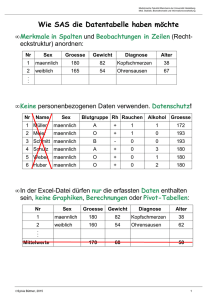
1 - Zweielementiger Buffer in Java
Werbung

1 - Zweielementiger Buffer in Java
Teil a)
1. In der Methode take wird eine if- statt einer while-Anweisung verwendet. Dadurch kann es bei einem
leeren Puffer dazu kommen dass ein Leser t1 zunächst wartet. Wird nun ein Wert geschrieben, könnten
sich T1 und ein neuer Leser t2 um den r-Lock bewerben. Erhält zunächst t2 den Lock, kann erst t2
lesen bevor dann t1 den Lock erhält, nicht erneut überprüft ob der Puffer leer ist, und nur null liest.
2. Analog hierzu kann es uum Überschreiben eines Wertes kommen, da in der Methode put eine if- statt
einer while-Anweisung verwendet wird. Ist der Puffer voll, so wartet ein Schreiber p1 zunächst. Wir ein
Wert gelesen, könnten sich p1 und ein neuer Schreiber p2 um den w-Lock bewerben. Erhält zunächst p2
den Lock, kann erst p2 schreiben bevor dann p1 den Lock erhält, nicht erneut überprüft ob der Puffer
voll ist, und so den Wert von p2 überschreibt.
3. Zu einem Deadlock kann es bei einem halbvollen Puffer kommen, wenn gleichzeitig ein Schreiber und ein
Leser den Puffer nutzen wollen. Der Schreiber sichert sich dann den w-Lock, der Leser den r-Lock. Da der
Puffer weder voll noch leer ist warten beide dann jeweils auf den anderen Lock.
Teil b)
1
package solution;
2
3
4
/** Two element buffer with synchronization. */
public class Buffer2<E> {
5
6
7
8
// element + empty flag
private E content, content2;
private boolean empty, full;
9
10
11
// synchronization object
private Object lock = new Object();
12
13
14
15
16
public Buffer2() {
empty = true;
full = false;
}
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/**
* take the element from the buffer; suspends on an empty buffer.
*
* @return element of the buffer
* @throws InterruptedException
*/
public E take() throws InterruptedException {
synchronized (lock) {
while (empty) {
lock.wait();
}
E res = content;
content = content2;
content2 = null;
empty = !full;
full = false;
lock.notifyAll();
return res;
}
1
}
37
38
/**
* put an element into the buffer; suspends on a full buffer
*
* @param o
*
Object to put into
* @throws InterruptedException
*/
public void put(E o) throws InterruptedException {
synchronized (lock) {
while (full) {
lock.wait();
}
if (empty) {
content = o;
} else {
content2 = o;
full = true;
}
empty = false;
lock.notify();
}
}
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/**
* Return whether the buffer is empty
*
* @return true if empty
*/
public boolean isEmpty() {
return empty;
}
62
63
64
65
66
67
68
69
70
/**
* Return whether the buffer is empty
*
* @return true if empty
*/
public boolean isFull() {
return full;
}
71
72
73
74
75
76
77
78
79
80
}
2 - Synchronisation in Java
Teil a)
Bei einem Programmablauf mit 2 Threads wäre folgendes Scheduling möglich:
T1:
T2:
T1:
T2:
sysout "flip"
sysout "flip"
state = true;
state = false;
2
T1:
T2:
T1:
T2:
...
sysout "flip"
sysout "flip"
state = true;
state = false;
Hierzu kommt es zu mehreren Zustandswechseln, ohne dass die Ausgabe flop erscheint.
Teil b)
Bei der Client-Side-Synchronization synchronisieren sich die Clients mit dem Lock-Objekt des Servers:
// Client
FlipServer s = new FlipServer();
...
synchronized (s) {
s.flip();
}
Bei der Server-Side-Synchronization ist die Methode flip des Servers selbst synchronisiert:
// Server
public synchronized void flip () {
...
}
Teil c)
Bei RMI ist es grundsätzlich so, dass die Clients von der RMI-Registry nicht das Serverobjekt selbst erhalten,
sondern nur ein lokales Stellvertreterobjekt. Da die Clients sich prinzipiell auch auf verschiedenen Rechnern
befinden können erhält jeder Client auch sein eigenes Stellvertreterobjekt.
Daher ist eine Client-Side-Synchronization nicht möglich, da die verschiedenen Stellvertreterobjekte nichts
voneinder wissen (können).
Die Server-Side-Synchronization ist mit RMI jedoch möglich, da das Serverobjekt ja nur ein einziges Mal
existiert und somit auch der Lock eindeutig ist.
3 - MergeSort in Haskell
1
2
3
4
5
6
mergesort :: Ord a => [a] -> [a]
mergesort = sort . map (:[])
where
sort []
= []
sort [xs] = xs
sort xss = sort (mergePairs xss)
7
8
9
10
mergePairs :: Ord a => [[a]] -> [[a]]
mergePairs (xs:ys:zss) = merge xs ys : mergePairs zss
mergePairs xss
= xss
11
12
13
14
15
16
merge
merge
merge
merge
:: Ord a => [a] -> [a] -> [a]
[]
ys
xs
[]
xs@(x:xs1) ys@(y:ys1) | x <= y
| otherwise
=
=
=
=
ys
xs
x : merge xs1 ys
y : merge xs ys1
3
4 - IO in Haskell
1
import System.Random (randomRIO)
2
3
4
5
6
7
8
9
readNumber :: IO Int
readNumber = do
putStr "Ihre Zahl: "
str <- getLine
case reads str of
[(n, [])] -> return n
_
-> putStrLn "Das ist keine Zahl." >> readNumber
10
11
12
randomNumber :: Int -> IO Int
randomNumber n = randomRIO (1, n)
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
guess :: Int -> IO ()
guess maxVal = do
n <- randomNumber maxVal
putStrLn $ "Willkommen zum Raten einer Zahl zwischen 1 und " ++ show maxVal
play 1 n
where
play try n = do
m <- readNumber
case compare m n of
LT -> do
putStrLn "Zu klein."
play (try + 1) n
EQ -> putStrLn $ "Hurra, " ++ show try ++ " Versuch(e)."
GT -> do
putStrLn "Zu groß."
play (try + 1) n
5 - Peano-Zahlen in Prolog
1
2
fromPeano(o
, 0).
fromPeano(s(P), N) :- fromPeano(P, M), N is M + 1.
3
4
5
toPeano(0, o
) .
toPeano(N, s(P)) :- N > 0, N1 is N - 1, toPeano(N1, P).
6
7
8
peano(N, P) :- var(N), !, fromPeano(P, N).
peano(N, P) :- toPeano(N, P).
9
10
11
% Alternativ:
% peano(N, P) :- var(N) -> fromPeano(P,N) ; toPeano(N,P).
Wenn beide Argumente von peano freie Variablen sind wird fromPeano verwendet, dass nacheinander alle
Paare von Peanozahl und natürlicher Zahl aufzählt. Dies ist bereits ein nützliches Verhalten, das wir nicht
weiter verbessern können.
6 - Verwandtschaftsbeispiel in Prolog
Folgender Code war vorgegeben:
4
1
2
3
4
5
6
% eltern(Mutter,
eltern(erika
,
eltern(erika
,
eltern(karin
,
eltern(britta ,
eltern(elfriede,
Vater, Kind)
achim , karl
).
achim , andreas ).
karl , gustav ).
karl , elfriede).
gustav, dagmar ).
7
8
9
10
11
% maennlich(Mann)
maennlich(andreas).
maennlich(gustav ).
maennlich(M
) :- eltern(_, M, _).
12
13
14
% grossvater(Grossvater,Enkel)
grossvater(G,E) :- eltern(_, G, K), (eltern(K, _, E) ; eltern(_, K, E)).
15
16
17
% vollgeschwister(Geschwister1, Geschwister2)
vollgeschwister(G1, G2) :- eltern(M, V, G1), eltern(M, V, G2), G1 \= G2.
18
19
20
% bruder(Kind, Bruder)
bruder(K, B) :- vollgeschwister(K, B), maennlich(B).
Teil a)
Zunächst nummerieren wir alle Regeln der Prädikate, die wir zum Beweis der Anfrage benötigen, durch:
(1)
(2)
(3)
(4)
(5)
eltern(erika
,
eltern(erika
,
eltern(karin
,
eltern(britta ,
eltern(elfriede,
achim ,
achim ,
karl ,
karl ,
gustav,
karl
).
andreas ).
gustav ).
elfriede).
dagmar ).
(6) maennlich(andreas).
(7) maennlich(gustav ).
(8) maennlich(M
) :- eltern(_, M, _).
(9) vollgeschwister(G1, G2) :- eltern(M, V, G1), eltern(M, V, G2), G1 \= G2.
(10) bruder(K, B) :- vollgeschwister(K, B), maennlich(B).
Und nun die Ableitung als Baum:
?- bruder(andreas, B).
|
| Regel (10)
| { K1 -> andreas, B -> B1 }
|
?- vollgeschwister(andreas, B1), maennlich(B1).
|
| Regel (9)
| { G11 -> andreas, G21 -> B1 }
|
?- eltern(M1, V1, andreas), eltern(M1, V1, B1), andreas \= B1, maennlich(B1).
|
| Regel (2)
| { M1 -> erika, V1 -> achim }
5
|
?- eltern(erika, achim, B1), andreas \= B1, maennlich(B1).
/
\
/ Regel (1)
\ Regel (2)
/ { B1 -> karl }
\ { B1 -> andreas }
/
\
?- andreas \= karl, maennlich(karl).
?- andreas \= andreas, maennlich(andreas).
|
% Fehlschlag
| ohne Regel
| { }
|
?- maennlich(karl).
|
| Regel (8)
| { X1 -> karl }
|
?- eltern(_, karl, _).
/
\
/ Regel (3)
\ Regel (4)
/ { }
\ { }
/
\
?-.
?-.
% Erfolg mit B = karl
% Erfolg mit B = karl
Berechnung der Lösung nach dem Suchverfahren von Prolog:
?- bruder(andreas, B).
|- { K1 -> andreas, B -> B1 } Regel (10)
?- vollgeschwister(andreas, B1), maennlich(B1).
|- { G11 -> andreas, G21 -> B1 } Regel (9)
?- eltern(M1, V1, andreas), eltern(M1, V1, B1), andreas \= B1, maennlich(B1).
|- { M1 -> erika, V1 -> achim } Regel (2)
?- eltern(erika, achim, B1), andreas \= B1, maennlich(B1). (*)
|- { B1 -> karl } Regel (1)
?- andreas \= karl, maennlich(karl).
|- { } ohne Regel
?- maennlich(karl).
|- { X1 -> karl } Regel (8)
?- eltern(_, karl, _). (**)
|- { } Regel (3)
?-.
Ausgabe: B = karl
Rücksetzen: Regel (4) bei (**)
|- { }
?-.
Ausgabe: B = karl
Rücksetzen: Regel (2) bei (*)
|- { B1 -> andreas }
?- andreas \= andreas, maennlich(andreas).
Fehlschlag
Teil b)
Das Problem kann man beheben, indem man wie folgt einen Cut verwendet:
21
22
% maennlich2(Mann)
maennlich2(andreas) :- !.
6
23
24
maennlich2(gustav)
maennlich2(M)
:- !.
:- eltern(_, M, _), !.
Der Cut in der ersten Zeile ist nicht zwingend notwendig, da andreas kein Kind hat, aber vielleicht ändert sich
das ja noch.
Allerdings ist diese Lösung nicht sinnvoll, wenn man maennlich2 mit einer freien Variablen aufruft, da dann
nur ein Mann (in diesem Fall andreas) geraten wird.
Teil c)
25
26
halbgeschwister(G1, G2) :- eltern(M1, V, G1), eltern(M2, V, G2), M1 \= M2, G1 \= G2.
halbgeschwister(G1, G2) :- eltern(M, V1, G1), eltern(M, V2, G2), V1 \= V2, G1 \= G2.
Teil d)
27
kinderVon(P, L) :- findall(K, eltern(P, _, K) ; eltern(_, P, K), L).
7