SQL Tuning Allgemein
Werbung

Inhalt
Allgemeines zum Tuning
Ø Tuningziele
Ø Tuningbereiche
Ø Defizite traditioneller Tuningstrategien
Ø Vorschlag einer methodischen Vorgehensweise
Ø Gute und schlechte SQL
Ø SQL-Verarbeitung
Ø Cursor Sharing
Ø Performance unterschiedlicher Systeme
Dr. Frank Haney
1
Tuningziele
Zufriedene Benutzer
• Antwortzeit (OLTP)
•
•
•
•
•
•
•
•
Durchsatz (Batch, DSS)
Trefferrate im Cache
Cachenutzung
Wiederverwendung von Code
Geringster Blockzugriff
Schnelles Lesen und Schreiben
Kein Warten auf Ressourcen
Minimale Beeinträchtigung durch Verwaltungsaufgaben
Dr. Frank Haney
2
Tuningbereiche
Geschäftsprozesse
Datendesign (logisches Schema)
Anwendung (SQL und Forms)
Speichernutzung (SGA und PGA)
I/O-Subsystem (Hintergrundprozesse)
Zugriffskonflikte (Locks und Latches)
Betriebssystem
Netzwerk
Von Schritt zu Schritt steigender Aufwand bei
sinkendem Effekt!
Dr. Frank Haney
3
Defizite traditionellen Performance Tunings
•
•
•
•
•
•
Es gibt im eigentlichen Sinne keine zielführende Methode, nur
Tips und Techniken, die gerade in komplexen Infrastrukturen
häufig versagen..
Fehlender Determinismus: Korrelation zwischen Aktionen
und Wirkungen ist meist schwach. Trial and Error!
Es muß häufig von Summen auf Details geschlossen werden,
z.B. bei Nutzung von Statspack und v$-views.
Erfolgskriterium ist oft nicht die Antwortzeit, sondern mehr
oder weniger relevante Benchmarks, Trefferquoten etc.
Es gibt Probleme bei der Eingrenzung der Nutzeraktionen, die
die wesentlichen Laufzeitprobleme verursachen.
Das Tuning setzt nicht bei den Ereignissen an, die den größten
Einfluß auf die Antwortzeit haben.
Dr. Frank Haney
4
Allgemeine Vorgehensweise
•
•
•
•
•
•
•
Ermittlung der performance-kritischsten (teuersten)
Nutzeraktionen der Anwendung
Erstellung eines Ressourcenprofils der Session (Wo bleibt
die Antwortzeit?)
Bestimmung der kostenintensivsten SQL
Welche Calls der Nutzeraktion tragen wie und womit (CPU,
Warteereignisse etc.) zur Antwortzeit bei?
Wo ist der größte Tuning-Effekt zu erwarten?
Wie kann das erreicht werden?
Was kostet das?
Dr. Frank Haney
5
Was bedeutet SQL-Tuning?
1. Identifizieren Sie Ursachen für schlechte
Performance.
2. Identifizieren Sie problematisches SQL.
•
Automatisch: ADDM, Top SQL
•
Manuell: V$-Views, Statspack
3. Wenden Sie eine Tuning-Methode an.
•
Manuelles Tuning
•
Automatisches SQL-Tuning
4. Implementieren Sie Änderungen an:
•
SQL-Anweisungskonstrukten
•
Zugriffsstrukturen wie Indizes
Dr. Frank Haney
6
Problematische SQL identifizieren
High-Load- oder problematisches
SQL identifizieren
• ADDM
• Top SQL-Bericht
Dr. Frank Haney
• Dynamische Performance Views
• Statspack
7
Tuningschritte
1. Sammeln Sie Informationen über die
referenzierten Objekte.
2. Sammeln Sie Optimizer-Statistiken.
3. Prüfen Sie Ausführungspläne.
4. Strukturieren Sie SQL-Anweisungen um.
5. Strukturieren Sie Indizes um, und erstellen Sie
Materialized Views.
6. Verwalten Sie Ausführungspläne.
Dr. Frank Haney
8
Was ist ein guter Ausführungsplan?
– Die steuernde Tabelle hat den besten Filter.
– An den nächsten Schritt werden so wenig Zeilen wie
nötig übergeben.
– Die Join-Methode entspricht der Zahl der
zurückgegebenen Zeilen.
– Views werden effizient verwendet.
– Es gibt keine ungewollten kartesischen Produkte.
– Auf jede Tabelle wird effizient zugegriffen.
– Die Prädikate in der SQL-Anweisung und die
Anzahl der Zeilen in der Tabelle müssen geprüft
werden.
– Ein Full Table Scan bedeutet nicht Ineffizienz.
Dr. Frank Haney
9
Beispiele I
1. Indexzugriff oder Full Table Scan?
Index auf einer Spalte:
... WHERE SUBSTR(name,1,6)='SCHULZ';
... WHERE name LIKE 'SCHULZ%';
... WHERE name LIKE '%UELLER';
... WHERE name IN ('SMITH', 'KING');
... WHERE TRUNC(einstellungsdatum)=TRUNC(sysdate-7);
... WHERE gehalt IS NULL;
... WHERE gehalt IS NOT NULL;
... WHERE gehalt < '2000';
... WHERE gehalt != 2000;
... WHERE gehalt > provision;
... WHERE gehalt + 3000 < 5000;
... WHERE name=COALESCE(&var, name);
... WHERE name || vorname = 'MUELLERGEHILFE';
Index über mehrere Spalten (name,abteilungs_nr):
... WHERE abteilungs_nr = 10;
... WHERE name LIKE ('KRA%');
Dr. Frank Haney
10
Beispiele II
2. NOT IN vs. NOT EXISTS (Index auf mitarbeiter.abteilungs_nr)
Gesucht sind Abteilungen, zu denen es keine Mitarbeiter gibt:
SELECT abteilungsname, abteilungs_nr
FROM abteilungen
WHERE abteilungs_nr NOT IN
(SELECT abteilungs_nr FROM mitarbeiter);
Oder?
SELECT abteilungsname, abteilungs_nr
FROM abteilungen
WHERE NOT EXISTS
(SELECT 1 FROM mitarbeiter
WHERE abteilungen.abteilungs_nr = mitarbeiter.abteilungs_nr);
Dr. Frank Haney
11
Beispiele III
3. OR vs. UNION ALL (Indizes auf fette Spalten)
SELECT * FROM mitarbeiter
WHERE beruf='GEHILFE'
OR abteilungs_nr=10;
Full Table Scan?
SELECT * FROM mitarbeiter
WHERE name = 'KRAUSE'
OR gehalt > provision;
Full Table Scan?
Dr. Frank Haney
SELECT * FROM mitarbeiter
WHERE beruf = 'GEHILFE'
UNION ALL
SELECT * FROM mitarbeiter
WHERE abteilungs_nr = 10 AND
beruf <> 'GEHILFE';
Zwei getrennte
Index Scans
SELECT * FROM mitarbeiter
WHERE name = 'KRAUSE'
UNION ALL
SELECT * FROM mitarbeiter
WHERE gehalt > provision;
Index Scan und
Full Table Scan
12
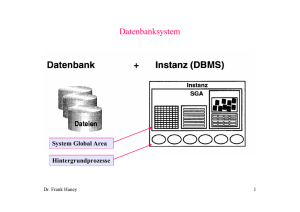
Komponenten des Datenbanksystems
System Global Area
Program Global Area
Hintergrundprozesse
Dr. Frank Haney
13
Program Global Area
Dr. Frank Haney
14
Shared Pool
Dr. Frank Haney
15
Bearbeiten von Abfragen (SELECT) I
Parse
Bind
Execute
Fetch
Parse-Phase:
Ø Sucht im Shared Pool nach der Anweisung
Ø Syntaxprüfung
Ø Prüft Semantik und Privilegien
Ø Führt View-Definitionen und Unterabfragen zusammen (Merging)
Ø Sperrt die währen der Parse-Phase verwendeten Objekte
Ø Erzeugt und speichert den Ausführungsplan (Optimizer)
Anmerkung: Die erste Wertzuweisung von BIND-Variablen ist ab 9i dem
Optimizer schon bekannt! = Bind Peeking
Dr. Frank Haney
16
Bearbeiten von Abfragen (SELECT) II
Parse
Bind
Execute
Fetch
Bind-Phase:
Ø Durchsucht die Anweisung nach Bind-Variablen
Ø Weist einen Wert (neu) zu
Execute-Phase
Ø Ausführungsplan wird angewendet
Ø I/Os werden ausgeführt
Fetch-Phase
Ø Zeilen werden abgerufen
Ø Erforderliche Sortierungen werden ausgeführt
Ø Array Fetch-Mechanismus wird verwendet
Dr. Frank Haney
17
Cursor Sharing I
Cursor werden wiederverwendet:
Ø Photographische Gleichheit der SQL (Leerzeichen, Kommentare etc.)
Ø Referenzierte Objekte gehören jeweils zum gleichen Schema
Ø Bindevariablen haben gleichen Datentyp (Name bedeutungslos)
Cursor Sharing wird gesteuert mit CURSOR_SHARING
Ø EXACT (Default): Nur exakt gleiche Cursor werden wiederverwendet.
Ø SIMILAR: Ähnliche Cursor werden wiederverwendet
Ø FORCE: Wie SIMILAR, aber Ausführungspläne können schlechter sein.
Cursor Sharing überwachen
Ø V$SQL
Ø V$SQLAREA
Ø V$SQLTEXT
Ø V$SQL_BIND_DATA
Dr. Frank Haney
18
Cursor Sharing II
Clientseitig wird gefragt:
Ø Handelt es sich um einen offenen Cursor?
Ø SESSION_CACHED_CURSORS>0 und der Cursor im Session Cache?
Eine der beiden Fragen wird mit JA beantwortet:
èCursor wird wiederverwendet
Keine der beiden Fragen wird mit JA beantwortet:
Serverseitig wird gefragt:
Ø Ist der Hash-Wert der Anweisung in der SQL-Area vorhanden?
Anweisung ist in SQL-Area:
èSoft Parse
Anweisung ist nicht in SQL-Area:
èHard Parse
Dr. Frank Haney
19
Cursor Sharing III
Session-Speicher (PGA)
Shared Pool (SGA)
Cursor Handles
Geöffnete Cursor
1
Geschlossene Cursor
3
2
Hash Chains
4
Parsing-Prozedur:
1.
2.
3.
4.
Geöffneten Cursor suchen und ausführen
Geschlossenen Cursor im Session Cache suchen
Hash Chains durchsuchen (Soft Parse)
Cursor konstruieren (Hard Parse)
Dr. Frank Haney
20
DML-Verarbeitung
1.
2.
3.
4.
Serverprozeß (SP) liest bei Bedarf Daten- und Rollback-Blöcke in den Cache
SP setzt Sperren auf die Zeilen, die geändert werden sollen
SP protokolliert Änderungen im Redo Log Buffer
SP speichert Before Image im Rollback-Block und aktualisiert den
Datenblock
Dr. Frank Haney
21
Commit-Verarbeitung
1.
2.
3.
4.
SP schreibt Commit-Datensatz mit SCN in den Redo Log Buffer
LGWR schreibt fortlaufend bis einschließlich CommitDatensatz in die Redo Log Dateien - Änderungen sind sicher
SP informiert Benutzer über Ausführung des Commit
SP gibt Ressourcen frei
Dr. Frank Haney
22
Performance verschiedener Systeme (OLTP vs. DSS)
Anforderungen OLTP
Ø Hoher Durchsatz (DML-Aktivität)
Ø Große, wachsende Datenmenge
Ø Konkurrierender Zugriff durch viele Nutzer
Ø Optimierungsziele
• Verfügbarkeit und Wiederherstellbarkeit
• Schnelligkeit (Durchsatz)
• Hoher Grad an Konkurrenz (Gleichzeitigkeit)
Anforderungen DSS
Ø Abfragen an große Datenmengen
Ø Häufige Full Table Scans
Ø Optimierungsziele
• Kurze Antwortzeit
• Genauigkeit der Antworten (OLAP, Data Mining)
Dr. Frank Haney
23
OLTP
Ø
Ø
Ø
Ø
Ø
Ø
Ø
Explizite Speicherplatzzuweisung
Sparsame und überlegte Indizierung
• B*-Baum-Indizes gegenüber Bitmap-Indizes bevorzugen
• Reverse-Key-Indizes für Folgeschlüssel
• Indizierung von Fremdschlüsselspalten reduzieren Sperren
• regelmäßiger Neuaufbau
Cluster
• Index-Cluster für anwachsende Tabellen
• Hash-Cluster für stabile Tabellen
• Hoher Grad an Konkurrenz (Gleichzeitigkeit)
Viele kleine Rollbacksegmente
Geschäftsregeln möglichst mit deklarativen Constraints durchsetzen
Parse Overhead reduzieren (Prozeduren und Bind-Variablen nutzen,
Library Cache optimieren)
Bei großer Nutzerzahl Multithreaded Server (MTS) verwenden.
Dr. Frank Haney
24
DSS
Ø
Ø
Ø
Ø
Ø
Ø
Ø
Ø
Ø
Parse-Zeit ist weniger wichtig
DB_FILE_MULTI_BLOCK_READ_COUNT und
DB_BLOCK_SIZE sorgfältig einstellen
Der Zugriffspfad kann drastische Auswirkungen auf die Antwortzeit
haben: Optimizer Hints verwenden.
Literale sind besser als Bind-Variablen (Verwendung von
Histogrammen möglich)
Möglichst keine Indizierung, wenn ja, dann
• Bitmap-Indizes gegenüber B*-Baum-Indizes bevorzugen
• IOTs verwenden zum Datenzugriff mittels PK
• Histogramme für nicht gleichförmig verteilte Daten verwenden
Hash-Cluster in Erwägung ziehen
Wenige große Rollbacksegmente für das Laden von Daten
Parallelverarbeitung bring Performancegewinn
Dedizierten Server verwenden
Dr. Frank Haney
25
Hybridsysteme
Ø
Ø
Ø
Oracle mitarbeiterfiehlt die Trennung von OLTP und DSS in
verschiedene DB, um divergierende Performance-Anforderungen zu
beherrschen.
Wenn das nicht möglich ist, sollten diese wenigstens tageszeitlich
geschieden werden. Das bedeutet:
• Lange Reports sollten außerhalb der OLTP-Spitzenzeiten laufen
• Getrennte Parameterdateien für Tag- und Nachtbetrieb
• Unterschiedliche Rollback-Konfiguration
• Serverkonfiguration umschalten (MTS vs. dedizierten Server)
Probleme, die sich in Hybridsystemen nur schwer lösen lassen:
• Wechselnder Indexstatus und –typ
• Overhead durch unnötige Statistiken bzw. Histogramme
• Tageszeitliche Änderung von Speicherparametern (PCTFREE)
• Umschalten auf Parallelverarbeitung und umgekehrt
• Bind-Variablen vs. Literale
Dr. Frank Haney
26