Auswertungs
Werbung

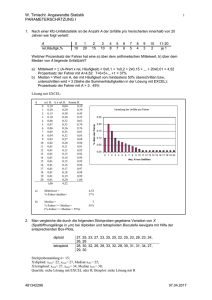
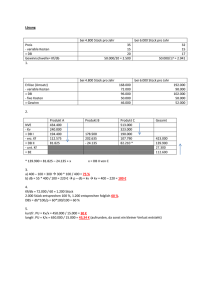
Quantitative Auswertung Korpuslinguistik Dr. Heike Zinsmeister 02.12.2011 Analysetypen • Deskriptive Statistik – Beschreibung der 'Gestalt' von Datenverteilungen – Grafische Darstellungen – Zentrale Maße (Mittelwert etc.) – Streuung der Daten (Varianz, Standardabweichung etc.) – Verhältnis zweier Variablen zueinander (Korrelation) • Analytische Statistik – Vom Speziellen auf das Allgemeine schließen (Testen von Hypothesen) 1 Zentrale Maße (1) • Modalwert (mode) – Häufigster Wert einer Verteilung – bei allen Datentypen einsetzbar, einschließlich nominalen/kategorialen Daten – Beispiel: Bewertung der Satzkomplexität "einfach", "mittel", "mittel", "einfach", "komplex", "einfach", "einfach", "mittel" Modalwert = 2 Datenbeispiel (1) • Durchschnittliche Temperaturen Jan Feb Mär Apr Mai Jun Jul Aug Sep Okt Nov Dez S1 -5 -12 5 12 15 18 22 23 20 16 8 1 S2 6 7 8 9 10 12 16 15 11 9 8 7 (Gries 2008: 117f.) 3 Datenbeispiel (2) • Grafische Darstellung 4 Zentrale Maße (3) • Median (median) – Zentralwert • die Werte nach ihrer Größe sortieren und den Mittleren wählen • bei einer geradzahligen Menge von Elementen das arithmetische Mittel der beiden Mittelwerte – geeignet für Ordinal-, Intervall- und Verhältnisvariablen Stadt1= (-5,-12,5,12,15,18,22,23,20,16,8,1) Sortiert: -12 -5 1 5 8 12 15 16 18 20 22 23 Median (Stadt1) = Stadt2= c(6,7,8,9,10,12,16,15,11,9,8,7) Sortiert: 6 7 7 8 8 9 9 10 11 12 15 16 Median (Stadt2) = 5 Zentrale Maße (4) • Arithmetisches Mittel (arithmetic mean) – Summe aller Werte geteilt durch die Anzahl n aller Werte – angemessen nur für metrische Variablen (Intervall- und Verhältnisvariablen) n ∑x µ= i i=1 n – Mittelwert (Stadt1) = € – Mittelwert (Stadt2) = Eine alternative Notation für µ ("my") ist: 6 Dispersion und Streuung • Bei Mittelwertangaben immer auch ein Dispersions- oder Streuungsmaß angeben. • Extremeres Beispiel: > Verteilung_1! [1] 5 5 5 5 5 5 5 5 5 5! > Verteilung_2! [1] 1 1 1 1 4 6 8 9 9 10! mean(Verteilung_1)! [1] 5! mean(Verteilung_2)! [1] 5! median(Verteilung_1)! [1] 5! median(Verteilung_2)! [1] 5 7 Streuungsmaße (1) • Spannweite / Variationsbreite (range) – Verhältnisskalierte Daten – Differenz des höchsten und niedrigsten Wertes – Einfach, aber empfindlich gegenüber „Ausreißern“ – Spannweite(Stadt1) = – Spannweite(Stadt2) = 8 Einschub: Quantilen • Median (median) = 50% Quantile Sortiert(S1): -12 -5 1 5 8 12 15 16 18 20 22 23 Median (Stadt1) = 13,5 Sortiert (S2): 6 7 7 8 8 9 9 10 11 12 15 16 Median (Stadt2) = 9 • Zusammenfassung S1: Min. 1st Qu. -12.00 4.00 S2: Min. 1st Qu. 6.000 7.750 Median 13.50 Median 9.000 Mean 3rd Qu. 10.25 18.50 Mean 3rd Qu. 9.833 11.250 Max. 23.00 Max. 16.000 9 Einschub: Boxplot (siehe Gries 2008: 125) > summary(Stadt1) Min. 1st Qu. Median -12.00 4.00 13.50 11.11.2010 Mean 3rd Qu. 10.25 18.50 Max. 23.00 > summary(Stadt2) Min. 1st Qu. Median 6.000 7.750 9.000 Mean 3rd Qu. 9.833 11.250 Max. 16.000 10 Einschub: Boxplot Legende zur Darstellung • horizontale fette Linie = Median • horizontale Linie, die obere und untere Grenze der Box darstellen = obere und untere Hinges (ca. der 75%- und 25%-Quartil) • die gestrichelte vertikale Linien mit den horizontalen Begrenzungen (Whiskers) markieren den höchsten und niedrigsten Werte, die nicht mehr als 1.5 Interquartilsabstände von der Box entfernt sind • Ausreißer außerhalb der Whiskers werden mit einzelnem Punkt dargestellt • die in R durch notch=true erzeugten Einschnürungen erstrecken sich über den Bereich ±1.58*IQR/sqrt(n): wenn sich die Einschnürungen nicht überlappen (sondern eine die andere einschließt), unterscheiden sich die Mediane wahrscheinlich nicht signifikant. 11 Streuungsmaße (2) • Durchschnittliche Abweichung (average deviation) – Für jeden Datenpunkt wird die Abweichung zum Mittelwert µ angegeben – Die absoluten Abweichungen werden summiert und gemittelt (d.h. durch die Anzahl n der Datenpunkte geteilt). n ∑( x AD = i − µ) i=1 n 12 € Streuungsmaße (3) • Varianz – Summe der quadratischen Abweichungen vom Mittelwert µ – Zähler immer positiv n 2 (x − µ ) ∑ i – aber falsche Größenordnung – In 'R' berechnet: var = > var(Stadt1) i=1 n [1] 123.6591 > var(Stadt2) [1] 9.969697 € 13 Streuungsmaße (4) • Wurzel der Varianz • ist das meist verbreitete Streuungsmaß • Nachteil – Ist abhängig von der Höhe des Mittelwerts – Schlechter Vergleich von Verteilungen mit unterschiedlichen Mittelwerten n sd(Stadt1)= 11.12021 sd(Stadt2)= 3.157483 sd(Stadt1*10)= 111.2021 2 (x − µ ) ∑ i sd = i=1 n 14 Streuungsmaße (5) Wenn man Standardabweichungen aus verschiedenen Verteilungen direkt vergleichen möchte • Variationskoeffizient – Normalisiert die Standardabweichung in Bezug auf die Größe des Mittelwerts – Division der Standardabweichung durch den Mittelwert sd(Stadt1) = 11.12021 sd(Stadt1*10)= 111.2021 sd(Stadt1)/mean(Stadt1) = 1.084899 sd(Stadt1*10)/mean(Stadt1*10) = 1.084899 sd(Stadt2)/mean(Stadt2)= 0.3210999 15 Standardisierung: z-Werte • Notwendig beim Vergleich von unterschiedlichen Skalen • Bsp.: Noten aus unterschiedlichen Klassenarbeiten; 'Magnitude Estimation' in einem psycholinguistischen Experiment – „Güte“ zweier Noten/Bewertungen, die zu zwei Verteilungen mit unterschiedlichen Durchschnitten (mean) gehören. • Transformation der Abstände zum jeweiligen Mittelwert in die Anzahl der jeweiligen Standardabweichungen, die der Wert abweicht. • Z-transformierte Werte besitzen einen Mittelwert von 0 und eine Standardabweichung von 1 x − mean(x) z(x) = sd(x) € Beachte: Von ordinalskalierten Daten wie Schulnoten darf mathematisch gesehen eigentlich nur der Median gebildet werden. Im Alltag wird auch hier oft der Mittelwert verwendet. 16 Konfindenzintervalle • Bisher: – Häufigkeiten einer Variablenausprägung / Mittelwerte etc. einer Variable in einer Stichprobe • Neu: – Wie gut charakterisiert der Kennwert der Stichprobe die Gesamtheit? • Wie lang sind (wahrscheinlich) die Vorfelder aller Texte des L2-Lernenden / aller L2-Lernenden (in Buchstaben)? • Wie häufig steht (wahrscheinlich) eine Nominalphrase im Vorfeld aller Sätze des L2-Lernenden / aller L2Lernenden? • Standard: 95%ige Konfidenz 17 Konfidenzintervall: Mittelwert Sinnvoll bei: mean(Buchstaben)= 7.857143! n≥30, normalverteilt Welche wahren Populationsmittelwerte könnten den Stichprobenmittelwert von ca. 7.86 mit einer 95%igen Wahrscheinlichkeit erzeugt haben?! t.test(Buchstaben, conf.level=0.95)$conf.int! [1] 5.240574 10.473712! Relevanz: Vergleich von zwei Mittelwerten . Mittelwert: 7,86 (95%-K.I.: 5,24 –10,47) Überlappen die Konfidenzintervalle nicht → Signifikanter Unterschied der Mittelwerte Die Umkehrung gilt nicht zwingend! (Vgl. Crawley 2005: 169f. nach Gries 2008: 130). 18 Konfidenzintervall: Häufigkeit • Häufigkeiten von Kategorien im Vorfeld Kategorie! AdvP NP 9 16 PP Satz ! 2 1 ! • 95%-Konfidenzintervall für den Prozentanteil von 55,17% für NP (16/29 = 0.5517241)! > prop.test(16,29, conf.level=0.95)$conf.int! [1] 0.3598046 0.7304604! • In 55,17% der Vorfelder steht eine NP (95%-K.I.: 35,98% - 73,05%) 19 Visualisierung von Häufigkeiten • Punkt-/Streu- und Liniendiagramme – Abbildung individueller Datenpunkte eines Vektors – Bsp. Vektor (1, 3, 5, 2, 4) plot(c(1,3,5,2,4))! plot(c(1,3,5,2,4), type="l")! plot(c(1,3,5,2,4), type=”b")! 20 Visualisierung von Häufigkeiten • Kreis- und Säulendiagramme – Nominal-/Kategorialvariablen – Bsp. Häufigkeiten von Pausenelementen pie(table(FILLER))! barplot(table(FILLER), col=c("grey20", "grey40", 21 "grey60"), names.arg=c("Aeh", "Aehm", "Stille")) Visualisierung von Häufigkeiten • Histogramme – Klassenbildung über Verhältnisdaten – Bsp. Häufigkeiten der Längen von Planungspausen abgebildet auf Längenklassen hist(LAENGE, main="", xlab="Laenge in ms", ylab="Haeufigkeit", xlim=c(0, 2000), ylim=c(0, 100), col="grey80") 22 Analytische Statistik 23 Testen • Anpassungstests (goodness of fit) – Weicht eine gegebene Verteilung signifikant von einer bekannten Verteilung ab? – Weicht der Mittelwert oder die Standardabweichung einer gegebenen Stichprobe signifikant von einem anderweitig gegebenen Mittelwert oder Standardabweichung ab? • Unterschiedstests – Weicht eine gegebene Verteilung signifikant von einer anderen ebenfalls gegebenen Verteilung ab? 24 Vorüberlegungen • Testen über das Bilden einer Nullhypothese H0, die widerlegt werden soll • der statistische Test erzeugt eine TestStatistik mit bekannter Verteilung • Idee – H0 nimmt an, dass die Teststatistik keinen extremen Wert annimmt – Hypothese H1 nimmt an, dass die Teststatistik einen extremen Wert annimmt – extrem = weit außen in den Rändern/Flügeln der Distribution 25 Normalverteilung library(languageR) shadenormal.fnc (qnts=c(0.025,0.975)) 26 Vorüberlegungen • "weit draußen" – p-Wert: Wahrscheinlichkeit aller summierten Teststatistik-Werte vom statistischen Prüfwert q bis zum Ende der Kurve (bzw. Fläche unter der Kurve) • Irrtumswahrscheinlichkeit, dass fälschlicherweise H1 angenommen wird – Festlegung: Signifikanzniveau α • p=0.05 (95%) • p=0.01 (99%) 27 • p=0.001 (99,9%) Schätzen des Mittelwerts • Problem – die Varianz eines Merkmals in der Grundgesamtheit ist unbekannt • Vorgehen – Schätzen aufgrund von einer Stichprobenvarianz • Beobachtung – der standardisierte Mittelwert normalverteilter Daten ist bei dieser Schätzung nicht mehr normalverteilt, sondern weist für kleine Werte des Parameters n eine größere Breite und Flankenbetonung ⇒ der Mittelwert ist t-verteilt (“Students tVerteilung”) • Hypothesentests, bei denen die t-Verteilung Verwendung wird: verschiedene “t-Tests” 28 t-Verteilung 29 Code: siehe ab Folie 9. df = degrees of freedom. Anzahl der frei veränderbaren Parameter. Hier: n-1 t-Verteilung 30 t-Verteilung 31 t-Verteilung • mit zunehmender Anzahl an Freiheitsgraden df (d.h. veränderbaren Parametern), nähert sich die t-Verteilung der Normalverteilung an • ab df>30 ist der Unterschied redundant 32 Anpassungstest • Fall 1 – eine abhängige Variable auf Verhältnisniveau – Test: sind die Daten normalverteilt? – Methode • Shapiro-Wilk-Test, shapiro.test() • Ablaufschema 1. Formulieren der Hypothesen 2. Graphische Betrachtung 3. Ermittlung der Prüfstatistik W und der Irrtumswahrscheinlichkeit p 33 Anpassungstest: Fall 1 • Beispiel: • eine abhängige Variable auf Verhältnisniveau • Normalverteilung? – Spracherwerbsdaten des Russischen zur Aspekthypothese (vgl. Stoll und Gries, Ms.) • anfänglich starke Korrelation von Präsens und imperfektivem Aspekt sowie Präteritum und perfektivem Aspekt – Frage: wie entwickelt sich das Korrelationsmaß über die Zeit? – Test: sind die Korrelationsmaße von 117 Aufnahmen normalverteilt? 34 Anpassungstest: Fall 1 • Hypothesen – H0: Die Datenpunkte weisen eine Normalverteilung auf; W = 1. – H1: Die Datenpunkte weisen keine Normalverteilung auf; W ≠1. 35 • eine abhängige Variable auf Verhältnisniveau • Normalverteilung? Anpassungstest: Fall 1 Graphische Betrachtung: 36 • eine abhängige Variable auf Verhältnisniveau • Normalverteilung? Anpassungstest: Fall 1 • eine abhängige Variable auf Verhältnisniveau • Normalverteilung? • Prüfstatistik shapiro.test(TEMPUS_ASPEKT) Shapiro-Wilk normality test data: TEMPUS_ASPEKT W = 0.9942, p-value = 0.9132 p>0.05 H0 gilt: Daten sind normalverteilt H1 darf nicht angenommen werden 37 Anpassungstest: Fall 1 • eine abhängige Variable auf Verhältnisniveau • Normalverteilung? • Schriftliche Zusammenfassung der Ergebnisse – "Die Verteilung der Cramers V-Werte [des Korrelationsmaßes] für die Tempus-AspektKorrelation bei diesem Kind weicht gemäß einem Shapiro-Wilk-Test nicht signifikant von der Normalverteilung ab: W= 0,9942; p = 0,9132." (nach Gries 2008: 156) 38 Weiterer Test auf Normalverteilung • Quantile-quantile Plot – Quantilen der Standardnormalverteilung auf der xAchse – Quantilen der beobachteten Verteilung auf der yAchse – Bei Normalverteilung bildet Plot eine diagonale Linie (unabhängige von Mittelwert und Standardabweichung) – ermöglicht eine intuitive "positive" Überprüfung von Normalverteilung, ersetzt aber nicht einen statistischen Test 39 Weiterer Test auf Normalverteilung qqnorm(TEMPUS_ASPEKT) qqline(TEMPUS_ASPEKT) • Unsere Beispieldaten: 40 Anpassungstest: Fall 2 • Fall 2 – eine abhängige Variable auf Nominal- oder Kategorialniveau – Frage: sind zwei Ausprägungen einer Variable gleich häufig? – Test: sind die Daten so verteilt, dass sie einer bekannten Verteilung entsprechen? – Methode: • Chi-Quadrat-Test; chisq.test() 41 Anpassungstest: Fall 2 • Methode: Chi-Quadrat-Test; chisq.test() • Voraussetzungen – Alle Beobachtungen sind von einander unabhängig – 80% der erwarteten Häufigkeiten sind größer oder gleich 5 – Alle erwarteten Häufigkeiten sind größer als 1 Falls die Häufigkeiten zu klein sind: Fisher Exact Test 42 Anpassungstest: Fall 2 • Methode: Chi-Quadrat-Test; chisq.test() • Ablaufschema 1. Formulierung der Hypothesen 2. Tabellierung der beobachteten Häufigkeiten; graphische Betrachtung 3. Ermitteln der Häufigkeiten, die gemäß H0 zu erwarten wären. 4. Testen der Voraussetzungen 5. Berechnen der Abweichungsmaße für alle beobachteten Häufigkeiten 6. Summierung der Abweichungsmaße zur Ermittlung der Prüfstatistik χ2 7. 43 Ermittlung der Freiheitsgrade df und der Irrtumswahrscheinlichkeit p Anpassungstest: Fall 2 • Beispiel – • a. He picked up the book Verb-Partikel-direktes_Objekt b. He picked the book up Verb-direktes_Objekt-Partikel Frage – 44 Worstellungsalternation Beide Konstruktionen werden von vielen für bedeutungsgleich gehalten. Sind sie gleich häufig? Anpassungstest: Fall 2 • Hypothesen • eine abhängige Variable auf Nominal-/Kategorialniveau • Chi-Quadrat-Verteilung? – H0: Die Häufigkeit der Variablenausprägungen der Variable Konstruktion sind identisch; die Variation in der gezogenen Stichprobe ist zufällig. – H1: Die Häufigkeiten der Variablenausprägungen der Variable Konstruktion sind nicht identisch; die Variation in der Stichprobe ist nicht zufällig. • In statistischer Form: – H0: nV PART DO = n V DO PART – H1: nV PART DO ≠ n V DO PART 45 Anpassungstest: Fall 2 • eine abhängige Variable auf Nominal-/Kategorialniveau • Chi-Quadrat-Verteilung? • Tabellierung der beobachteten Häufigkeiten • Experiment: Beschreibungen von Bildern (Peters 2001) Verb-Partikel-direktes_Objekt Verb-direktes_Objekt-Partikel 247 150 46 Anpassungstest: Fall 2 • Ermitteln der Häufigkeiten, die H0 zu erwarten wären. • eine abhängige Variable auf Nominal-/Kategorialniveau • Chi-Quadrat-Verteilung? gemäß Verb-Partikel-direktes_Objekt Verb-direktes_Objekt-Partikel 198,5 198,5 • Testen der Voraussetzungen: OK • Berechnen der Abweichungsmaße für alle beobachteten Häufigkeiten und Summierung der Abweichungsmaße zur Ermittlung der Prüfstatistik χ2 2 beobachtet − erwartet ) ( 2 Chi − Quadrat = χ = ∑ i=1 erwartet = ca. 23,7 47 n Einschub: Werte von χ2 • Große Abweichung – höherer Chi-Quadrat-Wert • Keine Abweichung – Chi-Quadrat-Wert = 0 • Statistische Hypothesen - reformuliert – H0: χ2 = 0. – H1: χ2 > 0. 48 Anpassungstest: Fall• eine 2 abhängige Variable auf Nominal-/Kategorialniveau • Chi-Quadrat-Verteilung • Interpretation des Chi-Quadrat-Werts • Ermittlung der Freiheitsgrade df und der Irrtumswahrscheinlichkeit p • df =1 • Kritische χ2-Werte für pzweiseitig df=1 df=2 df=3 49 p=0,05 3,841 5,991 7,815 p=0,01 6,635 9,21 11,345 p=0,001 10,827 13,815 16,266 Anpassungstest: Fall 2 • Interpretation des Ergebnisses – 23,7 > 10,827 – Ablehnung der Nullhypothese "Die Verteilung der beiden Konstruktionen weicht gemäß einem Chi-Quadrat-Anpassungstest hoch signifikant von der erwarteten Gleichverteilung ab (χ2 =23,7; df= 1; pzweiseitig < 0,001): Die Konstruktion V-PTK-DO wurde 247 Mal beobachtet, obwohl sie nur 199 Mal erwartet wurde. Die Konstruktion V-DO-PTK wurde nur 150 Mal beobachtet, obwohl sie 199 Mal erwartet wurde." 50 (nach Gries 2008: 161) Referenzen • Stefan Th. Gries. 2008. Statistik für Sprachwissenschaftler. Vandenhoeck & Ruprecht. – Kapitel 3, 4. • Andere: – K. Backhaus, W. Plinke und B. Erichson. 2006. Multivariate Analysemethoden – Eine anwendungsorientierte Einführung, Berlin: Springer. – Lothar Sachs und Jürgen Hedderich. 2009. Angewandte Statistik, Berlin: Springer. 1-2 51