Grundlegendes zum Verzeichnisentwurf
Werbung

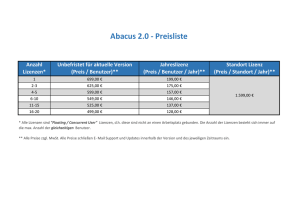
Grundlegendes zur Rolle von Verzeichnisdiensten im Vergleich zu relationalen Datenbanken (Engl. Originaltitel: Understanding the Role of Directory Services Versus Relational Databases) Datum: Februar 2001 Dieses Dokument untersucht die Rolle von Verzeichnisdiensten und relationalen Datenbanken und bietet einen konzeptuellen Überblick über die Optimierung dieser Ressourcen. Einführung Den meisten Unternehmen ist klar, dass die Installation, Verwendung und Wartung verteilter Systeme sich kostentechnisch auf das Endergebnis auswirken. Die meisten laufenden Kosten, so z. B. für tägliche Datensicherungen und die Benutzerverwaltung, sind relativ einfach nachzuvollziehen und vorherzusagen. Andere Kosten sind dagegen weniger offenkundig. Informationsvermehrung. Mittlerweile gibt es immer mehr anwendungsspezifische Verzeichnisse, die ähnliche Informationen zu Benutzern, Computern und anderen Netzwerkressourcen enthalten. In EMail-Systemen gibt es beispielsweise Adressbücher, die nahezu dieselben Benutzerinformationen wie ERP-Systeme (Enterprise Resource Planning) enthalten. Alle Verzeichnisse müssen auf dem aktuellen Stand bleiben und miteinander synchronisiert werden. Neben den Problemen, die sich ergeben, wenn die Synchronisierung der Informationen nicht gewährleistet werden kann, kann das Bestimmen der Ursache von Synchronisierungsproblemen (und Wiederherstellen der Verzeichniskonsistenz) sehr kostspielig werden. Clientkonfiguration. Dafür zu sorgen, dass Clientcomputer stets über die richtige installierte Software verfügen und ordnungsgemäß konfiguriert sind, ist ein wesentlicher und expandierender Kostenfaktor. Wenn z. B. ein Mitarbeiter in eine andere Abteilung wechselt, muss ein Administrator einige Anwendungen löschen und andere hinzufügen und dabei sicherstellen, dass alle ordnungsgemäß konfiguriert werden. Fehlerhafte Konfigurationen verursachen Probleme, die von Dienstunterbrechungen zu Anwendungen reichen, die Unternehmensdaten durch das Umsetzen veralteter Geschäftsregeln unbeabsichtigt beschädigen. Serverkonfiguration. Zum Zeitpunkt der Clientbereitstellung müssen Administratoren bei vielen Anwendungen Clients bestimmten Ressourcen auf der Serverseite zuordnen, wie z. B. Datenbanken und Anwendungskomponenten. Da Clients an bestimmte Computer gebunden sind, kann sich diese Art der statischen Konfiguration negativ auf die Dienstebenen auswirken. Benutzer müssen auf den Neustart der ausgefallenen Computer warten, bevor sie ihre Arbeit fortsetzen können. Wenn Benutzer servergespeicherte Profile verwenden, bleiben sie weiterhin mit denselben Ressourcen verbunden, auch wenn "nähere" Ressourcen vorhanden sind, die dieselben Dienste effizienter bereitstellen können. Wenn darüber hinaus die Serverlast steigt, müssen Benutzer mit langsameren Antwortzeiten rechnen, selbst wenn andere Server überschüssige Kapazitäten aufweisen. Fehlende Synergien zwischen Anwendungen. In den meisten Unternehmensinfrastrukturen gibt es sehr wenige Synergien zwischen Anwendungen, den zu Benutzern gespeicherten Informationen und Infrastrukturelementen wie Netzwerken. Die Anwendungen eines Mitarbeiters können dessen Wechsel zwischen verschiedenen Aufgaben im Unternehmen nicht erkennen und nicht entsprechend neu konfiguriert werden. Oder Teilnehmer einer wichtigen Videokonferenz über das Internet sehen wackelnde Bilder mit verzerrtem Klang, da andere Netzwerkbenutzer durch das Downloaden von Spielen Bandbreite belegen. Um diesen Problemen zu begegnen, benötigen Unternehmen dynamische Anwendungen, die bewusster auf die Umgebung reagieren, in der sie bereitgestellt werden, Änderungen erkennen und Anpassungen ermöglichen sowie Informationen über sich selbst mit anderen Anwendungen gemeinsam nutzen. Die ersten Ansätze basierten auf relationalen Datenbankarchitekturen, die jedoch großen Einschränkungen unterlagen. Aktuelle Weiterentwicklungen der Verzeichnisdiensttechnologien versprechen eine komplettere Lösung. Wie gewöhnlich handelt es sich nicht um sich gegenseitig ausschließende Optionen, so dass Systemarchitekten wissen müssen, wie sie die Rollen von Datenbanken und Verzeichnisdiensten in ihren Netzwerken gewichten. Grundlegendes zum Verzeichnisentwurf Um die Rolle von Verzeichnisdiensten im Vergleich zu Datenbanken zu verstehen, ist es hilfreich, die fünf Hauptmerkmale eines modernen Verzeichnisses zu betrachten. Hierarchische Datenorganisation Verzeichnisdienste organisieren Daten in einer hierarchischen Struktur. Innerhalb der Struktur gibt es zwei Typen von Entitäten: Organisationseinheiten (Organizational Units, OUs) und Objekte. Organisationseinheiten sind Container, in denen sowohl Organisationseinheiten als auch Objekte enthalten sein können. Eine passende Analogie ist ein herkömmliches Dateisystem mit Verzeichnissen (oder Ordnern wie beim Betriebssystem Microsoft Windows® 2000) und Dateien. Verzeichnisse können andere Verzeichnisse enthalten, die als Unterverzeichnisse bezeichnet werden. Unterverzeichnisse schließlich enthalten Dateien. Abbildung 1: Hierarchische Datenorganisation Ein solches Modell ist aus mehreren Gründen sinnvoll: Ein auf Containern basierendes Modell erleichtert die Verwaltung dadurch, dass zusammengehörende Entitäten gruppiert werden können. Dieser Vorteil wird nachvollziehbarer, wenn Sie sich vorstellen, wie schwierig die Verwaltung sehr großer Dateilisten wäre, wenn es nicht das Konzept der Unterverzeichnisse gäbe. Zur weiteren Erleichterung der Verwaltung können mithilfe der Verzeichnishierarchie Aspekte eines Netzwerkes oder einer Organisationsstruktur gespiegelt und modelliert werden. Letztlich kann die Hierarchie hinsichtlich des Wissens genutzt werden, das ihre Struktur repräsentiert. Wenn es beispielsweise im Verzeichnis die Organisationseinheit Alle Benutzer gibt und Vertrieb eine untergeordnete Organisationseinheit von Alle Benutzer ist, können Anwendungen folgern, dass die Mitglieder der Organisationseinheit Vertrieb Benutzer sind (und demzufolge verschiedene Merkmale anderer Benutzer erben sollten), jedoch zu einer Zusammenstellung gehören, die sich auf bestimmte Weise von anderen Benutzern in der Unterstruktur unterscheidet (und deshalb anders behandelt werden sollte). Die Leistungsfähigkeit einer mit einer baumartigen Struktur arbeiteten Organisation und die Rolle der Vererbung werden nachfolgend in den Abschnitten Abgestufte Sicherheit und Richtlinienbasierte Verwaltung weiter erläutert. Im Gegensatz dazu speichern Datenbanken Informationen in linearen Tabellen ohne inhärente Mechanismen zur Wiedergabe der Organisationsstruktur der Daten. Objektorientierte Entitätsmodellierung Verzeichnisdienste bilden Netzwerkentitäten als Objekte ab, die Attribute enthalten. Innerhalb eines gegebenen Verzeichnisses (und sogar auf der Organisationseinheitsebene) kann es viele verschiedene Objekttypen geben. Jeder Objekttyp (bzw. jede Objektklasse) kann eine beliebige Menge von Attributen enthalten, die erforderlich sind, um die Entität exakt zu modellieren, die von dem Objekt repräsentiert wird. Alle gängigen Verzeichnisdienste ermöglichen Administratoren das Erstellen neuer Objektklassen sowie das Erweitern vordefinierter Klassen (die z. B. Benutzer und Computer repräsentieren), die spezifische für ein einzelnes Unternehmen geltende Attribute enthalten. Durch die Modellierung von Netzwerkelementen (wie z. B. Benutzern und Computern) als Objekte und die Unterstützung verschiedener Objektklassen innerhalb einer einzelnen Struktur ergibt sich eine überaus flexible Möglichkeit, Informationen über die verschiedenen Entitäten in einem Netzwerk zu speichern. Im Gegensatz dazu erfordern relationale Datenbanken in der Regel für jeden Objekttyp eine neue Tabelle. Die Abbildung der in Containern enthaltenen Beziehungen wäre noch schwieriger. Unterstützung flexibler Abfragen Vor dem Hintergrund der Flexibilität von Verzeichnisdiensten bei der Speicherung von Daten und Modellentitäten müssen diese auch flexible Möglichkeiten zur Datensuche innerhalb der Struktur bieten. Insbesondere Verzeichnisse müssen einen einfachen Weg zum Lokalisieren von Objekten und Attributen innerhalb eines Interessenbereichs bereitstellen. Bereiche müssen den Speicherort innerhalb der Struktur (wie z. B. alle Objekte in der Organisationseinheit Marketing) und Objektklassen (wie z. B. alle Objekte der Klasse Benutzer) enthalten, und zwar unabhängig davon, wo sich diese in der Hierarchie befinden. Aufgrund der Unterstützung des Protokolls LDAP (Light-weight Directory Access Protocol) können alle gängigen Verzeichnisdienste diese Arten von Suchen auf einfache und effiziente Weise unterstützen. Die Einfachheit rührt von den Merkmalen der LDAP-API und die Effizienz von der Tatsache, dass die meisten Anbieter von Verzeichnisdiensten den Administratoren die Angabe ermöglichen, welche Attribute als Indizes im zugrunde liegenden Datenspeicher behandelt werden sollen. Durch eine solche Indizierung können Suchen nach "allen Benutzern, die Vorgesetzte sind und eine Ausgabenbegrenzung von über € 5000 haben" schnell erfolgen, ohne dass die gesamte Struktur durchsucht werden muss. Diese Art der Indizierung und Effizienz ist besonders wichtig, da die IT-Branche Verzeichnisdienste mit zehn Millionen Einträgen und mehr bereitstellt. Anbieter wie Microsoft bieten zudem andere Arten von Schnittstellen für den Datenzugriff, wie z. B. ADSI (Active Directory Service Interfaces) für auf dem COM-Modell (Component Object Model) basierende Suchen und ADO (Advanced Data Objects), die eine SQL-gemäße Syntax für den Zugriff auf Verzeichnisdaten bereitstellt. Außerdem arbeitet die IT-Branche an der Nutzung der Weiterentwicklungen der XMLTechnologien, um eine noch größere Flexibilität zu ermöglichen. Wenngleich es schwierig ist, die Ansicht zu vertreten, dass relationale Datenbanken keine flexible Abfrageunterstützung bieten, lässt sich mit Sicherheit sagen, dass Verzeichnisse Schnittstellen bereitstellen, die mindestens so flexibel und überaus angepasst an die besonderes Weise sind, in der Verzeichnisdienste Informationen speichern und modellieren. Abgestufte Sicherheit Da die gemeinsame Nutzung von Informationen ein Hauptanliegen ist, werden Verzeichnisdienste im Allgemeinen so bereitgestellt, dass allen Benutzern und Anwendungen ein Zugriff erlaubt wird, die das Verzeichnis lokalisieren und sich mit diesem über den TCP/IP-Anschluss 389 verbinden können. Um ein Chaos zu vermeiden und ordnungsgemäße Sicherheitsprüfungen zu aktivieren, weisen Verzeichnisse vier wichtige Merkmale auf: Bevor Benutzer auf Daten zugreifen können, müssen sie Anmeldeinformationen (Benutzernamen und Kennwort) angeben, mit deren Hilfe das Verzeichnis die Identität der Person überprüfen kann, die den Zugriff wünscht. Nach der Überprüfung verwendet der Verzeichnisdienst die Anmeldeinformationen, um die Sicherheitsfunktionen für alle Vorgänge (wie z. B. Lese- und Aktualisierungsvorgänge) auf der Ebene einzelner Objekte und Attribute zu aktivieren. Besitzer von Objekten und Organisationseinheiten können bestimmte Berechtigungen über ihre Daten an andere authentifizierte Benutzer delegieren. Dadurch kann ein Administrator die Berechtigung zum Hinzufügen von Benutzern zur Organisationseinheit Marketing an ein vertrauenswürdiges Mitglied der Marketingabteilung delegieren. Wenn ein Benutzer keine Anmeldeinformationen angibt, wird er als anonymer Benutzer behandelt, der nur auf Daten zugreifen darf, die im Verzeichnis ausdrücklich als "öffentlich" gekennzeichnet wurden. Abbildung 2: Active Directory aktiviert Sicherheitsfunktionen auf Attributebene Im Gegensatz dazu aktivieren Datenbanken in der Regel die Sicherheitsfunktionen nur auf der Spaltenebene und bieten keine vordefinierten Möglichkeiten der Delegierung. Wenn also ein Benutzer die Werte Gehalt anzeigen darf, kann er die Gehaltswerte aus allen Zeilen der Tabelle abrufen. Dieses Sicherheitsmodell ist geeignet, wenn nur "bekannte" Anwendungen (d. h. Anwendungen, die zentral überwacht und gesteuert werden können) Zugriff auf die Daten haben, denen vertraut werden kann, dass Benutzer mit unzureichenden Berechtigungen keinen Zugriff erhalten. Hier verfügt die Anwendung über einen Zugriff auf wesentlich mehr Informationen als unmittelbar der Benutzer. Sie enthält jedoch Geschäftsregeln, die eine abgestufteres Zugriffssteuerungsmodell als die Datenbank selbst implementieren. Da Verzeichnisdienste für die gemeinsame Nutzung von Daten eingesetzt und üblicherweise so bereitgestellt werden, dass ein umfassender Datenzugriff sichergestellt ist, gibt es leider keine Möglichkeit, die Identität aller Anwendungen zu überprüfen, die Informationen anfordern, und festzustellen, was diese Anwendungen mit den Daten nach dem Abruf anfangen. Aus diesem Grund muss der Verzeichnisdienst selbst die Sicherheitsfunktionen aktivieren, anstatt darauf zu bauen, dass die Anwendungen diese Aufgaben übernehmen. Darüber hinaus kann es Fälle geben, in denen der Besitzer der Daten in der Lage sein muss, einzelne Teile der Daten zu sperren, (z. B. Durchwahlnummer des Vorstandsvorsitzenden in einem Verzeichnis, in dem Telefonnummern allgemein zugänglich sind), um eine Granularität der Steuerung zu erreichen, die erforderlich ist, um diese Klasse von Daten für die gemeinsame Nutzung verfügbar zu machen. Wenn es beim Beispiel der Telefonnummer des Vorstandsvorsitzenden keine Sicherheitsfunktionen auf Attributebene gäbe, müsste der Zugriff auf alle Telefonnummern in allen Anwendungen verweigert werden. Wichtig ist der Hinweis, dass Administratoren nicht den einzelnen Attributen aller Objekte bestimmte Zugriffssteuerungsrechte zuweisen müssen. Stattdessen können sie einer Organisationseinheit ein Zugriffsrecht erteilen, die in der Struktur höher angesiedelt ist. Anschließend können sie dieses Recht nach unten an die Objekte, die in der Organisationseinheit, der das Recht erteilt wurde, enthalten sind, sowie an Organisationseinheiten, die der Organisationseinheit untergeordnet sind (und an dieser untergeordnete Organisationseinheiten usw.) vererben. Dadurch können Administratoren ein ideales Gleichgewicht bei der übergeordneten Verwaltung von Berechtigungen und der Fähigkeit zur bedarfsorientierten Erteilung von Berechtigungen finden. Multimasterreplikation Die vielleicht prägendste Eigenschaft von Verzeichnisdiensten ist die Weise, in der Daten auf andere Verzeichnisserver im Netzwerk repliziert werden. Insbesondere die modernsten Verzeichnisse (die größte Ausnahme ist das iPlanet-Verzeichnis) arbeiten mit einer so genannten Multimasterreplikation. Dieser Begriff bezieht sich auf die Tatsache, dass es in einem Netzwerk mehrere Replikate eines bestimmten Verzeichnisses gibt und dass alle Verzeichnisvorgänge (wie z. B. Lese- und Aktualisierungsvorgänge) in einem beliebigen Replikat ausgeführt werden können, selbst wenn dieses Replikat keinen Netzwerkkontakt mit den anderen Replikaten hat. Dies bedeutet, dass alle Replikate eine vollständige Kopie der Daten (einschließlich Zugriffssteuerungsinformationen) speichern und ein Protokoll aller Aktualisierungen aufzeichnen müssen, so dass Replikate, die zum Zeitpunkt der Aktualisierung nicht erreichbar waren, an einem bestimmten künftigen Zeitpunkt kontaktiert und aktualisiert werden können. Abbildung 3: Active Directory unterstützt die Multimasterreplikation, um Flexibilität, hohe Verfügbarkeit und Systemleistung zu ermöglichen Wenngleich die meisten relationalen Datenbanken eine Form der Multimasteraktualisierung unterstützen, werden diese doch eher in Einzelmasterkonfigurationen bereitgestellt, die synchrone transaktionsgesteuerte Aktualisierungen ermöglichen. Transaktionen werden entwurfsbedingt nicht in MultimasterVerzeichnisarchitekturen implementiert, da gegebenenfalls nicht alle Replikate zur gleichen Zeit erreichbar sind, so dass die Mehrzahl der Transaktionen abbrechen würde, da keine Sperren für alle Replikate aktiviert werden können. Dies bedeutet, dass Verzeichnisdienste die Funktionsmöglichkeiten von Transaktionen gegen einen Datenzugriff mit höherer Verfügbarkeit und die Fähigkeit zur Fortsetzung lokaler Vorgänge (z. B. in einer Zweigstelle) trotz Verlusts der Konnektivität mit einigen oder allen Servern im Netzwerk eintauschen. Das Aufgeben des Transaktionsschutzes hat jedoch auch Nachteile. Dazu zählen bei den Verzeichnisdiensten Folgende: Es gibt keine Möglichkeit, ein Objekt oder seine Attribute für eine Aktualisierung in allen Replikaten zu sperren. Bei Transaktionen werden solche Sperren in der Regel automatisch aktiviert. Demzufolge gibt es keine Möglichkeit der Aktualisierung einer Zusammenstellung von Objekten, wenn Unteilbarkeits- und Isolationssemantiken aktiviert sind. Dieselben Daten werden gegebenenfalls im selben Replikationsintervall in zwei Replikaten durch zwei verschiedene Anwendungen aktualisiert, was zu einer Kollision führt. Verzeichnisse lösen Kollisionen auf der Attributebene automatisch auf, indem eine "siegreiche" Aktualisierung (auf eher willkürliche Weise) ausgewählt wird, woraufhin diese Aktualisierung an alle Replikate weitergegeben wird, welche die "unterlegene" Aktualisierung enthalten. In beiden Fällen verfügen alle Replikate letztlich über dieselben Werte für alle Objekte und Attribute. Es gibt jedoch keine Möglichkeit, um sicherzustellen, dass andere Replikate dieselbe Menge an Aktualisierungen in derselben Reihenfolge wie das auslösende Replikat anzeigen oder dass alle Replikate eine gegebene Aktualisierung anzeigen (dies bedeutet, dass das Replikat, dessen Aktualisierung bei einer Kollision zum "Sieger" erklärt wurde, die "unterlegene" Aktualisierung nicht anzeigen kann). Dies bedeutet, dass zwar die Attributwerte in den Replikaten identisch sind, jedoch aus der Sicht der referenziellen Integrität oder Anwendungsrichtigkeit inkonsistent sind. Eine Anwendung kann z. B. "Kandidat = Gerhard Schröder" und "Partei = SPD" festlegen, während eine andere Anwendung "Kandidat = Angela Merkel" und "Partei = CDU" festlegen kann. Aufgrund von Kollisionen kann dann "Kandidat = Gerhard Schröder" und "Partei = CDU" das Ergebnis sein, auf das sich die beiden Replikate einigen. Ähnliche, jedoch vorübergehende Bedingungen können sich auch aus der Tatsache ergeben, dass Aktualisierungen, die sich auf mehrere Objekte auswirken, nicht mithilfe von Transaktionen zwischen Servern übertragen werden. Dies bedeutet, dass Anwendungen eine Gruppe von Objekten lesen können, die gerade mittels Replikation von einem anderen Server aktualisiert werden, und dadurch einen Zwischen- und somit inkonsistenten Datenstatus empfangen. Damit der Leser daraus nicht schließt, dass Verzeichnisdienste eine erhebliche Entwurfsfehlerstelle haben, soll Folgendes angemerkt werden: Ein solches Verhalten ist absolut erforderlich, um den Betrieb zu unterstützen, wenn Replikate vom Rest des Netzwerkes getrennt sind. Ein vom Netzwerk getrennter Betrieb ist überaus wichtig für Vorgänge wie das Hinzufügen neuer Benutzer oder das Zurücksetzen von Kennwörtern. Darüber hinaus sollte ein vom Netzwerk getrennter Betrieb ein Zweigstellensystem nicht dazu zwingen, die Arbeit einzustellen. Es gibt Methoden zum Erkennen und Behandeln von Inkonsistenzen aufgrund von Replikationswartezeiten und -kollisionen. Dazu gehört das Markieren von Gruppen aktualisierter Objekte mit einem eindeutigen Bezeichner (z. B. einer GUID), so dass Anwendungen, welche die Daten lesen, überprüfen können, ob alle Komponenten der Aktualisierung empfangen wurden. Nicht alle Anwendungen sind für die Verzeichnisintegration geeignet. Optimale Vorgehensweisen Verwendungsrichtlinien Basierend auf den fünf zuvor angegebenen Merkmalen ergeben sich verschiedene "optimale Vorgehensweisen", um zu bestimmen, welche Datentypen für die Speicherung in einem Verzeichnisdienst geeignet sind. Anwendungsentwickler sollten Verzeichnisdienste insbesondere dann in Betracht ziehen, wenn Folgendes zutrifft: Daten sind für das gesamte Netzwerk von Interesse. Die Replikation ist ein aufwendiger Prozess, weshalb in Netzwerken mit vielen Replikaten ein beträchtlicher Prozentsatz der verfügbaren Bandbreite nur durch die Weiterleitung von Aktualisierungen belegt wird. Deshalb muss vor dem Speichern von Daten in einem Verzeichnis (und dem Übertragen an die "äußersten Enden" des Netzwerkes mittels der Replikation) sichergestellt werden, dass einige Anwendungen an diesen Enden die Daten tatsächlich nutzen. Daten ändern sich langsam. Auch wenn die Informationen im gesamten Netzwerk von Interesse sind, kann der Replikationsverkehr selbst das schnellste Netzwerk ausbremsen, wenn Aktualisierungen zu häufig erfolgen. Es gibt zwei Faustregeln, um festzulegen, dass sich Daten "zu häufig" ändern: o o Das Verhältnis von Aktualisierungen zu Lesevorgängen ist größer als 1:100. Aktualisierungen erfolgen häufiger als zweimal die maximale Wartezeit der Replikationstopologie. Die meisten Verzeichnisdienste führen die Replikation in regelmäßigen Abständen (und nicht kontinuierlich) aus, so dass Topologien so konfiguriert werden können, dass eine Aktualisierung eines Replikats mehr als einen Hop benötigt, um alle Replikate zu erreichen. Nachdem die maximale Wartezeit des Systems berechnet wurde (eine Aktualisierung eines beliebigen Replikats benötigt beispielsweise zwei Stunden, um alle anderen Replikate zu erreichen), stellt der doppelte Wert (d. h. vier Stunden) sicher, dass jede Aktualisierung von allen Replikaten angezeigt wird und in den Replikaten für mindestens einen Replikationszyklus unverändert erhalten bleibt. Diese Methode hat zu einer Vereinfachung verschiedener Anwendungsprogrammierungsfaktoren geführt. Daten profitieren von den hierarchischen Speicherungs- und Sicherheitsmodellen. Verzeichnisdienste sind am wertvollsten, wenn die gespeicherten Daten von der containerbasierten Speicherung und der auf Vererbung basierenden Sicherheit profitieren. Daten, die zum Verwalten von NetzwerkBetriebssystemen und Kontakt- und Standortinformationen von Unternehmensmitarbeitern verwendet werden, können in der Regel gut in einem hierarchischen Modell abgebildet werden. Andere Daten, wie z. B. die, die zu großen B2C-E-Commerce-Sites (Business to Consumer, Unternehmen zu Kunden) gehören, bei denen Benutzer als große, lineare Listen gespeichert werden, sind in der Regel nicht so gut geeignet. Daten erfordern keine transaktionsgesteuerte Aktualisierung. Wie bereits erwähnt, unterstützen Verzeichnisdienste keine Transaktionen, so dass die Daten von Anwendungen, welche die Eigenschaften Unteilbarkeit, Konsistenz, Isolation und Beständigkeit befolgen müssen (wie z. B. Bestandsdatenbanken), nicht gut für die Speicherung in einem Verzeichnis geeignet sind. Daten erfordern keine Änderungsverlaufsinformationen. Aus vielen Gründen, die im Rahmen dieses Artikels nicht behandelt werden können, ist es nicht sinnvoll, ein zentrales Protokoll zu erstellen, das alle Aktualisierungen wiedergibt, die im gesamten Netzwerk auf alle Replikate angewendet wurden. Aus diesem Grund sind Anwendungen, die ein Protokoll der Änderungen an den Daten benötigen (z. B. aus Überwachungsgründen) nicht gut für einen Verzeichnisdienst geeignet. Daten sind hinsichtlich Replikationswartezeiten und Inkonsistenzen tolerant. Aufgrund der Speicherund Weiterleitungstechnik der von Verzeichnisdiensten verwendeten Replikation und der Tatsache, dass Replikate häufig mittels unzuverlässiger Netzwerkverbindungen verknüpft sind, dürfen Anwendungen nicht davon ausgehen, dass Aktualisierungen zwischen Replikaten gemäß einem bestimmten Zeitplan erfolgen oder in einer bestimmten Reihenfolge ankommen. Wichtig ist der Hinweis, dass ein Verzeichnisdienst auch dann eine Rolle spielen kann, wenn die Daten keine der zuvor genannten Anforderungen erfüllen. Eine Bestandsdatenbank kann z. B. in einem Verzeichnis veröffentlicht werden, so dass Anwendungen deren Speicherort dynamisch ermitteln können (siehe "Dienstveröffentlichung"), auch wenn die Daten aufgrund der Transaktionseigenschaften eigentlich nicht direkt in einem Verzeichnisdienst gespeichert werden sollten. Gute Beispiele Basierend auf den genannten Richtlinien sind die folgenden Daten für ein Verzeichnis geeignet: Kontakt- und Standortinformationen. Diese Informationen zu den Mitarbeitern sind im gesamten Netzwerk von Interesse und ändern sich in der Regel nur sehr langsam. Benutzeranmelde- und Sicherheitsgruppeninformationen. Sicherheitsinformationen können an verschiedenen Stellen im Netzwerk benötigt werden, um zu gewährleisten, dass Zugriffssteuerungsfunktionen konsistent und unabhängig vom Ort der Anmeldung des Benutzers beim Netzwerk angewendet werden. Auch diese Informationen ändern sich in der Regel langsam. Netzwerkkonfigurations- und Dienstrichtlinien. Dadurch, dass immer mehr Nischenprodukte (Geräte, z. B. Router und Switches, die den Übergang vom privaten Netzwerk zu dem des Dienstanbieters bestimmen) zur Unterstützung virtueller privater Netzwerke (Virtual Private Networking, VPN) für Benutzer und Geschäftspartner eingesetzt werden, ist es wichtig, dass Konfigurationsinformationen (z. B. welche Benutzer mit welchem Sicherheitsgrad zugreifen dürfen) allen Zugangspunkten zur Verfügung gestellt werden. Richtlinien zur Anwendungsbereitstellung. Durch das Integrieren von Richtlinien zur Anwendungsbereitstellung mit einem hierarchischen Verzeichnis können Administratoren die Verwaltung vereinfachen, indem Anwendungen Organisationseinheiten und Gruppen zugewiesen werden, anstatt die Benutzer einzeln zu verwalten. So können z. B. Anwendungen für die Personalabteilung mittels einer Richtlinie allen Mitgliedern der Organisationseinheit Personal zugewiesen werden. Weniger gute Beispiele Zu den Anwendungen, die nicht so gut für Verzeichnisdienste geeignet sind, zählen die Folgenden: Buchführung. Buchführungsanwendungen benötigen einen Transaktionsaktualisierungsschutz. Darüber hinaus erfolgen Aktualisierungen schnell. Zentrale Datenerfassung. Es ist verlockend, die Replikationsfunktionen eines Verzeichnisses zum Übertragen von Daten wie Ereignisprotokollinformationen von Remoteservern an einen zentralen Standort zu nutzen. Dies würde jedoch Netzwerkverkehr erzeugen, der sich auf alle und nicht nur auf lokal vorhandene Replikate auswirkt. Zusammen mit häufig erfolgenden Aktualisierungen wäre die Netzwerk-Bandbreite schnell belegt. Hardwarebestand. Die meisten Daten zur Hardwarekonfiguration von Client- und Servercomputern sind für Anwendungen im gesamten Netzwerk von geringer Bedeutung. In diesem Zusammenhang ist es wahrscheinlich besser, einen Verweis auf einen Speicherort mit Bestandsinformationen für jedes Computerobjekt im Verzeichnis zu speichern. Wenn eine Anwendung anschließend Konfigurationsdaten zu einem bestimmten Computer benötigt, kann sie den Computer im Verzeichnis bestimmen, die Schnittstellenattribute suchen und sich direkt an den Informationsspeicherort auf diesem Computer binden. Prozesssteuerung. Anwendungen, die vom Zeitpunkt der Datenweitergabe zwischen Replikaten abhängig sind, eignen sich nicht für einen Verzeichnisdienst. Verzeichnisintegrationsmodelle Auf der Grundlage der erwähnten Informationen zum Wesen von Verzeichnisdiensten kann eine Reihe von Architekturmodellen festgelegt werden, bei denen Verzeichnisse bei der Integration mit Anwendungen einen Mehrwert bieten. Verzeichnisobjekterweiterung Die meisten Anwendungen nutzen zur Speicherung von Informationen zu Benutzern und Dienstkonfigurationen einen zentralen Speicherort. In E-Mail-Systemen gibt es beispielsweise Adressbücher, die Listen mit Benutzern und deren E-Mail-Adressen sowie andere Informationen wie Telefonnummern enthalten. Zusätzlich zu grundlegenden Aufgaben wie Authentifizierung und Autorisierung bieten diese Informationen in Anwendungen wertvolle Funktionalität, wie z. B. die Möglichkeit zur Suche nach Personen oder gemeinsam genutzten Ressourcen. In den meisten Unternehmen befinden sich Informationen zu Personen und Ressourcen in vielen verschiedenen anwendungsspezifischen Verzeichnissen (die getrennt verwaltet werden müssen). Diese Datenvermehrung ist größtenteils darauf zurückzuführen, dass Entwickler nicht davon ausgehen, dass in den Netzwerken, für die sie ihre Anwendungen entwickeln, ein geeigneter zentraler Speicherort vorhanden ist. Mithilfe von Verzeichnisdiensten kann dieses Problem der Datenvermehrung eingedämmt werden. Aufgrund der Beliebtheit von Netzwerk-Betriebssystemen (Network Operation Systems, NOS) mit Verzeichnisfunktionen und Verzeichnisprodukten für Unternehmen ist es nun wahrscheinlicher als je zuvor, dass Netzwerke über einen auf Standards basierenden Verzeichnisdienst verfügen. Darüber hinaus sind die abgestuften und zentralen Sicherheitsmodelle von Verzeichnisdiensten ideal für Umgebungen mit Anwendungen aus mehreren Abteilungen oder Organisationen, die nicht darauf vertrauen möchten, dass andere Anwendungen Sicherheitsfunktionen korrekt implementieren. Schließlich können Verzeichnisse erweitert werden, um Änderungen ohne wesentliche Unterbrechungen für andere Anwendungen zu integrieren. Aufgrund dieser Merkmale können Anwendungen so entworfen werden, dass vorhandene Verzeichnisobjekte (wie diejenigen zur Abbildung von Benutzern) erweitert werden können, anstatt einen gänzlich neuen zentralen Speicherort zu implementieren. Dies gilt zumindest für die Datentypen, die zwischen Anwendungen möglicherweise redundant sind. Dadurch, dass Informationen zu Benutzern, Computern und anderen Objekten in einem Verzeichnisdienst zusammengefasst sind, können Administratoren Informationen zentral anzeigen, ändern und verwalten. Anwendungen können darüber hinaus Informationen nutzen, die von anderen Anwendungen im Verzeichnis gespeichert werden. Eine Anwendung für Personalabteilungen kann beispielsweise den Namen des Vorgesetzten der einzelnen Mitarbeiter als Zusatzattribut des zu jedem Mitarbeiter gehörenden Benutzerobjekts in einem Verzeichnis speichern. Im Kreditorensystem können im Benutzerobjekt jedes Vorgesetzten Höchstgrenzen für Spesenberichte gespeichert werden. Anschließend kann ein Onlinesystem für die Genehmigung von Spesenberichten entwickelt werden, das den Spesenbericht eines Mitarbeiters automatisch an die Person in der Hierarchie des Führungspersonals sendet, die über die Befugnis zur Genehmigung eines vorgelegten Berichts verfügt. Dienstveröffentlichung In einer vernetzten Computerumgebung werden viele verschiedene Anwendungskomponenten auf vielen verschiedenen Computern ausgeführt. Auf den Desktopcomputern der Benutzer werden clientseitige Anwendungen ausgeführt, bei denen es sich um Lohn- und Gehalts- und Buchführungsprogramme oder automatische Sicherungsprogramme handeln kann, die sich nach Geschäftsschluss selbständig ausführen. Auf anderen Computern werden serverseitige Elemente wie Datenbanken, gemeinsam genutzte Anwendungskomponenten und Netzwerkdienste wie Datei- und Druckserver ausgeführt. Herkömmlicherweise verfügen clientseitige Anwendungen über statische Konfigurationsdateien mit Informationen zum Speicherort der Dienste, auf die diese zugreifen. Dadurch, dass die meisten Netzwerkumgebungen immer dynamischer werden, wird das Erhalten von Verknüpfungen zwischen Client und Diensten immer schwieriger, wodurch sich die laufenden Verwaltungskosten beträchtlich erhöhen. Das Verschieben einer Ressource auf einen anderen Servercomputer ist häufig zeitaufwendig und kostspielig, da auf allen Clientcomputern die Konfigurationsdaten gegebenenfalls aktualisiert werden müssen. Verzeichnisdienste dämmen dieses Problem dadurch ein, dass die Serverseite von Anwendungen Informationen zu den bereitgestellten Diensten "veröffentlicht". Wenn eine Clientanwendung anschließend Zugriff auf eine bestimmte Anwendung oder einen Server benötigt, muss sie Folgendes ausführen: Die Ressource gemäß dem Namen im Verzeichnis mithilfe einer Programmierschnittstelle wie LDAP nachschlagen. Die zu der Ressource gehörenden Bindungsinformationen (z. B. Datenbankname, Verbindungspunkt oder Adresse des TCP/IP-Anschlusses) abrufen. Sich dynamisch mit der Ressource verbinden und beginnen, mit dieser zu arbeiten. Um eine höhere Verfügbarkeit und Systemleistung zu ermöglichen, können Anwendungen auch so programmiert werden, dass mehrere Anbieter desselben Dienstes im selben Netzwerk unterstützt werden. Jeder Anbieter registriert sich dann unter Verwendung desselben Namens selbst beim Verzeichnisdienst. Wenn alle Anbieter ausgeführt werden und erreichbar sind, ergibt sich eine bessere Systemleistung, da die Last auf mehrere Computer verteilt wird. Wenn ein Computer oder eine Netzwerkverbindung ausfällt, ergibt sich eine höhere Verfügbarkeit, da die entsprechenden Clientanwendungen andere Computer bestimmen können, die denselben Dienst bereitstellen. Die Dienstveröffentlichung erleichtert ferner Administratoren das Verschieben von Diensten zwischen Computern (z. B. um verfügbare CPU-Ressourcen zu nutzen), sogar auf täglicher Basis, da Clients nicht mehr neu konfiguriert werden müssen. Dieser Vorgang entspricht einem Anruf bei der Filiale einer Computerfirma, um nachzufragen, ob ein bestimmtes Produkt vorrätig ist. Wenn der Kunde den Namen der Firma kennt, kann er im Telefonbuch die Nummer der Filiale nachschlagen, die seinem Standort am nächsten ist. Wenn in der Filiale das Produkt nicht vorrätig oder die Leitung besetzt ist, kann der Kunde die Nummer anderer Filialen dieser Firma nachschlagen, bei denen das Produkt gegebenenfalls vorrätig ist. Servergespeicherte Profile (Roaming Profiles) Die erste Assoziation, die das Wort "Roaming" weckt, ist ein Mitarbeiter im Außendienst, der in einem Büro eines anderen Unternehmens oder von zu Hause aus über DFÜ-Leitungen mit dem eigenen Netzwerk kommuniziert. Roaming bedeutet in diesem Kontext der Zugriff auf Dienste wie E-Mail über einen anderen Kommunikationspfad und mithilfe anderer Geräte (wie z. B. Drucker) als gewöhnlich. Ein weiteres Beispiel ist das Arbeiten in einer Umgebung, in der Computer von mehreren Benutzern gemeinsam genutzt werden. In diesem Fall bezieht sich Roaming mehr auf den besonderen Computer, an dem der Benutzer arbeitet, und nicht auf den Netzwerkpfad, der für den Zugriff auf Dienste verwendet wird. In beiden Fällen gilt Folgendes: je reibungsloser der Arbeitsablauf ist (im Vergleich zum üblichen Arbeitsplatz oder zum zuletzt verwendeten Computer), desto produktiver kann der Benutzer arbeiten. Eine einfache Möglichkeit zum Sicherstellen eines reibungslosen Arbeitsablaufs ist das Speichern der Konfigurationsinformationen des Benutzers in einem Verzeichnisdienst und das Einlesen dieser Informationen bei der Anmeldung des Benutzers (oder dem Start einer Anwendung), um die Dienste in der zuletzt verwendeten Konfiguration einzurichten. Vorausgesetzt, Informationen zu gemeinsam genutzten Ressourcen sind im Verzeichnis gespeichert, können Einstellungen wie Standarddrucker automatisch auf geeignete Werte festgelegt werden, ohne dass der Benutzer eingreifen muss. Verzeichnisdienstfunktionen wie die Multimasterreplikation sorgen dafür, dass Konfigurations- und Dienstdaten unabhängig davon verfügbar sind, an welchen Arbeitsplatz sich der Benutzer im Netzwerk begibt, auch wenn LAN/-WAN-Verknüpfungen mit dem Replikat nicht zur Verfügung stehen, auf das normalerweise zugegriffen wird. Richtlinienbasierte Verwaltung Fast alle Unternehmen sind hierarchisch aufgebaut. Ein Unternehmen hat in der Regel mehrere Abteilungen wie Marketing, Vertrieb, Personal und Buchführung, die alle dem Vorstand Bericht erstatten müssen. Innerhalb der Vertriebsabteilung kann es eine Hauptsitzgruppe und vier regionale Leiter geben, die alle dem stellvertretenden Vertriebsleiter Bericht erstatten müssen. Und so weiter. Die meisten Unternehmen arbeiten darüber hinaus mit Gruppen, die sich über mehrere Bereiche und Abteilungen des Unternehmens erstrecken können. Die Personalabteilung kann z. B. Leitende Angestellte verwalten, auch wenn Leitende Angestellte sich als Gruppierungsgrundlage über die gesamte Unternehmenshierarchie erstrecken kann. In anderen Fällen müssen Mitarbeiter verschiedener Abteilungen mit verschiedenen Aufgaben (z. B. leitende und nicht leitende Angestellte) in Projekten zusammenarbeiten. Diese Mitarbeiter können auch als Gruppe angesehen werden. In Unternehmen werden Ressourcen, wie z. B. Systemverwaltungsfunktionen, Anwendungen, Dateizugriff und Speicherbeschränkungen, sehr häufig basierend auf der Position von Benutzern im Unternehmen und den Gruppen, zu denen sie gehören, zugewiesen und gesteuert. Unternehmen können festlegen, dass nur leitende Angestellte bestimmte Personalabteilungsanwendungen ausführen dürfen, oder Sicherungsanwendung so konfigurieren, dass vollständige (im Gegensatz zu inkrementellen) Sicherungen von Computern ausgeführt werden, die von Mitarbeitern in der Buchführungsabteilung verwendet werden. Auch wenn dies sehr intuitiv erscheint, müssen die meisten Unternehmen gegenwärtig einen sehr hohen Aufwand betreiben, um diese Arten von Richtlinien zu implementieren. Administratoren müssen in der Regel wissen, welche Anwendungen auf dem Computer eines Mitarbeiters installiert werden müssen, wenn dieser Mitarbeiter einer Abteilung oder Gruppe hinzugefügt wird. Wenn ein Mitarbeiter in eine andere Abteilung wechselt oder anderen Gruppen beitritt (z. B. aufgrund einer Beförderung), muss jemand sicherstellen, dass dieser Mitarbeiter über die Anwendungen und Berechtigungen verfügt, die der neuen Rolle entsprechen. Es ist ferner die Regel, dass Administratoren Anwendungen benutzerabhängig konfigurieren müssen, um Richtlinien wie Sicherungsintervalle und Speicherbeschränkungen zu implementieren. Doch selbst die besten Konfigurationsmanagementprozeduren können vereitelt werden, wenn sich Benutzer entschließen, ihre Anwendungseinstellungen so anzupassen oder zu ändern, dass eine standardisierte Unterstützung schwieriger wird. Um diese Probleme in den Griff zu bekommen, bieten verschiedene Verzeichnisdienste (wie z. B. Active Directory™) Funktionen, die Administratoren die Implementierung einer auf Richtlinien basierenden Installations-, Konfigurations- und Verwaltungsumgebung ermöglichen, die auf der Unternehmenshierarchie und den im Verzeichnis gespeicherten Gruppendefinitionsinformationen basiert. Mithilfe von Richtlinienverwaltungsfunktionen können Administratoren Richtlinienattribute, wie z. B. die Namen der Anwendungen, die installiert, oder Einstellungen, die festgelegt werden müssen, basierend auf der Mitgliedschaft in Organisationseinheiten verknüpfen, die in der Verzeichnisstruktur definiert sind. Darüber hinaus können Administratoren Richtlinien so anpassen, dass die Mitglieder von Sicherheitsgruppen ein- oder ausgeschlossen werden. Administratoren können Sie z. B. den Zugriff auf eine Zeitkartenanwendung standardmäßig verweigern und anschließend eine strukturübergreifende Richtlinie definieren, die einen Zugriff auf die Zeitkartenanwendung gewährt, wenn der Benutzer Mitglied der Gruppe Leitende Angestellte ist. Es ist ferner möglich, Anwendungen zu entwerfen, welche die Hierarchie- und Gruppeninformationen untersuchen und sich entsprechend der Position des Benutzers in der Struktur (d. h. der Organisationseinheit, in welcher der Benutzer gespeichert ist) und der Gruppenmitgliedschaft verhalten. Der Name eines Datenbankservers kann z. B. in einer Richtlinie gespeichert werden, die anschließend auf die Organisationseinheit Buchführungsabteilung angewendet wird. Wenn Benutzer der Organisationseinheit Buchführungsabteilung beitreten (oder in diese wechseln), können ihre Anwendungen automatisch für den Zugriff auf die korrekte Datenbank neu konfiguriert werden. Ein weiteres Beispiel einer auf Richtlinien basierenden Anwendungsintegration ist die von Microsoft und Cisco Systems gestartete DEN-Initiative (Directory-Enabled Networking), die sich auf die Entwicklung von DMTFStandards (Distributed Management Task Force) zur Verbesserung der Netzwerkverwaltung mithilfe eines Verzeichnisdienstes konzentriert. Hier sind die Anwendungen Netzwerk-Verwaltungssysteme, die mithilfe von Richtlinien die Dienstqualität (Quality of Service, QoS) und andere Faktoren (wie z. B. VPN-Sicherheitsgrade) innerhalb eines Netzwerkes definieren und umsetzen. Wenn eine Richtlinie zur Dienstqualität auf eine Organisationseinheit angewendet wird, kann Mitgliedern dieser Organisationseinheit mehr Bandbreite als Mitgliedern anderer Organisationseinheiten zugewiesen werden. Wenn z. B. ein Krankenhaus die Organisationseinheit Ärzte Notaufnahme aufweist, deren Mitglieder eine hohe Bandbreite zum Empfangen und Lesen von CAT-Scans und anderer Labortestberichte benötigen, macht die Umsetzung einer solchen Richtlinie durchaus Sinn. Dadurch, dass dieses Verhalten implementiert werden kann, indem eine Richtlinie einfach mit einer Organisationseinheit verknüpft wird, die ohne Aufwand die Ärzte in der Notaufnahme zu einem bestimmten Zeitpunkt abbildet, wird die Verwaltungskomplexität gemindert. Schlussfolgerung Viele Unternehmen haben bereits den Wert von Verzeichnisdiensten aufgrund der Möglichkeiten erkannt, die Verzeichnisse zur Vereinfachung der Benutzer- und Computerverwaltung in Netzwerk-Betriebssystemen und Unternehmensverzeichnisrollen bieten. Das hierarchische Speichern von Informationen zu Benutzern und Computern in einem Netzwerk-Betriebssystemverzeichnis ermöglicht Administratoren das Delegieren von Verwaltungsaufgaben an die gewünschten Mitarbeiter in Abteilungen und Gruppen. Dadurch können sich Administratoren auf andere Aufgaben konzentrieren. Gleichzeitig erhalten die Benutzer mehr Autonomie und Steuerungsmöglichkeiten. Das Einbeziehen der Anwendungsintegration in Verzeichnisse bietet Unternehmen die folgenden Vorteile: vereinfachte Verwaltung, weiter entwickelte Netzwerkdienste, größere Anwendungsfunktionalität, niedrigere Gesamtkosten sowie Synergien zwischen allen Komponenten mit Verzeichnisfunktionen der Netzwerkumgebung. Dadurch wird die Messlatte für die Leistungsfähigkeit von Verzeichnisdiensten weiter angehoben. Verzeichnisse, die lediglich eine Vereinfachung der Verwaltung oder Unterstützung einer einzelnen Anwendung bieten, halten ihren Benutzern viele wichtige Vorteile vor. Dennoch sind Verzeichnisdienste kein Ersatz für relationale Datenbanken und umgekehrt. Doch bei gemeinsamer Nutzung können Verzeichnisdienste und Datenbanken Kosten und Komplexität der Verwaltung gegenwärtiger verteilter Systeme deutlich senken. Weitere Informationen Integrating Applications with Windows 2000 and Active Directory (englischsprachig) Microsoft TechNet – Windows 2000 Server Technology Center (englischsprachig) Microsoft Windows 2000 Server Directory Services (englischsprachig)