SQL Lehrgang
Werbung

Bernhard Bausch
Datenbanken und Informationssysteme
08.01.11
Technikerschule TS
Kursunterlagen
Datenbanksysteme
SQL
Autor:
Bernhard Bausch
Versionsverzeichnis
Version:
Version 1.0
Version 1.1
Version 1.2
Version 1.3
Datenbank_SQL1.3.doc
Datum:
28.05.01
08.09.01
20.04.02
01.07.02
Revisionsgrund:
Erste Ausgabe
Ergänzung SQL-Befehlsübersicht
Semesterkorrekturen
Semesterkorrektur
Seite 1/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
Inhalt
1
SQL-Befehlsübersicht ..............................................................................................................................4
2
Mit SQL-Anweisungen Daten definieren, eingeben und verwalten .....................................................5
2.1 Datenbank anlegen, öffnen, schliessen und löschen ....................................................................5
2.1.1
2.1.2
2.2
Tabellen erstellen und löschen ......................................................................................................6
2.2.1
2.2.2
2.3
3.5
3.6
3.7
3.8
Operatoren............................................................................................................................................. 11
Spalten mit NULL-Werten Abfragen ...................................................................................................... 11
Zeilen mit verbundenen Bedingungen suchen und anzeigen ................................................................ 11
Logische Operatoren ............................................................................................................................. 12
Aggregatfunktionen ......................................................................................................................13
Rechenoperationen durchführen .................................................................................................14
Mit Funktionen arbeiten ...............................................................................................................15
3.7.1
3.7.2
3.7.3
3.7.4
Numerische Funktionen ......................................................................................................................... 15
Datumsoperatoren und Datumsfunktionen ............................................................................................ 15
Zeichenketten-, Umwandlungs- und anderer Funktionen ...................................................................... 15
Umwandlungsfuntionen .................................................................... Fehler! Textmarke nicht definiert.
Prädikate ......................................................................................................................................15
3.8.1
3.8.2
3.8.3
Operator LIKE ........................................................................................................................................ 16
Operator BETWEEN .............................................................................................................................. 16
Operator IN ............................................................................................................................................ 16
Daten aus mehreren Tabellen abfragen (Joins) ..................................................................................17
4.1 Kartesisches Produkt aus zwei Tabellen bilden ..........................................................................17
4.2 Logische Verbingungen mit Equi-Join herstellen.........................................................................17
4.3 Andersnamen bzw. Alias-Bezeichner für Tabellen vereinbaren ..................................................17
4.3.1
4.3.2
4.4
Synonyme Tabellen-Bezeichner ............................................................................................................ 17
Alias-Bezeichner definieren ................................................................................................................... 18
OUTER- oder LEFT-, RIGHT-Join ...............................................................................................18
4.4.1
5
Neue Spalte mit ADD einfügen ................................................................................................................ 9
Vorhandene Spalten mit MODIFY ändern ............................................................................................... 9
Vorhandene Spalten mit DROP löschen .................................................................................................. 9
Tabellen- und Spaltennamen ändern....................................................................................................... 9
Der SELECT-Befehl im SQL ...................................................................................................................10
3.1 Alle Zeilen einer Tabelle anzeigen ...............................................................................................10
3.2 Spalten auswählen .......................................................................................................................10
3.3 Inhaltlich gleiche Zeilen von der Ausgabe ausschliessen ...........................................................10
3.4 Zeilen mit Bedingungen auswählen .............................................................................................10
3.4.1
3.4.2
3.4.3
3.4.4
4
Eine Tabellenzeile vollständig eingeben .................................................................................................. 7
Werte in bestimmte Spalten einer Datenzeile eingeben .......................................................................... 7
Daten aktualisieren ........................................................................................................................8
Daten löschen ................................................................................................................................8
Ein Tabellenfeld nachträglich einfügen, ändern oder löschen. ......................................................9
2.6.1
2.6.2
2.6.3
2.6.4
3
Tabellen erstellen .................................................................................................................................... 6
Tabellen löschen...................................................................................................................................... 6
Daten in Tabellen eingeben (neuer Datensatz) .............................................................................7
2.3.1
2.3.2
2.4
2.5
2.6
Datenbank anlegen.................................................................................................................................. 5
Datenbank löschen .................................................................................................................................. 5
Verknüpfungen innerhalb der gleichen Tabelle (Self-Joins)................................................................... 19
Bedingungen in SELECT-Unterabfragen formulieren (Subqueries) ................................................21
5.1 Regeln für den Einsatz von Unterabfragen ..................................................................................21
5.2 Unterabfragen mit relationale Operatoren ...................................................................................21
5.3 Unterabfrage mit ALL und ANY ...................................................................................................22
5.3.1
5.3.2
5.4
Operator ALL ......................................................................................................................................... 22
Operator ANY ........................................................................................................................................ 23
Unterabfragen mit IN und EXISTS ...............................................................................................23
Datenbank_SQL1.3.doc
Seite 2/37
Bernhard Bausch
5.4.1
5.4.2
5.5
5.6
5.7
Schulungsunterlagen Datenbanken
Operator IN ............................................................................................................................................ 23
Operator EXISTS ................................................................................................................................... 23
Synchronisierte Unterabfragen ....................................................................................................24
Unterabfragen im Befehl INSERT ................................................................................................24
Unterabfragen im Befehl UPDATE ..............................................................................................25
5.7.1
5.7.2
Select-Unterabfrage in der WHERE-Klausel.......................................................................................... 25
SELECT-Unterabfrage in der SET-Klausel ............................................................................................ 25
6
Daten sortieren und gruppieren ............................................................................................................26
6.1 Daten Sortieren ............................................................................................................................26
6.2 Zeilen gruppieren .........................................................................................................................26
6.3 Gruppen bedingungsabhängig auswählen mit HAVING. ............................................................28
7
Ergebnisausgaben verbinden mit UNION, INTERSECT, EXCEPT .....................................................29
7.1 Operator UNION ..........................................................................................................................29
7.2 Operator INTERSECT ................................................................................................................29
7.3 Operator EXCEPT/MINUS ...........................................................................................................29
8
Sichten verwenden .................................................................................................................................30
8.1 VIEW erstellen .............................................................................................................................30
8.2 View ausgeben.............................................................................................................................31
8.3 View löschen ................................................................................................................................31
8.4 Mit VIEWS Daten aktualisieren ....................................................................................................31
9
Datenbank optimieren ............................................................................................................................32
9.1 Einfachindex erstellen. .................................................................................................................32
9.2 Index löschen ...............................................................................................................................32
9.3 Zusammengesetzten Index vereinbaren .....................................................................................32
9.4 Indexeintragungen überprüfen und reparieren ............................................................................33
9.5 Die referentielle Integrität einer Datenbank erhalten ...................................................................33
10
Daten schützen und sichern ..................................................................................................................35
11
Transaktionsorientiert arbeiten .............................................................................................................36
12
ODBC-Schnittstelle zum Zugriff auf Datenbanken einsetzen ............................................................37
Datenbank_SQL1.3.doc
Seite 3/37
Bernhard Bausch
1
Schulungsunterlagen Datenbanken
SQL-Befehlsübersicht
In der Praxis unterscheidet man sowohl bei den hierarchischen (z.B IMS von IBM), den Netzwerk- (z.B. IDMS von Cullinet) als auch bei den relationalen Datenbanksystemen zwei Gruppen
von Datenbankanweisungen.
DDL — Data Definition Language (Definitionssprache)
Dazu zählen alle Datenbankanweisungen, mit denen die logische Struktur der Datenbank
bzw. der Tabellen der Datenbank beschrieben bzw. verändert wird. Hierzu gehören folgende Befehle:
CREATE TABLE:
neue Basistabellen erstellen
CREATE VIEW:
Definieren einer logischen Tabelle
GRANT
Benutzerberechtigungen vergeben
DML — Data Manipulation Language (Datenmanipulationssprache)
Dazu zählen alle Anweisungen an das Datenbanksystem, die dazu dienen, die Daten zu
verarbeiten. Hierzu gehören folgende Befehle:
SELECT:
Daten aus der Datenbank lesen
DELETE:
Zeilen einer Tabelle löschen
UPDATE:
Zeilen einer Tabelle ändern
INSERT:
Zeilen einer Tabelle hinzufügen
Bei den hierarchischen und den Netzwerk-Datenbanken ist der Sprachumfang der DDL und DML
gross. Selbst bei der Erstellung einfacher Anwendungen ist ein relativ grosser Aufwand erforderlich, bis die dazugehörige Datenbank definiert ist und die DML-Programme geschrieben und gestestet sind.
die Sprache SQL dagegen besteht aus nur wenigen einfachen Befehlen, die sowohl den DDL- als
auch den DML-Teil abdecken.
Datenbank_SQL1.3.doc
Seite 4/37
Bernhard Bausch
2
Schulungsunterlagen Datenbanken
Mit SQL-Anweisungen Daten definieren, eingeben und verwalten
Für das Einrichten und Verwalten von Datenbanken und Tabellen werden eine Reihe von Anweisungen benötigt, mit denen Sie:
• Eine Datenbank mit ihren Tabellen anlegen,
• Daten in die Tabellen eingeben und abrufen sowie
• Tabellen ändern und löschen
Die meisten SQL-Anweisungen können in allen SQL-basierten Datenbanksystemen eingesetzt
werden. Trotz Standardisierung besitzt aber jedes Datenbanksystem eigene Ausprägungen von
SQL-Befehlen. Das gleiche gilt auch für die Datentypen, mit denen Spalten definiert werden.
Einige Unterschiede werden kurz erläutert.
2.1 Datenbank anlegen, öffnen, schliessen und löschen
2.1.1 Datenbank anlegen
Der Befehl
CREATE DATABASE Datenbankname
erstellt eine Datenbank mit ihren zugehörigen Systemtabellen. Mit dieser SQL-Anweisung wird
der Rahmen für die spätere Einrichtung der Tabellen geschaffen.
Wenn Sie sich nach der Anweisung CREATE DATABASE das Verzeichnis anschauen, in dem
die Datenbank aufgebaut worden ist, so finden Sie dort bereits eine Vielzahl von Dateien vor. Es
handelt sich um die Systemtabellen, auch Systemkatalog oder Data Dictionary genannt. In ihm
werden alle Informationen über die logische Struktur der Datenbank gesammelt. Er enthält unter
anderem Informationen darüber, welche Tabellen eine Datenbank enthält, wie viel Datensätze
vorhanden sind, wie die Spalten einer Tabelle heissen und mit welchen Datentypen die Spalten
definiert sind. Bei jeder SQL-Anweisung informiert sich das System zunächst in diesen Systemtabellen, bevor es die Anweisung durchführt. Sie können die in den Systemtabellen gespeicherten Informationen jederzeit abrufen und sich damit eine Übersicht über die Inhalte der Datenbank
verschaffen.
In ORACLE wird bei der Installation des Systems für das Data Dictionary eine eigene Datenbank
mit dem Namen oracle angelegt.
2.1.2 Datenbank löschen
Mit dem Befehl
DROP DATABASE Datenbankname
wird dort eine Datenbank gelöscht, wo ein System mehrere Datenbanken verwaltet. Vor dem löschen muss die entsprechende Datenbank mit dem Befehl
CLOSE DATABASE
geschlossen werden.
Das Löschen der Datenbank bedeutet, dass sie mit allen dazugehörigen Objekten entfernt wird.
Bei der Access JET-Datenbank, wo die ganze Datenbank eine einzige Datei ist, muss die entsprechende Datei gelöscht werden.
Datenbank_SQL1.3.doc
Seite 5/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
2.2 Tabellen erstellen und löschen
2.2.1 Tabellen erstellen
Mit der SQL-Anweisung "CREATE TABLE Tabellenname" wird eine neue Tabelle angelegt. Hinter dem Tabellennamen sind in Klammern die Spaltennamen, jeweils mit Datentyp und Längenangabe, zu definieren. Die einzelnen Spaltenbeschreibungen werden mit Kommata getrennt. Die
Liste der Spaltennamen muss von runden Klammern umschlossen sein.
CREATE TABLE Persdat
(
Pd_ID
INTEGER NOT NULL,
Pd_Name
CHAR(25),
Pd_VName
CHAR(25),
Pd_Geschlecht
CHAR(1),
Abt_ID
SMALLINT,
Pd_Eintritt
DATE,
Pd_Gehalt
DOUBLE
)
DOUBLE ist Access-Spezifische; SQL wäre DECIMALE(8,2)
Die Spaltenbedingung NOT NULL weist in diesem Beispiel auf eine Schlüsselspalte hin, legt aber
nur fest, dass unbedingt Werte eingegeben werden müssen. Eine weitere Spaltenbedingung ist
der UNIQUE-Index, welcher überwacht, dass, im Zusammenhang mit Schlüsselspalten, die in der
bezeichneten Datenspalte eingegebenen Werte eindeutig sind.
Dies ist die einfache Form eines CREATE TABLE-Befehls. Die erweiterte Form dieser Anweisung
bezieht sich zum grössten Teil auf die Definition der Integritätsregeln (wie UNIQUE-Index), auf
welche wir später noch eingehen. Die allgemeine Syntax der erweiterten Form dieser Anweisung
ist von System zu System leicht unterschiedlich.
In der Regel bietet eine relationale Datenbank ein Tool an, das die Erstellung der Tabellen mit
SQL-Befehlen hinfällig macht.
Erstellen Sie eine weitere Tabelle:
CREATE TABLE MGehalt
(Pd_ID
INTEGER NOT NULL,
Mg_Jahr
SMALLINT,
Mg_Monat
SMALLINT,
Mg_Gehalt
DOUBLE)
2.2.2 Tabellen löschen
Mit der Anweisung "DROP TABLE Tabellennamen" wird eine Tabelle mit den darin gespeicherten
Daten aus der Datenbank und in den Systemtabellen gelöscht.
Tabelle erstellen:
CREATE TABLE Ueb
(uebnr INTEGER, uebbez CHAR(20))
Tabelle löschen:
DROP TABLE Ueb
Bei verschiedenen Systemen kann man die Tabellen auch auf Betriebssystemebene löschen. Bei
Tabellen einer Datenbank riskieren Sie aber damit, dass die Integrität der Datenbank zerstört
wird.
Datenbank_SQL1.3.doc
Seite 6/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
2.3 Daten in Tabellen eingeben (neuer Datensatz)
Mit der INSERT-Anweisung können Daten in einer Tabelle erfasst werden.
Mit der Anweisung INSERT INTO tabellennamen VALUES() geben Sie Werte zeilenweise ein
2.3.1 Eine Tabellenzeile vollständig eingeben
INSERT INTO Persdat
VALUES ( 99, 'Willemann', 'Hans', 'M', 3, '31.05.2001',4500)
Datumswerte werden von Datenbank zu Datenbank sehr unterschiedlich behandelt.
In der Klammer hinter VALUES werden die Werte in der Reihenfolge der Tabellenstruktur aufgeführt. Dabei ist zu beachten, dass die angegebenen Werte mit den vereinbarten Datentypen in
den Tabellen übereinstimmen. Zeichenketten, Datumswerte und Zeitwerte werden in Hochkommata (') eingeschlossen.
UEBUNG:
Geben Sie folgende Datensätze in die Tabelle Persdat ein:
INSERT INTO Persdat VALUES ( 55, 'Hurter', 'Karl', 'M', 1, '1.1.1980',6800)
INSERT INTO Persdat VALUES ( 56, 'Frauental', 'Heidi', 'W', 2, '1.2.1995',3200)
INSERT INTO Persdat VALUES ( 57, 'Meyer', 'Karl', 'M', 3, '15.7.2000',5200)
INSERT INTO Persdat VALUES ( 58, 'Bolliger', 'Verena', 'W', 3, '31.05.2001',2500)
Legen Sie eine Tabelle Ueb an. Die Tabelle verfügt über die Spalten :
Ub_ID
INTEGER Not Null
Ub_Bez
CHAR(20)
Tragen Sie dann folgende Werte in die Tabelle ein:
3
Katolog
10
Handbuch
15
Sachbuch
2.3.2 Werte in bestimmte Spalten einer Datenzeile eingeben
Wenn Sie Werte nur in bestimmte Spalten einer Tabellenzeile eingeben wollen, müssen Sie hinter dem Tabellennamen zusätzlich die Namen der Spalten benennen, in denen die Daten gespeichert werden sollen.
INSERT INTO Persdat(Pd_Id, Pd_Name)
VALUES(3,'Müller')
So werden in Persdat nur Werte in den Spalten Pd_ID und Pd_Name gespeichert.
Datenbank_SQL1.3.doc
Seite 7/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
2.4 Daten aktualisieren
Mit der Anweisung "UPDATE Tabellennamen SET" werden Daten bedingungsabhängig geändert
UPDATE Ueb
SET Ub_ID = 25,
Ub_Bez = 'Lernfibel'
WHERE Ub_ID = 3
Im Anschluss an das Schlüsselwort UPDATE wird die zu ändernde Tabelle benannt.
Hinter SET werden den zu ändernden Spalten die neuen Werte zugewiesen.
Die Bedingung hinter WHERE definiert die Zeile, in der die Änderung durchgeführt werden soll
.
In diesem Beispiel wird in der Tabelle Ueb, in der Spalte Ub_ID, der Datensatz mit der Ub_ID = 3,
auf 25 verändert und der Inhalt von Feld Ub_bez mit "Lernfibel" überschrieben.
Achtung: Wird bei einem UPDATE-Befehl die WHERE-Bedingung weggelassen, so werden alle
Zeilen der Tabelle geändert.
Uebung:
Werte in einer Spalte können auch erhöht werden. In der Tabelle ueb sollen alle Werte in der
Spalte Ub_ID um 10 erhöht werden.
Ergänzen sie folgenden Eintrag in der Tabelle Persdat:
Alle Eintragungen gelten nur für Pd_ID = 3
Pd_Vname = Claudia
Pd_Geschlecht = W
Abt_ID = 2
Pd_Eintritt = 7.5.1995
Pd_Gehalt = 4500
Erfassen Sie folgende Daten in der Tabelle MGehalt
2.5 Daten löschen
Daten werden mit der Anweisung DELETE FROM Tabellennamen aus einer Tabelle entfernt. Mit
dem Zusatz WHERE erfolgt wiederum die Zeilenauswahl.
DELETE FROM Ueb WHERE Ub_ID = 35
Achtung: Ohne WHERE-Klausel werden alle Daten von Ueb gelöscht.
Datenbank_SQL1.3.doc
Seite 8/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
2.6 Ein Tabellenfeld nachträglich einfügen, ändern oder löschen.
Mit der Anweisung ALTER TABLE Tabellenname werden in vorhandenen Tabellenstrukturen
neue Spalten eingefügt, vorhandene Spalten geändert oder gelöscht.
2.6.1 Neue Spalte mit ADD einfügen
Hinter dem Schlüsselwort ALTER TABLE wird die Tabelle genannt, deren Struktur geändert werden soll. Mit dem Zusatz ADD wird das System angewiesen, eine oder mehrere Spalten einzufügen. Die einzufügenden Spalten werden mit Namen und Datentypen definiert.
Die Tabelle ueb soll um die Tabellenspalte Ub_Menge und Ub_Te ergänzt werden:
Access: Neue Datenfelder müssen einzeln definiert werden
ALTER TABLE Ueb ADD Ub_Menge DOUBLE
ALTER TABLE Ueb ADD Ub_Te Char(20)
DB2/2 In diesen Datenbanken wenden keine Klammern bei Spaltenfunktionen verwendet.
ALTER TABLE Ueb ADD Ub_Menge
Decimal(8,2),
ADD Ub_Te
Char(20)
Oracle/Informix
ALTER TABLE Ueb ADD
(Ub_Menge
Decimal(8,2),
Ub_Te
Char(20))
2.6.2 Vorhandene Spalten mit MODIFY ändern
Mit dem Zusatz MODIFY wird das System angewiesen, einer vorhandenen Spalte einen anderen
Datentyp zuzuweisen. Die Spalte wird mit Ihrem Namen benannt und der neue Datentyp wird danach definiert.
Beispiel: In der Spalte Ub_Menge soll der Datentyp von NUMERIC in SMALLINT geändert werden, Access kennt diesen Befehl nicht:
ALTER TABLE Ueb MODIFY
(Ub_Menge = SMALLINT)
Diese Anweisung läuft nur in Oracle und Informix..
2.6.3 Vorhandene Spalten mit DROP löschen
Mit dem Zusatz DROP wird das System angewiesen, eine vorhandene Spalte zu löschen. Die
Spalte wird mit ihrem Namen angesprochen.
Oracle kennt den Zusatz DROP nicht.
ALTER TABLE Ueb DROP Ub_Menge
2.6.4 Tabellen- und Spaltennamen ändern
In Informix und Oracle können Sie mit dem Datenbankbefehl RENAME Tabellen nachträglich
umbenennen. Access kennt diesen Befehl nicht.
RENAME TABLE Ueb TO Ueb1
In Informix können Sie mit RENAME nachträglich auch Spaltennamen ändern:
RENAME COLUMN Ueb1.Ub_Bez TO Ub_Bezeichnung
Datenbank_SQL1.3.doc
Seite 9/37
Bernhard Bausch
3
Schulungsunterlagen Datenbanken
Der SELECT-Befehl im SQL
Wenn die erforderlichen Daten in einer Datenbank gespeichert sind, können Sie auf verhältnismässig einfache Weise die gewünschten Informationen aus der Datenbank gewinnen. Das Suchen und Anzeigen gespeicherter Werte gehört zu den wichtigsten Fähigkeiten eines Datenbanksystems.
In einer Abfrage muss stets angegeben werden, aus welchen Spalten und aus welcher Tabelle
Daten abgerufen werden sollen.
3.1 Alle Zeilen einer Tabelle anzeigen
SELECT leitet die Anweisung ein, mit der Daten in der Datenbank gesucht und angezeigt werden. Hinter SELECT werden die Namen der auszuwählenden Spalten angegeben. Der Stern *
hinter dem Schlüsselwort veranlasst die Anzeige aller Tabellenspalten in der Reihenfolge, in der
die Spalten mit CREATE TABLE angelegt worden sind. Hinter dem Zusatz FROM wird der Name
der Tabellen genannt, aus der die Daten gewonnen werden sollen.
SELECT * FROM Adressen
3.2 Spalten auswählen
Meistens werden nur die Daten bestimmter Spalten benötigt. Mit der Auflistung der gewünschten
Spaltennamen hinter dem Schlüsselwort SELECT wird die Anzeige auf die namentlich genannten
Spalten beschränkt. Die Ausgabe erfolgt dabei in der Reihenfolge, in der die Spaltennamen hinter
SELECT angeordnet wurden.
SELECT Adr_Vorname, Adr_Nachname FROM Adressen
Mit dem Zusatz AS kann man die einzelnen Spalten benennen. Dies ist dann notwendig, wenn
z.B. in einem Sub-Select eine Spalte zweimal verwendet wird.
SELECT Adr_Vorname AS Vorname, Adr_Nachname AS Name FROM Adressen
3.3 Inhaltlich gleiche Zeilen von der Ausgabe ausschliessen
Manchmal möchte man lediglich wissen, welche Werte überhaupt in einer Spalte stehen, nicht
aber, wie oft sie vorhanden sind. Dazu ergänzt man die SELECT-Anweisung um den Zusatz
DISTINCT. Mit DISTINCT wird die Mehrfachausgabe inhaltlich gleicher Ausgaben unterdrückt.
DISTINCT kann nur eingesetzt werden, wenn sich die Abfrage auf nur eine Spalte bezieht.
SELECT DISTINCT Adr_Anrede From Adressen
3.4 Zeilen mit Bedingungen auswählen
Bei den meisten Abfragen sollen aus der Gesamtzahl der in einer Tabelle vorhandenen Zeilen
nur ganz bestimmte Zeilen gesucht und angezeigt werden. Dazu ist es notwendig, eine Suchbedingung zu vereinbaren.
Die Bedingung wird eingeleitet durch die Klausel WHERE. Darauf folgt der Bedingungsausdruck,
der sich wie folgt aufbaut:
WHERE
Spaltennamen
Vergleichsoperator
Vergleichswert
SELECT Adr_Vorname, Adr_Nachname, ATyp_ID
FROM Adressen
WHERE ATyp_ID = 2
Datenbank_SQL1.3.doc
Seite 10/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
3.4.1 Operatoren
Operatoren sind Symbole für eine auszuführende Operation. Mit SQL können verschiedene Arten
von Operatoren eingesetzt werden. In diesem Abschnitt verwenden wir nur Basisoperatoren, die
auch Vergleichsoperatoren oder relationale Operatoren genannt werden:
Operator
=
<
>
<>
<=
>=
Bedeutung
gleich
kleiner als
grösser als
ungleich
kleiner gleich
grösser gleich
Besteht der Vergleichswert aus einer Zeichenkette oder einem Datum, so muss er in Hochkommata eingeschlossen werden.
Bei Zeichenketten genügt bereits ein Buchstabe, um die Zeilenauswahl zu definieren:
Bitte beide Varianten probieren
SELECT Adr_Nachname FROM Adressen WHERE Adr_Nachname < 'M'
SELECT Adr_Nachname FROM Adressen WHERE Adr_Nachname > 'M'
In dieser Abfrage wird der erste Buchstaben des Namens mit den Textkonstanten verglichen. Der
Vergleichswert gibt somit an, wie viele Stellen des Namens zum Vergleich herangezogen werden.
Ein stellenweises Abfragen ist bei numerischen Spalten und Spalten mit Datumswerten nicht
möglich. Hier wird jeweils der gesamte Wert eines Spaltenfeldes in den Vergleich einbezogen.
Zum Beispiel werden bei "WHERE gehalt > 5000" alle Zeilen mit einem Wert über 5000 angezeigt.
3.4.2 Spalten mit NULL-Werten Abfragen
Tabellenspalten, in denen keine Werte gespeichert sind, haben den Wert NULL. Der Wert NULL
entspricht weder der Zahl 0 noch einer Zeichenfolge mit Leerzeichen. Der Wert NULL kann abgefragt werden.
Bitte beide Varianten probieren
SELECT Adr_Nachname, Adr_Anrede FROM Adressen WHERE Adr_Anrede IS NULL
SELECT Adr_Nachname, Adr_Anrede FROM Adressen WHERE Adr_Anrede IS NOT NULL
3.4.3 Zeilen mit verbundenen Bedingungen suchen und anzeigen
Eine Bedingung kann sich aus mehreren Teilbedingungen zusammensetzen.
Bedingungen können durch die Operatoren UND und ODER zu einem komplexen Bedingungsausdruck verknüpft werden.
UND wird in SQL durch AND, ODER durch OR ausgedrückt.
SELECT Adr_Vorname, Adr_Nachname, Adr_Anrede, ATyp_ID FROM Adressen
WHERE Adr_Anrede = 'Frau' AND ATyp_ID = 2
Versuchen Sie dieselbe Abfrage mir OR und Sie werden sehr unterschiedliche Auswertungen erhalten.
Datenbank_SQL1.3.doc
Seite 11/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
3.4.4 Logische Operatoren
Logischer
Operator
AND
Beispiel
Auswirkung
Anrede = 'Frau' AND
Adresstyp = 2
OR
Anrede = 'Frau' OR
Adresstyp = 2
NOT
NOT Anrede = 'Frau'
Es werden die Datenzeilen angezeigt, in denen beide
Einzelbedingungen erfüllt sind:
Angezeigt werden alle Frauen mit Adresstyp 2
Es werden die Datenzeilen ausgegeben, die entweder
die erste oder die zweite Bedingung erfüllen: Angezeigt werden alle Frauen sowie alle die dem Adresstyp
2 entsprechen (also auch Männer).
Es werden die Datenzeilen ausgegeben, die die Bedingung nicht erfüllen. Hier werden also nur die Männer ausgegeben.
Die Verknüpfung erfolgt nach folgenden Regeln:
AND-Verbindung
Teilbedingung 1
erfüllt
nicht erfüllt
erfüllt
nicht erfüllt
Teilbedingung 2
erfüllt
nicht erfüllt
nicht erfüllt
erfüllt
Gesamtbedingung
erfüllt
nicht erfüllt
nicht erfüllt
nicht erfüllt
OR-Verbindung
Teilbedingung 1
erfüllt
nicht erfüllt
erfüllt
nicht erfüllt
Teilbedingung 2
erfüllt
nicht erfüllt
nicht erfüllt
erfüllt
Gesamtbedingung
erfüllt
nicht erfüllt
erfüllt
erfüllt
Bedeutung von Klammern
Bei zusammengesetzten Bedingungsausdrücken kann die Reihenfolge der Auswertung durch
Klammern beeinflusst werden. Klammerinhalte werden immer zuerst bearbeitet.
Beispiel
1. Bedingung: Die Person muss eine Frau sein und
2. Bedingung: Die Person muss in Bern wohnen oder
3. Bedingung: Die Person muss in Zürich wohnen
Das Bedingungsgefüge ist so formuliert, dass die erste Bedingung unbedingt erfüllt sein muss.
Von der zweiten und dritten Bedingung braucht dagegen nur eine Bedingung erfüllt zu sein. Die
letzteren Bedingungen sind also durch OR zu verknüpfen und in ihrer Gesamtheit durch AND mit
der Geschlechtsbedingung zu verbinden.
Die SQL-Anweisung lautet:
SELECT Adr_Anrede, Adr_Vorname, Adr_Nachname,Adr_Ort FROM Adressen
WHERE Adr_Anrede = 'Frau' AND (Adr_Ort = 'Zürich' Or Adr_Ort = 'Bern')
Geben Sie zum Vergleich die Anweisung wie folgt ein.
SELECT Adr_Anrede, Adr_Vorname, Adr_Nachname,Adr_Ort FROM Adressen
WHERE Adr_Anrede = 'Frau' AND Adr_Ort = 'Zürich' Or Adr_Ort = 'Bern'
SELECT Adr_Anrede, Adr_Vorname, Adr_Nachname,Adr_Ort FROM Adressen
WHERE Adr_Anrede = 'Frau' OR Adr_Ort = 'Zürich' AND Adr_Ort = 'Bern'
Aus diesen Beispielen heraus sehen Sie, dass AND höhere Priorität hat bzw. bindet, gleich wie
eine Multiplikation gegenüber einer Addition.
Datenbank_SQL1.3.doc
Seite 12/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
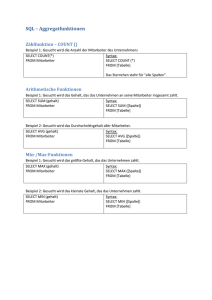
3.5 Aggregatfunktionen
Aggregatfunktionen (aggregate, deutsch: gesamt), auch Spaltenfunktionen genannt, ermitteln für
eine einzelne Tabellenspalte aus einer Gesamtmenge die Summe, den Minimal- oder Maximalwert, den Mittelwert oder die Anzahl.
Nachstehende Tabelle gibt eine Übersicht über Aggregatfunktionen und deren Ergebnisse:
Funktion:
MIN(spaltenname)
MAX(spaltenname)
COUNT(*)
COUNT(DISTINCT
spaltenname)
SUM(spaltenname)
AVG(spaltenname)
Ergebnis
Minimalwert
Maximalwert
Anzahl aller vorhandenen Zeilen
Anzahl der Zeilen mit unterschiedlichen Werten
Kann mit Access nicht verwendet werden.
Summe
Mittelwert
Der durchschnittliche Gehalt wird also wie folgt berechnet
SELECT AVG(Pd_Gehalt) FROM Persdat
In einer SELECT-Anweisung mit Aggregatfunktionen (und
ohne Gruppenbildung) können keine weiteren Spaltenwerte bzw. Spalten ohne Aggregatfunktionen angezeigt werden.
Folgende Anweisung macht also keinen Sinn
SELECT Pd_Name, MAX(Pd_Gehalt) FROM Persdat
Beispiele mit Aggregatfunktionen:
SELECT MAX(Pd_Name) From Persdat
Bei Zeichenketteninhalten wird der höchste Buchstaben nach dem ASCII-Code ermittelt. Das bedeutet, dass das "z" höher ist als das "a" und Sonderzeichen grösser sind als Kleinbuchstaben.
SELECT MIN(Pd_Eintritt) FROM Persdat
Diese Auswertung wird das Datum der ersten Anstellung hervorbringen. Möchte man den Namen
zu diesem Datum anzeigen, müsste der SELECT wie folgt lauten.
SELECT Pd_name, Pd_Vname, Pd_Eintritt FROM persdat
WHERE Pd_Eintritt = (SELECT MIN(Pd_Eintritt) FROM Persdat)
Hier arbeiten wir mit einem SUB-SELECT. Auf die Bedeutung von SUB-SELECT's gehen wir später ein. Da eine Aggregatfunktion immer nur einen gültigen Wert liefert, wird dieser SELECT auch
nur einen Namen hergeben, ausser es wurden am gleichen Datum mehrere Personen angestellt.
SELECT COUNT(*) As Anzahl_Personen FROM Persdat
Mit COUNT() wird festgestellt, wie viele Einträge vorliegen. Wenn Sie die Funktion COUNT() mit
dem Stern als Klammerinhalt benutzen, werden alle in der Tabelle enthaltenen Zeilen gezählt.
Wenn Sie die Anzahl von Zeilen mit unterschiedlichen Spaltenwerten suchen, müssen Sie in der
Klammer entsprechend verfahren.
SELECT DISTINCT COUNT(Pd_Eintritt) FROM Persdat
In diesem Beispiel werden nur Einträge mit unterschiedlichen Datumswerten gezählt. Weitere
Einschränkungen werden über die WHERE-Klausel geregelt.
Datenbank_SQL1.3.doc
Seite 13/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
In einer einzigen Abfrage können auch mehrere Aggregatfuntionen eingesetzt werden.
SELECT COUNT(*), AVG(Pd_Gehalt) FROM Persdat
WHERE Pd_Geschlecht = "W"
In diesem SELECT wird ermittelt, wie viele Mitarbeiterinnen es gibt und wie hoch ihr Durchschnittsgehalt ist. Beide Aggregatfunktionen beziehen sich auf die gesamte Datenmenge, welche
in diesem Fall über die WHERE-Klausel auf die Mitarbeiterinnen eingeschränkt wurde.
3.6 Rechenoperationen durchführen
Im SELECT-Befehl kann man Ausdrücke für arithmetische Operationen vereinbaren. Die Ausdrücke werden mit den Rechenoperationen +,-,*,/ und mit den Aggregatfunktionen SUM() und AVG()
gebildet.
Tabellenunabhängige Rechenoperationen
Man kann mit SQL-Anweisungen Rechenoperationen wie mit einem Taschenrechner durchführen. Man muss dabei jedoch immer eine in der Datenbank vorhandene Tabelle ansprechen und
wenn man die Ergebnisausgabe auf eine Zeile beschränken will, muss man auch eine WHEREBedingung vereinbaren.
SELECT 4.9 * 1.9 AS Resultat FROM Persdat
WHERE Pd_ID = 3
Ausgabe: 9.31
Mit Werten aus numerischen Spalten rechnen
Mit den Werten aus numerischen Tabellenspalten können auch Additionen, Subtraktionen, Divisionen und Multiplikationen durchgeführt werden.
SELECT Pd_name, Pd_Gehalt * 1.045 AS Neues_Gehalt FROM Persdat
Die Anzeige diese Auswertung würde die Grundgehälter um 4.5% erhöhen.
Es können auch die Ergebnisse von Aggregatfunktionen in Rechenoperationen einbezogen werden. Folgende Anweisungen ermitteln beide mit dem selben Ergebnis das durchschnittliche Monatsgehalt.
SELECT AVG(Pd_Gehalt) FROM Persdat
SELECT SUM(Pd_Gehalt) / COUNT(*) FROM Persdat
Datenbank_SQL1.3.doc
Seite 14/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
3.7 Mit Funktionen arbeiten
In jedem SELECT können Funktionen sowohl in der SELECT-Klausel wie auch in der WHEREKlausel eingesetzt werden. Eine Funktion liefert immer einen Wert, der entweder im SELECT-Teil
angezeigt wird oder im WHERE-Teil als Bedingung verwendet wird.
3.7.1 Numerische Funktionen
Numerische Funktionen sind diverse mathematische Funktionen, die der Manipulation numerischer Werte dienen.
Z.B ABS(zahl)
Absoluter Wert
SQR(zahl)
Quadratwurzel
RND()
Zufallszahl
Weitere Funktionen, die sehr Produktspezifisch sind, gibt es für Cosinus, Sinus,Tangens usw.
3.7.2 Datumsoperatoren und Datumsfunktionen
Die Rechenoperatoren + und – können mit Datumsspalten zum Addieren und Subtrahieren eingesetzt werden. Es gibt auch Funktionen wie MONTH_BETWEEN(datum,datum) (Oracle) wo
man direkt über die Funktion Datumsberechnungen anstellen kann.
Datumsfunktionen gehören nicht zum SQL-Standard. In jedem Datenbanksystem finden Sie deshalb andere Funktionen.
SELECT Format(#2000-3-1# -1,'dd.mm.yyyy') AS Datum
FROM Persdat
WHERE Persdat.Pd_ID=3
Dieses erste Beispiel gibt uns den letzten Tag des Monats Februar bekannt und ist eine Datumsberechnung ohne Einbezug von einem Attribut.
SELECT INT((NOW() - pd_eintritt)) AS Tage FROM Persdat
Dieses zweite Beispiel sagt uns, wie viele Tage alle Mitarbeiter bei der Firma arbeiten. Die Funktion INT() liefert uns Anzahl ganze Tage, weil sie Kommastellen unterdrückt, und die Funktion
NOW() liefert uns das aktuelle Datum.
3.7.3 Zeichenketten-, Umwandlungs- und anderer Funktionen
Mit Zeichenketten werden Strings (Textfelder) bearbeitet.
Beispiele sind
LTRIM() / RTRIM()
Löscht linksstehende bzw. rechtsstehende Leerzeichen.
TRIM()
Wie L- oder RTRIM, löscht leere Zeichen links und rechts.
SUBSTR() / MID()
Definiert Teile einer Zeichenkette. (Oracle / Access)
LENGTH()
Gibt die Anzahl Zeichen eines Strings an.
INSTR()
Nennt die Position eines Zeichens im String
3.7.4 Umwandlungsfunktionen
Eine Umwandlungsfunktion wandelt eine Zeichenkette in eine Zahl oder ein Datum um
und umgekehrt.
VAL(String)
Wandelt einen String in eine Zahl um.
STR(Zahl)
Wandelt eine Zahl in einen String um.
3.8 Prädikate
Ein Prädikat bezeichnet eine logische Bedingung. Folgende Operatoren sind Prädikate:
Alle Vergleichsoperatoren (siehe weiter oben)
LIKE-Operator
BETWEEN-Operator
IN-Operator
NULL-Operator
(Siehe Unterabfragen)
ALL- and ANY-Operator
Dito
EXIST-Funktion
Dito
Datenbank_SQL1.3.doc
Seite 15/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
3.8.1 Operator LIKE
Beim Vergleich eines Textfeldes darf nicht der Operator "=" verwendet werden. Wollte man alle
Namen die mit einem M anfangen Mittels "WHERE Pd_Name = 'M'" abfragen, so würde kein
Namen angezeigt, weil eine Übereinstimmung gesucht würde. Hier muss der Operator LIKE verwendet werden. Ausserdem ist dem System mitzuteilen, dass die übrigen Buchstaben des Textfeldes keine Bedeutung für den Suchvorgang haben. Es müssen Platzhalter bzw. Jokerzeichen
für unbekannte oder unerhebliche Zeichen in das Textmuster einbezogen werden. Man unterscheidet folgende Jokerzeichen:
%
_
steht für eine beliebige Anzahl zeichnen,
(Unterstrich) steht für ein einziges Zeichen.
SELECT Pd_Name FROM Persdat
WHERE Pd_Name LIKE 'M%'
Access: LIKE 'M*'
Dieser Select sucht alle Mitarbeiter die mit M beginnen. Der Platzhalter % steht für beliebig viele
Zeichen hinter dem M.
SELECT Pd_Name FROM Persdat
WHERE Pd_Name LIKE 'Me_er'
Access: LIKE 'Me*er*'
In diesem Fall würden alle Meier und Meyer erscheinen, weil der dritte Buchstaben ein beliebiges
Zeichen sein kann. Dieser SELECT funktioniert in DB2 nicht, weil dort die gesamte CHAR(25)Spalte mit allen Leerzeichen berücksichtigt wird.
3.8.2 Operator BETWEEN
Der Operator BETWEEN wird zur Formulierung von Bereichsabfragen eingesetzt. Er kann bei
Textspalten, Datumsspalten und bei numerischen Spalten verwendet werden. BETWEEN wählt
die Daten aus, die sich zwischen einem unteren und oberen Grenzwert befinden.
SELECT Adr_NachnameFROM Adressen
WHERE Adr_Nachname BETWEEN 'S' AND 'Z'
Dieser SELECT gibt alle Namen ab dem Buchstaben S aus.
SELECT Pd_Name, Pd_Eintritt FROM Persdat
WHERE YEAR(Pd_Eintritt) BETWEEN 1990 AND 2000
In diesem SELECT werden alle Mitarbeiter, die zwischen dem Jahr 1990 und 2000 angestellt
wurden, ausgegeben. Man könnte natürlich auch ohne YEAR()-Funktion arbeiten und direkt ein
Datum eingeben.
3.8.3 Operator IN
Der IN-Operator ist vergleichbar mit der Elementabfrage in der Mengenlehre. Er stellt fest, ob der
Inhalt der befragten Spalte in einer der angegebenen Mengen enthalten ist. Der Operator IN kann
auf Zeichenspalten, Datumsspalten und numerischen Spalten angewendet werden. Hinter dem
Schlüsselwort IN werden in runden Klammern die Suchbegriffe einfach hintereinander aufgelistet.
SELECT Pd_Name, Pd_Eintritt FROM Persdat
WHERE YEAR(Pd_Eintritt) IN (1990, 1995)
Dieser SELECT wird alle Mitarbeiter auswählen, die in den beiden angegebenen Jahren angestellt wurden.
SELECT Pd_Name, Abt_ID FROM Persdat
WHERE Abt_ID IN (2,3)
Hier werden alle Mitarbeiter ausgegeben die in den entsprechenden Abteilungen arbeiten.
Datenbank_SQL1.3.doc
Seite 16/37
Bernhard Bausch
4
Schulungsunterlagen Datenbanken
Daten aus mehreren Tabellen abfragen (Joins)
4.1 Kartesisches Produkt aus zwei Tabellen bilden
Bei normalisierten Datenbanken müssen häufig zwei und mehr Tabellen abgefragt werden, um
die gewünschte Information zu erhalten. Dabei tritt das Problem auf, die an der Abfrage beteiligten Tabellen logisch in der richtigen Weise miteinander zu verknüpfen. Werden Tabellen ohne eine Verknüpfungsvorschrift in einer Abfrage verbunden, so wird bei der Ausführung der Abfrage
das kartesische Produkt gebildet. Dabei wird jede nur mögliche Kombination der verschiedenen
Zeilen in den Tabellen dargestellt. Das führt dazu, dass Tabellen mit wenigen Records bereits
tausende von Datensätze liefern.
4.2 Logische Verbingungen mit Equi-Join herstellen
Eine Verknüpfung von Tabellen kann nur dann gelingen, wenn bereits beim Entwurf darauf geachtet wurde, dass sie sich über Schlüsselspalten miteinander verbinden lassen. Dies wird über
die Vererbung eines Hauptschlüssels (Primary-Key) in eine andere Tabelle als Fremdschlüssel
(Secondary-Key) erreicht.
Man bezeichnet diese Verbindung auch als Equi-Join. Abkürzung Equi steht für "Gleichheit" und
Join ist mit "Verknüpfung" zu übersetzen. Die Namen der Schlüsselspalten in beiden Tabellen
müssen nicht gleich sein. Sind sie gleich, muss der Spaltennamen Qualifiziert werden. Dies geschieht, indem man den Tabellennamen dem Spaltennamen voranstellt.
Das folgende Beispiel soll diese Verknüpfung demonstrieren:
SELECT Adressen.Adr_ID, Adr_Vorname, Adr_Nachname,US_Stao_Buero, US_Tel_Int
FROM Adressen,Userinfo
WHERE Adressen.Adr_ID = Userinfo.Adr_ID
Als Bindeglied wird die Spalte Adr_ID verwendet, die in beiden Tabellen vorkommt. Da das System so nicht feststellen kann, in welcher Tabelle der Wert gesucht werden soll, muss die Redundanz des Spaltennamens durch Hinzufügen des Tabellennamens aufgehoben werden; der Spaltennamen Adr_ID muss qualifiziert werden.
Die Tabellennamen der zu verknüpfenden Tabellen werden alle hinter der FROM-Klausel aufgelistet.
Die Equi-Join-Bedingung in der WHERE-Klausel besagt, dass jene Zeilen auszwählen sind, deren Adr_ID's gleich sind.
4.3 Andersnamen bzw. Alias-Bezeichner für Tabellen vereinbaren
Bei der Eingabe einer Abfrage kann es lästig werden, wenn man immer wieder lange Tabellennamen wie "fmitglieder" eintasten muss. Deshalb arbeitet man in Joins gerne mit TabellenKurznamen, Andersnamen oder Alternativnamen. Alternativnamen werden auch benötigt, wenn
Tabellen auf sich selber zu beziehen sind.
Alternativnamen können synonyme Namen oder Alias-Namen sein.
4.3.1 Synonyme Tabellen-Bezeichner
Synonyme Bezeichnungen müssen mit folgender SQL-Anweisung derfiniert werden.
CREATE SYNONYM p FOR Persdat
Nach erfolgter Eingabe dieses SYNONYM-Befehls können Sie die Daten der Tabelle persdat alternativ wie folgt ansprechen:
SELECT * FROM p
Die Löschung von Synonymen erfolgt durch die Anweisung:
DROP SYNONYM p
In der Access wird die synonyme Tabellenbezeichnung nicht unterstützt.
Datenbank_SQL1.3.doc
Seite 17/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
4.3.2 Alias-Bezeichner definieren
Es gibt auch die Möglichkeit, Kurzbezeichnungen nur für die Dauer einer Befehlsausführung zu
definieren. Wir nennen diese Bezeichner Alias-Bezeichner.
Alias-Namen werden in dem FROM-Zusatz des SELECT-Befehls vereinbart. Zwischen dem Tabellennamen und der nachgestellten Alias-Bezeichnung steht nur ein Leerzeichen. Sie können in
allen Datenbanksystemen eingesetzt werden.
Das weiter oben verwendete Beispiel für einen Equi-Join sieht mit Alias-Bezeichnungen wie folgt
aus:
SELECT A.Adr_ID, Adr_Vorname, Adr_Nachname,US_Stao_Buero, US_Tel_Int
FROM Adressen A,Userinfo U
WHERE A.Adr_ID = U.Adr_ID
4.4 OUTER- oder LEFT-, RIGHT-Join
Mit einem Inner-Equi-Join sind nicht alle Informationswünsche zu erfüllen. In ihm werden aus einer Tabelle sämtliche Records ausgegeben, denen aus einer anderen Tabelle Records aufgrund
übereinstimmender Schlüsselwerte zugeordnet werden.
In einem Equi-Join werden also nur Daten die gleiche Werte haben ausgegeben.
Nun gibt zusätzlich die Möglichkeit, dass von einer Tabelle sämtliche Records ausgegeben werden und von einer verbundenen Tabelle nur jene Records, wo eine Übereinstimmungen vorhanden ist. Eine solche Verbindung die uns das ermöglicht nennt man OUTER-Join.
Beim OUTER-Join ist zwischen der Haupttabelle und der nachgeordneten Tabelle zu unterscheiden. Jene ist die Haupttabelle, aus der sämtliche Records in die Ausgabe übernommen werden
sollen und von der nachgeordneten Tabelle werden nur jene Records übernommen die den gleichen Schlüsselwert haben.
Beispiel:
Im oben bereits erwähnten Beispiel sprechen wir zwei Tabellen an mit unterschiedlichen Daten.
In der Tabelle Adressen sind sämtliche Adressen gespeichert die im System vorhanden sind.
In der Tabelle Userinfo sind nur jene Adressen vorhanden (Schlüsselwert), die als Mitarbeiteradresse definiert wurde (Adresstyp = 1)
In unserem Beispiel ist also Adressen die Haupttabelle und Userinfo ist die nachgeordnete Tabelle. In der OUTER-Join-Abfrage muss nun die nachgeordnete Tabelle als solche kenntlich gemacht werden.
Left- und Right-Join sind Access-Speziefische Outer-Joins die definieren, ob die linke oder die
rechte Tabelle die nachgeordnete Tabelle ist.
Die verschiedenen Datenbanksysteme sind unterschiedlich in der Anwendung des OUTER-Join,
deshalb werden hier die wichtigsten vorgestellt.
INFORMIX
In INFORMIX wird in der FROM-Klausel die Tabelle durch ein vorangestelltes OUTER als nachgeordnete Tabelle gekennzeichnet. Der Outer-Join-Operator darf in einer Anweisung nur einmal
verwendet werden.
SELECT A.Adr_ID, Adr_Vorname, Adr_Nachname,US_Stao_Buero, US_Tel_Int
FROM Adressen A, OUTER Userinfo U
WHERE A.Adr_ID = U.Adr_ID
Datenbank_SQL1.3.doc
Seite 18/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
ORACLE
In ORACLE wird in der WHERE-Klausel die Outer-Join-Spalte der nachgeordneten Tabelle durch
ein nachgestelltes (+) markiert. Gleich wie in INFORMIX darf der Equi-Join-Operator in einer Anweisung nur einmal verwendet werden.
SELECT A.Adr_ID, Adr_Vorname, Adr_Nachname,US_Stao_Buero, US_Tel_Int
FROM Adressen A, Userinfo U
WHERE A.Adr_ID = U.Adr_ID(+)
JET-Datenbank (Access)
In der JET-Datenbank können Sie JOIN-Operationen mit den Operatoren INNER JOIN, LEFT
JOIN und RIGHT JOIN erstellen. INNER JOIN entspricht dem normalen Equi-Join. LEFT JOIN
bewirkt, dass aus der links von LEFT JOIN genannten Tabelle auch jene Datensätze angezeigt
werden, denen kein Schlüsselwert aus der rechts genannten Tabelle entspricht. Bei RIGHTJOIN
ist es die Tabelle auf der rechten Seite.
Beispiele:
SELECT Adressen.Adr_Firma, Adressen.Adr_Vorname, Adressen.Adr_Nachname,
Userinfo.Us_Stao_Buero, Userinfo.Us_Tel_Int
FROM Adressen INNER JOIN Userinfo ON Adressen.Adr_ID = Userinfo.Adr_ID;
SELECT Adressen.Adr_Firma, Adressen.Adr_Vorname, Adressen.Adr_Nachname,
Userifo.Us_Stao_Buero, Userinfo.Us_Tel_Int
FROM Adressen LEFT JOIN Userinfo ON Adressen.Adr_ID = Userinfo.Adr_ID
Dieses letzte Beispiel macht zwar kein Sinn, weil es in Userinfo weniger Datensätze hat wie in
Adressen. Es soll nur den RIHGT JOIN darstellen.
SELECT Adressen.Adr_Firma, Adressen.Adr_Vorname, Userinfo.Us_Tel_Int,
Userinfo.Us_Stao_Buero, Adressen.Adr_Nachname
FROM Adressen RIGHT JOIN Userinfo ON Adressen.Adr_ID = Userinfo.Adr_ID
4.4.1 Verknüpfungen innerhalb der gleichen Tabelle (Self-Joins)
Logische Verknüpfung von Zeilen innerhalb der gleichen Tabelle nennt man Self-Joins oder AutoJoins. Vor der Verknüpfung spaltet man die Tabelle mit Alias-Bezeichnungen auf. Self-Joins laufen nicht in der Access Jet-Datenbank.
Beispiel: Wir wollen von der Tabelle Persdat wissen, welche männlichen Mitarbeiter das gleiche
Gehalt beziehen wie weibliche Mitarbeiter.
SELECT ma.Pd_Gehalt, ma.Pd_name, ma.Pd_Geschlecht, frau.Pd_Name, frau.Pd_Gehalt
FROM Persdat ma, Persdat frau
WHERE ma.Pd_Geschlecht = 'M' AND
frau.Pd_Geschlecht = 'W' AND
ma.Pd_Gehalt = frau.Pd_Gehalt
Die Join-Analyse zeigt, dass alle Infromationen in der Tabelle Persdat stehen. Deshalb wird die
Tabelle durch folgende Angabe in der FROM-Klausel in zwei Untertabellen aufgeteilt:
FROM Persdat ma, persdat frau
Die logische Zuordnung der Tabellenzeilen zu den Untertabellen erfolgt mit Zuordnungsbedingungen:
ma.Pd_Geschlecht = 'M'
frau.Pd_Geschlecht = 'W'
Datenbank_SQL1.3.doc
Seite 19/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
Übung 1
Erstellen Sie ein Liste der vorhandenen Kundenadressen, mit den dazugehörigen Kontaktpersonen.
Attributte:
Relationen:
Adr_Firma, Adr_Adresse1, Adr_Plz, Adr_Ort, Kop_Name, Kop_Tel_intern
Adressen, Kontaktperson
Tip:
Kunden sind mit dem Adresstyp 3 definiert
Übung 2
Erstellen Sie eine Liste, welche pro Person alle zugeordneten Applikationen auflistet.
Attributte:
Relationen:
Adr_Name, Adr_Vname, Ap_Bez
Adressen, Applikationen, Appl_zu_User
Tips:
Namen und Applikation wurden über die Tabelle Appl_zu_User verknüpft
Übung 3
Erstellen Sie ein Inventar, das besagt, welche Person in welchem Büro besitzt was für Material.
Attributte:
Relationen:
Adr_Name, Adr_Vname, Ma_Bez, Us_Stao_Buero
Adressen, Userinfo, Mat_Detail, Mat_Art
Tips:
Mat_Detail ist die Verbindung zu Mat_Art
Datenbank_SQL1.3.doc
Seite 20/37
Bernhard Bausch
5
Schulungsunterlagen Datenbanken
Bedingungen in SELECT-Unterabfragen formulieren
(Subqueries)
Die Unterabfrage ist eine in Klammer eingeschlossene SELECT-Anweisung innerhalb der WHERE-Klausel einer anderen SELECT-Anweisung. Da die Unterabfragen innerhalb einer SELECTAbfrage angeordnet werden, nennt man sie auch nested queries. Man benötigt sie in den Fällen,
in denen die Suchbedingung vom Ergebnis einer anderen Abfrage abhängt.
Der Einsatz von Operatoren wie ALL, ANY, IN und EXISTS in Unterabfragen hat den Vorteil,
dass die zu suchenden Wert schneller geliefert werden, weil die Unterabfrage nur einmal ausgeführt werden muss. Wenn man einfache Vergleichsoperatoren verwendet muss eine Unterabfrage für jeden Record neu ausgeführt werden.
5.1 Regeln für den Einsatz von Unterabfragen
1. Wenn das Ergebnis einer Unterabfrage eine einzige Ergebnisreihe ist, kann die Unterabfrage
mit relationalen Operatoren eingeleitet werden.
2. Führt die Unterabfrage zu mehr als einer Ergebnisreihe, dann müssen die Operatoren ALL,
ANY, IN oder EXISTS eingesetzt werden
3. Wenn in der Unterabfrage nur geprüft werden soll, ob eine Tabellenzeile die gewünschte Bedingung erfüllt, wird der Operator EXISTS verwendet.
4. Unterabfragen werden in der Regel im Befehl SELECT eingesetzt. Sie können aber auch mit
den Befehlen INSERT und UPDATE verwendet werden.
5.2 Unterabfragen mit relationale Operatoren
Unterabfragen können in mehreren Ebenen geschachtelt sein. Sie werden in umgekehrter Reihenfolge der Ebenen abgearbeitet, die Unterabfrage auf der untersten Ebene immer zuerst. In
Unterabfragen können alle im Zugriff befindlichen Tabellen angesprochen werden, also auch die
Tabelle der Hauptabfrage. Ausser beim Einsatz des Operators EXISTS bezieht sich eine Unterabfrage stets nur auf eine Spalte.
Beispiel:
Wir wollen wissen, welche Mitarbeiter weniger als das durchschnittliche Gehalt beziehen.
Um diese Information zu erhalten sind zwei Schritte erforderlich
Schritt 1
SELECT AVG(Pd_Gehalt) FROM Persdat
Liefert als Ergebnis das Durchschnittsgehalt.
Schritt 2
SELECT Pd_Name, Pd_Gehalt FROM Persdat
WHERE Pd_Gehalt < (Ergebnis Schritt 1)
Unter Verwendung einer SELECT-Unterabfrage lautet die SQL-Anweisung wie folgt:
SELECT Pd_Name, Pd_Gehalt FROM Persdat
WHERE Pd_Gehalt <
(SELECT AVG(Pd_Gehalt) FROM Persdat)
Der Vergleichswert wird nicht mehr unmittelbar angegeben. Vielmehr wird er durch die eingeschachtelte Unterabfrage geliefert.
Beispiel:
SELECT Pd_Name, Pd_Vname, Pd_Gehalt FROM Persdat
WHERE Pd_Gehalt > (SELECT MAX(Pd_Gehalt) FROM Persdat
WHERE Abt_ID = 3)
Dieses Beispiel zeigt, welche Mitarbeiter mehr verdienen als jener mit dem höchsten Gehalt der
Abteilung 3.
Datenbank_SQL1.3.doc
Seite 21/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
5.3 Unterabfrage mit ALL und ANY
Ist eine Unterabfrage einzuleiten, die einen oder mehrere Werte liefert, so sind die Operatoren
ALL und ANY, zusammen mit den relationalen Operatoren (<;<=;>;>=), zu verwenden.
Die hinter der WHERE-Bedingung des Haupt-SELECTs eingesetzte Vergleichsspalte, muss auch
in der Unterabfrage als Vergleichsspaltenname verwendet werden.
5.3.1 Operator ALL
Mit ALL (englisch: alle) wird in der Unterabfrage ein Vergleichswert aus einer Gruppe abgefragt.
Eine Gruppe in Persdat könnten z.B. die Mitarbeiter der Abteilung 3 sein und der Vergleichswert
könnte das Gehalt sein.
SELECT Pd_Name, Abt_ID, Pd_Gehalt FROM Persdat
WHERE Pd_Gehalt >= ALL
(SELECT Pd_Gehalt FROM Persdat
WHERE Abt_ID = 3)
In dieser Unterabfrage ermittelt der ALL-Operator aus allen vorhandenen Gehälter aus der Abteilung 3 das Höchste und gibt diesen Wert an die Hauptabfrage zurück. Ist das höchste Gehalt der
Abteilung 3 5200, dann wir jede Zeile mit "WHERE Pd_Gehalt >= 5200" ausgewertet.
Eine Unterabfrage darf sich auch auf eine Spalte beziehen, die in der Hauptabfrage angesprochen wird. Diese Form der Unterabfrage nennt man abhängige, korrelierte Unterabfrage.
Folgendes Beispiel soll das Dokumentieren:
SELECT p.Pd_ID, Pd_Name FROM Persdat p
WHERE 4000 < ALL
(SELECT Mg_Gehalt FROM Mgehalt_Daten g
WHERE p.Pd_ID = g.Pd_ID AND
Mg_Jahr = 01 AND
Mg_Monat = 2)
Dieses Beispiel zeigt, welche Mitarbeiter im Februar 2001 mehr als Fr. 4000 verdienen. Die in
der Unterabfrage enthaltene JOIN-Verknüpfung der beiden Tabellen Persdat und MGehalt wird
über eine Spalte der Hauptabfrage gesteuert.
Die relationalen Operatoren bestimmen beim ALL-Operator ob jeweils der höchste oder der niedrigste Wert der selectionierten Datenmenge aus der Unterabfrage zum tragen kommt
Operator
> ALL
>= ALL
< ALL
<= ALL
Auswahl in der
Vergleichsgruppe
höchster Wert
höchster Wert
kleinster Wert
kleinster Wert
Anzeige mit der Hauptabfrage:
Alle Zeilen mit ...
grösseren Vergleichswerten
grösser oder gleichen Vergleichswerten
geringeren Vergleichswerten
geringeren oder gleichen Vergleichswerten
Zeichenfelder als Vergleichsspalte:
Bei Zeichenfeldern kommt an die Stelle grösserer und kleinerer numerischer Werte die Sortierung
im ASCII-Code zum Tragen.
Datumsfeld als Vergleichsspalte
Bei Datumsfelder wird das grössere oder kleinere Datum verglichen.
Beispiel für eine Auswertung der geringeren Vergleichswerte mit Datum.
SELECT Pd_Name, Pd_Eintritt FROM persdat
WHERE Pd_Eintritt < ALL
(SELECT Pd_Eintritt FROM Persdat
WHERE Abt_ID = 3)
Diese Auswertung wird alle Mitarbeiter ausgeben, die früher als der Mitarbeiter mit dem niedrigsten Eintrittdatum aus der Abteilung 3 eingetreten ist.
Datenbank_SQL1.3.doc
Seite 22/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
5.3.2 Operator ANY
Der Operator ANY (englisch: irgendeiner) fragt bei > ANY in der Unterabfrage ab, welcher Wert
grösser ist als irgendein Wert in der Vergleichsgruppe. Das ist jeder Wert der grösser ist als der
kleinste Gruppenwert.
Bei < ANY lautet die Frage: Welcher Wert ist kleiner als irgendein Wert in der Vergleichsgruppe?
Das ist jeder Wert, der kleiner ist als der grösste Gruppenwert.
Auch der ANY-Operator kann mit Zeichen- und Datumsfeldern kombiniert werden.
Die folgende Übersicht zeigt die Wirkungsweise der relationalen Operatoren mit ANY allgemein
an:
Operator Auswahl in der
Anzeige mit der Hauptabfrage:
Vergleichsgruppe Alle Zeilen mit ...
> ANY
kleinster Wert
grösseren Vergleichswerten
>= ANY
kleinster Wert
grösser oder gleichen Vergleichswerten
< ANY
grösster Wert
geringeren Vergleichswerten
<= ANY
grösster Wert
geringeren oder gleichen Vergleichswerten
Beispiel:
SELECT Pd_Name, Abt_ID, Pd_Gehalt FROM Persdat
WHERE Pd_Gehalt > ANY
(SELECT Pd_Gehalt FROM Persdat
WHERE Abt_ID = 3)
Dieser SELECT bringt jene Mitarbeiter, deren Gehalt grösser ist als das kleinste Gehalt der Abteilung 3.
5.4 Unterabfragen mit IN und EXISTS
Die Operatoren IN und EXIST prüfen in der Unterabfrage, ob eine in der Hauptabfrage gestellte
Bedingung erfüllt wird.
5.4.1 Operator IN
Der Operator IN wird in der Regel zur Suche in anderen Tabellen eingesetzt. Er prüft nacheinander für jeden Wert aus der Vergleichsspalte der Haupttabelle, ob dieser Wert in der Vergleichsspalte der Untertabelle steht, bei NOT IN, ob er nicht darin steht. Die Namen der Vergleichsspalten in der Hauptabfrage und in der Unterabfrage müssen gleich sein.
Die Hauptabfrage kann sich auf mehrere Tabellen beziehen. In der Unterabfrage ist auch eine
WHERE-Klausel zulässig.
Beispiel:
SELECT Pd_ID, Pd_Name, Pd_Vname FROM Persdat p
WHERE Pd_ID NOT IN
(SELECT Pd_ID FROM Familienmitglieder f
WHERE p.Pd_ID = f.Pd_ID)
In diesem Beispiel will man wissen, welche Mitarbeiter keine Familienmitglieder haben.
5.4.2 Operator EXISTS
Wenn in der Unterabfrage nur geprüft werden soll, ob die darin gültigen Vergleichswerte, im aktuellen Wert der Hauptaufgabe existieren, so wird der Operator EXISTS verwendet
Beispiel:
SELECT Pd_ID, Pd_Name FROM Persdat p
WHERE EXISTS
(SELECT * FROM Familienmitglieder f
WHERE p.Pd_ID = f.Pd_ID)
Datenbank_SQL1.3.doc
Seite 23/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
In der Untertabelle darf hinter FROM nur eine einzige Tabelle aufgeführt werden, weil der
EXISTS-Operator keine Join-Bedingungen zulässt. Vor dem EXISTS-Operator wird kein definitiver Spaltennamen eingesetzt.
Mit NOT EXISTS wird die Komplementärmenge der Tabelle angezeigt. Die Unterabfrage mit
EXISTS wird in der Regel mit SELECT * eingeleitet. An die Stelle des Sterns kann auch irgendein
Spaltennamen aus der Haupttabelle treten.
Da bei EXISTS keine Vergleichsspalte die Verbindung zwischen Haupt- und Unterabfrage herstellt, muss die Verknüpfung in der WHERE-Bedingung der Unterabfrage vereinbart werden.
5.5 Synchronisierte Unterabfragen
In synchronisierten Abfragen wird in der Unterabfrage dieselbe Tabelle wie in der Hauptabfrage
angesprochen. Um Vergleichsfelder in der Haupt- und in der Unterabfrage ansprechen zu können, wird die Tabelle aufgeteilt, indem der Tabelle in der Haupt- oder Unterabfrage oder in beiden
ein Alias-Bezeichner zugeordnet wird.
SELECT Pd_ID, Abt_ID, PD_Gehalt FROM Persdat a
WHERE Pd_Gehalt >
(SELECT AVG(Pd_Gehalt) FROM Persdat
WHERE Abt_ID = a.Abt_ID)
In diesem Beispiel werden jene Gehälter angezeigt, welche grösser als die Durchschnittsgehälter
der Mitarbeiter in der selben Abteilung sind.
In dieser Abfrage reicht es nicht aus, dass die Unterabfrage nur einmal ausgeführt wird. Es muss
jedem Gehalt aus der Hauptabfrage das Durchschnittsgehalt der zutreffenden Abteilung gegenübergestellt werden. Dazu wird die Hauptabfrage die Alias-Bezeichnung a zugeordnet, damit
über die Spalte Abt_ID die Verknüpfung innerhalb der gleichen Tabelle definiert werden kann.
Die Unterabfrage wird für jede Zeile der Hauptabfrage durchgeführt.
5.6 Unterabfragen im Befehl INSERT
Die SELECT-Unterabfrage im INSERT-Befehl überträgt Daten aus einer oder mehreren Quelltabellen in eine Zieltabelle, die bereits angelegt sein muss.
Die Anweisung INSERT SELECT gestattet die Übertragung aller oder ausgewählter Zeilen und
Spalten der Quelltabellen in die Zieltabelle. Die Spalten der Zieltabelle müssen im Typ und in der
Grösse genau den Spalten der Quelltabellen entsprechen. Eine Übereinstimmung der Spaltennamen kann mit dem Zusatz AS erfolgen.
Beispiel: Löschen Sie zuerst die Tabelle Ueb
Erstellen Sie mit CREATE TABLE die Tabelle ueb neu:
CREATE TABLE Ueb
(Pd_ID LONG, Ue_Gehaltfzu NUMERIC, Ue_Pdeckung NUMERIC)
INSERT INTO Ueb
SELECT Pd_ID, Pd_Gehalt as Ue_Gehaltfzu , Pd_Gehalt * 3.6 AS Ue_Pdeckung
FROM Persdat
In der neuen Tabelle ueb, werden aus der Tabelle persdat die Personalnummer (Pd_ID) und das
mit dem Faktor 3.6 multiplizierte Gehalt übertragen.
Übung:
Kopieren sie alle Daten aus der Tabelle MGehalt_Daten in die Tabelle MGehalt
Datenbank_SQL1.3.doc
Seite 24/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
5.7 Unterabfragen im Befehl UPDATE
SELECT-Unterabfragen können bei der UPDATE-Anweisung sowohl in der WHERE-Klausel als
auch in der SET-Klausel eingesetzt werden.
5.7.1 Select-Unterabfrage in der WHERE-Klausel
Mit der SELECT-Unterabfrage in der WHERE-Klausel des UPDATE-Befehls werden die Zeilen
und die Spalten definiert, in denen Aktualisierungen erfolgen sollen.
UPDATE ueb
SET Ue_Gehaltfzu = Ue_Gehaltfzu + 99
WHERE Pd_ID IN
(SELECT Pd_ID FROM MGehalt_Daten
WHERE
Mg_Jahr
=1
AND
Mg_Monat = 1
AND
Mg_Gehalt < 3000)
Im Beispiel wird das Gehalt in der Spalte Ue_Gehaltfzu der Tabelle Ueb um Fr. 99.— für die Mitarbeiter, die im Januar 2001 weniger als Fr. 3000.— verdient haben, erhöht.
In der SET-Klausel der UPDATE-Anweisung wird mit dem Ausdruck Ue_Gehaltfzu + 99 die Erhöhung vereinbart. In der SELECT-Unterabfrage wird definiert, dass nur die Zeilen in der Tabelle
ueb berüchsichtigt werden dürfen, in denen im Januar des Jahres 2001 (1) die Spalte Mg_Gehalt
der Tabelle MGehalt_Daten einen Betrag unter Fr. 3000 ausweist
5.7.2 SELECT-Unterabfrage in der SET-Klausel
Mit dem SELECT-Befehl direkt hinter SET wird der Wert definiert, der in die Spalte hineingeschrieben werden soll (läuft nicht in Access).
UPDATE Ueb
SET Ue_Gehaltfzu =
(SELECT SUM(FM_Zuschlag) + Ue_Gehaltfzu
FROM FMitglieder f
WHERE f.Pd_ID = Ueb.Pd_ID)
WHERE Pd_Id IN
(SELECT Pd_ID FROM FMitglieder)
In diesem Beispiel soll in der Tabelle Ueb, in die Spalte Ue_Gehaltfzu, die Familienzuschussbeträge aus der Tabelle FMitglieder addiert werden. Das können mehrere Einträge pro Mitarbeiter
sein, z.B. Kinderzulage. Familienzulage erhalten nur die Mitarbeiter, die in der Tabelle FMitglieder
auch einen Eintrag und somit Anspruch haben.
Der erste SUB-SELECT liefert den Betrag der geändert werden soll und ist mit der Tabelle Ueb
verbunden.
Der zweite SUB-SELECT beschränkt die Daten in der WHERE-Klausel auf die Einträge der Mitarbeiter, die Familienmitglieder haben. Ohne diese Einschränkung würden alle Gehälter der Mitarbeiter die keine Familienmitglieder haben auf 0 gesetzt. Das deshalb, weil ohne WHEREKlausel der UPDATE-Befehl für alle Datensätze gilt.
Datenbank_SQL1.3.doc
Seite 25/37
Bernhard Bausch
6
Schulungsunterlagen Datenbanken
Daten sortieren und gruppieren
Daten lassen sich leichter auswerten, wenn sie sortiert oder in Gruppen zusammengefasst werden. Im SELECT-Befehl gibt es für das Sortieren den Zusatz ORDER BY und für das Gruppieren
die Klausel GROUP BY.
6.1 Daten Sortieren
Beim Sortieren wird eine bestimmte Reihenfolge für die Ausgabe der Ergebniszeilen festgelegt.
Dabei können die Werte jeder Spalte als Sortierkriterium vereinbart werden.
Sortiert werden Ziffern und Zeichenfolgen nach dem ASCII-Code. Das bedeutet bei Zeichenketten, dass Ziffern vor Grossbuchstaben, Grossbuchstaben vor Kleinbuchstaben und Kleinbuchstaben vor Sonderzeichen angeordnet werden.
SELECT Pd_ID, Pd_Name, Pd_Vname FROM Persdat
WHERE Pd_Geschlecht = 'W'
ORDER BY Pd_Name DESC
Die Sortierung wird durch die ORDER-BY-Klausel veranlasst.
Die aufsteigende Sortierung ASC (ascending = aufsteigend) ist die Voreinstellung der ORDERBY-Klausel. Nur wenn absteigend DESC (descending = absteigend) sortiert werden soll, muss
dies im ORDER-Zusatz ausdrücklich vermerkt werden.
Sortiert wird nur, wenn der hinter ORDER BY genannte Spaltenname auch in der SELECTKlausel angegeben ist. Es genügt allerdings auch, wenn man zur Spaltenauswahl das Zeichen *
einsetzt. Die ORDER-BY-Klausel muss innerhalb der SELECT-Anweisung immer die letzte
Klausel sein. Man kann in der ORDER-BY-Struktur anstelle von Spaltennamen auch Spaltennummern einsetzen.
SELECT Pd_ID, Pd_Name, Pd_Vname FROM Persdat
WHERE Pd_Geschlecht = 'W'
ORDER BY 2 DESC
Die Reihenfolge, in der man hinter SELECT die Spaltennamen einsetzt, bestimmt die Spaltennummer. Pd_ID = 1, Pd_Name = 2, Pd_Vname = 3.
Es können mehrere Spalten benannt werden, nach denen die Sortierung durchgeführt werden
soll. Die Sortierung erfolgt dann hierarchisch so, dass die Sortierung nach dem zweiten Spaltennamen innerhalb der Sortierung nach dem ersten Spaltennamen erfolgt, die Sortierung nach dem
dritten Spaltennamen innerhalb der Sortierung nach dem zweiten Spaltennamen usw.
SELECT Pd_ID, Pd_Name, Pd_Vname, Abt_ID FROM Persdat
WHERE Pd_Geschlecht = 'W'
ORDER BY 4, 2 DESC, 3
Die Zeilen dieses Beispiels werden zuerst nach Abteilung sortiert und innerhalb der Abteilung
nach Namen (absteigend) und dann nach Vornamen.
Die Sortierklausel ist unabhängig davon, ob Joins eingesetzt werden oder nicht. Sie steht allein
im Zusammenhang mit der SELECT-Klausel.
6.2 Zeilen gruppieren
Eine Vielzahl von Informationswünschen bezieht sich auf Gruppen von Daten. So können Leistungen von verschiedenen Aufträgen in Gruppen zusammengefasst werden. Die Leistungen pro
Auftrag stellen in diesem Zusammenhang eine Gruppe dar.
Gruppieren heisst somit, dass solche Zeilen zu einer Ausgabe zusammengefasst werden, die die
Gleichen Werte haben. Ein Gruppenwechsel finden immer dann statt, wenn sich der Wert der
Gruppenspalte ändert.
Datenbank_SQL1.3.doc
Seite 26/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
Als Gruppenspalte könnte z.B. die Spalte Pd_Geschlecht in Persdat eingesetzt werden.
SELECT Pd_Geschlecht, Count(*) FROM Persdat
GROUP BY Pd_Geschlecht
Dieser SELECT würde zwei Zeilen ausgeben, je mit der Anzahl weiblicher und männlicher Angestellter.
In Verbindung mit GROUP-BY können in der SELECT-Klausel, zusätzlich zu den Aggregatfunktionen, Attribute verwendet werden.
Der GROUP-BY-Zusatz steht hinter der SELECT-Anweisung nach den Zusätzen FROM und
WHERE und vor der ORDER-BY-Klausel. Der Gruppenbegriff wird, durch eine Leerstelle getrennt, hinter die GROUP-BY-Klausel geschrieben.
SELECT A.Abt_ID, Abt_Bez, SUM(Pd_Gehalt) FROM Persdat P, Abteilung A
WHERE P.Abt_ID = A.Abt_ID and
P.Abt_ID BETWEEN 1 AND 3
GROUP BY A.Abt_ID, Abt_Bez
ORDER BY A.Abt_Bez
Dieser SELECT gibt die Lohnsumme der Abteilung 1, 2 und 3 aus. Die Gruppierung bezieht sich
eigentlich nur auf die Abt_ID, erfolgt aber auch auf Abt_Bez. Das ist aus folgendem Grund erforderlich:
Alle hinter einem SELECT angegebenen Spalten müssen auch hinter der GROUP-BY-Klausel
aufgeführt werden müssen.
Lediglich Aggregatfunktionen werden nicht in der GROUP-BY-Klausel aufgeführt.
Bitte beachten Sie auch in diesem Beispiel, dass Abt_Id aus der gleichen Tabelle stammen muss
wie die Aggregatfunktion. Versuchen Sie die gleiche Aufgabe mit der Abt_ID von Persdat.
Bei der obigen Aufgabenstellung handelt es sich um einen einstufigen Gruppenwechsel. Die
Gruppenwechsel können aber auch mehrstufig erfolgen.
SELECT P.Abt_ID, MG.Mg_Jahr, SUM(Mg_Gehalt) AS 'Total Jahr'
FROM Persdat P, MGehalt MG
WHERE P.Pd_ID=MG.Pd_ID
GROUP BY P.Abt_ID, MG.Mg_Jahr
ORDER BY P.Abt_ID, MG.Mg_Jahr
Bei dieser Abfrage handelt es sich um einen zweistufigen Gruppenwechsel. Die Abteilung
(Abt_ID) stellt die Obergruppe dar und das Jahr (Mg_Jahr) aus MGehalt stellt die Untergruppe
dar. Die Reihenfolge erfolgt durch die Reihenfolge der Einträge hinter der GROUP-BY-Klausel.
Zuerst wird die Abteilung bestimmt und dann innerhalb der Abteilung für jedes Jahr eine Gesamtlohnsumme berechnet.
Gruppierung in Unterabfragen
Gruppierungen können auch in verschachtelten Abfragen eingebracht werden.
Das unten stehende Beispiel soll nur verdeutlichen wie komplex verfahren werden kann.
Ansonst ist das Beispiel ohne Beschreibung.
SELECT p.Pd_ID, Pd_Name, p.Abt_Bez FROM Perdat p, Abteilung a
WHERE p.Pd_ID = a.Pd_ID AND
p.Pd_ID IN (Select Pd_ID FROM TPosten
WHERE TP_ID IN (SELECT Ta_ID FROM Tarten
WHERE Ta_Bez LIKE 'Kalkulation') AND
TP_AufNr = 1111
GROUP BY Pd_ID)
Datenbank_SQL1.3.doc
Seite 27/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
6.3 Gruppen bedingungsabhängig auswählen mit HAVING.
Bei der gruppenorientierten Auswertung interessieren oftmals nur die Gruppen, bei denen eine
bestimmte Bedingung erfüllt ist. Mit der HAVING-Klausel kann man eine Bedingung vereinbaren,
unter der ein Gruppenergebnis ausgegeben wird.
SELECT Abt_ID, COUNT(*) FROM persdat
GROUP BY Abt_ID
HAVING COUNT(*) > 2
In diesem Ergebnis werden nur die Abteilungen angezeigt, in denen mehr als 2 Mitarbeiter beschäftigt sind oder anders definiert, die HAVING-Klausel verlangt, dass mindestens 3 Datensätze
pro Abteilung verlangt werden um zur Anzeige zu gelangen.
Die HAVING-Klausel kann nur zusammen mit und für den Befehlsteil GROUP BY verwendet
werden. Für die Formulierung der Bedingung hinter HAVING gelten die gleichen Regeln wie bei
der WHERE-Klausel, mit der die Zeilenauswahl aus einer Tabelle vereinbart wird. Es können alle
Operatoren genutzt sowie Unterabfragen eingeleitet werden. Es gibt jedoch eine wichtige Einschränkung. Ausser den Aggregatfunktionen SUM(), AVG(), MIN(), MAX() und COUNT(), können
keine Funktionen in der HAVING-Bedingung eingesetzt werden.
SELECT Mg_Monat, Pd_Name, Pd_Geschlecht, SUM(Mg_Gehalt)
FROM Persdat p, MGehalt m
WHERE p.Pd_ID = m.Pd_ID
GROUP BY Mg_Monat, Pd_Name, Pd_Geschlecht
HAVING SUM(Mg_Gehalt) > 5000
ORDER BY Mg_Monat
In dieser Anweisung erfolgt die Gruppenbildung nach Massgabe des Monats, des Mitarbeiternamens sowie des Geschlechtes. Hier wird das Gehalt jeder Zeile als Summe definiert. So ist es
möglich, im Zusammenspiel mit GROUP BY, einzelne Attribute zusammen mit einer Aggregatfunktion darzustellen. Mit der HAVING-Klausel wird festgelegt, dass nur solche Zeilen anzuzeigen
sind, in denen das Gehalt den Betrag von 5000 übersteigt. In der WHERE-Klausel könnte noch
der Monat eingeschränkt werden.
Datenbank_SQL1.3.doc
Seite 28/37
Bernhard Bausch
7
Schulungsunterlagen Datenbanken
Ergebnisausgaben verbinden mit UNION, INTERSECT, EXCEPT
7.1 Operator UNION
Mit UNION können SELECT-Abfragen verbunden werden. Die Ergebnisausgabe des Verbundes
enthält sämtliche Ergebniszeilen der verbundenen Einzelabfragen. In der Sprache der Mengenlehre ausgedrückt, bewirkt der UNION-Operator die Vereinigung von Mengen.
Voraussetzung für die UNION-Klausel ist, dass die in der Spaltenauswahl genannten Spalten in
Typ und Grösse in beiden SELECT-Anweisungen übereinstimmen. Eine Namensübereinstimmung ist nicht erforderlich.
Die Übereinstimmung der Spaltentypen und Spaltengrössen kann auch mit Ersatzspalten hergestellt werden. Für ein Textfeld kann im zweiten SELECT eine Leerzeichenkette ("
") oder
für ein numerisches Feld eine (0) definiert werden. Dies ist allerdings von Datenbank zu Datenbank unterschiedlich.
SELECT 'Abt.Leiter: ', p.Pd_ID, Pd_Name, p.Abt_ID
FROM persdat p, Abteilungsleiter a
WHERE p.Pd_ID = a.Pd_ID AND
a.Abt_ID = 3
UNION
SELECT 'Mitarbeiter: ', Pd_ID, Pd_Name, Abt_ID
FROM persdat
WHERE Abt_ID = 3 AND
Pd_ID NOT IN (SELECT Pd_ID FROM Abteilungsleiter)
In diesem Beispiel gehen wir davon aus, dass wir eine Tabelle Abteilungsleiter haben, wo für
jede Abteilung einen Abteilungsleiter definiert ist.
Dieser SELECT gibt uns folgende Auswertung:
Abt.Leiter:
Mitarbeiter
Mitarbeiter
Pd_ID
57
58
99
Pd_Name
Meyer
3
Bolliger
Willemann
Abt_ID
3
3
Der erste SELECT ermittelt den Abteilungsleiter der Abteilung 3, wobei wir davon ausgehen,
dass die Tabelle Abteilungsleiter mind. die Attribute Pd_ID und Abt_ID und so als Verbindungstabelle fungiert. Um den Namen darzustellen muss die Tabelle Abteilungsleiter mit der Tabelle
Persdat verbunden werden.
Im zweiten SELECT werden die Mitarbeiter der Abteilung 3 hinzugefügt. Um zu verhindern, dass
der Abteilungsleiter zweimal erscheint, muss er in der Tabelle Persdat unterdrückt werden, weil
der Abteilungsleiter dort als Mitarbeiter der Abteilung 3 definiert ist.
Übung:
Fügen Sie diesem Beispiel noch den Abteilungsname (Abteilung.Abt_Bez) hinzu.
7.2 Operator INTERSECT
Der INTERSECT-Operator besteht aus der Schnittmenge zweier Mengen A und B und liefert uns
alle Elemente, die sowohl in der Menge A als auch in der Menge B enthalten sind.
Es werden aus zwei SELECT-Ergebnissen jene Zeilen aus der ersten SELECT-Abfrage angezeigt, die auch in der Ausgabe der zweiten Abfrage enthalten sind.
7.3 Operator EXCEPT/MINUS
Der EXCEPT Operator besteht aus der Differenzmenge zweier Mengen A und B. Es werden aus
der Menge A nur jene Element geliefert, die nicht auch zu Menge B gehören
Es werden aus zwei SELECT-Ergebnissen jene Zeilen aus der ersten SELECT-Abfrage angezeigt, die nicht in der zweiten Abfrage vorhanden sind.
Datenbank_SQL1.3.doc
Seite 29/37
Bernhard Bausch
8
Schulungsunterlagen Datenbanken
Sichten verwenden
Mit SELECT-Anweisungen werden Daten entsprechend einer gewünschten Sichtweise aus einer
oder mehreren Tabellen zusammengestellt. Solche Sichtweisen auf die Daten können mit der
Anweisung CREATE VIEW gespeichert werden. Gespeicherte Sichtweisen nennt man Views
(deutsch: Ansichten). Views enthalten keine Daten, sonden "Zeiger". Die Zeiger weisen auf die
Datenspalten in den Basistabellen. Views charakterisiert man deshalb auch als virtuelle oder
imaginäre Tabellen.
Mit Einschränkungen kann man mit Views in der gleichen Weise arbeiten wie mit Basistabellen.
Änderungen in Views bewirken gleichzeitig Änderungen in den echten Tabellen und umgekehrt.
Dies gilt jedoch nur, wenn sich die Sicht in der FROM-Klausel auf nur eine einzige Tabelle bezieht und die Spalten keine Funktionen oder arithmetischen Operationen enthalten.
Man kann sie mit:
- SELECT abfragen,
- INSERT ergänzen,
- UPDATE ändern und mit
- DELETE Daten löschen.
8.1 VIEW erstellen
Beim erstellen einer VIEW wird also eine virtuelle Tabelle erzeugt. Unter dem Namen, mit welchem man die View erstellt, wird in den Systemtabellen, in einer speziellen Viewtabelle, der zugehörige SELECT hinterlegt. Bei Datenabfragen mit Views werden zuerst die Anweisungen in der
Viewtabelle ausgeführt. Erst danach kann auf die Daten in den Basistabellen zugegriffen werden.
Views benötigen deshalb längere Laufzeiten und legen im Ablauf der Befehlsdurchführung mehrere temporäre Tabellen an. Das kann sogar dazu führen, dass fehlenden Speicherplatztes wegen eine Anweisung nicht ordnungsgemäss ausgeführt werden kann.
CREATE VIEW Gehalt1 AS
SELECT p.Pd_ID, Pd_Name, Abt_Bez, Mg_Gehalt
FROM Persdat p, Abteilung a, MGehalt m
WHERE p.Pd_ID = m.Pd_ID
AND
p.Abt_ID = a.Abt_ID
AND
Mg_Jahr = 99
AND
Mg_Monat = 1
Access kennt keine Views, es arbeitet mit Abfragen.
Hier werden die Werte der Spalten Pd_ID und Pd_Name aus der Tabelle Persdat, der Abteilungsname aus der Tabelle Abteilung und die Januargehälter aus der Tabelle MGehalt in die
View Gehalt1 übertragen.
Der erste Teil der CREATE-VIEW-Anweisung dient der Festlegung des View-Namens. Da keine
Angaben zu Spaltennamen gemacht wurden, übernimmt das System die Spaltennamen der Basistabellen.
Der zweite Teil der CREATE-VIEW-Anweisung – die AS-SELECT-Anweisung – definiert die
Auswahl in den Basistabellen.
ORDER-BY- und UNION-Klausel können in Views nicht eingesetzt werden.
CREATE VIEW Auftrab (TP_ID, Kosten) AS
SELECT TP_AufNr, SUM(TP_Std * TT_Preis)
FROM TPosten tp, Tarten ta
WHERE tp.TT_ID = ta.TT_ID
GROUP BY TP_AufNr
Beispiel ohne Beschreibung.
Werden im SELECT-Teil der View-Anweisung SQL-Funktionen und arithmetische Operationen
verwendet, so müssen die View-Spalten ausdrücklich hinter dem View-Namen in runden Klammern definiert werden. Ausnahme Access. In Access muss der Aliasnamen für Spalten in der
SELECT-Klausel definiert werden.
Datenbank_SQL1.3.doc
Seite 30/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
8.2 View ausgeben
Daten aus einer View werden wie Daten aus Basistabellen, mit dem SELECT-Befehl, angezeigt.
SELECT * FROM Gehalt1
8.3 View löschen
Mit der Anweisung DROP VIEW wird eine View wieder gelöscht.
DROP VIEW Auftrab
Access: DROP TABLE Auftrab
8.4 Mit VIEWS Daten aktualisieren
Aktualisieren ohne Prüfoption
Mit Views können die Daten in Basistabellen aktualisiert werden.
CREATE VIEW Maenner AS
SELECT Pd_ID, Pd_Name, Pd_Geschlecht
FROM Persdat
WHERE Geschlecht = 'M'
Diese View erlaubt nur eine Sicht auf alle männlichen Mitarbeiter.
INSERT INTO Maenner
VALUES(50, 'Frauenfelder', 'M'
Durch diese Anweisung wird ein neuer Datensatz in der Tabelle Persdat eingefügt.
UPDATE Maenner
SET Pd_Name = 'Braun'
WHERE Pd_ID = 50
Der Name Frauenfelder wird in den Wert Braun geändert.
In den vorliegenden Beispielen konnte UPDATE und INSERT verwendet werden, weil sich die
View auf nur eine Tabelle bezieht und keine SQL-Funktion beinhaltet.
Aktualisierung mit Prüfoption
Durch einen INSERT kann über eine View ein Datensatz in die Basistabelle eingebracht werden,
der über die View nicht mehr ausgegeben werden kann. Z.B. in der View Maenner können auch
Frauen erfasst werden. Durch die WITH-CHECK-OPTION-Ergänzung kann das verhindert werden. Die WITH-CHECK-OPTION läuft nicht in Access.
CREATE VIEW Frauen AS
SELECT Pd_ID, Pd_Name, Pd_Geschlecht
FROM Persdat
WHERE Geschlecht = 'F'
WITH CHECK OPTION
In dieser View können keine Männer mehr erfasst werden.
Datenbank_SQL1.3.doc
Seite 31/37
Bernhard Bausch
9
Schulungsunterlagen Datenbanken
Datenbank optimieren
Der Zugriff auf Daten der Datenbank kann beschleunigt werden, wenn die Werte der Suchspalte
in sortierter Form vorliegen. Das Erstellen eines sortierten Schlüssels für Spalten einer Tabelle
nennt man Indexieren. Bei Tabellen, die mit einem zusätzlichen Index ausgestattet sind, kann eine schnelle Suchmethode wie beispielsweise das binäre Suchen eingesetzt werden.
Beim binären Suchen wird ein Datensatz schneller gefunden als beim sequentiellen Suchen, bei
dem die Datensätze der Reihe nach gelesen werden. Bei 1024 Zeilen beispielsweise wird beim
binären Suchen die gewünschte Information spätestens beim 10. Zugriff gefunden, bei 2048 Zeilen beim 11. Zugriff. Beim sequenziellen Suchen müssten dagegen durchschnittlich 512 bzw.
1024 Sätze gelesen werden, um den gesuchten Datensatz zu erhalten.
Welche Spalten der Tabellen sollte man indexieren? Es ist keineswegs zweckmässig, alle Spalten einer Tabelle zu indexieren. Die Indexierungsreihenfolge werden nämlich in der Datenbank
gespeichert. Wenn in einer Tabelle mit den Befehlen INSERT, UPDATE oder DELETE die Sortierfolge einer Tabelle verändert wird, muss auch der Index neu angepasst werden. Diese Aktualisierungen kosten natürlich Zeit. Man kann deshalb sagen, dass das Indexieren das Suchen beschleunigt, aber das Aktualisieren verlangsamt.
Für das Indexieren gelten folgende Empfehlungen:
Spalten mit Primärschlüssel sollten mit dem UNIQUE-Zusatz indexiert werden.
Sind Reihen aus mehreren Tabellen logisch zu verknüpfen, so sollten die Bezugsschlüsselspalten (Fremdschlüssel) indexiert werden.
In grossen Tabellen sollten die Spalten indexiert werden, die häufig in WHERE-,
GROUP-BY- oder ORDER-BY-Klauseln eingesetzt werden.
Nicht mehr benötigte Indexierungen sollten gelöscht werden.
Spalten, welche für Suchoptionen verwendet werden, sollten Indexiert werden.
9.1 Einfachindex erstellen.
Der Indexierungsbefehl lautet allgemein:
CREATE [UNIQE] INDEX Indexname
ON Tabellenname
(Spaltenname [ASC/DESC],
Spaltenname [ASC/DESC],….])
Mit CREATE UNIQUE INDEX wird verhindert, dass in eine Spalte doppelte Werte eingegeben
werden können. Will man also einen eindeutigen Schlüssel definieren, z.B. Primary-Key, dann
muss man für dieses Schlüsselattribut einen Index anlegen.
CREATE UNIQUE INDEX In_Pd_ID
ON persdat (Pd_ID)
Für die Bildung von Indexnamen gelten die gleichen Regeln wie für Tabellenamen.
9.2 Index löschen
Ein Index kann jederzeit gelöscht werden. Der Befehl dazu lautet:
SQL =
DROP INDEX Indexname
Access =
DROP INDEX Indexname ON Tabellenname
9.3 Zusammengesetzten Index vereinbaren
Wenn der Primärschlüssel einer Tabelle aus zwei und mehr Spalten besteht, sollte dafür ein zusammengesetzter Index vereinbart werden.
CREATE UNIQUE INDEX I_PdID_FamNr
ON Familienmitglieder (Pd_ID, PD_FamNr)
Datenbank_SQL1.3.doc
Seite 32/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
9.4 Indexeintragungen überprüfen und reparieren
Es ist nicht auszuschliessen, dass ein angelegter Index beschädigt wird. Das kann zum Beispiel
passieren, wenn während der Bearbeitung der Datenbank der Strom ausfällt oder das System
nicht korrekt heruntergefahren wird. Zerstörte Indexeintragungen führen dann bei Suchprozessen
zu fehlerhaften Ergebnissen. Aus diesem Grund gibt es in den Datenbanksystemen Befehle, mit
denen beschäftigte Indexeintragungen festgestellt und repariert werden können. Befehle für solche Aktionen sind von Datenbank zu Datenbank unterschiedlich.
9.5 Die referentielle Integrität einer Datenbank erhalten
Um die referentielle Integrität vom System verwalten zu lassen, muss man bei der Erstellung von
Tabellen mit ihren Strukturen mit CREATE TABLE oder mit ALTER, die Zusätze PRIMARY KEY,
FOREIGN KEY und REFERENCES einsetzen. Bei Oracle und Access ist zusätzlich die
CONSTRAINT-Klausel zu verwenden. CONSTRAINTs (deutsch: zwangsweise Bindung) können
für einzelne Spalten und auf Tabellenebene vereinbart werden.
Nachfolgend ein paar Beispiele die diesen Vorgang dokumentieren sollen.
ORACLE
CREATE TABLE Abteilung
(Abt_ID
SMALLINT NOT NULL,
Abt_Bez
Char(20),
CONSTRAINT PkAbtID PRIMARY KEY (Abt_ID))
Hier wird also ein Primary-Key erzeugt, der mit einem Index, mit dem Namen PKAbtID, verbunden ist.
In INFORMIX ab Version 5.0 läuft die gleiche Anweisung wie folgt:
INFORMIX
CREATE TABLE Abteilung
(Abt_ID
SMALLINT NOT NULL,
Abt_Bez
Char(20),
PRIMARY KEY (Abt_ID))
ACCESS
CREATE TABLE Abteilung_Test
(Abt_ID SMALLINT CONSTRAINT PkAbtID PRIMARY KEY NOT NULL,
Abt_Bez Char(20))
Dependent-Tabellen (Dependend = abhängig) mit FOREIGN KEY und Referenzierung
erstellen
Im nachfolgenden Beispiel wird die Tabelle Persdat mit dem Zusatz FOREIGN KEY und einer
Referenzierung zur Tabelle Abteilung erstellt. Ausserdem wird die DELETE-Regel ON DELETE
RESTRICT eingesetzt. Dieses Beispiel soll die Zusammenhänge darstellen, Abweichungen von
Datenbank zu Datenbank müssen entsprechend berücksichtigt werden:
CREATE TABLE Persdat
(Pd_ID
SMALLINT NOT NULL,
Pd_Name
CHAR(20),
Pd_Vname
CHAR(20),
Pd_Geschlecht CHAR()
Abt_ID
SMALLINT NOT NULL,
CONSTRAINT PkPdID PRIMARY KEY (Pd_ID),
CONSTRAINT FKAbtID FOREIGN KEY (Abt_ID)
REFERENCES Abteilung (Abt_ID) ON DELETE RESTRICT
Datenbank_SQL1.3.doc
Seite 33/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
Zeilen mit Delete löschen
Im Zusatz REFERENCES kann eine von drei DELETE-Regeln eingesetzt werden:
ON
DELETE RESTRICT
DELETE CASCADE
DELETE SET NULL
Datenbank_SQL1.3.doc
In der Tabelle Abteilung können so lange keine Zeilen gelöscht werden, wie in der Tabelle Persdat Zeilen mit der gleichen Abt_ID stehen.
Beim Löschen einer Zeile in der übergeordneten Tabelle Abteilung
werden automatisch alle Zeilen mit der gleichen Abt_ID glöscht.
Beim Löschen einer Zeile in der übergeordneten Tabelle werden in
der abhängigen Tabelle in Zeilen mit gleichem Referenzwert die Werte NULL gesetzt.
Seite 34/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
10 Daten schützen und sichern
Wenn die in der Datenbank gespeicherten Informationen mehreren Benutzern zur Verfügung stehen, muss der Datenbank-Administrator durch geeignete Massnahmen den Zugriff nichtautorisierter Personen verhindern. Um die Gefahr des Datenverlustes, der Fälschung und des Datenmissbrauchs einzuschränken, erteilt er Benutzern Zugangsberechtigungen (subjektbezogener
Datenschutz) und Zugriffsberechtigungen (objektbezogener Datenschutz).
Die Zugangsstufen werden mit dem SQL-Befehl GRANT-Zugriffsstufe erteilt.
Benutzerkennungen und Passwörter
Den Zugang zu dem Datenbanksystem erhalten Benutzer mit der Eingabe ihrer Benutzerkennung
(User-Identifikation, User_ID) und der Eingabe des Passwortes. Die Benutzerkennung identifiziert
den Benutzer. Sie muss eindeutig sein. Das Passwort enthält keine Hinweise auf den Benutzer.
Zugangsstufen CONNECT, RESOURCE und DBA
Datenbanken sind mit Zugangsstufen ausgestattet. Der Administrator koppelt sie an die Benutzerkennung. die drei Datenbankzugriffsrechte CONNECT, RESOURCE und DBA haben unterschiedliche Rechte, die in der nachstehenden Tabelle skizziert werden.
Aus der nachstehenden Graphik wird die Hierarchie der Zugriffsberechtigung deutlich. CONNECT steht auf der niedrigsten Stufe, die DBA-Berechtigung berechtigt zu allen legalen Datenbankoperationen.
DBA
-
Vergeben und entziehen von Tabellenzugriffsrechten.
Tabellen, Indizes und Views für andere Benutzer erzeugen und löschen.
Datenbank löschen.
Datenbankzugriffsrechte gewähren und entziehen.
RESOURCE
- Basistabellen erstellen, ändern und löschen.
- Index erstellen, ändern und löschen.
- Recht auf Tabellenzugriff gewähren und entziehen.
CONNECT
- Bestehende Tabellen abfragen, ändern und löschen, sofern das
erforderliche Tabellenzugriffsrecht eingeräumt wurde.
- Erstellen, ändern und löschen von Views.
Datenbank_SQL1.3.doc
Seite 35/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
11 Transaktionsorientiert arbeiten
Eine Datenbank muss sich stets in einem konsistenten Zustand befinden. Eine Datenbank ist
konsistent, wenn die Daten inhaltlich richtig sind (semantische Integrität). Bei Änderungen im Datenbestand kann es zu Inkonsistenzen kommen, wenn eine Aktion nicht ordnungsgemäss abgeschlossen werden kann.
Bei der Bearbeitung von einzelnen Feldern besteht die Gefahr nicht, weil die Datenbank immer
beim Verlassen eines Feldes den Inhalt in der Datenbank speichert.
Tritt aber bei einer Änderungsaktion mehrer SQL-Anweisungen eine Störung infolge eines Plattenfehlers oder einer Fehlbedienung auf, könnte sich die Datenbank in einem inkonsistenten Zustand befinden. Ein Teil der Änderungen wurden vorgenommen und der andere Teil nicht. Die
daraus resultierende Inkosistenz hat zur Folge, dass die Daten danach nicht mehr kongruent
(übereinstimmend) sind.
Um sicherzustellen, dass Änderungen im Datenbestand nicht zu Inkonsistenzen führen, können
die Änderungsanweisungen in Form einer Transaktion ausgeführt werden. Unter einer Transaktion versteht man eine Folge von SQL-Anweisungen, die logisch zusammengehören. Bei einer
transaktionsorientierten Verarbeitung wird nach dem Alles-oder-nichts-Prinzip dafür Sorge getragen, dass die Anweisungsfolge komplett oder gar nicht ausgeführt wird. Eine Ausführung nur einzelner Anweisungen wird verhindert.
Die Transaktion wird vor Beginn der Ausführung gestartet und nach korrektem Ablauf oder nach
korrektem Beenden der Anweisungen wird mit einem COMMIT-Kommando die Änderung gespeichert. Treten Fehler auf wird die Verarbeitung mit dem ROLLBACK-Kommando zurück genommen. Treten technische Fehler während der Verarbeitung auf, wird automatisch nicht gespeichert, weil das COMMIT-Kommando nicht ausgeführt wird.
In Access beginnt eine Transaktion mit der Befehlszeile Begin Trans und endet mit CommitTrans
oder eben Rollback. Die Transaktion muss natürlich entsprechend implementiert sein.
Datenbank_SQL1.3.doc
Seite 36/37
Bernhard Bausch
Schulungsunterlagen Datenbanken
12 ODBC-Schnittstelle zum Zugriff auf Datenbanken einsetzen
Zu den wichtigsten Gütern eines Unternehmens zählen die auf unterschiedlichen Medien gespeicherten Informationen über Aufträge, Umsätze, Erträge, Aufwendungen und mehr. Diese Daten
stehen in Datenbanken auf Netzwerkservern oder Mainframes. Das Problem ist, dass die Datenbanken die Daten in unterschiedlichen Formaten aufzeichnen, und dass die unterschiedlichen
Betriebssysteme nicht auf die Daten zugreifen können.
Die ODBC-Programmschnittstelle hebt die Trennung von Anwendung und Datenbank auf:
Die standardisierte ODBC-Verbindungsschnittstelle (Open Database Connectivity) wurde für den
Zugriff auf Datenbanken 1992 von der SQL-Access-Group und Microsoft gemeinsam entwickelt.
Sie macht es möglich, dass von PCs, mit dem Betriebssystem WINDOWS, mit Anwendungen wie
EXCEL, WORD und anderen, auf Daten von Datenbanken, die ODBC unterstützen, zugegriffen
werden kann.
Voraussetzungen für den Einsatz der ODBC-Technik sind:
1.
2.
3.
4.
Ein Anwendungsprogramm, das ODBC unterstützt. Z.B. Office-Applikationen
Ein Treibermanager, der einen für die fremde Datenbank vorliegenden ODBC-Treiber lädt
und nach Abfrageende wieder schliesst (der Treibermanager ist in den WindowsBetriebsystemen enthalten).
ODBC-Treiber; das ist eine DLL-Datei (Dynamic-Link Library), die eine Abfrage in der aktuellen Anwendung in den Dialekt der angesprochenen Datenbank umwandelt.
Ein ODBC-fähiges Datenbankmanagementsystem. Für jedes Datenbanksystem ist ein
eigener Treiber erforderlich. Im Office-Paket sind ODBC-Treiber für ACCESS, DBASE,
FOXPRO, PARADOX, SQL-Server, Textdatenbanken und EXCEL bereitgestellt. Benötigt
man einen Treiber für eine andere Datenbank, muss dieser für WINDOWS verfügbar sein.
ODBC wird heute von den Datenbanken ORACLE, INFORMIX, INGREX, SYBASE, GUPTA und EDA/SQL unterstützt.
Um mit der ODBC-Technik auf die Datenbank zugreifen zu können, muss in WINDOWS für die
Datenbank eine sogenannte Datenquelle, in der Windows-Arbeitsoberfläche
Start Einstellungen Systemsteuerung 32-Bit-ODBC / ODBC,
eingerichtet werden.
Im ODBC-Datenquellen-Administrator wird ab Office 97 zwischen Benutzer-, System- und DateiDatenquellen unterschieden
1.
Benutzer-DSN
Die Benutzerdatenquelle ist auf dem lokalen Computer installiert und kann nur vom Benutzer, für welche sie eingerichtet wurde, verwendet werden. DSN steht für Data Source Name (Name der Datenquelle)
2.
System-DSN
Systemdatenquellen können im Netzwerk eingesetzt werden und stehen allen Anwendern
eines Comuters zur Verfügung.
3.
Datei-DSN
Bei Datei-DSN stehen die Informationen nicht in der WINDOWS-Registrierdatei, sondern in
einer gesonderten DSN-Datei
Im Register ODBC-Treiber finden man eine Liste der bereits installierten ODBC-Treiber. Alle diese von den jeweiligen Datenbanken installierten Treiber stehen zur Installation bzw. Konfiguration
zur Verfügung.
Datenbank_SQL1.3.doc
Seite 37/37