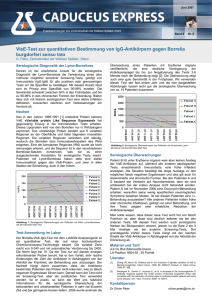
WinWord 6.0 Document
Werbung

Psychodiagnostik - Script zur Examensvorbereitung 1 Psychodiagnostik Psychodiagnostische Grundprobleme und Modelle 1. Einführung, Gegenstandsbestimmung und Entwicklung der Allgemeinen Psychodiagnostik 1.1 Einführung - diagnostische Urteile sind Wahrscheinlichkeitsurteile, die auf statistischen Schätzungen beruhen Beschränkungen der Psychodiagnostik: 1. Jede Diagnostik ist an einen methodischen Zugriff zur Datenquelle gebunden, von dem sie ihre diagnostischen Informationen gewinnt. - hierzu bedarf es aber operationalisierbarer Eigenschaften, Merkmale, Indikatoren etc. am zu diagnostizierenden Objekt (Diagnostikand) - dabei muß der Diagnostikand nicht nur eine Person sein, sondern es können auch seine Umgebungsbedingungen oder die Beziehungen zwischen beiden sein - vom Wert dieses Zugriffs und damit der relevanten und validen Operationalisierung hängt letztlich der Wert der Diagnose maßgeblich ab 2. Solche Zugriffsformen betreffen immer nur einen Ausschnitt des Diagnoseobjekts - für die Persönlichkeitsdiagnostik bedeutet das, daß man ausgewählte Persönlichkeitseigenschaften, deren Relationen, deren Bedingungen usw. diagnostizieren kann, aber nicht die gesamte Persönlichkeit 3. Diagnosen werden nicht um ihrer selbst willen gestellt, sondern man verfolgt mit ihnen stets ein oder mehrere Ziele - von der Systematik der Ziele hängt es ab, inwieweit eine Psychodiagnostik sinnvoll zu entwickeln ist - der diagnostische Urteilsprozeß ist durch die 3 Hauptstrukturkomponenten des Diagnostikers, des Diagnostikanden und des zwischen ihnen methodisch distanzierend-vermittelnden Wechselwirkungsprozesses bestimmt ein diagnostischer Urteilsprozeß stellt einen diagnoseziel- und i. d. R. auch interventi- onszielbezogenen Informationsaufnahme, -verarbeitungs-, -speicherungsund abgabeprozeß dar, der durch Komponenten des Diagnostikers, der Differentiellen Methodik, des Diagnostikanden und der wirksam werdenden Randbedingungen bestimmt wird Diagnostik: - “Werkzeug” zur Erhebung intra- und interindividueller Unterschiede - Methodologie (z. B. standardisiert, quantifizierend) - dient der Verhaltensvorsag und -steuerung (z. B. therapeutische Intervention) - auf Theorien basierend - Methoden- und Anwendungsfach, kein Grundlagenfach (d. h. sie ermittelt nicht selbst; dies ist Aufgabe der Differentiellen und Klinischen Psychologie) Diagnostische Urteilsbildung - Verdichten von Einzelinformationen zu einem Gesamturteil Gestaltbegriff (“das Ganze ist mehr als die Summe seiner Teile” Integrationsleistung des Diagnostikers Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 2 2 Lager: statistische diagnostische Urteilsbildung vs. klinische Diagnostik - statistische Absicherung wird als - intuitives Vorgehen notwendig erachtet Kritik am klinischen Vorgehen (nach Abraham): - unvollständige oder unsichere Infos werden zu hoch bewertet (empirisch bestätigt) - Informationen aus der Grundgesamtheit sind oft nicht bekannt - individuelle Infos über eine Person werden zu stark berücksichtigt (man meint, daß ein Überstülpen eines psychischen Etiketts der Vielschichtigkeit des Individuums nicht gerecht wird Kritik am statistischen Vorgehen (nach Meehl): - Kliniker schauen nicht nur nach Beweisen, sondern versuchen neue Überlegungen zu bilden - der zu beurteilende Sachverhalt, die Psyche, ist nicht statistisch zu untersuchen Faktoren, die zur Überlegenheit des statistischen Modells beitragen: - klar definierte Merkmalsbereiche - wenn präzise Daten bzw. Aussagen benötigt werden (z. B. Fehlerermittlung; Klassifikation) - die Art der Datenerhebung ist universell gültig (Referenzpopulation vorhanden) Fazit: - eine Konvergenz beider Methoden ist anzustreben - statistische Hilfsmittel solange wie möglich miteinbeziehen, aber eine intuitive Entscheidung am Schluß 1.3 Zur Entwicklung der Allgemeinen Psychodiagnostik 1.3.1 Die Analyse des diagnostischen Resultats - über die Zuverlässigkeit von Diagnosen Zuverlässigkeit : Übereinstimmungsgrad von Diagnosestellungen (nicht mit Reliabilität gleichzusetzen) Stabilität: - Übereinstimmungsgrad des diagnostischen Urteils eines Diagnostikers über einen Diagnostikanden auf der Basis der gleichen Daten zu verschiedenen Zeitpunkten (= Reliabilität) Konvergenz: - Übereinstimmungsgrad des diagnostischen Urteils eines Diagnostikers über einen Diagnostikanden zu einem bestimmten Zeitpunkt auf der Basis verschiedener Datenquellen bzw. verschiedener eingesetzter Methoden die dem gleichen Diagnoseziel dienen Konsensus: - Übereinstimmungsgrad des diagnostischen Urteils verschiedener Diagnostiker über einen Diagnostikanden auf der Basis der gleichen Daten und zum gleichen Zeitpunkt 1.3.2 Die Analyse des diagnostischen Prozesses 1.3.2.1 Das Linsenmodell von Brunswik (1956) - Grundannahme: die Urteilsbildung vollzieht sich unter stochastischen (probabilistischen) Bedingungen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 3 Vorhersageleistung ryeys Ökologische Validität Re = ryyee rrye rx2ye Geschätztes Urteil rxnye Merkmalsver- x1 wertung x2 rx2ys .. .. xn rxnys Rsy=s rys rys Vorhersagemöglichkeit ryeys Aufgabenwahrnehmung ye: tatsächlich empirisches Ereignis, distale Variable; liegt außerhalb des Diagnostikers xn: Cues, Hinweisreize; Grundlagen nach denen der Diagnostiker urteilt ys: das, was der Diagnostiker letztendlich diagnostiziert rxnye: - ökologische Validität; gibt an, wie hoch die cues mit ye korrelieren a, wie gut ist die Vorhersage von ye aufgrund der cues? b, wie sieht die spezielle Beziehung aus? - grundsätzliche Annahme: linearer Zusammenhang zwischen xn und ye - aber: möglicher Infoverlust durch diese Einschränkung (siehe z. B. Yerkes-DodsonGesetz) c, wie gut ist die additive Komponente der cues für die Vorhersage? rxnys: - Merkmalsverwertung a, inwieweit bedient sich der Benutzer der cues? b, wie werden die Einzelmerkmale gewichtet? c, welche Gewichtungsstrategie benutzt der Diagnostiker ryeys: Vorhersageleistung (ra) ryeys: Aufgabenwahrnehmung (G) ryerye: (multiple Regression); geschätztes Urteil (Re) rysrys: ´´ Vorhersagemöglichkeit des Urteils (Rs) (am interessantesten sind die Größen Vorhersageleistung und Aufgabenwahrnehmung) Grundgleichung des Linsenmodells: ra = f (G, Re; Rs) - Goldberg (1970) hat die Vorhersageleistung eines mit der von Diagnostikern verglichen - als Daten dienten 861 MMPI-Profile, die an Psychotikern und Neurotikern erhoben wurden - das “Modell” (d. h. das Computerprogramm) und 29 Klinische Psychologen mußten diese Profile den Nominalkategorien “Neurotiker”, “Psychotiker” zuordnen - das Modell war den Diagnostikern in der Richtigkeit der nominalen Zuordnung überlegen Untersuchung zeigt, wie bedeutend rationale Analysen des diagnostischen Urteilsprozesses sind - die Kritiker des Linsenmodells setzen v. a. an den Mitteln seiner mathematischen Formalisierung an aber: hoher heuristischer Wert des Linsenmodells Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 4 1.3.2.2 Informationstheoretische Ansätze Gurndannahme: Diagnoseprozeß ist ein Prozeß der Informationsverarbeitung zwischen Sender oder Informationsquelle (Diagnostikand), Empfänfer (Diagnostiker) und den unidirektional bzw. bidirektional zwischen ihnen (über den Übertragungskanal) vermittelten Informationsaustauschprozessen aufgefaßt und analysiert Ziel: Angabe der Informationsmenge, die zum gewünschten Urteil führt Diagnostische Daten Informationsverarbeitung (Diagnostiker) Diagnostisches Urteil - man konzentrierte sich zunächst auf die “Kanalkapazität”, d. h. die Informationsmenge, die der Diagnostiker behalten kann - Miller: Spanne ist 7, plus/minus 2; wobei sich in dieser Arbeit die Spanne auf das unmittelbare Behalten kontextarmer, sinnloser Elemente bezog (sinnlose Silben etc.) - später konzentrierte man sich auf den Einfluß der Variablen wie Anzahl der Informationsquellen, Komplexität verschiedener Informationsquellen und dem Einfluß der Anzahl vorhandener Antwortalternativen für den Diagnostikanden 1.3.2.3 Die Theorie des funktionalen Messens - Anderson geht davon aus, daß der Prozeß der “Informationsintegration” im wesentlichen durch 2 grundlegende Operationen realisiert wird: Bewertung und Integration (d. h. der Beurteiler führt 2 mentale Prozesse durch) Bewertung: - Schätzprozeß der zur Bestimmung des Skalenwertes und des Gewichts einer Objekteigenschaft oder eines Reizes führt - der Skalenwert ist dabei durch die Position der Objekteigenschaft auf dem Kontinuum der entsprechenden Urteilsdimension definiert - das Gewicht wird bestimmt durch Faktoren wie Reliabilität, Spezifität des Objektmerkmals bzw. Symptoms (in dieses Gewicht geht besonders die Erfahrung des Diagnostikers ein) Integration: - Kombination der Einzelinformationen mit dem Ergebnis eines globalen Urteils Integrationsmodell: R = wisi +C+ E wi R: Reaktion, Urteil C: personspezifische Parameter E: Fehler w: Merkmale s: Skalenwerte - dem Modell liegt die Annahme zugrunde, daß der Diagnostiker bzw. Beurteiler algebraische Durchschnitte, kognitive Subtraktionen etc. bildet (“kogntive Algebra”) Kritik: - der Bewertungsprozeß kann nicht expliziert werden - Kontextfaktoren werden nicht berücksichtigt 1.3.2.4 Kognitiv-logische und normative Ansätze Der diagnostische Urteilsprozeß als natürlicher psychodiagnostischer Arbeitsprozeß - nach Kaminsky ist ein diagnostischer Arbeitsprozeß ein zustands- und zielhypothesenbezogener, durch kognitive Mikroprozesse realisierter Beurteilungsprozeß, der mit Hilfe von Wissens- und Gewissensrepräsentationen erfolgt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 5 Ablaufschema des diagnostischen Urteilsprozesses: - der Prozeß beginnt mit einer differentiellen Datengewinnung, die zur gezielten Hypothesenbildung beiträgt - in diesen Prozeß der Hypothesenbildung und Datengewinnung gehen verschiedene Klassen an Wissensrepräsentationen ein 1. Speicher: - Wissen über Veränderungsmöglichkeiten a, durch die wissenschaftliche Ausbildung, v. a. empirische Belege b, durch die bisherige Berufserfahrung c, durch die bisherige Alltagserfahrung 2. Speicher: - enthält das Wissen, mit dessen Hilfe der Diagnostiker entscheiden muß, ob die bestehende Fragestellung für ihn relevant ist, ob sie in seinen Kompetenz- und Leistungsbereich fällt oder ob der Diagnostikand in die Hand eines anderen Fachmannes gehöhrt 3. Speicher: - umfaßt das Bedingungswissen - Wissen über die Faktoren der Entstehung und Aufrechterhaltung des Verhaltens 4. Speicher: - Gewissen, ethische Überlegungen - individuelle und gesellschaftliche Schwellenkriterien, unterhalb derer die Diagnostizierung nicht mehr verantwortet werden kann - der Ansatz Kaminskis stellt einen sequentiellen und rekursiven (zurückgehenden) Arbeitsprozeß dar (Rückkoppelungsprinzip) Fazit: - Kaminski betrachtet v. a. kognitive Verknüpfungen - Hypothesenbildung erfolt folgendermaßen: Änderungswissen Änderungsumstände (hier spielt das Bedingungswissen mit rein) Auswahl der methodischen Verfahren Gewissen Hypothesenprüfung Datenmenge ausreichend für die Hypothese? Ja-Nein Prozeßdiagnostik Kritik: - Westermeyer: Einwand des “kogntiver Essentialismus”, d. h. die unterschiedlichen kognitiven Operationen können kaum als existent angesehen werden - Mangel an Empirie; die empirische Verifizierung steht noch aus - aber hoher heuristischer Wert des Modells, daß die traditionelle Vorstellung von der Diagnostik als eines einstufigen Entscheidungsaktes überwunden hat Der diagnostische Urteilsprozeß als normative Diagnostik - während empirische Untersuchungen häufig Schwächen und Unzulänglichkeiten gegenwärtiger diagnostischer Praxis aufdecken, wird im Rahmen der normativen Diagnostik versucht, diagnostisches Handeln der Beliebigkeit und Subjektivität des einzelnen Diagnostikers zu entziehen - diagnostisches Handeln als regelgeleitetes Handeln, orientiert an einem idealisierten Prozeßmodell - der normativen Diagnostik geht es um die “Konstruktion eines präskriptiven Modells des diagnostischen Prozesses” (Westermeyer, 1976) -der normative diagnostische Prozeß ist durch die 3 Komponenten des “diagnostischen Arguments” bestimmt: 1. die Ausgangsfrage (Problemstellung; Fragestellung) 2. die Diagnose (Antwort auf die Ausgangsfrage) und 3. die “Verknüpfungsprinzipien”, die zwischen Ausgsangsfrage und Diagnose vermitteln Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 6 Allgemeines Strukturschema des normativen diagnostischen Prozesses: Ausgangsfrage A Algorithmensystem Wissensgrundlagen WGt Ziel: Diagnose Spezifizierung des diagnostischen Prozesses kann nur in zweierlei Hinsicht erfolgen: - in Hinblick auf die jeweils zu normierenden Wissensgrundlagen, die zur Diagnostik benutzt werden und - die ebenfalls zu normierenden Basisalgorithmen, die die Überführungsformen realisieren Nach Kaminski (1970) lassen sich dabei 5 unterschiedliche Wissensgrundlagen unterscheiden: 1. Bedingungswissen 2. Änderungswissen 3. technologisches Wissen (Anwendung der Methoden und Datenanalyse) 4. Vergleichswissen (die erhobenen Daten werden mit einem Bezugssystem, z. B. Referenzpopulation, verglichen) 5. Kompetenzwissen Es lassen sich 3 funktional unterschiedliche Basisalgorithmen differenzieren: 1. Prozeßalgorithmus: - steuert den Gesamtprozeß der diagnostischen Urteilsbildung - die Steuerung erfolgt durch den Aufruf der übrigen beiden Algorithmen an geeigneten Prozeßstellen und die Weiterverarbeitung der von ihnen gelieferten Informationen mit der jeweiligen Entscheidung darüber, ob das Zielkriterium erfüllt ist oder ob der Urteilsprozeß fortgeführt werden soll 2. Auswahllogarithmus: - wählt Wissensgrundlagen aus und führt sie in den Prozeß ein 3. Prüfalgorithmus: - regelt die systematische Prüfung der jeweiligen diagnostischen Hypothesen Fazit: - mit hohem Wissenschaftlichkeitsanspruch ausgestatteter Ansatz - aber: angesichts der oftmals “weichen” Daten, unzureichender psychologischer Theorien etc. ist der Diagnostiker überfordert, normative Hilfestellung von einer normativen Diagnostik in Anspruch zu nehmen (Empirie fehlt) Der diagnostische Urteilsprozeß als Entscheidungsprozeß - Diagnostik als sequentieller Entscheidungsprozeß und nicht nur als einmalige Ein-PunktErhebung - Vorteil dieser Strategie: es können auch solche Methoden eingesetzt werden, die nur mäßige Gütekriteriumswerte, d. h. Objektivitäts-, Reliabilitäts- und Validitätswerte besitzen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 7 - dieser Vorteil besteht darin, daß sequentielle Prozeduren schrittweise aufeinander aufbauende Prozeduren sind, die so lange fortgeführt werden können, bis ein vom Diagnoseziel her gesehen erwünschtes Datennivau erreicht ist - während in der klassische Diagnostik die Diagnostikprozedur im wesentlichen auf die Testung, d. h. die Bestimmung des Ausprägungsgrades eines oder mehrer Merkmale eines Merkmalträgers und ggf. noch zusätzlich auf die Abschätzung der Prognose dieser Eigenschaft bzw. des darauf aufbauenden Verhaltens reduziert wird, ist in der Entscheidungsprozedur nach Cronbach und Gleser als wesentliche Komponenten auch die Nutzenabschätzung integriert - so könne etwa einstufige oder mehrstufige Entscheidungsprozeduren vorgenommen werden - eine Entscheidung kann weiterhin terminaler (endgültiger) oder investigatorischer (zeitweiliger) Art sein Diagnostischer Entscheidungsprozeß nach Tack Darlegung des Problems Zielsetzung (theoriegeleitet, nicht intuitives Vorgehen) Methodenauswahl zur Erreichung eines Teilschrittes reflexives Überprüfen Strategie - bestimmte Regelsysteme - Untersuchungsmethoden Behandlung A - z. B. Weitervermittlung investigatorische Entscheidung vs. terminale Entscheidung - weitere Untersuchung, bzw. - keine weiteren Untersuchungsmaßnahmen mehr Beginn der Untersuchung erforderlich Weitervermittlung Ende des diagnostischen Kreislaufs Auswahl der Verfahren (zu bestimmten Fragestellungen) Information über eine Person - ausreichende Info? nein zurück zur Problemstellung ja neue Strategie terminale Entscheidung vs. investigatorische Entscheidung Evaluation - weitererer diagnostischer Prozeß bei falscher Behandlung bzw. mangelhaften Ergebnissen - von besonderer Bedeutung innerhalb eines diagnostischen Urteilsprozesses als Entscheidungsprozeß sind Strategieformen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 8 Untersuchungstrategien Strategie: - ein normatives System von Regeln, die angewandt auf vorliegende Infos, unter Berücksichtigung der jeweiligen Zielsetzung zu einer bestimmten Entscheidung führen (Tack) Strategiegruppen: Selektionsstrategien Modifikationsstrategien - Strategien mit vorgegebenen Bedingungen, - Person und Bedingung werden modifiziert unter denen man Personen ausselegiert (z. B. (Modifikation der Person an die Bedingung Schulreifeprüfung; Berufswahl) et vice versa) - die Strategiensuche sollte zu Beginn einsetzen uns sich der Frage widmen: “Welche Strategien und warum” (“bewußte Richtschnur”) Makrostrategien vs. - ganze Testarsenale werden vorgegeben, um eine bestimmte Entscheidung herbeizuführen - relativ unflexibel (man hat höchstens die Wahl zwischen unterschiedlichen Testformen, z. B. A- oder B-Form) - bedeutsamste und am häufigsten eingesetzte Methode Mikrostrategien - einzelne, relativ schnell zu erhaltende TestItems werden zur Fragestellungbeantwortung herangezogen - innerhalb der Methode und schrittweise wird entschieden (von Item zu Item), ob weitere Items bearbeitet werden müssen - falls weitere Items vorgelegt werden, muß über die Art und Güte der Items entschieden werden - Einzug der Mikrostrategien in die Diagnostik: Adaptives Intelligenz Diagnostikum (AID) von Kubinger; computerunterstützte Diagnostik Typen von Makrostrategien: 1. Nicht-sequentielle (Testsystem-)Strategie - alle Diagnostikanden werden dem (gesamten Testsystem) Test unterzogen und die ausgewählt, die (die höchsten Werte innerhalb der Testkombination) einen voher festgelegten Testwert (erhalten) überschreiten 2. Einfache sequentielle Strategie - dabei werden zunächst alle Diagnostikanden mit dem Test A untersucht, anschließend an Hand der Ergebnisse in die Kategorie “angenommen”, “abgelehnt” bzw. “unklar” eingeteilt - in einem weiteren Schritt werden nur die unklaren Fälle mit einem Test B untersucht und wiederum in die 3 Kategorien eingeteilt (dieses Vorgehen kann bis zu einem jeweils festzulegenden Abbruchkriterium wiederholt werden) 3. Sequentielle Strategien mit Vorablehnung (Vorakzeptierung) - alle Diagnostikanden werden mit einem Test A untersucht und anschließend anhand der Ergebnisse in die Kategorie “abgelehnt” (“angenommen”) bzw. “weiter zu untersuchen” eingeteilt - in dem nächsten Schritt werden die Diagnostikanden der zweiten Kategorie mit einem Test B oder mit einer AB-Kombination weiter untersucht Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung Typen von Mikrostrategien: adaptive Strategien a, routing b, stradaptiv c, pyramidal 9 vs. sequentielle Strategien Adaptive Mikrostrategien: zu a, Routing-Strategie - nicht alle Pbn werden mit demselben Test gemessen (individuumspezifische Testreihe je nach Fähigkeit der Pb; besonders bei heterogenen Gruppen relevant) - alle Pbn müssen voher einen Routing-Test durchlaufen (im klinischen Bereich auch “screening-Test” genannt - je nachdem, was für einen Skalenwert der Pb erreicht, wird ihm ein Test zugeordnet Person A - 0 + Meßtest 1 Meßtest 2 Meßtest 3 Meßtest 4 - Person A erhält Meßtest 1 die einzelnen Tests sind quantitativ, nicht qualitativ unterschiedlich! zu b, Stradaptive Strategien - Stradaptiv = Stratum (Meßwertbereich einer bestimmten Meßwertdimension) + adaptiv (angepaßt); auch taylored examination genannt 1-10 11-20 21-30 31-40 41-50 51-60 61-70 71-80 81-90 91-100 101-110 111-120 leicht 0 schwer - zu jedem Stratum wird ein Satz von Items zusammengestellt - der Pb beginnt bei einem mittleren Stratum; Beispiel: Item 31 (richtig gelöst: r) Item 41 (falsch gelöst:f) 32 (f) 21 (r) 33 - wichtig dabei ist die Festlegung eines Endes, d. h. bei Vorhandensein genügender Information - Festlegung des “typischen” Stratums durch “basal strata” und “ceiling strata” (hier: 21 und 41) zu c, pyramidale Strategien - ausgehend von unterschiedlichen Begabungslevels beim Pb werden kontinuierlich steigende und fallende Items unterschiedlicher Schwierigkeit vorgelegt - Nachteil des Schematas: bei stark schwankenden Antworten ist eine Zuordnung der Pb nur mit großer Unsicherheit zu vollführen - mögliche Modifikation: Erstellung mehrer Items pro Schwierigkeitsstufe Stufe 1: 1 Stufe 2: 2 3 Stufe 3: 4 5 6 Stufe 4: 7 8 9 10 höhere Flexibilität und Genauigkeit Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 10 10 9 8 7 6 5 4 3 2 1 leicht 11 12 13 14 15 16 17 18 19 mittelschwer schwer sequentielle Mikrostrategien: - im Voraus wird ein Kriterium nach inhaltlichen Faktoren festgelegt (z. B. Kriterium: 7 von 10 Items müssen richtig beantwortet werden) - Schritt für Schritt werden die Items beantwortet und jeweils entschieden, ob noch weitere Items beantwortet werden müssen “curtailed sampling” - werden z. B. am Anfang gleich 4 Fehler gemacht, führt dies zum Abbruch, da das Kriterium nicht mehr zu erfüllen ist 2. Grundlagen diagnostischer Urteilsprozesse Die psychodiagnostische Situation - jede diagnostische Situation ist durch ein distanzierend vermittelndes Subjekt-ObjektWechselwirkungsverhältnis gekennzeichnet - ihre Hauptkomponenten sind: der Diagnostiker (D), die Differentielle Methodik (DM) und der Diagnostikand (Dd) Diagnostiker Differentielle Methodik Diagnostikand - sie werden unter bestimmten Randbedingungen (z. B. situativer, sozialer, räumlicher, technischer Art) wirksam, die nach Möglichkeit hinreichend zu kontrollierend sind - aus der Forschungsmethodik bereits bekannte Randbedingungen, die auch in derartigen Diagnoseprozessen wirksam sind, sind dabei zu beachten Randbedingungen des Typs I: - können die Interpretation der Resultate verzerren; danach wird das Ergebnis auf das Wirksamwerden der bekannten bekannten UV zurückgeführt, obwohl es in Wahrheit durch das Wirken der unbekannten Randvariablen Typ I bedingt ist (z. B Rosenthal-Effekt) - treten an die Stelle einer oder mehrerer unabhängiger Variablen - beeinflussen die interne Validität Randbedingungen des Typs II: - sind vermittelnde, bedingende Variablen, ohne deren Existenz die UV nicht oder nur unwesentlich anders wirksam werden kann - diese Randbedingung bestimmt die externe Validität Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 11 Randvariablen des Typs III: - sind die bestehenden Wechselwirkungen, die in einer derartigen diagnostischen Situation wirksam werden - alle Randvariablen (die sowohl die externe wie interne Validität betreffen) müssen identifiziert und kontrolliert oder (als UV) variiert werden Implizite Voraussetzungen diagnostischer Urteilsprozesse - 3 Klassen impliziter Voraussetzungen, die zumeist unbewußt und unbekannt den diagnostischen Urteilsprozeß beeinflussen können unterschieden werden: I. die impliziten “Persönlichkeitstheorien” II. die kognitiven Voraussetzungen III. die sprachlichen ´´ - diese impliziten Voraussetzungen sollen expliziert und damit der Standardisierung zugänglich gemacht werden können, was für die Abschätzung der Testgütekriterien (Objektivität, Reliabilität und Validität) notwendig ist zu I, implizite persönlichkeitstheoretische Voraussetzungen - der Diagnostiker “macht sich ein Bild” vom Pb in das viele Informationen - und nicht nur Testinformationen (wie z. B. Testgütekritierien; Normierung etc.) - eingehen - auch der Pb mach sich vom Diagnostiker ein Bild, was jedoch i. d. R. für die Diagnose nicht so bedeutsam ist - dieses “Miniaturmodell” der Persönlichkeit des Diagnostikanden entsteht im diagnostischen Urteilsprozeß unter impliziter Beteiligung von 4 persönlichkeitspsychologischen Annahmen: 1. die Thematik (Validität, Relevanz etc.) 2. die Dimensionalität (Anzahl, Typik etc.) 3. die Struktur (Hierarchie, Relationen, Linearität etc.) 4. die Variabilität (Stabilität, Verteilung etc.) zu 2. Dimensionalität - die Art und Anzahl von Dimensionen bestimmen in maßgeblicher Weise die Typisierung und Differenzierung des Diagnostikers in bezug auf den Pb (dabei werden Beobachtungen selektiv und aktiv gemacht; nicht voraussetzungsfrei) zu 3. Struktur - betrifft die Annahme, die bezüglich der Relationen der Dimensionen und Eigenschaften gemacht werden (Hierarchie, Linearität, Nichtlinearität, Korrelationen) - ein Diagnostiker arbeitet mit für ihn typischen impliziten Unterscheidungen verschiedener Persönlichkeitseigenschaften zu 4. Variabilität - die Art der Unterscheidung psychischer Bedingungen und Erscheinungen als Klassen, Typen, usw. mit eingeschränkter oder erhöhter Variabilität innerhalb eines Individuums und zwischen Individuen bildet die wesentlichste Voraussetzung für den Grad der Sicherheit einer Diagnose - eine individualspezifische Aussage erhält ihren diagnostischen Wert erst durch eine Vergleichsprozedur mit einem (diagostikerinternen) Bezugssystem (ipsativ, d. h. in Bezug zu einem früheren Wert des Pb; kriteriumsorientiert, d. h. hinsichtlich eines beabsichtigten Zielkriteriums; populationsnormiert, d. h. hinsichtlich einer Referenzpopulation) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 12 zu II, implizite kognitive Voraussetzungen - hierzu gehören die gedächtnismäßig verankerten Repräsentationen des Wissens (nosologischer, symptomatologischer Art etc.), die einen angemessenen Diagnoseprozeß erst möglich machen - die kognitiven Voraussetzungen, die das diagnoserelevante Wissen repräsentiert und somit den diagnostischen Urteilsprozeß bestimmen, haben eine sehr enge Beziehungen zu den impliziten Persönlichkeitstheorien - 4 kognitive Voraussetzungen, die die spezifische Erkenntnisfähigkeit des Diagnostikers betreffen, lassen sich unterscheiden und unter Schulung kontrolliert und systematisch einsetzen 1. die Verfügbarkeit verschiedener “Sprachen” des Diagnostikers im und über den diagnostischen Prozeß - z. B. die regelgeleitete Beherrschung der verschiedenen nosologischen und sympotmatologischen, persönlichkeitspsychologischen Terminologien (sehr oft schulenabhängig!) - Jargon, Modeworte 2. die Diskriminationsfähigkeit des Diagnostikers im diagnostischen Gegenstandsbereich - betrifft die quantitative, dimensionale Unterscheidungsfähigkeit bezüglich psychischer Erscheinungen und Bedingungen 3. die Differenzierungsfähigkeit ´´ ´´ diskriminierten diagnostischen Gegenstandsbereich - graduelle Unterscheidungsfähigkeit im zuvor beobachteten Persönlichkeitsbereich 4. die Validitäts- und Nützlichkeitsabschätzung des Diagnostikers bezüglich der methodisch kontrolliert gewonnenen diagnostischen Daten als diagnoserelevante Daten - Einschätzung des Wahrheitsgehaltes und der Nützlichkeit der diagnostizierten Information - diagnostische Informationen müssen wahr und im Hinblick auf die Intervention nützlich sein - die Nützlichkeit wird aber auch durch die jeweiligen historisch-gesellschaftlichen Werte bestimmt zu III, implizite sprachliche Voraussetzungen Repräsentanzfunktion vs. - bezieht sich auf den Charakter der Sprache als Bezeichnungssystem objektiv-realer und bewußtseinsmäßig repräsentierter Sachverhalte Kommunikationsfunktion - bezieht sich auf die Funktion der Sprache innerhalb des diagnostischen Informationsaustauschprozesses - mit wem spreche ich (Diagnostikand, Diagnostiker etc.) - mit der Standardisierung der sprachlichen Voraussetzungen für diagnostische Urteilsprozesse sind einige Schwierigkeiten verbunden - die notwendige Aufrechterhaltung der Umgangssprache innerhalb des diagnostischen Kommunikationsprozesses (z. B. im Gespräch mit dem Diagnostikanden), ist stets mit einer gewissen Unschärfe der Terminologie sowie unerwünschten Konnotationen verbunden Grundzüge einer allgemeinen Methodentheorie diagnostischer Urteilsprozesse - methodologisch- wissenschaftstheoretische Grundprinzipien für die Diagnostik: 1. Relevanzprinzip - jede diagnostische Untersuchung muß auf ein Ziel, einen Nutzen interner und/oder externer Art gerichtet sein Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 13 - die Methodik der Datengewinnung und -analyse muß dabei dem Kriterium der Utilität entsprechen 2. Reduktionsprinzip - jede diagnostische Untersuchungsplanung und -realisierung setzt eine angemessene Variableneinschränkung voraus (Identifikation und Variation der konstituierenden und modifizierenden Bedingungen 3. Minimalitätsprinzip - Variablenreduktion auf das jeweilige notwendige und hinreichende Minimum 4. Analogprinzip - jede diagnostische Untersuchungsplanung muß intern und extern valide sein 5. Repräsentanzprinzip - die vor-empirischen Annahmen, die “hinter” jeder einzusetzenden Methode zur Datengewinnung und -analyse stehen, müssen berücksichtigt werden - in jeder diagnostischen Untersuchungplanung und -realisierung existiert ein sog. logisches Primat der Theorie gegenüber der Empirie (dies äußert sich bereits in der Methodenauswahl) 6. Verifikationsprinzip - die untersuchungsleitende(n) Hypothesen müssen so aufgebaut sein, daß sie falsifiziert oder bestätigt werden können Standardisierungstheorie und Standardisierungsmethodik - die Entwicklungen der Standardisierungstheorie und -methodik begannen zunächst im ersten Drittel dieses Jht. als sog. Testtheorie - die mit Recht bald einsetzende Kritik an den mangelhaft begründeten theoretischen Grundannahmen hatte aber mind. 3 sehr positive Folgen: 1. es wurden neue, theoretisch besser begründete und mathematisch besser ausgearbeitete Testtheorien entwickelt, die zunehmend mehr den Charakter ausschließlicher Testtheorien verloren und zu Verfahrenstheorien bzw. zu Meßtheorien wurden 2. es wurden neue und verbesserte Schätzverfahren zur Bestimmung der sog. Gütekriterien entwickelt 3. zunehmende international einheitlich werdende Terminologie im Bereich der Standardisierungstheorie und -methodik (Validität, Trennschärfe etc.) - aber auch der Urteilsprozeß und nicht nur die Methode muß als Gegenstand der Standardisierung angesehen werden, d. h. Diagnostikforschung ist nicht nur Testentwicklung, -anwendung und -auswertungslehre - die Standardisierungstheorie und -methodik leistet Beiträge zur Lösung folgender Probleme: Generalisierungsproblem - hierbei geht es darum, die Verallgemeinerbarkeit von Untersuchungsprozeduren und - ergebnissen abzuschätzen bzw. hinreichend zu gewährleisten (“interne und externe Validität”, “Rosenthal-Effekt”) Prognoseproblem - die Standardisierung soll hier nicht nur auf die Methoden der Verhaltensidentifikation, sondern auch auf die Methoden der Verhaltensvorhersage angewandt werden (prognostische Validität) Urteilsproblem - die Standardisierung soll auf den gesamten Diagnoseprozeß, d. h. gesamten Urteilsprozeß angewendet werden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 14 Veränderungsproblem - es gilt eine dynamische Standardisierungstheorie und -methodik zu entwickeln, die dem Verlaufscharakter des zu untersuchenden Phänomens gerecht wird (Veränderungsmessung, Prozeßanalyse) Normierungsproblem - Entwicklung angemessener Vergleichsmaßstäbe für den Vergleich mit empirischen Daten (in der humanwissenschaftlichen Diagnostik immer statistische Normen) Inferenzproblem - hier geht es darum, hinreichende Kriterien für die zufallskritische Beantwortung der Frage zu gewinnen, ob eine empirische Arbeitshypothese bestätigt worden ist oder nicht (statistische Signifikanz, Nullhypothese etc.) Zur Struktur des diagnostischen Urteilsprozesses - Kernstück der Allgemeinen Psychodiagnostik - aber die Mehrzahl der diagnostischen Informationen stammt aus den nicht- oder nur “intuitiv-standardisierten” diagnostischen Methoden - daher ergeben Zuverlässigkeitsanalysen diagnostischer Urteile im allg. nur Werte die um. .50 liegen oder darunter Entwicklung eines heuristischen Modells zum diagnostischen Urteilsprozeß 1. Problemfrage - Identifikation des potentiell diagnosefähigen Problems (z. B. durch Erfassung der Symptomatik, des Leidensdrucks; Bewerbungssituation) 2. Diagnostische Zielfunktion und Vor-Entscheidung - Formulierung der Ziele durch den Diagnostiker und Diagnostikanden - in diesen Bereich fallen auch die Ziele, Absichten des Diagnostikanden (z. B. Heilungswunsch, Abbau des Leidensdrucks, Arbeitsplatz) - aber auch die Hypothesen und Vorentscheidungen des Diagnostikers in bezug auf den Dd (z. B. Vorentscheidung über den einzuschlagenden Untersuchungsweg, Methodenauswahl, über die “wahren” Absichten des Dd) 3. Methodenauswahl und Diagnosestrategie - betrifft die Bewertung und Entscheidung über die einzusetzenden Mittel zur Informationsgewinnung anhand der Gütekriterien und der Normwerte des Verfahrens und der Utilitätsindikatoren 4. Methodenapplikation - Ausführung der Datengewinnungsprozeduren, einschließlich der Dokumentenanalyse (z. B. Zeugnisse etc.; aber Problem der Glaubwürdigkeit der Materialien beachten) 5. Datenanalyse - differentielle Auswertung der diagnostischen Information anhand der methodischen Analysevorschriften (Probleme bei sog. projektiven Verfahren) 6. Datensynthese - dient der Informationsverdichtung, z. B. systematische Darstellung der Einzelinformationen in einem Profil 7. Datenvergleich und -bewertung - betrifft den normativen Vergleich der Daten mit einem Bezugssystem und die bewertende Einschätzung der Ergebnisse in bezug auf die diagnostische Zielfunktion, Hypothesen etc. 8. Diagnostische Entscheidung - in deren Ergebnis wird die Diagnose und/oder eine neue bzw. spezifizierte Problemfrage vormuliert Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 15 9. Interventionsüberlegung und -entscheidung - nach hinreichender Diagnose 10. Intervention Datenvergleich und Datenbewertung in diagnostischen Urteilsprozessen 1. mit Hilfe einer zum Verfahren gehörenden Normskala ist dies unproblematisch (Diagnostiker muß kein “internen Normensystem” aufbauen) 2. Datenvergleich und -bewertung muß aber auch in bezug auf das Ziel der diagnostischen Beurteilung erfolgen - dies ist methodisch weitaus schwieriger beherrschbar; dieser Teil stellt einen besonders erfahrungsintensiven Bereich der diagnostischen Urteilsbildung dar - allerdings kann sich der Diagnostiker von 4 Gesichtspunkten leiten lassen: a, die Validität der Verfahren und somit der Daten (Inhalts-, Kriteriums- und Konstruktvalidität; Wahrheitsgehalt der Daten mit berücksichtigen) b, die Utilität der Daten im bezug auf das Ziel der Beurteilung (z. B. wie groß ist der Informationsumfang und wofür ist er nutzbar? Wie groß ist das Risiko einer Fehlentscheidung? Wie gestaltet sich das Kosten-Nutzen-Verhältnis?) c, die Inzeptionsweise (die methodologisch-methodische Erhebungsweise der Daten bzw. Zugriff auf die Datenquelle, wie z. B. Standardisierungniveau der Daten wie Quasiexperimentell oder experimentelle Methodiken, Skalenniveau der Daten, Operationalisierung) d, die sog. “Härtekriterien” der Daten (gemessene Daten sind härter als geschätzte, quantitative härter als qualitative, registrierte härter als protokollierte) zu 1, normativer Vergleich - Normen können ipsativer, gruppen- oder populationsnormativer Natur sein ipsative Normen: - stellen individualkriterienbezogene Normen dar (z. B. Ziele, Wünsche, Ideale) - Vergleich zwischen ipsativem Soll-Wert und bestehendem Ist-Wert Gruppennormen: - gruppenkriterienbezogene Normen wie Lernziele, Gruppenidole etc. Populationsnormen: - gruppenkriteriumsbezogene und verteilungsbezogene Normen (bilden in besonderem Maße die natürlich vorhande Variabilität auf der zur Normierung benutzten Dimension ab) - hohes Maß an Differenzierung möglich (Grob- und Feinnorm, ZNorm, T-Norm, Stanine-Norm etc.) Allgemeine Prinzipien diagnostischer Urteilsbildung 1. Prinzip der Überschaubarkeit der Bedingungen - Nachvollziehbarkeit der rekonstruierten und konstruierten Bedingungen für das Zustandekommen von Erscheinungen mit Symptomwert (entspricht dem Kriterium der Kontrollierbarkeit und Variierbarkeit in der experimentellen Forschung) 2. Prinzip der Vielfalt - die objektive Vielfalt der notwendigen Bedingungen muß berücksichtigt werden, d. h. der Suchraum an Bedingungen muß hinreichend vielfältig gestaltet werden 3. Prinzip der Positionsbezogenheit - der bewertende Standpunkt, der normative Bezug, der Auswahlgesichtspunkt muß berücksichtigt werden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 16 4. Prinzip der Anschaulichkeit - Strukturen und Prozesse, die zu diesen Erscheinungen geführt haben müssen möglichst unmittelbar und direkt veranschaulicht werden 5. Prinzip der Distanz - ein hinreichend vermittelnd-distanzierendes Verhältnis zwischen Diagnostiker und Dd muß realisiert werden 6. Prinzip der Optimalität - es muß ein Optimum an Information herangezogen werden (wird durch das Utilitätskriterium der Methode und das Relevanzprinzip der Untersuchungsplanung und -realisisierung bestimmt) Eine methodenorientierte Taxonomie der Diagnosen - in der diagnostischen Praxis werden verschiedene Diagnoseformen unterschieden - daher macht es Sinn eine Taxonomie von Diagnoseformen zu entwickeln - eine derartige Taxonomie hat 3 Vorteile: sie ist invariant gegenüber dem Diagnosebereich (Vergleich über verschiedene Diagnosen möglich) sie ermöglicht ein hinreichendes Diagnoseniveau, d. h. sie gestattet die Formulierung von Diagnosen genau auf dem erwünschten und/oder möglichen Diagnoseniveau sie ist spezifisch, d. h. sie gestattet die Hervorhebung genau der diagnostischen Eigenschaften einer Diagnose, die jeweils vom Diagnoseziel und Interventionsziel her erwünscht sind - Grundaufbau der Diagnosetaxonomie: Unterteilung nach 5 Gesichtspunkten 1. Normbezug - er betrifft den “hinter” der Diagnose stehenden Vergleichsmaßstab des Diagnostikers in bezug auf den Dd - das bedeutet Diagnosen stellen Vergleichsurteile dar Ipsativnormative Diagnose: - stellt eine individualkriterienbezogene Selbstdiagnose dar - z. B. eigene Ziele, Erwartungen, Hoffnungen etc. - individuell repräsentierte Zielkriterien - metrisch gesehen: geschätzte Distanz zwischen aktuellem Individualwert und individuellem Zielkriterium Gruppennormative ´´ - Benutzung eines für eine Gruppe festgelegten Bezugspunkt als Grenzwert (Lehrziele, Gebote etc.) - metrisch gesehen: geschätzte Distanz zwischen aktuellem Individualwert und gruppennormativem Zielkriterium Populationsnormative ´´ - die Mehrzahl der Diagnosen, die auf der Basis herkömmlicher psychodiagnostischer Tests gestellt werden, stellen derartige Diagnosen dar - sie ermöglicht die Ortsangabe eines Individualwertes in einer Referenzpopulation - es ist auch möglich die Abschätzung der Abweichung des Individualwertes von einem interventionsbezogenen erwünschten Wert vorzunehmen 2. Der Zielbezug - betrifft die vordiagnostische Aufgabenstellung des Diagnostikers und/oder Dd um deretwillen die Diagnose erfolgt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 17 Selektive Diagnose: - stellt eine einfache Einfachauswahldiagnose dar Klassifikative ´´ ´´ Mehrfachauswahldiagnose dar Placierende ´´ - ´´ mehrfache Mehrfach- oder Einfachauswahldiagnose dar 3. Der Erklärungsebenenbezug Deskriptive Diagnose: - stellt eine beschreibende Diagnose dar - entspricht einer Zustandsdiagnose einer Statusdiagnose - sie identifiziert etwas, erklärt aber nichts bezüglich der Bedingungen des Identifizierten Konditionale ´´ - sie ist das Ergebnis eines Diagnoseprozesses, der sowohl eine Aussage bezüglich eines bestehenden Zustandes als auch über die vermuteten Bedingungen dieses Zustandes macht - die Mehrzahl psychologischer Diagnosen sind konditionaler Art, weil die Datengewinnung und -analyse nur einen Schluß auf die verursachenden Bedingungen, nicht aber deren unmittelbare empirische Überprüfung ermöglichen Kausale ´´ - Diagnose bezüglich der experimentell nachgewiesenen Bedingungen - echte Kausaldiagnosen sind selten, weil sie den fallbezogenen Nachweis der verursachenden Bedingungen auf experimentellem Wege erfordern - der Regelfall der sog. Kausaldiagnosen ist der der quasikausalen Diagnosen; in diesem Fall wird das Wissen kausaler Art aus tierexperimentellen und/oder klinischen Studien auf den diagnostischen Einzelfall übertragen 4. Der Zeitbezug - betrifft die zeitliche Erstreckung auf die hin die Diagnostizierung der Symptome und ihrer Bedingungen erfolgt Aktuelle Diagnose: - sie ist das Ergebnis eines Diagnostizierungsprozeß, der eine Aussage über einen gegenwärtig bestehenden Zustand macht - zeitlich nicht koexistierende Bedingungen, z. B. ätiologischer Art wer den nicht zur Erklärung mit herangezogen Prognostische ´´ - stellt eine Diagnose über zukünftige Ereignisse dar Retrognostische ´´ - ´´ ´´ vergangene ´´ 5. Der Dimensionsbezug - er betrifft die Anzahl der in der Erklärungsebene herangezogenen Faktoren, Dimensionen etc. - das bedeutet: Diagnosen beziehen sich auf eine oder mehrere erklärende Diagnosen Unidimensionale ´´ : - es wird nur eine Ursache, Bedingung, Dimension, Faktor usw. zur Erklärung des diagnostizierten Zustandes herangezogen Bidimensionale ´´ - es werden zwei ´´ ´´ Multidimensionale ´´ - es werden mehr als zwei ´´ ´´ - weitere Unterscheidungen können sich daraus ergeben, in welchem Verhältnis (z. B. linear, nichtlinear) diese Bedingungen zueinander stehen - die Mehrzahl der Diagnosen sind mehrdimensional Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 18 Testtheorie 1. Zum Begriff des Tests und der Testtheorie - in der Psychologie hat der Terminus “Test” v. a. 3 Bedeutungen: 1. eine Untersuchung mit Stichprobencharakter 2. ein mathematisch- statistisches Prüfverfahren 3. ein standardisiertes diagnostisches Prüfverfahren (die Standardisierung bezieht sich auf die Instruktion für die VP, auf Anweisungen für den VL zur Durchführung und Auswertung, auf das Testmaterial sowie auf Hinweise zur Gestaltung der “Randbedingungen” (z. B. Raum, Zeit usw.) - wie im Experiment der Allgemeinpsychologie wird im diagnostischen Prüfexperiment wird durch die “Provozierung” diagnostisch relevanten Verhaltens unter möglichst streng kontrollierten Bedingungen Informationen gewonnen über Psychisches - dabei interessiert nicht wie im Forschungsexperiment die Erkenntnis von allgemeinpsychologischen Gesetzmäßigkeiten, sondern vielmehr die Erkenntnis von psychischen Besonderheiten des Individuums - wie in der experimentellen Psychologie strebt aber die Psychodiagnostik mit dem Test an, möglichst quantitative Aussagen v. a. über Personenmerkmale treffen zu können Vorteile eines Tests (gegenüber anderen diagnostischen Methoden wie z. B. Exploration, Verhaltensbeobachtung etc.): - größere Objektivierung des Diagnoseprozesses durch die Standardisierung der diagnostischen Situation - zeitökonomischer als andere diagnostische Methoden Test: Ein Test ist ein wissenschaftliches Routineverfahren zur Untersuchung eines oder mehrerer empirisch abgrenzbarer Persönlichkeitsmerkmale mit dem Ziel einer möglichst quantitativen Aussage über den relativen Grad der individuellen Merkmalsausprägung. (Lienert) - aber eine alleinige Orientierung auf Persönlichkeitseigenschaften im Sinne habitueller Merkmale (sog. traits im Sinne Cattells) ist nicht ausreichend; auch aktuelle Zustände (sog. states), Verhaltenstendenzen ohne Bezug auf Eigenschaften sowie Beziehungen zwischen Personen in einer Gruppe (z. B. Familiendiagnostik) sind zu berücksichtigen - auch die alleinige Orientierung auf die Klassifizierung und Normierung von Testresultaten auf der Grundlage einer Eichstichprobe ist zu bemängeln (auch Heranziehung von ipsativen und Gruppennormen) - auch eine alleinige Orientierung auf messende Verfahren ist unzulässig (z. B. Sceno-Test) - auch Fragebögen (z. B. zur Einstellungsmessung) werden zu den Testverfahren gezählt, soweit sie den psychometrischen Grundanforderungen bei ihrer Konstruktion und Gütekriterienüberprüfung entsprechen Testtheorie: die Lehre von den methodentheoretischen (einschließlich meßtheoretischen) Grundlagen der Verfahrensentwicklung in der Psychodiagnostik; stellt ein Regelsystem zur Entwicklung, Überprüfung, und Auswertung von psychodiagnostischen Verfahren dar; der Objektbereich der Testtheorie ist das Antwortverhalten von Personen auf sog. Itemmengen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 19 - die Testtheorie hat eine mehr formal mathematisch-statistische Seite (auch syntaktischer Aspekt genannt) und eine mehr psychologisch-inhaltliche Seite (auch semantischer Aspekt genannt) Argumente für und gegen die Messung in der Psychologie Für die Notwendigkeit des Messens in der Psychologie spricht: 1. Messungen zwingen uns zur Exaktheit und Bestimmtheit in unserem Denken und Vorgehen 2. Meßdaten erlauben die Zusammenfassung der Ergebnisse in sinnvoller und angemessener Form 3. Durch Messungen lassen sich präzise Kriterien für Objektivität, Zuverlässigkeit und Gültigkeit der diagnostischen Verfahren angeben 4. Messungen gestatten präzise Zuordnungen von Menschen zu Kategorien, bestimmen deren Orte in einem irgendwie skalierten Bezugssystem und liefern Kriterien für optimale Entscheidungen, deren Treffsicherheit wieder exakt überprüfbar ist Gegen ´´ : - psychische Eigenschaften und Prozesse können nicht unmittelbar, sondern nur über Indikatoren gemessen werden können; erst der Nachweis gesetzmäßiger Zusammenhänge zwischen Indikatoren und Eigenschaften (Indikatum) gestattet die Messung - ansonsten kann man nur von Zählungen bestimmter Verhaltensakte bzw. Verhaltensweisen sprechen, die als Rohwerte bzw. Daten aufzufassen sind, aber noch nicht als Meßwerte für das Indikatum - die Beachtung der Subjektposition des Untersuchungsobjektes “Mensch” läßt i. d. R. keine mechanistisch-deterministischen Erklärungs- und Prognoseansätze zu und widerspricht der Annahme, daß das Verhalten eines Individuums absolut sicher vorhergesagt werden kann (nur Wahrscheinlichkeitsaussagen möglich!) - psychische Sachverhalte sind zu komplex und vielfältig und jede Persönlichkeit ist einmalig - daher ist auch nur das ganzheitlich-einfühlende Vorgehen in der Diagnostik angemessen und das Messen einzelner Persönlichkeitsmerkmale inadäquat - aber neuere Entwicklungen in Richtung auf eine experimentell- statistisch begründete “Einzelfallanalyse” belegen, daß die Verwendung der Mathematik und Messung keinesfalls nur auf eine “Gruppenstatistik” , die das Individuum in einen populationsspezifischen Maßstab preßt beschränkt ist Einige Grundbegriffe der Meßtheorie Die Besonderheiten des Messens in der Psychodiagnostik lassen sich in 5 Punkten zusammenfassen: 1. - psychische Eigenschaften sind nicht direkt beobachtbar - man, kann nur aus dem manifesten (beobachtbaren) Verhalten, das eine Person bei bestimmten Anforderungen realisiert, auf die Qualität und die quantitative Ausprägung der entsprechenden psychischen Eigenschaft schließen 2. - zur Abschätzung des Meßfehlers kann die Messung psychischer Eigenschaften nicht hinreichend oft unabhängig oft unabhängig von den vorangegangenen Messungen wiederholt werden (Übungs- und Erinnerungseffekte) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 20 3. - psychische “Leistungen” als Indikatoren für Eigenschaften sind komplex, d. h. sie bestehen aus einer Vielzahl von miteinander in Beziehung stehenden Teileigenschaften bzw. -leistungen - es ist kaum möglich, bei der Messung komplexer psychischer Eigenschaften diese Teileigenschaften isoliert zu messen 4. - in der Psychodiagnostik gibt es bislang keine einheitlichen Meßvorschriften für psychische Eigenschaften(z. B. messen unterschiedliche Intelligentests unterschiedliche Intelligenzarten) 5. - in der Psychodiagnostik herrscht eine Subjekt-Subjekt-Relation vor - daher sind Objektivierungs- und Standardisierungsbestrebungen deutlich begrenzt Prinzipien des Messens in den Naturwissenschaften sind nicht ohne weiteres auf die Psychodiagnostik zu übertragen Messen: Eine Zuordnung von Zahlen zu Objekten oder Ereignissen, sofern diese Zuordnung eine homomorphe oder isomorphe Abbildung eines empirischen Relativs in ein numerisches Relativ ist Einige Grundbegriffe der Meßtheorie Repräsentationsproblem: - stellt die Frage, ob ein gegebenes empirisches Relativ in einem gewählten numerischen Relativ isomorph oder zumindest homomorph abgebildet (repäsentiert) wird - homomorphe Abbildung: jedem Element aus A wird genau ein Element aus B (reelle Zahl) zugeordnet - isomorphe ´´ : wenn auch umgekehrt jedem Element aus B ein Element aus A entspricht (eineindeutige Zuordnung) Eindeutigkeitsproblem: - besteht darin festzustellen, wie spezifisch die jeweils zulässigen Transformationsvorschriften sein müssen - einzelne Skalenniveaus sind dadurch gekennzeichnet, daß jeweils verschieden mathematische Transformationen zulässig sind - je höher die Skala, um so weniger Transformationen sind möglich Interpretationsmodell: - die Frage hier ist, inwieweit die numerischen Aussagen, die sich über die Beziehungen zwischen den Elementen (Zahlen) des numerischen Relativs machen lassen, inhaltlich interpretierbar sind 3. Grundannahmen und Hauptfragestellungen der sog. Klassischen Testtheorie (KTT) - die ersten Tests wurden entwickelt, um im Rahmen der Forschung zur sog. Differentiellen Psychologie und in der Praxis für Selektionsfragestellungen exakter, als es bisher möglich war, Unterschiede zwischen Menschen (interindividuelle Differenzen) in Merkmalsausprägungen feststellen zu können - implizit zugrunde liegende persönlichkeitstheoretische Auffassung: eigenschaftsorientierte (trait)-Theorien; man ging davon aus, daß Tests direkt Eigenschaften (traits) von Personen erfassen können, die sehr zeitstabil sind (also sich im Laufe des Lebens kaum verändern) und sich auch weitgehend unabhängig von der jeweiligen Situation im Verhalten auswirken Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 21 - die These von der Generalisierbarkeit der Eigenschaften über Zeit- und Situationsparameter hinweg, die heute immer mehr in Zweifel gezogen wird, war verbunden mit der Annahme, daß das Verhalten des Menschen, aus dem der Test eine Stichprobe darstellt, lediglich eine Funktion von irgendwie angelegten (zumindest aber stark verfestigten habitualisierten) Eigenschaften darstellt - der Test definierte in operationalistischer Betrachtungsweise gleichzeitig die zu messende Eigenschaft (siehe Borings Intelligenzdefinition: “Intelligenz ist das, was der Intelligenztest mißt”) - die Frage für die KTT lautete zunächst und v. a.: wie genau mißt ein Test die Eigenschaft, die er messen soll? - Ausgangspunkt: jede Messung ist mit einem sog. Meßfehler behaftet - die Vertreter der KTT strebten nach der Entwicklung von Meßinstrumenten (Tests), bei denen der Meßfehler möglichst klein gehalten wird, bzw. es werden Berechnungsprozeduren vorgeschlagen, mit deren Hilfe der jeweils im Test zu erwartende Meßfehler genauer bestimmt und damit der Bereich (Vertrauensintervall) näher abgegrenzt werden kann, in dem mit einer angebbaren statistischen Wahrscheinlichkeit der “wahre Wert” des Pb, d. h. der Grad der Merkmalsausprägung liegt - man geht also zunächst von der durchaus plausiblen Annahme aus, daß das mittels eines Meßinstruments (hier: Test) an einem Meßobjekt (Person) registrierte Meßresultat (beobachteter Testwert X) sich aus einem wahren Wert (T) und einem Fehlerwert (E) zusammensetzt Grundgleichung der KTT, das sog. Verknüpfungsaxiom: X=T+E (1) - der Fehlerwert wird als nichtsystematischer Fehler aufgefaßt, der sich aus zufälligen Schwankungen ergibt - das jeweilige Testergebnis wird in der KTT als Ergebnis eines Zufallsprozesses betrachtet - Einflüsse auf Testresultate, die sich aus systematischen Fehlerquellen ergeben (z. B. Übunngseffekte) sind nicht zum Meßfehler zu rechnen, sondern verändern die wahren Testwerte, so daß T als einziger systematischer Wert dann eventuell andere Eigenschaften widerspiegelt, als eigentlich mit dem Test untersucht werden sollte - da der Meßfehler also unsystematisch ist, kann man erwarten, daß bei häufigen Messungen dieser Fehler genauso häufig positiv wie negativ ausfällt, so daß hieraus die zweite Grundannahme (“Axiom”) resultiert: die Fehlerwerte mitteln sich aus, so daß der Erwartungswert (ER) der Meßfehler Null beträgt: Fehleraxiom: ER (E) = 0 (2) - hier liegt die Annahme zugrunde: ein und dasselbe Testinstrument läßt sich mehrmals und experimentell unabhängig voneinander an ein und derselben Person anwenden (“Achillesferse” der KTT; theoretische Annahme und praktische Überprüfbarkeit stehen im Widerspruch; Übungs- und Wiederholungseffekte) - diesem Dilemma versucht zu entfliehen, indem man die eigentlich erforderliche einzelfallstatistische Betrachtungsweise durch eine gruppenstatistische ersetzt - es wird angenommen, daß die Fehlervarianz in einer definierten Population dem Erwartungswert der Fehlervarianz des einzelnen Pb entspricht - die annähernde Replikation der Testergebnisse bei einer Stichprobe in einem Retest bzw. Paralleltest “ersetzt” die mehrfache Wiederholung des Tests an nur einer Vp - wegen der Unsystematik der Fehler kann man schließen, daß der durchschnittliche Meßfehler einer beliebigen Personenstichprobe bei Null liegt Schätzung der Fehlervarianz: VAR (X) = VAR (T) + VAR (E) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 22 - weiterhin gilt (aus dem 2. Axiom ableitbar): zwischen dem wahren Wert einer Person und der Fehlerkomponente besteht kein systematischer Zusammenhang r (T, E) = 0 Prinzip der lokalen stochastischen Unabhängigkeit bei der KTT ( PTT!): - die Fehlerwerte sind von Person zu Person und Item zu Item voneinander unabhängig - d. h. die Korrelation des Fehlers in einem Test (X1) mit dem Fehler in einem anderen Test (X2) ist Null r (E1, E2) = 0 - zudem ist die Korrelation des Meßfehlers in einem Test (X1) mit dem wahren Wert in einem anderen Test (X2) Null R (E1, T2) = 0 - die Meßgenauigkeit eines Verfahrens ist natürlich um so größer, je höher der Anteil der wahren Varianz an der Gesamtvarianz ist, d. h. auch je geringer die Fehlervarianz ist Bestimmung der Meßgenauigkeit (rtt = Zuverlässigkeit): rtt =VAR (T) VAR (X) VAR (E) VAR (X) - durch Auflösung nach VAR (E) ergibt sich aus der Formel die empirische Berechnung des Standardmeßfehlers (sE) sE = sX 1-rtt - bei einer Testdurchführung ist aber nur die Streuung der beobachtbaren Testwerte sX2 empirisch feststellbar; die Fehlerstreuung se2 dagegen nicht - sie wird durch sog. parallele Messungen abgeschätzt - grundlegende Annahme: zwei oder mehrere Messungen (Tests) ergeben bei demselben Pb jeweils dieselben wahren Werte, d. h. Differenzen zwischen den beiden Messungen seinen also nur durch die jeweiligen Fehlerkomponenten der Einzelmessungen hervorgerufen damit kann aber noch nichts darüber ausgesagt werden, welcher der Paralleltests ungenauer mißt - daher muß man zusätzlich die Annahme machen, daß beide Tests die gleiche Fehlerstreuung aufweisen von parallelen Tests im strengen Sinne spricht man in der KTT nur dann, wenn die Tests die gleichen wahren Werte für jede Person und die gleiche Fehlervarianz erge- ben - hier dreht sich die KTT aber im Kreise: denn wenn man nur jene Tests als parallel akzeptiert, die eine hohe Korrelation zeigen, dann muß mit dieser Methode zwangsläufig auch eine hohe Reliabilität des Tests gefunden werden! - Reliabilitätskoeffizienten werden aber nicht nur durch Paralleltestung (Retestreliabilität), sondern auch durch Vergleich der Testresultate bei Halbierung des Tests in 2 homogene Hälften - “split-half-Reliabilität” - oder bei Aufteilung in die einzelnen Testaufgaben (Items) auf Grund der Interkorrelationen der Items berechnet - prinzipiell liegt aber bei diesen Reliabilitätsarten das “Paralleltestkonzept” zugrunde, da auch die Testhälften und die einzelnen Itempaare eines homogenen Verfahrens als Paralleltests aufzufassen sind Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 23 Fazit: die 5 wesentlichen “Axiome” der KTT (wobei die ersten beiden grundlegend für die letzteren sind) 1. Der Testwert ergibt sich additiv aus “wahrem” Wert und Meßfehler. 2. Der wahre Wert ist der Erwartungswert über unabhängige Meßwiederholungen. 3. Der “Erwartungswert” der Meßfehler ist 0. 4. Es besteht kein systematischer Zusammenhang zwischen wahren Wert und Meßfehler. 5. ´´ ´´ den Meßfehlern verschiedener Personen oder den Meßfehlern bei derselben Person bei verschiedenen Testungen. Grundannahme der KTT: Jedem Meßwert ist ein wahrer Wert zuzuordnen, der die konstante individuelle Merkmalsausprägung abbildet. Verdienst der KTT: - Definition der sog. Gütekriterien und deren Berechnungsprozeduren - Reliabilität (als Kernfrage der KTT) - Objektivität oder Konkordanz (Durchführungs-, Auswertungs- und Interpretationsobjektivität); je mehr standardisiert, desto objektiver - das entscheidende Gütekriterium ist aber die Validität (Gültigkeit); mißt das Verfahren wirklich das, was es vorgibt zu messen (in der KTT ist allerdings nur die sog. kriterienbezogene Validität im numerischen Relativ abgedeckt, d. h. nur durch die Bestimmung der Gültigkeit eines Verfahrens durch die Berechnung der Korrelation der Testwerte mit einem Außenkriterium (z. B. Lehrerurteil) oder Binnenkriterium (Ergebnisse inhaltlich verwandter Tests) Weitere Gütekriterien: - Normiertheit (es liegen Normen für die Testauswertung vor) - Vergleichbarkeit (Parallelformen oder gültigkeitsähnliche Verfahren stehen für Vergleichszwecke zur Verfügung) - Ökonomie (Zeit- und Materialaspekt) - Attraktivität für die Benutzer - Nützlichkeit (Utilität; hierbei steht die Frage im Vordergrund, ob und in welchem Maße ein Test Entscheidungen in der Praxis sicherer macht und welchen Wert diese Entscheidungen für das Individuum bzw. die Institution besitzen - bevor man aber die Gütekriterien bestimmt, muß der Test konstruiert werden Testkonstruktionslehre: besondere Bedeutung hat hier die Aufgabenanalyse - Bestimmung der Schwierigkeit (Lösungsprozentsatz in einer Stichprobe) - Trennschärfe (Differenzierungsfähigkeit hinsichtlich der Merkmalsausprägung bei Personen) - Gültigkeit und Interkorrelationen der Einzelitems - der letzte Abschnitt der Testentwicklung beinhaltet die sog. Normierung (Entwicklung eines normativen Bezugsystems für einen Test) - die Normwerte werden meist über die Bestimmung von Mittelwert und Standardabweichung oder aber über deren Häufigkeitsverteilung (Prozentränge) in der Normierungsstichprobe gewonnen damit wird die Hauptzielstellung der KTT erreicht, die darin besteht, Dd auf einem in bestimmter Weise definierten Kontinuum zu ordnen bzw. in diese Ordnung einzufügen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 24 - schließlich gehört zur KTT auch die Probleme der Testauswertung (ab wann ist sind Testwerte einer bzw. zwischen zwei Personen signifikant unterschiedlich? wie hoch ist der Standardschätzfehler bei der Vorhersage eines bestimmten Kriteriumswertes aufgrund eines bestimmten Testwertes?) - fast alle Berechnungsprozeduren bei der Testentwicklung und -überprüfung in der KTT beruhen auf Intervallskalenniveau die KTT garantiert nirgends, daß die Scores ihrer Tests auf Intervallskalenniveau liegen, implizit wird dieses Niveau vorausgesetzt (“Messung per fiat” = Zustimmung) - Argument der Vertreter der KTT um Intervallskalenniveau der Testwerte zu begründen: psychische Eigenschaften sind wie biologische Größen normalverteilt - die Gauss´sche Normalverteilungsannahme wird aber zunächst nur auf Indikandenebene vorausgesetzt, d. h. hinsichtlich des der unmittelbaren Beobachtung nicht zugänglichen Kon-- tinuums von Merkmalsausprägungen - zweitens wird angenommen, daß eine lineare Beziehung zwischen der Lage der untersuchten Personen auf Indikanden- und Indikatorebene (Testergebnisse) besteht (außerdem müssen gleiche Abstände auf der Indikandenebene auf gleiche Abstände auf der Indikatorebene abgebildet werden) die Grundannahme zur Gewinnung von Fähigkeitswerten auf Intervallskalenniveau in der KTT besteht also darin, daß man die Normalverteilung auf Indikandenebene (Eigenschaftsebene) einfach annimmt - jede Normalverteilung läßt sich dann ohne Verletzung des Intervallcharakters in eine Standardnormalverteilung transformieren Kritik der sog. KTT Persönlichkeitspsychologisch fundierte Kritik: - trait-Konzept; menschliches Verhalten wird auf relativ unveränderliche, zeit- und situationsstabile psychische Eigenschaften zurückgeführt - die Interaktion von Umwelt (Situationsbedingungen) und Eigenschaften (vergl. hierzu bereits Lewin) und die Veränderbarkeit von Persönlichkeitseigenschaften bleibt unberücksichtigt - situationsbezogene und an Handlungsregulationsmodellen (vergl. Hacker) orientierte Diagnostik muß hervorgehoben werden Psychodiagnostik intraindividueller Variabilität: - rückt neben der Feststellung interindividueller Differenzen immer stärker in den Vordergrund - Diagnostik wird nicht nur für Selektionsfragestellungen benötigt und entwickelt (Statusdiagnostik) , sondern auch für Bereiche der Prozeßdiagnostik und Veränderungsmessung (Effektivitätsermittlung, Steuerung und Begleitung von sog. Verhaltensmodifikationsmaßnahmen (z. B. Psychotherapie) - die KTT ist aber ursprünglich entwickelt worden für Statustests, die einen Ist-Zustand feststellen, der sehr stabil ist (zeit- und situationsstabil) und die spätere Entwicklung so bestimmt, daß eine den Status gleichförmig fortschreibende Prognose zulässig und hinreichend ist daher gibt es Schwierigkeiten, die meßtheoretischen Probleme der Veränderungsmes- sung, Handlungs- und Prozeßdiagnostik mit Hilfe der KTT zu lösen (z. B. Reliabilitätsdilemma) Vorschlag von Pawlik (1976): Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 25 - der Modellansatz der KTT wird durch die Annahme zweier “wahrer Quellen” für interindividuelle Unterschiede erweitert: intraindividuell stabile und intraindividuell variable Werte - in der KTT wird geprüft, wieviel Prozent der wahren interindividuellen Testwertvarianz auf die wahre interindividuelle Merkmalsvarianz zurückzuführen sind - die bisher existierende Theorie paralleler Tests müßte also noch durch eine Theorie paralleler Situationen ergänzt werden - man könnte sogar davon ausgehen, daß jeder beobachtete Testwert einer Person ein “wahrer Wert” ist, dessen “Verunreinigung” durch sog. Zufallsabhängigkeit (Meßfehlerbelastetheit) nichts weiter ist als Ausdruck der “Spielbreite einer Eigenschaft” unter veränderten situativen (Anforderungen) und intrapsychischen Bedingungen - eine experimentell orientierte Psychodiagnostik intraindividueller Variabilität ist gerade an der Gewinnung einer Vielzahl solcher “wahren Werte” unter unterschiedlichen Situationsbedingungen interessiert, um das Verhalten einer Person umfassender und zuverlässiger diagnostizieren und prognostizieren zu können - der Meßfehler würde sich bei einer solchen Betrachtungsweise reduzieren auf “Meßfehler im engeren Sinne” (durch Meßinstrument und Anwender) Meßmethodische Einwände: - Kritik am True-Score-Konzept der KTT (beobachteter Testscore = wahrer Wert) durch Vertreter der probabilistischen Testmodelle - Annahme der probabilistischen Testtheorie: das Testergebnis ist lediglich ein Indikator einer latenten (nicht beobachtbaren) Variablen, die der Test erfassen soll - die “modernen” Testtheorien machen lediglich Aussagen über die Auftretenswahrscheinlichkeit von manifestem Verhalten; daher der Name probabilistische Modelle - trotz der Berücksichtigung von Zufallskomponenten (vergl. Meßfehlerkonzept) bezeichnet man dagegen die KTT als “deterministisches” Modell - in der KTT kommt im Gegensatz zu den probabilistischen Modellen die Probabilistik “gewissermaßen nachträglich” ins Spiel, d. h. nachdem der Meßwert schon feststeht, wird diesem ein Vertrauensbereich zugeordnet - Kritik an den Axiomen der KTT: hier wird häufig das Axiom 4 (r (T, E) = 0) kritisiert - schon einige Vertreter der KTT machen darauf aufmerksam, daß Meßfehler durchaus mit den wahren Werten im systematischen Zusammenhang stehen können [ 2 Annahmen hierzu: 1. besonders die Extremwerte in Tests sind im höheren Grade meßfehlerbehaftet - Phänomen der “Regression zur Mitte”; Personen im extremen unteren Skalenbereich sollen dazu neigen, bei Testwiederholung sich zu verbessern, während extrem leistungstarke Personen eher zu leichten Verschlechterungen tendieren 2. gerade im Mittelbereich treten die größten Fehlerwerte auf - ist ein Test für einen Pb sehr leicht bzw. sehr schwer, löst er also entweder fast alle oder nahezu keine Aufgaben, dann werden bei einer Testwiederholung die neuen Werte sich kaum von den alten Werten unterscheiden - die Pb, die aber etwa die Hälfte der Aufgaben gelöst haben, lassen größere Differenzen zwischen Erst- und Zweitmessung erwarten] - da es sich bei der Abschätzung der Reliabilität eines Tests stets um einen über die untersuchte Gesamtstichprobe “gemittelten Wert” handelt, hat dies zur Folge, daß strenggenommen die Reliabilitätskennwerte der KTT niemals für die einzelne Person oder eine Subgruppe aus der Gesamtpopulation voll gelten Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 26 - ein ansonsten hoch zuverlässiger Test kann für eine Subgruppe (z. B. für besonders Leistungsfähige) eine geringere Reliabilität (hoher Fehlervarianzanteil) aufweisen als für die Gesamtgruppe sämtliche Kennwerte der KTT (Aufgabenkennwerte wie Schwierigkeit und Trennschärfe sowie Gütekriterien) sind hochgradig stichprobenabhängig - die KTT krankt an der “Vermischung von Kennzahlen für Tests mit Kennzahlen für Stichproben” (Wottawa, 1980) - bekanntlich wird die Korrelationshöhe stark beeinflußt von der Streuung (Varianz) der Testwerte in einer Stichprobe; mit zunehmender Testwertstreuung wächst auch die Chance, eine hohe Korrelation zwischen 2 Meßwertreihen zu erhalten Beispiel: Variabilität der Oberschüler Rohwerte ..... der Test...... form B ....... .. ............ ... Variabilität der Gesamtstichprobe ....... ....... ..... Rohwerte der Testform A - im großen Rechteck (unausgelesene Gesamtstichprobe) ist deutlich eine stärkere Streuung, klarere Regressionslinie und damit höhere Korrelation zu erkennen, während in der unausgelesenen, hoch leistungsfähigen Subgruppe die Korrelation als Ausdruck der Zuverlässigkeit sinkt - aus dieser Tatsache wird in der KTT lediglich die Forderung abgeleitet, möglichst repräsentative Untersuchungsgruppen für die Testentwicklung und Gütekriterienbestimmung zu nutzen oder, wenn dies nicht möglich ist, durch entsprechende Korrekturformeln bei selegierten Stichproben die Kennwerte für die heterogenere Gesamtstichprobe zu schätzen - davon unberührt bleibt aber das Problem, daß auch bei einer repräsentativen Stichprobe die gewonnenen Aussagen über die Reliabilität eines Tests nicht ohne weiteres auf Untergruppen bzw. Einzelpersonen dieser Gesamtstichprobe zu beziehen sind - weiterer fundamentaler Kritikpunkt: die Annahmen der Normalverteilung psychischer Merkmale und die Intervallskaliertheit der Testdaten - Kritiker zufolge gibt es keine Beweise dafür, daß psychische Merkmale generell dem Normalverteilungsmodell folgen - für einige psychische Merkmale (z. B. Einstellungen) ist dies sogar sehr zweifelhaft - Gedankengang der Vertreter der KTT: - findet man mit einem Test eine Rohwertverteilung der Testergebnisse, die der Gauss´schen Normalverteilung entspricht oder stark ähnelt, dann spiegele der Test die “wahre Verteilung” der Eigenschaftsausprägungen in einer Population wahrscheinlich richtig wider, da diese theoretisch als Normalverteilung angenommen wird - bei Abweichungen von der erwarteten NV, zweifelt man entweder am Wert des Tests und ändert diesen so (z. B. durch Austausch von Items), daß nunmehr die erneute Testung einer Stichprobe die NV ergibt, oder man “normalisiert” die gewonnenen Rohwerte mit Hilfe eines statistischen Tricks (Flächentransformation) NV der Testrohpunktwerte sind stets im gewissen Maße nur ein “Kunstprodukt” (es gibt bislang keine “harten” Kriterien zur Prüfung der NV-Annahme) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 27 - die KTT geht von der Annahme aus, daß sich intervallskalierte Daten normalverteilen - findet man eine NV der Ergebnisse, wird der Schluß “herumgedreht”, indem man annimmt, daß die gewonnen Meßergebnisse nunmehr auch auf Intervallskalenniveau interpretierbar sind - aber: zwischen Skalenniveau und Verteilungsannahme bestehen keinerlei zwangsläufige Wechselbeziehungen (da man auch Tests so konstruiert oder deren Ergebnisse so transformiert, daß eine NV der Testwerte resultiert) - es bleibt zu fragen, ob die Gleichabständigkeit von Testwerten im numerischen Relativ als Widerspiegelung von im empirischen Relativ tatsächlich bestehenden gleichen Abständen zwischen Meßobjekten überhaupt gegeben ist Additivitätstheorem: dies besagt z. B., daß die summierten Leistungsfähigkeiten von 2 minderbefähigten Pb gleich der Leistungsfähigkeit eines höherbefähigten Pb sind; dies ist jedoch sehr zweifelhaft und ausgesprochen sinnlos im Bereich der Einstellungsmessung - die KTT geht von der Annahme aus, daß der Summenscore die volle Information über das Testergebnis erhält (verschiedene Antwortmuster haben also keine unterschiedlichen Bedeutung) - damit wird der Rohpunktscore als sog. erschöpfende Statistik behandelt, obwohl dies nicht problematisiert und geprüft wird - “Messung per fiat”: es wird also geglaubt, daß die Testresultate auf Intervallskalenniveau gemessen werden - ein Meßmodell zeichnet sich aber dadurch aus, daß man es an einem bestimmten empirischen Datensatz verifizieren oder falsifizieren kann - für das Meßmodell der KTT gibt es eine solche Falsifikationsmöglichkeit nicht, da die Grundgleichung der KTT X = T+ e stets als erfüllt gelten kann, da nur X empirisch bestimmbar ist und die additive Zerlegung in die Komponenten T und e rein hypothetisch bleibt Anwendungsbezogene Kritik: - kam zunächst aus dem Lager der pädagogischen Psychologie - Test wurden nicht nur eingesetzt um interindividuelle Unterschiede zwischen Schülern zu erfassen, sondern um zu überprüfen, ob und in welchem Grade die jeweiligen Lehrziele vom einzelnen Schüler oder einer Stichprobe erreicht bzw. vielleicht sogar überschritten wurde kriteriums- oder lehrplanorientierte Testentwicklung - bei diesen Tests könnte eine Varianz von 0 resultieren (z. B. nach einem sehr guten Unterrich, bei dem alle Schüler das Lehrziel erreichen); die Existenz der Varianz ist aber Voraussetzung für die Berechnung aller Testkennwerte der KTT - Kritik der Klinischen Psychologie: einseitige Orientierung auf statistische Durchschnittswerte (Normierung); Vernachlässigung des Individuellen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 28 Grundannahmen und Hauptfragestellungen der sog. Probabilistischen Testtheorie (PTT) Grundansatz und Grundbegriffe - menschliches Verhalten und somit auch Testverhalten stochastischen Charakter trägt (es ist in einer bestimmten Situation von soviel zufälligen Faktoren abhängig) - auch bei genauer Kenntnis des Ausprägungsgrades der latenten Eigenschaft (Indikand) können nur Aussagen über die Auftretenswahrscheinlichkeit von manifestem beobachtbarem Verhalten gemacht werden und daher niemals das Testverhalten mit völliger Sicherheit vorhergesagt werden kann - umgekehrt ist damit auch der Schluß vom Testverhalten auf latente Eigenschaften nur als Wahrscheinlichkeitsaussage denkbar - die Annahme über den grundsätzlich probabilistischen Charakter menschlichen Verhaltens entspricht mehr als die mechanisch-deterministische Annahme der KTT den Grundeinsichten der zeitgenössischen Psychologie - der zweite wesentliche Unterscheidungspunkt der PTT zur KTT: die PTT erhebt den Anspruch, die Testkennwerte (v. a. Aufgabenschwierigkeit) stichproben- bzw. populationsunabhängig zu messen und somit der “Vermischung” von Testkennwerten und Kennwerten jener Stichprobe von Pb, an denen der Test “ausprobiert” wurde, in der KTT zu entgehen - damit soll auch die diagnostische Erfassung des Individuums bzw. der Vergleich zweier Individuen (oder Testitems) möglich sein ohne Berücksichtigung der jeweiligen Referenzpopulation bzw. der gerade benutzten Itemstichprobe meßmethodisch befriedigendere Möglichkeiten für die Lernfortschrittsmessung Fazit: - die PTT erlaubt per Definition getrennte Aussagen über Items (Schwierigkeit) und Personen (Fähigkeit) - nicht so die KTT, da Item- und Personenparameter miteinander verknüpft sind, d. h. alle Ergebnisse sind stichprobenabhängig - die PTT versucht eine objektive Schwierigkeit von Items zu bestimmen, d. h. unabhängig vom Individuum - Grundlage aller PTT ist das Latent-trait-Modell von Lazarsfeld - die von Lazarsfeld entwickelte sog. latente Strukturanalyse geht davon aus, daß die Testwerte sich erklären lassen aus der Wechselwirkung zwischen der Verhaltensanforderung (Aufgabenschwierigkeit), die eine Meßvariable (Test) setzt, und der zu messenden Eigenschaft (z. B. Fähigkeit) des Untersuchungsobjektes (Pb) - beobachtbare Reaktionen werden grundsätzlich als Symptome bzw. Indikatoren für latente Dimensionen (Dispositionen, Eigenschaften) aufgefaßt Messen einer psychischen Eigenschaft ist also gleichbedeutend mit dem Schätzen eines unbekannten Parameters auf Grund einer Stichprobe von Beobachtungen Das RASCH-Modell - das Modell geht aus von dem Begriff der Lösungswahrscheinlichkeit einer Aufgabe (bzw. Beantwortungswahrscheinlichkeit bei Einstellungstests) - die Lösungswahrscheinlichkeit einer Aufgabe ergibt sich aus dem Verhältnis der Schwierigkeit einer Aufgabe und der Personfähigkeit der Person, die die Aufgabe bearbeitet hat Pri = f (Xr, Di) mit Pri= Wahrscheinlichkeit, daß die Person r die Aufgabe i löst Xr = Fähigkeitsparameter der Person r Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 29 Di = Schwierigkeits- bzw. Leichtigkeitsparameter der Aufgabe i - wenn Xr = Di, dann steht die Chance, die Aufgabe zu lösen, gleich 1:1 = 1 - Chance und Lösungswahrscheinlichkeit stehen in folgender Beziehung: Pri = C/1+C - ebenso ist ersichtlich, daß sich die Lösungswahrscheinlichkeit einer Aufgabe mit erhöhter Personenfähigkeit (Xr) erhöht und mit steigender Schwierigkeit (Di) der Aufgabe sinkt - ist die Fähigkeit einer Person gleich der Aufgabenschwierigkeit, dann ist die Lösungswahrscheinlichkeit Pri = 0,50 Itemcharakteristik-Kurve (ICC); mit Abszisse = Fähigkeitsparameter; Ordinate Lösungswahrscheinlichkeit für die Aufgabe Pri 1,0 0,5 0,0 Xr -3 -2 -1 0 +1 +2 +3 - Annahme dieser ICC: zwischen der Lösungswahrscheinlichkeit und Fähigkeitsparameter besteht zwar eine monotone, aber nicht streng lineare Beziehung, d. h. es gibt Bereiche auf dem Fähigkeitsparameter, bei denen die Lösungswahrscheinlichkeit mit wachsendem Fähigkeitsparameter schneller bzw. langsamer ansteigt als in anderen Bereichen - diese Form der ICC erhält man, wenn die Zahl der gelösten Aufgaben (Summenscore) eine “erschöpfende Statistik” darstellt, d. h. wenn es keine Rolle spielt, welche Items gelöst wurden, sondern nur wie viele; außerdem müssen die Postulate der spezifischen Objektivität und der lokalen stochastischen Unabhängigkeit erfüllt sein - die ICC zeigt, daß sich Leistungsverbesserungen in einem Test (also Erhöhung der Anzahl der Richtigantworten) bei schon extrem guten Leistungen schwerer erbringen lassen als im Mittelbereich Hauptfragestellung der PTT und speziell des Rasch-Modells: Ist ein Test homogen, mißt er also nur eine Dimension? - ein Test wird nur dann als homogen aufgefaßt, wenn die Lösungswahrscheinlichkeit aller Items nur durch die Ausprägung einer einzigen Eigenschaft und nicht etwa gleichzeitig durch die Vermischung von 2 Eigenschaften erklärt werden kann - ist also ein empirischer Datensatz, der mit einem Test an einer Stichprobe gewonnen wurde, mit dem RASCH-Modell konform, hat er die Modellprüfung positiv bestanden und mißt nur eine Dimension - die PTT macht aber keine Aussage, was das für eine Dimension ist Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 30 - erst die Gewährleistung der Homogenität gestattet die Additivität der Meßwerte, deren Berechtigung in der KTT nicht genügend überprüft wurde, obwohl sie bei der Summierung der Einzellösungen zu Gesamtrohpunkten vorausgesetzt wird Wie wird nun die Modellgültigkeit des RASCH-Modells bei einem bestimmten empirischen Datensatz festgestellt? - Prüfung am empirischen Datensatz, ob die sog. spezifische Objektivität gewährleistet ist - darunter versteht man 2 Aspekte: 1. die Schätzungen der Fähigkeitsparameter einer Person sollen immer gleich ausfallen, un abhängig davon, mit welcher Untermenge von Items bzw. mit welcher Stichprobe von Aufgaben diese Schätzung vorgenommen wurde (Bedeutungsinvarianz der Fähigkeiten) 2. die Schätzungen der Aufgabenparameter (Schwierigkeit) bleiben auch konstant, wenn man verschiedene Untermengen der Personenpopulation, für die der Test entwickelt wurde, zur Schätzung der Aufgabenparameter heranzieht (Bedeutungsinvarianz der Aufgaben) dem Prinzip der “spezifischen Objektivität” liegt das Vorbild des physikalischen Messens zugrunde; wenn wir 2 Gewichte miteinander vergleichen, wird das Ergebnis ja auch nicht davon bestimmt, welche Waage wir benutzen und welche Gewichte wir noch messen - es werden also die Personfähigkeiten unabhängig von der jeweiligen Aufgabenauswahl und die Aufgabenschwierigkeit unabhängig von der jeweiligen Personenstichprobe geschätzt (gerade dies wird in der KTT nicht gewährleistet, da die Aufgabenschwierigkeit je nach getesteter Stichprobe unterschiedlich bestimmt wird) Wie wird nun diese Stichprobenunabhängig erreicht? - Stichprobenunabhängigkeit meint nicht, daß die “einfachen Schwierigkeitswerte” im Sinne der KTT (also der Prozentsatz richtiger Lösungen in einer Stichprobe) irgendwie “populationsunabhängig” gemacht werden können - eine bestimmte Intelligenzaufgabe wird natürlich von einer höher intelligenten Gruppe häufiger gelöst als von einer minder intelligenten Gruppe, so daß sich die “klassischen Schwierigkeitsindizes” immer unterscheiden müssen - aber: die Rangfolge der Schwierigkeiten von Testitems soll unabhängig von der jeweils gewählten Stichprobe gleich bleiben, also die Relationen zwischen den Aufgaben und ihren Lösungsprozentsätzen (beim physikalischen Längenmessung fordern wir bei der Transformation der Meßwerte aus einem Maßsystem mit einer best. Standardeinheit (z. B. Metersystem) in Meßwerte eines anderen Maßsystems (Meilen) auch nicht, daß die Absolutangaben konstant bleiben, sondern lediglich, daß die Verhältnisse zwischen zwei Längen jedesmal genau repliziert werden, unabhängig davon, ob man die Entfernung in Metern oder Meilen angibt) - in Analogie zum physikalischen Messen müssen wir aber eine Maßeinheit (wie das “Urmeter”) als verbindlichen Bezugsmaßstab anerkennen - es wird daher eine bestimmte Stichprobe als Standardstichprobe ausgewählt und eine Aufgabe mit einer bestimmten Chance als “Standardaufgabe” definiert (z. B. 1,00) - alle anderen Aufgaben des Tests erhalten dann entsprechend ihren Lösungsprozentsätzen bzw. Lösungschancen Aufgabenparameter zugewiesen - in einer anderen Stichprobe (z. B. bei weniger Leistungsfähigen) brauchen wir nur die Chance der “Standardaufgabe” durch den Aufgabenparameter 1,00 zu ersetzen und alle anderen Chancen und damit auch die Lösungsprozentsätze entsprechend zu transformieren der Aufgabenparameter ist also durch das Verhältnis der Lösungsprozente, nicht durch den Lösungsprozentsatz selbst bestimmt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 31 - die Berechnung der Aufgabenparameter im Sinne der RASCH-Skalierung “klappt” aber nur, wenn das empirische Datenmaterial den Modellanforderungen entsprechend strukturiert ist, als die Schwierigkeitsrangfolge der Aufgaben in beiden Stichproben trotz der natürlich auftretenden Differenzen in den klassischen Schwierigkeitsindizes gleich bleibt - die Modellprüfung am empirischen Material kann durch grafische und rechnerische Modelle erfolgen; es wird dabei jeweils geprüft, ob es sich bei den natürlich stests vorhandenen Abweichungen von der idealen Übereinstimmung mit den Modellerwartungen noch um tolerierbare Zufallsschwankungen handelt - es können also modellunverträgliche Testitems bzw. Personen identifiziert werden - Voraussetzungen für die spezifische Objektivität und damit für die Modellgültigkeit sind im RASCH-Modell die sog. lokale stochastische Unabhängigkeit der Items und der Nachweis der erschöpfenden Statistik - lokal stochastisch unabhängig sind Testitems nur dann, wenn die Lösungswahrscheinlichkeit einer Aufgabe bei einer Person nicht abhängt von der Lösung der vorangegangenen Aufgabe - die Forderung nach “lokal stochastischer Unabhängigkeit” schließt nicht - wie man vielleicht annehmen könnte - die Existenz von Korrelationen zwischen den Items aus; diese kommen durch die unterschiedlichen Personenparameter der getesteten Stichprobe zustande, so daß z. B. 2 sehr schwierige Aufgaben miteinander hoch korrelieren, weil nahezu alle “sehr guten” Pb beide Aufgaben lösen und alle “sehr schlechten” Pb beide Aufgaben nicht lösen - haben wir eine homogene Stichprobe: dann sind bei Gewährleistung der stochastischen Unabhängigkeit der Aufgaben Nullkorrelationen zu erwarten, da die Nichtlösung einer Aufgabe bei Lösung einer anderen Aufgabe ebenso wie die Lösung beider Aufgaben nur noch als zufallsabhängig zu betrachten ist - liegen dagegen Reihungs-, Übungs- oder Ermüdungseffekte vor, dann ist die stochastische Unabhängigkeit nicht mehr zu erwarten Was versteht man unter einer “erschöpfenden Statistik”? - nur die Anzahl, nicht die Beschaffenheit der Items ist aussagekräftig - in der KTT wird nicht geprüft, ob die einfache Addition der Einzelwerte zu einem Summenscore überhaupt die volle erschöpfende Information über das Testverhalten enthält oder ob nicht durch die Summenbildung ein Informationsverlust auftritt wenn eine durch die Benutzung von Summenwerten (statt der Einzelwerte) vorgenommene Datenzusammenfassung keinen Informationsverlust bringt, bezeichnet man das als erschöpfende Statistik Wie prüft man die Annahme der “erschöpfenden Statistik”? - der erste Vorschlag stammt von Guttman (1944): Guttman-Skalierung - Annahme: ein Item wird immer dann gelöst (bzw. bejaht), wenn die Ausprägung der zu messenden Eigenschaft “groß genug ist” - es folgen hieraus Itemcharakteristiken, die nur die Werte 1 oder O annehmen (“Sprungcharakteristiken”) deterministisches Modell - genügt ein Itemsatz dem Modell, so muß jeder Pb, der ein schweres Item gelöst hat, alle anderen leichteren Items auch gelöst haben Item A - B - C - D + E + + Pb 1 2 3 usw. Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 32 mit einem einzigen Wert kann ich einen Pb charakterisieren Anforderungen an die Items: - eindimensional - ansteigende Schwierigkeit - dieses Modell ist natürlich auch stichprobenunabhängig; gilt für die Gesamtstichprobe dieses Modell, dann gilt es auch für jede Unterstichprobe - leider läßt sich das Guttman-Modell sehr selten in der empirischen Realität bestätigen - für die Praxis wurde in der RASCH-Skalierung ein Modell entwickelt, das die Vorteile der Guttman-Skala weitgehend beibehält, aber weniger “hart” ist - im Unterschied zur Guttman-Skala handelt es sich hierbei nicht mehr um ein deterministisches, sondern um ein stochastisches Modell, bei dem die Itemcharakteristik nicht sprunghaft, sondern kontinuierlich-stochastisch ist - mit dem Nachweis der “spezifischen Objektivität” im RASCH-Modell wird gleichzeitig angenommen, daß damit auch die “lokale stochastische Unabhängigkeit der Aufgaben” und die “erschöpfende Statistik” als bewiesen werden können, denn ohne die Erfüllung dieser Voraussetzungen ist spezifische Objektivität nicht denkbar - explizit geprüft wird aber nur die spezifische Objektivität! - die Tests der PTT können Messungen auf Intervallskalenniveau zulassen (die Lösungswahrscheinlichkeit eines Items ändert sich nicht, wenn man zu den beiden Parametern Xr und Di eine Konstante addiert) - während in der KTT das Problem auftritt, daß die Reliabilitätsschätzung auf Grund der Daten der gesamten Stichprobe gewonnen wird (“gemittelte Zuverlässigkeit”) und daher die Übertragbarkeit auf einzelne Pb eigentlich nicht gegeben ist, wird im RASCH-Modell die Meßgenauigkeit eines Verfahrens über die Berechnung von spezifischen Konfidenzintervallen bestimmt, die jeweils für die einzelnen möglichen Personparameter unterschiedlich ausfallen können - die Personenparameter lassen sich um so genauer schätzen, je größer die Anzahl der Testitems ist und je ähnlicher Itemschwierigkeiten und Personfähigkeiten sind - es läßt sich nachweisen, daß im RASCH-Modell v. a. jene Items eine besonders genaue Schätzung der Personenparameter zulassen, die mit einer Wahrscheinlichkeit von 0,5 gelöst werden (d. h. wenn der Personenparameter dem Schwierigkeitsparameter genau entspricht) - daraus läßt sich umgekehrt folgern, daß Pb, für die die Aufgaben sehr leicht bzw. sehr schwer sind nur relativ grob im obersten (bzw. untersten Skalenbereich) lokalisiert werden Fazit zum RASCH-Modell: 1. Im Gegensatz zur KTT wird der Testwert nicht als unmittelbarer Indikator der zu messenden Eigenschaft aufgefaßt, der lediglich durch einen Meßfehler verunreinigt wird, sondern prinzipiell als probabilisitisch bestimmter Wert, der bei Gültigkeit des Modells eine Schätzung der Person- und Aufgabenparameter erlaubt. 2. Die Reaktion eines Pb im Test wird in der Grundgleichung erklärt durch das Zusammenwirken von Aufgabenschwierigkeit und Personfähigkeit. 3. Mit dem Modell wird eine stichprobenunabhängige Schätzung der Aufgabenparameter bzw. Personparameter angestrebt. Hierzu wird die spezifische Objektivität mittels Teilung der benutzten Personen- und Aufgabengesamtstichprobe in “Unterstichproben” und Vergleich der in den Unterstichproben gewonnenen Aufgaben- und Personparameter geprüft. Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 33 4. Ist die spezifische Objektivität nachgewiesen, kann man auch davon ausgehen, daß eine lokale stochastische Unabhängigkeit der Aufgaben besteht und der Summenscore als erschöpfende Statistik zu betrachten ist. (lokale stochastische Unabhängigkeit bei der KTT: bezogen auf die Fehler ´´ ´´ PTT: von Itembeantwortung zu Itembeantwortung bzw. von Reaktion zu Reaktion; dies versucht die PTT durch eine hohe Anzahl von Pb und Items zu gewährleisten Gefahr der zu starken Selektion “Verknappung” des Merkmals) 5. Die Hauptfragestellung der PTT besteht im Nachweis der Eindimensionalität von Tests und des Intervallskalenniveaus der Meßwerte Wichtig: eine RASCH-Skalierung kann nur bei monoton steigenden Variablen angewendet werden! (Gegenbeispiel: Zusammenhang zwischen Aktivität und Leistung) Anwendung der PTT: - Neuentwicklungen von Tests auf der Basis der PTT sind noch sehr selten (Skalen von Wakenhut, Wienter Matrizentest, Adaptives Intelligenzdiagnostikum) - Veränderungen von Personenmerkmalen durch Lernen und Therapie können durch PTT meßtheoretisch exakter festgestellt werden als durch KTT, da die PTT den für die Differenzbildung (Prä-/Posttest) unerläßlichen Intervallcharakter der Daten und die Homogenität der Wiederholungstests eher garantieren Kritik der sog. PTT - PTT und psychische Realität lassen sich schwer in Einklang bringen - erhebliche technisch-mathematische Probleme der PTT und der beträchtliche Untersuchungs- und Rechenaufwand Technisch-mathematische Probleme der PTT: - irreführender Terminus der “populationsunabhängigen” Schätzung von Item- und Personparameter - was eigentlich durch das RASCH-Modell gewährleistet bzw. überprüft wird, ist nicht eine “Stichproben-“ oder gar “Populationsunabhängigkeit” im eigentlichen Sinne des Wortes, sondern lediglich die “Teilgruppenkonstanz” der Aufgaben- bzw. Personenparameter in der untersuchten Gesamtstichprobe - derselbe Test kann daher z. B. für die Gruppe der Zehnjährigen “Raschkonform” sein und für die Gruppe der Elfjährigen bereits nicht mehr modellverträglich - ein besonderes Problem stellt auch die Wahl der Teilungskriterien für die Untergruppenbildung zur Prüfung der spezifischen Objektivität dar - gewöhnlich werden z. B. bei Leistungstests Unterteilungen nach der Leistungsfähigkeit der Pb (über- /unterdurchschnittlich) oder nach dem Geschlecht vorgenommen - wenn man nun Modellkonformität erhält, besagt dieses Ergebnis aber überhaupt noch nicht, daß bei der Wahl eines anderen Teilungskriteriums (z. B. soziale Herkunft) ebenfalls Modellkonformität resultiert - für die Wahl adäquater Teilungskriterien gibt es aber keine Rezepte, so daß die Aussage daher auch immer nur heißen kann: Modellkonform bei diesem oder jenem Teilungskriterium - Modellkonformität ist umso leichter zu erreichen, je homogener die Gesamtstichprobe der Items und die Gesamtstichprobe der Pb von vorneherein sind Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 34 - damit sind modellvertägliche RASCH-skalierte Tests meist nur für sehr eng umschriebene Personenmerkmale und ebenso eng umschriebene Populationen zu erwarten - der Anspruch der PTT, daß sie im Gegensatz zur KTT keine Repräsentanzanforderungen hinsichtlich der Stichprobenziehung stellen und trotzdem ihre Aussagen für das gesamte relevante Aufgabenuniversum bzw. die angezielte Population gelten, ist nicht haltbar, da sich die Beweise (Modellprüfung) zunächst immer nur auf eine bestimmte Auswahl aus dem Aufgabenuniversum und eine bestimmte Personenstichprobe aus der Population beziehen - die Modellkonformität eines Tests wird aber nicht nur in bezug auf eine bestimmte Personenstichgruppe, Itemmenge und ein bestimmtes Teilungskriterium zu definieren sein, sondern ist auch abhängig von der Größe der Personenstichprobe, an der der Test auf Modellkonformität geprüft wird - wird derselbe Test an einer relativ kleinen und an einer sehr großen Stichprobe überprüft, dann besteht die Möglichkeit, daß der Test in der großen Stichprobe als modellunverträglich erscheint, in der kleinen Stichprobe dagegen noch als modellverträglich - je mehr Personen nämlich in eine Stichprobe einbezogen werden, desto kleinere Abweichungen vom Modell lassen sich dann als signifikant kennzeichnen und somit als modellunverträglich klassifizieren Psychologisch-inhaltlich begründete Einwände: - problematische Annahmen: lokale stochastische Unabhängigkeit und erschöpfende Statistik - der Beweis für die erschöpfende Statistik wird nur statistisch geführt, es fehlt aber die psychologisch-inhaltliche Begründung, daß tatsächlich bei dem Vorhandensein bestimmter statistisch regelmäßiger Beziehungen in den Daten (wie z. B. die eindeutige Reproduzierbarkeit des Antwortmusters aus dem Summenscore in der Guttman-Skalierung) jedes beliebige Antwortmuster bei gleichem Summenscore dieselbe psychologische Bedeutung besitzt - es müßte also eigentlich in jedem konkreten Anwendungsfall noch geprüft werden, ob tatsächlich alle Antwortmuster dieselbe psychologische Bedeutung haben, was allein auf Grund statistischer Analysen nicht möglich ist - Lerntransfer bzw. Übungstransfer gefährdet die Annahme der lokalen stochastischen Unabhängigkeit - Voraussetzung der Eindimensionalität der Fähigkeitsmessung ist nur bei wenigen Aufgaben auch psychologisch gegeben Kritik von Gutjahr: das RASCH-Modell leistet nicht mehr als die KTT und daher sind die gewonnenen Ergebnisse unmittelbar miteinander vergleichbar Fazit: - die PTT macht lediglich Aussagen zur Homogenität bzw. Eindimensionalität eines Tests und zur Meßgenauigkeit, aber keinerlei Aussagen zur doch entscheidenden Frage der Validität gestattet - fallen bei einer Modellgültigkeitsprüfung bestimmte Items als “modellunverträglich” heraus, dann ist dies oft psychologisch-inhaltlich nicht erklärbar - Retestreliabilitätsprobleme aufgrund unterschiedlicher Bedingungsfaktoren sind trotzdem vorhanden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 35 Grundannahmen und Hauptfragestellungen der Kriteriumsorientierten Messung (KOM) - die KOM keine neue Testtheorie, sondern wendet KTT und PTT auf eine neue Fragestellung in modifizierter Weise an - die neue Fragestellung entstand in der pädagogisch-psychologischen Forschung; diese interessiert sich nicht wie bei KTT für interindividuelle Differenzen, sondern ob ein Lehrziel erreicht wurde - es interessiert daher auch nicht der Vergleich einer Individualleistung zu einer statistisch gewonnenen Norm (wie bei der KTT), sondern das einzelne Testergebnis ist bereits ohne diesen populationsorientierten “Normbezug” interpretierbar Ein lehrzielorientierter Test ist ein wissenschaftliches Routineverfahren zur Untersuchung der Frage, ob und evtl. wie gut ein bestimmtes Lehrziel erreicht ist. Die hierbei verwendeten Testaufgaben sind nicht identisch mit dem Lehrziel, sondern repräsentieren es nur und dienen dazu, den individuellen Fähigkeitsgrad eines Schülers mit einem gewünschten Fähigkeitsgrad zu vergleichen. Für diesen Vergleich sind erforderlich: 1. eine Quantifizierung des Lehrziels, 2. eine quantitative Erfassung der Schülerleistung und 3. ein Meßmodell für die zufallskritische Entscheidung darüber, ob das Lehrziel erreicht ist. - in der KOM ist ein Kriterium eine kontentvalide definierte Variable, d. h. eine Variable, die durch Definition auf einen präzisierten Verhaltensbereich bezogen ist ( Außenkriterium bei der KTT) - entscheidend bei der Konstruktion von Verfahren im Rahmen der sog. KOM ist daher v. a. eine sehr exakte Definition und Operationalisierung des zu messenden Zieles (“Kriterium”) Spezielle mathematisch-statistische Probleme: - diese ranken sich v. a. um 2 Grundannahmen der KTT: 1. die angenommene Normalverteilung der Testrohwerte als Basis für die Gewinnung intervallskalierter Testwerte und 2. große interindividuelle Variabilität in den Testleistungen, die die Grundlage liefert für die Berechnung nahezu aller Testkennwerte und Testgütewerte - bei KOM kann aber diese interindividuelle Varianz, z. B. wenn alle das Optimalziel jedes Unterrichts oder der Therapie erreicht haben, gleich Null sein - die Reliabilität eines Verfahrens, das die Erreichung dieses Optimalziels registriert, ist dann nicht mehr bestimmbar, da bei Nullvarianz keine Korrelation berechnet werden kann - dies gilt dann auch für die Validitätsberechnungen - daher entwickelte FRICKE (1973) das Konzept der sog. Übereinstimmungskoeffizienten (Ü-Koeffizient) als Alternative zur herkömmlichen Berechnung der Gütekriterien in der KTT auf Grund von Korrelationsmaßen - Objektivität wird, wie in der KTT definiert, durch die Beurteilerübereinstimmung, nun aber bezogen auf die Feststellung der Kriteriumserreichung durch die getesteten Pb - der Ü-Koeffizient wird definiert als das Verhältnis von empirischer zu maximal möglicher Übereinstimmung - je höher diese Übereinstimmung ausfällt, desto größer ist auch der Ü-Koeffizient - der Ü-Koeffizient entspricht also in seiner Aussage dem Korrelationskoeffizienten, setzt aber nicht wie dieser eine bestimmte Varianz der Meßwerte voraus Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 36 - bei der Reliabilitätsberechnung wird keine Korrelation berechnet, sondern diese wird ebenfalls mit Hilfe eines speziellen Ü-Koeffizienten bestimmt, wobei die Retest- bzw. Paralleltestmethode der KTT zugrunde liegt - bei der KOM spielt die Inhalts- oder Kontentvalidität die entscheidende Rolle - inhaltsvalide ist ein Test, wenn seine Itemzusammensetzung nach der Meinung von Experten für das jeweilige Lehrziel eine repräsentative Stichprobe aus denjenigen Aufgaben darstellt, die durch das Kriterium als sog. Aufgabenuniversum festgelegt wird - geprüft werden kann nun die Inhaltsvalidität, indem z. B. mehrere Experten bzw. Testkonstrukteure unabhängig voneinander das Aufgabenuniversum beschreiben und generative Regeln zu Erzeugung von Testaufgaben aus diesem Universum ableiten (“known-group”Validierung) - unabhängig voneinander entwickelte Itemsammlungen (Tests) müßten bei hoher Inhaltsvalidität etwa gleiche Ergebnisse bringen - in der KTT und PTT bringen jene Aufgaben die besten Chancen zur Differenzierung der Pb, die eine mittlere Schwierigkeit aufweisen, deren Lösungswahrscheinlichkeit also bei 0,50 liegt (Chance für Lösung 1:1) - bei lehrzielorientierten Tests muß die Chance erheblich günstiger angesetzt werden, wenn das Urteil “Ziel erreicht” gefällt werden soll (häufig verwendet werden die Lösungswahrscheinlichkeiten 0,8/0,9 oder sogar 0,95) - während es bei “klassischen”, auf interindividuelle Differenzierung bedachten Tests ein Unglück wäre, wenn alle Schüler alle Testaufgaben lösen (sog. Testdeckeneffekt), da man keine Differenzierung mehr vornehmen kann, ist dies durchaus mit der Intention der KOM vereinbar - dies ist ja auch (das allerdings in der Realität selten erreichte,) Ideal einer Klassenarbeit - wenn aber nun die Mehrzahl der Schüler oder Trainingsteilnehmer alle Aufgaben löst, dann kann niemals mehr eine NV der Rohwerte resultieren - bei extremen Lösungsprozentansätzen läßt sich statt der NV die POISSON-Verteilung verwenden, oder auf Vorschlag Klauers das sehr einfach Binomial-Modell Binomial-Modell: - bei kriteriumsorientierten Tests will man die Pb zumindest 2 Klassen zuordnen: der Klasse, die das Lehrziel erreicht hat oder der Klasse, die das Lehrziel noch nicht erreicht hat - es entsteht nunmehr die Frage, wieviel Aufgaben einer bestimmten Aufgabenklasse im Test gelöst sein müssen, damit man von einem Erreichen des Lehrziels sprechen kann und wie lang der Test dazu sein muß (Anzahl der Aufgaben) - das binomiale Testmodell, das auch unter die probabilistischen Testmodelle zu subsumieren ist, gestattet bei sehr einfachen Berechnungen die Beantwortung dieser beiden Fragen innerhalb einer vorgegebenen Irrtumswahrscheinlichkeit Voraussetzungen zur Anwendung dieses Modells: 1. Die Testaufgaben können nur mit richtig oder falsch bewertet werden. 2. Zu dem Lehrziel, für das im Test n Aufgaben vorliegen, lassen sich beliebig viele Aufgaben konstruieren (allerdings gilt diese Voraussetzung bereits als erfüllt, wenn es mehr als 60 Aufgaben zu einem Ziel gibt). 3. Für Personen, die das Lehrziel erreicht haben, ist jede Testaufgabe gleich schwierig. Es gibt also keine Schwierigkeitsdifferenzen zwischen den Aufgaben ( RASCH-Modell). 4. Die Testaufgabenlösungen sind stochastisch unabhängig voneinander. 5. Jede Aufgabe bezieht sich auf dasselbe Lehrziel. Der Test ist also hochgradig homogen. Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 37 - problematisch: Voraussetzung 3 und 4, da erstens gleich schwere Aufgaben schwer zu konstruieren sind und zweitens dies auch im Widerspruch zu den Intentionen pädagogischer Leistungsmessung steht, wo man ja gerade erfahren möchte, wie Schüler mit Aufgaben unterschiedlichen Schwierigkeitsgrades fertig werden - ist die Gültigkeit der Modellvoraussetzung nachgewiesen, kann mit Hilfe der Binomialverteilung geprüft werden, ob ein Schüler das Kriterium (Lehrziel) erreicht hat oder nicht - vom Experten muß ein Kriteriumswert festgelegt werden, dessen Erreichung bzw. Überschreitung die Einordnung in die Kategorie “Ziel erreicht bzw. nicht erreicht” erlaubt - dieser Kriteriumswert muß aber höher liegen als der in der KTT empfohlene, besonders zur Differenzierung der Pb geeignete Schwierigkeitsgrad p = 0,50 - die für die KOM empfohlenen Richtwerte streuen von 60% bis 90%, das bedeutet, daß nur der das Kriterium erreicht hat, der mind. 60 bzw. 90% des maximal möglichen Wertes erreicht hat (unter Berücksichtigung der Irrtumswahrscheinlichkeiten) - ist nun das Kriterium (po) festgelegt, dann gilt das Kriterium als erreicht, wenn der theoretische Parameter po in einem Konfidenzintervall (1-) der empirischen Meßzahl pi liegt Beispiel: n = 40, po = 0,90, = 0,05 1- = 0,95 - Pb1 erzielte den Wert x1=30 und Pb2 den Wert x2 = 35 (d. h. 35 von 40 Aufgaben gelöst) - man erhält folgende Konfidenzintervalle: für p1 = 30/40 = 0,75 (Konfidenzintervall 0,588 ... 0,873) und für p2 = 35/40 = 0, 875 Konfidenzintervall 0,732 ... 0,958 - da 0,873<0,90 hat Pb1 das Kriterium nicht erreicht, Pb2 mit 0,958>0,90 dagegen schon - die Einteilung der Untersuchten in die Grobklassifikation “Ziel erreicht/nicht erreicht” ist zwar wertvoll, genügt aber meist nicht den Anforderungen Zielabstand bzw. Zielüberschreitung ist noch von Interesse - kritischer Einwand: es ist sehr utopisch zu erwarten, daß nach der Behandlung eines Lehrstoffes oder der Absolvierung eines Trainingslehrganges alle Absolventen alle Aufgaben in gleich guter Qualität lösen - Lehrplananforderungen sind vorwiegend als Mindestanforderungen zu überprüfen, d. h. es müssen nicht alle Schüler alles können - das Kriterium ist dann richtig festgelegt, wenn es eine untere Grenze fixiert, die nur von denjenigen Schülern überschritten werden darf, die über die erforderlichen Voraussetzungen für den nachfolgenden Unterricht verfügen - damit sind aber für kriteriumsorientierte Tests durchaus auch Lösungsprozentsätze zu tolerieren, die noch die Anwendung in der KTT gestatten - der herkömmlich normierte Ansatz der KTT und der anforderunsorientierte Ansatz der KOM sind ineinander überführbar (Austausch des normierenden Gruppenmittelwertes durch einen gruppenunabhängig definierten Kriteriumswert) - die Anwendung der KTT für die KOM wird aber v. a. deswegen oft für problematisch gehalten, da die KTT für Veränderungsmessungen wenig geeignet ist (trait-Gedanke; Problematik des Intervallcharakters der Daten) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 38 Kritik der KOM Generelle Probleme: 1. Ziele lassen sich leider nicht immer so exakt definieren, daß auf Grund dieser Definition ein Aufgabenuniversum bestimmt werden kann, aus dem der Test dann lediglich als eine repräsentative Stichprobe zu ziehen ist (noch relativ einfach aus dem Gebiet der Mathematik, aber problematisch in Bezug auf z. B. Erziehungs- oder Therapieziel) 2. Die in der Literatur oft vorgenommene starre Trennung populations- und anforderunsorientierter Maßstäbe ist realitätsfern, da sich natürlich auch die Anforderungen (z. B. der Lehrplan) auf die durchschnittlichen (also nicht auf die maximalen) Leistungsmöglichkeiten der Schüler in einer bestimmten Altersstufe in einer bestimmten konkreten historischen Epoche orientieren müssen. 3. Willkürliche Festlegung des Zielkriteriums und der zulässigen Fehlertoleranz, wenn man sich nicht auf den durchschnittlichen Realisierungsgrad in einer repräsentativen Stichprobe bezieht. Kritikpunkte bei der Anwendung der KOM: 1. Die Anwendung des Binomialmodells setzt voraus, daß die Aufgaben des Tests gleich schwierig und stochastisch voneinander unabhängig sind. Die erste Bedingung steht im Widerspruch zu den Intentionen schulischer Leistungsmessung, die zweite ist kaum erfüllbar, da aus der Testpraxis bekannt ist, daß die Lösung der nachfolgenden Aufgaben durch die Lösung vorangegangener Aufgaben beeinflußt wird (Übungs-, Serien- und Ermüdungseffekte) 2. Sowohl Binomial-Modell als auch RASCH-Modell stellen außerordentlich hohe Anforderungen an die Homogenität der Aufgaben. nur eine geringe Anzahl von Items erweist sich als modellkonform und bei den nichtmodellkonformen Items gelingt es in den seltesten Fällen schlüssig zu begründen, warum sie nicht modellkonform sind Modellkonformität kann zumeist nur bei Items erreicht werden, die inhaltlich so homogen sind (nur leichte Formulierungsunterschiede), daß man sich fragen muß, welche praktische Relevanz der damit gemessenen latenten Eigenschaftsdimension eigentlich noch zukommt 3. Da Personenparameter nicht völlig unabhängig von der gesamten Itemstichprobe des Tests geschätzt werden können, sind Aussagen konsequenterweise nur möglich in bezug auf die tatsächlich untersuchten Aufgaben. 4. Annahme der “erschöpfenden Statistik” ist wie bei PTT zu problematisieren. Zudem widerspricht dies der Forderung der pädagogisch-psychologischen Praxis, da man aus dem Antwortmuster einer Person Aussagen gewinnen will, die über das hinausgehen, was der Summenwert liefert. 5. Für präzise Aufgaben- und Personenparameterschätzungen sind in der PTT wie in der KTT “mittelschwere Aufgaben” erforderlich, die aber in der KOM bei Lösungsprozentsätzen von über 50% kaum präzise Fähigkeitsmessungen erlauben. Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 39 Gesamteinschätzung der Testtheorien, Synthese und Folgerungen Testtheorie-Kritik: - Nutzen der Testtheorie und auf ihr basierender Testinstrumente für die Systemrechtfertigung und Systemstabilisierung psychologische Realität und Meßmodell lassen sich oft nicht in Einklang bringen, bzw. die psychische Realität wird in ein Korsett gepreßt, damit sie dem Meßmodell entspricht - dieses Korsett ist in der KTT die angenommene oder “hergestellte” NV der Testrohwerte, in den PTT die Forderung nach lokaler stochastischer Unabhängigkeit der Items und die extremen Anforderungen im Hinblick auf die Homogenität von Personen- und Itemstichproben - andererseits ist zu bedenken, daß es außerordentlich schwierig, wenn nicht sogar unmöglich ist, ohne Meßinstrumente nähere psychologisch-inhaltliche Kenntnis über bestimmte Diagnostizierungsgegenstände zu erhalten - nicht nur die Theorie über ein Diagnoseobjekt, sondern auch die jeweilige diagnostische Fragestellung (z. B. Auswahl oder Effizienzmessung) sollten die Wahl eines Testmodells bestimmen - als entscheidender Einwand gegen das “messende Testen” wird oft die Nichtnachweisbarkeit des Intervallskalencharakters von Testergebnissen diskutiert (er kann nicht auf Indikatum-Ebene nachgewiesen werden, sondern nur mittels mathematischer Operationen im empirischen Relativ - heute wird von vielen Meß- und Testtheoretikern angenommen, daß in allen Sozialwissenschaften Messungen “nur” auf dem Ordinalskalenniveau beweisbar sind und Messungen auf Intervallskalenniveau lediglich angenommen werden können, wenn bestimmte statistische Voraussetzungen (z. B. NV in der KTT) als erfüllt gelten - eine Klassenzuordnung bzw. Typologisierung (z. B. Hilfsschulbedürftigkeit oder nicht), kann aber durchaus auch auf dem Niveau der Nominalskala bestehen Forderung nach einer stärker qualitativ orientierten Testtheorie (stärker an der psychischen Realität orientiert) ohne die gänzliche Verdammung der mathematisch-statistischen Messung Zum Dimensionalitätsproblem: - man argumentiert: nur wenn man die Eindimensionalität garantiert ist, könne man eigentlich genau sagen, was ein Test wirklich mißt, und nur auf der Grundlage der Homogenität könne man von einer Messung sprechen, die z. B. auch die Addition von Itempunktwerten zu einem Gesamtpunktwert erlaubt (vergl. Konzept der “erschöpfenden Statistik”) - Messung einer Eigenschaft setze also voraus, daß zwischen den individuellen Ausprägungen dieser Eigenschaft Relationen bestehen, die es ermöglichen, sie als unterschiedliche Abstufungen auf einem Kontinuum bzw. innerhalb einer Dimension anzusehen - in der KTT wird die Eindimensionalität durch die Anwendung der Trennschärfebestimmung und FA überprüft, wobei man allerdings bald die ursprünglich gehegte Hoffnung aufgab, völlig faktorreine Tests zu konstruieren - die KTT liefert im Gegensatz zur PTT eine Methode, die FA, mit der bewußt heterogen aufgebaute Tests auf ihre Mehrdimensionalität hin untersucht werden können - sowohl das FA Vorgehen in der KTT als auch die Homogenitätsprüfung in der PTT gehen lediglich von statistischen Beziehungen (Korrelationen bzw. Lösungswahrscheinlichkeiten in einer Stichprobe von Pb) aus, um die Homogenität nachzuweisen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 40 - solche statistische Beziehungen lassen sich denken, ohne daß inhaltliche Homogenität vorhanden sein muß (wenn Pb die schwierige Aufgabe b gelöst haben, dann werden sie auch die leichtere Aufgabe a lösen; es ist also zu erwarten, daß a und b die gleiche Fähigkeit ansprechen) es ist daher vor der statistischen Homogenitätprüfung die inhaltlich-psychologische Homogenitätsprüfung durchzuführen (über Kontentvalidität) - andere Kritiker führen an, daß über psychische Prozesse und Operationen, die den Fähigkeiten zugrunde liegen, zu wenig bekannt sei, so daß man weder über die anzuwendende Meßmethodik (Skalenniveau) noch über Homogenität eine Entscheidung treffen kann, da z. B. bei der Abarbeitung bestimmter Items in Fähigkeitstests ganz verschiedene psychische Prozesse ablaufen - die Eindimensionalität einer Fähigkeit besteht nach SCHONTZ aber nicht in einer besonderen “inneren Beschaffenheit” derselben (in einer spezifischen kognitiven Struktur), sondern einzig und allein in einem spezifischem Zusammenhang mit äußeren Anforderungen (Anforderungen sind gesellschaftlich vermittelt, historisch geworden und unterliegen auch gesellschaftlich bedingten Veränderungen) Synthese und Weiterentwicklungsmöglichkeiten: - Vor- und Nachteile der einzelnen Testtheorien sind abzuwägen und die Bedeutung der jeweiligen diagnostischen Fragestellung für die Auswahl des Testmodells hervorzuheben Synthese: - man konstruiert zunächst einen Test nach den Anforderungen der KTT und bestimmt hierbei die Trennschärfe - man schaltet dann die Aufgaben mit niedrigen Trennschärfen aus, so daß bei einer anschließenden RASCH-Skalierung die Homogenisierung auf einem insgesamt höheren Niveau erfolgt - die Ähnlichkeit beider Modelle wird darin deutlich, daß beide das Testverhalten als zufallsabhängigen Prozeß begreifen, daß in beiden Modellen die Aufgaben mit mittlerer Schwierigkeit die zuverlässigsten und trennschärfsten Aussagen zulassen und daß in beiden Theorien mit wachsender Testlänge auch die Zuverlässigkeit der Messung wächst - da die PTT bisher lediglich Aussagen über die innere Konsistenz eines Verfahrens bzw. seine Homogenität erlauben, sind die anderen Testgütekriterien auch bei einem RASCHskalierten Test noch über die KTT zu prüfen - die bei der RASCH-Skalierung gewonnenen Fähigkeitsparameter sind ohne Bezugnahme auf deren Verteilung in einer Referenzpopulation (Eichstichprobe) in der praktischen Diagnostik nahezu wertlos, so daß auch bei RASCH-skalierten Tests zum Schluß der Testentwicklung die Normierungsprozeduren der KTT angewendet werden müssen, falls man das Testergebnis eines Pb mit den Werten anderer Personen vergleichen will Entwicklungsmöglichkeiten für die Testtheorie: - Schaffung von neuen testtheoretischen Grundlagen, die es gestatten, Verfahren zu entwickeln, die nicht primär stabile wahre Merkmalsausprägungen erfassen (wie die KTT und die PTT), sondern in unterschiedlichen, aber doch hinsichtlich ihrer Anforderungsstruktur irgendwei vergleichbaren Situationen einen hohen Varianzanteil wahrer Merkmalsschwankungen - Entwicklungen von testtheoretischen Grundlagen, die es gestatten, die bisher ausschließlich gruppenstatistisch orientierte Testtheorie durch eine stärker dem Einzelfall angemessene Testtheorie zu ergänzen (Wiederholungsmessungen am Individuum) - Abkehr von den allzu hohen Anforderungen an das Skalenniveau der Testdaten; insbesondere in der Praxis sind neue Verfahren für klassifikatorische Entscheidungen (Nominalskala) auszuarbeiten Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 41 Grundzüge der Testkonstruktion und Testauswertung Aufbau eines Tests und Testprozeß - als Bestandteile eines Tests lassen sich unterscheiden: - Materialbestandteile und - Durchführungsbestandteile Die Materialbestandteile setzen sich zusammen aus: 1. Der Testhandanweisung (Testmanual) Dieses sollte informieren über - den jeweils angezielten Diagnostizierungsgegenstand (z. B. Intelligenz), - die praktisch-diagnostische Fragestellung bzw. über den Sachverhalt, - die theoretische Grundlegung des Verfahrens im Hinblick auf den Diagnostizierungsgegenstand (z. B. Theorie zur Intelligenz bzw. Intelligenzentwicklung) - die Methodik (z. B. warum wurde ein bestimmtes methodisches Paradigma, Status- oder Lerntest, gewählt) - Geltungsbereich des Verfahrens - einleitend ist auf den Begründungszusammenhang einzugehen - im Testmanual sollte weiterhin der Aufbau des Tests beschrieben sein und eine Kurzübersicht über die Entwicklungsetappen (Vorformen, Aufgabenanalysen, Gütekriterien, Normierung) - die Anweisung muß zudem alle Hinweise zur Durchführung, rechnerischen Auswertung und Interpretation der Testresultate enthalten - bei den psychometrischen Tests bilden die Normtabellen meist den Abschluß des Testmanuals 2. Das Testmaterial - Materialbestandteile (z. B. Bildkarten, technische Apparaturen) - Aufgabenhefte, Antwortbogen und Auswertungshilfen bei paper-pencil-Verfahren Die Durchführungsbestandteile eines Tests setzen sich zusammen aus: 1. Der Testanweisung oder Instruktion - Anweisung für den VL und - Instruktion für den Pb 2. Die Testdurchführung - hier muß der Pb praktische Handlungen vollziehen (möglichst schnell reagieren, eine Bilderfolge ordnen etc.), mit Hilfe von Papier und Bleistift Routineaufgaben bewältigen, Urteile und Stellungnahmen abgeben etc. 3. Die Testauswertung - sie kann intuitiv erfahrungsgeleitet (z. B. bei den meisten projektiven Verfahren) oder schematisch (oder sogar automatisch) erfolgen - die Interpretation des Testresultates sollte keinesfalls rein schematisch erfolgen MICHEL und CONRAD untergliedern die Durchführung noch etwas genauer in 4 Phasen: Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 42 a, Provokation des Testverhaltens - durch die Instruktion und Itemkonfiguration wird ein best. Testverhalten provoziert b, Registrierung - kann i. d. R. nicht vollständig sein - bezieht sich v. a. auf die Registrierung der in der Handanweisung primär interessierenden Ausschnitte aus dem Testverhalten, die als sog. Testdaten direkt in die Testauswertung eingehen - zumindest bei Individualtests sollten stets auch Verhaltensbeobachtungen bei der Testdurchführung gemacht werden c, Auwertung - sie besteht im einfachsten Fall nur aus der Auszählung der Richtig- oder Ja-Antworten - zunächst werden die sog. Rohpunkte bestimmt, die dann mit Hilfe von Normtabellen in Standardwerte oder Prozentränge umgewandelt werden können - oftmals schließen sich graphische Darstellungen der Punktwerte (“Testprofile”) an - weiterhin ist die Verrechnung von Einzelwerten zu Komplexwerten möglich, die dann als Syndrome fungieren d, Interpretation - hierunter versteht man die diagnostische Schlußfolgerung, die aus dem Testergebnis gezogen werden - während die anderen Phasen des Testprozesses durch Hilfskräfte übernommen werden können, ist diese schwierigste Phase dem Psychologen vorbehalten - stets muß das Testergebnis auf dem Hintergrund der diagnostischen Gesamtinformation (Anamnese, Exploration, Tests etc.) über die Persönlichkeit des Pb und unter Berücksichtigung der Verhaltensbeobachtungen während des Testprozesses interpretiert werden - allgemein streben Testkonstrukteure eine möglichst hochgradige Standardisierung aller 4 Phasen an, um die Objektivität der Untersuchung und die Vergleichbarkeit der Befunde zu gewährleisten - totale Standardisierung ist aber nicht möglich; Störfaktoren: Einstellungen und Erwartungen des Pb sowie VL, unkontrollierte Reaktionen des VL, Interaktion zwischen Pb und VL können die 4 Phasen erheblich beeinflussen - ebenso wirkt sich der aktuelle Gesundheits- und Befindlichkeitszustand z. T. erheblich auf die Ergebnisse z. B. von Intelligenztests aus Analyse des Diagnostizierungsgegenstandes - Bestimmung der Kontenvalidität - vor der Entwicklung eines Testes muß zunächst einmal genau bestimmt werden, was der Test eigentlich erfassen soll und welche Kenntnisse bisher über das “Wesen” und die Wirkungsweisen dieses “Gegenstandes” vorliegen - sowohl in der KTT als auch in der PTT wird aber dieser erste und wichtigste Schritt bei der Testkonstruktion kaum beachtet bzw. erst nach der Testkonstruktion bei der Überprüfung der Validität des Verfahrens in gewissem Umfang “nachgeholt” - die KTT ist ein formales Modell, also inhaltlos; diese Theorie ist erst dann verwendbar, wenn Testaufgaben vorliegen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 43 - es gilt zunächst in der Literatur und bei den jeweiligen Experten Informationen zum Diagnostizierungsgegenstand einzuholen, dabei sollten auch Nachbarwissenschaften, die an der “Schnittstelle” zur Psychologie liegen berücksichtigt werden - besonders in der KOT werden ja Kriterien nicht primär vom Psychologen bestimmt, sondern vom Fachmann für das jeweilige Gebiet - Probleme: keine einheitlichen und v. a. ungenügend operationalisierbare Definitionen des Diagnostizierungsgegenstandes - trotz dieser Probleme gilt es Testaufgaben nicht “auf gut Glück”, sondern stets auf theoretischen Einsichten, also theoriegeleitet vorzugehen Bei der Konstruktion von Testverfahren läßt sich “Theorie” auf mindestens 3 Ebenen einbringen: 1. Die Entwicklungsabfolge eines Diagnostizierungsgegenstandes - wie sie insbesondere von der Entwicklungspsychologie untersucht wurde, bildet die Grundlage für die Konstruktion einzelner Testaufgaben 2. Die Analyse der Sachstruktur eines Gegenstandes - dieses Vorgehen bietet sich besonders für die KOM bei schulischen Lernstoffen an - so sind Einsichten über den Strukturaufbau des Zahlbegriffes und der Zahloperationen wie sie von der Mathematik geliefert werden, die Grundlage für die Konstruktion eines Tests zur Prüfung der Beherrschung des Zahlbegriffs und der Zahloperationen - die Aufgaben sind nach ansteigender Komplexität im Sinne einer Hierarchie von Lernzielen zu ordnen, wobei zunächst die Elementarkenntnisse geprüft werden, deren Beherrschung die Voraussetzung für die Lösung der komplexeren Aufgaben, die später folgen, bildet 3. Handlungsstrukturanalysen - so läßt sich z. B. ein Test zur Analyse der Lesetätigkeit auf der Erkenntnis aufbauen, daß Lesen, wie jede Tätigkeit mit motorischen Anteilen, auf verschiedenen Regulationsebenen (intelektuell, perzeptiv-begrifflich, sensomotorisch etc.) gesteuert wird und daher ein “Lesetest” die Wirkungsweisen der einzelnen Regulationsebenen beim Leser und jeweiligen Lernstoff diagnostizieren sollte - Testkonstrukteure sollten aber auch die Frage beantworten, inwieweit Testanforderungen und Lebensanforderungen übereinstimmen - DRENTH hat Tests nach ihrer Übereinstimmung mit dieser sog. Außenanforderung (Kriterium) in 4 nicht trennscharfe Testtypen unterteilt: 1. Tests mit identischem Verhalten - hierbei werden im Test genau und vollständig die Anforderungen (Aufgaben) gestellt, die in der realen Lebenstätigkeit gestellt werden - die “Probeitems” sind von ihrer Anforderungen her mit der “Ernstsituation” völlig vergleichbar (z. B. bei einem Sekretärinneneignungstest schreibmaschineschreiben) - diese Tests besitzen “Augenschein-Validität (face validity), d. h. der Untersuchende erkennt sofort, was der Test messen soll 2. Test mit identischen Elementen - hierbei werden im Test nur wesentliche Elemente aus der jeweiligen Anforderungsstruktur der Alltagsprobleme übernommen, deren Bewältigung dann aber eine Aussage über die Befähigung des Pb zur Bewältigung der gesamten Anforderung zulassen soll (z. B. Fahrprüfung) 3. Tests mit vergleichbarem Verhalten Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 44 - hierbei wird angestrebt, daß das Testverhalten dem Kriteriumsverhalten lediglich möglichst ähnlich ist (z. B. Rollenspiel) 4. Tests mit Verhaltensindikationen - das Testverhalten und das Kriteriumsverhalten sind recht verschieden, trotzdem gestattet der Test Aussagen über das spätere Kriteriumsverhalten, da der Test z. B. “Grundmechanismen” überprüft, die auch in den komplexen Lebensanforderungen (wenn auch sozusagen in anders verpackter Form und bei anderem Inhalt) vorkommen (z. B. Subtests einer Testbatterie zur Intelligenzmessung; diese enthalten Aufgaben, die in dieser Form niemals im Beruf oder in der Schule vorkommen) - der Begriff Inhalts- oder Kontentvalidität wird in der KTT bisher lediglich für solche Testtypen in Anspruch genommen, bei denen - wie bei Typ 1 und 2 - Test und Kriteriumsverhalten identisch oder nahezu identisch sind - bei der KOM steht der Begriff Inhaltsvalidität in engen Zshg. mit der Bestimmung der sog. logischen Validität eines Verfahrens durch Experten - Experten für das jeweilige Sachgebiet schätzen ein, ob die einzelnen Testitems bzw. der gesamte Test inhaltsvalide ist, also die Aufgaben tatsächlich dem durch eine Definition abgegrenzten “Aufgabenuniversum” zugehören, bzw. eine repräsentative Auswahl darstellen - die Kontentvalidierung sollte erstens eine Grundlage für die Testkonstruktion jeglicher Art bilden, und zweitens soll die Kontentvalidierung nicht mehr am Ende der Testkonstruktion (also bei der Gütekriterienüberprüfung), sondern zu Beginn der Testkonstruktion erfolgen Gesucht wird ein Verfahren, das 1. die Erzeugung von Testaufgaben objektiviert, 2. gewährleistet, daß nur Aufgaben gebildet werden, die zur Messung des fraglichen Merkmals beitragen können, 3. sichert, daß die Grundmenge von Aufgaben, zu deren Lösung das fragliche Merkmal qualifiziert, in der Menge von Testaufgaben angemessen repräsentiert ist. - KLAUER meint, daß die Definition eines solchen Aufgabenuniversums erleichtert wird, daß ein Persönlichkeitsmerkmal zur Lösung einer bestimmter Aufgabenmenge qualifiziert folgende Schritte sind daher nach KLAUER bei der Testkonstruktion zu gehen: 1. - der Inhalt, der in Aufgaben umgewandelt werden soll, wird in einer präzisen Weise vollständig dargestellt - es werden evtl. auch Teilmengen des Aufgabenuniversums bestimmt, die sich qualitativ unterscheiden und die dann bei einer repräsentativen Stichprobenziehung für den Test in Proportionen, die z. B. der Alltagshäufigkeit in einer bestimmten Population entsprechen, auch im Test repräsentiert sind - dabei sind bei der Aufgabenkonstruktion nicht nur inhaltliche Komponenten (Aufgabenklassen), sondern auch Verhaltensaspekte (Wissen, Verständnis, Anwendung etc.) zu berücksichtigen 2. - es wird eine geeignete Aufgabenform gewählt 3. - es werden Transformationsregeln definiert, die die Umwandlung des jeweiligen Inhalts in eine bestimmte Aufgabenform steuern - mit dieser Regel lassen sich dann kontentvalide Aufgaben erzeugen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 45 Bestimmung des Geltungsbereiches und Stichprobenziehung Geltungsbereich eines Verfahrens vs. - die Zielpopulation, bei der das Verfahren zur Anwendung kommen soll Gültigkeitsbereich eines Verfahrens - Abgrenzung des Diagnostizierungsgegenstandes - in der Vergangenheit wurden mit Vorliebe Tests mit sehr weitem Geltungsbereich konstruiert (z. B. HAWIE; Alter 6-16) - heute setzt sich eher die Tendenz durch, Tests mit relativ engem Geltungsbereich und für eine spezifische Entscheidungssituation zu konstruieren - je größer der Geltungsbereich eines Verfahrens ist, desto problematischer wird auch die Frage einer adäquaten Stichprobenziehung - die an sich wünschenswerte “reine Zufallsauswahl” läßt sich aus untersuchungsorganisatorischen Gründen kaum realisieren (z. B. Entgegenkommen der Schulleitung notwendig) - man kann dann höchstens im nachhinein durch die Technik der Quotenstichprobe solche sog. anfallenden Stichproben so reduzieren bzw. ergänzen, daß die gewünschte repräsentative Verteilung der Auswahlmerkmale (z. B. sozioökonomischer Status) in der Stichprobe garantiert wird - die Entscheidung über bestimmte Auswahlmerkmale ist keinesfalls einfach, da man sich zunächst überlegen muß, welche Merkmale in der Population denn wahrscheinlich wesentlich für die unterschiedliche Ausprägung des zu messenden Merkmals sind - i. a. wird empfohlen, daß die sog. Analysenstichproben für die Erprobung eines Verfahrens ca. 200 Pb umfassen soll, während die Eichungsstichprobe, die also zur Normengewinnung dient, höheren Anforderungen an die Repräsentativität genügen muß und i. d. R. auch einige Tausend (je nach Größe des Geltungsbereiches) Pb umfassen soll - innerhalb der KTT kann darüber hinaus das Problem der Repräsentativität dadurch entschärft werden, daß man für Untergruppen einer Population (z. B. Jungen/Mädchen), die sich hinsichtlich der Ausprägung des zu messenden Personenmerkmals unterscheiden, gesonderte Normen aufstellt - in diesem Fall ist es nicht so “dramatisch”, wenn in der Eichungsstichprobe eine Untergruppe etwas stärker vertreten ist, als es ihrem Anteil an der Gesamtbevölkerung entspricht - die PTT dagegen erheben überhaupt nicht die Forderung nach einer repräsentativen Stichprobe für die Entwicklung eines “RASCH-skalierten” Tests; sie berufen sich dabei auf das Postulat der spezifischen Objektivität, nach dem die Schwierigkeits- und Fähigkeitsparameter in einem modellkonformen Test populationsunabhängig (besser: teilgruppenkonstant) geschätzt werden, so daß es nicht von Relevanz ist, ob eine Teilgruppe in der Stichprobe über- oder unterrepräsentiert ist siehe Kritik an der PTT: solche Aussagen sind aber strenggenommen stets nur für die untersuchte Gruppe (z. B. 10jährige Kinder) und im Hinblick auf das gewählte Teilungskriterium (z. B. Geschlecht) gelten, so daß auch die Normierung/Eichung eines prakisch umfassender einsetzbaren “RASCH-skalierten Tests den von der KTT entwickelten Kanon zur Gewinnung repräsentativer Eichstichproben beachten muß Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 46 Itemkonstruktion/Itemformen/Erstellung der Testvorform - es bleibt die Frage, ob die Testtheorie überhaupt einmal generelle Regeln zur Erzeugung von Items entwickeln kann, da diese doch stark vom jeweiligen Diagnostizierungsgegenstand (und damit auch von der inhaltlichen Theorie) her bestimmt werden müssen - möglicherweise können daher die Regeln der Testtheorie nur auf dem sehr allg. Niveau bleiben Zur inhaltlichen, v. a. sprachlichen Gestaltung von Testaufgaben empfiehlt Lienert (1967): 1. - die Aufgabe soll eine wesentlichen Aspekt des untersuchten Persönlichkeitsmerkmals betreffen - Items für die Testvorform wird man i. d. R. auch bei einer ausgebauten theoretischen Basis nicht nur am Schreibtisch entwickeln können - man wird zwar rein deduktiv aus theoretischen Vorarbeiten einige Items ableiten, aber meist gewinnt man die Items auch durch Vorbefragungen an der in Aussicht genommenen Zielpopulation bzw. bei sog. Experten 2. - jede Aufgabe sollte von den anderen noch im Test benutzten Items inhaltlich unabhängig sein, d. h. die Lösung einer bestimmten (vorhergehenden) Aufgabe darf nicht die Lösung der nachfolgenden Aufgabe erleichtern, bedingen oder erschweren (in der PTT unter dem Stichwort “stochastische Unabhängigkeit von Aufgaben” geführt; kaum realisierbar!) - in einem Fragebogen, der aus mehreren Subskalen besteht, sollten die Fragen, die zu einer Skala gehören, nicht nacheinander dargeboten werden 3. - jedes Item sollte möglichst konkret lebensnah-tätigkeitsbezogen gestaltet sein - auch diese Forderung gilt nicht uneingeschränkt, denn es gibt sowohl bewährte Fähigkeitstests (z. B. Raven-Test) als auch projektive Verfahren (z. B. HIT), deren Items keinesfalls lebensnah wirken und die trotzdem diagnostische Valenz haben - allerdings muß nachgewiesen werden, daß auch rein äußerlich nicht so lebensnah wirkende Items Anforderungen bzw. Prozesse provozieren, die in der realen Lebenspraxis des Pb von Bedeutung sind 4. - bei der Formulierung von Items vermeide man Begriffe, die mehrere Bedeutungen haben, da man ansonsten bei der Bewertung der Beantwortung nicht weiß, von welcher Bedeutung der Pb jeweils ausging 5. - man lege jedem Item nur einen sachlichen Inhalt oder Gedanken zugrunde 6. - man benutze möglichst positive Fragen bzw. Aussagen und vermeide v. a. doppelte Verneinungen - es ist empfehlenswert, nach Fertigstellung der Items in einer kleinen “Probestichprobe”, die später mit dem Test untersucht werden sollen, erst einmal zu prüfen, ob die Aufgaben überhaupt als solche verstanden werden; Items, die von mehr als 20% der Stichprobe sind herauszunehmen - Items haben einen sehr unterschiedlichen formalen Aufbau, aber sie bestehen immer aus 2 Komponenten: Stimulus- (Induktionsteil) und Reaktionskomponente (Antwortteil) - die Stimuluskomponente ist also die Frage bzw. die Behauptung, zu der Stellung genommen werden muß bzw. die Aufgabenformulierung bei Leistungstests - die Reaktionskomponente betrifft die geforderte Reaktion des Pb (Einfach- vs. Mehrfachantwort, offene vs. geschlossene Fragestellung) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 47 Itemanalyse (Aufgabenanalyse), Testanalyse und Itemselektion Aufgabenanalyse in der KTT - die Testvorform wird an einer sog. Analysenstichprobe, die der späteren Eichstichprobe möglichst ähnlich sein soll, aber nicht so viele Pb enthalten muß, “aufgabenanalysiert” - Zweck der Aufgabenanalyse: Identifizierung und Eliminierung der Items, die sich als diagnostisch wenig ergiebig erwiesen haben - da bei der Aufgabenanalyse mit ca. 1/3 Schwund gerechnet werden muß, wird empfohlen, in die Testvorform schon von vornherein mehr Aufgaben zu geben - die Gütekriterien der Items sind nicht absolut und immer geltende Gütekriterien, sondern beziehen sich auf die untersuchte Stichprobe und sind nur in bezug zum Gesamt aller in den Test einbezogenen Items zu interpretieren Es können folgende Itemkennwerte berechnet werden: 1. Die Schwierigkeit, 2. die Trennschärfe, 3. arithmetisches Mittel und Streuung aller Schwierigkeits- und Trennschärfeindizes, 4. Iteminterkorrelationen und damit zusammenhängende Kennwerte der Homogenität eines Tests (manchmal auch FA) 5. Validitätskennwerte - sehr selten werden auch Reliabilitätskennwerte für die Items (v. a. bei Einstellungsemessungen) und Objektivitätswerte bestimmt Der Schwierigkeitsindex bezeichnet den relativen Anteil der Pb, die das Item im Sinne des zu messenden Merkmals beantworten. p = NR/N bei p:= Schwierigkeitsindex (für dichotom zu beantwortende Items) NR:= Anzahl der Pb mit Richtiglösung N:= Gesamtzahl der Pb - kann nicht garantiert werden, daß alle Pb alle Items wirklich bearbeiten können (Zeitbegrenzung), müssen Korrekturformeln berücksichtigt werden, bei denen nur noch die Pb berücksichtigt werden, die tatsächlich die Aufgabe bearbeitet haben - hierbei besteht allerdings die Gefahr, daß infolge der Tatsache, daß bei einem nach der Schwierigkeit gestaffelten Test nur noch sehr leistungsfähige Pb überhaupt zu den letzten Aufgaben kommen, der p-Wert überschätzt wird, d. h. die Aufgabe leichter erscheint als sie in wirklich wäre, wenn alle Pb sie bearbeitet hätten Reihenfolge der Aufgaben per Zufall für jeden Pb festlegen (damit kann die sog. Inangriffnahmekorrektur entfallen - ratsam ist allerdings, für die ersten Items leichte Items zu wählen, damit nicht zufällig am Beginn eine sehr schwierige Aufgabe steht und damit der Pb gleich entmutigt wird - bei der Auswahl der Aufgaben für die Testendform nach der Schwierigkeit gibt es verschiedene Möglichkeiten der Optimierung - die Art des Tests und die diagnostische Fragestellung sowie die Eigenart der angezielten Population sind entscheidend für die jeweilige Aufgabenauswahl - i. a. gilt die Empfehlung, daß reine Schnelligkeitstests (wie z. B. der d2) Aufgaben mit extrem leichten Schwierigkeitswerten ( p=1) haben sollten Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 48 - manchmal wird bei diesen Tests auf die Berechnung von Schwierigkeitsindizes überhaupt verzichtet - bei Tests mit größerem Geltungsbereich sollten die Aufgaben im Bereich von p=20-80 streuen, wobei der Mittelwert aller p möglichst bei 0,50 liegen sollte, damit auch Pb mit extremen Merkmalsausprägungen (sehr leistungsstarke bzw. -schwache) überhaupt Aufgaben lösen bzw. bei extrem “positiver” Ausprägung durch die hoch schwierigen Aufgaben noch eine Differenzierung der Pb im Extrembereich möglich wird - in der KOM toleriert man durchaus auch Aufgaben mit p> 0,80, bzw. hält sie sogar für wünschenswert, da die Lehrzielerreichung von möglichst vielen Pb angenommen wird und der Test nicht primär differenzierenden Charakter haben soll, sondern den Grad der Lehrzielerreichung widerspiegeln soll - Item mit p= 0,50 haben eine maximal mögliche Varianz und bewirken damit auch ein Maximum an möglichen Differenzierungen zwischen den Pb - die Schwierigkeit einer Aufgabe steht im engen Zshg. mit der Trennschärfe der Items - die Trennschärfe wird aber nicht allein durch die Schwierigkeit einer Aufgabe bestimmt, sondern in noch stärkerem Maße durch den “Gemeinsamkeitsgrad dessen, was durch die Aufgabe ebenso wie durch den Test gemessen wird” (Lienert 1967) - dieser Gemeinsamkeitsgrad wird errechnet, indem man die Lösung des Items in Beziehung setzt zu den Lösungen bei den anderen Items, d. h. man korreliert das Item mit dem Gesamtpunktwert im Test - Alternativmöglichkeiten: man korreliert das Item mit Fremdskalen (Ziel: möglichst niedrige Korrelation) oder man führt eine Faktorenanalyse durch Die Trennschärfe (rit) als Maß für die Differenzierungsfähigkeit eines Items ist operational definiert als Korrelation des Items mit dem Gesamtpunktwert - die Art der zu berechnenden Korrelation richtet sich danach, ob das Item echt alternativ oder dichotom (künstlich alternativ) zu beantworten ist - bei echt alternativen Daten (z. B. richtig/falsch) berechnet man die sog. punktbiserale Korrelation rit = R- sx p/q bei rit:= Trennschärfekoeffizient als punktbiseriale Korrelation R:= Mittelwert der Testwerte der Pb, die das Item im Sinne hoher Merkmalsausprägung gelöst haben := Mittelwert aller Testwerte sx:= Streuung aller Testwerte p:= Schwierigkeitsindex q:= 1-p - ist die Beantwortung dichotom, d. h. es werden zwar nur 2 Ausprägungsgrade unterschieden, aber in Wirklichkeit liegte eine NV zugrunde, berechnet man die biseriale Korrelation ein trennscharfes Item (per Konvention Mindestwert von rit> 0,30) trennt gut die Pb der Stichprobe in jene, die eine hohe Merkmalsausprägung haben, und jene, die eine geringe Merkmalsausprägung zeigen - Trennschärfekoeffizienten sagen zunächst nur etwas über die Homogenität des Tests aus - enthält ein Test nur Items mit sehr hohen Trennschärfen, ist anzunehmen, daß alle Item mehr oder minder dasselbe messen - die Homogenität eines Testes läßt sich auch durch die Berechnung der Aufgabeninterkorrelationen bestimmen Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 49 - bei echt alternativen Items werden sog. Phi-Koeffizienten bestimmt - bei künstlich alternativen (dichotomen) Items empfiehlt sich die Verwendung der tetrachorischen Korrelation - sowohl Phi-Korrelationen als auch tetrachorische Korrelationen sind in ihrer Höhe nicht nur abhängig von der inhaltlichen Übereinstimmung (Homogenität) der Items, sondern auch von deren Schwierigkeiten - nur dann, wenn beide zu vergleichenden Items die gleiche Schwierigkeit aufweisen, kann überhaupt die Maximalkorrelation 1,00 auftreten - sind die Schwierigkeitsindizes sehr stark unterschieden, kann auch bei ansonsten idealer inhaltlicher Übereinstimmung niemals eine hohe Korrelation herauskommen, da bei der schwierigen Aufgabe zwangsläufig mehr Falschantworten als bei der leichteren Aufgabe resultieren - demzufolge können auch bei völlig homogenen Tests (z. B. im Sinne der Guttman-Skala) bei FA mehrere unterschiedliche Faktoren extrahiert werden, die lediglich als Gruppenbildung der Items nach Schwierigkeit zu interpretieren sind - die Faktoren sind demnach reine Schwierigkeitsfaktoren - um einer Vermischung von Schwierigkeits- und Inhaltskomponenten entgegenzuwirken, kann man die Phi-Koeffizienten durch eine Minderungskorrektur aufwerten - die Homogenität eines Verfahrens läßt sich in der KTT nicht nur durch Aufgabeninterkorrelationen untersuchen, sondern auch mit Hilfe des sog. Loevinger-Homogenitätsindexes - Grundlage hierfür ist das Konzept der GUTTMAN-Skala, bei deren Erfüllung ein völlig homogener Test resultiert - bei dieser Skala darf bekanntlich in einer schwierigkeitsgestaffelten Itemabfolge niemals von einem Pb ein schwieriges Item gelöst werden, wenn bereits, wenn dieser bereits bei davor liegenden leichteren Items versagt hat - im Homogenitätsindex werden nun 3 Varianzen in Beziehung gesetzt: 1. die beobachtete Varianz des Tests (sx2), 2. die Varianz, die ein völlig heterogener Test mit gleicher Verteilung der Schwierigkeitsindizes aufweisen würde (shet2) und 3. die Varianz, die ein völlig homogener Test mit gleicher Schwierigkeitsverteilung aufweisen würde (shom2) sx2 - shet2 H= shom2 - shet 2 dieser Homogenitätsindex ist wie ein Korrelationskoeffizient zu interpretieren - Trennschärfeindizes, Aufgabeninterkorrelationen und auch der Homogenitätsindex sagen nichts darüber aus, ob der Test wirklich das angezielte Merkmal mißt, sondern gestattet zunächst lediglich eine Aussage über die Homogenität des Verfahrens und die Tauglichkeit der Items zur Messung jenes Merkmals - man geht bei der Trennschärfenbestimmung von der noch ungeprüften Annahme aus, daß der Gesamtpunktwert tatsächlich den Ausprägungsgrad des zu erfassenden Merkmals widerspiegelt - diese Annahme wird aber erst später durch die Überprüfung der Validität explizit verifiziert bzw. falsifiziert - insbesondere bei Eignungstest wird daher manchmal auch bereits in der Phase der Aufgabenanalyse für jedes Item die Gültigkeitsannahme geprüft, indem z. B. mit Hilfe der Vierfelderkorrelationen Gültigkeitskoeffizienten für die einzelnen Items bestimmt werden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 50 - dabei ist es notwendig, daß zur Außenvalidierung benutzte Kriterium (z. B. Bewährung im Beruf) zu dichotomisieren, so daß Bewährung/Nichtbewährung Richtig/Falsch-Antworten im Item die Vierfeldertafel bilden Wichtig bleibt festzuhalten: die besten Trennschärfekoeffizienten resultieren bei mittelschweren Aufgaben (p=0,50), da hier die Varianz und damit die Differenzierungsmöglichkeiten der Aufgaben am größten sind da die Trennschärfe aber nicht nur durch die Schwierigkeit, sondern auch von der Homogenität der Items und des Gesamttests bestimmt wird, kann es durchaus vorkommen, daß trotz idealer Schwierigkeitskennwerte die Items schlechte Trennschärfenwerte aufweisen; in einem solchen Fall werden die Pb zwar gut differenziert, aber nicht in der eigentlich zu erwartenden Richtung - für die Itemsimulation müssen simultan Schwierigkeit, Trennschärfe und ggf. auch Validitätsindex beachtet werden - besteht ein Test nur aus schwierigkeitsähnlichen Items, ist die Selektion relativ einfach, da man dann nur nach der Höhe der Trennschärfenindizes auszuwählen braucht - die meisten Tests folgen aber ihrem Aufbau nach mehr der zweiten Empfehlung für die Schwierigkeitsgraduierung, d. h. , die Items variieren nach ihrer Schwierigkeit im Bereich von p=0,20 bis p=0,80 - in einem solchen Fall besteht die Gefahr, daß die Items mit sehr hohen bzw. geringen pWerten durch das “Sieb fallen”, weil sie wegen der paraboloiden Beziehung zwischen Schwierigkeit und Trennschärfe geringe Trennschärfen erhalten - aus 2 Gründen ist aber die Beibehaltung auch von einigen Aufgaben umit extremen pWerten empfehlenswert: 1. um beim “Einstieg in den Test” leichte Aufgaben zur Verfügung zu haben und 2. in Anbetracht der Relativität der Schwierigkeitskennwerte, bezogen auf die jeweilige Stichprobe Beispiel: - in einer sehr heterogenen Stichprobe wird ein für die Gesamtstichprobe sehr schwieriges Item (z. B. p=0,20) in der Untergruppe der sehr leistungsfähigen Pb möglicherweise gerade die ideale Schwierigkeit p=0,50 aufweisen, so daß es besonders zur Differenzierung in dieser Subgruppe beiträgt (ebenso gilt dies für sehr leichte Items im Hinblick auf leistungsschwache Pb) Selektionsindex (S) von Lienert; dieser verhindert nun, daß allzu viele Aufgaben mit extremen Schwierigkeitskennwerten ausgeschlossen werden, da er Trennschärfe und Schwierigkeit gleichzeitig berücksichtigt psup - pinf S= 4pq S= Selektionswert psup = Schwierigkeitsindex der überdurchschnittl. Gruppe pinf = ´´ ´´ unterdurchschnittl. ´´ p = Schwierigkeitsindex für die Gesamtgruppe q = 1-p - die Unterteilung in die beiden Leistungsgruppen erfolgt nach dem Median - die Aufgabenauswahl kann noch verbessert werden, wenn man außerdem Gültigkeitsindizes und die Expertenurteile über die Güte der Items ebenfalls beachtet - zur Testanalyse in der KTT gehört auch die Überprüfung der Häufigkeitsverteilung der Testrohpunkte im Gesamttest (Testautoren streben meist eine NV der Testrohpunkte an) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 51 - bei linksschiefen Verteilungen ist der Test für die Gesamtstichprobe zu schwierig, bei rechtsasymmetrischen Verteilungen dagegen zu leicht geworden - Schiefe und unregelmäßige Verteilungen können im wesentlichen 3 Ursachen haben: 1. Die Analysenstichprobe ist nicht repräsentativ zusammengesetzt 2. Der Test ist mangelhaft konstruiert (z. B. im Hinblick auf die Schwierigkeitsgraduierung und Abfolge der Items) 3. Das untersuchte Persönlichkeitsmerkmal verteilt sich realiter anormal (nach Lienert sollte die 3. Ursache erst dann angenommen werden, wenn man die beiden anderen Ursachen ausschließen kann) Aufgabenanalysen in den PTT und in der KOM - in der PTT erfolgt die Bestimmung der Aufgabenparameter (im RASCH-Modell lediglich die Schwierigkeit) “teilgruppenkonstant” (“populationsunspezifisch”), so daß die Schwierigkeitsparameter im Unterschied zur KTT absolut, d. h. auch für jede Untergruppe einer Gesamtstichprobe gelten - es werden aufgrund verschiedener vorgeschlagener Algorithmen die Schwierigkeitsparameter probabilistisch geschätzt (diese Algorithmen erfordern EDV-Programme) - mit Hilfe der PTT wird v. a. eine Aussage zur Homogenität eines Tests getroffen, wobei die Schwierigkeiten vermieden werden, die mit der Berechnung von Aufgabeninterkorrelationen als Basis der Homogenitätsbestimmung in der KTT verbunden sind - wie in der KTT tragen auch in der PTT diejenigen Items am besten zur Differenzierung der Pb bei, die für die jeweilige Zielgruppe mittlere Schwierigkeitswerte aufweisen - die personenunabhängige Auswahl der Items bewirkt aber, daß nur jene Items beibehalten werden, die in der Gesamtstichprobe gleiche Differenzierungsmöglichkeiten (Informationen) eröffnen (Homogenisierung nach der Trennschärfe) - damit ist aber möglich, daß gerade jene Items ausgeschaltet werden, die sich zwar von den anderen Items hinsichtlich ihrer Itemcharakteristika generell unterscheiden, aber in bestimmten wichtigen kritischen Bereichen des Tests (z. B. im cut-off-Bereich) besonders trennscharf (informationshaltig) sind - bei der KOM - insbesondere bei lehrzielorientierten Tests - spielt die Überprüfung der Kontentvalidität auch jeder einzelnen Aufgabe eine entscheidende Rolle - Experten schätzen also ein, ob die jeweilige Aufgabe wirklich das Lehrziel repräsentiert, das durch sie erfaßt werden soll - bei der Überprüfung des Tests in einer Analysestichprobe ist es notwendig, daß man die Kompetenz (Lehrziel erreicht/nicht erreicht) bzw. die Kompetenzstufe der Untersuchten auch an einem Außenkriterium einschätzen kann - hierfür kommen z. B. das Lehrerurteil oder die Ergebnisse anderer, bereits bewährter Tests in Frage; es wird dann überprüft, ob in 2 ausreichend großen Stichproben mit extremen Kompetenzunterschieden (Extremgruppen) auch die einzelnen Aufgaben in der erwarteten unterschiedlichen Weise gelöst werden Vortest-Nachtest- (Trainings-) Validierung: - durch ein effektives lehrzielbezogenes Trainieren (Unterrichten) wird das Lehrziel in der gewünschten Richtung verändert - setzt man nun dasselbe Item vor und nach dem Training ein, dann muß sich diese Kompetenzerhöhung in der Veränderung der Lösungswahrscheinlichkeit eines Items widerspiegeln Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 52 - hierzu wird der Diskriminationsindex bestimmt; dieser ist definiert als die Differenz der Schwierigkeitsindizes des Items vor und nach dem Training; je höher er ausfällt, desto geeigneter ist das Item - die Homogenität eines lehrzielorientierten Tests kann durch verschiedene Methoden überprüft werden - der Ü-Koeffizient von Fricke setzt im Unterschied zu den Kennwerten der KTT nicht die bei diesen erforderliche Varianz der Beobachtungswerte voraus, sondern kann auch bei minimaler Varianz bestimmt werden - der Ü-Koeffizient als Trennschärfekoeffizient bezieht sich auf die Prognose, die durch eine Aufgabe im Hinblick auf das Alternativmerkmal “Ziel erreicht/nicht erreicht” erzielt wurde (analog der “Prognose der Gesamtpunktwerte” bei der Bestimmung des klassischen Trennschärfekoeffizienten) - es wird die Zahl der Übereinstimmungen zwischen Zielerreichung und Lösung der betreffenden Aufgabe ausgezählt und auf die Gesamtzahl der Schüler relativiert - der Koeffizient Ü ist definiert als das Verhältnis der tatsächlichen Übereinstimmungen zur Zahl der maximal möglichen Übereinstimmungen (also wenn alle “Löser” der Aufgabe auch das Lehrziel erreicht haben) Gütekriterienüberprüfung Objektivität Objektivität: Unabhängigkeit der gewonnenen Testergebnisse von der Person des Testanwenders (Durchführungsobjektivität), des Testauswerters (Auswertungsobjektivität) und des Testinterpreten (Interpretationsobjektivität) - diese intersubjektive Übereinstimmung ist die unbedingt notwendige Vorraussetzung für die Vergleichbarkeit der Testergebnisse und für die Validität, allerdings ist sie natürlich noch keine hinreichende Bedingung - oft wird die Objektivität nicht explizit überprüft, da man bei hochstrukturierten Tests von vorneherein annimmt, daß hier kaum Beurteilungsdifferenzen auftauchen können (z. B. bei standardisierten Verfahren) - bei weniger strukturierten Verfahren (z. B. projektiven Verfahren) ist von vorneherein eine geringere Objektivität zu erwarten - Objektivitätskennwerte lassen sich bestimmen, wenn man verschieden Psychologen bittet, z. B. bei der Auswertungsobjektivität die gleichen Testprotokolle auszuwerten ( Ermittlung der Urteilerübereinstimmung) Reliabilität (Zuverlässigkeit, Meßgenauigkeit) - wurde zunächst in der KTT entwickelt Reliabilität: Grad der Genauigkeit, mit dem ein Test ein bestimmtes Persönlichkeits- oder Verhaltensmerkmal mißt, gleichgültig, ob er dieses Merkmal auch zu messen beansprucht - es interessiert also nicht was, sondern wie genau gemessen wird Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 53 - Reliabilität ist eine notwendige, aber wie die Konkordanz noch keine hinreichende Bedingung für die Validität eines Tests - Reliabilitätsabschätzungen eines Tests benötigt man auch, um statistische Signifikanz von Testwertdifferenzen feststellen zu können - die Reliabilität in der KTT ist als das Verhältnis “Varianz der wahren Testwerte/Varianz der beobachteten Testwerte definiert VAR (T) rtt = VAR (X) - infolge von Fehlereinflüssen ist die Varianz der beobachteten Werte stets größer als die Varianz der wahren Werte - in der Grundgleichung der KTT - bezogen auf eine Population (sx2 = sT2 + sE2) - wird die Vermischung der wahren Werte mit (unsystematischen) Fehlerfaktoren in den beobachteten Testwerten dargestellt Ziel der Reliabilitässchätzung ist die Abschätzung der Fehlervarianz eines Tests - da die Wurzel aus der Zuverlässigkeit (rtt) der Korrelation zwischen wahren und beobachteten Testwerten enspricht, vrtt = rTE kann man den Zuverlässigkeitskoeffizienten auch als Bestimmtheitsmaß bzw. Determinationskoeffizienten interpretieren - der Wert rtt x 100 gibt an, zu wieviel Prozent man die Varianz in den wahren Werten erklären kann, wenn man von den beobachteten Werten ausgeht und mittels der Regressionsgeraden die wahren Werte schätzt vereinfacht kann man sagen, daß mit der Reliabilität eines Tests die Fähigkeit eines Tests angegeben wird, Personen mit unterschiedlich wahren Testwerten zu diskriminieren - aber es gibt verschiedene Verfahren der Reliabilitätsschätzung, daher muß bei der Angabe der Zuverlässigkeitskennwerte stets mit angeben, mittels welcher Methode und bei welcher Stichprobe die Zuverlässigkeit geschätzt wurde - die einzelnen Verfahren zur Schätzung der Reliabilitätskennwerte (Retest, Paralleltest, Halbierungs- bzw. Konsistenzmethode) basieren im Prinzip alle auf dem Parallelitätskonzept die verschiedenen Methoden erfassen aber jeweils nur bestimmte Komponenten der Fehlervarianz! Fehlervarianz VAR (E) Fehlervarianz zu Lasten des Instruments - VARins. Fehlervarianz betreffend Testaufbaumängel VARconsist. Fehlervarianz zu Lasten der Durchführungsbedingungen VARstab. Fehlervarianz betreffend Objektivität VARobj. Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 54 Zunächst läßt sich die Fehlervarianz in 2 Komponenten aufteilen: 1. Komponente (VARinst.), die die instrumentelle Güte des Verfahrens selbst betrifft, also seinen Wert als Meßinstrument charakterisiert 2. Komponente, die die besonderen momentanen Bedingungen (Zeitpunkt, Raum) und der Situation des Pb während der Testdurchführung (z. B. augenblickliche Disposition) betrifft zu 1, - die erste Fehlerkomponente wird durch die Prüfung der internen Konsistenz, v. a. durch die Halbierungsmethode und die Konsistenzanalyse erfaßt - diese Methoden beantworten die Frage, in welchem Grade die jeweils im Test ausgewählte Itemstichprobe zur Fehlervarianz beiträgt - als hoch reliabel gilt ein Test, wenn die Pb in den einzelnen Testteilen (also Testhälften oder Items) zu sehr ähnlichen Ergebnissen kommen, die Ergebnisse der Pb in den Testhälften also hoch korrelieren zu 2, - die zweite Fehlervarianzkomponente erfaßt man mit der Retest- und Paralleltestmethode, also durch Wiederholungsmessungen - da hierbei aber neben der situativen Fehlerkomponente auch noch die “instrumentelle” Fehlerkomponente wirkt, liegen die Parallel- und Retestkoeffizienten meist unter den Halbierungs- und Konsistenzanalysekoeffizienten - es ist allerdings fraglich, ob es sich bei diesen am meisten benutzten Methoden der Retestbzw. Paralleltestverfahren um “echte” Zuverlässigkeitsbestimmungen handelt, denn: a, man muß annehmen, daß fast jede Persönlichkeitseigenschaft einen gewissen Schwankungs- und Veränderungsbereich hat, so daß Differenzen zischen Erst- und Zweitmessung nicht unbedingt zu Lasten, der Zuverlässigkeit des Testinstruments gehen, sondern Veränderungen in den wahren Werten widerspiegeln können b, nach dem Konzept der KTT ist der durch die Zuverlässigkeitsbestimmung zu erfassende Meßfehler ein zufälliger, unsystematischer Fehler; systematische Fehler (z. B. Übungseffekte) dürfen demzufolge auch nicht dem Testverfahren angelastet werden dem eigentlichen Konzept der Zuverlässigkeit entspricht daher am besten das Halbierungs- und Konsistenzanalyseverfahren - die instrumentelle Fehlerkomponente läßt sich noch weiter aufteilen in eine Fehlerkomponente, die mit dem Aufbau des Verfahrens selbst (v. a. also mit seiner Homogenität) zu tun hat, und in eine Komponente, die die Objektivität bei der Testauswertung betrifft - letztere läßt sich durch die oben erwähnte Verfahren der Urteilerübereinstimmung abschätzen - ist die Objektivität eindeutig gewährleistet, dann sind Mängel in der Halbierungszuverlässigkeit vornehmlich auf Mängel im Testaufbau (mangelnde Homogenität, Fehler in der Itemabfolge) zurückzuführen - bei Halbierungsanalyseverfahren muß der gewonnene Korrelationskoeffizient nocht aufgewertet werden, da er sich ja nur auf die Testhälften bezieht und in Anbetracht der Abhängigkeit der Zuverlässigkeit von der Testlänge der Bezug zum längeren Gesamttest hergestellt werden muß - dazu dient die sog. Spearman-Brown´sche Korrekturformel für die Testverlängerung: 2 x r12 rtt = 1 + r12 Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 55 - wie die Halbierungsmethodik beruht auch die Konsistenzanalyse auf nur einer Testsitzung und der Aufspaltung des Tests in Teile (Items) - Grundlage der Berechnung sind Aufgabenkennwerte, die aus der Aufgabenanalyse stammen Berechnung eines Konsistenzkoeffizienten nach Gulliksen (auch sog. Kuder-Richardson-Formeln möglich) für dichotome Items: n = Anzahl der Testaufgaben n pq p = Schwierigkeitsindex rtt = x 1q = 1-p rit = Trennschärfeindex n-1 ( rit x pq)2 Bei Items, die nicht dichotom, sondern intervallskaliert sind (z. B. Rating-Skalen) berechnet man als Konsistenkoeffizienten Cronbachs Alpha: st2 n = 1n-1 sx2 n = Anzahl der Items st2 = Varianz des (intervallskalieren) Items sx2 = Varianz des Tests Vorraussetzung für die Anwendbarkeit dieser Formel - wie auch der Halbierungsund Konsistenzverfahren - ist die Annahme, daß der Test von vorneherein als homogener Test konzipiert ist - will man die den Gesamtpunktwert eines heterogenen Tests auf seine Zuverlässigkeit überprüfen, ist die Retest- bzw. Paralleltestmethode die Methode der Wahl - die Zuverlässigkeit eines Verfahrens hängt von mehreren Faktoren ab - wie oben erwähnt, ist beim Paralleltestkonzept der Homogenitätsgrad des Tests von ausschlaggebender Bedeutung; hinzu kommen Besonderheiten der jeweils ausgewählten Stichprobe für die Zuverlässigkeitsbestimmung - da Korrelationskoeffizienten im hohen Grade durch die Streuung der Testwerte in einer Stichprobe bestimmt werden, wird bei einer Stichprobe mit geringerer Streuung der Zuverlässigkeitswert niedriger ausfallen als bei einer Stichprobe mit größerer Streuung - da gerade bei Zuverlässigkeitsprüfungen oft relativ kleine und sog. anfallende Stichproben verwendet werden, kann durchaus der Zuverlässigkeitskoeffizient schlechter ausfallen, als es z. B. bei der meist größeren und repräsentativeren Eichstichprobe der Fall ist - liegen daher aus dieser Varianzkennwerte vor, kann die Zuverlässigkeitsschätzung mit Hilfe bestimmter Umrechnungsformeln “hochgerechnet” werden - weiterhin besteht eine Abhänigigkeit der Zuverlässigkeit von der Testlänge (Anzahl der Items), die durch die folgende Formel abgeschätzt werden kann: n´ x rtt r´tt = vorauss. Zuverlässigkeit des verlängerten Tests n rtt = ursprüngl. Zuverlässigkeit des Tests r´tt = n = Anzahl der Aufgaben im ursprüngl. Test n´ 1+ - 1 rtt n´ = Anzahl der Aufgaben im veränderten Test n - der Test wird also mit wachsender Testlänge zuverlässiger - dies wird besonders deutlich bei Tests mit niedriger Zuverlässigkeit; bei schon relativ hoher Zuverlässigkeit führt eine Testverlängerung kaum noch zu Reliabilitätssteigerungen - auch ist zu beachten, daß es sich nur um eine Großschätzung handelt, und es muß gewährleistet sein, daß dem Test tatsächlich homogene (parallele) Items hinzugefügt werden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 56 - beachtet werden muß weiterhin, daß durch eine zu große Verlängerung evtl. die Pb extrem belastet werden (Ermüdung, Demotivation etc.) Einbuße der Reliabilität und Validität - ein solcher Einfluß kann aber durch die Formel natürlich nicht abgeschätzt werden, so daß eine nochmalige Reliabilitätsüberprüfung des verlängerten Tests i. d. R. notwendig sein dürfte Andere Möglichkeiten zur Reliabilitätsabschätzung: - hierbei geht man von folgender Überlegung aus: die höchste Korrelation, die ein Test (Beobachtungswert) überhaupt zu einer anderen Variablen haben kann, ist die Korrelation mit seinen eigenen “wahren Werten” - es kann keinen anderen Meßwert geben, der mit dem Testwert (Beobachtungswert) höher korreliert als der true-score, da bei Gültigkeit der Annahmen der KTT der Erwartungswert des Meßfehlers für jede Person Null ist und folglich kein systematischer Zusammenhang mit anderen Merkmalen der Person (über den Meßfehler möglich ist) - wir hatten oben bereits festgestellt, daß die Korrelation zwischen beobachteten Testwerten und “wahren Werten” - diese wird als Reliabilitätsindex bezeichnet - gleich der Wurzel der Reliabilität eines Tests ist (rTE = rtt) - da die Reliabilitätskoeffizienten zwischen Null und Eins liegen, fällt der Reliabilitätsindex höher aus als der Reliabilitätskoeffizient (z. B. bei rtt = 0,64 beträgt rTE = 0,8) der Reliabilitätsindex gibt also die höchstmögliche Korrelation eines Tests mit irgendeiner anderen Variablen an (die z. B. mit einem Außenkriterium oder gültigkeitsähnlichen Test im Rahmen der Validitätsüberprüfung gewonnen wird) - erhält man nun Korrelationen des Tests mit anderen Variablen, dann liegen diese also mit Sicherheit unter dem Reliabilitätsindex - demzufolge ist umgekehrt zu folgern, daß der Reliabilitätsindex höher bzw. zumindest gleich der höchsten Korrelation des Tests mit irgendeiner anderen Variablen ist, die z. B. im Rahmen der Gültigkeitsüberprüfung gewonnen wurde - diese Korrelation gestattet daher eine Abschätzung der zumindest (kleinstmöglichen) vorliegenden Reliabilität (hat z. B. ein Test eine Korrelation mit einem gültigkeitsähnlichen Test in Höhe von r = 0,90, so hat der Test zumindestens diesen Reliabilitätsindex von 0,81 Probleme der Retestreliabilität: - mögliche Unterschätzung der Reliabilität bei Persönlichkeitsverfahren durch situativ abhängige Beantwortung - Merkmalsveränderungen - Tagesform die Retestreliabilität hat die größte Störungswahrscheinlichkeit Intern Konsistenz als Reliabilitätswert: Vorteile: - fehlender Übungseffekt (Übungseffekt von Item zu Item können durch alternierende Itemaddition [Item 10+32, 43+3] begrenzt werden) - Veränderung des Merkmals fällt weg - keine Situationsabhängigkeit - mögliche Meßfehler können nur durch das Meßinstrument entstehen (niedrige interne Konsistenzwerte bedeuten immer ein schlechtes Meßinstrument Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 57 Zuverlässigkeitsbestimmung in der PTT: - Vertreter der PTT bezeichnen die sog. Populationunabhängigkeit der Zuverlässigkeitskennwerte der KTT als einen wesentlichen Mangel - infolge dieser Stichprobenabhängigkeit gelten die Reliabilitätskoeffizienten lediglich “im Schnitt”, können aber für Teilgruppen bzw. Einzelpersonen keine unumschränkte Gültigkeit beanspruchen - die Ansätze der PTT beziehen sich im Unterschied zur KTT primär auf Annahmen über Einzelpersonen - sie liefern daher auch keinen generellen Zuverlässigkeitskennwert eines Tests - bei der sog. Maximum-Likelihood-Methode zur Bestimmung der Fähigkeitsparameter im Rasch-Modell wird die Reliabilität durch die Art der Beziehung zwischen Personenparameter und Lösungswahrscheinlichkeit der Aufgabe bestimmt - je “sensibler” die Lösungswahrscheinlichkeit einer Aufgabe gegenüber Veränderungen in den Personenparametern reagiert, (d. h., um so größere Veränderungen in der Lösungswahrscheinlichkeit auch bei relativ geringen Fähigkeitsparameteränderungen auftreten) desto größer ist deren sog. Informationsbeitrag bei der Parameterbestimmung - es läßt sich zeigen, daß (ähnlich wie in der KTT) die Informationsfunktion eines Items für den Personenparameter maximal wird, bei einer Lösungswahrscheinlichkeit von p = 0,50 - zur Schätzung eines Personenparameters werden die im Test zusammengefaßten Items bzw. deren Informationsbeiträge addiert - die für die Meßgenauigkeit entscheidende Kennziffer - also die Information - variiert dann natürlich in Abhängigkeit von der Zahl der gelösten Items und damit vom Personparameter, so daß im Unterschied zur KTT für jeden Personparameter eine andere Meßgenauigkeit (Reliabilität) vorliegt - wie in der KTT birngen auch in der PTT die leichten Items mehr Information für die schwächeren Ausprägungsgrade eines Merkmals und die schweren Items mehr Informationen für die hohen Ausprägungsgrade, da die in der Gesamtstichprobe leichten bzw. schweren Items in den Extremgruppen zu jeweils mittleren Lösungswahrscheinlichkeiten (p 0,50) tendieren - für die Auswahl der Items zum Zwecke einer Zuverlässigkeitserhöhung ist es daher notwendig zu bestimmen, bei welcher Personengruppe man besonders an einer sehr genauen Parameterschätzung interessiert ist, denn danach wählt man bevorzugt leichte oder schwere Items (bezogen auf die Gesamtstichprobe) aus - man auch aus einem Test jene Items heraussuchen und nur deren Beantwortung in die Auswertung einbeziehen, die bei der betreffenden Gruppe von Menschen besonders hohe Meßgenauigkeit versprechen (Prinzip des tailored testing) - dazu ist man berechtigt, da bei Modellgültigkeit jede Itemstichprobe aus der Gesamtstichprobe die gleiche Dimension mißt Reliabilitätsbestimmung in der KOM: - in der KOM wird bei Fehlen der Varianz die Zuverlässigkeit mit Hilfe des Fricke´schen Übereinstimmungskoeffizienten bestimmt - Zunächst bestimmt man die Zuverlässigkeit der einzelnen Items, indem man die Anzahl der Pb, die im Ersttest und Zweittest (Retest oder Paralleltest) das gleiche Resultat haben, zur Gesamtzahl der Personen in Beziehung setzt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 58 Validität (Gültigkeit) Validität:Grad der Genauigkeit, mit dem ein Test mißt, was er messen soll - die Validitätsüberprüfung ist der letzlich entscheidende Abschnitt der Testentwicklung und überprüfung - Validitätskennwerte sagen aus, inwieweit ein Verfahren das eigentliche Diagnostizierungsziel, die möglichst exakte und wahre Abbildung von Ausprägungsgraden einer psychischen “Beschaffenheit” erreicht - von relativ untergeordneter Bedeutung ist dabei die Frage, ob die Ausprägungsgrade relativ zu den Ausprägungsgraden in einer Referenzpopulation (KTT), teilgruppenkonstant (PTT) oder in bezug auf die Erreichung einzelner Ziele (KOM) bestimmt werden - in Anbetracht der gewählten Kriterien, der Stichprobenabhängigkeit aller Validitätskoeffizienten und der Abhängigkeit der Validitätskoeffizienten von der diagnostischen Fragestellung muß man die Validitätsaussage jeweils spezifizieren und konkretisieren - dieser als differentielle Validität bezeichnete Sachverhalt wird von WESTMEYER (1972) folgendermaßen formalisiert: die Validität setzt sich aus den Variablen t, c, p, u, v und z zusammen Validität wird hier verstanden als die Validität des Tests t in bezug auf das Kriterium c bei Anwendung auf die Personenklasse p unter den Umgebungsbedingungen u durch den Versuchtsleiter v während des Zeitbereichs z Daraus folgen 2 praktische Schlußfolgerungen: 1. Entwicklung von Tests mit umgrenztem Geltungsbereich und exakt bestimmten Entscheidungskriterien, für die dann also auch eine zutreffende konkrete Validitätsbestimmung möglich ist. 2. Aufforderung an den Praktiker, durch eigene Untersuchungen an der jeweiligen Praxisstelle selbst zu klären, ob Verfahren mit umfangreicherem Gültigkeits- und Geltungsbereich auch für die jeweilige praktische Entscheidungssituation valide sind. Gültigkeitsarten - Möglichkeiten der Einteilung Es gibt 2 große Bereiche der Validität: a, das Testverhalten enstspricht dem (normalen) Verhalten außerhalb der Testsituation b, das Testverhalten ist Indikator eines latenten Merkmals zu a, eine Überprüfung erfolgt auf 2 Wegen: Repräsentationsschluß - es gilt hierbei zu überprüfen, ob das Testergebnis repräsentativ für das Verhalten außerhalb der Testsituation ist Inhaltsvalidität, logische Validität Korrelationsschluß - Validierung erfolgt anhand eines Außenkriteriums Kriteriumsvalidität zu b, entspricht dem Vorgehen der Konstruktvalidierung Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 59 Inhaltsvalidität und logische Validität Inhaltsvalidität: hierunter versteht man die Tatsache, daß ein Test eine repräsentative Stichprobe aus einer Gesamtaufgabenmenge darstellt, die zur Messung eines Personenmerkmals unter Beachtung bestimmter Merkmale von einem Expertengremium definiert und als geeignet zur Messung eines bestimmten Merkmals definiert wurde - wie bereits erwähnt ist nicht erst bei der Überprüfung des Tests die Kontentvalidität zu beachten, sondern bereits bei der Entwicklung der Testaufgaben - die gegebene Definition läßt erkennen, daß man sowohl bei der Testentwicklung als auch bei der Testüberprüfung die Kontentvalidität durch eine Expertenstichprobe näher abschätzen lassen sollte - sie haben zu beurteilen, ob der gesamte Test bzw. das einzelne Item dem vorher abgegrenzten Aufgabenuniversum entspricht, aus dem der Test eine Stichprobe darstellen soll - als Maß für die Bestimmung der Kontentvalidität über die sog. logische Validität (Anerkennung des Test durch Experten auf Grund logisch-wissenschaftlicher Einsicht) kann der Kontentvaliditätskoeffizient (content validity ratio CVR) nach LAWSHE berechnet werden: N Ne = Zahl der Beurteiler, die den Test Ne (bzw. das Item) für repräsentativ 2 halten CVR = N = Gesamtzahl der Beurteiler N 2 - der Koeffizient variiert wie der Korrelationskoeffizient zwischen -1 und +1 - je positiver der Wert, desto inhaltsvalider ist der Test bzw. das Testitem - FRICKE setzt in seinem Übereinstimmungskoeffizient die Varianz (s2) innerhalb der Beurteiler in Beziehung zur maximal möglichen Varianz der Beurteiler s2emp Ü=1s2max - ein besonders anspruchsvolles Verfahren zur Inhaltsvalidierung beginnt damit, daß 2 Gruppen von Testkonstrukteuren unabhängig voneinander lediglich auf Grund der Information über den angezielten Diagnostizierungsgegenstand ein “Aufgabenuniversum” beschreiben und generative Regeln zur Erzeugung von Testaufgaben entwickeln - die hieraus abgeleiteten 2 Tests müssen im Falle hoher Inhaltsvalidität bei gleichen Personen gleiche Ergebnisse bringen, was sich durch einfache Korrelationsrechnung nachprüfen läßt - von der logischen Validität ist die sog. psychologische Validität, Augenscheinvalidität oder face-validity zu unterscheiden - der Pb weiß um den Sinn und Zweck der Fragestellung und erkennt ihren offenen, gültigen Charakter (z. B. Bewerbung) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 60 Kriterienbezogene Validität - wie schon erläutert, ist die Bestimmung der Validität eines Testverfahrens durch die Korrelation der Testergebnisse mit einem Kriterium die eigentliche Validierungsstrategie der KTT, die in vielfacher Hinsicht ausgebaut wurde - positiv ist an dem Konzept der kriterienbezogenen Validierung gewiß die Praxisorientierung, d. h. die Erkenntnis, daß der Wert von Testverfahren durch deren Inbezugsetzung mit bestimmten Kriterien der Praxis- bzw. Lebensbewährung bestimmt werden soll - es ist also stets notwendig, ein sog. Kriterium außerhalb der Testsituation zu bestimmen, das direkt beobachtbar ist - zunächst muß man sich überlegen, welches Kriterium mit einem Testergebnis in Zusammenhang gebracht werden soll (z. B. die Schulleistung als Kriterium für die Gültigkeit eines Intelligenztests) - diesem sog. Kriteriumskonzept (Schulleistung) lassen sich unterschiedliche Kriteriumsmeßwerte zuordnen (Lehrerurteil, Zensuren), für die man sich zu entscheiden hat bzw. die man kombinieren kann Nach LIENERT lassen sich Kriterien nach a, dem Grad der Komplexität (z. B. nur Mathematiknote oder kombiniert mit Lehrurteil), b, der Objektivität (Zensuren vs. Bewährungsproben) und c, dem Grad der Quantifizierbarkeit (Globaleinstufung vs. feinstufige Ratingskalen) unterscheiden. - GHISELLI differenziert weiter in statische vs. dynamische Kriterien (dynamisches Kriterium wäre z. B. die Verbesserung der Schulleistung in einem best. Zeitabschnitt); so dürfte z. B. für die Validierung von Lerntests solche dynamischen Kriterien gegenüber den bisher dominierenden statischen Kriterien an Bedeutung gewinnen - innerhalb der Kriteriumsvalidität unterscheidet man die sog. Übereinstimmungsvalidität (bzw. konkurrente Validität) und die prognostische (prädiktive) Validität bzw. Vorhersagevalidität - die Übereinstimmungsvalidität betrifft die Enge des Zusammenhangs mit einem zeitlich koexistenten Kriteriums, d. h. Testaufnahme und Aufnahme des Kriteriumsmeßwertes (z. B. Lehrerurteil) erfolgen zur gleichen Zeit Innen- bzw. Binnenvalidierung; die Korrelation des neuen Tests mit den alten Tests gelten als Kennwerte für die Gültigkeit des neuen Tests (Problem: kein Erkenntnisfortschritt, da alte Konzepte und die damit verbundenen Fehler immer wieder aufgefrischt werden) - die prognostische Validität wird v. a. bei Eignungstests erhoben; hierbei wird die Korrelation der Testergebnisse zu einem zukünftigen (nach der Testaufnahme erhobenen) Kriteriumsmeßwert festgestellt - die rein rechnerische Bestimmung der Validitätskoeffizienten (meist Korrelationen) erfolgt unter Berücksichtigung der Datenqualität (Skalenniveau) von Test- bzw. Kriteriumsmeßwerten - die Höhe der Validitätskoeffizienten wird aber nicht nur durch die Güte des Tests, sondern auch durch die Zuverlässigkeit und Validität des Kriteriums mitbestimmt (diese lassen sich aber schwer bestimmen, da man wieder ein “besseres” Kriterium benötigen würde) sorgfältige Auswahl des Kriteriums (z. B. exakte Defintion der Kriteriumsmerkmale) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 61 - auch sollte man nicht nur globale Kriterien anstreben, sondern durch eine Vielzahl von Kriterumswerten (z. B. Verhalten in unterschiedlichen Situationen) der Differenziertheit des Meßinstruments Rechnung tragen - durch wiederholte Kriteriumserhebungen (Retests) kann man auch die Zuverlässigkeit des Kriteriums bestimmen - kennt man die Zuverlässigkeitskoeffizienten des Kriteriums, kann man eine sog. Minderungskorrektur des Validitätskoeffizienten durchführen - hierunter versteht man die Abschätzung der Validität eines Tests unter der Annahme, daß das Kriterium hoch zuverlässig ist - die doppelte Minderungskorrektur bedeutet, daß das Kriterium und der Test hoch reliabel sind - diese mögl. Aufwertung von Korrelationskoeffizienten ist allerdings umstritten; sie ist nur dann korrekt, wenn die Axiome der KTT voll gelten und auch kaum von praktischer Relevanz, da die Anwender nun einmal von den tatsächlich beobachteten Daten und nicht von “einem was wäre, wenn” ausgehen können - es gibt weiterhin verschiedene Formeln zur Beanwortung der Frage, inwieweit der Test zur Vorhersage des Kriteriums taugt, in welchen Grade durch die Testvarianz die Kriteriumsvarianz aufgeklärt wird - die einfachste Beziehung ist der Determinationskoeffizient; dieser ist der quadrierte Validitätskoeffizient (rtc2), der uns sagt, wieviel gemeinsame Varianz Test und Kriterium haben - korreliert etwa ein Test mit einem Kriterium in Höhe von rtc = 0,60, dann ist nur 36% der Varianz der Kriteriumsmeßwerte durch das Testverfahren “aufgeklärt”, d. h. exakt vorhersagbar - hieran erkennt man, wie groß auch bei relativ hohen Gültigkeitskoeffizienten noch die Differenz zwischen Test- und Kriteriumsmeßwerten sein kann - von besonderer Bedeutung ist daher auch die Bestimmung des Standardschätzfehlers, den man in Rechnung stellen muß, wenn man von einem gemessenen Testwert auf einen vermutlichen Kriteriumsmeßwert schlußfolgern will Cy = sy 1-r2xy Cy = Standarschätzfehler sy = Standardabweichung der Kriteriumsmeßwerte rxy (= rtc) = Korrelation Test/Kriterium - um mit dem Standardschätzfehler operieren zu können, muß man zunächst bestimmen, welchen Kriteriumsmeßwert man bei einem “neuen Pb” erwarten kann, wenn man von der vorher festgestellen Beziehung Test/Kriterium in einer Referenzstichprobe ausgeht - aufgrund der Regressionsgleichung kann der Kriteriumsmeßwert geschätzt werden C = geschätzter Kriteriumsmeßwert sy xi = Testwert des Pb C = rxy (xi - x) + y x = arith. Mittelwert der Testwerte in der Stichprobe ´´ ´´ Kriteriumswerte ´´ sx y= sx = Standardabweichung der Testwerte sy = Standardabweichung der Kriteriumswerte rxy = Korrelation Test/Kriterium - die nun für jeden einzelnen Testwert zu bestimmenden Kriteriumsmeßwerte sind also mit einem Standardschätzfehler behaftet (z. B. bei 5% Irrtumswahrscheinlichkeit liegt der wahre Kriteriumsmeßwert bei einem erwarteten Meßwert von 20 im Bereich von 16-24 Punkten bei C = 2) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 62 Zur Verbesserung der Gültigkeit eines diagnostischen Verfahrens - v. a. im Sinne der Erhöhung der prognostischen Validität - werden verschiedene Maßnahmen diskutiert und praktiziert: 1. Erhöhung der Reliabilität - da der Validitätskoeffizient nicht höher sein kann als der Reliabilitätsindex (rtc > rtt) kann durch eine Erhöhung der Reliabilität (z. B. Testverlängerung mit homogenen Items) im gewissen Maße auch eine Verbesserung der Gültigkeit erwartet werden 2. Aufstellen von Testbatterien - hierbei versucht man, durch eine möglichst optimale Zusammenstellung von einzelnen Testverfahren zu einer Batterie zu einer Erhöhung der prognostischen Validitätskoeffizienten zu gelangen - i. a. ist es günstig, wenn alle Tests mit dem Außenkriterium hoch und untereinander relativ niedrig korrelieren, damit gewährleistet wird, daß unterschiedliche Seiten des Kriteriums etwa unterschiedliche Aspekte der Berufstauglichkeit - tatsächlich erfaßt werden und nicht jeder Test das gleiche Merkmal mißt - durch die Berechnung sog. multipler Regressionen bzw. Korrelationen, in denen die Beziehung zwischen mehreren Meßwertreihen einerseits (z. B. Items eines Tests oder Untertests) und einer Meßwertreihe (Kriterium) bestimmt wird, lassen sich die Testwerte so gewichten, daß der dann bestimmte Summenwert eine möglichst hohe Korrelation mit dem Kriterium aufweist - die sog. Beta-Gewichte für die einzelnen Tests, mit denen dann also der jeweils erhaltene Testwert multipliziert werden muß, werden mit dieser Methode so bestimmt, daß in der vorliegenden Stichprobe “die Forderung nach möglichst hoher Korrelation zwischen dem so entstandenen Summenscore und dem Kriterium erfüllt wird” - allerdings überschätzen die daraufhin berechenbaren multiplen Korrelationen i. d. R. den Zusammenhang zwischen Test und Kriterium zum einen setzt die multiple Regression die stochastische Unabhängigkeit der Prädiktoren (Tests) voraus, die selten gegeben ist und zum anderen muß beachtet werden, daß die Gewichte lediglich so bestimmt werden, daß in dieser gerade untersuchten Stichprobe die maximal mögliche Test/Kriterium-Korrelation entsteht - es muß daher im Sinne der sog. Kreuzvalidierung an einer anderen Stichprobe geprüft werden, ob der gefundene Satz von Testgewichten auch in einer anderen Stichprobe die gleich hohe Validität erbringt - i. d. R. wird man eine Validitätssenkung registrieren - Kreuzvalidierung läßt sich am einfachsten realisieren, indem man von vornherein die Stichprobe in 2 Teile teilt - in der einen Datenmenge bestimmt man zunächst über multiple Regression die Gewichte der Tests, in der anderen Datenmenge wird dann die mit diesen gewichteten Tests erhaltene Summe mit dem Kriterium korreliert - wir hatten oben festgestellt, daß i. a. die Tests besonders hoch gewichtet werden, die mit dem Kriterium hoch korrelieren - es wird nun angenommen, daß man durch Abzug (negative Gewichtung gewonnen durch Einsatz eines Suppressortests) des im Test erhaltenen Punktwertes von der Gesamtsumme sozusagen eine “Bereinigung” der Testbatterie von einem für die Vorhersage des Kriteriums irrelevanten, aber in den Tests vorkommenden Faktor vornimmt und auf diese Weise eine Gültigkeitserhöhung der Batterie zustande kommt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 63 Suppressortest: ein Test in einer Testbatterie, der ein Merkmal mißt, das zwar in gewissem Maße auch von anderen Tests der Batterie gemessen wird, aber nicht für das Kriterium von Bedeutung ist, so daß die Korrelation des Tests mit dem Kriterium niedrig (evtl. sogar Null- bzw. Minuskorrelationen) und zu den anderen Tests mäßig hoch ist - in der Praxis findet man aber selten eine Testbatterie oder praktische Untersuchung, in der solche Suppressortests eingesetzt werden Beispiel: Überprüfung von Industriemechanikerbewerber auf ihre Berufseignung Test 1 (Fragebogen zur Ausbildung); Korrelation mit Kriterium rtc = 0,30 Test 2 (praktischer Mechaniker Test); rtc = 0,22 Test 3 (theoretisch mechanisches Verständnis); rtc = -0,04 - der dritte Test scheint ein Suppressortest zu sein, so daß er in der errechneten Regressionsgleichung negativ gewichtet wurde: C = 17T1 + 10T2 - 6T3 + 866 - ohne die Berücksichtigung dieses Suppressortests würde die Testbatterie die Leistung jener Personen im Beruf überschätzen, die im praktischen Test durch Anwendung theoretischer Kenntnisse zwar relativ hohe Werte erzielen, aber mangelnde praktische Fertigkeiten haben, die sich für die Berufsausübung in der betreffenden Bewährungsuntersuchung als ausschlaggebender erwiesen Kritik am Suppressorkonzept: - bereits der gesunde psychologische Menschenverstand protestiert gegen eine Vorgehensweise, bei der jemand um so ungünstiger abschneidet, je besser er in einem Test (Suppressortest) ist - es lassen sich auch rein statistische Bedenken gegen das Suppressorkonzept erheben; durch das Vorhandensein von hohen Testinterkorrelationen liegt eine grobe Verletzung des regressionsanalytischen Ansatzes (Unabhängigkeit der Prädiktoren als Voraussetzung) vor, was zu einer Überschätzung der Validität führt (JÄGER) - Suppressorwirkungen sind nach JÄGER lediglich statistische Artefakte 3. Verwendung von Moderatoren: - von größerer praktischer Relevanz als die zumindest problematische Suppressortestbestimmung ist die Beachtung des Phänomens der “differentiellen Diagnostizierbarkeit” bzw. Vorhersagbarkeit - hierunter versteht man den Sachverhalt, daß bei einem Test die Höhe des Zusammenhangs Test/Kriterium in Abhängigkeit von einer dritten Variable variiert - hierbei wird der sog. Moderatorenansatz zugrunde gelegt - unter Moderatorenvariablen werden Variablen verstanden, die bestehende Abhängigkeiten zwischen Variablen in der Größe und/oder Richtung beeinflussen - teilt man z. B. eine Gesamtstichprobe nach bestimmten Kriterien (Moderatoren) wie z. B. Geschlecht, Alter usw. und berechnet nun in den erhaltenen Teilstichproben Gültigkeitskoeffizienten, so fallen diese eventuell sehr unterschiedlich aus - es könnte z. B. sein, daß ein bestimmter Test für Mädchen sehr gut das Kriterium voraussagt, für Jungen dagegen schlecht Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 64 y y^ =bx + a C In einer Gesamtstichprobe C besteht keine Regression bzw. Korrelation y/x, dagegen in der Teilstichprobe B B x - will man daher die Aussagekraft eines Verfahrens genauer bestimmen und die Prognosegenauigkeit erhöhen, dann empfiehlt es sich, bei der hypothetischen Annahme von Moderatorenwirkungen bestimmter Variablen für die Substichprobe getrennte Validitätskennwerte zu bestimmen - man aber auch den Moderatorenansatz umkehren und Tests von vorneherein so konstruie ren, daß sie in den verschiedenen Subpopulationen gleiche Kennwerte erzielen - es können also für verschiedene Subgruppen jeweils getrennte Trennschärfe und andere Validitätskennwerte der Items bestimmt werden und nur solche Items in die Endform aufgenommen werden, die in allen Subgruppen etwa die gleichen Kennwerte erhalten - damit ist zwar nun die Gültigkeit des Verfahrens für eine Zielpopulation als Ganzes gegeben; ungeklärt ist aber oft die Frage, wieviel Teilpopulationen man bilden soll; außerdem besteht die Gefahr, daß man um der Homogenität der Validitätswerte in den Subpopulationen willen die vielleicht gerade besonders interessierenden Unterschiede zwischen den Populationen nivelliert und die nur in einer Population besonders trennscharfen Items selegiert 4. Erhöhung der Validität durch Itemselektion - so wie man in einer Testbatterie die Zusammestellung der Tests optimieren kann, so kann man auch in einem einzelnen Test die Zusammenstellung der Items optimieren, wenn man in einer Stichprobe Kriteriumswerte erhoben hat - hierbei wird auch die Technik der multiplen Regressionsanalyse benutzt - man kann somit auch gewichtete Punktvorgaben für die einzelnen Items erhalten - Kreuzvalidierung erweist sich aber auch hierbei als dringend erforderlich - bei einer schrittweisen multiplen Regression wird zunächst jenes Item ausgewählt, dasdie höchste Itemvalidität zeigt, dann fügt man jenes Item hinzu, das gemeinsam mit dem ersten die höchste multiple Korrelation mit dem Kriterium erbringt, dann wird ein drittes Item so gewählt, daß der vorliegende Satz von 3 Items die höchste multiple Korrelation zum Kriterium zeigt usw. (nur EDV-technisch zu bewerkstelligen) inkrementelle Validität: - den gegenüber den anderen angewandten Datenerhebungsmethoden zusätzlichen Beitrag ei- nes Tests zur Erklärung der Kriteriums-variablen bezeichnet man als “inkrementelle Validität” des Verfahrens - in der Praxis dient meist der Test nicht als ein alleiniger Prädiktor für die Prognose des Kriteriums bzw. für die Begründung einer diagnostischen Entscheidung - andere Test bzw. andere diagnostische Verfahren (Anamnese, Exploration) sowie andere Informationsquellen (z. B. Zensuren) sind oft noch von größerer Bedeutung für die Entscheidungsfindung Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 65 Konstruktvalidität Hauptkritikpunkte an der kriterienbezogenen Validität: - die Überschätzung des Wertes oft fragwürdiger und in ihrer Aussagekraft nicht genügend überprüfter sowie theoretisch ungenügend begründeter Außenkriterien - der rein behavioristische Schluß von Verhalten auf Verhalten ohne Bezug auf das vermittelnder psychische “Mittelglied” - Überschätzung der induktiven Methode gegenüber der deduktiven Methode bei der Erkenntnisgewinnung - die Kriteriumsvalidität kann weder zu einem wesentlichen theoretischen Erkenntnisgewinn führen noch bedenkliche Schlußfolgerungen auf Grund hoher Test/Kriterium-Korrelationen in Frage stellen - so hat man z. B. lange Zeit die meist zumindest mäßig hohen Korrelationen zwischen traditionellen Intelligenztests und später erbrachten Schulleistungen als entscheidenden Beweis für die Gültigkeit des Intelligenztests angesehen und hinterfragt erst in jüngerer Zeit diese prognostische Validitätskoeffizienten - man stellte z. B. fest, daß insbesondere in schlecht geförderten Klassen hohe Test/KriteriumKorrelationen auffindbar sind, gerigere dagegen in gut geförderten Klassen - es ist daher anzunehmen, daß die hohen Korrelationen nicht primär auf sich in der späteren Schulleistung manifestierenden interindividuelle Differenzen in der Intelligenzanlage zurückzuführen sind, sondern auf das Fortbestehen von vornehmlich milieubedingten Entwicklungsrückständen, die vor der Schule registriert und im schulischen Lernprozeß infolge mangelnder individueller Förderung nicht aufgehoben wurden - damit wurde der “Validitätsbeweis” der Intelligenztests (zumindest im Sinne stabiler intelektueller Potenzen) erschüttert und deutlich gemacht, daß Test/Kriterium-Korrelationen keinesfalls sichere Aussagen darüber gestatten, was denn mit dem Test eigentlich gemessen wird Einsatz anderer Methoden, die Aussagen über das was der Test psychologisch-inhaltlich eigentlich erfaßt, ermöglichen Konstruktvalidierung Konstrukt: zunächst hypothetisch angenommene Eigenschaft bzw. ein Eigenschaftskomplex, der dem äußerlich beobachtbaren Verhalten zugrunde liegt, aber selbst nicht direkt beobachtbar ist - ein wichtiger Schritt in der jeweiligen Konstruktdefinition besteht darin, daß man eine Vielzahl von empirisch beobachtbaren Verhaltensweisen theoretisch herausarbeitet, in denen sich das Konstrukt “entäußern” kann - das Ziel der Konstruktvalidierung besteht nun darin, den Nachweis darüber zu führen, daß ein bestimmter, durch eine spezifische psychologische Theorie begründeter, mehr oder minder expliziter “Begriff” (Konstrukt) tatsächlich durch den Test gemessen wird, daß also z. B. ein “Ängstlichkeitstest” tatsächlich mit Recht diesen Namen trägt, da er nachweisbar den “Begriff”, das Konstrukt “Ängstlichkeit” mißt - allerdings wird nicht der Test als solcher konstruktvalidiert, sondern die Interpretation von Testdaten; eigentlich wird bei der Konstruktvalidierung (KV) auch nicht nur die Güte des Tests bzw. der Testinterpretation überprüft, sonder auch die der Testkonstruktion zugrunde liegende Theorie, innerhalb derer das Konstrukt einen bestimmten Platz im sog. nomothetischen Netzwerk einnimmt Das grundsätzliche Vorgehen bei der Konstruktvalidierung Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 66 - es geht hierbei um den Weg, wie man theoretische Aussagen und speziell theoretische Aussagen über den Inhalt eines Tests überprüfen kann - die KV durchläuft i. d. R. folgende Stufen: 1. Stufe: - man sammelt auf der Grundlage der Theorie zum Diagnostizierungsgegenstand (z. B. Ängstlichkeit) eine Reihe von Aussagen und zwar a, über vermutetet positive Beziehungen zwischen dem durch den Test angezielten Konstrukt und anderen Konstrukten, b, über das vermutete Fehlen von Beziehungen zwischen dem untersuchten Konstrukt und anderen Konstrukten und c, über Beziehungen zwischen dem untersuchten Konstrukt und bestimmten beobachtbaren Variablen (z. B. Verhaltensweisen) 2. Stufe: - Auswahl, notfalls auch Entwicklung von Tests, die für die in a, und b, angegebenen Konstrukte angemessen erscheinen 3. Stufe: - Formulierung einer Reihe von Hypothesen vom Typ A, B und C, die die Messung des jeweiligen Konstrukts betreffen - ein Test gilt dann als konstruktvalide, wenn 1. die Testwerte hoch korrelieren mit geeigneten Maßen jener Konstrukte, die gemäß der Theorie mit dem zu untersuchten Konstrukt in Verbindung stehen (z. B. Neurotizisms mit affektiver Labilität) = konvergente Validität (Typ A) 2. die Testwerte nicht mit jenen Tests korrelieren, die Konstrukte erfassen, die nach der Theorie nicht mit dem zu untersuchenden Konstrukt in Verbingung stehen (z. B. Neurotizismus und Intelligenz) = diskriminante Validität (Typ B) 3. die Testwerte eine gute Vorhersage von Kriteriumswerten gestatten, die gemäß der Theorie mit dem Konstrukt in Verbindung stehen = Kriteriumsvalidität (Typ C) 4. Stufe: - Verifizierung/Falsifizierung bzw. auch Modifizierung der obigen Hypothesen auf Grund der Untersuchungsbefunde - je nach Bestätigung oder Ablehnung erfolgt eine Konkretisierung oder Modifikation - Einkreisung des angenommenen Konstrukts - im “Prozeß einer sukzessiven Approximation” im Prozeß der KV wird also nicht nur geprüft, ob ein Konstrukt in einem Test erfaßt wird, sondern gleichzeitig wird die theoretische Begründung und genaue Bestimmung dieses Konstrukts fortgeführt - die nähere Bedeutung eines Konstrukts ergibt sich aus der genaueren Bestimmung des Ortes, den ein Konstrukt in einem Netzwerk (“nomologischen Netzwerk”) von Beziehungen einnimmt - es gibt eine Vielzahl unterschiedlicher Methoden, die bei der KV anzuwenden sind - die bereits unter der kriterienbezogenen Validierung erwähnten Methoden sind quasi im Konzept der KV “aufgehoben”, bilden aber nur einen Teil der umfassenden KV a, Multitrait-multimethod-Methode - im Konzept der sog. Multitrait-Multimethod-Matrix spielen die Begriffe der konvergenten und diskriminanten Validität eine entscheidende Rolle - Grundprinzip: verschiedene Merkmale werden mit verschiedenen Methoden untersucht - Ausgangspunkt der Multitrait-multimethod-Matrix sind folgende Fragen: wie hoch ist die Validität des Tests als Korrelation zwischen dem Test und einem anderen Verfahren, das sich in der Methode unterscheidet, aber dasselbe Konstrukt mißt? wie groß ist die Korrelation zwischen dem Test und einem anderen Test, der ein konstruktfernes Merkmal erfaßt (diskriminante Validierung) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 67 wie hoch ist der methodenspezifische Varianzanteil eines Tests? Beispiel: - 3 Merkmale (traits, 1, 2, 3) werden jeweils durch 3 Methoden (A, B, C) erfaßt - die Merkmale sind Angst, Neurotizismus und “soziale Intelligenz” - die Methoden sind Frembeurteilung, Selbstbeurteilung und projektiver Test - die Interkorrelationen der 3x3 = 9 Tests ergeben dann die Multitrait-multimethod-Matrix Methoden traits A B C 1 1 2 3 1 2 3 1 2 3 A 2 r12 3 r13 r23 1 rAB rab rab B 2 rab rAB rab r12 3 rab rab rAB r13 r23 1 rAC C 2 3 rAC rAC rBC rBC r12 rBC r13 r23 - die Dreiecke mit den ausgezogenen Linien beinhalten die Interkorrelationen der unterschiedlichen traits mit derselben Methode (z. B. Selbstbeurteilung): Monomethodheterotrait-Korrelationen - in den Dreiecken mit den gestrichelten Linien befinden sich die Interkorrelationen zwischen den unterschiedlichen traits, ermittelt mit unterschiedlichen Methoden - die Korrelationskoeffizienten rAB, rAC und rBC sind die besonders interessierenden Heteromethod-monotrait-Korrelationen, die als Validitätskoeffizienten bei der sog. Binnenvalidierung bestimmt werden - die ausschließliche Orientierung auf diese Koeffizienten - wie üblicherweise in Testmanualen - reicht aber nicht aus - es müssen nicht nur die Validitätskoeffizienten (heteromethod-monotrait) signifikant sein, sondern diese müssen auch noch höher sein als die Monomethod-heterotrait-Koeffizienten - dies ist keinesfalls eine immer leicht zu erfüllende Forderung - so wurde in der empirischen Forschung relativ oft nachgewiesen, daß allein auf Grund gleicher methodischer Vorgehensweisen (z. B. Fragebogen) auch bei unterschiedlichen traits relativ hohe Korrelationen zustande kommen, die nur dadurch erklärbar sind, daß generelle methodenspezifische Varianzanteile (z. B. kognitive Vorgänge, die das Lesen und Beantworten der Fragen betreffen) eine erhebliche Bedeutung gewinnen - andereseits werden unbefriedigend niedrige Korrelationen zwischen verschiedenen methodischen Varianten (z. B. projektive Verfahren/Fragebogen) registriert, die das gleiche Merkmal (z. B. Neurotizismus) messen sollen; von einem theoretisch genügend begründeten Konstrukt erwartet man aber, daß auch verschiedene Methoden zu seiner Erfassung zumindest mäßig positiv miteinander korrelieren - weiterhin wird gefordert - und dies läßt sich meist leichter realisieren -, daß die Validitätskoeffizienten größer sind als die Heteromethod-heterotrait-Koeffizienten (spezielle Form der diskriminanten Validierung) b, faktorielle Validierung Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 68 - hierunter versteht man die Anwendung der FA auf Fragen der Validitätsbestimmung von Tests - die FA basiert auf Interkorrelationsmatrizen von Variablen (z. B. Tests), die mit ihrer Hilfe auf die kleinstmögliche Anzahl sog. gemeinsamer Faktoren zurückgeführt werden soll (Datenreduktionsmethode) - die FA dient zur Aufklärung von “Verwandtschaftsbeziehungen” zwischen Variablen (in unserem Fall Tests bzw. Testitems) - wir hatten bei der Darstellung der KTT die sog. Grundgleichung kennengelernt, nach der sich die beobachtete Varianz in einen wahren und einen Fehleranteil aufspalten läßt - in der FA wird nun der wahre Wert in weitere Faktoren aufgespaltet, und zwar in eine bzw. mehrere gemeinsame Komponenten, die der Test mit anderen Tests teilt, und in eine testspezifische Komponente - hinzu kommt noch der nicht aufgeklärte Fehlervarianzanteil - man kann die FA zunächst nur auf die Interkorrelationen der Items eines Tests anwenden, um die innere Struktur herauszufinden bzw., was theoretisch befriedigender ist, um eine theoretisch angenommene Struktur des Tests durch die FA bestätigen oder verwerfen zu lassen - unter faktorieller Validierung versteht man aber v. a. die Inbezugsetzung eines Tests (über Interkorrelationen) mit anderen gültigkeitsähnlichen (konstruktnahen) oder konstruktfernen Tests und mit verschiedenen Außenkriterien - auf der Basis einer solchen Interkorrelationsmatrix werden nun gemeinsame Faktoren extrahiert und anschließend so rotiert, daß sie eine möglichst einfache Lösung (Interpretation der gewonnenen Daten) erlauben Als Kennzeichen hoher faktorielle Validität gelten: 1. - der Test hat eine hohe Ladung (Gewicht) in jenem Faktor (= Korrelationen mit dem Faktor), der im Sinne der zu messenden Eigenschaft interpretiert werden kann - dieser Faktor wird dann auch hohe Ladungen in solchen Tests und Kriterien zeigen, die Identisches oder sehr Ähnliches erfassen 2. - der Test zeigt geringe oder Nulladungen in jenen Faktoren, die ihrerseits hohe Ladungen bei gültigkeitsverschiedenen Tests bzw. Kriterien zeigen 3. - der Test hat eine hohe Kommunalität (= aufgeklärter Varianzanteil eines Tests, den dieser mit anderen Tests gemeinsam hat) - der Faktorenanalytiker begrüßt es, wenn diese hohe Kommunalität nur durch eine extrem hohe Ladung in jenem Faktor zustande kommt, der gemessen werden soll, denn dann handelt es sich um einen “faktorreinen” Tests Beispiel: - aus den Interkorrelationen von Tests ließen sich in einer Untersuchung 4 Faktoren extrahieren Tests A B C Faktoren 1 0,90 0,70 0,00 2 0,00 0,20 0,80 3 0,10 0,00 0,00 4 0,00 0,00 0,00 - in diesem Beispiel läßt sich eine fast ideale faktorielle Validität erkennen, da der Test A nur in einem Faktor hoch lädt (in Faktor 1), eine hohe Kommunalität zeigt und der konstruktferne Test im relevanten Faktor nicht lädt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 69 aber: - die Ergebnisse einer FA hängen sehr stark von der Auswahl der jeweils eingegebenen Variablen und von der Eigenart der Stichprobe ab - dadurch können sich die Ergebnisse verschiedener FA zum gleichen Test, aber mit unterschiedlichen Bezugsvariablen (Tests) und unterschiedlichen Stichproben erheblich unterscheiden - es ist daher notwendig, bereits vor der Anwendung der FA eine theoretische Konzeption zum Testinhalt zu entwickeln und auf Grund dieser dann Bezugsvariablen und mögliche Faktoren abzuleiten - die FA dient dann nicht mehr wie häufig früher zur “Entdeckung” des Faktors oder der Faktoren, die im Test gemessen werden, sondern als sog. konfirmatorische FA zur Bestätigung oder Nichtbestätigung a priori aufgestellter theoretischer Konzepte zum Test Weitere Methoden der KV: 1. Analyse interindividueller Unterschiede in den Testresultaten und von Gruppenunterschieden, die gemäß der Theorie zu erwarten sind 2. Analyse intraindividueller Veränderungen bei wiederholter Durchführung mit und ohne systematische Variation der Durchführungsbedingungen (es ist zu erwarten, daß ein “Stimmungstest” im Gegensatz zu einem Intelligenztest eine höhere Variabilität der Testdaten zwischen verschiedenen Testsitzungen zeigt 3. inhaltlich-logische Analyse der einzelnen Testaufgaben (z. B. den Pb fragen, wie er bei der Testlösung vorgegangen ist, welche Schwierigkeiten es gab, welche Strategien er entwickelt hat; alle diese “Mikroprozeßanalysen” des Testverhaltens dienen zur besseren Aufklärung dessen, was eigentlich durch den Test gemessen wird - Konstruktvalidierung als Oberbegriff schließt alle anderen Validitätsarten ein Die Bestimmung der Gültigkeit in der PTT und KOM PTT: - die PTT hat kein eigenes Validitätskonzept - Vertreter der PTT meinen, daß die Konstruktvalidität eines Verfahrens nachgewiesen ist, wenn die Modellverträglichkeit der Daten z. B. mit dem RASCH-Modell festgestellt ist - demgegenüber gilt es aber zu betonen, daß der Nachweis der Modellverträglichkeit lediglich eine Aussage darüber gestattet, daß der Test höchstwahrscheinlich eine homogene Dimension mißt - über die Art der Dimension (des Konstrukts) ist damit noch gar nichts ausgesagt, d. h. auch bei RASCH-skalierten Tests müssen die o. g. Validierunsstrategien angewandt werden, wenn man etwas über die “wahre Testbedeutung” erfahren will - da aber in den “probabilistisch konstruierten Tests” die unterschiedliche genaue Erfassung der Personenparameter in den verschiedenen Skalenbereichen explizit berücksichtigt wird, bestehen bessere Möglichkeiten durch gezielte Auswahl von Items und im Hinblick auf bestimmte Ausprägungsbereiche des Merkmals die Validitätskennwerte zu optimieren KOM: - hier spielt die Bestimmung der Kontentvalidität die entscheidende Rolle - es werden zwar manchmal auch im Sinne der kriterienbezogenen Validität z. B. Korrelationen zwischen Fachzensuren und einem lehrzielorientierten Test ermittelt, aber hier weiß man nicht recht, ob nun der Test an der Zensur oder die Zensur am Test validiert wird Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 70 Weitere Gütekriterien - Ökonomie, Vergleichbarkeit, Normiertheit, (s. o.) Nützlichkeit: gefragt ist in der Praxis nicht primär ein isolierter Validitätskoeffizient, sondern es interessiert v. a., in welchem Maße ein Test eine Entscheidung sicherer macht, inwieweit er sich später als brauchbar erweisende Zuordnungen von Personen zu bestimmten Behandlungen gestattet Weitere Gütekriterien der Klinischen Psychologie Sensibilität: - inwieweit gelingt durch den Test eine eindeutige Zuordnung erkrankter Patienten innerhalb einer Stichprobe zu der durch eine umfassende diagnostische Untersuchung bestimmten Gruppe der pathologisch Auffälligen? Spezifität: - inwieweit ordnet der Test die unauffälligen Pb der Gruppe der Normalen auch richtig zu? - zwischen Sensibilität und Spezifität besteht oft ein gegensätzliches Verhältnis - erhöht man durch Senkung des sog. Cut-off-Wertes, d. h. jenes Testgrenzwertes, von dem ab man einen Pb als pathologisch auffällig bezeichnet, die Sensibilität des Verfahrens, führt dies umgekehrt oft zur Senkung der Spezifität, d. h., man erfaßt zwar nun mehr pathologische Auffällige durch das Verfahren richtig, aber gleichzeitig werden irrtümlicherweise auch nicht wenige unauffällige Pb als pathologisch auffällig fehlerhaft klassifiziert Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 71 Normierung (Eichung) - eine absolute Messung ist in der Psychodiagnostik leider nicht möglich - um aber ein Testergebnis zu interpretieren, benötigt man eine Bezugsbasis - diese wird in der KTT dadurch geschaffen, daß man die individuelle Testleistung in bezug setzt zur durchschnittlichen Testleistung und Standardabweichung in einer repräsentativen Stichprobe von Pb, aus der der Diagnostikand ein “Element” sein könnte - dies ist die sog. populationsbezogene Normierung der KTT - in der KOM wird dagegen das Bezugssystem durch das Kriterium hergestellt - man stellt fest, ob ein Pb ein bestimmtes Kriterium erreicht hat oder nicht bzw. in welchem Grade er es erreicht hat (“Idealnorm”) Populationsbezogene Normierung (Eichung) in der KTT - zunächst muß man sich darüber im klaren sein, welche Merkmale (z. B. Alter, Geschlecht etc.) evtl. das zu messende Merkmal beeinflussen könnten, und danach die Kriterien für eine repräsentative Eichstichprobe aufstellen - aber die aufgestellten Repräsentanzforderungen lassen sich in der Praxis der Testeichungen selten voll realisieren (es bleibt daher manchmal nichts anderes übrig, als auf die Vorläufigkeit der Normen hinzuweisen und zu hoffen, daß Nachuntersuchungen die Normwerte auf eine breitere Basis stellen) - Eichungen von Tests, die für mehrere Altersstufen gelten sollen, erfordern Tausende von Pb - wichtiger, aber meist noch weniger beachtet als die Repräsentativität der Stichproben ist die Repräsentativität der Untersuchungssituation - zumeist wird ein Test in Gruppen nach dem “Gefälligkeitsprinzip” geeicht, aber in einer individuellen “Ernstsituation” angewandt Forderung der Testeichung für unterschiedliche Untersuchungssituationen - werden in der Eichstichprobe signifikante Gruppendifferenzen registiert und ist man an gruppenspezifischen Normen interessiert, dann muß die Normierungsprozedur getrennt für diese Subgruppen durchgeführt werden Mehrfachnormierung Normarten - eine gewisse Normierung liefern bereits die Rohpunktwerte eines Tests (bei NV der Werte) - durch die Berechnung von Mittelwert und Standardabweichung lassen sich zumindest Aussagen darüber gewinnen, ob der Pb im durchschnittlichen, über- oder unterdurchschnittlichen Bereich des Tests liegt eine Bestimmung von Normwerten im engeren Sinne hat aber v. a. folgende Vorteile: 1. - Tests mit unterschiedlichen Verteilungen der Rohwerte (Mittelwerte, Streuungen) lassen sich unmittelbar miteinander vergleichen, wenn die Testrohpunkte auf eine einheitliche Normenskala (d. h. mit einheitlich festgelegten “Standardmittelwert” bzw. “Standardabweichung”) bezogen werden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 72 2. - es lassen sich mit Normwerten Testergebnisse von Subgruppen, die im Test unterschiedliche Testwerte erzielten (z. B. Mädchen/Jungen), jeweils auf ihre spezifischen Populationsparameter beziehen - auf Grundlage einer einheitlichen Skala ist dann ein direkter Vergleich möglich 3. - die (allerdings noch nicht realisierte) Einigung auf die Verwendung einer oder weniger Normskalen würde die Verständigung zwischen den Testanwendern und Auftraggebern erheblich erleichtern im Vergleich zur getrennten Normierung jedes einzelnen Tests und auch das Einarbeiten in die Testpraxis wesentlich begünstigen Äquivalentnormen - älteste Normierungsart; wurde von Binet und Simon (1905) begründet - Intelligenzalter: es muß zunächst an einer Stichprobe von unterschiedlich alten Kindern durch die Vorgabe einer Aufgabenreihe mit steigender Schwierigkeit geprüft werden, wie weit gewöhnlich Kinder eines bestimmten Alters in dieser Reihe vorstoßen, d. h. welche Aufgaben sie mit einer bestimmten Lösungswahrscheinlichkeit (meist 75%) noch lösen können - allerdings machte Stern darauf aufmerksam, daß ein Intelligenzaltersrückstand von 2 Jahren bei einem 4-jährigen viel bedeutsamer ist als der gleiche Zweijahresrückstand bei einem 12jährigen er schlug den relativierenden sog. Intelligenzquotienten vor IA/LA x 100 (um Kommastellen zu vermeiden) Äquivalentnormen werden heute als meßmethodisch unzureichend und als überholt bezeichnet; Gründe hierfür: 1. - IQs auf verschiedenen Altersstufen haben nur dann die gleiche Bedeutung (sind also vergleichbar), wenn die Streuung des IA direkt proportional mit dem Lebensalter wächst, was nicht angenommen werden kann 2. - die Summierung von Testpunkten zum Intelligenzalter ist meßmethodisch problematisch, da der Intervallcharakter und die Homogenität der Testrohwerte nicht nachgewiesen ist 3. - die Bestimmung des IA und des IQ bei Erwachsenen ist sehr problematisch - so ist es doch recht fragwürdig, für einen 45jährigen Mann das IA 18 Jahre oder 14Jahre zu bestimmen - als günstiger erscheint es, wenn man die Leistungen eines Menschen auf die durchschnittliche Leistung in der entsprechenden Referenzstichprobe bezieht, aus der der Pb stammt, wie das bei dem von WECHSLER vorgeschlagenen sog. Abweichungs-IQ der Fall ist, der als einer der ersten praktisch angewandten Standardnormwerte gelten kann Standardnormen diese sind nur dann zu berechnen, wenn die Testrohpunktverteilung einer Normalverteilung angeglichen ist - Grundlage der Normwertberechnung bildet die Bestimmung von Mittelwert und Standardabweichung in der Eichstichprobe - der einzelne Testwert wird also mit diesem Mittelwert verglichen - jede empirische NV läßt sich durch Transformation der Rohpunkte auf eine sog. standardisierte NV mit dem Mittelwert = 0 und der Standardabweichung = 1 zurückführen xX = Testrohwert des Pb z= , s = Mittelwert und Standardabweichung in s der normalverteilten Eichstichprobe Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 73 - diese Werte besagen, z. B., daß ein Pb dessen Testrohpunkt einem z-Wert von z = -1,00 entspricht, gerade noch zum durchschnittlichen Bereich des Tests zuzuordnen ist (vergl. im Bereich +/- 1,00 z-Werte liegen 68% der Pb der Eichstichprobe - die z-Werte werden aber als Normwerte ungern benutzt, da man hier mit negativen Werten und Dezimalstellen arbeiten muß - es werden daher sog. lineare Transformationen der z-Werte durchgeführt, um ganzzahlige positive Normwerte zu erhalten Folgende Transformationen sind besonders bekannt geworden: Z-Werte = 100 + 10z (also Mittelwert 100, Standardabweichung 10) IQ-Werte = 100 + 15z T-Werte = 50 -10z C-Werte = 5 + 2z - jeder feinstufigere Normwert kann ohne Schwierigkeiten auf eine grobere Norm übertragen werden - Grobnormen sind bei Tests - entgegen einer weitverbreiteten Praxis - den Feinnormen meist vorzuziehen, da sie in Anbetracht der häufig nur mäßigen Reliabilität der tatsächlich vorhandenen Differenzierungsfähigkeit von Tests besser Rechnung tragen und so keine (scheinexakte) Feindifferenzierung vortäuschen Standardnorm-Äquivalente - bei nichtnormalverteilten Häufigkeitsverteilungen der Testrohpunkte ist bekanntlich bereits die Berechnung des Mittelwerts und der Standardabweichung nicht statthaft - demzufolge lassen sich auch keine Standardwerte berechnen - McCALL hat aber eine sog. Technik der Flächentransformation entwickelt, mit deren Hilfe angeblich auch bei anomalen Verteilungen Standardnormwerte bestimmt werden können - bei dieser Transformation werden zunächst die Rohwerte in Prozentränge umgewandelt - diese werden als prozentuale Flächenanteile der normierten NV aufgefaßt - die Prozentränge stehen daher in einer funktionalen Beziehung zu den z-Werten, die Flächen unter der NV kennzeichnen - mit Hilfe der Prozentränge, die man bei jeder Verteilungsform berechnen kann, wird unter Benutzung der Normentabellen jeder beliebige andere Standardnormwert bestimmt aber: - die theoretische Berechtigung für die Transformation wird in der problematischen Normalverteilungshypothese der KTT gesehen, nach der anomal verteilte Testwerte als lediglich zufällig bedingte Abweichungen von dieser “wahren” NV der Indikandenausprägungen betrachtet werden und daher ausgeglichen werden können - insbesondere bei deutlich anomalen Verteilungen sollte man auf jeden Fall lieber nur die Prozentränge berechnen Prozentränge Vorteile der Prozentrangberechnung: 1. - sie kann bei jeder Verteilungsform der Daten eingesetzt werden 2. - bei den Daten ist kein Intervallskalenniveau erforderlich, Ordinalskalenniveau genügt (allerdings ist Intervallskalenniveau günstiger, da dieses die erforderliche Summation von Punktwerten meßmethodisch eher begründet) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 74 3. - Prozentränge lassen sich auch Laien leichter erklären - der Prozentwert zeigt an, wieviel Prozent der Pb einer Eichstichprobe unter den zugehörigen Testpunktwert fallen - entspricht z. B. ein Testrohpunktwert von 30 Punkten einem Prozentrangwert von 75, dann bedeutet dies: 75% der Eichstichprobe erreichten Testpunktwerte von 0-30 Punkten, 75% waren also schlechter als bzw. höchstens genausogut wie der Pb, nur 25% der Pb erzielten im Test bessere Werte - Prozentrangnormen gewinnt man aus der sog. kumulativen Häufigkeitsverteilung der Testrohpunkte, also durch fortlaufende Summierung der relativen Häufigkeiten (cum f) einer Punkteverteilung Die Prozentränge haben 2 Nachteile: 1. - da es sich nicht um intervallskalierte Daten handelt, dürfen keine Mittelwerte bestimmt werden 2. - auch die Berechnung numerischer Differenzen zwischen Prozenträngen ist nicht unpro blematisch - die Differenzen zwischen 2 Prozenträngen sind infolge der vorgenommenen Flächentransformationen nämlich nicht gleich zu interpretieren, sondern abhängig von der Position der Prozentränge auf der Skala - bei einer NV sind die Prozentränge im Bereich der größten Dichte der Rohwertverteilung (also im mittleren Bereich) zu stark, in den Bereichen geringer Dichte (also an den Extremen) zu schwach differenzierend - so ist z. B. die Prozentrangdifferenz 45-55 weniger aussagekräftig als die PR-Differenz 98-99, da die letztere eine größere Differenz auf der Rohwerteskala widerspiegelt - kenn man diese Besonderheiten und überschätzt daher im Mittelbereich nicht die Aussagekraft von Prozentrangdifferenzen unterschiedlicher Pb, dann bilden PR-Werte immer noch die angemessensten Normen für die meisten Tests - bei weniger zuverlässigen Tests empfiehlt sich die Bestimmung von Grobnormen (z. B. Quartile) - nur noch an den Zentil- bzw. Quartilgrenzen werden die Aussagen maßgeblich durch die Testungsgenauigkeit beeinflußt Normierung bei probabilistisch konstruierten Tests und bei KOM - es ist noch umstritten, ob die bei modellkonformen probabilistisch konstruierten Tests aus den Rohwerten geschätzten Personenparameter (Fähigkeitswerte) tatsächlich als absolute Normwerte (im Sinne einer physikalischen Messungen entsprechenden Absolutskala) aufgefaßt werden können - unabhängig von der Beantwortung dieser Frage, benötigt der Praktiker auch dann populationsspezifische Bezugssysteme, wenn er RASCH-skalierte Tests benutzt - so wird v. a. im Rahmen der angewandten Diagnostik die Bestimmung der relativen Position eines Pb in bezug auf eine relevante Referenzpopulation nach wie vor notwendig bleiben - aus diesem Grund dürfte sich eine nachträgliche Normierung im klassischen Sinne als vorteilhaft erweisen, ohne daß dadurch die Vorteile einer RASCH-Modell-getreuen Skala aufgegeben werden müssen - bei KOM interessiert zunächst die Frage: ist das Kriterium erreicht oder nicht? Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 75 Zu einigen Fragen der Testauswertung - Tests auf bestimmte Antwortmuste oder Verfälschungen durchsehen Tests lassen sich unter verschiedenen Zielstellungen auswerten: 1. Zur Beschreibung - eines psychischen Zustandes bzw. einer Dimension 2. Zur Einteilung in geordnete Kategorien - hierbei werden die Pb hinsichtlich einer Dimension oder verschiedener, aber voneinander unabhängiger Dimensionen geordnet, so daß sie sich hinsichtlich dieser Dimension nur quantitativ unterscheiden 3. Zur Einteilung in nichtordenbare Kategorien - Pb werden qualitativ unterschiedlichen Kategorien zugeordnet - es gibt hierbei i. d. R. keine Rangordnungen innerhalb der Kategorien - entscheidend ist, daß der Pb jener Kategorie richtig zugeordnet wird, die seinem meist multidimensional erfaßten Zustand am besten entspricht beachte: Tests sind nicht als Allroundverfahren zu konstruieren, sondern von vorneherein auf bestimmte Zielstellungen bezogen zu entwickeln! (v. a. für die Förderdiagnostik relevant) - bei allen 3 Zielstellungen von Testauswertungen interessiert die Frage: wo liegen denn Stärken und Schwächen im Intelligenz- bzw. Persönlichkeitsprofil eines Pb? - dazu muß man möglichst genau bestimmen, 1, in welchem Vertrauensintervall denn höchstwahrscheinlich der wahre Wert des Pb auf einer bestimmten Dimension liegt, und 2, bestimmen, welche Differenzen zwischen den Ausprägungen in den einzelnen Dimensionen zufallskritisch als signifikant abzusichern sind zu 1, Ableitung des Standardmeßfehlers - im Bereich des Standardmeßfehlers eines Tests, der durch seine Zuverlässigkeit bestimmt wird, liegt mit 68% Wahrscheinlichkeit der “wahre Wert” des Pb - da hier die Irrtumswahrscheinlichkeit noch zu groß ist (32%), wird das sog. Vertrauensintervall (CL) auf dem 5% Niveau (z-Wert für den Alpha-Fehler = 1,96 bei zweiseitiger Fragestellung) berechnet CL = X z sx 1-rtt CL = Konfidenzintervall X = Testwert (beobachteter) z = z-Wert für einen bestimmten Alpha-Fehler sx = Standardabweichung des Tests rtt = Zuverlässigkeit des Tests - mit Hilfe dieser Formel sind dann Aussagen möglich wie: bei einem gemessenen IQ von 113 im HAWIE liegt der wahre IQ des Pb mit einer Irrtumswahrscheinlichkeit von nur 5% zwischen den Grenzen 105,8 - 120,2 aber: - MÜLLER & MOOSBRUGGER kritisieren die übliche Nutzung des Standardmeßfehlers zur Abschätzung des wahren Wertes einer einzelnen Person, da gruppenstatistisch gewonnene Werte keine unmittelbare Relevanz für die Einzelperson haben Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 76 zu 2, - will man Unterschiede zwischen Pb im Test auf ihre Signifikanz prüfen, dann kann man zunächst davon ausgehen, daß im Falle des Nichtüberschneidens der nach Formel der Vertrauensintervalle berechnet wird, für die beiden beobachteten Testwerte offenbar ein signifikanter Unterschied besteht - überschneiden sich dagegen die Intervalle, dann muß gefragt werden, ob diese Überlappung noch mit der Nullhypothese in Übereinstimmung steht oder ob bereits signifikante Differenzen zwischen den Testwerten bestehen - dies wird bestimmt durch die Berechnung der sog. kritischen Differenzen, die die Fehlerbehaftetheit beider zu vergleichenden Werte berücksichtigt (X1 - X2)0,05 = 1,96 sx 2 (1 - rtt) - mit Hilfe dieser Formel lassen sich z. B. Aussagen folgender Art machen: 2 Pb müssen sich um mindestens 10 Standardwertpunkte im Test unterscheiden, damit man sie überhaupt als unterschiedlich intelligent bezeichnen kann - man sollte stets bedenken, ob die einseitige oder zweiseitige Fragestellung beim Vergleich von Testwerten angebracht ist - einseitig prüft man dann, wenn man z. B. aus einem vorangegangenen Testergebnis bereits einen Unterschied auch im neuen Test vermuten kann - außerdem sollte man beachten, ob ein Übersehen tatsächlich existierender Unterschiede praktisch bedenklicher ist als eine Überschätzung vielleicht nur zufälliger Differenzen - unter Berücksichtigung der jeweiligen diagnostischen Entscheidungssituation wählt man dann das entsprechende Irrtumsrisiko Fragestellung zweiseitig einseitig Irrtumsrisiko 5% 1,96 1,64 Irrtumsrisiko 1% 2,58 2,33 - die zweite Forderung bei der Auswertung von Testprofilen betrifft nicht interindividuelle Unterschiede oder Abweichungen vom Mittelwert einer Referenzpopulation, sondern intraindividuelle Differenzen - im einfachsten Fall interessiert lediglich die Frage, ob sich bei einem Pb die Ergebnisse in 2 Subtests einer Testbatterie signifikant unterscheiden Berechnung der kritischen Differenz dcrit = z sx 2 - (r11 + r22) r11 bzw. r22 Zuverlässigkeitskoeffizienten der beiden verglichenen Tests - in der klinischen Praxis ist es oft besonders wichtig zu wissen, ob das besonders schlechte Abschneiden eines Patienten in einem Subtest im Vergleich zum “Durchschnittsergebnis” in den anderen Tests signifikant ist - man kann die Frage der sog. diagnostischen Valenz einer Leistungsbeeinträchtigung in einem Subtest im Vergleich zum “Allgemeinbefund” als Vorhersageproblem behandeln und daher den regressionsanalytischen Ansatz nutzen = geschätzter Untertestpunktwert auf Grund des Gesamtwertes = rtc (x - x) + y rtc = Korrelation Untertest/Gesamttest sx sy = Streuung der Untertestwerte sx = ´´ Gesamttestwerte x = Gesamtwert des Gesamttestwertes/Untertestwertes x/ y = Mittelwert Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle sy Psychodiagnostik - Script zur Examensvorbereitung 77 Beispiel: - es soll geprüft werden, ob das schlechte Abschneiden im Zahlennachsprechtest des HAWIE mit nur 6 Wertpunkten ( y = 10 WP, sy = 3 WP) diagnostisch auffällig ist, wenn der Pb im HAWIE insgesamt 110 IQ-Punkte ( x = 100; sx = 15) erreicht hat - durch Einsetzen in die Formel erhält man einen erwarteten WP von 11,26 im Zahlennachsprechen - es wird nun die kritische Vorhersagedifferenz geprüft y- z= sy 1 - rtc2 - der erhaltene Wert von -2,26 ist auf dem 1,19%-Niveau signifikant - will man z. B. für Zwecke der Berufsberatung Fähigkeits-, Interessen- oder Eigenschaftsprofile auf Grund verschiedener Subtests bzw. Einzeltests einer Testbatterie interpretieren, dann muß man zunächst entscheiden, ob die beobachteten Testwertdifferenzen tatsächlich im Sinne eines Profils zu interpretieren sind je reliabler die Einzeltests einer Testbatterie sind und je geringer die Interkorrelationen zwischen den Tests sind, desto zuverlässiger ist auch das aus den Einzeltests abzuleitende Testprofil rtt - rtT profilrtt = 1- rtT rtt = Mittelwert der Reliabilitätskoeffizienten aller Tests des Profils rtT = Mittelwert aller Interkorrelationen aller Tests des Profils - Testprofile sollten mindestens eine Zuverlässigkeit von rtt > 0,50 aufweisen; Werte über 0,80 gelten (als selten erreichte) hohe Zuverlässigkeitskoeffizienten - sind in einem “Profil” die Interkorrelationen genausohoch wie die Einzeltestreliabilitäten, dann handelt es sich um ein “Scheinprofil”, da alle Tests mehr oder minder nur das gleiche Merkmal erfassen - insbesonder in der berufsberaterischen Forschung und Praxis spielen Vergleiche von Individualprofilen untereinander bzw. mit Gruppenprofilen eine große Rolle - hierzu werden die sog. KRISTOF-Formeln benutzt - alle in diesem Abschnitt besprochenen Formeln basieren im wesentlichen auf der Zuverlässigkeit der Tests aber: in der KTT sind die Reliabilitätskennwerte hochgradig populationsspezifisch und daher sind keine unmittelbaren Aussagen für den Einzelfall zulässig alle Aussagen gelten lediglich “im Schnitt” der Referenzstichprobe - Aussagen wie: der “wahre” IQ eines Pb liegt im Bereich von ... bis ... sind im strengen Sinne nur zulässig, wenn man zusätzlich zu den Annahmen der KTT noch annimmt, daß die Fehlerstreuung für jede Person bzw. für jede True-score-Ausprägung gleich ist - eine solche Annahme wird nicht gemacht und ist auch recht unwahrscheinlich - daraus ziehen die Vertreter der PTT den Schluß, daß für unterschiedliche True-ScoreBereiche auch unterschiedliche Konfidenzintervalle bestimmt werden Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 78 - bei der Auswertung von Tests - insbesondere bei Selektionsfragestellungen - aber auch bei psychopathologischen Klassifikationen, tritt das Problem der Bestimmung des sog. Cuttoff-Wertes in Tests auf Selektion: - Auswahl einer geringeren Pb-Anzahl aus einer Population definierte Aufnahmequote - meist Dichotomisierung: angenommen vs. abgelehnt Klassifikation: - Personen zu Klassen zuordnen (Diskriminationsfunktion) - Bilden von Klassen aus einem Konglomerat von Merkmalen (Klassenbildung) Klasse: - Teilpopulation von Individuen, die sich durch Ähnlichkeit in bestimmten Merkmalen auszeichnen Plazierung: - innerhalb der Klassen können Rangordnungen angegeben werden (wichtig bei definierte Aufnahmequote) - bei einer Selektionsfragestellung kann man zunächst nach folgender Strategie vorgehen: wenn von 100 Bewerbern nur 20 aufgenommen werden können, dann wählt man auf Grund des Tests die 20 aus, die von den 100 Bewerbern die besten Ergebnisse erzielt haben Problem: man weiß nicht, wie generell leistungsfähig die Bewerberstichprobe in dem betreffenden Aufnahmejahr ist bei manchen Auswahlentscheidungen muß das Überschreiten eines Mindestniveaus im Test vorausgesetzt werden - dies gilt v. a. bei den Berufen, die besonders hohe Zuverlässigkeitsanforderungen an die Arbeitshandlungen stellen, da bei Fehlhandlungen große materielle und Menschenverluste zu befürchten sind - ein vielleicht zunächst durch Experten festgelegter, später aber unbedingt durch empirische Bewährungsuntersuchungen überprüfter Grenzwert oder Cut-off-Wert im Test, bei dessen Unterschreitung “Nichteignung” und bei dessen Überschreitung “Eignung” diagnostiziert wird, soll eine populationsunabhängigere Entscheidung gewährleisten und gleichzeitig garantieren, daß Mindestvoraussetzungen beim Pb vorhanden sind - die Festlegung der Höhe des Cut-off-Wertes entscheidet oft darüber, ob die Sensibilität oder Spezifität eines klinisch-diagnostischen Verfahrens besser ausgeprägt ist, ob also mehr Auffällige (“Positive”) als solche richtig erkannt werden oder Nichtauffällige (“Negative”) auch richtig als “unauffällig” eingestuft werden - auf die Eignungsfeststellung bezogen, würde dies bedeuten, daß die Cut-off-Festlegung darüber bestimmt, ob mehr Geeignete als solche erkannt werden oder mehr Ungeeignete - näturlich ist es am günstigsten, wenn durch die Cut-off-Wertbestimmung beide Fehlerquellen minimiert werden - in der Praxis erfolgt aber oft die Minimierung einer Fehlerquelle - z. B. alle Nichtgeeigneten werden erfaßt - durch die Vergrößerung der anderen Fehlerquelle; es werden auch Geeignete fälschlicherweise als Nichtgeeignete eingestuft (z. B. Cut-off-Wert wird zu hoch angesetzt) - welche Fehlerquelle man v. a. minimiert, sollte man aus den Konsequenzen des diagnostischen Urteils ableiten - bei einen Screening-Test sollte durch die Festlegung des Cut-off-Wertes v. a. gewährleistet sein, daß alle vermutlich Auffälligen zunächst erfaßt werden, daher müßte dieser auch eher “niedrig” angesetzt werden - generell wird die Prognosegüte eines Tests nicht nur durch den Validitätskoeffizienten, sondern auch durch das Verhältnis “Grundrate” und “Selektionsrate” bestimmt Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 79 Grundrate: Anteil an Pb einer Population, die ein bestimmten Merkmal aufweisen A+D “natürlicher Eignungsquotient” A+B+C+D Prädiktoren krank gesund Kriterien krank A C B D gesund A und D machen Aussagen darüber, wie gut das Instrument mißt A = Sensitivität der Zuordnung D = Spezifität der Zuordnung (vom diagnostischen Standpunkt her nicht so interessant) A A+B = prädiktiver Wert D C+D = prädiktiver Wert der negativen Zuordnung prädiktiver Wert = selektiver Eignungsquotient Selektionsrate: - künstliche Festlegung - Verhältnis offener Stellen zur Gesamtbewerberzahl No SR = Selektionsrate SR = No = offene Stellen Ng Ng = Gesamtbewerberzahl geeignet Kriterium E F G H ungeeignet Prädiktor angenommen abgelehnt cut-off-Wert - die Aufnahmequote kann durch die waagrechte Achse geregelt werden (Veränderung des Kriteriums) - Sektor E = geeignet, aber nicht angenommen - Sektor H = zugelassen, aber ungeeignet Verringerung des H-Sektors erstrebenswert Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 80 - dies kann durch 3 Arten erfolgen: 1. Veränderung des Kriteriums - die waagrechte Achse wird nach unten verschoben - aber: Leute aus dem Sektor E steigen an 2. Veränderung des Prädiktors - senkrechte Achse nach rechts - der Test wird schwieriger; der F-Sektor nimmt ab 3. Erhöhung der Validität des Tests - mit Hilfe der TAYLOR-RUSSELL-Tafeln läßt sich bestimmen, wie hoch der Prozentsatz der Geeigneten unter der Voraussetzung bestimmter Grundquoten, Selektionsquoten und Testvaliditäten unter den vom Test als “geeignet” klassifizierten Pb tatsächlich ist - je ungünstiger, d. h. weniger ausgeglichen das Verhältnis zwischen Grund- und Selektionsquote ist, desto geringere Möglichkeiten bestehen für einen Test (auch bei relativ hohen Validitäten!), hohe Trefferquoten zu erzielen - wenn z. B. von 100 Bewerbern 50 geeignet sind, aber nur 10 aufgenommen werden können, muß ein Test auch bei hoher Validität 40 Fehlentscheidungen machen - die Anwendung der TAYLOR-RUSSEL-Tafeln wird allerdings dadurch erschwert, daß man in der Praxis oft vor umfangreichen empirischen Erhebungen noch keine Information über die Grundrate hat - außerdem ist das TAYLOR-RUSSEL´sche Tafelwerk für Gruppenuntersuchungen ausgelegt - 2 Voraussetzungen beschränken die Anwendbarkeit der TAYLOR-RUSSELL-Tafeln: 1. es wird angenommen, daß ein linearer Zusammenhang zwischen Prädiktor- und Kriteriumswerten besteht 2. der Einsatz eines neuen Verfahrens muß unabhängig von den anderen Prädiktorinstrumenten des bestehenden Auswahlsystems sein - ein ähnliches Problem taucht auch bei der Anwendung der sog. BAYES-Statistik im Hinblick auf die Zuordnung von Personen auf Grund von Tests zu diagnostischen Kategorien auf - hierbei wird nämlich explizit bei der Zuordnung berücksichtigt, wie häufig bestimmte diagnostische Kategorien (z. B. Krankheiten) in der Gesamtpopulation überhaupt besetzt sind bzw. wie häufig bestimmte Behandlungsformen für Menschen sich als geeignet erweisen - diese sog. A-priori-Wahrscheinlichkeiten werden im sog. BAYES-Theorem mitberücksichtigt, um den Pb jener Kategorie zuzuordnen, für die auf Grund der diagnostischen Befunde die jeweils höchste A-posteriori-Wahrscheinlichkeit besteht - außerordentlich schwierig ist es aber nun wieder, die A-priori-Wahrscheinlichkeiten zu bestimmen; man denke da z. B. an die unterschiedlichen Angaben über das Vorkommen von Schizophrenie in der Bevölkerung - außerdem besteht das Problem, daß Pb, die eigentlich einer sehr seltenen Kategorie zuge ordnet werden müßten, nur bei extremen Beobachtungen, auch tatsächlich als Angehörige dieser Gruppe erkannt werden Fazit: man sollte sich stets des oft relativ großen Irrtumsrisikos bewußt bleiben, das mit der Auswertung von Tests verbunden ist Einsatz verschiedener diagnostischer Methoden (nicht nur Tests, sonder auch z. B. Befragung von Bezugspersonen!) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 81 Probleme und Methoden der Veränderungsmessung mit Tests Gründe dafür, warum das Problem der VM mehr und mehr in den Focus unseres psychologisch-mehtodischen Denkens rückt: 1. rasch wechselnde Anforderungen des Lebens bedingen ein “dynamisches” Menschenbild mit der Charakterisierung des Menschen als bis ins hohe Alter lernendes, sich und die Umwelt veränderndes Wesen 2. die Psychologie wird heute stärker dazu aufgerufen, Programme für Verhaltensänderungen zu entwickeln und deren Effizienz durch psychodiagnostische Verfahren zu bestimmen 3. Intrawissenschaftliche Entwicklungstendenzen; endogenistische, statische und eigenschaftsisolierende Theorien entsprechen nicht dem momentanen psychischen Verhalten noch können sie die Realität der psychischen Entwicklung adäquat erklären (siehe Lewins Interaktion von Person und Umwelt) Generelle Zielstellungen von VM´s 1. Feststellung von Veränderungseffekten (VE) zur Effizienzkontrolle bei relativ kurzfristigen Interventionen 2. Feststellung von VE zur Kontrolle der Wirksamkeit länger einwirkender Sozialisationsbedingungen 3. Feststellung von VE in psychischen Prozeßcharakteristika in experimentellen Situationen, um die inneren Regulationsmechanismen des Verhaltens erfassen zu können 4. Feststellung von VE nach Testwiederholung um Diagnosen/Prognosen zu verbessern - auch die individuelle Veränderungsbereitschaft als diagnostischer Indikator sollte im Rahmen einer umfassenden Diagnostik einbezogen werden Veränderungsmessung in der Psychodiagnostik: - für die sozialpsychologische Diagnostik, speziell Einstellungsrforschung, meinen MUMMENDEY et al. (1977), daß die Wechselbeziehungen zwischen Einstellung und offenem Verhalten nur durch Mehrfachmessungen in unterschiedlichen Situationen und nach verschiedenen “treatments” diagnostizierbar sind Allgemeine Problemgebiete der Veränderungsmessung: - Definition von “Veränderung” und von “Veränderungsindikatoren” - Konstruktion und Überprüfung “änderungssensitiver” Meßinstrumente und für Wiederholungsmessungen geeignete Paralleltests - Entwicklung geeigneter Versuchsplantechniken (Probleme der Stichprobenziehung) - Anwendbarkeit verschiedener Meßmodelle für die VM Spezielle methodische Probleme der Veränderungsmessung 1. Ädäquate Berücksichtigung des Ausgangswertes bei der Bestimmung des Veränderungswertes - wird auch unter dem Begriffen Regressionseffekt bzw. Over-correction-under-correctionDilemma referiert - man stellt in psychologischen Untersuchungen oft fest, daß Zuwachsraten bei Wiederholungsmessungen um so höher sind, je niedriger die Ausgangswerte im Ernsttest waren Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 82 - nimmt man also nur die Rohwertveränderungen (Prätest/Posttest-Differenz) oder auch die Standarwertveränderungen zur Grundlage für die Bestimmung von Veränderungsmaßen, dann käme man oft zu paradoxen Resultaten, etwa in der Art, daß der intelligentere, der weniger Lernfähige ist die reine Rohwertdifferenz als Veränderungsmaß läßt sich aus verschiedenen Gründen nicht anwenden - viele Tests sind in ihrere Itemabfolge gestaffelt, so daß z. B. Pb, die in einem Test mit 30 Aufgaben im Prätest 26 und im Posttest 28 Aufgaben lösen, zwar auch nur 2 Aufgaben mehr lösen als jene, die 10 im Prätest und 12 im Posttest lösen, aber sie lösen beträchtlich schwierigere Aufgaben, was i. a. bei der Bestimmung des Veränderungsmaßes berücksichtigt werden sollte - nicht wenige Tests zeigen einen sog. “Decken-Effekt”, d. h. sehr gute Pb haben auf Grund der für sie relativ geringen Schwierigkeit gar nicht mehr die Möglichkeit, in einem Posttest ihre durch Training bzw. Erfahrung gesteigerte Leistungsfähigkeit voll zu offenbaren - außderm ist das Problem der sog. statistischen Regression zu beachten; hierunter versteht man die Tendenz zur Mitte - die Meßfehlerbelasteheit der Messung in der Psychologie determiniert die Richtung der Zufallsänderung in den extremen Bereichen der Meßskala, d. h. allein schon auf Grund der statistischen Regression beobachtet man bei hohen Werten in der Erstmessung oft etwas niedrigere in der nachfolgenderen Messung und bei niedrigeren Werten in der Erstmessung etwas höhere in der nachfolgenden - um die Ausgangswertabhängigkeit der Veränderungswerte zu berücksichtigen bzw. zu korrigieren, werden in der Literatur verschiedene Berechnungsprozeduren vorgeschlagen - am einfachsten sind die in der Lernforschung oft benutzten sog. Lerngewinnformeln - so bestimmt McGUIGAN den Lerngewinn (G) als das Verhältnis von Lernzuwachs und relativer Anfangsleistung: T G= Xmax - X1 T = Differenz zwischen Punktwert im Posttest und Punktwert im Prätest (X1 - X2) Xmax = maximal erreichbarer Punktwert im Test - diese Formel garantiert, daß der Pb der den Maximalwert im Posttest erreicht, immer auch den optimalen Veränderungswert (“Lerngewinn”) zugeschrieben bekommt aber: mangelnde meßtheoretische Fundierung - daher wird die Bestimmung eines regressionsanalytisch begründeten Residualgewinnwertes vorgeschlagen - hierbei wird mit Hilfe der Regressionsanaylse geschätzt, welchen Posttestwert man auf Grund eines bestimmten Prätestwertes erwarten kann - die Differenz zwischen erwartetem und tatsächlich erreichtem Posttestwert ist dann der Residualgewinn, der also einen ausgangswertrelativierten Lerngewinn darstellt - implizite Voraussetzung für die Anwendung dieser Methode ist aber die Annahme, daß tatsächlich in der jeweiligen empirischen Untersuchung von einer “statistischen Regression zur Mitte” ausgegangen werden kann, daß also die mathematische Methode der empirischen Realität entspricht - bei Anwendung der PTT auf die VM entfällt eine besondere Berücksichtigung des Ausgangswertes, da z. B. im Falle des RASCH-Modells von vorneherein eine nichtlineare logistische Funktion für die Itemcharakteristik besteht Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung 83 - demzufolge bedeutet z. B. ein bestimmter Lernzuwachs auf Personenparameterniveau (Eigenschaft bzw. Einstellung) nicht einen ebensogroßen Zuwachs auf dem Reaktionsniveau (Testrohpunkte in einem Prä- und Posttest) - es kann mit der PTT also durchaus ein gleichgroßer Lernzuwachs (im Sinne einer Fähigkeitssteigerung) registriert werden, wenn ein zu Beginn eines speziellen Trainings sehr guter Schüler nach dem Training nur wenig Aufgaben mehr löst, während ein durchschnittlicher Schüler nach dem Training bedeutend mehr Aufgaben löst als im Prätest 2. Reliabilitäts-Validitätsdilemma - wird auch als “Scheinproblem” der KTT bezeichnet - messen Vor- und Nachtest dieselbe Eigenschaft, auf die durch irgendeine Intervention Einfluß genommen werden soll, dann müssen beide Tests hoch miteinander korrelieren (valid sein) - wenn aber nun eine solch hohe Korrelation (Validität) bestehe, dann müsse zwangsläufig die Reliabilität der Differenzwerte gering sein, da kaum interindividuell unterschiedliche “wahre” Veränderungen vom Prä- zum Posttest vorliegen - reliable Differenzen würden also andererseits zeigen, daß das Meßinstrument (als Prä- und Posttest eingesetzt) nicht valide ist - eine solche Feststellung aber ist falsch, denn die Reliabilität der Differenzwerte hat keinerlei Implikationen hinsichtlich der Frage, ob beide Tests dasselbe messen, wenn zwischen den beiden Testungen Veränderungen der wahren Meßwerte stattgefunden haben - das Reliabilitäts-Validitätsdilemma läßt sich aber in der KTT auflösen, wenn man die unge eignete Retestmethodik zur Zuverlässigkeitsschätzung zugunsten der jeweils getrennt auf Prä- und Posttest angewandten, hier besser geeigneten Halbierungs- bzw. Konsistenzzuver lässigkeit aufgibt - außerdem sollte die Validität eines Tests und damit auch seine Homogenität mehr durch eine theoretisch begründete Aufgabenauswahl für Prä- und Posttest begründet werden, denn durch rein statistische Prozeduren (Korrelation) - bei den Modellen der PTT lasse sich dagegen die Frage, ob 2 Tests zu verschiedenen Zeitpunkten dieselbe Dimension messen wegen der bei Modellgültigkeit garantierten “spezifischen Objektivität” (also item- und personenstichprobenunabhängige Messung) unab hängig davon beantworten, ob zwischen den beiden Testzeitpunkten quantitative Veränderungen der Personenfähigkeiten stattgefunden haben 3. Mangelnde Reliabilität von Differenzwerten -dieses Problem läßt sich im Rahmen der KTT wie PTT dagegen schwerer lösen - die immer wieder festgestellte geringere Reliabilität von Differenzwerten gegenüber den Ausgangs- und Endwerten beruht im wesentlichen auf 2 Ursachen - da sowohl der Prätest als auch der Posttest mit einem Meßfehler versehen sind, kommt es bei der Differenzbildung quasi zu einer Summation zweier Meßfehler - die andere Ursache betrifft die Abhängigkeit des Meßfehlers von dem Ausmaß der interindividuellen Variation in den Veränderungseffekten - wie bereits erläutert, wird die Reliabilität eines Tests als Verhältnis zwischen wahrer Varianz VAR (T) und beobachteter Varianz VAR (X) definiert VAR (T) rtt = VAR (T) = VAR (X) VAR (T) + VAR (E) Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle Psychodiagnostik - Script zur Examensvorbereitung VAR (T2 - T1) rtt (x2 - x1) = 84 VAR (T2 - T1) = VAR (X2 - X1) VAR (T2 - T1) + VAR (E1) + VAR (E2) - hieraus ist ersichtlich, daß die Reliabilität der Differenzwerte zum einen von den Meßfehlern im Prä- und Posttest abhängig ist, zum anderen aber auch vom Ausmaß der Varianz der wahren Differenzen - sinnvoll ist die aus dieser Formel ableitbare Annahme, daß bei kleinen Meßfehlern und großen interindividuellen Unterschieden in den wahren Meßwerten im Prä- und Posttest auch die Reliabilität der Differenzwerte groß ist - paradox ist aber die Schlußfolgerung, daß bei sehr geringen interindividuellen Unterschieden in den wahren Merkmalsveränderungen auch bei nahezu optimaler Reliabilität von Präund Posttest (also bei geringen Meßfehlern) die Differenzwerte unreliabel werden - die Vertreter der PTT hatten der KTT v. a. den Vorwurf gemacht, daß sie wegen der Nichtnachweisbarkeit des Intervallskalencharakters ihrer “Messungen” (s. “Messung per fiat”) eigentlich gar keine Differenzmessungen durchführen kann - andereseits wird deutlich, daß die meßmethodisch besser begründeten PTT-Testmodelle mit so starken Restriktionen für die empirischen Daten verbunden sind, daß auch deren Anwendbarkeit für die VM in vielen Bereichen der diagnostischen Forschung und Praxis problematisch bleiben - daher wird in jüngster Zeit verstärkt darüber diskutiert, ob man nicht gänzlich auf eine Veränderunsmessung im engeren Sinne verzichten und Veränderungen lediglich auf Ordinal- oder sogar nur Nominalskalenniveau feststellen sollte Psychodiagnostik - Psychodiagnostische Grundprobleme und Modelle