Document
Werbung

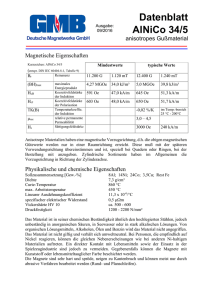
Budapester Wirtschaftshochschule Fakultät für Handel, Gastronomie und Tourismus Studiengang Tourismus und Hotel Management STATISTIK 2 AUFGABEN 2011/9 1. Wir haben 100 vermutlich normalverteilte Zufallszahlen wie folgendes klassifiziert. Intervall 0-bis unter 0.25 0.25-bis unter 0.5 0.5-bis unter 0.75 0.75-bis unter 1 Häufigkeit 28 22 19 31 Können wir die Nullhypothese (Normalverteilung) bei =5% verwerfen? Xbar= (28*0.125+22*0.375+19*0.625+31*0.875)/100=0,5075(=xb) Die Standardabweichung: sqrt((28*(0.125-xb)^2+22*(0.375-xb)^2+19*(0.625-xb)^2+31*(0.875-xb)^2)/99)=0.3 Also wir können die Werte runden und N(0.5,0.3) anpassen. Die erwartete Häufigkeiten (vergessen wir es nicht, dass man alle reelle Zahlen einteilen soll): Intervall Wahrsch. Häufigkeit bis unter 0.25 0.2 20 0.25-bis unter 0.5 0.3 30 0.5-bis unter 0.75 0.3 30 0.750.2 20 Daraus der Statistik: (20-28)^2/20+(22-30)^2/30+(19-30)^2/30+(31-20)^2/20=15.4. Weil FG=1 (wir haben 2 Parameter geschätzt), wir können die Normalität verwerfen (p<0.001, weil alle kritische Werte kleines sind als 15.4) 2. Wir haben die Anzahl von Kraftfahrzeugen per 1000 Einwohner sowie das GDP (per Person) in 5 Ländern untersucht. Kfz (pro 1000 Einw.) 450 850 600 750 900 GDP (Tausend €) 20 60 30 55 85 a/ Stellen wir die Daten in einem Streuungsdiagramm dar, und berechnen wir die Regressionsgerade mit GDP als Einflussfaktor und KFz-Zahl als erklärte Variable. b/ Bestimmen wir die geschätzten Werte und die Residuen! c/ Berechnen wir das Bestimmtheitsmass und die Korrelationskoeffizient! d/ Stellen wir die Regressionsgerade dar! e/ Testen wir mit α=5%, ob die Koeffizienten der linearen Regression signifikant sind! 20 60 30 55 85 50 5 450 850 600 750 900 y 710 5 x xi yi x x y y i i 20 60 30 55 85 450 850 600 750 900 -30 10 -20 5 35 -260 140 -110 40 190 x i x yi y x i x 2 y i y 2 7800 1400 2200 200 6650 900 100 400 25 1225 67600 19600 12100 1600 36100 18250 2650 137000 Die Berechnung der Koeffizienten der Regression: x n a i 1 i x yi y x n i 1 i x 2 18250 6.887 2650 b 710 6.887 50 365.660 xi yi geschaetzte Werte Residuen ( y yˆ )2 i i ( yˆi axi b ) ( yi yˆi ) 20 60 30 55 85 450 850 600 750 900 503,4 778,87 572,26 744,43 951,04 Bestimmtheitsmass: n 2 y i yˆ i R 2 1 i 1 n y i 1 y 1 2 i 53,4 -71,13 -27,74 -5,57 51,04 2851,16 5059,77 769,28 30,98 2604,85 0 11316,04 11316,04 0.92 137000 Korrelationskoeffizient: x n i 1 x n i 1 i i x yi y x y 2 n i 1 i y 2 18250 2650 137000 0,958 20 30 40 50 60 x 70 80 500 600 y 700 800 900 H0: a=a0=0 mit der t-test: t (aˆ a0 ) 2 ( x x ) i ̂ wo das Freiheitsgrad ist n-2 (wir haben diesmal 2 Parametern geschätzt). n ˆ y yˆ i 2 i i 1 n2 t (aˆ a0 ) 11316 61,42 3 2 ( x x ) i ˆ 6,887 0 2650 5,77 61,42 Der kritische Wert (für α=5%): t3,0.975=3,182 Also die Koeffizient a (die Trendkoeffizient) ist signifikant H0: b=b0=0 t t bˆ b0 1 x2 ˆ n ( xi x ) 2 365,66 - 0 1 50 2 61,42 5 2650 5,56 Der kritische Wert (für α=5%): t3,0.975=3,182 Also die b Koeffizient ist auch signifikant. 3. Stellen wir die folgenden Daten (wir haben die Alter und Verkaufspreis von 5 Wagen), die von einem Autohändler stammen graphisch dar. Schlagen wir verschiedene Modelle vor und Testen wir die Signifikanz deren Koeffizienten. Bewerten wir diese Modelle! Geben wir Schätzungen für den Verkaufspreis von einem 10 Jahre alten Wagen. Alter (Jahre) 2 3 4 6 7 Preis(TFt) 1200 1000 850 650 550 x 23 467 4,4 5 y 1200 1000 850 650 550 850 5 xi 2 3 4 6 7 xi x yi y yi 1200 1000 850 650 550 -2,4 -1,4 -0,4 1,6 2,6 x 2 x y y x x i i i 350 150 0 -200 -300 -840 -210 0 -320 -780 -2150 y i y 5,76 1,96 0,16 2,56 6,76 17,2 Die Berechnung der Koeffizienten der Regression: x n a i 1 i x n i 1 xi yi 1200 1000 850 650 550 i x 2 2150 125 , 17,2 geschätzte Werte ( 2 3 4 6 7 x yi y Residuen yˆi axi b ) ( yi yˆi ) 1150 1025 900 650 525 50 -25 -50 0 25 0 b 850 125 4,4 1400 ( yi yˆi )2 2500 625 2500 0 625 6250 2 122500 22500 0 40000 90000 275000 900 800 600 700 Preis (TFt) 1000 1100 1200 Beobachtungen und Regressionsgerade 2 3 4 5 6 7 Jahre n R2 1 y i yˆ i y y i 1 n i 1 H0: i 2 1 2 6250 0.977 275000 a=a0=0 mit der t-Test: n ˆ y i 1 i yˆ i n2 t (aˆ a0 ) 2 6250 45,64 3 (x i x)2 ˆ 125 0 17,2 -11,36 45,642 wo das Freiheitsgrad ist n-2 (wir haben diesmal 2 Parametern geschätzt). t bˆ b0 1 x2 ˆ n ( xi x ) 2 t 1400 - 0 1 4,4 2 45 5 17,2 26,64 Also beide Koeffizienten sind Signifikant. Ein anderes Modell: Y≈ax+bx2+c (es hat Sinn, weil die Punkte besser an eine Kurve zu passen scheinen, als an die Gerade) Die Schätzungen (man braucht die Formeln nicht zu wissen): a=-251,94 Die Residuen: yi=axi+bxi2+c 7,79 -10,07 -5.844 18.83 -10.714 Daraus das Bestimmtheitsmass : n R2 1 y i yˆ i y y i 1 n i 1 i 2 1 2 665,6 0.997 275000 Vorhersage1: 1400-1250=150 Vorhersage2: 1640+1396-2519=517 900 800 600 700 Preis (TFt) 1000 1100 1200 Beobachtungen und Regressionsgerade 2 3 4 5 Jahre Das zweite Modell scheint besser zu sein. 6 7 b=13,96 c=1640,3