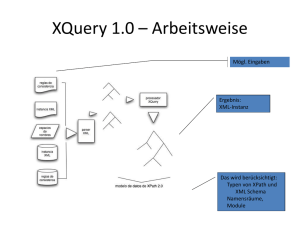
Inhalt Motivation XML Anfragesprachen XML Anfragesprachen W3C
Werbung

Inhalt
• Motivation / Einführung
• XQuery Datenmodell
181.139 VU Semistrukturierte Daten 2
• Ausdrücke (Expressions)
• Beispiele: relationale Datenbanken
XQuery (Teil 1)
23.3.2006
• XQuery Moduln und Funktionsdefinitionen
• Built-in Funktionen
Reinhard Pichler
• XQuery XML-Syntax (XQueryX)
Motivation
Einführung
XML Anfragesprachen
• XPath:
• Bedeutung von XML:
– wichtig als Basis für jegliche XML-Anfragesprachen
– Daten im Web
– Quasi-Standard für Datenaustausch
– Aber XPath alleine ist nicht genügend ausdrucksstark.
• Wesentliche Unterschiede zu relationalen DBs, z.B.:
•
–
–
–
–
–
• XSLT:
weniger regelmäßige Struktur
beliebig tiefe Schachtelung möglich
Metadaten („markup“) als Teil der Daten
Dokumentenordnung signifikant
etc. (vgl. VU SSD1)
– Sehr gut geeignet für Transformation XML -> XML oder
XML -> HTML. Die Benutzerakzeptanz für typische
Datenbank-Anwendungen ist hingegen fraglich.
– Eingeschränkte Optimierungsmöglichkeiten: XSLT-Prozessor
realisiert das XSLT-processing model. Bei DB-Sprachen wie
SQL ist wesentlich mehr Spielraum für Optimierungen.
=> Suche nach eigener XML-Anfragesprache
W3C
XML Anfragesprachen
•
World Wide Web Consortium
–
–
–
–
• Mehrere Vorschläge in der Literatur:
– Lorel: Stanford (Abiteboul et al.), 1997
gegründet von CERN, MIT und anderen
ca. 200 Mitglieder (Firmen)
Aufgabe: Standardisierung von Webformaten
nicht normativ: gibt nur "recommendations"
heraus, keine ISO artigen Standards
Note
Working Draft
– XQL („XML Query Language): 1998
– XML-QL: AT&T (Fernandez, Suciu, et al.), 1998
•
Sechs Arten von Dokumenten
–
– Quilt: IBM (Chamberlin et al.), 2000
–
• W3C: “XQuery 1.0, An XML Query Language“
–
– Candidate Recommendation (noch nicht „fertig“)
–
– beeinflusst von SQL
–
– Kompatibilität mit XSLT, XML Schema und vor allem XPath
–
– 2 Notationen: „human-oriented“ und als XML-Dokument
Note
• ist nicht Bestandteil des Standardisierungsprozesses
• keine Absichtserklärung des W3C steht dahinter
Working Draft (WD)
• dokumentieren aktuellen Diskussionsstand
Last Call WD
• wenn festgelegte Ziele erreicht
Candidate Recommendation (CR)
• Einreichungsbestätigung
Proposed Recommendation
• Erweiterung; Implementierungen der Bestandteile
Recommendation
• offizieller W3C Standard
Last Call WD
CR
PR
Recommendation
1
Einige W3C Dokumente
XQuery Systeme
(candidate recommendations / working drafts)
• XQuery 1.0: An XML Query Language
http://www.w3.org/TR/xquery
• XQuery 1.0 and XPath 2.0 Functions and Operators
http://www.w3.org/TR/xpath-functions
• XQuery 1.0 and XPath 2.0 Data Model
http://www.w3.org/TR/xpath-datamodel
• XQuery 1.0 and XPath 2.0 Formal Semantics
http://www.w3.org/TR/xquery-semantics
• XML Syntax for XQuery 1.0 (XQueryX)
http://www.w3.org/TR/xqueryx
• XML Query Use Cases
http://www.w3.org/TR/xquery-use-cases
• Übersicht: http://www.w3.org/XML/Query
• XQuery-Systeme, z.B.:
–
–
–
–
Nux (Berkeley Lab): http://dsd.lbl.gov/nux/
Qexo (GNU): http://www.gnu.org/software/qexo/
Galax (Fernandez/Simeon): http://www.galaxquery.org/
Saxon (Michael Kay): http://www.saxonica.com/
• XQuery Support in DB-Systemen, z.B.:
– Oracle Database 10g Release 2
– Microsoft: SQL Server 2005 Express
– XML-native DBs: Tamino, Berkeley DB XML 2.0
In der VL: Saxon 8 bzw.
XML Spy ( http://www.altova.com )
Charakterisierung von XQuery
• XQuery ist eine funktionale Programmiersprache:
– Basis-Konstrukt: Expression
– Expressions können beliebig geschachtelt werden
– Jede Expression hat einen Wert
– Keine Seiteneffekte
• XQuery ist streng-typisiert:
– Alle Operanden, Operatoren, Funktionen müssen mit einem
erwarteten Typ übereinstimmen (bzw. es muss möglich sein,
Typkonvertierungen zum erwarteten Typ durchzuführen).
• XPath 2.0:
– Wesentliche Erweiterung gegenüber XPath 1.0
XQuery Modul
• Ein XQuery Modul besteht aus Prolog und Query Body
• Der Prolog enthält Deklarationen (Importe, Variablen,
Funktionen, etc.)
• Der Query Body enthält genau 1 Expression.
• Kommentare:
– Im Prolog oder im Query Body
– Geklammert durch (: :)
– Kommentare können geschachtelt sein.
Beispiel 1
• XPath 2.0:
– Kein Prolog, gewisse Einschränkungen bei Expressions.
– Teilmenge von XQuery 1.0
Auswertung von Expressions
Namen in XQuery
• Immer relativ zu einem Expression Context, d.h.: alle
Informationen, die einen Einfluss auf das Ergebnis haben.
• Namen in XQuery sind case-sensitive,
mit optionalem Namespace-Prefix.
• 2 Arten von Contexts:
• Namespace-Prefixes können in XQuery definiert werden.
– Static context: Informationen, die bereits bei der statischen
Analyse der XQuery expression (unabhängig vom XMLInput) bekannt sind, z.B.:
bekannte Variablen/Funktionen/Namespaces/Schema-Definitionen,
statischer Variablentyp, default element/type/function namespace, etc.
– Dynamic context: Informationen, die erst zum Zeitpunkt
der Auswertung bekannt sind, z.B.:
context item (= Verallgemeinerung von Kontextknoten), context
position/size, Variablenbindungen, current dateTime, etc.
• Außerdem gibt es in XQuery vordefinierte Prefixes:
– xml = http://www.w3.org/XML/1998/namespace
– xs = http://www.w3.org/2001/XMLSchema
– xsi = http://www.w3.org/2001/XMLSchema-instance
– fn = http://www.w3.org/2005/xpath-functions
– xdt = http://www.w3.org/2005/xpath-datatypes
– local = http://www.w3.org/2005/xquery-local-functions
2
Datentypen in
XQuery
Schema Validierung
Datenmodell
• Jeder Wert ist eine Sequence.
• Eine Sequence ist eine geordnete Sammlung von 0 oder mehr
Items.
• Wiederholung von Items möglich, z.B.: (17, 18, 17)
• Keine Unterscheidung zwischen einem einzelnen Item und
einer Sequence der Länge 1, d.h.: (x) und x sind identisch.
• Ein Item ist entweder ein atomarer Wert oder ein Knoten
(also insbesondere keine Schachteltung von Sequences).
• Atomarer Wert: einer der 44 built-in types von XML Schema
oder ein davon abgeleiteter user-defined type.
• Jeder Knoten ist von einem der folgenden 7 Typen:
document node, element node, attribute node, text node,
comment node, processing-instruction node, namespace node
Wichtige Knoteneigenschaften
Node Identity:
z.B.: 2 Knoten <a>17</a> und <a>17</a> sind nicht identisch
(trotz gleichem Namen und gleichem Inhalt).
String value eines Knoten (vom Typ xs:string):
• entspricht der built-in Funktion fn:string
• Im wesentlichen wie in XPath 1.0 definiert (für die versch. Arten von
Knoten, z.B.: bei document/element Knoten: Konkatenation aller
descendant text nodes in document order).
Typed value:
• Input Dokumente werden gegen Schema validiert, um sie als
„XQuery Data Model Instance“ (= Wert + Typinformation)
darzustellen.
• Validierung gegen XSD oder DTD
• Jeder element / attribute node erhält „type annotation“.
• Falls für einen Knoten kein Schema bekannt ist:
– Attribute node erhält Typ „xdt:untypedAtomic“
– Element node erhält Typ „xdt:untyped“
• Innerhalb einer XQuery expression kann Validierung eines
document/element Knoten mittels validate-expression
erzwungen werden.
Beispiele:
• attribute node mit string value “0030“ und type annotation “xs:integer”
=> typed value = integer Wert 30
• attribute node mit string value “xx yy zz“ und type annotation
“xs:IDREFS” => typed value = sequence (“xx“, “yy“, “zz“)
(jeweils vom Typ “xs:IDREF”).
• element node mit simple content: wie bei attribute node
z.B.: string value “74.95“ und type annotation “xs:decimal”
=> typed value = decimal Wert 74.95
• element node mit mixed/empty content:
=> typed value entspricht string value
• element node mit element-only content:
=> typed value = undefined
• Sequence von atomaren Werten
• entspricht der built-in Funktion fn:data
• hängt von “type annotation“ des Knoten ab
Effective Boolean Value
Idee: Viele Ausdrücke erwarten bool‘schen Wert, z.B.:
• Operanden von and, or, not
• Filterbedingungen (Prädikate, where-Klauseln)
• Bedingungen bei if, some, every
Typkonvertierung nach xs:boolean, z.B.:
•
•
•
•
•
Empty sequence: false
Sequence dessen erstes Item ein Node ist: true
String: zero length <=> false
Number: 0 bzw. NaN <=> false
für die meisten Typen (z.B.: Datum, Zeit, etc.): undefiniert
Typ-Angaben in XQuery
• An verschiedenen Stellen in XQuery-Expressions
sind Typ-Angaben möglich bzw. erforderlich, z.B.:
– Parameter/Resultat von user-defined Funktionen
– Spezielle Ausdrücke wie instance of, cast as,
castable as, typeswitch, treat as
• XQuery-Syntax für Typ-Angaben: “Sequence Type“
– Definiert mittels Angabe des “Item Type“ und eventuell
eines „occurrence indicator“ (?, *, +)
– Item Type: Node oder atomic type
– Atomic Type: built-in Type von XML Schema oder davon
abgeleiteter user-defined Type
3
Beispiele
Sequence Type Declaration What it matches
empty()
empty sequence, written as ()
item()+
sequence of one or more nodes or atomic
values
xs:integer
single item of built-in type xs:integer (or
a schema type derived from xs:integer)
node()*
sequence of zero or more nodes of any kind
attribute()?
0 or 1 attribute node
element()
any element node
element(po:shipto,
po:address)
element node of name po:shipto and type
annotation po:address (or a schema type
derived from po:address)
element(customer)
element node of name customer with any
type annotation
XQuery
TypenHierarchie
Beispiele für Node Angaben
Beispiele für Element Angaben
Item Type Declaration
What it matches
Item Type Declaration
What it matches
node()
any node
element() or element(*)
any single element node
text()
any text node
element(person)
any element node of name person
processing-instruction()
any processing-instruction node
element(person, surgeon)
processing-instruction(
xml-stylesheet)
any processing instruction node named
“xml-stylesheet”
any non-nilled element node of name
“person” and type annotation “surgeon” (or
derived from “surgeon”)
comment()
any comment node
element(person, surgeon?)
document-node()
any document node
document-node(
element(customer))
any document node that contains an
element such that this element is matched
by element(customer)
any nilled or non-nilled element node of
name “person” and type annotation
“surgeon” (or derived from “surgeon”)
element(*, surgeon?)
any nilled or non-nilled element node of
type annotation surgeon (or derived from
surgeon) and any name
element(), attribute: see following slides
Beispiele für Attribute Angaben
Item Type Declaration
What it matches
attribute() or attribute(*)
any single attribute node
attribute(price)
any attribute node whose name is price
attribute(price, currency)
any attribute node whose name is price
and whose type annotation is currency
(or derived from currency)
attribute(*, xs:decimal)
any attribute node whose type annotation
is xs:decimal (or derived from it)
attribute(*, currency)
attribute node of type annotation
currency (or derived from currency)
•
•
•
•
•
•
•
•
•
•
•
•
•
Expressions
Primary Expressions
Sequence Expressions
Path Expressions
Arithmetic Expressions
Comparison Expressions
nicht in XPath 2.0:
Logical Expressions
• constructors
Constructors
FLWOR Expressions (“flower”) • “FLWOR”: nur “FR”
Ordered / Unordered Expressions • ordered/unordered
Conditional Expressions
• validate expressions
Quantified Expressions
Expressions on Sequence Types
Validate Expressions
Beispiel 2
4
Primary Expressions
• Numerisches Literal (xs:integer, xs:decimal, xs:double)
z.B.: 30, 17.5, 3.14E-2
• String Literal (xs:string)
– Es gibt viele built-in Funktionen in XPath 2.0 und XQuery
(wesentliche Erweiterung gegenüber XPath 1.0)
– Auch user-defined Funktionen in XQuery erlaubt
– Schreibweise, z.B.: my-func(expr)
• Beispiele:
– Begrenzt durch " " bzw. ' '
– Können auch enthalten:
Character-Referenzen (z.B.: &#211; &#xF3; ) und
predefined entities (&lt; &gt; &amp; &apos; &quot; )
• Variablen:
– three-argument-function(1, 2, 3)
– two-argument-function((1, 2), 3)
– two-argument-function(1, ())
– one-argument-function((1, 2, 3))
– one-argument-function(( ))
– Schreibweise: $ + Name, z.B.: $x
– Variablenbindung, z.B.: let $x := 17
– zero-argument-function( )
Sequence Expressions
• Comma Operator: ,
z.B.: (1, 2, 3, 4)
Bemerkung: Klammern sind nicht verpflichtend aber üblich
• Range Operator: to
z.B.:
oder
• Funktionsaufrufe:
(1 to 4)
(1, 2 to 4)
• Filterbedingungen („predicates“): [
• Mengen-Operationen auf node sequences:
– Vereinigung: union (= | wie in XPath 1.0):
– Durchschnitt: intersect
– Mengendifferenz: except
• Alle 3 Operatoren eliminieren Duplikate (bzgl. node identity)
• Falls ordering-mode = „ordered“, dann werden die Knoten des
Resultats in document order geordnet.
• Beispiel:
]
auf beliebige Sequences anwendbar (nicht nur Pfade), z.B.:
– (1 to 100)[. mod 5 eq 0] (: alle Vielfachen von 5:)
– (21 to 29)[5]
(: (25) :)
(: für XML-Dokument: <x><a/><b/><c/><d/></x>
und Variablen $s1 = (a,b,c) und $s2 = (c,d) :)
$s1
$s1
$s1
$s1
union $s2
| $s2
intersect $s2
except $s2
• Paths: absolute paths vs. relative paths:
mit bzw. ohne / am Anfang
• Path expression: step expressions getrennt durch /
• Step expression: axis :: nodetest [predicate]
(a,b,c,d) :)
(a,b,c,d) :)
(c) :)
(a,b) :)
Beispiel 3
Path Expressions
Im wesentlichen wie location paths in XPath 1.0
(mit einigen Erweiterungen)
(:
(:
(:
(:
Beispiele
• child::chapter/descendant::para
• child::para[fn:position() = fn:last()-1]
• preceding-sibling::chapter[fn:position() = 1]
• /descendant::chapter[fn:position() = 5]/
child::section[fn:position() = 2]
• following::*[self::chapter or self::appendix]
[fn:position() = fn:last()]
• para[fn:last()]
• //book/@version
• Achsen: „forward axes“ vs. „reverse axes“
• ../@lang
• Abkürzungen: abbreviated vs. unabbreviated Syntax
• para[./@type="warning"][5]
5
Arithmetic Expressions
Erweiterungen gegenüber XPath 1.0
• Operatoren: +, -, *, div, idiv, mod
• Path expression liefert sequence of nodes
•
=> beliebig kombinierbar mit anderen Expressions, z.B.:
– $book/(chapter union appendix)[fn:last()]
– id("x007")/title
• Erweiterung der “node tests“ zu “kind tests“
d.h.: wie Item-Type Angaben für Node Types, z.B.:
– descendant :: text() (auch in XPath 1.0 möglich)
– forward :: element(*, co:USAddress)
• Prädikate auf beliebige Sequences anwendbar, z.B.:
– (1 to 100)[. mod 5 eq 0]
– (21 to 29)[5]
Beispiel 4
• Division:
– div: Dezimal-Division
3 div 2
(: 1.5 :)
– idiv: ganzzahlige Division
3 idiv 2
(: 1 :)
• Unäre oder binäre Operatoren: +, • Minuszeichen und Leerzeichen:
– a-b
(: Name "a-b" :)
– a -b (: (Zahlenwert von) Element a minus Element b :)
– a - b (: (Zahlenwert von) Element a minus Element b :)
Comparison Expressions
Logical Expressions
• Value comparison: eq, ne, lt, le, gt, ge
• Operatoren: and, or
– Vergleich von 2 einzelnen Items, z.B.: a eq 17 (: a 1-elementig!! :)
– (1,2) eq (2,3) liefert error (weil Operanden nicht 1-elementig sind).
• General comparison: =, !=, <, <=, >, >=
– Vergleich von 2 Sequences
– exists-Semantik wie in XPath 1.0
– z.B.: //a = //b (: = true, wenn //a einen Knoten x und //b einen
Knoten y enthält mit x eq y
– (1,2,3) != (1,2,3) liefert true (weil 1 ne 2).
• Node Comparison: is, <<, >>
Beispiel 5
– Vergleich von 2 einzelnen Nodes
– is prüft node identity, z.B.: $a is $b
– << (bzw.) >> prüft, ob der erste node vor (bzw. nach) dem zweiten node
bzgl. document order liegt, z.B.: $a << $b
– Operieren auf 2 bool‘schen Werten (= effective boolean
value), z.B.: .//section and (@page eq 17)
– Reihenfolge der Auswertung und Optimierungen sind
implementation-dependent, z.B.:
(1 lt 2) or (3 div 0 = 1) liefert true oder error
• Built-in Funktionen: fn:not(), fn:true(),
fn:false()
– wie in XPath 1.0
Constructors
• Direct Element Constructor:
–
–
–
–
Erzeugt ein Element (mit konstantem Namen)
Vergleichbar mit LRE in XSLT
Angabe von Attributen und Namespaces möglich
Inhalt: geschachtelter Constructor, konstanter Text, Expression in { }
• Computed Element / Attribute Constructor:
– Der Element- bzw. Attribute-Name wird mittels Expression
(und nicht als konstanter String) angegeben.
• Weitere Computed Constructors:
– Auch Knoten der anderen Node-types können erzeugt werden
– document {expr}, text {expr}, comment {expr},
processing-instruction {expr1}{expr2}
(: expr1 = name-expression, expr2 = content-expression :)
Beispiele
• Direct Element Constructor:
<example number="1">
<p> Here is a query. </p>
<eg> $b/title </eg>
<p> Here is the result of the query. </p>
<eg>{ $b/title }</eg>
</example>
• Resultat:
<example number="1">
<p> Here is a query. </p>
<eg> $b/title </eg>
<p> Here is the result of the query. </p>
<eg><title>The Adventures … </title></eg>
</example>
6
Beispiele
Beispiele
Beispiel 6
• Attributes:
• Computed Element Constructor:
<shoe size="7"/>
<shoe size="{6+1}"/>
<shoe size="As big as {$hat/@size}"/>
<chapter ref="[{1, 5 to 7, 9}]"/>
(: string-value von ref: "1 5 6 7 9", d.h.:
Konkatenation der Items, mit blank als Separator :)
• Namespaces:
<box xmlns:metr = "http://example.org/metric"
xmlns:engl = "http://example.org/english">
<height><metr:meters>3</metr:meters></height>
<width><engl:feet>6</engl:feet></width>
<depth><engl:inches>18</engl:inches></depth>
</box>
element {fn:node-name($e)}
{$e/@*, 2*fn:data($e)}
(: kopiert das Element $e mit allen Attributen, wobei der
numerische Inhalt von $e verdoppelt werden soll. :)
• Bemerkung:
Attribut-Knoten in der content-expression werden als Attribute des
erzeugten Elements angehängt.
• Computed Attribute Constructor:
attribute
{ if ($sex = "M") then "husband" else "wife" }
{ <a>bla</a>, <b>bla</b> }
(: string-value: "bla bla" :)
FLWOR-Expressions
• for-Klauseln und let-Klauseln:
– Erzeugen einen „tuple stream“ (d.h.: Folge von Tupeln
von Variablenbindungen)
– Jede FLWOR Expression hat mindestens ein for oder let
• where-Klausel: optionaler Filter auf den tuple stream
• order by-Klausel: optionales Umordenen des tuple
stream
• return + expression:
– Liefert 1 Ergebniswert pro Tupel
– Gesamtergebnis: Sequence aus allen Ergebniswerten
for-Klauseln
• for var-name in expr (: expr liefert eine sequence :)
=> bindet Variable an ein Item nach dem anderen
• mehrere Variablen: for var1 in expr1, var2 in expr2
• Beispiel:
for $i in (1, 2), $j in (3, 4)
=> Tuple stream: ($i=1,$j=3), ($i=1,$j=4),
($i=2,$j=3), ($i=2,$j=4)
• Optional: Positionsvariable
for $lva at $i in ("VO", "UE", "PK", "SE")
=> Variablenbindungen: ($lva="VO",$i=1),
($lva="UE",$i=2), etc.
let-Klauseln
• let var-name := expr
=> bindet Variable an Wert von expr
• mehrere Variablen: let var1 := expr1, var2 := expr2
• Beispiel: let-Klausel
let $s := (<one/>, <two/>, <three/>)
return <out>{$s}</out>
liefert: <out><one/><two/><three/></out>
• Beispiel: for-Klausel
for $s in (<one/>, <two/>, <three/>)
return <out>{$s}</out>
liefert: <out><one/></out> <out><two/></out>
<out><three/></out>
where-Klausel
• where expr
=> selektiert jene Tupel im tuple stream, für die expr
den effective boolean value true hat.
• Beispiel:
for $x at $i in $inputvalues
where $i mod 10 = 0
return $x
Liefert jedes zehnte Item der Sequence $inputvalues
7
Order by-Klausel
Beispiel 7
• order by expr
=> expr liefert einen Schlüssel, nach dem die Tupeln
im tuple stream geordnet werden.
Ordered/Unordered Expressions
• In XQuery wird mittles ordering mode (ordered oder unordered)
zwischen definierter und beliebiger Reihenfolge unterschieden bei:
– Ergebnis von axis steps (document order / reverse order)
• Ist die einzige Möglichkeit in XQuery, um nach einem Value
(und nicht nach document order, etc.) zu sortieren
• Optionaler Zusatz: ascending bzw. descending
• Auch mehrere Schlüssel in order by-Klausel möglich:
– Ergebnis von union-, intersect-, except expressions
– tuple stream in FLWOR expression ohne order by Klausel
• Idee: Wenn Reihenfolge nicht wichtig ist, dann ermöglicht
“unordered“ mode eventuell Optimierungen bei der Auswertung
order by $b/title ascending, $b/price descending
• Festlegung des ordering mode:
• Beispiel:
– Global mittels ordering mode declaration im Prolog
for $e in $employees
order by $e/salary descending
return $e/name
– Lokal mittels ordered / unordered expression:
ordered{ expr } bzw. unordered{ expr }
Sortierung der Angestellten-Namen nach absteigendem Einkommen
Conditional Expressions
Quantified Expressions
• some var-name in expr1 satisfies expr2
• if expr1 then expr2 else expr3
– Berechne effective boolean value der test-expression expr1
– true => conditional expression liefert Wert der then-expression
– false => conditional expression liefert Wert der else-expression
– Erzeugen einen tuple stream wie for-Klauseln, d.h.: var-name wird
an ein Item nach dem anderen aus expr1 gebunden
– some-expression liefert true, wenn für mindestens eine solche
Variablenbindung die Bedingung expr2 true ergibt
• Beispiel:
if ($p/@waehrung = "ATS") then
else if ($p/@waehrung = "BEF")
else if ($p/@waehrung = "DEM")
...
else if ($p/@waehrung = "PTE")
else ()
bzw.
every var-name in expr1 satisfies expr2
– every-expression liefert true, wenn für jede solche
fn:data($p) div 13.7603
then fn:data($p) div 40.3399
then fn:data($p) div 1.95583
then fn:data($p) div 200.482
Beispiel 8
Variablenbindung die Bedingung expr2 true ergibt
• mehrere Variablen und Quantoren möglich, z.B.:
some var1 in expr1, var2 in expr2
every var3 in expr3, var4 in expr4
satisfies expr5
Expressions on Sequence Types
• Quantifizierung über empty sequence:
–
some var in () satisfies expr
(: liefert false :)
–
every var in () satisfies expr
(: liefert true :)
• Beispiele:
– every $b in //BUCH satisfies $b/@Vorhanden
liefert true, wenn jedes Element BUCH ein Attribut mit
Namen “Vorhanden“ hat.
– some $x in (1, 2, 3), $y in (2, 3, 4)
satisfies $x + $y = 4
(: liefert true :)
– every $x in (1, 2, 3), $y in (2, 3, 4)
(: liefert false :)
satisfies $x + $y = 4
• expr instance of sequence-type
testet, ob der Typ von expr den Typ laut sequence-type matcht,
z.B.: (5 + 1.4) instance of xs:integer (: false :)
• Typeswitch erlaubt Fallunterscheidung mittels Typangaben,
z.B.:
typeswitch($customer/billing-address)
case $a as element(*, USAddress) return
$a/state
case $a as element(*, CanadaAddress) return
$a/province
case $a as element(*, JapanAddress) return
$a/prefecture
default return "unknown"
8
• expr cast as atomic-type
Validate Expressions
konvertiert den (atomaren) Wert von expr in den Typ laut
atomic-type, z.B.: "51.4" cast as xs:decimal
-> konvertiert String "51.4" in Dezimalzahl
validate expr
– expr muss einen einzelnen element- oder document-node
(= „candidate-node“) ergeben.
• expr castable as atomic-type
testet ob der (atomaren) Wert von expr in den Typ laut
atomic-type konvertierbar ist, z.B.:
"51.4" castable as xs:decimal (: true:)
– Der „candidate-node“ wird mittels validate gegen eine
XML Schema-Definition validiert.
– Falls Validierung möglich: expr wird in entsprechende Data
Model Instance (= value + type annotation) umgewandelt.
• expr treat as sequence-type
– expr bekommt sequence-type als static type
ev. für static type checking bei Funktionsaufrufen wichtig
– Falls Validierung scheitert: => error
– zur Laufzeit: Überprüfung, ob der Typ von expr den
sequence-type matcht.
– Motivation: Damit expr einen bestimmten sequence-type
matcht, ist ev. vorher Validierung gegen ein Schema nötig.
Übungsbeispiel A
Übungsbeispiel B
Betrachten Sie die XML-Dateien Teilnehmer.xml und Gruppen.xml.
Schreiben Sie ein XQuery Programm Xml2Htm.xq, das aus diesen
2 XML-Dateien eine HTML-Datei mit folgender Tabelle erzeugt.
1.
Jede Zeile enthält Nachname, Vorname, MatrNr, Kennzahl,
Email und Gruppe eines Studenten.
Die Studenten sollen alphabetisch (nach dem Nachnamen – bei
Gleichheit nach dem Vornamen) sortiert werden.
Zusätzlich soll (als erste Spalte) eine fortlaufende Nummer
ausgegeben werden.
2.
3.
Verwenden Sie für die Zeilen der Tabelle abwechselnd zwei
verschiedene Formatierungen (z.B.: Hintergrundfarbe, Schriftfarbe,
etc. ).
Rang Raum
Vorlesungen
Name
2125
Sokrates
C4
226
MatrNr
Name
Semester
2126
Russel
C4
232
24002
Xenokrates
18
2127
Kopernikus C3
Popper
Stellen Sie jede Tabelle mit einer eigenen XML-Datei dar, z.B.:Studenten.xml
<Studenten>
<Student>
<MatrNr>24002</MatrNr>
<Name>Xenokrates</Name>
<Semester>18</Semester>
</Student>
<Student>
<MatrNr>25403</MatrNr>
<Name>Jonas</Name>
<Semester>12</Semester>
</Student>
...
<Studenten>
Die relationale Uni-DB
Professoren
PersNr
2133
Betrachten Sie die relationale Uni-DB (nächste Folie) mit den folgenden Tabellen:
Studenten, Professoren, Assistenten, Vorlesungen, voraussetzen, hören
C3
Studenten
310
25403
Jonas
12
52
26120
Fichte
10
2134
Augustinus
C3
309
26830
Aristoxenos
8
2136
Curie
C4
36
27550
Schopenhauer
6
2137
Kant
C4
7
28106
Carnap
3
hören
MatrNr
VorlNr
26120
5001
27550
5001
27550
4052
29120
Theophrastos
2
29555
Feuerbach
2
voraussetzen
VorlNr
Titel
5001
Grundzüge
4
2137
5041
Ethik
4
2125
5043
Erkenntnistheorie
3
2126
5049
Mäeutik
2
2125
4052
Logik
4
2125
5052
Wissenschaftstheorie
3
2126
5216
Bioethik
2
2126
5259
Der Wiener Kreis
2
2133
5022
Glaube und Wissen
2
2134
4630
Die 3 Kritiken
Assistenten
4
Vorgänger Nachfolger
28106
5041
28106
5052
5001
5041
PersNr
28106
5216
5001
5043
3002
28106
5259
5001
5049
3003
Name
SWS gelesen
von
Schreiben Sie ein XQuery-Programm sql.xquery, das ein HTML-Dokument mit
5 Tabellen erzeugt, die die Ergebnisse der folgenden SQL-Anfragen enthalten:
a) Informationen über Studenten, die Vorlesungen von Sokrates besuchen:
select h.MatrNr, v.Titel, v.VorlNr
from hören h, Vorlesungen v, Professoren p
where p.Name = ´Sokrates´ and v.gelesenVon = p.PersNr and
v.VorlNr = h.VorlNr;
2137
b) Informationen über die Lehrbelastung der Professoren in Rang C4:
Fachgebiet
Boss
Platon
Ideenlehre
2125
Aristoteles
Syllogistik
2125
Sprachtheorie
Fortsetzung (Übungsbeispiel B)
29120
5001
5041
5216
3004 Wittgenstein
29120
5041
5043
5052
3005
Rhetikus
Planetenbewegung
2127
29120
5049
5041
5052
3006
Newton
2127
29555
5022
5052
5259
Keplersche
Gesetze
2126
25403
5022
3007
Spinoza
Gott und Natur
2126
select PersNr, Name, ( select sum(SWS) as Lehrbelastung
from Vorlesungen where gelesenVon = PersNr )
from Professoren
where Rang = ´C4´
order by Name;
9
Fortsetzung (Übungsbeispiel B)
c) Informationen über Professoren, die überwiegend lange Vorlesungen halten:
select gelesenVon, Name, avg(SWS)
from Vorlesungen, Professoren
where gelesenVon = PersNr
group by gelesenVon, Name
having avg(SWS) >= 3;
d) Namen aller Uni-Angehörigen (Professoren, Asssistenten, Studenten) :
( select Name from Professoren ) union
( select Name from Assistenten ) union
( select Name from Studenten );
e) Liste aller Vorlesungen sowie zu jeder Vorlesung die Liste aller direkt oder
indirekt vorausgesetzten Vorlesungen (d.h.: transitiver Abschluss der Tabelle
„voraussetzen“ -> ist nicht ausdrückbar in SQL-92!!).
10