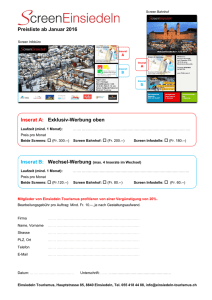
Screen Scraping wird zum Auslesen von Daten verwendet, die
Werbung

Erzwingen von Interoperabilität Screen Scraping, Bots und rechtliche Bestimmungen Abstract In der Ausarbeitung zum technischen Thema dieser Lehrveranstaltung wird vorrangig auf das Erzwingen von Interoperabilität, also auf die Verknüpfung nicht speziell Interoperabilität unterstützender Systeme, eingegangen. Besonderes Augenmerk soll dabei auf Screen Scraping, sowie auf dazu verwendete Software, gelegt werden. Weiters befasst sich die Arbeit mit den rechtlichen Fragestellungen, die durch die – vorab nicht beabsichtigte – Weiterverwendung dieser ausgelesenen Daten in den Vordergrund treten. Screen Scraping wird zum Auslesen von Daten verwendet, die ursprünglich nur als Output an das GUI oder auf die Website gelangen sollten. Daher müssen wertvolle Informationen durch Programmierung eines Scrapers von Formatierungscode, Redundanzen und von überflüssigen Kommentaren gefiltert werden. In einer kurzen Beschreibung diverser Methoden soll auf verschiedene programmiersprachenspezifische Rahmenbedingungen eingegangen werden. Der zweite Teil der Arbeit stellt vier der gängigsten Screen Scraper Tools vor, die zurzeit zum Einsatz kommen. Im Folgenden sei eine kurze Beschreibung dieser Wrapper angefügt: Dapper ist ein Tool zur flexiblen Generierung von Daten via Webbrowser. Sehr einfach können aus Services wie Youtube oder Flickr fertige Ausgaben produziert werden. Beispielsweise lassen sich neben fertigen RSS Feeds auch Google Maps Einträge oder Netvibes Module generieren. QL2s WebQL bietet eine SQL-ähnliche Syntax für die Datenextraktion. Dies vereinfacht es datenbankerfahrenen Entwicklern, sich schnell auf das Auslesen von Informationen zu konzentrieren. Nach erstmaliger Erstellung der WebQL Query kann diese auch serverseitig die Abfragen in regelmäßigen Zeitabständen durchführen. Neben Webseiten können auch Dokumente in allen gängigen Formaten, sowie Email Server, abgefragt und zusammengeführt werden. Ausgabeformate sind XML, Text, PDF, DOC, CSV und TAB. Lixto entstand als Spin-Off eines Forschungsprojektes der TU Wien. Lixto unterstützt die Auswahl der Daten für die Datenextraktion anhand eines graphischen User Interfaces. Basierend auf einem Algorithmus wird der (X)HTML/XML Wrapper generiert. Ähnlich der Konkurrenz kann Lixto die extrahierten Daten danach in verschiedenste Ausgabeformate, wie XML, Excel oder SQL, konvertieren. Des Weiteren kann die gewonnene Information auch über mobile Devices via WML rasch zugänglich gemacht werden. Kapow bietet mehrere Lösungen für das Screen Scraping an. Ähnlich wie bei seinen Konkurrenten ist es möglich, die gewünschten Daten erst via grafischen Editor auszuwählen. Daraus werden dann wiederum Regeln generiert, die nach Wunsch noch veränder t werden können. Auch hier sind die Ausgabeformate vielfältig und bieten außerdem die Möglichkeit einer Überführung der Daten in Development Toolkits wie AJAX, RUBY oder PHP. Des Weiteren können die Daten in IDEs wie Eclipse oder NetBeans integriert werden. Zuletzt werden rechtliche Komplikationen diskutiert, die durch die - oftmals nicht genehmigte Weiterverwendung gescrapeter Daten entstehen. Sowohl einzelne juristische Besonderheiten, als auch Methoden zum Schutz vor illegalem oder nicht berechtigtem Screen Scraping werden an dieser Stelle näher behandelt. Eine abschließende Analyse soll die Qualität der verschiedenen im Einsatz befindlichen Tools resümierend beleuchten, sowie deren weitere sinnhafte Verwendung in der Zukunft bewerten.