Microsoft PowerPoint - Vortrag_Fr\366schke.pptx
Werbung

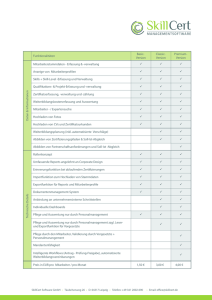
Neo4J & Sones GraphDB Graph-Datenbanken Von Toni Fröschke Problemseminar NoSQL-Datenbanken (WS 2011/12) Gliederung • Neo4J – – – – – Überblick Neo4J-Komponenten Datenhaltung/ -verwaltung Verfügbarkeit & Recovery I/O & Performance Transaktionsverwaltung • Sones GraphDB – – – – Storage Engines GraphFS GraphDB GraphDS • Implementierungsbeispiele Neo4J • Java implementierte Open-Source-Graphdatenbank • Entwicklung von Neo Technology entwickelt, – Sitz in Malmö/Schweden und San Francisco Bay/USA • • • • • Daten in Graphen anstelle in Tabellen strukturiert Neo4j Version 1.0 im Februar 2010 freigegeben Community-Edition unter (GPL) v3 Zusatzmodule unter (AGPL) v3 Freie oder kommerzielle Lizenz (6000 $ - 24000$) Neo4J-Komponenten Neo4J-Komponenten • Relationships Neo4J-Komponenten • Properties Neo4J-Komponenten • Property Datentypen Neo4J-Komponenten • Paths Neo4J-Komponenten • Traversierung Datenhaltung/ -verwaltung Datenintegration • Eventbasierende Synchronisation – Eventauslösung beim Speichern von Daten – Asynchron • Periodische Synchronisation – Periodischer Export aus RDBMS, Import mittels SQL Query – Master/Slave Sync. • Periodisch vollständiger Datenimport/ -export – Import großer Datenmengen in kurzer Zeit Datenhaltung/ -verwaltung Indexierung • Datenbank selbst als natürliche Indexierung • Separat – Apache Lucene als Standart-Backend mit Neo4j Datenhaltung/ -verwaltung Dateigröße • Dateigröße wird nur durch Betriebssystem begrenzt • Keine Limits durch Neo4j. • Konstruktion einer Speichermap durch Neo4j Datenhaltung/ -verwaltung Datengrößen • Begrenzung duch Adressierungsspeicher für Primärschlüssel • Verfügbar: – 2ˆ35 (~ 34 Billionen) Nodes – 2ˆ35 (~ 34 Billionen) Relationships – 2ˆ36 (~ 68 Billionen) Properties Datenhaltung/ -verwaltung Datenintegrität • Core Graph Engine – Speicherung des Datenmodells als Graph im Speicher – Referenzen zwischen Relationships, Nodes und Properties • Andere Datenquellen – Nicht Graph basierte Suchsoftware wie Apache Lucene – Zusätzliche Indexierung für Text-Queries – Zwei Phasen Commit mit Rollbackunterstützung Datenhaltung/ -verwaltung Datensicherheit • Keine explizite Datenverschlüsselung • Möglichkeit eigener Verschlüsselung mittels Java • Oder: Sicherung der Daten durch Verschlüsselten Datenspeicher • Datensicherung besser auf oberen Ebenen Verfügbarkeit & Recovery • Operationale Verfügbarkeit • Online Backup (Cold spare) • Online Backup (Hot spare) • High Availability Cluster – Cluster von Datenbankinstanzen – Ein Master mit n Slaves Verfügbarkeit & Recovery High Availability Cluster Verfügbarkeit & Recovery Notfall-Recovery • Prävention – Online Backups nicht lokal – High Availability Cluster • Erkennung – SNMP und JMX Monitoring • Korrektur – Online Backup – High Availability Cluster I/O & Performance Lesegeschwindigkeit • Kein Blockieren oder Sperren von Leseoperationen • Lesezugriffe über Threads möglich – Simultane Querieabarbeitung • Gute Skalierbarkeit I/O & Performance Schreibgeschwindigkeit • Kontinuierliche Operationen – Schreiboperationen parallel zu Leseoperationen möglich – Schreibgeschwindigkeit I/O-Kapazität begrenzt • Bulk-Operation – Batch Inserter für direktes Speichern – Batch Inserter für große nicht transaktionale Datenimporte optimiert Transaktionsverwaltung • ACID Eigenschaften – Atomicity • Consistency – Isolation » Durability • Cypher Query Language START john=node:node_auto_index(name = 'John') MATCH john-[:friend]->()-[:friend]->fof RETURN john, fof Transaktionsverwaltung Interaktionszyklus • Schreiboperationen im Graph nur über Transaktionen • Mehrere Threads für Transaktionen möglich • Rollback Verfügbarkeit über gesamte Transaktion • Interaktionszyklus – 1. Start der Transaktion – 2. Schreib-Operationen – 3. Transaktionsmarkierung als erfolgreich oder nicht – 4. Beenden der Transaktion Transaktionsverwaltung Isolationsebenen • Standart Isolationsverhalten: – Keine Blocks oder Locks auf bei Leseoperationen • Möglichkeit einer stärkeren Isolation – Manuelle Lese- und Schreiblocks Transaktionsverwaltung Standart Lockverhalten • Schreiblock bei – Hinzufügen, Verändern oder Entfernen von Node-Properties oder Relationships – Erstellen und Löschen von Nodes – Erstellen oder Löschen von Relationships • Locks sind Transaktionsgebunden Transaktionsverwaltung Deadlocks • Deadlocks oft verursacht durch konkurrierende Schreibanfragen • Deadlock-Erkennung vor dem Eintreten Exception • Lösen der Locks in der Finally-Clause • Abarbeitung wartender Transaktionen nach Lösen der Locks Transaktionsverwaltung Löschsemantik • Löschen von Nodes und Relationships Entfernen aller dazugehörigen Properties – Jedoch bleiben Relationships bestehen • Relationship-Bedingung beachten: – Notwedigkeit eines Start- und End-Node – Löschen eines Knotens mit Relationship Exception • Allgemeine Semantik: – Entfernen von Node oder Relationship Entfernen aller Properties – Gelöschter Node darf keine Relationships besitzen – Möglichkeit einer Referenz auf einen gelöschten Node oder Relationship Kein Commit! – Schreiboperationen auf Node oder Relationship nach Löschung (ohne Commit) Exception – Benutzen einer Referenz eines gelöschten Objektes nach Commit Exception SonesGraph DB • • • • Modellierungskonzept basiert gewichteten Graphen Entwicklung durch Firma sones in Erfurt und Leipzig Open Source Edition seit Juli 2010 Kommerziell verfügbare Enterprise Version: – Erweiterten Funktionsumfang • Implementierung komplett in C# • sones ist Mitglied der Open Source Business Alliance SonesGraph DB • Vollständige Eigenentwicklung • Gegebene Ansätze sollten neu durchdacht werden • Vier Anwendungsschichten – – – – StorageLayer Dateisystem Datenbankmanagementsystem Data Access Layer Architektur Storage Engines • Trennung von physikalischen Speichermedien und Applikationslogik • Schnittstelle bietet Möglichkeiten zur Performancemessung und Fehlermanagement Dateisystem - GraphFS • • • • • • Blockbasierte Speicherung der Objekte als Datenströme Datenstrom als Schnittstelle zwischen DS und SE Zugriff nicht an lokale Speichersysteme begrenzt Metadaten zur Performanceunterstützung ObjectLocation Indexierung gezielter Zugriff Möglichkeit Definition und Auswertung eigener Metadaten Dateisystem - GraphFS • Funktionen: – Speicherung der Daten in netzartigen Strukturen – Speicherung strukturierter Daten (Objekten) und Binärdaten – Automatische Datenstrukturierung und -optimierung – Direkte Verbindung mit dem Datenbankmanagementsystem – Versionierung von Datenobjekten Datenbankmanagementsystem - GraphDB • Hauptfunktion: Datenorganisation • Objektspeicherung und –bereitstellung • Datenzugriffe über Graph Query Language • Indirekte Abfrageauswertung möglich • Kein zusätzliches Mapping nötig Datenbankmanagementsystem - GraphDB • Funktionen – – – – – Attribute der Datenobjekte in typischen C#-Datentypen Vererbung von Objekten Versionierung von Objekten Datensicherheit auf Objektebene möglich Datenintegrität wird durch Prüfsummen DataStorage – GraphDS • Schnittstellen zum Produkt • Administration über GQL-Kommandozeile oder Benutzeroberfläche • Zusätzlich WebService, REST oder WebShell • SPARQL als weiteren Ansatz geplant Zusammenfassung Neo4J Sones GraphDB Implementierung Java (+ Apache Lucene) .Net & Mono Lizenz Duallizenz: GPLv3 und AGPLv3 / kommerziell AGPL, kommerziell Zugriff Java API, Cypher Java API, C# API, WebShell, REST, GQL Skalierbarkeit +(+) ++ Verschlüsselung 0 (Java) + Integrität Referenzen / Graph im RAM Prüfsummen Datenaktualität (verteilt) Event / Master-Slave sync Versionierung Performance + +