AK der Biostatistik - Multivariate Methoden (LVA-Nr
Werbung

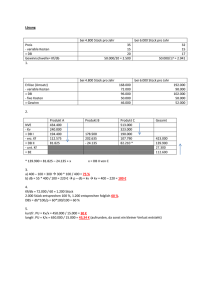
1 Ausgewählte Kapitel der Statistik: Regressions- u. varianzanalytische Modelle Lösung von Grundaufgaben mit SPSS (ab V. 11.0) Text: akmv1_v11.doc Daten: akmv1??.sav Lehrbuch: W. Timischl, Biostatistik. Wien - New York: Springer 2000 Problem 1.1: Abhängigkeitsanalysen - mehrfach lineare Regression Die folgenden Daten sind einer Studie entnommen, in der u.a. das Gesamtcholesterin Y (in mg/dl), das Gewicht X1 (in kg) und das Alter X2 (in a) bestimmt wurden. Es sollen (mit den von 12 Probanden stammenden Daten) im Rahmen eines zweifach-linearen Modells folgende Fragen untersucht werden: i) Hängt Y global von X1 und X2 ab? (globale Abhängigkeitsprüfung, α = 5%). Wenn ja, wie lautet das Regressionsmodell? ii) Ist eine Reduktion auf ein lineares Modell mit nur einem Regressor möglich? (partielle Abhängigkeitsprüfung, α = 5%) Daten: akmv111.sav i1) Daten, einfache Statistiken Analysieren - Berichte - Fälle zusammenfassen ... Zusammenfassung von Fällena 1 2 3 4 5 6 7 8 9 10 11 12 Insgesamt N Mittelwert Standardabweichung Varianz Gewicht/kg 82 60 82 58 80 30 65 33 70 54 68 62 12 62,00 17,008 289,273 Alter/a 48 51 55 30 58 25 45 35 50 40 30 28 12 41,25 11,419 130,386 Gesamtchol./ mg p.dl 350 395 440 290 400 210 350 230 310 290 255 320 12 320,00 70,421 4959,091 a. Begrenzt auf die ersten 100 Fälle. i2) Schätzung der Modellparameter, globale Abhängigkeitsprüfung Analysieren - Regression - linear ... Modellzusammenfassungb Modell 1 R R-Quadrat ,888 a ,789 Korrigiertes R-Quadrat ,742 Standardfehler des Schätzers 35,763 a. Einflußvariablen : (Konstante), Alter/a, Gewicht/kg b. Abhängige Variable: Gesamtchol./mg p.dl 2 ANOVAb Modell 1 Quadratsumme 43039,014 11510,986 54550,000 Regression Residuen Gesamt Mittel der Quadrate 21519,507 1278,998 df 2 9 11 F 16,825 Signifikanz ,001a a. Einflußvariablen : (Konstante), Alter/a, Gewicht/kg b. Abhängige Variable: Gesamtchol./mg p.dl Koeffizientena Modell 1 Nicht standardisierte Koeffizienten Standard B fehler 73,394 43,874 1,686 ,870 3,445 1,295 (Konstante) Gewicht/kg Alter/a Standardisierte Koeffizienten Beta ,407 ,559 T 1,673 1,939 2,660 Signifi kanz ,129 ,084 ,026 95%-Konfidenzintervall für B Untergren Obergren ze ze -25,855 172,644 -,281 3,653 ,515 6,374 a. Abhängige Variable: Gesamtchol./mg p.dl Regressionsfunktion: Y(erwartet) = 73,394 + 1,686 X1 + 3,445 X2 Anpassungsgüte: Es empfiehlt sich, die Modelladäquatheit an Hand eines mit den erwarteten und beobachteten Y-Werten gezeichneten Streudiagramms zu überprüfen. Ein Kennwert für die Anpassungsgüte ist das multiple Bestimmtheitsmaß (=Quadrat der Produktmomentkorrelation zwischen den erwarteten und beobachteten Y-Werten; im 2 Beispiel ist R =78,9%). 2,0 Standard. geschätzter Wert (Y) 1,0 0,0 -1,0 -2,0 R-Qu. = 0.7890 200 300 400 Gesamtchol./mg p.dl (Y) 500 3 ii1) partielle Abhängigeitsprüfung: Ist X1 (Gewicht) redundant? (reduziertes Modell: einfache lineare Regression von Y auf X2) Statistik - Regression - linear ... Modellzusammenfassung Modell 1 Korrigiertes R-Quadrat ,671 R R-Quadrat ,837 a ,701 Standardfehler des Schätzers 40,396 a. Einflußvariablen : (Konstante), Alter/a ANOVAb Modell 1 Quadrats umme 38231,846 16318,154 54550,000 Regression Residuen Gesamt df 1 10 11 Mittel der Quadrate 38231,846 1631,815 F 23,429 Signifikanz ,001 a a. Einflußvariablen : (Konstante), Alter/a b. Abhängige Variable: Gesamtchol./mg p.dl Partieller F-Test: TGs(X1|X2) = [SQRes(X2) - SQRes(X1,X2)]/MQRes(X1,X2) = (16318,154 – 11510,986)/1278,998 = 3,759; Testgröße ist F-verteilt mit dem Zählerfreiheitsgrad 1 und dem Nennerfreiheitsgrad 9 Æ P(TG > 3,759) = 8,45% ≥ α =5% Æ Verkleinerung von SQRes ist nicht signifikant! (dass X2 redundant ist, sieht man auch aus der Tabelle "Koeffizienten" unter i2) ii2) partielle Abhängigkeitsprüfung: Ist X1 redundant? nein! (siehe Tabelle "Koeffizienten" unter i2) Problem 1.2: Abhängigkeitsanalysen - polynomiale Regression Mit Hilfe angegebenen Daten soll die Photosynthese Y (in mmol CO2 pro m2 und s) einer Pflanze als Funktion der Temperatur X (in oC) bei konstant gehaltener (hoher) Lichintensität dargestellt werden. Man prüfe die Abhängigkeit der Variablen Y von X im Rahmen eines quadratischen Modells (α = 5%). Für welche Temperatur ist der Y maximal? Daten: akmv122.sav i) Grafische Untersuchung des Modelltyps (Art der Regressionsfunktion) Grafiken - Streudiagramm ... 25 22 Photosynth. 19 16 14 17 20 23 26 29 32 Temp. (C) Streudiagramm Æ quadratische Regressionsfunktion: Y(erwartet) = b0 + b1*X1 + b2*X2 mit X1 = X, X2 = X*X ii) Daten, einfache Statistiken 4 Zusammenfassung von Fällena 1 2 3 4 5 6 7 8 Insgesamt Temp. (C) 15 15 20 20 25 25 30 30 8 22,50 5,976 35,714 N Mittelwert Standardabweichung Varianz Photosynth. X2 17,91 225 18,30 225 24,52 400 24,41 400 21,77 625 22,73 625 19,09 900 20,57 900 8 8 21,1625 537,50 2,62036 270,251 6,866 73035,714 a. Begrenzt auf die ersten 100 Fälle. iii) Schätzung der Modellparameter, Abhängigkeitsprüfungen (global, partiell) Analysieren - Regression - linear ... Modellzusammenfassung Modell 1 R R-Quadrat ,906a ,820 Korrigiertes R-Quadrat ,748 Standardfehler des Schätzers 1,31482 a. Einflußvariablen : (Konstante), X2, Temp. (C) ANOVAb Modell 1 Regression Residuen Gesamt Quadrat summe 39,420 8,644 48,064 df 2 5 7 Mittel der Quadrate 19,710 1,729 F 11,401 Signifikanz ,014a a. Einflußvariablen : (Konstante), X2, Temp. (C) b. Abhängige Variable: Photosynth. Globaler F-Test: Signifikanz < α =5% Æ Y hängt (im Rahmen des Modells) signifikant von X (und X*X) ab. Koeffizientena Modell 1 (Konstante) Temp. (C) X2 Nicht standard. Koeffizienten B SE -21,875 9,040 4,010 ,841 -,088 ,019 Standard. Koeffizienten Beta 9,146 -9,055 T -2,420 4,769 -4,722 Signifikanz ,060 ,005 ,005 a. Abhängige Variable: Photosynth. Partieller F-Test: Wegen Sign. < α ist weder X (TEMP) noch X2=X*X im Modell redundant. 95%-Konfidenzint. für B UG OG -45,113 1,364 1,849 6,172 -,136 -,040 5 1,5 1,0 Standard. geschätzter Wert (Y) ,5 0,0 -,5 -1,0 -1,5 R-Qu. = 0.8202 16 19 22 25 Photosynth. Regressionsmodell: Y(erwartet) = -21,875 + 4,010 X – 0,088 X*X Optimale Temperatur: dY/dX = 4,010 - 2 x 0,088 X = 0 Æ X(opt.) = 22,8 Problem 1.3: Vergleich von Regressionsgeraden In einem Placebo-kontrollierten Parallelversuch wurde eine Größe vor Gabe des Präparates (Variable X1) und danach (Variable X2) gemessen. Die Präparatwirkung Y wird durch die Differenz X1 - X2 ausgedrückt. Jeweils zehn Versuchspersonen erhielten das Testpräparat, andere zehn das Kontrollpräparat (Placebo). i) Man zeige auf der Grundlage von linearen Regressionsmodellen, dass in jeder Präparatgruppe die Wirkung Y vom Anfangswert X1 abhängt (Prüfung auf Abhängigkeit). ii) Man zeige, dass sich die Anstiege der Regressionsgeraden nicht signifikant unterscheiden (Prüfung auf Abweichung von der Parallelität). iii) Man zeige, dass die Regressionsgeraden nicht zusammenfallen (Prüfung auf Koinzidenz). Als Testniveau sei für jede Einzelprüfung 5% angenommen; Daten: siehe "Daten, einfache Statistiken". i1) Daten, einfache Statistiken Analysieren - Berichte - Fälle zusammenfassen ... Tabelle: siehe nächste Seite i2) Grafische Überprüfung der Modelladäquatheit (lineares Modell) Grafiken - Streudiagramm - Einfach ... 100 80 60 40 20 Präparat 0 Placebo R-Qu. = 0,7805 Y -20 A -40 R-Qu. = 0,6980 40 X1 60 80 100 120 140 160 180 6 Zusammenfassung von Fällena X1 Präparat A 32 30 2 84 21 63 3 49 56 31 49 18 7 110 28 82 6 91 29 62 7 126 72 54 8 44 52 -8 9 132 56 76 94 67 27 10 10 10 84,80 43,70 41,10 9,99 5,65 9,66 31,59 17,85 30,56 997,733 318,678 933,656 10 Insgesamt N Mittelwert Standardfehler des Mittelwertes Standardabweichung Varianz 1 57 83 -26 2 146 79 67 3 163 92 71 4 158 122 36 5 68 68 0 6 112 76 36 7 77 68 9 8 136 98 38 9 74 56 18 10 110 99 11 10 10 10 110,10 84,10 26,00 12,49 6,07 9,43 Insgesamt N Mittelwert Standardfehler des Mittelwertes Standardabweichung Varianz Insgesamt N Mittelwert Standardfehler des Mittelwertes Standardabweichung Varianz 39,51 19,19 29,83 1560,767 368,322 889,778 20 20 20 97,45 63,90 33,55 8,31 6,14 6,80 37,15 27,48 30,39 1380,366 754,937 923,734 a. Begrenzt auf die ersten 100 Fälle. i3) Lineare Regression von Y auf X1 (getrennt nach Präparatgruppen) Aufteilung der Datei nach Gruppen: Daten – Datei aufteilen ... Regressionsprozedur: Analysieren - Regression - Linear .. Präparat = A Modellzusammenfassung b Modell 1 Y 62 4 5 Placebo X2 1 R ,835a R-Quadrat ,698 Korrigiertes R-Quadrat ,660 a. Einflußvariablen : (Konstante), Untersuchungsm. 1.US b. Präparat = A Standardfehler des Schätzers 17,81 7 ANOVA b,c Regression Quadrat summe 5865,178 Residuen Gesamt Modell 1 1 Mittel der Quadrate 5865,178 2537,722 8 317,215 8402,900 9 df F 18,490 Signifikanz ,003 a a. Einflußvariablen : (Konstante), Untersuchungsm. 1.US b. Abhängige Variable: Y c. Präparat = A Koeffizienten a,b Nicht standardisierte Koeffizienten Modell 1 (Konstante) Untersuchungsm. 1.US Standard. Koeffizienten B -27,4343 SE 16,9043 ,8082 ,1880 Beta ,835 T -1,623 Signifikanz ,143 4,300 ,003 a. Abhängige Variable: Y b. Präparat = A Präparat = Placebo Modellzusammenfassung b Modell 1 R Korrigiertes R-Quadrat ,753 R-Quadrat ,781 ,883a a. Einflußvariablen : (Konstante), Untersuchungsm. 1.US b. Präparat = Placebo Standardfehler des Schätzers 14,82 ANOVAb,c Regression Quadrat summe 6250,269 Residuen 1757,731 Modell 1 1 Mittel der Quadrate 6250,269 8 219,716 df F 28,447 Signifikanz ,001a Gesamt 8008,000 9 a. Einflußvariablen : (Konstante), Untersuchungsm. 1.US b. Abhängige Variable: Y c. Präparat = Placebo Koeffizienten a,b Nicht standardisierte Koeffizienten Modell 1 (Konstante) Untersuchungsm. 1.US B -47,4423 SE 14,5458 ,6671 ,1251 Standard. Koeffizienten Beta ,883 T -3,262 Signifikanz ,011 5,334 ,001 a. Abhängige Variable: Y b. Präparat = Placebo Ergebnisse: Regressionsmodell 1 (Präparat A): Y = b11 X1 + b10 + Fehler mit b11 = 0.8082 (sign. <> Null, P =0.003), b10 = -27.4343; Regressionsmodell 2 (Placebo): Y = b21 X1 + b20 + Fehler mit b1 = 0.6671 (sign. <> Null, P = 0.001), b0 = -47.4423. ii) Gibt es zwischen den Geradenanstiegen b11 und b21 einen signifikanten Unterschied (α=5%)? 8 ii1) Vergleich von b11 und b21 mit dem t-Test Voraussetzungen: b11 (Stichprobenfunktion, Anstieg - Präparat A) ist normalverteilt, Schätzwerte: Mittelwert = 0.8082, Standardabweichung = 0.1880 (Freiheitsgrad = n-2=8) b21 (Stichprobenfunktion, Anstieg - Placebo) ist normalverteilt, Schätzwerte: Mittelwert = 0.6671, Standardabweichung = 0.1251, (Freiheitsgrad = n-2=8) Manuelle Durchführung des t-Tests: F-Test: Varianzverhältnis (0.1880/0.1251)^2 = 2.258 <= F(8, 8, 0.975) = 4.43 spricht nicht gegen die Gleichheit der Varianzen. 2-Stichproben-t-Test (unabhängige Stichproben): mittlere (gepoolte) Varianz = (0.1880^2 + 0.1251^2)/2 = 0.04317 Testgröße = (0.8082-0.6671)/0.04317^(1/2)* (64/16)^(1/2) = 1.358 <= t(16, 0.975) = 2.120 Æ Unterschied der Anstiegswerte ist auf dem Testniveau 5% nicht signifikant. ii2) Vergleich der Anstiege im Rahmen eines mehrfach-linearen Regressionsmodells mit einer Indikatorvariablen ("dummy variable") Prinzip: Die zwei einfach-linearen Regressionsmodelle werden mit Hilfe der Indikatorvariablen z in ein mehrfach-lineares Regressionsmodell zusammengefasst. Der Hilfsvariablen z wird für alle Beobachtungen der Präparatgruppe A der Wert Null und für alle Beobachtungen der Placebo-Gruppe der Wert eins zugewiesen. Setzt man die abhängige Variabe Y als multiples lineares Modell mit den Regressorvariablen u1=X1, u2=z und u3=X1*z in der Gestalt (*) Y = b0 + b1*u1 + b2*u2 + b3*u3 + Fehler an, so geht diese Modellgleichung für z=0 (Gruppe A) über in (**) Y = b0 + b1*X1 + Fehler und für z=1 (Placebo-Gruppe) über in (***) Y = (b0+b2) + (b1+b3)*X1 + Fehler. Die Anstiege in den einfach-linearen Regressionsmodellen (**) und (***) sind genau dann verschieden, wenn im dreifach-linearen Regressionsmodells (*) der Koeffizient b3 ungleich Null ist, d.h. die Zielvariable von u3 abhängt. Die Abhängigkeitsprüfung von u3 erfolgt mit dem partiellen F-Test. Datenorganisation: Datenmatrix durch z-Spalte (=u2) und z*X1-Spalte (=u3) ergänzen. Zusammenfassung von Fällen a 1 32 30 U2 (=z) 0 2 A 84 21 63 0 0 3 A 49 31 18 0 0 4 A 56 49 7 0 0 5 A 110 28 82 0 0 6 A 91 29 62 0 0 7 A 126 72 54 0 0 8 A 44 52 -8 0 0 9 A 132 56 76 0 0 10 A 94 67 27 0 0 11 Placebo 57 83 -26 1 57 12 Placebo 146 79 67 1 146 13 Placebo 163 92 71 1 163 14 Placebo 158 122 36 1 158 15 Placebo 68 68 0 1 68 16 Placebo 112 76 36 1 112 17 Placebo 77 68 9 1 77 18 Placebo 136 98 38 1 136 19 Placebo 74 56 18 1 74 20 Placebo 110 99 11 1 110 20 20 20 20 20 Insgesamt X1 (=u1) 62 N 20 a. Begrenzt auf die ersten 100 Fälle. Hypothesen: X2 Y U3 (=z*X1) Präparat A 0 9 H0: Koeffizient von u3 in (*) ist Null (Nullmodell), H1: Koeffizient von u3 in (*) ist ungleich Null (Alternativmodell). Durchführung des partiellen F-Tests: Schritt 1: Fehlerquadratsumme SQRes(H1)=4295.453 und Freiheitsgrade FG(H1)= 16 aus dem Alternativmodell bestimmen (Statistik - Regression - Linear ... ; abhängige Variable = Y, unabhängige Variable = u1, u2, u3). ANOVAb Regression Quadrat summe 13255,5 Residuen Modell 1 Gesamt 3 Mittel der Quadrate 4418,499 4295,453 16 268,466 17551,0 19 df F 16,458 Signifikanz ,000 a a. Einflußvariablen : (Konstante), U3, Untersuchungsm. 1.US, U2 b. Abhängige Variable: Y Schritt 2: Fehlerquadratsumme SQRes(H0)=4404.569 und Freiheitsgrade FG(H0)= 17 aus dem Alternativmodell bestimmen (Statistik - Regression - Linear ... ; abhängige Variable = Y, unabhängige Variable = u1, u2). ANOVAb Modell 1 Regression Residuen Gesamt Quadrat summe 13146,4 2 Mittel der Quadrate 6573,190 4404,569 17 259,092 17551,0 19 df F 25,370 Signifikanz ,000 a a. Einflußvariablen : (Konstante), U2, Untersuchungsm. 1.US b. Abhängige Variable: Y Schritt 3: Testentscheidung Mittlere Reduktion der Fehlerquadratsumme bei Übergang vom Nullmodell zum Alternativmodell = MQRes(H1|H0) = [SQRes(H0) - SQRes(H1)]/[FG(H0)-FG(H1)] = (4404.569-4295.453)/(17-16) = 109.116. Schätzung der Fehlervarianz aus dem Alternativmodell durch MQRes(H1) = 268.466 mit FG(H1) = 16. Testgröße = MQRes(H1|H0)/MQRes(H1) = 0.406 <= F(1,16,0.95) = 4.49 Æ Unterschied zwischen den Anstiegen nicht signifikant. iii) Sind die Regressionsgeraden überhaupt verschieden? (hinsichtlich Anstiege und y-Achsenabschnitte) Prüfung im Rahmen des mehrfach-linearen Regressionsmodells (*) mit den Regressorvariablen u1 (=X1), u2 (=z) und u3 (=z*X1) durch Übergang vom Vollmodell (Alternativmodell) zum Nullmodell (Koeffizienten von u2 und u3 sind Null). Hypothesen: H0: Y hängt nicht von u2 und u3 ab (Nullmodell), H1: Y hängt von u1, u2 und u3 ab (Alternativmodell). Durchführung des partiellen F-Tests: Schritt 1: SQRes(H1) = 4295.453, FG(H1) = 16, MQRes(H1) = 268.466. Schritt 2: SQRes(H0) = 9292.591, FG(H0) = 18. ANOVAb Modell 1 Regression Residuen Gesamt Quadrat summe 8258,359 1 Mittel der Quadrate 8258,359 9292,591 18 516,255 17550,950 19 df a. Einflußvariablen : (Konstante), Untersuchungsm. 1.US b. Abhängige Variable: Y Schritt 3: F 15,997 Signifikanz ,001a 10 MQRes(H1|H0) = (9292.591-4295.453)/(18-16)=2498.569. Testgröße = MQRes(H1|H0)/MQE(H1) = 9.307 > F(2,16,0.95) = 3.63 Æ Regressionsgeraden fallen nicht zusammen! Problem 1.4: Abhängigkeitsanalysen - Versuche mit einem Haupt- und einem Blockfaktor Die folgende Datentabelle zeigt die an einer Messstelle der Donau erhaltenen monatlichen Messwerte des Gesamtphosphors (gesp_3) für die Jahre 1986 bis 1988. Man vergleiche die Jahresmittelwerte und verwende dabei den Monat als Blockfaktor. Das Testniveau ist mit 5% vorgegeben. Monat 1 2 3 4 5 6 7 8 9 10 11 12 1986 0.282 0.308 0.381 0.282 0.199 0.211 0.137 0.254 0.224 0.252 0.262 0.271 1987 0.365 0.202 0.192 0.170 0.111 0.085 0.274 0.183 0.186 0.166 0.218 0.209 1988 0.179 0.189 0.241 0.160 0.150 0.130 0.170 0.251 0.231 0.209 0.231 0.251 i) Problemlösung mit der Prozedur „Allgemeines lineares Modell“ Modell: Messwert = Basiswert + Faktor(=Jahres)-Effekt + Block (=Monats)-Effekt + Versuchsfehler Datenorganisation: monat 1 2 .. 12 jahr 86 86 .. 88 gesp_3 0.282 0.308 .. 0.251 i1) Globaltest (H0: kein Jahres-Effekt), Power Analysieren - Allgemeines lineares Modell – Univariat ... Tests der Zwischensubjekteffekte Abhängige Variable: Gesamt-P in mg/l /Wolfsthal) Quelle Korrigiertes Modell Quadratsumme vom Typ III Konstanter Term Mittel der Quadrate df b 8,125E-02 13 F Sign. NichtzentralitätsParameter Beobachtete a Schärfe 6,250E-03 2,237 ,046 29,078 ,824 1,697 1 1,697 607,349 ,000 607,349 1,000 MONAT 5,502E-02 11 5,002E-03 1,790 ,118 19,693 ,677 JAHR 2,622E-02 2 1,311E-02 4,693 ,020 9,385 ,727 Fehler 6,147E-02 22 2,794E-03 1,840 36 ,143 35 Gesamt Korrigierte Gesamtvariation a. Unter Verwendung von Alpha = ,05 berechnet b. R-Quadrat = ,569 (korrigiertes R-Quadrat = ,315) Geschätzte Randmittel 1. Gesamtmittelwert Abhängige Variable: Gesamt-P in mg/l /Wolfsthal) 95% Konfidenzintervall Mittelwert ,217 Standardfehler ,009 Untergrenze ,199 Obergrenze ,235 11 2. MONAT Abhängige Variable: Gesamt-P in mg/l /Wolfsthal) 95% Konfidenzintervall MONAT 1 Mittelwert ,275 Standardfehler ,031 Untergrenze ,212 Obergrenze ,339 2 ,233 ,031 ,170 ,296 3 ,271 ,031 ,208 ,335 4 ,204 ,031 ,141 ,267 5 ,153 ,031 9,004E-02 ,217 6 ,142 ,031 7,871E-02 ,205 7 ,194 ,031 ,130 ,257 8 ,229 ,031 ,166 ,293 9 ,214 ,031 ,150 ,277 10 ,209 ,031 ,146 ,272 11 ,237 ,031 ,174 ,300 12 ,244 ,031 ,180 ,307 3. JAHR Abhängige Variable: Gesamt-P in mg/l /Wolfsthal) 95% Konfidenzintervall JAHR 86 Mittelwert ,255 Standardfehler ,015 Untergrenze ,224 Obergrenze ,287 87 ,197 ,015 ,165 ,228 88 ,199 ,015 ,168 ,231 i2) Multiple Vergleiche (nach Scheffe und Dunnett) Mehrfachvergleiche Abhängige Variable: Gesamt-P in mg/l /Wolfsthal) Scheffé (I) JAHR (J) JAHR 86 87 95% Konfidenzintervall SE ,022 Sign. ,042 Untergr. 1,8703E-03 Obergr. ,11513 88 5,5917E-02 ,022 ,053 -7,1307E-04 ,11255 86 -5,85000E-02* ,022 ,042 -,11513 -1,870E-03 88 -2,58333E-03 ,022 ,993 -5,9213E-02 5,4046E-02 86 -5,59167E-02 ,022 ,053 -,11255 7,1307E-04 87 2,5833E-03 ,022 ,993 -5,4046E-02 5,9213E-02 87 86 -5,85000E-02* ,022 ,024 -,10949 -7,514E-03 88 86 -5,59167E-02* ,022 ,031 -,10690 -4,931E-03 87 88 Dunnett-T a (2-seitig) Mittlere Differenz (I-J) 5,8500E-02* Basiert auf beobachteten Mittelwerten. *. Die mittlere Differenz ist auf der Stufe ,05 signifikant. a. In Dunnett-T-Tests wird eine Gruppe als Kontrollgruppe behandelt, mit der alle anderen Gruppen verglichen werden. ii) Rangvarianzanalyse für verbundene Stichproben (Friedman-Test) Analysieren - Nichtparametrische Tests - K verbundene Stichproben ... Datenorganisation: monat 1 2 usw. gesp86 0.282 0.308 gesp87 0.365 0.202 gesp88 0.179 0.189 12 Ränge GESP86 Mittlerer Rang 2,67 GESP87 1,50 GESP88 1,83 Statistik für Test a N 12 Chi-Quadrat 8,667 df 2 Asymptotische Signifikanz ,013 a. Friedman-Test Problem 1.5: Abhängigkeitsanalysen - Einfaktorielle Versuche mit Messwiederholungen Um die Wirkung einer Behandlung auf eine Zielvariable Y zu untersuchen, wurden 10 Probanden der Behandlung unterzogen und die Zielvariable am Beginn und am Ende der Behandlung (Zeitpunkte 1 bzw. 2) sowie nach einem längeren zeitlichen Intervall (Zeitpunkt 3) gemessen. Die Messwerte sind in der folgenden Tabelle protokolliert. Es soll auf dem 5%-Niveau geprüft werden, ob sich die Zielvariable im Mittel verändert hat. Pers. 1 2 3 4 5 6 7 8 9 10 Zeitp. 1 568 668 441 466 521 696 761 605 504 469 Zeitp. 2 728 849 440 681 621 779 754 837 756 586 Zeitp. 3 713 820 465 340 611 555 640 696 297 520 i) Datenorganisation: wie in der Tabelle. ii) Problemlösung mit GLM - Messwiederholungen: Analysieren - Allgemeines lineares Modell - Messwiederholung ... Innersubjektfaktoren Maß: MESSWERT 1 Abhängige Variable X_1 2 X_2 3 X_3 ZEIT Deskriptive Statistiken Untersuchungsm.1.US Mittelwert 569,90 Standardabweichung 109,34 Untersuchungsm. 2.US 703,10 125,23 10 Untersuchungsm. 3.US 565,70 165,46 10 ii1) Lösung im Rahmen einer multivariaten Varianzanalyse N 10 13 Multivariate Tests c Wert ,703 F 9,465b Hypothese df 2,000 Fehler df 8,000 Sign. ,008 NZP 18,929 Beobachtete a Schärfe ,899 Wilks-Lambda ,297 9,465b 2,000 8,000 ,008 18,929 ,899 Hotelling-Spur 2,366 9,465b 2,000 8,000 ,008 18,929 ,899 Größte charakteristische Wurzel nach Roy 2,366 9,465 2,000 8,000 ,008 18,929 ,899 Effekt ZEIT Pillai-Spur b a. Unter Verwendung von Alpha = ,05 berechnet b. Exakte Statistik c. Design: Intercept Innersubjekt-Design: ZEIT ii1) Lösung im Rahmen einer Blockvarianzanalyse mit Korrektur der Fehlerfreiheitsgrade Mauchly-Test auf Sphärizität b Maß: MESSWERT a Epsilon Inner subjekt effekt ZEIT Mauchly-W ,670 Approximiertes Chi-Quadrat 3,208 df 2 Sign. ,201 GreenhouseGeisser ,752 HuynhFeldt ,869 Unter grenz e ,500 Prüft die Nullhypothese, daß sich die Fehlerkovarianz-Matrix der orthonormalisierten transformierten abhängigen Variablen proportional zur Einheitsmatrix verhält. a. Kann zum Korrigieren der Freiheitsgrade für die gemittelten Signifikanztests verwendet werden. In der Tabelle mit den Tests der Effekte innerhalb der Subjekte werden korrigierte Tests angezeigt. b. Design: Intercept Innersubjekt-Design: ZEIT Tests der Innersubjekteffekte Maß: MESSWERT Quadratsumme vom Typ III Quelle ZEIT Fehler(ZEIT) Mittel der Quadrate df F Sign. NZP Beob. a Schärfe Sphärizität angenommen 122128,800 2 61064,400 7,180 ,005 14,360 ,885 GreenhouseGeisser 122128,800 1,503 81234,491 7,180 ,011 10,795 ,802 Huynh-Feldt 122128,800 1,739 70242,594 7,180 ,008 12,484 ,847 Untergrenze 122128,800 1,000 122128,800 7,180 ,025 7,180 ,666 Sphärizität angenommen 153083,867 18 8504,659 GreenhouseGeisser 153083,867 13,531 11313,821 Huynh-Feldt 153083,867 15,648 9782,939 Untergrenze 153083,867 9,000 17009,319 a. Unter Verwendung von Alpha = ,05 berechnet 14 Tests der Innersubjektkontraste Maß: MESSWERT Quelle ZEIT ZEIT Linear Quadratsumme vom Typ III 88,200 Quadratisch Fehler (ZEIT) Linear 1 Mittel der Quadrate 88,200 122040,600 1 122040,600 78378,800 9 8708,756 9 8300,563 df Quadratisch 74705,067 a. Unter Verwendung von Alpha = ,05 berechnet F ,010 Sign. ,922 NZP ,010 Beob. a Schärfe ,051 14,703 ,004 14,703 ,925 Problem 1.6: Abhängigkeitsanalysen - Einfaktorielle Versuche mit einer Kovariablen In einem Placebo-kontrollierten Parallelversuch wurde eine Größe vor Gabe des Präparates (Variable X) und danach (Variable X') gemessen. Jeweils zehn Versuchspersonen erhielten das Testpräparat, andere zehn das Kontrollpräparat (Placebo). Die Messergebnisse sind in der folgenden Tabelle zusammengestellt. Es ist das Ziel des Versuches, das Testpräparat mit dem Kontrollpräparat hinsichtlich der Wirksamkeit zu vergleichen. Dabei ist die Wirksamkeit durch die Differenz Y=X-X' erfasst und eine allfällige Abhängigkeit vom Anfangswert zu berücksichtigen. Als Testniveau sei α = 5% vereinbart. Behandlungsfaktor (Präparat) Stufe 1 (Test) Stufe 2 (Placebo) X X' X X' 62 32 57 83 84 21 146 79 49 31 163 92 56 49 158 122 110 28 68 68 91 29 112 76 126 72 77 68 44 52 136 98 132 56 74 56 94 67 110 99 Wiederholungen i) Datenorganisation Y-Spalte mit "Transformieren - Berechnen ..." erzeugen: Präparat 1 ... 1 2 ... 2 X 62 X' 32 Y(=X-X') 30 94 57 67 83 27 -26 110 99 11 ii) Vergleich der Präparateffekte ohne Berücksichtigung des Anfangswertes Analysieren - Allgemeines lineares Modell – Univariat ... (ohne Anfangswert als Kovariable) Deskriptive Statistiken Abhängige Variable: Y Präparat A Mittelwert 41,10 Standardabweichung 30,56 Placebo 26,00 29,83 10 Gesamt 33,55 30,39 20 Levene-Test auf Gleichheit der Fehlervarianzen N 10 a Abhängige Variable: Y F df1 ,167 df2 1 18 Signifikanz ,687 Prüft die Nullhypothese, daß die Fehlervarianz der abhängigen Variablen über Gruppen hinweg gleich ist. a. Design: Intercept+PRAEP 15 Tests der Zwischensubjekteffekte Abhängige Variable: Y Quelle Quadratsumme vom Typ III Korrigiertes Modell Mittel der Quadrate df b 1140,050 1 1140,050 Intercept 22512,050 1 PRAEP 1140,050 1 Fehler 16410,900 18 911,717 Gesamt 40063,000 20 Korrigierte Gesamtvariation 17550,950 19 F Sign. Beob. a Schärfe NZP 1,250 ,278 1,250 ,185 22512,050 24,7 ,000 24,692 ,997 1140,050 1,250 ,278 1,250 ,185 a. Unter Verwendung von Alpha = ,05 berechnet b. R-Quadrat = ,065 (korrigiertes R-Quadrat = ,013) Ergebnis: Präparateffekt ns (Power nur 18,5%), höhere Power kann erreicht werden durch größere Stichproben oder Verkleinerung des Versuchsfehlers (Kovarianzanalyse). iii) Kovarianzanalyse - Test auf signifikante Präparateffekte Analysieren - Allgemeines lineares Modell – Univariat ... (mit Anfangswert als Kovariable) a Levene-Test auf Gleichheit der Fehlervarianzen Abhängige Variable: Y F df1 ,417 df2 1 18 Signifikanz ,526 Prüft die Nullhypothese, daß die Fehlervarianz der abhängigen Variablen über Gruppen hinweg gleich ist. a. Design: Intercept+PRAEP+X Tests der Zwischensubjekteffekte Abhängige Variable: Y Quelle Quadratsumme vom Typ III Korrigiertes Modell 13146,381 Mittel der Quadrate df b F Sign. Beob. a Schärfe NZP 2 6573,190 25,370 ,000 50,740 1,000 ,887 Konstanter Term 2931,426 1 2931,426 11,314 ,004 11,314 PRAEP 4888,022 1 4888,022 18,866 ,000 18,866 ,983 12006,331 1 12006,331 46,340 ,000 46,340 1,000 4404,569 17 259,092 Gesamt 40063,000 20 Korrigierte Gesamtvariation 17550,950 19 X Fehler a. Unter Verwendung von Alpha = ,05 berechnet b. R-Quadrat = ,749 (korrigiertes R-Quadrat = ,720) Parameterschätzer Abhängige Variable: Y 95% Konfidenzintervall B -53,502 SE 12,740 T -4,200 Sign. ,001 Untergr. -80,381 Obergr. -26,623 NZP 4,200 Beob. a Schärfe ,977 33,369 7,682 4,343 ,000 17,160 49,578 4,343 ,983 , , , , , , , ,722 ,106 6,807 ,000 a. Unter Verwendung von Alpha = ,05 berechnet b. Dieser Parameter wird auf Null gesetzt, weil er redundant ist. ,498 ,946 6,807 1,000 Parameter Konstanter Term [PRAEP=1] [PRAEP=2] X 0b 16 iv) iv1) Kovarianzanalyse - Überprüfung der Voraussetzungen (Linerarität, Parallelität) Grafisch an Hand des Streudiagramms Grafiken - Streudiagramm... (mit eingezeichneten Regressionsgraden) 100 80 60 40 20 0 Präparat -20 Placebo A Y -40 40 60 80 100 120 140 160 180 X iv2) Überprüfung der Parallelität im Rahmen von „Allgemeines lineares Modell – Univariat ...“ (Prüfung auf signifikante Wechselwirkung Faktor*Kovariable) Levene-Test auf Gleichheit der Fehlervarianzen a Abhängige Variable: Y F df1 ,774 df2 1 18 Signifikanz ,391 Prüft die Nullhypothese, daß die Fehlervarianz der abhängigen Variablen über Gruppen hinweg gleich ist. a. Design: Intercept+PRAEP+X+PRAEP * X Tests der Zwischensubjekteffekte Abhängige Variable: Y Quelle Korrigiertes Modell Quadratsumme vom Typ III b F Sign. NZP Beoh. a Schärfe 3 4418,499 16,458 ,000 49,375 1,000 3008,128 1 3008,128 11,205 ,004 11,205 ,881 214,789 1 214,789 ,800 ,384 ,800 ,134 11921,586 1 11921,586 44,406 ,000 44,406 1,000 109,116 1 109,116 ,406 ,533 ,406 ,092 4295,453 16 268,466 Gesamt 40063,000 20 Korrigierte Gesamtvariation 17550,950 19 Konstanter Term PRAEP X PRAEP * X Fehler 13255,497 Mittel der Quadrate df a. Unter Verwendung von Alpha = ,05 berechnet b. R-Quadrat = ,755 (korrigiertes R-Quadrat = ,709) Ergebnis: Wechselwirkung Faktor*Kovariable ns (vgl. auch Problem 1.3) Problem 1.7: Abhängigkeitsanalysen - Zweifaktorielle Versuche Im Zusammenhang mit einer Untersuchung des Wasserhaushaltes einer Pflanze wurde unter verschiedenen Nährstoff- und Lichtbedingungen die mittlere Spaltöffnungsfläche (Zielvariable Y) auf bestimmten Blättern gemessen. Die Nährstoffgaben bestanden in einer als Kontrolle verwendeten "Volllösung" sowie zwei weiteren Lösungen mit einem Mangel bzw. Überschuss an Kalium (im Vergleich zur Kontrolle). Die unterschiedlichen Lichtbedingungen simulierten eine "Langtag-Situation" (16 Stunden Helligkeit und 8 Stunden Dunkelheit) und eine "Kurztag-Situation" (8 Stunden Helligkeit und 16 Stunden Dunkelheit). Das in der folgenden Tabelle zusammengestellte Datenmaterial stellt eine Kreuzklassifikation der "durchschnittlichen Spaltöffnungsfläche" nach den betrachteten Faktoren dar. Zu jeder Kombination einer Nährstoff- und Licht-Faktorstufe sind fünf Messwerte des Untersuchungsmerkmals angeschrieben, die von fünf verschiedenen, unter der jeweiligen Bedingung kultivierten Pflanzen stammen. Es soll untersucht werden, ob die Haupteffekte (Licht, Nährstoff) signifikant sind und ob es eine signifikante Faktorwechselwirkung gibt (Testniveau = 5%). 17 Faktor B (Licht) 1 (Langtag) 2 (Kurztag) Faktor A (Nährstoff) 1/Kontrolle 2/K-Mangel 13.8 57.7 25.3 42.2 17.4 26.8 17.7 29.1 39.8 23.9 27.7 41.8 19.5 49.5 33.2 46.7 41.3 30.8 37.6 28.6 i) Datenorganisation nährstoff licht 1 1 ... 1 1 1 2 ... 1 2 2 1 usw. 3/K-Übersch. 29.9 30.8 36.7 24.8 17.3 34.0 33.1 15.7 23.3 19.6 y 13.8 39.8 27.7 37.6 57.7 ii) Test auf signifikante Haupt- und Wechselwirkungseffekte Analysieren - Allgemeines lineares Modell – Univariat ... Deskriptive Statistiken Abhängige Variable: Y A_NAEHR 1 B_LICHT 1 2 3 Gesamt Mittelwert 22,8000 Standardabweichung 10,3853 2 31,8600 8,5722 5 Gesamt 27,3300 10,1684 10 1 35,9400 14,0354 5 2 39,4800 9,3759 5 Gesamt 37,7100 11,4063 10 1 27,9000 7,2770 5 2 25,1400 8,1402 5 Gesamt 26,5200 7,4231 10 1 28,8800 11,5575 15 2 32,1600 10,0902 15 Gesamt 30,5200 10,7897 30 Levene-Test auf Gleichheit der Fehlervarianzen a Abhängige Variable: Y F df1 ,913 df2 5 24 Signifikanz ,489 Prüft die Nullhypothese, daß die Fehlervarianz der abhängigen Variablen über Gruppen hinweg gleich ist. a. Design: Intercept+A_NAEHR+B_LICHT+A_NAEHR * B_LICHT N 5 18 Tests der Zwischensubjekteffekte Abhängige Variable: Y Quadratsumm e vom Typ III Quelle Korrigiertes Modell 1034,304 Konstanter Term A_NAEHR Fehler Gesamt Korrigierte Gesamtvariation b F Sign. Beob. a Schärfe NZP 5 206,861 2,120 ,098 10,600 ,594 27944,112 1 27944,112 286,383 ,000 286,383 1,000 778,722 2 389,361 3,990 ,032 7,981 ,658 80,688 1 80,688 ,827 ,372 ,827 ,141 174,894 2 87,447 ,896 ,421 1,792 ,186 97,576 B_LICHT A_NAEHR * B_LICHT Mittel der Quadrate df 2341,824 24 31320,240 30 3376,128 29 a. Unter Verwendung von Alpha = ,05 berechnet b. R-Quadrat = ,306 (korrigiertes R-Quadrat = ,162) Mehrfachvergleiche Abhängige Variable: Y Scheffé (I) A_NAEHR (J) A_NAEHR 1 2 Mittlere Differenz (I-J) -10,3800 3 ,8100 4,418 ,983 -10,7145 12,3345 1 10,3800 4,418 ,083 -1,1445 21,9045 3 11,1900 4,418 ,058 -,3345 22,7145 1 -,8100 4,418 ,983 -12,3345 10,7145 2 -11,1900 4,418 ,058 -22,7145 ,3345 2 3 Dunnett-T a (2-seitig) 95% Konfidenzintervall SE 4,418 Sign. ,083 Untergr. -21,9045 Obergr. 1,1445 2 1 10,3800* 4,418 ,050 1,126E-03 20,7589 3 1 -,8100 4,418 ,976 -11,1889 9,5689 Basiert auf beobachteten Mittelwerten. *. Die mittlere Differenz ist auf der Stufe ,05 signifikant. a. In Dunnett-T-Tests wird eine Gruppe als Kontrollgruppe behandelt, mit der alle anderen Gruppen verglichen werden. Profildiagramm 50 Geschätztes Randmittel 40 30 B_LICHT 1 20 2 1 2 A_NAEHR Ergebnis: Nährstofffaktor sign.; Lichtfaktor, Faktorwechselwirkung ns. 3