verteilte TSP – Lösung mit Branch-and
Werbung

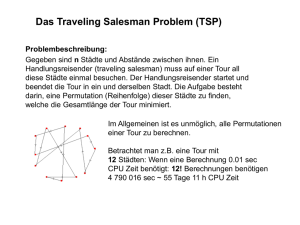
Modelle und Algorithmen für Planungsaufgaben verteilte TSP – Lösung mit Branch-and-Bound – Algorithmus Dennis Groppe 25.01.2006 1 Agenda 1. Thema 2. Traveling Salesman Problem 3. Branch-and-Bound - Branchen - Bounden 4. Lastverteilung auf Prozessornetzwerk 2 Thema ● ● ● Hardware: zur Verfügung steht ein Prozessortorus mit 1024 Prozessoren und eigenem Arbeitsspeicher Software: Einsatz eines auf Verteilung angepassten Branch-and-Bound – Algorithmus Ziel: finden einer „optimalen“ Lösung eines TSP. 3 Traveling Salesman Problem - Finden einer Rundreise mit minimalen Kosten, die alle Knoten einmal besucht und am Ende wieder am Ausgangspunkt ankommt (Hamiltonkreis) - Graph G=(V,E) - gewichtete Kanten w(ei) - Zielfunktion: n−1 z TSP =min ∑ w v i ,v i 1 w v n ,v 1 i=1 4 Branch-and-Bound – Algorithmus (1) TSP Є NP Komplexität liegt nicht unter exponentieller Laufzeit! => Heuristischer Algorithmus „Branch-and-Bound“ - gehört zu den Entscheidungsbaum-Verfahren - liefert bekanntermaßen gute TSP-Lösungen 5 Branch-and-Bound – Algorithmus (2) - Prinzip im wesentlichen: Suchen und Vergleichen aller Möglichkeiten - Einfügen eines neuen Knoten (Tourgröße m => m möglichen Verbindungen) - Einschränkungen - Nacheinander abarbeiten, nur wo Kosten unter Schwellenwert - bisher beste Tour abspeichern 6 Branch-and-Bound – Algorithmus (3) 1. Schritt: BRANCHEN (Verzweigung) rekursives Aufteilen des Problems in zwei oder mehrere Teilprobleme (Subprobleme) => Baumstruktur 2. Schritt: BOUNDEN (Beschränkung) Beschränken der Lösungsmenge durch Identifikation von suboptimalen Zweigen 7 Branchen (1) 8 Branchen (2) Best-First-Fit: ein Subproblem immer nach der besten „unteren Grenze“ (LB) auswählen und von dort aus weitersuchen => schnell gute Ergebnisse bekommen 9 Branchen (3): „1-tree“ Aufbau der Subprobleme als 1-tree: SP = Satz aller möglichen 1-trees 10 Branchen (4): 0-1-Integer – Programm n−1 P: n min ∑ ∑ i =1 j =i 1 c i , j x i , j so dass gilt: A1x=2 Beispiel: A1 * v1v1 v1v2 v1v3 v2v1 v2v2 v2v3 v3v1 v3v2 v3v3 v1 0 1 1 1 0 0 1 0 0 v2 0 1 0 1 0 1 0 1 0 v3 0 0 1 0 0 1 1 1 0 A 0 1 1 x =2 0 2 0 = 2 =2 0 2 0 1 11 0 Branchen (5): Relaxieren des Programms T T P'0: min C xπ A1 x −2 n−1 <=> P'1: min ∑ n ∑ i =1 j =i 1 c i , j π i π j x i , j π T: Lagrange – Multiplikator (je schlechter der 1tree, desto höher die Bestrafung) Jede Lösung für P' ist ein Lower Bound im Sinne der Länge einer optimalen Tour! optimale Lösung L für P' gefunden UND L auch Lösung von P => L ist optimal! 12 Branchen (6): Kantenauswahl alle Knoten haben Grad = 2 => fertig. ≥ 1 Knoten mit Grad ≥ 3 => Aufteilung in Subprobleme: 13 => Kantenmengen R(equired) und F(orbidden) Branchen (7): Knotenauswahl wähle im besten 1-tree einen Knoten: - verbunden mit einer Kante Є R - möglichst mit Grad 2 - insgesamt möglichst wenig verbundene Kanten 14 Bounden (1): Lower & Upper Bound LB: Gewicht des Weges von der Wurzel des Suchbaumes (Ausgangsknoten) bis zu einem Teilproblem = Gewicht eines 1-tree UB: ist der Wert der vorerst optimalen, zulässigen Lösung, d. h. die bis jetzt beste errechnete Lösung für das gegebene TSP Abschneiden (Bounden) bei LB > UB 15 Bounden (2): Berechnung des Upper Bound Heuristische Lösung: nehme die bis jetzt bekannte kürzeste Verbindung zu einem bekannten Stück dazu Erhöhe die Summe des Gewichtes des Weges um die minimale Kante, mit der man die Lösung zu einem neuen Knoten verbinden kann => Ergebnis: neue obere Grenze. 16 Reduktion des Lösungsraumes Identifikation von für Lösung irrelevanten Kanten Verbesserung der Einteilung in R und F mit - Edge Exchange - 2-opt-Algorithmus je mehr Kanten in R und F eingeteilt, desto besser der Upper Bound 17 Überblick: Lastverteilung auf Prozessornetzwerk - Torus von 1024 Prozessoren (jeweils 30MHz) - jeweils mit eigenem Arbeitsspeicher (4MB) für Heap mit Suchbaumknoten (Subprobleme) - ideal: n-faches Speedup - upper und lower bound ändern sich ständig! => damit auch die Prozessor- und Speicherauslastung 18 Lastverteilung – Ziele - Leerlauf minimieren - wenig Mittel für Kommunikation der Prozessoren aufwenden - wenig „search overhead“ - an möglichst vielen Prozessoren soll möglichst schnell der aktuell beste lower bound bekannt sein (beeinflußt Qualität der Berechnungen!) => Mittelweg führt zu bestem Speedup! 19 Gewichtsfunktionen (1) - haben einen parallel arbeitenden Branch-andBound – Algorithmus - genauso muss auf jedem Prozessor ein „LoadBalancer“ - Algorithmus arbeiten - Load Balancer entscheidet sowohl auf qualitativer (aktuell bester lower bound) als auch auf quantitativer (# Heapelemente) Basis 20 Gewichtsfunktionen (2) Qualität der Last: w LB pi =min LB spwobei sp∈H pi Quantität der Last: w# ( pi ) = |Hpi| wobei LB lower bound sp Subproblem |Hpi| Anzahl Heapelemente 21 Kommunikation (1) - jeder Prozessor hat 4 Nachbarn local decision: Lastverteilung auf Basis der Last der direkten Nachbarn ohne zentralen Prozessor local migration space: Last wird nur an die lokale Umgebung ausgelagert info.delay: konstante Zeit ohne Infos an Nachbarn => jetzt durchführen! (durchschn. Zeit für Berechnung eines Subproblems) 22 Kommunikation (2) 23 Kriterien zur Verteilung (1) Teilnahme an / Initiierung einer Lastverteilung, wenn... ΔLB: lower bounds zweier Nachbarn unterscheiden sich um mehr als 1,0. Δ#: Anzahl der Heapelemente zweier Nachbarn unterscheidet sich um 3. 24 Kriterien zur Verteilung (2) sendLB.rate: Anzahl der Unterprobleme, die während einer Balancierungsoperation verteilt werden. Liegt idealerweise zwischen mindestens 1 und höchstens 3. send#.rate: 65% erwieß sich als sinnvoll. 25 Kommunikation (3) – Nachrichten 4 Nachrichtentypen: IDLE: Prozessor ist im Leerlauf und wartet auf Teilprobleme SOLUTION: enthält upper bounds = die bis jetzt besten berechneten Lösungen. WORK: Enthält ein Unterproblem. INFO: Enthält die aktuellen Heapgewichte wLB und w# des sendenden Prozessors. 26 Loadbalancer - Algorithmus Beginn der Operation: 1. ein Prozessor p0 errechnet erstes Unterproblem 2. alle anderen Prozessoren senden IDLE 3. p0 sendet Teile des Unterproblems an seine 4 Nachbarn 4. Last verteilt sich auf den Prozessortorus 27 Ablauf: IDLE 1. Branch-and-Bound – Prozess hat keine Arbeit => setze IDLE-Zustand 2. wenn Heap nicht leer => bearbeite Subproblem aus Heap, sonst warte 3. Nachbarn informieren 28 Ablauf: Eingang eines neuen Subproblems (1) 29 Ablauf: Eingang eines neuen Subproblems (2) Bei Eingang eines neuen Subproblems: 1. Annahme durch Load Balancer 2. falls IDLE, Weitergabe an Branch-and-Bound – Prozess => Branch durchführen, Berechnung lower bounds für entstandene Unterprobleme 3. sonst: auf den Heap; evtl. Lastausgleich 4. zuerst wLB, dann w# balancieren 5. Nachbarn informieren 30 Ablauf: SOLUTION gefunden 1. Vergleich: errechneter lower bound < upper bound? 2. wenn ja: Neue SOLUTION an alle Nachbarn (außer Urheber) 31 Ablauf: INFO von den Nachbarn - jeder Prozessor speichert sich Infos über Last der 4 Nachbarn - wenn Nachbarn aktualisieren, wird Info auch lokal aktualisiert => Balancierung auf Grund aktueller Werte durchführen 32 sonstige Ablaufregeln - Bei Übermitteln von IDLE wird auch das beste Subproblem übergeben (1. Heapelement) - Bei info.delay: Wenn Prozessor merkt, er hat einen besseren LB als sein Nachbar, gibt er das 2. Heapelement ab (behält das Beste selber) - Wenn wLB gerade balanciert, aber w# unbalanciert: Abgabe der Elemente am Ende des Heaps 33 Ergebnisse (1) - TSP mit wenig Subproblemen: keine Auslastung (Speedup gering) - Startphase: ungenutzte Prozessoren => Clustering - Kommunikation: Ø 3x INFO, 0-1 WORK / 0,1s - kleiner Prozessortorus-Durchmesser = besseres Speedup 34 Ergebnisse (2) Verteilung der w# (# Heapelemente) 35 Ergebnisse (3) Verteilung der wLB - Werte 36 Vielen Dank für die Aufmerksamkeit! 37