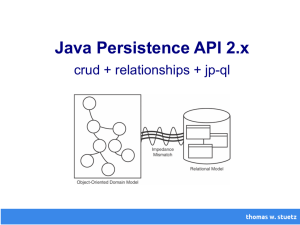
Skript Java Persistence API
Werbung

Java Persistence API © Arno Schmidhauser Letzte Revision: November 2006 Email: [email protected] Webseite: http://www.sws.bfh.ch/db Dieses Skript stützt sich wesentlich auf die Spezifikation JSR 220 Version 3.0 von Sun, Final Release, 2. Mai 2006 Inhalt I Wichtige Java Konstrukte II Übersicht Java Persistence API III Beziehungen zwischen Entities IV Spezielles V Objektverwaltung und Transaktionsmanagement VI JPA Query Language JPA – Java Persistence API Über diesen Kurs • Inhalt – Anwendung des Persistence API von EJB 3.0 • Voraussetzungen – Java 1.4, JDBC, SQL • Nicht Ziele – Einbettung der Persistenztechnologie in Container/AppServer ( Æ S. Fischli Business Tier) 2 Arno Schmidhauser November 2006 Seite 2 JPA – Java Persistence API I Wichtige Java Konstrukte 3 Java 5 hat einige wichtige Neuerungen. Drei davon, Enumerations, Annotations und Generics werden kurz vorgestellt. Diese Konstrukte sind für das JPA wichtig. Arno Schmidhauser November 2006 Seite 3 JPA – Java Persistence API Enumerations • Eine Aufzählung ist eine Klasse mit einer abschliessend definierten Menge von benannten Objekten. • Wichtige Teile einer Enumeration sind: – Der Name (die Klasse) der Aufzählung als Ganzes – Die Namen der einzelnen Aufzählungselemente – Eventuell der zugrundeliegende Wert (int, String usw.) • Eine Enumeration wird intern wie eine Klasse behandelt, und besitzt auch äusserlich die Eigenschaften einer Klasse: – Sie gehört zu einem Package – Sie kann public, protected, private sein – sie kann Attribute und Methoden besitzen 4 Enumerations ersetzen die bisher verwendeten Konstanten in Form statischer Klassen- oder Interface-Variablen. Enumerations sind in Java-API Dokumentation auf der gleichen Ebene wie Klassen, Interfaces, Exceptions und die noch zu besprechenen Annotations aufgeführt. Im Rahmen der JPA Spez. werden Enumeration innerhalb von Annotations verwendet, zur Beschreibung verschiedenster Optionen, beispielsweise CascadeType.PERSIST, CascadeType.REMOVE, LockModeType.READ, LockModeType.WRITE usw. In diesen Beispielen sind CascadeType und LockModeType die Aufzählungen, PERSIST, REMOVE, READ, WRITE die Elemente der Aufzählungen. Auch als Datentyp für persistente Daten kommen Enumerations in Frage, zum Beispiel für die Status-Beschreibung von Objekten. In der Datenbank können wahlweise der Name des jeweiligen Elementes einer Enumeration (in obigen Beispielen "PERSIST", "REMOVE" etc.) oder die dahinterliegenden Ordnungszahlen (0, 1 usw.) gespeichert werden. Die nachfolgende Anotation beim jeweiligen Klassenmember einer Entitiy wird dazu verwendet. @Enumerated(STRING) meineEnumerationMember oder @Enumerated(ORDINAL) meineEnumerationMember Arno Schmidhauser November 2006 Seite 4 JPA – Java Persistence API Enumerations, Beispiel 1 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. public enum Status { OPEN, CLOSED } ... Status s1 = Status.OPEN; Status s2 = Status.CLOSED; System.out.println( s1.toString() ); System.out.println( s1.ordinal() ); if(s1 == s2) System.out.println("Beide gleich."); Status s3 = Status.valueOf( "OPEN" ); Status all[] = Status.values(); for( int i = 0; i < all.length; i++ ) { System.out.println( all[i].toString() ); } 5 Obiges Beispiel zeigt die Definition und den Gebrauch einer einfachen Enumeration: Zeile 1 definiert die Enumeration Status. Die Definition ist in einem File Status.java abzulegen. Zeile 3 und 4 erstellen je eine Variable (Objekt) dieser Enumeration. Zeile 5 liefert den String "OPEN" als Ausgabe. Zeile 6 liefert die Zahl 0 als Ausgabe. Für das Element CLOSED wäre die Ausgabe die Zahl 1. Zeile 7: Zwei Elemente sind gleich, wenn sie denselben Namen haben. Das folgend Stück Code liefert bei der Bedingung true als Ergebenis: Status s1 = Status.OPEN; Status s2 = Status.OPEN; if ( s1 == s2 ) // liefert true Zeile 8: Die Methode valueOf() ermöglicht das dynamische Erzeugen eines EnumElements auf Grund eines gleichnamigen Strings. Zeile 9: Die Methode values() liefert sämtliche Elemente der Enumeration. Arno Schmidhauser November 2006 Seite 5 JPA – Java Persistence API Enumerations, Beispiel 2 Eigene Attribute und Methoden 1. public enum Status { 2. OPEN( "offen" ), CLOSED( "geschlossen" ); 3. protected String zusatzWert; 4. Status( String zusatzWert) { 5. this. zusatzWert = zusatzWert; 6. } 7. public String getZusatzWert(){ 8. return this. zusatzWert; 9. } 10. } 6 Das Verhalten ist grundsätzlich gleich wie im vorhergehenden Beispiel. Ein Enumeration-Element kann im Code beispielsweise wie folgt deklariert werden: Status s = Status.OPEN Zusätzlich kann von s die Methode getZusatzWert() aufgerufen werden, wie bei jedem anderen Java-Objekt eine definierte Methode aufgerufen wird, z.B. System.out.println( s2.getZusatzWert() ); Der Konstruktor muss private oder unspezifiziert sein. Arno Schmidhauser November 2006 Seite 6 JPA – Java Persistence API Annotations • Annotations fügen dem Java-Code zusätzliche Informationen hinzu, die nicht ausgeführt, aber zur Laufzeit abgefragt werden können. • Annotations sind typsicher, sie werden vom Compiler geprüft. • Annotations gehören zu Paketen, Klassen, Konstruktoren, Membern, Parametern, zu Annotationen und lokalen Variablen. • Annotations werden intern als Interfaces behandelt. 7 Arno Schmidhauser November 2006 Seite 7 JPA – Java Persistence API Annotation, Beispiel für Definition 1. import java.lang.annotation.*; 2. 3. 4. 5. 6. 7. 8. 9. 10. @Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Inherited @Documented @interface MyAnnotation { String was() default "Testen"; String[] wann(); Status status() default Status.OPEN; } 8 In diesem Beispiel wird eine Annotation definiert. Die Annotation ist einem File MyAnnotation.java abzulegen und zu kompilieren, wie Klassen, Interfaces, Exceptions und Enumerations. Zu 2: Das Target bestimmt, worauf die Annotation angewendet werden kann. In diesem Fall auf eine Klasse oder ein Interface (TYPE). Ist kein Target angegeben, ist jedes Target erlaubt. Zu 3: Die Retention (übersetzt etwa "Vorbehalt" oder "Halterung") bestimmt, ob die Annotation nur im Source-Code (SOURCE), zusätzlich im kompilierten ByteCode(CLASS), oder auch in der laufenden Applikation(RUNTIME). Default ist CLASS. Im JPA haben alle Annotations die Retention RUNTIME. Zu 4: Wenn @Inherited angegeben ist, gilt die Annotation auch für abgeleitete Klassen. Zu 5: Wenn @Documented angegeben ist, soll die Annotation in Dokumentation-Tools (javadoc) dokumentiert werden. Zu 6: Die eigentliche Annotation. Zu 7-9: Als Felder der Annotation können Strings, primitive Typen, Enumerations, andere Annotationen, oder Arrays von all diesen angegeben werden. Andere Klassen, ausser die Klasse Class, sind nicht erlaubt. Felder ohne Default müssen beim Gebrauch der Annotation angegeben werden, ansonsten tritt ein Compilerfehler auf. Im Rahmen der JPA Spez. sind Annotations mit komplexer Struktur durchaus üblich (z.B. @JoinTable). Eine Klasse kann auch ohne Weiteres mehrere vorangestellte Annotationen haben. Die Annotationen @Target, @Retention, @Inherited und @Documented heissen MetaAnnotationen, weil es Annotationen für Annotationen sind. Arno Schmidhauser November 2006 Seite 8 JPA – Java Persistence API Annotation, Beispiel für Anwendung 1. 2. 3. 4. 5. @MyAnnotation( was="Pruefen", wann={ "Anfang", "Ende" } ) public class MyAnnotatedClass { // ... } 9 Mit diesem Stück Code ist der Klasse MyAnnotatedClass eine Annotation des Typs MyAnnotation zugewiesen. Die gesamte Persistenz-Information im JPA wird via Annotations definiert. Der Vorteil liegt darin, dass die Angaben bereits zur Kompilationszeit typengeprüft werden können. Der Nachteil liegt darin, dass unter Umständen sehr viel Meta-Information im Source Code steht, insbesondere über das Mapping von Klassen-Feldern auf Datenbank-Felder. Damit kann der Source Code sehr unübersichtlich werden, respektive muss neu aufgebaut werden. Arno Schmidhauser November 2006 Seite 9 JPA – Java Persistence API Annotations abfragen 1. public class AnnotationsAbfragen { 2. public static void main( String args[] ) 3. throws Exception 4. { 5. Class c = Class.forName("MyAnnotatedClass"); 6. for (Annotation a : c.getAnnotations()) { 7. System.out.println( a.toString() ); 8. } 9. } 10. } 10 Mit der toString()-Methode erhält man eine textuelle Darstellung zurück: @pmq.MyAnnotation(status=OPEN, was=Pruefen, wann=[Anfang, Ende]) Die toString()-Methode ist für die Analyse von Annotationen meist zu ungenau. Man kann daher mit der Methode Annotation.annotationType() ein Objekt der Klasse Class abholen, und dieses dann mittels des Reflection API weiter analysieren. Arno Schmidhauser November 2006 Seite 10 JPA – Java Persistence API Generics • Bis Java 1.4: Object als generische Klasse. Beispiel: List list = new LinkedList(); list.add( new String( "foo" ) ); list.add( new Integer( 7 ) ); String s = (String) list.get(0) • Vorteil: übersichtlich und einfach. • Nachteile: – nicht typsicher, eine Collection kann fälschlicherweise Objekte verschiedener Klassen enthalten. – schwach dokumentiert, Klasse der Collection unklar. – Häufige Cast-Operation erforderlich. 11 Arno Schmidhauser November 2006 Seite 11 JPA – Java Persistence API Generics • Ab Java 5: Generische Klassen mit Angabe des konkreten Typs zum Zeitpunkt der Verwendung. Beispiel: List<String> list = new LinkedList<String>(); list.add( new String( "foo" ) ); list.add( new Integer( 7 ) ); // Compiler Fehler String s = list.get(0) // kein Cast nötig • Im Rahmen der Java Standard Edition treten Generics vorallem im Package java.util auf, z.B. List<T>, Set<T>, Map<K,V>, Comparator<T>, Iterator<T> usw. 12 Die alte Form kann nach wie vor verwendet werden. Der Compiler erzeugt jedoch eine Warnung. Die Angabe List<T> heisst generische Klasse Die Angabe T heisst Typvariable Die Angage String heisst Typargument Die Angabe List<String> heisst generischer Typ Arno Schmidhauser November 2006 Seite 12 JPA – Java Persistence API Eigene Generics, Definition public class Node<T> { protected T content; protected Node<T> parent; public Node( T content ) { this.content = content; } public T getContent() { return( this.content ); } public Node<T> getParent() { return parent; } public void setParent( Node<T> parent ) { this.parent = parent; } 13 Sehr oft hat eine generische Klasse nur einen Typparameter. Es ist aber durchaus möglich, mit mehreren zu arbeiten. Beispielsweise: public class Edge<K, T> { protected Node<T> left, right; protected K weight; public Edge( Node<T> left, Node<T> right, K weight ) { this.left = left; this.right = right; this.weight = weight; } } Weil K ein beliebiges Typargument aufnehmen kann, z.B. Double oder Integer, aber auch String, können keine spezifischen Methoden, wie etwa das Zusammenzählen von Kantengewichten implementiert werden. Dieses Problem lösen die Generics mit Wildcards (siehe weiter hinten). Generische Klassen können abgeleitet werden wie andere Klassen. Diese Situation ist beispielsweise bei Collections anzutreffen: TreeSet ist von AbstractSet, dieses von AbstractCollection abgeleitet. public class SpecialNode<T> extends Node<T> { public SpecialNode( T content ) { super( content ); } Für generische Interfaces gilt dasselbe wie für generische Klassen. Arno Schmidhauser November 2006 Seite 13 JPA – Java Persistence API Generics, Variablen // korrekt Node<Integer> ni = new Node<Integer>( 7 ); Node<Double> nd = new Node<Double>( 3.14 ); Node<String> ns = new Node<String>( "Heinz" ); System.out.println( ni.toString() ); // nicht korrekt, Kompilationsfehler: Node<Number> n = new Node<Integer>( 1 ); // geht auch nicht, Kompilationsfehler: Node<Number> n; n = (Node<Number>) new Node<Integer>( 1 ); 14 Ein Ziel der Generics ist die Möglichkeit einer strengen Typenprüfung zur Kompilationszeit. Werden generische Klassen, die mit unterschiedlichen Typparametern instanziert sind, als inkompatibel angesehen, ist diese strenge Typprüfung gewährleistet, und es können Laufzeitfehler, wie man sie von der Vererbung her kennt, vermieden werden. Typroblem bei der normalen Vererbung: Number ni = new Integer( 1 ); Number nd = (Double) ni; // Kompilation ok, aber dynamischer Fehler! Dieses Typproblem kann bei Generics nicht auftreten: Node<Number> nti = new Node<Integer>( 1 ); // Kompilations-Fehler! Node<Number> ntd = (Node<Double>) nti; Arno Schmidhauser November 2006 // Kompilations-Fehler! Seite 14 JPA – Java Persistence API Generics und Vererbung • Generics führen keine neue Art der Verbung ein! 1. Nicht erlaubt: List<Person> list1 = new LinkedList<Manager>(); 2. Erlaubt: List<Person> list1 = new LinkedList<Person>(); list1.add( new Person() ); list1.add( new Manager() ); 15 Der erste Fall betrifft die Kompatibilität der generischen Typen selbst. Hier gilt das im vorhergehenden Beispiel gesagte. Die Verwandtschaft von Typargumenten begründet keine Verwandtschaft der generischen Typen als Ganzes. Damit wird eine hohe Typsicherheit zum Kompilationszeitpunkt erreicht. Der zweite Fall betrifft die Kompatibilität in einer normalen Vererbungshierarchie. Hier will man natürlich nicht vom bisherigen Verhalten von Java abweichen. Ein Objekt der untypisierten Klasse Person kann jederzeit durch ein Objekt der abgeleiteten und untypisierten Klasse Manager vertreten werden. Arno Schmidhauser November 2006 Seite 15 JPA – Java Persistence API Generics, Wildcards 1. Wildcardvariable zur Aufnahme irgendeines Typs einer generischen Klasse: Node<?> x = new Node<Integer>(); 2. Wildcard, eingeschränkt auf Zahlen: Node<? extends Number> x; x = new Node<Integer>(); // ok x = new Node<String>(); // Fehler 3. Einschränkung des Typparameters einer generischen Klasse: public class NumberNode< T extends Number > { ... } 16 Im Fall 1 kann die Variable x nun einen beliebigen generischen Typ aufnehmen. Die Situation ist gegenüber der Deklaration Objekt o = new Node<Integer>(); anders, indem x nur Node-Typen aufnehmen kann. Im Fall 2 kann man die möglichen Zuweisungen an die Variable x weiter einschränken, indem x nur noch Nodes mit Zahlentypen entgegennehmen kann. Die Variable x kann gemäss Fall 1 und Fall 2 ein Objekt der Klasse NodeNumber entgegennehmen. Im Fall 3 wird der Typparameter einer generischen Klasse eingeschränkt (sogenannter Typebound). Beispielsweise kann man sagen, dass ein Node-Typ nur Sinn macht, wenn er eine Zahl enthält. In diesem Fall kann man in der Klassendefinition bereits darauf abstellen, dass das Typargument sicher alle Methoden der Klassen Number kennt, und man kann diese auch im Code verwenden. In diesem Beispiel stellt die Methode getDouble() darauf ab, dass als Typargument eine Zahl angegeben wird. public class NumberNode<T extends Number> { protected T aNumber; public double getDouble() { return aNumber.doubleValue(); // content ist mindestens Number } } Die Modifikation von Objekten über eine Wildcard-Variable oder einen Typebound ist nicht erlaubt. Der folgende Code führt zu einem Kompilationsfehler, weil x keine Kenntnis über den erlaubten Parameteryp von setContent() hat. Node<?> x = new Node<Integer>( 7 ); x.setContent( 5 ); // Kompilations-Fehler // ebenso zum Beispiel für Listen List<?> list = new LinkedList<Integer>; list.add( 123 ); // Kompilations-Fehler Arno Schmidhauser November 2006 Seite 16 JPA – Java Persistence API Frage: Wie ist folgende Deklaration aus der Java Standard Edition zu lesen? Collections.sort( List<T> list, Comparator<? super T> c ) Antwort: Die Operation sort() kann eine Liste vom Typ T sortieren. Der Comparator c muss Objekte vom Typ T vergleichen können. Damit dies möglich ist, müssen die Parameter der Methode compare( K obj1, K obj2 ) den Typ T oder eine Unterklasse davon haben. K muss also gleich T oder eine Oberklasse von T sein. Beispiel: import java.util.*; public class MySorter { public static void main( String args[] ) { List<Double> myList = new Vector<Double>(); myList.add( new Double( 3.14 ) ); myList.add( new Double( 1.41 ) ); Collections.sort( myList, new DoubleComparator() ); for ( Double d : myList ) { System.out.println( d.toString() ); } } } class DoubleComparator implements Comparator<Double> { public int compare ( Double n1, Double n2 ) { return Double.compare( n1, n2 ); } } Statt einen Comparator für Double-Werte, könnte man einen allgemeineren Comparator für Number erstellen. Dieser Comparator kann auch sehr grosse Zahlen miteinander vergleichen: class NumberComparator implements Comparator<Number> { public int compare ( Number n1, Number n2 ) { return ( (new BigDecimal(n1.toString())).compareTo( new BigDecimal(n2.toString())) ); } } Da ein Double ein Spezialfall einer Number ist, kann ohne weiteres der NumberComparator auf Double angewendet werden. Number ist ein Obertyp von Double, womit die Deklaration Comparator<? super T> nun verständlich ist. Arno Schmidhauser November 2006 Seite 17 JPA – Java Persistence API Generics, Eigenschaften • Generics sind Typkontrollen, die zur Kompilationszeit vorgenommen werden. • Nach der Kompilation wird die Typinformation mehrheitlich gelöscht im Byte-Code: // Vor Kompilation class Node<Number> { private T content; } // Nach Kompilation class Node { private Object content; } Æ Keine Abfrage der Typinformation zur Laufzeit mit Reflection. Æ Statische Attribute können keinen generischen Typ haben. Æ Primitive Typen (int, double, byte, char) können nicht als Typargumente verwendet werden. Æ Keine Arrays von Typvariablen erlaubt. 18 Nach der Kompilation wird nur noch soviel Typinformation über die Klasse und ihre Methoden in den Bytecode eingebaut, wie der Compiler für die Übersetzung anderer Java-Klassen benötigt. Aus Sicht der JVM ist die Typinformation für das Laufzeitsystem entfernt. Das Reflection API kann das Typargument nicht eruieren. Jedoch kann der Typ von Objekten an sich ermittelt werden. Um den Typ einer Collection festzustellen, müsste man den Typ der Objekte darin ermitteln, was grundsätzlich über Reflection möglich ist. Weil sich alle Typen einer generischen Klasse eine einzige Implementation dieser Klasse teilen, sind die statischen Attribute nur einmal vorhanden und tragen zur Laufzeit den Typ Object. Würden zur Laufzeit den Klassenvariablen verschiedene Typen von Objekten zugewiesen, zum Beispiel Double, Integer und String, entstünden völlig unvorhersgesehene Resultate, respektiv dynamische ClassCastExceptions beim Lesen und Schreiben dieser Objekte. Statische Attribute können daher keinen Typ haben. Primitive Typen können zur Laufzeit nicht als Objekte vom Typ Object behandelt werden, was aber mit der Art der Realisierung von Generics in Java notwendig wäre. Primitive Typen sind daher nicht erlaubt. Arrays von Typvariablen sind nicht möglich, weil der Typ zu Laufzeit nicht mehr bekannt ist, und damit die Speicherallokation nicht definiert ist. Arno Schmidhauser November 2006 Seite 18 JPA – Java Persistence API II Übersicht Java Persistence API 19 Referenz: JSR 220, EJB 3.0 Java Persistance API, Final Release 2. Mai 2006 Kurzform in diesem Skript: JPA oder JAPI Spez. Arno Schmidhauser November 2006 Seite 19 JPA – Java Persistence API Moderne Persistenz API's ↑ Arbeiten mit gewöhnlichen Java-Klassen für Daten (POJO's) ↑ Objekte können transient oder persistent sein ↑ Innerhalb und ausserhalb von Appservern verwendbar ↑ Vererbung, Aggregation, Komposition abbildbar ↑ Transitive Persistenz oder Persistence by Reachabiltiy • Lazy Fetching • Automatic Dirty Checking • Datenbank-Roundtrips minimieren, Outer Join Fetching • SQL-Generierung zur Laufzeit 20 Mit der Lösung des JPA in EJB 3.0 wurden wesentliche Verbesserungen ( ↑ ) erreicht werden gegenüber EJB 2.x Technologien. Das JPA ist ein Mix der Erfahrungen aus dem EJB 2.x Ansatz und dem JDO Konzept. JDO ist ein sehr ambitiöser Ansatz, mit dem Anspruch, den Source Code 100% von Mapping und Verhaltensangaben frei zu halten. Arno Schmidhauser November 2006 Seite 20 JPA – Java Persistence API Technologie Stack Session Beans / Java Applikation Java 1. & Annotations Persistence API EJB 3.0 Spezifikation Persistence API Implemetation Hibernate & CGLIB, ... JDBC 3.0 JDBC API Herstellerspez. JDBC - Driver SQL 2003 oder Dialekte SQL RDB 21 Auf der logischen Ebene sind Java-Annotations das Kernstück des JPA. Mit Ihnen wird das Mapping und das Verhalten der persistenten Klassen gesteuert. Die Anforderungen des Dirty Checking, Lazy Fetching und der transitiven Persistenz erfordern viel Aufwand in der JAPI Implementation: Wenn immer ein Programm eine Modifikation an Datenobjekten vornimmt, muss vorerst sichergestellt werden, dass das Objekt sich überhaupt im Speicher befindet (Lazy Fetch, Eager Fetch). Dann muss aufgezeichnet werden, dass das Objekt modifiziert wurde (Dirty Checking) und letztlich muss aufgezeichnet werden, ob ein Objekt zum CommitZeitpunkt transient oder persistent ist. Im letzteren Fall muss sein Zustand in die Datenbank zurückgeschrieben werden. Als Realisierungstechniken kommen typischerweise Source Code Modifikationen beim Deployment oder Byte Code Enhancement zur Kompilations- oder Laufzeit in Frage. Hibernate verwendet Byte Code Enhancement zur Laufzeit, indem jede Datenklasse über einen eigenen Classloader geladen wird. Dieser Classloader modifiziert den Code so, dass für jede Zugriffsoperation (Zuweisung eines Wertes, Increment/Decrement, Dereferenzierung, Array-Index-Auflösung) zusätzlich Verwaltungs-Code eingeschoben wird. Wichtige Datentypen, z.B. Set und List werden durch eigene Hibernate-Typen ersetzt. Dieses Verhalten ist gut im Debugger ersichtlich! Arno Schmidhauser November 2006 Seite 21 JPA – Java Persistence API JPA • Packages javax.persistence javax.persistence.spi • Classes Persistence • Interfaces EntityManagerFactory EntityManager EntityTransaction Query • Runtime Exceptions ( ~8 ) RollbackExceptione ption • Annotations ( ~64 ) Entity Id OneToOne OneToMany • Enumerations ( ~10 ) InheritanceType CascadeType FetchType 22 Das Package javax.persistence ist für die Entwicklerseite, das Pakage javax.persistence.spi definiert drei Interfaces für das Management der persistenten Klassen. Der Entwickler hat mit dem Package javax.persistence.spi nichts zu tun. Die Klasse Persistence ist quasi die Bootstrap-Klasse (im Container-Umfeld übernimmt dieser die Funktion von Persistence). Sie erzeugt eine EntityManagerFactory und in diesem Zug interne Instanzen von spi.PersistenceProvider, spi.PersistenceUnit und spi.ClassTransformer. Ausserdem wird ein neuer ClassLoader in der JVM installiert. Dieser ruft für die Entity-Klassen und alle Klassen, die mit Entities arbeiten, den Transformer auf, bevor diese Klassen in der JVM aktiv werden. Mit dem Transformer wird den geladenen Klassen zusätzliche Funktionalität für das Management der Persistenz hinzugefügt. Im Container-Umfeld übernimmt dieser die Aufgabe der Klasse Persistence. Ein Programm beginnt daher seine Persistenz-Aufgaben mit: EntityManagerFactor emf = Persistence.createEntityManagerFactory( persistenceUnitName ); EntityManager em = emf.createEntityManager() resp. im Container-Umfeld mit @PersistenceContext EntityManager em; Arno Schmidhauser November 2006 Seite 22 JPA – Java Persistence API Entities • • • • • Kennzeichnung mit Annotation @Entity Klasse kann Basisklasse oder abgeleitet sein Klasse kann abstrakt oder konkret sein. Serialisierbarkeit ist bezüglich Persistenz nicht erforderlich. Anforderungen: 1. No-Arg Konstruktur muss vorhanden sein. 2. Klasse darf nicht final, kein Interface und keine Enumeration sein und keine final-Methoden enthalten. 3. Felder müssen private oder protected sein. 4. Zugriff von Clients auf Felder nur über get/set- oder Business-Methoden erlaubt. 5. Jede Entity muss einen Primärschlüssel (@Id) haben. 23 Die Anforderungen 1 bis 4 sind technisch bedingt. Sie erlauben vernünftige Realisierungen der Persistenz, indem das Byte-Code Enhancement beispielsweise abgeleitete Klassen erzeugt, mit denen eine Applikation dann effektiv arbeitet. Die Anforderung 3 garantiert, dass nur über die –abgeleiteten- Methoden auf Felder zugegriffen wird, und in diesen Methoden das Persistenz-Management stattfinden kann. Arno Schmidhauser November 2006 Seite 23 JPA – Java Persistence API Entity, Beispiel @Entity public class Message { @Id protected long id; protected String sender; protected String receiver; protected int priority; @Temporal( TemporalType.TIMESTAMP ) protected Date date; public Message() {} // get, set and business methods } 24 Sehr pragmatisch gelöst ist das Mapping der Felder auf Datenbanktabellen: Ohne zusätzliche Angaben werden der Klassenname als Tabellenname und die Feldnamen als Spaltennamen verwendet. Mit folgenden Annotations kann man andere Mappings vornehmen: @Entity @Table( name="MyMessageTable" ) public class Message { // ... @Column( name="senderName" ) protected String sender; // ... } Zahlreiche weitere Mappingangabe, z.B. Datenbank- und Schema-Name bei der Tabelle, sind möglich. Siehe Kapitel 9.1 JPA Spez. Für gewisse Datentypen kann man Präzisierungen anbringen, z.B. @Temporal für die Java Typen Date und Calendar. Mit @Temporal wird angegeben, ob das Mapping in ein Datenbankattribut als DATE, TIME oder TIMESTAMP verstanden werden soll. Arno Schmidhauser November 2006 Seite 24 JPA – Java Persistence API persistente Datentypen • erlaubt: – Alle primitiven Typen, String – Alle Wrapperklassen und serialisierbaren Typen (z.B. Integer, BigDecimal, Date, Calendar) – byte[], Byte[], char[], Character[] – Enumerations – Beliebige weitere Entity-Klassen – Collections von Entities, welche als Collection<>, List<>, Set<> oder Map<> deklariert sind. • Nicht erlaubt: – Alle Arten von Arrays ausser die obgenannten – Collections von etwas anderem als Entities, also z.B. Wrapperklassen und andere serialiserbare Typen. 25 Der Umfang an persistenten Typen ist für die meisten Anwendungen ausreichend. Für technische Anwendungen könnte das Verbot von Array-Typen lästig sein. Dazu ist allerdings zu sagen, dass z.B. Hibernate wesentlich weiter geht als die JPA Spez., indem Arrays und Collections für sämtliche Arten von Objekten erlaubt sind, insbesondere auch Arrays von primitiven Typen. Felder von serialisierbaren Klassen, sei es von Java vordefinierte oder eigene Klassen, sind ebenfalls persistent. Während einige vordefinierte Typen wie Date, Calendar, Integer, BigDecimal usw. in die entsprechenden SQL-Typen gemapped werden, findet bei eigenen serialisierbaren Klassen einfach nur eine Ablage des serialisierten Byte-Stromes in der Datenbank statt (varbinary Datentyp o.ä.). Solche Objekte können nicht in einer Abfragebedingung von Queries auftreten. Zur Problematik der Elementreihenfolge in Listen siehe Kapitel IV. Transiente Felder können mit Java transient oder mit der @Transient Annotation markiert werden. Arno Schmidhauser November 2006 Seite 25 JPA – Java Persistence API Java-Type / SQL-Type Mapping • Implizit durch JDBC 3.0, Data Type Conversion Table, definiert. • Explizit durch die @Column Annotation, z.B. ... @Column( name="sender", columnDefinition="VARCHAR(255) NOT NULL" ) protected String sender; ... • Produktspezifisch durch Framework (Hibernate) oder im JDBC-Driver für die jeweilige Datenbank. 26 JDBC 3.0 Mapping Arno Schmidhauser November 2006 Seite 26 JPA – Java Persistence API Access-Typ • Es gibt zwei Zugriffspunkte für das Persistenz-Framework auf die Daten einer Klasse: das eigentliche Datenfeld, oder die zugehörigen set()/get() Methoden. • Field-based Access @Entity public class Message { @Id protected long id; } • Property-based Access @Entity public class Message { protected long id; @Id public long getId() {...} public void setId( long id ) {...} } 27 Welche Zugriffsart vorliegt, ist durch die Position der Mapping-Annotations gegeben. Alle Mapping Annotations müssen entweder bei Feldern stehen ( Field-based Access) oder bei der get() Methode für eine Eigenschaft. Bei Property-basedAccess müssen alle set- und get-Methoden zwingend paarweise vorkommen. Bei Field-based Access können get-Methoden oder anders benannte Methoden für den Zugriff auf private Felder verwendet werden. Bei Property-based Access wird in der Datenbank der von der get()-Methode zurückgelieferte Wert abgelegt, beim Erzeugen des Objektes in der Applikation wird die set()-Methode für das Setzen des Zustandes verwendet. Wäre also beispielsweise ein Personename in einem Java-Objekt in Kleinschreibung abgelegt, die getMethode liefert jedoch immer eine Grosschreibung zurück, so enthält die Datenbanktabelle den Personennamen in Grosschrift. Arno Schmidhauser November 2006 Seite 27 JPA – Java Persistence API Entity Identity - Primärschlüssel • Jede Entity-Klasse muss einen mit @Id bezeichneten Primärschlüssel besitzen. • Primärschlüssel können in Zusammenarbeit mit der Datenbank generiert werden. Beispiel: @Entity public class Message { @Id @GeneratedValue(strategy=IDENTITY ) public long id; • Stragegien sind Identity, Table, Sequence und Auto 28 Identity und Sequence: Das Datenbankssystem erzeugt eine fortlaufende Nummer. Sequence lehnt sich an die Oracle-Technologie an. Auto: vom Framework gewählte Strategie. Meist gleichbedeutend mit Identity. Table: Erzeugung via Tabelle in Datenbank. Diese Tabelle wird durch den Entwickler, resp. DBA, erstellt und initialisiert. Beispiel: public class Message { @TableGenerator( name="MyIdGenerator", table="KeyStore", pkColumnName="keyName", valueColumnName="keyValue", pkColumnValue="MessageId", initialValue=1000, allocationSize=1) @Id @GeneratedValue( strategy=GenerationType.TABLE, generator="MyIdGenerator") protected long id; // ... } create table KeyStore ( keyName nvarchar( 32 ) not null unique, keyValue bigint not null default 1 ); insert into KeyStore ( keyName, keyValue ) values ( 'MessageId', 1000 ); Arno Schmidhauser November 2006 Seite 28 JPA – Java Persistence API Zusammengesetzte Primärschlüssel • Es wird eine spezielle ID-Klasse benötigt. Beispiel: public class DocumentId implements Serializable { protected String name; protected BigDecimal version; // verlangte Methoden … @IdClass( pmq.DocumentId.class ) // Variante 1 @Entity public class Document { @Id protected String name; @Id protected BigDecimal version; @Entity public class Document { // Variante 2 @EmbeddedId public DocumentId docId; 29 Die ID-Klasse ist notwendig, damit ein einheitlicher Gebrauch aller Arten von Primärschlüsseln möglich wird, z.B. beim Aufruf der find() oder getReferenceMethode(), um bestimmte Objekte in der Datenbank zu finden. Genau genommen wird ja auch bei einfachen Primärschlüsseln mit einer ID-Klasse gearbeitet, allerdings von einem vordefinierten Java-Typ. An die ID-Klasse werden folgende Anforderungen gestellt: 1. No-arg Konstruktor 2. Serializable 3. Der Access-Typ (field oder property) muss dem Access-Typ in der verwendeten Entity-Klasse entsprechen. 4. Fields oder properties müssen public oder protected sein. 5. Die hashCode() und equals()-Methode müssen implementiert werden. 6. Name und Typ der einzelnen Felder/Properties müssen in der ID-Klasse und in der verwendeten Entity-Klasse übereinstimmen, wenn nicht @EmbeddedId verwendet wird. Bedingung 5 kann wie folgt realisiert werden: public int hashCode() { return (name + version.toString()).hashCode(); } public boolean equals( Object o ) { DocumentId oid = (DocumentId) o; return ( this.name.equals( oid.name ) && this.version.equals( oid.version ) ); } Arno Schmidhauser November 2006 Seite 29 JPA – Java Persistence API Eine Applikation darf nicht direkt die Felder eines ID-Objektes ändern (DocumentIDObjektes), sondern nur die entsprechenden Felder in der Entity-Klasse (Document), wenn mit @IdClass gearbeitet wird. wenn mit @EmbeddedID gearbeitet wird, kann ein Primärschlüsselobjekt zum Beispiel im Konstruktor der Datenklasse wie folgt erzeugt werden: public Document( String name, BigDecimal version, StringBuffer content ) { this.docId = new DocumentId( name, version ); // ... } Die zugehörige Datentabelle sieht in beiden Fällen(@IdClass oder @EmbeddedId) wie folgt aus: create table "Document" ( name nvarchar(64) not null, version numeric(4,2) not null default '1.0', -- ... primary key ( name, version ) ); Arno Schmidhauser November 2006 Seite 30 JPA – Java Persistence API Persistence Unit • Eine Persistence Unit ist eine logische Einheit von Entities. Sie wird beschrieben durch: – – – – – – – Einen Namen Die zu dieser Unit gehörenden Entity-Klassen Angaben zum Persistence Provider Angabe zum Transaktionstyp Angaben zur Datenquelle Weitere Properties Namen von XML OR-Mapping Files • Technisch wird die Beschreibung einer Persistence Unit in der Datei META-INF/persistence.xml abgelegt. 31 Der Name ist eine Identifikation, um in der Applikation dafür eine EntityManagerFactory erstellen zu können. Die Entity-Klassen werden als Information für den Class Transformer und die Generierung der SQL-Befehle angegeben. Der PersistenceProvider ist die implementationsspezifische "Urklasse" für das Persistenzmanagement in dieser Persistence Unit. Sie liefert die EntityManagerFactory zurück. Der Transaktionstyp (transaction-type) wird als JTA oder RESOURCE_LOCAL angegeben. eine JTA Persistence Unit muss u.A. verteilte Transaktionen über eine XA-Schnittstelle erlauben. Die Datenquelle kann als JNDI-Name angegeben werden im Rahmen einer J2EE-Umgebung. Je nachdem ob die Datenquelle JTA-fähig ist (verteiltes Transaktionsmanagement) verwendet man den Tag <jta-data-source> oder <non-jata-data-source>. Falls nicht mit JNDI gearbeitet wird, können in den Properties die üblichen JDBC-Verbindungsparameter angegeben werden. Beispiel: <persistence> <persistence-unit name="PMQ" transaction-type="RESOURCE_LOCAL"> <provider>org.hibernate.ejb.HibernatePersistence</provider> <class>pmq.PMQ</class> <class>pmq.Message</class> <non-jta-data-source>jdbc/MyPMQDB</non-jta-data-source> <jta-data-source>jdbc/MyPMQDB</jta-data-source> <properties> <property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver"/> <property name="hibernate.connection.username" value="hibuser"/> <property name="hibernate.connection.password" value="hibuser"/> <property name="hibernate.connection.url" value="jdbc:sqlserver://localhost;databaseName=hib_db"/> <property name="dialect" value="org.hibernate.dialect.SQLServerDialect"/> </properties> </persistence-unit> </persistence> Arno Schmidhauser November 2006 Seite 31 JPA – Java Persistence API Persistence Context • Der Persistence Context definiert das physische Umfeld von Entities zur Laufzeit: – Die Menge aller Managed Entities in der Applikation – Der Entity Manager für diese Entities – Die laufende Transaktion – Der Contexttyp @PersistenceContext(type=PersistenceContextType.EXTENDED) public class MessageProducer { // ... EntityManagerFactory emf = Persistence.createEntityManagerFactory("PMQ"); EntityManager em = emf.createEntityManager(); Transaction tx = em.getTransaction(); // ... 32 Arno Schmidhauser November 2006 Seite 32 JPA – Java Persistence API Persistence Context, Contexttyp • Contexttyp TRANSACTION – Lesender und schreibender Zugriff nur innerhalb der Transaktion. – Gelesene Objekte sind nach der Transaktion im Zustand detached. – Wiedereinkopplung in eine Transaktion mit merge(). • Contexttyp EXTENDED – Alle Objekte sind lesend und schreibend zugreifbar. – Modifikationen finden lokal statt. – Effekt von persist(), remove() usw. wird aufbewahrt. – Propagation von Efffekten und Änderungen in die DB aber nur, wenn nachträglich begin()/commit() ausgeführt wird. 33 Bei Hibernate ist für Java SE Applikationen immer der Transaktionstyp EXTENDED gesetzt. Ein Rollback führt in beiden Contexttypen dazu, dass bereits geladene Entities in den Zustand detached versetzt werden. Nach einem Rollback sollte nicht mehr mit den bestehenden Enitities gearbeitet werden (Kap. 3.3.2 JPA Spez.), weil der lokale Zustand beibehalten, der Zustand in der DB jedoch zurückgesetzt wird. Das kann z.B. Probleme mit generierten Primärschlüsseln verursachen, weil eine bereits vergebene ID seitens Datenbank nochmals vergeben wird. Dasselbe gilt sinngemäss für Versionennummern bei optimistischem Concurrency Control. Datenbankzugriffe arbeiten gemäss Spezifikation im Isolationsgrad read committed. Dies gilt auch für den Contexttyp Extended. Arno Schmidhauser November 2006 Seite 33 JPA – Java Persistence API Erzeugen persistenter Objekte // ... EntityManagerFactory emf = Persistence.createEntityManagerFactory("PMQ"); EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); Message m = new Message( ... ); em.persist( m ); tx.commit(); // ... 34 Arno Schmidhauser November 2006 Seite 34 JPA – Java Persistence API Kaskadierte Persistenz (1) • Kaskadierte Persistenz heisst: Alle von einem persistenten Objekt aus erreichbaren Objekte sind ebenfalls persistent. PMQ pmq = new PMQ( "Dringendes" ); em.persist( pmq ); Message m = new Message( ... ) pmq.append( m ); m wird automatisch persistent // ... em.remove( pmq ); m wird ebenfalls aus der db gelöscht • Es spielt keine Rolle, ob die persist() Methode vor oder nach der append()-Methode aufgerufen wird! 35 Arno Schmidhauser November 2006 Seite 35 JPA – Java Persistence API Kaskadierte Persistenz (2) • In JPA muss die Kaskadierung deklariert werden. • Die Kaskadierung kann für das Erstellen und das Löschen der Persistenz separat eingestellt werden. public class PMQ { @OneToMany( cascade={CascadeType.PERSIST, CascadeType.REMOVE } ) List<Message> messages; // ... } • Achtung: Die Kaskadierung bezieht sich nur auf die persist() und die remove()-Methode, nicht etwa auf das Ein- oder Austragen in der Message-Liste mit gewöhnlichen Java-Methoden! 36 Die Kaskadierung kann auch auf die Methoden EntityManager.refresh() und EntityManager.merge() bezogen werden, mit CascadeType.REFRESH resp. CascadeType.MERGE. Arno Schmidhauser November 2006 Seite 36 JPA – Java Persistence API Aufsuchen persistenter Objekte // ... tx.begin(); Message m = em.find( Message.class, Long.parseLong(1) ); // oder ... Message m = em.getReference(Message.class, Long.parseLong(1)); // oder ... Query qry = em.createQuery( "select m from Message m where m.id = 1 ); List list = qry.getResultList(); Iterator it = list.iterator(); // ... tx.commit(); // ... 37 Es sind zwei Varianten für das Auffinden von Objekten vorgestellt: Suchen via Primärschlüssel mit find() oder getReference() Es muss die Klasse und der Primärschlüsselwert im gleichen Datentyp wie in der Entity definiert übergeben werden. Die Methode find() liefert null, wenn das Objekt nicht existiert, die Methode getReference() erzeugt eine Exception, wenn das Objekt nicht existiert (spätestens beim ersten eigentlichen Zugriff auf das Objekt). Die Methode find() lädt auf jeden Fall die unmittelbaren Felder des gesuchten Objektes. Suchen mit einer Abfrage Objekte werden via eine Abfrage gesucht. Das Resultat wird als Liste zurückgegeben. Die resultierende Liste hat keinen Typparameter. Dies deshalb, weil der Resultattyp vom Query abhängt und dieses in jedem Fall dynamisch ausgewertet wird. Die Typsicherheit würde sich durch Verwendung von Typparametern nicht erhöhen. Im Weiteren ergäben sich Schwierigkeiten, wenn die select-Klausel mehrere Objekte enthält, das heisst eine Liste von Arrays zurückgeliefert wird. Ein Array von Typvariablen ist in Java nicht erlaubt. Arno Schmidhauser November 2006 Seite 37 JPA – Java Persistence API Aufgaben • Übung Persistent Message Queue PMQ. Erstellen einer Grundausstattung. MessageProducer MessageConsumer main() main() «verwendet» «Entity» PMQ «verwendet» messages id qname append() get() getAll() remove() isEmpty() size() 0..* «Entity» Message sender receiver priority date id 38 Aufgaben 1. Hibernate-Umfeld und Datenbank aufsetzen. 2. Entity-Klassen PMQ und Message definieren. 3. persistence.xml zusammenstellen. 4. Datenbanktabellen erstellen. 5. Producer (MessageProducer.java) und Consumer (MessageConsumer.java) für Messages programmieren, ev. Zusatzprogramm zum erstellen einer leeren PMQ (PMQInit.java). 6. Testen. Arno Schmidhauser November 2006 Seite 38 JPA – Java Persistence API III Beziehungen zwischen Entities 39 Arno Schmidhauser November 2006 Seite 39 JPA – Java Persistence API Beziehungen • Beziehungen zwischen Entities sind prinzipiell gegeben durch entsprechende Referenzen oder Collection-Member in den Entity-Klassen. Sie müssen jedoch deklariert werden, und sehr oft sind Details zum O/R-Mapping und zum Verhalten notwendig. • Folgende Beziehungs-Charakteristiken spielen eine Rolle: – – – – Unidirektional, bidirektional One to One, One to Many, Many to One, Many to Many Vererbung Aggregation, Komposition • Der korrekte Unterhalt der Beziehungen ist Sache des Programmes! 40 Der Unterhalt der Beziehungen obliegt dem Programm, respektive dem Entwickler. Wird beispielsweise bei einer bidirektionalen Beziehung eine Message in einer Message Queue eingetragen, muss das Programm selber in der Message die Referenz auf die MessageQueue nachführen. Das Persistenz-Framework tut das nicht. Die Deklaration der Beziehungen ist eine Mapping-Hilfe für das Framework und bringt keine zusätzliche Programmautomation mit sich! Arno Schmidhauser November 2006 Seite 40 JPA – Java Persistence API One To One, Unidirektional «Entity» PMQ «Entity» Owner owner id id 1..1 @Entity public class PMQ { @OneToOne( optional=false ) @JoinColumn( name="owner_id" ) protected Owner owner; // ... 41 Die Beziehung geht rein von der linken Seite aus. Es ist an sich nicht spezifiziert, ob ein Owner mehrere PMQ's oder nur eine PMQ haben kann. Die Owner-Klasse beinhaltet keine Angaben zu dieser Beziehung. Die Abbildung wird mit einem Fremdschlüssel in der PMQ-Tabelle realisert. Mit @OneToOne( optional=false) wird präzisiert, dass immer ein Owner vorhanden sein muss. Die Angabe bezieht sich also auf das Zielobjekt. In der Tabelle sollte sich dies darin wiederspiegeln, dass der Fremdschlüssel nicht null sein darf. create table "PMQ" ( id bigint not null identity primary key, qname nvarchar(64) not null unique, owner_id bigint not null ); Die obige Tabelle darf durchaus eine foreign key Klausel enthalten. Sie wurde hier nur aus Übersichtgründen weggelassen. Arno Schmidhauser November 2006 Seite 41 JPA – Java Persistence API One To One, Bidirektional «Entity» PMQ «Entity» Owner owner id id 0..1 1..1 @Entity public class PMQ { @OneToOne( optional=false ) @JoinColumn( name="owner_id" ) protected Owner owner; // ... @Entity public class Owner { @OneToOne( mappedBy="owner", optional=true ) protected PMQ pmq; //... 42 Die Klasse PMQ bleibt gleich wie in der unidirektionalen Variante. Auch die Datenbanktabelle für PMQ bleibt sich gleich, und die Owner-Tabelle muss nicht angepasst werden. Die Angabe mappedBy="owner" bezieht sich auf das Feld owner in der Klasse PMQ, und damit ist indirekt gesagt, dass der Fremdschlüssel sich auf der PMQ-Tabelle befindet. Mit optional=true kann das Owner-Objekt bestehen bleiben, wenn die PMQ gelöscht wird. Programmatisch wird nicht kontrolliert, ob eventuell dasselbe Owner-Objekt für zwei PMQ-Objekte verwendet wird. Dies ist nur zu kontrollieren, indem ein uniqueConstraint auf den owner_id Fremdschlüssel gesetzt wird. Damit können nicht zwei PMQ-Einträge in der Datenbank mit demselben owner_id existieren. Bei bidirektionalen Beziehungen spricht man oft vom Besitzer. Der Besitzer ist in diesem Beispiel die PMQ-Klasse. Der Besitzer ist die Klasse, welche nicht die mappedBy-Angabe enthält. Arno Schmidhauser November 2006 Seite 42 JPA – Java Persistence API One To Many, Unidirektional «Entity» PMQ «Entity» Message messages id id 0..* @Entity public class PMQ { @OneToMany @JoinTable( name="PMQ_Message", joinColumns={ @JoinColumn( name="PMQ_id" ) }, inverseJoinColumns={ @JoinColumn(name="messages_id") } ) protected List<Message> messages = new Vector<Message>(); // ... 43 Eine unidirektionale OneToMany-Beziehung wird mit einer Assoziationstabelle abgebildet, nicht mit einer direkten Primärschlüssel-/ Fremdschlüssel-beziehung. Begründung an diesem Beispiel: Eine Message kann nicht nur zu einer PMQ, sondern vielleicht noch zu anderen Klassen gehören. Wenn die Zugehörigkeit in eine (oder mehrere) Assoziationstabelle ausgelagert ist, braucht es nicht für jede Zugehörigkeit in der Message-Tabelle ein Fremdschlüssel-Attribut, von denen dann viele nicht belegt sind. Obige Angaben in der @JoinTable-Annotation entsprechen dem Default-Verhalten: Der Name der Assoziationstabelle setzt sich aus den Namen der beiden EntityKlassen zusammen. Die Attributnamen der Assoziations-Tabelle ergeben sich wie im folgenden Beispiel für die Tabellendefinition gezeigt, aus einer Kombination von Tabellenname links + id-Feld links, Beziehungsname links + id-Feld rechts. create table "Message" ( id bigint not null identity primary key, -- ... ); create table "PMQ" ( id bigint not null primary key, -- ... ); create table "PMQ_Message" ( PMQ_id bigint not null, messages_id bigint not null unique ); Arno Schmidhauser November 2006 Seite 43 JPA – Java Persistence API One To Many, Bidirektional «Entity» PMQ id messages «Entity» Message 0..1 0..* id pmq @Entity public class PMQ { @OneToMany( mappedBy = "pmq" ) protected List<Message> messages = new Vector<Message>(); //... @Entity public class Message { @ManyToOne( optional=true ) @JoinColumn( name="PMQ_id" ) protected PMQ pmq; //... 44 Die bidirektionale Beziehung wird als enger wie die unidirektionale angesehen und deshalb per Default als direkte Primärschlüssel-/Fremdschlüssel Verknüpfung realisiert. Die Annotation @JoinTable entfällt. Hingegen wird in der Klasse PMQ angegeben, welches Feld (nicht Tabellenattribut!) in der Message-Klasse für die Beziehung verantwortlich ist. Diese Angabe wird durch mappedBy="pmq" in der OneToMany-Annotation vorgenommen. In der Message-Klasse ist die Rückbeziehung durch die @ManyToOne-Annotation deklariert. Die @JoinColumnAnnotation deklariert den Namen des Fremdschlüssels. Achtung: Mit nur dem Java-Code wäre nicht zweifelsfrei festgehalten, dass es sich um eine echt bidirektionale Beziehung handelt. Das Feld Message.pmq könnte ja auf eine andere PMQ zeigen als diejenige von der es referenziert wird, und eine andere Bedeutung haben. Zu beachten ist auch der Unterschied zwischen einer ManyToOne 1..1 oder 0..1 Beziehung: Es wird entweder @ManyToOne( optional=false ) oder @ManyToOne( optional=true ) angegeben. Ausserdem ist die Tabellendefinition für den Fremdschlüssel mit null respektive not null zu deklarieren. create table "Message" ( id bigint not null identity primary key, PMQ_id bigint null -- foreign key to PMQ table -- ... ); Für die @OneToMany-Annotation gibt es keine optional=false respektive optional=true Angabe. Auf der Many-Seite gibt es also nur die Multiplizität 0..n. Andere Multiplizitäten, insbesondere 1..n, müssen programmatisch und allenfalls über Triggers in der Datenbank realisiert werden (check-Constraints sind nicht ausreichend, da der delete-Befehl keine Prüfung von check-Constraints auslöst). Arno Schmidhauser November 2006 Seite 44 JPA – Java Persistence API Many To One, Unidirektional «Entity» Address «Entity» Owner id 1..1 0..* id owner @Entity public class Address { @ManyToOne( optional=false ) @JoinColumn( name="Address_id", referencedColumnName = "id" ) protected Owner owner; // ... 45 Die unidirektionale ManyToOne-Beziehung dürfte eher selten sein. Der Default-Name für das Fremdschlüssel-Attribut ist der Name der Ursprungsklasse + "_" + Name des Primärschlüsselfeldes in der Zielklasse. Das obige Beispiel gibt diese Default-Benennung wieder. Arno Schmidhauser November 2006 Seite 45 JPA – Java Persistence API Many To Many, Bidirektional «Entity» PMQ «Entity» Message @Entity id id messages pmqs public class PMQ { 0..* 0..* @ManyToMany @JoinTable( name="PMQ_Message", joinColumns={@JoinColumn(name="pmqs_id" ) }, inverseJoinColumns={@JoinColumn(name="messages_id") } ) protected List<Message> messages = new Vector<Message>(); // ... @Entity public class Message { @ManyToMany( mappedBy = "messages" ) protected List<PMQ> pmqs = new Vector<PMQ>(); // ... 46 Abbildung mit Assoziationstabelle. create table "PMQ_Message" ( pmqs_id bigint not null, messages_id bigint not null ); Die unidirektionale ManyToMany-Beziehung entspricht aus Sicht Java Code der unidirektionalen OneToMany-Beziehung. Auf obiges Beispiel bezogen kann eine Message also zu mehreren Queues gehören, die Message kennt diese jedoch nicht. Nur die PMQ's kennen ihre Messages. Die Message-Klasse enthält damit das Feld pmqs gar nicht. Seitens Datenbank ist die Situation ebenfalls identisch zur OneToMany Beziehung, ausser dass der zweite Fremdschlüssel nicht unique ist: create table "PMQ_Message" ( PMQ_id bigint not null, messages_id bigint not null unique ); Für die @ManyToMany-Annotation gibt es keine optional=false respektive optional=true Angabe. Es existiert also nur die Multiplizität 0..n. Andere Multiplizitäten, insbesondere 1..n, müssen programmatisch und allenfalls über Triggers in der Datenbank realisiert werden (check-Constraints sind nicht ausreichend, da der delete-Befehl keine Prüfung von check-Constraints auslöst). Arno Schmidhauser November 2006 Seite 46 JPA – Java Persistence API Komposition / Aggregation «Entity» PMQ «Entity» Message id messages id 0..* @OneToMany( cascade={CascadeType.PERSIST, CascadeType.REMOVE}) protected List<Message> messages; «Entity» PMQ «Entity» Message id messages id 0..* @OneToMany( cascade={ CascadeType.PERSIST} ) protected List<Message> messages; 47 Die Komposition ist in der Regel ergänzt sein um eine 1..1 Beziehung von rechts nach links, im obigen Fall zum Beispiel: @ManyToOne( optional=false ) protected PMQ pmq; Achtung: Ohne Angabe der kaskadierten Löschung kann es auch mit einer deklarierten 1..1 Beziehung von rechts nach links zu Inkonsistenzen auf der Datenbank kommen. Der Befehl em.remove( pmq ) würde nämlich klaglos ablaufen, weil innerhalb des Programmes die beteiligten Objekte noch korrekt verknüpft sind, in der Datenbank jedoch nur die PMQ, nicht die Message gelöscht wird. Datenbankseitig könnte man dies durch einen not null constraint auf dem Fremdschlüssel in der Message-Tabelle verhindern. Die Aggregation kann ergänzt sein um eine 0..1 Beziehung von rechts nach links, im obigen Fall zum Beispiel: @ManyToOne( optional=true ) protected PMQ pmq; Arno Schmidhauser November 2006 Seite 47 JPA – Java Persistence API Vererbung, Grundsätzliches • Vererbungshierarchien können problemlos verwendet und abgebildet werden. • Klassen können abstrakt oder konkret sein. • Alle Klassen in der Vererbungshierachie müssen den Primärschlüssel der Basisklasse verwenden (erben). • Es gibt vier Mappingstrategien auf die Datenbank: – – – – Eine einzige Tabelle für die gesamte Verbungshierarchie Eine Tabelle für jede konkrete Klasse Eine Tabelle für jede Klasse Mapped Superclass 48 Zu den Strategien Die Strategie wird in der Basisklasse angegeben mit: @Entitiy @Inheritance(strategy=SINGLE_TABLE) @Entitiy @Inheritance(strategy=TABLE_PER_CLASS) @Entitiy @Inheritance(strategy=JOINED) @MappedSuperclass Arno Schmidhauser November 2006 Seite 48 JPA – Java Persistence API SINGLE_TABLE Strategie Die Attribute der Basisklasse gelten für jeden Datensatz. Attribute von abgeleiteten Klassen sind nur belegt, wenn der Datensatz ein Objekt dieser Klasse repräsentiert. Es ist ein Typ-Attribut erforderlich, dass für jeden Datensatz angibt, zu welcher Klasse das repräsentierte Objekt gehört. Vorteile: Kompakt, Abfragen über alle Objektarten sind einfach zu handhaben. Nachteile: Viele Attribute ohne Belegung mit Werten. Attributzuordnung zu Klasse nicht ersichtlich. Fehlverhalten möglich, indem Attributen Werte zugeordnet werden, die gar keine haben dürften → Integritätsbedingungen erforderlich. Anwendung: Hauptinformation in der Basisklasse, abgeleitete Klassen nicht zu umfangreich, oder insgesamt wenig Attribute zu implementieren. TABLE_PER_CLASS Strategie Es wird nur pro konkrete Klasse eine Tabelle erstellt. Die Attribute einer abstrakten Basisklasse werden in jeder Tabelle der abgeleiteteten Klasse erstellt. Für die Basisklasse selbst wird keine Tabelle erstellt. Vorteile: Jede Tabelle entspricht genau einer Klasse. Es sind keine nicht-belegten Attribute vorhanden. Nachteil: Abfragen über mehrere Klassen hinweg erfordern union-Abfragen (kann teilweise Probleme mit SQL geben). Änderungen an der Basisklasse erfordern Änderungen in allen Tabellen der abgeleiteten Klassen. Anwendung: Basisklasse nur schwach belegt und abstrakt. Meistens werden nur konkrete und einzelne, abgeleitete Klassen in einer Applikation benötigt. JOINED Strategie Jede Tabelle enthält nur die Attribute ihrer Klasse. Der Primärschlüssel der Basistabelle wird in allen abgeleiteten Klassen ebenfalls als Primärschlüssel verwendet und gleichzeitig als Fremdschlüssel auf die Basistabelle. Vorteile: Konzeptionelles Modell im Tabellenmodell noch ersichtlich. Punktuelle Änderungen am Konzept haben nur punktuelle Änderungen in den Tabellen zur Folge. Mit dieser Variante ist es datenbankseitig möglich, dass ein Objekt in mehreren Klassen vorkommt! Beispielsweise kann in einem CRM-System eine Person gleichzeitig Kunde und Lieferant sein. Nachteile: Gewisse Arten von Abfragen sind umständlich, beispielsweise wenn man wissen will, zu welcher Klasse ein Datensatz in der Basistabelle gehört. Es muss dann in jeder abgeleiteten Tabellen nach einem entsprechenden Datensatz gesucht werden. Anwendung: Viele Attribute, sowohl in der Basisklasse, wie in den abgeleiteten Klassen vorhanden. Mehrstufige Vererbungshierarchie. Flexible Datenstruktur für unterschiedlichste Bedürfnisse und Abfrage-Arten erforderlich. Häufige Änderung des Datenmodells wahrscheinlich. Mapped Superclass Strategie Die Basisklasse ist selbst keine Entity, stellt aber Attribute zur Verfügung für die abgeleiteten Klassen, welche als Entities deklariert sind. Die abgeleiteten EntityKlassen übernehmen die Felder von der Basisklasse, welche nicht transient deklariert sind. Die Felder werden in den Tabellen der abgeleiteten Entity-Klasse abgelegt. Kann angewendet werden, wenn die Basisklasse nicht als eigene Tabelle und nicht als Entity in Erscheinung treten soll (Praktische Beispiele?) @MappedSuperclass public class MeineBasisklasse{} @Entity public class MeineAbgeleiteteKlasse extends MeineBasisklasse{} Arno Schmidhauser November 2006 Seite 49 JPA – Java Persistence API Vererbung, Beispiel «Entity» Message id «Entity» SimpleMessage content «Entity» ImageMessage image contentType «Entity» XMLMessage xmlContent 50 Arno Schmidhauser November 2006 Seite 50 JPA – Java Persistence API Vererbung, SINGLE_TABLE-Mapping @Entity @Inheritance(strategy=InheritanceType.SINGLE_TABLE) @DiscriminatorColumn( name="messageType" ) public abstract class Message { @Id @GeneratedValue protected long id; // ... @Entity @DiscriminatorValue("SM") public class SimpleMessage extends Message {} @Entity @DiscriminatorValue("IM") public class ImageMessage extends Message {} … 51 Falls kein Discriminatorattribut angegeben wird, ist "DTYPE" der Default. Falls kein Discriminatorwert angegeben wird, ist der Klassenname der Default. Alle Tabellenattribute, welche nicht zur Basisklasse gehören, dürfen null-Werte enthalten. create table "Message" ( id bigint not null default primary key, messageType varchar( 64 ) not null, sender nvarchar( 64 ) not null, receiver nvarchar( 64 ) not null, priority int not null, date datetime not null, content nvarchar( max ) null, image varbinary( max ) null, contentType nvarchar( 64 ) null, description nvarchar( 255 ) null, xmlContent xml null ); Arno Schmidhauser November 2006 Seite 51 JPA – Java Persistence API Vererbung, JOINED-Mapping @Entity @Inheritance(strategy=InheritanceType.JOINED) public abstract class Message { @Id @GeneratedValue protected long id; // ... @Entity public class SimpleMessage extends Message {} @Entity public class ImageMessage extends Message {} … 52 create table "Message" ( id bigint sender nvarchar( 64 ) receiver nvarchar( 64 ) priority int date datetime ); not not not not not null identity primary key, null, null, null, null, create table "SimpleMessage" ( id bigint not null primary key, content nvarchar( max ) not null, foreign key ( id ) references Message( id ) ); create table "ImageMessage" ( id bigint not null primary key, image varbinary( max ) not null, contentType nvarchar( 64 ) not null, foreign key ( id ) references Message( id ) ); create table "XMLMessage" ( id bigint not null primary key, xmlContent xml not null foreign key ( id ) references Message( id ) ); Das TABLE_PER_CLASS Mapping funktioniert sinngemäss. Arno Schmidhauser November 2006 Seite 52 JPA – Java Persistence API Aufgaben • Implementieren Sie die verschiedenen Beziehungstypen am PMQ-Beispiel: – – – – OneToOne, unidirektional, Aggregation OneToMany, unidirektional, Komposition ManyToMany, bidirektional, Aggregation Vererbung 53 Arno Schmidhauser November 2006 Seite 53 JPA – Java Persistence API IV Spezielles 54 Arno Schmidhauser November 2006 Seite 54 JPA – Java Persistence API Listen • Listen haben eine implizite Ordnung. • Datenbanktabellen haben keine Ordnung. • Die Abbildung von Listen in Tabellen ist im JPA nicht vollständig transparent, sondern muss durch Annotations beschrieben werden. JPA Lösung Hibernate Lösung @OneToMany @OrderBy( "date ASC" ) List<Message> messages; @OneToMany @IndexColumn(name="position" ) List<Message> messages; 55 Für die @IndexColumn-Annotation ist noch die Hibernate-spezifische Annotation zu importieren: import org.hibernate.annotations.IndexColumn; Wird kein @OrderBy angegeben, findet die Sortierung zum Ladezeitpunkt nach dem Primärschlüssel statt. Die Sortierung wird nicht automatisch aufrecht erhalten zur Laufzeit. Bei Hibernate ist @OrderBy nur erlaubt, wenn das Mapping nicht mit einer Assoziationstabelle, sondern direkt mit Fremdschlüssel/Primärschlüssel erstellt wird. Es wird daher das Arbeiten mit der Hibernate-Annotation @IndexColumn empfohlen. Dies hat den Vorteil, dass die Positionierung nicht in der Entity-Tabelle (Message), sondern der Assoziationstabelle abgelegt ist. Damit kann die Positionierung auch im Fall einer ManyToMany-Beziehung abgebildet werden, wo eine Message in verschiedenen PMQ's verschiedene Positionen haben kann. @OrderBy erfordert ausserdem ein geeignetes Attribut für die Sortierung (das vom Programm unterhalten wird). Mit IndexColumn kann ein spezielles, generisches Attribut definiert werden, das vom Framework gepflegt wird. Arno Schmidhauser November 2006 Seite 55 JPA – Java Persistence API Die Abbildung von Listen tendiert zu Performance-Problemen. Wird beispielsweise keine @IndexColumn definiert in Hibernate, werden alle Beziehungsdatensätze beim Zurückschreiben in die Datenbank gelöscht und neu eingefügt. Ist die @IndexColumn definiert, wird beim Anfügen eines neuen Elementes auch nur der neue Datensatz in der Tabelle eingefügt. Das Einfügen eines Elementes zwischendurch hat jedoch einen Update auf allen Einträgen der Assoziationstabelle zur Folge: Für jede Position wird der Fremdschlüssel des Elementes an dieser Position neu gesetzt. Hibernate generiert für eine OneToMany Beziehung folgende Beziehungstabelle für die Liste: create table PMQ_Message ( PMQ_id bigint not null, messages_id bigint not null, position bigint not null, primary key ( PMQ_id, position ), unique ( messages_id ), foreign key ( PMQ_id ) references PMQ( id ) on delete restrict foreign key ( messages_id ) references Message( id ) on delete restrict ) Arno Schmidhauser November 2006 Seite 56 JPA – Java Persistence API Neben Listen werden auch Maps unterstützt. Der Nutzen von Maps für Entities ist allerdings fraglich. Maps ersetzen lediglich das Suchen von Objekten via Primär- oder Fremdschlüssel. Beispiel: import org.hibernate.annotations.IndexColumn; // … @Entity public class PMQ { @JoinTable( name="PMQ_Message", joinColumns = { @JoinColumn( name="pmqs_id" ) }, inverseJoinColumns = { @JoinColumn( name="messages_id" ) } ) @MapKey( name="position" ) protected Map<Long, Message> messages; // … Beispiel für das Arbeiten mit Arrays in Hibernate: import org.hibernate.annotations.IndexColumn; // … @OneToMany @JoinTable( name="EventDate", joinColumns = @JoinColumn(name="id", referencedColumnName="id") ) @Column( name="eventDate" ) @IndexColumn( name="position" ) protected Calendar eventDates[] = new Calendar[10]; // … create table "EventDate" ( id bigint not null, eventDate datetime not null, position smallint not null ); Arno Schmidhauser November 2006 Seite 57 JPA – Java Persistence API Persistente Enumerations • Enumerations können persistent sein. In der Datenbank wird entweder der Ordinalwert (Position) oder der Stringwert (Name der Konstante) abgelegt. @Entity public class MutableMessage extends SimpleMessage { @Enumerated(EnumType.ORDINAL) protected MessageStatus status; oder // ... @Enumerated(EnumType.STRING) 58 Default für die Datenbankablage ist ORDINAL. Der Datentyp in der Datenbank kann varchar oder int sein. varchar ist sowohl für den Stringwert wie für die Zahl geeignet. Anmerkung: Hibernate hat Schwierigkeiten mit der Datenbank, wenn bei bestehenden Daten der Ablagetyp geändert wird Æ Tabellenwerte gemäss aktueller Einstellung der @Enumerated-Annotation anpassen. Arno Schmidhauser November 2006 Seite 58 JPA – Java Persistence API Embedded Classes • Komposition: Mutterobjekt mit eingebetteten Objekten. • Eingebettete Objekte haben keine eigene Identität. • Mutterobjekt und eingebettete sind in derselben Tabelle abgelegt. @Entity public class PMQ { @Id @GeneratedValue private long id; @Embedded protected Owner owner; // ... } @Embeddable public class Owner { protected String name; //... } 59 Klassen, respektive deren Objekte, können in andere Klassen eingebettet sein: Ihre Felder werden in der Datenbank in derselben Tabelle abgelegt wie das Mutterobjekt. Die eingebetteten Objekte haben keine Identität und sind nicht shareable. Die Einbettung von Collections ist nicht unterstützt. Die Einbettung hat (im Gegensatz zu JDO) nichts mit Serialisierung zu tun. Die Felder der eingebetten Klassen kommen explizit in den SQL-Tabellen vor. Embedded Klassen müssen als solche markiert sein. Selbstdefinierte Klassen, welche Serializable und nicht als Entities gekennzeichnet sind, werden automatisch in die Datenbank serialisiert (Binärer Datentyp in der Datenbank). Solche Felder sind jedoch nicht abfragbar mit JPA Query Language. Embedded Classes sind eine echte Komposition im UML-Sinn. Leider nicht für OneToMany Beziehungen. create table "PMQ" ( id bigint not null identity primary key, -- ... name varchar( 32 ) not null ); Arno Schmidhauser November 2006 Seite 59 JPA – Java Persistence API Sekundär-Tabellen für Entities • Gelegentlich wird eine Entity in der Datenbank in mehrere Tabelle hineinmodelliert, oder muss umgekehrt aus mehreren Tabellen zusammengesetzt werden. • Eine Entity kann beliebig viele Sekundärtabellen haben: @Entity @Table( name = "Message" ) @SecondaryTable( name = "MessageExt", pkJoinColumns = { @PrimaryKeyJoinColumn(name="idRef", referencedColumnName = "id") } ) public class Message { // ... 60 Sollen mehrere Sekundärtabellen verwendet werden, muss die Annotation @SecondaryTables( {@SecondaryTable(...), @SecondaryTable(...), ... } ) verwendet werden. Für jedes Feld in der Klasse muss die Herkunft spezifiziert werden, beispielsweise: public class Message { @Column( table="Message", name="sender" ) protected String sender; @Column( table="MessageExt", name="receiver" ) protected String receiver; //... create table "Message" id bigint ( not null identity primary key, -- ... ); create table "MessageExt" idRef bigint ( not null primary key, -- ... ); Tests mit einer Vererbungshierarchie und einer Sekundärtabelle für die Basisklasse waren nicht erfolgreich in Hibernate. Ohne Vererbung klappten die Tests jedoch einwandfrei. Arno Schmidhauser November 2006 Seite 60 JPA – Java Persistence API Mapping von SQL-Views • Komplexe Abfragen werden in einer Datenbank gerne als (materialisierte-) View vorgehalten. Um Performance-Vorteile zu nutzen, kann eine View wie eine Entity angesprochen werden. Beispiel: @Entity public class MessageStatistics { @Id protected long id; @Column( insertable=false, updatable=false) protected int numQueues; // ... create view MessageStatistics ( id, numQueues ) as select m.id, count(*) from Message m left outer join PMQ_Message pm on (…) group by m.id 61 Obiges Beispiel berechnet, in wievielen PMQ's eine Message vorkommt. Die Tabelle PMQ_Message ist die Assoziationstabelle zwischen Message und PMQ. Die Spalten der Klasse sind read only gehalten, indem sowohl das Einfügen, wie der Update verboten ist. Java-technisch müsste man das Erzeugen neuer Statistikobjekte noch durch einen entsprechend privaten Konstruktor verbieten. Arno Schmidhauser November 2006 Seite 61 JPA – Java Persistence API Callbacks • Callbacks sind eine gängige Methode, um Einfluss auf den Lade- oder Speichervorgang von Objekten zu nehmen. • Callbacks werden vom Entwickler definiert, aber vom JPA Framework aufgerufen. Beispiel: @Entity public class ImageMessage extends Message { @PrePersist @PreUpdate protected void compress(){ ... } @PostLoad @PostUpdate protected void uncompress() { ... } 62 Folgende Callback-Annotations sind spezifiziert: • • • • • • • @PrePersist: Vor der entsprechenden Datenbank-Operation, nicht zwingend synchron zur persist()-Methode. Unmittelbar vor flush(). @PostPersist: Nach der entsprechenden Datenbank-Operation. Unmittelbar nach flush(). Ein generierter Primärschlüssel ist in dieser Methode verfügbar. @PreRemove: Vor der entsprechenden Datenbank-Operation, nicht zwingend synchron zur remove()-Methode. Unmittelbar vor flush(). @PostRemove: Nach der entsprechenden Datenbank-Operation. Unmittelbar nach flush(). @PreUpdate: Vor der entsprechenden Datenbank-Operation. Unmittelbar vor flush(). @PostUpdate: Nach der entsprechenden Datenbank-Operation. Unmittelbar nach flush(). @PostLoad: Nach implizitem Refresh, oder aufruf der refresh()-Methode. Die Callbacks werden auch für Objekte, die via kaskadierten Aufruf von persist(), remove() und refresh() betroffen sind, ausgeführt. Callbacks sind void und haben keinen Übergabeparameter. Sie können public, protected oder private sein. Arno Schmidhauser November 2006 Seite 62 JPA – Java Persistence API Foreign Key Constraints • Änderungsoperation von einem Peristenzframework erzeugen oft Konflikte mit Fremdschlüsselbedingungen, wenn Datensätze in der falschen Reihenfolge gelöscht werden. • Hibernate arbeitet mit einer sogenannten "Write Behind Queue" : SQL-Befehle werden so geordnet, dass die Löschung der abhängigen Datensätze zuerst erfolgt. 63 Arno Schmidhauser November 2006 Seite 63 JPA – Java Persistence API DDL Angaben in Annotations • Die Erzeugung von DDL kann, aber muss nicht durch eine Implementation der JPA Spez. angeboten werden. • In der JPA Spez. sind verschiedene Angaben (Annotations und Attribute davon) vorgesehen, welche die Erzeugung von DDL-Befehlen ermöglichen. Beispiel: public class Message { @Column (unique = false, nullable=false, columnDefinition="varchar", lenghth=64 ) public BigDecimal sender; // ... 64 In Hibernate kann man via folgende Einstellungen in persistence.xml die Erstellung von DDL-Code beeinflussen. DDL-Code soll von Hibernate jedesmal neu ausgeführt werden in der Datenbank: <property name="hibernate.hbm2ddl.auto" value="create"/> DDL-Code soll bei Änderungen von Hibernate ausgeführt werden: <property name="hibernate.hbm2ddl.auto" value="update"/> Arno Schmidhauser November 2006 Seite 64 JPA – Java Persistence API Aufgaben • Erstellen Sie ein Listenmapping für die Messages einer PMQ und untersuchen Sie, welche SQL-Befehle erzeugt werden, wenn einer Liste eine neue Message angefügt wird. Zum Tracen von SQL-Befehlen das File /etc/log4j.properties aus dem Hibernate Home in das Applikationsverzeichnis kopieren und anpassen: log4j.logger.org.hibernate.SQL=trace log4j.logger.org.hibernate.type=trace • Erstellen Sie eine eingebettete Klasse, zum Beispiel für den Owner einer PMQ. 65 Arno Schmidhauser November 2006 Seite 65 JPA – Java Persistence API V Objektverwaltung und Transaktionsmanagement 66 Arno Schmidhauser November 2006 Seite 66 JPA – Java Persistence API Grundsätze Der Transfer von Objekten von und zur Datenbank erfolgt automatisch: so spät wie möglich Æ Lazy Access. Der Transfer von Objekten von und zur Datenbank kann manuell erzwungen werden Æ synchron zum Aufruf. Selbstverständlich gilt ein Transaktionsmodell: Der Zugriff auf Objekte erfolgt ab Beginn der Transaktion, die Synchronisation mit der Datenbank wird spätestens beim Commit abgeschlossen und unterliegt der ACID-Regel. Auf Objekte kann auch ausserhalb von Transaktionen zugegriffen werden, jedoch ohne Konsistenz- und Synchronisationsgarantie. 67 Arno Schmidhauser November 2006 Seite 67 JPA – Java Persistence API Objektzustand • Objekte haben vier mögliche Zustände: – new Objekt ist neu erzeugt, hat noch keinen Zusammenhang mit der Datenbank und noch keine gültige ID. – managed Das Objekt hat eine Entsprechung in der Datenbank. Änderungen werden vom Entity Manager automatisch getracked und mit der DB abgeglichen. – detached Das Objekt hat eine Entsprechung in der Datenbank, wurde aber abgekoppelt. Der Zustand wird nicht mehr automatisch abgeglichen mit der Datenbank. – removed Das Objekt existiert noch, ist aber zum Löschen markiert. 68 Ein Objekt ist new wenn es java-mässig instantiiert, aber noch nicht mit persist() bearbeitet wurde. Nach dem persist() ist es managed. Der Aufruf von remove() hat für ein new-Objekt keine Auswirkungen, für ein detached-Objekt wird eine IllegalArgumentException geworfen, für ein managedObjekt wird effektiv der Zustand auf remove gesetzt. Ein Objekt wird detached nach einem Rollback, durch Serialisierung, durch Schliessen des Entity Managers, oder durch Aufruf der clear() Methode des Entity Managers. Eine Methode zum Feststellen des Objektzustandes exisitiert nicht. Arno Schmidhauser November 2006 Seite 68 JPA – Java Persistence API Fragen zur Objektverwaltung 1. Ab wann hat ein neues Objekt eine gültige ID (Wenn die ID via Datenbank-Resourcen vergeben wird und nicht manuell)? 2. Zu welchen Zeitpunkten wird der Objektzustand von der Datenbank eingelesen? 3. Zu welchen Zeitpunkten wird ein geändertes Objekt in die Datenbank zurückgeschrieben? 4. In welchem Zustand ist ein Objekt nach dem Commit? Kann es nach der Transaktion weiterverwendet werden? 5. Was passiert mit einem Objekt beim Rollback? 6. Können persistente Objekte serialisiert und von einer Applikation in eine anderen transportiert werden? 69 Siehe auch Kapitel 3.2 JPA Spezifikation. Arno Schmidhauser November 2006 Seite 69 JPA – Java Persistence API Objekt ID • Ein neues Objekt bekommt erst eine ID, wenn es das erste Mal physisch in die Datenbank transportiert wird. Message m = new Message(...) pmq.append( m ); System.out.println( m.getId() ) Æ Java Default 0 ! em.flush() System.out.println( m.getId() ) Æ gültige ID, z.B. 1 • Die persist()-Methode ist eine logische Operation. 70 @Entity public class PMQ implements Serializable { @Id protected long id; protected String qname; @OneToMany( cascade={ CascadeType.PERSIST } ) protected List<Message> messages = new Vector<Message>(); @Entity public class Message { @Id @GeneratedValue long id; // ... public long getId() { return id; } // ... } Arno Schmidhauser November 2006 Seite 70 JPA – Java Persistence API Einlesen • Der Objektzustand wird beim ersten Zugriff auf das Objekt eingelesen. • Wenn FetchType.EAGER gesetzt ist, werden referenzierte Objekte ebenfalls mitgeladen. • Wenn FetchType.LAZY gesetzt ist, werden referenzierte Objekte beim ersten Gebrauch eingelesen. • Der Objektzustand wird nie automatisch aufgefrischt, nur via die EntityManager.refresh()-Methode. • Eine neue Transaktion führt nicht automatisch zum erneuten Einlesen bestehender Objekte. 71 Der FetchType wird bei den Annotationen @Basic, @OneToOne, OneToMany etc. als Attribut angegeben, zum Beispiel: @Entity public class PMQ { @ManyToMany( fetch = FetchType.EAGER ) protected List<Message> messages = new Vector<Message>(); @OneToOne( fetch = FetchType.EAGER ) protected Owner owner; } @Entity public class Message { @ManyToMany( mappedBy = "messages", fetch = FetchType.EAGER ) protected List<PMQ> pmqs = new Vector<PMQ>(); } Defaultwerte für FetchType: OneToOne EAGER OneToMany LAZY ManyToOne EAGER ManyToMany LAZY Der Gebrauch von refresh() bezüglich Isolationsgrad in der Datenbank muss kritisch betrachtet werden: Bei Isolationsgrad READ_COMMITTED bringt die Methode keine absolute Sicherheit bezüglich Aktualität und Synchronisation mit der Datenbank, bei Isolationsgrad REPEATABLE_READ ist refresh() überflüssig. Für Applikationen, die nie terminieren und die periodisch Daten lesen und anzeigen/weitergeben kann die Funktion jedoch nützlich sein. Arno Schmidhauser November 2006 Seite 71 JPA – Java Persistence API Zurückschreiben • Das Zurückschreiben findet zum Commit-Zeitpunkt oder explizit mit der flush() Methode statt. • Das Zurückschreiben beinhaltet kein Refresh allfälliger Änderungen in der Datenbank in der Zwischenzeit. • Das Zurückschreiben betrifft nur Änderungen, nicht ungeänderte Daten. Applikation m.setContent("A") tx.commit() m.setContent("C") em.flush() Zustand von m in Appl in DB A A A B C C SQL-Client update Message set content = 'B'; commit 72 Bei Hibernate findet der Update so fein wie möglich statt, bei der Änderung eines Feldes eines Objektes, taucht nur dieses Feld im SQL-Update-Befehl auf. Arno Schmidhauser November 2006 Seite 72 JPA – Java Persistence API Objektzustand nach dem Commit, Weiterverwendung des Objektes • Wenn der Persistence Context EXTENDED ist, bleibt ein Objekt im Zustand managed nach dem Commit. – Änderungen nach dem Commit werden aufbewahrt und im Rahmen der nächsten Transaktion in die Datenbank übernommen. • Wenn der Persistence Context TRANSACTION ist, geht ein Objekt in den Zustand detached über nach dem Commit. – Änderungen müssen mit EntityManager.merge() innerhalb der nächsten Transaktion wieder eingekoppelt werden. 73 Der Persistence Context TRANSACTION ist der Normalfall bei Container Managed Entities. Der Persistence Context EXTENDED ist der Normalfall bei Java Standard Applications. Ein Objekt im Zustand detached ist vom EntityManager abgekoppelt. Es kann als eine Art Transfer-Objekt angesehen werden. Es kann serialisiert von einer Applikation in eine andere transportiert werden. Die EntityManager.merge()-Operation erlaubt das Einkoppeln des Objektes in eine Datenbank beim Zielsystem. Das Objekt wird nach folgenden Regeln eingekoppelt: • existiert ein Objekt mit derselben ID wird der Zustand des detached Objekt übernommen. • exisitiert die ID nicht, wird ein neues Objekt mit einer neuen ID angelegt und der Zustand des detached Objektes übernommen. • Weitere Fälle siehe Kap. 3.2.4.1 Wurde das Objekt in der Datenbank zwischen dem Detach und dem Merge geändert sind zwei Resultate möglich beim Commit der Transaktion: • Das Objekt enthält eine Versionsnummer (@Version-Annotation) zur Versionenkontrolle. In diesem Fall wird ein Fehler ausgegeben. • Das Objekt enthält keine Versionsnummer, dann wird der Zustand des gemergeden Objektes in die DB zurückgeschrieben. Es entsteht somit ein LostUpdate. Arno Schmidhauser November 2006 Seite 73 JPA – Java Persistence API Objektzustand nach dem Rollback • Nach einem Rollback ist jedes noch vorhandene Objekt im Zustand detached. Die Belegung der Felder wird durch den Rollback nicht geändert, jedoch der Zustand in der Datenbank. Æ Mögliche Inkonsistenzen. Æ Objekte via Methoden des Entity Manager neu laden: find(), getReference(), createQuery() usw. 74 Arno Schmidhauser November 2006 Seite 74 JPA – Java Persistence API Serialisierung und Transport • Objekte können zwecks Weitergabe in andere Persistenzkontexte oder Applikationen serialisert werden. FileOutputStream fos = new FileOutputStream( "myfile.ser" ); ObjectOutputStream os = new ObjectOutputStream( fos ); os.writeObject( pmq ); os.close(); 75 Für den Serialisierungvorgang wird ein Objekt nicht von der Datenbank geladen. Die Serialisierung funktioniert als nur, wenn die zu serialisierenden Objekte bereits im Cache (Persistence Context) sind. Auf logischer Ebene sichergestellt ist dies gemäss EJB Spezifikation (Kap 3.2.4) nur, wenn alle Beziehungen mit fetch=FetchType.EAGER deklariert sind. Arno Schmidhauser November 2006 Seite 75 JPA – Java Persistence API Serialisierung eines Objektes: FileOutputStream fos = new FileOutputStream( "myfile.ser" ); ObjectOutputStream os = new ObjectOutputStream( fos ); os.writeObject( pmq ); os.close(); Die zu serialisierenden Objekte müssen im Cache vorhanden sein. Ein geeigneter FetchType ist zu wählen: @Entity public class PMQ implements Serializable { @ManyToMany( fetch=FetchType.EAGER ) protected List<Message> messages = new Vector<Message>(); @OneToOne( fetch=FetchType.EAGER ) protected Owner owner; … @Entity public abstract class Message implements Serializable { @ManyToMany( mappedBy = "messages", fetch=FetchType.EAGER ) protected List<PMQ> pmqs = new Vector<PMQ>(); … Die serialisierten Objekte sind unabhängig vom verwendeten Persistenz-Framework (Hibernate), und können beispielsweise wie folgt benützt werden: //deserialize pmq and related ojects FileInputStream fis = new FileInputStream( args[0] + ".ser" ); ObjectInputStream is = new ObjectInputStream( fis ); PMQ pmq = (PMQ) is.readObject(); is.close(); Iterator<Message> it = pmq.getAll().iterator(); while( it.hasNext() ) { Message m = it.next(); System.out.println( m.toString() ); } Die serialisierten Objekte können auch wieder in die Datenbank eingekoppelt (abgeglichen oder neu erzeugt) werden, mit Hilfe der merge() Operation. emf = Persistence.createEntityManagerFactory("PMQ"); em = emf.createEntityManager(); tx = em.getTransaction(); tx.begin(); FileInputStream fis = new FileInputStream( args[0] + ".ser" ); ObjectInputStream is = new ObjectInputStream( fis ); PMQ pmq = (PMQ) is.readObject(); em.merge( pmq ); is.close(); tx.commit(); Damit der Merge kaskadiert arbeitet, muss der entsprechende CascadeType angegeben werden: @Entity public class PMQ implements Serializable { @ManyToMany( cascade={ CascadeType.MERGE } ) protected List<Message> messages = new Vector<Message>(); … Arno Schmidhauser November 2006 Seite 76 JPA – Java Persistence API Fragen zum Transaktionsmanagement 1. Ist der Objektzustand nach dem Lesen in die Applikation in der Datenbank eingefroren, währenddem die Transaktion läuft (Mit welchem Isolationsgrad wird gearbeitet)? 2. Ein Objekt wird geändert: Zu welchem Zeitpunkt wird es in der Datenbank gesperrt? 3. Kann entdeckt werden, ob Daten beim Commit in der Zwischenzeit von anderen Prozessen geändert wurden auf der DB? 77 Siehe auch Kapitel 3.4 JPA Spezifikation. Arno Schmidhauser November 2006 Seite 77 JPA – Java Persistence API Isolationsgrad • JPA arbeitet standardmässig im Isolationsgrad READ COMMITTED. Æ Gelesene Daten sind während der Transaktion nicht eingefroren. Æ Die Konsistenzprobleme Lost Update und Phantom können auftreten. 78 Die Spezifikation geht von einem Isolation Level 1 (READ COMMITTED) aus, respektive einem anderen Isolationsgrad, der keine langen Lesesperren hält. Das Setzen von strengeren Isolationsgraden über die EJB-Spez. ist nicht möglich. Hibernate erlaubt jedoch den Durchgriff auf die JDBC-Ebene und damit, abgesehen vom Abholen der JDBC-Connection, einen im Java-Umfeld standardisierten Zugriff auf Transaktionsbefehle. In Hibernate kann der Isolationsgrad entweder entweder via persistence.xml eingestellt werden: <property name="hibernate.connection.isolation" value="8" /> oder via Anzapfen der JDBC-Session: import java.sql.Connection; import org.hibernate.Session; import org.hibernate.ejb.EntityManagerImpl; // Create EntityManagerFactory for a persistence unit called pmq. emf = Persistence.createEntityManagerFactory("PMQ"); // create EntityManager em = emf.createEntityManager(); tx.begin() Connection con = ((EntityManagerImpl)em).getSession().connection(); con.setTransactionIsolation( Connection.TRANSACTION_SERIALIZABLE ); //… tx.commit() Arno Schmidhauser November 2006 Seite 78 JPA – Java Persistence API Sperrzeitpunkt • Daten werden in der Datenbank im Rahmen von SQLBefehlen gesperrt. • Da Änderungen vorerst lokal durchgeführt und erst zum Commitzeitpunkt in die DB propagiert werden, finden das Sperren erst beim Commit statt. Æ Allfällige Wartesituationen, Deadlocks, Integritätsverletzungen treten effektiv erst zum Commitzeitpunkt auf. 79 Arno Schmidhauser November 2006 Seite 79 JPA – Java Persistence API Explizites Locking • Der Entity Manager stellt einen expliziten lock() Befehl zur Verfügung. • Das Verhalten ist stark implementationsabhängig. • Beispiel: em.lock( pmq, LockModeType.WRITE ) 80 Explizites Locking ist mit EntityManager.lock( ) möglich, ist jedoch sehr unverbindlich definiert. Die Spezifikation verlangt lediglich, dass mit LockModeType.READ ein Lost Update für das gelockte Objekt verhindert wird. Die Implementation muss nicht unbedingt synchron mit dem Aufruf von lock() einen Lock setzen, sie kann grundsätzlich einfach mit Versionierung arbeiten und die Konfliktprüfung damit auf den commit-Zeitpunkt verschieben. Für LockModeType.WRITE ist von der Spezifikation lediglich verlangt, dass ein Lost Update für das gelockte Objekt verhindert wird, sowie, wenn mit Versionierung gearbeitet wird, der Versionenzähler erhöht wird. Für nicht versionierte Objekte besteht von der Spezifikation her kein Unterschied zwischen LockModeType.READ und LockModeType.WRITE. Die Arbeitsweise des lock()-Befehles ist sehr schwammig definiert in der JPA Spez. In Hibernate ist der lock()-Befehl sehr nützlich, weil unmittelbar gelockt wird. Damit ist ein pessimistisches Verfahren synchron zum Applikationsablauf möglich. Daten können lesend gesperrt werden, danach in der Applikation ausführlich bearbeitet werden, ohne dass die Gefahr zwischenzeitlicher Änderungen durch andere Prozesse besteht. Arno Schmidhauser November 2006 Seite 80 JPA – Java Persistence API Beispiel, wie Hibernate LockModeType.READ in einen SQL-Befehl umsetzt: select id from PMQ with (updlock, rowlock) where id =? and version =? Der SQL-Befehl verwendet den Primärschlüssel und das Versionenattribut (dieses ist deshalb notwendig bei Hibernate, ansonsten arbeitet das Locking nicht). Der gelesene Primärschlüssel wird nicht wirklich verwendet, sondern es geht nur darum, mit dem select-Befehl die Sperre auszulösen. Der Befehl wurde von Hibernate spezifisch für SQL-Server 2005 generiert. Da die Klausel with (updlock, rowlock) produktspezifisch ist, muss sie von Hibernate jeweils für einen bestimmten SQLDialekt generiert werden. Hibernate kennt den SQL-Dialekt aus dem Konfigurationsfile persistence.xml. Mit obigem SQL-Befehl sind auch Deadlocks ausgeschlossen, weil nicht nur ein Read-Lock sondern einen Update-Lock (updlock) gesetzt wird. Der SQLBefehl zur Realisierung von LockModeType.WRITE läuft ebenfalls über den Primärschlüssel und das Versionenattribut: update PMQ set version=? where id=? and version=? Bei diesem Update-Befehl wird gleichzeitig die Versionsnummer um 1 erhöht. Arno Schmidhauser November 2006 Seite 81 JPA – Java Persistence API JPA Versionierung • Die Versionierung im Rahmen von JPA ist als applikatorisches Locking zu verstehen. Mit der Versionierung kann ein Concurrency Control über Transaktion hinweg realisiert werden. • Mit einer Versionsnummer können Lost Updates detektiert und vermieden werden: @Entity public class PMQ { @Version protected long version; // ... create table "PMQ" ( version bigint not null, // ... 82 Die Versionennummer wird beim Lesen von Objekten mitgenommen. Beim Zurückschreiben wird der Wert im Objekt mit dem Wert in der Datenbank verglichen. Sind die beiden nicht gleich, wird die Transaktion zurückgesetzt und eine OptimisticLockException ausgeworfen. Das Versionierungsattribut darf nicht durch die Applikation geändert werden. Als Datentyp für die Versionierung kommen int, Integer, long, Long, short, Short und java.sql.Timestamp in Frage. Die Zahlentypen sind vorzuziehen, da nur diese garantiert monoton aufsteigend sind. Es können gleichzeitig versionierte und nicht-versionierte Entities existieren. Mit der @Version-Annotation wird für diese Entity das Versioning automatisch eingeschaltet. Der Begriff "Version" ist leicht missverständlich, weil nicht mehrere Zustandsversionen, sondern nur die Nummer einer einzigen, aktuellen Version verwaltet wird. Dies im Gegensatz zu einigen Datenbanksystemen, welche mit mehreren, vollständigen Versionen desselben Datensatzes arbeiten können. Der Versionierungsmechanismus und die Versionsprüfung tritt automatisch in Kraft, wenn ein Versionenfeld definiert ist. Die Versionierung ist ein sehr einfaches applikatorisches Verfahren, das mögliche Konflikte beim Zurückschreiben detektiert. Ein anderes applikatorisches Verfahren, dass Konflikte verhindert, ist das Checkout/Checkin: Liest eine Applikation einen Datensatz, setzt sie gleichzeitig für eine Marke, dass der Datensatz in Gebrauch ist. Ist diese Marke gesetzt, verpflichten sich andere Applikationen, den Datensatz nur lesend oder gar nicht in Gebrauch zu nehmen. Das Verfahren ist sehr flexibel, die Marke kann um Informationen über den Benützer und den Zeitpunkt des Checkout ergänzt werden. Nachteile: Jedes Lesen erfordert auch einen Schreibvorgang (Setzen der Marke). Stürzt die besitzende Applikation ab, kommt es nie zu einem Checkin. Nach dem Checkout muss sofort ein Commit durchgeführt werden, sonst sind Lesevorgänge technisch blockiert. Arno Schmidhauser November 2006 Seite 82 JPA – Java Persistence API Aufgaben • Entwickeln Sie die Producer und Consumer-Klasse für eine Message Queue so, dass Producer und mehrere Consumer gleichzeitig laufen können. Es muss ein korrekter Ablauf im Sinne der Queue Semantik garantiert sein: Jede Message wird nur einmal gelesen und angezeigt. 83 Arno Schmidhauser November 2006 Seite 83 JPA – Java Persistence API VI JPA Query Language 84 Der offizielle Name ist Java Persistence API Query Language. Der Name EJB QL ist für EJB Version 2 reserviert. Arno Schmidhauser November 2006 Seite 84 JPA – Java Persistence API Konzept 1. Auf das EJB-Modell ausgerichtete Abfragesprache zum Suchen und Bearbeiten von Entities, "SQL-Mapper". 2. Abfragen operieren auf dem Klassenmodell aller Entitäten, nicht dem SQL-Datenmodell. 3. Gegenüber EJB QL 2.1 wesentliche Erweiterungen: – direkte Update- und Delete-Operationen – OUTER |INNER JOIN, GROUP BY, HAVING Klauseln – Projektionen (Abfrage einzelner Attribute resp. Ausdrücke in der Select-Klausel) 85 Zu Punkt 2: Im Objektmodell gibt es keine Fremdschlüssel (in der DB schon, aber diese sind in der Query Language nicht verwendbar). Es können also nur Felder/Beziehungsattribute verwendet werden, die im Klassenmodell vorhanden sind. Will man beispielsweise alle Messages finden, die zu keiner PMQ gehören, so sind die Abfragen unterschiedlich, je nachdem ob zwischen PMQ und Message eine unidirektionale oder eine bidirektionale Beziehung definiert wurde (das relationale Modell ist für beide Fälle dasselbe). Abfrage bei unidirektionaler Beziehung von PMQ zu Message: select m from Message m where m not in ( select m2 from PMQ q JOIN q.messages m2 ) Abfrage bei bidirektionaler Beziehung zwischen PMQ und Message: select m from Message m where m.pmq is null Arno Schmidhauser November 2006 Seite 85 JPA – Java Persistence API Query erzeugen • Ausgangspunkt für Abfragen ist der Entity Manager mit den Funktionen: Query createQuery( String query ) Query createNamedQuery( String qryname ) Query createNativeQuery( String sql, String mapname ) 86 Die erste Funktion ist sicherlich die häufigste Form. Sie übernimmt einen Query Text in der JPA Query Language (JPA QL). In der zweiten Form kann im Java Source Code in Form einer Annotation ein Named Query definiert werden, beispielsweise: @NamedQuery( name="orphans", query=" select m from Message m where m.pmqs is empty " ) Auf dieses Query kann mit createNamedQuery( "orphans" ) Bezug genommen werden. Anwendung: Wenn dasselbe Query häufig gebraucht wird. Die dritte Form ist für die Ausführung von direktem SQL, mit definiertem Mapping auf Felder einer Klasse: createNativeQuery( "select id, sender, receiver from Message", "myMapping" ) @SqlResultSetMapping( name="myMapping", entities={ @EntityResult( entityClass=pmq.Message.class, fields={ @FieldResult( field="id", column="id" ), @FieldResult( field="sender", column="sender" ), @FieldResult( field="receiver", column="receiver" ) } )} ) Arno Schmidhauser November 2006 Seite 86 JPA – Java Persistence API Query, Beispiele • Unparametrisiertes Query Query q = em.createQuery( "select m from Message m where m.sender = 'Rolf'") • Parametrisierte Queries Query q = em.createQuery( "select m from Message m where m.sender = :sender") Query q = em.createQuery( "select m from Message m where m.sender = ?1") 87 Arno Schmidhauser November 2006 Seite 87 JPA – Java Persistence API Query, Parameterübergabe • Übergabe eines Namensparameters Query.setParameter( string name, Object value ) Beispiel q.setParameter( "sender", "Rolf" ); • Übergabe eines Positionsparameters Query.setParameter( int pos, Object value ) Beispiel q.setParameter( 1, "Rolf" ); 88 Für die Übergabe von Datums- und Zeitwerten existieren noch vier weitere Methoden, um festzulegen, welche Teile eines Datums-/Zeitwertes effektiv im Query verwendet werden sollen. setParameter(int pos, Calendar value, TemporalType temporalType) setParameter(int pos, Date value, TemporalType temporalType) setParameter(String name, Calendar value, TemporalType temporalType) setParameter(String name, Date value, TemporalType temporalType) Auch ganze Objekte dürfen Parameter sein. Arno Schmidhauser November 2006 Seite 88 JPA – Java Persistence API Query, Ausführung • Einschränken der Resultatmenge: setFirstResult( int pos ) setMaxResults( int max ) • Abholen des Resultates List getResultList() Object getSingleResult() int executeUpdate() • Synchronisation setFlushModeType( FlushModeType type ) 89 Die Methoden zum Einschränken der Resultatmenge können unter Umständen performance-kritisch sein. Es ist abzuklären, ob die zugrundeliegende Datenbank entsprechende SQL-Ergänzungen (beispielsweise select top ... ) vertsteht, welche bereits datenbankseitig zum Eliminieren der nicht gewünschten Objekte führen. Im Regelfall werden die Objekte mit getResultList als java.util.List abgeholt. Eine Liste ist für sortierte Abfragen der einzig korrekte Datentyp. Für nicht sortierte Abfragen ist eine Liste nicht störend. Einfachheitshalber wurde deshalb auf eine allgemeine Collection als Rückgabetyp verzichtet. Enthält die Abfrage atomare Datentypen, beispielsweise in "select m.priority from Message m" werden die atomaren Typen in die entsprechenden Objekttypen umgewandelt. Enthält die select-Klausel mehrere Werte oder Objekte, wird eine Liste von Arrays zurückgegeben. Mit getSingeResult() wird ein Abfrageresultat abgeholt, dass nur ein einziges Resultat liefert. Erzeugt eine Exception, wenn kein oder mehr als ein Resultat entsteht. Mit executeUpdate() können modifizierende Abfragen (update, delete) durchgeführt werden. Der FlushModeType ist wichtig, wenn vor der Query-Ausführung neue persistente Objekte erzeugt, gelöscht oder modifiziert wurden. Wenn der FlushModeType auf AUTO gesetzt ist, findet vor der Ausführung eine Synchronisation (flush()) zwischen dem Cache und der Datenbank statt, weil das Query gegen die Datenbank abgesetzt wird. Wenn der FlushModeType auf COMMIT gesetzt ist, findet keine Synchronisation statt, und das Query wird gegen den momentan in der Datenbank existierenden Zustand ausgeführt, ohne Berücksichtigung noch pendenter Änderungen der laufenden Transaktion. Arno Schmidhauser November 2006 Seite 89 JPA – Java Persistence API Query, Resultate abholen Query qry = em.createQuery( qrystring ); List result = qry.getResultList(); Iterator itm = result.iterator(); while( itm.hasNext() ) { Object o = itm.next(); if ( o instanceof Object[] ) { for( Object x : (Object[])o ) System.out.println( x.toString() ); } else{ System.out.println( o.toString() ); } } 90 Mit obigem Code-Stück kann jede Art von Query-Resultat abgeholt werden. Arno Schmidhauser November 2006 Seite 90 JPA – Java Persistence API Abfragen, Aufbau • Abfragen in JPA QL folgen demselben Befehlsaufbau wie SQL: select selectklausel from fromklausel [ group by groupklausel ] [ having havingklausel ] [ where whereklausel ] [ order by orderklausel ] 91 In der Selectklausel kann eine Objektreferenz stehen (die in der Fromklausel definiert wird), ein Pfadausdruck, ein Aggregatausdruck oder ein Wertausdruck oder eine Kombination der drei letzteren. Die Fromklausel enthält die Grundmengen an Objekten mit einem Referenznamen (der in JPA QL obligatorisch ist) . Beispiel: from PMQ q . Werden mehrere Grundmengen angegeben ohne Join-Bedingung, wird das Kreuzprodukt gebildet wie in SQL. Die Groupklausel, die Havingklausel und die Orderklausel arbeiten sinngemäss wie in SQL. Insbesondere sind auch Pfadausdrücke erlaubt und die Orderklausel erlaubt die Zusätze ASC und DESC für die Sortierung. Zu erwähnen ist, dass keine der Klauseln Methodenaufrufe auf den Objekten erlaubt. Andere OO-Abfragensprachen, z.B. JDO Query Language erlauben dies. Die Whereklausel kennt die üblichen Vergleiche und Operatoren: =, >, >=, <, <=, <> (not equal), [NOT] BETWEEN, [NOT] LIKE, [NOT] IN, IS [NOT] NULL, AND, OR, NOT, (), [NOT] EXISTS. In der Whereklausel sind die speziellen Prädikate IS [NOT] EMPTY und [NOT] MEMBER OF zu erwähnen. Beide beziehen sich auf Pfadausdrücke, die in Collections enden. Arno Schmidhauser November 2006 Seite 91 JPA – Java Persistence API Pfadausdrücke 1. Ein Pfadausdruck ermöglicht die direkte Navigation von einem äusseren zu inneren, referenzierten Objekten: select q.owner from PMQ q select q.owner.name from PMQ q 2. Ein Pfadausdruck kann in einer Collection enden: select q.messages from PMQ q 3. Ein Pfadausdruck kann nicht über eine Collection hinweg navigieren: select q.messages.sender from PMQ q 92 Zu 1: der Ausdruck nimmt keine Rücksicht auf die Kapselung der inneren Objekte. Auch wenn das Ojekt owner privat ist, kann darauf navigiert werden. Ist ein Objekt im Pfad null, so fällt die entsprechende Zeile aus dem Resultat weg. zu 2: Ein Pfadausdruck, der in einer Collection endet und in einer select-Klausel steht, ist von der JPA Spez. eigentlich nicht erlaubt. Er soll aber hier als Illustration dienen, insbesondere, weil er beispielsweise in Hibernate zugelassen ist. Ein Pfadausdruck, der in einer Collection endet, ist vorallem für die Vewendung in der from- oder der where-Klausel vorgesehen. zu 3: Der Versuch, solche Ausdrücke zu verwenden, ist ein häufiger Fehler. Bei genauerer Überlegung ist jedoch klar, dass das Konstrukt falsch ist. Wenn es zugelassen wäre, ist die Frage, ob sender ein Feld der Collection an sich, oder ein Feld der darin eingebetten Elemente ist. Es würde also eine Mehrdeutigkeit auftreten. Im Weiteren wäre zu bedenken, dass sender wieder eine Collection sein könnte. Damit wiederum kommen Probleme mit im Kreis herum referenzierten Objekten ins Spiel. Aus diesen Gründen wird auf dieses Konstrukt verzichtet in objektorientierten Abfragesprachen (Nicht hingegen im XML-Umfeld: XPath und XQuery bauen genau auf diesen Konstrukten auf). Arno Schmidhauser November 2006 Seite 92 JPA – Java Persistence API Join-Abfragen • Ein Join von zwei Grundmengen bedingt eine definierte Beziehung in den beiden Klassen. Beispiele: Alle Messages der PMQ q1 select m from PMQ q join q.messages m where q.qname = 'q1' Alle PMQs mit Messages der Priorität 1 select distinct q from PMQ q join q.messages m where m.priority = 1 Name jeder PMQ mit Absender aller Messages select q.qname, m.sender from PMQ q left join q.messages m 93 Im ersten Beispiel sind Message-Objekte gesucht. Der rechte Teil der Join-Operation entspricht einer SQL-Join-Bedingung zwischen PMQ und Message. Im zweiten Beispiel sind PMQ-Objekte gesucht. Zu beachten das Schlüsselwort distinct, damit jede PMQ nur einmal in das Resultat kommt. Im drittten Beispiel ist die Möglichkeit eines Outer Joins illustriert. Arno Schmidhauser November 2006 Seite 93 JPA – Java Persistence API in und exists • Die Operatoren IN und EXISTS sind ähnlich wie in SQL, in der Unterabfrage können auch Pfadausdrücke verwendet werden: • Suche alle Queues mit Meldungen der Priorität 1 select q from PMQ q where exists ( select m from q.messages m where m.priority = 1 ) • Suche alle Messages, die zu einer PMQ von Rolf gehören select m from Message m where m in ( select m from PMQ q JOIN q.messages where q.owner.name = 'Rolf' ) 94 Arno Schmidhauser November 2006 Seite 94 JPA – Java Persistence API is empty, member of • is empty und member of ergeben gut verständliche Abfragen auf Pfadausdrücken, die in Collections enden: 1. Suche leere PMQs select q from PMQ q WHERE q.messages IS EMPTY 2. Suche nicht-leere PMQs select q from PMQ q WHERE q.messages IS NOT EMPTY 3. Suche PMQ's in denen die Message m vorkommt Message m = ... ; // irgendwoher Query qry = em.createQuery( "select q from PMQ q where ?1 member of q.messages" ); qry.setParameter( 1, m ); List result = qry.getResultList(); 95 Grundsätzlich sind die beiden Operatoren nicht zwingend notwendig: Beispiel 1 könnte man ersetzen durch select q from PMQ q where not exists ( select m from q.messages ) Beispiel 2 könnte man ersetzen durch select distinct q from PMQ q join q.messages m oder select q from PMQ q where exists ( select m from q.messages ) Beispiel 3 könnte man ersetzen durch select distinct q from PMQ q join q.messages Arno Schmidhauser November 2006 m where m = ?1 Seite 95 JPA – Java Persistence API Abfragen in Vererbungshierarchien • Alle Objekte einer Klasse und ihrer Unterklassen: select m from Message m • Alle XMLMessages in einer PMQ: select xm from XmlMessage xm where xm in ( select m from PMQ q JOIN q.messages m where q.qname = 'q1' ) • Alle Messages, die konkret SimpleMessages sind: select m from Message m where m in ( select mm from SimpleMessage mm ) 96 Ein instanceof Operator wäre nützlich, existiert aber nicht. Folgende Abfrage für das Auffinden von Attributen aus SimpleMessage ist möglich: select m.sender, m.receiver, s.content from Message m, SimpleMessage s where s.id = m.id Arno Schmidhauser November 2006 Seite 96 JPA – Java Persistence API Erstaunliches ... • Die folgenden Abfragen liefern unter Hibernate (JBoss) ein gültiges Resultat: select distinct q from PMQ q where q.messages.sender = 'Bob' and q.messages.sender = 'Alice' select distinct q from PMQ q where q.messages.sender = 'Bob' or q.messages.sender = 'Alice' 97 Erstaunlich ist an den beiden Abfragen, dass eine Navigation über Collections hinweg (q.messages.sender) möglich ist. Dadurch entsteht eine nicht ganz klare Semantik: Bedeutet der Vergleich q.messages.sender = 'bob', dass alle bob heissen müssen, oder nur einer? Im vorliegenden Fall wird der Gleichheitsoperator offenbar als 'mindestens ein' interpretiert. Die Navigation über Collections hinweg ist vom Standard nicht vorgesehen. Die zweite der obigen Abfragen wird vom Framework in folgenden Join umgewandelt: select distinct pmq.id, from PMQ pmq, PMQ_Message pm1, Message m1, PMQ_Message pm2, Message m2 where pmq.id=pm2.PMQ_id and pm2.messages_id=m3.id and pmq.id=pm1.PMQ_id and pm1.messages_id=m2.id and ( m1.sender='Alice' or m2.sender='Bob' ) Arno Schmidhauser November 2006 Seite 97 JPA – Java Persistence API Fetch Join • Der Fetch Join erlaubt das Abfragen von Objekten, mit gleichzeitigem Laden assoziierter Objekte. • Der Fetch Join ist Teil der JPA Spez. • Der Fetch-Join ist ein reines Optimierungs-Hilfsmittel. • Der rechte Operand des Fetch Join hat keine Identifikationsvariable und darf in der Abfrage nicht weiter verwendet werden. select q from PMQ q left outer join fetch q.messages where q.qname = 'q1' 98 Der Fetch Join kann sowohl inner wie outer sein. Zu beachten: Die Join-Semantik hat natürlich zur Folge, dass die Abfrage eventuell mehrfach dasselbe Objekt zurückliefert. Ist dies nicht erwünscht, kann mit select distinct gearbeitet werden. Arno Schmidhauser November 2006 Seite 98 JPA – Java Persistence API Update und Delete • Gemäss Spezifikation können auch Update und DeleteOperationen als "Abfragen" durchgeführt werden. Der Hintergrund dürften Performance-Überlegungen sein. • Beispiel: delete from PMQ q where q.qname = 'q1' • die Löschung beinhaltet kaskadierte Löschungen, die im Rahmen von Beziehungen definiert sind. • Update- und Delete Befehle führen nicht automatisch eine Synchronisation zwischen Datenbank und Applikationscontext (Cache) aus. 99 Arno Schmidhauser November 2006 Seite 99 JPA – Java Persistence API Aufgaben • Erstellen Sie ein Abfrage-Applikation, um die Möglichkeiten von JPA Query Language auszuloten. Testen Sie mit: • Abfragen von Objekten mit Bedingungen / Sortierung • Abfragen in der Vererbungshierarchie • Gibt es Abfragen, die Schwierigkeiten bereiten, aber in SQL grundsätzlich möglich wären? 100 Arno Schmidhauser November 2006 Seite 100