Beispiellösung zu den ¨Ubungen Datenstrukturen und Algorithmen
Werbung

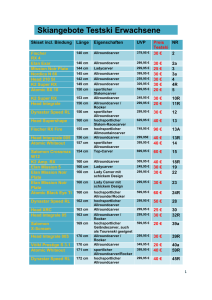
Robert Elsässer u.v.a. Paderborn, den 15. Mai 2008 Beispiellösung zu den Übungen Datenstrukturen und Algorithmen SS 2008 Blatt 5 AUFGABE 1 (6 Punkte): Nehmen wir an, “Anfang” bezeichne in einer normalen Queue (s. Vorlesung) die Position des Elements, das am längsten in der Schlange ist. Analog bezeichne “Ende” die Position des zuletzt eingefügten Elements. Eine beidseitige Schlange (deque, double-ended queue) erlaubt nun das Einfügen und Entfernen von Elementen an beiden Seiten (Anfang und Ende) der Datenstruktur. Schreiben Sie die O(1)-Operationen “Entfernen am Ende” und “Einfügen am Anfang” und nehmen Sie dazu an, dass die beidseitige Schlange als Array realisiert ist. Beachten Sie dabei die Randbedingungen, d. h. ob die Schlange leer oder vollständig gefüllt ist. a) Einfügen am Anfang (3 Punkte) EnqueueFront(Q, x) 1 if head[Q] = 1 2 then if tail[Q] = length[Q] 3 then Error(“Q is full”) 4 else head[Q] ← length[Q] 5 Q[head[Q]] ← x 6 else if head[Q] − 1 = tail[Q] 7 then Error(“Q is full”) 8 else head[Q] ← head[Q] − 1 9 Q[head[Q]] ← x b) Entfernen am Anfang (3 Punkte) DequeueBack(Q, x) → x 1 if head[Q] = tail[Q] 2 then Error(“Q is empty”) 3 else if tail[Q] = 1 4 then tail[Q] ← length[Q] 5 else tail[Q] ← tail[Q] − 1 6 x ← Q[tail[Q]] AUFGABE 2 (6 Punkte): Entwerfen Sie einen Algorithmus mit Laufzeit O(n log k), der k sortierte nicht-leere Listen in eine sortierte Liste zusammenfasst (mischt), wobei n (n > k) die Gesamtzahl aller Elemente (also summiert über alle k Eingabelisten) ist. Erläutern Sie kurz Ihre Idee, geben Sie den Pseudocode des Verfahrens an und beweisen Sie, dass Ihr Algorithmus korrekt ist und die Laufzeitschranke O(n log k) erreicht wird. Hinweis: Benutzen Sie einen Heap zum Mischen von k Elementen und bei Bedarf Satellitendaten zusätzlich zum Schlüsselelement! Punkteschlüssel: Idee + Algo: 4 Punkte, Korrektheit + Laufzeit: 2 Punkte Idee: Das jeweils erste Element jeder Liste in ein Array stecken, zusammen mit dem Satellitendatum, aus welcher Folge das Element stammt. Das Array zu einem Min-Heap machen und dann nacheinander immer das oberste Element des Heaps entfernen und aus der Liste, aus der das Element stammte, das nächste Element in den Heap einfügen (wieder zusammen mit dem Satellitendatum). Laufzeit ganz kurz: Heap-Aufbau in O(k), dann brauchen wir für jedes Element, das eingefügt und gelöscht wird, O(log k) und somit insgesamt O(n log k) Schritte. Merge-k-way(L1 , . . . , Lk , k) 1 2 3 4 5 6 7 8 9 10 11 12 13 15 for j ← 1 to k do H[j].key ← head[Lj ] H[j].data ← j head[Lj ] ← next[head[Lj ]] BuildMinHeap(H) while H not empty do elem ← ExtractMin(H) A[i] ← elem.key j ← elem.data if head[Lj ] 6= nil then elem.key ← head[Lj ] HeapInsert(H, elem) head[Lj ] ← next[head[Lj ]] return A Korrektheit: Schleifeninvariante: Vor dem i-ten Schleifendurchlauf der while-Schleife sind die i-1 kleinsten Elemente der Gesamtfolge in A[1..i-1] aufsteigend sortiert gespeichert. H speichert von jeder der k Listen L1 , . . . , Lk das jeweils kleinste Element, das noch nicht in A gespeichert sind (bzw. einen leeren Knoten, falls die Liste leer ist). Initialisierung: A ist noch leer, somit sind die 0 kleinsten Elemente enthalten. H enthält den jeweils ersten Knoten jeder Liste, wegen deren Sortierung ist dies der kleinste. Erhaltung: In Iteration i wird das kleinste Element des Heaps an die Position A[i] geschrieben und aus dem Heap gelöscht. Somit wird der erste Teil der Behauptung erfüllt. Der zweite Teil wird erfüllt, indem das erste Element aus der Liste in den Heap eingefügt wird (sofern vorhanden), aus der das gelöschte Element stammt. Terminierung: Da in jeder Iteration ein Element gelöscht wird und nur so lange ein Element eingefügt wird, bis die entsprechende Ursprungsliste leer ist, muss der Heap nach n Durchläufen leer sein und die Schleife terminieren. A enthält dann wegen i = n + 1 alle n Elemente in aufsteigend sortierter Reihenfolge. Laufzeit: Die for-Schleife wird k-mal durchlaufen, jede einzelne Operation darin benötigt konstante Zeit, insgesamt also O(k). BuildMinHeap hat laut Vorlesung linearen Aufwand, hier damit auch O(k). Die while-Schleife wird n-mal durchlaufen. Grund: Jedes der n Elemente in den Listen wird genau einmal in den Heap eingefügt und genau einmal daraus entfernt. Jeder Schleifendurchlauf kostet maximal O(log k) Schritte wegen des Einfügens eines neuen Elements in den k − 1-elementigen Heap. Alle anderen Operationen sind in konstanter Zeit möglich. Insgesamt braucht die while-Schleife daher O(n log k), was alle vorherigen Laufzeiten dominiert. AUFGABE 3 (6 Punkte): Die Operation Union auf dynamischen Mengen erhält als Eingabe zwei disjunkte Mengen L1 und L2 und gibt die Menge L = L1 ∪ L2 zurück, in der alle Elemente von L1 und L2 enthalten sind. Die Mengen L1 und L2 können durch diese Operation zerstört werden. Zeigen Sie, wie man Union so mit einer geeigneten Listen-Datenstruktur implementiert, dass die Operation in O(1) ausgeführt wird. Argumentieren Sie kurz, warum Ihr Verfahren korrekt ist und konstante Laufzeit hat! Idee: Statt nur eines Zeigers auf das erste Element wird zusätzlich ein Zeiger auf das letzte Element (tail) verwendet. Union besteht dann darin, die Elemente tail[L1] und head[L2] miteinander zu verketten. Schließlich fehlt noch, head[L] auf head[L1] zu setzen und tail[L] auf tail[L2]. Union(L1 , L2 ) (5 Punkte inkl. Beschreibung der Idee) 1 2 3 4 5 6 7 8 9 if head[L1 ] = nil then return L2 else if head[L2 ] = nil then return L1 next[tail[L1 ]] ← head[L2 ] prev[head[L2 ]] ← tail[L1 ] head[L] ← head[L1 ] tail[L] ← tail[L2 ] return L Laufzeit und Korrektheit (1 Punkt): Jede Operation ist in O(1) möglich, daher auch Union insgesamt. Für die Korrektheit bleibt zu zeigen, dass L eine doppelt verkettete Liste mit head und tail ist und L alle Elemente aus L1 ∪ L2 enthält. Falls eine der beiden Listen leer ist, folgt die Korrektheit trivialerweise. Andernfalls folgt die Aussage direkt aus den Operationen in den Zeile 5-8, die die Verkettung herbeiführen und head und tail neu setzen. AUFGABE 4 (6 Punkte): In der Vorlesung haben Sie den rekursiven Inorder-Durchlauf von binären Bäumen kennengelernt, in den Präsenzübungen den rekursiven Preorder-Durchlauf. Entwerfen Sie nun nicht-rekursive (sondern iterative) Funktionen, die diese beiden Durchläufe von binären Bäumen realisieren. Geben Sie dazu zunächst kurz Ihre Idee an, danach den jeweiligen Pseudocode. Zur Erinnerung: Preorder bedeutet, erst den Wurzelknoten zu besuchen, dann die beiden Teilbäume; Inorder bearbeitet erst den linken Teilbaum, besucht dann die Wurzel und zum Schluss den rechten Teilbaum. Tipp: Starten Sie mit Preorder und benutzen Sie bei beiden Verfahren einen Stack, um besuchte Knoten zu speichern! Da die Idee zur Konstruktion von Preorder m. E. einfacher als bei Inorder ist, sollten wir 2 Punkte für Preorder und 4 Punkte für Inorder vergeben. PreorderNonrec(x) 1 if x 6= nil 2 push(S, x) 3 while S not empty 4 x ← pop(S) 5 visit(x) 6 if rc[x] 6= nil 7 then push(S, rc[x]) 8 if lc[x] 6= nil 9 then push(S, lc[x]) InorderNonrec(x) 1 do 2 while x 6= nil 3 push(S, x) 4 x ← lc[x] 5 if S not empty 6 then x ← pop(S) 7 visit(x) 8 x ← rc[x] 9 while S not empty