Die Java Persistence API
Werbung

Die Java Persistence API
Seminararbeit im Studiengang
Scientific Programming
WS 2012 / 2013
Autor:
Andreas Kuck
Matrikelnummer:
846239
1. Betreuer:
Prof. Dr. Bodo Kraft
2. Betreuer:
Dipl.-Math. (FH) Michael Neßlinger
Datum:
15. Dezember 2012
Programmierer müssen heutzutage immer größere Datenmengen verarbeiten. Dabei bekommt
das dauerhafte Speichern, auch Persistieren genannt, von Daten eine wachsende Bedeutung. Die
Aufgabe eines Programmierers besteht oft darin, den Zustand eines Objekts festzuhalten und
an späterer Stelle wiederherzustellen. Die Java Persistence API kann den Entwickler zwar nicht
komplett von dieser Arbeit befreien, aber stellt ein solides Werkzeug dar, um Arbeit einzusparen.
Die vorliegende Seminararbeit gibt dem Leser einen groben Überblick über diese Technologie und
ihre vielfältigen Möglichkeiten, eine Brücke zwischen Objekten und der relationalen Datenbank
zu bauen.
Inhaltsverzeichnis
1 Einleitung
1
1.1
Vorwort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
1.2
Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
1.3
Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
2 Die Java Persistence API
3
2.1
Die Java Persistence API (JPA) . . . . . . . . . . . . . . . . . . . . . . . . . . .
3
2.2
Die Persistence XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4
2.3
Entity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4
2.4
Konfiguration des Mappings . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
2.5
Annotations an Attributen
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
2.6
Die Beziehungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
9
2.7
Die Vererbung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
2.8
Transaktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
16
2.9
Der EntityManager . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
18
3 Schlussteil
22
3.1
Zusammenfasseung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
3.2
Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
4 Literaturverzeichnis
23
1 Einleitung
1.1 Vorwort
Diese Arbeit ist im Rahmen meines Studiums im Fach Scientific Programming entstanden. Die
Themengebung stammt von dem Unternehmen TravelTainment, in dem ich parallel zu meinem
Studium, eine Ausbildung als Mathematisch-technischer Softwareentwickler mache. Sie soll ein
Grundstein für eine auf sie aufbauende Bachelorarbeit sein. Ziel dieser Arbeit ist es, dem Leser
einen groben Überblick über die Möglichkeiten und die Funktionsweise der Java Persistence API
(JPA) zu geben.
1.2 Motivation
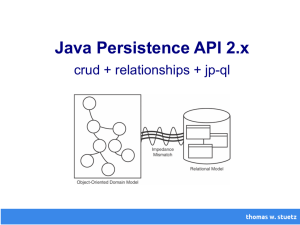
Wenn der Zustand von Objekten eines Programms dauerhaft gespeichert werden soll, bietet
es sich an, eine Datenbank zu benutzen. Die relationale Datenbank ist ein sehr verbreitetes
Modell zum Persistieren von Daten. Ihr Prinzip ist leicht zu verstehen und man kann einfach
Beziehungen zwischen Tabellen, auch Relationen genannt, darstellen. Die Programme werden
meist in objektorientierten Programmiersprachen entwickelt. Jedoch lassen sich Objekte und deren
Beziehungen zueinander nur schwer in einer relationalen Datenbank darstellen. Ähnlich schwierig
ist es auch, relationale Datenbestände in ein objektorientiertes Programm zu integrieren. Man
spricht hier häufig von dem “Impedance Mismatch”.
Impedance Mismatch (wörtlich: Impedanz-Fehlanpassung) ist ein aus der Elektro”
technik übernommener Begriff; auf dem Gebiet der Software bezieht er sich jedoch auf
den inhärenten1 Unterschied zwischen dem relationalen und dem objektorientierten
Datenmodell.“ [Fin12]
In dieser Arbeit soll das Konzept des objektrelationalen Mappings anhand der JPA erläutert werden. Dieses Konzept kann den Prozess des Persistierens erheblich vereinfachen. Objektrelationales
Mapping ist das Abbilden von Klassen in eine Datenbank. Es umfasst sowohl das Schreiben von
einfachen Objekten in eine Datenbank, als auch das Mapping von Klassen unter Beachtung von
Assoziationen und Vererbungshierarchien.
1.3 Aufbau der Arbeit
Die Arbeit beginnt mit einer kurzen Einführung in die JPA. Danach wird die persistence.xml
beschrieben, welche die Grundkonfiguration der JPA darstellt. Im Anschluss daran werden Begriffe
1
inhärent: einer Sache innewohnend (siehe Duden)
1
wie Entity und Embeddable eingeführt. Der Begriff Entity ist ein besonders zentraler Begriff in
der JPA, denn jedes Objekt, welches in der Datenbank abgebildet werden soll, muss als Entity
markiert sein. Des Weiteren wird erläutert, wie man Objekten zusätzliche Informationen im Bezug
auf das Mapping mitgeben kann. Die darauf folgenden zwei Unterkapitel gehen mehr in die
Tiefe und beschreiben, wie die JPA das objektrelationale Mapping, bezogen auf Vererbung und
Assoziationen, umsetzt. Im Anschluss daran wird beschrieben, wie die Datenbanktransaktionen
mithilfe des EntityManagers umgesetzt werden können. Im Schlussteil der Arbeit wird das gesamte
Thema reflektiert und ein Ausblick vorgestellt.
2
2 Die Java Persistence API
2.1 Die Java Persistence API (JPA)
Die JPA, die von der JSR 220 Expert Group enwickelt wurde, wurde im Jahr 2006 erstmals
veröffentlicht. Im Jahr 2009 wurde sie durch viele Funktionen unter dem Namen JPA 2.0 erweitert. [Wik] In dieser Arbeit werden die Funktionen, die nicht JPA 1.0 konform sind, explizit
gekennzeichnet.
Wie der Name schon sagt, handelt es sich bei JPA um ein Interface, welches Methoden zum Schreiben und Lesen von Java Objekten in eine Datenbank definiert. Es wird ein Interface benutzt, um
die Implementierung austauschbar zu machen. Wenn man sich komplett an den Standard hält,
kann man mit wenigen Klicks die Implementierung wechseln. Implementiert wird die API z.B.
durch Hibernate und EclipseLink. Der Nachteil, den ein solches Interface mit sich bringt, ist seine
Trägheit. Neue Funktionen werden immer erst von den Implementierungen eingeführt und, wenn
sie sich bewährt haben, ins Interface übernommen. Aus diesem Grund kann es passieren, dass
man auf Funktionen zurückgreifen muss, die nicht dem JPA Standard entsprechen. In diesem Fall
geht die Austauschbarkeit und mit ihr auch der Sinn der API verloren.
Zum Mapping kann man grob sagen, dass jedes Objekt eine eigene Tabelle und jedes Attribut
eines Objekts eine eigene Spalte in dieser Tabelle bekommt. Im späteren Verlauf dieser Arbeit
wird man sehen, dass dieses grobe Konzept, gerade im Bezug auf Vererbung und Assoziationen,
nicht sinnvoll ist und deswegen nicht immer in dieser Art umgesetzt wird.
Die Datenbankabfragen werden in der Java Persistence Query Language (JPQL) formuliert. Die
JPQL ähnelt SQL, basiert aber nicht auf Tabellen, sondern auf sogenannten Entities (s. Kapitel
Entities). Die erzeugte JPQL Anfrage wird dann zur Laufzeit in eine SQL-Abfrage umgewandelt
und an die Datenbank geschickt. Die JPA stellt einem die Möglichkeit zur Verfügung, den SQLDialekt, in den die Abfrage umgewandelt wird, auszutauschen. So kann man durch geringen
Aufwand z.B. von MySQL auf ein anderes relationales Datenbankmanagementsystem umstellen.
Desweiteren unterstützt die JPA die Nutzung von Annotations, um der Datenbank Informationen,
z.B. über die Namen der Tabellen und Attribute, mitgeben zu können. Ergänzend oder anstatt
diesen Annotations können auch XML-Dateien verwendet werden.
3
2.2 Die Persistence XML
Die Hauptkonfigurationsdatei in der JPA ist die persistence.xml. In dieser werden die grundlegenden Einstellungen konfiguriert. Man findet hier eine oder mehrere Persistenceunits“. Diese
”
Units werden dann im Code den für den Datenaustausch zuständigen Objekten übergeben. Sie
enthalten folgende Verbindungsparameter für die Datenbank:
• URL der Datenbank
• Benutzername
• Passwort
• Verbindungstreiber (z.B. jdbc.Driver)
Außerdem wird hier der sogenannte Provider angegeben. Dieser gibt an, welche Implementierung
von der JPA benutzt werden soll. In dem nachstehenden Beispiel einer persistence.xml wird Hibernate verwendet.
Beispiel einer persistence.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<?xml version=”1.0” encoding=”UTF−8”?>
<persistence version=”2.0” xmlns=”http://java.sun.com/xml/ns/persistence”
xmlns:xsi =”http://www.w3.org/2001/XMLSchema−instance”
xsi:schemaLocation=”http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence 2 0.xsd”>
<persistence−unit name=”myBeispiel” transaction−type=”RESOURCE LOCAL”>
<provider>org.hibernate.ejb . HibernatePersistence </provider>
<properties>
<property name=”hibernate.connection.username” value=”andi”/>
<property name=”hibernate.connection.driver class” value=”com.mysql.jdbc.Driver”/>
<property name=”hibernate.connection.password” value=”andi”/>
<property name=”hibernate.connection.url” value=”jdbc:mysql://localhost:3306/hiberdemo”/>
<property name=”hibernate.cache.provider class” value=”org.hibernate.cache.NoCacheProvider”/>
<property name=”hibernate.hbm2ddl.auto” value=”update”/>
</properties>
</persistence−unit>
</persistence>
2.3 Entity
Durch eine Entity werden im Allgemeinen Elemente beschrieben, die Attribute und Beziehungen
haben. Das Konzept der Entities ist älter als viele Programmiersprachen. Der Bergriff wurde in
diesem Kontext erstmals von Peter Chen eingeführt. [KS09] In der objektorientierten Programmierung fügt man den Entities Verhaltensweisen bzw. Methoden hinzu und nennt sie Objekte.
JPA betrachtet die Objekte, welche persistiert werden, als Entities. Jedoch müssen diese Objekte, damit sie erkannt und persistiert werden können, mit der Annotation @Entity gekennzeichnet
werden. Des Weiteren muss immer ein öffentlicher, parameterloser Konstruktor existieren. Genau
ein Attribut muss mit @Id als Primärschlüssel gekennzeichnet werden. Außerdem dürfen weder
4
die Klasse, noch die zu persistierenden Attribute mit dem Schlüsselwort final gekennzeichnet sein
sein. [O’C12] Eine Ausnahme bilden hier Attribute, die durch die Annotation @Transient von der
Persistierung ausgeschlossen werden.
Beispiel einer Entity:
1
@Eintity
2
public class Person() {
@Id
3
4
private Long id;
5
private String vorname;
6
private String nachname;
7
public class Person(){ }
8
//Getter, Setter ...
9
}
Abgebildet auf die Datenbank könnte die dazugehörige Relation wie folgt aussehen:
id
1
2
Person
Vorname nachname
Max
Mustermann
Laura
Schneider
Die ID
Wie bereits erwähnt, muss jede Entity einer eindeutigen ID zugeordnet sein. Die API stellt die
Annotation @GeneratedValue zur Verfügung, welche sich um das Setzten der ID im Falle einer
Übertragung zur Datenbank kümmert. Diese Annotation wird zusammen mit der Annotation @Id
der ID zugeordnet. Die JPA stellt dem Nutzer folgende Strategien zur Verfügung:
• @GeneratedValue(strategy= GenerationType.AUTO)/@GeneratedValue
Die Implementierung benutzt hier ihr Default-Verhalten.
• @GeneratedValue(strategy= GenerationType.IDENTITY)
Die Implementierung benutzt das Autoincrement der Datenbank (wird nicht von allen Datenbanken unterstützt).
• @GeneratedValue(strategy= GenerationType.SEQUENCE)
Die Implementierung benutzt Sequences (wird nicht von allen Datenbanken unterstützt).
• @GeneratedValue(strategy= GenerationType.TABLE)
Hier wird eine Sequenztabelle angelegt, in welcher die höchste ID der Entity gespeichert
wird. Wenn eine neue Entität eingefügt wird, wird dieser Wert um eins erhöht und der neuen
5
Entity zugewiesen. Die Benennung der Sequenztabelle und ihrer Spalten kann individuell
angepasst werden.
Sequenztabelle
sequenceName sequenceNextHiValue
Mustertabelle 2
Embeddables
Eine Entity kann auch Objekte von selbst definierten Klassen als Attribute besitzen. Grundbedingung dafür ist, dass diese entweder ebenfalls Entities sind oder aber sogenannte Embeddables.
Diese werden mit der Annotation @Embeddable gekennzeichnet und sind immer existenzabhängig
von einer Entity. Existenzabhängig bedeutet, dass diese ohne Entity, welche sie benutzt, keine
eigene Repräsentation in der Datenbank haben können. Die Beziehung zwischen Entity und Embeddable ist in Folge dessen eine Komposition. Dadurch, dass ein Embeddable Objekt immer zu
einer Entity gehört, ist es hier nicht nötig, einen Primärschlüssel zu definieren. Seit JPA 2 ist es
möglich Embeddables ineinander zu schachteln.[rei10]
Beispiel zur Benutzung eines Emeddables:
1
@Embeddable
2
public class Anrede{
3
private String vorname;
4
private String nachname;
//Getter, Setter und parameterloser Kostrunktor ...
5
6
}
1
@Entity
2
public class Person{
@Id
3
private long id ;
4
@Embedded
5
6
private Anrede anrede;
7
private int lebensdauer ;
//Getter und Setter und parameterloser Konstrunktor ...
8
9
}
In der Datenbank wird eine Person dann wie folgt abgebildet:
id
1
Person
lebensdauer vorname
40
Max
nachname
Mustermann
6
2.4 Konfiguration des Mappings
Die JPA bietet einem Anwender die Möglichkeit über die persistence.xml hinaus einzustellen,
wie die Entities in der Datenbank repräsentiert werden sollen. Dafür gibt es zwei Möglichkeiten,
welche im Folgenden aufgelistet werden.
• Die Mappinginformationen in eine XML auslagern
• Dem Quellcode Annotations hinzufügen
Welche dieser Möglichkeiten man lieber benutzen möchte, hängt von den individuellen Gegebenheiten ab. Die Annotations haben den Vorteil, dass man beim Lesen des Quellcodes sofort sieht,
auf welche Art und Weise die Klassen abgebildet werden. Andererseits hat die XML den Vorteil,
dass man eine Datei nutzen kann, in der ausschließlich Metainformationen zu finden sind. Dies
ist besonders hilfreich, wenn man JPA mit einer anderen Technologie zusammen benutzt welche
ebenfalls mit Annotations arbeitet. Im Fall, dass man beispielsweise JAXB1 parallel nutzt wird
der Code durch eine vielzahl von Annotations schnell unübersichtlich. Ein anderer Vorteil den das
nutzen von XML mit sich bringt ist, dass im falle von änderungen bezüglich des Mappings nicht
neu compiliert werden muss.
Alles was sich über das Mapping durch eine XML darstellen lässt, kann auch über Annotations abgebildet werden. Aufgrund dieses Sachverhalts, wird in dieser Arbeit nicht weiter auf die
Konfiguration über XML eingegangen.
2.5 Annotations an Attributen
Um Attribute mit Annotations zu versehen gibt es zwei Möglichkeiten, welche sich auch kombinieren lassen. Die beiden Darstellungen erzeugen ein unterschiedliches Verhalten bezüglich des
Zugriffs auf die Attribute durch den Provider.
Der Zugriffstyp einer Entity wird durch die Stelle, an der die Annotation der @Id steht, bestimmt.
Dieser ist innerhalb einer Entity für alle Attribute einheitlich. Sollen verschiedene Zugriffstypen
in einer Entity verwendet werden, muss dies explizit mithilfe von Annotations gekennzeichnet
werden. Entities, die von anderen Entities erben, übernehmen den Zugriffstyp der Vaterklasse.
Des Weiteren ist der Zugriffstyp von Embeddables gleich dem Zugriffstyp der Entity, welche diese
benutzt.
Field Access
Hier werden die Annotations direkt über die Attribute geschrieben.
Ein Beispiel:
1
@Id
2
@Column(name=”Identifier”)
3
private long id ;
1
JAXB - Programmierschnittstelle zur Transformation zwischen Java-Objekten und XML.
7
Diese Art der Annotation sorgt dafür, dass die Getter und Setter überflüssig für die Persistierung
der Daten werden. Der JPA-Provider spricht die Attribute in diesem Fall über Reflexion an.
Reflexion ist ein komplexes Thema. In dem folgenden Zitat wird die Idee hinter dem Konzept
skizziert.
Reflexion ist die Möglichkeit einer Programmiersprache, zur Laufzeit Informationen
”
über die Struktur und das Verhalten des Programms selbst herauszufinden und/oder
abzuändern.“[Zie08]
Standardmäßig bekommen die Attribute, welche mit Field Access angesprochen werden, den Namen aus der Klassendefinition. Wenn ein Attribut einen anderen Namen haben soll, muss dies über
Annotation @Column“ gekennzeichnet werden. In diesem Fall wird die ID in die Tabellenspalte
”
IDENTIFIER abgebildet.
Property Access
Hier werden die Annotations über die Getter-Methoden der Attribute geschrieben.
Ein Beispiel:
1
@Id
2
public void getIdentifier (){
return this . id ;
3
4
}
Diese Art der Annotation sorgt dafür, dass der Provider direkt auf die Getter und Setter der
Attribute zugreift. Der Name der Spalte, welche beim Abbilden in die Datenbank angelegt wird,
wird anders als beim Field Access durch die Getter und Setter ermittelt. Das bedeutet für das
gerade genannte Beispiel, dass die Spalte in der Datenbank nicht ID, sondern IDENTIFIER heißt.
Ferner ist zu beachten, dass die Namen der Getter und Setter immer mit get“ bzw. set“
”
”
anfangen müssen. Darüber hinaus muss der Rückgabetyp der Getter-Methode gleich dem Typ
des Übergabeparameters des Setters sein.
Mixed Access (JPA 2)
Manchmal ist es sinnvoll beide Zugriffsarten zu verwenden. Gegeben sei der Fall, dass von einer
Entity geerbt wird, die mit Field Access arbeitet und in der geerbten Entity Property Access benutzt werden soll. Wenn in diesem Fall die Entity, von der geerbt wird, auf Field Access umgestellt
wird, kann es zu Problemen bei anderen Entities, die sich in derselben Vererbungshierarchie befinden, kommen. Es bietet sich also an, nur die betroffene Entity auf Property Access umzustellen.
Hier gibt es zwei Möglichkeiten:
• Gesamte Entity kennzeichnen.
8
1
@Entity
2
@Access(AccessType.PROPERTY)
3
//oder
4
//@Access(AccessType.FIELD)
5
public class TestKlasse{
// ...
6
7
}
• Betroffenes Attribut bzw. Getter kennzeichnen.
1
@Access(AccessType.PROPERTY)
2
public getTestAttribut {
// ...
3
4
}
5
//bzw
6
//@Access(AccessType.FIELD)
7
// private String testAttribut ;
2.6 Die Beziehungen
Sowohl in der relationalen Datenbank als auch in der objektorientierten Programmierung stehen Entities in Beziehungen zueinander. Dabei unterscheidet man grob zwischen drei Arten von
Beziehungen zwischen zwei Entities. Im Folgenden werden diese aufgezählt:
• 1:1 (Annotaion: OneToOne): Eine Ente hat einen Schnabel.
• 1:n und n:1 (Annotation: ManyToOne/OneToMany): Eine Ente hat viele Federn./ Viele
Enten haben einen See.
• n:m (Annotation: ManyToMany): Viele Enten besuchen viele Teiche.
Diese Beziehungen können einseitig, wenn nur eine Entität von der Beziehung weiß, und zweiseitig,
wenn beide von der Beziehung wissen, sein. Gebräuchlich sind hier auch die Begriffe unidirektional
(einseitig) und bidirektional (zweiseitig), die im weiteren Verlauf verwendet werden.[KH06] Bei
einer unidirektionalen 1:1 Beziehung könnte man beispielsweise von einer Ente zu einem Schnabel
navigieren, nicht aber von einem Schnabel zu einer Ente.
Unidirektionale Beziehung
Bei der unidirektionalen Beziehung besitzt nur eine der beiden Eintities ein Attribut, welches die
mit ihr in Beziehung stehende Entity enthält. Dieses Attribut wird dann mit einer der folgenden
Annotationen versehen:
9
• @OneToOne - Mit @OneToOne wird ein einfaches Attribut vom Typ der Entity, zu der die
Beziehung hergestellt wird, versehen.
• @OneToMany - Das Attribut muss hier vom Typ Collection sein
• @ManyToOne - Ermöglicht der Gegenseite in einer OneToMany Beziehung mit der Entity
zu stehen. Ergibt bei einer unidirektionalen Beziehung jedoch keinen Sinn.
• @ManyToMany - Das Attribut muss hier vom Typ Collection sein. Ergibt aus demselben
Grund wie ManyToOne bei einer unidirektionalen Beziehung keinen Sinn.
Die Entity, von der die Beziehung nicht ausgeht, enthält keine Informationen über die Beziehung
und braucht deswegen auch nicht angepasst zu werden.
Bidirektionale Beziehung
Die bidirektionale Beziehung ist etwas komplizierter. Hier müssen beide Entities ein Attribut der
Gegenseite der Beziehung besitzen. Hinzu kommt, dass angegeben werden sollte, welche Seite
der Beziehung die Daten am Ende in die Datenbank abbildet. Man kann dies über die Ergänzung
des Parameters mappedBy“ zu der Verbindungsannotation angeben
”
1
@OneToOne(mappedBy = ”<Name des Beziehungsattributs der Gegenseite>”).
Dieser Parameter wird auf der Seite gesetzt, auf der das Mapping der Beziehung nicht erfolgen
soll. Wenn diese Angabe fehlt, werden die Beziehungen doppelt abgebildet und es entstehen
Redundanzen in der Datenbank.
Beispiel
Im Folgenden wird das Benutzen von Beziehunge, anhand eines einfachen Beispiels erläutert. Es
handelt sich um ein kleines Programm, welches Autoren und ihre Bücher verwalten soll. In dem
hier konstruierten Modell, kann ein Buch nur von genau einem Autor verfasst werden. Ein Autor
kann jedoch beliebig viele Bücher schreiben. Daraus ergibt sich zwischen dem Autor und dem
Buch eine 1:n Beziehung.
Die Klasse Buch:
1
@Entity
2
public class Buch {
3
@Id
4
@GeneratedValue
5
private long id ;
6
private String titel ;
7
//Leerer Konstruktor, Getter und Setter
8
// ...
9
}
10
Momentan ist die Klasse Buch noch eine einfache Entity mit einem über Autoinkrement erstellten Primärschlüssel und mit dem Titel des Buches als Attribut. Es wird noch keine Beziehung
dargestellt.
Die Klasse Autor:
1
@Entity
2
public class Autor {
3
@Id
4
@GeneratedValue
5
private long id ;
6
private String name;
7
private String vorname;
8
//Leerer Konstruktor, Getter und Setter
9
// ...
10
}
Die Klasse Autor enthält eine automatisch generierte ID und den Vor- und Nachnamen des Autors.
1
@Entity
2
public class Autor {
3
// ...
4
@OneToMany
private Collection <Buch> buch = new ArrayList<Buch>();
5
6
//Leerer Konstruktor, Getter und Setter
7
// ...
8
}
Um von einem Autor auf seine Bücher navigieren zu können, wurde der Klasse Autor das Attribut
buch“ hinzugefügt. Dieses wurde mit der passenden @OneToMany Annotation versehen um eine
”
1:n Beziehung herzustellen.
Damit haben wir unsere erste Beziehung aufgebaut. Ein einfaches Anwendungsbeispiel soll an
dieser Stelle zeigen, wie die JPA nun mit diesen Entities umgeht.
1
Autor autor = new Autor();
2
autor .setName(”Mustermann”);
3
autor .setVorname(”Max”);
4
em.getTransaction() .begin() ;
5
Buch buch = new Buch();
6
buch. setTitel (”Das erste Buch”);
7
Buch weiteresBuch = new Buch();
11
8
em. persist (weiteresBuch);
9
weiteresBuch. setTitel (”Das zweite Buch”);
10
autor .getBuch().add(buch);
11
autor .getBuch().add(weiteresBuch);
12
//Objekte werden dem Persistenzkontext hinzugefügt
13
em. persist (buch);
14
em. persist (weiteresBuch);
15
em. persist (autor) ;
16
em.getTransaction() .commit();
Erzeugte Tabellen:
id
1
2
buch
titel
Das erste Buch
Das zweite Buch
id
1
name
Mustermann
autor
autor
autor id
1
1
vorname
Max
buch
buch id
1
2
Auffällig ist, dass eine extra Verbindungstabelle aufgebaut wird, obwohl es sich bei dieser 1:n
Beziehung eher anbieten würde nur eine Verbindungsspalte bei Buch einzufügen.
Das Problem ist, dass die Beziehung von Autor ausgeht. Die einzige Möglichkeit, die bleibt um
auf eine Verbindungstabelle zu verzichten, ist die Verbindungsinformationen in die Tabelle autor“
”
zu schreiben.
Dies würde wie folgt aussehen:
id
1
name
Mustermann
autor
vorname
Max
buch
1,2
In der Spalte Buch“ ist die Atomarität der Daten nicht mehr gewährleistet. Ein Verstoß gegen
”
die Atomarität ist ein unerwünschter Konflikt mit der ersten Normalform. Mit dem zugrundeliegenden Quellcode besteht für die Implementierung nur die Möglichkeit eine Verbindungstabelle
zu erzeugen.
Zusammenfassend bezeichnet man die Beziehung, die wir hier erzeugt haben, als unidirektionale
1:n Beziehung. Man kann zwar vom Autor auf seine Bücher navigieren, jedoch nicht von einem
12
Buch auf den Autor. Um dies zu verändern müssen Anpassungen an der Entity Buch vorgenommen
werden.
1
@Entity
2
public class Buch {
3
// ...
4
@ManyToOne
private Autor autor ;
5
6
//Leerer Konstruktor, Getter und Setter
7
// ...
8
}
Die Entity Buch wurde um ein Attribut vom Typ Autor erweitert. Es wurde bereits angesprochen, dass sich bei einer bidirektionalen Beziehung beide Seiten um das Mapping der Beziehung
kümmern. Im Beispiel würde das bedeuten, dass wir sowohl eine Verbindungstabelle als auch
eine Verbindungsspalte in der Datenbank erzeugen. Um redundante Datenhaltung auf der Datenbankseite zu vermeiden, müssen wir einem der beiden Verbindungsattribute den Parameter
mappedBy“ übergeben. MappedBy zeigt an, dass das Mapping des Attributs an einer anderen
”
Stelle behandelt wird. Bei dem ersten Entwurf ist aufgefallen, dass eine Verbindungstabelle erstellt
wurde. Um das Erstellen einer solchen Tabelle und damit auch überflüssige Joins zu verhindern,
sollte darauf geachtet werden, dass bei einer 1:n Beziehung immer die n-Seite für das Mapping
der Beziehung zuständig ist. Die Entity Autor muss also, wie folgt, angepasst werden.
1
@Entity
2
public class Autor {
3
// ...
4
@OneToMany (mappedBy = ”autor”)
private Collection <Buch> buch = new ArrayList<Buch>();
5
6
//Leerer Konstruktor, Getter und Setter
7
// ...
8
}
Nach dieser Anpassung ist jetzt lediglich das Attribut autor“ in der Entity Buch für das Mapping
”
zuständig. Das Beispiel sieht dann, wie folgt, aus:
Buch
id
1
2
titel
Das erste Buch
Das zweite Buch
autor id
1
1
Autor
id
1
name
Mustermann
vorname
Max
13
Man findet hier eine bidirektionale 1:n Beziehung vor.
2.7 Die Vererbung
Die JPA bietet dem Programmierer auch die Möglichkeit eine Vererbungsstruktur in der Datenbank abzubilden. Insgesamt bietet die JPA drei verschiedene Möglichkeiten eine Vererbungshierarchie in der Datenbank abzubilden.
SINGLE TABLE
Zum einen gibt es die Möglichkeit die Klassen einer Vererbungshierarchie von Entities in dieselbe
Tabelle zu schreiben. Dies führt dazu, dass man eine Tabelle mit sehr vielen Spalten hat und
dementsprechend auch viele Nullwerte vorliegen. Dieses Verhalten ist das Defaultverhalten, es
nennt sich SINGLE TABLE.
Beispiel SINGLE TABLE:
id
1
2
DTYPE
Hoerbuch
EBook
Titel
Pro JPA 2
Pro JPA 2
Buch
Autor ID
1
1
Dateigroesse
NULL
2
Dauer
120
NULL
Eine Besonderheit ist hier die Spalte DTYPE, auf diese wird an späterer Stelle eingegangen.
JOINED
Ein weiteres Verhalten, welches die JPA zur Verfügung stellt, ist das sogenannte JOINEDVerhalten. Hierbei wird die Entity aufgesplittet. Die Attribute, die von der Vaterklasse geerbt
werden, werden bei diesem Verhalten auch in die Tabelle der Vaterklasse geschrieben. Die Attribute, die darüber hinaus in der geerbten Klasse definiert werden, werden dann in eine gesonderte
Tabelle ausgelagert. Wenn später auf ein so persistiertes Objekt zugegriffen wird, holt sich der
Provider über einen Join die Daten wieder aus der Datenbank. Der Join, der beim Laden einer
Entity durchgeführt werden muss, gibt diesem Verhalten seinen Namen.
Beispiel JOINED:
Buch
id
1
2
Titel
Pro JPA 2
Pro JPA 2
id
1
EBook
Dateigroesse
2
Autor Id
1
1
14
id
2
Hoerbuch
Dauer
120
TABLE PER CLASS
Eine weitere Möglichkeit besteht darin, pro Entity eine eigene Tabelle zu benutzen. Jede Entity
bekommt hier ihre eigene Tabelle, in der sie auch die Attribute, die sie von der Vaterklasse
übernommen hat, abbildet. Diese Strategie nennt sich TABLE PER CLASS. Um eine eindeutige
ID zu gewährleisten ist an dieser stelle eine Strategie wie IDENTITY zum Generieren der ID
nicht zu empfehlen. Identity benutzt das Autoinkrement der Datenbank und kann deswegen
nicht tabellenübergreifend für eine eindeutige ID sorgen.
Beispiel TABLE PER CLASS:
id
1
Hoerbuch
Titel
Autor ID
Pro JPA 2
1
Dauer
120
id
2
EBook
Titel
Autor ID
Pro JPA 2
1
Groesse
2
DiscriminatorValue
Bei SINGLE TABLE werden Entities unterschiedlicher Klassen in dieselbe Tabelle einer Datenbank
gemappt. Es ist dringend nötig zu wissen, zu welcher Klasse eine Entität gehört. An dieser Stelle
greift die JPA auf den sogenannten Discriminatorvalue zurück, welcher eine zusätzliche Spalte in
der Datenbank einnimmt. Er kann, wie folgt, einer Entity zugewiesen werden:
1
@Entity
2
@DiscriminatorValue(value=”Hörbuch”)
3
public class Hoerbuch extends Buch{
// ...
4
5
}
Standartmäßig ist der DTYPE Name der Spalte, die die JPA für den Discriminatorvalue verwendet. Dies kann aber auch über die Verwendung der Annotation @DiscriminatorColumn angepasst
werden.
Vergleich
Welche dieser Methoden die beste für eine bestimmte Anwendung ist hängt stark von dem
Verwendungszweck der Entity ab. Bei Entities mit sehr vielen Attributen ist beispielsweise die
Methode SINGLE TABLE nicht zu empfehlen, weil dadurch sehr viele Spalten entstehen. Wenn
15
jedoch nur wenig Attribute in die Datenbank geschrieben werden, sind SINGLE TABLE und
TABLE PER CLASS die beste Wahl, weil sie, im Gegensatz z.B. zum JOINED-Mapping, komplett
auf rechenaufwändige Joins verzichten.
Als Polymorphe Abfrage bezeichnet man Abfragen, welche verschiedene Entity”
Instanzen, die zu einer gemeinsamen Vererbungshierarchie gehören, als Ergebnis liefern.“ [KH06]
Im Fall, dass man viele polymorphe Abfragen hat, kann es sinnvoll sein statt TABLE PER CLASS
SINGLE TABLE zu wählen, weil so keine Abfragen über mehrere Tabellen nötig sind. Pauschal
zu sagen, dass eine Methode die Beste ist, ist hier nicht möglich.
2.8 Transaktion
Abbildung 2.1: Die Zustände einer Entity (Lifecycle)
Für die Transaktion, sprich die Kommunikation mit der Datenbank, ist der sogenannte EntityManager zuständig. Dieser arbeitet nach folgendem Prinzip. Der EntityManager leitet die Phase
der Transaktion ein. In dieser Phase können der Transaktion Entities hinzugefügt werden. Diese
Entities befinden sich dann im sogenannten Persistenzkontext.
Der Persistence Context (PC) ist keine API sondern ein Konzept bei der Arbeit mit
”
JPA. Ein PC ist die Abstraktion für einen Bereich, in dem Objektinstanzen und deren
persistente Repräsentierung konsistent gehalten werden. Aus einer etwas technischeren Sichtweise ist der PC eine Session begrenzter Lebensdauer, in der im Rahmen
16
einer oder mehrerer Transaktionen Änderungen an verwalteten Objektinstanzen vorgenommen werden. Der Lifecycle dieser Objektinstanzen bezieht sich auf den entsprechenden PC.“ [Dür]
Entities des Persistenzkontexts können als Zustände Managed und Removed annehmen. Entities,
welche sich im Persistenzkontext befinden, werden nach Abschluss der Transaktionsphase oder bei
Aufruf der Funktion Flush in der Form, wie sie im Programm vorliegen, in die Datenbank geschrieben oder, wenn sie sich im Zustand Removed befinden, entfernt. Die sich im Transaktionskontext
befindlichen Entities können aus der Datenbank oder aus dem Programm stammen. Nach Abschluss der Transaktionsphase befinden sich die involvierten Objekte im Detached-Zustand. Sie
befinden sich nicht mehr im Persistenzkontext, aber haben sowohl eine Repräsentation in der
Datenbank als auch im Programm.
Lazy Loading
Die JPA gibt einem die Möglichkeit Attribute einer Entity über Lazy Loading“ zu laden. Attribu”
te, die mit Hilfe von Lazy Loading aus der Datenbank geladen werden, werden nicht automatisch
beim Laden einer Entity mitgeladen. Wenn das Attribut dann später benötigt wird, wird es dynamisch nachgeladen. Das Benutzen von Lazy Loading kann bei großen Entities sinnvoll sein,
wenn sie über eine lange Zeit im Managed-Zustand bleiben. In diesem Fall kann LazyLoading
sich positiv auf die Auslastung des Arbeitsspeichers auswirken. Jedoch kann es im Bezug auf
Detached-Entities zu Problemen führen. Wenn man im Detached-Zustand auf ein noch nicht
geladenes Attribut zugreifen möchte, kann es nicht nachgeladen werden.
An dieser Stelle wird noch einmal auf das Beipiel mit den Autoren verwiesen:
1
@Entity
2
public class Autor {
3
// ...
4
@OneToMany (mappedBy = ”autor”, fetch = FetchType.LAZY)
private Collection <Buch> buch = new ArrayList<Buch>();
5
6
//Leerer Konstruktor, Getter und Setter
7
// ...
8
}
Aus Performancegründen wird hier darauf verzichtet, alle Bücher eines Autors direkt beim Laden
aus der Datenbank mit zu laden. Wenn eine Autoren Entity in den Detached-Zustand gebracht
wird, können nur noch Bücher angesprochen werden, auf die man bereits zugegriffen hat. Um
dadurch verbundene Probleme zu verhindern, könnte man entweder auf das defaultmäßig eingestellte Eager Loading“ zurückgreifen oder, bevor man in den Zustand Detached wechselt, die
”
Attribute, die benötigt werden, einmal ansprechen damit sie geladen werden.
17
Kaskadierung
Jede Entity, die persistiert werden soll, muss standardmäßig explizit dem Persistenzkontext hinzugefügt werden. Dies führt dazu, dass auch alle Entities, die mit einer zu persistierenden Entity in
Beziehung stehen, explizit dem Persistenzkontext hinzugefügt werden müssen. Häufig ist es sinnvoll, dass automatisch alle mit einer Entity in Beziehung stehenden Entities persistiert werden.
Hier kann der der Parameter cascade“ einem die Arbeit abnehmen.
”
1
// ...
2
@OneToMany (mappedBy = ”autor”, cascade= CascadeType.PERSIST)
3
4
private Collection <Buch> buch = new ArrayList<Buch>();
// ...
Wenn der CascadeTyp z.B. für die Beziehung von einer Ente zu einem Teich auf PERSIST
steht, braucht man lediglich die Ente zu Persistieren und alle mit ihr verbundenen Teiche werden
automatisch in die Datenbank geschrieben. Die Arbeit, die beim Persistieren gespart werden kann,
kann auch beim Löschen von Einträgen eingespart werden. In diesem Fall muss der CacadeTyp auf
DELETE gesetzt werden. Zu beachten ist, dass die Kaskadierung in beiden Fällen unidirektional
abläuft. Was bedeutet, dass, wenn der Parameter auf der einen Seite gesetzt wird, sich das
Verhalten beim Persistieren der anderen Seite nicht verändert.
Diese Möglichkeit sollte jedoch mit Bedacht benutzt werden. Wenn z.B. cascade auf DELETE
gesetzt ist und dann eine Ente gelöscht wird, werden alle Teiche, die zu dieser Ente gehören
mit gelöscht. Dadurch kann es sein, dass ein Teich gelöscht wird, obwohl eine andere Ente ihn
noch benutzt. Um Fehler zu vermeiden sollte der CascadeType remove nur in OneToMany und
OneToOne Beziehungen zum Einsatz kommen.
2.9 Der EntityManager
Wie bereits im Kapitel Transaktion 2.8 erwähnt, gibt es für das Durchführen von Transaktionen
mit JPA eine Klasse EntityManager. Sie wird von der EntityManagerFactory erzeugt. Die EntityManagerFactory bekommt bei ihrer Erstellung einen String mitgegeben, über diesen String wird
den EntityManager Objekten, die von ihr erzeugt werden, eine PersistenceUnit 2.2 zugeordnet.
18
Abbildung 2.2: Die Erzeugung eines EntityManagers
Der EntityManager weiß dadurch mit welcher Datenbank er kommunizieren soll. Er stellt dem
Programmierer einige Funktionen zur Verfügung. Die wichtigsten dieser Funktionen werden im
Folgenden vorgestellt.
Persist
Eine neu erzeugte Entity muss, um sie persistieren zu können, über die Funktion persist“,
”
welcher man diese Entity übergibt, dem Persistenzkontext hinzugefügt werden. In dem Fall, dass
kein Primärschlüssel existiert, wird, je nachdem wie die Entity konfiguriert ist, ein Primärschlüssel
erzeugt oder eine Exception geworfen. In dem Fall, dass man der Entity einen Primärschlüssel
zugeteilt hat, der bereits in der Datenbank vorhanden ist, wird eine Exception geschmissen.
Find
Eine sehr grundlegende Funktion ist die find“ Funktion. Sie ermöglicht dem Programmierer eine
”
Entity anhand ihres Primärschlüssels aus der Datenbank zu laden. Der Funktion wird zum einen
die Klasse der Entity übergeben und zum anderen der Primärschlüssel. Der Rückgabetyp ist der
Typ der Klasse die übergeben wird. Entities, die über find aus der Datenbank geladen werden,
befinden sich automatisch im Persistenzkontext.
Queries
Wenn eine Entity nicht anhand ihres Primärschlüssels aus der Datenbank geladen werden soll, ist
es auch möglich eine Entity mithilfe einer Anfrage (Eng.: query) zu erhalten. Der EntityManager
stellt in diesem Fall verschiedene Funktionen zur Verfügung.
19
Clear Close und Detach
Bei größeren Programmen kann es vorkommen, dass sich sehr viele Entities im Persistenzkontext
befinden und damit den Speicher belegen. Um alle Entitties aus dem Kontext zu entfernen,
dienen die Funktionen clear“ und close“. Die sich im Persistenzkontekt befindlichen Entities
”
”
gehen nach dem Aufruf alle in den Zustand Detached über. Eine Übertragung zur Datenbank
findet nicht statt. Nach einem Close ist zudem der EntityManager nicht mehr nutzbar. Soll dem
Persistenzkontext nur eine Entity entzogen werden, wird der Funktion detach“ diese übergeben.
”
Flush
Ein Flush wird immer im Falle eines Commits der Transaktion des EntityManagers aufgerufen.
Ein Flush kann aber auch manuell während der Transaktion über die Funktion flush()“ aufge”
rufen werden. Alle Objekte, die sich zum Zeitpunkt des Flushs im Persistenzkontext befinden,
werden dann mit der Datenbank synchronisiert. Außerdem erfolgt das Hinzufügen der Objekte
zum Persistenzkontext durch die Kaskadierung an dieser Stelle.
Refresh
Der Zustand einer sich im Persistenzkontext befindlichen Entity wird im Falle eines Flushes in die
Datenbank übertragen. Wenn man aber den Zustand der Entity im Programm durch den in der
Datenbank ersetzen möchte, kann man der Funktion refresh“ die betroffene Entity übergeben.
”
Der Zustand, den die Entity vorher hatte, geht dabei verloren. ???
Merge
Der EntityManager bietet eine Funktion merge“, mit deren Hilfe ein Detached-Entity wieder
”
in den Zustand Managed gebracht werden kann. Die Änderungen, die während dem DetachedZustand von der Anwendung an der Entity gemacht wurden, werden dann in die Datenbank
übertragen. Anders als z.B. beim persist“ wird nicht die übergebene Entity in den Zustand
”
Managed gebracht. Stattdessen wird eine Entity zurückgegeben, welche sich im Zustand Managed
befindet. Wenn sich die zu mergende Entity bereits im Managed Zustand befindet, ist das Objekt
der übergebenen Entity nach dem Merge identisch mit dem, welches beim Merge zurückgegeben
wurde.
Transaktion
Der EntityManager kann eine Transaktion durchführen. Dafür benutzt er ein Objekt vom Typ
EntityTransansaction. Dieses Objekt kann durch Aufruf der Methode getTransaction“ des Entity”
Managers angesprochen werden. Um eine Transaktion einzuleiten wird auf dem EntityTransactionObjekt die Methode begin“ aufgerufen. Um die Transaktion durchzuführen wird die Funktion
”
commit“ aufgerufen. Die EntityTransaction-Klasse bietet einem außerdem die Möglichkeit über
”
die Funktion rollback“ die laufende Transaktion rückgängig zu machen.
”
Eine Implementierung könnte wie folgt aussehen:
20
1
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory( ”
myBeispiel” ) ;
2
EntityManager em = entityManagerFactory.createEntityManager();
3
try{
em.getTransaction() .begin() ;
4
//Funktioenen die während der Transaktion aufgerufen werden
5
em.getTransaction() .commit();
6
7
}catch(Exception e){
em.getTransaction() . rollback () ;
8
9
10
}
em.close() ;
21
3 Schlussteil
3.1 Zusammenfasseung
In der Arbeit wurde auf die wichtigsten Funktionen der API eingegangen. Mithilfe von zahlreichen
Code- und Tabellenbeispielen wurde ein Einblick in die praktische Verwendung der JPA gegeben.
Beginnend bei Entities und der persistence.xml, wurden am Anfang der Arbeit die Grundlagen
zum Verwenden der JPA Geschaffen. Des Weiteren wurden Möglichkeiten zur Steuerung des
Mappings aufgezeigt. In diesem Kontext wurden auch die Zugriffsarten Property Access und
Field Access vorgestellt. Darauf aufbauend wurde beschrieben auf welche Art und Weise Vererbungshierarchien und Beziehungen zwischen Entities in die Datenbank abgebildet werden. Unter
anderem wurden Begriffe wie unidirektional und bidirektional zur Beschreibung der Richtung einer
Beziehung eingeführt. Die Annotationen @OneToOne, @ OneToMany, @ManyToMany und @ManyToOne, die zum Beschreiben der Kardinalitäten verwendet werden, wurden ebenfalls eingeführt
und anhand eines Beispiels illustriert. In den letzten Unterkapiteln liegt das Augenmerk auf der
Transaktion. Es wurden die Zustände von Entities und die Möglichkeiten der Steuerung durch
den EntityManager erläutert. Zusammenfassend kann man sagen, dass die wichtigsten Facetten
der JPA erwähnt wurden. Mithilfe des vermittelten Wissens ist es möglich, Vererbungshierarchien
und Beziehungen mithilfe der JPA in eine Datenbank zu schreiben.
3.2 Ausblick
In dieser Arbeit wurde nicht auf die Eigenheiten der Implementierungen eingegangen. Diese sind
für das Verständnis der JPA nicht erforderlich. Wer sich jedoch genauer mit dem objektrelationalen Mapping mit Java beschäftigen möchte, sollte einen Blick auf die Implementierungen nicht
scheuen. Diese bieten einige hilfreiche Funktionen die noch nicht ins Interface übernommen wurden. Es muss immer abgewogen werden ob einem die implementierungsspezifischen Funkionen
oder die Austauschbarkeit der Implementierungen wichtiger ist.
22
4 Literaturverzeichnis
[Dür]
Dr.
Christian
Dürr.
JPA
Einleitung.
http://www.prozesse-und-
systeme.de/jpaEinleitung.html. [Online; accessed 04-September-2012].
[Fin12] Mary A. Finn.
Den Impedance Mismatch auf der Datenbankebene vermeiden.
http://www.intersystems.de/cache/whitepapers/matchwp.html, 2012. [Online; accessed 04-September-2012].
[KH06] M. Kehle and R. Hien. Hibernate und das Java Persistence API: Einstieg und professioneller Einsatz. Entwickler.Press, 2006.
[KS09] M. Keith and M. Schincariol. Pro JPA 2: Mastering the Java Persistence API. Apresspod
Series. Apress, 2009.
[O’C12] John O’Conner.
Using the Java Persistence API in Desktop Applications.
http://java.sun.com/developer/technicalArticles/J2SE/Desktop/persistenceapi/, 2012.
[Online; accessed 03-September-2012].
[rei10]
Reihe Java-Magazin: Fachwissen für Programmierer. Software- und Support-Verlag,
2010.
[Wik]
Wikipedia. Java Persistence API. http://en.wikipedia.org/wiki/Java Persistence API.
[Online; accessed 04-September-2012].
[Zie08] Mathias Ziehmayer. Vergleich der Programmierkonzepte Vererbung, Generizität und
Reflexion in Java und Eiffel. Diplomarbeit, Institut für Computersprachen Technische
Universität Wien, 2008.
23