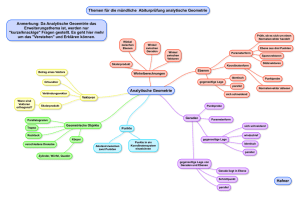
Analytische Datenbanken - IT
Werbung

Strategic Bulletin – März 2013 Analytische Datenbanken Trends in Data Warehousing und Analytik Eine Analyse von & Strategic Bulletin: Analytische Datenbanken Copyright Dieses Strategic Bulletin wurde vom Wolfgang Martin Team S.A.R.L. Martin und IT Research verfasst. Alle Daten und Informationen wurden mit größter Sorgfalt und mit wissenschaftlichen Methoden recherchiert und zusammengestellt. Eine Garantie in Bezug auf Vollständigkeit und Richtigkeit wird ausgeschlossen. Alle Rechte am Inhalt dieses Strategic Bulletin, auch die der Übersetzung, liegen bei dem Autor. Daten und Informationen bleiben intellektuelles Eigentum der S.A.R.L. Martin im Sinne des Datenschutzes. Kein Teil des Werkes darf in irgendeiner Form (Druck, Photokopie, Mikrofilm oder einem anderen Verfahren) ohne schriftliche Genehmigung durch die S.A.R.L. Martin und IT Research reproduziert oder unter Verwendung elektronischer Verfahren verarbeitet, vervielfältigt oder verbreitet werden. Die S.A.R.L. Martin und IT Research übernehmen keinerlei Haftung für eventuelle aus dem Gebrauch resultierende Schäden. © Copyright 2013 S.A.R.L. Martin, Annecy, und IT Research, Aying Disclaimer Die Wiedergabe von Gebrauchsnamen, Handelsnamen, Warenbezeichnungen etc. in diesem Werk berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Warenzeichen- und Markenschutz-Gesetzgebung als frei zu betrachten wären und daher von jedermann benutzt werden dürften. In diesem Werk gemachte Referenzen zu irgendeinem spezifischen kommerziellen Produkt, Prozess oder Dienst durch Markenname, Handelsmarke, Herstellerbezeichnung etc. bedeutet in keiner Weise eine Empfehlung oder Bevorzugung durch die S.A.R.L. Martin und IT Research. Gastbeiträge in diesem Strategic Bulletin sind freie Meinungsäußerungen der Sponsoren und geben nicht unbedingt die Meinung des Herausgebers wieder. Titelbild: © Shutterstock.com/agsandrew ISBN 3-936052-40-9 © S.A.R.L. Martin/IT Research März 2013 2 Titel Inhalt Strategic Bulletin: Analytische Datenbanken Inhaltsverzeichnis 1. Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2. Analytische Datenbanken – Einführung in das Thema . . . . . . . . . . . . . . . . . . . . . 6 2.1 Analytische Datenbanken – die Definition und die Treiber . . . . . . . . . . . . . . . . . . 6 2.2 Nutzenpotenziale analytischer Datenbanken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.3 Analytische Datenbanken – Markttrends . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 3. Analytischer Datenbanken – Technologien, Architekturen und Positionierung 10 3.1 Technologien analytischer Datenbanken. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 3.2 NoSQL-Technologien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 3.3 Analytik – Online versus Offline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 3.4 Big Data: Datenstrukturen und Latenz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 3.5 Information Management im Big Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 4. Analytische Datenbanken: Roadmap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 4.1 Klassifikation der Anbieter von analytischen Datenbanken . . . . . . . . . . . . . . . . 23 4.2 Klassifikation der Anbieter von Information Management . . . . . . . . . . . . . . . . . 24 4.3 Die Datenvielfalt meistern – Gastbeitrag von Datawatch . . . . . . . . . . . . . . . . . . 25 4.4 Erst Analytics macht aus Big Data Big Business – Gastbeitrag von InterSystems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 4.5 Big Data und die Datenbankstrategie der Zukunft – Gastbeitrag von SAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 4.6 Herausforderungen an Analytik und den Umgang mit analytischen Datenbanken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 5. Big Data-Analytik – Quo Vadis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 Realität – 2013 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 Trends – 2014/15 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 6. Profil: Wolfgang Martin Team und IT Research . . . . . . . . . . . . . . . . . . . . . . . . . . 33 7. Profil: Die Sponsoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 Datawatch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 InterSystems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 SAP AG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 © S.A.R.L. Martin/IT Research März 2013 3 Titel Strategic Bulletin: Analytische Datenbanken 1. Zusammenfassung “In the Age of Analytics, as products and services become ‘lighter’ (i.e., less physical and more digital), manufacturing and distribution costs – while still important – will be augmented with new metrics – the costs of know, the flow of know, and the costs of not knowing.” Thornton May [1], Futurist, Executive Director, and Dean of the IT Leadership Academy Analytische Datenbanken – Definition und Treiber Ein Unternehmen verfügt bereits über große Mengen strukturierter (in der Regel rund 20 % aller Unternehmensdaten) und poly-strukturierter Daten (die machen rund 80% aller Unternehmensdaten aus) wie Dokumente, Verträge, Protokolle, E-Mail, Podcasts, Videos end andere. Eine Flut von Daten wartet bekanntlich im Web auf uns. Und noch mehr Daten liefert und das Internet der Dinge: Hier konvergieren Internet und die reale Welt. Nicht nur mobile Telefone, Smartphones und Tablets gehören hier dazu, sondern Geräte aller Art wie Sensoren, Smart Meter, Home Entertainment bis hin zu selbstfahrenden Autos. Das alles fasst man heute unter dem Begriff Big Data zusammen. Es sind Daten aller Art über Konsum, Verhalten und Vorlieben, Orte und Bewegungen, Gesundheitszustand und viele andere Dinge. Analytik wird deshalb immer wichtiger für Unternehmen in allen Branchen, denn der Einsatz von Analytik schafft Wettbewerbsvorteile und vermeidet Risiken durch ein besseres und tieferes Wissen über Markt und Kunden. Analytik treibt daher auch den Einsatz innovativer Technologien, um diese Petabytes, sogar Exabytes von Daten auswerten zu können, da durch die schiere Menge an Daten die bisher im Markt dominierenden relationalen Datenbanksysteme an ihre Grenzen stoßen: Es etablieren sich so „Analytische Datenbanken“ und „NoSQL-Datenhaltungssysteme“ [2], die innovative Algorithmen zum Zugriff- und Speicher-Management mit innovativen Ansätzen wie Spalten-Orientierung und innovativer Hardware-Technologie wie In-MemoryVerarbeitung miteinander verbinden. Technologien analytischer Datenbanken In Folge dieser Datenflut braucht man für Analytik neue Technologien, die die Grenzen traditioneller relationaler Datenhaltung überwinden. Relationale Datenhaltungssysteme waren auf Transaktionsverarbeitung und -Sicherheit ausgerichtet. Analytische Datenbanken sind konzipiert für ein schnelles Lesen, wobei aber gemäß Brewers CAPTheorem Kompromisse mit der Sicherheit und Zuverlässigkeit von Transaktionsverarbeitung gemacht werden müssen. Die Methoden und Technologien, mit denen man ein schnelles Lesen erreichen kann sind vielfältig. In der Tat setzt man bei den verschiedenen analytischen Datenbanken auch verschiedene dieser Methoden und Technologien ein, die sich auch miteinander kombinieren lassen: Spaltenorientierung, Kompression, Parallelisierung, In-Memory-Verarbeitung sowie Bündelungen von Hardware und Software („Data Appliances“). Analytische Datenbanken – Nutzen Das erlaubt einerseits Analytik in Echtzeit: Große, sogar sehr große Datenmengen können im Sekundenbereich analysiert werden. Früher haben solche Analysen Stunden bis hin zu Tagen benötigt. Andererseits wird so auch Echtzeitanalytik ermöglicht. So werden operative Prozesse im Unternehmen wie Kundeninteraktionen, Produktion, Logistik etc. jetzt in Echtzeit („online“) steuerbar. Mittels operativer Kennzahlen erreicht man Automation, also schnelleren Durchsatz, weniger Fehler und bessere, individualisierte Prozesse. Hierzu sind insbesondere In-Memory Datenbanken geeignet, die analytische und transaktionale Daten gemeinsam verwalten. So lösen analytische Datenbanken die Probleme, mit denen die Kunden heute in der Analytik mit großen und sehr großen Datenmengen kämpfen: Performance, Skalierbarkeit und Kosten. Die Vorteile sind: Information ist flexibler abrufbar und steht bis zu 100mal schneller oder sogar noch schneller zur Verfügung. Die Nutzerzufriedenheit erhöht sich signifikant aufgrund des schnelleren und flexibleren Zugriffs auf Information. Es können jetzt Daten analysiert werden, die vorher ohne Nutzen, aber mit Kosten gespeichert wurden. Das unterstützt und schafft besse[1] Thornton May: „The New Know“, Innovation Powered by Analytics, 2009 [2] NoSQL = not only SQL, SQL = sequential query Language. © S.A.R.L. Martin/IT Research März 2013 4 Inhalt Strategic Bulletin: Analytische Datenbanken re Entscheidungen. Und schließlich wird die IT entlastet, da analytische Datenbanken hoch automatisiert sind und ein spezielles Wissen über Datenbankdesign und Tuning deutlich weniger gefragt ist. Analytische Datenbanken – Quo Vadis Natürlich darf man nicht die Kritik an Analytik vernachlässigen, denn ein mehr an Information bedeutet nicht unbedingt gleichzeitig bessere Information. Auch macht die Quellenvielfalt Probleme, was die Vergleichbarkeit der Daten angeht, denn unterschiedliche Quellen erzeugen durchaus auch Daten in unterschiedlicher Qualität und Beschaffenheit. Für den Statistiker erhebt sich dann auch noch die Frage, ob und wie Information aus dem Big Data überhaupt repräsentativ sein kann. Es gibt noch ein weiteres Problem: Um Analytik anwenden und verstehen zu können, braucht man analytische geschulte Manager und Mitarbeiter. Tom Davenport [3] geht sogar so weit, dass er im Fehlen von ausreichend analytisch geschulten Mitarbeitern einen der Gründe für die anhaltende Finanz- und Schuldenkrise sieht: Alle Finanzund Handelssysteme sind automatisiert und analytisch auf dem höchsten Stand, aber es fehlten die Mitarbeiter, die in der Lage waren (und sind), all die Metriken und analytischen Ergebnisse und Vorhersagen zu verfolgen, zu interpretieren und dem Management richtig zu erklären. In der Big Data-Analytik fehlt es ebenfalls an ausreichend geschulten Mitarbeitern: Data Scientists sind heute im Markt nur schwer zu finden. Hier ist noch eine große Aufgabe zu lösen, die uns noch einige Zeit beschäftigen wird. [3] Siehe: Henschen, D.: Analytics at Work, Q&A with Tom Davenport (Interview), InformationWeek Software, 04. Januar 2010. © S.A.R.L. Martin/IT Research März 2013 5 Inhalt Strategic Bulletin: Analytische Datenbanken 2. Analytische Datenbanken – Einführung in das Thema 2.1 Analytische Datenbanken – die Definition und die Treiber Analytische Datenbanken sind nicht neu. Es gibt sie schon seit rund 20 Jahren: Datenbanktechnologien, die darauf ausgelegt sind, riesige Bestände strukturierter Daten bei gleichzeitig hoher Anzahl von Abfragen durch viele bis sehr viele Nutzer in Sekundenschnelle zu analysieren. Aber erst heute finden sie wirkliche Beachtung. Der Einsatz solcher analytischen Datenbanken, wie sie jetzt genannt werden, nimmt zu, Tendenz steigend. Denn in den Unternehmen wächst die Nachfrage nach Analytik. Der Bedarf an Analytik ist insbesondere im Marketing hoch, wenn es um die Steigerung der Kundenprofitabilität durch Echtzeit-Kunden-Identifizierung und intelligente KundenInteraktionen geht. In der Supply Chain geht es um Prozess-Optimierung durch bessere Planung sowie um Identifizierung und Vermeidung von Risiken. Auf der Ebene der Unternehmenssteuerung geht es um rechtzeitiges Erkennen von Markttrends und von Innovationspotenzialen. Analytik durchdringt alle Unternehmensbereiche. Dazu kommt, dass wir auf dem Weg in die totale Digitalisierung der Welt sind. Reale und virtuelle Welt konvergieren. Das „Internet der Dinge“ wird mehr um mehr zur Realität: Geräte und Rechner verschmelzen miteinander. Das sieht man gerade sehr deutlich in der Branche der Versorger, wo „Smart Meter“ Verbrauchs- und Nutzungsdaten im Sekundentakt liefern können. Das sieht man auch in der Automobilindustrie: In Autos eingebettete Software nimmt nicht nur zu, sondern kontrolliert mehr und mehr das Fahrzeug bis hin zu ersten selbstfahrenden und lenkenden Autos. Das alles bedeutet: mehr und mehr Daten, Big Data (siehe auch Martin, Strategic Bulletin „Big Data“, 2012) wie man auch sagt. Big Data ist durch riesige Datenvolumen, große Datenvielfalt aus unterschiedlichsten Quellen und hohe Produktionsrate von Daten gekennzeichnet. Beispiel: Der Handel war immer eine der Branchen, in der Analytik Priorität hatte und die produzierten und vorhandenen Datenbestände ein großes bis sehr großes Volumen hatten, beispielsweise die Kassenbon-Daten. Die Analyse von Kassenbons bringt ein für den Handel entscheidendes Wissen über das Kundenverhalten, so dass kundenbezogene Prozesse personalisiert und optimiert werden können. Das steigert nachweislich die Kundenprofitabilität. Hier hatte man es schon lange mit Big Data zu tun, ohne dass man es so genannt hat. Um nämlich die Kundenprofitabilität steigern zu können, braucht man nicht nur die durchschnittliche Profitabilität eines Kunden über alle Produkte, sondern insbesondere die Kundenprofitabilität pro Produkt. Das ist eine wichtige Kennzahl zur Steuerung von personalisierten Kampagnen und Echtzeit-Produktempfehlungen, also eine im analytischen CRM typische Kennzahl im Handel für die Outbound- und Inbound-Kundenkommunikation. Das Ausrechnen dieser Kennzahlen übersteigt aber die Fähigkeit traditioneller relationaler Datenbanksysteme. Erst mit Hilfe analytischer Datenbanken lässt sich die Aufgabe lösen. Sie verkürzen die Rechenzeit, die beim Einsatz traditioneller Datenbanken einen oder mehrere Tage dauern konnte, auf einige Minuten oder liefern sogar Ergebnisse in Sekundengeschwindigkeit. Die Treiber für analytische Datenbanken sind also einerseits der gestiegene Bedarf an Analytik im Unternehmen und zum anderen, ein Datenvolumen das schneller steigt als die Leistung von traditionellen Datenbanken. Man schaffte es einfach nicht mehr, Daten im Detail zu analysieren, da es schlichtweg gesagt mit traditionelle Datenbanktechnologien zu lange dauerte. Gartner sagt bereits 2010 in seinem Bericht zum Magic Quadrat for Data Warehouse Database Management Systems: „Gartner-Klienten stehen bei der Abfrage von Data Warehouses immer häufiger vor erheblichen Performanceproblemen. Auf Grundlage dieser Informationen dürften rund 70 % aller Data Warehouses mit derartigen Problemen zu kämpfen haben.“ Definition: Analytische Datenbanken verbessern die Skalierbarkeit und die Performance von analytischen Datenbank-Abfragen deutlich gegenüber traditionellen Datenbanken. Zusätzlich helfen sie auch, die Betriebskosten zu senken. Das beruht auf der Kombination von bekannten und neuen Technologien wie Spaltenorientierung, Komprimierung, speziellen, intelligenten Zugriffsverfahren, massiv paralleler Verarbeitung sowie In-Memory-Technologien. © S.A.R.L. Martin/IT Research März 2013 6 Inhalt Strategic Bulletin: Analytische Datenbanken Diese Technologien, die analytische Datenbanken auszeichnen, wollen wir im Folgenden untersuchen. Vorher diskutieren wir aber noch die Nutzenpotenziale und Markttrends. 2.2 Nutzenpotenziale analytischer Datenbanken Analytische Datenbanken verbessern nicht nur die Analytik im Unternehmen durch eine höhere Geschwindigkeit, sondern erlauben auch den Einsatz von Analytik in Fragestellungen, die man aufgrund der notwendigen und teuren Rechenzeiten bisher nicht angehen konnte. Dadurch verbessern sie den bekannten Nutzen von Analytik wie Umsatzsteigerung, Kosteneinsparung, Erhöhung der Wettbewerbsfähigkeit und neue, innovative Geschäftsmodelle. Wenn man sich das etwas genauer anschaut, dann lassen sich fünf Nutzenpotenziale erkennen. 1. Transparenz. Hier bietet der Einsatz von Analytik in Netzwerken ein gutes Beispiel. In der Telekommunikationsbranche möchte man beispielsweise zur Optimierung von Verkehrs-Mustern das Anrufnetzwerk oder das Roaming-Verhalten von Anrufern analysieren. Dazu gilt es unter anderem, mögliche unsichere Pfade zu meiden, die Anzahl der Netzwerkwechsel beim Roaming zu reduzieren sowie Roaming-Muster zu optimieren, um Leistungsverträge einzuhalten. Ähnliche Aufgaben stellen sich auch für andere Anbieter, die Netzwerke in der Transport-, IT-, oder Energie- und Wasser-Versorgungsbranche betreiben. Um von diesem Nutzenaspekt zu profitieren, muss das „Silo-Denken“ in den Unternehmen allerdings endlich aufhören. Das Sammeln von Fachabteilungs-bezogenen Daten ist nicht ausreichend, um Kunden- und Marktwissen durch Analytik aufzubauen. Im Finanzwesen ist es immer noch üblich, Daten über die Finanzmärkte, über den Zahlungsverkehr und das Kreditwesen getrennt zu halten und nicht über Abteilungsgrenzen hinweg zu nutzen. Das hindert den Aufbau kohärenter Kundensichten und das Verstehen der Beziehungen und Beeinflussungen zwischen Finanzmärkten. 2. Erfolgskontrolle von Maßnahmen. Auf der Basis der Analysegeschwindigkeit, die mittels analytischer Datenbanken erreicht werden können, und neuen Datenquellen aus Big Data wie Lokalisierungsdaten im mobilen Internet, bieten sich neue Möglichkeiten, getroffene Maßnahmen auf ihre Wirksamkeit hin zu kontrollieren und mittels kontrollierter Experimente Hypothesen zu testen. Das erlaubt, Entscheidungen und Maßnahmen auf Basis von Fakten zu überprüfen und gegebenenfalls weiter anzupassen. So lassen sich auch Ursache-Wirkungsbeziehungen von reinen Korrelationen unterscheiden. Internet-Unternehmen wie Amazon und eBay waren mit bei den ersten, die solche kontrollierten Experimente nutzten, um die Konversionsraten von Besuchern ihrer Webseiten zu steigern. Dazu wurden gezielt bestimmte Funktionen und Verbindungen auf Webseiten geändert und die Wirkung entsprechend gemessen. So konnten die Faktoren ermittelt werden, die die Konversionsraten steigern. Mittels Lokalisierungsdaten aus dem mobilen Internet kann dieses Konzept aus der Webanalyse in die reale Welt übertragen werden. Jetzt kann beispielsweise die Wirkung von Außenwerbung bezogen auf den Standort gemessen und entsprechend optimiert werden. Das wird durch die Klickraten auf den QR-Codes auf Werbeflächen ermöglicht. So lässt sich durch Big Data-Analytik auch ein cross-mediales Marketing aufbauen. Weiter lassen sich Video-Aufzeichnungen von Kundenbewegungen in Kombination mit Kundeninteraktionen und Bestellmustern, die sich in Transaktionsdaten verbergen, zur Kontrolle von Marketing-Maßnahmen nutzen: So können Änderungen in Produkt-Portfolios und Platzierungen sowie Preisänderungen kontinuierlich und gezielt überprüft und optimiert werden. Daraus folgt eine Kosteneinsparung durch mögliche Reduktionen des Produktangebots ohne Risiko des Verlustes von Marktanteilen und sowie eine Steigerung der Marge durch den Verkauf höherwertiger Produkte. 3. Personalisierung in Echtzeit. Kunden- und Marktsegmentierung hat eine lange Tradition. Jetzt gibt es mit analytischen Datenbanken völlig neue Möglichkeiten durch Echtzeit-Personalisierung von Kundeninteraktionen. Im © S.A.R.L. Martin/IT Research März 2013 7 Inhalt Strategic Bulletin: Analytische Datenbanken Handel kennen wir solche Strategien bereits von Vorreitern wie Amazon und eBay, wo uns auf unser Profil zugeschnittene Produkte angeboten werden, und inzwischen auch von sozialen Netzen, wo uns Freundschaften vorgeschlagen werden. Natürlich profitiert man auch in anderen Branchen von solchen personalisierten Kundeninteraktionen, beispielsweise im Versicherungswesen. Hier können Versicherungspolicen auf den Kunden individuell zugeschnitten werden. Als Datenbasis dazu dienen kontinuierlich angepasste Profile der Kundenrisiken, Änderungen in der Vermögenslage oder auch Lokalisierungsdaten. Kraftfahrzeuge können mit speziellen Sendern ausgerüstet werden, so dass sie über eine Lokalisierung im Falle eines Diebstahls wiedergefunden werden können. 4. Prozess-Steuerung und Automation. Analytische Datenbanken erweitern den Einsatz von Analytik zur ProzessSteuerung und Automation. So können Sensor-Daten von Produktionsstraßen zur Autoregulierung von Produktionsprozessen genutzt werden. Damit lassen sich Kosteneinsparungen durch optimalen Materialeinsatz und durch Vermeidung von menschlichen Eingriffen erzielen, wobei gleichzeitig der Durchsatz erhöht werden kann. Proaktive Wartung ist ein anderes Einsatzgebiet. Maschinen können kontinuierlich über Sensoren überwacht werden, so dass auftretende Unregelmäßigkeiten sofort erkannt werden und rechtzeitig beseitigt werden können, bevor Schäden auftreten oder es zum Stillstand kommt. Andere Beispiele stammen aus der Konsumgüter-Branche. Getränke oder auch Speiseeis-Hersteller nutzen die täglichen Wettervorhersagen, um die eigenen Nachfrageplanungsprozesse an das aktuelle Wetter anzupassen. Dabei sind die Messdaten zur Temperatur, zur Niederschlagsmenge und zur täglichen Sonnenscheindauer entscheidend. Dieses Wissen erlaubt eine Prozessoptimierung durch die Verbesserung der Vorhersagewerte zwar nur um einige Prozent, aber das kann viel Geld bedeuten. 5. Innovative Informations-getriebene Geschäftsmodelle. Mit Hilfe analytischer Datenbanken wird Information nutzbar, die man früher nicht auswerten konnte, da der Nutzen möglicher Auswertungen die Kosten einer Auswertung nicht rechtfertigte. Das ist jetzt anders und so werden neue, innovative Geschäftsmodelle auf der Basis von Information möglich. Schauen wir uns als Beispiel die Information über Marktpreise an, die in den Zeiten des Internets und Internethandels in der Regel öffentlich verfügbar ist. Das erlaubt den Internet- und anderen Händlern die Preise des Mitbewerb zu überwachen und rechtzeitig auf Preisänderungen zu reagieren. Das erlaubt aber auch den Kunden, sich über die Preise zu informieren und so den besten Preis für ein gewünschtes Produkt zu erzielen. Darauf haben sich einige Anbieter spezialisiert, die über Konsolidierung, Aggregieren und Analyse von Preisinformation ihr eigenes Geschäftsmodell gefunden haben. Das gilt nicht nur im Handel, sondern auch im Gesundheitswesen, wo durch solche Informations-Anbieter Behandlungskosten transparent gemacht werden. 2.3 Analytische Datenbanken – Markttrends Die vier IT-Megatrends 2013 sind zweifellos Mobile, Cloud, Social und Big Data. Interessanterweise sind diese vier Trends miteinander verwoben, und alle vier bewirken eine weiter steigende Nachfrage nach analytischen Datenbanken. Das mobile Internet produziert Daten in großem Volumen und mit großer Geschwindigkeit, Big Data eben. Zum einen werden Lokalisierungs- und Navigations-Daten produziert. Im mobilen Internet konvergieren Zeit, Raum und Information: Man weiß heute exakt und genau, wo und zu welcher Zeit sich ein Kunde, eine Ware oder ein beliebiges Gerät sich befindet. Jedes Smartphone ist so Produzent von Daten. Zum anderen schafft die Konvergenz von Zeit, Raum und Information darüber hinaus eine neue Welt: Das Internet der Dinge. Wesentliche Elemente des IoT, die in einer Vielzahl von mobilen Geräten enthalten sein werden, sind Smart Meter und eingebettete Sensoren, Bilderkennungstechniken und die Bezahlung über NFC (Near-field Communication). Im Endergebnis wird der Begriff mobil sich nicht mehr ausschließlich auf Mobiltelefone oder Tablets beschränken und Mobilfunktechnik nicht mehr ausschließlich auf Mobilfunknetze. Die Kommunikation wird auch über NFC, Bluetooth, LTE und WLAN ablaufen und schon bald in viele neue Geräte integriert werden, beispielsweise in Displays von Armbanduhren, me- © S.A.R.L. Martin/IT Research März 2013 8 Inhalt Strategic Bulletin: Analytische Datenbanken dizinischen Sensoren, intelligenten Plakaten, Home-Entertainment-Systemen und in Autos. So werden schließlich noch mehr Daten produziert. Mobil treibt auch die Cloud, denn das mobile Internet arbeitet nach dem Prinzip des Cloud Computings. Jede App, die wir nutzen, arbeitet so. Cloud Computing ist auch mit Big Data eng verbunden, denn Cloud Computing ist ein IT-Bereitstellungsmodell, das aufgrund der Elastizität, Flexibilität und von Kostenvorteilen bestens Anforderungen von Big Data und Big Data-Analytik erfüllt. Viele Anbieter von analytischen Datenbanken bieten heute schon ein DWaaS (Data Warehouse as a Service). Wir können davon ausgehen, dass dieser Trend sich weiter verstärken wird. Mobil treibt auch Social, denn Social funktioniert eben dann am besten, wenn jeder immer und überall zu erreichen ist. Social wiederum treibt Big Data, denn jetzt haben wir in den sozialen Medien noch mehr und auch komplett neue Daten, beispielsweise Information über die Beziehungen zwischen Personen. Big Data hat damit seinen Platz unter den unverzichtbaren Kompetenzen eines Unternehmens. Die Masse an digitalen Inhalten ist 2012 auf 2,7 Zettabyte (ZB) gestiegen, ein Zuwachs um 48 Prozent im Vergleich zu 2011. Über 90 Prozent dieser Information sind unstrukturierte Daten (wie Photos, Videos, Audios und Daten aus den sozialen Netze und dem Internet der Dinge). Diese stecken voller reichhaltiger Information, und die Unternehmen sind mehr und mehr daran interessiert, aus Big Data wertvolle Erkenntnisse zu gewinnen. Damit können wir davon ausgehen, dass sich analytische Technologien wie analytische Datenbanken zum Mainstream entwickeln. Big Data bedeutet ja nicht nur große Datenvolumen, sondern auch Datenproduktion in großer Geschwindigkeit. Das treibt Echtzeitanalytik. Die ist nicht nur erfolgreich in der Kundenkommunikation, sondern geradezu essentiell im Internet der Dinge. Echtzeitanalytik im Internet der Dinge erlaubt die Anwendung von maschinellem Lernen. Algorithmen zum Selbst-Lernen, Selbst-Heilen und Selbst-Adjustieren dienen der Automation von Prozessen, steigern die Produktivität und senken Kosten und Risiken. Ein gutes Beispiel steht recht nahe an der Schwelle zur Wirklichkeit: Das führerlose, selbstfahrende Auto. Eine der wesentlichen technischen Voraussetzungen dazu ist In-Memory Computing, denn auf die Rechnerleistung kommt es hier an. Das stellt ein weiteres, riesiges Feld für analytische Datenbanken dar. Fazit Kapitel 2: Analytische Datenbanken – Treiber, Nutzen und Markttrends: • Die Treiber des Markts für analytische Datenbanken sind ein gestiegener und weiter steigender Bedarf an Analytik im Unternehmen und eine Datenproduktion, die schneller steigt als die Leistung traditioneller Datenbanken. • Die Nutzenpotenziale analytischer Datenbanken zielen auf die Bottom Line: Durch die bisher nie erreichte Geschwindigkeit von Analysen ergeben sich Kosteneinsparungen, Umsatzsteigerungen, Risikovermeidung, Erhöhung der Wettbewerbsfähigkeit und innovative Geschäftsprozesse und Modelle. • Die vier IT-Megatrends (Mobile, Cloud, Social, Big Data) bedingen sich untereinander und treiben so den Bedarf an analytischen Technologien wie analytischen Datenbanken. Damit werden analytische Datenbanken Mainstream-Produkte. Unternehmen sollten den Markt für analytische Datenbanken beobachten, um nicht den Anschluss zu verlieren. Es empfiehlt sich, Nutzenpotenziale für das Unternehmen jetzt zu identifizieren und in Abhängigkeit von einer solchen Analyse erste Piloten zu starten. Anbieter sollten eine glaubwürdige Position aufbauen und eine Roadmap, die klar erkennbare Werte bietet und die notwendige Flexibilität, um im Analytik-Markt zu prosperieren. © S.A.R.L. Martin/IT Research März 2013 9 Inhalt Strategic Bulletin: Analytische Datenbanken 3. Analytische Datenbanken – Technologien, Architekturen und Positionierung 3.1 Technologien analytischer Datenbanken. Analytische Datenbanken sind auf ein schnelles Lesen von Daten ausgerichtet, während die traditionellen relationalen Datenbanken auf Transaktionsverarbeitung hin ausgerichtet sind. Die Traditionellen Datenbanken sind exzellent, wenn es um den Zugriff auf den einzelnen Datensatz geht, aber bei einer Selektion von Gruppen sind die auf das Lesen optimierten analytischen Datenbanken schneller. Das ist die Basis für die Verabeitungsgeschwindigkeit von Analysen mit analytischen Datenbanken. Die Methoden und Technologien, mit denen man ein schnelles Lesen erreichen kann sind vielfältig. In der Tat setzt man bei den verschiedenen analytischen Datenbanken auch verschiedene dieser Methoden und Technologien ein, die sich auch miteinander kombinieren lassen: Spaltenorientierung, Kompression, Parallelisierung, In-Memory-Verarbeitung sowie Bündelungen von Hardware und Software („Data Appliances“). Spaltenorientierung. Bei einer spaltenorientierten Datenbank kann jede Spalte einer Tabelle in einer eigenen Datei liegen, d.h. auf einen Wert eines Attributs eines Datensatzes folgt in Lese-Reihenfolge nicht das nächste Attribut des selben Datensatzes, sondern das gleiche Attribut des nächsten Datensatzes: Die Zeilen und Spalten der Tabelle werden miteinander vertauscht. Intuitiv funktioniert dies, da in der Analytik meistens wenige Attribute von sehr vielen Datensätzen benötigt werden. Aufgrund der Spaltenorientierung müssen die restlichen Attribute nicht gelesen werden. Mit anderen Worten: das Lesen wird drastisch reduziert, weil man durch das Vertauschen von Zeilen und Spalten nur noch höchstens so viele Datensätze wie Attribute hat. Da die Anzahl der Attribute in der Regel klein ist gegen die Anzahl der Datensätze, bringt das einen hohen Performance-Gewinn. Jedoch wird das Schreiben von Datensätzen dadurch jedoch teurer, was man aber oft durch Differenzdateien zum Teil ausgleichen kann. Aufgrund dieser Basiseigenschaft von spaltenorientierten Datenbanken erhält man einen weiteren Vorteil. Man braucht keine Indizes und Aggregate mehr. Das macht die Datenbank schlanker, was wiederum das Lesen beschleunigt. Kompression. Zusätzlich lassen sich die Daten in einer spaltenorientierten Datenhaltung sehr gut komprimieren. Dazu werden Verfahren genutzt, die es erlauben, relationale Operationen auf den komprimierten Daten auszuführen. So können beispielsweise mehrfach vorkommende Werte durch Kürzel fixer oder variabler Länge ersetzt werden, die durch ein Wörterbuch bei Bedarf wieder in die ursprünglichen Werte übersetzt werden können. Folgen identische Werte direkt aufeinander, können diese Sequenzen lauflängencodiert abgelegt werden. Sortierte ganzzahlige Daten können durch Differenzbildung zum jeweiligen Vorgänger oder zu einem lokalen Minimum in wenigen Bits untergebracht werden. Ein solches Komprimieren bringt also Kostenvorteile, da die Datenbank „klein“ wird (Relativ zu einer zeilenorientierten Datenbank können die Daten bis zu 80% und mehr komprimiert werden.) Man erhält so weitere Performance-Vorteile. Reines Einfügen von Daten („insert only“). Neue Daten werden bei dieser Methode ausschließlich hinzugefügt (insert). Ein Überschreiben von bestehenden Datensätzen (update) findet nicht mehr statt. So bekommt man eine persistente Speicherung der kompletten Historien aller Daten, was natürlich einen erhöhten Speicherplatzbedarf bedeutet. Ein Vorteil ist dagegen, dass man so die Möglichkeit der Analyse historischer Daten bekommt, die heute in der Regel nur mittels Data Warehouse machbar ist. Die Konsistenz der Daten wird durch Snapshot Isolation bewahrt. Partitionierung („partitioning“) lässt sich in spalten-orientierten Datenbanken gut nutzen. Es bedeutet die Verteilung einer Spalte auf mehrere Server und/oder die Verteilung verschiedener Spalten einer Tabelle auf verschiedene Server. Dadurch erreicht man eine weitere Steigerung der Verarbeitungsgeschwindigkeit. Massiv parallele Verarbeitung. Eine weitere Beschleunigung lässt sich durch Parallelisieren der Verarbeitung auf Clustern erreichen. Das gilt sowohl für zeilen- wie auch spalten-orientierte Datenbanken. Daten werden dabei automatisch und gleichmäßig über alle Server eines Clusters verteilt, so dass für Abfragen alle Hardware- © S.A.R.L. Martin/IT Research März 2013 10 Inhalt Strategic Bulletin: Analytische Datenbanken Ressourcen optimal ausgenutzt werden. Die Software ist so konzipiert, dass jeglicher Tuningaufwand entfällt, wie er in konventionellen Systemen üblich ist. Die Datenbanklösung legt Indizes automatisch an, analysiert und komprimiert die Daten selbständig und verteilt sie optimal über die Knoten. Intelligente Algorithmen fangen Server-Ausfälle auf und sorgen dafür, dass das System für Nutzer innerhalb weniger Sekunden ohne dessen Zutun wieder zur Verfügung steht. In-Memory-Datenbanken. Eine In-Memory-Datenbank ist ein Datenbank-Managementsystem, das den Arbeitsspeicher eines Rechners als Datenspeicher nutzt. Sie arbeitet also im Gegensatz zu traditionellen Datenbank-Managementsystemen nicht mit Festplatten, sondern „plattenlos“. Sie vermeidet so den Flaschenhals der Ein-/Ausgabezeiten. Zudem bietet der Arbeitsspeicher eine wesentlich höhere Verarbeitungsgeschwindigkeit, und die Algorithmen für den Zugriff sind einfacher. Deshalb sind In-Memory-Datenbanken wesentlich schneller. Auch sind die Zugriffszeiten besser abschätzbar als die von Festplatten-basierten Systemen. Natürlich gibt es auch Nachteile: Zum einen ist Arbeitsspeicher deutlich teurer als Festplattenspeicher. Setzt man aber andere Methoden wie Spalten-Orientierung und Komprimierung in Kombination mit In-Memory ein, so werden die Datenvolumen deutlich reduziert, so dass der Arbeitsspeicherbedarf einer solchen Datenbank kleiner wird als der Festplattenspeicherbedarf einer vergleichbaren platten-basierten Datenbank. Zum anderen haben Rechner nicht beliebig viel Arbeitsspeicher. Daher greift man bei Datenbanken mit hoher Speicherkapazität auf GridComputing zurück, um auch Tera- und Petabyte-Volumen mit In-Memory-Datenbanken managen zu können. Die Persistenz der Daten stellt bei In-Memory-Datenbanken eine weitere Herausforderung dar: Da sie ihre Daten in flüchtigem Arbeitsspeicher speichern, der sie bei Systemabstürzen verliert, erfüllen sie nicht die Anforderung der dauerhaften Speicherung (Persistenz) erfolgreich abgeschlossener Transaktionen. Hier muss man mit Zusatzmethoden wie Schnappschuss- oder Protokoll-Dateien, nicht-flüchtigem RAM-Speicher oder mittels Replikation eine Hochverfügbarkeit anstreben. Data Appliances. Analytische Datenbanken können auch als sogenannte Data Appliances angeboten werden. Hier wird die Hardware an die Software angepasst. So lässt sich beispielsweise bei plattenbasierten Datenbanken die Kommunikation zwischen dem Datenbankserver und dem Speicher optimieren. Dazu kann man entweder die Zahl der Threads oder auch die Bandweite erhöhen. Zusätzlich kann man einen Mix aus großen, langsamen und kleinen, schnellen Speichereinheiten einsetzen und die Speicherung mittels Algorithmen dynamisch an das Verhalten des Datenbankspeichers anpassen. Das reduziert recht deutlich die Eingabe/Ausgabe-Geschwindigkeit, die bei plattenbasierten Datenbanken den Flaschenhals darstellt. Bei In-Memory-Datenbanken kann die Data Appliance sehr gut genutzt werden, um eine Hochverfügbarkeit der Datenbank herzustellen. All diese Methoden und Verfahren dienen der Beschleunigung des Suchens und Lesens in Datenhaltungssystemen. Aber diese Methoden und Verfahren schaffen an anderer Stelle Probleme: Die Transaktionsverarbeitung gemäß dem ACID-Prinzip [4] ist nicht so ohne weiteres möglich möglich. Das basiert auf Brewers CAP-Theorem [5], das besagt, dass in einem verteilten System die drei Eigenschaften Konsistenz, Verfügbarkeit und Partition-Toleranz nicht gleichzeitig erreichbar sind. (Abb. 1) Man kann sich diesem nicht existierenden „Ideal“-Zustand nur annähern, in dem man jeweils eine der drei Bedingungen abschwächt. So kann beispielsweise eine ACID-Transaktionskonsistenz abgeschwächt werden zu einer „eventual consistency“, also einer sich nach einigen Zwischenzuständen und nach einer gewissen Latenzzeit sich dann doch einstellenden Konsistenz. Das kann für gewisse Transaktionen ausreichend sein, für andere aber nicht. Daher muss man beim Einsatz von analytischen Datenbanken immer abwägen, was die tatsächlichen Anforderungen an die ACID-Transaktions-Konsistenz sind, und dann die entsprechenden analytischen Datenhaltungssysteme auswählen, die die geeigneten Eigenschaften haben. [4] ACID (atomicity, consistency, isolation, durability) ist eine Menge von Eigenschaften, die garantieren, dass Datenbank-Transaktionen zuverlässig abgewickelt werden. [5] siehe beispielsweise http://fr.slideshare.net/alekbr/cap-theorem © S.A.R.L. Martin/IT Research März 2013 11 Inhalt Strategic Bulletin: Analytische Datenbanken Brewers CAP-Theorem Verfügbarkeit: totale Redundanz Konsistenz: ACIDTransaktionen Es gibt kein verteiltes System, das gleichzeitig diese drei Eigenschaften hat. Partition-Toleranz: unbegrenzte Skalierbarkeit © S.A.R.L. Martin 2013 Abbildung 1: Brewers CAP-Theorem besagt, dass in einem verteilten System die drei Eigenschaften Konsistenz, Verfügbarkeit und Partition-Toleranz nicht gleichzeitig erreichbar sind. Dabei bedeutet Konsistenz, dass alle Knoten zur selben Zeit dieselben Daten sehen, Verfügbarkeit, dass alle Anfragen an das System immer beantwortet werden, und Partitionstoleranz, dass das System auch bei Verlust von Nachrichten, einzelner Netzknoten oder Partition des Netzes weiterarbeitet. Analytische Datenbanken lösen dagegen die Probleme, mit denen die Kunden heute in der Analytik kämpfen: Performance, Skalierbarkeit und Kosten. Fassen wir nochmal die Vorteile zusammen: • Information ist flexibler abrufbar und steht bis zu 100mal schneller oder sogar noch schneller zur Verfügung. • Nutzerzufriedenheit erhöht sich signifikant aufgrund des schnelleren und flexibleren Zugriffs auf Information. Es können jetzt Daten analysiert werden, die vorher ohne Nutzen, aber mit Kosten gespeichert wurden. Das unterstützt und schafft bessere Entscheidungen. • Die IT wird entlastet, da analytische Datenbanken hoch automatisiert sind und ein spezielles Wissen über Datenbankdesign und Tuning deutlich weniger gefragt ist. Zwei Dinge sollten zum Schluss noch klar gesagt werden: • Eine analytische Datenbank macht ein physikalisches Datenbankdesign und Tuning weitgehend obsolet, aber sie ersetzt keineswegs das logische, fachliche Design der analytischen Datenbank. In diesem Sinne bleibt weiterhin ein Information Management unabdinglich, auch wenn analytische Datenbanken eingesetzt werden. Denn ein Stamm- und Metadaten-Management, ein Datenqualitäts-Management, eine Information Governance und die anderen Aufgaben im Information Management bleiben auch mit analytischen Datenbanken kritische Erfolgsfaktoren. • Eine analytische Datenbank ersetzt aufgrund von Brewers CAP-Theorem nicht die herkömmlichen Datenbanken in der Transaktionsverarbeitung. Analytische Datenbanken sind eine neue Generation von Datenbanken, die eben besonders für analytische Aufgaben im Unternehmen geeignet sind. Daher gehen viele Unternehmen den Weg, zwei unterschiedliche Datenbanktechnologien einzusetzen, eine für die analytischen Aufgaben, eine andere für die Transaktionsverarbeitung. © S.A.R.L. Martin/IT Research März 2013 12 Inhalt Strategic Bulletin: Analytische Datenbanken • Doch es gibt Ausnahmen: Oracle Exadata, Kognitio WX2 und SAP HANA eignen sich sowohl für hoch-performante analytische als auch transaktionsorientierte Aufgaben, in dem sie gute Kompromisse bieten, um Brewers CAP-Theorem in seiner rigorosen Form zu „umgehen“ und den praktischen Anforderungen im operativen Unternehmensbetrieb befriedigende Lösungen zu bieten. Insbesondere SAP HANA bietet hier zukünftig ein großes Potenzial. Bei SAP HANA ist allerdings der Performance-Gewinn in der Transaktionsverarbeitung deutlich geringer, denn in der Transaktionsverarbeitung braucht man ein Select auf den Einzelsatz. Der Einzelsatzzugriff wird durch die von SAP HANA verwendeten Methoden aber kaum beschleunigt. Sie zeigen erst beim Select auf Gruppen die bekannten hohen Performance-Gewinne. 3.2 NoSQL-Technologien NoSQL-Datenhaltungssysteme werden heute vielfach im Kontext von Big Data diskutiert. Sie fokussieren auf der Haltung und Verarbeitung poly-strukturierter Daten und ergänzen so das traditionelle relationale Datenmodell, das im Wesentlichen für strukturierte Daten entworfen wurde. Das bedeutet im Endeffekt, dass die relationale Algebra keinen Alleinstellungsanspruch als „einziges“ Datenhaltungsmodell mehr hat. Genauso wie verschiedene Methoden analytischer Datenbanken nicht neu sind, sind auch verschiedene NoSQL-Ansätze schon seit zum Teil langer Zeit im Einsatz, gewinnen aber erst jetzt im Big Data neue Aufmerksamkeit und Anwendung. NoSQL-Datenhaltungssysteme lassen sich wie folgt klassifizieren (Abb. 2): Daten-Volumen NoSQL-Datenhaltungssysteme Casandra Couchbase Hadoop HBase SAP Sybase IQ Mongo DB Couchbase 2.0 Key Value Spaltenorientiert Neo4j Dokumentenorientiert InterSystems Graph Objektorientiert relational Daten-Komplexität Eine relationale Algebra löst nicht alle Datenprobleme. © S.A.R.L. Martin 2013 Abbildung 2: Klassifikation von NoSQL-Datenbanken und Positionierung anhand von Daten-Volumen und DatenKomplexität. Das ergibt einen guten Anhaltspunkt, welche NoSQL-Technologie zu welchen fachlichen Anforderungen passt. Die genannten Produkte stellen (typische) Beispiele dar. Eine detaillierte Aufstellung von spaltenorientierten Datenhaltungssystemen, die ja zu den analytischen Datenbanken gehören, befindet sich in Kap. 4.1. © S.A.R.L. Martin/IT Research März 2013 13 Inhalt Strategic Bulletin: Analytische Datenbanken Objektorientierte Datenbanken. In den 90er Jahren boten sie bereits Alternativen zum relationalen Modell. Sie hatten einen grundlegenden Ansatz, der in allen heutigen NoSQL-Datenhaltungssystemen zu finden ist. Sie sind schemafrei und setzen auf alternative Techniken, um festzulegen, wie Daten gespeichert werden. Dazu kommt der Einsatz anderer Protokolle als SQL für die Kommunikation zwischen Anwendung und Datenhaltungssysteme. Ähnlich wie bei den analytischen Datenbanken ist die Architektur vieler NoSQL-Datenbanken auf Skalierbarkeit ausgelegt: Die Verarbeitung und Verwaltung großer Datenbestände erfolgt verteilt mittels Cluster aus Standardsystemen. Graphen-Datenbanken (oder: Entity-Relationship-Datenbanken). Sie basieren auf der Darstellung von Daten als Knotenpunkte (Entitäten) und Beziehungen (Relationen) zwischen den Knoten. Statt traditioneller Datensätze erstellt man hier Knoten, die durch die Beziehungen, die man zwischen ihnen definiert, miteinander verknüpft werden. Dabei wird Information zu den Knoten und ihren Beziehungen als Eigenschaften (Attribute) gespeichert. Graphen-Datenbanken haben insbesondere Vorteile, wenn wie bei (sozialen) Netzen die Beziehungen zueinander im Mittelpunkt stehen, man also Netze abbilden will. Graphen-Datenbanken gehen auf Entwicklungen im Computer Aided Software Enginering (CASE) der späten 80er Jahre zurück. Dokumentenorientierte Datenbanken speichern „Texte“ von beliebiger Länge mit poly-strukturierter Information und ermöglichen das Suchen auf Basis von Dokumentinhalten. Die gespeicherten Dokumente müssen nicht die gleichen Felder enthalten. XML-Datenbanken sind dokumentorientierte Datenbanken mit semi-strukturierten Daten. Spaltenorientierte Datenbanken. Sie gehören gemäß der hier benutzten Klassifikation in die Klasse der analytischen Datenbanken, was zeigt, dass analytische und NoSQL-Datenhaltungssysteme sich nicht disjunkt zueinander verhalten: Es gibt eben analytische Datenbanksysteme, die immer noch auf dem relationalen Modell basieren, als auch solche, die spalten-orientiert, also NoSQL sind. Key-Value-Datenbanken. Hier weist ein Schlüssel auf einen Wert, der in seiner einfachsten Form eine beliebige Zeichenkette sein kann. Key-Value-Datenbanken sind auch nicht neu. Sie sind als traditionelle Embedded-Datenbanken wie dbm, gdbm und Berkley DB in der Unix-Welt bekannt geworden. Key-Value-Datenbanken arbeiten entweder als In-Memory-System oder als On-Disk-Version. Sie sind besonders zum schnellen Suchen geeignet. Hadoop ist dabei, einen Standard der Zukunft in Big Data-Datenhaltung und Daten-Management zu setzen. Es ist ein Apache Software Foundation Open Source-Entwicklungsprojekt. Es arbeitet wie ein Daten-Betriebssystem und besteht aus drei Komponenten: • der Speicherschicht HDFS (Hadoop Distributed File System), • der von Google vorgeschlagenen Programmierumgebung MapReduce zur parallelen Verarbeitung von Abfragen, • einer Funktionsbibliothek. Zu Hadoop gehört auch die HBase, ein skalierbares, analytisches Datenhaltungssystem zur Verwaltung sehr großer Datenmengen innerhalb eines Hadoop-Clusters. Die HBase ist eine Open Source-Implementierung der Google BigTable. Die Speicherschicht HDFS speichert in der Standardeinstellung Daten in 64MB Blöcken, was paralleles Verarbeiten unterstützt und exzellent zum Lesen großer Datenmengen geeignet ist. Der Nachteil ist, dass eine solche Verarbeitung naturgemäß Batch-orientiert ist und sich deshalb nicht für Transaktionsverarbeitung oder Echtzeitanalysen eignet. HDFS hat schließlich eingebaute Redundanz. Es ist designt, um über hunderte oder tausende von preiswerten Servern zu laufen, von denen man annehmen kann, dass immer wieder einige ausfallen. Daher wird in der Hadoop-Standardeinstellung jeder Datenblock dreimal gespeichert. Neue Daten werden zudem immer angehängt, niemals eingefügt („no insert“). Das erhöht die Geschwindigkeit des Speicherns und Lesens von Daten und erhöht auch die Zuverlässigkeit der Systeme. MapReduce (MR) wurde von Google in seiner spaltenorientierten BigTable implementiert, die auf dem Google File-System basiert. Es ist eine Programmier-Umgebung zur Parallelisierung von Abfragen, die die Verarbeitung © S.A.R.L. Martin/IT Research März 2013 14 Inhalt Strategic Bulletin: Analytische Datenbanken großer Datenmengen deutlich beschleunigt. MR ist keine Programmier- oder Abfragesprache. Die Programmierung innerhalb von MR kann in verschiedenen Sprachen wie Java, C++, Perl, Python, Ruby oder R erfolgen. MR Programm-Bibliotheken können nicht nur HDFS, sondern auch andere Datei- und Datenbanksysteme unterstützen. In einigen analytischen Datenbank-Systemen werden MR Programme als in-database analytische Funktionen unterstützt, die in SQL-Befehlen benutzt werden können. MapReduce ist allerdings nur im Batch einsetzbar, nicht in Echtzeit-Verarbeitung, also auch nicht interaktiv. Dazu kommen noch einige Ergänzungen wie die HLQL (high level query languages) Hive, Pig und JAQL. Hive ist eine Data Warehouse-Umgebung, die auf einer Entwicklung von Facebook beruht. Zu Hive gehört die HLQL „QL“, die auf SQL beruht. Da es für die Hadoop-Programmierumgebung MapReduce noch nicht sehr viele Ressourcen gibt, die damit umgehen können, sind HLQLs wie QL sehr willkommen, da sie den Entwicklern die Verwendung einer SQL-ähnlichen Syntax erlauben. Eine andere HLQL ist Pig, eine prozedurale Sprache. Mit Hilfe von Pig sind parallele Ausführungen komplexer Analysen einfacher als mit MapReduce nachvollziehbar und durchführbar. Darüber hinaus bietet Pig auch im Gegensatz zu MapReduce eine automatisierte Optimierung komplexer Rechenoperationen. Pig ist auch offen und lässt sich durch eigene Funktionalitäten ergänzen. Zum Managen von HadoopAnwendungen dienen Chukwa, das die Echtzeitüberwachung sehr großer verteilter Systeme ermöglicht, und ZooKeeper, das zur Konfiguration von verteilten Systemen dient. Achtung. Obwohl Hadoop auf Technologien und Konzepten beruht, die von Big Data-Unternehmen wir Facebook und Google stammen, so ist doch heute noch sehr deutlich zu sagen, dass diese Technologien noch sehr jung und auch unausgereift sind. Daraus folgt, dass der Einsatz solcher Technologien ausgewiesene und am Markt nur schwer zu findende Mitarbeiter benötigt. Dazu kommt, dass viel Funktionalität noch in Eigenentwicklung zu leisten ist. 3.3 Analytik – Online versus Offline Analytik lässt sich online und offline einsetzen. Offline-Analytik meint die Analyse einer statischen Datenmenge, Online-Analytik die Analyse einer dynamischen Datenmenge. Das beste Beispiel für Offline-Analytik ist das Data Warehouse. Daten werden hier aus operativen Prozessen mittels ETL-Prozessen vorverarbeitet und in einer Data Warehouse-Umgebung für analytische Adhoc-Abfragen oder analytische Anwendungen wie Berichte, Dashboards, Briefing Books, Data Mining etc. bereitgestellt. Hier lassen sich analytische Datenbanken bestens als Data Warehouse-Datenbank einsetzen. Man gewinnt so eine erhebliche Performance-Steigerung um Faktoren, die in der Regel zweistellig sind, aber unter bestimmten Bedingungen sogar dreistellig sein können: Man spricht auch von Analytik in Echtzeit. Hier kommen jetzt die im Kapitel 3.1 genannten Vorteile voll zum Tragen. Heute können solche Data Warehouse-Umgebungen erweitert werden, um Offline Big Data-Analytik zu unterstützen. Die Abbildung 3 zeigt eine solche Architektur, die einerseits einer existierenden Data Warehouse-Umgebung Investitionsschutz gibt und andererseits zeigt, wie Big Data-Analytik und existierende BI-Landschaften miteinander verknüpft werden können. Heutige Implementierungen einer solchen Offline Big Data-Analytik verwenden in der Regel zwei unterschiedliche Datenbank-Typen. Das Data Warehouse sitzt entweder immer noch auf traditionellen relationalen Datenbanken oder inzwischen auf einer analytischen Datenbank, während man vielfach, auch aus Kostengründen, zu einer Open Source NoSQL-Datenhaltung (wie Cassandra, Hadoop, MongoDB etc.) für das Managen von Big Data setzt. Zukünftig mit fortschreitender Reife von solchen NoSQL-Technologien wird man das heute physikalisch instanziierte Data Warehouse nur noch als logisches (virtuelles) Data Warehouse betreiben wollen. Es ist dann im Sinne von Datenvirtualisierung eine View auf das NoSQL-Datenhaltungssystem. © S.A.R.L. Martin/IT Research März 2013 15 Inhalt Strategic Bulletin: Analytische Datenbanken Big Data-Analytik: Architektur recherchieren/ identifizieren Datenanalyse Analytische Applikationen & Services NoSQL oder analytisches DBMS polystrukturierte Daten modellierte Daten gefilterte Daten analytische Ergebnisse Big Data DatenIntegration Datenarchivierung, Filterung, Transformation Datenanalyse strukturierte Daten ETL/ELT Enterprise Data Warehouse Analytische Applikationen & Services externe und Unternehmensdaten nach Colin White © S.A.R.L. Martin 2013 Abbildung 3: In der Offline Big Data-Analytik wird die traditionelle Data Warehouse-Architektur um die Analyse poly-strukturierter Daten ergänzt. Ein analytisches oder NoSQL-Datenhaltungssystem (beispielsweise Hadoop) wird mit den zu einer Problemlösung relevanten Daten aus dem Big Data und aus dem Enterprise Data Warehouse versorgt. Dann kann man dort recherchieren, identifizieren und analysieren. Analytische Ergebnisse und Daten, die für weitere Analysen in Frage kommen, werden gefiltert und ins Enterprise Data Warehouse zurückgeschrieben. So wird auch die traditionelle Datenanalyse durch Big Data Information angereichert. Hinzu kommt nach der Problemlösung die Datenarchivierung mittels Datenintegration inklusive möglicherweise anfallender Datenfilterung und -Transformation. Online-Analytik wird zur Steuerung operativer Prozesse in Echtzeit eingesetzt. Das Ziel ist, proaktiv mittels operativer Kennzahlen Unternehmen und Prozesse zu überwachen und zu steuern. Ein Beispiel gibt hier der Abgleich des Produktangebotes in einem Web-Shop mit der Produktverfügbarkeit. Die Produktverfügbarkeit ist eine operative Kennzahl, die den Bestand von Produkten an Hand der Verkaufs- und Lieferungs-Transaktionen misst. Die Produktverfügbarkeit ist also mit den Transaktionen synchronisiert. Sinkt nun die Produktverfügbarkeit unter einen vordefinierten Schwellenwert, so kann ein Alarm ausgelöst werden. Ein solcher Alarm könnte eine Nachlieferung automatisch auslösen. Ist eine Nachlieferung nicht möglich, dann könnte man das Produkt aus dem Katalog des Web-Shops herausnehmen oder sperren, so dass Kunden das Produkt nicht mehr bestellen können. Damit ist proaktiv sichergestellt, dass Kundenaufträge nicht storniert werden müssen, Kundenfrust wird vermieden und das Risiko eines Ausverkaufs wird minimiert. Zusätzlich könnte man auch noch automatisch einen Vermerk in den Web-Shop stellen, wann das Produkt wieder lieferbar wäre. Diese Kennzahl ist eine operative Steuerungsinformation, die mittels Online-Analytik in jeder Prozess-Instanz in Echtzeit ermittelt und genutzt wird. Basierend auf dem im Beispiel diskutierten Konzept kann man jetzt auch „Echtzeit“ definieren. Definition: Echtzeit im Business bedeutet die richtige Information zum richtigen Zeitpunkt am richtigen Ort zum richtigen Zweck verfügbar zu haben. © S.A.R.L. Martin/IT Research März 2013 16 Inhalt Strategic Bulletin: Analytische Datenbanken Die „Echtzeit“-Forderung im Business hat also nichts mit der Uhrzeit zu tun. Was für „Echtzeit“ entscheidend ist, ist die Verfügbarkeit von Information in der Geschwindigkeit, mit der sie benötigt wird. Monatliche, wöchentliche oder tägliche Informationsbereitstellung kann also durchaus „Echtzeit“ sein, wenn der zugrundeliegende Prozess entsprechend langsam abläuft (Beispiel: Fahrplan-Information bei Buchung versus Verspätungs-Information bei der Reise). In diesem Sinne bedeutet „Echtzeit“ nichts anderes als „Rechtzeitigkeit“. Das Beispiel zeigt weiter, dass Analytik nicht nur diagnostische Aufgaben hat wie früher in der traditionellen Business Intelligence, sondern insbesondere auch vorausschauenden Charakter im Sinne von Vorhersage („predictive analytics“) haben. Mittels Online-Analytik erhalten Prozesse die Fähigkeit, proaktiv und korrektiv zu agieren: Probleme und Risiken werden rechtzeitig erkannt und behandelt bevor Schäden auftreten. Das ist Geschäftssteuerung durch Echtzeit-Control basierend auf Analytik. (Abb. 4) Alles geschieht „voll“ automatisch, also ohne manuelle Eingriffe von Produktmanagern oder anderen am Prozess Beteiligten. So spart man Zeit, Ressourcen und Kosten. Echtzeitanalytik: Architektur Geschäftsprozess Sensoren Zusammengesetzter Service analytische, kollaborative & TransaktionsServices Datenvirtualisierung Events & Sensoren Operative Daten Files, XML, Spreadsheets externe Daten Data Warehouse Big Data Einbettung von Echtzeitanalytik. © S.A.R.L. Martin 2013 Abbildung 4: Online- oder Echtzeitanalytik dient der Prozesssteuerung und Automation. Sie wird erreicht durch die Einbettung von Analytik mittels Services in die Geschäftsprozesse. Die Analytik bedient sich aus unterschiedlichen Datenquellen mittels Datenvirtualisierung. So erreicht man eine Nulllatenzlösung. Die Ereignis- und Sensordaten stammen dabei nicht notwendigerweise allein aus dem Prozess, in den Analytik eingebettet wird, sondern in der Regel aus verschiedenen Prozessen und anderen Beobachtern, die die Außenwelt des Prozesses messen. Die Einbeziehung des Data Warehouses zeigt die Verknüpfung von Offline-Analytik und Online-Analytik. Die Anbindung von Big Data an das Data Warehouse entspricht der Big Data-Analytik von Abbildung 3. Die Ideen zu Online-Analytik stammen aus der Kontrolltheorie: Genauso wie man eine Raumtemperatur über einen geschlossenen Regelkreis überwachen und steuern kann, so will man jetzt Geschäftsprozesse auch operativ überwachen und steuern. Die Überwachung und Steuerung von operativen Systemen wird durch das Echtzeitprinzip ermöglicht: Es geht darum, die richtige Information zur richtigen Zeit am richtigen Ort für den richtigen Zweck © S.A.R.L. Martin/IT Research März 2013 17 Inhalt Strategic Bulletin: Analytische Datenbanken zur Verfügung zu haben. In der Online-Analytik wird also Information als Bringschuld behandelt, i. e. eine eingehende oder entstehende Information wird im Augenblick des Entstehens an alle registrierten Informationsverbraucher propagiert. Im traditionellen Data Warehouse Modell (Offline-Analytik) war dagegen Information eine Holschuld. Der Informationsverbraucher war dafür verantwortlich, sich seine Information selbst abzuholen. Die Technologien zur Online-Analytik arbeiten nach dem Prinzip einer Service-Orientierung. Wird ein Online-Analytik-Service gestartet, so werden im ersten Schritt die notwendigen Daten mittels Datenvirtualisierung bereitgestellt. Datenvirtualisierung meint den virtualisierten (logischen) Zugriff auf Daten aus unterschiedlichen Datenquellen mittels einer Abstraktionsebene, wobei der Zugriff auf Daten zentralisiert wird, ohne die Notwendigkeit die Daten zu replizieren bzw. zu duplizieren. Sie erlaubt beispielsweise relationale JOINs in einer logischen View. Die Ergebnis-Mengen werden als Information Services bei Benutzeranforderung bereitgestellt. Das ist dann besonders elegant und performant, wenn analytische und transaktionelle Daten sich in einer In-Memory-Datenbank befinden (was seit kurzem SAP HANA erlaubt). Im zweiten Schritt werden die definierten analytischen Operationen ausgeführt, die auch mit weiteren Services kombiniert werden können. Im dritten Schritt erfolgt dann die Anwendung des analytischen Ergebnisses im Kontext des Geschäftsprozesses (Abb. 4). Wesentlich ist natürlich, dass diese drei Schritte schneller ausgeführt werden können als die im Kontext des Prozesses gegebene Latenzzeit. Beispiel: Kaufempfehlungen im Rahmen von Kundeninteraktionen in einem Webshop sollen die Kunden begeistern. Sie müssen also „sofort“ (im Unter-Sekundenbereich) ausgesprochen werden können. Hier gilt es beispielsweise Data Warehouse-Daten zur Kunden-/Produkt-Profitabilität und zur Kundeneinstellung gewissen Produkten gegenüber (mittels Meinungsanalysen aus Big Data gewonnen) mit den Transaktionsdaten (Was liegt schon im Warenkorb?) und dem aktuellen Web-Klickstrom-Daten (Wie hat der Kunde aktuell im Webshop navigiert?) zu kombinieren, auszuwerten und mittels einer Regelmaschine eine Empfehlung auszusprechen. Wichtig ist es dann zu messen, ob die Empfehlung angenommen oder abgelehnt wurde. So bekommt man nicht nur eine Erfolgskontrolle, sondern kann auch eine lernende Komponente ins System einführen. 3.4 Big Data: Datenstrukturen und Latenz Analysen von Big Data lassen sich schließlich an Hand unterschiedlicher Datenstrukturen und Latenzanforderungen klassifizieren. Abbildung 5 visualisiert diese Klassifikation mittels der beiden Dimensionen Komplexität der Datenstrukturen und Verarbeitung in Batch (offline) oder Echtzeit (online). “Echtzeit” kann unterschiedliche Bedeutungen haben: Sie bezieht sich entweder auf Niedriglatenz-Zugriff auf bereits gespeicherte Daten oder auf die Verarbeitung und das Abfragen von Datenströmen mit Nulllatenz. Schauen wir uns die vier Quadranten der Abbildung 5 etwas genauer an: • Batch und hoch-strukturiert. Lösungen basieren hier auf einer massiv-parallelen Architektur und einer hochskalierbaren, virtuellen Infrastruktur. Ein solcher Ansatz reduziert deutlich die Speicherkosten und verbessert in hohem Maße die Verarbeitungs-Effizienz traditioneller Data Warehouses. Führende Anbieter sind hier Oracle mit Exadata, IBM mit Netezza und Teradata. • Echtzeit und hoch-strukturiert. Lösungen fokussieren hier auf analytischer Echtzeitverarbeitung und Data Mining-Ansätzen für prädiktive Analysen. Wenn es „nur“ um schnelle Analysen („Analyse in Echtzeit“) geht, dann sind analytische NoSQL-Datenhaltungssysteme gut geeignet. Wenn es aber um „Echtzeitanalytik“ geht, dann sind In-Memory-Datenbanken die Lösung, da sie analytische und Transaktions-Daten gemeinsam im Hauptspeicher statt auf Platten verwalten. Sie gewinnen zudem an Geschwindigkeit durch eine drastische Reduzierung der Eingabe-/Ausgabe-Zeiten beim Datenzugriff und bieten eine besser abschätzbare Performance als platten-basierte Datenbanken. Führende Anbieter sind einerseits SAP mit Sybase IQ und Teradata mit Aster und andererseits Oracle mit TimesTen und SAP mit HANA. © S.A.R.L. Martin/IT Research März 2013 18 Inhalt Strategic Bulletin: Analytische Datenbanken massiv parallele Data Warehouses (IBM Netezza, Teradata) hoch strukturiert Big Data: Strukturen und Latenz Analytische NoSQL DB (Aster, SAP Sybase IQ) verteilte Dateisysteme (Hadoop) Echtzeit (online) poly-strukturiert Batch (offline) In-Memory Datenbanken (Oracle x10, SAP HANA) NoSQL: Graph DB, OODB (Neo4J, InterSystems) DatenstromVerarbeitung (HStreaming, Streambase) Klassifikation von Big Data-Anbietern nach Datenstruktur- und Latenzanforderungen nach Forrester © S.A.R.L. Martin 2013 Abbildung 5: Big Data klassifiziert nach Datenstrukturen (hoch strukturiert und poly-strukturiert) und Latenzanforderungen (Batch und Echtzeit). Die genannten Anbieter stehen stellvertretend für ihre Klasse. Mehr zur Klassifizierung von analytischen Datenbanken befindet sich in Kapitel 4.1. • Batch und poly-strukturiert. Lösungen basieren hier auf einer Software-Struktur, die typischerweise ein verteiltes Datei-System, eine Verarbeitungsmaschine für große Mengen von Rohdaten und Anwendungen zum Managen der Software-Struktur enthalten. Ein prominentes Beispiel hierzu ist Hadoop. • Echtzeit und poly-strukturiert. Geht es wieder um Analytik in Echtzeit, dann sind NoSQL-Technologien wie graphische und objekt-orientierte Datenhaltungssysteme gut geeignet. Die Basis für Lösungen in Echtzeitanalytik ist hier Event Stream Processing, um multiple Ereignisströme zu verarbeiten und bedeutungsvolle Einsichten zu geben. Die Aufgabe ist die Erkennung komplexer Muster in mehreren Ereignissen, Ereignis-Korrelierung und -Abstraktion, also Complex Event Processing. Führende Anbieter sind hier Cassandra, HStreaming, Streambase und Splunk. 3.5 Information Management im Big Data Information Management im Big Data bedeutet neue Herausforderungen. Dabei setzen sich die drei Hauptkomponenten von traditionellem Information Management zunächst entsprechend fort: Datenintegration, Stamm- und Meta-Daten-Management und Datenqualitäts-Management. Eine Auflistung der entsprechenden Anbieter finden Sie in Kapitel 4.2. Datenintegration. Bei der Big Data-Integration werden zunächst einmal die traditionellen DatenintegrationsTechnologien wie ETL- und ELT-Prozesse und Echtzeit-Verarbeitung (change data capture, event triggering, Services) weiter genutzt. Aber es gibt auch einige weitere Anforderungen. Man braucht jetzt Konnektoren für alle Arten von analytischen und NoSQL-Datenbanken. Das setzt sich mit der Nutzung von Konstrukten zur Beschleu- © S.A.R.L. Martin/IT Research März 2013 19 Inhalt Strategic Bulletin: Analytische Datenbanken nigung von Integrationsprozessen fort: Basierend auf MapReduce gibt es eine schnelle und leistungsfähige Flat-FileVerarbeitung zum Sortieren, Filtern, Mischen und Aggregieren von Daten inklusive einiger Basis-arithmetischer Funktionen. Beispiel hierzu ist das FileScale-Verfahren von Talend. Alternativ kann man hier aber auch auf alte und sehr bewährte Hochleistungs-Extrakt-Technologien wie DMExpress von Syncsort zurückgreifen, die im Zuge von Big Data „wiederentdeckt“ werden und inzwischen auch Schnittstellen zu Hadoop haben. Eine weitere Herausforderung ist Datenintegration im Rahmen von Echtzeit-Analytik. Wir brauchen Informationsund Datenservices, die simultan Daten aus dem Data Warehouse und operativen Systemen mittels einer Datenintegrationsplattform bereitstellen. Selbst wenn es heute durch In-Memory-Datenbanken bereits möglich ist, ERP, CRM, SCM und andere Systeme auf gemeinsamen analytischen und Transaktions-Daten zu betreiben, werden wir in Zukunft weiterhin Datenintegrationsplattformen brauchen, da es außerhalb dieser Systeme ein großes Kontinuum weiterer Daten gibt, das es zu nutzen gilt. In der Vergangenheit hat man versucht, dieses zeitkritische Datenzugriffsproblem mit physischer (oder materialisierter) Datenintegration zu lösen. Die Daten werden mittels der ETL-Prozesse in das Zielmodell transformiert und in eine zentrale Datenbank kopiert, wo sie dann für rein lesende Verarbeitungen, beispielsweise Performance Management und Analytik zur Verfügung stehen. Heute nutzt man mehr und mehr Datenvirtualisierung, bei der die Integration erst bei einem Datenzugriff stattfindet. Kern ist ein logisches Datenmodell (kanonisches Schema). Es stellt einerseits die Schnittstelle zu den Quelldaten und deren Datenmodellen dar und bietet andererseits zugreifenden Services mittels Informations-Services eine integrierte globale sowohl lesende wie auch schreibende Schnittstelle zu den virtualisierten Daten. Datenvirtualisierung bedeutet auch, dass man alle Daten nur einmal hält und so redundante Datenhaltung vermeidet. Das ist im Big Data besonders wichtig, da man ja sowieso mit hohen Datenvolumen kämpfen muss. Durch Datenvirtualisierung lässt man alle Daten da wo sie sind: Man hält sie nur einmal. Datenvirtualisierung basiert also auf einer Abstraktion von Ort, Speicher, Schnittstelle und Zugriff. So werden relationale JOINs und andere Operationen in einer logischen View ermöglicht. Die Ergebnis-Mengen werden als Views oder Informations-Services bei Benutzeranforderung bereitgestellt. In solche Informations-Services lassen sich weitere Services zur Datenaufbereitung oder Anreicherung integrieren, beispielsweise Datenqualität-Services zu Gültigkeitsprüfungen. Datenvirtualisierung heute ist eine Weiterentwicklung der „data federation“, auch Enterprise Information Integration (EII) genannt. Datenvirtualisierung ist für Echtzeit-Analytik bestens geeignet und erlaubt eine Nulllatenz-Datenintegration, i.e. die Analytik arbeitet synchron mit den Transaktionsdaten. Eine solche Lösung war bisher wegen der PerformanzAnforderungen an die notwendige Netzwerk- und Hardware-Infrastruktur aber eine teure Lösung. Heute bietet In Memory-Verarbeitung interessante und preiswertere Alternativen. Datenintegration beschränkte sich bisher auf die Aufgabe, im Unternehmen vorhandene Daten zu integrieren, Adress- und Geo-Daten hinzuzukaufen und mit Attributen aus im Markt angebotenen Daten wie demo- und soziogeographischen Daten anzureichern. Das lässt sich mit den beschriebenen Methoden und Technologien machen. Heute im Zeitalter von Big Data kommt eine weitere Aufgabe auf die Datenintegration zu: Das Anreichern von Daten durch Social Media-Daten. Hier hat man jetzt die Aufgabe, die Kundendaten im Unternehmen mit den entsprechenden Daten aus den Social Media zusammenzuführen, denn Personen in den Social Media nennen sich teilweise anders, sind anonym oder benutzen falsche Identitäten. Ein solches Problem der „Identity Resolution“ hatte man auch schon in gewissem Umfang bei Adressdaten, wenn es um die Dublettenbereinigung ging. Jetzt ist das Problem im Big Data entsprechend schwieriger, denn wir haben es mit unterschiedlichen Social Media, unterschiedlichen Sprachen, mit unterschiedlichen Schrifttypen und deren unterschiedlichen Transkriptionen zu tun. Die Aufgabe ist es, ein „soziales Profil“ eines Kunden aufzustellen und mit dem Unternehmensprofil des Kunden abzugleichen. Das schafft man mit den Methoden und Technologien der sogenannten „Entity Identity Resolution“. Vor der Extraktion von Datenquellen im Web kommt noch das Identifizieren von relevanten Datenquellen. Dazu setzt man Suchmaschinen ein, die also inzwischen auch zu Werkzeugen im Information Management werden. Der © S.A.R.L. Martin/IT Research März 2013 20 Inhalt Strategic Bulletin: Analytische Datenbanken Einsatz von Suchmaschinen zur Quellenidentifikation ist heute zumeist ein manuelles Verfahren. Man definiert ein Relevanzmaß, um Quellen bewerten und miteinander vergleichen zu können. Durch Suchmaschinen gefundene Quellen werden dann gemäß dem Relevanzmaß gefiltert, und die identifizierten Quellen stehen dann zur Extraktion zur Verfügung. Stamm- und Meta-Daten-Management. Der Kern von Stamm- und Meta-Daten-Management ist und bleibt ein Repository zur Verwaltung von Metamodellen, Modellen und Metadaten sowie der Verwaltung aller Transformationsregeln. Das Vorgehen im Big Data ist analog, aber hier kommt gleich ein neues Problem, nämlich das der Gewinnung von Metadaten aus dem Big Data. Hier kann mittels Taxonomien per Textanalytik Abhilfe geschaffen werden. Hilfreich ist auch eine Wikifizierung der Daten. Gerade im Big Data kann ein Wiki-Ansatz, der auf der Intelligenz und dem Fleiß von vielen basiert, als Methodik dahin führen, dass Erkenntnisse aus dem Big Data schneller gewonnen werden und mit den anderen geteilt werden. So wie Wikipedia das Wissen der Menschheit in verschiedensten Domänen erschlossen hat, so sollten wiki-ähnliche Ansätze, egal welche Technologien zu Grunde liegen, das Wissen aus dem Unternehmen und aus seinem Ökosystem (Intranet und Internet) erschließen. Schließlich werden alle Objekte der Datenintegrations-Plattform im Big Data-Repository abgebildet, damit sie vom Ursprung bis zum Ziel über den gesamten Informationslebenszyklus verfolgt werden können und bei Änderungen so weit wie möglich auch alle betroffenen Objekte gleich mit geändert werden. Ein Big Data-Repository muss also in diesem Sinne aktiv sein und wie eine CMDB (configuration management database) arbeiten. Das ist im Big Data wichtiger denn je, denn sonst verliert man schnell den Überblick über die Menge an Metadaten und Vielzahl an Modellen. Idealerweise sollte deshalb ein Big Data-Repository Modelle wie das OMG M3-Modell unterstützen, also alles zusammen genommen, eine Ontologie verwalten können. Das zeigt, dass das Repository im Big Data noch wichtiger als bisher wird. Es kommt jetzt auch noch auf die Performanz an, die mit der Repository-Technologie erreicht werden kann. Viele Repository-Technologien basieren immer noch auf relationalen Datenbanken. Aufgrund der Vernetzung der Objekte in einem Repository sind aber zur Implementierung Graphen- und objekt-orientierte Datenbanken in der Regel besser geeignet, da sie nicht nur das physikalische Datenbankmodell vereinfachen, sondern auch eine höhere Performance bieten. Weitere Performance gewinnt man durch Parallelisierung der Verarbeitung. Hier bieten jetzt auch In-Memory-Datenbanken als Infrastruktur eines Big Data-Repositorys eine interessante Lösung. Wir betreten hier aber definitiv Neuland! Big Data Quality. Datenqualität spielt auch im Big Data weiterhin die große Rolle, vor allem dann, wenn Unternehmensdaten mit Information aus dem Big Data angereichert werden sollen, also beispielsweise Kundendaten durch Daten aus den sozialen Medien oder Patientendaten mit therapeutischen Daten im Gesundheitswesen. Die Grundaufgaben von Data Quality Management bleiben die gleichen. Es geht wie immer um das Profiling, das Cleansing und das Anreichern und Abgleichen mit Referenzdaten. Neu dazu kommt die schon genannte Entity Identity Resolution, um ein fehler-tolerantes Anreichern von Daten durch Social Media- und andere Web-Daten zu erlauben. Deutlich an Bedeutung im Big Data gewinnt Geocodierung Zunächst einmal ist es eine zusätzliche Methode im Datenqualitäts-Management: Eine Geocodierung wirkt wie ein zusätzliches Profiling und identifiziert Fehler in Adressdaten. Daher empfiehlt es sich, Geocodierungs- und Datenqualitäts-Management-Services gleichzeitig einzusetzen. So schafft man Adressdaten mit höchster Datenqualität. Am besten baut man Geocodierungs-Services in Echtzeit gleich in die Datenerfassung ein. Geocodierung hat zwei Komponenten, zum einen die Codierung von Adressdaten und zum anderen die Codierung von IP-Adressen. Letztere ist entscheidend, um im mobilen Internet Nutzer räumlich identifizieren zu können. Mit Hilfe von Lokalisierungs- und Navigationsdaten lässt sich Information nicht nur in einen zeitlichen Kontext stellen („Echtzeit-Information“), sondern auch in einen zeitlich-räumlichen Kontext. Jetzt kann man beispielsweise mit Kunden cross-medial interagieren: die virtuelle und die reale Welt verschmelzen. So wird Kundenwissen in den Zeit/Raum-Kontext gestellt und schafft Innovation in der Kundenkommunikation. © S.A.R.L. Martin/IT Research März 2013 21 Inhalt Strategic Bulletin: Analytische Datenbanken Fazit Kapitel 3: Analytische Datenbanken fokussieren auf schnelles Lesen von Daten. So wird Information flexibler verfügbar und steht bis zu 1.000mal und schneller zur Verfügung. • Schnelles Lesen von Daten erreicht man durch Kombination verschiedener Methoden und Technologien wie Spalten-Orientierung, Kompression, Parallelisierung, In-Memory-Verarbeitung und Bündelung von Hardund Software. Mit analytischen Datenbanken erreicht man Analytik in Echtzeit: Analysen werden machbar, die früher nicht machbar waren. NoSQL-Datenhaltungssysteme lassen sich nach Datenvolumen und Datenkomplexität klassifizieren. Das gibt einen guten Ansatz zu entscheiden, welche fachlichen Anforderungen an Analytik welche NoSQL-Datenhaltungssysteme brauchen. • Analytische Datenbanken können SQL- oder NoSQL-Datenhaltungssysteme sein. Echtzeitanalytik dient der Prozesssteuerung und Automation. Sie wird durch In-Memory-Verarbeitung erreicht. Sie erlaubt Prozessinnovationen und innovative neue Prozesse. Im Big Data-Management kommt es auf die Performance besonders an: Alle Werkzeuge, Services und Plattformen müssen entsprechend skalierbar sein. Dazu kommen die Anforderungen der neuen Methoden von Hadoop und anderen NoSQL-Ansätzen: Konnektoren und neue Verarbeitungsmethoden in Datenintegration, Stamm- und Meta-Daten-Management und Datenqualitäts-Management. © S.A.R.L. Martin/IT Research März 2013 22 Inhalt Strategic Bulletin: Analytische Datenbanken 4. Analytische Datenbanken: Roadmap 4.1 Klassifikation der Anbieter von analytischen Datenbanken Analytische Datenbanken lassen sich anhand der eingesetzten Speichertypen, Datenstrukturen und Bereitstellungsmodelle klassifizieren (Abb. 6) Klassifikation analytischer Datenbanken Bereitstellungsmodell Software On Premise Appliance Cloud relational Datenstrukturen Speicherung Analytische Datenbanken/ Plattformen In-Memory Platten-basiert NoSQL Hybrid © S.A.R.L. Martin 2013 Abbildung 6: Klassifikation analytischer Datenbanken über Speichermethoden, Datenstrukturen und IT-Bereitstellungsmodell. Die folgende Auflistung von Anbietern entsprechend der Klassifikation von Abbildung 6 erhebt keinen Anspruch auf Vollständigkeit. Sie fokussiert auf den deutschsprachigen Raum und enthält eine Reihe von lokalen Anbietern. Analytische, relationale MPP-Datenhaltungssysteme: IBM DB2 (InfoSphere Warehouse), IBM Smart Analytics System, IBM Netezza, Kognitio, SAS Scalable Performance Data Server (mit SAS Grid Computing und SAS In-Memory-Analytics), Teradata, XtremeData. Open Source: Actian VectorWise, EMC/Greenplum, VoltDB. Analytische, NoSQL-Datenhaltungssysteme (ohne In-Memory-Datenverarbeitung): Amazon DynamoDB, Illuminate, HP/Vertica, Kx Systems, Sand Analytics, SAP Sybase IQ, Teradata/AsterData, Vectornova. Open Source: Apache Cassandra, Apache Hadoop HBase, InfoBright, MongoDB. Analytische, NoSQL-Datenhaltungssysteme (mit In-Memory-Datenverarbeitung): 1010Data, Amazon Redshift, Exasol, IBM Smart Analytics Optimizer, ParAccel, SAP HANA Spezielle Datenhaltungssysteme (Technologie in Klammern): Actian/Versant (OODB), CrossZSolutions (QueryObject System), Drawn-to-Scale (Big Data Platform auf Hadoop), dimensio informatics (minimal-invasives Performance-Tuning), HPCC Systems (Big Data Framework à la Hadoop), InterSystems (OODB), Oracle Exadata Database Machine (Data Appliance mit Massive Parallel Grid), Oracle Exalytics In-Memory Machine (Spezialtechnologie für CEP), Panoratio (Database Images), Spire (Big Data operational SQL DB) © S.A.R.L. Martin/IT Research März 2013 23 Inhalt Strategic Bulletin: Analytische Datenbanken Hadoop-Distributoren: Amazon Elastic MapReduce, Cloudera, Hortonworks, IBM Infosphere BigInsights, Intel Apache Hadoop Distribution, MapR Technologies, Pivotal HD, Talend Platform for Big Data, VMWare (HVE, Serengeti) Zum Schluss dieser Aufstellung notieren wir noch führende Anbieter von „Data Warehouse as a Service“, also Cloud-Lösungen für analytische Datenhaltungssysteme und Data Warehouses: 1010Data, Amazon Redshift, ClickFox, Exasol, SAP HANA, Tresata. Fazit: Analytische Datenbanken bringen den Nutzern ganz neue Möglichkeiten, sowohl in der Skalierbarkeit, der Performance als auch in den Betriebskosten. Wer heute komplexe Analysen auf Big Data durch viele Benutzer mit vielen Abfragen ausführt und eine hohe Performance und Skalierbarkeit bei einfacher Wartbarkeit benötigt, sollte analytische Datenbanken auf jeden Fall berücksichtigen. Wir meinen: Eine Evaluation lohnt sich auf jeden Fall. Damit sollte man auf keinen Fall mehr warten! 4.2 Klassifikation der Anbieter von Information Management Die folgende Auflistung von Anbietern erhebt keinen Anspruch auf Vollständigkeit. Sie fokussiert auf den deutschsprachigen Raum und enthält eine Reihe von lokalen Anbietern. Datenintegration – Plattformen • die GROSSEN: IBM, Informatica, Oracle, SAP, SAS Institute/DataFlux • die Herausforderer: Actian/Pervasive, Adeptia, Astera, Attunity, Axway, CA/Inforefiner, Columba Global Systems, Comlab/Ares, Composite Software, DataStreams, DataWatch, Diyotta, ETI, Gamma Soft, HVR Software, Information Builders/iWay Software, Nimaya, Parity Computing, Progress Software, SnapLogic, Software AG, Stone Bond, Tibco, Uniserv, Versata • Open Source: CloverETL, JBOSS Enterprise Middleware, Jitterbit, JumpMind, Talend ETL/ELT: AbInitio, Actian/Pervasive, Astera Software, CA/Advantage Data Transformer, Datarocket, Datawatch, ETL Solutions, IBM, Informatica, Information Builders, iQ4bis, Menta, Microsoft, Open Text, Oracle, Pitney Bowes Software, SAP, SAS, Sesam Software, Software Labs, SQ Data, Syncsort, Theobald Software, Tonbeller AG, Uniserv, Versata Spezielle Werkzeuge zur Planung von DW („pre-ETL“): Wherescape 3D; und zum Managen von DWs: BIReady Open Source: Apatar, The Bee Project, CloverETL, Enhydra Octopus, KETL, Pentaho/Kettle, RapidMiner, Talend Datenqualität: Alteryx, AS Address Solutions, Ataccama, Business Data Quality, Clavis Technology, Datactics, DataMentors, Datanomic, Datras, emagixx, Eprentise Harte Henks, Human Inference, IBM, Informatica, Innovative Systems, Omikron, Oracle, Pervasive, Pitney Bowes Software, Posidex Technologies, Scarus, SAP, SAS, tekko, TIQ Solutions, Uniserv, Versata, X88 Software Open Source: CloverETL, Infosolve Technologies, RapidMiner, SQL Power, Talend © S.A.R.L. Martin/IT Research März 2013 24 Inhalt Strategic Bulletin: Analytische Datenbanken 4.3 Die Datenvielfalt meistern – Gastbeitrag von Datawatch Autor: Patrick Benoit, Regional Director EMEA Central, North and East bei Datawatch Unternehmen, die sich im Rahmen ihrer Big-Data-Projekte nur auf die strukturierten Informationen konzentrieren, erhalten leider nur „mehr vom Gleichen“. Aus gutem Grund besteht die Definition von Big Data nicht aus einem „V“ (Volumen), sondern bekanntlich aus drei „Vs“: Volumen, Velocity (Schnelligkeit) und eben Variety (Vielfalt). Für eine umfängliche Sicht ist potenziell jeder „Datenschnipsel” wertvoll - unabhängig von der Datenquelle und vom Datenformat. Die Auswertung von Reports, ECM-Dokumenten und anderen Dateien mit semi- und unstrukturierten Daten sowie die nachvollziehbare Verbindung unterschiedlichster Datenquellen muss aber nicht komplex und aufwändig sein. Semistrukturierte Daten in gewinnbringende Informationen umwandeln. Viele Unternehmen haben in den letzten Monaten Initiativen gestartet, unstrukturierte Informationen zu erschließen. Beispielsweise werden Daten aus Social Networks, aus Tweets und Foren ausgelesen und in strukturierte Daten überführt, um daraus verwertbare Informationen abzuleiten. Dagegen sind die in gemischten Formaten vorliegenden Daten - also semistrukturierte Daten, die in System-Berichten, EDI-Streams, PDF-Dateien oder Logfiles dokumentiert sind - vielfach noch unerschlossen, obwohl hier ebenfalls wertvolle Informationen schlummern. Viele Unternehmen konnten diese Quellen bislang gar nicht oder nur mit massivem manuellen Aufwand auswerten. Eine Aufarbeitung mittels Excel ist zeitintensiv und enorm fehleranfällig. Zudem lassen sich die Quellen der Daten, arbeitet man einmal in Excel, nicht mehr nachvollziehen. Dieses Problem stellt sich vielen Unternehmen, etwa bei der Kombination von SAP-Reports. Beispielsweise nutzt ein führender Hersteller der Halbleiterindustrie für die Berechnung von Finanzkennzahlen ein Werk aus mehreren verknüpften Excel-Tabellen. Darin werden Ergebnisse aus verschiedenen SAP-Berichten zusammengetragen. Eines Tages stellte man fest: In einem Tabellenblatt hatte sich ein Übertragungsfehler eingeschlichen. Dieser Fehler war zwar nicht gravierend für die Bilanzierung, dennoch dürfen bei der Berechnung der Kennzahlen einfach keine Fehler passieren. Um die Zuverlässigkeit der Zahlen zu gewährleisten, etablierte das Unternehmen eine InformationOptimization-Lösung. Ohne Zugriff auf Systemschnittstellen liest diese Software die Daten aus den verschiedensten Reports aus - und zwar unabhängig von Quelle oder Format der Daten. Im nächsten Schritt werden sie in Datenmodelle eingespielt und mit anderen Daten kombiniert. Um dies zu leisten, erkennt die Software Strukturen und Komponenten der einzelnen Datenarten in den unterschiedlichsten Datei-Formaten und zerlegt sie in kleinste Einheiten. Die Software leistet damit das, was sonst das menschliche Gehirn übernimmt, wenn ein Mensch einen Bericht oder ein Dokument betrachtet: Sie erfasst die Struktur und kann Text und Zahlen in den Zeile zu Kategorien zuordnen und unterteilen. Diese „Datenportionen” werden daraufhin neu kombiniert und im Anschluss erfolgt, wie gewohnt, die Auswertung. Dabei können alle Daten stets auf ihre ursprüngliche Quelle zurückverfolgt werden, um so den gesetzlichen und rechtlichen Anforderungen zu entsprechen. Sollen die aufbereiteten Daten nach diesem Schritt weiterverarbeitet werden, lassen sie sich einfach in relationale Datenbanken oder auch Hadoop importieren. Da Hadoop per se semistrukturierte Daten nur schwer verarbeiten kann, erweitern Unternehmen mit einer Information-Optimization-Lösung ihre Big-Data-Infrastruktur, da sie zusätzliche Informationsquellen in Hadoop auswertbar macht. Dokumente in ECM-Systemen auswerten. Neben Berichten aus ERP-Systemen haben sich auch im Enterprise Content Management (ECM) große Bestände wichtiger Informationen in Form von Dokumenten angesammelt. Sie sind eine weitere „Fundgrube” für wertvolle Informationen. Logica, internationaler Anbieter von Beratung- und Systemintegration, hat dies erkannt und sein Cloud-basiertes Enterprise Content Management (ECM) mit der Information-Optimization-Plattform von Datawatch erweitert. Durch die Verknüpfung der beiden Lösungen können Logica-Kunden alle textbasierten Dokumente, ob Geschäftsunterlagen oder Berichte, jederzeit abrufen und analysieren. Aus der Umwandlung der dort hinterlegten Berichte und Dokumente in Excel-Tabellen oder andere gängige Formate erhalten Anwender verwertbare, relevante Daten. Dabei spielt es keine Rolle, ob die Ausgangsdaten unstrukturiert, semistrukturiert oder hoch strukturiert vorliegen. Es lassen sich beliebige Dokumententypen und Dateiformate, darunter PDF, Text, Rechnungen, ERP-Reports oder Berichtslisten aus Großrechnern, verarbeiten. © S.A.R.L. Martin/IT Research März 2013 25 Inhalt Strategic Bulletin: Analytische Datenbanken Mehrere Datenquellen verknüpfen. Für Big-Data-Projekte müssen neben den strukturierten Daten beliebige andere Datenquellen erschlossen werden. Software-Lösungen, mit deren Hilfe die verschiedenen Outputs unterschiedlichster Datenquellen kombiniert werden können, kommt damit eine entscheidende Rolle zu. Indem Information-Optimization-Plattformen wie Datawatch diese Flexibilität ermöglichen und helfen, sämtliche losen Enden zu verknüpfen, sind sie der Schlüssel zum dritten V – der Variety. 4.4 Erst Analytics macht aus Big Data Big Business – Gastbeitrag von InterSystems Autor: Thomas Leitner – Regional Managing Director Europe Central & North bei InterSystems Big Data ist zweifellos eines der IT-Buzzwords der letzten Jahre, auch wenn wir von einer einheitlichen Begriffsbestimmung noch weit entfernt sind. Gemeinsamer Kern der meisten Definitionsversuche von Big Data ist jedenfalls der Bezug auf große und wachsende Datenmengen, die mit herkömmlichen technischen Mitteln, insbesondere typischen relationalen Datenbankwerkzeugen, nicht mehr ohne Weiteres optimal verarbeitet werden können. Gartner (2012) hat diese Quintessenz in seiner Definition mit Bezug auf die bekannten drei „V“ – „high volume, high velocity, high variety“ – weiter differenziert: Big Data sind demnach Informationsbestände, die aufgrund ihres hohen Datenvolumens, der großen Geschwindigkeit und der Vielfalt von Formaten und Formen, in denen sie anfallen, neue Formen der Verarbeitung erfordern, um aus ihnen Erkenntnisse und Entscheidungsunterstützung zu gewinnen. Evolution statt Revolution. Big Data ist keine neue Problematik. So hat InterSystems seine Technologien in den vergangenen dreißig Jahren in Auseinandersetzung mit genau den Problemstellungen entwickelt, die sich auch heute im Zusammenhang mit Big Data stellen: das Beherrschen komplexer Szenarien, großer Datenmengen, kontinuierlicher Ströme von Massendaten oder zahlreicher Transaktionen pro Zeiteinheit. InterSystems vertritt deshalb eine aus Anwendersicht pragmatische Position zu dem Thema: „Big Data“ betrifft heute Daten verschiedenen Umfangs und Formats, die gemeinhin nicht schon zentral verwaltet werden und die für das Geschäft eines Unternehmens wichtig sind oder sein können. Diese Daten – darunter z. B. Office-Dokumente, PDFs, E-Mails, Instant-Messaging-Nachrichten oder Texte und Mediendateien aus Blogs und sozialen Netzwerken, aber auch von Maschinen oder Sensoren automatisch erzeugte Daten – können in allen Bereichen des Unternehmens anfallen. Ob es sich vom Volumen her dabei dann um Terabyte oder Exabyte an Daten handelt, ist eigentlich nachrangig. Die Problemstellung ist immer dieselbe – in Echtzeit Informationen zur Entscheidungsunterstützung zu generieren. „Advanced“ BI ist zu wenig. Je nachdem, über welche Daten im Zusammenhang mit Big Data gesprochen wird, können quantitative Ansätze, die man aus dem Business Intelligence-Umfeld kennt, erste zusätzliche Erkenntnisse bringen. Unglücklicherweise wird in vielen Fällen versucht, dieses Konzept auch auf unstrukturierte Daten zu übertragen. Ein Ansatz, manchmal als Advanced BI bezeichnet, der der Natur dieser Daten nicht gerecht werden kann. Bei jeder Aggregation gehen Informationsinhalte verloren. Werden unstrukturierte Daten in strukturierte Formen gezwängt, erhält man Datensätze, deren statistische Relevanz bestenfalls das Prädikat „zweifelhaft“ verdient. Umso mehr, als dass beide Schritte heute überhaupt nicht mehr notwendig sind. Moderne Analysetools arbeiten gleichermaßen mit strukturierten wie unstrukturierten transaktionalen Daten. Active Analytics für unstrukturierte Daten. In vielen Bereichen gewinnt die Analyse von unstrukturierten Daten aus Texten, Bildern und Tonaufzeichnungen an Relevanz. Hier verbergen sich die so oft erwähnten 80 Prozent bislang nicht genutzter Daten. Moderne Technologien wie Active Analytics von InterSystems überwinden Grenzen, die der semantischen Analyse bislang gesetzt waren. Schon einfache Aufgabenstellungen, wie das Anreichern strukturierter Daten mit Informationen aus Freitextfeldern, stellte IT-Systeme bislang vor unlösbare Probleme. Mit iKnow, einer der Technologien aus Active Analytics, © S.A.R.L. Martin/IT Research März 2013 26 Inhalt Strategic Bulletin: Analytische Datenbanken konnte genau diese Herausforderung für ein führendes deutsches Online-Portal gelöst werden. Ein weiteres Einsatzgebiet ist das Aufspüren von Betrugsversuchen (Fraud Detection). Es gibt erkennbare Muster in Texten, wenn Menschen versuchen zu schummeln. Die letztendliche Prüfung obliegt natürlich weiterhin den Sachbearbeitern, aber eine überraschend präzise Evaluierung aller eingereichten Anträge, zum Beispiel bei Sachversicherern, erleichtert und beschleunigt die Arbeit der Spezialisten und spart bares Geld. Visualisieren, um Zusammenhänge zu erkennen. Um strategische Vorteile für Unternehmen zu generieren, muss sich Analytics aber von dem Konzept der Prozessoptimierung lösen. Schneller präzisere Informationen an Entscheidungsstellen nutzen zu können ist sicherlich ein Vorteil, aber es erlaubt keine Betrachtungen darüber, wie der Status quo geändert werden müsste, um als Organisation besser zu werden. Für diese Anforderung eignen sich visuelle Darstellungen deutlich besser als Tabellen oder Listen. An dieser Stelle kommt Erkenntnis wirklich von Erkennen. Flaschenhälse werden so genauso sichtbar gemacht wie bislang unvermutete Zusammenhänge. Data Cubes erlauben es, strategische Fragen aus allen Perspektiven zu betrachten und zu analysieren. Datengrundlage dafür sind dann 100 Prozent der Unternehmensdaten und nicht nur die 20 bis 30 Prozent, die BI-tauglich sind. Data Science und Visual Analytics erlauben es dem Senior Management somit, Unternehmen und Prozesse aus allen Blickwinkeln zu analysieren und auch externe Datenquellen, zum Beispiel Geoinformationen oder Sozialdaten, in die Betrachtungen mit einzubeziehen. Das Ergebnis ist eine kontinuierliche Weiterentwicklung und Optimierung, basierend auf harten Fakten. Die Frage, was Big Data ist, wird schlussendlich jedes Unternehmen für sich anders beantworten. Dass jedes Unternehmen über bislang ungenutzte Daten verfügt, sei es innerhalb des Unternehmens oder in Social Networks, ist dagegen unbestritten. Flexible Technologien wie die Produktfamilie von InterSystems bieten leistungsstarke Ansätze, ohne gleich massiv in Hardware investieren zu müssen. Big Data wird so zu Big Business. 4.5 Big Data und die Datenbankstrategie der Zukunft – Gastbeitrag von SAP Big Data stellt die IT in Unternehmen vor Herausforderungen ganz neuer Ausmaße, eröffnet aber auch ungeahnte Chancen. Die IT muss mit revolutionären Konzepten reagieren. Der Schlüssel ist eine einheitliche Datenbankstrategie. Mobile-, Cloud-, Social- und Monitoring-Daten: Beinahe stündlich wachsen die Informationsmassen in Unternehmen an. Traditionelle Datenbanksysteme sind damit oft überfordert. Sie sind vorrangig auf Transaktionen ausgelegt und für überschaubare Mengen optimiert. Entsprechend steigen die Verarbeitungszeiten, Unternehmen können nur noch verzögert auf neue Situationen reagieren. Dabei verspricht die Analyse strukturierter und vor allem unstrukturierter Daten enorme Wettbewerbsvorteile. Unternehmen müssen sich also umstellen, wenn sie das riesige Potenzial ihrer Informationen voll ausschöpfen wollen. Wie werden sie künftig ihre Daten halten? Die SAP-Datenbankstrategie. In Zusammenarbeit mit seinen Kunden hat SAP einen ganzheitlichen Ansatz entwickelt, der das Informationsmanagement auf ein sicheres, zukunftsfähiges Fundament setzt. Technologische Basis dieser Strategie ist die SAP® Real-Time Data Platform. Sie funktioniert wie ein automatischer Verteiler, der alle Daten in die jeweils passenden Systeme überträgt. Die Basis der Plattform bilden mehrere Datenbanken, die für unterschiedliche Aufgaben optimiert sind. Dazu zählen beispielsweise klassische Transaktionen, mobile Szenarien oder Analysen. Unternehmen definieren einfach, welche Informationen wie genutzt werden sollen und wie wichtig sie im Tagesgeschäft sind. Die Plattform verteilt sie dann automatisch zwischen den Datenbanken. Die wichtigsten Daten („Hot Data“) werden im Echtzeitspeicher gehalten, wo sie jederzeit sekundenschnell verfügbar sind. So haben Entscheider alle Kennzahlen rasch zur Hand, © S.A.R.L. Martin/IT Research März 2013 27 Inhalt Strategic Bulletin: Analytische Datenbanken Fertigungsleiter erkennen beispielsweise noch in der laufenden Produktion mögliche Normabweichungen. Die große Masse der Daten („Cold Data“) dagegen liegt in kostengünstigeren Speichern. Mit dieser Doppelstrategie lassen sich Petabytes an Informationen zuverlässig, zeitsparend und kostenoptimiert verwalten. Ganzheitliches Datenmanagement. Bislang bilden Datenbanksysteme meist isolierte Silos. Administratoren verwalten jede Datenbank einzeln und passen sie manuell an die Erfordernisse der Geschäftslösungen an. Ein Aufwand, der in Zeiten von Big Data nicht mehr zu stemmen ist. Die SAP Real-Time Data Platform revolutioniert das Konzept mit einer einfachen Grundidee: Sie fasst alle Datenbanken zusammen. Die IT-Abteilung kann sämtliche Informationen zentral verwalten, statt einzelne Systeme separat anzusprechen. Für Analysezwecke enthält die Plattform die Komponenten SAP Sybase® IQ und SAP HANA®. Der Analyse-Server SAP Sybase IQ. Die Datenbank SAP Sybase IQ hält Business-Intelligence-Daten vor und eignet sich besonders für Ad-hoc-Analysen. Im Gegensatz zu traditionellen Datenbanken ist SAP Sybase IQ mit ihrem spaltenorientierten Aufbau speziell für Abfragen strukturierter und unstrukturierter Daten optimiert. Patentierte Komprimierungsverfahren sorgen für einen vergleichsweise geringen Platzbedarf. Die OLAP-Datenbank (Online Analytical Processing) benötigt keine spezielle Serverhardware, sondern ist mit Standardkomponenten kompatibel, wie sie auch im privaten Umfeld üblich sind. Teure Vorabinvestitionen und eine komplexe Wartung entfallen. Speicherkosten und Administrationsaufwand sind damit niedriger als bei herkömmlichen Systemen. Hinzu kommt: Große Datenvolumina lassen sich 10- bis 100-mal schneller analysieren als über transaktionale Datenbanken. Die spaltenbasierte Architektur macht eine Optimierung für einzelne Abfragen überflüssig und vereinfacht so wichtige Einsatzzwecke wie die Mustererkennung (Data Mining). SAP Sybase IQ lässt sich reibungslos mit Apache Hadoop verbinden, wodurch sich selbst größte Datenmengen effizient verarbeitet lassen. Mitarbeiter in den Fachabteilungen können jetzt eigenständig viele Terabytes an Daten analysieren – ohne die Hilfe der IT-Abteilung. Die Echtzeit-Datenbank SAP HANA. SAP HANA ist eine revolutionäre In-Memory-Appliance, mit der sich in Sekundenschnelle enorme Informationsmengen auswerten lassen. Die Besonderheit: Daten werden statt auf Festplatten im wesentlich schnelleren Arbeitsspeicher verarbeitet und ähnlich wie bei SAP Sybase IQ für Analysezwecke spaltenweise abgelegt. Aktuell irrelevante Informationen erkennt SAP HANA und blendet sie aus. Auf diese Weise erreicht das System einen sehr hohen Komprimierungsgrad. Das ermöglicht extrem schnelle Auswertungen und Simulationen – im Vergleich zu herkömmlichen Datenbanken steigt die Verarbeitungsleistung um das bis zu 10.000-fache. SAP HANA unterstützt heute sämtliche Anwendungen der SAP Business Suite und damit alle wichtigen Geschäftsprozesse. Die Zukunft des Datenmanagements. Wer in der Big-Data-Ära ganz vorne mitspielen will, braucht mehr als eine effektive Datenbank. Mit leistungsstarken Analyse-Tools lassen sich in den Datenbergen wahre Schätze heben und neue Geschäftsfelder erschließen. Dabei unterstützt eine stabile Architektur aus verschiedenen Datenbanken und Anwendungen. SAP wird die SAP Real-Time Data Platform auf Jahrzehnte weiterentwickeln. Mit dieser zukunftssicheren Technologie sind Unternehmen für die digitalen Herausforderungen von heute und morgen bestens aufgestellt. 4.6 Herausforderungen an Analytik und den Umgang mit analytischen Datenbanken Die Analyse von großen und sehr großen Datenmengen wird von den Big Data-Vorreitern wie Amazon, eBay, Facebook, Google, Sears, Twitter, Walmart etc. zwar schon seit einiger Zeit betrieben, aber Vorgehensweisen in solcher Big Data-Analytik stützen sich auf eine noch überschaubare Menge von Erfahrungen. Hier haben wir fünf Herausforderungen zusammengestellt, die Nutzern helfen sollen, die ersten Schritte in Richtung Big Data-Analytik mit analytischen Datenbanken zu gehen. [6] Das unterstreichen einige neuere Marktstudien, siehe den Beitrag bei InformationAge http://www.information-age.com/channels/information-management/features/1687078/its-focus-shifts-to-data-management.thtml © S.A.R.L. Martin/IT Research März 2013 28 Inhalt Strategic Bulletin: Analytische Datenbanken 1. Herausforderung: Das Feststellen der Relevanz von Information für die Problemstellung. Welche Information bietet dem Unternehmen einen Mehrwert in Bezug auf die Kosten der Identifizierung, Extraktion, Speicherung und Analyse? Das ist die Grundsatzfrage, die man in priori in den seltensten Fällen beantworten kann. Ein Lösungsansatz stellt das „Drei-W-Vorgehen“ dar. Das erste W ist das „Was“. Diese Frage bezieht sich auf die Daten und die Information, die zur Analyse benötigt werden. Hier hilft beispielsweise das Aufstellen von Relevanzmaßen. Bei Stimmungsanalysen kann man beispielsweise eine Datenquelle danach bewerten, wie oft ein uns interessierender Begriff in welchen Zeitraum vorkommt. Dabei helfen die bekannten Suchfunktionen, um sich solche Statistiken zu erarbeiten. Hier sollte auch der externe Berater mit Best Practices helfen. Ansonsten gilt: Ausprobieren und iterieren („trial and error“). Man betritt hier definitiv Neuland. Die zweite Frage ist die nach dem „Wie“. Hier geht es um die Frage, welche Analyse-Methoden angewendet werden sollen oder können und wie der Prozess zum Verstehen und Interpretieren der Ergebnisse aussieht. Die dritte Frage ist die nach dem „Was nun“. Hier geht es um die Frage wie Entscheidungen abgeleitet und getroffen werden und welche Maßnahmen in Gang gesetzt werden. Denn im Endeffekt lässt sich der Wert von Information dann am besten verstehen, wenn die Information und das das daraus abgeleitete Wissen in Prozessen umgesetzt und der monetäre Nutzen gemessen werden. 2. Herausforderung: Das Aufsetzen einer Organisation für Analytik. Ein Analytik-Kompetenzzentrum bietet eine geeignete Organisationsstruktur. Es ist eine funktionsübergreifende Einheit im Unternehmen, die als interdisziplinäres Team verantwortlich ist, den Einsatz von Analytik im Unternehmen zu fördern. Es besteht aus einem Leitungsgremium, dem ein Analytik-Sponsor vorsitzt, dem eigentlichen Kompetenzzentrum und BusinessAnalysten und Data Stewards, die in den Fachbereichen sitzen. Der Sponsor sollte aus der Geschäftsführung oder dem Vorstand kommen, damit die Analytik-Strategie im gesamten Unternehmen auch durchgesetzt werden kann. Das Analytik-Kompetenzzentrum zentralisiert das Management der Analytik-Strategie und der AnalytikMethoden, -Standards, -Regeln und -Technologien. Sein Leitsatz ist: Das Analytik-Kompetenzzentrum plant, unterstützt und koordiniert Analytik-Projekte und sorgt für den effizienten Einsatz aller Ressourcen und der Technologie. Allerdings sind Experten für Big Data-Analytik noch rar im Markt. Hier sollte man auf jeden Fall auf spezialisierte Beratungsunternehmen zurückgreifen, denn sonst kann man schnell viel Zeit und Geld verlieren ohne einen Mehrwert aus Big Data-Analytik zu erzielen. Vor allem: Starten Sie nicht ins Big Data ohne externe Beratung, die neben den analytischen Technologien vor allem auch in Sachen Organisation berät. Jetzt braucht man neue Wege in der Zusammenarbeit IT und Fachabteilung sowie neue Rollen und Arbeitsplatzbeschreibungen wie die von Data Scientists. Das sind Mitarbeiter mit folgendem Profil: • Technische Expertise: Tiefe Kenntnisse in einer Natur- oder Ingenieurs-Wissenschaft sind notwendig. • Problembewusstsein: die Fähigkeit, ein Problem in testbare Hypothesen aufzubrechen. • Kommunikation: die Fähigkeit, komplexe Dinge per Anekdoten durch einfach verständliche und gut kommunizierbare Sachverhalte darzustellen. • Kreativität: die Fähigkeit, Probleme mit anderen Augen zu sehen und anzugehen („thinking out oft he box“). “Data scientists turn big data into big value, delivering products that delight users, and insight that informs business decisions. Strong analytical skills are given: above all a data scientist needs to be able to derive robust conclusions from data.” Daniel Tunkelang, Principal Data Scientist, LinkedIn © S.A.R.L. Martin/IT Research März 2013 29 Inhalt Strategic Bulletin: Analytische Datenbanken Im Endeffekt wird so Datenmanagement wieder zur eigentlichen und Hauptaufgabe der IT [6], während das Beherrschen der Prozesse und der Analytik die Hauptaufgabe der Fachbereiche ist. Als ständige Einrichtung kann das Analytik-Kompetenzzentrum sowohl innerhalb der IT-Organisation als auch in einer operativen Fachabteilung wie dem Finanzressort angesiedelt sein. Für Analytik-Kompetenzzentren gilt grundsätzlich: Sie sind unternehmensspezifisch und sollten auf jeden Fall an die Kultur und Business-Ethik des Unternehmens angepasst sein. 3. Herausforderung: Das Auswählen der Technologie und der Werkzeuge. Hier sollte auch der externe Berater helfen. Es empfiehlt sich zuerst die Business Cases auf ihre Anforderungen technologischer und methodischer Art hin zu untersuchen. Denn – wie schon gesagt – die Auswahl der Technologie und der Werkzeuge, sowie die Frage der Bereitstellung – Cloud oder nicht Cloud – hängt davon ab. Hier verweisen wir auch nochmal auf das Kapitel 3.4, dass eine Strukturierung der analytischen Technologien gibt. 4. Herausforderung: Das kontinuierliche „Anders-Denken“. Hier gilt als Regel: keine Annahmen treffen, keine Hypothesen haben, wenn es um Analytik in Echtzeit geht. Denn solche Big Data-Analysen dienen ja gerade dazu, Hypothesen zu finden, die man so nicht kannte und erwartet hatte. Das Testen solcher Hypothesen erfolgt erst in einem zweiten Schritt. Das Problem ist hier, dass wir aus der „alten“ Zeit, in der nur wenig Information zur Verfügung stand, es gewohnt sind, mit Hypothesen zu arbeiten, die man aus Erfahrungswissen her kannte. Analyse diente dann genau dem Testen solcher Hypothesen. Jetzt im Big Data dient Analyse zuerst eben dem Finden von Hypothesen. Das ist neues, anderes Denken, an das man sich erst noch gewöhnen muss. 5. Herausforderung: Bei Analyse in Echtzeit ein Ende finden und den Analyseergebnissen vertrauen. Hier können wir an den zweiten der fünf Nutzenaspekte aus Kapitel 2.2 anknüpfen: Erfolgskontrolle aller Maßnahmen und Testen aller Entscheidungen. Wenn eine Hypothese gefunden wurde, dann sollte man die schnell in einen Test umsetzen und Kunden und Markt entscheiden lassen, ob die Hypothese falsch ist oder zu positiven Auswirkungen geführt hat. Das entspricht dem Vorgehen der Big Data-Vorreiter, die ihre gefundenen Hypothesen zügig in Testumgebungen umgesetzt haben und dann die Wirkung gemessen haben. Das ist schnell und dann auch monetär bewertbar. Im Endeffekt ist das natürlich auch wieder ein iteratives Verfahren nach der “trial and error”-Methode. Da man aber Kunde und Markt einbezieht, hat man in jeder Iteration eine direkte Wirkung auf die Bottom-Line und damit eine zuverlässige Steuerung des Gesamtprozesses mit Umsatz und Profit als mögliche Zielgrößen. Hier sieht man auch, wie wichtig das Wissen eines externen Beraters in den organisatorischen Fragen ist: Nur wenn ein solches iteratives Verfahren in der Unternehmensorganisation machbar ist, kann Big Data-Analytik mittels analytischer Technologien tatsächlich einen messbaren Mehrwert erzeugen. Fazit Kapitel 4: Roadmap analytische Datenbanken: • Der Markt besteht zum einen aus den neuen, aufkommenden Anbietern, die mit innovativen Technologien in den Markt kommen. Zum anderen besteht er aus den „großen“ Anbietern, die sich entweder in Big Data-Analytik neu positionieren und/oder durch Akquisitionen sich neue, innovative Technologien beschaffen. Aber, keine Regel ohne Ausnahme wie beispielsweise SAP mit HANA. • Nutzer von Big Data stehen vor fünf Herausforderungen, die (wie immer) nicht nur im Meistern der Technologie bestehen, sondern vor allem in der Organisationsstruktur (Wie stelle ich mich für Big Data auf?) und in der Vorgehensweise (iterativ Hypothesen finden und testen) bestehen. Der Erfolg von Big Data-Analysen muss iterativ durch seine Auswirkungen auf Kunden- und Marktverhalten gemessen und monetär bewertet werden. © S.A.R.L. Martin/IT Research März 2013 30 Inhalt Strategic Bulletin: Analytische Datenbanken 5. Big Data-Analytik – Quo Vadis Realität – 2013 • Der Markt für analytische Datenbanken und Big Data-Analytik ist noch jung. Es gibt aber durchaus grundsätzliche Kritik am Ansatz: 3 Big Data-Analytik-Initiativen sind heute meist IT-getrieben. Daher erfolgt die Technologie-Auswahl, Datenidentifizierung und Analyse oft technischen Gesichtspunkten. Das Problem ist hier zumeist, dass eine Unternehmensstrategie für Analytik und den Einsatz analytischer Technologien fehlt. 3 Größere Datenmengen müssen nicht qualitativ bessere Daten sein. Die traditionell bewährten Maßnahmen von Datenqualitäts-Management werden vielfach nicht beachtet. 3 Betrachten wir nochmal die Frage der Interpretation: Die bekannte Problematik aus dem traditionellen Data Mining tritt natürlich in der Big Data-Analytik verschärft auf: Mathematische Zusammenhänge müssen nichts mit den Phänomenen in der realen Welt zu tun haben. Fehlschlüsse können zum Teil fatale Folgen haben. Deshalb ist das kontrollierte Testen und Bewerten von Ergebnissen aus der Big Data-Analytik so wichtig. 3 Nicht alle Datenquellen sind gleich und sind nicht unbedingt vergleichbar. Dabei werden auch statistische Grundprinzipien wie das einer repräsentativen Stichprobe oft vernachlässigt. 3 Big Data-Analytik hat zum Teil die Tendenz, ethische Grenzen zu überschreiten. Man sollte sich stets fragen, ob die mit Big Data-Analytik angestrebte Transparenz des Kunden im Sinne eines „Big Brother is watching you“ mit der Unternehmensethik vereinbar ist. • Trotz aller Kritik an Big Data-Analytik: die Big Data-Vorreiter Amazon, eBay, Facebook, Google und andere zeigen, dass Potenziale durch die Analyse großer und sehr großer Datenmengen existieren und geldwerten Vorteil bringen können. Das gilt in zunehmenden Masse für die Analyse von Daten aus dem Internet der Dinge. Hier öffnen sich sehr wohl Chancen zu Innovationen und innovativen Prozessen. • Trotz aller Skepsis zum Hype um Big Data-Analytik: Die IT-Anbieter investieren große Summen und erwarten viel von diesem schnell wachsenden Markt. • Schließlich sollte man auch nicht vergessen, dass all die genannten Datenquellen sprudeln. Die Informationsproduktion der digitalen Welt ist enorm und gleichzeitig stehen mächtige Analyseverfahren aus Mathematik, Statistik, Linguistik und aus der Welt der künstlichen Intelligenz zur Verfügung, mit denen man in der Tat Hypothesen finden kann, die sich kein Mensch je ausgedacht hätte. Das ist der Reiz, genauso wie im traditionellen Data Mining jetzt im Big Data „Nuggets“ zu finden, nur noch grösser und wertvoller. Trends – 2014/15 • Technologie-Trends: 3 Die traditionellen führenden Datenbankanbieter werden ihre SQL-Datenbanken zu hybriden Datenbanken ausbauen, in dem NoSQL-Techniken integriert werden, so dass man durch die Kombination der SQL mit der NoSQL-Welt die Vorteile beider Welten miteinander verbindet und die Marktführerschaft erhalten bleibt. Dazu kommt die sich weiter ausbreitende Nutzung von Data Appliances, die in die gleiche Richtung zielt. Die SAP wird mit der HANA-Technologie zu den führenden Datenbankanbietern aufschließen, jedenfalls in ihrer eigenen Kundenbasis. Sie hat zudem die Chance mit HANA ganz neue Anwendungsgebiete für Analytik zu öffnen. © S.A.R.L. Martin/IT Research März 2013 31 Inhalt Strategic Bulletin: Analytische Datenbanken 3 Es werden Datenanalyse-Bibliotheken entstehen, vor allem auf Basis von R, der freien Programmiersprache für statistisches Rechnen und statistische Grafiken. In einer solchen Bibliothek werden gemeinsame AnalyseMuster und Vorgehensweise als offene Services verfügbar sein, so dass man mittels Analyse-Best Practices schnell die Nutzenpotenziale von Big Data erkennen und nutzen kann. Das wird auch zum Teil die Schmerzen aufgrund des Mangels an Experten lindern. 3 Big Data-Technologien etablieren sich im Konzert mit den anderen vier IT-Megatrends: Mobile, Cloud Computing, Social Media und Consumerization. Die Anbieter werden ihre Technologien unter diesem gemeinsamen Blickwinkel weitertreiben. • Markt-Trends: 3 Im Markt für analytische Technologien werden wir – wie für einen jungen Markt ganz typisch – viele Übernahmen und Firmenzusammenschlüsse sehen. Die großen IT-Anbieter und Dienstleister werden auch hier vorne sein und bleiben. 3 Open Source-Angebote wie Hadoop und R werden in der Big Data-Analytik einen größeren Anteil erreichen und eine größere Rolle spielen als im traditionellen BI-Markt. Das folgt aus dem größeren Pool von verfügbaren Experten in Open Source-Technologien und einem Vorsprung an Funktionalität in den Open Source-Systemen aufgrund einer großen Anzahl von engagierten Entwicklern. 3 Gleiches gilt für Cloud-Angebote wie Data Warehouse as a Service. Die werden gewinnen, da man diese Services unkompliziert finanzieren kann und ohne großen Aufwand ein- und vor allem auch abschalten kann. Zudem werden solche Angebote zurzeit mit Kampfpreisen in den Markt gedrückt. • Business-Trends: 3 Start-Ups werden besonders von analytischen Technologien profitieren. Das unterstreichen die Big DataVorreiter, die alle so gestartet sind. Der Grund liegt in der Regel in der Flexibilität von Start-Ups, die Big DataDenken und Big Data-Organisationstrukturen viel leichter umsetzen und leben können als traditionelle Unternehmen. 3 Trotz des aktuellen Hypes wird sich Big Data bei der Mehrzahl der Unternehmen immer noch in der Pilotierungsphase befinden. Der große Bremser ist nicht die Verfügbarkeit und der Reifezustand der Technologie, sondern der Mangel an Experten und Beratern sowie die Schwierigkeit, die notwendigen neuen Denk- und Arbeitsweisen in den Alltag traditioneller Unternehmen zu verankern. 3 Big Data-Analytik setzt neue Richtlinien für die Zusammenarbeit zwischen IT und Business. Während die Fachabteilungen die Oberhoheit über die Strategie, Prozesse und Analytik festigen werden, wird die IT die Rolle des Information Management als Kernaufgabe wiedergewinnen. Die Schnittstelle zwischen diesen beiden Sichten bilden dann die Prozesse, denn es gilt ja auch im Big Data: Kein Prozess ohne Daten. 3 Mit der Nutzung von Big Data-Analytik ergeben sich neue Anforderungen an Compliance und Datenschutz, die zu meistern sind. Es werden sich neue gesetzliche Regeln entwickeln, die jetzt die gemeinsame Speicherung von Daten aus den unterschiedlichsten Quellen zu regulieren haben, beispielsweise Regeln, die beschreiben in welcher Art Finanz- und Gesundheitsdaten ein und der derselben Person gemeinsam gespeichert und genutzt werden dürfen. Weiterhin ist auch eine Regulierung der Nutzung der öffentlich zugänglichen Social Media-Daten zu erwarten, denn man wird eine solche Regelung besser nicht den Facebooks und Co. überlassen wollen. © S.A.R.L. Martin/IT Research März 2013 32 Inhalt Strategic Bulletin: Analytische Datenbanken 6. Profil: Wolfgang Martin Team und IT Research Dr. Wolfgang Martin ist ein europäischer Experte auf den Gebieten • Business Intelligence, Performance Management, Analytik und Big Data • Business Process Management, Information Management, Information Governance • Customer Relationship Management (CRM) • Cloud Computing (SaaS, PaaS) Sein Spezialgebiet sind die Wechselwirkungen technologischer Innovation auf das Business und damit auf die Organisation, die Unternehmenskultur, die Businessarchitekturen und die Geschäftsprozesse. Er ist Mitglied im BI Boulder Brain Trust (www.boulderbibraintrust.org), iBonD Partner (www.iBonD.net), Ventana Research Advisor (www.ventanaresearch.com) und Research Advisor des Instituts für Business Intelligence der Steinbeis Hochschule Berlin (www.i-bi.de). The InfoEconomist zählte ihn in 2001 zu den 10 einflußreichsten IT Consultants in Europa. Dr. Martin ist unabhängiger Analyst. Vor der Gründung des Wolfgang MARTIN Teams war Dr. Martin 5 ½ Jahre lang bei der META Group, zuletzt als Senior Vice President International Application Delivery Strategies. Darüber hinaus kennt man ihn aus TV-Interviews, durch Fachartikel in der Wirtschafts- und IT-Presse, als Autor der Strategic Bulletins zu den Themen BI, Big Data, EAI, SOA und CRM (www.it-research.net) und als Herausgeber und Co-Autor von Büchern, u.a. „Data-Warehousing – Data Mining – OLAP“, Bonn, 1998, „CRM – Jahresgutachten 2003, 2004, 2005, 2006 & 2007“, Würzburg, 2002, 2003, 2004, 2005 & 2007 und „CRM Trend-Book 2009“, Würzburg, 2009. Wolfgang Martin Team, 6, rue Paul Guiton, 74000 Annecy, France, E-Mail: [email protected] IT Research ist ein deutschsprachiges Unternehmen, das Studien, Bulletins und White Papers im Bereich der Informationstechnik erstellt. Ziel ist, auf neueste Technologien hinzuweisen, IT-Investitionen der Unternehmen noch rentabler zu machen, Fehlinvestitionen zu vermeiden und Risiken zu minimieren. Um dies zu erreichen, arbeiten wir mit einem Netzwerk von Kompetenzträgern auf den verschiedensten Gebieten der IT zusammen it verlag GmbH, Michael-Kometer-Ring 5, D-85653 Aying Tel. 0049 8104 649414, E-Mail: [email protected] © S.A.R.L. Martin/IT Research März 2013 33 Inhalt Strategic Bulletin: Analytische Datenbanken 7. Profil: Die Sponsoren Datawatch Die Datawatch Corporation (NASDAQ-CM: DWCH) ist ein Anbieter von Softwarelösungen für Information Optimization. Die Technologie-Plattform ermöglicht Unternehmen den einfachen Zugriff auf verschiedene Datenquellen und Umwandlung beliebiger Datenformate in strukturierte Daten. Damit erschließen sich Unternehmen wertvolle Informationsquellen für individuelle Analysen und unterstützen maßgeblich ihre Datenmanagement-und Reporting-Strategie im BI-Umfeld und operativen Bereich. Grundlage sind dabei statische Berichte, PDF-Dateien, Textdateien und sonstige Datenquellen aus ERP-, CRM- und anderen Unternehmensanwendungen. Bereits 40.000 Kunden in über 100 Ländern sind von Datawatch Lösungen überzeugt. Datawatch hat seine Firmenzentrale in Chelmsford, Massachusetts, USA, und unterhält Büros in München, London, Sydney und Manila. Weitere Informationen sind unter www.datawatch.com zu finden. InterSystems InterSystems ist der führende Anbieter von Software für ein vernetztes Gesundheitswesen. Das Unternehmen hat seinen Hauptsitz in Cambridge, USA, und Niederlassungen in 23 Ländern. InterSystems HealthShare™ ist eine strategische Plattform für die Informationsverarbeitung im Gesundheitswesen und den Aufbau regionaler oder nationaler elektronischer Gesundheitsakten. Die hochperformante Objektdatenbank InterSystems Caché® ist das weltweit meistgenutzte Datenbanksystem für klinische Anwendungen. InterSystems Ensemble® ist eine Integrations- und Entwicklungsplattform, die Anwendungen schnell miteinander verbindet und um neue Funktionen erweitert. InterSystems DeepSee™ ist eine Software, mit der Echtzeit-Analysefunktionen direkt in transaktionale Anwendungen eingebettet werden können, um bessere Entscheidungsgrundlagen für das Tagesgeschäft zu erhalten. InterSystems TrakCare™ ist ein webbasiertes, einheitliches Informationssystem für Krankenhäuser und Krankenhausverbünde bis hin zu landesübergreifenden Gesundheitsinformationssystemen, das schnell alle Leistungen einer elektronischen Patientenakte zur Verfügung stellt. Weitere Informationen finden Sie unter www.intersystems.de. © S.A.R.L. Martin/IT Research März 2013 34 Inhalt Strategic Bulletin: Analytische Datenbanken SAP AG Wer wichtige Daten in Echtzeit durchsuchen kann, gewinnt wertvolle Zeit im Wettlauf mit der Konkurrenz. SAP hat daher mit der „Real-Time Data Platform“ eine ganzheitliche Datenbankstrategie entwickelt, mit der Sie individuelle Anforderungen zuverlässig abdecken können: • SAP Sybase ASE ist die Basis für Ihre transaktionalen Daten (OLTP) aus SAP ERP, SAP Customer Relationship Management und anderen Anwendungen der SAP Business Suite. • SAP HANA® ermöglicht hochdetaillierte Auswertungen in Echtzeit (In-Memory-Computing). • SAP Sybase IQ unterstützt die Analyse von Business-Intelligence-Daten und dient als Speicher für SAP NetWeaver® Business Warehouse. Weiterführende Informationen finden Sie unter www.sap.de/datenmanagement, beziehungsweise zu SAP HANA unter www.sap.de/echtzeit Als Marktführer für Unternehmenssoftware unterstützt die SAP AG Firmen jeder Größe und Branche, ihr Geschäft profitabel zu betreiben, sich kontinuierlich anzupassen und nachhaltig zu wachsen. Vom Back Office bis zur Vorstandsetage, vom Warenlager bis ins Regal, vom Desktop bis hin zum mobilen Endgerät – SAP versetzt Menschen und Organisationen in die Lage, effizienter zusammenzuarbeiten und Geschäftsinformationen effektiver zu nutzen als die Konkurrenz. Mehr als 190.000 Kunden (inklusive Kunden von SuccessFactors) setzen auf SAP-Anwendungen und -Dienstleistungen, um ihre Ziele besser zu erreichen. Weitere Informationen unter www.sap.de. © S.A.R.L. Martin/IT Research März 2013 35 Inhalt Die Sponsoren: