Datenbankabfragen und Datenmanipulation
Werbung

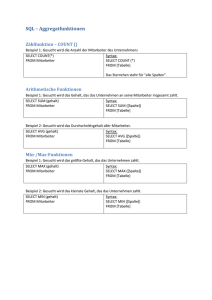
Datenbankabfragen und Datenmanipulation Datenbankabfragen auf einer Tabelle......................................................................................1 SELECT­Abfrage ...............................................................................................................1 Projektion ...........................................................................................................................2 Wertausdrücke....................................................................................................................3 Numerische Wertausdrücke ............................................................................................3 Zeichenkettenwertausdrücke...........................................................................................3 Datums­ und Zeitausdrücke ............................................................................................3 Fallunterscheidungen ......................................................................................................3 NULL­Wert ....................................................................................................................3 Selektion (WHERE­Klausel) ..............................................................................................4 Suchbedingung ...............................................................................................................4 Aggregatfunktionen ............................................................................................................6 Daten gruppieren ................................................................................................................6 Restriktionen von Gruppen .................................................................................................6 Daten sortieren ...................................................................................................................6 Datenbankabfragen auf mehren Tabellen ................................................................................7 Das kartesische Produkt......................................................................................................7 Kartesisches Produkt und Restriktionen ..............................................................................7 Verbundoperationen (joins) ................................................................................................8 Innerer Verbund (inner join) ...........................................................................................8 Äußerer Verbund (outer join)..........................................................................................8 Datenbearbeitung....................................................................................................................9 Datenbankabfragen auf einer Tabelle SELECT­Abfrage Mit der SELECT­ Abfrage werden Abfragen auf einer Tabelle oder auf mehreren Tabellen durchgeführt. Zunächst werden SELECT­Abfragen auf einer Tabelle vorgestellt. Die SE­ LECT­ Abfrage setzt sich aus folgenden Klauseln zusammen: · · · · · FROM­Klausel WHERE­Klausel GROUP BY­Klausel HAVING­Klausel ORDER BY­Klausel Das Ergebnis einer SELECT­Abfrage ist wiederum eine Tabelle. Sie wird Ergebnistabelle bezeichnet wird, oder der NULL­Wert. Die Ergebnistabelle kann aus einer oder mehreren Spalten, keinem, einem oder mehreren Datensätzen bestehen. Die Klauseln werden in der vorgestellten Reihenfolge verarbeitet. Bei jedem Schritt wird eine temporäre Ergebnistabelle erstellt. Beispielsweise liefert die FROM­Klausel eine temporäre Ergebnistabelle, auf der dann die WHERE­Klausel operiert, insofern sie spezifiziert ist. Projektion Eine Projektion bezieht sich auf alle Spalten oder eine Teilmenge der Spalten einer Tabelle. Im ersten Fall spricht man von einer vollständigen Projektion, im letzen Fall von einer einge­ schränkten Projektion. Es werden alle Spalten oder eine Teilmenge der Spaltenmenge ausge­ wählt. Auf jedem Fall werden alle Datensätze selektiert. Eine Projektion entspricht der gleich­ namigen mathematischen Operation auf einer Relation. Folgende Syntax wird verwendet: SELECT <Spaltenliste> FROM <Tabellenbezeichner> <Spaltenliste> := <Spaltenbezeichner> [,<Spaltenbezeichner>]* SELECT * FROM <Tabellenbezeichner> Der Ausdruck in den eckigen Klammen ([ ]) in der ersten SELECT­Anweisung ist optional, der Stern dahinter bedeutet, dass er beliebig oft vorkommen kann. Der Platzhalter „*“ in der zweiten SELECT­Anweisung ist Bestandteil von SQL und steht für alle Spalten. Der Reihenfolge der Spalten entspricht die der Tabellendefinition. Wird kein Platzhalter verwendet, dann entspricht die Reihenfolge der Spalten der Ergebnistabelle derje­ nigen Reihenfolge, in der die Spaltenbezeichner aufgelistet werden. 1 Durch Aliasbezeichner können den Ergebnisspalten andere Bezeichner zugewiesen werden. SELECT Kontonr, BLZ AS Bankleitzahl FROM Kunden; Unter einer Projektion werden unter umständen unterschiedliche Datensätze auf einen und denselben Datensatz abgebildet. In der Ergebnistabelle erschein er jedoch sooft wie Datensät­ ze auf ihn abgebildet werden. Dieses scheint zunächst der Interpretation einer Tabelle als Re­ lation und damit als Menge zu widersprechen. Dieser Widerspruch löst sich jedoch auf, wenn wir die Ergebnistabelle als eine Darstellung der Menge betrachten. In einer Darstellung einer Menge können ihre Elemente durchaus mehrmals genannt werden. Das gleiche gilt übrigens auch für die Reihenfolge. Eine Menge gibt keine Reihenfolge vor, aber selbstverständlich können Elemente einer Menge nur in einer gewissen Reihenfolge dargestellt werden. Die Darstellung einer Relation in Form einer Tabelle besitzt als i. A. mehr Struktur, und damit mehr Informationen als die zugrunde liegende Menge. Dennoch liegt eine Menge einer Tabel­ le zugrunde. Damit ist das Relationenmodell, dem die Mengenlehre zugrunde liegt, konsi­ stent. Sollen Datensätze, die mehrmals auftreten, nur einmal in der Ergebnistabelle erscheinen, dann kann dieses durch das Schlüsselwort DISTINCT, das der Spaltenliste voranzustellen ist, er­ reicht werden. SELECT DISTINCT <Spaltenliste> FROM <Tabellenbezeichner> Nullwerte werden durch die DISTINCT­Spezifikation als gleich angesehen. 1 Für die mathematische Struktur einer Relation ist es unerheblich, in welcher Reihenfolge die Spalten (Attribu­ te) erscheinen. In einer Darstellung erscheinen sie aber zwangsläufig immer in einer Reihenfolge, und diese können sie in der SELECT­Anweisung festlegen. Wertausdrücke Wertausdrücke können Bestandteil einer Ergebnistabelle sein. So kann beispielsweise in der Ergebnistabelle ein Bruttopreis erscheinen, wenn der Nettopreis und die Umsatzsteuer gege­ ben sind. Es werden folgende Wertausdrücke unterschieden: · Numerische Wertausdrücke, · Zeichenkettenwertausdrücke, · Datums­ und Zeitwertausdrücke, · Fallunterscheidungen. Numerische Wertausdrücke Es stehen die übliche arithmetischen Operatoren +, ­, *, /, % zur Verfügung. Als Operanden kommen numerische Werte von Spalten oder Literale in Frage. Ein Literal ist ein konstanter Wert, der wortwörtlich in den SQL­Text geschrieben wird. SELECT Nettopreis * 1.19 AS Bruttopreis FROM Artikel; Zeichenkettenwertausdrücke Hier steht nur der Verkettungsoperator + zur Verfügung: SELECT Vorname & ‘, ‘ + Nachname AS Name FROM Personen; Weiterhin stellen die meisten SQL Implementierung viele Funktionen zur Stringmanipulation zur Verfügung. Datums­ und Zeitausdrücke Es stehen vordefinierte Funktionen zur Verfügung. Fallunterscheidungen Hinter dem SELECT­Schlüsselwort kann eine Fallunterscheidung vorgenommen werden. In Abhängigkeit von dem Wert eines Ausdrucks wird eine gewisser Wert in die Ergebnistabelle geschrieben. Es wird die folgende Syntax verwendet: Select CASE Ausdruck when wert1 then rückgabewert1 [when … then …]* [ELSE rückgabewert] end from Buch NULL­Wert Wenn innerhalb eines Wertausdrucks ein NULL­Wert verwendet wird, dann liefert der ge­ samte Ausdruck den Wert NULL. Selektion (WHERE­Klausel) Mit der Selektion werden Datensätze aus einer Tabelle ausgewählt. Im Gegensatz zur Projek­ tion, die Spalten auswählt, werden hier Zeilen ausgewählt. Dazu wird eine Suchbedingung an die Werte einiger Spalten gestellt. Diese Bedingung wird in die WHERE­Klausel geschrieben. Um eine Bedingung zu formulieren, stehen beispielsweise Vergleichsoperatoren und boole­ sche Operatoren zur Verfügung. SELECT Vorname, Nachname FROM Kunde WHERE Ort = ’Duderstadt’; Suchbedingung Um eine Suchbedingung zu formulieren, stehen folgende Operatoren zur Verfügung: · Vergleichsoperatoren · Boolesche Operatoren · NULL ­ Operator · LIKE ­ Operator · SIMILAR ­ Operator · BETWEEN ­ Operator · IN ­ Operator Abgesehen von den booleschen Operatoren können alle anderen in einem allgemeineren Sinn zu den Vergleichsoperatoren gerechnet werden. Es werden Werte mit gewissen Ausdrücken verglichen. Als Rückgabewert erhält man eine Wahrheitswert (TRUE oder FALSE). Mit diesen Operatoren könne atomare boolesche Ausdrücke gebildet werden. Zusammenge­ setzte boolesche Ausdrücke erhält man durch die booleschen Operatoren: · AND, · OR, · NOT. Es gelten die übliche Vorrangregeln: NOT vor AND und OR, AND vor OR. Durch Klam­ mern kann aber eine eventuell abweichende Reihenfolge definiert werden. In Transact­SQL stehen folgende Vergleichsoperatoren zur Verfügung: Operator = <> != > < >= <= !> !< Bedeutung Gleich Nicht gleich Nicht gleich Größer als Kleiner als Größer gleich Kleiner gleich Nicht größer als Nicht kleiner als Bei den Vergleichsoperatoren werden NULL­werte ignoriert. D. h. eine Zeile mit einem Nullwert wird übersprungen, wenn er in eine Vergleichsoperation eingeht. Um auch Null­ Werte zu berücksichtigen, kann der NULL­Operator verwendet werden. Syntax: SELECT … WHERE …wert IS NULL. In dem folgenden Beispiel werden die Vor­ und Nachnamen von Personen selektiert, die kei­ ne Emailadresse haben, oder deren Emailadresse nicht bekannt ist: SELECT Vorname, Nachname FROM Personen WHERE Email IS NULL; Mit dem LIKE­Operator kann eine Zeichenkette mit einem Muster verglichen werden. (Eine Emailadresse hat z. B. ein typisches Muster). SELECT … WHERE …wert LIKE ‘muster’. Die folgende SELECT­Anweisung sucht alle Personen, deren Nachname mit einem ‘K’ be­ ginnt. SELECT Vorname, Nachname FROM Personen WHERE Nachname LIKE ‘K%’; Der Vergleichsausdruck ‚muster’ ist eine Zeichenkette. Eine besondere Bedeutung haben folgende Zeichen oder Zeichenketten: · % (Prozentzeichen) · _ (Unterstrich) · [zeichen1 ­ zeichen2 ] · [^zeichen1 ­ zeichen2] An der Stelle des Prozentzeichens % kann eine beliebige Zeichenfolge mit beliebig vielen alphanumerischen Zeichen stehen, an der Stelle des Unterstrichs _ ein alphanumerisches Zei­ chen. In der eckigen Klammer wird ein Zeichenbereich beschrieben, z. B. bedeutet [a­m] alle kleinen Buchstaben zwischen ‚a’ und ‚m’. Das ^­Zeichen ist das Komplementzeichen in der Menge aller Zeichen. Sollen in dem Muster einer der Sonderzeichen %, _, ^, [, ] gemeint sein, dann sind sie in eckige Klammern zu schreiben. Der SIMILAR­Operator kann so wir der LIKE­Operator verwendet werden, er erwartet je­ doch einen regulären Ausdruck. Dem BETWEEN­Operator müssen zwei Werte des gleichen Typs übergeben werden, die ver­ gleichbar sind. SELECT … WHERE …wert BETWEEN wert1 AND wert2. Mit dem IN­Operator kann überprüft werden, ob ein Wert in einer Menge von Literalen ent­ halten ist. Diese werden in runden Klammern durch Kommata getrennt aufgelistet, wie fol­ gendes Beispiel zeigt: SELECT Vorname, Nachname FROM Personen WHERE Ort IN (Göttin­ gen, Duderstadt, Northeim); Aggregatfunktionen Aggregatfunktionen beziehen nicht auf einzelne Werte, sondern auf eine Menge von Werten. So können beispielsweise Mittelwerte oder Extremwerte ermittelt werden. Im Standard SQL stehen folgende Aggregatfunktionen zur Verfügung: · COUNT · AVG · MIN · MAX · SUM Benutzerdefinierte Aggregatfunktion wie auch andere Funktionen und Datentypen können auf dem SQL­Server 2005 mit C# oder VB.NET programmiert werden. Daten gruppieren Die GROUP BY­Klausel führt eine Partitionierung der Ergebnistabelle anhand gleicher Werte in spezifizierten Spalten. Die GROUP BY Klausel wird i. A. im zusammen mit Aggregat­ funktionen verwendet. Diese werden dann auf die einzelnen Gruppen von Datensätzen ange­ wendet. SELECT Ort, COUNT(Ort) AS Kundenzahl FROM Kunden GROUP BY Ort; Spaltennamen können zusammen mit Aggregatfunktionen nur zur Gruppierung verendet wer­ den. Restriktionen von Gruppen Durch eine Suchbedingung können auch Gruppen selektiert werden. Dieser Vorgang wird auch Gruppenrestriktion genannt. SELECT Ort, COUNT(Ort) AS Kundenzahl FROM Kunden GROUP BY Ort HAVING COUNT(Ort)> 2; Daten sortieren Die Reihenfolge der Tupel einer Relation spielt keine Rolle. Jedoch können sie sortiert ausge­ geben werden. Vorraussetzung ist, dass eine Domäne eine Ordnungsstruktur besitzt. Im Rela­ tionenmodell wird also von solchen zusätzlichen Strukturen abstrahiert. ORDER BY <Sortierschlüssel> [ASC|DESC] [,<Sortierschlüssel> [ASC|DESC]]* Datenbankabfragen auf mehren Tabellen Normalisierte Daten liegen im Relationenmodell redundanzarm vor. Dieses erreicht man, in­ dem Daten auf mehrere Tabellen verteilt werden, die durch Fremdschlüsselbeziehungen zu­ sammenhängen. Will man Daten, die auf mehreren Tabellen verteilt sind, zusammenführen, dann muss sich eine Abfrage über mehrere Tabellen erstrecken. Wir lernen hier, wie eine Er­ gebnistabelle aus den Spalten von mehreren vorgegebenen Tabellen erhalten werden kann. Solche Operationen heißen Verbundoperationen (engl.: join). Genauer versteht man unter einer Verbundoperation eine Verknüpfung eines kartesischen Produktes mit einer Selektion (Restriktion) und einer Projektion. Das kartesische Produkt Die grundlegende mengentheoretische Operation, die allen Verbundoperationen zugrunde liegt, ist das Kartesische Produkt. SELECT * FROM Customers, Suppliers. Hier wird jeder Zeile aus Customer jeweils eine Zeile aus Suppliers angehängt. Die Anzahl der Datensätze ist das Produkt aus der Anzahl der Zeilen aus Customer und der Anzahl der Zeilen aus Suppliers. Es können in der FROM­Klausel auch mehrere Tabellen engegeben werden. Sie werden von links nach rechts abgearbeitet. Ein kartesisches Produkt von Tabellen wird auch Kreuzverbund (engl: cross join) genannt. Da das Ergebnis eines Kreuzverbundes wiederum eine Tabelle ist, können nun Projektion und Selektionen angewendet werden. Kartesisches Produkt und Restriktionen Im Allgemeinen interessiert man sich für eine Teilmenge des kartesischen Produktes und nicht für jede beliebige Verknüpfung von zwei Datensätzen. Das kartesische Produkt wird als durch eine Restriktion eingeschränkt. Dabei können drei Fälle auftreten: · Es werden zwei Tabellen verbunden, die mit einer Fremdschlüsselbeziehung zusam­ menhängen. Nur solche Datensätze werden selektiert, in denen die Werte für die Spal­ ten des Primär­ und des Fremdschlüssels identisch sind. · Die Tabellen besitzen gemeinsame Nichtschlüsselspalten. Nur die Datensätze werden in die Ergebnistabelle übernommen, die in den entsprechenden Nichtschlüsselspalten einen gemeinsamen Wert haben. · Die Verknüpfung durch gemeinsame Nichtschlüsselspalten geschieht nicht durch die Gleichheitsbedingung, sondern stattdessen kann jeder boolesche Ausdruck – i. A eine Vergleichsoperation ­ verwendet werden. Restriktionen werden in der WHERE­Klausel definiert. In sie gehen Spaltenbezeichner ein. Bezeichner einer Spalte einer Tabelle sind eindeutig. Jedoch können zwei Spalten aus zwei Tabellen durchaus den gleichen Bezeichner haben. Um sie dennoch zu unterscheiden, werden qualifizierte Bezeichner verwendet. Dabei wird vorausgesetzt, dass die Tabellenbezeichner einer Datenbank eindeutig sind. Ein Qualifizierter Bezeichner beginnt mit dem Tabellenbezeichner, dem durch ein Punkt getrennt der Spaltenbezeichner angehängt ist. Verbundoperationen (joins) In der FROM­Klausel wird eine Tabelle spezifiziert, auf die sich die abfrage bezieht. Diese Tabelle muss nicht notwendigerweise in physische Form vorliegen, sondern kann beispiels­ weise selbst wiederum das Ergebnis einer Abfrage sein. In der FROM­Klausel kann auch ein Kartesisches Produkt stehen. Das kartesische Produkt bildet die Grundlage für Verbundopera­ tionen. Da sie häufig verwendet werden, gibt es für sie eine eigen Sprachkonstruktion. Verbundoperationen auf zwei Tabellen werden durch eine gemeinsame Spalte definiert. An diese werden einschränkende Bedingungen gestellt. Natürlich erhält man das Ergebnis auch dann, wenn an das kartesische Produkt in der WHERE­Klausel passende Bedingungen ge­ stellt werden. Jedoch werden in diesem Fall zwei Ergebnistabellen erzeugt, zunächst das kar­ tesische Produkt, dann die Einschränkung. Innerer Verbund (inner join) In den inneren Verbund erscheinen nur solche Datensätze des kartesischen Produktes, deren gemeinsame Spalte gewissen Vergleichbedingungen genügen. Ist die Vergleichbedingung die Gleichheit, dann spricht man auch von Euijoin, wird ein anderer Vergleichsoperator verwen­ det, heißt der innere Verbund auch Thetajoin. Euqijoin: Select * from Categories join Products on Categories.CategoryID = Products.CategoryID; Thetajoin: Select * from Categories join Products on Categories.CategoryID <> Products.CategoryID; Tabellen können auch mit sich selbst verknüpft werden. Um sie zu unterscheiden, müssen Aliasnamen verwendet werden. Äußerer Verbund (outer join) Left outer join bzw. right outer join: an die gemeinsame Spalte der linken bzw. der rechten Tabelle werden keine Bedingungen gestellt. Falls in der anderen Tabelle die Bedingungen nicht zutreffen, werden NULL­werte gesetzt. SELECT <Spaltenliste> FROM tabelle1 left outer join tabelle2; SELECT <Spaltenliste> FROM tabelle1 right outer join tabelle2; Der volle äußere Verbund ist die Vereinigung des rechten und des linken äußeren joins. SELECT <Spaltenliste> FROM tabelle1 full outer join tabelle2; Datenbearbeitung INSERT INTO <Tabellenbezeichner> ([Spaltenbezeichner,..]) Values (wert1,…) [WHERE..] UPDATE SET Saltenbezeichner = …. [WHERE …] DELETE FROM…WHERE ….