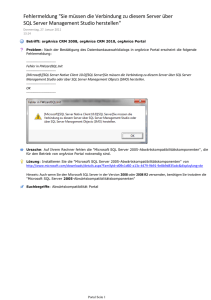
FILESTREAM-Speicherung
Werbung

Technischer Artikel zu SQL Server Autor: Paul S. Randal (SQLskills.com) Technische Bearbeiter: Alexandru Chirica, Arkadi Brjazovski, Prem Mehra, Joanna Omel, Mike Ruthruff, Robin Dhamankar Veröffentlicht: Oktober 2008 Betrifft: SQL Server 2008 Zusammenfassung: In diesem Whitepaper wird die FILESTREAM-Funktion von SQL Server 2008 beschrieben. Eine Kombination aus SQL Server 2008 und NTFS-Dateisystem ermöglicht neben der Speicherung auch den effizienten Zugriff auf BLOB-Daten. Hier werden die Wahl des richtigen BLOB-Speichers, die Konfiguration von Windows und SQL Server für FILESTREAM-Daten, Überlegungen zum Einsatz von FILESTREAM mit anderen Funktionen sowie Partitionierung und Leistung erörtert. Das Whitepaper richtet sich an Systemarchitekten, IT-Profis und Datenbankadministratoren, die sich mit der Evaluierung oder Implementierung von FILESTREAM befassen. Der Leser sollte mit Windows und SQL Server vertraut sein und grundlegende Datenbankkonzepte wie Transaktionen kennen. Einführung Nie wurden so viele Daten generiert wie heute. Die wachsende Datenflut verlangt nach kontrollierten, effizienten Speicherungs- und Zugriffsmechanismen. Welche der verschiedenen Technologien am besten für diese Aufgabe geeignet ist, richtet sich häufig nach den zu speichernden Daten, die in strukturierter, semistrukturierter oder unstrukturierter Form vorliegen können: Strukturierte Daten können problemlos in einem relationalen Schema gespeichert werden und dienen beispielsweise zur Darstellung von Umsatzdaten. Sie können in einer Datenbank gespeichert und thematisch gegliedert werden, sodass eine Tabelle Informationen zu Produkten, eine andere Kundeninformationen und eine weitere Details zu Produktverkäufen enthält. Die Daten können mithilfe einer leistungsfähigen Abfragesprache wie Transact-SQL abgerufen und bearbeitet werden. Semistrukturierte Daten weisen zwar ein lockeres Schema auf, eignen sich aber weniger für die Speicherung in Datenbanktabellen. Beispielsweise kann jeder Datenpunkt über völlig unterschiedliche Attribute verfügen. Zur Speicherung semistrukturierter Daten wird häufig der xml-Datentyp in der Microsoft® SQL Server®-Datenbanksoftware verwendet. Der Zugriff erfolgt über eine elementbasierte Abfragesprache wie XQuery. Unstrukturierte Daten verfügen u. U. über gar kein Schema (z. B. verschlüsselte Daten) oder bestehen aus Binärdaten in der Größenordnung vieler Megabytes und Gigabytes, die dem ersten Anschein nach kein Schema aufweisen. Tatsächlich folgen sie aber einem sehr einfachen, eigenen Schema, z. B. Bilddateien, Streamingvideos oder Soundclips. Mit Binärdaten sind Daten gemeint, die beliebige Werte darstellen können und nicht nur die auf der Tastatur eingegebenen Zeichen. Die Datenwerte werden häufig als BLOBs (so genannte Binary Large Objects) bezeichnet. In diesem Whitepaper wird die FILESTREAM-Funktion von SQL Server 2008 beschrieben. Eine Kombination aus SQL Server 2008 und NTFS-Dateisystem ermöglicht neben der Speicherung auch den effizienten Zugriff auf BLOB-Daten. Hier werden die FILESTREAM-Funktion, die Wahl des richtigen BLOBSpeichers, die Konfiguration von Windows® und SQL Server für FILESTREAM-Daten, Überlegungen zum Einsatz von FILESTREAM mit anderen Funktionen sowie Partitionierung und Leistung erörtert. Wahl des geeigneten BLOB-Speichers Während strukturierte und semistrukturierte Daten gut in einer relationalen Datenbank gespeichert werden können, fällt die Entscheidung bei unstrukturierten oder BLOB-Daten nicht so leicht. Folgende Anforderungen sollten bei der Wahl des BLOB-Speichers beachtet werden: 2 Leistung: Es ist wichtig zu wissen, wie die Daten verwendet werden. Falls Datenstreaming benötigt wird, ist der Zugriff auf die in einer SQL Server-Datenbank gespeicherten Daten langsamer als der Zugriff auf extern, z. B. in einem NTFS-Dateisystem, gespeicherte Daten. Bei Verwendung der Dateisystemspeicherung werden Daten aus der Datei gelesen und (direkt oder zusätzlich gepuffert) an die Clientanwendung übergeben. Wird das BLOB in einer SQL Server-Datenbank gespeichert, müssen die Daten zunächst in den Arbeitsspeicher des SQL-Servers (den Pufferpool) gelesen und dann über eine Clientverbindung an die Clientanwendung zurückübergeben werden. Die Daten durchlaufen nicht nur einen zusätzlichen Verarbeitungsschritt, sondern „überschwemmen“ den Arbeitsspeicher des SQL-Servers unnötigerweise auch noch mit BLOB-Daten, was weitere Leistungsprobleme in SQL Server verursachen kann. Sicherheit: Sicherheitsempfindliche Daten, die strengen Zugriffsbeschränkungen unterliegen, können in einer Datenbank gespeichert und mithilfe gängiger SQL Server-Zugriffssteuerungen geschützt werden. Werden dieselben Daten im Dateisystem gespeichert, sind andere Sicherheitsmethoden, wie Zugriffssteuerungslisten (ACLs), zu implementieren. Datengröße: Die Ergebnisse weiter unten in diesem Whitepaper legen nahe, dass BLOBs unter 256 KB (z. B. Widgetsymbole) besser in einer Datenbank und BLOBs über 1 MB besser außerhalb einer Datenbank gespeichert werden. Welche Speicherung für BLOBs zwischen 256 KB und 1 MB besser geeignet ist, richtet sich nach dem Verhältnis der Lese- und Schreibvorgänge sowie nach der „Überschreibungsrate“. Bei der Speicherung in der Datenbank (z. B. mit dem varbinary(max)-Datentyp) ist die BLOB-Größe jeweils auf 2 GB beschränkt. Clientzugriff: Das vom Client für den Zugriff auf SQL Server-Daten verwendete Protokoll, beispielsweise ODBC, ist für Anwendungen, die umfangreiche Videodateien streamen, möglicherweise nicht geeignet. In diesem Fall sollten die Daten im Dateisystem gespeichert werden. Transaktionssemantik: Wenn den BLOBs strukturierte Datenbankdaten zugeordnet sind, dürfen die BLOB-Daten nur in Übereinstimmung mit der Transaktionssemantik geändert werden, damit die beiden Datasets synchron bleiben. Beispiel: Wenn bei einer Transaktion BLOB-Daten und eine Zeile in einer Datenbanktabelle erstellt werden und dann ein Rollback ausgeführt wird, sollten sowohl die erstellten BLOB-Daten als auch die Tabellenzeile „zurückgesetzt“ werden. Wenn die BLOB-Daten im Dateisystem gespeichert sind, ohne dass eine Verknüpfung mit der Datenbank besteht, kann sich dies sehr komplex gestalten. Datenfragmentierung: Häufige Updates und Überschreibungen führen dazu, dass die BLOBs, je nachdem, wo sie gespeichert sind, innerhalb der SQL Server-Datenbankdateien oder innerhalb des Dateisystems verschoben werden. Dies führt insbesondere bei großen BLOBs zu Fragmentierungen (d. h., sie sind nicht mehr in einem zusammenhängenden Bereich des Datenträgers gespeichert). Fragmentierungsprobleme lassen sich in einem Dateisystem leichter beheben als in SQL Server. Verwaltbarkeit: Die Verwaltung einer Lösung mit mehreren, nicht integrierten Technologien gestaltet sich komplexer und kostenaufwändiger als die einer integrierten Lösung. Kosten: Die Kosten der Speicherlösung variieren abhängig von der verwendeten Technologie. Die obigen Ausführungen zur Größe und Fragmentierung sind dem viel beachteten Microsoft ResearchArtikel BLOB oder nicht BLOB: Speichern großer Objekte in einer Datenbank oder einem Dateisystem (Gray, Van Ingen und Sears) entnommen. Der Artikel enthält weitere Informationen zu den Vor- und Nachteilen und kann über folgenden Link heruntergeladen werden: http://research.microsoft.com/research/pubs/view.aspx?msr_tr_id=MSR-TR-2006-45 Es gibt zahlreiche Lösungen für die BLOB-Speicherung, die abhängig von den oben beschriebenen Anforderungen mit Vor- und Nachteilen behaftet sein können. In der folgenden Tabelle werden drei gängige Möglichkeiten zur BLOB-Speicherung in SQL Server 2008 verglichen, darunter auch FILESTREAM. Vergleichspunkt Maximale BLOB-Größe Streamingleistung bei großen BLOBs Sicherheit NTFS-Volumegröße Sehr gut Speicherlösung SQL Server (mit varbinary(max)) 2 GB – 1 Byte Schlecht Manuelle ACLs Integriert Dateiserver/Dateisystem Kosten pro GB Niedrig Hoch Verwaltbarkeit Schwierig Integriert Integration mit Schwierig Konsistenz auf strukturierten Daten Datenebene Anwendungsentwicklung Komplexer Einfacher und -bereitstellung Defragmentierung Sehr gut Schlecht Leistung bei häufigen Sehr gut Mittel kleineren Updates Tabelle 1: Vergleich von BLOB-Speichertechnologien vor SQL Server 2008 3 FILESTREAM NTFS-Volumegröße Sehr gut Integrierte + automatische ACLs Niedrig Integriert Konsistenz auf Datenebene Einfacher Sehr gut Schlecht FILESTREAM ist die einzige Lösung, die sowohl bei strukturierten als auch bei unstrukturierten Daten Transaktionskonsistenz, integrierte Sicherheits- und Verwaltungsfunktionen sowie eine kostengünstige, ausgezeichnete Streamingleistung bietet. Erreicht wird dies durch die Speicherung strukturierter Daten in Datenbankdateien und unstrukturierter BLOB-Daten im Dateisystem bei gleichzeitiger Transaktionskonsistenz zwischen beiden Speicherlösungen. Ausführliche Informationen zur FILESTREAM-Architektur finden Sie weiter unten in diesem Whitepaper im Abschnitt „Übersicht über FILESTREAM“. Übersicht über FILESTREAM FILESTREAM ist eine neue Funktion in SQL Server 2008. Sie ermöglicht die Speicherung strukturierter Daten in der Datenbank, während zugehörige, unstrukturierte Daten (BLOBs) direkt im NTFS-Dateisystem gespeichert werden können. Anstatt über SQL Server greifen Sie über hochleistungsfähige Win32®Streaming-APIs auf die BLOB-Daten zu und müssen keine Leistungseinbußen hinnehmen. FILESTREAM gewährleistet jederzeit Transaktionskonsistenz zwischen strukturierten und unstrukturierten Daten und ermöglicht mittels Protokollsicherungen sogar die Zeitpunktwiederherstellung von FILESTREAMDaten. Da SQL Server automatisch für konsistente Daten sorgt, muss in der Anwendung keine benutzerdefinierte Logik implementiert werden. Dazu verwendet der FILESTREAM-Mechanismus ein Äquivalent zum Datenbank-Transaktionsprotokoll, das auf sehr ähnliche Weise verwaltet wird (ausführliche Informationen im Abschnitt „FILESTREAM-Garbage Collection“ weiter unten im Whitepaper). Die Kombination aus Datenbank-Transaktionsprotokoll und FILESTREAM-Transaktionsprotokoll ermöglicht die aus Transaktionssicht ordnungsgemäße Wiederherstellung der FILESTREAM- und strukturierten Daten. FILESTREAM ist kein völlig neuer Datentyp, sondern ein Speicherattribut des bekannten varbinary(max)-Datentyps. Das Verhalten des varbinary(max)-Datentyps wird zu einem großen Teil in FILESTREAM fortgeführt. Die Speicherung von BLOB-Daten hat sich geändert: sie werden im Dateisystem und nicht in SQL Server-Datendateien gespeichert. Da FILESTREAM als varbinary(max)-Spalte implementiert wird und direkt in das Datenbankmodul integriert ist, können die meisten SQL ServerVerwaltungstools und -funktionen unverändert für FILESTREAM-Daten genutzt werden. Es sollte erwähnt werden, dass das Verhalten des regulären varbinary(max)-Datentyps, einschließlich des Größenlimits von 2 GB, in SQL Server 2008 unverändert bleibt. Durch das FILESTREAM-Attribut kann eine varbinary(max)-Spalte praktisch eine unbegrenzte Größe annehmen (die tatsächlich nur noch durch die Kapazität des zugrunde liegenden NTFS-Volumes beschränkt wird). FILESTREAM-Daten werden im Dateisystem in NTFS-Verzeichnissen, den so genannten Datencontainern, gespeichert, die spezielle Dateigruppen in der Datenbank abbilden. Der transaktionale Zugriff auf FILESTREAM-Daten wird durch SQL Server und einen Dateisystem-Filtertreiber gesteuert, der bei Aktivierung von FILESTREAM auf der Windows-Ebene installiert wird. Ein Dateisystem-Filtertreiber ermöglicht gleichzeitig den Remotezugriff auf FILESTREAM-Daten über einen UNC-Pfad. Da SQL Server einen Sortierungslink zwischen Tabellenzeilen und den zugehörigen FILESTREAM-Dateien erstellt, dürfen FILESTREAM-Dateien keinesfalls direkt im Dateisystem gelöscht oder umbenannt werden, weil andernfalls die Datenbank beschädigt werden könnte. Die Verwendung von FILESTREAM macht mehrere Schemaänderungen an den Datentabellen erforderlich (beispielsweise muss jede Zeile über eine eindeutige Zeilen-ID verfügen). Darüber hinaus bestehen Einschränkungen in Kombination mit anderen Funktionen (FILESTREAM-Daten können z. B. nicht verschlüsselt werden). Eine detaillierte Beschreibung finden Sie im Abschnitt „Konfigurieren von SQL Server für FILESTREAM“ weiter unten in diesem Whitepaper. 4 Für den Zugriff auf FILESTREAM-Daten und deren Bearbeitung stehen zwei Mechanismen zur Verfügung: das standardmäßige Transact-SQL-Programmiermodell oder die Win32-Streaming-APIs. Beide sind vollständig transaktionsfähig und unterstützen die meisten DML-Vorgänge, wie INSERT, UPDATE, DELETE und SELECT. FILESTREAM-Daten werden auch bei Wartungstasks wie Sicherungen, Wiederherstellungen und Konsistenzüberprüfungen unterstützt. Die wichtigste Ausnahme besteht darin, dass FILESTREAM-Daten keine partiellen Updates unterstützen. Bei jedem Update eines FILESTREAM-Datenwerts wird eine neue FILESTREAM-Datendatei erstellt. Die alte Datei wird asynchron entfernt, wie im Abschnitt „Konfigurieren der FILESTREAM-Garbage Collection“ weiter unten im Whitepaper beschrieben. Zwei Programmiermodelle für den Zugriff auf BLOB-Daten Nach der Speicherung in einer FILESTREAM-Spalte kann über Transact-SQL-Transaktionen oder Win32-APIs auf die Daten zugegriffen werden. Dieser Abschnitt bietet einen allgemeinen Überblick über die Programmiermodelle und deren Verwendung. Zugriff über Transact-SQL FILESTREAM-Daten können mit Transact-SQL auf folgende Weise eingefügt, aktualisiert und gelöscht werden: FILESTREAM-Felder können mithilfe eines Einfügevorgangs (leeren oder kleinen Werten ungleich NULL) vorab aufgefüllt werden. Allerdings bieten die Win32-Schnittstellen eine effizientere Möglichkeit zum Streamen großer Datenmengen. Bei der Aktualisierung von FILESTREAM-Daten werden die zugrunde liegenden BLOB-Daten im Dateisystem geändert. Wenn ein FILESTREAM-Feld auf NULL festgelegt wird, werden die dem Feld zugeordneten BLOB-Daten gelöscht. Segmentierte, als UPDATE.Write() implementierte Transact-SQL-Updates können nicht für Teilupdates von FILESTREAM-Daten eingesetzt werden. Wird eine Zeile mit FILESTREAM-Daten gelöscht bzw. eine Tabelle mit FILESTREAM-Daten gelöscht oder abgeschnitten, werden die zugrunde liegenden BLOB-Daten im Dateisystem ebenfalls gelöscht. Das physische Entfernen der FILESTREAM-Dateien findet in einem asynchronen Hintergrundprozess statt, wie im Abschnitt „Konfigurieren der FILESTREAMGarbage Collection“ weiter unten im Whitepaper erläutert. Weitere Informationen und Beispiele für den FILESTREAM-Datenzugriff mit Transact-SQL finden Sie in der SQL Server 2008-Onlinedokumentation unter dem Thema „Verwalten von FILESTREAM-Daten mit Transact-SQL“ (http://msdn.microsoft.com/de-de/library/cc645962.aspx). Win32-Streamingzugriff Um Transaktionen den Dateisystemzugriff auf FILESTREAM-Daten zu ermöglichen, liefert die neue intrinsische Funktion GET_FILESTREAM_TRANSACTION_CONTEXT() das Token zur Darstellung der aktuellen Transaktion, der die Sitzung zugeordnet ist. Die Transaktion muss gestartet sein, ohne dass bereits ein Commit oder Rollback ausgeführt wurde. Durch den Abruf eines Tokens bindet die Anwendung die Streamingvorgänge im FILESTREAM-Dateisystem an eine gestartete Transaktion. Die Funktion gibt NULL zurück, wenn keine explizit gestartete Transaktion vorliegt. Vor dem Zugriff auf FILESTREAMDateien muss ein Token abgerufen werden. 5 Der physische Dateisystemnamespace des BLOBs wird in FILESTREAM vom Datenbankmodul gesteuert. Eine neue intrinsische Funktion „PathName“ liefert den logischen UNC-Pfads des BLOBs, das jeweils einem FILESTREAM-Feld in der Tabelle entspricht. Die Anwendung verwendet diesen logischen Pfad, um das Win32-Handle abzurufen und die BLOB-Daten mithilfe der regulären Win32Dateisystemschnittstellen zu bearbeiten. Die Funktion gibt NULL zurück, wenn der Wert der FILESTREAM-Spalte gleich NULL ist. Dies verdeutlicht, dass eine FILESTREAM-Datei wie oben beschrieben vorab erstellt werden muss, damit auf Win32-Ebene auf sie zugegriffen werden kann. Das Win32-Streaming wird im Kontext einer SQL Server-Transaktion unterstützt. Nach einem Transaktionstoken und einem Pfadnamen wird mit der Win32-OpenSqlFilestream-API zusätzlich ein Win32-Dateihandle abgerufen. Alternativ kann die verwaltete SqlFileStream-API verwendet werden. Mit diesem Handle können Win32-Streamingschnittstellen, wie ReadFile() und WriteFile(), anschließend über das Dateisystem auf die Datei zugreifen und sie aktualisieren. Es sei nochmals darauf hingewiesen, dass FILESTREAMDateien nicht direkt im Dateisystem gelöscht oder umbenannt werden können. Andernfalls sind die Links zwischen Datenbank und Dateisystem nicht mehr konsistent (sodass die Datenbank beschädigt wird). Beim FILESTREAM-Dateisystemzugriff wird eine Transact-SQL-Anweisung durch File.Open und Close modelliert. Die Anweisung startet, wenn ein Dateihandle geöffnet wird, und endet, wenn das Handle geschlossen wird. Wenn ein Schreibhandle geschlossen wird, wird ein möglicher, für die Tabelle registrierter AFTER-Trigger so ausgelöst, als wäre eine UPDATE-Anweisung abgeschlossen worden. Weitere Informationen und Beispiele für den FILESTREAM-Datenzugriff mit Win32-APIs finden Sie in der SQL Server 2008-Onlinedokumentation unter dem Thema „Verwalten von FILESTREAM-Daten mit Win32“ (http://msdn.microsoft.com/de-de/library/cc645940.aspx). Transaktionssemantik Alle Dateihandles müssen geschlossen sein, bevor für die Transaktion ein Commit oder Rollback ausgeführt wird. Wenn ein Handle bei einem Transaktionscommit noch geöffnet ist, verursachen nicht nur das Commit, sondern auch Lese- und Schreibvorgänge für das Handle erwartungsgemäß einen Fehler. Für die Transaktion muss dann ein Rollback ausgeführt werden. Auch wenn die Datenbank oder eine Instanz des Datenbankmoduls heruntergefahren wird, werden alle geöffneten Handles ungültig. Sobald eine FILESTREAM-Datei für einen Schreibvorgang geöffnet wird, wird eine neue Datei der Länge NULL erstellt und der gesamte aktualisierte FILESTREAM-Datenwert in die Datei geschrieben. Die alte Datei wird asynchron entfernt, wie im Abschnitt „Konfigurieren der FILESTREAM-Garbage Collection“ weiter unten im Whitepaper beschrieben. Unter FILESTREAM gewährleistet das Datenbankmodul beim Commit Transaktionsdauerhaftigkeit für FILESTREAM-BLOB-Daten, die durch Streamingzugriffe auf das Dateisystem geändert werden. Dazu wird das bereits erwähnte FILESTREAM-Protokoll verwendet und der FILESTREAM-Dateiinhalt explizit auf den Datenträger geleert. Isolationssemantik Die Isolationssemantik wird durch die Transaktionsisolationsstufen des Datenbankmoduls bestimmt. Beim Zugriff auf FILESTREAM-Daten über die Win32-APIs wird ausschließlich die READ COMMITTEDIsolationsstufe unterstützt. Der Transact-SQL-Zugriff unterstützt zusätzlich die REPEATABLE READ- und SERIALIZABLE-Isolationsstufen. Darüber hinaus lässt der Transact-SQL-Zugriff Dirty Reads über die READ UNCOMMITTED-Isolationsstufe bzw. den NOLOCK-Abfragehinweis zu. In der Ausführung befindliche Updates von FILESTREAM-Daten sind bei dieser Zugriffsart jedoch nicht sichtbar. 6 Bei Dateisystemzugriffen zum Öffnen von Dateien wird nicht auf Sperren gewartet. Das Öffnen schlägt stattdessen sofort fehl, wenn aufgrund der Transaktionsisolation nicht auf die Daten zugegriffen werden kann. Die Streaming-API-Aufrufe verursachen eine ERROR_SHARING_VIOLATION, wenn das Öffnen aufgrund einer Isolationsverletzung nicht fortgesetzt werden kann. Teilupdates Damit Teilupdates durchgeführt werden können, kann die Anwendung einen Dateisystembefehl (FSCTL_SQL_FILESTREAM_FETCH_OLD_CONTENT) ausgeben, um den alten Inhalt in die Datei zu laden, auf die das geöffnete Handle verweist. Alternativ kann dazu auch die verwaltete SqlFileStream-API mit dem ReadWrite-Flag verwendet werden. Dadurch wird alter Inhalt auf Serverseite kopiert, wie oben bereits erläutert. Um die Anwendungsleistung zu verbessern und bei der Arbeit mit sehr großen Dateien Timeouts zu vermeiden, wird die Verwendung asynchroner E/As empfohlen. Wenn der FSCTL-Befehl ausgegeben wird, nachdem in die durch das Handle bezeichnete Datei geschrieben wurde, werden die Daten des letzten Schreibvorgangs persistent gespeichert, und alle zuvor geschriebenen Daten gehen verloren. Weitere Informationen zu Teilupdates finden Sie in der SQL Server 2008-Onlinedokumentation unter dem Thema „FSCTL_SQL_FILESTREAM_FETCH_OLD_CONTENT“ (http://technet.microsoft.com/de-de/ library/cc627407.aspx). Write-Throughs von Remoteclients Der Remotedateisystemzugriff auf FILESTREAM-Daten erfolgt über das SMB (Server Message Block)Protokoll. Bei Remoteclients richtet sich das Caching von Schreibvorgängen nach den festgelegten Optionen und der verwendeten API. APIs in systemeigenem Code verwenden standardmäßig WriteThroughs, und verwaltete APIs verwenden die Pufferung. Dieser Unterschied beruht auf Kundenfeedback zu verschiedenen APIs und deren Nutzung in den CTP-Vorabversionen von SQL Server 2008. Auf Remoteclients ausgeführte Anwendungen sollten kleine Schreibvorgänge (mittels Pufferung) möglichst konsolidieren, damit weniger Schreibvorgänge mit größeren Datenmengen durchgeführt werden. Zusätzlich sollte der Client vor dem Commit der Transaktion den Puffer explizit leeren. Die Erstellung im Speicher abgebildeter Sichten (im Speicher abgebildeter E/As) mit einem FILESTREAM-Handle wird nicht unterstützt. Wenn Speicherabbilder für FILESTREAM-Daten verwendet werden, kann das Datenbankmodul weder die Konsistenz und Dauerhaftigkeit der Daten noch die Datenbankintegrität gewährleisten. Verwendungsbereiche von FILESTREAM Obwohl die FILESTREAM-Technologie mit vielen überzeugenden Funktionen aufwartet, ist sie u. U. nicht für alle Anwendungsfälle optimal geeignet. Wie bereits erwähnt, richtet sich die Entscheidung, ob BLOBDaten vollständig in der Datenbank oder unter Verwendung von FILESTREAM gespeichert werden sollen, primär nach der Größe der BLOB-Daten und den Zugriffsmustern. 7 Die Größe beeinflusst: die Effizienz, mit der die Speichermechanismen auf die BLOB-Daten zugreifen können. Wie bereits erwähnt, ist der Streamingzugriff auf umfangreiche BLOB-Daten mit FILESTREAM effizienter, allerdings werden Teilupdates (möglicherweise deutlich) langsamer. die Effizienz, mit der die kombinierten strukturierten und BLOB-Daten mit einem der beiden Speichermechanismen gesichert werden können. Die Sicherung von SQL Server-Datenbankdateien zusammen mit einer großen Anzahl von FILESTREAM-Dateien beansprucht mehr Zeit, als wenn nur SQL Server-Datenbankdateien mit der gleichen Gesamtgröße gesichert werden müssten. Dies liegt an dem Mehraufwand, der beim Sichern der einzelnen NTFS-Dateien (eine pro FILESTREAM-Datenwert) entsteht. Noch deutlicher wird dies bei kleineren FILESTREAMDateien (da der prozentuale Zeitbedarf pro MB an Daten einen immer größeren Teil der gesamten Sicherungszeit ausmacht). Im folgenden Diagramm ist beispielsweise dargestellt, welchen relativen Durchsatz lokale Lesevorgänge bei unterschiedlich großen BLOB-Daten mit varbinary(max), FILESTREAM über Transact-SQL und FILESTREAM über NTFS erzielen. Die blaue Linie verdeutlicht, dass der Win32-Zugriff auf FILESTREAM-Daten mit zunehmender Datengröße um ein Vielfaches schneller als der Transact-SQLZugriff auf varbinary(max)-Daten ist. Der Durchsatz wurde in MBit/s (Megabits pro Sekunde) gemessen. Abbildung 1: Leseleistung bei verschiedenen BLOB-Größen Die NTFS-Zahlen umfassen folgende Angaben: Zeit bis zum Starten einer Transaktion, bis zum Abrufen des Pfadnamens und Transaktionskontexts von SQL Server und bis zum Öffnen eines Win32-Handles für die FILESTREAM-Daten. Jeder Test wurde unter Verwendung desselben Computers mit vier Prozessorkernen und einem betriebsbereiten SQL Server-Pufferpool durchgeführt. Als weiterer Faktor ist zu berücksichtigen, ob der Client oder die Mid-Tier für die Verwendung der Win32Streaming-APIs und den normalen SQL Server-Zugriff (um)geschrieben werden kann. Andernfalls ist FILESTREAM nicht geeignet, da die beste Performance mithilfe der Win32s-Streaming-APIs erzielt wird. 8 Konfigurieren von Windows für FILESTREAM Wie bei jeder Bereitstellung muss der Windows-Server, der die SQL Server-Datenbank und zugehörigen FILESTREAM-Datencontainer hostet, für eine Anwendung, die FILESTREAM nutzt, vorbereitet werden. In diesem Abschnitt wird beschrieben, wie Speicherhardware und das NTFS-Dateisystem zur Vorbereitung für FILESTREAM konfiguriert werden. Anschließend wird die Aktivierung von FILESTREAM unter Windows erläutert. Hardwareauswahl und Konfiguration Eine der häufigsten Ursachen für schwache Performance ist eine ungeeignete Hardwarekonfiguration. Manchmal reicht der Speicher nicht aus, was zu einer Überlastung des SQL Server-Pufferpools führt, oder aber der E/A-Durchsatz der Speicherhardware ist nicht für die anfallende Arbeitslast ausgelegt. Bei Anwendungen, die für das hochperformante Streaming von BLOB-Daten über Win32-APIs eingesetzt werden, ist die richtige Wahl und Konfiguration der Speicherhardware unverzichtbar. In den folgenden Abschnitten werden Best Practices für Speicherwahl und -layout vorgestellt. Ausführlicher wird dieses Thema im TechNet-Whitepaper „Planen des physischen Datenbankspeichers“ (http://www.microsoft.com/technet/prodtechnol/sql/2005/physdbstor.mspx) erörtert. Nachdem das optimale Layout gefunden wurde, muss die Leistungskapazität des E/A-Subsystems mithilfe von Auslastungstests beurteilt werden. Dies wird im TechNet-Artikel zu SQL Server Best Practices „E/A-System: Best Practices vor der Bereitstellung“ (http://www.microsoft.com/technet/prodtechnol/ sql/bestpractice/pdpliobp.mspx) näher beschrieben. Physisches Speicherlayout Bei der Standortwahl spielt die zu erwartende Arbeitsauslastung des FILESTREAM-Datencontainers sowie die der anderen beteiligten Datencontainer und SQL Server-Dateien eine wichtige Rolle. Jeder FILESTREAM-Datencontainer benötigt u. U. ein eigenes Volume, da bei einem einzigen Volume mehrere Datencontainer je nach Auslastungsgrad miteinander konkurrieren können. Fakt ist, dass die Verwendung nur eines Volumes für sämtliche Komponenten auch ohne hohe Auslastung immer zu Leistungsproblemen führen kann. In welchem Maße eine räumlichen Trennung erforderlich ist, ist von Kunde zu Kunde verschieden. Es ist auch möglich, die FILESTREAM-Datenlast mithilfe eines Tabellenschemas in SQL Server grob auf mehrere Volumes zu verteilen. Mehr dazu erfahren Sie im Abschnitt „Lastenausgleich für FILESTREAMDaten“. Wahl der RAID-Stufe Da die Vorteile der RAID-Technologie hinlänglich bekannt sind und die Wahl der geeigneten RAID-Stufe bereits Thema zahlreicher Veröffentlichungen war, wird in diesem Whitepaper nicht näher darauf eingegangen. Das oben genannte Whitepaper „Planen des physischen Datenbankspeichers“ enthält einen sehr informativen Abschnitt zur Verwendung und Wahl von RAID-Stufen. Im Folgenden werden die wichtigsten Punkte kurz angerissen. 9 RAID-Stufen unterscheiden sich in vieler Hinsicht, am deutlichsten jedoch bei Lese-/Schreibleistung, Resilienz und Kosten. RAID 5 ist beispielsweise relativ kostengünstig, bietet Redundanz für den Ausfall eines Laufwerks im RAID-Array und ist für schreibintensive Arbeitslasten eher ungeeignet. RAID 10 bietet im Gegensatz dazu eine ausgezeichnete Lese-/Schreibleistung, gewährleistet (je nach Grad der Spiegelung) Fehlertoleranz für mehrere ausgefallene Laufwerke, ist jedoch aufgrund der Tatsache, dass mindestens 50 Prozent der Laufwerke im RAID-Array redundant sind, auch teurer. Dies sind die drei Hauptfaktoren, die bei der Wahl einer RAID-Stufe zu berücksichtigen sind. Für Volumes mit Benutzerdatenbanken und sogar für diejenigen, auf denen die Datendateien oder Protokolldateien für einzelne Datenbanken gespeichert sind, können unterschiedliche RAID-Stufen zum Einsatz kommen. Kommt es beim Streamen von FILESTREAM-Daten in erster Linie auf hohe Leistung an, sollte für das Volume mit dem FILESTREAM-Datencontainer möglichst die RAID-Stufe mit der höchsten Leseleistung gewählt werden. Allerdings bietet diese Stufe keine hohe Resilienz bei Hardwareausfällen. Andererseits kann auch dieselbe RAID-Stufe wie für die übrigen Volumes verwendet werden, auf denen Datenbankdaten gespeichert sind, was u. U. aber nicht die nötige Leistung für die Arbeitslast bringt. Dieses Whitepaper soll verdeutlichen, dass die RAID-Stufe für die Volumes der FILESTREAMDatencontainer erst gewählt werden sollte, nachdem die Vor- und Nachteile abgewogen und sämtliche Einflussfaktoren beleuchtet wurden. Laufwerkschnittstellen In typischen Datenbanken mit BLOB-Speicherung kann die Gesamtgröße der BLOB-Daten um ein Vielfaches über der strukturierter Daten liegen. In Umgebungen, in denen FILESTREAM-Daten auf getrennten Volumes gespeichert werden, kann für die Volumes anstelle von SCSI-Speicher eine kostengünstigere Speicherlösung wie IDE oder SATA (im Folgenden „SATA“) verwendet werden. Zuvor sollten die Vor- und Nachteile dieser Technologien verstanden werden. Dieser Abschnitt bietet eine Übersicht über die unterschiedlichen Merkmale von SCSI und IDE/SATA, um den richtigen Kompromiss zwischen Leistung, Zuverlässigkeit und Kosten aufzuzeigen. Kapazität und Leistung SATA-Laufwerke verfügen häufig über eine höhere Kapazität als SCSI-Laufwerke, weisen jedoch niedrigere RPM-Werte (Rotations per Minute, Umdrehungen pro Minute) als SCSI-Laufwerke auf. Obwohl einige SATA-Laufwerke 10.000 U/min bieten, liegen die meisten bei 5.400 oder 7.200 U/min. Hochleistungsfähige SCSI-Laufwerke erreichen 10.000 bis 15.000 U/min. Wenngleich U/min als hilfreiche Referenzgröße dient, kommt es bei einem tragfähigen Vergleich auf die Latenz (wie lange es dauert, bis der Schreib-/Lesekopf neu auf der Festplatte positioniert ist) und die durchschnittlichen Übertragungsraten an (wie viele Daten pro Sekunde auf die bzw. von der Festplatte übertragen werden können). Außerdem ist es wichtig, dass die Laufwerke in der Lage sind, komplexe E/A-Muster zu unterstützen. Sie sollten bei der Laufwerkwahl darauf achten, dass SATA-Laufwerke NCQ (Native Command Queue) und SCSILaufwerke CTQ (Command Tag Queue) unterstützen, um mehrfache Interleaved-Datenträger-E/A und somit eine effizientere Leistung zu ermöglichen. Zusammenfassend lässt sich sagen, dass SCSI-Laufwerke aufgrund der geringeren Latenz und höheren Übertragungsraten eine bessere Streamingleistung bieten, aber auch teurer sind. 10 Zuverlässigkeit SQL Server gewährleistet Zuverlässigkeit und Wiederherstellbarkeit mithilfe des Write-AheadProtokollmechanismus, der auf garantierter Schreibreihenfolge und Dauerhaftigkeit basiert. Weitere Informationen zu diesen E/A-Anforderungen, finden Sie im TechNet-Whitepaper „Grundlagen zur E/A in SQL Server“ (http://www.microsoft.com/technet/prodtechnol/sql/2005/iobasics.mspx). SCSI ist in der Regel zuverlässiger als SATA, da diese Technologie im Gegensatz zu SATA das erzwungene Schreiben von Daten auf die Festplatte unterstützt. Dies geschieht entweder durch WriteThrough-Unterstützung, bei der die geschriebenen Daten gar nicht zwischengespeichert werden, oder durch das erzwungene Leeren des Cacheinhalts auf den Datenträger. Das Fehlen dieser Sicherheitsmechanismen kann die Wiederherstellbarkeit bei einem Hardware-, Software- oder Stromausfall beeinträchtigen. Um im Reparaturfall Verfügbarkeit zu gewährleisten, unterstützen alle Schnittstellen Hot Swaps. Die FILESTREAM-Funktion gewährleistet Schreibreihenfolge und Dauerhaftigkeit durch zwei Mechanismen: Datendauerhaftigkeit zum Commitzeitpunkt von Transaktionen Write-Ahead-Protokollierung für das Erstellen und Löschen von FILESTREAM-Dateien Die Dauerhaftigkeit der Daten wird erzielt, indem der FILESTREAM-Dateisystemtreiber vor einem Transaktionscommit eine explizite Leerung aller geänderten Dateien veranlasst (eine ausführlichere Erläuterung ginge über den Rahmen dieses Whitepapers hinaus). Dadurch wird vermieden, dass Festplatten, die keinen ausreichend batteriegepufferten Cache aufweisen, nach einem Stromausfall FILESTREAM-Daten enthalten, für die zwar ein Commit, aber keine Leerung ausgeführt wurde, sodass die Daten verloren gehen. Bei SATA-Laufwerken, die kein Forced-Flush (erzwungenes Leeren) unterstützen, kann die Wiederherstellbarkeit beeinträchtigt werden und ein Datenverlust auftreten. Die Write-Ahead-Protokollierung beruht auf konsistenten NTFS-Metadaten, die wiederum zuverlässige Laufwerke voraussetzen. SCSI ist in diesem Zusammenhang unproblematisch, wenn die SATALaufwerke jedoch kein Forced-Flushing unterstützen, können Änderungen an den NTFS-Metadaten bei einem Stromausfall verloren gehen. Die Ergebnisse sind wie folgt: 11 NTFS kann nicht wiederhergestellt und das Volume nicht eingebunden werden (d. h, der FILESTREAM-Datencontainer ist im Wesentlichen offline). NTFS wird zwar wiederhergestellt, Änderungen an NTFS-Metadaten gehen jedoch verloren, und SQL Server ist nicht in der Lage, für eine INSERT-Transaktion von FILESTREAM-Daten, für die kein Commit ausgeführt wurde, ein Rollback auszuführen (d. h, es entsteht ein FILESTREAM-Datenverlust). NTFS wird zwar wiederhergestellt, Änderungen an NTFS-Metadaten gehen jedoch verloren, und SQL Server ist nicht in der Lage, für eine DELETE-Transaktion von FILESTREAM-Daten, für die kein Commit ausgeführt wurde, ein Rollback auszuführen (d. h., es entsteht ein FILESTREAM-Datenverlust). Diese drei Szenarien sind nicht schlechter, als wenn die BLOB-Daten außerhalb der Datenbank auf einem NTFS-Volume gespeichert werden, wobei die zugrunde liegenden SAT-Laufwerke kein ForceFlushing auf die Festplatte unterstützen. Die Verwendung von FILESTREAM auf einem Volume mit SATA-Laufwerken ist in der Tat besser als die Speicherung der BLOB-Daten in NTFS-Rohdatendateien auf demselben Volume, da die FILESTREAM-Konsistenz auf Linkebene eine Möglichkeit bietet, diese „Beschädigungen“ zu erkennen (indem DBCC CHECKDB für die Datenbank ausgeführt wird). Zusammengefasst lässt sich sagen, dass FILESTREAM-Daten zuverlässig auf Volumes mit SATASpeicher gespeichert werden können, solange die SATA-Laufwerke das Forced-Flushing des Caches auf den Datenträger unterstützen. NTFS-Konfiguration Auch ein sorgfältig durchdachtes E/A-Subsystem auf der Basis von High-End-Hardware kommt an seine Grenzen, wenn das Dateisystem (in diesem Fall NTFS) nicht ordnungsgemäß konfiguriert ist. In diesem Abschnitt werden Konfigurationsoptionen beschrieben, die FILESTREAM-Arbeitslasten beeinflussen können. Weitere Informationen zu NTFS finden Sie in den Artikeln „Technische Referenz zu NTFS“ (http://technet.microsoft.com/de-de/library/cc758691.aspx) und „Arbeiten mit Dateisystemen“ (http://technet.microsoft.com/de-de/library/bb457112.aspx) in der TechNet Library. Optimieren der NTFS-Leistung NTFS ist standardmäßig nicht für die Verarbeitung anspruchsvoller Arbeitslasten mit Zehntausenden Dateien in einem einzelnen Dateisystemverzeichnis (d. h. das FILESTREAM-Szenario) ausgelegt. Zwei NTFS-Optionen müssen konfiguriert werden, um die FILESTREAM-Leistung zu unterstützen. Diese Optionen müssen unbedingt festgelegt werden, bevor Sie Vergleichstests ausführen, da sich die FILESTREAM-Leistung ansonsten nicht zuverlässig beurteilen lässt. Zunächst wird die Generierung von 8.3-Namen beim Erstellen neuer (oder Umbenennen vorhandener) Dateien deaktiviert. Bei diesem Verfahren wird nur aus Gründen der Abwärtskompatibilität mit 16-BitAnwendungen für jede Datei ein zweiter Name generiert. Der Algorithmus generiert einen neuen 8.3Namen und muss dann alle bestehenden 8.3-Dateinamen im Verzeichnis überprüfen, um sicherzustellen, dass der neue Name eindeutig ist. Während die Anzahl der Dateien im Verzeichnis anwächst (normalerweise über 300.000), dauert dieser Prozess immer länger. Da die Zeit zum Erstellen von Dateien ständig zunimmt und die Leistung abnimmt, lässt sich die Performance erheblich steigern, indem diese Option deaktiviert wird. Geben Sie dazu folgenden Befehl an einer Eingabeaufforderung ein, und starten Sie den Computer neu: fsutil behavior set disable8dot3 1 Hinweis: Durch diese Option wird die Generierung von 8.3-Namen auf allen NTFS-Servervolumes deaktiviert. 16-Bit-Anwendungen, die auf diese Volumes zugreifen, können nach der Änderung Probleme verursachen. Als Zweites muss verhindert werden, dass die Zugriffszeit bei jedem Dateizugriff aktualisiert wird. Wenn auf viele Dateien kurz zugegriffen wird, nur um die letzte Zugriffszeit jeder einzelnen Datei zu aktualisieren, kostet dies zu viel Zeit. Wird diese Option ebenfalls deaktiviert, kann die Leistung erheblich gesteigert werden. Geben Sie dazu folgenden Befehl an einer Eingabeaufforderung ein, und starten Sie den Computer neu: fsutil behavior set disablelastaccess 1 12 Clustergröße Alle Windows-Dateisysteme arbeiten nach dem Prinzip des „Clusters“, der bei der Speicherplatzzuordnung verwendeten Maßeinheit. Ein Cluster ist die kleinste Menge an Speicherplatz, die belegt werden kann. Bei sehr kleinen Dateien kann es vorkommen, dass ein Teil des Clusters ungenutzt bleibt. Um eine solche Vergeudung von Speicherplatz zu vermeiden, sind Cluster in der Regel recht klein. Große Dateien können entweder von vornherein zahlreiche Cluster belegen, oder bei Dateien, deren Größe im Laufe der Zeit zunimmt, kommen sukzessiv Cluster hinzu. Wenn eine Datei schnell, aber in kleinen Blöcken anwächst, erhöht sich die Wahrscheinlichkeit, dass die belegten Cluster auf dem Datenträger nicht zusammenhängend angeordnet (d. h. fragmentiert) sind. Je kleiner die Cluster sind und je mehr eine Datei wächst, umso stärker wird sie fragmentiert. Folglich muss bei der Clustergröße zwischen vergeudetem Speicherplatz und geringerer Fragmentierung abgewogen werden. Weitere Informationen zu unterschiedlichen Clustergrößen in Windows-Dateisystemen finden Sie im Knowledge Base-Artikel „Standard-Clustergröße für NTFS, FAT und exFAT“ (http://support.microsoft.com/kb/140365). Bei Verwendung von FILESTREAM wird pro BLOB-Dateneinheit eine Mindestgröße von 1 MB empfohlen. In diesem Fall kann die NTFS-Clustergröße für das FILESTREAM-Datencontainervolume auf 64 KB festgelegt werden, um die Fragmentierung zu reduzieren. Da der Standardwert für NTFS-Volumes bis 2 TB bei 4 KB liegt, muss die Änderung beispielsweise mit der Option „/A“ des format-Befehls manuell vorgenommen werden. Geben Sie an der Eingabeaufforderung z. B. Folgendes ein: format F: /FS:NTFS /V:MyFILESTREAMContainer /A:64K Diese Einstellung sollte mit umfangreichen Puffergrößen kombiniert werden, wie unter „Überlegungen zur Leistungsoptimierung und Vergleichstests“ weiter unten in diesem Whitepaper beschrieben. Fragmentierung Wenn viele Dateien auf einem Volume an Größe zunehmen, tritt wie bereits erwähnt eine stärkere Fragmentierung auf. Dies bedeutet, dass die von der Datei belegten Cluster nicht zusammenhängend sind. Wenn die Datei sequenziell gelesen wird, müssen die Leseköpfe alle Cluster nacheinander lesen, was bedeuten kann, dass eine Neupositionierung der Lese-/Schreibköpfe erforderlich ist. Wenn eine Datei auf einem Volume erstellt wird, dessen freier Speicherplatz nicht aus einem einzigen zusammenhängenden Block besteht, wird sie sofort fragmentiert, da die Speichercluster nicht nebeneinander liegen. Dies gilt selbst dann, wenn die anfängliche Dateigröße nicht weiter zunimmt. Bei dieser Fragmentierung ist die sequenzielle Leseleistung niedriger, als wenn keine (oder nur geringe) Fragmentierung auftreten würde. Ein ähnliches Problem ist bei der Indexfragmentierung innerhalb einer Datenbank zu beobachten, durch die die Leistung von Bereichsscanabfragen gemindert wird. Datenträger sollten mit einem Defragmentierungstool unbedingt regelmäßig defragmentiert werden, um die Leistung sequenzieller Lesevorgänge aufrechtzuerhalten. Wenn das Volume, das zum Hosten des FILESTREAM-Datencontainers verwendet wird, zuvor bereits eingesetzt wurde oder wenn es noch andere Daten enthält, sollte die Fragmentierung überprüft und ggf. beseitigt werden. 13 Komprimierung Die in NTFS gespeicherten Daten können komprimiert werden, um Speicherplatz zu sparen. Dies kostet jedoch zusätzliche CPU-Leistung, um die Daten bei Lese- bzw. Schreibzugriffen zu komprimieren und zu dekomprimieren. Die Komprimierung ist außerdem wenig hilfreich, wenn die Daten praktisch nicht komprimierbar sind. Zufallsdaten, verschlüsselte Daten oder bereits komprimierte Daten lassen sich nicht gut komprimieren, müssen aber trotzdem durch den NTFS-Komprimierungsalgorithmus verarbeitet werden und verursachen eine höhere CPU-Auslastung. Eine Komprimierung ist folglich nur sinnvoll, wenn die Daten stark komprimiert werden können und die Leistung der Arbeitslast durch den zusätzlichen CPU-Bedarf nicht abfällt. Darüber hinaus kann die Komprimierung nur bis zu einer NTFS-Clustergröße von 4.096 Bytes aktiviert werden. Die Komprimierung wird bei der Formatierung des FILESTREAM-Datencontainervolumes mit der Option „/C“ des format-Befehls aktiviert. Beispiel: format F: /FS:NTFS /V:MyFILESTREAMContainer /A:4096 /C Mithilfe folgender Schritte kann die Komprimierung auch für ein vorhandenes Volume aktiviert werden: 1. Klicken Sie unter Arbeitsplatz oder im Windows-Explorer mit der rechten Maustaste auf das Volume, das komprimiert oder dekomprimiert werden soll. 2. Klicken Sie auf Eigenschaften, um das Dialogfeld Eigenschaften anzuzeigen. 3. Aktivieren oder deaktivieren Sie auf der Registerkarte Allgemein das Kontrollkästchen Laufwerk komprimieren, um Speicherplatz zu sparen, und klicken Sie dann auf OK. 4. Legen Sie im Dialogfeld Änderungen der Attribute bestätigen fest, ob die Komprimierung auf das gesamte Volume oder nur auf den Stammordner angewendet werden soll. Siehe dazu folgende Abbildung. 14 Abbildung 2: Komprimieren eines vorhandenen Volumes mithilfe von Windows-Explorer Speicherplatzverwaltung Obwohl ein einzelnes Volume mehrere FILESTREAM-Datencontainer enthalten kann, sprechen einige Gründe für die Verwendung einer 1:1-Zuordnung zwischen Datencontainern und NTFS-Volumes. Abgesehen davon, dass Konflikte in Zusammenhang mit der Arbeitsaulastung auftreten können, gibt es keine Möglichkeit, die Speicherverwendung des FILESTREAM-Datencontainers innerhalb von SQL Server zu verwalten. Für diesen Fall sind NTFS-Datenträgerkontingente erforderlich. Da Datenträgerkontingente pro Benutzer/Volume verwaltet werden, lässt sich bei einem einzelnen Volume mit mehreren FILESTREAM-Datencontainern schwer feststellen, welcher Datencontainer mehr Speicherplatz beansprucht. Beachten Sie, dass alle FILESTREAM-Dateien unter dem SQL ServerDienstkonto erstellt werden. Wird das Konto geändert, wird der Speicherplatz unter dem neuen Dienstkonto abgerechnet. Für jedes NTFS-Volume, das über einen FILESTREAM-Datencontainer verfügt, sowie für jede SQL Server-Version mit einem FILESTREAM-Datencontainer auf dem Volume ist ein einzelner FILESTREAMDateisystem-Filtertreiber verfügbar. Jeder Filtertreiber ist für die Verwaltung aller FILESTREAM-Datencontainer des jeweiligen Volumes und für alle Instanzen zuständig, die eine bestimmte SQL Server-Version verwenden. Beispielsweise weist ein NTFS-Volume, das drei FILESTREAM-Datencontainer hostet (einen für jede der drei SQL Server 2008-Instanzen), nur einen FILESTREAM-Dateisystem-Filtertreiber für SQL Server 2008 auf. 15 Sicherheit Die Verwendung der FILESTREAM-Funktion stellt zwei Sicherheitsanforderungen. Erstens muss SQL Server für die integrierte Sicherheit konfiguriert sein, und zweitens muss bei Verwendung des Remotezugriffs SMB-Port (445) in allen Firewallsystemen durchlässig sein. Diese Anforderung entspricht dem normalen Zugriff auf Remotefreigaben. Weitere Informationen finden Sie im Knowledge Base-Artikel „Dienstübersicht und Netzwerkportanforderungen für das Windows Server-System“ (http://support.microsoft.com/kb/832017). Überlegungen zum Virenschutz Antivirensoftware ist aus heutigen Umgebungen nicht mehr wegzudenken. FILESTREAM kann Antivirensoftware nicht daran hindern, Dateien im FILESTREAM-Datencontainer auf Viren zu scannen (da Sicherheitsprobleme entstehen würden). Die Software weist normalerweise eine Richtlinieneinstellung auf, die vorgibt, wie mit einer potenziell virenbehafteten Datei zu verfahren ist: Entweder wird die Datei gelöscht oder der Dateizugriff eingeschränkt (d. h., die Datei wird unter Quarantäne gestellt). In beiden Fällen wird der Zugriff auf die BLOB-Daten in der betroffenen Datei verhindert, sodass SQL Server davon ausgeht, dass sie gelöscht wurde. Antivirensoftware sollte möglichst so konfiguriert werden, dass Dateien unter Quarantäne gestellt und nicht gelöscht werden. Fehlende Dateien können mithilfe von DBCC CHECKDB in SQL Server ermittelt, vom Windows-Administrator mit dem Protokoll der Antivirensoftware abgeglichen und anschließend ggf. korrigiert werden. Aktivieren von FILESTREAM in Windows Da FILESTREAM eine Hybridfunktion ist, müssen einige Schritte vom Windows-Administrator und andere vom SQL Server-Administrator ausgeführt werden, bevor die Funktion aktiviert wird. So ist insbesondere dann, wenn SQL Server-Administrator und Windows-Administrator nicht ein und dieselbe Person sind, eine Aufgabentrennung zwischen beiden Verwaltungsbereichen gewährleistet. Durch die Aktivierung von FILESTREAM auf Windows-Ebene wird ein Filtertreiber für das Dateisystem installiert. Diese Aufgabe ist dem Windows-Administrator vorbehalten. Unter Windows wird FILESTREAM durch die Installation von SQL Server 2008 oder mithilfe des SQL Server-Konfigurations-Managers aktiviert. Die Schritte lauten wie folgt: 1. 2. 3. 4. 5. 6. 7. 8. 16 Zeigen Sie im Menü Start auf Alle Programme, Microsoft SQL Server 2008 und auf Konfigurationstools, und klicken Sie dann auf SQL Server-Konfigurations-Manager. Klicken Sie in der Liste der Dienste mit der rechten Maustaste auf SQL Server Services, und klicken Sie dann auf Öffnen. Suchen Sie im Snap-In SQL Server-Konfigurations-Manager die SQL Server-Instanz, auf der FILESTREAM aktiviert werden soll. Klicken Sie mit der rechten Maustaste auf die Instanz, und klicken Sie dann auf Eigenschaften. Klicken Sie im Dialogfeld SQL Server-Eigenschaften auf die Registerkarte FILESTREAM. Aktivieren Sie das Kontrollkästchen FILESTREAM für Transact-SQL-Zugriff aktivieren. Wenn FILESTREAM-Daten unter Windows gelesen und geschrieben werden sollen, klicken Sie auf FILESTREAM für E/A-Streamingzugriff auf Datei aktivieren. Geben Sie den Namen der Windows-Freigabe in das Feld Windows-Freigabename ein. Wenn Remoteclients auf FILESTREAM-Daten auf dieser Freigabe zugreifen müssen, wählen Sie Streamingzugriff von Remoteclients auf FILESTREAM-Daten zulassen. 9. Klicken Sie auf Übernehmen. Die folgende Abbildung zeigt die in den Schritten beschriebene Registerkarte FILESTREAM. Abbildung 3: Konfigurieren von FILESTREAM mit dem SQL Server-Konfigurations-Manager Dieses Verfahren muss für jede SQL Server-Instanz ausgeführt werden, für die die FILESTREAMFunktion verwendet wird, bevor SQL Server darauf zugreifen kann. Zu diesem Zeitpunkt wird noch kein FILESTREAM-Datencontainer festgelegt. Dieser Schritt erfolgt beim Erstellen einer FILESTREAMDateigruppe in einer Datenbank, nachdem FILESTREAM in SQL Server aktiviert wurde. Der FILESTREAM-Zugriff unter Windows kann deaktiviert werden, auch wenn er in SQL Server aktiviert ist. Allerdings sind nach dem Neustart der SQL Server-Instanz keine FILESTREAM-Daten mehr verfügbar. Folgende Warnung wird eingeblendet. 17 Abbildung 4: Beim Deaktivieren von FILESTREAM mit dem SQL Server-Konfigurations-Manager angezeigte Warnung Konfigurieren von SQL Server für FILESTREAM Jede SQL Server-Instanz, für die FILESTREAM verwendet wird, muss sowohl unter Windows als auch in SQL Server separat konfiguriert werden. Nach der Aktivierung von FILESTREAM muss eine Datenbank für FILESTREAM-Daten konfiguriert werden, und erst danach können Tabellen mit FILESTREAM-Spalten definiert werden. In diesem Abschnitt wird beschrieben, wie FILESTREAM in SQL Server konfiguriert und wie FILESTREAM-aktivierte Datenbanken und Tabellen erstellt werden. Außerdem wird erläutert, wie FILESTREAM mit anderen Funktionen in SQL Server 2008 interagiert. Sicherheitsüberlegungen FILESTREAM erfordert integrierte Sicherheit (d. h. die Verwendung der Windows-Authentifizierung). Wenn eine Anwendung mit Win32 auf FILESTREAM-Daten zugreift, wird der Windows-Benutzer von SQL Server überprüft. Besitzt der Benutzer Transact-SQL-Zugriff auf FILESTREAM-Daten, wird der Zugriff ebenfalls auf Win32-Ebene gewährt, solange das Transaktionstoken im Sicherheitskontext des WindowsBenutzers abgerufen wird, der die Datei öffnet. Dass die Windows-Authentifizierung verwendet werden muss, ist auf die Datei-E/A-APIs von Windows zurückzuführen. Die einzige Möglichkeit, die Clientidentität während der Dateieingabe/-ausgabe von der Clientanwendung an SQL Server zu übergeben, besteht darin, das dem Clientthread zugeordnete Windows-Token zu verwenden. Der FILESTREAM-Datencontainer wird bei der Erstellung automatisch abgesichert, damit nur das SQL Server-Dienstkonto und Mitglieder der Gruppe builtin/Administrators auf dessen Verzeichnisstruktur zugreifen können. Der Inhalt des Datencontainers darf ausschließlich durch die unterstützten Transaktionsmethoden geändert werden, da jede andere Art der Änderung zur Beschädigung des Containers führt. Aktivieren von FILESTREAM in SQL Server Der zweite Schritt zur FILESTREAM-Aktivierung wird auf der SQL Server 2008-Instanz ausgeführt und sollte erst erfolgen, nachdem FILESTREAM auf der Windows-Ebene aktiviert und das NTFS-Volume zur Speicherung der FILESTREAM-Daten ausreichend vorbereitet wurde (wie oben unter „Konfigurieren von Windows für FILESTREAM“ beschrieben). Der FILESTREAM-Zugriff wird in SQL Server gesteuert, indem sp_configure mit filestream_access_level auf eine der folgenden drei Einstellungen festgelegt wird. Sie lauten: 18 0 = FILESTREAM-Unterstützung für diese Instanz deaktivieren 1 = FILESTREAM nur für Transact-SQL-Zugriff aktivieren 2 = FILESTREAM für Transact-SQL- und Win32-Streamingzugriff aktivieren Das folgende Beispiel veranschaulicht, wie FILESTREAM für den Transact-SQL- und Win32Streamingzugriff aktiviert wird. EXEC sp_configure filestream_access_level, 2; GO RECONFIGURE; GO Die RECONFIGURE-Anweisung ist erforderlich, damit der neu konfigurierte Wert wirksam wird. Wenn FILESTREAM noch nicht unter Windows aktiviert wurde und der oben gezeigte Code ausgeführt wird, bleibt die Funktion in SQL Server deaktiviert. Der aktuell konfigurierte Wert kann mithilfe des folgenden Codes ermittelt werden. EXEC sp_configure filestream_access_level; GO Wenn FILESTREAM unter Windows nicht konfiguriert ist, unterscheidet sich der „config_value“ im sp_configure-Resultset nach Ausführung der RECONFIGURE-Anweisung vom „run_value“ (und lautet 0). Erstellen einer für FILESTREAM aktivierten Datenbank Sobald FILESTREAM für Windows und SQL Server aktiviert wurde, kann ein FILESTREAM-Datencontainer definiert werden. Dazu wird eine FILESTREAM-Dateigruppe in einer Datenbank angelegt. Zwischen FILESTREAM-Dateigruppen und FILESTREAM-Datencontainern besteht eine 1:1-Beziehung. Eine FILESTREAM-Dateigruppe kann beim Erstellen der Datenbank oder separat mithilfe einer ALTER DATABASE-Anweisung definiert werden. Im folgenden Beispiel wird eine FILESTREAM-Dateigruppe in einer bereits bestehenden Datenbank erstellt. ALTER DATABASE Production ADD FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM; GO 19 Die CONTAINS FILESTREAM-Klausel ist notwendig, um die neue Dateigruppe von regulären Datenbank-Dateigruppen zu unterscheiden. Ist die FILESTREAM-Funktion deaktiviert, verursacht die Anweisung folgenden Fehler. Meldung 5591, Ebene 16, Status 3, Zeile 1 Die FILESTREAM-Funktion ist deaktiviert. Die Dateigruppe wird erstellt, wenn FILESTREAM unter Windows und in SQL Server aktiviert ist. Jetzt wird der FILESTREAM-Datencontainer definiert, indem der Dateigruppe eine einzelne Datei hinzugefügt wird. Der angegebene Pfadname entspricht dem Verzeichnis, das als Stamm des Datencontainers erstellt wird. Der vollständige Pfadname muss bis auf den Namen des letzten Verzeichnisses bereits bestehen. Im folgenden Beispiel wird der Datencontainer für die zuvor erstellte FileStreamGroup1Dateigruppe definiert. ALTER DATABASE Production ADD FILE ( NAME = FSGroup1File, FILENAME = 'F:\Production\FSDATA') TO FILEGROUP FileStreamGroup1; GO An diesem Punkt wird das Verzeichnis FSDATA erstellt. Es ist abgesehen von zwei Elementen leer: Der Datei filestream.hdr mit den FILESTREAM-Metadaten für den Datencontainer. Dem Verzeichnis $FSLOG, das für FILESTREAM die gleiche Funktion wie ein Datenbank- Transaktionsprotokoll hat. Eine Datenbank kann mehrere FILESTREAM-Dateigruppen enthalten, was z. B. hilfreich ist, wenn die BLOB-Speicherung für mehrere Tabellen in der Datenbank getrennt erfolgen soll. Erstellen einer Tabelle zum Speichern von FILESTREAM-Daten Sobald die Datenbank eine FILESTREAM-Dateigruppe aufweist, können Tabellen mit FILESTREAMSpalten erstellt werden. Wie bereits erwähnt, wird eine FILESTREAM-Spalte als varbinary(max)-Spalte definiert, die über das FILESTREAM-Attribut verfügt. Im folgenden Code wird eine Tabelle mit einer einzelnen FILESTREAM-Spalte erstellt. 20 USE Production; GO CREATE TABLE DocumentStore ( DocumentID INT IDENTITY PRIMARY KEY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID ()) FILESTREAM_ON FileStreamGroup1; GO Eine Tabelle kann über mehrere FILESTREAM-Spalten verfügen, die Daten sämtlicher FILESTREAMSpalten in einer Tabelle müssen aber in derselben FILESTREAM-Dateigruppe gespeichert sein. Wird die FILESTREAM_ON-Klausel nicht angegeben, wird die als Standardgruppe festgelegte FILESTREAMDateigruppe verwendet. Diese Konfiguration kann unbeabsichtigt sein und zu Leistungsproblemen führen. Nachdem die Tabelle erstellt wurde, enthält der FILESTREAM-Datencontainer ein weiteres Verzeichnis für die Tabelle sowie ein Unterverzeichnis, das der FILESTREAM-Spalte in der Tabelle entspricht. Im Unterverzeichnis werden die Datendateien gespeichert, sobald die Tabelle mit Daten aufgefüllt wird. Die Verzeichnisstruktur variiert je nachdem, wie viele FILESTREAM-Spalten in einer Tabelle enthalten sind und ob die Tabelle partitioniert ist. Damit eine Tabelle FILESTREAM-Spalten aufnehmen kann, muss sie zusätzlich über eine Spalte mit dem Datentyp uniqueidentifier verfügen, der das ROWGUIDCOL-Attribut aufweist. Diese Spalte darf keine NULL-Werte zulassen und muss eine UNIQUE- oder PRIMARY KEY-Einschränkung für einzelne Spalten aufweisen. Der GUID-Wert für die Spalte muss entweder durch eine Anwendung beim Einfügen von Daten oder durch eine DEFAULT-Einschränkung angegeben werden, die die NEWID()-Funktion nutzt (bzw. die NEWSEQUENTIALID()-Funktion, falls die Mergereplikation konfiguriert ist, wie im Abschnitt „Zusammenwirken mit anderen Funktionen und Einschränkungen“ weiter unten beschrieben). Weitere Informationen dazu, welche Details und Einschränkungen beim erforderlichen Tabellenschema sowie bei den Optionen zu beachten sind, finden Sie in der SQL Server 2008-Onlinedokumentation unter dem Thema „CREATE TABLE (Transact-SQL)“ (http://msdn.microsoft.com/de-de/library/ms174979.aspx). Konfigurieren der FILESTREAM-Garbage Collection Die FILESTREAM-Datendateien im FILESTREAM-Datencontainer unterstützen keine Teilupdates. Daher bewirkt jede Änderung an den BLOB-Daten in der FILESTREAM-Spalte, dass eine völlig neue FILESTREAM-Datendatei erstellt wird. Die alte Datei muss so lange vorgehalten werden, bis sie nicht mehr für Wiederherstellungen benötigt wird. Genauso werden Dateien beibehalten, die gelöschte FILESTREAM-Daten darstellen, oder eingefügte FILESTREAM-Daten, für die ein Rollback ausgeführt wurde. 21 Nicht mehr benötigte Dateien werden durch eine Garbage Collection entfernt. Die Bereinigung läuft – anders als in Windows SharePoint® Services, in denen die Garbage Collection im externen BLOBSpeicher manuell implementiert werden muss – völlig automatisch ab. Alle FILESTREAM-Dateivorgänge werden einer Protokollfolgenummer (Log Sequence Number, LSN) im Datenbank-Transaktionsprotokoll zugeordnet. Solange das Transaktionsprotokoll nach der LSN des FILESTREAM-Vorgangs abgeschnitten wurde, wird die Datei nicht mehr benötigt und kann speicherbereinigt werden. Wird das Transaktionsprotokoll aus bestimmten Gründen nicht abgeschnitten, kann eine FILESTREAM-Datei nicht physisch gelöscht werden. Einige Beispiele: Protokollsicherungen wurden nicht mit dem FULL- oder BULK_LOGGEDWiederherstellungsmodell ausgeführt Es liegt eine aktive Transaktion mit langer Ausführungszeit vor Der Protokollleserauftrag für die Replikation wurde nicht ausgeführt Die FILESTREAM-Garbage Collection wird im Hintergrund ausgeführt und vom DatenbankPrüfpunktprozess ausgelöst. Sobald das Transaktionsprotokoll eine bestimmte Größe erreicht hat, wird automatisch ein Prüfpunkt ausgeführt. Weitere Informationen finden Sie in der SQL Server 2008Onlinedokumentation unter dem Thema „CHECKPOINT und der aktive Abschnitt des Protokolls“ (http://msdn.microsoft.com/de-de/library/ms189573.aspx). Da FILESTREAM-Dateivorgänge nur in sehr geringem Umfang im Transaktionsprotokoll der Datenbank aufgezeichnet werden, kann es einige Zeit dauern, bis die im Transaktionsprotokoll generierten Datensätze einen Prüfpunktprozess auslösen und der Speicher automatisch bereinigt wird. Falls dies ein Problem darstellt, kann die Garbage Collection mit der CHECKPOINT-Anweisung erzwungen werden. Überlegungen zur Partitionierung Wenn die Tabelle mit den FILESTREAM-Daten partitioniert ist, muss mithilfe der FILESTREAM_ONKlausel ein für FILESTREAM-Dateigruppen und die tabelleneigene Partitionierungsfunktion geeignetes Partitionierungsschema angegeben werden. Dies liegt daran, dass das übliche Partitionierungsschema auf regulären Dateigruppen basiert, die nicht zum Speichern von FILESTREAM-Daten verwendet werden können. In der (entweder mit einer CREATE TABLE- oder CREATE CLUSTERED INDEX … WITH DROP_EXISTING-Anweisung angegebenen) Tabellendefinition sind dann beide Partitionierungsschemas aufgeführt. Das FILESTREAM-Partitionierungsschema kann vorsehen, dass alle Partitionen derselben Dateigruppe zugeordnet werden. Davon wird allerdings abgeraten, da Leistungsprobleme auftreten können. Der folgende exemplarische Code veranschaulicht die Syntax. CREATE PARTITION FUNCTION DocPartFunction (INT) AS RANGE RIGHT FOR VALUES (100000, 200000); GO 22 CREATE PARTITION SCHEME DocPartScheme AS PARTITION DocPartFunction TO (Data_FG1, Data_FG2, Data_FG3); GO CREATE PARTITION SCHEME DocFSPartScheme AS PARTITION DocPartFunction TO (FS_FG1, FS_FG2, FS_FG3); GO CREATE TABLE DocumentStore ( DocumentID INT IDENTITY PRIMARY KEY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID () ON Data_FG1) ON DocPartScheme (DocumentID) FILESTREAM_ON DocFSPartScheme; GO Hinweis: Damit die DocumentID-Spalte als Partitionierungsspalte verwendet werden kann, muss der zugrunde liegende, nicht gruppierte Index, der die UNIQUE-Einschränkung für DocGUID erzwingt, explizit in eine Dateigruppe eingefügt werden. Nur so kann die DocumentID-Spalte als Partitionierungsspalte fungieren. Dies bedeutet, dass Partitionswechsel nur möglich sind, wenn die UNIQUE-Einschränkungen, die nicht ausgerichtete Indizes darstellen, vor dem Partitionswechsel deaktiviert und danach wieder aktiviert werden. Im weiteren Verlauf des Codebeispiels wird eine Tabelle erstellt und ein Partitionswechsel versucht. CREATE TABLE NonPartitionedDocumentStore ( DocumentID INT IDENTITY PRIMARY KEY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID ()); 23 GO ALTER TABLE DocumentStore SWITCH PARTITION 2 TO NonPartitionedDocumentStore; GO Beim Partitionswechsel wird folgende Fehlermeldung angezeigt. Meldung 7733, Ebene 16, Status 4, Zeile 1 Fehler bei der ALTER TABLE SWITCH-Anweisung. Das Tabellenobjekt 'FileStreamTestDB.dbo.DocumentStore' ist partitioniert, während das Indexobjekt 'UQ_Document_8CC1617F60ED59' nicht partitioniert ist. Mit folgendem Code wird der eindeutige Index in der Quelltabelle deaktiviert und der Versuch wiederholt. ALTER INDEX [UQ__Document__8CC331617F60ED59] ON DocumentStore DISABLE; GO ALTER TABLE FileStreamTest3 SWITCH PARTITION 2 TO NonPartitionedFileStreamTest3; GO Auch dieser Versuch verursacht einen Fehler. Meldung 4947, Ebene 16, Status 1, Zeile 1 Fehler bei der ALTER TABLE SWITCH-Anweisung. In der FileStreamTestDB.dbo.DocumentStore-Quelltabelle ist kein identischer Index für den UQ_NonParti_8CC3316103317E3D-Index in der FileStreamTestDB.dbo.NonPartitionedDocumentStore-Zieltabelle vorhanden. Der eindeutige Index in der partitionierten und in der nicht partitionierten Tabelle müssen deaktiviert werden, bevor der Wechsel erfolgreich ausgeführt wird. ALTER INDEX [UQ__NonParti__8CC3316103317E3D] ON NonPartitionedDocumentStore DISABLE; GO 24 ALTER TABLE DocumentStore SWITCH PARTITION 2 TO NonPartitionedDocumentStore; GO ALTER INDEX [UQ__NonParti__8CC3316103317E3D] ON NonPartitionedDocumentStore REBUILD WITH (ONLINE = ON); ALTER INDEX [UQ__Document__8CC331617F60ED59] ON NonPartitionedDocumentStore REBUILD WITH (ONLINE = ON); GO Weitere Informationen zur Partitionierung von FILESTREAM-Daten werden im nächsten Whitepaper zur Partitionierung in SQL Server 2008 aufgegriffen. Lastenausgleich bei FILESTREAM-Daten Mithilfe der Partitionierung kann auch ein Tabellenschema entworfen werden, das die grobe Aufteilung der FILESTREAM-Datenlast auf mehrere Volumes unterstützt. So lassen sich beispielsweise Hardwareeinschränkungen umgehen und Hotspots in Tabellen auf unterschiedlichen Volumes speichern. Der folgende Code enthält eine Partitionierungsfunktion sowie ein auf der uniqueidentifier-Spalte basierendes Schema, durch das die FILESTREAM-Daten effektiv auf 16 Volumes und die strukturierten Daten mittels Striping auf zwei Dateigruppen verteilt werden. USE master; GO -- Datenbank erstellen CREATE DATABASE Production ON PRIMARY (NAME = 'Production', FILENAME = 'E:\Production\Production.mdf'), FILEGROUP DataFilegroup1 (NAME = 'Data_FG1', FILENAME = 'F:\Production\Data_FG1.ndf'), FILEGROUP DataFilegroup2 (NAME = 'Data_FG2', FILENAME = 'G:\Production\Data_FG2.ndf'), 25 FILEGROUP FSFilegroup0 CONTAINS FILESTREAM (NAME = 'FS_FG0', FILENAME = 'H:\Production\FS_FG0'), FILEGROUP FSFilegroup1 CONTAINS FILESTREAM (NAME = 'FS_FG1', FILENAME = 'I:\Production\FS_FG1'), FILEGROUP FSFilegroup2 CONTAINS FILESTREAM (NAME = 'FS_FG2', FILENAME = 'J:\Production\FS_FG2'), FILEGROUP FSFilegroup3 CONTAINS FILESTREAM (NAME = 'FS_FG3', FILENAME = 'K:\Production\FS_FG3'), FILEGROUP FSFilegroup4 CONTAINS FILESTREAM (NAME = 'FS_FG4', FILENAME = 'L:\Production\FS_FG4'), FILEGROUP FSFilegroup5 CONTAINS FILESTREAM (NAME = 'FS_FG5', FILENAME = 'M:\Production\FS_FG5'), FILEGROUP FSFilegroup6 CONTAINS FILESTREAM (NAME = 'FS_FG6', FILENAME = 'N:\Production\FS_FG6'), FILEGROUP FSFilegroup7 CONTAINS FILESTREAM (NAME = 'FS_FG7', FILENAME = 'O:\Production\FS_FG7'), FILEGROUP FSFilegroup8 CONTAINS FILESTREAM (NAME = 'FS_FG8', FILENAME = 'P:\Production\FS_FG8'), FILEGROUP FSFilegroup9 CONTAINS FILESTREAM (NAME = 'FS_FG9', FILENAME = 'Q:\Production\FS_FG9'), FILEGROUP FSFilegroupA CONTAINS FILESTREAM (NAME = 'FS_FGA', FILENAME = 'R:\Production\FS_FGA'), FILEGROUP FSFilegroupB CONTAINS FILESTREAM (NAME = 'FS_FGB', FILENAME = 'S:\Production\FS_FGB'), FILEGROUP FSFilegroupC CONTAINS FILESTREAM (NAME = 'FS_FGC', FILENAME = 'T:\Production\FS_FGC'), FILEGROUP FSFilegroupD CONTAINS FILESTREAM (NAME = 'FS_FGD', FILENAME = 'U:\Production\FS_FGD'), 26 FILEGROUP FSFilegroupE CONTAINS FILESTREAM (NAME = 'FS_FGE', FILENAME = 'V:\Production\FS_FGE'), FILEGROUP FSFilegroupF CONTAINS FILESTREAM (NAME = 'FS_FGF', FILENAME = 'W:\Production\FS_FGF'); GO USE Production; GO -- Partitionsfunktion auf Grundlage der letzten 6 Bytes der GUID erstellen CREATE PARTITION FUNCTION LoadBalance_PF (UNIQUEIDENTIFIER) AS RANGE LEFT FOR VALUES ( CONVERT (uniqueidentifier, '00000000-0000-0000-0000-100000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-200000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-300000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-400000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-500000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-600000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-700000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-800000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-900000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-a00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-b00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-c00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-d00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-e00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-f00000000000')); 27 GO -- FILESTREAM-Partitionierungsschema erstellen, das die Zuordnung zu 16 FILESTREAMDateigruppen ermöglicht CREATE PARTITION SCHEME LoadBalance_FS_PS AS PARTITION LoadBalance_PF TO ( FSFileGroup0, FSFileGroup1, FSFileGroup2, FSFileGroup3, FSFileGroup4, FSFileGroup5, FSFileGroup6, FSFileGroup7, FSFileGroup8, FSFileGroup9, FSFileGroupA, FSFileGroupB, FSFileGroupC, FSFileGroupD, FSFileGroupE, FSFileGroupF); GO -- Datenpartitionierungsschema für die Roundrobin-Zuordnung zwischen zwei Dateigruppen erstellen CREATE PARTITION SCHEME LoadBalance_Data_PS AS PARTITION LoadBalance_PF TO ( DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2); GO -- Partitionierte Tabelle erstellen CREATE TABLE DocumentStore ( DocumentID INT IDENTITY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL DEFAULT NEWID (), 28 CONSTRAINT DocStorePK PRIMARY KEY CLUSTERED (DocGUID), CONSTRAINT DocStoreU UNIQUE (DocGUID)) ON LoadBalance_Data_PS (DocGUID) FILESTREAM_ON LoadBalance_FS_PS; GO Der Lastenausgleich kann mit folgendem Code auf einfache Weise getestet werden. SET NOCOUNT ON; GO -- 10.000 Zeilen zum Testen des Lastenausgleichs einfügen DECLARE @count INT = 0; WHILE (@count < 10000) BEGIN INSERT INTO DocumentStore DEFAULT VALUES; SET @count = @count + 1; END; GO -- Verteilung überprüfen SELECT COUNT ($PARTITION.LoadBalance_PF (DocGUID)) FROM DocumentStore GROUP BY $PARTITION.LoadBalance_PF (DocGUID); GO Bei einem Probedurchlauf ergab der Test 631, 641, 661, 640, 649, 637, 618, 618, 576, 608, 595, 645, 640, 616, 602 und 623 Zeilen verteilt auf die FILESTREAM-Dateigruppen FS_FG0 bis FS_FGF. 29 Zusammenwirken mit anderen Funktionen und Einschränkungen Da die FILESTREAM-Funktion Daten im Dateisystem speichert, sind bei der Verwendung von FILESTREAM zusammen mit anderen SQL Server-Funktionen einige Einschränkungen zu berücksichtigen. Dieser Abschnitt bietet eine Übersicht über die Funktionskombinationen, die besonderer Beachtung bedürfen. Weitere Informationen finden Sie in der SQL Server 2008-Onlinedokumentation unter dem Thema „FILESTREAM-Kompatibilität mit anderen SQL Server-Funktionen“ (http://msdn.microsoft.com/de-de/library/bb895334.aspx). Replikation Sowohl die Transaktionsreplikation als auch die Mergereplikation unterstützen FILESTREAM-Daten, allerdings mit einigen Einschränkungen: Wenn die Replikationstopologie Instanzen mit unterschiedlichen SQL Server-Versionen umfasst, ist die Kapazität der an die Downlevelinstanzen übertragbaren Daten begrenzt. Die Replikationsfilteroptionen bestimmen, ob das FILESTREAM-Attribut bei der Transaktionsreplikation repliziert wird oder nicht. Der maximale varbinary(max)-Datenwert, der bei der Transaktionsreplikation ohne Replikation des FILESTREAM-Attributs repliziert werden kann, beträgt 2 GB. Bei der Mergereplikation ist sowohl für die Replikation als auch für FILESTREAM eine uniqueidentifier-Spalte erforderlich. Bei Verwendung der Mergereplikation erfordert das Tabellenschema besondere Aufmerksamkeit, da die GUIDs sequenziell sein müssen (d. h., NEWSEQUENTIALID() sollte anstelle von NEWID() verwendet werden). Datenbankspiegelung FILESTREAM wird von der Datenbankspiegelung nicht unterstützt. Auf dem Prinzipalserver kann keine FILESTREAM-Dateigruppe erstellt werden. Die Datenbankspiegelung kann nicht für eine Datenbank konfiguriert werden, die FILESTREAM-Dateigruppen enthält. Verschlüsselung FILESTREAM-Daten können nicht mithilfe der Verschlüsselungsmethoden von SQL Server verschlüsselt werden. FILESTREAM-Daten werden bei der transparenten Datenverschlüsselung nicht verschlüsselt. Failoverclustering Das Failoverclustering bietet umfassende FILESTREAM-Unterstützung. FILESTREAM muss für alle Knoten im Cluster auf Windows-Ebene aktiviert sein, und FILESTREAM-Datencontainer müssen im freigegebenen Speicher enthalten sein, damit die Daten für alle Knoten verfügbar sind. Weitere Informationen finden Sie in der SQL Server 2008-Onlinedokumentation unter dem Thema: „Vorgehensweise: Einrichten von FILESTREAM auf einem Failovercluster“ (http://msdn.microsoft.com/ de-de/library/cc645886.aspx). Volltext Die Volltextindizierung funktioniert bei einer FILESTREAM-Spalte genauso wie bei einer varbinary(max)Spalte. Die Tabelle muss über eine zusätzliche Spalte verfügen, in der die Dateinamenerweiterung für die in der FILESTREAM-Spalte gespeicherten BLOB-Daten enthalten ist. 30 Datenbankmomentaufnahmen SQL Server unterstützt keine Datenbankmomentaufnahmen für FILESTREAM-Datencontainer. Wenn eine FILESTREAM-Datendatei in eine CREATE DATABASE ON-Klausel eingeschlossen wird, verursacht die Anweisung einen Fehler. Selbst wenn eine Datenbank FILESTREAM-Daten enthält, kann weiterhin eine Datenbankmomentaufnahme der regulären Dateigruppen erstellt werden. In diesem Fall wird eine Warnmeldung zurückgegeben, und die FILESTREAM-Dateigruppen werden in der Datenbankmomentaufnahme als offline markiert. Abfragen der Datenbankmomentaufnahme funktionieren erwartungsgemäß, solange kein FILESTREAM-Datenzugriff erforderlich ist. In diesem Fall wird ein Fehler ausgegeben. Eine Datenbank, die FILESTREAM-Daten enthält, kann nicht von einer Momentaufnahme wiederhergestellt werden, weil nicht festgestellt werden kann, welchen Status die FILESTREAM-Daten zum Zeitpunkt der Datenbankmomentaufnahme hatten. Sichten, Indizes, Statistiken, Trigger und Einschränkungen FILESTREAM-Spalten können weder als Teil eines Indexschlüssels noch als INCLUDE-Spalte in einem nicht gruppierten Index angegeben werden. Zwar kann eine berechnete Spalte definiert werden, die auf eine FILESTREAM-Spalte verweist, allerdings kann die berechnete Spalte nicht indiziert werden. Für FILESTREAM-Spalten können keine Statistiken erstellt werden. Für FILESTREAM-Spalten können keine PRIMARY KEY-, FOREIGN KEY- und UNIQUE-Einschränkungen erstellt werden. Indizierte Sichten können im Gegensatz zu nicht indizierten Sichten keine FILESTREAM-Spalten enthalten. Für Tabellen mit FILESTREAM-Spalten können keine INSTEAD OF-Trigger definiert werden. Isolationsstufen Beim Zugriff auf FILESTREAM-Daten über die Win32-APIs wird ausschließlich die READ COMMITTEDIsolationsstufe unterstützt. Der Transact-SQL-Zugriff unterstützt zusätzlich die REPEATABLE READ- und SERIALIZABLE-Isolationsstufen. Darüber hinaus lässt der Transact-SQL-Zugriff Dirty Reads über die READ UNCOMMITTED-Isolationsstufe bzw. den NOLOCK-Abfragehinweis zu. In der Ausführung befindliche Updates von FILESTREAM-Daten sind bei dieser Zugriffsart jedoch nicht sichtbar. Sicherung und Wiederherstellung FILESTREAM unterstützt alle Sicherungs- und Wiederherstellungsmodelle (vollständig, differenziell und protokollgestützt). Wird in einem Notfallszenario für BACKUP oder RESTORE die CONTINUE_AFTER_ERROR-Option angegeben, werden die FILESTREAM-Daten (ähnlich wie bei der Wiederherstellung regulärer Daten mit CONTINUE_AFTER_ERROR) möglicherweise nicht vollständig wiederhergestellt. Sicherheit Falls Win32-Zugriff auf FILESTREAM-Daten erforderlich ist, muss die SQL Server-Instanz für integrierte Sicherheit konfiguriert werden. 31 Protokollversand Der Protokollversand bietet FILESTREAM-Unterstützung. Sowohl auf dem primären als auch auf dem sekundären Server muss SQL Server 2008 oder höher ausgeführt werden, und FILESTREAM muss auf Windows-Ebene aktiviert sein. SQL Server Express SQL Server Express unterstützt FILESTREAM. Die auf 4 GB beschränkte Datenbankgröße gilt nicht für den FILESTREAM-Datencontainer. Wenn FILESTREAM-Daten jedoch mit Service Broker an die SQL Server Express-Instanz gesendet werden, ist zu bedenken, dass das Speichern von FILESTREAM-Daten in der Übertragungs- oder Zielwarteschlange von Service Broker nicht unterstützt wird. Falls eine der Warteschlangen anwächst, kann das 4 GB-Datenbanklimit folglich erreicht werden. In diesem Fall empfiehlt sich ein alternatives Schema, bei dem Service Broker lediglich Benachrichtigungen überträgt, dass FILESTREAM-Daten gesendet oder empfangen werden müssen. Die eigentliche Übertragung der FILESTREAM-Daten findet dann über einen Remotezugriff mittels FILESTREAM-Freigabe des FILESTREAM-Datencontainers statt, der auf der SQL Server Express-Instanz eingerichtet wurde. Überlegungen zur Leistungsoptimierung und Vergleichstests Bei der Optimierung einer FILESTREAM-Arbeitsauslastung sind einige wichtige Faktoren zu beachten: Die Hardware muss ordnungsgemäß für FILESTREAM konfiguriert sein Die Generierung von 8.3-Namen muss in NTFS deaktiviert sein Die Nachverfolgung der Zugriffszeiten muss in NTFS deaktiviert sein Das Volume mit dem FILESTREAM-Datencontainer darf nicht fragmentiert sein Die BLOB-Datengröße muss für die Speicherung mit FILESTREAM geeignet sein Die FILESTREAM-Datencontainer müssen über eigene, dedizierte Volumes verfügen Auch die Puffergröße des zum Puffern von FILESTREAM-Datenlesevorgängen verwendeten SMBProtokolls sollte nicht außer Acht gelassen werden. In Tests unter Verwendung von Windows Server® 2003 konnte mit umfangreicheren Puffergrößen (einem Vielfachen von ca. 60 KB) ein besserer Durchsatz erzielt werden. Möglicherweise lässt sich die Effizienz unter anderen Betriebssystemen mit größeren Puffergrößen steigern. Beim Vergleich einer (bereits optimierten) FILESTREAM-Arbeitsauslastung mit anderen Speicheroptionen kommen weitere Überlegungen in Betracht: 32 Speicherhardware und RAID-Stufe müssen bei beiden Lösungen identisch sein Die Volumes müssen über dieselbe Komprimierungseinstellung verfügen Es muss berücksichtigt werden, ob FILESTREAM basierend auf der verwendeten API und den konfigurierten Optionen Write-Throughs ausführt Überlegungen zur Datenmigration Ein übliches Szenario für SQL Server 2008 ist die Migration vorhandener BLOB-Daten in den FILESTREAM-Speicher. Geeignete Tools zu empfehlen bzw. Migrationscode bereitzustellen, ist in diesem Whitepaper nicht beabsichtigt, dennoch dürfte der folgende einfache Workflow hilfreich sein: Lesen Sie die Informationen über die mit FILESTREAM zu verwendenden Datenmengen, um sicherzustellen, dass die durchschnittlichen Datenmengen für die FILESTREAM-Speicherung geeignet sind. Lesen Sie die Erläuterungen zur Kompatibilität mit anderen Funktionen und zu den Einschränkungen, um sicherzustellen, dass die FILESTREAM-Speicherung sämtlichen Anwendungsanforderungen gerecht wird. Befolgen Sie die Empfehlungen im Abschnitt „Überlegungen zur Leistungsoptimierung und Vergleichstests“ weiter oben. Achten sie darauf, dass die SQL Server-Instanz mit integrierter Sicherheit konfiguriert ist und dass FILESTREAM auf Windows- und SQL Server-Ebene aktiviert wurde. Vergewissern Sie sich, dass der Zielspeicherort für den FILESTREAM-Datencontainer genügend Kapazität zur Speicherung der migrierten BLOB-Daten aufweist. Erstellen Sie die erforderlichen FILESTREAM-Dateigruppen. Duplizieren Sie die verwendeten Tabellenschemas, und ändern Sie die erforderlichen BLOBSpalten in FILESTREAM-Spalten. Migrieren Sie alle Nicht-BLOB-Daten zum neuen Schema. Migrieren Sie alle BLOB-Daten zu den neuen FILESTREAM-Spalten. Best Practices zur Verwendung von FILESTREAM In diesem Abschnitt sind Best Practices zusammengefasst, die sowohl in internen als auch in unabhängigen Tests der FILESTREAM-Vorabversion gesammelt wurden. Da Best Practices naturgemäß verallgemeinerte Zusammenhänge darstellen, müssen sie nicht unbedingt auf jedes Szenario zutreffen. Die Empfehlungen lauten wie folgt (in willkürlicher Reihenfolge): 33 Es sollte vermieden werden, kleine Datenmengen einzeln an eine FILESTREAM-Datei anzufügen, da bei jedem Anfügen eine völlig neue FILESTREAM-Datei erstellt wird, was bei großen FILESTREAM-Dateien kostspielig werden kann. Vielmehr sollten mehrere Anfügevorgänge in einer varbinary(max)-Spalte gebündelt und erst bei Erreichen eines Größenlimits an die FILESTREAM-Spalte angefügt werden. Bei einer Schreibarbeitslast mit starkem Multithreading kann der AllocationSize-Parameter für die OpenSqlFilestream- oder SqlFilestream-API festgelegt werden. Durch die anfängliche Verwendung größerer Zuordnungen verringert sich das Fragmentierungsrisiko auf Dateisystemebene, und zwar insbesondere in Verbindung mit einem großen NTFS-Cluster (wie oben beschrieben). Bei großen FILESTREAM-Dateien sollten Transact-SQL-Updates vermieden werden, durch die Daten am Dateianfang bzw. -ende angefügt werden, da die Daten (normalerweise) zunächst in tempdb und dann zurück in eine neue physische Datei gespoolt werden, was die Leistung beeinträchtigt. Beim Lesen von FILESTREAM-Werten sollte Folgendes berücksichtigt werden: o Wenn nur die ersten Bytes gelesen werden müssen, sollten Sie mit Teilzeichenfolgen arbeiten. o Muss die gesamte Datei gelesen werden, empfiehlt sich der Win32-Zugriff. o o o Wenn Dateibereiche nach dem Zufallsprinzip gelesen werden sollen, könnten Sie das Dateihandle mit SetFilePointer öffnen. Soll eine vollständige Datei gelesen werden, geben Sie das FILE_SEQUENTIAL_ONLYFlag an. Verwenden Sie Puffergrößen, die ein Vielfaches von 60 KB (wie zuvor beschrieben) sind. Die Größe einer FILESTREAM-Datei kann ermittelt werden, ohne ein Dateihandle zu öffnen. Dazu fügen Sie der Tabelle, in der die FILESTREAM-Dateigröße gespeichert wird, eine permanent berechnete Spalte hinzu. Die berechnete Spalte wird aktualisiert, während die Datei bereits für Schreibvorgänge geöffnet ist. Schlussfolgerung In diesem Whitepaper wurde die FILESTREAM-Funktion von SQL Server 2008 beschrieben. Die kombinierte Verwendung von SQL Server 2008 und NTFS-Dateisystem ermöglicht neben der Speicherung auch den effizienten Zugriff auf BLOB-Daten. Im Anschluss sollen die wichtigsten Ergebnisse dieses Whitepapers zusammengefasst werden. Die FILESTREAM-Speicherung ist nicht immer die beste Wahl. Das Funktionsverhalten und bisherige Erfahrungen mit FILESTREAM besagen, dass BLOB-Daten ab einer Größe von 1 MB, auf die nicht über Transact-SQL zugegriffen wird, am besten als FILESTREAM-Daten geeignet sind. Auch die zusätzliche Arbeitslast durch Updates sollte nicht außer Acht gelassen werden, weil bei jedem Teilupdate einer FILESTREAM-Datei eine vollständige Kopie der Datei generiert wird. Besonders hohe Updatelasten können die Leistung beeinträchtigen und sprechen gegen FILESTREAM. Um eine erfolgreiche Bereitstellung zu gewährleisten, sollten Sie genau wissen, mit welchen Funktionen FILESTREAM kombiniert werden kann. Für FILESTREAM-Daten können unter SQL Server 2008 RTM beispielsweise keine Datenbankspiegelung und Momentaufnahmeisolation verwendet werden. Die kombinierte Verwendung mit anderen Funktionen ist meist möglich, zeitweise jedoch eingeschränkt (z. B. bei der Replikation). Dieses Whitepaper enthält keine systematische Aufstellung der Funktionen und Kompatibilitäten. Vor der Bereitstellung sollten Sie die neuesten Artikel in der SQL Server-Onlinedokumentation konsultieren, insbesondere da sich einige Einschränkungen u. U. erst in zukünftigen Versionen manifestieren. Bleibt noch zu sagen, dass die FILESTREAM-Leistung ohne die erforderliche Konfiguration auf Windows- und SQL Server-Ebene hinter den Erwartungen zurückbleiben kann. Die oben beschriebenen Best Practices und Konfigurationsinformationen sollen helfen, Leistungsprobleme im Vorfeld zu vermeiden. 34 Weitere Informationen: http://www.microsoft.com/sqlserver/: SQL Server-Website http://technet.microsoft.com/de-de/sqlserver/: SQL Server TechCenter http://msdn.microsoft.com/de-de/sqlserver/: SQL Server DevCenter War dieses Dokument hilfreich? Geben Sie uns Ihr Feedback. Bewerten Sie dieses Dokument auf einer Skala von 1 (schlecht) bis 5 (ausgezeichnet), und begründen Sie Ihre Bewertung. Beispiel: Bewerten Sie es hoch aufgrund guter Beispiele, ausgezeichneter Screenshots, klarer Formulierungen oder aus einem anderen Grund? Bewerten Sie es niedrig aufgrund schlechter Beispiele, ungenauer Screenshots oder unklarer Formulierungen? Dieses Feedback hilft uns, die Qualität von veröffentlichten Whitepapers zu verbessern. Feedback senden 35