Übersicht - Lehrstuhl für Informatik VI
Werbung

Übersicht
I Künstliche Intelligenz
II Problemlösen
III Wissen und Schlußfolgern
6. Logisch schließende Agenten
7. Prädikatenlogik 1. Stufe
8. Entwicklung einer Wissensbasis
9. Schließen in der Prädikatenlogik 1. Stufe
10. Logische Inferenzsysteme
IV Logisch Handeln
V Unsicheres Wissen und Schließen
VI Lernen
VII Kommunizieren, Wahrnehmen und Handeln
Kategorien von Schlussfolgerungssystemen
• Theorem Beweiser (SAM, AURA, OTTER)
und logische Programmiersprachen (Prolog, MRS, LIFE)
• Regelbasierte Produktionssysteme (OPS-5, CLIPS, SOAR)
• Frame-Systeme (OWL, FRAIL, KODIAK)
und semantische Netze (SNEPS, NETL, Conceptual Graphs)
• Terminologische Logiken (Beschreibungslogiken; KL-ONE,
CLASSIC, LOOM)
Grundaufgaben von Schlussfolgerungssystemen
1. Hinzufügen von Fakten (Wahrnehmungen oder
Schlußfolgerungen) zur Wissensbasis (Funktion TELL).
2. Herleiten von Fakten aus einem neuem Faktum und der
Wissensbasis (bei Vorwärtsverkettung Teil von TELL).
3. Fragen beantworten (Funktion ASK). Mit Ja/Nein oder durch
Instanziierungen).
4. Feststellen, ob eine Frage bereits in der Wissensbasis enthalten ist
(eingeschränkte Version von ASK).
5. Entfernen von Sätzen aus der Wissensbasis.
Implementierung der Datentypen
Vorbemerkung: Ein/Ausgabe für Interaktion mit Benutzer muss
gesondert behandelt werden.
Interne Repräsentation: Basis-Datentyp „Compound“ mit einem Feld
für den Operator und einem Feld für die Argumente,
z.B. wird der Satz c = „P(x) ∧ P(y)“
in folgende interne Darstellung umgesetzt:
OP(c) = ∧
ARGS (c) = [P(x), P(y)].
Naives Abspeichern von Sätzen in einer linearen Liste hat einen
Suchaufwand von O(n), ob ein Satz in der Liste enthalten ist, und beim
Abspeichern ebenfalls einen Aufwand von O(n), falls Duplikate erkannt
und entfernt werden sollen (ohne Duplikat-Erkennung nur O(1)).
→ Besser: Indexierung
Indexierung
Implementierung der Wissensbasis als Hash-Tabelle:
1. Ansatz: Reserviere jeweils eine Speicherzelle für jeden Satz.
Nachteile: 1. Reflektiert nicht die strukturbildenden Elemente der Logik
2. Kann nicht mit Variablen umgehen.
→ Daher nicht geeignet für Anfragen wie:
• Suche eine Implikation mit P auf der rechten Seite (Nachbedingung)
• Suche Match zu „∃x Bruder (Richard, x)“ mit „Bruder (Richard, John)“
2. Ansatz: Indiziere nach Prädikatsymbolen und teile nach 4 Kategorien
auf:
- Liste von positiven Literalen für das Prädikatsymbol
- Liste von negativen Literalen für das Prädikatsymbol
- Liste von Sätzen mit Prädikatssymbol in Nachbedingung
- Liste von Sätzen mit Prädikatssymbol in Vorbedingung
Verfeinerung des 2. Ansatz: Unterindex für die konstante Argumente
Beispiel für Indizierung logischer Sätze
Unifikationsalgorithmus (1)
Mit Indexierung ist die Unifikation ziemlich effizient, allerdings erhöht
der „Occur-Check“ in der Prozedur „Unify-Var“ die Komplexität von
O(n) auf O(n2), wobei n die Länge des Ausdrucks bezeichnet.
Unifikationsalgorithmus (2)
Logische Programmiersprachen
Programm und die Eingabe:
logische Sätze
Herleitung von Schlußfolgerung:
logische Inferenz (Beweis)
Algorithmus = Logik + Kontrolle
Logische Programmiersprachen ermöglichen das Schreiben von
Algorithmen, indem sie logische Sätze mit Informationen anreichern, um
den Inferenzprozess zu kontrollieren.
Verbreitetestes Beispiel: Prolog
Beispieldefinition:
member (X, [X | L])
∀ x, l Member (x, [x | l])
member (X, [Y | L]) :- member (X, L)
∀ x, y, l Member (x, l) ⇒ Member (x, [y | l])
Eigenschaften von Prolog
• Programm besteht aus Folge von (mit „und“ verknüpften) Sätzen, alle
Variablen sind allquantifiziert und disjunkt in verschiedenen Sätzen.
• Als Sätze sind nur Hornklauseln zugelassen.
• Terme: Konstanten, Variablen, Funktionsausdrücke
• Anfragen: Terme, Konjunktionen, Disjunktionen,
• Negation as Failure: Das Ziel ¬P gilt als bewiesen, wenn P nicht
hergeleitet werden kann.
• Syntaktisch disjunkte Terme sind disjunkt, d.h. man kann nicht A=B
oder A = f(x) ausdrücken, falls A eine Konstante ist.
• Viele eingebaute Prädikate für Arithmetik, Ein/Ausgabe usw., deren
Code bei Aufruf einfach ausgeführt wird.
Implementierung von Prolog
• Inferenz mittels Rückwärtsverkettung und Tiefensuche
• Reihenfolge der Abarbeitung: von links nach rechts & oben nach unten
• Kein Occur-Check aus Effizienzgründen
Prolog liefert alle Lösungen zu einer Anfrage nacheinander:
member (loc (X,X), [loc (1,1), loc (2,1), loc (2,2)]) → „X=1“ und „X=2“
Effizienzsteigerungen für den Interpreter
• Es werden nicht alle Lösungen für ein Teilziel generiert, sondern nur
eine Lösung, sowie ein Versprechen (choice point), weitere zu
generieren, wenn die erste Lösung vollständig untersucht wurde.
• Substitutionen für Variablen werden nicht als Bindungslisten, sondern
als Wertbindungen repräsentiert. Zum effizienten Rücksetzen der
Variablen wird ein Stack (Trail) verwendet.
Kompilierung von Prolog
Da der Instruktionsvorrat von den üblichen Computern schlecht zur
Semantik von Prolog passt, kompilieren die meisten Prolog-Compiler in
eine Zwischensprache, vor allem die Warren Abstract Machine oder
auch in andere Sprachen wie LISP oder C.
• Die Klauseln für Member werden nicht in einer Datenbasis gesucht,
sondern sind in die Prozedur eingebaut.
• Die Variablenbindungen werden auf einem Stack (trail) verwaltet.
• Continuation:Speichern von Informationen zur Fortsetzung des Aufrufs
Parallelisierung von Prolog
• Oder-Parallelität: Ein Ziel kann mit vielen Literalen unifiziert werden,
die unabhängig voneinander untersucht werden können.
• Und-Parallelität: Die Konjunktionen im Hornklausel-Rumpf werden
parallel überprüft. Problem: konsistente Bindungen für Variablen.
Effizienz (LIPS = Logical Instructions Per Second):
• Standard-Prolog-Compiler (1990 Workstations): 50 000 LIPS
• Hochleistungs-Compiler (1990): Millionen LIPS
• PIM (Parallel Inference Machine; 5th Gen Project: 64 000 000 LIPS
Logische Constraintsprachen (CLP)
Erweiterung von Prolog um Constraints über Werten, z.B. x > 3.
Beispiel: Definition eines Dreiecks:
Dreieck (x,y,z) ⇐ (x>0) ∧ (y>0) ∧ (z>0) ∧ (x+y>z) ∧ (y+z>x) ∧ (x+z>y)
Dreieck (3,4,5) kann sowohl in Prolog als auch CLP bestätigt werden.
aber
Dreieck (x,4,5) liefert nur in CLP die Antwort: {x>1 ∧ x<9}
Auch symbolische Constraints wie Person (p) möglich, die nicht wie in
Prolog sofort instantiiert werden, sondern verzögert ausgewertet werden
(Least Commitment).
Fortgeschrittene Kontrollmöglichkeiten
Metareasoning: Schlussfolgern über den Schlußfolgerungsprozess
Beispiel1: Was ist das Einkommen der Gattin des Präsidenten?
Einkommen (s,i) & verheiratet (s, p) & Beruf (p, Präsident)
→ Ineffizient, daher besser die Reihenfolge der Anfrage umdrehen.
Beispiel2: Welche Personen sind aus derselben Stadt wie der Präsident?
Bürger (p, stadt) & Bürger (x, stadt) & Beruf (p, Präsident)
→ Statt bei fehlgeschlagenem Beweis des letzten Literals eine andere
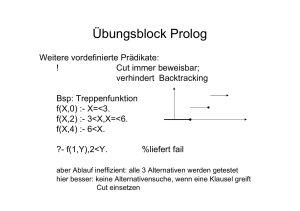
Alternative beim vorletzten zu probieren (Backtracking), sollte man
gleich zum ersten Literal zurückspringen (Backjumping).
→ Außerdem kann man sich die fehlgeschlagene Variablenkombination
merken (dependency directed backtracking).
→ Oft ist es günstig, sich durchgeführte Inferenzen zu merken, um diese
nicht noch mal herleiten zu müssen. Problem: Was soll man vergessen?
Theorem Beweiser (1)
Unterschied zwischen logischen Programmiersprachen und TheoremBeweisern:
- Hornklauseln vs. volle Prädikatenlogik 1. Stufe
- implizite vs. explizite Repräsentation der Kontrolle
Beispiel für Kontrollinformationen in OTTER:
- Aufteilung der Klauseln in wichtige und nutzbare gemäß der Set of
Support Strategie
- Umformung von Gleichungen in Rewrite-Regeln, die nur in einer
Richtung benutzt werden, z.B. x+0=x.
- Steuerungswissen (z.B. Gewicht von Klauseln) und Filterwissen
(Ignorieren von Teilzielen).
Theorem Beweiser (2)
Erweiterung von Prolog zu Theorem-Beweiser in PTTP
- Occur-Check
- Statt Tiefensuche iterative Tiefensuche
- Zulassen negierter Literale
- Eine Klausel mit n Literalen wird als n Klauseln gespeichert, z.B. für
A ⇐ B ∧ C zusätzlich ¬B ⇐ C ∧ ¬A sowie ¬C ⇐ B ∧ ¬A
(kann sehr ineffizient sein).
- Statt Input-Resolution lineare Input-Resolution
Theorem Beweiser als Assistenten
Einsatz zur Programmverifikation (und Synthese)
Architektur des OTTER - Theorem - Beweises
Vorwärtsverkettung mit Produktionsregeln
Vereinfachung zu Theorem-Beweiser: Es werden Regeln mit Variabeln
gegen eine Faktenbasis ohne Variablen abgeglichen
(Pattern Matching statt Unifikation).
Typischer Aufbau:
- Working Memory (Faktenbasis).
- Regeln mit Kondition und Aktion (jeweils typischerweise mit &
verknüpft). Aktionen dürfen auch Elemente des Working Memory
löschen oder verändern.
- Vergleichsphase: In einem Inferenzzyklus werden alle Regeln berechnet, deren Konditionen aufgrund des Working Memory erfüllt sind.
- Konfliktauflösung: Aus diesen Regeln wird eine ausgewählt und
deren Aktion ausgeführt.
Beispiele: OPS-5, SOAR, ACT.
Konfliktlösungstrategien
Beispiele:
- Keine Wiederholung (einer gerade gefeuerten Regel)
- Spezifizität (Bevorzuge spezifischere Regeln).
Bsp.: (1) Säugetier (x) => add Beine (x,4)
(2) Säugetier (x) & Mensch (x) => add Beine (x,2)
(2) ist spezifischer als (1).
- Regelprioritäten (Zusatzwissen).
- Aktualität (Bevorzuge Regeln, die auf gerade geänderte Einträge
im Working Memory Bezug nehmen)
Vergleichsphase
Beobachtungen:
(1) Oft enthalten Regeln gleiche Elemente in der Kondition. Sie sollten
nicht in jeder Regel neu überprüft werden müssen.
(2) Von einem Inferenzzyklus zum nächsten ändert sich das Working
Memory oft nur geringfügig. Daher sollten nur die Regeln überprüft
werden, die von den Änderungen betroffen sind.
Beispiel für Kompilierung im RETE-Algorithmus
Regelbasis:
A(x) & B(x) & C(y) => Add D(x)
A(x) & B(y) & D(x) => Add E(x)
A(x) & B(x) & E(x) => delete A(x)
Working Memory:
{A(1), A(2), B(2)
B(3), B(4), C(5)}
A=E
Frame-Systeme und semantische Netze
Grafische Wissensnotationen wurden schon Ende des 19. Jahrhunderts
als "Logik der Zukunft" propagiert. Auf semantischer Ebene besteht aber
kein grundlegender Unterschied zur Prädikatenlogik 1. Stufe.
Kernmechanismen:
- Vererbung entlang von Kanten mit Default-Werten
- Zugeordnete Prozeduren möglich, um die Beschränkungen in der
Ausdrucksstärke zu kompensieren.
Vorteile grafischer Notationen:
- bessere Lesbarkeit für Menschen.
- durch Vereinfachungen in der Ausdrucksstärke wird der Inferenzprozess effizienter und transparenter (z.B. Verfolgen von Kanten im Netz)
Nachteile:
- oft unklare Semantik der Graphen (z.B. bei multipler Vererbung);
Klärung nur im Programmcode.
- Effizienzprobleme aufgrund von Nicht-Monotonie wegen Defaults.
Beispiel für Frame
Grundlegende Beziehung in semantischen Netzen
Mehrfachvererbung
Basis-Interpreter für semantische Netze (1)
Basis-Interpreter für semantische Netze (2)
Beschreibungslogiken (Terminologische Logiken)
Ziel: Definition von Kategorien, so dass aufgrund der Eigenschaften
einer Kategorie bzw. eines Objektes dessen Zugehörigkeit zu einer
Kategorie ermittelt werden kann (Subsumption bzw. Klassifikation).
Beispiel1 (Junggeselle): And (Unverheiratet, Erwachsener, Männlich)
Beispiel2 (Mann mit mindestens drei arbeitslosen und mit einem Doktor
verheirateten Söhnen und zwei Töchtern, die Professor in Chemie
oder Physik sind):
And (Mann, AtLeast (3 Sohn), Atleast (2 Tochter)
(All (sohn, And (arbeitslos, verheiratet, all (Partner Doktor)))
(All (Tochter, And (Professor, Fills (Fach, Physik, Chemie))))
Effizienzfrage: Wie aufwendig ist Subsumption in Abhängigkeit der
Ausdrucksstärke der Sprache?
Sprache für Beschreibungslogik in CLASSIC
Effizient interpretierbaren Beschreibungslogiken fehlen meist Operatoren für Negation und Disjunktion (z.B. „Or“ oder „Some“; Fills &
OneOf erlauben Disjunktion nur für explizit aufgezählte Individuen).
Belief Revision (1)
Implementierung von "Retract": Rücknahme oder Änderung einer
Aussage, z.B. wegen
•
•
•
•
Speicherbereinigung (Vergessen)
Änderungen in der Welt
Änderungen von Default-Annahmen
Korrektur von Fehlinformationen
Problem: Gewährleistung der Konsistenz der Datenbasis, da aus den
geänderten Aussagen andere Aussagen hergeleitet sein können.
Lösung: Truth-Maintenance-Systeme (TMS)
Drei Varianten:
1. Chronologische Backtracking:
Ziehe alle Schlussfolgerungen bis zu dem Punkt zurück, wo die
geänderte Aussage das erste Mal benutzt wurde.
Belief Revision (2)
2. Justification-Based TMS (JTMS):
Speichere zu jeder Schlussfolgerung die direkten Gründe (justifications)
für ihre Herleitung. Wenn ein Grund ungültig wird, dann überprüfe, ob
für die betroffene Schlußfolgerung noch andere Gründe zutreffen. Wenn
nicht, ziehe sie zurück und überprüfe rekursiv die Auswirkungen.
Problem: zirkuläre Gründe.
Lösung: Unterscheidung in "sichere" und "unsichere" Gründe.
3. Assumption-Based TMS (ATMS):
Speichere zu jeder Schlussfolgerung die Basisannahmen (Assumptions),
die zu ihrer Herleitung geführt haben. Wenn sich etwas ändert, überprüfe
anhand ihrer Basisannahmen, ob eine Schlussfolgerung immer noch gilt.
Vorteile gegenüber JTMS: Kein Problem mit Zyklen,
Behandlung multipler Zustände möglich.
Nachteile: Skalierungsproblem, Behandlung von unsicherem Wissen.