3.1 SCORE-Konzept - Institute for Program Structures and Data
Werbung

Institut für Programmstrukturen und Datenorganisation
Lehrstuhl für Systeme der Informationsverwaltung
Prof. Dr. P. C. Lockemann
Fakultät für Informatik
Universität Karlsruhe (TH)
Entwicklung eines Systems zur
Erstellung von wiederverwendbaren
Lehr-/Lerninhalten im
Projekt SCORE
Alexander Fürbach
Verantwortlicher Betreuer: Prof. Dr.-Ing. P. Lockemann
Betreuender Mitarbeiter: Dipl.-Inform. Khaldoun Ateyeh
Postanschrift: Universität Karlsruhe - Fakultät für Informatik - IPD Lockemann - Postfach 6980 - 76128 Karlsruhe
2
Hiermit erkläre ich, dass ich die vorliegende Arbeit selbstständig verfasst und keine anderen als
die angegebenen Quellen und Hilfsmitteln verwendet habe.
Karlsruhe, 31.03.2002
Alexander Fürbach
3
4
1
EINLEITUNG UND MOTIVATION ........................................................................................................ 7
1.1
1.2
1.3
1.4
2
VERWANDTE ARBEITEN ..................................................................................................................... 15
2.1
2.2
3
MOTIVATION ........................................................................................................................................ 8
SZENARIO ........................................................................................................................................... 11
ZUSAMMENFASSUNG .......................................................................................................................... 13
LITERATUR ......................................................................................................................................... 14
SUMATRA UND DIE DIPLOMARBEIT ..................................................................................................... 18
LITERATUR ......................................................................................................................................... 20
LÖSUNGSANSATZ .................................................................................................................................. 21
3.1
SCORE-KONZEPT .............................................................................................................................. 21
3.2
METADATEN UND ONTOLOGIEN ......................................................................................................... 24
3.2.1
Metadaten-Standards .................................................................................................................... 24
3.2.2
Ontologien – als Klassifikationsinstrument für Lernobjekte ......................................................... 26
3.2.3
Ontolgien für Metadaten ............................................................................................................... 28
3.3
XML................................................................................................................................................... 29
3.3.1
Informationsmodellierung mit XML .............................................................................................. 29
3.3.2
XML-Dokumente ........................................................................................................................... 34
3.3.3
Document Type Definition............................................................................................................. 35
3.3.4
Parser ............................................................................................................................................ 36
3.3.5
Namensräume ................................................................................................................................ 38
3.3.6
XML Familie ................................................................................................................................. 39
3.3.7
XSL Transformation ...................................................................................................................... 40
3.3.8
XPath ............................................................................................................................................. 44
3.3.9
Document Object Model................................................................................................................ 48
3.3.10
XML Schema............................................................................................................................. 51
3.4
XML UND DATENBANKEN.................................................................................................................. 55
3.4.1
Datenzentrierte Dokumente ........................................................................................................... 55
3.4.2
Dokumentzentrierte Dokumente .................................................................................................... 57
3.4.3
Speichern von XML in relationalen Datenbanken ........................................................................ 57
3.4.4
Speichern von XML in XML-nativen Datenbanken ....................................................................... 59
3.4.5
DTD und relationales Schema ...................................................................................................... 63
3.5
LITERATUR ......................................................................................................................................... 64
4
KONZEPTIONELLE AUSARBEITUNG .............................................................................................. 65
4.1
4.2
4.2.1
4.3
4.3.1
4.3.2
4.4
4.4.1
4.4.2
4.4.3
4.5
4.5.1
4.5.2
4.5.3
4.6
4.6.1
4.6.2
4.7
4.8
5
METADATEN ....................................................................................................................................... 66
LERNATOME ....................................................................................................................................... 73
Check-In Prozess ........................................................................................................................... 74
INTEGRATIONSMODULE ...................................................................................................................... 75
Prozess: Integrationsmodul erzeugen ........................................................................................... 75
Realisierung des Integrationsmoduls ............................................................................................ 75
STRUKTURMODULE ............................................................................................................................. 76
Prozess: Erzeugen eines Strukturmoduls ...................................................................................... 77
Realisierung des Strukturmoduls ................................................................................................... 77
Realisierung des Struktur-Muster ................................................................................................. 79
PRÄSENTATIONSMODUL...................................................................................................................... 79
Prozess: Präsentationsmodul erzeugen ......................................................................................... 80
Realisierung des Präsentationsmoduls.......................................................................................... 81
Realisierung der XSLT-Templates................................................................................................. 82
KURS .................................................................................................................................................. 82
Prozess: Kurs erstellen .................................................................................................................. 83
Realisierung des Kurses ................................................................................................................ 83
ERWEITERUNG DER METADATEN........................................................................................................ 84
GESAMTÜBERSICHT ............................................................................................................................ 85
REALISIERUNG ...................................................................................................................................... 87
5.1
PRÄSENTATIONSMODULE .................................................................................................................... 88
5.2
ANWENDUNG ...................................................................................................................................... 90
5.2.1
Erstellen eines Lernatom-Repository ............................................................................................ 90
5.2.2
Erstellen eines Integrationsmoduls ............................................................................................... 92
5
5.2.3
5.2.4
5.2.5
5.2.6
6
Erstellen eines Strukturmoduls ...................................................................................................... 93
Erstellen eines Präsentationsmoduls ............................................................................................. 95
Erstellen eines Kurses ................................................................................................................... 96
Anpassen eines Kurses .................................................................................................................. 97
ZUSAMMENFASSUNG UND AUSBLICK ........................................................................................... 98
ANHANG A – DATENMODELLE ................................................................................................................. 100
I INTEGRATIONSMODUL – DTD ....................................................................................................................... 100
II STRUKTURMODUL – DTD............................................................................................................................ 100
III STRUKTUR-TEMPLATE – DTD.................................................................................................................... 100
IV XSL-TEMPLATE FÜR HTML-PRÄSENTATIONSMODUL ............................................................................... 100
V IMS-METADATEN SCHEMA ......................................................................................................................... 101
ANHANG B - ABBILDUNGSVERZEICHNIS .............................................................................................. 115
6
1 Einleitung und Motivation
Unsere Gesellschaft unterlag in den vergangenen Jahren radikalen Änderungen.
Getrieben durch die wachsende Bedeutung der Informationstechnologie wurde eines
immer klarer : Wissen ist Macht. Die Unternehmen erkannten das Human Capital als
wichtige Ressource im Kampf um Marktanteile.
Um den Wert des einzelnen Mitarbeiters zu steigern, muß er mit Wissen versorgt
werden. Dieses Wissen liegt in Unternehmen versteckt in Datenbanken, Mitarbeitern,
Patenten, Copyrights und Prozessen. Dieses Wissen aufzufinden und nutzbar zu
machen ist eine nicht selten schwierige Aufgabe.
Gerade in dieser sich schnell verändernden Zeit hat das Wissen aber auch eine
geringe Halbwertszeit. Immer wieder gilt es, sich an neue „Standards“ anzupassen,
die diesmal vielleicht eher den Namen Standard verdienen. Immer wieder entstehen
neue Programmiersprachen, die erlernt werden wollen. In immer kürzeren
Zeitabständen ist es notwendig, sich neue Qualifikationen und Fachkenntnisse
anzueignen. Diese Tatsache prägte den Begriff des lebenslangen Lernen.
Ziel ist es, eine Form des Lernens zu finden, die einer großen Anzahl von
Mitarbeitern, zeit- und ortsunabhängig, Wissen in kurzer Zeit vermittelt.
eLearning ist die passende Antwort für dieses Problem. Es verschmilzt die Ausbildung und das Internet miteinander. Durch den Einsatz von InformationsTechnologien bei der Ausbildung entstehen völlig neue Möglichkeiten:
1. Der Lernende kann von jedem Ort aus, von dem der Zugriff auf das Internet
möglich ist, auf Wissen zugreifen. Durch den Einsatz von mobiler Webtechnologie
ist der Student nur eingeschränkt durch die Abdeckung der Funknetze, folglich
ortsunabhängig.
2. Der Student kann selbst wählen wann er auf das Wissensangebot zugreifen will
und ist damit zeitunabhängig.
3. Der Student selbst legt fest mit welcher Geschwindigkeit er das Wissen
konsumieren möchte. Er ist also unabhängig von einer Geschwindigkeit, wie sie
ein Dozent im herkömmlichen System vorgeben würde.
4. Ein Kurs ist rollenbasiert bzw. personalisiert, d.h. ein Kurs ist auf die Rolle und
Bedürfnisse eines Studenten zugeschnitten und berücksichtigt somit die
individuellen Bedürfnisse.
5. Ein Kurs kann aus einer Vielzahl unterschiedlicher Medientypen
zusammengesetzt sein. Dazu gehören Audio, Video, Simulation, Text usw.
Dadurch können Inhalte in einer hohen Qualität vermittelt werden.
6. Dem Anbieter eines Kurses steht die Möglichkeit offen, den Fortschritt der
Studenten zu überwachen und mit Hilfe von Tests das angeeignete Wissen zu
überprüfen.
eLearning-System erlauben es Unternehmen Wissen zentral zu sammeln und den
Zugriff für alle Mitarbeiter zu ermöglichen. Das zeigt auch, daß eLearning nie
getrennt von Content Management und Knowledge Management betrachtet werden
darf.
Vom Marktforschungsunternehmen Gartner [1] gibt es zum Thema einige Aussagen:
7
„eLearning wird wohl letztendlich die einzige Möglichkeit sein, den enormen
Weiterbildungsbedarf in seinem Umfang und in der kürze der Zeit zu
gewährleisten“
„bis 2003 werden weltweit 22 Milliarden USD für eLearning von Unternehmen
aufgewendet“ (Report vom 7. April 2001)
„jährlicher Wachstum 100%“ (Report vom 7. April 2001)
„Marktführer [eLearning-Systeme] mit sehr geringem Marktanteil“ (Report vom 7.
April 2001)
„eLearning im IT-Bereich bis 2003 auf 50%“ (Report vom 28. September 2000)
Die letzte Aussage zeigt die Bedeutung des eLearning für die IT-Branche.
Hervorgerufen durch den momentanen Fachkräftemangel erfährt eLearning gerade
in diesem Bereich ein enormes Wachstum.
1.1 Motivation
Das Ziel dieser Diplomarbeit ist die Konzipierung und prototypische Implementierung
eines Kursentwicklungssystems, das die kooperative Entwicklung von wiederverwendbaren Lehr-/Lerninhalten erleichtert und unterstützt.
Ein Kursentwicklungssystem unterstützt den Prozeß der Kurserstellung. Das Wissen,
das in einem erstellten Kurs vorhanden ist, soll dann an einen Lernenden
weitergegeben werden können.
In einem solchen Kurs-Szenario lassen sich drei Benutzer-Rollen definieren. Zum
einen gibt es die Rolle des Autors. Er hat die Aufgabe Lehr-/Lernmaterial zu erstellen
und somit die Grundkomponenten eines Kurses zu schaffen. Diese Inhalte können
dann an einen Lernenden weitergegeben werden.
Für die Weitergabe des Lernmaterials ergeben sich zwei Möglichkeiten. Zum Einen
kann der Lernende das Wissen selbständig konsumieren. Zum Anderen kann ein
Lehrender einen Kurs im Rahmen einer Schulung oder einer Vorlesung präsentieren.
Neben der Rolle des Autors existieren also die Rollen Lehrender und Lernender. Zu
beachten ist, daß diese Rollen niemals als disjunkt betrachtet werden dürfen. So
kann z.B. ein Lehrender die Rolle eines Autors übernehmen und eigene Inhalte
erstellen.
Der Prozeß der Kurserstellung muß dabei nicht auf die Rolle eines Lehrenden
beschränkt sein. Man könnte sich vorstellen, daß Lernende ihre eigenen Kurse aus
vorhandenem Lernmaterial zusammenstellen.
Der zu erstellende Prototyp soll gleichermaßen für die Weiterbildung innerhalb eines
Unternehmens oder für eine Bildungseinrichtung z.B. eine Universität einsetzbar
sein. Dazu sollen zuerst die Vorbedingungen und Probleme, die sich daraus
ergeben, unter Berücksichtigung der unterschiedlichen Rollen eines Kurssystems
identifiziert werden.
Bereits vor der Einführung eines Lernsystems in ein Unternehmen oder an einer
Hochschule ist sehr viel an Wissen vorhanden. Dieses Wissen muß zuerst
identifiziert und zugänglich gemacht werden.
Das vorhandene Wissen liegt dabei teilweise in elektronischer Form vor, teilweise
sind die Informationen auf Papier niedergeschrieben und im schlimmsten Fall sitzt
das Wissen nur im Kopf einer Person. Es stellt sich nun die Frage wie all dieses
Wissen in eine für das Lernsystem nutzbare elektronische Form gebracht werden
8
kann. Dabei ist zu berücksichtigen, daß vorhandene elektronische Daten in
unterschiedlichster elektronischer Form vorliegen können. Als Beispiele können
Word-Dokumente, Powerpoint-Präsentationen oder HTML-Dokumente aber auch
Informationsträger wie Videos, Bilder oder Audio-Dateien genannt werden. Die
Informationen sollen dabei in dem Format erhalten bleiben, in dem sie am besten
durch einen Betrachter aufgefasst werden können. So kann z.B. die Information über
das Aussehen eines Gebäudes durch einen seitenlangen Text beschrieben werden,
am besten läßt sich diese Information dennoch per Bild übermitteln.
In die Erstellung der Informationen ist bereits viel Zeit und Geld investiert worden.
Ein Lernsystem, das proprietäre Datei-Formate verlangt bzw. die Menge der
unterstützten Datei-Formate klein hält, würde deshalb wenig Akzeptanz finden. Das
vorhandene Wissen müßte in entsprechende Formate transfomiert werden und im
schlimmsten Fall würde Wissen verlorengehen, das sich nicht transformieren lässt.
Ziel muß es deshalb sein alle Informationsformen für das Kursentwicklungssystem
nutzbar zu machen, also die Wiederverwendung aller vorhandener Informationsträger in den Mittelpunkt zu stellen.
Die Wiederverwendung bedeutet Qualitätsverbesserung und Zeit- bzw. Kostenersparnis. Die Qualitätsverbesserung ergibt sich daraus, daß Informationen mit
einem frei wählbaren Entwicklungswerkzeug erstellt werden können, das eine
bestmöglichste Darstellung des Wissens ermöglicht. Daneben erhöht sich die
Qualität des Wissens, da kein Wissen verloren gehen kann, aber gleichzeitig auf der
Grundlage des Vorhandenen neues Wissen erzeugt werden kann.
Eine Zeit- und Kostenersparnis ergibt sich aus der Tatsache, daß nicht alles Lehr/Lernmaterial neu formuliert werden muß, sondern auf vorhandenes Wissen zurückgegriffen werden kann.
Der Erfolg eines Unternehmens ist in starkem Maße davon abhängig, wie gut das
Zusammenspiel der einzelnen Abteilungen funktioniert. Jede Abteilung besitzt eine
Aufgabe und kann diese nur dann lösen, wenn der Informationsaustausch mit den
anderen Abteilungen gewährleistet ist.
Das Wissen eines solchen Unternehmens setzt sich aus vielen verschiedenen
Bauteilen zusammen. Um dieses Wissen als Ganzes zu vermitteln, müssen mehrere
Wissensträger zusammenarbeiten. Tun sie dies nicht, so wird die Wissensevolution
unterbrochen.
In einem Kursentwicklungssystem stellt sich das gleiche Problem. Die Erstellung
eines Kurses erfordert oftmals, Wissen aus verschiedenen Quellen
zusammenzuführen. Diese Form der Kooperation sollte von einem
Kursentwicklungssystem unterstützt werden.
Damit die Kooperation funktionieren kann, müssen einige Voraussetzungen
geschaffen werden. So muß eine Plattform existieren, die den Austausch von Wissen
ermöglicht.
Dieser Austausch kann für die kooperierenden Seiten positive Wirkungen haben.
So entsteht durch die Zusammenarbeit ein größerer Vorrat an Wissen. Aus diesem
Vorrat kann stets das qualitativ beste Wissen herausgenommen werden. Dadurch
daß verschiedene Sichtweisen und Herangehensweisen aufeinander treffen, können
Wissensgebiete aus verschiedenen Schwerpunkten betrachtet vermittelt werden.
Eine Kooperation bringt aber auch Probleme mit sich. So unterteilen unterschiedliche
Partner Wissensgebiete verschieden. Das kann zu Problemen führen, wenn Wissen
9
des einen Partners mit Wissen des anderen kombiniert werden soll. Es kommt dann
zwangsläufig zu Überschneidungen.
Bei der Kombination von Wissen tritt ein weiteres Problem auf. Behandeln zwei
Informationsträger das gleiche Thema, so sind diese nichts zwangsläufig
austauschbar. Das größte Problem ergibt sich z.B. durch die Nomenklatur. So kann
eine Komponente eines dargestellten Sachverhalts in der einen Darstellung anders
benannt sein als die gleiche Komponente der anderen Darstellung. Dies kann dann
schnell zu Mißverständnissen führen.
Auch können die Voraussetzungen für ein bestimmtes Thema völlig unterschiedlich
durch kooperierende Partner definiert werden. Der eine Partner führt vielleicht
umfassend in ein Thema ein, wohingegen der andere Partner für das selbe Thema
ein Vorwissen erwartet.
Neben diesen Problemen, die eher die Repräsentation von Wissen betreffen, ergibt
sich das Problem, welches Wissen die einzelnen Partner überhaupt bereit sind
auszutauschen. Es stellt sich hier die Frage wie Copyright-Rechte berücksichtigt und
wie die Zugriffsrechte gesteuert werden sollen.
Der größte Vorteil in der Kooperation sollte aber darin bestehen, daß der Aufwand,
und damit die Zeit und die Kosten, für das Erstellen eines Kurses erheblich reduziert
werden kann. Dies ergibt sich aus der Tatsache, daß sich die einzelnen Partner die
Arbeit teilen. Diese Aufteilung der Arbeit und das Verständigen, welcher Partner
welche
Teile
eines
Kurses
erstellt,
sollte
ebenfalls
von
einer
Kursentwicklungsumgebung unterstützt werden.
Das einmal zusammengestellte Wissen in Form eines Kurses soll nun an möglichst
viele Personen übermittelt werden. Diese Wissensempfänger haben jedoch alle eine
verschiedene Aufnahmefähigkeit für ein bestimmtes Thema. So reicht es z.B. einem
Entscheidungsträger ein Problem zu definieren und es gegebenenfalls an einem
Beispiel zu illustrieren, wohingegen ein Ingenieur sämtliche Algorithmen und
Strukturformeln, die zur Lösung des Problem beitragen, erlernen soll, d.h. die
unterschiedlichen Lernenden haben einen unterschiedlichen Kontext. Genauso
unterscheiden sich die vorhandenen Vorkenntnisse der Lernenden.
Das von mehreren Autoren erstellte Wissen muß also zielgruppenorientiert
vermittelt werden können.
An Universitäten oder in Unternehmen wird Wissen stets über unterschiedliche
Medien vermittelt. In Schulungen oder Vorlesungen kommt dabei häufig ein Beamer
zum Einsatz, der die Folien des Dozenten präsentiert. Gleichzeitig wird ein solcher
Vortrag auch auf Papier den Teilnehmern ausgehändigt.
Immer mehr Schulungen werden jedoch auch online zur Verfügung gestellt, d.h. ein
Kursteilnehmer navigiert mit einem Web-Browser durch den Kursinhalt.
Ein Kursentwicklungssystem sollte all diese und noch weitere unterschiedliche
Präsentationsformen unterstützen. Das bedeutet z.B. einer Zielgruppe, die einer
Vorlesung beiwohnt, den Kursinhalt im Powerpoint-Format zu präsentieren und
gleichzeitig eine PDF-Datei zur späteren Vertiefung des Inhalts zur Verfügung zu
stellen, während eine andere Zielgruppe den gleichen Inhalt in Form einer HTMLDatei online erlernt.
Die hier soeben dargestellten Probleme sollen zunächst in einem Beispiel-Szenario
illustriert werden.
10
1.2 Szenario
Anhand des folgenden Szenarios (siehe Abb. 1) sollen die Anforderungen an das
Kursentwicklungssystem ermittelt werden. Das Szenario beschreibt die Prozesse der
Kurserstellung und der Nutzung eines Kurses für die Lehre bzw. für das selbständige
Lernen.
Rolle: Lernender
Rolle: Dozent
HTML
PDF
HTML
Präsentationsformen
Student
Kurs erstellen
Schüler
Zielgruppen
Kurs erstellen
Kurs
Rolle: Kursentwickler
Gemeinsame
Wissensbasis
(inkl. Beschreibung)
Kooperation
Universität A
Universität B
Beschreibung
+
Rolle: Autor
Beschreibung
+
Vorhandenes
Wissen
Wiederverwendung
Vorhandenes
Wissen
Abbildung 1-1 : Szenario
11
Die in das Szenario integrierte Aktoren sind Autoren, Lehrende und Lernende zweier
Universitäten.
Die beiden Universitäten haben es sich zum Ziel gemacht im Bereich der Lehre
zusammenzuarbeiten.
Bevor mit der Kurserstellung begonnen werden kann, muß eine gemeinsame
Wissensbasis geschaffen werden. Dabei kann im Sinne der Wiederverwendung auf
vorhandene Daten zurückgegriffen werden. Die Erstellung der Wissensbasis ist ein
kooperativer Prozess. Die Universitäten vereinigen ihre vorhandenen Daten in einer
gemeinsamen Datenbank. Dieser Prozess der Vereinigung von Lehr-/Lernmaterial
wird immer dann gestartet, wenn neue Inhalte erstellt wurden. Das Erstellen dieser
Inhalte ist Aufgabe eines Autors.
Die zusammengeführten Daten unterscheiden sich in diesem hier dargestellten
Szenario sehr stark. So nutzt z.B. Universität A andere Dateiformate zur Darstellung
des Wissens als Universität B. Außerdem setzen sie für die selben Themen teilweise
auch andere Vorkenntnisse voraus. Desweiteren können Vorlesungen existieren, die
von Universität A bereits im Vordiplom gehalten werden, wohingegen Universität B
diese ins Hauptdiplom legt.
Damit diese Unterschiede nicht zu Problemen führen, müssen die Daten beschrieben
werden. So hat ein Partner, der für die Erstellung eines Kurses einen
Informationsträger sucht, die Möglichkeit anhand der Beschreibung festzustellen, ob
er eine geeignete Komponente gefunden hat.
Die Erstellung eines Kurses ist im allgemeinen Aufgabe des Lehrenden. Er sucht
geeignete Daten in der Wissensbasis und setzt aus ihnen einen Kurs zusammen.
Dieser Kurs soll nun unterschiedlichen Zielgruppen zugänglich gemacht werden.
Dazu ist es erforderlich Komponenten eines Kurses zu entfernen, andere hinzuzufügen oder die Anordnung der Komponenten verändern zu können. So könnte
eine Vorlesung z.B. neben der eigentlichen Zielgruppe Studenten, Schülern in einer
Informationsveranstaltung zum Informatikstudium zugänglich gemacht werden,
indem Komponenten entfernt werden, die von den Schülern nicht verstanden werden
können. Stattdessen könnten zusätzliche Beispiele präsentiert werden.
Nachdem ein Kurs für eine bestimmte Zielgruppe konfiguriert ist, soll nun eine
Darstellungsform gewählt werden können, d.h. ein Kurs soll in mehreren
Erscheinungsformen präsentiert werden können. Dies ist erforderlich um z.B. einen
Kurs gleichzeitig online im HTML-Format und zum Herunterladen im PDF-Format
anbieten zu können.
Ein so erstellter Kurs kann nun von einem Lernenden konsumiert werden. Entweder
direkt oder indirekt durch einen Dozenten, der einen Kurs für seine Vorlesung
verwendet.
Ein Lernender soll aber nicht auf die vorhandenen Kurse beschränkt bleiben. Das
Kursentwicklungssystems soll die Möglichkeit bieten, daß ein ein Lernender selbständig seine eigenen Kurse erstellt. Er soll dabei aber nicht auf das Erstellen eines
neuen Kurses durch Auswahl geeigneter Komponenten der Wissensbasis beschränkt
bleiben, sondern die Möglichkeit erhalten, vorhandene Kurse wiederzuverwenden
und auf seine Bedürfnisse anzupassen.
Im Sinne der Kooperation und der Wiederverwendung soll ein Lehrender der
Universität A die Möglichkeit erhalten, Kurse, die ein Lehrender der Universität B
erstellt hat, für seine eigene Vorlesung zu verwenden.
Daraus ergeben sich einige Probleme. Wie bereits erwähnt, kann der vorhandene
Kurs auf eine andere Zielgruppe ausgerichtet sein als die Zielgruppe, die für den neu
zu erstellenden Kurs anvisiert ist. Außerdem kann die Lernumgebung auf die der
12
erstellte Kurs angepasst ist variieren von der, in der der Kurs eingesetzt werden soll.
Ist der Kurs z.B. ursprünglich für eine Online-Schulung ausgelegt und macht
umfassend von Flash-Animationen gebrauch, so ergeben sich Probleme für einen
Lehrenden, der seine Vorlesung im Powerpoint-Format präsentiert.
Ein weiteres Hinderniss für die Wiederverwendung eines Kurses ergibt sich aus den
didaktischen Vorlieben der beiden Lehrenden, die sich widersprechen können.
1.3 Zusammenfassung
Anhand der im Szenario aufgezeigten Probleme können die Anforderungen an den
zu erstellenden Prototypen abgeleitet werden.
Die beiden wichtigsten Ziele des Kursentwicklungssystems, ist aus den genannten
Gründen, das Erstellen eines Prototyps, der die Wiederverwendung und die
Kooperation sicherstellt.
Die Wiederverwendung soll sich dabei sowohl auf vorhandene Lehr-/Lernmaterialien
als auch auf Teile eines Kurses erstrecken.
Eine Beschreibung der Daten soll die Wiederverwendung und Kooperation
unterstützen.
Desweiteren muß die Orientierung an einer Zielgruppe, die Didaktik sowie die Darstellungsform variabel gestaltet werden können, damit ein Kurs eines Lehrenden an
die Anforderungen eines anderen Lehrenden angepasst werden kann.
Auf die Lösung dieser Problemstellungen soll in Kapitel 4 näher eingegangen
werden. Zuvor werden in Kapitel 3 die notwendigen Grundlagen vorgestellt.
Zunächst möchte ich ein vorhandenes Kursentwicklungssystem vorstellen.
13
1.4 Literatur
[1]
Gartner Research, http://www.gartner.com
14
2 Verwandte Arbeiten
Die momentan am Markt vorhandenen eLearning-Systeme lassen sich in zwei
Kategorien einteilen. Lernsysteme wie Hyperwave Learning Space [1], WebCT [2]
und Lotus Learning Space [3]. Eine Stärke dieser Systeme sind die Möglichkeiten der
Kommunikation. Über chat, eMail, tele-conferencing, news groups und white boards
haben die Kursteilnehmer die Möglichkeit über das Wissen zu diskutieren und sich
gegenseitig zu unterstützen oder mit einem Tutor Kontakt aufzunehmen.
Leider unterstützen diese Systeme den Kursentwickler nur sehr mangelhaft und
fördern die Wiederverwendung von Lerninhalten nur mangelhaft. Oftmals ist ein
Texteditor das einzige Werkzeug, das einen Kursentwickler unterstützt.
In die andere Kategorie von Systemen fallen spezialisierte Autorenwerkzeuge wie
Macromedia Authorware [4], Macromedia Director [4] und Toolbook [5], die zwar die
Kurserstellung erleichtern aber die Wiederverwendung von Kursmateralien und die
Kooperation unter Autoren vernachlässigen.
An dieser Stelle soll ein vorhandenes Lern-System vorgestellt werden. Mit “Sumatra
System 3“ [7] existiert ein Produkt am Markt, das einen ähnlichen Ansatz wie diese
Diplomarbeit verfolgt. Sumatra ist ein Learning Managament System, das ebenso die
kooperative Erstellung und Wiederverwendung von Lernmaterial in den Mittelpunkt
stellt.
Um einen hohen Wiederverwendungsgrad zu erzielen, trennt Sumatra die Aspekte
Design und Verhalten.
Das Design wird mittels einer sogenannten Seite (Page) festgelegt. Diese Seite
gruppiert Multimedia-Daten, die in einem Repository abgelegt sind. Von außen kann
eine solche Seite mit einem Verhalten belegt werden. Dieses Verhalten legt z.B. fest
welche Seite nach einer bestimmten Aktion als nächstes angezeigt werden soll.
Die Seiten können über eine Navigationsstruktur zu einem Projekt, das einen Kurs
darstellt, zugeordnet werden.
Es werden nun die einzelnen Komponenten des Sumatra-Systems vorgestellt, und
ihre Rolle zur Erstellung eines Kurses beschrieben.
Ein Repository beinhaltet Multimedia-Daten, die zur Erstellung eines Kurses
verwendet werden können. Ein Kurs kann dabei auf mehrere Repositories
zurückgreifen. Die Repositories sind mehrsprachfähig, d.h. Multimedia-Daten können
in verschiedenen Sprachen abgelegt und gemeinsam verwaltet werden. Mit dem
Repository Browser können neue Komponenten in ein Repository eingefügt werden.
Der Repository Browser bietet außerdem einen Überblick über die vorhandenen
Daten und ermöglicht eine Vorschau-Ansicht.
Die Dokumente, Audio-Daten, Bilder und Video-Dateien eines Repositories werden
als BLOBs in einer relationalen Datenbank abgelegt.
Eine Seite übernimmt in Sumatra die Aufgabe eines Containers. Eine Seite wird aus
Repository- und GUI-Elementen aufgebaut. Zu den GUI-Komponenten gehören z.B.
Buttons, die mit einer Funktion belegt werden können, sowie Bilder und Drop-DownListen. Eine Seite wird mit dem Page Editor erstellt. Per Drag&Drop können die
einzelnen Komponenten auf die Seite gezogen und positioniert werden.
Eine Seite steht in Sumatra für den Design-Aspekt. Durch die Seite wird festgelegt,
wie die Information einem Lernenden präsentiert wird.
15
Ein Event-Modell beschreibt die Aktionen, die auf ein bestimmtes Ereignis folgen.
Diese Ereignisse werden von der Seite ausgelöst. Zu den möglichen Ereignissen
gehören z.B. das Beenden einer Seiten-Komponente, das Ablaufen eines Timers,
eine bestimmte Tastenkombination oder das Drücken eines Button. Für diese
Ereignisse wird mit dem Programming Editor eine auszuführende Aktion definiert.
Beispiele für Aktionen sind das Wechseln auf eine bestimmte Seite, das Prüfen einer
Bedingung oder das Starten einer Animation.
Mit einem Event-Modell wird der Verhaltens-Aspekt gekapselt. Für eine Seite, die
das Design einer Kurseinheit festlegt, kann orthogonal festgelegt werden, wie sie
sich in einem konkreten Kurs zu verhalten hat. So kann das Verhalten einer Seite
durch ein Benutzerprofil gesteuert werden. Das ermöglicht z.B. automatisch
Lerneinheiten zu überspringen, die ein Lernender schon in einem anderen Kurs
bearbeitet hat.
Durch diese Trennung von Design und Verhalten wird ein hohes Maß an
Wiederverwendung ermöglicht, da ein Kurs so in verschiedenen Kontexten
eingesetzt ewrden kann.
Mit dem Navigation Editor schließlich wird eine Navigationsstruktur in Form eines
Baumes definiert. Seiten können per Drag&Drop auf die Knoten des Baums plaziert
werden. Die Navigation entlang der Baumstruktur erfolgt über die in den EventModellen definierten Aktionen.
Ein Kurs wird aus den drei Aspekten Design, Verhalten und Navigation
zusammengesetzt. Die Abbildung 2-1 fasst die Erstellung eines Kurses noch einmal
zusammen. Der Project Browser erlaubt das Navigieren durch die Baumstruktur.
Neben den genannten Browsern und Editoren bietet Sumatra eine Reihe weiterer
Werkzeuge im Umfeld der Kurserstellung. Diese Werkzeuge sollen hier kurz
vorgestellt werden :
Release and Distribution Manager
Der Release and Distribution Manager verwaltet mehrere Versionen eines Kurses.
Diese Versionen können zu einer Distribution zusammengefasst werden und über
verschiedene Wege Benutzern zugänglich gemacht werden.
Projekt Server
Der Projekt Server ermöglicht die verteilte und kooperative Entwicklung von Kursen.
Kurse, die in Bearbeitung sind, werden von dem Server gesperrt. Sobald die
Bearbeitung beendet ist, wird die Sicht aller Benutzer auf den geänderten Kurs
aktualisiert. Zur Abstimmung von Änderungen ist ein Chat-Server integriert.
Translation Editor
Der Translation Editor unterstützt die Übersetzung einer Kurseinheit. Der Translation
Editor selektiert alle Texte einer Seite. Diese Texte können dann direkt im Editor
übersetzt werden. Ist die Übersetzung abgeschlossen, wird die Seite automatisch in
den Kurs integriert.
16
Kurs
SumatraProgramm
Navigationsschema
GUI -Komponenten
Button
HTML-Viewer
History
Seite
Event-Modell
Ereignis
Aktion
Verhalten
Design
Was Multimedia
ermöglicht Trennung
Repository
Abbildung 2-1: Sumatra-Modell
Animation Editor
Mit dem Animation Editor kann auf einfache Weise eine Animation aus einer Reihe
von Einzelbildern erzeugt werden.
Sumatra/Bridge
Dieses Tool ermöglicht den Import von Kursen die mit Toolbook [6] der Firma
Click2Learn erstellt wurden. Toolbook gehört zu den meistgenutzten Autorenumgebungen. Ein importierter Kurs wird vollständig in das Sumatra-Format konvertiert.
17
Neben der Möglichkeit einen Kurs zu importieren, ist Sumatra mit offenen
Schnittstellen ausgestattet, die es ermöglichen, erstellte Kurse aufzufinden und auf
diese zuzugreifen.
Sumatra ist voll zu SCORM [8] (Shareable Content Object Reference Model) kompatibel. Dieser Standard ist das Ergebins der ADL-Initiative (Advanced Distributed
Learning-Initiative) des US-Verteidigungsministeriums. Er definiert Metadaten für
Lernobjekte, Daten zur Beschreibung von Vorbedingung für die Nutzung eines
Kurses, eine API für den Aufruf von Lerneinheiten sowie Formate für den Export und
Import von Lerneinheiten.
2.1 Sumatra und die Diplomarbeit
Die Betrachtung von Sumatra zeigt, daß die Wiederverwendung im Mittelpunkt steht.
Sumatra folgt anderen am Markt befindlichen Lösungen und legt sich im ersten
Entwicklungsschritt auf die Präsentationsform eines Kurses fest. Dieses Vorgehen
schränkt die Wiederverwendbarkeit stark ein. Eine einmal erstellte Lerneinheit ist in
ihrem Aussehen eingefroren. Soll das Design einer Seite für einen neu zu
erstellenden Kurs verändert werden, so wirkt sich das auf alle Kurse aus, die diese
Seite verwenden. Die eigentliche Konfigurierbarkeit bietet Sumatra auf Ebene eines
Kurses. Innerhalb einer festgelegten Seitenhierarchie kann, je nach ausgelöstem
Ereignis, zwischen Seiten gesprungen und einzelne Komponenten gestartet werden.
Bei dem zu erstellenden Prototypen dagegen, soll die Präsentationsform erst mit
dem letzten Schritt festgelegt werden.
Sumatra selbst bietet eine Web-basierte Oberfläche um Kurse darzustellen. Aus den
Sumatra-Dokumenten ist nicht zu erfahren wie diese Oberfläche konkret aussehen
soll. Stattdessen wird die Fähigkeit einen Kurs als SCORM-Objekt zu exportieren
stark betont, was darauf hindeutet, daß es wohl am besten ist, einen Kurs zu
exportieren und mit den vorhandenen Web Based Training (WBT)- und Computer
Based Training (CBT)-Systemen zu präsentieren.
In den Sumatra-Dokumentationen ist nicht zu erfahren, wie man einen Kursentwickler
unterstützen will, relevante Daten zu finden und damit die Wiederverwendbarkeit zu
steigern. Mit Metadaten alleine nach Repository-Objekten zu suchen ist sicherlich
wenig komfortabel.
Ganz im Sinne der Zielgruppenorientierung ermöglicht SUMATRA es dem
Kursentwickler durch das Definieren von Event-Modellen, Einfluß auf den Ablauf
eines Kurses zu nehmen und damit je nach Benutzerprofil eines Lernenden
dynamisch den Pfad durch den Kurs zu beeinflußen.
Der verfolgte Ansatz in dieser Diplomarbeit soll ebenfalls die Möglichkeit Kursinhalte
auf bestimmte Zielgruppen auszurichten bieten.
In welcher Weise ein Kurs mit dem Prototyp präsentiert wird, soll nicht festgelegt
sein.
Prinzipiell wird aus den Dokumenten zu Sumatra wenig ersichtlich wie ein
Kursentwickler vorgehen soll, um einen Kurs zu erstellen und wie die SCORMMetadaten ihn unterstützen. Insgesamt erweckt Sumatra den Eindruck, daß hier eine
allgemein einsetzbare Multimedia-Entwicklungsumgebung um einige Funktionen
erweitert wurde, um auf den eLearning-Zug aufzuspringen.
18
Die Stärke von Sumatra liegt sicherlich in der Fähigkeit zur Laufzeit Kurse auf
Benutzer-Profile abzustimmen und Kurse im SCORM-Format zu exportieren, nicht
aber darin ein vollwertiges Kursentwicklungssystem zu sein.
Die Aufgabenstellung der Diplomarbeit stellt insbesondere im Bereich der Suche
nach geeignetem Kursmaterial höhere Anforderungen, als die reine Suche über
Metadaten.
Außerdem soll der Inhaltsapekt von Kurselementen stärker im Vordergrund stehen.
19
2.2 Literatur
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
Hyperwave eLearning Suite, http://www.hyperwave.de/e/products/els.html
WebCT, http://www.webct.com
Lotus Learning Space, http://www.lotus.com/home.nsf/welcome/learnspace
Macromedia Authorware, http://www.macromedia.com/software/authorware
Macromedia Director, http://www.macromedia.com/software/director
Click2Learn Toolbook, http://home.click2learn.com/en/toolbook/index.asp
Sumatra System 3 – Multimedia Development Center,
ST&C Software Tools Consulting GmbH, http://www.stc-de.com
Advanced Distributed Learning, http://www.adlnet.org
20
3 Lösungsansatz
Der zu erstellende Prototyp basiert auf einem Konzept das innerhalb des SCOREProjekts [1] entwickelt wurde. SCORE steht für “System for COurseware REuse” und
läuft als Projekt am Institut für Programmstrukturen und Datenorganisation der
Fakultät Informatik an der Universität Karlsruhe. Im folgenden möchte ich das
SCORE-Konzept vorstellen.
3.1 SCORE-Konzept
Das Konzept stellt einen Lösungsansatz für ein Kursentwicklunssystem dar, das die
Wiederverwendung und Kooperation in den Mittelpunkt stellt.
Um Zeit und damit Kosten zu sparen und gleichzeitig die Qualität des Lernmaterials
zu verbessern, soll sich die Wiederverwendung nicht allein auf einzelne atomare
Inhalte wie z.B. Texte oder Bilder konzentrieren, sondern auch Teile eines Kurses als
wiederverwendbare Einheiten betrachten. Aus diesen Kurskomponenten soll ein
neuer Kurs erstellbar sein.
Die Kooperation erlaubt den Austausch wiederverwendbarer Lernmaterialien. So
können z.B. zwei Universitäten ihre erstellten Kurse oder Teile daraus austauschen,
um bereits vorhandenes Lernmaterial nicht neu erstellen zu müssen. Durch diese
Kooperation kann den Lernenden ein noch größeres Wissensfundament vermittelt
werden.
Dabei soll sich die Kooperation nicht auf das gemeinsame Nutzen von
Multimediaelementen wie Videos, Bilder, Audio-Dateien, PDF-Dateien oder
Powerpoint-Präsentationen beschränken, sondern auch den Austausch von
Lerneinheiten, die ein bestimmtes Thema behandeln, ermöglichen.
Das SCORE-Projekt kommt zu dem Ergebnis, daß vorhandene Systeme und
Konzepte Lerneinheiten als unveränderliche Einheiten betrachten, die Aspekte wie
Inhalt, Didaktik und Präsentation vermischen, so daß ein einzelner Aspekt nicht
verändet werden kann ohne die anderen anpassen zu müssen.
Gerade die Anpassungsfähigkeit ist jedoch eine Voraussetzung dafür, daß eine
Lerneinheit wiederverwendet werden kann. Ohne diese Anpassung kann eine
Lerneinheit nur mit bestimmten anderen Lerneinheiten kombiniert werden und ist
dann auch nur in einem bestimten Kontext und nur für eine Zielgruppe einsetzbar.
Das SCORE-Konzept basiert auf zwei Entwurfsprinzipien. Das Prinzip der
Modularisierung zerlegt Lerngebiete in thematisch abgeschlossene Einheiten. Auf
diese Weise kann ein Kurs leicht aus vorgefertigten Einheiten zusammengesetzt
werden. Der Austausch von Lernmaterialien zwischen kooperierenden Kursentwicklern kann durch diese Modularisierung auf die Weitergabe dieser Einheiten
vereinfacht werden.
Neben diesem Prinzip setzt das SCORE-Konzept auf die Trennung von Aspekten.
Die Anpassung von Lernmaterial findet größtenteils auf den Ebenen Inhalt, Struktur
und Präsentationsform statt. Der Inhalt wird dann verändert, wenn ein Kursentwickler
neue Inhalte hinzufügen oder vorhandene Inhalte entfernen möchte. Änderungen an
der Struktur des Lernmaterials werden durchgeführt, um Inhalte in eine gewünschte
Reihenfolge zu bringen. Die Präsentationsform kann schließlich geändert werden,
um Inhalte in verschiedenen Formen zu präsentieren.
21
Sind die Aspekte Inhalt, Struktur und Präsentationsform vermischt, erfordert die
Anpassung eines einzelnen Aspekts in der Regel das gleichzeitige Variieren der
anderen Aspekte. Durch eine Trennung dieser Aspekte kann der Inhalt, die Struktur
oder die Präsentationsform unabhängig voneinander angepasst werden.
Um beide Prinzipien zusammenführen zu können, definiert SCORE eine Hierarchie
innerhalb der Modularisierung. Jede Ebene dieser Hierarchie kapselt einen der
Aspekte.
Durch die Aufteilung der Aspekte auf einzelne Modultypen kann ein Lehrender oder
ein Lernender wählen, welches Maß an Wiederverwendung er nutzen möchte.
Neben der Wiederverwendung einer rein auf den Inhalt bezogenen Lerneinheit kann
er auf fertig strukturierte Lerneinheiten oder sogar auf eine Lerneinheit, die bereits
den Präsentationsaspekt berücksichtigt, zurückgreifen.
Presentational Module
Presentational Module
Presentational Module
Presentational
Module Type
Structural Module
Structural
Module Type
1:n
View auf Lern-Atome
Structural Module
1:n
Lern-Atome
unterschiedlicher Autoren
Integration Module
Integration
Module Type
1:1
Learning Unit
Learning Unit
Learning Unit
1:n
Learning Subject
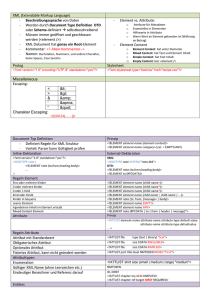
Abbildung 3-1 : Score-Modularisierungskonzept
Das Modularisierungskonzept ist in Abbildung 3-1 dargestellt. Ein Themengebiet
(Learning Subject) wird in einzelne Lerneinheiten unterteilt. Diese Lerneinheiten sind
thematisch abgeschlossen, d.h. sie motivieren normalerweise ein Problem und
geben dann eine Lösung zu diesem Problem. Im weitesten Sinne soll eine solche
Einheit kontextfrei sein. Um eine solche Lerneinheit wiederverwenden und anpassen
zu können, werden verschiedene Ebenen einer Lerneinheit definiert.
Jede Ebene dieser Modularisierung steht für einen anderen Aspekt, um die
Wiederverwendung zu erreichen.
Insgesamt werden folgende Komponenten benötigt, um das Konzept der
Modularisierung umzusetzen :
Lernatom: Ein Lernatom ist die kleinste wiederverwendbare Einheit eines
Lernmoduls. Es beschreibt nur einen Teil eines abgeschlossenen Themas und
kann erst im Kontext mit anderen Lernatomen innerhalb eines Lernmoduls ein
22
Thema vollständig abdecken. Als Beispiel für ein Thema kann ein Beispiel oder
ein Algorithmus genannt werden.
Lernmodul: Ein Lernmodul ist eine semantisch abgeschlossene, konfigurierbare
Einheit. Ein Lernmodul kapselt die Aspekte Inhalt, Didaktik und Präsentation. Aus
diesem Grund gibt es drei verschiedene Ausprägungen eines Moduls:
Integrationsmodul, Strukturmodul und Präsentationsmodul. Durch diese Trennung
kann ein Lernmodul in unterschiedlichen Kontexten verwendet werden.
Kurs: Ein Kurs deckt ein komplettes Themengebiet ab. Er besteht aus
Lernmodulen. Durch die Modularisierung können zu einem Themengebiet
verschiedene Kurse angeboten, da durch die Aspekte Didaktik und Präsentation
dieses eine Themengebiet verschiedenen Zielgruppen zugänglich gemacht
werden kann.
Im folgenden sollen die einzelnen Modularisierungsebenen eines Lernmoduls
beschrieben werden:
Integrationsmodul: Ein Integrationsmodul kann als Container für Inhalte
betrachtet werden, die allen potentiellen Nutzern des Kursentwicklungssystems
zur Verfügung stehen. Verschiedene Autoren und Kursentwickler können hier
Inhalte kooperativ ablegen. Es ist in keinster Weise vorgegeben wie dieser Inhalt
später zu nutzen ist. Das Integrationsmodul ist möglichst frei von Didaktik und
Präsentationsform und realisiert den Inhaltsaspekt. Die Implementierung des
Integrationsmodul muß folgende Prozesse unterstützen:
Hinzufügen von Lernatomen zu einem Integrationsmodul
Beschreibung eines Integrationsmodul erstellen
Strukturmodul: Ein Strukturmodul stellt eine Sicht auf eine Lerneinheit dar. Sie
kann der Sicht eines Autor, eines Kursentwickler oder eines Studenten
entsprechen. Diese Sicht konfiguriert eine Lerneinheit für einen bestimmten
Kontext. Dazu wird ein Strukturmodul aus einem Integratiosmodul gebildet. Dies
wird erreicht, indem die geeigneten Lernatome eines Integrationsmoduls anhand
einer vorgegebenen Zielgruppe und den didaktischen Vorlieben eines Dozenten
ausgewählt werden. Unterstützt werden soll dieser Prozess durch
Strukturtemplates, die automatisch eine Sicht auf ein Integrationsmodul erzeugen
können. So kann ein Kursentwickler schnell die Inhalte für einen zu erstellenden
Kurs in Form eines Integrationsmoduls auffinden und aus ihnen ein Strukturmodul
erzeugen lassen. Das Strukturmodul kapselt den Aspekt Didaktik.
Präsentationsmodul: Auf der nächsten Ebene sind die Präsentationsmodule
angesiedelt. Sie bestimmen die Erscheinungsform einer Lerneinheit und
implementieren den Präsentationsaspekt.
Um den Austausch und die Wiederverwendung von Lernobjekten zu ermöglichen, ist
es notwendig die Lernatome und Lernmodule mit standardisierten Metadaten zu
beschreiben. Diese Beschreibung muß neben inhaltlichen Aspekten die Didaktik wie
auch technische Eigenschaften berücksichtigen. So ist ein offenes
Kursentwicklungssystem gewährleistet, in dem Kursmaterial auf einfache Weise
aufgefunden, ausgetauscht und wiederverwendet werden kann.
Um eine möglichst große Benutzergemeinde anzusprechen, sollen dabei MetadatenStandards wie LOM, IMS und ARIADNE berücksichtigt werden.
23
Um die Lernobjekte selbst austauschbar zu machen, soll XML als Datenformat
verwendet werden. XML macht Daten auf einfache Weise portabel, ebenso wie Java
Code portabel macht. Dadurch kann der Austausch von Lernobjekten zwischen
Nutzern auf verschiedenen Anwendungssystemen gewährleistet werden.
Bevor aufbauend auf dem SCORE-Konzept mein Konzept zur Erstellung eines
Prototypen eines Kursentwicklungssystems vorgestellt wird, soll näher auf Metadaten
und XML eingegegangen werden.
3.2 Metadaten und Ontologien
Eines der Ziele der SCORE-Lernumgebung ist es, Lerninhalte einer großen Anzahl
von Personen zugänglich zu machen.
Dabei sollen sowohl Kurse ausgewählt, als auch neue Kurse erstellt werden können.
Für beide Fälle, den Zugriff auf fertige Kurse als auch das Wiederverwenden von
Kurskomponenten zum Erstellen eines Kurses, muß es einen effizienten
Suchmechanismus geben. Diese Suche kann auf zwei Arten realisiert werden: Zum
Einen ist es möglich, nach bestimmten Begriffen direkt im Text des Lernobjekts zu
suchen. Hier stellt sich aber das Problem, dass es häufig schwer ist, die geeigneten
Suchbegriffe zu finden. Außerdem kann man so nicht nach den Eigenschaften eines
Dokuments suchen. Soll z.B. ein Dokument gesucht werden, das sich an Studenten
im Vordiplom richtet, so ist es unwahrscheinlich, daß im Dokument die Zielgruppe
genannt ist. Ganz und gar unmöglich ist mit dieser Suchmethode das Auffinden von
Bildern.
Um all diesen Problemen aus dem Weg zu gehen, bedient man sich der Metadaten.
Metadaten sind Daten, die Daten beschreiben. Durch die Trennung von Daten und
ihrer Beschreibung ist es möglich, in einem Pool von Metadaten nach beliebigen
Ressourcen zu suchen. So ist es kein Problem, entsprechende Dokumente zu
finden, die einer bestimmten Zielgruppe entsprechen. Auch das Auffinden von
Bildern ist durch Metadaten möglich.
Für die Lernobjekte in der SCORE-Lernumgebung soll ein Metadaten-Modell
gefunden
werden,
das
Kurse,
Präsentationsmodule,
Strukturmodule,
Integrationsmodule und Lernatome gleichermaßen beschreibt.
Dazu sollen bereits vorhandene Metadatenstandards betrachtet werden.
3.2.1 Metadaten-Standards
LOM – IEEE Learning Technology Standards Committee (LTSC)
Das IEEE Komitee beschließt Standards, die sich mit der Entwicklung,
Instandhaltung und Vernetzung von Computersystemen für Lehre und Ausbildung
befassen. Die Arbeitsgruppe Learning Object Metadata (LOM) [2] hat die Aufgabe
Metadatenstandards zur Beschreibung von Lernobjekten zu schaffen.
Der LOM-Standard konzentriert sich auf einen minimalen Satz von Attributen zur
Beschreibung von Lernobjekten. Alle Attribute sind optional und können durch
weitere Attribute ergänzt werden.
24
Das LOM-Modell teilt die Metadaten in 8 Gruppen auf:
Die Gruppe General befasst sich mit Daten, die das Lernobjekt durch einen
Titel, eine kurze Beschreibung sowie Schlüsselwörter darstellen.
In der Gruppe Lifecycle werden die einzelnen Versionen eines Lernobjekts
verwaltet und Bearbeiter der einzelnen Versionen benannt.
Innerhalb der Gruppe Metametadata werden die Metadaten beschrieben. Hier
kann aufgeführt werden in welchem Katalog die Metadaten eingetragen sind
und welches Metadatenschema zugrunde liegt.
Die Gruppe Technical hält Informationen über den Datentyp, die Größe und
den Ort der Ressource bereit.
Innerhalb der Gruppe Rights werden Attribute zusammengefasst, die sich mit
Urheberrechten, Zugriffsrechten und Nutzungsgebühren beschäftigen.
In der Gruppe Relations werdem Beziehungen zwischen den Lernobjekten
definiert.
Die Gruppe Annotation erlaubt Bemerkungen und Bewertungen der
Lernressourcen zu speichern.
Innerhalb der Gruppe Classification werden Lernobjekten in eine Taxonomie
eingeordnet.
Instructional Management System (IMS)
Am IMS Projekt [3] waren zu Beginn cirka 600 Bildungseinrichtungen der USA
beteiligt. Das Projekt wurde in eine gemeinnützige Organisation überführt, deren
Mitglieder Bildungsorganisationen, Regierungseinrichtungen und Unternehmen
vertreten.
Die IMS-Spezifikationen sind frei nutzbar auch für Nicht-Mitglieder.
Das Metadatenmodell basiert auf dem LOM-Modell. Verändert wurden lediglich
die Bezeichnung einiger Attribute. Darüber hinaus wurden Pflichtfelder eingeführt.
Überlässt das LOM-Modell die Wahl eines Datenformats für die Metadaten dem
Benutzer, so empfiehlt IMS den XML-Standard. Speziell in Europa erhält IMS
sowohl von Seiten der Bildungseinrichtungen als auch von Seiten der
Unternehmen wachsenden Zuspruch. Im Januar 2001 wurde IMS Europe
gegründet und übt seit dem zunehmend Einfluß auf europäische Gremien aus.
Learning Technologies (LT) – CEN/ISSS
Die ISSS (Information Society Standardization System)-Organisation wurde durch
das Europäische Komitee für Standardisierung (CEN) gegründet, um die
Informationsgesellschaft in Europa zu fördern. Die Arbeitsgruppe Learning
Technologies [4] befasste sich anfänglich mit der Implementierung des LOM
Standards in den einzelnen europäischen Sprachen.
Auf einem Meeting Anfang 2001 wurden die Arbeitsgebiete für 2001 festgelegt:
LOM – Mitarbeit an LOM, um LOM auf alternative Sprachen auszurichten
Bewertung von Copyright-Lizenzstandards
Richtlinien für den Entwurf und die Qualitätssicherung von Lern-Ressourcen
Schaffung von Taxonomien für die europäische Lerngesellschaft
PROMETEUS
PROMETEUS (PROmoting Multimedia access to Education and Training in
European Society) [5] besteht aus über 500 europäischen Unternehmen und
akademischen Organisationen. PROMETEUS wurde zeitgleich mit CEN/ISSS LT
25
gegründet und konzentriert sich auf die Forschung. Empfehlungen und Richtlinien
die sich aus dieser Tätigkeit ergeben, werden an CEN/ISSS weitergegeben.
GESTALT
Getting Education Systems Talking Across Leading-edge Technologies
(GESTALT) [6] ist ein Konsortium aus Partnern von Universitäten und aus der
Wirtschaft Europas. Ziel war es, Lernenden Kursmaterial über Suchdienste
zugänglich zu machen. Die Arbeit von GESTALT geht ein in das IEEE Learning
Technology Standards Committee und damit in LOM, ARIADNE und IMS.
Neben einer Framework-Architektur für Lernumgebungen wurden Datenmodelle
zum Datenaustausch verschiedener Lernsysteme entwickelt.
Das Ergebnis im Bereich Metadaten wird GEMSTONES (Gestalt Educational
Metadata Standards for On-line Education Systems) genannt. Es werden
Metadatenmodelle für Kursinhalte, Studentenprofile und Lernüberwachung
definiert. Teile dieser Datenmodelle haben ihren Einfluß auf IEEE LTSC und IMS
ausgeübt.
Dublin Core
Dublin Core [7] wurde ursprünglich als Metadatenmodell für Content, der sich im
Internet befindet, entwickelt. Dublin Core wurde von einer großen Zahl an
Interessengemeinschaften weiterentwickelt und hat heute folgende Ziele :
Entwicklung von Basis-Metadatenstandards, die für unterschiedliche
Anwendungsfälle einsetzbar sind
Erweiterbarkeit von Metadatenmodellen für den Einsatz in speziellen
Umgebungen bei gleichzeitiger Kompatibilität der Modelle
Definition von Metadaten-Richtlinien um Metadatenmodelle durch
Transformation ineinander zu überführen
ARIADNE
Eine Erweiterung des Dublin Core Metadatenmodells war Ziel des ARIADNE
Projekts [8] des EU Telematics Education & Training Programme. Das Ergebnis
wurde mit dem IMS-Metadatenmodell abgeglichen und an die IEEE
herangetragen.
ADL
Die Advanced Distributed Learning (ADL)–Initiative [9] wurde durch das US
Verteidigungsministerium und das Ministerium für Wissenschaft und Technologie
ins Leben gerufen und dient dem Austausch von Technologien und
Entwicklungen im Bereich Courseware. Dabei wurden Ergebnisse von IMS
übernommen.
3.2.2 Ontologien – als Klassifikationsinstrument für Lernobjekte
Das Internet ist ein fast unendlich großes Informationsmedium. Informationen aller
Art können hier abgerufen werden. Täglich wächst das Internet und überflutet uns mit
immer mehr Daten. Ist man jedoch an ganz speziellen Informationen interessiert,
steht man vor einem großen Problem. Wie soll man das Gesuchte finden.
Suchmaschinen wie Yahoo, Altavista und Google erlauben die Suche nach mehreren
Schlüsselwörtern. Doch nach welche Schlüsselwörtern soll man suchen? Vielleicht
ist gerade ein Schlüsselwort nach dem man sucht nicht in dem Text enthalten der am
26
besten dem gesuchten Dokument entspricht. Gibt man zu viele Schlüsselwörter an
findet sich vielleicht gar kein Dokument. Gibt man dagegen zu wenig Schlüsselwörter
an kommt es nicht selten vor, daß man mit zehntausenden Dokumenten konfrontiert
wird, unter denen vielleicht nur ein Dokument dem Gesuchten entspricht.
Eine Möglichkeit dieses Dilemma zu beseitigen, besteht darin alle Dokumente zu
katalogisieren. So bieten Suchmaschinen oftmals Kataloge an, durch die man zu
einem gesuchten Dokument navigieren kann.
So finden sich aktuelle Nachrichten zu der Olympiade in Salt Lake City z.B. unter
dem Katalogpfad Nachrichten-Sport-Olympia2002.
Auf diese Weise würden jedoch nur Dokumente gefunden, die durch eine
Suchmachine vorher katalogisiert wurden.
Wünschenwert wäre eine Katalogisierung von Dokumenten direkt durch den Urheber
eines Dokuments. Die Katalogisierung müsste dabei nach fest vorgegebenen
Schlüsselwörtern erfolgen. Das würde bedeuten, daß für jedes Themengebiet
Schlüsselwörter definiert werden müßten und diese Themengebiete hierarchisch
miteinander kombiniert werden sollten.
So könnte jedes Dokument, das im Internet verfügbar ist, leicht aufgefunden werden.
Genau solch eine Klassifizierung von Dokumenten und anderen Daten wird durch
Ontologien ermöglicht. Ontologien wurden entwickelt, um eine Beschreibung von
Informationsquellen zu ermöglichen, die sowohl zur Verarbeitung innerhalb von
Computersystemen als auch zum Austausch zwischen Mensch und Maschine
genutzt werden können.
Eine formalere Definition für Ontologien lautet : Eine Ontologie ist eine formale,
explizite Spezifikation einer geteilten Miniwelt. [10] "Formal" drückt die Tatsache aus,
dass die Ontologie maschinenlesbar ist. "Explizit" bedeutet, daß die verwendeten
Konzepte und Bedingungen zur Beschreibung der Spezifikation wohldefiniert sind.
"Geteilt" bedeutet, daß die beschriebene Miniwelt von einer Gruppe von Benutzern
akzeptiert und verwendet wird. Da Ontologien von einer möglichst großen
Benutzergruppe akzeptiert werden sollen, ist deren Entwicklung ein kooperativer
Prozess, der viele Personen involviert.
Eine Ontologie erlaubt die Konstruktion eines Domain Model. Das Vokabular der
Ontologie modelliert die Domäne.
Als Beispiel kann hier eine Miniwelt benutzt werden, die die Vorlesung
Datenbankimplementierung modelliert. Eine Ontologie für diese Miniwelt könnte wie
in Abbildung 3-2 dargestellt aussehen.
Ist ein Student auf der Suche nach Dokumenten, die die Anfrageoptimierung
thematisieren, so kann er diese leicht finden, sofern er mit der Ontologie vertraut ist.
Er muss als Suchpfad nur "DatenbankimplementierungExterne logische
RessourcenVerarbeitung zentralisierter AnfragenAnfrageoptimierung" (in der
Abbildung 3-2 grau unterlegt) eingeben, und schon erhält er die gewünschten
Dokumente. Wird der Pfad nicht in voller Länge angegeben, sondern nur bis zu dem
Knoten "Verarbeitung zentralisierter Anfragen" so werden alle Dokumente
zurückgeliefert, die unter diesem Knoten hängen, also auch Dokumente, die die
Anfrageübersetzung behandeln.
27
Datenbankimplementierung
Ressourcenverwaltung und Datenbankarchitektur
Physische
Ressourcen
Fünf-SchichtenArchitektur
Verwaltung der
physischen Speicher
Ebene der
physischen
Datenstrukturen
Segment-Ebene
Interne logische
Ressourcen
Externe logische
Ressourcen
Verarbeitung
zentralisierter
Anfragen
Anfrageübersetzung
Anfrageoptimierung
Anfrageoptimierung
mit frei definierbaren
internen Dateien
Abbildung 3-2 : Beispiel einer Ontologie
3.2.3 Ontolgien für Metadaten
Die Suche nach Lernobjekten soll in dem von mir zu erstellenden Kursentwicklungssystems durch Ontologien unterstützt. In dem Attribut Keyword der MetadatenGruppe Classification werden Schlüsselwörter gepflegt, die den Pfad innerhalb einer
Ontologie beschreiben. So würde für das eben genannte Beispiel in den Metadaten
des Dokuments, das die Anfrageoptimierung thematisiert, unter dem MetadatenAttribut Classification.Keyword der Pfad "DatenbankimplementierungExterne
logische RessourcenVerarbeitung zentralisierter AnfragenAnfrageoptimierung"
stehen.
Natürlich kann nicht verlangt werden, daß der Erzeuger der Metadaten, geschweige
denn ein neuer Benutzer der Lernumgebung die Ontologie kennen muß, um
Metadaten zu pflegen oder nach geeigneten Lernobjekten zu suchen. Unterstützung
soll hier ein Ontologie-Browser bieten, mit dem durch die Hierarchie der Ontologien
gebrowst werden kann.
Die Anbindung dieses Ontologie-Browser sowie die Erstellung einer Beispielontologie
ist Teil einer weiteren Diplomarbeit, die zur Zeit von Jordi Navas bearbeitet wird.
28
3.3 XML
Bereits 1986 wurde die Standard Generalized Markup Language (SGML) als ISO
8879 Standard verabschiedet. Erst mehr als zehn Jahre später machte die Sprache
wieder von sich reden. Mittlerweile hatte das Internet seinen Siegeszug angetreten
und es wurde nach Informationsstrukturen gesucht, mittels derer Daten strukturiert
und selbstbeschreibend versendet werden konnten. Da SGML jedoch ein sehr
mächtiger und damit auch komplizierter Standard ist, wurde die eXtensible Markup
Language (XML) ins Leben gerufen. Sie kann als vereinfachtes SGML bezeichnet
werden, behält jedoch die volle Ausdrucksmöglichkeit von SGML.
3.3.1 Informationsmodellierung mit XML
Mittels XML [11] können Informationen durch Textstrukturen modelliert werden.
Informationen werden in Form von Text abgelegt und durch spezielle Textfolgen
(Markup) strukturiert, d.h. strukturierte Daten können in Form eines reinen
Textdokuments repräsentiert werden und als solches über Netzwerke hinweg
versendet werden.
Um strukturierte Informationen in ein Textdokument zu überführen, müssen die
einzelnen Informationseinheiten identifiziert werden. Unterschieden werden konkrete
Informationseinheiten und abstrakte Informationseinheiten. Konkrete Einheiten
tragen die eigentliche Information und abstrakte Einheiten gruppieren diese bzw.
zeichnen sie aus.
Elemente
Diese Dateneinheiten werden in XML durch Elemente dargestellt. Elemente werden
in Daten-Elemente, Container-Elemente und leere Elemente unterteilt. Das DatenElement trägt die konkreten Informationseinheiten während das Container-Element
Daten-Elemente gruppiert.
Ein Daten-Element, das den Namen des Autors eines Buches enthält, wird in XML
folgendermaßen deklariert :
<!ELEMENT author (#PCDATA)>
Diese Deklaration definiert ein Daten-Element vom Typ autor das Daten in Form
eines String (#PCDATA) enthält. Der Elementname autor beschreibt gleichzeitig die
Information, indem er den im Element enthaltenen String als Namen eines Autors
klassifiziert.
Das Buch selbst kann als Container-Element modelliert werden :
<!ELEMENT book (author, title, year, content)>
Die Deklaration eines Container-Elements ist an dem Vorhandensein eines
Inhaltsmodells erkennbar. Das Inhaltsmodell beschreibt Beziehung und Status der im
Container enthaltenen Elemente. In dem Beispiel besitzt ein Buch einen Autor, einen
Titel, ein Erscheinungsjahr und einen Inhalt.
Die Beziehungen werden durch einen logischen Ausdruck dargestellt. Mögliche
Operatoren sind in Tabelle 3-1 dargestellt.
29
Tabelle 3-1 : Operatoren des Informatonsmodells
Element A, Element B
Element A | Element B
Element A wird von Element B gefolgt
Element A oder Element B
Zusätzlich können Ausdrücke geklammert werden.
Der Status eines Elements gibt die Kardinalität eines Elements in Backus-NaurNotation an.
Tabelle 3-2 : Kardinalität eines Elements
Element A
Element A+
Element A?
Element A*
Das Element kommt genau einmal vor
Das Element kommt mindestens einmal vor
Das Element ist optional
Das Element kommt beliebig oft vor
Welche Elemente ein Container-Element enthält ist nicht festgelegt. So kann ein
Container-Element neben Daten-Elementen weitere Container-Elemente enthalten.
Diese Verschachtelung ist beliebig tief weiterführbar. So können strukturierte Daten
auf verschachtelte Elemente abgebildet werden. Genau dies macht das Grundprinzip
von XML aus : Elemente werden hierarchisch angeordnet. Deshalb werden
Informationen die mit XML modelliert sind oftmals als Baum dargestellt. Das obige
Buch hat beispielsweise folgende Baumdarstellung:
book
author
title
year
content
Abbildung 3-3 : Informationsmodellierung eines Buches
Attribute
Ein weiteres Mittel zur Repräsentation strukturierter Daten stellen Attribute dar.
Attribute versehen Elemente mit zusätzlicher Information.
Sollen z.B. Bücher danach unterschieden werden ob sie als Taschenbuch vorliegen
oder als gebundene Ausgabe, so kann das Element book mit einem entsprechenden
Attribut versehen werden:
<!ATTLIST book
cover (paperback|hardcover) #REQUIRED>
30
Hier hat das Inhaltsmodell die Aufgabe mögliche Werte für das Attribut zu definieren.
Mögliche Werte werden durch | getrennt. Kann das Attribut aus beliebigen
Zeichenketten bestehen, so ist steht anstelle des Informationsmodells der Datentyp
CDATA.
Zusätzlich gibt der Status #REQUIRED an, daß das Attribut mit einem Wert belegt
sein muß. Tabelle 3-3 zeigt einen Überblick über die einzelnen Stati.
Tabelle 3-3 : Status für Attribute
#REQUIRED
#IMPLIED
#FIXED
“Vorbelegung“
Das Attribut muß belegt sein
Das Attribut muß nicht belegt sein
Dem Attribut wird ein fester Wert zugewiesen
Das Attribut wird mit einem Wert vorbelegt
Ein Attribut dem der Status #IMPLIED zugeordnet ist, trägt automatisch den Wert
“unspecified“ sofern kein anderer Wert angegeben wird.
Durch Attribute ist es leicht einzelne Elemente aus einem Baum herauszugreifen. Es
können somit Teilbäume gebildet werden. So kann z.B. eine Bibliothek, die alle ihre
Taschenbücher auf ihren Zustand untersuchen möchte leicht die gesuchten
Elemente erfassen.
library
book
cover: paperback
book
cover: hardcover
book
cover: hardcover
book
cover: paperback
Abbildung 3-4 : Informationsmodellierung mit Attributen
Fixierte Attribute machen auf den ersten Blick wenig Sinn haben jedoch zwei wichtige
Anwendungen gefunden:
XML-Bäume verarbeitende Anwendungen werden häufig durch Parameter
konfiguriert, um den Baum in bestimmter Weise zu manipulieren. Dazu greifen
Anwendungen auf von ihr definierte Parameter zu. Soll für einen Baum stets die
gleiche Verarbeitung erfolgen, so kann dies durch vorgegebene, nicht änderbare
Parameter erfolgen.
Neben der Bildung von Untermengen durch Attribute können fixierte Attribute
dazu eingesetzt werden, um Obermengen zu bilden. So kann in einem fixierten
Attribut eines Element der Obertyp des Elements spezifiziert werden.
31
Attribute vs. Elemente
Wann sollten Informationen als Elemente und wann als Attribute repräsentiert
werden? Betrachtet man die Informationen aus der Sichtweise ihrer Aussagekraft, so
werden Attribute eingesetzt, um Informationen über Informationen darzustellen. So
beschreibt die Beschaffenheit (Taschenbuch oder gebundene Ausgabe) eines
Buches nicht die eigentliche Information des Buches und ist deshalb als Attribut
realisiert. Auf der anderen Seite stellen der Autor, der Titel, das Erscheinungsjahr
und der Inhalt die eigentliche Information dar.
Eine andere Trennung ergibt sich durch die Art der Deklaration von Elementen und
Attributen. Elemente können beliebigen Text enthalten. Container-Elemente
definieren eine Hierarchie und legen die Auftretungshäufikeit der einzelnen
enthaltenen Elemente fest.
Attribute hingegen erlauben es, die möglichen Werte einzuschränken um nur
bestimmte Ausdrücke zu erlauben.
So sollte jede Informationseinheit darauf untersucht werden, wie sie besser
implementiert werden kann.
Sollen in einem Informationsmodell häufig Teilmengen des Baumes gebildet werden,
so ist es ratsam, die Information, nach der die Teilmengenbildung erfolgt, als Attribut
zu realisieren wie folgendes Beispiel verdeutlicht:
book
author
name
lastname
Abbildung 3-5 : Informationsmodellierung ohne Attribute
Soll in dieser Baumstruktur nach Büchern eines bestimmten Autors gesucht werden,
so müssen für jedes Buch drei Ebenen in der Hierarchie des Baumes durchlaufen
werden, was sehr hohen Aufwand bedeutet. Ist der Autor stattdessen als Attribut
32
eines Buches abgelegt, so kann auf der obersten Ebene bequem nach dem Autor
selektiert werden.
Genauso wie bei der Anfrageoptimierung zur Laufzeit eine SQL-Anfrage
dahingehend optimiert wird, daß Selektionen und Projektionen möglichst früh
angewendet werden, um die zu bearbeitende Datenmenge klein zu halten, so ist
durch das Plazieren von Attributen auf oberen Ebenen eine Anfrage schon vor der
Laufzeit optimiert.
IDs und Verweise
Attribute können als eindeutige Identifikatoren gekennzeichnet werden. So kann ein
Buch eindeutig über seine Signatur identifiziert werden. Identifikatoren werden über
das Schlüsselwort ID definiert:
<!ATTLIST book
signature ID #IMPLIED>
Ein auf diese Weise definiertes Attribut muß im gesamten Baum eindeutig sein, d.h.
unabhängig vom Namen der Attribute darf es keine ID-Attribute geben, die den
selben Wert tragen.
Auf eine ID kann auch verwiesen werden. Dies geschieht über das Schlüsselwort
IDREF:
<!ATTLIST oldbook
signature ID #REQUIRED
new_signature IDREF #REQUIRED>
Das Beispiel beschreibt das Ersetzen eines Buches durch ein neues Buch (mit
anderer Signatur). Dabei verweist das Attribut new_signature auf ein Buch mit
Signatur signature.
Es können auch mehrere Referenzen innerhalb eines Attributs abgelegt werden.
Hierführ wird das Schlüsselwort IDREFS verwendet:
<!ATTLIST student
lend_books IDREFS #IMPLIED>
So könnnen die von einem Studenten geliehenen Bücher unter dem Attribut
lend_books zusammengefasst werden. Die Signaturen der geliehenen Bücher
müssen dabei stets Signaturen entsprechen, die unter einem ID-Attribut im selben
Baum auftreten.
Modularisierung
Treten Teilbäume an mehreren Stellen innerhalb eines Baumes auf, so können die
Elemente, die den Teilbaum beschreiben gekapselt werden. Diese Modularisierung
erfolgt mit Hilfe von Entitäten:
<!ENTITY teilbaum SYSTEM “Datei-URI“>
<!ENTITY teilbaum “Element Deklarationen“>
33
Die Deklaration nennt den Namen der Entität und verweist auf eine DeklarationsDatei bzw. deklariert die Elemente des Teilbaums direkt im Anschluß an den
Entitätsnamen.
An den Stellen im Baum, an denen der Teilbaum eingefügt werden soll, wird ein
Verweis auf die Entität abgelegt. Dies geschieht durch Voranstellen eines & vor den
Entitätsnamen:
<!ELEMENT baum (&teilbaum, Element A, ElementB, ....)>
Neben Entitäten die Elemente kapseln, gibt es Parameter-Entitäten, die folglich
Parameter deklarieren. Soll einem Element ein Attribut zugeordnet werden, so kann
dies mittels einer Parameter-Entität erfolgen:
<!ENTITY % augenfarbe “blaugrünbraun“>
<!ELEMENT person %augenfarbe>
Dem Element person wird das Attribut „augenfarbe“ inklusive Informationsmodell
zugewiesen. Dass es sich bei der Entität um eine Parameter-Entität handelt, ist an
dem vorangestellten % zu erkennen.
3.3.2 XML-Dokumente
Bisher wurde nur vorgestellt wie strukturierte Informationen mit Hilfe von Elementen
und Attributen modelliert werden. Wie aber werden die Informationsbäume in eine
Textdatei transformiert? Um die Hierarchie der Bäume auf eine eindimensionale
Form zu bringen, werden die einzelnen Elemente geklammert. Die Klammerung wird
durch sogenannte Tags (engl. Etikett) realisiert. Dabei wird ein Element durch ein
Anfangs-Tag und ein Ende-Tag identifiziert. Unterelemente und der Text von DatenElementen sind von den Tags umschlossen.
<book cover=“paperback“>
<author>
<firstname>Uwe</firstname>
<lastname>Keller</lastname>
</author>
.........
</book>
Start-Tags tragen den Namen des Elements. Bei Ende-Tags wird zusätzlich ein
Schrägstrich (/) vorangestellt. Attribute werden im Start-Tag des Elements belegt,
indem der Name von dem Wert des Attributs gefolgt wird.
Häufig werden die Tags zusätzlich eingerückt um die Struktur der Daten
hervorzuheben.
Bevor aber die Daten in XML-Form in einem Dokument abgelegt werden, wird am
Kopf des Dokuments die XML-Deklaration eingefügt. Die XML-Deklaration gibt die
XML-Version an und spezifiziert den verwendeten Zeichensatz:
34
<?xml version=“1.0“ encoding=“UTF-8“>
Mit ? beginnende Tags werden als Verarbeitungsanweisungen (Processing
Instructions) bezeichnet. Sie weisen das XML-Dokument verarbeitende
Anwendungen an. Diese Anweisung informiert den Prozessor des XML-Dokuments
über die verwendete XML-Version und den gewählten Zeichensatz.
Auf weitere Verarbeitungsanweisungen soll an dieser Stelle nicht eingegangen
werden.
Nach den Verarbeitungsanweisungen kann eine Dokument Type Definition (DTD),
(siehe nächstes Unter-Kapitel), deklariert werden, so daß ein XML-Dokument
folgende Struktur hat:
<?xml version=“...“ charset=“...“>
weitere Verarbeitungsanweisungen
<!DOCTYPE ...........>
<Elementname> Unterelemente </Elementname>
3.3.3 Document Type Definition
Eine Document Type Definition (DTD) kapselt die Deklaration der Elemente und
Attribute. Die Deklaration kann direkt in dem XML-Dokument oder in einer separaten
Datei erfolgen.
Im XML-Dokument wird die DTD wie folgt deklariert:
<!DOCTYPE Wurzel-Element-Name SYSTEM “Datei-URI“ [ weitere Dekl. ]>
Erfolgt die Deklaration aus einer Datei, so wird hinter dem Schlüsselwort SYSTEM
der Dateipfad der Datei angegeben, die die Deklarationen enthält. Alternativ können
Deklarationen lokal erfolgen. Diese werden durch eckige Klammern ([,])
eingeschlosen.
Mit der DOCTYPE-Deklaration wird gleichzeitig das Wurzel-Element des Baumes
spezifiziert. Dieses Element wird auch als “Document Element“ bezeichnet.
Ein Dokument-Baum der gemäß einer DTD aufgebaut ist, wird als „Instanz“ der DTD
bezeichnet.
Eine weitere Flexibilisierung bringt die gleichzeitige Angabe einer lokalen und einer
Deklaration mittels einer Datei. Die lokalen Deklarationen werden dabei als
Declaration Subset bezeichnet. Das Declaration Subset überschreibt dabei
Definitionen der externen Datei. So können z.B. Elemente hinzugefügt werden.
Der Einsatz von marked sections schließlich erlaubt, zusammen mit ParameterEntitäten, eine DTD für den aktuellen Gebrauch zu konfigurieren. Marked sections
fassen Teile einer DTD zu einem Abschnitt zusammen:
<![
INCLUDE [
<!ATTLIST book
signature CDATA #REQUIRED>
]]>
35
Der Abschnitt deklariert für das Element book ein Attribut signature. Das
Schlüsselwort INCLUDE bedeutet, daß der Abschnitt gültig ist. Soll der Abschnitt
ignoriert werden, ist das Schlüsselwort IGNORE zu gebrauchen.
Das Schlüsselwort kann in einer externen DTD durch eine Parameter-Entität ersetzt
werden:
<![
%switch; [
<!ATTLIST book
signature CDATA #REQUIRED>
]]>
Mit Hilfe der DOCTYPE-Deklaration kann nun im Declaration-Subset ausgewählt
werden, wie die Parameter-Entität zu belegen ist:
<!DOCTYPE book SYSTEM “externe.dtd“ [
<!ENTITY % switch “INCLUDE“>
]>
Dadurch daß der Parameter switch auf “INCLUDE“ gesetzt wird, wird dem Element
book das Attribut hinzugefügt.
Auf diese Weise kann sehr leicht ein Schalter innerhalb einer DTD implementiert
werden, der im Declaration Subset gesetzt werden kann.
Wohlgeformtheit und Gültigkeit
Ein XML-Dokument heißt wohlgeformt, wenn der Start-Tag und der Ende-Tag eines
Elements im selben umschließenden Element liegen, d.h. wohlgeformte Dokumente
weisen eine korrekte Baumstruktur auf.
Ein Dokument heißt gültig, wenn es gemäß seiner DTD validiert ist, d.h. ein
Dokument ist dann gültig, wenn es gemäß den Deklarationen seiner DTD aufgebaut
ist. Es muß also geprüft werden, ob ein Element gemäß seines Informationsmodell
aufgebaut ist und dabei die Kardinalitäten den Vorgaben entsprechen. Für Attribute
ist zu prüfen, ob die Werte den Vorgabewerten entsprechen und der Status nicht
verletzt wird.
Einfach zu prüfen ist die Gültigkeit eines Dokuments durch den Einsatz eines
Parsers.
3.3.4 Parser
Damit Programme auf XML-Dokumente zugreifen können, muß zunächst ein Parser
das Dokument zerlegen. Bei den Parsern unterscheidet man zwei Arten. Auf der
einen Seite stehen ereignisorientierte Parser auf der anderen Seite objektorientierte
Parser. Weiter werden Parser geteilt in validierende und nicht validierende Parser.
Validierende Parse prüfen die Gültigkeit eines Dokuments gegen sein DTD.
36
Ereignisorientierte Parser
Ein ereignisorientierter Parser liest ein XML-Dokument Element für Element ein und
ruft je nach Elementtyp definierte Funktionen auf, die Ereignishandler genannt
werden. Erreicht der Parser zum Beispiel ein Element <Diplomarbeit>, so ruft er den
Ereignis-Handler startElement() zur Behandlung eines Start-Tags auf.
Um ein XML-Dokument mit einem ereignisorientierten Parser zu bearbeiten, muß
also, nachdem der Parser instantiiert ist, für jedes zu bearbeitende Ereignis ein
Handler am Parser registriert werden. Der Handler kann dann auf den Inhalt des
aktuellen Elements zugreifen.
Parser, die die “Simple API for XML“ (SAX) implementieren, können als Beispiel
ereignisorientierter Parser gesehen werden.
Objektorientierte Parser
Objektorientierte Parser dagegen lesen ein XML-Dokument als ganzes ein. Erst
danach hat das Programm Zugriff auf das Dokument. Das XML-Dokument liegt als
vollständiger Objektbaum im Speicher vor. Zugriff auf das Dokument erhält das
Programm durch Durchlaufen des Baumes.
Als Beispiel für objektorientierte Parser können Parser betrachtet werden, die das
Document Object Model (DOM), einen W3C Standard, implementieren
Ereignisorientiert vs. objektorientiert
Ereignisorientierte Parser schlagen in Punkto Performance klar die Konkurrenz der
objektorientierten Parser.
Ein weiterer Nachteil der objektorientierten Parser liegt darin, daß sie für jedes
Dokument einen kompletten Objektbaum im Speicher halten, was bei größeren
Dokumenten schnell zu Speichermangel führen kann.
Trotzdem spricht ein gewichtiges Argument für objektorientierte Parser. Innerhalb der
Anwendung kann jederzeit auf sämtliche Knoten zugegriffen werden. Die Kosten für
einen Zugriff betragen O(1). Bei der sequentiellen Suche mit einem
ereignisorientierten Parser betragen die Kosten O(n). Denn hier muss um einen
Knoten zugreifen zu können stets das ganze Dokument durchlaufen werden.
Zusammengefasst können Anwendungen in zwei Klassen geteilt werden :
Einmaliger Zugriff auf Knoten (z.B. zum Ausgeben eines Dokuments am
Bildschirm) :
In diesem Szenario eignet sich der ereignisorientierte Parser am besten.
Wiederholter wahlfreier Zugriff auf Elemente (z.B. um einzelne Knoten zu
manipulieren) :
Hier lohnt sich der Aufwand zuerst den Dokument-Baum im Speicher aufzubauen.
Alle weiteren Zugriffe auf Elemente werden mit hoher Performance bedient.
37
3.3.5 Namensräume
Namensräume erlauben das Mischen verschiedener Markup-Vokabulare. Das
Problem des Mischen sei an folgendem Beispiel illustriert :
<diplomarbeit>
<author>Alexander Fürbach</author>
<literatur>
<book>
<title>Java and XML</title>
<author>Brett McLaughlin</author>
</book>
</litearatur>
</diplomarbeit>
Betrachtet man das Beispiel genauer, stellt man fest, daß zwei Tags mit dem Namen
author existieren. Diese Tags haben unterschiedliche Bedeutungen : im einen Fall
handelt sich um den Autor einer Diplomarbeit, im anderen Fall um den Autor eines
referenzierten Buches.
Die Lösung bringt der Einsatz von Namensräumen. Ein XML-Namensraum ist eine
Gruppierung von Element- und Attributnamen. Werden diese Namen in einem XMLDokument benutzt, so wird gleichzeitig ihr Namensraum ausgezeichnet. Dies
geschieht indem der Namensraum als Präfix vor den Elementnamen gestellt wird.
Dadurch ist eindeutig bestimmt, welche Bedeutung ein Elementname hat.
Das obige Beispiel könnte mit Verwendung von Namensräumen beispielsweise so
aussehen :
<da:dipomarbeit>
<da:author>Alexander Fürbach</da:author>
<da:literatur>
<book:book>
<book:title>Java and XML</book:title>
<book:author>Brett McLaughlin</book:author>
</book:book>
</da:literatur>
</da:diplomarbeit>
Deklarieren von Namensräumen
Eine Namensraumdeklaration hat folgende Form :
xmlns:prefix = "name"
Der Name eines Namensraums muß eine gültige URI sein.
<xsl:transform xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
...........
...........
<xsl:transform>
38
In dem obigen Beispiel wird der Namensraum, der Elementnamen für eine XSLTransformation (siehe Kapitel 3.3.7) beinhaltet, an den Präfix xsl gebunden.
Namensräume dienen zu einem großen Teil der Auszeichnung bestimmter Elemente.
XML-Prozessoren
interpretieren
so
gekennzeichnete
Elemente
als
Verarbeitungsanweisungen. Im Falle eines XSLT-Prozessors werden nur Elemente
des Namensraums xsl berücksichtigt. Andere Elemente werden unverändert in die
Ausgabe übernommen.
Der Präfix ist sowohl innerhalb des Elements in dem er deklariert wurde gültig, als
auch in allen untergeordneten Elementen.
3.3.6 XML Familie
Die eigentliche Mächtigkeit von XML liegt in dem Zusammenspiel von XML mit
weiteren Technologien. Der XML-Standard sollte niemals isoliert betrachtet werden,
sondern stets im Zusammenhang mit weiteren Standards, die sich rund um XML
gruppieren.
Nachfolgend eine kleine Übersicht über die XML-Familie:
Standards zur Formatierung und Transformation von XML-Dokumenten:
XSL
Die eXtensible Stylesheet Language erlaubt Dokumente zu formatieren und
Transformatieren
XSLT
Der eXtensible Stylesheet Language Transformation Standard definiert die
Transformation von XML-Dokumenten. Dabei kann ein XML-Dokument in ein
XML-Dokument überführt werden, genauso wie es in ein nicht-XML-Dokument
(z.B. HTML oder PDF) überführt werden kann.
Standards für Referenzen und Zeiger innerhalb XML-Dokumenten:
XLink
Der XLink Standard definiert eine attributbasierte Syntax für Hyperlinks
zwischen XML- und nicht-XML-Dokumenten. Neben den in eine Richtung
verlaufenden Links, wie in HTML, können Links in mehrere Richtungen laufen.
XPointer
Definiert eine Referenz auf Elemente innerhalb eines XML-Dokuments
XPath
Ermöglicht den Zugriff auf Elemente innerhalb eines XML-Dokuments. Der
Zugriffspunkt wird dabei durch logische Ausdrücke und Selektionsbedingungen bestimmt
Standards für den Zugriff auf XML-Dokumente aus Programmen:
DOM
Ein Modell für den objektorientierten Zugriff auf Dokumente
SAX
Ein Modell für den ereignisgesteuerten Zugriff auf Dokumente
39
Standards zur komplexen Datenmodellierung:
XML Schema
Die Schemadefinitionssprache, die die Ausdrucksmächtigkeit von DTDs im
Zusammenhang der Datenmodellierung erweitert. Mit Hilfe dieses Standards
können zusätzliche Bedingungen für Dokumente definiert werden.
3.3.7 XSL Transformation
Häufig existieren in unterschiedlichen Umgebungen XML-Dokumente, die ähnliche
Daten enthalten, deren Struktur aber unterschiedlich ist. Um diese Dokumente
ineinander zu transformieren, wurde die Transformationssprache eXtensible
Stylesheet Language Transformation (XSLT) [12] eingeführt. Neben der
Transformation eines XML-Dokuments in ein XML-Dokument mit einer anderen
Struktur, ermöglicht XSLT aber auch das Transformieren von XML nach HTML oder
PDF.
Grundlagen
Eine Transformation wird durch mehrere Regeln beschrieben. Diese Regeln werden
in einem Stylesheet zusammengefasst. Eine Regel (oder Template) wird durch ein
Muster und einen Rumpf definiert. Das Muster definiert, auf welche Elemente die
Regel anzuwenden ist. Für die gefundenen Elemente werden die im Rumpf
befindlichen Anweisungen ausgeführt.
Die Anwendung der Templates sei an einem Beispiel verdeutlicht:
<literature>
<book titel="Java und XML" author="Brett McLaughlin"/>
<book titel="XML Complete" author="Steven Holzner"/>
<book titel="Oracle XML Applications" author="Steve Muench"/>
<book titel="Teach Yourself XML" author="Simon North"/>
</literature>
Dieses XML Dokument soll in HTML transformiert werden, um die Daten im Browser
anzuzeigen. Das Stylesheet, das die Transformation beschreibt, könnte
folgendermaßen aussehen :
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="/1999/XSL/Transform">
<xsl:template match="/literature">
<html>
<head>
<title>Literatur</title>
</head>
<h1>Literatur</h1>
<table border=1>
<tr>
40
<th>Titel</th>
<th>Autor</th>
</tr>
<xsl:apply-templates select="*"/>
</table>
</html>
</xsl:template>
<xsl:template match="book">
<tr>
<td>
<xsl:value-of select="@title"/>
</td>
<td>
<xsl:value-of select="@author"/>
</td>
<tr>
</xsl:template>
</xsl:stylesheet>
Listing 3.1 : XSL-Transformation
Die Transformation des XML-Dokuments führt ein so genannter XSLT-Prozessor
durch. Er liest das Dokument Knoten für Knoten ein und prüft, ob ein Template
anwendbar ist. Bei der Transformation berücksichtigt der Prozessor nur die Elemente
des Stylesheet, die dem XSLT-Namensraum (der Präfix xsl ist an den Namensraum
"/1999/XSL/Transform" gebunden) entstammen. Andere Elemente kopiert er
unverändert in die Ausgabe.
XML
XSLTProzessor
Ausgabe
XSLTStylesheet
Abbildung 3-6 : XSL-Transformationsprozess
Das Ergebnis des Transformationsprozesses ist ein HTML-Dokument, das eine
Tabelle von Buchtiteln und Autoren zeigt.
41
Der Ablauf dieser Transformation kann so veranschaulicht werden:
Der Prozessor läuft solange durch den Dokumentbaum, bis er auf einen Knoten trifft,
der dem XPath-Ausdruck eines Match-Attributs entspricht. Dann wird der Rumpf des
Template ausgeführt. Im Beispiel trifft der Prozessor auf den Knoten “literature“ und
führt dann die entsprechende Regel aus. In die Ausgabe werden die Elemente
geschrieben, die später den Titel des HTML-Dokuments und eine Tabelle mit den
Spaltenüberschriften Titel und Autor erzeugen.
Trifft der Prozessor auf das Schlüsselwort xsl:apply-templates so werden auch die
untergeordneten Elemente bearbeitet. Im Beispiel bedeutet dies, daß auch die
“book“-Elemente bearbeitet werden sollen. Stünde das Schlüsselwort nicht an dieser
Stelle, würde der Kindknoten nicht berücksichtigt werden.
Die Unterknoten werden bearbeitet und passende Templates ausgeführt. Im Beispiel
wird der Knoten “book“ gefunden und das entsprechende Template wird ausgeführt.
Das Schlüsselwort xsl.value-of bewirkt, daß der Wert eines Elements in die Ausgabe
übernommen wird. Handelt es sich bei dem auszugebenden Knoten um ein Attribut,
so ist ein @ voranzustellen. Im Beispiel werden die Attribute des “book“-Element
ausgegeben.
Einfügen von Elementen und Attributen
Neue Elemente werden über das Schlüsselwort <xsl:element> eingefügt :
<xsl:element name="beliebigerTagName">
</xsl:element>
Neue Attribute werden über das Schlüsselwort <xsl:attribute> eingefügt:
<xsl:attribute name="Attributname">
</xsl:Attribute>
Das aktuell vom XSLT-Prozessor besuchte Element oder Attribut kann mit dem
Schlüsselwort <xsl:copy> in den Ausgabebaum kopiert werden. Das folgende
Template kopiert den kompletten Eingabebaum:
<xsl:template match=“@* node()“>
<xsl:copy>
<xsl:apply-templates select=““@*node()“/>
</xsl:copy>
</xsl:template>
Dabei wird durch den XPath-Ausdruck “@*node()“ auf alle Attribute und Elemente
zugegriffen.
Bedingungen
In Regeln können auch Konstrukte integriert werden, um bedingte Verarbeitung
durchzuführen. Hierfür gibt es die Schlüsselwörter xsl:if und xsl:choose.
42
xsl:if kann zum Beispiel eingesetzt werden, um in einem zu erzeugenden HTMLDokument ein Bild auszugeben, wenn das Wort “XML“ im Attribut “key“ enthalten ist:
<xsl:template match=“@key“>
<xsl:if test=“contains(string(),‘XML‘)“>
<img src=“xml.gif“/>
</xsl:if>
</xsl:template>
Das Schlüsselwort xsl:choose erlaubt gleichzeitig mehrere alternativeBedingungen
zu prüfen. Sollen auch für Elemente, die “HTML“ und “PDF“ im Attribut “key“
enthalten ein entsprechendes Symbol ausgegeben werden, so ist das
folgendermaßen realisierbar:
<xsl:template match=“@key“>
<xsl:choose>
<xsl:when test=“contains(string(),‘XML‘)“>
<img src=“xml.gif“/>
</xsl:choose>
<xsl:choose>
<xsl:when test=“contains(string(),‘HTML‘)“>
<img src=“html.gif“/>
</xsl:choose>
<xsl:choose>
<xsl:when test=“contains(string(),‘PDF‘)“>
<img src=“pdf.gif“/>
</xsl:choose>
</xsl:template>
Schleifen
Schleifen können durch die Anweisung <xsl:for-each> definiert werden. Das Attribut
“select“ enthält den relativen Pfadausdruck der Kinder-Knoten über die gelaufen
werden soll:
<xsl:template match=“student“>
<xsl:foreach select=“lend/book“>
<xsl:text>Signatur: </xsl:text>
<xsl:value-of select=“signature“/>
</xsl:for-each>
</xsl:template>
Dieses Template läuft über alle Bücher, die ein Student ausgeliehen hat und gibt die
Signatur aus.
43
Sortieren
xsl:sort erlaubt die Reihenfolge einer Knotenliste zu bestimmen. Sollen die Namen
aller Studenten, die Benutzer der Bücherei sind in alphabetischer Reihenfolge
ausgegeben werden so sieht das benötigte Template folgendermaßen aus:
<xsl:template match=“/library“>
<xsl:for-each select=“student“>
<xsl:sort select=“lastname“/>
<xsl:sort select=“firstname“/>
<xsl:value-of select=“lastname“/>
<xsl:value-of select=“firstname“/>
</xsl:for-each>
</xsl:template>
Variablen
Variablen werden in XSLT mittels xsl:variable definiert.
Eine Variable „semester“, die die Semesteranzahl eines Studenten enthält wird
folgendermaßen definiert:
<xsl:variable name=“semester“ select=“student/semester“/>
Eine Variable kann auch direkt mit einem Wert belegt werden, indem der Wert als
Inhalt in das Element geschrieben wird:
<xsl:variable name=“semester“>11</xsl:variable>
Auf den Wert der Variable kann zugegriffen werden, indem ein Dollarzeichen
vorangestellt wird ($semster).
3.3.8 XPath
Mit XPath [13] steht ein Standard zur Verfügung, der es erlaubt bestimmte Teile
eines Dokuments zu identifizieren. Dabei können Elemente sowohl über ihre
Container-Elemente identifiziert werden, indem z.B. auf das 3. Kind-Element
zugegriffen wird, als auch durch Selektion nach einem bestimmten Wert für ein
Attribut oder Element. XPath wird z.B. in XSLT verwendet, um das Ziel einer
Transformationsregel im select-Attribut zu definieren. Außerdem dient XPath als
Grundlage von XML-Querysprachen.
Lokalisierungspfade
Ein Lokalisierungspfad identifiziert eine Menge von Knoten in einem Baum. Der
Wurzelknoten wird über einen einfachen Schrägstrich (/) adressiert.
Elemente des Baums können ausgehend von dem Wurzelknoten erreicht werden,
indem der Weg von der Wurzel zum entsprechenden Knoten beschrieben wird.
Dabei werden die Elementnamen der Elemente, die auf dem Weg von der Wurzel
zum Zielknoten erreicht werden, durch Schrägstrich getrennt an den Pfad angehängt.
44
Diese Vorgehensweise zeigt eine Analogie zum Unix-Dateisystem. Auch dort wird
das Root-Verzeichnis über einen einfachen Schrägstrich adressiert.
Für Beispielpfade soll folgendes Beispieldokument betrachtet werden:
<studenten>
<student matrikelnr=“0123456“>
<name>
<vorname>Frank</vorname>
<nachname>Drewek<nachname>
</name>
<student>
</studenten>
Der XPath-Ausdruck “/student/name/vorname“ lokalisiert das Daten-Element name,
das den Text “Frank“ enthält (studenten ist hier das Wurzelelement).
Soll ein Attribut adressiert werden, so ist ein @ vor den Attributname zu setzen. Der
Pfad-Ausdruck “/studenten/studen/@matrikelnr“ identifiziert das Attribut matrikelnr.
Lokalisierungsschritt text()
Mit den einfachen Pfadangaben können Elemente und Attribute identifiziert werden.
Um einen Text-Knoten zu adressieren, wird eine spezielle Funktion verwendet. Auf
den Text-Knoten des aktuell identifizierten Kontext-Knoten wird mit der Funktion
text() zugegriffen. So kann auf den String “Frank“ des Knoten “vorname“ über den
Pfad “/student/name/vorname/text()“ zugegriffen werden.
Wildcards
Auch in XPath-Pfaden können Wildcards verwendet werden, um mehrere Knoten
gleichzeitig zu lokalisieren. Es stehen die Wildcards *, node() und @* zur Verfügung.
Mit dem Asterisk * werden alle Knoten außer Attribute und Textknoten
angesprochen.
node() hingegen spricht alle Knoten an.
Alle Attributknoten werden durch die Wildcard @* adressiert.
Oder-Verknüpfung
Um Elemente mehrerer Pfade zu lokalisieren, können die Pfade kombiniert werden.
Die einzelnen alternativen Pfade sind dabei durch einen senkrechten Strich (|) zu
trennen. Der Pfad “name/vorname|name/nachname“ adressiert sowohl das Element,
das den Vornamen enthält, als auch das Element das den Nachnamen enthält.
45
Relative Lokalisierungspfade
Neben der Identifizierung eines Knoten über einen absoluten Pfad, von der Wurzel
zum Knoten, kann ein Element auch ausgehend von einem ausgezeichneten Knoten,
dem Kontext-Knoten erreicht werden. Diese lokale Adressierung findet z.B. bei
XSLT-Templates statt:
<xsl:template match=“student“>
<xsl:value-of select=“name/vorname/text()“>
</xsl:template>
Von dem Kontext-Knoten “student“ wird auf den Vorname zugegriffen, indem der
relative Pfad “name/vorname/text()“ spezifiziert wird.
Für den Zugriff auf Elemente, relativ zu einem Kontextknoten, stehen außerdem
bestimmte Operatoren zur Verfügung:
“//“ :
“..“ :
“.“ :
Der doppelte Schrägstrich wählt den aktuellen Kontextknoten, sowie alle
Kinder und Kindeskinder. Der Ausdruck “//vorname“ wählt alle vornameElemente.
Über den doppelten Punkt werden die Eltern des aktuellen Knotens erreicht.
Wurde als Kontextknoten z.B. das vorname-Element eines Studenten erreicht,
so ist der Nachname durch folgenden XPath-Ausdruck erreichbar:
“../nachname“
Der einzelne Punkt adressiert das Kontext-Element selbst. Er wird
hauptsächlich für XSLT-Templates verwendet. So kann der Inhalt des aktuell
durch das Template erreichten Elemements folgendermaßen ausgegeben
werden:
<xsl:template match=“vorname“>
<xsl:value-of select=“.“>
</xsl:template>
Prädikate
Innerhalb des Lokalisierungspfades können Prädikate benutzt werden, um bestimmte
Knoten auszuwählen. Das Prädikat enthält einen booleschen Ausdruck, der auf den
aktuell, durch den Pfad, der vor dem Prädikat steht, erreichten Knoten ausgeführt
wird. Evaluiert sich der Ausdruck für einen Knoten zu wahr, dann wird er in die
Treffermenge aufgenommen. Der XPath-Ausdruck //student[name/vorname=“Frank“]
findet alle Studenten, deren Vorname “Frank“ ist. Dabei wird der boolesche Ausdruck
in eckigen Klammern dem Kontextknoten angehängt. Die Pfadangabe innerhalb des
logischen Ausdrucks ist relativ zu dem Kontextknoten zu verstehen. Auch innerhalb
des Prädikat-Ausdrucks gilt: Attribute werden durch voranstellen des @ adressiert.
Der Student mit Matrikelnummer 0123456 wird durch den Ausdruck
“//student[@matrikelnr=“0123456“] ermittelt.
Innerhalb der Prädikate können folgende relationale und boolesche Operatoren
gewählt werden :
<, >, <=, >=, !=
46
AND, OR
So kann die Matrikelnummer eines Studenten über den Namen ermittelt werden,
vorausgesetzt der Name ist eindeutig:
//student/@matrikelnr[..name/vorname=“Frank“ and ..name/nachname=“Drewek“]
Dabei sind Prädikatausdrücke nicht auf einen einzigen Kontextknoten beschränkt.
Innerhalb eines Pfades können mehrere Ausdrücke ausgewertet werden. So
lokalisiert der folgende Pfadausdruck alle Studenten, deren Matrikelnummer kleiner
als 0800000 ist und deren Name “Meier“ ist.
//student[@matrikelnr < 0800000]/name[nachname=“Meier“]/../..
Achse zur Richtungsangabe
Um die Richtung, die der Lokalisierungspfad ausgehend von einem Kontextknoten
nimmt, zu spezifizieren, gibt es den Begriff der Achse. Bisher wurden Operatoren
definiert, um sich entlang den Achsen Child, Parent (..), Self (.), Attribut (@) und
Descendant-or-Self (//) zu bewegen. Anstatt dieser abgekürzten Schreibweise kann
die Achse auch durch Doppelpunkt getrennt vor den Element- bzw. Attributnamen
gesetzt werden. “/child::student/attribute::matrikelnr“ ist folglich äquivalent zu
“/student/@matrikelnr“. Für die genannten Achsen macht es wenig Sinn auf die
einfache Schreibweise zu verzichten. Für einige weitere Achsen steht jedoch keine
abgekürzte Schreibweise zur Verfügung:
Ancestor-Achse
Diese Achse enthält alle Elternknoten des Kontextelements und rekursiv deren
Eltern bis zum Wurzelknoten
Following-sibling-Achse
Alle Knoten, die dem Kontextknoten folgen und das selbe Eltern-Element
haben
Preceding-sibling-Achse
Alle Knoten, die dem Kontextknoten vorangehen und das selbe Eltern-Element
haben
Following-Achse
Alle Knoten, die dem Kontextknoten folgen
Preceding-Achse
Alle Knoten, die dem Kontextknoten vorangehen
Namespace-Achse
Alle Namensräume im Bereich des Kontextknotens
Descendant-Achse
Alle Abkömmlinge des Kontextknotens
47
Ancestor-or-self-Achse
Alle Vorgänger des Kontextknotens und der Kontextknoten selbst
Arithmetische Operatoren
XPath-Ausgrücke haben nicht nur die Aufgabe Knoten zu lokalisieren. Sie können
auch dazu benutzt werden, um auf Werte des aktuell erreichten Knoten arithmetische
Operatoren anzuwenden. So kann z.B. die Zahl der Semester, die ein Student eine
andere Fachrichtung studiert hat aus den Hochschulsemestern abzüglich der
aktuellen Fachsemester bestimmt werden. Das folgende Template gibt diese Zahl
aus:
<xsl:template match=“student“>
<xsl:value-of select=“@hochsemest - @fachsemest/>
</xsl:template>
Insgesamt stehen Operatoren für die Addition (+), Subtraktion (-), Multiplikation (*),
Division (div) und das Teilen mit Rest (mod) zur Wahl.
Funktionen für Knotenmengen
position()
Gibt die Position des aktuellen Knotens in der Kontextknotenliste zurück. In
der Kontextknotenliste sind alle Knoten enthalten, die bis dahin vom Pfad als
Zielmenge bestimmt wurden.
count()
Gibt die Anzahl der Knoten einer Kontextknotenliste zurück
id(string)
Mit der Funktion id() werden alle Knoten lokalisiert, die ein Attribut vom Typ ID
besitzen, dessen Wert einer Id aus dem Argument der Funktion entspricht.
Mehrere IDs werden duch Leerzeichen getrennt.
3.3.9
Document Object Model
Ein Parser, der auf dem Document Object Model (DOM) [14] basiert, erzeugt aus
einem XML-Dokument einen Objektbaum.
Das folgende XMl-Fragment wird auf einen Baum wie in Abbildung (3-7) dargestellt
abgebildet:
<metadata>
<general>
<id>123</id>
</general>
</metadata>
48
Node
type=Element
name=“metadata“
Node
type=Element
name=“general“
Node
type=Element
name=“id“
Node
type=Text
data=“123“
Abbildung 3-7 : Erzeugter Objektbaum
Ursprung
Um HTML-Seiten auf Clientseite per Skript zu manipulieren, muß das Dokument in
eine Baumdarstellung gebracht werden. Microsoft und Netscape gingen dabei
unterschiedliche Wege und so entstand für jeden Browser ein eigenes ObjektDokument-Modell. Ein Entwickler, der HTML auf der Seite des Clients bearbeiten
wollte (Dynamic HTML) mußte, um beide Browser zu unterstützen zwei Skripte
schreiben.
Das Document Object Model wurde entwickelt, um dieses Manko zu überwinden.
Neben Schnittstellen für HTML enthält DOM Schnittstellen für CSS, Stylesheets und
XML.
DOM API
DOM definiert eine API für die Beschreibung und Bearbeitung von HTML- und XMLDokumenten.
Jede Komponente eines Dokuments wird durch eine Klasse repräsentiert. Mit diesen
DOM-Klassen werden XML-Dokumente als DOM-Baum dargestellt:
Node
Node stellt einen Knoten innerhalb des DOM-Baumes dar; alle folgenden Klassen
sind Unterklassen von Node (bzw. sind Kollektionen von Klassen des Typs Node)
Document : Document stellt das eigentliche Dokument dar
49
Document Type : Diese Klasse repräsentiert das DTD
Element : Element repräsentiert ein Element des XML-Dokuments
Attr : Attr stellt ein Attribut eines Elements dar
NodeList : Eine NodeList gruppiert mehrere Knoten vom Typ Node
NamedNodeMap : Eine NamedNodeMap gruppiert mehrere Knoten vom Typ Node
Node
Node definiert eine Menge von Methoden, die für Knoten jeden Typs benötigt
werden. Jede Instanz einer Klasse des DOM-Baums implementiert die NodeSchnittstelle.
Die Methoden der Node-Schnittstelle sind aber nicht für jeden Knoten-Typ sinnvoll zu
gebrauchen. Wird dennoch versucht eine Methode für einen Objekttyp aufzurufen,
für die die Methode keine Bedeutung hat, wird unterschiedlich reagiert.
So hat ein Attr-Knoten zum Beispiel keine Kinder. Der Versuch die Kinder eines AttrKnoten durch Aufruf von Attr.getChildern() zu erhalten resultiert in der Rückgabe
eines null-Pointer.
Anders reagiert die Laufzeitumgebung, wenn versucht wird ein Kind an ein AttrKnoten anzuhängen. Der Aufruf von Attr.appendChild() löst eine Ausnahme aus.
Eine Übersicht über die wichtigsten Methoden:
getChildNodes() : NodeList
Gibt eine Liste aller Kindknoten zurück
getFirstChild() : Node
Gibt den ersten Kindknoten zurük
getLastChild() : Node
Gib den letzten Kindknoten zurück
Element
Ein Element eines XML-Dokuments wird durch ein Objekt vom Typ Element
repräsentiert. Die Methoden erlauben das Auslesen des Namen, den Zugriff auf
Attribute sowie das Abfragen und Setzen von Unterknoten:
getTagName(): String
Gibt den Elementnamen zurück
getAttribute(name : String) : String
Gibt den Wert des Attributs zurück, das durch name identifiziert ist
setAttribute(name : String, value : String) : void
Setzt den Wert des Attributs, das durch name identifiziert ist auf value
removeAttribute(name : String) : void
Entfernt das Attribut name aus dem Element
getAttributeNode(name : String) : Attr
Gibt das Attribut mit der Bezeichnung name zurück
setAttributeNode(newAttr : Attr) : Attr
50
Fügt das Attribut newAttr dem Element hinzu und gibt einen Zeiger darauf
zurück
removeAttributeNode(oldAttr : Attr) : Attr
Entfernt das Attribut oldAttr aus dem Element und liefert einen Zeiger darauf
zurück
getElementsByTagName(name : String) : NodeList
Gibt eine Liste von Elementen zurück deren Tag-Name dem String name
entsprechen
Attr
Die Attr-Schnittstelle stellt ein Attribut dar. Auch wenn Attr von Node abstammt, kann
ein Attr-Objekt nur als Attribut eines Elements vorkommen.
Document
Ein Document-Objekt repräsentiert das gesamte XML-Dokument und ist die Wurzel
des DOM-Baums. Neue Elemente und Attribute werden durch Factory-Methoden der
Document-Klasse erzeugt.
getDocumentElement() : Element
Gibt das Root-Element zurück
createElement(tagName : String) : Element
Erzeugt ein Element mit dem Namen tagName
createTextNode(data: String) : Text
Erzeugt einen Textknoten dessen Text dem String data entspricht.
Ein Daten-Element wird im Document Object Model auf ein Objekt vom Typ
Element abgebildet dessen Sohn-Knoten vom Typ Text ist.
<text>
node
type=Element
name="text"
Ein Text
</text>
node
type=Text
data="Ein
Text"
createAttribute(name : String) : Attr
Gibt einen Attribut-Knoten dessen Name dem String name entspricht zurück
3.3.10 XML Schema
Die Document Type Definition (DTD) hat sich als Format zur Beschreibung von XMLVokabularen etabliert. In einigen Bereichen stößt man allerdings an die Grenzen der
Darstellungsmöglichkeiten. DTDs wurden ursprünglich zur Beschreibung von
51
dokumenten-zentrierten Daten entworfen. Da XML aber in immer größerem Maße
zum Austausch von Daten und auch zum Speichern in Datenbanken verwendet wird,
ist eine strengere Typisierung für einfache Daten gefragt.
XML Schema [15] ist ein Ersatz für DTDs. Kennen DTDs 10 Datentypen, so kommen
in XML Schema 40 primitive Datentypen zum Einsatz. Komplexere Datentypen
können auf Basis dieser Datentypen definiert werden. DTDs haben nur das
Einschränken der Wertebereiche von Attributen erlaubt. Mit XML Schema können
auch Wertebereiche von Elementen eingeschränkt werden. Neben dieser
Einschränkung können für einen Datentyp reguläre Ausdrücke definiert werden. So
kann z.B. für einen Datentyp festgelegt werden, daß der Wert aus zwei
alphanumerischen Zeichen und zwei Ziffern bestehen muß.
Datentypen können auch durch Vererbung erzeugt werden. Abgeleitete primitive
Datentypen dürfen in ihrem Wertebereich nur stärker beschränkt werden. Bei der
Ableitung komplexer Datentypen dagegen kann der Wertebereich auch erweitert
werden.
Schema deklarieren: xsi:noNamespaceSchemaLocation="bestellung.xsd"
Ein Schema besteht aus Deklarationen und Typdefinitionen. Sogenannte Facetten
beschreiben die Struktur und den Wertebereich der Typen.
Eine Typdefinition beschreibt einen einfachen Datentyp, der durch Ableitung von
einem Basistyp entsteht. Der definierte Typ muß dabei in seinem Wertbereich stärker
eingeschränkt sein als der Basistyp. Ansonsten wäre der abgeleitete Typ identisch
mit dem Basistyp, was nicht erlaubt ist.
<xs:simpleType name=“Matrikelnummer“>
<xs:restriction base=“xs:integer>
<xs:minInclusive value=”1”/>
<xs:maxInclusive value=”9999999”/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name=“KFZ_Kennzeichen“>
<xs:restriction base=“xs:string>
<xs:pattern value=”[A-Z]{1-2} - [A-Z]{1-2} - [0-9]”{1-4}/>
</xs:restriction>
</xs:simpleType>
Die Beispieldefinitionen definieren einen Datentyp Matrikelnummer, der Zahlen
zwischen 1 und 9999999 erlaubt und einen Datentyp KFZ_Kennzeichen, der KFZKennzeichen beschreibt, sieht man davon ab, dass die Ziffernfolge nicht mit “0“
beginnen darf.
Die Definitionen leiten jeweils einen Basistyp ab, der im Attribut “base“ des Element
“restriction“ spezifiziert wird.
Die Facette des ersten Beispiels schränkt den Wertebereich mit den Elementen
“minInclusive“ und “maxInclusive“ ein. Die andere Facette definiert mit dem Element
“pattern“ ein Muster dem der Datentyp “KFZ_Kennzeichen“ entsprechen muß.
52
Zu den insgesamt 40 eingebauten Basistypen gehören:
Tabelle 3-4 : XML-Datentypen
Datentyp
String
Byte
Integer
Float
Double
Boolean
Time
DateTime
Duration
Date
anyURI
language
Beispiel
16:29:03.000
2002-03-14T16:29:03.000
1999-05-31
http://www.ipd.uka.de/SCORE
de, en-US
Ein Element kann mit einem komplexen Datentyp deklariert werden. Der komplexe
Datentyp bestimmt die Struktur des Elements und kann selbst Elemente und Attribute
mit einfachen und komplexen Datentypen enthalten.
Ein komplexer Datentyp kann von einfachen oder komplexen Datentypen abgeleitet
werden.
Die Struktur eines komplexen Datentyps kann durch die Elemente xs:sequence,
xs:all, xs:choice und xs:anyType festgelegt.
Das Element sequence legt die Reihenfolge der Kind-Elemente fest:
<xs:complexeType name=“metadata“>
<xs:sequence>
<xs:element name=”general” type=”metadata_general”>
<xs:element name=”lifecycle” type=”metadata_lifecycle”>
</xs:sequence>
</xs:complexType>
Alle Elemente, die den Datentyp “metadata” verwenden, müssen die Elemente
general und lifecycle in genau dieser Reihenfolge enthalten.
Wird das Element „sequence“ durch das Element „all“ ersetzt, so muß ein
entsprechendes Element ebenso die Elemente „general“ und „lifecycle“ enthalten, die
Reihenflge ist jedoch beliebig.
Soll nur eines mehrerer möglichen Kind-Elemente eingefügt werden können, dann ist
das Element „choice“ zu verwenden:
53
<xs:complexeType name=“metadata“>
<xs:sequence>
<xs:choice>
<xs:element name=”general” type=”metadata_general”>
<xs:element name=”generalv2”
type=”metadata_generalv2”>
<xs:choice>
<xs:element name=”lifecycle” type=”metadata_lifecycle”>
</xs:sequence>
</xs:complexType>
Folgende zwei XML-Instanzen sind für diese Definition gültig:
<metadata>
<general>..............</general>
<lifecycle>.............</lifecycle>
</metadata>
<metadata>
<generalv2>..............</generalv2>
<lifecycle>.............</lifecycle>
</metadata>
Das Element xs:anyType erlaubt eine beliebige Elementstruktur, die nur durch die
Wohlgeformtheit beschränkt ist.
Eine Elementdeklaration deklariert ein Element mit Hilfe der Datentypen.
<xs:element name=”meta_repository” type=”metadata”
minOccurs=”1” maxOccurs=”unbound”/>
Durch die Deklaration enthält das Element meta_repository mindestens ein Element
des Typs “metadata“.
Durch den Einsatz der Attribute minOccurs und maxOccurs können verschiedene
Kardinalitäten modelliert werden:
Tabelle 3-5 : Typische Min/Max-Kardinalitäten
Element muss einmal vorkommen – Grundeinstellung, wenn
minOccurs und maxOccurs nicht spezifiziert sind.
(0,1)
Element kann einmal vorkommen (optional)
(0,0)
Element darf nicht vorkommen
(0,unbound) Element kann beliebig oft vorkommen
(1,unbound) Element muss mindestens einmal vorkommen
(1, 1)
54
3.4 XML und Datenbanken
In diesem Kapitel soll der Einsatz von Datenbanktechnologien zur Speicherung von
XML-Dokumenten betrachtet werden.
XML-Dokumente lassen sich in zwei Klassen teilen. Auf der einen Seite kann ein
XML-Dokument datenzentriert, auf der anderen Seite dokumentzentriert sein. Die
Klasse eines Dokuments entscheidet über die geeignete Speichertechnologie. Aus
diesem Grunde werden hier datenzentrierte und dokumentzentrierte Dokumente
getrennt betrachtet.
3.4.1 Datenzentrierte Dokumente
Datenzentrierte Dokumente sind durch eine ziemlich regelmäßige Struktur
charakterisiert. Elemente enthalten nur selten gemischten Inhalt. Häufig werden
solche Dokumente als portables Datenformat zum Austausch von Informationen über
Systemgrenzen hinweg genutzt. Datenzentrierte Dokumente können direkt von einer
Anwendung verarbeitet werden.
Für die persistente Speicherung datenzentrierter Dokumente in Datenbanken gibt es
mehrere Möglichkeiten.
Das Model-Driven Mapping wird zur Abbildung von datenzentrierten XMLDokumenten auf relationale Datenbanken eingesetzt. Es können zwei Formen
unterschieden werden.
Damit ein XML-Dokument mit Table Based Mapping auf relationale Datenbanken
abgebildet werden kann, muß es einer definierten Form entsprechen. Die Daten
müssen so strukturiert sein, wie sie in eine Tabelle geschrieben werden sollen. Das
bedeutet die Tags kennzeichnen Tabellen und Zeilen.
Ein XML-Dokument, das über Table Based Mapping abgebildet werden soll, könnte
z.B. so aussehen:
<database>
<table>
<column>LH</column>
<column>900</column>
<column>Februrary 24, 2002 10:23</column>
<column>Februrary 24, 2002 14:24</column>
</table>
</database>
Um Dokumente in eine solche Struktur zu pressen, werden häufig XSLTransformationen durchgeführt.
Eine andere Form des Model Driven Mapping stellt das Object-Relational Mapping
dar. Dieses Verfahren wird hauptsächlich von XML-fähigen relationalen Datenbanken
eingesetzt, um XML-Dokumente auf Tabellen abzubilden. Eine Abbildungsvorschrift
pro Dokumenttyp definiert hier in welche Tabelle die Informationen eines Elements
gespeichert werden. Pro Element, das weitere komplexe Elemente enthält, wird
dabei eine eigene Tabelle erzeugt. Text-Elemente und Attribute eines komplexen
55
Elements werden in dieser Tabelle abgelegt. Für enthaltene komplexe Elemente wird
ein Fremdschlüssel hinterlegt.
Umgekehrt bedarf es schließlich auch einer Abbildung von relationalen Datenbanken
auf XML-Dokumente.
Beim Template Driven Mapping existiert keine vorderfinierte Abbildungsvorschrift.
Stattdessen werden Kommandos in ein XML-Dokument integriert, die einen
Prozessor veranlassen, Operationen auf der Datenbank auszuführen und das
Ergebnis dieser Operation an die Stelle des Kommandos zu setzen.
So kann ein Dokument z.B. ein Select-Statement enthalten. Der Prozessor erkennt
das Select-Kommando und ersetzt es durch das Ergebnis der Select-Anfrage. Dabei
wird das Ergebnis von einem Tag umschlossen, dessen Name dem Tabellenname
entspricht. Ein Row-Tag strukturiert die einzelnen Ergebniszeilen. Die einzelnen
Attribute der Zeilen werden von Tags umschlossen, die den Attributnamen tragen.
Das Ergebnis einer Anfrage stellt das folgende Beispiel dar:
Nach der Ausführung des folgenden Templates
<?xml version="1.0"?>
<FlightInfo>
<SelectStmt>SELECT Airline, FlNr, Departure, Arrival FROM Flights>
</FlightInfo>
wird dieses Dokument zurückgeliefert:
<?xml version="1.0"?>
<FlightInfo>
<Flights>
<Row>
<Airline>LH</Airline>
<FlNr>900</FlNr>
<Depart>February 24, 2002 10:23</Depart>
<Arrive>February 24, 2002 14:24</Arrive>
</Row>
</Flights>
</FlightInfo>
Neben der Möglichkeit XML-Daten durch Abbildung auf relationale Datenbanken zu
speichern, kann ein datenzentriertes Dokument in einer nativen XML-Datenbank
abgespeichert werden.
In einer XML-Datenbank wird ein XML-Dokument zusammenhängend gespeichert.
Eine Abbildung ist hier nicht nötig.
Für die Speicherung in einer XML-Datenbank sprechen die folgenden Gründe:
1. Die native Speicherung eignet sich für Daten, die nur schwach strukturiert sind.
Daten sind schach strukturiert, wenn eine regelmäßige Struktur existiert, diese
jedoch stark variiert. Wird eine solche Struktur auf eine relationale Datenbank
abgebildet, so führt die zu einer großen Menge von NULL-Werten, was
Speicherplatz verschwendet oder zu einer großen Anzahl von Tabellen, die alle
über einen Join vereinigt werden müssen, was sehr ineffizient ist.
56
2. XML-native
Datenbanken
speichern
XML-Dokumente
physikalisch
zusammenhängend oder benutzen physikalische Pointer zwischen Teilen des
Dokuments. Dadurch ist die Zugriffsgeschwindigkeit um einiges höher als bei
relationalen Datenbanken, die logische Pointer benutzen und das Ergebnis einer
Anfrage durch einen Join über eine Vielzahl von Tabellen erhalten.
3. XML Datenbanken sprechen stets XML, d.h. alle XML-Techniken werden von der
Datenbank unterstützt. So kann eine XQuery direkt auf das Dokument
angewendet werde und muß nicht umständlich auf einen Select-Ausdruck
abgebildet werden.
3.4.2 Dokumentzentrierte Dokumente
Dokumentzentrierte Dokumente sind Dokumente, die für den menschlichen Benutzer
entworfen sind. Sie sind durch weniger regelmäßige Strukturen und viel Mixed
Content charakterisiert. Als Beispiel kann ein XML-Dokument genannt werden, das
Informationen enthält, die nach einer XSL-Transformation einem Benutzer als HTML
dargestellt werden sollen.
Da dokumentzentrierte Dokumente kaum eine regelmäßige Struktur besitzen und zu
einem großen Teil aus Text bestehen, macht es keinen Sinn diese auf Tabellen
abzubilden. Soll ein Dokument dennoch in einer relationalen Datenbank abgelegt
werden, so kann dies nur durch den Einsatz von BLOBs erfolgen.
Besser ist hier der Einsatz von nativen XML-Datenbanken. Sie speichern
dokumentenzentrierte Daten ebenfalls zusammenhängend und bieten darüber
hinaus viele Funktionen für den Umgang mit XML-Daten.
3.4.3 Speichern von XML in relationalen Datenbanken
Das Speichern von XML-Dokumenten in einer relationalen Datenbank soll nun am
Beispiel der Datenbank Oracle 9i [17] näher erläutert werden.
Für das Speichern eines dokumentzentrierten XML-Dokuments hat Oracle den
Datentyp XMLType eingeführt. Auf diesem Datentyp lassen sich Funktionen
ausführen, die das Erzeugen, Extrahieren und Suchen von XML-Daten ermöglichen.
Der Datentyp lässt sich als Spalte einer Tabelle benutzen.
Die interne Adtenstruktur von XMLType ist der DOM-Baumstruktur angelehnt.
Gespeichert wird diese Baumstruktur als CLOB.
Das Erzeugen einer Tabelle zur Speicherung eines dokumentenzentrierten
Dokuments zeigt das folgende Beispiel:
CREATE TABLE metadata(
meta_id NUMBER(3),
metadata SYS.XMLTYPE);
Um ein XML-Dokument in die Tabelle einzufügen, kann die Funktion createXML des
Datentyps XMLType verwendet werden, wie folgendes Beispiel zeigt:
57
INSERT INTO metadata (meta_id, metadata)
VALUES (2000,
sys.XMLType.createXML('<metadata>
<general>
<title>UML</title>
</general>
</metadata>');
Der Zugriff auf das Dokument oder Teile daraus erfolgt über die Funktion extract. Als
Parameter wird ihr ein XPath-Ausdruck übergeben, der ein bestimmtes Element
lokalisiert. Um den Titel des über Metadaten beschriebenen Objekts aus obigem
Beispiel zu erhalten, ist folgende Anfrage erforderlich:
SELECT m.metadata.extract('/metadata/general/title').getStringVal()
FROM metadata m
WHERE m.meta_id = '2000';
Für den Zugriff aus Anwendungen heraus stellt Oracle die Java-Klasse
oracle.xdb.XMLType zur Verfügung. Diese Klasse ist eine Unterklasse der Klasse
oracle.sql.OPAQUE, die Teil des Oracle JDBC-Pakets ist.
Um das Dokument zu erhalten, das den gesuchten Titel aus dem hervorgehenden
Beispiel enthält, ist innerhalb einer Java-Anwendung folgender Code erforderlich:
import oracle.xdb.XMLType;
OraclePreparedStatement stmt =
(OraclePreparedStatement) conn.prepareStatement(
"select m.metadata from metadata m where m.meta_id = '2000'");
ResultSet = rset = stmt.executeQuery();
OracleResultSet orset = (OracleResultSet) rset;
XMLType metadataxml = XMLType(orset.getOPAQUE(1));
String xmlString = metadataxml.getStringVal();
Zusammenfassend kann festgestellt werden, daß XMLType in den folgenden Fällen
sinnvoll einsetzbar ist:
1. Wenn ein XML-Dokument nur als Ganzes gespeichert und geladen werden soll
2. Wenn SQL-Queries über ein Dokument verlangt werden
3. Wenn keine elementweisen Updates erfolgen
Die Verarbeitung datenzentrierter Dokumente wird in Oracle 9i durch das XML SQL
Utility [18] unterstützt. Sowohl die Abbildung von objektrelationalen Daten auf XMLDokumente, als auch die Abbildung in umgekehrter Reihenfolge, wird durch ein
Model-Driven Mapping realisiert.
Der Zugriff auf gespeicherte Metadaten könnte folgende XML-Struktur erzeugen:
58
<?xml version='1.0'?>
<ROWSET>
<ROW num="1">
<metadata>
<general>
......
</general>
<lifecycle>
......
</lifecycle>
......
</metadata>
</ROW>
</ROWSET>
Die Strukturinformationen komplexer verschachtelter Dokumente erhält das SQL
Utility durch Zugriff auf die objektrelationale Infrastruktur über Objektviews. Um die
oftmals störenden Tags „ROWSET“ und „ROW“ zu eliminieren, kann ein XSLTStylesheet definiert werden, das automatisch nach einer Abbildung vom SQL Utility
prozessiert wird.
In genau dem gleichen Format muß ein XML Dokument vorliegen, damit es in der
Datenbank gespeichert werden kann.
Das XML SQL Utility prüft dabei, welche Teile des Dokuments sich verändert haben
und führt nur auf den entsprechenden Tabellen ein Update aus.
3.4.4 Speichern von XML in XML-nativen Datenbanken
XML-native Datenbanken, sind speziell für das Speichern von XML Dokumenten
ausgelegt. Sie bieten wie relationale Datenbanken die Funktionalitäten
Transaktionen, Security, Mehrbenutzerzugriff und Querysprachen.
Der Tamino XML Server der Software AG [19] ist eine Lösung für das Speichern und
Verwalten von XML-Dokumenten. Der Zugriff auf Dokumente erfolgt URL-basiert.
Dazu wird ein HTTP-Server benötigt, über den der XML Server kommuniziert.
Neben dem Speichern von XML-Dokumenten kann Tamino als Repository für nicht
XML-Daten wie Bild- und Video-Dateien genutzt werden und kann dadurch innerhalb
eines Content Management Systems eingesetzt werden.
Daten werden in Tamino in Kollektionen gruppiert. Für eine Kollektion können
mehrere XML Schemata definiert werden, denen in der Kollektion abzulegende
Dokumente entsprechen müssen.
Nicht XML-Daten werden in speziellen Kollektionen abgelegt. Für jede gespeicherte
Datei wird automatisch ein XML-Dokument erzeugt, das Informationen wie z.B. die
Dateigröße und den Datentyp enthält. Dieses Dokument ist eine Instanz eines fest
vorgegeben XML Schema. Kern des XML Server ist die XML-Engine. Ihre Aufgabe
ist das Speichern und Wiederauffinden von XML-Dokumenten. Dabei stützt sich die
Engine auf die Data Map, ein Datenwörtebuch, das unter anderem Schemata der
gespeicherten XML-Dokumente verwaltet.
Die Abbildung 3-8 zeigt die Architektur der XML-Engine.
59
XML
Output
XML
Objekte,
DTDs
Query
(URL)
XML-Engine
Query
Interpreter
XML
Parser
Object
Composer
Object
Processor
Utilities
Daten aus
internem
XML
Speicher
Data Map
Daten für
internem
XML
Speicher
Abbildung 3-8 : XML-Engine
Die XML-Engine besteht im wesentlichen aus folgenden Komponenten:
Parser:
XML Dokumente, die gespeichert werden sollen, sind Instanzen der Schemata, die in
der Data Map abgelegt sind.
Beim Speichern prüft der eingebaute Parser die Dokumente auf Wohlgeformtheit und
auf Korrektheit bezüglich des entsprechenden Schema.
Object Processor:
Der Object Processor übernimmt die eigentliche Aufgabe des Speicherns von
Objekten innerhalb Tamino und gibt die Daten an den Speicher weiter.
XML Query Interpreter:
Der Query Interpreter löst eingehende Anfragen auf und interagiert mit dem Object
Composer um XML Objekte zu gewinnen.
Object Composer:
Der Objekt Composer generiert aus einer Anfrage ein XML Dokument. Handelt es
sich bei dem Ergebnis einer Anfrage um mehrere XML Dokumente, so erzeugt er ein
künstliches Wurzelelement, um die Dokumente in ein Dokument zu hüllen.
Utilities:
Zahlreiche Utilities unterstützen den XML Server. So können zum Beispiel alle XML
Objekte eines Verzeichnisses auf einmal geladen werden.
Neben dem Zugriff mittels HTTP stellt die Software AG einen WebDAV Server zur
Verfügung, der einen komfortablen Zugriff auf Daten des Tamino Server ermöglicht.
WebDAV ist ein weit verbreiteter Standard der den HTTP/1.1 Standard erweitert und
damit einen einfachen Zugriff auf gemeinsam benutzte Daten ermöglicht.
60
Der WebDAV Server befindet sich in der Mitte einer 3-Schichten-Architektur
zwischen einer WebDAV-enabled Client-Applikation, z.B. einem Webbrowser oder
dem Windows Explorer, und dem XML Server.
WebDAV
Client
Tamino
WebDAV Server
HTTP
Tamino
Abbildung 3-9 : WebDAV Server
WebDAV ergänzt den XML Server um Namespace-Funktionalität (Verzeichnisse),
Metadaten (z.B. last-modified, content length oder content type) und einen
Sperrmechanismus.
Der WebDAV Server ermöglicht das Speichern und Bearbeiten von Dokumenten wie
z.B. Powerpoint und Word direkt aus WebDAV-fähigen Anwendung heraus, wie z.B.
Word 2000 oder Powerpoint.
Es werden nun die einzelnen Schritte beschrieben, die für das Erzeugen und InBetrieb-Nehmen einer Datenbasis innerhalb des XML Servers erforderlich sind.
Über eine graphische Administrationskonsole kann eine neue Datenbasis erzeugt
werden. Die Datenbasis wird über ihren Namen identifiziert.
Der Zugriff auf diese Datenbank per HTTP erfolgt über den URL
“http://hostname/tamino/<Name_der_Datenbasis>/“.
Eine neue Kollektion wird über das Interaktive Interface, eine graphische
Benutzeroberfläche, erzeugt. Im Feld “Database“ ist der Datenbankpfad einzugeben.
Die Kollektion, die erzeugt werden soll, muß im Feld “Kollektion“ genannt werden.
Durch Auswahl des “Create“-Button wird die gewünschte Kollektion erzeugt.
Ein Schema kann mit Hilfe des Schema-Editors deklariert werden.
Bevor ein Schema definiert werden kann, muß eine Verbindung zur Datenbank
hergestellt werden. Dazu ist der Menüpunkt Verbindung auszuwählen. Im Pop-up
Fenster muß der Datenbankpfad spezifiziert werden.
Das neue Schema kann aus einer vorhandenen DTD- oder XSD-Datei übernommen
werden. Das Schema wird für eine Kollektion erzeugt, wenn der Menüeintrag Upload
Schema gewählt wird. In dem folgenden Pop-up ist der Kollektionsname einzutragen.
Existiert die spezifizierte Kollektion noch nicht, so wird sie automatisch erzeugt.
Für das Speichern von XML-Dokumenten kann das Interaktive Interface verwendet
werden. Im Feld “Process“ ist der Dateipfad der einzufügenden Datei einzugeben.
61
Bei Auswahl des “Process“-Buttons wird das Dokument innerhalb der angegebenen
Datenbank in die spezifizierte Kollektion geschrieben.
Zum Laden von XML-Dokumenten kann jede Anwendung benutzt werden, die ein
HTTP-Request absenden kann.
Um alle XML-Dokument einer Kollektion, die Instanzen eines bestimmten Schemas
sind zu laden, ist an den Datenbankpfad der Name der Kollektion und des Schema
anzuhängen.
Soll ein bestimmtes Dokument über eine Query ermittelt werden, so ist hinter dem
Name des Schemas ein XPath-Ausdruck anzuhängen. Soll z.B. auf ein XMLDokument zugegriffen werden, das Metadaten zu der Metadaten-ID “2000“ enthält,
so ist folgende URL in den Adresspfad eines Web-Browsers einzutragen:
“http://hostname/eLearning/metadata/metadata?_xql=metadata[/general/id]=‘2000‘“.
Mit einer Query kann auch auf nicht-XML Dokumente zugegriffen werden. An den
Pfad, der die Kollektion und das Schema spezifiziert, ist die ID des gespeicherten
Objekts anzuhängen. Diese ID wird jedem Objekt bei der Speicherung zugewiesen.
Innerhalb einer Kollektion ist diese ID eindeutig. Die URL “http:/hostname/eLearning/
ino:etc/ino:nonXML/@1“ greift auf das Objekt mit der ID 1 zu. Die Kolektion ino:etc ist
die Standardkollektion in Tamino zum Speichern von nicht-XML Objekten.
Für den Zugriff auf die Datenbank steht auch eine Java-API zur Verfügung. Die
Klasse TaminoClient enthält Methoden für das Lesen und Speichern von XMLDokumenten. Die Methoden kapseln im wesentlichen den Zugriff auf den XMLServer mittels HTTP.
Die Klasse com.softwareag.tamino.api.dom.TaminoClient enthält auszugsweise
folgende Methoden:
TaminoClient(“http://hostname/tamino/databasename/collection“)
Der Konstruktor setzt den Datenbankpfad
putDocument(“dtdname“, org.w3c.dom.element element)
Speichert ein Dokument in der durch den Konstruktor angegebenen Kollektion.
Das Dokument wird der angegebenen DTD zugewiesen. Das Dokument wird in
Form seines Wurzelknotens übergeben.
query(“XPath-Ausdruck“, ““)
Führt eine Query auf der Kollektion durch, die im Datenbankpfad spezifiziert ist.
deleteByQuery(“XPath-Ausdruck“, ““, “dtdname“)
Dokumente, die durch den XPath-Ausdruck lokalisiert werden, werden gelöscht.
setPageSize(int pageSize)
Diese Methode setzt die Grenze für die Anzahl an Treffern einer Anfrage
Die TaminoClient-API ist auf den Zugriff von XML Dokumenten beschränkt. Der
Zugriff auf nicht XML-Dokumente erfolgt über die TaminoNonXml-API:
Die Klasse com.softwareag.tamino.api.dom.TaminoNonXml enthält auszugsweise
folgende Methoden:
TaminoNonXml(“http://hostname/tamino/databasename/collection“)
Der Konstruktor legt den Datenbankpfad fest
setNonXML(“dtdname/dateiname.endung“, filepath, contenttype)
62
Ein nicht XML Objekt wird in der Datenbank gespeichert. Das Objekt wird durch
seinen Dateipfad identifiziert. Das Objekt ist später unter dem Pfad erreichbar, der
als erster Parameter übergeben wird. Die im Pfad integrierte DTD deklariert die
Metadaten für nicht XML Objekte. In diesen Metadaten wird unter anderem der
im MIME-Format übergebene Content-type gespeichert. Bei einem späteren
Zugriff, z.B. von einem Brower, wird der Content-type benötigt, um das Objekt
korrekt darzustellen.
getNonXML(“dtdname/dateiname.endung“, filepath)
Das Objekt wird in eine Datei geschrieben, die durch den Dateipfad gegeben ist.
Die Methoden query, setNonXML und getNonXML geben ein Objekt vom Typ
TaminoResult zurück. Dieses Objekt liefert Informationen über die Ausführung der
Operationen in Form eines DOM Objekts. Im Falle von query beinhaltet das DOM
Objekt die gefundenen XML Dokumente.
Die Methode getDocument() der Klasse TaminoResult gibt ein gefundenes XMLDokument als DOM Document-Object zurück.
3.4.5 DTD und relationales Schema
Zum Schluß dieses Kapitels soll noch ein Algorithmus vorgestellt werden, der eine
Orientierung gibt, wie ein XML-Dokument auf ein relationales Schema abgebildet
werden kann.
Ronald Bourret [16] schlägt für das Abbilden einer DTD auf ein relationales Schema
folgendes Verfahren vor:
1. Erzeuge für jeden Elementtyp mit Subelementen bzw. gemischtem Inhalt eine
Tabelle mit einer Primärschlüsselspalte.
2. Erzeuge für jeden Elementtyp mit gemischtem Inhalt eine separate Tabelle zur
Speicherung der PCDATA-Komponente. Diese Tabelle wird mit der Tabelle des
Elementtyps über deren Primärschlüssel verknüpft.
3. Erzeuge in der Tabelle eines Elementtyps für jedes einwertige Attribut des
Elementtyps und jeden nur einmal vorkommenden Subelementtyp, der nur
PCDATA enthält, eine Spalte.
4. Erzeuge für jedes mehrwertige Attribut eines Elementtyps und für jeden
Subelementtyp, der ein Mehrfachvorkommen erlaubt, aber nur PCDATA enthält,
eine separate Tabelle. Diese Tabelle wird mit der Tabelle des Elementtyps über
deren Primärschlüssel verknüpft.
5. Verknüpfe für jeden Subelementtyp mit Subelementen oder gemischtem Inhalt die
Tabelle des Elementtyps mit der Tabelle des Subelements über den
Primärschlüssel des Elementtyps.
63
3.5 Literatur
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
Khaldoun Ateyeh und Jutta A. Mülle, Making Courseware Reusable,
Department of Computer Science, Universität Karlsruhe, Germany,
Accepted for the Conference Networked Learning 2002, Berlin, May 1-4, 2002
IEEE Learning Technology Standard Committee
http://www.manta.ieee.org/p1484
Instructional Management System
http://www.imsproject.org
CEN/ISSS Learning Technology Workshop
http://cenorm.be/isss/Workshop/lt/Default.htm
PROMETEUS
http://prometeus.org
GESTALT
http://fdgroup.co.uk/gestalt
Dublin Core
http://purl.org/dc
ARIADNE
http://ariadne.unil.ch
Advanced Distributed Learning
http://www.adlnet.org
Dieter Fensel, Ontologies: A Silver Bullet for Knowledge Management and
Electronic Commerce, Springer Verlag
Henning Lobin, Informationsmodellierung in XML und SGML,
Springer Verlag
Fabio Arciniegas, XML Developers Guide, Franzis Verlag
Elliotte Rusty Harold & W. Scott Means, XML in a Nutshell, OReilly
Brett McLaughlin, Java und XML, Oreilly
http://xml.ipsi.fhg.de/WBT
http://www.rpbourret.com/xml/XMLAndDatabases.htm
Oracle9i Application Developer's Guide – XML, Kap. 5
Oracle9i Application Developer's Guide – XML SQL Utility, Kap. 7
Tamino XML Server White Paper, Software AG
Tamino Core Architecture and Services, Software AG
Tamino XML Server Technical Details, Software AG
Tamino XML Server Manual, Software AG
Tamino Interactive Interface Manual, Software AG
64
4 Konzeptionelle Ausarbeitung
Aufbauend auf dem im vorigen Kapitel vorgestellten SCORE-Konzept erarbeite ich
nun ein Konzept, das in dem zu erstellenden Prototypen realisiert werden soll.
Um die Wiederverwendung von Kursen und deren Komponenten zu maximieren
gliedert sich die Erstellung eines Kurses in mehrere Stufen.
Auf der untersten Stufe befinden sich die Lernatome. Sie repräsentieren Wissen in
einem bestimmten Datenformat. Atomar bedeutet, daß der Inhalt nur einen Teil eines
Themas abdeckt. Ein Lernatom kann z.B. eine Einleitung, ein Beweis oder ein
Algorithmus sein.
Die Lernatome, die ein Thema behandeln, werden zu einem Integrationsmodul
zusammengefasst. Das Integrationsmodul hatt alein die Aufgabe mögliche
Lernatome für ein bestimmtes Thema anzubieten. Eine solche thematisch
abgeschlossene Lerneinheit kann als Teil eines Themengebiets einem Kurs
zugeordnet werden.
Die in einem Integrationsmodul zusammengefassten Atome sind jedoch ohne
Ordnung und ihre Inhalte können überlappen. In dieser Form ist es nicht sinnvoll sie
einem Lernenden zu präsentieren. Für die Kurserstellung ist ein Integrationsmodul
jedoch die Basis, da durch dieses Modul über eine Metadatensuche schnell die für
ein Thema relevanten Atome aufgefunden werden können.
Das Bilden einer Teilmenge der Lernatome eines Integrationsmoduls und das
Definieren einer Ordnung auf dieser Menge ist die Aufgabe des Strukturmoduls. Das
Strukturmodul erzeugt also eine Lerneinheit, die den didaktischen Vorlieben eines
Lehrenden oder eines Lernenden entsprechen. Gleichzeitig werden die Lernatome
ausgewählt, die am besten geeignet sind einer bestimmten Zielgruppe in einer
bestimmten Lernumgebung das entsprechende Thema zu vermitteln.
Das Strukturmodul bildet also eine Lerneinheit, die Inhalte für eine bestimmte
Zielgruppe in einer gewünschten Ordnung enthält.
Diese Inhalte müssen nun in eine bestimmte Form gebracht werden, d.h. die
Lernatome, die unterschiedliche Dateiformate besitzen können, müssen in eine Form
gebracht werden, in der sie gemeinsam darstellbar sind. Diese Aufgabe übernimmt
das Präsentationsmodul. Das Präsentationsmodul stellt eine thematisch
abgeschlossene, darstellbare Lerneinheit dar, die als Teil eines Kurses präsentiert
werden kann.
Entlang dieser Stufen von einem Integrationsmodul zu einem Präsentationsmodul
werden Lerninhalte immer stärker auf eine Zielgruppe und eine Lernumgebung
festgelegt. Gleichzeitig sinkt das Maß an Wiederverwendbarkeit, da die Lernmodule
immer weniger anpassbar sind und damit einer potentiell kleineren Gruppe von
Lernenden zugänglich gemacht werden können. Für die Erstellung eines Kurses aus
vorhandenen Lernmodulen ist deshalb stets zu prüfen auf welche Stufe der
Modularisierung eingestiegen werden kann.
Bevor ich auf die Lernatome und die verschiedenen Typen von Lernmodulen
eingehe, möchte ich eine zentrale Frage behandeln, die für die Realisierung des
Prototypen von großer Bedeutung ist: Wie sollen die Metadaten aussehen, die die
einzelnen Lernobjekte beschreiben?
65
4.1 Metadaten
Ziel ist es, vorhandene Metadatenstandards zu berücksichtigen.
In diese Metadatenstandards sind über Jahre hinweg die Ideen und Kritiken einer
großen Anzahl von Personen geflossen, die aus allen Bereichen der Lehre über
nationale Grenzen hinweg zusammengearbeitet haben.
Betrachtet man die im Kapitel 3 vorgestellten Metadatenstandards und
Arbeitsgruppen, die sich mit Metadaten zur Beschreibung von Lernmaterial befassen,
so kann ohne Zweifel gesagt werden, daß der LOM-Standard im Mittelpunkt steht
und alle anderen Arbeiten entweder auf diesem Standard basieren oder ihn direkt
beeinflussen.
Aus diesem Grunde habe ich LOM als Basis zur Beschreibung der Lernobjekte
gewählt.
Anstatt den LOM-Standard selbst zu implementieren, nutze ich den IMS-Standard,
der eine weltweit anerkannte Implementierung des LOM-Standards darstellt. Das
IMS-Projekt stellt fertige Schema-Dateien zur Verfügung.
Im Folgenden werden die einzelnen Metadatenattribute vorgestellt und erörtert in
wieweit es sinnvoll ist, diese für die Realisierung des Kursentwicklungssystems zu
verwenden.
General.Identifier: Dieses Attribut identifiziert die Metadaten eindeutig.
Auf dieses Schlüsselattribut kann nicht verzichtet werden.
General.Title: Dieses Attibut trägt den Titel eines Lernobjekts. Dieses Atribut ist
vom Typ LangString und erlaubt den Titel in mehreren Sprachen anzugeben. Der
Titel eines Lernobjekts ist die erste Beschreibung die ein Nutzer des
Kursentwicklungssystems sehen kann.
General.Language: Dieses Attribut spezifiziert die Sprache des Lernobjekts. Es
können bis zu 10 Sprachen angegeben werden. Dieses Attribut ist unerläßlich um
das Kursentwicklungssystems Lernenden unterschiedlicher Sprachen zugänglich
zu machen.
General.Description: Eine Beschreibung des Lernobjekts kann in diesem Attribut
abgelegt werden. Dieses Attribut wird ebenfalls übernommen.
General.Keyword: Das Lernobjekt wird in diesem Attribut über Schlüsselwörter
beschrieben. Bis zu zehn Schlüsselwörter können in mehreren Sprachen
gleichzeitig abgelegt werden. Dieses Attribut wird übernommen, da es für die
Suche nach Lernobjekten verwendet werden.
General.Coverage: Dieses Attribut beschreibt die zeitlichen und räumlichen
Charakteristika eines Lernobjekts. Dieses Attribut gibt kein Vokabular vor, d.h. ein
Nutzer hat die freie Wahl, was er in dieses Feld eintragen möchte. Das macht
eine sinnvolle Suche über dieses Attribut schwer. Außerdem wird es in den
meisten Fällen nicht möglich sein, zeitliche und räumliche Charakteristika zu
einem Lernobjekt zu bestimmen. Das Feld wird dann entweder leer bleiben oder
ein Nutzer sieht sich gezwungen etwas einzutragen, das vielleicht nicht der Sache
dient. Aus diesem Grund wird das Attribut General.Coverage nicht übernommen.
General.Structure: Dieses Attrbiut beschreibt die zugrundeliegende
Organisationsstruktur einer Ressource. Für die Struktur stellt das Vokabular die
Begriffe Collection, Mixed, Linear, Hierarchical, Networked, Branched, Parceled
und Atomic bereit. Mit Hilfe dieses Attributs kann die innere Struktur eines
Strukturmoduls oder eines Kurses beschrieben werden. Deshalb findet das
Attribut Verwendung in der Realisierung des Prototyps.
66
General.Aggregationlevel: Dieses Attribut dient der Klassifizierung der
funktionellen Größe eines Lernobjekts. Die funktionelle Größe wird durch Zahlen
von 1 bis 4 ausgedrückt. Dieses Attribut wird in dem Prototyp die Aufgabe haben
den Typ eines Lernobjekts zu bestimmen. Ein Lernatom wird durch eine “1”
repräsentiert, ein Lernmodul erhält die “2” und ein Kurs die “3”.
Lifecycle.Version: Die aktuelle Versionsnummer des Lernobjekts wird durch
dieses Attribut verwaltet und wird deshalb übernommen.
Lifecycle.Status: Dieses Attribut bestimmt den Status eines Lernobjekts. Für den
Status schreibt das Vokabular eines der vier Wörter Draft, Final, Revised oder
Unavailable vor.
Lifecycle.Contribute.Role: Dieses Attribut zeigt an, welche Rolle eine Person
oder Organisation bei der Entstehung der aktuellen Version des Lernobjekts
eingenommen hat. So werden über die Rolle Author alle Autoren genannt.
Lifecycle.Contibute.Entity: Bis zu 40 Personen und Organisationen werden
durch dieses Attribut einer rolle zugeordnet. Die Personen oder Organisationen
werden im vCard-Format definiert.
Lifecycle.Contribute.Date: Der Zeitpunkt der letzten Bearbeitung durch
Mitglieder der definierten Rolle wird durch dieses Attribut festgehalten.
Metametadata.*: Die Attribute der Gruppe Metametadata haben die Aufgabe
festzulegen, in welchen Katalogen die Metadaten geführt werden und wer an der
Entstehung der Metadaten beteiligt war. Da der Prototyp nur Metadaten für
Lernobjekte, die innerhalb des Prototypen gespeichert sind, verwaltet, kann die
Angabe von Katalogen entfallen. Genauso ist es ohne Bedeutung wer die
Metadaten erstellt hat. Aus diesem Grunde wird die komplette Gruppe
Metametadata für den Prototyp nicht berücksichtigt.
Technical.Format: Dieses Attribut beinhaltet den Datentyp der Ressource. Der
Datentyp wird im MIME-Format angegeben.
Technical.Size: Die Größe der Datei in Byte kann über dieses Attribut erfragt
werden.
Technical.Location: Der Zugriffspfad für die Ressource wird in diesem Attribut
als URL abgelegt.
Technical.Requirement.*:
Diese
Untergruppe
beschreibt
technische
Voraussetzungen für die Nutzung der Ressource. Dazu gehören z.B. die
Beschränkung auf bestimmte Betriebssystemversionen oder Browserversionen.
Die Attribute dieser Untergruppe können als überflüssig bezeichnet werden. In
dem Prototypen sollen aussschließlich bekannte Dateiformate eingesetzt werden.
Zudem ist an dem Attribut Technical.Format leicht zu erkennen, ob ein Lernobjekt
in einer bestimten Zielumgebung eingesetzt werden kann.
Technical.Duration: Dieses Attribut gibt die Zeit in Sekunden an, die für das
Abspielen einer dynamischen Ressource, z.B. ein Video, benötigt wird. Die
Kenntnis hierüber ist unwichtig für den Protoyp.
Educational.Interactivitytype: Dieses Attribut beschreibt das Maß an
Interaktivität einer Ressource. Das Vokabular bietet die Werte Active, Expositive,
Mixed und Undefined. Dieses Attribut beschreibt inwieweit ein Lernobjekt für eine
selbständige Konsumierung oder für einen Vortrag durch einen Dozenten
geeignet ist.
Educational.Learningresourcetype: Die Art der Ressource wird durch dieses
Attribut beschrieben. Das Vokabular schreibt mögliche Formen des
Ressourcentyps vor. Dazu gehören unter anderem Excercise, Simulation, und
Diagram. Dieses Attribut ist von großer Bedeutung, wenn eine thematisch
abgeschlossene Einheit von Lernatomen gebildet werden soll. Für die Erstellung
67
eines Strukturmoduls kann mit diesem Attribut gezielt nach Lernatomen gesucht
werden, die für die Vollständigkeit des Strukturmoduls benötigt werden. So kann
z.B. wenn das Strukturmodul noch kein Beispiel enthält, innerhalb des zugrundeliegenden Integrationsmoduls nach Lernatomen gesucht werden, deren Attribut
Educational.Learningresourcetype den Wert “Example” enthält.
Educational.Interactivitylevel: Dieses Attribut beschreibt das Maß an
Interaktivität. Das Vokabular erlaubt die Begriffe very low, low, medium, high und
very high. Dieses Attribut ist entscheidend für die Wahl eines Lernobjekts für eine
bestimmte Zielgruppe.
Educational.Semanticdensity: Dieses Attribut soll ein Maß dafür sein, welchen
Nutzen ein Lernobjekt im Vergleich zu seiner Größe hat. Diese Beurteilung ist
sehr schwer durchzuführen und außerdem rein subjektiv. Bevor hier definierte
Werte zu Mißverständnissen führen, entfällt dieses Attribut für den Prototyp.
Educational.Intendedenduserrole: Die Benutzerrolle wird mit diesem Attribut
festgelegt. Das Vokabular definiert unter anderem die Rollen Teacher, Learner
und Manager. Bis zu 10 Rollen können hier genannt sein.
Educational.Context: Dieses Attribut beinhaltet die Zielgruppe des Lernobjekts.
Primary Education, Iuniversity First Cycle und University Postgrade sind Beispiele
aus dem Vokabular. Maximal 4 Zielgruppen können eingetragen werden.
Educational.Typicalagerange: Das Alter des typischen Endbenutzers wird durch
dieses Attribut spezifiziert. Ein Lernobjekt einem Alter zuzuordnen stellt sicherlich
ein großes Problem dar. Bevor hier falsche Werte stehen, wird dieses Attribut
vom Prototyp nicht unterstützt. Eine bessere Orientierung als das Alter sollte das
Attribut Educational.Context geben.
Educational.Typicallearningtime: Die durchschnittliche Zeit zum Bearbeiten
einer Ressource durch den Lernenden ist durch dieses Attribut verfügbar. Die
Zeitangabe bezieht sich dabei auf die genannten Zielgruppen.
Educational.Description: Dieses Attribut beschreibt wie die Ressource zu
nutzen ist. Hier können z.B. Angaben gemacht werden, in welcher Form ein
Dozent das Wissen vermitteln oder wie ein Student das Lernmaterial
konsumieren sollte.
Rights.*: Diese Gruppe betrifft Nutzungsrechte eines Lernobjekts. An dieser
Stelle kann jedoch nur festgelegt werden, ob ein Lernobjekt durch ein Copyright
geschützt ist und ob für die Nutzung Gebühren erhoben werden. In die zu
implementierende Kursentwickulungsumgebung sollen jedoch nur die Objekte
abgelegt werden, die von allen Beteiligten benutzt werden können. Um
Lernobjekte gegen Veränderungen schützen zu können, wäre jedoch die Vergabe
von Schreibrechten interessant. Dies wird jedoch von der Gruppe Rights nicht
unterstützt. Aus den genannten Gründen wird die Gruppe Rights nicht unterstützt.
Relation.Kind: Die Art einer Beziehung des Lernobjekts zu anderen Objekten ist
in diesem Attribut verfügbar. Das Vokabular schreibt die Beziehungsformen vor.
Dazu gehören z.B. IsPartOf, IsBasedOn und Requires. Dieses Attribut ist wichtig
für Kursentwickler zur Auswahl geeigneter Zusammenhänge.
Relation.Resource.Identifier: Dieses Attribut trägt die ID des Objekts mit dem
das Lernobjekt in Beziehung steht.
Annotation.Person: Der Urheber einer Anmerkung zu einem Lernobjekt ist in
diesem Attribut im vCard-Format genannt.
Annotation.Date: Der Zeitpunkt der Anmerkung ist in diesem Attribut enthalten.
Annotation.Description: In diesem Attribut kann die Anmerkung in mehreren
Sprachen gespeichert werden.
68
Classification.*: Diese Gruppe klassifiziert ein Lernobjekt anhand eines
Klassifizierungskatalogs. Die meisten Attribute dieser Gruppe sind für die
Auswahl
dieses
Katalogs
bestimmt.
Das
zu
implementierende
Kursentwicklungssystem erlaubt jedoch nur die Klassifizierung eines Lernobjekts
mit Hilfe einer Ontologie. Aus diesem Grunde wird nur das Attribut
Classification.Keyword benötigt, um einen Ontologie-Pfad zu spezifizieren.
Nachdem die Attribute im einzelenen besprochen wurden, kann nun ein Überblick
über das Metadatenschema gegeben werden, wie ich es für den Prototyp einsezten
werde.
Tabelle 4-1 : Metadaten
Gruppe
General
Lifecycle
Technical
Educational
Relations
Kard. <=100
Attribut
Identifier
Title
Language
Description
Keyword
Aggregationlevel
Version
Status
Contribute
Role
Entity
Date
Format
Size
Location
Interactivitytype
Learningresourcetype
Interactivitylevel
Intendedenduser
role
Context
Typicallearningtime
Description
Kind
Resource
Identifier
Annotation
Person
Kard. <=30
Date
Description
Classification Keyword
Kard. <=40
Bemerkung
Eindeutiger Schlüssel
Titel des Lernobjekts
Sprache des Lernobjekts
Beschreibung des LO
Schlüsselwörter für LO
Typ des Lernobjekts
Version des Lernobjekts
Status des Lernobjekts
Bearbeiter des LO
Art der Beteiligung
Beteiligte Personen/Org.
Zeitpunkt der Beteiligung
Datentyp der Ressource
Größe der Ressource
Zugriffspfad für Ressource
Art der Inteaktivität
Art der Ressource
Kard.
1
1
<=10
<=10
<=10
1
1
1
<=30
1
<=40
1
<=40
1
<=10
1
<=10
Datentyp
String
LangString
String
LangString
LangString
Vocabulary
LangString
Vocabulary
Maß der Interaktivität
Benutzerrolle
1
Vocabulary
<=10 Vocabulary
Zielgruppe
Bearbeitungszeit für LO
<=4
1
Vocabulary
DateType
Nutzungsbeschreibung
1
Art der Beziehung
1
Ressource, die in Bz.
1
steht
Schlüssel des Zielobjekts
1
Urheber der Anmerkung
1
Zeitpunkt der Anmerkung
1
Anmerkung
1
Klassifizierung des LO
<=40
LangString
Vocabulary
Vocabulary
String
DateType
String
String
String
Vocabulary
Vocabulary
String
String
DateType
LangString
LangString
69
Die Tabelle gibt zu jedem Attribut die Kardinalität und den Datentyp an. Für Attribute
des Datentyps Vocabulary steht ein fest vorgegebenes Vokabular zur Verfügung.
Dieses Vokabular ist im Anhang ausführlich dargestellt.
Attribute des Datentyps LangString erlauben einen String in mehreren Sprachen
anzugeben. So kann z.B. der Titel eines Lernobjekts in deutscher und englischer
Sprache angegeben werden:
Title:
langstring lang=“de“ :
langstring lang=“en“ :
“Einführung in ein Lagerverwaltungsbeispiel“
“Introduction to the example of storage
management“
Als Schema für die Metadaten kann eine Teilmenge des vom IMS-Projekt
ausgelieferten XML Schema genutzt werden. Das Schema definiert die einzelnen
Datentypen und berücksichtigt die Kardinalität der Attribute.
Es stellt sich nun die Frage, wie eine Metadatenbeschreibung als XML-Datei
abgespeichert werden kann.
Zu diesem Zweck wird das Metadatenschema mit Hilfe des Algorithmus von Ronald
Bourret (siehe Kapitel 3, S. 69) auf ein relationales Schema abgebildet. An dieser
Stelle ist es unerheblich ob eine DTD oder ein Schema für die Abbildung verwendet
wird. Das DTD und das Schema unterscheiden sich lediglich in der Möglichkeit
Kardinalitäten und Datentypen zu definieren. An dieser Stelle möchte ich deshalb
wegen der einfacheren Lesbarkeit ein DTD der Metadatenattribute, wie sie in der
Tabelle 4-1 dargestellt sind, erzeugen.
<!-- Root Element -->
<!ELEMENT Metadata (General, Lifecycle, Technical, Educational, Relation+,
Annotation+, Classification+)>
<!-- Complexe Elemente -->
<!ELEMENT General (Identifier, Title, Language+, Description+, Keyword+,
Aggregationlevel)>
<!ELEMENT Lifecycle (Version, Status, Contribute+)>
<!ELEMENT Technical (Format+, Size, Location+)>
<!ELEMENT Educational (Interactivitytype, Learningresourcetype+, Interactivitylevel, Intendedenduserrole+, Context+, Typicallearningtime,
Description)>
<!ELEMENT Relation (Kind, Resource)>
<!ELEMENT Annotation (Person, Date, Description)>
<!ELEMENT Classification (Keyword+)>
<!ELEMENT Title (Langstring+)>
<!ELEMENT Description (Langstring+)>
<!ELEMENT Keyword (Langstring+)>
<!ELEMENT Aggregationlevel (Source, Value)>
70
<!ELEMENT Version (Langstring+)>
<!ELEMENT Status (Source, Value)>
<!ELEMENT Contribute (Role, Entity+, Date)>
<!ELEMENT Role (Source, Value)>
<!ELEMENT Entity (vcard)>
<!ELEMENT Interactivitytype (Source, Value)>
<!ELEMENT Learningresourcetype (Source, Value)>
<!ELEMENT Intendedenduserrole (Source, Value)>
<!ELEMENT Context (Source, Value)>
<!ELEMENT Typicallearningtime (Datetime?, Description?)>
<!ELEMENT Kind (Source, Value)>
<!ELEMENT Resource (Identifier)>
<!ELEMENT Person (vcard)>
<!ELEMENT Date (Datetime?, Description?)>
<!-- einfache Elemente -->
<!ELEMENT Identifier (#PCDATA)>
<!ELEMENT Language (#PCDATA)>
<!ELEMENT Langstring (#PCDATA)>
<!ATTLIST Langstring
lang CDATA #IMPLIED>
<!ELEMENT Format (#PCDATA)>
<!ELEMENT Size (#PCDATA)>
<!ELEMENT Location (#PCDATA)>
<!ELEMENT Interactivitylevel (#PCDATA)>
<!ELEMENT vcard (#PCDATA)>
<!ELEMENT Datetime (#PCDATA)>
<!ELEMENT Source (#PCDATA)>
<!ELEMENT Value (#PCDATA)>
Listing 4.1: Metadaten-DTD
Das komlexe Element General wird durch den Algorithmus auf folgende Relationen
abgebildet:
General (id, Aggregationlevel)
Title (id, lang, title)
Language (id, language)
GeneralDescription (id, lang, nr, description)
GeneralKeyword (id, lang, nr, keyword)
Das komplexe Element Lifecycle lässt sich wie folgt darstellen:
71
Lifecycle (id, version, status)
Contribute (id, role, entity, date)
Das komplexe Element Technical lässt sich in einer Relation darstellen:
Technical (id, format, size, location)
Das komplexe Element Educational wird auf diese Relationen abgebildet:
Educational (id, interactivitytype, interactivitylevel, typicallearningtime)
EducationalDescription (id, lang, description)
Learningresourcetype (id, type)
Enduserrole (id, role)
Context (id, context)
Das komplexe Element Relation kann durch folgende Relation realisiert werden:
Relation (id, kind, resource)
Das komplexe Element Annotation wird ebenfalls durch eine einzelne Relation
repräsentiert:
Annotation (id, person, date, lang, annotation)
Das komplexe Element Classification wird mit dieser Relation abgebildet:
Classification (id, lang, nr, classification)
Die Abbildung der Metadaten auf eine relationale Datenbank führt also in der Summe
zu 16 Relationen. Vor diesem Hintergrund möchte ich nun eine geeignete Auswahl
zur Speicherung der Metadaten treffen. Dazu werden die in Kapitel 3 vorgestellten
Datenbanktechnologien bewertet.
Bei dem vorliegenden XML-Datenmodell für Metadaten handelt es sich um eine
ausgesprochen komplexe, verschachtelte Struktur. Die Daten sind nur schwach
strukturiert, was zu vielen NULL-Werten führen kann.
Innerhalb der Anwendung wird auf diese Daten über das komplette XML-Dokument
zugegriffen, d.h. die Anwendung erwartet von der Datenbank die Übergabe des
gesamten XML-Dokuments. Dies bedeutet, daß wann immer ein Dokument
angefordert wird, ein Join über 16 Tabellen erfogen wird. Aus einigen dieser Tabellen
müssen mehrere Zeilen ausgelesen werden, um ein hierarchisches XML-Dokument
zu erzeugen.
Gegen die Speicherung der Metadaten mit dem Oracle XML SQL Utility spricht die
bloße Anzahl an Tabellen, denn hier müßten die Daten auf 16 Tabellen abgebildet
werden. Der Join über diese Tabellen würde einiges an Rechenzeit verbrauchen und
ist damit ineffizient.
Für das Speichern der Metadaten als XMLType spricht das physikalisch
zusammenhängene Speichern von XML Dokumenten. Die Zugriffsgeschwindigkeit
kann dadurch entscheidend erhöht werden.
Gegen XMLType spricht das umständliche Abbilden einer XML-Query in einen
Select-Ausdruck.
XMLType wirkt insgesamt wie eine schnelle Notlösung von Oracle, um nicht mit XML
die Vorherrschaft im Datenbankbereich zu verlieren. Insgesamt fehlt es an
72
Funktionalitäten wie z.B. dem Validieren eines Dokuments gegenüber seiner DTD
oder der Definition von Indizes für den schnellen Zugriff, die den Einsatz von XML
unterstützen.
Für den Einsatz des Tamino XML Server spricht das zusammenhängende
Speichern. Die Zugriffsgeschwindigkeit kann durch spezielle Indizes zusätzlich
erhöht werden. Diese Indizes können bei der Definition eines XML-Schemas
innerhalb des Schema Editors erstellt werden.
Der größte Vorteil: Tamino spricht XML. XML-Querys können direkt an die
Datenbank gestellt werden. Eingestellte Dokumente können stets gegen ein Schema
validiert werden. Tamino ist rein auf XML ausgelegt und entsprechend optimiert im
Gegensatz zu einer relationalen Datenbank, die XML unterstützt aber nicht dafür
optimiert ist. Neueste XML-Standards werden schnellstens implementiert.
Aus diesen hier aufgeführten Gründen fällt die Wahl auf den Tamino XML Server zur
Speicherung der Metadaten.
4.2 Lernatome
Als nächstes sollen die kleinsten wiederverwendbaren Einheiten des
Kursentwicklungssystems betrachtet werden: die Lernatome. Lernatome sind Träger
des eigentlichen Inhalts, der einem Lernenden vermittelt werden soll. Um das
Lernsystem offen zu gestalten, können Lernatome in verschiedenen Datenformaten
in das Lernsystem eingebunden werden. Dadurch können bereits erstellte Inhalte
wiederverwendet werden und auch zukünftige Datei-Standards finden in dem System
Verwendung. Gleichzeitig kann je nach Anforderung an ein Lernatom auf die
Anwendung zurückgegriffen werden, die am besten geeignet ist, um das Lernatom
zu gestalten.
Um dem Ziel der Kooperation gerecht zu werden, müssen mehrere kooperierende
Nutzer des Entwicklungssystems Zugriff auf die Lernatome haben. Eine Speicherung
an einem zentralen Ort, einem Repository ist deshalb unbedingt erforderlich. Auch
hierfür bietet sich das Speichern in einer Tamino-Kollektion an. Zur Speicherung
eines nicht-XML Dokuments ist lediglich die Angabe des Datentyps erforderlich. Der
Datentyp eines Lernatoms kann automatisch vom Kursentwicklungssystem bestimmt
werden.
Ein nicht-XML Dokument, das in Tamino abgespeichert ist, wird über eine vom XML
Server erzeugten ID identifiziert. Aus diesem Grunde muß zur Identifikation eines
Lernobjekts gegenüber dem Benutzer ein anderer Weg gewählt werden. Dem
Benutzer wird ein Lernatom ausschließlich über seine Metadaten präsentiert. Das
Metadatenattribut Technical.Path identifiziert das Lernatom auf der Datenbank
transparent für den Benutzer.
Für das Einbringen eines Lernatoms in Form einer Datei in das
Kursentwicklungssystems ist ein Check-In Prozess verantwortlich, der im Folgenden
beschrieben wird.
Über diesen Check-In Prozess können die beiden kooperierenden Universitäten des
Szenarios ihre Inhalte vereinigen und ein gemeinsam nutzbares Wissens-Repertoire
schaffen.
73
4.2.1 Check-In Prozess
Bevor ein Lernatom für die Ertsellung eines Kuses verwendet werden kann, muß es
dem System bekannt gemacht werden.
Diese Anmeldung eines Lernatoms erfolgt durch einen “Check-In”. Dieser Prozess ist
in Abbildung 4-1 illustriert.
Metadaten
Lernatom
Check-In
Tamino
SCORE – Courseware-System
Abbildung 4-1 : Check-In Prozeß
Der Check-In Prozess hat zweierlei Funktionen. Zum Einen übernimmt er ein nicht
XML-Dokument in das Kursentwicklungssystem, d.h. er legt das Lernatom in Form
einer Datei in der Tamino-Datenbank ab. Nur auf diese in der Datenbank abgelegten
Dateien kann später für die Kurserstellung zurückgegriffen werden.
Zum Anderen werden beim Check-In Metadaten generiert, mit deren Hilfe das
Lernatom innerhalb des Systems identifiziert werden kann. Die Metadaten können
vom Benutzer in Form einer Datei mitgegeben werden. Sind noch keine Metadaten
zu einem Lernatom vorhanden, so werden diese vom System erzeugt. Für diesen
Fall müssen vom Benutzer ein Minimum an Metadaten erfragt werden. Dazu gehören
das Attribut Educational.Contenttype und General.Title.
Die ID eines Lernatoms wird ebenfalls beim Check-In erzeugt. Als ID wird eine GUID
erzeugt, die aus der Kombination aus MAC-Adresse, Datum und einer Zufallszahl
generiert wird. Zusätzlich wird diese GUID mit einem Hash-Algorithmus transformiert.
Dieses Verfahren wird für alle weiteren Lernobjekte zur Erzeugung der Metadaten-ID
verwendet.
Nachdem ein Lernatom in der Datenbanbk abgelegt ist, wird der Zugriffspfad des
Lernatoms im Metadatenattribut Technical.Path gespeichert. Sind Lernatome erst
einmal durch einen Check-In registriert, so erfolgt der Zugriff ausschließlich über die
74
Metadaten, d.h. es wird niemals direkt auf die Lernatome zugegriffen. Ein Lernatom
ist dadurch eindeutig durch die Metadaten-ID identifizierbar.
4.3 Integrationsmodule
Integrationsmodule sind die nächsten Elemente in der Hierarchie des
Kursentwicklungssystems.
Ein
Integrationsmodul
gruppiert
thematisch
zusammengehörende Lernatome und bildet folglich eine thematisch abgeschlossene
Einheit. Die Lernatome eines solchen Moduls sind potentielle Kandidaten für die
Erstellung einer Lerneinheit.
Das heißt ein Integrationsmodul hat folglich allein die Aufgabe Lernatome zu
gruppieren. Welche Lernatome Teil eines Moduls werden, entscheidet alleine ein
Benutzer des Systems.
4.3.1 Prozess: Integrationsmodul erzeugen
Die Erzeugung eines Integrationsmodul gliedert sich in zwei Phasen. In der ersten
Phase wird eine Instanz eines Lernmoduls vom Typ Integration Module erzeugt. In
der zweiten Phase werden Metadaten generiert, die das spätere Auffinden eines
Integrationsmoduls erlauben.
4.3.2 Realisierung des Integrationsmoduls
Für das Speichern der Integrationsmodule bietet sich ebenfalls das Speichern
innerhalb der Tamino-Datenbank als XML-Instanz an.
Das XML-Dokument sollte folgende Daten enthalten:
ID
Titel
Referenz auf Lernatome
Die ID wird benötigt, um ein Integrationsmodul eindeutig zu identifizieren. Diese ID
entspricht der Metadaten-ID, um eine direkte Abbildung zwischen Integrationsmodulen und ihren Metadaten zu erhalten.
Der Titel repräsentiert das Lernmodul auf der Benutzeroberfläche gegenüber dem
Benutzer.
Lernatome werden nicht physikalisch in ein Integrationsmodul eingefügt, sondern um
Redundanzen zu vermeiden, über eine Referenz repräsentiert. Die Referenz ist
durch die Metadaten-ID der Lernatome gegeben.
Das Integrationsmodul dient als Grundlage für ein Strukturmodul. Für die
Entscheidung, welche Lernatome in einem Strukturmodul übernommen werden
sollen, ist hauptsächlich der ‘educational type’ und der ‘content type’ maßgebend.
Damit diese Daten nicht jedesmal durch Laden eines Metadaten-Dokuments besorgt
werden müssen, sollen diese Attribute mit der Referenz in einem Integrationsmodul
gespeichert werden.
Aus diesen Vorgaben ergibt sich für ein Integrationsmodul die folgene Document
Type Definition:
75
<!ELEMENT interation_module (learning_atom)*>
<!ATTLIST integration_module
id
CDATA #REQUIRED
title CDATA #REQUIRED>
<!ELEMENT learning_atom #PCDATA>
<!ATTLIST learning_atom
educational_type CDATA #REQUIRED
content_type
CDATA #REQUIRED>
Listing 4.2: Integrationsmodul-DTD
Das folgende Beispiel zeigt ein Integrationsmodul, das Lernatome zum Thema SQL
kapselt. Die Lernatome liegen als Powerpoint-Präsentationen vor und decken das
Thema mit einer Einleitung, einem Beispiel und einer Beschreibung ab.
id=‘00000507-0000-0010-8000-00AA006D2EA4‘
title=‘SQL-Einfühung‘>
<learning_atom
educational_type=‘description‘
content_type=‘application/vnd.ms-powerpoint‘>
00000507-0100-0010-8060-00AA006D2IA4
</learning_atom>
<learning_atom
educational _type=‘introduction‘
content_type=‘application/vnd.ms-powerpoint‘>
00IA0507-0102-0I10-8060-00AA006D2IA4
</learning_atom>
<learning_atom
educational _type=‘example‘
content_type=‘application/vnd.ms-powerpoint‘>
00000507-0100-0010-806A-00AI006D2IF4
</learning_atom>
</integration_module>
Listing 4.3: Instanz eines Integrationsmodul
<integration_module
Das Integrationsmodul ist die Basis für das Erstellen eines Kurses. Das Bilden und
Erweitern dieser Einheiten sollte Aufgabe von Autoren sein, die Lernatome für ein
bestimmtes Thema erzeugen. Aber auch ein Lehrender sollte in der Wissensbasis
vorhandene Lernatome nach Bedarf in ein Integrationsmodul einfügen können, wenn
er zusätzliche Lernatome für ein Thema innerhalb eines Kurses benötigt.
Die kooperierenden Universitäten könen so die von dem jeweiligen Partner erstellten
Lernatome zusammenhängend auffinden und auf einfache Weise widerverwenden.
Gleichzeitig ergänzen sich die Lernatome, wenn die Lernatome der beiden
Universitäten in eine thematische Einheit zusammengefasst werden.
4.4 Strukturmodule
Ein Lernmodul des Typs Structural Module hat die Aufgabe, Lernatome eines
Integrationsmodul auszuwählen, diese in eine gewünschte Reihenfolge zu bringen
und damit auf eine bestimmte Zielgruppe und deren didaktischen Bedürfnisse
abzustimmen.
76
4.4.1 Prozess: Erzeugen eines Strukturmoduls
Ein Integrationsmodul wird auf Basis eines Integrationsmodul erzeugt. Der Benutzer
hat die Möglichkeit die Atome eines Integrationsmodul in die gewünschte
Reihenfolge zu bringen. Dabei können einzelne Atome auch weggelassen werden.
Die Erzeugung eines Strukturmoduls läuft in vielen Fällen nach einem bestimmten
Muster ab. So ist z.B. die Reihenfolge oftmals durch die Auswahl einer Einleitung,
eines Beispiels, eines Satzes und eines Beweises gegeben. Um die Erzeugung
eines Strukturmoduls zu erleichtern, können deshalb Templates genutzt werden, die
automatisch eine Struktur auf den Integrationsmodulen erzeugen.
Integration
Module
2
Lernatom
Structural
Template
Struktur
erzeugen
Lernatom
1
Lernatom
Structural
Module
Abbildung 4-2 : Erzeugen eines Strukturmoduls
4.4.2 Realisierung des Strukturmoduls
Ein Strukturmodul wird ebenfalls als XML-Dokument in Tamino abgelegt.
Es enhält stets Referenzen auf alle Atome, die im zugrundeliegenden
Integrationsmodul enthalten sind. Dadurch ist sichergestellt, daß ein Strukturmodul
schnell und einfach angepasst werden kann, ohne daß auf das Integrationsmodul
zurückgegriffen werden muß. Auf diese Weise kann ein Strukturmodul einfach
verändert werden, indem auf ihm ein Struktur-Muster angewendet wird.
Für jede Referenz wird zusätzlich eine Positionskennzahl abgelegt. Sie legt die
Position eines Lernatoms innerhalb des Strukturmoduls fest. Für Lernatome, die nicht
im Strukturmodul dargstellt werden sollen, wird die Positionskennzahl auf den Wert ‘-‘
gesetzt.
77
Damit zu einem in Bearbeitung befindlichen Strukturmodul effizient das
zugrundeliegende Integrationsmodul bestimmt werden kann, muß zusätzlich die ID
des Integrationsmoduls gespeichert werden.
Aus diesen Anforderungen läßt sich das folgende DTD für ein Strukturmodul
erstellen:
<!ELEMENT structural_module (learning_atom)*>
<!ATTLIST structural_module
id
CDATA #REQUIRED
title CDATA #REQUIRED
im_id CDATA #REQUIRED>
<!ELEMENT learning_atom #PCDATA>
<!ATTLIST learning_atom
position
CDATA #REQUIRED
educational_type CDATA #REQUIRED
content_type
CDATA #REQUIRED>
Listing 4.4: Strukturmodul-DTD
Das Integratinsmodul aus dem vorigen Beispiel kann z.B. in folgendes Strukturmodul
überführt werden:
id=‘00000507-0030-0010-80F0-00AA0L6D2EA4‘
title=‘SQL-Einfühung‘
im_id=‘00000507-0000-0010-8000-00AA006D2EA4‘>
<learning_atom
educational_type=‘description‘
content_type=‘application/vnd.ms-powerpoint‘
position=‘2‘>
00000507-0100-0010-8060-00AA006D2IA4
</learning_atom>
<learning_atom
educational _type=‘introduction‘
content_type=‘application/vnd.ms-powerpoint‘
position=‘-‘>
00IA0507-0102-0I10-8060-00AA006D2IA4
</learning_atom>
<learning_atom
educational _type=‘example‘
content_type=‘application/vnd.ms-powerpoint‘
position=‘1‘>
00000507-0100-0010-806A-00AI006D2IF4
</learning_atom>
</integration_module>
Listing 4.5: Instanz eines Strukturmodul
<structural_module
Das Strukturmodul erlaubt es den Universitäten das kooperativ erstellte und
gruppierte Lernmaterial auf die jeweiligen Zielgruppen auszurichten. Die Lernatome
eines Themas werden also für verschiedene Zielgruppen angepasst wiederverwendet.
78
Ein Lernender erhält durch das Strukturmodul die Möglichkeit sich selbst Lernatome
zu einem Thema auszuwählen, um sich damit seinen eigenen Kurs zusammenzustellen.
4.4.3 Realisierung des Struktur-Muster
Das Strukturmuster legt fest, wie die einzelnen Atome eines Integrationsmoduls
innerhalb des Struktumoduls geordnet werden sollen. Die Reihenfolge wird dabei
über den Content-Type, also das Attribut der Metadaten, das festlegt, ob es sich um
eine Einleitung, ein Beispiel oder einen Beweis handelt, festgelegt.
Ein Strukturtemplate wird aus einzelnen Filtern aufgebaut. Ein Filter enthält den
Content-Type. Die Lernatome werden in der Reihenfolge angeordnet, in der die Filter
im Strukturtemplate definiert sind.
Dabei kann eine so definierte Reihenfolge in Einzelfällen unangemessen sein.
Enthält ein Integrationsmodul z.B. 2 Beispiele und 2 Erläuterungen zu den
Beispielen, dann ist die Reihenfolge “Beispiel vor Erläuterung“, die ein Template
definiert, unangebracht. Stattdessen sollte die Reihenfolge “1. Beispiel, Erläuterung,
2. Beispiel, Erläuterung“ lauten.
Deshalb darf ein Strukturtemplate nur als eine Vorgabe betrachtet werden, die das
Erstellen eines Strukturmoduls erleichtert, in vielen Fällen jedoch vom Benutzer
angepasst werden muß.
Ein Structural Template, das das obige Integrationsmodul in das Strukturmodul
überführt hat folgendes Aussehen:
<structural_template>
<filter type=‘example‘/>
<filter type=‘description‘/>
</structural_template>
Listing 4.6: Instanz eines Strukturtemplates
Allgemein ist der Aufbau eines Structural Template durch folgendes DTD bestimmt:
<!ELEMENT structural_template filter*>
<!ELEMENT filter EMPTY>
<!ATTLIST filter
type CDATA #REQUIRED>
Listing 4.7: Strukturtemplate-DTD
4.5 Präsentationsmodul
Das Präsentationsmodul schließlich hat die Aufgabe, die durch das Strukturmodul in
eine Ordnung gebrachte, Lernatome in eine darstellbare Form zu konzentrieren.
Dazu muß eine Transformation auf das Strukturmodul angewendet werden. Das
Ergebnis dieser Transformation kann als Datei abgespeichert werden. Diese Datei
kann z.B. ein PDF-Dokument, eine Powerpoint-Präsentation oder ein HTMLDokument sein.
79
4.5.1 Prozess: Präsentationsmodul erzeugen
Das Präsentationmodul selbst wird durch die aus der Transformation
hervorgegangenen Datei repräsentiert. Identifiziert wird diese Datei ausschließlich
über die Metadaten.
Gesucht ist an dieser Stelle eine Transformation, die in der Lage ist aus den
Vorgaben eines XML-Dokuments, dem Strukturmodul, eine ausgabefähige und durch
vorhandene Anwendungen darstellbare Datei zu erzeugen.
Diese Transformation könnte leicht als Teil der Anwendung implementiert werden.
Der Aspekt verschiedener Präsentationsformen auf
der Ebene der
Präsentationsmodule zu realisieren, wäre dadurch allerdings abgeschwächt.
Es ist unmöglich alle existierenden und zukünftigen Dateiformate zu unterstützen.
Außerdem soll der Anwender die Transformation selbst implementieren können.
Gefragt ist also eine Schnittstelle, für ein XML-Dokument und eine
Transformationsvorschrift. Genau diese Schnittstelle bietet ein XSLT-Prozessor (vgl.
Kapitel 3). Darum soll XSLT zur Transformation eines Strukturmoduls in ein
Präsentationsmodul genutzt werden. Der Anwender hat damit die Möglichkeit durch
ein XSLT-Dokument das Erscheinungsbild eines Präsentationsmoduls selbst zu
bestimmen.
Structural
Module
2
Lernatom
XSLTDokument
P.-Modul
erzeugen
Lernatom
1
Lernatom
Presentational
Module
Abbildung 4-3 : Erzeugung eines Präsentatonsmoduls
Das Dokument, das die Transformation durchführt sollte dabei folgenden Algorithmus
implementieren:
1. Besuche die Elemente vom Typ “learning_atom“ in der durch das Attribut
“position“ vorgegebenen Reihenfolge.
2. Führe für jedes besuchte Element die Regel aus, die für den entsprechenden im
Attribut “content_type“ gespeicherten Content-Type vorgesehen ist.
80
3. Füge das durch die Regelanwendung erhaltene Objekt an die Ausgabedatei an.
Das folgende Beispiel veranschaulicht die Vorgehensweise:
Ein Strukturmodul enthalte ein Beispiel und eine Erklärung als Lernatome. Dem
Beispiel sei die Position “1“ und der Erklärung die Position “2“ zugeordnet. Beide
Atome seien eine Powerpoint-Präsentation. Es sei angenommen, daß die, in dem
Strukturmodul enthaltenen Inhalte für eine Web-Schulung zur Verfügung gestellt
werden sollen. Das XSLT-Dokument könnte dafür eine HTML-Datei erstellen, die auf
das Beispiel und die Erklärung verweist.
Structural
Module
1
Beispiel.ppt
HTML
Container
erzeugen
(Template)
Transformation
2
Erklärung.ppt
Container.html
Abbildung 4-4 : Transformation
4.5.2 Realisierung des Präsentationsmoduls
Das erzeugte Präsentationsmodul liegt in Form einer Datei vor, die in der Tamino
Datenbank abgelegt wird. Am einfachsten kann man sich eine HTML-Datei
vorstellen, die auf die einzelnen Lernatome veweist. Genauso gut könnte eine PDFDatei oder eine Powerpoint-Präsentation aus den Lernatomen aufgebaut werden.
Dazu sind lediglich spezielle XSL-Transformationen zu definieren.
Bevor die XSL-Transformation stattfinden kann, müssen jedoch die Verweise auf die
Lernatome in Form der Metadaten-ID durch einen Unified Resource Identifier (URI)
ersetzt werden, da die Transformation nur auf den realen Lernatomen erfolgen kann.
Identifiziert wird ein Presentational Module durch seine Metadaten. In den Metadaten
ist zusätzlich das zugrundeliegende Strukturmodul und das für die Transformation
81
verantwortliche XSL-Template hinterlegt. Auf diese Weise ist sichergestellt, daß falls
sich das zugrundeliegende Strukturmodul verändert, auf die passende
Transformation zurückgegriffen werden kann, um das Präsentationsmodul zu
aktualisieren.
Das Präsentationsmodul erlaubt einem Lernenden bzw. einem Lehrenden die durch
eine Didaktik belegten Lernatome in eine darstellbare Form zu überführen.
So kann ein Strukturmodul von einem Lernenden oder einem Lehrenden
wiederverwendet und auf eine bestimmte Lernumgebung angepasst werden. Ein
Lehrender kann ein Präsentationsmodul für seinen Vortrag und ein Präsentationsmodul zum Ausdrucken erstellen.
Ein Lernender hat z.B. die Möglichkeit, die Inhalte des gleichen Strukturmoduls für
das Online-Lernen zu konfigurieren.
4.5.3 Realisierung der XSLT-Templates
Die XSLT-Templates werden ebenfalls in der Tamino Datenbank abgelegt. Etwas
schwieriger gestaltet sich hier die Suche nach einer Möglichkeit, die Templates zu
identifizieren. Das Template selbst muß einer definierten Form entsprechen. Die
einzige Möglichkeit bestände in der Nutzung eines Kommentars als ID-Attribut. Das
würde jedoch einen Kommentar-Knoten zweckentfremden. Außerdem könnte so nur
durch erheblichen Aufwand sichergestellt werden, daß eine ID eindeutig ist. Besser
ist hier der Einsatz von Metadaten, die eine Transformation beschreiben.
Folgendes XML-Dokument verweist auf eine XSLT-Datei, die ein HTML-Dokument
erzeugt:
<xslt_meta>
<name>HTML</name>
<description>
Erzeugt HTML-Datei, die auf Lernatome verweist.
</description>
<path>html.xslt</path>
</xslt_meta>
Der Textknoten “description“ beschreibt die Wirkungsweise der Transformation. Auf
diese Weise kann ein Benutzer leicht auf vorhandene Transformationen
zurückgreifen. Das zugehörige DTD hat folgende Form:
<!ELEMENT xslt_meta name,description,path>
<!ELEMENT name #PCDATA>
<!ELEMENT description #PCDATA>
<!ELEMENT path #PCDATA>
4.6 Kurs
Ein Kurs stellt das oberste Element der Hierarchie dar. Er hat die Aufgabe eine
Navigationsstruktur über die Lernmodule zu legen. Durch diese Strukturen kann ein
Lernender sich entlang der einzelnen Lernmodule bewegen.
82
4.6.1 Prozess: Kurs erstellen
Ein Kurs entsteht, indem die Lernmodule in eine Baumstruktur eingefügt werden.
Dazu ist zunächst eine Navigationsstruktur zu erzeugen, in die dann die Lernmodule
übernommen werden können.
Kurs
Presentational
Module
Abbildung 4-5 : Kurserstellung
4.6.2 Realisierung des Kurses
Der Kurs wird als ein XML-Dokument abgespeichert. Das Dokument legt die
Baumstruktur fest. In den Knoten sind Verweise auf die Lernmodule enthalten.
id=‘00000507-0030-0010-80F0-00AA0L6D2EA4‘
title=‘Datenbankeinsatz‘>
<node module_ref=‘0000E507-0070-0010-80F0-00DA0L6D2EA4 ‘>
<node module_ref=‘00000507-0030-0010-80F0-00AA0L6D2EA4 ‘/>
</node>
<node module_ref=‘00000507-0030-0010-80F0-00AL0L6D2E84 ‘>
<node module_ref=‘AA000507-0030-0010-80F0-00AA0L6D2EA4 ‘/>
</node>
<node module_ref=‘0F000507-90I0-0010-80F0-00AA0L6D2EA4 ‘>
<node module_ref=‘0000E507-0030-0C10-80F0-00A80L6D2E24 ‘/>
</node>
</course>
Listing 4.8: Instanz eines Kurses
<course
83
Der Baum selbst wird durch das rekursive Element “node“ aufgebaut. Die Referenz
auf ein Lernmodul wird in dem Attribut “module_ref“ eingetragen. Die DTD für einen
Kurs hat folglich die Struktur:
<!ELEMENT course (node)*>
<!ELEMENT node (#PCDATA | node)*>
<!ATTLIST node
module_ref CDATA #REQUIRED>
<!ATTLIST course
id
CDATA #REQUIRED
title CDATA #REQUIRED>
Listing 4.9: Kurs-DTD
4.7 Erweiterung der Metadaten
Durch die konzeptionelle Umsetzung der einzelnen Modultypen sind neue
Anforderungen an die Metadaten entstanden. Es ist daher erforderlich die Metadaten
zu erweitern. Dafür bietet der IMS-Standard die Gruppe Extensions an. In dieser
Gruppe können Attribute, die nicht durch den Standard abgedeckt sind, eingefügt
werden.
Da das Präsentationsmodul physisch nur als eine Datei abgelegt wird, müssen
sämtliche benötigten Informationen in den Metadaten abgelegt werden. Dazu
gehören das zugrundeliegende Strukturmodul und das verwendete TransformationsTemplate. Auch für ein Strukturmodul macht es Sinn, in den Metadaten das
zugrundeliegende Integrationsmodul zu speichern.
Bisher nicht berücksichtigt wurde, daß in den Metadaten nicht gekennzeichnet ist, um
welchen Modultyp es sich bei einem Lernmodul handelt. Das Metadaten-Attribut
General.Aggregationlevel sagt nur aus, ob es sich bei einem Lernobjekt um ein
Lernatom, ein Modul oder einen Kurs handelt. Folglich wird ein Attribut benötigt, das
den Modultyp bestimmt.
Das Metadaten-Schema muß folglich um die Attribute
moduletype
submodule
xsltemplate
erweitert werden und hat damit folgenden endgültigen Aufbau:
Tabelle 4-2 : Metadaten 2
Gruppe
General
Lifecycle
Attribut
Identifier
Title
Language
Description
Keyword
Aggregationlevel
Version
Status
Contribute
Role
Bemerkung
Eindeutiger Schlüssel
Titel des Lernobjekts
Sprache des Lernobjekts
Beschreibung des LO
Schlüsselwörter für LO
Typ des Lernobjekts
Version des Lernobjekts
Status des Lernobjekts
Bearbeiter des LO
Art der Beteiligung
Kard.
1
1
<=10
<=10
<=10
1
1
1
<=30
1
Datentyp
String
LangString
String
LangString
LangString
Vocabulary
LangString
Vocabulary
Vocabulary
84
Technical
Educational
Relations
Kard. <=100
Entity
Date
Format
Size
Location
Interactivitytype
Learningresourcetype
Interactivitylevel
Intendedenduser
role
Context
Typicallearningtime
Description
Kind
Resource
Identifier
Annotation
Person
Kard. <=30
Date
Description
Classification Keyword
Kard. <=40
Extensions
Moduletype
Submodule
XSLTemplate
Beteiligte Personen/Org.
Zeitpunkt der Beteiligung
Datentyp der Ressource
Größe der Ressource
Zugriffspfad für Ressource
Art der Inteaktivität
Art der Ressource
<=40
1
<=40
1
<=10
1
<=10
Maß der Interaktivität
Benutzerrolle
1
Vocabulary
<=10 Vocabulary
Zielgruppe
Bearbeitungszeit für LO
<=4
1
Vocabulary
DateType
Nutzungsbeschreibung
1
Art der Beziehung
1
Ressource, die in Bz.
1
steht
Schlüssel des Zielobjekts
1
Urheber der Anmerkung
1
Zeitpunkt der Anmerkung
1
Anmerkung
1
Klassifizierung des LO
<=40
LangString
Vocabulary
Typ des Moduls (I/S/P)
ID d. untergeordn. Moduls
XSL-Template für P.modul
String
String
String
1
1
1
String
DateType
String
String
String
Vocabulary
Vocabulary
String
String
DateType
LangString
LangString
4.8 Gesamtübersicht
Um die Zusammenhänge zwischen den einzelnen Modulen, Atomen, den
Strukturvorlagen, den Transfomationsmustern und den Metadaten nochmals zu
verdeutlichen stellt die folgende Abbildung (Abb. 4-6) das Zusammenspiel der
Komponenten auf einen Blick dar.
Die Lernatome bestehen aus zwei Komponenten. Der eigentliche Inhalt des
Lernatoms ist in einer Datei gekapselt. Das Atoms selbst wird nach außen nur über
die Metadaten sichtbar. Identifiziert wird das Lernatom über die Metadaten-ID.
Ein Integrationsmodul beinhaltet mehrere Lernatome, auf die es über die MetadatenID verweist. Das Modul wird durch Metadaten beschrieben.
Ein Strukturmodul geht aus einem Integrationsmodul hervor. Dazu wird ein Structural
Template benötigt. Sowohl das Strukturmodul als auch das Strukturmuster liegen in
Form eines XML-Dokuments vor. Das Dokument, welches das Modul beschreibt,
verweist auf das zugrundeliegende Integrationsmodul. Metadaten beschreiben das
Strukturmodul.
Das Präsentationsmodul schließlich geht aus der Transformation eines
Strukturmoduls hervor. Wie das Lernatom besteht das Präsentationsmodul aus zwei
Komponenten. Der Inhalt ist in einer Datei gebündelt. Der Zugriff auf das Modul
85
erfolgt indirekt über die Metadaten. Die Metadaten beschreiben gleichzeitig das
zugrundeliegende Strukturmodul und die verwendete Transformation. Diese wird
ebenfalls über Metadaten identifiziert und liegt in Form einer XSLT-Datei vor.
Metadaten
Presentational
Module
Datei
Metadaten
transformiert aus
XSL-Transformation
Datei
Metadaten
Structural
Module
beschrieben durch
Structural Template
hervorgegangen aus
Metadaten
Integration
Module
beschrieben durch
beinhaltet
Metadaten
Metadaten
Metadaten
Lernatom
Lernatom
Lernatom
Datei
Datei
Datei
Abbildung 4-6 : Gesamtübersicht
86
5 Realisierung
Die Kursentwicklungsumgebung ist in einer 3-Schichten-Architektur aufgebaut (Abb
5-1). Auf der untersten Ebene ist die Tamino-Datenbank angesiedelt. Alle Objekte
der Lernumgebung werden in ihr abgelegt. Dafür werden insgesamt sechs
Kollektionen erzeugt:
nonXML : Hier sind alle nicht-XML Objekte enthalten. Dazu gehören Lernatome
und die Präsentationsmodule, die beide in beliebigen Formaten vorliegen können
Metadata : In dieser Kollektion werden die Metadaten gehalten, die als XMLDokumente vorliegen
Templates : Die Kollektion “Templates“ enthält sowohl die XSLT-Dateien als auch
die Struktur-Templates
Integration Module : XML-Dokumente, die ein Integrationsmodul beschreiben,
sind in dieser Kollektion abgelegt
Structural Module : Strukturmodule sind in der Kollektion “Structural Module“
enthalten
Course : Diese Kollektion speichert die Kurse
XSLT
Structural Template
Lernatom
Export
GUI
Check
In
Search
Engine
XPath
Meta
Editor
Module
Builder
XSLT
Tamino Java-API
DOM
Course
Builder
DOM
Datenbank
nonXML
Lernatom
Präsentation
Metadata
Templates
Integration
Module
Structural
Module
Course
XSLT
Structural Template
Abbildung 5-1 : Systemarchitektur
87
Über der Datenebene befindet sich die Applikationsebene. Hier siedeln sich die
Elemente an, welche die Anwendungslogik der Lernumgebung implementieren:
Check-In : Ein Check-In erfolgt für Daten, die von außen in das System zu
bringen sind. Dazu gehören XSLT-Dokumente, Structural Temlates und die
Lernatome
Search Engine : Die Search-Engine ermöglicht die Suche nach Lernatomen,
Lernmodulen, Kursen und XSL-Transformationen über deren Metadaten
Meta-Editor : Der Meta-Editor erlaubt das Editieren von Metadaten
Module-Builder : Der Module-Builder konfiguriert die einzelnen Lernmodule. Dazu
bedient er sich Structural Templates und XSL-Transformationen
Course-Builder : Der Course-Builder hat die Aufgabe aus Lernmodulen einen
Kurs aufzubauen
Der Zugriff auf die Datenbank erfolgt über eine Java-API. Über diese API können
Anfragen an die Datenbank über XPath gestellt werden. Handelt es sich bei dem
Ergebnis einer Anfrage um ein XML-Dokument, so kann dieses in Form seiner DOMRepräsentation übergegeben werden.
Der Endanwender selbst bedient die Autorenumgebung, indem er über eine
graphische Benutzeroberfläche auf die einzelnen Komponenten zugreift. Über diese
Schnittstelle
importiert
er
auch
Lernatome,
Strukturvorlagen
und
Transformationmuster. Kurse die durch einen Anwender erstellt wurden, können
auch exportiert werden.
5.1 Präsentationsmodule
Der wohl am schwierigsten zu realisierende Schritt innerhalb der Kurserstellung liegt
in der Erstellung eines XSLT-Stylesheets zur Transformation eines Strukturmoduls in
eine Präsentationsform. Das folgende Beispiel zeigt deshalb exemplarisch wie diese
Erstellung funktionieren kann.
Gegeben sei ein Strukturmodul, das die Lerneinheit “Beispiel Lagerverwaltung”
kapselt. Dieses Beipiel besteht aus einem Beispiel und einer Beschreibung. Die
Lernatome liegen als Powerpoint-Präsentationen vor.
Das Strukturmodul habe die folgende Form:
id=‘00000507-0030-0010-80F0-00AA0L6D2EA4‘
title=‘Beispiel Lagerverwaltung‘
im_id=‘00000507-0000-0010-8000-00AA006D2EA4‘>
<learning_atom
educational _type=‘example‘
content_type=‘application/vnd.ms-powerpoint‘
position=‘2‘>
http://host/eLearning/ino:etc/ino:nonXML/@2
</learning_atom>
<learning_atom
educational _type=‘description‘
content_type=‘application/vnd.ms-powerpoint‘
position=‘1‘>
http://host/eLearning/ino:etc/ino:nonXML/@1
<structural_module
88
</learning_atom>
</structural_module>
Listing 5.1: Beispiel eines Strukturmoduls
An dieser Stelle sei angenommen, daß das zu erstellende Präsenationsmodul als
Teil einer webbasierten Schulung verwendet werden soll, d.h. das
Präsentationsmodul soll als HTML-Dokument vorliegen.
Ein geeignetes XSLT-Stylesheet, das aus dem vorliegenden Strukturmodul eine
HTML-Datei erzeugt, kann dann folgende Form annehmen:
<?xml version=“1.0“?>
<xsl:stylesheet version=“1.0“ xmlns:xsl=“http://www.w3.org/1999/XSL/Transform“>
<xsl:template match=“/structural_module“>
<html>
<head>
<title>
<xsl:value-of select=“@title“/>
</title>
</head>
<xsl:for-each select=“learning_atom“>
<xsl:sort select=“@position“/>
<p>
<xsl:if test=“not(@position=‘-‘)“>
<xsl:element name=“a“>
<xsl:attribute name="href">
<xsl:value-of select="text()"/>
</xsl:attribute>
<xsl:value-of select=“@educational_type“/>
</xsl:element>
</p>
</xsl:if>
</xsl:for-each>
</html>
</xsl:template>
</xsl:stylesheet>
Listing 5.2: Beispiel einer XSL-Transformation
Dieses Stylesheet kann als Basisstylesheet betrachtet werden. Es kann für sämtliche
Strukturmodule und Typen von Lernatomen verwendet werden. Das erzeugte
Präsentationsmodul liegt als HTML-Datei vor und verweist auf die einzelnen
Lernatome. Die Transformation läuft nach folgendem Schema ab:
1. Setze den Titel des Strukturmoduls als Titel der zu erzeugenden HTML-Datei
2. Füge alle Knoten des Typs “learning_atom“ in eine Liste
89
3. Sortiere die Knotenliste nach der Position eines Lernatoms
4. Erzeuge einen Link für jedes Lernatom der sortierten Knotenliste, für das die
Position ungleich ‘-‘ ist. (zur Erinnerung: Atome die in dem View des
Strukturmoduls nicht enthalten sind, werden mit der Position ‘-‘ ausgezeichnet)
Das erzeugte Dokument hat das folgende Aussehen:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Beispiel Lagerverwaltung</title>
</head>
<p>
<A href="http://host/eLearning/ino:etc/ino:nonXML/@2">description</A>
</p>
<p>
<A href=" http://host/eLearning/ino:etc/ino:nonXML/@2">example</A>
</p>
</html>
Listing 5.3: Erzeugtes HTML-Dokument
5.2 Anwendung
Es soll nun aufgezeigt werden, wie die einzelnen Szenarien der Kurserstellung mit
Hilfe des Kursentwicklungssystems abgebildet werden können.
Die vorgestellten Bildschirmmasken stammen noch aus der Designphase, da zum
Zeitpunkt der Fertigstellung der Diplomarbeit der Prototyp noch nicht vollständig
implementiert wurde. Auch wenn die endgültigen Masken von diesen Masken abweichen, so zeigen die hier vorgestellten Masken die implementierte Funktionalität.
5.2.1 Erstellen eines Lernatom-Repository
Bevor die zwei Universitäten ein gemeinsames Lernatom-Repository erstellen
können, müssen sie sich auf ein gemeinsam benutztes Klassifizierungssystem
einigen. Nur so wird ermöglicht, daß Lern-/Lehrmaterialien, die durch Mitarbeiter der
einen Universität erstellt wurden, durch Mitarbeiter der anderen Universität leicht aufgefunden werden können.
Am besten eignet sich für die Klassifizierung eine Ontologie. Die Universitäten
müssen diese Ontologie gemeinsam entwerfen und sich zu ihr bekennen. Wollen die
beiden Universitäten z.B. im Bereich Datenbankeindatz zusammenarbeiten, so
müssen sie eine Ontologie erschaffen, die diese Miniwelt formal und explizit
spezifiziert.
Die Lernatome, die die beiden Universitäten austauschen wollen, müssen sich in
diese Miniwelt einordnen lassen. Über den gemeinsamen Wortschatz lassen sich die
gesuchten Atome leicht auffinden.
Zunächst aber müssen die verfügbaren Inhalte auf das Konzept der Lernatome abgebildet werden. Bisher liegen Inhalte einer Vorlesung in Form eines Dokuments
unterteilt in Kapiteln vor. Die Lernatome jedoch kapseln nur einen Teil eines Themas
90
und haben eine wohlfdefinierte Lehrform. Vorhandene Dokumente müssen folglich
zerlegt werden.
Über die die Strukturierung des Inhalts in Kapiteln können oftmals thematisch
zusammenhängende Inhalte ausgemacht werden. Diese Inhalte können dann in
Lernatome zerlegt werden. Die Zerlegung wird durch die Lehrform bestimmt. So wird
z.B. für eine Einleitung, ein Beispiel, ein Diagramm oder einen Beweis jeweils ein
eigenes Lernatom erstellt.
Ein Lernatom kann dann über seine thematische Klassifizierung innerhalb der
Ontologie und die Lehrform, die als Metadaten-Attribut “educationaltype” abgelgt ist,
aufgefunden werden.
Neben diesem Attribut beschreiben weitere Metadaten-Attribute die Eigenschaften
eines Lernatoms.
Diese Metadaten werden zusammen mit der Datei, die den Inhalt trägt, über die
Check-In Funktion des Kursentwicklungssystems übernommen.
Nach dem Check-In stehen die Inhalte in Form von Lernatomen zur Verfügung.
Beschrieben werden die Lernatome durch die Metadaten.
Das einmal erstellte Repository kann jederzeit um weitere Atome ergänzt werden.
Ebenso können die Metadaten im Laufe der Zeit angepasst werden.
Lernatom
Einstellungen
SCORE
Hilfe
Lernatom
file://C:/atome/examplefordifference.ppt
Dateityp
application/vnd.ms-powerpoint
Metadaten
file://C:/atome/examplefordifference.xml
Titel
Example for difference
Lehrform
Example
Check-In
Lösche
Suche
Suche
Check-Out
Abbildung 5-2 : Check-In Maske
Abbildung 5-2 zeigt die Bildschirmmaske des Check-In Prozesses. In das Eingabefeld “Lernatom” wird der Dateipfad der Datei eingegeben, die als Lernatom innerhalb
des Kursentwicklungssystems zur Verfügung stehen soll. Zu dieser Datei wird
91
automatisch der Datentyp ermittelt. Existieren bereits Metadaten, die das Lernatom
beschreiben, so kann in dem Eingabefeld “Metadaten” die entsprechende XMLDatei, die die Metadaten enthält, spezifiziert werden. Die Metadateb werden dann in
die Tamino-Datenbank übernommen, um die Lernatome zu beschreiben.
Der Titel des Lernatoms und die Lehrform wird in diesem Fall aus den Metadaten
gelesen und auf die Maske geschrieben.
Sind keine Metadaten vorhanden, so muß der Titel und die Lehrform des Lernatoms
vom Benutzer eingegeben werden. Aus diesen Daten werden dann automatish
Metadaten erzeugt.
Mit dem Check-In werden die Metadaten und die Datei, die das Lernatom darstellt in
die Datenbank übernommen.
Um die Lernatome wieder in eine Datei zu schreiben, kann ein Check-Out erfolgen.
Es wird dann eine Kopie des Lernatoms erstellt.
Um ein Lernatom auf der Datenbank zu löschen, kann die Funktion “Lösche”
verwendet werden.
5.2.2 Erstellen eines Integrationsmoduls
Damit die Lernatome innerhalb eines Kurses verwendet werden können, müssen sie
zunächst innerhalb eines Integrationsmoduls gruppiert werden. Die Lernatome die in
ein Integrationsmodul gesetzt werden, sollten so gewählt werden, daß eine
thematisch abgeschlossene Einheit ensteht und eine Teilmenge daraus als
Lerneinheit eines Kurses verwendet werden kann.
Das Integrationsmodul kann von einem speziellen Kursentwickler erstellt werden
oder einem Dozenten, der Lerneinheiten als Teil seiner Vorlesung verwenden
möchte.
Geeignete Lernatome für ein Integrationsmodul können über eine Metadatensuche
gefunden werden. Am komfortabelsten kann die Suche über einen OntologieBrowser erfolgen. Dieser Browser strukturiert graphisch eine Lerndomäne. Durch
eine Navigation entlang dieser Domäne kann ein gewünschtes Teilgebiet ausgewählt
werden. Alle Lernatome, die diesem Teilgebiet über das Metadaten-Attribut
Classification.Keyword zugeordnet sind, werden dem Benutzer präsentiert und
können per Knopfdruck dem Integrationsmodul zugewiesen werden.
Alternativ kann die Suche auch rein über die Metadaten erfolgen, wobei hier die
Suche über Schlüsselwörter wohl am geeignetsten sein wird.
Die Suche mit Hilfe der Ontologie wird nicht bis zum Ende der Diplomarbeit realisiert
sein. Dies ist Aufgabe einer weiteren Diplomarbeit.
92
Integrationsmodul
Lernatom
Integrationsmodule
Datenbankschema
Einstellungen
SCORE
Hilfe
Inhalt
Introduction to the exampl..
Lernatome
Example schema for stora..
Example schema for stora..
Example for difference
Example for attributes in E..
Introduction to the exampl..
Example for a use case di..
Example for attributes in E..
Neues Modul
Lernatom +
Suche Modul
Lernatom -
Suche
Abbildung 5-3 : Integrationsmodul-Maske
Die Maske zur Bearbeitung eines Integrationsmoduls ist in Abbildung 5-3 dargestellt.
Sie gliedert sich in drei Datenbereiche. Auf der linken Seite werden eine Menge von
Integrationsmodule dargestellt. Die dargestellten Integrationsmodule können durch
eine Suche über den Integrationsmodulen bestimmt werden. Die dargestellten
Module sind die Treffermenge dieser Modulsuche. So können mehrere Module
parallel bearbeitet werden. Dies können z.B. die Module eines bestimmten Kurses
sein. Die Suchfunktion erlaubt dabei eine Suche über die Metadaten und soll später
durch einen Ontologie-Browser erweitert werden.
Der mittlere Bereich stellt die Lernatome dar, die dem Integrationsmodul bereits
zugeordnet sind.
Der rechte Bereich zeigt die Lernatome, die über eine Metadatensuche auf den
Lernatomen gefunden wurden. Sie können dem Integrationsmodul durch die
Funktion “Lernatom +“ zugeordnet werden.
5.2.3 Erstellen eines Strukturmoduls
Der Kursentwickler oder der Dozent kann nun auf das soeben erstellte
Integrationsmodul zurückgreifen, um es für den Einsatz innerhalb eines Kurses zu
konfigurieren, d.h. auf eine bestimmte Zielgruppe auszurichten.
Genauso kann er ein anderes zuvor erstelltes Integrationsmodul auswählen, um
dieses in einem Kurs einzusetzen. Auch hierfür steht eine Suche über die Ontologie
oder die Metadaten zur Verfügung.
93
Ein Kursentwickler hat auch die Möglichkeit, Integrationsmodule zu suchen, die zu
anderen, in einem Kurs enthaltenen, Integrationsmodulen in Beziehung stehen.
Diese Beziehungen werden durch die Metadatengruppe Relation repräsentiert. Hat
ein Kursentwickler z.B. ein Integrationsmodul für einen Kurs ausgewählt, so kann er
über die Metadatensuche die Integrationsmodule suchen, die Voraussetzung für das
ausgewählte Integrationsmodul sind, und diese ebenfalls in den Kurs integrieren.
Hat der Kursentwickler auf eine der dargestellten Weisen ein Integrationsmodul
ausgewählt, so kann er daraus ein Strukturmodul erstellen.
Nach der Wahl eines Strukturmusters wird ein Strukturmodul erzeugt, das eine
Reihenfolge auf den Lernatomen erzeugt. Diese automatisch erzeugte Reihenfolge
kann nun von Hand angepasst werden, und je nach Wunsch können einzelne
Lernatome aus- und eingeblendet werden.
Strukturmodul
Einstellungen
Strukturmodule
Datenbankschema
SCORE
Hilfe
Struktur
Lernatome
Introduction to the exampl..
1 Introduction to the exam..
Example schema for stora..
2 Example schema for stor..
- Example for attributes in ..
Neues Modul
Integrationsmodul
Suche Modul
Datenbankschema
Strukturiere
Abbildung 5-4 : Strukturmodul-Maske
Die Maske für das Erstellen eines Strukturmoduls ist ebenfall in drei Bereiche
gegliedert. Im linken Bereich werden wieder die Module dargestellt, die über eine
Metadatensuche gefunden wurden und parallel bearbeitet werden können. Das
aktuell in Bearbeitung befindliche Modul wird farblich hinterlegt.
Einmalig beim Anlegen eines Strukturmoduls wird das zugrundeliegende
Integrationsmodul festgelegt. Dieses Modul wird im Ausgabefeld “Integrationsmodul“
dargestellt.
Im rechten Bereich werden alle Lernatome des Integrationsmoduls dargestellt. Über
die Funktion “Strukturiere“ kann ein Struktur-Template spezifiziert werden, die diese
94
Lernatome strukturiert. Nach dem Aufruf dieser Funktion wird die Positionsnummer
vor die einzelnen Lernatome gestellt. Diese Positionsnummern können anschließend
von Hand angepasst werden.
Der mittlere Datenbereich zeigt nur die Lernatome, die für das Strukturmodul
verwendet werden, in ihrer Reihenfolge.
5.2.4 Erstellen eines Präsentationsmoduls
Um eine Lerneinheit innerhalb eines Kurses präsentieren zu können, muß ein
Strukturmodul in ein Präsentationsmodul überführt werden.
Eine Lerneinheit, die Teil eines Kurses werden soll, findet der Kursentwickler oder
der Dozent in Form eines Strukturmoduls über die Ontologie, die Beziehung zu
anderen Modulen oder eine reine Metadatensuche. Nachdem ein Strukturmodul
gefunden ist, wählt der Kursentwickler anhand der Dateitypen der enthaltenen
Lernatome eine geeignete XSL-Transformation aus, um ein Präsentationsmodul zu
erhalten.
Zu einem Strukturmodul können mehrere Präsentationsmodule erzeugt werden. So
kann eine Lerneinheit z.B. als Powerpoint-Präsenation, aber auch als HTML-Version
zugänglich gemacht werden.
Präsentationsmodul
Einstellungen
SCORE
Hilfe
Präsentationsmodule
Lernatome
Datenbankschema
Introduction to the exampl..
Example schema for stora..
Transformationsmuster
HTML Container
Transform
Neues Modul
Suche Modul
Strukturmodul
Datenbankschema
Abbildung 5-5 : Präsentationsmodul-Maske
95
Die Abbildung 5-5 zeigt den Pflegedialog für ein Präsentationsmodul. Der linke
Bereich zeigt wieder die Präsentationsmodule, die bearbeitet werden können.
Das zugrundeliegende Strukturmodul wird in dem Ausgabefeld “Strukturmodul”
angegeben. Im rechten Bereich werden dessen Lernatome dargestellt.
Im Eingabefeld Transfomationsmuster kann ein XSL-Template gewählt werden, das
das Strukturmodul in das Präsentationsmodul transformiert. Durch Auswahl der
Funktion “Transform” wird diese Transformation ausgeführt.
5.2.5 Erstellen eines Kurses
Ein Kurs besteht aus mehreren Lerneinheiten. Diese sind in einer Navigationsstruktur
angeordnet. Als Navigationsstruktur wird eine Baumstruktur verwendet. Diese
Baumstruktur wird vom Kursentwickler oder dem Dozenten mit Hilfe der graphischen
Benutzeroberfläche erstellt. Nachdem diese Struktur erstellt ist, können
Lerneinheiten auf den Knoten plaziert werden. In erster Linie sollten einem Kurs nur
Präsentationsmodule zugeordnet werden, denn nur diese können einem Lernenden
präsentiert werden.
Es ist jedoch auch möglich Strukturmodule und Integrationsmodule dem Kurs
zuzuordnen. Diese Möglichkeit ist vorgesehen, damit bei der Erstellung eines Kurses
frühstmöglichst eine geeignete Lerneinheit zugeordnet werden kann. So gehen keine
Ideen verloren, und ein Kursentwickler ist stets im Bilde zu welchen Lerneinheiten
noch eine Struktur oder eine Präsentationsform erstellt werden muß.
Kurs
Einstellungen
SCORE
Hilfe
Kurs
Module
Datenbankeinsatz
Datenbankschema
SQL
Datenbankschema
SQL
Neuer Kurs
Erzeuge Knoten
Suche Kurs
Entferne Knoten
Suche
Abbildung 5-6 : Kurs-Maske
96
Die Maske für die Erstellung und Pflege eines Kurses ist in Abbildung 5-6 dargestellt.
In dem linken Bereich kann die Hierarchie eines Kurses in Form eines Baumes
erzeugt werden. Über die Funktionen “Erzeuge Knoten” und “Entferne Knoten”
können neue Knoten hinzugefügt oder vorhandene Knoten entfernt werden. Der
rechte Bereich zeigt Lernmodule, die über eine Metadatensuche gefunden wurden.
Diese Lerneinheiten können per Drag&Drop auf die Knoten der Navigationsstruktur
gezogen werden.
5.2.6 Anpassen eines Kurses
Einem Lernenden ist die Möglichkeit gegeben seine eigenen Kurse zu erstellen,
wenn die angebotenen Kurse nicht seinen Bedürfnissen entsprechen. Dazu kann er
einen Kurs von null auf entwickeln, indem er auf die Ebene der Integrationsmodule
absteigt oder er “kopiert” einen Kurs und tauscht einzelen Lernmodule aus.
Dabei kann er die Lernmodule austauschen, die nicht seinen Bedürfnissen
entsprechen. Für das zu ersetzende Modul sollte der Student dabei zunächst auf der
Ebene der Präsentationsmodulenach Ersatz suchen. Findet sich kein geeigneter
Ersatz, so kann er unter den Strukturmodulen suchen. Zu einem gefundenen
Strukturmodul kann dann ein Präsentationsmodul erzeugt werden. Wird auch kein
Strukturmodul gefunden, so kann der Student unter den Integrationsmodulen
suchen. Enthält keines der Integrationsmodule die Menge der gesuchten Lernatome,
so hat der Student die Möglichkeit mehrere Integrationsmodule zu einem neuen
Integrationsmodul zu vereinigen, das die gewünschten Lernatome enthält. Für dieses
Integrationsmodul geht er dann den normalen Weg der Kurserstellung um seinen
eigenen Kurs zu erstellen.
Alternativ kann ein Student auch direkt auf die Stufe der Integrtionsmodule springen,
um seinen eigenen Kurs anzupassen. Dies wird vermutlich der normale Weg der
Anpassung sein, da ein Student am ehesten inhaltliche Aspekte eines Kurses
verändern will, weil er z.B. neben dem in einem vorgegebenen Kurs dargestellten
Beipiel ein weiteres Beispiel innerhalb des thematisch abgeschlossenen
Integrationsmoduls suchen möchte.
Ein Student hat auch die Möglichkeit seine Kopie des Kurses so zu verändern, daß
er Lerneinheiten, die er bereits kennt, aus dem Kurs entfernt.
97
6 Zusammenfassung und Ausblick
An dieser Stelle soll noch einmal auf die Autorenumgebung zurückgeblickt werden.
Mit der Implementierung ist ein Tool vorhanden, das es erlaubt einen Kurs aus einer
Menge vom Lernatomen zu erstellen.
Dazu werden die Lernatome gemäß den Aspekten Inhalt, Didaktik und Präsentation
auf den Ebenen der Lernmodule konfiguriert.
Als Ergebnis liegt ein Kurs vor, der Präsentationsmodule in eine
Navigationshierarchie ordnet.
Als nächstes ist ein Kurs-Browser zu implementieren, mit dem über die einzelnen
Präsentationsmodule navigiert werden kann. Dieser Browser könnte auf HTML
basieren, um die Präsentationsmodule zu verknüpfen.
Die Autorenumgebung ist wie bereits mehrmals erwähnt auf die Wiederverwendung
ausgerichtet. Dies hat auch zur Folge, daß die Qualität der Autorenumgebung mit
der Anzahl an vorhandenen Komponenten wächst. Zu Beginn muß für die meisten
Kurse der komplette Prozess vom Erstellen eines Lernatoms bis hin zu einem
Präsentationsmodul durchlaufen werden. Je mehr die Datenbank gefüllt ist, umso
weniger tief muß ein Kursentwickler absteigen. So kann nach einiger Zeit auf
Integrationsmodule zurückgegriffen werden, bis schließlich Kurse aus
Präsentatinsmodulen zusammengesetzt werden können.
Genauso wie bei den Atomen und Lernmodulen, muß auch erst ein Pool an
Strukturvorlagen und XSL-Transformationen erzeugt werden. Die Erstellung der
Transformations-Stylesheets stellt hierbei ein besonderes Hindernis dar, da dieser
Prozeß sehr technischer Natur ist und von einem Kursentwickler sicherlich nicht
durchgeführt werden sollte. Gerade deshalb ist es wichtig eine Menge an Stylesheets
zur Verfügung zu stellen. Ist diese kritische Masse an Vorlagen vorhanden, sollten
alle Formen von Kursen erstellbar sein.
Der Faktor Sicherheit spielte bei der Implementierung der Autorenumgebung keine
Rolle, d.h. der Zugriff auf die Komponenten ist nicht gesichert. Jeder Benutzer der
Autorenumgebung kann Lernatome, Lernmodule, XSL-Templates und Metadaten
editieren. Wünschenswert wäre an dieser Stelle ein benutzergruppenbezogenes
Zugriffsrecht. So könnten Benutzergruppen erstellt werden, die jeweils den Zugriff auf
Atome, Module, Kurse, XSL-Templates und Metadaten erlauben.
Wünschenswert für den Benutzer wäre auch eine Erweiterung der
Navigationsmöglichkeiten. Die Navigation für den Benutzer erfolgt ausschließlich
entlang
der
Hierarchie
Lernatom-Integrationsmodul-StrukturmodulPräsentationsmodul-Kurs. In einigen Szenarien wäre es allerdings sinnvoll z.B. alle
Kurse anzuzeigen, die ein bestimmtes Lernatom enthalten.
Sinnvoll wäre ein solcher Verwendungsnachweis auch für das Behandeln von
Updates. Wird z.B. der Titel eines Strukturmoduls verändert, so ändert sich auch der
Titel des Präsentationsmodul. Über den Verwendungsnachweis könnte der Benutzer
die entsprechenden Änderungen vornehmen. Genauso könnte ein Benutzer, der ein
Lernatom löschen will, vorher prüfen, ob das Lernatom noch verwendet wird. So
kann er z.B. den Ersteller eines Kurses, der das zu löschende Atom enthält über sein
Vorhaben informieren.
98
Es lassen sich noch viele weitere Update-Szenarien denken. In einem nächsten
Schritt könnten diese Szenarien unterstützt und eine automatische Behandlung
implementiert werden.
Generell bleibt die Frage, wie sich Lernsysteme weiterentwickeln werden. Es werde
ständig neue Produkte präsentiert. An einem Angebot mangelt es also nicht.
Eingesetzt werden sie von Unternehmen, Volkshochschulen und anderen
Bildungsinstitutionen. Allein der Zielkunde, nämlich der Lernende selbst, wird
entscheiden, ob er ein solches Produkt nutzen will und sich elektronische
Lernsysteme damit durchsetzen können.
99
Anhang A – Datenmodelle
I Integrationsmodul – DTD
<!ELEMENT interation_module (learning_atom)*>
<!ATTLIST integration_module
id
CDATA #REQUIRED
title CDATA #REQUIRED>
<!ELEMENT learning_atom #PCDATA>
<!ATTLIST learning_atom
educational_type CDATA #REQUIRED
content_type
CDATA #REQUIRED>
II Strukturmodul – DTD
<!ELEMENT structural_module (learning_atom)*>
<!ATTLIST structural_module
id
CDATA #REQUIRED
title CDATA #REQUIRED
im_id CDATA #REQUIRED>
<!ELEMENT learning_atom #PCDATA>
<!ATTLIST learning_atom
position
CDATA #REQUIRED
educational_type CDATA #REQUIRED
content_type
CDATA #REQUIRED>
III Struktur-Template – DTD
<!ELEMENT structural_template filter*>
<!ELEMENT filter EMPTY>
<!ATTLIST filter
type CDATA #REQUIRED>
IV XSL-Template für HTML-Präsentationsmodul
<?xml version=“1.0“?>
<xsl:stylesheet version=“1.0“ xmlns:xsl=“http://www.w3.org/1999/XSL/Transform“>
<xsl:template match=“/structural_module“>
<html>
<head>
<title>
<xsl:value-of select=“@title“/>
</title>
</head>
<xsl:for-each select=“learning_atom“>
<xsl:sort select=“@position“/>
<p>
100
<xsl:if test=“not(@position=‘-‘)“>
<xsl:element name=“a“>
<xsl:attribute name="href">
<xsl:value-of select="text()"/>
</xsl:attribute>
<xsl:value-of select=“@educational_type“/>
</xsl:element>
</p>
</xsl:if>
</xsl:for-each>
</html>
</xsl:template>
</xsl:stylesheet>
V IMS-Metadaten Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema targetNamespace="http://www.imsglobal.org/xsd/imsmd_v1p2"
xmlns:x="http://www.w3.org/XML/1998/namespace"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.imsglobal.org/xsd/imsmd_v1p2"
elementFormDefault="qualified"
version="IMS MD 1.2.3">
<xsd:import
namespace="http://www.w3.org/XML/1998/namespace"
schemaLocation="ims_xml.xsd"/>
<!-- ******************** -->
<!-- ** Change History ** -->
<!-- ******************** -->
<xsd:annotation>
<xsd:documentation>2001-04-26 T.D.Wason. IMS meta-data 1.2 XML-Schema.
</xsd:documentation>
<xsd:documentation>2001-06-07 S.E.Thropp. Changed the multiplicity on all
elements to match the
</xsd:documentation>
<xsd:documentation>Final
1.2
Binding
Specification.
</xsd:documentation>
<xsd:documentation>Changed all elements that use the langstringType to a
multiplicy of 1 or more
</xsd:documentation>
<xsd:documentation>Changed centity in the contribute element to have a
multiplicity of 0 or more.
</xsd:documentation>
<xsd:documentation>Changed the requirement element to have a multiplicity of 0
or more.
</xsd:documentation>
<xsd:documentation> 2001-07-25 Schawn Thropp. Updates to bring the XSD up
to speed with the W3C
</xsd:documentation>
<xsd:documentation> XML Schema Recommendation. The following changes
were made: Change the
</xsd:documentation>
<xsd:documentation> namespace to reference the 5/2/2001 W3C XML Schema
Recommendation,the base
</xsd:documentation>
101
<xsd:documentation> type for the durtimeType, simpleType, was changed from
timeDuration to duration. </xsd:documentation>
<xsd:documentation> Any attribute declarations that have use="default" had to
change to use="optional" </xsd:documentation>
<xsd:documentation> - attr.type. Any attribute declarations that have value
="somevalue" had to change </xsd:documentation>
<xsd:documentation> to default = "somevalue" - attr.type (URI)
</xsd:documentation>
<xsd:documentation>
2001-09-04
Schawn
Thropp
</xsd:documentation>
<xsd:documentation> Changed the targetNamespace and namespace of schema
to reflect version change
</xsd:documentation>
<xsd:documentation>
2001-11-04
Chris
Moffatt:
</xsd:documentation>
<xsd:documentation> 1. Changes to enable the schema to work with commercial
XML Tools
</xsd:documentation>
<xsd:documentation> a. Refer to the xml namespace using the "x" abbreviation
instead of "xml"
</xsd:documentation>
<xsd:documentation>
b. Remove unecessary non-deterministic constructs
from schema.
</xsd:documentation>
<xsd:documentation>
i.e. change occurrences of "#any" to "#other"
</xsd:documentation>
<xsd:documentation> 2. Revert to original IMS MD version 1.2 namespace.
</xsd:documentation>
<xsd:documentation>
i.e. "http://www.imsglobal.org/xsd/imsmd_v1p2"
</xsd:documentation>
<xsd:documentation> This change done to support the decision to only change
the XML namespace with </xsd:documentation>
<xsd:documentation>
major revisions of the specification ie. where the
information model or binding </xsd:documentation>
<xsd:documentation>
changes (as opposed to addressing bugs or omissions).
A stable namespace is </xsd:documentation>
<xsd:documentation>
necessary to the increasing number of implementors.
</xsd:documentation>
<xsd:documentation> 3. Changed name of schema file to "imsmd_v1p2p2.xsd"
and
</xsd:documentation>
<xsd:documentation>
version attribute to "IMS MD 1.2.3" to reflect minor
version change
</xsd:documentation>
</xsd:annotation>
<!-- *************************** -->
<!-- ** Attribute Declaration ** -->
<!-- *************************** -->
<xsd:attributeGroup name="attr.type">
<xsd:attribute name="type" use="optional" default="URI">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:enumeration value="URI"/>
<xsd:enumeration value="TEXT"/>
</xsd:restriction>
102
</xsd:simpleType>
</xsd:attribute>
</xsd:attributeGroup>
<xsd:group name="grp.any">
<xsd:annotation>
<xsd:documentation>Any namespaced element from any namespace may be
used for an &quot;any&quot; element. The namespace for the imported
element must be defined in the instance, and the schema must be imported.
</xsd:documentation>
</xsd:annotation>
<xsd:sequence>
<xsd:any namespace="##other" processContents="strict" minOccurs="0"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:group>
<!-- ************************* -->
<!-- ** Element Declaration ** -->
<!-- ************************* -->
<xsd:element name="aggregationlevel" type="aggregationlevelType"/>
<xsd:element name="annotation" type="annotationType"/>
<xsd:element name="catalogentry" type="catalogentryType"/>
<xsd:element name="catalog" type="catalogType"/>
<xsd:element name="centity" type="centityType"/>
<xsd:element name="classification" type="classificationType"/>
<xsd:element name="context" type="contextType"/>
<xsd:element name="contribute" type="contributeType"/>
<xsd:element name="copyrightandotherrestrictions"
type="copyrightandotherrestrictionsType"/>
<xsd:element name="cost" type="costType"/>
<xsd:element name="coverage" type="coverageType"/>
<xsd:element name="date" type="dateType"/>
<xsd:element name="datetime" type="datetimeType"/>
<xsd:element name="description" type="descriptionType"/>
<xsd:element name="difficulty" type="difficultyType"/>
<xsd:element name="educational" type="educationalType"/>
<xsd:element name="entry" type="entryType"/>
<xsd:element name="format" type="formatType"/>
<xsd:element name="general" type="generalType"/>
<xsd:element name="identifier" type="xsd:string"/>
<xsd:element name="intendedenduserrole" type="intendedenduserroleType"/>
<xsd:element name="interactivitylevel" type="interactivitylevelType"/>
<xsd:element name="interactivitytype" type="interactivitytypeType"/>
<xsd:element name="keyword" type="keywordType"/>
<xsd:element name="kind" type="kindType"/>
<xsd:element name="langstring" type="langstringType"/>
<xsd:element name="language" type="xsd:string"/>
<xsd:element name="learningresourcetype" type="learningresourcetypeType"/>
<xsd:element name="lifecycle" type="lifecycleType"/>
103
<xsd:element name="location" type="locationType"/>
<xsd:element name="lom" type="lomType"/>
<xsd:element name="maximumversion" type="minimumversionType"/>
<xsd:element name="metadatascheme" type="metadataschemeType"/>
<xsd:element name="metametadata" type="metametadataType"/>
<xsd:element name="minimumversion" type="maximumversionType"/>
<xsd:element name="name" type="nameType"/>
<xsd:element name="purpose" type="purposeType"/>
<xsd:element name="relation" type="relationType"/>
<xsd:element name="requirement" type="requirementType"/>
<xsd:element name="resource" type="resourceType"/>
<xsd:element name="rights" type="rightsType"/>
<xsd:element name="role" type="roleType"/>
<xsd:element name="semanticdensity" type="semanticdensityType"/>
<xsd:element name="size" type="sizeType"/>
<xsd:element name="source" type="sourceType"/>
<xsd:element name="status" type="statusType"/>
<xsd:element name="structure" type="structureType"/>
<xsd:element name="taxon" type="taxonType"/>
<xsd:element name="taxonpath" type="taxonpathType"/>
<xsd:element name="technical" type="technicalType"/>
<xsd:element name="title" type="titleType"/>
<xsd:element name="type" type="typeType"/>
<xsd:element name="typicalagerange" type="typicalagerangeType"/>
<xsd:element name="typicallearningtime" type="typicallearningtimeType"/>
<xsd:element name="value" type="valueType"/>
<xsd:element name="person" type="personType"/>
<xsd:element name="vcard" type="xsd:string"/>
<xsd:element name="version" type="versionType"/>
<xsd:element name="installationremarks" type="installationremarksType"/>
<xsd:element name="otherplatformrequirements"
type="otherplatformrequirementsType"/>
<xsd:element name="duration" type="durationType"/>
<xsd:element name="id" type="idType"/>
<!-- ******************* -->
<!-- ** Complex Types ** -->
<!-- ******************* -->
<xsd:complexType name="aggregationlevelType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="annotationType" mixed="true">
<xsd:sequence>
<xsd:element ref="person" minOccurs="0"/>
<xsd:element ref="date" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
104
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="catalogentryType" mixed="true">
<xsd:sequence>
<xsd:element ref="catalog"/>
<xsd:element ref="entry"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="centityType">
<xsd:sequence>
<xsd:element ref="vcard"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="classificationType" mixed="true">
<xsd:sequence>
<xsd:element ref="purpose" minOccurs="0"/>
<xsd:element ref="taxonpath" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="description" minOccurs="0"/>
<xsd:element ref="keyword" minOccurs="0" maxOccurs="unbounded"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="contextType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="contributeType" mixed="true">
<xsd:sequence>
<xsd:element ref="role"/>
<xsd:element ref="centity" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="date" minOccurs="0"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="copyrightandotherrestrictionsType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
105
<xsd:complexType name="costType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="coverageType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="dateType">
<xsd:sequence>
<xsd:element ref="datetime" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="descriptionType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="difficultyType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="durationType">
<xsd:sequence>
<xsd:element ref="datetime" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="educationalType" mixed="true">
<xsd:sequence>
<xsd:element ref="interactivitytype" minOccurs="0"/>
<xsd:element
ref="learningresourcetype"
minOccurs="0"
maxOccurs="unbounded"/>
<xsd:element ref="interactivitylevel" minOccurs="0"/>
<xsd:element ref="semanticdensity" minOccurs="0"/>
<xsd:element
ref="intendedenduserrole"
minOccurs="0"
maxOccurs="unbounded"/>
<xsd:element ref="context" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="typicalagerange" minOccurs="0" maxOccurs="unbounded"/>
106
<xsd:element ref="difficulty" minOccurs="0"/>
<xsd:element ref="typicallearningtime" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
<xsd:element ref="language" minOccurs="0" maxOccurs="unbounded"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="entryType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="generalType" mixed="true">
<xsd:sequence>
<xsd:element ref="identifier" minOccurs="0"/>
<xsd:element ref="title" minOccurs="0"/>
<xsd:element ref="catalogentry" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="language" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="description" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="keyword" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="coverage" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="structure" minOccurs="0"/>
<xsd:element ref="aggregationlevel" minOccurs="0"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="installationremarksType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="intendedenduserroleType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="interactivitylevelType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="interactivitytypeType">
<xsd:sequence>
107
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="keywordType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="kindType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="langstringType">
<xsd:simpleContent>
<xsd:extension base="xsd:string">
<xsd:attribute ref="x:lang"/>
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
<xsd:complexType name="learningresourcetypeType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="lifecycleType" mixed="true">
<xsd:sequence>
<xsd:element ref="version" minOccurs="0"/>
<xsd:element ref="status" minOccurs="0"/>
<xsd:element ref="contribute" minOccurs="0" maxOccurs="unbounded"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="locationType">
<xsd:simpleContent>
<xsd:extension base="xsd:string">
<xsd:attributeGroup ref="attr.type"/>
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
<xsd:complexType name="lomType">
108
<xsd:sequence>
<xsd:element ref="general" minOccurs="0"/>
<xsd:element ref="lifecycle" minOccurs="0"/>
<xsd:element ref="metametadata" minOccurs="0"/>
<xsd:element ref="technical" minOccurs="0"/>
<xsd:element ref="educational" minOccurs="0"/>
<xsd:element ref="rights" minOccurs="0"/>
<xsd:element ref="relation" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="annotation" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="classification" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="metametadataType" mixed="true">
<xsd:sequence>
<xsd:element ref="identifier" minOccurs="0"/>
<xsd:element ref="catalogentry" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="contribute" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="metadatascheme" minOccurs="0"
maxOccurs="unbounded"/>
<xsd:element ref="language" minOccurs="0"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="nameType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="otherplatformrequirementsType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="personType">
<xsd:sequence>
<xsd:element ref="vcard"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="purposeType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
109
<xsd:complexType name="relationType" mixed="true">
<xsd:sequence>
<xsd:element ref="kind" minOccurs="0"/>
<xsd:element ref="resource" minOccurs="0"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="requirementType" mixed="true">
<xsd:sequence>
<xsd:element ref="type" minOccurs="0"/>
<xsd:element ref="name" minOccurs="0"/>
<xsd:element ref="minimumversion" minOccurs="0"/>
<xsd:element ref="maximumversion" minOccurs="0"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="resourceType" mixed="true">
<xsd:sequence>
<xsd:element ref="identifier" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
<xsd:element ref="catalogentry" minOccurs="0" maxOccurs="unbounded"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="rightsType" mixed="true">
<xsd:sequence>
<xsd:element ref="cost" minOccurs="0"/>
<xsd:element ref="copyrightandotherrestrictions" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="roleType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="semanticdensityType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="sourceType">
110
<xsd:sequence>
<xsd:element ref="langstring"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="statusType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="stringType">
<xsd:simpleContent>
<xsd:extension base="xsd:string">
<xsd:attribute ref="x:lang"/>
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
<xsd:complexType name="structureType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="taxonpathType">
<xsd:sequence>
<xsd:element ref="source" minOccurs="0"/>
<xsd:element ref="taxon" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="taxonType">
<xsd:sequence>
<xsd:element ref="id" minOccurs="0"/>
<xsd:element ref="entry" minOccurs="0"/>
<xsd:element ref="taxon" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="technicalType" mixed="true">
<xsd:sequence>
<xsd:element ref="format" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="size" minOccurs="0"/>
<xsd:element ref="location" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="requirement" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element ref="installationremarks" minOccurs="0"/>
<xsd:element ref="otherplatformrequirements" minOccurs="0"/>
<xsd:element ref="duration" minOccurs="0"/>
111
<xsd:group ref="grp.any"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="titleType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="typeType">
<xsd:sequence>
<xsd:element ref="source"/>
<xsd:element ref="value"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="typicalagerangeType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="typicallearningtimeType">
<xsd:sequence>
<xsd:element ref="datetime" minOccurs="0"/>
<xsd:element ref="description" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="valueType">
<xsd:sequence>
<xsd:element ref="langstring"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="versionType">
<xsd:sequence>
<xsd:element ref="langstring" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<!-- ****************** -->
<!-- ** Simple Types ** -->
<!-- ****************** -->
<xsd:simpleType name="formatType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
<xsd:simpleType name="sizeType">
112
<xsd:restriction base="xsd:int"/>
</xsd:simpleType>
<xsd:simpleType name="datetimeType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
<xsd:simpleType name="idType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
<xsd:simpleType name="metadataschemeType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
<xsd:simpleType name="catalogType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
<xsd:simpleType name="minimumversionType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
<xsd:simpleType name="maximumversionType">
<xsd:restriction base="xsd:string"/>
</xsd:simpleType>
</xsd:schema>
Für die einzelnen Attribute
Wertebereiche zur verfügung:
des
Datentyps
Vocabulary
stehen
folgende
Lifecycle.Status: {Draft, Final, Revised, Unavailable}
Lifecycle.Contribute.Role: {Author, Publisher, Unknown, Initiator, Terminator,
Validator, Editor, Graphical Designer, Technical
Implementer, Content Provider, Technical Validator,
Educational Validator, Script Writer, Instructional
Designer}
Educational.Interactivitytype: {Active, Expositive, Mixed, Undefined}
Educational.Learningresourcetype: {Excercise, Simulation, Questionnaire, Diagram,
Figure, Graph, Index, Slide, Table, Narrative,
Text, Exam, Experiment,
PreoblemStatement, SelfAssesment}
Educational.Interactivitylevel: {very low, low, medium, high, very high}
Educational.Intendedenduserrole: {Teacher, Author, Learner, Manager}
113
Educational.Context: {Primary Education, Secondary Education, Higher Education,
University First Cycle, University Second Cycle, University
Postgrade, Technical School First Cycle, Technical School
Second Cycle, Professional Formation, Continuous
Formation, Vocational Training}
Relation.Kind: {IsPartOF, HasPart, IsVersionOf, HasVersion, IsFormatOf,
HasFormat, References, IsReferencedBy, IsBasedOn,
IsBasisFor, Requires, IsRequiredBy}
114
Anhang B - Abbildungsverzeichnis
Abbildung 1-1 : Szenario .......................................................................................... 11
Abbildung 2-1: Sumatra-Modell ................................................................................ 17
Abbildung 3-1 : Score-Modularisierungskonzept ...................................................... 22
Abbildung 3-2 : Beispiel einer Ontologie ................................................................... 28
Abbildung 3-3 : Informationsmodellierung eines Buches .......................................... 30
Abbildung 3-4 : Informationsmodellierung mit Attributen .......................................... 31
Abbildung 3-5 : Informationsmodellierung ohne Attribute ......................................... 32
Abbildung 3-6 : XSL-Transformationsprozess .......................................................... 41
Abbildung 3-7: Erzeugter Objektbaum ...................................................................... 49
Abbildung 3-8 : XML-Engine ..................................................................................... 60
Abbildung 3-9 : WebDAV Server .............................................................................. 61
Abbildung 4-1 : Check-In Prozeß .............................................................................. 74
Abbildung 4-2 : Erzeugen eines Strukturmoduls ....................................................... 77
Abbildung 4-3 : Erzeugung eines Präsentationsmoduls ........................................... 80
Abbildung 4-4 : Transformation ................................................................................ 81
Abbildung 4-5 : Kurserstellung.................................................................................. 83
Abbildung 4-6 : Gesamtübersicht ............................................................................. 86
Abbildung 5-1 : Systemarchitektur ............................................................................ 87
115