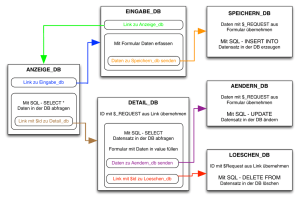
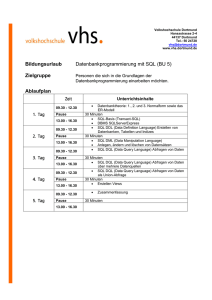
MS SQL Server 2005 T-SQL Programmierung und Abfragen
Werbung

MS SQL Server 2005 T-SQL Programmierung und Abfragen Marco Skulschus Marcus Wiederstein 1 2 MS SQL Server 2005 T-SQL Programmierung und Abfragen Marco Skulschus Marcus Wiederstein Webseite zum Buch: www.comelio-medien.com/dedi3_357.php © 2006 Comelio Medien 3 Alle Rechte vorbehalten. Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Jeder Verwertung außerhalb der engen Grenzen des Urheberrechtsgesetzes ist ohne Zustimmung des Verlages unzulässig und strafbar. Das gilt insbesondere für die Vervielfältigung, Übersetzung, Mikroverfilmung und die Einspeicherung und Verbreitung in elektronischen Systemen. © Comelio GmbH Rellinghauser Straße 10, D-45128 Essen Tel (0201) 437517-0, Fax (0201) 437517-10 www.comelio.com, [email protected] Umschlaggestaltung: Daniel Winter Umschlag- & Autorenfoto: Daniel Winter Satz: Daniel Winter Druck und Bindung: Bookstation GmbH Hilzingerstr. 14 in 78244 Gottmadingen, www.bookstation.de Printed in Germany ISBN 3-939701-02-5 | 978-3-939701-02-6 4 Inhaltsverzeichnis Vorwort ............................................................................................................. 11 Zu dieser Reihe.............................................................................................. 13 Autoren .......................................................................................................... 14 Aufbau des Buchs.......................................................................................... 15 Beispieldateien............................................................................................... 18 Kontakt zu Autoren und Verlag...................................................................... 18 1 2 Grundlagen............................................................................................... 19 1.1 Installation ........................................................................................ 21 1.2 Erste Schritte .................................................................................... 28 1.2.1 Management Studio ..................................................................... 29 1.2.2 Abfragen direkt ausführen............................................................ 39 1.2.3 Abfragen im Editor ausführen ...................................................... 43 1.2.4 Vorlagen-Editor ............................................................................ 55 1.2.5 Dokumentation ............................................................................. 57 1.3 Programmierbarkeit.......................................................................... 59 1.4 Beispieldatenbank AdventureWorks ................................................ 66 1.4.1 Allgemeine Design-Prinzipien ...................................................... 67 1.4.2 Darstellung einzelner Tabellenbereiche....................................... 71 Einfache Abfragen ................................................................................... 79 2.1 2.1.1 Grundstruktur von SELECT.............................................................. 81 Spaltenauswahl............................................................................ 83 5 2.1.2 Aliasnamen ...................................................................................84 2.1.3 Qualifizierte Spaltennamen ..........................................................86 2.2 2.2.1 Einfache Bedingungen und Operatoren .......................................87 2.2.2 Boolesche Operatoren..................................................................91 2.2.3 Mathematische Operatoren: .........................................................97 2.2.4 Mengen-Operatoren .................................................................. 102 2.3 Duplikate ein-/ausblenden ......................................................... 109 2.3.2 Ergebnisse sortieren.................................................................. 112 2.3.3 Standard-Aggregate .................................................................. 114 2.3.4 Gruppieren................................................................................. 117 2.3.5 Zufällige Datenauswahl ............................................................. 122 Eingebaute Funktionen .................................................................. 124 2.4.1 Datums- und Zeitfunktionen ...................................................... 125 2.4.2 Mathematische Funktionen ....................................................... 131 2.4.3 Zeichenkettenfunktionen ........................................................... 140 2.4.4 Systemfunktionen ...................................................................... 147 Komplexe Abfragen .............................................................................. 151 3.1 6 Ergebnisse aufbereiten .................................................................. 109 2.3.1 2.4 3 Bedingungen .....................................................................................87 Verknüpfungen............................................................................... 153 3.1.1 Manuelle Verknüpfungen........................................................... 153 3.1.2 ANSI-SQL-Verknüpfungen ........................................................ 161 3.2 3.2.1 Einfache Unterabfragen ............................................................. 175 3.2.2 Spaltenunterabfragen................................................................. 180 3.2.3 Abgeleitete Tabellen .................................................................. 182 3.2.4 Korrelierte Unterabfragen .......................................................... 189 3.2.5 Operatoren für Unterabfragen.................................................... 193 3.3 CASE mit Selektor ..................................................................... 198 3.3.2 Selektorlose CASE-Anweisung.................................................. 201 Zusätzliche Aggregate.................................................................... 203 3.4.1 Rangfolgen................................................................................. 204 3.4.2 Untersummen und Würfel .......................................................... 207 Datenmanipulation................................................................................. 219 4.1 Datenstrukturen anlegen ................................................................ 222 4.1.1 Tabellen ..................................................................................... 222 4.1.2 Sichten ....................................................................................... 255 4.2 5 Verzweigungen............................................................................... 197 3.3.1 3.4 4 Unterabfragen................................................................................. 175 Daten bearbeiten ............................................................................ 262 4.2.1 Vorbereitung............................................................................... 262 4.2.2 Einfügen ..................................................................................... 268 4.2.3 Aktualisieren............................................................................... 278 4.2.4 Löschen...................................................................................... 294 Grundlagen T-SQL ................................................................................. 303 5.1 T-SQL Blöcke ................................................................................. 305 7 5.1.1 Variablen und Anweisungen...................................................... 306 5.1.2 Datentypen ................................................................................ 308 5.2 5.2.1 Fallunterscheidungen ................................................................ 316 5.2.2 Schleifen .................................................................................... 318 5.3 Einsatz von EXEC ..................................................................... 321 5.3.2 Einsatz von sp_executesql ........................................................ 324 Fehlerbehandlung .......................................................................... 327 5.4.1 Ausnahmen................................................................................ 327 5.4.2 Traditionelle Fehlerbehandlung ................................................. 337 5.5 Cursor ............................................................................................ 340 5.5.1 Cursor-Varianten ....................................................................... 340 5.5.2 Verwendung............................................................................... 344 5.5.3 Beispiele .................................................................................... 348 5.6 Transaktionen ................................................................................ 360 5.6.1 Einfache Transaktionen............................................................. 361 5.6.2 Sicherungspunkte ...................................................................... 370 5.6.3 Erweiterte Transaktionssteuerung............................................. 372 Analysen................................................................................................. 377 6.1 6.1.1 8 Dynamische Anweisungen............................................................. 320 5.3.1 5.4 6 Kontrollanweisungen...................................................................... 316 Tabellenausdrücke......................................................................... 379 Grundprinzip .............................................................................. 380 6.1.2 Erweiterte Tabellenausdrücke ................................................... 384 6.1.3 Datenmanipulation und CTEs .................................................... 393 6.2 6.2.1 Aggregate mit OVER.................................................................. 396 6.2.2 Akkumulationen und Durchschnitte ........................................... 405 6.2.3 Hitparaden.................................................................................. 412 6.2.4 Bereiche/Quantile....................................................................... 426 6.3 7 Aggregate und Rangfolgen ............................................................ 396 Pivot................................................................................................ 430 6.3.1 Klassisches Pivotieren ............................................................... 431 6.3.2 Einsatz von (UN)PIVOT ............................................................. 435 Programmierbarkeit............................................................................... 449 7.1 Prozeduren ..................................................................................... 451 7.1.1 Einführung.................................................................................. 452 7.1.2 Prozedurarten ............................................................................ 460 7.1.3 Parameter und Aufruf................................................................. 465 7.1.4 Sonderfälle ................................................................................. 474 7.2 Funktionen...................................................................................... 478 7.2.1 Skalare Funktionen .................................................................... 481 7.2.2 Tabellenwertfunktion .................................................................. 486 7.2.3 Optionen..................................................................................... 494 7.2.4 APPLY-Operator ........................................................................ 501 7.3 7.3.1 Verwaltungsarbeiten....................................................................... 504 Katalogsichten für Objekte......................................................... 504 9 7.3.2 Funktionen ................................................................................. 508 7.3.3 Sicherheit................................................................................... 510 Index ............................................................................................................... 517 10 Vorwort Vorwort 11 Vorwort 12 Vorwort Vorwort Herzlich Willkommen zu einem Fachbuch von Comelio Medien, ein Bereich der Comelio GmbH. Wir hoffen sehr, dass Sie mit der Darstellung und Aufbereitung zu den verschiedenen Themengebieten im Bereich MS SQL Server zufrieden sind und die für Ihren Berufsalltag wesentlichen und hilfreichen Lösungen finden. Zu dieser Reihe Diese Buchreihe konzentriert sich auf verschiedene Aspekte der Verwendung des Microsoft SQL Servers 2005. Dies soll alle Themen umfassen, welche bei der Verwendung als Programmierer und Administrator auftreten. Zusammen genommen sollen alle geplanten Bücher der Reihe die Themenvielfalt und Einsatzmöglichkeiten des SQL Servers abdecken. Es ist dabei nicht unbedingt notwendig, alle Bücher zu lesen, weil die Themen so auf die einzelnen Werke verteilt werden sollen, dass jedes für sich als einzelnes Werk gelten kann; es ist jedoch ratsam. Die Reihe enthält folgende Themen: Programmierung einer SQL Server Datenbank und Einstieg in den SQL Server mit der Abfragesprache T-SQL (dieses Buch). Administration der SQL Server-Datenbank unter MS Windows Server 2003. Erzeugen von XML aus relationalen Daten und speichern, verarbeiten von XML mit Hilfe von T-SQL. Programmierung des MS SQL Servers mit .NET. Nutzung der Bereiche Reporting und Analysis Services sowie Gestaltung von OLAP- und Data Warehouse-Anwendungen mit SQL Server. 13 Vorwort Autoren Die beiden Autoren Marco Skulschus und Marcus Wiederstein blicken bereits auf zahlreiche Bücher zu Themen rund um Programmierung und auch Datenbanken zurück. Bei der Comelio GmbH sind sie im Bereich Softwareentwicklung als Projektleiter tätig und stehen mit Hilfe der Veröffentlichungen ihre Erfahrungen im Bereich der Softwareentwicklung einem breiteren Publikum zur Verfügung. Dies geschieht auch im Bereich Weiterbildung, der von der Comelio GmbH im gesamten deutschsprachigen Raum angeboten wird. Marco Skulschus (Jahrgang 1978) studierte Ökonomie in Wuppertal und Paris. Er ist nach der Beschäftigung mit PHP und Java im Jahre 2004 auf .NET umgestiegen und setzt nun C# und den MS SQL Server für Kundenprojekte ein. Nichtsdestoweniger ist er auch in anderen Themenbereichen aktiv, wobei insbesondere der Themenbereich Datenbanken, Datenmodellierung und XML an erster Stelle steht. Seine Spezialthemen sind Ontologien auf Basis von XML-Standards wie XTM oder OWL. Neben den gemeinsamen Veröffentlichungen mit Marcus Wiederstein ist er Autor von verschiedenen Büchern zum Einsatz von PHP im Zusammenhang mit Oracle und XML. Marcus Wiederstein (Jahrgang 1971) studierte Elektrotechnik in Bochum und Dortmund. Er ist schon sehr früh, im Jahre 2002, von Java auf .NET umgestiegen und beschäftigt sich nicht nur mit Softwareentwicklung auf Basis von MicrosoftTechnologien, sondern auch mit der Administration von Microsoft-Servern. Seine speziellen Interessensgebiete sind die Sicherheit und die Planung von sicheren Anwendungsstrukturen. Marco Skulschus und Marcus Wiederstein haben zusammen bereits vier Bücher zu XML (XML Schema, XSLT und XSL-FO) sowie zu Datenbanken (ein Programmierhandbuch zu Oracle und ein Werk zu Standard-SQL) herausgebracht. Sie haben unterschiedliche Zertifizierungen von Microsoft und Oracle erworben. 14 Vorwort Aufbau des Buchs Als Leser haben wir uns die Teilnehmer, welche die verschiedenen T-SQL-Seminare im Bereich MS SQL Server besuchen, vorgestellt. Hierbei handelt es sich um Programmierer, die für eine oder in einer MS SQL Server-Datenbank Software entwickeln. Ihre Aufgabe ist es normalerweise nicht, diese Datenbank einzurichten, von den Datenstrukturen her zu planen oder von Grund auf neu aufzubauen. Die Tabellen und die allgemeinen Strukturen sind bereits vorgegeben, sodass ihre Aufgabe daraus besteht, umfangreiche Abfragen und Analysen auszuführen, die Datenbank mit Hilfe von Funktionen und Prozeduren in T-SQL oder .NET zu erweitern und möglicherweise auch mit XML umzugehen. Weitere Bücher in dieser Reihe behandeln die an anderer Stelle erwähnten weiteren Themen. 1. Das erste Kapitel stellt verschiedene Grundlagen zum (neuen) MS SQL Server vor. Es beschreibt im Wesentlichen die Installation der Datenbank, den Umgang mit dem grafischen Werkzeug Management Studio sowie die Beispieldatenbank AdventureWorks. Dieses Kapitel stellt an verschiedenen Beispielen dar, wie man fast ohne SQL, was einen Hauptteil des Buchs bestimmt, Tabellen anlegt, mit Daten füllt bzw. Abfragen durchführt. Ob man später diese grafischen Hilfsmittel weiterhin benutzen wird, ist dem persönlichen Belieben überlassen, doch im Normalfall sollten insbesondere die vielen Beispiele zur Verwendung von SQL und T-SQL dafür Sorge tragen, dass man verstärkt doch eher den entsprechenden Quelltext schreibt anstatt ihn über grafische Werkzeuge zu erzeugen. 2. Das zweite Kapitel stellt Standard-SQL am Beispiel vom MS SQL Server und vor allen Dingen der AdventureWorks-Datenbank vor. Dabei beginnt es ausdrücklich mit der einfachen Standardabfrage SELECT * FROM tabelle und arbeitet sich dann durch die typischen Bereiche wie filtern, sortieren und gruppieren, die nicht nur mit dem MS SQL Server, sondern mit jeder Datenbank möglich sind. Es stellt anschließend die verschiedenen Standard-SQL-Funktionen für Aggregate und damit für Datengruppierungen vor, ehe es schließlich sehr ausführlich die vielen 15 Vorwort Funktionen vom MS SQL Server vorstellt, welche für viele Fragestellungen eine Lösung bieten, ohne die Daten in einer äußeren Anwendung zu verarbeiten, und die sich für jede Datenbank anders darstellen. Hier sind von System zu System große Unterschiede hinsichtlich de Funktionsumfangs und der Fähigkeiten der Funktionen zu beobachten. 3. Das dritte Kapitel konzentriert sich auf die Darstellung von so genannten komplexen Abfragen. Dies bedeutet zunächst, dass man die Daten nicht nur aus einer einzigen Tabelle abruft, sondern mehrere Tabellen miteinander über ihre Primärschlüssel-Fremdschlüssel-Verknüpfung verbinden muss. Hier stellt das Kapitel die traditionelle Variante den neuen, so genannten ANSI-SQL-Verknüpfungen gegenüber. Eine zweite Stufe hinsichtlich der Verwendung von komplexen Abfragen ist dann der Einsatz von Unterabfragen. Hier folgt eine Darstellung von einfachen Unterabfragen, Spaltenunterabfragen, abgeleiteten Tabellen und korrelierten Unterabfragen. Die verschiedenen Techniken sind in vielen Datenbanken gleich oder wenigstens ähnlich nutzbar, sind auch in der Praxis sehr sinnvoll und werden häufig eingesetzt - jedoch gibt es hier eine große Menge an Programmierern, die einen viel zu großen Bogen um diese Techniken machen und es vorziehen, in einer äußeren Anwendung die gleichen Operationen nachzuvollziehen. Dieses Kapitel möchte allerdings gerade Lust auf diese Techniken machen, da eine viel kürzere Syntax zu gleichen Ergebnissen führt. Schließlich folgt noch die Darstellung, wie man Fallunterscheidungen über die CASE-Anweisung in SQL realisiert und wie zusätzliche Aggregate errechnet werden können. Darunter sind Rangfolgen, Untersummen und Würfel zu verstehen, wobei hier auf der einen Seite verschiedene spezielle MS SQL Server-Techniken als auch StandardTechniken, die allerdings selten auswendig niedergeschrieben, sondern vielmehr auf Basis eines fertigen Beispiels angewandt, zum Einsatz kommen. 16 Vorwort 4. Das vierte Kapitel arbeitet den Bereich der Datenmanipulation durch. Dies erfordert in verschiedenen Beispielen bereits einige einfache Techniken aus T-SQL. In einem ersten Teil erstellt man über SQL die Datenstrukturen für Tabellen und Sichten. Hierbei geht es weniger um den Administrationsaspekt als um die Grundlagen, welche für den Programmierer wesentlich sind. In einem zweiten, umfangreicheren Teil werden dann für verschiedene vereinfachten Tabelle der Beispieldatebank die typischen Bearbeitungsszenarien von Datenerfassung-, -bearbeitung, aktualisierung und -löschung vorgestellt. Dabei werden neben den Standard-Möglichkeiten, wie sie in den meisten Datenbanksystemen möglich sind, gerade auch die seltenen und weniger geläufigen Möglichkeiten der verschiedenen Anweisungen vorgestellt. 5. Das fünfte Kapitel bietet schließlich eine ausführliche Einführung in die SQL-Erweiterung von MS SQL Server mit dem Namen Transact SQL (TSQL). Zwar gibt es in einigen vorherigen Kapiteln bereits verschiedene Beispiele, die mit einfachen Mitteln von T-SQL operieren, doch die Erstellung von Variablen, die Verwendung und die Auswahl von geeigneten Datentypen, die Erstellung und Nutzung von Cursorn sowie schließlich auch die Erstellung von Prozeduren und Funktionen ist den einzelnen Abschnitten dieses fünften Kapitels vorbehalten. 6. Das sechste Kapitel greift noch einmal den Bereich der Abfragen auf, wobei hier die sehr fortgeschrittenen und teilweise auch neuen Techniken für mehr in den Bereich der Analysen reichende Anweisungen dargestellt werden. Hier wird die neue Technik der Common Table Expressions eingefügt, die in vielen Beispielen dieses Kapitels genutzt wird. Als Beispiele für Analysen finden sich dann fortgeschrittene Aggregate wie Akkumulationen und Durchschnitte und auch die Erstellung von Rangfolgen bzw. Hitparaden in diesem Kapitel wieder. Auch das Thema der Pivot-Abfragen wird behandelt. Neben klassischen Lösungen stellt dieses Kapitel auch insbesondere die neuen Technologien der Version 2005 vor. 17 Vorwort Beispieldateien Als Beispiel-Datenbank dient die sehr umfangreiche Datenbank AdventureWorks, welche im kommenden Kapitel kurz eingeführt und vorgestellt wird. Sie ersetzt die seit Jahren bekannte Datenbank Nordwind. Sie ist wesentlich umfangreicher als die bekannte Nordwind-Datenbank und ermöglicht es nun auch mit einer speziellen DataWarehouse-Variante sämtliche Themengebiete des SQL Servers 2005 hervorragend darzustellen. Die Datenbank selbst kann entweder direkt bei der Installation des SQL Servers zusätzlich installiert oder auch direkt von der Microsoft-Webseite herunter geladen werden. Die verschiedenen Abfragen und Programmdateien, welche in diesem Buch erstellt und diskutiert werden, liegen ebenfalls im Internet zum Download bereit. Die einzelnen Quelltexte sind vollständig dokumentiert und enthalten neben dem eigentlichen Quelltext auch in einem Kommentarbereich die Ergebnisse. Dies ermöglicht es, die Dateien auch ohne Testen vollständig zu verwenden. Es werden nur für sehr wenige Beispiele eigene Tabellen erstellt, da der Leser, für den dieses Buch geschrieben ist, im Normalfall eine bereits bestehende Datenbank bearbeiten, erweitern und vor allen Dingen nutzen soll. Das Administrationsbuch geht verstärkt auf die Techniken der Erstellung ein. Kontakt zu Autoren Sie erreichen die Autoren unter [email protected] und [email protected]. Die Verlagswebseite finden Sie unter der Adresse http://www.comelio-medien.com. MS SQL Server-Dienstleistungen: http://www.comelio.com/dedi2_318.php MS SQL Server-Seminare: http://www.comelio.com/deti3_PHP.php 18 Grundlagen 1 Grundlagen 19 Grundlagen 20 Grundlagen 1 Grundlagen Dieses Buch geht davon aus, dass allgemeine Grundkenntnisse zu Datenbanken vorhanden sind, dass allerdings die Beschäftigung mit dem Datenbanksystem von Microsoft erst ab Version 2005 zu den Arbeitsinhalten gehört. Dieses Buch als erstes in der MS SQL Server-Serie soll daher auch einige einleitende Worte zur Installation, zur Architektur und zu den ersten Schritten mit dem Management Studio als Programm zur Nutzung der Datenbank verlieren. Für Leser, die bereits eine fertige Installation besitzen und sich schon mit der Version 2000 auskennen, sind daher die Abschnitte zur Installation und den ersten Schritten nicht relevant, sondern möglicherweise nur der Abschnitt zur Architektur. 1.1 Installation Für gewöhnlich stellt die Installation von Software heute kein größeres Problem mehr da, sodass wir dieses Thema auch auf die notwendigen Informationen beschränken möchten. Grundsätzlich ist die Installation des SQL Servers 2005 ebenfalls sehr einfach, solange nur Testzwecke oder reine Anwendungsentwicklung betroffen ist und nicht etwa der Aufbau eines realistischen Systems. Dies soll dann auch im Rahmen des Buchs zur Administration thematisiert werden. Wichtig ist vielmehr, dass für die Funktionstüchtigkeit der Beispiele deutlich ist, welche Version zum Einsatz kommt und welche Voraussetzungen im Rahmen der Installation getroffen werden. Der SQL Server 2005 ist in unterschiedlichen Varianten erhältlich. Eine sehr umfassende Übersicht der möglichen Download-Dateien befindet sich unter www.microsoft.com/ germany/sql/downloads/default.mspx. Im Normalfall interessiert man sich für die Testversion (www.microsoft.com/germany/sql/downloads/testsoftware.mspx), die 180 Tage gültig ist oder die Developer Edition, da beide Versionen den vollen Umfang der Datenbank bieten. Zusätzlich ist auch noch eine SQL Server 2005 Express Edition verfügbar, welche die Datenbankgröße auf 4 Gigabyte und maximal eine CPU sowie bis zu 1 GB Arbeitsspeicher unterstützt. Sie ist für die kostenlose Weiterverteilung und Einbet- 21 Grundlagen tung in Anwendungen gedacht. Eine Übersicht über die verschiedenen Editionen und ihre einzelnen Fähigkeiten findet man unter http://www.microsoft.com/ germany/sql/editionen/default.mspx. Wie man sich leicht denken kann, unterscheiden sich die Versionen insbesondere in leichten Bedienbarkeit und den sehr fortgeschrittenen Anwendungen. Für gewöhnlich verhält es sich so, dass Anwendungen, die überhaupt mit einer Großdatenbank wie dem MS SQL Server oder Oracle erstellt werden, auch umfangreiche Technologien erfordern, sodass die Enterprise-Ausgabe notwendig ist. Sie bietet als einziges System folgende Möglichkeiten an, die für fortgeschrittene Anwendungsszenarien notwendig sein können. Allerdings ist insbesondere der Bereich Business Intelligence besonders an der neuen Version hervorzuheben, da hier auf der einen Seite deutliche Erweiterungen und Verbesserungen im Gegensatz zur Vorgängerversion zu begrüßen sind, und auf der anderen Seite die totale Integration mit anderen Microsoft-Produkten, wodurch vielfältige Anforderungen mit geringem oder wenigstens akzeptablem Aufwand umgesetzt werden können. Die nachfolgende kurze Aufstellung stellt für die einzelnen Bereiche dar, welche Fähigkeiten die Enterprise-Version bietet, welche die anderen nicht bieten. 22 Bereich Skalierbarkeit und Leistung: – Partitionierung für umfangreiche Datenbanken – Parallelindexoperationen für die Parallelverarbeitung von Indexoperationen – Indizierte Ansichten mit Vergleichen Bereich Hochverfügbarkeit: – Onlineindizierung – Onlinewiederherstellung – Schnelle Wiederherstellung Bereich Integration und Interoperabilität: Grundlagen – Integration Services mit erweiterten Transformationen mit Data Mining, Text Mining und Datenbereinigung – Oracle-Replikation mit Transaktionsreplikation mit Oracle als Publisher Bereich Business Intelligence: – Berichtsserver mit Lastverteilung – Datengesteuerte Abonnements – Uneingeschränktes Durchklicken – Erweiterte Geschäftsanalyse bietet Kontointelligenz, Metadatenübersetzung, perspektivische und semiadditive Measures – Proaktives Caching bietet automatische Zwischenspeicherung für verbesserte Skalierbarkeit und Leistung – Erweiterte Datenverwaltung – Erweiterte Leistungsoptimierung – Datenflussintegration in SQL Server Integration Services – Text Mining Für die Beispiele verwenden wir die Developer-Version, wobei Sie bei einem Test zuhause oder in der Firma auf die angesprochene 180-Tage-Testversion zurückgreifen. Wir haben uns ganz bewusst gegen die Express-Ausgabe entschieden (so wie wir dies auch im Rahmen eines Oracle-Buchs machen würden), da die Software, die wir im Rahmen von Projekten betreuen, typischerweise damit bei Weitem nicht lauffähig wäre und wir hier daher nur wenig sinnvollen Einsatz sehen würden. Nichtsdestoweniger gibt es eine Reihe Spezialliteratur zu diesem Thema, die diese leichtgewichtige Alternative im Einsatz zeigt. Die meisten Beispiele dieses Buch funktionieren auch mit den unterschiedlichen Versionen, da in diesem Band die Fähigkeiten von der Enterprise-Ausgabe noch nicht genutzt werden. Folgende Schritte sind für eine Standardinstallation notwendig: 23 Grundlagen 1. Nach dem Starten der Installation öffnet sich das Dialogfenster Installationsvoraussetzungen, das darüber informiert, dass das .NET Framework 2.0 (immer eine gute Wahl), das entsprechende Sprachpaket sowie der Microsoft SQL Native Client (eine unverzichtbare Voraussetzung) installiert werden müssen. Es bleibt nicht mehr zu tun, als die Schaltfläche INSTALLIEREN zu wählen. 2. Nachdem die genannten Voraussetzungen geschaffen wurden, erscheint ein ähnliches Dialogfenster mit Bestätigungen der installierten Teile. Hier wählt man WEITER. 3. Es folgt die so genannte Systemkonfigurationsüberprüfung, welche im Normalfall mit einer Reihen an Erfolgen beendet wird. Bei einem gewöhnlichen Windows XP Professional-Rechner sollten keine Schwierigkeiten und damit Misserfolge auftreten. Ansonsten müssen die entsprechenden Korrekturen vorgenommen werden, auf die allerdings in deutlichen Fehlermeldungen hingewiesen wird. Dieses Dialogfenster verlassen Sie mit WEITER. 4. Schließlich gelangen Sie in das Dialogfenster Zu installierende Komponenten. Je nach ausgewählter Datenbankversion bieten sich hier auch unterschiedliche Komponentenlisten, da ja nicht alle Komponenten in jeder Version verfügbar sind. Für dieses Buch und auch für andere Bücher aus dieser Reihe werden insbesondere auch die Reporting- und AnalysisServices ausgewählt. 5. Im Dialofenster Instanzname wählen Sie die Option Standardinstanz aus und bestätigen mit WEITER. 6. Im Dialogfenster Dienstkonto können Sie die Anmeldekonten angeben. Hier verzichten wir darauf, für jedes Dienstkonto eigene Anmeldeinformationen anzugeben. Stattdessen genügt die einfachste Lösung, die aus dem integrierten Systemkonto besteht. Da die Beispieldatenbank AdventureWorks verwendet wird und wenigstens im Rahmen des Buchs 24 Grundlagen keine geheimen Informationen in die Datenbank gelangen, ist dies völlig ausreichend. Zusätzlich wählen Sie im unteren Bereich des Dialogfensters aus, welche Dienste am Ende der Installation gestartet werden sollen. Für dieses Buch sind zwar die Reporting- und Analysis-Services noch nicht wichtig, doch sind sie derart interessant, dass es sich lohnt, sie für die Zeit nach Transact SQL zu starten. Das Dialogfenster verlassen Sie mit WEITER. 7. Auch eine Anmeldung über die Windows-Informationen ist völlig ausreichend, sodass Sie im Dialogfenster Authentifizierungsmodus die Option Windows-Authentifizierungsmodus auswählen. Klicken Sie auf WEITER. 8. Schließlich müssen Sie noch die Sortierreihenfolge sowie einige Sprachmerkmale angeben. Wir haben uns für eine Unterscheidung von Groß-/Kleinschreibung entschieden, da man durch Funktionen wie UPPER und LOWER leicht die Schreibung ignorieren kann und sie ansonsten sehr wohl auf exakt Gleichheit prüfen kann. Auch Akzente unterscheiden einen Buchstaben erheblich, sodass diese Unterscheidungsoption ebenfalls gewählt wird. Klicken Sie auf WEITER. 9. Im Dialogfenster Berichtsserver-Installationsoptionen belassen Sie die Voreinstellungen, um später eine Konfiguration durchzuführen. 10. Im Dialogfenster Einstellungen für Fehler- und Verwendungsberichte entscheiden Sie, ob Sie Microsoft Hilfeinformationen zur Verbesserung senden wollen. 11. Zum Schluss erscheinen noch zwei letzte Bestätigungsfenster. 25 Grundlagen 1 2 3 4 Abbildung 1.1: Installation (1) 26 Grundlagen 1 2 3 4 Abbildung 1.2: Installation (2) 27 Grundlagen 1 2 3 4 Abbildung 1.3: Installation (3) 1.2 28 Erste Schritte Grundlagen Wie alle Microsoft-Produkte ist auch der MS SQL Server 2005 auf eine einfache Bedienung ausgelegt, damit bereits von Anfang an einfache Aufgaben erledigt werden können. In diesem Zusammenhang ist dies für den Programmier oder für den DBAnfänger die Verwendung von SQL in der Datenbank und die Ausführung von Abfragen und Anweisungen. In diesem Kapitel soll die für die Datenbank wesentliche Desktop-Anwendung SQL Server Management Studio vorgestellt werden. Im Vergleich zur Vorgängerversion haben sich allerlei Änderungen ergeben, doch der Grundaufbau ähnelt natürlich der Version 2000 und auch anderen Anwendungen, die einen GUIorientierten Zugriff auf Datenbanken erlauben. 1.2.1 Management Studio Abbildung 1.4: Management Studio Starten Das Management Studio ist die zentrale Anlaufstelle für die Arbeit mit dem neuen MS SQL Server 2005. Starten Sie das Programm, indem Sie unter Start / Programme / Microsoft SQL Server 2005 / SQL Server Management Studio auswählen. Zusätzlich zeigt die nachfolgende Abbildung auch noch, wie Sie die überaus wichtige Hilfe zur 29 Grundlagen Datenbank öffnen. Dazu öffnen Sie innerhalb des Eintrags Microsoft SQL Server 2005 den Eintrag Dokumentation und Lernprogramme / SQL Server-Onlinedokumentation. Auf der linken Seite des sich öffnenden Fensters befindet sich der so genannte ObjektExplorer, der - wie sein Name schon verspricht - die Objekten des Servers anzeigt. Dies sind zunächst die Datenbanken selbst, danach gefolgt von weiteren Bereichen wie Sicherheit, Verwaltung, unterschiedliche Dienste und Datensicherung. Abbildung 1.5: Objekt-Explorer einer Datenbank 1. Wählen Sie den Eintrag Datenbanken / AdventureWorks aus, um die AdventureWorks-Datenbank zu öffnen. Wie Sie sehen, sind bereits zwei verschiedene Beispiel-Datenbanken installiert, nämlich zum einen die gewöhnliche AdventureWorks-DB und zum anderen die für die Vorführung 30 Grundlagen der Data Warehouse-Funktionalitäten des SQL Servers angepasste AdventureWorksDW-Datenbank. Sie wird in einem anderen Buch verwendet. 1 3 2 4 Abbildung 1.6: Abrufen von Tabellen- und Spalteninformationen 12. Navigieren Sie zu einer einzelnen Tabelle, indem Sie Datenbanken / AdventureWorks / Tabellen / Production.Product auswählen. Es öffnet sich 31 Grundlagen eine Übersicht über die in dieser Tabelle vorhandenen Spalten, Schlüssel, Einschränkungen und Programmierobjekte mit ihren jeweiligen Eigenschaften. So gibt die Übersicht der Spalte ProductID der Tabelle Production.Product in einer kleinen Übersicht neben dem Spaltennamen bereits an, dass es sich hierbei um den Primärschlüssel (PS) handelt, der vom Datentyp einer Ganzzahl (int) und nicht leer (Nicht NULL) sein darf. Da der Primärschlüssel eine Spalte eindeutig referenziert und daher für die Tabelle von entscheidender Bedeutung für die Identifikation einer Datenzeile ist, ist zusätzlich als Erkennungsmerkmal noch ein Schlüsselsymbol neben der Spalte angebracht. Dieser Schlüssel hat eine gelbe Färbung, während ein grauer Schlüssel neben den so genannten Fremdschlüsselspalten (FS) angebracht ist. Bspw. ist die Spalte SizeUnitMeasureCodes ein solcher Fremdschlüssel vom Datentyp nchar(3). Diese Spalte darf allerdings auch leer sein, d.h. den Standardwert NULL enthalten. Der Wert in diesen Spalten ist in einer anderen Tabelle ein Primärschlüsselwert, sodass man diesen Wert für die Verknüpfung von beiden Tabellen verwenden kann. Diese Verknüpfung ermöglicht es, zusätzliche Informationen zu diesem Fremdschlüsselwert abzurufen. Die Zahlen neben den einzelnen Datentypen wie bspw. bei nchar(3) gibt an, dass insgesamt drei Zeichen (Buchstaben oder Zahlen) in dieser Spalte gespeichert werden dürfen. Sie informiert also über die Länge des zulässigen Spaltenwerts. 13. Die Schlüssel befinden sich zusätzlich auch noch im Ordner Schlüssel, wobei auch hier wiederum die gelb gefärbten Schlüssel die Primärschlüssel und die grau gefärbten die Fremdschlüssel enthalten. Die meisten Tabellen haben nur eine Primärschlüsselspalte, wobei grundsätzlich auch mehrere zulässig sind. Der vollständige Primärschlüsselwert setzt sich dann aus den einzelnen Werten der Primärschlüsselspalten zusammen. Es ist allerdings keine Seltenheit, dass eine Tabelle mehrere Fremdschüsselspalten enthält. Diese sind normalerweise einzeln zu betrachten und führen im Regelfall auch zu verschiedenen Tabellen. Lediglich in Sonderfällen und bei Tabellen mit einem zusammengesetztem Primärschlüssel 32 Grundlagen müssen natürlich die einzelnen Schlüssel auch wieder als Fremdschlüssel in einer anderen Tabelle erscheinen. 14. Weitere Informationen zu einem einzigen Schlüsselwert erhalten Sie über das Detailmenü, das mit Hilfe eines Doppelklicks zu öffnen ist. 1 2 Abbildung 1.7: Schlüssel und Fremdschlüssel Dieses Detailmenü hat den Titel Spalteneigenschaften und entspricht der Anzeige wie sie auch für gewöhnliche Spalten existiert. Insbesondere für Schlüsselfelder ist diese Übersicht allerdings besonders interessant. Unter der Überschrift IDENTITÄT befindet 33 Grundlagen sich der Name für dieses Schlüsselfeld sowie eine allgemeine Beschreibung in Form eines Kommentars. Der Name soll genau diese Schlüsselangabe identifizieren, da ja grundsätzlich der Spaltenname auch in einer anderen Tabelle als Fremdschlüssel oder in ganz anderer Bedeutung erscheinen kann. Über den eindeutigen Namen lassen sich dann auch Fehlermeldungen viel besser interpretieren, da man aus ihnen ablesen kann, welche Schlüsselangabe oder -beziehung verletzt wurde. Unter der Überschrift TABELLEN-DESIGNER sind verschiedene zusätzliche Aktionen angegeben, die bspw. automatisch geschehen sollen, sobald eine Datenänderung (eintragen, löschen oder aktualisieren) erfolgt. 1 2 Abbildung 1.8: Check-Bedingungen 15. Wählen Sie den Order EINSCHRÄNKUNGEN aus, um die für die Tabelle angegebenen Überprüfungsregeln für Wertänderungen und Werterfassungen zu kontrollieren. 34 Grundlagen Unter einer Einschränkung oder einer CHECK-Bedingung, welche ihren Namen von der sie erstellenden SQL-Syntax herleitet, versteht man eine Überprüfung des Wertebereichs. Diese Überprüfung hat nur indirekt etwas mit der reinen Überprüfung zu tun, ob die einzutragenden Daten zu dem für die Spalte angegebenen Datentyp passen. Sie enthalten darüber hinaus vielmehr weitere Regeln und Ausdrücke, die zur genauen Überprüfung von zulässigen Werten herangezogen werden. Dies können Bereiche, Grenzen und Intervalle genauso sein wie der Vergleich mit anderen Spalten oder sonstigen Vergleichen und Wertbeschreibungen von zulässigen Einträgen in dieser Spalte. Auch diese Einschränkungen besitzen einen eindeutigen Namen, damit man im Fehlerfall exakt nachvollziehen kann, gegen welche Einschränkung eine Operation verstoßen hat. 16. Öffnen Sie den Ordner TRIGGER, um die für die Tabelle zugewiesenen automatischen Operationen zu lesen. 2 1 ALTER TRIGGER [uProduct] ON [Production].[Product] AFTER UPDATE NOT FOR REPLICATION AS BEGIN SET NOCOUNT ON; UPDATE [Production].[Product] SET [Production].[Product].[ModifiedDate] = GETDATE() FROM inserted WHERE inserted.[ProductID] = [Production].[Product].[ProductID]; END; Abbildung 1.9: Trigger Bei einem Trigger handelt es sich um ein programmierbares Objekt in der Syntax von Transact SQL, der Spracherweiterung von SQL für den MS SQL Server. Bisweilen bezeichnet man auch die gesamte SQL-Sprache für den SQL Server als Transact SQL. Ein Trigger wird automatisch durch eine in ihm angegebene DB-Aktion ausgelöst, in- 35 Grundlagen dem bspw. Daten in eine Tabelle neu eingetragen oder einer Tabelle gelöscht oder aktualisiert werden sollen. Einen Trigger kann man nur über eine solche Aktion auslösen, d.h. ein direkter Aufruf wie bei einer Funktion oder Prozedur ist ausgeschlossen. Die Anweisungen eines Triggers dienen der erweiterten Überprüfung von Benutzeraktionen und sollen die Datenintegrität noch besser schützen als bspw. ein einfacher Wertebereich oder eine Einschränkung. Erlauben die Einschränkungen nur einfache Überprüfungsregeln, so kann man in einem Trigger nahezu beliebige Programmanweisungen vorgeben. 17. Für die Optimierung von Abfragen, d.h. für ihre beschleunigte Ausführung, kann man Indizes (Singular: Index) für eine Tabelle angeben. Öffnen Sie mit einem Klick den Ordner Indizes und wählen Sie einen der verschiedenen schon vorhandenen Indizes aus. Sie gelangen in die Detailansicht des gewählten Index, indem neben seinem Typ auch solche Eigenschaften wie die indizierte Spalte, Sortierreihenfolge, Datentyp und Größe angegeben werden. An dieser Stelle befinden sich auch in einer Ordner-Hierarchie verschiedene weitere Dialogfenster für die IndexBearbeitung bzw. ihre Speicherung und sonstige Eigenschaften. Mit Hilfe des in einem späteren Kapitel erläuterten Schlüsselworts SELECT ist es möglich, die Daten einer Tabelle auszugeben bzw. zu bestimmen, welche Spalten in die Ergebnismenge übernommen werden sollen und welchen Bedingungen die Daten genügen sollen. Dabei kann die Suche nach passenden Datensätzen entweder sequenziell oder indiziert vorgenommen werden. Die Möglichkeit eines sequenziellen Vorgehens bedeutet, dass die Bedingung für jede einzelne Zeile der Tabelle überprüft wird. Man kann sich hier vorstellen, dass man mit dem Finger jeden Datensatz einzeln berührt und ihn untersucht. Dies geschieht in der gespeicherten Reihenfolge der Daten auf der Festplatte. Da dies bei sehr großen Tabellen lange dauern kann, gibt es die Möglichkeit, die Spalten, in denen häufig gesucht wird bzw. in denen die Bedingungen enthalten sind, nach denen die Daten gefiltert werden sollen, zu indizieren. Dabei handelt es sich hierbei um eine gezielte Suche wie in einem Lexikon oder Wörterbuch. 36 Grundlagen Mit einem so genannten Clustered Index ordnet man die Reihen der Tabelle nach der angegebenen Sortierung physikalisch, d.h. auf der Festplatte, bereits in der benötigten Reihenfolge. Da die Daten nur einmal physikalisch geordnet werden können, ist auch nur ein solcher Index pro Tabelle zulässig. Sofern die Tabelle einen Primärschlüssel besitzt, wird dieser Clustered Index automatisch erstellt. Im Gegensatz dazu kann man auch einen Non-Clustered Index erstellen. Er betrifft nicht die physikalische Speicherung bzw. Sortierung der Daten. Stattdessen befindet sich die Sortierung in einer zusätzlichen Baumstruktur, die wie die schon erwähnten Techniken Lexikon, Wörterbuch oder Stichwortverzeichnis fungieren. Neben diesen beiden Hauptformen lassen sich noch weitere Arten unterscheiden. 2 1 3 Abbildung 1.10: Indizes 18. Wählen Sie den Ordner Statistiken aus, um die Entscheidungsgrundlage für die Verwendung eines Index zu sehen. Für die Bearbeitung einer Anfrage 37 Grundlagen stehen meistens unterschiedliche Vorgehensweisen zur Verfügung, die unter dem Namen Ausführungsplan bekannt sind. Welcher konkreter Ausführungsplan und damit auch welcher Index tatsächlich genutzt wird, um eine Anfrage zu beantworten, beeinflusst die so genannte Indexselektivität. 1 2 Abbildung 1.11: Statistiken Je höher diese Indexselektivität ist, desto höher ist die Wahrscheinlichkeit, dass der entsprechende Ausführungsplan zum Einsatz kommt. Der Optimierer ermittelt den benötigten Wert anhand der erstellten Statistiken. Sie enthalten solche Informationen wie die Anzahl der Tabellenzeilen, die Verteilungsschritte oder die physikalischen Speicherseiten. 38 Grundlagen 1.2.2 Abfragen direkt ausführen Das Management Studio bietet die Möglichkeit, über einen einfachen Texteditor Abfragen an die Datenbank zu senden bzw. T-SQL-Programme wie die erwähnten Trigger und Prozeduren zu erstellen. Neben diesem Programm gibt es auch noch rein kommandozeilenbasierte Werkzeuge. Im Wesentlichen sollen Sie in diesem Buch lernen, welche verschiedenen Syntaxanweisungen ein Programmierer (im Gegensatz zu einem Administrator) in dieses Textfeld eingetragen soll. Empfehlenswert ist natürlich immer, sowohl Datenbankadministrationskenntnisse als auch Programmierkenntnisse zu erwerben. 1. Um eine Abfrage oder allgemein eine DB-Anweisung auszuführen, wählen Sie die Schaltfläche NEUE ABFRAGE. 2. In der Auswahlliste, welche die verschiedenen Datenbanken enthält, die gerade innerhalb des Datenbankservers enthalten sind, wählen Sie die AdventureWorks-Datenbank aus, da die Anweisung in dieser DB ausgeführt werden soll. 3. Tragen Sie dann Ihre SQL-Anweisungen wie bspw. SELECT * FROM Production.Product in das sich öffnende Textfenster ein. 4. Wählen Sie die AUSFÜHREN-Schaltfläche oder drücken Sie die F5-Taste. 5. Das Ergebnis erscheint standardmäßig in der so genannten Raster-Ansicht (engl. Grid View) im Bereich ERGEBNISSE. Zusätzliche Meldungen oder natürlich Fehlermeldungen erscheinen dagegen im Bereich MELDUNGEN. Die vorher genannten Schritte sind neben der Anmeldung die nahezu wichtigsten für die Arbeit mit der Datenbank. Sie lassen sich noch um weitere Schritte wie das Öffnen einer fertigen SQL-Datei mit Anweisungen oder die Speicherung von Anweisungen und Ergebnissen vervollständigen, doch für den Einstieg in die Arbeit mit dem SQL Server sind dies die wesentlichen Aktivitäten. Im Bereich der Administration und natürlich der Erstellung von Datenbankobjekten bietet das Management Studio noch weitere Möglichkeiten. 39 Grundlagen Um eine Folge von SQL-Anweisungen wie bspw. eine Abfrage, die Sie später noch einmal ausführen wollen, als Textdatei zu speichern, wählen Sie DATEI / SQL1QUERY.SQL SPEICHERN oder DATEI / SQL1QUERY.SQL SPEICHERN ALS... aus. Die Endung der Datei ist für die Funktionstüchtigkeit der Datei bedeutungslos, d.h. die Endung .txt wäre genauso sinnvoll. Allerdings können Sie die .sql-Endung mit dem Management Studio verknüpfen und ist sie die gebräuchliche Endung für Datenbankanweisungen. Eine solchermaßen gespeicherte Datei lässt sich dann über Datei / Öffnen wieder laden und zur Ausführung bringen. 1 4 2 3 Abbildung 1.12: Ausführen einer Abfrage Bisweilen hat man allerdings gerade nicht nur eine einzige Datei, sondern für einen bestimmten Arbeitsbereich eine ganze Reihe von zusammenhängenden Skripten. Zu 40 Grundlagen ihrer Organisation lässt sich ein ganzes Projekt erstellen. Es enthält neben den Skripten auch die Verbindungsangaben zur Datenbank. 1. Wählen Sie DATEI / NEU / PROJEKT. 2. Wählen Sie aus den drei verschiedenen Projektarten den Eintrag SQL SERVER-SKRIPTS aus. Geben Sie einen neuen Namen für das Projekt sowie auch über die DURCHSUCHEN-Schaltfläche einen Speicherort an. Bestätigen Sie alle Einstellungen mit OK. 1 2 3 Abbildung 1.13: Erstellen eines Projekts 3. Richten Sie mit dem Kontextmenü unter Verbindungen eine neue Verbindung ein oder nutzen Sie die bereits bestehende. Fügen Sie neue 41 Grundlagen Skripte, Abfragen und Anweisungen mit Hilfe des Kontextmenüs unter Abfragen hinzu. Es öffnet sich in diesem Fall ein neues Abfragefenster, welche Sie direkt im Projekt speichern können. Die Abbildung zeigt, wie eine einfache Abfrage ausgeführt wurde und dieses Skript inklusive der benutzten Datenbankverbindung in der Projektmappe gespeichert wurde. Beachten Sie bitte, dass Sie die Möglichkeit haben, in einer Projektmappe mehrere Projekte zu speichern. In diesem Beispiel haben sowohl die Projektmappe als auch das Projekt den selben Namen. Dies ist allerdings nicht notwendig. Stattdessen könnte man sich für AdventureWorks-Datenbank eine große Projektmappe vorstellen, in der Ihre im Rahmen des Buch erstellten Skripte nach Kapiteln sortiert enthalten sind. Abbildung 1.14: Projektmappe im Einsatz Um dann neue Elemente in einer Projektmappe hinzuzufügen, stehen die diversen Kontextmenüs zur Verfügung. Im Kontextmenü der Projektmappe fügen Sie neue oder vorhandene Projekte hinzu, während sie im Kontextmenü des Projekts sowohl neue Datenbankverbindungen als auch neue Abfragen hinzufügen. Diese beiden letzteren Elemente lassen sich auch in den jeweiligen Projektabteilungen neu erstellen. 42 Grundlagen Abbildung 1.15: Projekte und Abfragen einer Projektmappe hinzufügen 1.2.3 Abfragen im Editor ausführen Eigentlich müsste man gar kein T-SQL lernen, um einfache Daten aus dem MS SQL Server zu extrahieren oder solche Operationen wie Daten einfügen, löschen oder aktualisieren durchzuführen. Mit einigem Geschick, wenngleich auch nicht mit demselben professionellen Effekt, könnte man sich diese vier typischen Operationen einfach auch im Abfrage-Editor grafisch zusammenstellen. Dabei handelt es sich um eine einfach zu bedienende Oberfläche, wie sie in ähnlicher Weise auch bspw. in MS Access vorhanden ist. Leider ist dies auf einfachste Abfragen beschränkt, sodass man wohl doch besser mit T-SQL arbeitet. Für die Nutzung des Abfrage-Editors müssen Sie zunächst ein leeres Abfrage-Fenster öffnen, da ansonsten der Menü-Eintrag für den Editor nicht erscheint. Um eine Abfrage auszuführen sind folgende Schritte notwendig: 1. Wählen Sie ABFRAGE / ABFRAGE IN EDITOR ENTWERFEN. Im sich öffnenden großen Dialogfenster sieht man drei Bereiche. Im oberen Bereiche befindet sich der Tabellenbereich, in welchem die verschiedenen 43 Grundlagen ausgewählten Tabellen mit ihren Spalten und Verknüpfungen angezeigt werden. Im mittleren Teil befindet sich der Bearbeitungsbereich, in dem man Spalten, ihre Aliasnamen, Werte für Filter, Sortierungen etc. angeben kann. Einige Werte lassen sich aus Listenfeldern abrufen, andere müssen dagegen tatsächlich eingegeben werden. 1 2 3 Abbildung 1.16: Tabellen im Editor auswählen 2. Zunächst wählen Sie aus der sich öffnenden Tabellenliste die von Ihnen gewünschte Tabelle aus. In diesem Beispiel handelt es sich um die beiden Tabellen Production.Product und Production.ProductSubcategory, wobei der erste Namensteil für das so genannte Datenbankschema (übergeordnete Struktur) und der zweite Teil für den Tabellennamen steht. Beide Tabellen sind über eine Primärschlüssel-Fremdschlüssel- 44 Grundlagen Verknüpfung verbunden, sodass automatisch ein entsprechende Pfeil gezogen wird. Dabei gibt das Schlüsselsymbol an, dass der Primärschlüssel in der Tabelle ProductSubcategory gespeichert ist, während das Symbol für die Unendlichkeit angibt, dass dieser Schlüssel beliebig oft in der Product-Tabelle referenziert wird. N Produkte aus der Product-Tabelle stehen mit einem Datensatz aus der ProductSubcategory-Tabelle in Beziehung. Möchten Sie später weitere Tabellen auswählen, öffnen Sie das Kontextmenü im Tabellenbereich. 1 2 3 Abbildung 1.17: Spalten(namen), Filter und Sortierung vorgeben 3. Wählen Sie danach die Spalten aus den benötigten Tabellen aus. Dies gelingt entweder im Tabellenbereich, indem Sie die Spalten markieren, oder 45 Grundlagen Sie können unten im Eingabebereich die Spalten aus einer Auswahlliste auswählen. Die markierten Spalten aus den Tabellen werden automatisch auch als anzuzeigende Spalten in der Ergebnismenge verwendet. Es ist allerdings nicht nowendig, tatsächlich alle Spalten, auf die Sie im Laufe der Abfrage zugreifen, auch tatsächlich auszugeben. Wenn eine Spalte nur für einen Filter verwendet werden soll, besteht keine Notwendigkeit, sie auch tatsächlich auszugeben. Dies ist dann umso wichtiger, wenn der Filter immer zum gleichem Wert führen würde und dieser Wert dann in jeder Spalte wieder genannt wird. In der Spalte AUSGABE im Bearbeitungsbereich können Sie daher noch einmal genau angeben, dass zwar diese Spalte bspw. für eine Sortierung oder für einen Filter verwendet werden, aber gerade nicht ausgegeben werden soll. 4. In der Spalte ALIAS im Bearbeitungsbereich geben Sie dann bei den Spalten, welche in der Ergebnismenge erscheinen sollen, einen möglichen Ersatznamen für die Spaltenköpfe an. Dieser Name wird als Alias(name) bezeichnet, und sollte einer guten Bezeichnung dienen, wenn der originale Tabellenspaltenname nicht für eine Ausgabe geeignet ist, weil bspw. eine Abkürzung verwendet wurde. Im aktuellen Beispiel sollen bspw. der Name des Produktkategorie und der Produktname ausgegeben werden. Da beide Spalte in der Tabelle Name heißen, erhalten Sie für die Abfrage einen Aliasnamen. 5. Sofern das Ergebnis nach einer Spalte sortiert werden soll, geben Sie einfach in der Spalte SORTIERUNGSART für die zu sortierende Spalte die entsprechende Reihenfolge mit Aufsteigend oder Absteigend an. Die Sortierung erfolgt automatisch so, dass sie für den Spaltendatentyp korrekt ist, d.h. von A-Z, 1-x oder auch nach dem Kalender. 6. Beim Auswahl der Sortierung werden automatisch in der Reihenfolge der Auswahl die Werte für die Spalte SOTIERREIHENFOLGE gesetzt. Wenn man also erst nach dem Produktnamen und dann nach der Kategorie sortieren 46 Grundlagen möchte, dann trägt man in die Spalte für den Produktnamen den Wert 1 und in der Spalte für den Kategorienamen den Wert 2 ein. 7. Schließlich möchte man möglicherweise gar nicht alle Werte aus der Tabelle abrufen, sondern einen so genannten Filter anwenden, d.h. nur alle Produkte einer bestimmten Kategorie, mit einer bestimmten Produktnummer oder einem bestimmten Preis. Es ist dabei auch möglich, mehrere Bedingungen anzugeben, da neben der Spalte FILTER noch weitere Oder-Spalten sind, in denen zusätzliche Bedingungen eingetragen werden können. Die Angabe einer solchen Bedingung gelingt über einen Ausdruck, der die Vergleichsoperatoren >, >=, <, <=, =, != sowie die besonderen SQLOperatoren, die in einem späteren Kapitel vorgestellt werden, erwartet. Im aktuellen Beispiel soll der Produktnamen kleiner C und der Preis größer 100 sein. Abbildung 1.18: Ausgabe und Einsatz der Abfrage 8. Nachdem alle Angabe getroffen sind, klicken Sie auf OK, verlassen dadurch den Abfrage-Editor und gelangen mit dem fertig erstellten Quelltext in das Abfragefenster. Dort führen Sie die Abfrage so aus, als hätten Sie sie selbst nicht nur erstellt, sondern sogar selbst nieder geschrieben. 47 Grundlagen Neben Abfragen werden Sie in diesem Buch auch lernen, wie Sie Daten über SQL aktualisieren können. Dies gelingt nicht über den SELECT-Befehl, den Sie gerade unter Einsatz des Abfrage-Editors erstellt haben, sondern über UPDATE. Einige Grundbestandteile in dieser Anweisung sind allerdings gleich denen der Abfrage. 1. Wählen Sie ABFRAGE / ABFRAGE IN EDITOR ENTWERFEN. 2. Ändern Sie den Typ der zu erstellenden Abfrage über das Kontextmenü über TYP ÄNDERN / AKTUALISIEREN in eine Aktualisierungsabfrage. 1 2 3 Abbildung 1.19: Aktualisierungsabfrage 3. Wählen Sie wie zuvor eine Tabelle aus, die Sie aktualisieren möchten. Dies gelingt über das Kontextmenü mit dem Eintrag TABELLE HINZUFÜGEN. In diesem Beispiel wählen Sie die Product-Tabelle aus. 48 Grundlagen 4. Wählen Sie im Bearbeitungsbereich die Spalten aus, die Sie für die Abfrage benötigen. Dies sind im Normalfall zwei Spaltentypen, nämlich zum einen eine Spalte, die einen neuen Wert erhalten soll, und zum anderen eine Spalte, auf die ein Filter angewendet wird, um die entsprechenden zu aktualisierenden Datensätze zu finden. Geben Sie keinen Filter an, werden alle Datensätze aktualisiert. Möchten Sie allerdings einen Filter verwenden, können Sie sich aussuchen, ob der Filter auf eine Spalte als die zu aktualisierende angewandt werden soll, oder ob Filter und neuer Wert auf die gleiche Spalte angewendet werden sollen. In diesem Fall soll der ListPrice den Wert 100 erhalten, wenn das zuvor ausgewählte Produkt gefunden wird. Daher ist der Filter in der Name-Spalte auf den Ausdruck ='All-Purpose Bike Stand'. Das zusätzlich eingefügte N ist für die Abfrage nicht von Bedeutung, sondern kennzeichnet die Zeichenkette. Weitere Bedingungen können Sie wie zuvor in die ODER-Spalten einfügen. 5. Wählen Sie OK und führen Sie, wenn Sie wollen, die Abfrage auch tatsächlich aus. Um die Änderungen nachher wieder ungeschehen zu machen, geben Sie zusätzlich noch die Anweisungen GO und ROLLBACK ein. Neben Abfragen und Aktualisierungen lässt sich auch das SQL erstellen, mit dessen Hilfe Datensätze aus der Datenbank gelöscht werden können. Es wird letztendlich mit den gleichen Mechanismen erstellt, die auch schon bei den vorherigen Aktionen angewandt wurden. 1. Wählen Sie ABFRAGE / ABFRAGE IN EDITOR ENTWERFEN. 2. Ändern Sie den Typ der zu erstellenden Abfrage über das Kontextmenü über TYP ÄNDERN / LÖSCHEN in eine Löschabfrage. 3. Wählen Sie wie zuvor eine Tabelle aus, aus der Sie Daten löschen möchten. Dies gelingt über das Kontextmenü mit dem Eintrag TABELLE HINZUFÜGEN. In diesem Beispiel wählen Sie die Product-Tabelle aus. 4. Wählen Sie im Bearbeitungsbereich die Spalten aus, die Sie für die Abfrage benötigen. Dies sind bei einer Löschabfrage nur die Spalten, für die ein 49 Grundlagen Filter vorgegeben werden soll. Bei einer Abfrage waren es im Vergleich dazu Filter- und Anzeigespalten, bei einer Aktualisierungsabfrage Spalten, die einen neuen Wert erhalten sollten, und natürlich auch Filter. Da einfach der gesamte Datensatz entfernt werden soll, benötigt man nur Filter-Spalten. In diesem Fall sollen dies Datensätze mit einer Produktnummer BETWEEN 879 AND 882 sein. 5. Wählen Sie OK und führen Sie, wenn Sie wollen, die Abfrage auch tatsächlich aus. Um die Änderungen nachher wieder ungeschehen zu machen, geben Sie zusätzlich noch die Anweisungen GO und ROLLBACK ein. 1 2 3 Abbildung 1.20: Löschabfrage Die beiden Möglichkeiten, eine Tabelle zu erstellen und eine so genannte Einfügeabfrage zu erstellen, sind untereinander sehr ähnlich und ähneln auch sehr der gewöhnlichen Abfrage. Während diese einfach nur eine flüchtige Ergebnismenge erzeugt, erlauben es 50 Grundlagen die beiden anderen diese Ergebnismenge entweder in einer neu zu erstellenden Tabelle oder in einer bereits vorhandenen zu speichern. 1. Wählen Sie ABFRAGE / ABFRAGE IN EDITOR ENTWERFEN. 2. Ändern Sie den Typ der zu erstellenden Abfrage über das Kontextmenü über TYP ÄNDERN / TABELLE ERSTELLEN in eine Erstellungsabfrage. 3. Geben Sie den Namen der zu erstellenden Tabelle ein. 4. Geben Sie die Namen der zu erstellenden Spalten vor. Die Datentypen werden direkt aus der Abfrage bzw. aus der befragten Tabelle übernommen. Die Strukturen von Abfrage und Zieltabelle müssen also übereinstimmen. Alternativ können Sie auch zunächst wie zuvor eine Tabelle bestimmen, aus der Sie Daten auswählen möchten. Dies gelingt über das Kontextmenü mit dem Eintrag TABELLE HINZUFÜGEN. 5. Geben Sie mögliche Abfrageeigenschaften wie Filter, Aliasnamen für die Spaltennamen der zu erzeugenden Tabelle und Sortierungen vor. 6. Wählen Sie OK und führen Sie, wenn Sie wollen, die Abfrage auch tatsächlich aus. Da die Tabelle tatsächlich sofort angelegt wird, folgt im nächsten Quelltext eine Erweiterung zu dem automatisch erzeugten Quelltext. Er enthält zu Beginn noch eine Löschanweisung für die gesamte Tabelle mit Hilfe des DROP-Befehls von SQL und am Ende noch eine Testabfrage der gesamten erstellten Tabelle. Dies soll nachweisen, dass sie erstens existiert und zweitens auch Daten übernommen worden. Die einzelnen Anweisungen werden durch das GO-Schlüsselwort getrennt. DROP TABLE [Shirts-Produkte] GO SELECT ProductID, Name, ListPrice INTO [Shirts-Produkte] 51 Grundlagen FROM Production.Product WHERE (Name LIKE N'%Shorts%') GO SELECT * FROM [Shirts-Produkte] selectinto.sql: Löschen, Neuerstellung und Abfrage 1 2 3 4 5 Abbildung 1.21: Erstellungsabfrage Man erhält als Ergebnis der gesamten Abfrage folgende Daten in der erzeugten Tabelle: ProductID 52 Name ListPrice Grundlagen ----------- -------------------------------------- --------841 Men's Sports Shorts, S 59,99 849 Men's Sports Shorts, M 59,99 868 Women's Mountain Shorts, M 69,99 869 Women's Mountain Shorts, L 69,99 … Ein letztes Wort soll noch zu dem sehr schönen Werkzeug des Abfrage-Editors verloren werden. In den zurückliegenden Beispielen wurden immer nur Tabellen ausgewählt, in denen Daten zu bearbeiten oder auszuwählen waren. Im Dialogfenster Tabelle hinzufügen, welches sich im Kontextmenü des Editors des Tabellenbereichs öffnet, sind allerdings vier verschiedene Reiter angebracht, die - je nach Operation - auch alle genutzt werden können. Die drei zusätzlichen Möglichkeiten, um Daten auszuwählen oder überhaupt Zugriff auf Daten zu haben, sollen hier nur kurz erwähnt werden. Sie sind allerdings Themen späterer Kapitel: Tabellen (Relationen) bilden in jeder Datenbank den zentralen Speicherort für Daten bzw. bieten auch für die anderen Möglichkeiten die eigentliche Datenquelle. Sie enthalten die Daten tatsächlich und erlauben bei entsprechender Berechtigung Zugriff auf den gesamten Datenbestand. Ansichten oder auch Sichten stellen gespeicherte Abfragen dar. Sie enthalten also nicht tatsächlich die Daten, sondern nur das SQL der Abfrage, welches zu den Abfragen führt. Dies wird auch oft als virtuelle Tabelle bezeichnet, da man die Sicht in SQL wie eine gewöhnliche Tabelle nutzen kann, sie in Wirklichkeit aber nur eine gespeicherte Abfrage mit einem eigenen Namen darstellt. Sofern eine Sicht wiederum indiziert ist, werden dann auch die Daten in der Sicht gespeichert. 53 Grundlagen Abbildung 1.22: Mögliche Datenquellen Funktionen stellen nicht nur wie Prozeduren eine Möglichkeit dar, um Softwarebausteine in der Datenbank zu entwickeln, sondern erlauben auch die Erstellung von parametrisierten gespeicherten Abfragen. Dabei enthält die Funktion die SQL-Anweisung für die Abfrage, während die möglichen Filter-Werte über die Funktionsparameter angegeben werden können. Dieser Parameter ist bei Sichten nicht möglich, sodass Funktionen als zusätzliche Möglichkeit dienen, Abfragen aus Zeitersparnis- oder auch Sicherheitsgründen vorzubereiten. Synonyme stellen einen Spitz- oder Aliasnamen für DB-Objekte dar. Im Fall des Datenabrufs ist dies vor allen Dingen für Tabellen wichtig. So hat man die Möglichkeit, eine Abstraktionsschicht zwischen den so genannten Basis-Objekten 54 Grundlagen und den DB-Klienten einzuziehen. Unterliegende Namen können sich verändern, wobei das Synonym seinen Namen behält. Ein weiterer Vorteil liegt darin, dass lange Namenskonstrukte wie Server1.AdventureWorks. Person.Employee für server.datenbank.schema.[tabelle|sicht] überflüssig werden, da das kürzere Synonym zum Einsatz kommen kann. 1.2.4 Vorlagen-Editor Für häufig wiederkehrende Aufgaben, die in Form von Skripten ausgeführt werden können, gibt es die Möglichkeit, so genannte Vorlagen zu erstellen. Dies sind halb fertige T-SQL-Skripte, in denen Textbereiche wie Objektnamen oder einfache Werte angegeben und beim konkreten Aufruf gegen konkrete Werte ausgetauscht werden können. Verschiedene fertige Vorlagen sind ebenfalls bereits vorhanden. Gehen Sie für die Erstellung und den Aufruf solcher Vorlagen folgendermaßen vor: 1. Wählen Sie ANSICHT / VORLAGEN-EXPLORER. 2. In diesem Vorlagen-Explorer können Sie entweder eine bereits vorhandene und/oder von Ihnen erstellte Vorlage aus einem von Ihnen benannten Ordner auswählen. Alternativ können Sie aber auch eine neue Vorlage erstellen. Wählen Sie dazu aus dem Kontextmenü NEU / VORLAGE. Möchten Sie einen neuen Ordner für die Sortierung Ihrer Vorlagen einfügen, wählen Sie an dieser Stelle den Eintrag ORDNER. 3. Die eingefügte Vorlage können Sie mit Befehlen aus dem Kontextmenü bearbeiten. Wählen Sie UMBENENNEN für einen neuen Namen, LÖSCHEN zum Löschen etc. Wählen Sie BEARBEITEN, um T-SQL-Quelltext anzugeben. 55 Grundlagen 1 2 3 4 5 6 7 Abbildung 1.23: Vorlagen erstellen und nutzen 56 Grundlagen 4. Die Erstellung eines Vorlagen-Textes ist relativ simpel. Die wichtigste Überlegung besteht darin, den Quelltext so zu formulieren, dass er nachher durch die Vorgabe von einigen Parameterwerten in möglichst vielen Fällen eingesetzt werden kann. Diese Parameter werden mit Hilfe von spitzen Klammern in der Form <Parametername, Datentyp, Vorgabewert> angegeben. Sie müssen nicht extra angemeldet werden, sondern werden automatisch anhand dieser Syntax aus dem Vorlagentext extrahiert und nachher beim Verwenden dieser Vorlage in einem Dialogfenster angegeben, um dort ersetzt zu werden. An dieser Stelle soll nicht auf die T-SQL-Syntax eingegangen werden, da dies ja Thema der vielen nachfolgenden Kapitel des Buchs ist. Wesentlich ist daher nur die Erstellung, Speicherung und Verwendung einer Vorlage neben der Angabe und Verwendung eines Parameters. 5. Wenn Sie die Vorlage erstellt, Parameter hinzugefügt und die Vorlage gespeichert haben, wollen Sie sie beizeiten aufrufen. Dazu öffnen Sie einfach die gewünschte Vorlage aus dem Vorlagen-Explorer und wählen dann ABFRAGE / WERTE FÜR VORLAGENPARAMETER ANGEBEN. 6. In dem sich öffnenden Dialogfenster stehen die verschiedenen Parameter mit ihren Datentypen und ihren möglichen Vorgabewerten. Ersetzen Sie ggf. die Werte und bestätigen Sie dieses Dialogfenster. Dadurch ersetzen Sie die Parameter durch die Vorgabewerte oder die an ihrer Stelle eingegebenen Werte im Vorlagentext. 7. Führen Sie die geänderte Anweisung aus und erfreuen Sie sich an der gesparten Arbeitszeit durch Ihre hervorragende Vorlage. 1.2.5 Dokumentation Trotz der MS SQL Server-Literatur, die Sie bspw. in Form dieses Buchs oder anderer Bücher dieser Reihe in der Hand halten bzw. im Schrank besitzen, werden Sie letztendlich in der Dokumentation noch mehr Informationen finden. Diese sind vielleicht nicht 57 Grundlagen mit so vielen Beispielen erläutert wie in einem Buch, doch dafür sind sie sehr detailreich hinsichtlich der verwendeten Technik. Abbildung 1.24: Dokumentation Verwenden Sie die Dokumentation folgendermaßen: 1. Rufen Sie die Dokumentation auf, indem Sie START / PROGRAMME / MS SQL SERVER 2005 / DOKUMENTATION UND LERNPROGRAMME / SQL SERVER-ONLINEDOKUMENTATION auswählen. 2. Sofern Sie einen bestimmten SQL-Befehl suchen, ist dies eigentlich besonders einfach, denn dann sollten Sie einfach unter dem Reiter SUCHEN diesen SQL-Befehl eingeben und die SUCHEN-Schaltfläche betätigen. 3. Wählen Sie innerhalb der verschiedenen Reiter auf der linken Seite einen Bereich aus, indem Sie die Hilfetexte anzeigen wollen. Dies kann die lokale Hilfe, die MSDN-Online-Dokumentation auf Deutsch oder Englisch oder sonstige Informationsplattformen sein. Innerhalb dieser einzelnen Reiter erscheinen dann im mittleren Bereich verschiedene Artikel, wobei für den T-SQL-Programmierer in vielen Fällen der erste Artikel bereits der richtige ist, da hier die Suchfunktion anhand eines SQL-Schlüsselworts aus verständlichen Gründen besonders gut funktioniert. 58 Grundlagen 1.3 Programmierbarkeit Unter dem sehr ungewöhnlichen deutschen Wort Programmierbarkeit versteht der MS SQL Server nicht nur die Fähigkeit, überhaupt nützlichen Quelltext in verschiedenen Sprachen in der Datenbank zu speichern oder - wie im Fall von T-SQL - direkt auszuführen, sondern auch die verschiedenen programmierten Objekte. Die Syntax, mit der diese Objekte erstellt werden können, ist neben der sehr umfangreichen Darstellung von Abfragen und Analysen ein zentrales Thema dieses Buchs. Daher dient dieser Abschnitt nur als Appetithappen. Sie sollen also sehen, welche Objekte programmiert und sogar in der Datenbank gespeichert werden können. Die AdventureWorks-Datenbank ist bereits mit sehr vielen programmierten Objekten und damit, um im Jargon von MS SQL Server zu bleiben, mit sehr viel Programmierbarkeit ausgestattet. Daher kann es sehr hilfreich sein, diese verschiedenen Objekte aufzurufen und versuchen, auf ihre Einsatzweise hin zu verstehen. 1.3.1.1 Prozeduren Eine Prozedur stellt ein kleines Programm dar, das in der Datenbank gespeichert ist und das innerhalb der Datenbank über SQL oder außerhalb der Datenbank über eine beliebige Programmiersprache aufgerufen werden kann. Typische Einsatzbereiche von Prozeduren sind vereinfachte Datenbearbeitungsroutinen. In diesem Fall verwendet man in der Anwendung, welche die Datenbank nutzt, nicht den entsprechenden SQL-Befehl für die Erfassung, Löschung oder Aktualisierung von Daten, sondern ruft die entsprechende Prozedur auf und übergibt die Daten. Dadurch kann man Validierungen oder beliebige, über die einfache Datenbearbeitung hinausgehende Anweisungen automatisiert ausführen, ohne in der äußeren Anwendung darauf Rücksicht zu nehmen. Ein weiterer Einsatzbereich, der gerade für den MS SQL Server sehr wichtig ist, stellt gespeicherte Abfrage in Form von Prozeduren dar, wobei hier Filterwerte als Parameter übergeben werden können und dadurch der Datenabruf besonders einfach gestaltet wird. Eine solche Prozedur liefert eine Ergebnismenge wie eine Abfrage in SQL zurück. 59 Grundlagen 1 2 Abbildung 1.25: Prozeduren untersuchen Rufen Sie vorhandene Prozeduren folgendermaßen auf. Sie können über den folgenden Weg auch neue Prozeduren erstellen, sofern Sie nicht einfach den dazu notwendigen TSQL-Quelltext in ein leeres Abfragefenster eingeben. Interessant ist das gleich erwähnte Kontextmenü noch für den Aufruf der Objekte, die von der Prozedur abhängig sind. Sofern solche abhängigen Objekte existieren, kann diese Prozedur nicht einfach gelöscht werden, weil die abhängigen Objekte dadurch ungültig würden. 1. Öffnen Sie im Objekt-Explorer im Knoten PROGRAMMIERBARKEIT einer Datenbank den Knoten GESPEICHERTE PROZEDUREN. Dort sind die verschiedenen Datenbankprozeduren aufgelistet. Im Knoten GESPEICHERTE SYSTEMPROZEDUREN befinden sich dagegen für das gesamte Datenbanksystem nutzbare Prozeduren. 60 Grundlagen 2. Wählen Sie für eine Sie interessierende Prozedur aus dem Kontextmenü den Eintrag SKRIPT FÜR GESPEICHERTE PROZEDUREN ALS und wählen Sie dann aus der sich öffnenden Liste einen der Einträge. CREATE steht für Erstellung, ALTER für Änderung, DROP für Löschung und EXECUTE für Ausführung. Jeder Befehl kann in einem neuen Abfrage-Fenster geöffnet in eine Datei bzw. in die Zwischenablage kopiert werden. Um sich also einfach das Erstellungsskript einer solchen Prozedur anzusehen, wählen Sie den Eintrag CREATE IN / NEUES ABFRAGE-EDITORFENSTER. 3. Sofern Sie über die Schaltfläche CREATE den Quelltext der Prozedur in einem neuen Abfragefenster geöffnet werden, sehen Sie die Prozedur so, wie Sie sie in T-SQL nach der Lektüre des Buchs ebenfalls hätten vorgeben können. Mit dem sich öffnenden Quelltext lässt sich eine Prozedur in der Datenbank speichern. Er sieht im Falle einer Änderung bis auf die erste Zeile genauso aus, wobei in dieser ersten Zeile dann die ALTERAnweisung steht. Diese Ansicht erhalten Sie über die entsprechende ALTER-Schaltfläche im vorher beschriebenen Kontextmenü. Eine Änderung löscht eine Prozedur nicht, sodass abhängige Objekte Schaden nehmen könnten, sondern verändert ihren Quelltext, um bspw. neue Anforderungen zu berücksichtigen oder Fehler zu korrigieren. Während diese Schatlflächen mehr für einen Leser des Quelltextes interessant sind, aber nicht besonders viele Möglichkeiten bieten, mit der Prozedur kreativ umzugehen, ist die Schaltfläche EXECUTE dagegen darauf ausgerichtet, in einem T-SQL-Skript die Prozedur auch tatsächlich auszuführen. Wenn die Verwendung von T-SQL nicht gewünscht wird, obwohl nur noch die Parameterwerte vorgegeben werden müssen, dann kann man auch die Schaltfläche GESPEICHERTE PROZEDUR AUSFÜHREN aus dem Kontextmenü verwenden. Es führt nicht zu einem T-SQL-Skript, sondern vielmehr zu einem Dialogfenster, in welchem die benötigten bzw. gewünschten Parameterwerte eingetragen werden können. Dies ist eine vereinfachte grafische Darstellung der in diesem Schritt beschriebenen T-SQL-Lösung. 61 Grundlagen 1 2 2 3 Abbildung 1.26: Ausführen einer Prozedur 4. Es öffnet sich wiederum ein neues Fenster, in dem nun allerdings nicht die Erstellung der Prozedur und damit auch ihr Quelltext angegeben wird, sondern die Ausführung derselben. Das T-SQL-Skript stellt nicht das bereits zuvor kurz vorgestellte Standard-SQL dar, sondern bietet eine Variablendeklaration und die Ausführung der Prozedur über die EXECAnweisung, wobei die erstellten Variablen als Parameter übergeben 62 Grundlagen werden. Die Parameter werden nur deklariert, erhalten allerdings noch keinen Wert. Dies ist vom Benutzer durchzuführen, wobei hier jede beliebige T-SQL-Anweisung zum Einsatz kommen kann. Dies schließt einfache und direkte Wertvorgaben genauso ein wie auch komplexe Ausdrücke, den Abruf von Abfrageergebnissen, die Verwendung von Funktionen oder Berechnungen. Im Beispiel, das im Bildschirmfoto für die Nachwelt festgehalten wurde, handelt es sich zum einen um den klassischen Fall einer Wertvorgabe und zum anderen um den Abruf eines Aggregats (größtes Datum) aus der von der Prozedur abgefragten Tabelle. -- TODO: Set parameter values here. SET @StartProductID = 970 SET @CheckDate = (SELECT MAX(StartDate) FROM Production.BillOfMaterials) 5. Schließlich kann man die ausgewählte Prozedur über das bearbeitete Skript starten, indem man die AUSFÜHREN-Schaltfläche wählt. Im Fall der ausgewählten Prozedur uspGetBillOfMaterials erhält man für eine StartProduktnummer und ein Vergleichsdatum die zugehörigen Materiallisten in Form eines Abfrageergebnisse zurück. In diesem Fall hat man also eine in einer Prozedur versteckte parametrisierte Abfrage ausgeführt. In einem anderen Fall hat man möglicherweise Daten- oder Systemänderungen vorgenommen. 1.3.1.2 Funktionen Eine Funktion hat viele Gemeinsamkeiten mit einer Prozedur, was sich insbesondere auch in ihrer Darstellung in der grafischen Oberfläche und in diesem einleitenden Niveau dieses Abschnitts deutlich widerspiegelt. Es handelt sich ebenfalls um ein kleines Programm, das in der Datenbank gespeichert ist und das einen klar begrenzten Verantwortungsbereich im Rahmen der Datenbankbenutzung ausfüllt. Eine Funktion hat ebenfalls die Fähigkeit, Übergabeparameter anzunehmen, kann über das gleiche Kontextme- 63 Grundlagen nü verschiedentlich in ihrem Quelltext betrachtet oder ausgeführt werden. Daher soll aus Platzgründen auf eine erneute Darstellung dieses Kontextmenüs verzichtet werden. Man findet im vorherigen Abschnitt ausreichendes Bildmaterial dazu. Im Gegensatz zu einer Prozedur besitzt eine Funktion allerdings einen so genannten Rückgabewert, sodass man sie mit Methoden oder Funktionen einer gewöhnlichen Programmiersprache vergleichen kann, wenn in diesem Vergleich vorausgesetzt wird, dass die erwähnte Funktion oder Methode ebenfalls einen Rückgabewert liefert. Einige Programmiersprachen unterscheiden ja auch mit Hilfe verschiedener syntaktischer Elemente, ob sich eine Funktionalität eher als Prozedur oder eher als Funktion bezeichnen lassen würde - auch dann, wenn die Programmiersprache an sich diese Unterscheidung nicht trifft. Entweder handelt es sich um das Schlüsselwort void, um anzugeben, dass diese Methode keinen Rückgabewert liefert, oder nur um die Verwendung der returnAnweisung für die tatsächliche Rückgabe eines Wertes. Eine Prozedur kann über einen Ausgabeparameter ebenfalls einen Wert an das aufrufende Programm zurückgeben, doch ein Rückgabewert zeichnet sich dadurch aus, dass man den Funktionsaufruf auf die rechte Seite einer Zuweisung bzw. überall dort platzieren kann, wo ein Ausdruck erwartet wird. Eine Prozedur ist kein solcher Ausdruck, da man den Ausgabeparameter zunächst abrufen und dann die Variable mit dem abgerufenen Wert wieder als Ausdruck verwenden könnte. Wenn eine Funktion sich dadurch auszeichnet, einen Rückgabewert zu haben und als Ausdruck verwendet werden zu können, dann kann man sie so gestalten, dass sie auch direkt in SQL zum Einsatz kommen können. Dies bedeutet, dass sie neben solchen Standardfunktionen wie COUNT, MIN oder SUM in einer SQL-Anweisung stehen und Werte für einen Filter oder eine Berechnung liefern können. Sie ermöglichen es damit genauso wie Prozeduren, die Arbeit mit der Datenbank sehr zu vereinfachen, wobei in einem solchen Fall allerdings ganz gewöhnliches SQL dadurch vereinfacht werden kann, weil die selbst erstellte Funktion komplexe Berechnungen, Auswertungen oder Verknüpfungen selbst vornimmt und nur noch die gewünschten, vielleicht sogar parametrisierten Werte zurückliefert. 64 Grundlagen Wie gerade schon gesehen, ist eine Prozedur in der Lage, ein Abfrageergebnis zurückzuliefern. Diese Fähigkeit besitzt eine Funktion auch, wobei sie allerdings in der FROMKlausel einer Abfrage erscheinen kann, die normalerweise eine Tabellen- oder Sichtreferenz erwartet. Über eine solche Funktion ist es möglich, fertige Teilabfragen mit bspw. komplexen, sicherheitsrelevanten Bedingungen sowie Verknüpfungen parametrisiert aufzurufen. 1.3.1.3 Trigger Trigger sind ein weiteres programmierbares Schema-Objekt. Es wird allerdings nur in ganz wenigen Beispielen genutzt und im Rahmen des Buchs nicht weiter vertieft. Im Wesentlichen ist die Erstellung von Triggern zwar mit den T-SQL-Fähigkeiten, die in diesem Buch vermittelt werden, zu bewerkstelligen. Allerdings handelt es sich um ein hauptsächlich administratives Thema, sodass es besonders gut im Administrationsbuch aufgehoben ist. Während eine Prozedur ausdrücklich über ihren Namen aufgerufen wird, ist ein Trigger entweder einem Schema-Objekt wie einer Tabelle oder einer Sicht zugeordnet oder wartet auf die Ausführung bestimmter DDL (Data Defintion Language)-Befehle. Die eine Trigger-Art wird als DML (Data Manipulation Language)-Trigger bezeichnet, da sie auf die SQL-Anweisungen INSERT, UPDATE und DELETE wartet, welche den Trigger auslösen und damit seine Anweisungen zur Ausführung bringen. Die andere Art bezeichnet man als DDL-Trigger, weil diese Trigger auf Anweisungen wie CREATE, ALTER oder DROP warten, welche zur DDL gehören. Innerhalb eines solchen Triggers lassen sich nahezu beliebige Anweisungen wie auch in einer Prozedur oder Funktion angeben. Die Besonderheit von Trigger liegt tatsächlich ausschließlich in der automatischen Ausführung auf Basis von anderen Befehlen. Dadurch ist es möglich, bestimmte Sicherheits- oder Datenkonsistenzregeln zu programmieren, die mit gewöhnlichem SQL oder sonstigen Datenbankeinstellungen administrativer Art nicht abgebildet werden können. Da innerhalb eines Triggers die gesamte T-SQL-Syntax zur Verfügung steht, 65 Grundlagen stellen Trigger eine wesentliche Fähigkeit von Datenbanken ab, um sicher zu sein und konsistent zu bleiben. 1.3.1.4 Assemblies Mit Hilfe der Anweisung CREATE ASSEMBLY name FROM 'C:\assembly.dll' lassen sich .NET-Assemblies in der Datenbank verankern. Dies eröffnet für den MS SQL Server ganz neue Möglichkeiten der Datenbank- und Softwareentwicklung. Bislang konnte besonders Oracle neben der datenbankeigenen Programmiersprachen PL/SQL auch noch zusätzlich anbieten, kompilierte Klassen einer so umfangreichen Programmiersprache wie Java für die Entwicklung von Datenbankmodulen zu verwenden. Dies ist nun für den MS SQL Server auch in Form der .NET-Technologie möglich geworden. Assemblies aus den Sprachen C#.NET oder VB.NET sowie natürlich anderen .NET-fähigen Sprachen lassen sich nun direkt in die Datenbank laden. Dies eröffnet Möglichkeiten, objektrelational zu arbeiten, indem komplexe Datenstrukturen in Form von Klassen mit mehreren Eigenschaften/Feldern und Methoden abgebildet werden, als auch Prozeduren, Funktionen und Trigger nicht mehr über T-SQL, sondern direkt über .NET zu erstellen und sie dann wie gewöhnliche, in T-SQL erstellte Module zu verwenden. T-SQL-Vorwissen ist dennoch notwendig, weil die Organisation und Verwaltung der Assemblies über T-SQL funktioniert und Abfragen sowie die Erstellung von sonstigen Schema-Objekten weiterhin über T-SQL erfolgt. 1.4 Beispieldatenbank AdventureWorks Im Normalfall haben wir für die verschiedenen Bücher im Bereich Datenbanken immer auch eigene Datenbanken entwickelt. In diesem Fall allerdings hat sich dieses Vorgehen als nicht sonderlich weltverbessernd herausgestellt. Da die AdventureWorks-Datenbank die Schwächen der sehr vereinfachten Nordwind-Datenbank vollständig überwindet und sich seit längerer Zeit auch steigender Beliebtheit erfreut sowie, was eigentlich sehr viel wichtiger ist, derart umfangreich ist, dass eine selbst erstellte Datenbank (sogar im Vergleich zu unseren vorherigen Datenbanken) nicht besser sein kann, haben wir uns ent- 66 Grundlagen schlossen, zum ersten Mal auf eine vom Hersteller bereit gestellte Beispieldatenbank zurückzugreifen. 1.4.1 Allgemeine Design-Prinzipien Die Datenbank ist in unterschiedliche Schemata eingestellt, die mit ihren wesentlichen Tabellen im nachfolgenden kurz vorgestellt werden. Es werden in diesem Buch aus Gründen der Übersichtlichkeit nicht alle Tabellen genutzt. Der Umfang der gesamten Datenbank wäre dafür ein wenig zu groß, doch um keine Langeweile aufkommen zu lassen, sollte auch nicht nur solch klassische Tabellen wie solche zur Produkt- und Kundendaten genutzt werden. Bis auf wenige Fälle werden keine eigenen Tabellen erstellt oder benötigt, sodass die zusammen mit dem Datenbanksystem installierte AdventureWorks-DB unmittelbar mit den bereitgestellten Skripten dieses Buchs Ergebnisse produzieren sollte. Daten von Angestellten befinden sich im Schema HumanResources. Dabei ist ganz wesentlich, dass solche typischen Spalten für Name und Adresse gerade nicht in einer Tabelle wie Employee gespeichert werden. Stattdessen existieren eigene Tabellen namens Contact und Address im Schema Person, welche sämtliche Personen wie Verkäufer und Kunden jeweils verknüpfen. Dies ist eine Design-Entscheidung, die es verhindert, die gesamten Kontaktattribute für jedes Objekt des Weltmodells jeweils neu zu erfassen. Es erschwert allerdings auch gleichzeitig Abfragen, da bereits eine Verknüpfung durchgeführt werden muss, um für Daten aus einer Tabelle wie Employee, SalesOrderHeader oder VendorContact auch die entsprechenden Kontaktinformationen abzurufen. Eine weitere wichtige Designentscheidung, die in der AdventureWorks-DB vorgestellt wird, ist in der Tabelle Address zu erkennen. Auch sie sammelt für alle möglichen Objekte im Weltmodell von AdventureWorks, die Adresse besitzen können, zentral diese große Anzahl von Adressen. Eine andere Möglichkeit wäre gewesen, die Felder dieser Tabelle ebenfalls wie die Felder von der Contact-Tabelle in die einzelnen Tabellen der referenzierenden Tabellen einzufügen. Da im Gegensatz zu den ContactFeldern allerdings auch mehrere Adressen pro Objekt gespeichert werden sollten, d.h. 67 Grundlagen eine 1:n- (ein Objekt hat mehrere Adressen) oder sogar eine n:m-Beziehung (mehrere Objekte teilen sich eine Adresse bzw. mehrere Objekte teilen sich mehrere Adressen) notwendig ist, hätte man neben den Beziehungstabellen, die nun von den einzelnen Objekten zu dieser zentralen Address-Tabelle führen, die gesamte Address-Tabelle für die einzelnen Objekte neu erstellen müssen. Entstanden wären dann solche Tabellen wie EmployeeAddress oder VendorAddress. Darüber hinaus zeigt die Datenbank genau in diesem Bereich auch noch die Technik einer so genannten Werteliste. Bei wiederholenden Begriffen, die allerdings nur in einem einzigen Feld einer Tabelle auftauchen, ist es oftmals eine wichtige Frage des Datenbankdesigns, inwieweit hier noch einmal eine eigene Tabelle für diese sich wiederholenden Werte entwickelt werden sollen. Mit Blick auf solche Tabellenkalkulationsprogramme wie MS Excel, in denen Werte, die bereits in der Spalte benutzt wurden, automatisch angezeigt werden, sobald die ersten identifizierenden Buchstaben eingegeben werden, findet man oftmals kleinere Datenbanklösungen, die solche Wertelisten (oder besser gesagt: Kandidaten für Wertelisten) nicht eigens auslagern, sondern stattdessen direkt in vollem Wortlaut in der Spalte speichern. Auswahlmenüs in einer äußeren Anwendung lassen sich dann hervorragend mit SELECT DISTINCT-Abfragen ermitteln, die mögliche Duplikate ausblenden und daher quasi genau die Werte anzeigen, die in einer solchen Wertelistentabelle erscheinen könnten. Allerdings besteht immer auch die Gefahr, dass unkorrekte Schreibweisen (zusätzliche Leerzeichen, Bindestriche, allgemeine Rechtschreibfehler sowie korrekte Schreibvarianten oder Singular-/PluralUnterschiede) dazu führen, dass gleichartige Werte verschieden gespeichert werden und daher Filter schlecht funktionieren oder inkonsistente Daten entstehen. Dies kann teilweise durch eine weitere Normalisierung (Prozess der Bildung eines guten relationalen Modells) verhindert werden, was konkret bedeutet, Wertelistentabellen zu erstellen. Solche Tabelle sind die ganzen Type-Tabelle, d.h. Tabellen wie ContactType oder AddressType. Im klassischen Fall besteht eine solche Tabelle wie ein Array in einer beliebigen Programmiersprache nur aus dem Primärschlüsselfeld und dem gespeicherten Wert für diesen Schlüssel. Im beschriebenen Fall von AdventureWorks gibt es noch weitere Spalten wie bspw. das Änderungsdatum, die allerdings für das grundlegende Verständnis unwichtig sind. Eine solche Werteliste kann man ebenfalls hervorragend in 68 Grundlagen einem Auswahlmenü in einer äußeren Anwendung abrufen. Man kann darüber hinaus allerdings auch für konsistente Daten sorgen, sofern Einträge in dieser Wertelistentabelle nicht einfach unkontrolliert von jedem Benutzer vorgenommen werden können und plötzlich doch wieder die erwähnten verschiedenen Schreibweise für den gleichen Begriff erscheinen. Neben diesem Vorteil bietet dieses Vorgehen den Nachteil, dass ein Datenabruf mit Textinhalten und nicht nur den Schlüsselwerten zu vielen Verknüpfungen führt, um die ganzen Primärschlüssel-Fremdschlüssel-Beziehungen wieder aufzulösen, die nötig sind, um aus den Schlüsselwerten wieder die eigentlich gemeinten Werte zu erzeugen. Ob solche Lösungen gut oder schlecht sind, kann abschließend nicht beurteilt werden. Wesentlich ist vielmehr, dass man im Rahmen des DB-Designs (was nicht Thema dieses Buchs ist, sondern eines anderen Buchs im Bereich Datenbanken von Comelio Medien sein wird) verschiedene typische Lösungsansätze kennt und sich bewusst für den einen oder anderen Weg entscheidet. Im Fall von AdventureWorks muss man davon ausgehen, dass bei einer so großen Datenstruktur dieses Vorgehen dafür sorgt, dass von jeder Person die gleichen Kontaktdaten gespeichert werden können, ohne dass die Feldstrukturen in mehreren Tabellen erscheinen müssen. Auch wenn objektrelationale Techniken aus Gründen der Didaktik in der AdventureWorks umgesetzt sind und auch in diesem Buch diskutiert werden, so zeigt dieses Datenmodell bereits Grenzen des relationalen Modells. Dies soll keinesfalls als Technologiekritik verstanden werden, denn die vielen so genannten Alternativen und Verbesserungen konnten sich bislang in keiner Weise durchsetzen. Im Rahmen von Beratungsveranstaltungen und Seminaren gibt es auch an uns oft Fragen mit fast schon spionageartigen Unterton, ob wir denn Datenbanken bzw. Unternehmen wüssten, welche neue Techniken des relationalen Modells einsetzen. Ab und an treffen wir tatsächlich auf solche Ansätze, doch im Großen und Ganzen bleibt es bei einigen Buchkapiteln oder Zeitschriftenbeiträgen, die sich diesem Thema immer wieder annehmen. Was ist damit gemeint? Ohne bereits die Vorstellung der Technik umfassend vorweg zu nehmen, soll dennoch kurz auf dieses Thema eingegangen werden, weil die Tabellen, an denen man es sehr gut erläutern kann, bereits genant wurden. Darüber hinaus handelt es 69 Grundlagen sich dazu auch noch um solche eigentlich trivialen Datenstrukturen wie Kontaktdaten. Diese müssten doch selbstverständlich hervorragend und vor allen Dingen problemlos mit geschlossenen Augen diskussionsfrei modelliert werden können. Interessanterweise bieten sie allerdings gerade das Paradebeispiel für die scheinbare Notwendigkeit von weiter gehenden Techniken der Datenbankmodellierung. Das traditionelle relationale Modell kennt keine Vererbung und keine Möglichkeit, gleichartige Feldstrukturen mehrfach zu benutzen. Wenn Kunden, Angestellte und Verkäufer die gleichen zehn Felder für Kontaktdaten (Name und Adresse mit jeweiligen Unterfeldern) benutzen, verwendet man folgendes Vorgehen: jede Tabelle für die drei genannten Objekte erhält die gleichen zehn Felder. Der Aspekt, dass zusätzlich auch noch mehrere Adressen einem Objekt zugeordnet werden können, kann vernachlässigt werden, da er nur ein Spezialproblem darstellt. Wenn man sich eine solche Datenbankstruktur näher ansieht, scheint man auch nicht zufrieden, vor allen Dingen dann nicht, wenn ähnliche (Teil-)SQL-Befehle für die Datenerfassung notwendig sind oder Änderungen an den zehn Feldern (Datentypen oder Namen) an allen betroffenen Objekten gleichzeitig vorgenommen werden müssen, um das gesamte Modell wieder konsistent zu machen. Möglicherweise wird sogar eine Änderung vergessen, sodass die eigentlich gleich strukturierten zehn Felder doch in einigen wenigen Punkten in den einzelnen Objekten fehlerhaft verschieden modelliert sind. Schaut man sich in einem solchen Fall dagegen eine mögliche objektorientierte Softwaremodellierung an, so gibt es eine ganze Reihe von Techniken, um mit solchen gleichartigen (Unter-)Strukturen umzugehen. Man könnte eine Elternklasse oder eine abstrakte Klasse erstellen, welche die gemeinsamen Felder/Eigenschaften besitzt und welche als Elternklasse für die erwähnten Objekte dient. Änderungen in der abstrakten Klasse oder der Elternklasse würden sich dadurch auf die Kindklassen auswirken. Um die Vererbungshierarchie nicht auf Basis einer vermutlich nicht so zentralen Struktur wie den Kontaktdaten aufzubauen (Mehrfachvererbung nicht möglich), kann man stattdessen eine eigene Klasse für die Kontaktfelder entwickeln, welche als Typ in einer/m Eigenschaft/Feld der erwähnten Objekte genutzt wird. So wirken sich Änderungen der Oberstruktur weiterhin in den Klienten aus. Als Ergänzung könnte man sich auch noch 70 Grundlagen eine Schnittstelle denken, welche Methoden anbietet, um Klassen mit Kontakt(unter)feldern zu nutzen und bspw. Adresszeilen oder zusammen gesetzte Namensbestandteile zu liefern. In einer relationalen Datenbank ist dies alles nicht möglich. Weder Vererbung von Tabellenstrukturen noch Datentypen mit mehreren Unterfeldern sind möglich. Erst die objektrelationalen sowie natürlich hierarchischen Techniken bieten hier einen Ansatz an, wobei insbesondere die objektrelationalen oft diskutiert werden. Dies bedeutet nichts Anderes, als dass man in einer nahezu beliebigen .NET-Sprache für den MS SQL Server (andere Datenbanksysteme wie Oracle nutzen hier PL/SQL oder Java) die erwähnte Klasse erstellt und sie mit den benötigten Feldern ausstattet, um die in verschiedenen Objekten verwendeten gleichen Feldstrukturen gut und zentral abzubilden. Eine Alternative stellt dagegen eine zentrale Tabelle dar, welche von allen betroffenen Objekten referenziert wird. Dies ermöglicht es, die gleichartigen Strukturen auszulagern und dadurch zentral ggf. sogar zu verändern. Es erfordert allerdings Verknüpfungen zwischen den Tabellen, um auf diese Strukturen zuzugreifen. Dieses Verfahren wurde in der AdventureWorks-DB verwendet. 1.4.2 Darstellung einzelner Tabellenbereiche Innerhalb der Personaldaten werden die Angestellten in einer Employee-Tabelle gespeichert. Sie arbeiten in einer Abteilung, die in einer Department-Tabelle dargestellt ist. Da ein Angestellter nicht notwendigerweise permanent in der gleichen Abteilung arbeitet, sondern von Zeit zu Zeit auch wechselt, ist keine direkte Beziehung zwischen Department und Employee vorhanden, sondern stattdessen eine Beziehungstabelle EmployeeDepartmentHistory eingefügt, welche insbesondere den Eintritt in eine neue Abteilung und den möglichen Austritt enthält. Darüber hinaus arbeiten die Mitarbeiter in Schichten, wobei die Schichteinteilung in der Shift-Tabelle angegeben ist. Betreten Sie eine Abteilung werden sie ebenfalls zu einer Schicht zugeordnet, sodass in der erwähnten EmployeeDepartmentHistory-Tabelle auch eine Verknüpfung zu dieser Shift-Tabelle existiert. 71 Grundlagen Abbildung 1.27: Schema HumanResources Die Kontaktdaten aller Objekte des modellierten Weltausschnitts, die Kontaktdaten aufweisen können, sind zentral in zwei Tabellen gespeichert. Die Contact-Tabelle enthält die allgemeinen persönlichen Daten wie Vorname, Nachname etc. Die Address-Tabelle dagegen enthält Addressinformationen mit Straße, Stadt und PLZ. Für beide Tabellen existieren dann auch noch jeweils zwei Type-Tabelle, d.h. eine Tabelle namens ContactType und eine AddressType-Tabelle, durch die die jeweiligen Datensätze kategorisiert werden können. Länder und allgemeine geografische Bereiche, die außerhalb von konkreten Adressen liegen bzw. die wie Wertelisten angesehen wer- 72 Grundlagen den können, sind dann in verschiedenen weiteren Tabellen untergebracht. Dies sind solche Tabellen wie CountryRegion oder StateProvince. Abbildung 1.28: Schema Person Die Produkte werden im Schema Production in eine Vielzahl von Tabellen eingeteilt. Davon werden in den Beispielen in diesem Buch nicht alle verwendet, da die Gesamtzahl der Informationen nicht für alle Beispiele didaktisch wertvoll ist, sofern man nicht gerade ein Beispiel benötigt, um zehn Tabellen zu verknüpfen. Die zentrale Tabelle ist Product, in der die wesentlichen Informationen eines Produkts wie Nummer, Bezeichnung, Farbe, Sicherheitsbestand im Lager, Standardkosten und Listenpreis enthalten sind. Für die beiden Attribute Größe und Verkaufseinheit gibt es ausgelagerte Tabellen mit Wertelisten. Kunden bewerten die Produkte in einer ProductReview-Tabelle. Fotos zu den Produkten speichert die Tabelle ProductPhoto in Form eines Pfads. Die historischen Preise werden in einer ProductListPriceHistory gespeichert. Die Kategorien schließlich, die wieder für verschiedene Beispiele sehr hilfreich sind, um Produkte zu kategorisieren und über diese Kategorien Aggregate abzubilden, sind in 73 Grundlagen zwei Tabellen gespeichert. Man unterscheidet zwei Kategorieebenen: zum eine die ProductSubcategory und zum anderen die ProductCategory, wobei die Product-Tabelle zunächst die Unterkategorie verknüpft und diese Unterkategorie wiederum die Oberkategorien. Abbildung 1.29: Schema Production Die Verkaufsinformationen befinden sich im Schema Sales, wobei aus den sehr vielen Tabellen in den Beispielen im Wesentlichen nur die SalesOrderHeader-Tabelle benutzt wird, da sie die zusammenfassenden Informationen für einen Verkauf (Kopfdaten) enthält. Sie referenziert in sehr vielen Fremdschlüsselspalten eine große Menge an anderen Tabellen, da sie als typische Buchungstabelle die Geschäftsaktivitäten der Firma abbildet. Zu den Kopfdaten eines Auftrags gehören solche Informationen wie drei verschiedene Zeiten (Bestell-, Auslieferungs-, Fälligkeitsdatum), Preise (Netto, Steuer, Total, Fracht) und die erwähnten Referenzen wie Adressen (Liefer-, Rechnungsadresse), Kunden- und Kontaktinformationen sowie Verkaufsgebiet. 74 Grundlagen Abbildung 1.30: Schema Sales Neben diesen Kopfdaten, die ja bereits umfangreich genug sind, wenn man nur die ganzen Referenzen auflöst, gibt es noch weitere Tabellen in diesem Schema. Jede Bestellung enthält natürlich auch einzelne Positionen, die in SalesOrderDetail gespeichert werden, welche insbesondere eine Referenz zur Product-Tabelle enthält. Die Bestelldetails werden in fast allen Beispielen außer Acht gelassen. Ähnliches gilt auch für die verschiedenen Währungen, die man eigentlich für die Bildung von Umsatzaggregaten mit Wechselkursen berücksichtigen müsste. Dazu gibt es die Tabellen CurrencyRate-Tabelle mit den zeitbezogenen Wechselkursdaten und die Currency-Tabelle mit dem Währungsnamen als Werteliste. Die ermittelten Umsatzzahlen, die in den verschiedenen Aggregatbeispielen genutzt werden, müssten also eigentlich noch jeweils in eine gemeinsame Währung umgerechnet werden, was jedoch zu nebensächlichem Zusatzquelltext führt, der das eigentliche Beispiel nur vernebelt. Die einzelnen Bestellungen, sofern Sie nicht über den Webshop eingegangen sind, können einem Verkäufer zugeordnet werden, die Personen darstellen, einem Gebiet zugeordnet sind, Verkaufszahlengeschichte besitzen und Quoten erfüllen müssen. Dieser Bereich wird nur in wenigen Beispielen betrachtet. 75 Grundlagen Abbildung 1.31: Schema Purchasing Die Produkte werden teilweise hergestellt, teilweise aus verschiedenen Bestandteilen montiert und teilweise nur weiterverkauft. Für die verschiedenen Fertigteile, die beschafft werden müssen, existiert ein eigenes Schema namens Purchasing, in dem diese Einkäufe abgebildet werden. Dieses Schema wird in den verschiedenen Beispielen nur wenig genutzt, kann allerdings hervorragend für eigenes Arbeiten auf Basis der Beispiele zum Sales-Schema genutzt werden, da der Einkauf von den Datenstrukturen her ähnlich aufgebaut ist. Die zentrale Tabelle ist hier PurchaseOrderHeader, welche die Kopfdaten einer Bestellung enthält. Die eine Bestellung konstituierenden Posten befinden sich in der PurchaseOrderDetail-Tabelle, welche eine Referenz zur Product-Tabelle enthält, da diese Tabelle sowohl die zu kaufenden als auch die zu verkaufenden Produkte enthält. Die Kopfdaten enthalten wiederum Zeitinformationen (Bestell-, Lieferdatum) 76 Grundlagen sowie Referenzen wie den Angestellten, der die Bestellung ausgelöst hat, und den Verkäufer. Die letzte Abbildung enthält eine Komplettansicht des Datenmodells, welches zwar völlig unleserlich ist, aber kurz zeigen soll, wie umfangreich die Datenstruktur in Wirklichkeit ist. Auch wenn in den Beispielen bereits deutlich mehr Tabellen genutzt werden als bei einem Buch, welches die Nordwind- oder die Pubs-DB einsetzen, so gibt es in Wirklichkeit noch viel mehr interessante Daten und Strukturen zu entdecken. Für Beispiele stehen damit sehr viel mehr Möglichkeiten zur Verfügung als früher, sodass es für uns nur logisch schien, bei einer neu beginnenden Reihe zum MS SQL Server auch die neue, sehr viel bessere Datenbank zu verwenden. Abbildung 1.32: Komplettansicht 77 Grundlagen 78 Einfache Abfragen 2 Einfache Abfragen 79 Einfache Abfragen 80 Einfache Abfragen 2 Einfache Abfragen Dieses Kapitel stellt den ersten Teil der beiden Kapitel zu Abfragen dar. Der SELECTBefehl ist sicherlich der wichtigste SQL-Befehl, sobald überhaupt eine Datenbank vorhanden (schon erledigt) und Daten eingetragen (ebenfalls schon eledigt) sind. Er ermöglicht den Zugriff auf die einzelnen Tabellen und Sichten in Form einfacher Abfragen oder innerhalb eines vollständigen Transact SQL-Programms wie ein Skript oder eine Prozedur/Funktion bzw. ein Trigger. Sofern man die Datenbank verlässt, taucht SQL wiederum in beliebigen Programmiersprachen wie C#.NET auf und besitzt dort den gleichen Aufbau wie innerhalb der Datenbank. Es steht zu befürchten, dass einige Leser nicht zum ersten Mal eine Datenbank befragen, sodass der Beginn bei der berühmten Hallo-Welt-Abfrage SELECT * FROM tabelle womöglich zu einfach scheint. Beide Kapitel sollen allerdings auch die Klauseln zeigen, die möglicherweise nicht so bekannt sind, sodass Fortgeschrittene vielleicht nur 10 oder 20 Seiten überschlagen sollten, ehe man wieder mit dem Text beginnt. 2.1 Grundstruktur von SELECT Wie schon erwähnt, stellt der SELECT-Befehl einen der mächtigsten bzw. wenigstens umfangreichsten SQL-Befehle dar, weil er im Gegensatz zu vielen anderen derart viele Klauseln aufweist, dass die allgemeine Syntax fast schon eine ganze Buchseite füllen kann. Im Gegensatz zu anderen ebenfalls umfangreichen Anweisungen verhält es sich bei SELECT zudem auch noch so, dass man tatsächlich für kniffelige Fragestellungen in die Randbereiche der Syntax kriechen muss, sofern man nicht über Umwege das gleiche Ergebnis erhalten möchte. Die allgemeine Syntax für einfache Abfragen hat folgendes Format: SELECT spaltenliste [ FROM tabelle ] [ WHERE bedingung ] 81 Einfache Abfragen [ GROUP BY gruppierungsausdruck ] [ HAVING bedingung ] [ ORDER BY sortierungsausdruck [ ASC | DESC ] ] Wie man sehen kann, sind alle Klauseln, welche direkt nach SELECT folgen, optional und haben zusammen mit SELECT selbst folgende Bedeutung: Spaltenliste: Hier zählt man die einzelnen Spalten auf, die im Abfrageergebnis wieder erscheinen sollen. Die Reihenfolge der Spalten entscheidet darüber, in welcher Reihenfolge sie in der Ergebnismenge erscheinen. Auch nicht angegebene Spalten können in anderen Klauseln referenziert werden. Zusätzlich können in dieser Liste so genannte Aliasnamen für Spalten angegeben werden. Tabellenangabe: Nach der FROM-Klausel schließt sich wenigstens eine Tabellenoder Sichtangabe an, aus der die Daten abgerufen werden sollen und in der die genannten Spalten auftreten müssen. Es besteht mit Blick auf die komplexen Abfragen auch die Möglichkeit, mehrere Tabellenreferenzen zu nennen, um Daten aus mehreren Tabellen abzurufen. Suchbedingung: Nach der WHERE-Klausel folgt wenigstens eine Suchbedingung, welche die Anzahl der Werte in der Ergebnismenge auf diejenigen verringert, welche die Bedingung erfüllen. Innerhalb dieser Klausel können mehrere Bedingungen aufeinander folgen und über Gruppenbildung zusammengefügt werden, um komplexe Bedingungen zu formulieren. Gruppierung: Nach der GROUP BY-Klausel folgt ein Gruppierungsausdruck, mit der gleichartige Werte anhand eines Spaltennamens (Standardfall) oder eines anderen Ausdrucks wie bspw. eines Funktionsaufrufs zusammengefügt / gruppiert werden können. Dies wird im Normalfall in Zusammenhang mit so genannten Aggregatfunktionen wie Zählen oder Summieren in der Spaltenliste genutzt und liefert einfache analytische Ergebnisse. Gruppensuchbedingung: Nach der HAVING-Klausel ist es möglich, Bedingungen für die Gruppen anzugeben, um nur solche Gruppen in die Ergebnisliste 82 Einfache Abfragen aufzunehmen, welche die Bedingung erfüllen. Syntaktisch entspricht die HAVINGKlausel der WHERE-Klausel und bietet auch die Möglichkeit, komplexe Bedingungen zu formulieren. Sortierung: Nach der ORDER BY-Klausel folgt wenigstens eine Spalte oder ein Funktionsaufruf mit der optionalen Angabe ASC (Standardwert, aufsteigende Sortierung) oder DESC (absteigender Sortierung), um anhand dieser Spalte die gesamte Ergebnismenge zu sortieren. Mehrere Spaltenangaben führen dazu, dass die Ergebnisse mehrfach sortiert werden. 2.1.1 Spaltenauswahl Die einfachste Abfrage enthält anstelle einer einzigen Spalte oder einer Spaltenliste nur den Asteriskus, das Sternchen. Sie entspricht quasi einem Hallo-Welt-Beispiel in einer beliebigen Programmiersprache und ist in jeder Datenbank lauffähig. Sie liefert alle Spalten und alle Zeilen der Tabelle zurück. Aus diesem Grund sollte in einer realen Datenbank mit unbekanntem Datenbestand dieser Befehl nicht aufs Geratewohl zum Einsatz kommen sollen. Stattdessen sollte man die Ergebnismenge mit Hilfe der COUNTFunktion zählen bzw. wenigstens anhand des Primärschlüssels einschränken. Die nachfolgende Abfrage ruft die gesamte Employee-Tabelle aus dem HumanResources-Schema ab. Da einige Spalten sehr viele Zeichen zulassen und sie auch aufgrund ihrer Anzahl nicht abgedruckt werden können, gibt es keinen Ergebnisausdruck. SELECT * FROM HumanResources.Employee 211_01.sql: Auswahl aller Spalten Die nachfolgende Abfrage grenzt die Spaltenliste auf die drei Spalten EmployeeID, Gender (Geschlecht mit den Werten m und f) und Title (Positionstitel in der Firma) ein. SELECT EmployeeID, Gender, Title FROM HumanResources.Employee 83 Einfache Abfragen 211_02.sql: Auswahl weniger Spalten Man erhält als Ergebnis eine hier deutlich gekürzte Ergebnismenge, in der die Spalten in der in der Spaltenliste angegebenen Reihenfolge ausgegeben werden. Eine andere Anordnung in der Spaltenliste führt auch zu einer anderen Reihenfolge in der Ergebnismenge. EmployeeID Gender Title ----------- ------ ----------------------------------------1 M Production Technician - WC60 2 M Marketing Assistant 2.1.2 Aliasnamen Es ist möglich, so genannte Aliasnamen für Spalten anzugeben. In einer einfachen Abfrage dienen diese Aliasnamen zunächst nur der schöneren Ausgabe in der Ergebnisliste. Dies ist insbesondere dann sehr wichtig, wenn ein Spaltenwert über einen Funktionsaufruf erzeugt wird und ansonsten der Funktionsname auch im Spaltennamen erscheint. In einer komplexen Abfrage dagegen sind sie teilweise sogar notwendig, wenn die Ergebnisse der Abfrage in einem anderen Zusammenhang von einer so genannten äußeren Abfrage weiter verwendet werden und dann gewöhnliche Bezeichner benötigt werden. SELECT EmployeeID AS [Pers-Nr], Gender AS Geschlecht, Title AS [Titel in der Firma] FROM HumanResources.Employee 211_03.sql: Aliasnamen Man erhält im Ergebnis tatsächlich die Aliasnamen inkl. Bindestrich und Leertaste in den Spaltenköpfen: 84 Einfache Abfragen Pers-Nr Geschlecht Titel in der Firma ----------- ---------- -------------------------------------1 M Production Technician - WC60 2 M Marketing Assistant SELECT EmployeeID AS [Pers-Nr], Gender AS Geschlecht, Title AS [Titel in der Firma] FROM HumanResources.Employee Pers-Nr Geschlecht Titel in der Firma ----------- ---------- --------------------------------------1 M Production Technician - WC60 2 M Marketing Assistant Abbildung 2.1: Zusammenhang zwischen Anweisung und Ausgabe Für Tabellen ist die Vorgabe eines Aliasnamen ebenfalls möglich. Sie verändert nicht die Ausgabe, sondern die Möglichkeit, wie Tabellen angesprochen werden können. Diese Aliasnamen eignen sich bei so genannten qualifizierten Spaltennamen, um sie bei sehr langen Tabellennamen als Abkürzung, Selbstverknüpfungen sowie so abgeleiteten Tabellen zu verwenden. Die letzten beiden Themen werden in einem späteren Abschnitt behandelt. FROM HumanResources.Employee AS emp 211_04.sql: Aliasnamen für Tabellen Zusätzlich ist es möglich, das AS-Schlüsselwort sowohl bei Spalten- wie auch bei Tabellenaliasnamen wegzulassen. Dies ändert natürlich nur die Syntax und nicht die Ausgabe des Ergebnisses. Allerdings wird die Lesbarkeit durch die Verwendung von AS und 85 Einfache Abfragen natürlich die hübsche Formatierung erhöht, was die Mühe, zwei zusätzliche Buchstaben zu schreiben, möglicherweise wieder ausgleicht. SELECT EmployeeID [Pers-Nr], Gender Geschlecht, Title [Titel in der Firma] FROM HumanResources.Employee emp 211_05.sql: Aliasnamen ohne AS-Schlüsselwort 2.1.3 Qualifizierte Spaltennamen Die Spaltennamen können qualifiziert auftreten, was bedeutet, dass Schema- und Tabellename vor den Spaltennamen geschrieben werden. Dabei kann man entweder den tatsächlichen Namen oder den innerhalb der Abfrage vergebenen Aliasnamen verwenden. Bei einfachen Abfragen ergibt sich dadurch kein besonderer Vorteil und besteht auch keine Verpflichtung, qualifizierte Spaltennamen zu verwenden. Die Qualifizierung ist dagegen zu verwenden, wenn mehrere Tabellen miteinander verknüpft werden und gleiche Spaltennamen in den einzelnen Tabellennamen auftreten. Um diese dann wiederum zu unterscheiden, ist die Qualifizierung notwendig. SELECT HumanResources.Employee.EmployeeID, HumanResources.Employee.Gender, HumanResources.Employee.Title FROM HumanResources.Employee SELECT emp.EmployeeID, emp.Gender, Title 86 Einfache Abfragen FROM HumanResources.Employee AS emp 211_06.sql: Qualifizierte Spaltennamen 2.2 Bedingungen Im Normalfall ist es nicht sonderlich interessant, einfach alle Daten einer Tabelle abzurufen. 2.2.1 Einfache Bedingungen und Operatoren Die einfachste Bedingung besteht aus einem Vergleich auf Gleichheit. Bei diesem Operator wie auch bei anderen Operatoren ist zu unterscheiden, ob man einen Vergleich für einen Zahlendatentyp oder einen Zeichenkettendatentyp formuliert. Bei Zahlen tritt der zu vergleichende Wert ohne Anführungszeichen auf. Bei Zeichenketten dagegen muss der entsprechende Wert innerhalb von Anführungszeichen gesetzt werden. 2.2.1.1 Prüfung auf Gleichheit Die nachfolgende Abfrage ruft nur die Datensätze aus der Contact-Tabelle ab, welche den Wert Mr. in der Spalte Title enthalten. SELECT Title, FirstName, LastName FROM Person.Contact WHERE Title = 'Mr.' 221_01.sql: Einfache Bedingung Die nächste Abfrage nimmt zusätzlich noch die Spalte ContactID hinzu, welche den Primärschlüssel enthält. Da hier eine Ganzzahl gespeichert ist, entfallen – wie oben erwähnt – die Anführungszeichen. SELECT ContactID, Title, FirstName, LastName FROM Person.Contact 87 Einfache Abfragen WHERE ContactID = 15 221_02.sql: Einfache Bedingung Man erhält als Ergebnis im ersten Fall eine längere Liste und im zweiten Fall nur noch einen einzigen Datensatz, da ja eine Gleichheitsbedingung auf den Primärschlüssel ausgeführt werden. ContactID Title FirstName LastName ----------- -------- ----------------- ----------15 Ms. Kim Akers Neben dem Gleichheitszeichen gibt es die auch in anderen Sprachen und natürlich Datenbanken vorhandenen Operatoren für Vergleiche, die in nachfolgender Tabelle aufgelistet sind. Operator Bedeutung > größer als < kleiner als >= größer gleich als !< nicht kleiner als <= kleiner gleich als !> nicht größer als = gleich != oder <> Ungleich BETWEEN ausdruck1 AND ausdruck2 größer gleich ausdruck1 und kleiner gleich ausdruck2 IS [NOT] NULL (un)gleich NULL [NOT] 88 IN (ausdruck1, (un)gleich ausdruck1 oder (un)gleich Einfache Abfragen ausdruck2,...) ausdruck2 Operatoren Neben den gewöhnlichen Vergleichsoperatoren, die exakt so funktionieren wie in den bekannten Programmiersprachen sind insbesondere die in der Tabelle zum Schluss aufgeführten Vergleichsoperatoren sehr nützlich. Sie ermöglichen die Verkürzung von ansonsten nur in Kombination einzusetzenden Operatoren. Die nachfolgenden Beispiele zeigen einige dieser Operatoren im Einsatz. 2.2.1.2 Prüfung auf Verhältnisse Die erste Abfrage prüft darauf, ob der LastName kleiner gleich dem Buchstaben B ist. -- Nachname kleiner B SELECT ContactID, Title, FirstName, LastName FROM Person.Contact WHERE LastName < 'B' 221_03.sql: Verhältnisse 2.2.1.3 Prüfung auf Wertebereiche Die zweite Abfrage prüft analog darauf, ob der LastName zwischen B und D liegt, wobei die beiden Grenzen eingeschlossen sind. -- Nachname zwischen B und D (jeweils eingeschlossen) SELECT ContactID, Title, FirstName, LastName FROM Person.Contact WHERE LastName BETWEEN 'B' AND 'D' 221_04.sql: Wertebereiche 89 Einfache Abfragen 2.2.1.4 Prüfung auf NULL Die dritte Abfrage prüft dagegen mit IS [NOT] NULL darauf, ob die Title-Spalte den Wert NULL enthält. Dies ist nicht dasselbe wie der Einsatz der gewöhnlichen Operatoren zum Test auf Gleichheit und Ungleichheit. NULL gilt als eigenständiger Wert, der auch nicht dasselbe ist wie eine leere Zeichenkette oder gar der Zahlwert 0. Stattdessen beschreibt der Wert NULL den Feldzustand, dass kein Wert vorhanden ist bzw. kein Wert bekannt ist. Dabei kann NULL für jeden Datentyp eintreten, sofern in der jeweiligen Spalte der NULL-Wert zulässig ist. -- Anrede unbekannt (gleich NULL) SELECT ContactID, Title, FirstName, LastName FROM Person.Contact WHERE Title IS NULL 221_05.sql: NULL-Werte 2.2.1.5 Prüfung auf Wertelisten Die vierte Abfrage setzt dagegen den [NOT] IN-Operator ein. Er ersetzt eine längere Abfrage, in der jeweils die einzelnen Werte in der Werteliste auf Gleichheit geprüft werden. Daher untersucht die nachfolgende Abfrage diejenigen Angestellten mit den in der IN-Klausel angegebenen Namen. -- Nachname gleich Adams, Miller, Perez SELECT Title, FirstName, LastName FROM Person.Contact WHERE LastName IN ('Adams', 'Miller', 'Perez') 221_06.sql: Wertelisten 90 Einfache Abfragen 2.2.2 Boolesche Operatoren Oftmals genügt es überhaupt nicht, nur auf eine einzige Bedingung zu prüfen. Bedingungen können gleichzeitig oder auch nur alternativ zutreffen; sie können sogar in unterschiedlichen Kombinationen auftreten, wobei diese Kombinationen wiederum gleichzeitig oder alternativ gelten. Mit Hilfe der booleschen Operatoren ist es möglich, solche komplexen WHERE-Bedingungen zu formulieren. 2.2.2.1 Einfache Bedingungen Im einfachsten Fall möchte man zwei Bedingungen gleichzeitig überprüfen, d.h. diese beiden Bedingungen müssen von den Datensätzen erfüllt sein, welche in die Ergebnismenge übernommen werden. Dabei schließt man weitere Bedingungen mit Hilfe von AND an die ursprüngliche Bedingung n der WHERE-Klausel an. Im nachfolgenden Beispiel sind nur solche Produkte gesucht, die die Größe S aufweisen und von gelber Farbe sind. -- Produkte in Größe S und Gelb SELECT Name, Size, Color FROM Production.Product WHERE Size = 'S' AND Color = 'Yellow' 222_01.sql: UND-Verknüpfung Man erhält genau einen Datensatz zurück, auf den beide Bedingungen gleichzeitig zutreffen. Name Size Color ----------------------------------- ----- -------Short-Sleeve Classic Jersey, S S Yellow 91 Einfache Abfragen Anders verhält es sich mit einer Alternative. In diesem Fall ist die Ergebnismenge im Normalfall deutlich größer als bei der Verwendung von AND. So kehrt man im nachfolgenden Beispiel ganz einfach die Suche um und interessiert sich für Produkte von Größe S oder gelber Farbe. Dies drückt man mit Hilfe des OR-Operators anstelle von AND für die Bedingungen nach der ersten Bedingung aus. -- Produkte in Größe S oder Gelb SELECT Name, Size, Color FROM Production.Product WHERE Size = 'S' OR Color = 'Yellow' 222_01.sql: ODER-Verknüpfung Man erhält eine größere Menge, für die der eine oder der andere Wert zutrifft. Wie man leicht sehen kann, ist in den Datensätzen die Größe S vorhanden, wenn die Farbe möglicherweise gerade nicht Gelb ist. Andererseits ist in den Datensätzen die Farbe Gelb vorhanden, wenn die Größe möglicherweise gerade nicht S ist. Lediglich bei dem Datensatz, der auch schon in der vorherigen Abfrage gefunden wurde, treffen beide Bedingungen zu. Er ist zwar nicht noch einmal abgedruckt, gehört aber auch zur Ergebnismenge. Name Size Color ---------------------------------- ----- -------Long-Sleeve Logo Jersey, S S Multi Road-550-W Yellow, 38 38 Yellow ML Road Frame-W - Yellow, 48 48 Yellow Men's Sports Shorts, S S Black Women's Tights, S S Black 92 Einfache Abfragen 2.2.2.2 Verschachtelte Bedingungen Auf Basis der einfachen kombinierten Bedingungen lassen sich durch Einsatz von Klammern auch erweiterte Kombinationen bzw. Gruppen von Bedingungen bilden. So soll in der nachfolgenden Abfrage die Größe fixiert werden und in jedem Fall den Wert S aufweisen. Mit Blick auf die Farbe ist dies allerdings nicht so. Hier genügt es, dass die Farbe entweder Gelb oder Schwarz ist, wobei nun der OR-Operator zwischen den beiden Bedingungen für die Farbe sitzt und diese gesamt Gruppe mit Hilfe des AND-Operators an die Bedingungen zur Größensuche angeschlossen wird. -- Produkte in Größe S und Gelb oder Schwarz SELECT Name, Size, Color FROM Production.Product WHERE Size = 'S' AND (Color = 'Yellow' OR Color = 'Black') 222_02.sql: Innere UND-Verknüpfung Durch die Fixierung auf die Größe findet man in der Ergebnismenge ausschließlich Produkte der Größe S. In der Spalte für die Farbe allerdings befinden sich entweder die beiden Werte für Gelb oder Schwarz, die mit Hilfe des AND-Operators angeschlossen und in Kombination über den OR-Operator angeschlossen wurden. Name Size Color -------------------------------- ----- --------------Men's Sports Shorts, S S Black Women's Tights, S S Black Short-Sleeve Classic Jersey, S S Yellow 93 Einfache Abfragen WHERE Size = 'S' AND (Color = 'Yellow' OR Color = 'Black') Name Size Color ------------------------------------------ ----- --------------Men's Sports Shorts, S S Black Women's Tights, S S Black Short-Sleeve Classic Jersey, S S Yellow Abbildung 2.2: Funktionsweise verschiedener Operatoren Sofern man diese Operatoren zum ersten Mal im Einsatz sieht, kann es sein, dass man sich im Kurs zu einer Frage oder beim Lesen (und natürlich Ausprobieren!) eines Buchs zur Frage verführt sieht, was wohl passieren würde, wenn statt des OR-Operators zwischen den beiden Bedingungen für die Farbe ein AND stünde. Sobald man die Antwort hört, ist man dann typischerweise ganz verblüfft, dass man sich so hat verwirren lassen. Selbstverständlich ist dann die Ergebnismenge mehr als übersichtlich, weil sie keine Zeilen enthält. Es gibt kein Produkt, das gleichzeitig zwei verschiedene Werte im selben Feld besitzen kann. Für eine Datenbank weist jedes Produkt nur eine Farbe auf. Wie man sich darüber hinaus denken kann, lässt sich die Formulierung von solchen Ausdrücken nahezu beliebig komplex aufbauen, indem ganz einfach weitere Bedingungen angehängt und kombiniert werden. Das nachfolgende Beispiel zeigt eine erweiterte Suche, die eine Größe von S oder M fordert und gleichzeitig eine Kategorie von 21 und 18. Gleichzeitig soll die Farbe entweder reines Gelb oder gemischt sein. Der Quelltext zeigt darüber hinaus auch noch die alternative Formulierung von OR-Ketten über den [NOT] IN-Operator, der in diesen Fällen immer die richtige Wahl darstellt. -- Produktkategorie T-Shirt oder kurze Hose -- UND Größe S oder M -- UND Farbe Gelb oder gemischt 94 Einfache Abfragen SELECT Name, Size, Color, ProductSubcategoryID FROM Production.Product WHERE Size IN ('S', 'M') AND (ProductSubcategoryID = 21 OR ProductSubcategoryID = 18) AND (Color = 'Yellow' OR Color = 'Multi') -- Alternative Formulierung SELECT Name, Size, Color, ProductSubcategoryID FROM Production.Product WHERE Size IN ('S', 'M') AND ProductSubcategoryID IN (21, 18) AND Color IN ('Yellow', 'Multi') 222_02.sql: Komplexe Verknüpfung und Alternative Als Ergebnis erhält man eine Liste mit Produkten, die allen Bedingungen gleichzeitig genügen. Die Größe ist nur S oder M, und die Farbe ist Gelb oder gemischt, und die Kategorie ist 18 oder 21. Name Size Color Product SubcategoryID ------------------------------ ----- --------- -------------Long-Sleeve Logo Jersey, S S Multi 21 Long-Sleeve Logo Jersey, M M Multi 21 Men's Bib-Shorts, S S Multi 18 95 Einfache Abfragen Men's Bib-Shorts, M M Multi 18 Short-Sleeve Classic Jersey, S S Yellow 21 Short-Sleeve Classic Jersey, M M Yellow 21 Zum Schluss folgt noch ein Beispiel, das zeigen soll, wie auch alle anderen Operatoren für den Vergleich zum Einsatz kommen können. Neben der Forderung, dass die Größe S oder XL sein soll, darf der Listenpreis nur zwischen 30 und 50 mit eingeschlossenen Grenzen liegen. Alternativ lässt sich ein solchermaßen beschriebenes Werteintervall auch mit Hilfe von BETWEEN…AND beschreiben, dem in jedem Fall der Vorzug zu geben ist. -- Größe nicht S oder XL UND Listenpreis zwischen 30 und 50 SELECT Name, ListPrice FROM Production.Product WHERE Size NOT IN ('S', 'XL') AND (ListPrice >= 30 AND ListPrice <= 50) -- alternative Formulierung -- AND ListPrice BETWEEN 30 AND 50 222_02.sql: Komplexe Verknüpfung und Alternative Die stark gekürzte Ergebnisliste zeigt, dass die Größen und die beiden Preise genau zu den gewünschten Bedingungen passen. Name ListPrice --------------------------------- --------------------Long-Sleeve Logo Jersey, M 49,99 Full-Finger Gloves, L 37,99 96 Einfache Abfragen 2.2.3 Mathematische Operatoren: Neben den Vergleichsoperatoren und den gerade gezeigten booleschen Operatoren gibt es auch noch mathematische Operatoren, die besonders interessante Ergebnismengen ermöglichen. Diese ergeben teilweise sogar Werte, die in dieser Art gar nicht in der Datenbank gespeichert waren, sondern aufgrund von Berechnungen entstanden sind. 2.2.3.1 Berechnete Spalten Es ist möglich, in einer Abfragemenge auch Spalten auszugeben, deren Werte aus dynamischen Berechnungen auf Basis einer oder mehrerer Spalten und weiteren festen Werten beruhen. Ein Schulbeispiel in diesem Zusammenhang ist die Ausgabe eines Netto-Preises, des Mehrwertsteueranteils und des Bruttorpreises. Als Beispiel für eine solche berechnete Spalte soll die Tabelle PRODUCT untersucht werden. Sie enthält eine Spalte ListPrice mit dem Listenpreis, eine Spalte StandardCost mit den Kosten für einen Artikel und eine weitere Spalte SafetyStockLevel mit dem Sicherungs- oder Reservebestand auf dem Lager. Diese drei Spalten kann man zu interessanten Rechnungen verknüpfen. Es ist syntaktisch nicht in jedem Fall notwendig, Aliasnamen zu vergeben, doch erfordert es eine gute Ausgabe durchaus, keine Spalten ohne Spaltennamen auszugeben. In der nachfolgenden Abfrage bspw. ermittelt man den Bruttogewinn eines Produkts aus der Differenz zwischen ListPrice und StandardCost. Dazu muss man lediglich die beiden Spalten wie zwei Variablen in einer Programmiersprache durch ein MinusZeichen verbinden, um dann für jeden einzelnen Datensatz die entsprechende Differenz ausrechnen lassen. Eine Voraussetzung für diese und andere Rechnungen ist lediglich, dass die Datentypen gleich sind oder wenigstens miteinander genutzt werden können. Um den Warenwert dieses Sicherungsbestandes auf dem Lager zu ermitteln, genügt es, die Werte der SafetyStockLevel-Spalte mit denen der ListPrice-Spalte zu multiplizieren. Schließlich folgt noch eine weitere berechnete Spalte, in der die Punkt-vor-StrichRechnung-Regel berücksichtigt werden muss und deswegen sogar auf Klammern zu- 97 Einfache Abfragen rückgegriffen werden muss, um die korrekte Berechnung vornehmen zu können. Sie ermittelt den Bruttowarengewinn, der sich aus dem Sicherungsbestand ermittelt. Dies bedeutet, dass die Differenz aus dem Listenpreis und den Standardkosten mit der Anzahl der Produkte im Sicherungsbestand multipliziert werden muss. SELECT ProductNumber AS Nr, ListPrice AS Liste, SafetyStockLevel AS Sicherung, ListPrice - StandardCost AS BruttoGewinn, SafetyStockLevel * ListPrice AS Warenwert, (ListPrice - StandardCost) * SafetyStockLevel AS BruttoWarenGewinn FROM production.product WHERE ListPrice != 0 223_01.sql: Diverse Berechnungen Wie schon oben erwähnt, ist es nicht so, dass die Aggregate, d.h. die Gesamtwerte einer Spalte multipliziert werden, sondern dass stattdessen die angegebenen Berechnungen für jeden einzelnen Datensatz durchgeführt werden, sodass demzufolge für die einzelnen Datensätze der Ergebnismenge unterschiedliche Ergebnisse zu erwarten sind. Nr Liste Sicherung ------------------------- --------------------- --------SA-M198 133,34 500 SA-M237 147,14 500 BruttoGewinn BruttoWarenGewinn 98 Warenwert Einfache Abfragen --------------------- --------------------- ---------------34,57 66670,00 17285,00 38,15 73570,00 19075,00 2.2.3.2 Zeichenketten verknüpfen Es besteht die Möglichkeit, die Ausgabe von vorneherein bereits durch die Verknüpfung von Zeichenketten so aufzubereiten, dass eine Verarbeitung in Form eines Berichts besonders einfach gelingt. Das Schulbeispiel in diesem Bereich ist die Erzeugung eines Feldes in der Ergebnisliste, in dem Anrede, Vorname und Nachname durch Leerzeichen getrennt in einer einzigen Zeichenkette erscheinen. Im nachfolgenden Beispiel setzt man mit Hilfe des Plus-Operators, der offensichtlich für verschiedene Operationen einsetzbar ist, die Felder für den Produktnamen, die Größe und die Farbe zusammen, wobei zusätzlich auch noch Größe und Farbe in runden Klammern gesetzt und durch ein Komma mit Leertaste getrennt werden. SELECT Name + ' (' + Size + ', ' + Color + ')' AS Produkt, ListPrice AS Preis FROM Production.Product WHERE Size IS NOT NULL 223_02.sql: Zeichenketten verknüpfen Wenngleich beim Verknüpfen von Zeichenketten sehr einfach Fehler geschehen, weil man mit Plus- und Anführungszeichen gleichzeitig operieren muss, so ist die Ausgabe wie auch in diesem Fall doch besonders hübsch anzusehen. Produkt Preis --------------------------------------------- --------HL Road Frame - Black, 58 (58, Black) 1431,50 Mountain Bike Socks, M (M, White) 9,50 99 Einfache Abfragen 2.2.3.3 Berechnete Bedingungen Schließlich müssen die mathematischen Operatoren nicht nur für Berechnungen eingesetzt werden, deren Ergebnis der Benutzer in der Abfrage lesen kann, sondern es ist auch möglich, jene einfach nur innerhalb der WHERE-Klausel zu verwenden. Sie lassen sich also überall dort sinnvoll einsetzen, wo ein gültiger Ausdruck erwartet wird. In nachfolgender Abfrage sucht man also die Produkte heraus, deren Bruttogewinn, d.h. die Differenz zwischen Listenpreis und Standardkosten größer als 30 sind. Um dies zu kontrollieren, wird zwar auch das Ergebnis dieser Berechnung in der Ergebnisliste ausgegeben, aber wesentlich ist hier die Verwendung der Berechnung als Bedingung in der WHERE-Klausel. -- Bruttogewinn größer 30 SELECT ProductNumber AS Nr, ListPrice - StandardCost AS BruttoGewinn, ListPrice AS Liste FROM production.product WHERE ListPrice != 0 AND ListPrice - StandardCost > 30 223_03.sql: Linksseitige Berechnungen Man erhält eine entsprechende Liste, der man es vom reinen Aufbau oder Format her nicht ansieht, dass sie eine solch spektakuläre Bedingung besitzt. Nr BruttoGewinn Liste ------------------------- --------------------- -----------SA-M198 34,57 133,34 SA-M237 38,15 147,14 100 Einfache Abfragen SA-M687 51,05 196,92 Viele SQL-Benutzer können sich nur langsam daran gewöhnen, dass sehr viele Formulierungen in SQL ein gültiger Ausdruck sind und daher an höchst ungewöhnlichen oder für den Laien an unvermuteten Orten erscheinen. Das nächste Beispiel zeigt nämlich nun, wie eine solche Berechnung auch auf der linken Seite untergebracht werden kann. Rechnet man einmal selbst den entsprechenden Ausdruck im Kopf aus oder stellt sich vor, dass auf der linken Seite bislang immer nur Spaltennamen standen, in Wirklichkeit dort aber auch eine einfach Zahl erscheinen kann, dann gewinnt diese Abfrage auch für Zwecke, in denen diese Zahl fest vorgegeben wird, an Bedeutung. Die Abfrage prüft also darauf, ob der Bruttogewinn (Listenpreis weniger Standardkosten) größer als die halben Standardkosten sind und ob die prozentualen Kosten (Standardkosten pro Listenpreis) größer als 50% sind. Über den Sinn und Zweck einer solchen Abfrage mag man sich streiten, aber für eine gute Formulierung muss man schon einmal tief in die Trickkiste der ungelesenen Managementberichte greifen. Die Berechnungen für das Verhältnis und die Differenz der beiden Werte erscheint bei dieser Abfrage links vom Vergleichsoperator, ändert sich bei jedem neuen Datensatz und kann daher für einen Vergleich sinnvoll genutzt werden. -- Mehr als 50% Bruttogewinn -- UND Bruttogewinn mehr als die Hälfte der Kosten SELECT ProductNumber AS Nr, ListPrice - StandardCost AS BruttoGewinn, ListPrice AS Liste, StandardCost / ListPrice * 100 AS [%-Gewinn], StandardCost AS Kosten, StandardCost / 2 AS [Halbe Kosten] FROM production.product 101 Einfache Abfragen WHERE ListPrice != 0 AND ListPrice - StandardCost > StandardCost / 2 AND StandardCost / ListPrice * 100 > 50 223_03.sql: Llinksseitige Berechnungen Zur Kontrolle gibt man die errechneten Werte in der Ergebnismenge auch aus. Nr BruttoGewinn Liste ------------------------- --------------------- --------FR-R92R-62 562,8658 1431,50 FR-R38R-44 150,0629 337,22 %-Gewinn Kosten Halbe Kosten --------------------- --------------------- ----------------60,68 868,6342 434,3171 55,50 187,1571 93,5785 2.2.4 Mengen-Operatoren Die einzelnen Tabellendaten, die man mit oder ohne Bedingung abruft, können genauso wie das Ergebnis selbst als Menge betrachtet werden. Sofern man sich mit den Grundlagen der relationalen Datenbanktheorie beschäftigt, ist dies eine wesentliche Erkenntnis, die aber auch bei einer allgemeinen Beschäftigung mit SQL quasi wie von selbst entsteht. Insbesondere die Kenntnis um die Mengen-Operatoren zeigt diese Tatsache noch einmal deutlich. Sie erlauben nämlich, zwei Abfragen des gleichen Aufbaus zu verbinden, zu schneiden oder voneinander abzuziehen, also genau typische Mengenoperationen durchzuführen. 102 Einfache Abfragen Eine (Teil-)Ergebnismenge gilt dabei als passend für eine andere, wenn man sich vorstellen kann, dass eine sinnvolle neue Ergebnismenge auf der Grundlage der beiden einzelnen Mengen erstellt werden kann. Dies betrifft die Spaltenzahl, welche gleich sein sollte, und die Datentypen, die zueinander passen müssen, d.h. die ineinander konvertiert werden können. Die Konvertierung erfolgt dabei so, dass die zweite Teilmenge auf die Datentypen der ersten angepasst wird. Zusätzlich sollte natürlich auch ein gewisser inhaltlicher Bezug zwischen den verschiedenen Spalten bestehen, d.h. eine Produktnummer mit der Anzahl der Kinder eines Angestellten sind zwar vom Datentyp möglicherweise überaus geeignet, in einer Spalte in der Ergebnismenge zu erscheinen, bieten aber keine sinnvolle Kombinationsmöglichkeit. Die Spaltennamen rekrutieren sich bei allen drei Operatoren aus den Spalten(alias)namen der ersten Teilmenge. Die allgemeine Syntax mit den Operatoren UNION für die Verbindung von zwei Ergebnismengen mit Ausschluss von Duplikaten UNION ALL für die Verbindung mit Übernahme der Duplikate EXCEPT für die Differenzbildung zweier Mengen INTERSECT für die Schnittmengenbildung zweier Mengen ist nachfolgend aufgelistet: { <Abfrageangabe> oder (<Abfrageausdruck>) } UNION [ ALL ] <Abfrageangabe> oder (<Abfrageausdruck>) [ UNION [ ALL ] <Abfrageangabe> oder (<Abfrageausdruck>) [ ...n ] ] { <Abfrageangabe> oder (<Abfrageausdruck>) } 103 Einfache Abfragen { EXCEPT | INTERSECT } { <Abfrageangabe> oder (<Abfrageausdruck>) } 2.2.4.1 Abfragemengen verbinden Die Schulbeispiele für den sinnvollen Einsatz einer Verknüpfung von Abfrageergebnissen sind folgende zwei: 1. Die einzelnen möglichen Abfrage-SQL-Zeichenketten liegen in verschiedenen einzelnen Variablen in einer beliebigen Programmiersprache vor. Durch Benutzerinteraktion oder einen sonstigen Anstoß wählt man im Programm immer nur eine Teilmenge der möglichen SQL-Anweisungen aus, deren Ergebnismengen zu einer gemeinsamen verbunden werden sollen. 2. Die Daten, auf die sich die Abfrage bezieht, liegen in verschiedenen Tabellen vor, gehören aber inhaltlich zusammen. Dies kann bspw. auch dann möglich sein, wenn eine Sicht Daten wieder zusammenfügt, die aus Gründen der Zugriffs- und Speicheroptimierung in mehrere einzelne/partitionierte Tabellen aufgeteilte wurden. Das nachfolgende Beispiele ist im Gegensatz zu den beiden gerade genannten gut für das Verständnis des Einsatzbereichs von UNION geeignet, aber doch deutlich trivialerer Natur. Die erste Abfrage ermittelt die Produkte der Größe S, die zweite die Produkte der Farbe Gelb. Beide Abfragen liefern die gleichen Spaltenstruktur, die daher von Anzahl und Datentypen übereinstimmen, wobei die Aliasnamen der ersten Abfrage die Spaltennamen der Ergebnismenge bestimmen. -- Gelbe T-Shirts in S und M SELECT Name Size AS Bezeichnung, AS Größe, Color AS Farbe FROM Production.Product WHERE Size = 'S' AND Color = 'Yellow' 104 Einfache Abfragen UNION SELECT Name, Size, Color FROM Production.Product WHERE Size = 'M' AND Color = 'Yellow' 224_01.sql: Verbindung von Ergebnissen S Yellow S Yellow S Yellow M Yellow S Yellow S Yellow M Yellow M Yellow S Yellow M Yellow UNION ALL UNION M Yellow M Yellow S Yellow S Yellow UNION M Yellow M Yellow M Yellow M Yellow M Yellow S Yellow M Yellow S Yellow M Yellow M Yellow Abbildung 2.3: Funktionsweise von UNION [ALL] Man erhält die gleiche Ausgabe wie bei einer Formulierung mit [NOT] IN. Bezeichnung Größe Farbe -------------------------------- ----- -------Short-Sleeve Classic Jersey, S S Yellow 105 Einfache Abfragen Short-Sleeve Classic Jersey, M M Yellow Während die vorherige Abfrage mögliche Duplikate, die in beiden Ergebnismengen erschienen, ausblendete, sorgt UNION ALL dafür, dass diese Duplikate erhalten bleiben. Die nächste Abfrage prüft daher in der ersten Teilabfrage darauf, ob die Größe S oder M und die Farbe Gelb ist, während die zweite Teilabfrage erneut auf die Größe M und die Farbe Gelb prüft. Beide Mengen liefern Duplikate, die ebenfalls in der Ergebnismenge angezeigt werden. -- Gelbe T-Shirts in 'S', 'M' mit 'M' SELECT Name, Size, Color FROM Production.Product WHERE Size IN ('S', 'M') AND Color = 'Yellow' UNION ALL SELECT Name, Size, Color FROM Production.Product WHERE Size = 'M' AND Color = 'Yellow' 224_02.sql: Duplikate zusätzlich ausgeben 2.2.4.2 Abfragemengen abziehen Mit Hilfe des Operators EXCEPT ist es leicht möglich, die Ergebnisse der ersten Teilmenge anzuzeigen, die nicht in der Ergebnismenge der zweiten Abfrage erscheinen. So ruft die erste Abfrage die Produkte mit verschiedenen Größen, darunter auch M, ab und prüft in beiden Fällen auf gelbe Farbe. Das bedeutet, dass die gelben Produkte in Größe M, die in der zweiten Abfrage gefunden werden, im gemeinsamen Ergebnis nicht mehr erscheinen, da sie von der ersten Menge abgezogen werden. 106 Einfache Abfragen -- Gelbe T-Shirts in 'S', 'L', 'XL', 'M' ohne 'M' SELECT Name, Size, Color FROM Production.Product WHERE Size IN ('S', 'L', 'XL', 'M') AND Color = 'Yellow' EXCEPT SELECT Name, Size, Color FROM Production.Product WHERE Size = 'M' AND Color = 'Yellow' 224_03.sql: Abziehen von Ergebnissen Im Ergebnis erscheinen eine Menge gelber Produkte, aber keiner in Größe M. Name Size Color ----------------------------------- ----- ------Short-Sleeve Classic Jersey, S S Yellow Short-Sleeve Classic Jersey, L L Yellow Short-Sleeve Classic Jersey, XL XL Yellow 2.2.4.3 Abfragemengen schneiden Schließlich lassen sich zwei Ergebnismengen auch schneiden, das bedeutet, es werden nur die Datensätze, welche in beiden Ergebnismengen erscheinen, in der gemeinsamen Ergebnismenge angezeigt. Diese Schnittmenge erstellt man mit Hilfe des Operators INTERSECT. Im nachfolgenden Beispiel ruft die erste Ergebnismenge die gelben Pro- 107 Einfache Abfragen dukte mit Größe S oder M ab, die zweite die gelben Produkte in M, sodass im Ergebnis nur die gelben Produkte in M erscheinen. -- Gelbe T-Shirts in 'S', 'M' verglichen mit 'M' SELECT Name, Size, Color FROM Production.Product WHERE Size IN ('S', 'M') AND Color = 'Yellow' INTERSECT SELECT Name, Size, Color FROM Production.Product WHERE Size = 'M' AND Color = 'Yellow' 224_04.sql: Ergebnismengen schneiden Das Ergebnis besteht aus gelben Produkten in Größe M. Name Size Color -------------------------------- ----- ------Short-Sleeve Classic Jersey, M 108 M Yellow Einfache Abfragen M Yellow S Yellow L Yellow EXCEPT M Yellow S Yellow M Yellow S Yellow INTERSECT M Yellow L Yellow S Yellow Abbildung 2.4: Funktionweise von INTERSECT und EXCEPT 2.3 Ergebnisse aufbereiten In diesem Abschnitt werden einige Techniken vorgestellt, die dazu dienen, Ergebnismengen zu erzeugen, die weniger durch die Verwendung von Bedingungen erstellt werden, sondern die durch Sortierungs- oder Gruppierungsanweisungen bzw. durch das Ausblenden von Duplikaten erstellt werden. 2.3.1 Duplikate ein-/ausblenden Das Schlüsselwort DISTINCT ermöglicht es, Duplikate einer Ergebnismenge bzw. einer Tabelle auszublenden. Im Normalfall sollten in einer Tabelle natürlich keine Duplikate vorhanden sein, aber dieser Fall ist syntaktisch mit DISTINCT zu lösen. Dennoch können Duplikate in einer Ergebnismenge erscheinen. Da sich die SQL-Abfrage nicht doppelte Daten ausdenken kann, kann es nur daran liegen, dass die Abfrage so formuliert 109 Einfache Abfragen ist, dass durch das Auslassen der unterscheidenden (Schlüssel-)Spalten doppelte Werte abgerufen werden. Dies geschieht immer dann, wenn in der zu Grunde liegenden Datenmenge die Werte durch einen Schlüssel unterschieden werden können. Dies muss in keinem Fall der tatsächliche Primärschlüssel der gesamten Spalte sein, sondern kann auch eine andere Spalte sein, die allerdings für die abgerufenen Werte die Schlüsselfunktion übernehmen kann. Durch das Weglassen bzw. durch den fehlenden Abruf dieser Spalte entstehen Duplikate in der Ergebnismenge. Das Schulbeispiel für die Entstehung und schließlich das Ausblenden von Duplikaten ist die Erzeugung von Wertelisten. Beim Zivilstand bspw. gibt es in der gesamten Tabelle Employees nur die beiden Werte M (verheiratet) oder S (unverheiratet). Würde man die Werte ohne DISTINCT abrufen, dann würde man eine lange Liste mit wechselnden Werten für M oder S erhalten, die den Werten und der Zeilenanzahl der gesamten Employees-Tabelle entspräche. -- Nur verschiedene Werte für Zivilstatus SELECT DISTINCT MaritalStatus FROM HumanResources.Employee 231_01.sql: Duplikate ausblenden SELECT MaritalStatus FROM HumanResources.Employee M S S M S SELECT DISTINCT MaritalStatus FROM HumanResources.Employee M S S M S Abbildung 2.5: Funktionweise von DISTINCT Durch das Ausblenden der Duplikate entsteht eine Liste, in der nur noch die verschiedenen Werte für die Spalte MaritalStatus abgerufen werden. Solche Abfragen kann man leicht an einer Formulierung wie „Welche verschiedenen Zivilstände gibt es überhaupt in der Tabelle?“ erkennen. 110 Einfache Abfragen MaritalStatus ------------M S Nimmt man noch eine weitere Spalte wie das Geschlecht hinzu, dann erhält man die verschiedenen Kombinationsmöglichkeiten von Geschlecht und Zivilstand, sofern sie in der Tabelle auftreten. Die DISTINCT-Klausel wirkt sich also hier auf die gesamte Ergebnismenge aus und ist als Anhängsel zu SELECT und nicht als zu einer bestimmten Spalte gehörend zu betrachten. Dies ist insoweit auch sehr einleuchtend, da in einer tabellenorientierten Ergebnismenge schlecht in der einen Spalte die verschiedenen Werte und in der anderen Spalte eine lange Liste an sich wiederholend auftretender Werte entstehen kann. -- Nur verschiedene Werte für Zivilstatus und Geschlecht SELECT DISTINCT MaritalStatus, Gender FROM HumanResources.Employee 231_02.sql: Duplikate von kombinierten Werten ausblenden In diesem Fall sind in der Employees-Tabelle alle möglichen Kombinationen enthalten, sodass sowohl Männer als auch Frauen verheiratet oder ledig sein können. MaritalStatus Gender ------------- -----M F M M S F S M 111 Einfache Abfragen 2.3.2 Ergebnisse sortieren Ergebnismengen zu sortieren ist eine ganz häufige Aufgabe, die teilweise für die schöne oder sinnvolle Ausgabe und teilweise auch für die Kontrolle nach größtem oder kleinstem Wert in einer Ergebnismenge durchgeführt werden muss. Die Anweisung für die Sortierung lautet ORDER BY und erwartet wenigstens eine Spalte. Die aufsteigende Sortierung lässt sich über das zusätzliche Schlüsselwort ASC (engl. ascending) ausdrücken, das allerdings der Standardwert ist. Eine absteigende Sortierung richtet man dann über DESC (engl. descending) ein. Beide Schlüsselwörter folgen dem Spaltennamen, der übrigens auch ein Aliasnamen sein kann. Sofern kein Spaltenalias vergeben wurde und eine Funktion oder Berechnung den Spaltenwert erzeugt, die man nicht noch einmal in der ORDER BY-Klausel einfügen möchte, oder wenn die SQL-Anweisungen dynamisch aus Zeichenketten zusammen gesetzt werden, kann man auch die 1-basierte Positionsnummer der Spalte verwenden. Schließlich werden mehrere Spaltennamen wie LastName, FirstName so abgearbeitet, dass erst nach der ersten und dann innerhalb der ersten Spalte nach der zweiten sortiert wird. Das Prinzip ist sehr einfach, und das Ergebnis dementsprechend schnell erreicht. Im nachfolgenden Beispiel ruft man aus der Contact-Tabelle Personen mit den Nachnamen Adams und Navarro ab, um die Ergebnismenge zunächst nach dem Nachnamen und dann nach dem Vornamen zu sortieren. Dabei sind im Quelltext verschiedene Varianten angegeben, welche alle die gleiche aufsteigende Sortierung von LastName und dann FirstName ergeben. In der Standardvariante nennt man die beiden Spaltennamen ohne ASC, in der Alternative folgt nach jeder Spalte oder nach einer einzigen Spalte die ausdrückliche ASC-Anweisung für die aufsteigende Sortierung. In einer dritte Variante spart man die Nennung der Spaltennamen und ersetzt sie durch die Positionsnummern, welche natürlich auch wieder um ASC ergänzt werden könnten. -- Nachname, Vorname von A-Z geordnet SELECT LastName, FirstName FROM Person.Contact WHERE LastName IN ('Adams', 'Navarro') 112 Einfache Abfragen ORDER BY LastName, FirstName -- ORDER BY LastName ASC, FirstName ASC -- ORDER BY 1, 2 232_01.sql: Alphabetische Ordnung A-Z In der Ergebnismenge erscheint zunächst Adams und dann Navarro, wobei innerhalb der beiden Namen die Vornamen jeweils wieder aufsteigend sortiert sind. LastName FirstName -------------- ---------Adams Aaron Adams Adam Adams Alex Navarro Adrienne Navarro Albert Navarro Alberto Im nächsten Beispiel sollen die Nachnamen weiterhin aufsteigend, die Vornamen allerdings absteigend sortiert werden. Neben den beiden Varianten, die Spaltennamen oder die Positionsnummern der Spalten zu nennen, ist hier wichtig, dass die absteigend zu sortierende Spalte um die Anweisung DESC ergänzt wird, welche den Vorgabewert überschreibt. -- Nachname, Vorname von Z-A geordnet SELECT LastName, FirstName FROM Person.Contact WHERE LastName IN ('Adams', 'Navarro') 113 Einfache Abfragen ORDER BY LastName, FirstName DESC -- ORDER BY LastName ASC, FirstName DESC -- ORDER BY 1 ASC, 2 DESC 232_02.sql: Alphabetische Ordnung gemischt In der Ergebnismenge bleibt die Reihenfolge der Nachnamen unverändert, lediglich die Vornamen sind nun von Z-A sortiert. LastName FirstName ---------- -----------Adams Xavier Adams Wyatt Adams Thomas 2.3.3 Standard-Aggregate Standard-SQL bietet eine Reihe von Funktionen, die in jeder Datenbank nutzbar sind und als so genannte Standard-Aggregate bekannt sind. Sie verdienen diesen Namen aufgrund der Universalität ihres Einsatzes in den verschiedenen Datenbanksystemen, die man auch außerhalb des SQL Servers nutzen könnte (aber wer wollte das schon?). Die nachfolgende Tabelle listet diese universellen Funktionen kurz auf, wobei die COUNT_BIG-Funktion nicht zum Standard gehört, aber ebenso zählt wie COUNT, wobei sehr große Werte auch gezählt werden können. Funktion Bedeutung AVG Durchschnitt der Spalte MIN Minimum der Spalte MAX Maximum der Spalte SUM Summe der Spalte 114 Einfache Abfragen COUNT Anzahl der Einträge einer Spalte COUNT_BIG Standardaggregate Die nächsten Beispiele erzeugen entweder jeweils einen einzigen Wert und stellen damit eine ganz klassische Form der Aggregatabfrage dar, oder werden in Verbund mit anderen Aggregaten (bzw. im nächsten Abschnitt mit einer Gruppierung) verwendet. Wie man sieht, ist die Verwendung nicht weiter schwierig: Die COUNT-Funktion zählt die Anzahl der Datensätze in einer Spalte, wobei sie auch noch in einer COUNT(DISTINCT *)-Variante auftritt und dabei die Duplikate ausblendet. Im einfachsten Fall verwendet man einen Asteriskus, ansonsten kann man auch einen Spaltennamen einsetzen. Die Funktionen für die Summen- und Durchschnittsberechnung können nicht mit dem Asteriskus zusammen eingesetzt werden. Stattdessen ist hier eine numerische Spalte notwendig, die also eine entsprechende Berechnung erlaubt. Die beiden Funktionen zur Ermittlung Maximum und Minimum werden in den meisten Fällen mit numerischen Werten eingesetzt, können allerdings auch für Zeichenketten zum Einsatz kommen. In diesem Fall würde eine Abfrage wie SELECT MAX(lastname) FROM Person.Contact den schönen Wert Zwilling liefern. -- Wieviele Datensätze sind in Contact? SELECT COUNT(*) AS Anzahl FROM Person.Contact -- Wie hoch sind die Verkäufe? SELECT SUM(SalesYTD) AS Verkäufe, SUM(SalesLastYear) AS LetzteVerkäufe 115 Einfache Abfragen FROM Sales.SalesPerson WHERE TerritoryID < 5 -- Wie hoch sind die Durchcshnittsverkäufe? SELECT AVG(SalesYTD) AS Verkäufe, AVG(SalesLastYear) AS LetzteVerkäufe, AVG(SalesYTD) - AVG(SalesLastYear) AS Differenz FROM Sales.SalesPerson -- Wie hoch waren die maxi-/minimalen Verkäufe? SELECT MAX(SalesYTD) AS Maxi, MIN(SalesLastYear) AS Mini FROM Sales.SalesPerson 233_01.sql: Anwendung von Aggregatfunktionen Die verschiedenen angekündigten Ergebnisse der Aggregate sind nachfolgend aufgelistet. Interessant ist insbesondere die Abfrage, welche mehrere Aggregate einer Tabelle zugleich ermittelt. Anzahl ----------19972 Verkäufe LetzteVerkäufe -------------- --------------22152408,0054 116 10558949,205 Einfache Abfragen Verkäufe LetzteVerkäufe Differenz -------------- --------------- -------------2605530,949 Maxi 1393291,9779 1212238,9711 Mini ------------- ------5200475,2313 2.3.4 0,00 Gruppieren Eine besondere Technik der Ergebnisaufbereitung sorgt für Abfragemöglichkeiten, die bereits sehr informative Ergebnisse über Aggregate in der Datenbank liefern und zusätzlich deutlich anspruchsvollere Daten erzeugen als eine einfache Ausgabe der gespeicherten Werte. Die hierbei verwendete Klausel lautet GROUP BY und ermöglicht die Gruppierung von Werten nach einem bestimmten Kriterium, wobei in den meisten Fällen auch eine oder gar mehrere Aggregatfunktionen auf diese Gruppen angewandt werden. 2.3.4.1 Einfache Gruppierung In einer der vorherigen Abfragen rief man die verschiedenen Werte ab, die in der Spalte MaritalStatus von Employee gespeichert sind. In einer anderen Abfrage wurden diese Werte wiederum zusätzlich mit den Werten der Spalte Gender verglichen, wobei das nicht sonderlich überraschende Ergebnis entstand, dass sowohl Männer als auch Frauen in verheirateter und lediger Form auftreten. Interessant wäre nun in diesem Zusammenhang zu erfahren, wie viele Angestellten denn jeweils diese verschiedenen Werte aufweisen. Genau eine solche Untersuchung lässt sich mit Hilfe der Gruppierung durchführen. 117 Einfache Abfragen Als Regel gilt, dass alle Spalten in der Spaltenliste, die nicht durch den Einsatz einer (Standard-)Aggregatfunktion gebildet werden, in der GROUP BY-Klausel erscheinen müssen. Je mehr Spalten also abgerufen werden, desto mehr verschiedene Werte können eine Gruppe bilden, was natürlich die Aggregate sehr beeinflusst und zu kleineren aggregierten Werten führt, da ja die zu betrachtenden Merkmale zunehmen. Um das vorher erwähnte Beispiel aufzugreifen, indem der Zivilstand mit oder ohne Bezug auf das Geschlecht ermittelt wurde, sollen nun in den nächsten beiden Beispielen die Anzahl pro Zivilstand und die Anzahl von Männern und Frauen pro Zivilstand ermittelt werden. Es entstehen also zunächst die gleichen bzw. schon bekannten Wertegruppen, die nun allerdings um eine Spalte für die Anzahl ergänzt wurden. Dabei ruft man weiterhin die Spalte MaritalStatus ab, kann allerdings auf das DISTINCT verzichten, da die Spalte mit Hilfe von GROUP BY gruppiert und damit auch auf die überhaupt vorhandenen Werte reduziert wird. In der zweiten Spalte der Ergebnismenge sollen dann die verschiedenen Werte pro Gruppe ermittelt werden, wozu lediglich die COUNT(*)-Funktion zum Einsatz kommt. Sobald wie in der zweiten Abfrage weitere Merkmale bzw. Spalten in die Gruppen aufgenommen werden, entstehen im Normalfall mehr Gruppen und müssen diese Spalten auch zusätzlich in der GROUP BY-Klausel erscheinen. -- Anzahl pro Zivilstand SELECT MaritalStatus AS Zivilstand, COUNT(*) AS Anzahl FROM HumanResources.Employee GROUP BY MaritalStatus -- Anzahl pro Zivilstand und Geschlecht SELECT MaritalStatus AS Zivilstand, Gender 118 AS Geschlecht, Einfache Abfragen COUNT(*) AS Anzahl FROM HumanResources.Employee GROUP BY MaritalStatus, Gender ORDER BY Gender 234_01.sql: Gruppierung für eine Spalte und für zwei Man erhält als Ergebnis der ersten Abfrage nur die beiden Gruppen M (verheiratet) und S (ledig) mit den jeweiligen Zahlen. In der zweiten Ergebnismenge jedoch erfährt man zusätzlich, dass es überhaupt Männern und Frauen in beiden Gruppen gibt und wie hoch die Anzahl in den beiden Gruppen ist. Verloren geht nun die Aggregatinformation, wie viele Werte es in jeder Gruppe insgesamt (nur Männer oder nur verheiratet) gibt. Dazu sind noch diverse Erweiterungen der Gruppierung nötig. Zivilstand Anzahl ---------- ----------M 146 S 144 Zivilstand Geschlecht Anzahl ---------- ---------- ----------M F 49 S F 35 M M 97 S M 109 Alle Aggregatfunktionen lassen sich mit GROUP BY sinnvoll kombinieren und zu interessanten Ergebnissen führen. So ermittelt die nächste Abfrage bspw. für jede Bestel- 119 Einfache Abfragen lung die Summe der Posten und den Durchschnittswert der Postenwerte sowie die Anzahl der bestellten Posten. Damit werden drei verschiedene Aggregatfunktionen für die Gruppenbildung auf Basis der Bestellnummer angewandt. -- Summe einer Bestellung, -- Durchschnitt/Anzahl von Posten SELECT SalesOrderID AS Nr, SUM(LineTotal) AS Summe, AVG(LineTotal) AS Schnitt, COUNT(*) AS Anzahl FROM Sales.SalesOrderDetail GROUP BY SalesOrderID ORDER BY Summe DESC 234_02.sql: Mehrere Aggregatfunktionen Man erhält die angekündigten Aggregate pro Bestellung. Nr Summe Schnitt Anzahl -------- --------------- -------------- ------51131 163930.394292 2732.173238 60 55282 160378.391334 3144.674339 51 46616 150837.438737 2320.575980 65 2.3.4.2 Gruppenbedingungen Bisweilen kann es passieren, dass eine ganze Reihe von Gruppen mit nur einem einzigen Datensatz in der Datenbank entsteht und sie daher trotz geringerer Zeilenzahl im Vergleich zu den Originaldaten immer noch zu viele Daten liefert. Dann kann ebenso 120 Einfache Abfragen der Fall eintreten, dass ganz einfach eine zusätzliche inhaltliche Bedingung auf die Aggregatwerte angewandt werden soll. Dies lässt sich mit Hilfe der HAVING-Klausel abbilden, die der GROUP BY-Klausel folgt und als WHERE-Klausel der Gruppierung angesehen werden kann. Sie greift eines der Aggregate auf und verknüpft mehrere Bedingungen durch die booleschen Operatoren, die hier genauso wie in der WHERE-Klausel gelten, um zusätzliche Bedingungen für die Gruppenaggregate anzugeben. Die nächste Abfrage ermittelt die Anzahl der Produkte pro Kategorie und als Aggregate den durchschnittlichen, maximalen und minimalen Bedarf an Produktionstagen. Es sollen allerdings nur solche Kategorien in die Ergebnismenge übernommen werden, welche mehr als 10 Produkte aufweisen und deren Produktionszeit ungleich 0 ist. Der Gruppierung folgt dann – wie in diesem Beispiel zu sehen ist – wiederum der Sortierung, die stets die letzte Klausel bildet. -- Anzahl von Produkten pro Subkategorie -- Durchschnittliche, maxi-/minimale Produktionsdauer SELECT ProductSubcategoryID COUNT(*) AS Kategorie, AS Anzahl, AVG(DaysToManufacture) AS [Prod-Tage], MAX(DaysToManufacture) AS Maxi, MIN(DaysToManufacture) AS Mini FROM Production.Product GROUP BY ProductSubcategoryID HAVING COUNT(*) > 10 AND AVG(DaysToManufacture) != 0 ORDER BY ProductSubcategoryID 234_03.sql: Bedingungen für Aggregate 121 Einfache Abfragen Als Ergebnis erhält man eine auf die Bedingung reduzierte Menge. Kategorie Anzahl Prod-Tage Maxi Mini ----------- ----------- ----------- ----------- ----------1 32 4 4 4 33 1 2 1 ... 14 2.3.5 Zufällige Datenauswahl Um zufällige Daten auszuwählen, gibt es eine eigene Klausel, die innerhalb der FROMKlausel in den Befehlen SELECT, UPDATE und DELETE zusätzlich angegeben werden kann. Der Zufallsalgorithmus oder die Genauigkeit sind nicht besonders raffiniert, aber für eine einfache Lösung eines solchen Problems reicht sie völlig aus. Ihre allgemeine Syntax lautet: TABLESAMPLE [SYSTEM] ( sample_number [ PERCENT | ROWS ] ) [ REPEATABLE ( repeat_seed ) ] Die einzelnen Bestandteile haben folgende Bedeutung: SYSTEM weist die Klausel an, eine implementationsbedingte, d.h. vorgegebene, Stichprobenmethode zu verwenden. Dieser Zusatz ist von Standard-SQL übernommen und bezieht sich dort auf verschiedene Datenbanken. Für die Version 2005 ist nur eine Stichprobenfunktion vorhanden, die eine zufällige Anzahl von Datenseiten auswählt. sample_number enthält einen festen Wert oder eine Prozentangabe, welche die Anzahl der Zeilen, die zufällig ermittelt werden sollen, angibt. Wenn zusätzlich PERCENT gesetzt wird, dann gilt die Zahl als float, ansonsten als bigint. 122 Einfache Abfragen PERCENT legt fest, dass die prozentuale Menge aus der Tabelle ermittelt werden soll. Der Wertebereich liegt zwischen 0 und 100. ROWS (bigint größer 0) legt fest, dass die angegebene Zahl in Reihen ausgegeben werden soll. REPEATABLE legt fest, dass die zuvor ausgewählte Zeilenmenge noch einmal ermittelt werden darf, d.h. dass zwei aufeinander folgende Ergebnisse gleich sein dürfen. Sofern der derselbe repeat_seed (bigint größer 0) für den Zufallsgenerator verwendet wird, ist dies immer die gleiche Datenmenge, sofern keine Änderungen im Datenbestand erfolgt sind. Die nachfolgenden Beispiele zeigen die verschiedenen Einsatzmöglichkeiten dieser zusätzlichen Angabe in FROM. Dabei muss man sich darauf einstellen, dass bei sehr kleinen Werte und kleinem Datenbestand auch schon einmal gar keine Ergebnisse ausgegeben werden sollen. Bei Testläufen und entsprechendem Testdatenbedarf kann dies manchmal erwünscht sein. Sofern man einen nachvollziehbaren und wiederholbaren Test ausführen will, sollte man in jedem Fall die REPEATABLE-Anweisung zusätzlich mit einem festen Wert als Zufallszahl anfügen. -- 20% abrufen SELECT * FROM Production.Product TABLESAMPLE SYSTEM (20 PERCENT) -- 20 Reihen abrufen SELECT * FROM Production.Product TABLESAMPLE SYSTEM (20 ROWS) -- 200 Reihen wiederholbar abrufen SELECT * FROM Production.Product TABLESAMPLE SYSTEM (200 ROWS) REPEATABLE(50) 123 Einfache Abfragen 235_01.sql: Zufällige Ergebnismenge 2.4 Eingebaute Funktionen Jede relationale Datenbank besitzt einen Blumenstrauß an so genannten eingebauten Funktionen. Einige wie SUM() oder COUNT() sind darüber hinaus nicht nur in einer Datenbank verfügbar, sondern werden als Standardaggregatfunktionen auch im SQLStandard definiert und können getrost in jeder Datenbank als unterstützt vorausgesetzt werden. Neben diesen Funktionen sind solche wie für die Bearbeitung von Zeichenketten oder mathematischen Aufgaben in der einen oder anderen Form ebenfalls in den meisten Datenbanken verfügbar, wenngleich sie auch in jeder einzelnen Datenbank vom Namen her neu gelernt werden müssen. Viele andere Funktionen jedoch sind nicht einfach so verfügbar, sondern müssen teilweise sogar selbst implementiert werden oder durch eine Kombination von vorhandenen Funktionen realisiert werden. Dieser Abschnitt stellt die im MS SQL Server 2005 vorhandenen Funktionen vor, wobei der Schwerpunkt auf Abfrage und Umwandlung von Ergebnissen oder Berechnungen und weniger auf administrative Aufgaben liegt. Diese so genannten Systemfunktionen werden zwar auch erwähnt, sind allerdings im Buch zur Datenbankadministration genauer erläutert und dort auch grundsätzlich besser aufgehoben. Folgende Funktionsgruppen werden von der Dokumentation vorgestellt: Konfigurationsfunktionen liefern Informationen zur Konfiguration der Datenbank. Cursorfunktionen liefern Informationen zu Cursorn. Datums- und Zeitfunktionen ermöglichen Operationen für Datums- und Zeitwerte und bieten als Rückgabewerte Zeichenketten, Zahlen-, Datums- oder Zeitwerte. Mathematische Funktionen ermöglichen Berechnungen auf der Grundlage der Funktionsparameter und liefern einen numerischen Wert. Metadatenfunktionen Datenbankobjekten. 124 liefern Informationen zur Datenbank und zu Einfache Abfragen Sicherheitsfunktionen liefern Informationen über Benutzer und Rollen zurück. Zeichenkettenfunktionen ermöglichen Operationen für Parameter vom Typ char oder varchar und liefern eine Zeichenfolge oder einen numerischen Wert. Systemfunktionen ermöglichen Operationen bezüglich Werten, Objekten und Konfigurationseinstellungen der Datenbank aus und liefern diesbezügliche Informationen. Statistische Systemfunktionen liefern statistische Informationen zum System. Text- und Imagefunktionen ermöglichen Operationen zu Text- bzw. Image-Daten aus und liefern Informationen zu diesen Daten. In den nachfolgenden Listen taucht die Unterscheidung deterministisch und nicht deterministisch auf. Eine deterministische Funktion liefert bei gleichen Eingabewerten die gleichen Ausgabewerte, eine nicht deterministische nicht. Ein typisches Beispiel für eine nicht deterministische Funktion ist der Abruf der aktuellen Uhrzeit oder der Abruf des aktuellen Benutzernamens. 2.4.1 Datums- und Zeitfunktionen Datums- und Zeitwerte stellen besondere Datenstrukturen dar, von denen in jeder Datenbank Teile extrahiert werden sollen oder die in irgendeiner Weise formatiert werden müssen. Sollten solche Funktionen fehlen, bleibt nichts anders übrig als die Datumswerte in Zeichenketten umzuwandeln und Extraktionen, Formatierungen und natürlich auch Sortierungen und Gruppierungen auf der Ebene von Zeichenketten vorzunehmen. Dies ist allerdings aufgrund des mathematischen Systems (24 Stunden für einen Tag, 7 Tage für eine Woche etc.) bei Berechnungen überaus kompliziert, sodass entsprechende Funktionen, die dies alles berücksichtigen, überaus wichtig sind. 2.4.1.1 Referenz Die verschiedenen Funktionen erwarten ab und an Parameter, die für einzelne Zeitbestandteile stehen. In der nachfolgenden Tabelle sind diese Namen sowie ihre Abkürzungen zusammen gefasst. 125 Einfache Abfragen Datumseinheit Abkürzungen Bedeutung year yy, yyyy Jahr quarter qq, q Quartal month mm, m Monat dayofyear dy, y Tag des Jahres (fortlaufend) day dd, d Tag week wk, ww Woche, Kalenderwoche Hour hh Stunde minute mi, n Minute second ss, s Sekunde millisecond ms Millisekunde Zeiteinheiten Folgende Funktionen sind in dieser Kategorie vorhanden: DATEADD (deterministisch) berechnet einen neuen datetime-Wert, welche als Summe eines Datums und eines Zeitraums ermittelt wird. Syntax: DATEADD (datepart , number, date ) DATEDIFF (deterministisch) berechnet einen neuen datetime-Wert, welche als Differenz eines Datums und eines Zeitraums ermittelt wird. Syntax: DATEDIFF ( datepart , startdate , enddate ) DATENAME (nicht deterministisch) liefert eine Zeichenkette zurück, die den Textwert eines Datumsteils angibt. Syntax: DATENAME ( datepart ,date ) DATEPART (deterministisch mit Ausnahme von DATEPART (dw, date), wobei dw den Datumsteil für den Wochentag bestimmt, welcher wiederum von dem durch 126 Einfache Abfragen ersten Tag der Woche abhängt) liefert eine Ganzzahl, welche den abgefragten Teil des Datums angibt. SET DATEFIRST festgelegten Syntax: DATEPART ( datepart , date ) DAY (deterministisch) liefert eine Ganzzahl, welche den Tagesanteil des Datums angibt. Syntax: DAY ( date ) oder DATEPART(dd,date). GETDATE (nicht deterministisch) liefert das aktuelle Systemdatum inkl. Uhrzeit zurück, wobei das eingestellte SQL Server 2005-Format zum Einsatz kommt. Syntax: GETDATE ( ) GETUTCDATE (nicht deterministisch) liefert die aktuelle UTC-Zeit (Coordinated Universal Time oder Greenwich Mean Time) zurück, wobei die Zeit(zonen)einstellungen des Rechners zum Einsatz kommen, welcher den MS SQL Server 2005 enthält. Syntax: GETUTCDATE() MONTH (deterministisch) liefert eine Ganzzahl, welche den Monatsanteil des Datums angibt. Syntax: MONTH ( date ) anstelle von DATEPART(mm, date). YEAR (deterministisch) liefert eine Ganzzahl, welche den Jahressanteil des Datums angibt. Syntax: YEAR ( date ) oder DATEPART(yy, date). 2.4.1.2 Beispiele Das nächste Beispiel addiert zu verschiedenen Datumswerten weitere Zeiteinheiten hinzu. Hierbei sind insbesondere einige „gefährliche“ Datumswerte ausgewählt, die dennoch zu richtigen Ergebnissen führen. -- Datumsteil mit vollem Namen 127 Einfache Abfragen SELECT DATEADD(day, 21, '01.01.2006') AS TagPlus, DATEADD(month, 1, '28.02.2006') AS MonatPlus, DATEADD(month, 1, '30.01.2006') AS MonatPlus, DATEADD(minute, 1, '30.01.2006 01:10:30.000') AS MinutePlus -- Datumsteil mit abgekürztem Namen SELECT DATEADD(q, 2, '09.01.2006') AS QuartalPlus, DATEADD(dy, 1, '28.02.2006') AS TagPlus, DATEADD(wk, 1, '30.01.2006') AS WochePlus, DATEADD(mi, 1, '30.01.2006 01:10:30.000') AS MinutePlus 241_01.sql: Berechnungen mit der Zeit Man erhält als Ergebnis die folgenden Datumswerte. TagPlus MonatPlus ----------------------- ----------------------2006-01-22 00:00:00.000 2006-03-28 00:00:00.000 MonatPlus MinutePlus ----------------------- ----------------------2006-02-28 00:00:00.000 2006-01-30 01:11:30.000 QuartalPlus 128 TagPlus Einfache Abfragen ----------------------- ----------------------2006-07-09 00:00:00.000 2006-03-01 00:00:00.000 WochePlus MinutePlus ----------------------- ----------------------2006-02-06 00:00:00.000 2006-01-30 01:11:30.000 Das nächste Beispiel ruft Namen von Datumswerten ab. -- Datumsteil mit vollem Namen SELECT DATENAME(day, '01.01.2006') AS Tag, DATENAME(month, '28.02.2006') AS Monat, DATENAME(quarter, '30.01.2006') AS Quartal, DATENAME(year, '30.01.2006 01:10:30.000') AS Jahr -- Datumsteil mit abgekürztem Namen SELECT DATENAME(q, '09.01.2006') AS Quartal, DATENAME(dy, '28.02.2006') AS Tag, DATENAME(dw, '28.02.2006') AS Tag, DATENAME(wk, '30.01.2006') AS Woche, DATENAME(mi, '30.01.2006 01:10:30.000') AS Minute 241_01.sql: Namen auslesen Man erhält als Ergebnis folgende Werte: Tag Monat Quartal Jahr Quartal Tag Tag Woche Minute 129 Einfache Abfragen ----- -------- -------- ---- ------- --- -------- ----- ----1 Februar 1 2006 1 59 Dienstag 6 10 Die Funktion DATEPART() ruft einzelne Zeitbestandteile eines Datums ab. -- Datumsteil mit vollem Namen SELECT DATEPART(day, '01.01.2006') AS Tag, DATEPART(month, '28.02.2006') AS Monat, DATEPART(quarter, '30.01.2006') AS Quartal, DATEPART(year, '30.01.2006 01:10:30.000') AS Jahr -- Datumsteil mit abgekürztem Namen SELECT DATEPART(q, '09.01.2006') AS Quartal, DATEPART(dy, '28.02.2006') AS Tag, DATEPART(dw, '28.02.2006') AS Tag, DATEPART(wk, '30.01.2006') AS Woche, DATEPART(mi, '30.01.2006 01:10:30.000') AS Minute 241_03.sql: Datumsteil abrufen Man erhält als Ergebnis: Tag Monat Quartal Jahr Quartal Tag Tag Woche Minute ----- -------- -------- ---- ------- --- ---- ----- ------1 2 1 2006 1 59 2 6 10 Das nächste Beispiel verwendet alternativ verschiedene spezielle Funktionen: SELECT DAY('01.01.2006') 130 AS Tag, Einfache Abfragen MONTH('28.02.2006') AS Monat, YEAR('30.01.2006') AS Jahr 241_04.sql: Spezialfunktionen verwenden Man erhält als Ergebnis die folgenden Werte: Tag Monat Jahr ----------- ----------- ----------1 2 2006 Schließlich zeigt das nächste Beispiel, wie aktuelle Zeitinformationen abgerufen werden können. SELECT DAY(GETDATE ()) GETDATE () AS Tag, AS [System-Datum], YEAR(GETUTCDATE()) AS Jahr, GETUTCDATE() AS [Greenwich Mean Time] 241_05.sql: Zeit abrufen Man erhält als Ergebnis: Tag System-Datum Jahr Greenwich Mean Time ---- ----------------------- ----- ----------------------4 2.4.2 2005-08-04 11:20:19.967 2005 2005-08-04 09:20:19.967 Mathematische Funktionen Die mathematischen Funktionen erlauben diverse Berechnungen, aus denen auch komplexe Berechnungen in SQL zusammengesetzt werden können. Sofern diese Funktionen auch in Kombination nicht die gewünschten Ergebnisse liefern, bleibt dazu – wie auch bei den Zeit- oder Zeichenkettenfunktionen – immer noch die Alternative, die Um- 131 Einfache Abfragen wandlungen und Berechnungen nicht in SQL sondern in der abrufenden Programmiersprache durchzuführen. 2.4.2.1 Referenz ABS liefert den absoluten Wert einer Zahl, d.h. die Zahl ohne Vorzeichen. Syntax: ABS ( numeric_expression ) ACOS liefert für den angegebenen Kosinuswert den Winkel im Bogenmaß. Syntax: ACOS ( float_expression ) ASIN liefert für den angegebenen Arkussinuswert den Winkel im Bogenmaß. Syntax: ASIN ( float_expression ) ATAN liefert für den angegebenen Arkustangenswert den Winkel im Bogenmaß. Syntax: ATAN ( float_expression ) ATN2 liefert für den Quotienten der beiden angegebenen (Arkustangenswert) den Winkel im Bogenmaß. Syntax: ATN2 ( float_expression ,float_expression ) CEILING liefert die nächstgrößere ganze Zahl, größer oder gleich dem angegeben Ausdruck. Syntax: CEILING ( numeric_expression ) COS liefert den Kosinus des als Bogenmaß angegebenen Winkels zurück. Syntax: COS ( float_expression ) COT liefert den Kotangens des als Bogenmaß angegebenen Winkels zurück Werten Syntax: COT ( float_expression ) 132 DEGREES liefert den Winkel als Gradzahl für den als Bogenmaß angegebenen Winkel zurück. Syntax: DEGREES ( numeric_expression ) Einfache Abfragen EXP liefert den exponentiellen Wert des Ausdrucks zurück. Syntax: EXP ( float_expression ) FLOOR liefert die nächstkleinere Ganzzahl zurück, kleiner oder gleich dem Ausdruck ist. Syntax: FLOOR ( numeric_expression ) LOG liefert den natürlichen Logarithmus des Ausdrucks zurück. Syntax: LOG ( float_expression ) LOG10 liefert den dekadischen (Basis 10) Logarithmus des Ausdrucks zurück. Syntax: LOG10 ( float_expression ) PI liefert den konstanten Wert von PI (3.14159...). Syntax: PI ( ) POWER liefert den um y potenzierten Wert des Ausdrucks zurück. Syntax: POWER ( numeric_expression , y ) RADIANS liefert das Bogenmaß für einen in Grad angegebenen Winkel zurück. Syntax: RADIANS ( numeric_expression ) RAND liefert eine Zahl zwischen 1 und 0 zurück. Der Parameter seed erlaubt die Angabe eines Startwertes, der ansonsten zufällig ermittelt wird. Syntax: RAND ( [ seed ] ) ROUND liefert einen Wert zurück, der auf die in length angegebene Genauigkeit gerundet ist. Der Parameter function erlaubt bei einer Zahl ungleich 0 die Kürzung und nicht Rundung der Zahl. Syntax: ROUND ( numeric_expression , length [ ,function ] ) SIGN liefert das Vorzeichen positiv (+1), Null (0) oder negativ (-1) der angegebenen Zahl zurück. Syntax: SIGN ( numeric_expression ) SIN liefert den Sinus des im Bogenmaß angegebenen Winkels zurück. Syntax: SIN ( float_expression ) 133 Einfache Abfragen SQRT liefert die Quadratwurzel des Ausdrucks. Syntax: SQRT ( float_expression ) SQUARE liebert die Quadratzahl (Potenz 2) der Ausdrucks zurück. Syntax: SQUARE ( float_expression ) TAN liefert den Tangens des Ausdrucks zurück. Syntax: TAN ( float_expression ) Für die Erläuterung der trigonometrischen Funktionen ist folgendes rechtwinklige Dreieck gegeben: b = Ankathete a = Gegenkathete ß a c = Hypothenuse Abbildung 2.6: Rechtwinkliges Dreieck Es gelten die in nachfolgender Liste angegebenen Beziehungen: Sinus Į = a/c = Gegenkathete / Hypothenuse Cosinus ȕ = b/c = Ankathete / Hypothenuse Tangens Į = a/b = Gegenkathete / Ankathete = Sinus Į / Cosinus ȕ Kotangens Į = b/a = Ankathete / Gegenkathete = Cosinus Į / Sinus ȕ = 1 / Tangens Į 134 Einfache Abfragen Für die Funktionen des Bogenmaßes gelten auf dem Einheitskreis folgende Beziehungen. Der Einheitskreis besitzt einen Radius r = 1 und einen Umfang vom U = 2ʌ. Die Umrechnungsformel von Grad in Bogenmaß lautet x / 2 ʌ = ij / 360 oder x = ʌ / 180 * ij. Bogenmaß x = x (f ) f -f r=1 Bogenmaß: x = -x (f ) Abbildung 2.7: Einheitskreis und Bogenmaße 2.4.2.2 Beispiele Die mathematischen Funktionen bedürfen weitestgehend keiner Erklärung. Wie bei einem Taschenrechner werden die den Funktionen zu Grunde liegenden Rechnungen auf die übergebenen Werte angewendet. SELECT ABS(-0.5) AS Betrag, ROUND(-0.7345, 2) AS Rund1, FLOOR(2.2) AS AbRund, 135 Einfache Abfragen CEILING(2.2) AS AufRund, PI() AS [Pi] AS [PI], SQUARE(5) AS Quadrat, POWER(5,2) AS Potenz, POWER(25, 0.5) AS Wurzel, EXP(1) AS [Eulersche Zahl], LOG(2) AS [Nat. Logarithmus], LOG(EXP(1)) AS [1], EXP(LOG(2)) AS [2] 242_01.sql: Einfache mathematische Berechnungen Man erhält die nachfolgenden Werte: Betrag Rund1 AbRund AufRund Pi ----------- -------- ------- ------- ---------------0.5 -0.7300 Quadrat Potenz Wurzel 2 3 3,14159265358979 Eulersche Zahl Nat. Logarithmus 1 2 ------- ------ -------- -------------- ----------------- --25 25 5 2,718281828 0,69314718055 1 2 Nach dem Satz von Pythagoras gilt a² + b² = c², d.h. ein rechtwinkliges Dreieck wird bspw. durch 3² + 4² = 5², d.h. 9 +16 = 25, gebildet. Diese Zahlenfolge wird zudem auch 136 Einfache Abfragen noch als pythagoreisches Zahlentripel bezeichnet, weil aufeinander folgende Ganzzahlen die Seitenlängen bilden und dies schon seit der Antike als formschön gilt und für diverse tägliche Anwendungen bspw. in der Landvermessung genutzt wurde. Im nachfolgenden Beispiel sollen diese Zahlen ebenfalls genutzt werden. DECLARE @a int, @b int, @c int SELECT @a = 3, @b = 4, @c = 5 SELECT SIN(@a/@c) AS Sinus, COS(@b/@c) AS Kosinus, TAN(@a/@b) AS Tangens, COT(@b/@a) AS Kotangens 242_02.sql: Trigonometrische Funktionen Als Ergebnis erhält man die nachfolgenden Werte: Sinus Kosinus Tangens Kotangens --------- --------- -------- -----------------0 1 0 0,642092615934331 Die Zufallszahlenfunktion RAND() bietet im Gegensatz zu den anderen Funktionen sicherlich einen größeren Einsatzbereich, wenn es bspw. darum geht, Testdaten zu erzeugen oder sonstiges zufälliges Verhalten zu implementieren. Sie tritt in zwei Varianten auf. In der parameterlosen Variante liefert die Zufallszahlenfunktion Werte auf Basis eines vom System zufällig bestimmten Ausgangswertes. Dieser Ausgangswert ist wichtig, da die Zufallszahlenfunktion auf Basis desselben Ausgangswertes auch die gleichen Ergebnisse liefert. In der Variante mit Parameter kann dieser Ausgangswert vorgegeben werden. Für die Verwendung ist zu beachten, dass der gleiche Aufruf mit gleichem Ausgangswert immer die gleichen Zufallszahlen liefert, sodass das Zufallsexperiment wiederhol- 137 Einfache Abfragen bar bleibt und die gleiche Zahlenfolge liefert. Dies lässt sich sehr schön am ersten Teil des Beispiels erkennen, wenn man nur diesen Teil mehrfach ausführt. Im zweiten Teil des Beispiels erstellt man ein kleines Transact-SQL-Programm. Zunächst gibt es zwei Wertespeicher für Zufallszahlen bis 10 und 100 sowie einen Zählerwert, der bei 1 beginnt. Die beiden Wertespeicher stellen einfache Zeichenketten dar, in die nacheinander die Zufallszahlen abgelegt werden sollen. Um Zufallszahlen bis 10 zu erzeugen, muss man die durch RAND() erzeugte Zahl mit 10 multiplizieren, genauso wie bei einer Zufalls im Bereich zwischen 1 und 100 den Faktor 100 verwenden muss. Dies verschiebt eine erzeugte Zufallszahl zwischen 0 und 1 in den Bereich 1 bis 100. Um dann nur noch Ganzzahlen zu erhalten, muss man in jedem Fall einfach runden. Um die Zahlen überhaupt als Zeichenkette verarbeiten zu können, ist es zudem notwendig, sie mit der STR()-Funktion in eine Zeichenkette umzuwandeln. SELECT RAND(100) AS Zufall1, RAND(100) AS [Zufall2=1], RAND() AS Z3, RAND() AS Z4 DECLARE @i int, @bisZehn VARCHAR(100), @bisHundert VARCHAR(100) SELECT @i = 1, @bisZehn = '', @bisHundert = '' WHILE @i < 10 BEGIN SET @i = @i+1 SET @bisZehn = @bisZehn + LTRIM(STR(ROUND(RAND()*10,0))) + ' | ' 138 Einfache Abfragen SET @bisHundert = @bisHundert + LTRIM(STR(ROUND(RAND()*100,0))) + ' | ' END PRINT @bisZehn PRINT @bisHundert 242_03.sql: Zufallszahlen Man erhält als Ergebnis die nachfolgenden Zeilen. Bemerkenswert ist die Tatsache, dass gleicher Startwert zu gleichen Zufallszahlen fügt, was man sehr schön in der ersten Ausgabe in den beiden ersten Spalten erkennen kann. Die letzten beiden Zeilen stellen die ermittelten und in einer Zeichenkette gespeicherten Zufallszahlen zwischen 1 und 10 sowie 1 und 100 dar. Zufall1 Zufall2=1 Z3 ---------------------- ---------------------- --------------0,715436657367485 0,715436657367485 0,28463380767982 Z4 ---------------------0,0131039082850364 3 | 3 | 4 | 7 | 2 | 4 | 4 | 9 | 2 | 10 | 87 | 58 | 30 | 82 | 29 | 62 | 23 | 68 | Die nachfolgenden Beispiele erstellen aus Bogenmaß wieder Gradzahlen und beschreiten den umgekehrten Weg. 139 Einfache Abfragen SELECT DEGREES((PI()/4)) AS [Bogen->Grad] SELECT RADIANS(90) AS [Grad->Bogen], RADIANS(50) AS [Grad->Bogen] 242_04.sql: Grad und Bogenmaß 2.4.3 Zeichenkettenfunktionen Während die gerade gezeigten trigonometrischen Funktionen sicherlich in einer kaufmännischen Anwendung nicht gerade zu den absoluten Schlaglichtern im Rahmen von Abfragen gehören, sondern ihr Einsatz eher für technische Daten und Spezialfälle aufgespart bleibt, sind die Zeichenkettenfunktionen wesentlich häufiger im Einsatz. Sie erlauben die Formatierung von Zeichenketten sowie die Auswahl von Teilen eines Zeichenkettenwerts. Neben diesem sehr häufigen Anwendungsfall lässt sich auch noch an die Entfernung oder das Hinzufügen von Leerzeichen sowie das Ersetzen von Werten denken. 2.4.3.1 Referenz Folgende Funktionen sind in dieser Kategorie verfügbar: ASCII liefert den ASCII-Codewert des ersten Zeichens einer Zeichenkette. Syntax: ASCII ( character_expression ) CHAR liefert aus einem ASCII-Codewert als Ganzzahl ein Zeichen. Syntax: CHAR ( integer_expression ) liefert die Startposition des Suchausdrucks innerhalb einer Zeichenkette zurück. CHARINDEX Syntax: CHARINDEX ( expression1 ,expression2 [ , start_location ] ) 140 DIFFERENCE liefert den Unterschied zweier SOUNDEX-Werte als Ganzzahl. Einfache Abfragen Syntax: DIFFERENCE ( character_expression , character_expression ) LEFT liefert den linken Teil einer Zeichenfolge mit der angegebenen Menge an Zeichen. Syntax: LEFT ( character_expression , integer_expression ) LEN liefert die Zeichenanzahl einer Zeichenkette ohne nachfolgende Leerzeichen. Syntax: LEN ( string_expression ) LOWER wandelt die Zeichenkette in Kleinbuchstaben um. Syntax: LOWER ( character_expression ) LTRIM liefert eine Zeichenkette ohne führende Leerzeichen. Syntax: LTRIM ( character_expression ) NCHAR liefert das Unicode-Zeichen auf Basis eines ganzzahligen Codes. Syntax: NCHAR ( integer_expression ) PATINDEX liefert die Position des ersten Auftretens des angegebenen Musters in der Zeichenkette. Syntax: PATINDEX ( '%pattern%' , expression ) QUOTENAME liefert eine Unicode-Zeichenkette mit zusätzlichen Trennzeichen, sodass ein gültig begrenzter Bezeichner entsteht. Syntax: QUOTENAME ( 'character_string' [ , 'quote_character' ] ) REPLACE liefert eine Zeichenkette, in der die Fundstellen der zweiten Zeichenkette in der ersten durch die dritte Zeichenkette ersetzt wurden. Syntax: REPLACE ( 'string_expression1' , 'string_expression2' , 'string_expression3' ) 141 Einfache Abfragen REPLICATE wiederholt eine Zeichenkette. Syntax: REPLICATE ( character_expression ,integer_expression ) REVERSE kehrt eine Zeichenkette um. Syntax: REVERSE ( character_expression ) RIGHT liefert den rechten Teil einer Zeichenfolge mit der angegebenen Menge an Zeichen. Syntax: RIGHT ( character_expression , integer_expression ) RTRIM liefert eine Zeichenkette ohne folgende Leerzeichen. Syntax: RTRIM ( character_expression ) SOUNDEX liefert eine vierstellige Zeichenkette, welche die Ähnlichkeit von zwei Zeichenketten angibt. Syntax: SOUNDEX ( character_expression ) SPACE liefert eine Zeichenfolge aus mehreren Leerzeichen. Syntax: SPACE ( integer_expression ) STR wandelt Daten in Zeichenkette um. Syntax: STR ( float_expression [ , length [ , ] ] ) STUFF ersetzt in einer Zeichenkette einen Bereich durch eine andere Zeichenkette. Syntax: STUFF ( character_expression , start , length ,character_expression ) SUBSTRING liefert eine Teilzeichenausdruck ab der Startposition für eine angegebene Länge zurück. Syntax: SUBSTRING ( expression ,start , length ) 142 UNICODE liefert den Unicode-Codewert des ersten Zeichens einer Zeichenkette. Einfache Abfragen Syntax: UNICODE ( 'ncharacter_expression' ) UPPER wandelt die Zeichenkette in Großbuchstaben um. Syntax: UPPER ( character_expression ) 2.4.3.2 Beispiele Die Zeichenkettenfunktionen sind überaus einfach zu verwenden und bieten eine große Anwendungsvielfalt. Die nachfolgenden Beispiele erklären sich weitestgehend selbst. Es wird eine längere Zeichenkette in einer Variable gespeichert, aus der ein Teil ausgewählt und in einer anderen Zeichenkette gespeichert wird. Dann gibt man die kürzere Zeichenkette in Groß- und Kleinbuchstaben aus, kehrt die Reihenfolge der Buchstaben um, ersetzt das kleine M durch ein kleines N, löscht die Leertasten auf der rechten Seite der längeren Zeichenkette und ersetzt schließlich ab der Stelle 5 die nächsten 20 Zeichen durch die Zeichenkette wo. Insbesondere die beiden Ersetzungsmethoden sollte man vergleichen, denn während REPLACE() jedes einzelne Vorkommen einer Testzeichenkette ersetzt, ist es mit STUFF() möglich, einen numerisch beschriebenen Bereich durch eine Zeichenkette verschiedener Länge zu ersetzen. DECLARE @text1 varchar(200), @text2 varchar(200), @zahl int SET @text1 = 'Ene, mene, muh, und weg bist du. ' SET @text2 = SUBSTRING(@text1, 11, 4) SET @zahl = 12345 SELECT LEN(@text1) AS Länge, LOWER(@text2) AS Klein, UPPER(@text2) AS GROSS, REVERSE (@text2) AS Spiegel, 143 Einfache Abfragen REPLACE ( @text2 , 'm' , 'n' ) AS Ersatz1, RTRIM(@text1) AS LZweg, @text2 + SPACE(3) + @text2 AS LZhinzu, STUFF (@text1, 5, 20, 'wo ') AS Ersatz2 243_01.sql: Verwendung einfacher Zeichenkettenfunktionen Man erhält die verschiedenen malträtierten und umgewandelten Zeichenketten in der Ergebnismenge zurück. Länge Klein GROSS Spiegel Ersatz1 LZweg ------ ------ ------ --------- -------- ---------------- 32 ... weg bist du. muh LZhinzu MUH hum nuh Ersatz2 --------- ---------muh muh Ene,wo bist du. Bisweilen kann es interessant sein, Buchstaben in ASCII-Werten vorliegen zu haben und aus diesen Werten wieder Buchstaben zu generieren oder aus existierenden Buchstaben ASCII-Werte zu erstellen. Dies zeigt das nachfolgende Beispiel, welches ein ähnliches Beispiel aus der Dokumentation aufgreift. Die Zeichenkette Hallo Welt soll mit Hilfe einer Schleife durchwandert werden, wobei jeder Buchstaben in einen ASCIIWert umgewandelt wird, um diesen in einer anderen Zeichenkette zu speichern. Gleichzeitig soll aber auch gezeigt werden, wie man aus einem solchen Wert wieder einen Buchstaben macht, sodass in einem anderen Schritt an diese Umwandlung wieder eine Rückumwandlung in einen Buchstaben angeschlossen wird. Die beiden Funktionen ASCII() für die Umwandlung in einen ASCII-Wert und CHAR() für die Rückumwand- 144 Einfache Abfragen lung sowie die Funktionen STR() für die Umwandlung einer Zahl in eine Zeichenkette wie auch LEN() für die Ermittlung der Länge einer Funktion sind hierbei notwendig. DECLARE @text varchar(200), @ausgabeASCII varchar(200), @ausgabeVARCHAR varchar(200), @position int SELECT @text = 'Hallo Welt.', @ausgabeASCII = '', @ausgabeVARCHAR = '', @position = 1 -- Wanderung durch einzelne Zeichen WHILE @position <= LEN(@text) BEGIN -- Umwandlung in ASCII SET @ausgabeASCII = @ausgabeASCII + LTRIM(STR(ASCII(SUBSTRING(@text, @position, 1)))) + '|' -- Umwandlung von Zeichen -> ASCII -> Zeichen SET @ausgabeVARCHAR = @ausgabeVARCHAR + CHAR(ASCII(SUBSTRING(@text, @position, 1))) SET @position = @position + 1 END -- Ausgabe PRINT @ausgabeASCII PRINT @ausgabeVARCHAR 145 Einfache Abfragen 243_02.sql: Umwandlung nach ASCII und zurück Man erhält schließlich zwei Zeichenketten mit dem ursprünglichen Wert der bearbeiteten Zeichenkette und den einzelnen Buchstaben in ASCII-Nummern. 72|97|108|108|111|32|87|101|108|116|46| Hallo Welt. Schließlich folgt noch einmal eine Reihe von Zeichenkettenfunktionen, die aus Platzgründen nicht in den vorherigen Beispielen untergebracht werden konnten. Dabei ist QUOTENAME() besonders hervorzuheben und möglicherweise häufiger im Einsatz als die beiden Ähnlichkeitsfunktionen. QUOTENAME() erstellt aus einer beliebigen Zeichenkette mit bspw. Leertaste oder eckigen Klammern einen gültigen Bezeichner, d.h. umschließt die Bestandteile der Zeichenkette mit entsprechenden Entwerterzeichen. Die Funktion CHARINDEX() kann auch nützliche Dienste leisten, da sie innerhalb einer Zeichenkette oder erst ab einer bestimmten Position in einer Zeichenkette die Position eines angegebenen Zeichens ermittelt. SOUNDEX() bietet die Möglichkeit, eine Zeichenkette in eine alphanumerische Zeichenfolge umzuwandeln, welche es für die englische Sprache ermöglichen soll, Wörter aufgrund ihrer ähnlichen Aussprache zu vergleichen. Der Algorithmus besteht aus folgenden Schritten: 1. Der erste Buchstabe bleibt erhalten. 2. Die Buchstaben a, e, h, i, o, u, w, y werden entfernt, sofern es sich nicht um den ersten Buchstaben handelt. 3. Den Buchstaben werden folgende Zahlen zugeordnet: b, f, p, v ersetzt man durch 1, c, g, j, k, q, s, x, z ersetzt man durch 2, d, t ersetzt man durch 3, l ersetzt man durch 4, m und n ersetzt man durch 5, r ersetzt man durch 6. 4. Doppelte Werte sollen gestrichen werden. 5. Nur die ersten vier Bytes werden zurückgeliefert und werden mit 0-Werten aufgefüllt. Wie man sich denken kann, gibt es viele verschiedene Varianten und Verbesserungen dieses Verfahrens, um ähnliche Zeichenketten leicht zu identifizieren oder überhaupt die Ähnlichkeit abzubilden. Die beiden Entwickler dieser Methode sind Robert Russel und Margaret Odell im Jahre 1918. 146 Einfache Abfragen Die DIFFERENCE()-Funktion ermittelt eine Ganzzahl, der den Unterschied ausdrückt, der zwischen zwei SOUNDEX-Werten vorhanden ist. Diese Zahl liegt zwischen 0 und 4, wobei 0 auf eine geringe und 4 auf eine hohe Ähnlichkeit zwischen zwei Zeichenketten hinweist. SELECT QUOTENAME('Bez{}eich ner[]') AS Bezeichner, CHARINDEX ('l', 'Hallihallo' , 5 ) AS Position, DIFFERENCE ( 'Welle' , 'Kelle' ) AS U1, DIFFERENCE ( 'Eins' , 'Zwei' ) AS U2, DIFFERENCE ( 'x' , 'u' ) AS U3, SOUNDEX('Welle') AS U4, SOUNDEX('Kelle') AS U5, SOUNDEX('Eins') AS U6, SOUNDEX('Zwei') AS U7 243_03.sql: Weitere Zeichenkettenfunktionen Man erhält die nachfolgenden Werte. Bezeichner Pos U1 U2 U3 U4 U5 U6 U7 ------------------- ------ ------ --- --- ----- ----- ---- [Bez{}eich ner[]]] 2.4.4 8 3 1 3 W400 K400 E520 Z000 Systemfunktionen Die Systemfunktionen sind zwar sehr zahlreich, werden allerdings hier mehr der Vollständigkeit halber erwähnt. Sie sind zwar für den Programmierer, der administrative Aufgaben mit T-SQL erledigt, sehr nützlich, doch ist dies nicht die Perspektive dieses Buches. 147 Einfache Abfragen Folgende Funktionen sind u.a. in dieser Kategorie verfügbar: APP_NAME (nicht deterministisch) prüft, ob die aktuelle Sitzung vom Typ SQL Server Management Studio ist. Syntax: APP_NAME ( ) CAST und CONVERT (deterministisch außer bei datetime, smalldatetime oder sql_variant) wandelt einen Ausdruck in einen anderen Datentyp um. Syntax: CAST ( expression AS data_type [ (length ) ]) und CONVERT ( data_type [ ( length ) ] , expression [ , style ] ) COALESCE (deterministisch) prüft n verschiedene Ausdrücke darauf, ob sie den Wert NULL haben. Ist dies bei einem der aufgelisteten Ausdrücke der Fall, wird der für diesen Fall angegebene Ausdruck ausgeführt. Sollte kein Ausdruck NULL sein, dann liefert diese Funktion NULL zurück. Die gleiche Fallunterscheidung lässt sich daher auch mit einer CASEAnweisung ausdrücken: CASE WHEN (ausdruck1 IS NOT NULL) THEN ausdruck1 WHEN (ausdruckN IS NOT NULL) THEN ausdruckN ELSE NULL END Syntax: COALESCE ( expression [1,...n ] ) 148 COLLATIONPROPERTY (nicht deterministisch) liefert den Namen der in der Datenbank verwendeten Sortierung im Datentyp nvarchar(128) zurück. Mögliche Werte sind: CodePage für Nicht-Unicode-Codepage, LCID für Windows-LCID, ComparisonStyle für die Windows-Vergleichstechnik, Version für die Sortierungsversion mit den Werten 1 für MS SQL Server 2005-Sortierverfahren und 0 für frühere Sortierverfahren. Einfache Abfragen Syntax: COLLATIONPROPERTY( collation_name , property ) COLUMNS_UPDATED (nicht deterministisch) Syntax: COLUMNS_UPDATED ( ) (nicht deterministisch) ist ein Alias der Funktion GETDATE() und liefert das aktuelle Datum und die aktuelle Uhrzeit. CURRENT_TIMESTAMP Syntax: CURRENT_TIMESTAMP CURRENT_USER (nicht deterministisch) liefert den Namen des aktuellen Benutzers. Syntax: CURRENT_USER DATALENGTH (Deterministisch) liefert die Byteanzahl zurück, die für die Ausgabe und Darstellung des angegebenen Ausdrucks notwendig sind. Syntax: DATALENGTH ( ausdruck ) fn_servershareddrives (nicht deterministisch) liefert eine Übersicht über freigegebene Laufwerke, welche zur selben Clustergruppe gehören, zu der auch der aktuelle MS SQL Server gehört. 149 Einfache Abfragen 150 Komplexe Abfragen 3 Komplexe Abfragen 151 Komplexe Abfragen 152 Komplexe Abfragen 3 Komplexe Abfragen Während die Abfragen des letzten Kapitels ausschließlich immer eine einzige Tabelle bearbeiteten und von den syntaktischen Möglichkeiten der Abfragegestaltung bei Weitem noch nicht alles ausgeschöpft haben, was überhaupt an SQL-Syntax im SQL Server in spezieller Weise oder im SQL-Standard als solchem bereit steht, soll dieses Kapitel nun zeigen, wie man Daten aus mehreren verknüpften Tabellen abruft, Unterabfragen formuliert und erweiterte Aggregate erzeugt. 3.1 Verknüpfungen Das Prinzip des relationalen Modells liegt gerade darin, dass die Objekte der realen Welt mit einzelnen Entitäten (Relationen) abgebildet werden. Sie besitzen jeweils einen Primärschlüssel, der aus einem oder mehreren Feldern besteht. Die Verbindungen zwischen den einzelnen Tabellen richtet die so genannte Primärschlüssel-FremdschlüsselBeziehung ein. Dabei erscheint der Schlüsselwert einer Primärschlüsselspalte in einer anderen Tabelle als so genannter Fremdschlüssel und erlaubt über die Verknüpfung mit der anderen Tabelle bzw. einer Lektüre der zu diesem Schlüsselwert passenden Zeile der anderen Tabelle, die zusätzlichen Informationen dieser anderen Tabelle abzurufen. Dieses Prinzip ist in allen relationalen Datenbanken umgesetzt und führt dazu, dass möglichst keine redundanten Daten gespeichert werden. Dies bezieht sich auf die verknüpften Daten, die ja in ihrer jeweiligen Merkmalsausprägung für die einzelnen Spalten nur einmal erscheinen, aber in der Tabelle, die den Fremdschlüssel enthält, mehrfach verknüpft sein können. 3.1.1 Manuelle Verknüpfungen Es gibt zwei Möglichkeiten, Tabellen miteinander zu verknüpfen, von denen die in diesem Abschnitt beschriebene manuelle Verknüpfung die ungünstigere von beiden Varianten ist, da sie weniger gut lesbar ist und insgesamt fehleranfälliger ist. Da allerdings die ANSI-SQL-Verknüpfungstechnik in vielen bestehenden Anwendungen immer 153 Komplexe Abfragen noch diese Verknüpfungstechnik verwendet wird, da sie vor einigen Jahren noch nicht so verbreitet im Einsatz war oder von Datenbanken nicht unterstützt wurde, soll zunächst diese Technik vorgeführt werden. Er soll allerdings nur dazu dienen, ein allgemeines Verständnis für die Verknüpfungstechnik als solche zu fördern und die Lektüre bestehender SQL-Skripte zu ermöglichen, aber in keinem Fall dazu führen, sie auch zu verwenden. 3.1.1.1 Einfache Verknüpfung Bislang war es nicht möglich, zu einem Angestellten auch Vor- und Nachname abzurufen, weil in der Tabelle Employee nur allgemeine Informationen zum Angestellten als solchen gespeichert waren, und die Informationen zu seiner Person, die er mit anderen Personenarten wie bspw. externem Verkaufspersonal gemeinsam hatte, in einer zentralen Tabelle Contact gespeichert waren. Zwischen diesen beiden Tabellen besteht eine so genannte 1:1-Verknüpfung, da jeweils ein Datensatz aus der Employee-Tabelle mit genau einem Datensatz aus der Contact-Tabelle über die Spalte ContactID der Employee-Tabelle verbunden ist. Diese ContactID ist in der Employee-Tabelle der Fremdschlüssel und in der Tabelle Contact dagegen der Primärschlüssel. Bei einer Verknüpfung von beiden Tabellen ist also genau der Datensatz aus Contact auszuwählen, der den gleichen Wert in der ContactID-Spalte besitzt wie in der EmployeeTabelle. Dies ist das Grundprinzip des so genannten Equijoins, da hier über die Gleichheit abgefragt wird. Syntaktisch richtet man eine solche Verknüpfung manuell in der FROM- und WHEREKlausel ein. In der Tabellenliste der FROM-Klausel schreibt man ganz einfach die Tabellen, aus denen gleichzeitig Daten abgerufen werden sollen, in einer Komma-getrennten Liste nieder. Da in diesem Datenmodell die Tabellen einen langen Namen aufweisen und zudem in einzelnen Schemata untergebracht sind, ist es hier lohnenswert, so genannte Tabellenaliase zu vergeben, die einen deutlich kürzeren Namen aufweisen. Sie ermöglichen dann später in der WHERE-Klausel einen deutlich vereinfachten Zugriff auf die Primärschlüssel-/Fremdschlüssel-Spalten, welche als Bedingung gleichgesetzt werden. 154 Komplexe Abfragen In natürlicher Sprache könnte man sich dieses Vorgehen so vorstellen: „Wähle die Spalten FirstName, LastName und HireDate aus den beiden Tabellen Employee, die mit der Abkürzung emp angesprochen werden soll, und der Tabelle Contact, die mit der Abkürzung con angesprochen werden soll, für die Datensätze aus, welche in beiden Tabellen die gleiche ContactID aufweisen. Als Filter soll gelten, dass nur Mitarbeiter mit einem Nachname kleiner B ausgewählt werden sollen.“ Innerhalb der WHERE-Klausel besitzt man also zwei verschiedene Arten von Bedingungen: Zum einen eine Verknüpfungsbedingung, welche die ContactID-Spalten beider Tabellen gleich setzt, und zum anderen eine inhaltliche Filterung/Einschränkung wie er auch in einer gewöhnlichen Abfrage mit Blick auf eine Tabelle erscheinen würde. -- Angestellte mit Kontaktdaten SELECT FirstName, LastName, HireDate FROM HumanResources.Employee AS emp, Person.Contact AS con WHERE emp.ContactID = con.ContactID AND LastName < 'B' 311_01.sql: Verknüpfen von zwei Tabellen Als Ergebnis erhält man neben den Informationen aus der Employee-Tabelle auch die Informationen aus der Contact-Tabelle. Die Anzahl der Datensätze entspricht dabei aufgrund der 1:1-Verknüpfung der Anzahl der auch ansonsten beim Filter auf den Nachnamen ausgewählten Datensätzen. Allerdings müsste man dafür in der ContactTabelle wissen, welche Kontakte für Mitarbeiter gelten. FirstName LastName HireDate ------------- ------------- ----------Greg Alderson 1999-01-03 Sean Alexander 1999-01-29 155 Komplexe Abfragen ContactID HireDate ----------- ----------------------1076 1998-02-07 00:00:00.000 1173 1999-01-03 00:00:00.000 1270 1999-01-29 00:00:00.000 1050 1999-01-30 00:00:00.000 ContactID FirstName LastName ----------- ------------------------ --------------------1173 Greg Alderson 1270 Sean Alexander 1304 Sean Alexander FirstName LastName HireDate ------------------------ ------------------------ ---------------------------------Greg Alderson 1999-01-03 00:00:00.000 Sean Alexander 1999-01-29 00:00:00.000 Abbildung 3.1: Verknüpfung von Tabellen 3.1.1.2 Qualifizierte Spaltennamen Im vorherigen Kapitel wurden die qualifizierten Spaltennamen eingeführt, die aus Gründen der Syntaxvorstellung sehr gut an die dort gewählte Stelle passten, aber leider keinen besonderen Nutzen stifteten, außer einen Spannungsbogen aufzubauen, der nun seinen Höhepunkt findet. Sollten nämlich durch die Verknüpfung zwei Spalten den gleichen Namen erhalten und beide in der Ergebnismenge ausgegeben werden bzw. werden gleichnamige Spalten verknüpft, dann muss man angeben, aus welcher Tabelle diese Spalten stammen. Dies hat man auch schon im vorherigen Beispiel in der Zeile WHERE emp.ContactID = con.ContactID gesehen. Im nachfolgenden Beispiel verhält es sich so, dass jeweils eine Title-Spalte in der Employee- und in der Contact-Tabelle vorhanden ist, von denen die eine die Anrede und die andere die Position im Unternehmen bezeichnet. Um nun in der Spaltenliste anzugeben, welche von beiden Spalten im Ergebnis angezeigt werden soll, oder um in der WHERE-Klausel eine bestimmte Einschränkung auf eine von beiden Spalten vorzunehmen, muss man die jeweiligen Spaltennamen qualifizieren. Dies gelingt entweder über den gewöhnlichen Tabellennamen oder bei sehr langen Namen über den Tabellenalias. -- Angestellte mit Kontaktdaten SELECT emp.Title, con.Title, LastName 156 Komplexe Abfragen FROM HumanResources.Employee AS emp, Person.Contact AS con WHERE emp.ContactID = con.ContactID AND con.Title IS NOT NULL 311_02.sql: Doppelte Spaltennamen Title LastName ContactID -------- -------------------------- ----------Ms. Erickson 1005 Mr. Goldberg 1006 Ms. Galvin 1008 Mr. Welcker 1010 NULL Saraiva 1020 NULL Brown 1030 Ms. Williams 1035 Mr. Ting 1088 ContactID Title ----------- -------------------------------------------------1005 Design Engineer 1006 Design Engineer 1035 Marketing Specialist 1032 Marketing Specialist 1088 Production Technician - WC20 1008 Tool Designer 1025 Sales Representative Title Title ContactID LastName -------- -------------------------------------------------- ------------- --------------------------Ms. Design Engineer 1005 Erickson Mr. Design Engineer 1006 Goldberg Ms. Marketing Specialist 1035 Williams Mr. Production Technician - WC20 1088 Ting Ms. Tool Designer 1008 Galvin Mr. Vice President of Sales 1010 Welcker Mr. Sales Representative 1027 Mensa-Annan Mr. Pacific Sales Manager 1012 Abbas Abbildung 3.2: Funktionsweise der qualifizierten Spaltennamen Im Ergebnis erhält man die beiden unterschiedlichen Title-Spalten im Ergebnis. Title Title LastName --------------------- -------- ---------Design Engineer Ms. Erickson Design Engineer Mr. Goldberg 157 Komplexe Abfragen Sollte man die Qualifizierung in der WHERE-Klausel oder in der Spaltenliste vergessen, dann ist die Fehlermeldung überaus deutlich und lautet: Meldung 209, Ebene 16, Status 1, Zeile 2 Mehrdeutiger Spaltenname 'Title'. 3.1.1.3 Mehrfache Verknüpfung Für gewöhnlich reicht bei einem großen Datenmodell die Verknüpfung von nur zwei Tabellen überhaupt nicht aus, um die interessanten Daten zu beschaffen. Daher müssen meistens mehr als zwei Tabellen verbunden werden. Dies gelingt ganz einfach dadurch, indem man die Tabellenliste in der FROM-Klausel um weitere Tabellen und ihre Aliasnamen ergänzt und in der WHERE-Klausel die entsprechenden Bedingungen mit AND anhängt. So verknüpft die nachfolgende Abfrage insgesamt vier Tabellen, nämlich Employee, Contact, EmployeeDepartmentHistory und Shift, um herauszufinden, welcher Angestellte auf welcher Schicht eingesetzt ist. -- Angestellte mit Kontaktdaten, Schicht SELECT emp.EmployeeID, emp.Title, LastName, StartTime, EndTime FROM HumanResources.Employee AS emp, Person.Contact AS con, HumanResources.EmployeeDepartmentHistory AS edh, HumanResources.Shift AS sh WHERE emp.ContactID = con.ContactID AND emp.EmployeeID = edh.EmployeeID AND edh.ShiftID = sh.ShiftID AND emp.EmployeeID = 119 158 Komplexe Abfragen 311_03.sql: Verknüpfung mit mehreren Tabellen Man erhält für den Mitarbeiter 119 seine Arbeitszeiten und seinen Vor- und Nachnamen in einer einzigen Ergebnismenge. EmployeeID Title LastName StartTime EndTime ----------- -------------- ----------- ------------ -------119 3.1.1.4 Marketing ... Williams 07:00:00 15:00:00 Ungewollte Kreuzverknüpfung Die manuelle Verknüpfung ist zwar von der Syntax her einfacher zu verstehen als die im nächsten Abschnitt vorgestellte ANSI-SQL-Verknüpfung, doch birgt sie die Gefahr einer ungewollten Kreuzverknüpfung, die auch unter dem Namen kartesisches Produkt berühmt und berüchtigt ist. Bisweilen möchte man sogar ein solches kartesisches Produkt ausdrücklich einrichten, doch die Anwendungsfälle dafür sind deutlicher seltener als die ungewollte Erzeugung. Der Fehler entsteht, wenn ganz einfach in der WHERE-Klausel eine der notwendigen Verknüpfungsbedingungen fehlt. Im Normalfall hat man bei n Tabellen n-1 Verknüpfungsbedingungen, sofern immer nur ein Primärschlüssel-/Fremdschlüsselfeld an jeder Verknüpfung teilnehmen, ansonsten natürlich dementsprechend mehr Bedingungen. Vergisst man eine von diesen Bedingungen, dann enthält die Ergebnismenge die Kombinationen von allen Werten der korrekt verknüpften Tabellen mit den Datensätzen der nicht korrekt verknüpften Tabellen also bei fehlendem sonstigen Filter das Produkt aus Zeilenzahl (Kardinalität) der einen Zwischenergebnismenge oder Tabelle und der Zeilenzahl der aufgezählten, aber nicht verknüpften Tabellen. Es entstehen also ungewollt besonders umfangreiche Ergebnismengen, die syntaktisch richtig, aber inhaltlich völlig falsch, da sie Werte enthalten, die nicht einmal in der Datenbank so gespeichert waren. Wie man sich leicht denken kann, ist eine solche syntaktisch richtige und logisch falsche Ergebnismenge sehr gefährlich, da man bei Unkenntnis des ungefähren Umfangs der Ergebnismenge durch Schätzung zu völlig falschen Ergebnissen kommt. Insbesondere bei großen Datenbanken mit umfangreicher Tabellenzahl, die zudem auch noch 159 Komplexe Abfragen sehr gut normalisiert sind, hat man oft nur noch Zahlen in der Ergebnismenge und wenige Zeichenketten, die möglicherweise helfen würden, zu erkennen, dass die Anzahl der Datensätze für einen bestimmten Sachverhalt der abgebildeten Welt völlig ausgeschlossen ist. Der Grund, warum zu Beginn dieses Abschnitts die manuellen Verknüpfung nicht empfohlen wurde, liegt nun gerade darin, dass man natürlich bei sehr vielen Tabellen und möglicherweise umfangreichen Filtern immer schneller in die Gefahr gerät, tatsächlich eine Verknüpfungsbedingung zu vergessen. Es findet kein syntaktischer Schutz statt bzw. man kann im Gegensatz zu den ANSI-SQL-Verknüpfungen auch gar nicht ausdrücklich angeben, mit welcher Art von Verknüpfung nun die Tabellen verbunden werden sollen. Durch die Vermischung von Verknüpfungsbedingungen und einschränkenden/filternden Bedingungen in der WHERE-Klausel kann man nicht ausreichend unterscheiden, welche Bedingung zur einen oder anderen Gruppe gehört bzw. ob alle notwendigen Verknüpfungsbedingungen vorhanden sind. Die nächste Abfrage erzeugt eine solche ungewollte Kreuzverknüpfung, um das deutliche und unschöne Ergebnis vorzuführen. Dabei listet die FROM-Klausel ganz einfach die beiden Tabellen EmployeDepartmentHistory und Shift auf, ohne überhaupt eine Verknüpfungsbedingung anzugeben. Stattdessen begrenzt die WHERE-Klausel die Datensätze nur auf die Angestelltennummer kleiner drei. SELECT edh.EmployeeID, edh.ShiftID, sh.ShiftID, sh.StartTime FROM HumanResources.EmployeeDepartmentHistory AS edh, HumanResources.Shift AS sh WHERE edh.EmployeeID <3 311_04.sql: Ungewollte Kreuzverknüpfung Man erhält ein Ergebnis, in dem man deutlich sehen kann, wie die Gruppe aus EmployeeID und Schichtnummer aus der EmployeeDepartmentHistory-Tabelle mit allen 160 Komplexe Abfragen verfügbaren Schichtnummern aus der Shift-Tabelle verknüpft werden. Dies ist genau das kartesische Produkt, das sicherlich inhaltlich völlig unnütz ist. EmployeeID ShiftID ShiftID StartTime ----------- ------- ------- -----------1 1 1 07:00:00.000 1 1 2 15:00:00.000 1 1 3 23:00:00.000 2 1 1 07:00:00.000 2 1 2 15:00:00.000 2 1 3 23:00:00.000 3.1.2 ANSI-SQL-Verknüpfungen Während die manuellen Verknüpfungen nur für das Leseverständnis von älteren Skripten vorgestellt wurden, sollen nun die ANSI-SQL-Verknüpfungen auch als richtige Technik vorgestellt und ausführlicher behandelt werden. Die besondere Verbesserung der ANSI-SQL-Verknüpfungen besteht nun daraus, dass sowohl die Tabellen, aus denen die Daten übernommen werden sollen, als auch die Verknüpfungsbedingungen komplett in der FROM-Klausel stehen. Dadurch enthält die WHERE-Bedingung nur noch die einschränkenden Bedingungen. Dies verhindert ein ungewolltes Vergessen von Verknüpfungsbedingungen, da diese vollständig in der FROM-Klausel erwartet werden. 3.1.2.1 Innere Verknüpfung Die zuvor vorgestellten Verknüpfungen lassen sich in ANSI-SQL-Syntax mit einer so genannten inneren Verknüpfung und Gleichheitsverbindung (häufigster Fall) abbilden. Dabei prüft die innere Verknüpfung darauf, dass nur die Datensätze in die Ergebnismenge übernommen werden, die in beiden verknüpften Tabellen einen Treffer haben, d.h. die Verknüpfungsbedingung erfüllen. Die Syntax für die innere Verknüpfung er- 161 Komplexe Abfragen wartet, dass zunächst die erste Tabelle genannt und möglicherweise umbenannt wird. Dann folgt die Klausel INNER JOIN und die zweite Tabelle mit optionalem Aliasnamen. Die ansonsten auch in der manuellen Verknüpfung angegebene Verknüpfungsbedingung folgt dann nach dem Schlüsselwort ON. Das nachfolgende Beispiel verknüpft die beiden Tabellen SalesPerson und SalesTerritory miteinander, um die Nummer des Verkäufers und seine Verkaufsregion sowie das übergeordnete Gebiet dieser Verkaufsregion herauszufinden. Dabei müssen die beiden TerritoryID-Spalten in beiden Tabellen miteinander verbunden werden. -- Verkäufer, Gebiete und Länder SELECT sp.SalesPersonID, Name, [Group] FROM Sales.SalesPerson AS sp INNER JOIN Sales.SalesTerritory AS st ON sp.TerritoryID = st.TerritoryID 312_01.sql: Einfache Verknüpfung Man erhält die angekündigte Liste mit Verkäufernummer und Verkaufsgebiet. SalesPersonID Name Group ------------- -------------- ---------------275 Northeast North America 276 Southwest North America Möchte man mehrere Tabellen miteinander verknüpfen, dann schließt man mit weiteren INNER JOIN-Klauseln die benötigten Tabellen an. Die genaue Verknüpfungsbedingung spezifiziert man dann jeweils nach ON. Grundsätzlich gibt es keine Notwendigkeit, die Reihenfolge der Verknüpfung von der Reihenfolge der Tabellen oder von inhaltlichen Erwägungen abhängig zu machen. Es empfiehlt sich zwar, eine korrekte Reihenfolge 162 Komplexe Abfragen aus Gründen der besseren Lesbarkeit und Kontrolle einzuhalten, doch letztendlich zählt nur, dass alle benötigten Tabellen aufgerufen werden. Im nächsten Beispiel nimmt man zur gerade vorher gezeigten Abfrage noch die Tabelle SalesTerritoryHistory hinzu und schränkt die Ergebnisse auf eine einzige Ver- kaufsregion ein, um herauszufinden, welche verschiedenen Verkäufer diese Region bereisten oder bearbeiten. -- Verkäufer, Gebiete und Zeiten SELECT sp.SalesPersonID, Name, StartDate, EndDate FROM Sales.SalesPerson AS sp INNER JOIN Sales.SalesTerritoryHistory AS sth ON sp.SalesPersonID = sth.SalesPersonID INNER JOIN Sales.SalesTerritory AS st ON sth.TerritoryID = st.TerritoryID WHERE Name = 'Northwest' ORDER BY StartDate 312_02.sql: Mehrfache Verknüpfung Man erhält nun für die ausgewählte Region mehrere Verkäufer mit unterschiedlichen und teilweise anschließenden Einstiegs- und Ausstiegsdaten. SalesPersonID Name StartDate EndDate ------------- ---------------- ----------- ----------280 Northwest 2001-07-01 2002-10-31 283 Northwest 2001-07-01 NULL 287 Northwest 2002-11-01 NULL 163 Komplexe Abfragen 3.1.2.2 Äußere Verknüpfung Während die innere Verknüpfung nur die Datensätze aus der einen Tabelle übernimmt, die in der anderen Tabelle einen Partnerdatensatz finden, der über die Primärschlüssel/Fremdschlüssel-Verknüpfung zu finden ist, betrachtet die äußere Verknüpfung auch die Datensätze, die gerade keinen Partnerdatensatz finden. Die Abfragen, die u.a. mit einer äußeren Verknüpfung zu lösen sind, interessieren sich immer für alle Datensätze einer Tabelle, unabhängig davon, ob sie mit der anderen Tabellen verknüpft sind, oder sie fordern, nur die Datensätze anzuzeigen, die gerade keine Verknüpfung mit der anderen Tabellen aufweisen. Als syntaktische Alternative stehen in unterschiedlicher Weise auch die Mengenoperatoren zur Verfügung. Die natürlich-sprachliche Frage für das nächste Beispiel lautet daher: „Zeige alle Produkte an, die überhaupt gespeichert sind, und gebe – falls verfügbar – ihre zugehörigen Lagerplatznummer an.“ Hier kann man sich vorstellen, dass in der Tabelle Product eine umfangreiche Liste an Produkten enthalten ist, die überhaupt nicht mehr angeboten ist oder aus anderen Gründen nicht mehr auf Lager gehalten wird. Die Abfrage soll allerdings nicht nur die Produkte abrufen, die auch einen Lagerplatz und damit eine Verknüpfung zur Tabelle ProductInventory haben, sondern einfach alle Produkte, ganz unabhängig vom Lagerplatz. Ist allerdings ein solcher Lagerplatz verfügbar, dann soll er selbstverständlich angezeigt werden. Im direkten Vergleich zu einer inneren Verknüpfung erscheinen in der Ergebnismenge also mehr Datensätze. Das sind diejenigen, die in der Spalte ProductID der Tabelle ProductInventory nicht erscheinen. Sie erhalten als Wert eine NULL in der Ergebnismenge, da ja tatsächlich kein Wert für dieses Feld vorhanden ist. Die Abfrage wird als äußere Verknüpfung formuliert, indem man die allgemeine Syntax tabelle [LEFT | RIGHT] OUTER JOIN verwendet. In Seminaren ist nicht nur die äußere Abfrage an sich häufig ein großes Gesprächsthema und teilweise mit einigem Mythos umgeben, weil es schon einmal einen Kollegen gibt, der diese Abfragetechnik tatsächlich beherrscht und man sich erstaunlich viel unter einer äußeren Abfrage vorstellt. Eine gewisse Enttäuschung ist leider hier regelmäßig zu bemerken. So auch bei der Information, dass die Angabe LEFT oder RIGHT wirklich nichts anderes bedeutet als 164 Komplexe Abfragen die Information, welche von beiden Tabellen (die linke oder die rechte) die Wertedominanz erhalten soll, d.h. welche ihre Daten trotz fehlender Verknüpfung komplett in die Ergebnismenge übergeben soll. Im aktuellen Beispiel sollen alle Daten aus der Tabelle Product in der Ergebnismenge erscheinen. Daher hat die Tabelle Product Wertedominanz und man formuliert Product LEFT OUTER JOIN ProductInventory, wenn Product links steht, und ProductInventory RIGHT OUTER JOIN Product, wenn Product rechts steht. Um es also – wie im Seminar – noch einmal ganz deutlich zu formulieren: lediglich die Position der wertedominanten Tabelle entscheidet darüber, ob es LEFT oder RIGHT ist. Möglicherweise entsteht nun die Frage, wie man denn die wertedominante Tabelle erkennen könne. Sofern man die Abfrage so deutlich formuliert wie zuvor, dann sollte in dieser natürlich-sprachlichen Frage bereits deutlich zu erkennen sein, dass man überhaupt alle Produkte (und nicht nur die gekauften), alle Kunden (und nicht nur die, die auch in der Telefonsupport-Tabelle erscheinen) oder alle Mitarbeiter (und nicht nur die, die an einem Projekt beteiligt sind) abrufen will. Sollte dies nicht reichen, dann hilft ein kritischer Blick auf das Datenmodell. Im aktuellen Fall würde man die ProductTabelle auch als Eltern-Tabelle bezeichnen, weil die ProductInventory-Tabelle ihren Primärschlüssel als Fremdschlüssel enthält und mehrere Einträge in der ProductInventory-Tabelle Bezug zum gleichen Produkt haben können. Eine wertedominante ProductInventory-Tabelle ist eigentlich bei einer korrekten Funktionsweise der referenziellen Integrität (Primärschlüssel-Fremdschlüssel-Verknüpfung) nicht denkbar. Eine Abfrage würde hier bspw. lauten: „Zeige alle Lagerplätze, und – falls verfügbar – auch die zugehörigen Produkte an.“ Das klingt zunächst ganz logisch, wenn man voraussetzt, dass die ProductInventory-Tabelle alle möglichen Lagerplätze enthält. In Wirklichkeit zeigt aber ein Blick auf das Datenmodell, dass es sich hierbei um die Beziehungstabelle zwischen Product und Location handelt, wobei Location die überhaupt verfügbaren Lagerplätze speichert. Sofern also ein Datensatz in der ProductInventory-Tabelle erscheint und kein passendes Produkt mehr finden kann, stellt sich die Frage, wie überhaupt das zugehörige Produkt gelöscht werden könnte und warum bspw. eine automatische Lösch-Aktion in der ProductInventory-Tabelle nicht implementiert wurde und fehlgeschlagen ist. Dies ist allerdings eine Frage des Datenmo- 165 Komplexe Abfragen dells bzw. der Einrichtung der konkreten Tabellen und Thema eines ganz anderen Buchs (nämlich Administration und Grundlagen zu relationalen Datenbanken). -- Alle Produkte und mögliche Lagerplätze SELECT p.ProductID AS [P-ID], piv.ProductID AS [PIV-ID], LocationID AS [Loc-ID], Shelf AS Regal, Bin AS Kasten FROM Production.Product AS p LEFT OUTER JOIN Production.ProductInventory AS piv ON p.ProductID = piv.ProductID ORDER BY piv.ProductID 312_03.sql: Äußere Verknüpfung mit Anzeige aller Daten Wie angekündigt, enthält die Ergebnismenge sowohl die Produkte, die auch einem Lagerplatz zugewiesen sind, und diejenigen, die keinem oder nicht mehr einem Lagerplatz zugewiesen sind. Dies bedeutet, dass für diese Produkte natürlich die Spalten aus der ProductInventory-Tabelle einen Standardwert erhalten müssen. Dies ist der Wert NULL, da ja keine Information für die entsprechenden Felder in der Ergebnismenge vorliegt. P-ID PIV-ID Loc-ID Regal Kasten ----------- ----------- ------ ---------- -----717 NULL NULL NULL NULL 718 NULL NULL NULL NULL ... 166 Komplexe Abfragen 1 1 1 A 1 1 1 6 B 5 Der nächste Schritt kann dann in vielen Fällen die Frage sein, welche Datensätze denn nun genau keinen Partner in der anderen Tabelle finden. In natürlich-sprachlicher Formulierung wäre dies für das aktuelle Beispiel: „Zeige die Produkte, die keinem Lagerplatz zugewiesen sind.“ Der grundsätzliche Aufbau der Abfrage bleibt derselbe wie in der vorherigen Abfrage. Es tritt nur eine einzige zusätzliche Anweisung noch hinzu, nämlich die einschränkende Bedingung, dass gerade die Fremdschlüsselspalte in der Kind-Tabelle – in diesem Fall ProductInventory – den Wert NULL enthalten muss. Dies lässt sich mit Hilfe des IS [NOT] NULL-Operators einrichten. -- Nur Produkte ohne Lagerplatz SELECT p.ProductID, piv.ProductID, LocationID FROM Production.Product AS p LEFT OUTER JOIN Production.ProductInventory AS piv ON p.ProductID = piv.ProductID WHERE piv.ProductID IS NULL 312_04.sql: Anzeige nur nicht verknüpfter Daten Man erhält die für die vorherige Abfrage ermittelte Ergebnismenge, die allerdings nur noch die unverbundenen Datensätze der Eltern-Tabelle Product enthält. Im Normalfall würde man sich natürlich hier gerade nicht für die vielen NULL-Felder interessieren, sondern vielmehr einen größeren Teil der Spalten der Product-Tabelle ausgeben. ProductID ProductID LocationID ----------- ----------- ---------680 NULL NULL 706 NULL NULL 167 Komplexe Abfragen 717 NULL NULL Wie oben kurz erwähnt, ist die äußere Abfrage eine syntaktische Möglichkeit unter verschiedenen Varianten. Die zweite Alternative, die ebenfalls noch keine Lösung in irgendeiner äußeren Programmiersprache erfordert, stellt ganz einfach der MengenOperator EXCEPT dar. Dieser ermöglicht es, zunächst eine Abfrage zu formulieren, welche auf die Product-Tabelle zugreift und alle Produkte abruft. Von dieser Menge zieht man genau die Produkte ab, welche in der ProductInventory-Tabelle referenziert werden. Insgesamt erhält man dann die gleichen Daten wie durch eine äußere Abfrage. -- Nur Produkte ohne Lagerplatz SELECT ProductID FROM Production.Product EXCEPT SELECT ProductID FROM Production.ProductInventory 312_05.sql: Einsatz eines Mengen-Operators Wie gerade erwähnt, erhält man die gleichen Informationen wie bei einer Formulierung mit Hilfe einer äußeren Abfrage. ProductID ----------680 706 717 168 Komplexe Abfragen Wie schon bei der inneren Verknüpfung ist es auch bei der äußeren Verknüpfung möglich, mehr Tabellen als nur zwei zu verknüpfen. Dabei ist grundsätzlich nur zu beachten, dass eine an einer Stelle geforderte äußere Verknüpfung auch mit jeder weiteren Tabelle wieder als äußere Verknüpfung fortgesetzt wird. Vergisst man dies, erhält man keine Fehlermeldung und hat auch keinen Fehler verursacht. Stattdessen werden nur die ganzen NULL-Werte, die bislang erfolgreich eingerichtet wurden, durch die nun folgende innere Verknüpfung wieder gelöscht, weil die beiden Mengen so verarbeitet werden, dass ausschließlich die Partnerdatensätze in die weitere Ergebnismenge übernommen werden. Man verliert also bei einer einmaligen Nennung von INNER JOIN die über OUTER JOIN zusätzlich abgerufenen Datensätze. Im nachfolgenden Beispiel hängt man also an die schon zuvor verwendete Abfrageanweisung noch die Tabelle Location an, welche die überhaupt zur Verfügung stehenden Lagerplätze enthält. Spätestens jetzt sollte man erkennen, dass die ProductInventory-Tabelle eine Beziehungstabelle mit einigen zusätzlichen Attribute wie bspw. der gelagerten Produktmenge darstellt, welche die Produkte den verfügbaren Lagerplätzen zuordnet. Da die Product-Tabelle weiterhin auf der linken Seite steht, werden nun alle weiteren Tabellen ebenfalls mit LEFT OUTER JOIN angeschlossen. -- Alle Produkte und mögliche Lagerplätze mit Namen SELECT p.ProductID AS [P-ID], piv.ProductID AS [PIV-ID], l.LocationID AS [Loc-ID], Shelf AS Regal, Bin AS Kasten, l.Name FROM Production.Product AS p LEFT OUTER JOIN Production.ProductInventory AS piv 169 Komplexe Abfragen ON p.ProductID = piv.ProductID LEFT OUTER JOIN Production.Location AS L ON l.LocationID = piv.LocationID ORDER BY piv.ProductID 312_06.sql: Mehrfache äußere Verknüpfung Als Ergebnis erhält man wie zuvor sowohl Produkte, die einen Lagerplatz haben bzw. einem solchen zugeordnet sind, als auch diejenigen, die nur in der Product-Tabelle gespeichert sind und nicht gelagert und möglicherweise auch nicht angeboten werden. Als zusätzliche Spalte wird aus der Location-Tabelle noch der Name des Lagerortes im Lager abgerufen. P-ID PIV-ID Loc-ID Regal Kasten Name ----------- ----------- ------ ---------- ------ -----------925 NULL NULL NULL NULL NULL 902 NULL NULL NULL NULL NULL 1 1 1 A 1 Tool Crib 1 1 6 B 5 50 A 5 ... Miscellaneous 1 3.1.2.3 1 Subassembly Selbstverknüpfung Eine inhaltlich andere Form der Verknüpfung, die allerdings mit den gleichen syntaktischen Mitteln eingerichtet wird wie eine innere oder äußere Verknüpfung, ist die so genannte Selbstverknüpfung. Dabei verknüpft man die gleichen Tabelle mit Hilfe einer 170 Komplexe Abfragen oder mehrere Spalten, die durch einen Aliasnamen unterschieden werden, miteinander und fügt einen Filter hinzu, der auf unterschiedliche Werte bei gleichem Schlüssel überprüfen soll. Dabei muss der Schlüssel, der für die Verknüpfung verwendet wird, nicht notwendigerweise auch der Tabellenschlüssel sein, sondern kann jede beliebige Spalte sein, die für die Beantwortung einer Abfrage sinnvoll genutzt werden kann. Die nächsten Beispiele sollen die Selbstverknüpfung über mehrere Stufen hinweg erklären. Zunächst ruft die nachfolgende Anweisung die Verkaufsgebiete mit ihrem Verkäufer und dem Enddatum ihrer Geschäftstätigkeit in dieser Region ab. -- Verkaufsgebiete und ihre Verkäufer SELECT TerritoryID, SalesPersonID, EndDate FROM Sales.SalesTerritoryHistory ORDER BY TerritoryID 312_07.sql: Abfrage aller Daten Man erhält also eine Liste mit Gebieten, wobei es bspw. solche Gebiete wie 1 und 4 gibt, die von mehreren Verkäufern gleichzeitig oder nacheinander betreut wurden, während andere Gebiete wie 5 nur von einem einzigen Verkäufer betreut werden und dieser zudem auch noch der erste in diesem Gebiet ist. TerritoryID SalesPersonID EndDate ----------- ------------- ----------------------1 280 2002-10-31 00:00:00.000 1 283 NULL 1 287 NULL 276 NULL ... 4 171 Komplexe Abfragen 4 281 NULL 5 279 NULL (17 Zeile(n) betroffen) Interessant ist es nun herauszufinden, welche Gebiete nun ausschließlich von mehreren Verkäufer bearbeitet wurden oder werden. Dies ist nicht die gleiche Fragestellung wie herauszufinden, welches Gebiet wie viele Verkäufer hat oder welches davon eine Verkäuferanzahl größer 1 aufweist. Dies ist zwar eine sehr schöne Aggregationsabfrage mit der Funktion COUNT und einer Gruppensuchbedingung per HAVING, doch liefert sie nicht unmittelbar die gewünschten Ergebnisse. Die Liste der Verkaufsgebiete könnte dann allerdings in einer Unterabfrage über den IN-Operator angeschlossen werden. Die nachfolgende Abfrage zeigt nun die Lösung mit Hilfe einer Selbstverknüpfung, wobei zunächst die so genannten Rohdaten ermittelt werden. Diese Daten sind also noch nicht für die Beantwortung der Frage zu verwenden, sondern zeigen nur die Funktionsweise der Selbstverknüpfung und wie ihre Daten für die eigentliche Antwort zu verwenden sind. Man ruft also in der FROM-Klausel jeweils die gleiche Tabelle auf und vergibt einen passenden Aliasnamen, der im einfachsten Fall nummeriert wird. Als Verknüpfungsbedingung verwendet man die Spalten, welche tatsächlich miteinander verglichen werden sollen, was nicht notwendigerweise der Primärschlüssel der Tabelle sein muss. In diesem Fall sollen die Verkaufsgebiete gleich sein. In der WHERE-Klausel filtert man dann den ungleichen Spaltenwert heraus. In diesem Fall ist dies der Verkäufer, welche ungleich sein soll. Um zu verstehen, wie die Daten aufbereitet werden, gibt die Spaltenliste jeweils die beiden verknüpften Gebiete und die darin gefundenen Verkäufer aus. -- Verkaufsgebiete mit verschiedenen Verkäufern (Rohdaten) SELECT sth1.TerritoryID AS [Terr-ID 1], sth2.TerritoryID AS [Terr-ID 2], sth1.SalesPersonID AS [P-ID 1], 172 Komplexe Abfragen sth2.SalesPersonID AS [P-ID 2] FROM Sales.SalesTerritoryHistory AS sth1 INNER JOIN Sales.SalesTerritoryHistory AS sth2 ON sth1.TerritoryID = sth2.TerritoryID WHERE sth1.SalesPersonID != sth2.SalesPersonID ORDER BY sth1.TerritoryID 312_07.sql: Abfrage der Rohdaten (mit Kreuzbeziehungen) Man erhält also im Ergebnis vier Spalten, die beide jeweils aus der gleichen Tabelle bzw. aus unterschiedlich benannten Kopien der gleichen Tabelle stammen. Dabei wird insbesondere deutlich, dass zu viele Reihen ausgegeben werden, da die Daten miteinander per Kreuzverknüpfung kombiniert werden. Aus der vorbereitenden Abfrage ist bekannt, dass die beiden Gebiete 1 und 4 jeweils drei Datensätze aufweisen, die unterschiedliche Verkäufer bezeichnen. Hier ist nun allerdings die doppelte Menge entstanden, da der Wert 283 und 280 noch einmal als 280 und 283 erscheinen. Die Ausgabe dieser Rohdaten hilft allerdings, sich zu vergewissern, dass die Selbstverknüpfung erfolgreich verlief und man nun die passende Anpassung für das Endergebnis vornehmen kann. Terr-ID 1 Terr-ID 2 P-ID 1 P-ID 2 ----------- ----------- ----------- ----------1 1 283 280 1 1 287 280 1 1 280 287 1 1 283 287 1 1 280 283 173 Komplexe Abfragen 1 1 287 283 4 4 281 276 4 4 276 281 ... (18 Zeile(n) betroffen) Für diese endgültige Lösung nun wählt man nur die Daten einer der beiden Tabellenkopien aus und setzt noch ein DISTINCT vor die Spaltenliste, um die Duplikate auszublenden. -- Verkaufsgebiete mit verschiedenen Verkäufern -- (ohne Duplikate) SELECT DISTINCT sth1.TerritoryID AS [Terr-ID 1], sth1.SalesPersonID AS [P-ID 1] FROM Sales.SalesTerritoryHistory AS sth1 INNER JOIN Sales.SalesTerritoryHistory AS sth2 ON sth1.TerritoryID = sth2.TerritoryID WHERE sth1.SalesPersonID != sth2.SalesPersonID ORDER BY sth1.TerritoryID 312_07.sql: Duplikatlose Lise mit gewünschten Daten Schließlich erhält man nur noch die Gebiete mit mehreren Verkäufern. Terr-ID 1 P-ID 1 ----------- ----------1 174 280 Komplexe Abfragen 1 283 1 287 … 4 276 4 281 (12 Zeile(n) betroffen) 3.2 Unterabfragen Im letzten Beispiel des vorherigen Abschnitts fiel schon die Bemerkung, dass es überhaupt Unterabfragen gibt und dass bspw. mit ihnen auch die letzte Fragestellung zu beantworten wäre. Unterabfragen sind eigenständige Abfragen, die an Stelle von anderen Ausdrücken nach unterschiedlichen Operatoren, innerhalb von FROM und sogar innerhalb der Spaltenliste erscheinen können. Sie ermöglichen überaus komplexe Abfragen, die teilweise die Verwendung von mehreren einzelnen Abfragen und bspw. die Zwischenspeicherung der von ihnen gelieferten Werte in Variablen vermeiden. Teilweise stellen sie auch nur Alternativen zu Lösungen mit anderen Techniken dar. 3.2.1 Einfache Unterabfragen Als einfache Unterabfrage kann man solche bezeichnen, die einen einzelnen Wert oder eine ganze Werteliste zurückliefern und die daher innerhalb der WHERE-Klausel eingesetzt werden können. Die einzige Alternative zu einer solchen Unterabfrage ist, es die entsprechenden Werte in einer Variable oder einem Cursor zu vorzuhalten und dann bspw. mit „richtigem“ Transact SQL ein kleines Programm zu schreiben, in dem die gleiche Abfrage als Programm abgebildet wird. Alternativ kann man natürlich auch zuerst die Werte ermitteln und dann in der nächsten Abfrage direkt im Quelltext vorgeben, doch dann ist die gesamte Abfrage nicht mehr so dynamisch wie beim Einsatz einer Unterabfrage oder eines kleinen Programms. 175 Komplexe Abfragen 3.2.1.1 Einzelne Werte Unterabfragen eignen sich also dazu, einzelne Werte, wie sie bspw. von einer Aggregatfunktion geliefert werden, direkt in die umschließende Abfrage hinein zu übermitteln. Das nächste Beispiel ermittelt zunächst den Durchschnittspreis aller Produkte in der Tabelle Product. Den ermittelten Werte würde man im Normalfall ohne Unterabfrage einfach so als festen, nicht dynamisch ermittelten Wert in die WHERE-Klausel übernehmen. Da allerdings jeder gültige Ausdruck links oder rechts vom Vergleichoperator erwartet wird, kann man in runden Klammern auch sofort die gesamte Aggregatabfrage verwenden. Bei den Vergleichoperatoren ist in diesem Fall wichtig, dass sie nur einen einzigen Wert (eine Reihe, eine Spalte) liefern. -- Durchschnittspreis (= 438,6662) SELECT AVG(ListPrice) AS Schnitt FROM Production.Product -- Produkte teurer als Durchschnitt SELECT ProductID, Name, ListPrice FROM Production.Product WHERE ListPrice > (SELECT AVG(ListPrice) AS Schnitt FROM Production.Product) ORDER BY ListPrice ASC 321_01.sql: Ersatz von Wertvorgaben 176 Komplexe Abfragen SELECT ProductID, Name, ListPrice FROM Production.Product WHERE ListPrice > (SELECT AVG(ListPrice) AS Schnitt 438,6662 FROM Production.Product) ORDER BY ListPrice ASC Abbildung 3.3: Funktionsweise der einfachen Unterabfrage Man erhält trotz spektakulär neuer Syntax das erwartete Ergebnis, das man auch bei herkömmlicher direkter Wertvorgabe erhalten hätte. ProductID Name ListPrice ----------- -------------------------------- ---------977 Road-750 Black, 58 539,99 989 Mountain-500 Black, 40 539,99 3.2.1.2 Wertelisten Der Operator [NOT] IN kann nicht nur mit einem einzigen Wert umgehen, sondern stattdessen mit einer ganzen Werteliste. Die nächste Abfrage liefert die Nummern von Produkten, die an Sonderaktionen teilgenommen haben. Diese Liste wird dann in der darauf folgenden Anweisung verwendet, um anstelle einer Verknüpfung die Detailinformationen von Produkten herauszufinden, die an Sonderaktionen teilnahmen. Das Beispiel zeigt allerdings auch, wie man die gleiche Information mit Hilfe einer INNER JOIN-Anweisung ermitteln kann. -- Produkte, die an Sonderaktionen teilnahmen SELECT DISTINCT ProductID FROM Sales.SpecialOfferProduct 177 Komplexe Abfragen -- Produkte in Sonderaktionen SELECT ProductID, Name, ListPrice FROM Production.Product WHERE ProductID IN (SELECT DISTINCT ProductID FROM Sales.SpecialOfferProduct) SELECT DISTINCT p.ProductID, Name, ListPrice FROM Production.Product AS p INNER JOIN Sales.SpecialOfferProduct AS sop ON p.ProductID = sop.ProductID 321_03.sql: Einsatz von Unterabfragen für Wertelisten Man erhält in beiden Fällen die Produkte aus Sonderaktionen. ProductID Name ListPrice ----------- ---------------------------------- ----------680 HL Road Frame - Black, 58 1431,50 706 HL Road Frame - Red, 58 1431,50 707 Sport-100 Helmet, Red 178 34,99 Komplexe Abfragen SELECT ProductID, Name, ListPrice FROM Production.Product WHERE ProductID IN (SELECT DISTINCT ProductID FROM Sales.SpecialOfferProduct) 680 706 707 Abbildung 3.4: Funktionsweise der Unterabfrage einer Liste Zum Schluss soll noch ein Beispiel folgen, welches zeigt, dass wirklich alle Operatoren die Möglichkeit bieten, Ergebnisse aus Unterabfragen zu verarbeiten. Dies liegt weniger am Operator als mehr an der Tatsache, dass eine Unterabfrage ein erlaubter gültiger Ausdruck ist, der einem direkt vorgegebenen Wert oder einer Werteliste entspricht. So liefert die nachfolgende Anweisung die Produkte mit einem Preis zwischen Durchschnitt und Maximum. Hierzu setzt man den Operator BETWEEN…AND ein, der zwei einzeilige Ausdrücke erwartet. Beide lassen sich unter Einsatz von Unterabfragen bilden. -- Produkte mit Preis zwischen Durchschnitt und Maximum SELECT ProductID, Name, ListPrice FROM Production.Product WHERE ListPrice BETWEEN (SELECT AVG(ListPrice) AS Schnitt FROM Production.Product) AND (SELECT MAX(ListPrice) AS Maxi FROM Production.Product) ORDER BY ListPrice ASC 321_02.sql: Unterabfrage bei BETWEEN und AND 179 Komplexe Abfragen 3.2.2 Spaltenunterabfragen Während die gerade gezeigten Unterabfragen besonders häufig vertreten sind und schnell verständlich sind, gibt es verschiedene andere Unterabfragenarten, die etwas mehr Beschäftigung mit ihnen erfordern, um ihren Sinn und Zweck zu verstehen. Dabei besteht eine Spaltenunterabfrage tatsächlich aus einer Unterabfrage, die innerhalb der Spaltenliste erscheint. Mit dieser Technik lassen sich zusätzliche Werte in einer Spalte ausgeben, die entweder mit anderen Daten korrelieren (korrelierte Spaltenunterabfragen) oder die ganz einfach eine Übersichtsabfrage bilden. Die nachfolgende Abfrage liefert ein einfaches Aggregat, nämlich die Anzahl von Mitarbeitern pro Geschlecht. Hierbei handelt es sich natürlich um keine Spaltenunterabfrage, sondern um eine gewöhnliche Abfrage mit Aggregatfunktion und Gruppierung. -- Anzahl von Männern und Frauen in Belegschaft SELECT Gender AS Geschlecht, COUNT(*) AS Anzahl FROM HumanResources.Employee GROUP BY Gender 322_01.sql: Aggregatermittlung mit Gruppierung Man erhält zwei Reihen mit den beiden Gruppen und den dazugehörigen Aggregatwerten. Geschlecht Anzahl ---------- ----------F 84 M 206 (2 Zeile(n) betroffen) 180 Komplexe Abfragen Möchte man aber nicht mehrere Reihen erzeugen, sondern viel lieber nur eine einzige, welche die verschiedenen gerade ermittelten Werte enthält, dann kann man mehrere Spaltenunterabfragen verwenden. Sie ermöglichen es, jede interessante Aggregatabfrage, welche genau einen Wert liefert, als neuen Spaltenwert auszugeben, wobei nicht einmal die gleiche Tabelle befragt werden muss. So liefert das nächste Beispiel die Anzahl von Frauen und Männern in der Belegschaft in einem einzeiligen Ergebnis mit zwei Spalten. Dazu werden die einzelnen Abfragen in runden Klammern pro Spalte angegeben. Um die entstehenden Duplikate zu unterdrücken, setzt man noch das Schlüsselwort DISTINCT vor beide Abfragen. -- Anzahl von Männern und Frauen in Belegschaft SELECT DISTINCT (SELECT COUNT(*) FROM HumanResources.Employee WHERE Gender = 'M') AS [Anzahl M], (SELECT COUNT(*) FROM HumanResources.Employee WHERE Gender = 'F') AS [Anzahl F] FROM HumanResources.Employee 322_01.sql: Aggregatermittlung als Übersichtsabfrage Man erhält die beiden Aggregate in einer Zeile und zwei Spalten. Anzahl M Anzahl F ----------- ----------206 84 (1 Zeile(n) betroffen) 181 Komplexe Abfragen 3.2.3 Abgeleitete Tabellen Eine weitere ungewöhnliche, aber für viele komplexe Fragestellungen sehr nützliche und die Arbeit sogar vereinfachende Technik ist die der abgeleiteten Tabellen. Dabei befindet sich die Unterabfrage innerhalb der FROM-Klausel und stellt quasi die lokale Tabelle dar, welche die äußere Abfrage abfragt. 3.2.3.1 Standardfall Um das Prinzip und die Syntax zu zeigen, folgt zunächst der Standardfall, den man inhaltlich auch viel einfacher hätte formulieren können. Doch hier soll es nun darum gehen, die allgemeine Funktionsweise zu demonstrieren. Innerhalb der FROM-Klausel platziert man zunächst eine funktionstüchtige Abfrage, die also auch alleine syntaktisch (und inhaltlich) korrekt ist. Die bereits in den zu Grunde liegenden Tabellen vorhandenen Spaltennamen bzw. die optional vorhandenen Aliasnamen bilden von dieser lokalen temporären Tabellen die neuen Spaltennamen, welche in der äußeren Abfrage referenziert werden können. Jede dieser abgeleiteten Tabellen benötigt einen Aliasnamen, der ganz einfach an die Unterabfrage angeschlossen wird. Die Spaltennamen können dann bei Bedarf qualifiziert werden. So liefert die Unterabfrage im nächsten Beispiel zwei Spalten aus der EmployeeTabelle zurück, die auch genauso von der äußeren Abfrage ausgegeben bzw. abgerufen werden. Zusätzlich erstellt die Unterabfrage allerdings auch noch eine Spalte, die sich aus den beiden Spalten FirstName und LastName der Person-Tabelle sowie einem Leerzeichen zusammensetzt. Diese neue zusammengesetzte Spalte erhält den Namen Name und steht für weitere Bearbeitung in der äußeren Abfrage zur Verfügung. Man kann sich hier bereits gut vorstellen, wie sinnvoll die abgeleiteten Tabellen eingesetzt werden können, wenn es um Funktionen und Berechnungen geht, die in der abgeleiteten Tabelle erstellt und dann als neue Rohdaten für weitere Bearbeitungszwecke der äußeren Tabelle zur Verfügung gestellt werden. -- Liste aller weiblichen Angestellten SELECT Name, Phone 182 Komplexe Abfragen FROM (SELECT FirstName + ' ' + LastName AS Name, Phone, Gender FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS c ON emp.ContactID = c.ContactID) AS emp WHERE Gender = 'F' 323_01.sql: Einfache abgeleitete Tabelle SELECT Name, Phone FROM (SELECT FirstName + ' ' + LastName AS Name, Phone, Gender FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS c ON emp.ContactID = c.ContactID) AS emp WHERE Gender = 'F' Abbildung 3.5: Funktionsweise der abgeleiteten Tabellen In diesem Fall wählt man aus den zur Verfügung gestellten Spalten der abgeleiteten Tabelle nur die beiden Spalten Name und Phone aus, wobei zusätzlich ein Filter auf die weiblichen Angestellten gelegt wird. Dieser zeigt, dass man vom Blickwinkel der äuße- 183 Komplexe Abfragen ren Abfrage genauso auf die Daten einer abgeleiteten Tabelle zugreifen kann sowie auf die Daten jeder beliebigen anderen Tabelle. Name Phone -------------------------- ---------------JoLynn Dobney 903-555-0145 Ruth Ellerbrock 145-555-0130 Gail Erickson 849-555-0139 3.2.3.2 Mehrstufige Verschachtelung Wie man sich vorstellen kann, ist es erlaubt, innerhalb von abgeleiteten Tabellen wiederum abgeleitete Tabellen zu verwenden. Ein Beispiel soll dieses Prinzip illustrieren. Zunächst ruft die nachfolgende Anweisung die überhaupt vorhandenen ManagerIDWerte in der Employee-Tabelle ab. Damit erhält man eine Liste der Mitarbeiter, die als Führungskraft referenziert werden. Da sie typischerweise mehrere Mitarbeiter als Untergebene besitzen, ist hier wiederum DISTINCT notwendig, um die Duplikate auszublenden. -- Liste aller ManagerIDs SELECT DISTINCT ManagerID AS EmployeeID FROM HumanResources.Employee WHERE ManagerID IS NOT NULL 323_02.sql: Einfache Auflistung Man erhält eine längere Liste, die u.a. die nachfolgenden Werte enthalten. EmployeeID ----------- 184 Komplexe Abfragen 3 6 7 Mit Hilfe dieser Liste ist es nun möglich, die ContactID-Werte zu ermitteln, welche die solchermaßen identifizierten Mitarbeiter besitzen. Dazu verknüpft man ganz einfach die gerade erstellte Abfrage in Form einer abgeleiteten Tabelle über INNER JOIN mit der Employee-Tabelle. Interessant an der Syntax dieser Abfrage ist natürlich, dass auf der einen Seite eine tatsächlich vorhandene Tabelle wie Employee mit einer nur als abgeleiteter Tabelle erstellten Tabelle so verbunden wird wie bei einer ganz gewöhnlichen Tabelle. -- Liste der EmployeeIDs und ContactIDs SELECT emp.EmployeeID, ContactID FROM (SELECT DISTINCT ManagerID AS EmployeeID FROM HumanResources.Employee WHERE ManagerID IS NOT NULL) AS man INNER JOIN HumanResources.Employee AS emp ON emp.EmployeeID = man.EmployeeID 323_02.sql: Ermittlung von ContactID auf Basis von EmployeeIDs Diese Abfrage liefert nun wiederum eine Liste der EmployeeID-Werte von als Führungskräften erkannten Mitarbeitern sowie deren ContactID. EmployeeID ContactID ----------- ----------3 1002 6 1028 185 Komplexe Abfragen 7 1070 Zu guter letzt wollte man natürlich weniger eine Liste mit Schlüsselwerten erhalten, sondern vielmehr die tatsächlichen Kontaktdaten der Führungskräfte. Dies lässt sich wiederum mit Hilfe einer abgeleiteten Tabelle einrichten. Sie dient in diesem Fall dazu, die ContactID bereitzustellen, welche für die Verknüpfung mit der Contact-Tabelle notwendig ist. Dabei wird das gerade gezeigte Abfrageergebnisse, bestehend aus EmployeeID und ContactID, zur abgeleiteten Tabelle und dient als Verknüpfungspartner für die Contact-Tabelle, aus der man FirstName und LastName abruft und zusammen mit der Mitarbeiternummer ausgibt. -- Liste aller Führungskräfte SELECT EmployeeID, FirstName, LastName FROM Person.Contact AS c INNER JOIN (SELECT emp.EmployeeID, ContactID FROM (SELECT DISTINCT ManagerID AS EmployeeID FROM HumanResources.Employee WHERE ManagerID IS NOT NULL) AS man INNER JOIN HumanResources.Employee AS emp ON emp.EmployeeID = man.EmployeeID) AS emp ON c.ContactID = emp.ContactID 323_02.sql: Verwendung der Unterabfragen für Manager-Liste Man erhält für die drei schon zuvor gezeigten Mitarbeiter nun auch die Kontaktdaten neben ihrer Mitarbeiternummer in der Ergebnisliste. 186 Komplexe Abfragen EmployeeID FirstName LastName ----------- ------------------ -----------3 Roberto Tamburello 6 David Bradley 7 JoLynn Dobney 3.2.3.3 Vereinfachte Berechnungen Ganz zu Beginn, als die abgeleiteten Tabellen vorgestellt wurden, wurde bereits erwähnt, dass insbesondere dann ein großer Vorteil dieser Technik besteht, wenn man Berechnungen und Funktionen einsetzt. Hier erstellt man die eigentlichen Rohdaten, auf die man nachher noch weitere Untersuchungen, Filter oder zusätzliche Berechnungen anwenden möchte, in Form einer abgeleiteten Tabelle und erspart sich dadurch die doppelte Nennung von Berechnungsvorschriften und Funktionsaufrufen. Die Abfrage kann man in den meisten Fällen auch völlig ohne abgeleitete Tabelle erstellen, doch vereinfacht sie die spätere Weiterverwendung der einmal erstellten Ergebnisse. So erstellt hier die abgeleitete Tabelle zunächst die benötigten Rohdaten, indem die Tabellen Product, ProductInventory und ProductSubcategory verknüpft und die benötigten Spalte von Produkt- und Kategoriename sowie Menge und Sicherheitsbestand übersetzt werden, um dann in der äußeren Abfrage diese Aliasnamen aufzurufen und mit ihnen rechnen zu können. Als Alternative kann man sich vorstellen, dass innerhalb der abgeleiteten Tabelle ebenfalls schon Berechnungen und Funktionsaufrufe durchgeführt werden. -- Produkt und LagerDifferenz-Ermittlung SELECT Produkt, Sicherheit - Menge AS [Lager-Differenz] FROM (SELECT p.ProductID, p.Name AS Produkt, 187 Komplexe Abfragen psc.Name AS Kategorie, piv.Quantity AS Menge, p.SafetyStockLevel AS Sicherheit FROM Production.Product AS p INNER JOIN Production.ProductInventory AS piv ON p.ProductID = piv.ProductID INNER JOIN Production.ProductSubcategory AS psc ON p.ProductSubcategoryID = psc.ProductSubcategoryID) AS lager ORDER BY [Lager-Differenz] 323_03.sql: Vereinfachung von Berechnungen Man erhält eine Produktliste mit der Differenz zwischen Sicherheit und vorhandener Menge, die für Bestellungen genutzt werden könnte. Produkt Lager-Differenz -------------------------------- --------------Sport-100 Helmet, Black -320 ... Mountain-100 Silver, 48 -2 Mountain-100 Black, 44 0 ... Mountain-100 Silver, 44 188 25 Komplexe Abfragen 3.2.4 Korrelierte Unterabfragen Mit Hilfe einer korrelierten Unterabfrage lassen sich zwei Mengen zueinander in Beziehung setzen und Werte der äußeren Abfrage dazu verwenden, in der inneren Abfrage als eingehende Parameter für weitere Werteermittlung genutzt zu werden. Man erkennt sie oftmals daran, dass ein Aggregat für eine bestimmte Gruppe benötigt wird und das Wörtchen „pro“ in der Abfrage erscheint. 3.2.4.1 Standardfall Das nachfolgende Beispiel zeigt den typischen Standardfall einer korrelierten Unterabfrage. Es sucht für jede Kategorie das billigste Produkt. Hier soll also genau ein Aggregat für ermittelte Gruppenwerte gefunden werden. Dies geschieht in einer ganz typischen Syntax, die am besten über Aliasnamen verstanden wird, die deutlich machen, dass hier eine äußere Abfrage Werte an eine innere liefert. In der äußeren Abfrage ermittelt man zunächst die Namen von Produktunterkategorien. Zusätzlich gibt man den Produktnamen des billigsten Produkts aus. Die Ermittlung dieses billigsten Produkts lässt sich durchführen, indem man den Listenpreis mit dem Ergebnis einer Unterabfrage vergleicht, die eine Spalte und eine Reihe zurückliefert. Dabei sucht die MIN-Funktion aber gerade nicht das billigste Produkt in der ganzen Tabelle, sondern vergleicht in einer WHERE-Klausel den in der äußeren Abfrage gerade verarbeiteten Subkategorienamen. Dies geschieht durch den Aufruf des Tabellenalias der außen genutzten ProductTabelle. In diesem Fall greift man auch in der korrelierten Unterabfrage auf diese Tabelle zu, was allerdings nicht notwendig ist. Im Vordergrund steht vielmehr, dass man überhaupt Werte aus der äußeren mit Werten der inneren Abfrage in Beziehung setzt und sie dadurch korreliert. -- Pro Kategorie das billigste Produkt SELECT psc.Name, a.Name, ListPrice FROM Production.Product AS a INNER JOIN Production.ProductSubcategory AS psc ON a.ProductSubcategoryID = psc.ProductSubcategoryID 189 Komplexe Abfragen WHERE ListPrice = (SELECT MIN(ListPrice) FROM Production.Product AS b WHERE a.ProductSubcategoryID = b.ProductSubcategoryID) ORDER BY ListPrice 324_01.sql: Standardfall der Korrelierten Unterabfrage Patch Kit/8 Patches Water Bottle - 30 oz. SELECT psc.Name, a.Name, ListPrice Bike Wash - Dissolver FROM Production.Product AS a INNER JOIN Production.ProductSubcategory AS psc ON a.ProductSubcategoryID = psc.ProductSubcategoryID WHERE ListPrice = (SELECT MIN(ListPrice) Tires and Tubes Bottles and Cages Cleaners FROM Production.Product AS b 2,29 4,99 7,95 WHERE a.ProductSubcategoryID = b.ProductSubcategoryID) ORDER BY ListPrice Abbildung 3.6: Funktionsweise der korrelierten Unterabfrage Man erhält eine Liste, in der Kategorien und Produkte mit dem billigsten Preis innerhalb dieser Kategorie erscheinen. Dies muss nicht bedeuten, dass jede Kategorie nur einmal erscheint, da es sein kann, dass mehrere Produkte einer Kategorie den gleichen Preis besitzen, der zufällig auch der kleinste innerhalb der Kategorie ist. Name Name ListPrice --------------------- ----------------------------- --------- 190 Komplexe Abfragen Tires and Tubes Patch Kit/8 Patches 2,29 Bottles and Cages Water Bottle - 30 oz. 4,99 Cleaners Bike Wash - Dissolver 7,95 3.2.4.2 Korrelierte Spaltenunterabfragen Die Technik der korrelierten Unterabfrage ist auch beim Einsatz von Spaltenunterabfragen möglich. Dabei verwendet man wiederum den gerade in der äußeren Abfrage bearbeiteten Datensatz als Filter für die Unterabfrage. Da nun allerdings nicht ein Filter wie einer gewöhnlichen korrelierten Unterabfrage verwendet wird, sondern eine neue Spalte in die Ergebnismenge gelangen soll, befindet sich die Unterabfrage in der Spaltenliste, weist allerdings die gleiche Korrelationstechnik wie eine gewöhnliche korrelierte Unterabfrage auf. Im Beispiel sollen die Mitarbeiternummern und Namen ausgegeben werden, die zu einer Führungskraft gehören. In der korrelierten Spaltenunterabfrage ermittelt man zunächst den zusammengesetzten Namen aus FirstName und LastName der Contact-Tabelle für den Datensatz, der gerade in der äußeren Abfrage bearbeitet wird. Dies geschieht durch die Korrelation WHERE c.ContactID = emp.ContactID. Die Filterung der Mitarbeiter auf die Führungskräfte geschieht dann in einer Unterabfrage, welche für den IN-Operator angegeben wird, -- Liste aller Führungskräfte SELECT EmployeeID, (SELECT FirstName + ' ' + LastName FROM Person.Contact AS c WHERE c.ContactID = emp.ContactID) AS Name FROM HumanResources.Employee AS emp WHERE EmployeeID IN (SELECT DISTINCT ManagerID AS EmployeeID 191 Komplexe Abfragen FROM HumanResources.Employee WHERE ManagerID IS NOT NULL) ORDER BY EmployeeID 342_01.sql: Korrelation in der Spaltenunterabfrage Die nachfolgende Abbildung versucht, die verwendete Syntax noch einmal aufzubereiten. Roberto Tamburello David Bradley JoLynn Dobney SELECT EmployeeID, (SELECT FirstName + ' ' + LastName FROM Person.Contact AS c 3 6 7 WHERE c.ContactID = emp.ContactID) AS Name FROM HumanResources.Employee AS emp WHERE EmployeeID IN (SELECT DISTINCT ManagerID AS EmployeeID FROM HumanResources.Employee WHERE ManagerID IS NOT NULL) Abbildung 3.7: Funktionsweise der korrelierten Spaltenunterabfrage Man erhält eine Liste mit Führungskräften, bestehend aus ihrer Mitarbeiternummer und ihrem Namen. EmployeeID Name ----------- --------------------3 192 Roberto Tamburello Komplexe Abfragen 6 David Bradley 7 JoLynn Dobney 3.2.5 Operatoren für Unterabfragen Neben den schon bekannten Operatoren wie den Vergleichsoperatoren, BETWEEN...AND und [NOT] IN gibt es noch weitere Operatoren, welche ausschließlich mit einer Unterabfrage genutzt werden können und daher in der Beschreibung der möglichen Operatoren von WHERE fehlten. Dies soll nun im Rahmen der Unterabfragen geschehen. Teilweise ermöglichen sie die vereinfachende Formulierung von Anweisungen, teilweise jedoch können sie genauso gut durch andere Techniken, die meistens beliebter sind, vermieden werden. 3.2.5.1 Operator ALL Der Operator ALL führt einen Vergleich zwischen einem skalaren Wert und einer einzelnen Spalten durch und ähnelt damit dem [NOT] IN-Operator. Man erhält dann den Wert TRUE, wenn der verwendete Vergleich für alle einzelnen Paare des skalaren Ausdrucks und der in der Unterabfrage ermittelten Werteliste. Anderenfalls wird FALSE zurückgegeben. Die allgemeine Syntax hat die Form: skalarerAusdruck { = | <> | != | > | >= | !> | < | <= | !< } ALL ( unterabfrage ) Die nachfolgende Abfrage ermittelt in der Unterabfrage die Preise von allen Produkten. Diese Werteliste wird dann mit Hilfe von >= ALL verwendet, um die teuersten Produkte herauszufinden. Das sind nämlich gerade die, welche gleich teurer oder teurer als die angegebenen Preise sind. In diesem Fall lässt sich das gleiche Ergebnis mit einer einfachen Aggregatunterabfrage über MAX(ListPrice) herleiten. -- Artikel, die teurer als ALLE anderen sind 193 Komplexe Abfragen -- Der teuerste Artikel SELECT ProductID, Name, ListPrice FROM Production.Product WHERE ListPrice >= ALL (SELECT ListPrice FROM Production.Product) 325_01.sql: Einsatz von ALL Man erhält mehrere Ergebniszeilen, da verschiedene Produkte aufgrund unterschiedlicher Größen den gleichen Preis haben. ProductID Name ListPrice ----------- --------------------- -----------749 Road-150 Red, 62 3578,27 750 Road-150 Red, 44 3578,27 Die nachfolgende Abfrage ermittelt, welche Kunde die Bestellung mit der größten Fracht aufgegeben hatte. Auch hier kann man entweder eine einfache Unterabfrage mit MAX(Freight) verwenden, oder man ruft zunächst sämtliche Frachten ab und fordert, dass der gesuchte Kunde eine Bestellung aufgegeben hat, deren Fracht größer gleich allen Frachtwerten in den Bestellungen ist. SELECT c.CustomerID, Freight FROM Sales.Customer AS c INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID WHERE Freight >= ALL (SELECT Freight FROM Sales.SalesOrderHeader) 194 Komplexe Abfragen /* WHERE Freight = (SELECT MAX(Freight) FROM Sales.SalesOrderHeader)*/ 325_02.sql: Ersatz einer einfachen Unterabfrage Man erhält den entsprechenden Kunden mit der höchsten Fracht zurück. CustomerID Freight ----------- ----------599 5608,9121 3.2.5.2 Operator [NOT] EXISTS Der Operator [NOT] EXISTS prüft darauf, ob in einer Unterabfrage Zeilen vorhanden sind. Die allgemeine Syntax ist besonders einfach und lautet nur [NOT] EXISTS unterabfrage. Auch hier lassen sich andere Operatoren wie [NOT] IN oder auch =ANY verwenden. Im nachfolgenden Beispiel ermittelt man mit Hilfe von IN und einer direkten Angabe von Größe wie S oder M verschiedene Bekleidungsprodukte. Im nächsten Schritt wird dann versucht, die gleiche Abfrage mit Hilfe von EXISTS einzurichten. Dabei muss man sogar eine korrelierte Unterabfrage einsetzen, da man natürlich nur die Größen zum Vergleich in der Unterabfrage heranziehen möchte, die überhaupt zu den Werten der äußeren Abfrage gehören. Für die Datensätze, für die also ein Wert in der Unterabfrage existiert, erhält man den entsprechenden Wert der äußeren Abfrage. -- Produkte mit bestimmten Größen SELECT Name, Size, Color, ProductSubcategoryID FROM Production.Product WHERE Size IN ('S', 'M', 'XL') AND productSubcategoryID = 21 195 Komplexe Abfragen SELECT Name, Size, Color, p1.ProductSubcategoryID FROM Production.Product AS p1 WHERE EXISTS (SELECT DISTINCT Size FROM Production.Product AS p2 WHERE p2.ProductSubcategoryID = 21 AND p1.ProductSubcategoryID = p2.ProductSubcategoryID) AND Size >= 'M' 325_03.sql: Verwendung von EXISTS statt IN Im Ergebnis erhält man eine Reihe von Pullovern in den bereits in der ersten Abfrage fest vorgegebenen Größen, die nun allerdings dynamisch ermittelt werden. Name Size Color ProductSubc~ID ------------------------------ ----- ------- ---------------Long-Sleeve Logo Jersey, S S Multi 21 Long-Sleeve Logo Jersey, M M Multi 21 3.2.5.3 Operatoren SOME und ANY Auch die beiden Operatoren SOME und ANY führen einen Vergleich durch, bei dem ein skalarer Wert mit den in einer Unterabfrage ermittelten Werten einer einzigen Spalte paarweise in Beziehung gesetzt wird. Beide Operatoren geben dann den Wert TRUE zurück, sobald irgendein (any) Paar bzw. einige (some) Paare bei diesem paarweisen Vergleich den Wert TRUE liefern. 196 Komplexe Abfragen Die allgemeine Syntax lautet: skalarerAusdruck { = | < > | ! = | > | > = | ! > | < | < = | ! < } { SOME | ANY } ( unterabfrage) Die Unterabfrage liefert eine Reihe von Versanddaten von Bestellungen eines angegebenen Bereichs. Die äußere Abfrage dagegen liefert nur die Bestellungen und ihre Versanddaten, wenn das Bestelldatum gleich oder später als das einer der in der Unterabfrage ausgewählten Bestelldaten liegt. -- Bestellungen mit späterem Versanddatum -- als in wenigstens einer Zeile der Unterabfrage SELECT SalesOrderID, ShipDate FROM Sales.SalesOrderHeader WHERE OrderDate > SOME (SELECT DISTINCT ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderID BETWEEN 68806 AND 71613) 325_04.sql: Überprüfung auf (irgend)einen Wert 3.3 Verzweigungen Für die Ausgabe anhand von Untersuchungen in Form einer Fallunterscheidung wie sie auch in gängigen Programmiersprachen erscheint, steht in SQL eine CASE-Anweisung zur Verfügung. Sie erlaubt es, einen Ausdruck direkt vorzugeben oder eine Berechnungsvorschrift, Funktion oder Unterabfrage zu verwenden, um in Abhängigkeit einer Untersuchung unterschiedliche Spaltenwerte in der Ergebnisliste zu erzeugen. 197 Komplexe Abfragen 3.3.1 CASE mit Selektor Die erste Variante dieser Fallunterscheidung mit Hilfe des CASE-Ausdrucks wird „Case mit Selektor“ genannt. Der Selektor ist dabei der Ausdruck, welcher in mehreren Fällen, die auf Gleichheit prüfen, untersucht wird. Hier ist es also nur möglich, tatsächlich exakt so vorhandene Werte abzuprüfen oder einen Standardfall vorzugeben. Trotz der komplexen Syntax handelt es sich bei der CASE-Anweisung um einen Spaltenausdruck, d.h. um die Erzeugung eines einzigen Spaltenwerts. Der Datentyp, welcher durch die Anweisungsausdrücke in den einzelnen Fällen vorgegeben wird, muss natürlich immer derselbe sein. Sollte es zufällig geschehen, dass bei unterschiedlichen Datentypen in den einzelnen Fällen im Endergebnis doch immer nur die Fälle gleichen Datentyps ausgewählt werden, erhält zwar man keine Fehlermeldung, doch läuft die gesamte Abfrage natürlich dann schief, sobald ein Fall mit anderem Anweisungsdatentyp ausgewählt wird. Auch wenn in den meisten Fällen sicherlich ausdrücklich nur feste Werte als Anweisungsausdruck zum Einsatz kommen, so ist jeder beliebige gültige Ausdruck richtig. Dies kann sowohl eine Funktion oder Berechnung als auch eine ganze Unterabfrage sein, welche genau einen Wert zurückliefert. Die allgemeine Syntax hat folgendes Aussehen: CASE Selektor WHEN Testausdruck THEN Ergebnisausdruck [ ...n ] [ ELSE Standardausdruck ] END 198 Komplexe Abfragen Das Standardbeispiel für die Verwendung von CASE besteht daraus, einen Spaltenwert, der für die Ausgabe nicht geeignet ist, weil er bspw. einen verschlüsselten Wert oder einen Ja-/Nein-Wert enthält, mit einer verständlichen Übersetzung zu füllen. Als Ergänzung lässt sich diese Technik auch auf Aggregate anwenden, wobei hier die bspw. als Zahlenwerte ermittelten Aggregatwerte in Texte umgewandelt werden wie „Kategorie A“ oder „Sehr wichtig.“ Als Beispiel soll nun also die Spalte ActiveFlag in der noch gar nicht so häufig verwendeten Vendor-Tabelle für die Lieferanten in Textwerte übersetzt werden. Die Spalte enthält den Wert 1, wenn der Lieferant noch aktiv ist, d.h. von ihm Waren bezogen werden, und sie enthält den Wert 0, wenn er inaktiv ist, d.h. von ihm keine Werte bezogen werden. Die CASE-Anweisung nimmt nun den Spaltennamen als Selektor, sodass die einzelnen Fälle darauf prüfen, ob der Spaltenwert gleich eines der angegeben Fallwerte ist. Da nur zwei Werte möglich sind, gibt es einen WHENAusdruck, der unmittelbar von einem ELSE-Ausdruck gefolgt wird. Ansonsten sind auch mehrere WHEN-Ausdrücke möglich. Nach den WHEN-Ausdrücken folgt der Testwert, der in diesem Fall gleich einem der Spaltenwerte ist und von einem THEN mit Anweisungsausdruck gefolgt wird. Diese Anweisung bildet ganz schlicht die in der Ergebnismenge benötigte Ausgabe mit den Wörtern „Aktiv“ und „Inaktiv“ ab. Beide sind vom Datentyp her eine Zeichenkette, sodass die gesamte entstehende Spalte von diesem Datentyp ist. Es ist, wie schon oben erwähnt, nicht möglich, verschiedene Datentypen in einer Spalte auszugeben. Sofern allerdings für eine gesamte Abfrage immer der gleiche Datentyp ausgewählt wird, ist dies auch korrekt. -- Übersetzung der Status-Angabe SELECT VendorID, Name, CASE ActiveFlag WHEN 1 THEN 'Aktiv' ELSE 'Inaktiv' END AS Status 199 Komplexe Abfragen FROM Purchasing.Vendor 331_01.sql: Übersetzung von ausgabeuntauglichen Werten Als Ergebnis erhält man eine Aufstellung der Lieferanten mit Nummer und Name sowie ihrem Status mit Hilfe der Werte „Aktiv“ und „Inaktiv“. VendorID Name Status ----------- ----------------------------------- ------1 International Aktiv 2 Electronic Bike Repair & Supplies Aktiv 48 Gardner Touring Cycles Inaktiv Wie schon oben erwähnt, muss sich der Anweisungsausdruck durchaus nicht auf einen einfachen Wert begrenzen, sondern kann neben Funktionen und Berechnungen auch gleich eine ganze Unterabfrage umfassen. Dies soll im nachfolgenden Beispiel einmal demonstriert werden. Hierbei geht es ganz einfach darum, dass bei aktiven Lieferanten die Stadt aus der Address-Tabelle ermittelt werden soll, während bei inaktiven Lieferanten weiterhin das Wort „Inaktiv“ erscheinen soll. Dazu muss man lediglich die entsprechend korrelierte Unterabfrage nach dem Schlüsselwort THEN platzieren. In diesem Fall testet also CASE zunächst darauf, ob der Spaltenwert 1 ist. Ist dies der Fall, verknüpft man Vendor mit VendorAddress und Address, wobei dies nur für den Datensatz der Fall sein soll, der in der äußeren Abfrage gerade bearbeitet wird. -- Ermittlung der Stadt bei "aktiv" SELECT VendorID, Name, CASE ActiveFlag WHEN 1 THEN (SELECT City 200 Komplexe Abfragen FROM Purchasing.Vendor AS v2 INNER JOIN Purchasing.VendorAddress AS va ON v1.VendorID = va.VendorID INNER JOIN Person.Address AS a ON a.AddressID = va.AddressID WHERE v1.VendorID = v2.VendorID) ELSE 'Inaktiv' END AS Stadt FROM Purchasing.Vendor AS v1 331_02.sql: Unterabfrage innerhalb von CASE Man erhält wiederum eine Ergebnisliste mit Lieferantennummer und Namen, wobei allerdings in der dritten Spalte entweder die Stadt bei aktiven Lieferanten oder das Wort „Inaktiv“ bei inaktiven Lieferanten ausgegeben wird. VendorID Name Stadt ----------- -------------------------------- -----------1 International Salt Lake City 2 Electronic Bike Repair Tacoma 48 Gardner Touring Cycles Inaktiv 3.3.2 Selektorlose CASE-Anweisung Im vorherigen Format der CASE-Anweisung war es nur möglich, auf Gleichheit zu prüfen und einen Standardfall anzugeben. Dies ist allerdings nicht sehr flexibel, weil ganz einfach nicht jede (aggregierte) Spalte zu einer überschaubaren Menge an Werten führt oder man ganz einfach eine Menge von Werten zu Bereichen zusammenfassen möchte. 201 Komplexe Abfragen In diesem Fall spricht man von einer „selektorlosen Case-Anweisung“, weil nach dem CASE-Schlüsselwort gerade kein zu untersuchender Ausdruck fällt, sondern ganz gewöhnliche Vergleiche nach den WHEN-Schlüsselwörtern folgen. Dies ermöglicht es, gewöhnliche if-/else if-/else-Konstruktionen von gängigen Programmiersprachen abzubilden und erhöht den Nuzen der CASE-Anweisung um ein Vielfaches. Die allgemeine Syntax hat die Form: CASE WHEN Vergleichsausdruck THEN Ergebnisausdruck [ ...n ] [ ELSE Standardausdruck ] END Im nachfolgenden Beispiel kombiniert man diese selektorlose Case-Aweisung noch mit einer abgeleiteten Tabelle, in welcher die zu untersuchenden Rohdaten für die äußere Abfrage ermittelt werden. Diese abgeleitete Tabelle erstellt eine Liste von Lieferantennummern und Namen sowie eine Spalte namens Orders mit der Anzahl der erhaltenen Bestellungen. Die Fallunterscheidung in der äußeren Abfrage fragt nun in zwei Fällen und einem Standardfall ab, ob die Bestellungen bei diesem Lieferanten größer, kleiner oder gleich 50 sind liefert einen Zahlwert zur Angabe der Bedeutung des Lieferanten als Statuswert. SELECT Name, CASE WHEN Orders > 50 THEN 1 WHEN Orders = 50 THEN 2 202 Komplexe Abfragen ElSE 3 END AS Status FROM (SELECT v.VendorID, Name, COUNT(PurchaseOrderID) AS Orders FROM Purchasing.Vendor AS v INNER JOIN Purchasing.PurchaseOrderHeader AS poh ON v.VendorID = poh.VendorID GROUP BY v.VendorID, Name) AS d 332_01.sql: Einsatz von Vergleichsoperatoren Man erhält die angekündigte Liste mit den Statusinformationen, die sich auf die Anzahl der Bestellungen beziehen. Name Status ------------------------------------- --------International 1 Electronic Bike Repair & Supplies 1 Premier Sport, Inc. 2 3.4 Zusätzliche Aggregate Neben den schon bekannten Standardaggregatfunktionen und ihre Einsatzmöglichkeiten für die Erstellung von Summen, Zählungen und Ermittlung von Extremwerten gibt es weitere Syntaxtechniken, die eine weitere Aggregierung oder besondere Auswahl von Werten ermöglichen. Diese sollen in diesem Abschnitt vorgestellt werden. Dabei sind insbesondere die Möglichkeiten hervorzuheben, mit denen erweiterte Gruppierungen 203 Komplexe Abfragen und die Erstellung von Gruppensummen oder Berichtssummen möglich sind. Einfache Anforderungen lassen sich mit den hier vorgestellten Techniken bereits umsetzen, wobei sie allerdings nur die Tür zu einem ganz anderen Universum darstellen, das mit einer umfassenden Technik im SQL Server 2005 und .NET aufwartet und unter den Begriffen Reporting Services und Analysis Services bekannt ist. 3.4.1 Rangfolgen Bisweilen möchte man Rangfolgen oder auch Hitparaden erstellen. Dazu gibt es im SQL Server eine sehr schöne Syntax, mit der solche Hitparade abgerufen werden können. Die einfachste Möglichkeit, überhaupt Rangfolgen zu erstellen, ist natürlich der Einsatz einer Sortierung mit Hilfe der Klausel ORDER BY. Sie dient auch als Basis für die zusätzliche Syntax. Im nächsten Beispiel ruft man zunähst die Kundennummern und ihre Anzahl an Bestellungen ab. Die Ergebnismenge sortiert man dabei absteigend anhand der Bestellungszahl. -- Kunden und ihre Anzahl an Bestellungen SELECT c.CustomerID, COUNT(soh.SalesOrderID) AS Orders FROM Sales.Customer AS c INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID GROUP BY c.CustomerID ORDER BY Orders DESC 341_01.sql: Einfache Sortierung Als Ergebnis erhält man sämtliche ermittelten Werte. Um nun eine weitere Einschränkung vorzunehmen, könnte man eine WHERE-Klausel einfügen, welche einen Wert aus der Anzahl der Bestellungen zum Vergleich nimmt und beispielsweise nur die Kundennummern ausgibt, welche eine Bestellung größer als 20 ausgelöst haben. 204 Komplexe Abfragen CustomerID Orders ----------- ----------11091 28 11176 28 11185 27 11223 27 Die Vorgehensweise, eine WHERE-Klausel einzusetzen, ermöglicht es allerdings überhaupt nicht, eine Hitparade mit den ersten 10 Kunden auszugeben. Dazu setzt man ganz einfach eine so genannte TOP-n-Abfrage ein. Sie hat ihren Namen von der allgemeinen Syntax SELECT TOP n spaltenliste. Dabei gibt die Zahl nach dem TOPSchlüsselwort an, wie viele Datensätze in der Hitparade enthalten sein sollen. Die Anzahl der ausgewählten Werte lässt sich dabei entweder numerisch direkt vorgegeben (TOP 10) oder prozentual (TOP 10 PERCENT). Die allgemeine Syntax lautet: SELECT [ TOP (zahlausdruck) [PERCENT] [ WITH TIES ]] spaltenliste Ändert man die oben verwendete Abfrage wie in folgendem Ausschnitt um, indem man noch TOP 5 angibt, dann erhält man nur die ersten fünf Datensätze der ursprünglichen Ergebnismenge. SELECT TOP 5 c.CustomerID, COUNT(soh.SalesOrderID) AS Orders ... 341_01.sql: Einfache Rangfolge Man erhält – wie angekündigt – fünf Datensätze. CustomerID Orders ----------- ----------- 205 Komplexe Abfragen 11091 28 11176 28 11185 27 11223 27 11200 27 (5 Zeile(n) betroffen) Wie die gerade ausgegebene Ergebnismenge zeigt, haben viele Kunden die gleichen Werte, d.h. die gleiche Anzahl an Bestellungen. Um diese gleichen Werte auch in der Hitparade zu berücksichtigen und mehr Zeilen zurückzugeben, wenn gleiche Werte ermittelt werden, dann schließt man an die TOP n-Klausel noch WITH TIES an. SELECT TOP 5 WITH TIES c.CustomerID, COUNT(soh.SalesOrderID) AS Orders ... 341_01.sql: Einfache Rangfolge mit Duplikaten Diese Anweisung sorgt dafür, dass insgesamt 13 ausgegeben werden und damit deutlich mehr als fünf. Dies geschieht nur dann, wenn in der Hitparade mehrfach die gleichen Werte ausgegeben werden wie bspw. die mehrfach auftretenden Bestellzahlen. Alle Kunden mit 27 und 28 Bestellungen werden ausgegeben, wobei weitere Kunden nicht mehr ausgegeben werden, da hier nur ein Datensatz für 25 Bestellungen gefunden wird. CustomerID Orders ----------- ----------11091 28 11176 28 11185 27 206 Komplexe Abfragen 11223 27 11200 27 ... (13 Zeile(n) betroffen) Schließlich lässt sich TOP n auch in DML-Anweisungen für einfügen (INSERT), löschen (DELETE) und aktualisieren (UPDATE) von Datensätzen verwenden, wobei allerdings hier der Wert in runden Klammern angegeben werden muss. 3.4.2 Untersummen und Würfel Zwischen gewöhnlichen Abfragen und komplexen Berichten, die auch nicht mehr mit einfachem SQL erstellt werden können und Thema eines anderen Buchs sind, gibt es noch eine weitere Möglichkeit, erweiterte Abfragen zu formulieren. Sie erlauben es bspw., Untersummen zu ermitteln und für Gruppen oder den gesamten Bericht auszugeben. Eine weitere Möglichkeit ergibt sich durch die Erzeugung von Würfeln, die quasi verschiedene Abfragen mit unterschiedlich vielen Spalten vereinen und die Ergebnisse in so genannten Dimensionen ausgeben. Diese Form ist eine sehr vereinfachte Form von Datawarehouse-Abfragen, die ansonsten nur mit entsprechenden SQL ServerWerkzeugen umgesetzt werden können. SQL erlaubt allerdings, einfache Aggregate bereits ohne besonderen Technikeinsatz zu erzeugen. 3.4.2.1 Untersummen bilden Wie schon erwähnt, hat man die Möglichkeit, unter einem Bericht bzw. unter Gruppen von Werten Untersummen auszugeben. Die nachfolgende Abfrage ermittelt zunächst die Rohdaten, welche für dieses und die nachfolgenden Beispiele verwendet werden sollen. Es handelt sich um eine Liste, welche Kunden, Gebiete und Jahre gruppiert und für diese drei Dimensionen die Anzahl der Bestellungen ausgibt. Alle drei Spalten bilden jeweils eine Gruppe, was durch verschiedene Techniken in diesem Kapitel geändert werden soll, ohne mehrere Abfragen nacheinander zu formulieren. SELECT c.CustomerID AS Kunde, 207 Komplexe Abfragen c.TerritoryID AS Gebiet, YEAR(OrderDate) AS Jahr, COUNT(soh.SalesOrderID) AS Bestellungen FROM Sales.Customer AS c INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID GROUP BY c.CustomerID, c.TerritoryID, YEAR(OrderDate) ORDER BY Jahr, Gebiet, Bestellungen DESC 342_01.sql: Einfache Aggregate Man erhält – wie schon gerade erwähnt – die Kombination aus Kunden- und Gebietsnummer sowie Jahr mit der entsprechenden Anzahl der Bestellungen. Dies beantwortet die Frage „Wie viele Bestellungen hat ein Kunde in seinem Gebiet in einem Jahr aufgegeben?“. Kunde Gebiet Jahr Bestellungen ----------- ----------- ----------- -----------344 1 2001 2 218 1 2001 2 401 1 2001 2 73 1 2001 2 Diese Abfrage liefert allerdings keine Informationen darüber, wie viele Verkäufe überhaupt zu verzeichnen sind oder wie sich diese Verkäufe auf die einzelnen Kunden auswirken. Dies gelingt allerdings mit dem sehr einfachen WITH ROLLUP, das man an die GROUP BY-Klausel anschließt. Die nachfolgende Abfrage wiederholt die Anweisung der vorherigen, ergänzt sie allerdings genau um diese Klausel. 208 Komplexe Abfragen ... GROUP BY c.CustomerID, c.TerritoryID, YEAR(OrderDate) WITH ROLLUP ORDER BY Jahr, Gebiet, Bestellungen DESC 342_01.sql: Untersummen bilden Die WITH ROLLUP-Klausel gibt die Aufforderung, zusätzlich zu den ohnehin ermittelten Zeilen auch noch eine zusammenfassende Summe für die Aggregatspalte zu ermitteln und darüber hinaus die Gesamtverkäufe der Kunden und die Gesamtverkäufe der Kunden in ihrem Gebiet auszugeben. Diese Zeilen sind an den NULL-Werten in den jeweils anderen Spalten zu erkennen, da ja für diese Felder gerade kein Wert ausgegeben werden kann. Kunde Gebiet Jahr Bestellungen ----------- ----------- ----------- -----------NULL NULL NULL 6 1 NULL NULL 4 2 NULL NULL 2 1 1 NULL 4 2 1 NULL 2 1 1 2001 2 1 1 2002 2 2 1 2002 2 209 Komplexe Abfragen 3.4.2.2 Würfel Die Erzeugung eines Würfels stellt eine Erweiterung dar, die im Vergleich zu WITH ROLLUP für jede Spalte, die als Dimension bezeichnet wird, eine solche Gesamtsumme ausgibt und zusätzlich auch noch die Kombinationen von ihnen berücksichtigt. Dies bedeutet eine erhöhte Zeilenanzahl durch die verschiedenen ermittelten Aggregate, die bisweilen die benötigten Werte erheblich übersteigt. Die nachfolgende Abfrage entspricht der vorherigen und wird allerdings aus Gründen der Übersichtlichkeit noch einmal abgedruckt. Zur Erzeugung des Würfels schließt man die WITH CUBE-Klausel noch an GROUP BY an. SELECT c.CustomerID AS Kunde, c.TerritoryID AS Gebiet, YEAR(OrderDate) AS Jahr, COUNT(soh.SalesOrderID) AS Bestellungen FROM Sales.Customer AS c INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID GROUP BY c.CustomerID, c.TerritoryID, YEAR(OrderDate) WITH CUBE ORDER BY Jahr, Gebiet, Bestellungen DESC 342_02.sql: Bildung von Würfeln Um die Funktionsweise und den Nutzen sowie den Aufbau des Ergebnisses zu verstehen, folgt für eine Einschränkung auf wenige Kunden das vollständig ausgegebene Ergebnis. Die erste Gruppe entspricht der Gesamtanzahl aller Bestellungen, d.h. einer Summe über alle gruppenweise aggregierten Werte. Dann folgen die Bestellungen für die Dimensionen Kunde, Gebiet, Kunde und Gebiet, Kunde und Jahr, Kunde Gebiet und 210 Komplexe Abfragen Jahr sowie Jahr. Die einzelnen zusätzlichen Spalten kann man an den NULL-Werten erkennen, wobei grundsätzlich natürlich auch NULL-Werte aus der Datenbank hier erscheinen können. Dies ist allerdings hier nicht der Fall, da beim Löschen der WITH CUBE-Klausel die Rohdaten keine NULL-Werte anzeigen. Dies hätte der Fall sein können, wenn nicht alle Kunden einem Gebiet zugeordnet wären und daher das Gebiet NULL auch ein Wert in der Ergebnismenge gewesen wäre. Kunde Gebiet Jahr Bestellungen ----------- ----------- ----------- -----------NULL NULL NULL 6 1 NULL NULL 4 2 NULL NULL 2 NULL 1 NULL 6 1 1 NULL 4 2 1 NULL 2 1 NULL 2001 2 NULL NULL 2001 2 NULL 1 2001 2 1 1 2001 2 NULL NULL 2002 4 1 NULL 2002 2 2 NULL 2002 2 NULL 1 2002 4 1 1 2002 2 211 Komplexe Abfragen 2 1 3.4.2.3 2002 2 GROUPING-Funktionen Wie schon eben bei der Vorstellung des Ergebnisses erläutert, stellt sich die wesentliche Frage, welche Felder den NULL-Wert enthalten, d.h. ob sie durch die Dimensionierung und Würfelbildung leer bleiben müssen oder ob der Wert tatsächlich so in der Datenbank gespeichert war. Dies ist die eigentliche Funktion der Funktion GROUPING, welche auf die Nicht-Aggregat-Spalten, d.h. auf die Dimensionsspalten angewandt werden kann. Sie liefert den Wert 1, wenn der NULL-Wert durch die Würfelbildung zu Stande kommt, und den Wert 0, wenn er ein Datenbankwert ist. SELECT c.CustomerID AS Kunde, c.TerritoryID AS Gebiet, YEAR(OrderDate) AS Jahr, COUNT(soh.SalesOrderID) AS [Best.], GROUPING(YEAR(OrderDate)) AS J, GROUPING(c.TerritoryID) AS G, GROUPING(c.CustomerID) AS K FROM Sales.Customer AS c INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID GROUP BY c.CustomerID, c.TerritoryID, YEAR(OrderDate) WITH CUBE ORDER BY Jahr, Gebiet, [Best.] DESC 342_03.sql: Markierung der erzeugten NULL-Felder 212 Komplexe Abfragen Der zweite, für Programmierer sehr nützliche Einsatzbereich, liegt darin, dass man durch eine Sortierung der Spalten die einzelnen Dimensionen in sehr guter Sortierung erhält und auch bei einem automatischen Abruf der Daten in einer beliebigen Programmiersprache in der Ergebnismenge erkennen kann, wann eine neue Dimension beginnt und endet bzw. welche Reihen zu einer bestimmten Dimension gehören. Wie man an der Ergebnismenge sehen kann, entstehen solche Gruppen wie (1,1,0) oder (1,0,1). Jede Gruppe entspricht einem solchen Schlüssel, wobei die Gruppen durch die Sortierung der GROUPING-Spalten entstehen und dann in C#.NET oder VB.NET verarbeitet bzw. zunächst überhaupt erkannt werden können. Kunde Gebiet Jahr Best. J G K ----------- ----------- ----------- ----------- ---- ---- --NULL NULL NULL 6 1 1 1 1 NULL NULL 4 1 1 0 2 NULL NULL 2 1 1 0 NULL 1 NULL 6 1 0 1 1 1 NULL 4 1 0 0 2 1 NULL 2 1 0 0 1 NULL 2001 2 0 1 0 NULL NULL 2001 2 0 1 1 NULL 1 2001 2 0 0 1 1 1 2001 2 0 0 0 NULL NULL 2002 4 0 1 1 1 NULL 2002 2 0 1 0 2 NULL 2002 2 0 1 0 213 Komplexe Abfragen NULL 1 2002 4 0 0 1 1 1 2002 2 0 0 0 2 1 2002 2 0 0 0 (16 Zeile(n) betroffen) 3.4.2.4 Berichts- und Gruppenuntersummen Bisweilen interessiert man sich bei sehr umfangreichen Ergebnismengen, d.h. bei sehr vielen Spalten und damit möglichen Dimensionen nicht für alle Aggregatwerte bzw. Kombinationen von ihnen, sondern begnügt sich mit einigen wenigen zusätzlichen Ergebnissen. Dies gelingt über die COMPUTE [BY]-Anweisung, welche eine Untersumme für genau benannte Spalten ermittelt. Die allgemeine Syntax ist: [ COMPUTE { { AVG | COUNT | MAX | MIN | STDEV | STDEVP | VAR | VARP | SUM } ( ausdruck) } [ ,...n ] [ BY ausdruck) [ ,...n ] ] ] Wie man sehen kann, lässt sich auch die Art und Weise, wie das zusätzliche Berichtsoder Gruppenaggregat ermittelt wird, mit einer der bekannten Aggregatfunktionen angeben und besteht nicht nur aus einer Summenbildung. Die COMPUTE [BY]-Anweisung folgt der Sortierung und erzeugt – was ein gewisser Nachteil ist – eine zusätzliche Ergebnismenge, die nicht so einfach in einer beliebigen Programmiersprache verarbeitet werden kann wie die zusätzlichen Zeilen und NULL-Felder von WITH ROLLUP und WITH CUBE. 214 Komplexe Abfragen Die nachfolgende Variante der schon mehrfach verwendeten Abfrage fügt am Ende der ersten Ergebnismenge noch zusätzlich die Gesamtanzahl aller Bestellungen und Kunden ein. SELECT c.CustomerID AS Kunde, c.TerritoryID AS Gebiet, YEAR(OrderDate) AS Jahr, COUNT(soh.SalesOrderID) AS [Best.] FROM Sales.Customer AS c INNER JOIN Sales.SalesOrderHeader AS soh ON c.CustomerID = soh.CustomerID GROUP BY c.CustomerID, c.TerritoryID, YEAR(OrderDate) ORDER BY Jahr, Gebiet, [Best.] DESC COMPUTE SUM(COUNT(soh.SalesOrderID)), COUNT(c.CustomerID) 342_04.sql: Erzeugung von Berichtsuntersummen Man erhält zunächst das gewöhnliche Ergebnis. Danach folgen erst mögliche Aggregate in einer eigenen Ergebnismenge. Kunde Gebiet Jahr Best. ----------- ----------- ----------- ----------1 1 2001 2 1 1 2002 2 2 1 2002 2 7 1 2002 2 215 Komplexe Abfragen 2 1 2003 4 7 1 2003 2 sum cnt ----------- ----------14 6 Die vorherige Variante der schon bekannten Abfrage ermittelte eine so genannte Berichtsuntersumme. Die allgemeine Syntax der Klausel lautet allerdings COMPUTE [BY], was es ermöglicht, nach dem BY-Schlüsselwort noch die Spalte anzugeben, welche für die Gruppenuntersummen genutzt werden soll. In der nächsten Variante soll also für die einzelnen Jahre jeweils die Summe der gezählten Bestellungen ermittelt werden. Dies ist nur möglich, wenn die Spalte mit der Jahreszahl auch sortiert wird. … GROUP BY c.CustomerID, c.TerritoryID, YEAR(OrderDate) ORDER BY Jahr ASC COMPUTE SUM(COUNT(soh.SalesOrderID)) BY Jahr 342_05.sql: Erzeugung von Gruppenuntersummen Man erhält tatsächlich jeweils eine Untersumme mit der Anzahl der Bestellungen für die einzelnen Jahre. Kunde Gebiet Jahr Best. ----------- ----------- ----------- ----------1 sum 216 1 2001 2 Komplexe Abfragen ----------2 Kunde Gebiet Jahr Best. ----------- ----------- ----------- ----------1 1 2002 2 2 1 2002 2 7 1 2002 2 sum ----------6 Diese Möglichkeiten schöpfen den Sprachumfang von SQL aus, wobei allerdings zusätzliche Techniken über die Reporting Services und die Analysis Services zur Verfügung stehen, mit denen weitaus komplexere Abfragen und ganze Abfrageanwendungen erzeugt werden können. 217 Komplexe Abfragen 218 Datenmanipulation 4 Datenmanipulation 219 Datenmanipulation 220 Datenmanipulation 4 Datenmanipulation Dieses Buch geht grundsätzlich davon aus, dass die Datenbank, die Sie verwenden, auf die eine oder andere Art vom Himmel gefallen ist. Das bedeutet, dass Sie, wie es viele Teilnehmer in den entsprechenden T-SQL-Seminaren berichten, eine bestehende Datenbank abfragen oder mit Funktionen und Prozeduren versehen sollen. Dazu gehört in vorrangiger Weise gerade nicht die Administration oder die Erstellung neuer Datenstrukturen. Daher ist in diesem Kapitel die Beschreibung von SQL DDL (Data Definition Language) im Gegensatz zu den vielen Beispielen zu SQL DML (Data Manipulation Language) zur Abfrage und Bearbeitung von Daten auf die absoluten Grundlagen beschränkt. Im Band zur Administration dagegen beschäftigen sich die Beispiele ausdrücklich mit dem vielschichtigen und wichtigen Aspekt der Erstellung und Verwaltung von Schema-Objekten in der Datenbank. In einem ersten Teil dieses Kapitels soll also nun in Grundzügen dargestellt werden, wie Sie Tabellen und Sichten über die grafische Oberfläche oder direkt in T-SQL anlegen. An dieser Stelle sei bereits darauf verwiesen, dass die Erstellung von Tabellen auch innerhalb eines T-SQL-Programms von großer Bedeutung sein kann, weil T-SQL keine eigenen Array- oder Collection-Strukturen verwendet, sondern für die Abbildung von Listenwerten mit einer oder mehreren Spalten auf so genannte temporäre Tabellen zurückgreift. Diese müssen in T-SQL weitestgehend genauso erstellt werden wie gewöhnliche Tabellen, die dauerhaft in der Datenbank verbleiben. In einem zweiten Teil stellen wir dann vor, wie Sie Daten in bestehende oder neue Tabellen eintragen, aus ihnen löschen oder Daten aktualisieren. Dies sind Standardanweisungen aus SQL, welche lediglich in T-SQL genutzt werden können und ansonsten in ähnlicher Weise auch in beliebigen anderen relationalen Datenbanken zum Einsatz kommen können. 221 Datenmanipulation 4.1 Datenstrukturen anlegen Eine relationale Datenbank zeichnet sich dadurch aus, dass die Daten in Tabellen gespeichert werden. Diese sind meistens nach Objekten (Entitäten), welche in der zu abzubildenden Modellwelt auftreten, geordnet, wobei die Entwicklung von normalisierten, d.h. gut strukturierten und für eine Weiterentwicklung der Datenbank ohne Datenredundanzen (doppelte Datenspeicherung) und gute Leistungsfähigkeit notwendigen Datenstrukturen eine Tätigkeit darstellt, die sowohl Programmierer als auch Administratoren betrifft. In diesem Fall ist die AdventureWorks-Datenbank bereits vollständig erstellt und zeigt ein sehr umfassendes Bild einer sehr weit normalisierten Datenbank. Tabellen dienen also im MS SQL Server selbstverständlich der Datenspeicherung, wie dies auch in allen anderen relationalen Datenbanken der Fall ist. Zusätzlich weisen sie allerdings noch die Besonderheit auf, dass sie nur temporär angelegt werden können. Eine solche temporäre Tabelle, mit den gleichen SQL-Anweisungen erstellt wie eine dauerhaft gespeicherte, bildet dann Array-Strukturen in T-SQL-Programmen ab. Während die dauerhaft gespeicherten Tabellen sehr gut über die Oberfläche erstellt werden können, ist dies bei den temporären Tabellen nicht möglich, sofern man aus der grafisch modellierten Tabelle nicht einfach das sie beschreibende SQL automatisch generieren lässt, um dieses dann in seinem eigenen Programm zu verwenden. Neben den Tabellen, die sich nachher mit dem schon hinreichend bekannten SELECTBefehl abfragen lassen, gibt es eine zweite Struktur für die Abbildung von Daten. Dies sind Sichten, die bisweilen auch schon einmal in der MS SQL Server-Dokumentation oder sogar in der grafischen Oberfläche als Ansichten bezeichnet werden. Eine solche Sicht oder View, wenn man das auch weit verbreitete englische Wort verwenden möchte, entspricht einer gespeicherten Abfrage, auf die man genauso wie auf einer Tabelle mit dem SELECT-Befehl zugreifen kann. Diese Technik soll ebenfalls in diesem Abschnitt erläutert werden. 4.1.1 Tabellen Tabellen werden im MS SQL Server Management Studio im Objekt Explorer unterhalb des DATENBANKEN-Knotens aufgelistet, wenn man eine der Datenbanken öffnet. In 222 Datenmanipulation diesem Fall ist das der Knoten der AdventureWorks-Datenbank. Öffnet man hier wiederum den Ordner Tabellen, dann erhält man eine Liste der Tabellen, sortiert nach dem Schema (übergeordnete Strukturierung), in dem sie angelegt wurden. Dabei gibt es neben den vom Datenbankentwickler der AdventureWorks-DB angelegten Schemata auch das Standardschema dbo (database owner), in dem automatisch alle Strukturen erstellt werden, sofern man keine Vorkehrungen trifft, sie in einem neuen oder bereits bestehenden Schema zu speichern. Es gibt zwei Möglichkeiten, neue Tabellen zu erstellen. Sofern man sehr viele komplexe Einstellungen zu treffen hat, wird man dies sicherlich mit Hilfe der grafischen Oberfläche erledigen. Sofern man allerdings die Einstellungen in Textform erfassen möchte, um sie möglicherweise besser planen zu können, schreibt man die über die grafische Oberfläche automatisch erstellten SQL-Anweisungen direkt auf. Diesen Weg muss man ohnehin beschreiten, sobald man etwas anspruchsvollere T-SQL-Programme schreiben möchte. 4.1.1.1 Tabellen grafisch anlegen Führen Sie folgende Schritte durch, um eine neue Tabelle anzulegen: 1. Öffnen Sie die Datenbank, in der Sie eine neue Tabelle anlegen wollen. Dies ist im aktuellen Beispiel immer die AdventureWorks-Datenbank. 2. Öffnen Sie das Kontextmenü des Ordners TABELLEN mit der rechten Maustaste und wählen sie den Eintrag NEUE TABELLE. Es erscheint eine tabellarische Darstellung, in der Sie im oberen Bereich Spaltenname und Datentyp angegeben bzw. aus einer Auswahlliste auswählen können. In der dritten Spalte geben Sie an, ob der Wert NULL in die Spalte eingetragen werden darf, d.h. ob die Zelle leer sein kann (Kontrollkästchen markiert) oder nicht. Dieser leere Wert ist dann nicht etwa die leere Zeichenkette oder irgendein magischer Standardwert, sondern der Wert NULL, den Sie bereits mit Hilfe des IS [NOT] NULL in einer Abfrage abgeprüft haben. Die Datentypen haben neben ihrem Namen, 223 Datenmanipulation der sie charakterisiert, auch ab und an eine Länge, die sie über die Tastatur vorgeben können, sobald Sie überhaupt einen Datentyp ausgewählt haben. In diesem Beispiel handelt es sich um eine Tabelle, welche einige Spalte aus der Employee-Tabelle mit dem Primärschlüsselfeld der DepartmentTabelle enthält. Daher gibt es in dieser Tabelle die Spalten ID mit dem Primärschlüsseldatentyp uniqueidentifier. Dieser Datentyp stellt einen komplex aufgebauten eindeutigen Wert für den Datensatz dar und hat bspw. die Form 6F9619FF-8B86-D011-B42D-00C04FC964FF. Ein neuer Wert wird über die NEWID()-Funktion erzeugt. Möglich wären auch Ganzzahlen wie int gewesen, die auch als Alternative bei 1 beginnend schrittweise automatisch um 1 erhöht werden könnten. Die Spalte Name bezieht sich auf den Abteilungsnamen, während DepID die Abteilungsnummer enthält. Sie tritt als smallint-Wert auf, während der Name in nvarchar(50) gespeichert wird. Die nächsten beiden Spalten sind FirstName und LastName des Mitarbeiters. 3. Um eine Spalte einzufügen oder zu löschen, markieren Sie die zu löschende Spalte bzw. die Spalte, vor der eine andere Spalte einzuügen ist. In diesem Fall zeigt die Abbildung, wie vor der Spalte FirstName noch eine Spalte eingefügt werden soll, welche die Anrede speichern soll. 4. Spalten können eine Vielzahl von zusätzlichen Eigenschaften neben Namen, Datentyp und der Zulassung oder dem Verbot von NULL-Werten haben. Drei wichtige Eigenschaften für den Anfänger sind in jedem Fall die Angabe, ob die Spalte den Primärschlüssel enthält, d.h. die Tabelle eindeutig referenziert, ob die Tabelle den Wert einer anderen Spalte enthält und daher einen Fremdschlüssel abbildet und ob es einen Standardwert gibt. 224 Datenmanipulation 2 1 3 4 5 6 Abbildung 4.1: Tabellen über die grafische Oberfläche erstellen 225 Datenmanipulation Diesen Standardwert trägt man unterhalb der tabellarischen Darstellung im Bereich SPALTENEIGENSCHAFTEN ein. Sobald kein Wert für diese Spalte angegeben wird, wenn neue Daten eingetragen werden sollen, würde dieser Standardwert verwendet werden. In diesem Fall soll in der Title-Spalte für die Anrede der Wert Mr vorab eingetragen werden, da die meisten Angestellten (wenngleich auch nur mit einer leichten Überzahl) Herren sind. Sobald man die Eingabetaste betätigt, wird die Zeichenkette noch als solche gekennzeichnet, indem ein N vor den Text und einfache Hochkommata zur Begrenzung um den Vorgabewert gesetzt werden. 5. Möglicherweise haben Sie sich gewundert, dass Sie bislang noch gar nicht nach dem Tabellennamen gefragt wurden. Sie müssen über DATEI / TABELLE_1.SQL SPEICHERN das aktuelle Skript und damit auch die Tabelle speichern. Erst in diesem Moment kann man den Namen vergeben. In diesem Fall handelt es sich um EmpDep für Employee-Department als Zusammenstellung. Den Wert tragen Sie im sich öffenden Dialogfenster ein. Möchten Sie zusäztlich ein spezielles Schema auswälen, in dem die Tabelle gespeichert werden soll, dann können Sie dieses hier auch eintragen. Ansonsten wird das Standardschema dbo verwendet. 6. Schließlich erhalten Sie die neu erstellte Tabelle in der Liste von Tabellen, die für die ausgewählte Datenbank im Objekt-Explorer angezeigt werden. Die Informationen zu einer Spalte kann man sich in einem umfassenden Dialogfenster anschauen, welches große Gemeinsamkeit mit dem Bereich SPALTENEIGENSCHAFTEN beim Anlegen der Tabelle hat. Wählen Sie hierzu aus dem Kontextmenü der Spalte den Eintrag EIGENSCHAFTEN. 226 Datenmanipulation 2 1 Abbildung 4.2: Spalten-Eigenschaften anzeigen Möglicherweise möchten Sie die Eigenschaften der gesamten Tabelle untersuchen. Dies betrifft allerdings im Wesentlichen Einstellungen, welche in den Bereich der Administration hineinragen. Um die Eigenschaften sehen zu können, wählen Sie im Kontextmenü der Tabelle ganz einfach den Eintrag EIGENSCHAFTEN, so wie sie dies auch schon im Kontextmenü für die Spalte gemacht haben, um die Spalteneigenschaften zu sehen. In der Abbildung können Sie erkennen, dass dieses Kontextmenü überhaupt sehr interessant ist, um mit der Tabelle zu arbeiten. Neben der Anzeige von Eigenschaften kann man auch eine neue Tabelle anlegen, die Daten einer Tabelle anzeigen, d.h. eine Tabelle öffnen sowie andere Operationen ausführen. 227 Datenmanipulation 2 1 Abbildung 4.3: Tabellen-Eigenschaften anzeigen Um die Spalteneigenschaften nicht nur zu lesen, sondern tatsächlich zu ändern, sind folgende Schritte notwendig, wobei in diesem Fall ein Primärschlüssel festgelegt wird. 1. Wählen Sie für eine der Tabellenspalten, die im Objekt-Explorer angezeigt werden, aus dem Kontextmenü den Eintrag ÄNDERN. 2. Wählen Sie in der Spalte, in welcher der Primärschlüssel angelegt werden soll, das Kontextmenü. Wenn Sie andere Änderungen durchführen wollen, können Sie dies natürlich genauso in der tabellarischen Aufbereitung der Spalten durchführen, die Sie ja schon vorhin genutzt haben, um die Spalten erstmalig anzulegen. 228 Datenmanipulation 2 1 3 4 Abbildung 4.4: Spalten-Eigenschaften ändern 3. Um die Änderungen in der Tabelle festzushreiben, müssen Sie noch die Tabelel speichern. Dies entspricht dem erstmaligen Speichervorgang, wenn man die Tabelle gerade vollständig neu erstellt. Dies können Sie entweder im Menu DATEI durchführen oder im Kontextmenü des Reiters, unter dem die tabellarische Darstellung angeboten wird. 4. Im Normalfall werden die Änderungen nicht sofort auch in der Eigenschaftenliste im Objekt-Explorer angezeigt. In diesem Fall wählen Sie aus dem Kontextmenü der Tabelle den Eintrag AKTUALISIEREN. 229 Datenmanipulation Eine wichtige Eigenschaft von Tabellen (Relationen) in einem relationalen Datenbanksystem sind die Beziehungen zwischen den Tabellen. So steht bspw. die neue erstellte Tabelle EmpDep mit der Tabelle Department in einer 1:n-Beziehung, da n Datensätze der EmpDep-Tabelle mit einem Datensatz aus der Department-Tabelle in Beziehung stehen. In der abgebildeten Welt bedeutet dieser Umstand, dass n Angestellte in einer Abteilung arbeiten. Grundsätzlich ist es für die Benutzung der Datenbank und den in ihr gespeicherten Tabelle unwichtig, ob diese Beziehungen tatsächlich auch ausformuliert werden. Man kann sie in der Anwendung oder auch nur im Kopf genau so berücksichtigen. Es ist allerdings möglich, sie explizit als Eigenschaften der Tabelle zu formulieren und darüber hinaus mit dieser Angabe dafür zu sorgen, dass bspw. nur solche Fremdschlüsselwerte in der EmpDep-Tabelle erscheinen, die auch tatsächlich in de Department-Tabelle vorhanden sind. Eine andere Regel lautet, dass nur dann ein Datensatz in der Department-Tabelle gelöscht werden kann, wenn kein Datensatz in der EmpDepTabelle auf diesen Datensatz verweist. Aus Sicht der Department-Tabelle ist die EmpDep-Tabelle eine Kindtabelle der Elterntabelle Department, weil die Datensätze der EmpDep-Tabelle sich auf Informationen in der Department-Tabelle beziehen. Diese gesamte Technik lässt sich auf verschiedene Art und Weise einstellen und konfigurieren. Dies betrifft bspw. die Frage, was denn in der Kindtabelle geschehen soll, wenn ein Datensatz doch in der Elterntabelle gelöscht oder aktualisiert wird. Man nennt dies die referenzielle Integrität, was im DBA-Band dieser Reihe beschrieben wird. Für das aktuelle Beispiel soll nur eine einfache Verknüpfung angelegt werden, damit auch nachher ein Datenbankdiagramm automatisch erzeugt werden kann. 1. Wählen Sie aus dem Kontextmenü der Tabelle den Eintrag ÄNDERN. 2. Wählen Sie aus dem Kontextmenü der Spaltenliste den Eintrag BEZIEHUNGEN. 230 Datenmanipulation 2 1 3 4 5 6 7 8 Abbildung 4.5: Beziehung / Fremdschlüssel hinzufügen 231 Datenmanipulation 3. Es öffnet sich ein umfangreiches Dialogfenster, in dem die Beziehungen und ihre Eigenschaften angezeigt und verwaltet werden können. Wenn eine Beziehung schon vorhanden ist, können Sie sich im rechten Bereich über ihre Eigenschaften informieren. Die für dieses Beispiel interessanten Basisangaben sind leider in der Standardansicht ausgeblendet und müssen erst über die zweite Plus-Schaltfläche eingeblendet werden. Wählen Sie die Schaltfläche HINZUFÜGEN. 4. Es öffnet sich ein weiteres Dialogfenster, in dem die Eltern- und Kindtabelle sowie die Primärschlüsselspalte der Eltern- und die Fremdschlüsselspalte der Kindtabelle ausgewählt werden. Hier ist unbedingt auf die richtige Zuordnung zu achten. Für das aktuelle Beispiel ist unter dem Auswahlmenü PRIMÄRSCHLÜSSELTABELLE die Schlüsselspalte DepartmentID der Tabelle Department auszuwählen. Im rechten Bereich wählt man dann als Kindtabelle aus dem Auswahlmenü FREMDSCHLÜSSELTABELLE die EmpDep-Tabelle und ihre Fremdschlüsselspalte DepID. Es ist möglich, einen Schlüssel über mehrere Spalten zu verteilen, sodass an dieser Stelle auch mehrere Einträge denkbar sind. Bestätigen Sie alles mit OK. 5. Unter der zweiten Plus-Schaltfläche namens TABELLEN- UND SPALTENSPEZIFIKATION sollten nun die richtigen Zuordnungen von Tabellen und Spalten erscheinen. Dies betrifft insbesondere die korrekte Zuweisung von Eltern- und Kind-Eigenschaft. Dies ist am besten genauestens zu kontrollieren. Weitere DBA-Tätigkeiten schließen sich dann in diesem Bereich an wie bspw. die erwähnten Regelungen zur referenziellen Integrität. 6. Bestätigen Sie das sich öffnende Dialogfenster mit OK. 7. Eigentlich ist nun für das aktuelle Beispiel die Spalte Name nicht mehr notwendig, denn ihr Wert hängt von der DepID ab, welche wiederum eine Fremdschlüsselbeziehung zur Department-Tabelle enthält. Mit Blick auf 232 Datenmanipulation das Datenbankdesign würde man feststellen müssen, dass die Tabelle nicht normalisiert ist, weil eine Spalte von einer anderen direkt abhängt, diese Spalte aber nicht der Primärschlüssel der Tabelle ist. Dies ist ja nicht DepID, sondern vielmehr ID. Um hier keine Fehler bei Aktualisierungen zu riskieren, sollte man eine solche Spalte löschen. Sofern in einem anderen Arbeitsgang eine solche Spalte überhaupt nicht vorhanden ist, sollte man nur aus dem Kontextmenü der Tabelle oder Spalte den Eintrag AKTUALISIEREN wählen, um zu kontrollieren, ob alle Zuordnungen korrekt sind. In umfangreichen Datenbanken ist es nicht besonders einfach, den Überblick zu bewahren. Sofern man kein fertiges Datenbankdiagramm wie von der AdventureWorks-DB besitzt, kann man sich mit Hilfe von MS Visio oder natürlich dem MS SQL Server Management Studio selbst ein solches Datenbankdiagramm erstellen. Dies ist sehr einfach, sodass Sie diese fünf Minuten Arbeit in jedem Fall investieren sollten. Für die beiden verknüpften Tabellen soll gezeigt werden, wie man ein solches Diagramm erstellen kann. 1. Wählen Sie den ersten Order unterhalb des Datenbankknotens namens DATENBANKDIAGRAMME aus und wählen Sie im Kontextmenü den Eintrag NEUES DATENBANKDIAGRAMM. 2. Sie erhalten sofort eine Liste der in dieser Datenbank vorhandenen Tabellen, aus der Sie diejenigen auswählen, welche im Diagramm erscheinen sollen. Im aktuellen Beispiel sind das Department und EmpDep. Über HINZUFÜGEN können Sie diese Tabellen Ihrem Diagramm hinzufügen. 233 Datenmanipulation 1 2 3 4 5 6 7 8 6 7 Abbildung 4.6: Diagramm erstellen 234 Datenmanipulation 3. Die beiden Tabellen werden nicht nur hinzugefügt, sondern werden auch sofort aufgrund der Einstellungen in der Datenbank verbunden. Der Schlüssel am Ende der Beziehungslinie zeigt an, dass hier der Primärschlüssel und damit die Elterntabelle vorhanden ist, während das Unendlichkeitszeichen für die Kindtabelle und den Umstand steht, dass hier mehrere Primärschlüsselreferenzen in Form von Fremdschlüsseln auftauchen. 4. Sie können das Diagramm dann über das DATEI-Menü speichern und nachher im DATENBANKDIAGRAMME-Knoten wiederfinden. Unabhängig von den beschriebenen Schritten, ein Diagramm zu erstellen, welche ja tatsächlich sehr leichtfüßig zu bewerkstelligen sein müssten, enthält die Abbildung noch zwei Kontextmenüs. Das größere ist das Kontextmenü einer Tabelle. Hier befinden sich insbesondere die Einstellungen für die Tabellenansicht. Sollte man nur am allgemeinen Schema interessiert sein, ist die Ansicht mit den Spaltennamen sicherlich die beste, weil sie besonders übersichtlich ist. Wie man an der Abbildung erkennen kann, gibt es aber auch eine reine Tabellendarstellung für sehr große Modelle bzw. sehr oberflächliche Darstellungen der Datenbank und auch die Möglichkeit, sehr viele Details wie bspw. die Datentypen anzuzeigen und dies auch als benutzerdefinierte Sicht abzuspeichern. An den verschiedenen Einträgen in diesem Kontextmenü sieht man allerdings auch, dass man die Tabellen aus dem Diagramm oder sogar aus der Datenbank löschen kann, dass man die Tabelle genauso bearbeiten kann wie in der gewöhnlichen EigenschaftenAnsicht und dass man automatisch die direkt verknüpften Tabelle zu den ausgewählten Tabellen hinzufügen kann. Dies ist insbesondere dann nützlich, wenn man ein Diagramm für eine unbekannte Datenbank erstellt. Das kleinere Kontextmenü zeigt die Operationen, die bei einem ganzen Datenbankdiagramm durchgeführt werden können. Hier ist es möglich, neue Tabellen zum Diagramm hinzuzufügen und aus der Datenbank abzurufen, bzw. sogar eine ganz neue Tabelle zu erstellen. Als Alternative für eine strukturierte Erstellung innerhalb des Objekt- 235 Datenmanipulation Explorers kann man diese Arbeit also auch unmittelbar im Diagramm durchführen. Dieses Diagramm kann dann zusätzlich auch noch mit Textanmerkungen versehen werden und dadurch also auch kommentiert werden. Für einen Ausdruck eines großen Modells stellt sich immer die Frage, ob man durch Skalierung versucht, alles auf eine DIN A4-Seite zu quetschen oder ob man schon - falls vorhanden - DIN A3 oder mehrere A4-Seiten drucken möchte, um diese dann zusammenzukleben. Eine Vorschau und eine Einstellung zu den Seitenumbrüchen sind in diesem Kontextmenü ebenfalls erreichbar genauso wie ein Zoom. Nachdem man mögliche neue Tabellen für eine bestehende, vom Himmel gefallene Datenbank erstellt hat, möchte man – vielleicht auch aus Gründen des Lernens oder der Sicherung – ein SQL-Skript generieren, das genau die gleiche Tabelle wieder einrichten kann. Hätte man das Skript selbst geschrieben, wäre es möglicherweise in einfacherer Syntax entstanden, doch dies ist ja bei derartigen Abrufen immer der Fall. 1. Öffnen Sie den Knoten einer Tabelle. 2. Wählen Sie aus dem Kontextmenü Skript für TABELLE ALS / CREATE IN. Je nachdem, ob man das SQL-Skript im Abfrage-Editor oder gleich als Datei speichern bzw. in die Zwischenablage kopieren möchte, wählt man einen entsprechenden Eintrag. 3. Als Alternative sehen Sie schon in der Abbildung, dass man die Löschanweisung über DROP IN ebenfalls erstellen kann. Nach der Trennungslinie kann man dann die Operationen abfragen, einfügen, aktualisieren und löschen über die gleiche grafische Oberfläche ausführen, die schon vom Abfrage-Fenster aus abzurufen ist und bereits erklärt wurde. 236 Datenmanipulation Abbildung 4.7: SQL-DDL erstellen Man erhält das nachfolgende Skript, dessen Syntax im nächsten Abschnitt erläutert wird. CREATE TABLE [dbo].[EmpDep]( [ID] [uniqueidentifier] NOT NULL, [Name] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [DepID] [smallint] NULL, [Title] [nchar](8) COLLATE SQL_Latin1_General_CP1_CI_AS NULL CONSTRAINT [DF_EmpDep_Title] DEFAULT (N'Mr'), [FirstName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [LastName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, 237 Datenmanipulation CONSTRAINT [PK_EmpDep] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] 411_01.sql: Erzeugtes SQL-DDL 4.1.1.2 Tabellen mit SQL erstellen Mit Hilfe von SQL lässt sich unter Einsatz des CREATE-Befehls eine Tabelle anlegen, wobei über CREATE sämtliche so genannte Schema-Objekte, d.h. Objekte in der Datenbank, angelegt werden können. Dazu zählen auch Sichten, also gespeicherte Abfragen, und auch die für diesen Band sehr wichtigen Funktionen und Prozeduren. Der Befehl ist wie der SELECT-Befehl von erschreckendem Umfang und bietet eine Vielzahl an Optionen und Angaben, die sehr tief in die Administration und den technischen Aufbau der Datenbank eingreifen. 238 Datenmanipulation CREATE TABLE 1 [ database_name . [ schema_name ] . | schema_name . ] table_name ( { <column_definition> | <computed_column_definition> } [ <table_constraint> ] [ ,...n ] ) [ ON { partition_scheme_name ( partition_column_name ) | filegroup | "default" } ] [ { TEXTIMAGE_ON { filegroup | "default" } ] [;] <data type> ::= 3 [ type_schema_name . ] type_name [ ( precision [ , scale ] | max | [ { CONTENT | DOCUMENT } ] xml_schema_collection ) ] <column_definition> ::= 2 column_name <data_type> [ COLLATE collation_name ] [ NULL | NOT NULL ] [ [ CONSTRAINT constraint_name ] DEFAULT constant_expression ] | [ IDENTITY [ ( seed ,increment ) ] [ NOT FOR REPLICATION ] ] [ ROWGUIDCOL ] [ <column_constraint> [ ...n ] ] Abbildung 4.8: Basisstruktur für die Tabellenerstellung Die Abbildung zeigt den grundlegenden Aufbau der CREATE-Anweisung, wie er auch für diesen Band notwendig ist. Er zeigt die allgemeine Syntax der Tabellenerstellung in einer zusammengefassten Darstellung und zwei Erweiterungen, die in der allgemeinen Syntax nur über Ausdrücke in spitzen Klammern wie <column_definition> notiert werden. Dies ist eine in der Dokumentation oft genutzte Möglichkeit, eine große Syntaxstruktur zu vereinfachen. So enthält der mit der Nummer 1 versehene Bereich den gesamten CREATE-Befehl in einer sehr stark vereinfachten Fassung. Anstelle von der in Nummer 2 angegebenen Spaltendefinition erscheint in Nummer 1 schlichtweg <column_definition>. Gleiches gilt für die in Nummer 2 referenzierte Abkürzung <data_type>. Die Datentypangabe ist wiederum in Nummer 3 angegeben. 239 Datenmanipulation CREATE TABLE 1 [ database_name . [ schema_name ] . | schema_name . ] table_name ( { <column_definition> | <computed_column_definition> } [ <table_constraint> ] [ ,...n ] ) [ ON { partition_scheme_name ( partition_column_name ) | filegroup | "default" } ] <computed_column_definition> ::= [ { TEXTIMAGE_ON { filegroup | "default" } ] column_name AS computed_column_expression [;] [ PERSISTED [ NOT NULL ] ] 2 [ [ CONSTRAINT constraint_name ] { PRIMARY KEY | UNIQUE } [ CLUSTERED | NONCLUSTERED ] [ WITH FILLFACTOR = fillfactor | WITH ( <index_option> [ , ...n ] ) ] | [ FOREIGN KEY ] REFERENCES referenced_table_name [ ( ref_column ) ] [ ON DELETE { NO ACTION | CASCADE } ] [ ON UPDATE { NO ACTION } ] [ NOT FOR REPLICATION ] | CHECK [ NOT FOR REPLICATION ] ( logical_expression ) [ ON { partition_scheme_name ( partition_column_name ) | filegroup | "default" } ] ] Abbildung 4.9: Berechnete Spalten Wie man in der Nummer 1 sehen kann, folgt nach CREATE TABLE der Name der Tabelle, wobei dieser auch den Namen der Datenbank und des Schemas, in dem die Tabelle erstellt werden soll, enthalten kann. Diese drei Bereiche werden jeweils durch einen Punkt getrennt. Im einfachsten Fall genügt allerdings der Tabellenname. Nach der Nennung des Namens folgt in zwei runden Klammern die Angabe der einzelnen Spalten und danach weitere allgemeine Angaben zur Tabelle wie Einschränkungen und Integritätsregeln. Die Erstellung der Spalten ist neben den administrativen Angaben der wesentliche Bereich der gesamten SQL-Anweisung. Hier gibt es insgesamt zwei Möglichkeiten, welche in den beiden Abbildungen angezeigt werden. 240 Datenmanipulation Unter <column_definition> versteht man die Angabe eines Spaltennamens und eines Datentyps für diese Spalte sowie weitere Angaben für die Spalte, die ihre Eigenschaften betreffen: zulassen von NULL-Werten, Zeichensatz, Standardwertangabe, Angabe der Einzigartigkeit des Wertes für Primärschlüssel. Unter <computed_column_definition> versteht man die Angabe eines Spaltennamens und des Schlüsselwortes AS, der zu einem Ausdruck führt, der eine so genannte berechnte Spalte erstellt. In diese Spalte lässt sich später kein Wert eintragen, sondern er wird automatisch und dynamisch auf Basis der angegebenen Berechnungsvorschrift ermittelt. Die nachfolgenden Beispiele sollen zeigen, wie man direkt in SQL eine Tabelle erstellen kann. Neben der Speicherung in der Datenbank sind die Beispiele von ihrem grundsätzlichen Aufbau her auch relevant für die Erstellung von so genannten temporären Tabellen. Dies sind Tabellen, die in zwei Ausprägungen erscheinen. Die gewöhnliche temporäre Tabelle kennzeichnet man mit einem Rautenzeichen vor ihrem Namen, was angibt, dass sie temporär und nur für die aktuelle Sitzung gespeichert wird. Eine globale temporäre Tabelle dagegen kennzeichnet man durch zwei Rautenzeichen, was wiederum angibt, dass sie zwar nicht fix in der Datenbank gespeichert ist, aber für alle Sitzungen – also global – verfügbar ist. Um eine Tabelle zu löschen, verwendet man den DROP-Befehl, der nicht nur für Tabelle, sondern für alle Schema-Objekte zur Verfügung steht und vor Nennung des SchemaObjektnamens noch die Art des Schema-Objekts erwartet. In diesem Fall ist das TABLE, im Falle einer Prozedur PROCEDURE und im Falle einer Funktion FUNCTION. Um das Beispiel mehrfach auszuführen, ist es notwendig, die bereits erstellte Tabelle zu löschen. Die beiden Anweisungen DROP und CREATE sind durch GO getrennt, was ankündigt, dass der eine Befehl abgeschlossen ist und ein neuer beginnt. Auf Basis der schon in der Datenbank vorhandenen Tabelle Address erstellt das nachfolgende Beispiel eine ähnliche Tabelle Address2. Man erkennt sehr gut den Aufbau, mit der die Spalten erstellt werden: name datentyp [NOT] NULL. 241 Datenmanipulation Dabei zeigt bereits die erste Zeile, dass die AddressID-Spalte zusätzlich auch den Primärschlüssel bildet und daher zusätzlich noch das Schlüsselwort PRIMARY KEY enthält. Die Eigenschaft IDENTITY [ (seed , increment) ] bietet die Möglichkeit, einen automatisch aufsteigenden Schlüssel zu verwenden, der mit jeder neuen Einfügen-Operation bei seed beginnend um den Wert, der in increment angegeben ist, erhöht wird. Die optionale [NOT] NULL-Angabe legt fest, ob NULL-Werte in der Spalte zulässig sind oder nicht. Auch wenn diese Angabe nicht verpflichtend ist, so stellt sie doch eine sehr wichtige Angabe dar, um die Funktionsweise der Spalte genau anzugeben. Während der Großteil der Spalten sich nach dem gerade beschriebenen Schema richtet, fällt nur noch die letzte Spalte namens ModifiedDate wieder aus dem Rahmen. Sie enthält zusätzlich noch eine DEFAULT-Angabe mit einem Standardwert. Sollte beim Einfügen kein Wert für diese Spalte angegeben werden, so würde dieser Standardwert verwendet werden. Im Normalfall ist dieser Standardwert fix vorgegeben, d.h. der wahrscheinlichste und damit häufigste Wert, der für neue Datensätze gilt. IF OBJECT_ID ('Person.Address2', 'T') IS NOT NULL DROP TABLE Person.Address2 GO CREATE TABLE Person.Address2 ( AddressID int IDENTITY(1,1) NOT NULL PRIMARY KEY , AddressLine1 nvarchar(60) NOT NULL, AddressLine2 nvarchar(60) NULL, City nvarchar(30) NOT NULL, StateProvinceID int NOT NULL, PostalCode NOT NULL, 242 nvarchar(15) Datenmanipulation ModifiedDate datetime NOT NULL DEFAULT (getdate())) GO 411_02.sql: Erstellen einer Tabelle Sobald man die neue Address2-Tabelle angelegt hat, sollte sie nach dem Aktualisieren im Objekt-Explorer ebenfalls erscheinen. Da es ja bereits eine ähnliche Tabelle gibt, kann man diese beiden gut vergleichen. Abbildung 4.10: Tabellen mit automatischen / eigenen Bezeichnern Die Spalten sind weitestgehend dieselben bzw. nur um wenige abgekürzt. Da allerdings im gerade gezeigten Skript die verschiedenen Einstellungen wie Primärschlüssel und Einschränkungen wie ein Standardwert nicht ausdrücklich einen eigenen Namen erhalten haben, wurden automatische Standardnamen vergeben. Dies ist bei einer gespeicherten Tabelle keine so gute Lösung, weil in Fehlermeldungen diese Namen wieder erscheinen und man sie dann nicht so leicht zuordnen kann wie ein selbst definierter, weitestgehend selbst-erklärender und -sprechender Name. Bei den erwähnten temporären Tabellen ist dies oft nicht so bedeutsam, wenn sie mehr wie eine Array-Struktur genutzt werden und vielleicht auch gar keine solchen Beziehungen zu anderen Tabellen enthalten. 243 Datenmanipulation Zusätzlich wurde die OBJECT_ID()-Funktion eingesetzt. Sie hat die allgemeine Syntax: OBJECT_ID ( '[ database_name . [ schema_name ] . | schema_name . ] object_name' [ ,'object_type' ] ) Sie dient dazu, die so genannte Objekt-ID zurückliefern, wie es der Name der Funktion ja schon nahe legt. Ein Ausdruck wie SELECT OBJECT_ID('Person.Address') AS Tabelle ermittelt den Wert 53575229 für die im Testsystem vorhandene Datenbankinstallation. Sollte man dagegen ein nicht vorhandenes Schema-Objekt aufrufen, so erhält man den Wert NULL zurück, sodass dies ein einfacher Test ist, ob ein SchemaObjekt vorhanden ist oder nicht. Bei einer temporären Tabelle muss man in jedem Fall den Namen der Datenbank für die temporären Objekte vor den Namen des Objekts setzen. Hier ändert sich dann die Abfrage zu SELECT OBJECT_ID('tempdb..#temptable') um. Mit Hilfe der Abfrage SELECT DISTINCT type FROM sys.objects erhält man die derzeit verfügbaren möglichen Abkürzungen für Schema-Objekte wie bspw.: AF = Aggregatfunktion (CLR) SN = Synonym C = CHECK-Einschränkung SQ = Dienstwarteschlange D = DEFAULT (Einschränkung oder eigenständig) TA = Assembly-DML-Trigger (CLR) F = FOREIGN KEY-Einschränkung PK = PRIMARY KEY-Einschränkung IF = Inline-Tabellenwertfunktion von SQL P = Gespeicherte SQL-Prozedur TF = Tabellenwertfunktion von SQL PC = Gespeicherte Assemblyprozedur (CLR) U = Tabelle (benutzerdefiniert) FN = SQL-Skalarfunktion V = Sicht FS = Assemblyskalarfunktion (CLR) X = Erweiterte gespeicherte Prozedur FT 244 = Assembly-Tabellenwertfunktion TR = SQL-DML-Trigger UQ = UNIQUE-Einschränkung Datenmanipulation (CLR) IT = Interne Tabelle R = Regel (vom alten Typ, eigenständig) RF = Replikationsfilterprozedur Im nächsten Beispiel wird die Address2-Tabelle noch einmal abgewandelt. In Ergänzung zum vorherigen Beispiel werden nun sowohl selbst benannte Einschränkungen als auch Angaben zu Zeichensätzen verwendet, die in den Zeichenkettenspalten genutzt werden sollen. Dabei folgt der Name der [NOT] NULL-Angabe nach dem Schlüsselwort CONSTRAINT. Diese Namen erscheinen dann auch im Objekt-Explorer, sobald man die Anzeige aktualisiert und zu den Eigenschaften der erstellten Tabelle navigiert. CREATE TABLE Person.Address2 ( AddressID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Address_AddressID2 PRIMARY KEY , AddressLine1 nvarchar(60) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, AddressLine2 nvarchar(60) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, City nvarchar(30) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, StateProvinceID int NOT NULL, PostalCode nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, 245 Datenmanipulation ModifiedDate datetime NOT NULL CONSTRAINT DF_Address_ModifiedDate2 DEFAULT (getdate())) 411_03.sql: Erweiterte Tabellendefinition Nachdem eine typische Tabelle erzeugt wurde, die zwar als Referenz und damit als Elterntabelle für andere Tabellen dienen kann, erstellt wurde, soll nun im nachfolgenden Beispiel eine Tabelle definiert werden, die neben den üblichen Eigenschaften auch Fremdschlüsselbeziehungen zu anderen Tabellen hat. Dazu eignen sich im Schema der AdventureWorks-Datenbank sehr viele Tabellen, da das Schema für eine Beispieldatenbank durchaus sehr komplex ist und daher viele Verknüpfungen zwischen den Tabellen besitzt. Tabellenbeziehungen lassen sich über die FOREIGN KEY-Klausel angeben, die entweder direkt in der Spaltendefinition erscheint oder nach der Spaltendefinition angeschlossen wird. In einem automatisch erzeugten Skript ist auch zu erkennen, dass keine von beiden Varianten, die in den nächsten Beispielen benutzt werden, tatsächlich umgesetzt werden. In einem erzeugten CREATE-Skript wird zunächst die Tabelle erstellt, ehe dann mit diversen ALTER-Anweisungen die Tabelle geändert und weitere Angaben angehängt werden, nachdem die eigentliche Tabelle erstellt wurde. Ein Vorteil dieser Technik besteht darin, dass ein Teil der Anweisungen im Fehlerfall durchaus ausgeführt werden kann, während innerhalb der umfassenden Reihe an zusätzlichen Anweisungen auch bisweilen ein Fehler entstehen kann, der zwar zu einer Fehlermeldung führt, das gesamte Skript aber zunächst nicht beendet. Im nachfolgenden Beispiel erstellt man eine Variante der Product-Tabelle, die weniger Spalten als die originale Tabelle in der DB besitzt. Der Primärschlüssel wird wiederum automatisch erzeugt, weil die ProductID-Spalte die IDENTITY-Eigenschaft besitzt. Nach einigen im zuvor beschriebenen Verfahren definierten Spalten für die Abbildung von Produkten folgen die Fremdschlüsselverknüpfungen. Sie gelten für die Verknüpfungen zu den beiden Tabellen UnitMeasure, welche Maßeinheiten sammelt, die im 246 Datenmanipulation Rahmen der Datenbank an verschiedenen Stelle genutzt werden, und ProductSubcategory, welche zusammen mit der von ProductSubcategory aus verknüpften Tabelle ProductCategory die Produkte in Kategorien und Unterkategorien einteilt. Hierbei muss natürlich zunächst die ProductSubcategory für die Zuweisung zu einer Untergruppe verbunden werden, weil die Untergruppen dann wiederum zu wenigen Kategorien zusammengefasst werden. Es sind zwar nur zwei Tabellen verbunden, dennoch findet man insgesamt drei Fremdschlüsselbeziehungen. Neben der Spalte SizeUnitMeasureCode verknüpft nämlich auch die Spalte WeightUnitMeasureCode die Spalte UnitMeasure bzw. sogar die gleiche Spalte UnitMeasureCode, da einfach die beiden Spalten für Größe und Gewicht eine Maßeinheit benötigen, die in der umfassenden Tabelle mit standardisierten Maßeinheiten gespeichert werden. An anderer Stelle wurde bereits erwähnt, dass es möglich ist, in mehreren Spalten die gleiche Tabelle zu referenzieren. In diesem Fall handelt es sich allerdings nicht um den viel häufigeren Fall eines zusammen gesetzten Schlüssels, der aus mehreren Feldern erstellt wird, sondern stattdessen sind tatsächlich verschiedene Datensätze aus der UnitMeasure-Tabelle verbunden. CREATE TABLE Production.Product2 ( ProductID int IDENTITY(1,1) NOT NULL PRIMARY KEY, Name varchar(30) NOT NULL, ProductNumber nvarchar(25) NOT NULL, ListPrice money NOT NULL, Size nvarchar(5) NULL, SizeUnitMeasureCode nchar(3) NULL FOREIGN KEY REFERENCES Production.UnitMeasure (UnitMeasureCode), 247 Datenmanipulation WeightUnitMeasureCode nchar(3) NULL FOREIGN KEY REFERENCES Production.UnitMeasure (UnitMeasureCode), Weight decimal(8, 2) NULL, ProductSubcategoryID int NULL FOREIGN KEY REFERENCES Production.ProductSubcategory (ProductSubcategoryID), ModifiedDate datetime NOT NULL CONSTRAINT DF_Product_ModifiedDate2 DEFAULT (getdate())) 411_04.sql: Anlegen von Fremdschlüsseln 248 Datenmanipulation Abbildung 4.11: Verknüpfungen der Tabelle Erstellt man ein Diagramm oder wirft man einen Blick in das Schema der Datenbank erkennt man deutlich, wie die Tabelle Product und damit auch die hier erstellte Tabelle Product2 mit zwei Tabellen verbunden ist. Neben der Möglichkeit, die Fremdschlüssel direkt bei der Spaltendefinition anzugeben, besteht – wie schon erwähnt – ebenfalls die Möglichkeit, sie nach der gesamten Spaltenliste gesammelt anzugeben oder sie über den ALTER-Befehl nachträglich anzuhängen. In allen drei Varianten ist es möglich, für die Verknüpfung einen Namen zu geben, wie dies schon bei den vorherigen Beispielen vorgeführt wurde. Daher folgt ein SQL-Skript, in dem gerade nach der verkürzten Spaltenliste zwei der Verknüpfungen angegeben werden, während eine benannte Verknüpfung unter Angabe des CONSTRAINTSchlüsselworts weiterhin in der Spaltenliste zu finden ist. In diesem Fall ist die Angabe allerdings um den Namen der Verknüpfung erweitert. DROP TABLE Production.Product2 GO 249 Datenmanipulation CREATE TABLE Production.Product2 ( ProductID int IDENTITY(1,1) NOT NULL PRIMARY KEY, ..., ProductSubcategoryID int NULL CONSTRAINT FK_Product_ProductSubcategory_ ProductSubcategoryID2 FOREIGN KEY(ProductSubcategoryID) REFERENCES Production.ProductSubcategory (ProductSubcategoryID), ..., CONSTRAINT FK_Product_UnitMeasure_SizeUnitMeasureCode2 FOREIGN KEY(SizeUnitMeasureCode) REFERENCES Production.UnitMeasure (UnitMeasureCode), CONSTRAINT FK_Product_UnitMeasure_WeightUnitMeasureCode2 FOREIGN KEY(WeightUnitMeasureCode) REFERENCES Production.UnitMeasure (UnitMeasureCode)) 411_05.sql: Benannte Fremdschlüsselverknüpfungen 250 Datenmanipulation Abbildung 4.12: Aufbau einer Selbstverknüpfung Die Selbstverknüpfung ist bereits im Rahmen der verschiedenen Verknüpfungsarten aus Sicht von Abfragen vorgeführt worden. An dieser Stelle sei auf dieses Thema noch einmal verwiesen. Eine FOREIGN KEY-Klausel kann selbstverständlich auch auf die gleiche Tabelle verweisen. Das klassische Schulbeispiel einer Selbstverknüpfung befindet sich in der Employee-Tabelle, in der einige Mitarbeiter als Manager erscheinen, da ihre EmployeeID in der ManagerID-Spalte genannt werden. Dies führt dazu, dass die EmployeeID weiterhin der Primärschlüssel ist und dass die ManagerID-Spalte den Fremdschlüssel enthält. Dies ist dann eine selbstbezügliche Verknüpfung, wo die gleiche Tabelle einmal in der Rolle der Kind- und ein anderes Mal in der Rolle der ElternTabelle auftritt. Nach der Erstellung einer Tabelle kann es bisweilen schon einmal geschehen, dass die Strukturen einer Tabelle geändert werden sollen. Dies betrifft die Veränderung der 251 Datenmanipulation Datentypangabe wie bspw. die Veränderung des Wertebereichs, das Hinzufügen eines Fremdschlüsselwerts oder einer ganzen Tabelle sowie eines Standardwerts wie auch die Umbenennung einer Spalte. Während die ersten Beispiele gerade durch den ALTERBefehl durchgeführt werden können, gibt es für die Umbenennung von Spalten keine Möglichkeit, dies mit SQL direkt durchzuführen. ALTER TABLE [ database_name . [ schema_name ] . | schema_name . ] table_name { ALTER COLUMN column_name { [ type_schema_name. ] type_name [ ( { precision [ , scale ] | max | xml_schema_collection } ) ] [ NULL | NOT NULL ] [ COLLATE collation_name ] | {ADD | DROP } { ROWGUIDCOL | PERSISTED } } | [ WITH { CHECK | NOCHECK } ] ADD DROP { { <column_definition> [ CONSTRAINT ] constraint_name | <computed_column_definition> [ WITH ( <drop_clustered_constraint_option> [ ,...n ] ) ] | <table_constraint> | COLUMN column_name } [ ,...n ] } [ ,...n ] | [ WITH { CHECK | NOCHECK } ] { CHECK | NOCHECK } CONSTRAINT { ALL | constraint_name [ ,...n ] } | { ENABLE | DISABLE } TRIGGER { ALL | trigger_name [ ,...n ] } | SWITCH [ PARTITION source_partition_number_expression ] TO [ schema_name. ] target_table [ PARTITION target_partition_number_expression ] } Abbildung 4.13: Ändern von Eigenschaften Die vorherige Abbildung zeigt die beiden Teile der allgemeinen Syntax. Innerhalb des ALTER-Befehls gibt es die Möglichkeit, eine Spalte zu ändern oder sie bzw. ihre Einstellungen zu löschen. Dies geschieht jeweils mit einem weiteren ALTER-Befehl oder dem auch für die Schema-Objekte verfügbaren DROP-Befehl. Die nachfolgenden Beispiele zeigen kurz, wie man typische Anwendungsfälle direkt in SQL umsetzt. Im DBA-Buch werden die einzelnen Befehle sowie natürlich die verschiedenen Spalteneinschränkungen und Schema-Objekte ausführlicher dargestellt. In 252 Datenmanipulation den meisten Fällen dürfte es daher ausreichen, die Änderungen direkt in der grafischen Oberfläche auszuführen. Die Tabelle Address2 soll zunächst ihre Einschränkung, die die Fremdschlüsselverknüpfung zur Tabelle StateProvince enthält, verlieren, wenn diese bereits existiert. Ansonsten soll später genau diese Einschränkung eingerichtet, eine neue Spalte eingefügt, diese vom Datentyp geändert und schließlich gelöscht werden. IF OBJECT_ID ('FK_Address_StateProvince_StateProvinceID2', 'C') IS NOT NULL ALTER TABLE Person.Address2 DROP CONSTRAINT FK_Address_StateProvince_StateProvinceID2 GO ALTER TABLE Person.Address2 WITH CHECK ADD CONSTRAINT FK_Address_StateProvince_StateProvinceID2 FOREIGN KEY (StateProvinceID) REFERENCES Person.StateProvince (StateProvinceID) GO ALTER TABLE Person.Address2 ADD AddressLine3 nvarchar(30) NULL GO ALTER TABLE Person.Address2 ALTER COLUMN nvarchar(50) GO ALTER TABLE Person.Address2 DROP COLUMN AddressLine3 GO 411_06.sql: Beispiele von Änderungen 253 Datenmanipulation Wie oben schon erwähnt, ist es nicht möglich, mit einfachen SQL-Anweisungen ein Objekt umzubenennen. Es gibt zwar grundsätzlich in anderen Datenbanken auch eine RENAME-Option innerhalb von ALTER, doch natürlich muss man darauf hinweisen, dass gerade das Umbenennen von Schema-Objekten eine deutlich gefährlichere Aktion darstellt als das einfache Ändern. Hier können abhängige Objekte wie Funktionen, Prozeduren sowie andere Tabellen ungültig werden, was die ganze DB-Struktur zerstören kann. Daher vermutlich gibt es für die MS SQL Server-DB eine System-Prozedur, mit deren Hilfe eine solche Umbenennung möglich ist. Sie hat folgende allgemeine Syntax: sp_rename [ @objname = ] 'object_name' , [ @newname = ] 'new_name' [ , [ @objtype = ] 'object_type' ] Folgende Werte sind für den Objekttyp möglich: COLUMN für Spalte (benutzerdefiniert) DATABASE für Datenbank (benutzerdefiniert) INDEX für Index OBJECT für Objekt aus sys.objects wie bspw. Einschränkungen (CHECK, FOREIGN KEY, PRIMARY/UNIQUE KEY), Benutzertabellen und Regeln USERDATATYPE für Benutzerdefinierter Aliasdatentyp (CREATE TYPE) oder CLR- benutzerdefinierter Typ (sp_addtype) aus .NET. Im nachfolgenden Beispiel benennt man zunächst eine Tabelle um. Danach ändert man in der neu benannten Tabelle einen Spaltennamen ab. Im Kommentar steht zusätzlich, wie die gleiche Operation über Namensnotation (Nennung der Parameternamen) im Gegensatz zur Positionsnotation erfolgt. EXEC sp_rename 'Person.Address2', 'Person.AddressNew' GO 254 Datenmanipulation EXEC sp_rename 'Person.AddressNew.City', 'Person.AddressNew.CityNew', 'COLUMN' /* EXEC sp_rename @objname = 'Person.AddressNew.City', @newname = 'Person.AddressNew.CityNew', @objtype = 'COLUMN'; */ GO 411_07.sql: Umbenennen von Spalten und Tabellen 4.1.2 Sichten Neben den Tabellen, die für die Erstellung von Abfragen mehr innerhalb von Transact SQL-Programmen als Array-Struktur von der anvisierten Zielgruppe dieses Buchs genutzt werden dürften, sind zusätzlich noch Sichten eine interessante Lösung für die Erstellung von Abfragen. Sie stellen gespeicherte Abfrage dar, welche mit einer SELECT-Anweisung gebildet werden wie eine gewöhnliche Abfrage und zusätzlich unter einem Namen als Schema-Objekt in der Datenbank gespeichert werden. Als besonderer Clou wirken sie in ihrer Funktionsweise und Benutzung wie gewöhnliche Tabellen, d.h. als Benutzer muss man nicht unterscheiden, ob man eine Sicht oder eine Tabelle abfragt bzw. kann es auch nicht in jeder Situation oder mit jeder Berechtigung herausfinden. Dabei speichert man bei der Sicht tatsächlich nur das Relationenschema, d.h. die Regel, welche Daten zu beschaffen sind, und gerade nicht die Daten selbst. Diese werden dynamisch und aktuell aus den vorhandenen Tabellen abgerufen. Für Administratoren ist diese Technik interessant, weil so im tatsächlichen Sinne des Wortes eine zusätzliche Sicht auf die Datenstrukturen und auf die Daten erstellt werden kann, welche als Schutzschild für die in Wirklichkeit vorhandenen Strukturen und Daten dienen. Die beiden Aspekte lassen sich getrennt betrachten: 255 Datenmanipulation Strukturen: Durch die Erstellung einer Sicht ist es möglich, bspw. mehrere Tabellen zu verknüpfen und dadurch die Komplexität von sehr weit und damit sehr gut normalisierten Datenmodellen wieder zu vereinfachen. Der Benutzer, der SQL für die Bearbeitung der Daten eingibt, ist nicht gezwungen, selbst mehrere Tabellen miteinander zu verbinden und damit möglicherweise zusätzlich zu berücksichtigen, dass mehrere Schlüsselfelder sich zu einem Schlüssel zusammensetzen. Dadurch können Fehler und falsch erzeugte Daten verhindert werden. Daten: Durch die Erstellung einer Sicht ist es möglich, die Daten bereits soweit zu filtern, dass ein Benutzer gerade nicht alle Daten sehen kann, sondern nur einen Teil. Dies betrifft teilweise auch wiederum die Strukturen, da man nicht nur einzelne Zeilen, sondern ganz einfach auch ganze Spalten verbergen kann, indem sie in der Sicht nicht erscheinen. Der Fall, an dem man möglicherweise sofort denkt, wenn man Datensicherheit über eine Sicht herstellen möchte, ist die Verwendung geeigneter Bedingungen in der WHERE-Klausel, um geheime Daten auszublenden. Die allgemeine Syntax zur Erstellung einer Sicht ist relativ einfach, da ein Großteil der Arbeit natürlich von der SELECT-Anweisung.ausgeführt wird und die restliche Syntax nur für die Erstellung der Sicht als solche existiert. Wie eine Tabelle kann man sie über CREATE erstellen, wobei hier anstelle von TABLE das Schlüsselwort VIEW steht. Eine Sicht kann ebenfalls in einem speziellen Datenbankschema oder im Standardschema dbo liegen. Danach folgt eine optionale Spaltenliste, mit der direkt die Spaltennamen angegeben werden können, welche von der Sicht nach außen angeboten werden sollen. Als Alternative werden einfach die Spalten(alias)namen der Abfrage verwendet. Dies ist die einfachste Lösung und dürfte auch am häufigsten zum Einsatz kommen. Vor der eigentlichen Abfrage folgt dann noch die WITH-Klausel, während nach der Abfrage die Anweisung WITH CHECK OPTION folgen kann. Folgende allgemeine Syntax ist für die Erstellung einer Sicht verfügbar: CREATE VIEW [ schema_name . ] view_name [ (column [ ,...n ] ) ] 256 Datenmanipulation [ WITH [ ENCRYPTION | SCHEMABINDING | VIEW_METADATA ] [ ,...n ] ] AS select_statement [ ; ] [ WITH CHECK OPTION ] Die nachfolgende Abbildung zeigt die Funktionsweise einer Sicht. Sie würde in fast der gleichen Weise auch die Funktionsweise einer Abfrage darstellen, wenn man die SQLAnweisung im Textkasten um CREATE VIEW kürzt und sich vorstellt, dass die Abfrage als solche gerade nicht in der Datenbank gespeichert wird. Aus den drei Tabellen Employee, Contact und EmployeeAddress, wobei die dritte Tabelle nur eine Beziehungstabelle zwischen Employee und Contact darstellt, um Mitarbeitern einen Kontakt aus allen möglichen Kontakten zuzuordnen. Aus diesen drei Tabellen ruft man aus Employee und Contact (die dritte wird nur für die Verknüpfung verwendet) nicht alle Spalten ab, sondern nur solche wie EmployeeID, die Namensbestandteile sowie die Kontaktdaten für Telefon und E-Mail. Dies wäre dann ein Beispiel für die Struktursicherheit oder die Strukturänderung und -vereinfachung, die durch eine Sicht realisiert werden können. Die Vereinfachung liegt darin, dass man nachher bei der Verwendung der Sicht die Beziehungstabelle nicht mehr einsetzen muss, um die Daten abzurufen. Die Sicherheit könnte darin liegen, dass zusätzlich auf Zeilenebene noch ein weiterer Teil der Daten ausgeblendet wird. Dies ist im aktuellen Beispiel nicht gegeben und wäre mit Blick auf das reine Datenmodell nicht sichtbar, da hier schließlich nur die Spalten zu erkennen sind. Eine WHERE-Klausel könnte allerdings die Daten für bestimmte Benutzergruppen filtern. 257 Datenmanipulation CREATE VIEW HumanResources.vEmployee2 AS SELECT e.EmployeeID, c.FirstName, c.MiddleName, c.LastName, c.Phone, c.EmailAddress FROM HumanResources.Employee e INNER JOIN Person.Contact c ON c.ContactID = e.ContactID INNER JOIN HumanResources.EmployeeAddress ea ON e.EmployeeID = ea.EmployeeID Abbildung 4.14: Spaltenzuordnung in Sicht Die gerade in der Abbildung gezeigte Syntax folgt noch einmal im nachfolgenden Beispiel. Die Spalten, welche durch die Sicht angeboten werden, tragen die Namen der abgerufenen Spalten, wie man auch später in der der ausgeführten SQL-Anweisung sehen kann. Diese soll auch verdeutlichen, dass die Sicht wie eine Tabelle innerhalb der FROM-Klausel verwendet werden kann und alle Abrufoptionen bietet wie eine Tabelle. IF OBJECT_ID ('HumanResources.vEmployee2', 'V') IS NOT NULL DROP VIEW HumanResources.vEmployee2 GO 258 Datenmanipulation CREATE VIEW HumanResources.vEmployee2 AS SELECT e.EmployeeID, c.FirstName, c.MiddleName, c.LastName, c.Phone, c.EmailAddress FROM HumanResources.Employee e INNER JOIN Person.Contact c ON c.ContactID = e.ContactID INNER JOIN HumanResources.EmployeeAddress ea ON e.EmployeeID = ea.EmployeeID GO -- Sicht abfragen SELECT Firstname, LastName, EmailAddress FROM HumanResources.vEmployee2 WHERE EmployeeID < 4 412_01.sql: Sicht erstellen (Spaltennamen der Abfrage) Man erhält als Ergebnis der Abfrage eine Ergebnismenge, welche die Daten aus der Abfrage aktuell anzeigt und zusätzlich die Spaltennamen der Abfrage und damit die zu Grunde liegenden Spaltennamen verwendet. 259 Datenmanipulation Firstname LastName EmailAddress ---------------- --------------- ---------------------------Guy Gilbert [email protected] Kevin Brown [email protected] Roberto Tamburello roberto0@adventure- works.com Als Alternative für die vorherige Lösung bietet sich an, die Spaltennamen als Aliasnamen anzugeben. Dies zeigt das nachfolgende Beispiel, in dem Spalten wie die EmployeeID aus der Tabelle Employee als ID angegeben wird, wozu lediglich der Aliasname benötigt wird. In der Abfrage dieser Sicht kann man dann sehen, wie die entsprechenden Spaltennamen der Sicht, welche die Aliasnamen aus der zu Grunde liegenden Abfrage darstellen, für den Datenabruf aus der Sicht genutzt werden. CREATE VIEW HumanResources.vEmployee2 AS SELECT e.EmployeeID AS ID, c.FirstName + ' ' + c.LastName AS Name, c.Phone AS Phone, c.EmailAddress AS Email FROM ... GO -- Sicht abfragen SELECT Name, Email FROM HumanResources.vEmployee2 260 Datenmanipulation WHERE ID < 4 412_02.sql: Spaltennamen aus Aliasnamen Schließlich kann man sich auch noch dafür entscheiden, die Spaltennamen der Abfrage oder sogar die Aliasnamen der Spalten durch einen Klammerausdruck zu überschreiben. Dieser folgt dem Namen der Sicht und enthält die richtige Anzahl und in der richtigen Reihenfolge die Spaltennamen, welche von der Sicht zurückgeliefert werden sollen. Während die korrekte und damit inhaltlich sinnvolle Zuordnung nicht automatisch kontrolliert werden kann, muss die Anzahl der Spaltennamen im Klammerausdruck mit der Spaltenanzahl in der SELECT-Anweisung übereinstimmen. CREATE VIEW HumanResources.vEmployee2 (ID, Name, Phone, Email) AS SELECT e.EmployeeID, c.FirstName + ' ' + c.LastName, c.Phone, c.EmailAddress FROM ... 412_03.sql: Spaltennamen aus Spaltenliste Sichten sind eine hervorragende Möglichkeit, um komplexe Datenstrukturen für den Abruf zu vereinfachen, in dem die Sichtdefinition bereits benötigte Umrechnungen, Funktionsaufrufe und natürlich Verknüpfungen sowie Filter enthält. Insbesondere durch die Auswahl von Daten durch einen Filter und die Anzeige von Daten, welche durch die Spaltenauswahl bereits eingeschränkt werden, ist es möglich, verschiedene Vereinfachungen und Sicherheitsstrategien umzusetzen. 261 Datenmanipulation 4.2 Daten bearbeiten Auch wenn der anvisierte Leser dieses Buch eigentlich nur eine Datenbank bearbeitet, deren Daten quasi „vom Himmel“ gefallen ist, so wie auch die ganze Datenbank in den entscheidenden Teilen vom Himmel gefallen ist, gibt es natürlich doch eine große Anzahl an Datenbankbenutzern, die nicht nur Abfragen erstellen, sondern mit Blick auf Prozeduren/Funktionen auch Daten erfassen, ändern und löschen müssen. Dies dürfte im Normalfall durch eine Anwendung geschehen, welche entsprechende Formulare bereitstellt, kann allerdings auch gerade dann notwendig werden, wenn größere Teile Software direkt in der Datenbank realisiert werden oder wenn für die Bearbeitung/Weiterentwicklung der Datenbank auch solche Arbeiten anfallen. Die SQL-Anweisungen, mit deren Hilfe Datenmanipulationen durchgeführt werden können, gehören ebenfalls zu dem Teil von SQL, der mit dem Akronym DML (Data Manipulation Language) umschlossen wird und zu dem auch der den größten Teil des gesamten Buchs einnehmende SELECT-Befehl gehört. Die SQL-Sprache zeichnet sich hier durch eine sehr große Konsequenz und Schönheit aus, weil Bestandteile wie die FROM- und WHERE-Klausel zur Gänze als auch weitere Konstrukte wie die Nennung von Spaltennamen in Form von Klammernausdrücken wieder in der Syntax erscheinen und dadurch INSERT, UPDATE und DELETE von ihrer Grundsyntax her sehr mit SELECT vergleichbar sind, obwohl sie wirklich völlig unterschiedliche Tätigkeiten ausführen. 4.2.1 Vorbereitung In den meisten Fällen, in denen die drei genannten Anweisungen auftreten, handelt es sich um eine Standardanweisung, welche die vielen Möglichkeiten und Alternativen, welche die jeweilige Syntax bietet, gar nicht nutzt. Dies liegt nicht zuletzt daran, dass eine entsprechende Schichtung in der Software genutzt wird, welche nicht nur einen Großteil der auftretenden Abfragen völlig vereinfacht und daher ohne besondere Raffinesse abbildet, sondern die auch das Einfügen, Löschen und Bearbeiten von Datensätzen derart einfach abbildet, dass die gleiche Methode für alle möglichen im Rahmen der Anwendung auftretenden Situationen die gleiche ist. Arbeit man allerdings direkt mit der Datenbank, sind oft auch versierte Programmierer überrascht, was SQL zu leisten 262 Datenmanipulation imstande ist. Dies ist insbesondere bei Abfragen immer wieder zu sehen, da der Abruf von Daten – und sei es nur aus Kontrollzwecken – doch noch häufiger ab und an in SQL vorgenommen wird als das Einfügen bzw. Bearbeiten von Daten. Daher versucht dieser Abschnitt die Komplexität und die verschiedenen Anweisungsmöglichkeiten, welche sich durch INSERT, UPDATE und DELETE ergeben, an möglichst eingängigen Beispielen zu zeigen. Leider setzen die verschiedenen Beispiele auch schon einmal Sprachstrukturen ein, die erst später erklärt werden. Da hier allerdings das Huhn-und-Ei-Problem mit unterschiedlichen Vor- und Nachteilen nur gelöst werden kann, dürfte es wohl so sein, dass die entsprechenden Beispiele erst später vollständig verstanden werden und an dieser Stelle die Beispiele eher der Vollständigkeit halber aufgenommen werden und bei eine ersten Lektüre des Buchs noch nicht so genutzt werden können wie bei einem wiederholten Aufruf. In den drei relevanten Befehlen befinden sich einige Syntaxinseln, die wenigstens zwei Anweisungen auftreten und daher an dieser Stelle vorweg angegeben werden: Anstelle des referenzierten <object> kann die Nennung eines Schema-Objekts stehen, wobei dieses auf unterschiedliche Weise adressiert werden kann. Es handelt sich dabei um die Möglichkeit, eine Tabelle oder ein Schema mit zusäztlicher Nennung von Schema und/oder Datenbank sowie Servernamen aufzurufen. <object> ::= { [ server_name . database_name . schema_name . | database_name .[ schema_name ] . | schema_name . ] table_or_view_name 263 Datenmanipulation } Die <output_clause> liefert Daten aus einzelnen Zeilen zurück, die von einer DML-Anweisung betroffen waren. Diese Daten stehen dann außerhalb der Anweisung für Kontrollen, Bestätigungen und Validierungen zur Verfügung, ohne dass eine eigene, das Netzwerk und die DB belastende Abfrage zur Kontrolle formuliert werden müsste. Insbesondere für berechnete Spalten, Spaltenwerte aus Triggeraktionen oder natürlich automatischen Zählungen (IDENTITY) von Primärschlüsselwerten ist dies von Bedeutung. <OUTPUT_CLAUSE> ::= { [ OUTPUT <dml_select_list> INTO { @table_variable | output_table } [ ( column_list ) ] ] [ OUTPUT <dml_select_list> ] } Innerhalb der <output_clause> ruft man Spaltennamen oder Ausdrücke (Kombination von Spaltennamen, Aufruf von zusätzlichen Funktionen etc.) auf, um die zurückzuliefernden und interessanten Spalten zu bezeichnen. <dml_select_list> ::= { <column_name> | scalar_expression } [ [AS] column_alias_identifier ] [ ,...n ] 264 Unter einem Spaltennamen in einer <output_clause> versteht man in einem Trigger dabei nicht nur ihren tatsächlichen Namen, sondern auch die Angabe, ob man sich auf die gelöschten oder eingefügten Daten bezieht. Dazu stehen die beiden Tabellenaliasnamen DELETED und INSERTED zur Verfügung, welche solche Datenmanipulation Verweise auflösen. Ansonsten lässt sich natürlich in anderen Zusammenhängen auch der gewöhnliche Tabellenname verwenden. <column_name> ::= { DELETED | INSERTED | from_table_name } . { * | column_name } Um die Beispiele möglichst kurz zu halten, sollen zwei neue Tabellen erstellt werden, in denen zwar wenige Spalten enthalten sind, die allerdings eine Vielzahl von interessanten Effekten zeigen. Es handelt sich in beiden Fällen um eine Tabelle für Produkte, wobei Product2 allerdings eine berechnete Spalte und verschiedene Standardwerte besitzt. Eine weitere Spalte mit einem automatischen Wert stellt der Primärschlüssel dar, welcher die so genannte IDENTITY-Eigenschaft besitzt und daher einen automatischen Zählwert besitzt. Zusätzlich gibt es für diese Tabelle auch noch einen Trigger. Auch wenn Trigger nicht in aller Ausführlichkeit in diesem Buch dargestellt werden sollen, da es sich doch um ein sehr administratives Thema handelt, soll der Einsatz eines Triggers zeigen, wie neben einer berechneten Spalte auch über einen Trigger automatische Wertaktualisierungen durchgeführt werden können. Ein Trigger ist darüber hinaus auch in diesem Fall notwendig, weil der Wert der Profit-Spalte sich aus der Differenz der beiden Spalten ListPrice und StandardCost ermittelt. Es ist nicht möglich, eine berechnete Spalte zu erzeugen, deren Wert sich auf die beschriebene Art aus zwei anderen Spalten zusammensetzt. Daher ist ein Trigger notwendig. Der Trigger ist nicht sonderlich lang, sodass er schnell erklärt ist: Ein Trigger ist ein in der Datenbank gespeichertes Modul, welches darauf lauert, dass eine Anwendung/der Benutzer eine bestimmte Operation (AFTER INSERT, UPDATE) an einer Tabellen (ON Production.Product2) durchführt. Dies löst den Trigger aus, was wiederum bedeutet, dass sein Inhalt/seine Anweisungen ausgeführt werden. In diesem Fall setzt man einen UPDATE-Befehl für die Aktualisierung ab. Diese Aktualisierung trägt in die Spalte Profit genau die Differenz aus ListPrice und StandardCost ein. Um die geänderten Produkte zu ermitteln, nutzt man die Tabelle inserted, in der 265 Datenmanipulation alle eingetragenen bzw. geänderten Datensätze enthalten sind. Mit Hilfe einer Unterabfrage kann man die ProductID aus dieser Tabelle abrufen und im IN-Operator mit den ProductID-Werten der Product2-Tabelle vergleichen, um die richtigen Werte zu aktualisieren. Der qualifizierte Spaltenname in der Unterabfrage ist für die Funktionsweise wesentlich und führt bei Vergessen dazu, dass gar keine Spalte aktualisiert wird.. -- Erstellen einer Tabelle IF OBJECT_ID ('Production.Product2', 'T') IS NOT NULL DROP TABLE Production.Product2 GO CREATE TABLE Production.Product2 ( ProductID int IDENTITY(1,1) NOT NULL PRIMARY KEY, Name varchar(30) NOT NULL, ProductNumber nvarchar(25) NOT NULL, ListPrice money NOT NULL DEFAULT 0, StandardCost money NOT NULL DEFAULT 0, Profit money NULL, ModifiedDate datetime NOT NULL CONSTRAINT DF_Product_ModifiedDate2 DEFAULT (getdate())) GO -- Erstellen eines Triggers IF OBJECT_ID ('Production.ProfitCalc','TR') IS NOT NULL DROP TRIGGER Production.ProfitCalc GO 266 Datenmanipulation CREATE TRIGGER Production.ProfitCalc ON Production.Product2 AFTER INSERT, UPDATE AS UPDATE Production.Product2 SET Profit = ListPrice - StandardCost WHERE ProductID IN (SELECT i.ProductID FROM inserted AS i) GO 421_01.sql: Erstellen einer Tabelle und eines Triggers Dann erstellt man noch eine sehr viel einfachere Tabelle, in der weder eine Spalte mit IDENTITY-Eigenschaft, noch eine berechnete Spalte und nicht einmal Standardwerte vorhanden sind. Es gibt darüber hinaus auch keinen Trigger, der auf Operationen an dieser Tabelle prüft und Korrekturen oder Kontrollen vornimmt. -- Erstellen einer Tabelle IF OBJECT_ID ('Production.Product3', 'T') IS NOT NULL DROP TABLE Production.Product3 GO CREATE TABLE Production.Product3 ( Name varchar(30) NOT NULL, ProductNumber nvarchar(25) NOT NULL, ListPrice money NOT NULL, StandardCost money NULL) GO 421_02.sql: Erstellen einer sehr einfache Tabelle 267 Datenmanipulation 4.2.2 Einfügen Der Befehl für das Einfügen von Datensätzen ist – wie schon an anderer Stelle erwähnt – sehr komplex und besteht aus verschiedenen Bestandteilen, die auch in ähnlicher oder sogar gleicher Form in den anderen DML-Befehlen auftauchen. Nicht alle Möglichkeiten sind häufig im Einsatz, sodass zunächst der Standardfall beschrieben wird, gefolgt von weiteren Optionen. Der Standardfall von INSERT ruft über die INTO-Klausel einen Tabellennamen auf. Dieser kann von einer Spaltenliste in runden Klammern gefolgt werden, die allerdings nur dann angegeben sein muss, wenn nicht in alle Spalten der Tabelle nicht in der richtigen Reihenfolge geschrieben wird. Ansonsten nennt diese Spaltenliste die verschiedenen Spalten, in die Werte geschrieben werden sollen, in der Reihenfolge, wie die Werte in der darauf folgenden VALUES-Klausel erscheinen. Die Zuordnung zwischen Spalten und Werten erfolgt also ganz einfach und pragmatisch über die Position. Wenn in der VALUES-Klausel die Werte angegeben werden, dann kann man Zahlen ohne Hochkommata, Zeichenketten und Datumswerte mit Hochkommata, weitere Ausdrücke wie Funktionen und Berechnungen, Variablen oder auch den Wert NULL bzw. DEFAULT für den Standardwert der Spalte benutzen. Dies alles kann bunt gemischt werden. Die Werte können allerdings anstelle einer direkten Wertvorgabe über VALUES, was sicherlich der häufigste Fall ist, aus einer Abfrage (abgeleitete Tabelle, d.h. eine einfache SELECT-Anweisung) oder einem Prozeduraufruf stammen, wobei diese Prozedur dann genauso eine Ergebnismenge zurückliefern muss wie eine gewöhnliche Abfrage. Dies ist eine sehr schöne Lösung, wenn Daten aus der einen Tabelle in eine andere übetragen werden sollen. Typische Szenarien sind in diesem Bereich Datenbereinigung, Normalisierung, Datenstrukturveränderung. Sofern die Anweisung im Rahmen eines T-SQL-Programms genutzt wird und nicht nur eine einfache Anweisung darstellt, dann können über die OUTPUT-Klausel Werte, die man gerade in die Tabelle eingetragen hat, zurückgegeben werden. Dies 268 Datenmanipulation ist insbesondere für berechnete Spalten, IDENTITY-Spalten oder Werte aus Triggern interessant. Wenn man anstelle von festen Wertvorgaben eine Abfrage oder Prozedur einsetzt, welche die einzufügenden Werte ermittelt, dann kann man die Werte, die diese zurückgibt, über eine TOP n-Klausel mit statischen oder dynamischen Werten für n begrenzen. Die allgemeine Syntax hat die Form: [ WITH <common_table_expression> [ ,...n ] ] INSERT [ TOP ( expression ) [ PERCENT ] ] [ INTO] { <object> | rowset_function_limited [ WITH ( <Table_Hint_Limited> [ ...n ] ) ] } { [ ( column_list ) ] [ <OUTPUT Clause> ] { VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) | derived_table | execute_statement } } | DEFAULT VALUES 269 Datenmanipulation [; ] 4.2.2.1 Standardfälle Die möglichen Formen der INSERT-Anweisung kann man am besten anhand von Beispielen lernen. Im ersten Beispiel folgen zwei typische Standardfälle. In der ersten Anweisung wird zunächst die Tabelle Product3 komplett gelöscht. Dies ist dann notwendig, wenn man das Beispiel mehrfach durchführen möchte und nicht alle Zeilen mehrfach in der Tabelle speichern möchte bzw. wenn der Primärschlüsselwert bereits in der Tabelle vorhanden ist. Der erste Standardfall fügt in die Tabelle Product3, die keine berechneten Spalten hat und die daher sich für diesen Fall besonders eignet, in jeder Zeile einen Wert ein. Da die Reihenfolge der Werte mit der Reihenfolge der Spalten(datentypen) und insgesamt mit der Anzahl der benötigten Werte/vorhandenen Spalten übereinstimmt, kann hier die Auflistung der Spaltennamen entfallen. Der zweite Standardfall fügt in die Tabelle Product2 nur in eine Auswahl von Spalten Werte ein. Da hier sowohl die Anzahl der Werte nicht mit der Anzahl der Spalten übereinstimmt und zusätzlich auch die Reihenfolge anders sein kann, ist die der Tabelle folgende Spaltenliste in Klammern notwendig. Sie ordnet die Werte in der VALUESKlausel den richtigen Spalten zu. -- Standardfall "alle Spalten" DELETE FROM Production.Product3 GO INSERT INTO Production.Product3 VALUES ('LL Mountain Seat Assembly', 'SA-M198', 133.34, 98.77) GO INSERT INTO Production.Product3 270 Datenmanipulation VALUES ('ML Mountain Seat Assembly', 'SA-M237', 147.14, 108.99) GO -- Standardfall "Spaltenauswahl" INSERT INTO Production.Product3 (Name, ProductNumber, ListPrice, StandardCost) VALUES ('HL Mountain Seat Assembly', 'SA-M687', 196.92, 145.87) GO INSERT INTO Production.Product2 (Name, ProductNumber, ListPrice, StandardCost) VALUES ('LL Road Seat Assembly', 'SA-R127', 133.34, 98.77) GO -- Überprüfung SELECT ProductID, ProductNumber, Profit, ModifiedDate FROM Production.Product2 422_01.sql: Standardfälle des Einfügens Die Überprüfung dieser kleinen Tests lässt sich insbesondere einfach durch die vorher genannte Abfrage durchführen. Dabei sind insbesondere die Spalten interessant, die berechnet oder deren Wert über einen Trigger automatisch eingefügt werden. ProductID ProductNumber Profit ModifiedDate ----------- ---------------- ---------- ------------------1 SA-R127 34,57 2005-09-05 22:04:48 271 Datenmanipulation 4.2.2.2 Erfassung aus Abfrage Eine besonders schöne Variante, um Daten von einer Tabelle zu anderen zu transportieren, stellt die INSERT-Anweisung bereit, wenn sie mit einer Abfrage kombiniert wird. Nützlich ist dieses Vorgehen, wenn bspw. aus mehreren Tabellen eine Tabelle erzeugt werden soll, oder wenn gerade andersherum aus einer Tabelle mehrere andere Tabelle im Rahmen einer Normalisierung über SQL erreicht werden soll. Interessant ist dies natürlich auch gerade für temporäre Tabellen, die als Wertespeicher ähnlich eines Arrays genutzt werden, und welche Daten aus einer oder mehreren Tabellen enthalten sollen. Das nächste sehr kurze Beispiel zeigt genau dieses Vorgehen. In die Tabelle Product2 fügt diese Anweisung Daten aus der Tabelle Product3 ein, wobei eine solche Abfrage genutzt wird. INSERT INTO Production.Product2 (Name, ProductNumber, ListPrice, StandardCost) SELECT * FROM Production.Product3 422_02.sql: Einfügen über eine Abfrage 4.2.2.3 Standard- und NULL-Werte Als weitere Möglichkeiten, Werte in eine Spalte einzutragen, kann man noch NULL für einen nicht vorhandenen Wert, DEFAULT für den Standardwert und jeden beliebigen Ausdruck verwenden, der zu einem geeigneten Wert führt, verwenden. Insbesondere der beliebige Ausdruck erscheint oftmals in Form einer Rechnung oder eines Funktionsaufrufs, wobei dann die Funktion als Rückgabewert einen geeigneten Ausdruck zurückliefert. Im nachfolgenden Beispiel ist auch noch angegeben, wie in jede Spalte Standardwerte eingefügt werden. Dies ist allerdings sehr selten, da nicht viele Tabellen einfach nur aus Spalten mit Standardwerten bestehen. INSERT INTO Production.Product2 272 Datenmanipulation (Name, ProductNumber, ListPrice, StandardCost, Profit) VALUES ('LL Road ' + 'Seat Assembly', 'SA-R127', DEFAULT, DEFAULT, NULL) GO -- INSERT INTO tabelle DEFAULT VALUES 422_03.sql: Sonderfälle beim Einfügen 4.2.2.4 Rückgabewerte Interessant ist auch die Möglichkeit, eingetragene Daten unmittelbar nach dem Eintrag wieder zurückzuholen, ohne dabei ausdrücklich eine neue, die DB belastende Abfrage zu formulieren. Darüber hinaus gelingt die Rückgabe sehr einfach und kurz. Die Syntax der OUTPUT-Klausel wird hier noch einmal wiederholt, weil es viele Optionen gibt, sie einzusetzen, welche allerdings letztendlich alle sehr ähnlich sind und daher nicht unbedingt ein eigenes Beispiel erfordern. Zunächst ruft man die OUTPUT-Klausel nach der möglichen Spaltenliste, welche die Zuordnung der Werte vornimmt, auf. Es folgt eine Liste mit Spaltennamen, wobei diese im Normalfall zur Identifizierung/Qualifizierung der Spalten bei Einfüge/Aktualisierungsvorgängen mit INSERTED und bei Löschvorgängen mit DELETED qualifiziert werden. Bei INSERT ist die Verwendung der mit einem Aliasnamen umbenannten FROM-Tabelle nicht möglich, da es keine FROM-Klausel und damit auch keine FROMTabelle gibt. Dies ist nur bei DELETE der Fall. Es sind auch Spaltenaliase möglich, welche bei Einsatz von Funktionsaufrufen/Berechnungen zum Einsatz kommen können. Nach der bereits in der gewöhnlichen INSERT-Klausel bekannten INTO-Klausel, die allerdings hier nicht optional ist, folgt das Zuweisungsziel. Bei diesem handelt es sich entweder um eine Tabellenvariable oder eine tatsächliche Ausgabetabelle. Die Ausgabetabelle ist eine in der Datenbank tatsächlich vorhandene oder lediglich eine temporäre Tabelle. Da diese oftmals gar nicht vorhanden ist und teilweise sogar die Definition einer temporären Tabelle zu umständlich ist, kann man eine Tabellenvariable verwen- 273 Datenmanipulation den. Sie nutzt eine bislang noch nicht aufgetretene Technik, ein Array-ähnliches Konstrukt zu erzeugen, das mehrere Spalten und Reihen enthalten kann. Die allgemeine Syntax hat zur Wiederholung folgenden Aufbau: <OUTPUT_CLAUSE> ::= { [ OUTPUT <dml_select_list> INTO { @table_variable | output_table } [ ( column_list ) ] ] [ OUTPUT <dml_select_list> ] } <dml_select_list> ::= { <column_name> | scalar_expression } [ [AS] column_alias_identifier ] [ ,...n ] <column_name> ::= { DELETED | INSERTED | from_table_name } . { * | column_name } Im ersten Beispiel befindet sich die Grundform der zuvor beschriebenen allgemeinen Technik. Als Ziel der nach einem Einfügevorgang gespeicherten Zeile dient die erwähnte Tabellenvariable, welche mit dem Schlüsselwort table und der üblichen Auflistung von Spalten und ihren Datentypen erzeugt wird. Den Eintrag der einen Zeile, welcher zu verschiedenen automatisch erzeugten Werten führt, lenkt man mit OUTPUT in diese Variable. Dabei ruft man die eingefügten Werte über die INSERTED-Tabelle ab und weist sie mit INTO tabellenvariablenname den Spalten der Tabellenvariable zu. 274 Datenmanipulation Wie man sich vorstellen kann, ist dabei jede beliebige Reihenfolge möglich. Schließlich kontrolliert man sowohl die Tabellenvariable als auch die tatsächliche Tabelle. -- Variablen erstellen DECLARE @outputTable table(ProductID Profit int, money, ModifiedDate datetime) -- Daten löschen DELETE FROM Production.Product2 -- Eintragen und abrufen INSERT INTO Production.Product2 (Name, ProductNumber, ListPrice, StandardCost) OUTPUT INSERTED.ProductID, INSERTED.Profit, INSERTED.ModifiedDate AS Date INTO @outputTable (ProductID, Profit, ModifiedDate) VALUES ('LL Road Seat Assembly', 'SA-R127', 133.34, 98.77) -- Überprüfung SELECT * FROM @outputTable SELECT ProductID, Profit FROM Production.Product2 422_04.sql: Ausgabewerte Man erhält als Ergebnis die über die IDENTITY-Eigenschaft und die automatische Spaltenberechnung erzeugten Werte zurück. Der Trigger-Wert wird allerdings nicht ermit- 275 Datenmanipulation telt, was sehr ärgerlich ist. Nichtsdestoweniger ist er dennoch in der Tabelle eingetragen, wie die unmittelbar im Anschluss ausgeführte Kontrolle zeigt. ProductID Profit ModifiedDate ----------- -------------- -------------10 NULL 2005-09-08 (1 Zeile(n) betroffen) ProductID Profit ----------- --------------------10 34,57 (1 Zeile(n) betroffen) Die durch OUTPUT ermittelten Spalten zeigen also genau die Werte, die vor Ausführung des Triggers vorhanden sind. Hat man einen so genannten INSTEAD OF-Trigger erstellt, der anstelle einer anderen Anweisung ausgeführt wird, erhält man die Werte zurück, die bei einer tatsächlichen Ausführung der ja eigentlich umgangenen Ausführung gespeichert worden wären. Dies gilt sogar dann, wenn gar keine Änderungen vorgenommen werden. Der Abruf von eingefügten Daten beschränkt sich durchaus nicht auf eine einzelne Zeile, sodass der Aufwand, eine Tabellenvariable zu erstellen, die möglicherweise nur eine einzige Spalte hat, geringer erscheinen lassen sollte. Das nächste Beispiel ist etwas gekürzt, da es im Wesentlichen die gleichen Inhalte besitzt wie das vorherige. Der einzige Unterschied besteht darin, dass wieder eine SELECT...INTO-Abfrage zum Zug kommt, die drei Datensätze in die Product2-Tabelle einträgt. Auch hier bleiben die Trigger-Werte leider außen vor. INSERT INTO Production.Product2 (Name, ProductNumber, ListPrice, StandardCost) 276 Datenmanipulation OUTPUT INSERTED.ProductID, INSERTED.Profit, INSERTED.ModifiedDate AS Date INTO @outputTable (ProductID, Profit, ModifiedDate) SELECT * FROM Production.Product3 422_05.sql: Abruf mehrerer Zeilen Wie ein allgemeiner Tabellenausdruck im Rahmen von INSERT zu verwenden ist, zeigt der Abschnitt, in dem die CTE (common table expressions) präsentiert werden. Daher entfällt hier eine Erklärung zur in eckigen Klammern angegebenen WITH-Klausel vor dem INSERT-Befehl. 4.2.2.5 Zufällige Werte aus Abfragen Schließlich besteht noch die Möglichkeit, im Rahmen einer Abfrage, deren Ergebnisse in eine andere Tabelle eingefügt werden sollen, die ausgewählten und damit eingefügten Datensätze zu begrenzen. Dabei setzt man die schon bekannte TOP n-Klausel ein. Hierbei bestehen folgende Möglichkeiten: Entweder gibt man einen numerischen Wert an, der genutzt wird, oder man beschränkt sich auf eine Prozentangabe, indem noch das Schlüsselwort PERCENT angehängt wird. In beiden Fällen kann man entweder feste und damit genaue Werte vorgeben oder einen dynamischen Ausdruck verwenden. Im Normalfall dürfte diese einen Variablenaufruf enthalten. Im nächsten Beispiel ist dies allerdings eine Unterabfrage, welche die Anzahl der Produkte in der originalen ProductTabelle ermittelt und diese Zahl halbiert. Das nächste Beispiel führt zwar nur die gerade beschriebene dynamische Verwendung ausdrücklich aus, doch zeigt es auch, wie man einen festen absoluten und prozentualen Wert vorgibt. -- Einfügen über Abfrage DELETE FROM Production.Product3 277 Datenmanipulation GO -- INSERT TOP (5) INTO Production.Product3 -- INSERT TOP (10) PERCENT INTO Production.Product3 INSERT TOP ( (SELECT COUNT(*) FROM Production.Product) / 2) INTO Production.Product3 (Name, ProductNumber, ListPrice, StandardCost) SELECT Name, ProductNumber, ListPrice, StandardCost FROM Production.Product GO -- Überprüfung SELECT COUNT(*) AS Products FROM Production.Product3 422_06.sql: Zufälliges Einfügen Man erhält als Information, dass 252 Produkte eingefügt worden sind, wenn man die Hälfte ermittelt, wie gerade angegeben. Ansonsten werden genau fünf oder fünf Prozent der Daten aus der originalen Product-Tabelle eingefügt. 4.2.3 Aktualisieren Sind die Daten erst einmal in der Datenbank gespeichert, dauert es nicht lange, ehe man sie wieder ändern muss. Dies gelingt über den UPDATE-Befehl. Er besitzt ebenfalls eine sehr umfangreiche allgemeine Syntax mit folgenden wesentlichen Merkmalen: 278 Datenmanipulation Der Standardfall ruft die UPDATE-Anweisung mit einem Tabellen- oder Sichtnamen auf, setzt neue Werte über die SET-Klausel, wobei auch mehrere Spalten aktualisiert werden können. Zusätzlich können die Zeilen, die aktualisiert werden sollen, über die WHERE-Klausel begrenzt werden. Wenn die Werte, die in eine angegebene Spalte neu gespeichert werden sollen, um bestehende Werte zu überschreiben, nicht fest als Zeichenketten oder Zahlen vorgegeben sind, können folgende andere Optionen gewählt werden: das Schlüsselwort DEFAULT für den Standardwert, das Schlüsselwort NULL für den NULL-Wert, ein beliebiger Ausdruck wie ein Funktionsaufruf, eine Berechnung oder eine Variable und schließlich natürlich auch eine Eigenschaft, ein Methodenrückgabewert eines benutzerdefinierten Typs aus .NET. Um geänderte Werte wieder für Kontrolle oder Ausgabe zurückzugeben, kann man die OUTPUT-Klausel verwenden. Sie erlaubt die Speicherung einzelner oder aller Spalten einer bearbeiteten Tabelle in eine Tabellenvariable. Sofern die Aktualisierung und damt die Anwendung von UPDATE in einem Cursor vorgenommen wird, um den aktuell abgerufenen Datensatz des Cursors zu bearbeiten, kann man anstelle des Primärschlüssels in der WHERE-Klausel auch WHERE CURRENT OF mit Namen des Cursors bzw. der Cursovariable verwenden. Dies vereinfacht die Adressierung des gerade abgerufenen Datensatzes. Ansonsten ist die WHERE-Klausel wie bei einer SELECT-Anweisung als Filter zu verwenden. Soll nur eine bestimmte Menge an Datensätzen, die absolut oder prozentutal vorgegeben sein kann, bearbeitet werden, kann man auch noch die TOP n-Klausel unmittelbar nach UPDATE verwenden. Sie begrenzt die bearbeiteten Zeilen auf die statisch oder dynamisch angegebene Menge. Die zusätzliche FROM-Klausel, welche der OUTPUT-Klausel folgt, kann genauer angegeben, in welcher Tabelle die Daten aktualisiert werden sollen. Dies ist insbesondere interessant, wenn die Daten bspw. aus einer Verknüpfung gelöscht werden sollen und nicht nur auf Basis einer einzigen Tabelle. Die vollständige allgemeine Syntax lautet: 279 Datenmanipulation [ WITH <common_table_expression> [...n] ] UPDATE [ TOP ( expression ) [ PERCENT ] ] { <object> | rowset_function_limited [ WITH ( <Table_Hint_Limited> [ ...n ] ) ] } SET { column_name = { expression | DEFAULT | NULL } | { udt_column_name.{ { property_name = expression | field_name = expression } | method_name ( argument [ ,...n ] ) } } | column_name { .WRITE ( expression , @Offset , @Length ) } | @variable = expression | @variable = column = expression [ ,...n ] } [ ,...n ] [ <OUTPUT Clause> ] [ FROM{ <table_source> } [ ,...n ] ] [ WHERE { <search_condition> | { [ CURRENT OF 280 Datenmanipulation { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ] [ OPTION ( <query_hint> [ ,...n ] ) ] [ ; ] 4.2.3.1 Standardfall Das nächste Beispiel setzt die von Skript 422_06.sql gefüllte Product3-Tabelle voraus. Sie enthält 252 Produkte, d.h. die Hälfte der in Product gespeicherten Produkte. Um die Daten von Prodcut3 nicht dauerhaft zu verändern, sondern um das Beispiel auch variieren zu können, wird eine Transaktion um die Bearbeitungen gesetzt. Über die Anweisung BEGIN TRANSACTION kündigt man an, dass die nachfolgenden Anweisungen einen Verbund bilden und nur als Ganzes ausgeführt werden. Die Anweisung ROLLBACK setzt daher die gesamten Anweisungen wieder zurück. Das Beispiel enthält drei Standardfälle: eine einfache Aktualisierung, bei der ein Filter zum Einsatz kommt und ein statischer Wert gespeichert wird; eine dynamische Aktualisierung, bei der neben dem statischen Filter nun eine dynamische Aktualisierung stattfindet und schließlich eine mehrfache Aktualisierung, bei der mehrere Spalten betroffen sind. Insbesondere der zweite Standardfall ist interessant, denn er zeigt, wie die Adressierung einer Spalte in der Zuweisung durch SET die aktuelle Zeile nutzt. Eine andere dynamische Aktualisierung lässt sich denken, wenn man eine Funktion oder eine Berechnung verwendet. -- Standardfälle der Aktualisierung 281 Datenmanipulation BEGIN TRANSACTION -- Einfache Aktualisierung mit Filter UPDATE Production.Product3 SET ListPrice = 1 WHERE ListPrice = 0 -- Dynamische Aktualisierung mit Filter UPDATE Production.Product3 SET ListPrice = ListPrice * 1.1 WHERE ListPrice != 1 -- Mehrfache Aktualisierung UPDATE Production.Product3 SET ListPrice = ListPrice * 1.1, StandardCost = StandardCost * 1.1 GO ROLLBACK 423_01.sql: Standardfälle der Aktualisierung Als Ergebnis liefern die drei Aktualisierungen: (200 Zeile(n) betroffen), (52 Zeile(n) betroffen), (252 Zeile(n) betroffen). Insgesamt sind in der Product3-Tabelle also 200 Produkte mit Preis 0, deren Preis auf einen Euro erhöht werden. Da dann insgesamt 52 Produkte einen Preis ungleich 1 haben, werden diese in der nächsten Anweisung bearbeitet. Schließlich gibt es noch eine Preis- und Kostensteigerung von 10%, die alle 252 Produkte betrifft. 282 Datenmanipulation 4.2.3.2 Ausgabe von Änderungen Um die interessanten Effekte und den Nutzen zu sehen, wenn man die aktualisierten Werte über die OUTPUT-Klausel wieder abruft, müssen Sie zunächst das Skript 422_07.sql ausführen. Es übertragt die Hälfte aller Werte aus der Product-Tabelle in die Product2-Tabelle und funktioniert damit ähnlich wie 422_06.sql. So haben Sie genügend Daten, mit denen Sie spielen können und die Sie zerstören können. Um die Werte abzurufen, benötigt man wieder eine tatsächlich in der Datenbank permanent oder temporäre vorhandene Tabelle oder eine Tabellenvariable. Da diese schneller zu erstellen ist und zudem in solchen Fällen üblicher, erstellt man zunächst eine solche Tabelle, welche insbesondere die durch Wertvorgaben oder Automatismen (berechnete Spalten, Trigger) geänderten Spalten enthalten soll. Für die Aktualisierungsanweisung enthält dieses Beispiel einen komplexen Ausdruck in Form von CASE auf der Wertzuweisungsseite von SET. Dadurch ist es möglich, die Preise mit dem Wert 0 auf einen Euro und die Preise ungleich 0 um 10% zu erhöhen. Unabhängig von diesem Schmankerl setzt die Anweisung auch die OUTPUT-Klausel ein, welche die geänderten Werte zusätzlich noch in die Tabellenvariable speichert, die später zu Kontrollzwecken ausgegeben wird. -- Variablen erstellen DECLARE @outputTable table(ProductID int, ListPrice money, Profit money, ModifiedDate datetime) -- Daten ändern und abrufen BEGIN TRANSACTION UPDATE Production.Product2 SET ListPrice = (CASE ListPrice 283 Datenmanipulation WHEN 0 THEN 1 ELSE ListPrice * 1.1 END) OUTPUT INSERTED.ProductID, INSERTED.Profit, INSERTED.ListPrice, INSERTED.ModifiedDate AS Date INTO @outputTable (ProductID, Profit, ListPrice, ModifiedDate) -- Überprüfung SELECT TOP (3) * FROM @outputTable SELECT TOP (3) * FROM Production.Product2 ROLLBACK 423_02.sql: Einsatz von OUTPUT Bei der Überprüfung ergibt sich das gleiche Bild, das man zuvor schon bei der INSERTAnweisung und der Verwendung von OUTPUT gesehen hat. In der Tabellenvariable befinden sich die durch Wertvorgabe oder Ausdrücke vorgegebenen sowie die durch berechnete Spalten ermittelten neuen oder alten Werte, aber leider nicht die Werte, die durch Trigger erzeugt wurden. Diese sind jedoch sehr wohl in der Tabelle enthalten, wie die Abfrage der bearbeiteten Tabelle zeigt. (252 Zeile(n) betroffen) (252 Zeile(n) betroffen) ProductID 284 ListPrice Profit ModifiedDate Datenmanipulation ----------- ----------- --------- -------------14 1,00 0,00 2005-09-10 15 1,00 0,00 2005-09-10 16 1,00 0,00 2005-09-10 (3 Zeile(n) betroffen) Name ListPrice StandardCost Profit ModifiedDate ---------------- ---------- ------------- ------- ----------Adjustable Race 1,00 0,00 1,00 2005-09-10 Bearing Ball 1,00 0,00 1,00 2005-09-10 BB Ball Bearing 1,00 0,00 1,00 2005-09-10 (3 Zeile(n) betroffen) Ändert man nur eine Zeile wie bspw. im Rahmen einer Cursor-Verarbeitung, dann steht auch nur eine weitere Möglichkeit bereit, gerade geänderte Werte direkt in Variablen abzurufen. Die Einschränkung, dass dies nur bei einer einzigen Zeile erlaubt ist, weil eine Variable nur einen Wert und nicht eine Liste/Spalte von Werten empfangen kann, grenzt den Nutzen dieser Technik etwas ein, bedeutet allerdings eine deutlich kürzere Syntax als bei einem Einsatz der OUTPUT-Klausel. Im folgenden Beispiel führt man die gleiche Aktualisierung wie in einem vorherigen Beispiel durch, d.h. Preis und Standardkosten erfahren eine zehnprozentige Preiserhöhung, welche vor und nach der Durchführung in Form eine SELECT-Anweisung überprüft wird. Um nur eine einzige Zeile zu ändern, filtert die WHERE-Klausel anhand der Produktnummer genau einen Datensatz heraus. Den geänderten Wert speichert man dann in die vorangestellte Variable, die man für Kontrollen etc. weiterhin benutzen kann. 285 Datenmanipulation -- Deklaration DECLARE @listPrice money, @standardCost money -- Kontrolle vorher SELECT ListPrice, StandardCost FROM Production.Product3 WHERE ProductNumber = 'FR-R38B-44' -- Daten ändern und abrufen BEGIN TRANSACTION UPDATE Production.Product3 SET @listPrice = ListPrice = ListPrice * 1.1, @standardCost = StandardCost = StandardCost * 1.1 WHERE ProductNumber = 'FR-R38B-44' -- Kontrolle SELECT @listPrice, @standardCost ROLLBACK 423_03.sql: Abruf einzelner Spalten in Variablen Als Ergebnis erhält man zunächst die ursprünglichen und dann die neuen Werte. ListPrice StandardCost --------------------- --------------------337,22 (1 Zeile(n) betroffen) 204,6251 (1 Zeile(n) betroffen) 286 Datenmanipulation --------------------- --------------------370,942 225,0876 (1 Zeile(n) betroffen) 4.2.3.3 Aktualisierung auf Basis anderer Tabellendaten In vielen Fällen ist es gar nicht damit getan, einfach nur einen statischen oder einen dynamischen Wert vorzugeben, der aus einer Berechnung mit der zu verändernden Spalte oder einer sonstigen Datensituation herrührt. Stattdessen sollen Tabellendaten angeglichen werden. Insbesondere bei Datenbereinigungsoperationen im Rahmen von Import-/Export-Schnittstellen ist dies ein wesentliches Unterfangen. Damit ist gemeint, dass der Wert in einer Spalte von Tabelle A mit dem Wert einer Spalte in Tabelle B aktualisiert werden soll. Dazu ist zunächst die FROM-Klausel in der UPDATE-Anweisung nötig, welche zusätzlich um eine korrelierte Unterabfrage in der SET-Klausel ergänzt wird. Das nachfolgende Beispiel führt folgende Regel aus: Setze für jedes Produkt die Werte von ListPrice aus Product in ListPrice von Product2. In der FROM-Klausel ruft man noch einmal die zu bearbeitende Tabelle auf und gibt ihr einen Aliasnamen, der für die korrelierte Unterabfrage notwendig ist. Diese Unterabfrage befindet sich in der Zuweisung der SET-Klausel. Hier ruft man aus der zu vergleichenden Tabelle Product ebenfalls die ListPrice-Spalte ab, wobei der Filter den Datensatz heraussucht, dessen Produktnummer der inneren Tabelle mit der Produktnummer aus der äußeren Tabelle übereinstimmt. UPDATE Production.Product2 SET ListPrice = (SELECT ListPrice FROM Production.Product AS p WHERE p2.ProductNumber = p.ProductNumber) FROM Production.Product2 AS p2 287 Datenmanipulation 423_04.sql: Aktualisierung gemäß anderer Tabelle 4.2.3.4 Zufällige Änderungen Auch bei der Aktualisierung kann man die Änderungen mit Hilfe einer TOP n-Klausel auf eine zufällige Auswahl an Datensätzen begrenzen. Dabei gibt es wiederum die Möglichkeiten, einen festen oder dynamischen Wert anzugeben, wobei dies zusätzlich absolut oder unter Angabe von PERCENT prozentual verstanden wird. Als dynamische Wertvorgaben kommt jeder Ausdruck in Betracht, sei es eine Variable, eine skalare Unterabfrage oder eine Berechnung. Wichtig ist lediglich, dass sie zu einem numerischen Wert führen. Das nächste Beispiel zeigt die verschiedenen Varianten für die TOP n-Klausel in UPDATE. Die erste wählt genau fünf, die zweite fünf Prozent und die dritte die Hälfte aus, wobei diese Zahl in einer Variable gespeichert ist. -- Variable erstellen DECLARE @rowCount int SET @rowCount = 5 -- Daten ändern BEGIN TRANSACTION -- UPDATE TOP (5) Production.Product2 -- UPDATE TOP (5) PERCENT Production.Product2 UPDATE TOP (@rowCount) Production.Product2 SET ListPrice = 10000 ROLLBACK 423_05.sql: Zufällige Änderung 288 Datenmanipulation 4.2.3.5 Bearbeiten großer Datentypen Spalten, deren Werte durch die Datentypen varchar(max)-, nvarchar(max)- und varbinary(max) beschrieben werden, haben eine eigene Methode, mit denen Inhalte in die Spalte geschrieben oder bestehende Inhalte ersetzt werden können. Es handelt sich um eine Methode und keine (Spalten-)Funktion, was auch daran zu erkennen ist, dass sie mit dem Punkt-Operator an den Spaltennamen angeschlossen wird und dieser Spaltennamen nicht als Parameter im Funktionsaufruf übergeben wird. Die allgemeine Syntax dieser Funktion lautet: WRITE (expression, @Offset, @Length) In expression steht im Normalfall eine Zeichenkette, ansonsten kann es ein beliebiger Ausdruck sein, der schließlich in der bestehenden Zeichenkette gespeichert werden oder sie ersetzen soll. In @Offset befindet sich die Position, an der die neue Zeichenkette platziert werden soll, während in @Length die Länge des zu ersetzenden Bereichs enthalten ist. Sofern der neue Text nur eingefügt und ansonsten der bestehende Text nicht ersetzt werden soll, ist hier der Wert 0 richtig. Ein NULL-Wert kann und braucht auch als neuer Inhalt nicht vorgegeben werden. Das nachfolgende Beispiel bearbeitet in den Produktkommentaren einen Kommentar so, dass die verfügbaren Größen des Fahrrades, das hier diskutiert wird, in Zukunft in Parenthese ebenfalls angegeben ist. Dazu setzt man Comments.WRITE (N'(Sizes: 38-44, 48) ',15, 0) ein, da der neue Text an Stelle 15 eingefügt werden und nicht ersetzen soll. Das vorgeschaltete N kennzeichnet die Zeichenkette noch einmal deutlich als solche, wobei dies nicht unbedingt erforderlich ist. Da man die ursprüngliche ProductReview-Tabelle unangetastet lassen möchte und zudem hier auch in der Comments-Spalte der falsche Datentyp enthalten ist, müssen die Daten zunächst in eine Spiel-Tabelle übertragen werden, deren Comments-Spalte den nvarchar(max)Datentyp aufweist. -- Tabelle mit nvarchchar(max) anlegen CREATE TABLE Production.ProductReview2 ( 289 Datenmanipulation ProductReviewID int NOT NULL PRIMARY KEY, Comments nvarchar(max) NULL ) -- Daten übernehmen INSERT INTO Production.ProductReview2 SELECT ProductReviewID, Comments FROM Production.ProductReview GO -- Tabellenvariable anlegen DECLARE @review table ( ProductReviewID int NOT NULL, CommentsBefore nvarchar(max), CommentsAfter nvarchar(max)) -- Daten aktualisieren BEGIN TRANSACTION UPDATE Production.ProductReview2 SET Comments.WRITE (N'(Sizes: 38-44, 48) ',15, 0) OUTPUT INSERTED.ProductReviewID, DELETED.Comments, INSERTED.Comments INTO @review WHERE ProductReviewID = 4 290 Datenmanipulation ROLLBACK -- Kontrolle SELECT SUBSTRING(CommentsBefore, 1, 20), SUBSTRING(CommentsAfter, 1, 30) FROM @review 423_06.sql: Ändern großer Datentypen Als Ergebnis erhält man die Bestätigung der Änderung, da sich nun der korrigierte Kommentar in der Tabelle befindet. (1 Zeile(n) betroffen) ----------------------- ------------------------------The Road-550-W from The Road-550-W (Sizes: 38-44, (1 Zeile(n) betroffen) Sofern keine Spalte, die durch einen der Datentypen von varchar(max)-, nvarchar(max)- und varbinary(max) beschrieben wird, bearbeitet werden soll, muss man dann die verschiedenen Zeichenkettenfunktionen verwenden. Für die gleiche Ersetzung wie zuvor könnte dies mit der STUFF()-Funktion geschehen. UPDATE Production.ProductReview2 SET Comments = STUFF (Comments,16,0,N'(Sizes: 38-44, 48) ') WHERE ProductReviewID = 4 423_07.sql: Ändern großer Datentypen Man erhält als Ergebnis auch in diesem Fall die Bestätigung der Änderung. -------------------- --------------------------------------- 291 Datenmanipulation The Road-550-W from The Road-550-W (Sizes: 38-44, 48) from A (1 Zeile(n) betroffen) 4.2.3.6 Zusätzliche FROM-Klausel Es ist möglich, neben der Angabe einer Tabelle direkt nach der UPDATE-Klausel noch eine weitere Tabelle bzw. vielmehr eine Tabellenverknüpfung in einer FROM-Klausel zwischen der OUTPUT-Klausel und der WHERE-Klausel zu verwenden. Diese wirkt im Grunde genommen wie ein weiterer Filter, da hier festgelegt wird, auf Basis welcher Daten die Daten in der nach UPDATE angegebenen Tabelle aktualisiert werden sollen. Im Falle einer inneren Verknüpfung würden also daher nur solche Daten der UPDATETabelle aktualisiert werden, die genau an dieser Verknüpfung teilnehmen. Weitere Angaben in der WHERE-Klausel schränken natürlich die möglicherweise zu aktualisierende Datenmenge weiter ein. Ein typischer Einsatz für diese zusätzliche FROM-Klausel kann ein Datenabgleich zwischen Tabellen sein, d.h. wenn Daten in eine Tabelle eingetragen/aktualisiert werden, wobei die Werte aus einer Tabelle übernommen werden sollen. Dies ist ein häufiges Szenario im Fall von SQL-basierten Datenbereinigungen und korrekturen. Das nachfolgende Beispiel zeigt die Technik der zusätzlichen FROM-Klausel, wobei darüber hinaus noch die erweiterte Variante vorgeführt wird, denn es nutzt ebenfalls die OUTPUT-Klausel. Dies ist insoweit interessant, als dass man die geänderten Daten der Tabelle, die direkt nach UPDATE benannt wird, aus der INSERTED-Tabelle abruft, während andere Daten aus verknüpften Tabellen gerade aus den Aliasnamen dieser verknüpften Tabellen stammen, da sie ja nicht verändert wurden. Die Preise der Tabelle Product2 sollen erneut um 10% erhöht werden, sofern die Preise ungleich 0 sind. Dies ist allerdings nicht die einzige Einschränkung. Stattdessen verknüpft die FROM-Klausel auch noch die Daten der Product2-Tabelle mit den Produkten, welche in der ProductInventory-Tabelle referenziert werden. Das sind also gerade die Produkte, die sich auf Lager befinden, was bedeutet, dass innerhalb dieser Menge die Produkte mit einem Preis ungleich 0 eine 10-prozentige Preiserhöhung er- 292 Datenmanipulation fahren. Zur Kontrolle überträgt man die aktualisierten Produkte und ihre LocationID (Lagerplatz) in die vorher erzeugte Tabellenvariable, wobei die Felder aus der aktualisierten Product2-Tabelle aus INSERTED und die Spalte LocationID aus der ProductInventory-Tabelle über den Tabellenalias aufgerufen werden. -- Variable erstellen DECLARE @outputTable table(ProductID ListPrice int, money, ModifiedDate datetime, LocationID int) -- Daten ändern und abrufen UPDATE Production.Product2 SET ListPrice = ListPrice * 1.1 OUTPUT INSERTED.ProductID, INSERTED.ListPrice, INSERTED.ModifiedDate, pinv.LocationID INTO @outputTable (ProductID, ListPrice, ModifiedDate, LocationID) FROM Production.Product2 AS p2 INNER JOIN Production.ProductInventory AS pinv ON p2.ProductID = pinv.ProductID WHERE ListPrice > 0 -- Überprüfung 293 Datenmanipulation SELECT TOP (3) * FROM @outputTable 423_08.sql: Zusätzliche FROM-Klausel In der Kontrolle ergibt sich, dass nur insgesamt 46 Produkte die Bedingung erfüllen, auf Lager zu sein und einen Preis ungleich 0 zu besitzen. (46 Zeile(n) betroffen) ProductID ListPrice ModifiedDate LocationID ----------- --------------------- ------------------ -------452 146,674 2005-09-11 1 453 161,854 2005-09-11 1 454 216,612 2005-09-11 1 (3 Zeile(n) betroffen) 4.2.4 Löschen Schließlich gibt es auch noch eine weitere Situation eines Datensatzes, die unter den Begriff der Datenmanipulation fällt. Nachdem er eingefügt, abgefragt und ggf. sogar geändert wurde, kann es ihm passieren, dass er aus der Datenbank gelöscht wird. Dies gelingt über die DELETE-Anweisung. Sie hat in vielfältiger Weise eine sehr ähnliche Syntax wie die anderen beiden vorgestellten Anweisungen: Es gibt zwei Standardfälle, von denen der eine nur aus DELETE FROM tabellenname besteht und den gesamten Datenbestand der Tabelle löscht, ohne allerdings die Tabelle selbst zu löschen. Der zweite ergänzt diese Anweisung noch um eine WHERE-Klausel, sodass auch hier ein Filter zum Einsatz kommen kann, welcher die zu löschenden Daten weiter einschränkt. 294 Datenmanipulation Es können wiederum zufällige Datensätze gelöscht werden, in dem die TOP nKlausel benutzt wird. Dabei kann die Menge der zu löschenden Datensätze absolut oder bei zusätzlicher Verwendung von PERCENT auch relativ angegeben werden. Die Mengenvorgabe ist im Normalfall eine direkt vorgegebene Zahl; man kann allerdings auch einen beliebigen Ausdruck verwenden, der sich schließlich zu einem Zahlwert auflöst. Im Rahmen der Cursor-Verarbeitung (nicht in diesem Kapitel) kann man innerhalb von WHERE nicht nur einen üblichen Filter angeben, sondern über die Klausel WHERE CURRENT OF cursor den aktuell abgerufenen Datensatz eines Cursors löschen. Die gelöschten Werte können über die OUTPUT-Klausel aus der DELETED-Tabelle nach außen zurückgegeben werden. Die zusätzliche FROM-Klausel, welche der OUTPUT-Klausel folgt, kann genauer angeben, aus welcher Tabelle die Daten gelöscht werden sollen. Dies ist insbesondere interessant, wenn die Daten bspw. aus einer Verknüpfung gelöscht werden sollen und nicht nur auf Basis einer einzigen Tabelle. Die allgemeine Syntax hat die Form: [ WITH <common_table_expression> [ ,...n ] ] DELETE [ TOP ( expression ) [ PERCENT ] ] [ FROM ] { <object> | rowset_function_limited [ WITH ( <table_hint_limited> [ ...n ] ) ] } [ <OUTPUT Clause> ] [ FROM <table_source> [ ,...n ] ] 295 Datenmanipulation [ WHERE { <search_condition> | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ] [ OPTION ( <Query Hint> [ ,...n ] ) ] [; ] 4.2.4.1 Standardfälle Um die Funktionsweise von DELETE zu sehen, müssen Sie zunächst das Skript 422_07.sql ausführen. Es überträgt auch für diesen Abschnitt die Hälfte der Produkte aus Product in Product2, um die Datensätze problemlos löschen zu können. Das nachfolgende Beispiel zeigt die Standardfälle, welche im Rahmen von Löschvorgängen auftreten und daher auch die häufigsten Anweisungen bilden. Der erste Standardfall wählt wie eine SELECT-Anweisung über einen in WHERE angegebenen Filter Datensätze aus einer Tabelle aus und löscht diese. Dies ist sicherlich die häufigste Form des DELETE-Befehls. Die zweite Anweisung löscht ganz einfach den gesamten Datenbestand, wobei die Tabelle an sich allerdings bestehen bleibt. Dies ist in jedem SQLBuch immer ein wichtiges Beispiel (und kommt nun in unserem dritten Buch in dieser Form vor), da ja dafür der DROP TABLE tabelle-Befehl existiert und man als Anfänger Gefahr läuft, dies zu verwechseln. -- Löschen mit Filter 296 Datenmanipulation DELETE FROM Production.Product2 WHERE ListPrice = 0 -- Vollständiges Löschen DELETE FROM Production.Product2 424_01.sql: Standardfälle des Löschens Als Ergebnis erhält man Zunächst (200 Zeile(n) betroffen), da 200 Produkte einen Preis von 0 haben, und dann (52 Zeile(n) betroffen), da nur noch 52 Produkte in der Tabelle übrig sind und – wie schon bekannt sein sollte – insgesamt 252 Produkte in der Tabelle enthalten waren. 4.2.4.2 Zufällige Löschung Über die bekannten Formen der TOP n-Klausel, die schon in den anderen Anweisungen der Datenmanipulationssprache von SQL vorgestellt wurden, lässt sich eine zufällig ausgewählte Menge an Datensätzen löschen. Dabei zeigen die drei Zeilen, von denen zwei als Kommentar im Quelltext stehen, wie die Menge der zu löschenden Zeilen absolut oder prozentual mit PERCENT angegeben werden kann. Neben einem direkten numerischen Wert kann man auch jeden beliebigen Ausdruck einsetzen, der zu einem Zahlwert führt. In diesem Fall handelt es sich mal nicht um die schon bekannte Abfrage zur halben Zeilenzahl, sondern um eine Variable, deren Wert aus einer Abfrage stammt. -- Variable erstellen DECLARE @rowCount int SET @rowCount = 5 -- Daten löschen -- DELETE TOP (5)FROM Production.Product2 -- DELETE TOP (5) PERCENT Production.Product2 DELETE TOP (@rowCount) FROM Production.Product2 297 Datenmanipulation WHERE ListPrice = 0 424_02.sql: Zufällige Löschung 4.2.4.3 Löschen mit Rückgabe Auch DELETE bietet über die OUTPUT-Klausel an, die gerade gelöschten Werte abzurufen und für Kontrollen und Validierungen in eine Tabellenvariable oder eine (temporäre) Tabelle zu speichern. Dabei kann es keine Überlegungen hinsichtlich berechneter Spalten oder Trigger-Werte geben, da exakt die gelöschten Werte, die ja bereits durch Berechnungen oder Trigger in die Tabelle gebracht worden sind, auch wieder abgespeichert werden. Im nächsten Beispiel erstellt man zunächst die benötigte Tabellenvariable mit vier Spalten für Produktnummern, Listenpreis, Profit und Änderungsdatum. In der LöschAnweisung ruft man genau die Werte für diese Spalten aus der DELETED-Tabelle ab, welche die gelöschten Werte speichert (im Gegensatz zur INSERTED-Tabelle, welche die gerade eingefügten/geänderten Werte enthält). -- Variablen erstellen DECLARE @outputTable table(ProductID int, ListPrice money, Profit money, ModifiedDate datetime) -- Daten löschen und abrufen DELETE FROM Production.Product2 OUTPUT DELETED.ProductID, DELETED.Profit, DELETED.ListPrice, DELETED.ModifiedDate AS Date 298 Datenmanipulation INTO @outputTable (ProductID, Profit, ListPrice, ModifiedDate) WHERE ListPrice = 0 424_03.sql:Löschen mit Rückgabe Das Ergebnis muss nicht ausgegeben werden, da in diesem Fall keine Besonderheiten hinsichtlich Trigger oder berechneten Spalten und damit automatisch generierten Werten bestehen. In der ursprünglichen Tabelle fehlen genau die Datensätze, die in der Tabellenvariable noch abgerufen und genutzt werden können. 4.2.4.4 Löschen mit zusätzlicher FROM-Anweisung Es besteht, wie die allgemeine Syntax auch für die DELETE-Anweisung gezeigt hat, auch hier die Option, noch eine weitere FROM-Klausel einzufügen. Dabei gibt die erste FROM-Klausel die Tabelle an, aus welcher man tatsächlich löschen will, während die zweite FROM-Klausel den Datenbestand angibt, der für diesen Löschvorgang zu Rat herangezogen werden soll. Dies muss man sich so vorstellen, dass auf Basis der über diese zweite FROM-Klausel abgerufenen und durch die optionale WHERE-Klausel gefilterten Daten wie bei einer Abfrage diejenigen identifiziert werden, die zu löschen sind. Das folgende Beispiel zeigt bereits die fortgeschrittene Verwendung dieser Technik. Auf der einen Seite sollen aus der Production.Product-Tabelle Produkte entfernt werden. Auf der anderen Seite sollen dies nur Produkte sein, die keinen Lagerplatz besitzen. Diesen erkennt man daran, dass sie an der Verknüpfung mit der Tabelle Production.ProductInventory nicht teilnehmen, also in der äußeren Abrage einen NULL-Wert in der Spalte LocationID aufweisen. Dieser NULL-Wert dient als Filter, während die Verknüpfung in der zweiten FROM-Klausel überhaupt den Datenbestand beschreibt, auf den dieser Filter Anwendung finden soll. Neben der Tatsache, dass man überhaupt auf diese Art und Weise einen Datenbestand angeben kann, der für den Löschvorgang als Vergleich und damit auch als zusätzlicher 299 Datenmanipulation Filter genutzt werden kann, wobei überhaupt eine WHERE-Klausel hinzutritt, zeigt das Beispiel auch, wie die OUTPUT-Klausel hier zu nutzen ist. In der Tabellenvariable ist in diesem Beispiel aus Kontrollgründen auch noch eine LocationID-Spalte, in der natürlich aufgrund der Löschanweisung nur NULL-Werte zu finden sein sollten. Da allerdings diese LocationID gar nicht in der Product2-Tabelle enthalten ist, können diese Werte auch nicht aus der der DELETED-Tabelel stammen, da diese Werte nicht aus der bearbeiteten Tabelle stammen. Es handelt sich um eine zusätzliche Spalte aus einer nicht durch den Löschvorgang betroffenen Tabelle. Für die Referenzierung dieser Spalte ist in diesem Fall der Aliasname aus der FROM-Klausel zu benutzen. -- Variable erstellen DECLARE @outputTable table(ProductID int, ListPrice money, LocationID int) -- Daten löschen und abrufen DELETE FROM Production.Product2 OUTPUT DELETED.ProductID, DELETED.ListPrice, pinv.LocationID INTO @outputTable (ProductID, ListPrice, LocationID) FROM Production.Product2 AS p2 LEFT OUTER JOIN Production.ProductInventory AS pinv ON p2.ProductID = pinv.ProductID WHERE pinv.LocationID IS NULL -- Überprüfung 300 Datenmanipulation SELECT COUNT(*) AS Deleted FROM @outputTable 424_04.sql: Zusätzliche FROM-Klausel Das Beispiel liefert den Wert von 66. Führt man eine einfache Abfrage mit der äußeren Verknüpfung und dem Filter auf den Datensätze aus, die gerade an der Verknüpfung nicht teilnehmen, dann findet man als Antwort die gleichen 66 Datensätze. 4.2.4.5 Vereinfachtes Löschen Als grundsätzliche Alternative zu DELETE gibt es noch die Anweisung TRUNCATE. Sie funktioniert grundsätzlich wie DELETE FROM tabelle, d.h. wie eine DELETEAnweisung ohne WHERE-Klausel und löscht daher ebenfalls alle Zeilen. Die Anweisung löscht die Zeilen einer Tabelle, wobei sie allerdings die verschiedenen Löschoperationen nicht protokolliert. Sie ist schneller als DELETE und verbraucht weniger (System)Ressourcen für die Transaktionsprotokollierung. Während IDENTITY-Spaltenwerte bei DELETE ihren Zählerstand behalten, wird er bei TRUNCATE wieder auf den Standardwert oder 1 zurückgesetzt. Darüber hinaus aktiviert TRUNCATE auch keinen Trigger, da ja gerade die Löschoperationen für die einzelnen Zeilen nicht protokolliert/bemerkt werden. Allerdings kann TRUNCATE nicht für alle Tabellen eingesetzt werden. Die folgenden Einschränkungen sind zu beachten: Tabellen, die Ziel einer FOREIGN KEYReferenz sind, können nicht geleert werden (aufgrund der IDENTITY-Rücksetzung). Zu leerende Tabelle dürfen an keiner indizierten Sicht teilnehmen. Die Tabelle wird durch Transaktionsreplikation oder Mergereplikation veröffentlicht. Die Anweisung hat die allgemeine Syntax: TRUNCATE TABLE [ { database_name.[ schema_name ]. | schema_name . } ] table_name [ ; ] 301 Datenmanipulation 302 Grundlagen T-SQL 5 Grundlagen T-SQL 303 Grundlagen T-SQL 304 Grundlagen T-SQL 5 Grundlagen T-SQL Die in den Kapitel 2 und 3 dargestellten Techniken für die Datenabfrage sind bis auf wenige Ausnahmen auch in anderen Datenbanken gültig und entsprechen in vielfältiger Weise dem Umfang von Standard-SQL. Dies trifft gleichfalls für die Anweisungen der Datenmanipulation für Einfüge-, Lösch- und Aktualisierungsanweisungen zu. Viele Datenbanken bieten allerdings zusätzlich auch umfassende Erweiterungen von SQL oder sogar eigene Programmiersprachen an bzw. erlauben, eine oder mehrere gängige Programmiersprachen innerhalb der Datenbank für die Anwendungsentwicklung zu nutzen. Dies betrifft nicht nur solche Großdatenbanken wie den MS SQL Server oder Oracle (PL/SQL, Java, C++), sondern auch kleinere Lösungen wie MySQL oder MS Access. In MS Access lässt sich seit vielen Jahren mit VBA arbeiten, während der MS SQL Server die SQL-Erweiterung Transact SQL (T-SQL) und seit Version 2005 ebenfalls auch .NET anbietet. Bisweilen wird auch die gesamte SQL-Variante vom MS SQL Server als T-SQL bezeichnet. Wir wollen es in diesem Buch so handhaben, dass alle Strukturen, die weitestgehend mit dem Standard übereinstimmen und so oder sehr ähnlich in anderen Datenbanken funktionieren würden, als SQL bezeichnet werden, und lediglich die Anweisungen und Schlüsselwörter für die Anwendungsentwicklung (Funktionen, Prozeduren, Trigger) als T-SQL. 5.1 T-SQL Blöcke Der Einsatzbereich von T-SQL betrifft den gesamten Bereich der Anwendungsentwicklung mit der Zielsetzung, die Datenbank aus Administratorensicht zu automatisieren, Sicherheits- und Integritätsmerkmale der Datenbank zu realisieren, di e mit einfachem SQL bzw. einfachen Datenstrukturanweisungen nicht möglich wären, strukturierten und vereinfachten Zugriff auf die Datenbank zu gewähren, wobei gleichzeitig auch Sicherheits- und Filteraspekte im Vordergrund stehen. In diesem Sinne ist T-SQL also nicht nur ein Werkzeug für Programmierer oder Anwender, welche die Datenbank lediglich für Datenabruf und –bearbeitung nutzen, sondern gerade auch für Administratoren. Sie benötigen dieses Buch, um die Syntax von SQL zu lernen, wie sie für die Da- 305 Grundlagen T-SQL tenbearbeitung notwendig ist, sowie für die Erfassung der allgemeinen Sprachstruktur. Ihre Aufgabe können Sie dann allerdings nur mit dem zusätzlichen Wissen um die technischen Möglichkeiten der Datenbank selbst erfüllen, die Inhalt des zweien Bandes dieser Reihe sind. T-SQL enthält zwar eine Vielzahl an gängigen Programmierkonstrukten von einfachen Programmiersprachen, ist jedoch in keiner Weise so umfangreich und vielschichtig wie bspw. PL/SQL, die Variante von SQL von Oracle. In Oracle kann man dann u.a. auch noch mit Java programmieren, was teilweise das gesonderte Erlernen von PL/SQL überflüssig machte, Da allerdings PL/SQL tatsächlich einen umfangreichen Sprachschatz bietet, lassen sich die meisten Aufgaben auch vollständig mit PL/SQL erledigen. Im Vergleich zum MS SQL Server 2000 musste man schlichtweg feststellen, dass TSQL nur eine sehr einfache Erweiterung von Standard-SQL war und nicht wirklich eine eigene Programmiersprache darstellte. In der Version 2005 sind auch nur sehr wenige neue Konstrukte hinzugekommen, sodass man feststellen muss, dass Microsoft diese Erweiterung offensichtlich nicht weiter verfolgt und nur in dem Umfang, wie er bereits in der Vergangenheit bekannt war, anbieten möchte. Stattdessen – um den MS SQL Server 2005 fortzuentwickeln und gegenüber der Konkurrenz sehr viel besser zu positionieren als früher – besteht nun die Möglichkeit, in vielfältiger Weise mit .NET zu arbeiten, was sowohl Thema in diesem Buch als auch in weiteren Bänden dieser Reihe sein wird. 5.1.1 Variablen und Anweisungen Nach der kurzen Einführung in die Datenbankprogrammierung innerhalb der Datenbank sollen nun die Grundzüge von T-SQL dargestellt werden. Anwendungen können in Form von Prozeduren, Funktionen oder Trigger auftreten, wenn sie in der Datenbank gespeichert sind. In Form von Textdateien lassen sich allerdings T-SQL-Programme ebenfalls speichern und dann unmittelbar ausführen, wie dies auch für gewöhnliches SQL der Fall ist. Diese einfachen Blöcke sollen zunächst als Bespiel dienen. In den Beispielen in diesem Kapitel sind die Schlüsselwörter groß geschrieben. Dies entspricht der Syntax in den offiziellen Microsoft-Dokumenten und verbessert sehr die Lesbarkeit, 306 Grundlagen T-SQL um zwischen Schlüsselwörtern und den Datenstrukturen wie Schema-, Tabellen- und Spaltennamen zu unterscheiden. Allerdings ist die Unterscheidung von Groß- und Kleinschreibung irrelevant für die Funktionstüchtigkeit eines Programms. Ob man nun also für eine Fallunterscheidung IF oder if verwendet, ist letztendlich Geschmackssache. Eine Variable lässt sich mit Hilfe der DECLARE-Anweisung. Sie erlaubt die Deklaration von mehreren Variablen direkt nacheinander, welche durch ein Komma getrennt sind. Vor den Variablennamen setzt man ein @-Zeichen, das auch zur Unterscheidung zwischen Spalten- und Variablennamen nützlich ist. Dem Variablennamen folgt dann einer der Datenbank-Datentypen mit optionaler Längenangabe. Die allgemeine Syntax hat die Form: DECLARE {{ @variable [AS] datentyp } | { @cursor_variable CURSOR } | { @tabellen_variable_name < tabellen_definition > } } [ ,...n] Die allgemeine Syntax zeigt auch, dass neben der Variablendeklaration auch Cursor für den Abruf und die zeilenweise Verarbeitung von mehreren Datenreihen sowie die Erstellung von lokalen Tabellen zur Erzeugung von Array-Strukturen deklariert werden können. Beiden Themen ist ein eigener Abschnitt gewidmet, sodass diese zwei Wege hier nur erwähnt, aber nicht weiter ausgeführt werden. Die Initialisierung einer Variablen, d.h. die Speicherung eines Wertes, erfolgt dann entweder über das Schlüsselwort SET oder ganz einfach mit Hilfe einer SELECTAnweisung. Sobald eine Variable deklariert wird, ist ihr anfänglicher Wert zunächst NULL. Dabei ist die SET-Anweisung durchaus umfangreicher als in der nachfolgenden allgemeinen Darstellung angegeben. Es fehlt in dieser Darstellung die Möglichkeit, einen Cursor zu verwenden, was im Abschnitt zu den Cursorn erläutert wird. Angege- 307 Grundlagen T-SQL ben ist stattdessen die Möglichkeit, auch die Eigenschaft oder ein Feld eines benutzerdefinierten Datentyps zu setzen. Dabei kann auch eine Instanzmethode (ein Punkt zum Aufruf) oder eine statische Methode (einen Doppelpunkt zum Aufruf) verwendet werden, um einen Wert zu ändern. Dies sind Techniken, welche mit CLR (Common Language Runtime) in einem gesonderten Kapitel beschrieben werden und entscheidend sind für die Weiterentwicklung des MS SQL Servers 2005 und die Integration des .NETFrameworks in der Datenbank aus Sicht des Programmierers und Entwicklers. SET { @lokale_variable [:: eigenschaft | feld ] = ausdruck | benutzerdefiniert_datentyp { . | :: } methode (argument [ ,...n ] ) } Eine weitere Möglichkeit, um eine Variable zu instanziieren, besteht darin, sie in einer SELECT-Anweisung aufzurufen. Im typischen Fall wird dies genutzt, um innerhalb einer Abfrage einen Spaltenwert bzw. unter Einsatz einer Funktion einen berechneten oder umgewandelten Spaltenwert abzurufen. Es ist auch möglich, mehrere Werte abzurufen, wobei allerdings nur der letzte Wert tatsächlich zurückgegeben wird. Sofern keine Abfrage verwendet wird, lässt sich jeder beliebige andere Ausdruck verwenden und damit auch eine SET-Anweisung ersetzen. SELECT { @local_variable = expression } [ ,...n ] [ ; ] 5.1.2 Datentypen Spalten, Ausdrücke in Abfragen und Anweisungen in T-SQL sowie natürlich Variablen lassen sich mit Hilfe eines Datentyps beschreiben. Dabei gibt ein Datentypen an, welche Werte in einer Variable oder Spalte gespeichert werden können. Diese allgemeinen 308 Grundlagen T-SQL Wertebereiche lassen sich noch mit weiteren Bedingungen beschränken. Dazu gibt es bspw. die Möglichkeit, in SQL bei der Tabellendefinition Einschränkungen anzugeben, welche den Wertebereich noch weiter eingrenzen. Neben dieser Aufgabe ermöglicht es ein Datentyp auch, zwischen verschiedenen semantischen Bedeutung zu unterscheiden und bspw. berechnende Funktionen oder vergleichende/berechnende Operatoren auf die Werte, die von einem Datentyp beschrieben werden, anzuwenden. Der Plus-Operator kann bspw. bei zwei Werten, die als Zahl angegeben sind, eine Addition durchführen, während für Zeichenfolgen stattdessen eine Verknüpfung stattfindet und die beiden Zeichenketten miteinander kombiniert werden. Ein anderes Beispiel ist die Verarbeitung von Datumswerten, wobei zwei Datumswerte voneinander abgezogen oder ein Datum um eine bestimmte Dauer erhöht wird und entweder Dauern oder weitere Datumswerte liefern. Zusätzlich können Optimierungsverfahren implementiert werden, welche die Sortierung, den Zugriff oder ganz allgemein die Verarbeitung beschleunigen. Dies sind allerdings Optimierungen, welche direkt in der Datenbank oder in der ausführenden Umgebung der Programmiersprache stattfinden und die nicht in allen Programmiersprachen vorhanden sind. Für Datenbanken dagegen sind Datentypen jedoch gang und gäbe; man könnte sich gar keine DB ohne Datentypen vorstellen. Die verschiedenen Datentypen lassen sich in unterschiedliche Gruppen einordnen, wobei einige Datentypen je nach Gruppenordnung auch in unterschiedliche Gruppen gehören könnten. Die Dokumentation vom MS SQL Server findet die folgenden Gruppierungen für die vorhandenen Datentypen: Genaue numerische Werte mit einer festen Vorgabe für Stellen vor und nach dem Komma Ungefähre numerische Werte mit einer flexiblen Anzahl an Stellen vor und nach dem Komma Unicode-Zeichenfolgen für Zeichenketten in Unicocde Zeichenfolgen für Zeichenketten, die nicht inUnicocde angegeben sind Binärzeichenfolgen für die Abbildung und Verarbeitung von Binärdaten, welche in ihrer Zeichenkettenrepräsentation vorliegen (Bilder, große Objekte) 309 Grundlagen T-SQL Datum und Zeit für die Abbildung von Werten, die aus Zeiteinheiten wie Tagen, Monaten, Jahren oder Stunden, Minuten und Sekunden bestehen. Andere Datentypen für T-SQL-Programme wie Cursor oder spezielle Datentypen mit besonderen Fähigkeiten wie der XML-Datentyp Die nachfolgende Aufstellung liefert einen Überblick über die vorhandenen Datentypen. Typ Bereich Größe bigint -2^63 (-9.223.372.036.854.775.808) (9.223.372.036.854.775.807) int -2^31 (-2.147.483.648) bis 2^31-1 (2.147.483.647) 4 Byte smallint -2^15 (-32.768) bis 2^15-1 (32.767) 2 Byte tinyint 0 bis 255 1 Byte bis 2^63-1 8 Byte Genaue numerische Werte Für die Speicherung von Zahlen mit fester Genauigkeit und mit fester Anzahl von Dezimalstellen eignen sich die beiden Datentypen decimal und numeric mit dem folgenden allgemeinen Aufbau: decimal[ (p[ , s] )] numeric[ (p[ , s] )] Sofern man die Genauigkeit maximiert, liegt der Wertebereich im Intervall - 10^38 +1 bis 10^38 - 1. In der allgemeinen Syntax steht p für Genauigkeit (engl. precision) und damit für die maximal speicherbare Gesamtzahl an Dezimalstellen links und rechts vom Dezimalkomma. Der Wertebereich für diese Zahl ist das Intervall 1 bis 38 mit einem Standardwert 18. Der Buchstabe s dagegen steht für die Anzahl der Dezimalstellen (engl. scale). Die zulässigen Werte liegen zwischen 0 und p, da ja die Genauigkeit sowohl die Zahlen links als auch rechts vom Dezimalkomma angibt. Ein Wert für s ist 310 Grundlagen T-SQL optional und kann nur angegeben werden, wenn auch eine Genauigkeit angegeben ist, wobei ein Standardwert von 0 gilt. Insgesamt gilt die Beziehung: 0 <= s <= p. Genauigkeit Bytes Genauigkeit Bytes 1-9 5 20-28 13 10-19 9 29-38 17 Speicherplatz in Bytes Spezielle für Währungen gibt es zwei unterschiedlich große Datentypen, die bis zu einem Zehntausendstel genau einen Wert erfassen. Typ Bereich Größe money 922.337.203.685.477.5808 bis 922.337.203.685.477.5807 8 Byte smallmoney -214.748.3648 bis 214.748.3647 4 Byte Datentypen für Währungen Bit-Werte können mit dem Datentyp bit als ganzzahliger Datentyp, der den Wert 1, 0 oder NULL annehmen kann, gespeichert werden. Neben den Zahlen mit fester Genauigkeit, gibt es zwei weitere für die Speicherung von ungefähren Werten mit Gleitkomma. Dabei hat float die allgemeine Syntax float [ ( n ) ] und erwartet eine Ganzzahl zwischen 1 und 53 (Standardwert) für die Angabe, wie viele Bits in der wissenschaftlichen Schreibweise zum Speichern der Mantisse verwendet werden sollen. Dies definiert auch die Genauigkeit und Speichergröße. Typ Bereich Größe float - 1.79E+308 bis -2.23E-308. 0 und 2.23E-308 bis 1.79E+308 Abhängig von n real - 3.40E + 38 bis -1.18E - 38. 0 und 1.18E - 38 bis 3.40E + 38 4 Bytes 311 Grundlagen T-SQL Ungefähre numerische Werte Für float gelten die in nachfolgender Tabelle angegebenen Speicherplätze. n Genauigkeit Bytes 1-24 7 Stellen 4 Bytes 25-53 15 Stellen 8 Bytes Speicherplatz in Bytes Für die Abbildung von Datums- und Tageszeitangaben stehen die beiden Datentypen datetime und smalldatetime zur Verfügung. Typ Bereich Genauigkeit datetime 1. Januar 1753 bis 31. Dezember 9999. 3,33 Millisekunden smalldatetime 1. Januar 1900 bis 6. Juni 2079 1 Minute Zeit- und Datumstypen Für Zeichenfolgen sind folgende Datentypen vorhanden: Für die Abbildung Nicht-Unicode-Zeichendaten mit fester Länge steht char [ ( n ) ] mit n Byte Länge zur Verfügung. Dabei ist n ein Wert zwischen 1 und 8.000 und bestimmt auch gleichzeitig die Speichergröße in Byte. Für die Abbildung Nicht-Unicode-Zeichendaten mit variabler Länge steht varchar [ ( n | max ) ] zur Verfügung. Dabei ist n ein Wert zwischen 1 bis 8.000, während die Angabe von max dazu führt, dass die maximale Speichergröße 2^31-1 Byte verwendet wird. Tatsächlich ermittelt sich die Speichergröße aus der tatsächlich genutzten Länge + 2 Byte. 312 Grundlagen T-SQL Für die Abbildung Unicode-Zeichendaten mit fester Länge steht nchar [ ( n ) ] mit n Byte Länge zur Verfügung. Dabei ist n ein Wert zwischen 1 und 4.000, wobei die Speichergröße der doppelte Wert von n in Bytes ist. Für die Abbildung Unicode-Zeichendaten mit variabler Länge steht nvarchar [ ( n | max ) ] zur Verfügung. Dabei ist n ein Wert zwischen 1 bis 4.000, während die Angabe von max dazu führt, dass die maximale Speichergröße 2^31-1 Byte verwendet wird. Tatsächlich ermittelt sich die Speichergröße aus der doppelten tatsächlich genutzten Länge + 2 Byte. Für die Abbildung sehr großer Unicode-Zeichendaten variabler Länge steht ntext mit einer maximalen Länge von 2^30 - 1 (1.073.741.823) Zeichen zur Verfügung. Dabei entsteht eine Speichergröße von der doppelten Anzahl gespeicherter Zeichen. Für die Abbildung von sehr umfangreichen Nicht-Unicode-Daten variabler Länge steht text zur Verfügung. Die maximale Länge beträgt 2^31-1 (2.147.483.647) Zeichen. Schließlich gibt es noch den Datentyp image für die Speicherung von Binärdaten bis zu einer Länge von 0 bis 2^31-1 (2.147.483.647) Bytes. In Ergänzung zu den gerade beschriebenen Datentypen, die sowohl für Tabellenspalten als auch für T-SQL-Variablen verwendet werden können, gibt es noch eine kleine Sammlung an weiteren Datentypen. Sie bilden Datenstrukturen ab, die in Sonderfällen genutzt werden können. Teilweise können dies auch Spaltendatentypen sein, teilweise jedoch lassen sie sich nur in T-SQL verwenden. Nicht alle diese Datentypen sind auch in dieser Form in anderen Datenbanken verfügbar, so wie auch die beiden Datentypen für Währungen typisch für den MS SQL Server sind. Diese besonderen Datentypen sind: Der Datentyp cursor bietet die Möglichkeiten, Variablen oder OUTPUT-Parameter gespeicherter Prozeduren mit einem Verweis auf einen Cursor abzubilden. Der NULL-Wert ist auch möglich. 313 Grundlagen T-SQL Der Datentyp timestamp kann einmal in einer Tabelle verwendet werden. Diese Spalte enthält dann einen Zähler, der beim Einfügen und Aktualisieren von Datensätzen automatisch erhöht wird. Es handelt sich dabei nicht um eine tatsächliche Zeit, sondern vielmehr um das Fortschreiben eines relativen Zeitpunkts der Datenbank. Der Einsatzbereich dieses Zählers ist die Versionierung von Tabellenzeilen. Der Datentyp sql_variant bietet die Möglichkeit, Spalten, Parametern, Variablen und Rückgabewerten von benutzerdefinierten Funktionen mit der Fähigkeit auszustatten, verschiedene Datentypen auf einmal zu unterstützen. Dies gilt nicht für die Datentypen varchar(max), varbinary(max), nvarchar(max), xml, text, ntext, image, timestamp, benutzerdefinierte Typen und sql_variant selbst. Der Datentyp uniqueidentifier stellt einen 16-Byte Schlüssel dar (GUID). Dieser Datentyp bietet sich für Primärschlüsselspalten an, wobei der neue Wert besonders einfach mti Hilfe der newid()-Funktion eingefügt werden kann. Der Datentyp table stellt einen Datentyp dar, welcher eine Ergebnismenge in Form einer Tabelle abbildet. Dies kann zum Speichern von Datenmengen in einer Variablen oder als Rückgabewert für eine Tabellenfunktion genutzt werden. Der Datentyp xml bildet XML-Instanzen ab, die sogar mit Hilfe eines XML Schemas validiert werden können. XML-Strukturen können sowohl in einer Spalte als auch in einer Tabelle gespeichert werden. Mit einem Beispiel sollen die verschiedenen Konzepte und Basis-Techniken der zurückliegenden Abschnitte nun abgeschlossen werden. Zunächst werden drei Variablen für den Namen, die Nummer und die Farbe eines Produkts erstellt. Die Datentypen dieser drei Variablen entsprechen genau den Datentypen der Tabellenspalten, welche die Variablen beschreiben. Dies gewährleistet, dass die Inhalte bei einer Datenabfrage in diese Variablen abgerufen werden können bzw. dass Vergleiche erfolgreich durchgeführt werden können, d.h. ohne Konvertierungen zu benötigen. 314 Grundlagen T-SQL Die Variable vProductNumber wird direkt über eine Initialisierung mit einem Wert gefüllt, der im nächsten Schritt dazu führt, dass diese Variable als Bindevariable für die Abfrage von Farbe und Name des entsprechenden Produkts genutzt wird. Diese Werte werden schließlich über die PRINT-Anweisung in der Standardausgabe ausgegeben. Die allgemeine Syntax lautet PRINT zeichenkette | @lokale_variable | zeichenketten_ausdruck und erwartet entweder eine Zeichenkette, eine Variable oder einen beliebigen Ausdruck, welcher eine Zeichenkette zurückgibt. Dies kann eine Verknüpfung von Zeichenketten oder Variablen sowie natürlich Funktionen mit passendem Rückgabewert sein. -- Deklaration DECLARE @vName nvarchar(50), @vProductNumber nvarchar(25), @vColor nvarchar(15) -- Initialisierung durch direkte Wertvorgabe SET @vProductNumber = 'SO-B909-L' -- Initialisierung per Abfrage SELECT @vName = Name, @vColor = Color FROM Production.Product WHERE ProductNumber = @vProductNumber -- Ausgabe PRINT @vName + ' Nr.:' + @vProductNumber + ', Farbe: ' + @vColor 512_01.sql: Variablen und einfache Anweisungen 315 Grundlagen T-SQL Man erhält als Ergebnis im Nachrichtenfenster, in dem normalerweise die Abfrageergebnisse ausgegeben werden, eine Nachricht mit den Produktinformationen. Mountain Bike Socks, L Nr.:SO-B909-L, Farbe: White 5.2 Kontrollanweisungen Für die Erstellung von Programmen mit bedingten Abläufen bietet T-SQL einfache Konstrukte, um Fallunterscheidung sowie Schleifen zu formulieren. Sie sollen in diesem Abschnitt vorgestellt werden. 5.2.1 Fallunterscheidungen Fallunterscheidungen lassen sich mit if-else-Strukturen abbilden, wobei leider keine weiteren Fälle angegeben werden können. Sofern der Testausdruck im IF-Zweig den Wahrheitswert TRUE liefert, werden die Anweisungen in seinem Anweisungsblock ausgeführt, ansonsten diejenigen des ELSE-Blocks. Bei einer einzigen Anweisung ist es nicht notwendig, den Anweisungsblock mit den beiden Schlüsselwörtern BEGIN und END zu umschließen. Bei mehreren Anweisungen in einem Block ist dies dagegen verpflichtend. Die allgemeine Syntax lautet: IF Testausdruck { SQL-Anweisung | Anweisungsblock } [ ELSE { SQL-Anweisung | Anweisungsblock } ] Im folgenden Beispiel erstellt man im Deklarationsabschnitt verschiedene Variablen für die Kundennummer, die Gebietsnummer sowie Adresszeile und –nummer sowie die Stadt. Die Kundennummer gibt man direkt über eine SET-Anweisung vor. Die Gebietssowie die Adressnummer erfolgt über eine Abfrage, welche die beiden Tabellen Customer und CustomerAddress verknüpft. 316 Grundlagen T-SQL Die Fallunterscheidung prüft nun darauf, ob (ganz rein zufällig natürlich) die Gebietsnummer 4 lautet. In diesem Fall soll die Adresse ausgegeben werden. In diesem Zweig befinden sich zunächst eine Abfrage und die entsprechende Ausgabeanweisung. Da sich in diesem Zweig mehr als eine Anweisung befinden, müssen die beiden Schlüsselwörter BEGIN und END die Anweisungen umschließen. Im ELSE-Zweig ist dies dagegen unnötig, weil sich hier nur eine einzige Anweisung befindet. -- Deklaration DECLARE @vCustomerID int, @vTerritoryID int, @vAddressID int, @vAddressLine nvarchar(200), @vCity nvarchar(30) -- Initialisierung durch direkte Wertvorgabe SET @vCustomerID = 6 -- Initialisierung per Abfrage SELECT @vTerritoryID = TerritoryID, @vAddressID = AddressID FROM Sales.Customer AS c INNER JOIN Sales.CustomerAddress AS ca ON c.CustomerID = ca.CustomerID WHERE c.CustomerID = @vCustomerID PRINT 'Gebiet: ' + CAST(@vTerritoryID AS nvarchar(1)) PRINT 'Adresse: ' + CAST(@vAddressID AS nvarchar(3)) 317 Grundlagen T-SQL -- Fallunterscheidung IF @vTerritoryID = 4 BEGIN SELECT @vAddressLine = AddressLine1, @vCity = City FROM Person.Address WHERE AddressID = @vAddressID PRINT @vAddressLine + ' ' + @vCity END ELSE PRINT 'Gebiet ungleich 4' 521_01.sql: Fallunterscheidung Da tatsächlich die Gebietsnummer 4 lautet, wird in der Standardausgabe die Adresszeile ausgegeben. Gebiet: 4 Adresse: 989 39933 Mission Oaks Blvd Camarill 5.2.2 Schleifen Um Anweisungen mehrfach aufgrund einer Bedingung auszuführen, gibt es auch ein Schleifenkonstrukt. Wie in anderen Programmiersprachen auch lautet sie WHILE und enthält die beiden optionalen Schlüsselwörter BREAK zur vorzeitigen und bedingten Unterbrechung der Schleife sowie CONTINUE für die bedingte Fortsetzung der Schleife vor der Ausführung der nachfolgenden Anweisungen. Die allgemeine Syntax lautet: 318 Grundlagen T-SQL WHILE Testausdruck { SQL-Anweisung | Anweisungsblock } [ BREAK ] { SQL-Anweisung | Anweisungsblock } [ CONTINUE ] { SQL-Anweisung | Anweisungsblock } Als Beispiel setzt man eine Zählervariable sowie zwei Variablen für die Speicherung von Vor- und Nachnamen von Angestellten ein. Innerhalb der Schleife erhöht man den Zählerwert und ruft mit diesem Wert als Primärschlüssel über eine Abfrage einen neuen Employee-Datensatz ab. Wenn der Zähler den Wert 4 erreicht, soll die Schleife unterbrochen werden. Dies geschieht mit Hilfe der BREAK-Anweisung. Dies führt dazu, dass nur vier Angestellten ausgegeben werden. -- Deklaration DECLARE @vZaehler int, @vFirstName nvarchar(50), @vLastName nvarchar(50) -- Initialisierung SET @vZaehler = 1 -- Initialisierung per Abfrage WHILE @vZaehler <= 10 BEGIN SELECT @vFirstName = FirstName, @vLastName = LastName 319 Grundlagen T-SQL FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS c ON emp.ContactID = c.ContactID WHERE emp.EmployeeID = @vZaehler -- Inkrementation SET @vZaehler = @vZaehler + 1 -- Ausgabe PRINT CAST(@vZaehler AS nvarchar(2)) + ' ' + @vFirstName + ' ' + @vLastName -- Fallunterscheidung IF @vZaehler = 4 BREAK ELSE CONTINUE END 522_01.sql: Schleife 5.3 Dynamische Anweisungen T-SQL bietet die sehr interessante Möglichkeit, SQL-Anweisungen dynamisch zusammenzusetzen, indem Zeichenketten aus Variablen oder aus direkten Vorgaben mit Hilfe von Fallunterscheidungen kombiniert werden. Dies erlaubt es, sehr dynamische Anweisungen auszuführen, welche wiederum zu besonders interessanten Funktionen und Prozeduren umgesetzt werden können. 320 Grundlagen T-SQL 5.3.1 Einsatz von EXEC Es gibt zwei Wege, um T-SQL-Anweisungen dynamisch auszuführen. Sie unterscheiden sich in der Komplexität der möglichen Syntax und damit auch im Umfang der Möglichkeiten. Die allgemeine Syntax der EXEC-Anweisung, welche die einfachere und damit etwas begrenzte Variante darstellt, lautet: { EXEC | EXECUTE } ( { @string_variable | [ N ]'tsql_string' } [ + ...n ] ) [ AS { LOGIN | USER } = ' name ' ] Es ist auch möglich, eine solche Anweisungen gegen einen verlinkten Server auszuführen. Dann verändert sich die allgemeine Syntax zu: { EXEC | EXECUTE } ( { @string_variable | [ N ] 'command_string' } [ + ...n ] [ {, { value | @variable [ OUTPUT ] } } [...n] ] ) [ AS { LOGIN | USER } = ' name ' ] [ AT linked_server_name ] Die Parameter beider Varianten sind die folgenden: @string_value enthält für die dynamische Ausführung den Namen einer lokalen Variable in den Datentypen char, varchar, nchar oder nvarchar, in welcher die Anweisungen gespeichert sind. [N] 'tsql_string' erwartet eine auszuführende Anweisung als Zeichenkette. 321 Grundlagen T-SQL AS { LOGIN | USER } = ' name ' legt den so genannten Ausführungskontext fest. Hier kann man angeben, unter welchem Benutzernamen man die Anweisung ausführen möchte. @variable enthält eine Bindevariable, die in die Anweisung Werte übergibt. value enthält dagegen direkt diesen gebundenen Wert. OUTPUT legt fest, dass ein Ausgabeparameter der ausgeführten Anweisung per Referenz in diese Variable übergeben werden soll. AT linked_server_name enthält den Namen eines verlinkten Servers, auf dem die Anweisung ausgeführt werden soll. Über die Prozedur sp_addlinkedserver können solche Verbindungen eingerichtet werden. Zur Illustration erstellt man zwei Variablen für die Speicherung von Fragmenten für SQL-Anweisungen. Diese beiden Variablen unterscheiden sich in der Spaltenauswahl, d.h. in sql1 werden drei und in sql2 vier Spalten aus der SalesOrderHeaderTabelle genannt. Dabei verknüpft die Variable sql2 zusätzlich die Variable sql1 mit einer zusätzlichen Spalte. Die Ausführung erfolgt dann ganz einfach mit Hilfe der EXECUTE-Anweisung, in der sowohl die Variable sql2 als auch weitere notwendige Zeichenkettenfragmente zur Bildung einer vollständigen SQL-Anweisung aufgerufen werden. Dies könnte auch noch mit einer Fallunterscheidung oder entsprechenden Parametern einer Funktion/Prozedur verbunden werden. -- Deklaration von SQL-Variablen DECLARE @sql1 nvarchar(100), @sql2 nvarchar(100) -- Initialisierung SET @sql1 = 'CustomerID, OrderDate, ShipDate' SET @sql2 = @sql1 + ', DueDate' -- Dynamische Ausführung 322 Grundlagen T-SQL EXECUTE ('SELECT ' + @sql2 + ' FROM Sales.SalesOrderHeader') 531_01.sql: Dynamische Ausführung von SQL Im Ergebnis zu den vorherigen Beispielen erhält man nun im Ergebnisbereich gerade keine Textausgabe über eine PRINT-Anweisung, sondern stattdessen eine ganz gewöhnliche Ergebnismenge. Dies ist eine besonders attraktive Fähigkeit von T-SQL, welche in anderen Datenbanken nicht möglich ist. Man ist nicht gezwungen, ein T-SQLProgramm so zu beenden, dass ein Ergebnistext ausgegeben wird, der in einer anderen Programmiersprache nicht sinnvoll genutzt werden kann. Stattdessen kann man über überaus variantenreiche Techniken Ergebnismengen erzeugen, die in einer äußeren Programmiersprache aus dem .NET-Umfeld genau wie eine Ergebnismenge auf Basis einer SQL-Anweisung verarbeitet werden kann. CustomerID OrderDate ShipDate DueDate ----------- ---------- ---------- ----------676 2001-07-01 2001-07-08 2001-07-13 117 2001-07-01 2001-07-08 2001-07-13 442 2001-07-01 2001-07-08 2001-07-13 Das nächste Beispiel zeigt, wie die Verbindung zu einer MS Access-Datenbank eingerichtet, auf verschiedene Arten genutzt und schließlich gelöscht wird. Mit den gleichen Prozeduren, die hier aus Platzgründen nicht alle dargestellt werden sollen, lassen sich Verbindungen auch zu anderen Datenbanksystemen oder sogar MS Excel einrichten. Dabei befindet sich in der Access-Datenbank die exportierte Product-Tabelle. -- Verlinkten Server einrichten EXEC sp_addlinkedserver @server = 'AWAccess', @provider = 'Microsoft.Jet.OLEDB.4.0', 323 Grundlagen T-SQL @srvproduct = 'OLE DB Provider for Jet', @datasrc = 'C:\Product.mdb' -- Ausgabemöglichkeit einrichten EXEC sp_serveroption 'AWAccess', 'rpc out', true; -- Kontrolle EXEC sp_helpserver; -- Einfache Abfrage EXEC ( 'SELECT * FROM Product;') AT AWAccess; -- Übergabe eines einfachen Paramters EXEC ( 'SELECT * FROM Product WHERE Color = ?;', 'Black') AT AWAccess; -- Übergabe eines Parameters als Variable DECLARE @vColor varchar(10); SET @vColor = 'Blue'; EXEC ( 'SELECT * FROM Product WHERE Color = ?;', @vColor) AT AWAccess; -- Verlinkten Server löschen EXEC sp_dropserver @server = 'AWAccess'; 531_02.sql: Ausführen von Anweisungen an verlinktem Server 5.3.2 Einsatz von sp_executesql Eine technisch anspruchsvollere Lösung, um dynamische T-SQL-Anweisungen auszuführen, bietet die Systemprozedur sp_executeql. Ihre allgemeine Syntax lautet: 324 Grundlagen T-SQL sp_executesql [ @stmt = ] stmt [ {, [@params=] N'@parameter_name data_type [ [ OUT [ PUT ][,...n]' } {, [ @param1 = ] 'value1' [ ,...n ] } ] Folgende Parameter kommen zum Einsatz: [ @stmt = ] stmt enthält die Anweisung als Zeichenkette oder als Variable in ntext-Form sein bzw. sich in diesen Datentyp konvertieren lassen. Der Verkettungsoperator + darf zwar nicht zum Einsatz kommen, aber die Verkettung kann in einer Variablen zum Einsatz kommen, die dann verwendet wird. Diese Zeichenkette darf Variablen enthalten, welche allerdings nicht durch den Verkettungsoperator hinzugefügt werden müssen, sondern die anhand des @Zeichens erkannt werden. [ @params = ] N'@parameter_name data_type [ ,... n ] ' enthält die verschiedenen Parameter aus der auszuführenden T-SQL-Zeichenkette mit Namen und Datentyp. Dies ähnelt der Spaltenliste einer Tabelle oder von Modulparametern. Der Standardwert für diesen Parameter ist NULL. [ @param1 = ] 'value1' enthält jeden definierten Parameter mit seinem Wert als Zeichenkette oder Variable. Jeder Parameter muss angegeben werden. OUTPUT gibt an, dass der jeweilige Parameter ein Rückgabeparameter ist, wie dies bei Prozeduren möglich ist. Die dynamische Rückgabe eines Cursors ist ebenfalls möglich. Die nachfolgenden Beispiele zeigen unterschiedliche Standardfälle von sp_executesql. Im ersten Beispiel führt man eine einfache Abfrage aus. Hier ist es nicht notwendig, Parameter zu verwenden, sodass hier auch keine besondere Berück- 325 Grundlagen T-SQL sichtigung von Parametern für die Abfrage notwendig ist. Man verwendet einfach nur den @stmt-Parameter, um die Anweisung anzugeben. Das zweite Beispiel stellt eine Erweiterung des einfachen Standardfalls dar und verwendet direkt innerhalb der nicht zusammen gesetzten T-SQL-Zeichenkette zwei Parameter. Sie müssen innerhalb vom Parameter @params angekündigt werden und werden schließlich im dritten Parameter der Reihe nach mit Werten gefüllt. Dabei ist dieser Teil der Parameterliste dynamisch. Auf der einen Seite erwartet die Prozedur so viele Parameter wie angekündigt, auf der anderen Seite gibt man die Werte über ihre tatsächlichen Namen an. Das dritte Beispiel schließlich fügt noch einen Ausgabeparameter hinzu. Dies kann sowohl ein Rückgabewert aus einer Abfrage oder der Verwendung einer Prozedur mit Ausgabeparameter sein. In diesem Fall beschränkt man sich darauf, den ermittelten Aggregatwert einer Zählung in einen solchen Parameter zu speichern und diesen Wert dann zurückzuliefern. -- Einfache Abfrage EXEC sp_executesql @stmt = N'SELECT * FROM Production.Product'; -- Übergabe zweier Parameter EXEC sp_executesql @stmt = N'SELECT * FROM Production.Product WHERE Color = @Color AND Size = @Size', @params = N'@Color varchar(10), @Size varchar(2)', @Color = 'Black', @Size = '40'; -- Angabe eines Ausgabeparameters 326 Grundlagen T-SQL DECLARE @vProducts int EXEC sp_executesql @stmt = N'SELECT @vCount = COUNT(*) FROM Production.Product', @params = N'@vCount INT OUTPUT', @vCount = @vProducts OUTPUT; PRINT STR(@vProducts) 532_01.sql: Einsatz von sp_executesql 5.4 Fehlerbehandlung Selbstverständlich ist davon auszugehen, dass nach der Lektüre des Buchs die Behandlung von Fehlern zu den Aufgaben gehören, die am ehesten vernachlässigt werden können, doch gerade wenn man die Aufgabe erhält, von Kollegen Quelltext zu überarbeiten, ist es sicherlich nicht verkehrt, sich doch schon einmal mit diesem Thema zu beschäftigen. Daher kommt diesem Abschnitt auch die Aufgabe zu, einen kleinen Teil für die Gemeinschaft zu tun („Jeden Tag eine gute Tat.“). Dieser Abschnitt stellt daher die neue Ausnahmebehandlung und die klassische Fehlerbehandlung vor. 5.4.1 Ausnahmen In der Version 2005 ist ein neues Programmierkonstrukt für die Fehlerbehandlung hinzugekommen, welches bereits in anderen Sprachen wie C# oder Java bekannt ist. Es bietet eine Basislösung für die dort vorhandene Ausnahmebehandlung über die Syntax von TRY und CATCH an, d.h. nicht die gesamten Fähigkeiten der Ausnahmebehandlung der beispielhaft erwähnten Sprachen sind auch in T-SQL vorhanden. Die Funktionsweise ist einfach und entspricht denen anderer Sprachen: Ein Abschnitt, der möglicherweise einen Fehler liefern könnte, kann mit Hilfe einer IF-Konstruktion 327 Grundlagen T-SQL auf diesen Fehler abgeprüft werden. Dies führt allerdings dazu, dass im Quelltext sowohl Fallunterscheidungen, welche die Logik des Programms abbilden, als auch solche Fallunterscheidungen auftreten, welche für die Fehlerbehandlung eingefügt wurden. Dies erschwert häufig das Verständnis des Algorithmus und führt immer zu sehr tief verschachtelten Fallunterscheidungen und dadurch zu schwer lesbarem Quelltext. Ein solcher Block wird von der neuen Syntax BEGIN TRY und END TRY umschlossen. Jeder Fehler, der die Datenbankverbindung nicht schließt und der einen Schweregrad größer als 10 besitzt, führt nicht zu einer Fehlermeldung, sondern zu einem Sprung in den auf den TRY-Block folgenden CATCH-Block. Dieser Block wird von der neuen Syntax BEGIN CATCH und END CATCH umschlossen und muss unmittelbar nach END TRY folgen. Es darf also ausdrücklich kein anderer Quelltext zwischen den beiden Blöcken stehen. Die gesamte Konstruktion muss innerhalb eines einzigen Blocks Platz finden und kann nicht mehrere Batches, mehrere Blöcke, die durch BEGIN und END umschlossen werden, sowie keine Fallunterscheidungen überspannen. In den Fällen, in denen der versuchte Quelltext aus beliebigen Gründen keinen Fehler auslöst, werden die Anweisungen im CATCH-Block übersprungen und die Ausführung mit dem auf ihn unmittelbar folgenden Anweisungen fortgesetzt. Die allgemeine Syntax hat die Form: BEGIN TRY { SQL-Anweisung | Anweisungsblock } END TRY BEGIN CATCH { SQL-Anweisung | Anweisungsblock } END CATCH [ ; ] Zu Anfang des Abschnitts wurde diese neue Technik als Basislösung von ähnlichen Möglichkeiten anderer Programmiersprachen bezeichnet. Dies liegt daran, dass durch 328 Grundlagen T-SQL die fehlende Objektorientierung keine typisierte Untersuchung der möglichen Fehler angegeben werden kann. So ist es also nicht möglich und wäre auch unsinnig, mehrere CATCH-Blöcke anzugeben. In objektorientierten Programmiersprachen bietet sich hierüber die Möglichkeit, verschiedene Fehlertypen abzufangen und sogar über das Substitutionsprinzip Eltern-Fehlerarten anstelle ihrer Kinder anzugeben, um mehrere abgeleitete Fehler in einem CATCH-Block zu sammeln. Aufgrund der fehlenden Objektorientierung in T-SQL ist dies nicht möglich. Da zudem auch keine Fehler aus Prozeduren oder Funktionen aufgefangen werden können auch keine Ausnahmen geworfen werden können, muss der Nutze der neuen Syntax mit Vergleich auf ähnliche Implementierungen etwas eingeschränkt werden. Die wesentliche Zielsetzung, eine strukturierte Fehlerbehandlungstechnik anzugeben, welche sich syntaktisch von Fallunterscheidungen für die Formulierung von Algorithmen unterscheidet, ist allerdings gelungen. Darüber hinaus ist es zulässig, die Ausnahmebehandlungen zu verschachteln, sodass nicht nur eine einzige Ebene von Fehlern solchermaßen behandelt werden kann. 5.4.1.1 Fehlermeldungen Wie schon gerade in den allgemeinen Erläuterungen dargestellt, können nicht alle Fehler durch eine Ausnahmebehandlung tatsächlich abgerufen werden. Dies sind nur die Fehler mit einem Schweregrad zwischen 11 und 16. Diese und andere Schweregrade werden in der nachfolgenden Tabelle kurz vorgestellt. Die Fehlermeldungen mit einem Schweregrad zwischen 19 und 25 erfasst das Fehlerprotokoll und sollten dem Administrator gemeldet werden (sofern man dies nicht selbst ist). Schweregrad Beschreibung 0-9 Nicht schwerwiegende Fehler oder Statusinformationen zurückgeben, die vom Datenbankmodul (Database Engine) nicht ausgelöst werden. 10 Statusinformationen oder nicht schwer wiegende Fehler, die vor der Rückgabe vom Datenbankmodul aus Kompatibilitätsgründen in den Schweregrad 0 konvertiert werden. 11 Das Objekt oder die Entität ist nicht vorhanden. 329 Grundlagen T-SQL 12 Spezielle Abfragehinweise verhindern Sperren in Abfragen, die im Rahmen von Lesevorgängen zu inkonsistenten Daten führen können. 13 Deadlockfehler der Transaktion. 14 Sicherheitsbezogene Fehler wie fehlende Berechtigungen. 15 Syntaxfehler in Transact-SQL. 16 Allgemeine Fehler, die vom Benutzer behoben werden können. 17-19 Softwarefehler, die vom Benutzer nicht behoben werden können. 17 Anweisung führte zu fehlenden Ressourcen wie Arbeitsspeicher, Sperren, Speicherplatz sowie Grenzwertverletzungen. 18 Softwarefehler des Datenbankmoduls, die weder die Ausführung beendet noch die Verbindung schließt. 19 Datenbankmodul überschreitet einen nicht konfigurierbaren Grenzwert, was den aktuellen Batchprozess beendet. 20-25 Systemprobleme (schwerwiegende Fehler), welche den Task des Datenbankmoduls mehr ausgeführt und normalerweise auch die Anwendungsverbindung beenden und protokolliert werden. 20 Eine Anweisung löst in einem Task ein Problem aus.. 21 Eine Anweisng löst sich auf alle Tasks in der aktuellen Datenbank auswirkt. 22 Eine Tabelle oder ein Index, wurden durch ein Software- oder Hardwareproblem beschädigt. Weitere Hilfe mit DBCC CHECKDB und Neustart der Instanz oder Neuerstellung des Objekts 23 DB- Integrität der Datenbank ist durch ein Hardware- oder Softwareproblem gestört. Weitere Hilfe mit DBCC CHECKDB und Neustart der Instanz oder Neuerstellung des Objekts 24 Medien- und Hardwarefehler. Fehlerarten 330 Grundlagen T-SQL 5.4.1.2 Standardfall Um die Ausnahmebehandlungstechnik von T-SQL gut zu nutzen, ist es vor allen Dingen wichtig zu wissen, welche Fehler überhaupt erkannt und daher entsprechend behandelt werden können. Die verschiedenen Beispiele in diesem Kapitel zeigen diverse Einsatzbereiche bzw. behandelbare Fehler, die auch die Übersichtstabelle des letzten Abschnitts im Mittelteil mit dem Schweregrad 11 bis 16 zeigte. Das erste Beispiel zeigt den einfachsten Standardfall, in dem ein kritischer Bereich lediglich in einem TRY-Block platziert wird und die selbst erstellte Fehlerbehandlung (Ausgabe einer Fehlermeldung) darauf folgt. Im TRY-Block versucht man, einen durch eine Primärschlüssel-Fremdschlüssel-Beziehung referenzierten Datensatz zu löschen. Dies gelingt nicht, sodass die Anweisungen im CATCH-Block ausgeführt werden. BEGIN TRY DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode = 'CM' END TRY BEGIN CATCH PRINT 'Löschen nicht möglich' END CATCH 541_01.sql: Ausnahme bei referenzieller Integrität Einige Fehler können unmittelbar im gleichen Block, d.h. in der gleichen Ebene behandelt werden. Andere erfordern dagegen, dass Fehler und ihre Behandlung in einer anderen Ausführungsebene behandelt werden. Dazu zählen Kompilierungsfehler, welche die Ausführung eines Batch verhindern, und auch Fehler bei der Auflösung von Objektnamens auftreten. Ein nicht vorhandenes Objekt kann nur in einem kompilierten Block wie bspw. einer Prozedur oder Funktion erkannt werden. Daher setzt das nächste Beispiel nicht nur einen einfachen Block ein, sondern besteht aus einer (wenig sinnvollen) 331 Grundlagen T-SQL Prozedur. Diese ist allerdings in der Lage, folgende drei Überlegungen abzubilden: 1. Ein erwarteter Parameter, der beim Aufruf der Prozedur nicht gesetzt wird, führt zu einer Ausnahme. 2. Ein syntaktisch korrekter und keine referenzielle Integrität verletzende SQL-Anweisung für die Aktualisierung oder Löschung führt zu keiner Ausnahme. Dies ist eigentliche trivial, aber mit Blick auf das vorherige Beispiel und vielleicht wenig Erfahrung mit Programmiersprachen oder Datenbanken scheint das Beispiel für Anfänger gut geeignet, falsche Erwartungen zu beheben. 3. Der Aufruf eines nicht vorhandenen Objekts führt zu einer Ausnahme. CREATE PROCEDURE uspWrongObject ( @test int) AS DECLARE @empNr int SELECT @empNr = MAX(EmployeeID) FROM HumanResources.Employee IF @test = 1 BEGIN -- Löschen eines nicht vorhandenen Datensatzes DELETE FROM HumanResources.Employee WHERE EmployeeID = @empNr + 1 END ELSE -- Oder: Löschen aus nicht vorhandenem Objekt DELETE FROM HumanResources.Employees WHERE EmployeeID = @empNr + 1 541_01.sql: Prozedur für Ausnahmetest Der erste Test ruft die Prozedur ohne Parameter auf, obwohl diese Aufrufmöglichkeit nicht vorgesehen ist, und daher eine Ausnahme auslöst. Im Gegensatz zum ersten Bei- 332 Grundlagen T-SQL spiel, in dem die PRINT-Anweisung eine eigene Fehlermeldung ausgab, setzen diese Beispiele jeweils die beiden Funktionen ERROR_NUMBER() und ERROR_MESSAGE() ein. Diese und weitere Funktionen werden später noch einmal als Gruppe vorgestellt. Sie erlauben es, weitere Informationen über Ausnahmen zu ermitteln. -- Fehlender Parameter BEGIN TRY EXEC uspWrongObject END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage END CATCH Da eine Ausnahme ausgelöst wird, lautet das Ergebnis: ErrorNumber ErrorMessage ----------- ------------------------------------------------201 Die Prozedur oder Funktion 'uspWrongObject' erwartet den '@test'-Parameter, der nicht bereitgestellt wurde. Im Gegensatz zum vorherigen Beispiel mit einer Lösch-Aktion löst der nachfolgende Test gerade keine Ausnahme aus, da ein nicht gefundener Datensatz kein Problem im Sinne der Ausnahmebehandlung darstellt. -- Kein Datensatz gelöscht BEGIN TRY 333 Grundlagen T-SQL EXEC uspWrongObject 1 END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage END CATCH 541_03.sql: Fehlender Datensatz ohne Ausnahme Als Ergebnis erhält man daher nur die sicherlich schon bekannte Information: (0 Zeile(n) betroffen) Da Fehler, die im Bereich der Namensauflösung entstehen, nicht in der gleichen Ausführungsebene als Ausnahme erkannt werden, ist der nachfolgende Aufruf der Prozedur und die Auslösung dieses Falls die einzige Situation, in dem dies überhaupt erkannt wird. Die Prozedur ruft man mit einer beliebigen Zahl ungleich 1 auf, um den Standardfall der Fallunterscheidung auszulösen. -- Falscher Objektname BEGIN TRY EXEC uspWrongObject 2 END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage END CATCH 541_02.sql: Test der Ausnahmebehandlung 334 Grundlagen T-SQL Als Ergebnis erhält man in diesem Fall: ErrorNumber ErrorMessage ----------- ------------------------------------------------208 Ungültiger Objektname 'HumanResources.Employees'. 5.4.1.3 Funktionen zur Fehleruntersuchung Zur Untersuchung des aufgetreten Fehlers kann man folgende Funktionen im CATCHBlock verwenden. Zwei wichtige Funktionen, welche die Fehlernummer und den zusammen fassenden Fehlertext ausgeben, wurden bereits in den vorherigen Beispielen genutzt. Folgende Funktionen sind verfügbar: ERROR_NUMBER() liefert die Fehlernummer. ERROR_SEVERITY() liefert den Schweregrad. ERROR_STATE() liefert die Fehlerstatusnummer. ERROR_PROCEDURE() liefert den Namen der gespeicherten Prozedur oder des Triggers, welche den Fehler verursachten. ERROR_LINE() liefert die Zeilennummer in dem Modul, in dem der Fehler aufgetreten ist. ERROR_MESSAGE() liefert den Text der Fehlermeldung. Das nächste Beispiel greift noch einmal die die referenzielle Integrität verletzende Anweisung eines vorherigen Beispiels auf und ersetzt die dort erfasste eigene Fehlermeldung durch sämtliche Funktionen, die für die Ausnahmebehandlung möglich sind. BEGIN TRY DELETE FROM Production.UnitMeasure 335 Grundlagen T-SQL WHERE UnitMeasureCode = 'CM' END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_SEVERITY() AS ErrorSeverity, ERROR_STATE() AS ErrorState, ERROR_PROCEDURE() AS ErrorProcedure, ERROR_LINE() AS ErrorLine, ERROR_MESSAGE() AS ErrorMessage END CATCH 541_04.sql: Verwendung der Ausnahmefunktionen Das Ergebnis und die Nützlichkeit der Informationen spricht eigentlich für sich. Insbesondere solche Informationen wie der Prozedurname, in der der Fehler aufgetreten ist (hier NULL, da ein einfaches Skript erstellt wurde), als auch die Zeilennummer, die den Fehler ausgelöst hat, sind neben der sehr ausführlichen Fehlermeldung sehr interessante Daten, die auch gut protokolliert werden können, wenn dies notwendig sein sollte. ErrorNumber ErrorSeverity ErrorState ErrorProcedure ----------- ------------- ----------- ----------------547 16 ErrorLine ErrorMessage 0 NULL ----------- ------------------------------------------------- 336 Grundlagen T-SQL 3 Die DELETE-Anweisung steht in Konflikt mit der REFERENCE-Einschränkung "FK_Product_UnitMeasure _SizeUnitMeasureCode". Der Konflikt trat in der "AdventureWorks"-Datenbank, Tabelle "Production. Product", column 'SizeUnitMeasureCode' auf. (1 Zeile(n) betroffen 5.4.2 Traditionelle Fehlerbehandlung Dieser Abschnitt stellt die traditionelle, d.h. im MS SQL Server 2000 eingesetzte Fehlerbehandlung dar, die natürlich weiterhin genutzt werden kann. Auf der einen Seite zeichnet sie sich durch eine kurze Syntax aus, die durch die Funktion @@error und ihren alleinigen Aufruf bedingt ist. Auf der anderen Seite sieht man bereits im ersten Beispiel dieses Abschnitts, wie die verschachtelte Fallunterscheidung zu schwer lesbaren Quelltext führen kann. 5.4.2.1 Fehler abrufen Es gibt in der T-SQL-Syntax verschiedene Strukturen, die mit zwei @-Zeichen begonnen werden und daher wie globale Variablen wirken. Offiziell nennt man diese Strukturen allerdings Funktionen, was allerdings mehr historisch ist, weil sie aus einer Zeit stammen, in der im MS SQL Server noch keine Funktionen im eigentliche Sinne erstellt werden konnten. Diese Funktion liefert den Wert 0, wenn die vorherige SQLAnweisung keine Fehler hervorbracht, und ansonsten die Fehlernummer der vorherigen Anweisung. Die möglichen Fehler, die über diese Funktion abgerufen werden können, stehen mit mehrsprachigen Fehlermeldungen in der sys.messages-Katalogsicht. Diese können wiederum über eine SQL-Anweisung in folgender Form abgerufen werden: SELECT * FROM sys.messages WHERE language_id = 1031 337 Grundlagen T-SQL AND severity > 0 ORDER BY severity 542_02.sql: Abruf der Fehlerarten Da die Fehlermeldungen sehr umfangreich sind und vermutlich ohnehin schon bei verschiedenen selbstständigen Versuchen mit T-SQL gelesen wurden, soll nur kurz die Liste der Spaltennamen zeigen, welche Informationen in dieser Katalogsicht enthalten sind: message_id (Nachrichtennummer), language_id (Sprachnummer), severity (Schweregrad), is_event_logged (protokolliert oder nicht), text (Fehlermeldungstext). Da die Funktion immer nur Informationen über den letzten Fehler liefert, sollte man diese Informationen unmittelbar nach der SQL-Anweisung, die einen Fehler auslöst, auch abrufen und in einer lokalen Variable speichern. Dies zeigt auch das nachfolgende Beispiel. Zunächst erstellt man zwei Variablen, welche die Werte für die Fehlernummer und die Anzahl der betroffenen Reihen speichern sollen. Diese Information stammt aus @@rowcount, einer weiteren Funktion, die nach diesem Beispiel kurz erläutert wird, und welche in diesem Fall die Anzahl betroffener Reihen enthält. Die Ausführung der fehlerhaften Anweisung, welche einen verwendeten Datensatz zu löschen versucht und daher gegen die Regeln der referenziellen Integrität verstößt, löst einen Fehler aus, der mit @@error abgerufen werden kann. Um herauszufinden, ob überhaupt ein Fehler aufgetreten ist, kann man @@error auf den Wert 0 prüfen. Ist ein Fehler aufgetreten, ist ein Wert ungleich 0 vorhanden, der dann bei Bedarf wieder untersucht werden kann. Im aktuellen Beispiel löst man einen Fehler mit der Nummer 547 aus, der daher auch direkt geprüft und mit einer passenden eigenen Fehlerbehandlung bzw. einfach Fehlermeldung versehen werden kann. -- Variablen zur Fehleranalyse DECLARE @vError int, @vRowCount int -- Fehlerhafte Anweisung 338 Grundlagen T-SQL DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode = 'CM' -- Speichern von @@ERROR und @@ROWCOUNT SELECT @vError = @@ERROR, @vRowCount = @@ROWCOUNT -- Untersuchung und Ausgabe IF @vError <> 0 BEGIN IF @vError = 547 BEGIN PRINT 'Fehler bei referenzieller Integrität' END ELSE BEGIN PRINT 'Fehler ' + RTRIM(CAST(@vError AS NVARCHAR(10))) END END 542_02.sql: Traditionelle Fehlerbehandlung Man erhält als Ergebnis sowohl die eigentliche Fehlermeldung als auch die eigene Fehlermeldung. Meldung 547, Ebene 16, Status 0, Zeile 5 Die DELETE-Anweisung steht in Konflikt ... Die Anweisung wurde beendet. Fehler bei referenzieller Integrität Das vorherige Beispiel setzte neben der Funktion @@error auch die Funktion @@rowcount ein, um die Anzahl betroffener Reihen zu ermitteln, die aufgrund des Fehlers gleich null war. Dies ist einer der wesentlichen Einsatzbereiche von 339 Grundlagen T-SQL @@rowcount. Im Zusammenhang mit Cursorn, die es ermöglichen, durch eine mehrzei- lige Ergebnismenge zu navigieren, liefert diese Funktion die aktuelle Zeilennummer. Die Funktion liefert bei Anweisungen, die tatsächlich keine Zeilen abrufen, wie USE, SET <Option>, DEALLOCATE CURSOR, CLOSE CURSOR, BEGIN TRANSACTION oder COMMIT TRANSACTION den Wert 0. Die EXEC(UTE)-Anweiung behält darüber hinaus den vorherigen Status bei. 5.5 Cursor Bislang wurden ausschließlich Anweisungen ausgeführt, die jeweils eine einzige Datenzeile abriefen. Dies betrifft auch das Beispiel, in welchen mehrere Datensätze über eine Schleife abgerufen wurden. Gerade diese Lösung zum Abruf mehrerer Zeilen ist eigentlich überhaupt gar keine, weil sie eine geringe Leistungsfähigkeit besitzt. Stattdessen gibt es die so genannte Cursor-Technik, welche eine Abfrage unter einem (Variablen)Namen speichert und so für die Nutzung verfügbar macht. 5.5.1 Cursor-Varianten Es gibt zwei Varianten für die Deklaration eines Cursors, die sich in ihrem Verhalten unterscheiden. Dies betrifft das Scrollverhalten und damit die Möglichkeiten, wie der Cursor letztendlich in T-SQL genutzt werden kann. 5.5.1.1 SQL92-Syntax Die folgenden Bestandteile erscheinen in der allgemeinen Syntax für einen Cursor, welcher der Syntax von SQL-92 folgt: DECLARE name [ INSENSITIVE ] [ SCROLL ] CURSOR FOR abfrage [ FOR { READ ONLY | UPDATE [ OF column_name [ ,...n ] ] } ] [;] Folgende Attribute können diesem Cursor mitgegeben werden: 340 Grundlagen T-SQL name: Der Name eines Cursors muss den allgemeinen Regeln für einen Bezeichner bzw. für eine Variable erfüllen. Unter diesem Namen ist der Cursor später zu verwenden. INSENSITIVE: Sinn und Zweck eines Cursors ist es, eine Abfrage abzubilden, die mehrere Zeien abrufen kann. Bei der Angabe dieses Schlüsselworts erzeugt der Cursor beim Abruf der Daten eine temporäre Kopie der Daten in der tempdbDatenbank. Dies bedeutet, dass Änderungen, die an den Daten erfolgen, die durch die Abfrage abgerufen werden, bei einem Abruf vom Cursor nicht erkannt werden. Darüber hinaus sind im Umkehrschluss auch keine Datenänderungen an den so genannten Basistabellen möglich und werden Änderungen, die gerade an den Basistabellen bspw. von einem anderen Benutzer vorgenommen werden, auch im Cursor so zurückgegeben. SCROLL: Diese Angabe richtet den Cursor so ein, dass sämtliche Abrufoptionen (FIRST, LAST, PRIOR, NEXT, RELATIVE, ABSOLUTE) genutzt werden können. Sofern auf SCROLL verzichtet wird, kann ansonsten nur immer die nächste Zeile abgerufen und damit nur NEXT eingesetzt werden. abfrage: Der Cursor repräsentiert eine Abfrage, die auch mehrere Basistabellen umfassen kann und an sich auch komplexer Natur sein kann. Allerdings ist es nicht, die Schlüsselwörter COMPUTE, COMPUTE BY, FOR BROWSE und INTO zu verwenden. READ ONLY: Im Normalfall ist es möglich, die Daten, die ein Cursor abruft, auch zu bearbeiten, d.h. mit einer UPDATE-Anweisung zu aktualisieren und mit einer DELETE-Anweisung zu löschen. Dies geschieht am einfachsten mit Hilfe der WHERE CURRENT OF-Klausel, welche den aktuell abgerufenen Datensatz kennzeichnet. Durch die READ ONLY-Einstellung allerdings ist der Cursor tatsächlich nur lesbar. UPDATE [OF column_name [,...n]]: Wenn ein Cursor aktualisierbar sein soll, dann kann man entscheiden, ob man alle Spalten aktualisierbar machen möchte oder nicht. Sofern man die UPDATE OF-Klausel nicht verwendet, können Änderungen an allen Spalten vorgenommen werden. UPDATE OF dagegen erlaubt 341 Grundlagen T-SQL es, ausdrücklich die Spalten anzugeben, welche im Rahmen der CursorVerwendung geändert werden sollen. Wie man sehen kann, gibt es verschiedene Möglichkeiten, änderbare und nichtänderbare Cursor oder auch nur Cursor-Teile anzugeben. Es ist unbedingt notwendig, nur die Cursor überhaupt änderbar zu machen, die tatsächlich geändert werden sollen, und auch dann nur die Spalten änderbar zu machen, welche im Laufe eines T-SQLProgramms geändert werden sollen. So kann die Datenbank wesentlich besser, Transaktionen und Zeilensperren schneller durchführen 5.5.1.2 Transact-SQL Extended Syntax Neben der Syntax für den SQL-92-Cursor stellt der MS SQL Server noch eine erweiterte Syntax für Cursor zur Verfügung. Ihre allgemeine Form lautet: DECLARE name CURSOR [ LOCAL | GLOBAL ][ FORWARD_ONLY | SCROLL ] [ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ] [ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ] [ TYPE_WARNING ]FOR abfrage [ FOR UPDATE [ OF spalte [ ,...n ] ] ] [;] Folgende Attribute sind für einen T-SQL-Cursor verfügbar: name: Der Name des Cursors, unter dem er später angesprochen werden kann. LOCAL: Dieses Schlüsselwort bestimmt den Gültigkeitsbereich des Cursors. Er ist lokal zu der ihn erstellenden Folge von Anweisungen (Batch), der gespeicherten Prozedur oder dem Trigger. Sein Bezeichner ist daher nur innerhalb von den genannten Bereichen gültig, sodass der Cursor nur dort aufgerufen werden kann. Die aufrufende Umgebung kann auf ihn nur zugreifen, wenn er an einen OUTPUT- 342 Grundlagen T-SQL Paramter gebunden und dementsprechend zurückgegeben wird. Sobald der genannte Bereich beendet wird, weil bspw. die letzte Anweisung abgelaufen ist, dann wird der Cursor auch wieder aufgelöst, d.h. seine Zuordnung wird aufgelöst. Die Standardeinstellung für den Gültigkeitsbereich ist LOCAL. GLOBAL: Wie bereits LOCAL gibt auch GLOBAL den Gültigkeitsbereich eines Cursors an. Dabei bestimmt ihn GLOBAL als von jeder Prozedur oder jedem Batch abrufbar. FORWARD_ONLY: Ein mit diesem Attribut ausgestatteter Cursor liefert die Zeilen nur in aufsteigender Richtung und erlaubt damit als einzige Abrufoption NEXT. Dies ist der Standardfall, wenn weder FORWARD_ONLY noch SCROLL angegeben ist. Zusätzlich können noch drei weitere Schlüsselwörter (STATIC, KEYSET und DYNAMIC) angegeben werden, von denen DYNAMIC der Standardfall ist, wenn FORWARD_ONLY nicht im Zusammenhang mit einem dieser Schlüsselwörter benutzt wird. Sofern dagegen FORWARD_ONLY fehlt, und eines dieser drei Schlüsselwörter erscheinen, wird SCROLL für die Richtungsoptin angenommen. STATIC gibt an, dass der Cursor innerhalb der tempdb-Daten die abgerufenen Daten zwischenspeichern soll. Dieser Cursor lässt keine Änderungen zu, da sich die Änderungen nur temporär auswirken würden. KEYSET legt fest, dass die Reihenfolge und die Existenz von Zeilen innerhalb der abgerufenen Daten fest ist. Die abgerufenen Schlüssel werden dabei in der keysetTabelle der tempdb gespeichert. Ändert der Besitzer des Cursors oder ein anderer Benutzer durch COMMIT Nichtschlüsselwerte in den Tabellen, die dem Cursor zu Grunde liegen, machen sich diese durch Scroll-Vorgänge im Cursor bemerkbar. Einfügungen werden dagegen nicht wahrgenommen. Löschungen liefert einen @@FETCH_STATUS-Wert von -2. Neue Werte sind dann sichtbar, wenn die WHERE CURRENT OF-Klausel verwendet wird. DYNAMIC gibt an, dass der Cursor Datenänderungen unmittelbar bei ScrollVorgängen anzeigt. Dadurch können sich die Werte, die Reihenfolge von Datensätzen sowie ihre Existenz innerhalb der abgerufenen Menge jeweils ändern. 343 Grundlagen T-SQL FAST_FORWARD erzeugt einen Cursor mit FORWARD_ONLY READ_ONLY mit erhöhter Leistung. Dabei dürfen SCROLL und FOR UPDATE nicht verwendet werden. READ_ONLY erzeugt einen Cursor, der nur für Lesevorgänge genutzt werden kann. Die WHERE CURRENT OF-Klausel in UPDATE oder DELETE kann nicht genutzt werden. SCROLL_LOCKS legt fest, dass positionierte Aktualisierungen oder Löschungen erfolgreich geschehen, da die abgerufenen Zeilen gesperrt werden. Dies schließt die Verwendung von FAST_FORWARD aus. TYPE_WARNING legt fest, dass eine Warnmeldung an den Client geschickt wird, sobald der Cursortyp sich implizit ändern sollte. select_statement enthält die Abfrage, welche die Cursor-Daten beschafft. Die Klauseln COMPUTE, COMPUTE BY, FOR BROWSE und INTO sind unzulässig. Sofern die verwendete SQL-Anweisung für die zuvor dargestellten Anweisungen ungeeignet ist, wird der Typ implizit konvertiert. FOR UPDATE [OF column_name [,...n]] legt die Spalten an, die im Rahmen der Bearbeitung aktualisiert werden sollen. Sofern Spaltennamen angegeben sind, können Änderungen dann nur in diesen Spalten ausgeführt werden. Ansonsten stehen alle Spalten bereit. 5.5.2 Verwendung Für die tatsächliche Benutzung eines Cursors sind eine Reihe von speziellen Anweisungen, Funktionen und Prozeduren verfügbar, die hier dargestellt werden sollen. 5.5.2.1 Anweisungen Neben der umfangreichen Anzahl von Einstellungen ist die eigentliche Verwendung eines Cursors grundsätzlich einfach, weil ein sehr schematisches Vorgehen notwendig ist, um sie zu verwenden. Dabei müssen nach der eigentlichen Deklaration noch folgende Anweisungen zum Einsatz kommen. In der allgemeinen Syntax ist dabei immer von 344 Grundlagen T-SQL zwei möglichen Ausprägungen eines Cursors zu lesen. Zunächst gibt es den klassischen über DECLARE erzeugten Cursor, der unter einem eigenen Namen (cursor_name) verfügbar ist. Dann gibt es allerdings auch noch eine Cursorvariable, die über den Datentyp CURSOR angegeben und unter diesem Variablennamen (cursor_variable_name) verfügbar ist. Es ist möglich, im Rahmen von Prozeduren auch Cursor zurückzugeben. Um sie zu verwenden, muss im aufrufenden Programm eine entsprechende Variable bereitstehen. Das Schlüsselwort GLOBAL in den folgenden Erläuterungen gibt immer an, dass sich diese Anweisung auf eine globalen Cursor bezieht. Der erste Schritt besteht darin, den Cursor überhaupt zu öffnen. Die Daten werden dabei abgerufen und stehen bereit. OPEN { { [ GLOBAL ] cursor_name } | cursor_variable_name } Der zweite Schritt besteht darin, die Daten aus dem Cursor zeilenweise in lokale Variablen zu übertragen. Dabei besteht die Möglichkeit, bei einem scrollbaren Cursor absolute und relative Positionierungen anzugeben. FETCH [ [ NEXT | PRIOR | FIRST | LAST | ABSOLUTE { n | @nvar } | RELATIVE { n | @nvar } ] FROM ] { { [ GLOBAL ] cursor_name } | @cursor_variable_name } [ INTO @variable_name [ ,...n ] ] Der dritte Schritt besteht darin, den Cursor wieder zu schließen. Er ist dadurch nicht zerstört, sondern kann wieder geöffnet werden. Die Zuordnungen zwischen der aktuellen Ergebnismenge und dem Cursor werden genauso wie die Zeilensperren aufgehoben. 345 Grundlagen T-SQL CLOSE { { [ GLOBAL ] cursor_name } | cursor_variable_name } Der vierte Schritt besteht darin, die Referenz zwischen Cursornamen/-variablen und dem Cursor aufzuheben. Dies sorgt dafür, dass alle dem Cursor zugeordneten Ressourcen freigegeben werden. DEALLOCATE { { [ GLOBAL ] cursor_name } | @cursor_variable_name } 5.5.2.2 Cursor-Funktionen Bei der Ermittlung von Cursor-Zuständen gibt es eine Reihe von speziellen Funktionen (zwei der mysteriösen @@-Funktionen und eine ()-Funktion), die Informationen zu einem Cursor zurückliefern. @@FETCH_STATUS ermittelt den Status der letzten FETCH-Anweisung und liefert die Werte 346 – 0 für einen erfolgreichen Abruf – -1 für einen fehlgeschlagenen Abruf – -2 für eine Zeile, die nicht mehr in der Ergebnismenge vorhanden ist @@CURSOR_ROWS ruft die Anzahl der Zeilen ab, die im Cursor abrufbar sind. Die Funktion liefert folgende Werte: – -m liefert bei einem asynchron aufgefüllten Cursor die Werte, die aktuell verfügbar sind (keyset-Tabelle). – -1 zeigt an, dass es sich um einen dynamischen Cursor handelt und daher die Anzahl der abgerufenen Zeilen nicht definitiv ermittelt werden kann. – 0 zeigt an, dass kein Cursor offen ist oder der zuletzt geöffnete Cursor nun geschlossen ist und die Information nicht abgerufen werden kann. – n liefert die Anzahl der verfügbaren Zeilen. Grundlagen T-SQL Die Skalarfunktion CURSOR_STATUS liefert die Information zurück, ob eine Prozedur einen Cursor und eine relationale Ergebnismenge zurückgeliefert hat. Die allgemeine Syntax lautet: CURSOR_STATUS ( { 'local' , 'cursor_name' } | { 'global' , 'cursor_name' } | { 'variable' , 'cursor_variable' } ) Die drei Angaben local, global und variable stehen für die verschiedenen Cursor-Arten und werden als konstante Zeichenfolgen übergeben. Die anderen beiden verschiedenen Parameter enthalten den Namen eines DECLARE-Cursors oder einer Cursor-Variable. Die Funktion hat folgende Rückgabewerte (EM = Ergebnismenge): Wert Cursorname Cursorvariable EM (auch INSENSITIVE- und Zugeordnete Cursor ist offen. KEYSET-Cursor) hat mind. eine Zeile. EM (auch INSENSITIVE- und KEYSETCursor) hat mind. eine Zeile. EM eines dynamischen Cursors hat (k)eine oder mehrere Zeilen. EM eines dynamischen Cursors (k)eine oder mehrere Zeilen. 0 Leere EM (nicht bei dynamischen Cursorn). Zugeordneter Cursor offen, EM aber leer. -1 Cursor geschlossen. Zugeordneter Cursor geschlossen. -2 Nicht verfügbar. Prozedur wies OUTPUT-Variable keinen Cursor zu. 1 hat Durch Prozedur zugewiesener Cursor 347 Grundlagen T-SQL wurde nach Prozedurabschluss geschloss. Die Zuordnung zwischen OUTPUTVariable und Cursor ist aufgehoben. Cursorvariable zugeordnet. -3 Angegebener vorhanden. Cursor nicht erhielt keinen Cursor Cursorvariable nicht vorhanden oder kein zugewiesener Cursor vorhanden. Rückgabewerte 5.5.3 Beispiele Um die wesentlichen Schritte bei der Erstellung eines Cursors zu zeigen, ruft man im folgenden Beispiel nur einige Daten zu Abteilungen ab und gibt sie über die PRINTAnweisung aus. Der Cursor wird über die DECLARE-Anweisung erstellt und als scrollbar definiert. Im Wesentlichen befindet sich tatsächlich eine ganz gewöhnliche SELECTAnweisung in dieser Definition, die bis auf die erwähnten Ausnahmen mit allem aufwarten kann, was eine SELECT-Anweisung bieten kann. Danach deklartiert man eine Reihe von Die Zuordnungen zwischen der aktuellen Ergebnismenge und dem Cursor werden genauso wie die Zeilensperren aufgehoben. Danach deklariert man eine Reihe von Variablen, deren Datentypen zu dem Cursor abgerufenen Spalten passen. Im einfachsten Fall sind dies die Datentypen der Spalten, wenn im Cursor keine Berechnungen, Funktionsaufrufe oder Aggregate vorhanden sind. Um den Cursor tatsächlich zu benutzen, folgen die vier Schritte: 1. Man öffnet den Cursor über die OPEN-Anweisung. 2. Im zweiten Schritt ruft man die Daten zunächst einmal ab, um zu prüfen, ob überhaupt Daten vorhanden sind und bereits Daten zu besitzen. Dies ist ein Schönheitsfehler der T-SQL-Syntax, die es in anderen Datenbanken nicht gibt. Hier muss man leider einmal vorher abrufen, um dann im Rahmen einer Schleife weitere Abrufe durchzuführen. Sofern also sehr viele Spalten abgerufen werden, ist eine große Menge Quelltext zu kopieren, was 348 Grundlagen T-SQL sicherlich nicht von besonders gutem Quelltext zeugt. Leider ist allerdings keine andere Möglichkeit verfügbar. Die Schleife wird über den mit @@FETCH_STATUS ermittelten Status des Cursors durchgeführt. Er liefert drei Werte: 0 (erfolgreicher Abruf), -1 (fehlgeschlagener Abruf) oder -2 (Zeile nicht mehr in der Ergebnismenge vorhanden). Innerhalb der Schleife muss man dann zunächst die vom ersten Abruf empfagenen Zeilen verarbeiten, bevor man wieder neue Daten abruft, da man ansonsten die erste Zeile verliert. 3. Im dritten Schritt schließt man den Cursor und könnte ihn noch einmal öffnen. 4. Im vierten Schritt löscht man die Referenzen auf den Cursor und stellt den Ursprungszustand wieder her. -- Cursor DECLARE cDepartment CURSOR SCROLL FOR SELECT TOP 5 DepartmentID, Name, GroupName FROM HumanResources.Department -- Variablen DECLARE @vDepID smallint, @vName nvarchar(50), @vGroupName nvarchar(50) -- 1. Schritt: Öffnen OPEN cDepartment -- 2. Schritt: Abrufen FETCH NEXT FROM cDepartment INTO @vDepID, @vName, @vGroupName 349 Grundlagen T-SQL WHILE @@FETCH_STATUS = 0 BEGIN PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName + ' ' + ' ' + @vGroupName FETCH NEXT FROM cDepartment INTO @vDepID, @vName, @vGroupName END -- 3. Schritt: Schließen CLOSE cDepartment -- 4. Schritt: Löschen DEALLOCATE cDepartment 553_01.sql: Verwenden eines einfachen Cursors Man erhält eine Ausgabe der Ergebnisse in gedruckter Form: 1 Engineering Research and Development 2 Tool Design Research and Development Wie oben erwähnt, gibt es eine Vielzahl an Möglichkeiten, die Daten aus dem Cursor abzurufen. Im nächsten Skript werden die verschiedenen Varianten einmal im Zusammenhang gezeigt. Es handelt sich dabei um den Cursor, der bereits im vorherigen Beispiel erzeugt wurde. Daher wird hier nur noch der zweite Schritt vorgeführt. Es lassen sich direkt die erste und letzte Zeile abrufen. Man kann die vorherigen und die folgenden Datenreihen abrufen, sodass man nach vor und zurück scrollen kann. Darüber hinaus kann man auch direkt absolut oder relativ Zeilen angeben, zu denen man springen möchte. 350 Grundlagen T-SQL -- 2. Schritt: Abrufen -- Letzte Reihe FETCH LAST FROM cDepartment INTO @vDepID, @vName, @vGroupName PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName -- Vorherige Reihe, relativ zur aktuellen FETCH PRIOR FROM cDepartment INTO @vDepID, @vName, @vGroupName PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName -- Absolut zweite FETCH ABSOLUTE 2 FROM cDepartment INTO @vDepID, @vName, @vGroupName PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName -- Relativ dritte Reihe zur aktuellen FETCH RELATIVE 3 FROM cDepartment INTO @vDepID, @vName, @vGroupName PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName -- Relativ zweite Reihe vor der aktuellen FETCH RELATIVE -2 FROM cDepartment INTO @vDepID, @vName, @vGroupName PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName 553_02.sql : Abrufoptionen 351 Grundlagen T-SQL Man erhält als Ergebnis die folgenden Zeilen: 5 Purchasing 4 Marketing 2 Tool Design 5 Purchasing 3 Sales Mit den drei Cursor-Funktionen lassen sich die verschiedenen Zustände von Cursorn abrufen. Dazu folgen zwei gleichartige aufgebaute Programme, welche für die verschiedenen Ereignisse im Lebens eines Cursors seine Zustände abrufen. Es handelt sich um den Cursor für die Abteilungsdaten, der bereits zuvor auch eingesetzt wurde. Das erste Programm konzentriert sich auf einen mit der bisher schon genutzten Syntax angelegten Cursor über DECLARE. Der im Quelltext gefettete Teil stellt die Abfrage der verschiedenen Funktionen dar, die in den späteren Ereignissen nicht mehr vollständig abgedruckt wird. -- Variablen DECLARE @vDepID smallint, @vName nvarchar(50), @vGroupName nvarchar(50) -- Cursor deklarieren DECLARE cDepartment CURSOR SCROLL FOR SELECT TOP 5 DepartmentID, Name, GroupName FROM HumanResources.Department SELECT @@CURSOR_ROWS AS Reihen, @@FETCH_STATUS AS [F-Status], 352 Grundlagen T-SQL CURSOR_STATUS('global', 'cDepartment') AS [C-Status] -- 1. Schritt: Öffnen OPEN cDepartment SELECT ... -- 2. Schritt: Abrufen FETCH FIRST FROM cDepartment INTO @vDepID, @vName, @vGroupName SELECT ... -- 3. Schritt: Schließen und löschen CLOSE cDepartment SELECT ... -- 4. Schritt: Löschen DEALLOCATE cDepartment SELECT ... 553_03.sql: Testen der Cursorfunktionen Man erhält als Ergebnis mehrere Ergebnismengen, die als Zusammenfassung folgendes Aussehen haben. Deutlich ist zu sehen, dass der FETCH-Status jeweils 0 ist, da innerhalb dieser Verbindung ein vorheriger Cursor eine Zeile erfolgreich zurückgeliefert hatte. Die Anzahl der Reihen verrät allerdings sehr deutlich, dass erst, nachdem man den Cursor auch tatsächlich geöffnet hat, fünf Zeilen abgerufen wurden. Nachdem der Cursor geschlossen ist, sind keine Reihe mehr verfügbar. Der Cursor-Status, der über die ()Funktion abgerufen wird, gibt an, dass der Cursor bei der Deklaration und nach dem Schließen geschlossen und nach dem Öffnen und während des Abrufens geöffnet ist. Reihen F-Status C-Status 353 Grundlagen T-SQL +----------- ----------- -------Deklaration | 0 0 -1 1. Schritt: Öffnen | 5 0 1 2. Schritt: Abrufen | 5 0 1 3. Schritt: Schließen | 0 0 1 4. Schritt: Löschen 0 -1 | 0 Das Programm wird noch einmal umgewandelt, um zu zeigen, wie es bei Cursorvariablen funktioniert. Es wird nur der veränderte Teil im nachfolgenden Quelltext angegeben. Zunächst deklariert man die Cursorvariable, dann weist man ihr eine Abfrage zu, um dann die verschiedenen weiteren Lebenszustände zu testen. ... -- Cursorvariable deklarieren DECLARE @cDepartment cursor -- Cursorvariable mit Abfrage verbinden SET @cDepartment = CURSOR SCROLL FOR SELECT TOP 5 DepartmentID, Name, GroupName FROM HumanResources.Department SELECT @@CURSOR_ROWS AS Reihen, @@FETCH_STATUS AS [F-Status], CURSOR_STATUS('variable', '@cDepartment') AS [CStatus] ... 553_04.sql: Testen der Cursorfunktionen 354 Grundlagen T-SQL Die Anzahl der Reihen wird genauso ermittelt wie zuvor. Der FETCH-Status ist jeweils 0, da im Laufe der Verbindung ein Cursor (nach dem Aufrufen dieses Cursors dann der aktuelle) Daten zurückgeliefert hat. Insbesondere der Cursor-Status, der über die ()Funktion abgerufen wird, liefert nun andere Werte, da es sich um eine Cursorvariable handelt, die sie untersucht. Zunächst ist der zugeordnete Cursor geschlossen, da ja tatsächlich nur die Variable an sich deklariert wurde. Dann ist der zugewiesene Cursor geöffnet, und man erhält den Wert 1 zurück. Nachdem der Cursor geschlossen ist, springt der Wert wieder auf -1 um, bis dann zum Schluss mit dem Wert -2 gemeldet wird, dass kein Cursor mehr zugewiesen wird. Reihen F-Status C-Status +----------- ----------- -------Deklaration | 0 0 -1 1. Schritt: Öffnen | 5 0 1 2. Schritt: Abrufen | 5 0 1 3. Schritt: Schließen | 0 0 -1 4. Schritt: Löschen 0 -2 | 0 Auch wenn zuvor bereits ein Beispiel für Cursorvariablen angegeben wurde, soll dieses Thema noch einmal gesondert behandelt werden. Ein gewöhnlicher Cursor ist mit seiner SQL-Anweisung direkt verknüpft. Sie kann später nicht noch einmal geändert werden. Stattdessen müsste man einen neuen Cursor deklarieren und diesem die geänderte Fassung zuweisen. Eine Cursorvariable hingegen steht als Patzhalter für unterschiedliche SQL-Befehle bereit. Dabei kann man sowohl eine neue SQL-Anweisung über die SETAnweisung, als auch einen gewöhnlichen Cursor zuweisen. Im letzten Fall ist es darüber hinaus auch noch möglich, aus einer Prozedur einen Cursor zu empfangen. Dies wird später im Rahmen der Vorstellung von Prozeduren gezeigt. Die SET-Anweisung spielt hierbei eine wichtige Rolle. Sie hat folgende allgemeine Syntax. Insbesondere die direkte Angabe einer SQL-Anweisung zeigt, dass hier jeder 355 Grundlagen T-SQL beliebige Cursor auch dynamisch erstellt werden kann. Die einzelnen Attribute, mit denen der Cursor beschrieben wird, sind dieselben wie bei einem gewöhnlichen Cursor. SET { @local_variable = expression } | { @cursor_variable = { @cursor_variable | cursor_name | { CURSOR [ FORWARD_ONLY | SCROLL ] [ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ] [ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ] [ TYPE_WARNING ] FOR select_statement [ FOR { READ ONLY | UPDATE [ OF column_name [ ,...n ] ] } ] } } } Im nächsten Beispiel sieht man, wie ein globaler Cursor erstellt und einer Cursorvariable zugewiesen wird. Dies ist eine der drei erwähnten Möglichkeiten - Zuweisung, SQLAnweisung vorgeben oder Prozedur-Ausgabeparameter. Die Cursorvariable erstellt man nur durch Angabe des Datentyps cursor. Die Referenz zum Cursor kann man über die SET-Anweisung einrichten. Die Verarbeitung dieser Cursorvariable ist dann grundsätzlich genauso wie bei einem gewöhnlichen Cursor. Der wesentliche Unterschied in der Syntax ist nur die Verwendung des Variablen- und nicht des Cursornamens, d.h. hier ist 356 Grundlagen T-SQL in den verschiedenen Anweisungen wie OPEN, FETCH etc. überall ein @-Zeichen zu verwenden. -- Variablen DECLARE @vDepID smallint, @vName nvarchar(50), @vGroupName nvarchar(50) -- Cursor deklarieren DECLARE cDepartment CURSOR SCROLL GLOBAL FOR SELECT TOP 5 DepartmentID, Name, GroupName FROM HumanResources.Department -- Cursorvariable deklarieren DECLARE @cvDepartment CURSOR -- Cursorvariable einem Cursor zuordnen SET @cvDepartment = cDepartment -- Test SELECT CURSOR_STATUS('global', 'cDepartment') AS [C-Status], CURSOR_STATUS('variable', '@cvDepartment') AS [CV-Status] -- 1. Schritt: Öffnen OPEN @cvDepartment -- 2. Schritt: Abrufen FETCH LAST FROM @cvDepartment INTO @vDepID, @vName, @vGroupName 357 Grundlagen T-SQL PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName + ' ' + ' ' + @vGroupName -- Test SELECT CURSOR_STATUS('global', 'cDepartment') AS [C-Status], CURSOR_STATUS('variable', '@cvDepartment') AS [CV-Status] -- 3. Schritt: Schließen CLOSE @cvDepartment -- 4. Schritt: Löschen SELECT CURSOR_STATUS('global', 'cDepartment') AS [C-Status], CURSOR_STATUS('variable', '@cvDepartment') AS [CV-Status] DEALLOCATE @cvDepartment DEALLOCATE cDepartment 553_05.sql: Cursor und Cursorvariable Als Ergebnis erhält man den abgerufenen Daten als viel interessantere Information, die verschiedenen gleichartigen Statusmeldungen der beiden verschiedenen Einheiten. Wenn der Cursor geschlossen ist und daher den Wert -1 zurückliefert, dann hat auch die Cursorvariable diesen Wert, wobei hier dieser Wert sich auf den eigentlichen Cursor bezieht, der auch aus Sicht der Cursorvariable noch geschlossen ist. Der Wert 1 nach dem Öffnen zeigt beim Cursor an, dass mindestens ein Wert in der Abfrage enthalten ist, während der gleiche Wert für die Cursorvariable bedeutet, dass der referenzierte Cursor geöffnet ist. C-Status CV-Status -------- --------- 358 Grundlagen T-SQL -1 -1 5 Purchasing 1 1 -1 -1 Inventory Management Die zweite Variante besteht daraus, die Cursorvariable zu erstellen, die eigentliche Abfrage allerdings in der SET-Anweisung vorzugeben. Dies ermöglicht es bspw., in Abhängigkeit von äußeren Werten und daher im Rahmen einer Fallunterscheidung verschiedene SET-Anweisungen und damit dynamisch die eigentliche Abfrage zu verändern. Im Normalfall belässt man hier natürlich die Spaltenstruktur der Rückgabe, verändert aber Filter oder Berechnungen. Das nächste Beispiel zeigt, wie eine solche Abfrage direkt vorgegeben wird und wie man mit einem solchen Cursor umgeht. -- Variablen DECLARE @vDepID smallint, @vName nvarchar(50), @vGroupName nvarchar(50) -- Cursorvariable deklarieren DECLARE @cvDepartment CURSOR -- Cursorvariable eine Abfrage zuordnen SET @cvDepartment = CURSOR SCROLL GLOBAL FOR SELECT TOP 5 DepartmentID, Name, GroupName FROM HumanResources.Department -- 1. Schritt: Öffnen OPEN @cvDepartment -- 2. Schritt: Abrufen 359 Grundlagen T-SQL FETCH ABSOLUTE 2 FROM @cvDepartment INTO @vDepID, @vName, @vGroupName PRINT CONVERT(nvarchar(10), @vDepID) + ' ' + @vName + ' ' + ' ' + @vGroupName -- 3. Schritt: Schließen CLOSE @cvDepartment -- 4. Schritt: Löschen DEALLOCATE @cvDepartment 553_06.sql: Cursorvariable und SQL-Anweisung 5.6 Transaktionen Im Rahmen von Datenbearbeitungsvorgängen ist es wichtig, mit Transaktionen zu arbeiten, wenn mehrere Anweisungen in einer Serie zusammen gehören und sie nur als Ganzes durchgeführt werden sollen. Ein Schulbeispiel, um Transaktionen zu erklären, stellt eine Überweisung von einem Bankkonto zum nächsten dar. Wenn das Geld gerade von Konto A abgehoben ist, aber noch nicht auf Konto B gutgeschrieben ist, passiert in diesem Szenario ein elektronisches Unglück, und das Geld landet im finanziellen Nirvana. Bei einem elektronischen Unglück, in dem die Transaktionssteuerung der Datenbank oder der Anwendung noch eingreifen kann, würde bereits die Abbuchung wieder rückgängig gemach und damit der ganze Prozess zurückgedreht. Transaktionsverwaltung ist bei Mehrbenutzerbetrieb ein sehr wichtiges Thema und taucht als Unterthema in verschiedener Weise auf. Es schimmerte beispielsweise gerade auch durch die Darstellung der verschiedenen Cursor-Arten. Hier bestand die Möglichkeit, einem Cursor mitzugeben, welche Spalten aktualisierbar sein sollen, oder dass er die Änderungen an den abgerufenen Daten auch im Cursor widerspiegeln soll oder nicht. Dies sind Entscheidungspunkte und Einstellungen, die aus den Überlegungen zum Mehrbenutzerbetrieb gehören. 360 Grundlagen T-SQL Dieser Abschnitt möchte die verschiedenen T-SQL-Anweisungen, mit denen die Transaktionssteuerung eingerichtet werden kann, darstellen. Der MS SQL Server ist selbstverständlich eine transaktionsfähige Datenbank und führt auch automatisch Transaktionen für einzelne Anweisungen, während denen ein Fehler auftritt, durch, aber für den Programmierer ist es wichtig, mehrere Anweisungen zusammenzustellen. Wenn viele Datensätze in eine Tabelle eingefügt werden, und ein Fehler tritt auf, würde die Datenbank automatisch die gesamten Einzelaktion zurücksetzen, sobald der Fehler auftritt, doch wenn diese Aktion in Verbund mit anderen auftritt und bei einem Fehler alle Aktionen gemeinsam zurückgesetzt werden sollen, dann muss dies im T-SQL-Skript auch genauso eingetragen sein. 5.6.1 Einfache Transaktionen Einfache Transaktionssteuerung meint, dass Anfang und Ende einer Reihe von zusammenhängenden Anweisungen angegeben werden und dass ggf. die kompletten Anweisungen bestätigt oder zurückgesetzt werden. Dazu ist nicht viel mehr zu tun, als die nachfolgenden, sehr einfachen Anweisungen für Transaktionen zu verwenden. Sie sind in der Grundform in jeder Datenbank vorhanden. Aus Programmiersprachen, welche außerhalb der Datenbank Software erstellen können, bieten ebenfalls ähnliche Anweisungen über die Datenbankschnittstelle an, sodass die Transaktionssteuerung sowohl außen als auch innen durchgeführt werden kann. 5.6.1.1 Anweisungen Um eine Transaktion zu beginnen, verwendet man BEGIN TRANSACTION. Dadurch legt man auch einen Zeitpunkt oder einen Zustand fest, an dem die Daten logisch und physisch konsistent sind. Dies betrifft insbesondere die referenzielle Integrität sowie den Datenbestand. Sobald ein Fehler durch die Datenbank oder durch ein T-SQLProgramm identifiziert wird, können Anweisungen nach dieser Angabe zurückgesetzt werden. Man startet über diese Anweisung eine so genannte lokale Transaktion, die dann auch zu einer Aufzeichnung führt, sobald Anweisungen aus dem DML-Bereich durchgeführt 361 Grundlagen T-SQL werden. Andere Anweisungen, die keine Datenänderungen bewirken, können ohne Aufzeichnung ausgeführt. Verschachtelte Transaktionen mit einem eigenen Namen bedeuten keine Auswirkungen auf die äußere Transaktion und ermöglichen es auch nicht, zu einem solchen Namen zurückzuspringen. Dies ist nur mit Sicherungspunkten möglich. Ein Zurücksetzen der äußeren Transaktion setzt die gesamte Transaktion zurück. Eine lokale Transaktion wandelt die Datenbank in eine verteilte um, wenn vor einer Bestätigung oder einem Zurücksetzen eine DML-Anweisung auf einer Remotetabellen (OLE DB-Anbieter unterstützt die ITransactionJoin-Schnittstelle nicht) ausgeführt wird oder eine remote gespeicherte Prozedur (REMOTE_PROC_TRANSACTIONS auf ON) ausgeführt wird. Die allgemeine Syntax lautet: BEGIN { TRAN | TRANSACTION } [ { transaction_name | @tran_name_variable } [ WITH MARK [ 'description' ] ] ] Folgende Parameter kann man verwenden: transaction_name enthält den Namen der Transaktion. Es wird empfohlen, Namen nur beim äußersten Paar von geschachtelten Transaktionen zu verwenden. @tran_name_variable enthält als Variablen einen Transaktionsnamen. Sie hat einen der Datentypen char, varchar, nchar oder nvarchar. WITH MARK [ 'description' ] legt fest, dass die Transaktion im Protokoll markiert wird,wobei description eine beschreibende Unicode-Zeichenkette mit 255 Zeichen und eine Nicht-Unicode-Zeichenkette mit 510 Zeichen ist. Die Speicherung erfolgt in der msdb.dbo.logmarkhistory-Tabelle. Sobald diese Einstellung verwendet wird, muss auch ein Transaktionsname angegeben werden, wobei man hier zu dieser Markierung zurücksetzen kann. 362 Grundlagen T-SQL Um eine Transaktion zu beenden, verwenden man den COMMIT-Befehl, der in einer Kurzfassung (SQL 92) und einer Langfassung möglich ist. Die Langfassung ermöglicht es dann auch, den Namen einer Transaktion wieder aufzugreifen, der wie zuvor als Zeichenkette oder als Variable angegeben werden kann. Die allgemeine Syntax beider Befehle lautet: COMMIT [ WORK ] COMMIT { TRAN | TRANSACTION } [ transaction_name | @tran_name_variable ] ] Um eine Transaktion und damit sämtliche Aktivitäten, die seit dem letzten BEGIN ausgeführt wurden, wieder zurückzusetzen verwendet man ROLLBACK, welches ebenfalls in einer Kurzform (SQL 92) und einer Langform existiert. Sie unterscheiden sich wieder darin, dass man bei der Langform noch den Namen der Transaktion oder einen Sicherungspunkt (Zwischenstand) angeben kann. Sie kann kein COMMIT überspringen, sondern setzt nur bis zum letzten COMMIT zurück. Setzt man Anweisungen in einer Prozedur zurück, wirkt sich dies auf alle Anweisungen bis zum äußersten Transaktionsbeginn aus. Die im Batch vor dem Prozeduraufruf angegebenen Anweisungen werden also ebenfalls zurückgesetzt. Die Batch-Anweisungen nach dem Aufruf werden weiterhin ausgeführt. Wird in einem Trigger eine Kette von Anweisungen zurückgsetzt, werden neben allen Datenänderungen, die bis zum automatischen Trigger-Aufruf durchgeführt wurden, auch die Änderungen vom Trigger zurückgesetzt. Sofern Anweisungen nach der ROLLBACK-Anweisung im Trigger verbleiben, werden diese weiterhin ausgeführt. Lediglich die Anweisungen nach der Trigger-Ausführung, d.h. die im äußeren Programm, werden nicht ausgeführt. Auf einen Cursor wirkt sich ein Zurücksetzen folgendermaßen aus, wobei hier drei Regeln angegeben werden können. – Sofern CURSOR_CLOSE_ON_COMMIT den Wert ON hat, schließt man alle offenen Cursor, belässt allerdings die Referenzen. 363 Grundlagen T-SQL – Sofern CURSOR_CLOSE_ON_COMMIT den Wert OFF hat, wirkt sich das Zurücksetzen nicht auf geöffnete synchrone STATIC- oder INSENSITIVE-Cursor oder vollständig gefüllte asynchrone STATIC-Cursor aus. Andere offene Cursor werden wie zuvor behandelt. – Sobald ein Fehler einen Batch beendet und ein Rollback auslöst, werden die Referenzen gelöscht. Dies ist Typ-unabhängig und berücksichtigt nicht CURSOR_CLOSE_ON_COMMIT. Dies reicht auch auf Cursor von Prozeduren. Die gleichen Regeln gelten für in Triggern angegebene ROLLBACK-Anweisungen. ROLLBACK [ WORK ] ROLLBACK { TRAN | TRANSACTION } [ transaction_name | @tran_name_variable | savepoint_name | @savepoint_variable ] 5.6.1.2 Funktionen Schließlich gibt es noch zwei Funktionen, die im Rahmen der Transaktionsverwaltung nützlich sind: 364 XACT_STATE() liefert den aktuellen Transaktionsstatus einer Sitzung zurück. Folgende Werte sind möglich: – 1 gibt an, dass die Sitzung eine aktive Transaktion aufweist. In diesem Fall können Änderungen bestätigt und zurückgesetzt werden. – 0 gibt an, dass in der Sitzung keine Transaktion aktiv ist. – -1 gibt an, dass die Sitzung eine aktive, fehlerhafte Transaktion aufweist. Durch einen Fehler können Anweisungen weder bestätigt noch zu einem Sicherungspunkt zurückgesetzt werden. Allerdings kann die gesamte Transaktion zurückgesetzt werden, was auch dazu führt, dass man wieder Schreibvorgänge durchführen kann, denn in diesem Zustand sind nur Lesevorgänge zulässig. Grundlagen T-SQL Solche Situation können im Rahmen der Ausnahmebehandlung auftreten und gelöst werden. @@TRANCOUNT liefert einen Statuswert zurück, ob eine Transaktion geöffnet ist oder nicht. Eine BEGIN TRANSACTION-Anweisung erhöht den Zähler um 1, während ROLLBACK ihn wieder auf 0 zurücksetzt. Der Rücksprung zu einem Sicherungspunkt führt keine Änderung am Zahlwert aus. Die Anweisung COMMIT reduziert den Wert um 1. 5.6.1.3 Beispiele Für die verschiedenen Beispiele setzt man noch einmal die schon mehrfach verwendete Product3-Tabelle mit folgender Struktur ein. Sie wird Skript 561_01.sql ebenfalls erstellt. CREATE TABLE Production.Product3 ( Name varchar(30) NOT NULL, ProductNumber nvarchar(25) NOT NULL, ListPrice money NOT NULL, StandardCost money NULL) Das erste Beispiel zeigt eine einfache Transaktion, die als Grundlage für weitere Beispiele benutzt werden kann. Das einfachste denkbare Beispiel besteht nur aus BEGIN TRAN und COMMIT oder ROLLBACK, was allerdings schon bei einigen Beispielen zu DML-Befehlen zum Einsatz gekommen ist. In diesem Fall ist die Transaktion auch benannt und kann über ihren Namen später zurückgesetzt werden. Dabei mischt man die Möglichkeiten, den Namen als Zeichenkette vorzugeben oder aus einer Variable abzurufen. -- Transaktionsnamen als Variable erstellen DECLARE @TranName varchar(20) SET @TranName = 'Produkterfassung' 365 Grundlagen T-SQL -- Transaktion starten BEGIN TRANSACTION @TranName -- DML-Anweisungen ausführen DELETE FROM Production.Product3 INSERT INTO Production.Product3 VALUES ('LL Mountain Seat Assembly', 'SA-M198', 133.34, 98.77) INSERT INTO Production.Product3 VALUES ('ML Mountain Seat Assembly', 'SA-M237', 147.14, 108.99) -- Test: Eingetragene Datensätze und Status SELECT COUNT(*) AS Eingetragen, @@TRANCOUNT AS [T-Count], XACT_STATE() AS Status FROM Production.Product3 -- Bestätigen COMMIT TRANSACTION Produkterfassung -- Test: Eingetragene Datensätze und Status SELECT COUNT(*) AS Eingetragen, @@TRANCOUNT AS [T-Count], XACT_STATE() AS Status FROM Production.Product3 366 Grundlagen T-SQL 561_01.sql: Erstellung und Bestätigung einer Transaktion Als Ergebnis der beiden Testabfragen erhält man folgende Ergebnisse. Die eingetragenen Datensätze bleiben auf den Wert von 2 stehen, da die Transaktion ja bestätigt wird. Führt man das gleiche Beispiel mit ROLLBACK aus, so stünde hier in der zweiten Ergebnismenge der Wert 0. In der Funktion @@TRANCOUNT befindet sich zunächst der Wert 1, da eine Transaktion geöffnet wurde, und dann der Wert 0, weil sie wieder beendet wurde. Ähnliches bedeuten auch die Werte, die von XACT_STATE zurück geliefert wurden. Beim ersten Schritt ist eine Transaktion aktiv, beim zweiten Schritt nicht mehr. Eingetragen T-Count Status ----------- ----------- -----2 1 1 2 0 0 Im nächsten Beispiel sieht man, wie zwei Transaktionen ineinander verschachtelt werden. Dabei lohnt es sich nur, für die äußere auch einen Namen zu vergeben, da ein Rollback zu einer inneren nicht möglich ist und daher der Name nicht für diesen Zweck genutzt werden kann. Dies lässt sich mit den später darzustellenden Sicherungspunkten realisieren. Dennoch lässt sich eine innere Transaktion bestätigen und dann die äußere Transaktion zurücksetzen, sodass auch die Anweisungen der inneren zurückgesetzt werden. Genau dies zeigt das Beispiel. Zunächst löscht man die zwei Datensätze aus dem vorherigen Beispiel in einer eigenen Transaktion, trägt dann in einer eigenen Transaktion einen neuen Datensatz ein, was auch bestätigt wird, um dann schließlich wieder die äußere Transaktion zurückzusetzen, was dazu führt, dass die ursprünglichen zwei Datensätze wieder in der Tabelle gespeichert sind. -- Äußere Transaktion BEGIN TRANSACTION Produktbearbeitung DELETE FROM Production.Product3 -- Test: 0 Datensätze (zwei gelöscht) 367 Grundlagen T-SQL SELECT COUNT(*) AS Eingetragen FROM Production.Product3 -- Innere Transaktion (ROLLBACK nicht möglich) BEGIN TRANSACTION INSERT INTO Production.Product3 VALUES ('LL Mountain Seat Assembly', 'SA-M198', 133.34, 98.77) -- Test: 1 Datensatz SELECT COUNT(*) AS Eingetragen FROM Production.Product3 -- Bestätigung des einen Datensatzes COMMIT TRANSACTION -- Zurücksetzen der äußeren Transaktion ROLLBACK TRANSACTION Produktbearbeitung -- Test: 2 Datensätze (aus vorherigem Beispiel) SELECT COUNT(*) AS Eingetragen FROM Production.Product3 561_02.sql: Verschachtelte Transaktionen Das nächste Beispiel zeigt den Standardfall, wie die Transaktionsverwaltung im Rahmen der Ausnahmebehandlung verwendet wird. Außerhalb eines BEGIN..CATCHBereichs beginnt man eine Transaktion, um dann bei einem Fehler die Transaktion zurückzusetzen. Dabei testet man mit Hilfe der @@TRANCOUNT-Funktion, ob überhaupt eine Transaktion existiert, um einen Fehler zu vermeiden. Sollte kein Fehler aufgetreten sein, folgt nach dem BEGIN..CATCH-Bereich die gewöhnliche Bestätigung, da ja offensichtlich die versuchte Aktion erfolgreich war. 368 Grundlagen T-SQL BEGIN TRANSACTION BEGIN TRY DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode = 'CM' END TRY BEGIN CATCH IF @@TRANCOUNT > 0 PRINT 'Transaktion zurückgesetzt' ROLLBACK TRANSACTION END CATCH IF @@TRANCOUNT > 0 BEGIN PRINT 'Transaktion bestätigt' COMMIT TRANSACTION END 561_03.sql: Transaktion in Ausnahmebehandlung Mit der Anweisung SET XACT_ABORT { ON | OFF } legt man fest, ob eine Transaktion automatisch zurückgesetzt werden soll, wenn ein Laufzeitfehler entsteht. Dies betrifft genau die Fehler, welche auch im Rahmen einer Ausnahmebehandlung erkannt und daher auch innerhalb des CATCH-Blocks behandelt werden können. Das nächste Beispiel zeigt, wie zunächst für die Sitzung die beschriebene Einstellung aktiviert wird und wie dann innerhalb des CATCH-Blocks über die Funktion XACT_STATE() abgerufen wird, ob die Anweisungen bestätigt werden können oder nicht. Durch die vorherige Einstellung sind sie allerdings nicht commitfähig, sodass in der Fallunterscheidung ein ROLLBACK stattfindet. 369 Grundlagen T-SQL SET XACT_ABORT ON BEGIN TRANSACTION BEGIN TRY DELETE FROM Production.UnitMeasure WHERE UnitMeasureCode = 'CM' END TRY BEGIN CATCH IF XACT_STATE() = -1 BEGIN PRINT N'T nicht zu bestätigen. ROLLBACK notwendig.' ROLLBACK TRANSACTION END IF XACT_STATE() = 1 BEGIN PRINT N'T zu bestätigen. COMMIT möglich.' COMMIT TRANSACTION; END END CATCH 561_03.sql: Transaktion in Ausnahmebehandlung 5.6.2 Sicherungspunkte Wie schon gerade erwähnt, kann man innere Transaktionen nicht zurücksetzen. Um allerdings doch eine Möglichkeit zu besitzen, verschiedene einzelne Zwischenstationen zu speichern und auch zu ihnen zurückzukehren, gibt es die SAVE-Anweisung, mit der so genannte Sicherpunkte erstellt werden können. Sie erhalten einen Namen, der wie bei Transaktionsnamen aus einer Variable oder einer Zeichenkette stammen kann. 370 Grundlagen T-SQL SAVE { TRAN | TRANSACTION } { savepoint_name | @savepoint_variable } Um eine Transaktion schließlich zu einem Sicherungspunkt zurückzusetzen, ist die erweiterte Form der ROLLBACK-Anweisung zu verwenden. Sie erwartet zusätzlich den Namen eines Sicherungspunktes. ROLLBACK { TRAN | TRANSACTION } [ transaction_name | @tran_name_variable | savepoint_name | @savepoint_variable ] Das nächste Beispiel zeigt die Sicherungspunkte in Aktion und stellt damit auch eine Variation des vorherigen Beispiels dar. Es gibt dieses Mal nur eine einzige Transaktion. Die vorherige innere Transaktion wurde ungefähr durch die Sicherungspunkte ersetzt, sodass nun nach dem Lösch- und dem Eintragungsvorgang jeweils ein solcher Sicherungspunkt angelegt wird. Dadurch kann man später entweder den Zustand wiederherstellen, in dem die Tabelle leer war oder in dem ein Datensatz eingetragen war. Um auch zu zeigen, dass man Sicherungspunkte überspringen kann, entscheidet man sich bei der ROLLBACK-Anweisung für den ersten und damit vorletzten Sicherungspunkt. Dies führt dazu, dass eine leere Tabelle zurückbleibt. -- Transaktion starten BEGIN TRANSACTION Produktbearbeitung DELETE FROM Production.Product3 -- Test: 0 Datensätze SELECT COUNT(*) AS Eingetragen FROM Production.Product3 -- Zustand speichern SAVE TRANSACTION Geloescht INSERT INTO Production.Product3 371 Grundlagen T-SQL VALUES ('LL Mountain Seat Assembly', 'SA-M198', 133.34, 98.77) -- Test: 1 Datensatz SELECT COUNT(*) AS Eingetragen FROM Production.Product3 -- Zustand speichern SAVE TRANSACTION Eingetragen -- Zurücksetzen der Transaktion zum vorherigen Zustand ROLLBACK TRANSACTION Geloescht -- Test: 0 SELECT COUNT(*) AS Eingetragen FROM Production.Product3 562_01.sql: Sicherungspunkte einsetzen 5.6.3 Erweiterte Transaktionssteuerung Unabhängig von den Anweisungen, die bislang diskutiert wurden, besteht noch die Möglichkeit, innerhalb einer Verbindung erweiterten Einfluss auf das Verhalten zu nehmen, wie Zeilensperren und Zeilen versioniert werden, oder um verteilte Transaktionen einzurichten. 5.6.3.1 Isolationsstufen Dazu gibt es die Anweisung SET TRANSACTION ISOLATION LEVEL, welche eine von fünf verschiedenen Arten anbietet, dieses Verhalten zu steuern. Es ist also nicht möglich, mehrere Isolationsstufenoptionen auf einmal festzulegen; sie gelten alternativ. Man kann innerhalb einer Verbindung diese Stufe wechseln, ansonsten ist sie für die gesamte Sitzung gültig. Die allgemeine Syntax der Anweisung lautet: SET TRANSACTION ISOLATION LEVEL 372 Grundlagen T-SQL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SNAPSHOT | SERIALIZABLE } Sofern man eine Isolationsstufe in einer Prozedur/Funktion oder einem Trigger/benutzerdefinierten Typ vorgibt, gilt innerhalb dieses Aufrufs die angegebene Stufe. Sie wird dann wieder zurückgesetzt, wenn das aufgerufene Objekt die Steuerung zurückgibt. Die Bedeutung und Funktionsweise der verschiedenen Angaben ist nachfolgende erläutert: READ UNCOMMITTED legt fest, dass Zeilen, die gerade von anderen Transaktionen bearbeitet werden und noch nicht bestätigt sind, ebenfalls gelesen werden können (genaues Gegenteil von READ COMMITTED). READ COMMITTED legt fest, dass Zeilen, die gerade von anderen Transaktionen bearbeitet werden und noch nicht bestätigt sind, nicht gelesen werden können (genaues Gegenteil von READ UNCOMMITTED). Diese Stufe ist von den Einstellungen in der Datenbankoption READ_COMMITTED_SNAPSHOT abhängig: Der Wert OFF (Standard) sorgt dafür, werden automatisch gemeinsame Sperren verwendet, um die Änderung durch andere Transaktionen von gerade gelesenen Datensätzen zu verhindern. Der Wert ON sorgt dafür, dass die so genannte Zeilenversionsverwaltung eingesetzt wird. Hier wird der aktuellen Transaktion ein konsistenter Datenzustand vor Anweisungsbeginn gezeigt. Für Aktualisierungen werden keine Sperren verwendet. REPEATABLE READ legt fest, dass dass Zeilen, die gerade von anderen Transaktionen bearbeitet werden und noch nicht bestätigt sind, nicht gelesen 373 Grundlagen T-SQL werden können. Zusätzlich sind auch die Datensätze, die von der aktuellen Transaktion bearbeitet werden, für andere Transaktionen so lange unsichtbar, bis sie bestätigt werden. SNAPSHOT legt fest, dass die Daten, die in einer Transaktion gelesen werden, einem konsistenten Zustand der Datenbank entsprechen, welcher zu Beginn der Transaktion gegeben war. Nur bestätigte Daten können so gelesen werden. Dies sorgt dafür, dass andere Transaktionen unbeeinflusst Daten schreiben können und dass die SNAPSHOT-Transaktion unbeeinflusst lesen kann. Die Datenbankoption ALLOW_SNAPSHOT_ISOLATION muss auf ON gestellt sein. SERIALIZABLE legt fest, dass Anweisungen keine von anderen Transaktionen geänderte Daten lesen können, die noch nicht bestätigt sind, dass andere Transaktionen auch erst nach eigener Bestätigung geänderte Daten lesen können und dass andere Transaktionen erst nach der aktuellen Transaktion Daten mit neuen Schlüsselwerten einfügen können, die für die aktuelle Transaktion reserviert waren. Die nachfolgende Tabelle gibt eine Übersicht über die verschiedenen Einstellungen und die zulässigen Parallelitätsnebeneffekte wider. Dabei sind in der Kopfzeile drei Begriffe eingetragen, die genau solche Parallelitätsnebeneffekte bezeichnen. Die drei Phänomene beschreiben zwar durchaus unterschiedliche Situationen, sind aber natürlich aufgrund der Voraussetzung, dass sie Lese- und Schreibvorgänge beschreiben, sehr vergleichbar. Dirty Read oder verlorene Aktualisierung: Transaktion A liest Daten, die von Transaktion B geändert und nicht bestätigt wurden. Dadurch kann es geschehen, dass die Daten nachträglich wieder geändert werden. Nicht wiederholbarer Lesevorgang: Wiederholte Lesevorgänge liefern verschiedene Ergebnisse. Phantom: Suchergebnisse ändern sich bei wiederholter Ausführung, weil Änderungen am Datenbestand vorgenommen werden. Transaktion A liest Datensätze, die von Transaktion B geändert werden. Beim nächsten Abruf von Transaktion A befinden sich bei gleichen Filtern andere Datensätze in der Ergebnismenge. 374 Grundlagen T-SQL Allgemeine gilt immer, dass der Wunsch nach wenigen Nebeneffekten mit höherem Systemressourcenverbrauch einher geht, sodass hier bei intensiver Nutzung von Transaktionsvorgaben von Fall zu Fall das notwendige Maß verwendet werden muss. Isolationsstufe Dirty Read Nicht wiederholbarer Lesevorgang Phantom Read Uncommitted Ja Ja Ja Read Committed Nein Ja Ja Repeatable Read Nein Nein Ja Snapshot Nein Nein Nein Serializable Nein Nein Nein Parallelitätsnebeneffekte 5.6.3.2 Verteilte Transaktionen Neben den Transaktionen, die nur auf einem Server ausgeführt werden, gibt es auch so genannte verteilte Transaktionen, die auf mehreren Servern ausgeführt werden können. Die Server-Instanz, welche die BEGIN DISTRIBUTED TRANSACTION-Anweisung abschickt, wird dabei als Transaktionsurheber bezeichnet. Sie ist für die Ausführung und den Abschluss dieser Transaktion verantwortlich. Durch diese Anweisung werden alle Anweisungen, die auf anderen Servern ausgeführt werden - darunter auch gespeicherte Prozeduren etc. - innerhalb der gleichen verteilten Prozedur ausgeführt. BEGIN DISTRIBUTED { TRAN | TRANSACTION } [ transaction_name | @tran_name_variable ] [ ; ] 375 Grundlagen T-SQL 376 Analysen 6 Analysen 377 Analysen 378 Analysen 6 Analysen Um umfangreiche Analysen auf Datenbeständen auszuführen, genügt oft das gewöhnliche SQL nicht mehr, was in den zurückliegenden Kapiteln dargestellt wurde und das in ähnlicher Form in den meisten Datenbanken in dieser Form eingesetzt werden kann. Mit einigen weiteren Besonderheiten und natürlich auch mit der Syntax, die im T-SQLKapitel vorgestellt wurde, kann man Ergebnisse produzieren, die ansonsten nur mit umfangreichen Programmen, Einsatz von Arrays, Vergleichen und Schleifen erzeugt werden könnten. Dieses Kapitel soll nun für eine Reihe von typischen Anwendungsfällen Lösungen bieten. Einige dieser Lösungen sind bereits in anderen Büchern beschrieben worden, da sie nicht nur für MS SQL Server genutzt werden können, sondern von ihren SQL-Fundamenten her auch in anderen Datenbanksystemen genutzt werden können. Allerdings ist die genaue Syntax doch in jedem Datenbanksystem anders bzw. teilweise lassen sich für die gleiche Problemstellung einfachere Wege beschreiten, weil diverse Zusatzhilfsmittel bereit stehen. Viele Lösungen können auch schon in der Vorgängerversion eingesetzt werden, wobei allerdings der Fokus der gesamten Beispiele durchaus auf der Version 2005 liegt. 6.1 Tabellenausdrücke Die abgeleiteten Tabellen, also die Unterabfragen in der FROM-Klausel,, sind in den meisten Datenbanken, welche Unterabfragen nicht erlauben, nicht nutzbar. Diese Abfragen wären dagegen auch in Oracle nutzbar. In diesem Kapitel soll aber der Fokus auf speziellen Techniken liegen, die gerade nur im MS SQL Server so genutzt werden können, weswegen eine sehr ähnliche Lösung erst hier erwähnt wird, obwohl sie zu den interessantesten Neuerungen im MS SQL Server 2005 gehört, was T-SQL anbetrifft. Mit den Tabellenausrücken oder Common Table Expressions, welche die Dokumentation und die Microsoft-Werbung mit dem Akronym CTE abkürzt, steht eine Alternative zur Verfügung, welche vermutlich relativ schnell die abgeleiteten Tabellen ersetzen dürfte, da sie zu besser lesbarem Quelltext führt und einige Schwierigkeiten, die mit 379 Analysen abgeleiteten Tabellen bestehen, löst. Grundsätzlich sind CTEs Fall deckungsgleich mit abgeleiteten Tabellen, bieten jedoch einen darüber hinaus gehenden größeren Nutzen. 6.1.1 Grundprinzip Ein allgemeiner Tabellenausdruck erfüllt die gleiche Funktionalität wie eine abgeleitete Tabelle und kann in vielen Fällen den Einsatz von temporären Tabellen zur Speicherung von Zwischenergebnissen ersetzen. Er erlaubt es, eine temporäre Ergebnismenge zu erzeugen, die mit Hilfe einer beliebigen Abfrage definiert wird, die nur wenige, unwesentliche Einschränkungen besitzt. Im Gegensatz zu einer abgeleiteten Tabelle ist es möglich, mehrfache Referenzen auf eine solche CTE zu formulieren, sie rekursiv aufzurufen und sie darüber hinaus in solchen Anweisungen wie INSERT, UPDATE und DELETE zu verwenden. Wie eine abgeleitete Tabelle kann sie auch innerhalb von CREATE VIEW genutzt werden, um die Ergebnismenge einer Sicht festzulegen. Das neu eingeführte Schlüsselwort ist WITH, welches erfordert, dass vorherige Anweisungen mit einem Semiklon abgeschlossen werden. Dies kennzeichnet auch eine deutliche Fehlermeldung. Diesem Schlüsselwort folgt der Name, unter dem die temporär erzeugte Ergebnismenge wie eine abgeleitete Tabelle oder eine temporäre Tabelle angesprochen werden kann. Die Spaltennamen kann man innerhalb runder Klammern direkt angeben oder aus den Spalten(alias)namen erzeugen lassen. Die allgemeine Syntax hat die folgenden Form: [ WITH <common_table_expression> [ ,...n ] ] <common_table_expression>::= expression_name [ ( column_name [ ,...n ] ) ] AS ( CTE_query_definition ) Ein einfaches Beispiel soll das Grundprinzip der CTE illustrieren. Die nachfolgende CTE erstellt unter dem Namen Sales eine Ergebnismenge mit den Spaltennamen Customer, Turnover, Region und Year. Sie werden aus den Spaltenaliasnamen ab- 380 Analysen geleitet. Würden diese fehlen, so bedeutete dies lediglich für die letzte Spalte ein Problem, da sie unter Verwendung einer Funktion beschrieben wird und daher einen Aliasnamen benötigt. Auch wenn die Abfrage, welche Sales erstellt, sehr einfach ist, so kann man sich sicherlich komplizierte Berechnungen, beliebige Unterabfragen und natürlich eine WHERE-Klausel denken. Die so erstellte CTE lässt sich dann wie eine gewöhnliche Tabelle innerhalb der FROMKlausel der direkt folgenden Abfrage nutzen. Man kann gut erkennen, wie die einzelnen Spaltennamen der CTE in SELECT aufgerufen, für Aggregate genutzt und umbenannt bzw. auch in GROUP BY verwendet werden. Sie lassen sie sich genauso einsetzen wie sonstige Spaltennamen. WITH Sales AS ( SELECT CustomerID AS Customer, TotalDue AS Turnover, TerritoryID AS Region, YEAR(OrderDate) AS Year FROM Sales.SalesOrderHeader ) SELECT Year, COUNT(Customer) AS Customers, SUM(Turnover) AS Turnover FROM Sales GROUP BY Year 611_01.sql: Allgemeine Funktionsweise von CTEs 381 Analysen Man erhält zunächst als Ergebnis durch die CTE eine Aufstellung der Kundenanzahl und des Gesamtumsatzes pro Region und Jahr. Customer Turnover Region Year ----------- --------------------- ----------- ----------676 27231,5495 5 2001 117 1716,1794 5 2001 209,9169 6 2004 ... 18759 (31465 Zeile(n) betroffen) Das endgültige Ergebnis ist dann eine Darstellung der Jahre, der Kundenanzahl und des Gesamtumsatzes – ein Ergebnis, das zwar auch mit anderen Mitteln erstellt werden kann, welches aber nicht besonders tief verschachtelt war und letztendlich einfacher formuliert und verstanden werden konnte. Year Customers Turnover ----------- ----------- --------------------2004 13951 32196912,4165 2001 1379 14327552,2263 2002 3692 39875505,095 2003 12443 54307615,0868 (4 Zeile(n) betroffen) Folgende allgemeine Regeln gelten für den Einsatz von CTEs: 382 Nach dem allgemeinen Tabellenausdruck muss eine DML-Anweisung folgen, welche sich auf eine Unterauswahl der durch die CTE definierten Spalten bezieht. Analysen Verweise auf andere CTE oder sich selbst sind möglich, wenn die referenzierten CTEs zuvor definiert wurden. CTEs dürfen nicht geschachtelt erscheinen, d.h. innerhalb von WITH kann nicht ein weiteres WITH verwendert werden. Wie auch bei Sichten ist die Verwendung folgender Schlüsselwörter verboten: COMPUTE oder COMPUTE BY, ORDER BY ohne vorherige TOP-Klausel, INTO, OPTION-Klausel mit Abfragehinweisen, FOR XML und FOR BROWSE. Eine CTE kann für eine Cursor-Definition zum Einsatz kommen. Tabellen auf Remoteservern können aufgerufen werden. Im nächsten Beispiel definiert man die Spaltennamen der CTE gerade nicht mit Hilfe der Aliasnamen oder ermittelt sie direkt aus den abgerufenen Spaltennamen, sondern setzt sie runden Klammern direkt nach dem Namen der CTE. Dabei müssen die Spaltenreihenfolge und -anzahl mit den abgerufenen Spalten übereinstimmen, um eine sinnvolle und korrekte Datenstruktur zu erzeugen. WITH Sales (Customer, Turnover, Region, Year) AS ( SELECT CustomerID, TotalDue, TerritoryID, YEAR(OrderDate) FROM Sales.SalesOrderHeader ) SELECT Year, COUNT(Customer) AS Customers, SUM(Turnover) AS Turnover FROM Sales GROUP BY Year 611_02.sql: Explizite Angabe von Spaltennamen 383 Analysen Es ist auch möglich, dynamisch die tatsächliche Ergebnismenge einer CTE zu beeinflussen. Dazu setzt man im nächsten Beispiel ganz einfach eine Variable ein, welche einen festen Wert hat. Dies ist zwar nicht sonderlich dynamisch, doch man kann sich vorstellen, dass dieser Wert auch ein Funktion-/Prozedurparameter sein könnte. Diese Variable enthält nun den Wert einer Jahreszahl, welches innerhalb der WHERE-Klausel als Filter zum Einsatz kommt. An diesem Beispiel kann man auch sehr schön die Notwendigkeit sehen, eine vorherige Anweisung mit einem Semikolon abzuschließen, um keinen Fehler auszulösen. DECLARE @year int SET @year = 2002; WITH Sales (Customer, Turnover, Region, Year) AS ( SELECT CustomerID, TotalDue, TerritoryID, YEAR(OrderDate) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) >= @year ) SELECT Year, COUNT(Customer) AS Customers, SUM(Turnover) AS Turnover FROM Sales GROUP BY Year 611_03.sql: Dynamische CTE 6.1.2 Erweiterte Tabellenausdrücke Nach den einleitenden Beispielen, welche vor allen Dingen die neue und in anderen Datenbanksystemen unbekannte Syntax einführten, folgen nun einige anspruchsvollere 384 Analysen Beispiele, welche die Flexibilität und den Nutzen von CTEs besser herausstellen können. Das erste Beispiel erstellt nicht nur eine einzige CTE, sondern stattdessen folgt dem ersten allgemeinen Tabellenausdruck nach einem Komma ein weitere, wobei hier einfach nur der Name und das AS-Schlüsselwort angeschlossen werden. Interessant ist hier, dass diese beiden CTEs später sogar miteinander verknüpft werden. Es wäre genauso möglich gewesen, dass die zweite CTE SalesPerson die erste CTE Sales aufruft. Die Verknüpfung macht deutlich, wie solche allgemeinen Tabellenausdrücke sehr komplexe SQL-Anweisungen zu vereinfachen helfen, da man zunächst die Rohdaten bzw. in diesem Fall sogar zwei verschiedene Menge an Rohdaten besorgt, welche dann später genutzt werden können. Die einzelnen Abfragen lassen sich dann sogar getrennt testen (markieren, Anweisung ausführen), sofern keine Verweise auf Variablen oder andere CTEs etc. existieren. WITH Sales (Customer, Turnover, Region, Year) AS ( SELECT CustomerID, TotalDue, TerritoryID, YEAR(OrderDate) FROM Sales.SalesOrderHeader ), SalesPerson AS ( SELECT LastName AS Name, TerritoryID AS Region FROM Person.Contact AS c INNER JOIN HumanResources.Employee AS emp ON c.ContactID = emp.ContactID INNER JOIN Sales.SalesPerson AS sp ON emp.EmployeeID = sp.SalesPersonID ) SELECT Name, COUNT(Customer) AS Customers 385 Analysen FROM Sales AS s INNER JOIN SalesPerson AS sp ON s.Region = sp.Region GROUP BY Name 612_01.sql: Mehrfache CTEs In diesem Fall ermittelte die erste CTE die Kundennummer, den zugehörigen Gesamtumsatz, Region und Jahr aus der Tabelle SalesOrderHeader, während die zweite CTE den Nachnamen und die Region aus der Tabelle SalesPerson abrief. Diese beiden Ergebnismengen lassen sich dann anhand der TerritoryID, welche in der neu erzeugten Region-Spalte enthalten ist, verknüpfen, um ganz einfach die Namen der Verkäufer und die Anzahl der Kunden auszugeben. Name Customers -------------------------------------------------- ---------Mensa-Annan 4594 Campbell 4594 Reiter 486 Während zwar die letzte Formulierung mit abgeleiteten Tabellen noch möglich gewesen wäre, aber schon sehr exotisch wirkt und mehr verstört als zur gemütlichen Lektüre einlädt, lässt sich die Formulierung aus dem nachfolgenden Beispiel nur mit einer CTE so einfach formulieren. Wiederum erzeugt man die schon bekannte CTE Sales, wobei allerdings dieses Mal eine Aggregation stattfindet und nur noch die Spalten Turnover für den Gesamtumsatz, Region und Year übrig bleiben. Diese Werte werden nun benutzt, um die Umsatzzahlen des aktuellen Jahres mit den Werten des vorherigen Jahres zu vergleichen. Eine Lösung für die Version 2000 bestand daraus, anstelle eine CTE eine temporäre Tabelle zu erstellen, um die Beziehung cur.Year = prv.Year + 1 einzurichten, d.h. um die temporäre Ergebnismenge mehrfach zu referenzieren. Eine abgeleitete Tabelle ist hier leider gar nicht nützlich, sodass tatsächlich ohne CTE nur die 386 Analysen Erstellung eines ganzen T-SQL-Skripts übrig bleibt. Setzt man allerdings allgemeine Tabellenausdrücke, vereinfacht sich die gesamte Arbeit auf eine Abfrage, in der man ganz einfach die Rohdaten mehrfach referenziert und so das Jahr 2002 mit dem Jahr 2000+1 in Beziehung setzt, um für die gleiche Region den Vorjahresumsatz zu ermitteln. Darüber hinaus ist hier auch noch ein OUTER JOIN erforderlich, wenn Werte für Regionen aus dem aktuellen Jahr auch dann in die Ergebnismenge übernommen werden sollen, die noch gar nicht im vorherigen Jahr bestanden oder abgerufen werden können, was in jedem Fall für das erste Jahr der Fall ist. WITH Sales (Turnover, Region, Year) AS ( SELECT SUM(TotalDue), TerritoryID, YEAR(OrderDate) FROM Sales.SalesOrderHeader GROUP BY YEAR(OrderDate), TerritoryID ) SELECT cur.Year, cur.Region, cur.Turnover, prv.Turnover FROM Sales AS cur LEFT OUTER JOIN Sales AS prv ON cur.Year = prv.Year + 1 AND cur.Region = prv.Region WHERE cur.Region BETWEEN 5 AND 7 ORDER BY cur.Year 612_02.sql: Mehrfache Referenzen Man erhält die gerade beschriebene Ausgabe der Umsatzzahlen in einer Kombination aus Jahr und Region mit den Vorjahreswerten. Für das erste Jahr entstehen dabei NULLWerte in der Vorjahresumsatzspalte, weil es sich um das erste Jahr handelt. Ohne die äußere Abfrage würden diese Werte unterdrückt werden. Die Werte für diese Jahre 387 Analysen erscheinen dann allerdings als Vorjahreswerte für die gleiche Region in den folgenden Zeilen, welche spätere Jahre abbilden. Year Region Turnover Turnover ----------- ----------- --------------------- --------------2001 6 2173647,1453 NULL 2001 7 199531,723 NULL 2001 5 1928148,6139 NULL 2002 5 3814944,144 1928148,6139 2002 6 7215430,5017 2173647,1453 2002 7 1717145,7439 199531,723 In vielen Datenmodellen werden Bäume innerhalb einer einzigen Tabelle abgebildet. Das Schulbeispiel in diesem Zusammenhang ist immer ein Blick in die Personaltabelle, welche möglicherweise eine der ManagerID-Spalte entsprechenden Spalte enthalten könnte. Dies ist im Fall der AdventureWorks ebenfalls gegeben. Auch für solche Fälle, die Bäume oder Hierarchien abbilden sollen, lassen sich CTEs hervorragend einsetzen, wobei es sich dann um so genannte rekursive allgemeine Tabellenausdrücke handelt. Dabei gelten die folgenden Regelungen: Auch wenn die zu Grunde liegenden Spalten NOT NULL sind, so erlaubt die CTE dennoch NULL-Werte. Es ist möglich, eine Endlos-Schleife einzurichten, wenn ein logischer Fehler besteht. Dies geschieht, wenn gleiche Werte für über- oder untergeordnete Objekte miteinander verglichen werden. Eine solche Rekursion lässt sich über die Anzahl der Rekursionsebenen (ähnlich Schleifeniterationen) beschreiben. Mit Hilfe des Abfragehinweises MAXRECURSION und einem Wert zwischen 0 und 32767 lässt sich eine definitive Grenze angeben. 388 Analysen Eine rekursive CTE lässt sich nicht für Datenaktualisierungen (UPDATE) verwenden, da eine völlig neue Ergebnismenge entsteht, in welcher der gleiche Datensatz mehrfach referenziert werden kann, wenn dies in der zu Grunde liegenden Hierarchie so eingerichtet ist. Remotetabellen werden lokal zwischengespeichert (Spool), um den Netzwerkverkehr zu minimieren. Als Cursorarten sind nur schnelle Vorwärtscursor und statische (Snapshot) Cursor möglich. Andere Cursor werden zu statischen Cursorn umgewandelt. Das erwähnte Schulbeispiel lässt sich nun tatsächlich mit Hilfe der AdventureWorksDB nachvollziehen, denn die Angestellten, denen andere Angestellte untergeordnet sind oder denen sie berichten müssen, sind in der ManagerID-Spalte gespeichert. Diese enthält im Grunde genommen einfach nur einen Wert aus der EmployeeID-Spalte, der an einer anderen Stelle zu den entsprechenden Daten des Mitarbeiters führt, welcher für andere ein Vorgesetzter ist. Es handelt sich um eine umfangreiche Hierarchie, d.h. es kann sein, dass auch dieser Angestellte wiederum einen Vorgesetzten hat und dass sein Attribut ManagerID die EmployeeID eines anderen Angestellten aufweist. Dieser gesamte Baum soll durch eine Abfrage unter Einsatz eines rekursiven allgemeinen Tabellenausdrucks ermittelt werden. Zunächst erstellt man eine Unterauswahl aus der Employee-Tabelle, welche mit der Contact-Tabelle verknüpft wird, um für eine leichtere Lektüre der Ergebnismenge auch den Nachnamen des Angestellten zur Verfügung zu haben. Diese Menge für die Angestellten mit laufenden Nummern 3 und 7 wird dann um die Menge mit gleichem Aufbau (EmployeeID, ManagerID, LastName) ergänzt, wobei aufgrund des UNION ALL-Operators auch Duplikate übernommen werden. Diese zweite Abfrage in der gleichen CTE steht mit der ersten Abfrage in einem Korrelationszusammenhang, weil hier die ManagerID (Eltern-Knoten) aus der neu abgerufenen Employee-Tabelle mit der EmployeeID (Kind-Knoten) aus der ersten Abfrage in einem INNER JOIN verknüpft wird. Dies ist dann nicht nur eine Korrelation, sondern eine Rekursion, weil die Abfrage sich selbst mit Hilfe der CTE-Technik referenzieren lässt. Dadurch befinden sich in der 389 Analysen endgültigen Ergebnismenge die Datensätze der Angestellten mit den Angestelltennummern 3 und 7 (erster Teil der Abfrage) sowie die Datensätze der eigenen Untergebenen (zweite Abfrage mit B) wie auch deren Untergebenen. Der Baum beginnt also bei 3 und 7 und klappt sich dann vollständig auf. Der letzte Schritt ist dann sehr einfach und verblüfft jedoch möglicherweise ein wenig, denn für die Darstellung des gesamten Baumes kann man ganz einfach die gesamte zweite CTE abrufen. Eine Lösung ohne den Einsatz von allgemeinen Tabellenausdrücken lässt sich auch sehr leicht denken. In diesem Fall sieht die herkömmliche T-SQLLösung vor, zwei temporäre Tabellen zu erstellen, die den gleichen Aufbau haben und welche über die auch für die CTE verwendeten Abfragen in einem INSERT…SELECTBefehl gefüllt werden. Diese zweite erstellte Tabelle enthält dann die Daten, wie sie nun in der CTE insgesamt nach der Rekursion vorhanden sind. Das Skript ist um Einiges länger und umständlicher als die neue Lösung, weil die CREATE-, INSERT- und SELECT-Befehle zu erstellen sind. WITH EmpHierarchy AS ( SELECT EmployeeID, ManagerID, LastName FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS C ON emp.ContactID = c.ContactID WHERE EmployeeID IN (3,7) UNION ALL SELECT emp.EmployeeID, emp.ManagerID, c.LastName FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS C ON emp.ContactID = c.ContactID INNER JOIN EmpHierarchy AS emph 390 Analysen ON emp.ManagerID = emph.EmployeeID ) SELECT * FROM EmpHierarchy 612_03.sql: Rekursion In diesem Fall muss einmal die gesamte Ergebnismenge abgedruckt werden, da die Funktionsweise der Abfrage und die Nützlichkeit der Lösung sich erst dann wirklich erschließt. Um die Menge einfacher lesbar zu machen, wurden von Anfang an nur die beiden Angestellten mit EmployeeID 3 und 7 ausgewählt. Sie bilden auch die ersten beiden Datensätze, wobei sie als Vorgesetzte die Angestellten mit den Nummern 12 und 21 besitzen, deren Datensätze später folgen. EmployeeID ManagerID LastName ----------- ----------- --------------3 12 Tamburello 7 21 Dobney 37 7 Rapier 76 7 Kramer 84 7 Anderson 122 7 Baker 156 7 Kogan 194 7 Michaels 4 3 Walters 9 3 Erickson 11 3 Goldberg 391 Analysen 158 3 Miller 263 3 Cracium 267 3 Sullivan 270 3 Salavaria 5 263 D'Hers 265 263 Galvin 79 158 Margheim 114 158 Matthew 217 158 Raheem (20 Zeile(n) betroffen) Eine zweite Form des gerade vorgeführten Beispiels liefert der nächste Quelltext. Er wird um eine weitere CTE ergänzt, welche die Employee-Tabelle mit der ContactTabelle verknüpft. Dadurch ist es nachher möglich, die doppelte Verknüpfung, welche in der oberen und unteren Abfrage im vorherigen Beispiel notwendig war, um den jeweiligen Nachnamen des Angestellten herauszufinden, zu löschen. Stattdessen greift man in beiden Abfragen der zweiten CTE auf die Abfrage der ersten CTE zurück, welche sowohl die beiden Zahlen für Angestellten- und Vorgesetztennummer als auch den Nachnamen liefert. WITH EmpCon AS ( SELECT EmployeeID, ManagerID, LastName FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS C ON emp.ContactID = c.ContactID ), 392 Analysen EmpHierarchy AS ( SELECT EmployeeID, ManagerID, LastName FROM EmpCon WHERE EmployeeID IN (3,7) UNION ALL SELECT EmpCon.EmployeeID, EmpCon.ManagerID, EmpCon.LastName FROM EmpCon INNER JOIN EmpHierarchy AS emph ON EmpCon.ManagerID = emph.EmployeeID ) SELECT * FROM EmpHierarchy 612_04.sql: Rekursion und mehrfache CTE 6.1.3 Datenmanipulation und CTEs Schließlich ist es auch noch möglich, eine CTE im Rahmen von DML-Anweisungen als Datenquelle für Vergleiche oder Datenabrufe zu verwenden. Dies hat zwar nichts mit Analysen und Abfragen zu tun, kann allerdings bei der in diesem Kapitel vorgenommenen Vorstellung von CTEs besonders gut untergebracht werden. Als Beispiel wird wiederum die schon zuvor verwendete Tabelle Product3 mit allen Produktdaten verwendet. CREATE TABLE Production.Product3 ( Name varchar(50) NOT NULL, ProductNumber nvarchar(25) NOT NULL, ListPrice money NOT NULL, StandardCost money NULL) 393 Analysen 613_01.sql: Beispieltabelle für CTE und DML 6.1.3.1 INSERT Beim INSERT-Befehl kann man die Daten nicht nur aus einer Tabelle, Sicht, Prozedur oder Tabellenwertfunktion abrufen, sondern auch aus einer direkt zuvor und damit innerhalb der INSERT-Anweisung erstellten CTE. So wird die Tabelle Product3 mit Daten aus der Product-Tabelle gefüllt, wobei diese zunächst in der CTE ProductTemp abgerufen werden. WITH ProductTemp AS ( SELECT Name, ProductNumber, ListPrice, StandardCost FROM Production.Product ) INSERT INTO Production.Product3 (Name, ProductNumber, ListPrice, StandardCost) SELECT * FROM ProductTemp 613_01.sql: Einfügen aus CTE 6.1.3.2 UPDATE Im Rahmen einer Aktualisierung lässt sich eine CTE als Vergleichsziel und damit ebenfalls als Datenquelle nutzen. Im nächsten Beispiel ruft man zunächst in der ProductTemp-CTE die Produktdaten mit erhöhten Preisen und Standardkosten ab, um sie dann im Rahmen der Aktualisierung als neue Daten zu verwenden. WITH ProductTemp (Name, ProductNumber, ListPrice, StandardCost) AS ( SELECT Name, ProductNumber, 394 Analysen ListPrice * 1.1, StandardCost * 1.05 FROM Production.Product ) UPDATE Production.Product3 SET ListPrice = pt.ListPrice, StandardCost = pt.StandardCost FROM Production.Product3 AS p INNER JOIN ProductTemp AS pt ON p.ProductNumber = pt.ProductNumber 613_02.sql: Aktualisieren mit CTE 6.1.3.3 DELETE Analog zu Update kann man schließlich auch den DELETE-Befehl mit Hilfe einer CTE erweitern. Auch hier dienen diese Daten dem Vergleich, um die Datensätze zu ermitteln, die tatsächlich zu löschen sind. Hierbei kann man eine Unterabfrage genauso verwenden wie eine Tabellenverknüpfung. Die CTE ruft alle Produkte mit einem Preis von 0 ab, welche dann durch die Verknüpfung in der FROM-Klausel der DELETE-Anweisung verwendet werden, um die zu löschenden Datensätze zu ermitteln. WITH ProductTemp AS ( SELECT ProductNumber FROM Production.Product WHERE ListPrice = 0 ) DELETE Production.Product3 FROM Production.Product3 AS p INNER JOIN ProductTemp AS pt 395 Analysen ON p.ProductNumber = pt.ProductNumber 613_03.sql: Löschen mit CTE 6.2 Aggregate und Rangfolgen Eine häufige Anforderung ist es, Aggregate und Rangfolgen zu ermitteln, die teilweise auch miteinander verbunden sind, wenn bspw. die Rangfolgen anhand von Aggregaten aufgebaut sein sollen und dafür nicht die Rohwerte verwendet werden sollen. In beiden Fällen gibt es eine Reihe von alten Techniken, die auch schon im MS SQL Server 2000 funktioniert haben. Das neue T-SQL liefert allerdings auch eine Reihe an neuen Techniken, mit denen diese Fragestellungen einfacher beantwortet werden können. 6.2.1 Aggregate mit OVER Die Darstellung der neuen OVER-Klausel soll zunächst auf Basis einer herkömmlichen Lösung erfolgen, mit denen früher Aggregate berechnet werden konnten. Dazu ist vor allen Dingen die SalesOrderHeader-Tabelle sehr nützlich, weil man mit ihr all die schönen Umsatzabfragen durchführen kann, die Managerherzen höher schlagen lassen und daher für Programmierer auch besonders interessant sein sollten. In der nächsten Abfrage werden neben dem Jahr die Aggregate für den gesamten Umatz, den prozentualen Anteil vom Jahresumsatz zum Gesamtumsatz und die Differenz vom Jahresumsatz zum durchschnittlichen Umsatz berechnet. Die Ermittlung für den Jahresumsatz ist besonders einfach, da dies ja genau das Standardbeispiel für die Verwendung von GROUP BY in Zusammenhang mit Aggregatfunktionen wie bspw. SUM darstellt. Für die beiden anderen Aggregate aber benötigt man den Gesamtumsatz der Tabelle, der nicht zunächst in einer Variable ermittelt werden soll, um ihn dann wieder später zu verwenden, sondern der ebenfalls in der gleichen SQL-Anweisung berechnet werden soll. Die Unterscheidung zwischen dem Jahresumsatz und dem gesamten Umsatz aller Datensätze in der SalesOrderHeader-Tabelle ist sehr wichtig, da dies zwei völlig getrennte Informationen sind. Während die eine Information über Gruppierung und Aggregierung ermittelt wird, stellt die andere ein Gesamttabellenaggregat dar, das 396 Analysen eigentlich mit der Gruppierung kollidiert, die syntaktisch notwendig ist, um die Aggregate pro Jahresszahl auszugeben. Eine erste spontane Lösung muss hier meistens verworfen werden. Hierzu gibt es zwei Lösungen, von denen möglicherweise die zweite häufiger anzutreffen ist als die erste, da Lösungen mit Kreuzverknüpfungen grundsätzlich eher vermieden werden. Diese ist allerdings übersichtlicher formuliert. Sie setzt eine abgeleitete Tabelle – oder ab 2005 natürlich auch eine CTE ein –, um die Gesamttabellenaggregate zu ermitteln. In diesem Fall sind das der Gesamtumsatz und der Gesamttabellendurchschnitt. Diese Abfrage befindet sich in der Beispiellösung nun als zweite Tabelle innerhalb der FROM-Klausel, damit man auf diese Werte zugreifen kann. Es ist allerdings keine Verknüpfung notwendig, da nach den beiden uns interessierenden Spalten Gesamtumsatz und Umsatzdurchschnitt genauso gruppiert wird wie nach dem Jahr. Diese beiden Spalten können dann für die Berechnung der Umsatzdifferenz und des Verhältnisse des Jahresumsatzes zum Gesamtumsatz verwendet werden. SELECT YEAR(OrderDate) SUM(TotalDue) AS Year, AS Turnover, (SUM(TotalDue) / agg.Turnover)*100 AS "%", AVG(TotalDue) - agg.AvgTurnover AS "/" FROM Sales.SalesOrderHeader, (SELECT SUM(TotalDue) AVG(TotalDue) AS Turnover, AS AvgTurnover FROM Sales.SalesOrderHeader) AS agg GROUP BY YEAR(OrderDate), agg.Turnover, agg.AvgTurnover 621_01.sql: Standardlösung für Aggregate Man erhält als Ergebnis eine Aufstellung der Jahre, in denen überhaupt Umsatz erwirtschaftet worden ist, mit den angefragten Werten. 397 Analysen Year Turnover % / ------ ---------------- -------- ------------2001 14327552,2263 10,18 5917,9368 2002 39875505,095 28,33 6328,6398 2003 54307615,0868 38,59 -107,3649 2004 32196912,4165 22,88 -2164,0193 Mit einer CTE sieht das Ergebnis ungleich verständlicher aus, weil hier ja zunächst die Aggregate innerhalb der WITH-Klausel ermittelt werden, auf die dann nachher zugegriffen werden kann. Die Kreuzverknüpfung bleibt zwar erhalten, aber die Abfrage sieht insgesamt übersichtlicher aus. WITH Agg AS (SELECT SUM(TotalDue) AVG(TotalDue) AS Turnover, AS AvgTurnover FROM Sales.SalesOrderHeader) SELECT YEAR(OrderDate) SUM(TotalDue) AS Year, AS Turnover, (SUM(TotalDue) / Agg.Turnover)*100 AS "%", AVG(TotalDue) - Agg.AvgTurnover AS "/" FROM Sales.SalesOrderHeader, Agg GROUP BY YEAR(OrderDate), Agg.Turnover, Agg.AvgTurnover 621_01.sql: Lösung mit CTE Wenn die Kreuzverknüpfung als Lösung nicht gefällt, bietet sich als zweite Lösung an, auf gewöhnliche Spaltenunterabfragen zu setzen. Dies ist dann eine gute Idee, wenn 398 Analysen bspw. nur eine Spalte ein Gesamtaggregat für eine Berechnung benötigt. Im nächsten Beispiel kann man sehen, wie innerhalb der verschiedenen Spalten, welche unterschiedliche Gesamtaggregate abrufen, die gleiche Bedingung vorhanden sein muss, um die Abfrage inhaltlich richtig zu formulieren. Auf diese Weise kann man auch die Berechnungen aus dem vorherigen Beispiel durchführen, indem die Werte aus den Unterabfragen mit Rechenoperatoren mit einer weiteren Spalte verknüpft werden. Man erkennt allerdings auch, dass bspw. bei einem Filter innerhalb der WHERE-Klausel dieser Filter in jeder Spaltenunterabfrage zum Einsatz kommen muss, wenn die Werte miteinander vergleichbar sein müssen. Für die Differenz zum Durchschnitt einmal die des Jahres bis 2003 und für die Berechnung des prozentualen Anteils die des Jahres bis 2004 zu verwenden, erzeugt zwar interessante, aber in keinem Fall logisch richtige Ergebnisse. Daher ist diese Technik nur für einmalig auftretende Aggregate sinnvoll und nicht für mehrfache Berechnungen. Allerdings kann man an diesem Beispiel auch sehen, dass ja dies letztendlich die gleiche Technik ist, mit der die in einem anderen Kapitel als Übersichtsabfragen bezeichneten Ergebnismengen erzeugt werden können; denn die Filter können natürlich auch unterschiedlich sein, wenn dies gewollt ist und an den Spaltennamen zu erkennen ist. SELECT SalesOrderID, (SELECT SUM(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) < 2002 AND TerritoryID < 3) AS Turnover, (SELECT MIN(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) < 2002 AND TerritoryID < 3) AS Min, (SELECT AVG(TotalDue) 399 Analysen FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) < 2002 AND TerritoryID < 3) AS Avg FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) < 2002 AND TerritoryID < 3 621_02.sql: Gesamtaggregate mit Spaltenunterabfrage Die vorherige Lösung lässt sich nun ab Version 2005 auch wieder mit einer CTE viel einfacher formulieren. Es bleibt zwar weiterhin die Notwendigkeit bestehen, einzelne Spaltenunterabfragen auf Basis der in der CTE ermittelten Rohdaten zu formulieren, doch sind diese viel einfacher. Dies liegt daran, dass die benötigten Rohdaten mit Filter und Funktionseinsatz sowie weiteren möglichen Berechnungen und Verknüpfungen zentral in de CTE erstellt werden, sodass dann in der eigentlichen Abfrage nur noch die verschiedenen Aggregate aufgerufen werden müssen. WITH Agg AS ( SELECT * FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) < 2002 AND TerritoryID < 3 ) SELECT SalesOrderID, (SELECT SUM(TotalDue) FROM agg) AS Turnover, (SELECT MIN(TotalDue) FROM agg) AS Min, (SELECT AVG(TotalDue) FROM agg) AS Avg 400 Analysen FROM Agg GROUP BY SalesOrderID 621_02.sql: Aggregate mit CTE Weitere Möglichkeiten in T-SQL bestehen dann darin, eine temporäre Tabelle mit den Rohdaten zu erstellen (ähnlich einer CTE), um auf dieser dann die einzelnen Aggregate auszuführen, und natürlich für häufig wiederkehrende Aggregate wie den Gesamtumsatz den Wert über eine Abfrage in einer Variablen zu speichern. Diese sollen nicht noch vorgestellt werden, da sie weder kürzere Programme liefern noch moderne Techniken wie CTE einsetzen. Nach diesem längeren Ausflug in alte Techniken und auch ihre Übertragung auf neue Techniken wie CTE folgt nun eine überaus elegante und kurze Lösung, die allerdings eine neue Klausel einsetzt. In ihrer einfachsten Form ist sie tatsächlich sehr einfach verständlich und wird vermutlich unmittelbar Einlass in den Syntaxsprachschatz von SQL-Benutzern finden. Sie löst sämtliche Entscheidungsprobleme der vorherigen Lösungen in Nichts auf und bietet schlichtweg die kürzeste und am leichtesten zu verstehende Syntax. Nach der Verwendung einer Aggregatfunktion setzt man OVER() mit leerer Parameterliste in die Spalte. Dadurch ermittelt man genau die Gesamtaggregate für die in der FROM-Klausel aufgerufenen Tabellen. Im aktuellen Beispiel verkürzt sich daher eine Übersichtsabfrage auf folgende Weise. SELECT SalesOrderID, SUM(TotalDue) OVER() AS Turnover, MIN(TotalDue) OVER() AS Min, AVG(TotalDue) OVER() AS Avg, (TotalDue / SUM(TotalDue) OVER()) AS Schnitt FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) < 2002 401 Analysen AND TerritoryID < 3 621_02.sql: Aggregate mit OVER() Man erhält als Ergebnis die Auflistung der einzelnen Bestellnummern, die Aggregate für Gesamt-, Minimal- und Durchschnittsumsatz sowie den prozentualen Anteil der einzelnen Bestellung am gesamten Umsatz. Dieses Ergebnis ist natürlich durch die Wiederholung der Gesamtaggregate nicht sonderlich sinnvoll oder lobenswert, aber es zeigt sehr schön, wie einfach man die Gesamtaggregate ermittelt und dass man sie auch für weitere Berechnungen wie den prozentualen Anteil etc. verwenden kann. SalesOrderID Turnover Min Avg Schnitt ------------ -------------- -------- ----------- --------43664 3458314,9992 6,8234 15438,9062 0,0093 43665 3458314,9992 6,8234 15438,9062 0,0054 Die OVER()-Klausel ist in der vorher gezeigten Variante sehr einfach anzuwenden. Sie bietet allerdings noch die Möglichkeit, innerhalb der runden Klammern einen Bereich anzugeben. Dies gelingt über PARTITION BY, gefolgt von einem Ausdruck, der für eine Gruppierung innerhalb von GROUP BY verwendet werden darf. Es handelt sich dabei also um eine referenzierte Spalte aus den Tabellen, die in der FROM-Klausel aufgerufen werden, ergänzt um eine Funktion. Spaltenaliasnamen sind wie bei einer normalen Gruppierung nicht erlaubt. Wie bei GROUP BY sind hier auch mehrere Ausdrücke möglich, sodass sich ursprüngliche Lösungen sehr vereinfachen lassen. Die allgemeine Syntax für die gesamte Klausel lautet: Fensterrangfunktion < OVER_CLAUSE > :: = OVER ( [ PARTITION BY value_expression , ... [ n ] ] <ORDER BY_Clause> ) Fensteraggregatfunktion 402 Analysen < OVER_CLAUSE > :: = OVER ( [ PARTITION BY value_expression , ... [ n ] ] ) Die beiden Darstellungen sind sehr ähnlich. Sie unterscheiden sich zunächst in den unterschiedlichen Funktionen, die einer OVER()-Klausel vorangehen. Ein weiterer Unterschied besteht darin, dass bei den Fensterrangfunktionen auch noch eine Sortierung über ORDER BY folgen kann. Folgende beiden Funktionstypen können also verwendet werden: Aggregatfunktionen: AVG, MIN, CHECKSUM, SUM, CHECKSUM_AGG, STDEV, COUNT, STDEVP, COUNT_BIG, VAR, GROUPING, VARP, MAX Rangfolgefunktionen: RANK, NTILE, DENSE_RANK, ROW_NUMBER Während die gewöhnlichen Aggregatfunktionen durch die Ausführungen und Beispiele mittlerweile hinlänglich bekannt sein sollten, sind die Rangfolgefunktionen noch unbekannt. Sie werden später noch in einigen speziellen Beispielen erläutert. Im Wesentlichen dienen sie dazu, Rangfolgen wie bspw. Hitparaden zu erzeugen. Im nächsten Beispiel werden die Aggregate für Gesamtsumme, Minimum und Durchschnitt nicht für die ganze Tabelle ermittelt, sondern vielmehr für die Jahreszahl. Hier hätte man entweder die gewöhnliche OrderDate-Spalte mit der YEAR-Funktion bearbeiten können oder man verwendet einfach den Spaltenaliasnamen aus der Unterabfrage. Es soll also ein Bereich (Partition) gebildet werden, was durch die zusätzliche Angabe PARTITION BY ausdruck ermöglicht wird. Wären wie bei einer gewöhnlichen Gruppierung weitere Spaltenausdrücke notwendig, dann könnten sie diesem ersten Ausdruck folgen. SELECT YEAR, TerritoryID, SUM(TotalDue) OVER(PARTITION BY YEAR) AS Turnover, MIN(TotalDue) OVER(PARTITION BY YEAR) AS Min, AVG(TotalDue) OVER(PARTITION BY YEAR) AS Avg, 403 Analysen (TotalDue / SUM(TotalDue) OVER(PARTITION BY YEAR) * 100) AS "%" FROM (SELECT YEAR(OrderDate) AS Year, SUM(TotalDue) AS TotalDue, TerritoryID FROM Sales.SalesOrderHeader GROUP BY YEAR(OrderDate), TerritoryID) AS d WHERE TerritoryID <= 3 ORDER BY 1,2 621_03.sql: Aggregate mit OVER() und Partitionen Man erhält ein sehr schönes Ergebnis, in dem die prozentualen Werte nun für die einzelnen Jahre ermittelt werden, wobei in einem Jahr in mehreren Gebieten Umsatz erwirtschaftet worden ist. Der Gesamtumsatz ist hier also für die einzelnen Jahre der gleiche, so wie auch die anderen beiden Aggregate natürlich immer gleich sind. Lediglich beim Verhältnis der einzelnen Umsätze pro Region sieht man sehr schön, wie ein Jahr insgesamt immer 100 % ergeben. YEAR Terr-ID Turnover Min Avg % ------- ------- -------------- ------------- ------------ --2001 1 4722199,10 754833,2045 1574066,3672 2 4722199,10 754833,2045 1574066,3672 3 4722199,10 754833,2045 1574066,3672 57,25 2001 15,98 2001 26,76 404 Analysen 2002 1 12445196,31 3275322,1694 4148398,7711 2 12445196,31 3275322,1694 4148398,7711 3 12445196,31 3275322,1694 4148398,7711 45,41 2002 26,31 2002 28,26 6.2.2 Akkumulationen und Durchschnitte Neben einfachen Aggregaten, die als fester Wert für eine ganze Tabelle oder natürlich für einen bestimmten Bereich ermittelt werden, gibt es auch die Anforderung, Akkumulationen und verschiedene Arten von Durchschnitten zu errechnen. Für die verschiedenen Beispiele könnte man natürlich auch wieder eine CTE verwenden. Es soll allerdings doch wieder eine ältere Lösung in Form von einer temporären Tabelle eingesetzt werden, die mit Hilfe der beiden Rautenzeichen als globale temporäre Tabelle angelegt wird und daher von verschiedenen Sitzungen aufgerufen werden kann. Diese erstellt das nachfolgende Beispiel, sodass man für die späteren Beispiele eine Tabelle mit Rohdaten besitzt. Sie besteht aus der Kundennummer, dem Bestelldatum und dem Gesamtumsatz. Das Bestelldatum ist dabei die Kombination aus Jahr und Monat. IF OBJECT_ID('#Sales') IS NOT NULL DROP TABLE ##Sales GO CREATE TABLE ##Sales ( CustomerID int, OrderDate varchar(7), TotalDue money ) 405 Analysen GO INSERT INTO ##Sales SELECT CustomerID, LTRIM(STR(YEAR(OrderDate))) +'-' +LTRIM(STR(MONTH(OrderDate))) AS OrderDate, SUM(TotalDue) FROM Sales.SalesOrderHeader GROUP BY CustomerID, LTRIM(STR(YEAR(OrderDate))) +'-' +LTRIM(STR(MONTH(OrderDate))) GO SELECT * FROM ##Sales 622_01.sql: Erstellung der Beispieldaten Mit der nachfolgenden Ausgabe soll noch einmal gezeigt werden, welche Daten für die Beispiele relevant sind. Die verschiedenen Kundennummern führen in einer Jahr/Monat-Kombination zu einem mehr oder minder großen Umsatz. CustomerID OrderDate TotalDue ----------- --------- -------------16308 2002-8 2410,6266 306 2002-9 250,6771 12602 2003-8 9,934 406 Analysen 15866 6.2.2.1 2003-9 42,9624 Akkumulation Im ersten Beispiel, welche die gerade abgerufenen und zwischengespeicherten Daten benutzt, erstellt man eine einfache Akkumulation. Für dieses und für alle folgenden Beispiele gilt, dass man im Alltag vermutlich die exakte Syntax oder den Lösungsweg nicht auswendig weiß und für eine beliebige Abfrage niederschreiben kann. Die Aufgabe besteht dann im praktischen Leben mehr darin, den vorgezeichneten Lösungsweg auf die gerade zu bearbeitenden Tabellen anzuwenden. Bei einer Akkumulation soll eine Spalte geführt werden, welche die Zahlwerte aus einer anderen Spalte addiert, d.h. in der letzten Reihe befindet sich dann die Gesamtsumme, welche sich auch durch eine entsprechende Aggregierung für die gesamte Tabelle ergeben hätte. Zur Lösung dieser Anforderung kann man bei einer einzigen Spalte, in der eine solche Berechnung genutzt bzw. ausgegeben wird, eine Spaltenunterabfrage verwenden. Sie enthält eine Verknüpfung mit der äußeren Datentabelle anhand des Primärschlüssels CustomerID. Hier handelt es sich also um eine korrelierte Spaltenunterabfrage, deren zusätzliche Bedingung für die erfolgreiche Teilsummenbildung bis zum aktuellen Datum ist, dass nur die Datensätze mit einem Datum, welches kleiner gleich dem aktuellen Datensatz der äußeren Abfrage ist. SELECT s1.CustomerID, s1.OrderDate, s1.TotalDue AS Month, (SELECT SUM(s2.TotalDue) FROM dbo.##Sales AS s2 WHERE s2.CustomerID = s1.CustomerID AND s2.OrderDate <= s1.OrderDate)AS Total FROM dbo.##Sales AS s1 407 Analysen GROUP BY s1.CustomerID, s1.OrderDate, s1.TotalDue ORDER BY s1.CustomerID, s1.OrderDate 622_02.sql: Akkumulation Man erhält die angekündigte Ausgabe von Datensätzen, wobei in der äußeren Spalte die Akkumulation enthalten ist. Rechnet man einmal selbst die ersten drei Werte für die Monatsumsätze zusammen, dann erhält man genau die Summe, welche auch als akkumulierter Wert ermittelt wird. CustomerID OrderDate Month Total ----------- --------- --------------- -------------1 2001-11 26128,8674 26128,8674 1 2001-8 14603,7393 40732,6067 1 2002-2 37643,1378 78375,7445 1 2002-5 34722,9906 113098,7351 2 2002-11 5469,5941 5469,5941 2 2002-8 10184,0774 15653,6715 6.2.2.2 Gleitender Durchschnitt Sofern ohnehin nur eine einzige Spalte den akkumulierten Wert nutzt, kann man eine korrelierte Spaltenunterabfrage verwenden. Im nächsten Beispiel gibt es einmal einen gleitenden Durchschnitt als neues Thema und zusätzlich auch eine Akkumulation. Hier kann man zum einen sehen, wie man die gleiche Abfrage von oben mit Hilfe einer Selbstverknüpfung innerhalb der FROM-Klausel löst, und wie man gleichzeitig einen Durchschnitt ermittelt, der gleitend ist. Ein solcher gleitender Durchschnitt zeichnet sich dadurch aus, dass er auf der Basis aller vorherigen Datensätze ermittelt wird. Im Gegensatz dazu wird ein Gesamtdurchschnitt auf Basis aller Datensätze ermittelt. Ein solcher gleitender Durchschnitt stellt natürlich nur dann einen sinnvollen Wert dar, wenn die 408 Analysen Werte, auf deren Basis er ermittelt wird, in einer sinnvollen Reihenfolge aufeinander folgen. Dies ist typischerweise durch eine zeitliche Abfolge gegeben. Als Anweisung ist nichts anderes zu tun, als die AVG-Funktion zu verwenden. Die Daten werden wiederum durch eine Selbstverknüpfung in der FROM-Klausel oder eine korrelierte Spaltenunterabfrage erzeugt. Die beiden Beispiele zeigen darüber hinaus auch, dass sich natürlich sämtliche anderen Aggregate ebenfalls über diese Techniken ermitteln lassen. Nur in wenigen Fällen dürfte es zwar gewünscht sein, das Minimum oder Maximum der vorherigen Werte zu ermitteln, doch stellt dies kein syntaktisches Problem dar. SELECT s1.CustomerID, s1.OrderDate, s1.TotalDue AS Month, SUM(s2.TotalDue) AS Total, AVG(s2.TotalDue) AS Avg FROM dbo.##Sales AS s1 INNER JOIN dbo.##Sales AS s2 ON s1.CustomerID = s2.CustomerID AND s2.OrderDate <= s1.OrderDate GROUP BY s1.CustomerID, s1.OrderDate, s1.TotalDue ORDER BY s1.CustomerID, s1.OrderDate 622_02.sql: Gleitender Durchschnitt und Akkumulation Das Ergebnis zeigt vermutlich besser als die obige Erklärung, wie beide Berechnungen und die gesamte Technik mit der abgeleiteten Tabelle funktionieren. Eine CTE wäre natürlich auch möglich gewesen, wenngleich die angegebene Lösung die traditionelle Variante ist und in den meisten Fällen völlig ausreichend sein dürfte, da keine mehrfachen Referenzen oder ähnliche Vorteile von CTEs notwendig sein dürften. In der Spalte 409 Analysen für den gleitenden Durchschnitt wird immer für den aktuellen Wert und die zurückliegenden Werte der Durchschnitt ermittelt. CustomerID OrderDate Month Total Avg ----------- --------- ------------- ------------ ----------1 2001-11 26128,8674 26128,8674 26128,8674 1 2001-8 14603,7393 40732,6067 20366,3033 1 2002-2 37643,1378 78375,7445 26125,2481 1 2002-5 34722,9906 113098,7351 28274,6837 2 2002-11 5469,5941 5469,5941 5469,5941 2 2002-8 10184,0774 15653,6715 7826,8357 6.2.2.3 Fenster-Aggregate Für die tägliche Arbeit bei der Erstellung von statistischen Auswertungen gelten noch die Fenster-Aggregate, welche nicht einfach nur einen gleitenden Durchschnitt ermitteln und damit sehr stark auf Schwankungen reagieren, sondern mehrere Datensätze aus der Vergangenheit und/oder der Zukunft in die Berechnung einfließen lassen. Diese Bereichsaggregate sind bspw. als Zwei-Monats-durchschnitt bekannt und begrenzen dadurch die Auswahl der Datensätze sehr stark. Das Prinzip, wie überhaupt die Aggregatbildung durchgeführt wird, bleibt unverändert. Man setzt eine Selbstverknüpfung ein, verknüpft dabei anhand der Kundennummer bzw. des Primärschlüssel und wählt die Datensätze für die Berechnung aus, indem nicht einfach nur eine Größer-/Kleiner-Beziehung zum Einsatz kommt, sondern stattdessen eine Berechnung. SELECT s1.CustomerID, s1.OrderDate, 410 Analysen s1.TotalDue AS Month, SUM(s2.TotalDue) AS Total, AVG(s2.TotalDue) AS Avg FROM dbo.##Sales AS s1 INNER JOIN dbo.##Sales AS s2 ON s1.CustomerID = s2.CustomerID AND (CAST(s2.OrderDate+'-1' AS DATETIME) > DATEADD(MONTH, -3,CAST(s1.OrderDate+'-1' AS DATETIME)) AND CAST(s2.OrderDate+'-1' AS DATETIME) <= CAST(s1.OrderDate+'-1' AS DATETIME)) GROUP BY s1.CustomerID, s1.OrderDate, s1.TotalDue ORDER BY s1.CustomerID, CAST(s1.OrderDate+'-1' AS DATETIME) 622_03.sql: Fenster-Aggregate In der Ergebnismenge kann man viel besser erkennen, wie die Fenster bzw. Bereiche gebildet werden. Immer innerhalb von drei Monaten (Achtung: nicht Datensätzen) wird ein neuer Durchschnitt gebildet. Über die oben angegebene Berechnung kann man auch erkennen, dass man tatsächlich beliebige Fensterbereiche selbst vorgeben kann, darunter auch solche, die weniger gebräuchlich sind und in die Vergangenheit und in die Zukunft unterschiedliche Anzahl von Zeiteinheiten blicken. CustomerID OrderDate Month Total Avg ----------- --------- ------------- ----------- -----------1 2001-8 14603,7393 14603,7393 14603,7393 1 2001-11 26128,8674 40732,6067 20366,3033 411 Analysen 1 2002-2 37643,1378 37643,1378 37643,1378 1 2002-5 34722,9906 72366,1284 36183,0642 2 2002-8 10184,0774 10184,0774 10184,0774 2 2002-11 5469,5941 15653,6715 7826,8357 2 2003-2 1739,4078 1739,4078 1739,4078 6.2.3 Hitparaden Eine häufige Anforderung ist es, die x größten, erfolgreichsten, kleinsten und sonstigen –sten Datensätze zu beschaffen. Für die Erfüllung dieser Aufgabe kann man auf der einen Seiten ORDER BY, einen Cursor oder natürlich die schon bekannte TOP n-Abfrage einsetzen. Die eine oder andere Lösung ist je nach genauem Anwendungszusammenhang die empfehlenswerte, wobei aller Wahrscheinlichkeit nach insbesondere TOP n in vielen Fällen die beste Wahl darstellen dürfte. Zusätzlich zu diesen Möglichkeiten gibt es noch eine Reihe von neuen Funktionen, mit deren Hilfe ähnliche Ergebnisse erzeugt werden können, wobei hier der Fokus mehr auf die Erstellung einer Hitparade bzw. die Ausgabe einer Reihenfolge liegt. Dies ist zwar mit einer Standardsortierung ebenfalls möglich, aber in diesem Abschnitt sollen Lösungen vorgestellt werden, mit deren Hilfe nicht nur die Sortierung überhaupt durchgeführt werden kann, sondern mit denen auch die Rangnummern und Plätze ausgegeben werden, die ansonsten bei Einsatz eine einfachen Sortierung nicht in der Ergebnismenge erscheinen. 6.2.3.1 Zeilennummern erstellen Bisweilen möchte man in einer Abfrage Zeilennummern haben, um seitenweise (immer die nächsten 50 Datensätze) oder in Form einer Hitparade (die ersten 10) die Ergebnismenge zu lesen bzw. auch weiterzuverarbeiten. Bisweilen kann man hier schon einfach den Primärschlüssel verwenden, wenn die Ergebnismenge direkt mit dem Schlüsselwert 1 beginnt und sich dann aufsteigend fortsetzt. In den seltensten Fällen dürfte dies allerdings gegeben sein. Daher wird eine Möglichkeit gesucht, solche Zeilennummern extra 412 Analysen auszugeben. Eine neue und besonders schnelle und damit auch für umfangreiche Ergebnismengen interessante Lösung stellt die ROW_NUMBER()-Funktion dar. Ihre allgemeine Syntax lautet: ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> ) Sie erwartet keine Parameter, wird aber um die OVER()-Klausel ergänzt. Diese ermöglicht es dann in einer ORDER BY-Klausel anzugeben, nach welcher Spalte die Datensätze sortiert werden sollen und kann um eine PARTITION BY-Klausel ergänzt werden, welche die Bereiche angibt, in denen neue Reihenfolgen gebildet werden sollen. Im nachfolgenden Beispiel wird anstelle einer möglichen CTE einmal wieder eine herkömmliche temporäre Tabelle erstellt, in der sowohl Werte aus einer Abfrage als auch die möglichen Zeilennummern gespeichert werden sollen. Dies ist natürlich nicht zwingend notwendig, weil die ROW_NUMBER()-Funktion gerade auch sehr gut in einer einfachen Abfrage eingesetzt werden kann, doch soll der Einsatz einer temporären Tabelle noch einmal als allgemeines Beispiel zu diesem Thema zusätzlich genutzt werden. Die Tabelle #Sales enthält die drei Spalten TerritoryID, Year und Turnover in passenden Datentypen, um für Jahre und Regionen Umsatzzahlen zu speichern. Die Tabelle füllt man dann durch eine SELECT…INTO-Abfrage, sodass man für beliebige Abfragen Rohdaten besitzt, die sich auf die originale Sales.SalesOrderHeaderTabelle beziehen. Basierend auf dieser Tabelle erstellt man dann eine Abfrage, welche drei verschiedene Aufrufe der ROW_NUMBER()-Funktion besitzt. ROW_NUMBER() OVER (ORDER BY Year, TerritoryID) ist bereits die erweiterte Form des Funktionsaufrufs und gibt zwei Spaltennamen in der ORDER BY-Klausel an. Da dies auch die Sortierung der gesamten Abfrage ist, verlaufen diese Nummern kontinuierlich ansteigend. Dies lässt sich an den Werten der beiden anderen Spalten nicht nachvollziehen. ROW_NUMBER() OVER (ORDER BY Year) erzeugt eine Nummerierung der Ergebnisse anhand des Jahres. Dadurch ist bspw. der zweite Datensatz die Kombination aus dem ersten Jahr und dem zweiten Gebiet. Dies ist allerdings in der Geschwisterspalte mit der Sortierung nach Jahr und Gebiet die Nummer 16. Schaut 413 Analysen man die Ergebnisse genauer an, erkennt man auch, dass zwar auf der einen Seite durch die unterschiedliche Sortierung in der gesamten Abfrage und in den einzelnen ROW_NUMBER()-Funktionen verschiedene Zeilennummern entstehen, dass aber auf der anderen Seite viele Reihen doppelt ausgegeben werden, um den unterschiedlichen Sortierungen Genüge zu tun, welche in den ROW_NUMBER()-Funktionen gefordert werden. Damit zeigt dieses Beispiel sowohl, wie einfach Zeilennummern ausgegeben werden können, aber auch, dass es in den meisten Fällen am sinnvollsten ist, die Sortierung der gesamten Abfrage mit der ROW_NUMBER()-Funktion abzustimmen. Durch die Kombination und Ausgabe von mehreren Sortierungen mit widersprüchlichen Angaben zwingt man die Ergebnismenge dazu, doppelte Werte zu erzeugen. IF OBJECT_ID('#Sales') IS NOT NULL DROP TABLE #Sales GO CREATE TABLE #Sales ( TerritoryID int NULL, Year int NULL, Turnover money NULL ) GO INSERT INTO #Sales SELECT TerritoryID, YEAR(OrderDate) AS Year, SUM(TotalDue) AS Turnover FROM Sales.SalesOrderHeader GROUP BY YEAR(OrderDate), TerritoryID 414 Analysen ORDER BY 1,2 GO SELECT TerritoryID, Year, Turnover, ROW_NUMBER() OVER (ORDER BY Year) AS [RN-Y], ROW_NUMBER() OVER (ORDER BY Year, TerritoryID) AS [RN-YT], ROW_NUMBER() OVER (ORDER BY TerritoryID) AS [RN-T] FROM #Sales ORDER BY Year, TerritoryID 623_01.sql: Einsatz von ROW_NUMBER() Die Ergebnismenge zeigt, wie einfach und schön man Zeilennummern ausgeben kann. Sie zeigt allerdings auch, dass man durch Kombination von mehreren Spalten mit Sortierungen doppelte Werte ausgeben kann. Im Normalfall sollte dies zu keinem Problem führen, da man wohl mit einer einzigen Spalte Zeilennummern auskommen dürfte. Sollte dies nicht der Fall sein, ist darauf zu achten, dass eine zusätzliche Nummerierung nicht zu dem beschriebenen Phänomen von doppelten Zeilen führt. Wenigstens die Angabe ROW_NUMBER() OVER (ORDER BY TerritoryID) sollte entfallen, da die anderen Zeilennummernangaben wenigstens nach der Jahreszahl sortieren. TerritoryID Year Turnover RN-Y RN-YT RN-T ----------- ----- ---------------- ------ --------- -----1 2001 2703481,7947 1 1 1 1 2001 2703481,7947 11 2 2 415 Analysen 2 2001 754833,2045 12 3 15 2 2001 754833,2045 2 4 16 9 2004 3823410,2386 62 78 72 10 2004 3039555,8775 71 79 73 10 2004 3039555,8775 61 80 74 ... (80 Zeile(n) betroffen) Im nächsten Beispiel verzichtet man auf die Verwendung einer temporären Tabelle, sondern erstellt die Zeilennummern unmittelbar in einer Abfrage, die eine vorhandene Tabelle der Datenbank abfragt. In diesem Fall erzeugt man auch nur eine einzige Spalte mit Zeilennummern, was auch dem Standardfall entspricht. In diesem Beispiel ist neben diesen Überlegungen auch noch ein Syntax-Aspekt neu hinzugetreten. Die Zeilennummer erstellt man nicht nur anhand der aufsteigend sortierten Umsätze, sondern fordert darüber hinaus auch noch, dass die Jahreszahlen einen Bereich bilden sollen. Das bedeutet, dass immer dann, wenn ein neues Jahr abgearbeitet wird, die Sortierung der Umsätze für dieses Jahr neu beginnen soll und dadurch erneut mit der Zeilennummer 1 begonnen werden soll. Damit ist die Syntax von ROW_NUMBER() ausgeschöpft: Man eine Nummerierung anhand einer Gruppierung. SELECT TerritoryID, YEAR(OrderDate) AS [Year], SUM(TotalDue) AS Turnover, ROW_NUMBER() OVER(PARTITION BY YEAR(OrderDate) ORDER BY SUM(TotalDue)) FROM Sales.SalesOrderHeader WHERE TerritoryID BETWEEN 5 AND 7 416 AS RN Analysen GROUP BY TerritoryID, YEAR(OrderDate) 623_02.sql: Verwendung einer Partition Die Funktionsweise und Nützlichkeit von ROW_NUBMER() zeigt sich sehr schön im nachfolgend abgedruckten Ergebnis. Die einzelnen Jahre folgen in der Year-Spalte als Gruppen untereinander. Für jedes neue Jahre startet die Zeilennummerierung neu, sodass man für drei abgerufene Gebiete jeweils die Zahlen von 1 bis 3 in der Spalte findet, wenn pro Jahr in allen drei Gebieten Umsatz erwirtschaftet wurde. Wie man auch schon bei der ORDER BY-Klausel mehrere Spalten angegeben werden können, so ist dies auch bei PARTITION BY-möglich. In komplexen Abfragen kann man die Partition sowohl nach dem Jahr als auch dem Kontinent durchführen. Für die Beispielabfrage ist hier keine sinnvolle weitere Partitionierung denkbar, da die Werte bereits weit genug aggregiert sind. TerritoryID Year Turnover RN ----------- ----------- --------------------- --7 2001 199531,723 1 5 2001 1928148,6139 2 6 2001 2173647,1453 3 7 2002 1717145,7439 1 5 2002 3814944,144 2 6 2002 7215430,5017 3 Auch wenn es in der Version 2005 keinen Grund mehr geben kann, bei neu erstellten Abfragen auf die alten Techniken zur Erzeugung von Reihennummern zurückzugreifen, so kann es natürlich geschehen, dass man in bereits bestehenden Anwendungen genau diese alten Techniken für die Version 2000 findet. Daher sollen kurz einige Möglichkeiten beschrieben oder auch mit einem Beispiel belegt werden. 417 Analysen Wenn man eine mengenbasierte Lösung sucht, dann stößt man auf die COUNT-Funktion, welche man in Kombination mit einer korrelierten Spaltenunterabfrage einsetzen kann. Diese zählt dann die Anzahl der Zeilen, welche bereits zuvor verarbeitet worden sind. Die Lösung ist grundsätzlich nicht schwierig zu verstehen, dauert allerdings immer deutlich länger als der Einsatz von ROW_NUMBER(). Bedingungen, die in der äußeren Abfrage geprüft werden, muss man auch in diesem Fall wieder in der WHERE-Klausel der korrelierten Spaltenunterabfrage prüfen. Hier ist in Version 2000 auch keine abgeleitete Tabelle möglich, welche den Filter enthält, da ja keine Mehrfachverweise zulässig sind. Der Einsatz einer CTE ist zwar in Version 2005 möglich, doch hier sollte man die nachfolgend angegebene Technik aus Leistungsgründen gar nicht einsetzen. SELECT SalesOrderID, TerritoryID, TotalDue, (SELECT COUNT(s2.SalesOrderID) FROM Sales.SalesOrderHeader AS s2 WHERE s2.SalesOrderID <= s1.SalesOrderID) AS RN FROM Sales.SalesOrderHeader AS s1 WHERE s1.SalesOrderID < 43662 623_03.sql: Traditionelle Rangfolgen (einfach) Auch wenn über die vorherige Lösung allerhand Schmähungen aufgrund der geringen Geschwindigkeit ausgestoßen wurden, so liefert sie doch zuverlässig das gewünschte Ergebnis. SalesOrderID TerritoryID TotalDue RN ------------ ----------- --------------------- ----------43659 418 5 27231,5495 1 Analysen 43660 5 1716,1794 2 43661 6 43561,4424 3 (3 Zeile(n) betroffen) Auch eine komplexe Variante der mengenbasierten Ausgabe von Zeilennummern ist möglich. Dabei kann man durch eine Gruppierung dafür sorgen, dass Partitionen gebildet werden. So wird auch noch einmal deutlich, dass die Partitionen der ROW_NUMBER()-Funktion tatsächlich nichts Anderes als Gruppen darstellen. Zusätzlich setzt das nächste Beispiel auch noch einen Filter auf die Regionen 5 bis 7 ein. Auf der einen Seite soll dadurch das Ergebnis für den Nachweis, dass Bereiche entstehen, deutlicher hervorgehoben werden, auf der anderen Seite sieht man hier, dass – wie oben angekündigt – dieser Filter sowohl in der äußeren als auch in der inneren Abfrage gleichlautend angegeben werden muss. SELECT TerritoryID, YEAR(OrderDate) AS [Year], SUM(TotalDue) AS Turnover, (SELECT COUNT(DISTINCT s2.TerritoryID) FROM Sales.SalesOrderHeader AS s2 WHERE s2.TerritoryID <= s1.TerritoryID AND s2.TerritoryID BETWEEN 5 AND 7) AS RN FROM Sales.SalesOrderHeader AS s1 WHERE TerritoryID BETWEEN 5 AND 7 GROUP BY TerritoryID, YEAR(OrderDate) ORDER BY YEAR(OrderDate), s1.TerritoryID 623_03.sql: Traditionelle Rangfolgen (komplex) 419 Analysen Im Ergebnis erhält man die angekündigten Bereiche und ihre jeweiligen neu beginnenden Nummerierungen. TerritoryID Year Turnover RN ----------- ----------- --------------------- --7 2001 199531,723 1 5 2001 1928148,6139 2 6 2001 2173647,1453 3 7 2002 1717145,7439 1 5 2002 3814944,144 2 6 2002 7215430,5017 3 Diese beiden Techniken sollten sowohl für die Version 2005 als auch für die Version 2000 genügen, um Reihennummern in jeder beliebigen Abfrage zu erstellen. Sofern die Version 2005 genutzt wird, lohnt sich nur der Einsatz der neuen ROW_NUMBER()Funktion, da dieser von beiden vorgestellten Varianten die Ergebnisse am schnellsten produziert. Für die Version 2000 ist die so genannte IDENTITY-Variante auf Platz 1, obwohl sie leider nicht so schnell geschrieben werden kann wie die mengenbasierte, ausformulierte Variante des letzten Beispiels. Sofern allerdings die Geschwindigkeit aufgrund der abgerufenen Zeilen vernachlässigt werden kann, ist die sicherlich kein so wichtiges Kriterium. Bei der IDENTTIY- und de Cursor-Variante erstellen jeweils eine temporäre Tabelle, in welcher über einen SELECT…INTO-Ausdruck oder über eine WHILE-Schleife und einen aufsteigenden Zähler die Werte eingetragen werden, ergänzt um einen aufsteigenden Zählerwert. Während dieser beim Cursor tatsächlich über einen Zähler generiert wird, ermöglicht die schnellere Variante den Vorteil, dass eine Spalte direkt in der SELECT…INTO-Anweisung mit der Funktion IDENTITY(int, 1,1) gefüllt wird und daher automatisch aufsteigend gefüllt wird. Man erhält dann eine Syntax wie SELECT 420 Analysen spalte1, spalte2, IDENTITY(int, 1,1) AS RN INTO #tempTab FROM tabelle. 6.2.3.2 Rangfolgefunktionen In der Version 2005 gibt es einige neue so genannte Rangfolgefunktionen, die in folgender Liste kurz vorgestellt werden. Sie besitzen alle eine zusätzliche PARTITION BYKlausel, welche in der Lage ist, die Funktion auf einzelne Bereiche anzuwenden und dadurch Gruppierungen und eine sehr flexible Nutzung ermöglicht. Zusätzlich greifen sie optional auf eine Sortieranweisung zurück, um die Reihenfolge zu bestimmen. RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > ) erzeugt für jede Zeile innerhalb einer Ergebnismenge oder eines Bereichs (Partition) eine Rang in Form einer Ganzzahl an. Sollten mehrere Reihen gleichwertig sein, dann erhalten sie alle denselben Rang. Hier können Lücken auftreten: Wenn zwei Datensätze gleichwertig sind, erhalten sie die gleiche Nummer. Der nächste Datensatz überspringt einen Zählerwert und lautet dann bspw. auf 3, wenn die ersten beiden Datensätze den Wert 1 erhalten haben, da insgesamt drei Datensätze einzuordnen sind. DENSE_RANK ( ) OVER ( [ < partition_by_clause > ] erzeugt für jede Zeile innerhalb einer Ergebnismenge oder eines Bereichs (Partition) eine Rang in Form einer Ganzzahl an. Sollten mehrere Reihen gleichwertig sein, dann erhalten sie alle denselben Rang. Hier können keine Lücken auftreten. < order_by_clause > ) ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] 421 Analysen liefert von 1 beginnend aufsteigende Ganzzahlen in einer eigenen Spalte. Dadurch ersetzt man ältere Vorgehensweisen, die temporäre Tabellen mit IDENTITY-Spalten eingesetzt haben. <order_by_clause> ) Das nächste Beispiel summiert die Umsätze pro Gebiet und erzeugt dafür Spalten mit den Werten aller drei Funktionen. SELECT TerritoryID, SUM(TotalDue) AS Turnover, RANK() OVER (ORDER BY SUM(TotalDue)) AS R, DENSE_RANK() OVER (ORDER BY SUM(TotalDue)) AS DR, ROW_NUMBER() OVER (ORDER BY SUM(TotalDue)) AS RN FROM Sales.SalesOrderHeader GROUP BY TerritoryID ORDER BY SUM(TotalDue) 623_04.sql: Einsatz und Vergleich von Rangfolgefunktionen Man erhält als Ergebnis durch die ROW_NUMBER()-Funktion die aufsteigenden Zeilennummern, die einfach nur eine Art Schlüsselwert für jede einzelne Zeile bieten. Die DENSE_RANK()-Funktion ermittelt die Plätze dagegen in diesem Fall genauso wie die RANK()-Funktion, da keine doppelten Werte auftreten (bei Umsätzen auch unwahrscheinlich). TerritoryID Turnover R DR RN ----------- --------------------- -------- -------- ---8 5939763,4963 1 1 1 7 9136704,474 2 2 2 ... 422 Analysen 6 21501812,4574 9 9 9 4 31213459,5756 10 10 10 (10 Zeile(n) betroffen) Die nächste Abfrage verwendet darüber hinaus noch eine Sortierung, wobei hier RANK() und DENSE_RANK() entgegen gesetzte Sortierrichtungen besitzen. SELECT TerritoryID, SUM(TotalDue) AS Turnover, RANK() OVER (ORDER BY SUM(TotalDue)) AS R, DENSE_RANK() OVER (ORDER BY SUM(TotalDue) DESC) AS DR, ROW_NUMBER() OVER (ORDER BY SUM(TotalDue)) AS RN FROM Sales.SalesOrderHeader GROUP BY TerritoryID ORDER BY SUM(TotalDue) DESC 623_05.sql: Sortierreihenfolge Die ausgegebenen Werte stimmen mit denen zuvor ermittelten Werten überein, doch die Sortierreihenfolge ist jeweils umgekehrt. Da DENSE_RANK() und ROW_NUMBER() die gleiche absteigende Sortierung aufweisen, sind diese Spalten gleich. TerritoryID Turnover R DR RN ----------- --------------------- ------- ------- ---4 31213459,5756 10 1 10 6 21501812,4574 9 2 9 423 Analysen Nun benötigt man noch eine Abfrage, welche gleiche Werte hervorbringt und daher auch Lücken aufweist, wenn man mit der RANK()-Funktion die Ränge vergibt. Für die Kombination Land/Region sollen die verschiedenen Verkaufsgebiete gezählt werden, wobei in einigen Ländern die gleiche Anzahl an Verkaufsgebieten vorhanden ist. SELECT d.*, RANK () OVER (ORDER BY Provinces DESC) AS R, DENSE_RANK () OVER (ORDER BY Provinces DESC) AS DR FROM (SELECT CountryRegionCode, COUNT(StateProvinceCode) AS Provinces, TerritoryID FROM Person.StateProvince GROUP BY CountryRegionCode, TerritoryID HAVING TerritoryID < 5) AS d ORDER BY Provinces DESC 623_06.sql: Vergleich von RANK() und DENSE_RANK() Wie man in der Ergebnisliste sehen kann, werden von RANK() tatsächlich gleiche Werte mit gleichen Rangplätzen versehen, was zu Lücken führt, um die nicht besetzten Plätze zu überspringen und beim ersten unterschiedlichen Datensatz mit der Reihennummer fortzufahren. CountryRegionCode Provinces TerritoryID R DR ----------------- ----------- ----------- -------- -----US 14 2 1 1 US 14 3 1 1 US 9 1 3 2 424 Analysen US 5 4 4 3 AS 1 1 5 4 (5 Zeile(n) betroffen) Sofern diese schönen Funktionen nicht bereit stehen, gibt es eine andere Lösung, die – allerdings ohne CTE – auch in Version 2000 lauffähig ist und mengenbasiert arbeitet. Im nächsten Beispiel ermittelt man mit korrelierten Spaltenunterabfragen die benötigten Werte für die dichte und nicht-besetzte Rangfolgeneinordnung. Die dichte Besetzung ermittelt man dagegen, indem man die Duplikate durch DISTINCT ausblendet und daher nicht zählt. Möchte man die Lösung für die Version 2000 lauffähig erstellen, muss man die CTE-Daten in eine temporäre Tabelle speichern oder eine abgeleitete Tabelle in jeder Spaltenunterabfrage verwenden. WITH Sales AS ( SELECT CountryRegionCode, COUNT(StateProvinceCode) AS Provinces, TerritoryID FROM Person.StateProvince GROUP BY CountryRegionCode, TerritoryID HAVING TerritoryID < 6 ) SELECT s1.*, (SELECT COUNT(*) FROM Sales AS s2 WHERE s2.Provinces < s1.Provinces) + 1 AS R, (SELECT COUNT(DISTINCT Provinces) 425 Analysen FROM Sales AS s2 WHERE s2.Provinces < s1.Provinces) + 1 AS DR FROM Sales AS s1 ORDER BY Provinces 623_07.sql: Lösung für Version 2000 Man erhält ebenfalls eine Aufstellung der Länder mit den Anzahlen der Verkaufsgebiete. CountryRegionCode Provinces TerritoryID R DR ----------------- ----------- ----------- ------ ---AS 1 1 1 1 VI 1 5 1 1 US 5 4 3 2 US 9 1 4 3 US 11 5 5 4 US 14 2 6 5 US 14 3 6 5 (7 Zeile(n) betroffen) 6.2.4 Bereiche/Quantile Schließlich ist auch noch die NTILE()-Funktion vorhanden, die in der Lage ist, die Daten in einem sortierten Bereich in Gruppen zu verteilen. Dabei ist die Gruppenanzahl vorher ebenfalls angegeben. Als Rückgabewert liefert diese Funktion die Gruppennummer, zu welcher der Datensatz gehört. Im Parameter der Funktion steht die Anzahl 426 Analysen der Gruppen. Innerhalb der OVER-Klausel folgen die Spalten, anhand derer die Einteilung in Gruppen durchgeführt wird. NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > ) SELECT ProductID, ListPrice, ProductSubcategoryID, NTILE(3) OVER (ORDER BY ListPrice, ProductSubcategoryID) Quantil FROM Production.Product WHERE ProductID BETWEEN 800 AND 831 AND ProductSubcategoryID BETWEEN 10 AND 14 ORDER BY ListPrice, ProductSubcategoryID 624_01.sql: Dreiteilung einer Ergebnismenge Man erhält eine Einteilung in die einzelnen Gruppen sowie die eigentlichen Daten. Auf Basis einer solchen Ergebnismenge kann man dann wiederum gruppengesteuerte Ausgaben machen. ProductID ListPrice ProductSubcategoryID Quantil ----------- ------------ -------------------- --------805 34,20 11 1 806 102,29 11 1 807 124,73 11 1 802 148,22 10 1 427 Analysen 803 175,49 10 2 804 229,49 10 2 830 348,76 12 2 831 348,76 12 3 814 348,76 12 3 822 594,83 14 3 (10 Zeile(n) betroffen) Sofern keine Zahlen ausgegeben werden sollen, kann man sich mit Hilfe der CASEAnweisung auch Zeichenketten erzeugen. Man muss lediglich die zurück gelieferten Zahlen abprüfen und übersetzen. SELECT ProductID, ListPrice, ProductSubcategoryID, CASE NTILE(3) OVER (ORDER BY ListPrice, ProductSubcategoryID) WHEN 1 THEN 'niedrig' WHEN 2 THEN 'mittel' WHEN 3 THEN 'hoch' END AS Quantil FROM Production.Product 624_02.sql: Übertragung der Zuordnung in Texte In diesem Fall erhält man eine Einordnung in Gruppen per Text. 428 Analysen ProductID ListPrice ProductSubcategoryID Quantil ----------- --------------------- -------------------- -----805 34,20 11 175,49 10 594,83 14 niedrig ... 803 mittel ... 822 hoch Neben dieser Spielerei kann man unter Verwendung einer abgeleiteten/temporären Tabelle und natürlich eines allgemeinen Tabellenausdrucks Aggregate pro Bereich ermitteln, indem man ganz einfach eine Gruppierung pro Bereich durchführt und für die einzelnen Bereiche das Aggregat anwendet. WITH Production AS ( SELECT ProductID, ListPrice, ProductSubcategoryID, NTILE(3) OVER (ORDER BY ListPrice) AS Quantil FROM Production.Product ) SELECT Quantil, COUNT(ProductID) AS Number, 429 Analysen MIN(ListPrice) AS MinP, MAX(ListPrice) AS MaxP, AVG(ListPrice) AS AvgP FROM Production GROUP BY Quantil 624_03.sql: Aggregate bei Quantilen Man erhält pro Quantil die entsprechenden Aggregatwerte als Ergebnis. Quantil Number MinP MaxP AvgP --------- ----------- -------- ------- ----------1 168 0,00 0,00 0,00 2 168 0,00 330,06 76,687 3 168 333,42 3578,27 1239,3116 (3 Zeile(n) betroffen) 6.3 Pivot Ein besonders schwieriges Problem ist die Erstellung einer Pivot-Tabelle. Dies mag zwar für eine gewöhnliche Abfrage weniger häufig notwendig sein, aber wenn ein Bericht erstellt werden soll oder eine einfache äußere Anwendung die Daten in pivotierter Form erhalten soll, dann kann man sich verschiedene Strategien überlegen, wie und wo die Tabellendrehung am einfachsten auszuführen ist. Letztendlich ist es vermutlich auch in diesem Fall so, dass eine Lösung in SQL aufgrund der Sprachstruktur einfacher zu bewerkstelligen ist als in einer äußeren Anwendung unter dem Einsatz von Schleifen, Fallunterscheidungen und einem dadurch komplizierten Algorithmus. Die Lösung ist leider in T-SQL auch nicht besonders einfach, insbesondere dann nicht, wenn nicht die Version 2005 bereit steht und genutzt wird. Im direkten Vergleich zwischen alter und 430 Analysen neuer Fassung ist der Einsatz von 2005 besonders lohnenswert, wobei auch die neue Lösung leider nicht nur mit einer einzigen Anweisung auskommt. 6.3.1 Klassisches Pivotieren Die Funktionsweise einer Pivot-Abfrage sowie die Implikationen, die sich auf dem Weg zum endgültigen Ziel ergeben, soll langsam aufgebaut werden, wobei gleichzeitig auch die herkömmliche Technik, die nicht nur im MS SQL Server, sondern in allen Datenbanken auf ähnliche Weise funktioniert, vorgeführt werden. Zunächst benötigt man die Rohdaten für eine zu drehende Abfrage. Dies sollen die Jahreszahlen und ihre entsprechenden Umsätze sein. SELECT YEAR(OrderDate) AS [Year], SUM(TotalDue) AS Total FROM Sales.SalesOrderHeader GROUP BY YEAR(OrderDate) 631_01.sql: Rohdaten Man erhält eine einfache Ausgabe aus zwei Spalten mit den vier Jahreszahlen, in denen Umsatz erwirtschaftet wurde, und natürlich den zugehörigen Umsätzen. Eine PivotTabelle enthält nun gerade nicht vier Zeilen, sondern nur eine, wobei als Spaltenköpfe gerade die Jahreszahlen und als Werte die Umsatzzahlen auftreten. Year Total ----------- --------------------2004 32196912,4165 2001 14327552,2263 2002 39875505,095 2003 54307615,0868 431 Analysen (4 Zeile(n) betroffen) Die einfachste Möglichkeit, eine Pivot-Darstellung zu erreichen, gelingt über eine Folge von Spaltenunterabfragen. In jeder einzelnen dieser Unterabfragen wird genau ein Wert ermittelt. Dies ist leider nicht dynamisch, da ja die Anzahl der Jahre bereits von vornherein feststehen muss. Dieses Problem wird sich in allen nachfolgenden Beispielen nicht beheben lassen. SELECT DISTINCT (SELECT SUM(TotalDue) FROM Sales.SalesOrderHeader WHERE Year(OrderDate) = 2001) AS [2001], (SELECT SUM(TotalDue) FROM Sales.SalesOrderHeader WHERE Year(OrderDate) = 2002) AS [2002] FROM Sales.SalesOrderHeader 631_01.sql: Spaltenweises Pivotieren mit Spaltenunterabfragen Da die obige Abfrage nicht alle Jahreszahlen umfasste und sie ansonsten auch viel zu umfangreich geworden wäre, besteht die Ergebnismenge aus zwei Spalten und einer Zeile mit den Werten für zwei Jahre. 2001 2002 --------------------- --------------------14327552,2263 39875505,095 (1 Zeile(n) betroffen) Die vorherige Lösung gelingt, erfordert aber die mehrfache Kopie der gleichen Abfrage mit unterschiedlichen Filterwerten. Um dies zu verhindern, lässt sich eine Lösung mit 432 Analysen Fallunterscheidung denken, die rund um den Globus mit Erfolg eingesetzt wird. In ihrer Urform erzeugt sie zunächst noch nicht die benötigen Tabelle, sondern die Rohdaten, mit deren Hilfe man das Prinzip verstehen kann. In der angekündigten Fallunterscheidung, die man wiederum wie eine Spaltenunterabfrage für jede Spalte und damit für jeden Wert in der x-Achse durchführt, untersucht man die Jahreszahl. Sofern die richtige Jahreszahl (2001, 2002, etc.) im Datensatz vorliegt, soll die Summe berechnet werden, während bei falschem Wert für die Jahreszahl NULL ausgegeben werden soll. SELECT CASE WHEN YEAR(OrderDate) = 2001 THEN SUM(TotalDue) ELSE NULL END AS [2001], CASE WHEN YEAR(OrderDate) = 2002 THEN SUM(TotalDue) ELSE NULL END AS [2002] FROM Sales.SalesOrderHeader GROUP BY YEAR(OrderDate) 631_01.sql: Einsatz von CASE Man erhält die erwarteten Spalten, erzeugt jedoch auch die angekündigten NULL-Werte, sodass insgesamt wiederum vier Zeilen entstehen. 2001 2002 --------------------- --------------------NULL NULL 14327552,2263 NULL 433 Analysen NULL 39875505,095 NULL NULL (4 Zeile(n) betroffen) Um dieses Problem zu beheben, platziert man die Summierung für jede Spalte nicht innerhalb der CASE-Anweisung, sondern legt diese vielmehr in die SUM-Funktion hinein. Weil NULL-Werte nicht summiert werden können, blendet man automatisch diese Werte aus. SELECT SUM(CASE YEAR(OrderDate) WHEN 2001 THEN TotalDue ELSE NULL END) AS [2001], SUM(CASE YEAR(OrderDate) WHEN 2002 THEN TotalDue ELSE NULL END) AS [2002] FROM Sales.SalesOrderHeader 631_01.sql: Pivotieren mit CASE Als Ergebnis erhält man eine tatsächlich gedrehte Tabelle. Diese wird um eine Warnung ergänzt. Diese gibt an, dass durch die Summierung/Aggregierung NULL-Werte, die solchermaßen bearbeitet werden sollten, gelöscht wurden. 2001 2002 --------------------- --------------------14327552,2263 39875505,095 Warnung: Ein NULL-Wert wird durch einen Aggregat- oder sonstigen SET-Vorgang gelöscht. (1 Zeile(n) betroffen 434 Analysen 6.3.2 Einsatz von (UN)PIVOT Da die zurückliegenden Beispiele doch eine gewisse Mühseligkeit bedeuten und man bei einer einfachen Abfrage von vorneherein wissen muss, wie viele Werte nachher in der Spaltenliste zu einer eigenen Spalten führen müssen, gibt es in Version 2005 einen neuen Operator mit dem verständlichen Namen PIVOT. Er ermöglicht die Erzeugung von Pivottabellen innerhalb einer einzigen Abfrage ohne die berühmten CASEAnweisungen. Seine allgemeine Syntax hat die Form: <pivoted_table> ::= table_source PIVOT <pivot_clause> table_alias <pivot_clause> ::= ( aggregate_function ( value_column ) FOR pivot_column IN ( <column_list> ) ) <column_list> ::= column_name [ , ... ] Die gesamte Syntax besteht aus verschiedenen Teilen, die ineinander verzahnt sind und welche bei den ersten eigenen Beispielen zunächst verschiedene Hürden bilden. Daher bauen die nachfolgenden Beispiele aufeinander auf und führen das vorherige Beispiel weiter fort, um die alternative, moderne Lösung direkt mit der herkömmlichen vergleichen zu können. Folgende Bestandteile lassen sich identifizieren: Die eingehende Tabelle, welche vor dem PIVOT-Operator genannt wird bzw. in Form einer CTE vorab oder in Form einer abgeleiteten Tabelle direkt in der FROM-Klausel erstellt wird, erfährt eine Gruppierung wie durch GROUP BY. Dies erfolgt anhand er Gruppierungsspalten, die optional angegeben sein können. Sie bilden bei einer Kreuzta- 435 Analysen belle die verschiedenen Gruppen ab, für die Werte für die Gruppe der Ausgabespalten ermittelt werden. Ausgabespalten wiederum sind die Spalten, welche früher individuell durch die CASE-Anweisungen erstellt wurden. Diese direkte und individuelle Erstellung ist auch weiterhin notwendig. Um die endgültige Ausgabe zu ermitteln, generiert die Abfrage die verschiedenen Werte auf die folgende Weise: 1. Weitere Gruppierung der Zeilen für die Pivotspalte, welche bereits durch die Gruppierung mit GROUP BY im vorherigen Schritt erstellt wurde. Wahl einer Untergruppe für die einzelnen Ausgabespalten anhand der Bedingung pivot_column = CONVERT(<data type of pivot_column>, 'output_column'). 5. Auswertung der möglicherweise angegebenen Aggregatfunktion für die einzelnen Wertespalten dieser Untergruppe. Die Wertespalte bildet bei einer Kreuztabelle (mehrere Zeilen) typischerweise die Werte der meist einzelnen linken Spalte, während die zugehörigen Werte in die meist mehrfach auftretenden output_columns eingetragen werden. Bei einer leeren Untergruppe entsteht eine NULL, sofern keine Zählung mit COUNT durchgeführt wird, die automatisch den Wert 0 zurückgibt. Die gesamte Konstruktion führt dazu, dass ein so genannter Tabellenwertausdruck (also eine Abfrage, die zu einer Ergebnismenge führt) pivotiert wird. Dabei ordnet der PIVOT-Operator eindeutige Werte aus der Ergebnismenge Spalten der geplanten und durch den Operator sowie die Spaltenliste definierten Ausgabetabelle zu. Andere Werte aggregiert er dabei nach der vorgeschriebenen Weise, sofern dies notwendig ist und die Aggregation nicht ohnehin schon an anderer Stelle (abgeleitete Tabelle, CTE) vorgenommen wurde. Der UNPIVOT-Operator kehrt den gesamten Prozess um und kann auf Basis einer pivotierten Tabelle wieder die Ausgangswerte erzeugen. 6.3.2.1 Pivottabellen einrichten Die Funktionsweise der neuen Operatoren ist beeindruckend, doch leider nicht wirklich einfach zu verstehen. Daher dürfte das nachfolgende Beispiel die allgemeinen Erläuterungen der Einführung gut untermauern. Zunächst erstellt man wiederum die Rohdaten, 436 Analysen wie dies schon zuvor geschehen ist, um für die gleiche Aufgabestellung, die zur Darstellung des traditionellen Lösungswegs genutzt wurde, die moderne Lösung anzugeben. In der CTE Turnover befindet sich nun der Abruf einer zweispaltigen Ergebnismenge OrderDate und TotalDue, welche man im nächsten Schritt pivotieren möchte. In dieser Ergebnismenge sind allerdings noch keine aggregierten Werte, sondern nur ein kompletter Zeilenabruf der SalesOrderHeader-Tabelle. Die Aggregierung könnte man hier bereits vornehmen; sie lässt sich jedoch auch direkt im PIVOT-Operator durchführen. Da im Vorfeld bereits klar ist, dass die Jahreszahlen zwischen 2001 und 2004 in der CTE abgerufen werden, erstellt man nun für diese Jahreszahlen Spalten, in die nachher die entsprechenden Umsätze für diese Jahre übernommen werden sollen. Auch bei dieser Lösung muss das eigentliche Ergebnis also von vorneherein klar sein. Lediglich die lange CASE-Anweisung und damit ein Großteil der unleserlichen Syntax der traditionellen Lösung verschwinden. Nachdem man die CTE in der FROM-Klausel referenziert hat, folgt nun endlich der lange angekündigte PIVOT-Operator. Zunächst gibt man an, was mit der Spalte TotalDue geschehen soll, deren Werte zu den einzelnen Ausgabespalten für die Jahreszahlen zugeordnet werden soll. Diese Zuordnung gelingt über die Gruppierung, wie sie auch durch GROUP BY OrderDate hätte eingerichtet werden können. In diesem Fall allerdings folgt in der FOR-Klausel der Spaltennamen, für die gruppiert werden soll, und in der IN-Klausel folgenden Werte, welche für die Zuordnung der Werte zu den Ausgabespalten genutzt werden. Dies stellt nun die verkürzte CASE-Anweisung dar. Sobald ein Wert von 2001 erscheint, wird der zugehörige Umsatz zur akkumulierten Umsatzzahl von allen Werten aus 2001 hinzugefügt. Schließlich hat man für alle angegebenen und schon im Vorfeld bekannten Jahreszahlen die nötigen Gesamtumsatzzahlen zusammen, welche in der pivotierten Ergebnismenge ausgegeben werden können. Die Zuordnung zu den Ausgabespalten erfolgt dabei über die Spaltenliste und die IN-Klausel, da hier die gleichen Werte erscheinen. WITH Turnover AS ( 437 Analysen SELECT YEAR(OrderDate) AS OrderDate, TotalDue FROM Sales.SalesOrderHeader ) SELECT [2001], [2002], [2003], [2004] FROM Turnover PIVOT (SUM(TotalDue) FOR OrderDate IN ([2001], [2002], [2003], [2004])) AS p 632_01.sql: Standardfall von PIVOT Man erhält wie zuvor folgende Ergebnismenge: 2001 2002 2003 2004 -------------- ------------ ------------- ------------14327552,2263 39875505,095 54307615,0868 32196912,4165 Die erzeugten Spaltennamen in der endgültigen Ausgabetabelle enthalten nun die Werte, welche in der Spaltenliste angegeben sind bzw. in der IN-Klausel aufgerufen werden. Dies ist nicht wirklich verwunderlich, da in der Spaltenliste immer auch die Spaltennamen angegeben sind, welche nachher in der Ausgabe erscheinen. In diesem Fall dienen sie allerdings auch dazu, die Wertzuordnungen für die Pivotierung einzurichten. Daher sei an dieser Stelle noch einmal darauf hingewiesen, dass ein Aliasname dafür sorgt, dass die Werte zugewiesen werden, in der Ausgabe allerdings ganz andere Spaltennamen entstehen. SELECT [2001] AS Year1, [2002] AS Year2 FROM Turnover 438 Analysen PIVOT (SUM(TotalDue) FOR OrderDate IN ([2001], [2002])) AS p 632_01.sql: Erzeugen von anderen Spaltennamen In diesem Fall erhält man als Ergebnis gerade nicht die vorgegebenen Jahreszahlen als Spaltennamen, sondern die Aliasnamen. Year1 Year2 --------------------- --------------------14327552,2263 39875505,095 Neben dieser einfachen Pivotierung benötigt man beizeiten auch Kreuztabellen. Dies sind Tabellen, welche sich gerade nicht dadurch auszeichnen, nur eine einzige Zeile zu besitzen, sondern eine Gruppierung anhand von erweiterten Gruppenmerkmalen, die sich nicht nur an der Spaltenliste (Jahreszahlen) orientieren. Im nächsten Beispiel ruft man daher in der CTE noch die TerritoryID mit dem Aliasnamen Region ab. Diese Spalte gelangt dann über die eigentliche Abfrage auf Basis der CTE in die endgültige, pivotierte Ergebnismenge. Nur durch ihre Nennung, werden die Werte in den Ausgabespalten noch einmal gruppiert, sodass für jede Region in den angegebenen Jahren die entsprechenden Werte ermittelt werden. Dies entspricht einer Anweisung wie GROUP BY Region, Year. Mehr als eine Spalte ist selbstverständlich möglich, sodass weitere Gruppierungen möglich sind. WITH Turnover AS ( SELECT TerritoryID AS Region, YEAR(OrderDate) AS OrderDate, TotalDue FROM Sales.SalesOrderHeader 439 Analysen ) SELECT Region, [2001], [2002] FROM Turnover PIVOT (SUM(TotalDue) FOR OrderDate IN ([2001], [2002])) AS p 632_02.sql: Kreuztabelle Man erhält eine als Kreuztabelle bekannte Ausgabe, in der man sich vorstellen kann, in der ersten Zeile und in der ersten Spalte jeweils Spaltenköpfe zu besitzen. Region 2001 2002 ----------- --------------------- --------------------1 2703481,7947 5651688,6685 2 754833,2045 3275322,1694 322207,5294 1778804,7452 ... 10 (10 Zeile(n) betroffen) Wie man nun diese Tabelle tatsächlich ausgibt, ist völlig beliebig. Auf Basis der gerade angegebenen Lösung könnte man sich genauso gut vorstellen, dass die Regionen in der ersten Zeile und die Jahreszahlen in der ersten Spalte erscheinen. Dies erfordert nur, die Regionsnummern in der Spaltenliste und in der IN-Klausel zu erwähnen, wobei in der IN-Klausel nun die Region-Spalte und nicht mehr die OrderDate-Spalte aufgerufen wird. SELECT OrderDate, [1], [2], [3] FROM (SELECT TerritoryID AS Region, YEAR(OrderDate) AS OrderDate, TotalDue 440 Analysen FROM Sales.SalesOrderHeader) AS Turnover PIVOT (SUM(TotalDue) FOR Region IN ([1], [2], [3])) AS p 632_03.sql: Variante der Kreuztabelle Man erhält die angekündigte Variante der vorherigen Lösung, die nur noch vier Zeilen enthält, da ja als Zeilen nur noch vier Jahre abgerufen werden. OrderDate 1 2 3 ----------- ------------- -------------- --------------2001 2703481,7947 754833,2045 1263884,1024 4952772,2793 1406555,6861 1771532,7396 ... 2004 (4 Zeile(n) betroffen) Grundsätzlich stellt der (UN)PIVOT-Operator eine große Vereinfachung dar, welche auch nach einigen Übungen gut und schnell ins Repertoire aufgenommen werden kann. Allerdings ist das Problem noch nicht gelöst, eine dynamische Ermittlung der möglichen Ausgabespalten einzurichten. Auch bei diesem neuen Operator muss man vor der Ausführung der Abfrage wissen, dass im aktuellen Beispiel genau die Jahre zwischen 2001 und 2004 abgerufen werden. Sollte man doch einmal Werte für 2005 in der Datenbank besitzen, würde man dies nicht bemerken, weil die Abfrage nur auf diese Werte prüft. Mit einem kleinen T-SQL-Programm ist es allerdings grundsätzlich möglich, wenigstens mit ein wenig Arbeit eine dynamische Abfrage einzurichten. Dabei setzt man die benötigte SQL-Anweisung mit drei, vier oder fünf Jahren dynamisch zusammen, sodass bei jedem neuen Aufruf die aktuellen Jahre zum Einsatz kommen. Zunächst benötigt man einen Cursor für die wechselnden und eigentlich statisch anzugebenden Ausgabespalten; in diesem Fall also für die Jahre. Er dürfte in den meisten Fällen über eine DISTINCT-Abfrage erstellt werden können. Um die aktuelle Spalte, die 441 Analysen gewünschte Zeichenkette in der Form [2001], [2002] zu erstellen und auch noch die Tatsache zu berücksichtigen, dass nach dem letzten Wert des Cursors kein Komma zu Trennung der Werte benötigt wird, erstellt man hiernach eine Variable für die gerade abgerufene Spalte, eine Variable für die gesamte, sukzessiv abzubauende Zeichenkette und eine Zählervariable. Insbesondere die Zählervariable ist von einiger Bedeutung, um zu unterscheiden, ob man sich beim Abruf der Zeilen beim ersten Cursorwert, in der Cursormitte oder gar an seinem Ende befindet. Die Überprüfung kann auf unterschiedliche Weise durchgeführt werden. Im aktuellen Beispiel prüft man auf den ersten Datensatz. Es lässt sich auch eine Vorgehensweise finden, in der man den ersten Wert über eine einzelne FETCH-Anweisung abruft und danach erst die Schleife einrichtet. In jedem Fall muss man die Ausgabespalten korrekt zusammensetzen und schließlich zweimal in die auszuführende SQL-Anweisung kopieren, ehe man sie dynamisch mit EXEC ausführt. Über diesen sehr einfachen Trick gelingt es schließlich, dynamisch Pivotierungen einzurichten. -- Cursor für die Abfrage der Regionen DECLARE c_region CURSOR SCROLL FOR SELECT DISTINCT TerritoryID FROM Sales.SalesOrderHeader ORDER BY TerritoryID -- Zeichenketten für Zähler, Ausgabespalte(n) erstellen DECLARE @spalte int, @spalten varchar(255), @i int -- Vorgabewerte SET @spalten = '' SET @i = 1 -- Verarbeitung Cursor c_region OPEN c_region 442 Analysen FETCH c_region INTO @spalte WHILE (@@FETCH_STATUS = 0) BEGIN -- Zusammensetzen der Zeichenkette IF @i = 1 BEGIN SET @spalten = @spalten + '[' + LTRIM(STR(@spalte)) + ']' END ELSE BEGIN SET @spalten = @spalten + ', [' + LTRIM(STR(@spalte)) + ']' END -- Inkrementation SET @i = @i + 1 -- Nächster Abruf FETCH c_region INTO @spalte END CLOSE c_region DEALLOCATE c_region -- SQL zusammensetzen und ausführen EXEC ('SELECT OrderDate, ' + @spalten + ' FROM (SELECT TerritoryID AS Region, YEAR(OrderDate) AS OrderDate, TotalDue FROM Sales.SalesOrderHeader) AS Turnover 443 Analysen PIVOT (SUM(TotalDue) FOR Region IN (' + @spalten + ')) AS p') 632_04.sql: Dynamisches PIVOT mit T-SQL 6.3.2.2 Pivottabellen zurückwandeln In einer korrekt normalisierten und überhaupt ordentlich geplanten Datenbank sollten eigentlich keine schon vorab pivotierten Daten enthalten sein. Die einzig denkbaren Situationen, in denen es zu solchermaßen aufbereiteten Daten kommen kann, die man abrufen, verarbeiten und vor allen Dingen wieder umwandeln soll, wären Sichten und Import-Tabellen, die nur als Zwischenspeicher für bspw. pivotierte Date aus MS Excel verfügbar sind. Solche Daten lassen sich allerdings einfach mit dem UNPIVOT-Operator wieder in nicht-pivotierte Daten umwandeln. Im nächsten Beispiel erzeugt man zunächst wieder die pivotierten Daten für die Umsätze und die Jahre, in denen sie erbracht worden sind. Auf Basis dieser zwei CTEs erstellt man dann eine Abfrage, in der die beiden Spalten OrderDate und TotalDue erscheinen. Dabei soll die Spalte TotalDue wieder aus den einzelnen Spalten für die Jahre gelöscht und in einzelne Zeilen kopiert werden. Daher ruft man innerhalb des UNPIVOTOperators diese umzuwandelnde Spalte auf, nennt in FOR die Spalte, welche für die Zuordnung zu den Ausgabespalten (Jahreszahlen) genutzt wurde, und gibt in der INKlausel wieder die Werte an, die in diesen Ausgabespalten erscheinen. WITH Turnover AS ( SELECT YEAR(OrderDate) AS OrderDate, TotalDue FROM Sales.SalesOrderHeader ), [Pivot] AS ( 444 Analysen SELECT [2001], [2002], [2003], [2004] FROM Turnover PIVOT (SUM(TotalDue) FOR OrderDate IN ([2001], [2002], [2003], [2004])) AS p ) SELECT OrderDate, TotalDue FROM [Pivot] UNPIVOT (TotalDue FOR OrderDate IN ([2001], [2002], [2003], [2004])) AS p 632_05.sql: Standardfall von UNPIVOT Wie schon zuvor muss man auch bei der Umkehrung der Pivotierung unterscheiden, ob man nur eine einzige Zeile und damit eine einfach gekippte Tabelle erstellt und wieder umwandelt, oder ob man eine Kreuztabelle bearbeitet. Im nachfolgenden Beispiel erstellt man daher noch einmal eine Pivot-Tabelle, welche für die einzelnen Regionen die Umsatzzahlen für jedes Geschäftsjahr ermittelt. Diese soll dann wiederum in ihre ursprüngliche Form umgekehrt werden. Dazu gibt man in der Spaltenliste die benötigten drei Spalten der originären Tabelle Region, OrderDate und TotalDue an. Im UNPIVOT-Operator nennt man zunächst die TotalDue-Spalte, da sie die gruppierten und berechneten Werte enthält. Die Ausgabespalten werden aus der OrderDate-Spalte ermittelt, sodass diese in FOR und die erzeugten Werte in der IN-Klausel aufgezählt werden müssen. Die Region-Spalte muss dagegen gar nicht extra berücksichtigt werden, denn durch ihre Nennung in der Spalten- 445 Analysen liste und ihre Existenz in der pivotierten Tabelle berücksichtigt sie der Operator automatisch, sodass die ursprünglichen Werte wieder erscheinen. WITH Turnover AS ( SELECT TerritoryID AS Region, YEAR(OrderDate) AS OrderDate, TotalDue FROM Sales.SalesOrderHeader ), [Pivot] AS ( SELECT Region, [2001], [2002] FROM Turnover PIVOT (SUM(TotalDue) FOR OrderDate IN ([2001], [2002])) AS p ) SELECT Region, OrderDate, TotalDue FROM [Pivot] UNPIVOT (TotalDue FOR OrderDate IN ([2001], [2002])) AS p 632_06.sql: Kreuztabelle auflösen Dadurch erstellt man aus einer pivotierten Ergebnismenge wie 446 Analysen Region 2001 2002 ----------- --------------------- --------------------1 2703481,7947 5651688,6685 2 754833,2045 3275322,1694 3 1263884,1024 3518185,4756 ... (10 Zeile(n) betroffen) die ursprüngliche Darstellung, die nun bspw. aus der Zwischen-/Übernahme-/ImportTabelle in eine „korrekte“ Datenbanktabelle übernommen werden könnte. Region OrderDate TotalDue ----------- -------------- --------------1 2001 2703481,7947 1 2002 5651688,6685 2 2001 754833,2045 10 2001 322207,5294 10 2002 1778804,7452 ... (20 Zeile(n) betroffen) Schließlich ist es auch noch möglich, nicht nur die ursprünglichen Daten und ihre Struktur zu erzeugen, sondern vielmehr auch weitere Berechnungen und Umwandlungen durchzuführen, die direkt auf den pivotierten Daten basieren und im Rahmen der Umkehrung vorgenommen werden. Dies versteht sich eigentlich von selbst, soll allerdings als Anregung für eigene Arbeiten auf Basis der vom vorherigen Beispiel übernommen, aber nicht noch einmal in den beiden abgedruckten CTEs gezeigt werden. Anstatt die 447 Analysen drei Spalten Region, OrderDate und TotalDue und damit die vormalige Struktur auszugeben, beschränkt man sich in der nächsten Abfrage direkt nur auf die Regionund TotalDue-Spalte, wobei die letzte zusätzlich noch mit SUM aggregiert wird. SELECT Region, SUM(TotalDue) AS Turnover FROM [Pivot] UNPIVOT (TotalDue FOR OrderDate IN ([2001], [2002])) AS p GROUP BY Region 632_07.sql: Weitere Verarbeitung Man erhält in diesem Fall eine Ergebnismenge, die sofort einen Verarbeitungsschritt nach dem eigentlichen Unpivotieren darstellt und eine um die Jahreszahlen befreite Aggregation der Umsatzzahlen pro Region darstellt. Region Turnover ----------- --------------------1 8355170,4632 2 4030155,3739 ... 10 2101012,2746 (10 Zeile(n) betroffen) 448 Programmierbarkeit 7 Programmierbarkeit 449 Programmierbarkeit 450 Programmierbarkeit 7 Programmierbarkeit Unter dem schönen, neuen Wort ‚Programmierbarkeit’ verbirgt sich im MS SQL Server 2005 die Möglichkeit, Prozeduren, Funktionen und Trigger als T-SQL- und .NETModule zu hinterzulegen, welcher der Datenbank eine zusätzliche Schicht hinzufügen. Diese enthält in Form der genannten Module bereits einen Teil der Software, welcher die Datenbank erneut von der eigentlichen Software in bspw. .NET verbirgt. Neben dem Effekt des Verbergens und Schützens ist diese Technik auch deswegen so interessant, weil durch sie eine vereinfachte Benutzung der Datenbank gelingt. Ein typisches Beispiel ist in diesem Zusammenhang die Entwicklung einer Prozedur, welche für eine ganze Reihe an Parametern einen Einfügevorgang in eine Tabelle vereinfacht. Die äußere Software und damit auch der Programmierer ist nicht gezwungen, entsprechende INSERT-Anweisungen zu formulieren oder daran zu denken, welche Parameter für einen sinnvollen Datensatz notwendig sind. Stattdessen ruft er nur noch diese Prozedur auf, was darüber hinaus auch noch in verschiedenen Programmiersprachen gelingt. Dieses Kapitel stellt die beiden Themen Funktionen und Prozeduren vor, während Trigger dem Buch zur MS SQL Server-Administration und die Programmierbarkeit von .NET einem entsprechenden .NET-Buch vorbehalten sind. Insbesondere die Verwendung von .NET ist zwar sicherlich als Fähigkeit extrem interessant, allerdings nützt ein solches Kapitel für Leser nichts, die zunächst noch .NET an sich lernen müssten. 7.1 Prozeduren Die Erstellung von Prozeduren und Funktionen ist grundsätzlich in allen kommerziellen Großdatenbanken wie MS SQL Server oder Oracle und mittlerweile auch in Open Source-Produkten wie MySQL möglich. Während Oracle hier entweder die eigene Programmiersprache PL/SQL (eine sehr stark erweiterte Form von T-SQL) sowie auch die Verwendung von Java erlaubt, bietet hier der MS SQL Server entweder T-SQL oder .NET an. Dabei entspricht eine Prozedur einem Konstrukt, das unter vielen verschiedenen Namen wie Modul, DB-Routine, Unterprogramm oder - wie es Microsoft selbst 451 Programmierbarkeit vorschlägt - als Auflistung von T-SQL-Anweisungen, die unter einem Namen in der DB gespeichert ist. Dabei ermöglicht es eine Prozedur, nicht nur wie ein Makro mehrere Anweisungen der Reihe nach auszuführen und für einen späteren wiederholten Aufruf verfügbar zu machen, sondern bietet darüber hinaus auch die Fähigkeit, Parameter einer äußeren Anwendung entgegen zu nehmen und diese zu verarbeiten. Prozeduren erscheinen im Normalfall als permanent in der Datenbank gespeicherte Objekte, können allerdings auch wie Tabellen als temporär für eine Sitzung und global temporär für alle Sitzungen verfügbar gemacht werden. 7.1.1 Einführung Die Anweisung in T-SQL, um eine Prozedur zu erstellen, ist sehr ähnlich zur Funktionserstellung. Die Unterschiede ergeben sich in den Details und in den Einsatzbereichen. Die nachfolgende Abbildung zeigt die verschieden Arten von Prozeduren, die im MS SQL Server erstellt werden können. Auf der unteren Hälfte der Abbildung befinden sich sechs beispielhaft angegebene Tabellen, die zu zwei verschiedenen Bereichen zusammen gefasst werden. Zwischen einer Anwendung wie das schon leidlich bekannte Management Studio und einer anderen, individuell erstellten Anwendung liegt eine Schicht von Prozeduren. Sie sollen bspw. den Abruf und die Manipulation von Daten beeinflussen. Gründe können hier erhöhte Sicherheit, erweiterte Möglichkeit zur Validierung oder auch vereinfachte Benutzbarkeit von außen sein. Auf der linken Seite der drei unterschiedlichen Prozedurarten werden die drei DMLBefehle INSERT, UPDATE und DELETE aufgelistet. Sie sollen zeigen, dass Prozeduren zum Einsatz kommen können, wenn Datenmanipulation bspw. für komplexe Datenstrukturen durch das Angebot einer zentralen Zugriffsschicht von Prozeduren vereinfacht werden sollen. 452 Programmierbarkeit Individuelle Software T-SQL (Management Studio) Relationale Ergebnis Menge & Cursor Rückgabewerte Prozedur INSERT UPDATE DELETE Prozedur SELECT Prozedur DBAAufgaben Datenbank Tab 1 Tab 2 Tab 1 Tab 2 Tab 2 ... Bereich 1 Tab 3 ... Bereich 2 Abbildung 7.1: Typologie von Prozeduren Direkt rechts neben diesen Prozeduren gibt es eine weitere Gruppe. Sie wirkt sich notwendigerweise auf Tabellen aus, sofern diese Tabellen nicht Administrationsdaten speichern. Stattdessen führen sie wie Skripte in einem Server häufig wiederkehrende Aufgaben aus, die von einem Administrator ansonsten durch im Dateisystem gespeicherte Skripte oder Eingaben in der grafischen Benutzerschnittstellen durchgeführt werden müssten. Solche Prozeduren bzw. das entsprechende SQL wie bspw. MassendatenImport/-Export oder allgemeine Verwaltungsaufgaben werden im Buch zur Administration beschrieben. Diese und die DML-Prozeduren haben die Möglichkeit, Rückgabewerte zurückzuliefern. Diese können per Referenz aus der Parameterliste abgerufen werden. Dies bedeutet, dass Prozeduren nicht wie Funktionen auf der rechten Seite einer Zuweisung stehen können, sondern als eigenständige Anweisung. Dies bedeutet allerdings auch, dass Prozeduren mehrere Rückgabewerte zurückliefern können. 453 Programmierbarkeit Auf der rechten Seite schließlich wird eine Besonderheit im MS SQL Server dargestellt, welche insbesondere für Umsteiger von Oracle überraschend sein kann. Eine Prozedur bietet die Möglichkeit, relationale Ergebnismengen und Cursor zurückzuliefern. Insbesondere die erste Technik ist besonders interessant, da im Gegensatz zu Sichten hier die Möglichkeit besteht, vorgefertigte Filter über die Prozedurparameter anzubieten. Es ließe sich auch noch eine andere Ordnung für Prozeduren finden: Man kann zwischen temporären und tatsächlich gespeicherten („normalen“) Prozeduren unterscheiden, wobei innerhalb der temporären wiederum zwischen globalen und nur auf eine Sitzung bezogenen Prozeduren unterschieden werden kann. Man kann allerdings auch noch die Gruppe der so genannten erweiterten Prozeduren zählen, die früher mit C und der ODS API (ähnlich wie in C-geschriebene MySQL-Prozeduren) erstellt werden konnten, und zu denen man heute die .NET-Prozeduren zählen müsste, wenn der Begriff in der 2005-Literatur nicht weitestgehend verschwunden wäre. Man kann dann auch noch zwischen benutzerdefinierten Prozeduren und Systemprozeduren unterscheiden, wobei die eine Gruppe in diesem Kapitel besonders interessiert, weil sie über den CREATE-Befehl vom Benutzer erstellt werden können, während die anderen Prozeduren bereits wie SQL-Funktionen in der Datenbank vorhanden sind. In diesem Zusammenhang muss erwähnt werden, dass dies Prozeduren sind, deren Namen mit sp_ beginnt und die in der Master-Datenbank gespeichert werden. Diese Prozeduren können (sollten aber nicht) auch selbst erstellt werden, wobei diese dann wie ein Chamäleon arbeiten und dafür sorgen, dass auf den aktuellen DB-Kontext bezogene Anweisungen (und sei es nur der Abruf des DB-Namens wie DB_NAME()) auf die Datenbank bezogen werden, in der man sich gerade befindet, obwohl die Prozedur aus der Master-DB abgerufen wird. Schließlich gelangt man innerhalb von diesem sich abzeichnendem Baum zu der Unterscheidung, die gerade getroffen wurde, die für die Zwecke dieses Kapitels eigentlich am besten geeignet ist. Eine Prozedur wird im Standardschema des Benutzers gespeichert, sofern nicht ausdrücklich ein anderes Schema angegeben ist. Sie wird nur in der aktuellen Datenbank gespeichert. Lediglich temporäre Prozeduren speichert man automatisch in der tempdb. Um den Quelltext einer Prozedur zu sichern, kann man ebenfalls ein .sql-Skritp erstel- 454 Programmierbarkeit len, wobei man allerdings darauf achten muss, dass vorherige Anweisungen mit GO von der Anweisung CREATE PROCEDURE getrennt sind. Nachfolgend ist die allgemeine Syntax angegeben: CREATE { PROC | PROCEDURE } [schema_name.] procedure_name [ ; number ] [ { @parameter [ type_schema_name. ] data_type } [ VARYING ] [ = default ] [ [ OUT [ PUT ] ] [ ,...n ] [ WITH <procedure_option> [ ,...n ] [ FOR REPLICATION ] AS { <sql_statement> [;][ ...n ] | <method_specifier> } [;] <procedure_option> ::= [ ENCRYPTION ] [ RECOMPILE ] [ EXECUTE_AS_Clause ] <sql_statement> ::= { [ BEGIN ] statements [ END ] } <method_specifier> ::= EXTERNAL NAME assembly_name.class_name.method_name 455 Programmierbarkeit Die verschiedenen Argumente, von denen sich verschiedene bereits anhand ihres Namens verstehen lassen, sind nachfolgend aufgelistet: schema_name enthält den Namen des Schemas, in dem die Prozedur gespeichert wird. procedure_name enthält den Namen der Prozedur, der den allgemeinen Benennungsregeln entspricht und im Schema eindeutig sein muss. Das Präfix sp_ ist dabei am besten zu vermeiden, da es für gespeicherten Systemprozeduren bereits verwendet wird. Ob eine Prozedur lokal oder global temporär erstellt wird, kann man wie bei Tabellen über ein (temporär nur für die aktuelle Sitzung) oder zwei Rautenzeichen (##, global temporär für alle Sitzungen) zu Beginn des Namens festlegen. Insgesamt ist der Name auf 128 Zeichen und der Name einer lokalen temporären Prozedur inkl. dem Rautenzeichen auf 118 Zeichen begrenzt. ; number enthält eine optionale Zahl. Sie erlaubt es, mehrere Prozeduren unter dem gleichen Namen in einem Schema anzugeben. Diese unterscheiden sich in der Nummer, werden allerdings durch den gemeinsamen Namen gruppiert. Die Zahl kann auch für den Löschvorgang aller Prozeduren der Gruppe genutzt werden. Bsp.: meineProzedur;1, meineProzedur;2. Diese Eigenschaft ist auf das Abstellgleis geschoben und wird irgendwann aus der Datenbank entfernt. @parameter enthält einen Parameter der Prozedur, von dem es maximal 2100 geben darf. Sofern kein Standardwert oder ein berechneter Bezug auf einen anderen Parameter angegeben ist, ist es notwendig, beim Aufruf der Prozedur einen Wert für diesen Parameter bereitzustellen. Hier muss der Namen auch den allgemeinen Bezeichnungsregeln entsprechen und wird - ähnlich einer Variable mit Datentyp und Standardwert angegeben. [ type_schema_name. ] data_type enthält den Datentyp eines Parameters sowie sein optionales Schema. Alle Datentypen außer table können hier eingesetzt werden. Der Datentyp cursor kann nur für einen Ausgabeparameter eingesetzt werden. Die Prozedur liefert so einen Cursor zurück. 456 Programmierbarkeit VARYING kann nur für den Datentyp cursor verwendet werden und gibt an, dass die Struktur der relationalen Ergebnismenge, die zurückgeliefert wird, variieren kann. default enthält einen möglichen Standardwert für den Parameter. Dies ist eine Konstante oder auch NULL. OUTPUT legt fest, dass dieser Parameter einen Rückgabewert an die aufrufende Anweisung liefert, welcher per Referenz übertragen wird. Auch text-, ntext- und image-Parameter können verwendet werden, solange es keine .NET-Prozedur ist. RECOMPILE legt für reine T-SQL-Prozeduren fest, dass das Datenbankmodul den Ausführungsplan dieser Prozedur nicht zwischenspeichert, sondern zur Laufzeit kompiliert. ENCRYPTION legt reine T-SQL-Prozeduren fest, sodass der Quelltext, in der die Prozedur erstellt wurde, chiffriert wird und damit nur für Benutzer mit sehr weiten Rechten den Text abrufen können. AS legt fest, unter welchem Berechtigungskontext die Prozedur ausgeführt werden darf. Dabei gilt die allgemeine Syntax { EXEC | EXECUTE } AS { CALLER | SELF | OWNER | 'user_name' }. Dieses Thema wird später noch ausführlich behandelt. FOR EXECUTE REPLICATION legt fest, dass diese Prozedur nur im Rahmen von Replikationen und damit DB-Sicherungsvorgängen ausgeführt wird. Sie darf keine Parameter enthalten, ist nicht für .NET-Prozeduren zulässig, die RECOMPILEOption ist untersagt, und sie wird nicht auf dem Abonennten einer Replikation durchgeführt. <sql_statement> enthält die T-SQL-Anweisungen und damit den eigentlichen Programmtext der Prozedur. NAME , assembly_name.class_name.method_name gibt die statische Methode einer .NET-Assembly (dll) an, die als Prozedur verfügbar gemacht werden soll. EXTERNAL 457 Programmierbarkeit Um eine Prozedur zu ändern, ist anstelle der CREATE-Anweisung nur das Schlüsselwort ALTER anzugeben. Dieses sorgt dafür, dass die vorhandene Prozedur mit dem nun angegebenen Quelltext überschrieben wird. ALTER { PROC | PROCEDURE } [schema_name.] procedure_name [ ; number ] [ { @parameter [ type_schema_name. ] data_type } [ VARYING ] [ = default ] [ [ OUT [ PUT ] ] [ ,...n ] [ WITH <procedure_option> [ ,...n ] ] [ FOR REPLICATION ] AS { <sql_statement> [ ...n ] | <method_specifier> } Aus der Datenbank kann der Quelltext zur Überarbeitung aus dem Kontextmenü einer gespeicherten Prozedur abgerufen werden. Dazu wählt man SKRIPT FÜR GESPEICHERTEN PROZEDUREN ALS / ALTER IN und dann eine der drei Optionen, um den Quelltext in die Zwischenablage zu kopieren, einer Datei zu speichern oder sofort in einem neuen Abfragefenster zu öffnen. 458 Programmierbarkeit Abbildung 7.2: Abrufen eines Quelltexts zur Überarbeitung Um eine Prozedur zu löschen, ist wie sonst auch bei Schema-Objekten die DROPAnweisung einzusetzen. DROP { PROC | PROCEDURE } { [ schema_name. ] procedure } [ ,...n ] Unter dem Stichwort „verzögerte Namensauflösung“ ist das Phänomen bekannt, dass innerhalb einer Prozedur auf Tabellen oder Sichten zugegriffen werden kann, die noch gar nicht vorhanden sind. Bei der Erstellung einer Prozedur wird zwar die Syntax auf Fehler geprüft, nicht allerdings die Existenz von Schema-Objekten. Dies ist erst der Fall, wenn die kompilierte Prozedur zur ersten Ausführung kommt, was bei dann weiterhin bestehender fehlerhafter Referenzierung auch zu einem Fehler führt. 459 Programmierbarkeit 7.1.2 Prozedurarten Die verschiedenen Arten von Prozeduren sind bereits zuvor kurz in einer Abbildung vorgestellt worden. Sie sollen nun noch einmal jeweils mit einem typischen Beispiel unterlegt werden. 7.1.2.1 Rückgabe einer Ergebnismenge Eine wesentliche Eigenschaft des MS SQL Servers ist es, Prozeduren erstellen zu können, die eine relationale Ergebnismenge zurückliefern können. Dies bietet eine Sicht selbstverständlich ebenfalls an. Hier allerdings ist es notwendig, eine WHERE-Klausel selbst zu schreiben, die einen zusätzlichen Filter auf die Daten anwendet. Bei der Verwendung einer Prozedur dagegen kann man eine Reihe von Parametern vorgeben, welche typische Filter bzw. gewünschte Filterangaben (aus Sicherheits-, Validierungs- oder Bequemlichkeitsgründen) bereits vorgeben. Dies wird im nächsten Beispiel gezeigt. Die Prozedur liefert Produktinformationen anhand der Produktnummer. Kein anderer Filter ist notwendig, um an Produktdaten zu gelangen. Auch muss man die Ergebnismenge nicht so gut kennen, um einen eigenen Filter auf eine bestimmte Untermenge an Spalten anzuwenden. Lediglich die spätere Übergabe eines geeigneten Wertes ist notwendig. Die Prozedur legt man mit der CREATE-Anweisung an und hängt dann die Parameterliste an ihren Namen an. Als Parameter übergibt man eine Produktnummer, die verpflichtend ist und die auch keinen Standardwert besitzt. Mit Hilfe dieser Produktnummer sucht man in einer einfachen Abfrage verschiedene Spaltenwerte aus der Product-Tabelle heraus. Die Prozedur endet auch mit dieser Abrage, sodass sie insgesamt genau dieses relationale Ergebnis zurückliefert. -- Existenzprüfung und Erstellung einer Pozedur IF OBJECT_ID ( 'Production.usp_GetProductByNumber', 'P' ) IS NOT NULL DROP PROCEDURE Production.usp_GetProductByNumber; GO 460 Programmierbarkeit CREATE PROCEDURE Production.usp_GetProductByNumber (@vProductNumber nvarchar(25)) AS BEGIN SELECT Name,Color, ListPrice, Size FROM Production.Product WHERE ProductNumber = @vProductNumber END GO EXEC Production.usp_GetProductByNumber 'SO-B909-L' 712_01.sql: Standardprozedur Der vorherige Quelltext zeigte neben der einfachen Prozedur auch noch, wie man sie innerhalb von T-SQL aufrufen kann. Unter Angabe des Parameterwerts für ein beliebiges Paar Socken erhält man das Ergebnis genau so zurück, als hätte man eine Tabelle oder Sicht befragt. Name Color ListPrice Size ------------------------ ------- ---------- ----Mountain Bike Socks, L White 9,50 L (1 Zeile(n) betroffen) Dies war ein Beispiel zu den Prozeduren, die mit einer SELECT-Anweisung enden und daher insgesamt nicht einen Rückgabewert zurückliefern, sondern eine Abfrage ausführen. Hierbei gibt es grundsätzlich keine Beschränkungen, was den Quelltext anbetrifft, der vor der letzten Abfrage steht und welcher damit quasi das Ergebnis einleitet. Man könnte sich vorstellen, dass man eine Art Produktsuchmaschine mit Hilfe einer Prozedur realisiert, die ansonsten nur in einer äußeren Anwendung denkbar wäre. Unter Angabe eines variierenden Datentyps oder ganz einfacher Zeichenkette kann man ver- 461 Programmierbarkeit schiedene Spalten in der Product-Tabelle untersuchen und die passenden Ergebnisse in eine table-Variable speichern, welche schließlich abgefragt wird. In der ersten Abfrage könnte man die Ergebnisse beschaffen, indem der Suchbegriff in der Produktnummer gesucht wird. Die zweite Abfrage, welche die table-Variable auffüllt, könnte im Namen suchen. Wenn schließlich alle relevanten Spalten untersucht sind, die man in diese Suchmaschine aufnehmen möchte, fragt man die table-Variable ab und liefert so das gesamte Ergebnis. In der nachfolgenden Abbildung ist dieses Prinzip noch einmal dargestellt. In der unteren Hälfte befindet sich die zu Grunde liegende Tabelle in Form ihrer Daten, deren Struktur sehr viel umfassender ist, als es die Rückgabedaten der Prozedur vermuten lassen. Es ist also möglicherweise für die Anwendung, welche diese Daten über die Prozedur anspricht, gar nicht notwendig bzw. für den Benutzer möglicherweise sogar untersagt, mehr über die Daten und damit sowohl Struktur als auch Inhalte zu erfahren. Die Prozedur fragt in ihrer Eigenschaft als eigenes Schema-Objekt anstelle einer direkten Abfrage, die in der äußeren Anwendung abgesetzt wird, die Daten ab und verhindert so einen allzu großzügigen Blick auf diese Daten. 462 Programmierbarkeit Prozedur Software Grundlegende Datenstruktur Abbildung 7.3: Funktionsweise einer Prozedur 7.1.2.2 Sonstige Prozeduren Neben den zuvor erläuterten Prozeduren gibt es noch diejenigen, welche nicht die Abfragen, sondern die Datenmanipulation steuern und vereinfachen sollen. Die nachfolgende Prozedur erleichtert es bspw., ein neues Produkt einzufügen. Man könnte sich hier noch vorstellen, dass der erzeugte Primärschlüsselwert zurückgeliefert wird. Dazu setzt man die OUTPUT-Klausel ein, was in einem späteren Beispiel vorgeführt wird. Die Prozedur erwartet diejenigen Werte für ein Produkt, die man in jedem Fall benötigt und könnte auch noch mit NULL ausgestattete weitere Parameter erwarten, die in der Tabelle nicht verpflichtend sind. Solche Prozeduren sind überaus interessant, um eine vereinfachte Datenschnittstelle für Aktualisierungs- und Einfügevorgänge anzubieten. Es könnte sein, dass für eine An- 463 Programmierbarkeit wendung nicht alle Spalten relevant sind und daher nach außen nur eine begrenzte Spaltenauswahl angeboten werden soll. Es könnte genauso gut sein, dass besondere Berechnungen oder Validierungen stattfinden sollen, die nicht mit Hilfe einer CHECKBedingung realisiert werden können oder sollen. Sofern keine Trigger als automatisch ausgeführte Prozedur, die an eine Tabelle gebunden ist, zum Einsatz kommt, bietet sich eine solche Prozedur besonders an, da hier der Aspekt des vereinfachten Zugriffs zusätzlich realisiert werden kann. Das nachfolgende Beispiel zeigt nur, wie überhaupt die schon in Kapitel 4 erstellte Product3-Tabelle, die im Download-Listing ebenfalls enthalten ist und zuvor angelegt wird, gefüllt wird. Sämtliche andere T-SQL-Anweisungen sind nicht spezifisch für Prozeduren, sondern können mit der bisher gezeigten Syntax umgesetzt werden. CREATE PROCEDURE Production.usp_InsertProduct ( @vName varchar(30), @vProductNumber nvarchar(25), @vListPrice money, @vStandardCost money ) AS BEGIN INSERT INTO Production.Product3 (Name, ProductNumber, ListPrice, StandardCost) VALUES (@vName, @vProductNumber, @vListPrice, @vStandardCost) END 712_02.sql: DML-Prozedur 464 Programmierbarkeit Diese Prozedur kann man in T-SQL ebenfalls über die EXEC-Anweisung aufrufen. In diesem Fall setzt man aus Gründen der besseren Lesbarkeit allerdings ein anderes Format ein, in welchem die einzelnen Parameterwerte nicht einfach in der richtigen Reihenfolge nach dem Prozedurnamen aufgelistet werden, sondern in dem in einer Parametername-Werte-Struktur ausdrücklich auch die Parameternamen genannt werden. So kann man gut nachvollziehen, welcher Parameter welchen Wert erhalten hat. EXEC Production.usp_InsertProduct @vName = 'HL Mountain Seat Assembly', @vProductNumber = 'SA-M687', @vListPrice = 196.92, @vStandardCost = 145.87 712_02.sql: DML-Prozedur 7.1.3 Parameter und Aufruf Wie schon zuvor gezeigt, gibt es wenigstens zwei verschiedene Varianten, eine Prozedur aufzurufen und ihr Parameterwerte zu übergeben. Die eine Variante bezeichnet man als Positionsnotation, da hier die Position/Reihenfolge der Parameterwerte über ihre Zuordnung zu Prozedurparametern entscheidet. Die andere Variante bezeichnet man dagegen als Namensnotation, da in diesem Fall nur der Name über die Zuordnung entscheidet und hier also auch eine andere Reihenfolge genutzt werden kann. Insbesondere diese Namensnotation ermöglicht es auch, einfach Standardwerte aufzurufen, ohne die Parameter eigens anzusprechen. Der Aufruf einer Funktion oder Prozedur erfolgt mit der EXEC-Anweisung, welche folgende allgemeine Syntax besitzt: [{ EXEC | EXECUTE } ] { 465 Programmierbarkeit [ @return_status = ] { module_name [ ;number ] | @module_name_var } [ [ @parameter = ] { value | @variable [ OUTPUT ] | [ DEFAULT ] } ] [ ,...n ] [ WITH RECOMPILE ] } Folgende Parameter kommen zum Einsatz: @return_status erwartet eine Ganzzahl mit dem so genannten Rückgabestatus eines Moduls. Bei einer Skalarfunktion ist dies der gewöhnliche Rückgabewert, welcher in jedem beliebigen Datentyp abgerufen werden kann. module_name erwartet den (voll qualifizierten) Namen von Prozedur oder Skalarwertfunktion. ; number erwartet die nicht mehr empfohlene Nummer eines Moduls, das in einer Gruppe von gleich benannten, sich aber durch die Nummer unterscheidenden Prozeduren erstellt wurde. @module_name_var erwartet eine Variable, welche den Namen des auszuführenden Moduls für sehr dynamische Modulauswahl und -angabe enthält. @parameter erwartet den Namen eines Parameters mit voran gestelltem @- Zeichen. Sofern der Namen ausdrücklich angegeben wird, muss die Reihenfolge der Parameter von Aufruf und Deklaration nicht übereinstimmen (Namensnotation). 466 Programmierbarkeit value erwartet den zugewiesenen Wert des Parameters. Sofern nur der Wert angegeben wird, ist die Reihenfolge der Parameter in Aufruf und Deklaration einzuhalten (Positionsnotation). @variable enthält eine Variable, die den Wert eines Parameters oder Ausgabeparameters speichert. OUTPUT gibt an, dass dieser Parameter ein Ausgabeparameter ist und Werte per Referenz zurückgibt. Innerhalb des Moduls ist derselbe Parameter ebenfalls mit OUTPUT angegeben. DEFAULT gibt an, dass der Standardwert verwendet werden soll. WITH RECOMPILE lässt einen neuen Ausführungsplan kompilieren, der nach der Ausführung wieder gelöscht wird. Dies ist zu verwenden, wenn die Parameterwerte sehr unterschiedlich sind und die Daten in großem Maße geändert werden. 7.1.3.1 Standardwerte Wie auch bei Tabellen und ihren Spalten ist es bei Prozeduren ebenfalls erlaubt, Standardwerte anzugeben. Sie werden dann verwendet, wenn sie keine tatsächlichen Parameterwerte beim Aufruf überschreiben. Das nachfolgende Beispiel zeigt, wie ein solcher Standardwerte angegeben wird. Die Syntax erinnert sehr an eine Variablendeklaration, bei der die SET-Anweisung ausgelassen wurde. Inhaltlich sucht diese Prozedur wiederum Produkte heraus, wobei allerdings nicht die Produktnummer anzugeben ist, sondern stattdessen der minimale Listenpreis, die Farbe und die Produktkategorie. Diese Kategorie wird nun auf den Standardwert 1 gesetzt, so wie man sich auch noch vorstellen könnte, den Minimalpreis auf 0 zu setzen. CREATE PROCEDURE Production.usp_GetProduct ( @vListPrice money, @vColor nvarchar(15), @vCategory int = 1) 467 Programmierbarkeit AS BEGIN SELECT Name, Color, ListPrice, Size, ProductSubcategoryID FROM Production.Product WHERE Color = @vColor AND ListPrice > @vListPrice AND ProductSubcategoryID = @vCategory END 713_01.sql: Erstellung einer Prozedur mit Standardwert Das nachfolgende Skript listet dann die verschiedenen Varianten auf, in denen diese Prozedur aufgerufen werden kann. Bei der Positionsnation (erster Fall) übergibt man die Parameterwerte in der erwarteten Reihenfolge. Dies ist bei der Verwendung von Methoden in den meisten Programmiersprachen ebenfalls so geregelt. Sofern der Standardwert als letzter erscheint, kann darauf verzichtet werden. Steht er dagegen innerhalb von anderen Parametern oder sind mehrere solcher Parameter nacheinander, gibt man den Standardwert mit dem Schlüsselwort DEFAULT an (zweiter Fall). Möchte man diesen Standardwert überschreiben (dritter Fall), setzt man an seiner Stelle einfach den gewünschten Wert ein. Bei der Namensnotation (vierter Fall) schließlich muss man sich gar keine Gedanken um die Berücksichtigung von Standardwerten machen, da man hier ohnehin nur die Parameter nennt, die man auch tatsächlich mit einem Wert belegen will. -- Aufruf mit Positionsnotation und Standardwert EXEC Production.usp_GetProduct 250.00, 'Black' EXEC Production.usp_GetProduct 250.00, 'Black', default -- Aufruf mit Positionsnotation und Nicht-Standardwert EXEC Production.usp_GetProduct 250.00, 'Black', 14 -- Aufruf mit Namensnotation 468 Programmierbarkeit EXEC Production.usp_GetProduct @vColor = 'Black', @vListPrice = 250.00 713_01.sql: Aufruf eines Standardwerts 7.1.3.2 Rückgabewert Im Normalfall kommen Funktionen zum Einsatz, wenn Rückgabewerte benötigt werden. Dabei steht der Funktionsaufruf auf der rechten Seite einer Zuweisung bzw. erscheint als Ausdruck und liefert so diesen Rückgabewert direkt an eine Variable oder das diesen Ausdruck verarbeitende Ziel zurück. Eine Prozedur hingegen kann als eigenständige Anweisung fungieren, sodass es zunächst kein Ziel von Rückgabewerten gibt. Dies ist allerdings durch die Wertübergabe per Referenz und einen Parameter, der zusätzlich mit dem Schlüsselwort OUTPUT ausgezeichnet wurde, möglich. Bei einer Prozedur gibt es in diesem Zusammenhang auch keine Einschränkung bei der Anzahl an Rückgabewerten. Das nachfolgende Beispiel zeigt zum einen, wie ein solcher Rückgabewerte eingerichtet, mit einem Wert gefüllt auch in der äußeren Anwendung (in diesem Fall T-SQL) abgerufen wird. Die Prozedur soll wieder Produktinformationen liefern, wobei diese allerdings in Form einer zusammenfassenden Zeichenkette zurückgeliefert werden sollen. Dazu gibt es den dritten Parameter, der mit OUTPUT ausgezeichnet wurde. Die anderen beiden Parameter bilden wie zuvor den Minimalpreis und die Farbe ab. Eigentlich müsste man einen Cursor erstellen, um alle Produktinformationen zusammen abzurufen und bspw. als HTML-Text aufzubereiten, doch um das Beispiel zu verkürzen werden nur die Werte des ersten abgerufenen Datensatzes abgerufen und im Rückgabeparameter zusammen gesetzt. CREATE PROCEDURE Production.usp_GetProduct ( @vListPrice money, @vColor nvarchar(15), @vSummary nvarchar(255) OUTPUT) 469 Programmierbarkeit AS BEGIN -- Variablen deklarieren DECLARE @vName nvarchar(50), @vDetails nvarchar(505) -- Daten abrufen SELECT @vName = Name, @vDetails = Color + ' ' + STR(ListPrice) FROM Production.Product WHERE Color = @vColor -- Output-Parameter setzen SET @vSummary = @vName + ' ' + @vDetails END 713_02.sql: Erstellung eines Rückgabewerts Um einen solchen Rückgabewert abzurufen, benötigt man außen zunächst eine entsprechende Variable, die einen für den Rückgabewert geeigneten Datentyp besitzt. Diese Variable wird bei der Positionsnotation einfach ebenfalls mit dem Schlüsselwort OUTPUT an die Stelle in der Parameterliste gesetzt, an der ein Rückgabeparameter erwartet wird. Bei der Namensnotation dagegen ist die Position grundsätzlich egal, weil vor Nennung der Variablen auch noch der Parametername angegeben werden muss. Das Schlüsselwort OUTPUT bleibt bestehen. Nach dem Aufruf ist die zuvor deklarierte und mit keinem Wert versehene Variable gefüllt. Ein möglicher vorhandener Wert wäre überschrieben worden. -- Aufruf mit Output-Parametern DECLARE @vProductText nvarchar(255) 470 Programmierbarkeit EXEC Production.usp_GetProduct 300.00, 'Black', @vProductText OUTPUT PRINT @vProductText -- Aufruf mit Namensnotation EXEC Production.usp_GetProduct @vColor = 'Blue', @vListPrice = 220.00, @vSummary = @vProductText OUTPUT PRINT @vProductText 713_02.sql: Abruf eines Rückgabewerts 7.1.3.3 Hinweise für ADO.NET Auch wenn dieses Buch einen Bogen um .NET schlägt, um Nicht-.NET-Benutzer nicht mit zuviel Papier über für sie uninteressante Programmiersprachen zu ärgern, sollen doch einige kurze Hinweise folgen, wie denn diese Prozeduren in einer .NETAnwendung mit ADO abgerufen werden können. Vorausgesetzt wird also, dass innerhalb einer MS SQL Server-Datenbank eine ganze Schicht an unterschiedlichen Prozeduren gibt, die (laut offizieller Lesrichtung) das Leben der Daten sicherer und das Leben des Programmierers einfacher gestalten. Mit den folgenden Techniken kann man die beschriebenen Ergebnisse einer Prozedur abrufen. Dabei müsste noch einmal angemerkt werden, dass sie natürlich grundsätzlich keinen Rückgabewert erzeugen muss, dass dieser aber allein aus Gründen der Kontrolle sehr nützlich ist. Einfache Ergebnismenge: Eine Prozedur erzeugt eine einfache Ergebnismenge, wenn sie nach einigen T-SQL-Anweisungen schließlich mit einer SELECTAnweisung endet. Ein Objekt der Klasse SqlDataReader sowie ein Objekt der Klasse SqlDataAdapter kann bei bestehender und permanenter DB-Verbindung eine solche Ergebnismenge abrufen. Von DataSet abgeleitet, gibt es noch die 471 Programmierbarkeit DataTable-Klasse, deren Objekte auch in einem Kontext ohne permanente DB- Verbindung mit den zwischengespeicherten Daten arbeiten können. Auch sie können diese Daten empfangen. Mehrere Ergebnismengen: Eine Prozedur kann mehrere Ergebnismengen zurückliefern, wenn innerhalb der Anweisungen tatsächlich mehrere SELECTAnweisungen durchgeführt werden, die zur Rückgabe von Ergebnismengen führen. Diese können abgerufen werden, wenn man von der SqlDataReader-Klasse die NextResult()-Methode verwendet. Ausgabeparameter: Ein Objekt der Klasse SqlCommand besitzt eine Collection namens Parameters, in denen sich die veschiedenen Parameterarten befinden. Sie haben die Typen bzw. Richtungen Input, Output, InputOutput oder ReturnValue. Die Ausgabeparameter, die von einer MS SQL Server-Prozedur zurückgeliefert werden, benötigen die Richtung InputOutput, da sie auch Werte in die Prozedur bringen können, die vor einem Überschreibevorgang auch zunächst gelesen werden können. Die anderen Parameter werden mit Input übergeben. Ein Rückgabewert wird mit der ReturnValue-Richtung eines SqlParameterObjekts abgerufen. Anzahl betroffener Reihen: Sofern die Option SET NOCOUNT ON vom Benutzer eingesetzt wird, ist es nicht möglich, die Anzahl betroffener Reihen direkt von der Datenbank zu erhalten, weil die Ausgabe unterdrückt wird. Die Eigenschaft RecordsAffected eines SqlDataReader-Objekts lässt sich zwar in DMLAnweisungen verwenden, allerdings nicht bei SELECT. Darüber hinaus liefert es die Menge aller betroffenen Zeilen von allen DML-Anweisungen einer Prozedur, sodass hier keine Differenzierung möglich ist. Die beste Möglichkeit besteht darin, für alle DML-Anweisungen, deren Anzahl betroffener Reihen nach außen gemeldet werden sollen, einen eigenen Ausgabeparameter anzugeben. Den Wert ermittelt man dann unmittelbar nach der Anweisung über den Aufruf der Systemfunktion (globale Variable) @@rowcount. 472 Programmierbarkeit Fehler: Um Fehler abzurufen, muss man lediglich mit try und catch arbeiten, sodass der Prozeduraufruf innerhalb von try liegt. Sollte hier ein Fehler (Schweregrad größer als 10) zurückgeliefert werden, verlagert dies die Ausführung in den catch-Block. Hier kann man dann das SqlException-Objekt untersuchen, welches eine Errors-Collection mit SqlError-Objekten besitzt. Dieses besitzt wiederum die beiden Eigenschaften Number und Message. Warnungen: Eine Warnung ist eine Fehlermeldung mit einem Schweregrad kleiner gleich 10. Es wird ein InfoMessage-Ereignis vom SqlConnection-Objekt ausgelöst, wenn eine Warnung ausgegeben wird, der wiederum ein SqlInfoMessageEventArgs-Objekt übergeben wird. Dieser Parameter besitzt eine Errors-Collection, die analog zu derjenigen von SqlException verarbeitet werden kann. Ausgabe mit PRINT: Dies gelingt über die gleiche Technik wie bei Warnungen. XML-Ausgabe: ADO.NET 2.0 empfängt zurückgegebene XML-Daten einer Spalte im SqlDataReader-Objekt. Wird nur XML zurückgegeben, kann man auch ein XmlReader-Objekt verwenden, wobei zuvor vom SqlCommand-Objekt die besondere Methode ExecuteXmlReader() verwendet werden muss. Benutzerdefinierte Datentypen (UDT): Im Rahmen der .NET-Unterstützung bietet der MS SQL Server 2005 nun für die Erstellung von objektrelationalen Strukturen auch an, eigene Datentypen mit .NET-Klassen zu erstellen. Diese können ebenfalls wie alle anderen Spalten- oder Parametertypen abgerufen werden, solange der Quelltext der Klasse beim Klienten ebenfalls verfügbar ist. Dies ist in Form einer DLL der Fall. Struktur der Ergebnismenge abrufen: Der SqlDataReader in ADO.NET 2.0 erlaubt es, die Metadaten der Ergebnismenge mit der Methode GetSchemaTable() abzurufen. Sie liefert ein DataTable-Objekt mit diesen Metadaten. 473 Programmierbarkeit 7.1.4 Sonderfälle Als die allgemeine Syntax vorgestellt wurde, gab es noch verschiedene zusätzliche Schlüsselwörter und Anweisungen, welche eine Prozedur betreffen können. Sie sollen in diesem Abschnitt vorgestellt werden. 7.1.4.1 Neukompilierung Wie schon in der allgemeinen Syntax erwähnt, bestimmt die Option WITH RECOMPILE, dass das Datenbankmodul den erzeugten Abfrageplan, d.h. die vordefinierte und normalerweise die Geschwindigkeit positiv beeinflussende Art und Weise der (wiederholten) Ausführung zu verwerfen. Dies zwingt den Abfrageoptimierer, bei jeder Abfrage einen neuen Plan zu kompilieren, da dieser nicht zwischengespeichert wird. Sofern gar nicht ein neuer Abfrageplan für die gesamte Prozedur erstellt werden soll, sondern nur für eine einzelne Anweisung innerhalb derselben, können sie außer bei INSERT auch direkt in einer einzelnen Abfrage auf der obersten Ebene angegeben werden. Dies gelingt über die Anweisung OPTION ( <query_hint> [ ,...n ] ), welche der gesamten Abfrage folgt und in diesem Fall das einfache Schlüsselwort RECOMPILE enthält. CREATE PROCEDURE Production.usp_GetProductByNumber (@vProductNumber nvarchar(25)) WITH RECOMPILE AS BEGIN ... 714_01.sql: Neukompilierung bei Ausführung 7.1.4.2 Verschlüsselung Der Quelltext der Prozedur kann normalerweise über die Prozedur sp_helptext abgerufen werden. Es besteht allerdings die Möglichkeit, diesen Quelltext zu verschlüsseln, was über die Klausel ENCRYPTION gelingt. Benutzer ohne Zugriff auf die Systemtabellen können dann den Prozedurquelltext nicht mehr abrufen. 474 Programmierbarkeit CREATE PROCEDURE Production.usp_GetProductByNumber (@vProductNumber nvarchar(25)) WITH ENCRYPTION AS BEGIN ... GO EXEC sp_helptext 'Production.usp_GetProductByNumber' 714_02.sql: Verschlüsselung bei Erstellung Man erhält bei einem Aufruf der sp_helptext-Prozedur den mysteriösen Hinweis: Der Text für das 'Production.usp_GetProductByNumber'-Objekt ist verschlüsselt. 7.1.4.3 Cursor-Rückgabe Eine besonders schöne Technik neben der Rückgabe von relationalen Ergebnismengen ist die Rückgabe eines Cursors, der dann in der äußeren Anwendung (hauptsächlich TSQL) verarbeitet werden kann. Dies soll am nachfolgenden Beispiel demonstriert werden. Zunächst muss ein Parameter wiederum mit dem Schlüsselwort OUTPUT versehen werden, weil es sich ja tatsächlich um einen Ausgabeparameter handelt. Als Datentyp verwendet man CURSOR und VARYING, wenn die Struktur Ergebnismenge wechselnd ist. In diesem Zusammenhang wird also die schon verwendete Prozedur usp_GetProduct noch einmal abgewandelt. Weder eine Ergebnismenge noch eine zusammenfassender Text wird ausgegeben, sondern stattdessen ein Cursor, der die Tabelle Product anbietet und sie vorab mit Hilfe der anderen Parameter für Listenpreis, Farbe und Kategorie gefiltert hat. Innerhalb der Prozedur öffnet man den als Cursor schon bekannt gemachten Ausgabeparameter über die SET-Anweisung und fügt die CURSOR-Klausel sowie natürlich die ihn konstituierende Abfrage hinzu. Vielmehr ist nicht mehr zu tun als den Cursor 475 Programmierbarkeit schließlich als letzte Anweisung der Prozedur über OPEN zu öffnen. Dies sorgt dafür, dass man in der äußeren Anwendung Zugriff auf diese Daten erhält. CREATE PROCEDURE Production.usp_GetProduct ( @vListPrice money, @vColor nvarchar(15), @vCategory int = 1, @cProducts CURSOR VARYING OUTPUT) AS BEGIN SET @cProducts = CURSOR FORWARD_ONLY STATIC FOR SELECT Name, Color, ProductSubcategoryID FROM Production.Product WHERE Color = @vColor AND ListPrice > @vListPrice AND ProductSubcategoryID = @vCategory OPEN @cProducts END 714_05.sql: Rückgabe eines Cursors Interessant ist nun natürlich, wie man einen solch ungewöhnlichen Ausgabeparameter in der äußeren Anwendung nutzen kann. Dazu erstellt man eine Variable mit dem Datentyp CURSOR, verzichtet allerdings darauf, auch eine Abfrage anzugeben. Diese Variable setzt man dann an die Stelle des Ausgabeparameters beim Aufruf der Prozedur, indem man das OUTPUT-Schlüsselwort anschließt und die richtige Position oder den entsprechenden Parameternamen für die Zuordnung wählt. 476 Programmierbarkeit Da der Cursor bereits innerhalb der Prozedur geöffnet wurde, kann man unmittelbar mit der FETCH-Anweisung den ersten Datensatz abrufen und dann über die WHILE-Schleife die schon bekannte Verarbeitung durchführen. Nach dieser Verarbeitung schließt man den Cursor wieder in äußeren Anwendung und gibt den Speicher frei. - Cursor und einfache Variablen erstellen DECLARE @cProductsOut CURSOR, @vName varchar(50), @vColor nvarchar(15), @vCategory int -- Prozedur ausführen EXEC Production.usp_GetProduct @cProducts = @cProductsOut OUTPUT, @vListPrice = 150, @vColor = 'Black' -- Abrufen 1 FETCH NEXT FROM @cProductsOut INTO @vName, @vColor, @vCategory -- Schleife WHILE (@@FETCH_STATUS = 0) BEGIN -- Abrufen 2..n FETCH NEXT FROM @cProductsOut INTO @vName, @vColor, @vCategory PRINT @vName + ' ' + @vColor END 477 Programmierbarkeit -- Aufräumen CLOSE @cProductsOut DEALLOCATE @cProductsOut 714_05.sql: Abruf eines Cursors 7.2 Funktionen Neben den Prozeduren gibt es auch noch die Möglichkeit, benutzerdefinierte Funktionen zu erstellen. Beide Modularten haben – wie in allen Datenbanken, die überhaupt solche Strukturen anbieten – große Gemeinsamkeiten. Daher werden viele Aspekte bereits bekannt sein, weswegen die Darstellung von Funktionen ein wenig kürzer ausfallen kann. Eine Funktion kann als Ausdruck, auf der rechten Seite einer Zuweisung (was ebenfalls ein Ausdruck ist) oder auch in einer FROM-Klausel erscheinen. Die ersten beiden Möglichkeiten sollten angesichts der verschiedenen, schon in der Datenbank vorhandenen Systemfunktionen sowie natürlich aufgrund der gängigen SQL-Funktionen schon bekannt sein. Neu ist möglicherweise die Überlegung, dass solche Funktionen auch vom Benutzer erstellt werden und direkt in SQL-Anweisungen wie bspw. SELECT aufgerufen werden können. Neu dürfte auch sein, dass eine Funktion innerhalb einer FROM-Klausel anstelle einer Tabelle auftreten kann. In diesem Sinne ähnelt sie einer Prozedur, die eine relationale Ergebnismenge zurückgibt, welche wiederum mit zusätzlichen Filtern, Sortierungen und Gruppierungen sowie auch Spaltenauswahlen genutzt wird. Eine Prozedur hingegen könnte an dieser Stelle niemals stehen, sondern bildet bereits die gesamte Abfrage an. Ein wesentlicher Unterschied von Funktionen und Prozeduren besteht darin, dass eine Funktion den Status einer Datenbank nicht ändern kann. Die folgende Liste enthält Anweisungen, die innerhalb einer benutzerdefinierten Funktion überhaupt zulässig sind: 478 Variablendeklarationen und zugehörige Zuweisungen, sowie Kontroll-strukturen und gängige T-SQL-Programmstrukturen außer Ausnahme-behandlung. Die Erstellung von Cursorn ist dagegen erlaubt. Programmierbarkeit SELECT-Anweisungen, welche ihre Werte lokalen Variablen zuweisen, sowie die Verarbeitung von Cursorn. Nutzung von lokalen Cursorn, die also innerhalb der Funktion erstellt und wieder gelöscht werden. Die Rückgabe von Cursorn an den Klienten sowie die Nutzung von Prozedur-Cursorn ist nicht zulässig. INSERT-, UPDATE- und DELETE-Anweisungen, die sich auf lokale table- Variablen auswirken. Eine Änderung von tatsächlichen DB-Tabellen ist in Funktionen nicht gestattet. EXECUTE-Anweisungen, die gespeicherte Prozeduren aufrufen, sofern sie die oben angegebenen Regeln nicht verletzen, oder erweiterte gespeicherte Prozeduren. Funktionen können daher verschiedene Eigenschaften haben, die ihnen automatisch zugewiesen werden und die sich aus der Gesamtheit der in ihnen enthaltenen T-SQLAnweisungen ergeben. Folgende Anweisungen sind in 2005 verfügbar: IsDeterministic meint, dass eine Funktion bei gleichen Eingabedaten und gleichem Datenbankstatus das gleiche Ergebnis liefert. Solche Funktionen, die aktuelle Informationen wie Uhrzeiten abrufen, sind bspw. nicht deterministisch. IsPrecise prüft die Nutzung von Gleitkommatransaktionen, die in unpräzisen Funktionen auftreten. IsSystemVerified gibt an, ob die Präzisions- und Determinismus-eigenschaften vom MS SQL Server geprüft werden können. SystemDataAccess gibt an, ob die Funktion in der lokalen MS SQL Server- Instanz auf Systemdaten wie den Systemkatalog oder virtuelle Systemtabellen zugreift. UserDataAccess prüft, ob eine Funktion auf Benutzerdaten in der lokalen Instanz von SQL Server zugreift, wobei benutzerdefinierte und temporäre Tabellen, aber keine Tabellenvariablen eingeschlossen sind. 479 Programmierbarkeit Die nachfolgende Abbildung ist analog zu derjenigen, welche bereits bei Prozeduren zum Einsatz kam, aufgebaut. Sie stelle die verschiedenen Arten von Funktionen sowie ihre typische Verwendungsweise vor. Auf der rechten Seite befindet sich wieder ein Datenbanksymbol, welches zeigen soll, dass sich diese Funktionen nicht in der Software, sondern vielmehr in der Datenbank selbst befinden. Oben sieht man zwei Kästen, von denen der eine bspw. in .NET geschriebene, individuelle Software und der andere ein beliebiges T-SQL-Skript, wie es im Management Studio ausgeführt werden kann, symbolisiert. Beide können die verschiedenen Prozeduren in T-SQL-Anweisungen, die zur Datenbank geschickt werden, aufrufen. Individuelle Software T-SQL (Management Studio) Relationale Ergebnismenge Rückgabewerte Tabellenwertfunktion SELECT Skalarfunktionen Datenbank Tab 1 Tab 2 Tab 1 Tab 2 Tab 2 ... Bereich 1 Tab 3 ... Bereich 2 Abbildung 7.4: Typologie von Funktionen Man unterscheidet im Wesentlichen zwei Arten von benutzerdefinierten Funktionen, die wie die Prozeduren zuvor als Rauten innerhalb der Abbildung zu sehen sind: 480 Programmierbarkeit Skalarfunktionen entsprechen bekannten SQL-Funktionen, welche auf Basis keines, eines oder mehrerer Parameter einen Rückgabewert zurückliefern, der überall dort, wo ein Ausdruck erwartet wird, benutzt werden kann. Diese Funktionen können ihre Werte aus Tabellen abrufen; sie können dagegen allerdings auch beliebige Berechnungen ohne Tabellenbezug ausführen. Tabellenwerfunktionen dagegen führen eine SELECT-Anweisung aus und liefern meist auf Basis einer oder mehrerer Tabellen ein relationales Ergebnis zurück. Da diese Funktionen innerhalb einer FROM-Klausel aufgerufen werden, können alle möglichen SELECT-Techniken auf diese Daten angewandt werden. .NET-Funktionen: Es ist möglich, in .NET geschriebene Funktionen aus DLLs im MS SQL Server zu speichern und genauso zu verwenden wie in T-SQL geschriebene. Dies wird allerdings nicht in diesem Buch erläutert, weil natürlich .NET-Kenntnisse erforderlich sind. An dieser Stelle folgte bei der Darstellung der Prozeduren die allgemeine Syntax für CREATE, ALTER und DROP. Wenn Funktionen vorgestellt werden, ist dies jedoch nicht sinnvoll, weil die zwei verschiedenen Arten von Funktionen eine unterschiedliche Erstellungs-/Änderungssyntax aufweisen. Sie folgt später in eigenen Abschnitten. Gleich bleibt für alles Irdische jedoch die Löschung: DROP FUNCTION { [ schema_name. ] function_name } [ ,...n ] 7.2.1 Skalare Funktionen Eine skalare Funktion liefert einen Wert zurück, sodass sie überall dort, wo ein Ausdruck erwartet wird, aufgerufen werden kann. Man erstellt sie ebenfalls über den CREATE-Befehl und kann sie in einem Schema speichern. Parameter werden mit ihrem Namen und dem vorangestellten @-Zeichen angegeben, können auch einen Standardwert aufweisen oder natürlich NULL sein. Ein solcher Standardwert muss allerdings beim Aufruf in einer SQL-Anweisung immer auch mit default angegeben werden. Man kann nicht wie bei einer Prozedur diese Parameter auslassen. Die Besonderheit einer skalaren Funktion besteht darin, dass sie einen Rückgabewert besitzt und dass dessen 481 Programmierbarkeit Datentyp in der RETURNS-Klausel angegeben ist. Danach folgt nach einem optionalen AS innerhalb von BEGIN und END die Reihe an T-SQL-Anweisungen, welche die Funktion speichert und die mit einer RETURN-Anweisung enden, welche den Rückgabewert schließlich zurückliefern. Dies erinnert insgesamt sehr an eine Methode gängiger Programmiersprachen. CREATE FUNCTION [ schema_name. ] function_name ( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type [ = default ] } [ ,...n ] ] ) RETURNS return_data_type [ WITH <function_option> [ ,...n ] ] [ AS ] BEGIN function_body RETURN scalar_expression END [ ; ] Ein Beispiel soll diese Technik zeigen. Zunächst prüft man mit Hilfe der OBJECT_IDFunktion, ob die entsprechende Funktion überhaupt schon in der Datenbank vorhanden ist, um sie ggf. zu löschen. Dabei ist zu beachten, dass die verschiedenen Funktionsarten 482 Programmierbarkeit eigene Testwerte haben. Eine skalare Funktion prüft man bspw. mit der Zeichenkette FN. Die Funktion soll nun endlich ein Problem in Angriff nehmen, das während des bisher noch keine Berücksichtigung fand: die Währungsrechnung. Innerhalb der Bestellungen, die von Kunden eingehen, gibt es eine Verknüpfung zu einer Währungstabelle namens CurrenyRate, welche historisierte Wechselkurse enthält, und die wiederum mit einer Tabelle Currency verbunden ist. Sie enthält die Namen von Währungen. Die Funktion ufnGetBuyerCurrency erwartet die Nummer eines Verkaufs sowie einen Währungsbetrag in Dollar, der umgerechnet werden soll. Da in einem Datensatz der SalesOrderHeader-Tabelle mehrere Spalten vom Datentyp money enthalten sind, soll diese Funktion dynamisch zwar den zurzeit der Bestellung gültigen Wechselkurs ermitteln - doch die Summe, die umgerechnet werden soll, wird als Wert übergeben. So kann man diese Funktion für die Gesamtsumme genauso wie für die Steuerlast oder die Frachtkosten nutzen. Innerhalb der Funktion steht ein letztlich ganz gewöhnliches TSQL-Skript, welches den für die übergebene Bestellnummer gültigen Wechselkurs ermittelt, die Berechnung durchführt und diese schließlich in der RETURNS-Klausel zurückliefert. Letztlich ist es nur die RETURNS-Klausel, welche dieses innere Skript von einem nicht gespeicherten unterscheidet. An seiner Stelle hätte man möglicherweise sonst eher die PRINT-Anweisung verwendet. -- Auf Existenz prüfen und ggf. löschen IF OBJECT_ID (N'dbo.ufnGetBuyerCurrency', N'FN') IS NOT NULL DROP FUNCTION dbo.ufnGetBuyerCurrency GO -- Erstellen CREATE FUNCTION ufnGetBuyerCurrency( @salesOrderID int, 483 Programmierbarkeit @sum money ) RETURNS varchar(15) AS BEGIN -- Lokale Variablen DECLARE @averageRate float, @currency varchar(5) -- SQL-Anweisungen SELECT @averageRate = cr.AverageRate, @currency = cr.ToCurrencyCode FROM Sales.SalesOrderHeader AS sh INNER JOIN Sales.CurrencyRate AS cr ON sh.CurrencyRateID = cr.CurrencyRateID WHERE sh.SalesOrderID = @salesOrderID -- Rückgabe RETURN RTRIM(LTRIM(STR(@sum * @averageRate) + ' ' + @currency)) END 721_01.sql: Skalarwertfunktion Spektakulär ist nun insbesondere, dass die doch sehr schwierige Umrechnung aufgrund der Verknüpfungen völlig in der Funktion gekapselt ist und die ansonsten im Buch 484 Programmierbarkeit vermiedene Berücksichtigung der tatsächlichen Währungen überaus einfach in dieser Funktion durchgeführt wird. Dies alles gelingt in einem T-SQL-Programm genauso gut, lässt sich aber gerade auch in einer gewöhnlichen SELECT-Anweisung nutzen. Andere typische SQL-Anweisungen könnten hier ebenfalls mit dieser Funktion umgangen werden. So wäre es möglich, den einzutragenden oder zu aktualisierenden Wert mit Hilfe dieser Funktion zu erzeugen. SELECT SalesOrderID, dbo.ufnGetBuyerCurrency(SalesOrderID, SubTotal) AS SubTotal, dbo.ufnGetBuyerCurrency(SalesOrderID, TaxAmt) AS Tax, dbo.ufnGetBuyerCurrency(SalesOrderID, Freight) AS Freight, dbo.ufnGetBuyerCurrency(SalesOrderID, TotalDue) AS Total FROM Sales.SalesOrderHeader WHERE SalesOrderID IN (43661, 43662) 721_01.sql: Skalarwertfunktion testen Man erhält für die beiden angeforderten Bestellungen die jeweiligen Werte in kanadischen Dollar. SalesOrderID SubTotal Tax Freight Total ------------ ------------ --------- --------------- --------43661 57718 CAD 4617 CAD 1443 CAD 63778 CAD 485 Programmierbarkeit 43662 50789 CAD 4063 CAD 1270 CAD 56122 CAD (2 Zeile(n) betroffen) 7.2.2 Tabellenwertfunktion Die zweite Gruppe an Funktionsarten wird aus den beiden verschiedenen Arten von Tabellenwertfunktionen gebildet. Man kann sie als parametrisierte Sicht verstehen, da hier auf der einen Seite eine gespeicherte Abfrage unter einem eigenen Namen existiert, diese hingegen auf der anderen Seite über Parameterwerte gefiltert werden kann. Im Gegensatz zu einer Sicht oder einer gewöhnlichen Tabelle ist hier also für die Filterung zunächst keine WHERE-Klausel notwendig, weil die vom Besitzer der Funktion als wesentlich erachteten Filtermöglichkeiten schon vorgegeben wurden und besonders einfach in ihrer Verwendung sind. Davon ist unberührt, zusätzliche Filterungen in der WHERE-Klausel anzugeben. 7.2.2.1 Einfache Tabellenwertfunktion Die erste Untergruppe der Tabellenwertfunktionen bezeichnet man als „einfach,“ weil hier der Charakter einer Sicht besonders deutlich zum Tragen kommt. Diese Funktion besitzt die Möglichkeit, Parameter anzulegen, die durch einen Datentyp beschrieben sind und einen Standardwert oder NULL enthalten können. Im Gegensatz zu den Skalarfunktionen kündigt man hier den Rückgabewert in der RETURNS-Klausel mit dem Datentyp table an. Bei einer einfachen Tabellenwertfunktion folgt hier nun kein BEGIN…END-Block, sondern lediglich nach einem optionalen AS die SELECT-Anweisung nach dem Schlüsselwort RETURN. Sie kann zwar die verschiedenen Parameter enthalten und auch eine stattliche Größe erreichen, doch alles, was sich nicht in einer einzelnen SELECT-Anweisung ausdrücken lässt, ist dann für diese einfache Form nicht mehr geeignet. CREATE FUNCTION [ schema_name. ] function_name ( [ { @parameter_name [ AS ] [ type_schema_name. ] 486 Programmierbarkeit parameter_data_type [ = default ] } [ ,...n ] ] ) RETURNS TABLE [ WITH <function_option> [ ,...n ] ] [ AS ] RETURN [ ( ] select_stmt [ ) ] [ ; ] Als Beispiel möchte man nun die zuvor über die Skalarfunktion erstellte Ausgabe weiter verwenden und unter Angabe der Bestellnummer, welche einfach weitergereicht wird, die zuvor erzeugte Abfrage zurückliefern. -- Auf Existenz prüfen und ggf. löschen IF OBJECT_ID (N'dbo.ufnGetBuyerCurrencyTable', N'IF') IS NOT NULL DROP FUNCTION dbo.ufnGetBuyerCurrencyTable GO -- Erstellen CREATE FUNCTION ufnGetBuyerCurrencyTable ( @salesOrderID int ) RETURNS table 487 Programmierbarkeit AS -- Unmittelbares RETURN, kein BEGIN..END RETURN ( SELECT SalesOrderID, dbo.ufnGetBuyerCurrency(SalesOrderID, SubTotal) AS SubTotal, dbo.ufnGetBuyerCurrency(SalesOrderID, TaxAmt) AS Tax, dbo.ufnGetBuyerCurrency(SalesOrderID, Freight) AS Freight, dbo.ufnGetBuyerCurrency(SalesOrderID, TotalDue) AS Total FROM Sales.SalesOrderHeader WHERE SalesOrderID = @salesOrderID) GO 722_01.sql: Einfache Tabellenwertfunktion erstellen Der Aufruf ist dann besonders einfach möglich, indem in der FROM-Klausel die entsprechende Funktion aufgerufen wird. Sie empfängt dann den Parameter, der eine Bestellnummer darstellt. SELECT * FROM dbo.ufnGetBuyerCurrencyTable(43661) 722_01.sql: Tabellenwertfunktion testen Wie gerade eben in der Test-Abfrage gesehen, liefert der Asterikus (*) alle Spaltennamen, wie sie in der SELECT-Anweisung innerhalb der Funktion angegeben wurden. Über die Angabe von Aliasnamen in der Funktion kann man hie also die Spaltennamen ändern. Darüber hinaus erkennt man an der nachfolgenden Ausgabe, dass weitere SQL- 488 Programmierbarkeit Anweisungen innerhalb der SELECT-Anweisung, welche die Funktion aufruft, genau über die Spaltennamen eingegeben werden können. SalesOrderID SubTotal Tax Freight Total ------------ ---------- --------- ---------- ----------43661 57718 CAD 4617 CAD 1443 CAD 63778 CAD (1 Zeile(n) betroffen) 7.2.2.2 Erweiterte Tabellenwertfunktion Als erweiterte Tabellenwertfunktion bezeichnet man tatsächlich eine erweiterte Form der zuvor angegebenen. Sie besitzt ebenfalls die Möglichkeit, Parameter über die bekannte Methode anzugeben, präsentiert allerdings eine ganz andere Form der RETURNSAnweisung. Sie dient auf der einen Seite dazu, die Rückgabevariable vom Typ table zu deklarieren, um sie später auffüllen zu können, und auf der anderen Seite auch die Struktur der Tabelle anzugeben. Innerhalb dieser Tabellendefinition folgt die übliche Auflistung an Spaltennamen und Datentypen, wie sie auch innerhalb einer tableDefinition üblich ist, weil es sich ja auch genau um diesen Datentyp handelt. Diese erweiterte Form der Tabellenwertfunktionen erlaubt es dann, in ihrem BEGIN…ENDBlock, wie in einer Prozedur beliebigen T-SQL-Anweisungen zu verwenden. Die Tabellenvariable füllt man dann wie jede andere Variable vom Typ table über DMLOperationen auf, aktualisiert die Daten oder löscht sie. Diese Tabelle wir dann quasi zurückgeliefert – quasi deshalb, weil die RETURN-Klausel leer ist und die Rückgabevariable schon in der RETURNS-Klausel angekündigt wurde. CREATE FUNCTION name( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type [ = default ] } [ ,...n ] ] 489 Programmierbarkeit ) RETURNS @return_variable TABLE < table_type_definition > [ WITH <function_option> [ ,...n ] ] [ AS ] BEGIN function_body RETURN END [ ; ] Die Tabellenvariable kann man über die folgende allgemeine Syntax beschreiben und gleichzeitig anlegen: <table_type_definition>, ( { <column_definition> <column_constraint> , | <computed_column_definition> } , [ <table_constraint> ] [ ,...n ], ) } Das nächste Beispiel zeigt, wie man eine solche erweiterte Tabellenfunktion erstellt, mit der grundsätzlich alle Anforderungen umgesetzt werden können. Sie soll eine relational fragwürdige, dafür allerdings als table-Variable lohnenswerte Darstellung von Abteilungen und zugehörigen Mitarbeitern erstellen. Innerhalb der RETURNS-Klausel definiert man den Aufbau der zurück gelieferten Tabellenstruktur, welche aus zwei Spalten für die Abteilung und drei Spalten für den Mitarbeiter besteht. Innerhalb der Anweisungen der Funktion gibt es dann einen Cursor, der verarbeitet wird und welcher die Daten so in die Tabellenvariable einfügt, dass beim Abruf durch die NULL-Werte automatisch auch eine Gruppierung (ähnlich eines kleinen Berichts) stattfindet. Dass genau diese Tabellenvariable, deren Werte über solche Anweisungen wie INSERT, UPDATE oder 490 Programmierbarkeit DELETE erstellt oder bearbeitet werden, an den Klienten geliefert werden soll, ist bereits im Kopf der Funktion angegeben, und muss daher nicht noch einmal in der RETURNKlausel angegeben werden. -- Existenzprüfung IF OBJECT_ID (N'dbo.ufnGetEmployeesTable', N'TF') IS NOT NULL DROP FUNCTION dbo.ufnGetEmployeesTable GO -- Erstellung CREATE FUNCTION dbo.ufnGetEmployeesTable ( @vGroupName nvarchar(50) ) -- Genaue Angabe der Rückgabestruktur RETURNS @retEmployees TABLE ( GroupName nvarchar(50) NULL, DepName nvarchar(50) NULL, EmployeeID int NULL, EmpTitle nvarchar(50) NULL, EmpName nvarchar(255) NULL ) AS BEGIN -- Variablen- und Cursor-Deklaration DECLARE @vDepID int, @vDepName nvarchar(20) DECLARE cDepartment CURSOR FOR 491 Programmierbarkeit SELECT DepartmentID, Name FROM HumanResources.Department WHERE GroupName = @vGroupName -- Öffnen und Vorab-Laden OPEN cDepartment FETCH NEXT FROM cDepartment INTO @vDepID, @vDepName -- Schleife WHILE @@FETCH_STATUS = 0 BEGIN -- Einfügen Kopfzeile einer Abteilung INSERT INTO @retEmployees (GroupName, DepName) VALUES (@vGroupName, @vDepName) -- Einfügen Mitarbeiterzeilen INSERT INTO @retEmployees (EmployeeID, EmpTitle, EmpName) SELECT emp.EmployeeID, emp.Title, FirstName + ' ' + LastName FROM HumanResources.Employee AS emp INNER JOIN Person.Contact AS c ON emp.ContactID = c.ContactID 492 Programmierbarkeit INNER JOIN HumanResources.EmployeeDepartmentHistory AS dep ON dep.EmployeeID = emp.EmployeeID WHERE dep.DepartmentID = @vDepID -- Nächster Abruf FETCH NEXT FROM cDepartment INTO @vDepID, @vDepName END -- Aufräumen CLOSE cDepartment DEALLOCATE cDepartment -- Leere Rückgabe bzw. Rückgabe der Tabelle RETURN END 722_02.sql: Erweiterte Tabellenfunktion Schließlich setzt man diese Tabellenwertfunktion genauso ein wie die vorherige. Innerhalb der FROM-Klausel kann man sie nun unter Angabe eines Abteilungsgruppennamens, zu dem eine Reihe von Untergruppen gehören, aufrufen. Interessant ist auch hier, zu sehen, wie nicht alle Spalten der zurückgelieferten Tabelle genutzt werden, sondern nur drei. SELECT GroupName, DepName, EmpName FROM dbo.ufnGetEmployeesTable('Manufacturing') 722_02.sql: Erweiterte Tabellenfunktion abrufen 493 Programmierbarkeit Man erhält eine Ausgabe, die möglicherweise auch besser zeigt, welche Art Datenstruktur überhaupt gewählt wurde: wie eine Überschrift kann man Ober- und Untergruppe der Abteilung sehen, unter die sich dann die einzelnen Datensätze der Angestellten anfügen. Dies ist relational zwar bedenklich, wird aber von vielen Datenbanksystemen genau auf diese Weise automatisch im Bereich der automatischen Berichtserstellung angeboten. GroupName DepName EmpName -------------- ---------------------- ----------------Manufacturing Production NULL NULL NULL Guy Gilbert NULL NULL JoLynn Dobney Manufacturing Production Control NULL NULL NULL Peter Krebs NULL NULL A. Scott Wright 7.2.3 Optionen Die Funktionen besitzen noch verschiedene zusätzliche Optionen, von denen nur zwei (ENCRYPTION und EXECUTE AS) wiederum mit denen von Prozeduren und von denen eine mit Sichten (SCHEMABINDING) übereinstimmen. Sie sollen hier vergleichend dargestellt und dann für die Funktionsoptionen mit Beispielen erläutert werden. Folgende Optionen sind für eine Funktion möglich: <function_option>::= { [ ENCRYPTION ] | [ SCHEMABINDING ] | [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ] 494 Programmierbarkeit | [ EXECUTE_AS_Clause ] } Folgende Optionen sind für eine Prozedur möglich: <procedure_option> ::= { [ ENCRYPTION ] [ RECOMPILE ] [ EXECUTE_AS_Clause ] } Zur Erinnerung: Für Prozeduren legte RECOMPILE fest, dass kein Ausführungsplan gespeichert wird, weil davon auszugehen war, dass keine sinnvolle Annahmen über den Wert der Parameter getroffen werden konnten und daher die Berücksichtigung des ansonsten die Ausführung beschleunigenden Ausführungsplans die Ausführung tatsächlich nur behindern würde. Mit der Klausel EXECUTE AS konnte man den so genannten Sicherheitskontext festlegen, was später noch einmal im Zusammenhang erläutert wird. Mit ENCRYPTION konnte man festlegen, dass der Quelltext verschlüsselt wird und nur mit großen Berechtigungen wieder lesbar gemacht wird. Für Funktionen gibt es neben diesen schon von Prozeduren bekannten Optionen noch die folgenden weiteren: SCHEMABINDING legt fest, dass Funktionen, die in anderen Objekten, welche gleichfalls schemagebunden sind, nicht gelöscht werden können. RETURN NULL ON NULL INPUT liefert bei Funktionsaufruf mit lauter NULL- Werten als Parameter automatisch den Wert NULL zurück, ohne die Funktion überhaupt auszuführen. Die Standardvariante CALLED ON NULL INPUT führt dagegen die Funktion aus. 7.2.3.1 Schemabindung Das Konzept der Schemabindung, das auch für Sichten existiert, in diesem Buch allerdings nicht ausführlich erläutert wurde, nun aber für Funktionen wenigstens eingeführt werden soll, könnte man mit der referenziellen Integrität von Daten und den entspre- 495 Programmierbarkeit chenden Beziehungen zwischen Tabellen vergleichen. Hat man eine Funktion erstellt, die nicht nur im Rahmen von T-SQL-Anweisungen und wieder anderen Prozeduren, Funktionen oder Triggern genutzt wird, sondern die sogar bei der Erstellung von Sichten und Tabellen als Skalarfunktion zum Einsatz kommt, dann ist es wichtig, dass man sie nicht einfach löschen oder so verändern kann, dass die von ihr abhängigen Objekte ungültig werden. In einer Sicht kann eine solche Funktion sowohl als Skalar- als auch in Form einer Tabellenwertfunktion erscheinen, wenn die Sicht eine solche Funktion in einer Spalte für eine Berechnung aufruft oder als Abfragequelle benutzt. In einer Tabelle kann sie für berechnete Spalten oder CHECK-Bedingungen zum Einsatz kommen. In allen anderen Objekten kann sie in diversen T-SQL-Anweisungen zum Einsatz kommen. Was soll nun geschehen, wenn die Funktion gelöscht wird, obwohl eine Sicht/Tabelle weiterhin diese Funktion nutzt? Wie kann eine Prozedur funktionieren, wenn die wichtigste Berechnung in Form der Funktion nicht mehr korrekt ausgeführt wird? Als Antwort gibt es zwei Alternativen: Es gibt bei Ausführung eine sehr unangenehme Fehlermeldung, oder es gibt einen automatischen bzw. vom Benutzer eingerichteten Mechanismus, der das Löschen verhindert. Dies entspricht der referenziellen Integrität, in der ein Datensatz der Eltern-Tabelle ebenfalls nicht gelöscht werden kann, wenn noch ein Kind-Datensatz auf ihn verweist. Dies kann man einrichten oder auch unterlassen - mit dem Ergebnis, eine sehr flexible Datenbank ohne Ärger bei Löschoperationen zu besitzen, die allerdings schnell dazu neigt, völlig inkonsistent zu werden. Mit der Option SCHEMABINDING legt man nun fest, dass die Funktion an DB-Objekte gebunden ist, welche auf diese Funktion verweisen. Dadurch sind Lösch- und Änderungsoperationen untersagt. Folgende Bedingungen müssen zutreffen, wenn die Schemabindung genutzt werden soll: Bei der Funktion muss es sich um eine in T-SQL geschriebene Funktion handeln. Andere benutzerdefinierte Funktionen und Sichten, welche die Funktion nutzen, müssen gleichfalls schemagebunden sein. Verweise auf andere Objekte innerhalb der Funktion sind mit dem zweiteiligen Namen schema.name angegeben. 496 Programmierbarkeit Die abhängigen Objekte und die Funktion gehören zur selben Datenbank. Der Benutzer, welche die Funktion erstellt hat, besitzt die REFERENCESBerechtigung für die DB-Objekte, auf die die Funktion verweist. In der Datei 723_01.sql befindet sich ein vollständiges Beispiel, in dem verschiedene Teile der vorherigen Beispiele aufgegriffen werden, um es leichter verständlich zu machen. Daher ist es allerdings auch nicht vollständig abgedruckt, um den Blick auf das wesentliche zu lenken. Zunächst erstellt man eine Funktion mit Schemabindung, die wiederum die bekannte Währungsumrechnung unter dem schon bekannten Namen durchführt. -- Auf Existenz prüfen und ggf. löschen IF OBJECT_ID (N'Sales.ufnGetBuyerCurrency', N'FN') IS NOT NULL DROP FUNCTION Sales.ufnGetBuyerCurrency GO -- Funktion mit Schema-Bindung erstellen CREATE FUNCTION Sales.ufnGetBuyerCurrency ( @salesOrderID int, @sum money ) RETURNS varchar(15) WITH SCHEMABINDING AS BEGIN ... 723_01.sql: Anlegen einer Funktion mit Schemabindung 497 Programmierbarkeit Danach erstellt man eine ebenfalls schemagebundene Sicht, welche die gerade erstellte Funktion aufruft. Dies wäre dann auch ein Beispiel, in dem man eine Sicht und eine Tabellenwertfunktion miteinander vergleichen kann, denn grundsätzlich liefert die Sicht auch die verschiedenen Bestellungen mit ihren umgerechneten Preisspalten. -- Sicht erstellen, welche die Funktion benötigt IF OBJECT_ID (N'Sales.vBuyerCurrency', N'V') IS NOT NULL DROP VIEW Sales.vBuyerCurrency GO CREATE VIEW Sales.vBuyerCurrency WITH SCHEMABINDING AS SELECT SalesOrderID, Sales.ufnGetBuyerCurrency(SalesOrderID, SubTotal) AS SubTotal, ... 723_01.sql: Anlegen einer Sicht mit Schemabindung Nachdem man die Sicht erfolgreich getestet hat, versucht man, die Funktion zu löschen, womit man genau die Regeln der Schemabindung verletzt. -- Test von Sicht und gleichzeitig der Funktion SELECT * FROM Sales.vBuyerCurrency WHERE SalesOrderID BETWEEN 43661 AND 43663 GO -- Löschversuch der Funktion 498 Programmierbarkeit DROP FUNCTION Sales.ufnGetBuyerCurrency 723_01.sql: Test und Löschversuch der Funktion Man erhält die sehr deutliche Fehlermeldung: Meldung 3729, Ebene 16, Status 1, Zeile 1 Das DROP FUNCTION von 'Sales.ufnGetBuyerCurrency' ist nicht möglich, da das 'vBuyerCurrency'-Objekt darauf verweist. In de Datei 723_02.sql findet man das gesamte Beispiel noch einmal, wobei hier allerdings die gesamte Schemabindung entfernt wurde. Alles funktioniert hervorragend und genauso wie zuvor. Sogar der Löschversuch gelingt problemlos. Lediglich der Test, ob denn die Sicht nach dem Löschen der Funktion noch ausgeführt wird, bringt folgende Fehlermeldung, die es an Deutlichkeit ebenfalls nicht zu wünschen übrig lässt, hervor. Auch wenn man sie wohlwollend liest, muss man zugeben, dass Schemabindung überaus nützlich zu sein scheint. Meldung 4121, Ebene 16, Status 1, Zeile 1 Die "Sales"-Spalte oder die benutzerdefinierte Funktion bzw. das benutzerdefinierte Aggregat "Sales.ufnGetBuyerCurrency" wurde nicht gefunden, oder der Name ist mehrdeutig. Meldung 4413, Ebene 16, Status 1, Zeile 1 Die Sicht oder Funktion 'Sales.vBuyerCurrency' konnte aufgrund von Bindungsfehlern nicht verwendet werden. 7.2.3.2 NULL-Werte ausgeben Schließlich gibt es noch zwei Optionen, die sich mit der Übergabe von NULL-Werten beschäftigen. Die Standardvariante CALLED ON NULL INPUT gibt vor, dass die Funktion durchaus aufgerufen werden soll, wenn alle übergebenen Parameter NULL sein sollten. Wenn innerhalb der Prozedur dafür Sorge getragen wurde, dass ein sinnvoller Wert oder auch NULL als geeigneter Rückgabewert ermittelt wird, dann ist dies auch 499 Programmierbarkeit durchaus sinnvoll. Die Variante RETURNS NULL ON NULL INPUT dagegen liefert automatisch den Wert NULL zurück, wenn alle übergebenen Werte NULL sind. Dies ist dann interessant, wenn die Funktion in einem solchen Fall tatsächlich NULL zurückliefern soll und die Ausführung der Funktion zu lange dauert. Durch den fehlenden Aufruf erhält man das gleiche Ergebnis bei deutlich kürzerer Gesamtausführungszeit. Das nachfolgende Beispiel kann durch Ändern der Kommentare bei gleich bleibender Ausführung zu ganz anderen Ergebnissen kommen und dieses Phänomen eindrucksvoll vorführen. Wenn die Option RETURNS NULL ON NULL INPUT vorgeben ist, dann liefert der Aufruf mit lauter NULL-Werten tatsächlich NULL, obwohl ganz am Ende der Funktion in einer Fallunterscheidung dieser Wert extra abgefangen und in den Zahlwert 0 umgewandelt wird. Im anderen Fall sorgt die Option CALLED ON NULL INPUT dafür, dass die Funktion – wie sonst auch – ausgeführt wird und im Fall von lauter NULLWerten der Zahlwert 0 ausgegeben wird, wie ihn die Fallunterscheidung ermittelt. CREATE FUNCTION Sales.ufnGetBuyerCurrency ( @salesOrderID int, @sum money ) RETURNS varchar(15) -- Liefert NULL bei Angabe eines NULL-Preises WITH RETURNS NULL ON NULL INPUT -- Liefert den Wert ermittelten Wert 0 (Standard) --WITH CALLED ON NULL INPUT AS BEGIN ... -- Rückgabe 500 Programmierbarkeit SET @result = RTRIM(LTRIM(STR(@sum * @averageRate) + ' ' + @currency)) IF @result IS NULL BEGIN RETURN '0' END RETURN @result END 723_03.sql: Einstellungen für NULL-Parameter Der Aufruf sollte dann mit folgender Anweisung getestet werden: SELECT Sales.ufnGetBuyerCurrency(NULL, NULL) 7.2.4 APPLY-Operator Es gibt noch einen weiteren neuen Operator, der zur T-SQL-Syntax der Version 2005 hinzugefügt wurde, und der innerhalb der FROM-Klausel genutzt werden kann. Dabei kann man diesen Operator sowohl mit Unterabfragen als auch mit Tabellenwertfunktionen nutzen. Die allgemeine Syntax lautet: left_table_source { CROSS | OUTER } APPLY right_table_source Beide Ausdrücke links und rechts vom APPLY-Operator stellen Tabellenausdrücke dar. Dabei können beide Ausdrücke neben Unterabfragen auch Tabellenwertfunktionen enthalten. Die rechte kann als Argument eine ganze Spalte aus dem Tabellenausdruck auf der linken Seite empfangen. Dies ist für die linke nicht möglich. Sofern keine solche Tabellenwertfunktion genutzt wird, kommt für den rechten Tabellenausdruck eine korrelierte Unterabfrage zum Einsatz kommen. Die Funktionsweise des Operators lässt sich wie folgt beschreiben: Der rechte Ausdruck wertet den linken Ausdruck aus, um Ergebnisse zu ermitteln. Dies lässt sich entweder durch eine Korrelation erklären oder durch die Übergabe von Rückgabewerten. Da er 501 Programmierbarkeit insbesondere für die Nutzung mit Funktionen geschaffen wurde, wird er in diesem Kapitel beschrieben. Das erste Beispiel zeigt allerdings zunächst seine Funktionsweise anhand von zwei Unterabfragen und damit auch diese Einsatzalternative. Auf der linken Seiten des Operators ruft man die Tabelle ProductSubcategory auf. Sie liefert die Eingabedaten für den rechten Ausdruck, der in Form einer Korrelationsunterabfrage auftritt. Dabei handelt es sich um die Daten aus der Product-Tabelle, welche zu den Kategorien aus dem linken Tabellenausdruck passen. Anstelle eines solchen Operators hätte man im Normalfall einfach beide Tabellen über einen INNER JOIN verbunden, um das gleiche Ergebnis zu erzielen. Der Operator CROSS sorgt dafür, dass nur die Datensätze, welche in beiden Tabellen Treffer finden, in die Ergebnismenge kommen. SELECT sc.Name AS Category, p.Name, ProductNumber FROM Production.ProductSubcategory AS sc CROSS APPLY (SELECT Name, ProductNumber, Color, Size FROM Production.Product WHERE ProductSubCategoryID = sc.ProductSubCategoryID) AS p WHERE sc.Name LIKE '%Bike%' 724_01.sql: APPLY und Unterabfrage Im nächsten Beispiel soll das Schlüsselwort OUTER präsentiert werden, welches inhaltlich so funktioniert wie ein OUTER JOIN. Die nachfolgende Abfrage beschafft alle Produktdaten und zeigt – aufgrund der LEFT OUTER JOIN-Verknüpfung – für diejenigen Produkte, die einer Kategorie zugeordnet sind, auch die entsprechende Kategorie an. In der WHERE-Klausel beschränkt man dies auf diejenigen Datensätze, die keiner Kategorie zugeordnet sind. In der zweiten Lösung geschieht dies über die gleiche Abfrage wie zuvor, wobei hier einfach nur OUTER APPLY verwendet wird. 502 Programmierbarkeit SELECT * FROM Production.Product AS p LEFT OUTER JOIN Production.ProductSubcategory AS sc ON p.ProductSubcategoryID = sc.ProductSubcategoryID WHERE p.ProductSubcategoryID IS NULL SELECT p.Name, p.ProductNumber, sc.Name FROM Production.Product AS p OUTER APPLY (SELECT * FROM Production.ProductSubcategory AS sc WHERE p.ProductSubcategoryID = sc.ProductSubcategoryID) AS sc WHERE p.ProductSubcategoryID IS NULL 724_01.sql: APPLY und Unterabfrage Solange gewöhnliche Tabellen, Sichten oder Unterabfragen zum Einsatz kommen können, ist es sicherlich empfehlenswert, die Standard-Techniken zu benutzen. Das nachfolgende Beispiel allerdings zeigt, wie man mit Hilfe einer Tabellenwertfunktion den APPLY-Operator nutzen kann. Die Funktion ufnGetProducts() erwartet eine SubCategoryID und liefert für diesen Schlüsseln die zugeordneten Produkte in Form einer Tabelle, bestehend aus dem Produktnamen, Nummer, Größe und Farbe. Nachdem die Funktion erstellt wurde, lässt sie sich rechts vom APPLY-Operator verwenden. Eine linksseitige Verwendung ist auch erlaubt, wobei hier allerdings kein sol- 503 Programmierbarkeit cher Übergabewert möglich ist. Anstelle einer Korrelation wie zuvor übergibt man den vom linksseitigen Tabellenausdruck gelieferten Wert der Unterkategorienummer. CREATE FUNCTION dbo.ufnGetProducts ( @SubCategoryID int ) RETURNS table AS RETURN ( SELECT Name, ProductNumber, Color, Size FROM Production.Product WHERE ProductSubCategoryID = @SubCategoryID) GO SELECT sc.Name AS Category, p.Name, ProductNumber FROM Production.ProductSubcategory AS sc CROSS APPLY dbo.ufnGetProducts(sc.ProductSubCategoryID) AS p WHERE sc.Name LIKE '%Bike%' 724_01.sql: APPLY und Tabellenwertfunktion 7.3 Verwaltungsarbeiten Die Abschnitt gibt neben ausführlichen Hinweisen zur Sicherheit von Modulen auch zusätzliche Informationen, wie Informationen über Funktionen und Prozeduren abgerufen werden können. 7.3.1 Katalogsichten für Objekte Die Abfrage SELECT * FROM sys.sql_modules liefert eine Aufstellung der in der jeweiligen Datenbank, in der Abfrage ausgeführt wird, vorhandenen Funktionen, Prozeduren und Trigger. Es handelt sich dabei um eine so genannte Katalogsicht, welche 504 Programmierbarkeit Daten über das System in relationaler Form liefern, die ansonsten nur in der Oberfläche abgerufen werden können. Folgende Spalten sind in der Ergebnismenge enthalten: object_id (int) enthält eine in der Datenbank eindeutige ID des Objekts. definition (nvarchar(max)) enthält den T-SQL-Quelltext des Moduls oder NULL, wenn es verschlüsselt ist. uses_ansi_nulls (bit) gibt an, ob das Modul mit SET ANSI_NULLS ON erstellt wurde und ist immer 0 für Regeln und Standardwerte. uses_quoted_identifier (bit) gibt an, ob das Modul mit SET QUOTED_IDENTIFIER ON erstellt wurde. is_schema_bound (bit) gibt an ob, das Modul mit der Option SCHEMABINDING erstellt wurde. uses_database_collation (bit) liefert 1, wenn die richtige Auswertung der schemagebundenen Definition des Moduls abhängig von der Standardsortierung der Datenbank ist, ansonsten 0. Sollte hier eine Abhängigkeit bestehen, wird eine Änderung der Standardsortierung der Datenbank verhindert. is_recompiled (bit) gibt an, ob die Prozedur mit der Option WITH RECOMPILE erstellt wurde. null_on_null_input (bit) gibt an, ob das Modul so erstellt wurde, dass die Übergabe von NULL-Werten der Wert NULL folgt. execute_as_principal_id (int) liefert die ID des Besitzers in EXECUTE AS. Der Standardwert ist NULL oder EXECUTE AS CALLER. Ansonsten wird die ID des Benutzers bei EXECUTE AS SELF oder EXECUTE AS <user> geliefert. Der Wert -2 entsteht bei EXECUTE AS OWNER. 505 Programmierbarkeit Die Abfrage SELECT * FROM sys.objects liefert die benutzerdefinierten Objekte und u.a. Funktionen und Prozeduren, aber keine Trigger, da sie nicht schemagebunden sind. Trigger findet man dagegen in sys.triggers. In einigen Spalten werden mit Hilfe von Buchstabenkürzeln Objekttypen angegeben. Dies sind die folgenden, wobei .NET-bezogene nicht in diesem Buch erklärt wurden und einige Objekte im DBA-Buch zu finden sind: AF = Aggregatfunktion (.NET), C = CHECK-Einschränkung, D = DEFAULT (Einschränkung oder eigenständig), F = FOREIGN KEY-Einschränkung, PK = PRIMARY KEY-Einschränkung, P = Gespeicherte SQLProzedur, PC = Prozedur (.NET), FN = SQL-Skalarfunktion, FS = Skalarfunktion (.NET), FT = Tabellenwertfunktion (.NET), R = Regel (Version 2000, eigenständig), RF = Replikationsfilterprozedur, SN = Synonym, SQ = Dienstwarteschlange, TA = DML-Trigger (.NET), TR = DML-Trigger, IF = Einfache Tabellenwertfunktion, TF = Tabellenwertfunktion, U = Tabelle (benutzerdefiniert), UQ = UNIQUE-Einschränkung, V = Sicht, X = Erweiterte gespeicherte Prozedur, IT = Interne Tabelle. Die gleiche Struktur weisen die Sichten sys.system_objects sys.all_objects auf. Diese Struktur besteht aus folgenden Spalten: und name (sysname) enthält den Objektnamen. object_id (int) enthält die innerhalb der Datenbank eindeutige Objekt-ID. schema_id (int) enthält die Schema-ID, in dem das Objekt enthalten ist. Für die in Version 2005 vorhandenen Systemobjekte in einem Schema ist dies immer IN (schema_id('sys'), schema_id('INFORMATION_SCHEMA'). principal_id (int) enthält die Besitzer-ID, falls es nicht der Schemabesitzer ist, oder NULL bei folgenden Objekten: C, D, F, PK, R, TA, TR, UQ parent_object_id (int) enthält die Eltern-Objekt-ID oder 0. type (char(2)) enthält den Objekttyp: AF, C, D, F, PK, P, PC, FN, FS, FT, R, RF, SN, SQ, TA, TR, IF, TF, U, UQ, V, X, IT 506 Programmierbarkeit type_desc (nvarchar(60)) beschreibt das Objekt mit den folgenden Werten: AGGREGATE_FUNCTION, CHECK_CONSTRAINT, FOREIGN_KEY_CONSTRAINT, DEFAULT_CONSTRAINT, PRIMARY_KEY_CONSTRAINT, SQL_STORED_PROCEDURE, CLR_STORED_PROCEDURE, SQL_SCALAR_FUNCTION, CLR_SCALAR_FUNCTION, CLR_TABLE_VALUED_FUNCTION, RULE, REPLICATION_FILTER_PROCEDURE, SYNONYM, SERVICE_QUEUE, CLR_TRIGGER, SQL_INLINE_TABLE_VALUED_FUNCTION, USER_TABLE, SQL_TRIGGER, SQL_TABLE_VALUED_FUNCTION, UNIQUE_CONSTRAINT, VIEW, EXTENDED_STORED_PROCEDURE, INTERNAL_TABLE create_date (datetime) enthält das Erstelldatum. modify_date (datetime) enthält das letzte Änderungsdatum über ALTER oder durch einen Index. is_ms_shipped (bit) gibt an, ob es eine interne SQL Server-Komponente ist. is_published (bit) gibt an, ob das Objekt veröffentlicht wurde. is_schema_published (bit) gibt an, ob nur das Schema des Objekts veröffentlicht wurde. Die Sicht sys.procedures liefert eine Zeile für jede Prozedur vom Typ sys.objects.type = P, X, RF und PC. Zusätzlich zu den Spalten von sys.objects gibt es noch folgende Spalten: is_auto_executed (bit) liefert bei Prozeduren in der master-DB 1, wenn die Prozedur Serverstart automatisch ausgeführt wird, sonst 0. is_execution_replicated (bit) gibt an, ob die Ausführung der Prozedur repliziert wird. is_repl_serializable_only (bit) gibt an, ob die Ausführung der Prozedur nur repliziert wird, wenn die Transaktion serialisiert werden kann. 507 Programmierbarkeit skips_repl_constraints (bit) gibt an ob, die Prozedur Einschränkungen überspringt, die mit NOT FOR REPLICATION angegeben sind. 7.3.2 Funktionen Neben den zuvor vorgestellten Katalogsichten gibt es noch verschiedene Funktionen, mit deren Hilfe Objekteigenschaften abgefragt werden können. Die Funktion OBJECT_ID() liefert die Objekt-ID eines Objekts. Die allgemeine Syntax lautet: OBJECT_ID ( '[ database_name . [ schema_name ] . | schema_name . ] object_name' [ ,'object_type' ] ) Das nächste Beispiel prüft auf Existenz und ermittelt dann weitere Daten. IF OBJECT_ID (N'AdventureWorks.Production. usp_GetProduct', N'P') IS NOT NULL BEGIN SELECT OBJECT_ID(N'AdventureWorks.Production. usp_GetProduct') AS 'Object ID' SELECT name, type_desc FROM sys.procedures WHERE [Object_ID] = OBJECT_ID(N'AdventureWorks. Production.usp_GetProduct') END 732_01.sql: Abrufen der Objekt-ID Man erhält als Ergebnis: 508 Programmierbarkeit Object ID ----------320720195 name type_desc ----------------- ---------------------usp_GetProduct SQL_STORED_PROCEDURE Die Funktion OBJECT_NAME() liefert den Objektnamen. Die Funktion hat die allgemeine Syntax: OBJECT_NAME ( object_id ) Im nächsten Beispiel ermittelt man den Objektnamen über die ID. SELECT * FROM sys.objects WHERE name = OBJECT_NAME( OBJECT_ID(N'Production.usp_GetProduct')) 732_01.sql: Ermittlung des Objektnamens OBJECTPROPERTY() mit der allgemeinen Syntax OBJECTPROPERTY ( id , property ) liefert jede beliebige Eigenschaft zu einem Objekt zurück. Darunter fallen die Art des Objekts, seine unterschiedlichen Zustände und seine möglichen Zustände. Die Liste enthält so viele Einträge, dass auf die Dokumentation verwiesen wird. Es lässt sich allerdings mit Sicherheit jede Information abrufen, die benötigt wird. Die Eigenschaft wird als Zeichenkette erwartet und stammt aus der in der Dokumentation aufgeführten Liste. Die Rückgabewerte sind meistens 1 für TRUE und 0 für False. In wenigen Ausnahmen gibt es noch weitere Werte. Die Funktion OBJECTPROPERTYEX ( id , property ) liefert weitere Eigenschaften zurück. Sollten die Eigenschaften in der vorherigen Funktion nicht verfügbar sein, 509 Programmierbarkeit dann kann man noch Hoffnung haben, in der ebenfalls beeindruckend langen Liste dieser Funktion fündig zu werden. Die Funktion OBJECT_DEFINITION ( object_id ) liefert den Quelltext und ähnelt damit der Prozedur sp_helptext [ @objname = ] 'name' [ , [ @columnname = ] computed_column_name ]. Die Prozedur sp_help [ [ @objname = ] 'name' ] liefert schließlich eine relationale Ergebnismenge, d.h. eine Tabelle zurück, in der ebenfalls verschiedene Informationen zu einem Objekt aufgeführt sind. Die Tabellenstruktur ist bei den einzelnen Objektarten sehr unterschiedlich. 7.3.3 Sicherheit Die Ausführung von gespeicherten Prozeduren beinhaltet verschiedene sicherheitsrelevante Aspekte, da hier kleine Softwarebausteine direkt in der Datenbank ausgeführt werden, deren gespeicherte Anweisungen verschiedene Schema-Objekte ansprechen können. Dies betrifft grundsätzlich alle Datenbanken, in denen Prozeduren erstellt werden können. Hier muss man sich lediglich vorstellen, dass ein Benutzer einem anderen Benutzer die Ausführrechte an seiner Prozedur erteilt, welche in ihren Anweisungen eigentlich für den ausführenden Benutzer verbotene Schema-Objekte benutzt. Im Normalfall greift eine Reihe von T-SQL-Anweisungen nacheinander auf mehrere Objekte zu. Wenn diese Objekte nicht nur Tabellen sind, sondern auch Prozeduren und Funktionen, ist es leicht vorstellbar, dass innerhalb dieser Module wiederum auf anderen Module bzw. wenigstens auf Tabellen oder Sichten zugegriffen wird. Dies wird als Kette bezeichnet, da ein Objekt das nächste aufruft. Dabei gelten besondere Sicherheitsregeln, die nicht denen entsprechen, als hätte ein Benutzer, der die Kette angestoßen hat, selbst die einzelnen Objekte angesprochen. Mit dem Begriff der Besitzkette wird nun das Prinzip beschrieben, dass die von einem Objekt nachfolgend aufgerufenen Objekte mit Hilfe einer speziellen Sicherheitsverwaltung tatsächlich aufrufbar sind. So soll ein Leistungsabfall vermieden werden, der entstehen würde, wenn permanent einzelne Berechtigungsprüfungen durchgeführt werden, wie dies bei einem getrennten, nacheinander erfolgenden Aufruf der Fall wäre. 510 Programmierbarkeit Wird innerhalb einer Kette aufgerufen, dann prüft der MS SQL Server zunächst, ob der Besitzer (= Benutzer) des aufrufenden Objekts auch tatsächlich der Besitzer des aufgerufenen Objekts ist. Ist dies der Fall, hat der Besitzer (=Benutzer) auch die entsprechenden Berechtigungen am nachfolgend aufgerufenen Objekt und die Berechtigungen werden nicht weiter ausgewertet. Was soll allerdings geschehen, wenn dies nicht der Fall ist? Der MS SQL Server 2000 prüfte hier zunächst danach, ob die gespeicherte Prozedur und die angesprochenen Objekte im gleichen Schema liegen, ob die Aktivität statisch ist und damit kein dynamisches SQL enthält und ob schließlich die Aktivität nur DMLOperationen (SELECT, INSERT, UPDATE und DELETE) enthält oder eine andere gespeicherte Prozedur aufruft. Trafen alle Fälle zu, so konnte ein anderer Benutzer, der nur die Ausführrechte einer Prozedur, aber keine direkten Rechte an den durch die Prozedur bearbeiteten Objekten besaß, sehr wohl die Prozedur benutzen. Im MS SQL Server 2005 wurde dieses Berechtigungskonzept zunächst übernommen, sodass hier Abwärtskompatibilität und Vergleichbarkeit vorherrscht. Allerdings bietet die neue Version auch nun verfeinerte Vorgabemöglichkeiten bei der Prozedurerstellung. Schließlich ist es auch möglich, datenbankübergreifende Besitzverkettungen zu ermöglichen. Sie ist standardmäßig deaktiviert. In der Abbildung soll das Grundproblem noch einmal grafisch dargestellt werden: Verschiedene Objekte haben verschiedene Besitzer, wobei Benutzer B selbst gar kein Besitzer irgendeines Objekts ist, sondern er nur von Benutzer A die Berechtigungen erhalten hat, die Prozedur von Benutzer A auszuführen. In (1) ist er autorisiert, die Prozedur auszuführen, weil er die Berechtigung von A erhalten hat. Diese Prozedur ruft in (2) eine Sicht von Benutzer C ab, wobei nun allerdings die vollständigen Berechtigungen abgerufen werden, weil sich beide Besitzer unterscheiden. Sofern hier auch Benutzer B für die Sicht autorisiert ist, werden die Daten zurückgeliefert. Diese Sicht wirkt sich nun wiederum in (3) auf eine Tabelle aus, deren Besitzer Benutzer D ist. Da hier erneut ein Besitzerwechsel stattfindet, müssen die gesamten Berechtigungen abgerufen werden, und auch Benutzer B wird auf Nutzungsberechtigung dieser Tabelle überprüft. Schließlich ist in (4) auch noch die datenbankübergreifende Besitzverkettung dargestellt, die hier funktioniert, weil sie entsprechend aktiviert wurde. Benutzer B hat die 511 Programmierbarkeit Berechtigung von Benutzer A an dieser Sicht und darf daher sogar von einer anderen DB die Daten abrufen. Die Besitzkette ist also mehrfach unterbrochen, weil sich die Besitzer unterscheiden. Unter eine fortlaufenden Besitzkette versteht man dagegen den verketteten Aufruf von Objekten eines einzigen Benutzers. Benutzer A Prozedur Benutzer A 1 4 Sicht 1 Benutzer A Benutzer B 2 Sicht 1 Benutzer C Datenbank B 3 Tabelle 1 Benutzer D Datenbank A Abbildung 7.5: Besitzketten Unter Einsatz der neuen Klausel EXECUTE AS kann man nun innerhalb einer Prozedur den Sicherheitskontext einer Prozedur genau festlegen. Folgende allgemeine Syntax 512 Programmierbarkeit existiert für Funktionen, Prozeduren und Trigger, wobei die Syntax für Trigger noch zusätzliche Erweiterungen besitzt: Funktionen (außer inline table-valued-Funktionen), Prozeduren und DML-Trigger { EXEC | EXECUTE } AS { CALLER | SELF | OWNER | 'user_name' } Die Bedeutung der verschiedenen Einstellungen ergeben sich fast schon aufgrund ihres Namens: CALLER (Standardwert) legt fest, dass die Prozedur im Sicherheitskontext des Aufrufenden, d.h. des Benutzers, ausgeführt wird. Dies ist auch der Standard unter der Vorgänverversion MS SQL Server 2000. SELF legt fest, dass die Prozedur im Sicherheitskontext des Besitzers der Prozedur oder desjenigen, der den ALTER-Befehl abgesetzt hat, ausgeführt wird. Dies entspricht der <user_name>-Option, wobei hier als Benutzername automatisch der erstellende oder ändernde Benutzer eingetragen wird. OWNER legt fest, dass die Prozedur nur im Sicherheitskontext des Besitzers ausgeführt wird. Hier ist keine Rolle oder Gruppe möglich, nur ein einzelnes Benutzerkonto. <user_name> legt einen speziellen Benutzer fest, in desse Sicherheitskontext die Prozedur ausgeführt werden soll. Dabei darf der Benutzer kein(e) Gruppe, Rolle, Zertifikat, Schlüssel oder integriertes Konto sein. Schließlich soll noch in Transact SQL kurz erklärt werden, wie die Ausführberechtigung erteilt und wieder entzogen wird. Die beiden Befehle GRANT und REVOKE werden im Administrationsbuch noch ausführlich erläutert, sodass hier nur eine Kurzfassung folgt. Folgende Rechte können für Prozeduren und Funktionen erteilt und entzogen werden. Sie werden gleichzeitig über die ALL-Option zusammen gefasst. Skalarfunktionen: EXECUTE, REFERENCES. 513 Programmierbarkeit Tabellenwertfunktionen: DELETE, INSERT, REFERENCES, SELECT, UPDATE. Prozeduren: EXECUTE, SYNONYM, DELETE, INSERT, SELECT, UPDATE. Die allgemeine Syntax für GRANT, mit dem Berechtigungen zugewiesen werden können, lautet: GRANT <permission> [ ,...n ] ON [ OBJECT :: ][ schema_name ]. object_name [ ( column [ ,...n ] ) ] TO <database_principal> [ ,...n ] [ WITH GRANT OPTION ] [ AS <user_name> ] <permission> ::= ALL [ PRIVILEGES ] | permission [ ( column [ ,...n ] ) ] Im Fall von Prozeduren und Funktionen können alle Berechtigungen mit ALL erteilt werden, was sich auf die oben angegebenen Berechtigungen bezieht. Dies ist gleichzeitig auch die Liste der zu erstellenden einzelnen Berechtigungen. Um also eine einfache Berechtigung zu erstellen, verwendet man: GRANT EXECUTE ON OBJECT::Production.usp_GetProduct TO kunde; Folgende wesentliche Parameter sind zu verwenden: ON [ OBJECT :: ] [ schema_name ] . object_name gibt das Objekt an, für das Berechtigungen erteilt werden sollen. TO <user_name> enthält den Benutzernamen, für den Berechtigungen erteilt werden können. Dies können eine ganze Reihe an unterschiedlichen Konten sein: Datenbankbenutzer, einem Windows-Anmeldename zugeordneter 514 Programmierbarkeit Datenbankbenutzer, einer Windows-Gruppe zugeordneter Datenbankbenutzer, keinem Serverprinzipal zugeordneter Datenbankbenutzer, Datenbankrolle oder eine Anwendungsrolle. Diese erfordern teilweise zusätzliche Eigenschaften und Einträge. WITH GRANT OPTION erlaubt die Weitergabe der Rechte. AS <user_name> enthält die Rolle, unter der die Berechtigung erteilt wird und entspricht inhaltlich dem in TO <user_name> aufgelisteten Bereich. Die allgemeine Syntax für REVOKE, mit dem Berechtigungen entzogen werden können, lautet: REVOKE [ GRANT OPTION FOR ] <permission> [ ,...n ] ON [ OBJECT :: ][ schema_name ]. object_name [ ( column [ ,...n ] ) ] { FROM | TO } <user_name> [ ,...n ] [ CASCADE ] [ AS <user_name> ] <permission> ::= ALL [ PRIVILEGES ] | permission [ ( column [ ,...n ] ) ] Folgende wesentliche Parameter sind zu verwenden: ON [ OBJECT :: ] [ schema_name ] . object_name enthält das Objekt, für das Rechte entzogen werden sollen. { FROM | TO } <user_name> enthält u.a. die bereits bei GRANT aufgelisteten Konten für den Benutzer, dem Rechte entzogen werden sollen. 515 Programmierbarkeit GRANT OPTION hebt die Berechtigung auf, Rechte weiterzugeben, ohne die Berechtigung an sich aufzuheben. CASCADE gibt an, dass allen nachfolgenden Benutzern, welche Rechte von dem Benutzer erhalten haben, dem sie nun entzogen werden, ebenfalls die Rechte entzogen werden (kann wie ein Flächenbrand wirken). Im Falle von Prozeduren und Funktionen können alle oben angegebenen Berechtigungen mit ALL entzogen werden. Dies ist gleichzeitig auch die Liste der zu aufzuhebenden einzelnen Berechtigungen. Analog zum vorherigen Fall würde man die Berechtigungen folgendermaßen entziehen: REVOKE EXECUTE ON OBJECT::Production.usp_GetProduct FROM kunde; 516 Index Index 517 Index 518 Index Index .NET-Funktionen 481 ALL 193 [NOT] EXISTS 195 ALTER 252 [NOT] IN 90 ALTER PROCEDURE 458 Abfrage speichern 40 AND 92 Abfrage-Editor: Grafisch 43 Ansicht 53 Abfrage-Editor 39 ANSI-SQL-Verknüpfungen 161 Abgeleitete Tabellen 182; Mehrstufige Verschachtelung 184; Vereinfachte Berechnungen 187 ANY 196 ABS 132 ACOS 132 ADO.NET 471 AdventureWorks 66; Tabellenbereiche 71 Aggregate 396; Akkumulation 407; Fenster-Aggregate 410; Gleitender Durchschnitt 408; Hitparaden 412 APPLY-Operator 501 ASCII 140 ASIN 132 Assemblies: Definition 66 ATAN 132 ATN2 132 Äußere Verknüpfung 164 Authentifizierungsmodus 25 AVG 114, 403 Aggregatfunktionen 403 Bedingungen 87 Akkumulation 407 Berechnete Bedingungen 100 Aktualisieren: Grafisch 48 Berechnete Spalten 97 Aliasnamen: Spalten 84; Tabellen 85 519 Index Berechtigungen: Erteilen 514 Entziehen 515; Bereiche 426 Berichts- und Gruppenuntersummen 214 Besitzkette 512 Boolesche Operatoren 91 CALLED ON NULL INPUT 500 CASE 428, 434; Mit Selektor 198; Ohne Selektor 201 CEILING 132 CHAR 140 CHARINDEX 140 CHECK-Bedingung 35 CHECKSUM 403 CHECKSUM_AGG 403 Clustered Index 37 Common Table Expression 380 COMPUTE [BY] 214 CONSTRAINT 249 COS 132 COT 132 COUNT 403 520 COUNT und COUNT_BIG 115 COUNT_BIG 403 CREATE PROCEDURE 455 CREATE FUNCTION 482, 489 CREATE TABLE 51, 240, 242 CROSS APPLY 502 CTE 380; Aggregate 398; Datenmanipulation 393; Dynamisch 384; Mehrfach 386; Pivot 435; Prinzip 381; Rekursiv 391; Spaltennamen 383 Cursor: Rückgabe aus Prozedur 475 Cursor-Rückgabe 475 DataTable 472 DATEADD 126 DATEDIFF 126 DATENAME 126 Datenbankdiagramme 233 Datenschnittstelle mit Prozedur 463 DATEPART 126 Datums- und Zeitfunktionen 125 DAY 127 DEFAULT 467 Index DEGREES 132 FLOOR 133 DELETE 49; CTE 395 FOR REPLICATION 457 DENSE_RANK 403 FOREIGN KEY-Klausel 246 Dienstkonto 24 Fremdschlüssel anlegen 248 DIFFERENCE 140 Funktionen 478; Definition 54; Definition 63; Einfache Tabellenwertfunktionen 486; Erweiterte Tabellenwertfunktionen 489; NULL-Werte ausgeben 499; Schemabindung 495; Sicherheit 510; Skalarfunktionen 481; Tabellenwertfunktionen 486; Typologie 480 DISTINCT 109 Dokumentation 57 DROP 252 DROP FUNCTION 481 Duplikate ein-/ausblenden 109 Einfache Unterabfragen 175 ENCRYPTION 474 ENCRYPTION 457 ENCRYPTION 494 Ergebnismenge aus Prozedur 460 EXCEPT 106, 168 EXEC 465 EXECUTE AS 457, 494, 512 EXP 133 Express-Edition 23 Fenster-Aggregate 410 Fensterrangfunktion 402 GETDATE 127 GETUTCDATE 127 Gleitender Durchschnitt 408 GRANT 514 GROUP BY 118 GROUPING 212, 403 Gruppenbedingungen 120 Gruppensuchbedingung: Definition 82 Gruppieren 117 Gruppierung: Definition 82 HAVING 121 521 Index Hierarchien 389 Hitparaden 412 IDENTITY 242 Index 36 INNER JOIN 162 Skript generieren anlegen 222 236; Tabellen Management-Studio: Einschränkungen 34; Schlüssel 32; Spalteneigenschaften 33; Statistiken 37; Tabellen anzeigen 31; Trigger 35 Innere Verknüpfung 161 Manuelle Verknüpfungen 153 INSERT: CTE 394 MAX 114, 403 INTERSECT 107 Mengen-Operatoren 102 JOIN: INNER JOIN 162 MIN 114, 403 JOIN: OUTER JOIN 165 MONTH 127 Katalogsichten für Objekte 504 Korrelierte Spaltenunterabfragen 191 MS SQL Server 2005: Download 21; Standardinstallation 23 Korrelierte Unterabfragen 189 Namensnotation 465 Kreuzverknüpfung 159 NCHAR 141 LEFT 141 Neukompilierung von Prozeduren 474 LEN 141 Non-Clustered Index 37 LOG 133 NTILE 403, 426, 427 Löschen: Grafisch 49 OBJECT_DEFINITION() 510 LOWER 141 OBJECT_ID 244 LTRIM 141 OBJECT_ID() 508 Management Studio 29; Beziehungen anlegen 230; Datenbankdiagramme 233; Prozeduren öffnen 458; SQL- OBJECTPROPERTY() 509 522 OBJECTPROPERTYEX() 509 Index Objekt-Explorer 30 Positionsnotation 465 Operatoren: Mathematische Operatoren 97 POWER 133 Operatoren 88, 97; AND 92; Boolesche Operatoren 91; IN 90; IS [NOT] NULL 90; OR 92 Operatoren: Mengen-Operatoren 102 Operatoren: ALL 193 Operatoren: [NOT] EXISTS 195 Operatoren: SOME 196 Operatoren: ANY 196 OR 92 Programmierbarkeit 59, 451 Projektmappe 42 Projektverwaltung 41 Prozeduren 451; Cursor-Rückgabe 475; Datenschnittstelle 463; Definition 59; Ergebnismenge zurückliefern 460; Neukompilierung 474; Rückgabewerte 469; Sicherheit 510; Standardwerte 467; Syntax 455; Typologie 453, 460; Verschlüsselung 474 ORDER BY 112 Prozedurparameter 465 OUTER APPLY 503 Qualifizierte Spaltennamen 86, 156 OUTER JOIN 164 Quantile 426 OUTPUT 467, 470, 475 QUOTENAME 141 OUTPUT 457 RADIANS 133 OVER 396, 427; Aggregate 402 RAND 133 PARTITION BY 403, 416 Rangfolgefunktionen 403, 421 PATINDEX 141 Rangfolgen 204, 418 PI 133 RANK 403 Pivot: CTE 437; Dynamisch Klassisch 431 444; Rekursive CTE 391 523 Index Relation 53 Sortierreihenfolge 25 REPLACE 141 Sortierung 112; Definition 83 REPLICATE 142 SOUNDEX 142 RETURNS NULL ON NULL INPUT 500 sp_helptext 475 REVERSE 142 REVOKE 515 RIGHT 142 ROUND 133 ROW_NUMBER 403 ROW_NUMBER() 413 RTRIM 142 Rückgabewerte 469 SCHEMABINDING 496 Schemabindung 495 Selbstverknüpfung 170, 251 SELECT 43; Grundstruktur 81 Sicht: Definition 53 SIGN 133 SIN 133 Skalarfunktionen 481 SOME 196 524 SPACE 142 Spaltenliste: Definition 82 Spaltenunterabfrage 400 Spaltenunterabfragen 180 SqlCommand 472 SqlDataAdapter 471 SqlDataReader 471 SqlException 473 SqlInfoMessageEventArgs 473 SQRT 134 SQUARE 134 Standard-Aggregate 114 Standardwerte 467 STDEV 403 STDEVP 403 STR 142 STUFF 142 SUBSTRING 142 Index Suchbedingung: Definition 82 TOP n 205 SUM 114, 403 Trigger: Definition 65 Synonym 54 Trigger 35 sys.objects 506 UNICODE 142 sys.procedures 507 UNION [ALL] 105 Systemfunktionen 147 UNPIVOT 435, 444 Tabelle: Definition generieren 236 53; SQL-Skript Tabelle erstellen: Grafisch 51 Tabellen: Ändern durch ALTER 252; Erweiterte Tabellendefinition 246; Fremdschlüssel anlegen 248; Grafisch anlegen 223; Löschen mit DROP 252; Mit SQL erstellen 238 Tabellenangabe: Definition 82 Tabellenausdrücke 379 Tabellen-Designer 34 Tabellenwerfunktionen 481 Tabellenwertfunktionen 486; Einfach 486; Erweitert 489 Unterabfrage: Einzelne Werte 176 Unterabfragen 175; Einfach 175; Korrelierte Spaltenunterabfragen 191; Korrelierte Unterabfragen 189; Spaltenunterabfrage 180; Wertelisten 177 Untersummen 207 UPDATE 48; CTE 394 UPPER 143 VAR 403 VARP 403 VARYING 475 VARYING 457 table-Variable 490 Verknüpfung: Äußere 164; Einfach 154; Innere 161; Mehrfach 158; Selbstverknüpfung 170 TAN 134 Verschlüsselung 474 Testversion 21 Verzögerte Namensauflösung 459 TABLESAMPLE 122 525 Index Verzweigungen 197 Würfel 210 Vorlagen-Explorer 55 YEAR 127 Wertedominante Tabelle 165 Zeichenketten verknüpfen 99 WITH 380 Zeichenkettenfunktionen 140 WITH CUBE 214 Zeilennummern erstellen 412 WITH RECOMPILE 467 Zufällige Datenauswahl 122 WITH ROLLUP 214 526 527 528 529 530 531 532