Einführung in Enterprise JavaBeans - RWTH
Werbung

Einführung in Enterprise JavaBeans
Seminararbeit im Studiengang
Scientific Programming
WS 2012/2013
Autor:
Ralf Penners
Matrikelnummer:
841698
1. Betreuer:
Prof. Dr. rer. nat. Bodo Kraft
2. Betreuer:
Dipl.-Math. (FH) Michael Neßlinger
Datum:
20. Dezember 2012
Die vorliegende Seminararbeit gibt dem Leser einen Einstieg in Enterprise JavaBeans. Dabei handelt
es sich um einen Bestandteil der Java Enterprise Edition, welche eine Technologie zur Entwicklung
von Geschäftsanwendungen ist. Parallel dazu werden auch technische Hintergründe und Voraussetzungen beleuchtet, die für einen erfolgreichen Einsatz von Bedeutung sind.
Inhaltsverzeichnis
1. Einleitung
1.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.2. Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3. Voraussetzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
1
1
1
2. Enterprise Edition
2.1. Application Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2. Rückblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3. Komponenten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
2
3
4
3. Enterprise JavaBeans
3.1. SessionBeans . . . . . . . . . . . . . . . . . . . . . .
3.1.1. Stateless SessionBeans . . . . . . . . . . . . .
3.1.2. Stateful SessionBeans . . . . . . . . . . . . .
3.1.3. Singleton SessionBeans . . . . . . . . . . . .
3.2. Business-Interface . . . . . . . . . . . . . . . . . . .
3.2.1. Local . . . . . . . . . . . . . . . . . . . . . .
3.2.2. Remote . . . . . . . . . . . . . . . . . . . . .
3.2.3. No-Interface View . . . . . . . . . . . . . . .
3.3. MessageDrivenBeans . . . . . . . . . . . . . . . . . .
3.3.1. Point-To-Point . . . . . . . . . . . . . . . . .
3.3.2. Public-Subscribe . . . . . . . . . . . . . . . .
3.3.3. Aufbau und Beispiel einer MessageDrivenBean
3.4. Benutzung . . . . . . . . . . . . . . . . . . . . . . .
3.4.1. Java Naming and Directory Interface . . . . .
3.4.2. Dependency Injection . . . . . . . . . . . . .
3.4.3. Asynchronous . . . . . . . . . . . . . . . . .
3.4.4. Scheduling . . . . . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
5
5
5
7
8
9
9
10
11
11
11
11
12
14
14
15
15
16
4. Technik
17
4.1. Serialisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2. Reflection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.3. Proxy-Objekte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5. Fazit und Ausblick
20
5.1. Vor- und Nachteile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2. Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Literatur - und Quellenverzeichnis
21
A. Abkürzungen
23
1. Einleitung
1.1. Motivation
Bei der Entwicklung von Geschäftsanwendungen gibt es einige Komponenten, welche in fast jeder
Anwendung benötigt werden. Da es sich um serverseitige Anwendungen handelt, muss beispielsweise
eine Schnittstelle für die Kommunikation mit entsprechenden Clients und den Komponenten untereinander implementiert werden. Da aber die Anforderungen an die Schnittstelle bei jedem neuen
Projekt ein wenig von den vorherigen abweichen, muss diese stets neu programmiert werden. Somit
sind die Entwickler immer wieder mit der Implementierung von trivialen Anforderungen beschäftigt,
anstatt sich um die eigentliche Problemlösung zu kümmern. Die Java Enterprise Edition bietet nun
für genau diese immer wiederkehrenden Aufgaben Standardimplementierungen an, sodass sich die
Entwickler voll und ganz auf die Geschäftslogik konzentrieren können. Außerdem sorgt die Standardisierung zugleich für eine Austauschbarkeit und Wiederverwendbarkeit, sodass einmal entwickelte
Module problemlos und ohne großen Aufwand im nächsten Projekt wiederverwendet werden können.
Im Rahmen dieser Seminararbeit im Studiengang Scientific Programming soll eine Einführung in
die Enterprise JavaBeans, als eine der Kernkomponenten aus der Java Enterprise Edition, gegeben
werden.
1.2. Aufbau
Zu Beginn wird ein kurzer Überblick über die Java Enterprise Edition im Allgemeinen gegeben. Im
Anschluss erfolgt eine genauere Betrachtung der einzelnen Arten von Beans und ihren Aufgaben.
Dabei werden auch jeweils kleine Beispiele zum besseren Verständnis verwendet. Im vorletzten Kapitel werden schließlich die Techniken genauer beleuchtet, die bei den Enterprise JavaBeans verwendet
werden, um dem Entwickler die Arbeit letztlich zu erleichtern. Abschließend werden Vor- und Nachteile der Technologie aufgezeigt und ein kleiner Ausblick auf die aufbauende Bachelorarbeit gegeben.
1.3. Voraussetzungen
In dieser Arbeit wird davon ausgegangen, dass der Leser Grundkenntnisse der objektorientierten
Programmierung und Informatik besitzt. Somit wird nicht mehr jeder Fachbegriff, sofern er nicht
speziell auf die Java Enterprise Edition oder Enterprise JavaBeans bezogen ist, komplett neu erklärt
oder eingeführt, sondern als bekannt vorausgesetzt.
1
2. Enterprise Edition
Die Java Enterprise Edition, oft als J2EE, JavaEE oder einfach EE abgekürzt, erweitert die Java
Standardbibliothek um Komponenten, Funktionen und Dienste zur Entwicklung von Geschäftsanwendungen. Derartige Anwendungen laufen meist auf Serversystemen, sodass hier der Fokus speziell
auf die Anforderungen in diesem Bereich gerichtet ist. Somit stehen unter anderem Komponenten für
die Entwicklung von Webseiten und Verarbeitung von HTTP-Anfragen, die Abbildung von Objekten
auf relationalen Datenbanken und vice versa, sowie für die Implementierung von Webservices zur
Verfügung. Dem Entwickler soll damit eine Sammlung von Funktionalitäten angeboten werden, die
er bei der Entwicklung verwenden und sich somit voll und ganz auf die Geschäftslogik konzentrieren
kann. Im Gegensatz zur Standard Edition (kurz SE), welche von Oracle1 in Form des Java Runtime Environments (JRE) und Java Development Kits (JDK) konkret implementiert wird, wird die
Enterprise Edition durch eine Spezifikation beschrieben. Dort wird für jede Komponente und jeden
Dienst festgelegt, welche Funktionalität zu erfüllen ist und über welche Schnittstelle diese verwendet
werden kann. Die konkrete Implementierung der einzelnen Schnittstellen wird von diversen Herstellern durch einen Application Server realisiert, wobei einige dieser Implementierungen auch losgelöst
davon verwendet werden können.
2.1. Application Server
Ein Application Server implementiert die spezifizierten Funktionalitäten und stellt sie der Enterprise
Anwendung zur Verfügung, er ist also die Laufzeitumgebung. Dadurch hat er die volle Kontrolle
über die Anwendung und kann diverse weitere Aufgaben, wie beispielsweise die Einhaltung von Sicherheitsrichtlinien, Transaktionsmanagement, Verwaltung des Lebenszyklus von Objekten oder die
Zugriffskontrolle auf das zugrundeliegende Betriebssystem übernehmen. Der Server selbst unterteilt
sich nochmal in mehrere logische Einheiten, den sogenannten Containern. Jeder Container verwaltet
eine bestimmte Art von Komponenten. Derzeit gibt es den Web-Container für alle Webkomponenten
und den Business-Container oder oft auch als EJB-Container bezeichnet, für die Geschäftslogik. Eine
entwickelte Anwendung wird je nach Funktionalität in einen der beiden Container installiert, auch
Deployment genannt. Insgesamt fungiert ein Application Server somit als Middleware und wird als
solche eingesetzt. Eine Middleware ist eine Software, welche zwischen anderen Anwendungen und
Schichten vermittelt, indem sie der einen Schnittstellen zu anderen anbietet und damit die Komplexität dahinter verbirgt. Ein Application Server erfüllt diese Aufgabe teils in mehrfachen Situationen.
So sorgt er beispielsweise dafür, dass eine Komponente aus dem Web-Container mit einer anderen
Komponente aus dem EJB-Container kommunizieren kann. Außerdem ist er für die Kommunikation
zwischen den verschiedenen Anwendungen, welche gerade auf ihm ausgeführt werden, verantwortlich.
Des Weiteren regelt er den Austausch zwischen Anwendungen und Komponenten auf verschiedenen
Rechnersystemen bzw. Application Servern, da zum Beispiel aus Gründen der Lastverteilung und
Skalierbarkeit Web- und EJB-Container auf mehreren Systemen verteilt sein können. Bekannte Application Server sind der GlassFish von Oracle (Referenzimplementierung), JBoss Application Server,
1
bis 2010 Sun Microsystems, wurde danach von Oracle übernommen
2
Apache Geronimo, Oracle WebLogic oder IBM WebSphere. Auch wenn die spezifizierten Funktionalitäten bei den einzelnen Herstellern unterschiedlich implementiert sein können, so sollte dennoch
eine Enterprise Anwendung theoretisch auf jedem Application Server lauffähig sein. Dabei steht es
den Herstellern natürlich frei, weitere zusätzliche Funktionalitäten hinzuzufügen. Allerdings dürfen
diese Extras nicht im Konflikt mit der Spezifikation stehen. Außerdem sollte jedem Entwickler bewusst sein, dass eine Verwendung von herstellerspezifischen Funktionen die Austauschbarkeit bzw.
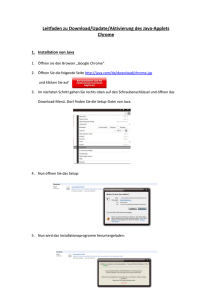
Wiederverwendbarkeit der Anwendung einschränkt. Abbildung 1 zeigt ein Schema eines Application
Servers mit einer Enterprise Anwendung.
Abbildung 1: Schemaabbildung eines Application Servers
2.2. Rückblick
Bereits 1998 kam die Idee einer Java Version für Geschäftsanwendungen auf, welche 1999 zusammen
mit der Java-2-Platform als J2EE 1.2 veröffentlicht wurde. Das Ziel bestand darin, die Entwicklung
von komplexen Anwendungen zu vereinfachen. Dazu sollten immer wieder benötigte Funktionen
standardisiert und dem Entwickler zur Verfügung gestellt werden. In den Folgeversionen 1.3 und 1.4
wurden stets weitere Funktionen und Dienste hinzugefügt. Allerdings mussten diese über komplizierte
XML-Dateien, sogenannte Deployment-Deskriptoren, konfiguriert werden, sodass die Entwicklung
alles andere als vereinfacht wurde. Aus diesem Grund sind in dieser Zeit einige Community-Projekte
wie etwa das Spring-Framework oder Hibernate entstanden, welche die ursprüngliche Idee besser
umsetzten. Einige dieser Umsetzungen sind schließlich im Jahr 2006 mit in den Enterprise Standard
übernommen worden. Besonders die Einführung von Annotationen als Konfigurationselement hat
maßgeblich zur Vereinfachung beigetragen. In diesem Zug wurde dann auch der Name von Java2-Platform Enterprise Edition 1.4 auf JavaEE 5 verkürzt. Mit der aktuellen Version 6, welche 2009
veröffentlicht wurde und auch Ausgangspunkt dieser Arbeit ist, sind zahlreiche weitere Neuerungen
hinzugekommen, sodass die Java Enterprise Edition wieder eine interessante Technologie für die
Entwicklung von Enterprise Anwendung darstellt.
3
2.3. Komponenten
Der Enterprise Standard umfasst zahlreiche Komponenten und Dienste, welche jede für sich in einer
eigenen Spezifikation beschrieben sind. Dabei werden nicht alle direkt für die Entwicklung verwendet,
sondern einige davon stellen Hilfsfunktionalitäten bereit oder laufen im Hintergrund als Bestandteil
des Application Servers. In dieser Arbeit werden die Enterprise JavaBeans, kurz EJBs, als eine der
Kernkomponenten für die Entwicklung von Anwendungen vorgestellt. Sie beinhalten den Großteil
der eigentlichen Geschäftslogik, welche von einer Enterprise Anwendung angeboten wird. Dabei werden sie im EJB-Container des Application Servers ausgeführt und verwaltet. Oft wird für solche
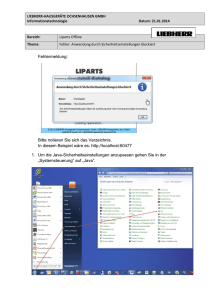
Komponenten auch der Ausdruck Container managed Komponenten“ verwendet. Abbildung 2 zeigt
”
eine Übersicht der Bestandteile von JavaEE 6. Seit dieser Version sind die Profiles neu hinzugekommen. Das Web-Profile ist eine Art leichtgewichtige Variante des Full-Profiles und soll alle benötigten
Komponenten für eine kleine Webanwendung anbieten, ohne dass für die Ausführung zwingend
ein kompletter Application Server verwendet werden muss. So existiert beispielsweise eine Version
TomEE“ des Apache Tomcats, welcher eigentlich nur ein Servlet-Container ist, und zusätzlich das
”
Web-Profile unterstützt. Alle Komponenten des Web-Profiles sind natürlich auch im Full-Profile enthalten.
Abbildung 2: Komponentenübersicht der Enterprise Edition Version 6
4
3. Enterprise JavaBeans
Enterprise JavaBeans sind einfache Java-Klassen, d.h. sie müssen kein Interface implementieren oder
von einer bestimmten Basisklasse erben, um ihre Funktionalität zu erfüllen. Eine derartige Klasse wird
häufig auch als Plain Old Java Object oder kurz POJO bezeichnet. Grundsätzlich wurde mit JavaEE 5
das Prinzip der Convention over Configuration“ eingeführt, was bedeutet, dass ein Standardverhalten
”
für die meisten Komponenten bereits definiert ist. Damit muss nur dann etwas konfiguriert werden,
wenn es von diesem Standard abweicht. Dazu stehen insgesamt zwei Möglichkeiten zur Auswahl,
einmal in Form einer XML-Konfigurationsdatei (Deployment-Deskriptor) oder über Annotationen.
Auch wenn die Verwendung von Annotationen seit JavaEE 6 die empfohlene Variante ist, so gibt es
gelegentlich auch kritische Stimmen unter den Entwicklern. Da eine Annotation nämlich direkt im
Quelltext an der entsprechenden Stelle verwendet wird, werden so Konfiguration und Funktionalität
ein Stück weit vermischt. Auf der anderen Seite kann argumentiert werden, dass gerade dadurch
schneller der Zusammenhang deutlich wird, wo sonst zuerst noch die entsprechende XML-Datei
gesucht und analysiert werden müsste. Generell ist es auch möglich, beide Varianten zu kombinieren.
Dies sollte aber nur mit Vorsicht verwendet werden, da aufgrund der Abwärtskompatibilität zu
Vorgängerversionen stets die Einstellung im Deployment-Deskriptor die Annotation überschreibt.
Im weiteren Verlauf dieser Arbeit werden ebenfalls Annotationen verwendet. Damit der Container
nun weiß, dass es sich um eine Enterprise JavaBean handelt und er diese als solche verwalten soll,
muss die Klasse mit einer entsprechenden Annotation gekennzeichnet werden. Diese ist je nach Art
der EJB unterschiedlich, welche in den folgenden Abschnitten erläutert werden. Außerdem muss
mindestens ein parameterloser Konstruktor implementiert sein, weitere Konstruktoren mit beliebigen
Parametern dürfen natürlich ergänzt werden. Insgesamt unterteilen sich die EJBs dann nochmal in
SessionBeans und MessageDrivenBeans.
3.1. SessionBeans
SessionBeans bieten den Clients über ihre Methoden Zugriff auf die Geschäftslogik. Ein Bezeichnung
wie BusinessBeans“ würde den Kern daher wahrscheinlich besser treffen [Kul11]. Insgesamt gibt es
”
drei Arten von SessionBeans: Stateless, Stateful und Singelton.
3.1.1. Stateless SessionBeans
Stateless SessionBeans besitzen keinen Zustand, was bedeutet, dass sämtliche Änderungen, die während der Verarbeitung einer Anfrage an dem entsprechenden Objekt vorgenommen wurden, danach
wieder zurückgesetzt werden. Aus Sicht des Clients sind also alle Stateless SessionBeans identisch.
Möchte zum Beispiel ein Client bestimmte Informationen aus einer Datenbank haben, dann wird
ihm für diese Anfrage vom Container eine Bean zur Verfügung gestellt, welche die gewünschten Daten aus der Datenbank anfordert. Sollte also nun das ResultSet in dieser Bean zwischengespeichert
worden sein, wird es nach der Ergebnisrückgabe wieder gelöscht. Da also alle Stateless SessionBeans
immer die gleiche Objektstruktur vorweisen und keine clientspezifischen Daten speichern müssen,
kann der Container mehrere Objekte dieser Art in einem Pool vorhalten. Für den Client ist es also
5
unerheblich, mit welcher Bean er konkret während einer Anfrage kommuniziert. Sind alle Beans aus
dem Pool besetzt, kann der Container entweder eine neue Bean instanziieren oder warten, bis eine
andere ihre Aufgabe erledigt hat und in den Pool zurückkehrt. Auf diese Weise wird gleichzeitig für
eine Lastverteilung und Skalierung der Anwendung gesorgt. Die Größe des Pools kann in der Konfigurationsdatei des Application Servers definiert werden. Die genaue Konfiguration ist allerdings
vom jeweiligen Hersteller abhängig. Listing 1 zeigt eine Stateless SessionBean, die beispielsweise in
einem Onlineshop nach einem bestimmten Artikel sucht. Die Annotation @Stateless kennzeichnet
die Klasse dabei zum einen als EJB und definiert sie zum anderen entsprechend als zustandslos. Ein
Client könnte nun die Geschäftsmethode sucheArtikel aufrufen, um nach einem bestimmten Artikel zu suchen. Die beiden Annotationen @PostConstruct und @PreDestroy an den beiden anderen
Methoden sind sogenannte Lifecycle-Callbacks, welche vom Container zu bestimmten Zeitpunkten
automatisch aufgerufen werden. Die @PostConstruct Annotation wird nach der Instanziierung ausgeführt und die Methode mit der @PreDestroy Annotation entsprechend kurz vor der Zerstörung
der Bean. Hier können etwa Initialisierungen bzw. Aufräumarbeiten durchgeführt werden, wie im
Beispiel das Erzeugen und Trennen einer Datenbankverbindung. Dabei dürfen diese Methoden keine
Parameter übergeben bekommen und auch keinen Rückgabewert haben. Der Zugriffsmodifizierer,
also ob public, protected, package private oder privat ist hingegen irrelevant.
1
2
3
4
import
import
import
import
java . sql . ResultSet ;
javax . annotation .PostConstruct;
javax . annotation .PreDestroy;
javax . ejb . Stateless ;
5
6
7
@Stateless
public class ArtikelSuche {
8
private ResultSet
9
artikelliste ;
10
public Artikel sucheArtikel ( String artikelname ) {
// Datenbankanfrage stellen und Artikel zurueckgeben
}
11
12
13
14
@PostConstruct
public void erstelleVerbindungZurDatenbank() {
// Datenbankverbindung aufbauen
}
15
16
17
18
19
@PreDestroy
public void trenneVerbindungZurDatenbank() {
// Datenbankverbindung trennen
}
20
21
22
23
24
}
Listing 1: Beispiel einer Stateless SessionBean
6
3.1.2. Stateful SessionBeans
Im Gegensatz zu Stateless besitzen Stateful SessionBeans einen Zustand. Bei der nächsten Anfrage
wird dem Client wieder seine“ Bean zugeteilt und ihm stehen die Daten der vorherigen Anfrage
”
wieder zur Verfügung. Diese Art von Bean hat also eine Identität, welche mit dem jeweiligen Client
assoziiert ist. Damit ist nun auch kein Pooling dieser Beans mehr möglich, da alle Objekte unterschiedliche Informationen beinhalten. Während zwei Anfragen eines Clients kann allerdings einige
Zeit vergehen und der Container muss die Beans die komplette Zeit über im Arbeitsspeicher vorhalten. Bei mehreren tausend Clients und damit auch entsprechend vielen Beans kann dort schnell
der Speicherplatz knapp werden. Deshalb kann der Container länger nicht mehr benötigte Beans
auf den Hintergrundspeicher auslagern. Bei einer neuen Anfrage des jeweiligen Clients wird diese Bean dann komplett wiederhergestellt. Damit er aber dazu überhaupt in der Lage ist, sollten
Stateful SessionBeans das Serializable-Interface implementieren. Als klassisches Anwendungsbeispiel
kann hier ein Warenkorb in einem Onlineshop genommen werden. Jeder Kunde hat seinen eigenen
Warenkorb und legt seine Artikel, die er kaufen möchte, dort ab. Selbst wenn er eine andere Seite im Onlineshop aufruft, steht ihm nach wie vor sein persönlicher Warenkorb zur Verfügung und
nicht die eines anderen Kunden oder wieder ein komplett leerer, wie es beim Einsatz einer Stateless
SessionBean der Fall wäre. Listing 2 zeigt den Quelltext dieses Beispiels. Die @Stateful Annotation
definiert die Klasse als zustandsbehaftete Bean und sämtliche Artikel, die in der Instanzvariable warenkorb gespeichert werden, bleiben für den Client die komplette Sitzung über erhalten. Neben den
Lifecycle-Callbacks @PostConstruct und @PreDestroy wie bei den Stateless SessionBeans, können
hier Methoden auch mit den Annotationen @PostActivate und @PrePassivate, sowie @Remove versehen werden. @PostActivate- und @PrePassivate-Methoden werden vom Container jeweils nach der
Einlagerung bzw. vor der Auslagerung aufgerufen und können beispielsweise auch hier eine Datenbankverbindung vor der Auslagerung trennen und beim Einlagern wieder verbinden. Weder die Bean
selbst noch der Container kann jedoch wissen, wann die Bean nicht mehr benötigt wird. Darum
kann der Client, wenn er die Verbindung trennt, die entsprechende Methode mit der @Remove Annotation aufrufen, sodass die Bean sauber entfernt wird. Dabei können noch einige Aufräumarbeiten
getätigt werden oder sie kann, wie im Beispiel zu sehen, auch einfach leer sein. Alternativ gibt es
einen Timeout-Mechanismus im Container, welcher dafür sorgt, dass Stateful SessionBeans nach
einer bestimmten Zeit ohne Benutzung automatisch gelöscht werden. Das entsprechende Intervall
kann abhängig vom Hersteller an einer Stelle in der Konfiguration des Application Servers angegeben
werden.
1
2
3
4
5
6
7
import
import
import
import
import
import
import
java . io . Serializable ;
java . util . ArrayList ;
java . util . List ;
javax . ejb . PostActivate ;
javax . ejb . PrePassivate ;
javax . ejb .Remove;
javax . ejb . Stateful ;
8
7
9
10
@Stateful
public class Warenkorb implements Serializable {
11
public List <Artikel> warenkorb;
12
13
public Warenkorb() {
this .warenkorb = new ArrayList<Artikel>();
}
14
15
16
17
// Methoden zum Hinzufuegen und Entfernen von Artikeln
18
19
@PostActivate
public void erstelleVerbindungZurDatenbank(){
// Datenbankverbindung wiederherstellen
}
20
21
22
23
24
@PrePassivate
public void trenneVerbindungZurDatenbank() {
// Datenbankverbindung trennen
}
25
26
27
28
29
@Remove
public void entfernen () {}
30
31
32
public void kaufen() {
// Alle Artikel im Warenkorb bezahlen
}
33
34
35
36
}
Listing 2: Beispiel einer Stateful SessionBean
3.1.3. Singleton SessionBeans
Ein Singelton ist ein Design Pattern und sorgt dafür, dass in einer Anwendung nur maximal eine
Instanz der entsprechenden Klasse vorhanden ist. So existiert also nur eine einzige Singleton SessionBean innerhalb der Enterprise Anwendung. Diese kann natürlich wie eine Stateful Bean ihren
Zustand über mehrere Clientanfragen hinweg festhalten, da sie die komplette Anwendung über bestehen bleibt. Allerdings sollte beachtet werden, dass alle Clients immer nur mit dieser einen Instanz
kommunizieren, sodass der Zugriff schnell zum Flaschenhals werden kann. Ein sinnvoller Verwendungszweck wäre zum Beispiel ein Cache. Im Normalfall gibt es nur einen Cache pro Anwendung,
weshalb sich dieser wunderbar mit einer Singleton SessionBean umsetzen lässt. Listing 3 zeigt ein
entsprechendes Beispiel. Die @Singleton Annotation definiert die Bean zum Singleton. Auch hier
könnten bei Bedarf die Lifecycle-Callbacks @PostConstruct und @PreDestroy verwendet werden. Die
@Startup Annotation ist nicht speziell für Singleton SessionBeans gedacht, sorgt hier aber dafür,
dass die Instanz direkt beim Starten der Anwendung erzeugt wird. Ansonsten würde das Objekt beim
ersten Zugriffsversuch instanziiert werden, was je nach Initialisierungsaufwand eine gewisse Zeit in
8
Anspruch nehmen könnte.
1
2
3
4
import
import
import
import
java . util .HashMap;
java . util .Map;
javax . ejb . Singleton ;
javax . ejb . Startup ;
5
6
7
8
@Singleton
@Startup
public class Cache {
9
private Map<Integer, String> cache;
10
11
public Cache() {
this .cache = new HashMap<Integer, String>();
}
12
13
14
15
public void setWert( Integer schluessel , String wert) {
this .cache.put( schluessel , wert) ;
}
16
17
18
19
public String getWert(Integer schluessel ) {
return this .cache.get( schluessel ) ;
}
20
21
22
23
}
Listing 3: Beispiel einer Singleton SessionBean
3.2. Business-Interface
Bisher können alle public-Methoden einer SessionBean in einer Anwendung ohne Weiteres verwendet
werden. Um nun den Zugriff für die Clients auf bestimmte Methoden zu beschränken, kann bzw.
in Fällen, wo der Client sich auf einem anderen System befindet, muss sogar ein Interface vorgeschaltet werden. Ein solches Interface wird häufig auch als Business-Interface bezeichnet, welches
entweder als Local- oder Remote-Interface verwendet werden kann. Ein Client ist hierbei nicht immer
zwingend direkt eine Desktopanwendung oder Webbrowser, sondern kann beispielsweise auch eine
Webkomponente innerhalb derselben Anwendung sein. So ist aus Sicht des EJB-Containers sowohl
eine andere Anwendung als auch der Web-Container auf demselben Application Server ein Client.
Während vor JavaEE 6 ein solches Interface bei jeder Bean verpflichtend war, unabhängig von lokalem oder entfernten Zugriff, gibt es nun auch die No-Interface View. Diese drei Arten werden im
Folgenden vorgestellt.
3.2.1. Local
Soll ein lokaler Zugriff auf die Methoden der SessionBean möglich sein, werden die benötigten Geschäftsmethoden in einem Interface definiert. Zusätzlich muss entweder das Interface selbst mit
9
@Local oder die implementierende Klasse mit @Local(NameDesInterfaces.class) annotiert werden.
Mit lokalem Zugriff ist hier ausschließlich innerhalb der gleichen Anwendung oder genauer innerhalb derselben Java Virtual Machine (JVM) gemeint. Zugriffe aus einer anderen JVM, etwa von
einem anderen System oder einer anderen Anwendung aus, sind nicht möglich. Die Parameter der
Geschäftsmethoden werden hier per Referenz übergeben, was die lokalen Zugriffe natürlich im Vergleich zu denen über das Netzwerk deutlich schneller macht. In Bezug auf Änderungen an Objekten
sollte diese Eigenschaft jedoch stets berücksichtigt werden. Listing 4 und 5 zeigen das Beispiel der
Warenkorb-Bean in Kombination mit einem Local-Interface. Wenn die Warenkorbklasse jetzt noch
mehrere Geschäftsmethoden hätte, dann könnte ein Client jedoch nur die im Interface definierten
Methoden, hier also die kaufen-Methode, verwenden.
1
import javax . ejb .Local;
2
3
4
@Local
public interface IWarenkorbLocal {
5
public void kaufen() ;
6
7
}
Listing 4: Beispiel für ein Local-Business-Interface
1
2
@Stateful
public class Warenkorb implements IWarenkorbLocal, Serializable {
3
// ...
4
5
@Override
public void kaufen() {
// Alle Artikel im Warenkorb bezahlen
}
6
7
8
9
10
}
Listing 5: Implementierung des Local-Business-Interfaces
3.2.2. Remote
Sollen auch Clients aus einer anderen JVM auf die Geschäftsmethoden zugreifen können, so muss das
Interface mit @Remote bzw. die implementierende Klasse mit @Remote(NameDesInterfaces.class)
gekennzeichnet werden. Prinzipiell kann eine Klasse mit Remote-Interface natürlich auch lokal verwendet werden, allerdings werden die Parameter bei der Übergabe serialisiert, die Daten also kopiert.
Auch wenn ein lokales Interface für Zugriffe innerhalb einer Anwendung daher schneller wäre, kann
eine Verteilung der einzelnen Komponenten auf mehrere Systeme die Gesamtleistung deutlich steigern, sodass der geringe Overhead eines Remote-Zugriffs im Vergleich minimal wird. Nichtsdestotrotz
sollten die Aspekte Serialisierung und Latenz bei Netzwerkkommunikation dem Entwickler immer im
Hinterkopf bewusst sein. Grundsätzlich kann eine Bean auch mehrere unterschiedliche Interfaces
10
implementieren, wodurch sowohl ein lokaler als auch ein entfernte Zugriff ermöglicht wird. Es ist
jedoch nicht erlaubt, dass ein und dasselbe Interface sowohl @Local als auch @Remote verwendet.
Wird überhaupt keine Annotation an das Interface geschrieben, ist es implizit lokal.
3.2.3. No-Interface View
Bei ausschließlich lokaler Verwendung der SessionBeans ist nicht immer zwingend ein Interface notwendig. Darum gibt es seit JavaEE 6 die No-Interface View. Implementiert somit eine SessionBeanKlasse kein Interface, sind automatisch alle public-Methoden als Geschäftsmethoden verwendbar.
Allerdings natürlich nur lokal, also in derselben JVM. Auch wenn diese Art des Zugriffs eigentlich
keiner separaten Annotation bedarf, gibt es der Vollständigkeit halber die @LocalBean Annotation,
die an die entsprechende Klasse geschrieben werden kann.
3.3. MessageDrivenBeans
MessageDrivenBeans oder kurz MDBs ermöglichen die asynchrone Verarbeitung von Nachrichten in
einer Enterprise Anwendung. Auch wenn sie offiziell zu den Enterprise JavaBeans zählen, so basiert
ihre eigentliche Funktionalität auf dem Java Message Service Application Programming Interface,
kurz JMS API. Diese bietet dem Entwickler Schnittstellen an, um eine Nachrichtenkommunikation
in Java-Anwendungen zu verwenden und ist im Application Server implementiert. Neben der asynchronen Verarbeitung wird gleichzeitig für eine sichere Nachrichtenzustellung gesorgt. Zum einen
können dazu die gesendeten Nachrichten auf der Festplatte zwischengespeichert werden, sodass sie
auch bei einem Serverabsturz erhalten bleiben. Zum anderen sorgt ein Bestätigungsmechanismus für
einen korrekten und verlustlosen Empfang der Daten. Insgesamt gibt es zwei Kommunikationsarten:
Point-To-Point oder Public-Subscribe.
3.3.1. Point-To-Point
Bei Point-To-Point (kurz PTP) wird eine Queue verwendet, in welche der Sender seine Nachrichten
ablegt und wo der Empfänger sie abholen kann. Die Queue stellt dabei sicher, dass die Nachrichten
solange vorgehalten werden, bis der Empfänger sie abgeholt hat oder ein gewisses Timeout-Intervall
abgelaufen ist. Der Wert des Intervalls kann jeweils im Application Server konfiguriert werden. Während ein Sender nur die Queue adressieren muss, muss sich ein Empfänger an einer Queue anmelden,
sodass es durchaus möglich ist, dass mehrere Empfänger vorhanden sind. Hier gilt dann das FirstCome-First-Serve-Prinzip, d.h. holt einer der Empfänger die Nachricht ab, ist sie für die anderen
nicht mehr zugänglich. Punkt-zu-Punkt bedeutet hier also nicht, dass es nur einen Sender und einen
Empfänger gibt, sondern dass die gesendete Nachricht immer nur genau einen Empfänger erreicht.
Abbildung 3 zeigt eine Schemaansicht dieser Kommunikationsvariante.
3.3.2. Public-Subscribe
Public-Subscribe (kurz Pub/Sub) nutzt eine sogenannte Topic zur Nachrichtenverteilung. Genau wie
die Queue bei Point-To-Point können sich die Empfänger an diese Topic anmelden und ein Sender
11
Abbildung 3: Schemaansicht der Point-To-Point-Kommunikation
adressiert seine Nachrichten dorthin. Bei dieser Variante erhalten jedoch zum einen alle Empfänger
die Nachricht und zum anderen werden diese sofort zugestellt. Während die Queue also wartet, bis
ein Empfänger die Nachricht abholt, verteilt die Topic die Nachrichten sofort an alle angemeldeten
Empfänger. Ist ein Empfänger gerade nicht verfügbar, verpasst er die Nachricht. Natürlich gibt es
hier auch die Möglichkeit, dieses Standardverhalten je nach Bedarf entsprechend zu konfigurieren.
So kann die Topic eine Nachricht auch solange speichern, bis ein Empfänger wieder angemeldet und
bereit ist, die Nachricht zu empfangen. Abbildung 4 zeigt die entsprechende Schemaansicht.
Abbildung 4: Schemaansicht der Public-Subscribe-Kommunikation
3.3.3. Aufbau und Beispiel einer MessageDrivenBean
MDBs werden nicht von einem Client explizit aufgerufen, sondern vom Container. Darum implementieren diese Beans auch kein Business-Interface. Stattdessen müssen sie das MessageListenerInterface aus der JMS API implementieren, welches eine onMessage-Methode vorschreibt. Diese
Methode wird dann vom Container automatisch aufgerufen, sobald eine Nachricht in einer Queue
oder Topic vorhanden ist. Da beide selbst Bestandteil des Application Servers sind, kann für die
Verwendung eine Referenz über die @Resource Annotation injiziert oder über den JNDI-Dienst erfragt werden. Nähere Informationen zu diesen beiden Möglichkeiten folgt in den Abschnitten 3.4.1
und 3.4.2. Listing 6 zeigt ein einfaches Beispiel einer MessageDrivenBean. Durch die @MessageDrivenBean Annotation wird diese Klasse zur MDB und ab sofort vom Container verwaltet. Über
12
die Attribute hinter der Annotation wird angegeben, ob Nachrichten von einer Topic oder Queue
empfangen werden sollen, unter welchem Namen diese im JNDI registriert ist und ob empfangene Nachrichten automatisch bestätigt werden sollen oder der Entwickler dies manuell vornehmen
möchte. Die onMessage-Methode bekommt schließlich die Nachricht als Objekt vom Typ Message
übergeben. Um diese nun korrekt weiterverarbeiten zu können, muss sie erst in ein entsprechendes
Format überführt werden. Zur Auswahl stehen folgende Unterklassen von Message: TextMessage,
MapMessage, BytesMessage, StreamMessage oder ObjectMessage. Im Beispiel wird die Message
in eine TextMessage umgewandelt, um die übermittelte Nachricht, welche ein String ist, ausgeben
zu können. Wie eine Message beispielsweise an eine Queue gesendet werden kann, zeigt Listing 7
in Form einer SessionBean. Zuerst wird hierzu eine Verbindung zu der Queue aufgebaut und eine
Session für die Kommunikation erzeugt. Der erste Parameter der createSession-Methode gibt dabei
an, ob die Kommunikation in einer Transaktion ausgeführt werden soll und der zweite Parameter auf
welche Weise gesendete Nachrichten bestätigt werden. Danach können über den MessageProducer
verschiedene Nachrichten dorthin versendet werden.
1
2
3
4
5
6
import
import
import
import
import
import
javax . ejb . ActivationConfigProperty ;
javax . ejb .MessageDriven;
javax .jms.JMSException;
javax .jms.Message;
javax .jms.MessageListener;
javax .jms.TextMessage;
7
8
9
10
11
12
@MessageDriven(mappedName = ”jms/Queue”, activationConfig = {
@ActivationConfigProperty(propertyName = ”acknowledgeMode”, propertyValue = ”Auto−acknowledge”),
@ActivationConfigProperty(propertyName = ”destinationType”, propertyValue = ”javax .jms.Queue”)
})
public class TextMessageDrivenBean implements MessageListener {
13
@Override
public void onMessage(Message message) {
try {
TextMessage textMessage = (TextMessage)message;
System.out. println (textMessage.getText()) ;
} catch (JMSException e) {
// Fehler behandeln
}
}
14
15
16
17
18
19
20
21
22
23
}
Listing 6: Beispiel einer MessageDrivenBean
1
2
3
4
5
import
import
import
import
import
javax . annotation .Resource;
javax . ejb . Stateless ;
javax .jms.Connection;
javax .jms.ConnectionFactory;
javax .jms.MessageProducer;
13
6
7
8
import javax .jms.Queue;
import javax .jms. Session ;
import javax .jms.TextMessage;
9
10
11
@Stateless
public class TextMessageSender {
12
@Resource(mappedName = ”jms/QueueConnectionFactory”)
private ConnectionFactory connectionfactory ;
@Resource(mappedName = ”jms/Queue”)
private Queue queue;
13
14
15
16
17
public void sendMessage(String message) {
try {
Connection connection = connectionfactory .createConnection() ;
Session session = connection. createSession ( false , Session .AUTO ACKNOWLEDGE);
MessageProducer messageProducer = session.createProducer(queue);
TextMessage txtMessage = session.createTextMessage(message);
messageProducer.send(txtMessage);
} catch (Exception e) {
// Fehler behandeln
}
}
18
19
20
21
22
23
24
25
26
27
28
29
}
Listing 7: Beispiel einer SessionBean mit einer Methode zum Versenden von Nachrichten
3.4. Benutzung
Da EJBs vom Container verwaltet werden, sollte nicht der new-Operator zur Instanziierung verwendet
werden. Stattdessen stehen dazu das Java Naming and Directory Interface oder Dependency Injection
zur Verfügung. Außerdem können die Methoden einer SessionBean asynchron und zeitgesteuert
ausgeführt werden.
3.4.1. Java Naming and Directory Interface
JNDI ist ein Namens- und Verzeichnisdienst, welcher im Application Server integriert ist. Dieser
verwaltet Objektreferenzen unter einem Namen. Eine Komponente stellt also bei Bedarf eine Anfrage an diesen Dienst mit dem Namen des gewünschten Objekts. Sofern ein entsprechendes Objekt
beim JNDI registriert ist, wird daraufhin die passende Referenz zurückgegeben. Dieser Prozess wird
auch als JNDI-Lookup bezeichnet. Der Dienst ist sowohl für alle Anwendungen auf dem Application Server, als auch von außen für andere Anwendungen bzw. Systeme erreichbar. Abhängig vom
Application Server müssen dafür aber noch einige Konfigurationen getroffen werden, welche aber
von Hersteller zu Hersteller verschieden sein können. Speziell bei einem Remote-Zugriff ist eine
Angabe der IP und des Ports natürlich unerlässlich. Listing 8 zeigt die Warenkorb-Bean, welche
von einer anderen Anwendung über das Remote-Interface aufgerufen wird. Der String, welcher der
14
doLookup-Methode übergeben wird, ist der JNDI-Name, unter welchem das Objekt registriert ist
und kann in der Regel über die Administrationskonsole des jeweiligen Application Servers ermittelt
werden. Sollten zu einem Business-Interface mehrere Implementierungen existieren, dann muss bei
den einzelnen Implementierungen hinter der Annotation @Stateless, @Stateful oder @Singleton ein
eindeutiger Name über das mappedName-Attribut definiert werden.
1
2
IWarenkorbRemote warenkorb = InitialContext.doLookup(”java: global /JNDI/Warenkorb!IWarenkorbRemote”);
warenkorb.kaufen() ;
Listing 8: Beispiel eines JNDI-Lookups
3.4.2. Dependency Injection
Soll eine Bean innerhalb einer Anwendung verwendet werden, bietet Dependency Injection, kurz DI,
neben dem JNDI-Lookup einen deutlich komfortableren Zugriff. Dazu muss lediglich die Annotation
@EJB über die entsprechende Instanzvariable in der Klasse oder über die Setter-Methode geschrieben
werden. Dann sucht der Container automatisch nach einer passenden Referenz und injiziert diese.
Bei der Lookup-Variante müsste sich der Entwickler immer noch Gedanken darüber machen, wie er
die Objekte vom Instanziierungsort an die gewünschte Stelle bekommt. Bei Nutzung von DI kann er
die Aufgabe an den Container übergeben. Diese Technik wird auch Inversion of Control“ genannt,
”
was bedeutet, dass nicht die Anwendung die Kontrolle übernimmt, sondern wie hier die Enterprise
Edition bzw. konkret der Container im Application Server. Also ganz nach dem Hollywood-Motto:
Don’t call us, we’ll call you!“ [Wik12c]. Listing 9 zeigt die Benutzung der Warenkorb-Bean in einer
”
anderen Klasse durch die @EJB Annotation an der Instanzvariablen oder am entsprechenden Setter.
Bei mehreren Implementierungen zu einem Business-Interface muss hier nur hinter dem @EJB über
das beanName-Attribut angegeben werden, welche konkrete Implementierung injiziert werden soll.
1
2
@EJB
private IWarenkorbLocal warenkorb;
3
4
5
6
7
@EJB
public void setIWarenkorbLocal(IWarenkorbLocal warenkorb) {
this .warenkorb = warenkorb;
}
Listing 9: Beispiel für die Dependency Injection
3.4.3. Asynchronous
Generell werden die Methodenaufrufe der SessionBeans synchron ausgeführt. Der Aufrufer blockiert
also an der entsprechenden Stelle solange, bis die Methode vollständig abgearbeitet wurde. Durch
Verwendung der @Asynchronous Annotation wird die Programmkontrolle direkt nach dem Aufruf
wieder an den Aufrufer zurückgegeben. Auf diese Weise können Aufgaben, welche für den weiteren
15
Programmablauf keine große Relevanz besitzen, im Hintergrund ausgeführt werden. Dazu muss die
Methode allerdings entweder keinen Rückgabetyp oder eine Implementierung vom Future-Interface
besitzen. Ein Future repräsentiert ein Objekt, welches erst in der Zukunft existieren wird. Im Hauptprogramm kann das Ergebnis dann zu einem späteren Zeitpunkt über die get-Methode ermittelt
werden. Listing 10 zeigt dazu ein Beispiel, sowie Listing 11 die aufgerufene Methode, welche eine
E-Mail asynchron versendet und anschließend eine Erfolgsmeldung zurückgibt. Diese könnte etwa in
einem Onlineshop nach jeder erfolgreichen Bestellung ausgeführt werden.
1
2
3
4
5
6
7
Future<String> status = warenkorb.sendeEmail();
// weitere Methoden aufrufen oder Code ausfuehren
try {
System.out. println ( status . get()) ; // hier dann auf das Ergebnis warten und ausgeben
} catch (Exception e) {
// Fehler behandeln
}
Listing 10: Beispiel eines asynchronen Methodenaufrufs mit anschließender Ergebnisabfrage
1
2
3
4
5
@Asynchronous
public Future<String> sendeEmail() {
// E−Mail versenden
return new AsyncResult<String>(”Email versendet!”);
}
Listing 11: Beispiel für eine asynchron ausgeführte Methode
3.4.4. Scheduling
Sollen Prozesse zeitgesteuert ausgeführt werden, kann auch dies vom Container übernommen werden. Dazu wird an die gewünschte Methode die @Schedule Annotation geschrieben. Dahinter wird
dann über die Attribute in einer cronjob2 ähnlichen Syntax festgelegt, in welchen Abständen diese ausgeführt werden soll. Die Methode darf aber keinen Rückgabetyp besitzen, keine Parameter
übergeben bekommen und keine Exceptions werfen. Listing 12 zeigt eine Methode, die in einem Onlineshop Werbung schalten könnte. In diesem Beispiel würde die Methode also alle zehn Sekunden
aufgerufen werden. Das persistent-Attribut legt zusätzlich fest, ob die Aufrufe gespeichert werden
sollen. Steht der Wert auf true und der Server stürzt zwischenzeitlich ab, dann werden die Aufrufe
wiederholt, sobald der Server wieder hochgefahren wurde.
1
2
3
4
@Schedule(second = ”∗/10”, minute = ”∗”, hour = ”∗”, persistent = false )
public void schalteWerbung() {
// Werbung schalten
}
Listing 12: Beispiel für eine in gewissen Zeitabständen vom Container ausgeführte Methode
2
Zeitbasierter Prozess in UNIX-Systemen
16
4. Technik
Nachdem nun die Enterprise JavaBeans vorgestellt wurden, soll in diesem Kapitel die dahinterstehende Technik etwas näher betrachtet werden. Gerade weil die einzelnen Beans auf sehr einfache
Art und Weise verwendbar sind, passiert umso mehr hinter den Kulissen im Container. Denn es darf
nicht vergessen werden, dass auch der Application Server selbst eine in Java geschriebene Software
ist. Also alles, was der Entwickler durch den Einsatz der Enterprise Edition nicht selber zu implementieren braucht, muss dennoch im Hintergrund von der Laufzeitumgebung übernommen werden.
Spätestens wenn die ersten Fehler in solch einer Anwendung auftreten, wird ein Entwickler mehr
oder minder gezwungen sein, sich mit der dahinterliegenden Technik näher zu befassen. Neben der
Serialisierung von Objekten, sollen im Folgenden zusätzlich noch Reflection und die Verwendung von
Proxy-Objekten erläutert werden.
4.1. Serialisierung
Durch Serialisierung kann ein Objekt in eine Bytestruktur überführt werden, sodass es zum Beispiel auf der Festplatte gespeichert oder über das Netzwerk versendet und empfangen werden kann.
Dabei werden neben den Instanzvariablen und Methoden, auch alle anderen referenzierten Objekte
oder Oberklassen mit in Datenstrom überführt. In Java muss eine Klasse dazu nur das Interface
Serializable implementieren. Anschließend kann das Objekt mit Hilfe der Methoden writeObject aus
der ObjectOutputStream-Klasse serialisiert und mit readObject aus der ObjectInputStream-Klasse
deserialisiert werden. Der Container wird genau diese Technik nutzen, wenn er wie bei den Stateful SessionBeans die Objekte auf die Festplatte auslagert oder für die Kommunikation mit einem
Remote-Business-Interface die Objekte über das Netzwerk verschickt werden sollen. Listing 13 zeigt
einen Ausschnitt, wie eine Serialisierung und anschließende Deserialisierung eines Artikels aussehen
könnte. Das erzeugte Artikel-Objekt wird also zuerst in einer Datei gespeichert und anschließend
daraus wieder rekonstruiert. Hier wird eine einfache Textdatei zu Abspeicherung genommen, das
Format ist aber generell vom Entwickler frei wählbar. Bei der Serialisierung wird zusätzlich noch
ein Hashcode über die Daten, auch SerialVersionUID genannt, mit abgespeichert, welcher standardmäßig automatisch generiert wird. Damit können nur Daten deserialisiert werden, wenn die
abgespeicherte UID mit dem Hashcode der entsprechenden Klasse übereinstimmt. Ansonsten wird
eine Fehlermeldung geworfen. Da aber beispielsweise nur das Hinzufügen eines weiteren Getters
zwar die UID verändert, aber die eigentlichen Daten nicht beeinflusst, kann der Entwickler diese UID
auch selber verwalten. Dazu wird diese in der entsprechenden Klasse als statische Instanzvariable
angelegt. Somit kann der Entwickler selber bestimmen, wann eine Änderung vorliegt, sodass eine
verlustfreie Deserialisierung der Daten nicht mehr gewährleistet werden kann. Prinzipiell kann auch
die komplette Serialisierung und Deserialisierung vom Entwickler in die Hand genommen werden,
indem er die oben genannten Methoden in der jeweiligen Klasse selber implementiert. Auf diese
Weise kann beeinflusst werden, was genau gespeichert bzw. gelesen werden soll oder ob weitere Aktionen während der Prozesse durchgeführt werden sollen. Außerdem können Instanzvariablen durch
Benutzung des Schlüsselworts transient“ grundsätzlich von der Serialisierung ausgenommen werden.
”
17
1
Artikel
serialisierbarerArtikel
= new Artikel() ;
2
3
4
5
FileOutputStream dateiSerialisierung = new FileOutputStream(new File(”Artikel . txt ”)) ;
ObjectOutputStream ausgabeStrom = new ObjectOutputStream(dateiSerialisierung);
ausgabeStrom.writeObject( serialisierbarerArtikel ) ;
6
7
8
9
FileInputStream dateiDeserialisierung = new FileInputStream(new File(”Artikel . txt ”)) ;
ObjectInputStream eingabeStrom = new ObjectInputStream(dateiDeserialisierung) ;
Artikel deserialiserterArtikel = ( Artikel ) eingabeStrom.readObject();
Listing 13: Beispiel einer Serialisierung und anschließender Deserialisierung
4.2. Reflection
Die Java Reflection API ermöglicht es, Klasseninformationen zur Laufzeit auszuwerten und zu verwenden. So können neue Objekte erzeugt, Methoden aufgerufen und Variablen verändert werden,
welche zum Zeitpunkt des Kompiliervorgangs noch gar nicht bekannt waren. Dazu stehen jeweils
die Klassen java.lang.Class, java.lang.refelct.Method und java.lang.reflect.Field mit entsprechenden
Methoden zur Verfügung, um die jeweils benötigten Informationen zu erhalten [Mic12]. Der Container nutzt diese Technik zum Beispiel, um die Konfiguration einer Klasse über die Annotationen
zu ermitteln oder bei der Dependency Injection eine passende Instanz des zu injizierenden Objekts
zu erzeugen. Beim Deployment der Anwendung auf den Application Server analysiert der entsprechende Container den gesamten Programmcode und kann durch die Funktionen der Reflection API
alle benötigten Informationen sammeln. Listing 14 zeigt einige Beispielfunktionen anhand der Stateful SessionBean Warenkorb“, wie sie unter anderem im Container verwendet werden. Nachdem ein
”
neues Class-Objekt anhand des Klassennames erzeugt wurde, werden in den beiden folgenden Zeilen
die Klassenmethoden und die Annotationen ermittelt. Für jedes einzelne Method-Objekt könnte nun
wiederum auch die getAnnotations-Methode aufgerufen werden, um die Annotation an den Methoden zu erhalten. In den nächsten drei Zeilen wird ein neues Warenkorb-Objekt instanziiert und die
kaufen-Methode aufgerufen. Dazu wird die aufzurufende Methode über den Namen angegeben und
die Typen der erwarteten Parameter über ein Class-Array. In diesem Fall ist dieses Array leer, da die
Methode keine Parameter erwartet. Ähnlich wird im Anschluss das Objekt, auf dem die Methode
aufgerufen werden soll, der invoke-Methode übergeben und ein Object-Feld mit den Übergabeparametern. Auch hier ist in diesem Beispiel das Feld leer. Somit wird nun auch ersichtlich, warum bei
den EJBs ein parameterloser Konstruktor vorgeschrieben ist. Auch wenn der Container prinzipiell
über Reflection die Möglichkeit besitzt, alle vorhandenen Konstruktoren inklusive der erwarteten
Parameter zu ermitteln, kann er nicht wissen, wo die zu übergebenen Daten konkret vorhanden sind.
Gleiches gilt für die Methoden wie etwa die Lifecycle-Callbacks, welche vom Container aufgerufen
werden. Da auch hier der Container nicht wissen kann, welche Daten genau zu übergeben sind und
wie die Rückgabewerte weiterverarbeitet werden sollen, müssen diese Methoden sowohl parameterlos, als auch ohne Rückgabetyp definiert werden.
18
1
2
3
Class klasse = Warenkorb.class;
Method[] methoden = klasse.getDeclaredMethods();
Annotation[] klassenAnnotationen = klasse .getAnnotations() ;
4
5
6
7
Object instanz = klasse .newInstance();
Method methode = klasse.getDeclaredMethod(”kaufen”, new Class[]{});
methode.invoke(instanz , new Object[]{}) ;
Listing 14: Einige Beispielfunktionen aus der Reflection API
4.3. Proxy-Objekte
Der Container benötigt Zugriff auf die Anwendung, damit er entsprechend agieren kann. Dazu werden sogenannte Proxy-Objekte verwendet. Ein solches Objekt ist ein Stellvertreter einer Enterprise
JavaBean und besitzt die gleichen Geschäftsmethoden wie diese. Die Erzeugung eines solchen Objekts ist Aufgabe des Containers. Anschließend werden alle Anfragen über das Proxy-Objekt an das
entsprechende EJB delegiert. Der Client merkt nichts davon, für ihn sieht es so aus, als würde er
direkt mit der jeweiligen Bean kommunizieren. Somit sind die Proxy-Objekte also die Schnittstelle für
den Container, sodass dieser nun interagieren kann. Noch deutlicher wird das bei einer Kommunikation über das Netzwerk. Hier kennt der entsprechende Client nur das Remote-Interface und schickt
seine Anfragen über dieses an die eigentliche Bean. In diesem Zusammenhang wird häufig auch von
Stubs und Skeletons gesprochen. Das Stub ist der Stellvertreter auf der Clientseite, welcher Anfragen
vom Skeleton auf der Serverseite entgegennimmt bzw. dorthin verschickt. Wird zum Beispiel nun
eine Anfrage an eine Stateless SessionBean gestellt, kann vom Container über das entsprechende
Proxy-Objekt geprüft werden, ob noch eine freie Bean im Pool vorhanden ist oder ob eine neue
instanziiert werden muss. Abbildung 5 zeigt zur allgemeinen Veranschaulichung eine Schemaansicht.
Abbildung 5: Schemaansicht für Proxy-Objekte im Application Server
19
5. Fazit und Ausblick
Zum Abschluss sollen die wesentlichen Aspekte der Enterprise JavaBeans nochmal in Form von Vorbzw. Nachteilen zusammengefasst werden. Außerdem wird ein kurzer Ausblick auf die aufbauende
Bachelorarbeit gegeben.
5.1. Vor- und Nachteile
Der Application Server bietet dem Entwickler viele Funktionalitäten an und nimmt ihm damit zugleich
viele Arbeiten ab. Speziell die EJBs sind aufgrund ihrer einfachen Form leicht zu verwenden. Das
Konzept der Convention over Configuration“ reduziert den Konfigurationsaufwand auf ein Minimum,
”
welcher durch Annotationen aber ebenfalls komfortabel erledigt werden kann. Außerdem sorgt Dependency Injection für eine einfache Benutzung der Beans und vermeidet große Controller“-Klassen
”
oder ein Durchreichen von Objekten über mehrere Schichten hinweg. Gleichzeitig sorgt der Container durch Pooling und Ein- bzw. Auslagerungsstrategien für eine hohe Leistung und ausgeglichenen
Ressourcenverbrauch der Anwendung. Mit MessageDrivenBeans steht zusätzlich der Benutzung von
JMS-Techniken nichts mehr im Wege, sodass Nachrichten verlustfrei und asynchron verarbeitet werden können.
Auf der anderen Seite müssen einige dieser Vorteile auch kritisch betrachtet werden. So kann die
Vermischung von Quelltext und Annotationen gerade für neue Entwickler für Verwirrung sorgen
und durch Dependency Injection wird nicht mehr direkt deutlich, wo eine Objektinstanz herkommt.
Generell kann es zusätzlich Entwickler geben, die ungern die Kontrolle an einen Application Server
abgeben und sich auf die Magie“ dahinter verlassen wollen. Um eine intensive Beschäftigung mit der
”
Technik führt somit ohnehin kein Weg vorbei. Auch der Pool von Stateless SessionBeans und das
Auslagern auf den Hintergrundspeicher bei Stateful SessionBeans kosten zum einen Zeit und zum
anderen Ressourcen, was besonders bei Systemen unter hoher Last schnell problematisch werden
kann. Da es sich außerdem jeweils um standardisierte Lösungen handelt, können diese in bestimmten Situationen ungeeignet sein. Gerade wenn es um absolut hohe Performanz geht, ist der native
Weg meist doch immer noch der bessere.
Jede Technologie hat ihre Vor- und Nachteile. Dennoch kann vorerst festgehalten werden, dass Enterprise JavaBeans die Entwicklung deutlich vereinfachen und eine interessante Komponente für die
Entwicklung von komplexen Geschäftsanwendungen sind.
5.2. Ausblick
In der aufbauenden Bachelorarbeit soll der Einsatz der Java Enterprise Edition und damit natürlich
auch von EJBs anhand eines Praxistests evaluiert werden. Dazu soll eine Anwendung auf Basis dieser
Technik entwickelt und anschließend getestet werden. Neben der Evaluation generell sind speziell die
oben genannten Nachteile interessant. Dabei soll geprüft werden, wie sich der Ressourcenverbrauch
des Application Servers unter hoher Last verhält und wie er optimiert werden kann. Außerdem soll
auch die Entwicklung auf Basis dieser Technologie bewertet werden, ob sie zum Beispiel für gewisse
Projekte oder in bestimmten Situationen eventuell eher ungeeignet ist.
20
Literatur - und Quellenverzeichnis
[Bie10a] Adam Bien. Enterprise JavaBeans 3.1 with Contexts and Dependency Injection: The Perfect
Synergy. http://www.oracle.com/technetwork/articles/java/ejb-3-1-175064.
html, 2010. Stand: 20. Dezember 2012.
[Bie10b] Adam Bien. SIMPLEST POSSIBLE EJB 3.1 TIMER. http://www.adam-bien.com/
roller/abien/entry/simplest_possible_ejb_3_16, 2010. Stand: 20. Dezember
2012.
[Bie11] Adam Bien. Contexts and Dependency Injection in Java EE 6. http://www.oracle.com/
technetwork/articles/java/cdi-javaee-bien-225152.html, 2011. Stand: 20. Dezember 2012.
[Bie12] Adam Bien.
Lightweight Java EE.
http://tv.adam-bien.com/ und http://
www.youtube.com/watch?feature=player_embedded&v=p4uSu_NvwCE, 2012. Stand:
20. Dezember 2012.
[Chr11] Christian Ullenboom. Java ist auch eine Insel. E-Book (Galileo): http://openbook.
galileocomputing.de/javainsel9/, 2011. ISBN:978-3-8362-1506-0; Stand: 20. Dezember 2012.
[Gib12] Andy Gibson. Comparing JSF Beans, CDI Beans and EJBs. http://www.andygibson.
net/blog/article/comparing-jsf-beans-cdi-beans-and-ejbs/#more-1879,
2012. Stand: 20. Dezember 2012.
[Hef10] David R. Heffelfinger.
Setting up GlassFish for JMS and Working
with
Message
Queues.
http://www.packtpub.com/article/
setting-glassfish-jms-and-working-message-queues, 2010.
Stand: 20. Dezember 2012.
[Hol12] Jens Hollman. Einführung in die komponentenbasierte Softwareentwicklung. Technical report, RZ RWTH Aachen, 2012.
http://www.rz.rwth-aachen.de/
aw/cms/rz/Zielgruppen/rz_auszubildende/veranstaltungen/informatik/
Wahlpflichtkurse/~tof/komponentenbasierte_Softwareentwicklung/?lang=de,
Stand: 20. Dezember 2012.
[Kul11] Michael Kulla. Java EE 6. video2brain, 2011. DVD, ISBN: 978-3-8273-6117-2.
[Mag10] Java Magazin. Java EE 6 - Die neue Leichtigkeit. Software und Support Media GmbH,
2010.
[Mic06] Micah Silverman, Rima Patel Sriganesh und Gerald Brose.
Mastering Enterprise JavaBeans.
E-Book: http://www.theserverside.com/news/1369778/
Free-Book-Mastering-Enterprise-JavaBeans-30, 2006. ISBN: 978-0-471-78541-5;
Stand: 20. Dezember 2012.
21
[Mic12] Simon Michel. Java Reflection. http://www.itblogging.de/java/java-reflection/,
2012. Stand: 20. Dezember 2012.
[Mky10] Mkyong. How To Use Reflection To Call Java Method At Runtime. http://www.
mkyong.com/java/how-to-use-reflection-to-call-java-method-at-runtime/,
2010. Stand: 20. Dezember 2012.
[Ora12] Oracle. The Java EE 6 Tutorial. http://docs.oracle.com/javaee/6/tutorial/doc/,
2012. Stand: 20. Dezember 2012.
[Pro09a] Java Community Process. JSR-000316 Enterprise Edition 6 (“Specification“). http://
jcp.org/en/jsr/detail?id=316, 2009. Stand: 20. Dezember 2012.
[Pro09b] Java Community Process. JSR-000316 Enterprise Edition 6 Web Profile (“Specification“).
http://jcp.org/en/jsr/detail?id=316, 2009. Stand: 20. Dezember 2012.
[Pro09c] Java Community Process. JSR-000318 Enterprise JavaBeans (“Specification’”). http:
//jcp.org/en/jsr/detail?id=318, 2009. Stand: 20. Dezember 2012.
[TV10] JAX TV. 60 Minutes with Java EE. http://it-republik.de/jaxenter/news/
Adam-Bien-60-Minuten---mit-Java-EE-6-058320.html und http://vimeo.com/
19787312, 2010. Stand: 20. Dezember 2012.
[Wik12a] Wikipedia. Dependency Injection. http://de.wikipedia.org/w/index.php?title=
Dependency_Injection&oldid=111689740, 2012. Stand: 20. Dezember 2012.
[Wik12b] Wikipedia. Enterprise JavaBeans. http://de.wikipedia.org/w/index.php?title=
Enterprise_JavaBeans&oldid=110289184, 2012. Stand: 20. Dezember 2012.
[Wik12c] Wikipedia. Inversion of Control. http://de.wikipedia.org/w/index.php?title=
Inversion_of_Control&oldid=108491094, 2012. Stand: 20. Dezember 2012.
[Wik12d] Wikipedia. Java Platform, Enterprise Edition. http://de.wikipedia.org/w/index.
php?title=Java_Platform,_Enterprise_Edition&oldid=111579488, 2012. Stand:
20. Dezember 2012.
[Wik12e] Wikipedia.
Middleware.
http://de.wikipedia.org/w/index.php?title=
Middleware&oldid=110849739, 2012. Stand: 20. Dezember 2012.
22
A. Abkürzungen
API
DI
EE
EJB
HTTP
JDK
JNDI
JRE
JVM
MDB
POJO
SE
UID
XML
Application Programming Interface
Dependency Injection
Enterprise Edition
Enterprise JavaBean
Hypertext Transfer Protocol
Java Development Kit
Java Naming and Directory Interface
Java Runtime Environment
Java Virtual Machine
MessageDrivenBean
Plain Old Java Object
Standard Edition
Unique Identification Number
Extensible Markup Language
23