Flussdiagramm der ökonometrischen Methode
Werbung

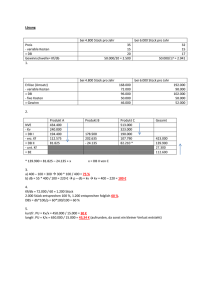
Flussdiagramm der ökonometrischen Methode Sach− verhalt phäno− menologische Modellierung oder z.B Sättigungs− modell Spezifikation des ökonometrischen Modells z.B linear exogene Variable endogene Variable Parameter− schätzung Parameter Unbestimmter Term geschätztes Modell Schätzer für alle Parameter Daten Varianzen und Kovarianzen der Schätzer Hypothesentest z.B. Anstiegsparameter < 0 Prognose Extrapolation auf x ungleich Datenwerte Modellspezifikation I: Funktionale Spezifikation 1 Nutzung ÖPNV β0 y x 2 Geschwin− digkeit y 111111111111 000000000000 000000000000 111111111111 000000000000 111111111111 000000000000 111111111111 000000000000 111111111111 β111111111111 000000000000 2 000000000000 111111111111 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 000000000000 111111111111 β1 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 000000000000 111111111111 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 000000000000 000000000000000000000000000000000000000000111111111111 111111111111111111111111111111111111111111 000000000000 111111111111 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 000000000000 000000000000000000000000000000000000000000111111111111 111111111111111111111111111111111111111111 000000000000 111111111111 000000000000 111111111111 ÖPNV− Fahrleistung y x1 Preis ^y(x , x ) 1 2 Stadt i Preis x1 ÖPNV− Fahrleistung x2 Geschwindigkeit 1. Alle relevanten Einflussfaktoren sind berücksichtigt (oben, nicht aber unten) Modellspezifikation I: Funktionale Spezifikation 2 . ^y(x) wahrer Zusammenhang y ^y (x) lin data falscher linearer Zusammenhang x 2. Das Modell ist linear, was hier nicht erfüllt ist Modellspezifikation I: Funktionale Spezifikation 2 y y ^y(x) ^y(x) data x= z data x Manchmal kann das Modell durch Transformationen der exogenen und/oder endogenen Variablen linearisiert werden z Modellspezifikation I: Funktionale Spezifikation 3 y Verkehrstote ^y(x) Strukturbruch! ^y(x) data 1970 1990 2010 3. Homogenitätskriterium (z.B. kein Strukturbruch im Raum der exogenen Variablen, wie hier gezeigt) x Modellspezifikation II: Statistische Spezifikation 1 y y ^y(x) ^y(x) data data x 1. Der Erwartungswert der Störgröße muss verschwinden. x Modellspezifikation II: Statistische Spezifikation 2 y y ^y(x) ^y(x) data data x 2. Der Residualterm ǫ ist homoskedastisch (rechts), nicht etwa heteroskedastisch (links) x Modellspezifikation II: Statistische Spezifikation 3 y y ^y(x) ^y(x) data data x Keine Korrelationen von ǫ bezüglich xi oder y (rechts), während das Modell links fehlspezifiziert ist x Modellspezifikation II: Statistische Spezifikation 4 y y ^y(x) data ^y(x) data x Der Residualterm ǫ ist gaußverteilt (rechts), nicht etwa bimodal verteilt (links) x Modellspezifikation III: Datenspezifikation y x2 nicht OK nicht OK data x1 x x2 OK x1 Keine der exogenen Variablen darf sich als Linearkombination aus Konstanten und anderen exogenen Variablen darstellen lassen (oben); nichtperfekte Korrelationen sind aber erlaubt (unten) Lineares Modell mit zwei exogenen Variablen (schematisch) Nutzung ÖPNV β0 y x 2 Geschwin− digkeit 1111111111111 0000000000000 0000000000000 1111111111111 0000000000000 1111111111111 0000000000000 1111111111111 0000000000000 1111111111111 β2 0000000000000 1111111111111 0000000000000 1111111111111 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 0000000000000 1111111111111 β 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 0000000000000 1111111111111 1 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 0000000000000 1111111111111 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 0000000000000 1111111111111 000000000000000000000000000000000000000000 111111111111111111111111111111111111111111 0000000000000 1111111111111 0000000000000000000000000000000000000000001111111111111 111111111111111111111111111111111111111111 0000000000000 ^y(x , x ) 1 2 Stadt i Preis Die Daten gehorchen hier dem linearen Modell exakt! x1 Konfidenzintervalle und die Entstehung der Student-Verteilung ^ 2σ β . 1. Stichprobe 2. Stichprobe 8. Stichprobe f(t) ^ f( β ) Gaußverteilung t−Verteilung β Dichte f 1. Stichprobe ^ β −1 0 Eine geschätzte Standardabw. Chi 2 − Verteilung ^ 2σ β 1 Abweichung t in Einheiten der geschätzten Standardabw. ^ β−β ^σ β Dichten der Standardnormal vs. Student-t-verteilung 0.4 Standardnormalverteilung Student−Verteilung mit ν=1 FG Student−Verteilung mit ν=2 FG Dichtefunktion fz(z) bzw. ft(t) 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 −2 −1 0 1 2 z bzw. t 3 4 5 6 Standardnormal vs. Student-t-verteilung Verteilungsfunktion Fz(z) bzw. Ft(t) 1 0.8 0.6 Standardnormalverteilung Student−Verteilung mit ν=1 FG Student−Verteilung mit ν=2 FG z (1)0.95 t 0.95 0.4 0.2 0 −2 −1 0 1 2 z bzw. t 3 4 5 6 Konfidenzintervalle Konfidenzintervall zu H0: β1/2 und σ wie geschätzt unter α=0.05 Konfidenzintervall zu H0: β1/2 und σ wie geschätzt unter α=0.05 0.4 1 0.35 Dichte Konfidenzintervall 0.8 Verteilungsfunktion F(t) Dichtefunktion f(t) 0.3 F KI F=0.05 F=0.95 0.25 0.2 0.15 0.1 0.6 0.4 0.2 0.05 0 −4 −3 −2 −1 0 1 Testvariable t 2 3 4 0 −4 −3 −2 −1 0 1 Testvariable t KI zu einer Fehlerwahrscheinlichkeit α = 5 % für n − J − 1 = 2 Freiheitsgrade. 2 3 4 Fehler erster und 2. Art allgemein H 0 nicht abgelehnt H 0 trifft zu H 0 trifft nicht zu H 0 abgelehnt Fehler erster Art Fehler zweiter Art Definition der Fehler erster und zweiter Art bei Signifikanztests Fehler erster und 2. Art bei H0: β ≤ β0 Wahrscheinlichkeit 1 0.8 α−Fehler β−Fehler Gütefunktion 0.6 0.4 0.2 0 −4 −2 0 ∆Z=(β−β0)/σβ 2 4 Einseitiger Test auf <, ≤ in Abhängigkeit des skalierten Abstandes ∆z = (βj −β0j )/σβ̂j des wahren Parameterwertes vom Grenzwert der Nullhypothese (bekannte Varianz des Schätzers, α = 0.1) Fehler erster und 2. Art bei H0: β ≤ β0 Wahrscheinlichkeit 1 0.8 α−Fehler β−Fehler Gütefunktion 0.6 0.4 0.2 0 −4 −2 0 ∆T=(β−β0)/sβ 2 4 Das Gleiche bei unbekannte Varianz und n − J − 1 = 2 Freiheitsgraden. Der skalierte Abstand ist nun ∆t = (βj − β0j )/σ̂β̂j . Fehler erster und 2. Art bei H0: β ≥ β0 Wahrscheinlichkeit 1 α−Fehler β−Fehler Gütefunktion 0.8 0.6 0.4 0.2 0 −4 −2 0 ∆Z=(β−β0)/σβ Einseitiger Test auf >, ≥ (bekannte Varianz, α = 0.1) 2 4 Fehler erster und 2. Art bei H0: β ≥ β0 Wahrscheinlichkeit 1 α−Fehler β−Fehler Gütefunktion 0.8 0.6 0.4 0.2 0 −4 −2 0 ∆T=(β−β0)/sβ 2 4 Einseitiger Test auf >, ≥ (unbekannte Varianz, n − J − 1 = 2 Freiheitsgrade, α = 0.1) Fehler erster und 2. Art bei H0: β = β0 Wahrscheinlichkeit 1 0.8 0.6 α−Fehler β−Fehler Gütefunktion 0.4 0.2 0 −4 −2 0 ∆T=(β−β0)/sβ 2 4 Zweiseitiger Test auf Gleichheit (unbekannte Varianz, n − J − 1 = 2 Freiheitsgrade, α = 0.1) Fehler erster und 2. Art allgemein P(t<t α/2)= α/2 α/2 P(t>t 1−α/2 )= w t= 0 t Ablehnungs− bereich t α/2 Annahme− bereich Ablehnungs− bereich t 1−α/2 Annahme- und Ablehnungsbereiche bei zweiseitigen Tests (Tests einer Punkt-Hypothese). Die Verteilungsfunktion ist nur bei Zutreffen von H0 gültig! Parameter-Schätzfehler (bedingte W-Dichte) bei linearer Einfachregression n=20; Standardabweichung des Residualfehlers: σε=3 0.6 abhaengige Variable y 10 0.5 8 6 0.4 4 0.3 2 0.2 2σ ε n 0 0.1 -2 0 -6 -4 -2 0 2 4 6 8 unabhaengige Variable x Die Residualfehler sind i.i.d. verteilt 10 12 Konkretes Beispiel: ÖPNV-Nutzung bei 10 Städten β0+β1 x1+β2 x2 Daten εi y 280 260 240 220 200 180 160 140 120 100 45 40 35 30 1 25 1.5 20 2 x1 x2 15 2.5 3 10 Türkisgrünen Striche: unbestimmten Anteile ǫi (positiv, wenn Über dem Datenpunkt) Projizierte Streudiagramme 45 Geschwindigkeit x2 (km/h) 40 Die exogenen Variablen sind korreliert, aber nicht perfekt kolinear 35 30 25 20 1 1.5 2.5 3 280 Daten Einfachregression(x1) Mehrfachregression(x1,x2) 260 Fahrgastzahlen y (Fahrten/Person/Jahr) Fahrgastzahlen y (Fahrten/Person/Jahr) 280 2 Fahrpreis x1 (Euro) 240 220 200 180 160 140 120 100 Daten Einfachregression(x1) Mehrfachregression(x1,x2) 260 240 220 200 180 160 140 120 100 1 1.5 2 Fahrpreis x1 (Euro) 2.5 3 10 15 20 25 30 35 Geschwindigkeit x2 (km/h) 40 x1=Preis (Euro), x2=Geschwindigkeit (km/h), y = Nutzungszahl 45 Akzeptanzintervalle des Teilmodells M1 (nur x1) hat y(x1|Modell 1) x1quer,yquer y (Fahrten/Jahr/Person) 2.5% und 97.5%−Quantile 280 0.07 260 0.06 240 0.05 220 200 0.04 180 0.03 160 0.02 140 120 0.01 100 0 1 1.5 2 2.5 3 3.5 x1 (Euro/Fahrt) 4 4.5 5 Konfidenzintervall zu H01: β1 = β̂1 = 70 (volles Modell) Konfidenzintervall zu H0: β1 und σ wie geschätzt und α=0.05 0.04 Dichte Konfidenzbereich Dichtefunktion f(hat β1) 0.035 0.03 0.025 0.02 0.015 0.01 0.005 0 −100 −90 −80 −70 −60 hat β1 −50 −40 −30 −20 Konfidenzintervall zu H0: β1 und σ wie geschätzt und α=0.05 Verteilungsfunktion F(hat β1) 1 F KI F=0.025 F=0.975 0.8 0.6 0.4 0.2 0 −100 −90 −80 −70 −60 hat β1 −50 −40 −30 −20 Konfidenzintervall zu H02: β2 = β̂2 = 6.5 (volles Modell) Konfidenzintervall zu H0: β2 und σ wie geschätzt und α=0.05 0.35 Dichtefunktion f(hat β2) 0.3 Dichte Konfidenzintervall 0.25 0.2 0.15 0.1 0.05 0 4 6 8 10 12 hat β2 Konfidenzintervall zu H0: β2 und σ wie geschätzt und α=0.05 Verteilungsfunktion F(hat β1) 1 F KI F=0.025 F=0.975 0.8 0.6 0.4 0.2 0 4 6 8 hat β2 10 12 Likelihoodfunktion der Anstiegsparameter 2d−Dichte hat βj unter H0: σ und βj wie gemessen 0.016 10 0.014 0.012 8 hat β2 0.01 6 0.008 0.006 4 0.004 2 H0 − Konfidenzregion F−Test H0 − Konfidenzregion t−Test 0.002 0 0 −100 −80 −60 hat β1 −40 −20 0 Korrelation der Schwankungsbreiten von β̂1 und β̂2 : rβ̂ ,β̂ = 0.60. 1 2 • t-Test: Die zwei separaten Nullhypothesen H01 : β1 = β10 und H02 : β2 = β20 sind beide erfüllt • F -Test für verbundene die Nullhypothese H0∗ : β1 = β10 , β2 = β20 Hotelbeispiel I: Geschätztes Modell und Residualfehler β0+β1 x1+β2 x2 Daten εi y 120 100 80 60 40 20 20 40 x2 β0+β1 x1+β2 x2 120 100 80 60 40 20 1 1.5 x1 1 1.5 2 2.5 3 3.5 Daten εi y 60 80 100 120 β0+β1 x1+β2 x2 4 2 2.5 3 3.5 x1 4 20 40 60 80 100 x2 Zwei Perspektiven der Ebene des deterministischen Teils des geschätzten Modells ŷ = β̂0 + β̂1 x1 + β̂2x2 , mit β̂0 = 25.5, β̂1 = 38.2 und β̂2 = −0.953 sowie die Abweichung ǫi = yi − ŷi der Datenpunkte vom Modell 120 Hotelbeispiel II: Zweidimensionale Konfidenzregionen Konfidenzintervalle T−Test β1, β2 Konfidenzintervalle T−Test GamH01, GamH02 Grenze Test β1 + 30 β2<0 0 Konfidenzregion F−Test Verbundene Nullhypothese H01 Verbundene Nullhypothese H03 1 0.9 −0.2 0.8 −0.4 β2 − Schätzer Konfidenzregion 0.7 −0.6 0.6 −0.8 0.5 −1 0.4 −1.2 0.3 −1.4 0.2 −1.6 0.1 0 20 25 30 Verbundene Nullhypothesen: 35 40 β1 − Schätzer 45 50 • = H01 : β10 = 30 und β20 = −1 △ = H02 : β10 = 34 und β20 = −1 Hotelbeispiel III: Falsch geschätzt! β1 und β2 um ∆β1 bzw. − ∆β2 verschoben β1 und β2 um ∆β1 bzw. ∆β2 verschoben Endogene Variable y 100 120 ydach(x1=1 Stern, x2) ydach (x1=2 Sterne, x2) ydach (x1=3 Sterne, x2) ydach (x1=4 Sterne, x2) 100 Endogene Variable y 120 80 60 ydach(x1=1 Stern, x2) ydach (x1=2 Sterne, x2) ydach (x1=3 Sterne, x2) ydach (x1=4 Sterne, x2) 80 60 40 40 20 20 20 40 60 80 Exogene Variable x2 100 20 120 120 ydach(x1=1 Stern, x2) ydach (x1=2 Sterne, x2) ydach (x1=3 Sterne, x2) ydach (x1=4 Sterne, x2) 100 Endogene Variable y Endogene Variable y 100 60 80 Exogene Variable x2 100 120 β1 und β2 um − ∆β1 bzw. +∆β2 verschoben β1 und β2 um − ∆β1 bzw. − ∆β2 verschoben 120 40 80 60 ydach(x1=1 Stern, x2) ydach (x1=2 Sterne, x2) ydach (x1=3 Sterne, x2) ydach (x1=4 Sterne, x2) 80 60 40 40 20 20 20 40 60 80 Exogene Variable x2 100 120 20 40 60 80 Exogene Variable x2 100 120 Übereinstimmung zwischen Modell und Daten für vier verschiedene Parametrisierungen Hotelbeispiel IV: F-Test zweier verbundenen Nullhypothesen Kumulierte Fisher−F−Verteilung F 2,n−3 (f) 1 0.8 0.6 0.4 0.2 Realisierter f−Wert bei β10=30,β20=−1 Realisierter f−Wert bei β10=34,β20=−1 F=0.95 0 0 2 4 6 8 10 12 14 f Verbundene Nullhypothesen: • = H01 : β10 = 30 und β20 = −1 △ = H02 : β10 = 34 und β20 = −1 Logistische Regression mit naiver LSE-Schätzung der log-Odd-Ratios: RC-Umfrage WS14/15 und WS15/16 kumuliert Unbeobachtete Variable y ∗ = ln(f1 /(1 − f1 )) Daten und Ergebnis mit 4 Entfernungsklassen 3.5 3 0.9 2.5 0.8 2 y*=ln(f/(1−f)) Modal Split OEV/MIV zusammen [%] 1 0.7 0.6 1.5 1 0.5 0.5 0 0.4 −0.5 Daten Logistische Regression 0.3 0 1 2 3 Entfernung x1 [km] 4 −1 5 β0 = −0.58, Daten Logistische Regression 0 β1 = 0.79 1 2 3 Entfernung x1 [km] 4 5 Logistische Regression mit naiver LSE-Schätzung der log-Odd-Ratios: 5. Datenpunkt addiert mit f=0.9999 Unbeobachtete Variable y ∗ = ln(f1 /(1 − f1 )) 1 16 0.9 14 0.8 12 0.7 10 0.6 8 y*=ln(f/(1−f)) Modal Split OEV/MIV zusammen [%] Daten und Ergebnis mit 4 Entfernungsklassen 0.5 0.4 6 4 0.3 2 0.2 0 0.1 −2 Daten Logistische Regression 0 0 1 2 3 4 5 Entfernung x1 [km] 6 7 −4 8 9 β0 = −3.12, Daten Logistische Regression 0 1 β1 = 2.03 2 3 4 5 Entfernung x1 [km] 6 7 8 9 Vergleich: “echte” Maximum-Likelihood-Schätzung Alternativen 0 (kein ÖV) und 1 (ÖV) Vi (r) = β0 δi1 + β1 rδi1 1 Relative Haeufigkeit OEV/MIV 0.9 0.8 0.7 β0 = −0.50 ± 0.65, β1 = +0.71 ± 0.30 0.6 0.5 0.4 Daten OEV/MIV Modell 0.3 0 1 2 3 Entfernung [km] 4 5 Vergleich: “echtes” Maximum-Likelihood-Schätzung mit 5. Datenpunkt Alternativen 0 (kein ÖV) und 1 (ÖV) Vi (r) = β0 δi1 + β1 rδi1 1 Relative Haeufigkeit OEV/MIV 0.9 0.8 0.7 β0 = −0.55 ± 0.63, β1 = +0.75 ± 0.27 0.6 0.5 0.4 Daten OEV/MIV Modell 0.3 0 2 4 6 Entfernung [km] 8 10