Vom Gen zum Protein
Werbung

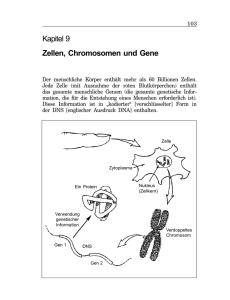
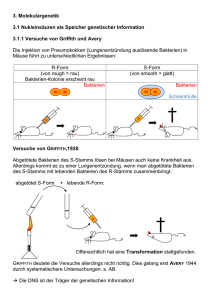
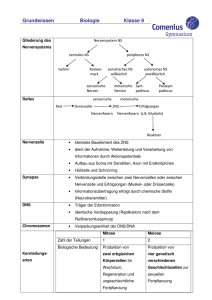
42 02522 Vom Gen zum Protein Seite 1 Vom Gen zum Protein Arbeitsvideo / 3 Kurzfilme VHS 42 02522 18 min Kurzbeschreibung Das Wissen um Gene und deren Rolle innerhalb der Zelle machte die Biologie zur Leitwissenschaft unserer Zeit. An einem alltagsbezogenen Beispiel, dem Wachstum von Haaren, verfolgt das Arbeitsvideo in anschaulichen Tricksequenzen und Realaufnahmen den Weg vom Gen zum Protein. 1 Bau der DNS 2 Genetischer Code 3 Proteinbiosynthese Lernziele Kenntnis des molekularen Baus der DNS und Abgrenzung der Begriffe „DNS“, „Gen“ und „Chromosom“; Einsicht in den Zusammenhang zwischen Basensequenz der DNS und Aminosäuresequenz eines Proteins (genetischer Code). Verständnis der grundlegenden Vorgänge der Transkription und Translation während der Proteinbiosynthese Zum Inhalt Haare bestehen neben dem Pigment Melanin vor allem aus Keratin, einem relativ harten Proteinmaterial. Jedes Haar wächst täglich etwa 0,3 mm, die Zellen der Haarwurzel produzieren neben Melanin ständig Keratin. Jeder der drei Kurzfilme geht von diesem alltagsbezogenen Beispiel aus und leitet dann zum jeweiligen Schwerpunktthema über. 1 Bau der DNS Ein Trick zeigt eine Haarwurzel, deren stoffwechselaktive Zellen sich ständig teilen. Im Zellkern einer Keratin produzierenden Zelle befinden sich 46 Chromosomen. Jedes Chromosom enthält DNS (Desoxyribonukleinsäure). Die Bausteine der DNS (Desoxyribose, Phosphatgruppen und die vier Nukleinsäurebasen Cytosin, Guanin, Thymin und Adenin) werden als Symbole vorgestellt und zu zwei komplementären Strängen verknüpft. In der DNS liegt Adenin immer gegenüber von Thymin, Guanin immer gegenüber von Cytosin. Zwischen den Basenpaaren halten Wasserstoffbrückenbindungen die beiden Stränge zusammen. Ein dreidimensionaler Trick zeigt die räumliche Anordnung der Stränge als Doppelhelix. Die außerordentliche Länge der Doppelhelix für zelluläre Maßstäbe wirft die Frage auf, wie die DNS im Zellkern untergebracht ist. Die Aufspiralisierung und Faltung der DNS um Hilfsproteine wird im Trick vorgeführt und führt zum Begriff „Chromosom“. Abschließend werden im Labor isolierte Chromosomen gezeigt. 2 Genetischer Code Im Trick werden das Gen und das Genprodukt gegenübergestellt: Ein bestimmter Abschnitt der DNS trägt die Bauanleitung für ein bestimmtes Protein. Zunächst wird das Bauprinzip eines Proteins geklärt. Proteine bestehen aus 20 verschiedenen Aminosäuren, die zu einer langen Kette verknüpft sind. Verschiedene Proteine unterscheiden sich in der © FWU Institut für Film und Bild 42 02522 Vom Gen zum Protein Seite 2 Kettenlänge und in der Abfolge der Aminosäuren. Diese Abfolge steht in Zusammenhang mit der Abfolge der Basen in der DNS. Eine Trickdarstellung demonstriert, dass je drei Basen für eine bestimmte Aminosäure kodieren. Die Tripletts für die Aminosäuren Prolin, Serin und Arginin werden exemplarisch vorgestellt (auf die Degeneration des genetischen Codes wird nicht eingegangen). Der Abschnitt der DNS, der den Code für ein bestimmtes Protein enthält, wird als „Gen“ definiert. 3 Proteinbiosynthese Nachdem die wichtigsten Grundlagen kurz wiederholt wurden, zeigt ein Trick die Transkription eines Abschnitts der DNS im Zellkern. Sie erfolgt nach dem Prinzip der komplementären Basenpaarung. Allerdings wird statt Thymin Uracil gebunden. Auf die RNSPolymerase, den chemischen Bau der RNS bzw. auf die RNS-Prozessierung wird nicht weiter eingegangen. Die messenger-RNS verlässt den Zellkern durch eine Kernpore und gelangt zu einem Ribosom ins Zellplasma. Hier befinden sich sowohl die 20 proteinogenen Aminosäuren als auch transfer-RNS-Moleküle. Die tRNS mit dem Basentriplett GGC bindet die Aminosäure Prolin und transportiert sie zum passenden Triplett der mRNS. Der Trick macht deutlich, dass jede Aminosäure von einer „eigenen“ tRNS gebunden und transportiert wird. Während die mRNS Triplett für Triplett das Ribosom durchläuft, bringen die tRNS-Moleküle eine Animosäure nach der anderen. Das Ribosom knüpft die Bindung zwischen den einzelnen Aminosäuren. So entsteht Schritt für Schritt ein Protein. Ergänzende Informationen Bis in die 40er Jahre des zwanzigsten Jahrhunderts hinein konnte man sich die DNS nicht als Träger der Erbinformation vorstellen. Einerseits war sehr wenig über Nukleinsäuren bekannt, andererseits schienen die chemischen und physikalischen Eigenschaften der DNS viel zu einfach und einförmig zu sein. Die meisten Forscher favorisierten die vielfältigen und hochspezifischen Proteine als Erbträger. Die Experimente von Griffith, Avery, Hershey und Chase, Chargaff und anderen änderten diese Sichtweise allmählich. Als die DNS endlich als Erbmaterial akzeptiert war, begann in den 50er Jahren ein Wettrennen um die Aufklärung der Struktur dieses Moleküls. Watson und Crick gewannen dieses Rennen 1953 (Nobelpreis 1962) mithilfe Franklins Röntgenbeugungsmustern und selbst gebauter Drahtmolekülmodelle. Die DNS ist eine Doppelhelix, in der sich zwei komplementäre Stränge wie die beiden Holme einer Strickleiter umeinander winden. Eine Windung ist 3,4 nm lang. Die Holme entsprechen den hydrophilen Desoxyribose-Phosphat-Ketten. Die Bindung zwischen Desoxyribosemolekülen und Phosphatresten erfolgt stets am 3’- bzw. 5’-Kohlenstoffatom des Zuckers. Die beiden komplementären Stränge sind antiparallel: Die DesoxyribosePhosphat-Kette des einen Strangs endet mit dem 3’-Ende, die des anderen mit dem 5’Ende, d. h. einer der beiden Stränge steht gewissermaßen „auf dem Kopf“. Die relativ hydrophoben Nukleinsäurebasen sind am 1’-Kohlenstoffatom der Desoxyribose gebunden und befinden sich im Inneren des Moleküls. Ein Desoxyribose-Molekül mit einem Phosphatrest am 5’- und einer Nukleinsäurebase am 1’-Kohlenstoffatom wird Nukleotid genannt. Adenin und Guanin sind Purinbasen. Sie besitzen ein fast doppelt so großes Molekülgerüst wie die Pyrimidinbasen Thymin und Cytosen. Der Durchmesser der Doppelhelix ist mit 2 nm gerade so breit, dass eine Purinbase und eine Pyrimidinbase nebeneinander Platz finden. Die Art und Anordnung der jeweiligen chemischen Gruppen jeder einzelnen Base sind dafür verantwortlich, dass Adenin zwei Wasserstoffbrückenbindungen zu Thymin und Guanin drei Wasserstoffbrückenbindungen zu Cytosin ausbilden kann. Daher ist Adenin in einem Strang stets mit Thymin im anderen Strang gepaart und Guanin stets mit Cytosin. In © FWU Institut für Film und Bild 42 02522 Vom Gen zum Protein Seite 3 der Doppelhelix beträgt der Abstand von einem Basenpaar zum nächsten 0,34 nm. Entlang der Doppelhelix ändert sich nur die Abfolge der einzelnen Basen, die Basensequenz. Sie ist von Gen zu Gen, von Chromosom zu Chromosom, von Mensch zu Mensch und von Art zu Art unterschiedlich. Eines der Ziele des Human-Genom-Projekts ist die Sequenzierung der menschlichen DNS, also die Auflistung der Reihenfolge der einzelnen Basen in jedem Chromosom. Die Gesamtzahl der zu sequenzierenden Basenpaare wird auf drei Milliarden geschätzt. Kennt man die Reihenfolge der Basen in der DNS, kann man auf den Bau des von dieser Sequenz kodierten Proteins schließen. Der genetische Code wurde in den frühen 60er Jahren entschlüsselt. Je drei Basen (ein Basentriplett oder Codon) kodieren für eine bestimmte Aminosäure. Zusätzlich gibt es ein Startcodon und drei Stoppcodons. 61 der 64 Codons haben Aminosäurebedeutung. Die meisten Aminosäuren werden durch zwei oder mehr synonyme Codons verschlüsselt. Diese Tatsache bezeichnet man als Degeneration des genetischen Codes. Fast alle Lebewesen der Erde benutzen den gleichen genetischen Code. In der Evolution des Lebens muss dieser Code daher sehr früh entstanden sein. Diese Universalität des genetischen Codes ist eine wichtige Voraussetzung für die Gentechnik: Nur wenn alle Lebewesen die gleiche „genetische Sprache“ sprechen, kann eine Bakterienzelle beispielsweise ein menschliches Gen exprimieren. In Kurzfilm 2 wird ein Gen funktionell als der Abschnitt der DNS definiert, der für ein bestimmtes Protein kodiert. Eukaryotische Gene bestehen jedoch nicht nur aus kodierenden DNS-Abschnitten, den sog. Exons. Zwischen diesen sinntragenden DNS-Bereichen liegen nichtkodierende Abschnitte, die Introns. Während der Transkription werden auch die Introns in RNS übersetzt. Danach werden sie aus der prä-mRNS wieder entfernt. Zu jedem Gen gehören regulatorische Sequenzen, die die Transkription und damit die Expression des Gens kontrollieren. Vor der ersten kodierenden Sequenz liegt der Promotor, an den die RNS-Polymerase bindet. Der Komplex aus Promotor, RNS-Polymerase und weiteren notwendigen zusätzlichen Transkriptionsfaktoren wird erst dann stimuliert, wenn ein spezifischer Transkriptionsfaktor an eine Enhancer-Sequenz bindet. Die EnhancerSequenz liegt oft Tausende von Basenpaaren entfernt von dem Gen, dessen Expression sie reguliert. In Anbetracht der notwendigen regulatorischen Einheiten kann man ein Gen auch definieren als „alle Abschnitte der DNS, die zur Herstellung eines mRNS-Moleküls benötigt werden). Nach der Transkription und der Prozessierung der mRNS beginnt die Translation an den Ribosomen im Zellplasma. Der tRNS kommt hier eine besondere Bedeutung zu. Es gibt für jede Aminosäure eine oder mehrere tRNS-Moleküle, insgesamt jedoch nur 31 bis 45. Sie bestehen aus einem einzelnen RNS-Strang von etwa 80 Nukleotiden Länge, sind also wesentlich kürzer als die mRNS. Die zweidimensionale „Kleeblattstruktur“ entspricht einer dreidimensionalen L-förmigen Gestalt. Am langen Ende des L befindet sich die Schleife mit dem Anticodon, das für jede tRNS spezifisch ist. Am kurzen Ende des L wird die zum Anticodon passende Aminosäure gebunden. Diese Bindung zwischen tRNS und Aminosäure ist ein ATP-verbrauchender Prozess und wird durch eine Gruppe von Enzymen, die Aminoacyl-tRNS-Synthetasen, katalysiert. Für jede Aminosäure gibt es eine spezifische Aminoacyl-tRNS-Synthetase und (mindestens) eine spezifische tRNS. Das Protein macht während und nach der Translation einen Faltungsprozess durch. Erst dann liegt es in seiner biologisch aktiven Tertiär- bzw. Quartärstruktur vor. Das im Arbeitsvideo mit „Keratin“ bezeichnete Haarprotein besteht aus etwa zehn verschiedenen Proteinen, die durch eine Serie von Polymerisationsreaktionen vernetzt werden. Gleichzeitig dringen Melanozyten in die Haarfaser ein und sorgen für die individuelle Haarfarbe. © FWU Institut für Film und Bild 42 02522 Vom Gen zum Protein Seite 4 Zur Verwendung Die drei Kurzfilme stellen die Grundlagen der Speicherung und Realisierung genetischer Information klar und einfach dar. Daher eignen sie sich für die Sekundarstufen I und II sowohl als Einstieg als auch als abschließende Zusammenfassung der Unterrichtsinhalte. Weitere Medien 42 02516 Reifeteilung: Arbeitsvideo/2 Kurzfilme. VHS 15 min 42 02517 Kern- und Zellteilung: Arbeitsvideo/3 Kurzfilme. VHS 15 min Bearbeitete Fassung und Herausgabe FWU Institut für Film und Bild, 2000 Produktion Rod Rees, im Auftrag von VEA, Video Education Australasia Buch und Regie Rod Rees Bearbeitung und Begleitkarte Dr. Christine Fischer Bildnachweis VEA, Video Education Australsia Pädagogische Referentin im FWU Sonja Riedel Nur Bildstellen/Medienzentren: öV zulässig © 2000 FWU Institut für Film und Bild in Wissenschaft und Unterricht gemeinnützige GmbH Geiselgasteig Bavariafilmplatz 3 D-82031 Grünwald Telefon (089) 6497-1 Telefax (089) 6497-240 E-Mail [email protected] Internet www.fwu.de © FWU Institut für Film und Bild