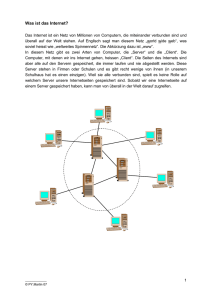
Ein bisschen TCP/IP
Werbung

Ein bisschen TCP/IP
David Vajda
25. Januar 2016
1
1.1
TCP/IP
Der Protokollstack
Was ist ein Protokoll?
Wenn zwei Menschen miteinander reden, können Sie dabei verschiedene Regel
entwickeln, wie sie es tun. So gibt es diplomatische Protokolle. Diplomatische
Protokolle schreiben vor, wie und in welcher Reihenfolge was wo gesagt wird. Es
gibt Notwendigkeiten für Protokolle, wenn zwei Computer miteinander reden.
Es genügt nicht einfach Daten irgendwo hin zu übertragen. Wenn zwei Computer miteinander kommunizieren, muss zum Beispiel der eine schon bereit sein
und zu hören. Aber wenn zwei Computer miteinander reden, gibt es einerseits
Technische Notwendigkeiten und andererseits technische Pragmatismen. Zum
Beispiel ist es pragmatisch, einen Strom von Byte in viele Pakete zu zerlegen.
Kommunizieren zwei Computer miteinander, dann ist es besser, man verteilt
den Gesamtinhalt der Kommunikation auf verschiedene Pakete. Da wären wir
bei einem Protokoll zum Beispiel schon gefragt: Wo beginnt ein Paket? Wie
erkenne ich ein Paket? Wann endet ein Paket? Wann kommt ein Paket? Die
nächste Frage, wäre die Frage der Addressierung. Wenn wir per Post Briefe verschicken, kann jeder überall Briefe verschicken. Das ist beim Computer generell
auch so: Jeder Computer muss mit jedem Computer kommunizieren können.
Dann müssen aber die Computer wissen, wer gerade mit wem redet und wer
mit wem reden will. Das ist auch beim Telefon so. Betrachten wir nun das Telefon. Der Vorgang des Telefonierens besteht aus den Schritten, den Hörer zu
nehmen, eine Nummer zu wählen und zu warten bis jemand an den Hörer geht
oder das Besetztzeichen erscheint. Erscheint das Besetztzeichen, legen wir wieder auf. Danach besteht für den anderen beim Klingeln die Pflicht, den Hörer zu
nehmen. Am Schluss legen beide den Hörer auf. Das ist Beispielsweise ein Protokoll. Hier findet mehr statt, als dass einfach eine Botschaft übertragen wird.
Und zwar könnten wir das Telefonieren als einen einzigen Ablauf betrachten.
Von dem Beginn an, dass der Wähler den Hörer nimmt bis zum Schluss, wo der
Telefonhörer aufgelegt wird. Wenn man so will kann man das Telefonieren als
eine einzige Einheit sehen, die zwischendrin, die wahren Nutzdaten enthält. Das
wäre nämlich das, was einer dem anderen beim Telefonieren sagt. Trotzdem ist
das Telefonieren eine einzige Einheit, mit samt dem Wählen. Das Telefonieren
hat einen Vorspann, nämlich das der eine den Telefonhörer nimmt usw. und
eine Botschaft, die die eigentliche Botschaft ist und ein Ende. Der Vorspann ist
quasie der Botschaft des Miteinander sprechens vorangestellt. Ebenso ist das
1
auch im Internet mit den Paketen. Den Paketen wird etws vorangehängt. Notwendige Informationen, die den Datenaustausch erst möglich machen, damit
der Datenaustausch stattfinden kann. Ein vollkommen anderes Problem ist das
der Addressierung. Das gibt es bei dem Brief, wie beim Telefonieren. Dort wäre
beim Brief die Addresse, die aus Name, Straße und Stadt mit PLZ besteht. Bei
dem Telefon wäre es die Telefonnummer, die aus Ortsanteil und der eigentlichen
Telefonnummer besteht. Ein Computernetzwerk managet das Ähnlich. Einem
jedem Paket werden Dinge vorrangespannt. Natürlich enthält ein Paket an irgendeiner Stelle Nutzdaten. Aber es muss zum Beispiel vielleicht die Nummer
des Pakets enthalten. Desweiteren muss es die Addresse des Ziels enthalten. Die
Adressierung ist etwas vollkommen anderes, als die Aufteilung in Pakete. Ebenso wie die Telefonnummer und der Bereich der Telefonnumer, das Nachschlagen
in einem Telefonbuch, kurz die Verständnis der Telefonnumer, ebenso wie beim
Brief das Verständnis für die Addresse etwas anderes ist, als den eigentlichen
Vorgang des Verschickens oder Telefonierens.
Bei dem Internet muss in jedem Paket die Adresse des Ziels angegeben sein.
Aber das Internet regelt den Unterschied zwischen Aufteilung in Pakete und
die Addressierung zum Beispiel in verschiedenen Protokollen. Bei dem einem
Protokoll steht die Addressierung im Vordergrund, bei dem nächsten die Aufteilung in Pakete. Trotzdem enthält jedes Paket auf jeden Fall Nutzdaten. Die
verschiedenen Gesichtspunkte, die hier verschiedene Protokolle darstellen oder
durch verschiedene Protokolle realisiert werden, haben alle Informationen, die
einem Datenpaket beigebracht werden, oder die an einem Datenpaket angebracht werden. Dabei durchlaufen die Daten verschiedene Protokollschichten.
Die Protokollschichten werden als solche auch als ein Stapel dargestellt, aber
ebenso wie die Protokollschichten als ein Stapel dargestellt werden, nämlich
von ihrer Funktion, durchlaufen die Daten auch diese Protokollschichten. Jeder
der Protokollschichten fügen einem zu sendenden Paket weitere Daten hinzu,
die für den Gesichtspunkt des jeweiligen Protokolls notwendig sind. Die Nutzdaten sind dabei in einem Paket irgendwo enthalten. Die Daten durchwandern
die Protokollschichten und wenn sie gesendet werden, durchlaufen sie die Protokollschichten nach unten, von der ersten zur nächsten und es wird jeweils etwas
an das Paket vorne und hinten angefügt. Das bedeutet nicht mal, dass die Daten
als Paket weitergereicht werden. Das zerlegen der Daten in Pakete ist selbst wieder ein Protokoll. Trotzdem jedes Protokoll und jede Protokollschicht hat eigene
spezifische Informationen und die Daten, die jeweils angefügt werden müsen und
die Daten oder das Paket wird an die nächst untere Schicht weiter gegeben, wo
weitere Daten hinzugefügt werden. Beim Empfänger der Daten durchlaufen die
Daten die Protokollschicht in umgekehrter Reihenfolge von unten nach oben
und die nur für das Protokoll interessanten Daten werden wieder entfernt, so
dass am Schluss die eigentlichen Daten vorhanden sind.
Man unterscheidet bei Computernetzwerken zwei Arten von wesentlichen Architekturmodellen:
• Das ISO (Internation Standard Organisation) OSI (Open Systems Interconnect) Reference Model
• Den TCP/IP Protokoll Stack
2
Das ISO OSI-Reference Modell wird häufig als Basisreferenzmodell herangezogen. Das Basisreferenzmodell besteht aus 7 Schichten:
1. Bitübertragungsschicht
2. Sicherungsschicht
3. Vermittlungsschicht
4. Transportschicht
5. Kommunikationssteuerschicht
6. Darstellungsschicht
7. Anwendungsschicht
• Anwenderschicht: Hier sind Prozesse, auf die der Benutzer direkten Zugang
hat
• Darstellungsschicht: Gibt es nicht bei TCP/IP
• Kommunikationsschicht: Gibt es nicht bei TCP/IP
• Transportschicht: Die Daten gelangen genauso zum Empfänger, wie sie der
Abesnder auf den Weg gebracht hat. Dies ist innerhalb von TCP/IP das
TCP (Transmission Control Protocol) oder UDP (User Datagram Protcol). TCP ist dafür zuständig Daten in Pakete zu zergliedern
• Vermittlungsschicht: Entspricht dem Internet Protocol (IP), also der Addressierung
• Sicherungsschicht: Gibt es so nicht bei TCP/IP, übernimmt die nächste
Schicht
• Bitübertragungsschicht: Hardware: Bei TCP/IP wäre das zum Beispiel
Ethernet, was einer LAN-Schnittstelle entspricht, oder WLAN. Desweiteren gibt es auch Verbindungen mit Koaxialkabel, wie beim Fernsehen.
Bei der TCP/IP Protokolarchitektur gibt es vier Schichten:
1. Netzzugangsschicht
2. Internetschicht
3. Host-zu-Host Transportschicht
4. Anwendungsschicht
Die Daten werden nach unten weitergerreicht. Jede Schicht fügt ihre eigenen
Kontrollinformationen hinzu. Diese Informationen nennt man Header (Kopf),
da sie den Daten vorrangestellt werden. Dabei wird an die gesamten Daten der
vorhergehenden Schicht, der Kopf angefügt. Dieses Hinzufügen von Kontrollinformationen nennt man Encapsulation (Kapselung)
3
Anwendungsschicht:
Transportschicht:
Internetschicht:
Netzzugangsschicht:
Daten
Header Daten
Header Header Daten
Header Header Header Daten
Die Daten der jeweiligen Schicht werden bezeichnet als:
1. Netzzugangsschicht: Frame
2. Internetschicht: Datagram
3. Transportschicht: Segment
4. Anwendungsschicht: Stream
1.1.1
Die Internetschicht und die IP-Addresse
Die Internetschicht bezieht sich auf die Adressierung.
Addressierung wird mittels IP-Adresse. Dabei werden einzelne Pakete addressiert. Die Daten müssen schon vorher durch TCP in Pakete zerlegt worden sein,
bevor eine Adresse hin zu gefügt wird.
Wir verwenden Router. Warum und was bedeutet das? Das Bedeutet wir benutzen Subnetting? Was bedeutet das nun wiederum? Wenn wir Rechner miteinander vernetzen, dann muss jeder Rechner mit jedem Rechner kommunizieren
können. Wie soll man die Computer miteinadner verbinden. Zunächst ist es so,
dass an einem Knoten im Netzwerk wiederum mehrere Knoten angeschlossen
sein können und an diese wiederum mehrere Knoten. Dann müssen aber Knoten über andere Knoten im Netzwerk miteinander kommunizieren. Eine andere
Möglichkeit wäre jeden Knoten mit jedem Knoten zu verbinden, das ist sicher
nicht effektiv. Noch eine Möglichkeit wäre einen Knotenmittelpunkt zu schaffen, an dem alle Knoten angeschlossen sind. Das ist in der Realität nicht gut.
Denn dann muss jeder Knoten eine Leitung zum Mittelpunkt haben. Und da
die Welt groß ist, müssten viele Kabel verlegt werden. Darum hat man sich
zu etwas anderem entschieden: An einem Knoten können Knoten liegen und
diese kommunizieren nun wiederum über den Knoten an dem sie angeschlossen sind miteinander. Knoten und Netzwerke, die aus Knoten und Netzwerken
bestehen, die an einem Knoten angeschlossen sind, der wiederum für alle und
für sich selbst mit weiteren Knoten weiter weg kommuniziert, werden Subnetze
genannt. Das Netzwerk ist in Subnetze unterteilt und diese sind wiederum in
Subnetze unterteilt. Eine Addresse im Netzwerk muss eindeutig sein. Man kann
Addressen nicht verdopppeln oder verfielfachen, sonst, kommen die Daten an
mehreren Stellen im Netzwerk gleichzeitig an. Addressen müssen eindeutig sein
und die Unterteilung in Subnetze ist notwendig. Das regelt das IP-Protokoll.
Ebenso wir das Zerlegen und Netze und Subnetze.
• Der Netzadresse
• Der Adresse des Rechners
Desweiteren gilt:
• Eine IP-Adresse ist 4 Byte lang:
4
• Eine IP-Addresse entspricht in C also long int
• Eine IP-Adresse wird durch Zahlen die durch 3 Punkte voneinander getrennt wird geschrieben
• Jede dieser Zahlen ist zwischen 000 und 255 groß.
• Das entspricht genau einem Byte mit dem Werte zwischen 0 und 255
darstellbar sidn
• Man schreibt also etwas in der Art, wie 255.255.255.255 oder 000.000.000.000
oder 192.168.137.2 oder 191.127.111.001
Man unterscheidet drei Addressklassen:
1. A
2. B
3. C
Dabei gilt:
1. A: Wenn das erste Bit der IP-Addresse 0 ist, handelt es sich um eine
Addresse der Klasse A. Die nächsten 7 Bits identifieren das Netzwerk und
die restlichen 24 Bit den Rechner
2. B: Wenn die ersten beiden Bits einer IP-Addresse 10 sind, handelt es sich
um eine Addresse der Klasse B, die nächsten 14 Bit identifizieren das
Netzwerk und die letzten 16 Bit den Rechner
3. C: Wenn die ersten drei Bits einer IP-Adresse 110 sind, handelt es sich um
eine Addresse der Klasse C. Die nächsten 21 Bit bestimmen das Netzwerk,
die letzten 8 Bit den Rechner
Man hat zwei bestimmte Addressen die etwas besonderes bezeichnen:
1. Das Netzwerk 0 ist die Defaultroute
2. Das Netzwerk 127: Die Loopbackaddresse
Das Subnetting funktioniert so:
Routing-Tabelle, Forwarding-Table:
UNIX-Befehl: netstat -nr
-r: Routing-Tabelle anzeigen
-n: Numerische Darstellung der Adresse
Felder:
Destination: Zielnetzwerk
Gateway: ber welchen Gateway
Flags: U,H,G,D
Refcnt: Wie häufig wurde die Route benutzt
Use: Wie viele Pakete wurden Transportiert
5
Interface: Gibt den Namen des Netzwerk-Interfaces für die Route an
Loopback-Route (000.000.000.000): Erster Eintrag
Default-Route (127.000.000.000): Zweiter Eintrag
Unter Interface steht unter Linux entweder eth0, eth1, eth2, eth3, . . . und l0
Unter Windows: 192.168.2.1, 192.168.137.1, 192.168.0.3
Unter Windows ist jeder Netzwerschnittstelle eine IP-Adresse zugeordnet. Jede Netzwerkschnittstelle hat eine IP-Adrese. Unter Windows zeigt es die IPAdresse an, die der Netzwerkschnittstelle zugeordnet ist und somit, reicht es die
IP-Adresse zu zeigen. Linux zeigt l0, eth0, eth1, eth2, . . .
Wozu die Netzwerkmaske.
Na ja, wir befinden uns in einem Router, angenommen. Sobald eine Routingtabelle da ist, sind wir ein Router. Ein Router hat im Gegensatz zu einem Host,
zum Beispiel 4 Netzwerkkarten. Es gehen auch 5,6,7,8,...,16,... An einem Router sind mehr Netzwerkkarten, als an einem Host. Eine Netzwerkkarte ist das,
an das das Netzwerkkabel angeschlossen ist. Da steckt man ein Kabel rein, ein
Ethernet-Kabel. So wie man mehrere Soundkarten haben kann, oder mehrere
Festplatten, oder mehrere Monitore, kann man mehrere Ethernetkarten haben.
Diese Ethernetkarten werden bezeichnet als eth0, eth1, eth2, eth3, ... Daneben
gibt es noch l0, als Loopback Interface. Fungiert der Rechner als Router, so ist
eine Routing Tabelle aufgestellt. Nun gibt es IP-Adressen, aus Klasse A, Klasse
B, Klasse C. Jetzt betreiben wir aber Subnetting: Vorsicht: Eine IP-Adresse im
gesamten Netzwerk ist eindeutig. Es kann eine IP-Adresse nur ein Mal geben,
wenn zwischen den Netzwerken eine Verbindung besteht. Das heißt es wurde
eine Routingtabelle aufgestellt. Wenn wir nun ein Paket auf der einen Schnittstelle erhalten und sollen es an die andere weiterleiten, woher weiß der Rechner,
an welche der Netzwerkkarten. Nun gut, angenommen wir haben 4 Netzwerkkarten, dann haben wir:
eth0,
eth1,
eth2,
eth3,
1
2
3
4
Das heißt wir haben 4 durchnummerierte Netzwerkkarten. Alle Netzwerke an
eth0, stellen das Netzwerk 1 dar, alle Netzwerke an eth1, stellen das Netzwerk
2 dar, ... Wenn wir nun Klasse A, Klasse B, Klasse C, endeutig benutzen, dann
wissen wir 255.000.000.000 ist die Netzwerkmase. Dann haben wir zum Beispiel
IP-Adressen
123.0.0.0
124.0.0.0
125.0.0.0
126.0.0.0
6
Wenn wir in Klasse B sind, zum Beispiel
131.66.0.0
131.67.0.0
131.68.0.0
131.69.0.0
Wenn wir in Klasse C sind, zum Beispiel
192.168.12.0
192.168.13.0
192.168.14.0
192.168.15.0
Was ist jetzt, wenn wir in kleinere Subnetze aufgeteilt sind. Wir haben einen
harmlosen Router, am Ende des Netzwerks. Wir sind eine Organisation, zum
Beispiel eine Universität. Wenn dem so ist: Wir haben vier Subnetze. Genau
vier Netzwerkkarten. In diesen Subnetzen hängen jetzt wieder vereinzelt, wenige
Rechner. Na dann benutzen wir nicht 255.255.255.0 Sondern 255.255.255.192
als Netzwerkmaske.
Das ist 11111111.11111111.11111111.11000000 Dann haben wir vier Subnetze:
192.168.137.000:
Das ist 11000000.10101000.10001001.00000000,
eth0, mit Netzwerkmaske 255.255.255.192
192.168.137.064:
Das ist 11000000.10101000.10001001.01000000,
eth1, mit Netzwerkmaske 255.255.255.192
192.168.137.128:
Das ist 11000000.10101000.10001001.10000000,
eth2, mit Netzwerkmaske 255.255.255.192
192.168.137.192:
Das ist 11000000.10101000.10001001.11000000,
eth3, mit Netzwerkmaske 255.255.255.192
Das sind die Netzwerkadressen von
192.168.137.000 bis 192.168.137.63:
Das ist 11000000.10101000.10001001.00000000
bis 11000000.10101000.10001001.00111111
eth0
192.168.137.064 bis 192.168.137.127:
Das ist 11000000.10101000.10001001.01000000
bis 11000000.10101000.10001001.01000000
eth1
7
192.168.137.128 bis 192.168.137.191:
Das ist 11000000.10101000.10001001.10000000
bis 11000000.10101000.10001001.10000000
eth2
192.168.137.192 bis 192.168.137.255:
Das ist 11000000.10101000.10001001.11000000
bis 11000000.10101000.10001001.11000000
eth3
Wenn wir das Routing nicht verwenden, dann müssen wir ein Kabel von jedem
Rechner zu einem Gewissen Punkt auf der Erde legen. Das Subnetting dient
nicht dazu, dass wir Adressen vervielfachen oder verdoppeln. Jede IP-Adresse
ist eindeutig. Es dient nur dazu, dass zum Beispiel ein Kabel von einem Rechner
zum anderen führt und an dem hängen wieder mehrere Rechner, also ein Netzwerk, an dem wieder viele Rechner hängen können, also wieder ein Netzwerk.
Sollten wir an einem Rechner mehrere Netzwerkkarten haben, verschwenden wir
nicht mehr IP-Adressen, wenn die Netzwerkkarten nicht durch eine Routingtabelle miteiannder verbunden sind. Welche Pakete wohin weiter geleitet werden
entscheidet die Routingtabelle. Und sind an einem Rechner mehrere Netzwerkkarten, die eine ist ans Internet angeschlossen, zu den anderen besteht keine
Routingtabelle, dann gibt es keine Verschwendung durch die anderen.
Man kann das auch anders machen, zum Beispiel, kleinere Subnetze
Dann haben wir vier Subnetze:
192.168.137.240:
Das ist 11000000.10101000.10001001.11110000,
eth0, mit Netzwerkmaske 255.255.255.240
192.168.137.244:
Das ist 11000000.10101000.10001001.11110100,
eth1, mit Netzwerkmaske 255.255.255.240
192.168.137.248:
Das ist 11000000.10101000.10001001.11111000,
eth2, mit Netzwerkmaske 255.255.255.240
192.168.137.252:
Das ist 11000000.10101000.10001001.11111100,
eth3, mit Netzwerkmaske 255.255.255.240
Das sind die Netzwerkadressen von
192.168.137.240 bis 192.168.137.243:
Das ist 11000000.10101000.10001001.11110000
bis 11000000.10101000.10001001.11110011
eth0
8
192.168.137.244 bis 192.168.137.247:
Das ist 11000000.10101000.10001001.11110100
bis 11000000.10101000.10001001.11110111
eth1
192.168.137.248 bis 192.168.137.251:
Das ist 11000000.10101000.10001001.11111000
bis 11000000.10101000.10001001.11111011
eth2
192.168.137.252 bis 192.168.137.255:
Das ist 11000000.10101000.10001001.11111100
bis 11000000.10101000.10001001.11111111
eth3
2
2.1
Die IP-Addresse unter Windows und Linux
und erste Möglichkeiten sein Netzwerk unter
Linux und Windows ein zu richten
Die Systemsteuerung unter Windows, die IP-Addresse
und die Netzwerkschnittstelle unter Windows
Unter Windows erreichen wir die IP-Adresse über die Systemsteuerung:
Dort gehen wir auf Netzwerk und Internet
9
Dort gehen wir nicht auf Netzwerkcomputer und -geräte anzeigen“, sondern
”
auf Netzwerkstatus und -aufgaben anzeigen“
”
Unter Windows 10 öffnet sich dieses Fenster:
Unter Windows 7 öffnet sich dieses Fenster:
10
Dort gehen wir auf die LAN-Verbindung und erhalten:
Nun gehen wir auf Eigenschaften und erhalten:
11
Dort gehen wir auf TCP/IPv4
und erhalten
12
Wir können wie wir hier eben sehen die IP-Addresse eintragen, oder wir lassen
sie leer:
Dann gilt DHCP.
Sollten wir nun noch einen weiteren Adapter anschließen erhalten wir diesen wie
vorher:
13
Die Verbindungen unter Windows tragen den Namen Ethernet“oder Netz”
”
werkverbindung“oder wie auch immer.
Bei dem Programm route wird die IP-Addresse des Netzwerkadapters angezeigt.
2.2
Yast2 unter Linux, die IP-Addresse und die Netzwerkschnittstelle unter Linux
Unter Linux tragen die Netzwerschnittstellen die Namen
eth0
eth1
eth2
Wir erreichen eine bequeme Konfiguration über Yast2, wenn wir OpenSuSE als
Linux verwenden:
14
Dies öffnen wir und erhalten:
Dort gehen wir auf Netzwerkgeräte
15
Und innerhalb dessen auf Netzwerkeinstellungen und erhalten:
Dort lässt sich die IP-Addresse einstellen:
16
Andererseits lässt sich die Netzwerkkarte in der Konsole anzeigen:
17
3
3.0.1
Die Anwenderschicht
Windows WORKGROUP
Haben wir die IP-Addressen richtig eingetragen, bei allen Computern im Computernetzwerk, so können wir in Windows automatisch auf die anderen Computer zugreifen. Die Computer erscheinen unter Netzwerk im Fileexplorer.
3.0.2
Samba
Eine Möglichkeit Linux in ein
3.0.3
Apache und Yast2
Ein Webbrowser lässt sich prima mittels OpenSuSE, Yast2 installieren.
18
Hier kann man den Namen und den Ort der HTML-Datei index.html eintragen.
Diese Datei befindet sich irgendwo auf dem Computer. Sollte der Computer
nun an ein Netzwerk angeschlossen sein, dann kann man von einem anderen
Computer mittels Webbrowser auf diese Seite zugreifen.
19
4
C und TCP/IP
C-Programmierung und der Zugriff auf TCP/IP erfolgt mittels Sockets/innerhalb
C arbeiten wir mit Sockets. Während man in C den Dateizugriff mittels Filehandler realsiert und in Dateien ließt und schreibt funktioniert der Zugriff
bei TCP/IP ähnlich, aber mittels Sockets. Während man beim Dateizugriff
Filehandler verwendet, verwendet man bei TCP/IP-Netzwerken Sockets. Zwei
Rechner sind mittels Sockets miteinander verbunden. Dabei spielt der eine die
Rolle des Servers, der andere die Rolle des Clients. Das betrifft alle Protokolle der Anwenderschicht, wie HTTP, SMTP, POP, POP3, IMAP, FTP. Über
TCP/IP liegen andere Protokolle wie HTTP, SMTP, POP, POP3, IMAP, FTP.
TCP Man stellt über die Sockets eine Verbindung her, dabei fungiert der eine
Computer als Client, der andere als Server. Vorsicht: Server und Client, das ist
Software und nicht der Computer. Haben Server und Client eine Verbindung
hergestellt, könen sie zum Beispiel über Textbotschaften miteinander kommunizieren.
Das naheliegendste wäre, dass sie sich mit Textbotschaften miteinader unterhalten. Wenn sich zwei unterhalten, sagt der eine etwas, der andere hört etwas. Beim
Dateizugriff unterscheiden wir zwischen Lesen und Schreiben. Es gibt während
dem Verkehr zwischen Client und Server, zwei grundsätzliche Strukturen: Lesen und Schreiben. Zunächst muss die Verbindung hergestellt werden. Dann
schreibt der eine, was der andere ließt, der andere kann auch lesen, was der andere schreibt. Dabei können sowohl Server als auch Client lesen und schreiben.
Bevor gelesen, muss die Verbindung aufgebaut werden. Der Server läuft bereits,
wenn der Client gestartet wird. So kann der Server, auf den Client warten.
Während dem Verkehr wird dann gelesen und geschrieben. Dafür gibt es zwei
Funktionen:
send()
recv()
Man muss nun drei Dinge unterscheiden, zum Beispiel bei HTTP:
1. Zum einen, das senden und empfangen, innerhalb von C: send und recv
2. Das HTTP-Protokoll zum Beispiel. Ähnlich wie SMTP oder POP3, lässt
sich HTTP, in für Menschen verständliche Botschaften verstehen. Ein
Mensch kann die Botschaften verstehen, die dort gesendet und empfangen werden, er kann sie auch per Hand in die Konsole eingeben. Das sind
Botschaften, wie Gib mir die Seite“oder Sende mir die E-Mail“nur in
”
”
der entsprechenden Sprache ausgedrückt. Wenn diese Botschaften in der
Konsole eingeben werden, verwenden sie aber unter Garantie ein Programm, was, wenn es in C geschrieben wurde, Sockets verwendet. D.h. die
Botschaften werden innerhalb des Programms mittels Sockets übermittelt
3. HTML: Ist die Seite angekommen, dann steht sie natürlich in HTML da.
HTML muss nicht formatiert ausgegeben werden, es kann auch als eine
reine Textform am Bildschirm ausgegeben werden.
Das Entscheidende ist, dass der POP3-Client eine für den Menschen verständliche Textbotschaft den den POP3-Server schicken kann, die nicht die E-Mail
selber ist, aber für den Menschen verständlich ist und die Auslieferung der EMail zum Beispiel erst initisiert. So kann der POP3-Client an den POP3-Server
20
den Befehl send schicken. Dieser Befehl send hätte dann aber nichts mit der
Funktion send() zu tun, die innerhalb des C-Programms verwendet wird. Dann
sendet der Client mittels send() innerhalb des C-Prgoramms die Botschaft send
und der Server hört mittels recv() zu und empfängt send. Die E-Mail selber
wird aber genauso als Text übertragen, wie die Botschaft send. Man unterscheidet also die Schicht des TCP/IP, bei der es die zwei Befehle send() und
recv() gibt, dann wiederum Befehle innerhalb der Anwenderschicht, wie send
und dann gibt es zum Beispiel beim HTTP-Server die HTML-Datei selber.
Letzten Endes, könnte man ganz einfach einen HTTP-Client schreiben, Internet
Explorer, Firefox und Safari, Chrome, das sind alles HTTP- Clients. Und im
Gegensatz dazu könnte man einen reinen HTTP-Client selber schreiben. Reinen
heißt: Ich persönlich kenne zwar nicht die Befehle von HTTP, aber die würden
zum Beispiel so lauten: Liefere mir die Webseite so und so und sie wird an den
HTTP-Client von dem HTTP-Server übermittelt. Dann kommt bei Ihnen die
HTML-Seite so oder so an. Ob diese dann schön dargestellt wird ist eine andere
Frage, Sie können auch einen Text erhalten, der sieht so aus: <BODY>...</BODY>
und der wird nicht entsprechend dargestellt, sondern ist die reine Textform
der Seite und enthält halt die HTML-Befehle, ohne das sie bei der Darstellung am Bildschirm irgendetwas ausrichten. Dann steht da nicht die berschrift
groß gedruckt, oder irgendein Text dick, sondern da steht anstelle der berschrift
<H1>...</H1> und wird auch genauso ausgegeben. Die Darstellung, dass aus
<H1>...</H1> gemacht wird überlassen Sie jemand anderen. Dann sieht das
entsprechend formatiert aus, die berschrift ist Dick und <H1>...</H1> sind reine Angaben an die Darstellung und werden so nicht ausgegeben. Ebenso können
Sie mit Sockets einen POP3-Client schreiben und Sie werden sehen, alleine mit
wenigen Befehlen wie SEND können Sie, indem Sie diese Befehle dann als Text
über ihr Programm, was Sockets verwendet, eine E-Mail lesen, an einem selbstgeschrieben Client.
Ein Server zum Beispiel hat eine Aufgabe, die meistens für ihn Typisch ist: Ein
POP3- Server speichert auf seiner Festplatte E-Mails innerhalb von Dateien, ein
Webserver, auch HTML-Seiten für Ihre HTTP-Seite in Form von Dateien. Die
speichert er bei sich auf der Festplatte und wir hatten es eben von Sockets. Davor von Filehandlern und der Server ist ein Programm, was sowohl Sockets als
auch Filehandler benutzt. Der Server ist ein Programm, was einerseits Sockets
geöffnet hat, für die TCP-IP-Verbindung zum Client, andererseits Filehandler
um die Dateien zu lesen und über die TCP/IP-Verbindung zu übertragen, auf
der der Client, entsprechende Daten zum Beispiel HTML-Dateien als Webseiten
anfordert. Der HTTP-Server ließt die Dateien auf seiner Festplatte und übermittelt sie wie oben beschrieben über das Netzwerk oder die Netzwerk Verbindung.
Jetzt gibt es einen Haufen Programme. Wie gesagt der Webserver ist ein Programm, warum sollte man, wenn man Programme wie Office hat oder Programme wie Latex und dafür Standardanwendungen nimmt, warum sollte man nicht
eine Standardanwendung für einen Webserver nehmen, der ja auch nur ein Programm ist. Für das Web gibt es zum Beispiel den Apache“.
”
Nun ist es so: Ein Computer kann mehrere Programme gleichzeitig ausführen,
so können mehrere Server auf einem Computer gleichzeitig arbeiten. Mehrere
Server für unterschiedliche Aufgaben, bernimmt ein Provider die Anforderung,
E-Mails und HTTP-Seiten zu verteilen, dann wäre es ja möglich sich einen
großen Computer an zu schaffen und der ist sowohl für E-Mails als auch für
HTTP zuständig. Dann ist auf einem Computer alles. Man kann auch einen
21
Computer für SMTP einen für HTTP, aber man kann auch einen nehmen für
SMTP und HTTP. Oder man kann mehrere nehmen, die dann wiederum HTTP
und SMTP jeweils beide gleichzeitig betreiben. Nun ist es so: Wenn ich einen
Computer über eine IP-Adresse im Netzwerk identifiziere, auf einem Computer,
der Server (Server ist zunächst ein Programm) läuft und zwar der für E-Mails
und für Webseiten, dann muss ich einen Port öffnen. Es gibt die typischen Ports
(zum Beispiel 80 für HTTP), damit der Computer, auf dem die Server laufen
auch weiß, was er jetzt bei der aktuellen Verbindung bedienen soll. Laufen auf
dem Computer, der das bereitstellt, beide Dienste, muss er jeweils immer wissen, welchen er denn bedienen soll.
Reden zwei Computer miteinander, dann kommunizieren Client und Server miteinander. Der Server bleibt ber die Verbindung hinaus und war auch schon vor
der Verbindung am laufen. Man nimmt nicht einfach Kontakt zu einem anderen
Computer auf. Ein Server, wie ein HTTP-Server ist eine ständig laufende Software, auf einem vielleicht ganz normalen Computer, die auf Signale eines Clients
wartet. D.h. die Software des Servers läuft schon, bevor die Verbinundung zustande kommt, sie läuft permanent. Dann kann der Client zu dieser Software
eine Verbindung aufbauen.
Webserver sind Software, wie jeder Server: Zum Beispiel Apache Clients sind
zum Beispiel Webbrowser, wie Internetexplorer, Chrome, Firefox. Die Darstellung der HTML-Dateien, dass sie am Bildschirm so gut aussehen, hat nichts mit
der Funktion des Clients an sich zu tun oder mit dessen, was ein Client eigentlich
ist, der Client fordert schlicht und ergreifend eine HTML-Datei an und zwar ber
ein TCP/IP-Netzwerk, die Darstellung ist ein zweiter Schritt. Wir müssen zwei
Anwendungen mit C Programmieren: Einen Client und einen Server. Socket =
Kommunikationsendpunkt
Egal, ob Client oder Server, fordern wir zunächst einen Socket vom Betriebssystem an. Es spielt dabei keine Rolle, ob wir ein Server oder ein Client sind, es
ist auch egal, mit wem wir kommunizieren möchten.
Socket = Kommunikationsendpunk
22
Fangen wir an:
4.1
Client-Anwendung
Socket für Linux:
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Socket für Windows
#include <winsock.h>
SOCKET socket(int af, int type, int protocol);
Wird die Funktion aufgerufen und es geschieht ein Fehler, gibt sie den Wert -1
zurück.
1. Parameter: domain : Protokollfamilie
Protokollfamilien sind:
• AF_UNIX: Für Interprozesskommunikation verwendet.
• AF_INET: Internet IP-Protokoll Version 4 (dies verwenden wir, wir
erinnern uns an die IP-Adressen unter Windows)
• AF_INET6: Internet IP-Protokoll Version 6
• AF_IRDA: Infrarot, ...
• AF_BLUETOOTH: Bluetooth-Sockets
2. Parameter:
• SOCK_STREAM: für TCP
• SOCK_DGRAM: UDP
3. Parameter:
• Es besteht ein Zusammenhang zum zweiten Parameter, bzw. dem
davor
Code:
if((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0)
/* Fehler */
}
Wenn alles mit socket(); funktioniert hat, kann der Client versuchen eine
Verbindung zum Server auf zu bauen:
connect();
Linux:
23
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sock, const struct sockaddr *addr, int addrlen);
Windows:
#include <winsock.h>
int connect(SOCKET sock, const struct sockaddr FAR* addr, int addrlen);
Als erster Parameter dient der Socket, den wir von socket“erhalten haben. Der
”
Rückgabewert ist negativ, wenn ein Fehler entstand. Für den zweiten Parameter
gilt:
Entweder:
struct sockaddr {
sa_family_t sa_family;
char sa_data[14];
};
Oder:
struct sockaddr_in {
sa_family sin_family;
unsigned short int sin_port;
struct in_addr sin_addr;
unsigned char pad[8];
};
Mit dem letzten Parameter geben wir die Länge von dem zweiten Parameter in
Bytes mittels des ßizeofOperators an. sockaddr_in:
• sin_family: Addressfamilie (Protokollfamilie): Dasselbe wie in Socket
• sin_port: Portnummer: Ports wie HTTP (80), SMTP (25), IMAP, POP3,
...
• sin_addr: IP-Adresse
Das ganze sieht dann so aus:
struct sockaddr_in server;
unsigned long addr;
memset(&server, 0, sizeof (server));
/* Wir initialisieren die gesamter Strukturvariable server vom Typ sockaddr_in,
die gerade beschrieben wurde, mit 0 */
addr = inet_addr(argv[1]);
/* Wir wandeln unsere Schreibweise einer IP-Adresse in eine 4-Byte Zahl um*/
memcpy((char *)&server.sin_addr, &addr, sizeof(addr));
/* Wir setzen die IP-Addresse, die wir als 4-Byte Zahl haben (long) in der Variablen
24
server vom Typ sockaddr_in*/
server.sin_family = AF_INET;
/* Wir setzen das Protokoll */
server.sin_port = htons(80);
/* Wir setzen den Port */
if(connect(sock,(struct sockaddr*)&server, sizeof(server)) < 0){
/* Fehler */
}
/* Wir bauen eine Verbindung auf */
Nun steht die Verbindung.
Senden und Empfangen:
Nun haben wir eine stehende Verbindung von unserem Client zu einem bestehenden Server. Die Sockets lassen sich mit Filedeskriptoren vergleichen, die zum
Öffnen und Schließen einer Datei verwendet werden. So wie es beim Dateizugriff read() und write() gibt, gibt es bei einer Verbindung send() und recv()
1. Senden:
Linux:
#include <sys/types.h>
#include <sys/socket.h>
ssize_t send(int socketfd, const void *data, size_t data_len, unsigned int flags);
Windows:
#include <winsock.h>
int send(SOCKET s, const char FAR* data, int data_len, int flags );
Parameter:
•
•
•
•
Unser Socket
Einen Pointer auf den Arbeitsspeicherbereich, wo unsere Daten liegen
Die Größe unserer Daten
Ein paar Flags.
Im Falle eines Fehlers erhalten wir den Rückgabewert -1
2. Empfangen:
Linux:
#include <sys/types.h>
#include <sys/socket.h>
ssize_t recv(int socketfd, void *data, size_t data_len, unsigned int flags );
25
Windows:
#include <winsock.h>
int recv(SOCKET s, char FAR* data,
int data_len,
int flags);
Das beenden der Verbindung:
Linux:
#include <unistd.h>
int close(int s);
Windows:
#include <winsock.h>
int closesocket(SOCKET s);
Also: Client:
• Funktionen:
– socket
– connect
– send
– recv
– close
• Strukturen:
– struct sockaddr_in:
∗ Enthält: IP-Adresse vom Server
∗ Port
∗ Noch mal demselben wie in der Funktion socket, einfach dass wir
TCP/IP verwenden
∗ Ein paar Bytes, die zum Auffüllen der Struktur dienen
• Wichtige Parameter und Konstanten:
– socket:
∗ AF_INET, bei socket(), erster Parameter: wir wollen eine TCP/IPVerbindung mit IPv4
∗ SOCK_STREAM, bei socket(), zweiter Parameter: Wir wollen TCP
verwenden und nicht UDP
∗ 3. Parameter von socket(): Einfach 0
∗ Rückgabewert von socket(): Eine Nummer, die den Socket identifiziert, änlich einem Dateideskriptor.
– connect:
26
∗ erster Parameter: Der Socket oder die Nummer des Sockets, ähnlich dem Dateideskriptor, Rückgabewert von socket();
∗ zweiter Parameter: Struktur struct sockaddr_in, mit Informationen zu
· IP-Adresse vom Server
· Port
· Noch mal die Angabe wie in der Funktion socket, dass wir
TCP/IP verwenden
· Ein paar Bytes, die zum Auffüllen der Struktur dienen
∗ dritter Parameter: Die Grösse in Bytes der Struktur sockaddr_in
4.2
Erstellen einer Server Anwendung
Auch auf der Serverseits
socket();
verwenden.
Bei dem Server verwenden wir statt connect();: bind();
Linux:
#include <sys/types.h>
#include <sys/socket.h>
int bind(int s, const struct sockaddr name, int namelen);
Windows:
#include <winsock.h>
int bind(SOCKET s, const struct sockaddr_in FAR* name, int namelen);
Danach folgt:
struct sockaddr_in server;
memset(&server, 0, sizeof (server));
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
server.sin_port = htons(1234);
if(bind(sock, (struct sockaddr*)&server, sizeof( server)) < 0) {
/* Fehler */
}
Danach folgt
listen();
Linux:
#include <sys/types.h>
#include <sys/socket.h>
int listen( int s, int backlog );
27
Windows:
#include <winsock.h>
int listen( SOCKET s, int backlog );
Wir hatten ja gesagt, wenn Server und Client eine Verbindung aufbauen wollen, muss der eine vorher da sein, als der andere, das ist natürlich der Server.
Beide sind Software. Während die eine Software schon läuft, muss der andere die Verbindung aufbauen. Die Verbindung zum Server baut der Client auf.
Doch wie soll man das mit der Verbindung bewerkstelligen? Man kann nicht
beide gleichzeitig einschalten, so dass sie dann unter Garantie eine Verbindung
aufbauen. Stattdessen läuft der Server und der Client baut eine Verbindung zu
ihm auf. Also ist der Client später gestartet als der Server. Aber es kommt noch
besser: Ein Server kann mehrere Clients akzeptieren. Zum gleichen Zeitpunkt
können mehrere Menschen auf dieselbe Webseite zugreifen. Dass ein Client eine
Verbindung zu einem Server aufbauen will und zu erkennenn, dass er das will,
was die Aufgabe des Servers ist, muss der Server ständig überprüfen. Er horcht,
ob ein Client die Verbindung aufbauen will. Dieses Horchen bezeichnet man als
listen();
Danach kommt
#include <sys/types.h>
#include <sys/socket.h>
int accept(int s, struct sockaddr *addr, socklen_t addrlen );
Windows:
#include <winsock.h>
SOCKET accept(SOCKET s, struct sockaddr FAR* addr, int FAR* addrlen );
Warum: Nun mehrere Clients haben eventuell eine Verbindung zum Server aufgebaut, also lagern die Wünsche der Clients, also die Clients, in einer Warteschlange. Es wird immer der nächste aus der Verbindung der Warteschlangs
geholt. Dafür ist accept() zuständig.
struct sockaddr_in client;
int sock, sock2;
socklen_t len;
...
while(1) {
len = sizeof(client);
sock2 = accept(sock, (struct sockaddr*)&client, &len);
if(sock2 < 0) {
/* Fehler */
}
/* Hier beginnt der Datenaustausch. */
}
28
Deswegen gibt es bei dem Server auch sock und sock2. sock ist die des Servers selber und sock2, der socket des Clients bzw. aller Clients, die zum Server
Kontakt aufgenommen haben.
4.3
Der komplette Quelltext
Linux, Client:
/* Dies ein Quelltext fuer Linux */
/* Das Programm muss mit g++ uebersetzt werden */
#include
#include
#include
#include
#include
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
<netdb.h>
<arpa/inet.h>
#include
#include
#include
#include
<stdio.h>
<string.h>
<stdlib.h>
<unistd.h>
#define PORT 3142
int main(int argc, char *argv[]) {
int sock;
struct sockaddr_in server;
char addr_str[50];
long addr;
char echo_str[50];
if(argc < 3) {
printf("usage: client server-ip echo-word\n");
printf("server-ip musst be an numeric ip-address\n");
printf("programm exits\n");
return -1;
}
strcpy(addr_str, argv[1]);
strcpy(echo_str, argv[2]);
if((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("Beim Erzeugen des Sockets trat auf Client Seite ein Fehler auf\n");
printf("Programm beendet sich\n");
return -1;
}
29
memset(&server, 0, sizeof(server));
addr = inet_addr(addr_str);
memcpy((char *)&server.sin_addr, &addr, sizeof(addr));
server.sin_family = AF_INET;
server.sin_port = htons(PORT);
if(connect(sock, (struct sockaddr *)&server, sizeof(server)) < 0) {
printf("Fehler beim Verbindungsaufbau auf Seite des Clients,",
"Client kann keine Verbindung zu Server herstellen\n");
printf("Programm beendet sich\n");
return -1;
}
if(send(sock, echo_str, strlen(echo_str), 0) != strlen(echo_str)) {
printf("send() hat eine andere Anzahl von Bytes gesendet als erwartet\n");
printf("Programm beendet sich\n");
return -1;
}
close(sock);
return 0;
}
Linux, Server:
/* Dies ein Quelltext fuer Linux */
/* Das Programm muss mit g++ uebersetzt werden */
#include
#include
#include
#include
#include
<sys/types.h>
<sys/socket.h>
<netinet/in.h>
<netdb.h>
<arpa/inet.h>
#include
#include
#include
#include
#include
<stdio.h>
<string.h>
<stdlib.h>
<unistd.h>
<fcntl.h>
#define PORT 3142
int main(int argc, char *argv[]) {
struct sockaddr_in server, client;
int sock, client_sock;
unsigned int len;
char msg[50];
int msg_len;
30
if((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("Beim Erzeugen des Sockets trat auf Seiten des Server ein Fehler auf\n");
printf("Programm beendet sich\n");
return -1;
}
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
server.sin_port = htons(PORT);
if(bind(sock, (struct sockaddr*)&server, sizeof( server)) < 0) {
printf("Server: Kann den Socket nicht binden\n");
printf("Programm beendet sich\n");
return -1;
}
if(listen(sock, 5) == -1 ) {
printf("Server: Fehler bei listen\n");
printf("Programm beendet sich\n");
return -1;
}
while(1) {
len = sizeof(client);
client_sock = accept(sock, (struct sockaddr*)&client, &len);
if(client_sock < 0) {
printf("Server: Fehler bei accept\n");
printf("Programm beendet sich\n");
return -1;
}
if((msg_len = recv(client_sock, msg, 50, 0)) < 0) {
printf("Ermittelte Nachricht zu kurz\n");
printf("Programm beendet sich\n");
return -1;
}
msg[msg_len] = 0;
printf("Client mit der Adresse %s sagt: %s\n", inet_ntoa(client.sin_addr), msg);
close(client_sock);
}
return 0;
}
Windows Client:
/* Dies ein Quelltext fuer Windows */
/* Das Programm muss mit einem Borland C++ Compiler uebersetzt werden */
#include <winsock.h>
31
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define PORT 3142
int main(int argc, char *argv[]) {
SOCKET sock;
struct sockaddr_in server;
char addr_str[50];
long addr;
char echo_str[50];
if(argc < 3) {
printf("usage: client server-ip echo-word\n");
printf("server-ip musst be an numeric ip-address\n");
printf("programm exits\n");
return -1;
}
strcpy(addr_str, argv[1]);
strcpy(echo_str, argv[2]);
if((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("Beim Erzeugen des Sockets trat auf Client Seite ein Fehler auf\n");
printf("Programm beendet sich\n");
return -1;
}
memset(&server, 0, sizeof(server));
addr = inet_addr(addr_str);
memcpy((char *)&server.sin_addr, &addr, sizeof(addr));
server.sin_family = AF_INET;
server.sin_port = htons(PORT);
if(connect(sock, (struct sockaddr *)&server, sizeof(server)) < 0) {
printf("Fehler beim Verbindungsaufbau auf Seite des Clients,",
"Client kann keine Verbindung zu Server herstellen\n");
printf("Programm beendet sich\n");
return -1;
}
if(send(sock, echo_str, strlen(echo_str), 0) != strlen(echo_str)) {
printf("send() hat eine andere Anzahl von Bytes gesendet als erwartet\n");
printf("Programm beendet sich\n");
return -1;
}
32
closesocket(sock);
return 0;
}
Windows, Server:
/* Dies ein Quelltext fuer Windows */
/* Das Programm muss am Besten mit einem Borland c++ Compiler uebersetzt werden */
#include <winsock.h>
#include
#include
#include
#include
<stdio.h>
<string.h>
<stdlib.h>
<fcntl.h>
#define PORT 3142
int main(int argc, char *argv[]) {
struct sockaddr_in server, client;
SOCKET sock, client_sock;
int len;
char msg[50];
int msg_len;
if((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("Beim Erzeugen des Sockets trat auf Seiten des Server ein Fehler auf\n");
printf("Programm beendet sich\n");
return -1;
}
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
server.sin_port = htons(PORT);
if(bind(sock, (struct sockaddr*)&server, sizeof( server)) < 0) {
printf("Server: Kann den Socket nicht binden\n");
printf("Programm beendet sich\n");
return -1;
}
if(listen(sock, 5) == -1 ) {
printf("Server: Fehler bei listen\n");
printf("Programm beendet sich\n");
return -1;
}
33
while(1) {
len = sizeof(client);
client_sock = accept(sock, (struct sockaddr*)&client, &len);
if(client_sock < 0) {
printf("Server: Fehler bei accept\n");
printf("Programm beendet sich\n");
return -1;
}
if((msg_len = recv(client_sock, msg, 50, 0)) < 0) {
printf("Ermittelte Nachricht zu kurz\n");
printf("Programm beendet sich\n");
return -1;
}
msg[msg_len] = 0;
printf("Client mit der Adresse %s sagt: %s\n", inet_ntoa(client.sin_addr), msg);
closesocket(client_sock);
}
return 0;
}
4.4
Ein HTTP-Client
#include <stdio.h>
#include <errno.h>
#include <string>
#include <winsock.h>
#include <io.h>
#define HTTP_PORT 80
int main(int argc, char **argv) {
int sock;
struct sockaddr_in host_addr;
struct hostent *hostinfo;
char *host, *file;
char command[1024];
char buf[1024];
unsigned int bytes_sent, bytes_recv;
if(argc != 3) {
printf("Aufruf: httprecv host file\n");
return -1;
}
host = argv[1];
file = argv[2];
WSADATA wsaData;
34
if(WSAStartup (MAKEWORD(1, 1), &wsaData) != 0) {
printf ("WSAStartup(): Kann Winsock nicht initialisieren.\n");
return -1;
}
if((sock = socket (AF_INET, SOCK_STREAM, 0)) == -1) {
printf("socket()");
return -1;
}
memset(&host_addr, 0, sizeof (host_addr));
host_addr.sin_family = AF_INET;
host_addr.sin_port = htons (HTTP_PORT);
host_addr.sin_addr.s_addr = inet_addr (host);
if(host_addr.sin_addr.s_addr == INADDR_NONE) {
hostinfo = gethostbyname (host);
if(hostinfo == NULL) {
printf("gethostbyname()");
return -1;
}
memcpy((char*) &host_addr.sin_addr.s_addr, hostinfo->h_addr, hostinfo->h_length);
}
if(connect(sock, (struct sockaddr *) &host_addr, sizeof(struct sockaddr)) == -1) {
printf("connect()");
return -1;
}
/* HTTP-GET-Befehl erzeugen */
sprintf(command, "GET %s HTTP/1.0\nHost: %s\n\n", file, host);
/* Befehl senden */
if((bytes_sent = send(sock, command, strlen (command), 0)) == -1) {
printf("send()");
return -1;
}
/* Antwort des Servers empfangen und ausgeben */
while((bytes_recv = recv (sock, buf, sizeof(buf), 0)) > 0) {
write (1, buf, bytes_recv);
}
if(bytes_recv == -1) {
printf("recv()");
return -1;
}
printf ("\n");
closesocket(sock);
WSACleanup();
35
return 0;
}
Auf zu rufen ist dieses Programm mit der Adresse der zu zeigenden HTMLDatei und /“. Das /“bewirkt, dass die erste Seite aufgerufen wird, also zum
”
”
Beispiel index.html“. Man darf hier nicht index.html“verwenden, man hält
”
”
sich einfach an den Baum auf der entsprechenden Seite.
Die Befehle von HTTP sind einfach. Wir hatten vorher gesagt, dass wir ein
SEND“per der Funktion send()“versenden, wenn wir innerhalb eines C-Programms
”
”
sind. Das SEND“ist eine Textbotschaft, SEND“ist eine Textbotschaft, die an den
”
”
Server in Form von Text übermittelt wird. Daraufhin könnte zum Beispiel der
HTTP-Server, wie Apache uns eine HTML-Datei zurückliefern, an den Client,
die auch in Textform bei uns ankommt. Die HTML-Datei befindet sich auf dem
Rechner, auf dem Apache läuft als Datei in einem Ordner und wurde Apache
zugeordnet. Er ließt die Datei und übermittelt sie uns. Dabei kann man Apache zum Beispiel über Yast2 einrichten. In Yast2 unter OpenSuSE stellen wir
den Ordner ein, indem die HTML-Dateien sind. Nun (!) verwenden wir nicht
SEND“als Befehl an den HTTP-Server, sondern GET“. Es ist wichtig zu wis”
”
sen, dass ein Protokoll, wie HTTP bestimmte Befehle verwendet. Das regelt
das Protokoll HTTP. Es gibt nicht einen HTTP-Server, der so funktioniert und
einen der anders funktioniert. Kurz, einer verwendet solche Befehle, ein anderer
andere, das gibt es nicht. Jeder HTTP-Server verwendet dieselben Befehle, oder
die selbe Sprache. Was hat ein Protokoll mit Befehlen zu tun. Betrachten wir
zum Beispiel IDE oder SATA bei den Festplatten in dem Computer, so sind
das auch Protokolle. Hier werden auch Befehle übermittelt, Befehle, wie Lese
”
den Block so und so“oder Schreibe auf den Block so und so“. Hier werden die
”
Befehle kodiert als Zahlen über den Datenbus übertragen. Dort bedeutet, bei jeder Festplatte gleich, die dem SATA oder IDE Standard genügt, eine bestimmte
Zahl, immer das gleiche, immer den selben Befehl. Das ist nicht mal so oder so.
Das Protokoll regelt nicht nur, in welcher Reihenfolge Befehle eintreffen, sondern auch welche es gibt und wie diese Kodiert sind oder welchen Namen sie
tragen. Kodiert heißt nicht, mit welchen Mitteln von Kodierungsalgorithmen,
sondern wie das Wort genau lautet.
Bei HTTP sind die Befehle und das sind wenige:
• GET
• POST
• HEAD
• PUT
• OPTIONS
• DELETE
• TRACE
• CONNECT
Diese werden als Text übertragen. Wichtig wäre zum Beispiel der Befehl
36
GET / HTTP/1.0\nHost: 192.168.137.198\n\n
Die IP-Addresse ist frei erfunden. Mein Apache-Server, den ich auf meinem
Linux-Rechner mit OpenSuSE eingerichtet habe, läuft unter der Addresse. (Nur
zum Spaß), keine Sorge ist nicht am Internet angeschlossen. Wichtig ist das /“.
”
Das bedeutet, dass (zum Beispiel in meinem Fall), die Datei index.html“aufgerufen
”
wird. Wir können den Aufruf auch starten mit
GET /index.html HTTP/1.0\nHost: 192.168.137.198\n\n
5
HTML-Programmierung im Web
Eine Möglichkeit eine HTML-Seite zu erstellen ist entweder ganz in HTML, oder
mittels einer Software, die entweder ein WYSIWYG Editor verwendet oder eine Webseite mittels zum Beispiel LaTeX2html. Latex2html bietet den Vorteil,
dass die Webseite einer Norm unterliegt. LaTeX2HTML ist ein Standard. Im
Gegensatz zu HTML selber ist Latex so, dass es viel mehr auf die genormte
Darstellung von Dokumenten achtet. Das heißt es hält sich an die Regeln, wie
ein Dokument nach allen Standards und Regeln aussehen soll und die Stimmen
nach all den Jahren und Jahrhunderten, der Erfassung von Regeln auf jeden
Fall. LaTeX2HTML ist wieder ein Standard, weil alles was in LaTeX2HTML
sieht gleich aus, so wie eben, dass sich Latex um äußere Standards bemüht. Des
Weiteren, wenn man sich mit all den regeln des äußeren und optischen bemüht,
hat man es mit HTML nicht leicht, denn man muss hier Dinge kenne, die beziehen sich auf weitreichende Bereich, wie man Dokumente überhaupt nach allen
Regeln so darstellt, dass sie nach etwas aussehen. Latex ist selber aber auch
eine Skriptsprache zur Dokumentenbeschreibung wie HTML. Es benutzt auch
Befehle in dieser Art. Und eignet sich gut zum Beispiel zur Darstellung von Mathematischen Text und Formeln. Mathematische Formeln lassen sich gut damit
darstellen.
Seiten, die mit Latex2HTML geschrieben wurden, sehen immer gleich aus. Und
damit ist das ein Standard, vor allem weil jeder, der Latex2HTML verwendet,
jedes Mal eine ähnlich aussehende Seite erhält. Und da Latex2HTML eine Anwendung ist, die so zu sagen bekannt ist, oder immer wieder verwendet wird
oder zumindest so ist, dass sie bekannt ist und immer wieder verwendet werden
kann, kann man sich sicher sein, dass die Seiten damit nicht schlecht aussehen. Latex ist eine Dokumentenbeschreibungssprache wie HTML und dient vor
allem zur Darstellung von mathematischen Formelsatz. Es handelt sich dabei
allerdings um eine Dokumentenbeschreibungssprache, wo mit Sie Texte quasi so
schreiben können, dass sie wie ein echtes Dokument aussehen und auch wirklich
eines sind, es gibt ja gewisse Regeln, nach denen ein Dokument aus zu sehen
hat, ist das eine vollkommen legitime Sprache. Was halt nicht, wie in HTML
sein kann, ist, dass der Button oder die Tabelle irgendwo im Raum liegen kann.
Da ist nicht in der rechten oberen Ecke zum Beispiel vollkommen fehl platziert
irgendetwas, was auch immer.
37
6
Neuer Text vom User, auf meiner Webseite
Was das Einbetten von Texten auf einer Webseite betrifft: Facebook funktioniert
auf diese Art und Weise, wie jede Seite, die Code einbettet. Es gibt Java-Script.
In Java-Script gibt es Eingabeberreiche. Dort gebe ich Text ein. Die Seite ist
schon da, auf der ein Eingabefenster ist. Ich gebe dort den Text ein und der
Text geht mittels Java-Script zurrück an den Server, auf dem die Seite ist. Doch
diese Seite auf dem das Eingabefenster ist, ist eine HTML-Seite. Sie wurde in
HTML geschrieben. Dazwischen ist Code mit Java- Script. Aber die Teile von
HTML, die Text und Bilder darstellten, gehören zu HTML. Wenn ich nun einen
Text eingebe, dann geht der Text zurück an den Server. Dieser speichert nun an
einer bestimmten Stelle in der HTML-Datei den neu zurückgekommenen Text
und speichert es als Text, wie jeden anderen Text einer HTML-Datei. Nun wird
die Webseite neu angezeigt mit dem eingebenen Text. Doch diese HTML-Datei
befindet sich ja auf dem Server. Also wird dort was als Text auf der Datei auf
dem Server geändert, bzw. hinzugefügt. Und nun die Frage: Was ist wenn dort
jemand Java-Script-Code einfügt. Das funktioniert nicht, denn der Server bringt
den Code so an, dass er als Text ausgeführt bzw. gelesen wird. Dort wird kein
Code ausgeführt, weil er als Textform auf der Seite untergebracht ist, so dass
er nur als Text gelesen wird. Dann fragt man sich und wenn ich nun etwas an
dem HTML-Code der Seite ändere? Das geht nicht, denn ich kann zwar die
Seite speichern und bei mir auf dem Computer was ändern, aber nicht auf dem
Server. Ich kann auf dem Server nichts an der Datei ändern. Die Datei ist auf
dem Server gespeichert und auf der auf dem Server gespeicherten Datei kann ich
nichts ändern. Doch sagen manche, ich kann doch Java-Script Code einfügen,
nein, das kann ich nicht, denn dann muss ich ja wieder was auf der Datei auf
dem Server ändern. Die HTML-Datei wird trotz Java-Script per Apache oder
einem anderen Webserver verteilt. Der führt den Code nicht aus. Das tut der
Webbrowser.
38