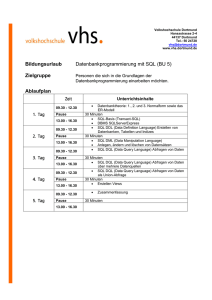
PDF - NEWSolutions
Werbung

Nummer 06/09, Juni 2009 - B 30885, ISSN 1617-948X www.newsolutions.de Unternehmens-IT – Strategie, Technik, Implementierung 6 7 35 Definitionen, Kategorien, Meinungen, Miederwaren: DMS & CMS 12 14 16 Pro & Contra: Cloud Computing aus unterschiedlichen Perspektiven 18 20 Konzepte hochverfügbarer Systemlandschaften 26 Neue SQL-Funktion in V6R1 38 XML-Dateien durchsuchen mit SQL und UDTFs 18, 20 Konzepte hochver- fügbarer Systemlandschaften 12, 14, 16 Was spricht für Cloud Computing 38 XML-Dateien durchsuchen mit SQL und UDTFs 6, 7, 35 DMS & CMS: Definitionen und Kategorien Internet-Inhalt mit zusätzlichen Artikeln und Exklusiv-Beiträgen 4 Cloud Computing Kein Silberstreifen am Horizont 16 Risiken einer Cloud-basierten Infrastruktur Serie Hochverfügbarkeit MANAGEMENT Konzepte hochverfügbarer Systemlandschaften, Teil 2 Serie DMS DMS & CMS: Definitionen und Kategorien 6 Die Autoren stellen Content Management-Systeme als eine Weiterentwicklung der vorab betrachteten Dokumenten-Management-Systeme dar und beschreiben die wesentlichen Aufgaben dieser Systeme von Eldar Sultanow und Edzard Weber 18 Aus der Vielfalt angebotener Lösungen gilt es, jene individuell passende für gegebene Anforderungen zu isolieren und anzupassen. In diesem Artikel werden die Funktionsweise und die Architektur hochverfügbarer Systemlandschaften erläutert und beispielhaft einige Module genannt von Titus Aust und Eldar Sultanow Expertenkommentar Expertenkommentar Ihr Konjunkturpaket schlummert im DokumentenManagement 7 Vermindern Sie Risiken und vermeiden Sie Pingpong-Effekte 20 von Robert Jokisch von Horst Barthel Expertenkommentar Nutzen Sie enormes Einsparungspotential! 7 IT-MANAGEMENT von Rüdiger Peschke Expertenkommentar Viele Potentiale lauern auf ihre Entdeckung 7 Cloud Computing Infrastruktur-Virtualisierung „in den Wolken“, Teil 2 12 Cloud Computing hat viele Ausprägungen. Eine davon – die Virtualisierung der Infrastruktur – bietet eine Reihe neuer Optionen für die Kapazitätserweiterung von Servern, für die Business Continuity Planung und die Wiederherstellung im Katastrophenfall. Der zweite Teil befasst sich mit ökonomischen Aspekten, Verwaltung und Ausbildung von Mel Beckman von Heinz-Günter Meser 22 IBM DB2 für i 6.1 ist eine leistungsstarke Lösung für viele BI-Problemstellungen. Überdies sind in dieser neuen Version interessante Erweiterungen der SQL Query Engine enthalten, die darauf abzielen, die bestmögliche Performance zu erreichen. Im dritten Teil dieses Artikels setzt Mike Cain die Vorstellung von konzeptionellen Elementen für eine gute BI-Performance mit IBM DB2 für i fort von Mike Cain Expertenkommentar Expertenkommentar Vom IT-Leiter zum IT-Prozessmanager Serie Business Intelligence Die besten Methoden für eine gute BI-Performance mit IBM DB2 für i, Teil 3 von Andreas Ahmann 14 Replikation senkt die Datenbanklast 24 von Dr.-Ing. Helmut Knappe 8JSNBDIFONFISBVT*ISFO%PLVNFOUFO %PLVNFOUFO.BOBHFNFOUNJU6OJ¾FE.FTTBHJOH "SDIJW1MVT F$PN1MVT XXXHSBFCFSUHTFEF 5FM 22, 24, 34 Beste BI-Performance mit IBM DB2 für i Serie SQL SELECT from INSERT – Neue SQL-Funktion in V6R1, Teil 2 26 Zwei zuvor separate Funktionen (SELECT und INSERT) sind mit V6R1 nun zu einer neuen Funktion zusammengeführt worden. Im zweiten Teil dieses Artikels befassen die Autoren sich mit dem Einsatz von SELECT from INSERT auf dem System i von Jinmei Shen und Karl Hanson PROGRAMMIERUNG XML-Dateien durchsuchen mit SQL und UDTFs Erweitern Sie DB2 für i mit dieser nützlichen UDTF, die es ermöglicht, XML-Dateien im IFS mit SQL zu durchsuchen von Jagannath Lenka Security und Web Unternehmen werden zum größten Sicherheitsrisiko ihrer eigenen Kunden Der Downloadbereich enthält folgende Codes zu diesem Artikel: 30 Die Sicherheitsspezialisten des IBM X-Force Teams haben für den Trend und Risiko Report 2008 zwei herausragende Entwicklungen identifiziert, wie Kriminelle über Website-Attacken Internet-Nutzern Schaden zufügen UNTERNEHMEN UND PRODUKTE 38 SrchXML SrchXML SQL RPGLE SQL-Anweisung zum Erstellen der UDTF Programmcode der UDTF Anzeigen-/Anbieterindex, Impressum Mehr Wissen – gleich anfordern 42 Kurz und bündig 43 Industrie-Trends und Unternehmens-News Lösungsbrevier Security GoAnywhere™ 33 Vereinfachter gesicherter Datenaustausch mit Vogelbusch Lösungsbrevier Business Intelligence „Umfassend informiert“ 34 BI – schnell und übersichtlich mit der AS/point-Lösung PioSUITE Fallstudie Anita – Miederwaren, Bademoden und medizinische Produkte 35 Zuverlässiger Output-Allrounder von ROHA Sonderseiten Middleware 36 Lösungen verschiedener Anbieter 8JSNBDIFONFISBVT*ISFO%PLVNFOUFO %PLVNFOUFO.BOBHFNFOUNJU6OJ¾FE.FTTBHJOH "SDIJW1MVT F$PN1MVT XXXHSBFCFSUHTFEF 5FM Internet-Exklusiv-Beiträge von NEWSolutions Hot Tip: Wann war das letzte IPL? Wenn man zum Beispiel die aktuelle Laufzeit des Systems seit dem letzten Systemstart berechnen möchte, muss man das Datum und die Uhrzeit des letzten IPL kennen. Leider werden diese Werte nicht in einem Systemwert abgespeichert. Der Systemwert QIPLDATTIM enthält diese Angaben für das nächste automatische IPL, nicht für das zuletzt erfolgte. Lesen Sie den Trick, mithilfe des APIs QUSRJOBI (Retrieve Job Information) die Startzeit des Jobs auszulesen. Passwortberechtigung: NEWSabo plus Passwort IT-Sicherheit endet nicht an den Unternehmensgrenzen: Die größten Gefahren lauern außerhalb. Wenn Mitarbeiter sensible Daten auf ihre mobilen Geräte kopieren, sollten bei IT-Leitern die Alarmglocken läuten, denn die Welt außerhalb des Firmengeländes ist gefährlich. Schnell sind Notebooks oder auch mitgeführte mobile Speichermedien wie USB-Sticks, Festplatten oder DVDs verloren oder gestohlen, schnell ein Passwort geknackt und genauso schnell sind die kritischen Daten kopiert. Wer die Geräte nicht wirksam absichert, spielt russisches Roulette. Die wichtigsten Tipps, wie Unternehmen ihre Mitarbeiter unterwegs vor Datenmissbrauch schützen, hat Utimaco in zehn Punkten zusammengefasst. Passwortberechtigung: Beiträge für Gäste – frei verfügbar Burgy Zapp Mit dem Notebook unterwegs: Zehn Tipps zum Schutz vor Datenklau Die Einführung virtueller Technologien führt nach Meinung der Unternehmen zu deutlichen Veränderungen im Management der IT-Infrastruktur. Einer Erhebung der xTigo Software AG zufolge sind die herkömmlichen ManagementSysteme in den Augen der Anwender dafür jedoch nur bedingt geeignet. Danach sind 42 Prozent der rund 200 befragten IT-Verantwortlichen der Auffassung, dass der Einsatz virtueller Systeme und Anwendungen einen höheren Aufwand beim Infrastrukturmanagement erzeugt. Für weitere 29 Prozent gilt dies teilweise, während jeder achte IT-Manager von ähnlichen Bedingungen wie bisher ausgeht. 17 Prozent verfügen hierzu noch über keine klare Einschätzung. Passwortberechtigung: Beiträge für Gäste – frei verfügbar 4 Juni 2009 Burgy Zapp Klassische Infrastrukturtools nur bedingt geeignet für virtuelle Landschaften NEWSolutions NEWSolutions abonnieren und alle Vorteile genießen! Nummer 06/09, Juni 2009 - B 30885, ISSN 1617-948X Nummer 04/09, April 2009 - B 30885, ISSN 1617-948X www.newsolutions.de www.newsolutions.de Cloud Computing Unternehmens-IT – Strategie, Technik, Implementierung 6 7 35 Definitionen, Kategorien, Meinungen, Miederwaren: DMS & CMS 12 14 16 Pro & Contra: Cloud Computing aus unterschiedlichen Perspektiven 18 20 Konzepte hochverfügbarer Systemlandschaften 26 Neue SQL-Funktion in V6R1 38 Cloud Computing hat viele Ausprägungen. Eine davon – die Virtualisierung der Infrastruktur – bietet eine Reihe neuer Optionen für die Kapazitätserweiterung von Servern, für die Business Continuity Planung und die Wiederherstellung im Katastrophenfall. Der zweite Teil befasst sich mit ökonomischen Aspekten, Verwaltung und Ausbildung. XML-Dateien durchsuchen mit SQL und UDTFs Unternehmens-IT – Strategie, Technik, Implementierung 25 34 16 ERP, Lager & Co. 27 www BI-Performance mit IBM DB2 für i 6.1 8 Lernen Sie PHP kennen Gestalten Sie Webseiten mit Cascading Style Sheets 38 Nummer 05/09, Mai 2009 - B 30885, ISSN 1617-948X Ein großer Schritt nach vorne mit DB2 für V6R1 5 www 14 Vorzüge des Cloud Computing 18 34 Erfolgreiche Wiederherstellung Ihrer Security-Informationen www Business Intelligence: Strategie, Experten & Lösungen 38 Zu viel Formatierungscode in HTML schafft zwei Probleme: Die Neugestaltung von Webseiten wird so schwierig, dass man lieber gleich die Finger davon lässt, und der eigentliche Inhalt wird so verschleiert, dass jede Anpassung zur Qual wird. Diese Probleme kann man lösen, indem man HTML-Formatierungen durch CSS ersetzt. www.newsolutions.de Unternehmens-IT – Strategie, Technik, Implementierung Die Verbesserungen in DB2 für i5/OS V6R1 beinhalten diverse neue Funktionen, die der Datenbank eine gesteigerte Performance verleihen und eine schnelle und einfache Bereitstellung neuer Lösungen ermöglichen. Mit Cascading Style Sheets geben Sie Ihren Webseiten Stil Beste BI-Performance mit IBM DB2 für i IBM DB2 für i 6.1 ist eine leistungsstarke Lösung für viele BI-Problemstellungen. Überdies sind in dieser neuen Version interessante Erweiterungen der SQL Query Engine enthalten, die darauf abzielen, die bestmögliche Performance zu erreichen. Unicode-fähige ILE-Anwendungen mit ICU Ihre Werkzeugkiste für die Virtualisierung PHP auf IBM i PHP ist viel einfacher zu lernen als die meisten neuen Sprachen für IBM i und bietet eine Menge von Vorteilen: Natives PHP auf IBM i bringt Ihnen preisgünstige Anwendungen, Flexibilität bei der Programmierung und eine neue Sprache, die dem RPG-orientierten Denken entgegenkommt. Virtualisierung ist ein fester Bestandteil der IBM i Welt, weshalb sind also die Diskussionen hierüber mit der Ankündigung der Power Server plötzlich so stark in den Vordergrund gerückt? Hier finden Sie einen Überblick über Virtualisierung generell, über die Unterschiede zwischen den Plattformen und über die Möglichkeiten, die sich aus dieser Technologie zur Steigerung Ihrer Server-Performance ergeben. Als Neu-Abonnent erhalten Sie für den Preis eines Jahres die Inhalte vieler Jahre! Wenn Sie jetzt abonnieren haben Sie vollständigen Zugriff auf alle Print- und Internet-Beiträge der letzten Jahre. Abo-Beratung: Tel. 08196/7084 www.newsolutions.de MANAGEMENT DMS & CMS Burgy Zapp Systeme für DokumentenManagement (DMS) und Content Management (CMS): Definitionen und Kategorien VON ELDAR SULTANOW UND EDZARD WEBER Dokumenten-Management-Systeme beziehungsweise Content Management-Systeme stellen jene Systemkategorie dar, die Unternehmensanwendungen zur Verwaltung räumlich verteilter, digitaler Inhaltsbestände umfasst. Die Inhalte können aus heterogenen Quellen stammen und operativ (Berichte, Rechnungen, Formulare), arbeitsgruppen-spezifisch (Checklisten, Präsentationen, E-Mails), gescannt (Urkunden, Verträge) oder multimedial (Audio, Video) sein. Dieser Beitrag führt in das Thema Dokumenten-Management ein und gibt einen Überblick zu den Applikationen und deren Eigenschaften. In Entsprechung zu Bächle und Kolb [BäKo07, S. 32] handelt es sich bei Dokumenten-Management-Systemen um Vorgänger der heutigen CMS mit folgender Definition: „Ein Dokumenten-Management-System (auch: Dokumenten-Verwaltungs-System; kurz: DMS) unterstützt das Einfügen, Aktualisieren und Archivieren von nicht strukturierten Dokumenten in einem Repository, Versionskontrolle, die Rechteverwaltung, Document-Imaging, elektronische Unterschriften, Integration in WorkflowSysteme und … Suche innerhalb der Dokumente.“ 6 Juni 2009 Zu den wesentlichen Aufgaben eines DMS zählen fünf Schritte, welche den Dokumenten-ArchivierungsProzess1 gestalten – die Erfassung nicht digitaler Dokumente, deren Indizierung, Speicherung, Suchmöglichkeiten und Anzeige – sowie zwei weitere Schritte, die Dokumentenverteilung und Administration des Systems [BäKo07, S. 30, 31]. 1 Regelungen zur Archivierung finden sich mitunter in den Grundsätzen zum Datenzugriff und zur Prüfbarkeit digitaler Unterlagen [GDPdU] und in den Grundsätzen ordnungsmäßiger DV-gestützter Buchführungssysteme [GoBS]. NEWSolutions MANAGEMENT DMS & CMS Ihr Konjunkturpaket schlummert im Dokumenten-Management von Horst Barthel, Geschäftsführer der Gräbert Software + Engineering GmbH Dokumenten-Management muss Dokumente schnell und sicher verwalten, kommunizieren und archivieren. Es muss flexibel einsetzbar und einfach in der täglichen Anwendung sein. Die individuelle DMS-Strategie eines Unternehmens muss den täglichen Anforderungen gewachsen sein und sich leicht an sich ändernde Anforderungen in den Geschäftsprozessen anpassen. Dabei sind die zukunftsweisenden Möglichkeiten von der papierlosen Bearbeitung der Geschäftsprozesse über die automatisierte Daten-Extraktion bis hin zur endgültigen Archivierung von E-Mails, Faxen, Spoolbelegen etc. zu berücksichtigen. Eine modulare Umsetzung allerdings in praxisbewährten Projektschritten hält die Kosten im Rahmen und sorgt für eine hohe Akzeptanz beim Anwender. Gut strukturierte DMS-Projekte amortisieren sich bereits innerhalb von vier bis zwölf Monaten, auch bereits bei kleineren Belegmengen. Zögern Sie nicht, Ihr individuelles Konjunkturpaket jetzt zu heben, wir unterstützen Sie gern bei der Kalkulation des ROI für Ihr DMS-Projekt. Nutzen Sie enormes Einsparungspotential! von Rüdiger Peschke, Geschäftsführer der CSP GmbH Der Einsatz einer intelligenten und hochflexiblen Software zur Druckprozesssteuerung, -automatisierung und -optimierung bietet Unternehmen heutzutage enormes Einsparungspotential. Systeme, die eigenständig entscheiden, ob Dokumente gedruckt, verfaxt, vermailt oder Archivsystemen übergeben werden, reduzieren hierbei die Kosten für Operating, individueller Anwendungsprogrammierung und Planungskosten bei der Einführung z.B. neuer ERP-Systeme. Statistikfunktionen und Kostenstellenzuweisung von Drucksystemen und Dokumentenprozessen ermöglichen einen genauen Überblick darüber, wo die Kosten entstehen und bieten somit Informationen, an welchen Stellen Arbeitsabläufe und Prozesse optimiert werden können. Wichtig dabei ist die Modularität einer solchen Outputmanagement-Software, ermöglicht sie doch so die individuelle und kundenspezifische Implementierung in die Unternehmensstrukturen. Die zentrale Administration der Outputprozesse sollte dabei den Aufwand für das Operating auf ein Minimum reduzieren. Viele Potentiale lauern auf ihre Entdeckung von Andreas Ahmann, Bereichsleiter Business Development, Prokurist bei Ceyoniq Technology GmbH Unter dem Oberbegriff „Enterprise Content Management“ (ECM) lauern viele Potentiale auf ihre Entdeckung. Eines dieser Potentiale ist die Erfolg versprechende Möglichkeit den Umsatz des Unternehmens zu steigern und die Kosten zu senken. Aber auch eine höhere Kundenbindung durch besseren Service sowie einen stärker Wert schöpfenden Einsatz der vorhandenen Ressourcen durch optimierte Prozesse zu erreichen. Viele ECM-Systeme bieten integrierte Prozess Management-Lösungen mit denen man häufig auftretende und homogene Prozesse automatisieren kann. Die Laufzeit eines Prozesses setzt sich zumeist neben den eigentlichen Wert schöpfenden Tätigkeiten auch aus Teilen zusammen, die viel Zeit kosten. Dieses sind Transportzeiten (z.B. die Hauspost), Liegezeiten (z.B. wenn Unterlagen nicht umgehend bearbeitet werden) und die „sonstigen“ Tätigkeiten (z.B. das Zusammentragen der Aktenlage aus dem Archiv im Keller). Mit einer Automatisierung werden Transportzeiten eliminiert, Liegezeiten überwacht (z.B. Rechnungen vor Ablauf der Skontofrist automatisch an den Manager eskaliert) und der Gang ins Archiv ist hinfällig. Das beeinflusst zumeist auch die externen Prozesse positiv. Kunden erhalten nicht nur schneller Antwort, sondern auch vielfach in einer besseren Qualität und honorieren das nicht selten mit einer gesteigerten Kundenbindung. Neben allen diesen Vorteilen sorgt ein ECM-System praktisch „nebenbei“ noch dafür, dass den gesetzlichen Anforderungen zur Aufbewahrung von unternehmenskritischen Dokumenten entsprochen wird. NEWSolutions Juni 2009 7 MANAGEMENT DMS & CMS Dokumenten. Sie bieten eine schnelle, komfortable Grundsätzlich wird im DMS-Umfeld in physische und vollständige Suche anhand unterschiedlicher Atund digitale Dokumente differenziert. Erstere liegen tribute beziehungsweise Attributkombinationen. üblicherweise in Papierform, als Mikrofilm oder in • Archivsysteme: Im Hinblick anderen analogen Formaten auf Raum- und Materialvor. Diese Dokumente lassen kosteneinsparungen dienen sich (durch Scanner) digitaliArchivsysteme der langfrissieren und die in ihnen enthaltigen, großvolumigen Dokutenen Informationen nur von mentenablage insbesondere Menschen direkt verarbeiten. der Massenbeleg- und ForZweitere, sprich digitale Domulararchivierung. Sie erkumente, speichern Informatimöglichen nur simple Suchonen in Dateiform, wobei sich anfragen über eindeutige wiederum zwei grundlegende Attribute wie Kunden- oder Informationsarten voneinanBelegnummer. der unterscheiden [GuSS02, S. • Standardapplikationen: Sie 278]: Non Coded Information stellen die zur Dokumentener(NCI) und Coded Information stellung und -bearbeitung (CI). Bei NCI handelt es sich notwendigen Applikationen um Informationen, die zwar dar und werden vom DMS mit dem Monitor oder Drucker automatisch aufgerufen und reproduzierbar sind, jedoch Abbildung 1: Klassifikation von DMS-Anwendungen integrieren DMS-Funktionen erst nach Interpretation durch nach [Dand99, S. 13] wie etwa das unmittelbare den Anwender Sinn erhalAbspeichern von Dokumenten aus der Applikationsten oder sich erst nach Umwandlung durch Text- oder GUI in das DMS. Spracherkennung maschinell interpretieren und weiterverarbeiten lassen. Als CI werden Informationen beWie bereits eingangs erwähnt, sind Content Mazeichnet, welche für die maschinelle Interpretation (z.B. nagement-Systeme eine Weiterentwicklung der vorab der Informationsgehalt von Bildern oder Audiodateien) betrachteten Dokumenten-Management-Systeme und oder Weiterverarbeitung nicht der genannten Umwandlassen sich folgendermaßen definieren: lung bedürfen. So ist beispielsweise in CI-Dokumenten eine Volltextsuche möglich. „Ein Content Management-System (CMS) ist ein betriebliches Informationssystem, das die gemeinZur Klassifikation von Dokumenten-Managementschaftliche Erstellung und Bearbeitung von sog. ConApplikationen leitet Dandl [Dand99, S. 13] aus vertent ermöglicht und organisiert. Der Begriff Content schiedenen Anwendungssystemen das in Abbildung 1 umfasst neben Dokumenten … multimediale Infordargestellte DMS-Typenschema ab: mationen …, also auch Bilder, Filme, Audio-Dateien, Grafi ken.“ • Workflow-ManagementSysteme: Sie übernehmen Mit einfacher Bedienung An diese Definition die informationstechnische komplexe Schriften bis zum [BäKo07, S. 32] anknüpAbwicklung von ProzesCorporate Design erstellen fend unterscheiden Bächle sen in Büroorganisationen, und per Mail zu versenden ... und Kolb Content-Arten beschleunigen und flexibi... macht den SpoolDesigner entsprechend ihres Struklisieren die manuelle Vorturiertheitsgrades (struktugangsbearbeitung und senriert, schwach strukturiert, ken damit deren Kosten. für unstrukturiert) und nennen • Recherchesysteme: Der zu einer echt sexy zwei fundamentale CMSSchwerpunkt von RecherAnwendung Ralf Bartels, IT Leiter, Kategorien: die unternehchesystemen liegt auf dem www.the-tool-company.de Orion Versand GmbH & Co. KG mensweit einsetzbaren schnellen Auffinden von 8 Juni 2009 NEWSolutions FOFSHJFLPTUFO TDISVNQGFOÑ VOEEJFMFJTUVOH XBDITU/ SiemchtendieEnergiekostensenkenÐabernichtauf KostenderLeistung?DannwirdIhnenIBMDynamic Infrastructuregefallen:EsistunsereVorstellungdavon, wiezuknftigeRechenzentrenIhrGeschftvoranbringen. EfÞzient,ßexibel,umweltfreundlichundma§geschneidert. EineVorstellung,dieschoninmehrals2.000UnternehmenerfolgreicheRealittwurde. Tztufnf-TpguxbsfvoeTfswjdft g sfjofotnbsufoQmbofufo/ jcn/dpn0hsffo0ebubdfoufs0ef 0)4\UKKHZ0)43VNVZPUK4HYRLUVKLYLPUNL[YHNLUL4HYRLUKLY0U[LYUH[PVUHS)\ZPULZZ4HJOPULZ*VYWVYH[PVUPUKLU=LYLPUPN[LU:[HH[LU\UKVKLYHUKLYLU3pUKLYU(UKLYL5HTLU]VU-PYTLU7YVK\R[LU\UK+PLUZ[SLPZ[\UNLURUULU4HYRLU VKLYLPUNL[YHNLUL4HYRLUPOYLYQL^LPSPNLU0UOHILYZLPU 0)4*VYWVYH[PVU(SSL9LJO[L]VYILOHS[LU 640)40; MANAGEMENT DMS & CMS Enterprise Content Management-Systeme (ECMS) und auf Internettechnologie basierende Web Content Management-Systeme (WCMS). Letztere Kategorie zeichnet sich typischerweise durch eine integrierte Versions- und Benutzerverwaltung, einen Freigabezyklus sowie durch Import- und Exportschnittstellen zu anderen Informationssystemen aus [BäKo07, S. 33]. Diese Eigenschaften und gleichermaßen die Kategorisierung der Content Management-Systeme in ECMS und WCMS decken sich nahezu vollständig mit den von Rosenblatt und Dykstra [RoDy03] genannten. Ergänzend bringen Rosenblatt und Dykstra die Kategorie der DAM (Digital Asset Management)Systeme vor (Tabelle 1) und führen die gemeinsamen Grundbestandteile aller CMS-Kategorien auf. Der Schwerpunkt von DAM liegt in der Verwaltung digitaler Mediendateien wie etwa Text, Audio, hochauflösende Bilder und High Definition Video (HDV). Die fundamentalen Technologiebestandteile von Content Management-Systemen [RoDy03] lassen sich durch folgende sechs Punkte wiedergeben: 1. Metadaten: Textanalyse, Extraktion von Schlüssel- wörtern und Suchkriterien wie Erstellungsdatum, Autor, Bildauflösung 2. Workflow: Versionskontrolle über und rollenbasierter Zugriff auf Inhalte durch Autoren, Content-Manager oder Leser 3. Datenbanksysteme (DBS): Verwaltung der Inhalt beschreibenden Metadaten 4. Ablagesysteme: Archivierung heterogener Formate, von XML bis HDV, auf Datenträger und in Speichernetzwerken 5. Distribution: Verteilung der Inhalte im Web und an Geschäftspartner über FTP oder Syndication-Protokolle wie RSS, ICE 6. Suchindizes: Indexbasierte Volltextsuche in großen Beständen An dieser Stelle sei erwähnt, dass in der Literatur teilweise Definitionen für ein Dokumenten-ManagementSystem zu finden sind, die sich mit jenen anderer Softwarekategorien überschneiden. So verstehen beispielsweise Kampffmeyer und Merkel [KaMe99, S. 26] unter dem Begriff auch Produktkategorien wie Groupware Segmentierung nach zu verwaltendem Inhalt [Rock02, S. 334] Web Content Management System (WCMS) Automatisierung in der Inhaltserstellung und Auslieferung im Web oder an drahtlose Endgeräte Transactional Content Management System (TCMS) Abbildung von Prozessen zur Abwicklung von E-Commerce-Transaktionen Integrated Document Management System (IDMS) Administration von betrieblichen Dokumenten und Inhalten Publication-oriented Content Management System (PCMS) Lebenszyklusverwaltung von Veröffentlichungsmaterial wie Betriebsanleitungen, Bücher und Hilfesysteme Learning Content Management System (LCMS) Verwaltung des Lebenszyklus webbasierter Lerndokumente Enterprise Content Management System (ECMS) Multipler Bereich für Prozessübernahme: Lebenszyklus von Web-, Publikationsund/oder Transaktionsinhalten Inhaltsbezogene Segmentierung nach [RoDy03, S. 2, 3] Digital Asset Management (DAM) Verwaltung von Rich Media-Beständen wie digitales Audio- und Video in Medienproduktionsumgebungen Web Content Management (WCM) Seitenvorlagen, redaktionelle Ablauforganisation, Umgebung für die Ver– öffentlichung von Webinhalten Enterprise Content Management (ECM) Verwaltung von Dokumenten für den internen Gebrauch, Geschäftspartner, Kunden, Behörden und Öffentlichkeit Tabelle 1: Segmentierung von Content Management-Systemen 10 Juni 2009 NEWSolutions MANAGEMENT DMS & CMS und Workflow. Sie stellen überdies einen Segmentierungsansatz vor, der DMS aus vier Blickwinkeln betrachtet: das Dokument, die Daten, Prozesskontrolle und kooperative Arbeit. Einen aktuellen Marktüberblick zu DMS und CMS im Kontext von Wissens-Management gibt Bahrs [Bahr09]. Weitere ins Detail gehende Literaturquellen liefern auch Rockley [Rock02] und Keyes [Keye06]. Erstere Quelle unterscheidet die sechs in Tabelle 1 genannten CMS-Typen und letztere vereint DMS, CMS, ECMS und DAM neben weiteren Unterkategorien zu so genanntem Enterprise Information Management (EIM). Abschließend sei kurz zusammengefasst, dass Dokumenten-Management-Systeme beziehungsweise Content Management-Systeme der Verwaltung verschiedener Dokumente und Inhalte dienen. Auch wenn es sich bei den Inhalten um beispielsweise E-Commerce- Die Autoren Eldar Sultanow und Edzard Weber ([email protected]) ([email protected]) Transaktionen oder Lerninhalte handelt, ist ein CMS vom elektronischen Marktplatz (kurz EMP) oder von einer E-Learning-Plattform abzugrenzen. Denn der Schwerpunkt von Content Management-Systemen liegt auf der gemeinschaftlichen Inhaltserstellung und -bearbeitung. ♦ Literaturverzeichnis [Bahr09] Bahrs, Julian; Gronau, Norbert (Hrsg.): Anwendungen und Systeme für das Wissensmanagement. 3. Auflage, GITO, 2009. [BäKo07] Bächle, Michael; Kolb, Arthur: Einführung in die Wirtschaftsinformatik. Oldenbourg Verlag, Mai 2007. [Dand99] Dandl, Jörg: Dokumenten-Management-Systeme: Eine Einführung, in: Arbeitspapiere WI Nr. 9/1999, Johannes Gutenberg-Universität. Mainz. [GDPdU] Bundesministerium der Finanzen: Grundsätze zum Datenzugriff und zur Prüfbarkeit digitaler Unterlagen (GDPdU). BMFSchreiben vom 16. Juli 2001 - IV D 2 - S 0316 - 136/01. [GoBS] Bundesministerium der Finanzen: Grundsätze ordnungsmäßiger DV-gestützter Buchführungssysteme (GoBS). BMF-Schreiben vom 7. November 1995 - IV A 8 - S 0316 - 52/95. [GuSS02] Gulbins, Jürgen; Seyfried, Markus; Strack-Zimmermann, Hans: Dokumenten-Management. Auflage 3, Springer-Verlag, August 2002. [KaMe99] Kampffmeyer, Ulrich; Merkel, Barbara: Dokumentenmanagement – Grundlagen und Zukunft. Aufl age 2, PROJECT CONSULT GmbH, September 1999. [Keye06] Keyes, Jessica: Knowledge Management, Business Intelligence, and Content Management: The IT Practitioner‘s Guide. Auflage 1, Auerbach Publications, Mai 2006. [Rock02] Rockley, Ann: Managing Enterprise Content: A Unified Content Strategy. Auflage 1, New Riders Verlag, Oktober 2002. [RoDy03] Rosenblatt, Bill; Dykstra, Gail: Integrating Content Management with Digital Rights Management: Imperatives and Opportunities for Digital Content Lifecycles. GiantSteps Media Technology Strategies, Mai 2003. Wir sind umgezogen! Die Straße hat sich geändert: Zugspitzstraße 7 Beim Umzug haben wir im Lager doch noch einige Exemplare der bereits vergriffenen Bücher gefunden – jetzt wieder für Sie verfügbar: AS/400 Blackbox geöffnet TCP/IP und die AS/400 Restexemplare zum Preis von 49,00 Euro von Frank G. Soltis von Michael Ryan Dr. Frank Soltis beantwortet in seinem Buch alle wichtigen Fragen zur AS/400. Manager können sich einen sachkundigen Überblick verschaffen und Programmierer finden hier alle technischen Details in den besonders gekennzeichneten Technik-Passagen. Dr. Frank Soltis entmystifiziert das System mit Berichten zur Funktionsweise und einem Blick in die Zukunft. Für erfahrene Anwender von TCP/IP auf anderen Systemplattformen gibt dieses Buch Einblick in Konfiguration und Verwaltung der AS/400 TCP/IP Funktionen. Dem AS/400 Spezialisten mit nur geringem TCP/IP Wissen wird dieses Buch die Bedeutung von TCP/IP in der Welt des Systems AS/400 und generell in der Welt der Netzwerke näher bringen. Restexemplare zum Preis von 52,00 Euro DUKE Communications GmbH · Zugspitzstraße 7 · 86932 Pürgen Tel. 0151/119386851 oder Tel. 08196/7084 · [email protected] NEWSolutions Juni 2009 11 Burgy Zapp MANAGEMENT Cloud Computing Infrastruktur-Virtualisierung „in den Wolken“, Teil 2 Cloud Computing eröffnet neue Optionen für Kapazitätserweiterungen und Wiederherstellung im Katastrophenfall VON MEL BECKMAN Cloud Computing ist das jüngste Modewort und es steckt voller begeisternder Möglichkeiten. Aber wie bei den meisten Modewörtern ist auch hier eine solide Definition schwer zu umreißen. Cloud Computing ist ein sehr breit angelegter Begriff und deckt fast alle Ausprägungen von Computing außer Haus oder StorageServices ab. Aber solche Services gibt es schon seit fast 50 Jahren – seit den ersten Computer Time-Sharing Services der 1960er Jahre. Sie könnten nun argumentieren, das Internet selbst sei bereits eine gigantische Cloud Computing Ressource, die Off-Site Computing in Form des Zugriffs auf verteilte Server, virtuelles Hosting und wissenschaftliches High-Performance Computing unterstützt. Worin hat Cloud Computing also sein Alleinstellungsmerkmal? Im ersten Teil (Mai 2009) haben Sie die Cloud-Mechanismen kennen gelernt. MANAGEMENT Cloud Computing Ökonomische Aspekte der InfrastrukturVirtualisierung (IV) Da reduzierte Kosten eine der primären Triebfedern für IV sind, ist es nur vernünftig, nach den Kosten zu fragen. Es ist allerdings nicht weiter verwunderlich, dass diese Frage nicht ganz einfach zu beantworten ist. Der Preis ist von der Kapazität des Providers und der Art der benötigten Ressourcen abhängig. Ein Server mit einer Basisausstattung (2 GHz-Prozessor, 2 GB Speicher und 120 GB Plattenvolumen) kann beispielsweise bereits zum Preis von 0,10 $ pro Stunde angemietet werden. Ein Aufrüsten auf einen schnelleren MultiCore Server mit größerem Speicher könnte diesen Preis auf 0,50 $ pro Stunde oder auch mehr anheben. Zusätzlich zu der stündlichen Rate für jede Server-Instanz fallen Gebühren für den öffentlichen Netzwerkverkehr oder den Verkehr zwischen geographischen Regionen an. Eingehender Verkehr wird dabei gewöhnlich mit geringeren Raten berechnet als ausgehender Verkehr. Typische Preise sind 0,10 $ für eingehenden, 0,15 $ für ausgehenden Verkehr. Provider bieten fast immer Sonderpreise für Benutzer mit hohem Transaktionsvolumen an, die in Kraft treten, sobald das Volumen ein oder zwei Terabyte übersteigt. In IV-Clouds wird der einer Server-Instanz zugeordnete Plattenspeicher gelöscht, sobald der Server neu gebootet oder heruntergefahren wird. Soll der Plattenspeicher erhalten bleiben, muss beständiger CloudPlattenspeicher – üblicherweise in GB-Schritten – angemietet werden. Die Kosten bewegen sich hier um 0,10 $ pro GB und Monat. Auf lange Sicht gerechnet entsprechen die Kosten hier in etwa den anfallenden Gesamtkosten bei eigener Anschaffung und eigenem Betrieb vergleichbarer Kapazitäten. Darüber hinaus ist IV-Speicher ebenso schnell wie eigene Platteneinheiten, da dieser Speicher zusammen mit den betriebenen Server-Instanzen in SAN-Arrays implementiert ist. Die Übertragungsgeschwindigkeit beim Einstellen oder Auslesen von Daten hängt allerdings eher von der Geschwindigkeit der Internet-Verbindung ab; ein Faktor, der speziell bei Anwendungen zur Wiederherstellung im Katastrophenfall äußerst sorgfältig bedacht werden sollte. Es ist oft noch sinnvoll, für das erstmalige Hochladen der Daten oder für schnelle Downloads bei einer Wiederherstellung im Katastrophenfall temporäre Internet-Services mit hoher Übertragungskapazität – zumeist auf Stundenbasis – anzumieten. Zusätzlich zur Server-Instanz, zum Datenverkehr und Speicher können weitere Software-Lizenzkosten anfallen, wenn Ihre Server-Instanz mit einem vom Provider oder einem Dritthersteller bereitgestellten, lizenzierten Image arbeitet. So berechnen Provider für die ImageNutzung generell einen Aufschlag auf die Gebühr für das Basis-OS in Höhe von 15 bis 25 % pro Stunde sowie zusätzliche Aufschläge für lizenzierte Komponenten wie z. B. SQL Server. Auf diese Weise erspart man sich zwar die Anschaffungskosten für eine WindowsLizenz, da sich aber die auf Stundenbasis anfallenden Gebühren im Laufe der Zeit zu erheblichen Beträgen summieren können, kann der Fall eintreten, dass es günstiger gewesen wäre, direkt eine eigene Lizenz zu kaufen. Auf jeden Fall sollte auch bedacht werden, dass für die eine oder andere Lizenz-Software Mindestanforderungen an Geschwindigkeit und Kapazität des Servers vorgegeben sind, was wiederum zur Steigerung der stündlich anfallenden Kosten beitragen kann. Die Cloud-IV Preisgestaltung kann auf den ersten Blick erheblich günstiger erscheinen, als sie tatsächlich ist. Obwohl die günstigsten Server-Instanzen bereits für „Pfennige“ zu haben sind, können daraus sehr schnell Beträge von mehr als einem Dollar pro Stunde werden, wenn weitere Leistungen wie schnellere Prozessoren, zusätzlicher Speicher, Software-Lizenzen und ergänzende Services wie Load-Balancing und statische IPAdressen angemietet werden. Nehmen wir ein simples Beispiel mit einer Dual-Core 8 GB Server-Instanz, auf der Windows 2003 Server mit SQL Server 2005 ausgeführt wird. Bei Gesamtgebüh- MANAGEMENT Cloud Computing ren von 1 $ pro Stunde würde der Betrieb einer solchen Server-Instanz 720 $ pro Monat kosten. Hinzu kämen noch die Kosten für die Datenübertragung. Das macht – gerechnet auf eine Periode von drei Jahren – Kosten von annähernd 26.000 $ aus. Wenn der Server überdies ein hohes Transaktionsvolumen verarbeiten muss, kann daraus leicht ein Vielfaches dieses Betrages werden. Die Wahrheit ist, dass IV für ständig anfallende Arbeitslasten – basierend auf der heutigen Preisgestaltung – absolut nicht kosteneffektiv ist, solange die abzuwickelnden Aufgaben nicht extrem zeitkritisch sind oder außergewöhnliche Bandbreiten erfordern. In den meisten Fällen ist es erheblich günstiger, die Server selbst zu erwerben und im eigenen Hause oder einer nahe gelegenen Außenstelle zu betreiben. Werden die Server in eigener Regie betrieben, kann zusätzliche Kapazität vorgesehen werden, um moderate Belastungsspitzen abzufangen. Belastungen bis zum zwei- bis dreifachen der normalen Transaktionsraten Vom IT-Leiter zum IT-Prozessmanager von Heinz-Günter Meser, Keos Software Service GmbH Die Rolle von Administratoren steht vor einem grundlegenden Wandel: Die Welt und die Unternehmen verändern sich immer schneller, ebenso wie Technologien, Anwendungen und Anforderungen an die IT. Cloud Computing, Virtualisierung, steigende Datenvolumen und Web 2.0 sind nur einige Schlagworte. Viele Technologien lassen sich outsourcen, viel wichtiger ist jedoch die optimale Unterstützung der Geschäftsprozesse – dafür sind interne Kenntnisse unverzichtbar. Damit entwickelt sich der ITLeiter immer mehr zu einem IT-Prozessmanager. Für diese neue Herausforderung sind Dienstleister und Technologien gefragt, die ihn unterstützen und entlasten. Um die steigenden Anforderungen an die Ausfallsicherheit zu gewährleisten, kommen skalierbare Hochverfügbarkeitslösungen wie MiMiX, iTera oder Double Take zum Einsatz. Zudem gewinnen Lösungen für das Business Service Management an Bedeutung, z.B. das Visual Message Center von Tango/04, die eine messbare Verfügbarkeit (SLA) von Geschäftsprozessen ermöglichen und die Abhängigkeiten zwischen IT-Systemen und dem eigentlichen Geschäftsprozess aufzeigen. 14 Juni 2009 können durch eine Auslegung von CPU und Speicher auf 50 % über der eigentlich benötigten Größe abgedeckt werden. Schwanken die Arbeitsbelastungen um mehr als diese Werte, beginnt IV, in kosteneffektive Bereiche zu gelangen, weil Cloud-Ressourcen nur während der kurzen Perioden mit hohen Belastungsspitzen aktiviert werden müssen. Auch für den Fall, dass IV für Business Continuity oder Wiederherstellung im Katastrophenfall genutzt werden soll, sind die höheren Kosten zu rechtfertigen, da auch hier die Cloud-Ressourcen nur während eines tatsächlichen Katastrophenfalls und vielleicht für Routine-Tests von kurzer Dauer benötigt werden. Für die Nutzung als virtuelles IT-Labor allerdings ist IV ein riesiger Gewinn, da die zu bewältigenden Aufgaben meist nur für kurze Zeit anstehen und IV den Zugriff auf annähernd unendliche Hard- und Software-Ressourcen ermöglicht. Tatsache ist, dass der Betrieb von Servern in eigener Regie auch eine Reihe von indirekten Kosten verursacht – für Raum, Energie, Kühlung und Wartung. In den Hardware-Investments stecken überdies auch immaterielle Technologiekosten – nicht die Kosten der Hardware, sondern die Nachteile, die sich aus dem Beibehalten veralteter Technologie ergibt. Cloud IV Provider haben hingegen eine hohe Motivation, mögliche Upgrades auf effizientere Technologien schnell vorzunehmen, da sich daraus Vorteile ergeben können, die sich positiv auf ihr Größen-/Kostenverhältnis auswirken. Bei einem kleineren Betreiber wirken sich diese Vorteile nicht in messbarem Umfang aus, was letztlich dazu führt, dass ältere Hardware länger beibehalten wird. Der letzte, absolut indirekte Vorteil von IV, der vielleicht nicht den eigentlichen Betrieb, aber möglicherweise die Kaufentscheidungen beeinflussen könnte, ergibt sich aus den geringeren Umwelteinflüssen – verglichen mit dem Betrieb eigener Server. Die meisten traditionellen Anwendungs-Server werden mit einer durchschnittlichen Auslastung von 10 bis 25 % betrieben, was letztlich bedeutet, dass zumindest 75 % der Energie- und Kühlungskosten umsonst aufgewendet werden. Diese Auslastung lässt sich durch Virtualisierung im eigenen Hause vielleicht auf bis zu 60 % steigern. IV bei namhaften Cloud-Providern hingegen kann zu Auslastungen von bis zu 95 % führen, weil diese Provider Hardware einsetzen, die sich lastabhängig schrittweise erweitern lässt – Hardware, die sich in kleineren Rechenzentren nicht kosteneffektiv betreiben lässt. Ein IV NEWSolutions MANAGEMENT Cloud Computing Provider ist in der Lage, unbenutzte Plattenlaufwerke und CPUs abzuschalten, was zu erheblichen Einsparungen bei Energie- und Kühlungskosten führt. Zusammengefasst macht die heutige Preisgestaltung IV für Anwendungen interessant, die nur unregelmäßig durchgeführt werden oder erhebliche Schwankungen in der Workload beinhalten. Die Nutzung von IV für ständig laufende Anwendungen mit gleichmäßiger Workload wird sich in aller Regel nicht als kosteneffektiv erweisen. Die Implementierung von IV-basierten Anwendungslösungen kann aber durchaus für durchschnittliche Unternehmen eine Menge von Vorteilen bieten. Über die ökonomischen Faktoren hinaus sollten bei der Entscheidung für die Implementierung von IVTechnologien aber auch die Gesichtspunkte Zuverlässigkeit, Sicherheit und haftungsrelevante Aspekte nicht außer Acht gelassen werden. Weitergehende Betrachtungen hierzu finden Sie in dem gesonderten Kasten „Kein Silberstreifen am Horizont“. Management ist von entscheidender Bedeutung IV Cloud Provider bieten meist nur eine minimale Auswahl an Management-Tools. Diese Tools lassen viele wesentliche, für den seriösen IV-Einsatz im geschäftlichen Umfeld unabdingbare Funktionen vermissen: Performance-Überwachung, Kostenkontrolle, Sicherheitsüberprüfung und Problemanalyse. Hier können selbst erstellte Tools eingesetzt oder bereits vorhandene Tools wie beispielsweise eine SNMP-basierte Netzwerk-Management-Station eingesetzt werden. Alternativ halten viele Drittanbieter IV-spezifische Management-Tools bereit. Performance-Überwachung ist erforderlich, um die Vorteile der SLAs (Service Level Agreements) der Provider nutzen zu können, da letztlich der Benutzer in der Pflicht ist, jede Form von Ausfällen oder mangelnder Funktionalität selbst nachweisen zu müssen. Eine Performance-Überwachung kann frühzeitig auf drohende Probleme aufmerksam machen, indem angezeigt wird, wenn die Antwortzeiten von den üblichen Werten abweichen oder die Anwendungs-Ressourcen sich den angemieteten Kapazitätsgrenzen nähern. Probleme werden Sie sicherlich nicht erst dann erkennen wollen, wenn Ihre Kunden sich beschweren, dass sie keine AufNEWSolutions Juni 2009 15 MANAGEMENT Cloud Computing träge mehr platzieren können! Eine eigene Kostenkontrolle ist äußerst wichtig, weil Provider naturgemäß keinerlei Anreiz verspüren, dies für Sie zu übernehmen. Deren Geschäft ist es, Services zu verkaufen. Wenn ein Abnehmer durch Unaufmerksamkeit oder Unkenntnis zu viele Ressourcen gebucht hat, ist es sein Fehler und nicht der Fehler des Providers. Erwarten Sie kein großes Entgegenkommen, wenn Sie versehentlich eine Server-Instanz ungenutzt laufen lassen und anschließend eine hohe Rechnung erhalten. IV-Provider sind überdies notorisch schlecht in der Bereitstellung detaillierter Kostenaufschlüsselungen. Amazon’s EC2 liefert zum Beispiel fein detaillierte Transaktions-Logs, berechnet aber eine monatliche Pauschalsumme ohne jegliche Aufschlüsselung, was dieser Betrag im Einzelnen beinhaltet. Auch die Verantwortung für die Sicherheit ruht voll und ganz auf Ihren Schultern, nicht auf denen des Providers. Sie allein sind für die Sicherheitskontrolle verantwortlich, auch wenn Sie eine Firewall-Instanz des Providers implementiert haben. Sie sind verantwortlich für Passwörter und digitale Zertifikate, die zur Verschlüsselung Ihrer Daten verwendet werden und ebenso für deren Verteilung und Überwachung. Auf ähnliche Weise müssen Sie für Antivirus-Software und Erkennung von Schadprogrammen auf den von Ihnen betriebenen Servern sorgen. Dabei sollten Sie den Standard-IT-Praktiken folgen, wie beispielsweise routinemäßige Prüfungen auf Schwachstellen, um vielleicht versehentlich aufgetretene Sicherheitslücken frühzeitig zu erkennen. Schließlich stehen Sie, wenn Probleme auftreten, in der ersten Verteidigungslinie. Zuerst muss eine grundlegende Problemanalyse durchgeführt werden, um zu ermitteln, wo der Fehler aufgetreten ist. Die häufigsten IV-Fehler treten durch mangelnde Ressourcen – z. B. Speicher, CPU oder Plattenplatz – auf. Diesen Fehlern kann man recht gut mit entsprechender PerformanceÜberwachung begegnen. Die zweithäufigste Ursache liegt in fehlerhaften Konfigurationen, wogegen eigentlich nur entsprechendes Wissen hilft. Über diese beiden Kein Silberstreifen am Horizont Eine Cloud-basierte Infrastruktur kann zwar die gesamten IT-Operationen Ihres Unternehmens erheblich kostengünstiger gestalten, aber in drei Kategorien gibt es Vorbehalte: in der Zuverlässigkeit, der Sicherheit und der Verantwortlichkeit. Bisher gestaltet sich die Cloud-Zuverlässigkeit – speziell bei kleineren Cloud-Providern – eher unausgewogen. Selbst große Clouds wie Amazon’s EC2 (Elastic Compute Cloud) hatten Ausfallzeiten zu verzeichnen, die sich über mehrere Stunden erstreckten und letztlich zu Verlusten von Kundendaten führten. Amazon argumentiert, dass das EC2-Problem zu einem Zeitpunkt auftrat, als der Service sich noch im Beta-Stadium befand. Amazon bietet nun ein SLA (Service Level Agreement) an, um die Kunden gegen solche Ausfälle – und sogar gegen übermäßig verlangsamte Antwortzeiten – zu schützen. Wie auch immer, SLAs wie das von Amazon erkennen keine Schäden an und erstatten den Kunden nur einen Anteil der Kosten für den nicht gewährten Service. Solch ein SLA bedeutet für Sie – den Kunden, dessen Verlust an Produktivität und Umsatz vermutlich erheblich größer ist als die zu erwartende SLA-Rückvergütung – keinen eigentlichen Schutz. Um die Situation noch zu verschlimmern, bürden die meisten SLAs dem Kunden die Verpflichtung auf, Ausfälle oder Verzögerungen in hohem Detaillierungsgrad, teilweise sogar bis auf die Millisekunde, zu dokumentieren. Eine Möglichkeit, die Zuverlässigkeitsproblematik abzumildern, besteht darin, Cloud-Operationen auf mehrere Provider zu verteilen. Da sich aber Standards für Cloud-basierte Serveradministration noch in der Entwicklung (durch Organisationen wie das Open Cloud Consortium – opencloudconsortium.org) befinden, erfordert dieser Ansatz erhebliche zusätzliche Bemühungen und Kosten auf der Seite des Kunden. Darüber hinaus kann ein großflächiger Internet-Ausfall, von dem eventuell Ihre sämtlichen Cloud-Provider oder die Internet-Pfade dorthin betroffen sind, diesen Ansatz zunichte machen. Wie auch immer, das letztere Risiko besteht eigentlich immer, gleichgültig, ob Sie Ihre Server im eigenen Hause, in verteilten Außenstellen oder in der Cloud betreiben. Ein wirklich geeignetes Mittel dagegen gibt ist nicht, eine Tatsache, die letztlich aufzeigt, wie abhängig das Geschäftsleben heute vom Internet geworden ist. Sicherheit kann immer zum Thema werden, sobald Daten das eigene Haus verlassen und Unternehmensfremden zum Schutze anvertraut werden. Die Übertragung sensitiver Daten in die Cloud steigert die Möglichkeit, versehentlich die Kontrolle über die Inhalte oder gar die Inhalte selbst zu verlieren. Die Daten könnten unterwegs von einem Hacker, der in 16 Juni 2009 NEWSolutions MANAGEMENT Cloud Computing geläufigen Fehlersituationen hinaus können Probleme in der Anwendungs-Software, dem verwendeten Betriebssystem, der Netzwerk- oder Speicher-Infrastruktur des Providers oder dem Internet-Pfad, der zum Erreichen der IV-Ressourcen verwendet wird, auftreten. Bevor man sich für ein IV-Projekt entscheidet, sollte sichergestellt sein, dass die entsprechenden Skills und Tools vorhanden sind, um IV-Diagnostikaufgaben wahrnehmen zu können. Der Wert von Analyse-Tools zur Überwachung des Datenverkehrs (Sniffer und Flow Analyzer) liegt in deren Fähigkeit, den tatsächlichen Netzverkehr exakt wiederzugeben. Können zwei Einheiten nicht miteinander kommunizieren, lässt sich die Ursache gewöhnlich durch Analyse des Netzverkehrs aufspüren. Vielleicht führen von einer Einheit gesandte Requests niemals zu Reaktionen der Zieleinheit oder die Antworten verschwinden irgendwo im Netz. Durch Einsatz eines Netzwerk-Prüfprogramms (Network Probe) lassen sich Kommunikationsprobleme meist schnell isolieren und identifizieren. Ausbildung und Vermeidung von Überraschungen Nun, da Sie ein wenig mit den Funktionen und Limitierungen von IV „in den Wolken“ vertraut sind, sind Sie in der Lage, einkaufen zu gehen. Ein Teil Ihres Einkaufsprozesses sollte das praktische Ausprobieren unterschiedlicher IV-Provider-Produkte sein. Glücklicherweise macht die grundsätzliche Natur des Cloud Computing dies zu einem recht kostengünstigen Geschäft. Sie zahlen eine geringfügige Gebühr für die Nutzung der Ressourcen und müssen nur Ihre Zeit und Ihre Bemühungen aufwenden. Im Laufe dieses Prozesses gewinnen Sie Kenntnisse und Erfahrungen, die Sie letztlich zu der für Sie passenden „Ecke des Himmels“ führen werden. ♦ Mel Beckman ist als leitender technischer Autor für NEWSolutions tätig. Übersetzt und für den deutschsprachigen Markt überarbeitet von Joachim Riener. Ihren virtuellen Server oder Cloud-basierten Speicher eingebrochen ist, ausgelesen oder entwendet werden. Die Risiken sind hier höher als bei im eigenen Hause gespeicherten Daten, da die Möglichkeit zur physischen Kontrolle des Zugriffs auf die Computing- und Speicherressourcen, die die Cloud-Daten beherbergen, fehlt. Glücklicherweise lassen sich Daten in einer Weise schützen, die sich nicht auf das Vertrauen zu dem Cloud Provider oder anderen Dritten beschränkt. Dies kann bei jeglichen Datenübertragungs-Operationen durch Verschlüsselung der Daten, Signierung der Code-Objekte und Benutzung digitaler Zertifikate zur Berechtigungsprüfung beider Seiten geschehen. Diese Maßnahmen müssen allerdings von Ihnen selbst getroffen werden. Die Verantwortlichkeit für Ihr Unternehmen und vielleicht auch für Sie persönlich wird vom Cloud Computing auf unterschiedliche Weise tangiert. Gesetzliche Regelungen schreiben beispielsweise bestimmte Sicherheitsvorkehrungen für sensitive Daten wie Finanzinformationen oder Patientendaten vor. Aber die Verantwortlichkeit erstreckt sich auch auf Services, die Sie Ihren Kunden anbieten sowie auf die Kosten für Cloud-basierte Verarbeitung, die sich schnell explosiv entwickeln können, sofern sie nicht sorgfältig überwacht werden. Im letzteren Fall werden Sie Ihren Kunden, die Sie über Cloud-Computing bedienen, keine höhere Zuverlässigkeit garantieren wollen, als Sie selbst von Ihrem Cloud-Provider erwarten können. Hierzu ist es erforderlich, die Kostenstruktur für Cloud-Services, die Sie einkaufen und überwachen, vollständig zu verstehen. Da Cloud-Services nutzungsabhängig berechnet werden, können durch versehentlichen Betrieb ungenutzter Server- und Speicherressourcen schnell erhebliche Kosten entstehen. Beim Lesen des Kleingedruckten in der Service-Vereinbarung mit dem Provider werden Sie feststellen, dass Sie für sämtliche Nutzung in Ihrem Account verantwortlich sind, auch wenn die Nutzung versehentlich erfolgte oder durch Hacker vorgenommen wurde. Machen diese Risiken Cloud Computing unbrauchbar? Auf keinen Fall, was zumindest für die meisten Anwendungen gilt. Aber bevor Services in die Cloud übertragen werden, sollten die Risiken und Kosten sorgfältig abgewogen werden und es sollte ein bestimmter Kostenblock für kompromisslose Überwachung der Performance (zur Verfolgung von PerformanceProblemen), der Sicherheitsereignisse, der Nutzung und der Berechnung eingeplant werden. NEWSolutions Juni 2009 17 Burgy Zapp MANAGEMENT Hochverfügbarkeit VON TITUS AUST UND ELDAR SULTANOW Konzepte hochverfügbarer Systemlandschaften Teil 2 Die stete Konnektivität komplexer Systeme zählt im Informationszeitalter bereits zu den wettbewerbskritischen Faktoren hochtechnisierter und effizient arbeitender Unternehmen. Dies bedeutet konkret – auch unter limitierenden Bedingungen wie Wartung, Serverarbeiten oder Aktualisierung der Software – eine uneingeschränkte Verfügbarkeit sowie einwandfreie Funktionstüchtigkeit dieser Systeme und der damit verbundenen Geschäftsprozesse zu gewährleisten. Denn eine Vielzahl dieser Prozesse müssen für den Kunden fortwährend erreichbar sein, obgleich Internetportale, soziale Netzwerke, Elektronische Marktplätze (EMP) oder behördliche Online-Registrierungsverfahren diese abbilden. Allerdings greifen die genannten Anwendungen auf eine Vielzahl von Ressourcen (etwa auf Datenbanken bei der Nutzer-Authentifizierung) gleichzeitig zu, wodurch eine enge Vernetzung einzelner IT-Komponenten unumgänglich wird. Aufgrund dieser Tatsache stellt die Aufrechterhaltung aller Anwendungsfunktionen während Reparatur- oder Wartungsarbeiten am Server eine enorme Herausforderung dar. Teil 1 des Artikels ist in der Aprilausgabe erschienen. Die Autoren behandelten die Themen Hochverfügbarkeit auf Datenspeicherebene und Shadow-Service. In NEWSolutions sind folgende Beiträge zum Thema Hochverfügbarkeit erschienen: Brian Bohner: Sind Sie auf eine Katastrophe vorbereitet? Teil 1; März 2008 Fallstudie S+S: Datenspiegelung beim Verpackungshersteller; März 2008 Fallstudie: NCT wächst mit Application Hosting; Juni 2008 John Ghrist: Verfügbarkeitsüberwachung; Produktmonografie August 2008 Lösungsbrevier pheron: Ein Hoch auf die Verfügbarkeit; Produktmonografie August 2008 Lösungsbrevier KEOS: Endlich Business Continuity Planning für alle Unternehmen; Oktober 2008 Brian Bohner: Wie hochverfügbar ist Ihre Hochverfügbarkeit? Teil 2; November 2008 Titus Aust und Eldar Sultanow: Konzepte hochverfügbarer Systemlandschaften, Teil 1; April 2009 Fallstudie KEOS: Hochverfügbare Bankanwendungen mit MiMiX; Mai 2009 18 Juni 2009 NEWSolutions MANAGEMENT Hochverfügbarkeit Backup (Offline/Online) Bei einem Backup im OfflineModus handelt es sich um eine bei heruntergefahrener Datenbank durchgeführte Sicherung, die entweder von handelsüblicher Backup-Software oder betriebssysteminternen Applikationen durchgeführt wird. In der Fachliteratur, z.B. in (Fröhlich et al. 2005) ist hierfür oftmals der Begriff „Cold Backup“ zu finden, da jenes im „kalten“ Zustand prozessiert wird. In (Gschoßman/Langenegger 2008, S. 94) findet sich dazu konkret folgende Definition: Unter einem (…) Offline-Backup versteht man die physische Sicherung aller für das Wiederherstellen einer Datenbank notwendigen Daten im „kalten“ Zustand. Durch das Abschalten der Datenbanken wird sichergestellt, dass während des Backups keine Änderungen mehr an dieser vorgenommen werden können. Hierbei werden die vom User ausgewählten Daten zur Sicherung üblicherweise einfach auf ein entsprechendes Sicherheitsmedium dupliziert oder dort in einer komprimierten Datei zusammengefasst. Nach erfolgreichem Abschließen des Prozesses erhält der User eine konsistente Sicherung der gesamten Datenbank. Betriebssysteme wie etwa Microsoft Windows bieten Tools zur Sicherung der Einstellungen und Dateien an, mit deren Hilfe der Benutzer mühelos ein einfaches und rasches System-Backup ausführen kann. Die praktische Anwendung dieser Methodik stößt allerdings dann an ihre Grenzen, alsbald ein Datenbankstillstand (Downtime) nicht in Kauf genommen werden kann. Um auch diesem Anspruch Rechnung zu tragen, gibt es für eine Reihe von Datenbanken auch die Möglichkeit des Online-Backups. Hier wird gegensätzlich zur vorherigen Prozedur bei laufender Datenbank ein Backup durchgeführt. Als praxisnahes Beispiel lässt sich auch das Disk-ArrayVerfahren nennen, ein Subsystem bestehend aus mehreren Festplatten, die es verschiedenen Servern zur Verfügung stellt. Wie bereits vorgegriffen, werden die Datenbanken im Kontrast zur vorangehenden Methodik nicht geschlossen, sondern ab einem bestimmten Status bei voller Einsatzfähigkeit und Verfügbarkeit gesichert. Der signifi kante Unterschied (neben der Datenbankverfügbarkeit) zur Offline-Variante des Backup ist, dass auch sämtliche während der Online-Sicherung vorgenommenen Änderungen gleichsam mit in die Backup-Datei einfließen. Dem Benutzer wird unter anderem freigestellt, einzelne Tablespaces (Tabellenräume) oder den gesamten Datenspeicher zu sichern. Im Prozess werden Datensätze bei laufender Datenbankinstanz auf ein Sicherungsmedium kopiert, müssen allerdings im Vorfeld eine KEOS-Leistungsübersicht DR & HA Lösungen • MiMiX, iTera, Echostream • DoubleTake • Skalierbar, sicher, günstig • OS/400, AIX, Windows • Virtuelle Systeme Business-Service-Management • SLA-Monitoring auf Geschäftsprozessebene • Prozessüberwachung / Visualisierung • Verfügbarkeitsmessung • ITIL-Reporting IT-Service- und Infrastrukturmonitoring • Multiplattform-Systemüberwachung • Frühwarnsysteme • Alarmierung • Automation • Reporting (SOX, Basel II) Sicherheit / Auditing • Automatisierte Sicherheits- / Auditprüfungen • Alarmierung • Auditreporting Services • Disaster Recovery / Hochverfügbarkeitsstudien • Service-Level-Konzepte / Realisierung • IT-Systemoptimierung • Rechnerkonsolidierung • Webdesign und -entwicklung • Anwendungsentwicklung Profitieren Sie von unseren erstklassigen Konditionen und Serviceleistungen! KEOS Software Service GmbH Odenwaldstraße 8 63517 Rodenbach Tel. 06184/9503-0 [email protected] • www.keos.de Quellen: Fröhlich, L., Czarski, C. und Maier, K. (2005): Oracle 10 g. Grid Computing, Self-Management, Enterprise Security. Pearson Education, 2005. Gschoßmann, C. und Langenegger, K. (2008): Das Oracle Backup und Recovery-Praxisbuch. Pearson Education, 2008. Störl, U. (2001): Backup und Recovery in Datenbanksystemen. Verfahren, Klassifikation, Implementierung und Bewertung. Vieweg+Teubner Verlag, 2001. NEWSolutions Juni 2009 19 iTERA HA MANAGEMENT Hochverfügbarkeit Reihe von Prozeduren durchlaufen. Dabei gilt es, die einzelnen Tablespaces des Speichers inkrementell in einen Backup-Status zu versetzen, um sie anschließend mit Software- oder Betriebssystembefehlen einzeln sichern zu können. Beim Backup der Gesamtdatenbank werden unweigerlich noch alle angelegten Log-Dateien der parallel zur Sicherung vorgenommenen Änderungen benötigt, um diese bei der anschließenden Wiederherstellung auch berücksichtigen zu können. Es existiert noch eine Reihe anderer Verfahren (vgl. Gschoßmann/Langenegger 2008), aus der nachfolgend drei kurz erläutert werden sollen. dem letzten Vollbackup (Level-0 Backup) veränderten Datensätze, Einstellungen und Transaktionen gesichert. Diese Variante ist dann sinnvoll, wenn in kurzen Abständen schnelle Sicherungen vorgenommen werden müssen. Partielles Backup Hier werden mitunter nur bestimmte Teile einer Datenbank gesichert, wie zum Beispiel einzelne Dateien oder gar Tablespaces. Dies kann von praktischem Nutzen sein, wenn für das Backup nur eine vordefinierte Zeitspanne zur Verfügung steht. Um die ganzheitliche Sicherung durchzuführen, müssen also die einzelnen Abbildung 1: Hochverfügbarkeitskomponenten auf Teil-Backups auf verschiedene Datenspeicherebene Zeiträume gelegt und die darParallelisierung aus entstandenen Sicherungsdaten schlussendlich wieUnter diesem Verfahren versteht man in der Prader zusammengeführt werden. Dieses Verfahren kann xis das Sichern einer aktiven Datenbank auf mehrere sowohl offline als auch online angewendet werden. Speichermedien gleichzeitig. Hierdurch können die Zusammenfassend lässt sich anmerken, dass ein OnLaufzeiten eines Backups unter der Prämisse der Effiline-Backup die gängigste und bequemste Option ist, zienz deutlich verkürzt werden. Dafür sollten die Zielda die Datenbank während des Vorgangs verfügbar medien allerdings direkt mit dem Datenserver verbunbleibt. Unter Umständen ist jedoch der hohe materielden sein, und nicht über ein Netzwerk. le Aufwand durch gesteigerte Leistungsansprüche der Applikationen nicht immer unproblematisch. Inkrementelles Backup ♦ Viele Lösungen bieten dem Kunden auch die MögDie Autoren Eldar Sultanow und Titus Aust erreichen lichkeit eines inkrementellen oder schrittweisen Sie unter [email protected] und aust@ Backups, in der Praxis auch häufig „Level-1 Backup“ entire-media.de. genannt. Bezeichnenderweise werden hier nur die seit Vermindern Sie Risiken und vermeiden Sie Pingpong-Effekte von Robert Jokisch, Meinikat Informationssysteme GmbH In iSeries Umgebungen gibt es in der Regel mehr geplante Stillstände – wie Hardware-Wartung (HW), IBM PTF oder Releasewechsel des ERP-Anbieters – als ungeplante Stillstandszeiten. Während die meisten Lösungen mit HW und PTF umgehen können, sind Releasewechsel des ERPAnbieters häufig ein Problem. Datenbankänderungen oder die Erweiterung von Schnittstellen erhöhen das Risiko eines längeren Stillstandes. Egal, ob als Datei im IFS oder als Datenaustausch via Socket – ohne Test mit dem echten Partner statt mit einer Simulation bleibt ein erhöhtes Restrisiko. Kann die HVF SW mit den neuen Techniken meines ERP-Anbieters arbeiten? (Constrain, Trigger, Commitment, Userindex, Userspace … ) Ist eine Rückkehr (schlimmstenfalls) zur alten Version möglich? Kann ich identische Pfade im IFS nutzen (aktiv/passiv) ohne einen Pingpong-Effekt auszulösen? Diese Problematiken gilt es als zusätzliche Fragestellungen zur einfachen Datengleichheit zu bedenken. 20 Juni 2009 NEWSolutions m{z{aw{7 m{{]{z zy_~k{{~{{}{y~ }y~ \{{~wU i {{i{_~{X{{x {P Yify {Jwz{zy{{¢y~{Zw{{ B zw { i{ {{{ z ~{ w|C z}{f }w z{}{fw{}{xwy~{z{ {DZw}| ~wz{{z|}{i{{ _~{d{{DWÊ{z{{|wz {z{Yif Wyy EJFF_~}{w{Zy {Bzwi{{z{C {{{y~}{iw_~{Zy {~wx{D m~{|{_~{xw{]{zw{D iy~GPd{i{z{{Y 7 i {z{i{w}{}{~ ~{ `WB {a {{z{{7 Zy {P Y w|{ z w _| {{i{{xzy~x{ z{ Yif j{{|wCd{P FLGFLCLGKLF {z{D \w Wx{} iwÊ{ fbpEe dw{ j{{| Yify {J7 Yif [C cw X{z{a y~{ w{{Bwi{ x{ z{{{{D IT-MANAGEMENT Business Intelligence Burgy Zapp Die besten Methoden für eine gute BI-Performance mit IBM DB2 für i, Teil 3 VON MIKE CAIN IBM DB2 für i eröffnet neue Möglichkeiten zur Steigerung der BI-Performance Im dritten Teil dieses Artikels setzt Mike Cain die Vorstellung von konzeptionellen Elementen für eine gute BI-Performance mit IBM DB2 für i fort. Der Autor stellte in Teil 1 (April 2009) das Datenmodell, die Indexierung, Query Tables und Datenbank Parallelismus vor. In Teil 2 (Mai 2009) behandelte er die Themen Isolation und Locking und berichtete über Query und Reporting Tools und ausgewogene Konfigurationen. Work Management DB2 für i Work Management und Non-Database Workloads verfügen über Gemeinsamkeiten, aber auch über erhebliche Unterschiede. Das IBM i Betriebssystem handelt Datenbankaufgaben in gleicher Weise wie alle anderen Aufgaben ab. Anders als andere Datenbankverwaltungssysteme nötigt DB2 den 22 Juni 2009 Anwender aber nicht, separate Subsysteme, Speicherbereiche und Bufferpools einzurichten und zu konfigurieren. Jobs oder Threads, die DB2-Aufgaben abwickeln, werden von OS-Subsystemen initiiert und verwaltet und verfügen über eigene Ablaufprioritäten und Zeitscheiben. Ausgehend von der Tatsache, dass es die Aufgabe des Query Optimizer ist, den besten (und schnellsten) Plan zu identifizieren und zusamNEWSolutions IT-MANAGEMENT Business Intelligence menzustellen – was sollte ihn davon abhalten, einen Plan aufzustellen, der die gesamten Computing- und I/O-Ressourcen für sich in Anspruch nimmt? Es ist also durchaus wichtig, die Unterschiede im Work Management zu verstehen, bevor man sich mit QueryOptimierung befasst. Zwei der wichtigsten zu bedenkenden Punkte sind der Grad der Parallelität für den Job, der die Query ausführt und der angemessene Anteil an Speicher, den der Query Optimizer für sich in Anspruch nehmen kann. Die SMP- oder Parallelitätsgrad-Werte *NONE, *IO und *OPTIMIZE (auch als ANY bekannt) weisen den Optimizer an, einen angemessenen Speicheranteil für den Job zu berechnen und zuzuweisen. Der Wert *MAX gestattet dem Query Optimizer, gegebenenfalls auch den gesamten Speicher des Pools, in dem der Job abläuft, in Anspruch zu nehmen. Der angemessene Speicheranteil lässt sich grob aus der Größe des Speicherpools dividiert durch den Wert der maximal für den Pool erlaubten Aktivitäten berechnen. Somit kann der Query Optimizer abhängig von der Poolgröße und dem Max Active-Wert einen aggressiven Plan (d. h. größerer Speicheranteil) oder einen anämischen Plan (d. h. geringerer Speicheranteil) zusammenstellen. Der Query Optimizer sollte pro Job einen angemessenen Speicheranteil zuordnen, um die bestmöglichen verfügbaren Optionen für die Durchführung der Query zu nutzen. Eine adäquate Speicherzuordnung bietet den Vorteil, Query-Pläne in höherem Maße CPU-lastig auszulegen, was konsequenterweise zu verringerten oder gar eliminierten I/O-Wartezeiten führt. Der Schlüssel zu dieser Praktik ist einerseits eine gute Kapazitäts- und Performance-Planung und andererseits die Einstellung des Max Active-Wertes für den Pool auf einen Wert, der angibt, wie viele Jobs gleichzeitig Queries in diesem Pool ausführen können. In anderen Worten, wie viele Jobs werden vermutlich wirklich NEWSolutions gleichzeitig Query-Pläne in diesem Pool ausführen? Auch das Verhalten der automatischen PerformanceAnpassung sollte sorgfältig bedacht werden. Viele Systeme verwenden diese Funktion, die über den Systemwert QPFRADJ gesteuert wird. Veränderungen, die die automatische Performance-Anpassung an den Max Active-Einstellungen und den Poolgrößen vornimmt, beeinflussen die angemessenen Speicheranteile, die der Query Optimizer ermittelt. Verringert sich der Speicheranteil des Jobs, wird der Query-Plan vermutlich weniger aggressiv und letztendlich im Ablauf langsamer ausfallen. Eine geringere CPU-Auslastung und ein geringerer Datenbank-Durchsatz sind die Indikatoren dieses Phänomens. PWRDWNSYS und IPL – Ja oder Nein? Beim Erstellen von SQL Queries teilen Sie DB2 mit, was geschehen soll, aber nicht wie es geschehen soll. Letztlich ist es der Query Optimizer („a little programmer in a box“), der die erforderliche Logik schreibt, um die gestellten Aufgaben zu erfüllen. Diese Logik (die Query-Pläne) wird für zukünftige Wiederverwendung gespeichert. Das erspart die Notwendigkeit, die Arbeit nochmals zu erledigen, wenn dieselbe Query erneut angefordert wird. Diese Query-Pläne werden in einem temporären Speicherbereich gespeichert und „überleben“ das nächste IPL des Systems oder der LPAR nicht. Der DB2 für i Query Optimizer und die Database Engine verwenden für nicht permanente Objekte, wie z. B. Indizes temporäre Datenstrukturen, um die Query CPU-lastiger und damit schneller werden zu lassen. Mit SQE lassen sich diese temporären Datenstrukturen wieder verwenden und sogar von mehreren Queries und Jobs gemeinsam nutzen. Bei der QueryAusführung über SQE findet ein Lern- und Adaptionsprozess statt. Ein Nebenprodukt dieses Verhaltens ist die Erstellung, Sicherung und Wiederverwendung von Juni 2009 23 IT-MANAGEMENT Business Intelligence Replikation senkt die Datenbanklast von Dr.-Ing. Helmut Knappe, HiT Software Business Intelligence Lösungen helfen, die Unternehmensentwicklung besser zu überwachen und zu steuern und leisten so auch einen Beitrag zur Krisenbewältigung. Dafür ist es wichtig, dass alle verfügbaren Informationsquellen einbezogen werden, gleich aus welcher Datenbank. Direkte Abfragen auf operationale Quell-Datenbanken verlangen aber – wie der Artikel zeigt – erheblichen Aufwand. Deshalb ist die allgemein empfohlene Übertragung der Daten von den produktiven Datenbanken in eine separate Analysedatenbank besonders für nicht ganz so große Unternehmen der bessere Weg, denn sie vermeidet diesen Aufwand, erlaubt zusätzlich die Bereinigung und Standardisierung der Daten und entkoppelt die Belastungen. Mit Ihren aktuellen Daten können Sie trotzdem arbeiten, wenn Sie dafür eine herstellerunabhängige Replikationslösung einsetzen, die auf Basis der Transaktionsprotokolle arbeitet, alle benötigten Datenbanken unterstützt, ohne Programmierung einfach einsetzbar ist und im Budget bleibt. Datenstrukturen und sogar die Fähigkeit, das endgültige Ergebnis einer Query zu sichern und bei zukünftigen Ausführungen derselben Query über dieselben basierenden Daten wieder zu verwenden. In mancher Hinsicht trägt diese Funktion Züge eines autonomen Selbst-Tunings. Die temporären Datenstrukturen gehen allerdings bei einem IPL des Systems oder der LPAR verloren. Aus Sicht der Datenbank erscheint es als ratsam, häufige IPLs des Systems oder der LPAR zu vermeiden. Durch selteneres Herunterfahren des Systems lassen sich Vorteile aus der Selbst-Tuning-Unterstützung ziehen und der „Monday-morning slowdown“ der Queries vermeiden. Ein möglicher Vorschlag könnte sein, IPLs nur monatlich oder vierteljährlich einzuplanen, um PTFs einzuspielen und gegebenenfalls Hardware-Anpassungen vorzunehmen. 24 Juni 2009 Überwachung und Tuning-Einrichtungen Mit V5R4 wurden neue und verbesserte SQ-Überwachungs- und -Tuning-Einrichtungen bereitgestellt. Mit V6R1 stehen noch mehr Möglichkeiten zur Verfügung, Queries zu überwachen und in der Leistung zu optimieren. Auf diese Einrichtungen kann überwiegend über den Navigator für i5/OS-Unterstützung und DB2 für i Server-Unterstützung zugegriffen werden. Überdies sind zusätzliche Tools über Drittanbieter erhältlich. Queries lassen sich kontinuierlich mit Funktionen wie SQL-Plan Cache, Plan Cache Snapshot und Monitoren überwachen und optimieren. Plan Cache stellt ein Repository für alle SQE-Pläne dar und enthält eine Vielzahl nützlicher Informationen über die Query-Pläne und das Ausführungszeit-Verhalten sowie Hinweise für das Erstellen von Indizes. Obwohl der Plan Cache eine LiveInstitution und somit nicht beständig ist, ermöglicht es die Funktion Plan-Cache Snapshot, den Query-Plan und die Ausführungszeit-Informationen aufzulösen und in einer beständigen Datenbanktabelle abzuspeichern. Das bietet dem Datenbank-Performance-Analysten die Möglichkeit, Query-Pläne zu sammeln, zu speichern und Pläne von unterschiedlichen Zeitpunkten miteinander zu vergleichen. Anders als SQL-Plan Cache erlaubt es der SQL-Performance-Monitor (oder Datenbankmonitor), alle SQL-Statements für einen Job oder eine Reihe von Jobs zu verfolgen. Die gesammelten Informationen werden in einer beständigen Datenbanktabelle gespeichert und lassen sich mit dem integrierten i5/OS Navigator für Reporting analysieren oder direkt per Query in einem individuellen Bericht darstellen. Der SQL-PerformanceMonitor verfügt über zahlreiche Filteroptionen, die eine Fokussierung auf spezielle Queries, Benutzer, Jobs oder Database Clients erlauben. Eine weitere Funktion der DB2 für i kostenbasierten Optimierung sind die vorhersagenden Query Governors. Es existiert ein Time-Limit Governor und ein Temporary-Storage-Limit Governor. Während der Optimierung werden die geschätzte Laufzeit und der geschätzte Speicherbedarf ermittelt. Vor der Ausführung werden diese Werte dann mit dem Threshold des Benutzers verglichen. Wenn entweder die Laufzeit oder der Speicherbedarf den Threshold überschreiten, kann das System je nach Konfiguration der Werte die Query beenden oder das Limit ignorieren. Überdies kann das System für jede Query, die die ThresholdWerte überschreitet, detaillierte OptimierungsinforNEWSolutions IT-MANAGEMENT Business Intelligence mationen in einer SQL-Performance-Monitortabelle sammeln. Um die Anzahl von lange laufenden Queries zu reduzieren, müssen entsprechende Zeitlimits und temporäre Speicherlimits gesetzt werden. Für alle SQL Requests, die diese Limits überschreiten, lassen sich anhand der detaillierten Monitordaten tiefer gehende Untersuchungen anstellen. Dabei ist zu bedenken, dass die Angaben des Monitors bezüglich Laufzeit und temporärem Speicherbedarf nur Schätzungen darstellen und möglicherweise nicht das tatsächliche Ausführungszeit-Verhalten wiedergeben. Die Schätzungen des Query Optimizer sollen primär dazu dienen, die besten Methoden und Strategien ausfindig zu machen. Je besser die Statistiken (aus permanenten Indizes und Zeilenstatistiken) sind, desto akkurater fallen die Schätzungen aus. Testen, Tunen und Übergabe an die Produktion Query-Optimierung basiert auf vielen Faktoren, die alle zusammen einen Plan ergeben. Ein angenommener Plan ist in direkter Linie abhängig vom SQL Request, den anzusprechenden Daten und der gesamten Computing-Umgebung. SQL-basierte Anwendungen sollten daher in derselben Umgebung und mit denselben Daten getestet und getunt werden, in der sie in der Produktion später laufen werden. Testen und überwachen Sie vor der endgültigen Live-Phase auch die ETL und Endbenutzer-Queries. Als Teil des Aufbaus eines erfolgreichen Qualitätssicherungs- und PerformanceTestplans ist es zwingend erforderlich, ein volles Verständnis für die Query-Antwortzeit-Erwartungen, die Anzahl gleichzeitiger Benutzer und das erwartete Datenwachstum zu entwickeln. Die Zusammenarbeit mit erfahrenen Power-Benutzern aus dem Unternehmen kann einen wesentlichen Beitrag zur Sicherstellung einer erfolgreichen BI-Implementierung liefern. Behalten Sie ein wachsames Auge Nach der Übergabe einer BI-Lösung an die Produktion sollte der Überwachungsprozess fortgesetzt werden. Dieser Prozess kann unter anderem ein Data Profiling beinhalten. Der Begriff Data Profiling umfasst das NEWSolutions Sammeln, die Analyse und das Verständnis der Daten im Data Warehouse und in Data Marts. Zum Beispiel: Wie groß werden die Tabellen? Wie schnell wachsen sie an? Wie mächtig sind die Spaltenwerte? Wie ist die Verteilung eines gegebenen Sets von Spaltenwerten? Das Verstehen der Daten trägt zum Verständnis und damit zur richtigen Konfiguration des DB2Verhaltens bei. Wenn Sie ein wachsames Auge auf die Datenbanknutzung und das Benutzerverhalten haben, können Sie eventuell aufkommende Probleme leichter vorhersehen und mit weniger Stress und Frustration lösen. Ein weiterer Aspekt der Überwachung ist die Möglichkeit, neue oder sich verändernde Anforderungen frühzeitig zu erkennen, so dass sich zukünftige Verbesserungen an der Query- und Berichtsumgebung leichter planen lassen. So kann sich durch die Überwachung beispielsweise ergeben, dass für die Unterstützung neuer Bereiche zusätzliche Fact- und Dimension-Tabellen benötigt werden. Auch Veränderungen in der Organisation, die eine adäquate Anpassung der Dimensionen erfordern, lassen sich durch gezielte Beobachtung frühzeitig erkennen. Denken Sie immer daran, dass eine BILösung nur dann wertvoll ist, wenn sie in effizienter Weise genutzt wird. Erweitern Sie Ihren Horizont Mit DB2 für i 6.1, den heutigen leistungsfähigen IBM Servern und den hier von mir beschriebenen Methoden liegt eine hervorragende BI-Performance für Sie in greifbarer Nähe. Weitere Informationen über viele dieser Methoden sind in englischer Sprache auf der DB2 für i Website (ibm.com/systems/i/software/db2) verfügbar. Klicken Sie auf die Registerkarte Getting Startet und dann auf die Links zu White Papers oder Online Presentations. ♦ Mike Cain ([email protected]) ist leitendes Mitglied des technischen Stabes. Er befasst sich überwiegend mit der Untersuchung, Quantifizierung und Darstellung der i5/OS Unterstützung für sehr große Datenbanken, BI und SQL Query Performance. Übersetzt und für den deutschsprachigen Markt überarbeitet von Joachim Riener. Juni 2009 25 IT-MANAGEMENT SQL SELECT LECT from INSERT eue SQL-Funktion – Neue in V6R1, Teil 2 Zwei Operationen werden zu einer neuen Funktion VON JINMEI SHEN UND K ARL HANSON INSERT und SELECT waren vor V6R1 in DB2 für i5/OS zwei getrennte Operationen. Um eingefügte Spaltenwerte abzufragen, konnte eine nachfolgende SELECT Operation benutzt werden, um auf das Ziel einer INSERT Operation zuzugreifen. Nach Erläuterung der neuen Funktion, praktischen Informationen und syntaktischen Beispielen im ersten Teil des Artikels (Ausgabe Januar/Februar) befassen sich die Autoren im zweiten Teil mit dem Einsatz von SELECT from INSERT auf dem System i. Der Einsatz von SELECT from INSERT auf dem System i Die folgenden Szenarien beschreiben einige Einsatzmöglichkeiten von SELECT from INSERT in DB2 für i5/OS und geben einen kurzen Einblick in die beteiligten Prozesse. Abfrage eines generierten Spaltenwertes für eine einzelne hinzugefügte Spalte Voraussetzungen: • Die Zieltabelle des INSERT ist vorhanden und enthält eine Spalte mit generierten Werten. • Der Requester, der das INSERT ausführt, verfügt über die Berechtigung, der Zieltabelle Zeilen hinzuzufügen. Ablauf: 1. Ein Anwendungsprogramm wird aufgerufen, das ein SQL SELECT INTO Statement mit einem INSERT Statement in der FROM Klausel enthält. Das INSERT benutzt die VALUES Klausel, um eine einzelne neue Zeile in die Tabelle einzufügen (Abbildung 10). 26 Juni 2009 NEWSolutions IT-MANAGEMENT SQL 2. Das Anwendungsprogramm führt das SELECT INTO Statement aus und übergibt einen Wert für die Eingabespalte (custnum host variable) an den Datenbankmanager. 3. DB2 verarbeitet den INSERT Request (eingebunden in das SELECT INTO) und fügt eine neue Zeile in die Tabelle orders ein. Hierbei wird ein Wert für die Spalte Auftragsnummer generiert. 4. DB2 verarbeitet den SELCT INTO Request und gibt den für die Spalte Auftragsnummer generierten Wert zurück an das Anwendungsprogramm. Abfrage einer gesonderten, mit den eingefügten Zeilen in Verbindung stehenden Spalte mit Hilfe einer Subquery Voraussetzungen: • Es existieren zwei Tabellen: Das Ziel des INSERT und die Quelle der abgefragten Daten, die eingefügt werden sollen. • Der Requester, der das INSERT ausführt, verfügt über die Berechtigung, der Zieltabelle Zeilen hinzuzufügen. • Der Requester, der das INSERT ausführt, verfügt über die Berechtigung, Daten aus der abzufragenden Tabelle zu lesen. EXEC SQL SELECT inorder.ordernum INTO :ordnum FROM FINAL TABLE (INSERT INTO orders (custno) VALUES(:custnum) ) inorder ; Abbildung 10: SQL Beispiel-Statement SELECT * FROM FINAL TABLE ( INSERT INTO bonus_candidates (empname, empserial, empsalary) INCLUDE inc_ytd_sales SELECT name, serial, salary, ytd_sales FROM sales_ summary WHERE ytd_sales > 700000.00 ) Abbildung 11: SQL Beispiel-Statement mit einem INSERT in der FROM Klausel VALUES ( SELECT AVG(C2) FROM FINAL TABLE (INSERT INTO VALI1 SELECT * FROM VALI2) WHERE C1 > ? ) ) INTO ? Abbildung 12: CLI-Programm bereitet ein SQL-Statement vor String sql = "INSERT INTO authors (last, first, home) VALUES " + "'Shara', 'Ron', 'Minnesota, USA'"; int rows = stmt.executeUpdate(sql, Statement.RETURN_GENERATED_KEYS); ResultSet rs = stmt.getGeneratedKeys(); if (rs.next()) { ResultSetMetaData rsmd = rs.getMetaData(); int colCount = rsmd.getColumnCount(); do { for (int i = 1; i <= colCount; i++) { String key = rs.getString(i); System.out.println("key " + i + " is " + key); } } while (rs.next()); } else { System.out.println("There are no generated keys."); } Ablauf: 1. Der Requester stellt eine Verbindung zu der DB2 für i5/OS Datenbank her. Abbildung 13: Java Programm mit 2. Der Requester führt ein SQL Script aus, das ein RETURN-GENERATED_KEYS Optionen SELECT Statement mit einem INSERT Statement in Outer SELECT). Jede zurückgegebene Zeile enthält der FROM Klausel enthält. Das INSERT verwendet alle in die bonus_candidates Tabelle eingefügten eine Query, um die einzufügenden Zeilen zu ermitSpaltenwerte sowie die entsprechenden Werte der teln und spezifiziert eine INCLUDE-Spalte, die dem ytd_sales Spalten. Result-Set (jedoch nicht der Zieltabelle) hinzugefügt werden soll (Abbildung 11). Query-Abfrage eines einzelnen Wertes, der sich aus 3. DB2 verarbeitet den (im SELECT enthaltenen) einer variablen Anzahl der in eine Tabelle eingefügINSERT Request. Zeilen aus der Query der sales_ ten Zeilen ergibt summary Tabelle werden in die bonus_candidates Spools trennen, mit PDF Voraussetzungen: Tabelle eingefügt. Die gleizusammenfügen und als PDF/A • Es existieren zwei Tabellen: chen Zeilen werden ebenspeichern ... Das Ziel des INSERT und falls – zusammen mit den die Quelle der abgefragten Werten der ytd_sales SpalDaten, die eingefügt werte aus der sales_summary ... macht den den sollen. Tabelle – in eine temporäre SpoolDesigner für • Der Requester, der das Ergebnistabelle eingefügt. INSERT ausführt, verfügt 4. Der Script-Prozessor über- zu einer sehr lohnenswerten über die Berechtigung, der nimmt die Zeilen aus der Mathias Hammerlage, IT-Leiter MÖLK Pressegrosso Zieltabelle Zeilen hinzutemporären Ergebnista- Anschaffung www.the-tool-company.de Vertriebs GmbH & Co. KG zufügen. belle (Result-Set für das NEWSolutions Juni 2009 27 IT-MANAGEMENT SQL #include <string.h> /* used for strcpy() */ #include <stdio.h> #include <stdlib.h> /* defines system() */ #include <errno.h> EXEC SQL INCLUDE SQLCA; EXEC SQL INCLUDE SQLDA; EXEC SQL BEGIN DECLARE SECTION; char stmt[1500]; long c1val; char c2val[21]; long countval; EXEC SQL END DECLARE SECTION; /*********************************************************************/ /* MAIN routine */ /*********************************************************************/ void main(int argc, char* argv[]) { c1val = 0; strcpy(c2val, "XXX"); exec sql WHENEVER SQLERROR CONTINUE; exec sql DROP TABLE VALI1; exec sql DROP TABLE VALI2; exec sql WHENEVER SQLERROR GOTO ERROR; exec sql CREATE TABLE VALI1 ( C1 SMALLINT, C2 CHAR(20), C3 TIMESTAMP ) ; exec sql CREATE TABLE VALI2 LIKE VALI1; exec sql INSERT INTO VALI2 VALUES(1,'row1',CURRENT TIMESTAMP); exec sql INSERT INTO VALI2 VALUES(2,'row2',CURRENT TIMESTAMP); exec sql INSERT INTO VALI2 VALUES(3,'row3',CURRENT TIMESTAMP); exec sql COMMIT; /* Attempt VALUES INTO from an INSERT with 1 row */ exec sql WHENEVER SQLERROR GOTO ERROR; EXEC SQL VALUES ( SELECT C1,C2 FROM FINAL TABLE ( INSERT INTO VALI1 VALUES( 1, 'row1', CURRENT TIMESTAMP) ) WHERE C1 > 0 ) INTO :c1val, :c2val ; printf(" C1, C2 returned: %d exec sql COMMIT; %20s \n", c1val, c2val); /* Attempt VALUES INTO from an INSERT with subselect countval = 0; */ EXEC SQL VALUES ( SELECT COUNT(*) FROM FINAL TABLE ( INSERT INTO VALI1 SELECT * FROM VALI2 ) WHERE C1 > 1 ) INTO :countval ; printf(“ count(*) returned: %d \n”, countval); exec sql COMMIT; return; ERROR: exec sql WHENEVER SQLERROR CONTINUE; exec sql ROLLBACK; printf(“Error, bad SQLCODE received. SQLCODE = %d”, SQLCODE); return; } Abbildung 14: Beispiel für VALUES INTO • Der Requester, der das INSERT ausführt, verfügt über die Berechtigung, Daten aus der abzufragenden Tabelle zu lesen. Ablauf: 1. Der Requester ruft eine Anwendung auf, die die CLI SQL-Schnittstelle bedient und übergibt einen einzelnen Parameterwert, der die in die Tabelle einzufügenden Zeilen spezifiziert. 2. Das CLI-Programm stellt eine SQL-Verbindung zu der DB2 für i5/OS Datenbank her. 28 Juni 2009 3. Das CLI-Programm bereitet ein SQL-Statement vor, um einerseits eine variable Anzahl von Zeilen in eine Tabelle einzufügen und andererseits einen einzelnen Wert aus dem Result Set der eingefügten Zeilen zurückzugeben. (Abbildung 12). 4. Das CLI-Programm bindet Programmvariablen sowohl für den input parameter marker (WHERE Klausel) als auch für den output parameter marker des zuvor vorbereiteten Statements z.B. mit der API SQLSetParam(). Als Programmvariable für den input parameter marker wird der mit dem CLI-Programmaufruf übergebene Input-Parameterwert übernommen. 5. Das CLI-Programm führt das vorbereitete Statement aus. 6. DB2 verarbeitet den (im SELECT enthaltenen) INSERT Request. Zeilen aus der Tabelle sales_ summary werden in die Tabelle bonus_candidates eingefügt. Die gleichen Zeilen werden in eine temporäre Ergebnistabelle eingefügt. Die Zeilen der temporären Ergebnistabelle dienen als Eingabe für die Funktion AVG() in der Outer Query. Das Ergebnis dieses AVG() wird in die Programmvariable für den output parameter marker eingestellt. Einfügen einer Zeile in eine Tabelle und Abfrage aller generierten Spaltenwerte der eingefügten Zeile unter Einsatz von JDBC Voraussetzungen: • Die Zieltabelle des INSERT existiert und verfügt über zumindest eine Spalte, die generierte Werte enthält. • Der Requester, der das INSERT ausführt, verfügt über die Berechtigung, der Zieltabelle Zeilen hinzuzufügen. Ablauf: 1. Der Requester stellt eine SQL-Verbindung zu der i5/OS Datenbank her. 2. Der Requester führt ein JAVA-Programm aus, das die Option RETURN_GENERATED_KEYS aus der executeUpdate() Methode und die getGeneratedKeys() Statement Methode verwendet (Abbildung 13). 3. Das JAVA-Programm führt die executeUpdate Methode aus und veranlasst dadurch den JDBC-Treiber, das INSERT Statement in ein SELECT Statement einzubinden. 4. DB2 verarbeitet den (in das SELECT eingebundenen) NEWSolutions IT-MANAGEMENT SQL INSERT Request. Eine neue Zeile wird in die Tabelle authors eingefügt und die Werte für Spalten wie beispielsweise die IDENTITY-Spalte oder Spalten mit Unterlassungswerten, deren Werte nicht mit dem INSERT übergeben wurden, werden generiert. Die gleichen Zeilendaten (einschließlich der generierten Spaltenwerte) werden zusammen mit dem cursor für das vom JDBC Treiber gelieferte SELECT in eine temporäre Ergebnistabelle eingefügt. 5. Das JAVA-Programm führt die getGeneratedKeys() Methode aus, die den cursor für das SELECT öffnet und den Zugriff auf das Result Set des cursors erlaubt. Weitere Result Set Methoden laufen ab, um die generierten Spaltenwerte abzufragen. Anmerkung: Für die executeUpdate() Methode kann auch eine alternierende Syntax verwendet werden, bei der anstelle der Option .RETURN_GENERATED_KEYS der Name der generierten Spalte spezifiziert wird. Die beiden letzten Abbildungen beinhalten SELECT from INSERT Beispiele, in denen in Programme eingebundenes SQL verwendet wird. Abbildung 14 zeigt ein C-Programm mit einem VALUES INTO Statement, Abbildung 15 zeigt ein RPG-Programm, das ein geblocktes Einfügen von Daten enthält, die in einer Host-Struktur enthalten sind. Steigerung der SQL-Performance Die neue V6R1 Funktion SELECT from INSERT kombiniert zwei Operationen in einem SQL Statement. Diese Erweiterung erlaubt es, Informationen aus einer INSERT Operation für eine einzelne oder mehrere eingefügte Zeilen abzufragen. Bei Verwendung des INSERT in der FROM Klausel einer SELECT Operation können Benutzer die Daten eingefügter Zeilen abfragen. Diese Möglichkeit erweist sich bei der Abfrage generierter Spalteninformationen wie ROWID, Identity Column, Reihenfolge, bei dyna- Demprow1 DS QUALIFIED DIM(3) D age 4B 0 INZ(0) D empname 10A INZ('TEST INZ') D dept 9B 0 INZ(111) D* D whereage S 9B 0 INZ(25) D hvbump S 9B 0 INZ(1) D hvres S 9B 0 INZ(0) D numrows S 9B 0 INZ(3) D ind1 S 4B 0 INZ(0) D ind2 S 4B 0 INZ(0) D ind3 S 4B 0 INZ(0) D* C C* /free EVAL emprow1(1).empname='TOM' ; EVAL emprow1(2).empname='MARY' ; EVAL emprow1(3).empname='JOE' ; EVAL emprow1(1).age=25 ; EVAL emprow1(2).age=50 ; EVAL emprow1(3).age=21 ; EVAL emprow1(1).dept=123 ; EVAL emprow1(2).dept=234 ; EVAL emprow1(3).dept=345 ; // EXEC SQL WHENEVER SQLERROR GOTO FAILTAG ; // EXEC SQL DECLARE C1 CURSOR FOR SELECT age + :hvbump :ind1 FROM FINAL TABLE ( INSERT INTO table1 :numrows ROWS VALUES( :emprow1 )) AS X WHERE age >= :whereage :ind3 ; // // Fetch result row EXEC SQL OPEN C1 ; EXEC SQL FETCH C1 INTO :hvres :ind2 ; dsply ('Result: ' + %char(hvres) ) ; EXEC SQL CLOSE C1 ; // /end-free C FAILTAG TAG C SETON Abbildung 15: Block Insert Beispiel in RPG mischen Werten oder generierten Ausdrücken eingefügter Zeilen als ausgesprochen hilfreich. Da die Aufgaben, die zuvor zwei separate Funktionen (mit dem entsprechenden Overhead) erforderten, nun mit einer einzigen Funktion erledigt werden kann, lässt sich mit dieser neuen Funktion Die Autoren erreichen Sie: Jinmei Shen (jinmeis@ us.ibm.com), Karl Hanson ([email protected]). Übersetzt und für den deutschsprachigen Markt überarbeitet von Joachim Riener. Burgy Zapp IT-MANAGEMENT Security IBM X-Force Report: Unternehmen werden zum größten Sicherheitsrisiko ihrer eigenen Kunden Trend und Risiko Report des IBM X-Force Teams identifiziert WebAnwendungen als Achilles-Ferse der IT-Sicherheit von Unternehmen Cyberkriminelle nutzen zunehmend Sicherheits-Schwachstellen in Unternehmen, um auch an die Daten der Kunden dieser Unternehmen zu gelangen. Dies ist eines der zentralen Ergebnisse des IBM X-Force Trend und Risiko Reports 2008. Die Zahl der Hacker-Angriffe, die im vergangenen Jahr von seriösen UnternehmensWebseiten ausgingen, ist laut Report alarmierend angestiegen. Unternehmen werden somit zum Sicherheitsrisiko für ihre eigenen Kunden. Die Sicherheitsspezialisten des IBM X-Force Teams haben für den Trend und Risiko Report 2008 zwei herausragende Entwicklungen identifiziert, wie Kriminelle über Website-Attacken Internet-Nutzern Schaden zufügen: Webseiten, das zeigt der Report sehr deutlich, sind zur Achilles-Ferse der IT-Sicherheit von Unternehmen geworden. Cyberkriminelle konzentrieren ihre Angriffe auf Internet-Anwendungen der Unternehmen, um die PCs der Nutzer zu infizieren. Viele Unternehmen sind nicht richtig davor geschützt: Sie nutzen oft StandardLösungen, die mit vielen Schwachstellen behaftet sind. Oder noch schlimmer: Sie arbeiten mit individuellen Lösungen, die Schwachstellen aufweisen, die nicht gepatched, das heißt korrigiert werden können. Im vergangenen Jahr hatten mehr als die Hälfte aller offen gelegten Schwachstellen in irgendeiner Form mit Web30 Juni 2009 Anwendungen zu tun – und mehr als 74 Prozent davon hatten keinen Patch. „Ziel dieser Attacken ist es, Web-Nutzer zu täuschen, heimlich auf andere Webseiten umzuleiten und auf diese Weise ihre Daten auszuspionieren“, sagt Frank Fischer, Leader Security@IBM, IBM Deutschland. „Dies ist eine der ältesten Formen von groß angelegten Angriffen, die wir heute haben. Es ist Besorgnis erregend, dass selbst zehn Jahre nachdem die so genannten SQL Injection Attacks bekannt wurden, dieser Missbrauch immer noch im großen Stil möglich ist, weil die nötigen Patches nicht implementiert wurden. Cyberkriminelle kennen diese Schwachstellen und haben es deshalb verstärkt auf Unternehmen abgesehen, weil sie dort leichtes Spiel haben, um praktisch jedem zu schaden, der im Netz unterwegs ist.“ NEWSolutions IT-MANAGEMENT Security Schwerpunkt IT-Sicherheit Unternehmen bewegen sich in einem sich immer schneller wandelnden Markt. Neben den entstehenden Chancen müssen auch zunehmend Risiken proaktiv betrachtet werden. Nur die Integration von Risiko- und Performance-Management führt zu einem kontrollierbaren Geschäftsmodell. Analog ist die zugrunde liegende Informationstechnologie einer Vielzahl von Bedrohungen ausgesetzt. Damit werden Unternehmen anfälliger für finanziell motivierte Angriffe. Wenn beispielsweise sensible Informationen elektronisch ausspioniert oder Online-Transaktionen manipuliert werden, hat das sehr direkte Auswirkungen auf das gesamte Unternehmen und dessen Marktposition. Ein nachhaltiges Modell für das Risiko- und (IT-)Sicherheits-Management ist die Grundlage für ein prosperierendes Geschäft. Welche Risiken sind dies? Es sind zunächst alle regulatorischen Risiken, zusammengefasst unter dem Begriff Governance, Risk und Compliance. In diesem Segment richten sich die Fragestellungen zum Risiko-Management mehr auf den Business Level: Welches geschäftliche Risiko haben wir? Wie können wir aus der persönlichen (Geschäftsführer)Haftung herauskommen? Wie vermeiden wir Strafzahlungen bei non-compliance? Wie managen wir potentiell existenzbedrohende Risiken? Bei Risiken im Bereich Innere Sicherheit liegt der Schwerpunkt auf den aktuellen Themen Diebstahl von Identitäten, Informationen und geistigem Eigentum, dem „Feind von innen“. Aber auch auf den „soften“ Risiken (Menschen, Prozesse, Applikationen) und wie diese mitbestimmungskonform einer besseren Kontrolle unterworfen werden können ohne den Datenschutz zu gefährden. Damit in Zusammenhang stehen Betrugs- und Erpressungsfälle, Produktpiraterie und Manipulation von Informationen/Transaktionen (Integritätsverlust) bis hin zur Kolportierung von Firmeninterna in die Öffentlichkeit. Die Risiken im Bereich Äußere Sicherheit ranken sich um den Klassiker, die Bedrohungslage aus dem Internet, die einem rasanten Wandel unterworfen NEWSolutions ist und sich in einer Dynamik ändert, die die meisten internen IT-Abteilungen überfordert. Im Kommen sind vor allem intelligente Trojaner, Botnetze und durch Phishing oder Social Engineering entstehende Schäden. Hinzukommen Risiken durch Diebstahl von Geräten, Datenträgern und Vandalismus, die erheblichen finanziellen und ideellen Schaden hervorrufen können. Abschließend bestehen Risiken auch im Bereich des sicheren Betriebs (Security Operations), die sich um vielfältige Facetten der Manipulation, ServiceUnterbrechung, Diebstahl von Daten und Kontrollverlust drehen. Deshalb ist für Unternehmen wichtig, sich rechtzeitig über den passenden Schutz Gedanken zu machen. Moderne Sicherheitslösungen erkennen Bedrohungen, Angriffe und Gefahren rechtzeitig und reagieren selbstständig darauf, noch bevor es zum Ernstfall kommt. IBM bietet mit Security@IBM und den IBM Information-Security-Framework-Lösungen von der strategischen Risiko-Management-Beratung über das Design von Information-Security-ManagementSystemen bis hin zur Implementierung operativer Security-Lösungen einen umfassenden Katalog von Sicherheits-Lösungsbausteinen. Ein wertbasiertes Risiko-Management ist die Grundlage einer pragmatischen Sicherheitsarchitektur. Entscheidend dabei ist, die wesentlichen Risiken auf Business und IT-Ebene in integrierter und betriebswirtschaftlich sinnvoller Weise zu adressieren. Damit sind Unternehmen in der Lage, die lückenlose Einhaltung der sich verschärfenden Bestimmungen zu gesetzlichen und regulatorischen Vorschriften sicherzustellen, geistiges Eigentum besser zu schützen und sich gegen zunehmende interne und externe Bedrohungen ihrer IT-Infrastruktur, vor allem der Netzwerke, Systeme und Anwendungen, zu wappnen. Juni 2009 31 IT-MANAGEMENT Security Weitere Ergebnisse des X-Force Trend und Risiko Reports 2008: Niemals zuvor wurden so viele Sicherheits-Schwachstellen aufgedeckt wie im Jahr 2008 – 13,5 Prozent mehr als im Jahr 2007. Ende 2008 waren 53 Prozent der über das Jahr hinweg aufgedeckten Schwachstellen Barcelona 22.-24. September 2009 Messe Köln www.zukunft-personal.de 32 Juni 2009 Budapest noch immer nicht von den betroffenen Herstellern beseitigt. Etwa 44 Prozent der Schwachstellen aus 2007 und 46 Prozent aus 2006 waren Ende 2008 noch immer nicht gepatched. China hat die USA als Land mit der höchsten Anzahl an bösartigen Webseiten von Platz eins der Weltrangliste verdrängt. Etwa 90 Prozent aller Phishing-Attacken sind auf Finanz-Institutionen gerichtet. Die meisten davon befinden sich in den USA. Im Jahr 2008 waren Trojaner mit einem Anteil von 46 Prozent die am häufigsten eingesetzte Malware. Ihr Ziel waren meist die Nutzer von Online-Spielen oder von Internet-Banking. Das IBM X-Force Team katalogisiert, analysiert, entdeckt und veröffentlicht Sicherheits-Schwachstellen seit 1997. Mit beinahe 40.000 katalogisierten Einträgen verfügt die IBM X-Force über die größte SchwachstellenDatenbank der Welt. Keine vergleichbare Organisation deckt jährlich so viele Sicherheitsrisiken und Schwachstellen auf wie das IBM X-Force-Team. Den vollständigen Report lesen Sie im Internet: www.ibm.com/services/us/iss/xforce/trendreports. ♦ Genf Köln Moskau München Stuttgart Zukunft Personal Wien Zürich 2 0 0 9 Der zweite große Trend, den die IBM X-Force ausgemacht hat, ist die Streuung von schädlichen Filmdateien (z.B. Flash) und Dokumenten (z.B. PDFs) im Internet. Allein im vierten Quartal 2008 hat das IBM X-Force Team eine 50-prozentige Zunahme von Internetadressen festgestellt, hinter denen sich manipulative und bösartige Dateien befinden. Dies waren mehr Adressen, als die X-Force im Jahr 2007 insgesamt entdeckt hat. Sogar Spammer versuchen, über bekannte Webseiten ihre Reichweite zu erhöhen. Die Zahl der auf Blogs und Nachrichten-Seiten gehosteten Spam-Nachrichten ist in der zweiten Jahreshälfte 2008 um mehr als 50 Prozent gestiegen. Europas größte Fachmesse für Human Resource Management NEWSolutions LÖSUNGSBREVIER Security GoAnywhere™ Automated Data Movement for the Enterprise GoAnywhere vereinfacht den gesicherten Datenaustausch mit Ihren Kunden, Handelspartnern und Servern. Es ermöglicht die Konsolidierung Ihrer gesamten Datentransfers und Verarbeitungsanforderungen mit zentraler Konsole und Administration. GoAnywhere spart signifikant Zeit und Geld durch Eliminierung individueller Programmierung und Vermeidung manueller Schritte. Durch intuitives Interface und Templates können Transferprozesse sehr einfach definiert und von autorisierten Mitarbeitern und Anwendungen ausgeführt werden. GoAnywhere nutzt Industriestandards für Austausch, Formatierung, Verschlüsselung und Kompression von Daten, was die Integration zu Ihren Handelspartnern vereinfacht. Die Open Systems Lösung kann auf jedem IBM System i, Microsoft Windows, Linux und UNIX Server installiert werden. Server Connectivity GoAnywhere tauscht Informationen mit einer Vielzahl von Servern und Dateisystemen aus. Die Verbindungen werden mit Standard-Protokollen hergestellt. Es muss keine zusätzliche Software installiert werden. Organisationen sparen dadurch signifikant administrative Zeiten und Lizenzgebühren. Datenbank Server: DB2, Oracle, SQL Server, MySQL, Sybase, Informix Protokolle: FTP, FTPS, SFTP, HTTP(S), E-Mail (SMTP), Mailbox (POP3, I-MAP), JDBC Dateisysteme: System i, Windows, Linux, UNIX User Interface GoAnywhere bietet ein browser-basiertes User Interface (s. Abbildung 1) für Konfiguration und Monitoring von Datenprozessen. Es werden die populären Browser unterstützt, einschließlich Internet Explorer, FireFox und Safari. GoAnywhere Templates können genutzt werden, um schnell und einfach die erforderlichen Serververbindungen und Datenprozessanforderungen zu definieren. Datenübersetzung GoAnywhere liest und schreibt Daten in zahlreichen Formaten mit einer Vielzahl anpassbarer Optionen, die für jeden Transfer konfiguriert werden können. NEWSolutions Unterstützte Formate: Excel, XML, Delimited Text (CSV), Fixed-Width Text, Database Verschlüsselung und Kompression GoAnywhere nutzt etablierte Technologiestandards zur Verschlüsselung und zum Schutz sensitiver Datentransfers. Dabei können die Daten auch komprimiert werden, um Transferzeiten zu minimieren. Abhängig von den Anforderungen Ihrer Handelspartner können Sie auswählen, welchen Standard Sie jeweils zur Kompression und/oder Verschlüsselung bei den einzelnen Datenübertragungen verwenden möchten. Standards: OpenPGP, SSH, SSL, ZIP, AES, GZIP Lokale Prozesse GoAnywhere ermöglicht auch das Management lokaler Dateien und Prozesse. • Umbenennen, Verschieben und Löschen von Dateien • System i Programme aufrufen • Verzeichnisse erstellen • Native Befehle ausführen Ausführung und Überwachung GoAnywhere Prozesse können sofort oder zeitgesteuert mit dem integrierten oder einem vorhandenen Scheduler ausgeführt werden. Solche Prozesse können auch durch remote Anwendungen oder Systeme durch GoAnywhere Befehle und APIs gestartet werden. GoAnywhere bietet umfassende Job Control und Logging Features, um den anspruchvollsten Umgebungen gerecht zu werden, inkl. Job Queues, Multi-Threading, Priority Settings, Real-Time VOGELBUSCH GmbH Monitoring und detaillierter Software Management Consulting Jobprotokolle. Aktive und [email protected] vollständige Joblogs können www.vogelbusch.de jederzeit mit jedem Browser Tel. +49 (0) 2054/94070-0 angezeigt werden. ♦ Juni 2009 33 t t t t Business Intelligence mit pioSUITE t t t t Suite UNTERNEHMEN UND PRODUKTE Fallstudie Anita – Miederwaren, Bademoden und medizinische Produkte Als Spezialanbieter für Miederwaren, Bademoden und spezielle medizinische Produkte für die Nachsorge bei Brustoperationen bildet Anita ein kompetentes, international tätiges Netzwerk aus 20 Einzelgesellschaften mit insgesamt über 1.200 Mitarbeitern und einem jährlichen Umsatz von ca. 80 Millionen Euro. Die eigenen Produktionsstandorte befinden sich in Deutschland, Österreich, Portugal, der Tschechischen Republik und Fernost. Der Umsatzanteil außerhalb der Kernmärkte Deutschland und Österreich beträgt bereits deutlich mehr als 50 % (Tendenz steigend). Im globalen Markt genießt die Unternehmensgruppe einen exzellenten Ruf als Nischenanbieter für hochqualitative Spezialwäsche – sie darf sich zu den erfolgreichsten Unternehmen der Textilbranche zählen. Für einen Konzern dieser Größe ist ein zuverlässiger Output-Allrounder, der den Mitarbeitern die Arbeit in allen Output-Management-Bereichen erleichtert, unverzichtbar. In diesem Fall soll er Auftragsbestätigungen automatisch per E-Mail versenden, wenn die iSeries 525 neue Internet-Bestellungen verzeichnet. Er muss Außendienstmitarbeiter regelmäßig mit automatisch generierten Statistiken versorgen. Zentral erzeugte Rechnungen sollen länderweise verteilt und die passenden AGBs auf der ersten Rückseite gedruckt werden. Auf eingehende Anfragen muss die Output-ManagementLösung die jeweiligen Produkte aus einem Pool an PDF-Prospekten heraussuchen und gemeinsam Angebote zum Versand sortieren und ausdrucken. Zu guter Letzt muss eine digitale Archivierung überall dort erfolgen, wo Kosten für Manipulation und Papier eingespart werden können. Auf der Suche nach der geeigneten Lösung, erschien der SpoolMaster der Firma ROHA Software Support GmbH am geeignetsten. Dank seiner modularen Aufbauweise müssen Kunden nur diejenigen Funktionen bezahlen, die sie auch tatsächlich brauchen. Außerdem ist das System jederzeit erweiterbar und kann bei Bedarf auch auf Spezialanforderungen individuell angepasst werden. Ein weiteres Kriterium war die zügige Implementierung auf dem bestehenden System (iSeries 525 mit rund 350 Terminals, Betriebssystem V5R4M0), weshalb eine anpassbare Standardlösung einer individuell erstellten Software vorgezogen wurde. Auch bei der Wahl des Anbieters erschien die ROHA Software Support GmbH mit ihrem zwölfjährigen Bestehen und über 700 internationalen Referenzkunden als solider und zuverlässiger Partner. Schon zu Beginn des Projekts gab eine ausgiebige NEWSolutions Analyse einen positiven Ausblick auf das ungeheure Einsparungspotenzial, das durch die Implementierung der Output-Management-Lösung zu erwarten war. Nicht zuletzt aus diesem Grund wurde die Integration von SpoolMaster rasch beschlossen und die Umsetzung vorangetrieben. Die zügige Einrichtung des Systems erfolgte mit Fingerspitzengefühl, um den laufenden Betrieb nicht zu stören. Schon nach den ersten Wochen konnte Anita von den Vorteilen von SpoolMaster profitieren. Die eingesetzten Funktionen in der Praxis: • Prospekte werden automatisch aus einem PDF-Pool herausgesucht und passend zu Kundenanfragen gemeinsam mit dem Angebot angedruckt. • Rechnungen werden zentral erstellt und weltweit automatisch als PCL-Datenstrom auf die einzelnen Niederlassungen verteilt, wobei die jeweiligen landesspezifischen AGBs auf der ersten Rückseite mitgedruckt werden. Rechnungskopien werden im PDF-Format abgespeichert. • Die vom Webshop eingehenden Bestellungen werden in der iSeries gespeichert. Auftragsbestätigungen werden automatisch vom SpoolMaster per E-Mail an die Kunden gesandt. • Außendienstmitarbeiter erhalten diverse Statistiken automatisch in ihre E-Mail Inbox, die von SpoolMaster erzeugt und verschickt werden. Resümee Der Einsatz eines fähigen Output-Management-Systems wie SpoolMaster hat bei Anita zu erheblichen Einsparungen in der Administration geführt. Tätigkeiten, die noch vor kurzem manuell erledigt wurden und für die eine Unzahl an Handgriffen täglich nötig war, erfolgen nun vollkommen automatisch. ♦ Juni 2009 35 SONDERSEITEN Middleware cellity launcht Communicator für iPhone und Android G1 cellity AG Stahltwiete 23 22761 Hamburg www.cellity.com cellity hat seinen kostenlosen Communicator für das iPhone von Apple optimiert. Damit macht es seine mobilen Kommunikations-Funktionen dem wohl beliebtesten Smartphone zugängig. Dem Apple-Nutzer ist es somit ab sofort möglich, mobil über das iPhone sowie über den Safaribrowser des Mac seine Kontaktdaten aus sozialen Netzwerken und anderen Quellen, wie Outlook und Webmail-Anbietern, an einer Schnittstelle zu synchronisieren und zu verwalten. Mit der charakteristischen iPhone-Navigation kann der User den cellity Communicator im Look & Feel des Smartphones komfortabel einrichten und nutzen. Zudem weitet cellity seine Dienste auf das Android Phone G1 von Google aus. Dabei profitieren die Besitzer der beiden gefragtesten Smartphones von cellitys wachsendem Angebot im Bereich der sozialen Netzwerke und von den neu erschlossenen Adressquellen, wie dem Empfehlungsportal Qype und Telegate. Online Anbindung: mobil + stabil auf bestehende Programme zugreifen Wir leben in einer mobilen Welt. Kurze Reaktionszeiten, schlanke Prozesse und eine IT-Verfügbarkeit „anywhere/anytime“ sind Aufgaben, die jeden IT-Verantwortlichen egal welcher Branche beschäftigen. Die GOERING iSeries Solutions aus Bruchsal hat diesen Trend schon frühzeitig erkannt und kann daher eine breite Lösungspalette anbieten. Entscheidend dabei: auf der iSeries Seite ist keine Änderung an bestehender Programm- und Businesslogik notwendig. Kunden wie Fressnapf, Neimcke, UHU und Stabila konnten so in wenigen Tagen ihre Prozesse optimal gestalten und den ROI in kürzester Zeit erreichen. Telnet-Clients auf modernen Endgeräten einzusetzen hält Andreas Göring, Geschäftsführer der Bruchsaler, für sehr fragwürdig, weshalb diese Technologie auch bei seriösen Empfehlungen keine Rolle spielen kann. GOERING präferiert den Einsatz von Middleware zur Bereitstellung von Webservices, die den mobilen Clients als Datenlieferant dienen. Einen kompletten Überblick über die GOERING mobile Solutions finden Sie unter www.goering.de/de/mobile.html MCA bietet JTAPI als Schnittstelle für Telefonie mit Java-Applikationen MCA GmbH Steinfurt 37 52222 Stolberg Tel. 02402/86559-0 [email protected] www.mca-gmbh.de 36 Juni 2009 Die MCA GmbH bietet mit JTAPI eine Schnittstelle, um von Java-Applikationen aus die Telefonanlagen aller wichtigen Hersteller anzusteuern. Konkret bedeutet dies, dass sich damit Telefoniefunktionen in Java- und Weblösungen integrieren lassen und Nutzer aus diesen Applikationen heraus telefonieren können. So entwickelt sich der Browser aus User-Sicht zur Kommunikationszentrale auf dem Arbeitsplatz-PC. Dies ist vor allem für Unternehmen von großem Wert, die Webapplikationen an mehreren, auch weltweit verteilten Standorten nutzen. Sie greifen via JTAPI von allen Standorten aus auf eine zentrale Telefonanlage zu, so dass im Extremfall ein Unternehmen trotz beliebig vieler Niederlassungen mit nur einem einzigen System auskommt. JTAPI ist bereits bei den ersten Kunden im Einsatz. Dort hat das Interface dazu beigetragen, webbasierende Kommunikationsprozesse zu optimieren und gleichzeitig die Telekommunikationskosten zu senken. Die Java-Telefonieschnittstelle ergänzt das breite Portfolio an Connectoren und Middleware-Lösungen, mit denen MCA technologieunabhängig nahezu jedes Telekommunikationssystem in eine beliebige IT-Infrastruktur integrieren kann. MCAs Fähigkeit, Unified Communications „für alle Fälle“ zu realisieren, wird von großen Unternehmen sowohl auf der IT- als auch auf der Telekommunikationsseite anerkannt. Sie hat zu intensiven und zertifizierten Partnerschaften mit IBM und dem Geschäftskundenbereich der Deutschen Telekom AG geführt. NEWSolutions SONDERSEITEN Middleware iWay Software bringt unternehmenskritische Applikationen mit IBM WebSphere zusammen iWay Software, eine Tochtergesellschaft von Information Builders, hat ihre Universal Adapter Suite für IBM WebSphere weiter ausgebaut. Der Vorteil für Unternehmen: Sie profitieren von einer optimalen Integration der IBM-Middleware mit allen bedeutenden Unternehmensapplikationen. Die Universal Adapter Suite von iWay Software unterstützt jetzt auch den IBM WebSphere Message Broker, das WebSphere Message Broker Toolkit, den WebSphere Process Server, den WebSphere ESB und den WebSphere Integration Developer. Unternehmen sind damit in der Lage, ohne großen Programmieraufwand leistungsstarke SOA- und WebSphere-Lösungen zu erstellen. Fester Bestandteil der Universal Adapter Suite sind vorgefertigte, wieder verwendbare Bausteine, die einen einfachen Zugang zu einer Vielzahl von Anwendungssystemen bieten. Der Integrationsbaukasten umfasst darüber hinaus Datenadapter, Adapter für die Transaktionsverarbeitung, Adapter für die Terminalemulation, Adapter für Search Engines, Adapter für Realtime Dashboards, Adapter für Scoring und viele andere mehr. Information Builders Frankfurter Straße 92 65760 Eschborn Tel. 06196/77576-30 www.informationbuilders.de Grenzenlose Modernisierung mit iNEXT Suite Die iNEXT Suite ist ein Softwarepaket für die Modernisierung bestehender System i Anwendungen und deren Integration in die moderne .NET-Welt. Ohne die vorhandenen System i Lösungen ändern zu müssen, generiert iNEXT Suite aus dem 5250-Datenstrom einen sofort einsetzbaren .NET-Client. Über eine benutzerfreundliche Oberfläche mit verbesserter Menüführung und Office-Anbindung macht er die volle Funktionalität der System i Anwendungen zugänglich. Wem dies schon ausreicht, der kann durch den Einsatz des Standard-Clients sofort die Anwenderakzeptanz und Nutzereffizienz erhöhen. Kostenloser Download unter www.iNEXT-suite.com. Für die weitere Modernisierung bietet iNEXT Suite das gesamte Spektrum der .NETProgrammierung. Dadurch sind der Weiterentwicklung des iNEXT-Clients faktisch keine Grenzen gesetzt. Sogar Änderungen an den zu Grunde liegenden System i Programmen werden automatisch in den .NET-Client übernommen. Wichtiger Vorteil: Es werden wirklich nur die Funktionen implementiert, die tatsächlich benötigt werden. Das spart nicht nur Zeit und Geld, sondern bringt auch den meisten Nutzen. ML-Software GmbH Hertzstraße 26 76275 Ettlingen Tel. 07243/56550 Fax 07243/565516 [email protected] www.ml-software.com Mittelständischer Dienstleister bringt Warenwirtschaft ins Web Das mittelständische Dienstleistungsunternehmen Steyer Textilservice hat seinen Kunden via Web einen kontrollierten Zugang zu seinem Warenwirtschaftssystem verschafft. Die neue Lösung konnte mit dem Tool OnWeb von Micro Focus mit minimalem Programmieraufwand innerhalb weniger Tage realisiert werden. Steyer Textilservice bietet seinen rund 2.000 gewerblichen Kunden einen Rundum-Service für Berufskleidung, Hotel- und Krankenhauswäsche, der von der Bereitstellung bis zum regelmäßigen Waschen reicht. Das Unternehmen betreibt dafür seit Jahren eine RPG/COBOL-basierte Warenwirtschaftslösung auf einem AS/400/iSeries-System. Um den Kunden einen direkten Zugriff auf Informationen und Prozesse dieser Applikation zu ermöglichen, hat Steyer Textilservice nun mit dem Werkzeug OnWeb von Micro Focus eine sichere Verbindung zwischen dem Warenwirtschaftssystem und dem Web geschaffen. OnWeb ist eine Middleware, die es erlaubt, Host-Systeme in Web-Applikationen zu integrieren. Dabei holt sich OnWeb die benötigten Daten direkt aus den vorhandenen Bildschirmmasken der Host-Lösung, so dass die jeweilige Applikation nicht verändert werden muss. NEWSolutions Micro Focus GmbH Carl-Zeiss-Ring 5 85737 Ismaning Tel. 089/42094-0 www.microfocus.com/de Juni 2009 37 PROGRAMMIERUNG Load ’n’ go Burgy Zapp XML-Dateien durchsuchen mit SQL und UDTFs Wie kann man in DB2 für i XML-Dateien durchsuchen? Mit diesem Utility. VON JAGANNATH LENKA Üblicherweise werden geschäftliche Daten in Datenbanktabellen gespeichert, aber die Arbeit mit Daten in XML-Dokumenten gewinnt seit einiger Zeit immer mehr an Bedeutung. Ein großer Vorteil von XML ist, dass es den Austausch von Daten zwischen unterschiedlichen Datenbanksystemen vereinfacht. Beim Austausch empfängt ein Datenbanksystem Daten von einem anderen System in einem allgemeinen XML-Format und überträgt diese Daten dann zur weiteren Verarbeitung in Datenbanktabellen. Aber die Arbeit mit XML kann auch schwierig sein, wenn man z.B. nach einer Fehlerquelle in den Daten suchen muss. Solange man mit Datenbanktabellen arbeitet, ist es relativ einfach, mit SQL-Abfragen auf die Tabellen die Daten zu analysieren und das Problem zu lokalisieren. Wenn die Daten aber in XML-Dateien stehen, kann es sehr schwierig und zeitraubend sein, alle XML-Dateien zu untersuchen, die von anderen Systemen empfangen wurden. Im Gegensatz zu vielen anderen Datenbanksystemen bietet die Standardinstallation von DB2 für i (ohne XML Extender) keine einfache Funktion zum Abfragen von XML-Dateien. Deshalb möchte ich Ihnen zeigen, wie man die User Defined Table Functions (UDTF) von DB2 für i einsetzen kann, um XML-Dateien zu durchsuchen und Datenfehler aufzuspüren. Zunächst möchte ich etwas genauer auf UDTFs eingehen und zeigen, wie man sie zum Abfragen von XML-Daten nutzen kann. Danach stelle ich Ihnen mein Utility vor, das Ihnen ermöglicht, mit SQL nach bestimmten Daten in XML-Dokumenten zu suchen. CustOrd CustOrd/Header/Buyer <CustOrd> <Header> <OrderNum>12345></OrderNum> <Buyer>Jagannath</Buyer> <Header> <Detail> <Item>1234</Item> <ItemDesc>Test1</ItemDesc> </Detail> <CustOrd> CustOrd/Detail/Buyer Header Detail OrderNum Buyer Item ItemDesc 12345 Jagannath 1234 Test1 Abbildung 1: XML-Beispiel mit XPath-Ausdrücken 38 Juni 2009 NEWSolutions PROGRAMMIERUNG Load ’n’ go UDTFs als Ausweg Die UDTFs von DB2 für i bieten Datenbankanwendern die Möglichkeit, mit HLL-Programmen Ergebnistabellen zu generieren und diese dann abzufragen. Auf diese Weise ist SQL nicht mehr darauf beschränkt, Datenbanktabellen zu durchsuchen, sondern kann auch auf Ergebnistabellen zugreifen, die ein HLL-Programm aus anderen Quellen generiert. Mein Utility ist aus einer Aufgabe entstanden, die ich kürzlich zu lösen hatte. Auf meinem Tisch lagen vom Kunden BUY01 platzierte Aufträge, die die falsche Lieferantenanschrift enthielten. Ich wurde gebeten, die Ursache für dieses Problem zu finden. Die Daten stammten aus XML-Dateien, die ein anderer Computer (z.B. unser Lagerverwaltungs-System) vom Host empfangen hatte. Als erstes musste ich also herausfinden, welche vom Host-System empfangenen Aufträge vom Kunden BUY01 stammten. Um an diese Information zu gelangen, musste ich entweder alle XML-Dateien manuell durchsuchen oder ein Programm schreiben, das den entsprechenden Tag aus den Dateien heraussucht. Viel einfacher wäre es, wenn man eine kleine SQLAbfrage wie diese benutzen könnte: Select IFSName, TagValue From TABLE(SRCHXML (‚/XML/Orders‘,‘CustOrd/Header/Buyer‘)) Tab Where TAGVALUE=‘BUY01‘ Diese Abfrage verwendet eine UDTF, die eine weiter durchsuchbare Ergebnistabelle an die Datenbank zurückgibt. Wenn man weiß, in welchem Verzeichnis die XML-Dateien stehen und wie der XML-Pfad zum gewünschten Tag lautet, kann man sich alle in Frage kommenden XML-Dateien auflisten lassen. Die UDTF SRCHXML Als Hilfsmittel für meinen Suchauftrag schrieb ich eine UDTF namens SRCHXML, die alle XML-Dateien in einem gegebenen Verzeichnis nach Daten unter einem gegebenen XML-Pfad durchsucht. Das oben angeführte Beispiel durchsucht XMLDateien im Verzeichnis „/ XML/Orders“ und liefert die Daten unter dem XPath „CustOrd/Header/Buyer“. NEWSolutions für CREATE FUNCTION QGPL/SRCHXML (Dirname VARCHAR(256), XPath VARCHAR(256)) RETURNS TABLE ( IFSName varchar(256), OutXPath varchar(256), tagValue varchar(50) ) EXTERNAL NAME 'QGPL/SRCHXML(SRCHXML)' LANGUAGE RPGLE PARAMETER STYLE DB2SQL NO SQL NOT DETERMINISTIC NO EXTERNAL ACTION NOT FENCED NO SCRATCHPAD NO FINAL CALL DISALLOW PARALLEL CARDINALITY 1 Abbildung 2: Die SQL-Komponente von SRCHXML Der Downloadbereich enthält folgende Codes zu diesem Artikel: SrchXML SrchXML SQL RPGLE SQL-Anweisung zum Erstellen der UDTF Programmcode der UDTF XPath (XML Path Language) ist eine Sprache zum Lokalisieren von Daten in einem XML-Dokument. Mit XPath kann man Ausdrücke schreiben, die bestimmte Knoten in der Baumstruktur eines XML-Dokuments nach verschiedenen Kriterien auswählen. Abbildung 1 zeigt ein XML-Beispiel neben einem Diagramm, das die XPath-Knoten in der XML-Hierarchie des Dokuments darstellt. In diesem Dokument lautet der XPath für das Datenelement Item „CustOrd/Detail/Item“ (die rote Linie im Diagramm), während das Datenelement Buyer mit dem Xpath „CustOrd/Header/Buyer“ (grüne Linie) lokalisiert wird. Weitere Informationen zu XPath finden Sie unter www.w3schools.com/xpath/default.asp. Jede UDTF besteht aus zwei Komponenten: Aus einer SQL-Komponente, die die UDTF im DatenbankKatalog registriert und einer HLL-Komponente, die die Ergebnistabelle an die Datenbank zurückgibt. Die SQL-Komponente Die UDTF SRCHXML erwartet zwei Eingabeparameter: Das XML-Verzeichnis und den XPath-Namen. Die UDTF Auch für große Druckausgaben gibt für eine erfolgreiche nur ein kleiner Aufwand ... XML-Abfrage drei Spalten ... dadurch wurde der zurück: Den Dateinamen, die SpoolDesigner XPath-Angabe und den Inhalt des angeforderten Elements. Abbildung 2 zeigt die UDTF mit Beispielparametern. zu einer unverzichtbaren Erweiterung www.the-tool-company.de Elmar Siebrecht, DJH Service GmbH Die HLL-Komponente Abbildung 3 zeigt einen Auszug des HLL-Programms Juni 2009 39 PROGRAMMIERUNG Load ’n’ go /Free //Main Processing n_OutxPath = IS_NOTNULL ; n_tagValue = IS_NOTNULL; // Call Subroutines based on the parameter sent from the SQL Select; When CallType = CALL_OPEN; OpendirS(); When CallType = CALL_FETCH; Wrk_GotArecord = *Off; If SQL_State = '00000'; ProcessIFS(); else; CloseDirS(); EndIf; When CallType = CALL_CLOSE ; CloseDirS(); Other; SQL_State = SQL_ERROR; *InLr = *On; EndSL; Return; /End-Free A //----------------------------------------------------------------* // Procedure : OpenDirS * // Description : Open the directory and initialize the variable * //----------------------------------------------------------------* P OpenDirS B D OpenDirS Pi /Free Wrk_ReadNextIfs = *On; //Strip out the last '/' from the directory name If %Subst(Dirname:%Len(%trim(Dirname)):1) = '/' ; Wrk_DirName = %Subst(Dirname:1:%Len(%trim(Dirname))-1) ; Else; Wrk_DirName = DirName; EndIf; dirh = opendir(%trim(Wrk_dirname)); If dirh = *NULL; SQL_State = SQL_ERROR ; MsgText = 'Dir not found:'+ %trim(Wrk_DirName); EndIf; Return; /End-Free P OpenDirS B E //*----------------------------------------------------------------* //Procedure : ProcessIFS * //Description : Read the directory and get all the IFS for scan* //-----------------------------------------------------------------* P ProcessIFS B D ProcessIFS Pi /Free DoW SQL_State If = '00000'; Wrk_ReadNextIfs = *On; Wrk_ReadNextIfs = *Off; SQL_State = '00000'; //Read the directory for next IFS ReadDirS(); If SQL_State ='00000'; ParseXML(); EndIf; EndIf; C //If a valid IFS is found then Parse the XML If SQL_State ='00000' and numElements >0 ; for Wrk_Elem = Wrk_elem+1 to numElements; tagValue= Wrk_Data(Wrk_Elem); return; endFor; EndIf; Wrk_Elem = 0; Wrk_ReadNextIfs = *On; EndDO; return; /End-Free P ProcessIFS E //---------------------------------------------------------------* //Procedure : ReadDirS * //Description : Read the IFS directory * //---------------------------------------------------------------* P ReadDirS B D ReadDirS Pi /Free Wrk_Dire = 40 Juni 2009 readdir(dirh); Fortsetzung auf Seite 41 für dieses Beispiel, das in RPGLE geschrieben ist. (Das komplette Programm und die übrigen Komponenten des Utilities stehen wie immer für unsere Abonnenten zum Download bereit.) Hier eine kurze Beschreibung des Programms: Bei Markierung A ruft DB2 das HLL-Programm auf und übergibt verschiedene Parameter für die einzelnen Funktionen. Der erste Aufruf signalisiert dem HLL-Programm, die Variablen zu initialisieren oder die Ressourcen zu öffnen. Hier wird das angegebene Verzeichnis mit Hilfe der Prozedur OpenDirS geöffnet. Nachfolgende Aufrufe rufen das Abfrageergebnis aus dem HLL-Programm ab. Der nächste Aufruf (Abb. 3, Markierung B) führt die Prozedur ProcessIFS aus, die jede XML-Datei im angegebenen IFS-Verzeichnis liest und mit Hilfe der Prozedur ParseXML (Markierung E) durchsucht. Die Prozedur ParseXML parst die XML-Dateien mit dem Operationscode XML-INTO und speichert das Ergebnis im Array Wrk_Data. Die eingebaute Funktion %XML verwendet die Klausel „case=any“ um Probleme wegen unterschiedlicher Schreibweise im XPath-Ausdruck und in der eigentlichen XMLDatei zu vermeiden. Wenn die Prozedur ParseXML die XML-Datei erfolgreich durchsucht hat (was man an der Anzahl der durchsuchten Elemente erkennt), liest das Programm in einer Schleife alle geparsten Daten aus dem Array Wrk_Data (Markierung C in Abbildung 3) und gibt das Ergebnis an die Datenbank zurück. Beachten Sie, dass sich die Gesamtzahl der geparsten Elemente, die als Begrenzung für diese Schleife dient, in der Programmdatenstruktur befindet. Wenn das Programm den angeforderten XPath in einer XML-Datei nicht findet oder wenn ein anderer Fehler auftritt, wird kein Ergebnis an die Datenbank zurückgegeben, und die Verarbeitung wird mit der nächsten XML-Datei im angegebenen Verzeichnis fortgesetzt. Ich umgebe die Operation XML-INTO mit einer MONITOR-Anweisung, um Fehler abzufangen und die Steuerung an die Prozedur ProcessIFS zurückzugeben. Falls ein schwerwiegender Fehler auftritt, z.B. weil ein ungültiger Verzeichnisname übergeben wurde, wird das Programm beendet, nachdem es eine entsprechende Fehlermeldung an die Datenbank zurückgegeben hat. In diesem Fall wird die SQL-Abfrage mit einer Fehlermeldung („Abfrage kann nicht ausgeführt werden. Siehe Nachrichten der unteren Ebene.“) abgebrochen. Die unteNEWSolutions PROGRAMMIERUNG Load ’n’ go re Nachrichtenebene im Jobprotokoll zeigt die komplette Fehlerinformation an. Nachdem das Programm alle XML-Dateien im gewünschten Verzeichnis verarbeitet hat, ist seine nächste Aufgabe, der Datenbank den Status SQL_EOF zurückzumelden (Abbildung 3, Markierung D). Dadurch wird die Datenbank angewiesen, das Programm zum letzten Mal aufzurufen, um die Ressourcen zu schließen. In unserem Fall wird mit der Prozedur CloseDirS das geöffnete Verzeichnis geschlossen. D Wrk_Dire= *Null; SQL_State = SQL_EOF; Return; Else; Wrk_IfsName= %subst(d_name:1:d_namelen); EndIf; Return; /End-Free P ReadDirS E Erstellen der UDTF Zum Erstellen der UDTF SRCHXML gehen Sie folgendermaßen vor: 1. Erstellen Sie das Modul SRCHXML aus der RPGLE-Komponente des Code-Pakets zu diesem Artikel, und erstellen Sie aus diesem Modul das Serviceprogramm SRCHXML in der Bibliothek QGPL. 2. Kopieren Sie die CREATE FUNCTIONAnweisung von Abbildung 2 in die Teildatei SRCHXML in einer Ihrer Quellendateien, z.B. QSQLSRC. Danach erstellen Sie die Funktion mit dieser Anweisung: RUNSQLSTM SRCFILE(MYLIB/QSQLSRC) SRCMBR(SRCHXML) Nachdem Sie beide Komponenten erstellt haben, können Sie das Utility wie jede andere SQL-Anweisung im interaktiven SQL und in SQLRPGLE-Programmen verwenden. Es gibt eine Einschränkung für die Verwendung von SRCHXML, die Sie bedenken sollten. Wenn das Verzeichnis eine große Anzahl von IFS-Dateien enthält, kann die Abfrage viel Zeit benötigen, was unter Umständen dazu führen kann, dass der Datenbankmanager die UDTF wegen Zeitüberschreitung abbricht. Der Timeout kann vermieden werden, indem die Option QUERY_TIME_LIMIT in der Datei QAQQINI entsprechend angepasst wird. SRCHXML für Fortgeschrittene Sie können mit SRCHXML auch komplexe Abfragen gestalten. Nehmen wir z.B. an, ich müsste in der weiter oben beschriebenen Situation auch die betroffenen Auftragsnummern ermitteln, so könnte ich meine Abfrage entsprechend anpassen, wenn ich den XPath für die Auftragsnummer kenne: NEWSolutions If E //-----------------------------------------------------------------* // Procedure : ParseXML * // Description : Parse the XML read from directory * //-----------------------------------------------------------------* P ParseXML B D ParseXML Pi /Free Wrk_GotArecord = *On; Monitor; Wrk_FullPath = %Trim(Wrk_DirName) +'/'+ %Trim(Wrk_IfsName); xml-into Wrk_Data %XML(Wrk_FullPath: 'case=any doc=file + allowmissing=yes allowextra=yes + path=' + XPath); IFSName = Wrk_IfsName; OutxPath = XPath; n_OutxPath = IS_NOTNULL; n_TagValue= IS_NOTNULL; Wrk_GotArecord = *On; On-Error; Wrk_GotArecord = *Off; EndMon; Return; /End-Free P ParseXML E //----------------------------------------------------------------* //Procedure : CloseDirS * //Description : Write to the IFS file * //----------------------------------------------------------------* P CloseDirS B D CloseDirS Pi /Free // Close the File closedir(dirh); *Inlr = *On; /End-Free P CloseDirS E Abbildung 3: Die RPGLE-Komponente von SRCHXML Select TAGVALUE PO# from TABLE(SRCHXML (‚/xml/Orders‘,‘CustOrd/Header/ OrderNum‘)) a Where IFSNAME in ( Select b.IFSNAME from TABLE(SRCHXML (‚/xml/Orders‘, ‚CustOrd/Header/Buyer‘)) b Where b.TAGVALUE=‘BUY01‘ ) Ein wichtiges Tool Die UDTF SRCHXML erweitert DB2 für i, indem sie dem Anwender ermöglicht, XML-Dateien zu verarbeiten, wie es auch in DB2 9 für Linux, Unix und Windows möglich ist. Mit ziemlicher Sicherheit werden Sie einmal mit XML-Daten arbeiten müssen, falls dies noch nicht der Fall ist. Und dann kann die UDTF SRCHXML sehr nützlich sein. ♦ Jagannath Lenka ([email protected]) ist Projektmanager bei Infosys Technologies. Er arbeitet seit 2000 mit dem System i. Juni 2009 41 Mehr Wissen - gleich anfordern Verzeichnis der Anbieter/Anzeigen Seite Unternehmen 2, 3 5 6 8 9 11 12, 13 15 19 21 23 25 27 29 32 Anzeigen Gräbert Software + Engineering GmbH DUKE Communications GmbH Abonnement HiT Software Meinikat Informationssysteme GmbH IBM Deutschland GmbH DUKE Communications GmbH DC Press OGS Gesellschaft für Datenverarbeitung und Systemberatung mbH GOERING iSeries Solutions KEOS Software Service GmbH CSP Computer-Schnittstellen-Peripherie GmbH Symtrax AJE Consulting GmbH & Co. KG Meinikat Informationssysteme GmbH FTSolutions Messe Zukunft Personal 2009 33 34 Lösungsbreviere VOGELBUSCH GmbH Advertorial: AS/point Software und Beratungsgesellschaft mbH 35 Fallstudie ROHA Software Support GmbH 36 36 36 37 37 37 Sonderseiten Middleware cellity AG GOERING iSeries Solutions MCA GmbH Information Builders ML-Software GmbH Micro Focus GmbH 39 Anzeige Meinikat Informationssysteme GmbH 43 43 43 43 Kurz und bündig AJE Consulting GmbH & Co. KG IBM Deutschland GmbH IST - Integrierte System Technik SSS-Software GmbH 43 U4 Anzeigen ML-Software GmbH VOGELBUSCH GmbH NEWSolutions Impressum NEWSolutions ISSN 1617-948X DUKE Communications GmbH, Zugspitzstraße 7, 86932 Pürgen Tel.: 0151-119386851 Tel.: ++49 (0) 8196-7084 www.newsolutions.de Beispiel für alle E-Mails: [email protected] Redaktion Chefredakteurin: Isabella Pridat-Zapp Redaktionsleitung, Lektorat, Schlussredaktion: Kirsten Steer (ltd.), Andrea Heyner-Graf Anwendungsentwicklung/Fachübersetzungen: Michael Hellriegel, Mathias Spateneder, Joachim Riener Autoren dieser Ausgabe: Andreas Ahmann, Titus Aust, Horst Barthel, Mel Beckman, Mike Cain, Karl Hanson, Robert Jokisch, Dr.-Ing. Helmut Knappe, Jagannath Lenka, Heinz-Günter Meser, Rüdiger Peschke, Jinmei Shen, Eldar Sultanow, Edzard Weber Anzeigen Publisher/Anzeigenberatung: Isabella Pridat-Zapp, Andrea Heyner-Graf Anzeigenproduktionsleitung: Ingrid Abenthum www.newsolutions.de NEWS/400, DC-Press, Foren, Newsletter, NEWSwatch Verantwortlicher Redakteur: Burgy Zapp Redakteure/Moderatoren: M. Fuerchau, Michael Hellriegel, Mathias Spateneder, Kirsten Steer, Bruno Jakob DC-Press AS/400 Bücher/Abonnements: Kunden-Kontakte: Ingrid Abenthum Verlag Geschäftsführende Gesellschafterin: Isabella Pridat-Zapp Gerichtsstand: Amtsgericht Landsberg/Lech Handelsregister: Nr. 14590 Satz, Layout und Druck: GD Gotha Druck, Gutenbergstr. 3, 99869 Wechmar, Tel.: 036256/280-0 Urheberrecht: Alle Urheberrechte an Programmcodes und Beiträgen dieser Ausgabe, ob im Heft abgedruckt oder im Internet, sind Eigentum von Penton Media/Duke Communications. Copyright 1994 - 2009. Copyright 2009: Kunstwerke: Burgy Zapp Reproduktionen, gleich welcher Art, bedürfen der schriftlichen Genehmigung des Herausgebers. Auch die Verbreitung hiervon abgeleiteter Arbeiten ist ausdrücklich untersagt. Keine Haftung für Programmcodes! Bei Nichtlieferung im Fall höherer Gewalt, bei Störungen des Betriebsfriedens, Arbeitskampf (Streik, Aussperrungen etc.) bestehen keine Ansprüche gegen den Verlag. Die namentlich gezeichneten Beiträge spiegeln nicht unbedingt die Meinung der Redaktion wider. US-Redaktion: Penton Media Inc., Loveland, CO 80538 Alle Warenzeichen sind eingetragene Warenzeichen der entsprechenden Unternehmen. Alle Produkte sind Marken oder eingetragene Marken der jeweiligen Firmen. Name Telefon/Fax E-Mail Firmenstempel/Adresse Bitte unterstreichen Sie das Unternehmen über das Sie informiert werden möchten und faxen Sie diese Seite an: DUKE Communications GmbH, Fax: 0 81 96 -12 39 42 Juni 2009 NEWSolutions KURZ UND BÜNDIG Automatisierte Gewichts- und Volumenvermessung Das Erfassungssystem Cubiscan vermisst präzise Gewicht und Volumen unterschiedlicher Güter. Die ermittelten Daten dienen zur Vervollständigung der Stammdaten. Mithilfe einer flexiblen Schnittstelle ist die direkte Anbindung an ein führendes LVS möglich. Auf Basis dieser verlässlichen Daten werden systemgestützt Optimierungsvorhaben im Lagerhaltungs-, Verpackungs- und Verladungsprozess errechnet und umgesetzt. Durch die eingebundene Kamera ist zudem eine digitale Bildfixierung möglich. Weitere Informationen unter www.aje.de Leserservice AJE Consulting GmbH & Co. KG Messenger-Produkte 6.0 jetzt kompatibel mit OS V6R1M0 MessengerPlus und MessengerConsole sind jetzt für alle OS-Betriebssysteme von Version 5.4 bis Version 6.1 kompatibel. Mit den Messenger-Produkten verwalten Sie die Arbeitsabläufe und Aktivitäten Ihrer iSeries zuverlässig und ökonomisch. MessengerPlus kann nach einem Ereignis eine unbegrenzte Zahl von Aktionen durchführen. Mit eigenen Aktions-Skripten, Aktions-Eskalation und Aktions-Planung definieren Sie, wie MessengerPlus auf Fehler reagiert. MessengerPlus und MessengerConsole liefern alle Funktionalitäten, um große und kleine IT-Abteilungen mit wenig Aufwand sicher zu verwalten. Ab jetzt auch mit automatischem PTF-Update und DiskÜberwachungs-Funktion. Kontaktieren Sie IST: Telefon: 04221/20966 oder Mail: [email protected] Leserservice IST - Integrierte System Technik NEWSolutions Neue POWER-Funktionen SSS-Software GmbH hat Transfer Data 7.0 im neuen Release um viele neue Funktionen erweitert, wie z.B. das Erstellen aller gebräuchlichen PC-Formate in XLS, CSV, PDF, HTML, XML … direkt auf System i, den automatischen Datentransfer von Dateien und Spool-Files in PCFormate, das Einbinden in bestehende Batch-Abläufe zur Erstellung von EXCEL-Tabellen, den direkten Versand aller Ausgabeformate per E-Mail oder als FTP. EXCELTabellen können direkt in System i Datenbanken eingelesen und zur Weiterverarbeitung genutzt werden. Kopf- und Fußzeilen im Spool können vor der Übertragung ausgeblendet werden. Auswertungen können in alle Interaktiv- oder Batch-Anwendungen integriert werden. Aus Spool-Files oder Dateien kann 1:1 PDF erzeugt werden und dann per E-Mail versendet werden. Download zum Test: www.sss-soft ware.de/downloads/SSS_setup.zip Leserservice SSS-Software GmbH Instructor-led-OnlineTraining IBM Training stellt in Deutschland ein neues Konzept zur Schulung von IT-Fachkräften vor, das die Vorteile von Klassenraumtraining und Onlinetraining kombiniert, aber gleichzeitig deren Nachteile vermeidet: Mit dem neuen Instructorled-Online-Training (ILO) haben Kursteilnehmer in einem virtuellen Klassenraum zu festgelegten Zeiten einen Instruktor per Voice-over-IP zur Verfügung. Sie vermeiden aber unnötige und kostspielige Reisekosten und Reisezeiten. Themen und weitere Informationen: www.ibm.com/training/de/aix Leserservice IBM Deutschland GmbH iNEXT-Suite.com Evolution statt Revolution Nutzen und entwickeln Sie Ihre System i Applikationen weiter Profitieren Sie zusätzlich von neuesten .NET-Technologien Bringen Sie so Ihre Software stabil und sicher in die Zukunft Und sparen Sie dabei noch viel Zeit und Geld Erleben Sie Ihre Applikationen im modernsten Look and Feel. Kostenfreie Demo: iNEXT-Suite.com www.ml-software.info ML Software GmbH · Hertzstr. 26 · 76275 Ettlingen Tel. 0 72 43 56 55 - 0 · Fax 072 43 56 55 -16 Juni 2009 43