48 . Der zugehörige Relationentyp kann wie folgt definiert werden: PLZBuch = ( Ort: string; Straße: string; PLZ: integer; ) Einige Beispieltupel aus der zugehörigen Relation plzbuch zeigt die folgende Tabelle: 48 Tatsächlich kann die Postleitzahl auch noch von der Hausnummer abhängen, und es gibt Städte, bei denen die Postleitzahl nicht von der Straße abhängt. Ferner haben in einigen Gegenden verschiedene Orte die gleiche Postleitzahl. 254 Entwurf redundanzfreier Datenbankschemata Tabelle: Ort Siegen Siegen Siegen Siegen Siegen Siegen Siegen plzbuch Straße Grabenstr. Kohrweg Hölderlinstr. Poststr. Marktstr. Ruhrststr. Schulstr. PLZ 57072 57074 57076 57076 57078 57078 57080 Es liegen folgende funktionale Abhängigkeiten vor: – {Ort, Straße}→PLZ – PLZ→Ort Ort PLZ Straße Abbildung 10.6: Graphische Darstellung der funktionalen Abhängigkeiten im Relationentyp PLZBuch {Ort, Straße} ist offensichtlich Identifizierungsschlüssel. Aus PLZ→Ort folgt mittels der Erweiterungsregel, daß auch {PLZ, Straße}→{Ort, Straße}; somit ist auch {PLZ, Straße} ein Identifizierungsschlüssel. Wir betrachten nun folgende Zerlegung von PLZBuch: – PLZBuch1 = {PLZ, Ort} mit Identifizierungsschlüssel {PLZ} – PLZBuch2 = {PLZ, Straße} mit Identifizierungsschlüssel {PLZ, Straße} Die beiden Identifizierungsschlüssel stellen die einzigen nichttrivialen Abhängigkeiten der beiden Relationentypen dar. Entwurf redundanzfreier Datenbankschemata Tabelle: plzbuch1 PLZ Ort 57072 Siegen 57074 Siegen 57076 Siegen 57078 Siegen 57080 Siegen 255 Tabelle: plzbuch2 PLZ Straße 57072 Grabenstr. 57074 Kohrweg 57076 Hölderlinstr. 57076 Poststr. 57078 Marktstr. 57078 Ruhrststr. 57080 Schulstr. Abbildung 10.7: Zerlegte Postleitzahlen-Relation Bild 10.7 zeigt die beiden entstehenden Relationen. Diese Zerlegung ist verlustfrei, denn PLZBuch1 ∩ PLZBuch2 = { PLZ } und PLZ ist Identifizierungsschlüssel für PLZBuch1. Die Zerlegung ist nicht unabhängig, denn {Ort, Straße}→PLZ ist nicht von den lokal überwachbaren Abhängigkeiten ableitbar. Dies beweist man leicht, indem man mit dem in Abschnitt 10.3.5 vorgestellten Algorithmus die Menge der von {Ort, Straße} abhängigen Attribute berechnet. Wenn man z.B. in plzbuch versuchen würde, das Tupel (Siegen, Hölderlinstr., 57080) einzufügen, obwohl schon (Siegen, Hölderlinstr., 57076) vorhanden ist, würde dieser Fehler erkannt werden. Bei der Zerlegung müßte man entsprechend in der Relation plzbuch1 das Tupel (57080, Siegen) einfügen (was sich hier zufällig erübrigt, weil es schon vorhanden ist) und in der Relation plzbuch2 das Tupel (57080, Hölderlinstr.); beide Einfügungen sind mit den lokalen Abhängigkeiten konsistent. Um herauszufinden, ob dem Paar (Siegen, Hölderlinstr.) nicht auf einmal zwei verschiedene Postleitzahlen zugeordnet werden, müßte bei Einfügungen auf die jeweils andere Relation zugegriffen werden und ein auf die vorliegenden Werte des Verbundattributs PLZ beschränkter Verbund gebildet werden. Das vorstehende Beispiel ist insofern wichtig, als es zeigt, daß es Relationentypen gibt, die keine unabhängige Zerlegung in kleinere Re- 256 Entwurf redundanzfreier Datenbankschemata lationentypen, die das Boyce-Codd-Kriterium erfüllen, haben. Im einzelnen: – PLZBuch erfüllt das Boyce-Codd-Kriterium nicht, denn PLZ→Ort widerspricht dem. PLZ→Ort ist nicht trivial und {PLZ} ist kein Identifizierungsschlüssel für PLZBuch. – Das in Abschnitt 10.4.2 vorgestellte Verfahren zur Erzeugung einer Boyce-Codd-Zerlegung führt gerade zu der vorstehenden Zerlegung. Dieser erfüllt nach Konstruktion das Boyce-Codd-Kriterium, ist aber nicht unabhängig. – Andere verlustfreie Zerlegungen existieren nicht; es müßte entweder Ort oder Straße als Verbundattribut benutzt werden; in keinem Fall ist dies ein Identifizierungsschlüssel für eine der entstehenden Teil-Relationentypen. R K Y1 X Y2 Abbildung 10.8: Varianten von transitiven Abhängigkeiten Bild 10.8 zeigt zwei Alternativen, wie eine unzulässige funktionale Abhängigkeit liegen kann. Hieran können wir die Ursache des Problems beim Postleitzahlenbuch-Schema generell diskutieren. Gegeben ist ein Relationentyp R mit einem Identifizierungsschlüssel K und der transitiven Abhängigkeit K→X→Y1. Um diese Abhängigkeit zu entfernen, müssen wir R zerlegen und die Attributmenge Y1 aus R entfernen. Dadurch werden aber die Attribute des Identifizierungsschlüssels K “auseinandergerissen”, die Abhängigkeit K→X wird zu einer nichtlokalen. Da Identifizierungsschlüssel i.a. nicht von anderen Abhängigkeiten impliziert werden, geht die Unabhängigkeit der Zerlegung verloren. Entwurf redundanzfreier Datenbankschemata 257 Bild 10.8 ist zusätzlich die transitive Abhängigkeit K→X→Y2 eingezeichnet. Diese hat nicht die Form einer “Schlinge”, es ist also nicht Y2 ⊂ K, deshalb kann man scheinbar problemlos das übliche Zerlegungsverfahren anwenden. Dies stimmt aber nicht ganz, denn wenn es einen zweiten Identifizierungsschlüssel K2 gibt und wenn Y2 ⊂ K2 ist, dann haben wir das gleiche Problem. Entscheidend ist also, ob die indirekt abhängige Attributmenge in einem Identifizierungsschlüssel liegt49 oder nicht. Falls ja, haben wir ein Problem. 10.6 Die dritte Normalform 10.6.1 Motivation und Definition In den vorigen Abschnitten wurde gezeigt, daß einerseits das BoyceCodd-Kriterium sehr naheliegend ist und die natürliche Konkretisierung des Wunsches nach Redundanzfreiheit ist, daß andererseits aber nicht immer eine unabhängige Boyce-Codd-Zerlegung existiert. Sofern letzteres der Fall ist, muß man entweder auf die Redundanzfreiheit oder die lokale Überwachbarkeit verzichten. I.a. wird man der lokalen Überwachbarkeit die höhere Priorität einräumen (in Ausnahmefällen kann die Entscheidung auch zugunsten der Redundanzfreiheit ausfallen). Wir benötigen somit ein Qualitätskriterium für Relationentypen, das schwächer als das Boyce-Codd-Kriterium ist und bei dem in gewissem Umfang Redundanz erlaubt wird. Ein solches Kriterium ist die dritte Normalform50 , die in diesem Abschnitt vorgestellt wird. Sie ist folgendermaßen definiert: Definition: Sei R ein Relationentyp, F die Menge der für R gültigen funktionalen Abhängigkeiten. R ist in dritter Normalform (abgekürzt 3NF) ⇐⇒ ∀ X→Y ∈ F gilt: 49 Sie muß eine echte Teilmenge sein, wenn sie identisch mit dem Identifizierungsschlüssel wäre, wäre auch X ein Identifizierungsschlüssel und die Abhängigkeit wäre zulässig. 50 Offensichtlich gibt es dann auch eine erste und zweite Normalform. Beide sind im Moment irrelevant, wir gehen in Abschnitt 10.8 kurz darauf ein. 258 Entwurf redundanzfreier Datenbankschemata 1. X→Y ist trivial, also Y ⊆ X oder 2. X→R, d.h. X ist Superschlüssel von R oder 3. Y ist Teilmenge eines Identifizierungsschlüssels, d.h. ∃ K ⊆ R mit K→R und Y ⊆ K Die dritte Art von zulässigen Abhängigkeiten stellt gerade die angekündigte Aufweichung gegenüber dem Boyce-Codd-Kriterium dar. Informell ausgedrückt bedeuten solche Fälle, daß ein Schlüsselattribut von einer Attributmenge, die kein Schlüssel ist, abhängig ist. Unser Relationentyp Postleitzahlenbuch ist in dritter Normalform; die beim Boyce-Codd-Kriterium unzulässige Abhängigkeit PLZ→Ort stört hier nicht mehr, denn {Ort} ist Teilmenge des Identifizierungsschlüssels {Ort, Straße}, d.h. sie fällt unter die dritte Art zulässiger Abhängigkeiten. Ein Relationentyp, der das Boyce-Codd-Kriterium erfüllt, ist offensichtlich auch in dritter Normalform. Das Beispiel des Postleitzahlenbuchs zeigt, daß die Umkehrung dieser Aussage nicht gilt. Die dritte Normalform ist somit ein schwächeres Korrektheitskriterium als das Boyce-Codd-Kriterium. 10.6.2 Konstruktion einer Zerlegung in dritter Normalform Bei jedem Qualitätskriterium für Relationentypen stehen wir vor der Frage, ob wir zu einem gegebenen Relationentyp, der das Qualitätskriterium nicht erfüllt, immer eine verlustfreie und unabhängige Zerlegung finden können, die das Kriterium erfüllt. Beim Boyce-CoddKriterium war die Antwort nein. Bei der dritten Normalform ist die Antwort hingegen ja, es gibt einen Algorithmus, der zu einem Relationentyp und einer Menge funktionaler Abhängigkeiten zu diesem Relationentyp eine Zerlegung in dritter Normalform konstruiert. Die Grundidee zu diesem Algorithmus ist informell sehr einfach zu erklären: Jede funktionale Abhängigkeit X→Y muß ja überwacht werden, am einfachsten und direktesten durch eine eigene Tabelle mit Entwurf redundanzfreier Datenbankschemata 259 dem Relationentyp (X∪Y, {X→Y}). Wenn man nun für alle “wichtigen” funktionalen Abhängigkeiten eine derartige Tabelle vorsieht, hat man eine verlustfreie Zerlegung, und die einzelnen Relationen haben nach Konstruktion nur eine nichttriviale Abhängigkeit. Die Frage nach den “wichtigen” Abhängigkeiten läßt sich durch Rückgriff auf den Begriff kanonische Überdeckung lösen. Die genaue Vorgehensweise, anhand der wir zu einem gegebenen Relationentyp (R, F ) eine Zerlegung in dritter Normalform konstruieren, ist wie folgt: 1. Wir wählen eine kanonische Überdeckung von F . Dieser Schritt ist nichtdeterministisch, denn es kann i.a. mehrere kanonische Überdeckungen geben. Sei Fc diese Menge von Abhängigkeiten. Es sei daran erinnert, daß bei einer kanonischen Überdeckung keine Abhängigkeit und kein Attribut in den Abhängigkeiten überflüssig ist. Wir unterstellen, daß Fc in der normierten Darstellung vorliegt, bei der die linken Seiten der Abhängigkeiten eindeutig sind. 2. Zu einer Abhängigkeit X→Y ∈ Fc bilden wir den Relationentyp ( X∪Y, { A→B | A→B ∈ Fc ∧ A∪B ⊆ X∪Y } ). Sei S die Menge der so entstandenen Relationentypen. 3. Sofern keine der Relationentypen in S ein Superschlüssel für R ist, bilden wir einen beliebigen Identifizierungsschlüssel K für R und fügen zu S die Relation (K, ∅) hinzu. 4. In der Menge S können wir nun solche Relationentypen (Ri , Fi ) löschen, die ganz in einem “größeren” Relationentyp enthalten sind, d.h. für die gilt ∃ (Rj , Fj ) ∈ S: Ri ⊆ Rj Anmerkung zu Schritt 3: Daß nicht immer automatisch eine der Relationentypen in S einen Superschlüssel für R umfaßt, mag auf den ersten Blick überraschen. Ein Beispiel für solche Relationentypen sind “Verbindungstabellen”, die eine m:n-Beziehung realisieren, die nur zwei Attribute X und Y haben und bei denen {X, Y}, also der komplette Relationentyp R, der einzige Identifizierungsschlüssel ist. Die 260 Entwurf redundanzfreier Datenbankschemata Abhängigkeit R→R ist aber trivial und daher in der kanonischen Überdeckung nicht enthalten. Es gibt aber auch Beispiele mit nichttrivialen Abhängigkeiten, z.B. R = {A, B, C, D, E, F, G} und F = { A→BC, D→EF }. Hier ist ADG der einzige Identifizierungsschlüssel. Diese Attributmenge ist aber in keinem der Relationentypen Ri enthalten, denn ADG→R wird von den o.g. Abhängigkeiten impliziert und ist daher in der kanonischen Überdeckung nicht enthalten. Anmerkung zu Schritt 4: Ein Beispiel hierfür ist der Relationentyp PLZBuch. Eine kanonische Überdeckung ist {{Ort, Straße}→PLZ, PLZ→Ort}; in den beiden ersten Schrittes unseres Algorithmus entstehen daraus die Relationentypen {Ort, Straße, PLZ} und {PLZ, Ort}. Der zweite ist Teilmenge des ersten, wird also in Schritt 4 wieder eliminiert. Auf diese Eliminierung könnte man übrigens auch verzichten, die eliminierten Relationentypen sind auch alle in 3NF. Allerdings wären die zugehörigen Relationen natürlich redundant, und Redundanzvermeidung ist ja gerade das Ziel der Normalformen. Der obige Algorithmus wird auch Synthesealgorithmus genannt, weil hier zunächst die funktionalen Abhängigkeiten betrachtet werden und auf Basis einer kanonischen Überdeckung sofort die Relationentypen zusammengesetzt werden. Im Gegensatz dazu ist das Verfahren, mit dem wir die Boyce-Codd-Zerlegung hergestellt haben, ein Dekompositionsverfahren, bei dem schrittweise immer wieder neue Relationentypen bestimmt werden. Behauptung: Eine mit dem Synthesealgorithmus erzeugte Zerlegung ist verlustfrei und unabhängig und alle entstandenen Relationentypen sind in 3NF. Beweis: Daß es sich hier um eine Zerlegung von R handelt, ergibt sich aus den Eigenschaften einer Überdeckung, d.h. alle Attribute aus R treten in den Abhängigkeiten in Fc und somit auch wieder in wenigstens einem der Relationentypen in S auf. Die Unabhängigkeit der Zerlegung läßt sich leicht zeigen: Nach der Entwurf redundanzfreier Datenbankschemata 261 Konstruktion der Zerlegung sind alle funktionalen Abhängigkeiten aus Fc lokal prüfbar, vgl. Schritte 2 - 4 des Synthesealgorithmus. Da Fc eine kanonische Überdeckung ist, gilt weiter Fc+ = F + , d.h. die Zerlegung ist unabhängig. Die Verlustfreiheit beweisen wir wie folgt: Seien ri = πRi (r) die zu den Relationentypen gehörenden Relationen. Zu zeigen ist, daß bei einem Verbund aller ri keine Tupel entstehen, die nicht in der ursprünglichen Relation r vorhanden waren. Nach Konstruktion enthält S immer einen Relationentyp K, der ein Superschlüssel für R ist, also K+ = R bzw. K→R. Diese Abhängigkeit wird von den Abhängigkeiten in der Überdeckung impliziert. Wenn man K+ mit dem in Abschnitt 10.3.5 angegebenen Algorithmus berechnet, konstruiert man in einer Kette von Ableitungsschritten immer größere Attributmengen Ki (mit K0 = K), wobei irgendwann Kn = R gilt. Bei jedem Schritt wird die Menge der von K abhängigen Attribute erweitert, indem die Erweiterungsregel und eine einsetzbare Abhängigkeit Xi →Yi mit Xi ⊆ Ki ausgenutzt werden. Wir nutzen nun die zu K gehörige Relation k als Ausgangsbasis für unsere Verbundbildung. Offensichtlich ist |k| = |r|, k enthält schon alle in r auftretenden Wertekombinationen in den Schlüsselattributen K. Wir bilden nun schrittweise den Verbund mit einer Relation, die die Attribute Xi ∪Yi enthält; sei dies ri , somit ki = ri 1 ki−1 Wir nehmen zunächst an, daß Ri =Xi ∪Yi ist. Der vorstehende Verbund ist verlustfrei, da die Attribute Xi die Verbundattribute und Identifizierungsschlüssel von ri sind. Es gilt also |ki | = |ki−1 |. Ferner ist K Superschlüssel für ki . Durch Induktion über i zeigt man leicht, daß |k0 | = |kn | ist. Die Zahl der Tupel erhöht sich also bei keinem Schritt. Wegen der Kommutativität und Assoziativität des Verbundoperators kommt dann, wenn man die Verbunde in einer anderen Reihenfolge bildet, am Ende das gleiche Ergebnis heraus; allerdings können bei einer anderen Reihenfolge Zwischenergebnisse auftreten, die mehr Tupel als r enthalten. Es bleibt bei der Bildung von ki der Fall zu behandeln, daß S keinen 262 Entwurf redundanzfreier Datenbankschemata Relationentyp Ri mit Ri = Xi ∪Yi enthält. Dieser Relationentyp kann in Schritt 4 des Synthesealgorithmus entfernt worden sein. Es muß dann wenigstens einen Relationentyp Ri mit Ri ⊃ Xi ∪Yi geben. Wir verwenden dann zunächst statt ri die Relation πXi ∪Yi (ri ) für die Verbundbildung und bilden ganz zum Schluß noch einmal den Verbund kn 1 ri . Offensichtlich gilt: ri = πXi ∪Yi (ri ) 1 ri d.h. unser künstlich eingeführter Zwischenschritt ändert wegen der Kommutativität und Assoziativität des Verbundoperators nichts am Gesamtergebnis. Die 3NF beweisen wir wie folgt: Der Relationentyp (K, ∅), den wir ggf. in Schritt 3 des Synthesealgorithmus hinzugenommen haben, ist trivialerweise in 3NF. Für die restlichen Relationentypen zeigen wir, daß die Annahme, sie seien nicht in 3NF, zu einen Widerspruch führt. Sei also (Ri , Fi ) ein Relationentyp, der durch eine Abhängigkeit Xi →Yi in Fc entstanden ist, also Ri = Xi ∪ Yi . Xi Yi A U Abbildung 10.9: Beweissituation Angenommen, Ri ist nicht in 3NF, dann existiert eine Abhängigkeit U→A in Fi , worin U kein Identifizierungsschlüssel und A ein Attribut ist, das zu keinem Identifizierungsschlüssel gehört. A muß entweder in Xi oder Yi liegen. A kann nicht in Xi liegen, denn Xi ist Identifizierungsschlüssel für Ri : Nach Konstruktion gilt Xi →Ri , und wegen der Linksminimalität der Abhängigkeiten in Fc ist keine echte Teilmenge von Xi Identifizierungsschlüssel für Ri . Nehmen wir also A∈Yi an. U kann keine echte Teilmenge von Xi sein, Entwurf redundanzfreier Datenbankschemata 263 dies widerspräche der Konstruktion von Fc (genauer gesagt der Linksminimalität der Abhängigkeit Xi →A). U muß also wenigstens ein Attribut aus Yi enthalten, s. Skizzierung der Lage in Bild 10.9. Nach unseren bisherigen Annahmen gilt: Xi →U wird von Fc impliziert, U→A ist in Fc enthalten. Beide Abhängigkeiten implizieren zusammen Xi →A. Dies widerspricht aber der Annahme Xi →Yi ∈ Fc und A ∈ Yi : eine kanonische Überdeckung enthält keine überflüssigen Attribute in den Abhängigkeiten. 10.7 Überwachung funktionaler Abhängigkeiten Wir hatten schon oben erwähnt, daß funktionale Abhängigkeiten als Integritätsbedingungen anzusehen sind und innerhalb eines Informationssystems überwacht werden müssen. Man kann zwei grundlegend verschiedene Ansätze unterscheiden: – Die Applikationen sind verantwortlich: Sofern z.B. freie Dateneingaben möglich sind, muß die Applikation entsprechende Tests durchführen und die Eingaben im Fehlerfall zurückweisen. Alternativ kann man die Dateneingabeschnittstellen oder Kommandos so gestalten, daß inkonsistente Zustände gar nicht erzeugt werden können. Ein prinzipieller Schwachpunkt dieses Ansatzes ist, daß er unsicher ist. Zum einen sind die Konsistenzprüfungen im ApplikationsCode “versteckt” und nicht automatisch überprüfbar; selbst wenn die Absicht bestand, entsprechende Prüfungen einzubauen, kann dies durch Programmierfehler nicht korrekt realisiert worden sein. Wenn man ferner ein Datenbanksystem als eine relativ offene Basis zur Entwicklung von Applikationen ansieht, stellt sich die Notwendigkeit, das Wissen über die notwendigen Konsistenzprüfungen unter allen Applikationsprogrammierern zu verbreiten, als kritischer Punkt dar. – Das DBMS ist verantwortlich: Das DBMS muß hier eine geeignete Schnittstelle anbieten, über die ihm mitgeteilt werden kann (im 264 Entwurf redundanzfreier Datenbankschemata Rahmen der Schemadefinition), welche Abhängigkeiten überwacht werden sollen. Für Identifizierungsschlüssel (insb. Primärschlüssel und “eindeutige” Attribute) sind derartige Schnittstellen üblicherweise vorhanden. Das DBMS muß unzulässige Einfügungen und Änderungen dementsprechend mit einer Fehlermeldung ablehnen. Da es zu einer Relation mehrere funktionale Abhängigkeiten geben kann und Einfügungen auch mengenorientiert erfolgen können, ist die Struktur der Fehlermeldung notwendigerweise recht komplex. Es stellt sich allerdings die Frage, ob ein DBMS nicht besser Konzepte und Schnittstellen anbieten sollte, die das Problem der Korrektheit der Daten allgemeiner angehen (z.B. TriggerMechanismen). Funktionale Abhängigkeiten sind nur einer von mehreren Typen von Korrektheitsbedingungen Hinsichtlich des Laufzeitaufwands zur Kontrolle der Abhängigkeiten sind natürlich Identifizierungsschlüssel, die als Primärschlüssel realisiert werden, unübertroffen günstig. Bei allen anderen Verfahren muß im Prinzip immer dann, wenn eine Abhängigkeit X→Y vorliegt und ein Tupel t erzeugt werden soll, gesucht werden, ob schon in den Attributen X die Wertekombination t[X] vorliegt. Damit eine solche Suche effizient durchgeführt werden kann, muß i.a. ein Sekundärindex für X oder eine vergleichbare Datenstruktur vorhanden sein; der Platzbedarf und Pflegeaufwand hierfür ist vergleichbar mit einer zusätzlichen Relation mit dem Typ (X∪Y, {X→Y}), wie sie bei Boyce-Codd-Zerlegungen entsteht. Generell ist daher anzustreben, möglichst alle Abhängigkeiten nach einer Boyce-Codd-Zerlegung auf einen Primärschlüssel abzubilden. 10.8 Weitere Normalformen 10.8.1 Die erste Normalform Die erste Normalform besteht nur aus dem Kriterium, daß alle Attribute unstrukturierte, “atomare” Wertebereiche haben müssen, also Entwurf redundanzfreier Datenbankschemata 265 Zahlen, Boolesche Werte, Zeichenketten51 usw., aber keine Arrays, Listen oder Mengen. Letztere kann man auch als mehrwertige Attribute auffassen. Die Forderung nach atomaren Attributen ist einerseits dadurch motiviert, daß die resultierenden statischen Datenstrukturen deutlich effizienter sind als dynamische. Weiter müßten die Abfragesprachen sonst syntaktisch und semantisch deutlich komplizierter sein, weil jetzt ja auch einzelne Elemente innerhalb eines Datenwerts adressierbar sein müssen (z.B. für eine Abfrage wie “liefere alle Tupel, die im Feld A [das einen Array-Typ hat] als 3. Element eine 5 haben”). Die erste Normalform haben wir bisher schon immer stillschweigend vorausgesetzt, sie liegt ja schon der Denkwelt der relationalen Algebra zugrunde. Während alle anderen Normalformen immer irgendeine Form von Redundanz adressieren (bzw. verbieten), ist dies bei der ersten Normalform nicht der Fall; sie ist eher eine Art syntaktisches Kriterium. Sofern von der Anwendung her Attribute mehrwertig sind, muß man ein Tupel, in dem ein mehrwertiges Attribut mit n Werten auftritt, durch n Tupel ersetzen, in denen jeweils einer der Werte auftritt und der Rest des Tupels jeweils gleich ist. Als Beispiel betrachten wir ein Bücherverzeichnis; ein Buch kann mehrere Autoren haben: Tabelle: bücherverzeichnis ISBN Titel 12345 Software Engineering .. .. Autoren Naur, P.; Randell, B. .. Jahr 1968 .. Das mehrwertige Attribut Autoren muß durch ein atomares ersetzt werden, um z.B. Abfragen wie “welche Bücher hat Autor X (mit-) verfaßt” korrekt beantworten zu können: 51 Man könnte hier ketzerisch fragen, ob Zeichenketten nicht eigentlich doch eine Struktur haben und z.B. als Array angesehen werden können... 266 Entwurf redundanzfreier Datenbankschemata Tabelle: bücherverzeichnis2 ISBN Titel 12345 Software Engineering 12345 Software Engineering .. .. Autor Naur, P. Randell, B. .. Jahr 1968 1968 .. In der Regel stellen die bei der Umwandlung mehrwertiger Attribute entstehenden gleichen Teile der Tupel Redundanzen dar, die das Boyce-Codd-Kriterium verletzen. In unserem Beispiel liegt die Abhängigkeit ISBN→{Titel, Jahr} vor, während {ISBN, Autor} einziger Identifizierungsschlüssel ist; das Boyce-Codd-Kriterium ist somit verletzt. Die Boyce-Codd-Zerlegung weist hier die Besonderheit auf, daß alle Attribute außer dem ursprünglichen Identifizierungsschlüssel und dem mehrwertigen Attribut aus der zu zerlegenden Relation (hier: bücherverzeichnis2) entfernt werden müssen und die “neue” Relation bilden; intuitiv wird man eher diese neue Relation als Nachfolger der ursprünglichen Relation empfinden als den kleinen Rest der ursprünglichen Relation. In unserem Beispiel erhalten wir also: Tabelle: autoren ISBN Autor 12345 Naur, P. 12345 Randell, B. .. .. Tabelle: bücherverzeichnis3 ISBN Titel Jahr 12345 Software Engine- 1968 ering .. .. .. Im Endeffekt muß man i.a. statt eines mehrwertigen Attributs eine eigene Relation benutzen, die neben dem Identifizierungsschlüssel der Ausgangsrelation das mehrwertige Attribut in der atomaren Variante enthält. Unter dem Namen NF2 (non first normal form) DBMS sind auch DBMS entstanden, bei denen einzelne Attribute als Werte Relationen enthalten können; auf diese DBMS gehen wir hier aus Platzgründen und wegen der geringen praktischen Relevanz nicht ein. Entwurf redundanzfreier Datenbankschemata 10.8.2 267 Die zweite Normalform Die zweite Normalform fordert, daß kein Nichtschlüsselattribut von einer echten Teilmenge eines Identifizierungsschlüssel abhängen darf. Unser vorstehendes bücherverzeichnis2 war nicht in zweiter Normalform, da z.B. Titel von ISBN abhängt und da {ISBN} eine echte Teilmenge des Identifizierungsschlüssels {ISBN, Autor} ist. Zulässig bei der zweiten Normalform sind Abhängigkeiten X→Y, bei denen – X ein Nichtschlüsselattribut enthält oder – Y ein Schlüsselattribut ist M.a.W. schließt die zweite Normalform nur eine spezielle Form von Redundanzen aus. Die zweite Normalform ist daher nicht hinreichend im Sinne der Redundanzvermeidung und wird hier nur der Vollständigkeit halber erwähnt. 10.8.3 Mehrwertige Abhängigkeiten und die vierte Normalform Mehrwertige Abhängigkeiten stellen eine weitere Form von Konsistenz bzw. Redundanz dar, die sich mit den bisherigen Begriffen nicht fassen läßt. Als Beispiel modifizieren wir das Beispiel aus Abschnitt 10.8.1 dahingehend, daß wir nicht mehr ein Verzeichnis unterschiedlicher Bücher (im Sinne von Buchtiteln) haben, sondern den Bestand einer Bibliothek, in der mehrere Exemplare eines Buchs stehen können. Jedes Exemplar ist durch eine Katalognummer (Attribut KatNr) identifiziert. Wenn z.B. von einem Buch mit 2 Autoren 3 Exemplare vorhanden sind, könnte, eine Relation bibliothek, deren Relationentyp Bibliothek sei, folgenden Inhalt haben: 268 Entwurf redundanzfreier Datenbankschemata Tabelle: bibliothek KatNr ISBN Titel 2744 12345 Software 2744 12345 Software 2745 12345 Software 2745 12345 Software 2746 12345 Software 2746 12345 Software .. .. .. Engineering Engineering Engineering Engineering Engineering Engineering Autor Naur, P. Randell, B. Naur, P. Randell, B. Naur, P. Randell, B. .. Jahr 1968 1968 1968 1968 1968 1968 .. Diese Relation hat die Abhängigkeiten KatNr→ISBN und ISBN→{Titel, Jahr} und den Identifikationsschlüssel {KatNr, Autor}. Wenn wir nun das letzte der 6 Tupel weglassen, sind die vorstehenden Abhängigkeiten nach wie vor erfüllt, der Datenbestand aber dennoch nicht mehr korrekt, denn das dritte Exemplar des Buchs hat einen Autor weniger als die anderen. Das Konsistenzkriterium ist hier, daß zu jedem Wert von ISBN eine Gruppe von Werten des Attributs Autor “gleichmäßig auftritt” (die Gruppen entsprechender Tupel sind in der vorstehenden Tabelle durch zusätzliche Trennstriche gekennzeichnet). Wenn t ein Tupel der Relation bibliothek ist und i = t[ISBN] die in t auftretende ISBN, dann gehört zu i folgende Gruppe von Werten von Autor: πAutor (σISBN=i (bibliothek)) In unserem obigen Beispiel ist πAutor (σISBN=12345 (bibliothek)) = {“Naur, P.”, “Randell, B.”}. Diese Abfrage liefert also alle Autoren, die bei irgendeinem Exemplar des Buchtitels mit ISBN 12345 genannt werden. Das “gleichmäßige Auftreten” der Wertegruppe bedeutet, daß die Menge σISBN=i (bibliothek) in mehrere gleichgroße Teilmengen aufgeteilt werden kann, für die folgendes gilt: – Jede Teilmenge hat in Z = Bibliothek - {Autor} die gleichen Werte (und enthält die Tupel, die genau ein Buchexemplar repräsentie- Entwurf redundanzfreier Datenbankschemata 269 ren). Wenn t1 ein Element einer solchen Teilmenge ist, dann kann man die Teilmenge angeben als σZ=t1[Z] (bibliothek) – Im Attribut Autor treten alle geforderten Werte auf, d.h. πAutor (σZ=t1[Z] (bibliothek)) = πAutor (σISBN=t1[ISBN] (bibliothek)) Die Notation σZ=t1[Z] soll bedeuten, daß diejenigen Tupel selektiert werden, deren Werte in Z mit denen von t1 übereinstimmen. Man nennt die vorstehende Integritätsbedingung eine mehrwertige Abhängigkeit. Bild 10.10 zeigt die Struktur einer mehrwertigen Abhängigkeit der Attribute B von den Attributen A an einem allgemeiner gehaltenen Beispiel. Tabelle: r R-(A∪B) xx xx xx yy yy yy uu uu vv vv A a1 a1 a1 a1 a1 a1 a2 a2 a2 a2 B b1 b2 b3 b1 b2 b3 b3 b4 b3 b4 Abbildung 10.10: Beispiel für eine mehrwertige Abhängigkeit A→→B In diesem Beispiel wird dem Wert a1 in Attribut A die Wertemenge {b1, b2, b3} in B zugeordnet und dem Wert a2 die Wertemenge {b3, b4}. Die einzelnen Wertemengen können also völlig verschieden sein (auch die einzelnen Buchtiteln zugeordneten “Mengen von Autoren” sind individuell verschieden). Allgemein ist eine mehrwertige Abhängigkeit wie folgt definiert: 270 Entwurf redundanzfreier Datenbankschemata Definition: Sei R ein Relationentyp und seien A, B ⊆ R zwei Attributmengen, Z = R - (A∪B) ∪ A52 . B ist mehrwertig abhängig von A (notiert als A→→B) ⇐⇒ ∀ Relation r mit dem Relationentyp R, ∀ t1, t2 ∈ r : t1[A] = t2[A] ⇒ πB (σZ=t1[Z] (r)) = πB (σZ=t2[Z] (r)) Im Relationentyp Bibliothek liegt die mehrwertige Abhängigkeit ISBN→→Autor vor. Wenn wir als weiteres mehrwertiges Attribut Stichwort hinzunehmen, hätten wir eine zweite mehrwertige Abhängigkeit ISBN→→Stichwort. Wenn ein Buch 2 Autoren und 5 Stichworte hat, müssen 10 Tupel für das Buch vorhanden sein: jeder Autor kombiniert mit jedem Stichwort. Mehrwertige Abhängigkeiten drücken letztlich aus, daß die Gruppe der Werte der abhängigen Attribute frei kombiniert werden mit den “vorderen” Tupelabschnitten (vgl. Bild 10.10), daß also eine Art lokaler Verbund gebildet wird. Formal kann man dies so ausdrücken: A→→B ⇐⇒ ∀ Relation r mit dem Relationentyp R, ∀a ∈ πA (r) gilt mit ra = σA=a (r): πR−(A∪B) ∪ B (ra) = πR−(A∪B) (ra) 1 πB (ra) Wenn man also nur die Tupel mit dem Wert a in A betrachtet und die Spalten A wegläßt, dann ist der Rest der Verbund aus der Menge der “links” auftretenden Abschnitte (also πR−(A∪B) (ra)) und der Menge der “rechts” auftretenden Abschnitte (also πB (ra)). Durch genaues Hinsehen erkennt man, daß die funktionalen Abhängigkeiten ein Sonderfall der mehrwertigen Abhängigkeiten sind: die Menge πB (σZ=t1[Z] (r)) besteht dann nämlich nur noch aus einem einzigen Tupel, und zwar t1[Z]. Triviale mehrwertige Abhängigkeiten. Triviale mehrwertige Abhängigkeiten sind solche, die immer aufgrund der Definition gelten und die somit nichts über den Datenbestand aussagen. 52 vgl. Bild 10.10. A∩B ist nicht unbedingt leer. Unter der Bedingung A∩B = ∅ ist aber Z = R - B. Entwurf redundanzfreier Datenbankschemata 271 Behauptung: A ⊇ B ⇒ A→→B. Zu zeigen ist, daß eine Tupelmenge σA=a (r) durch die Attribute B in gleichmäßige Untergruppen aufgeteilt wird. Wegen A ⊇ B sind in dieser Tupelmenge in B nur gleiche Werte vorhanden, d.h. alle Untergruppen enthalten genau ein Tupel und unterscheiden sich nur in den Attributen R - A. Dem Wert a in A wird genau ein Wert in B zugeordnet (nämlich a projiziert auf B). Hiermit ist die Bedingung für die mehrwertige Abhängigkeit erfüllt. Formaler Beweis: Durch Einsetzen in der Definition. Es sei t1[A] = t2[A]. Zu zeigen ist πB (σZ=t1[Z] (r)) = πB (σZ=t2[Z] (r)). B⊆A impliziert Z = R-(A∪B) ∪ A = R. Hieraus folgt für ein Tupel t∈r: σZ=t[Z] (r) = σR=t (r) = {t} und πB (σZ=t[Z] (r)) = {t[B]}. Aus t1[A] = t2[A] folgt wegen B⊆A t1[B] = t2[B]. Somit gilt πB (σZ=t1[Z] (r)) = πB (σZ=t2[Z] (r)). Behauptung: A ∪ B = R ⇒ A→→B. Die Annahme A ∪ B = R impliziert B ⊇ R - A. Intuitiv kann man sich die Behauptung für den Fall B = R - A damit erklären, daß innerhalb einer Tupelmenge σA=a (r) die Wertetupel in den restlichen Attributen (R - A) alle verschieden sein müssen, denn in A steht nach Konstruktion überall a. In den restlichen Attributen tauchen also keine Duplikate auf, es werden daher gar keine Untergruppen gebildet. Die Bedingung für die mehrwertige Abhängigkeit ist daher trivialerweise erfüllt. Für Obermengen von R - A gilt die vorstehende Argumentation erst recht. Formaler Beweis: Übung (ähnlich wie voriger formaler Beweis). Anwendungsprobleme. Mit mehrwertigen Abhängigkeiten kann man leicht unangemessene Konsistenzkriterien erstellen. Dies sei am folgenden Beispiel illustriert. Wir erweitern unsere Relation bibliothek um ein Feld AkadG, das den akademischen Grad des Autors angibt. Offensichtlich gilt die funktionale Abhängigkeit Autor→AkadG. Hieraus und aus ISBN→→Autor kann man 272 Entwurf redundanzfreier Datenbankschemata ISBN→→AkadG ableiten. Diese mehrwertige Abhängigkeit ist aber unsinnig und zusammen mit der davon unabhängigen Abhängigkeit ISBN→→Autor sogar falsch. Der Fehler liegt darin, daß die Werte in Autor und AkadG gerade nicht frei kombinierbar sind. Richtig wären die folgende Menge von funktionalen und mehrwertigen Abhängigkeiten: ISBN→→{Autor, AkadG} Autor→AkadG D.h. eine ISBN bestimmt eine Menge von Paaren von Werten der Attribute Autor und AkadG. Die vierte Normalform. Nichttriviale mehrwertige Abhängigkeiten stellen offensichtlich unerwünschte Redundanzen dar. Es liegt nahe, sie analog zur Boyce-Codd-Normalform zu verbieten: Definition: Sei (R, M ) ein Relationentyp, M die Menge der für R gültigen mehrwertigen Abhängigkeiten. (R, M ) ist in vierter Normalform ⇐⇒ ∀ X→→Y ∈ R gilt: – X→→Y ist trivial oder – X→R, d.h. X ist Superschlüssel von R Der obige Relationentyp Bibliothek ist nicht in vierter Normalform, weil die mehrwertige Abhängigkeit ISBN→→Autor nicht trivial und {ISBN} kein Superschlüssel von R ist. Beseitigt werden kann eine störende nichttriviale mehrwertige Abhängigkeit durch das gleiche Dekompositionsverfahren, das wir schon bei der Boyce-Codd-Zerlegung kennengelernt haben. Im Fall des Relationentyps Bibliothek würde also ein separater Relationentyp mit den Attributen ISBN und Autor gebildet und das Attribut Autor in Bibliothek entfernt. (Der verkleinerte Relationentyp ist übrigens noch nicht korrekt und muß weiter zerlegt werden. Übungsaufgabe: Wie?) Entwurf redundanzfreier Datenbankschemata 273 Glossar Abhängigkeit, funktionale: einer Attributmenge B von einer Attributmenge A: Konsistenzbedingung; wenn zwei Tupel in A die gleichen Werte haben, haben sie auch in B die gleichen Werte Abhängigkeit, mehrwertige: einer Attributmenge B von einer Attributmenge A: Konsistenzbedingung; für jeden Wert w in A kann die Menge der Tupel, die in A den Wert w haben, als Kreuzprodukt einer Menge von Tupeln über dem Schema B und einer Menge von Tupeln über den restlichen Attributen dargestellt werden. Abhängigkeit, transitive: funktionale Abhängigkeit a → B, bei der A kein Identifizierungsschlüssel ist Änderungsanomalie: Folgeproblem einer redundanten Datenspeicherung; bei Änderung eines Sachverhalts müssen viele Tupel verändert werden Armstrong-Axiome: Satz von grundlegenden Rechenregeln, durch die funktionale Abhängigkeit abgeleitet werden können Boyce-Codd-Kriterium: Korrektheitsbegriff für Schemata; auch BoyceCodd-Normalform (BCNF) genannt; verbietet alle Abhängigkeiten außer den trivialen und Schlüsselabhängigkeiten Boyce-Codd-Zerlegung: Verfahren zum verlustfreien Zerlegen eines Schemas, das das Boyce-Codd-Kriterium nicht erfüllt; die entstehenden Teilschemata erfüllen das Boyce-Codd-Kriterium Einfügeanomalie: Folgeproblem einer falschen Datenmodellierung mit transitiven Abhängigkeiten; beschreibt das Phänomen, daß ggf. künstliche Tupel mit Nullwerten benutzt werden müssen, um bestimmte Daten abspeichern zu können Hülle, transitive (einer Menge funktionaler Abhängigkeiten F ): Menge aller aus F ableitbaren Abhängigkeiten Löschanomalie: Folgeproblem einer falschen Datenmodellierung mit transitiven Abhängigkeiten; beschreibt das Phänomen, daß ggf. Daten ungewollt gelöscht werden Normalform, dritte: Korrektheitsbegriff für Schemata; verbietet alle Abhängigkeiten außer den trivialen, den Schlüsselabhängigkeiten und transitiven, bei denen die abhängigen Attribute Teilmenge eines Identifizierungsschlüssels sind Normalform, vierte: Korrektheitsbegriff für Schemata; verallgemeinert das Boyce-Codd-Kriterium dahingehend, daß alle mehrwertigen 274 Entwurf redundanzfreier Datenbankschemata Abhängigkeiten außer den trivialen und den Schlüsselabhängigkeiten verboten sind Synthesealgorithmus: Verfahren zur Berechnung einer verlustfreien und unabhängigen Zerlegung eines Schemas, so daß die Teilschemata in dritter Normalform sind Überdeckung, kanonische: einer Menge funktionaler Abhängigkeiten F : minimale Menge von funktionalen Abhängigkeiten, die zu F äquivalent ist, d.h. die gleiche transitive Hülle wie F hat Verlustfreiheit: einer Zerlegung eines Schemas: Zerlegung: eines Schemas S: Aufteilung der Attribute von S in mehrere, nicht notwendig disjunkte Teilschemata Zerlegung, unabhängige: eines Schemas S: besagt, daß alle funktionalen Abhängigkeiten von S durch die “lokalen” Abhängigkeiten der Teilschemata impliziert werden; lokal sind solche Abhängigkeiten, deren Attribute im dem Teilschema enthalten sind Literaturverzeichnis [BaM72] Bayer, R.; McCreight, E.M.: Organization of large ordered indexes; Acta Informatica 1, p.173-189; 1972 [Co70] Codd, E.F.: A relational model for large shared data banks; CACM 13:6, p.377-387; 1970/06 [El92] Elmagarmid, A. (ed.): Database transaction models for advanced applications; Morgan Kaufmann; 1992 [Fu05] Fuhr, N.: Information Retrieval (Skriptum zur Vorlesung im SS 05); Universität Duisburg; http://www.is.informatik.uniduisburg.de/courses/ir ss05/folien/irskall.pdf [Ke00] Kelter, U.: Das Konzept der Kernfächer in der universitären Ausbildung in Praktischer Informatik; GI SoftwaretechnikTrends 20:1, p.7-9; 2000/02 [UML-IS06] Unified Modeling Language: Infrastructure, Version 2.0; OMG, Dokument formal/05-07-05; 2006 [Vo99] Vossen, G.: Datenmodelle, Datenbanksprachen und Datenbank-Management-Systeme; Oldenbourg; 1999 [AMU] Kelter, U.: Lehrmodul “Analysemuster (Stichworte)”; 2006 [DMER] Kelter, U.: Lehrmodul “Datenmodellierung mit ER-Modellen”; 2005 [SASM] Kelter, U.: Lehrmodul “Systemanalyse und Systemmodellierung”; 2003 [SAR] Kelter, U.: Lehrmodul “Software-Architekturen”; 2003 [TAE] Kelter, U.: Lehrmodul “Transformation von Analyse-Datenmodellen in Entwurfsdokumente”; 2003 275 276 Stichwortverzeichnis [TRD] Kelter, U.: Lehrmodul “Transportdateien und die SGML”; 2004 Stichwortverzeichnis F + , 236 ≈, 236 | .. |, 97 X+ , 236 3-Ebenen-Schema-Architektur, 39, 47, 112, 116 3-Schichten-Architektur, 16, 47 3-Wege-Verbund, s. Verbundberechnung 3NF, 251 Abfrage interne Darstellung, 170 Intervall-∼, 157, 161 Korrektheitsüberprüfung, 170, 171 Optimierung, 170 Verarbeitung, 170 Zwischenergebnis, 163, 167, 173, 174, 179, 180 Abfragesprache, 170 Abhängigkeit, 228 Ableitung, 232 Analyse, 229 funktionale, 227, 228, 264, 267 graphische Darstellung, 228 Identifizierungsschlüssel, 230 Integritätsbedingung, 230 mehrwertige, 261, 263, 264, 267 Menge von ∼en Äquivalenz, 235 kanonische Überdeckung, s. Überdeckung transitive Hülle, s. transitive Hülle normierte Darstellung, 238, 239 relationsübergreifende, 246 Superschlüssel, 230 transitive, 242, 267 triviale, 228, 264 Überwachung, 235, 257 Verletzung, 231 Administration, 85 Änderungsanomalie, 223, 267 Äquivalenz, 172, 173, 175, 187 Aggregation, 137, 152 Bedingungen, 140 Applikations-Framework, 45 Architektur, 67 Archiv, 27 Armstrong-Axiome, 232, 267 abgeleitete Axiome, 234 graphische Darstellung, 233 Assoziativgesetz, 176 Attribut, 86, 117 Reihenfolge, 87 Wertebereich, 88 Wertzuweisung, 87 Ausführungsplan, 173, 183, 187 Kosten, 173 Auswertungsfunktion, 26 B*-Baum, 63, 65, 112, 157 B-Baum, 65 Ausgleich zwischen Knoten, 60, 63 Einfügung, 58 Löschung, 60 Merkmale, 56 Optimierungsziele, 53, 55, 56, 63 277 278 Ordnung, 56, 65 Suche, 58 Suchgeschwindigkeit, 56, 64 Teilen von Knoten, 59, 62 Überlauf, 58, 59, 65 Unterlauf, 60, 65 Verschmelzen von Knoten, 60, 61, 63 Backup, 27 Basisdatentyp, 51 Basistabelle, 152 Baum, s. Suchbaum BCNF, 241 Bereichskalkül, 120, 128 Betriebssystem, 33 Block, 74 Blockadreßtabelle, 158 Blockübertragung, 53 Blockungsfaktor, 161 Boyce-Codd-Kriterium, 241, 266, 267 Boyce-Codd-Zerlegung, 243, 267 closure, 236 Codierung, 35 Concurrency Control, 31, 41, 47 Dateimanagementsystem, 74 Dateisystem, 19, 20, 33, 45, 47 journaling, 29 Arraystruktur, 34 indexsequentielles, 34 satzorientiertes, 34 sequentielle Struktur, 34 variable Satzlänge, 34 Verzeichnisstruktur, 34 zeichenorientiertes, 34 Daten, 14 externe Darstellung, 17 alternative, 17 formatierte, 35 Layout-∼, 18 unscharfe, 43 unsichere, 45 Stichwortverzeichnis Datenbank, 20, 86 Datenbankmanagementsystem, 19, 47 Datenbankmodell, 38, 47 hierarchisches, 47 konventionelles, 85 Netzwerk-, 47 nichtkonventionelles, 38 relationales, 85, 86 Datenbankschema, 221, 231 Entwurfsfehler, 222, 224 Datenbanksprache, 85 Datenbanksystem, 20 Datendefinitionssprache, 38, 47 Datenintegration, 32, 48 Datenmodell, 221 navigierendes, 170 Datenmodellierung, 23 Datentransport, 27 Datenunabhängigkeit, 33 Datenverlust, 221, 224 Datenverwaltungssystem, 18, 48 Auswahl, 19 Dienstprogramme, 22 Laufzeitkern, 22 DB2, 130 DBMS, 19 Administration, 67 erweiterbares, 20 Laufzeitkern, 67 DBS, 20 deduktive Datenbank, 19 Dienstprogramm, 22 directory [S,I], s. Verzeichnis Distributivgesetz, 176 Division, 103, 117, 124 Dokumentarchivierungssystem, 19 Dokumenttypdefinition, 36 DTD, 36, 208 Duplikate, 87, 89, 132 Duplikateliminierung, 184 DVS, 18 Editor, 36 Stichwortverzeichnis Einfügeanomalie, 224, 267 Entwurfsdatenbank, 19 equi-join, 103 Erweiterungsregel, 233 Fakten, 15, 45 Formatierung, 191 Fremdschlüssel, s. Schlüssel funktionale Abhängigkeit, s. Abhängigkeit gADT, 51 generischer abstrakter Datentyp, 51, 65 directory [S,I], 52 Typ-Parameter, 51 Geo-Datenbank, 19 Gleichheitsverbund, 103 Grammatik, 208 Gruppierung, 137, 139 Hash-Verfahren, 157 erweiterbares, 158, 167 Hauptspeicher, 74 Heterogenität von Rechnern, 30 hierarchisches Datenbankmodell, 38 Hülle, s. transitive Hülle transitive, 267 Identifizierungsschlüssel, s. Schlüssel Implementierungsebenen von Datenbankobjekten, 206, 211 Index, 40, 80, 83, 157 Indexblock, 157 Indexknoten, 64 Information, 14, 15 Repräsentation, 16, 44 Information Retrieval, 42, 44 Informationssystem, 16 Inkonsistenz, 223 Instanz-von-Beziehung, 198, 216 Integritätsbedingung, 90, 230 dynamische, 90 statische, 90 Überprüfung, 90 279 Interaktivität, 43 invertierter Datenbestand, 159, 168 IR-System, 19, 24, 28, 42 Kalkül, s. relationale Kalküle kanonische Überdeckung, s. Überdeckung Katalog, 146, 152 Kommutativgesetz, 175 Konsistenz, 222, 225, 226, 265 Korrekheitsüberwachung, 24 Korrektheit, s. Konsistenz Kostenmaß, 175 Kostenschätzung, 183 Kreuzprodukt, 185 Projektion, 184 Selektion, 184 Verbund, 185 Kreuzprodukt, 96, 101, 103, 131, 175– 178, 180, 181, 185 Längenfeld, 80 Laufzeitkern, 22, 67, 83 Layout-Daten, 18, 191 linksminimal, 237 Löschanomalie, 224, 267 lokale Überwachbarkeit, 246 Medienadresse, 74, 75 Mehrbenutzerzugriff, 29, 69 mehrwertige Abhängigkeit, 263 mehrwertiges Attribut, 259 memory-mapped IO, 23 Mengenoperationen, 123, 175, 176 Meta-CASE, 215, 218 Meta-Metadaten, 202–204, 219 Metadaten, 189, 190, 219 administrative, 191 entitätsbezogene, 195 Hierarchie, 203, 204 in Datenbanken, 189, 190 in der Dokumentverwaltung, 189, 191 280 in Programmen, 189 instantiierbare, 196–198 Instanzbildung, 197 Nutzung, 192 persistente, 190 semantische, 190 Speicherung, 192, 193, 206 transiente, 190 Typ-Annotationen, 209 typbezogene, 195, 209 vs. Nutzdaten, 192, 194 Metamodell, 214 UML∼ - Ebene M0, 213 UML∼ - Ebene M1, 213, 217 UML∼ - Ebene M2, 214, 218 Metaschema, 202, 219 Metasprache erster Stufe, 194 Metasprache zweiter Stufe, 195 Metatyp, 202 Misch-Verbund, s. Verbundberechnung Modellierung, 16 Multimedia-Datenbank, 19 natural join, 101 nested loop join, 163 Netzwerk-Datenbankmodell, 38 Normalform, 32, 48, 222, 241 non first normal form, 260 Boyce-Codd-, 241 dritte, 251, 267 Zerlegung, 252 erste, 258 vierte, 266, 267 zweite, 261 normierte Darstellung, s. Abhängigkeit Notationskonventionen, 89 Nullwert, 103, 142, 144, 153 Aggregationsoperatoren, 146 Vergleich, 145 Nutzdaten, 53, 189, 219 Objektsprache, 194 OLAP-System, 19 Stichwortverzeichnis OLTP, 19, 48 OLTP-System, 24, 26, 37, 41 Versionierung, 27 Operationsaufruf entfernter, 71 Optimierer, 173 Optimierung, 82, 108, 171, 187 Abarbeitung von Ausdrücken, 172 algebraische, 173, 175, 187 Algorithmus, 181 Ansätze, 171 Heuristik, 179 interne, 173, 187 Kostenmaß, 175 Kostenschätzung, s. Kostenschätzung Kriterien, 174 Meßgrößen, 174 Projektion, 163 relative, 174 Selektion, 160 Verbundberechnung, 163 von Elementaroperationen, 155, 171 zusammengefaßte Operationen, 180 Ordnung, s. B-Baum Parallelität, 31 Persistenz, 18 Primärindex, 58, 81, 83, 157 Primärschlüssel, s. Schlüssel Projektion, 93, 117, 122, 132, 176–178, 181, 184 Prozeßarchitektur, 68 1-Prozeß, 69 von Informationssystemen, 70 Pseudotransitivitätsregel, 235 QMF, 130 Rechteverwaltung, 85 rechtsminimal, 237 Stichwortverzeichnis Recovery, 28, 48 Redundanz, 221, 223, 242, 260 referentielle Integrität, 113 Reflexivitätsregel, 233 Relation, 39, 88 virtuelle, 171 relationale Algebra, 91, 117, 127, 133, 170 äußerer Verbund, 103 Ausdrücke, 108 Auswertung, 108 Differenz, 94 Division, 103 Gleichheitsverbund, 102 Kreuzprodukt, 96 natürlicher Verbund, 100 Projektion, 93 Schnitt, 94 Theta-Verbund, 102 Umbenennung, 95 Vereinigung, 94 relationale Kalküle, 86, 120 relationale Vollständigkeit, 108, 126 relationales Datenbankmodell, 38 Relationenformat, 88 Relationenschema, 88, 117 Relationentyp, 88 als Menge von Attributen, 89 Normalform, 241 Notation, 231 Qualitätskriterien, 241 Relevanz, 25 remote procedure call, 70 Rolle, 32 RTK, 120 sr , 160 Satz, 83 feste Länge, 79 Inhalt, 52, 63 Realisierung, 79 Schlüsselwert, 52 variable Länge, 80 281 Schaden, 28 Schema, 48, 85, 146, 190, 196–198, 214 Änderung, 151 externes, 41 generische DVS-Funktionen, 197 Konfigurierung, 203 internes, 40, 190 konzeptuelles, 40 Schichtenmodell, 73 Schlüssel, 109, 110, 113, 117 als Integritätsbedingungen, 111 Fremdschlüssel, 114, 116, 117, 149, 165, 185 Identifizierungsschlüssel, 24, 39, 110, 117, 148, 185, 230, 258 Auswahlkriterien, 114 künstlicher, 113 Prüfung, 111 Wiederverwendung von Schlüsselwerten, 115 Primärschlüssel, 57, 112, 113, 116, 117, 149 Auswahl, 112 Schlüsselattribut, 110 Schlüsselkandidat, 115–117 Sekundärschlüssel, 116, 117 Sortierschlüssel, 115–117 Suchschlüssel, 159 Superschlüssel, 110, 116, 117, 230, 232, 236 Schlüsselkandidat, s. Schlüssel Schlüsselwert, 34, 52, 78, 110 Schlüsselwertbereich, 55, 78 Intervall, 55 secondary key, 116 Segment, 73 Seite, 73, 75, 79, 83 Sekundärindex, 81, 83, 159, 162, 165, 168, 258 Aktualisierung, 159 Sekundärschlüssel, s. Schlüssel Selbstreferentialität, 193, 219 Änderung von Metadaten, 201, 202 282 Stichwortverzeichnis bei administrativen Metadaten, 200 bei Metatypen, 206 bei schwach strukturierten Daten, 209 bei Sprachen, 208 in relationalen Datenbanken, 199 in XML, 208 UML, 212 Selektion, 91, 117, 121, 132, 133, 176, 177, 179, 181, 184 Bedingung mit all-Quantor, 106 komplexe ∼sbedingung, 176 Selektivität, 161, 168 Semantik, 15, 45 semantische Modellierung, 16 SEQUEL, 130 Serverprozeß, 70, 83 Kommunikationsaufwand, 71 Sicherheit, 70, 128 RTK-Ausdrücke, 125 Sicht, 32, 41, 152, 153 Sichtenauflösung, 171, 187 sort key, 115 Sortierschlüssel, s. Schlüssel Spalte, 86, 117 Speichermedium Einkapselung, 21 persistentes, 18, 21 Speichersatz, 73, 83 Sperrverfahren, 31 Sprachebenen, 194 SQL, 130, 153 ALL-Operatoren, 137 ALTER TABLE-Kommando, 151 AVG, 138 CASCADE, 150 CHAR, 147 COUNT, 138 CREATE DOMAIN-Kommando, 148 CREATE TABLE-Kommando, 147 CREATE VIEW-Kommando, 152 DATE, 148 DEC, 147 DEFAULT, 148 DELETE-Kommando, 142 DISTINCT, 132 DROP-Kommando, 152 FLOAT, 148 FOREIGN KEY, 149 FROM-Klausel, 131 GROUP BY-Klausel, 138 HAVING-Klausel, 141 INSERT-Kommando, 141 INT, 148 IS NULL, 146 LIKE, 134 MAX, 138 MIN, 138 NATURAL JOIN, 135 NO ACTION, 150 NOT, 134, 136, 146 NULL, 145 ON DELETE, 151 ON UPDATE, 151 ORDER BY, 137 PRIMARY KEY, 149 SELECT-Klausel, 132 SET DEFAULT, 151 SET NULL, 151 SOME-Operatoren, 137 SUM, 138 UNIQUE, 148 UPDATE-Kommando, 144 VALUES-Klausel, 142 VARCHAR, 147 WHERE-Klausel, 131 API, 131 Attributdefinition, 147 geschachtelte Abfragen, 136, 141, 143, 144 Integritätsbedingungen, 148 interaktive Sprache, 131 Tupelvariable, 135 SQL/Data System, 130 SQL1, 130 Stichwortverzeichnis SQL2, 130 SQL3, 131 SQL86, 130 SQL92, 130 SRTK, 126 Standardeditoren, 45 Suchbaum, 51 Balancierung, 59 Effizienz, 50, 60 Verzweigungsgrad, 63 Vielweg-∼, 54, 55 Suche, 25 exakte, 25 in Dateien, 37 vage, 25, 42, 44 Superschlüssel, s. Schlüssel Syntax, 15, 35 Synthesealgorithmus, 254, 268 Systemabsturz, 28 t[A], 93 Tabelle, 86, 117 tag, 36 Textprozessor, 37 Transaktion, 41, 48 transitive Hülle, 235, 236 Algorithmus, 237 Transitivitätsregel, 233 Trennschlüsselwert, 55 Tupel, 88, 118 Tupel-Kalkül, 120, 121, 128 sichere Ausdrücke, 125 Syntax von Ausdrücken, 124 Tupelvermehrung, 225, 228 Typ-Annotationen, 209, 219 Typ-Parameter, 51 Typkonstruktor, 51 Überdeckung kanonische, 237, 238, 268 Berechnung, 238 Eindeutigkeit, 240 Minimalität, 240 283 Überlauf, s. B-Baum Umbenennung, 95 unabhängig, 247 Unterlauf, s. B-Baum V(A,r), 161, 185 Verbund, 118, 123, 135, 175–177, 180– 182, 185 äußerer, 103, 118 Gleichheits-, 102, 118 natürlicher, 100, 118 Theta-, 102, 118 Verbundattribute, 101 Verbundberechnung 3-Wege-Verbund, 167 blockorientiertes Iterieren, 164 einfaches Iterieren, 163, 167 Misch-Verbund, 166, 168 mit Index, 165 Verbundpartner, 101 Vereinigungsregel, 234 Verlustfreiheit, s. Zerlegung Versionierung, 27 Verteilung, 30 Verzeichnis, 50, 52, 65 ∼-Operationen, 52 Vielweg-Suchbaum, 55, 65 view, 41, 152 Vollständigkeit, 107 wechselseitiger Ausschluß, 31 Wissen, 15, 45 XML, 19, 36 Zeile, 86, 118 Zerlegung, 226, 268 Boyce-Codd-∼, 243 Synthesealgorithmus, 254 unabhängige, 247, 249, 254, 268 verlustbehaftete, 226 verlustfreie, 226, 231, 232, 244, 249, 255, 268 Zerlegungsregel, 235 284 Zugriffskontrollen, 29, 69 Administration von Rechten, 29 Zugriffsmethode, 75, 83 Zugriffsstruktur, 76, 83 Direktzugriffsstruktur, 77, 79 sequentielle, 76, 77 Verzeichnisstruktur, 77 Stichwortverzeichnis