RA_Spicker
Werbung

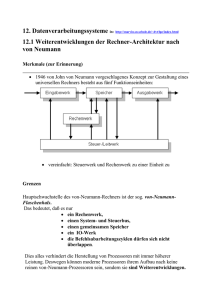
Architekturen RISC (reduced instruction set computer): min. Anzahl an Befehlen im Befehlssatz (-> fest verdrahtete Logik); 1. Load-Store-GPR-Architektur: Verarbeitungsbefehle greifen nur auf Universalregister zu; es können nur L/S Befehle auf Speicher zugreifen ||| 2. Befehlsformat fester Länge: Register mit gleicher Funktion werden dabei an die gleiche Stelle kodiert -> erleichtert das Pipelining da stelle des nächsten OP-Codes vor IDPhase bekannt ist ||| 3. fest verdrahtete Steuerung ohne microcode: mit maximaler Taktfrequenz möglich (1. und 2., einfache Adressierungsarten) ||| 4. überwiegend Ein-Zyklus-Ops: ermöglicht durch Pipelining und optimierte Compiler ||| 5. kleinere Chip-Fläche, höhere Ausbeute, kürzere Entwicklungszeit: durch geringere HW des Prozessors, mehr Platz für Cache CISC (complex ISC): komplexe Befehle möglich (-> Mikroprogrammsteuerung) Leistungsbewertung IPS (instr/s): (+) einfache Bestimmung, da alle Instr. gezählt werden ||| (-) gleiche Bewertung von Befehlen untersch. Laufzeiten -> IPS-Wert sehr abh. von der Befehlszusammensetzung der Befehlsroutine, Zerlegung der CISC-Befehele unterscheidet sich stark IOPS (int-ops/s): (+) Zerlegung spielt geringere Rolle da bspw. load und store ops nicht mitgezählt werden ||| (-) arithm OPs werden gleich bewertet, abh. von der IU-Anzahl auf der CPU, Relevanz abh. vom Einsatzzweck (häufig Gleitkommazahlen mit hoher Genauigkeit von Bedeutung) FLOPS: (+) weit verbreitet, viele Benchmarks ||| (-) siehe IOPS IOOPS (input/output ops/s): total IOOPS (alle), Read/Write, sequentiell oder random Zugriffe ||| (+) Metrik entscheidend für resultierende Rechenleistung ||| (-) häufig keine Aussage was genau gemessen wurde, Datentransfergröße pro IOOP muss bekannt sein Von-Neumann-Architektur CPU: Steuerwerk+Rechenwerk, sequentielle Befehlsabarbeitung; befehlszählergetriebene Ablaufsteuerung; binäre Interpretation der Signale; taktgesteuert, Befehlsebenenparallelität, Super scalar CPU; out of order execution; IF-ID-EX-WB Rechenwerk: ALU, Rechenops ausführen, Akkumulator, beeinflusst Kontrollfluss des Steuerwerks durch arithm. Flags Speicher: linear adressierbar, Befehle und Daten, Zugriff über gemeinsamen Systembus; häufig hierarchisch aufgebaut Systembus: verbindet Komponenten; Adress-Daten-Steuerbus; einer kann schreiben, alle können lesen (geregelt durch Arbiter) Steuerwerk: Befehlszähler, Befehlsdekoder, Befehlsregister, Statusregister, Stuerregister, zentrale Steuerschleife E/A-Einheit: Kommunikation mit Außenwelt Flaschenhälse: physikalisch: 1 Kanal zw. CPU und MEM (Daten+Instr.); intellektuell: sequenzielle Abarbeitung Speedup: Geschwindigkeitsgewinn mittels mehreren Prozessoren Scaleup: wievielfach größere Probleme mit mehreren Prozessoren lösbar Effizienz: Geschwindigkeit je Prozessor, Wirkungsgrad Harvard-Architektur: getrennter Speicher für Daten und Instr. => 2 Busse; heute: in L1/L2 Cache (geringe Flexibilität da statische Verteilung auf Daten und Instruktionen) Programmierschnittstelle in der RA: Wortbreite, Registerstruktur, Maschinensatzbefehle, Adressierungsmodi, Interrupt-Behandlung, Ein/Ausgabefunktionalität Giloi: Hardwarestruktur, Operationsprinzip (Informationsstruktur, Steuerungsstruktur) Hardwarestruktur: HW-Betriebsmodi(Prozessorstruktur, Speicherstrukturen), Verbindungsstrukturen, Kooperationsregeln Informationsstruktur: niedere, höhere, Gruppen-, Struktur- Datentypen Steuerungsstruktur: Ablaufsteuerung, Ressourcenverwaltung, Datenzugriffssteuterung Moores Law: Anz. Der Transistoren auf Prozessoren verdoppelt sich alle 18 Monate Speicher: 98% des Platzes für Cache: Cache schneller als HS, Speichergeschw. Steigt 7%/Jahr, => Verkleinerung der Lücke zw. Rechenleistung und Speicherzugriffsgeschw. durch Caches Rechenleistung: früher: Erhöhung Taktfrequenz (Verlustleistung zu hoch, Verkürzung der Leistungslängen am Limit (Kosten-Nutzen-Faktor); Lösung: mehr Recheneinheiten (FPUs, IUs), mehr phys. Cores; alternativ: energieeffiziens Flynnsche Klassifikation: SISD (VN), SIMD (Vektorr., Feldr.), MISD (leer), MIMD (Multicore, Multiprozessor), Befehlsstom und Datenstom auf selber Betrachtungsebene; Baum: SISD, SIMD (Vektor, Arrayprozessoren), MISD, MIMD (speichergekoppelte Multiprozessoren (UMA (Bus, Switch), COMA, NUMA (CC-NUMA, NC-NUMA)), nachrichtengek. Multiproz. (MPP (Gitter, Hypercube), COW)) UMA: uniform memory access, ein globaler Speicher NUMA: non-UMA, lokaler Speicher bei jedem Prozessor => Zugriffszeit lokalitätsabhängig COMA: wie NUMA, aber schreiben nur in eigenen Cache CC-NUMA: cache coherent NUMA NC-NUMA: ohne Cache Feldrechner: 1 Steuerprozessor, viele Verarbeitungseinheiten, SIMD, Integrierung in aktuellen Prozessoren: MMX, SSE Vektorrechner: Verarbeitung von Vektoren, arithm. Pipelining (lange arithm. Ops (DIV) blockieren keine schnelleren (ADD); SIMD (SISD, MIMD auch möglich); Chaining (Verkettung arithm. Pipelines -> keine Zwischenspeicherung von Werten nötig), Vektorregister statt Cache, viele Speicherbänke (nach refresh-Zeit der Speicherbänke ist Zugriff ohne Verzögerung möglich), mehrere Vektorprozessoren Leistungskurve Vektorrechner: max. Rechenleistung bei großer Problemgröße, x=N, y=MFLOPS, Abfall nach jedem N, Annäherung an Rmax, Rmax/2 liegt bei N/2 Leistungskurve Cacherechner: max. Rechenleistung bei kleiner Problemgröße, Abflachung bei jedem neuen Cache MMX, SSE: SIMD auf CPU ||| MMX (multimedia extension): große Register von 64Bit; Befehle werden auf alle Register gleichz. ang. ||| SSE (streaming SIMD extension): größere Register von 128Bit; kene Kombinationen von Datentypen möglich! => finden von Ops zur Ausnutzung der SSE Register abh. von Compiler, Programm Adressierungsarten: implizit: Adressen/Operanden durch Opcode festgelegt; immediate: Direktoperand direkt: Direktadresse; indirekt: Zeiger auf Adresse; relativ: offset von Basisadresse ; indiziert: Basisadresse, Berechnung mit Index; überdeckt: Speicherung nach Operand; Scaled indexed Adressing mode: Zugriff auf Elemente eines Arrays ohne Änderung des Displacements, Indexregister muss nach jedem Zugriff neu gesetzt werden 𝑆𝑝𝑒𝑒𝑑𝑢𝑝 𝑆𝑝 = 𝑇1 𝑍𝑒𝑖𝑡𝑠𝑐ℎ𝑟𝑖𝑡𝑡𝑒 𝑚𝑖𝑡 1 𝑃𝑟𝑜𝑧𝑒𝑠𝑠𝑜𝑟 = 𝑇𝑝 𝑍𝑒𝑖𝑡𝑠𝑐ℎ𝑟𝑖𝑡𝑡𝑒 𝑚𝑖𝑡 𝑝 𝑃𝑟𝑜𝑧𝑒𝑠𝑠𝑜𝑟𝑒𝑛 𝐸𝑓𝑓𝑖𝑧𝑖𝑒𝑛𝑧 𝐸𝑝 = 𝑆𝑝 𝑝 𝑂𝑝𝑒𝑟𝑎𝑡𝑖𝑜𝑛𝑠𝑟𝑒𝑑𝑢𝑛𝑑𝑎𝑛𝑧 𝑅𝑝 = 𝐴𝑢𝑠𝑙𝑎𝑠𝑡𝑢𝑛𝑔 𝑈𝑝 = 𝑍𝑝 𝑝 ∗ 𝑇𝑝 𝐸𝑓𝑓𝑒𝑘𝑡𝑖𝑣𝑖𝑡ä𝑡 𝐹 = 𝑆𝑝 ∗ 𝐸𝑝 𝑇1 𝑍𝑝 𝐴𝑛𝑧. 𝑂𝑝𝑠 𝑚𝑖𝑡 𝑝 > 1 = 𝑍1 𝐴𝑛𝑧. 𝑂𝑝𝑠 𝑚𝑖𝑡 𝑝 = 1 Allzwecksystem: FlOPS und IOPS zur Bewertung der Rechenleistung; IOOPS geben Aufschluss ob th. Rechenleistung (peak-performance) erreicht werden kann; IPS geben einen generellen Überblick über Verarbeitungsleistung (auf gleiche Zerlegung achten!); generell: möglichst identische Messroutinen Single-thread-Performance (STP), Durchsatz Paralleler Programme (DPP) Pipelining: STP:+ DDP:+ ||| starke Verbgesserung der Rechenleistung mit wenig HW-Aufwand SIMD-Erweiterung: STP:+ DDP:- ||| Erhöhung der Peak-Perf.; autom. Nutzung durch Compiler, Verbesserung nicht immer ideal, Praxis: nur2530% des Maximums Out-of-order-Execution: STP:+ DDP:- ||| Transistoren dafür können bei parallelen Anwendungen effizienter eingesetzt werden => z.B. mehr inorder Kerne (GPUs) Frequenzsteigerung STP:+ DDP:- ||| geht quadr. in Engergieverbrauch ein => parallel effizienter mehr CPUs mit ger. Freq. Multithrading: STP:- DDP:+ ||| bessere Auslastung verfügbarer Ressourcen, pro Thread langsamer Multicore: STP:- DDP:+ ||| teilweise Verschlechterung der Singe-threadperf da geteilter Speicher (häufig ab L2 oder L3) DLX Pipelinestufen: [IF|ID|EX|MEM|WB] ID: inkl. operand fetch; MEM: Speicherzugriff bei LOAD/STORE, Verzögerungsglied für 2-Takt-Instr. Hazards NOPs: Hazard-Aufhebung; Verlängerung der Ausführungszeit um 1Takt/NOP; ineffiziente Auslastung der Ressourcen Steuerungshazard: aktueller Befehl Verzweigungsbefehl mit Sprung woanders hin; Lösung: IF-Phase des nachfolgenden Befehls nach MEMPhase vom Sprungbefehl; Einfügen eines unabh. Befehls der in beiden Zweigen vorkommt; zus. ALU in der ID-Phase bereitstellen für Sprungziel/Bedingungen Datenhazard: RAW (Ergebnis von WB wird im nächsten Befehl benötigt); Lösung: ID des lesenden Befehls nach WB des schreibenden Befehls; unabh. Befehl einfügen welcher nicht lesend auf Register zugreift welches zuvor beschrieben wurde, Bypasses (Weitergabe der Ergebnisse an darauffolgende EX-Phasen) Strukturhazard: nur ein Speicherport (IF, ID und MEM greifen auf Speicher zu); Lösung: IF-Phase nach MEM-Phase von LOAD/STORE; mehr Speicherports oder Harvard Bypassing & Forwarding: OF-Phase: Operanden lesen ohne Rücksicht auf Fehler -> Quelladresse -> FW Übergeben; Abspeichern in FW Unit, Vergleich Zieladr. vom Vorgänger mit Quelladresse => Konflikte werden erkannt; im Konfliktfall: FW greift auf Ausgang vom Rechenwerk zu, vorher geholter (falscher) OP wird überschrieben; Übergabe von Operanden aus Rechenwerk Superskalarität: Nebenläufigkeit; mehrere Instruktionen gleichzeitig pro Takt Superpipelining: 1 Instr/Takt; sehr viele Pipelinestufen Orthogonalität: jeder Befehl kann jede Adressierungsart des Prozessors verwenden Sparsamkeit: ein Befehl kann für mehrere Aufgaben verwendet werden Netzwerke statische Verbindungsnetzwerke: feste Leitungen zu Nachbarknoten => keine Veränderung im Routing; Netzwerk entscheidet nicht Route, ist vorher bestimmt dynamische Netzwerke: Verbindungen sind im Netz schaltbar; Schaltung während Kommunikationszeit Crossbar: Gitter mit Schalter an jedem Knotenpunkt Leitungsvermittlung: Durchschalteverbindung (circuit switching) während der gesamten Informationsübertragung; hohe Nettodatenrate nach dem Verbindungsaufbau möglich; Ressourcenblockierung Paketvermittlung: relativ kleine Nachrichtenpakete, die verschiedenen logischen Verbindungen zugehören können, werden gleichzeitig durch das Netzwerk gesandt. Die Leitungen zwischen den Vermittlungsstationen können kurz nacheinander von mehreren verschiedenen Datenpaketen mit unterschiedlichen Zielen benutzt werden; bessere Ressourcenausnutzung; kleinere Nettodatenraten; geeignet für Parallelrechner (kleine Pakete) Nachrichtenvermittlung: Kombination von Leitungs- und Paketvermittlung Store-and-forward: vollst. Zwischenspeicherung der Nachricht auf Zwischenknoten; danach Weiterversenden in Richtung des Empfängers; (+) Zwischensp. im Blockierungsfall (-) langsam, hoher Realisierungsaufwand Virtual-cut-through: Nachricht wird als Kette von Übertragungseinheiten von Zwischenknoten zu Zwischenknoten transportiert. Der Header bestimmt den zu wählenden Weg. Die restlichen Übertragungseinheiten folgen in Analogie zum Pipelineprinzip. Die Zwischenspeicherung erfolgt nur im Konfliktfall, ist aber in jedem Zwischenknoten für das ganze Nachrichtenpaket möglich.; (+)Zwischensp. im Blockierungsfall, schnell (o) mittlerer Aufwand Wormhole-routing: identisch mit virtual-cut-through, solange keine Nachrichtenkanäle blockiert sind. Falls der Header auf einen belegten Kanal trifft, wird er abgeblockt. Bis zur Aufhebung der Blockierung verbleiben alle nachfolgenden Übertragungseinheiten ebenfalls in ihrer Position.; (+) schnell, geringer HW-Aufwand; (-) Blockierung anderer Verbindungen im Fehlerfall Kennwerte Topologien: Grad (Verbindungen/Knoten), Durchmesser (max. Weg), BSW (min. Schnitt in 2 gleich große Teile), Konnektivität (Abtrennen eines Knotens, min. aus Kantenkonn. und Knotenk.), mittl. Knotenabstand OMEGA-Netzwerke: Beta-Zellen: N/2 Zellen/Stufe, ld(N) Stufen, c=1=> überkreuzen Weg: von beliebigem Eingang, 0=oberer Ausgang, 1=unterer Ausgang Steuersignale: Eingangsknoten XOR Ausgangsknoten, 0=gerade, 1=kreuz Cache Skalierbarkeit: CPUs ohne Cache: enge Grenzen wegen Konkurrenz vieler CPUs; mit Cache: Verbesserung des Systemverhaltens durch Busentlastung Datenkohärenz: ohne Cache: kein Problem; mit Cache: bei lesen unkritisch; kritisch bei schreiben von mehrfach vorhandenem Datum Cache-Konsistenz: in allen Cachestufen sind gültige Daten enthalten, strikt -> schwer realisierbar, aufwendig Cache-Kohärenz: temp. Inkonsistenzen (Daten in HS nicht mehr gültig, Änderungen im Cache realisiert), Sicherung der Rücklieferung des aktuellsten Datums (z.B. Write-Back-Buffer) Ansätze Herstellung Konsistenz: 1) write through, 2) copy back, write back (dirtyBit) Protokollansätze für Kohärenz: 1) write-update-Protokoll, 2) writeinvalidate-Protokoll MESI: Konsistenz mittels copy back, Kohärenz mittels write-invalidateProtokoll; Snooping-caches nötig: angepasster cache-controller zur Belauschung vom Bus Signale: invalid (Datum wurde verändert!), shared (Datum wurde schon geladen!) , retry (Auf write back warten!) Write-Through: Speicher wird auch bei Schreibops konsistent gehalten, einfach überschreiben, Non-Write Allocate (write around) Write-Back: Speicherop aktualisiert nur Cache und setzt Dirty-Flag, Write Allocate Write Allocate: falls Block nicht vorhanden wird er geladen und im Cache überschrieben Non-Write Allocate: falls Block nicht vorhanden wird er direkt in HS geschrieben ohne Cache Missing: Floating-Point-Kurve Vektorrechner, Cache-basierter <-- R1<--R2 M R1<--M[x] <--n M[y]<--16M[x] Xn R10<--0 Xm..n R324..31<--M[x] Xm R30..23<--024 ## R3<--024##M[x] F2##F3<--64M[x] << R1<<5 >> R1>>8 >>a R1>>a16 == != <> <= >= & | ^ ! + * / (R1==R2) &(R3!=R4) Transfer, logisch R2 wird nach R1 gemäß Länge (R1) übertragen Speicherzugriff Wenn R1 32 Bit breit, dann werden bei Byteadressierung die Bytes M[x], M[x+1] , M[x+2] , M[x+3] übertragen Transfer mit expliziter Längenangabe Übertragung von 16 Bit von Platz x nach Platz y Zugriff auf Einzelbit Löschen des Sign-Bits, d.h. MSB (Most Significant Bit) (Linksnummerierung) Zugriff auf eine Bitkette Übertrage Byte M[x] in das niederwertigste Byte von R3 Wiederholungsspezifikation Die oberen 3 Byte von R3 werden auf “Null” gesetzt Verkettungsoperator rechte Seite M[x] im niederen Byte und obere 24 Bit = 0 Verkettungsoperator linke Seite Es werden 64 Bit vom Speicher zu dem Gleitkomma-Doppelregister F2/F3 übertragen Verschiebeoperator Verschiebe R1 logisch nach links um 5 Bit Verschiebeoperator Verschiebe R1 logisch nach rechts um 8 Bit Verschiebeoperator Verschiebe R1 arithmetisch nach rechts um 16 Bit Relationale Operatoren Ausdruck relationaler Operatoren ist true, wenn die Relation “R1 gleich R2” true ist und die Relation “R3 ungleich R4” true ist (R1 & (R2 | R3)) Logische Operatoren Bitweise ODER-Verknüpfung von R2 mit R3; das Ergebnis wird UND-verknüpft mit R1 (R1+R2)/R3 Arithmetische Operatoren Vorrangregeln wie in HLL C z:= ((IR16)16##IR16..31) Nullerweiterten Byte aus Speicher lesen Vorzeichenerweiterten Byte aus Speicher lesen Nullerweitertes Halbwort aus Big-Endian-Speicher lesen Multiplikation und in 64bit Doppelregister speichern LBU Rd, D(Rs1) LB Rd, D(Rs1) LHU Rd, D(Rs1) MULT Rd, Rs1, Rs2 GPR[rd]<-024##M[GPR[rs1]+z] GPR[rd]<-(M[GPR[rs1]+z])024##M[GPR[rs1]+z] GPR[rd]<-016##M[GPR[rs1]+0+z]##M[GPR[rs1]+1+z] (?) GPR[rd]##GPR[rd+1]<- GPR[rs1]*GPR[rs2] Das MESI-Protokoll ordnet jeder Cache-Zeile einen der folgenden vier Zustände zu: • Exclusive Modified (M): Die Zeile befindet sich exklusiv in diesem Cache und wurde modifiziert. • Exclusive Unmodified (E): Die Zeile befindet sich exklusiv in diesem Cache und wurde nicht modifiziert. • Shared Unmodified (S): Die Zeile befindet sich noch in einem anderen Cache und wurde nicht modifiziert. • Invalid (I): Die Zeile ist ungültig. w.R.: with Replacement Read w. I. t. M.: Read-with-Intent-to-Modify (1) Cache-Zeile wird in den Hauptspeicher zurückkopiert (line flush) (2) Cache-Zeilen in anderen Caches mit gleicher Blockadresse werden invalidiert (line clear) (2)* wie (2), gilt jedoch nur für „WriteMiss with Replacement“ (3) Retry-Signal wird aktiviert und danach Cache-Zelle in den Hauptspeicher zurückkopiert Steuerwerk: IEEE-754 Speicheradresse: 0x100 0x101 0x102 0x103 Wert 14 C1 E2 FF Little-Endian: FF|E2|C1|14 Big-Endian: 14|C1|E2|FF Natürliches Alignment: Zahlen pro Takt ablegen(-> Leerstellen vorhanden!, z.B. 32 Bit übertragbar und 8 Bit Wert =8Bit+3x Leerstellen) Dichter Code: Besitzen bei einem Code alle Worte die gleiche Wortlänge n, so lassen sich k=2n unterschiedliche Folgen von Binärzeichen bilden und 2n-1 < q (wobei q Anzahl der verschiedenen Informationen) Befehlsabarbeitung: (1)ABZ,MREQ,RD (2)IBZ (3)LBR (4)DEC Rechenwerk: JMP: (5) ABR, LBZ JC: (5)ABR,LBZ RET: (5) RST, LBZ CALL: (5) ABZ, WST (6) ABR,LBZ Addition/Subtraktion: 1. Exponenten ausrechnen (e=c-B=c+1000 0001) 2. Exponenten angleichen auf höheren Exp. und f entsprechend verschieben 3. Addieren/Subtrahieren 4. Werte angleichen, umrechnen Multiplikation: 1. c=c1+c2-B (e=e1+e2) 2. f1 und f2 multiplizieren 3. Werte angleichen, umrechnen Division: 1. c=c1-c2+B (e=e1-e2); e1, e2 berechnen und f gleich machen falls möglich 2. f1 und f2 dividieren 3. Werte angleichen, umrechnen Zweierkomplement: Not(B)+1 (pos. => neg.), Not(B-1) (neg. => pos.) (B… Binärzahl) Overflow-Flag: V=0, außer wenn erstes Bit beider Operanden gleich und im Ergebnis anders(V=1) Vollassoziativer Cache: Speicherplatzwahl durch gleichzeitigen Vergleich einer Information mit mehreren Einträgen => langsam und für keinen Treffer(MISS) zu viel Ressourcenaufwand Direct-mapped Cache: (+) da pro Index nur ein Tag gespeichert werden kann, braucht nur ein Vergleicher implementiert werden (-) Sehr unflexibel, da jedes neues Datum nur an einer Stelle im Cache gespeichert werden kann => geringe Trefferrate n-way-set associative Cache: (+) höhere Flexibillität bei Cache-Einträgen => höhere Trefferrate (-) höherer Hardwareaufwand für Entscheidungen, in welcher Zeile bei bestimmten Index ein neuer Eintrag erfolgen soll ist eine Auswahllogik erforderlich.(z.B. LRUStrategie(Least Recently Used), FIFO-Strategi(auch bei vollassoziativen Cache erforderlich), zufallsgesteuertes Ersetzen(Random) => gute Treffer-Raten, wenn Cache groß ist.)