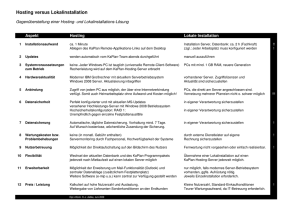
Einführung - Microsoft
Werbung

Erstellen skalierbarer Dienste (Engl. Originaltitel: Building Scalable Services) Zusammenfassung In diesem Whitepaper werden die Elemente vorgestellt, die beim erfolgreichen Entwerfen, Erstellen und Betreiben sehr großer Internetdienste eine Rolle spielen. Die Daten basieren auf einer von Microsoft durchgeführten internen Untersuchung 17 sehr großer Internetdienste. Im Zusammenhang mit diesem Whitepaper wird ein sehr großer Internetdienst als ein Dienst definiert, für dessen Ausführung mehr als 50 Computer benötigt werden und der von mehr als 1.000.000 eindeutigen Benutzern genutzt wird. Einführung Aufgrund der schnell wachsenden Internetmärkte steht im IT-Bereich (Internet Technology) immer häufiger der Dienstleistungsgedanke und nicht mehr nur das Produkt im Vordergrund. Von Internetdiensten wird mehr erwartet als lediglich Produktfeatures; sie müssen die Features auch bereitstellen können, wenn Benutzer sie anfordern und erwarten. Internetdienstanbieter müssen die Kundenansprüche und die Verwendungsmuster kennen, um diesen Ansprüchen gerecht zu werden und ihre Dienste entsprechend anzupassen. Bisher standen bei Systemuntersuchungen die Kosten und die Leistung im Vordergrund, während Verfügbarkeit, Skalierbarkeit und Verwaltbarkeit weitgehend außer Acht gelassen wurden. Auch das Interesse von Anwendungs- und Betriebssystementwicklern galt bisher den Features und der Leistung und weniger der Verwaltung und Bereitstellung. Überraschenderweise zeigten sich Internetbenutzer sehr tolerant gegenüber Systemen, die nicht über alle oder zumindest über eine große Anzahl von Features verfügten, solange deren Zuverlässigkeit und eine schnelle Antwortzeit sichergestellt waren. Diese Einstellung ist vermutlich symptomatisch für die Unausgereiftheit des Marktes und die Unbeständigkeit des Internets. Sie deutet darauf hin, dass der Verwaltbarkeit und der Betriebsbereitschaft eine größere Bedeutung beigemessen werden sollte als dem ständigen Hinzufügen neuer Features. Wenn Internetdienstanbieter vor der Herausforderung stehen, einen sehr großen Internetdienst zu erstellen, müssen sie sich zunächst mit der systeminternen Dienstqualität (Quality of Service, QoS) beschäftigen. Internetdienste müssen immer betriebsbereit sein. Darin besteht ein großer Unterschied zu traditionellen Computerumgebungen. Um eine Grundlage für das E-Business bilden zu können, müssen sie immer verfügbar sein und zumindest eine gewisse Dienstqualität unterstützen. Das Erstellen skalierbarer Systeme ist eine anspruchsvolle Aufgabe, und das Erstellen großer verlässlicher Internetdienste stellt eine noch größere Herausforderung dar. Da eine permanente Betriebsbereitschaft und eine gleichbleibende Antwortzeit äußerst wichtig sind, müssen Dienstanbieter beim Entwerfen die Stabilität berücksichtigen. Stabile Systeme sollten eine sehr hohe Kapazität verarbeiten können und über besonders zuverlässige Lastenausgleichssysteme verfügen. In der folgenden Liste sind die Faktoren aufgeführt, die beim Erstellen eines großen Internetdienstes zu beachten sind: Große Anzahl von Benutzern. Die kumulierten Zugriffsmuster mehrerer Millionen Benutzer können von zufälligen Auffälligkeiten nicht unterschieden werden. Inhärenter Parallelismus der Netzwerkaktivität. Ein Beispiel für inhärenten Parallelismus ist, dass ein Front-End-Server eine E-Mail-Nachricht als HTML rendert, während bei einem SMTP-Server (Simple Mail Transfer Protocol) für denselben Benutzer gleichzeitig eine andere E-Mail eintreffen kann. Ununterbrochene Internetaktivität. Jede Minute erreichen Tausende von E-Mails einen beliebigen SMTP-Server und weitere Mails folgen. Das Internet, die Konkurrenz und auch die Auslastung eines Dienstes ändern sich. Ständige Änderungen machen die Veränderlichkeit und Verwaltbarkeit eines Dienstes erforderlich. Nach der Markteinführung eines Dienstes muss dieser auf unbestimmte Zeit rund um die Uhr überwacht werden. Zu den zusätzlichen Komponenten einer Internetdienstarchitektur zählen der Dateispeicher, die Datenbankspeicherung (beispielsweise mithilfe von Microsoft® SQL Server™), Mechanismen für den Datenbankzugriff [wie beispielsweise Open Database Connectivity (ODBC)], Einschränkungen bezüglich der Netzwerkbandbreite und die Serverhardware (z. B. die Anzahl der CPUs und die Hardwareklasse). Nicht jeder Dienst beinhaltet all diese Architekturkomponenten, aber bei einigen Diensten ist dies der Fall. Zukünftige Dienste werden vermutlich alle Komponenten beinhalten müssen (bei einigen Dienste ist bereits jetzt eine ausreichende Skalierbarkeit erforderlich). Zusammenfassung der Dienstuntersuchung Die während der ersten Untersuchung von 17 sehr großen Internetdiensten gesammelten Daten werden hier nicht vollständig vorgestellt. Stattdessen wird zur näheren Ausführung der in diesem Whitepaper vorgestellten Ergebnisse eine Zusammenfassung verschiedener architektonischer Grundlagen bereitgestellt. 1 Anderen untersuchten, aber hier nicht beschriebenen Websites liegen ähnliche Infrastrukturen zugrunde. Zu den untersuchten sehr großen Internetdiensten zählen u. a. folgende: E-Mail-Dienst über das Internet. Bei MSN™ Hotmail™ handelt es sich um eine aus 15 Clustern bestehende Website mit Zweistufenarchitektur, wobei jedes Cluster aus ca. 300 Front-End-Webservern und 10 Back-End-Speichercomputern besteht. Jedes Cluster unterstützt 4-20 Millionen Benutzer. Der gesamte Dienst besteht aus mehr als 6.000 Computern. Der Dienst wächst durch das Hinzufügen neuer Cluster. MSN Hotmail verwendet DNS-Round Robin für den Lastenausgleich zwischen Clustern und einen eigenständigen Lastenausgleich innerhalb der Cluster. Der E-Mail-Internetdienst MSN Hotmail kann kurz gesagt in die folgenden vier Klassen von Computern unterteilt werden: o Front-End-Webserver. Dabei handelt es sich um statusfreie Webserver, die zum Anzeigen der Benutzeroberfläche HTML verwenden. Diese Server führen auch ausgehende E-Mails aus. o Benutzerdatenspeicher. Dabei handelt es sich um statusbehaftete Server, auf denen E-MailOrdner für bis zu zwei Millionen Benutzer gespeichert werden. o Mitgliedscomputer mit Index Server. Es gibt statusfreie Server, die alle Zuordnungsinformationen vom Benutzerkennwort bis hin zu Benutzerdatenspeichern beinhalten. o SMTP-Eingangsserver. Diese Server nehmen eingehende EMails an und speichern sie in dem betreffenden Benutzerdatenspeicher. Internetdienst für Nachrichten und Unterhaltung. Diese Website wird von 42 Front-EndWebservern bedient, von denen jeder Internetinformationsdienste (Internet Information Services, IIS) mit Active Server Pages (ASP), Extensible Markup Language (XML), Windows Media Player (WMP) und SQL Server ausführt. Bei diesem Dienst bestehen ca. 500 gleichzeitige Onlineverbindungen pro Server. Der höchste Ausgabewert vom Server ist ca. 50-60 MB/s. Serverseitige ASP-Objekte speichern häufig verwendeten Inhalt. Die Front-End-Server sind in sieben Cluster mit jeweils sechs Servern aufgeteilt. Ein Lastenausgleich zwischen Clustern wird mithilfe von DNS-Round Robin erreicht; innerhalb eines Clusters wird der Netzwerklastenausgleich über eine gemeinsam genutzte IP-Adresse verwendet. Zwei Front-End-Computer mit SQL Server enthalten Onlineinhaltindizes, Bestenlisten und Umfragen. Zwei Stagingserver und ein Server für die SQL-Replikation aktualisieren die gesamte Website jede Stunde für jeden Front-End-Server. Einzelhandel (E-Commerce). Dieser Dienst besteht aus 4 Komponenten: 11 statusfreien Front-EndWebservern, mittelstufigen Servern, 8 externen Back-End-Servern und 4 lokalen Back-EndDatenbankservern. Der Status der Verbindung wird auf dem Browser in einem Cookie verwaltet. Die lokalen Datenbanken enthalten Benutzerprofile und andere benutzerspezifische Informationen. Der Zugriff auf Datenbanken auf den Back-End-Servern erfolgt über mit SQL Server gespeicherte Prozeduren. Back-End-Server stellen generische Dienste für die Front-End-Server bereit. Ein Lastenausgleich wird durch das Verwenden des Netzwerklastenausgleichs erzielt. Portal zu einer Internetdomänenpräsenz eines großen Unternehmens. Diese Site besteht aus sieben Clustern mit jeweils sechs Computern. Jeder Server ist mit drei Netzwerken verbunden: dem Internet, einem Verwaltungs-LAN und einem LAN für freigegebene Dienste. Die Netzwerklast wird zwischen den Clustern mithilfe von DNS-Round Robin und innerhalb jedes Clusters mithilfe des Netzwerklastenausgleichs ausgeglichen. Instant Messaging-Dienst. Benutzer werden über eine persistente TCP-Verbindung mit diesem Instant Messaging-Dienst verbunden. Es gibt sechzehn Benachrichtigungsserver, und die Clients behalten eine persistente Verbindung zu einem der Benachrichtigungsserver bei. Zwei Mitgliedscomputer mit Index Server dienen als globales Verzeichnis und weisen Datenspeichern Benutzer zu. Alle Mitgliedscomputer mit Index Server nutzen eine gemeinsame IP-Adresse und jeder dieser Server enthält das gesamte Benutzerverzeichnis. Fünf Switchboardserver dienen als Host für Onlineverbindungen, und diese Server übertragen ihren Status an die Benachrichtigungsserver für den Lastenausgleich. Onlineunterhaltungsführer. Dieser Dienst umfasst drei Front-End-Server mit Microsoft InternetInformationsdienste (Internet Information Services, IIS), auf denen ein benutzerdefiniertes ISAPIRenderingmodul (Internet Server Application Programming Interface) ausgeführt wird. Front-EndServer sind sowohl mit dem Internet als auch mit einem lokalen publizierenden 100BaseT-LAN verbunden. Die Last zwischen den Front-End-Servern wird mithilfe von DNS-Round Robin ausgeglichen. Zwischen drei Computern der mittleren Stufe mit SQL Server und den Front-EndComputern mit IIS besteht eine 1:1-Beziehung. Der gesamte Seiteninhalt wird auf den Computern mit SQL Server gespeichert. Ein vierter Computer der mittleren Stufe mit SQL Server speichert Daten, die keinen Inhalt enthalten. Ein Stagingcomputer mit IIS und ein Stagingcomputer mit SQL Server stellen Stagingspeicherplatz bereit. Freigegebene Hostwebsite für kleine Unternehmen. Dieser Dienst befindet sich auf einem alle Anzeigen- und Benutzerinformationen enthaltenen Oracle-Datenbankserver. Dieser Server umfasst 11 Front-End-Anzeigenserver zum Verarbeiten von Anzeigeninformationen und angeboten, einen Server zur Verarbeitung der durch Klicken innerhalb eines Menüs weitergeleiteten Benutzeranfragen zu Anzeigen, einen Server für die Anzeigenplanung, mehrere unterschiedliche Server für das Abbilderstellen und das Protokollieren sowie 20 Anwendungsserver. Anwendungen beinhalten Inventurtools (für den Verkauf), Tools zur Profilerstellung für die Site und zur Protokollarchivierung. Jeder der untersuchten Internetdienste umfasst Front-End-Server, Back-End-Server und eine Form von Lastenausgleich. In Abbildung 1 ist die allgemeine Topologie dieser Sites dargestellt. Abbildung 1 Beispiel für die Topologie eines großen Internetdienstes Die Kapazität dieser Dienste macht eine genaue Betrachtung der Architektur und der Vorgänge erforderlich. MSN Hotmail wird zurzeit von 110 Millionen eindeutigen aktiven Benutzern genutzt und erhält täglich ca. 450 Millionen E-Mails. Noch vor zwei Jahren wurde der Internetdienst für Nachrichten und Unterhaltung täglich von 100.000 eindeutigen Benutzern genutzt, heute sind es 2,5 Millionen eindeutige Benutzer täglich (10 Millionen eindeutige Benutzer pro Monat). Innerhalb der ersten 36 Stunden nach der Markteinführung diente der Instant Messaging-Dienst als Host für 50.000 Onlineverbindungen gleichzeitig. Inzwischen werden regelmäßig über 1,5 Millionen aktive Verbindungen verwaltet. Bei Zahlen dieser Größenordnung lassen sich die Schwierigkeiten beim Erstellen und Verwalten solch großer Internetdienste leicht absehen. Zum Erstellen und Verwalten sehr großer Internetdienste müssen sich Entwickler, Architekten und Administratoren auf folgende drei Bereiche konzentrieren: Verfügbarkeit, Skalierbarkeit und Verwaltbarkeit. Verfügbarkeit Internetdienste müssen immer verfügbar sein. Sie müssen Benutzern zur Verfügung stehen, und zwar unabhängig vom Ausmaß eines eventuellen internen Fehlers. Dienstdesigner müssen bei der Planung das Auftreten möglicher Fehler berücksichtigen. Wenn einzelne Komponenten ausfallen, sollte das System zumindest teilweise funktionsfähig bleiben. Bei inkonsistentem Status sollten Komponenten schnell ausfallen: Je schneller eine fehlerhafte Komponente ausfällt, desto schneller kann das übrige System den Fehler umgehen. Benutzer erwarten, dass der Dienst funktionsfähig ist: Manchmal erwarten sie eine uneingeschränkte Funktionsfähigkeit, und manchmal werden sie sich mit weniger zufrieden geben. Wenn beispielsweise ein EMail-Posteingang offline geschaltet ist, sollten betroffene Benutzer trotzdem auf eine E-Mail-Webseite zugreifen und E-Mails senden können. Ein Homepagedienst kann eine Startseite rendern, auch wenn E-Mail-, Anzeigenund Börsentickerdienste ausfallen. Andererseits wurde im Zusammenhang mit einer der Einzelhandelswebsites festgestellt, dass den Benutzern im Fall einer Unterbrechung der Verbindung zum Back-End-Server der Zugriff vollständig verweigert werden sollte, anstatt sie den halben Kaufvorgang ausführen zu lassen, bevor dieser unterbrochen wird. Um die Verfügbarkeit einplanen zu können, muss untersucht werden, wie sich Komponenten auf die Benutzererfahrung auswirken. Darüber hinaus muss die optimale Verfügbarkeitsdauer für minimale Dienste so geplant werden, das sie den Benutzern sinnvoll erscheint. Beim Entwerfen und Testen von Systemen sollte das Ausfallen von Komponenten als Regelfall und nicht als Ausnahme betrachtet werden. Systemdesigner müssen zwischen den Aspekten Verfügbarkeit und Kosten abwägen. Es ist relativ einfach, durch einen Lastenausgleich auf statusfreien Front-End-Servern Redundanz zu erstellen, aber das Spiegeln und Erstellen von Clustern für statusbehaftete Computer (besonders Back-EndServer) kann sich schwierig gestalten, vor allem wenn der Status in einem temporären Speicher gespeichert wurde. Für den Ablauf kann es einfacher und kostengünstiger sein, eine Anwendung mit einer Fehlererkennung zu versehen und den Sitzungszustand wiederherzustellen, wobei dies möglicherweise zu einer zulässigen Verzögerung für die Benutzer führen kann. Sie sollten sich auf einen Datenserverausfall größeren Ausmaßes vorbereiten, indem Sie innerhalb der Architektur Redundanz einrichten. Eine Möglichkeit ist das Spiegeln von Daten auf mehreren Servern und das Verwenden von Stripe Sets, was der Funktionsweise des RAID-Verfahrens (Redundant Arrays of Independent Disks) ähnelt. Die Standardmethode zum Entwerfen von Kommunikationskomponenten für das Internet unterscheidet sich maßgeblich von den traditionellen Modellen, bei denen ein LAN verwendet wird. In der Regel verwenden Internetdienstkomponenten einfache socketbasierte Protokolle, wenn sie nicht ein vorhandenes Webprotokoll verwenden können. Diese Protokolle sind zwar nicht alle so entworfen, dass sie nach einem Ausfall wiederhergestellt werden können, aber sie sind bei einem Ausfall so schnell wie möglich wieder einsatzbereit. Die im Zusammenhang mit diesem Dokument überprüften Dienste verwendeten keine komplexen Protokolle wie RPC (Remote Procedure Call, Remoteprozeduraufruf) und DCOM (Distributed Component Object Model), weil diese häufig die Umstände des Ausfalls verdecken. Dem Betriebsteam sollten auch Testsuites als Teil der Plattform geliefert werden. Mithilfe der vom Entwicklungsteam verwendeten Testsuites sollten regelmäßig die Fehlerfreiheit und die Leistung des Systems überprüft werden. Viele Sites verfügen über eine ausgeblendete Webseite, die wichtige Features der Site ausführt. Wird die ausgeblendete Seite angezeigt, werden dem Betriebsteam Probleme bezüglich der Funktionalität oder der vom Benutzer wahrgenommenen Leistung gemeldet. Datenspeicherung Bei einer Site wird die Datenspeicherung für den Back-End-Server von zwei Servern verwaltet, die den Microsoft Clusterdienst über eine Fibre Channel-Verbindung zu einem freigegebenen RAID5-Datenträgerarray ausführen. Beim Ausfall eines einzelnen Servers wird die Verfügbarkeit durch das Servercluster sichergestellt und beim Ausfall eines einzelnen Datenträgers durch das RAID-Array. Die bei modernen Servern und Arrays bereitgestellte Datenträgertechnologie kann mögliche Datenträgerausfälle vor dem Auftreten erkennen. Wenn ein Datenträgerausfall vom System vorhergesagt wird, kann der fehlerhafte Datenträger im RAID5-Array ausgetauscht und ohne Einschränkungen des Dienstes für die Site ersetzt werden. Während RAID5-Arrays mithilfe der integrierten Microsoft Windows NT® Server Enterprise Edition oder der integrierten Windows® 2000 Advanced Server-Dienste in die Software implementiert werden können, verwenden die untersuchten Sites zur Steigerung der Datenzugriffsleistung eine Hardwareimplementierung. Auch die Offlinespeicherung ist bei der Datenwiederherstellung von Bedeutung. Anmerkung Die Art des bei dieser Konfiguration verwendeten Dateisystems spielt eine wichtige Rolle. Alle in dieser Architektur verwendeten Datenträger müssen so formatiert sein, dass sie das NTFS-Dateiformat verwenden, denn es bietet eine größere Sicherheit und Datenintegrität als das FAT-Dateiformat. Skalierbarkeit Desktopanwendungen und Internetdienste verfügen über grundlegend unterschiedliche Skalierungsmodelle für Einzelbenutzer. Die Entwickler von Desktopanwendungen wie Microsoft Office, Microsoft Flight Simulator und Microsoft Visual Studio® liefern mehr CD-ROMs und skalieren so eine größere Anzahl von Benutzern. Die Entwickler großer Internetdienste müssen ihre Server und die Software zur Unterstützung mehrerer Millionen Benutzer physisch skalieren. Die Skalierbarkeit eines Dienstes wird durch die Leistung einzelner Komponenten beeinflusst. Beispielsweise verwendet ein Dienst auf den Front-End-Servern die größeren Festplatten nicht wegen des Speicherplatzes, sondern wegen der durch die hochwertigen Diskettenlaufwerke sichergestellten geringeren Drehwartezeit. Bei einer anderen Site wurde die durchschnittliche Antwortzeit von 32 Millisekunden auf 8 Millisekunden pro Seite gesenkt, indem die vier am häufigsten abgefragten Seiten von einer ISAPI-Erweiterung (statt von ASP) gerendert wurden. Anmerkung Bei diesen Sites wird zur Steigerung der Geschwindigkeit sowie für eine größere Zuverlässigkeit und eine verbesserte Funktionalität über ASP und ISAPI-Erweiterungen die Verwendung von ASP.NET erwogen. Skalierbarkeit wird häufig am besten durch einfache Lösungen erzielt. Aus der Sicht der parallelen Datenverarbeitung könnten viele Webdienst als extrem parallel bezeichnet werden, d. h., die Daten werden i. d. R. auf Einzelbenutzerbasis problemlos partitioniert (auch MSN Hotmail nutzt beispielsweise die Einfachheit der E-Mail-Partitionierung auf Einzelbasis). Das Erstellen eines Dienstes, der die natürliche Partitionierung der Domäne widerspiegelt, resultiert häufig in einem überraschend einfachen Modell, das eine außergewöhnlich gute Skalierbarkeit und Leistung bietet. Unabhängig davon, ob E-Mail-Daten nach Benutzerkonten und Chatrooms nach Themen unterteilt werden, erfolgt die Datenzerlegung parallel und ist für gewöhnlich offensichtlich. Es ist wahrscheinlich, dass die Granularität der Partitionierung durch die Entwicklung des Webs zunimmt (beispielsweise könnte sie sich von der Einzelbenutzerbasis zur Communitybasis verschieben), aber viele Möglichkeiten für die Datenpartitionierung und den parallelen Betrieb werden weiter bestehen. MSN Hotmail skaliert problemlos nach Benutzerkonto und kann jede der vier Computerklassen unabhängig voneinander skalieren. Zurzeit besteht dieser Dienst aus mehr als 5.700 Front-End-Servern und 150 Benutzerdatenspeichern. Benutzer werden regelmäßig zwischen Datenspeichern migriert. Die Migration von Benutzern von einem Server auf einen anderen ist ein gutes Beispiel für die dynamische Partitionierung, wobei ein einzelnes Postfach die kleinste Einheit der Granularität darstellt. Skalierungskonzepte Internetbasierte Sites werden entweder durch vertikale Skalierung, d. h. durch das Ersetzen von Servern durch größere Server, oder durch horizontale Skalierung, d. h. durch das Hinzufügen weiterer Server, vergrößert. Die Sammlung aller Server, Anwendungen und Daten an einer bestimmten Site wird als Farm bezeichnet. Farmen umfassen viele spezialisierte Dienste, wobei wiederum jeder dieser Dienste über eigene Anwendungen und Daten verfügt (beispielsweise ein Verzeichnis, Sicherheit, HTTP, E-Mail, Datenbank und andere). Die gesamte Farm wird als Einheit verwaltet und verfügt über gemeinsame Verwaltungsrichtlinien, Einrichtungen und ein gemeinsames Netzwerk. Die Fehlertoleranz der Farm wird dadurch sichergestellt, dass die Hardware, Anwendungen und Daten bei einer oder mehreren geografisch verteilten Farmen dupliziert werden können. Eine solche Sammlung von Farmen wird als Geoplex bezeichnet. Fällt eine Farm aus, werden Dienste von den übrigen Farmen bereitgestellt, bis die ausgefallene Site repariert wurde. Geoplexe sind entweder aktiv-aktiv, d. h., die Last wird auf alle Farmen verteilt, oder sie sind aktiv-passiv, so dass eine oder mehrere Farmen im Standbymodus verfügbar sind. Das Unterstützen von zwei Datenzentren kann zu einer Verdoppelung der Betriebskosten führen, und im Hinblick auf die Topologie des Internets sind die Vorteile der geografischen Verteilung für verteilte Benutzer fragwürdig. Die sinkenden Preise für Netzwerkbandbreite ermöglichen die Realisierung kostengünstiger Alternativen zur geografischen Verteilung. Aber abgesehen von finanziellen Erwägungen wird durch die verteilte Skalierung auch die Zuverlässigkeit des Dienstes gefährdet. Für Dienste, die viele geografische Gegenden abdecken, ist die Bereitstellung in einem einzelnen Datenzentrum aus praktischen Gründen u. U. nicht zu empfehlen. Auch aufgrund anderer unerwarteter physischer Probleme kann die Notwendigkeit bestehen, Geoplexe einzurichten. So verfügt z. B. eine Site möglicherweise nicht über die zum Ausführen der erforderlichen Computer an einem zentralen Ort benötigte Elektrizitäts- und Kühlungskapazität. Farmen können auf zwei Arten vergrößert werden, durch Klonen oder durch Partitionieren. Ein Dienst kann auf vielen Replikationsknoten geklontwerden, wobei jeder Knoten über dieselbe Software und dieselben Daten verfügt. Anforderungen werden dann an die einzelnen Mitglieder der durch Klonen entstandenen Gruppe weitergeleitet. Die Sammlung von Klonen für bestimmte Dienste wird als zuverlässiges Array geklonter Dienste (Reliable Array of Cloned Services, RACS) bezeichnet. Sowohl mithilfe von RACS als auch durch das Klonen werden Skalierbarkeit und Verfügbarkeit erzielt. In der Regel kann ein Administrator einen ordnungsgemäß entworfenen und auf Hunderten von Klonen ausgeführten Dienst verwalten. RACS und das Klonen sind zwei ausgezeichnete Möglichkeiten zur Steigerung der Verarbeitungsleistung sowie zur Vergrößerung der Netzwerkbandbreite und der Speicherbandbreite für eine Farm. Allerdings bietet sich RACS ohne gemeinsame Datenträger, bei dem jeder Klon den gesamten Speicher lokal dupliziert, nicht zum Vergrößern der Speicherkapazität an. Die Klone verfügen über identische Speicher, und alle Aktualisierungen müssen auf die Speicher aller Klons angewendet werden. Deshalb eignet sich das Klonen nicht zur Vergrößerung der Speicherkapazität. Tatsächlich ist das Klonen bei schreibintensiven Diensten problematisch, denn alle Klone müssen alle Schreibvorgänge ausführen, so dass der Durchsatz nicht verbessert wird und zur korrekten Ausführung der gleichzeitigen Aktualisierungen erhebliche Änderungen erforderlich sind. Klone sollten vor allem bei schreibgeschützten Anwendungen mit geringen Speicheranforderungen implementiert werden. Eine Möglichkeit zur Senkung der Kosten und zur Verringerung der Komplexität geklonter Speicher ist das Einrichten einer gemeinsam genutzten Speicherverwaltung für alle Klone. Dieser Entwurf eines RACS mit gemeinsam genutzten Datenträgern wird häufig als Cluster bezeichnet und beinhaltet statusfreie Server, die jeweils auf einen gemeinsamen Back-End-Speicherserver zugreifen. Bei diesem Entwurf muss der Speicherserver zum Sicherstellen der Verfügbarkeit fehlertolerant sein. Er benötigt aber dennoch genaue Algorithmen zum Verwalten von Aktualisierungen (beispielsweise eine Speicherentwertung, Sperrverwaltung und Transaktionsprotokolle). Während das System heraufskaliert wird, kann der durch die Aktualisierung entstehende Datenverkehr zu einem Leistungsengpass führen. Trotz dieser Einschränkungen bietet RACS mit gemeinsam genutzten Datenträgern viele Vorteile. Dieser Entwurf würde über 20 Jahre lang gerne eingesetzt. Partitionen erweitern einen Dienst, indem sie Hardware und Software duplizieren und die Daten auf alle Knoten verteilen. Im Wesentlichen entspricht dies einem Klon ohne gemeinsam genutzten Datenträger, es sei denn, nur die Software wird geklont. Die Daten werden auf alle Knoten verteilt. Durch das Partitionieren werden beim Hinzufügen eines Knotens die Berechnungsleistung, Speicherkapazität, Speicherbandbreite und die Netzwerkbandbreite des Dienstes erhöht. Die Sammlung von Partitionen für einen bestimmten Dienst wird als zuverlässiges Array partitionierter Dienste (Reliable Array of Partitioned Services, RAPS) bezeichnet. Idealerweise werden die Daten zum Ausgleichen der Speicher- und Berechnungslast beim Hinzufügen einer Partition automatisch neu auf die Knoten verteilt. Für gewöhnlich verteilt die Anwendungsmiddleware die Daten und die Arbeitsauslastung auf die Objekte. Mailserver verteilen diese beispielsweise auf die Postfächer, während Vertriebsanwendungen sie eventuell auf die Benutzerkonten oder Produktfamilien verteilen. Die Partitionierung sollte beim Hinzufügen neuer Daten und bei einer Änderung der Auslastung automatisch angepasst werden. Da die Daten nur an einem Ort gespeichert werden, führt das Partitionieren nicht zu einer verbesserten Verfügbarkeit. Fällt ein Datenträger oder der den Datenträger verwaltende Server aus, ist dieser Teil des Dienstes nicht verfügbar - der Inhalt dieses Postfaches kann nicht gelesen, dieses Konto kann nicht belastet oder dieser Benutzerdatensatz kann nicht gefunden werden. Anders als beim Klonen ohne gemeinsam genutzten Datenträger, bei dem redundanter Speicher hinzugefügt wird, wird beim einfachen Partitionieren (und beim Klonen mit gemeinsam genutzten Datenträgern) nur eine Kopie der Daten erstellt. Ein Geoplex kann vor diesem Speicherverlust schützen, aber normalerweise wird der Speicher durch Duplex (RAID1) oder Parität (RAID5) lokal geschützt, so dass die meisten Ausfälle vom Benutzer unbemerkt repariert werden. Klone und RACS können für größtenteils schreibgeschützte Anwendungen mit niedrigen Konsistenz- und Speicheranforderungen (weniger als 100 GB) verwendet werden. Webserver, Dateiserver, Sicherheitsserver und Verzeichnisserver sind gute Beispiele für klonfähige Dienste. Geklonte Dienste erfordern das automatische Replizieren von Software und Daten auf neuen Klonen und das automatische Weiterleiten von Anforderungen zum Ausgleichen der Arbeitslast, zum Umgehen von Ausfällen und zum Erkennen reparierter und neuer Knoten. Zusätzlich benötigen Klone einfache Tools zum Verwalten von Software- und Hardwareänderungen sowie zum Erkennen und Reparieren von Ausfällen. Klone und RACS eignen sich nicht für Komponenten einer Anwendung, die aufgrund ihres Freigabestatus in Verbindung mit häufig durchgeführten Aktualisierungen nicht parallel ausgeführt werden kann. Das Verwenden eines Klons mit gemeinsam genutzten Datenträgern kann einige dieser Probleme verringern, aber irgendwann wird die Belastung des Speicherservers zu groß, so dass eine Partitionierung erforderlich wird. Große und häufig aktualisierte Datenbankanwendungen sollten durch das Weiterleiten von Anfragen zu Servern bedient werden, die zum Bedienen einer Datenpartition (wie beispielsweise RAPS) bestimmt sind. Dieses Weiterleiten nach Affinität liefert einen besseren Überblick über die Daten und ermöglicht das Speichern von Daten im Hauptspeicher ohne das erhöhte Risiko einer Speicherentwertung. E-Mail, Instant Messaging, Enterprise Resource Planning (z. B. Systeme wie SAP und BAAN) und Datensatzverwaltung sind beispielsweise Anwendungen, bei denen sich die Partitionierung von Daten und das Weiterleiten nach Affinität positiv auswirken. Jede dieser Anwendungen kann problemlos partitioniert werden und profitiert von der partitionierten, dezentralen Skalierung. Darüber hinaus können Datenbanksysteme von parallel durchgeführten Suchvorgängen profitieren, bei denen eine Abfrage von mehreren Prozessoren auf mehreren Festplatten parallel ausgeführt wird. Zur Sicherstellung der Verfügbarkeit müssen partitionierte Systeme in irgendeiner Form gepackt werden, so dass der statusbehaftete Dienst (und sein Status) beim Ausfall eines Knotens schnell zu einem zweiten Knoten migrieren können. Partitionierte Systeme müssen die gleiche Verwaltbarkeit aufweisen wie geklonte Systeme. Abgesehen davon muss die Middleware eine transparente Partitionierung und die Möglichkeit des Lastenausgleichs bieten. Dies ist ein Dienst auf Anwendungsebene, der vom E-Mail-System (zum Migrieren von Postfächern zu neuen Servern), von Datenbanksystemen (zum Teilen und Zusammenführen von Datenpartitionen) und anderer Middleware bereitgestellt wird. Die Middlewaresoftware verwendet zum Erstellen eines Dienstes mit hoher Verfügbarkeit den Failover-Mechanismus des Betriebssystems (Pakete). Die Dienste sind auch dazu konzipiert, das Weiterleitungssystem zum Weiterleiten von Anfragen zu der entsprechenden Dienstpartition zu programmieren. Die wichtigste Skalierungstechnik ist das Replizieren eines Dienstes auf vielen Knoten. Bei der einfachsten Form der Replikation werden sowohl die Programme als auch Daten kopiert. Diese Klone ohne gemeinsam genutzte Datenträger können ebenso leicht verwaltet werden wie eine Einzelinstanz, aber sie bieten sowohl Skalierbarkeit als auch Verfügbarkeit (wie RACS). Klone ohne gemeinsam genutzte Datenträger eignen sich nicht für große Datenbanken oder häufig aktualisierte Dienste. Für diese Anwendungen können Dienste gepackten Partitionen zugeordnet werden. Als Pakete erhalten Partitionen eine hohe Verfügbarkeit, denn fehlerhafte Partitionen auf anderen Knoten werden neu gestartet und haben dabei Zugriff auf den Speicher der fehlerhaften Partition. Die Middleware hat die Aufgabe, die Verwaltung dieser Partitionen so einfach zu gestalten wie die Verwaltung eines einzelnen Knotens (wie beispielsweise RAPS). Server, Verbindungen und Netzwerk Praktisch alle der überprüften Dienste verteilen ihren Dienst auf Front-End-Server und Back-End-Server. Die Front-End-Server verarbeiten normalerweise eingehende Benutzeranfragen und erfassen, generieren oder lesen Daten, rendern diese Daten in das HTML-Format und stellen anschließend eine Antwort für den Benutzer aus. Für Dienste, die das Protokoll HTTP 1.0 unterstützen, wird eine TCP-Verbindung erstellt und für jede einzelne Benutzeranfrage unterbrochen. Der allgemeine Aufbau der untersuchten großen Internetdienste umfasst vier Komponenten: statusfreien Lastenausgleich, statusfreie Front-End-Server, statusbehafteten Lastenausgleich und statusbehaftete Back-EndServer. Statusbehafteter Lastenausgleich wird fast ausnahmslos auf den Front-End-Servern bereitgestellt. Diese Architektur und Bereitstellung zugunsten der Skalierbarkeit sind gut durchdacht. Bei den meisten der untersuchten Sites haben die Front-End-Server den Status bezüglich der Verfügbarkeit der einzelnen Back-End-Server und bezüglich der Verfahrensweise zum Zuordnen der bei einem Back-End-Server eingehenden Benutzeranfragen beibehalten. Den Status bezüglich der Benutzeranfragen behalten sie jedoch nicht bei. Beachten Sie den Unterschied: Ein Front-End-Server speichert den Status "Ich habe die Anfrage von Benutzer A an Back-End-Server 3 gesendet" und nicht "Ich sende alle Anfragen der Benutzer A bis F an BackEnd-Server 3". Letzteres würde bedeuten, dass Front-End-Server ersetzt werden können, weil sie keine anfrageabhängigen Informationen enthalten. Beachten Sie, dass eine bestimmte Transaktion (oder ein bestimmter Dialog) u. U. viele Front-End-Server durchläuft, aber alle Front-End-Server werden die Transaktion zu demselben Back-End-Server weiterleiten. Bei MSN Hotmail wird der Status des Lastenausgleichs auf einem separaten Mitgliedscomputer mit Index Server gespeichert, weil der Status sehr groß ist: Ein Eintrag pro Benutzer, durch den definiert wird, welcher Benutzerdatenspeicher die E-Mails der einzelnen Benutzer enthält. Der größte Nachteil der vollständig statusfreien Front-End-Architekturmodelle besteht darin, dass der Status entweder zum Client oder zum Back-End-Server übermittelt werden muss. Das Übermitteln des Status zum Server setzt voraus, dass die Site das Anzeigen einer eindeutigen Kennung (oder einer Anmeldung) unterstützt und über eine Statusdatenbank verfügt. Das Übermitteln des Status zum Client setzt voraus, dass der Status entweder im URL eingebettet ist oder in einem Browsercookie transportiert wird. Das Verwenden von Cookies zum dauerhaften Speichern von Benutzerprofilinformationen ist problematisch, weil Cookies nicht zwangsläufig das unstete Verhalten der Benutzer unterstützen (Wechseln von einem Browser zum nächsten). Eine der Sites verwendet Cookies erst nach dem Einrichten einer Sitzung und nicht als dauerhaften Mechanismus. Es herrscht noch immer keine Einigkeit über Cookies und deren Verwendung. Cookies sind aus Datenschutzgründen zwar nicht bedenklich, aber Dienstentwickler sollten sich der bekannten Bedenken und der Alternativen bewusst sein. Back-End-Server sind i. d. R. statusbehaftet und werden zum Abrufen und zum Speichern von Daten verwendet. Zu den Beispielen für Back-End-Komponenten zählen SQL- oder Oracle-Datenbanken und Dateispeicherserver. Back-End-Dienste müssen auf Plattformen mit hoher Verfügbarkeit gehostet werden. Eine hohe Verfügbarkeit kann entweder durch zentrales oder dezentrales Skalieren erzielt werden. Die Hardware der Back-End-Server wird so ausgewählt, dass eine maximale Leistung erzielt wird, damit die Anzahl der kostenintensiven Server verringert und das Einrichten großer Pools von Front-End-Servern ermöglicht wird. Endbenutzer kommunizieren nur selten direkt mit Back-End-Servern. Um skalieren zu können, müssen Dienste den Ablauf des internen Datenflusses verstehen. Einer der Gründe, die eine Unterscheidung zwischen Front-End- und Back-End-Servern sinnvoll erscheinen lassen, ist die Tatsache, dass der Front-End-Server den mit langsamen Clientverbindungen zusammenhängenden Leistungsengpass auslagern kann und so eine höhere Parallelität unter den Back-End-Servern ermöglicht. Im Allgemeinen ist die Impedanzübereinstimmung von Dienstkomponenten auf der Basis von Verbindungsmustern und der Bandbreite ein wichtiger Aspekt des Internetdienstentwurfs. Die Front-End/Back-End-Serververbindung hat eine Wartezeit, so dass die Front-End-Server ein Multiplexing für viele Anfragen ausführen können. Dieses Vorgehen wirkt sich entscheidend auf die interne Netzwerktopologie aus. Zwischen einem Front-End-Server und dem entsprechenden Back-End-Server können gleichzeitig viele Verbindungen bestehen. Darüber hinaus spielt die Netzwerktopologie, einschließlich der Platzierung von Routern, Switches und Subnetzen, hinsichtlich der Skalierbarkeit des Dienstes eine wichtige Rolle. Das Platzieren von Switches und Subnetzen ist beim Minimieren der zwischen den Diensten erforderlichen Bandbreite und zum Erzielen der maximalen Multicastleistung bei der Skalierbarkeit von großer Bedeutung. Einige Dienste verwenden Multicast zum Verteilen von Anwendungen und Inhalt. Lastenausgleich Abgesehen von sehr kleinen Diensten sollte bei allen Diensten zum Verteilen der Last eingehender Verbindungen auf die Front-End-Server ein Mechanismus für den Lastenausgleich vorhanden sein. Viele große Internetdienste enthalten Teildienste, bei denen auch ein Lastenausgleich ausgeführt wird. Zusammen mit dem Partitionieren ermöglicht der Lastenausgleich Skalierbarkeit. Die Anforderungen für den Lastenausgleich und für das Weiterleiten sind auf jeder Stufe unterschiedlich. Auf der obersten Stufe schaffen Lastenverteilungsschemas auf IP-Ebene einen guten Ausgleich, wenn eine große Menge potenzieller Clients und Anfragen keine Affinität besitzen. Die mittlere Stufe verarbeitet die Anfragesemantik und kann Daten erzeugen und spezielle Lastensteuerungsentscheidungen verarbeiten. Auf der Datenstufe besteht die Schwierigkeit im Weiterleiten der Anforderung zu der entsprechenden Partition. Derzeit existieren drei Standardmechanismen für den Lastenausgleich: Mehrere IP-Adressen (DNS-Round Robin), eigenständige IP-Adresszuordnungen in Richtung virtuell-zu-tatsächlich und eingebettete IPAdresszuordnungen in Richtung virtuell-zu-tatsächlich. Mehrere IP-Adressen (DNS-Round Robin) Dies ist die DNS-Namensauflösung beim Übersetzen eines Domänennamens in eine IP-Adresse. Bei DNSRound Robin wird eine andere IP-Adresse mit jeder DNS-Auflösungsanforderung zurückgegeben (wenn in dem DNS-Eintrag mehrere Einträge vorhanden sind). Der Zweck von Round Robin besteht darin, zum Verteilen der Verbindungslasten mehrere HTTP-Server (mit identischen Inhalten) zuzulassen. Round Robin ist nicht zufällig, auch wenn seine Auswirkungen zufällig wirken. Round Robin erfolgt in einer Kette hintereinander, so dass die Antwortdatensatzsequenz bei jeder Antwort um eine Stelle verschoben wird. Eine Adresse wird ausgegeben und an das Ende der Liste gesetzt, und anschließend wird die nächste Adresse für die nächste Übersetzungsanforderung ausgegeben, so dass eine Art Übersetzungsliste entsteht. Viele Sites verwenden DNS-Round Robin zumindest für den Lastenausgleich auf oberster Ebene, weil DNS gut auf angehaltene Systeme reagiert. Die Benutzererfahrung hat gezeigt, dass DNS funktionsfähig ist, weil Benutzer bei einer langsamen Verbindung auf Aktualisieren klicken, so dass der Name erneut aufgelöst wird. Auf diese Weise ermöglichen Benutzer letztendlich selbst den Ausgleich. DNS-Round Robin hat gegenüber den anderen beiden Mechanismen den Vorteil, dass der Client den Server, mit dem er kommuniziert, direkt identifizieren kann (anhand der IP-Adresse). Bei den anderen beiden Mechanismen erkennt der Client nicht direkt die IP-Adresse des Servers, der möglicherweise die Anforderung bedienen wird (weil dort vom Rand des Netzwerkes aus nachgeschaltet eine virtuell physische Zuordnung erfolgt). Dies hat verschiedene Folgen, beispielsweise wird dadurch das Debuggen auf der aktiven Site schwieriger. Eigenständige Lösungen Es gibt verschiedene Unternehmen, die eigenständige Lösungen für den Lastenausgleich herstellen. Bei den meisten dieser Lösungen handelt es sich um Switches oder Brücken mit zusätzlicher Software zum Verwalten spezieller Weiterleitungen. Die eigenständige Lastenausgleichsmethode lernt die IP-Adressen aller mit ihr verbundenen Server. Je nach Verfügbarkeit der Computer und je nach Ausgleichsalgorithmus nimmt die Lastenausgleichsmethode alle eingehenden Pakete mit derselben IP-Zieladresse entgegen und schreibt sie um, so dass sie die entsprechende IP-Adresse des ausgewählten Servers enthalten. Eingebettete Lösungen: Microsoft-Netzwerklastenausgleich Der Netzwerklastenausgleich von Microsoft Windows 2000 ist eine in Windows 2000 Advanced Server und Windows 2000 Datacenter eingebettete Lastenausgleichslösung. Der Netzwerklastenausgleich erstellt eine freigegeben virtuelle IP-Adresse (Virtual IP, VIP) für ein Cluster von Computern mit Windows. Der Netzwerklastenausgleich gleicht eingehende TCP-Verbindungen zwischen den Mitgliedern des Clusters mithilfe der virtuellen IP-Adresse aus. Der Netzwerklastenausgleich ist ein NDIS-Paketfiltertreiber. Der Netzwerklastenausgleich befindet sich über dem NDIS-Treiber des Netzwerkadapters und unter dem TCP/IP-Stapel. Jeder Computer im Cluster erhält alle für die virtuelle IP-Adresse bestimmten Pakete. Der Netzwerklastenausgleich entscheidet bei jedem einzelnen Paket, auf welchem Computer es verarbeitet werden soll. Wenn das Paket von einem anderen Computer im Cluster verarbeitet werden soll, verwirft der Netzwerklastenausgleich das Paket. Wenn das Paket lokal verarbeitet werden soll, wird es an den TCP/IP-Stapel weitergeleitet. Auf jedem Computer erkennt der Treiber für den Netzwerklastenausgleich alle eingehenden Pakete, weil sich alle Mitglieder des Clusters auf einem freigegebenen Netzwerksegment befinden. Im Wesentlichen wird jedes Paket an jeden Computer übermittelt, und jeder Computer entscheidet, welche Pakete verarbeitet werden. Der Netzwerklastenausgleich verwendet eine verteilte Hashfunktion, um zu ermitteln, welche Pakete auf einem bestimmten Computer angenommen werden sollen. Der Netzwerklastenausgleich hostet Meldungen zum Austauschtakt in beide Richtungen im Sekundentakt. Die Meldung zum Takt enthält einen Überblick über das Clusters aus der Sicht des Hosts. Auf der Grundlage der Meldungen zum Takt erkennt jeder Host den Status jedes Clustermitglieds. Jeder Host entscheidet unabhängig und auf der Grundlage der Hostkennung, der Anzahl der im Cluster vorhandenen Hosts und der im IP-Header des Pakets enthaltenen Informationen, welche Pakete angenommen und welche abgelehnt werden. Tatsächlich partitioniert der Netzwerklastenausgleich den Speicherplatz auf dem IP-Client (durch Hashing) auf alle verfügbaren Clusterhosts und lässt jeden Host einen Teil der Arbeitslast verarbeiten. Beim Netzwerklastenausgleich werden die im Paket enthaltenen Informationen nicht geändert. Durch das Verwenden einer MMC-Konsole kann der Systemadministrator jeden der Hosts aus dem Cluster jederzeit entfernen bzw. zum Cluster hinzufügen. Anwendungsentwurf Internetdienste auf Anwendungsebene sind oft rekursiv aufgebaut und bestehen aus mehreren Diensten, die sich auf vielen Computern befinden. Diese einfache Tatsache ist mit schwerwiegenden Auswirkungen verbunden. Der Anwendungsentwickler ist dafür verantwortlich, der Hardware den geeigneten Code zuzuweisen und die Kommunikationsfähigkeit des i. d. R. großen und komplizierten Computerclusters sicherzustellen. Wegen der unterschiedlichen Computertypen und mehreren Instanzen jedes Typs muss der Entwickler auch die Netzwerkverbindung berücksichtigen. Der Entwickler muss Kommunikationsmuster zwischen Computern sowie den zum Ausgleichen der Computerlast und der internen/externen Netzwerkkapazität erforderlichen und auch angestrebten Mechanismus berücksichtigen. Da Dienste skaliert werden, ist auch die Datenpartitionierung zu bedenken. Bei einem weniger umfangreichen Dienst mit nur einem Back-End-Server spielt die Verfahrensweise bei der Datenpartitionierung keine wichtige Rolle. Da das System skaliert wird und die erforderliche Ausgaberate des Back-End-Servers die Ressourcen eines einzelnen Computers übersteigt (z. B. CPU-Zyklen, Netzwerkbandbreite und Anzahl der Datenträgerspindeln), besteht häufig die Notwendigkeit, eine naheliegende Lösung zum Partitionieren der Daten zu finden. Viele der zurzeit entwickelten Dienste sind sehr parallel, d. h., Daten können problemlos partitioniert werden. Der Entwickler überlegt sich nicht nur, in welcher Weise Daten partitioniert werden können und müssen, sondern auch, wie auf die Daten zugegriffen wird. Zudem entwirft er die Topologie für die Verbindung zwischen den die Anforderungen verarbeitenden Front-End-Computern und den Back-End-Computern. Der Entwickler muss darauf achten, dass er nicht Netzwerkverbindungen zwischen allen Front-End- und allen BackEnd-Computern erstellt. Ein solches Netz kann, je nach Verwendung, positiv oder negativ bewertet werden. Wenn der Dienst jedoch über Active Data Objects (ADO) in ASP auf Computer mit SQL Server zugreift, wird er für jede HTTP-Anforderung Verbindungen zwischen den Front-End- und Back-End-Computern öffnen und unterbrechen. In diesem Fall hätte ein solches Netz selbstverständlich schwerwiegende Folgen. Der Entwickler muss nicht nur ermitteln, in welcher Weise die Datenpartitionierung angesichts der aktuellen Erweiterung der Back-End-Server vorzunehmen ist, sondern auch Vorbereitungen für zukünftige Erweiterungen und neue Versionen treffen. Zu diesem Zeitpunkt muss der Entwickler eine Art virtuelle Ressourcenverwaltung (Virtual Resource Manager, VRM) zur Verfügung stellen oder erstellen, damit zwischen den logischen Daten und der physischen Partition ein gewisses Maß an indirekter Steuerung vorliegt. Wenn neue Back-End-Server online geschaltet werden, muss der Entwickler zur Wiedergabe der neuen Datenpartitionierung die virtuelle Ressourcenverwaltung anpassen. Aufgrund dieser neuen Partitionierung müssen vermutlich die auf einem oder mehreren Back-End-Geräten gespeicherten Daten zu anderen Back-End-Geräten migriert werden. Der Entwickler muss die Migration entweder direkt im Dienst vornehmen oder entsprechende Supporttools bereitstellen. Da ein Dienst mit der Zeit größer und wichtiger wird, wird den kleinsten Einzelheiten bezüglich der Leistung immer mehr Beachtung geschenkt. Da jeder einzelne Computer für eine bestimmte Funktion des Dienstes eingesetzt wird, wird die Aufmerksamkeit des Entwicklers immer stärker auf die einzelnen Vorgänge in den Computern gelenkt. Sind bezüglich der Leistung Veränderungen zu beobachten? Sind bei einem Computer Aspekte zu beobachten, die zu Problemen führen können? Werden auf diesem Computer nicht benötigte Dienste oder Prozesse ausgeführt? Wird die Leistung bestimmter Anwendungen und untergeordneter Anwendungen durch die Dienste verbessert oder verschlechtert? Sie sollten daran denken, dass eine Unterkomponente auf einer großen Anzahl von Computern ausgeführt werden kann. Bei MSN Hotmail haben beispielsweise mehr als 5.700 Front-End-Computer dieselbe Aufgabe. Die Kosten für eine zusätzliche Optimierung werden auf alle Computer verteilt, auf denen die Anwendung oder der Dienst ausgeführt wird. Ebenso wie die Anzahl der Komponenten des Dienstes steigt auch die Wahrscheinlichkeit eines Komponentenfehlers. Aufgrund der verteilten Struktur wird ein Teil des Dienstes wahrscheinlich betriebsbereit bleiben, auch wenn eine Funktion (oder eine lediglich eine Teilmenge der Benutzergemeinde bedienende Funktion) nicht betriebsfähig ist. Der Entwicklers kann die partiellen Ausfälle auswerten. Unter Berücksichtigung von partiellen Ausfällen muss der Entwickler Fehler und/oder die fehlende Verfügbarkeit von untergeordneten Diensten (oder Infrastrukturdiensten) beim Schreiben von Komponenten besonders berücksichtigen und sorgfältig behandeln. Ausfälle sollten von allen externen Komponenten möglichst sorgfältig behandelt werden, und dabei sollten auf keinen Fall neue Fehler verursacht werden, die sich wiederum deutlich auf den Benutzer auswirken würden. Fertige, konfigurierbare Lösungen werden im Allgemeinen gegenüber benutzerdefiniertem Code bevorzugt. Das Design eines Clusters sollte nach Möglichkeit so angepasst werden, dass optimierte Hardware oder Software eingesetzt werden kann und kein benutzerdefinierter Code geschrieben werden muss. Hardwareswitches werden häufig aus folgenden Gründen bereitgestellt: Sie sind zuverlässig, vertraut, vorhersehbar und können problemlos und ohne negative Konsequenzen in ein Netzwerk eingebracht werden. Bei den untersuchten Sites würde eine Lösung den Vorzug erhalten, bei der ein ganzes System aus fertigen, vorkonfigurierten Anwendungen erstellt wird. Obwohl Code eine sehr allgemeine Lösung darstellt, bedarf er für gewöhnlich einer größeren Betriebskoordination als die einfache konfigurationsgesteuerte Lösung. Gleichermaßen wird bei vielen Sites aber auch eine fertige Statusverwaltung für die Benutzerprofile und die Inhaltsverwaltung angestrebt. Das Serveranwendungsmodell wurde in vielen bekannten, kommerziellen Internetsites anderer Unternehmen erfolgreich eingesetzt. Wenn das Verwenden von benutzerdefiniertem Code nicht umgangen werden kann, ist es empfehlenswert, sich beim Entwerfen an bestimmten Aspekten zu orientieren. Dazu gehört z. B., ob tatsächlich ein allgemeines Problem auf einer gemeinsamen Plattform vorliegt oder ob die Situation dem objektorientierten Programmieren entspricht, bei dem eine Klassenbibliothek einfach nicht auf eine sehr große, ausfallgefährdete Domäne skaliert werden kann. Lösungen, die zunächst einfach erscheinen, können sehr schnell kompliziert werden. Mehrere gleichzeitige HTTP-Verbindungen eines Benutzers können entweder kostenintensive Warteschlangen oder Sperren erforderlich machen. Front-End-Server und SMTP-Server können statusbehaftet werden und den Lastenausgleich dadurch sehr kompliziert gestalten. Schließlich können HTTP-Verbindungen von sehr kurzer Dauer sein: HTTP 1.0-Clients werden bei jeder Seiten- oder Elementanforderung neu verbunden. ActiveX®Steuerelemente können aufgrund der großen Unterschiede zwischen den Clients beim Debuggen Probleme erzeugen. Daher ist DHTML in einigen Fällen die bessere Lösung, weil es so strukturiert ist, dass kompatible Clients ordnungsgemäß heruntergestuft werden. Das Skalieren der Netzwerkverbindung von Front-End-Computern mit SQL Server stellt eine enorme Herausforderung dar. Computer mit SQL Server werden bei einer SQL-Replikation, in deren Verlauf eine hohe Anzahl von Transaktionen durchgeführt wird, schnell überlastet. Folgende Probleme sind bei einem Computer mit SQL Server oder einem anderen Datenbanksystem zu erwarten und einzuplanen: Irrtümliches Löschen wichtiger Daten. Einfügen "problematischer" Daten. (Daten, die eigentlich gar nicht hätten eingefügt werden sollen.) Programmgesteuerte Beschädigung von Daten. (Daten, in die von einer Anwendungskomponente absichtlich Fehler eingefügt wurden oder die von den Komponenten absichtlich unbrauchbar gemacht wurden.) Daten, die Anwendungseinschränkungen verletzen. (Daten, die zum System in korrekter Weise hinzugefügt wurden, die aber von einer oder mehreren Anwendungskomponenten nicht verarbeitet werden können.) Durch diese Probleme kann der Verarbeitungsprozess unterbrochen werden, auch wenn die zur Verarbeitung erforderliche Hardware vollständig verfügbar ist. Abgesehen von diesen Problemen kann sich eine RogueTransaktion (beispielsweise ein schlecht gestalteter Bericht, der während des Generierens wichtige Anwendungsdaten sperrt) so negativ auf das System auswirken, dass die Anwendung durch die Ausführung der Transaktion stark beeinträchtigt wird, auch wenn Hardwareressourcen für die Ausführung zur Verfügung stehen. Um den Bedenken bezüglich dieser Daten und dem seltenen Fall eines vollständigen Clusterausfalls vorzubeugen, sollten für das die Transaktionen verarbeitende Cluster Daten- und Protokollsicherungen durchgeführt werden. Eine vollständige Sicherung der Anwendungsdatenbank sollte jede Nacht erfolgen, während es sich empfiehlt, Protokollsicherungen alle 15 Minuten auszuführen. Die Daten- und Protokollsicherungen sollten fortwährend auf einem im Standbymodus bereitgestellten Server angewendet werden. Der Server sollte sich auf demselben Netzwerksegment befinden wie das die Transaktion verarbeitende Cluster, und er sollte für den Fall schwerwiegender Datenprobleme über die zum Behandeln der Anwendungslast erforderlichen Hardwareressourcen verfügen. Die Datenbank ist ein universelles Repository, auf das häufig zugegriffen wird. Zentralisierte Datenbanken können bezüglich der Netzwerkverbindungen und der Bandbreite Probleme verursachen. Es ist sinnvoll, die Zeit und Arbeit zu investieren, eine verteilte Datenbank mit hoher Verfügbarkeit zu erstellen. In einer Dienstarchitektur hostet jede Dienstgruppe für globale Anforderungen ihre eigene Datenbank mit einem Aggregator für höhere Schichten. Diese Architektur maximiert die Unabhängigkeit einer Dienstgruppe und verbessert die Skalierbarkeit des Dienstes als Ganzes. Freigegebene Adressraumdienste können beim Verwenden von benutzerdefiniertem Code sehr anfällig sein. Während das Debuggen einzelner Threads auf einem Onlineserver schwierig oder sogar unmöglich sein kann, sind isolierte Prozesse stabil und können problemlos debuggt und neu gestartet werden. Sowohl Threads als auch Prozesse befinden sich auf einer zu niedrigen Ebene, um clusterweite Parallelität darzustellen, weil dabei viele Computer beteiligt sind. Daher schließen Dienste Synchronisierung häufig direkt in ihre Infrastruktur ein. Bei einem der Internetdienste wurde ASP vermieden, weil der Eindruck entstand, dass das Modell die Verwaltung der Objektlebensdauer und die Verwaltung des Status2 komplizierter gestaltete. Derartige Probleme können im Allgemeinen durch eine gute Programmierung vermieden werden. Probleme im Zusammenhang mit Schleifen, umfangreicher Datenbankberechnung (wie beispielsweise Minimum, Maximum und Sortierung) und einem erhöhten Datenbankzugriff sollten möglichst vermieden werden. Die Speicherverwaltung ist beim Rendern vieler Seiten von zentraler Bedeutung. Unabhängig von anderen Änderungen bleibt die maximale Anzahl von Seitenfehlern konstant, die vom Computer pro Sekunde behandelt werden können. Zur Verbesserung der Leistung sollte vor dem Auftreten des nächsten Seitenfehlers möglichst viel Arbeit erledigt werden. Weitere Informationen zur automatischen Speicherverwaltung finden Sie unter ASP.NET und im .NET Framework (englischsprachig). Die an einem Standort befragten Designer erwarten, dass Anwendungen ausfallen. Sie entwerfen getreu dem Grundsatz: Wenn eine Anwendung heruntergefahren werden muss, muss dies schnell geschehen, und sie muss schnell wieder verfügbar sein - sie sollte nicht in einem nicht reagierenden Zustand beibehalten werden.. Der Dienst-Manager von Windows 2000 startet ausgefallene Dienste automatisch neu. Bei einer der Sites wurde versucht, bei einem Ausfall den bestmöglich herabgestuften Dienst bereitzustellen. Wenn beispielsweise ein untergeordneter Dienst nicht in eine Datenbank schreiben kann, stellt er die im schreibgeschützten Modus erforderliche Funktionalität bereit. Vorgänge nutzen schreibgeschützte Vorgänge, um Onlinesicherungen der Benutzerdatenbank zu ermöglichen. Die Homepage rendert alle enthaltenen Informationen, damit der Server nicht HTML-Informationen im Zusammenhang mit Schlagzeilen einschließt, falls beispielsweise Nachrichtenschlagzeilen nicht verfügbar sind. Die meisten Dienste können Fehler selbstständig beheben. Wenn beispielsweise der E-Mail-Dienst erkennt, dass der Nachrichtenindex mit keiner der Nachrichten übereinstimmt, erstellt er den Index automatisch neu. Anwendungsaktualisierungen Ein webbasierter Dienst muss durchgehend ausgeführt werden, d. h., eventuelle Herabstufungen des Dienstes dürfen für den Kunden nicht sichtbar sein. Selbst eine kurzzeitige Unterbrechung der Verfügbarkeit pro Monat kann vom Kunden als zu starke Herabstufung wahrgenommen werden. Außer bei einem Update des Betriebssystems sollte der Server beim Aktualisieren einer Anwendung immer weiter ausgeführt werden. Eine Möglichkeit besteht darin, Server hinter Lastenausgleichsgeräten zu platzieren und sie zum Aktualisieren und zum Warten auszuschalten. Es gibt zwei Arten von Anwendungsaktualisierungen: Inhalts- und Codeaktualisierungen. Sowohl bei Inhalts- als auch bei Codeaktualisierungen ist es wichtig, den Dienst nicht anzuhalten. Durch Inhaltsaktualisierungen werden nur Datendateien geändert, und zwar i. d. R. die Dateien, die ermitteln, was dem Benutzer auf dem Bildschirm angezeigt wird. Inhaltsaktualisierungen werden nach einem eigenen Zeitplan ausgeführt. Für Aktualisierungen kann kein Rolloutprozess direkt ausgeführt werden, wenn die Daten vor Ort aktualisiert werden. Sie können auch befristet sein. Die Aktualisierungen werden zusammen mit Batchaufträgen für die Aktualisierung, die zum gewünschten Zeitpunkt ausgelöst werden, auf den Servern an einem Stagingstandort ausgeführt. Die befristete Aktualisierung wird verwendet, wenn es für die Integrität einer Anwendung eine Rolle spielt, dass die gesamte Site gleichzeitig aktualisiert wird. Dies kann jedoch beim Aktualisieren von mehreren Tausend Servern innerhalb eines einzigen Netzwerkes nicht erreicht werden. Da bei Benutzereingriffen für gewöhnlich viele Mausklicks ausgeführt werden, sollte ein Benutzer nicht zwischen verschiedenen Codeversionen (bei denen verschiedene Front-End-Server beteiligt sind) vor und zurück springen. Dies könnte zu Problemen wie der Inkonsistenz im Format bis zu (offensichtlich) halbimplementierten neuen Features führen. Hinweis Eine gute Lösung dieses Problems sollte beinhalten, dass Benutzer, deren Besuch der Site vor der Aktualisierung mit Version x begonnen hat, während des Besuches weiterhin zu Servern mit Version x geleitet werden. Neue Benutzer werden zur Version x+1 geleitet. Die Markteinführung einer neuen Version eines Dienstes und der untergeordneten Komponenten ist mit Risiken verbunden. Das gleichzeitige Bereitstellen neuer Komponentversionen für den Rolloutprozess ist sehr wichtig. Im Fall eines Fehlers sollte jede neue Bereitstellung auch wieder rückgängig gemacht werden können. Zudem sollte eine inkrementelle Rolloutstrategie vorliegen, die in Echtzeit angepasst werden kann. Bei vielen Sites werden für umfassende Aktualisierungen gleichzeitige physische Vorgänge verwendet. Die neue Version eines Dienstes wird auf neuer Hardware parallel zum vorhandenen Dienst bereitgestellt. Zur Aktivierung des neuen Dienstes wird entweder ein DNS- oder ein Routerswitch verwendet. In anderen Sites werden Aktualisierungen auf derselben Hardware in parallelen Verzeichnisstrukturen ausgeführt. Da das Überwachen von Änderungen beim Verwalten einer auf allen Stufen konsistenten Site eine wichtige Rolle spielt, sollte ein Stagingserver bereitgestellt werden. Der Stagingserver dient als Speicherort für die bereitgestellte Website sowie für SQL-Skripts oder andere Skripts. Der Stagingserver wird zwischen der Entwicklung/Test-Site und der Produktionsumgebung platziert. Das Entwicklungsteam entwirft, erstellt und testet Websiteinhalte in einer überwachten Testumgebung, bis diese Inhalte als für die Produktionsumgebung geeignet angesehen werden. Diese Daten werden anschließend an einen Stagingserver gesendet, auf dem die Freigabe für die Produktionsumgebung überwacht wird. Nach der Aktualisierung eines Clustercontrollers mit neuem Inhalt vom Stagingserver verwendet der Controller zum Replizieren der Inhalte auf die Mitgliedsserver des Clusters einen Mechanismus für die Inhaltsreplikation. Verwaltbarkeit Bei allen großen Internetdiensten bestehen im Zusammenhang mit dem Betrieb und der Wartung bestimmte Risiken. In jeder Instanz verwendet der Dienst verschiedene identisch konfigurierte Computer. Bei einer solchen Architektur besteht die Notwendigkeit, dass alle standardmäßigen Systemverwaltungsfunktionen, einschließlich des Betriebssystems und der Anwendungsaktualisierungen, sehr schnell, zuverlässig, remote verwendbar und nicht interaktiv sind sowie in Skriptform vorliegen können. Der Administrator kann sich nicht mit allen Computern gleichzeitig beschäftigen. Das Integrieren der Verwaltung mehrerer Server bedarf einer konsistenten, umfassenden und durchdachten Lösung. Ziel ist es, alle Computer als ein Aggregat zu verwalten. Dies gilt gleichermaßen für die Anwendungsverteilung und die Systemoptimierung. Die meisten Aufgaben werden pro Website, pro Postfach, pro Benutzer, pro Kunden und nicht pro Knoten ausgeführt. Da Web- und Objektdienste sehr CPU-intensiv sind, ist es verständlich, warum die meisten Websites für diesen Teil des Dienstes kostengünstige Klone verwenden. Ein weiterer Vorteil besteht darin, dass Warensoftware wesentlich leichter zu verwalten ist als die traditionellen Dienste, die besondere Fähigkeiten der Betreiber und Administratoren voraussetzen. Bei dieser Art von Diensten bestehen hinsichtlich der Architektur keine Größeneinschränkungen. Erwartungsgemäß wächst eine Internetsite immer weiter, und eingebaute Beschränkungen, die anfangs zu hoch erscheinen, reichen irgendwann nicht mehr aus und müssen mithilfe von Ressourcen neu festgelegt werden, die zum Steigern der Siteleistung dienen. Als MSN Hotmail von Microsoft erworben wurde, existierten 9 Millionen Konten, inzwischen sind es über 110 Millionen Konten. Während der Standarddatenfluss im Wesentlichen unverändert ist, sind bezüglich der Skalierung der Software- und Hardwarearchitektur entscheidende Änderungen vollzogen worden. MSN Hotmail besteht aus mehreren Modulen, wobei jedes Modul in verschiedenen Duplikaten vorliegt und beinahe unbegrenztes Skalieren möglich ist. Die Front-End-Webserver beinhalten die gesamte Logik der Benutzeroberfläche und einen Teil der Unternehmenslogik. Der Großteil dieser Server führt bei jedem Mausklick irgendeinen Generierungscode für Seiten aus. Einige Server bedienen statischen Inhalt. Die Verwaltung dieser Server verwendet dieselben Methoden wie die Front-End-Server. Die Anzahl der Front-EndServer beläuft sich auf über 5.700, die alle identisch konfiguriert sind. Für die Verwaltung der Site ist es wichtig, dass die Server im Wesentlichen identisch sind. Hinsichtlich der Hardware gelten andere Regeln - nach dem Einrichten der Hardwarekonfiguration ist es einfacher, Rollouts von Kopien ausführen, als ein neueres Modell zu qualifizieren. Bei einem solchen Umfang werden die Systemkosten durch verschiedene Dinge beeinflusst. Das Hinzufügen eines VGA-Monitors oder eines zweiten Netzwerkadapters zu einem Server oder das Anschließen eines seriellen Kabels an einen Server ist für einen einzelnen Computer möglicherweise sehr kostengünstig. Beim Erwerb Tausender derartiger Geräte handelt es sich jedoch bereits um eine bedeutende Investition, für die überzeugende Gründe vorliegen sollten. Bei einem Dienst war das serielle Netzwerk für die Out-of-Band-Verwaltung für jeden Anschluss teurer als das Netzwerk für den 100 Mbit/s umfassenden Inhalt. Remoteverwaltung Das Verhältnis von Administratoren zu Servern war bei den untersuchten Sites im Normalfall sehr gering (beispielsweise war bei einer Site ein Administrator jeweils für 250 Computer zuständig). Ein Modell mit einem Verhältnis von 1:1 ist nicht realisierbar. Abgesehen davon ist das Verwaltungspersonal häufig geografisch von den Computern getrennt. Deshalb muss alles außer der physischen Installation und der Reparatur automatisch erfolgen und mit einer Remoteverwaltung ausführbar sein. Im Allgemeinen sollten Computer sich selbst überwachen und Fehler beheben. Entweder bedienen sie Seiten, oder sie sind nicht aktiv. Wenn die Anzahl der nicht aktiven Computer einen gewissen Schwellenwert übersteigt (i. d. R. 5-10 % eines Clusters), ergreift ein Administrator einfache Schritte, um den Computer zu reparieren. Oft ist es einfacher (und kostengünstiger), neue Abbilder der Computer zu erstellen oder diese zu ersetzen, als das Problem vollständig zu diagnostizieren. Nach dem Aufbau und dem Verkabeln eines Computers kann das Betriebspersonal einen Start ohne Diskette ausführen, ein aktuelles Betriebssystem sowie Anwendungssoftware laden und den neuen Computer zum Dienst hinzufügen. Der Computer selbst wird danach nur noch angerührt, wenn bei einer der Hardwarekomponenten ein Fehler auftritt oder wenn er zu einem späteren Zeitpunkt gegen ein neueres Modell ausgetauscht wird. Vorgänge unterliegen einer Remoteüberwachung, d. h., die gesamte Verwaltung erfolgt über Remoteshells und das Erstellen von Skripts. Aktualisierungen werden mithilfe von Tools zur Softwarereplikation gleichzeitig an alle aktiven Computer weitergeleitet. Featureaktualisierungen werden inkrementell angewendet. Zum Verwalten einer großen Site muss das Verwalten aller Komponenten von einer einzigen Remotekonsole aus möglich sein, wobei RACS und RAPS als Entitäten behandelt werden sollten. Alle Geräte und Dienste sollten Ausnahmeereignisse generieren, die von einem automatischen Operator gefiltert werden. Die Betriebssoftware behandelt normale Ereignisse, fasst sie zusammen und hilft dem Operator beim Verwalten von Ausnahmeereignissen wie dem Nachverfolgen des Reparaturprozesses und dem Verwalten des Farmwachstums und der Entwicklung. Die Betriebssoftware erkennt die Fehler und koordiniert die Reparatur. Die Herausforderungen wachsen exponentiell, wenn die Anfrageverarbeitung sich auf mehrere funktionelle Stufen erstreckt. Automatische Vorgänge vereinfachen das Verwalten der Farm, aber bei der Sicherstellung der Siteverfügbarkeit spielen sie eine noch wichtigere Rolle. Das Automatisieren verringert die Anzahl manueller Verfahrensweisen und vermindert das Risiko eines Operatorfehlers. Bei der Software und auch bei den Hardwarekomponenten müssen Onlinewartung und Ersetzungen zugelassen sein. Tools zum Unterstützen der Bereitstellung neuer Softwareversionen und für das Staging (Vorbereiten) innerhalb einer Site werden benötigt, damit der Aktualisierungsprozess geregelt verläuft. Dies gilt sowohl für die Anwendungs- als auch die Systemsoftware. Einige große Internetsites stellen wöchentlich oder sogar täglich Anwendungsänderungen bereit. Für den Remotezugriff auf Computer können Terminaldienste verwendet werden. Andere Remoteverwaltungskonsolen wie Virtual Network Computing (VNC), eine Remotekonsole von AT&T, oder PCAnywhere ermöglichen Remotedebuggen und Remotevorgänge von nahezu jeder Plattform. Skripterstellung, Leistungsüberwachung und Optimierung Beim Verwalten einer Site mit mehreren Tausend Computern sind Tools, bei denen eine Skripterstellung möglich ist, gegenüber einem GUI-Tool (Graphical User Interface, grafische Benutzeroberfläche), bei dem dies nicht möglich ist, zu bevorzugen. Bei der Messaginginfrastruktur der Internetdienste ist diese Bewertung besonders offensichtlich. Nur eine der besuchten Sites verwendet das computerübergreifende DCOM (Distributed Component Object Model). Sogar Sites, die Kommunikationsmuster wie den Remoteprozeduraufruf (Remote Procedure Call, RPC) und proprietäre Software verwenden, verwenden das einfache Weiterleiten von Nachrichten. Befehlszeilentools haben den Vorteil, dass sie sofort skriptfähig sind. In einigen Fällen können auch für Tools ohne Befehlszeile Skripts erstellt werden, wie beispielsweise für Windows Scripting Host. Bei Sites mit Hunderten von Computern sind Filter-, Warn- und Visualisierungstools ein absolutes Muss. Bei einem Schwellenwert von mehr als ein paar Dutzend Computern sind Visualisierungstools zum Filtern von Auffälligkeiten, zum Erkennen wichtiger Ereignisse und zum Beurteilen des Servicestatus erforderlich. Zudem sind geeignete Messtools wichtig. Ein Administrator muss jedes Ereignis protokollieren können, aber u. U. muss er die Ereignisdaten ändern, wenn sich die Anforderungen ändern. Einige der Selbsttest- und Überwachungsfeature der Server werden von benutzerdefinierten Vorgängen (i. d. R. Skripts) und in vordefinierten Intervallen ausgeführt. Diese Intervalle können Zeiträume von einer Minute bis zu einer Woche umfassen. Bei den untersuchten Internetdiensten werden umfassendes Protokollieren und zählerbasiertes Überwachen und, soweit möglich, Remoteverwaltung verwendet, um eine permanente Verfügbarkeit sicherzustellen und Daten zur Verbesserung der Infrastruktur bereitzustellen. Neben der Remoteverwaltung wird bei diesen Sites auch Remoteüberwachung verwendet. Die Leistungsüberwachung erfolgt entweder durch Serverabfragen oder automatisch. Auf jedem Server steht für dieses Überwachen ausreichend freier Netzwerkplatz zur Verfügung, so dass der primäre Vorgang nicht beeinträchtigt wird. Der Entwickler muss Laufzeitinstrumentation hinzufügen. Die Quellen für die Daten der Laufzeitinstrumentation dienen zwei unterschiedlichen Zwecken: dem Unterstützen der Zustandsüberwachung des aktuellen Systems und dem Nachvollziehen des Systemverhaltens während tatsächlicher Onlinevorgänge. Ein besseres Verständnis des aktuellen Systems erhöht die Möglichkeit einer Verbesserung der Implementierung. Bei den erfolgreichsten Diensten wurden umfassende Überwachungs- und Protokollierungsfunktionen in die Architektur integriert. Integrierte Verwaltungsfunktionen Das Integrieren aller Schichten der Dienstentwicklung und -verwaltung hat drei wichtige Vorteile. Zum einen werden so verschiedene Abwehrschichten für die Sicherheit und die Fehlertoleranz geboten. Zum anderen liefert es umfassende Optimierungsmöglichkeiten, da Probleme dort gelöst werden können, wo es am einfachsten ist. Wenn eine Lösung nicht das gewünschte Ergebnis liefert, kann das Problem häufig auf einer anderen Systemschicht behoben werden. Zudem wird durch das Integrieren das Teamgefühl gestärkt, denn das gesamte Team arbeitet zusammen. Probleme können leicht und ohne die Hilfe Dritter gelöst werden. Die folgenden Zitate aus einer der Sites stehen als Beispiele für den Umgang mit Entwicklung und Vorgängen: "Die Anwendung kann sich nicht selbst schützen, deshalb fügen wir Schutz (in Form von Paketfilterung) auf der Netzwerkschicht hinzu. Der Host kann sich möglicherweise selbst schützen, falls beim Host jedoch ein Fehler auftritt, muss der Netzwerkschutz vorhanden sein." "Die softwaregestützte Methode für den Lastenausgleich bietet uns grundlegendes Dienstrouting. Unser Netzwerkteam wird größtenteils Switches zur Netzwerkstruktur hinzufügen, um das vorhandene Dienstrouting zu erweitern." Der monitorlose Betrieb bei diesen Systemen und die Tatsache, das sie an einem Remotestandort stehen, hat einen großen Einfluss auf die Verwaltung der Systeme. Monitorloser Betrieb bedeuten, dass jede direkte Interaktion über eine Remotesitzung (Telnet oder Terminaldienste) erfolgt. Es ist keine Person zum Erkennen eines wichtigen Dialogfeldes auf der Konsole vor Ort, und nicht einmal ein STOP-Fehler ist offensichtlich. Der Remotebetrieb beinhaltet, dass der Zugriff auf einen Computer mit bestimmten Kosten verbunden ist. Die Sites werden häufig von beauftragten Unternehmen bedient, deren Aufgabe sich darauf beschränkt, ausgefallene Server zu ersetzen und auf Anfrage Neustarts auszuführen. Auch wenn es möglich ist, einen Monitor und eine Tastatur an ein ausführendes System anzuschließen, stellt dies doch eine Ausnahme dar. Personal Bei der Einführung einer großen Internetsite werden vor allem Architekten und Entwickler mit fundierten Kenntnissen in verteilter Datenverarbeitung benötigt. Zum Sicherstellen einer hohen Verfügbarkeit reicht auch eine große Anzahl von Entwicklern und Architekten nicht aus, nur besonders fachkundiges Betriebspersonal kann diese Verfügbarkeit sicherstellen. Beim Entwickeln eines großen Internetdienstes spielen die Anforderungen, die durch die betriebsbedingten Einschränkungen an den Dienst gestellt werden, eine ebenso wichtige (oder vielleicht sogar eine größere) Rolle wie die durch die Endbenutzer gestellten Anforderungen. In der Umgebung der dedizierten PC-Hardware, in der eine große Anzahl von Ressourcen zur Verfügung steht, haben Entwickler sich häufig weniger um eine leichte Handhabung als um für den Endbenutzer erkennbare Anwendungsfeatures bemüht. Bei einem Internetdienst spielen eine unkomplizierte Verwaltung, eine einfache Handhabung bei der Konfiguration sowie permanente Statusüberwachung und Fehlererkennung eine ebenso wichtige Rolle wie alle anderen Anwendungsfeatures. Deshalb müssen Entwickler den Kontext, in dem ein Dienst bereitgestellt und ausgeführt wird, vollständig verstehen. Andererseits muss das Betriebspersonal alle Partitionierungsschemas, Verwaltungstools und Kommunikationsmuster verstehen, die für den Dienst und dessen Laufzeitpräsenz im Web charakteristisch sind. Da in erster Linie die Betreiber für die Aufrechterhaltung des Dienstes sorgen, sind sie diejenigen, die sich am häufigsten an die Entwickler wenden. Es muss unbedingt bekannt sein, dass Entwickler Code und Betreiber den Prozess erstellen. Ebenso wie für einen Dienst gute Entwickler benötigt werden, sind zum Erstellen geeigneter Prozesse auch gute Betreiber erforderlich. Der Code ist zwar die wichtigste Komponente der Produkte, aber die wichtigste Komponente der Dienste sind die Prozesse. Je größer ein Unternehmen wird, desto wichtiger wird das genaue Dokumentieren von Prozessen und Prozeduren, die von Tools unterstützt werden. In einer Produktionsumgebung spielen Kommunikation und Koordination eine sehr wichtige Rolle. In den meisten Fällen ist eine unsachgemäße Handhabung (meistens aufgrund von Kommunikationsproblemen) der häufigste oder zweithäufigste Grund der für den Kunden offensichtlichen Dienstausfälle. Betreiber sind nicht nur Kunden, sie müssen auch eng mit den Entwicklern zusammenarbeiten. Das Betriebspersonal muss nicht nur an der Entwicklung, sondern auch an der Bereitstellungsplanung des Dienstes beteiligt werden. Während die Entwickler den Dienstcode erstellen, erstellen die Betreiber (manchmal gemeinsam mit den Entwicklern) die Prozesse, durch die die permanente Funktionsfähigkeit des Dienstes ermöglicht wird. Oberstes Ziel der Entwickler sollte es sein, die Arbeit der Betreiber zu erleichtern Bei den größten und erfolgreichsten der für das vorliegende Whitepaper untersuchten Dienste sind die Betreiber intensiv an der Produktentwicklung beteiligt. Die Betreiber probieren Feature häufig schon in ein oder sogar zwei Vorabversionen vor der eigentlichen Softwareversion aus. Mindestens in einem Fall beurteilten die Betreiber die Skalierbarkeit eines bestimmten Features als unzureichend, lange bevor die Entwickler zu dem gleichen Ergebnis gelangten. Die Dienstarchitektur sollte von den Betreibern nicht nur oberflächlich verstanden werden. Bei zwei Sites haben die Betreiber den Dienst während eines ernsten Betriebsproblems wiederholt aufrechterhalten, da sie ihre Kenntnisse in Bezug auf die Systemarchitektur einsetzen konnten. Dabei wurden Features teilweise in einer Weise genutzt, die von den Entwicklern gar nicht vorgesehen war. Auswahl des Betriebssystems für den Server: Windows 2000 Server Während anfangs keiner der untersuchten Internetdienste zur Verwendung von Windows 2000 entwickelt wurde, wurde bei all diesen Diensten zu einem späteren Zeitpunkt der Großteil der oder sogar alle Server entsprechend aktualisiert oder nach Windows 2000 migriert (MSN Hotmail führt Windows 2000 auf den Front-End-Servern aus). Wenn Windows 2000 als Basisbetriebssystem für besonders große Internetdienste verwendet wird, wird für eine optimale Leistung das Deaktivieren nicht benötigter Dienste und das Installieren möglichst weniger Optionen empfohlen. Bei der Entwicklung von Windows stehen viele Ressourcen zur Verfügung. Windows weist mit hoher Wahrscheinlichkeit eine größere Komplexität als die freien Unix-Verteilungen auf und bietet bei korrekter Verwendung eine effektive Lösung. (Die Herausforderung besteht darin, den Administratoren dies verständlich zu machen.) Die Entwicklungsplattform von Windows 2000, insbesondere Visual Studio, bietet gegenüber anderen Plattformen einen großen Vorteil. Die Leistungsfähigkeit von Visual Studio auf FreeBSD ist besonders hoch, obwohl auch Solaris und Linux einige leistungsfähige Tools beinhalten. Auch die hervorragende Entwicklungsplattform hat einen positiven Einfluss auf den Betrieb. Windows 2000 bietet wohl auch eine bessere Überwachungsinfrastruktur als die eher elementaren Tools zum Erstellen von Ereignisberichten und zur Leistungsüberwachung von UNIX. Windows 2000 bietet eine Reihe leistungsstarker integrierter Features zur Ereignisprotokollierung und Leistungsüberwachung. Beachten Sie, dass diese mit Bedacht verwendet werden sollten, denn besonders die Ereignisprotokollierung verursacht Personal- und Systemkosten, die berücksichtigt werden sollten. Mithilfe besserer Tools für die Entwicklung und das Debuggen können Features schneller entwickelt werden und Leistungsengpässe schneller und besser erkannt werden. Im Allgemeinen sind die für die Entwicklung der MSN Hotmail-Site zuständigen Mitarbeiter wesentlich zufriedener und produktiver, wenn sie zur Erstellung der Codebasis für die Front-End-Server eine moderne interaktive Entwicklungsumgebung verwenden. Sie berichten, dass Sie das Verwenden des WindDBG-Debuggers (im Lieferumfang von Windows 2000 enthaltener Debugger für Betriebssysteme) in einer aktiven Site zum Nachverfolgen und Diagnostizieren von auftretenden Problemen in Echtzeit als effektiver bewerten, als beispielsweise GDB an einen vorübergehenden CGI-Prozess anzuhängen oder den Befehl printf zum Debuggen zu verwenden. Entwickler kamen zu dem Ergebnis, dass sie Fehler nun innerhalb weniger Minuten und nicht erst nach Tagen identifizieren und beheben können. Durch das Verwenden von IceCAP und Quantify können Entwickler und Betreiber die Leistung optimieren und tatsächlich nachvollziehen, was der Code bewirkt, und haben somit eine bessere Kontrolle. Das Installieren von UNIX auf einem PC ist insofern schwieriger, als ein besseres Wissen bezüglich der Hardware erforderlich ist. Einer der Vorteile der Verwendung kommerzieller, vorkonfigurierter Betriebssysteme besteht darin, dass die gesamte Verifizierung der Treiber bereits abgeschlossen ist. Es kann problemlos bestätigt werden, dass die Hardware keine offensichtlichen Schwierigkeiten mit dem Betriebssystem hat und dass sie daher bedenkenlos bereitgestellt werden kann. Auch im Hinblick auf die Leistung und die Kosten ist die Verwendung von Windows 2000 Server zu empfehlen. Das CGI-Modell mit nur einem Prozess pro Socket ist nicht besonders effektiv. Durch das Verschieben zu einer Anwendung mit mehreren Threads wird der Durchsatz der einzelnen Computer wesentlich verbessert, und dadurch kann die Anzahl der Computer pro Site verringert werden. Einer der wesentlichen Gründe, die für das Verschieben zu Windows 2000 sprechen, ist die Internationalisierung. Windows 2000 enthält eine systemeigene Unterstützung des Unicode-Zeichensatzes, so dass zum Unterstützen mehrerer Sprachen keine Codeseiten oder andere Problemumgehungen benötigt werden. Die in Windows 2000 verfügbaren Softwaretools, die verschiedene lokalisierte Lösungen liefern, sind vermutlich weiter entwickelt als die meisten UNIX-Systeme. Besonders bei Internetdiensten ist es wichtig, dass das Lokalisieren von Sites unkompliziert und effektiv ist. Beim Einrichten oder Aktualisieren einer großen Internetsite müssen Betreiber viele Computer gleichzeitig bereitstellen. Dazu werden Abbilder der Software benötigt. Im Lieferumfang von Windows 2000 Server ist das Dienstprogramm Sysprep enthalten, durch dessen Verwendung das Vorbereiten von Abbildern des Betriebssystems vereinfacht wird. Nachdem mithilfe von Sysprep ein Abbild erstellt wurde, kann dieses unter Verwendung von Ghost, ImageCast oder der Remoteinstallationsdienste (Remote Installation Services) verteilt werden. Schlussfolgerungen Beim Verlagern des Interesses vom Produkt zu dienstleistungsorientierten Märkten müssen Entwickler und Architekten ihre Einstellung ändern und sich vor allem auf die Verwaltbarkeit, Skalierbarkeit und Verfügbarkeit konzentrieren. Die wichtigste Veränderung hinsichtlich der Einstellung und Vorgehensweise beim Erstellen und Verwalten sehr großer Internetdienste ist die Erkenntnis, dass Internetdienste immer verfügbar sein müssen. Durch diese Tatsache wird alles beeinflusst, von den anfänglichen Entwurfskriterien bis hin zu langfristigen Aspekten im Zusammenhang mit der Verwaltung. Weitere Informationen Weitere Informationen zu den in diesem Whitepaper vorgestellten Technologien finden Sie in folgenden Ressourcen: Scalability Terminology: Farms, Clones, Partitions, and Packs: RACS and RAPS (englischsprachig) Introducing Windows 2000 Clustering Technologies (englischsprachig) Windows Clustering Technologies: Cluster Service Architecture (englischsprachig) Network Load Balancing Technical Overview (englischsprachig) Cluster Service and Load Balancing Products from Industry Partners (englischsprachig) Internet Information Services 5.0 Technical Overview (englischsprachig) Application Services Technical Overview (englischsprachig) Microsoft Windows DNA Building Web Solutions (englischsprachig) Monitoring Reliability and Availability of Windows 2000-based Server Systems (englischsprachig) Windows DNA-Architekturmodell: Eine skalierbare Geschäftsobjektarchitektur mit höchster Verfügbarkeit oder Architectural Design: A Scalable, Highly Available Business Object Architecture (englischsprachig) Microsoft SQL Server Home Site (englischsprachig) Danksagung Für die technische Beratung und das zur Verfügung gestellte Quellenmaterial danken wir: Galen Hunt, Researcher, Microsoft Research Steven Levi, Senior Researcher, Microsoft Research David Brooks, Program Manager, US-BED Server OS Jeremy Doig, Operations Manager, MSN Hotmail Für Auszüge aus ihrem Dokument "Scalability Terminology: Farms, Clones, Partitions, and Packs: RACS and RAPS" (englischsprachig) danken wir: Bill Devlin, Group Manager, US-PACE Jim Gray, Distinguished Engineer, Microsoft Research Bill Laing, Architect, Microsoft Enterprise Server Products George Spix, Architect, Microsoft Enterprise Server Products © 2001 Microsoft Corporation. Alle Rechte vorbehalten. Die in diesem Dokument enthaltenen Informationen stellen die behandelten Themen aus der Sicht der Microsoft Corporation zum Zeitpunkt der Veröffentlichung dar. Da Microsoft auf sich ändernde Marktanforderungen reagieren muss, stellt dies keine Verpflichtung seitens Microsoft dar, und Microsoft kann die Richtigkeit der hier dargelegten Informationen nach dem Zeitpunkt der Veröffentlichung nicht garantieren. Bei diesem Dokument handelt es sich um ein vorläufiges Dokument, das ausschließlich zu Informationszwecken dient. MICROSOFT SCHLIESST FÜR DIESES DOKUMENT JEDE GEWÄHRLEISTUNG AUS, SEI SIE AUSDRÜCKLICH ODER KONKLUDENT. Die Benutzer/innen sind verpflichtet, sich an alle anwendbaren Urheberrechtsgesetze zu halten. Unabhängig von der Anwendbarkeit der entsprechenden Urheberrechtsgesetze darf ohne ausdrückliche schriftliche Erlaubnis der Microsoft Corporation kein Teil dieses Dokuments für irgendwelche Zwecke vervielfältigt oder in einem Datenempfangssystem gespeichert oder darin eingelesen werden, unabhängig davon, auf welche Art und Weise oder mit welchen Mitteln (elektronisch, mechanisch, durch Fotokopieren, Aufzeichnen usw.) dies geschieht. Microsoft Corporation kann Inhaber von Patenten oder Patentanträgen, Marken, Urheberrechten oder anderem geistigen Eigentum sein, die den Inhalt dieses Dokuments betreffen. Die Bereitstellung dieses Dokuments gewährt keinerlei Lizenzrechte an diesen Patenten, Marken, Urheberrechten oder anderem geistigen Eigentum, es sei denn, dies wurde ausdrücklich durch einen schriftlichen Lizenzvertrag mit der Microsoft Corporation vereinbart. © 2001 Microsoft Corporation. Alle Rechte vorbehalten. Microsoft, Windows, Windows NT, ActiveX, Hotmail, SQL Server und Visual Studio sind entweder eingetragene Marken oder Marken der Microsoft Corporation in den USA und/oder anderen Ländern. Weitere in diesem Dokument aufgeführte Produkt- oder Firmennamen können geschützte Marken ihrer jeweiligen Inhaber sein. Microsoft Corporation • One Microsoft Way • Redmond, WA 98052-6399 • USA 0601 1 Aufgrund der schnellen Veränderungen im Zusammenhang mit Internetdiensten sind die in diesem Dokument genannten Zahlen zum Zeitpunkt der Veröffentlichung möglicherweise nicht mehr aktuell. 2 Bei der Verwendung von ASP.NET treten diese Probleme nicht auf.