Dynamische Softwarekomponentenverwaltung einer
Werbung

Technische Universität Ilmenau
Fakultät für Elektrotechnik und Informationstechnik
Masterarbeit
Dynamische Softwarekomponentenverwaltung einer
Kommunikationsmiddleware
vorgelegt von:
eingereicht am:
Aalbrecht Alby Irawan
15. 11. 2012
geboren am:
Studiengang:
Studienrichtung:
Ingenieurinformatik
Multimediale Informations- und
Kommunikationssysteme
Anfertigung im Fachgebiet:
Kommunikationsnetze
Fakultät für Elektrotechnik und Informationstechnik
Verantwortlicher Professor:
Wissenschaftlicher Betreuer:
Prof. Dr. rer. nat. Jochen Seitz
Dipl.-Ing. Karsten Renhak
Kurzfassung
Ziel dieser Masterarbeit ist die Entstehung eines Verwaltungssystem zur automatischen individuellen An- und Abmeldung verschiedener Gateways. Die Gateways sollen
sich zur Laufzeit dynamisch im System registrieren können, ohne das Gesamtsystem
neugestartet werden zu müssen.
Demnach gliedert sich die Arbeit in 2 Teile. Erstens in die Recherche über verschiedene Verfahren zum dynamischen Komponentenmodell und die Unterschiede zwischen relationale Datenbankschnittstelle und objektrelationale Datenbankschnittstelle.
Zweitens in die Konzeption und Umsetzung eines optimalen dynamischen SoftwareVerwaltungssystems.
Im ersten Teil werden 4 Ansätze recherchiert: CORBA, Jini, EJB, und OSGi. Anhand ausgewählter Kriterien, wie z.B. Plattformunabhänigkeit, Kapselung und Versionierung werden sie anschließend miteinander verglichen. OSGi wird letzendlich gewählt, da OSGi die neueste und optimalste Variante ist. Die Vor- und Nachteile von
verschiedenen Datenbankschnitstellen werden auch berücksichtigt. Eine relationale Datenbank ist leichter zu realisieren, aber bei einer objektorientierten Progammierung hat
objektrelationale Datenbank einen klaren Vorsprung. Mit Hilfe von einer Objekt Relational Mapping- (ORM)Software, wie z.B. EclipseLink oder Hibernate sei dies kein
großes Problem mehr.
Im zweiten Teil wird ein Konzept zur Verwaltung verschiedener Kommunkationsgateways erläutert. Hierbei stellt ein zentrales Element der Middleware einerseits eine
Schnittstelle zum Assistenzsystem zur Verfügung und andererseits übernimmt dieses
Modul die Verwaltung der einzelnen Gateways. Die Kommunikation zwischen der zentralen Schnittstelle und den Kommunikationsgateways soll ausschließlich über die vorhandene Message Oriented Middleware (MOM), in diesem Fall Advanced Message
Queuing Protocol (AMQP), erfolgen. Die notwendige Speicherung vorhandener Informationen durch das zentrale Modul soll auf Basis der objektrelationalen Datenbankschnittstelle erfolgen.
Abstract
Goal of this thesis is the development of a management system for automatic individual registration and deregistration of different gateways. The gateways can register
dynamically at runtime without having the entire system to be restarted.
Accordingly, the work is divided into 2 parts. First, in the research on various methods for dynamic component models, and the differences between relational database
interface and object-relational database interface. Second, in the design and implementation of an optimal dynamic software management system.
In the first part 4 approaches are investigated: CORBA, Jini, EJB and OSGi. They
are compared based on selected criteria, such as platform independency, encapsulation
and versioning. OSGi is ultimately chosen because OSGi is the latest and the most
optimal variant. The pros and cons of various database interface are also be considered.
A relational database is easier to implement, but in such an object-oriented programming, object-relational database has a clear lead. Using an Object Relational Mapping
(ORM) software, e.g. EclipseLink or Hibernate, there shouldn’t be any big problem.
The second part is an approach to managing various communication gateways. Therefore, a core element of the middleware provides an interface for the assistance system
and at the other hand it watches over the individual gateways. The communication
between the central interface and the communication gateways is only via the existing Message Oriented Middleware (MOM), in this case Advanced Message Queuing
Protocol (AMQP). The required storage of existing information by the central module
should be based on the object-relational database interface.
Inhaltsverzeichnis
i
Inhaltsverzeichnis
1 Einleitung
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.2 Aufgabenstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2 Dynamische Verwaltung von
2.1 CORBA . . . . . . . . .
2.2 JINI . . . . . . . . . . .
2.3 EJB . . . . . . . . . . .
2.4 OSGi . . . . . . . . . . .
2.5 Vergleich der Ansätze . .
Softwarekomponenten
. . . . . . . . . . . . . .
. . . . . . . . . . . . . .
. . . . . . . . . . . . . .
. . . . . . . . . . . . . .
. . . . . . . . . . . . . .
1
1
2
.
.
.
.
.
4
4
8
11
13
17
.
.
.
.
21
21
22
23
24
4 Konzeption eines dynamischen Software-Verwaltungssystems
4.1 Anforderungen an das Software-Verwaltungssystem . . . . . . . . . . .
4.2 Struktur des Verwaltungssystems . . . . . . . . . . . . . . . . . . . . .
26
26
26
5 Umsetzung des Konzepts
5.1 RabbitMQ . . . . . .
5.2 EclipseLink . . . . .
5.3 Apache Derby . . . .
5.4 OSGi . . . . . . . . .
.
.
.
.
29
29
32
34
37
6 Zusammenfassung/Ausblick
6.1 Zusammenfassung der Ergebnisse . . . . . . . . . . . . . . . . . . . . .
6.2 Ausblick auf Erweiterungen . . . . . . . . . . . . . . . . . . . . . . . .
40
40
40
3 Datenbankschnittstelle
3.1 Relationales Datenbanksystem . . . .
3.2 Objektrelationales Datenbanksystem
3.3 Java Datenbank Connectivity . . . .
3.4 Java Persistence Query Language . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Masterarbeit Aalbrecht Alby Irawan
Inhaltsverzeichnis
ii
Literaturverzeichnis
41
Abbildungsverzeichnis
43
Tabellenverzeichnis
44
Abkürzungsverzeichnis und Formelzeichen
45
Thesen zur Masterarbeit
47
Erklärung
48
Masterarbeit Aalbrecht Alby Irawan
1 Einleitung
1
1 Einleitung
1.1 Motivation
Das Fachgebiet Kommunikationsnetze befasst sich mit Infrastrukturen und Anwendungen für Assistenzsysteme zur Unterstützung des täglichen Lebens. Um die Qualität und
vor allem die Akzeptanz des Assistenzsystems zu erhöhen, ist es von Vorteil, möglichst
viele Nutzungsmöglichkeiten anzubieten.
Seit mehr als 20 Jahren haben sich Ingenieure damit beschäftigt, ein monolitisches
System mit einem Komponentenmodell zu ersetzen. Im Gegensatz zum monolitischen
System bietet ein modulares System viele Nutzungsmöglichkeiten. So ist es leicht, andere Module hinzuzufügen. und entsprechend können alte Module gegen neue Module
ausgetauscht werden. Außerdem ist ein bestehendes Modul in einem anderen System
wiederverwendbar. Hierdurch können die Entwicklungskosten sinken und schnellere
Produktzyklen erreicht werden.
Dieses Modell kann allerdings auch zu neuen Problemen führen, vorallem bei der Sicherheit und Kompatibilität. Da die Ressourcen jetzt für alle zugreifbar sind, muss das
System gegen Angreifer geschützt sein. Eine Authentifizierung ist erforderlich, sodass
kein unauthorisierter Teilnehmer den Zustand des Systems verändern kann. Im Markt
finden sich viele verschiedene Realisierungen einer Spezifikation. Oft gibt es Probleme
bei der Kommunikation, sodass die Interoperabilität nicht gewährleistet werden kann.
Diese Inkompatibilität kann auch innerhalb einer Software gleichen Herstellers vorkommen, z.B. wenn ein Client und ein Server andere Versionen der Software benutzen.
Ein anderer Aspekt, der eine große Rolle spielt, ist die Dynamik. Bei früheren Systemen muss das System heruntergefahren und neugestartet werden, wenn sich eine
Komponente ändert, denn sonst ist der Name oder die Adresse eines Objekt für die
anderen Komponenten unbekannt. Erst nach dem Neustart wird eine Zusammenarbeit
ermöglicht. Deshalb soll das Verwaltungssystem in dieser Masterarbeit die dynamische
An- und Abmeldung einer Komponente unterstützen.
Eine Datenbank ist eine Sammlung von Informationen wie z.B. Texte, Zahlen und
Bilder. Sie ist so organisiert, dass sie leicht zugänglich und zuzuordnen ist. Eine Da-
Masterarbeit Aalbrecht Alby Irawan
1 Einleitung
2
tenbank kann nach ihrem organisatorischen Ansatz eingestuft werden. Der häufigste
Ansatz ist die relationale Datenbank, auch tabellarische Datenbank genannt. Sie wird
durch ihre Attribute (Spalten) und ihre Tupel (Zeilen) charakterisiert. Eine objektrelationale Datenbank hingegen wird mit den Daten der Objekte in Klassen und
Unterklassen definiert.
Eine relationale Datenbank ist sehr leicht zu realisieren, aber bei objektorientierter
Programmierung ist sie kaum nutzbar. Im Gegensatz dazu ist eine objektrelationale
Datenbank relativ schwierig zu realisieren, aber sie wurde genau für objektorientierte Programmierung entwickelt. Deshalb soll man eine Schnittstelle anwenden, welche
die Zuordnung und die Übertragung von Daten der Objekte zu einer tabellarischen
Datenbank ermöglicht, sogenannte Object-Relational-Mapping (ORM)-Software.
1.2 Aufgabenstellung
Eine am Fachgebiet Kommunikationsnetze entwickelte Kommunikationsmiddleware
für Assistenzsysteme wird eingesetzt, um möglichst viele verschiedene Kommunikationsarten und -technologien mit dem Assistenzsystem zu nutzen. Diese Kommunikationsmiddleware verwendet unter anderem eine nachrichtenbasierte Middleware (Message Oriented Middleware - MOM) zur internen Kommunikation. Die Anbindung der
verschiedenen Kommunikationssysteme erfolgt durch unabhängige Gateways, die über
eine MOM mit der Kommunikationsschnittstelle des Assistenzsystems verbunden sind.
Im Rahmen der Erweiterung und Pflege der Kommunikationsmiddleware soll ein Verwaltungssystem zur automatischen individuellen An- und Abmeldung der Gateways
entstehen.
Um dieses Ziel zu realisieren, sind folgende Arbeitsschritte erforderlich:
• Recherche zu Verfahren und Ansätzen zur dynamischen Verwaltung von Softwarekomponenten
• Recherche zu objektrelationalen Java-Datenbankschnittstellen
• Konzeption und Umsetzung eines dynamischen Software-Verwaltungssystems
Abbildung 1.1 stellt eine mögliche Realisierung eines solchen Verwaltungssystems
dar.
Hierbei stellt ein zentrales Element der Middleware einerseits eine Schnittstelle zum
Assistenzsystem zur Verfügung. Und andererseits übernimmt dieses Modul die Verwaltung der einzelnen Gateways. Die Kommunikation zwischen der zentralen Schnittstelle
Masterarbeit Aalbrecht Alby Irawan
1 Einleitung
3
Abbildung 1.1: Beispiel für Realisierung eines Verwaltungssystems
und den Kommunikationsgateways soll ausschließlich über einen AMQP-Server erfolgen. Die Verwaltung des Gateways ist weiterhin auf Basis der übermittelten Metadaten
in XML-Format umzusetzen. Die Speicherung vorhandener Informationen durch das
zentrale Modul soll auf Basis einer objektrelationalen Datenbankschnittstelle erfolgen.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
4
2 Dynamische Verwaltung von
Softwarekomponenten
Dieses Kapitel befasst sich mit verschiedenen Ansätzen, welche die dynamische Verwaltung von Softwarekomponenten ermöglichen sollen. Die Ansätze werden nach nach
Erscheinungsjahr aufgelistet.
2.1 CORBA
Common Object Request Broker Architecture (CORBA) ist eine Spezifikation, die
1991 zum ersten Mal von der Object Management Group (OMG) verabschiedet wurde. Federführend bei der Entwicklung dieses Standards sind die Unternehmen Sun und
IBM [Lan02]. Weil CORBA nur eine Spezifikation ist, gibt es im Markt viele herstellerabhängige Anwendungen, die CORBA implementieren. Dennoch soll mittels Interface
Definition Language (IDL) Interoperabilität und Sprachunabhängigkeit gewährleistet
werden.
Anders als herkömmliche Programmiersprachen wie C, COBOL, Python, C++ oder
Java ist die IDL eine reine Spezifikationssprache. Ein mit der CORBA-IDL erzeugtes Interface wird in einem normalen Text-File abgespeichert und muss in die jeweils
verwendete Programmiersprache übersetzt werden. Diese Übersetzung wird von den
IDL-Compilern im ORB übernommen. Da dieser Compiler und dessen Übersetzung
standardisiert ist, sollen Clients und Server verschiedener Hersteller problemlos kommunizieren können, solange keine herstellerspezifische Erweiterungen installiert werden.
Grundlage für die Spezifikation ist die sogenannte Object Management Architecture
(OMA), die aus fünf Komponenten besteht:
• Object Request Broker (ORB)
• Common Object Service (COS)
• Common Facilities
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
5
• Domain Objects
• Application Objects
ORB steht im Zentrum. Dieser funktioniert als ein Broker, der Kommunikation und
Interaktion von verschiedenen und entfernten Objekten verbindet. Der IDL Compiler
im ORB erzeugt ein Server-Skeleton und einen Clienten-Stub. Diese fungieren als Proxy
des Clients bzw. Servers. Wenn ein Client eine Server-Methode aufruft, übernimmt der
Stub das Verpacken der Parameter und gibt den Aufruf an den ORB weiter. Dieser
ist dafür zuständig, das Server-Objekt zu lokalisieren und den Aufruf weiterzuleiten.
Die Rückgabe des Ergebnisses geschieht in umgekehrter Richtung analog. Da nur Parameter (input und output) benötigt werden, bleibt das Objekt vor der Außenwelt
versteckt. Dieser Ablauf wird in Abbildung 2.1 veranschaulicht.
Abbildung 2.1: Methodenaufruf bei CORBA [Haa01]
CORBA ermöglicht auch dynamische Methodenaufrufe. Während bei einem statischen Aufruf der Client die Schnittstellendefinition des Servers kennen muss, können
mit Hilfe des Dynamic Invocation Interface (DII) Aufrufe zur Laufzeit konstruiert
werden. Analog dazu können auf der Server-Seite über das Dynamic Skeleton Interface
(DSI) beliebige Aufrufe ohne Kenntnis der Schnittstellenbeschreibung entgegengenommen werden [Haa01].
Der ORB beinhaltet auch ein Implementation Repository. In dieser Datenbank wird
gespeichert, welcher Server welche CORBA-Objekte beinhaltet und wie ein Server bei
Bedarf zu starten ist. Auf diese Weise kann CORBA einen automatischen Aktivierungsmechanismus bieten. Wenn ein Client nach einem bestimmten CORBA-Objekt
verlangt, das derzeit von keinem Server angeboten wird, kann der ORB im Implementation Repository nach einem passenden Server-Programm suchen und dessen Ablageort
und Konfigurationsdaten ermitteln, um ihn anschließend zu starten [GT00].
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
6
Common Object Services bieten Dienste an, die benötigt werden, um Objekte und
Daten zu finden und zu verwalten. Einige wichtige COS sind etwa Naming Service,
Trading Service, Persistent Object Service und Event Service. Der Naming Service
verknüpft einen abstrakten Namen zu einem Objekt. Der Client muss dann nur den
entsprechenden Namen eingeben, um das Objekt zu erreichen. In diesem Fall fungiert
der Naming Service als eine Datenbank.
Ein Objekt kann nicht nur einen Namen haben, sondern auch Eigeschaften. Der
Trading Service wird benutzt, um ein Objekt zur Laufzeit zu finden. Im Gegensatz
zum Naming Service werden Objekte nicht durch ihre Namen identifiziert, sondern
durch den Vergleich von Eigenschaften. Nach dem Vergleich können mehrere Objekte
gefunden werden.
Mit dem Persistent Object Service wird eine vordefinierte Schnittstelle ermöglicht,
um Persistenz für CORBA-Objekte auf verschiedenen Systemen zu gewährleisten.
Der Event Service ermöglicht asynchrone Kommunikation mittels Ereignismeldungen. Dabei wird zwischen Objekten unterschieden: Supplier und Consumer. Supplier
erzeugen Ereignismeldungen und versenden sie an Consumer. Ein Consumer empfängt
die Ereignismeldungen und verarbeitet sie weiter. Dabei werden das Push-Modell und
das Pull-Modell unterstützt.
Common Facilities bieten Dienste an, die auf den COS aufbauen und in ihrer Funktionalität über sie hinausgehen. Die Dienste der Common Facilities sind weniger allgemein als die COS, aber sie erledigen noch komplexere Aufgaben. Die Comon Facilities
sind in die folgende Bereiche untergliedert:
• Information Management
• Benutzerschnittstellen
• Systemmanagement
• Taskmanagement
Domain Objects stellen die nächste Abstraktionsstufe nach den COS und den Common Facilities dar. Sie sind auf einen bestimmten Anwendungsbereich zugeschnitten,
etwa Telekommunikation, Bankwesen oder Medizin.
Application Objects stellen die eigentlichen verteilten Applikationen dar. Sie kommunizieren miteinander und mit den anderen OMA-Komponenten über den ORB. Für
ihre Realisierung verwenden sie die COS, die Common Facilities sowie die Domain
Objects. Die Application Objects selbst sind nicht Teil der Standardisierung.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
7
Die 5 Komponenten der OMA und ihre Beziehungen zueinander sind in Abbildung
2.2 graphisch dargestellt.
Abbildung 2.2: Object Management Architecture der OMG [Haa01]
Trotz der IDL könnte es noch Probleme mit der Interoperabilität geben. Einfachstes
Beispiel ist der Einsatz von VisiBroker als ORB. Wenn ein CORBA-Programm diesen
Broker als Kommunikationsplattform einsetzt, müssen die Bibliotheken von VisiBroker
sowohl client- als auch serverseitig eingebunden werden. Eine Zusammenarbeit mit
einem anderen Broker ist nicht garantiert [Lan02].
Konkurrenz erhält CORBA vor allem von Microsoft mit seiner .NET-Plattform. Die
.NET-Plattform verwendet das Simple Object Access Protocol (SOAP), das entfernte
Methodenaufrufe auf der Basis von eXtensible Markup Language (XML) realisiert.
Außerdem kann es mit dem Protokoll Hyper Text Transfer Protocol (HTTP) arbeiten,
das die Einsetzbarkeit noch weiter steigert. Im Allgemeinen ist zu empfehlen, CORBA
nur zu verwenden, wenn die Komponenten mit unterschiedlichen Programmiersprachen
entwickelt werden sollen.
Es ist jedoch anzunehmen, dass Großunternehmen, die bereits CORBA einsetzen,
nicht von dieser Technologie abweichen werden. Besonders in den Bereichen der Banken, Versicherungen und Luftfahrten werden diese Systeme schon seit sehr langer
Zeit eingesetzt und haben sich entsprechend bewährt. CORBA erfordert eine enormes Know-how der Mitarbeiter. Erst ab ca. 20 Mitarbeitern lassen sich große Projekte
entsprechend bewältigen. Deshalb sollte bei der Weiterentwicklung von CORBA das
Ziel sein, die Komplexität des Projektes zu reduzieren [Lan02].
Im Zuge der Weiterentwicklung verabschiedete OMG auch noch CORBA 2 und
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
8
CORBA 3. In CORBA 2 wird der GIOP und IIOP dazu addiert und in CORBA 3 die
Interoperabilität mit den anderen Komponentenmodellen. General Inter ORB Protocol
(GIOP) ist ein Protokoll, mit dem ORB miteinander kommunizieren. Internet Inter
ORB Protocol (IIOP) ist die Umsetzung der GIOP über TCP/IP. Da IIOP nicht
immer Port 80 [IAN12] wie bei XML/SOAP verwendet, kann es Probleme mit einer
sehr strengen Firewall geben. Unter http://www.omg.org/spec/CORBA/ findet man
die genauere Spezifikation von CORBA 2 und CORBA 3.
2.2 JINI
Jini ist eine Service-orientierte Architektur, die Java-Technologie erweitert, um sichere und verteilte Systeme aufzubauen. Diese Systeme bestehen aus Föderationen von
Diensten und Clients. Jini wurde 1999 von Sun Microsystems verabschiedet. Ab 2007
wurde das Projekt Jini von Apache übernommen und in Apache River umbenannt.
Jini unterstützt nur Java-Systeme und bestimmte Plattformen wie Solaris, Ubuntu
und Windows. Jini hat den Ansatz, die automatische Vermittlung zwischen Client und
Server zu ermöglichen. Die Firma Sun, die Jini entwickelt hat, nennt diese Eigenschaft
Spontaneous Networking [Haa01].
Jini besteht aus 3 Komponenten:
• Client
• Server
• Lookup Service
Der Lookup Service ermöglicht einem Client, die verfügbaren Dienste in verteilten
Systemen zu finden. Die Dienste können sofort benutzt werden, ohne das System neu zu
starten. Lookup Service arbeitet ähnlich wie CORBA Naming oder Trading Services.
Auf diese Art können Client bzw. Server auch in dynamisch konfigurierten Netzen den
Lookup Service finden.
Eine übliche Realisierung ist, bestimme Dienste auf reservierten TCP- oder UDPPorts zu hören. Ein Client muss dann aber immer noch die IP-Adresse oder den logischen Rechnernamen des Server-Rechners kennen, um den Dienst zu adressieren.
Wenn dies nicht der Fall ist, verwendet Jini IP-Multicast zwischen 224.0.0.0 und
239.255.255.255. So gibt es für jede aktive Jini-Föderation einen Registrierbaum, der
sich potenziell über das gesamte Internet erstreckt [Haa01].
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
9
Wenn ein Jini Lookup Service gestartet wird, gibt dieser seine Anwesenheit durch ein
Announcement auf eine Multicast-Adresse. z.B. 224.0.1.84. bekannt. Somit erfahren
Clients und Dienste von der Existenz eines neuen Lookup Service. Dann trägt sich
der Lookup Services in die Multicast-Gruppe 224.0.1.85 ein. Alle Clients und Dienste
melden sich auf der Adresse 224.0.1.85, wenn sie den Lookup Service finden möchten.
Dieser Vorgang wird Lookup-Discovery genannt. Die angesprochenen Lookup Services
antworten, in dem sie einen Java Proxy zurückschicken. Der Client bzw. Dienst kann
den Proxy verwenden, um Anfragen an den Lookup Service zu stellen.
Dienste in Jini stehen nicht unbedingt dauerhaft zur Verfügung, deshalb wurde das
Leasing eingeführt. Wenn ein Jini-Dienst einen oder mehrere passende Lookup Services
gefunden hat, kann er sich bei ihnen anmelden. Dazu hinterlegt er seinen eigenen Proxy
und ggf. benutzerdefinierte Attribute. Im Gegenzug erhält der Dienst ein Lease. Leases
müssen regelmäßig erneuert werden, so kann festgestellt werden, ob ein Dienst noch
existiert ist oder nicht. Wenn keine Erneuerung des Leases innerhalb einer Zeitspanne
erfolgt, wird der Dienst aus dem Lookup Service gelöscht.
Ein Client nutzt den Lookup Service, um nach passenden Diensten zu suchen. Dazu
sendet er den Typ des gesuchten Dienstes und die Werte der Attribute. Falls der Lookup
Service über einen passenden Dienst verfügt, schickt er dessen Proxy zum Client. Der
Client kann dann auf diesem Proxy arbeitet. So als wäre der Dienst lokal verfügbar.
Abbildung 2.3: Ablauf der Jini-Anfrage [New12]
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
10
Zum Starten des Lookup Services muss auch ein HTTP-Server gestartet werden.
Wenn Dienste ihre Proxy senden, ist der erste Teil der Datenstroms ein Uniform Resource Locator (URL). Diese URL gibt bekannt, wo die benötigte JAR heruntergeladen
werden kann. Oft geht diese URL zurück bis zu einem bestimmten HTTP-Server.
Um zu kommunizieren, wird kein Standard vorausgesetzt. Früher wurde Java RMI
verwendet. Aber ab Jini 2.0 wird ein Protokoll namens Jini Extensible Remote Invocation (Jeri) vorgeschlagen. Jeri ist eine neue Implementierung des RMI-Modells und
gewährt noch höhere Sicherheit [Art12]. Der Client unterscheidet nicht, ob Jeri, RMI
oder IIOP verwendet werden solange das Protokoll mit der Semantik der Schnittstelle
übereinstimmt.
Ein Verbund von Clients, Diensten, einem oder mehreren Lookup Services wird
Djinn oder Federation genannt. Obwohl sich Jini selbst nicht erfolgreich durchgesetzt
hat, wird sein Ansatz in JavaSpace verwendet. JavaSpace ist ein Verbund von JiniDiensten, die Java-Objekte speichern und als eine geschlossene Einheit zusammen arbeiten. JavaSpaces ist sehr einfach und besteht aus 7 Methoden. Vier von denen sind:
schreiben Ein Objekt wird in JavaSpace geschrieben.
lesen Ein Objekt wird aus JavaSpace gelesen. Dies liefert eine Kopie und hinterlässt
eine Kopie in JavaSpace
nehmen Ein Objekt wird aus JavaSpace genommen. Dies liefert eine Kopie und entfert
das Objekt aus JavaSpace
notifizieren Lookup Service wird benachrichtigt, wenn Änderungen in JavaSpace festgestellt.
Anfangs war Jini Konkurrenz für CORBA und DCOM. Distributed Component
Object Model (DCOM) ist eine frühere Microsoft-Spezifikation, die schon absorbiert
und abgeschafft wurde zugunsten der .NET-Technologie. Auch innerhalb der JavaGesellschaft konnte sich Jini nicht gegen Enterprise Java Beans (EJB) durchsetzen.
Jini läuft in Java Standard Edition (Java SE), denn es wird eine Java Virtual Machine (JVM) gebraucht, um die nötigen Operationen durchzuführen. Somit ist Jini
für Kleingeräte mit beschränkten Ressourcen nicht geeignet. Außerdem gibt es zurzeit
kaum Dokumentation und Tutorials für Jini. Seit der Übergabe an Apache ist die Seite http://www.jini.org, die als Bezugpunkt für Einsteiger dienen sollte, nicht mehr
verfügbar.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
11
2.3 EJB
Enterprise Java Beans (EJB) wurde im Jahr 2001 von Sun Microsystems verabschiedet.
EJB kann leicht mit JavaBeans verwechselt werden, aber EJB ist völlig unabhängig von
JavaBeans. EJB-Technologie ist die serverseitige Komponente der Architektur für Java
Enterprise Edition (Java EE). EJB ermöglicht die schnelle und vereinfachte Entwicklung verteilter Anwendungen. JavaBeans hingegen ist eine Schnittstellen-Spezifikation
für wiederverwendbarer Komponenten in Java. Sie definiert die Java-Komponenten und
wie sie zusammen arbeiten sollen. Bei JavaBeans handelt es sich um einen Verbund von
mehreren Java-Objekten, genannt Beans. Ein Java-Entwickler, der eine Funktion oder
ein Objekt braucht, muss dann nicht selbst alles schreiben. Er kann den entsprechende
Bean herunterladen und einsetzen.
Mit EJB soll die Entwicklung von verteilten, komponentenbasierten Java-Anwendungen
vereinfacht werden. EJB sorgt zudem für eine Komplexitätsreduktion: Die Ansteuerung von Mechanismen wie Verteilung, Sicherheit und Transaktionsverwaltung muss in
anderen Umgebungen oft vom Entwickler explizit ausprogrammiert werden, was aufwendig und fehleranfällig ist. EJB verlagert diese Komplexität in die EJB-Server bzw.
EJB-Container, so dass sich der Komponentenentwickler auf die eigentlichen fachlichen
Anforderungen, also auf die Business-Logik konzentrieren kann [GT00].
EJB besteht aus 4 Teilen:
• Client-Anwendungen
• EJB-Server
• EJB-Container
• EJB-Komponenten
Die Grundstruktur entscpricht einer Drei-Schicht-Anwendung aus einer Präsentations, einer Geschäftslogik- und einer Datenebene. In einer typischen Geschäftsanwendung
verwendet man für die Datenebene eine Datenbank und für die Präsentationsebene
entweder GUI-Front-End oder einen Webserver. Die Geschäftslogikebene ist normalerweise am schwierigsten zu entwerfen. Man muss herausfinden, wie der eigene Code
mit der Datenbank und mit Clients zusammenarbeiten wird. Wie mit den Clients interagiert wird, entscheidet häufig darüber, wie man mit der Datenbank interagiert
[Wut02].
Abbildung 2.4 veranschaulicht den Aufbau der EJB-Architektur.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
12
Abbildung 2.4: EJB-Architektur [Int12]
Viele Entwickler stellen sich unter einem Container eine Datenstruktur wie ein Array, eine verkettete Liste oder einen Vektor vor. In Java EE ist ein Container jedoch
fast wie ein Mini-Server. Er stellt die Laufzeitunterstützung für die Elemente bereit, die
er enthält. Ein EJB-Container enthält EJB-Komponenten und sorgt für die Bildung
eines Verbindungspools und die Transaktionsverarbeitung. Ein Server kann mehrere
Container haben. Und die Objekte in den einzelnen Container sind voneinander isoliert, obwohl Objekte in einem Container mit Objekten in einem anderen Container
kommunizieren können.
Der Unterschied zwischen einer Komponente und einem Objekt ist nicht immer klar.
Aber i.A. ist eine Komponente ein Software-Modul, das so entworfen ist, dass man es
in vielen Anwendungen verwenden kann, ohne es zu verändern. Ein Objekt kann zwar
eine Komponente sein, aber normalerweise stellt man sich unter Komponenten etwas
Größeres als Objekte vor. EJB sind verteilte Objekte und daher eher Komponenten als
Objekte. Und tatsächlich ist eine EJB nicht als einzelnes Objekt, sondern als Gruppe
von Objekten definiert. [Wut02]
EJB-Container enthalten drei Typen von Beans:
• Session Beans
• Message Driven Beans
• Entity Beans
Session Beans führen die Anwendungslogik im Auftrag des Kunden. Sie wird nicht
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
13
in der Datenbank gespeichert, kann dennoch auf die Datenbank zugreifen. Session Beans sind relativ kurzlebig, meist nur innerhalb einer Client-Sitzung. Man unterscheidet
stateful und stateless Session Beans. Eine stateful Session Bean kann Daten speichern
für die spätere Wiederverwendung. Ein EJB-Container kann mehrere stateful Session
Beans enthalten, deshalb wird an jede einzelne Session Bean eine eindeutige ID vergeben. Im Gegensatz dazu können stateless Session Beans keine Daten speichern. Sie
werden daher von anderen stateless Session Beans nicht unterschieden und haben keine
eindeutige ID.
Message Driven Beans sind für asynchrone Kommunikation gedacht. Sie führen die
Anwendungslogik nach Erhalt einer Nachricht vom Kunden. Hierzu wird Java Message
Service (JMS) verwendet. Message Driven Beans sind auch relativ kurzlebig. Wenn das
System währen der Sitzung abstürtzt, muss eine neue Bean etabliert werden.
Entity Beans stellen eine persistente Entität dar. Sie werden häufig in einer relationalen Datenbank gespeichert. Sie haben eine eher lange Lebensdauer und sind nicht
auf die Dauer einer Client-Sitzung beschränkt. Anders als Session Beans können mehrere Clients gleichzeitig auf dieselbe Entity Bean zugreifen. Seit EJB 3.0 sind Entity
Beans obsolet und werden nicht mehr gebraucht. Sie werden von Java Persistence API
ersetzt.
Eine Komponente, die in EJB 3.0 geschrieben wurde, ist kompatibel mit einer Komponente, die in EJB 2.1 oder in früherer Version geschrieben wurde. Solche KomponentenKombination von verschiedenen Versionen der EJB kann die Migration von bestehenden Anwendungen erleichtern. Außerdem ermöglicht sie die Wiederverwendung von
Komponenten aus früheren EJB-Spezifikationen.
2.4 OSGi
Open Service Gateway Initiative (OSGi) Framework ist ein modularisches System und
eine Service-Plattform, die ein dynamisches Komponentenmodell implementiert. Installation, Start, Stopp und Deinstallation erfolgen über das Netzwerk und benötigen
keinen Neustart des Gesamtsystems. Außerdem ermöglicht OSGi auch eine Versionierung, d.h. Komponenten können zur Laufzeit auf eine neuere Version upgegradet
werden. OSGi ist nicht sprachunabhängig, nur Java wird hier unterstützt.
OSGi wurde von der OSGi-Allianz verabschiedet, die 1999 gegründet wurde. Die
OSGi-Allianz besteht aus vielen bekannten Großunternehmen im Bereich Service- und
Content-Anbieter, Infrastruktur- und Netzbetreiber sowie Software-Entwicklung. Dazu
gehören z.B. Adobe Systems, Oracle, IBM, Deutsche Telekom, Mitsubishi Electric
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
14
und NTT [OSG12a]. Durch so ein großes Konsortium ist es kein Wunder, dass die
Entwicklung von OSGi anderen Ansätzen überlegen ist.
Die aktuellste Version der OSGi-Framework ist Version 5 (Juni 2012). Diese Masterarbeit befasst sich jedoch nur mit der OSGi Version 4.2, die im Juni 2009 verabschiedet
wurde.
Abbildung 2.5 veranschaulicht die OSGi-Architektur.
Abbildung 2.5: OSGi-Architektur[OSG12b]
Bundles Bundles sind die OSGi-Komponenten, die von den Entwicklern erstellt werden.
Service-Schicht Die Service-Schicht verbindet Bundles in einer dynamischen Art und
Weise.
Life-Cycle-Schicht Hier wird die Installation, Starten, Stoppen, Update und Deinstallation von Bundles ermöglicht.
Module-Schicht Die Module-Schicht definiert wie Bundles Codes importieren und
exportieren können.
Security-Schicht Sie behandelt Sicherheitsaspekte und die digitale Signatur.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
15
Execution Environment Bundles, die nur in einer bestimmten Ausführungsumgebung
wie JavaSE-1.6 oder J2SE-1.5 lauffähig sind, müssen dies in der Execution Environment Schicht angeben.
In OSGi werden Softwarekomponenten als Bundles bezeichnet. Ein Bundle ist eine
Menge von Java-Klassen und anderen Ressourcen, verpackt in ein Java-Archiv (JAR)
mit zusätzlichen Header-Informationen (Manifest). Informationen über das Bundle,
wie z.B. Name, Version und Abhängigkeit (Dependencies) werden in der ManifestDatei gespeichert. Alles, was nicht explizit exportiert wird, bleibt im Bundle versteckt.
Anders als bei OSGi ist im Standard-Java der gesamte Inhalt einer JAR-Datei für
alle sichtbar. Analog zum Export muss ein Bundle die Teile, die es aus einem anderen
Bundle nutzen will, explizit importieren.
Die Lebenszyklusschicht in der OSGi-Framework ermoglicht die Installation, Starten, Stoppen, Update und Deinstallation von Bundles, unabhängig von der Lebensdauer der JVM. Sie sorgt auch dafür, dass Pakete nur gestartet werden, wenn alle ihre
Abhängigkeiten aufgelöst wurden. Dadurch sinkt das Auftreten von der ClassNotFoundException-Ausnahme zur Laufzeit. Falls sich ungelöste Abhängigkeiten ergeben, wird
das Bundle nicht gestartet und eine Problemmeldung wird erstellt.
Jedes Bundle kann eine Bundle-Activator-Klasse haben, die im MANIFEST.MF als
solche gekennzeichnet ist. Ein Bundle-Activator muss über einen öffentlichen Konstruktor ohne Parameter, zum Erzeugen eines Objektes durch Class.newInstance() verfügen.
Für jedes auf einer OSGi-Plattform installierte Bundle gibt es ein assoziiertes BundleObjekt über das der Lebenszyklus des Bundles direkt gesteuert werden kann. Ein
Bundle kann sich in sechs verschiedenen Zuständen befinden [WBB10]:
INSTALLED Das Bundle wurde erfolgreich auf der OSGi-Plattform installiert.
RESOLVED Alle Java-Klassen, die das Bundle benötigt, sind verfügbar. Das Bundle
ist bereit, gestartet zu werden oder wurde gerade gestoppt.
STARTING Das Bundle wird über den Aufruf der Start-Methode des BundleActivators gestartet. Die Methode ist noch nicht beendet. Oder die Methode ist beendet,
aber das Bundle wird erst aktiv, wenn es von anderen Bundles benötigt wird.
ACTIVE Das Bundle läuft. Die Start-Methode wurde erfolgreich beendet.
STOPPING Die BundleActivator. Stopp-Methode wurde zum Stoppen des Bundles
aufgerufen, aber noch nicht beendet.
UNINSTALLED Das Bundle wurde deinstalliert.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
16
Die Dienste-Schicht in OSGi unterstützt eine service-orientierte Architektur durch
ihre Service-Registry-Komponente. Bundles veröffentlichen Dienstleistungen für das
Service-Registry. Ein OSGi-Dienst ist ein normales Java-Objekt (Plain Old Java Object
- POJO), und das Service-Registry ist ein normales Java-Interface. Andere Bundles
können diese Dienstleistungen entdecken und aus dem Service-Registry herunterladen.
Diese Dienste sind das wichtigste Mittel für die Zusammenarbeit zwischen Bundles.
Dienste sind vollständig dynamisch und haben i.d.R. die gleiche Lebensdauer wie das
Bundle, das sie zur Verfügung stellt.
Ein Objekt kann unter einer oder mehreren Dienstleistungen bei dem Service-Registry
durch ein Bundle registriert werden. Die Registrierung erfolgt über die Register-ServiceMethoden des BundleContext-Objekts jederzeit während der drei Zustände STARTING, ACTIVE und STOPPING, üblicherweise in der Start-Methode des BundleActivators [WBB10].
Die Standard-Java-Plattform unterstützt Module nur unzureichend. Viele Java-basierte Plattformen wie beispielweise JBoss und NetBeans definieren sich daher ein
eigenes Modulsystem mit einem eigenen, spezialisierten Class-Loader. Das OSGi-Framework schließt diese Lücke und stellt eine generische und standardisierte Lösung zur
Verfügung. Mehrere Bundles können gleichzeitig in einer Java Virtual Machine laufen.
Dabei können Bundles Packages und Klassen anderer Bundles nutzen, aber auch im
Bundle vorhandene Packages und Klassen vor anderen Bundles verstecken [WBB10].
Seit dem OSGi-Release 4 impliziert der Export eines Packages keinen Import mehr.
Dadurch kann ein Bundle ein Package für andere Bundles zur Verfügung stellen, ohne
berücksichtigen zu müssen, dass das Package durch das gleiche Package von einem
anderen Bundle substituiert werden könnte. Selbstverständlich ist es auch möglich,
Bundles einer älteren OSGi-Spezifikation und den nativen Code in ein aktuelles OSGibasiertes Projekt einzubinden [WBB10].
Die OSGi-Sicherheitsschicht ist eine optionale Schicht. Sie basiert auf Java-2-Sicherheitsarchitektur. Und ermöglicht Codes mittels einer digitalen Signatur zu authentifizieren. Für jede Signatur muss dem Bundle eine Signature-Instruction-Datei (mit
einem Aufbau ähnlich der Manifest-Datei) hinzugefügt werden.
Die digitale Signatur ist eine Sicherheitsausstattung, die den Unterzeichner authentiziert und dafür sorgt, dass der Inhalt seit dem Signieren nicht verändert wird. In einem
OSGi-Framework wird der Unterzeichner mit den von ihm unterzeichneten Bundles assoziiert.
Dank der frei verfügbaren Open-Source-Implementierungen verbreitet sich die OSGiPlattform rasant. Deren wichtigste Vertreter sind:
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
17
• Eclipse Equinox
• Apache Felix
• Makewaves Knopflerfish
Equinox ist die am meisten verwendete OSGi-Implementierung und verdankt seinen
Erfolg vor allem der weiten Verbreitung von Eclipse Integrated Development Environment (IDE) und seiner Derivate.
Diese Entwicklung lässt sich auf wenige, aber entscheidende Erfolgskriterien zurückführen: Eclipse propagiert nicht nur die Verwendung der OSGi-Plattform, sondern ist
selbst das beste Beispiel dafür. Das Eclipse Plugin Development Environment (PDE)
hilft Entwicklern über die ersten Hürden eines eigenen Plugins hinweg und bietet
einen Einrichtungsassistenten, einen Manifest-Editor und Tools zur Internationalisierung und zur Classpath-Verwaltung. Zum Testen steht eine konfigurierbare OSGiLaufzeitumgebung zur Verfügung, die das Deployment der erstellten Plugins/Bundles
und das Debuggen auf Knopfdruck ermöglicht. Einem potentiellen Plugin-Entwickler
werden damit alle notwendigen Werkzeuge kostenlos an die Hand gegeben, um den
OSGi-Kosmos auf Basis von Equinox/Eclipse zu erweitern [WBB10].
2.5 Vergleich der Ansätze
Für den Vergleich der Ansätze wurden einige Vergleichskriterien identifiziert, die nachfolgend kurz erläutert und anschließend einzeln auf die verschiedenen Komponentenmodelle angewendet werden. Die Auswahl der Kriterien soll die wichtigsten Eigenschaften
eines Verwaltungssystems behandeln.
Plattformunabhänigkeit Ist das Verwaltungssystem auf mehreren Betriebssystemplattformen einsetzbar?
Dynamik Können Gateways integriert und entfernen werden, ohne dass das Gesamtsystem neu gestartet werden muss?
Kapselung Berücksichtigt das Verwaltungssystem das Prinzip der Kapselung? Die
Module sollen von außen betrachtet unsichtbar und unzugänglich sein.
Versionierung Falls mehrere verschiedene Versionen eines Gateways zugelassen werden oder in der Zukunft neuere Version von Gateways erscheinen sollen, würde es
einen Versionskonflikt geben? Können die Module trotz verschiedener Versionen
miteinander kommunizieren?
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
18
Persistenz Wird die Persistenz von Daten unterstützt? Wie werden die logischen Verbindungen verwaltet?
Sicherheit Wie werden Zugriffe verwaltet und welcher Sicherheitsmechanismus wird
eingeführt?
Metadaten Haben die Module ein Metadaten-Schema? Wie wird darauf zugegriffen?
Die Interoperabilität über Betriebssystemplattformen ist eines der wesentlichen
Architekturmerkmale von CORBA. Durch IIOP können mehrere ORB und damit auch
die auf ORB registrierten CORBA-Objekte auf unterschiedlichen Plattformen miteinander kommunizieren. Jini, EJB und OSGi erzielen eine grundsätzliche Plattformunabhängigkeit durch die Programmiersprache Java. Sie können auf allen Plattformen
eingesetzt werden, für die passende JDK-Releases und eine Java Virtuelle Maschine
(JVM) verfügbar ist.
CORBA erlaubt die Suche von Objekten zur Laufzeit und den dynamischen Aufruf
von deren Operationen über das DII und DSI. Der Lookup Service ermöglicht Jini
Client, Dienste und Objekte dynamisch zu finden. Bei EJB ist die Fähigkeit zum
dynamischen Laden von Klassen bereits in der Schnittstelle java.lang.ClassLoader
eingebaut. Die instantiate-Methode der Klasse java.beans.Beans erwartet ein Objekt,
das diese Schnittstelle implementiert. Unbekannte Schnittstellen können mittels der
Metadaten erforscht werden [GT00]. Anhand der Service-Schicht wird dynamisches
Laden bei OSGi ermöglicht.
CORBA befolgt das Kapszelungsprinzip durch den Einsatz von Stubs und Skeleton. Eine ähnliche Vorgehensweise wird bei Jini durch den Einsatz von Proxies eingeführt. EJB steuert den Zugriff auf Objekte mittels Session Beans, Entity Beans und
Message Driven Beans. Alles, was für andere Anwendung sichtbar ist, soll bei OSGi
explizit in der Manifest-Datei deklariert werden. Ansonsten bleiben die Instanzen und
Methoden im Bundle versteckt.
Anhand der DSI und GIOP kann die Zusammenarbeit von CORBA mehrerer Versionen ermöglicht werden. Seit der Jini-Übergabe an Apache scheint es, dass die Weiterentwicklung von Jini abgebrochen wurde. Somit kann keine Versionsinteroperabilität festgestellt werden. Bei EJB wird die vorwärtige und rückwärtige Kompatibilität
gewährleistet. Obwohl seit EJB 3.0 die Entity Beans obsolet sind und durch JPA ersetzt werden, enthält EJB 3.0 noch die Entity Beans. OSGi bietet eine Versionierung
an, wenn die Version und die Abhängigkeiten in der Manifest-Datei richtig deklariert
werden.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
19
CORBA definiert mit dem Persistent Object Service einen Persistenzmechanismus. Es gibt hingegen keinen bekannten Persistenzmechanismus für Jini. EJB und
OSGi werden von Java Persistence API (JPA) unterstützt. JPA wird im Kapitel 3.2
noch ausführlicher beschrieben.
CORBA spezifiert Sicherheitsmechanismen durch den Security Service. Mit der
Einführung von Jini Extensible Remote Invocation (Jeri) soll die Sicherheit der Jini-Komponenten verstärkt werden. Unter http://www.artima.com/intv/jeri.html
findet man ein Beispiel der Jeri-Implementierungen. Enterprise Java Beans stützen sich
auf das java.security- Paket. Und bei OSGi kann zusätzlich die digitale Signatur
durch die Sicherheits-schicht überprüft werden.
CORBA verwaltet Metadaten aller ihm bekannten Objekte im Interface Repository. Bei Jini gibt es keinen bekannten Metadatenmechanismus. Die Administration
von Metadaten bei EJB soll von der Schnittstelle javax.ejb.EJBMetaData geführt
werden. Klassen, die diese Schnittstelle implementieren, werden normalerweise von
den EJB-Entwicklungswerkzeugen automatisch generiert [GT00]. OSGi verwaltet alle
Metadaten in der Datei MANIFEST.MF. Diese Datei liegt in einem eindeutigen Ordner META-INF. Hier sind die Abhängigkeiten des Bundles, sowie der Name und die
Versionsnummer enthalten.
Die untenstehende Tabelle 2.1 fasst die Eigenschaften und die Ansätze zusammen.
Eigenschaften
Plattformunabhängigkeit
Dynamik
Kapselung
Versionierung
Persistenz
Sicherheit
Metadaten
CORBA
JA
JA
JA
JA
JA
JA
JA
Jini
JA
JA
JA
NEIN
NEIN
JA
NEIN
EJB
JA
JA
JA
JA
JA
JA
JA
OSGI
JA
JA
JA
JA
JA
JA
JA
Tabelle 2.1: Vergleich der Ansätze
Anhand der Tabelle lässt sich feststellen, dass Jini nicht die nötigen Eigenschaften für
das Verwaltungssystem besitzt. Wie im Kapitel 2.1 beschrieben wurde, ist CORBA für
große Systeme mit verschiedenen Betriebssystemen und Programmiersprachen besser
geeignet. Obwohl CORBA die oben genannten Anforderungen erfüllt, erhöht sich die
Komplexität bei der Verwendung von CORBA in Java. Das Verwaltungssystem, das in
dieser Masterarbeit gefordert wird, soll jedoch in Java entwickelt werden, was CORBA
ausschließt.
Masterarbeit Aalbrecht Alby Irawan
2 Dynamische Verwaltung von Softwarekomponenten
20
Obwohl EJB und OSGi alle Anforderungen erfüllen, ist OSGi im Vergleich zu EJB
einfacher zu programmieren und zu verwalten. EJB ist ein Teil der Java EE-Spezifikation.
Der Einsatz von EJB in den Rechnern mit Java SE und begrenzten Ressourcen ist
deshalb nicht zu empfehlen. OSGi hingegen ist dank der OSGi-Allianz welt verbreitet. Sowohl Client-seitig als auch Server-seitig benötigt OSGi nur Java SE, was die
Realisierung des Verwaltungssystems vereinfacht. Ein anderer entscheidender Vorteil
für OSGi ist die Möglichkeit, bereits existierende JARs und Java-Module in OSGiBundles umzuwandeln. Somit können die Entwicklungskosten sinken und schnellere
Produktzyklen erreicht werden.
Masterarbeit Aalbrecht Alby Irawan
3 Datenbankschnittstelle
21
3 Datenbankschnittstelle
Eine Datenbank ist eine Sammlung von Daten, die einen Ausschnitt der realen Welt
beschreiben [EN09]. Diese Definition ist sehr allgemein. Man betrachtet z.B. die Sammlung von Wörtern in einem Buch als zusammenhängende Daten und somit als Datenbank. Der übliche Gebrauch des Begriffs Datenbank wird in vielen Fällen aber
eingeschränkt. Für die vorliegende Arbeit gilt: Unter Datenbank versteht man eine
integrierte, d.h. logisch zusammenhängende Sammlung von Daten für einen festgelegten Zweck. Sie wird von einer bestimmten Benutzergruppe in Anwendungen eingesetzt
[Kud07].
Traditionelle Datenbanken sind in Feldern, Datensätzen und Dateien organisiert.
Ein Feld ist ein Einzelteil von Informationen. Ein Rekord ist eine komplette Reihe von
Feldern und eine Datei ist eine Sammlung von Datensätzen. Ein Telefonbuch ist ein
gutes Beispiel für eine Datei. Es enthält eine Liste von Datensätzen, die jeweils aus
drei Feldern bestehen: Name, Adresse und Telefonnummer.
Ein Datenbankmanagementsystem (DBMS) ist ein Softwaresystem (d.h. eine Sammlung von Programmen), das dem Benutzer das Erstellen und die Pflege einer Datenbank ermöglicht. Dies umfasst die Definition, die Erzeugung und Manipulation der
Datenbank. Ein DBMS zusammen mit einer oder mehreren Datenbanken wird als Datenbanksystem (DBS) bezeichnet [Kud07].
Datenbanksysteme gibt es in verschiedenen Formen. Die gebräuchlichsten Formen
eines Datenbanksystems sind das relationale Datenbanksystem und das objektrelationale Datenbanksystem.
3.1 Relationales Datenbanksystem
Ein relationales Datenmodell ist eine Sammlung von Relationen, die wie eine Wertetabelle aussieht. Jede Zeile wird Tupel genannt. Die Spalten werden als Attribute der
Relation bezeichnet. Der Datentyp, der die Werte beschreibt, wird als Wertebereich
definiert. Die Abbildung 3.1 veranschaulicht das relationale Datenbanksystem.
Masterarbeit Aalbrecht Alby Irawan
3 Datenbankschnittstelle
22
Abbildung 3.1: Grundlegende Konzepte eines relationalen Datenmodells [Kud07]
Für die Verwendung der Modellelemente des relationalen Datenmodells sind die
folgenden Grundregeln [Kud07] zu beachten:
• Jede Relation wird als zweidimensionale Tabelle mit einer definierten Anzahl von
Attributen und variabler Anzahl von Tupeln dargestellt.
• Tupel einer Relation müssen eindeutig sein, d.h. es dürfen keine zwei identischen
Tupel existieren. Die Position eines Tupels in der Relation ist variabel.
• Der Name eines Attributs muss eindeutig sein. Die Position des Attibuts in der
Relation ist variabel.
• Attributwerte müssen atomar sein, d.h. zusammengesetzte und mehrwertige Attribute sind nicht zulässig.
• Ein Attributwert kann ein Nullwert sein. Ein Nullwert steht für einen nicht bekannten oder nicht verfügbaren Wert.
3.2 Objektrelationales Datenbanksystem
Dank der objektorientierten Programmiersprache Java hat sich die Objektorientierung
in der Datenbank-Anwendungsprogrammierung durchgesetzt. Eine Objektdatenbank
wird nicht durch die relationalen Verfahren beschränkt. Sie braucht die Daten nicht
in Tabellen zu speichern, sondern kann sie in vielen verschiedenen Kombinationen
arrangieren und dem Nutzer dennoch das Suchen ermöglichen [Wut02]. Obwohl sich
objektorientierte Datenbanksysteme letzendlich nicht etablieren konnten, fand die Objektorientierung mit sogenanntem Object-Relational-Mapping (ORM) ihren Weg in die
Masterarbeit Aalbrecht Alby Irawan
3 Datenbankschnittstelle
23
Datenbankwelt. Die ORM-Tools fungieren als Middleware-Technologie und Brückenschlag zwischen der objektorientierten Programmierung und der relationalen Datenbankwelt.
Sie übernehmen die Abbildung zwischen den Java-Objekten und den relationalen
SQL-Tabellen. Da die Abbildung der Java-Objekte in der Middleware erfolgt, hat das
Datenbanksystem bei diesem Ansatz kein Wissen über die Anwendungsobjekte. Folglich kann das hier üblicherweise eingesetzte relationale Datenbanksystem im Gegensatz
zu einem objektrelationalen System nicht die Semantik der Anwendungsobjekte etwa
zur Optimierung von Anfragen oder zur effizienteren Synchronisation von Transaktion
ausnutzen [Kud07].
Das erste praktisch einsetzbare ORM-Tool war in die Java EE-Spezifikation Version 1.2 eingebunden, die im Dezember 1999 veröffentlich wurde. Sie enthielt EJB 1.1
und damit bereits ein ORM, das Container Managed Persistence (CMP) hieß. Später wurde mit Java Data Objects (JDO) eine weitere offizielle Spezifikation für das
Mapping von Java-Objekten auf Datenbanken veröffentlicht. Diese früheren offiziellen Java-Spezifikationen für das OR-Mapping wurden aus verschiedenen Gründen von
der Entwicklergemeinde nicht angenommen. Insbesondere wurde der Konfigurationsund Programmieraufwand als zu hoch kritisiert [MW12]. Stattdessen wird die Java
Persistence API (JPA) öfter eingesetzt.
JPA wurde 2006 als Teil von Enterprise Java Beans 3.0 verabschiedet. Mittlerweile
gilt JPA als eine leichtgewichtige Schnittstelle für das Mapping von Java-Objekten
in relationalen Datenbanksystemen. Hibernate, lange Jahre der De-facto-Standard in
diesem Bereich, ist vom Marktführer zu einem von mehreren JPA-Implementierungen
geworden [MW12]. Außer Hibernate existieren noch andere Implementierungen von
JPA, wie z.B. EclipseLink und OpenJPA. EclipseLink spielt eine größere Rolle als die
anderen Implementierungen, da Oracle EclipseLink als die Referenzimplementierung
von JPA 2.0 übernommen hat.
3.3 Java Datenbank Connectivity
Java Database Connectivity (JDBC) ist ein Teil des Java SE- und Java EE-Standards
zum datenbankunabhängigen Zugriff auf relationale Datenbanken. Alle erforderlichen
Klassen sind in den Paketen java.sql.* und javax.sql.* enthalten.
Die meisten Datenbanken haben für die Kommunikation mit der Datenbank unterschiedliche APIs. Auf einer Windows-Plattform und sogar einigen Unix-Plattformen
liefert das API Open Datenbank Connectivity (ODBC) ein Standard-Datenbank-API,
Masterarbeit Aalbrecht Alby Irawan
3 Datenbankschnittstelle
24
das mit vielen verschiedenen Datenbanken funktioniert. JDBC löst das Problem auf
dieselbe Weise, da es ebenfalls ein Standard-Datenbank-API liefert. Das Paket JDBC
weiß selbst nicht, wie es eine Verbindung zu irgendeiner Datenbank herstellen soll. Es
ist nur eine API-Architektur, die sich bei der Bereitstellung der Implementierung auf
andere Pakete stützt [Wut02].
Für jede spezifische Datenbank sind eigene Treiber erforderlich. Diese Treiber sind
in Form von *.jar- oder *.zip-Archiven für die jeweilige Datenbank vom Hersteller
des Datenbank-Systems erhältlich [Kud07]. Es gibt vier Arten von JDBC-Treibern:
Typ 1: JDBC-ODBC-Bridge Dieser Treibertyp verbindet JDBC und ODBC. Also
kann der Funktionsumfang der JDBC-Schnittstelle durch Verwendung der ODBCSchnittstelle und Datenbanken realisiert werden. Der Treiber ist daher generisch
und für alle Datenbanken verwendbar.
Typ 2: Native-API-Treiber Dieser Treibertyp greift über eine native Bibliothek auf
einen datenbankspezifischen Treiber zu. Der Treiber konvertiert JDBC-Methodenaufrufe in nativen Aufrufen des Datenbank-API.
Typ 3: Middleware-Treiber Dieser Treibertyp braucht eine Middleware-Architektur,
die die Verbindungen zu irgendeiner Datenbank verwaltet. Der Treiber konvertiert JDBC-Methodenaufrufe in eine Sprache, die der Middleware-Server versteht. Also findet die Konvertierung nicht auf dem Client statt, sondern in der
Middleware.
Typ 4: Purer Java-Treiber Dieser Treibertyp wurde komplett in Java geschrieben. Er
wird innerhalb der JVM des Clients installiert. Da kein Vorhandensein anderer
Software wie z. B. ein ODBC-Treiber erforderlich ist, kann dieser Treibertyp
schneller als die anderen Treibertypen arbeiten.
3.4 Java Persistence Query Language
Java Persistence Query Language (JPQL) ist eine plattformunabhängige objektorientierte Abfragesprache. Sie wird als Teil der JPA-Spezifikation definiert. JPQL dient
der Abfrage von Objekten (Entity) in einer relationalen Datenbank. Sie ist an Structured Query Language (SQL) stark angelehnt, die den gleichen Zweck hat. Deswegen
haben die beiden eine ähnliche Syntax. Neben dem Abruf von Objekten (SELECTAbfragen) unterstützt JPQL auch UPDATE-Abfragen und DELETE-Abfragen. JPQL
unterscheidet Großschrift von Kleinschrift nicht.
Masterarbeit Aalbrecht Alby Irawan
3 Datenbankschnittstelle
25
Die Syntax der JPQL sieht wie folgt aus:
//Select-Abfrage
"select x from Gateway x"
//Update-Abfrage
"UPDATE Gateway x set x.status = false where x.name = ’Gateway 01’"
//Delete-Abfrage
"DELETE FROM Gateway x WHERE x.name = ’Gateway 01’"
Abbildung 3.2: Die Syntax von Java Persistence Query Language
Masterarbeit Aalbrecht Alby Irawan
4 Konzeption eines dynamischen Software-Verwaltungssystems
26
4 Konzeption eines dynamischen
Software-Verwaltungssystems
Dieses Kapitel befasst sich mit der Konzeption eines dynamischen Software-Verwaltungssystems. Zunächst werden die Anforderungen festgelegt, die benötigten Komponenten untersucht und abschließend ein Vorschlag zur Realisierung des dynamischen
Software-Verwaltungssystems vorgelegt.
4.1 Anforderungen an das Software-Verwaltungssystem
Im Kapitel 2.5 wurden bereits einige wichtige Eigenschaften erläutert, die das SoftwareVerwaltungssystem bieten soll:
• Plattformunabhänigkeit
• Dynamik
• Kapselung
• Versionierung
• Persistenz
• Sicherheit
• Metadaten
Die oben genannte Eigenschaften werden durch die Verwendung von OSGi unterstützt.
4.2 Struktur des Verwaltungssystems
Abbildung 4.1 zeigt die Struktur des Verwaltungssystems. Das Verwaltungssystem
muss dazu in der Lage sein, die Attribute des eingehenden Gateways zu lesen und
Masterarbeit Aalbrecht Alby Irawan
4 Konzeption eines dynamischen Software-Verwaltungssystems
27
Abbildung 4.1: Konzeption des Verwaltungssystems
sie persistent zu speichern. Gegebenenfalls soll sich das Verwaltungssystem einen Zugriff auf das Gateway verschaffen um seine Attribute zu verändern oder es zu deaktivieren. Außerdem muss das Verwaltungssystem die Erstellung einer Liste von vorher
abgespeicherten Attributen ermöglichen.
Für den Nachrichten-Austausch zwischen den einzelnen Gateways und dem Verwaltungssystem wird ein AMQP-Server benötigt. Im AMQP-Server wird eine eindeutige
Warteschlange (Queue) namens Status reserviert. Sie dient als ein Interrupt-Empfänger für Nachrichten von den Gateways zum Verwaltungssystem. Eine andere Queue
mit dem Namen Action wird ebenfalls reserviert, um die Nachrichten aus dem Verwaltungssystem zu den Gateways zu speichern.
Ein Gateway soll die folgenden Attribute, auch Metadaten genannt, besitzen:
• Id
• Name
• Kategorie
• Status
• Preis
Die Id und der Name des Gateways müssen eindeutig sein, um eine Kollision auszuschließen. Die Metadaten werden vom Gateway generiert und durch den AMQPServer in der Queue gespeichert. Anschließend empfängt das Verwaltungssystem die
Metadaten und speichert sie in der Datenbank. Es muss weiterhin auch eine Methode
Masterarbeit Aalbrecht Alby Irawan
4 Konzeption eines dynamischen Software-Verwaltungssystems
28
zum Aufruf der bereits in der Datenbank vorhandenen Metadaten geben, um diese zu
kontrollieren.
Um die Metadaten abzuspeichern, wird EclipseLink, eine Implementierung des ORMTools, eingesetzt. ORM-Tools und objektorientierte Datenbanksysteme wurden bereits
im Kapitel 3.2 erläutert.
Als Realisierung der Datenbank wird Apache Derby verwendet. Bei der Verwendung anderer Datenbank-Software müssen keine großen Änderungen vorgenommen
werden. Man muss nur das korrekte Bundle-Version herunterladen, die Abhängigkeiten in der Datei MANIFEST.MF richtig deklarieren und die passende Einstellung in
persistence.xml setzen.
Wenn man sich für das MySQL-System von Oracle entscheidet, treten jedoch Probleme auf. Der richtige JDBC-Treiber kann hierbei nicht gefunden werden, denn das offizielle MySQL-OSGi-Bundle ist nicht vorhanden. Auf der Wiki-Seite von EclipseLink[Ecl12]
wird erklärt, wie man ein OSGi-Bundle für den MySQL-JDBC-Treiber erstellt. Da die
MySQL-JAR-Dateien verschiedene Versionen haben können, variieren auch die Inhalte
des Bundles.
Bei der Verwendung von Apache Derby tritt dasselbe Problem nicht auf. Offizielle
Derby-Bundles stehen im Apache Maven - oder Eclipse-Repository zur Verfügung. Man
muss sich nur das passende Bundle aussuchen und herunterladen.
Durch den Einsatz des AMQP-Servers muss die Metadaten-Übermittlung nicht im
XML-Format erfolgen wie in der anfängliche Aufgabenstellung beschrieben wurde. Anders als JMS benutzt AMQP keine Nachricht-Properties. Alle Nachrichten werden als
reine String-Typen übertragen und verarbeitet.
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
29
5 Umsetzung des Konzepts
In diesem Kapitel werden die wichtigsten Methoden aufgeführt. Weiterhin werden die
verwendeten Komponenten erläutert und deren Zusammenarbeit im Verwaltungssystem gezeigt.
5.1 RabbitMQ
RabbitMQ ist eine der vielen AMQP-Implementierungen. In [Ira12] kann weiteres über
AMQP und RabbitMQ gelesen werden. Ein RabbitMQ-Broker wurde vom Fachgebiet
Kommunikationsnetze der TU Ilmenau zur Verfügung gestellt. Um die Sicherheit zu
gewährleisten, muss ein Nutzer vor jedem Verbindungsaufbau einen Benutzername und
das dazugehörige Passwort vorlegen. Nur dann kann ein Zugriff zum Server zugelassen
werden.
Dem letzten Kapitel zufolge, soll jedes Gateway spezifische Metadaten (einen Name,
eine Kategorie, einen Status und einen Preis) haben. Da RabbitMQ nur Daten vom
Typ-String verarbeiten und versenden kann, müssen erstmal Status und Preis in eine
String-Variable konvertiert werden. Danach werden die Metadaten-Variablen zusammengefügt und zu der Status-Queue geschickt. Damit die Variablen wieder zerlegt und
bearbeitet werden können, dient ein Semikolon “;“ als Trennzeichen. Dieser Ablauf
ist auf Abbildung 5.1 zu sehen.
Die Metadaten, die das Gateway zu der Status-Queue schickt, werden vom Verwaltungssystem konsumiert. Die konsumierte Nachricht wird auf das Trennzeichen
“;“ geprüft und in vier Substrings zerlegt. Anschließend sollen die Status- und PreisVariablen in Boolean- bzw. Double-Typ umgewandelt werden. Dieser Ablauf ist auf
Abbildung 5.2 nachvollziehbar.
Analog dazu kann das Verwaltungssystem die Metadaten des Gateways verändern.
Dieser Vorgang läuft über die Action-Queue ab. Jedes Gateway hört auf diesem Kanal
mit und konsumiert jede verfügbare Nachricht. Falls der Name, der in der Nachricht
enthalten ist, mit dem Namen des Gateways übereinstimmt, ändert das Gateway seine
Metadaten dementsprechend. Ansonsten wird die Nachricht ignoriert und verworfen.
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
30
private final String StatusQueueName = "Status";
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(mAMQPServer);
factory.setUsername(mAMQPUsername);
factory.setPassword(mAMQPPassword);
mConnection = factory.newConnection();
mChannel = mConnection.createChannel();
mChannel.queueDeclare(StatusQueueName, true, false, false, null);
Gateway g = new Gateway();
name_String = g.getName();
category_String = g.getCategory();
status_Bool = g.getStatus();
price_Double = g.getPrice();
if (status_Bool == true)
status_String = "aktiv";
else status_String = "nicht aktiv";
price_String = String.valueOf(price_Double);
message = name_String + ";" + category_String + ";"
+ status_String + ";" + price_String;
mChannel.basicPublish("", StatusQueueName, null, message.getBytes());
System.out.println(" [x] Sent ’" + message + "’");
mChannel.close();
mConnection.close();
Abbildung 5.1: Versenden der Metadaten zum RabbitMQ-Server
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
31
private final String StatusQueueName = "Status";
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(mAMQPServer);
factory.setUsername(mAMQPUsername);
factory.setPassword(mAMQPPassword);
mConnection = factory.newConnection();
mChannel = mConnection.createChannel();
mChannel.queueDeclare(StatusQueueName, true, false, false, null);
mConsumer = new QueueingConsumer(mChannel);
mChannel.basicConsume(WBSMSOutQueueName, mConsumer);
QueueingConsumer.Delivery delivery = mConsumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [x] Received ’" + message + "’");
mChannel.close();
mConnection.close();
x = message.indexOf(";");
y = message.indexOf(";", x+1);
z = message.indexOf(";", y+1);
name_String = message.substring(0, x);
category_String = message.substring(x+1, y);
status_String = message.substring(y+1, z);
price_String = message.substring(z+1);
if (status_String.equals("aktiv"))
status_Bool = true;
else status_Bool = false;
price_Double = Double.valueOf(price_String).doubleValue();
Abbildung 5.2: Bearbeitung der Metadaten durch das Verwaltungssystem
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
32
5.2 EclipseLink
EclipseLink ist eine JPA-Implementierung der Eclipse Foundation. Sie wurde basierend auf TopLink von Oracle entwickelt. Außerdem hat Oracle EclipseLink als die
Referenzimplementierung von JPA 2.0 ausgewählt.
In EclipseLink repräsentiert ein persitentes Objekt eine bestimmte Zeile einer Datenbanktabelle, eventuell auch mehrere Zeilen in verschiedenen Tabellen, die ihrerseit
durch je einen Primärschlüssel identifiziert werden. Dieser Primärschlüssel ist ein Realisierungsdetail der Objektpersistenz und muss somit im Mapping verwendet werden.
Abbildung 5.3 veranschaulicht ein persistentes Entity mit einem Primärschlüssel (Id).
Die Annotation @Entity macht aus einer gewöhnlichen, nicht persistenten JavaKlasse ein persistentes Entity. Die Instanzvariable ID ist mit @Id annotiert und wird
damit von EclipseLink als der Primärschlüssel verwendet. Die beiden genannten Annotationen sowie alle weiteren JPA-Annotationen sind im Package javax.persistence
enthalten und müssen vorher importiert werden [MW12].
Es gibt mehrere Alternativen zur Generierung von Primärschlüsseln. Ausgangspunkt
ist die Annotation @GeneratedValue, die nach @ID deklariert wird. EclipseLink sieht
folgende alternativen Generatorarten vor [MW12]:
AUTO Die Wahl des Verfahrens wird EclipseLink überlassen. In der Regel werden
IDENTITY oder SEQUENCE ausgewählt.
IDENTITY Hier wird die Datenbankfunktionalität einer selbstinkrementierenden Spalte verwendet.
TABLE Eine zusätzliche Tabelle wird zur Verwaltung des zuletzt generierten Primärschlüssel genutzt.
SEQUENCE Es wird die Datenbankfunktionalität einer Sequence verwendet.
Um eine Kollision zu verhindern, wird der Primärschlüssel als Typ-IDENTITY generiert. Es kann keine zwei Entities mit einem identischen Primärschlüssel geben. Selbst
wenn ein Gateway von der Datenbank entfernt und gelöscht werden soll, wird sein
Primärschlüssel nicht wiederverwendet. Die Klasse Gateway enthält auch mehrere getbzw. set-Methoden. Sie dienen dazu, die Metadaten des Gateways abzufragen und
gegebenenfalls zu setzen.
Die zentrale Einheit zur Verwaltung von Entities ist die Klasse EntityManager.
Jede EntityManager-Klasse wird durch eine “Fabrikërzeugt’, das sogenannte Interface EntityManagerFactory. Die Konfiguration aller EntityManager erfolgt anhand
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
import
import
import
import
33
javax.persistence.Entity;
javax.persistence.GeneratedValue;
javax.persistence.GenerationType;
javax.persistence.Id;
@Entity
public class Gateway {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
private String name;
private String category;
private boolean status;
private double price;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Verfuegbar [id =" + id + ", name =" + name + ", category ="
+ category + ", status =" + status + ", price =" + price + "]";
}
}
Abbildung 5.3: Die Struktur des Gateway-Entitys
der Konfigurationsdatei persistence.xml im Ordner META-INF. Diese ist mit einem eindeutigen Namen versehen, so dass in einer Anwendung zwischen mehreren
EntityManagerFactory-Objekten und somit auch zwischen mehreren Verbindungen
zu verschiedenen Datenbanken unterschieden werden kann [MW12]. Abbildung 5.4
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
34
veranschaulicht die Verwendung der EntityManagerFactory- und EntityManagerKlasse
EntityManagerFactory emf = Persistence
.createEntityManagerFactory("gateway.verwaltung");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
Gateway neuerInput = new Gateway();
neuerInput.setName(name_String);
neuerInput.setCategory(category_String);
neuerInput.setStatus(status_Bool);
neuerInput.setPrice(price_Double);
em.persist(neuerInput);
em.getTransaction().commit();
em.close();
emf.close();
Abbildung 5.4: Bereitstellung und Verwendung von Entity-Manager
In einer Java-Anwendung ist die Schnittstelle zur Transaktionsverwaltung das Interface EntityTransaction. Eine Instanz erhält man durch die Entity-Manager-Methode getTransaction(). Die Schnittstelle umfasst die erwarteten Methode begin(),
commit() und rollback() vom Typ void, sowie die boolesche Methode isActive(),
die anzeigt, ob zum Ausführungspunkt des aktuellen Threads eine Transaktion aktiv
ist. Die Methode persist() macht ein Entity persistent und nachdem die Methode
commit() ausgerufen wurde, wird das Entity in der Datenbank gespeichert [MW12].
5.3 Apache Derby
Apache Derby ist ein relationales Datenbank Management System (DBMS) von der
Apache Software Foundation, das in Java entwickelt wurde und leicht in Java-Programmen eingebettet werden kann. Apache Derby wird als ein Open-Source-Projekt
unter der Apache-Lizenz registriert. Oracle vertreibt die gleichen Binärdateien in der
JDK und bezeichnet die als Java DB. Dank dem kleinen Footprint, etwa 2,6 Megabyte
für die Basis-Maschine und den eingebetteten JDBC-Treiber, gehört Apache Derby zu
den leichtgewichtigen Datenbanken. Apache Derby basiert auf dem Java-, JDBC- und
SQL-Standard.
Apache Derby kann in einem Server-Modus und im eingebetteten Modus (embedded mode) verwendet werden. Wenn Derby im Server-Modus läuft, wird ein Derby-
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
35
Netzwerkserver gestartet, der die Verantwortung für den Umgang mit den DatenbankAnfragen übernimmt. Im eingebetteten Modus arbeitet Derby innerhalb der Java Virtual Machine (JVM) von der Anwendung. Der Nachteil von diesem Modus ist, dass
kein anderer Benutzer und keine andere Anwendung auf die Datenbank zugreifen können, wenn die Datenbank gerade von einer Anwendung benutzt wird. Also muss nach
jeder Session die Verbindung zur Derby-Datenbank abgeschlossen sein.
Die Einstellungen von Apache Derby und EclipseLink werden in der persistence.
xml-Datei innerhalb des META-INF Ordners deklariert. Anders als der META-INF
Ordner, der die MANIFEST.MF-Datei von OSGi enthält, liegt dieser Ordner im srcVerzeichnis des Projekts. Der eigentliche Pfad zur Datenbank wird mit dem Attribut
javax.persistence.jdbc.url spezifiziert. Zurzeit weist dieser zu einer Datenbank
GatewayTest im Eclipse-Workspace. Um die Sicherheit zu gewährleisten, kann optional ein Benutzername und dessen Passwort angelegt werden. Aber in dieser Masterarbeit handelt es um einen Prototyp, also wird auf Benutzername und Passwort
verzichtet.
Mit dem Attribut eclipselink.ddl-generation kann die Erstellung der Datenbank konfiguriert werden. drop-and-create-tables bedeutet, dass die bereits bestehenden Einträge gelöscht werden sollen und eine neue Tabelle erstellt werden soll.
create-tables deutet an, dass der neue Eintrag an die alten Daten angehängt werden
soll. In dieser Masterarbeit wird mit dem Wert create-tables gearbeitet.
Abbildung 5.5 stellt dar, wie eine persistence.xml-Datei aussieht.
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
36
<persistence version="1.0"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="gateway.jpa.derby">
<class>gateway.jpa.derby.Gateway</class>
<properties>
<!-- Embedded Derby Login -->
<property name="javax.persistence.jdbc.driver"
value="org.apache.derby.jdbc.EmbeddedDriver"/>
<property name="javax.persistence.jdbc.url"
value="jdbc:derby:GatewayTest;create=true"/>
<!-- don’t need userid/password in embedded Derby -->
<property name="eclipselink.target-database" value="Derby"/>
<property name="eclipselink.jdbc.read-connections.min" value="1"/>
<property name="eclipselink.jdbc.write-connections.min" value="1"/>
<property name="eclipselink.jdbc.batch-writing" value="JDBC"/>
<!-- Database Schema Creation -->
<property name="eclipselink.ddl-generation"
value="create-tables"/>
<property name="eclipselink.ddl-generation.output-mode"
value="both"/>
<!-- Logging Settings -->
<property name="eclipselink.logging.level" value="FINE" />
<property name="eclipselink.logging.thread" value="false" />
<property name="eclipselink.logging.session" value="false" />
<property name="eclipselink.logging.exceptions" value="true" />
<property name="eclipselink.logging.timestamp" value="false"/>
</properties>
</persistence-unit>
</persistence>
Abbildung 5.5: Beispiel einer persistence.xml-Datei
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
37
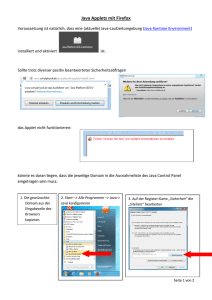
5.4 OSGi
OSGi hat mehrere Implementierungen, z.B. Eclipse Equinox, Apache Felix und Makewaves Knopflerfish. In dieser Masterarbeit wird Eclipse Equinox verwendet, denn
Equinox ist die Referenzimplementierung der OSGi-Spezifikation und außerdem die
Laufzeitumgebung, auf der die Eclipse-Anwendung basiert.
In Eclipse ist die kleinste Einheit der Modularisierung ein Plug-in. Die Begriffe
Plugin und Bundle sind fast austauschbar. Ein Eclipse-Plugin ist auch ein OSGi-Bundle
und umgekehrt. Eclipse Equinox erweitert das Konzept der Bundles mit dem Konzept
der Extension-Points (Installation vom Eclipse-Repository).
Technisch gesehen sind OSGi-Bundles JAR-Dateien mit den zusätzlichen Meta-Informationen. Diese Meta-Informationen werden innerhalb des META-INF-Ordners gespeichert. Die MANIFEST.MF-Datei ist ein Teil der Standard-JAR-Spezifikation, in
die OSGi zusätzliche Metadaten einfügt. Jede Nicht-OSGi-Laufzeitumgebung ignoriert
die OSGi-Metadaten. Deshalb können OSGi-Bundles auch ohne Einschränkungen in
einer Nicht-OSGi-Umgebung eingesetzt werden.
Abbildung 5.6 veranschaulicht die Struktrur einer MANIFEST.MF-Datei. Die einzelnen Attribute werden kurz erläutert:
Bundle-Name Kurzbeschreibung des Bundles.
Bundle-SymbolicName Die eindeutige Kennung für das Bundle.
Bundle-Version Die Definition der Bundle-Version. Diese muss erhöht werden, falls
eine neue Version des Bundles veröffentlicht wird.
Bundle-Activator Ist optional und definiert einen Activator. Diese Klasse wird aufgerufen, wenn das Bundle gestartet oder gestoppt wird.
JPA-PersistenceUnits Definiert den Namen der Persistence-Units.
META-Persistence Zeigt den Pfad zur persistence.xml.
Import-Package Deklariert die Bundles, von der dieses Bundle abhängig ist.
Bundle-RequiredExecutionEnvironment Bestimmt die Java-Version, die erforderlich
ist, um das Bundle auszuführen. Wenn diese Voraussetzung nicht erfüllt ist, dann
wird dieses Bundle von der OSGi-Laufzeitumgebung nicht geladen.
Require-Bundle Ähnlich wie Import-Package, aber das Bundle ist manuell von einer JAR-Datei konvertiert und liegt nicht im Plug-in-Verzeichnis, sondern im
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
38
Eclipse-Workspace. Ein Beispiel dafür ist das RabbitMQ-Bundle, das im Eclipse-Repository nicht enthalten ist.
Manifest-Version: 1.0
Bundle-ManifestVersion: 2
Bundle-Name: Verwaltungssystem
Bundle-SymbolicName: gateway.jpa.derby
Bundle-Version: 1.0.0.qualifier
Bundle-Activator: gateway.jpa.derby.Activator
JPA-PersistenceUnits: gateway.jpa.derby
META-Persistence: META-INF/persistence.xml
Import-Package: javax.persistence;version="2.0.4",
org.apache.derby.jdbc;version="10.5.1.1",
org.eclipse.persistence.jpa.jpql;version="2.0.0",
org.osgi.framework;version="1.3.0"
Bundle-RequiredExecutionEnvironment: JavaSE-1.6
Require-Bundle: com.rabbit.bundle;bundle-version="1.0.0"
Abbildung 5.6: Beispiel einer MANIFEST.MF-Datei
OSGi ist verantwortlich für die Verwaltung von Abhängigkeiten zwischen den Bundles. OSGi liest die MANIFEST.MF-Datei eines Bundles während der Installation. Es
sorgt dafür, dass alle abhängigen Bundles auch geladen werden, wenn das Bundle aktiviert ist. Falls die Abhängigkeiten nicht erfüllt sind, wird das Bundle nicht geladen.
Falls es mehrere Pakete geben, die die Abhängigkeiten erfüllen, dann wird das Bundle
mit der höchsten Version verwendet. Wenn die Versionen auch identisch sind, dann
wird das Bundle mit der niedrigsten ID verwendet. Beim Starten wird der Status
STARTING angezeigt, danach erhält das Bundle den Status ACTIVE.
Eclipse Equinox verfügt über eine OSGi-Konsole. Die OSGi-Konsole verhält sich
wie eine MS-DOS-Konsole. In dieser Konsole kann man einen Befehl eintippen, um
bestimmte OSGi-Aktionen auszuführen. Die folgenden Pakete müssen in die LaufzeitKonfiguration hinzugefügt werden, um die OSGi-Konsole zu verwenden, falls Eclipse
Juno verwendet wird. Bei den früheren Versionen von Eclipse wie Eclipse Indigo
oder Eclipse Helios werden die Pakete automatisch geladen.
• org.apache.felix.gogo.command
• org.apache.felix.gogo.runtime
• org.apache.felix.gogo.shell
Masterarbeit Aalbrecht Alby Irawan
5 Umsetzung des Konzepts
39
• org.eclipse.equinox.console
• org.eclipse.osgi
Die wichtigsten OSGi-Befehle werden nachfolgend erläutert:
ss zeigt die installierten Bundles und deren Status und ID an.
help listet die verfügbaren Befehle auf.
start id startet das Bundle mit der ID.
stop id stoppt das Bundle mit der ID.
install url installiert ein Bundle aus einer URL oder einem Pfad.
uninstall id deinstalliert das Bundle mit der ID.
bundle id zeigt die Informationen über das Bundle mit der ID an, einschließlich der
registrierten und genutzten Dienste.
Masterarbeit Aalbrecht Alby Irawan
6 Zusammenfassung/Ausblick
40
6 Zusammenfassung/Ausblick
6.1 Zusammenfassung der Ergebnisse
Anhand der Zielstellungen dieser Masterarbeit wurde ein dynamisches Software-Verwaltungssystem konzipiert und realisiert. Die wichtigsten Eigenschaften wurden ausführlich besprochen und im System implementiert. Die verfügbaren vier Ansätze wurden recherchiert und verglichen.
Das dynamische Software-Verwaltungssystem lässt sich mittels OSGi-Framework,
RabbitMQ-Server, EclipseLink und Apache Derby realisieren. Das OSGi-Framework
bietet die Möglichkeit, die Komponenten modular und dynamisch zu verwalten. Rabbit-MQ ermöglicht, eine sichere Verbindung zum Zweck der Metadaten-Übermittlung
aufzubauen und abzubauen. EclipseLink wurde verwendet, um das Gateway in einer
relationalen Datenbank abzubilden. Außerdem kann die Persistenz mehrerer Java-Objekte durch EclipseLink leicht realisiert werden. Apache Derby bietet die Möglichkeit,
ein leichtgewichtiges Open-Source-Datenbank-System umzusetzen.
6.2 Ausblick auf Erweiterungen
Die Sicherheitsaspekte von OSGi wurde in dieser Masterarbeit nicht behandelt. OSGi
bietet optional das Überprüfen der digitalen Signatur. Falls ein Bundle von Dritten
angewendet werden soll, macht es Sinn, seine digitale Signatur zu beachten.
Interessant für die Erweiterbarkeit ist der Einsatz von Java Native Interface (JNI).
Mittels JNI soll ein Modul, das in C oder C++ entwickelt wurde, als ein Java-Modul
fungieren. Grundsätzlich bietet es die gleiche Verwendung wie in eigenständigen Anwendungen. Der einzige Unterschied besteht in der zusätzlichen Information, die an
die Manifest-Datei hinzugefügt werden muss.
Masterarbeit Aalbrecht Alby Irawan
Literaturverzeichnis
41
Literaturverzeichnis
[Art12]
Artima Developer (Hrsg.): Jini Extensible Remote Invocation. Artima
Developer, Novemberr 2012. http://www.artima.com/intv/jeri.html
[Ecl12]
Eclipse Foundation (Hrsg.): Create and Export MySQL JDBC driver.
Eclipse Foundation, November 2012. http://wiki.eclipse.org/Create_
and_Export_MySQL_JDBC_driver_bundle
[EN09]
Elmasri, Ramez A. ; Navathe, Shamkant B.: Grundlagen von Datenbanksystemen. Pearson Studium, 2009. – 550 Seiten
[GT00]
Gruhn, Volker ; Thiel, Andreas: Komponentenmodelle. Addison-Wesley,
2000. – 310 Seiten
[Haa01]
Haase, Oliver: Kommunikation in verteilten Anwendungen. Oldenbourg,
2001. – 163 Seiten
[IAN12]
IANA: Service Name and Transport Protocol Port Number Registry.
http://www.iana.org/assignments/service-names-port-numbers/
service-names-port-numbers.xml. Version: Mai 2012
[Int12]
InterSystems Corp. (Hrsg.): EJB Background. InterSystems Corp.,
Oktober 2012. http://vista.intersystems.com/csp/docbook/DocBook.
UI.Page.cls?KEY=TJAV_EJBBackground
[Ira12]
Irawan, Aalbrecht A.: MOM-Client für Android. 2012
[Kud07]
Kudraß, Thomas: Taschenbuch Datenbanken. Carl Hanser Verlag, 2007.
– 582 Seiten
[Lan02]
Langner, Torsten: Verteilte Anwendungen mit Java. Markt+Technik,
2002. – 453 Seiten
[MW12]
Müller, Bernd ; Wehr, Harald: Java Persistence API 2. Hanser, 2012.
– 339 Seiten
Masterarbeit Aalbrecht Alby Irawan
Literaturverzeichnis
[New12]
42
Newmarch, Jan ; Monash University (Hrsg.): Jini for DistJava. Monash University, Mai 2012. http://jan.newmarch.name/distjava/jini.
2.0/jini.html
[OSG12a] OSGi Alliance (Hrsg.): OSGi Alliance Members. OSGi Alliance, November 2012. http://www.osgi.org/About/Members
[OSG12b] OSGi Alliance (Hrsg.): OSGi Architecture. OSGi Alliance, September
2012. http://www.osgi.org/Technology/WhatIsOSGi
[WBB10] Weber, Bernd ; Baumgartner, Patrick ; Braun, Oliver: OSGI für Praktiker. Hanser, 2010. – 252 Seiten
[Wut02]
Wutka, Mark: J2EE Developer’s Guide. Markt+Technik, 2002. – 1200
Seiten
Masterarbeit Aalbrecht Alby Irawan
Abbildungsverzeichnis
43
Abbildungsverzeichnis
1.1
Beispiel für Realisierung eines Verwaltungssystems . . . . . . . . . . . .
2.1
2.2
2.3
2.4
2.5
Methodenaufruf bei CORBA [Haa01] . . . . . . . .
Object Management Architecture der OMG [Haa01]
Ablauf der Jini-Anfrage [New12] . . . . . . . . . . .
EJB-Architektur [Int12] . . . . . . . . . . . . . . .
OSGi-Architektur[OSG12b] . . . . . . . . . . . . .
.
.
.
.
.
5
7
9
12
14
3.1
3.2
Grundlegende Konzepte eines relationalen Datenmodells [Kud07] . . . .
Die Syntax von Java Persistence Query Language . . . . . . . . . . . .
22
25
4.1
Konzeption des Verwaltungssystems . . . . . . . . . . . . . . . . . . . .
27
5.1
5.2
5.3
5.4
5.5
5.6
Versenden der Metadaten zum RabbitMQ-Server . . . . .
Bearbeitung der Metadaten durch das Verwaltungssystem .
Die Struktur des Gateway-Entitys . . . . . . . . . . . . . .
Bereitstellung und Verwendung von Entity-Manager . . . .
Beispiel einer persistence.xml-Datei . . . . . . . . . . .
Beispiel einer MANIFEST.MF-Datei . . . . . . . . . . . .
30
31
33
34
36
38
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
Masterarbeit Aalbrecht Alby Irawan
Tabellenverzeichnis
44
Tabellenverzeichnis
2.1
Vergleich der Ansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . .
19
Masterarbeit Aalbrecht Alby Irawan
Abkürzungsverzeichnis und Formelzeichen
45
Abkürzungsverzeichnis und
Formelzeichen
AMQP . . . . . . . . . . . . .
API . . . . . . . . . . . . . . . .
CMP . . . . . . . . . . . . . . .
CORBA . . . . . . . . . . . .
COS . . . . . . . . . . . . . . .
DB . . . . . . . . . . . . . . . . .
DBMS . . . . . . . . . . . . .
DBS . . . . . . . . . . . . . . .
DCOM . . . . . . . . . . . . .
DII . . . . . . . . . . . . . . . . .
DSI . . . . . . . . . . . . . . . .
EJB . . . . . . . . . . . . . . . .
GIOP . . . . . . . . . . . . . .
HQL . . . . . . . . . . . . . . .
HTTP . . . . . . . . . . . . .
IDE . . . . . . . . . . . . . . . .
IDL . . . . . . . . . . . . . . . .
IIOP . . . . . . . . . . . . . . .
IP . . . . . . . . . . . . . . . . . .
JAR . . . . . . . . . . . . . . .
JDBC . . . . . . . . . . . . . .
JDK . . . . . . . . . . . . . . .
JDO . . . . . . . . . . . . . . .
Jeri . . . . . . . . . . . . . . . .
JMS . . . . . . . . . . . . . . .
JPA . . . . . . . . . . . . . . . .
JPQL . . . . . . . . . . . . . .
Advanced Message Queuing Protocol
Application Programming Interface
Container Managed Persistence
Common Object Request Broker Architecture
Common Object Service
Datenbank
Datenbank Management System
Datenbank System
Distributed Component Object Model
Dynamic Invocation Interface
Dynamic Skeleton Interface
Enterprise Java Beans
General Inter ORB Protocol
Hibernate Query Language
Hyper Text Transfer Protocol
Integrated Development Environment
Interface Definition Language
Internet Inter ORB Protocol
Internet Protocol
Java ARchive
Java Datenbank Connectivity
Java Development Kit
Java Data Objects
Jini Extensible Remote Invocation
Java Message Service
Java Persistence API
Java Persistence Query Language
Masterarbeit Aalbrecht Alby Irawan
Abkürzungsverzeichnis und Formelzeichen
JVM . . . . . . . . . . . . . . .
MOM . . . . . . . . . . . . . .
ODBC . . . . . . . . . . . . .
OMA . . . . . . . . . . . . . .
OMG . . . . . . . . . . . . . .
ORB . . . . . . . . . . . . . . .
ORM . . . . . . . . . . . . . .
OSGi . . . . . . . . . . . . . . .
PDE . . . . . . . . . . . . . . .
POJO . . . . . . . . . . . . . .
RMI . . . . . . . . . . . . . . .
SOAP . . . . . . . . . . . . . .
SQL . . . . . . . . . . . . . . . .
TCP . . . . . . . . . . . . . . .
UDP . . . . . . . . . . . . . . .
URL . . . . . . . . . . . . . . .
XML . . . . . . . . . . . . . . .
46
Java Virtual Machine
Message Oriented Middleware
Open Datenbank Connectivity
Object Management Architecture
Object Management Group
Object Request Broker
Object Relational Mapping
Open Service Gateway initiative
Plugin Development Environment
Plain Old Java Object
Remote Method Invocation
Simple Object Access Protocol
Structured Query Language
Transmission Control Protocol
User Datagram Protocol
Universal Resource Locator
eXtensible Markup Language
Masterarbeit Aalbrecht Alby Irawan
Thesen zur Masterarbeit
47
Thesen zur Masterarbeit
1. OSGi ist für ein dynamisches Verwaltungssystem ein guter Ansatz.
2. OSGi ermöglicht die Umwandlung bereits existierender JARs und Java-Objekte
in OSGi-Bundles.
3. Mit Hilfe von EclipseLink und Apache Derby lassen sich Java-Objekte in einer
relationale Datenbank leicht abbilden.
4. Apache Derby bietet eine einfach zu verwaltende leichtgewichtete Datenbank an.
Ilmenau, den 15. 11. 2012
Aalbrecht Alby Irawan
Masterarbeit Aalbrecht Alby Irawan
Erklärung
48
Erklärung
Die vorliegende Arbeit habe ich selbstständig ohne Benutzung anderer als der angegebenen Quellen angefertigt. Alle Stellen, die wörtlich oder sinngemäß aus veröffentlichten Quellen entnommen wurden, sind als solche kenntlich gemacht. Die Arbeit ist in
gleicher oder ähnlicher Form oder auszugsweise im Rahmen einer oder anderer Prüfungen noch nicht vorgelegt worden.
Ilmenau, den 15. 11. 2012
Aalbrecht Alby Irawan
Masterarbeit Aalbrecht Alby Irawan