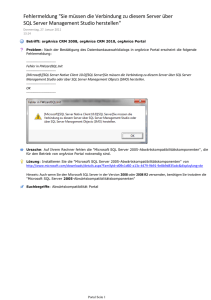
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL
Werbung

SMART DATA Developer Conference 2016
18.-19. April 2016, München
Titel:
Entwickeln von Datenpipeline-Komponenten für
die Microsoft SQL Server Integration Services
Speaker:
Thomas Worm
Softwareentwickler
Build und Qualitätssicherung
DATEV eG, Nürnberg
Thomas Worm arbeitet als Softwareentwickler im Bereich des Softwarebaus und
der Qualitätsicherung der DATEV eG. Dort ist er für das System Design der Buildund Qualitätssicherungs-Infrastruktur sowie Automatisierung der Prozesse zuständig. Weiterhin berät er Entwickler in Architekturfragen hinsichtlich der Buildaspekte und -abhängigkeiten. Durch mehrjährige Erfahrung im Bereich ASP- und
Cloud-Services und der Betreuung der dazugehörigen Business Intelligence Lösung
hat er sich umfangreiche Kenntnisse beim Entwurf und der Implementierung von
Datentransferprozessen und integrierter Berichtssysteme angeeignet.
Abstract:
Microsoft stellt mit den Microsoft SQL Server Integration Services (SSIS) ein Produkt zur Verfügung, das die Integration von Datenbanken in die vorhandene ITLandschaft eines Unternehmens ermöglicht. Mit wenigen Klicks lassen sich gängige Datenabgleichsprozesse entwerfen und Datentransformationen vornehmen. Der
Erfolg eines Unternehmens liegt aber meist darin begründet, was es neben den
allseits gängigen Aktivitäten macht. So werden ggfs. auch individualisierte und
komplexere Datentransfer- und -transformationsbausteine benötigt. SSIS lässt sich
deshalb flexibel durch eigenentwickelte Datenpipeline-Komponenten erweitern.
Hierzu muss der Entwickler das Konzept hinter der Datenpipeline, das Framework/die Schnittstelle und Eigenheiten von SSIS kennen- und verstehen lernen. Die
SQL Server-Dokumentation zeigt hierzu nur das Nötigste. In der Session wird deshalb die Entwicklung von Datenpipeline-Komponenten, die dahinterliegenden Konzepte und dazu nötige Schritte erläutert.
Erläuterung:
Sowohl im operativen als auch strategischen Management von Unternehmen
sind aktuelle Daten und Fakten eine Grundvoraussetzung. Deshalb müssen
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL Server Integration Services
Thomas Worm, DATEV eG
1
SMART DATA Developer Conference 2016
18.-19. April 2016, München
Softwaresysteme im Unternehmen integriert werden und Daten untereinander
austauschen. Im Bereich der klassischen Datenbanken erfolgt dieser Austauch
über ETL-Prozesse (Extract, Transform, Load). Microsoft stellt hierzu die Microsoft SQL Server Integration Services (SSIS) als Lösung bereit. Mit Hilfe der SSIS
ist es möglich auf graphische Weise Datenfluss zwischen Systemen und Transformationen in Form von Pipelines zu modellieren. Hierzu werden an der Datenpipeline einzelne Quell-, Transformations- und Zielkomponenten platziert.
Dem Entwickler steht dazu bereits ein umfassendes Set an Komponenten zur
Verfügung. Dennoch kommt man gerade in komplexere Szenarien nicht umhin
die SSIS durch Entwicklung eigener Datenpipeline-Komponenten zu erweitern.
Hierzu ist ein .NET-Projekt (beispielsweise in C#) zu erstellen. Als Referenzen
werden die Assemblies Microsoft.SqlServer.PipelineHost, Microsoft.SqlServer.DTSPipelineWrap, Microsoft.SQLServer.ManagedDTS und
Microsoft.SqlServer.DTSRuntimeWrap benötigt. Für jede Komponente ist eine
Subklasse der Klasse „PipelineComponent“ anzulegen und über Metainformationen in Form eines DtsPipelineComponent-Attributs den SSIS bekannt zu machen.
[DtsPipelineComponent(DisplayName="Beispielkomponente",
ComponentType=ComponentType.Transform)]
public class SamplePipelineComponent : PipelineComponent
{
// Und hier die Komponentenimplementierung rein.
}
In den Metainformationen ist neben dem Namen der Komponente auch deren
Typ anzugeben. Es gibt Komponenten, die den Beginn einer Pipeline (eine
Quelle), einen Zwischenschritt einer Pipeline (eine Transformation) oder das
Ende einer Pipeline (ein Ziel) darstellen. Anhand dieses Typs entscheidet sich
auch, ob eine Komponente Eingänge, Ausgänge oder beides hat. Für die zu implementierenden Methoden innerhalb der Komponentenklasse spielt der gewählte Typ eine entscheidende Rolle. Deswegen wird hier im Folgenden ggfs.
immer auf unterschiedliche Varianten hingewiesen.
Bei der Nutzung der Komponente durchläuft diese mehrere Stati und Ereignisse, auf die in den entsprechenden Implementierungsmethoden einzugehen ist.
Diese sind in Abbildung 1 dargestellt und gliedern sich nach Entwurfs- und
Laufzeit. Unter Entwurfszeit ist dabei die Bearbeitung der Pipeline in den SQL
Server Data Tools zu verstehen. Die Laufzeit ist die Ausführung der Komponente innerhalb der SSIS, wenn das SSIS-Paket gestartet wurde.
Beim ersten Einfügen einer Komponenteninstanz in das SSIS-Paket wird die
Methode „ProvideComponentProperties“ aufgerufen. Diese ist somit eine Art
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL Server Integration Services
Thomas Worm, DATEV eG
2
SMART DATA Developer Conference 2016
18.-19. April 2016, München
Konstruktor der Komponente. In der Implementierung sind hier die Grundeigenschaften einer Komponente zu setzen, wie z.B. die Anlage von PropertyEinträgen, fester Ein- und Ausgänge und deren Spalten.
Abbildung 1: Stati und Ereignisse einer Datenpipeline-Komponente
Hierzu wird auf die ComponentMetaData-Property zugegriffen, die mit dem
IDTSMetaData100-Interface den Aufbau der Komponente beschreibt. Zunächst
sind ein paar Grundeigenschaften wie die Kontaktinformationen des Autors
(ContactInfo-Property) und die Komponentenversion (Version-Property) zu setzen. Über die CustomPropertyCollection lassen sich dann weitere Komponenteneigenschaften erzeugen. Die InputCollection und OutputCollection stellen die
Ein- und Ausgänge dar und beschreiben der Spalten.
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL Server Integration Services
Thomas Worm, DATEV eG
3
SMART DATA Developer Conference 2016
18.-19. April 2016, München
Immer wenn eine Komponente zur Entwurfsansicht geladen wird, wird die Methode PerformUpgrade einbezogen, um Anpassungen vornehmen zu können,
wenn die installierte Implementierung der Komponente eine höhere Version
aufweist. Dies ist dann wichtig, wenn mit der neuen Komponentenversion neue
Properties oder Ein-/Ausgänge bzw. Spalten hinzukommen.
Nun könnte verwundern, warum neue Properties einer Komponente bekannt zu
machen sind. Der technische Hintergrund hierzu ist, dass die SSIS-Pakete in
einer XML-Struktur gespeichert werden und verwendete Komponenten darin
auch XML-serialisiert vorliegen. Wenn diese Serialisierung allerdings mit der
alten Komponentenversion erfolgt ist, so fehlt der XML-Tag für das neue Property. Deshalb muss über die PerformUpgrade-Methode die neue Property bekannt gemacht werden.
Weitere Ereignisse treten auf, während die Komponente und Verknüpfungen zu
anliegenden Komponenten in den SQL Server Data Tools bearbeitet werden. So
wird beispielsweise die Methode OnDeletingInputColumn aufgerufen, wenn eine Eingabespalte gelöscht wird. Die Methoden OnInputPathAttached und OnOutputPathAttached reagieren auf das Verbinden eines Komponentenein- bzw.
ausgangs mit einer anderen Komponente. Ein weiteres Beispiel ist SetUsageType. Diese Methode wird bei Änderung der Verwendungsart einer Eingabespalte (nur Lesen oder Abändern in der Ausgabe) aufgerufen. In der Session
werden beim Live-Coding einer Beispielkomponente die wichtigsten Ereignismethoden vorgestellt und präsentiert.
Die während der Entwurfszeit konfigurierte Komponente wird zur Laufzeit auch
mit Ereignissen, die den Ablauf der Komponentennutzung charakterisieren,
aufgerufen. Dabei gibt es die beiden Methoden AcquireConnections und ReleaseConnections, die sich um den Auf- bzw. Abbau benötigter Datenverbindungen
kümmern. Diese Methoden werden wiederverwendet, und zwar in der ersten
Phase, die mit der Methode Validate zur Validierung der Komponenteneinstellungen dient und in der nachfolgenden Phase der eigentlichen Datenverarbeitung. Diese beginnt zunächst mit der Methode PrepareForExecute, die alle nötigen Vorarbeiten leistet. Nach Aufbau der Verbindungen werden dann weitere
Vorbereitungen mit PreExecute ausgeführt. Erst dann erfolgt die eigentliche
Verarbeitung und Ausgabe der Daten.
Hier ist zwischen den unterschiedlichen Komponentenarten zu unterscheiden.
Während Quellkomponenten lediglich PrimeOutput implementieren, um Daten
auszugeben, implementieren Zielkomponenten ProcessInput, um Daten entgegenzunehmen. Komponenten, die eine Transformation durchführen müssen
sowohl Daten entgegennehmen als auch ausgeben. Bei Transformationen ist
weiterhin zwischen synchronen und asynchronen Transformationen zu unterscheiden. Als synchrone Transformationen werden solche angesehen, die pro
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL Server Integration Services
Thomas Worm, DATEV eG
4
SMART DATA Developer Conference 2016
18.-19. April 2016, München
Eingabedatensatz einen Ausgabedatensatz produzieren, also Datensätze nur
modifizieren bzw. durch weitere Daten erweitern, und bei denen es zu jedem
Eingang genau einen Ausgang gibt. Asynchrone Transformationen filtern Datensätze, geben zusätzliche aus, modifizieren und erweitern Datensätze und
duplizieren diese gegebenenfalls. Auch kann die Anzahl an Ein- und Ausgängen
variieren.
Für synchrone Transformationen reicht es aus, die Methode ProcessInput zu
implementieren. Diese bekommt den aktuellen Datensatz als Eingabe. Dieser
wird innerhalb der Implementierung modifiziert. Der neue Zustand des Datensatzes wird nach Verarbeitung ausgegeben. Die synchrone Transformation unterbricht damit den Datenfluss nicht, IDs zu Spalten bleiben innerhalb der Pipeline erhalten.
Asynchrone Transformationen hingegen unterbrechen die Pipeline. Dies wird
alleine schon in dem Fall deutlich, wenn nicht immer genau ein Ausgang zu einem Eingang existiert. Dadurch kann die Pipeline nicht am Stück weiterfliesen,
sondern muss zum Beispiel bei einem Eingang mit zwei Ausgängen in zwei
Pipelines kopiert werden. In der Implementierung spiegelt sich dies so wieder,
als ob eine asynchrone Transformation gleichzeitig eine Ziel- und eine Quellkomponente ist. Es wird somit die PrimeOutput-Methode implementiert, um
Daten ausgeben zu können und die PrimeInput-Methode implementiert, um Daten entgegennehmen zu können.
Dabei fällt auf, dass zunächst die PrimeOutput-Methode und dann die PrimeInput-Methode durchlaufen wird. Kommen nicht erst Daten an und werden dann
ausgegeben? Um diese „verkehrte“ Reihenfolge zu verstehen, muss die Implementierung des Datenflusses in den SSIS betrachtet werden. Der Datenfluss
erfolgt linienweise in Pipelines, die einen durchgängigen Datenfluss von einer
Datenquelle durch synchrone Transformationen bis zu einem Datenziel oder
einer asynchronen Transformation darstellen. Zwischen den einzelnen Stationen einer Pipeline existieren Buffer, über die die Daten von einer Komponente
zur nächsten transportiert werden, d.h. Komponenten geben Daten aus, indem
sie am Ausgang in den zugehörigen Buffer schreiben und nehmen Daten entgegen, indem sie am Eingang aus diesem Buffer lesen. Nun muss zur Laufzeit die
Komponenteninstanz mit den entsprechenden Buffern verbunden werden. Da
eine Komponente sofort bei ankommenden Daten über den Eingangsbuffer mit
der ProcessInput-Methode reagiert, diese Daten weiterverarbeitet und an den
Ausgabebuffer weitergibt, muss zunächst der Ausgabebuffer verbunden werden. Deshalb wird zunächst die PrimeOutput-Methode durchlaufen, die Informationen über die Ausgabebuffer erhält. Bei einer asynchronen Transformation
werden diese anhand der Eingabedaten gefüllt. Daher muss sich die Komponente die Referenz auf den Ausgabebuffer merken (am besten über interne In-
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL Server Integration Services
Thomas Worm, DATEV eG
5
SMART DATA Developer Conference 2016
18.-19. April 2016, München
stanzvariablen) und dann in der ProcessInput-Methode als Reaktion auf die Eingabedaten auf den Ausgabebuffer schreiben.
Zur ProcessInput-Methode ist dabei anzumerken, dass diese lediglich eine Sicht
auf den Eingabebuffer erhält. Der dieser Methode übergebene Eingabebuffer ist
ein Chunk des eigentlichen Buffers und enthält normalerweise bis zu 1.000 Datensätze. Dies hat den Vorteil, dass nicht auf alle Daten gewartet werden muss,
um die Datensätze zu transformieren, sondern immer auf Teilstücken der Daten
gearbeitet werden kann. Benötigt eine Komponente allerdings die komplette
Eingabe als Grundlage für die Ausgabe (beispielsweise weil eine Summe über
alle Datensätze berechnet werden soll), dann muss die Komponente die einzelnen Eingabebuffer zunächst verarbeiten und cachen. Erst wenn auf dem Eingabebuffer die EndOfRowset-Property wahr ist, sind alle Daten vorhanden.
Der Zugriff auf Buffer wird durch den Buffermanager unterstützt. Mit ihm ist
eine Ermittlung des zum Ein- oder Ausgang passenden Buffers möglich. Weiterhin führt er die Zuordnung von Spalten im Buffer zu den Spalten der Pipeline
im entworfenen Modell durch, die mit einer sogenannten LineageID gekennzeichnet sind.
Nach Verarbeitung der Daten werden die Verbindungen wieder abgebaut und
Aufräumarbeiten mit der Methode Cleanup durchgeführt.
Die Session wird die angesprochen Aspekte anhand des Live-Codingbeispiels
ausführlich erläutern und somit ein Grundverständnis für das Modell hinter Datenpipeline-Komponenten schaffen.
Abschließend wird gezeigt, wie die eigenen Komponenten durch Implementierung von Editorfenstern benutzerfreundlich mit einer leichten Bearbeitungsoberfläche ausgestattet werden können. Hierzu stellt Microsoft das Interface
IDtsComponentUI zur Verfügung, das vier Methoden zur Reaktion auf die Editorereignisse New, Edit, Delete und Help enthält. Durch Implementierung dieser
Methoden kann die Komponente auf Benutzerinteraktion reagieren.
Zusätzlich wird die Session an passenden Stellen auf das Deployment und Debuggen von eigenen SSIS-Datenpipeline-Komponenten eingehen.
Entwickeln von Datenpipeline-Komponenten für die Microsoft SQL Server Integration Services
Thomas Worm, DATEV eG
6