Projektaufgabe 2
Werbung

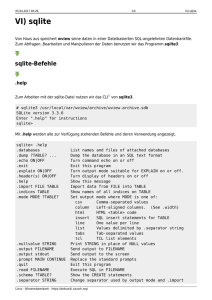
Prof. Dr.-Ing. Klaus Berberich Information Retrieval Sommersemester 2017 Telefon: 06 81 58 67-243 [email protected] Projektaufgabe 2 Die Projektaufgabe wird in der Veranstaltung am 19. Juni besprochen. Sofern Sie Bonuspunkte erhalten möchten, reichen Sie Ihre Lösung bis zum 18. Juni um 23.59 Uhr per E-Mail ein. Die Aufgaben bauen auf denen aus Projektaufgabe 1 auf – eine Beispiellösung finden Sie auf der Webseite zur Vorlesung. Aufgabe 2.1 SQLite und Xerial (1 Punkt) Installieren Sie SQLite (https://www.sqlite.org) auf Ihrem System. Laden Sie den JDBC-Treiber Xerial (https://bitbucket.org/xerial/sqlite-jdbc) in der Version 3.18.0 herunter. Machen Sie sich mit dem Zugriff auf eine SQLite-Datenbank von der Kommandozeile und per JDBC aus Java vertraut. Code-Beispiele hierzu finden Sie unter den genannten URLs. Reichen Sie als Lösung zu dieser Aufgabe die Ausgabe des Kommandos .version aus der SQLite-Kommandozeile ein. Aufgabe 2.2 Datenbank erstellen (1 Punkt) Erstellen Sie nun eine SQLite-Datenbank mit dem Namen nyt.sqlite zum Verwalten unserer Dokumentensammlung. In dieser soll es zwei Tabellen geben: In der Tabelle docs werden die Meta-Daten der Dokumente verwaltet. Sie soll folgende Attribute haben: (i) did als eindeutige ID des Dokumentes, (ii) title als Titel des Dokumentes und (iii) url als URL des Dokumentes In der Tabelle tfs wird verwaltet, welches Dokument, identifiziert durch seine ID, welchen Term mit welcher Häufigkeit enthält. Sie soll folgende Attribute haben: (i) did als ID des Dokumentes, (ii) term als Term und (iii) tf als Häufigkeit des Terms im Dokument. Wählen Sie für die Attribute sinnvolle Datentypen aus. Eine Übersicht der in SQLite verfügbaren Datentypen finden Sie unter folgender URL: https://www.sqlite.org/datatype3.html Geben Sie als Lösung geeignete CREATE TABLE Kommandos an. htw saar · Hochschule für Technik und Wirtschaft des Saarlandes · Fakultät für Ingenieurwissenschaften Goebenstraße 40 · 66117 Saarbrücken · http://www.htwsaar.de Prof. Dr.-Ing. Klaus Berberich Aufgabe 2.3 Importieren der Dokumente (2 Punkte) Wir möchten die Dokumente nun in die Datenbank importieren. Hierzu erweitern wir die Klassen Importer und Parser aus Projektaufgabe 1. Die Methode importDirectory von Importer soll nun für jede gefundene Datei mit der Endung .xml die Methode parse von Parser aufrufen. Die zurückgelieferte Instanz von Document soll in die Datenbank importiert werden. Für jedes Dokument wird eine neue Zeile in die Tabelle docs eingefügt. Je unterschiedlichem Term im Attribut content wird eine Zeile in die Tabelle tfs eingefügt. Für ein Dokument mit den Attributen • id : 23 • title : ABC • url : http://www.nytimes.com/abc • content : [a, b, c, a, b, a] soll also eine Zeile mit den Werten • 23, ABC, http://www.nytimes.com/abc in die Tabelle docs eingefügt werden. In die Tabelle tfs sollen insgesamt drei Zeilen mit folgenden Werten eingefügt werden • 23, a, 3 • 23, b, 2 • 23, c, 1 Um das Einfügen in die Datenbank möglichst effizient zu gestalten, empfiehlt es sich die Klasse java.sql.PreparedStatement zu verwenden. Diese ermöglicht vorkompilierte SQL-Kommandos und erlaubt zudem das stapelweise Einfügen mehrerer Zeilen in die Datenbank. Machen Sie sich hierzu mit den Methoden addBatch und executeBatch der Klasse vertraut. Eine sinnvolle Stapelgröße in unserem Fall sind zehn Dokumente. Reichen Sie Ihren Code als Lösung ein. Aufgabe 2.4 Berechnen von Statistiken über die Dokumentensammlung (1 Punkt) Bei der Besprechung von IR-Modellen haben wir verschiedene Statistiken kennengelernt. In dieser Aufgabe sollen Sie weitere Tabellen anlegen, die solche Statistiken aus der Tabelle tfs berechnen. Verwenden Sie hierzu Kommandos der Bauart CREATE TABLE ... AS (SELECT ...). Es sollen folgende Tabellen erzeugt werden: Eine Tabelle dls mit den Attributen (i) did und (ii) len, welche zu jedem Dokument seine Länge, d.h. die Gesamtzahl der Termvorkommen darin, enthält. Eine Tabelle dfs mit den Attributen (i) term und (ii) df, welche zu jedem Term seine Dokumentenhäufigkeit enthält. Eine Tabelle d mit dem Attribut (i) size. Darin soll nur eine Zeile enthalten sein mit der Gesamtzahl der Dokumente als Wert. Geben Sie die verwendeten SQL-Kommandos als Lösung an. 2/2