XML-Datenbanken
Werbung

XML-Datenbanken
1. Traditionale Datenbanken
1.1
Heutzutage, wenn wir von Datenbanken reden, denken wir vielleicht zuerst an
den traditionale Datenbaken, bzw relationale Datenbanken, die wir schon seit
lange kennen gelernt haben.
Konzeptionell ist eine relationale Datenbank eine Ansammlung von Tabellen.
Hinter den Tabellen steht mathematisch die Idee einer Relation, ein
grundlegender Begriff, der dem gesamten Ansatz den Namen gegeben hat.
Jede Tabelle stellt eine Relation dar und jede Zeile in einer Tabelle
repräsentiert ein bestimmtes Objekt an. Jede Tabelle hat einen eindeutigen
Primärschlüssel, durch den die Zeilen voneinander zu unterscheiden sind, Im
Idealfall sind deshalb niemals zwei Zeilen einer Tabelle gleich. Eine
Datenbank besteht im relationalen Modell aus einer Menge von Basistabellen.
Ein Datenbanksystem kann mehrere Datenbanken aufweisen.
Die folgenden zwei Tabellen sollen die Daten einer Bibliothekausleihe
darstellen. Eine Tabelle beinhaltet die Ausleihdaten, die zweite die
Informationen über die verwalteten Bücher alle
Ausleih
INVENTARNR
4711
1201
0007
4712
Buch
INVENTARNR
0007
1201
4711
4712
4717
Anfragesprache—SQL
NAME
Meyer
Schulz
Müller
Meyer
TITEL
Dr.No
Objektbanken
Datenbanken
Datenbanken
XML in Bioinformatik
BENUTZNR
150230
140160
150180
150230
ISBN
3-125
3-111
3-765
3-891
3-999
AUTOR
James Bond
Heuer
Vossen
Ullman
Wirth
SQL ist eine standardisierte Datenbanksprache. Sie enthält alle nötigen
Sprachbausteine für den Umgang mit einer relationale Datenbank. Die
Anweisung, über die SQL verfügt, lassen sich in Gruppen zusammenfassen:
• Data Definition Language ( DDL)
Unter der Gruppe DDL stehen verschiedene Anweisungen, die sich mit
der Definition von Daten beschäftigen. Im Einzelnen kann man leere
Datenbank einrichten ( z.B.Tabellen , Indizes, Views und weitere
Objekte), die Strukturdefinitionen existierender Objekte verändern und
Objekte löschen.
Syntax Beispielen in SQL
create database datenbankname --- Eine Datenbank datenbankname
wird erzeugt.
drop database datenbankname --- Eine Datenbank datenbankname
wird gelöscht.
create table tabellenname (spaltenname datentyp not null)
--- Erzeugt eine neue Tabelle „tabellenname” und eine Spalte
„spaltenname“. Der Spalte muss ein zulässiger Datentyp zugewiesen
werden. Die Option not null bestimmt , dass in jeder Spalte ein Wert
stehen muss.
• Data Manipulation Language (DML)
Die Gruppe DML dient der Manipulation von Daten und deren
Auswertung. Es gibt Operatoren zum Einfügen, Ändern und Löschen.
Die Anweisung SELECT hat eine zentrale Bedeutung, da sie
Auswertungen fast jeder Komplexität ermöglicht.
Beispiel:
select … from tabellenname [ where bedingung]
konkret in unserem vorherigen Beispiel:
select name from Ausleih
die Ergebnisrelation
Name
Meyer
Schulz
Müller
Meyer
•
Data Control Language (DCL)
In der DCL sind die Anweisungen zur Steuerung der Vergabe von
Zugriffsrechten zusammengefasst, mit denen man Benutzern
Systemprivilegien und Rechte auf Datenbankobjekte gewähren und
entziehen
2. XML-Datenbanken
2.1
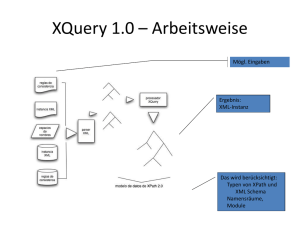
XML bietet viele Sache ,um ein Datenbanksystem zu bauen.
storage: XML- documents
shemas: DTD , XML schema languages
query languages XQuery, XPath, XQL,etc.
programming interfaces :SAX, DOM
Vorteile: Die Benutzer kann passendes Format selbst auswählen.
Größtmögliche Flexibilität.
Nachteil: Effizient
Zeitliche Entwicklung XML:
XPath 2.0 XQuery 1.0
XML
Schema
2001
2000
1999
XUpdate
Quilt
XPath 1.0
W3C Empfehlungen
1998
XQL
XML-QL
DOM
noch in der Entwicklung
1997
XML
andere Vorschläge
2.2 XPath
Xpath ist eine Sprache, mit der Sie bestimmte Teile eines XML-Dokuments
Selektieren können. XPath verwendet keine XML-Syntax, sondern eine Art
Pfadangabe(daher auch der Name XPath) , um Elemente aus einem XMLDokument anzusteuern
2.2.1 XPath-Datenmodell
Ein XML-DOkument
<?xml version=“1.0“?>
<presentation status=“draft“ date=“2003-01-29“>
<title>XML</title>
<author>User</author>
<slide>
<title toc=“yes“>What is XML?</title>
<ilist>
<item>XML is not a markeup language (unlike HTML)</item>
<item>XML instances can be <emph>well formed</emph>or even
<emph>validating</emph></item>
</ilist>
</slide>
<slide>…</slide>
</presentation>
root
presentation
status
date
title
text
author
text
slide
title
toc
text
ilist
slide
item
text
item
text
Eine XML-Datei als Baum
XPath kennt folgende Arten von Knoten:
• Wurzelknoten root
• Elementknoten
• Textknoten
• Attributknoten
• Namensraumknoten
• Processing-Instruction-Knoten
• Kommentarknoten
Nicht abgebildet sind aber z.B.Dokumenttyp-Deklarationen und CDATAAbschnitte.
2.2.2 Achsen in XPath
Achsen sind Wege oder Pfade, entlang derer Sie durch die Baumstruktur
navigieren können. Sie beginnen bei einem bestimmten Knoten, dem
Kontextknoten( context node), und folgen den Achsen zwischen den Knoten.
In der Regel entspricht der Kontextknoten in XPath dem gegenwärtigen
Knoten).
XPath kennt 13 Achsen:
ancestor, ancestor-or-self, attribute, child, descendant, descendant-orself, following,following-sibling, namespace, parent, preceding,
preceding-sibling, self.
ancestor:Diese Achse wählt alle Knoten aus, die Vorfahren des
Kontextknotens sind. Die Knoten werden in umgekehrter
Dokumentordnung aufgelistet.
2
1
Der Kontextknoten ist grau markiert.
attribute: Wenn der Kontextknoten ein Element ist, selektiert diese Achse alle
seine Attribute in beliebiger Reihenfolge. Ansonsten wird nichts selektiert.
child: Diese Achse wählt alle Kinder (die direkten Nachfahren) des
Kontextknotens in Dokumentordnung aus.
1
2
2.2.3. Knoten auswählen mit XPath
Lokalisierungspfade
Es ist sehr ähnlich wie in einem Dateisystem
• absoluter Pfad : Wegbeschreibung vom Wurzelverzeichnis
/vol/gnu/bin/ls
• relativer Pfad : Wegbeschreibung vom „ aktuellen“ Verzeichnis
../juser/manual.txt
• Unterschied bei XML: gleichnamige Kindknoten erlaubt.
/
homes
juser
manual.txt
nzhang
vol
gnu
bin
local
lib
tex
share
ls
Lokalisierungsschritte
Achsenname::Knotentest[Pädikat]
Knotentests: bestimmt den Typ oder den Name des Knotens, der durch den
Lokalisierungsschritt ausgwählt werden soll.
Knotenfunktionen ,die bestimmte Knotentypen selektieren:
• * für alle Elementknoten,
• text() für alle Textknoten,
• comment() für Kommentarknoten
• processing-instruction() für Processing-Instruction-Knoten
• node() für beliebige Knotentypen
Prädikate: Ausdrücke, mit deren Hilfe Sie eine weitere Spezifizierung der
Knotenauswahl vornehmen können, also so etwas wie ein zusätzlich Filter.
Beispiel:
child::tiltle – alle <title> Elemente ,die Kinder des Kontextknoten sind
attribute::* -- alle Attribute des Kontextknotens
/Child::presentation/attribute::status -- das status-Attribute von presentationElement
Abgekürzte XPath-Syntax
• child:: kann einfach weg lassen
• // = descendant-or-self::node()
• . =self::node() ; .. =parent::node()
• @ =attribute::
slide/title
/presentation/author/text()
/presentation/@status
/presentation/slide[1]/ilist/item[2]
/presentation/slide/title[@toc=”yes”]
2.3 XQuery
XQuery wurde erstmals im Februar 2001 als working Draft vorgestellt. Die
Sprache übernimmt von XPath die Pfadausdruckssyntax für hierarchische
Dokumente.
2.3.1 XQuery-Datenmodell
Das in XQuery verwendete Datenmodell ist eine Erweiterung von XPath.
2.3.2 XQuery Ausdrücke
In XQuery werden die Anfragen mit verschiedenen Arten von Ausdrücken
Formuliert .Diese Ausdrücke können beliebig verschachtelt sein und zu einem
einzigen Anfrageausdruck kombiniert werden. Als Ergebnis liefert ein
Ausdruck immer eine Liste, die sowohl einzelne Werte als auch Knoten
enthalten kann.
2.3.2.1 Einfache Beispiele
Erste Beispiele:
let $x:=5 let $y:=6 return 10*$x+$y
> 56
Sequenz:
let $a:=3,4
let $b:=($a, $a)
let $c:=99
let $d= ()
return (count($a), count($b), count($c), count($d))
>(2, 4, 1, 0)
Kommentar beginnt mit #
2.3.2.2 Pfadausdrücke
gleich wie in XPath 2.0
Erweiterung gegenüber XPath1.0: ein Ausdruck in XQuery liefert immer eine
Sequenz , hat Ordnung (XPath kennt nur Knotenmengen)
Beispiele:
let $book := document(“mybook.xml”)/book
return $book/chapter
document Funktion gibt die Wurzelknoten von einem Dokument zurück. Der
/book Ausdruck selektiert das <book>-Element direkt unterhalb des
Wurzelknotens. Das Programm gibt einen Sequenz aus alle <chapter>Elemente unter <book>-Element.
oder
return $book//para[@class=“waring“]
2.3.2.3FLWR-Ausdrücke
Die wichtigsten Ausdrücke in XQuery sind die FLWR-Ausdrücke (gesprochen
„Flower-Ausdrücke“) .Sie setzen sich aus den Teilen FOR bzw. LET, WHERE
und RETURN zusammen.
for $ x in (1 to 3) return ($x,10+$x)
>1,11,2,12,3,13
for $c in customers
for $o in orders
where $c.cust_id=$o.cust_ id and $o.part_id=”xx”
return $c.name
entspricht ähnlich Funktion in SQL
select customers.name
from customers, order
where customer.cust_id=orders.cust_id
and orders.part_id=”xx”
2.3.2.4Funktionen
define funktion descendant-or-self($x)
{
$x,
for $y in children($x)
return descendant-or-self($y)
}
descendant-or-self(<a>X<b>Y</b></a>)
> <a>X<b>Y</b></a>; ”X”; <b>Y</b>; “Y”
2.3.2.5 Sortieren
$books sortby (author/name)
Was kann XQuery nicht ?
Insert ,Delet ,Update
2.4XUpdate
• Erzeugen und Löschen von allen XPath-Elementtypen (element,
attribute, text)
• Aktualisierung von Elementen (Update)
• Umbenennen von Elementen
3.Daten und Dokumente
• Daten-zentrierte Dokumente
strukturiert, regulär
Beispiele: Produktkataloge, Bestellungen, Rechnungen
• Dokument-zentrierte Dokumente
unstrukturiert, irregulär
Beispiele: wissenschaftliche Artikel, Bücher, E-Mails, Webseiten
• Semistrukturierte Dokumente
datenzentrierte und dokumentenzentrierte Anteile
Beispiele: Veröffentlichungen, Amazon
XML-fähige Datenbanken:
Oracle8i RDBMS mit vielen Erweiterungen und Werkzeugen für XML
Native XML-Datenbank:
Tamino