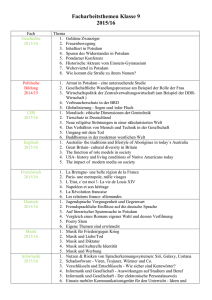
Seminarplan mit Literaturhinweisen: Grundlegende
Werbung

Seminarplan mit Literaturhinweisen: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse 1. Sitzung: Kausalanalyse mit Tabellenanalyse und mit partieller Korrelation Einführendes Beispiel für die Elaboration von Zusammenhängen durch Teilgruppenvergleich; Statistischer Kausalbegriff; Experiment und Tabellenanalyse; Scheinkorrelation; Intervenierende Variable (Skript, Kap. 2.-2.2.1 oder Benninghaus, Kap. 9 oder Kühnel/Krebs, Kap. 15) 2. Sitzung: Modellierung des einführenden Beispiels durch ein log-lineares Modell; Zerlegung von Zusammenhangsmaßen nach Drittfaktor; „pfadanalytische“ Interpretation des einführenden Beispiels (Skript, Kap. 2.2.1 oder Litz, Kap. 6.3) 3. Sitzung: Suppressor Variable; Distorter Variable; Vorzeichenregel und Zerlegungsformel; (Skript, Kap. 2.2.3-2.2.4.3) 4. Sitzung: Interaktion, Spezifikation und typologische Effekte; Interaktionseffekte aus Sicht der Varianzanalyse (Skript, Kap. 2.2.4.4-2.2.4.8) 5. Sitzung: Partielle Korrelation; Multiple Regression (Grundlagen) (Skript, Kap.2.3 oder Litz Kap. 3) 6. Sitzung: Multiple Regression (Zerlegung von R2) (Skript, Kap. 3.-3.1.5 oder Backhaus et al., Kap. 1.1-1.2.2 oder Bortz Kap. 13.2) 7. Sitzung: Multiple Regression (u.a. Logistische Regression) (Skript, Kap. 3.1.6, 3.1.7 oder Litz Kap. 6.2) 8. Sitzung: Varianzanalyse (Skript, Kap. 3.1.8-3.1.11 und Kap. 4 oder Litz Kap. 5) 9. Sitzung: Pfadanalyse (Grundlagen) (Skript, Kap. 3.2-3.2.4 oder Opp/Schmidt, Teil 4 oder Bortz, Kap. 13.3) 10. Sitzung: Pfadanalyse (Beispiele) (Skript, Kap. 3.2.5- 3.2.8 oder Opp/Schmidt, Teil 5) 11. Sitzung: Ausblick: Grundlegende versus fortgeschrittene multivariate Modelle der sozialwissenschaftlichen Datenanalyse Literatur: Skript (Holtmann, 2010³, Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse) Backhaus et al. 200310 Multivariate Analysemethoden Benninghaus, 20029, Deskriptive Statistik Bortz 20056, Statistik für Human- und Sozialwissenschaftler Kühnel/Krebs, 2001, Statistik für die Sozialwissenschaften Litz, H. P., 2000, Multivariate statistische Methoden und ihre Anwendung in den Wirtschafts- und Sozialwissenschaften Opp/Schmidt 1976, Einführung in die Mehrvariablenanalyse Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse (Meth. II) (Gliederung für die ersten Sitzungen) 1. Überblick über die multivariaten Modelle der sozialwissenschaftlichen Datenanalyse .................................................................................................................. 1 2. 2..1 2..2 2..2.1 2..2.2 2.2.2.1 2..2.3 2..2.4 2..2.4.1 Kausalanalyse mit Tabellenanalyse und partieller Korrelation............................ 13 Statistischer Kausalbegriff ........................................................................................... 13 Tabellenanalyse ............................................................................................................ 15 Ein Beispiel für Korrelation ohne Kausalität ............................................................... 16 Zerlegung der Vier-Felder-Tafel an einem einführenden Beispiel.............................. 17 Log-lineare Modellierung des einführenden Beispiels ................................................ 21 Die Grundgleichung (Zerlegungsformel für Maßzahlen) ............................................ 24 Typologie von Kausalstrukturen mit drei Variablen ................................................... 29 Typen mit: [xy : z] = [xy : ¬z] („Scheinkorrelation“, Intervenierende Variable, Suppressor, Distorter) .................................................................................................. 29 2..2.4.2 Zerlegungsformel am Beispiel eines Suppressor- sowie Distorter-Phänomens .......... 32 2..2.4.3 Vorzeichenregel nach Davis für Suppressor- und Distorter Phänomene .................... 39 2..2.4.4 Typen mit: [xy : z] ≠ [xy ¬z] (Spezifikation) .............................................................. 43 2..2.4.5 Conjoint influence ........................................................................................................ 43 2..2.4.6 Verschiedene typologische Effekte und Interaktionseffekte ....................................... 45 2..2.4.6.1 Varianzanalytische Interpretation von Rosenbergs Mobilitäts-Beispiel ..................... 46 2..2.4.7 Interaktion, Spezifikation und typologische Effekte aus Sicht der Varianzanalyse ............................................................................................................. 54 2..2.4.8 Kausale Interpretation von Zusammenhängen ............................................................ 65 2..3 Partielle Korrelation ..................................................................................................... 67 Literaturverzeichnis ..................................................................................................................... 73 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 1 Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse 1. Überblick über den Gegenstand a) Drittvariablenkontrolle/ Elaboration von Zusammenhängen durch Teil gruppenvergleich (nominales Messniveau) oder durch partielle Korrelation (metrisches Messniveau) b) Multiple Regression und Pfadanalyse zur Analyse metrischer Daten Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 2 2. Kausalanalyse mit Tabellenanalyse und partieller Korrelation Ein Beispiel zur Einführung (vgl. Kap. 2.2.2): Wie ist es möglich, dass ein Zusammenhang bei Aufgliederung nach einem Drittfaktor verschwindet? Bsp. (Mayntz et al., nach Zeisel) Stichprobe von Arbeitnehmerinnen Häufigkeit des wenig Fernbleibens vom viel Betrieb (y) Familienstand (x) ledig verheiratet 1000 600 600 1000 1600 1600 1600 1600 3200 Differenz der Kreuzpunkte [xy] = 10002 - 6002 (Anzahl der konkordanten Paare minus Anzahl der diskordanten Paare) [xy] > 0 ([xy] noch keine normierte Maßzahl) Kausalmodell: x → y Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 3 z1 (wenig Hausarbeit) y Fern- webleiben nig viel x Familienstand led. verh. 900 300 1200 300 100 400 1200 400 1600 [xy : z1] = 0 z2 (viel Hausarbeit) y Fern- webleiben nig viel x Familienstand led. verh. 100 300 400 300 900 1200 400 1200 1600 [xy : z2] = 0 (Technisch liegt es also an den Randverteilungen, inhaltlich an den Beziehungen zu dem Drittfaktor, dass der Zusammenhang in den Teilgruppen verschwindet.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 4 Hausarbeit (z) wenig viel Familienstand (x) ledig verheiratet 1200 400 1600 400 1200 1600 1600 1600 3200 [xz] > 0 Häufigkeit des Fernbleibens vom Betrieb (y) wenig viel Hausarbeit (z) wenig viel 1200 400 400 1200 1600 1600 1600 3200 1600 [zy] > 0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 5 Differenzierteres Kausalmodell: z x y (Es gibt einen indirekten Kausaleffekt von x auf y, aber keinen direkten.) z ist eine intervenierende Variable. Familienstand (x) strukturiert Belastung mit Hausarbeit (z). Belastung mit Hausarbeit (z) strukturiert Fernbleiben vom Betrieb (y). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 6 „Baumdarstellung“ der Daten: Hierarchische Aufgliederung nach X, nach Z und nach Y n = 3200 X (Familienstand) ledig 1600 verheiratet 1600 Z (Hausarbeit) Z (Hausarbeit) wenig 1200 viel 400 wenig 400 viel 1200 Y (Fernbl.) Y (Fernbl.) Y (Fernbl.) Y (Fernbl.) wenig 900 viel 300 wenig 100 viel 300 wenig 300 viel 100 wenig 300 Aber: Ein Kausalmodell ist viel hilfreicher für das Verständnis. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 7 viel 900 2.1 Kausalanalyse und statistischer Kausalbegriff Aussagen in den Sozialwissenschaften sind ganz überwiegend stochastisch, d.h. nicht deterministisch. Deterministisch: Immer: Wenn A, dann B. (Gesetz) (All-Ausage) ( ∀ x: Ax ⇒ Bx) (Ein Teil der naturwissenschaftlichen Aussagen). Stochastisch: Wenn A, dann mit hoher Wahrscheinlichkeit B. („A begünstigt B“) (Oder: „strukturiert“) (Empirische Regelmäßigkeit) Deshalb haben Hyman und Lazarsfeld einen abgeschwächten „statistischen Kausalbegriff“ vorgeschlagen: (x „verursacht“ y): ⇔ 1) Es gibt einen statistischen Zusammenhang. 2) x geht y kausal voran, wobei die zeitliche Reihenfolge nicht hinreichend ist. 3) Es handelt sich nicht um eine „Scheinkorrelation“, d.h. eine tatsächliche Korrelation, die aber bei Kontrolle von Drittfaktoren verschwindet (scheinkausale Korrelation). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 8 Diskussion des Definitionsvorschlags: Zu 1) Es gibt auch die Möglichkeit, dass der Kausalzusammenhang erst nach der Kontrolle von Drittfaktoren sichtbar wird (scheinbare Nicht-Kausalität). Zu 2) Statistischer Zusammenhang: symmetrisch Kausalzusammenhang: asymmetrisch Zeitliche Reihenfolge reicht nicht. Zu 3) Im Experiment unproblematisch: Einfluss der Störfaktoren ist durch Untersuchungsdesign kontrolliert. Aber: In den Sozialwissenschaften häufig nicht anwendbar. (Z. B. sind viele Merkmale nicht manipulierbar: Alter, Geschlecht, ...) Als „Simulation“ eines Experiments: Einfluss von einigen wichtigen Drittfaktoren kontrollieren. Die Absicherung gilt dann aber auch nur für die kontrollierten Drittfaktoren. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 9 Kausalität und Experiment: Experiment: 1) Manipulierbarkeit der unabhängigen Variablen. 2) Kontrolle der Dritt- bzw. Störfaktoren. Zu 2): a) Randomisierung: Zwei Zufallsstichproben b) Matching: Für einige Variablen mit Zufallsverfahren die Zuordnung zu den Experimentalgruppen entscheiden. Bei (a) im Prinzip gegen alle möglichen Stör faktoren abgesichert, bei (b) gegen die beim Matching berücksichtigten Störfaktoren abgesichert. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 10 Beispiel für ein Experiment y = Vorurteilsmessung Messung t1 Experimentalgruppe G1 Kontrollgruppe G 2 yG1 ,t1 yG2 ,t1 Film t2 ja nein Messung t3 y G1 ,t3 y G2 ,t3 yG1 ,t1 = yG2 ,t1 Effekt des Films: y G1 ,t3 - y G2 ,t3 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 11 2.2 Tabellenanalyse Die Tabellenanalyse (elaboration; Einführung von Drittfaktoren) beinhaltet den Versuch, durch nachträgliche Homogenisierung mittels statistischer Manipulation des Datenmaterials unabhängige Variablen mit Kausalwirkung zu finden. Im Gegensatz zum Experiment, das durch die Tabellenanalyse approximiert wird, sind die unabhängigen Variablen in der Tabellenanalyse nicht einfach einzeln zu verändern. Die Merkmale treten in Kombinationen auf. - Absicherung nur gegen die Drittfaktoren, die man selbst getestet hat. (Experiment mit Randomisierung: gegen alle Drittfaktoren abgesichert) - Aber: Viele relevante mögliche unabhängige Variablen in den Sozialwissenschaften sind gar nicht manipulierbar. (Z. B. Alter, Geschlecht, Ethnie, Herkunftsland, ...) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 12 Also: In den Sozialwissenschaften Simulation des Experiments durch Kontrolle einiger Drittfaktoren. In den Sozialwissenschaften: „Quasi-Experiment“ Auf nominalem Messniveau: Tabellenanalyse [Metrisch: Partielle Korrelation] Tabellenanalyse (Elaboration, Kontrolle von Drittfaktoren, Teilgruppenvergleich) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 13 2.2.1 Ein Beispiel für Korrelation ohne Kausalität (nach Hirschi und Selvin) (Stichprobe von Jugendlichen) x: Kirchenbesuch y: Delinquenz Ja Nein Ja 44 % 56 % Nein 56 % 44 % 100 % [xy] ≠ 0 100 % Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 14 z1: Alter ≤ 14 Kirchenbesuch Delinquenz Ja Nein Ja 33 % 33 % Nein 67 % 67 % 100 % 100 % [xy: z1] = 0 z1: Alter > 14 Kirchenbesuch Delinquenz Ja Nein Ja 67 % 67 % Nein 33 % 33 % 100 % 100 % [xy: z2] = 0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 15 Kirchenbesuch Nicht-Delinquenz Alter („Marionettenspieler“) „Scheinkorrelation“ (Tatsächliche Korrelation, aber nicht kausal zu interpretieren) Scheinkausale Korrelation Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 16 Kausalmodell der „Scheinkorrelation“ X Y Z Der Zusammenhang zwischen x und y ist nicht kausal zu interpretieren. („Scheinkorrelation“) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 17 Beispiel: Anzahl der Störche Anzahl der Kinder Land (Stadt) „Scheinkorrelation“ Beipiel: Anzahl der Pumpen Höhe des Schadens „Scheinkorrelation“ Größe des Feuers Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 18 Auf der Basis von statistischen Zusammenhängen kann man nicht immer zwischen Kausalmodellen entscheiden. „Scheinkorrelation“ x y z [xy] ≠ 0 [xy :z1] = 0 [xy : z2] = 0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 19 Intervenierende Variable x z y [xy] ≠ 0 [xy : z1] = 0 [xy : z2] = 0 Unterschied zwischen „Scheinkorrelation“ und intervenierender Variable: Kausale Ordnung „Scheinkorrelation“: z ist antezedierend. Intervenierende Variable: z ist intervenierend. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 20 2.2.4 Typologie von Kausalstrukturen mit 3 Variablen Typen mit: [xy : z1] = [xy : z2] 1) „Scheinkorrelation“ Kausalmodell: x y z Korrelationen: [xy : z1] = [xy : z2] = 0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 21 Beispiel: x Krankenhaus y Sterberate hoch z Gesundheitszustand Beispiel: x mittleres Kind y Delinquenz z Kinderzahl in Herkunftsfamilie (als Schichtindikator) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 22 2) Intervenierende Variable Kausalmodell: x → z → y Korrelationen: [xy : z1] = [xy : z2] = 0 Bsp.: (Durkheim: Le suicide) [Voraussetzung: Homogene Altersgruppe] Korrelation: x Protestanten x Protestanten → y höhere Selbstmordgefährdung z niedrige Integration → y höhere Selbstmordgefährdung Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 23 Beispiel: [Voraussetzung: Homogene Altersgruppe] Korrelation: x verheiratet x verheiratet → y niedrige Selbstmordgefährdung z Kinder → y niedrige Selbstmordgefährdung Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 24 (Älteres) Bsp.: x Frauen x Frauen → y autoritärer z niedrige Bildung → y autoritärer Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 25 Beispiel: (Homans) x Räumliche Nähe x Räumliche Nähe → y Sympathie z Interaktion → y Sympathie Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 26 Log-lineare Modellierung des einführenden Beispiels (2.2.2.1) Das einführende Beispiel für eine intervenierende Variable beinhaltete, dass die Belastung durch Hausarbeit in der Kausalbeziehung zwischen Familienstand und Fernbleiben im Betrieb insofern interveniert, dass ledige Frauen stärker belastet sind durch Hausarbeit und dass stärker durch Hausarbeit belastete Frauen häufiger dem Betrieb fern bleiben müssen. Dieses Beispiel soll nun dadurch modelliert werden, welche der möglichen Interaktionen zwischen diesen drei Merkmalen berücksichtigt werden müssen, um die beobachteten (Kombinations-) Daten zu reproduzieren. Da man eine sparsame Modellierung anstrebt, will man nur die zwingend notwendigen Interaktionen herausarbeiten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 27 Log-lineare Modelle zur Analyse von Kreuztabellen Kreuztabelle zweier Merkmale A und B: B j A i fij fi+ f+j n (Notation: f wie frequencies) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 28 Das Konzept der statistischen Unabhängigkeit f i+ f + j ⋅ f ij = n ⋅ n n ist eigentlich ein multiplikatives Konzept. Beispiel: Falls die Chance für SPD-Wahl statistisch unabhängig ist vom Geschlecht, so ist z. B. die Anzahl der weiblichen SPDWähler gleich dem Anteil der Frauen multipliziert mit dem Anteil der SPD-Wähler und multipliziert mit dem Stichprobenumfang. D. h. die absolute Häufigkeit einer Kombination ergibt sich aus den Chancen in den beiden Randverteilungen multipliziert mit dem Stichprobenumfang. Durch Logarithmieren lässt sich die statistische Unabhängigkeit additiv ausdrücken: ln f ij f+ j fi+ = ln n + ln + ln n n Dies heißt, dass sich im Falle der statistischen Unabhängigkeit die Zellenhäufigkeiten f ij aus dem Stichprobenumfang und den beiden Randwahrscheinlichkeiten ergeben, die Informationen aus den Interaktionen also nicht benötigt werden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 29 Der Soziologe und Statistiker Leo A. Goodmann (University of Chicago) hat zur Analyse von Kontingenztafeln die log-lineare Modellierung entwickelt (1970, 1972 etc.). Mit f ij werden die beobachteten Häufigkeiten bezeichnet, mit Fij die unter der Annahme des Modells zu erwartenden Häufigkeiten. Die Idee dieser Modellierung besteht nun darin, dass die logarithmischen Häufigkeiten log F ij sich aus dem additiven Zusammenwirken eines Bezugspunktes θ (theta) und der Effekte der RandverA B teilungen λ i bzw. λ j (lambda) bzw. der Effekte der Interaktion λ AB ij darstellen lassen. Multiplikativ: fij = n Stichprobenumfang • f i+ n • f+ j • n Effekt von A i f ij / n fi+ / n ⋅ f + j / n Effekt von B j Effekt der Interaktion A i B j (Abweichung von der Unabhängigkeit) Additiver Modellansatz für die Grundgesamtheit: ln Fij = θ + λ A i + λ B j + λ AB ij Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 30 Das Modell der statistischen Unabhängigkeit lässt sich bei dieser Modellierung also dadurch charakterisieren, dass λ AB = 0 (für alle i, j). ij Beispiel: Fernbleiben vom Betrieb Die pfadanalytische Interpretation des Beispiels lautete: Familienstand (A) strukturiert Belastung mit Hausarbeit (B). Belastung mit Hausarbeit (B) strukturiert Fernbleiben vom Betrieb (C). Drei Merkmale lassen sich z.B. in der Form einer dreidimensionalen Tabelle (A, B, C) analysieren. Das (vollständige) log-lineare Modell würde lauten: A B C + λ + λ ln Fijk = θ + λ i j k ABC BC AC AB λ +λ + λ + λ ijk jk ik ij + Das vollständige oder saturierte Modell umfasst also alle denkmöglichen Parameter und ist nur eine (evtl. sogar zu umfangreiche) Umformung der Daten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 31 Die Idee der log-linearen Modellierung besteht nun darin, eine „sparsame“ Modellierung vorzunehmen, d.h. ein so einfaches Modell wie nur möglich, wobei Einfachheit bedeutet, mit Parametern möglichst ge(λ ringer Ordnung auszukommen nung, λ AB ij ist 2. Ordnung, λ ABC ijk B j ist z. B. 1. Ord- ist 3. Ordnung). Es lässt sich nun zeigen, dass in dem Beispiel die Randverteilungen A, B, C, (AB), (BC) hinreichend sind („suffiziente Statistiken“), um die Daten des Beispiels perfekt zu reproduzieren. Belastung mit Hausarbeit (B) B 1 wenig B 2 viel Familienstand (A) Fernbleiben (C) C 1 wenig C 2 viel A 1 ledig 900 300 A 2 verheiratet 300 100 A 1 ledig 100 300 A 2 verheiratet 300 900 Die Parameter des log-linearen Modells werden mit Hilfe der Maximum-Likelihood-Methode geschätzt, dies ist gerade die Leistung des Modells von Goodman. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 32 Schätzungen der log-linearen Parameter für das Beispiel Theta (Mean) 5,704 Effekt A1 A A 2 Lambda 0 0 B B1 B2 0 0 C C1 C2 0 0 A1 B1 .549 AB A B 1 2 -.549 A2 B1 A2 B2 -.549 B1C1 BC B C 1 2 B2C1 B2C2 .549 .549 -.549 -.549 .549 D.h. es gibt keine Haupteffekte, sondern nur die beiden Interaktionseffekt (AB) und (BC). Zusammenhänge ungleich Null liegen nur vor für die Beziehung Familienstand und Belastung sowie die Beziehung Belastung und Fernbleiben. Ein Beispiel für die perfekte Anpassung des Modells als Illustration, dass die gemäß dem Modell zu erwartenden Häufigkeiten F ijk den beobachteten Häufigkeiten f ijk genau entsprechen: ln FA ,B ,C = θ 1 2 1 + = 5,704 + λ A 1 0 + λ + 0 B 2 + λ + 0 C 1 + λ AB 12 λ BC 21 + (-0,549) + (-0,549) = 4,606 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 33 + = e 4, 606 FA1 ,B2 ,C1 = 100 = f A1 ,B2 ,C1 2.2.3 Zerlegungsformel Analog zur Zerlegung der Gesamttabelle in zwei Partialtabellen soll nun eine Zerlegung für Maßzahlen formuliert werden. Einfachste Zerlegung gilt für δ (delta) = nij − nˆij (= n11 − nˆ11 ) (In Vier-Felder-Tafel ist dies – absolut gesehen – eine feste Größe) Vier-Felder-Tafel x y a b a + b = S1 = n y1 c d c + d = S2 = ny2 a+c b+d a+b+c+d =n = S3 = S4 = n x1 = nx2 Nc – Nd ist gleich der Differenz der Kreuzprodukte: ad – bc δ = a− (a + b ) ⋅ (a + c ) ⋅ n = ad − bc n n n Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 34 ┌ Einschränkung: δ ist streng genommen noch keine „fertige“ Maßzahl, denn ist nicht normiert auf: [-1, +1] 5 0 25 └ Beispiel: δ ; = = 2,5 0 5 10 └ δ Zerlegungsformel für beliebige Maßzahl [xy] [ xy ] = α [ xy : z1 ] + β [ xy : z 2 ] + γ [ xz ][ yz ] Die Gewichte α , β , γ in der Zerlegungsformel sind abhängig von den gewählten Maßzahlen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 35 Zerlegungsformel für delta δ = δ xy Gesamtzusammenhang xy:z1 ++ δ Zusammenhang in Partialtabelle z1 xy:z 2 ++ Zusammenhang in Partialtabelle z2 n nz1 nz 2 δ xz δ yz Beziehungen zu dem Drittfaktor n α = 1, β = 1, γ = n n z z 1 1 Da δ nicht normiert ist, soll nun analog die Zerlegung für die Maßzahl Φ (Phi) formuliert werden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 36 S1S 2 S3 S 4 δ= Φ n Φ ( x, y ) = nx1:z1 ⋅ nx2:z1 ⋅ n y1:z1 ⋅ n y2:z1 n nz1 nx1 ⋅ nx2 ⋅ n y1 ⋅ n y2 S1S 2 S3 S 4 ] Φ(xy : z1 ) nx1:z2 ⋅ nx2:z2 ⋅ n y1:z2 ⋅ n y2:z2 n + n z2 ad − bc Φ= [Weil: nx1 ⋅ nx2 ⋅ n y1 ⋅ n y2 Φ(xy : z2 ) + Φ ( xz )Φ ( yz ) ┌ γ= Denn: nx1 ⋅ nx2 ⋅ nz1 ⋅ nz2 ⋅ n y1 ⋅ n y2 ⋅ nz1 ⋅ nz2 1 ⋅ =1 nz1 ⋅ nz2 nx1 ⋅ nx2 ⋅ n y1 ⋅ n y2 Hierbei lauten die Varianzen: s x2 = nx1 ⋅ nx2 n2 und s y2 = n y1 ⋅ n y 2 n2 bzw. sz2 = nz1 ⋅ nz 2 n2 Als Spezialfall von r lautet Phi: Φ xy = s xy sx s y = Nc − Nd n² = n x1 ⋅ n x2 n y1 ⋅ n y2 ⋅ n² n² Nc − Nd n x1 ⋅ n x2 ⋅ n y1 ⋅ n y2 Die Zerlegung ließe sich also auch formulieren als: nz1 ⋅ s x:z1 ⋅ s y:z1 nz2 ⋅ s x:z2 ⋅ s y:z2 Φ xy = ⋅ Φ xy:z1 + ⋅ Φ xy:z2 + Φ xz ⋅ Φ yz n ⋅ sx ⋅ s y n ⋅ sx ⋅ s y └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 37 Beispiel: y Fernbleiben wenig im Betrieb (y) viel Familienstand (x) ledig verheiratet 1000 600 1600 600 1600 1000 1600 Φ xy = 0,25 Nämlich: Φ xy = 10002 − 6002 16004 = 0,25 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 38 1600 Familienstand (x) Hausarbeit (z) wenig viel ledig 1200 verheiratet 400 1600 400 1600 1200 1600 1600 3200 Φ xz Fernbleiben wenig im Betrieb (y) viel = 0,5 Hausarbeit (z) ledig verheiratet 1200 400 1600 400 1600 1600 3200 Φ yz 1200 1600 = 0,5 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 39 Φ xy = α ⋅ Φ( xy : z1 ) + β ⋅ Φ( xy : z2 ) + Φ( xz ) Φ ( yz ) 0,25 0 0 0,5 0,5 Pfadmodell: (Hier: Kausalkette) 0,25 x y 0,5 0,5 Familienstand z Fernbleiben vom Betrieb Belastung durch Hausarbeit - Es gibt keinen direkten Kausaleffekt, sondern nur einen indirekten. Bei Egalisierung der Belastung durch Hausarbeit gäbe es keinen Kausaleffekt von Familienstand auf Fernbleiben im Betrieb mehr. - Die Größe des Gesamtzusammenhanges ergibt sich als Produkt der Effekte: Φ yx = Φ yz ⋅ Φ zx (Notation: y ist eine Funktion von z, z ist eine Funktion von x, y ist eine Funktion von x.) - Als intervenierende Variablen kommen nur Faktoren z in Frage, die sehr hoch mit x und y Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 40 korrelieren. (Denn ein Produkt von Zahlen Φ < 1 wird ja kleiner.) („Scheinkorrelation“: analog) Weitere Kausaltypen ( 2.2.4.1) 3) Suppressor Variable (Dämpfende Variable) Bei Einführung des Testfaktors z wird die Beziehung zwischen x und y größer, als sie vorher sichtbar war. Beispiel: Korrelation: x hohes Einkommen y hoher Milchkonsum Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 41 hohe Kinderzahl z - + x hohes Einkommen (hohe Schicht) + y hoher Milchkonsum Unter Kontrolle von z in beiden Teilgruppen positiver Zusammenhang. ges Gesamtzusammenhang [xy] = 0 = ⊕ + = dir + indir direkter Kausaleffekt indirekter Kausaleffekt Vorzeichenregel: (-) * (+) = (-) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 42 In dem Beispiel handelt es sich um einen indirekten Kausaleffekt. Bei Scheinkomponente würde gleiche Vorzeichenregel gelten: z x y Bsp.: (Durkheim, Le suicide) [x , Juden (stark integriert) y hohe Selbstmordrate ]=0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 43 Stadt vs. Land z + + - x Juden y hohe Selbstmordrate (vs. andere Konfession) ges Gesamtzusammen hang (vs. niedrige) ⊕ = + = dir + indir direkter Kausaleffekt indirekter Kausaleffekt Vorzeichenregel: (+) * (-) = (+) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 44 4) Distorter Variable (Verzerrende Variable) Bei Einführung des Testfaktors z wird ein zu dem ursprünglichen Zusammenhang [xy] entgegengesetztes Vorzeichen in [xy : z1] und [xy : z2] sichtbar. Beispiel: (Durkheim) [x , y verhohe heiratet Selbst(intemordrate griert) ] = + Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 45 höheres Alter z + x verheiratet + - y hohe Selbstmordrate Neben dem direkten Kausaleffekt gibt es also eine Scheinkomponente aufgrund von z in dem Zusammenhang zwischen x und y. + ges = Gesamtzusammenhang dir + direkter Kausaleffekt ++ spurious Scheinkomponente Vorzeichenregel: (+) * (+) = (+) [Bei indirektem Kausaleffekt würde gleiche Vorzeichenregel gelten.] Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 46 Zerlegungsformel am Beispiel eines Suppressor-Phänomens (2.2.4.2) Rosenberg (1968) entnimmt einer Untersuchung von Arnold M. Rose folgendes Beispiel: „What do you think of having Jews on the union staff?“ Es stellt sich heraus, dass Jüngere ( < 29 Jahre) mit wenig Gewerkschaftssozialisation (< 4 Jahre) dies zu 56,4 % eher neutral sehen, während die mittlere Altersgruppe (30 - 49 Jahre) mit wenig Gewerkschaftssozialisation dies nur zu 37,1 % und die höhere Altersgruppe ( > 50 Jahre) mit wenig Gewerkschaftssozialisation dies nur zu 38,4 % neutral sehen. Um nur mit Dichotomien zu arbeiten, fasse ich die letzten beiden Gruppen zusammen, da sie sich ja auch ähnlich verhalten. Dauer Gewerkschaftsmitglied (x) Jews on < 4 Jahre > 4 Jahre Neutral 62 129 191 Nicht neutral 64 127 191 126 256 382 union staff (y) [ yx] = 62 ⋅ 127 − 64 ⋅ 129 = −382 δ yx = [ yx] / n = −1 s yx = [xy ] / n 2 = −0,003 Φ yx = [ yx]/ 34304 = −0,011 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 47 Die Sozialisation in der Gewerkschaft (operationalisiert durch die Dauer der Gewerkschaftsmitgliedschaft) haben Jüngere systematisch weniger erfahren als Ältere, andererseits könnten Jüngere „toleranter“ (hier gemessen als Neutralität) sein. Deshalb wird Alter (z) als Testfaktor eingeführt, da eine Scheinkomponente aufgrund des Alters vermutet werden kann. Alter (z = z 1 ) < 29 Jahre Jews on union staff (y) Alter (z = z 2 ) > 30 Jahre in Gewerkschaft (x) in Gewerkschaft (x) < 4 Jahre > 4 Jahre < 4 Jahre > 4 Jahre Neutral 44 32 76 Nicht neutral 34 19 53 78 51 129 Jews on Neutral union staff (y) Nicht neutral 18 97 115 30 108 138 48 205 253 [yx : z 2 ] = −966 [ yx : z1 ] = −252 δ yx:z = [ yx : z 2 ] / n 2 = −3,818 δ yx: z = [ yx : z1 ] / n1 = −1,953 2 1 s yx:z1 = [ yx : z1 ] / n1 = −0,015 s yx:z2 = [ yx : z 2 ] / n2 = −0,015 2 2 Φ yx:z1 = [ yx : z1 ] / 4003 = −0,063 Φ yx:z2 = [ yx : z 2 ] / 12496 = −0,077 (In den Teilgruppen ergibt sich also eine sehr ähnliche Beziehung: [xy : z1 ] ≈ [xy : z 2 ] ) Diese Ergebnisse sind nur möglich wegen der Beziehungen der Ausgangsvariablen x und y zu dem Drittfaktor z. Alter (Jüngere) z + Dauer der GewerkschaftsMitgliedschaft (< 4 Jahre) Bilanz: x ges dir spurious − -- + + y -- Toleranz („Neutral“) − Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 48 in Gewerkschaft (x) Alter (z) < 4 Jahre > 4 Jahre < 29 Jahre 78 51 129 > 30 Jahre 48 205 253 126 256 382 [xz ] = 13542 δ xz = [xz ] / n == 35,450 s xz = [xz ] / n 2 = 0,093 Φ xz = [xz ] / 32446 = 0,417 Alter (z) Jews on < 29 Jahre > 30 Jahre Neutral 76 115 191 Nicht neutral 53 138 191 129 253 382 union staff (y) [yz ] = 4393 δ yz = [ yz ] / n = 11,500 s yz = [ yz ] / n 2 = 0,030 Φ yz = [ yz ] / 34506 = 0,127 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 49 Die Zerlegung für δ yx (Dies ist die klassische Version.) δ yx = δ yx:z + δ yx:z 1 2 n + δ xz δ yz n1 n2 382 − 1 = −1,953 − 3,818 + 129 ⋅ 253 35,450 ⋅ 11,500 Die Zerlegung für [yx] (Dies ist die rechnerisch einfachste Version.) 1 n n [xz ] [ yx] = [ yx : z1 ] + [ yx : z2 ] + n1 n2 n1n2 [ yz ] 382 382 1 − 382 = (−252) + (−966) + 13542 ⋅ 4393 129 253 129 ⋅ 253 Die Zerlegung für die Kovarianz syx (Die Kovarianz hat hierbei die günstigsten Eigenschaften, s.u.) s yx s xz s yz n1 n2 s yx: z1 + s yx: z 2 + = n1 n2 n n n n − 0,003 = 129 253 0,093 ⋅ 0,030 (−0,015) + (−0,015) + 129 253 382 382 382 382 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 50 Die Zerlegung für Phi (Phi ist die wichtigste Maßzahl für die Vierfeldertafel.) n Φ ( x, y ) = nz1 n + nz1 nx1:z1 ⋅ nx2:z1 ⋅ n y1:z1 ⋅ n y2:z1 nx1 ⋅ nx2 ⋅ n y1 ⋅ n y2 nx1:z2 ⋅ nx2:z2 ⋅ n y1:z2 ⋅ n y2:z2 nx1 ⋅ nx2 ⋅ n y1 ⋅ n y2 Φ(xy : z1 ) Φ(xy : z2 ) + Φ ( xz )Φ ( yz ) 78 ⋅ 51 ⋅ 76 ⋅ 53 382 (−0,063) − 0,011 = 129 126 ⋅ 256 ⋅ 191 ⋅ 191 382 48 ⋅ 205 ⋅ 115 ⋅ 138 + (−0,077) 253 126 ⋅ 256 ⋅ 191 ⋅ 191 + 0,127 ⋅ 0,417 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 51 Zerlegungsformel am Beispiel eines Distorter-Phänomens (2.2.4.2) Rosenberg (1968) illustriert das Distorter-Phänomen an folgendem Beispiel, das ich für die Illustration der Zerlegungsformel verwenden möchte. Die Arbeiterschicht scheint eine stärkere Affinität zu den Bürgerrechten zu haben. Wenn man aber Ethnie kontrolliert, wird das Gegenteil sichtbar: Die Mittelschicht befürwortet die Bürgerrechte stärker, der falsche Eindruck kommt nur dadurch zustande, dass „Schwarze“ überproportional Arbeiter und gleichzeitig überproportional für die Bürgerrechte sind. Social class (x) Civil rights score (y) Middle class Working class High 44 54 98 Low 76 66 142 120 120 240 [ yx] = −1200 δ yx = [ yx]/ n = −5 s yx = [ yx] / n 2 = −0,021 Φ yx = [ yx] / 14156 = −0,085 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 52 Ethnie (z = z 1 ) „Schwarze“ Civil rights score (y) Ethnie (z = z 2 ) „Weiße“ Social class (x) Social class (x) Middle Working class class Middle Working class class High 14 50 64 Low 6 50 56 20 100 120 Civil rights score (y) [ yx : z1 ] = 400 δ yx:z = [ yx : z1 ] / n1 = 3,333 2 s yx:z = [ yx : z1 ] / n1 = 0,028 Φ yx:z = [ yx : z1 ] / 2677 = 0,149 High 30 4 34 Low 70 16 86 100 20 120 [ yx : z 2 ] = 200 δ yx:z = [ yx : z 2 ] / n2 = 1,667 2 s yx:z = [ yx : z 2 ] / n 2 = 0,014 Φ yx:z = [ yx : z 2 ] / 2418 = 0,083 1 2 1 2 1 2 In den beiden Teilgruppen ergibt sich bei etwas großzügiger Betrachtung eine ähnliche Beziehung: [xy : z1 ]≈[xy : z 2 ] . Es liegt also wieder an den Beziehungen der Ausgangsvariablen x und y zu dem Drittfaktor z. Ethnie (z) („Schwarze“) -- Social class (x) (Middle class) ++ Civil rights score (y) (High) + Bilanz: ges - dir + spurious -- Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 53 Social class (x) Ethnie (z) Middle class Working class “Schwarze” 20 100 120 „Weiße“ 100 20 120 120 120 240 [xz ] = −9600 δ xz = [xz ]/ n = −40 s xz = [xz ] / n 2 = −0,167 Φ xz = [xz ]/ 14400 = −0,667 Ethnie (z) Civil rights score (y) “Schwarze” “Weiße” High 64 34 98 Low 56 86 142 120 120 240 [yz ] = 3600 δ yz = [ yz ]/ n = 15 s yz = [ yz ] / n 2 = 0,063 Φ yz = [ yz ] / 14156 = 0,254 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 54 Die Zerlegung für δ yx δ yx = δ yx:z + δ yx:z 1 2 n + δ xz δ yz n1 n2 240 − 5 = 3,333 + 1,667 + 120 ⋅ 120 (−40) ⋅ 15 Die Zerlegung für [yx] 1 n n [xz ] [ yx] = [ yx : z1 ] + [ yx : z2 ] + n1 n2 n1n2 − 1200 = 240 240 1 400 + 200 + (−9600) ⋅ 3600 120 120 120 ⋅ 120 Die Zerlegung für die Kovarianz sxy sxz s yz n2 n1 s yx = s yx: z1 + s yx: z 2 + n1 n2 n n n n − 0,021 = [ yz ] 120 120 (−0,167) ⋅ 0,063 0,028 + 0,014 + 120 120 240 240 240 240 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 55 Die Zerlegung für Phi n Φ ( x, y ) = n z1 n + n z1 n x1:z1 ⋅ n x2 :z1 ⋅ n y1:z1 ⋅ n y2 :z1 n x1 ⋅ n x2 ⋅ n y1 ⋅ n y2 n x1:z2 ⋅ n x2 :z2 ⋅ n y1:z2 ⋅ n y2 :z2 n x1 ⋅ n x2 ⋅ n y1 ⋅ n y2 Φ ( xy : z1 ) Φ ( xy : z 2 ) + Φ (xz )Φ ( yz ) 240 20 ⋅ 100 ⋅ 64 ⋅ 56 0,149 − 0,085 = 120 120 ⋅ 120 ⋅ 98 ⋅ 142 240 100 ⋅ 20 ⋅ 34 ⋅ 86 + 0,083 120 120 ⋅ 120 ⋅ 98 ⋅ 142 + 0,254 ⋅ (− 0,667 ) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 56 2.2.4.3 Vorzeichenregel nach Davis für Suppressor- und Distorter-Phänomene Suppressor Bei Einführung von z wird die BezieVariable hung zwischen x und y größer. („Dämpfend“) a) Falls das Einführen von z eine positive Korrelation verstärkt, so muss gelten: sign [xz] = -sign [yz] b) Falls das Einführen von z eine negative Korrelation verstärkt, so muss gelten: sign [xz] = sign [yz] Distorter Bei Einführung von z wird ein zu dem Variable ursprünglichen Zusammenhang [xy] („Verzerrend“) entgegengesetztes Vorzeichen in [xy:z1] und [xy:z2] sichtbar: z.B. Falls [xy] > 0: sign [xz] = sign [yz] b) Falls [xy] < 0: sign [xz] = -sign [yz] Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 57 Mit „Bilanzen“ formuliert: Gesamt- Direkter Kau- Indirekter Kauzusamsaleffekt saleffekt oder menhang Spurious Suppressor Variable +(0) ++(+) - (-) - (0) -- (-) +(+) „Scheinbare NichtKausalität“ 0 + - 0 - + Distorter Variable + - ++ - + -- Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 58 Vorzeichenregel und/oder perfekte Maßzahl? [ xy ] = α [ xy : z1 ] + β [xy : z 2 ] + γ [ xz ][ yz ] Bei Typen mit: [xy : z1] = [xy : z2] [xy] = a [xy : z] + b [xz] [yz] ges ber res Man vergleicht den Gesamtzusammenhang und den bereinigten Zusammenhang: Wenn a = 1, dann: res = ges – ber Ob die Vorzeichenregel perfekt gilt, hängt von den Koeffizienten a und b ab, welche wiederum spezifisch sind für die gewählte Maßzahl bzw. „Quasi-Maßzahl“ [xy]. Falls a = 1, so gilt perfekte Vorzeichenregel. (b ist immer positiv und stört deshalb nicht, denn: (res > 0) ⇔ ([xz] [yz] > 0) ) ┌ z.B. für δ ( δ ist „Quasi-Maßzahl“, denn δ ist nicht normiert.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 59 δ xy = δ xy:z + δ xy:z 1 ges (res > 0) (<) 2 + direkter Kausaleffekt bzw. bereinigter Zusammenhang γ ⋅ δ xzδ yz res (Residuum) genau dann wenn (Beziehungen von x und y zu dem Testfaktor z sind gleichlautend (gegenlautend) im Vorzeichen) D.h.: Die Vorzeichenregel von Davis ist implizit in meinen Bilanzgleichungen enthalten. └ Relativierung („Dilemma“ gemäß Davis): Die Vorzeichenregel für δ ist perfekt, für Φ eine Daumenregel, weil α und β i.a. bei Φ nicht einfach gleich 1 sind. Andererseits ist Φ eine perfekte Maßzahl, während δ nicht normiert ist: z.B.: 10 0 0 10 δ = 10 ⋅10 =5 10 + 10 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 60 Die Vorzeichenregel auf Basis der Kovarianz Eine Kompromisslösung in diesem „Dilemma“ ergibt sich nach meiner Auffassung für die Kovarianz sxy: sxy ist im allgemeinen Fall nicht normiert, d.h. i.a. gilt nicht: │sxy │ < 1 Aber: Für den einfachen Fall der Vierfeldertafel ist die Kovarianz normiert. ad − bc s xy = n2 ad − bc −1 ≤ ≤ +1 2 n sxy ist also normiert, jedoch nicht so perfekt wie Φ xy , die Maximalwerte + 1 können in vielen Datenkonstellationen gar nicht erreicht werden. Dennoch ist die Kovarianz normiert und lässt sich auf eine Weise zerlegen, die ähnlich einfach ist wie bei δ , wobei δ andererseits nicht normiert ist. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 61 Zerlegungsformel für die Kovarianz s xy = s xy⋅z + s xz s yz / s z2 , wobei: s 2 = n1 n2 z n Hierbei ist die partielle Kovarianz sxy.z gleich einem gewogenen arithmischen Mittel aus den beiden bedingten Kovarianzen für die beiden Teiltabellen: s xy. z n1 n2 = s xy:z1 + s xy:z 2 n n Aus dem Vergleich der Kovarianz mit der partiellen Kovarianz ergibt sich unmittelbar die Vorzeichenregel: sign (sxy – sxy.z) = sign (sxz ∙ syz) In diesem Sinne ist die Kovarianz nach meiner Auffassung ein Kompromiss in dem „Dilemma“ (Davis) zwischen Vorzeichenregel und perfekter Maßzahl. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 62 Gesamtzusammenhang > bereinigter Zusammenhang/direkter Effekt? (<) Erster Mechanismus, der wirkt: Direkter Kausaleffekt 1. Fall: Der zweite Mechanismus ist indirekt kausal. z β zx x rxy = β xy β yz y β yx + direkter Kausaleffekt β yz β zx indirekter Kausaleffekt Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 63 2. Fall: Der zweite Mechanismus beinhaltet eine Scheinkomponente. z β xz β yz x rxy = β yx β yx y β yz β xz + direkter Kausaleffekt Scheinkomponente auf Grund von z Vorzeichenregel für Fall 1 und 2: Gesamtzusammenhang Bereinigter zusammenhang ber Residuum ges = + res (res > 0) ⇔ (<) (Die Effekte von x und y in Relation zu dem Drittfaktor z sind gleichlautend (gegenlautend) im Vorzeichen.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 64 3. Fall: Der zweite Mechanismus ist ein korrelierter Effekt. Z rxz X rxy = β yz Y β yx β yx + direkter Kausaleffekt rxz β yz korrelierter Effekt Eine Vorzeichenregel ist nicht so sinnvoll, da es sich hier um unterschiedliche Konzepte handelt. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 65 Mit „Bilanzen“ formuliert: „Scheinkorrelation“ (Besser: Scheinbare Kausalität) Gesamtzusammenhang direkter Kausal- spurious oder effekt Scheinkomponente + - 0 0 + - „Scheinkorrelation“ Z X Y (Gegen-Typ: Scheinbare Nicht-Kausalität) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 66 Intervenierende Variable Gesamtzusammenhang direkter Kausal- indirekter Kaueffekt saleffekt + - 0 0 + - Intervenierende Variable x → z → y (Nur indirekter Kausaleffekt, kein direkter) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 67 Liegen ein oder zwei Mechanismen vor? X Y Z x hat indirekten und direkten Effekt auf y. (Zwei Kausalmechanismen) x → z → y x hat nur indirekten Effekt auf y. (Intervenierende Variable) x y z x hat direkten Kausaleffekt auf y; und: es gibt Scheinkomponente in dem Gesamtzusammenhang zwischen x und y, die auf z zurückzuführen ist. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 68 X Y Z x hat keinen direkten Kausaleffekt auf y. („Scheinkorrelation“) (Bessere Bezeichnung: Scheinkausalität) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 69 Bilanz für die Fälle, in denen zwei Mechanismen das gleiche Vorzeichen haben: z x y Bei Scheinkomponente: „Überlagerung“ z x y Bei indirektem Kausaleffekt: „Verstärker“ Gesamtzusammenhang ++ -- direkt kausal + - spurious oder indirekt kausal + - Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 70 Nur direkter Kausalmechanismus Z X Y Gesamtzusammenhang + - direkt kausal + - spurious oder indirekt kausal 0 0 Résumé: Die Lösung des „Kausalitätsproblems“ liegt nach meiner Auffassung nicht in einer perfektionierten Definition der Kausalität, denn einerseits beginnt man mit der Forderung, es solle ein statistischer Zusammenhang vorliegen, andererseits zeigt die Diskussion der Kausaltypen, dass dies im Fall der scheinbaren Nicht-Kausalität gerade nicht gegeben ist. Die Lösung liegt nach meiner Auffassung in der Interaktion von theoretischen Vorstellungen, die in Modellen verdichtet werden, und Erfahrungswissen, das als Empirie aufbereitet wird. Sind die tatsächlichen Beobachtungen verträglich mit Beobachtungen, die aufgrund eines theoretischen Modells zu erwarten wären? Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 71 Diese Frage wird i.a. nicht in einem einzigen Schritt beantwortet, sonder in Zyklen von Modellgenerierung und Modell-Modifikation aufgrund von Konsistenzüberlegungen und Erfahrungswissen. Falls [xy] als Zusammenhang in der Gesamttabelle ermittelt ist, sollte man Kausalmodelle formulieren mit den Mechanismen, die den Zusammenhang produzieren: - direkter Kausaleffekt? - indirekte/r Kausaleffekt/e? - spurious bzw. Scheinkomponente/n des Zusammenhangs? An diese Denkfigur knüpft die Pfadanalyse an. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 72 B) Typen mit [xy : z1] ≠ [xy : z2] (Spezifikation; 2.2.4.4) (Die Pfadanalyse dagegen berücksichtigt jeweils einen Effekt einer Variablen.) 5) Spezifikation Häufigstes Ergebnis: In den beiden Teilgruppen gibt es unterschiedliche Zusammenhänge. Kausalstruktur: x y z z spezifiziert die Beziehung zwischen x und y. Z.B. Spezifikation nach Ort, Zeit, Geschlecht etc. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 73 Beispiel, dass es scheinbar keinen Zusammenhang gibt, tatsächlich aber in den beiden Teilgruppen gegenläufige Zusammenhänge vorliegen. [x, y] = 0 x = Zufriedenheit mit Beruf y = Teilhabe an Aktivitäten in der Wohngemeinde z1 (white collar-Beruf): Unzufriedenheit mit dem Beruf → Aktiv in der Wohngemeinde z2 (blue collar-Beruf): Zufriedenheit mit dem Beruf → Aktiv in der Wohngemeinde Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 74 C) „Conjoint influence“ (Rosenberg) (2.2.4.5) z wird betrachtet als weitere unabhängige Variable. a) Unabhängiger Einfluss: Kausalstruktur x y z a1) Wenn sich die beiden unabhängigen Variablen (x und z) stark überschneiden, stellt sich die Frage, ob sie die abhängige Variable noch beeinflussen, wenn die jeweils andere unabhängige Variable kontrolliert wird. Ist dies der Fall, so handelt es sich um einen unabhängigen Einfluss. Statistische Beziehungen: [xy : z] ≠ 0, [zy : x] ≠ 0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 75 a2) Relativer Einfluss: Falls zwei voneinander unabhängige Einflussfaktoren (x und z) vorliegen, stellt sich die Frage, welcher Faktor den größeren Einfluss auf die abhängige Variable (y) hat. [xy : z] größer oder kleiner [zy : x]? a3) Ein kumulativer Einfluss tritt auf, falls der Gesamteinfluss der beiden unabhängigen Variablen größer ist als jeder der beiden einzelnen Einflüsse. Bei Überschneidungen ist es möglich, dass der kumulative Einfluss kaum größer ist als die einzelnen Einflüsse. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 76 Streuung in Y (als Rechteck dargestellt) X Z Variabilität und Erklärungsbeitrag von x bzw. y Erklärt z etwas von der Streuung von y über den Erklärungsbeitrag von x hinaus? Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 77 b) Typologische Effekte: Z.B.: Ein Effekt in der abhängigen Variablen y tritt erst auf, wenn beide unabhängigen Variablen gemeinsam wirken. (Dies ist ein multiplikativer Effekt, im Unterschied zu der Betrachtung additiver Effekte in (a1), (a2), (a3).) x y z Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann Seite 78 Beispiel: Nach Mayntz et al. (1971: 193) erzeugt ein Misserfolg (x) nur dann Unzufriedenheit (y), falls das Anspruchsniveau (z) hoch ist. Diese Interaktion von Merkmalen entspricht „multiplikativem Wirken“ von Merkmalen. 1: Merkmal x liegt vor 0: Merkmal x liegt nicht vor 1x: = 1 z analog 1 x . 1z = 1, falls: Merkmal x und Merkmal z liegen vor 0, sonst In dem Beispiel von Mayntz et al. gibt es nur einen Interaktionseffekt, keine „direkten Effekte“. Ein Modell, das gleichzeitig „Haupt-Effekte“ (von x und z) sowie einen „Interaktionseffekt“ (von x ∙ z) berücksichtigt, würde z.B. lauten (vgl. die Regressionsanalyse, Kap. 3): ŷ = α wobei x + β z +γ x ⋅ z , α,β und γ Parameter für die Gewichtung sind. Graphisch könnte man dies wie folgt veranschaulichen: Abb. 2.6: x y Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann z Seite 79 2.2.4.6 Verschiedene typologische Effekte und Interaktionseffekte Rosenberg (1968) unterscheidet vier typologische Effekte: 1. Distinctive type Beispiel: Eine spezielle Kombination – z.B. ein jüngerer Sohn mit überwiegend älteren Schwestern – weist die höchste Selbstachtung auf. 2. Modifying type Beispiel: In den USA haben Italo-Amerikaner, Katholiken, Schwarze und Juden eher eine Parteiaffinität zu den Demokraten, weiße Protestanten dagegen eher eine Parteiaffinität zu den Republikanern. Die Identifikation mit einer Ethnie hat allein keinen Effekt auf die Parteiaffinität, aber sie verstärkt den Effekt der Ethnien auf die Parteiaffinität. 3. The consistent-inconsistent type Beispiel: Statusinkonsistente weisen eher Stresssymptome auf als Statuskonsistente. 4. The relative type Beispiel (gemäß Lenski): Das Erziehungsziel Autonomie (versus Gehorsam) wird am stärksten von Mittelschichtangehörigen vertreten, die selbst aus der Arbeiterschicht aufgestiegen sind, und am wenigsten von Arbeiterschichtangehörigen, die selbst aus der Mittelschicht abgestiegen sind. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 80 Tabelle: Prozentsatz derer, die das Erziehungsziel Autonomie (versus Gehorsam) befürworten Schicht des Sohnes Mittelschicht Arbeiterschicht 74 % 48 % 77 % 55 % Schicht Mittelschicht des Vaters Arbeiterschicht Der Informationsgehalt dieser Typen besteht für Rosenberg gerade in den speziellen Kombinationen der Ausgangsvariablen, sodass Rosenberg die „Haupteffekte“ der eigenen Schicht und der Herkunftsschicht gar nicht berichtet, sondern nur die „Kombinationseffekte“. Bei den Söhnen, die selbst in der Mittelschicht sind, zeigt sich, dass Aufsteiger in die Mittelschicht häufiger für Autonomie sind, als dies bei Mittelschicht-„Stayer“ der Fall ist. Bei den Söhnen, die selbst in der Arbeiterschicht sind, zeigt sich, dass die Abgestiegenen den Wert Autonomie seltener aufweisen als die Arbeiterschicht-„Stayer“. Insgesamt scheint also der Wert Autonomie am wenigsten charakteristisch für Absteiger und am stärksten charakteristisch für Aufsteiger. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 81 2.2.4.6.1 Varianzanalytische Interpretation von Rosenbergs Mobilitäts-Beispiel Zur Erinnerung an die Deskriptivstatistik: Einfache Varianzanalyse Abhängigkeit einer metrischen Variablen (y) von einer nominalen unabhängigen Variablen (x). Einkommen erklären durch Stellung im Beruf. Beispiel: Effekte in der Varianzanalyse: Allgemeiner Durchschnitt als Bezugspunkt: y = 1964 Schätzung mit Vor- Effekt der Stellung information über die im Beruf auf das Stellung im Beruf Einkommen y1 = 3225 y1 − y = 1261 j = 1: Selbstständige j = 2: y2 = 2502 Beamte j = 3: y3 = 1846 Angestellte j = 4: y 4 = 1718 Arbeiter yi = Mittelwert der i-ten Gruppe y 2 − y = 538 y3 − y = -118 y 4 − y = -246 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 82 Varianzanalyse: Haupteffekte und Interaktionseffekte Einfache Varianzanalyse des Einkommens (y) durch die Stellung im Beruf (x) j = 1: Selbstständige j = 2: Beamte j = 3: Angestellte j = 4: Arbeiter Prognose aufgrund des additiven Modells 1964 + 1261 Tatsächlicher Durchschnitt Abweichung von Prognose 3225 0 1964 + 538 2502 0 1964 - 118 1846 0 1964 - 246 1718 0 Wenn man nun als zweite unabhängige Variable Geschlecht betrachtet, so gibt es entsprechende Effekte des Geschlechts. Die Effekte der Stellung im Beruf und des Geschlechts jeweils allein heißen Haupteffekte. Die Prognose des additiven Modells der zweifachen Varianzanalyse mit Stellung im Beruf (A) und Geschlecht (B) lautet: y + ( y Ai − y ) + ( y B j − y ) Interaktionseffekte bzw. nicht-additive Effekte gibt es in dem Ausmaß, wie der tatsächliche Durchschnitt y ij in den Kombinationen A i, B j von dieser Prognose auf Basis des additiven Modells der zweifachen Varianzanalyse abweicht. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 83 Interaktionseffekte in der zweifachen Varianzanalyse in Rosenbergs Beispiel Um Rosenbergs Beispiel genauer analysieren zu können, habe ich die absoluten Fallzahlen der Typen, die bei Rosenberg fehlen, aus dem Original von Lenski rekonstruiert (Gerhard Lenski: The religious factor. New York 1961. 19772). Befragt wurden 469 Personen, von denen 84 den Mobilitätsstatus Middle: non-mobile haben (davon 74 % pro Autonomie), 118 Middle: upwardly mobile (davon 77 % pro Autonomie), 40 Working: downwardly mobile (davon 48 % pro Autonomie) und 227 Working: non-mobile (davon 55 % pro Autonomie). Das angemessene Analysemodell scheint mir zunächst die Varianzanalyse der abhängigen Variablen Autonomie vs. Gehorsam mit Hilfe der zwei Erklärungsfaktoren „Schicht des Sohnes“ und „Schicht des Vaters“ (deshalb: zweifache Varianzanalyse). Die eigene soziale Lage ist bzgl. der Einstellung zur Autonomie deutlich trennschärfer als die Herkunftslage ( y z1 − y z2 = 21,8 vs. y x1 − y x2 = 2,7 ). Wenn man von der eigenen Lage ausgeht, so geht die Differenzierung nach der Herkunftsschicht jeweils in die Richtung, dass Personen mit Arbeiterherkunft den Wert Autonomie etwas stärker aufweisen (77,1 % vs. 73,8 % (Differenz 3,3) bzw. 55,1 % vs. 47,5 % (Differenz 7,6)). Dies ist erstaunlich, da bei Arbeiterherkunft insgesamt der Wert eher weniger anzutreffen ist (nämlich nur 62,6 % vs. 65,3 % bei Mittelschicht-Herkunft, Differenz = -2,7). Da es sich bei der Randverteilung um gewogene arithmetische Mittel handelt, liegt dies daran, dass die etwas geringere Ausprägung pro Autonomie bei Mittelschicht-„Stayer“ mit 73,8 % vs. der Aufsteiger mit 77,1 % dennoch stärker zu Buche schlägt, weil die „soziale Vererbung“ bei der Mittelschicht mit 67,7 % stark ausgeprägt ist (bei der Arbeiterschicht ähnlich mit 65,8 %, aber die Arbeiterschicht-„Stayer“ sind mit 55,1 % deutlich weniger pro Autonomie). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 84 Anteil der Personen, die persönliche Autonomie hoch bewerten, in Abhängigkeit von der eigenen bzw. der Herkunftsschicht bzw. vom Mobilitätsstatus (Aufstieg, Abstieg etc.) n y /(n y + n y ) = f ( x, z ) 2 1 2 Schicht des Sohnes (z) Mittelschicht Schicht Mitteldes schicht Vaters (x) Arbeiterschicht 62 = 73,8% 84 19 = 47,5% 40 81 = 65,3% 124 Prognose: 63,3+12,4+2,0=77,7 Prognose: 63,3-9,4+2,0=55,9 Abweichung von Prognose: 73,8-77,7=-3,9 Abweichung von Prognose: 47,5-55,9=-8,4 y x1 − y = 65,3 – 63,3 = +2,0 Arbeiterschicht 91 = 77,1% 118 125 = 55,1% 227 216 = 62,6% 345 Prognose: 63,3 + 12,4-0,7 = 75,0 Prognose: 63,3-9,4-0,7 = 53,2 Abweichung von Prognose: 77,1-75,0=+2,1 Abweichung von Prognose: 55,1-53,2=+1,9 y x2 − y = 62,6-63,3=-0,7 153 = 75,7% 202 y z1 − y 144 = 53,9% 267 = 75,7 - 63,3 = +12,4 y z2 − y = 53,9 – 63,3 = -9,4 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 85 297 = 63,3% 469 Insgesamt: 84 62 40 19 81 ⋅ + ⋅ = 124 84 124 40 124 (50,0) (15,3) 67,7 ⋅ 73,8 + 32,3 ⋅ 47,5 = 65,3 ∧ ∧ ∨ 34,2 ⋅ 77,1 + 65,8 ⋅ 55,1 = 62,6 (26,4) (36,2) 118 91 227 125 216 ⋅ + ⋅ = 345 118 345 227 345 Das Beispiel ist also viel komplexer, als es bei Lenski und Rosenberg dargestellt wird. Der angemessene Bezugspunkt scheint mir zunächst das additive Modell der zweifachen Varianzanalyse, das hier zur Prognose verwendet wird: yˆij = y + ( yi + − y ) + ( y+ j − y ) Die vier Interaktionseffekte bestehen dann in den vier Abweichungen der tatsächlichen Durchschnitte ( yij ) in den Kombinationen von den beim ˆ ˆ additiven Modell zu erwartenden Werten ( yij ) : yij − yij Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 86 Gegenüber dem allgemeinen Durchschnitt und den Haupteffekten der Herkunftslage und der eigenen Lage weisen Aufsteiger eine um 2,1 % stärker ausgeprägte Präferenz für Autonomie (selbstständiges Denken) auf. Absteiger dagegen weisen diese Präferenz unterproportional auf (-8,4 %). (Mittelschicht-„Stayer“ bleiben mit –3,9 % unterproportional und Arbeiter-„Stayer“ mit +1,9 % überproportional, was noch zu erklären wäre.) Vieles spricht dafür, dass Autonomie, d.h. der Wert, selbstständig zu denken, eher eine Ursache des Aufstiegs ist als eine Folge. Dies sah auch Lenski so, da eine Überanpassung von Aufsteigern noch plausibel sein könne, nicht aber eine Überanpassung von Absteigern. Deshalb soll diese Kausalrichtung nach einer kurzen Diskussion der „Effekt-Codierung“ weiter verfolgt werden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 87 Nicht gewogene Daten bzw. „Effekt-Codierung“ führen zu falschen Schlüssen. Wenn man die Lenski-Daten ohne die Fallzahlen analysieren würde, die bei Rosenberg fehlen, wäre man zur Analyse mit „nicht gewogenen“ Daten gezwungen. An diesem Beispiel soll gezeigt werden, dass dies zu – im Sinne Lenskis – eher unsinnigen Ergebnissen führt, dann wären nämlich Aufsteiger und Absteiger ähnlich in ihrer Einstellung, während Lenski das selbstständige Denken (Autonomie) gerade für ein Charakteristikum von Aufsteigern hält. Unter „Effekt-Codierung“ versteht man eine Codierung Ti , bei der die Gewichte b i gerade die Effekte bzgl. des nicht gewogenen Mittelwerts der Mittelwerte sind: yˆ = bo + b1 T1 + ... + bk −1 Tk −1 k bo = ∑ y j / k = : y j =1 bi = yi − y (= „Effekt“ der i-ten Ausprägung) (Die bessere Art, Effekte zu messen, läge in der Wahl des tatsächlichen (= gewogenen) Mittelwerts y als Bezugspunkt: yi − y ) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 88 Nicht gewogene Daten Schicht des Sohnes (z) Mittelschicht Schicht des Vaters (x) Mittelschicht Arbeiterschicht Arbeiterschicht 74 48 61 Prognose: 63,5 + 12 - 2,5 =73 Prognose: 63,5 – 12 – 2,5 = 49 61 – 63,5 = -2,5 Abweichung von Prognose: +1 Abweichung von Prognose: -1 77 55 66 Prognose: 63,5 + 12 + 2,5 =78 Prognose: 63,5 – 12 + 2,5 = 54 66 – 63,5 = +2,5 Abweichung von Prognose: -1 Abweichung von Prognose: +1 75,5 51,5 75,5 - 63,5 = +12 51,5 – 63,5 = -12 63,5 Der Effekt von Aufstieg und Abstieg wäre jeweils „-1 %“ weg vom Wert Autonomie, während Lenski und Rosenberg gerade den Unterschied von Aufstieg und Abstieg herausstellen wollten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 89 Hypothese: Der Wert Autonomie strukturiert das Mobilitätsverhalten Zu erklären seien die Chancen, zu einem der vier Mobilitätstypen zu gehören. Relative Häufigkeit der Mobilitätstypen als Bezugspunkt. Schicht des Sohnes Mittelschicht Mittelschicht Arbeiterschicht 84 = 17,9% 469 40 = 8,5% 469 Schicht des Vaters 227 = 48,4% 469 118 = 25,2% 469 Arbeiterschicht Effekte, wenn man Autonomie als Wert präferiert. Schicht des Sohnes Mittelschicht Schicht des Vaters Arbeiterschicht Mittelschicht Arbeiterschicht 62 = 20,9% 297 19 = 6,4% 297 20,9 % - 17,9 % = +3,0 % 6,4 % - 8,5 % = -2,1 % 91 125 = 30,6% = 42,1% 297 297 30,6 % - 25,2 % = +5,4 % 42,1 % - 48,4 % = -6,3 % Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 90 Der Wert Autonomie begünstigt also das Auftreten des Typs „Aufstieg“ derart, dass man ihn zu +5,4 % überproportional vorfindet. Entsprechend findet man Abstieg mit –2,1 % unterproportional. (Mit Wert Autonomie verbleibt man zu +3,0 % überproportional in der Mittelschicht. Mit Wert Autonomie verbleibt man mit -6,3 % unterproportional in der Arbeiterschicht.) Die Effekte sind noch deutlicher, wenn man den Zusammenhang aus der Perspektive betrachtet, dass man den Wert Autonomie nicht präferiert. Effekte, wenn man Autonomie als Wert nicht präferiert. Schicht des Sohnes Mittelschicht Arbeiterschicht 21 = 12,2% 172 22 = 12,8% 172 Mittelschicht 12,8 % - 17,9 % = -5,1 % 27 = 15,7% 172 Arbeiterschicht Schicht des Vaters 15,7 % - 25,2 % = -9,5 % 12,2 % - 8,5 % = +3,7 % 102 = 59,3% 172 59,3 % - 48,4 % = +10,9 % Wenn man Autonomie nicht als Wert präferiert, ist man beim Typ Aufstieg mit –9,5 % stark unterproportional vertreten und beim Typ Abstieg mit +3,7 % überproportional. Besonders groß ist der Effekt auf den Typ Arbeiter-„Stayer“. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 91 Berücksichtigung der „Randeffekte“, dass man von der Spitze nicht aufsteigen kann und von unten nicht absteigen kann. In dem vorliegenden Beispiel gibt es nur zwei soziale Lagen in der Hierarchie, sodass sich die „Randeffekte“ hier darin zeigen, dass man bei Mittelschicht-Herkunft nicht aufsteigen und bei Arbeiterschicht-Herkunft nicht absteigen kann. Um dies angemessen zu berücksichtigen, könnte man als Bezugspunkte jeweils die Mittelschicht-Herkunft bzw. die Arbeiterschicht-Herkunft gesondert betrachten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 92 Personen mit Mittelschicht-Herkunft Schicht des Sohnes Schicht des Vaters: Mittelschicht Mittelschicht Arbeiterschicht 84 = 67,7% 124 40 = 32,3% 124 Personen mit Präferenz für den Wert Autonomie Schicht des Sohnes Mittelschicht Arbeiterschicht 62 = 76,5% 81 19 = 23,5% 81 Schicht des Vaters: Mittelschicht 76,5 % - 67,7 % = +8,8 % 23,5 % - 32,3 % = -8,8 % Der Wert Autonomie fördert das Verbleiben in der Mittelschicht mit +8,8 %, andererseits sind diese Personen bei den Absteigern mit den spiegelbildlichen –8,8 % unterproportional vertreten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 93 Personen mit Arbeiterschicht-Herkunft Schicht des Sohnes Schicht des Vaters: Arbeiterschicht Mittelschicht Arbeiterschicht 118 = 34,2% 345 227 = 65,8% 345 Personen mit Präferenz für den Wert Autonomie Schicht des Sohnes Mittelschicht Arbeiterschicht 91 = 42,1% 216 Schicht des Vaters: Arbeiterschicht 42,1 % - 34,2 % = 7,9 % 125 = 57,9% 216 57,9 % - 65,8 % = -7,9 % Bei Arbeiterschicht-Herkunft steigt man bei der Präferenz für Autonomie zu +7,9 % überproportional auf und verbleibt spiegelbildlich zu –7,9 % unterproportional in der Arbeiterschicht. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 94 Effekte, wenn man Autonomie als Wert nicht präferiert. Personen mit Mittelschicht-Herkunft Schicht des Sohnes Mittelschicht Schicht des Vaters: Mittelschicht Arbeiterschicht 22 = 51,2% 43 21 = 48,8% 43 51,2%-67,7%=-16,5% 48,8%-32,3%=+16,5% Bei Mittelschicht-Herkunft verbleibt man ohne den Wert Autonomie mit –16,5 % deutlich unterproportional in der Mittelschicht und steigt spiegelbildlich mit +16,5 % deutlich überproportional ab. Personen mit Arbeiterschicht-Herkunft Schicht des Sohnes Mittelschicht Schicht des Vaters: Arbeiterschicht Arbeiterschicht 27 = 20,9% 129 102 = 79,1% 129 20,9%-34,2%=-13,3% 79,1%-65,8%=+13,3% Ohne den Wert Autonomie steigt man bei Arbeiterschicht-Herkunft mit –13,3 % unterproportional häufig auf und verbleibt spiegelbildlich mit +13,3 % überproportional häufig in der Arbeiterschicht. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 95 2.2.4.7 Interaktion, Spezifikation und typologische Effekte aus Sicht der Varianzanalyse Die fruchtbarste Art, Interaktionseffekte in der Tabellenanalyse für 3 Variablen zu behandeln, wenn es eine zu erklärende Variable y gibt (asymmetrische Fragestellung), ist aus meiner Sicht die Orientierung an der zweifachen Varianzanalyse: y = f ( x, z ) In der Varianzanalyse wird versucht, die Variation in y dadurch zu erklären, dass sie auf Muster zurückgeführt wird, die sich aus Mechanismen und Effekten „möglichst niedriger Ordnung“ ergeben ( y xi , y z j wären 1. Ordnung, y xi z j wäre 2. Ordnung). (Auch die log-lineare Modellierung wurde genau aus dieser Analogie heraus entwickelt, allerdings für die symmetrische Fragestellung, aufgrund welcher Mechanismen es zu den Beobachtungen ( xi , z j , yu ) kommt.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 96 Unter Interaktionen in der zweifachen Varianzanalyse versteht man die Abweichungen von dem Muster, das sich aufgrund des allgemeinen Bezugspunkts y und der Haupteffekte ( y xi − y und y z j − y ) prognostizieren lässt: y xi z j − ( y + ( y xi − y ) + ( y z j − y )) Deshalb ist es sinnvoll, diese Effekte als „nicht additive“ Effekte zu interpretieren. „Multiplikativ“ sollte man dann nur Effekte auf y nennen, die genau und nur bei dem gemeinsamen Vorliegen zweier Bedingungen x i und zj auftreten. Im allgemeinen Fall gibt es also vier Interaktionseffekte bzw. nicht additive Effekte (nämlich für die vier Kombinationen ( xi , z j )). Die typologischen Effekte, die Rosenberg und wir bisher unterschieden haben, sind also alles spezielle Interaktionseffekte. Wenn es einen Interaktionseffekt gibt wie z.B. (xz) y , dann lässt sich dies asymmetrisch so formulieren, dass x die Beziehung (zy) spezifiziert und z die Beziehung (xy). (Wenn y nicht als abhängige Variable betrachtet wird, gilt auch : y spezifiziert die Beziehung (xz).) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 97 Anschaulich: z y x Oder auch: x y z Dies soll im folgenden Beispiel an der Analyse der Lebenszufriedenheit in Abhängigkeit von den Zufriedenheiten mit dem Beruf und mit Primärbeziehungen (Familie, Freundeskreis) gezeigt werden. Die Zahlen sind von Mayntz et al. (1971: 204f.), die dies als Beispiel für die multikausale Abhängigkeit einer Variablen y von den beiden Ursachen x und z angeben, wobei die Ursachen nicht korrelieren: x y z Was Mayntz et al. übersehen haben, ist, dass man in diesem Modell die starke Interaktion mit berücksichtigen sollte, was ich im Folgenden ausführe: x (xz) y z Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 98 Erläuterung der varianzanalytischen Tabelle So wie man bei statistischer Unabhängigkeit in einer Kontingenztabelle aus der Randverteilung die Besetzungszahlen in den einzelnen Kombinationszellen vorhersagen kann, lässt sich in der folgenden varianzanalytischen Tabelle eine Prognose für die Kombinationszellen aufgrund der Haupteffekte bzw. der Randverteilungen vornehmen. Beispiel: Personen mit großer Berufszufriedenheit und kleiner Zufriedenheit mit den Primärbeziehungen: Ausgegangen wird von der durchschnittlichen Lebenszufriedenheit von 57,89 %. Bei großer Berufszufriedenheit liegt man um 18,11 % über der durchschnittlichen Lebenszufriedenheit. Bei kleiner Zufriedenheit mit den Primärbeziehungen liegt man um –7,89 % unter dem Durchschnitt. Die Prognose aufgrund des additiven Modells beträgt also 57,89 – 7,89 + 18,11 = 68,11 %. Tatsächlich wird aber eine durchschnittliche Lebenszufriedenheit von 85,71 % beobachtet. Personen mit dieser Kombination weisen also eine um 85,71 – 68,11 = + 17,60 % höhere Lebenszufriedenheit auf, als bei dem additiven Modell (aufgrund der Haupteffekte) zu erwarten. Die Berufszufriedenheit erweist sich in dieser Kombination als relativ wichtig für die allgemeine Lebenszufriedenheit. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 99 Anteil der Personen mit großer Lebenszufriedenheit in Abhängigkeit von den Zufriedenheiten mit dem Beruf und den Primärbeziehungen n y2 /( n y1 + n y2 ) = f ( x, z ) Zufriedenheit mit Primärbeziehungen (x) klein groß 30 klein Zu= 18,75% 30 + 130 frieden -heit Prognose: 57,89 - 7,89 - 20,11 = 29,89 mit Abweichung von Prognose: 18,75-29,89 = dem -11,14% Beruf (z) Anteil des Typs: 160/950 = 16,84 % groß 140 = 48,28% 140 + 150 170 = 37,78% 170 + 280 Prognose: 57,89+3,65-20,11=41,43 % y z1 − y = Abweichung von Prognose: 48,28-41,43= +6,85 Anteil des Typs: 290/950 = 30,53 % 260 = 72,22% 260 + 100 120 = 85,71% 120 + 20 37,78 – 57,89 = -20,11 % n z1 = 450 ; 450/950 = 47,37 % 380 = 76,00% 380 + 120 yz2 − y = Prognose: 57,89 - 7,89 + 18,11 = 68,11 % Prognose: 57,89 + 3,65 + 18,11 = 79,65 % Abweichung von Prognose: 85,71-68,11 = Abweichung von Prognose: 72,22-79,65= + 17,60% -7,45% 76,00 – 57,89 = +18,11 % Anteil des Typs: 140/950 = 14,74 % Anteil des Typs: 360/950 = 37,89 % n z2 = 500 ; 500/950 = 52,63 % 150 = 50,00% 150 + 150 400 = 61,54% 400 + 250 n = 950 y x1 − y = 50,00 – 57,89 = -7,89 % y x2 − y n x1 = 300 ; 300/950 = 31,58 % n x2 = 650 ; 650/950 = 68,42 % = 61,54 – 57,89 = +3,65 % D.h. Die Interaktionseffekte sind nennenswert verschieden von Null. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 100 550 = 57,89% 550 + 400 Das „saturierte Modell“ (=vollständige Modell mit allen möglichen Effekten) läßt sich auf folgende beiden äquivalenten Arten darstellen: 1) Deskription der 4 Kombinations-Typen 4 Typen: y x =0, z =0 = 18,75% y x =1, z =0 = 48,28% y x =0, z =1 = 85,71% y x =1, z =1 = 72,22% Interpretation: Die Zufriedenheit mit dem Beruf (z) geht einher mit einem stärkeren Zuwachs in der allgemeinen Lebenszufriedenheit als die Zufriedenheit mit den Beziehungen (x). Interpretation: Der Kombinations-Typ weist entgegen der Erwartung nicht die höchsten allgemeine Lebenszufriedenheit auf, denn: y x = 0, z =1 = 85,71% > 72,22% = y x =1, z =1 2) Strukturerklärung durch Haupteffekte und Interaktionseffekte Beispiel für Typ (2,2): 72,22% = y x 2 , z 2 = ( ( ) ( y + y x2 − y + y z 2 − y ( ( ) ( + yx2 , z 2 − y + yx2 − y + yz 2 − y = ) ))) 57,89 + (+ 3,65) + (+ 18,11) + (72,22 − (57,89 + (+ 3,65) + (+ 18,11))) Interaktionseffekt (x 2 ,z 2 ) = -7,45% Interpretation: Der (Haupt-) Effekt des Berufs (z) ist mit + 18,11 größer als der (Haupt-) Effekt der Beziehungen (x). Der Interaktionseffekt für (x 2 ,z 2 ) zeigt, daß die allgemeine Lebenszufriedenheit unter diesen Bedingungen um 7,45% weniger groß ist, als nach dem additiven Modell aufgrund der Haupteffekte zu erwarten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 101 Anteil der Personen mit kleiner Lebenszufriedenheit in Abhängigkeit von den Zufriedenheiten mit dem Beruf und den Primärbeziehungen n y1 /( n y1 + n y2 ) = f ( x, z ) Zufriedenheit mit Primärbeziehungen (x) klein groß 130 klein Zu= 81,25% 130 + 30 frieden -heit Prognose: 42,11+7,89+20,11=70,11 mit Abweichung von Prognose: 81,25-70,11= dem +11,14 Beruf Anteil des Typs: 160/950 = 16,84 % (z) groß 150 = 51,72% 150 + 140 280 = 62,22% 280 + 170 Prognose: 42,11-3,65+20,11= +58,57 y z1 − y = Abweichung von Prognose: 51,72-58,57=6,85 62,22 – 42,11 = +20,11 Anteil des Typs: 290/950 = 30,53 % n z1 = 450 ; 450/950 = 47,37 % 20 = 14,29% 20 + 120 100 = 27,78% 100 + 260 120 = 24,00% 120 + 380 Prognose: 42,11 + 7,89-18,11 = 31,89 Prognose: 42,11-3,65-18,11 = 20,35 Abweichung von Prognose: 14,29-31,89 = 17,60 Abweichung von Prognose: 27,78-20,35= +7,43 Anteil des Typs: 140/950 = 14,74 % Anteil des Typs: 360/950 = 37,89 % 150 = 50,00% 150 + 150 250 = 38,46% 250 + 400 y x1 − y = 50,00 – 42,11 = +7,89 % nx1 = 300 ; 300/950 = 31,58 % y x2 − y = 38,46 – 42,11 = -3,65 nx2 = 650 ; 650/950 = 68,42 % Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 102 yz2 − y = 24,00 – 42,11 = -18,11 % n z2 = 500 ; 500/950 = 52,63 % 400 = 42,11% 950 Lebenszufriedenheit und Zufriedenheit mit den Primärbeziehungen (yx) Zufriedenheit mit den Primärbeziehungen (x) Lebenszufriedenheit (y) [xy] = 22500 150 250 400 150 400 550 300 650 950 δ xy = [xy ]/ n = 23,684 s xy = [xy ] / n 2 = 0,025 Φ xy = [xy ] / 207123 = 0,109 Lebenszufriedenheit und Berufszufriedenheit (yz) Berufszufriedenheit (z) Lebenszufriedenheit (y) [yz ] = 86000 280 120 400 170 380 550 450 500 950 δ yz = [ yz ]/ n = 90,526 s yz = [ yz ] / n 2 = 0,095 Φ yz = [ yz ] / 222486 = 0,387 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 103 Berufszufriedenheit und Zufriedenheit mit den Primärbeziehungen (zx) Zufriedenheit mit den Primärbeziehungen (x) Berufszufriedenheit (z) 160 290 450 140 360 500 300 650 950 [zx] = 17000 δ zx = [zx ]/ n == 17,895 s zx = [zx ] / n 2 = 0,019 Φ zx = [zx ] / 209464 = 0,081 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 104 Kombinationen (Typen) von Lebenszufriedenheit, Zufriedenheit mit dem Beruf und Zufriedenheit mit den Primärbeziehungen (y, x, z) Berufszufriedenheit klein (z = z 1 ) Berufszufriedenheit groß (z = z 2 ) Zufriedenheit mit den Primärbeziehungen (x) klein Lebens- klein 130 zufrieden(/160 = 81,25 %) heit (y) Anteil des Typs: 130/950=13,68 % groß 30 (/160 = 18,75 %) Anteil des Typs: 30/950=3,16 % 160 Zufriedenheit mit den Primärbeziehungen (x) groß klein 280 150 (/290 = 51,72 %) Anteil des Typs: 150/950=15,79 % Lebens- klein 20 zufrieden(/140 = 14,29 %) heit (y) Anteil des Typs: 20/950=2,11% 100 groß 120 (/140 =85,71 %) 260 170 140 (/290 = 48,28 %) Anteil des Typs: 140/950=14,74 % 290 groß 120 (/360 = 27,78 %) Anteil des Typs: 100/950=10,53% 380 (/360 = 72,22 %) Anteil des Typs: Anteil des Typs: 120/950=12,63% 260/950=27,37% 450(/950 = 47,37 %) 140 360 [yx : n ] = −6800 [ yx : z1 ] = 13700 500 (/950=52,63%) z2 δ yx = [ yx]/ nz == 30,444 δ yx = [ yx] / n z == −13,600 1 2 s yx = [ yx] / n z1 = 0,068 s yx = [ yx] / n z2 = −0,027 2 2 Φ yx = [ yx] / 46996 = 0,292 Φ yx = [ yx] / 47940 = −0,142 n = 950 Deskriptiv sind diese Typen besonders informativ: Die höchste allgemeine Lebenszufriedenheit findet sich mit 85,71 % bei Personen mit großer Berufszufriedenheit und kleiner Zufriedenheit mit den Primärbeziehungen, was auf eine reine Berufsorientierung dieser Personen hindeutet. Die geringste Lebenszufriedenheit findet sich mit 18,75 % bei den Personen mit geringer Zufriedenheit sowohl mit dem Beruf als auch mit den Primärbeziehungen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 105 Kovarianzzerlegung von yx nach z (z spezifiziert yx) s yx = nz1 n s yx: z1 + nz 2 n s yx: z 2 sxz + nz1 s yz nz 2 n n 0,019 ⋅ 0,095 0,025 = 0,474 ⋅ 0,068 + 0,526 ⋅ (−0,027) + 0,474 ⋅ 0,526 = 0,032 + 0,007 − 0,014 Der geringe Zusammenhang zwischen der Lebenszufriedenheit und der Zufriedenheit mit den Primärbeziehungen (syx = 0,025) setzt sich daraus zusammen, dass in den beiden Teilgruppen Gegenläufiges auftritt: Bei geringer Berufszufriedenheit hängen die Lebenszufriedenheit und die Zufriedenheit mit den Primärbeziehungen schwach positiv zusammen, während bei großer Berufszufriedenheit die Lebenszufriedenheit und die Zufriedenheit mit den Primärbeziehungen schwach negativ zusammenhängen. Das Produkt der Beziehungen mit dem Drittfaktor (z) fällt nicht ins Gewicht. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 106 Kombinationen (Typen) von Lebenszufriedenheit, Zufriedenheit mit den Primärbeziehungen und Zufriedenheit mit dem Beruf (y, z, x) Primärbeziehungen klein (x = x 1 ) Primärbeziehungen groß (x = x 2 ) Zufriedenheit mit dem Beruf (z) klein Lebensklein 130 zufrieden(/160=81,25%) heit (y) Anteil des Typs: 130/950=13,68 % groß 30 (/160=18,75%) groß klein 150 20 (/140=19,29%) Anteil des Typs: 20/950=2,11% 120 Lebens- klein 150 zufrieden(/290=51,72%) heit (y) Anteil des Typs: 150/950=15,79% 150 groß 140 (/290=48,28%) (/140=85,71%) Anteil des Typs: 30/950=3,16 % Anteil des Typs: 120/950=12,63 % 160 140 [ yz : x1 ] = 15000 Zufriedenheit mit dem Beruf (z) 300 = 31,58% 950 groß 250 100 (/360=27,78%) Anteil des Typs: 100/950=10,53% 400 260 (/360=72,22%) Anteil des Typs: 140/950=14,74% Anteil des Typs: 260/950=27,37% 290 360 650 = 68,42% 950 [yz : x ] = 25000 z2 δ yz = [ yz ] / n x = 50 δ yz = [ yz ] / n x = 38,462 1 2 s yz = [ yz ] / nx2 = 0,059 s yz = [ yz ] / nx1 = 0,167 2 2 Φ yz = [ yz ] / 22450 = 0,668 Φ yz = [ yz ] / 202176 = 0,245 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 107 n = 950 Kovarianzzerlegung von yz nach x (x spezifiziert yz) s yz = nx1 n s yz:x1 + n x2 n s yz:x2 s yx + nx1 s zx n x2 n n 0,025 ⋅ 0,019 0,095 = 0,316 ⋅ 0,167 + 0,684 ⋅ 0,059 + 0,316 ⋅ 0,684 = 0,053 + 0,040 + 0,002 Der mittelgroße Zusammenhang zwischen der Lebenszufriedenheit und der Berufszufriedenheit (syz = 0,095) setzt sich daraus zusammen, dass in der schwächer besetzten Gruppe mit kleiner Zufriedenheit mit den Primärbeziehungen (31,58%) ein relativ starker Zusammenhang zwischen Lebenszufriedenheit und Berufszufriedenheit besteht (syz = 0,167) und in der stärker besetzten Gruppe mit großer Zufriedenheit mit den Primärbeziehungen (68,4%) ein ebenfalls positiver, aber kleinerer Zusammenhang zwischen Lebenszufriedenheit und Berufszufriedenheit besteht. Das Produkt der Beziehungen zu dem Drittfaktor (x) fällt nicht ins Gewicht. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 108 Berücksichtigung von Drittfaktoren auf metrischem Messniveau: 2.3 Partielle Korrelation Zusammenhang zweier Variablen unter der Bedingung, dass der Einfluss einer oder mehrerer anderer Variablen herausgerechnet („rauspartialisiert“) wird. x y z Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 109 Einfluss von z auf x O.B.d.A.: Standardisierte Variablen s xz = r Korrelation xz sx sz ┌ 1 n (xi − x )(zi − z ) Kovarianz sxz = n ∑ i =1 1 n 2 2 ( ) s = x − x = s i x Varianz xx n ∑ i =1 Standardisierung von x: x−x sx (Die Standardisierung von x hat den Mittelwert 0 und die Streuung 1) └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 110 ┌ Falls x und y standardisiert: s xy = 1 (xi − x )( yi − y ) ∑ n ( x = 0; y = 0) 1 n = ∑ xi yi n i =1 n ⟨ x, y⟩ = ∑ xi yi Inneres Produkt oder Skalarprodukt i =1 der Datenvektoren (x1, ..., xn) und (y1, ..., yn) (s xy = 0) ⇔ (⟨ x, y⟩ = 0) ⇔ (Die Achsen x und y stehen senkrecht aufeinander. Oder: Die Achsen sind orthogonal.) └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 111 y rxy = 0 ( s xy = 0) (< x, y = 0) • rxy ≠ 0 x y x Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 112 x y z Einfluss von z auf x: Durch Regression geschätzt. xˆ = rxz z (weil die Variablen standardisiert sind) Bereinigung der Variablen x um den möglichen Störfaktor z x − xˆ = x − r xz z ┌ Die bereinigte Variable x- x̂ hat keinen Zusammen hang mehr mit z: ⟨ x − rxz z , z ⟩ = ⟨ x, z ⟩ − rxz ⟨ z , z ⟩ n └ = n rxz – n rxz =0 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 113 x y z Analog: Bereinigung von y um die mögliche Störung z [ ŷ =ryz z Einfluss von z auf y] (Weil y und z standardisiert sind.) y − yˆ = y − ryz z Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 114 Die partielle Korrelation ist die Korrelation zwischen den beiden um den Störfaktor (Drittfaktor) z bereinigten Variablen. := rx − xˆ ( z ), y − yˆ ( z ) rxy. z Zusammenhang von x und y unter Kontrolle von z x y z Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 115 Beispiel: Erklärung der durchschnittlichen Ausbildungsvergütung in einem Betrieb x: In dem Betrieb gibt es einen Betriebsrat. y: Höhere Ausbildungsvergütung. ryx = 0,41 S. = .03 Liegt es an Beschäftigtenzahl z? ryx.z = 0,39 S. = .05 Aber: Für z = Bereich Industrie ryx.z = 0,04 S. = .40 Betriebsrat y Höhere Ausbildungsvergütung x z Bereich Industrie Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 116 Formel für die partielle Korrelation: rxy. z = rxy − rxz ryz 1 − rxz 1 − ryz 2 2 Zerlegungsformel in Analogie zur Tabellenanalyse: rxy = 1 − rxz 2 1 − ryz 2 Gesamt- Koeffizient zusam- i.a. ≠ 1 menhang rxy. z + rxz ryz BereiZusammenhänge nigter mit dem Drittfaktor Zusammenhang [xy] = a [xy : z] + b [xz] [yz] Für z = Dichotomie: [xy] = α [xy : z1] + β [xy : z2] + γ [xz] [yz] Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 117 ┌ „Dilemma“ zwischen perfekter Vorzeichenregel und Aussagen über „perfekte“ Maßzahlen. Tabellenanalyse: δ xy = δ xy:z + δ xy:z + γ δ xz δ yz 1 2 Für δ : perfekte Vorzeichenregel, aber: δ nicht normiert. Für Φ : Vorzeichenregel nur „Daumenregel“, aber: Φ ist normierte Maßzahl. Partielle Korrelation: Für r: Vorzeichenregel nur „Daumenregel“, aber: r ist normierte Maßzahl. Für Kovarianz: 1 sxy = sxy. z + 2 sxz s yz sz Perfekte Vorzeichenregel, aber: sxy ist keine „perfekte“ Maßzahl, da die Maximalwerte +1/-1 bei vielen Datenkonstellationen gar nicht angenommen werden können. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 118 Die Kovarianz ist im Allgemeinen nicht normiert, im Fall der Vierfeldertafel allerdings erfüllt sie die Normierungsbedingung, denn: ad − bc −1 ≤ ≤ +1 2 n In dem Sinne, dass sie diese notwendige Bedingung für eine Maßzahl erfüllt, löst sie das „Dilemma“ von Davis zwischen Vorzeichenregel und Maßzahl. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 119 Pfadanalyse: z rxz β yz x β yx y rxy = β yx + rxz β yz Gesamtzusammenhang gleich - Direkter (bereinigter) Effekt plus: - Indirekter Effekt über z ( β yz β zx ) - Bzw. Scheinkomponente aufgrund von z ( β yz β xz ) - Bzw. korrelierter Effekt ( rxz β yz ) In den ersten beiden Fällen gilt die Vorzeichenregel für den Vergleich des Gesamtzusammenhangs mit den jeweiligen Effekten ( β ). Im dritten Fall ist eine Vorzeichenregel nicht so sinnvoll, da es sich um unterschiedliche Konzepte handelt. └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 120 Formales Beispiel: Keine Störung durch Drittfaktor z x y z Falls: rxz = 0, ryz = 0 rxy − rxz ryz = rxy . z = rxy 2 2 r r 1 1 − − xz yz Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 121 Inhaltliches Beispiel: Politisches Interesse (Vater, Mutter, Befragte) V M B rVM = 0,37, rVB = 0,27, rMB = 0,23, S = .001 S = .001 S = .001 rVB.M = 0,21, S = .001 rMB.V = 0,15, S = .006 Das politische Interesse des Befragten korreliert sowohl mit dem politischen Interesse des Vaters als auch der Mutter, deren politisches Interesse ebenfalls korreliert. Kontrolliert man den Einfluss jeweils eines Elternteils, so geht zwar der bereinigte Zusammenhang zwischen dem anderen Elternteil und dem Befragten zurück, die Korrelation bleibt aber signifikant. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 122 (Gliederung für die Sitzungen zur multiplen Regression) 3.1 Multiple Regressionsanalyse ............................................................. 75 3.1.1 Das Grundprinzip der einfachen Regression, geometrische Interpretation und Matrixschreibweise ................................................ 77 3.1.2 Die Regressionskoeffizienten b und beta ............................................ 79 3.1.3 Gleichungsansatz der multiplen Regression und Matrixschreibweise 81 3.1.4 Multipler Korrelationskoeffizient R .................................................... 84 3.1.5 Interpretation der Koeffizienten........................................................... 86 3.1.6 Schrittweise Regression ....................................................................... 88 3.1.7 Zuordnung der gesamten erklärten Varianz zu den Prädiktoren ......... 89 3.1.7.1 Einführung in die Problemstellung ...................................................... 89 3.1.7.2 Charakterisierung der Koeffizienten mit Hilfe von Residuen ............. 90 3.1.7.3 Zwei Zerlegungen von Multiple R2 ..................................................... 94 3.1.7.4 Darstellung der erklärten Varianz durch Kovarianzen und Effekte .... 95 3.1.8 Interaktion in der Regression ............................................................... 96 3.1.8.1 Anknüpfung an die Tabellenanalyse: Regressionsanalyse der Lebenszufriedenheit ............................................................................. 97 3.1.9 Statistische Inferenz ........................................................................... 103 3.1.10 Die Verletzung der Modellannahmen ................................................ 107 3.1.11 Beispiel für die Regressionsanalyse .................................................. 109 3.1.12 Die multivariate Regression............................................................... 118 3.1.13 “Weighted least squares” ................................................................... 118 Literaturverzeichnis ........................................................................................... 121 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 123 3.1 Multiple Regression Eine abhängige metrische Variable y (auch bezeichnet als: Prädikand oder zu erklärende Variable) soll erklärt werden durch mehrere (k ≥ 2) unabhängige Variablen x1, ..., xk (auch bezeichnet als: Prädiktoren, Erklärungsfaktoren oder ähnliches). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 124 Zu erklärende Variable y: Affinität zu den Jusos (versus „Basisgruppen“) „Bereinigte“ „BereinigPrädiktoren Gesamtzu- Erklärungs- Direkter (Signi- Muliple R2 Erklärungskraft fikanz-) bei schrittter“ ZuEffekt oder sammenkraft bei sammen„bereinighang isolierter Test- weiser Rer 2 y , x − xˆ hang gression Betrachtung ter“ Effekt wert F ry , x 2 2 β y, x r y,x 1− R r i i ∆ R bei 2 schrittweiser Regression i i i y , xi − xˆi = F ⋅ n − k − 1 x 1 : Affinität zu „grüner“ Kommunalprartei - 0,56 31 % - 0,38 - 0,35 12 % 49,3 31 % 31 % x 2 : Affinität zur SPD 0,48 23 % 0,31 0,30 9% 37,4 47 % 16 % x 3 : Pro Frauenerwerbstätigkeit 0,24 6% 0,36 13 % 53,3 57 % 10 % x 4 : Pro Wohngemeinschaft als Lebensform 0,39 15 % - 0,21 - 0,20 4% 15,1 65 % 8% x 5 : Verdienst wichtig bei Berufsentscheidung 0,29 8% 0,27 0,26 7% 28,6 71 % 6% x 6 : Vater gewerkschaftsnah 0,28 8% 0,23 0,22 5% 22,3 77 % 6% - 0,46 21 % - 0,22 - 0,20 4% 17,2 82 % 5% 0,40 16 % 0,20 0,20 4% 14,7 85 % 3% x 7 : Kommunistische Partei positiv x 8 : Eigene Berufsaussichten positiv ↑ 0,37 ↑ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 125 Muliple R2 = 85,4 % ( ∑ > 100 %) ( ∑ = 58 %) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 126 3.1.4 Multipler Korrelationskoeffizient R Wieviel erklären die Prädiktoren insgesamt? Abhängige Variable: y Unabhängige Variablenen: x1, ..., xk Multiple Regression: Gesucht wird die lineare Prognose: yˆ = β 1 x1 + ... + β k xk , [Beta-Koeffizient: Bezeichnung bei standardisierten Variablen.] n bei der der Schätzfehler ∑ ( y i =1 − yˆ i ) 2 i minimal ist. Streuungszerlegung: 2 2 2 ˆ ˆ ( ) ( ) ( ) − = − + − y y y y y y ∑ i ∑ i i ∑ i SSy SSresidual SSregression (total) (nicht erklärt) (erklärt) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 126 Anteil erklärter Varianz: SS regression SS total Dieser Anteil heißt: Multiple R2 (Ausführlicher: R 2 y ; x1 ,..., xk ) Im Beispiel: Die 8 Prädiktoren erklären R2 = 85,4 % der Streuung in der abhängigen Variablen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 127 Interpretation der Koeffizienten (3.1.2 und 3.1.5) Wie wichtig sind die verschiedenen Prädiktoren im Hinblick auf die Erklärung der abhängigen Variablen? - Falls man jeden Prädiktor xi isoliert betrachtet: ry , xi 2 y , xi r = Gesamtzusammenhang von y und xi (bei isolierter Betrachtungsweise) = gesamte Erklärungskraft von xi (bei isolierter Betrachtungsweise) [„Einzelne Erklärungskraft“] Veranschaulichung von „Überschneidungen“ in der Erklärung y x1 x2 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 128 xk y xi xj ┌ Warnung: Es gibt auch Suppressor-, Distorter- etc. Phänomene. └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 129 Nicht ädäquat als Interpretation der β i yˆ = β1 x1 + ... β i xi ∆ + ... + β k xk xi = 1 „ β i ist der Effekt in y, wenn xi um eine Einheit geändert wird und die übrigen Prädiktoren konstant gehalten werden.“ Aber: I.a. bleiben die übrigen Prädiktoren dabei nicht konstant. xi xj βi βj y Eventuell gibt es indirekten Effekt. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 130 Deshalb statt (Gesamt-) Effekt adäquater: β i = direkter [Kausal-] Effekt von xi auf y. ┌ Nicht kausal: β i ist das Prognosegewicht der Va riablen xi (oder auch nicht-kausaler „Effekt“ von xi) └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 131 In einfacher Regression: byx = sy,x s 2 x Es lässt sich zeigen, dass für β i der multiplen Regression gilt: βi = s y , xi − xˆi s 2 xi − xˆi xi − xˆ i ist der „bereinigte Prädiktor“, nämlich um den Einfluss der übrigen Prädiktoren bereinigt. [ x̂i = Regressionsschätzung von xi auf alle xj, j ≠ i] βi der multiplen Regression ist gleich dem Gesamteffekt des bereinigten Prädiktors xi − xˆ i . Abkürzend: bereinigter Effekt (kausal bzw. nicht kausal) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 132 Insgesamt: zwei Interpretationen von β i 1) β i = direkter Effekt von xi auf y 2) β i = Gesamt-Effekt des bereinigten Prädiktors xi − xˆi Abkürzend: bereinigter Effekt [Nicht kausal: 1) im technischen Sinne: Prognosegewicht, 2) bereinigter „Effekt“] 2 2 r β Weder ∑ y , x i noch ∑ i ergeben i.a. Multiple R2, da es Überschneidungen, Suppressor- und Distorter-Phänomene etc. gibt. Nur in dem unrealistischen Fall, dass alle Prädiktoren unabhängig wären, erhielte man ein so einfaches Ergebnis. ┌ Stattdessen ist es fruchtbar, von folgender Cha rakterisierung auszugehen: βi = s y , xi − xˆ i sx2i − xˆ i └ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 133 Graphische Darstellung des Ansatzes der multiplen Regression ( y = yˆ + ( y − yˆ ) x1 β1 y − yˆ xi βi 1 xk βk ) y βj xj Dabei sind die β i die direkten (Kausal-)Effekte der Erklärungsfaktoren xi. Alternative Darstellung: Statt die nicht-erklärten Anteile durch die Residualvariable y − yˆ zu repräsentieren, kann man auch umgekehrt den erklärten Anteil sichtbar machen: y Multiple R2 (Dabei gilt: Multiple R2 = s y , yˆ ) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 134 Der um den Einfluss der übrigen Prädiktoren „bereinigte“ Zusammenhang ist: ry , xi − xˆi Beta-Koeffizient und „bereinigter“ Zusammenhang haben das gleiche Vorzeichen, denn: β y,x = s y , xi − xˆi ry , xi − xˆi = s y , xi − xˆi i s 2 xi − xˆi s xi − xˆi Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 135 Erklärungskraft des bereinigten Prädiktors (Abkürzend: bereinigte Erklärungskraft) (Unabhängiger Erklärungsbeitrag von xi) (Warnung: Es gibt auch Suppressor-/ DistorterPhänomene) ry2, xi − xˆi = R 2 − R(2i ) 2 r ( y , xi − xˆi ist eine semi-partielle Korrelation; aus xi werden alle xj, j ≠ i, durch die Regressionsschätzung „herausgerechnet“.) R 2 = Erklärung von y durch alle Prädiktoren x1, ..., xk gemeinsam. R(i2 ) = Erklärung von y durch alle Prädiktoren Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 136 ohne xi. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 137 x1 y x3 x2 Schraffiert: Erklärungskraft von x 1 und x 2 (ohne x 3) Schattiert: Erklärungskraft von x 3 über x1 und x 2 hinaus. Dies ist die Differenz der Gesamterklärungskraft (von x1, x 2, x 3) und der Erklärungskraft ohne x 3: R 2 − R 2 ( x3 ) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 138 3.1.7 Zuordnung der gesamten erklärten Varianz zu den Prädiktoren Zerlegung von Multiple R2 Nicht zulässige Interpretation der Produkte ry , xi ⋅ β y , xi : Rein rechnerisch gilt: Multiple k R 2 = ∑ ry , xi β y , xi i =1 β Dies verleitet dazu, y , xi ry , xi als Beitrag des i-ten Prädiktors zur gesamten erklärten Varianz zu interpretieren. Aber: Die Produkte ry , xi β y , x können (Distorter Phänomen) i Also: y negativ sein. nicht als Anteil erklärter Varianz interpretierbar. x1 x2 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 139 Distorter Phänomen (Darstellungsart: Die erklärte (Ko-) Variation von y ( s yˆ , yˆ ) wird dargestellt als Saldo von positiven und negativen Beiträgen) - + z x y Bei isolierter Betrachtungsweise: Erklärungsbeitrag von x insgesamt positiv Bei Berücksichtigung des Drittfaktors z: Bereinigter Erklärungsbeitrag von x insgesamt negativ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 140 Suppressor Phänomen - + z x y Bei isolierter Betrachtungsweise: Erklärungsbeitrag von x insgesamt positiv Bei Berücksichtigung von z: Bereinigter Erklärungsbeitrag wird insgesamt größer, wenn z herausgerechnet wird. [Bemerkung: Analoges gilt für Effekte statt Erklärungskraft; dann keine flächige Darstellung, sondern „Strecken“, „Abschnitte“.] Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 141 Erklärte (Ko-) Varianz als Saldo von positiven und negativen Beiträgen darstellen - + 1) Positive Beiträge: ∑r yxi β yx i i ( ryxi β yxi > 0 ) 2) Negative Beiträge: ∑r yxi β yx i i ( ryxi β yxi < 0 ) 2 ∑ = Multiple R Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 142 R 2 = ∑ ry , xi β y , xi ry , xi β y , xi = Beitrag von x i zur erklärten (Ko-)Varianz Falls 0 < ry , xi < β y , xi oder Suppressor-Beitrag 0 < ry , xi < β y , xi ( ) ( Falls sign ry , xi ≠ sign β y , xi ) Distorter-Beitrag Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 143 Darstellung der erklärten Varianz (Multiple R2) als Kovarianz: 2 2 2 s / s = s yˆ Multiple R = yˆ y 2 = s yˆ , yˆ = s yˆ , y (Weil: y − yˆ ⊥ xi für alle i = 1, ..., k und deshalb auch: y − yˆ⊥ ŷ ) s yˆ , y = sk ∑ βi xi , y i =1 k = ∑β i =1 i k = ∑r i =1 y,x s xi , y β y, x i Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 144 Meine neue Interpretation besteht darin, Multiple R2 durch „erklärte Kovarianz“, die auch negativ sein kann, auf die einzelnen Prädiktoren zurückzuführen. Multiple R2 = s y , yˆ = ∑ β y , xi s y , xi β y ,x x1 1 β y, x xi s y ,x1 i β y, x s y , xi ŷ k xk s y , xk y Die Kovarianz zwischen y und ŷ(d.h. R2) ist das Resultat der Kovariationen von y und den Prädiktoren x i, welche mit der Gewichtung β y, xi (direkter Effekt, bereinigter Effekt) in die lineare Modellschätzung einfließen. ŷ Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 145 Erklärte Varianz in dem einfachen Fall, dass alle Faktoren xi statistisch unabhängig sind – wie bei den Faktorkonstrukten in einem cartesischen Koordinatensystem, nicht aber bei Erklärungen mit empirischen Variablen. Falls alle Faktoren xi statistisch unabhängig wären, hätte man einfache Zusammenhänge: β y , x = ry , x Effekt gleich Zusammenhang i i β 2 y , x = r 2 y , x Effekt2 = Erklärungskraft i i Multiple R2 = ∑β r y, xi y , xi = ∑ r 2 y , xi = ∑ β 2 y, xi D.h. Gesamterklärungskraft = Summe der einzelnen Erklärungskräfte. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 146 3.1.6 Schrittweise multiple Regression Schritt: Welcher Prädiktor erklärt am meisten? y x1 x2 x3 xi derart aussuchen, dass r 2 y , xi maximal. 2. Schritt: Mit dem feststehenden besten ersten Prädiktor wird der zusätzliche Prädiktor gesucht, der zusammen mit dem ersten das höchste R2 ergibt. 3. Schritt: Mit dem feststehenden besten ersten Prädiktor wird der zusätzliche Prädiktor ausgesucht, der zusammen mit den beiden ersten Prädiktoren das höchste R2 ergibt. Etc. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 147 yˆ y . x1 =β y , x1 x1 β y , x = ry , x 1 1 yˆ y . x1 , x2 = β y , x1 . x2 x1 + β y , x2 . x1 x2 I.A.: β y , x1 . x2 ≠ β y , x1 D.h. bei Einführung von weiteren Variablen ändern sich i.a. die Beta-Koeffizienten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 148 Der Stellenwert standardisierter und unstandardisierter Koeffizienten für die Erklärung Falls man die relative Wichtigkeit von Erklärungsfaktoren innerhalb einer Untersuchungsmenge beurteilen will, so sind die standardisierten Korrelationskoeffizienten angemessen. Falls man Vergleiche zwischen verschiedenen Untersuchungsmengen durchführen will, so ist zu berücksichtigen, dass sich die Streuungen der Variablen zwischen den Untersuchungsmengen i.A. unterscheiden. In diesem Fall sind die unstandardisierten Koeffizienten vorzuziehen, da die Erklärung von y durch y und die direkten Effekte der xi von der Charakterisierung der Untersuchungsmengen durch die Variabilitäten der Merkmale getrennt wird. Der Zusammenhang zwischen unstandardisierten und standardisierten Koeffizienten lautet: β y , x = by , x ⋅ i i s xi sy Relative Bedeutung von Multiple R² und den Effekten für die Erklärung Multiple R ² kann im Sinne der Kausalanalyse auch „Scheinkomponenten“ der Erklärung enthalten. Insofern ist für die Erklärung die Größenordnung der Effekte noch wichtiger als die „Gesamterklärungskraft“ Multiple R². Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 149 3.1.9 Statistische Inferenz in der multiplen Regression Test, ob die Gesamterklärung (bzw. der Erklärungsbeitrag jedes einzelnen Prädiktors) statistisch signifikant ist. H 0 (Nullhypothese für die Gesamterklärung): Es gibt keinen Erklärungsbeitrag. (R2 = 0) Varianzanalyse als Test für die multiple Regression von y auf x 1, …, x k. Varianz Freiheitsgrade (Mean Squ(df) are) Sum of Square durch Regression erklärt nicht erklärt (Residuum) insgesamt ∑ ( yˆ − y ) 2 ∑ ( yi − yˆ i ) ∑ k i 2 n-k-1 SS Re gression k SS Re siduum (n − k − 1) n-1 (degree of freedom (y − y ) 2 i Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 150 Die Testgröße F = ssRegression / k SS Resid. /(n − k − 1) ist Fk ,n −k −1 - verteilt. f(x) 95 % kritischer Wert 5% x Ablehnungsbereich für die Nullhypothese (f(x) = Dichtefunktion der Verteilung der Testgröße) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 151 Die Tabelle für den F-Test liefert: Bei 95% Sicherheitswahrscheinlichkeit F8, 61 ≈ 2,1 (kritischer Wert) Die vorliegenden Daten ergeben für die Testgröße: F = 44,5 D.h.: Die Nullhypothese (kein Erklärungsbeitrag) wird deutlich verworfen. - Andere Charakterisierung der Testgröße R 2 /k F= (1 − R 2 ) /(n − k − 1) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 152 SPSS-Output: Significance = Wahrscheinlichkeit, unter Annahme der Nullhypothese einen so großen oder größeren FWert zu erhalten wie bzw. als in den vorliegenden Daten. f(x) Significance kritischer Wert (hier: 2,1) x Testwert für die vorliegenden Daten Anwender inspiziert, ob Significance S≤ .05. Im Beispiel: Significance = 0,000 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 153 Test, ob der i-te Prädiktor einen signifikanten Erklärungsbeitrag leistet H0 (Nullhypothese für die Erklärung durch den i-ten Prädiktor): Der i-te Prädiktor leistet keinen Erklärungsbeitrag. Testgröße: F= ry2, xi − xˆi /1 (1 − R ) /(n − k − 1) 2 ist F1,n −k −1-verteilt. Getestet wird also die bereinigte (unabhängige) Erklärungskraft von xi. y x1 x2 (Hier: Bsp. i = 2) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 154 Kritischer Wert nach Tabelle: F1, 61 ≈ 4 f(x) z.B. Significance S =.03 x Kritischer Wert: 4 Testwert für die vorliegenden Daten Für alle 8 Prädiktoren im Beispiel gilt: Die Nullhypothese („xi leistet keinen unabhängigen Erklärungsbeitrag“) kann deutlich verworfen werden. - Inspektion der Significance ist abkürzende Anwendung des Tests. - Wenn ein Computerprogramm nicht den F-Test ausdruckt (für die einzelnen Prädiktoren), sondern den T-Test, so gilt ebenfalls: Die Significance ist zu inspizieren. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 155 Problem der Multikollinearität Falls einige der unabhängigen Variablen in der multiplen Regression sehr hoch miteinander korrelieren, ist die Regression im Extremfall technisch nicht mehr durchführbar. Beispiel: Konfession: katholisch, protestantisch, ohne Dummies: = 1 0 falls katholisch sonst 1prot = 1 0 falls protestantisch sonst 1ohne = 1 0 falls ohne Konfession sonst 1kath Dummie-Variablen sind formal metrisch [Aber: Nicht als abhängige metrische Variable verwenden. (Vgl. z.B. Manfred Küchler: Multivariate Analysemethoden)] Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 155 Wenn man zwei Dummies als Prädiktoren berücksichtigt hat, dann ist der dritte redundant. In diesem fall ist die Korrelationsmatrix mit den 3 Dummies nicht invertierbar. Also: Im allgemeinen Fall nur k-1 der k Ausprägungen als Dummies berücksichtigen. (Im Beispiel: Nur 2 der 3 Dummies verwenden.) Inhaltliches Beispiel: Drei Schichtindikatoren als unabhängige Variablen, die sehr hoch korrelieren. Zwei Auswege: 1) Zusammenfassen zu Index 2) Nur einen der hoch korrelierenden Indikatoren als Prädiktor verwenden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 156 3.1.8. Interaktion (von Variablen) in der Regression Falls die Kombination von unabhängigen Variablen einen Effekt auf die unabhängige Variable hat, lässt sich dies in der Regression wie folgt prüfen: 1kath., 1weibl. Kombination: 1kath * 1weibl = 1 falls kath. und weibl. 0 sonst Ein entsprechender Effekt ist also ein multiplikativer Interaktionseffekt. ┌ COMPUTE V3 = V1 * V2, wobei: V1 = 1kath. und V2 = 1weibl. Dann Regression auf: V1, V2, V3 └ Beispiel: Übernahme unbezahlter Familienarbeit (* Arbeit aus Liebe*) Bei katholischer Sozialisation sind Frauen überproportional bereit, unbezahlte Familienarbeit zu übernehmen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 157 3.1.10 Verletzung der Modellannahmen der multiplen linearen Regression 1) Multikollinearität: Falls die unabhängigen Variablen zu stark untereinander korrelieren, so wird die Regressionsschätzung beeinträchtigt. (Ausweg: Reduktion der Variablen oder Indexbildung) 2) Nichtlinearität: Ob Nichtlinearität vorliegt, lässt sich in SPSS mit Streudiagrammen untersuchen. 3) Heteroskedastizität: Falls die Varianz der Fehler nicht homogen ist, verzerrt dies die Schätzungen. (Ausweg: Weighted least squares statt einfache Least squares.) 4) Normalverteilung der Residuen? Ob die Residuen normalverteilt sind, lässt sich in SPSS mit Streudiagrammen untersuchen. 5) Autokorrelation Bei Längsschnittdaten muss man mit Autokorrelation rechnen, was in SPSS mit einem Test beurteilt werden kann. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 158 3.1.10 Logistische Regression In der Varianzanalyse will man die Unterschiede von Gruppenmittelwerten schätzen und/oder testen, wobei man voraussetzt, dass die Gruppen eine gleiche Variation aufweisen, damit die unterschiedliche Variation (σ) nicht als Störfaktor bei dem Vergleich wirkt. Wenn die abhängige Variable (y) eine Dichotomie ist, so gilt für die Gruppe Gi : σ i = pi (1 − pi ) , so dass die Streuung mit den Mittelwertunterschieden variieren würde. (Hierbei ist pi der Anteil der Einheiten mit Ausprägung y 1 in der Gruppe G i .) 2 Aus diesem Grund wird die abhängige Variable vor der Analyse erst durch Logit-Transformation ln p 1 − p „geglättet“. Denn während ein Anteil p im Intervall [0,1] p variiert, variiert 1 − p im Intervall ]0, ∞[ und ln p 1 − p im Intervall ]-∞, +∞[. Die abhängige Variable passt dadurch besser zu einem linearen Modell. Eine Gerade y = a + bx ist nur dann in den Werten von y beschränkt, wenn b = 0, d. h. in dem wenig interessanten Fall, dass es keinen Zusammenhang gibt. Der Modellansatz Regressionsansatz: entspricht ansonsten dem üblichen p ln 1 − p = b0 + b1 x1 + ... + bk xk Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 159 linearen Beispiel für die logistische Regression: Lebenszufriedenheit in Abhängigkeit von der Zufriedenheit mit den Primärbeziehungen (x), der Berufszufriedenheit (z) und ihrer Interaktion (x · z) y = ln p 1− p , wobei p die Wahrscheinlichkeit für Lebenszufriedenheit und 1-p die komplementäre Wahrscheinlichkeit ist, nicht lebenszufrieden zu sein. Variablen in der Gleichung Regressionskoeffizient Signifikanz Exp. (B) B x (1) 1,397 ,000 4,044 z(1) 3,257 ,000 25,984 x (1) by z (1) -2,233 ,000 ,107 Konstante -1,466 ,000 ,231 Cox und Snell R-Quadrat: 0,187 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 160 Interpretation der Quotienten („Odds“) und der logarithmierten Quotienten („Log Odds“ oder auch „Logits“) Ausgangspunkt: Kreuztabelle für zwei dichotome Merkmale (Vierfeldertafel) z.B. zufrieden nicht zufrieden mit mit Beziehungen Beziehungen a b c d a/c nennt man Odds, d.h. Chance, und zwar hier die spaltenbezogene Chance, dass ein Fall in die erste Zeile fällt, und nicht in die zweite Zeile. (Eine Art Wette um das Eintreten der ersten gegenüber der zweiten Möglichkeit.) Z. B. Gesamtzufriedenheit ja vs. nein. Analog ist b/d die Chance bzgl. der zweiten Spalte. a / c ad = b / d bc nennt man Odds-Ratio. Wenn dieses multiplikative Konzept des Odds-Ratio durch Logarithmieren in eine additive Form gebracht wird, so spricht man von Log-Odds oder Logits: ln ad bc Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 161 Zur Interpretation in dem konkreten Beispiel In einem Gedankenexperiment kann man sich quasi-experimentell vorstellen, was für einen Effekt es hat, wenn eine Person zufrieden mit ihren Primärbeziehungen wird. p ln Als direkter Effekt würde sich 1 − p um 1,397 erhöhen und p 1 − p um 4,044. (Die Änderung in x kann neben dem direkten Effekt auch indirekte Effekte anstoßen, wie es in dem Beispiel mit dem Interaktionseffekt x · z ja auch offensichtlich der Fall ist.) p Da 1 − p einfacher zu formulieren ist, wird die Erklärung für p das Chancenverhältnis 1 − p formuliert. Erklärt wird in dem Beispiel also die Chance der Gesamtzufriedenheit mit dem Leben p (statt insgesamt nicht zufrieden zu sein): 1 − p p ist hierbei die Chance der Gesamtzufriedenheit. 1 – p ist die Chance, insgesamt nicht zufrieden zu sein. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 162 Eine Person, die zufrieden ist mit den Primärbeziehungen, hat insgesamt (d.h. in der gesamten Zufriedenheit mit dem Leben) eine ca. 4-mal so große Chance zufrieden zu sein (statt unzufrieden) wie eine Person, die nicht zufrieden ist mit den Primärbeziehungen. Entsprechend: Eine Person, die zufrieden ist mit dem Beruf, hat insgesamt eine ca. 26 mal so große Chance zufrieden zu sein wie eine Person, die nicht zufrieden ist mit dem Beruf. Ferner: Eine Person, die sowohl zufrieden ist mit den Primärbeziehungen als auch mit dem Beruf, weist nach den vorliegenden Daten von Mayntz et al. in der Gesamtzufriedenheit nur ein Zehntel der ZufriedenheitsChance der Personen mit den übrigen Kombinationen auf. In diesem Beispiel liegt dies wohl daran, dass ein Teil der Personen stärker berufsorientiert und ein Teil der Personen stärker beziehungsorientiert ist, so dass sich die Effekte nicht einfach kumulieren. Insgesamt: Mit einer logistischen Regression lassen sich die relativen Effekte verschiedener Variablen innerhalb eines Modells vergleichen. Für verschiedene Gruppen oder Modelle sind die Effekte nicht zu vergleichen (vgl. Mood, Carina: Logistic regression: Why we cannot do what we think we can do, and what we can do about it. In: European Sociological Review 26, 2010: 67 – 82). Also lässt sich die logistische Regression auch nicht einfach pfadanalytisch erweitern wie die lineare Regression. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 163 Zum Vergleich: Untersuchung der Lebenszufriedenheit mit dem üblichen linearen Regressionsansatz (3.1.9) In der Darstellung der Tabellenanalyse wurde in Kapitel 2.2.4.7 gezeigt, dass man bei einem Beispiel von Mayntz et al. (1978) zur Erklärung der Lebenszufriedenheit durch die Zufriedenheit mit den Primärbeziehungen und die Zufriedenheit mit dem Beruf die Interaktion der beiden Erklärungsfaktoren zusätzlich berücksichtigen muss. Der Effekt der Interaktion soll im Folgenden mit Hilfe der multiplen Regression herausgearbeitet werden. Koeffizienten Nicht standardis. Koeffizienten B Standardisierte Koeffizienten Beta T Signifikanz 5,347 ,000 Konstante ,188 Zufriedenheit Primärbez. (x) ,295 ,278 6,759 ,000 Berufszufr. (z) ,670 ,677 13,044 ,000 Interaktion -,430 -,423 -6,923 ,000 SS Regression SS Residuum SS Total = 45,425 = 186,154 = 231,579 R-Quadrat = 45,425 231,579 = 0,196 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 164 Regression von y und x bzw. auf z bzw. auf x, z bzw. xz bzw. auf x, z, xz y auf x y auf z y auf x, z y auf xz y auf x, z, xz Multiple R2 Multiple R2 Multiple R2 Multiple R2 Multiple R2 2,733 = 0,012 231,579 34,601 = 0,149 231,579 35,993 = 0,155 231,579 11,899 = 0,051 231,579 45,425 = 0,196 231,579 Prädiktoren B Konstante 0,500 x 0,115 z Beta B Beta B 0,378 0,325 0,109 0,382 Beta 0,387 34,601 231,579 Beta 0,188 0,078 0,295 0,278 0,376 0,380 0,670 0,677 -0,430 -0,423 35,993 231,579 11,899 231,579 B = Unstandardisierte Koeffizienten; Beta = Standardisierte Koeffizienten Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 165 B 0,083 0,231 2,733 231,579 Beta 0,492 xz SS Regression SS total B 0,227 45,425 231,579 Einfache Regression von y auf x (Primärbeziehungen) y x 150 250 400 150 400 550 300 650 950 550 = 0,579 950 650 = 0,6 x= 950 y= [ yx] = 22.500 Die Differenz der Kreuzprodukte ist die einfachste Quasi-Maßzahl. 300 650 ⋅ = 0,316 ⋅ 0,684 = 0,2160 Varianz von x 950 950 s yx = [ yx]/ n 2 = 0,025 Die Kovarianz ist eine besonders wichtige Normierung s x2 = s xx = der Differenz der Kreuzprodukte. b yx = s yx s x2 0,025 = = 0,115 0,216 Den Regressionskoeffizienten erhält man mit Hilfe von Kovarianz und Varianz des Prädiktors. a = y − bx = 0,579 − 0,115 ⋅ 0,684 = 0,500 = 150 = yx=0 300 231,579 SS y 400 550 s = s yy = = ⋅ = 0,421 ⋅ 0,579 = 0,244 = n 950 950 950 2 y β yx s yx sx = ryx = b yx ⋅ = s y s y ⋅ sx = (Nur bei einfacher Regression gilt: βyx = ryx) Regressionskonstante Varianz von y BetaKoeffizient 0,025 = 0,109 0,494 ⋅ 0,465 Prozentsatzdifferenz d yx = 400 150 − = 0,615 − 0,500 = 0,115 650 300 b yx lässt sich also interpretieren als Unterschied in der Lebenszufriedenheit (y) zwischen den Gruppen (x = 0) und (x = 1). Bzw.: b yx ist der „Effekt“ in y aufgrund von x. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 166 Einfache Regression von y auf z (Beruf) z y 280 170 450 120 380 500 400 550 950 [ yz ] = 86.000 450 500 = 0,474 ⋅ 0,526 = 0,2493; s z = 0,4993 ⋅ s = s zz = 950 950 s yz = [ yz ]/ n 2 = 0,0953 2 z byz = s yz s z2 = 0,095 = 0,382 0,249 170 a = y − bz = 0,579 − 0,382 ⋅ 0,526 = 0,378 = = yz =0 450 Prozentsatzdifferenz d = 380 − 170 = 76,00 − 37,78 = 38,22% yz 500 450 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 167 Regression von y auf x, z Zusammenhang der beiden Prädiktoren x, z: Zufriedenheit mit den Primärbeziehungen (x) 160 290 450 140 360 500 300 650 950 Berufszufriedenheit (z) [zx] = 17.000 s zx = [zx ]/ n 2 = 0,019 s zx2 = 0,00036 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 168 Um den Einfluss von z bereinigter Regressionskoeffizient b x.z: s yx − s xz s yz s z2 2 s s x2 − xz2 sz bx. z = 0,019 ⋅ 0,095 0,249 0,01775 = 0,0827 0,00036 = 0,216 − 0,21455 0,249 0,025 − = Um den Einfluss von x bereinigter Regressionskoeffizient b z.x : s yz − bz . x = s xz s yx 2 x 2 xz 2 x s s 2 sz − s 0,019 ⋅ 0,025 0,216 0,0931 = = 0,3760 0,00036 0,2493 − 0,2476 0,216 0,0953 − = Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 169 βx .z = bx .z ⋅ sx 0,465 = 0,0827 ⋅ = 0,078 0,494 sy s 0,499 β z.x = bz.x ⋅ z = 0,3760 ⋅ = 0,380 sy 0,494 Bezugspunkt: a = y − bx. z x − bz . x z 500 650 = 0,579 − 0,0827 ⋅ − 0,3760 ⋅ 950 = 0,325 950 Erklärte Varianz: s y , yˆ = s yx ⋅ b yx + s yz ⋅ b yz = 0,025 ⋅ 0,0827 + 0,0953 ⋅ 0,3760 = 0,002 + 0,0358 = 0,0378 Multiple R² = Anteil der erklärten = s y ,ŷ / s 2y = 0,0378 / 0,244 = 15,5% Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 170 Varianz Regression von y auf xz Dies ist eine einfache Regression mit einem komplizierteren Prädiktor. Es handelt sich um den Kontrast der Kombination (1,1) vs. dem Rest. 260 = 72,22% 360 Typ (1,1): Typ ((x,z) ≠ 30 + 140 + 120 290 = = 49,15% (1,1)): 160 + 290 + 140 590 B0 = B( x , z )≠(1,1) = 49,15% B1 = B( x , z )=(1,1) = 72,22 − 49,15 = 23,07% Anteil der Personen mit großer Lebenszufriedenheit in Abhängigkeit von den Zufriedenheiten mit dem Beruf (z) und den Primärbeziehungen (x) x z klein = 0 groß = 1 klein = 0 30 160 120 140 groß = 1 140 290 260 360 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 171 Regression von y auf x, z, xz („Saturiertes Modell“) Zur Erinnerung (vgl. den Abschnitt zur Interaktion in der Tabellenanalyse): Anteil der Personen mit hoher Lebenszufriedenheit in Abhängigkeit von der Beziehungszufriedenheit und Berufszufriedenheit Zufriedenheit klein (z = 0) mit Beruf (z) groß (z = 1) Zufriedenheit mit Beziehungen (x) klein (x = 0) groß (x = 1) 18,75 % 48,28 % 85,71 % 72,22 % B0 = Bx =0, z =0 = 18,75% Bx =1, z =0 = 48,28 − 18,75 = 29,53% Bx =0, z =1 = 85,71 − 18,75 = 66,96% Bx =1, z =1 = (72,22 − 18,75) − (29,53 + 66,96) = 53,47 − 96,49 = −43,02% (Der „multiplikative Effekt“ ist kleiner als die „Summe der additiven Effekte“.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 172 sx 0,465 = 0,295 ⋅ = 0,278 Beta x = B x ⋅ 0,494 sy sz 0,499 Beta z = Bz ⋅ = 0,670 ⋅ = 0,677 sy 0,494 Beta( xz ) = B( xz ) ⋅ s( xz ) sy 0,4851 = −0,430 ⋅ = −0,423 0,4937 360 590 ⋅ = 0,2353 ( xz ) 950 950 s( xz ) = 0,4851 Denn: s 2 = Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 173 Erklärte Varianz: s y , yˆ = s yx ⋅ byx + s yz ⋅ byz + s y , xz ⋅ by , xz s yx = nx ⋅ ( y x =1 − y ) (vgl. n Sitzung 10 (Meth. Ib)); byx = y x =1, z = 0 − y0, 0 nx ⋅ (61,54% − 57,89% ) ⋅ (48,28% − 18,75% ) n ⋅ (+ 29,53% ) = 0,6842 ⋅ (+ 3,65% ) = 0,00238 s yx ⋅ b yx = nz ⋅ ( y z =1 − y ) ; byz = y x = 0, z =1 − y0, 0 n s yz ⋅ byz = 0,5263 ⋅ (76,00% − 57,89% ) ⋅ (85,71% − 18,75% ) s yz = y s y , xz = = 0,5263 ⋅ (+ 18,11% ) ⋅ (+ 66,96% ) = 0,0638 xz=0 xz=1 klein 300 100 groß 290 260 950-360 360 950 = 590 49.000 s y , xz = = 0,0543 950 ⋅ 950 n xz =1 ⋅ ( y xz =1 − y ) ; b y , xz n = y x =1, z =1 − ( y1,1 + ( y1,0 − y 0,0 ) + ( y 0,1 − y 0,0 )) s y , xz ⋅ by , xz = 0,3789 ⋅ (72,22% − 57,89% ) ⋅ (72,22% − 115,24% ) = 0,3789 ⋅ (+ 14,33% ) = −0,02336 ⋅ (− 43,02% ) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 174 Also: s y , yˆ = 0,00238 + 0,0638 − 0,02336 = 0,0478 Multiple R 2 = s y , yˆ / s y2 = 0,0478 / 0,244 = 19,6% Graphische Veranschaulichung der erklärten Varianz nx ( yx − y) n nz ( yz − y) n x y1, 0 − y0, 0 y0,1 − y0, 0 z ŷ y1,1 − (y0,0 +(y1,0 − y0,0 ) + (y0,1 − y0,0 ) ) xz n( xz ) n ( y( xz ) − y ) y Die erklärte Varianz ergibt sich daraus, dass y mit den Prädiktoren x und z sowie xz kovariiert, die bei der 1-0-Codierung die angegebenen Effekte haben. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 175 (Gliederung für das Kapitel zur Varianzanalyse) 4. Varianzanalyse und Kovarianzanalyse........................................... 161 4.1 Einfache Varianzanalyse als Verallgemeinerung des t-Tests ............. 162 4.1.1 Varianzzerlegung ................................................................................ 162 4.1.2 Signifikanztest ..................................................................................... 165 4.1.3 Einfache Varianzanalyse und t-Test ................................................... 168 4.1.4 Anteil erklärter Varianz als Deskription ............................................. 168 4.2 Zweifache Varianzanalyse .................................................................. 169 4.2.1 Gleiche Zellenhäufigkeiten ................................................................. 169 4.2.2 Ungleiche Zellenhäufigkeiten ............................................................. 172 4.3 Dreifache Varianzanalyse ................................................................... 175 4.4 Die einfache Varianzanalyse als Spezialfall der multiplen Regression ........................................................................................... 177 4.5 Die zweifache Varianzanalyse als Spezialfall der multiplen Regression mit Interaktionstermen ..................................................... 179 4.5.1 Beispiel für die zweifache Varianzanalyse mit ungleichen Zellenhäufigkeiten: Untersuchung der Lebenszufriedenheit .............. 181 4.6 Unterschiedliche Codierung in der Varianzanalyse ........................... 190 4.6.1 Codierung durch Dichotomien in der einfachen Varianzanalyse ....... 190 4.6.2 Effekt-Codierung in der einfachen Varianzanalyse ............................ 191 4.6.3 Effekt-Codierung in der zweifachen Varianzanalyse ......................... 192 4.7 Die Design-Matrix .............................................................................. 193 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 176 4.8 Kovarianzanalyse .................................................................................. 196 4.8.1 Kovarianzzerlegung .............................................................................. 197 4.8.1.1 Kovarianzzerlegung nach einer nominalen unabhängigen Variablen .. 197 4.8.1.2 Anwendung der Kovarianzzerlegung: Aggregatdaten und Mehrebenenanalyse............................................................................... 199 4.8.1.3 Die Kovarianz- und Korrelationszerlegung nach einer nominalen unabhängigen Variablen als Spezialfall einer allgemeinen Kovarianzund Korrelationszerlegung nach metrischen Variablen ........................ 202 4.9 Kontrastgruppenanalyse (tree analysis) ................................................ 209 4.10 Anwendungsbeispiel zur Varianzanalyse: Vergleich der Erklärungskraft verschiedener Berufsstruktur- und Klassenmodelle für die Bundesrepublik Deutschland ..................................................................................... 216 4.10.1 Probleme des Modellvergleichs und Kriterien zur Beurteilung der Erklärungskraft...................................................................................... 216 4.10.1.1 Indikatoren für die Hierarchie der materiellen Lage 217 4.10.1.2 Indikatoren für den ideologischen Standort (Bewusstsein) 217 4.10.2 Vergleich der Erklärungskraft der verschiedenen Berufsstrukturund Klassenmodelle .............................................................................. 218 4.10.3 Graphische Darstellung der verschiedenen Berufsstruktur- und Klassenmodelle ..................................................................................... 221 4.10.4 Berufsstrukturmodell auf Basis der bundesdeutschen Sozialstatistik nach Einkommen und Bewusstseins-Index .......................................... 221 Literaturverzeichnis........................................................................................... 228 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 177 Zum Vergleich: Untersuchung der Lebenszufriedenheit mit der Varianzanalyse (4.5.1) Abhängige Variable: Lebenszufriedenheit Primärbeziehung klein groß Gesamt Beruf klein groß Gesamt klein groß Gesamt klein groß Gesamt Mittelwert ,1875 ,8571 ,5000 ,4828 ,7222 ,6154 ,3778 ,7600 ,5789 N 160 140 300 290 360 650 450 500 950 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 178 Ansatz der Varianzanalyse: Test der additiven und Interaktionseffekte Beispiel für eine zweifache Varianzanalyse Klassischer Ansatz (Experimentelle Methode) ANOVA: Lebenszufriedenheit nach Primärbeziehung, Beruf Quadratsumme Lebenszufriedenheit Haupteffekte 2-WegWechselwirkungen Modell Residuen Insgesamt (Kombiniert) Primärbeziehung Beruf Primärbeziehung * Beruf df Experimentelle Methode Mittel der Quadrate F Sig. 35,993 2 17,996 91,454 ,000 1,391 33,260 1 1 1,391 33,260 7,071 169,020 ,008 ,000 9,432 1 9,432 47,934 ,000 45,425 186,154 231,579 3 946 949 15,142 ,197 ,244 76,947 ,000 1) Zunächst wird getestet, ob die Haupteffekte insgesamt (additiven Effekte insgesamt) signifikant sind. SS A,B = 35,993; gemäß dem F-Wert und der Significance leisten die additiven Effekte einen signifikanten Erklärungsbeitrag. 2) Die Interaktionseffekte, d.h. die Effekte der Kombinationen von A und B über die additiven Effekte hinaus, ergeben eine Variation von SS AB = 9,432, die nach dem F-Wert und der Significance signifikant ist. 3)Das gesamte Modell weist eine erklärte Variation von SS A,B,AB = 45,425 auf, welche nach dem F-Test und der Significance signifikant ist. 4) Die gesamte Variation beträgt SS y = 231,579, davon entfällt auf die nicht erklärte Variation ein Betrag von SS Residuen = 186,154. 5) Da die Erklärungsbeiträge von A und B sich überschneiden können bzw. auch Suppressor etc. möglich sind, gilt nicht einfach die Additivität, denn i.a.: SS A, B ≠ SS A + SS B Für dieses Problem gibt es nun unterschiedliche Lösungsvorschläge. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 179 In der klassischen (experimentellen) Methode werden die Faktoren jeweils gegeneinander bereinigt, ihr Erklärungsbeitrag wird definiert als: SS A, adjusted for B = SS A,B – SSB = 35,993 – 34,601 = 1,391 SS B, adjusted for A = SS A,B – SS A = 35,993 – 2,733 = 33,260 In der hierarchischen Methode wird der Erklärungsbeitrag des Faktors A vollständig berücksichtigt und der Faktor B dann um A bereinigt: SS A = 2,733 SS B, adjusted for A = SS A,B - SS A = 35,993 – 2,733 = 33,260 Im Regressions-Ansatz (Unique-Methode) werden die Faktoren und die Interaktionen gegeneinander bereinigt. Dies entspricht der Regression von y auf A, B und (AB). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 180 Lebenszufriedenheit Haupteffekte 2-WegWechselwirkungen Modell Residuen Insgesamt Lebenszufriedenheit Haupteffekte 2-WegWechselwirkungen Modell Residuen Insgesamt (Kombiniert) Primärbeziehung Beruf Primärbeziehung * Beruf (Kombiniert) Primärbeziehung Beruf Primärbeziehung * Beruf Hierarchische Methode Mittel der Quadrate F 17,996 91,454 Quadratsumme 35,993 df 2 Sig. ,000 2,733 33,260 1 1 2,733 33,260 13,888 169,020 ,000 ,000 9,432 1 9,432 47,934 ,000 45,425 186,154 231,579 3 946 949 15,142 ,197 ,244 76,947 ,000 Eindeutige Methode Mittel der Quadrate F 22,453 114,102 Sig. ,000 Quadratsumme 44,906 df 2 1,310 42,126 1 1 1,310 42,126 6,659 214,079 ,010 ,000 9,432 1 9,432 47,934 ,000 45,425 186,154 231,579 3 946 949 15,142 ,197 ,244 76,947 ,000 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 181 Gesamtvariation SS y = 950 ⋅ 550 400 ⋅ = 231,579 950 950 Nicht erklärte Variation nij SS Re siduen = SS within = ∑∑∑ ( yiju − yij . ) 2 i u =1 j = ∑∑ nij MS(ij ) i j MS (ij) = Streuung von y in der Kombination (ij) In dem Beispiel: SS Re siduen = 160 ⋅ 30 130 140 150 ⋅ + 290 ⋅ ⋅ 160 160 290 290 + 140 ⋅ 120 20 260 100 ⋅ + 360 ⋅ ⋅ 140 140 360 360 = 186,154 Erklärte Variation Die erklärte Variation ist dann die Differenz: SS Modell = SS y − SS Re siduen = 45,425 Die erklärte Komponente ließe sich auch direkt berechnen: SS Modell = ∑∑∑ ( yij . − y ) 2 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 182 Additive Komponente der Variation Die Regression von y auf x,z ergab einen Erklärungsanteil von 35,993 = 15,5% . 231,579 SS A,B = 35,993 Interaktionskomponente der Variation Die Interaktionskomponente der Variation ergibt sich als Differenz der erklärten Variation und der additiven Komponente der Variation. SS AB = SS A, B , AB − SS A, B = 45,425 − 35,993 = 9,432 Gesamterklärungskraft Die Regression von y auf x, z, xz ergab einen Erklärungsanteil von 45,425 = 19,6% . 231,579 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 183 Erklärte Varianz Einfache Varianzanalyse In der einfachen Varianzanalyse von y durch das Merkmal A lässt sich die Varianz anschaulich darstellen durch das Zusammenwir- 1Ai mit dem direkten Effekt ken der Kovarianz von y und y Ai − y von 1Ai auf y. Erklärte Variation: k ni ( y Ai − y ) 2 ∑ i =1 n ˆ Regressionsschätzung: y = k ∑y 1 i =1 i Ai k = y + ∑ ( yi − y ) 1Ai i =1 In der multiplen Regression ist y − yˆ orthogonal zu den Prädiktoren x i, also auch zu ŷ . s y2ˆ = s yˆ , yˆ = s y , yˆ Deshalb gilt: k s y , yˆ = ∑ s y , xi β i i =1 In der Varianzanalyse: s y ,1 Ai = ( ni y Ai − y n ) k ni ( y Ai − y ) ⋅ ( y Ai − y ) Also: Erklärte Varianz = ∑ i =1 n s y ,1Ai Effekt von 1Ai Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 184 Meine „pfadanalytische“ Veranschaulichung der erklärten Varianz: 1A1 1Ai y A1 − y y Ai − y ŷ y Ak − y ni ( y Ai − y ) n 1Ak y Die erklärte Varianz ist gleich der Kovarianz von Kovarianz von diktoren 1 Ai y und ŷ y und ŷ . Die ergibt sich auch daraus, dass y mit den Prä- kovariiert und die Prädiktoren 1 Ai einen Effekt y Ai − y haben. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 185 Zweifache Varianzanalyse Wenn y durch die Merkmale A und B erklärt werden soll, so gibt es zunächst die Erklärungsbeiträge der Haupteffekte von A bzw. B, wobei sich die Erklärungsbeiträge überschneiden können. Erklärte Variation durch A: Erklärte Variation durch B: In der Varianzanalyse werden k ni 2 − y y ( ) ∑ Ai n i =1 l n j 2 ( ) y y − ∑ Bj n j =1 y Ai − y als (Haupt-) Effekte von A und y B j − y als (Haupt-) Effekte von B bezeichnet. Die Modell-prognose aufgrund des „additiven Modells“ würde dann für (i, j) lauten: y + y Ai − y + y B j − y ( ) ( ) (Achtung: Dies ist nicht identisch mit der Regression von y auf die 1 Ai und 1B j , da die direkten Effekte in der multiplen Regression berechnet werden, indem jeweils alle übrigen Prädiktoren in ihrem Einfluß herauspartialisiert werden. Das „additive Modell“ der Varianzanalyse ist insofern zu einfach, als zunächst ein unabhängiges Wirken von A und B angenommen wird und erst im nächsten Schritt die Abweichung als Interaktion betrachtet wird. Die Regression dagegen rechnet die Beziehung zwischen den Prädiktoren sofort heraus.) Aus der Forderung, dass die Abweichungen der Beobachtungen von den aufgrund des Modells zu erwartenden Beobachtungen (d.h. der Fehler) minimal sein soll, ergibt sich, dass der Effekt der Interaktion 1Ai 1B j lautet: Effekt von 1Ai1B j : y Ai B j − ( y + ( y Ai − y ) + ( y B j − y )) D.h. der Effekt der Interaktion 1Ai 1B j ist das Ausmaß, in dem der Durchschnitt der Kombination von dem bei additivem Wirken der Haupteffekte zu erwartenden Wert abweicht. Die erklärte Varianz soll nun wieder mit Hilfe von Kovarianzen und Effekten dargestellt werden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 186 Die Kovarianz zwischen y und 1A 1B lässt sich berechnen als: i j s y ,1 A 1B = j i nAi B j n (y Ai B j −y ) Wegen dieser Ergebnisse können die Effekte von 1Ai1B j und die Kovarianz von y und 1Ai1B j unterschiedliche Vorzeichen haben. Die erklärte Varianz lautet: k s = s y , yˆ = ∑ 2 yˆ k i =1 l + ∑∑ i =1 j =1 n Ai B j n n Ai n l nB j j =1 n ( y Ai − y ) + ∑ 2 ( yB j − y)2 ( y Ai B j − y )( y Ai B j − ( y + ( y Ai − y ) + ( y B j − y )) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 187 Meine „pfadanalytische“ Veranschaulichung der erklärten Varianz für die zweifache Varianzanalyse: 1Ai n Ai n ( y Ai − y ) nB j n yB j 1B j y Ai − y −y ŷ y Ai B j − ( y + ( y Ai − y ) + ( y B j − y )) ( yB j − y ) 1Ai1B j nAi B j n ( y Ai B j − y ) y Die erklärte Varianz ergibt sich daraus, dass y mit den Prädiktoren und 1B j sowie nen Effekt haben. 1 Ai 1 Ai 1B j kovariiert, die jeweils den angegebe- Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 188 Berechnung der erklärten Varianz für das Beispiel Lebenszufriedenheit (y) in Abhängigkeit von Beziehungszufriedenheit (x) und Berufszufriedenheit (z) Varianz der Lebenszufriedenheit: s = 2 y n y1 n (1 − n y1 n ) = 0,579 ⋅ (1 − 0,579) = 0,244 Durch Faktor x erklärte Variation: 0,316 ⋅ (−0,079) 2 + 0,684 ⋅ (0,037) 2 = 0,003 Dies sind 1,18 % erklärte Varianz. Durch Faktor z erklärte Variation: 0,474 ⋅ (−0,201) 2 + 0,526 ⋅ (0,181) 2 = 0,036 Dies sind 14,93 % erklärte Varianz. Durch Interaktion x 1 z 1 erklärte Variation: 0,168 ⋅ (0,188 − 0,579) ⋅ (−0,111) = 0,007 -0,391 Durch Interaktion x 1 z 2 erklärte Variation: 0,147 ⋅ (0,857 − 0,579) ⋅ (0,176) = 0,007 0,278 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 189 Durch Interaktion z 1 x 2 erklärte Variation: 0,305 ⋅ (0,483 − 0,579) ⋅ (0,069) = −0,002 -0,096 Durch Interaktion x zz 2 erklärte Variation: 0,379 ⋅ (0,722 − 0,579) ⋅ (−0,075) = −0,004 0,143 Durch Interaktionen insgesamt erklärte Variation: 0,009 Dies sind 3,49 % der erklärten Varianz. Insgesamt erklärt: Durch x: Durch z: Durch Interaktionen: 0,003 0,036 0,007 0,007 -0,002 -0,004 ∑ = 0,048 Anteil erklärter Varianz = 0,048/0,244 = 19,60 % Durch x werden 1,18% erklärt und durch z werden 14,93% der Varianz erklärt. Rechnerisch ergäbe die Summe 16,11%, aber dies ist wegen der Überschneidungen überzeichnet. Gemäß der Regression erklären x und z (ohne Interaktionen) nur 15,5% der Varianz. Die Überzeichnung durch SS A +SS B wird in der vorliegenden Berechnung gerade durch das Zusammenwirken von Kovariationen und Effekten ausgeglichen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 190 Die nicht erklärte Varianz ist die Varianz innerhalb der Kombinationen: 0,164 ⋅ 0,188 ⋅ (1 − 0,188) + 0,305 ⋅ 0,483 ⋅ (1 − 0,483) + 0,147 ⋅ 0,857 ⋅ (1 − 0,857) + 0,379 ⋅ 0,722 ⋅ (1 − 0,722) =0,196 Die erklärte Varianz (0,048) und die nicht erklärte Varianz (0,196) ergeben zusammen die Gesamtvarianz (0,244). Die erklärte Varianz für „Nicht-Zufriedenheit“ würde rechnerisch zu den gleichen Ergebnissen führen. (Es handelt sich ja auch um die spiegelbildliche Fragestellung.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 191 GeschätztesRandmittel Randmittel Lebenszufriedenheit Geschätztes vonvon Lebenszufr Primärbeziehung klein groß Geschätztes Randmittel 0,80 0,60 0,40 0,20 klein groß Beruf Bei großer Zufriedenheit mit den Primärbeziehungen unterscheiden sich Personen mit großer Berufszufriedenheit von solchen mit geringer Berufszufriedenheit um 72,22 – 48,28 = 23,94 %. Verglichen damit unterscheiden sich bei geringer Zufriedenheit mit den Primärbeziehungen Personen mit großer Berufszufriedenheit mit 85,71 – 18,75 = 66,96 % deutlich überproportional von solchen mit geringer Berufszufriedenheit. Dies ist eine Charakterisierung der Interaktionseffekte, die sich graphisch veranschaulichen lässt. In dem Beispiel bedeutet dies, dass die Berufszufriedenheit besonders wichtig ist für die allgemeine Lebenszufriedenheit. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 192 Stellenwert der Multiple Classification Analysis (MCA) Der Kern der Varianzanalyse besteht in den Tests, ob die additiven Effekte (im Sinne der Regression von y auf die Variablen A und B) und die Interaktionseffekte (Kombinationseffekte über die additiven Effekte hinaus) einen signifikanten Erklärungsbeitrag leisten. Zur Deskription der Effekte ist in SPSS die MCA (Multiple Classification Analysis) verfügbar. In dem Beispiel erklärt die MCA 15,5% der Varianz, d.h. es handelt sich um eine Deskription mit Hilfe der additiven Effekte im Sinne der multiplen Regression: Effekt von A: β A.B (= 0,078) Effekt von B: β B. A (= 0,380) Falls es starke Interaktionseffekte gibt, macht eine Beschränkung auf die additiven Effekte wie in der MCA nicht viel Sinn. Das Design der Regressionsanalyse ist an dieser Stelle flexibler. Der Anwender erhält auch den Beta- Koeffizient der Interaktion, falls er eine Regression von y auf x, z, xz durchführt: β y,x = 0,278 β y,z = 0,677 β y , xz = -0,423 Die allgemeine Lebenszufriedenheit steigt also mit der Beziehungszufriedenheit (x) und noch stärker mit der Berufszufriedenheit (z), während die Interaktion einen negativen Effekt hat. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 193 (Gliederung für die Sitzungen zur Pfadanalyse) 3.2 Pfadanalyse ....................................................................................... 122 3.2.1 Ein klassisches Beispiel von Blau und Duncan ................................. 122 3.2.2 Kausale Ordnung und Rekursivität .................................................... 123 3.2.3 Vollständiges Modell und unvollständiges Modell ........................... 124 3.2.3.1 Kausale Geschlossenheit eines Modells gegenüber weiteren Einflussfaktoren....................................................................................................126 3.2.3.2 Pfaddiagramm und Effekte für das vollständige Modell mit 2, 3 und 4 Variablen ............................................................................................ 127 3.2.3.3 Unvollständiges Modell ..................................................................... 131 3.2.3.4 Standardisierte oder unstandardisierte Koeffizienten? ...................... 131 3.2.4 Die vier Mechanismen zur Erklärung einer Korrelation ................... 132 3.2.5 Anwendungsbeispiel: Parteienwahl in Abhängigkeit von Parteiidentifikation und Einstellungen ....................................................................... 134 3.2.6 Multiple R2 in der Pfadanalyse .......................................................... 136 3.2.6.1 Zentrale Konzepte der statistischen Analyse gemäß der Pfadanalyse137 3.2.7 Effekte und Erklärungskraft in der Pfadanalyse ................................ 137 3.2.7.1 Korrelierte Effekte (Multiple Regression) ......................................... 137 3.2.7.2 Indirekte Effekte (Pfadanalyse) ......................................................... 139 3.2.7.3 Problematisierung der Pfadanalyse.................................................... 139 3.2.7.4 Vergleich von Gesamtzusammenhang und bereinigtem Zusammenhang: Typologie und Zerlegung von R2 ...................................................... 140 3.2.8 Partielle Korrelation oder Pfadkoeffizient? ....................................... 156 Literaturverzeichnis ........................................................................................... 159 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 194 3.2 Pfadanalyse (Voraussetzung: metrische Variablen, die standardisiert werden) Kausalmodelle lassen sich mit Hilfe der multiplen Regression überprüfen. 3.2.1 Beispiel: Status attainment (Nach Daten von Blau und Duncan für die USA) Pfaddiagramm u2 .86 Vater .52 x1 Schulbildung .31 .03 x2 Beruf -.01 .22 .12 .28 Sohn x3 Schulbildung .43 x4 erster Beruf .28 x5 aktueller Beruf .40 .86 u3 .82 u4 .75 u5 x 2 = .52 x 1 + .86 u 2 (Äquivalent: x̂ 2 = .52 x1 ; R2 = 26 %) x 3 = .31 x 1 + .28 x 2 + .86 u 3 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 195 x 4 = .03 x 1 + .22 x 2 + .43 x 3 + .82 u 4 x 5 = -.01 x1 + .12 x 2 + .40 x 3 + .28 x 4 + .75 u 5 (x 1 exogen; x 2, ..., x 5 endogen) Regressionsschätzung: x̂ 2 = .52 x1 ; R2 = 26 % 1 - R2 = 74 % 1-R2 = .74 = .862 Darstellung mit exogener Variablen u2: u2 ↓ .86 x1 → .52 x2 74 % der Variation wird nicht erklärt durch das Modell; diese nicht erklärte Variation wird in der Darstellung der Variablen u2 (= nicht berücksichtigte Faktoren) zugeordnet. Erklärte Varianz: .522 = .26 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 196 Regressionsschätzung: x̂3 = .31 x1 + .28 x2 R2 = 26 % Pfadanalyse: 1 – R2 = 74 % (Anteile) (Prozentsätze) Die Pfadanalyse wird häufig wie folgt dargestellt: Die unerklärte Variation wird wieder sichtbar gemacht, indem sie einem Restfaktor u3 als Effekt zugeordnet wird. 0, 7 4 = 0, 8 62 x1 x2 .31 .28 x3 .86 u3 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 197 Äquivalente Darstellung mit Multiple R2 R2 = 26 % x1 .52 x2 .31 .28 x3 R2 = 26 % Entsprechendes für x4: Regressionsschätzung: x̂ 4 = .03x1 + .22 x 2 + .43x 3 + .82u 4 R² = 33%; 1 - R² = 67 %. x1 x3 x2 .03 .43 .22 x4 .82 u4 Die nicht erklärte Variation von 67% wird dem Restfaktor u2 zugeordnet: .82²=.67 Schließlich für x5: R² = 44%; 1 – R² = 56%. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 198 3.2.2 Kausale Ordnung Eine Ordnungsrelation für eine Menge von Einheiten ist zunächst dadurch charakterisiert, dass für je zwei Elemente a und b eindeutig feststehen muss, ob entweder a kleiner b (im Sinne der Ordnung) oder b kleiner a oder a gleich b. Ferner muss eine Ordnungsrelation die Bedingungen der NichtReflexivität, Asymmetrie und Transitivität erfüllen. Eine („starke“) kausale Ordnung von Variablen wäre analog zu definieren. Aber: Für den speziellen Anwendungszusammenhang von Kausalmodellen ist es günstiger, die Anforderungen an eine kausale Ordnung abzuschwächen, um die Anwendungsmöglichkeiten zu erhöhen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 199 (Schwache) kausale Ordnung von Variablen x1, ..., xk: In der Reihenfolge der Nummerierung vorhergehende Variablen können einen (Kausal-) Effekt auf in der Reihenfolge folgende Variablen haben, müssen aber nicht. Ferner: Es gibt keine Wechselwirkungen bzw. allgemeiner keinen Effekt gegen diese Reihenfolge. (In der Reihenfolge nachfolgende Variable dürfen also nicht als Ursachen modelliert werden.) Beispiel: X1 . . . Xu Indikatoren Xu+1 . . . Xu+v Einstellungs- Xu+v + 1 . . . Xu+v+w Verhaltens- Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 200 der objekindikatoren tiven Situation indikatoren Rekursives (= rückbezügliches) Modell: Keine Wechselwirkung x1 x2 Kein Pfeil „gegen“ die schwache Kausalordnung x2 x1 x3 Keine „loops“ x1 [Sonst spricht man von: nicht-rekursiven Modellen] Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 201 3.2.3 Vollständiges (rekursives) Modell Falls alle in der Reihenfolge der Variablen xi vorhergehenden Variablen (x1, ..., xi - 1) in dem Modell tatsächlich einen Effekt auf xi haben. (Für alle i = 2, ..., k) Ausführlich: x1 hat Effekt auf x2 x1, x2 haben Effekt auf x3 x1, x2, x3 haben Effekt auf x4 x1, x2, x3, x4 haben Effekt auf x5 Etc. Unvollständiges (rekursives) Modell Falls nicht alle nach dem rekursiven (bzgl. der Reihenfolge der Nummerierung rückbezüglichen) Ansatz theoretisch möglichen Effekte durch das vorliegende Modell behauptet werden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 202 Test eines (rekursiven) Modells Sobald ein rekursives System unvollständig ist, ist das System überdeterminiert und testbar. Das vollständige Modell ist eindeutig bestimmt, die Daten werden dabei nur umgeformt (= anders dargestellt). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 203 Test des „unvollständigen Modells“ Falls der direkte Effekt β yx zwischen x und y in der Grundgesamtheit gleich Null ist, wie ist dies zu ermitteln? z x y 1) Vollständiges Modell testen. Als Ergebnis müsste man erhalten, dass β yx nicht signifikant verschieden von Null ist. 2) Unvollständiges Modell schätzen: x →z →y β zx = rzx β yz = ryz Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 204 Als Ergebnis müsste man erhalten, dass ryx. z nicht signifikant verschieden von Null ist. 3.2.4 Die vier Mechanismen zur Erklärung einer Korrelation Wie die Variation von y erklärt werden kann, wurde anlässlich der multiplen Regression dargestellt. Im Folgenden wird nun gezeigt, dass sich die Korrelation zwischen x und y dadurch erklären lässt, dass sie aufgrund von vier gleichzeitig wirkenden Mechanismen zustande kommt. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 205 Mit Hilfe der Pfadanalyse lassen sich die vier Mechanismen angeben, auf Grund derer ein beliebiger statistischer Zusammenhang zustande kommt. (Nach Finney 1972; bei Finney werden zwei Beispiele verwendet für die vier Mechanismen, es reicht aber ein Beispiel.) Beispiel β (SV) V W (SM) β (SB) xv β yv β β X xw β Z (P1.Beruf) yx Y yw zx β yz (Paktueller Beruf) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 206 Wie kommt die Korrelation ryx zustande? Mögliche Komponenten: - Direkter Kausaleffekt - Indirekte Kausaleffekte - Scheinkomponenten - Korrelierte Effekte (bzw. Assoziationseffekte) (In dem Beispiel sind V und W exogene Variablen, d.h. sie werden im Modell nicht erklärt.) (Endogene Variable dagegen werden im Modell zu erklären versucht.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 207 Pfadtheorem: ryx = ∑ rx , x j β y , x j j y ist die abhängige Variable. Die Summation bezieht sich auf alle Variablen x j, die im Modell eine direkte Ursache der zu erklärenden Variablen sind. Den Zusammenhang des Prädiktors x mit der zu erklärenden Variablen y erhält man, indem man von x per Korrelation jeweils zu einem der übrigen Prädiktoren x j geht und von dort per direktem Effekt β y, x zur abhängigen Variablen y. j Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 208 Meine graphische Veranschaulichung des Pfadtheorems: β y ,x x i i x rx , x i rx , x β y ,x j y j β y ,x j ry , x x Die Größenordnung der Korrelation ry ,x resultiert also daraus, dass einerseits x einen direkten Kausaleffekt auf y haben kann und andererseits x mit den übrigen Prädiktoren jeweils korrelieren kann, welche wiederum selbst einen direkten Kausaleffekt auf die zu erklärende Variable y haben können. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 209 Für das oben genannte Modell gilt nach dem Pfadtheorem: ryx = β yx + rxv β yv + rxw β yw + rxz β yz rxz (= rzx ) = β zx (nach Pfadtheorem) rxv = β xv + β xw rvw (nach Pfadtheorem) rxw = β xw + β xv rvw (nach Pfadtheorem) ryx = β yx + β xw β yw + β xv β yw rvw + β xv β yv + β xw β yv rvw + β yz β zx Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 210 Der Gesamtzusammenhang r yx setzt sich zusammen aus folgenden 4 Komponenten: 1) 2) β yx (direkter Kausaleffekt) β yz β zx (indirekter Kausaleffekt) 3) Scheinkomponente der Korrelation auf Grund des verursachenden Faktors W: β xw β yw Scheinkomponente auf Grund von V: β xv β yv Insgesamt: Scheinkomponente: β xw β yw + β xv β yv 4) Komponente auf Grund der Korrelation von exogenen Variablen (Korrelierte Effekte bzw. Assoziationseffekte) β xv β yw rvw + β xw β yv rvw (Exogen: im Modell nicht erklärt; im Modell nur als unabhängige Variable) (Im Gegensatz dazu: Endogen: im Modell erklärt; im Modell abhängige Variable) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 211 Beispiel: Mehr indirekte Effekte von x auf y x z1 z2 y z3 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 212 Beispiel: Mehr Scheinkomponenten in der Beziehung zwischen x und y v x w y u Scheinkomponenten könnten auch über Kausal ketten entstehen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 213 Beispiel: Mehr „korrelierte Effekte“ in der Beziehung zwischen x und y v x w y u Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 214 3.2.5 Anwendungsbeispiel: Parteienwahl in Abhängigkeit von Parteiidentifikation und Einstellungen (nach Herbert B. Asher: Causal modeling.) RPI .39 .71 RV .46 RPA RPI RPA RV - Effekte Party identification Partisan attitudes R2 = 62 % respondent`s partisan identification respondent`s partisan attitudes respondent`s vote Kausaleffekt Direkter Effekt .39 Kausaleffekt Indirekter Effekt Gesamter Kausaleffekt .33 (=.71 x .46) .72 .46 - .46 Größerer direkter Effekt: Einstellungen, und nicht Parteiidentifikation. Wegen des zusätzlichen indirekten Effekts über die Einstellungen hat die Parteiidentifikation den größeren Gesamteffekt. 215 Beziehung zwischen RPI und RV direkt .39 indirekt .71 ⋅ .46 = .33 s RV, RPI = .72 (alles kausal) Beziehung zwischen RPA und RV direkt .46 spurious .71 ⋅ .39 = .28 s RV, RPA = .74 (Komponente .28 nicht kausal) 216 Die Parteienwahl lässt sich in diesem Fall zu 62 % durch Parteiidentifikation und Einstellungen erklären. k Erklärte Varianz: Multiple R2 = s y , yˆ = ∑ ryx β yx i i =1 i Meine "pfadanalytische" Darstellung der erklärten Varianz: RPI sRV, RPI = .72 .39 RV .46 RPA sRV, RPA = .74 RV Multiple R2 ist die Kovarianz von y und yˆ . Der Zusammenhang von Effekten und Erklärungskraft besteht darin, dass man die gesamte erklärte Varianz erhält, wenn man von der zu erklärenden Variablen per Kovarianz jeweils zu einer der „Ursachen“ geht, die jeweils die angegebenen „Kausaleffekte“ haben. .72 ⋅ .39 + .74 ⋅ .46 = 0,62 = R 0,28 2 0,34 Der Bestandteil .28 · .46 = .13 ist nicht kausal, sodass die „kausale“ Erklärung nur die Größenordnung R2 – 0,13 = 0,49 hat. In diesem Sinne sind Kausaleffekte noch wichtiger als die Erklärungskraft. 217 3.2.6 Multiple R2 in der Pfadanalyse Die Grundelemente der Zerlegung sollen exemplarisch dargestellt werden, wobei das Beispiel aus Gründen der Übersichtlichkeit um den direkten Effekt von w auf x reduziert wird. β (SV) V W (SM) β (SB) xv β yv β yw β X Z (P1.Beruf) yx Y (Paktueller Beruf) 218 zx β yz Multiple R2 = ryx ⋅ β yx + ryz ⋅ β yz + ryv ⋅ β yv + ryw β yw ryx ⋅ β yx = β yx ⋅ β yx + β yz β zx ⋅ β yx + β xv β yv ⋅ β yx + rvw β yw β xv ⋅ β yx direkt direkt von x von x indirekt von x spurious durch v direkt von x korreliert direkt von v direkt von x in (yx) in (yx) in (yx) in (yx) direkt von x ryz ⋅ β yz = β yz ⋅ β yz + β zx β yx ⋅ β yz + β xv β zx β yv ⋅ β yz + rwv β xv β zx ⋅ β yw ⋅ β yz direkt von z direkt direkt spurious von z von z durch x in (yz) direkt von z spurious durch v in (yz) in (yz) korreliert direkt von w direkt von z in (yz) ryv ⋅ β yv = β yv ⋅ β yv + β yx β xv ⋅ β yv + rvw β yw ⋅ β yv + β xv β zx β yz ⋅ β yv direkt von v direkt indirekt von v von v in (yv) direkt von v korreliert von v in (yv) direkt von v indirekt von v direkt von v in (yv) in (yv) ryw ⋅ β yw = β yw ⋅ β yw + rwv β yv ⋅ β yw + rwv β xv β yx ⋅ β yw + rwv β xv β zx β yz ⋅ β yw direkt direkt korreliert direkt korreliert von w von w von w von w von w in (yw) in (yw) in (yw) direkt von w korreliert von w direkt von w in (yw) Insgesamt setzt sich Multiple R2 also zusammen aus: 4 direkte Beiträge von x, z, v, w 3 Kombinationen von direktem und indirektem Effekt (von x und v) 3 Kombinationen von direktem und spurious (durch v und x) Effekt 4 Kombinationen von direktem und korreliertem (von v und w) Effekt 2 Kombinationen von direktem und korreliert • direktem (von v und w) Effekt 219 Zentrale Konzepte der statistischen Analyse gemäß der Pfadanalyse Direkte Effekte Indirekte Effekte Korrelierte Effekte Ferner: Die „spurious“-Effekte müssen bei der erklärten Varianz relativierend berücksichtig werden. In diesem Sinne sind die Effekte noch wichtiger als die erklärte Varianz. Die relative Wichtigkeit von Erklärungsfaktoren für ein zu erklärendes Phänomen (y) kann einerseits anhand der direkten Beiträge diskutiert werden, andererseits anhand der Gesamtbeiträge. Durch eine Korrelation r yx allein kann man insofern getäuscht werden, als es „Scheinkorrelationen“, Suppressor und Distorter Phänomene etc. gibt, wie sich im Vergleich zum eigentlichen direkten Kausalmechanismus (direkter Effekt) ergibt. D.h. die Bearbeitung des Problems von Korrelation und Kausalität sollte in der schrittweisen Elaborierung „pfadanalytischer“ Modellierungen geschehen. 220 Modellierung der Partizipationsfelder und Problembereiche von Jugendlichen In der aktuellen Brandenburger Jugendstudie (vgl. Dietmar Sturzbecher/ Dieter Holtmann (Hg.): Werte, Familie, Politik, Gewalt – Was bewegt die Jugend? Münster 2007: LIT Verlag) werden die verschiedenen Partizipationsfelder und Problembereiche der Jugendlichen jeweils gesondert dargestellt und diskutiert. Im Folgenden sollen mit Hilfe der Pfadanalyse einige Hauptgesichtspunkte zu den Lösungsmöglichkeiten modelliert werden (Dieter Holtmann, Tilo Görl, Detlef Landua u.a.). Im Folgenden soll dargestellt und diskutiert werden, wie die verschiedenen untersuchten Problembereiche (Abwanderungswunsch, Politikverdrossenheit, Gewaltbereitschaft und intolerante Einstellungen) zusammenhängen und welche Maßnahmen zur Vorbeugung dieser Probleme sich aus den erhobenen Daten als Erfolg versprechend erschließen lassen. Zu diesem Zweck wird im Folgenden – auf der Basis der bisherigen Untersuchungsergebnisse – ein die Problembereiche übergreifendes Pfadmodell entwickelt. 221 Soziale Lagen, Wertorientierungen, Partizipationsfelder und Problembereiche der Jugendlichen Das folgende Modell für das Handeln von Jugendlichen im Beziehungsfeld von Familie, Schule und Freizeitbereich ist in Form eines – bis auf die Rückmeldung der Jugendlichen an die verschiedenen Teilbereiche - rekursiven Pfadmodells formuliert, weil dies die effizienteste Art ist, Teile des Modells zu schätzen bzw. zu testen. Die Einschränkungen aufgrund der Rekursivität (d.h. das Modell hat eine Richtung) haben zur Folge, dass man eine der Richtungen einer möglichen Wechselwirkung als die dominierende begründen muss. (Die Alternative, die Größenordnungen von Wirkungen in beide Richtungen offen zu modellieren, ist unverhältnismäßig aufwändiger bei Schätzung und Test.) Um einen Strukturierungspfad jeweils eindeutig ablesen zu können, ist bei den Problembereichen die Richtung der Ausprägung angegeben: Z.B. enthält das Modell die Hypothesen, dass die Möglichkeiten für konkrete politische Partizipation in die Richtung wirken, dass dann eher wenig Rechtsextremismus, Ausländerfeindlichkeit und Antisemitismus vorzufinden ist. 222 Jugendliche handeln gemäß ihren Interessen und insbesondere ihren Werten, sodass die Individualisierungsschübe und die Pluralisierung von Werten und Einstellungen gerade für das Handeln von Jugendlichen einen hohen Stellenwert haben. Während bis Ende der 1980er Jahre ein Vordringen individualistischer Wertorientierungen beobachtet wurde, zeigte sich nach 1989/90 unter den angespannteren wirtschaftlichen Rahmenbedingungen infolge des Anwachsens der ökonomischen Konkurrenz wieder eine stärkere Orientierung an Werten der sozialen Stabilität und Sicherheit. Konkret ist dabei für die Jugendlichen die schlechtere Lage bei den Ausbildungsstellen von Bedeutung, aber auch die Probleme der Berufseinmündung in einem schwierigeren wirtschaftlichen Umfeld. Stefan Hradil (2002) hat diese neueren Entwicklungen in den Wertorientierungen prägnant als Individualisierung und ihre Gegenbewegungen zusammengefasst. Auch in der vorliegenden Studie zeigt sich eine Verschiebung der Priorität von Hedonismus („das Leben genießen“) hin zur sinnstiftenden Arbeit („Arbeit, die erfüllt“) und gemeinschaftsorientierten Haltungen („für andere da sein“) 223 Qualität der Freizeitangebote (Wenig) Abwanderung Wertorientierungen Beachtung von Jugendinteressen Familie, Persönlichkeit, Geschlecht, Alter, Ethnie, Region Kommunale Aktivitätsmöglichkeiten (Wenig) Politikverdrossenheit (Geringe) Gewaltbereitschaft Peer Group Bewertung der Institutionen (umgesetzt insbesondere durch politische Programme) Beteiligung am politischen Leben Soziale Lage (u.a. Schultypen) Soziale Schulqualität (Wenig) Rechtsextremismus, Ausländerfeindlichkeit, Antisemitismus Abbildung 1: Soziale Lagen, Wertorientierungen, Partizipationsfelder und Problembereiche der Jugendlichen 224 Die hierarchische Schichtung sozialer Lagen ist nach wie vor von großer Bedeutung für die durchschnittlichen Lebenschancen. So zeigen sich in der vorliegenden Studie ungünstige Auswirkungen z.B. der Arbeitslosigkeit eines Elternteils, weshalb der Schaffung günstigerer ökonomischer Rahmenbedingungen hohe politische Priorität zukommt. Allerdings zeigen sich gerade in diesem Bereich auch die Grenzen kommunaler Präventionsstrategien. Als wichtige Partizipationsfelder und Kontexte werden im Rahmen unserer Analysen insbesondere die Familie, die Schule, der Freizeitbereich, der Sport und die Freiwilligenvereinigungen sowie das politische Leben berücksichtigt (vgl. Abbildung 1). Dabei zeigt sich, dass in aller Regel mit einer besseren Qualität der Angebote, mit einer stärkeren Partizipation und Integration in diese Teilbereiche gleichzeitig vorgebeugt wird gegen die Gefährdungen, die in der vorliegenden Studie vorrangig berücksichtigt werden: Mit einer stärkeren Partizipation und Integration verringert sich die Wahrscheinlichkeit der Abwanderung (wobei gleichzeitig die Mobilitätsbereitschaft zur Wahrnehmung von Berufschancen grundsätzlich nicht negativ bewertet werden sollte.) Mit einer guten Schulqualität sinkt die Gewaltbereitschaft. Mit einer besseren Partizipation und Integration von Jugendlichen steigt ihr Selbstbewusstsein und ihre Zufriedenheit, was eine günstige Voraussetzung für die Offenheit gegenüber Neuem und zunächst Fremdem ist. Bei höherer Zufriedenheit mit Schule, Freizeit und politischer Beteiligung gibt es weniger Anlass für Projektionen von Unzufriedenheiten auf vermeintliche „Sündenböcke“. 225 Deshalb ist die gesellschaftliche Investition in die Unterstützung von Familien, in die soziale Schulqualität, in die Infrastruktur für die Freizeitgestaltung, in die Möglichkeiten der Partizipation in Sport- und Freiwilligenvereinigungen sowie in die Beteiligungsmöglichkeiten am gesellschaftlichen und politischen Leben das nahe liegende politische Programm zur Vorbeugung gegen Gefährdungen wie Gewaltbereitschaft, Ausländerfeindlichkeit, Rechtsextremismus sowie Antisemitismus. Die besondere Förderung von Kindern und Jugendlichen ist ein zentrales Performanzkriterium, bei dem sich Gesellschaften im Hinblick auf ihre Zukunftsfähigkeit bewähren müssen, vgl. hierzu auch Esping-Andersen: „A child-centred social investment strategy“ (in: Derselbe et al. „Why we need a new welfare state“ (Oxford 2002)). Aufgrund der Performanz der Gesellschaft, die sichtbar wird in den Leistungen der verschiedenen gesellschaftlichen Teilbereiche (Schulqualität, Infrastruktur der Freizeitbereiche etc.) nach den diversen Qualitätskriterien, bewerten die Jugendlichen aufgrund ihrer Präferenzen diese zahlreichen Aspekte und – dies ist die Rückkoppelungsschleife des ansonsten rekursiven Modells – entwickeln ihre eigenen Vorstellungen, Konzepte und Präferenzen weiter sowie melden ihr Votum an die verschiedenen gesellschaftlichen Teilbereiche und Teilpolitiken zurück. 226 Mit dieser im wesentlichen rekursiven Formulierung soll modelliert werden, dass Jugendliche in Institutionen und Teilbereichen nach ihren Vorstellungen und Werten agieren, einerseits also auch von diesen Kontexten geprägt werden, andererseits aber auch ihren partiellen Beitrag zur Umgestaltung dieser Institutionen und Teilbereiche leisten können. Pfadmodell zu den Zusammenhängen der Problembereiche und zu möglichen Lösungsansätzen In der folgenden Abbildung 2 sind die Ergebnisse zusammengefasst, die sich aus der pfadanalytischen Modellierung der Wirkungsmechanismen zwischen Risikofaktoren und Problemlagen der Jugendlichen ergeben. Gleichzeitig werden die Mechanismen aufgezeigt, mit denen durch staatliche Interventionen Problembereiche vorzeitig und vorsorgend bearbeitet werden könnten. 227 Das Pfadmodell und seine Parameter wurden mittels des Programms AMOS visualisiert und geschätzt (vgl. Arbuckle, Wothke 1999). In der Pfadanalyse werden die Zusammenhänge der verschiedenen Faktoren durch Pfeile dargestellt, wobei z.B. der Pfeil von der politischen Partizipationsbereitschaft zur Ausländerfeindlichkeit so zu interpretieren ist, dass höhere Partizipationsbereitschaft geringere Ausländerfeindlichkeit begünstigt, was also vom Vorzeichen her ein negativer Zusammenhang ist, der in diesem Fall die Größenordnung (Pfadkoeffizient) -.10 hat. Die Größenordnung drückt die relative Wichtigkeit eines Einflussfaktors auf ein zu erklärendes Phänomen aus. Jede Variable, die in dem Modell erklärt werden soll, erkennt man daran, dass die Pfeile von einem oder mehreren Einflussfaktoren auf das Kästchen für diese Variable weisen. Oberhalb des Kästchens steht der Anteil der erklärten Varianz in dem Maßstab von 0 bis 100 Prozent, wobei die erklärte Varianz z.B. der Ausländerfeindlichkeit .24 bzw. 24 Prozent beträgt, was besagt, dass die Variabilität der Ausländerfeindlichkeit von Personen sich zu 24 Prozent auf die Unterschiede der Personen bei den Erklärungsfaktoren zurückführen lässt: In dem Beispiel wirken Politikverdrossenheit und Gewaltbereitschaft stärkend in Richtung Ausländerfeindlichkeit (+0.3), während höhere Bildung (-0.23) und politische Partizipationsbereitschaft (-0.10) vorbeugend gegen Ausländerfeindlichkeit wirken. In unserem Beispiel beträgt die zusammenfassende Anpassungsgüte (Goodness of Fit Index: GFI) 0.87, was ein akzeptables Gesamtergebnis ist. 228 Im biographischen Verlauf der Jugendlichen ist zunächst der Familienhintergrund die prägende Kraft, weshalb dieses Konzept in der Kausalordnung am weitesten vorgelagert ist. Wenn Kinder und Jugendliche in der Familie vernachlässigt werden, gehen sie bereits mit Hypotheken in die nächsten Aktivitätsfelder. Es zeigt sich, dass die Jugendlichen bei einem solchen Hintergrund überproportional mit Unlust an die Schule herangehen. Letzteres ist eines der wichtigsten Verbindungsglieder, die über eine Spirale von Frustration (z.B. Schulunlust) und Aggression zu einer erhöhten Gewaltbereitschaft führen können. Deshalb sind die kontinuierliche Evaluation und Verbesserung der Schulqualität nahe liegende Vorbeugungsmaßnahmen, um solche Negativspiralen zu vermindern. In Familien, die eher durch Strenge zu Gehorsam erziehen, statt die Fähigkeiten der Kinder und Jugendlichen zu erkennen und unterstützend zu fördern, entstehen eher rigide Persönlichkeitsstrukturen, wie Adorno et al. in ihrer klassischen Studie „Die autoritäre Persönlichkeit“ (1950) herausgearbeitet haben. Auch unsere Ergebnisse weisen darauf hin , dass bei Jugendlichen, die familiale Vernachlässigungen erfahren, eher externale Kontrollüberzeugungen entstehen, d.h. Vorstellungen derart, dass Mächtigere die Rahmenbedingungen diktieren, sodass man selbst ein geringes Selbstwirksamkeitsempfinden und keine starken Anreize hat, sein Leben in gesellschaftlich erwünschter Weise auszugestalten. Jugendliche mit einer solchen Persönlichkeitsdisposition gehen auch an schulische Aufgaben und Anforderungen eher mit Unlust heran, was die Spirale in Richtung Gewaltbereitschaft eröffnen bzw. verstärken kann. Wie in der Studie „Die autoritäre Persönlichkeit“ 229 zeigt sich auch in der vorliegenden Analyse, dass „autoritäre“ Persönlichkeitsstrukturen die Anfälligkeit für Rechtsextremismus und Ausländerfeindlichkeit erhöhen. Um solche Negativspiralen nicht entstehen zu lassen, müssten also Familien, die Unterstützung der Gesellschaft benötigen, früh genug betreut werden. Je früher die Gesellschaft solchen Familien hilft, desto Erfolg versprechender sind solche gesellschaftlichen Unterstützungsleistungen. Entsprechend sollten lokale Bündnisse für Familien und das Modell der Familienpaten gestärkt werden. Wenn man bei dem Bereich Familie solche mit günstigen Randbedingungen betrachtet, d.h. bildungs- und einkommensstärkere Familien, die die Bildung ihrer Kinder stärker fördern und auf diese Weise eine Positivspirale auszulösen vermögen, so zeigt sich: Durch stärkere Förderung der Bildung erhöht sich das allgemeine Interesse an gesellschaftlichen und politischen Problemen. Die Jugendlichen gehen dann aufgeschlossener an Lernsituationen heran, sie sind eher befähigt, in den verschiedenen Aktivitätsfeldern zu partizipieren: in der Wohngemeinde, im Freizeitbereich, in der Jugendselbstverwaltung und bei der Mitgestaltung der jugendspezifischen Rahmenbedingungen. Durch das Training von Diskursen wird das Einüben von Argumentationen gefördert, weshalb die Anfälligkeit für stereotypes Denken und Vorurteile sinkt und damit auch die Anfälligkeit für Ausländerfeindlichkeit, Rechtsextremismus und Antisemitismus. 230 Die Ergebnisse unseres Pfadmodells zeigen weiterhin, dass kommunale Aktivitätsmöglichkeiten und jugendspezifische, konkrete Formen der politischen Partizipation – d.h. Partizipation unterhalb der Mitgliedschaft in Verbänden, Parteien, Vereinen etc. –relevant sind als vorbeugende Schutzfaktoren gegen eine Vielzahl von Gefährdungen der Jugendlichen. Es findet sich weniger Politikverdrossenheit, wenn es Aktivitätsmöglichkeiten in der Wohngemeinde gibt und wenn die Jugendlichen Möglichkeiten der konkreten politischen Partizipation sehen. Die Gewaltbereitschaft ist geringer, wenn – neben einer geringeren Schulunlust – die Jugendlichen Möglichkeiten der konkreten politischen Partizipation sehen, wodurch wiederum die Politikverdrossenheit sinkt, die selbst ein direkter Einflussfaktor der Gewaltbereitschaft ist. 231 Freizeit (Wenig Langeweile) -,30 ,13 ,35 Gute reg. ,42 Netzwerke Ortsverbundenheit ,23 Wohnort pos. verändert ,10 ,19 -,22 Abwanderungswunsch -,10 Beachtung von Jugendinteressen ,59 230 Komm. Aktivitätsmöglichkeiten ,12 ,01 -,15 Interesse an Politik -,16 -,14 Politikverdrossenheit -,10 ,37 ,17 ,08 ,15 -,06 -,10 ,07 ,08 ,19 ,36 ,46 ,30 -,23 ,24 Ausländerfeindlichkeit ,11 ,12 Familiale Vernachlässigung ,05 -,14 -,16 ,18 Gewaltbereitschaft -,04 Pol.Partizipationsbereitschaft Höhere Bildung ,06 ,15 -,14 ,36 -,07 Schulunlust ,19 ,23 ,08 Externale Kontrollüberzeugung ,32 -,12 ,31 Rechtsextremismus ,12 ,13 ,24 Antisemitismus Abbildung 2: Pfadmodell: Partizipationsfelder und Problembereiche der Jugendlichen (GFI=0,87) Auch Ausländerfeindlichkeit, Rechtsextremismus und Antisemitismus werden durch Politikverdrossenheit und insbesondere durch Gewaltbereitschaft eher gefördert, während sie geringer ausfallen, wenn die Jugendlichen Möglichkeiten zur konkreten politischen Partizipation sehen. Die Tatsache, dass sich viele Jugendliche aufgrund ökonomischer Zwänge dazu entschließen, einen Ausbildungs- oder Arbeitsplatz fern des Heimatorts zu suchen, ist keineswegs nur negativ zu beurteilen. Zu einem sozialräumlichen und politischen Problem wird Migration dann, wenn sie – in Verbindung mit demographischen Veränderungen – zur Entleerung ganzer Regionen führt. Eine Chance für strukturschwache Regionen, dauerhafte Abwanderungsverluste zu vermeiden, besteht darin, die Verwurzelung Jugendlicher mit dem Heimatort bereits in jungen Jahren zu fördern. Dies kann unseren Ergebnissen zufolge z.B. über die aktive Einbindung Jugendlicher bei der Gestaltung von Freizeitangeboten gelingen. Die so geförderte Heimatverbundenheit kann in der Folge dazu beitragen, dass Jugendliche eher bereit sind, nach abgeschlossener Ausbildung in den Heimatort zurückzukehren – sofern sich dort eine berufliche Perspektive bietet. 233 Bearbeitung jugendspezifischer Problemlagen durch verstärkte Bildungsangebote und Mitwirkungsmöglichkeiten In der vorliegenden Studie wurden als Problemlagen einerseits der Abwanderungswunsch und andererseits Schulunlust, Politikverdrossenheit, Gewaltbereitschaft, Ausländerfeindlichkeit, Rechtsextremismus und Antisemitismus berücksichtigt, wobei die letzteren Problemlagen in einem gewissen Ausmaß zusammenhängen. Gemäß den in den einzelnen Kapiteln dargestellten Analysen der verschiedenen Teilbereiche lassen sich als Lösungsansätze erschließen, dass unterstützungsbedürftige Familien frühzeitig erkannt und dann entsprechend in Ausstattung und Erziehung gefördert werden müssen, um weiteren Problemspiralen präventiv begegnen zu können. Denn familiäre Vernachlässigungen begünstigen eher autoritäre Persönlichkeitsstrukturen, Schulunlust und eine Anfälligkeit für Gewaltbereitschaft sowie für Ausländerfeindlichkeit, Rechtsextremismus und Antisemitismus. Entsprechend sind niederschwellige Angebote des Familiencoachings zu fördern. Auf der anderen Seite können durch frühzeitige Förderung in Kitas, Schulen, in der Jugendarbeit und Freizeit die Weichen gestellt werden, dass Kinder und Jugendliche aufgeschlossen an die Schule und die Bildungs- und Ausbildungsinstitutionen herangehen sowie offen werden für das Abwägen von Argumenten im Diskurs, was als Vorbeugung gegen stereotypes Denken und Projektionen von Problemlagen auf „Sündenböcke“ wirkt. 234 In Schule, Ausbildung und Freizeit müssen die Jugendinteressen stärker berücksichtig werden und es müssen Aktivitätsmöglichkeiten für die Jugendlichen ausgebaut werden, damit die Partizipationsbereitschaft der Jugendlichen stärker zum Zuge kommen kann. Die Partizipationsbereitschaft der Jugendlichen lässt sich dadurch fördern, dass sie bei den jugendspezifischen Bereichen und Themen stärker an Planung und Durchführung beteiligt werden. Die personenspezifische Förderung der Jugendlichen durch Bildung und Ausbildung, die Aktivitätsmöglichkeiten der Jugendlichen in Schule und Freizeit sowie die Möglichkeiten, die Jugendinteressen stärker einzubringen, sind also mögliche Lösungsansätze, um die Heranwachsenden stärker an der Gestaltung der jugendspezifischen Bereiche zu beteiligen und dadurch noch besser zu befähigen, jugendtypische Problemlagen erfolgreich zu bewältigen. 235 Ausblick: Grundlegende versus fortgeschrittene multivariate Modelle der sozialwissenschaftlichen Datenanalyse 1. Überblick über die multivariaten Modelle der sozialwissenschaftlichen Datenanalyse ...............................................1 1.1 Charakterisierung verschiedener Datenanlyseverfahren..........1 1.2 Abhängigkeiten vs. Zusammenhänge (Asymmetrische und symmetrische Fragestellungen) ...............................................3 1.3 Erforderliches Messniveau der Variablen ................................4 1.4 Charakterisierung einiger Verfahren durch Diagramme..........5 1.5 Gegenüberstellung der Logik der Verfahren der multiplen Regression, der Faktorenanalyse und der Varianzanalyse ......8 1.6 Bewertung .................................................................................9 1.7 Pragmatische Abgrenzung von grundlegenden und fortgeschrittenen multivariaten Modellen .......................................11 Literaturverzeichnis .............................................................................12 Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 236 1. Überblick über die multivariaten Modelle der sozialwissenschaftlichen Datenanalyse Im Folgenden werden die wichtigsten multivariaten Modelle der sozialwissenschaftlichen Datenanalyse, d.h. die Modelle, die Zusammenhänge und Abhängigkeiten von mehr als zwei Merkmalen berücksichtigen, kurz charakterisiert und systematisiert. 1.1 Charakterisierung verschiedener Datenanalyseverfahren Den Übergang von der Analyse des Zusammenhangs je zweier Variablen/Faktoren zur multivariaten (= Mehrvariablen-) Analyse bildet die Tabellenanalyse, bei der im einfachsten Fall der Einfluss eines Drittfaktors auf den Zusammenhang zweier Variablen bei nominalem oder ordinalem Messniveau untersucht wird. Auf metrischem Messniveau entspricht dem die Berechnung der partiellen Korrelation. Sowohl in der Tabellenanalyse als auch in der partiellen Korrelation braucht man sich nicht auf die Kontrolle eines Drittfaktors zu beschränken, sondern kann mehrere „Dritt“-Faktoren gleichzeitig kontrollieren. Als Alternative zur Tabellenanalyse kann man die Regressionsanalyse verwenden – bei nominalem oder ordinalem Messniveau wird die Regression mit Dummyvariablen als Repräsentanten von Merkmalsausprägungen ausgeführt. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 237 In der multiplen Regressionsanalyse wird eine metrische abhängige Variable (Prädikand) durch zwei oder mehr metrische unabhängige Variablen (Prädiktoren) statistisch erklärt. Die Pfadanalyse besteht in der mehrfachen Anwendung der Regression, indem mit jeder Variablen eine Regression auf alle Variablen durchgeführt wird, die dieser Variablen kausal vorangehen. Es muss also eine kausale Ordnung der Variablen für das Verfahren vorgegeben werden. Nicht-rekursive Modelle lassen in Erweiterung der Pfadanalyse auch Wechselwirkungen zwischen Variablen zu. In der Varianzanalyse wird die Streuung der abhängigen metrischen Variablen in Bestandteile zerlegt, die der Variation der nominalen unabhängigen Variablen und ihrer Interaktionen zugerechnet werden können bzw. als unerklärter Rest interpretierbar sind. Die einfache Varianzanalyse, bei der eine unabhängige Variable als Prädiktor auftritt, ist ein Spezialfall der multiplen Regression mit Dummyvariablen als Prädiktoren, die mehrfache Varianzanalyse ist ein Spezialfall der multiplen Regression mit Interaktionstermen. Die „tree analysis“ entsteht durch mehrfache Anwendung der Varianzanalyse jeweils auf Dichotomien (= Variablen mit zwei Ausprägungen). Sie liefert eine Baumdarstellung, bei der die Varianz der abhängigen Variablen dadurch erklärt wird, dass sie nach der jeweils besten PrädiktorDichotomie zerlegt wird. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 238 Die Faktorenanalyse ist eine Art multiple Regression einer Vielzahl manifester (direkt beobachtbarer) Variablen auf wenige latente Dimensionen (= Faktoren). Auf diese Weise wird eine Vereinfachung der Struktur erzielt. Die Korrelationszusammenhänge zwischen mehreren Variablen werden ohne größeren Informationsverlust durch wenige Faktoren reproduziert. Da die gefundenen Faktoren i.d.R. hypothetische sind, kann an sie die Forderung der statistischen Unabhängigkeit (Orthogonalität) gestellt werden. Eine bessere inhaltliche Interpretation der Faktoren erfordert jedoch oftmals oblique (nicht orthogonale) Faktoren. Die Faktorenanalyse dient u.a. der graphischen Darstellung von Zusammenhangsstrukturen. Ein wichtiger Aspekt ist dabei auch die Bestimmung der erforderlichen Anzahl von Dimensionen. Die kanonische Korrelation ist eine Verallgemeinerung der multiplen Regression (oder der Faktorenanalyse) auf zwei Mengen von Variablen: Aus jeder der beiden Variablenmengen werden diejenigen Linearkombinationen bestimmt, welche die maximale Korrelation liefern. Auf diese Weise soll der Zusammenhang von zwei Mengen von Variablen untersucht werden. Die Diskriminanzanalyse ist ein Klassifikationsverfahren, bei dem die Zuordnung von Fällen oder Variablen zu Gruppen mit Hilfe von Klassifikationsgleichungen für jede der Gruppen durchgeführt wird. Diese Gleichungen erhält Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 239 man mit Hilfe der Varianzanalyse. Die Fälle werden denjenigen Gruppen zugeordnet, für die sie die höchste Wahrscheinlichkeit haben. Die Variablen, mit denen die Gruppenzugehörigkeit vorhergesagt wird, haben metrisches Messniveau. Die Gruppenzugehörigkeit selbst ist die abhängige Variable und hat nominales Messniveau. Man kann die Diskriminanzanalyse auch als kanonische Korrelation der Ausgangsvariablen und der Variablen der Gruppeneinteilung behandeln. Ein Anwendungsgebiet ist z.B. die Analyse unterschiedlicher Wählergruppen nach soziodemographischen Merkmalen. Die multidimensionale Skalierung (MDS) liefert einen „smallest space“ zur Darstellung der Analyseeinheiten – ähnlich wie die Faktorenanalyse. In der multidimensionalen Skalierung liegt das Schwergewicht häufig auf der Konfiguration von Punkten für die Analyseeinheiten und der graphischen Darstellung der Konfiguration, in der Faktorenanalyse auf der Interpretation der Faktoren und ihrer Erklärungskraft. Im Gegensatz zur Faktorenanalyse braucht die Ausgangsinformation über Ähnlichkeitsmaße nur auf ordinalem Messniveau vorzuliegen und liefert dennoch metrische Ergebnisse. Die MDS dient u.a. zur Rekonstruktion von Wahrnehmungsräumen z.B. für Parteipräferenzen. Die Clusteranalyse ordnet die Analyseeinheiten ebenfalls aufgrund von Ähnlichkeitsmaßen in Gruppen. Sie kann unmittelbar ansetzen bei den Ähnlichkeitsmaßen oder von einer Konfiguration von Punkten für die Analyseeinheiten Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 240 ausgehen, wie sie eine vorhergehende Faktorenanalyse oder multidimensionale Skalierung liefert. Im Unterschied zur Faktorenanalyse wird nicht eine Bündelung von Variablen, sondern von Analyseeinheiten angestrebt. Der χ -Test zur Untersuchung des Zusammenhangs zweier nominaler Variablen mittels einer Kontingenztafel kann auf k (> 2) Variablen erweitert werden. Ferner kann die Varianzanalyse auch bei einer nominalen abhängigen Variablen (mit l Ausprägungen) angewendet werden, wenn man l - 1 Ausprägungen durch Dichotomien (= formal metrische Variablen) darstellt. Der erste Ansatz ermöglicht die Analyse von Zusammenhängen, der letztere von Abhängigkeiten. Da häufig mit logarithmierten Variablen gearbeitet wird, spricht man auch von log-linearen Modellen. 2 Mit Hilfe der Korrespondenzanalyse lassen sich die Zusammenhänge zwischen nicht-metrischen Merkmalen in einer graphischen Darstellung dadurch visualisieren, dass Unähnlichkeiten zwischen Verteilungen bzw. Profilen als Distanzen repräsentiert werden. Die Konfigurationsfrequenzanalyse verwendet die Kontingenztafel, um (über- oder unterproportional besetzte) Typen zu ermitteln. Man kann sie auch als spezielles Cluster-Verfahren ansehen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 241 Die „latent structure analysis“ sucht aufgrund dichotomer Information eine Entmischung in latente, zugrunde liegende Gruppen. Man kann die „latent structure analysis“ als eine Art Faktorenanalyse für Dichotomien ansehen, wovon wiederum die Guttman-Skalierung ein Spezialfall für ordinale Gruppeneinteilung ist. Als Entmischungsmodell ist sie ein spezieller Fall solcher Modelle, die auch in der Clusteranalyse eine Rolle spielen. Das Allgemeine Lineare Modell verbindet das lineare Kausalmodell mit einer Messfehlertheorie, die wie die Faktorenanalyse ansetzt: Die beobachteten Indikatoren werden als lineare Funktionen der zugrunde liegenden „wahren“ Dimensionen betrachtet. Es wird nicht die deterministische Faktorenanalyse verwendet, sondern die statistische Maximum-Likelihood-Faktorenanalyse. (Bei der Theorieüberprüfung handelt es sich um eine konfirmatorische Faktorenanalyse, ansonsten um eine explorative.) Die Abhängigkeiten unter den latenten Variablen stehen im Zentrum des Interesses, wobei die Faktorenanalyse das Messmodell für die latenten Konstrukte beiträgt. 1.2 Abhängigkeiten vs. Zusammenhänge (Asymmetrische und symmetrische Fragestellungen) Die Datenanalyseverfahren lassen sich zum größten Teil danach unterscheiden, ob sie Abhängigkeiten oder Zusammenhänge untersuchen. Dies ist in Abbildung 1 zusammenVeranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 242 gefasst. Das Schema umfasst auch die Beziehungen zwischen den Verfahren, die schon in den kurzen Charakterisierungen der Verfahren angesprochen worden sind. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 243 Abbildung 1-1: Zusammenhänge zwischen den multivariaten Analyseverfahren Multivariate Analyse Analyse von Abhängigkeiten (Asymmetrische Fragestellung) Multiple Regression (alles metrisch) Pfadanalyse, nicht-rekursive Modelle (zusätzliche Kausalannahmen) Analyse von Zusammenhängen (Symmetrische Fragestellung) Varianzanalyse (Prädiktoren nominal) tree analysis (Prädiktoren Dichotomien) Kontingenztafelanalyse (nominale Variablen) Loglineare Modelle Korrespondenzanalyse Faktorenanalyse (latente Variablen) Clusteranalyse Multidimensionale Skalierung (ordinale Ähnlichkeitsinformation) Kanonische Korrelation von zwei Mengen von Variablen Konfigurationsfrequenzanalyse Latent structure analysis (nominale Variablen) Diskriminanzanalyse Guttman-Skalierung (ordinale Gruppeneinteilung) Allgemeines lineares Modell Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 244 Diese Zuordnung ordnet drei Verfahren als Kombination beider Konzepte ein: Log-lineare Ansätze gibt es sowohl zur Analyse von Abhängigkeiten (wie die Varianzanalyse) als auch von Zusammenhängen (wie die Kontingenztafelanalyse). Die Diskriminanzanalyse ist eher ein Verfahren zur Untersuchung von Abhängigkeiten, wobei die (gesuchte) Gruppeneinteilung die abhängige Variable ist (bzw. Funktionen, die die Gruppen repräsentieren wie z.B. die Wähler einer bestimmten Partei). Die unabhängigen Variablen (z.B. sozialstrukturelle Merkmale von SPD-Wählern, CDUWählern etc.) dienen der Charakterisierung bzw. Vorhersage der verschiedenen Teilgruppen (z.B. Wählergruppen). Man kann eine Diskriminanzanalyse auch als kanonische Korrelation zwischen den Ausgangsvariablen und den Variablen für die Gruppeneinteilung (Dichotomien) durchführen. In diesem Sinne spielt auch der Aspekt der Analyse von Zusammenhängen eine Rolle. Das allgemeine lineare Modell ist eher ein Modell zur Analyse von Abhängigkeiten. Der Aspekt der Gleichbehandlung von Variablen (d.h. nicht nach abhängig oder unabhängig zu unterscheiden) kommt nur durch die Faktorenanalyse herein, bei der jeweils mehrere Indikatoren eine Dimension repräsentieren. Die Beziehungen zwischen den Indikatoren werden in gleicher Weise benutzt, um diese latenten Variablen zu ermitteln. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 245 Allgemein stehen aber Abhängigkeiten und Zusammenhänge in einer engen Beziehung: So lässt sich aus der einfachen Regression (als Konzept der Abhängigkeit) der Korrelationskoeffizient (als Zusammenhangsmaß) ableiten. Die Analyse von Abhängigkeiten scheint mir deshalb tendenziell als Konzept ursprünglicher zu sein, ebenso wie empirische Phänomene der ersten Art mir tendenziell häufiger zu sein scheinen. Dass man die Faktorenanalyse unter die Verfahren zur Analyse von Zusammenhängen subsumiert, liegt daran, dass man bei den Indikatoren nicht zwischen abhängig und unabhängig unterscheiden kann. Letzteres aber ist darin begründet, dass die Indikatoren als kausal abhängig von den wahren Dimensionen (= Faktoren) angesehen werden. In diesem Sinne ist die Faktorenanalyse ein Verfahren zur Untersuchung von Abhängigkeiten. Bei diesem weiteren Begriff von Abhängigkeit würde im Wesentlichen nur das symmetrische Konzept der statistischen Unabhängigkeit als Verfahren zur Analyse von Zusammenhängen im strengen Sinne übrig bleiben. Eine scharfe Trennung in Verfahren zur Analyse von Abhängigkeiten und von Zusammenhängen ist also nicht immer möglich. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 246 1.3 Erforderliches Messniveau der Variablen 1) Alle Variablen sind metrisch. a) Multiple Regression; Pfadanalyse; nicht rekursive Modelle; Rozebooms Zusammenhangsmaß für n Variablen. b) Zusätzliche Verwendung von latenten Variablen: Faktorenanalyse; kanonische Korrelation; allgemeines lineares Modell. 2) Gemischt: Die Variablen müssen bei den folgenden Ansätzen nicht alle metrisch sein. a) Abhängige Variable metrisch: Varianzanalyse (unabhängige Variablen nominal); tree analysis (unabhängige Variablen Dichotomien). b) Diskriminanzanalyse: Die eigentliche abhängige Variable, die Gruppeneinteilung, ist nominal; bei der Klassifikation wird aber jede Gruppe durch eine metrische abhängige Variable vertreten; die Ausgangsvariablen sind metrisch. c) Clusteranalyse: Die Gruppeneinteilung (= nominal) wird bestimmt aufgrund von Ausgangsvariablen, die ein gleiches, aber beliebiges Messniveau haben. d) Multidimensionale Skalierung: Aus ordinaler Information über Ähnlichkeitsmaße wird metrische Information gewonnen. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 247 e) Guttman-Skalierung: Die latente ordinale Gruppeneinteilung wird aufgrund von dichotomer Information ermittelt. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 248 3) Alle Variablen sind nominal. a) Kontingenztafelanalyse; log-lineare Modelle; Konfigurationsfrequenzanalyse. b) Zusätzliche Verwendung von latenten Variablen: Latent structure analysis (Die latente Gruppeneinteilung (nominal) wird aufgrund von dichotomer Information ermittelt.) Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 249 1.4 Charakterisierung einiger Verfahren durch Diagramme Multiple Regression Abbildung 1-2: Multiple Regression x1 ey x2 . . y xm (x 1,..., Xm = unabhängige Variablen; y = abhängige Variable; e y = error term (Fehlerterm), dem die nicht erklärte Varianz zugeschrieben wird.) Die Pfeile stehen für Einflussrichtungen. Die Varianzanalyse hat als Spezialfall der multiplen Regression den gleichen formalen Aufbau. Die logistische Regression hat die gleiche Struktur, aber die abhängige Variable ist dichotom und wird deshalb zuerst logarithmisch transformiert. Die Diskriminanzanalyse hat formal den gleichen Aufbau, wobei die abhängige Variable aber eine Gruppeneinteilung (nominales Merkmal) ist, die durch metrische Prädiktoren vorhergesagt wird. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 250 Pfadanalyse Abbildung 1-3: Pfadanalyse e2 x2 e3 x1 x3 Es handelt sich hier um eine Regression von x 2 auf x 1 und eine anschließende Regression von x3 auf x1 und x 2 . Nicht-rekursive Modelle Abbildung 1-4: Nicht-rekursive Modelle e2 x2 x1 x3 e3 Zwischen x 2 und x 3 gibt es eine Wechselwirkung. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 251 Faktorenanalyse Abbildung 1-5: Faktorenanalyse x1 F1 x2 F2 x3 Theoretische Ebene (Faktoren) Beobachtungsebene (Indikatoren) Die latenten Faktoren F i schlagen sich in den manifesten Indikatoren x j nieder. Kanonische Korrelation Abbildung 1-6: x1 y1 u1 v1 x2 y2 u2 y3 Kanonische Korrelation v2 x3 x4 (u 1, v 1) und (u 2, v 2) sind die ersten beiden Paare von kanonischen Faktoren. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 252 Allgemeines lineares Modell (z.B. LISREL oder AMOS) Abbildung 1-7: Allgemeines lineares Modell (z.B. LISREL) Regressions- und Pfadanalyse oder auch nicht-rekursive Modelle zwischen den theoretischen Konstrukten η1 ξ1 η2 ξ2 ξ3 Theoretische Ebene Konfirmatorische Faktorenanalyse als Messfehlertheorie für die unabhängigen theoretischen Konstrukte Beobachtungsebene (Indikatoren) x1 x2 x3 x4 x5 x6 x7 Konfirmatorische Faktorenanalyse als Messfehlertheorie für die abhängigen theoretischen Konstrukte x8 x9 x10 x11 x12 Aus beobachteten Variablen lässt sich nicht die Existenz nicht beobachteter, latenter Variablen ableiten. Es geht vielmehr um die Verträglichkeit von Modellen mit empirischen Daten. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 253 1.5 Gegenüberstellung der Logik der Verfahren der multiplen Regression, der Faktorenanalyse und der Varianzanalyse Variablen Modellansatz Multiple Regression y = β x + ... + β x Metrische Variablen; y, x i bekannt; eine abhängige β = BetaVariable y, Koeffizienten werden unabhängige bestimmt. Variablen x 1, Die x i können mitei..., xm. nander korrelieren. 1 1 m m i Interpretation Multiple R2 = Anteil der durch die Regression erklärten Varianz von y; r = Anteil der durch Prädiktor x i insgesamt erklärten Varianz von y; Anteil der von x i unabhängig von den anderen Prädiktoren erklärten Varianz ( = r , s.u.) 2 y , xi 2 y , x i − xˆ i Faktorenanalyse Metrische Z i = a i1 F 1 + ... a im F m Variablen; + diUi gleichgestellte Die Zi , i = 1, ..., n, Variablen Z1 , sind bekannt; die Faktoren F j, U i ..., Z n (= Indikatoren) werden dadurch charakterisiert, dass die Ladungen aij bestimmt werden. Die Faktoren F j, U i sind untereinander unkorreliert. = Anteil der Varianz von z i, der durch Faktor F j erklärt wird; d = Anteil der Restvarianz; ∑ a = Anteil der aij2 2 i n i =1 2 ij Varianzen von Z1 , ..., Z n, der durch den Faktor F j erklärt wird. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 254 Varianzanalyse Eine metrische Streuungszerlegung abhängige m = 1 (einfache Variable y, m Varianzanalyse): nominale ss y = ss A + ss error unabhängige ( y −µ =α +ε ) Variablen A, B, m = 2 (zweifache ... Varianzanalyse): m = 1: Einfa- ss y = ss A + ss B + che Variss AB + ss error , falls anzanalyse A und B statistisch m = 2: Zweifa- unabhängig sind. che Varianzanalyse, etc. ij i R2 = ss A = ss y Anteil der Varianz von y, die durch A erklärt wird. ij ss y − ss error ss y = Anteil der Varianz von y, die durch A und B insgesamt erklärt wird. ss AB ss y = Anteil der Varianz von y, die durch Interaktion von A und B erklärt wird. ss B ss y = Anteil der Varianz von y, die durch B erklärt wird (für A entsprechend). Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 255 1.6 Bewertung Die multiple lineare Regression dürfte das wichtigste Datenanalyseverfahren sein. Das bei der Regressionsanalyse benutzte Konzept der kleinsten Quadrate, um den Fehler einer linearen Schätzung zu messen, ist auch Ausgangspunkt verschiedener anderer Verfahren. Ein zweites grundlegendes Konzept ist die Faktorenanalyse, die eine Regression auf latente, zugrunde liegende Faktoren ist. Multiple Regression Korrelierte Regressoren Beobachtete Regressoren Faktorenanalyse Unkorrelierte Faktoren Latente Faktoren Während die multiple Regression eine möglichst gute Erklärung der Struktur des Zusammenhangs einer beobachteten abhängigen Variablen mit beobachteten unabhängigen Variablen anstrebt, werden in der Faktorenanalyse nicht beobachtete Dimensionen gesucht, die die beobachteten Daten möglichst gut im statistischen Sinne erklären sollen. Da die Faktoren einerseits ein „künstliches Produkt“ sind, insofern sie ja nicht einfach beobachtet werden, kann man andererseits solche Faktoren suchen, die besonders wünschenswerte Eigenschaften haben. Unter dem Gesichtspunkt einer möglichst einfachen Darstellung der Daten strebt man deshalb (i.a.) unkorrelierte Faktoren an. Die beiden Aspekte hängen also zusammen: Weil es sich um Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 256 „Kunstprodukte“ handelt, kann man von ihnen gewünschte Eigenschaften verlangen. Empirisch beobachtete Variablen, über die man in der Regressionsanalyse nicht hinausgeht, korrelieren dagegen in der Regel. Als drittes grundlegendes Konzept ist die Varianzanalyse zu nennen. Konzeptuell ist sie in ihrer einfachsten Form Bestandteil der multiplen Regressionsanalyse und allgemein ein Spezialfall der multiplen Regressionsanalyse für nominale unabhängige Variablen. Es handelt sich aber keineswegs um einen einfachen Spezialfall, da in der Varianzanalyse in der Regel Interaktionen untersucht werden1, was schon eine Regressionsanalyse mit mindestens zwei verschiedenen Prädiktor-Mengen und deren Interaktionstermen beinhaltet. Die meisten anderen Verfahren sind abgeleitet aus diesen drei grundlegenden Konzepten (vgl. Abbildung 1-8). 1 Man sollte nicht dem Verfahren überlassen, ob man Interaktionen untersucht. Dies lässt sich z.B. auch in der Regressionsanalyse berücksichtigen, dort aber ist es viel weniger verbreitet als in der Varianzanalyse, wo dies „automatisch“ geschieht. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 257 Abbildung 1-8: Multiple Regression, Faktorenanalyse und Varianzanalyse als grundlegende Konzepte Faktorenanalyse Multiple Regression Varianzanalyse Kanonische Korrelation Logistische Regression Diskriminanzanalyse Pfadanalyse Nicht-rekursive Modelle Tree analysis Multidimensionale Skalierung Log-lineare Modelle Allgemeines lineares Modell Die multiple Regression, Varianzanalyse und Faktorenanalyse sowie die kanonische Korrelation und Diskriminanzanalyse würde ich als „klassische“ Datenanalyseverfahren bezeichnen. Relevante neuere Entwicklungen sind die loglinearen Modelle zur Analyse von Nominal-Daten, die logistische Regression, die multidimensionale Skalierung zur Analyse von Ordinal-Daten, die neuere Rezeption des (ansonsten älteren) Verfahrens der Pfadanalyse, die Entwicklung nicht-rekursiver Modelle und die Entwicklung des allgemeinen linearen Modells. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 258 Wie bereits in der Übersicht in Abbildung 1-1 dargestellt, ist auch die Analyse von Kontingenztafeln ein elementares Konzept. Die χ -Analyse für die Kontingenz von 2 Merkmalen gehört (nach der hier benutzten Definition: multivariat = Verwendung von mehr als zwei abhängigen/unabhängigen Variablen) noch nicht zur multivariaten Analyse. Die Erweiterung dieses Konzepts auf mehr als zwei Merkmale erlaubt Aussagen darüber, ob es signifikante Interaktionseffekte gibt. Obwohl die Analyse nominaler Daten in starker Entwicklung ist (vgl. das Jahrbuch „Sociological Methodology“ und die Zeitschrift „Sociological Methods and Research“), erscheinen mir die Analyse- und Interpretationsmöglichkeiten als weniger anschaulich als die metrischen Ansätze. Die neueren Entwicklungen der multidimensionalen Skalierung in Nachfolge der Faktorenanalyse findet man vor allem in der Zeitschrift „Psychometrika“. 2 Die Anschlussfähigkeit an die Theoriebildung in den Sozialwissenschaften versprechen vor allem die linearen Kausalmodelle zu leisten. Diese Modellierungen der Sozialwissenschaftler werden insbesondere auch von den Ökonometrikern verfolgt, wo die häufige Voraussetzung, dass es sich um metrische Variablen handelt, am unproblematischsten ist. Die fruchtbarsten Entwicklungen scheinen mir in der Weiterentwicklung pfadanalytischer Modelle mit beobachteten oder auch latenten Variablen zu liegen, da in diesen Modellierungen als Erklärung die Mechanismen von direkten und indirekten Kausalbeiträgen herausgearbeitet werden. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 259 1.7 Pragmatische Abgrenzung von grundlegenden und fortgeschrittenen multivariaten Modellen sowie Aufbau des vorliegenden Bandes Im Band zu den grundlegenden multivariaten Modellen werden Tabellenanalyse, multiple Regression, Pfadanalyse und Varianzanalyse (mit einer abhängigen Variablen und mehreren unabhängigen Variablen) als grundlegende Modelle behandelt. Im folgenden Band werden die „fortgeschrittenen“ multivariaten Modelle dargestellt und diskutiert. Pragmatisch als „fortgeschritten“ werden die Ansätze angesehen, zu deren Lösung man ein mathematisches Eigenwertproblem lösen muss und die deshalb hier gemeinsam behandelt werden: Faktorenanalyse, kanonische Korrelation sowie Diskriminanzanalyse und multivariate Varianzanalyse. Die log-linearen und verwandte Modelle für nichtmetrische Daten sind später entwickelt worden als die metrischen, was ein Hinweis auf ihre geringere Anschaulichkeit ist. Andererseits haben sie den Vorzug, geringere Anforderungen an das vorausgesetzte Messniveau zu stellen. Die Korrespondenzanalyse ist geeignet zur Analyse des Zusammenhangs von nicht-metrischen Daten, wobei an Grundüberlegungen der Faktorenanalyse angeknüpft wird. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 260 Schließlich sind Clusteranalyse, multidimensionale Skalierung und ähnliches i.a. zusätzliche Gesichtspunkte für die Analyse, weshalb sie in diesem Band ebenfalls in einem Kapitel behandelt werden. Die Mehrebenenanalyse und die Analyse zeitbezogener Daten beinhalten weitere vertiefende Analyseansätze. Der Mehrebenenanalyse liegt die Idee zu Grunde, eine abhängige Variable auf individueller Ebene durch Effekte auf verschiedenen Ebenen zu erklären. Die Analyse zeitabhängiger Daten bringt den Gesichtspunkt der Dynamik sozialen Wandels mit ein. Betrachten die vorangegangenen Kapitel eher statische Daten zu einem Zeitpunkt, stehen hier zeitliche Veränderungen im Mittelpunkt. Veranstaltung: Grundlegende multivariate Modelle der sozialwissenschaftlichen Datenanalyse Universität Potsdam - Prof. Dr. Dieter Holtmann 261