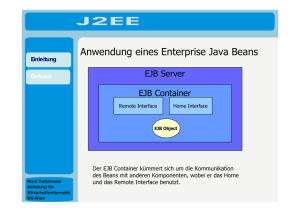
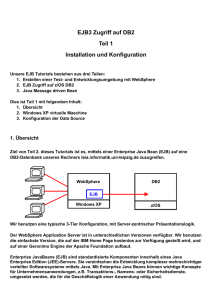
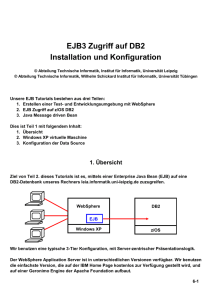
esentri Whitepaper zu JNDI
Werbung

esentri AG Pforzheimer Straße 132 DE – 76275 Ettlingen Tel +49 (0) 7243 / 354 90 0 Fax +49 (0) 7243 / 354 9099 E-Mail [email protected] esentri.com Referenzierung von EJBs mit JNDI im WebLogic Server Whitepaper Agenda Agenda ............................................................................................................................................................. 2 ! Einleitung ......................................................................................................................................................... 3 ! Vorwort .................................................................................................................................................................................................................................. 3! Glossar .................................................................................................................................................................................................................................... 4! 1 Enterprise Java Beans ................................................................................................................................ 5 ! 1.2 EJB Allgemein .............................................................................................................................................................................................................. 5! 1.1.1 Entity Beans................................................................................................................................................................................................... 5! 1.1.2 Message-Driven Beans ........................................................................................................................................................................... 6! 1.1.3 Session Beans ............................................................................................................................................................................................... 6! 1.3 Referenzierung der EJB.......................................................................................................................................................................................... 6! 1.2.1 remote ............................................................................................................................................................................................................. 6! 1.2.2 lokal ................................................................................................................................................................................................................... 6! 1.4 EJB Annotationen ..................................................................................................................................................................................................... 7! 1.3.1 @EJB .................................................................................................................................................................................................................. 7! 1.3.2 @Stateful & @Stateless .......................................................................................................................................................................... 7! 1.3.3 Deployment Descriptor ........................................................................................................................................................................ 8! 2 Java Naming and Directory Interface (JNDI) ...................................................................................... 10 ! 2.1 Namensrichtlinien.................................................................................................................................................................................................. 11! 2.2 Context und InitialContext.............................................................................................................................................................................. 15! 2.2.1 Context erzeugen .................................................................................................................................................................................. 15! 2.2.2 Lookup ausführen................................................................................................................................................................................... 16! 2.2.3 Manueller Lookup VS. Dependency Injection ....................................................................................................................... 16! 3 Anwendungsszenarien ............................................................................................................................. 17 ! 3.1 Lookup einer EJB im Java EE 6 Namensraum über einen Java SE Client .............................................................................. 20! 3.2 Lookup einer EJB mit „mappedName“ über einen Java SE Client ........................................................................................... 21! 3.3 Lokale Referenz von EJBs im selben Modul über DI ........................................................................................................................ 22! 3.4 JNDI Lookup innerhalb eines Moduls (JAR) .......................................................................................................................................... 24! 3.5 JNDI Lookup innerhalb einer Applikation (EAR) ................................................................................................................................ 24! 3.6 E2E Call, applikationsübergreifend (mehrere EAR) ........................................................................................................................... 25! 3.7 Zugriff auf eine EJB mit mehreren Interfaces ......................................................................................................................................... 26! 3.8 Aufruf einer EJB über ein Servlet und JSP ............................................................................................................................................... 28! 4 Lookup im W ebLogic Cluster ................................................................................................................ 30 ! 4.1 Zugriff auf WebLogic Cluster ......................................................................................................................................................................... 30! 4.2 Load Balancing......................................................................................................................................................................................................... 31! 4.2.1 Round Robin ............................................................................................................................................................................................. 31! 4.2.2 Weight-Based ........................................................................................................................................................................................... 31! 4.2.3 Random ........................................................................................................................................................................................................ 32! 4.2.4 Serveraffinität ............................................................................................................................................................................................ 32! 4.3 Failover ........................................................................................................................................................................................................................ 35! 4.3.1 Failover Detection ................................................................................................................................................................................. 35! 4.3.2 Replica-Aware Stubs............................................................................................................................................................................. 35! 4.4 Anwendungsfälle im Cluster ........................................................................................................................................................................... 36! 4.4.1 externer Client......................................................................................................................................................................................... 36! 4.4.2 clusterinterne Lookups ........................................................................................................................................................................ 38! 5 Best Practices & Empfehlungen ............................................................................................................. 39 ! Abbildungsverzeichnis ................................................................................................................................. 41 ! Quellen .......................................................................................................................................................... 42 ! 2 Einleitung Vorwort Ziel des Whitepapers ist die Erläuterung wie die Referenzierung von EJBs mit JNDI im WebLogic Server funktioniert. Darüber hinaus werden die verschiedenen Möglichkeiten erklärt und Empfehlungen für deren Einsatz aufgezeigt. Beim Lesen des Dokumentes wird Java EE Knowhow vorausgesetzt. Beim Deployment im WebLogic Server wird eine EJB mit einem Namen im Naming Service registriert. Um auf eine Instanz dieser EJB zugreifen zu können, wird mit dem JNDI-Interface auf den Naming Service zugegriffen – dieser Vorgang wird als Lookup bezeichnet. Dieses Whitepaper soll den Lesern einen Überblick über die Möglichkeiten eines Lookups auf EJB nach Java EE 5 und 6 Konventionen bieten. Es wird ebenfalls aufgezeigt, wie der Vorgang im Cluster inklusive Failover-Betrachtung aussieht. Im ersten Kapitel wird eine Einführung Enterprise Java Beans gegeben sowie die Unterschiede zwischen den lokalen und remote Interfaces beschrieben. Das zweite Kapitel beschäftigt sich mit JNDI, was es mit den Namensräumen auf sich hat, wie JNDI verwendet und wie im WebLogic Server damit umgegangen werden kann. Einige Anwendungsfälle im Bezug auf die Verwendung von JNDI mit den unterschiedlichen Namensräumen werden im dritten Kapitel aufgezeigt. Das vierte Kapitel umfasst die Funktionsweise von JNDI im Cluster und beschreibt das Verhalten und den Einsatz des JNDI in einem WebLogic Cluster unter der Berücksichtigung von Load Balancing und Failover-Szenarien. Abschließend werden Best Practices im Umgang mit Referenzen auf EJB im Java EE ausgesprochen und sollen dem Leser als Hilfestellung dienen. 3 Glossar Dieses Kapitel behandelt häufig auftretende Begriffe und Abkürzungen, welche in diesem Dokument verwendet werden. Abkürzung API DD Begriff Application Programming Interface Deployment Descriptor DI Dependency Injection DMI Direct Method Invocation EAR Enterprise Archive Die Methode eines lokalen Objektes wird direkt (nicht über einen Stub) aufgerufen (vgl. RMI) Applikationscontainer für JAR und WAR EE Enterprise Edition Java EE; Javaspezifikation für Businessapplikationen EIS Enterprise Information System Enterprise Java Bean Java EE Jargon für die Datenhaltungsschicht (z.B. Datenbank, ERP System,...) Java EE Standard; Java Klassen zur Umsetzung von u.a. Transaktionen und Geschäftslogik in mehrschichtigen Enterprise Applikationen Software für Ressourcenmanagement (z.B. Personal, Rohstoffe, Lieferungen,...) Protokoll zur Kommunikation verteilter Objekte EJB ERP Erläuterung Eine bereitgestellte Programmierschnittstelle, über welche ein System in andere Programme integriert werden kann XML-Konfigurationsdatei mit Informationen für das Deployment (z.B. Referenzen auf benötigte Ressourcen) Konzept zur Auflösung von Abhängigkeiten zur Laufzeit JAR Enterprise Resource Planning Internet Inter-ORB Protocol Java Archive JDBC Java Database Connectivity JNDI JVM Java Naming and Directory Interface Java Virtual Machine Mit Metadaten angereicherte ZIP-Datei, welche mehrere Javaklassen enthalten kann Datenbankschnittstelle für relationale Datenbanken auf der Java Plattform Eine SPI für Namens- und Verzeichnisdienste; Objekte und Daten können über einen Namen registriert und abgerufen werden Teil der Java Laufzeitumgebung; exekutiert Java Bytecode LB Load Balancing Verfahren zur Lastverteilung auf Servern RMI Remote Method Invocation SPI Service Provider Interface WAR Web Archive WLS WebLogic Server Aufruf einer Methode eines entfernten (Java) Objektes; ein Stub als Proxy kümmert sich um den Transport durch das Netzwerk API im Java EE Umfeld, welches von Dienstanbietern implementiert und zur Verfügung gestellt wird Eine JAR mit Ressourcen für Webapplikationen (u.a. Servlets, JavaServer Pages,HTML,JavaScript,..) Applikationsserver von Oracle IIOP 4 1 Enterprise Java Beans 1.2 EJB Allgemein In klassischen Java EE Applikationen (siehe Abb. 01) wird die Geschäftslogik in EJBs gekapselt. Diese sind Java Klassen, welche über Annotationen im Sourcecode oder Deployment Deskriptoren (XML-Dateien) konfiguriert werden. EJBs bieten ein lokales und remote-Interface an, welche von Clients für den Zugriff auf die EJB verwendet werden. Abb. 1: Übersicht über die Java Enterprise Edition Architektur Wenn die EJB auf dem Server deployed wird, so wird ihre Position mit einem Namen im Naming Service registriert. Über das Java Naming and Directory Interface ist es dem Client dann möglich, den Aufenthaltsort der EJB zu ermitteln. Das JNDI greift hierbei auf ein Factory Object zu, eine Art Fabrik für die aufgerufene EJB. Diese Fabrik generiert eine Instanz der EJB, sodass der Client über RMI auf deren Funktionalitäten und die darunterliegenden Daten zugreifen kann. Die Java EE Umgebung definiert eine Reihe von Schnittstellen, welche bestimmte Funktionsbereiche – z.B. Webanwendungen, Datenbankzugriff etc. – umfassen. Ein Application Server muss diese Schnittstellen konform zur Spezifikation implementieren. Diese Schnittstellen werden als SPI bezeichnet. Das JNDI ist ebenfalls ein SPI, weshalb sich der Einsatz des JNDI in Funktionsumfang oder Funktionsweise unter den verschiedenen Providern unterscheidet. Dieses Whitepaper geht dabei auf die JNDI Implementierung und –Funktionsweise des WebLogic Server von Oracle ein. Grundsätzlich existieren drei Arten von EJBs: Entity Beans, Message-Driven Beans und Session Beans. 1.1.1 Entity Beans Die Entity EJB repräsentieren Geschäftsdaten bzw. –Objekte aus einer Datenquelle, meist einer Datenbank oder ERP System. Diese Geschäftsobjekte sind stellvertretend für die im Geschäftsprozess manipulierten Daten. Die Bean stellt Methoden zur Manipulation der Daten (Lese- und Schreibzugriffe) bereit. Zusammen mit Session Beans stellen sie die Geschäftsfunktionalitäten zur Verfügung. Seit Java EE 5 (EJB 3.0) sind Entity Beans als obsolet deklariert. Als Alternative steht die Java Persistance API (JPA) zur Verfügung, welche als eigene Java EE Spezifikation als Nachfolger von Entity Beans gelten. Aus diesem Grund werden Entity Beans in diesem Dokument nicht näher berücksichtigt. 5 1.1.2 Message-Driven Beans Message-Driven Beans bieten die Möglichkeit, Nachrichten asynchron zu versenden oder zu empfangen. Jede Message-Driven Bean ist hierbei an eine bestimmte Message Queue gebunden. Jedes Mal wenn eine Nachricht an dieser Message Queue ankommt wird diese an eine Instanz dieser Message-Driven Bean geliefert. 1.1.3 Session Beans Session Beans umfassen im Wesentlichen eine Reihe von Geschäftsfunktionen respektive Methoden, welche über eine synchrone API zur Verfügung gestellt werden. Sie abstrahiert die Komplexität der Geschäftslogik gegenüber dem Client. 1.3 Referenzierung der EJB Um die angebotene Funktionalität einer EJB verwenden zu können, stellt die Bean ein Interface zur Verfügung. Dieses Interface kann – abhängig von der Nutzung und dem Deployment der EJB – als lokal oder remote deklariert werden. In diesem Kapitel werden die wesentlichen Unterschiede dieser beiden Zugriffsmethoden aufgezeigt. Ebenfalls wird die Möglichkeit in Erwähnung gezogen das Interface als Hybrid (lokal und remote) zur Verfügung zu stellen und welche Konsequenzen sich daraus ziehen lassen. Die Interfaces (lokal wie remote) werden ausschließlich von Session und Entity EJBs verwendet. 1.2.1 remote Der Zugriff auf EJB in einem verteilten System geschieht über die RMI (Remote Method Invocation). Hierbei ist es möglich, Funktionalitäten von EJB eines anderen Applikationsservers respektive eines anderen Clusterknotens aufzurufen. Die meisten Applikationsserver nehmen hierbei weitere Optimierungen für den Fernzugriff ( @Remote ) vor. Obwohl lokale EJB ebenfalls über das Remote Interface einen Zugriff auf andere EJB erhalten können, wird davon abgeraten. Remote EJB generieren einen größeren Overhead, da beim Aufruf die Argumente serialisiert werden müssen, damit sie über das Netzwerk transportiert und anschließend wieder ausgelesen werden können. Per Default verwendet der Applikationsserver eine pass-by-value Semantik. Hierbei werden die Argumente kopiert, bevor sie an die EJB Komponente gesendet werden, auch wenn sie sich auf derselben JVM befinden. 1.2.2 lokal Wenn der Client sich auf derselben JVM befindet wie die EJB, so kann auf diese über ein lokales Interface ( @Local ) mittels DMI zugegriffen werden. Befindet sich der Client hingegen nicht auf demselben Applikationsserver, so wird über das Remote Interface auf die EJB zugegriffen. Die Nutzung von lokalen Interfaces kann ebenfalls von Vorteil sein, wenn mehrere Beans voneinander abhängig sind und oft miteinander kommunizieren. Um eine bessere Performance zu gewährleisten sollte wenn möglich ein lokales Interface zur Verfügung gestellt werden, falls die EJB Komponenten lokal in derselben JVM liegen. Lokale Aufrufe folgen der pass-by-reference Semantik und sind performanter als die Remote Variante. Es sollte daher anstatt der für remote Zugriffe vorbehaltenen pass-by-value Semantik eher die pass-by-reference Semantik angestrebt werden. Die Argumente welche über diese Semantik übertragen werden müssen als Referenz und nicht als Wert übergeben werden. 6 1.4 EJB Annotationen Neben den gängigen Annotationen um den Zugriff auf das Bean Interface als remote oder lokal zu deklarieren bieten sich dem Entwickler weitere Möglichkeiten. 1.3.1 @EJB Die EJB Annotation wird verwendet, um eine Abhängigkeit zu einer anderen EJB anzugeben. Die referenzierte EJB kann über den lokalen Kontext der referenzierenden EJB aufgerufen werden. Parameter name beanInterface beanName mappedName description Beschreibung Gibt den Namen an unter welchem JNDI Namen die Bean im Komponentennamensraum (java:comp/env) gefunden werden kann. Spezifiziert das Interface der referenzierten Bean (notwendig bei mehreren implementierten Interfaces); Standardwert ist Object.class. Gibt den Namen der referenzierten EJB an. Entspricht dem name Attribut der @Stateful/@Stateless Annotation. Die EJB lässt sich über ihren globalen JNDI mappedName Namen referenzieren. Dieses Attribut ist produktspezifisch. Eine Beschreibung der EJB Referenz. WebLogic initialisiert automatisch die annotierte Variable mit der Referenz über Dependency Injection. Beispiel: @EJB(name="Friend",<beanName="Red",<mappedName="redbean")< public<class<BlueBean<implements<Friend{< Im Falle von Unklarheiten können die Attribute beanName, beanInterface oder mappedName verwendet werden um die abhängige EJB explizit zu benennen. Die Verwendung von mappedName sollte mit Bedacht erfolgen, da dieses Attribut herstellerspezifisch ist. 1.3.2 @Stateful & @Stateless Mit diesen Annotationen wird angegeben, ob eine Session Bean stateful oder stateless ist. Diese Annotationen markieren die EJB als Session Bean, sodass der EJB Container diese Bean entsprechend konfiguriert und sich um das Transaktionsmanagement kümmert. Parameter name mappedName description Beschreibung Gibt den Namen an unter welchem die Bean im JNDI hinterlegt ist Definiert im WebLogic JNDI root einen globalen JNDI Namen namens „bluesclues“, unter welchem die Bean gefunden werden kann Eine Beschreibung der Session Bean Beispiel: @Stateless(name="Blue",<mappedName="bluebean")< public<class<BlueBean<implements<Friend{< Im oberen Beispiel wurde die EJB unter dem Namen „Blue“ im JNDI Tree hinterlegt. Die Bean kann im Namensraum unter diesem Namen gefunden werden, z.B. java:global/appName/moduleName/Blue. Da ein mappedName angegeben wurde, lässt sich die Bean auch direkt über diesen Namen im JNDI Tree zu finden. Es gilt hier zu beachten dass mappedName stets providerspezifisch ist. Nicht alle Applikationsserver unterstützen jedoch den Gebrauch dieses Parameters und bieten untereinander wenig Portabilität. In WebLogic wird ein Lookup auf ein mit mappedName gebundenes Objekt über ein Hashtag, gefolgt von der vollständigen Interfacebezeichnung, ausgeführt. Die Form des Lookup folgt dabei einer strengen Richtlinie und setzt sich folgendermaßen zusammen: <mappedName>#<fully.qualified.interface.name>5 7 Beispiel: Der mappedName ist „bluesclues“, das verwendete Interface namens BlueManGroupCall liegt im Package com.acme.blue, dann wäre der Lookup: Object<obj<=<ctx.lookup(„bluesclues#com.acme.blue.BlueManGroupCall“);<< 1.3.3 Deployment Descriptor Der Deployment Descriptor ist eine XML-Konfigurationsdatei zur Verwaltung von EJB und deren Abhängigkeiten. Vor Version 3.0 war es notwendig, die EJB Definition in ihnen einzutragen. Sie zeigte den Zusammenhang zwischen den Bean-Implementierungen und den Interfaces. Bis zur Version 3.0 konnte eine EJB ausschließlich über einen Deployment Descriptor konfiguriert werden. Mit Beginn der Version 3.0 können die meisten Konfigurationseinstellungen über Annotationen beschrieben werden. Der umgekehrte Fall gilt ebenfalls: Einträge im Deployment Descriptor können Annotationen ersetzen. Wichtig ist hierbei zu beachten, dass die Einträge über Annotationen und über den DD durchaus unterschiedliche Werte besitzen können. In diesem Fall wird die Konfiguration des DD die Annotation in der EJB beim Deployment bevorzugt. Im Deployment Descriptor ejb-jar.xml sind die EJB angegeben welche in diesem Modul residieren. Der WebLogic Deployment Descriptor weblogic-ejb-jar.xml verwendet die in der ejb-jar.xml verwendeten Referenzen und bereitet sie für das Deployment vor. Für Stateless Session Beans besteht bei Letzterem die Option im statelessR sessionRdescriptor das statelessRclustering zu definieren – Parameter welche sich auf das Verhalten dieser EJB im Cluster auswirken. So kann darin der Load Balancing Algorithmus für das Home Interface und die Bean angegeben werden (siehe Abb. 02). In ejb-reference-description können Referenzen auf eine andere EJB erstellt werden. Die weiteren Parameter ejb-refname und jndi-name geben den Namen der Bean an, welchen man der Bean im name Attribut ihrer Beschreibung gegeben hat. Ist beispielsweise eine Ressource mit @EJB(name=“myBean“)<annotiert, so kann die Bean diese über folgenden Eintrag referenzieren: <ejbRrefRname>myBean</ejbRrefRname>< Der Container, welcher die EJB behandelt kümmert sich um die Auflösung der Referenzen per Annotation. Die Ressource wird dann im komponentenweiten Namensraum der EJB (java:comp/env) registriert. Im oberen Beispiel löst der Container die Referenz nach java:comp/env/myBean auf. Wenn die Annotation keinen Namen definiert, so wird die Referenz aufgelöst auf java:comp/env/[ejb.klasse.mit.paketpfad]/[name des annotierten Feldes] Ist beispielsweise die EJB in welcher die DI stattfindet im Paket com.esentri.jndi mit dem Namen MyBean hinterlegt und das annotierte Feld @EJB< MyBeanInterface<fieldName;< dann wäre die annotierte Ressource im komponentenweiten Namensraum unter folgendem JNDI Pfad: java:comp/env/com.esentri.jndi.MyBean/fieldName< Über den Deployment Descriptor als auch über die @EJB Annotation referenzierte Ressourcen sind demnach im komponentenweiten Namensraum der Komponente in welcher sie referenziert sind verzeichnet. Die Ressource muss sich hierfür nicht in derselben Applikation befinden. Wichtig ist jedoch, dass sie sich auf derselben Serverinstanz befindet und im JNDI eingetragen ist. 8 Abb. 2: Auszug des Quellcode aus einem weblogic-ejb-jar.xml Der Deployment Descriptor der EJB für den WebLogic ist im JDeveloper als weblogic-ejb-jar.xml vorhanden. Dieser DD sorgt dafür dass die EJB des DD ejb-jar auf einen JNDI Namen gemapped werden. Hierbei kann unter Overview die Konfiguration der gewünschten Bean betrieben werden ohne dass die Konfiguration von Hand vorgenommen werden muss (siehe Abb. 03). Abb. 3: Konfiguration des weblogic-ejb-jar.xml Standardmäßig sind die EJB sowie das Home Interface bereits so vorkonfiguriert, dass sie im Cluster betrieben werden können. Hierbei ist zu beachten, dass ein Home Interface seit dem EJB Standard 3.0 (Java EE 5) nicht mehr benötigt wird. Dieses Interface musste damals von allen Remote Interfaces einer EJB erweitert werden um Methoden wie create() oder remove(). Hierbei wurde beim Client über das RMI auf das Home Interface zugegriffen und beim Client eine Instanz der EJB erstellt. Der Zugriff auf EJB wird über die JNDI und die neu dazugekommenen Namensräume vereinfacht. 9 2 Java Naming and Directory Interface (JNDI) Das Java Naming and Directory Interface bietet auf Java basierenden Applikationen ein einheitliches Interface an, über welches mehrere Namens- und Verzeichnisservices verwendet werden können. Es ermöglicht einen einheitlichen Zugriff auf Services wie LDAP, DNS oder CORBA. Das JNDI ist auf für Java EE als SPI verfügbar, wobei der Provider für eine Java EE konforme Implementierung zuständig. Das JNDI wird in diesem Dokument verwendet, um Lookups auf EJB im Java EE Umfeld durchzuführen. Alle hier behandelten Themen werden hier spezifisch im Bezug auf Java EE und EJB betrachtet. Die Klassen für die Nutzung von JNDI befinden sich im javax.naming.* Paket. In das JNDI werden Werte zusammen mit einem Namen abgelegt. Über ein Lookup wird das Objekt zurückgegeben, welches im JNDI unter dem gesuchten Namen abgelegt wurde. Ist ein Name bei der Ablage bereits vergeben, so wird eine NameAlreadyExistException ausgegeben. Wird beim Aufruf eine NameNotFoundException ausgelöst, so wurde im JNDI kein Objekt unter dem gesuchten Namen abgelegt. Eine NotFoundException hingegen könnte Hinweise darauf geben dass ein Eintrag unter besagtem Namen zwar existiert, das dazugehörige Objekt aber nicht mehr existiert und womöglich das JNDI Verzeichnis nicht aktualisiert wurde. Das JNDI speichert seine Einträge in einer Baumstruktur, welche auch als JNDI Tree bezeichnet wird. In WebLogic kann der JNDI Tree über die WebLogic Server Administration Console eingesehen werden (siehe Abb. 04). Die Einträge enthalten jeweils ! ! ! ! Einen Binding Name unter dem das Objekt verzeichnet ist Den Klassennamen des Objektes Einen Hashcode (dezimal) sowie Das toString() Ergebnis, welcher sich wie folgt zusammenbaut: <ClassName>@<HashCode(Hexadecimal)>5 < < Abb. 4: Beispiel eines WebLogic JNDI Tree in der Administrationskonsole Der JNDI Tree des WebLogic Servers kann über die Administration Console mit der nach-folgenden URL betrachtet werden. http://[adresse]:[port]/console Beispiel: http://localhost:7001/console 10 Im linken Panel erfolgt die Navigation über Umgebung -> Server (Environment -> Server). In der neuen Ansicht wird unter den Tabs Konfiguration -> Allgemein eine Übersicht über den Server ermöglicht. Über den Kennzahlen befindet sich der Link JNDI-Baum anzeigen (siehe Abb. 05). In einem neuen Fenster respektive Tab wird der JNDI Tree für den Server angezeigt. Abb. 5: WebLogic Server Administrationskonsole, Zugriff auf den JNDI Tree Im neu öffnenden Tab/Fenster befindet sich nun auf der linken Seite die Baumstruktur des JNDI. Im oberen Beispielbild existiert noch keine Applikation. Dennoch nutzt WebLogic JNDI – in einem integrierten LDAP Repository speichert WebLogic sicherheitsrelevante Daten, unter anderem über seine Nutzer, Gruppen oder Sicherheitsrichtlinien. Der Lookup mit JNDI war im Java EE Umfeld bis Version 5 stark kontextuell abhängig und es existierten keine globalen Einträge für Ressourcen (z.B. EJB). Die Ressource wurde abhängig von der Position des Aufrufs mit einem unterschiedlichen JNDI Namen aufgerufen. Um auf eine EJB außerhalb der Applikation zugreifen zu können musste über RMI das Home Interface der gewünschten Bean herangezogen werden um anschließend eine Instanz davon auf dem Client zu erzeugen, über welche dann die Methodenaufrufe der EJB gingen. Da nur der komponentenweite Namensraum existierte musste man für jede Komponente auf welche man von der Bean aus lokal zugreifen wollte eine Referenz über den DD erstellen. Auf diese Problematik wurde in Java EE 6 eingegangen und durch das Hinzufügen drei neuer Namensräume vereinfacht. Dies ermöglichte den Zugriff über JNDI für jede auf dem Server abgelegte Komponente unter einem eindeutigen Namen, womit auch der Zugriff auf Komponenten auf anderen Servern vereinfacht wurde. Auch lokal wurde eine Referenz nicht mehr benötigt, da nun über modulweite (JAR/WAR) als auch applikationsweite (EAR) Namensräume ein direkter JNDI Lookup ausgeführt werden konnte. 11 2.1 Namensrichtlinien Das JNDI definiert keine Richtlinien, nach denen Namen erstellt werden müssen. Jedoch ist es in der Praxis weitgehend üblich nach der Java EE Konformität zu gehen. Diese sieht vor dass ein logischer Namensraum (namespace) vom Container der EE Komponente (z.B. EJB) zur Verfügung gestellt wird. Die Komponente wird in einem Deployment Descriptor vermerkt welcher neben den Daten auch Informationen über den logischen Namen, den Ressourcentypen sowie Referenzen der Komponente beinhalten. Der Enterprise Namensraum beruht auf einem Java URL Schema. Dieses Präfix ist Java EE Standard und ist die Standardreferenz für alle nicht-serialisierbaren Ressourcen. Zu diesem Präfix zählen vier Namensbereiche, auch Scopes genannt. Die Verwendung dieses Konzeptes ermöglicht es Namenskonflikte zu vermeiden, welche vom Context.INITIAL_CONTEXT_FACTORY, auch InitionalContext genannt, verwaltet werden. Mit einem / (Slash) wird ein Unterverzeichnis angesprochen. Die letzten drei Scopes wurden mit Java EE 6 eingeführt. Die Bezeichnungen in den [eckigen Klammern] sind optional. Das Wissen um die unterschiedlichen Namensräume mit JNDI ist unerlässlich. Das JNDI arbeitet in einem bestimmten Kontext - das heißt dass der Lookup stets vom Client, der aufrufenden Komponente, abhängig ist. Die Namensräume werden von comp über module und app bis zum global immer größer. Da ein größerer Namensraum einen größeren Overhead verursacht wird empfohlen möglichst auf einer feingranularen Ebene zu beginnen. java:comp/env, Bis inklusive Java EE 5 existierte nur der java:comp<Namensraum. Das comp ist eine Abkürzung für Components und bezeichnet den für eine Komponente gültigen Namensraum. Wurde an dieser Komponente (manuell) eine Referenz zu einer anderen Komponente hergestellt, so konnte auf diese über den Namensraum java:comp/env/5 zugegriffen werden. Dieser Namensraum ist stark Kontextabhängig, da jede Komponente ihren eigenen java:comp/env Namensraum besitzt. Ist die referenzierte Komponente hierbei eine EJB, so wird diese in einem Unterordner namens ejb in diesem Namensraum abgelegt. Selbiges gilt für Datenquellen mit jdbc. < Beispiele: Java:comp/env/ejb/OrdersEntityBean< Java:comp/env/jdbc/Salary< Bei einem Lookup wird für gewöhnlich der komplette Name der Komponente (siehe obiges Beispiel) angegeben. Im WebLogic ist es bereits ausreichend, den Verzeichnispfad nach java:comp/env anzugeben (z.B. ejb/Orders). Zu diesem Namensraum sind folgende Aspekte zu beachten: ! Jede Komponente besitzt ihren eigenen java:comp/env Namensraum ! Einträge im Namensraum müssen explizit im DD angegeben werden ! Wenn EJB A eine Referenz auf EJB B deklariert, so hat A in seinem Namensraum eine Referenz auf EJB B Dies bedeutet dass jede Komponente welche auf eine andere Komponente zugreifen wollte diese als Referenz deklarieren musste. Hat man Java EE 5 im Einsatz so sollte man bedenken dass Servlets diesen Namensraum anders interpretieren. Während der java:comp/env Namensraum bei EJB für jede Bean einzeln existiert, so teilen sich alle Servlets innerhalb einer WAR untereinander diesen Namensraum (siehe Abb. 06). Dies bedeutet, dass Servlets ohne Angabe von Referenzen andere Servlets über diesen Namensraum erreichen können. Eine EJB kann jedoch nicht auf den privaten komponentenweiten Namensraum einer anderen EJB zugreifen. 12 Abb. 6: java:comp/env Namensraum der EJB1 mit Referenz auf EJB2 Der java:comp Namensraum sollte für EJB nur dann verwendet werden, wenn diese eine Referenz auf die Zielkomponente besitzt. Beispielsweise lassen sich für Servlets entfernte Ressourcen (resource-ref) in der web.xml angeben, welche dann über den komponentenweiten Namensraum verwendet werden können. Hierbei wird der Name angegeben unter welchem man vom Servlet aus auf die Ressource zugreift sowie den Namen der Ressource unter welcher sie im JNDI hinterlegt ist. Beispiel: <resourceRref>< < <resRrefRname>myUsedResourceName</resRrefRname>< < <jndiRname>RealJNDIResourceName</jndiRname>< </resourceRref>< Eine Referenz über Dependency Injection sorgt ferner dafür dass die injizierte Ressource am komponentenweiten Namensraum eingetragen wird. Über DI injizierte Ressourcen sind somit ebenfalls stets über diesen Namensraum aufrufbar. java:module/, Der Namensraum des java:module wird verwendet um (lokale) EJB innerhalb eines Moduls zu addressieren. Die Syntax für den java:module Scope lautet wie folgt: java:module/<bean-name>[!<fully-qualified-interface-name>] Der Name des Interface wird nur dann benötigt, wenn die EJB mehrere Interfaces implementiert. Der Namensraum beschränkt sich auf das Modul der Applikation (siehe Abb. 07). Ein Modul ist hierbei ein JAR oder ein WAR innerhalb einem EAR und beherbergt mehrere Komponenten (z.B. EJBs). 13 java:app/, Der java:app Scope wird verwendet, um einen Lookup auf lokale EJB zu betreiben welche innerhalb derselben Applikation gepackt sind. Dieser Scope wird verwendet wenn eine EJB in einer EAR gepackt ist welche mehrere Java EE Module enthält (siehe Abb. 07). JNDI Adressen im java:app Namensraum besitzen folgende Form: java:app/<module-name>/<bean-name>[!<fully-qualified-interface-name>] Der Name des Interface wird nur dann benötigt, wenn die EJB mehrere Interfaces implementiert. java:global/, Der java:global Namensraum bietet die meisten Möglichkeiten um auf EJB innerhalb der Applikation zuzugreifen. Innerhalb dieses Namensraumes können applikationsweit remote EJB addressiert werden. Klassischer Aufbau: java:global[/<app-name>]/<module-name>/<bean-name>[!<fully-qualifiedinterface-name>] Die Parameter <appRname> sowie <moduleRname> sind entsprechend ihrer Paketnamen (ohne die Dateiendungen). Dabei ist <appRname> nur dann erforderlich, wenn die Ressource sich in einem EAR befindet. Der Name des Interface wird nur dann benötigt, wenn die EJB mehrere Interfaces implementiert. Der Container der EJB muss bei der Verwendung des global Namensraumes im JNDI einen Eintrag für jedes implementierte Interface – lokal wie remote – erstellen. Das folgende Schaubild demonstriert in abstrakter Weise wie JAR, WAR und EAR in einer Enterprise Applikation gepackt werden und wie der Lookup auf unterschiedlichen Namensräumen zu interpretieren ist. Abb. 7: Enterprise Application über mehrere EAR, Java EE 6 Namensräume Ein Lookup auf Modulebene würde den Inhalt einer einzelnen JAR betreffen. Hier sind die EJB lokal verpackt. Vom Standpunkt der Applikationsebene kann dort ein Lookup zwischen mehreren JAR innerhalb einer EAR erfolgen. Der globale Zugriff ermöglicht letztendlich einen LookUp über mehrere EAR hinweg. Wichtig zu beachten ist die Verwendung der @Stateful, @Stateless und @Singleton Annotationen in EJBs. Für gewöhnlich entspricht der Name der Bean im JNDI seinem Klassennamen. Werden die eben erwähnten Annotationen jedoch angewandt und mit ihnen ein Name für die Bean deklariert, so ist diese Bean im JNDI über den Namen in der Annotation erreichbar. 14 2.2 Context und InitialContext 2.2.1 Context erzeugen Um das JNDI nutzen zu können, wird ein sogenanntes Context Objekt erzeugt. Mit diesem ist es möglich, lokale Lookups zu erstellen. Um mit dem JNDI ein Lookup auf einen bestimmten Server (oder wie später gezeigt wird auch Servercluster) vorzunehmen, wird ein sogenannter InitialContext erzeugt. Dieser InitialContext wird zunächst initialisiert, indem ihm Umgebungsvariablen des Servers in Form einer HashTable mitgegeben werden. Möchte man das JNDI auf einem Server verwenden, so ist es auch erlaubt die Umgebungsvariablen wegzulassen und einen „leeren“ InitialContext zu erzeugen. Der JNDI Kontext bezieht sich dann auf den lokalen Server, welcher die EE Komponente hostet. Folgende Umgebungsvariablen können in der HashTable für den InitialContext gesetzt werden: Umgebungsvariable INITIAL_CONTEXT_FACTORY< PROVIDER_URL< SECURITY_PRINCIPAL< SECURITY_CREDENTIALS< Beschreibung Diese Variable spezifiziert den Namen der InitialContext Factory, welche den InitialContext erzeugt. Für den WebLogic wird WLInitialContextFactory verwendet um auf den WLS JNDI Service zuzugreifen. Die URL des Servers oder Clusters, auf dessen JNDI man zugreifen will. Das Kontextobjekt wird von diesem Provider gestellt. Wenn der Client einen Zugriff auf den WebServer benötigt, muss man Nutzernamen und Passwort angeben damit man sich als Nutzer des WLS identifizieren kann. Entspricht dem Passwort des Nutzers, mit dessen Nutzernamen man sich anmelden will. Standardwert leer t3://localhost:7001 guest guest Beispiel für die Erstellung eines InitialContext: import<java.util.Hashtable;< import<javax.naming.*;< < public<class<TestingBean<{< private<InitialContext<context<=<null;<< < < public<InitialContext<getInitialContext()<throws<NamingException<{< < < if<(context<==<null){< < < < Hashtable<environment<=<new<Hashtable();< < < < environment.put(Context.INITIAL_CONTEXT_FACTORY,< "weblogic.jndi.WLInitialContextFactory");< < < < environment.put(Context.PROVIDER_URL,<"t3://localhost:7001");< < < < context<=<new<InitialContext(environment);< < < }< < < < < return<context;< < }< Eine weitere Möglichkeit um ein InitialContext Objekt zu erzeugen besteht im Einsatz der Environment-Klasse von WebLogic (weblogic.jndi.environment). Erstellt man ein neues Environment-Objekt, so werden die Standardwerte der Umgebungsvariablen eingesetzt. Man kann mittels Environment env = new Environment(); Context ctx = env.getInitialContext(); einen InitialContext mit Standardwerten erzeugen. Die Klasse bietet Methoden an um die Standardparameter zu überschreiben, zum Beispiel auf diese Weise: 15 Environment env = new Environment(); env.setProviderURL("t3://myweblogiccluster.com:7001"); Context ctx = env.getInitialContext(); 2.2.2 Lookup ausführen Über den Kontext kann über die Namensräume ein Objekt geholt werden, welche im JNDI verzeichnet ist. Im Beispiel wird mit dem Lookup eine Bean namens OrdersBean geholt. Hierbei wird über den Lookup ein Objekt der Klasse Object zurückgegeben, welcher vom JNDI unter dem gesuchten Namen abgelegt wurde. try { OrdersBean ordBean = (OrdersBean)context.lookup("java:global/myEAR/myJAR/ OrdersBean"); } catch (NameNotFoundException e) { // unter dem gesuchten Namen existiert im JNDI kein Eintrag } catch (NamingException e) { // ein Fehler ist aufgetreten } 2.2.3 Manueller Lookup VS. Dependency Injection In diesem Dokument wird überwiegend ein manueller Lookup mit JNDI auf die EJB betrieben. Dies ist dafür gedacht die Arbeitsweise mit JNDI im Java EE Bereich mit EJB zu demonstrieren. Dieses Unterkapitel stellt den Lookup mit JNDI und DI gegenüber, sodass ein Überblick über beide Techniken entsteht. ! Für einen Zugriff auf entfernte Objekte (anderer Server) muss ein manueller Lookup über den InitialContext betrieben werden, da dies mit DI nicht möglich ist. Die Ressource ist mit einem manuellen Lookup von überall aus erreichbar. ! Die Referenz auf Objekte auf demselben Server ist über DI einfacher, da der Container mit dem Management der Ressource beauftragt wird. Dies spart Code ein (u.a. try-catch Block um den InitialContext) und erfordert nicht die Angabe des vollständigen exakten JNDI Namens. ! Die Session einer Stateful Session Bean ist in beiden Fällen dieselbe Instanz. Führt man aus dieser Session heraus einen Lookup auf die EJB aus oder greift über DI auf diese zu so wird dieselbe Instanz damit angesprochen. ! Mit Java EE 6 ist eine EJB mit JNDI standardmäßig über drei Namensräume verfügbar: modulweit (java:module, JAR/WAR), applikationsweit (java:app, EAR) sowie über mehrere EAR und auch Server hinaus (java:global). Mit DI lassen sich die Referenzen nur innerhalb eines Servers (mit mappedName) ansprechen. Über DI bezogene Ressourcen sind in der referenzierenden Komponente im komponentenweiten Namensraum (java:comp) registriert. ! Ändert sich der Aufenthaltsort einer Ressource, so muss jeder Lookup welcher diese Ressource anpeilt angepasst werden. Da sich bei DI der Container um die Auflösung der Referenz kümmert ist eine lose Kopplung gegeben, der Entwickler muss keine Anpassungen vornehmen. ! Aufgrund des String-basierten Lookup kann erst zur Laufzeit ermittelt werden, ob die Referenz aufgelöst werden kann. Über DI wird die Ressource zur Kompilierungszeit bereits geprüft ob die Ressource erreichbar ist. 16 3 Anwendungsszenarien In diesem Kapitel werden verschiedene Anwendungsszenarien vorgestellt, wie man auf eine EJB mit JNDI zugreifen kann. Folgende Beispiele werden erläutert: ! Lookup einer EJB im Java EE 6 Namensraum über einen Java SE Client ! Lookup einer EJB mit „mappedName“ über einen Java SE Client ! Lokale Referenz von EJBs im selben Modul über DI ! JNDI Lookup innerhalb eines Moduls (JAR) ! JNDI Lookup innerhalb einer Applikation (EAR) ! JNDI Lookup über mehrere EAR ! Zugriff auf eine EJB mit mehreren Interfaces ! Aufruf einer EJB über ein Servlet und JSP Zunächst werden die wichtigsten Elemente vorgestellt welche für die Ausführung der Szenarien notwendig sind. Die Szenarien sind teilweise aufeinander aufbauend und verwenden einen externen Client. Die Beispiele wurden im JDeveloper Studio 12.1.3 entwickelt und auf dessen integrierten WebLogic Server deployed. Manche Szenarien könnten auf anderen Applikationsservern nicht lauffähig sein. Anwendungsszenarien zu Lookups im WebLogic Cluster werden in Kapitel 4 behandelt. Bevor die Anwendungsszenarien erläutert werden, werden zunächst die verwendeten Interfaces und Klassen näher betrachtet. Die Szenarien beinhalten stets eine Stateless Session Bean mit dem Namen CarBean, welche ein Interface namens TravelOption implementiert. CarBean.java package com.esentri.jndi; import com.esentri.jndi.transportation.TravelOption; import javax.ejb.Stateless; import javax.naming.Context; import javax.naming.InitialContext; import javax.naming.NamingException; @Stateless(name = "Car", mappedName = "car-vehicle") public class CarBean implements TravelOption{ @Override public String vehicle() { return "car"; } @Override public String travelledDistance(int i) { return "Average distance travelled with "+vehicle()+" after "+i+"hour(s): " + i*65 + " mile(s)."; } @Override public String compareTravelDistance(int i) { try { Context ctx = new InitialContext(); TravelOption bike = (TravelOption) ctx.lookup("java:global/s1_seclient/vehicles/Bike"); return travelledDistance(i)+"\n"+bike.travelledDistance(i); } catch (NamingException e) { return "An error occurred with catching the context.\n" + e.getStackTrace(); } } } 17 TravelOption.java (Interface) package com.esentri.jndi.transportation; import javax.ejb.Local; import javax.ejb.Remote; @Remote @Local public interface TravelOption { public String vehicle(); public String travelledDistance(int i); public String compareTravelDistance(int i); } Das obere Interface stellt drei Methoden zur Verfügung, welche von der Bean implementiert werden müssen. Die Methode vehicle gibt einen String zurück um welches Transportmittel es sich handelt. Die travelledDistance Methode gibt als Rückgabewert die durchschnittliche zurückgelegte Strecke nach i Stunden in Meilen zurück. Innerhalb der compareTravelDistance Methode wird travelledDistance aufgerufen sowie die Methode travelledDistance einer anderen EJB, welche dasselbe Interface implementiert und aus der EJB über einen Lookup referenziert wird. Im späteren Verlauf wird ein weiteres Interface namens VehicleColor einbezogen, welches die Farbe des Transportmittels angibt. VehicleColor.java package com.esentri.jndi.transportation; import javax.ejb.Local; import javax.ejb.Remote; @Remote @Local public interface VehicleColor { public String vehicleColor(); } Weitere in den Anwendungsszenarien angegebenen EJB sind strukturiell an der CarBean angelehnt und verwenden die oben erwähnten Interfaces. Der initiale Lookup erfolgt stets aus einem externen Java Client, einer Klasse namens Lookup. Weitere interne Lookups erfolgen aus der EJB heraus. 18 Lookup.java //…package & imports public class Lookup { //Hashtable und Umgebungsvariablen zur Initialisierung des Context Objektes static Hashtable<String,String> env; static String icFactory = "weblogic.jndi.WLInitialContextFactory"; static String providerURL = "http://localhost:7101"; static String wlsPrincipal = "username"; // Nutzername wenn nötig static String wlsCredentials = "password"; // Passwort zum Nutzer static String lookuptarget = "java:global/s1_seclient/vehicles/Car"; public static void main(String[] args) { try { env = new Hashtable<String, String>(); env.put(Context.INITIAL_CONTEXT_FACTORY, icFactory); env.put(Context.PROVIDER_URL, providerURL); // Nutzerdaten, falls notwendig //env.put(Context.SECURITY_PRINCIPAL, wlsPrincipal); //env.put(Context.SECURITY_CREDENTIALS, wlsCredentials); InitialContext ctx = new InitialContext(env); Object obj = ctx.lookup(lookuptarget); TravelOption option = (TravelOption) obj; System.out.println("Chosen vehicle: " + option.vehicle()); System.out.println(option.travelledDistance(3)); } catch (NamingException nnfe) { nnfe.printStackTrace(); } } } 19 3.1 Lookup einer EJB im Java EE 6 Namensraum über einen Java SE Client Um einen Lookup durchführen zu können muss vorerst eine Applikation auf den Server abgelegt werden, auf welche später zugegriffen werden kann. In dieser Applikation befindet sich das Projekt (Modul) Vehicles, welches die zu Beginn in Kapitel 3 erwähnte CarBean beinhaltet welche das TravelOption Interface implementiert. Nach dem Deployment im integrierten WebLogic Server ist die Applikation mit dem Namen des Deploymentprofils als Applikationsname im JNDI Tree registriert. Die Module der EJB tragen standardmäßig die Bezeichnung <ApplikationsName>_<ModulName>_ejb im JNDI Tree. In diesem Anwendungsbeispiel heißt das Deploymentprofil der Applikation s1_seclient. Unterhalb von java:global befindet sich ein Knoten mit diesem Namen, worunter auch das Modul vehicles zu finden ist1(siehe Abb. 08). Abb. 8: Auszug aus dem JNDI Tree der BlueBean (nach der Anpassung am Deploymentprofil) Nach dem Start ist der integrierte WebLogic Server per Default unter http://localhost:7101 verfügbar, die Konsole lässt sich unter dieser Adresse unter /console/console.portal aufrufen. Von einer einfachen Javaklasse heraus lässt sich der Lookup ausführen.< < Da die CarBean EJB unter dem Namen Car abgelegt wurde kann unter dem globalen Namensraum des Servers auf diese zugegriffen werden (siehe Abb. 09). Abb. 9: Beispielausgabe des Methodenaufrufs nach dem Lookup 1 Für eine bessere Lesbarkeit wurde ein Deploymentprofil für das Modul erstellt und auf vehicles abgeändert. 20 3.2 Lookup einer EJB mit „mappedName“ über einen Java SE Client Um eine EJB aufzurufen muss der Lookup nicht zwingend in einem Namensraum erfolgen. Es ist ebenfalls möglich bei der Referenzierung der Stateless Bean ein Attribut namens mappedName anzugeben. Dieses sorgt dafür, dass die EJB unter einer Art providerspezifischem Shortlink aufrufbar sind. Hierfür reicht es aus das Attribut bei der Stateless Annotation hinzuzufügen. @Stateless(name="Car",<mappedName=“carRvehicle“)< Der Vorteil hierbei liegt darin begründet, dass nicht mehr der ganze Pfad angegeben werden muss (Applikationsname und Modulname) und die EJB somit direkt referenzierbar ist. Mit der neuen Annotation kann man nun nicht nur über String<name<=<"java:global/s2_mappedname/vehicles/Car";< Auf die EJB zugreifen, sondern auch über deren mappedName: String<name<=<"carRvehicle#com.esentri.jndi.transportation.TravelOption"; Der Zugriff auf die durch mappedName gekennzeichneten EJB wird im WebLogic mit folgender Syntax ausgeführt (Beispiel siehe Abb. 10): <mappedName>#<paketpfad.zum.Interface> Abb. 10: Beispiel der CarBean mit car-vehicle als mappedName Jedoch ist hier Vorsicht geboten. Der Bezeichner muss stets eindeutig sein um Namenskonflikte zu vermeiden. Da das Attribut von den Providern unterschiedlich implementiert wird, ist dieselbe Applikation in den seltensten Fällen auf unterschiedlichen Applikationsservern lauffähig. Es wird stark empfohlen daher auf die Verwendung von mappedName ab Java EE 6 zu verzichten, um die Portabilität und Qualität der Applikation weitläufig zu gewährleisten. 21 3.3 Lokale Referenz von EJBs im selben Modul über DI Befinden sich mehrere EJB im selben Modul, so können sie sich untereinander lokal über eine Referenz kommunizieren. Hierfür wird die @EJB Annotation verwendet, um eine lokale Referenz auf eine andere EJB zu ermöglichen. Diese wird vor der Klassendefinition gesetzt. @EJB(beanName<=<"Bike",<name<=<"otherVehicle")< Das Attribut beanName ist der Name unter welchem die referenzierte Bean im Deployment Descriptor hinterlegt ist. Das Attribut name hingegen ist der Name unter welchem die referenzierte Bean innerhalb des privaten Namensraumes (java:comp/env) aufrufbar ist. Falls die Ziel-EJB mehrere Interfaces implementiert muss das Attribut beanInterface mit dem Klassennamen des Interface angegeben werden über welches die EJB referenziert werden soll. Um die referenzierte Bean anzusprechen wird die compareTravelDistance Methode verwendet: <<<<public<String<compareTravelDistance(int<i)<{< <<<<<<<<try<{< <<<<<<<<<<<<Context<ctx<=<new<InitialContext();< <<<<<<<<<<<<TravelOption<bike<=<(TravelOption)< ctx.lookup("java:comp/env/otherVehicle");< <<<<<<<<<<<<return<travelledDistance(i)+"\n"+bike.travelledDistance(i);< <<<<<<<<}<catch<(NamingException<e)<{< <<<<<<<<<<<<return<"An<error<occurred<with<catching<the<context.\n"<+< e.getStackTrace();< <<<<<<<<}< <<<<} Ferner erhält das Interface die @Local Annotation, um eine lokale Referenz zu ermöglichen und somit Overhead zu vermeiden. Eine weitere Stateless SessionBean namens BikeBean wird erstellt, welche dasselbe TravelOption Interface implementiert. Die Bean befindet sich während des Anwendungsbeispiels im selben Modul in der Applikation wie die CarBean. Der Aufbau der Bean ist analog zur BikeBean, die Rückgabewerte und sind entsprechend angepasst. Die CarBean hat über die @EJB Annotation die EJB welche im Deployment Descriptor unter dem Namen Bike eingespeichert ist als Referenz stehen und somit in seinem privaten Umgebungsnamensraum. Da die Ziel-EJB als Referenz lokal in derselben JVM vorliegt und das Interface ebenfalls als lokal deklariert wurde, lässt sich über java:comp/env/otherVehicle der Lookup auf die referenzierte EJB ausführen. Lookups sind mit Ausnahme der java:global Namensräume stets kontextabhängig. Der hier durchgeführte Lookup konnte nur deswegen ausgeführt werden weil ! ! ! Die EJB auf der selben JVM laufen Die aufzurufende EJB als Referenz angegeben wurde Die aufzurufende EJB im DD unter dem beanName existiert. Dieser private Namensraum wird jedoch nicht im JNDI Tree der Administrationskonsole des (integrierten) WebLogic Servers sichtbar, da dieser für jede Komponente individuell ist. In Abbildung 11 wird eine Beispielausgabe angezeigt. 22 Abb. 11: Beispielausgabe – Die EJB Car führt einen Lookup über java:comp/env aus Die Referenz kann auch direkt über Dependency Injection hergestellt werden. In diesem Fall ist ein manueller Lookup nicht notwendig. Hierfür wird die @EJB Annotation nicht an der Klasse angebracht sondern als Variable in der Bean. //…< @Stateless(name=“Car“)< public<class<CarBean<implements<TravelOption{< < @EJB(beanName<=<„Bike“)< TravelOption<bike;< //…< Die Notwendigkeit einen InitialContext aufzubauen und das Objekt über einen Lookup zu referenzieren würde somit entfallen. Die Methode compareTravelledDistance in der CarBean könnte wie folgt aussehen: public<String<compareTravelDistance(int<i)<{< <<<<<<<<<<<<return<travelledDistance(i)+"\n"+bike.travelledDistance(i);< <<<<} 23 3.4 JNDI Lookup innerhalb eines Moduls (JAR) Um Ressourcen innerhalb eines Moduls innerhalb einer Applikation (EAR) ansprechen zu können, kann der java:module Namensraum verwendet werden. Der wesentliche Unterschied zu den anderen Namensräumen liegt in der Einschränkung der Reichweite sowie dem Overhead welcher bei den Lookups entsteht. Es sollte stets darauf geachtet werden den möglichst kleinsten Namensraum zu verwenden um eine höhere Performanz und Codelesbarkeit zu gewährleisten. Der im vorhergehenden Beispiel verwendete Lookup wird erneut verwendet, allerdings erfolgt dann die Namensreferenz entsprechend den in Kapitel 2.1 erwähnten Richtlinien: TravelOption<bike<=<(TravelOption)<ctx.lookup("java:module/Bike");< Hierbei ist zu beachten dass die Referenzen aus dem vorhergehenden Beispiel nicht mehr gültig sind. Die getätigten Referenzen sind nur im privaten Namensraum nutzbar und sind in höherstufigen Namensräumen unter diesem Namen nicht einsetzbar. 3.5 JNDI Lookup innerhalb einer Applikation (EAR) Existieren in einer Applikation (EAR) mehrere Module (JAR oder WAR), so können deren Komponenten über den java:app Namensraum miteinander kommunizieren. In der Beispielapplikation wird ein neues Modul namens AdvancedVehicles angelegt, welches ebenfalls eine Stateless Session Bean namens PlanesBean enthält. Somit existiert eine CarBean im Modul/JAR Vehicles als auch eine PlaneBean in AdvancedVehicles. Der Aufruf wäre wie folgt: TravelOption<plane<=<(TravelOption)<ctx.lookup("java:app/advancedvehicles/Plane");<< Ruft man den JNDI Tree in der Administrationskonsole des WebLogic Servers auf, so sind die Mappings auf diese Namen entsprechend den in den Deploymentprofilen vergebenen Namen (siehe Abb. 12): Abb. 12: Die Mappings innerhalb der EAR auf den beiden Modulen 24 3.6 JNDI Lookup über mehrere EAR Um applikationsübergreifende Lookups über mehrere EAR hinweg tätigen zu können, müssen diese über den Namensraum java:global referenziert werden. Dies ist der Toplevel Namensraum und ermöglicht auch Lookups über die JNDI anderer Server. Sind die EAR auf demselben Server und wird der Kontext aus einer Komponente des Servers heraus gerufen, so kann mit einem einfachen new InitialContext() der Kontextbaum des Servers initialisiert werden. In anderen Fällen ist es notwendig die Umgebungsvariablen in einer Hashtable abzulegen und diese dann bei der Initialisierung mitzugeben, damit eine Verbindung zum Server hergestellt werden kann. Auf diese Weise ist es dann auch möglich, auf Ressourcen zuzugreifen welche auf einem anderen Server deployed sind. Im folgenden Beispiel wurde eine neue Applikation namens s6_globlookup angelegt. In dieser befindet sich die Stateless Session Bean ShipBean im Modul Vehicles. Ähnlich wie im vorangehenden Beispiel erfolgt erneut ein Vergleich über die zurückgelegte Distanz. Diesmal jedoch erfolgt der initiale Lookup auf die ShipBean, welche dann ihre zurückgelegte Distanz mit der der PlaneBean aus dem vorherigen Anwendungsbeispiel vergleicht. Die Abfrage erfolgt diesmal nicht im applikationsweiten Namensraum, da sich die PlaneBean in einer anderen Applikation befindet. Aus diesem Grund muss die Abfrage über den globalen Namensraum erfolgen. Die ShipBean baut sich daher wie folgt auf: package<com.esentri.jndi;< < import<com.esentri.jndi.transportation.TravelOption;< import<com.esentri.jndi.transportation.VehicleColor;< < import<javax.ejb.Stateless;< < import<javax.naming.Context;< import<javax.naming.InitialContext;< import<javax.naming.NamingException;< < @Stateless(name<=<"Ship")< public<class<ShipBean<implements<TravelOption<{< <<<< <<<<@Override< <<<<public<String<vehicle()<{< <<<<<<<<return<"ship";< <<<<}< < <<<<@Override< <<<<public<String<travelledDistance(int<i)<{< <<<<<<<<return< "Average< distance< travelled< with< "+vehicle()+"< after< "+i+"hour(s):< "<+<i*25<+<"<mile(s).";< <<<<}< < <<<<@Override<<<<public<String<compareTravelDistance(int<i)<{< <<<<<<<<try<{< <<<<<<<<<<<<Context<ctx<=<new<InitialContext();< <<<<<<<<<<<<TravelOption< plane< =< (TravelOption)< ctx.lookup("java:global/s5_applookup/advancedvehicles/Plane");< <<<<<<<<<<<<return<travelledDistance(i)+"\n"+plane.travelledDistance(i);< <<<<<<<<}<catch<(NamingException<e)<{< <<<<<<<<<<<<return< "An< error< occurred< with< catching< the< context.\n"< +< e.getStackTrace();< <<<<<<<<}< <<<<}< }<< 25 Es ist drauf zu achten, dass in diesem Falle beide Beans das gleiche Interface implementieren. Beide Applikationen sind im selben WebLogic untergebracht, sodass sie den InitialContext ohne weitere zu übergebende Parameter aufrufen können. Sind die Applikationen (EAR) hingegen auf unterschiedlichen Servern untergebracht, so muss wie in der in Kapitel 3 erwähnten Klasse Lookup eine Hashtable mit Umgebungsvariablen mitgegeben werden. Abb. 13: Pfad der ShipBean in der Beispielapplikation Die Verwendung von Umgebungsvariablen ist vor allem dann notwendig, wenn auf eine Applikation einer anderen JVM respektive eines anderen Servers zugegriffen werden muss. Die genaue Angabe der Provider URL sowie des Nutzernamens und Passwort für den Zugriff zum Server sind hierbei essentiell. 3.7 Zugriff auf eine EJB mit mehreren Interfaces In den vorhergehenden Kapiteln waren die Beispiele derart ausgelegt, dass jede EJB nur ein einziges Interface implementierte. In diesem Kapitel wird darauf eingegangen wie es sich mit der Nutzung und dem Lookup von EJB verhält, welche zwei oder mehr Interfaces implementiert haben. Als Grundlage wird hierbei der Anwendungsfall von Kapitel 3.4 verwendet. Die BikeBean implementiert hierbei noch ein weiteres Interface: VehicleColor. Dieses soll einen einfachen String zurückgeben welches die Farbe des Transportmittels ausgeben soll. Ein globaler Lookup in der Form java:global/applicationName/moduleName/BeanName reicht nicht aus, da nun mehrere Interfaces implementiert werden und man nun nicht weiß über welches der Interfaces man auf die Bean zugreifen möchte. In diesem Falle muss das gewünschte Interface vollqualifiziert angegeben werden, das heißt samt Paketpfad (siehe Abb. 14). Das Interface wurde im Package com.esentri.jndi.transportation untergebracht. Aus diesem Grund wird !com.esentri.jndi.transportation.VehicleColor als Suffix angehängt. Damit ist der vollständige Pfad zur BikeBean zur Verwendung des Interface folgendermaßen: java:global/s7_twointerfaces/vehicles/Bike!com.esentri.jndi.transportation.TravelO ption< 26 Abb. 14: Lookup der BikeBean mit mehreren Interfaces Wenn eine EJB mehrere Interfaces implementiert ist es nicht immer ersichtlich auf welche Funktionen man zugreifen möchte, da der Zugriff auf die EJB eben über das Interface geschieht. Auch im WebLogic JNDI Tree wurde die Baumstruktur auf die mehreren implementierten Interfaces angepasst (siehe Abb. 15). Abb. 15: Interfaces der BikeBean im JNDI Tree Somit ist die Angabe des Interface notwendig, wenn die EJB mehrere Interfaces implementiert. Innerhalb der implementierten Methode eines Interfaces ist es jedoch möglich intern die implementierten Methoden eines anderen Interface aufzurufen, da das Interface lediglich den Zugriff auf die EJB bereitstellt. Beispielsweise könnte die Funktion vehicle() des TravelOption-Interface aufgerufen werden: @Override public String vehicleColor() { return „The color of the „ + vehicle() + „ is oracle red.“; } Die Syntax funktioniert bei allen Namensräumen nach dem gleichen Schema. Unabhängig vom Namensraum wird bei einer EJB mit mehreren Interfaces der oben erwähnte Suffix angehängt. 27 3.8 Aufruf einer EJB über ein Servlet und JSP In den vorangehenden Kapiteln wurden JNDI Lookups besprochen welche sich ausschließlich um Aufrufe zwischen Komponenten oder aus einer POJO heraus bewegten. In diesem Beispiel erfolgt der Lookup auf eine EJB sowohl aus einem Servlet als auch aus einer JSP heraus. Die verwendete EJB im Beispiel ist erneut die EJB CarBean aus den vorangehenden Anwendungsszenarien. Das Servlet zur Bean hat mehrere Möglichkeiten mit dieser zu kommunizieren. Eine Möglichkeit davon wäre die Referenzierung im komponentenweiten Namensraum: BlueBeanServlet.java: package<com.esentri.servlets;< import<…;< < public<class<CarBeanServlet<extends<HttpServlet<{< < @EJB(beanName<=<"Car“)< TravelOption<car;< < < protected<void<doGet(HttpServletRequest<request,<HttpServletResponse< response)< < < throws<ServletException,<IOException< < {< < < execute(request,<response);< < }< < < protected<void<doPost(HttpServletRequest<request,<HttpServletResponse< response)< < < throws<ServletException,<IOException< < {< < < execute(request,<response);< < }< < < private<void<execute(HttpServletRequest<request,<HttpServletResponse< response)< < < throws<ServletException,<IOException< < {< <<<<<<<request.setAttribute("carBean",<car.vehicle());< <<<<<<<request.setAttribute("distance",<car.travelledDistance(5));< <<<<<<<request.getRequestDispatcher("/CarBean.jsp").forward(request,<response);<<<< < }< }< Auf diese Weise kann über den privaten Namensraum nach der EJB gesucht werden. Dies ist nur solange gültig das Servlet sich auf derselben Serverinstanz befindet. Es werden zwei Attribute an die CarBean.jsp gesendet, welche diese dann verarbeitet. In diesem Falle ist es auch nicht mehr notwendig ein Lookup zu betreiben, da die Bean über Dependency Injection verwendet wird.< Da sich das Servlet in derselben Applikation befindet, kann über den java:global Namensraum sowie java:app auf die EJB zugegriffen werden. TravelOption<ejb<=<(TravelOption)< ctx.lookup("java:global/s8_servlet/vehicles/Car");< < Friend<ejb<=<(Friend)<ctx.lookup("java:app/vehicles/Car");< 28 CarBean.jsp: <%@<page<import="com.esentri.jndi.transportation.TravelOption"<%>< <%@<page<import="javax.naming.InitialContext"<%>< <%@<page<import="javax.naming.Context"<%>< <%@<page<import="java.util.Hashtable"<%>< <%@<page<import="com.esentri.servlets.*"<%>< <html>< <head><title>Calling<an<EJB<from<Servlet<and<JSP</title></head>< <body>< <%!< TravelOption<car;< %>< <%< try<{< <<<<<<<<Context<ctx<=<new<InitialContext();< <<<<<<<<car<=<(TravelOption)<ctx.lookup("java:global/08_servlet/VehiclesEJB/Car");< }< catch(Exception<e)<{< //<exception<code<here< }< %>< <p>< Chosen<travel<option<(JSP):<<%=<car.vehicle()<%><br>< Distance<after<5<hours<(JSP)<:<<%=<car.travelledDistance(5)<%>< </p>< <p>< Chosen<travel<option<(Servlet)<:<<%=<request.getAttribute("carBean")%><br>< Distance<after<5<hours<(Servlet)<:<<%=<request.getAttribute("distance")<%>< </p>< </body>< </html> Hiermit wird die EJB direkt über die JSP aufgerufen, der Lookup ist demnach direkt möglich. Eine sauberere Variante besteht jedoch darin die gewünschte EJB über das Servlet zu beziehen und die Kommunikation mit der EJB über das Servlet zu betreiben (siehe Abb. 16). Abb. 16: Beispielausgabe der JSP beim Zugriff über JSP und Servlet auf die EJB 29 4 Lookup im WebLogic Cluster 4.1 Zugriff auf WebLogic Cluster Die WebLogic Implementierung des JNDI ist auch im Cluster verwendbar. Führt ein Client eine Anfrage an den Cluster über einen Kontext aus, so wird dieses nach einem Load Balancing Algorithmus – als Standard das Round Robin Verfahren - von einer Serverinstanz aus dem Cluster zurückgegeben. Dieser Vorgang wird vom WebLogic automatisch verwaltet. Als Vorraussetzung für das Load Balancing ist die Angabe aller Cluster-Knoten in der Provider-URL als kommaseparierte Liste oder ein DNS Name welcher repräsentativ für den Cluster steht. Wird als Provider-URL nur ein Server ausgewählt, so findet kein Load Balancing statt, das InitialContext Objekt wird von diesem Server zurückgegeben. Wird eine EJB auf mehreren Cluster-Knoten deployed, so enthält der JNDI Tree jedes Servers einen sogenannten Replica-Aware Stub für diese EJB. In diesem Stub sind alle Serverinstanzen im Cluster verzeichnet, welche diese EJB hosten. Sollte die Ressource während einer Transaktion nicht erreichbar sein wird ein Failover ausgeführt. Hierbei übernimmt eine Kopie der Ressource welche auf einem anderen Clusterknoten deployed ist die Transaktion. Der WebLogic Server trägt die Verantwortung dafür dass alle Server im Cluster ihren JNDI Tree auf demselben Stand haben. Das Beispiel demonstriert ein LookUp auf ein Objekt, das auf allen Cluster-Knoten verfügbar ist: Hashtable<env<=<new<Hashtable(<);< env.put(Context.INITIAL_CONTEXT_FACTORY,< < „weblogic.jndi.WLInitialContextFactory“);< env.put(Context.PROVIDER_URL,<„t3://myclusteraddress:7007“);< < //Verbindung<zum<clusterübergreifenden<JNDI<Tree< Context<ctx<=<new<InitialContext(env);< //Ab<hier<kann<der<LookUp<auf<das<Objekt<erfolgen< Im klassischen Fall wird die Adresse über ein DNS Namen repräsentiert. Im oberen Beispiel wird der Wert für die Property PROVIDER_URL auf den DNS Namen mycluster gesetzt. Dieser ist stellvertretend für jeden Server im Cluster. Anstattdessen ist es ebenfalls möglich eine durch Kommata getrennte Liste von Serveradressen anzugeben. env.put(Context.PROVIDER_URL,<„t3://ManagedServer1:7001,< ManagedServer2:7002,ManagedServer3:7003“);< Für den WebLogic Server entwickelte Oracle ein eigenes Protokoll für die Kommunikation über RMI Objekte, namentlich das T3 Protokoll. Laufen mehrere Teilnehmer des Clusters unter dem gleichen Port, so kann der Umgebungsvariablenparameter zur Provider URL wie folgt angegeben werden. Env.put(Context.PROVIDER_URL,< „t3://ManagedServer1,ManagedServer2,ManagedServer3:7001“);< Zum Aufbau des InitialContext im Cluster ist es nicht zwingend notwendig, alle Server anzugeben. Die Angabe des Cluster DNS ist hierbei ausreichend. Wird nur einer der Server aus dem Cluster als Provider angegeben, so wird explizit zu diesem Server der Kontext aufgebaut, es findet kein Load Balancing statt. Die Methodenaufrufe auf die Ressourcen erfolgen dann stets gegen den explizit gewählten WebLogic Server. Da alle Serverknoten jedoch die gleiche Information miteinander teilen, kann somit dennoch auf alle Ressourcen im Cluster zugegriffen werden. 30 4.2 Load Balancing Lookup-Anfragen auf einen nicht mehr erreichbaren Server werden auf einen einen noch „lebenden“ Server umgeleitet. Obwohl das Kontextobjekt an einen bestimmten Server gebunden ist, so ist es sich dennoch über den Rest des Cluster „bewusst“ – es kennt alle teilnehmenden Server im Cluster. Wenn ein Server an welches das Kontextobjekt gebunden ist ausfällt so werden Anfragen auf das Kontextobjekt automatisch als Failover auf einen anderen verfügbaren Server weitergeleitet. Folgendes Beispiel zwischen drei Clusterteilnehmern demonstriert diese Eigenschaften. Context<ctx<=<null;< Hashtable<env<=<new<Hashtable();< env.put(Context.INITIAL_CONTEXT_FACTORY,<„weblogic.jndi.WLInitialContextFactory“);< env.put(Context.PROVIDER_URL,< „t3://ClusterMember1,ClusterMember2,ClusterMember3:7001“);< ctx<=<new<InitialContext(env);< for<(int<i<=<0;<i<<<100;<i++)<{< DataSource<ds<=<(DataSource)<ctx.lookup(„myDS“);< }< 4.2.1 Round Robin Fällt nun ein Clustermitglied aus, so wird standardmäßig im Round Robin Verfahren der Lookup auf die beiden verbleibenden Server alterierend ausgeführt. Fällt einer dieser beiden verbliebenen Server ebenfalls aus, so wird das Round Robin Verfahren eingestellt. Die Context Factory erkennt die ausgefallenen Server, die Datenquelle wird ab dann nur noch vom letzten verbleibenden Server zur Verfügung gestellt. Das Round Robin Verfahren bei den Anfragen auf das Kontextobjekt alteriert allerdings nur in obigem Beispiel, da hier mehrmals der Token von einem Server auf den nächsten Eintrag in der Provider URL übergeben wird. Das Kontextobjekt ändert sich nur im Falle eines Failover. Wenn ein Server an welchen der Kontext gebunden ist ausfällt, so wird der Kontext im Round Robin Verfahren an den nächsten Server weitergereicht. Eine Anfrage zu einer Datenquelle eines ausgefallenen Servers A wird demnach die Datenquelle des noch lebenden Servers B zurückgeben. Round Robin wird als Standardverfahren im WebLogic Server für Load Balancing bei EJBs wie auch RMIs angewandt. Dieses Standardverfahren wird durch den Parameter weblogic.cluster.defaultLoadAlgorithm bestimmt und lässt sich in der Administrationskonsole des WebLogic konfigurieren. In den EJB Deployment Descriptor lässt sich das Load Balancing ebenfalls mittels home-load-algorithm oder stateless-bean-load-algorithm bestimmen. Derart ausgeführte Anpassungen überschreiben für diese Komponenten das Standardverhalten des Load Balancing des Clusters. Dieses Load Balancing für EJBs und RMIs wird über sogenannte replica-aware Stubs kontrolliert und wird in Kapitel 4.3.2 näher erläutert. Ferner wird das Verfahren im Cluster nicht immer ausgeführt – sollte der Server welcher die Anfrage stellt ein Replikat der EJB bei sich lokal liegen haben, so wird auf diese lokale Kopie zurückgegriffen. Das Round Robin Verfahren kommt somit nicht zum Einsatz, da die Ressource nicht von einem anderen Clustermitglied bezogen werden muss. Es wird empfohlen, diesen Standardalgorithmus beizubehalten, wenn das Load Balancing in einem homogenen Cluster betrieben werden muss. 4.2.2 Weight-Based Neben dem Standardalgorithmus Round Robin ist es möglich stattdessen andere Algorithmen für das Load Balancing einzusetzen. Eine davon ist das Weight-Based Verfahren, welches eine verbesserte Form des Round Robin darstellt indem einzelne Server im Cluster gewichtet werden und diese Gewichtung in das Load Balancing mit einfließt. In der Administrationskonsole lässt sich die Gewichtung für jeden Server einzeln einstellen, in welchem Verhältnis dieser Server zu den anderen Clustermitgliedern gewichtet wird. Wählt man den zu gewichtenden Server, so kann unter Konfiguration -> Cluster im Feld Clustergewichtung eine Zahl zwischen 1 und 100 eingetragen werden welche die Gewichtung dieses Servers darstellt (siehe Abb. 17). 31 Abb. 17: Konfiguration der Gewichtung einzelner Server im Cluster Besitzt beispielsweise ein Server eine Gewichtung von 50 und die anderen Server im Cluster eine Gewichtung von 100, so wird diese Last auf diesem Server nur halb so hoch sein wie auf den anderen Servern. Dies ermöglicht einen Round Robin Ansatz in homogenen Clustern. Beim Einsatz dieses Algorithmus müssen folgende Aspekte in die Bewertung mit einfließen: ! ! Die Leistungskapazität des Servers im Vergleich mit anderen Clustermitgliedern (z.B. Anzahl und Performanz der CPU des WLS) Die Anzahl der Objekte welche nicht im Cluster repliziert werden (pinned Objects) Die Information über die Gewichtung des Servers wird über die Replica-Aware Stubs im Cluster verbreitet. Das Weight-Based Load Balancing wird im WebLogic Server 12.1.3 für Objekte nicht unterstützt, welche über das RMI/IIOP Protokoll kommunizieren. Falls ein heterogener Cluster im Einsatz ist sollte dieses Load Balancing Verfahren angewandt werden um eine optimale Lastenverteilung zu gewährleisten. 4.2.3 Random Bei einem Random Load Balancing Algorithmus werden die Anfragen zufällig an die Clusterserver verteilt. Es wird empfohlen dieses Verfahren nur in einer homogenen Clusterumgebung zu verwenden, in der jede Serverinstanz die gleiche Konfiguration und Hardware vorweist. Existiert im Cluster ein Server mit wenig Rechenleistung, so wird diesem Server dennoch genauso viele Anfragen zugeteilt wie einem Server des Clusters mit mehr Rechenleistung. Bei einer ausreichend hohen Anzahl an Serveranfragen behandeln alle Server des Clusters gleichviele Anfragen durch diesen Load Balancing Algorithmus und ist mit einer höheren Anzahl ausgeglichener. Beim Random Load Balancing wird mit jedem Request eine Zufallszahl generiert, weshalb die Performanz etwas beeinträchtigt ist. Durch den Zufallsalgorithmus kann es ebenfalls oft vorkommen dass bei einer geringen Requestanzahl keine gleichmäßige Verteilung der Anfragen stattfindet. Diese zufällige Lastenverteilung könnte daher nur in einem homogenen Cluster stattfinden. Dieser Algorithmus ist nur bei einer hohen Anzahl an Requests ausgeglichen. Da jedoch zu jedem Request eine Zufallszahl generiert werden muss kann dies die Performance einschränken. Fällt der Server aus an welchen der Request gerichtet war so wird erneut eine Zufallszahl ermittelt. Es ist daher empfehlenswert eher auf Round Robin oder einer gewichteten Lastenverteilung zurückzugreifen. 32 4.2.4 Serveraffinität WebLogic Server unterstützt über die drei in den vorangegangenen Load Balancing Algorithmen für RMI Objekte, welche die sogenannte Serveraffinität (server affinity) unterstützen. Diese Serveraffinität hat zur Folge dass bei Requests eines externen Clients diese nicht im Load Balancing Algorithmus verteilt werden sondern stets an den Server gehen mit welchem der externe Client bereits verbunden ist. Wird ein Objekt für Serveraffinität konfiguriert, so greift der externe Client auf dieses Objekt immer über den Server zu mit welchem er bereits verbunden ist und führt von diesem die Methoden aus. Falls die Serverinstanz ausfällt, so wird ein Failover auf eine Serverinstanz ausgeführt, mit welcher der Client bereits verbunden ist. Mit dem Einsatz der Serveraffinität wird das Ziel verfolgt eine möglichst geringe Anzahl an offenen IP Sockets zwischen einem externen Client und Serverinstanzen eines Clusters zu halten. Der WebLogic Server wird Methodenaufrufe auf Objekte stets über eine bereits bestehende Verbindung ausführen, anstatt die Aufrufe über Load Balancing auf andere Clustermitglieder zu verteilen. Die Verbindung wird erst dann gewechselt, wenn die Serverinstanz an welche die Methodenaufrufe gerichtet waren ausfallen sollte. Das Load Balancing ist jedoch nur für die Verbindungen von externen Clients ausgeschaltet – das Load Balancing zwischen Servern ist weiterhin aktiv. Wenn eine Serverinstanz auf eine Ressource zugreifen möchte welche nicht in der eigenen Instanz verfügbar ist (pinned Object), so wird die Ressource über den gewählten Load Balancing Algorithmus aus einem der anderen Serverinstanzen bezogen welche diese Ressource haben. Über die Administrationskonsole lässt sich ein Load Balancing Algorithmus auswählen, sowohl mit als auch ohne die Option der Serveraffinität. Hierfür muss im JNDI Tree zu Umgebung -> Cluster navigiert und anschließend der gewünschte Cluster ausgewählt werden. Unter dem Tab Konfiguration -> Allgemein lässt sich das Load Balancing unter Standardauslastungsalgorithmus auswählen, welches Clusterweit gültig ist (siehe Abb. 18). Auf dieser Seite lässt sich ebenfalls die DNS Adresse des Clusters angeben oder auch kommatagetrennt eine Liste der Managed Server im Cluster. Abb. 18: Konfiguration des Default Load Balancing Ein (externer) Client kann einen initialen Context zu einem Cluster als auch von einem einzelnen Server anfragen. Die Serveraffinität kann bei der Initialisierung der Umgebungsvariablen gesetzt werden. h.put(weblogic.jndi.WLContext.ENABLE_SERVER_AFFINITY,<„true“);< 33 Dies kann jedoch nur erfolgen, wenn die Anfrage an das Context Objekt an den Cluster gerichtet ist. Der Verbindungsprozess hängt vom Kontext ab: ! Wird die Anfrage um das InitialContext Objekt an einen bestimmten ManagedServer gestellt, so wird eine Verbindung zu diesem Server hergestellt. Das Context Objekt sowie alle Anfragen über dieses Objekt gehen über die gewählte Instanz. ! Wird die Anfrage um das IntialContext Objekt an den Cluster gestellt, so werden alle Anfragen welche über diesen Kontext versendet werden per Load Balancing an die Clustermitglieder verteilt. Um eine bestehende Verbindung aufrecht zu erhalten wird die Serveraffinität eingesetzt. Falls eine Verbindung noch nicht existiert wird eine neue Verbindung aufgebaut. Die Serveraffinität hat hierbei jedoch nur dann Auswirkung wenn die Anfrage auf das Context Objekt an den Cluster gerichtet ist. Der InitialContext wird demnach im Round Robin Verfahren von einem Server des Clusters zurückgegeben. Bei einem Lookup auf eine EJB über diesen Kontext wird vom selben Server der Stub zurückgegeben. Dieser Stub weiß auf welchen Servern die gewünschte Bean sich befindet – auch wenn das Objekt sich nicht auf dem Server befindet, an welchen der Lookup gerichtet ist (näheres dazu in Kapitel 4.3.2). Das Load Balancing findet auf Verbindungslevel statt. Möchte man das Load Balancing auch über jeden Lookup ausführen, so muss in der Umgebungsvariable folgender Parameter hinterlegt sein: env.put(„LoadBalanceOnLookup“,<„true“);<< 34 4.3 Failover Wenn eine Applikation auf einem Server läuft und dieser ausfallen sollte, so kann auf die Applikation nicht mehr zugegriffen werden. Um die Verfügbarkeit zu erhöhen werden Applikationen auf einem Servercluster betrieben, auf welchem die Applikation auf jeder Serverinstanz läuft. Findet nun beim Zugriff auf eine Ressource ein Serverausfall statt, so wird der Request zu dieser Ressource an eine andere Serverinstanz weitergeleitet. Diesen Vorgang bei welchem ein Request bei Serverausfall von einem anderen Server angenommen wird nennt man Failover. 4.3.1 Failover Detection WebLogic Serverinstanzen entdecken Ausfälle im Cluster indem ein Monitoring betrieben wird auf: ! Socketverbindungen zu einem Server ! Sogenannte Heartbeat Nachrichten Wenn ein WebLogic Server über einen Socket Daten überträgt und dieser Socket sich unerwartet schließt, so wird der Server als failed markiert. Alle Services welche über diesen Server verfügbar waren werden aus dem JNDI Tree entfernt. Falls Clustermitglieder keine Sockets für eine Verbindung geöffnet haben, so können ausgefallene Server über den Heartbeat ermittelt werden. Alle Serverinstanzen im Cluster senden den anderen Mitgliedern regelmäßig eine Nachricht. Diese Nachricht enthält Daten über welche der sendende Server eindeutig identifiziert werden kann. Diese Nachricht wird dabei mit multicast oder unicast an andere Clustermitlieder in einem Intervall von 10 Sekunden versendet. Jeder Server sendet dabei über Multicast oder an die Unicast Adresse. Wird von einem Server nach drei Heartbeatperioden hintereinander keine Nachricht empfangen so markiert der observierende Server diesen Server als ausgefallen. Es aktualisiert danach seinen JNDI Tree um die Einträge der Services des ausgefallenen Servers zu entfernen. 4.3.2 Replica-Aware Stubs Für EJB und RMI Objekte im Cluster wird das Failover von sogenannten Replica-Aware Stubs gemanaged. Führt man im Cluster ein Lookup auf eine EJB durch, so wird dem Client ein Stub zurückgegeben. Dieser Stub beinhaltet eine Liste aller auf dem Server befindlichen Replika dieser EJB. Jedes Clustermitglied auf welchem eine Instanz der EJB deployed wurde wird als Replika bezeichnet. Der Stub, welche der Client erhält, ist sich über den Aufenthaltsort der Replikate bewusst (replica-aware). Der Stub weiß demnach, auf welchen Servern die EJB als Instanz (Replika) vorliegt. Diese Replika-Aware Stubs ist die Schlüsseltechnologie im WebLogic, um das Clustering von Objekten zu ermöglichen. Wenn eine EJB deployed wird, so werden deren Interfaces an den rmic Compiler gesendet. Dieser Compiler generiert die Replica-Aware Stubs für die EJB. Versucht der Client nun über diesen Stub eine EJB aufzurufen deren Server ausgefallen ist, so entdeckt der Stub diesen Ausfall und leitet einen Failover auf einen anderen Server um, auf welchem ebenfalls eine Replika dieser EJB vorhanden ist. Der Stub einer EJB welcher dem Client gegeben wird beinhaltet neben einer Liste der Replika auf den Serverinstanzen auch den Load Balancing Algorithmus. Eine EJB kann ihren eigenen Load Balancing Algorithmus verwenden, welcher den vom WebLogic voreingestellten Load Balancing Algorithmus überschreibt. Wird eine Methode der EJB aufgerufen, so entscheidet der Stub anhand des ihm gegebenen Algorithmus (von der Bean oder vom WebLogic) welche Replika der EJB diese Methode ausführen wird. Tritt ein Fehler beim Aufruf einer EJB auf so fängt der Stub diesen Fehler ab und versucht den Aufruf erneut auf einer anderen Replika. Wenn ein neuer Service (EJB) auf dem Server deployed wird, so sendet der Server den Stub zu den anderen Clustermitgliedern. Über die Unicast oder Multicast Adresse erfahren die anderen Server ob eine Serverinstanz im Cluster einen neuen Service bzw. Komponente bietet. Somit besitzt jede Serverinstanz ihre eigene lokale Kopie eines clusterweiten JNDI Tree und tauschen untereinander Informationen über ihre bereitgestellten Services aus. Die JNDI Bäume der WebLogic Serverinstanzen aktualisieren sich automatisch. 35 4.4 Anwendungsfälle im Cluster Um ein besseres Verständnis zum Load Balancing und Failover im WebLogic zu bieten, beschäftigt sich dieser Abschnitt mit möglichen Anwendungsfällen im Cluster. Es wird aufgezeigt, wie sich Lookups im Cluster unter der Berücksichtigung von Load Balancing und Failoverszenarien für externe Clients sowie Clusterintern verhalten. 4.4.1 externer Client Dieser Abschnitt soll anhand eines Zugriffs von einem externen Client aus mögliche Anwendungs-szenarien darstellen. Wie in Abb. 19 ersichtlich wird fragt der externe Client den Cluster nach einem initialen Kontext an, über welchen die Lookups betrieben werden können. Abb. 19: Szenario eines externen Clientzugriffes Das Kontextobjekt wird anhand der als Parameter mitgegebenen Umgebungsvariablen erstellt. Als Provider des Kontextobjektes wird eine Kommaseparierte Liste der einzelnen Clustermitglieder mitgegeben. Alternativ kann auch eine virtuelle Adresse des Clusters angegeben werden, welches eine DNS Adresse darstellt und nach den Adressen der einzelnen Clustermitglieder auflöst. Im Round Robin Verfahren erhält der Client den Kontext einer der in der Umgebungsvariable angegebenen Provider, beispielsweise den Kontext des Managed Servers 1 (MS1). Alle Lookups über dieses Kontextobjekt laufen über denselben Kontext. Da jeder Server sich über alle im Cluster hinterlegten Objekte bewusst ist, ist es prinzipiell irrelevant von welchem Server der externe Client den Kontext erhält. Der Client führt nun einen Lookup auf das Objekt A und erhält den Replica-Aware Stub des Objektes A zurück. In diesem ist verzeichnet, auf welchen Servern dieses Objekt deployed ist. Im oberen Beispiel befindet sich das Objekt A auf den Servern MS1, MS2 und MS4. Würde der Client erneut mit denselben Umgebungsvariablen einen InitialContext anfordern, würde er den Kontext vom nächsten MS in der Providerliste erhalten. Wird nun auf die EJB zugegriffen (Methodenaufruf), so geschieht dies über den Replica-Aware Stub. Dieser Stub leitet die Methodenaufrufe im für den WebLogic konfigurierten Load Balancing Verfahren durch die Clustermitglieder, auf welchen das Objekt hinterlegt ist. 36 Wurde beispielsweise ein Round-Robin Verfahren gewählt, so geht der erste Methodenaufruf an MS1, der zweite an MS2, der dritte an MS4, die darauf folgenden beginnen erneut mit MS1. Wurde ein Random Load Balancing gewählt, so wird der Methodenaufruf zufällig an eine der drei Managed Server verteilt. Wurden im Deployment Descriptor Angaben über ein Load Balancing Verfahren für diese EJB angegeben, so werden für diese EJB nur das im DD angegebene Load Balancing Verfahren angewandt. Das ist insbesondere soweit interessant, da ein mit Serveraffinität konfiguriertes LB Verfahren im Cluster für diese EJB unwirksam werden kann, sofern das Load Balancing im Deployment Descriptor entsprechend angegeben wurde. Wurde ein serveraffines Load Balancing gewählt, so wird für externe Clients das Load Balancing abgeschaltet. Da der Client im oberen Beispiel bereits mit MS1 verbunden ist und dieser eine Replika von Objekt A besitzt, werden alle auf Objekt A gehenden Methodenaufrufe an MS1 geleitet. Möchte der Client auf Objekt D zugreifen und macht einen Lookup über den Kontext von MS1, so erhält er den Stub zu Objekt D, welcher dann die Methodenaufrufe über MS2, MS3 und MS4 im LB Verfahren des Servers oder DD (sofern angegeben) verteilt. Im Falle eines serveraffinen Load Balancing wird zunächst der Load Balancing Algorithmus verwendet um eine Verbindung zum Server herzustellen. Alle Methodenaufrufe welche ab diesem Punkt auf Objekt D gehen laufen über die bestehende Verbindung. Wenn der Client auf A zugreifen möchte und MS1 ausfallen sollte, so wird der Methodenaufruf an eine der beiden verbliebenen Server im LB Verfahren weitergeleitet. Solange wie MS1 nicht erreichbar ist, wird MS1 nicht mehr in der Liste des Stub als Provider von Objekt A aufgeführt. Im Falle eines Failover werden auch Lookups an andere Server weitergeleitet, sodass der Stub von einem anderen Server kommt. 37 4.4.2 clusterinterne Lookups Abschließend soll hier die serverinterne Kommunikation über Lookups betrachtet werden, da einige Aspekte sich von dem Zugriff über externe Clients unterscheiden. Das untere Schaubild Abb. 20 zeigt auf, dass ein Kontextaufbau von einem Clustermitglied ohne Umgebungsvariablen auskommt. Da die Serverinstanz selbst ein Mitglied des Clusters ist und weiß welche Server in seinem Cluster welche Objekte anbieten werden die Umgebungsvariablen nicht benötigt. Bei einem Lookup wird über den eigenen Replica-Aware Stub auf das Objekt zugegriffen. Abb. 20: Szenario eines internen Zugriffes mit Load Balancing und Failoveroptionen Im oberen Beispiel führt ein Objekt aus MS3 einen Lookup auf Objekt A durch. Als Provider sind MS1, MS2 und MS4 gelistet. Methodenaufrufe auf Objekt A werden im LB Algorithmus (WebLogic oder DD) unter den Providern verteilt. Die Besonderheit hierbei ist, dass Serveraffinität nicht greift. Gleichgültig ob die Serveraffinität im WebLogic oder im DD der EJB angegeben wurde werden Methodenaufrufe clusterintern stets im Load Balancing Verfahren verteilt. Fällt Serverinstanz MS1 aus auf welcher Objekt A hinterlegt war, so aktualisiert MS3 seinen Stub und nimmt MS1 aus der Liste heraus. Die Methodenaufrufe alterieren fortan zwischen MS2 und MS4. Möchte ein Objekt B aus MS3 auf ein Objekt D einen Lookup betreiben, so wird kein Load Balancing ausgeführt. Die Serverinstanz MS3 besitzt selbst eine Replika von Objekt D und gibt als Ergebnis des Lookup keinen ReplicaAware Stub sondern einen lokalen Stub zurück. Da der Client und das Ziel des Lookup sich auf derselben Instanz befinden ist es effizienter und performanter wenn das Ergebnis von derselben Instanz geliefert wird. 38 5 Best Practices & Empfehlungen Dieses Kapitel fasst abschließend alle in diesem Whitepaper ausgesprochenen Empfehlungen zusammen und ermöglicht einen Überblick für Best Practices in der Referenzierung von EJBs im WebLogic. @Local statt @Remote Häufig miteinander kommunizierende Beans sollten sich mit einem lokalen Interface aufrufen können und sollten daher wenn möglich auf derselben JVM hinterlegt sein. Die Verwendung von lokalen Interfaces folgt der pass-byreference Semantik und ist wesentlich performanter als die remote pass-by-value Semantik, bei welcher Argumente erst kopiert und dann über das Netz übertragen werden müssen. mappedName wenn möglich vermeiden Das providerspezifische Attribut mappedName sollte so weit wie möglich vermieden werden. Jede auf dem Server hinterlegte Ressource ist unter einem Namen hinterlegt. Wird mappedName für eine EJB oder eine andere Ressource gesetzt, so muss man dafür Sorge tragen dass jeder Name auf dem Server nur einmal vorhanden ist. Ferner implementieren alle Provider den mappedName auf ihre eigene Art, sodass ein gesetzter mappedName auf einem Applikationsserver nicht zwingend auf anderen Servern akzeptiert wird. MappedName sollte verwendet werden wenn die Applikation nur auf einem bestimmten Applikationsserver lauffähig sein soll. In allen anderen Fällen sollte darauf verzichtet werden. Keine manuellen DD Anpassungen in Java EE 6 Die Java EE 6 Spezifikation wurde so erstellt, dass wenig bis keine manuellen Anpassungen im Deployment Deskriptor mehr notwendig sind. Die Arbeit sollte dem Container überlassen werden um sich die Mühe der Konfiguration zu ersparen. Deployment Deskriptoren sollten erst dann händisch konfiguriert werden, wenn dieselbe Konfiguration nicht durch Annotationen erreicht werden kann. Neuere Technologie verwenden Es sollte Java EE 6 oder höher zusammen mit EJB 3.1 verwendet werden. Für EJBs muss nicht mehr explizit RMI spezifischer Code geschrieben werden, es sind weniger Konfigurationen am DD erforderlich und die durch Java EE 6 hinzugekommenen Namensräume ermöglichen eine höhere Flexibilität. Die Verwendung neuerer Versionen bietet einen geringeren Aufwand in der Entwicklung und Wartung von Applikationen. Dependency Injection statt Lookups innerhalb der Applikation Referenzen innerhalb einer Applikation (EAR) sollten mit DI gesetzt werden. Dies erfordert wesentlich weniger Programmcode und mögliche Referenzprobleme werden bereits zur Kompilierzeit aufgedeckt. Referenzen außerhalb der EAR können mit Lookups erreicht werden. Kleinsten Namensraum bei Lookups verwenden Wird eine Referenz über einen Lookup erstellt, so sollte stets über den kleinstmöglichen Namensraum diese referenziert werden. Für eine Ressource im selben Modul sollte java:module verwendet werden, eine Ressource innerhalb derselben EAR sollte java:app verwendet werden. Darüber hinaus wird java:global eingesetzt, um Referenzen auf Ressourcen außerhalb der EAR und des Servers herzustellen. Je weitreichender der Namensraum ist, umso höher ist der Overhead. Hier sollte ebenfalls bereits bei der Erstellung der Applikation darauf geachtet werden, dass möglichst oft miteinander kommunizierende Ressourcen beieinander liegen. Namen logisch für Lookups definieren Der WebLogic Server bezieht die Namensgebung für das JNDI aus den Namen der Deploymentprofile für die Module und Applikationen. Das Deploymentprofil sollte demnach für Modul wie Applikation einen für das Modul logischen passenden Namen beinhalten. 39 Clusterrepräsentativen DNS Namen wählen Damit das Load Balancing richtig funktioniert und die Server die Lastenverteilung optimiert durchführen können wird empfohlen einen DNS Namen repräsentativ für den Cluster anzugeben. In diesem Falle kann das Load Balancing Verfahren eingesetzt werden, bei der Erstellung der Umgebungsvariablen für den InitialContext muss nur diese eine Adresse angegeben werden. Load Balancing an Hardware anpassen Über die WebLogic Konsole lässt sich ein Load Balancing Algorithmus einstellen, standardmäßig kommt Round Robin zum Einsatz. Der Algorithmus sollte sich an der Hardware des Clusters anpassen falls Server im Cluster auf unterschiedlichen Maschinen laufen. Sollte der Cluster heterogen sein (d.h. die Maschinen auf welchen die Server laufen unterschiedliche Rechenleistung haben), so sollte ein gewichteter Load Balancing Algorithmus gewählt werden um die Last auf weniger leistungsstarken Maschinen zu verringern. In homogenen Clustern kann Round Robin beibehalten werden. Wenn der Cluster eine hohe Anzahl an Transaktionen verarbeitet kann alternativ ein Zufallsalgorithmus angewandt werden. 40 Abbildungsverzeichnis Abb. 1: Übersicht über die Java Enterprise Edition Architektur .................................................................................................................... 5! Abb. 2: Auszug des Quellcode aus einem weblogic-ejb-jar.xml ................................................................................................................... 9! Abb. 3: Konfiguration des weblogic-ejb-jar.xml ....................................................................................................................................................... 9! Abb. 4: Beispiel eines WebLogic JNDI Tree in der Administrationskonsole ...................................................................................... 10! Abb. 5: WebLogic Server Administrationskonsole, Zugriff auf den JNDI Tree ................................................................................ 11! Abb. 6: java:comp/env Namensraum der EJB1 mit Referenz auf EJB2 ................................................................................................... 13! Abb. 7: Enterprise Application über mehrere EAR, Java EE 6 Namensräume................................................................................... 14! Abb. 8: Auszug aus dem JNDI Tree der BlueBean (nach der Anpassung am Deploymentprofil) ......................................... 20! Abb. 9: Beispielausgabe des Methodenaufrufs nach dem Lookup ............................................................................................................ 20! Abb. 10: Beispiel der CarBean mit car-vehicle als mappedName ............................................................................................................. 21! Abb. 11: Beispielausgabe – Die EJB Car führt einen Lookup über java:comp/env aus ................................................................. 23! Abb. 12: Die Mappings innerhalb der EAR auf den beiden Modulen ..................................................................................................... 24! Abb. 13: Pfad der ShipBean in der Beispielapplikation ..................................................................................................................................... 26! Abb. 14: Lookup der BikeBean mit mehreren Interfaces ............................................................................................................................... 27! Abb. 15: Interfaces der BikeBean im JNDI Tree .................................................................................................................................................. 27! Abb. 16: Beispielausgabe der JSP beim Zugriff über JSP und Servlet auf die EJB.............................................................................. 29! Abb. 17: Konfiguration der Gewichtung einzelner Server im Cluster ..................................................................................................... 32! Abb. 18: Konfiguration des Default Load Balancing........................................................................................................................................... 33! Abb. 19: Szenario eines externen Clientzugriffes ................................................................................................................................................ 36! Abb. 20: Szenario eines internen Zugriffes mit Load Balancing und Failoveroptionen ................................................................. 38! 41 Quellen [BOND, Martin; HAYWOOD, Dan; LAW, Debbie; LONGSHAW, Andy; ROXBURGH, Peter] „SAMS Teach Yourself J2EE in 21 Days“, 2002 Sams Publishing [ORACLE Corporation] „The Java EE 6 Tutorial“ [CHUGH, Avinash; MOUNTJOY, Jon] WebLogic: The Definitive Guide, Februar 2004 https://gardiary.wordpress.com/2009/01/05/the-most-basic-call-ejb-3-from-servlet-or-jsp/ http://tomee.apache.org/examples-trunk/lookup-of-ejbs/README.html http://docs.oracle.com/javaee/5/tutorial/doc/bncji.html http://www.onjava.com/pub/a/onjava/2006/01/04/dependency-injection-java-ee-5.html http://docs.oracle.com/javase/tutorial/jndi/ https://docs.oracle.com/cd/B12166_01/web/B10324_01/cluster.htm https://docs.oracle.com/middleware/1213/wls/CLUST/load_balancing.htm https://www.safaribooksonline.com/library/view/weblogic-the-definitive/059600432X/ch10s06.html http://what-when-how.com/enterprise-javabeans-3/accessing-resources-using-di-and-jndi-ejb-3/ 42