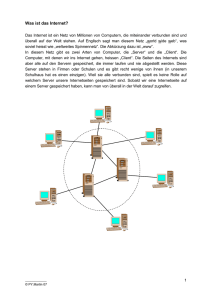
Echtzeitdatenuebertragung in Automatisierungsumgebungen
Werbung

Bachelorarbeit EchtzeitdatenübertragunginAutomatisierungsumgebungen Bearbeiter: Eike Björn Schweißguth Matrikelnummer 209204206 Studiengang Elektrotechnik 8. Fachsemester Universität Rostock 1 2 Inhaltsverzeichnis Abkürzungsverzeichnis ............................................................................................................................ 5 1 2 Einleitung ......................................................................................................................................... 7 1.1 Motivation und Zielsetzung ................................................................................................... 7 1.2 Aufbau der Arbeit .................................................................................................................. 7 Kad‐Netzwerk .................................................................................................................................. 7 2.1 Kad‐Grundlagen ..................................................................................................................... 8 2.1.1 Hashwerte und XOR‐Metrik ..................................................................................... 8 2.1.2 Routingverfahren .................................................................................................... 10 2.1.3 Wartungsoperationen ............................................................................................ 11 3 2.2 Hard Real‐Time Kad (HaRTKad) ........................................................................................... 12 2.3 Implementierungsaspekte .................................................................................................. 15 2.4 HaRTKad im Vergleich zu bestehenden IE‐Systemen .......................................................... 17 2.5 Zusammenfassung ............................................................................................................... 19 Übertragungsprotokoll .................................................................................................................. 20 3.1 Wahl des Protokolls ............................................................................................................. 20 3.2 Constrained Application Protocol (CoAP) Grundlagen ........................................................ 20 3.2.1 Funktionsprinzip ..................................................................................................... 20 3.2.2 Nachrichtenformat ................................................................................................. 24 3.2.3 Optionen ................................................................................................................. 25 3.2.4 Kommunikationsteilnehmer ................................................................................... 30 3.3 Implementierung ................................................................................................................. 31 3.3.1 Kommunikationsmechanismus .............................................................................. 31 3.3.2 Server ...................................................................................................................... 32 3.3.3 Client ....................................................................................................................... 36 3.3.4 Reverse Proxy ......................................................................................................... 40 4 5 3.4 Determinismus bei der Übertragung .................................................................................. 42 3.5 Ausblick ............................................................................................................................... 44 Fehlerkorrektur .............................................................................................................................. 45 4.1 Aufgaben der Fehlerkorrektur............................................................................................. 45 4.2 Reed Solomon Codes ........................................................................................................... 45 4.3 Implementierung ................................................................................................................. 46 4.4 Ausblick ............................................................................................................................... 50 Tests und Messungen .................................................................................................................... 51 5.1 Testaufbau ........................................................................................................................... 51 3 5.2 Szenarios.............................................................................................................................. 52 5.2.1 Windows Client, direkter Serverzugriff, ohne Reed Solomon ................................ 52 5.2.2 Windows Client, direkter Serverzugriff, mit Reed Solomon ................................... 53 5.2.3 Windows Client, via Reverse Proxy, mit Reed Solomon ......................................... 55 5.2.4 Zedboard Client, direkter Serverzugriff, ohne Reed Solomon ............................... 56 5.2.5 Zedboard Client, direkter Serverzugriff, RS ............................................................ 57 5.3 Auswertung der Messdaten ................................................................................................ 57 6 Zusammenfassung ......................................................................................................................... 60 I. Abbildungsverzeichnis ................................................................................................................... 62 II. Tabellenverzeichnis ....................................................................................................................... 62 III. Literaturverzeichnis ....................................................................................................................... 64 IV. Selbstständigkeitserklärung ........................................................................................................... 66 4 Abkürzungsverzeichnis ACK: Acknowledgement ARP: Address Resolution Protocol CON: Confirmable CoAP: Constrained Application Protocol CoRE: Constrained RESTful Environment CSMA/CD: Carrier Sense Multiplexed Access/Collision Detection DHT: Distributed Hash Table DST: Dynamische Suchtoleranz FIFO: First In‐First Out FPGA: Field Programmable Gate Array FT: First Triggered HTTP: Hyper Text Transfer Protocol HaRTKad: Hard Real‐Time Kad Network I/O: Input/Output IDST: Inverse Dynamische Suchtoleranz IE: Industrial Ethernet IEEE: Institute of Electrical and Electronics Engineers IETF: Internet Engineering Taskforce IP: Internet Protocol M2M: Machine‐to‐Machine MD4: Message Digest Algorithm 4 MD5: Message Digest Algorithm 5 MTU: Maximum Transmission Unit NDP: Neighbor Discovery Protocol NON: Non‐Confirmable OSI: Open Systems Interconnection P2P: Peer‐to‐Peer REST: Representational State Transfer RS: Reed Solomon RST: Reset RTT: Round Trip Time SPoF: Single Point of Failure ST: Suchtoleranz STL: Standard Template Library 5 TCP: Transport Control Protocol UDP: User Datagram Protocol URI: Uniform Ressource Identifier 6 1 Einleitung 1.1 MotivationundZielsetzung Diese Arbeit stellt ein neues Konzept zur echtzeitfähigen Datenübertragung und verteilten Speicherung unter Nutzung von Ethernet‐Verbindungen vor. Die Echtzeitfähigkeit soll einen Einsatz in Automatisierungsumgebungen ermöglichen. Als Grundlage dient ein Peer‐to‐Peer (P2P)‐Netzwerk, dessen Protokoll so modifiziert und implementiert wurde, dass es Echtzeitanwendungen erlaubt. Das entwickelte Gesamtsystem stellt eine Alternative zu bestehenden Industrial Ethernet (IE)‐Systemen (EtherCAT, Profinet, Ethernet Powerlink, CC‐Link IE, u.a.) dar, basiert jedoch durch den Einsatz von P2P‐Technologie auf Prinzipien zur Administration des Netzwerkes und Steuerung des Datenverkehrs, die sich deutlich von denen der bestehenden IE‐Systeme unterscheiden. Durch den Einsatz von P2P‐Technologie in Automatisierungsumgebungen soll der manuelle Aufwand zur Konfiguration des Netzwerkes gesenkt und gleichzeitig die Ausfallsicherheit und Skalierbarkeit verbessert werden. Das P2P‐Netzwerk stellt den auf den P2P‐Clients laufenden Anwendungen Zeitschlitze bereit, in denen sie ihre Nutzdaten übertragen können. Das im Rahmen dieser Arbeit implementierte Verfahren zur Datenübertragung und verteilten Speicherung ist dementsprechend mit einer Übertragung in solchen Zeitschlitzen kompatibel. Es verwendet zudem ausschließlich UDP/IP‐Pakete, da TCP‐Verbindungen sich nicht für eine Echtzeitkommunikation eignen. Da das UDP‐Protokoll keine Zustellgarantie von Paketen mit sich bringt, wird eine redundante Datencodierung verwendet, die die gewünschte Robustheit gegen Paketverluste besitzt. Diese Datencodierung ist ebenfalls für die verteilte Speicherung hilfreich, da die P2P‐Clients, auf denen Daten verteilt gespeichert werden, von Ausfällen betroffen sein können. Hier sorgt die redundante Codierung bei Ausfällen ebenfalls dafür, dass die Daten unbeschadet wiederherstellbar sind. Neben dem Einsatz von P2P‐Technologie hebt sich das entwickelte System von den meisten bekannten IE‐Systemen dadurch ab, dass es keine spezielle Hardware erfordert. Es ist vollständig in Software implementiert und ist im Netzwerkprotokoll‐Stack auf Anwendungsebene einzuordnen. 1.2 AufbauderArbeit Kapitel 2 stellt das zu Grunde liegende P2P‐Netzwerk einschließlich der zugehörigen Modifikationen und der Implementierung vor. Diese Bestandteile wurden nicht im Rahmen dieser Arbeit entwickelt sondern dienen nur als Basis, während die zugehörige Entwicklungsarbeit in [1], [2], [3] und [4] geleistet wurde. Kapitel 3 und 4 stellen das Übertragungsprotokoll und die Fehlerkorrektur vor, welche im Rahmen dieser Arbeit implementiert wurden. Kapitel 5 überprüft die Leistungsfähigkeit des Systems an Hand von Messungen, gefolgt von einer Zusammenfassung in Kapitel 6. 2 Kad‐Netzwerk In diesem Kapitel sollen die Grundprinzipien des Kad‐Protokolls vorgestellt werden, da dessen Funktionsweise wichtig für eine Vielzahl der Eigenschaften des darauf aufbauenden Gesamtsystems ist. Die Verwendung des Kad‐Protokolls (bzw. einer erweiterten Form von diesem) ermöglicht den Determinismus beim Auffinden von Daten im Netzwerk, sorgt für die Robustheit des Netzwerks gegen Knotenausfälle und stellt einen Mechanismus zur intelligenten Verteilung redundanter Daten im Netzwerk bereit. 7 2.1 Kad‐Grundlagen Das Kad‐Protokoll definiert ein strukturiertes P2P‐Netz ohne eine zentrale Instanz. Um das Prinzip dezentralisierter, strukturierter P2P‐Netze zu erläutern, soll kurz auf das gegenteilige Prinzip der zentralisierten und unstrukturierten Netze eingegangen werden. In zentralisierten P2P‐Netzen existiert ein Master‐Knoten. Dieser übernimmt wichtige Verwaltungsaufgaben, wie das Speichern einer vollständigen Liste der vorhandenen Peers, sowie der auf ihnen gespeicherten Daten. Will ein Peer Daten anfordern, so muss er beim Master‐Knoten den für die entsprechenden Daten zuständigen Peer anfragen. Die Speicherung der Daten erfolgt unstrukturiert, d.h. jeder beliebige Peer kann jedes beliebige Datum speichern. Solche unstrukturierten und zentralisierten Netze weisen allerdings einige Schwächen auf. Auf Grund des Master‐Knotens besitzen sie einen Single Point of Failure (SPoF) und das Netz ist schlecht in der Größe skalierbar, da die Rechenleistung, Speichergröße und Netzwerkanbindung des Master‐Knotens limitierende Faktoren darstellen [1]. Einziger großer Vorteil solcher Netze ist die schnelle Suche nach Daten, da der Master‐Knoten immer sofort den zuständigen Peer kennt. Eine weitere Form der P2P‐Netze stellen unstrukturierte, dezentralisierte Netze dar. Durch das Fehlen eines Master‐Knoten weisen sie eine bessere Skalierbarkeit und keinen SPoF auf. Der gravierende Nachteil dezentralisierter und unstrukturierter Netze ist jedoch die Suche nach dem zuständigen Peer für ein Datum. Durch die unstrukturierte Speicherung von Daten kann nicht systematisch nach einem Datum gesucht werden, sondern es muss praktisch jeder Peer angefragt werden, ob er das gesuchte Datum besitzt. Zu diesem Zweck wird bei einer Suche das P2P‐ Netz mit der Anfrage geflutet, in der Hoffnung, dass sie auch den für das Datum zuständigen Peer erreicht. Dieses Vorgehen macht die Suche in einem solchen Netzwerk langsam und unsicher (Ziel wird evtl. nicht gefunden). Zudem erzeugt das Fluten eine hohe Netzwerkauslastung. Der einzige Vorteil dieses Suchverfahrens ist, dass jeder Peer nur einige wenige andere Peers kennen muss und eine Suchanfrage mit Hilfe dieser relativ kleinen Kontaktlisten weitergeleitet werden kann. Strukturierte, dezentralisierte Netze wie das Kad‐Netz sollen die gravierenden Mängel der beiden anderen Typen von P2P‐Netzen durch ein intelligentes Verfahren bei der Speicherung von Daten sowie bei der Erstellung von Kontaktlisten beheben. Die strukturierte Speicherung sowie das Routingverfahren zum Auffinden eines Datums basieren beim Kad‐Netz auf verteilten Hashtabellen (distributed hash table, DHT). 2.1.1 HashwerteundXOR‐Metrik Beim Kad‐Netz wird mit Hilfe eines Algorithmus‘ zur Hashwertberechnung zu jedem Peer sowie zu jedem Datum ein Bit Hashwert gebildet. In der Standardimplementierung von Kad wird der Message‐Digest Algorithm 4 (MD4) zu Hashwertberechnung genutzt und die Hashwerte umfassen 128 Bit [1]. Es existieren also 2 verschiedene Hashwerte. Zur Bildung des Hashwertes sollten einzigartige Merkmale verwendet werden. Im Falle der Hashwertbildung zu den Peers ist es daher sinnvoll, die IP‐Adressen zu nutzen, für die Hashwertbildung zu Dateien können Dateinamen genutzt werden. Die Zuordnung von Dateien zu bestimmten Peers erfolgt durch die Hashwerte: Ein Peer ist für Dateien zuständig, die einen ähnlichen Hashwert aufweisen wie der Peer selbst. Die Ähnlichkeit zweier Hashwerte bezeichnet hier die Distanz zwischen zwei Hashwerten in der XOR‐ Metrik. Bei der XOR‐Metrik werden zwei Hashwerte XOR verknüpft und der entstehende Binärwert entspricht der Distanz zwischen den Hashwerten. Die XOR‐Metrik soll an einem Beispiel mit 4 Bit Hashwerten verdeutlicht werden: Hashwert von Peer 1: 1001 8 Hashwert von Datum : 0011 Distanz von Datum und Peer 1: ⊕ 1001 ⊕ 0011 1010 Um die Zuordnung von Daten zu Peers zu regeln, wird für das gesamte Netzwerk die sogenannte Suchtoleranz festgelegt. Ein Peer ist für ein Datum zuständig, wenn seine Distanz zum Datum kleiner als die Suchtoleranz ist: . Die Suchtoleranz muss unter Berücksichtigung der Hashwerte der existierenden Peers so gewählt werden, dass für jeden möglichen Hashwert mindestens 1 Peers zuständig sind. In [1] ist ein Algorithmus beschrieben, der die Suchtoleranz nach diesem Kriterium dynamisch an das P2P‐Netz anpassen kann, sodass Peers dem Netz beitreten und es verlassen können, ohne das Lücken in der Hashwertabdeckung entstehen. Dieses Verfahren wird als Dynamische Suchtoleranz (DST) bezeichnet. Beim DST‐Algorithmus wird die Suchtoleranz zunächst mit 2 initialisiert. Das bedeutet, jeder beliebige Knoten ist für alle Hashwerte zuständig. Davon ausgehend wird die Suchtoleranz schrittweise halbiert, was zu einer Unterteilung aller Hashwerte in Segmente führt, bei der die Suchtoleranz die Größe eines Segments angibt. Der Vorgang wird fortgesetzt, solange nach der Halbierung der Suchtoleranz in jedem Segment noch Knoten sind. Abbildung 1: Beginn des DST‐Algorithmus' mit einer Abbildung 2: Erste Halbierung: Knoten auf der linken Seite sind für die Hashwerte 1000 bis 1111 zuständig, Knoten Suchtoleranz von . auf der rechten Seite für die Hashwerte 0000 bis 0111. Abbildung 1 bis Abbildung 4 zeigen den DST‐Algorithmus an einem Beispiel mit 4 Bit Hashwerten. Da die Suchtoleranz nach diesem Verfahren nur Potenzen von zwei annehmen kann, entspricht die Prüfung, ob ein Knoten für einen Hashwert zuständig ist, einem binären Präfix‐Matching. Sind mehrere Peers für einen Hashwert zuständig, bedeutet dies, dass bei der Speicherung eines Datums Redundanz erzeugt werden kann, indem das Datum auf mehreren der zuständigen Peers gespeichert wird. Auf wie vielen der zuständigen Peers der Speichervorgang ausgeführt wird ist implementierungsabhängig. 9 Abbildung 3: Zweite Halbierung: In jedem der vier Segmente des Kreises sind noch zwei Knoten enthalten, die jeweils für Hashwerte entsprechend der Kennzeichnung des Viertelkreises zuständig sind. Hier wird das Präfix‐Matching deutlich. Knoten sind jeweils für Hashwerte zuständig, die mit ihrem eigenen Hashwert eine Übereinstimmung der ersten beiden Bits aufweisen. Abbildung 4: Letzter Schritt des DST‐Algorithmus: Präfix‐ Matching mit Übereinstimmung der ersten drei Bits. Knoten auf dem Rand zwischen zwei Segmenten sind für Hashwerte des angrenzenden höherwertigen Segments zuständig. Ein weiterer Schritt ist nicht möglich, da einige Hashwerte dann nicht mehr abgedeckt wären. Die Suchtoleranz wird abschließend auf 2 eingestellt. 2.1.2 Routingverfahren Als strukturiertes P2P‐Netz bietet Kad ein systematisches Routingverfahren, welches auf den Hashwerten der Peers basiert und ein deterministisches Auffinden von Daten bzw. zuständigen Peers erlaubt. Jeder Peer merkt sich die Kontaktdaten einer vorgegebenen Anzahl weiterer Peers mitsamt dem zugehörigen Hashwert. An Hand der Hashwerte werden diese Kontaktinformationen in einem binären Baum geordnet. 1111 XOR‐Distanz (4 Bit Hashwerte) 1 d >= 2^(n‐1) d >= 1000 Peer Peer‐Kontakte k‐Bucket 0000 0 1 2^(n‐2) <= d < 2^(n‐1) 0100 <= d < 1000 0 1 0 1 0 2^(n‐3) <= d < 2^(n‐2) 0010 <= d < 0100 d = 1 Abbildung 5: Kad‐Routingtabelle als binärer Baum [1] Die Sortierung der Kontakte im binären Baum erfolgt an Hand ihrer XOR‐Distanz zum Peer. Der Peer selbst steht rechts im binären Baum, da er zu sich selbst eine Distanz von Null aufweist. Alle weiteren Peers sind in sogenannten ‐Buckets angeordnet. Ein entsprechendes Bucket kann maximal Kontakte beinhalten. Für jedes Bit der Hashwerte existiert ein entsprechendes Bucket, in Abbildung 5 gibt es daher 4 Buckets. Das Beispiel zeigt die Anordnung der Peers in den Buckets als Blätter des binären Baumes. An jedem Bucket ist außerdem gekennzeichnet, welche XOR‐Distanz die Kontakte 10 besitzen müssen, um in diesem gespeichert werden können. Diese Strukturierung der Routingtabelle hat zur Folge hat, dass jeder Peer nur wenige sehr weit entfernte Kontakte speichert, jedoch sehr viele Kontakte aus der direkten Nachbarschaft (in Bezug auf die XOR‐Distanz). Während eines Suchvorgangs wird zuerst der Hashwert der gesuchten/zu speichernden Datei gebildet und dann der am dichtesten gelegene Peer aus der Routingtabelle bestimmt. Von diesem Punkt aus können zwei Lookup‐Strategien verfolgt werden. Hier soll nur auf die verwendete iterative Lookup Strategie eingegangen werden. Bei einem iterativen Lookup wird dem am dichtesten gelegenen Kontakt eine Suchanfrage mit dem gesuchten Hashwert zugesendet. Dieser antwortet mit einer Kontaktliste, welche noch dichter am Ziel gelegene Peers enthält. An einen dieser Peers kann der suchende Knoten eine weitere Suchanfrage stellen. Dieser Vorgang wird so lange fortgesetzt, bis ein Kontakt gefunden wurde, der innerhalb der Suchtoleranz zum gesuchten Hashwert liegt. Durch den Aufbau der Routingtabelle mit je einem Bucket pro Bit der Hashwerte ist garantiert, dass der suchende Knoten durch jede Anfrage um mindestens 1 Bit näher an einen zuständigen Knoten herankommt. So ergibt sich für ein Netzwerk mit maximal Knoten bei passend gewählter . Hashwertgröße (nicht mehr Bits als für Knoten notwendig) eine Suchkomplexität von Implementierungen mit größeren Routingtabellen mit zusätzlichen Buckets erlauben es, die Distanz zu einem zuständigen Knoten um Bits pro Suchschritt zu verringern. Die Suchkomplexität beträgt in . Nach dem Auffinden eines zuständigen Knotens kann die gewünschte diesem Fall Aktion, wie das Speichern oder Lesen einer Datei, durchgeführt werden. Um den Suchvorgang auf Kosten einer höheren Netzwerkauslastung zu beschleunigen, können bei jeder Suchanfrage auch mehrere näher am Ziel gelegene Knoten angesprochen werden. Auf diesem Weg kann ein zuständiger Knoten im Durchschnitt nicht nur schneller gefunden werden, sondern wie bereits beschrieben können auch mehrere Knoten gefunden werden, die innerhalb der Suchtoleranz liegen. In diesem Fall kann eine Speicheroperation auf mehreren Knoten erfolgen, um für eine redundante und damit zuverlässigere Speicherung zu sorgen. 2.1.3 Wartungsoperationen Die Routingtabellen eines Peers müssen beim seinem Eintritt in das Netzwerk mit einigen Kontakten initialisiert werden und im Laufe der Zeit aktualisiert werden, da Peers das Netz verlassen können und neue Peers beitreten können. Hierzu sind verschiedene Operationen im Kad‐Protokoll vorgesehen. Der Bootstrap‐Vorgang wird von einem Knoten ausgeführt, der dem Netz beitreten möchte. Um den Vorgang starten zu können, muss der Knoten vorab einen anderen Knoten kennen, der sich bereits im Netz befindet. Dieser sogenannte Bootstrap‐Knoten kann beispielsweise durch eine Benutzereingabe übergeben werden. Der beitretende Knoten sendet dem Bootstrap‐Knoten eine Anfrage, dass er dem Netz beitreten will. Dieser trägt den beitretenden Knoten in seine eigene Routingtabelle ein und antwortet mit einer Kontaktliste zufälliger Kontakte aus seiner Routingtabelle. Diese Kontakte kann der neue Knoten seiner Routingtabelle hinzufügen um den Betrieb aufzunehmen sowie um weitere Wartungsoperationen zu starten [2]. Das Aktualisieren der Routingtabelle geschieht bereits während einer einfachen Kad‐Suche. Die in den Antworten anderer Peers enthaltenen Kontaktlisten mit dem Ziel nahegelegenen Kontakten werden genutzt, um die eigene Routingtabelle zu erweitern, wenn diese noch nicht vollständig gefüllt ist. 11 Um die Routingtabellen aktuell zu halten, besitzen ihre Einträge eine Lebensdauer. Sie wird regelmäßig auf Kontakte mit abgelaufener Lebensdauer geprüft. Entsprechende Peers werden kontaktiert und falls diese antworten, wird der Eintrag in der Routingtabelle beibehalten und die Lebensdauer aktualisiert, andernfalls wird der Kontakt entfernt. Weitere regelmäßig stattfindende Wartungsoperationen sind der Random‐Lookup und der Self‐ Lookup. Dabei wird im Kad‐Netz nach einem zufälligen Hashwert bzw. nach dem eigenen Hashwert gesucht, um die Buckets verschiedener Hashwertbereiche zu füllen. Der Self‐Lookup dient z.B. zum Kennenlernen von Kontakten in der Nähe des Peers. 2.2 HardReal‐TimeKad(HaRTKad) Das vorgestellte Kad‐Protokoll ist nicht auf eine Echtzeitkommunikation in Automatisierungsumgebungen ausgelegt und erfordert daher noch einige Anpassungen um diesem Einsatzbereich gerecht zu werden. Ein Kritikpunkt des Kad‐Protokolls ist, dass es auf normaler Ethernet‐Kommunikation basiert, ohne dass ein geregelter Zugriff auf das Medium stattfindet. Problematisch daran ist, dass selbst beim Einsatz von Full‐Duplex Switched Ethernet Verzögerungen bei der Übertragung von Paketen entstehen können, welche es zu vermeiden gilt. Diese werden in der Regel dadurch verursacht, dass mehrere Clients zur gleichen Zeit Daten an den gleichen Adressaten versenden, was zu einer Verzögerung von Paketen im Switch‐Puffer führt. Bei sehr hoher Aktivität der Clients kann es sogar vorkommen, dass Pakete durch einen Pufferüberlauf im Switch verworfen werden. In einem solchen System kann nicht vorhergesehen werden, wann es einem Client möglich ist, Daten erfolgreich an einen anderen Client zu versenden, selbst wenn sowohl die Clients als auch das Übertragungsmedium fehlerfrei arbeiten. Dies widerspricht dem für Automatisierungsumgebungen gewünschten deterministischen Verhalten. Eine weitere Eigenschaft, die in Automatisierungsumgebungen häufig benötigt wird und durch das standardmäßige Kad‐ Protokoll nicht gegeben ist, ist die Synchronisierung der Uhren der Kommunikationsteilnehmer. Die HaRTKad‐Erweiterung des Kad‐Protokolls soll diese Funktionen bieten. Es wird ein Synchronisierungsmechanismus für die Uhren der Clients eingeführt und auf Basis dieser eine geregelte Kommunikation realisiert, um ein deterministisches Übertragungsverhalten zu erzielen. Die Kommunikation wird durch ein Zeitschlitzverfahren geregelt. Für den in [3] eingeführten Synchronisierungsmechanismus sind einige Voraussetzungen zu erfüllen. Zur Realisierung von HaRTKad dürfen keine fremden (nicht‐HaRTKad) Teilnehmer im Netzwerk vorhanden sein. Diese fremden Teilnehmer könnten durch ihren ungeregelten Zugriff auf das Medium unerwünschte Verzögerungen bei der Übertragung verursachen und so eine präzise Synchronisierung der Netzwerkteilnehmer verhindern. Auch bei der normalen Datenübertragung außerhalb der Synchronisierungsphasen würde der ungeregelte Zugriff wie bereits erläutert einen Determinismus bei der Übertragung verhindern. Außerdem werden symmetrische Pfade zwischen zwei Knoten vorausgesetzt, weshalb Full‐Duplex Verbindungen genutzt werden müssen. Der Synchronisierungsmechanismus von HaRTKad arbeitet in 6 Phasen: I. Kad‐Initialisierung Beim erstmaligen Starten des Systems werden Standard Kad‐Operationen wie das Bootstrapping und Lookup‐Vorgänge zum Füllen der Routingtabellen durchgeführt. Zusätzlich zu den Informationen über einen Peer, die bereits durch das normale Kad‐Protokoll gespeichert werden, wird im Falle von HaRTKad auch die zugehörige MAC‐Adresse 12 II. III. IV. V. VI. gespeichert. Dies ist nötig, um im späteren Verlauf zusätzlichen Datenverkehr zur Auflösung von IP‐Adressen zu vermeiden (Address Resolution Protocol (ARP)‐Pakete und Neighbor Discovery Protocol (NDP)‐Pakete). Festlegung der Suchtoleranz Nach der Initialisierungsphase muss einer der Knoten einen Trigger erhalten. Dieser wird in der Regel durch den Benutzer ausgelöst. Der Knoten, der den Trigger erhalten hat, wird First Triggered (FT) Node genannt. Der FT‐Knoten führt den DST‐Algorithmus durch, um die Suchtoleranz für alle Knoten zu bestimmen. Synchronisierung Die Synchronisierung zwischen zwei Knoten wird durch die symmetrische Verbindung ermöglicht. Ein Knoten sendet eine Ping‐Nachricht an den zu synchronisierenden Knoten und misst dabei die Zeit bis zur Antwort (Round Trip Time, ). Die Synchronisierung erfolgt, indem der Knoten /2 zu seiner Systemzeit addiert und diese Zeit an den zu synchronisierenden Knoten sendet. In der einfachsten Form der Synchronisierung werden alle im Netz vorhandenen Knoten durch den FT‐Knoten der Reihe nach synchronisiert. Bei einer sehr großen Anzahl von Knoten ist dieses Vorgehen jedoch problematisch, da es sehr lange dauert, bis alle Knoten synchronisiert wurden. Daher ist der Synchronisierungsvorgang konfigurierbar und kann in Gruppen erfolgen. Dabei werden alle vorhandenen Knoten in Gruppen aufgeteilt und aus jeder Gruppe wird ein Helferknoten bestimmt, der für die Gruppensynchronisierung zuständig ist. Zuerst synchronisiert sich der FT‐Knoten mit den Helferknoten und anschließend synchronisiert jeder Helferknoten seine Gruppe. Da die Synchronisierung der Gruppen parallel erfolgt, ist durch Paketverzögerungen mit höheren Ungenauigkeiten zu rechnen, die Dauer der Synchronisierung nimmt allerdings stark ab. Datenaustausch Der Datenaustausch stellt die wichtigste Phase des Systems dar, da hier Nutzdaten übertragen werden können. Alle anderen Phasen stellen praktisch nur die nötigen Verwaltungsaufgaben bereit, um eine deterministische Kommunikation innerhalb dieser Phase zu ermöglichen. Der Datenaustausch sollte daher alle anderen Phasen zeitlich deutlich übertreffen. Der Zugriff auf das Medium wird in dieser Phase durch ein Zeitschlitzverfahren geregelt, welches die gemeinsame Zeitbasis aller Knoten ausnutzt. Das im Rahmen dieser Arbeit entwickelte Übertragungsverfahren und System zur verteilten Speicherung kommuniziert in dieser Phase und somit innerhalb der Zeitschlitze. Wartungsoperationen In den Phasen des Datenaustausches und der Synchronisierung können keine Instandhaltungsoperationen des Kad‐Netzes ausgeführt werden, da diese den Determinismus und die Genauigkeit des Systems stören würden. In der Wartungsphase signalisiert der FT‐Knoten daher durch ein Broadcast‐Signal, dass jetzt Bootstrap Operationen durchgeführt werden dürfen. Außerdem können typische Wartungsoperationen wie Random‐ und Self‐Lookup durchgeführt werden, um die Routingtabellen zu aktualisieren. Resynchronisierung Eine erneute Synchronisierung muss regelmäßig ausgeführt werden, da die Uhren der Knoten einem Drift unterliegen. Da dieser nicht auf allen Knoten gleichermaßen ausgeprägt ist, stimmen die Uhren nach einer gewissen Zeit nicht mehr exakt überein. Die maximal erlaubte Abweichung der Uhren verschiedener Knoten hängt vom Anwendungsbereich ab. Je mehr Abweichung erlaubt ist, desto länger kann ein Datenaustausch zwischen zwei Synchronisierungsphasen erfolgen. Genaue Betrachtungen, wie häufig eine Synchronisierung 13 durchgeführt werden muss, sind in [3] zu finden. Die Resynchronisierung erfolgt nach den gleichen Prinzipien wie die Synchronisierung. Die Phasen I. bis III. werden nur einmal ausgeführt, während IV. bis VI. zyklisch ausgeführt werden. Um zu vermeiden, dass durch HaRTKad mit dem FT‐Knoten ein SPoF entsteht, kann jeder Knoten überwachen, nach welcher Zeit er spätestens für einen Resynchronisierungsvorgang kontaktiert werden sollte. Bleibt dies aus, so kann der Knoten selbst die Rolle des FT‐Knoten übernehmen. Es ist vorgesehen, dass in diesem Fall der Knoten mit der geringsten XOR‐Distanz zu Null die Funktion des FT‐Knoten übernimmt [3]. Das Zeitschlitzverfahren, nach dem der Datenaustausch in Phase IV. organisiert werden soll, ist in [4] definiert. Das Verfahren nutzt die Hashwerte der Knoten, um jedem Knoten einen Zeitschlitz für den exklusiven Zugriff auf das Medium zuzuweisen. Im ersten Schritt wird der DST‐Algorithmus in leicht veränderter Form angewendet. Anstatt bei der Verwendung von Bit breiten Hashwerten die Suchtoleranz ausgehend von 2 solange zu halbieren, dass für jeden Hashwert noch mindestens ein Knoten zuständig ist, wird der Vorgang fortgesetzt, bis höchstens ein Knoten für jeden Hashwert zuständig ist. Dieser Algorithmus wird daher als Inverse Dynamische Suchtoleranz (IDST) bezeichnet kann genutzt werden, um die Anzahl der benötigten und die so gefundene Suchtoleranz Zeitschlitze zu ermitteln [4]: 2 jedem Knoten mitgeteilt wird, kann jeder Knoten selbstständig die zu ihm gehörende Da Zeitschlitznummer ermitteln [4]: Anschaulich kann man sich das Verfahren so vorstellen, dass alle vorhandenen Hashwerte durch den die Größe eines IDST‐Algorithmus in gleichgroße Segmente eingeteilt werden, wobei Segments angibt. wird so eingestellt, dass in jedem Segment höchstens ein Knoten ist. Die Bestimmung der Zeitschlitznummer entspricht praktisch einer Bestimmung der Segmentnummer, in dem sich der Knoten befindet. Jedem Segment wird nun ein Zeitschlitz zugeordnet, wodurch sichergestellt ist, dass pro Zeitschlitz nur ein Knoten die Sendeerlaubnis hat. Damit ein Knoten bestimmen kann, ob er sich zeitlich gerade innerhalb seines Zeitschlitzes befindet, sind noch einige weitere Betrachtungen notwendig. Zunächst wird die durch den Synchronisierungsvorgang geschaffene einheitliche Zeitbasis benötigt. Diese allen Knoten bekannte bezeichnet. Alle Zeitslots sind gleich lang und besitzen die Dauer . Die Zeit wird mit Zykluszeit, nach der ein Knoten erneut senden darf, beträgt demnach: ∗ Ein Knoten darf unter folgender Bedingung senden, befindet sich also in seinem Zeitschlitz [4]: ∗ 1 ≫ ∗ 14 Der Operator ≫ muss an dieser Stelle gewählt werden, da der Knoten nur senden darf, wenn er sich noch weit genug entfernt vom Ende seines Zeitschlitzes befindet, um seine Übertragung vor Beginn des nächsten Zeitschlitzes abzuschließen. Innerhalb der Zeitschlitze kann theoretisch jede beliebige Anwendung Daten senden und dabei unterschiedliche Protokolle auf der Anwendungsebene verwenden. Auf Grund der Zeitschlitze gibt es jedoch praktisch einige Einschränkungen. Die Anwendung sollte ihre Kommunikation entweder innerhalb eines Zeitschlitzes abschließen können oder darauf ausgelegt sein, die Kommunikation eine gewisse Zeit zu unterbrechen und im nächsten Zeitschlitz fortzusetzen. Auf Grund der Unterbrechung der Kommunikation zwischen zwei Zeitschlitzen ist außerdem von TCP als Transportprotokoll abzusehen. Da bei HaRTKad angestrebt wird, auf Anwendungsebene eine zu harter Echtzeit fähige Kommunikation zu realisieren, ist TCP jedoch ohnehin ungeeignet und diese Einschränkung kaum relevant. Das in den Kapiteln 3 und 4 vorgestellte System zur echtzeitfähigen Datenübertragung und verteilten Speicherung stellt eine mögliche Anwendung dar, die zum Datenaustausch innerhalb der Zeitschlitze verwendet werden kann. 2.3 Implementierungsaspekte Zur Umsetzung des bisher beschriebenen Konzepts wird eine Plattform benötigt, die sowohl harte Echtzeit als auch eine allgemein hohe Performance ermöglicht. Diese beiden Eigenschaften sind keinesfalls gleichzusetzen, da harte Echtzeit nur bedeutet, dass die maximale Dauer einer Übertragung determiniert ist, sie muss aber nicht zwangsläufig auch sehr gering sein, um die Kriterien harter Echtzeit zu erfüllen. Je nach Anwendungsbereich müssen jedoch in Automatisierungsumgebungen sehr geringe obere Schranken für die Dauer einer Übertragung eingehalten werden und zudem viele Geräte miteinander kommunizieren und große Datenmengen ausgetauscht werden. Daher ist auch eine hohe Verarbeitungsgeschwindigkeit der Netzwerkteilnehmer wichtig. Die Geschwindigkeit des Übertragungsmediums stellt praktisch keine Limitierung dar, da Full‐Duplex Switched Ethernet mit bis zu 1 Gbit/s bereits eine sehr hohe Bandbreite zur Verfügung stellt und in der Regel kein limitierender Faktor im Gesamtsystem ist. Um ausreichend Rechenleistung für die Implementierung eines HaRTKad‐Prototyps zur Verfügung zu haben, werden sogenannte Zedboards verwendet, welche einen 667 MHz ARM Prozessor und ein FPGA zur Verfügung stellen [4]. Das FPGA wird derzeit noch nicht verwendet, bietet jedoch für zukünftige Entwicklungen auf dieser Basis eine hervorragende Möglichkeit Verarbeitungsprozeduren auf der Anwendungsebene stark zu beschleunigen, indem besonders rechenintensive Schritte in Hardware ausgeführt werden. Dieser Aspekt wird später noch aufgegriffen und ein möglicher Einsatzzweck des FPGAs genannt. Prinzipiell ist das FPGA jedoch nicht zwingend notwendig und eine Portierung des implementierten HaRTKad‐Clients auf andere Plattformen mit Standard‐Hardware möglich. Als Betriebssystem wird FreeRTOS eingesetzt, da es sich hierbei den Anforderungen entsprechend um ein echtzeitfähiges Betriebssystem handelt. Es ist geeignet, um Anwendungen mit mehreren Threads ablaufen zu lassen, wobei der Determinismus durch eine strikte Priorisierung der Threads erreicht wird. In FreeRTOS bekommt jeder Thread eine Priorität zugewiesen und besitzt einen Zustand. Die zur Verfügung stehenden Zustände sind [5]: 15 Ready: Der Thread steht zur Ausführung bereit, wird derzeit jedoch noch nicht ausgeführt, da noch ein anderer Thread mit höherer oder gleicher Priorität aktiv ist. Running: Der Thread wird gerade ausgeführt und verwendet dementsprechend den Prozessor. Blocked: Ein Thread der gerade auf ein Ereignis wartet befindet sich im Zustand „Blocked“. Er kann dementsprechend derzeit nicht weiter ausgeführt werden. Das Warten auf eine Semaphore ist ein Beispiel, warum sich ein Thread im Zustand „Blocked“ befinden kann. Suspended: Ein Thread kann durch einen expliziten Befehl dazu gebracht werden seine Aktivität zu pausieren und befindet sich dann im Zustand „Suspended“. Threads in diesem Zustand stehen ebenso wie „Blocked“ Threads nicht zur Ausführung bereit. Bei der Priorisierung der Threads wird so vorgegangen, dass aus allen zur Ausführung bereiten Threads („Ready“) stets der Thread mit der höchsten Priorität ausgeführt wird und die volle Rechenleistung zur Verfügung gestellt bekommt. Von allen zur Ausführung bereiten Threads wird also der Thread mit der höchsten Priorität in den Zustand „Running“ versetzt [5]. Existieren mehrere Threads der gleichen Priorität, die zur Ausführung bereit sind, wird den entsprechenden Threads abwechselnd, also in einem Zeitschlitzverfahren, Rechenzeit zur Verfügung gestellt. Durch derart priorisierte Threads kann gewährleistet werden, dass während der Verarbeitung einer Anfrage (z.B. Benutzerinteraktion, Interrupt oder Netzwerkpaket) keine konkurrierenden Aufgaben durch den Prozessor erledigt werden. So können wichtige Anfragen schnellstmöglich und jedes Mal in der gleichen Zeit bearbeitet werden. Die Verarbeitungszeit ist vollständig durch Programmcode und Eingabedaten vorherbestimmt (und selbstverständlich abhängig von der Hardware). Das Betriebssystem FreeRTOS bietet außerdem die Möglichkeit, zusätzliche Funktionalität durch optionale Komponenten hinzuzufügen [5]. Dieses Konzept soll das Betriebssystem anpassbar auf verschiedene Anwendungsgebiete machen, ohne dabei unnötig viele Ressourcen für nicht benötigte Funktionen zu verbrauchen. Für die Implementierung des HaRTKad‐Prototyps wird von einem TCP/IP‐Stack als optionale Komponente Gebrauch gemacht, dem lwIP‐Stack. Dieser bietet bei einem geringen Ressourcenverbrauch und der damit einhergehenden Eignung für hardwareseitig eingeschränkte Systeme eine voll funktionsfähige Implementierung vieler bekannter und weit verbreiteter Netzwerkprotokolle. Der HaRTKad‐Prototyp und die im Rahmen dieser Arbeit implementierten Funktionen zur Datenübertragung zwischen den Kad‐Clients nutzen vor allem die zur Verfügung gestellten Socket‐Funktionen und die Übertragung über UDP/IP‐Pakete. Mit Hilfe der Zedboards, FreeRTOS und lwIP wurde in [2] ein echtzeitfähiger Kad‐Client entwickelt. Wie in [4] und [2] beschrieben, gibt es in diesem Kad‐Client standardmäßig bereits verschiedene Threads. Neben dem Idle‐Thread des Betriebssystems gibt es einen Hauptthread, der die höchste Priorität (5) hat und von FreeRTOS somit zuerst vollständig abgearbeitet wird. Er startet alle anderen benötigten Threads. Ein Thread mit der Priorität 4 verarbeitet Pakete, die in einer Automatisierungsumgebung beispielsweise von Steuerrechnern stammen können. Da solche Pakete wichtige Befehle zur Änderung des Betriebszustandes einer Maschine enthalten können, ist deren Priorität besonders hoch. Nachfolgend gibt es zwei Threads mit der Priorität 3, welche beide verschiedene Aufgaben im Sinne des Kad‐Protokolls ausführen. Sie dienen der Überwachung eigener Kad‐Suchen und der Beantwortung von Kad‐Anfragen anderer Knoten. Der für lwIP benötigte Thread des Netzwerkinferfaces besitzt die Priorität 2, da eingehende Pakete nicht die Verarbeitung zuvor eingegangener Pakete unterbrechen sollen. Außerdem sind Wartungsthreads mit der Priorität 1 16 vorgesehen. Diese führen Kad‐Wartungsoperationen zur Instandhaltung der Routingtabelle durch. Diese Wartungsthreads sind in dem für diese Arbeit verwendeten Prototypen allerdings noch nicht implementiert. Um den Kad‐Client echtzeitfähig zu halten, wurden in [2] bereits einige Modifikationen an der originalen Kad‐Implementierung durchgeführt. Wie in Kapitel 2.1 vorgestellt, ist vorgesehen, dass nach dem Auffinden eines zuständigen Knotens durch die Kad‐Suche eine Aktion ausgeführt wird. Dabei kann es sich um eine Speicher‐ oder Leseroutine handeln. In der originalen Kad‐ Implementierung wird hierzu eine TCP‐Verbindung zum Datenaustausch zwischen den Knoten aufgebaut. Da diese ungeeignet für eine Echtzeitkommunikation sowie die Kommunikation in Zeitschlitzen ist, besteht diese Aktion hier nur noch aus einem einfachen Datenaustausch innerhalb von einem UDP‐Paket. Größere Datenmengen können erst durch den im Rahmen dieser Arbeit implementierten Mechanismus übertragen werden. Da der echtzeitfähige Kad‐Client vorerst nur zur Echtzeitkommunikation in einem Subnetz vorgesehen ist, werden zudem Hashwerte von 8 Bit verwendet, statt der ursprünglichen 128 Bit. Zur Bildung der Hashwerte wird der MD5 (statt MD4) Algorithmus verwendet. Die weiteren Funktionen von HaRTKad, wie der DST‐Algorithmus, die Zeitsynchronisierung und die Zeitschlitze sind im verwendeten Prototyp noch nicht vorhanden. Sie werden derzeit parallel zu dieser Arbeit in weiteren Projekten implementiert. Dies stellt jedoch für diese Arbeit keine Einschränkung dar, da für diese Arbeit nur relevant ist, dass der implementierte Kommunikationsmechanismus kompatibel zum Zeitschlitzverfahren sein soll. Tests und Performancemessungen des implementierten Kommunikationsverfahrens sind auch ohne Zeitschlitze möglich. 2.4 HaRTKadimVergleichzubestehendenIE‐Systemen In Automatisierungsumgebungen existiert bereits eine Vielzahl von Möglichkeiten zur Vernetzung. Angefangen hat der Trend zur umfangreichen Fabrikvernetzung bereits in den 80er Jahren mit den Feldbussen. In der heutigen Zeit werden diese auf Grund der vielen Erfahrung, die in der Industrie mit solchen Systemen vorliegen, und auch auf Grund der erwiesenen Zuverlässigkeit der Systeme, immer noch eingesetzt. Innerhalb der letzten 10 Jahre konnten sich allerdings auch Ethernet‐basierte Lösungen zur Fabrikvernetzung etablieren. Die Ethernet‐Lösungen zur Fabrikvernetzung bieten einige Vorteile gegenüber den herkömmlichen Feldbussen. Eine wichtige Eigenschaft ist die Vernetzung der Fabrik mit dem Büronetzwerk ohne aufwändige Gateways [6]. Geräte in der Fabrik können IT‐Dienste zur Verfügung stellen, auf die vom Büro aus mit Standardprotokollen zugegriffen werden kann. Die Kommunikation erfolgt hierfür über die gleichen Ethernet‐Verbindungen wie die Übermittlung der zeitkritischen Steuer‐ und Regelungsinformationen. Die Kommunikation wird dabei so geregelt, dass die Übermittlung der Steuerinformationen Echtzeitanforderungen erfüllt. Dies kann beispielsweise durch eine Priorisierung des Datenverkehrs oder durch Zeitschlitze erfolgen. Als weiterer Vorteil von Ethernet‐basierter Vernetzung ist die Hardware zu sehen. Hier kann auf eine große Auswahl existierende Produkte zurückgegriffen werden, da Ethernet ein wesentlich breiteres Anwendungsspektrum besitzt als die industriellen Feldbusse. Dadurch wird die Flexibilität erhöht und die Kosten gesenkt. Je nach Anforderung kann sogar auf günstige Consumer‐Elektronik zurückgegriffen werden. Ein weiterer Vorteil ist die hohe Bandbreite von Ethernet, welche die von Feldbussen bei weitem übertrifft. 17 Ethernet‐basierte Lösungen zur Echtzeitkommunikation in industriellen Umgebungen müssen sich alle der Herausforderungen stellen, dass Ethernet an sich nicht auf eine Echtzeitkommunikation ausgelegt ist, ebenso wie die üblichen über Ethernet verwendeten Protokolle auf den darüberliegenden Ebenen des Netzwerk‐Stacks [7]. Das ursprüngliche CSMA/CD‐Zugriffsverfahren von Ethernet ist auf Grund der möglichen Kollisionen und den darauf folgenden erneuten Übertragungsversuchen prinzipiell nicht echtzeitfähig. Dieses Problem spielt heutzutage nur noch eine untergeordnete Rolle, da in der Regel Full‐Duplex Switched Ethernet verwendet wird, bei dem keine Kollisionen mehr auftreten können. IE‐Systeme, die ein Zeitschlitzverfahren zum Zugriff auf das Medium verwenden, können jedoch auch Half‐Duplex Verbindungen mit Hubs verwenden, da durch die Zeitschlitze Kollisionen verhindert werden. Ein weiteres Problem ist die Übertragung in größeren Netzwerken. Hierbei kommt typischerweise Routing mittels Internet Protocol zum Einsatz, welches ohne statische Routen nicht deterministisch ist. Viele bekannte IE‐Systeme sowie die derzeitige Version von HaRTKad ermöglichen eine deterministische Kommunikation daher nur innerhalb von einem Subnetz, so dass kein Routing nötig ist. Auf der Transportschicht wird zur Übertragung großer Datenmengen in der IT‐Welt normalerweise eine TCP‐Verbindung genutzt. Auch diese ist zur Echtzeitdatenübertragung ungeeignet, da bei Paketverlusten mehrfach versucht wird, das Paket nach einer Wartezeit erneut zu übertragen. Außerdem wird basierend auf der Anzahl der Paketverluste die Übertragungsgeschwindigkeit angepasst. Diese Mechanismen ermöglichen eine zuverlässige Datenübertragung inklusive Überlastkontrolle des zur Verfügung stehenden Mediums, machen die maximale Dauer einer Übertragung jedoch schwer berechenbar und sind daher nicht für Echtzeitumgebungen geeignet. Die beschriebenen Probleme werden von den IE‐Systemen auf unterschiedliche Art und Weise gelöst. Gemeinsam ist den Systemen, dass ein geregelter Zugriff auf das Medium erfolgen muss, sowie dass ein Protokoll zur Datenübertragung benötigt wird, welches im Gegensatz zu TCP eine berechenbare Übertragungszeit bietet. In [7] wurde die Funktionsweise einiger bekannter IE‐Systeme bereits untersucht und soll hier noch einmal aufgegriffen werden und mit dem geplanten Konzept von HaRTKad verglichen werden. IE‐System Ethernet Powerlink EtherCAT TCnet TTEthernet CC‐Link IE Field Verwendete Anwendungsprotokolle bei RT‐Kommunikation CANopen CANopen, Servodrive TCnet Common Memory beliebig CC‐Link/SLMP Profinet IO Profibus Erfordert spezielle Hardware Besitzt SPoF: Master o.ä. optional Ja, ESC Ja, TCnet Controller Ja,TTEthernet Switches optional Ja, MN Ja, Master Keine Angabe Nein Ja, Token‐ Master Ja, Profinet Switches für Ja, Clock IRT‐Kommunikation Master für IRT‐ Kommunikation Tabelle 1: Übersicht über einige bekannte IE‐Systeme [7] Typisch für die meisten bestehenden IE‐Systeme ist eine Zugriffskontrolle auf das Medium, die durch einen Master‐Knoten gesteuert wird. Nach bestem Wissen des Autors existiert derzeit kein IE‐ System, welches wie HaRTKad auf ein P2P‐Netz und damit selbständige, verteilte Verwaltungsfunktionen zur Regelung des Datenverkehrs setzt. Damit besitzen diese IE‐Systeme in der Regel auch einen SPoF, welcher auch eine begrenzte Skalierbarkeit zur Folge hat. Zur Erhöhung 18 der Ausfallsicherheit sehen solche Systeme beispielsweise Hardwareredundanz vor – fällt ein Master aus, so steht ein Ersatzsystem zur Verfügung, das die Aufgaben übernehmen kann. Ein weiteres Problem, dass durch HaRTKad vermieden werden soll, ist proprietäre Hardware. HaRTKad kann vollständig mit Standard‐Ethernet Hardware und einer entsprechenden Softwareimplementierung ausgeführt werden. Diese Möglichkeit besteht bei den untersuchten IE‐Systemen nur bei Ethernet Powerlink und CC‐Link IE Field, während die anderen Systeme eine angepasste Hardware voraussetzen. Insgesamt existiert nach bestem Wissen des Autors kein Gesamtkonzept zur deterministischen Datenübertragung in Automatisierungsumgebungen, das mit HaRTKad vergleichbar ist. Einzig TTEthernet hat mit der transparenten, deterministischen Übertragung beliebiger Daten und einer Regelung des Medienzugriffs ohne Master eine vergleichbare Zielsetzung, welche jedoch auf eine sich deutlich unterscheidende Art und Weise umgesetzt wurde und im Vergleich zu HaRTKad einen höheren manuellen Konfigurationsaufwand besitzt und zudem auf spezielle Hardware angewiesen ist. 2.5 Zusammenfassung An dieser Stelle soll noch einmal ein Überblick über das geplante Gesamtkonzept gegeben werden, um besser verständlich zu machen, wie die in den einzelnen Kapiteln detailliert beschriebenen Funktionen miteinander verbunden werden. Gesucht ist ein Netzwerk, welches einen echtzeitfähigen Datenverkehr ermöglicht, da es in industriellen Bereichen Anwendung finden soll. Für die Echtzeitfähigkeit ist im Gegensatz zu Standard‐Ethernet ein geregelter Datenverkehr nötig. Dieser soll allerdings nicht wie üblich durch einen Server oder einen Master geregelt werden, da dieser einen SPoF darstellt, eine schlechte Skalierbarkeit und hohen Netzwerkadministrationsaufwand mit sich bringt. Daher fällt die Wahl der Netzwerkarchitektur auf ein P2P‐System. Dieses ist gut skalierbar und kann selbstständig eine geregelte Kommunikationsstruktur schaffen. Da DHT‐basierte P2P‐Systeme besonders effizient hinsichtlich der Suche nach bestimmten Knoten sind und dennoch nur wenig Speicher für Routingtabellen benötigen, fällt die Wahl auf das DHT‐basierte Kad‐Protokoll. Dieses wird so modifiziert, dass es zu einer echtzeitfähigen Kommunikation fähig ist. Hierzu wird die vorgesehene TCP‐basierte Datenübertragung entfernt. Um weiterhin große Datenmengen zuverlässig übertragen zu können, die nicht in einen Ethernet Frame/ein UDP‐Paket passen, tritt der in den folgenden Kapiteln dieser Arbeit erläuterte Kommunikationsmechanismus an dessen Stelle. Name Zedboard FreeRTOS Kad HaRTKad CoAP (siehe Kapitel 3) Reed Solomon (siehe Kapitel 4) Funktion Hardware‐Plattform des Prototypen Betriebssystem, dass deterministische und damit echtzeitfähige Software ermöglicht Netzwerkarchitektur, die selbständige Verwaltungsaufgaben ohne SPoF und mit guter Skalierbarkeit ermöglicht Kad‐Erweiterung, die Knoten synchronisiert und Kommunikation regelt (Zeitschlitze) Echtzeitfähige Übertragung großer Datenmengen Erhöht Verfügbarkeit von Daten durch Redundanz Tabelle 2: Hauptbestandteile des entwickelten Systems zur Echtzeitdatenübertragung in Automatisierungsumgebungen 19 Dieser ermöglicht sowohl eine gezielte Übertragung von Daten zwischen zwei Kad‐Knoten, als auch eine verteilte, redundante Speicherung und ist dabei weiterhin echtzeitfähig. Er arbeitet innerhalb von Zeitschlitzen, welche durch die HaRTKad genannte Erweiterung des Kad‐Protokolls definiert werden, um die Kommunikation zu regeln. Neben einem Zeitschlitzverfahren bringt HaRTKad ein Synchronisierungsverfahren für die Kad‐Knoten mit sich. Als Basis für die Tests dienen Zedboards und das echtzeitfähige Betriebssystem FreeRTOS. Das insgesamt echtzeitfähige System benötigt jedoch nur Standard‐Hardware, da alle Mechanismen die das Netzwerk echtzeitfähig machen in Software implementierbar sind. Tabelle 2 fasst das Gesamtsystem übersichtlich zusammen. 3 Übertragungsprotokoll 3.1 WahldesProtokolls Die Wahl des Übertragungsprotokolls wurde maßgeblich durch den angestrebten Einsatzbereich bestimmt. Als Transportprotokoll soll UDP zum Einsatz kommen, da das Übertragungsverhalten von TCP nicht vorab berechenbar ist und Modifikationen nötig wären, um TCP‐Übertragungen in Zeitschlitzen auszuführen, da TCP keine Pause innerhalb einer Übertragung vorsieht. Daher wäre eine Datenübertragung, die nicht in einem Zeitschlitz abgeschlossen werden kann, über TCP nur schwer realisierbar. Durch die Entscheidung für UDP wird gleichzeitig die Auswahl der Protokolle auf Anwendungsebene eingeschränkt. Weit verbreitete Protokolle wie HTTP und FTP sind für eine Übertragung mittels TCP konzipiert und scheiden daher aus. Die Wahl fällt auf das Constrained Application Protocol (CoAP). Dieses setzt standardmäßig auf eine Übertragung in UDP‐Paketen und erfüllt damit die Anforderungen wie die Kompatibilität zu Zeitschlitzen und ein berechenbares Übertragungsverhalten. Ein weiterer Vorteil von CoAP ist, dass es auch für die Verwendung auf Systemen mit geringer Rechenleistung und wenig Ressourcen ausgelegt ist und dies beim Einsatz in einer Automatisierungsumgebung von Vorteil ist, da das Protokoll beispielsweise auf eingebetteten Systemen mit den entsprechenden Hardwareeinschränkungen verwendbar ist. 3.2 ConstrainedApplicationProtocol(CoAP)Grundlagen 3.2.1 Funktionsprinzip Die in dieser Arbeit implementierte Datenübertragung zwischen den Kad‐Clients bzw. einem Kad Client und einem PC basiert auf CoAP. Das Protokoll befindet sich derzeit in der Entwicklung durch die Constrained RESTful Environments (CoRE) Arbeitsgruppe der Internet Engineering Taskforce (IETF) [8]. REST steht dabei für Representational State Transfer und bezeichnet die typische Arbeitsweise der meisten Internetdienste. Das derzeit am weitesten verbreitete Beispiel für REST ist das Hyper Text Transfer Protocol (HTTP). Da CoAP ebenfalls eine REST‐Architektur darstellt, sollen in Tabelle 3 einige wichtige Merkmale einer solchen Architektur erläutert werden. Eine umfassende Beschreibung von REST‐Merkmalen ist z.B. in [9] zu finden. 20 Client/Server Stateless (zustandslos) Uniform Interface (einheitliche Schnittstelle) Cache Resources and Representations Software der Datenverwaltung (Server) und der Benutzeroberfläche (Client) werden voneinander getrennt. Beide Komponenten des REST‐ Systems können unabhängig voneinander weiterentwickelt, verbessert sowie auf verschiedene Plattformen portiert werden. Der Server speichert zwischen zwei Client‐Interaktionen keine Sitzungsinformationen. Alle Anfragen werden daher vollkommen unabhängig voneinander behandelt. Die Nachvollziehbarkeit von Aktionen auf dem Server wird dadurch stark erhöht, da jede Anfrage einzeln betrachtet werden kann. Auch Zuverlässigkeit und Skalierbarkeit werden verbessert. Der Nachrichtenoverhead wird jedoch erhöht, da bestimmte Informationen in jeder Client‐Anfrage wiederholt werden müssen, welche im Falle einer anderen Architektur auf dem Server zwischengespeichert werden können. Für den Client sind Zustandsinformationen jedoch auch bei REST unerlässlich. Ein REST‐Protokoll besitzt eine stark verallgemeinerte und vereinfachte Schnittstelle zwischen Client und Server. Die Interaktionsmöglichkeiten sind somit nicht auf ein spezielles Anwendungsgebiet angepasst. Dies macht solche Systeme weiträumig einsetzbar und einfach implementierbar, kann in speziellen Anwendungsbereichen jedoch ineffizient sein, wenn die gegebenen Interaktionsmöglichkeiten die gewünschten Aufgaben nur schwer realisierbar machen. Ein Beispiel für Interaktionsmöglichkeiten sind die PUT, GET, DELETE und POST Methoden, welche in HTTP und CoAP zum Einsatz kommen. Bei gleich bleibender Schnittstelle kann die zu Grunde liegende Implementierung stetig weiterentwickelt werden. Um das Client‐Cache‐Stateless‐Server Prinzip zu vervollständigen, benötigt der Client noch einen Cache. In diesem Speicher können Daten gespeichert werden, die vom Server in einer Antwort als „cacheable“ markiert wurden. Folgende Anfragen des Clients können dann vollständig oder teilweise aus dem Cache beantwortet werden, sodass sich der Kommunikationsaufwand reduziert. So können Effizienz und Skalierbarkeit des Netzwerks auf einfache Weise gesteigert werden. Sinnvoll einsetzbar ist der Cache besonders für Daten, die sich nur relativ selten verändern, sodass keine Inkonsistenz zwischen Cache‐Daten und Server‐Daten entsteht. Eine Ressource befindet sich auf dem Server und steht dem Client für verschiedene Arten des Zugriffs (z.B. PUT, GET, usw.) bereit. Sie wird durch den Uniform Resource Identifier (URI) identifiziert. Von einer Ressource können auf dem Server mehrere Repräsentationen vorliegen. Diese geben in der Regel den gleichen Inhalt in unterschiedlichen Dateiformaten wieder, sodass Anfragen eines Clients jeweils in einem Format beantwortet werden können, mit dem dieser umgehen kann. Der Inhalt aller Repräsentationen einer Ressource wird aus derselben Quelle erzeugt (im Falle einer Automatisierungsumgebung z.B. verschiedene Darstellungsformen der Daten eines Sensors). Tabelle 3: Merkmale einer REST Architektur [9] Der besondere Fokus von CoAP im Vergleich zu HTTP als etablierte REST‐Architektur besteht in der Ausrichtung auf Netzwerke mit geringerer Bandbreite und Rechnersysteme mit weniger Rechenleistung (Einschränkung von CPU, RAM und ROM). Der Overhead durch den CoAP Header soll gering gehalten werden, um auch bei eingeschränkten Netzwerken mit geringer Maximum Transmission Unit (MTU) Nachrichten unfragmentiert übertragen zu können. Der Header besteht 21 daher aus einem statischen Anteil, welcher nur 4 Byte umfasst, sowie einem dynamischen Anteil, in dem dem Header optional weitere Informationen hinzugefügt werden können. Durch einen einheitlichen Aufbau aller optionalen Felder soll die Komplexität des Header‐Parsings dennoch gering gehalten werden, um der Verwendung auf Rechnersystemen mit wenig Rechenleistung gerecht zu werden. Wie bereits im vorigen Kapitel erwähnt, ist die Kommunikation über das vergleichsweise unzuverlässige UDP‐Protokoll ein weiteres besonderes Merkmal von CoAP. Durch die Verwendung von UDP fällt jedoch nicht nur der bei TCP nötige Verbindungsaufbau weg, sondern CoAP muss selbst Funktionen bereitstellen, die die Zuverlässigkeit der Datenübertragung sicherstellen, da UDP im Gegensatz zu TCP keine Kontrollmechanismen bereitstellt, die den Erhalt von Nachrichten bestätigen oder die korrekte Reihenfolge der erhaltenen Pakete garantieren. Hierzu kann man sich die Kommunikation über CoAP als in zwei Schichten aufgeteilt vorstellen [8]. 3.2.1.1 Nachrichtenebene Die untere Ebene wird als Nachrichtenebene bezeichnet [8], in der 4 verschiedene Nachrichtentypen zur Verfügung stehen. Diese heißen Confirmable (CON), Non‐Confirmable (NON), Acknowledge (ACK) und Reset (RST). Mit Confirmable‐Nachrichten kann eine zuverlässige Übertragung realisiert werden. Bei diesem Nachrichttyp wartet der Absender stets auf eine Acknowledge‐Nachricht der Gegenseite. Zugehörige Nachrichten werden dabei über eine Nachrichten‐ID erkannt. Konnte eine Nachricht nicht verarbeitet werden, so kann dies der Gegenseite durch eine Reset‐Nachricht mitgeteilt werden. Bei allen Nachrichtentypen kann die Nachrichten‐ID des Weiteren zur Identifikation von Duplikaten genutzt werden. Zur Identifikation von Duplikaten wird neben der ID außerdem die Absenderadresse verwendet, damit es bei der Kommunikation von mehreren Clients mit demselben Server nicht zu ID‐ Konflikten kommen kann. Erhält der Absender einer Confirmable‐Nachricht keine Antwort, so wiederholt er die Nachricht in exponentiell ansteigenden Zeitabständen, bis die vordefinierte maximale Anzahl von Versuchen erreicht wurde. Non‐Confirmable Nachrichten können dagegen für eine unzuverlässige Nachrichtenübertragung verwendet werden. Für sie erhält der Absender keine Empfangsbestätigung. Diese Arbeit behandelt vorwiegend Non‐Confirmable Nachrichten, da diese für eine deterministische Datenübertragung geeignet sind. Die Absicherung der Kommunikation gegen Paketverluste erfolgt dabei durch die in Kapitel 4 beschriebenen Mechanismen. 3.2.1.2 Request/Response‐Ebene Die sich logisch über der Nachrichtenebene befindende Request/Response‐Ebene kann weitgehend getrennt betrachtet werden. Die sogenannte CoAP‐Methode gibt an, ob es sich bei einer Nachricht um eine Anfrage (Request) oder Antwort (Response) handelt. Die Methoden PUT, GET, POST und DELETE sind Anfragen, während die Anzahl der möglichen Antworten wesentlich umfangreicher ausfällt und eine vollständige Liste [8] entnommen werden kann. PUT GET POST DELETE PUT kann verwendet werden um eine Repräsentation einer Ressource zu aktualisieren oder eine neue Repräsentation zur Ressource hinzuzufügen. Durch GET kann eine Repräsentation einer Ressource angefragt werden. Als Antwort sollte die entsprechende Repräsentation vom Server an den Client gesendet werden. Die Funktion von POST ist abhängig vom Server und kann zum modifizieren oder hinzufügen von Ressourcen verwendet werden. Löscht eine Repräsentation einer Ressource. Tabelle 4: CoAP Request Methoden 22 Anfragen (Requests) können in CON und NON Nachrichten versendet werden, während Antworten (Responses) in CON, NON sowie „piggy‐backed“ in ACK Nachrichten übertragen werden dürfen. Abbildung 6 und Abbildung 7 zeigen das Kommunikationsprinzip. In Abbildung 6 kann der Server die zu den Anfragen gehörenden Antworten sofort liefern und fügt diese daher der ACK Nachricht an („piggy backed“ Response). In Abbildung 7 dagegen dauert das Ermitteln der Antwort eine Zeit lang und es wird daher erst die ACK Nachricht als Empfangsbestätigung einer CON Nachricht versendet (Nachrichtenebene) und später in einer neuen CON Nachricht die Antwort auf die Anfrage (Request/Response‐Ebene) Abbildung 6: Zwei GET Requests mit "piggy‐backed" Response [8] [7] In den genannten Abbildungen ist das bereits in 3.2.1.1 erläuterte Prinzip der Nachrichten‐IDs zu sehen. Außerdem wird die CoAP‐Methode (hier: GET, 2.05 Content und 4.04 Not Found) gezeigt. Das Token wird zur Zuordnung von Anfrage und Antwort verwendet und ist nicht mit der Nachrichten‐ID zu verwechseln. Besonders in Abbildung 7 wird der Unterschied zwischen Token und Nachrichten‐ID deutlich, da hier in der separaten Antwort das ursprüngliche Token, jedoch eine neue Nachrichten‐ID verwendet wird. 23 Abbildung 7: GET Request mit separater Antwort [8] [7] Werden Anfragen in NON‐Nachrichten versendet, so kann die Antwort ebenfalls in einer NON‐ Nachricht erfolgen. Erhält der Client keine Antwort, so wird bei der Verwendung von NON‐ Nachrichten, im Gegensatz zu einem fehlenden ACK als Reaktion auf eine CON‐Nachricht, keine erneute Nachricht durch die Mechanismen der Nachrichtenebene versendet. Der Client hat jedoch auch hier die Möglichkeit, eine fehlende Antwort auf der Request/Response‐Ebene zu erkennen und die Anfrage erneut zu senden. Im folgenden Abschnitt soll das Nachrichtenformat gezeigt und erläutert werden, wobei sich die bereits genannten Felder im Header wiederfinden. 3.2.2 Nachrichtenformat Wie bereits beschrieben, besitzt der CoAP Header mit 4 Byte einen relativ geringen statischen Headeranteil, um den Overhead gering zu halten. Der folgende, dynamische Headeranteil enthält das Token und eine flexible Anzahl Optionen. Auf den Header folgen Payload Marker und Payload. Abbildung 8: Aufbau des CoAP Protokolls [1] [3] Version (Ver): Type (T): Token Length (TKL): Gibt die Versionsnummer des Protokolls an und muss derzeit immer den Wert 1 enthalten. Angabe des Nachrichtentyps: o CON (0) o NON (1) o ACK (2) o RST (3) Längenangabe des Token‐Feldes in Byte. Werte von 0 bis 8 sind gültig. 24 Code: Message ID: Token: Request/Response Code. Die Werte 1 31 stehen für Request Codes zur Verfügung, während 64 191 für Response Codes reserviert sind. Leere ACK‐Nachrichten und RST‐Nachrichten können hier außerdem den Wert 0 enthalten. ID zur Zuordnung von CON‐Nachrichten zu den entsprechenden ACK‐ und RST‐Nachrichten. In Verbindung mit der Absenderadresse außerdem zur Erkennung von Duplikaten genutzt. Token zur Zuordnung zusammengehöriger Requests und Responses. Die Optionen besitzen eine variable Länge und sind in Kapitel 3.2.3 erläutert. Das Payload Feld wird zur Übertragung von Daten verwendet. So kann es z.B. bei einer PUT Nachricht die zu aktualisierende Repräsentation einer Ressource enthalten, oder bei der Antwort auf ein GET die angefragte Repräsentation. Eine Längenangabe der Nutzlast gibt es nicht, da sie ab dem Payload Marker das restliche Paket ausfüllt. 3.2.3 Optionen In diesem Kapitel soll der Aufbau der Optionen im CoAP‐Paket erklärt werden und die Optionen vorgestellt werden, welche vollständig oder teilweise implementiert wurden. Eine Liste der derzeit definierten CoAP‐Optionen befindet sich in [8]. Die CoAP‐Optionen stellen neben dem Token den dynamischen Header‐Anteil dar. Die darin transportierten Informationen besitzen keine reservierten Felder im statischen Header, da sie nicht in jedem Paket benötigt werden. Durch das dynamische Hinzufügen bei Bedarf wird verhindert, dass Header‐Overhead durch ungenutzte Felder entsteht. 3.2.3.1 Aufbau Jeder CoAP‐Option ist eine Optionsnummer zugeordnet, sowie eine zulässige Länge in Bytes. Wird eine Option dem Header hinzugefügt, so besitzt diese daher immer die drei Einträge Nummer, Länge und Wert. Dabei wurde auch hier auf eine Minimierung des Overheads geachtet. Die Nummer wird nicht absolut, sondern als Deltawert relativ zur vorhergehenden Optionsnummer innerhalb des Pakets angegeben. Hierdurch werden die in das Paket einzufügenden Zahlen gering gehalten und die benötigten Bits reduziert. Negative Werte dürfen für das Optionsdelta nicht auftreten, sodass die Optionen sortiert nach ihrer Optionsnummer hinzugefügt werden müssen. Es existieren Optionen, die mehr als einmal pro Paket auftreten dürfen. In diesem Fall befinden sich alle Einträge hintereinander im Paket und verwenden ab dem zweiten Eintrag ein Optionsdelta von 0. Für das erste Optionsfeld wird eine vorhergehende Optionsnummer von 0 angenommen. Ein Optionsfeld beginnt mit einem 4 Bit Wert für das Optionsdelta, gefolgt von einem 4 Bit Wert für die Optionslänge. Sowohl für das Delta als auch für die Länge werden nur die Werte von 0 bis 12 direkt als Delta bzw. Länge gewertet, während die Werte von 13 bis 15 eine besondere Bedeutung besitzen (Tabelle 5) [8]. 25 Delta 13 14 15 Länge 13 14 15 Dem ersten Byte des Optionsfeldes folgt 1 Byte zur Angabe des Deltas abzüglich 13. Dem ersten Byte des Optionsfeldes folgen 2 Byte zur Angabe des Deltas abzüglich 269. Reserviert für den Payload Marker 0xFF. Vor dem Optionswert existiert ein 1 Byte zur Angabe der Länge abzüglich 13. Vor dem Optionswert existieren 2 Byte zur Angabe der Länge abzüglich 269. Derzeit nicht definiert und daher nicht erlaubt. Tabelle 5: Delta‐ und Längenfeld der CoAP‐Optionen Abbildung 9 verdeutlicht den beschriebenen Aufbau des variablen CoAP‐Optionsfeldes inklusive der möglichen Erweiterungen für Delta und Länge. Die Länge des Optionswertes muss mit der angegebenen Länge übereinstimmen, da nur an Hand der Längenangabe das Ende eines Optionsfeldes erkannt werden kann. Abbildung 9: CoAP Optionsfeld [8] An bestimmten Bits in der Optionsnummer sind außerdem einige Eigenschaften der Option ablesbar. Es gibt ein Critical/Elective‐Bit, sowie ein Unsafe/Safe‐To‐Forward‐Bit, wobei beide die Behandlung nicht erkannter Optionen regeln. Dass ein Kommunikationsteilnehmer eine Option nicht erkennt, kann beispielsweise auftreten, wenn dessen CoAP‐Implementierung weniger umfangreich ausfällt als die der weiteren Kommunikationsteilnehmer. Wurde eine Option nicht erkannt, die als Critical markiert wurde, so muss das Paket abgelehnt werden und wird nicht bearbeitet. Elective Optionen können einfach ignoriert werden, wenn diese dem Kommunikationsteilnehmer unbekannt sind. Das Unsafe/Safe‐To‐Forward‐Bit ist dagegen für die Weiterleitung über Proxies vorgesehen. Erkennt ein Proxy eine Option nicht, so darf er das Paket nur weiterleiten, wenn keine Option als Unsafe markiert ist. Weiterhin gibt es Bits in der Optionsnummer, die anzeigen, ob die Option bei der Beantwortung von Anfragen aus dem Cache mit der Option der ursprünglichen Anfrage bei der Erstellung des Cache‐Eintrages übereinstimmen muss (NoCacheKey‐Bits). Auf diese speziellen Eigenschaften der 26 Optionen soll hier nicht näher eingegangen werden, da sie in der derzeitigen Implementierung auf dem ZedBoard nicht berücksichtigt wurden. Derzeit findet kein Caching statt und alle Kommunikationsteilnehmer kennen die gleichen Optionen. 3.2.3.2 Uri‐Host,Uri‐Port,Uri‐Path,Uri‐Query Die Optionen Uri‐Host, Uri‐Port, Uri‐Path und Uri‐Query werden genutzt, um die Ziel‐Ressource für eine Anfrage festzulegen. Der Zusammenhang zwischen den Optionen und einer vollständigen CoAP‐ URI soll hier an einem einfachen Beispiel gezeigt werden, während die vollständigen Spezifikationen in [8] zu finden sind. Vollständige URI: coap://192.168.0.171:5783/test/test.txt Uri‐Host: 192.168.0.171 Uri‐Port: 5783 Uri‐Path: test Uri‐Path: test.txt Die Uri‐Host Option stimmt in der Regel mit der IP Adresse des angefragten Servers überein, ebenso wie die Uri‐Port Option mit dem angesprochenen Serverport der Transportschicht übereinstimmt. Die Uri‐Path Option darf mehrfach auftreten und gibt den Pfad der Ressource auf dem Server an. In der vollständigen URI werden die Segmente der Path‐Option durch ein „/“ getrennt. Die URI‐ Optionen werden von Clients in dieser Form verwendet, um einen Server direkt und ohne Proxying anzusprechen. 3.2.3.3 Content‐Format Die Content‐Format Option gibt das Datenformat einer als Nutzlast transportierten Repräsentation an. Sie kann bei einer PUT‐Anfrage verwendet werden, um dem Server zu signalisieren, welche Repräsentation zu modifizieren ist bzw. welches Format die hinzuzufügende Repräsentation besitzt, oder aber in der Antwort auf eine GET‐Anfrage, um dem Client mitzuteilen welches Datenformat die vom Server übertragene Repräsentation besitzt. Der Client benötigt diese Information um die korrekten Programme oder Funktionen zur Darstellung der Repräsentation auszuwählen. Den derzeit von CoAP zur Übertragung vorgesehenen Formaten sind Nummern zugeordnet, welche in [8] nachgeschlagen werden können. Da diese Option keinen Standardwert besitzt, ist das Format bei Fehlen der Option unbestimmt. 3.2.3.4 BlockOptionen:Block1,Block2undSize Wichtige Optionen im Rahmen dieser Arbeit sind die in [10] definierten Optionen zur Übertragung von Repräsentationen in mehreren Blöcken. Diese Optionen werden benötigt, wenn Repräsentationen übertragen werden sollen, die die maximale Größe der Nutzlast eines CoAP‐ Paketes überschreiten. Die maximale Größe der Nutzlast ergibt sich durch die Maximum Transmission Unit (MTU) des verwendeten Übertragungskanals abzüglich der Header der verwendeten Protokolle. Im Falle der Übertragung von CoAP in UDP/IP‐Paketen über Ethernet bedeutet dies ( ): 27 Die standardmäßige MTU für Ethernet beträgt 1500 Bytes, die übliche Headerlänge von IPv4 beträgt 20 Bytes, der UDP Header besitzt 8 Byte und der CoAP Header mindestens 4 Byte. So ergibt sich folgende maximale Größe der Nutzlast: 1500 20 8 4 1468 Dennoch wird in der Regel von einer kleineren, maximal möglichen Nutzlast ausgegangen, da sowohl der CoAP Header als auch der IPv4 Header durch das Auftreten optionaler Einträge deutlich größer sein können. Deshalb muss ein Sicherheitsabstand zur maximalen Nutzlastgröße eingehalten werden. In dieser Arbeit wird eine maximale Nutzlastgröße von 1024 Bytes angenommen. Repräsentationen, die diese Größe überschreiten, müssen in mehreren CoAP‐Paketen unter Verwendung der Block Optionen übertragen werden. Zunächst soll mit Abbildung 10 der Aufbau der Block Optionen eingeführt werden. Abbildung 10: Aufbau der Block Optionen [10] SZX: Bei SZX handelt es sich um eine exponentielle Größenangabe, aus der sich die in der Nutzlast des Paketes übertragene Anzahl Bytes einer Repräsentation nach folgender Formel berechnen lässt: 2 M: Dieses Bit gibt an, ob die Übertragung der Repräsentation mit dem in dem entsprechenden Paket enthaltenen Block abgeschlossen ist. Ist das Bit gesetzt, bedeutet dies, dass weitere Blöcke zu übertragen sind, um die Repräsentation zu vervollständigen. NUM: Hierbei handelt es sich um die Blocknummer. Diese steht immer in Bezug zu SZX. Besteht eine Repräsentation z.B. aus 3000 Bytes und wird in 1024 Byte Blöcken (SZX = 6) übertragen, so werden die Blocknummern 0 (Byte 0 1023), 1 (Byte 1024 2047) und 2 (Byte 2048 2099) verwendet. Die Berechnung des Startbytes eines übertragenen Blocks, also dem Byte, an dem der Block in der Repräsentation einzuordnen ist, erfolgt durch folgende Formel: ∗2 ≪ 4 Bei den Block Optionen wird zwischen der Block1 Option und der Block2 Option unterschieden, wobei deren Einsatz davon abhängt, ob PUT‐ oder GET‐Anfragen bearbeitet werden sollen. Die Block1 Option übernimmt folgende Aufgaben [10]: I. II. Bei PUT‐Anfragen eines Clients übermittelt die Block1 Option Informationen dazu, wie viele Bytes der Repräsentation pro Paket übertragen werden (SZX), ob weitere Pakete folgen (M), sowie eine Blocknummer (NUM), die angibt, um den wievielten Block der Übertragung es sich handelt. Bei Antworten auf PUT‐Anfragen wird durch Block1 angegeben, der wievielte Block vom Server erhalten wurde (NUM), ob weitere Pakete erwartet werden (M), um die Übertragung abzuschließen, sowie die gewünschte Größe der Nutzlast (SZX) für die folgenden PUT‐ Anfragen. 28 Solange das M Bit gesetzt ist, ist die Übertragung der Repräsentation nicht abgeschlossen und die Größe der Nutzlast entspricht der durch SZX angegebenen Größe. In der letzten PUT‐Anfrage sowie der darauf folgenden Antwort ist M nicht mehr gesetzt. Die letzte PUT‐Anfrage mit nicht gesetztem M Bit darf eine kürzere Nutzlast besitzen als durch SZX angegeben. Abbildung 11 verdeutlicht die Übertragung mit Hilfe der Block1 Option an Hand eines 3000 Byte großen Beispiels. NON, PUT, /test.txt, Block1:0/1/6 Übertragung der Bytes 0‐1023 NON, 2.04 Changed, Block1:0/1/6 Bestätigung der ersten 1024 Bytes NON, PUT, /test.txt, Block1:1/1/6 Übertragung der Bytes 1024‐2047 Client NON, 2.04 Changed, Block1:1/1/6 Bestätigung der nächsten 1024 Bytes Server NON, PUT, /test.txt, Block1:2/0/6 Übertragung der Bytes 2048‐2999 NON, 2.04 Changed, Block1:2/0/6 Bestätigung der letzten 952 Bytes Abbildung 11: Kommunikationsbeispiel mit Block1 Option Block2 übernimmt ebenfalls verschiedene Aufgaben: III. IV. Bei Antworten auf GET‐Anfragen übermittelt der Server in Block2 die Menge der übertragenen Bytes der Repräsentation pro Paket (SZX), die Blocknummer (NUM), sowie die Information ob weitere Blöcke gesendet werden müssen (M), um die Übertragung abzuschließen. Bei GET‐Anfragen kann der Client Block2 nutzen, um dem Server mitzuteilen, wie viele Bytes der Repräsentation er in der nächsten Antwort erhalten möchte (SZX) und den wievielten Block er benötigt (NUM). Abbildung 12 zeigt die Verwendung der Block2 Option an Hand eines 2000 Bytes großen Beispiels unter Verwendung der Größenanpassung durch den Client, wie sie in IV. beschrieben wurde. Dabei muss die Blocknummer entsprechend dem neuen Wert von SZX angepasst werden. In der zweiten Anfrage des Clients wird daher die Blocknummer 2 statt 1 verwendet, da die Übertragungsgröße von 1024 auf 512 Byte reduziert wurde. Die Angabe der Blocknummer bezieht sich also immer auf die durch SZX angegebene Übertragungsgröße. Ähnlich hierzu könnte bei der in Abbildung 11 gezeigten Kommunikation mit der Block1 Option eine Größenanpassung durch den Server erfolgen, indem dieser SZX in seiner Bestätigungsnachricht reduziert. 29 NON, GET, /test.txt Erste Anfrage ohne Block2 NON, 2.05 Content, Block2:0/1/6 Übertragung der Bytes 0‐1023 NON, GET, /test.txt, Block2:2/0/5 Anfrage der Bytes 1024‐1535 Client NON, 2.05 Content, Block2:2/1/5 Übertragung der Bytes 1024‐1535 Server NON, GET, /test.txt, Block2:3/0/5 Anfrage der Bytes 1536‐2047 NON, 2.05 Content, Block2:3/0/5 Übertragung der Bytes 1536‐1999 Abbildung 12: Kommunikationsbeispiel mit Block2 Option und Größenanpassung Weitere Anwendungsszenarios für die Block Optionen sind in [10] zu finden. Die Size Option kann ebenfalls auf verschiedene Art und Weise verwendet werden. Sie kann einer PUT‐Anfrage eines Clients zusammen mit Block1 hinzugefügt werden, um dem Server die Gesamtgröße der in mehreren Blöcken übertragenen Repräsentation bereits zu Beginn der Übertragung mitzuteilen. Der Server kann diese Information nutzen, um seine Speicherverwaltung auf die zu erwartende Datenmenge hin auszurichten. So kann beispielsweise bei der Speicherung der Daten im Arbeitsspeicher im Voraus ausreichend Speicher reserviert werden. Ebenso kann die Size Option zusammen mit Block2 in einer Antwort auf eine GET‐Anfrage verwendet werden, um dem anfragenden Client mitzuteilen, wie groß die in der folgenden Kommunikation zu übermittelnde Repräsentation ist. 3.2.4 Kommunikationsteilnehmer 3.2.4.1 Server Ein CoAP Server ist ein Endpunkt der Kommunikation, der zur Beantwortung von Anfragen dient. Er muss eine Datenbank zur Speicherung von Ressourcen bzw. deren Repräsentation besitzen und empfängt in der Regel Anfragen auf einem vordefinierten UDP‐Port. Die Repräsentation einer Ressource können durch Client‐Aktionen wie PUT und POST erzeugt werden, oder aber durch den Server selbst generiert werden. So ist z.B. in einer Automatisierungsumgebung vorstellbar, dass der Server Daten von einem oder mehreren angeschlossenen Sensoren empfängt und diese Daten in verschiedenen Repräsentationen und Ressourcen den Clients zur Verfügung stellt. Der Server erzeugt selbst keine Anfragen. 30 3.2.4.2 Client Der Client erzeugt Anfragen und sendet diese an andere Kommunikationsteilnehmer wie Proxies oder Server. Die gesendeten Anfragen dienen der Modifikation von Repräsentationen auf dem angesprochenen Server (PUT, POST und DELETE) oder der Beschaffung von Informationen (GET). Beschaffte Informationen dienen entweder der Weiterverarbeitung in anderen Programmen (z.B. bei Machine‐To‐Machine Kommunikation) oder werden dem Benutzer dargestellt. Der Client selbst hat keinen Ressourcenspeicher, kann jedoch Antworten cachen um zukünftige, äquivalente Anfragen aus dem Cache‐Speicher zu beantworten und die Netzwerkauslastung zu reduzieren. 3.2.4.3 ForwardProxy Ein Forward Proxy nimmt Anfragen von Clients entgegen und leitet diese an den zuständigen Server weiter. Die Antworten des Servers werden wiederum über den Forward Proxy zurück an den Client geleitet. Hierdurch wird eine direkte Kommunikation zwischen Client und Server unterbunden. Der Client muss in diesem Fall wissen, dass er mit einem Proxy kommuniziert und muss der Anfrage bestimmte Proxy Optionen hinzufügen, in denen die URI inklusive des zuständigen Servers angegeben sind. Ohne die Angabe der vollständigen URI inklusive Server‐IP und Server‐Port hat ein Forward Proxy keine Möglichkeit den zuständigen Server, an den die Anfrage weiterzuleiten ist, zu bestimmen. Auf die Proxy Optionen wird in dieser Arbeit nicht näher eingegangen, da sie hier keine Anwendung finden. 3.2.4.4 ReverseProxy Der Reverse Proxy nimmt ebenfalls Anfragen von Clients entgegen und leitet diese an den zuständigen Server weiter. Auch hier werden die Antworten des Servers über den Reverse Proxy zurück an den Client geleitet. Der Unterschied zum Forward Proxy besteht in der Ermittlung des zuständigen Servers. Im Falle des Reverse Proxy weiß der Client nicht, dass er nicht mit dem Server selbst sondern mit einem Proxy kommuniziert. Daher können auch keine speziellen Proxy Optionen verwendet werden. In diesem Fall besitzt der Client keine Informationen über den Server, auf dem die gesuchte Ressource tatsächlich existiert und kann dem Reverse Proxy daher keine solchen Informationen bereitstellen. Es ist die Aufgabe des Reverse Proxies, den Server, der für die angefragte Ressource zuständig ist, zu ermitteln. Wie dies konkret abläuft ist von der Implementierung abhängig. Diese Form des Proxies wird in dieser Arbeit verwendet und die entsprechende Implementierung ist in Kapitel 3.3.4 erläutert. 3.3 Implementierung 3.3.1 Kommunikationsmechanismus Der implementierte Kommunikationsmechanismus basiert vollständig auf CoAP NON‐Nachrichten. Mit Abbildung 13 soll die Kommunikation über CoAP NON‐Nachrichten an Hand eines einfachen Beispiels eingeführt werden. Warum die Verwendung von NON‐Nachrichten für die angestrebte deterministische Datenübertragung die optimale Kommunikationsform darstellt, ist in Kapitel 3.4 erläutert. 31 Abbildung 13: GET Request über NON‐Nachrichten [8] Kann eine Übertragung auf Grund der Größe der transportierten Datei nicht mit einem Paket abgeschlossen werden, so kann auch bei Verwendung von NON‐Nachrichten auf die Block Optionen zurückgegriffen werden (siehe Abbildung 11 und Abbildung 12). Sowohl der Client als auch der Server erkennen selbständig ob die Übertragung mit Hilfe der Block Option erfolgen muss und fügen diese bei Bedarf dem Paket hinzu. Auch die Size Option wird in diesem Fall verwendet. Ein Client übermittelt dem Server also bei einer PUT‐Anfrage neben der Block1 Option auch eine Size Option, um den Server über die Größe der in mehreren Blöcken übertragenen Datei zu informieren. Bei einer GET‐Anfrage erhält dagegen der Client bei entsprechend großen Dateien eine Antwort vom Server, die eine Block2 Option sowie eine Size Option enthält. Außerdem implementiert sind die Verwendung von Uri‐Host, Uri‐Port und Uri‐Path. Dabei kann der Uri‐Path aus beliebig vielen Segmenten (getrennt durch „/“) bestehen. Vorbereitungen für die Verwendung der Content‐Format Option sind getroffen, derzeit wird sie allerdings noch nicht genutzt. 3.3.2 Server Der CoAP Server besitzt eine Ressourcendatenbank zur Speicherung von prinzipiell beliebig vielen Ressourcen, welche wiederum beliebig viele Repräsentationen besitzen können. Da die Ressourcen vollständig im Heap gespeichert werden, wird die Anzahl der gespeicherten Ressourcen bzw. Repräsentationen allein durch die Größe des zu Verfügung stehenden Heap‐Speichers begrenzt. Pseudocode Erläuterung map[„Name“] = „Eike“ Dem Schlüssel „Name“ wird der Wert „Eike“ zugewiesen. Dem Schlüssel „Nachname“ wird der Wert „Schweißguth“ zugewiesen. Dem Schlüssel „Alter“ wird der Wert „23“ zugewiesen. map[„Nachname“] = „Schweißguth“ map[„Alter“] = „23“ zeige map[„Name“] zeige map[„Nachname“] zeige map[„Alter“] Anzeige von „Eike“ Anzeige von „Schweißguth“ Anzeige von „23“ map[„Alter“] = „100“ Änderung der Wertes Schlüssel „Alter“ Anzeige von „100“ zeige map[„Alter“] unter dem Tabelle 6: Prinzip einer Map 32 Die Ressourcendatenbank ist als map der C++ Standard Template Library (STL) implementiert. In dieser können Schlüssel‐Wert‐Paare abgelegt werden. Durch Angabe des gleichen Schlüssels erhält man also immer Zugriff auf den gleichen Wert. Die Datentypen für den Schlüssel und den zugeordneten Wert sind dabei für eine map frei wählbar. Tabelle 6 zeigt dieses Prinzip einer map an einem Beispiel welches in Pseudocode formuliert ist und als Datentyp für Schlüssel und Wert Zeichenketten ( ) verwendet. Im Falle der Ressourcendatenbank werden C++ Strings als Schlüssel verwendet und der zugeordnete Wert ist eine Liste von Repräsentationen. Das bedeutet, dass der vollständig zusammengesetzte Uri‐ Path als Schlüssel zum Zugriff auf eine Liste von Repräsentationen einer Ressource genutzt wird. Die Liste von Repräsentationen kann Repräsentationen einer Ressource in unterschiedlichen Formaten enthalten. In der derzeitigen Implementierung umfasst die Liste nie mehr als eine Repräsentation mit undefiniertem Format, da die Content‐Format Option nicht verwendet wird. Durch PUT‐Anfragen kann ein Client einen Eintrag in der Ressourcen‐Map unter dem von ihm durch die Uri‐Path Optionen definierten Schlüssel hinzufügen. Auf GET‐Anfragen reagiert der Server mit dem Senden der Repräsentation, die unter dem übermittelten Uri‐Path in der Datenbank hinterlegt ist. Die Datenverarbeitung durch den Server findet in zwei Threads statt. Der erste Thread öffnet einen UDP Socket und empfängt auf diesem kontinuierlich Daten. Empfangene Pakete werden einer Warteschlange hinzugefügt, die vom zweiten Thread der Reihe nach bearbeitet wird. Bei der Warteschlange handelt es sich also um einen einfachen First In‐First Out (FIFO)‐Speicher. Dem zweiten Thread wird durch eine Semaphore signalisiert, dass sich Pakete in der Warteschlange befinden. Solange sich Pakete in der Warteschlange befinden, arbeitet der zweite Thread diese der Reihe nach ab. Die Pakete werden aus der Warteschlange entfernt und analysiert, um welche Art der Anfrage es sich handelt. Derzeit können von der implementierten Form des CoAP Servers PUT‐Anfragen sowie GET‐Anfragen bearbeitet werden. DELETE und POST werden nicht unterstützt. Zu jeder Art von Anfrage gibt es eine Verarbeitungsroutine, hier also derzeit Funktionen mit den Namen ProcessPUT und ProcessGET. In beiden Funktionen wird zunächst eine Antwortnachricht erstellt und die in jedem Fall benötigten Felder der Nachricht besetzt (ID, Nachrichtentyp, Protokollversion, Tokenlänge, Token). Die anschließende Bearbeitung der Pakete ist im Folgenden beschrieben. 3.3.2.1 BearbeitungvonPUT‐Anfragen In ProcessPUT wird, falls vorhanden, die Block1 Option ausgelesen, um festzustellen, um welchen Block der übertragenen Repräsentation es sich handelt. Außerdem müssen die Uri‐Path Optionen ausgelesen werden und wieder zu einem vollständigen Uri‐Path zusammengesetzt werden. Anschließend wird die übertragene Nutzlast unter dem angegebenen Uri‐Path in der Ressourcendatenbank gespeichert. Bei vorhandener Block1 Option wird diese beim Speichervorgang berücksichtigt und die Nutzlast an der entsprechenden Stelle in der Repräsentation gespeichert, während das Speichern bei nicht vorhandener Block1 Option immer an Stelle des ersten Bytes der Repräsentation erfolgt. Falls außerdem eine Size Option im Paket enthalten ist, wird für die Repräsentation entsprechend viel Speicher reserviert. Nach dem Speichern der Daten wird eine entsprechende Antwort (2.01 Created für neu erstellte Repräsentationen oder 2.04 Changed für veränderte Repräsentationen) an den Client gesendet. Wurde die Anfrage mit einer Block1 Option 33 gestellt, wird diese auch der Antwort wieder hinzugefügt, wie bereits in Abbildung 11 zu sehen. Abbildung 14 zeigt den Funktionsablauf bei der Bearbeitung einer PUT‐Anfrage auf dem Server. Abbildung 14: Funktionsablauf von ProcessPUT 3.3.2.2 BearbeitungvonGET‐Anfragen ProcessGET liest ebenfalls die Uri‐Path Optionen aus und setzt den vollständigen Uri‐Path zusammen. An Hand dieser Information wird die entsprechende Repräsentation in der Ressourcendatenbank gesucht. Wurde die Repräsentation nicht gefunden, wird eine entsprechende Antwort (4.04 Not Found) an den Client gesendet. Konnte die Repräsentation gefunden werden, wird die Block2 Option 34 aus der Anfrage ausgelesen (falls vorhanden). Ist die Repräsentation zu groß, um innerhalb eines Paketes übertragen zu werden, so wird der durch die Block2 Option definierte Block dem Antwortpaket hinzugefügt, bzw. der erste Block, falls Block2 in der Anfrage nicht enthalten war. Kann die Repräsentation nicht in einem Paket übertragen werden, so wird in jedem Fall Block2 der Antwort hinzugefügt, um den Client darüber zu informieren, dass weitere Pakete übertragen werden müssen. Dieses Vorgehen wurde bereits mit Abbildung 12 vorgestellt. In der Antwort, in der der erste Block übermittelt wird, wird außerdem die Size Option hinzugefügt. Abbildung 15: Funktionsablauf von ProcessGET In Abbildung 15 ist die Verarbeitung einer GET‐Anfrage gezeigt. Dabei ist zu sehen, dass das Auslesen der Block2 Option bereits vor der Überprüfung, ob die Repräsentation in ein Paket passt, erfolgt. Dies ist nötig, um dem Client die Möglichkeit zur Größenanpassung zu bieten, wie in Kapitel 3.2.3.4 beschrieben. Kann der Client beispielsweise höchstens mit einer Nutzlast von 256 Byte pro Paket umgehen, kann dies an dieser Stelle signalisiert werden. Macht der Client keine Angabe, so wird vom implementierten CoAP Server immer von einer maximalen Nutzlast von 1024 Bytes ausgegangen. Der im Rahmen dieser Arbeit implementierte Client arbeitet standardmäßig ebenfalls mit 1024 35 Bytes, sodass Größenanpassung derzeit nicht genutzt wird und nur für zukünftige Arbeiten mit diesem System vorgesehen ist. Bei den beschrieben Funktionsabläufen des Servers wurde bereits deutlich, dass das Stateless‐Server‐ Prinzip eingehalten wurde. Jede Anfrage wird durch denselben Funktionsablauf bearbeitet – vorige Pakete spielen für den Server keinerlei Rolle. Andererseits wird durch dieses Prinzip eine höhere Rechenleistung vom Server verlangt, da z.B. bei einer Übertragung einer Repräsentation in Blöcken bestimmte Informationen, die in allen Blöcken identisch sind, nicht zwischengespeichert werden. So wird der Uri‐Path bei einer Übertragung in Blöcken aus jedem Paket erneut ausgelesen, obwohl er in allen Paketen identisch ist. Dieser zusätzliche Verarbeitungsaufwand hat einen spürbaren Einfluss auf die Performance des Servers. Im Gegenzug ist ein solcher zustandsloser Server einfacher zu implementieren. 3.3.3 Client Der CoAP Client wurde sowohl für Windows als auch für FreeRTOS auf dem Zedboard implementiert. Die Windows Version wird benötigt, um Daten zwischen einem PC und einem Zedboard zu transportieren. Nur so ist es möglich, Daten von außen in das Kad‐Netz einzubringen. Die FreeRTOS‐ Version des Clients wird dagegen benötigt, um Performancemessungen der Kommunikation über CoAP innerhalb des Kad‐Netzes durchzuführen. Die beiden Versionen unterscheiden sich nur in ihrer Benutzerschnittstelle. In der Windows Version kann der Benutzer über die Kommandozeile spezifizieren, welche Aktion ausgeführt werden soll. Folgende Angaben müssen über die Kommandozeile gemacht werden: IP des CoAP Servers Port des CoAP Servers Auszuführende CoAP Methode: PUT, GET, TRIGGERPUT, TRIGGERGET Dateipfad der Quelldatei (PUT) bzw. Dateipfad der Zieldatei (GET) Uri‐Path In der FreeRTOS‐Version sind diese Optionen statisch im Quellcode festgelegt. IP und Port des Servers sind also bereits zum Zeitpunkt des Kompiliervorgangs festgelegt, ebenso wie der Uri‐Path. Als Quelldatei für PUT‐Aktionen sowie als Zieldatei für GET‐Aktionen dient ein Bereich des Heap‐ Speichers, da dem Zedboard kein Dateisystem auf einer Festplatte zur Verfügung steht, wie es in der Windows‐Version der Fall ist. Für Performancemessungen der CoAP‐Kommunikation innerhalb des Kad‐Netzes stellen diese festen Vorgaben jedoch keine Einschränkung dar. Später können diese festen Vorgaben an den jeweiligen Einsatzbereich des Kad‐Netzes angepasst werden. Ausgelöst werden kann eine Aktion des CoAP Clients auf dem Zedboard durch das Senden eines TRIGGERPUT bzw. TRIGGERGET Paketes ausgehend von der Windows‐Version an den entsprechenden CoAP Client. Die FreeRTOS‐Version des CoAP Clients hat zum Empfang der Triggerpakete stets einen entsprechenden Socket geöffnet. Ebenso wie für den Server sind derzeit nur PUT‐ und GET‐Aktionen für den Client implementiert, deren Ablauf in den folgenden Teilen des Kapitels vorgestellt werden soll. Außerdem soll kurz auf Performanceaspekte eingegangen werden. 36 3.3.3.1 PUT‐Aktion Wird eine PUT‐Aktion gestartet, so findet zunächst der Aufbau einer Nachricht statt, es werden also die in jeder Nachricht benötigten Felder (ID, Nachrichtentyp, Protokollversion, Methode: PUT, Tokenlänge, Token) besetzt. Anschließend werden die in jedem Fall benötigten CoAP Optionen hinzugefügt (Uri‐Host, Uri‐Port, Uri‐Path). Die Uri‐Path Optionen werden dabei aus dem an die Funktion übergebenen Uri‐Path erstellt, indem eine Trennung des Pfades durch „/“ Zeichen vorgenommen wird. Anschließend wird die Bearbeitung einer PUT‐Aktion in drei Threads fortgesetzt. Zwei dieser Threads besitzen einen relativ einfachen Aufbau. Ein Thread erwartet am Client Socket eintreffende Antworten des Servers. Erhaltene Antworten werden in eine Warteschlange (FIFO‐ Speicher) zur Verarbeitung eingereiht. Dem nächsten Thread wird durch eine Semaphore signalisiert, dass Pakete zur Verarbeitung bereitstehen. Dieser Thread entnimmt die Pakete aus der Warteschlange verarbeitet diese. Im Falle einer PUT‐Aktion besteht die Verarbeitung der Antworten nur aus zwei Aufgaben: Wird die Übertragung mit Hilfe der Block1 Option durchgeführt, so wird die Block1 Option aus dem ersten Antwortpaket des Servers ausgelesen, damit der Client eine Größenanpassung folgender an den Server übermittelten Pakete vornehmen kann. Wie bereits beim Server beschrieben, findet diese Größenanpassung derzeit nicht statt, da sowohl der implementierte Client als auch der Server mit einer Nutzlast von 1024 Bytes umgehen können. Außerdem signalisiert dieser Thread dem dritten Thread durch eine Semaphore, dass eine Antwort verarbeitet wurde. Abbildung 16: Client PUT‐Aktion Hauptthread 37 Der dritte Thread ist für das Senden der Repräsentation der Ressource zuständig, wenn nötig mit Hilfe der Block1 Option in mehreren Paketen. Abbildung 16 soll das Vorgehen dieses Threads einführen, bevor auf einige wichtige Punkte näher eingegangen wird. Dieser Thread erhält die zu Beginn bereits größtenteils aufgebaute Nachricht. Zu Abbildung 16 ist anzumerken, dass für alle versendeten Blöcke das ursprüngliche Paket verwendet wird. Es wird nur die Size Option entfernt und im weiteren Verlauf die Block1 Option sowie die Nutzlast angepasst. Dieses Vorgehen ist wesentlich effizienter, als für jeden Block ein neues Paket vollständig aufzubauen. Dies liegt unter anderem daran, dass die Erstellung des dynamischen Headeranteils viel Rechenzeit in Anspruch nimmt. In einer ersten Version der Implementierung wurde für jeden Block ein vollständig neues Paket erstellt, was sich deutlich negativ auf die Performance des Clients ausgewirkt hat. Aus diesem Grund wurde die Wiederverwendung des Paketes eingeführt. Bei einer Übertragung mehrerer Blöcke wird außerdem vor dem Senden eines jeden Paketes auf eine Antwort des Servers gewartet. Dies ist nötig, da eine kontinuierliche Übertragung ohne das Abwarten von Antworten schnell zu einer Überlastung des Servers führen gewartet, wobei die Definition von Tabelle 7 kann. Dennoch wird höchstens entnommen werden kann. Höchste Übertragungsverzögerung im betrachteten Netzwerk (in der Regel durch den längsten Pfad bestimmt). Verarbeitungszeit eines Paketes im Server. 2∗ Maximale Wartezeit bis zum Erhalt einer Antwort durch den Server. Tabelle 7: Definition von Diese zeitliche Begrenzung ist nötig, da nach dem Ablauf von nicht mehr mit dem Erhalt einer Antwort zu rechnen ist und Anfrage oder Antwort offensichtlich bei der Übertragung verloren gegangen sind. Das Senden weiterer Blöcke wird jedoch unbeeinflusst fortgesetzt. Die maximale Wartezeit ist wichtig für den Determinismus der Übertragung. Die Tatsache, dass trotz eines verloren gegangenen Paketes weitergesendet wird, erscheint zunächst nicht sinnvoll. Berücksichtigt man jedoch, dass durch den später vorgestellten Fehlerkorrekturmechanismus sichergestellt ist, dass auch bei unvollständiger Übertragung die Originaldaten wiederherstellbar sind, ist das Vorgehen nachvollziehbar. 3.3.3.2 GET‐Aktion Vergleichbar zur PUT‐Aktion beginnt auch die GET‐Aktion des Clients mit dem Aufbau einer ersten CoAP Nachricht, auch hier werden die Felder ID, Protokollversion, Nachrichtentyp, Tokenlänge und Token initialisiert und anschließend die auf jeden Fall benötigten Optionen Uri‐Host, Uri‐Port und Uri‐ Path zur Nachricht hinzugefügt. Anschließend findet auch hier der weitere Ablauf der Anfrage verteilt auf drei Threads statt. Der Empfangsthread nimmt Pakete am Client Socket entgegen und fügt diese einer Warteschlange zur Verarbeitung hinzu, während dem Pakete verarbeitenden Thread durch eine Semaphore mitgeteilt wird, dass Pakete zur Verarbeitung bereit stehen. Der Verarbeitungsthread muss mehrere Informationen aus den eintreffenden Paketen auslesen. Aus der ersten eintreffenden Antwort des Servers wird (falls vorhanden) die Size Option entnommen. Durch die Größenangabe der angefragten Repräsentation weiß der Client, wie viele Blöcke er im Folgenden vom Server anfordern muss, um die 38 vollständige Repräsentation zu erhalten. Fügt der Server seiner ersten Antwort keine Size Option hinzu, so muss der Client in der folgenden Kommunikation aus jeder Antwort des Servers durch das M Bit der Block2 Option ermitteln, ob er weitere Blöcke anzufragen hat. Ist weder eine Size Option, noch eine Block2 Option in der Antwort des Servers enthalten, bedeutet dies implizit, dass die Repräsentation in einer Antwort des Servers vollständig übertragen werden konnte und keine weiteren Anfragen nötig sind. Neben der Ermittlung, ob weitere Blöcke angefragt werden müssen, muss selbstverständlich auch der weitere Inhalt der Antwort bearbeitet werden. Enthält eine Antwort den Nachrichtencode 4.04 „Not Found“ oder 4.00 „Bad Request“, bedeutet das, dass der Client eine nicht existierende Repräsentation bzw. einen nicht existierenden Block der Repräsentation vom Server erfragt hat, und dass die GET‐Aktion abgebrochen werden muss. Bei einer Antwort mit dem Nachrichtencode 2.05 „Content“ enthält die Nachricht die angefragte Repräsentation als Nutzlast. Diese kann dann in der entsprechenden Zieldatei auf der Festplatte (Windows‐Client) bzw. im entsprechenden Heap‐Speicher (FreeRTOS‐Client) gespeichert werden. Dabei wird (sofern vorhanden) die übermittelte Block2 Option berücksichtigt und die Daten an der der Blocknummer entsprechenden Stelle in der Zieldatei/im Heap‐Speicher gespeichert. Außerdem signalisiert der Thread, wenn ein Paket verarbeitet wurde, um dem Hauptthread das Senden neuer Anfragen an den Server zu erlauben. Der Ablauf des zum Senden der GET‐Anfragen genutzten Hauptthreads ist in Abbildung 17 zu sehen. Auch hier arbeitet der Thread mit dem zu Beginn erstellten Paket und führt für das Senden mehrerer GET‐Anfragen nur die notwendigen Modifikationen am Paket durch. Auch hier wurde dieses Vorgehen der vollständigen Neuerstellung von Paketen aus Performancegründen vorgezogen. Abbildung 17: Hauptthread der GET‐Aktion Bei der in Abbildung 17 gezeigten Abfrage, ob bereits eine Antwort vom Verarbeitungsthread bearbeitet wurde, ist beim ersten Mal sichergestellt, dass dies der Fall ist, da die GET‐Aktion ansonsten bereits zuvor abgebrochen wird. Außerdem ist das Verhalten dieses Thread unterschiedlich, in Abhängigkeit davon, ob der Verarbeitungsthread in der ersten Antwort eine Size Option vorgefunden hat. War eine Size Option in der ersten Antwort enthalt, so wird die dort angegebene Größe der Repräsentation vom Hauptthread genutzt, um zu beurteilen, ob weitere 39 Blöcke zu erfragen sind. In diesem Fall kann der Client seine Anfragen fortführen, auch wenn nicht innerhalb von eine Antwort des Servers verarbeitet wurde (Keine entsprechende Signalisierung durch den Verarbeitungsthread). War in der ersten Antwort keine Size Option enthalten, so kann die Beurteilung, ob weitere Blöcke zu erfragen sind, nur an Hand des M Bits der Block2 Option der letzten Antwort des Servers erfolgen. Geht in diesem Fall eine Antwort verloren, so wird davon ausgegangen, dass keine weiteren Blöcke mehr zu erfragen sind und die GET‐Aktion wird beendet. Aus diesem Grund übermittelt der hier implementierte Server immer eine Size Option zusammen mit dem ersten Block einer Repräsentation. Trifft auf die erste Anfrage keine Antwort ein, so wird die Aktion abgebrochen, da der Client nicht wissen kann ob nur ein Paketverlust aufgetreten ist, oder ob es auf Grund eines Ausfalls des angesprochenen Servers zwecklos ist die Anfrage zu wiederholen. Ein Wiederholen der Anfrage wäre schlecht für den Determinismus des Systems, da die Dauer, die im worst case für eine Aktion eingeplant werden muss, steigen würde. 3.3.4 ReverseProxy Der implementierte Reverse‐Proxy ist für eine einfache Client‐Server Kommunikation nicht notwendig, im Falle der CoAP Implementierung für das P2P‐Netz HaRTKad ist er jedoch von großer Bedeutung. Bei der einfachen Client‐Server Kommunikation muss der Client den Server, auf dem eine Repräsentation gespeichert werden soll (PUT) bzw. von dem eine Repräsentation angefragt werden soll (GET), selbst kennen, um ihn dann direkt anzusprechen. Im Falle einer verteilten Speicherung ist ein solches statisches Vorgehen jedoch nicht wünschenswert, sondern die Ressourcen sollen auf alle zur Verfügung stehenden Knoten im Netzwerk verteilt werden. Damit die Verteilung der Ressourcen auf alle Knoten stets an die Größe des P2P‐Netzes angepasst ist, bietet es sich an, das Hash‐basierte Routingverfahren des Kad‐Netzes zu diesem Zweck zu nutzen. Das zu Grunde liegende Konzept soll also sein, beim Speichern oder Lesen einer Repräsentation ein Merkmal dieser Repräsentation zur Bildung eines Hashwertes zu nutzen. Abbildung 18: CoAP Kommunikation im HaRTKad‐Netz An Hand des Hashwertes wird dann der zuständige Knoten ermittelt und die Repräsentation auf den dort aktiven CoAP Server gespeichert bzw. von diesem gelesen. Das Ermitteln des zuständigen 40 Knotens soll nicht Aufgabe des Clients sein, sondern von einer separaten Instanz. Der Reverse Proxy stellt die entsprechende Instanz dar. Nach der CoAP Spezifikation aus [8] wird er vom Client wie ein Server angesprochen, ermittelt jedoch selbständig den tatsächlich für die gesuchte Ressource zuständigen Server, hier mit Hilfe des Kad‐Routings. Abbildung 18 zeigt eine vollständige Übersicht über die vorgesehene Kommunikation zur verteilten Speicherung mit Hilfe von CoAP innerhalb des HaRTKad Netzes. Damit das System keinen Single Point of Failure (SPoF) besitzt, läuft auf jedem Kad‐Knoten sowohl ein Server (generell notwendig zur verteilten Speicherung), als auch ein Reverse Proxy. Ein Client kann also zum Zugriff auf Ressourcen einen beliebigen Kad‐Knoten auf dem Port des Reverse Proxy ansprechen. Dieser sorgt dann für die Weiterleitung der Anfrage an den zuständigen Server. Außerdem kann jeder Kad‐Knoten als Client agieren. Durch den Reverse Proxy kann auch der Windows‐Client vollständig die verteilte Speicherung des Kad‐Netzes nutzen. Des Weiteren ist anzumerken, dass die miteinander kommunizierenden Client‐, Proxy‐ und Server‐Prozesse nicht zwangsläufig auf unterschiedlichen Kad‐ Knoten ausgeführt werden müssen. Es ist also möglich, dass ein Client eine Anfrage an den Reverse Proxy auf dem eigenen Zedboard stellt. Ebenso können sich der angefragte Reverse Proxy und der zuständige Server auf dem gleichen Kad‐Knoten befinden. Die Anfrage wird dann intern vom Proxy‐ Prozess an den Server‐Prozess übergeben. Der Reverse Proxy besitzt ebenso wie der Server einen Thread, der einen Port öffnet und dann kontinuierlich Pakete auf diesem empfängt und die empfangenen Pakete einer Warteschlange zur Verarbeitung hinzufügt. Dem Verarbeitungsthread wird mittels Semaphore signalisiert, dass Pakete zu verarbeiten sind. An Hand des Nachrichtencodes wird zunächst beurteilt, ob es sich um eine Anfrage (nur PUT, GET, DELETE, POST) oder eine Antwort handelt, um die entsprechende Verarbeitungsroutine zu starten. Im Falle einer Anfrage werden die Uri‐Path Optionen genutzt, um einen Hashwert zur Ermittlung des zuständigen Kad‐Knotens zu bilden. Wird dabei festgestellt, dass der Knoten, der die Anfrage aktuell verarbeitet, selbst innerhalb der Suchtoleranz liegt, wird die Anfrage direkt dem ebenfalls auf dem Knoten laufenden Server übergeben. Da im Kad‐Netz mehrere Knoten für einen Hashwert zuständig sein können, wird, unabhängig davon ob der Knoten selbst bereits für die Anfrage zuständig war, eine Kad‐Suche nach weiteren zuständigen Knoten gestartet. Hierzu wird ein Kad‐Suchobjekt erstellt, welches nach Kontakten sucht, die für den entsprechenden Hashwert zuständig sind. Wurde die (frei konfigurierbare) gewünschte Anzahl zuständiger Kontakte gefunden, erhält der Reverse Proxy diese in Form einer Kontaktliste. Die Kontaktliste wird zusammen mit dem Ziel‐Hash für weitere Anfragen abgespeichert. Diese Form des Zwischenspeicherns ist besonders für die Performance beim Transport von Daten mittels der Block Optionen wichtig. Durch das Zwischenspeichern von Hash‐ Kontaktlisten‐Paaren kann bei jeder folgenden Anfrage zuerst geprüft werden, ob bereits eine zuständige Kontaktliste für den Hash existiert, bevor eine Kad‐Suche gestartet wird. Außerdem wird der Anfrage das Token entnommen und ein Token‐Client Paar gespeichert. Anschließend wird die zuständige Kontaktliste abgearbeitet, indem jedem enthaltenen Kontakt die Anfrage weitergeleitet wird. Die Weiterleitung erfolgt wie bereits gezeigt immer an den Serverport des Knotens. Bei den vom Proxy weitergeleiteten Paketen wird jeweils die Uri‐Host Option sowie die Uri‐Port Option an den entsprechenden Kontakt angepasst. 41 Die Verarbeitung von eintreffenden Antworten ist vergleichsweise einfach. An Hand des Tokens wird aus den für jede Anfrage gespeicherten Token‐Client Paaren der zugehörige Client ermittelt. An diesen wird die Antwort weitergeleitet und das Token‐Client Paar aus dem Speicher entfernt. Um bei Paketverlusten zu vermeiden, dass Token‐Client‐Paare ewig im Speicher bleiben und bei längerem Betrieb einen Überlauf produzieren können, gibt es eine maximale Anzahl gespeicherter Token‐Client Paare. Treffen neue Anfragen ein, wenn die maximale Anzahl bereits erreicht ist, werden die ältesten Einträge gelöscht. Ebenso kann der Cache für Hash‐Kontaktlisten Paare keinen Speicherüberlauf produzieren, da auch hier eine maximale Anzahl definiert ist. Ein Mechanismus zur Erkennung von Duplikaten an Hand der Nachrichten‐ID und dem Absender ist von CoAP zwar vorgesehen, da der Prototyp nur innerhalb eines Subnetzes arbeitet und hier praktisch keine Duplikate entstehen können, wurde der Mechanismus noch nicht implementiert. 3.4 DeterminismusbeiderÜbertragung Das vorgestellte Constrained Application Protocol bietet durch die Verwendung von NON‐ Nachrichten die Möglichkeit, Daten verbindungslos und ohne Absicherung zu übertragen. Im Gegenzug kann eine Übertragung mit Hilfe dieses Verfahrens innerhalb einer vergleichsweise niedrigen vordefinierten oberen Schranke abgeschlossen werden. Andere Übertragungsprotokolle wie TCP oder CoAP mit CON‐Nachrichten sind hingegen für eine deterministische Übertragung ungeeignet, da diese durch ihre wiederholten Übertragungsversuche die obere Schranke stark erhöhen würden. In Kapitel 3.3.3 wurde bereits der Parameter definiert, welcher angibt, wie lange sinnvollerweise auf eine Antwort gewartet werden sollte. Auf Basis dieses Parameters kann angegeben werden, wie lange der Übertragungsvorgang eines Paketes mit Hilfe von CON‐ und NON‐ an, wie viele Nachrichten dauert. Im Falle der CON‐Nachricht gibt der Parameter Übertragungsversuche für ein Paket gestartet werden. Bei jedem Versuch wird die Wartezeit auf eine . So muss für die Übertragung einer CON‐Nachricht im Antwort verdoppelt, beginnend bei schlechtesten Fall folgende Zeit eingeplant werden: ∗ 2 1 Dagegen wird bei der Übertragung einer NON‐Nachricht vom Client nur ein Versuch gestartet und auf die Antwort gewartet. Auch ohne Antwort werden PUT‐ bzw. GET‐Aktionen dann wie in Kapitel 3.3.3 beschrieben fortgesetzt. So gilt für die maximale Dauer der Übertragung im Falle der NON‐ Nachricht: Insgesamt bietet CoAP unter Verwendung von NON‐Nachrichten also die besten Voraussetzungen für eine deterministische Datenübertragung. Des Weiteren ist zu berücksichtigen, dass es sich bei um einen Parameter handelt, in den die Verarbeitungszeit einer Anfrage auf dem Server sowie die Übertragungsverzögerung einfließen. Unter Kenntnis des längsten Pfades im Netzwerk und der typischen Verarbeitungszeit einer Anfrage kann der Parameter entsprechend gewählt werden und die obere Schranke für eine Datenübertragung reduziert werden. Zur Berechnung der Dauer einer kompletten PUT‐ bzw. GET‐Aktion sind jedoch neben der maximalen Antwortzeit auf ein Paket weitere Betrachtungen notwendig. Zunächst soll angegeben werden, wie 42 lange ein vollständiger Request‐Response‐Vorgang dauert. Gegenüber der maximalen Antwortzeit muss bei der Betrachtung eines vollständigen Request‐Response‐Vorganges auch die Bearbeitungszeit im Client hinzugenommen werden. Der Client benötigt sowohl Zeit zur Erstellung des Request‐Paketes, als auch zur Verarbeitung des Response‐Paketes. Diese Verarbeitungszeit im zusammengefasst. Wie bereits erläutert, dauert die Client wird unter der Bezeichnung Erstellung des ersten CoAP Request‐Paketes bei einer Übertragung in Blöcken länger als die Erstellung der folgenden CoAP Requests, da das ursprüngliche Paket wiederverwendet wird. Daher als Teil des ersten Request‐Response‐ werden die Client‐Verarbeitungszeiten Vorganges und als Teil der folgenden Request‐Response‐Vorgänge definiert. Für die bzw. ) Berechnung der Dauer eines vollständigen Request‐Response‐Vorganges ( des CoAP Protokolls ergeben sich so unter Hinzunahme der Antwortzeit folgende Formeln: Soll eine große Datei in Paketen mittels Block Option übertragen werden, so ergibt sich folgende : Übertragungszeit 1 ∗ Bei der Realisierung der Kommunikation über einen Reverse Proxy muss dieser bei Erhalt der ersten Anfrage eine Kad‐Suche starten, um den für die Datei zuständigen Kad‐Knoten zu ermitteln. Die Dauer der Kad‐Suche wird bestimmt durch Zeit, die zur Erstellung eines Suchobjektes benötigt wird ), sowie die Dauer eines Suchschrittes im Kad‐Netz ( ). Außerdem muss die Anzahl der ( Suchschritte berücksichtigt werden, welche in einem Kad‐Netzwerk : ergibt sich die folgende Suchdauer ∗ log log beträgt [11]. Somit gibt dabei die XOR‐Distanz zwischen dem Knoten, der die Suche startet, und dem Datum an. Diese Suche wird für die Übertragung einer Datei in mehreren Blöcken dennoch nur genau einmal ausgeführt, da der zuständige Kad‐Knoten zwischengespeichert wird und ab dem zweiten Request‐ Paket keine Suche mehr durchgeführt werden muss. Dennoch wird ausnahmslos jedes Request‐ und Response‐Paket durch die Verarbeitung im Proxy verzögert. Diese Verarbeitungszeiten im Reverse Proxy werden unter der Bezeichnung zusammengefasst. Die in Kapitel 3.3.3 definierte muss bei der Kommunikation über einen Proxy daher um diese Zeit maximale Antwortzeit erweitert werden, sodass die neue Definition des Parameters folgendermaßen lautet: 2∗ Die gesamte Dauer einer CoAP‐Aktion bei Kommunikation über einen Reverse Proxy lautet demnach: log log ∗ ∗ 1 ∗ 1 ∗ 43 Wird für alle diese Zeiten ein entsprechender worst case Wert eingesetzt, so erhält die maximale Dauer einer Aktion. Der Determinismus des Übertragungsverfahrens ist somit gegeben. 3.5 Ausblick Nachdem das Konzept der Datenübertragung vollständig beschrieben und implementiert wurde, soll an dieser Stelle auf einige Aspekte eingegangen werden, die die Leistungsfähigkeit des Systems in Zukunft steigern könnten, sowie auf Probleme, welche bei der Weiterentwicklung bearbeitet werden sollten. Bei der Beschreibung der Client‐Implementierung wurde bereits erläutert, dass es für die Performance relevant ist, ob bei einer Übertragung mittels Block Option für jeden Block vollständig ein neues Paket aufgebaut wird, oder ob in einem bestehenden Paket nur die Block Option so modifiziert wird, dass sie die nächste Blocknummer enthält, und bei einer PUT‐Anfrage entsprechend die Nutzlast geändert wird. Nach ersten Tests während der Implementierungsphase konnte die Leistungsfähigkeit der Client Implementierung durch geringe Codeveränderungen etwa um den Faktor 20 gesteigert werden. Das gleiche Performance‐Problem existiert beim Server. Auf Grund seiner zustandslosen Natur muss dieser während einer Übertragung mittels Block Option jedes Paket des Clients vollständig neu analysieren und beispielsweise die Suche nach der ensprechenden Ressource in der Datenbank für jede Anfrage erneut ausführen. Auch der Aufbau eines neuen Antwortpaketes muss vollständig wiederholt werden. Soll der Server häufig für die Übertragung großer Datenmengen eingesetzt werden, kann der entsprechende Code überarbeitet werden, um das Parsing eingehender Pakete, die Suche in der Datenbank und die Erstellung von Paketen zu beschleunigen. Außerdem problematisch ist derzeit die Bestimmung der Speicherziele durch den Reverse Proxy in Verbindung mit der Suchtoleranz. In einigen Fällen kann es vorkommen, dass trotz korrekter Speicherung bei einer späteren GET‐Anfrage ein entsprechendes Datum nicht wiedergefunden wird. Das Problem soll an einem Beispiel veranschaulicht werden. Durch eine ungleiche Verteilung der Knoten‐Hashwerte kann es vorkommen, dass in einem bestimmten Hashwerte‐Bereich mehr Knoten dicht beieinander liegen als in einem anderen Bereich der Hashwerte. Die Suchtoleranz wird durch den DST‐Algorithmus so bestimmt, dass auch im weniger dicht „besiedelten“ Gebiet der Hashwerte die gewünschte Mindestanzahl zuständiger Knoten für einen Hashwert erreicht wird. Im dichter besiedelten Gebiet kann diese Mindestanzahl zuständiger Knoten unter Umständen deutlich übertroffen werden, da hier die gleiche Suchtoleranz gilt. Wie viele zuständige Knoten es genau gibt, ist jedoch nicht bekannt. Bei einem Speichervorgang kann nur auf einer vorgegebenen Anzahl an Knoten gespeichert werden. Da die exakte Anzahl zuständiger Knoten nicht bekannt ist, wird der Vorgang also möglicherweise nicht auf allen zuständigen Knoten ausgeführt – nämlich nur auf den durch den Suchvorgang zuerst gefundenen. Folgt später eine GET‐Anfrage aus einem anderen Teil des Netzwerks, so wird möglicherweise durch die dort vorhandenen Routingtabellen einer der für den Hashwert zuständigen Knoten zuerst gefunden, auf dem der Speichervorgang nicht ausgeführt wurde. Das Ergebnis wäre ein „False Negative“. Der Server meldet, dass die Repräsentation nicht existiert, obwohl sie auf dem Server eines anderen Knotens verfügbar wäre. Des Weiteren soll hier noch einmal darauf hingewiesen werden, dass zum Zeitpunkt der Implementierung des Übertragungsprotokolls noch keine Zeitschlitze für den HaRTKad‐Prototypen implementiert waren. Daher ist das implementierte Protokoll zwar prinzipiell zu einer Übertragung in 44 Zeitschlitzen in der Lage, es können jedoch noch geringfügige Modifikationen nötig werden um die Zusammenarbeit mit den Zeitschlitzen zu ermöglichen. 4 Fehlerkorrektur 4.1 AufgabenderFehlerkorrektur Die Fehlerkorrektur des zu implementierenden Gesamtsystems muss Korrekturmaßnahmen für 2 Fehlerquellen umfassen. Die primäre Aufgabe der Fehlerkorrekturmaßnahmen besteht darin, eine hohe Verfügbarkeit und Ausfallsicherheit der Daten zu gewährleisten, obwohl als Speicherplattform zum Teil von Ausfällen betroffene P2P‐Clients dienen. Dies erfordert sowohl eine intelligente Aufteilung der zu speichernden Daten auf mehrere Speicherziele, als auch eine ausreichende Redundanz, um aus nur anteilig aus dem Netzwerk zurückgewonnen Daten die Originaldaten vollständig wiederherzustellen. Bei einer realistischen Annahme über die Ausfallwahrscheinlichkeit der als Speicher verwendeten P2P‐Clients soll mit Hilfe der Redundanz eine Datenverfügbarkeit von 99,999% erzielt werden. Die zweite Aufgabe der Fehlerkorrekturmaßnahmen ist es, die fehlende Fehlerkorrektur des in Kapitel 3 vorgestellten Übertragungsverfahrens auszugleichen. Da das Übertragungsverfahren bei Paketverlusten keinerlei Korrekturversuche vornimmt, sondern mit der Übertragung konsequent fortfährt, muss die in diesem Kapitel vorgestellte Fehlerkorrektur geeignet sein auch bei vereinzelten Paketverlusten durch Leitungsstörungen die Originaldaten nach einer unvollständigen Übertragung wiederherzustellen. Beide Aufgaben können durch fehlerkorrigierende Codes erfüllt werden. Eine bekannte Form der fehlerkorrigierenden Codes sind die Reed Solomon Codes. Diese sind nicht nur hervorragend für den angestrebten Einsatzzweck geeignet, sondern auch seit vielen Jahren weit verbreitet im Einsatz. Sie werden bei modernen Datenträgern wie CDs und DVDs sowie in der Kommunikationstechnik (ADSL, DVB, Satellitenkommunikation) eingesetzt [12]. 4.2 ReedSolomonCodes Bei Reed Solomon Codes werden Binärdaten als eine Reihe von Bit breiten Symbolen aufgefasst. Es gibt also 2 verschiedene Symbole. Beim Codieren werden Symbole aus den Nutzdaten entnommen und durch ein mathematisches Verfahren, welches hier nicht näher erläutert werden soll, Symbole gebildet. Bei den hinzugefügten Symbolen handelt es sich um die sogenannten Paritätssymbole [12]. Bits pro Symbol Symbolanzahl der Nutzdaten Anzahl der Paritätssymbole Anzahl der Symbole pro Codewort Tabelle 8: Reed Solomon Bezeichner Im Falle einer sogenannten systematischen Codierung (ob es sich um eine systematische Codierung handelt, ist abhängig vom gewählten Codierungsverfahren) bestehen die Symbole des Codewortes aus den unveränderten Originaldaten ( Symbole) mit angehängten Paritätssymbolen. Hierbei muss außerdem für folgende Regel gelten: 45 2 1 Die maximale Länge der Codewörter ist also abhängig von der Anzahl der Bits pro Symbol. Das gewünschte Maß an Redundanz kann nun unter Einhaltung der Formeln und 2 1 durch Veränderung der Parameter und erzielt werden. Bezeichnet werden Reed Solomon Codes üblicherweise als , ‐Code. Stehen seitens der Nutzdaten weniger als Symbole zur Verfügung (Datei zu kurz), so können die fehlenden Symbole vor dem Codiervorgang mit Nullen gefüllt werden, welche anschließend wieder entfernt werden. Bestehen die Nutzdaten aus mehr als Symbolen (Datei zu lang), so wird der Codiervorgang einfach sequentiell für jeweils Symbole durchgeführt und mehrere Codewörter generiert. Beim Decodiervorgang können Reed Solomon Codes zwei Arten von Fehlern beheben. Die erste Art von Fehlern sind fehlerhafte Symbole. Sobald ein Bit eines Symbols falsch ist, gilt das Symbol als fehlerhaft. Ein Reed Solomon Decoder kann die originalen Nutzdaten sicher wiederherstellen, solange höchstens /2 Symbole fehlerbehaftet sind. Dabei spielt es keine Rolle, ob in einem Symbol alle Bits falsch sind oder nur eines [12]. Die zweite Art von Fehlern sind bekannter weise fehlende Symbole. Wird dem Decoder mitgeteilt, welche Symbole fehlen, so dürfen bis zu Symbole des Codewortes fehlen und die originalen Daten können weiterhin sicher wiederhergestellt werden. Treten beide Fehler gemischt auf, so können die Daten wiederhergestellt werden, solange gilt: 2 ; , An Hand der vorgestellten Eigenschaften der Reed Solomon Codes wird deutlich, dass diese besonders gegen Burst Fehler geeignet sind, da bei Burst Fehlern trotz vieler falscher Bits nur wenige Symbole betroffen sein können. Verteilte, einzelne Bitfehler sind hingegen für Reed Solomon Codes problematisch, da in diesem Fall viele Symbole durch wenige Bitfehler zerstört werden können. 4.3 Implementierung Bei der Implementierung eines Reed Solomon Codes zur Absicherung einer Datenübertragung über das Netzwerk müssen im Voraus noch einige auftretende Probleme betrachtet werden und entsprechende Maßnahmen getroffen werden, um Reed Solomon Codes auf diesem Gebiet sinnvoll einsetzen zu können. Das Hauptproblem besteht darin, dass die Nutzlast eines CoAP Paketes in der hier implementierten CoAP Version bis zu 1024 Bytes betragen darf, während typische Symbolgrößen für Reed Solomon Codes deutlich darunter liegen. Am häufigsten werden Reed Solomon Codes mit 1 Byte (8 Bit) Symbolen verwendet. Die maximale Länge eines Codewortes mit 8 Bit Symbolen beträgt: 2 1 255 Ein Codewort passt also vollständig in die Nutzlast eines CoAP Paketes. Werden so vollständige Codewörter innerhalb der CoAP Pakete übertragen, bedeutet der Verlust eines Paketes bereits eine Beschädigung der Daten. Reed Solomon bietet hier keinen praktischen Nutzen. Die Codierung schützt hier weder bei einzelnen Paketverlusten, noch beim Ausfall von Kad‐Knoten. Das Problem soll weiter an einem Beispiel verdeutlicht werden, welches mit 8 Bit Symbolen und einer 255, 127 ‐ Codierung arbeitet. Zu jeweils 127 Bytes der Originaldatei werden also 128 Paritätsbytes durch den Codiervorgang erzeugt. Das Beispiel arbeitet mit einer 381 Bytes großen Datei. 46 Abbildung 19: Reed Solomon Encoding in Segmenten Die codierte Datei umfasst 765 Bytes und kann somit vollständig in einem CoAP Paket transportiert werden. Bei einem Paketverlust sind dennoch alle Daten verloren. Um den Vorteil des Reed Solomon Encoding zu nutzen, darf nie mehr als ein Symbol eines Codewortes in einem Paket transportiert werden. Auf Grund des Overheads durch die Netzwerkprotokolle ist es jedoch nicht sinnvoll in jedem Paket nur 1 Byte Nutzlast zu transportieren. Die Symbolgröße wesentlich größer als ein Byte zu wählen, um Pakete, die nur ein Symbol transportieren, besser auszulasten, ist nicht praktikabel: Computersysteme arbeiten byteorientiert und es sollen Dateigrößen ab einem Byte Größe verarbeitet werden können. Es gibt keine effizienten Implementierungen für Reed Solomon Codes mit sehr großen Symbolgrößen (z.B. 1024 Bytes) Es wird also am 255, 127 ‐Code mit 8 Bit Symbolen festgehalten. Die Lösung des Problems ist ein Interleaving Verfahren, welches die Codewörter miteinander verschränkt. So wird erreicht, dass in einem Paket nicht mehr als ein Symbol des selben Codewortes und dennoch mehr als ein Byte pro Paket transportiert wird. Abbildung 20 zeigt das Interleaving am Beispiel Abbildung 20: Codewort Interleaving Parallel zu [13] wird hier die Bezeichnung Chunk für einen Teil der verschränkten Datei gewählt. In [13] werden die Chunks zwar auf einem anderen Weg erzeugt (implizites Interleaving beim Encoding), sind jedoch in Bezug auf den Reed Solomon Code vergleichbar: Ein Chunk enthält nie mehr als ein Symbol desselben Codewortes. Chunk 1 enthält z.B. das jeweils erste Symbol aller Codewörter, Chunk 2 das jeweils zweite Symbol aller Codewörter, usw. 47 Bei Verwendung von 8 Bit Symbolen kann zum Encoding ein beliebiger , ‐Code mit 255 gewählt werden. Nach dem Interleaving existieren Chunks, darunter Chunks mit Paritätssymbolen aus dem Kodiervorgang. Die Größe eines Chunks entspricht der Anzahl der Codewörter. Die Chunks werden in CoAP Paketen übertragen. Solange 1024 gilt, kann ein Chunk in der vorliegenden Implementierung innerhalb von einem Paket übertragen. Im ungünstigen Fall einer sehr kleinen Datei existiert nur ein Codewort, sodass ein Chunk eine Größe von einem Byte hat. Der Overhead durch die Netzwerkprotokolle ist in diesem Fall relativ betrachtet am größten. Mit zunehmender Anzahl der Codewörter verringert sich der relative Overhead. Ist 1024, so findet die Übertragung eines Chunks in CoAP Paketen mit Hilfe der Block Option statt. Auf Basis der Chunks lässt sich außerdem eine einfache Methode zur Verteilung der Daten auf viele Kad‐Knoten realisieren. Jedem Chunk wird beim Speichervorgang ein eigener Uri‐Path zugewiesen, welcher systematisch zusammengesetzt wird. Er besteht aus dem durch den Benutzer definierten Uri‐Path und der Nummer des Chunks. Der zuständige Kad‐Knoten wird dabei für jeden Chunk an Hand des zusammengesetzten Uri‐Paths durch den Reverse Proxy bestimmt. Die Chunks werden so über die zur Verfügung stehenden Kad‐Knoten verteilt. Je nach Verhältnis von (Anzahl der Chunks) und der Anzahl der Kad‐Knoten werden ein oder mehrere Chunks auf einem Knoten gespeichert. Da der verwendete Reed Solomon Code und damit die Anzahl der vorhandenen Chunks zur Kompilierzeit festgelegt werden, kann der Client bei der Wiederherstellung der Datei problemlos die benötigte Anzahl an Chunks aus dem Kad‐Netz anfragen. Das gezeigte Konzept ist robust gegen beide zu Beginn des Kapitels erläuterten Fehler. Paketverluste stellen kein Problem dar, da im Falle eines Paketverlustes nur ein Teil eines Chunks verloren geht (bzw. ein Chunk, falls dieser in ein einziges Paket passt). Damit bedeutet ein Paketverlust den Verlust von einem Symbol pro Codewort, wobei maximal 1024 Codewörter betroffen sind. Einzelne Symbolverluste stellen jedoch kein Problem für die Rekonstruktion der Daten aus einem Codewort dar, da nur Symbole von jedem Codewort benötigt werden, je nach Anzahl der ausgefallenen Knoten jedoch bis zu Symbole von jedem Codewort übertragen werden. Durch den Ausfall von Kad‐Knoten gehen vollständige Chunks verloren. Wie viele Chunks auf einem Kad‐Knoten gespeichert sind, hängt von der Größe des zur Verfügung stehenden Netzes ab. Im Idealfall, also für die maximale Robustheit, sollte nur ein Chunk pro Kad‐ Knoten gespeichert werden. Doch auch der Ausfall von kompletten Chunks stellt kein Problem für die Rekonstruktion der Originaldaten dar, da der Ausfall von einem Chunk die Auslöschung von jeweils einem Symbol aller Codewörter bedeutet. Es dürfen dementsprechend bis zu Chunks vollständig ausfallen. Die Wahrscheinlichkeit, dass sich die Originaldaten vollständig wiederherstellen lassen, lässt sich berechnen. Folgende Parameter werden zu diesem Zweck definiert: : Wahrscheinlichkeit, dass Originaldaten wiederherstellbar, wenn nur Knotenausfälle, jedoch keine Paketverluste berücksichtigt werden. : Wahrscheinlichkeit für die Wiederherstellbarkeit der Originaldaten unter Berücksichtigung von Knotenausfällen und Paketverlusten. Annahme: 1 Paket pro Chunk 48 : Wahrscheinlichkeit für die Wiederherstellbarkeit der Originaldaten unter Berücksichtigung von Knotenausfällen und Paketverlusten. Annahme: Pakete pro Chunk : Knotenverfügbarkeit : Wahrscheinlichkeit, dass ein Paket erfolgreich übertragen werden kann 1 Bei der Berechnung von wird ermittelt, wie wahrscheinlich es ist, dass oder mehr (höchstens ) Chunks intakt sind und zur Wiederherstellung der Daten zur Verfügung stehen. Dabei wird davon ausgegangen, dass immer nur ein Chunk auf einem Knoten gespeichert wird. Nur so kann die Wahrscheinlichkeit, dass ein Chunk intakt ist, mit der Knotenverfügbarkeit gleichgesetzt werden und die Berechnung mittels unabhängiger Zufallsvariablen erfolgen. Bei mehr als einem Chunk pro Knoten entstehen Abhängigkeiten, die die Berechnung erschweren würden. Komplizierter ist der Zusammenhang unter Berücksichtigung von , also bei der Berechnung von . Es muss dann nicht nur berechnet werden, wie wahrscheinlich es ist, dass mindestens Knoten verfügbar sind, sondern auch die Wahrscheinlichkeit, dass mindestens Pakete der intakten Knoten erfolgreich übertragen werden können. 1 ∗ 1 gilt dennoch nur, wenn pro Chunk nur ein Paket übertragen werden muss. Besteht ein Chunk aus Paketen, müssen mal mindestens Pakete erfolgreich übertragen werden. Die Wahrscheinlichkeit für die Übertragung von mindestens Paketen von intakten Knoten muss hierzu potenziert werden. 1 ∗ 1 Die Reihenfolge in der die Pakete eines Chunks übertragen werden spielt dabei keine Rolle, da es sich bei der Übertragung zweier Pakete um unabhängige Ereignisse handelt. Es ist also egal, ob erst alle Pakete von Chunk 1, dann von Chunk 2, usw. übertragen werden, oder ob erst von jedem Chunk das erste Paket, dann von jedem Chunk das zweite Paket, usw. übertragen wird. Bei der implementierten Version des Reed Solomon Codes lassen sich die Parameter und anpassen, sodass die Anzahl der vorhandenen Chunks an die Anzahl der vorhandenen Knoten angepasst werden kann. Durch diese Anpassung kann dafür gesorgt werden, dass wie gewünscht nur ein Chunk pro Knoten gespeichert wird. Standardmäßig sind die Parameter für und wie im Beispiel gewählt, es wird also ein 255, 127 ‐Code verwendet. Die Robustheit der derzeit implementierten Version ist noch geringer, als in den Berechnungen angegeben, da kein Erasure Decoder verwendet wird. Das 49 bedeutet, dem Decoder wird nicht mitgeteilt, welche Symbole verloren gegangen sind. Dadurch werden zum sicheren decodieren /2 statt Symbole pro Codewort benötigt. Dementsprechend dürfen auch nur maximal /2 Chunks bzw. Knoten ausfallen. Ein Aspekt, welcher die Datenredundanz bei der verteilten Speicherung im Kad‐Netz erhöht, ist die Konfiguration der Suchtoleranz des Kad‐Netzes. Je nach eingestellter Suchtoleranz können für einen Hashwert mehrere Knoten zuständig sein. Beim Speichervorgang kann es also vorkommen, dass ein Chunk auf mehreren Knoten gespeichert wird. Trotz Knotenausfall kann der entsprechende Chunk also weiterhin verfügbar sein. Zur Implementierung des Reed Solomon Codes sowie des Interleaving‐Verfahrens wurde die Codebibliothek aus [14] entnommen. Zur Übertragung der Chunks werden die selbst implementierten und in Kapitel 3 beschriebenen PUT‐ und GET‐Aktionen verwendet. Für jeden Chunk wird eine separate Aktion ausgeführt. 4.4 Ausblick Wie auch bei der Implementierung des Übertragungsprotokolls besteht auch bei der Fehlerkorrektur noch Potential zur Steigerung der Leistungsfähigkeit und Robustheit. Eine Maßnahme zur Steigerung der Robustheit ist es, bei GET‐Aktionen zu protokollieren, welche Pakete verloren gegangen sind. Dadurch kann dem Decoder übergeben werden, welche Symbole fehlen. Da fehlende Symbole dementsprechend nicht mehr wie Fehler behandelt werden, wird die Anzahl der erlaubten Paketverluste von /2 auf gesteigert und das volle Potential der Reed Solomon Codierung ausgenutzt. Eine Änderung, bei der sich das „worst case“ Verhalten des Systems zwar nicht verbessert, aber die durchschnittliche Übertragungszeit, die benötigte Rechenzeit und damit auch der Energieverbrauch von GET‐Aktionen gesenkt werden können, ist durch die Ausnutzung der systematischen Struktur der Reed Solomon Codewörter möglich. Reed Solomon Codewörter sind bei bestimmten Codierungsalgorithmen systematisch aufgebaut, d.h. die Originaldaten bleiben unverändert und die Redundanzsymbole werden angehängt. Ist es bei einer Übertragung möglich, die ersten Symbole unbeschadet zu erlangen, so müssen die Redundanzsymbole nicht mehr übertragen werden und auch der Decodiervorgang entfällt, da es sich bei den ersten Symbolen um unveränderte Originaldaten handelt. Auch bei Paketverlusten innerhalb der ersten Symbole kann noch Übertragungszeit eingespart werden, indem nur so viele Redundanzsymbole übertragen werden, wie auf Grund von Paketverlusten benötigt werden. Im Endeffekt sollen nie mehr als die mindestens benötigten Symbole übertragen werden. Handelt es sich dabei nicht um die ersten Symbole, muss allerdings der Decodiervorgang erfolgen. Der Codier‐ sowie Decodiervorgang wiederum kann beschleunigt werden, indem das FPGA der Zedboards genutzt wird. Da Reed Solomon Codes sehr rechenintensiv sind, handelt es sich hier um einen sinnvollen möglichen Einsatzzweck des FPGAs, der den Datendurchsatz deutlich steigern könnte. Ein Problem, dass derzeit noch in Bezug auf die Fehlerkorrektur gelöst werden muss, ist die Bearbeitung von unvollständigen Codewörtern. Unvollständige Codewörter können auftreten, wenn sich die zu codierenden Daten nicht ganzzahlig durch teilen lassen. Werden Symbole codiert, so werden wie üblich Redundanzsymbole hinzugefügt, sodass ein Codewort der Länge 50 – entsteht. Zur erfolgreichen Decodierung muss das Codewort auch in dieser Länge wieder dem Decoder übergeben werden. Durch Paketverluste kann es vorkommen, dass die Länge des verkürzten Codewortes nicht bekannt ist und die Decodierung fehlschlägt. In Zukunft muss daher eine Lösung gefunden werden, die Länge des unvollständigen Codewortes sicher zu ermitteln. 5 TestsundMessungen Abschließend muss die Leistungsfähigkeit des implementierten Verfahrens überprüft werden, um festzustellen, ob ein Einsatz in dem angestrebten Umfeld einer industriellen Automatisierungsumgebung möglich ist. Hierzu wird wie in [2] eine fiktive Automatisierungsanlage betrachtet, bei der es unterschiedliche Ebenen gibt, welche verschiedene Anforderungen an die zu transportierende Datenmenge sowie die hierfür maximal erlaubte Übertragungsdauer stellen. Ebene Leitebene Zellebene Feldebene Max. Übertragungsdauer 100 1000 20 1 Max. Datenmenge 1000 100 10 Tabelle 9: Anforderungen an das Datenübertragungsverfahren in einer Automatisierungsanlage Die Übertragung der entsprechenden Datenmengen muss im Rahmen dieser Arbeit allerdings hinsichtlich mehrerer Kriterien untersucht werden. Als erstes muss die Performance der Übertragung mittels CoAP betrachtet werden. Die Reed Solomon Codierung zur Erhöhung der Zuverlässigkeit wird dabei noch nicht verwendet. Dementsprechend wird auch nicht verteilt gespeichert und nicht über den Reverse Proxy, sondern direkt zwischen Client und Server kommuniziert. Als nächstes wird der Einfluss der Reed Solomon Codierung auf die Performance untersucht, jedoch weiterhin direkt zwischen Client und Server kommuniziert. Die Reed Solomon Chunks werden also alle auf einem Kad‐ Knoten gespeichert, sodass der einzige Vorteil der Reed Solomon Codierung in einer Robustheit gegenüber Paketverlusten besteht. Als drittes Szenario wird die ursprünglich angestrebte, robuste, verteilte Speicherung betrachtet. Die Daten werden also mittels Reed Solomon codiert und die Chunks mit Hilfe der Kommunikation über den Reverse Proxy verteilt auf mehreren Kad‐Knoten gespeichert. Zusätzlich zu den für Automatisierungsumgebungen üblichen Datenmengen soll die Übertragung von 10000 Byte betrachtet werden, da im Rahmen dieser Arbeit besonderer Wert darauf gelegt wurde, dass das implementiere Übertragungsverfahren keine Einschränkung hinsichtlich der Datenmenge besitzt. Konkret bedeutet dies, dass auch Datenmengen, die nicht innerhalb von einem Ethernet Frame transportiert werden können, übertragen werden können. Da die Übertragung von 1000 Byte noch innerhalb von einem Frame stattfinden kann, musste 10000 Byte als weitere Testdatenmenge eingeführt werden. 5.1 Testaufbau Für die Tests werden zwei Zedboards verwendet, auf denen jeweils das vollständige Softwaresystem, bestehend aus FreeRTOS, Kad, CoAP Client, CoAP Reverse Proxy und CoAP Server, aktiv ist. Zusätzlich wird ein PC mit einem Intel Core 2 Duo P9700 Prozessor (2,8 GHz Dual Core), Windows 7 und der entsprechenden Windows‐Implementierung des CoAP Clients genutzt. Die Zedboards und der Windows PC werden über einen Ethernet Switch (TP‐LINK TL‐SG1008D Ver 5.1) mit einer Geschwindigkeit von 1GBit/s verbunden. 51 Alle drei der beschriebenen Szenarios werden mit dem Windows Client getestet, während mit dem Zedboard Client nur für die ersten beiden Szenarios Messwerte aufgenommen werden. Eine Aufnahme von Messwerten bei Verwendung des Zedboard Clients, mit Reed Solomon Encoding und einer Kommunikation über den Reverse Proxy ist nicht nötig, da der Einfluss der Kommunikation über den Reverse Proxy bei der Verwendung des Zedboard Clients identisch zum Einfluss bei Verwendung des Windows Clients ist. Für die Verzögerung der Pakete im Reverse Proxy ist der verwendete Client irrelevant. 5.2 Szenarios 5.2.1 WindowsClient,direkterServerzugriff,ohneReedSolomon Bei allen für den Windows Client angegebenen Messwerten handelt es sich um Mittelwerte von Messreihen, bei denen die entsprechende Aktion jeweils 100 Mal ausgeführt und die Aktionsdauer gemessen wurde. Im Falle des Windows Clients ist die Varianz innerhalb einer Messreihe in allen Fällen sehr hoch gewesen. Der Grund dafür liegt in der Verwendung einer normalen Windows Umgebung. In dieser wird eine Vielzahl von Threads und Prozessen ausgeführt, und die Geschwindigkeit der Datenübertragung mit Hilfe des CoAP Clients hängt maßgeblich davon ab, wie viele der anderen Threads bzw. Prozesse zum Zeitpunkt der Übertragung ebenfalls die Rechenleistung der CPU beanspruchen. Je mehr Prozesse gleichzeitig Rechenzeit benötigen, desto weniger bleibt letzten Endes für einen einzelnen Prozess, in diesem Fall den CoAP Client. Auf Grund der vielen im Hintergrund aktiven Prozesse in der Windows Umgebung unterliegt die dem CoAP Client zur Verfügung stehende Rechenleistung einem ständigen Wechsel und verursacht so die große Varianz. Daher lässt sich über den Windows Client sagen, dass dieser zwar problemlos mit dem Kad‐ Netz kommunizieren kann, aber für eine Echtzeit‐Kommunikation nur bedingt geeignet ist. Dennoch lassen sich an Hand der Messdaten des Windows Clients bereits viele wichtige qualitative Aussagen treffen. Anzahl übertragener Bytes Aktionsdauer in µs 10 100 1000 10000 Datenrate in KB/s 1507 1519 1576 6494 6,48 64,29 619,65 1503,79 Tabelle 10: Zeitmessungen von PUT‐Aktionen des Windows Clients ohne Reed Solomon Encoding und bei direkter Kommunikation mit dem Server In Tabelle 10 und Tabelle 11 ist deutlich erkennbar, dass die Übertragung von 10, 100 und 1000 Byte jeweils eine nahezu identische Übertragungsdauer besitzt. Dies ist darauf zurück zu führen, dass diese Datenmengen alle in jeweils einem CoAP‐Paket übertragen werden können. Die gesamte Kommunikation zwischen Client und Server besteht also aus einem CoAP Request und einer CoAP Response. Die Aktionsdauer wird dabei hauptsächlich durch die Erstellung der CoAP‐Pakete im Client sowie im Server geprägt, da der Aufbau des dynamischen Headers viel Rechenzeit in Anspruch nimmt. Hinzu kommt die Suche nach der entsprechenden Repräsentation auf dem Server. Die Größe der Nutzlast (10, 100 oder 1000 Byte) ist kaum relevant, da der einzige Unterschied darin besteht, dass beim Speicherzugriff auf dem Client sowie auf dem Server mehr Bytes kopiert werden müssen. Zeitlich entspricht der Kopiervorgang eines Bytes jedoch nur einigen Nanosekunden, sodass der Einfluss auf die gesamte Aktionsdauer sehr gering ist. Außerdem muss bei größerer Nutzlast ein längeres Paket über die Ethernet‐Verbindung gesendet werden, doch auch das Senden größerer 52 Pakete schlägt zeitlich nur mit einigen Nanosekunden pro Byte zu Buche. Der Einfluss der Nutzlast ist daher nur bei der Übertragung von 1000 Byte geringfügig an der Aktionsdauer erkennbar. Anzahl übertragener Bytes Aktionsdauer in µs 10 100 1000 10000 Datenrate in KB/s 1902 1906 2048 10986 5,13 51,24 476,84 888,92 Tabelle 11: Zeitmessungen von GET‐Aktionen des Windows Clients ohne Reed Solomon Decoding und bei direkter Kommunikation mit dem Server Die Aktionsdauer einer solchen Kommunikation mit genau einem CoAP Request und einer CoAP bezeichneten Zeit. Bei der Übertragung von Response entspricht der in Kapitel 3.4 mit 10000 Byte werden dagegen 10 CoAP Requests und 10 CoAP Responses gesendet, da für die große Nutzlast der Transfer in Blöcken benötigt wird. Hier wird deutlich, dass die auf das erste Request‐ Response‐Paar folgenden 9 Übertragungen wesentlich weniger Zeit beanspruchen. Im Falle der PUT‐ Aktion werden für ein Request‐Response‐Paar durchschnittlich 546,45μ benötigt, im Falle der GET‐Aktion 993,11μ . Diese Zeit ist mit aus Kapitel 3.4 gleichzusetzen und verändert sich auch bei beliebig großer Anzahl an Paketen nicht mehr. Bei der Übertragung größerer abhängt und der Einfluss Dateien steigt jedoch die Datenrate, da diese praktisch nur noch von von geringer wird. Der Grund für die geringere Dauer folgender Request‐Response‐ Paare ist die Wiederverwendung des Paketes im Client, wie in Kapitel 3.3.3 beschrieben. Diese Paketwiederverwendung gilt nur während der Übertragung einer Datei mittels CoAP Block Option, nicht bei zwei aufeinander folgenden CoAP Aktionen (wie z.B. der wiederholten Übertragung der gleichen 10 Byte Datei während einer Messreihe). Die mittels CoAP‐Übertragung erreichbare Datenrate ist daher von der Dateigröße abhängig. Große Dateien können mit wesentlich höherer Datenrate übertragen werden, da hier relevant ist und die größtmögliche Nutzlast transportiert wird. Bei kleinen Dateien ist hingegen relevant und die Datenrate sinkt außerdem, wenn die Nutzlast nur wenige Bytes statt der maximal möglichen 1024 Bytes beträgt. Ein hundertfaches Ausführen der Übertragung einer 10 Byte Datei ist daher nicht vergleichbar mit der Übertragung einer 1000 Byte Datei. Bei der Übertragung großer Dateien mit Hilfe der Block Option haben erste Untersuchungen zum größten Teil durch die Verarbeitung eines Requests im Server bestimmt ergeben, dass wird. Wie bereits in Kapitel 3.5 erwähnt, stellt der Server damit eine große Verbesserungsmöglichkeit bezüglich der Datenrate bei der Übertragung großer Dateien dar. Mit einer experimentellen Serverversion, welche aus Stabilitätsgründen noch nicht für die Messungen in dieser Arbeit verwendet werden konnte, wurden bereits Datenraten von über 10 MB/s erzielt. ist dagegen stark von der Client‐Implementierung abhängig, bietet jedoch ebenfalls noch Potential, um die Aktionsdauer zur Übertragung kleiner Datenmengen zu verringern. 5.2.2 WindowsClient,direkterServerzugriff,mitReedSolomon Bei der Angabe der Messdaten mit Reed Solomon Codierung in Tabelle 12 und Tabelle 13 ist die Zeit für En‐ und Decoding in der Aktionsdauer enthalten. Um die reine Übertragungsdauer zu erhalten, muss die Codierungszeit von der Aktionsdauer abgezogen werden. Außerdem ist die berechnete Datenrate die effektive Datenrate. Durch die Verwendung von Reed Solomon werden eigentlich 53 mehr Daten gesendet, welche allerdings Redundanz darstellen und die effektive Datenrate nicht erhöhen. Generell lässt sich über das Verfahren mit Reed Solomon Codierung sagen, dass sich die Performance um einige Größenordnungen verschlechtert. Ein Grund hierfür ist die Dauer des Encodings bzw. Decodings, welches sehr rechenintensiv ist und entsprechend viel Zeit in Anspruch nimmt. Auch beim Encoding und Decoding zeigen sich außerdem Eigenschaften, die große Dateien begünstigen und die Datenrate bei kleinen Dateien herabsetzen. Für die Reed Solomon Codierung fallen Initialisierungsoperationen an, die vor dem Encoding bzw. Decodingvorgang ausgeführt werden müssen, welche hier ca. 100 ms einnehmen. Nach diesen Operationen ist die Zeit für das Encoding bzw. Decoding proportional zur Anzahl der Codewörter. Anzahl übertragener Bytes Aktionsdauer in µs Dauer RS Encoding Datenrate in B/s 10 447898 124999 22,33 100 448802 124908 222,82 1000 614011 275652 1628,64 10000 2278801 1802747 4388,27 Tabelle 12: Zeitmessungen von PUT‐Aktionen des Windows Clients mit Reed Solomon Encoding und bei direkter Kommunikation mit dem Server Bei der Verwendung eines ergebenden Codewörter durch , ‐Codes berechnet sich die Anzahl der sich beim Encoding öß . Nach dem Interleaving ergeben sich aus diesen Codewörtern Chunks, wobei die Größe eines Chunks der Anzahl der Codewörter entspricht. Da jedes der Chunks in einer separaten CoAP‐Aktion übertragen wird, ergibt sich für kleine Dateien das Problem, dass die Chunkgröße gering ist und diese Übertragungen auf Grund der kleinen Nutzlast sehr ineffizient sind. Dies soll an einem Beispiel erläutert werden. Beim Encoding einer 1000 Byte großen Datei mit dem hier verwendeten 255, 127 ‐Code ergeben sich 8 Codewörter. Durch das Interleavingverfahren werden diese auf 255 Chunks mit einer Größe von jeweils 8 Byte aufgeteilt. Jedes Chunk wird nun in einer eigenen CoAP‐Aktion übertragen, welche die Dauer beansprucht. Aus diesem Grund ist bei der Verwendung des Reed Solomon Codes zur Erhöhung der Zuverlässigkeit nicht nur die Dauer der En‐ und Decodingvorgänge problematisch, sondern auch die Dauer der Übertragung. Anders ausgedrückt kann man sagen, dass durch den 255, 127 ‐Code die Datenmenge verdoppelt wird, die Übertragungszeit sich jedoch nicht um den Faktor 2 erhöht, sondern bedingt durch die Aufteilung in Chunks wesentlich stärker ansteigt. Diese Problematik ist jedoch stark von der zu übertragenden Dateigröße und dem verwendeten Reed Solomon Code abhängig. Ergibt sich eine Anzahl von Codewörtern, die einem ganzzahligen Vielfachen der maximalen Nutzlastgröße eines CoAP‐Paketes entspricht, so wird die maximale Effizienz bei der Übertragung erreicht. Auch dieser Zusammenhang soll kurz an einem Beispiel erläutert werden. Die maximale Nutzlastgröße in der hier verwendeten Implementierung beträgt 1024 Bytes. Ein Chunk muss also genau diese Größe besitzen, um eine effiziente Übertragung zu ermöglichen. Da die Chunkgröße der Anzahl der Codewörter entspricht, werden also 1024 Codewörter benötigt. Diese ergeben sich bei der Verwendung des 255, 127 ‐Codes bei einer zu codierenden Datei von exakt 127 KB. Bei den hier getesteten Dateigrößen wird die maximal mögliche Nutzlast eines CoAP‐Paketes jedoch bei weitem nicht ausgenutzt und die Übertragung ist daher höchst ineffizient. 54 Anzahl übertragener Bytes Aktionsdauer in µs Dauer RS Decoding Datenrate in B/s 10 516372 142620 19,37 100 527528 143432 189,56 1000 827201 373538 1208,90 10000 3188824 2679798 3135,95 Tabelle 13: Zeitmessungen von GET‐Aktionen des Windows Clients mit Reed Solomon Decoding und bei direkter Kommunikation mit dem Server 5.2.3 WindowsClient,viaReverseProxy,mitReedSolomon In diesem Abschnitt soll der Einfluss des Reverse Proxies untersucht werden. In Tabelle 14 und Tabelle 15 sind jeweils die Aktionsdauer inklusive Encoding‐ bzw. Decodingdauer sowie die effektive Datenrate dargestellt. Anzahl übertragener Bytes Aktionsdauer in µs Dauer RS Encoding Datenrate in B/s 10 575549 124484 17,37 100 576221 125068 173,54 1000 739814 275593 1351,69 10000 2399819 1800389 4166,98 Tabelle 14: Zeitmessungen von PUT‐Aktionen des Windows Clients mit Reed Solomon Encoding und bei Kommunikation über den Reverse Proxy Anzahl übertragener Bytes Aktionsdauer in µs Dauer RS Decoding Datenrate in B/s 10 648973 142521 15,41 100 660026 139018 151,51 1000 957567 372677 1044,31 10000 3310437 2680683 3020,75 Tabelle 15: Zeitmessungen von GET‐Aktionen des Windows Clients mit Reed Solomon Decoding und bei Kommunikation über den Reverse Proxy Der Reverse Proxy führt beim Erhalt der ersten Anfrage zunächst eine Kad‐Suche nach dem ). Da nur zwei Kad‐Knoten im Netzwerk vorhanden sind, ist die zuständigen Server durch ( Suche nach dem zuständigen Knoten nach einem Suchschritt abgeschlossen und benötigt insgesamt 507μ (Wert ebenfalls experimentell ermittelt). In größeren Netzwerken muss mit einer längeren Suche gerechnet werden. Nach [2] benötigt jeder weitere Suchschritt etwa 150 µs. Bei allen folgenden Anfragen wird keine erneute Kad‐Suche durchgeführt, da der Reverse Proxy den Kontakt zwischenspeichert. Datenmenge Übertragungsdauer in Bytes mit Reverse Proxy (effektiv) in µs 10 100 1000 10000 451065 451153 464221 599430 Übertragungsdauer Gesamtverzögerung ohne Reverse Proxy durch den Proxy in in µs µs 322899 323894 338359 476054 128166 127259 125862 123376 Verzögerung pro Request‐ Response‐Paar in µs 502,61 499,05 493,57 483,82 Tabelle 16: Berechnung der Verzögerung durch den Reverse Proxy Da der Reverse Proxy sowohl die Anfrage des Clients als auch die Antwort des Servers verarbeiten muss und somit verzögert, ist es sinnvoll, die Verzögerung durch den Reverse Proxy pro Request— 55 Response‐Paar anzugeben ( ). Um diese zu ermitteln, kann die Übertragungsdauer bei der Kommunikation mit und ohne Reverse Proxy verglichen werden. Bei der Berechnung der Werte für Tabelle 16 wurde also auf Werte aus Tabelle 12 und Tabelle 14 zurückgegriffen. Es wurde jeweils die Übertragungsdauer (Aktionsdauer abzgl. Dauer RS Encoding) berechnet, die Differenz der Übertragungsdauer mit und ohne Reverse Proxy gebildet und dieser Werte durch die Anzahl der Request‐Response‐Paare (hier bedingt durch die Anzahl der Chunks immer 255) geteilt. Die hier berechnete Verzögerung durch den Reverse Proxy entspricht aus Kapitel 3.4. Die Berechnung wurde an Hand der Messdaten für PUT‐Aktionen durchgeführt. Die Abnahme der Verzögerung bei größeren Datenmengen ist nicht systematisch erklärbar. Es wären weitere Tests notwendig, um zu verifizieren, dass es sich nicht um eine zufällige Abweichung auf Grund der ungenauen Messung mit Hilfe des Windows Clients handelt. 5.2.4 ZedboardClient,direkterServerzugriff,ohneReedSolomon Bei den Messdaten für den Zedboard Client ohne Verwendung von Reed Solomon handelt es sich ebenfalls um Mittelwerte von Messreihen, bei denen eine Aktion jeweils 100 Mal ausgeführt wurde. Die Messreihen haben dabei eine wesentlich geringere Varianz aufgezeigt als die Messreihen mit dem Windows Client. Hier macht sich der Einsatz des Echtzeit‐Betriebssystems FreeRTOS bemerkbar. Auf Grund der strengen Priorisierung der Threads sowie der generell wesentlich geringeren Anzahl an Hintergrundprozessen existieren keine zu den Client Threads konkurrierenden Threads und die CoAP Client‐Anwendung bekommt jederzeit die volle Rechenleistung zur Verfügung gestellt. Anzahl übertragener Bytes Aktionsdauer in µs 10 100 1000 10000 Datenrate in KB/s 907 914 964 4390 10,77 106,84 1013,03 2224,52 Tabelle 17: Zeitmessungen von PUT‐Aktionen des Zedboard Clients ohne Reed Solomon Encoding und bei direkter Kommunikation mit dem Server Tabelle 17 und Tabelle 18 zeigen, dass der CoAP Client auf dem Zedboard deutlich schneller arbeitet als auf dem Windows PC. Dementsprechend höher fallen die Datenraten aus. Die bereits über den Windows Client getroffenen qualitativen Aussagen bleiben jedoch erhalten. Auch hier ist gut ersichtlich, dass die Kommunikation mit der Block Option bei der Übertragung von 10000 Bytes ab dem zweiten Request‐Response‐Paar wesentlich schneller arbeitet als beim ersten Request‐ 380,67μ als Mittelwert für eine PUT‐ Response‐Paar. So ergibt sich hier Aktion. Bemerkenswert ist, dass der Geschwindigkeitsunterschied zwischen PUT‐Aktion und GET‐ Aktion auf dem Zedboard wesentlich geringer ausfällt als auf dem Windows PC. Da beide Clients einen weitgehend identischen Quellcode besitzen, ist dieses Verhalten nur schwer erklärbar. Anzahl übertragener Bytes Aktionsdauer in µs 10 100 1000 10000 Datenrate in KB/s 914 919 968 4404 10,68 106,26 1008,85 2217,44 Tabelle 18: Zeitmessungen von GET‐Aktionen des Zedboard Clients ohne Reed Solomon Decoding und bei direkter Kommunikation mit dem Server 56 Ein möglicher Grund hierfür ist, dass der Zedboard Client alle Daten im Arbeitsspeicher ablegt, während der Windows Client die Festplatte nutzt. Die Schreibzugriffe auf die Festplatte während einer GET‐Aktion des Windows Clients könnten also für die erhöhte Aktionsdauer verantwortlich sein. 5.2.5 ZedboardClient,direkterServerzugriff,RS Bei der Geschwindigkeitsuntersuchung des Zedboard Clients unter Verwendung der Reed Solomon Codierung musste aus Stabilitätsgründen auf Messreihen mit 100 Wiederholungen verzichtet werden und die vorgestellten Ergebnisse zeigen den Mittelwert von jeweils drei Aktionen. Anzahl übertragener Bytes Aktionsdauer in µs Dauer RS Encoding Datenrate in B/s 10 393568 153470 25,41 100 400077 152468 249,95 1000 674617 429245 1482,32 10000 3508551 3232532 2850,18 Tabelle 19: Zeitmessungen von PUT‐Aktionen des Zedboard Clients mit Reed Solomon Encoding und bei direkter Kommunikation mit dem Server Wieder bestätigen sich die qualitativen Aussagen, die bereits zu den Ergebnissen des Windows Clients getroffen wurden. Auch hier sind die Datenraten wesentlich geringer als ohne Reed Solomon Codierung, was auf die Zeit für En‐ und Decodingvorgänge zurück zu führen ist, sowie auf die Unterteilung der Daten in 255 Chunks, welche in separaten CoAP‐Aktionen versendet werden und auf Grund der kleinen Nutzlast pro Paket zu einer ineffizienten Übertragung führen. Anzahl übertragener Bytes Aktionsdauer in µs Dauer RS Decoding Datenrate in B/s 10 388004 144047 25,77 100 395607 143728 252,78 1000 571771 326278 1748,95 10000 2450804 2175338 4080,29 Tabelle 20: Zeitmessungen von GET‐Aktionen des Zedboard Clients mit Reed Solomon Decoding und bei direkter Kommunikation mit dem Server 5.3 AuswertungderMessdaten Bevor die Eignung des entworfenen Systems zur robusten Datenübertragung und verteilten Speicherung für den Einsatz in Automatisierungsumgebungen betrachtet wird, soll zusammengefasst werden, inwiefern sich das System den Erwartungen entsprechend verhält. Viele der aufgenommenen Messungen lassen sich mit Hilfe der zu Grunde liegenden Theorie erklären und entsprechen damit vollständig den Erwartungen. Die Abhängigkeit der Datenraten von der übertragenen Dateigröße ist bei der Übertragung ohne Reed Solomon Codierung problemlos durch die unterschiedliche Ausnutzung der maximal möglichen Nutzlast eines CoAP‐Paketes erklärbar. Ebenso macht sich die in Kapitel 3.3.3 vorgestellte Paketwiederverwendung des Clients bemerkbar. Auch die drastische Performanceverschlechterung durch die Reed Solomon Codierung sowie die Aufteilung in Chunks ist nachvollziehbar. Die gemessene Zeit für eine Kad‐Suche mit einem Suchschritt entspricht außerdem weitgehend den Ergebnissen aus [2]. Einige derzeit nicht nachvollziehbare Phänomene bedürfen jedoch weiterer Untersuchungen, die auf Grund des gegebenen zeitlichen Rahmens nicht mehr Bestandteil dieser Arbeit sind. So ist derzeit nicht nachvollziehbar, warum das Reed Solomon Decoding auf dem Zedboard derzeit schneller abläuft, als das Encoding, obwohl das Zeitverhalten auf dem Windows PC genau umgekehrt ist. Ein 57 Fehler beim Codierungsverfahren kann jedoch ausgeschlossen werden, da die Datenintegrität nach allen Übertragungsvorgängen geprüft wurde. Außerdem ist bei der Übertragung mit Reed Solomon Codierung fragwürdig, warum die reine Übertragungszeit bei zunehmender Datenmenge ansteigt, obwohl alle Übertragung in diesen Szenarien in 255 Paketen stattfinden und zuvor festgestellt wurde, dass die Größe der pro Paket übertragenen Nutzlast nur einen sehr geringen Einfluss auf die Übertragungszeit besitzt. Zur Beurteilung der Einsetzbarkeit des Systems in Automatisierungsumgebungen müssen die Szenarien getrennt betrachtet werden. Wird keine Reed Solomon Codierung verwendet, so ist die Übertragung mittels CoAP auf jeden Fall zum Datenaustausch auf Feldebene, also in Netzwerken mit hohen Echtzeitanforderungen, geeignet. Außerdem sind sowohl seitens des Servers als auch seitens des Clients Verbesserungen möglich, die die Dauer des Datenaustausches soweit verringern, dass selbst eine Kad‐Suche und der anschließende Datenaustausch mittels CoAP voraussichtlich in unter 1 ms ermöglicht werden, wobei Datenmengen von bis zu 1024 Byte übertragen werden. In Bereichen oberhalb der Feldebene mit geringeren zeitlichen Anforderungen ist der Einsatz eines solchen Systems ohnehin jederzeit denkbar und auch eine Übertragung großer Datenmengen mit Hilfe der CoAP Block Optionen möglich. Neben der Frage, inwiefern das Übertragungsverfahren die zeitlichen Anforderungen der Automatisierungsumgebung prinzipiell erfüllt, muss geklärt werden, wie groß das entsprechende Netzwerk bei der Verwendung eines Zeitschlitzverfahrens sein darf. Das Problem ist dabei, dass jeder Knoten im Netzwerk einen Zeitschlitz für sich beansprucht, und dieser Zeitschlitz muss mindestens die Dauer für eine vollständige Übertragung besitzen. Als Dauer eines Zeitschlitzes soll hier 970μ verwendet werden, da dies für eine PUT‐Aktion oder GET‐Aktion über 1000 Byte bei Verwendung des Zedboard Clients ausreicht. Dabei wird von einer Übertragung von maximal 1000 Byte ausgegangen, da dies für typische Steuer‐ und Regelungsdaten ausreichend ist. Die Zykluszeit berechnet sich dann mit der Anzahl der Slots folgendermaßen: ∗ die maximale Größe des An Hand dieser Formel kann bei gegebenem und einer Vorgabe von ) bestimmt werden. hängt vom Anwendungsbereich ab. In [2] werden die drei Netzwerks ( Anwendungsklassen Human Control, Process Control und Motion Control eingeführt und festgelegt. entsprechende Werte für Anwendungsklasse Human Control 103 Process Control Motion Control 10 1 Tabelle 21: Maximale Größe des Netzwerkes in Abhängigkeit der Anwendungsklasse bei direkter Client Server Kommunikation Tabelle 21 zeigt die maximale Netzwerkgröße bei Verwendung der Zedboard Clients und in den verschiedenen Anwendungsklassen. Dabei muss allerdings berücksichtigt werden, dass diese Werte gelten, wenn eine direkte Client Server Kommunikation ohne Reverse Proxy und ohne Kad‐Suche verwendet wird. Für eine Kommunikation via Reverse Proxy inklusive Kad‐Suche muss auf etwa 2000 µs angehoben werden, sodass sich die Netzwerkgrößen wie in Tabelle 22 angegeben ergeben. 58 Anwendungsklasse Human Control Process Control 50 Motion Control 5 0 Tabelle 22: Maximale Größe des Netzwerkes in Abhängigkeit der Anwendungsklasse bei Kommunikation via Reverse Proxy und inklusive Kad‐Suche Zudem kann sich das Ergebnis weiter verschlechtern, wenn berücksichtigt wird, dass bei der entsprechenden Netzwerkgröße mehr Zeit für die Kad‐Suche benötigt wird, da mehr als ein Suchschritt nötig wird. Die Netzwerkgröße bei Verwendung des Windows Clients wird hier nicht ermittelt, da ein Einsatz von diesem für Steuer‐ und Regelungsaufgaben erst sinnvoll ist, wenn ein Weg gefunden wurde, die Performance zu erhöhen und die Varianz zu verringern. Eine verteilte Speicherung mit hoher Ausfallsicherheit, welche durch Übertragung von Reed Solomon Chunks mittels CoAP realisiert wird, genügt den Anforderungen der Feldebene und der Zellebene jedoch derzeit noch nicht. Dementsprechend wurden für dieses Szenario auch keine maximalen Netzwerkgrößen bestimmt. Für den Datenaustausch auf der Leitebene ist das System allerdings auch jetzt schon schnell genug. Außerdem zeigt das Gesamtkonzept großes Potential, sodass mit einigen Anpassungen auch ein Einsatz in Netzwerken mit extrem hohen zeitlichen Anforderungen denkbar ist. Folgende zukünftige Anpassungen könnten einen solchen Einsatz ermöglichen: Die Initialisierungsoperationen für Reed Solomon müssen nicht direkt vor jeder Datenübertragung stattfinden. Sie können bereits direkt nach dem Start des Systems stattfinden und die Ergebnisse gespeichert werden, sodass keine Wiederholung nötig ist und die Reed Solomon Bearbeitungszeit immer proportional zur Anzahl der Codewörter ist. Alternativ ist eine Verlagerung aller Reed Solomon Operationen in Hardware denkbar. Für den verwendeten Reed Solomon Code können und angepasst werden, sodass bei geringerer Redundanz eine wesentlich höhere Performance erzielt wird. Durch die Verringerung von und kann die Anzahl der produzierten Chunks verringert werden und die Effizienz der Übertragung gesteigert werden, indem die CoAP‐Pakete auch bei kleinen Datenmengen besser ausgelastet werden. Dadurch werden die Daten zwar auf weniger Stationen verteilt, durch die gesteigerte Effizienz bei der Übertragung jedoch wesentlich geringere Übertragungszeiten ermöglicht Die Zeit für Reed Solomon En‐ und Decodingvorgänge kann in einigen Bereichen möglicherweise vernachlässigt werden, da die Codierung nicht direkt vor dem Versand der Daten erfolgen muss, sondern fertig codierte Daten bereitstehen und nur deren Übertragung hohe zeitliche Anforderungen besitzt. Ebenso sind Szenarien denkbar, in denen der Erhalt (GET‐Aktion) von codierten Daten hohe zeitliche Anforderungen besitzt, die Decodierzeit jedoch nicht weiter relevant ist. Auch der Reverse Proxy bietet noch Verbesserungsmöglichkeiten, die das System zur verteilten Speicherung einem Einsatz auf Zell‐ und Feldebene näher bringen. Der Windows Client unterliegt zwar den Einschränkungen des Betriebssystems und ist derzeit bei einigen Vorgängen langsamer als die Zedboard‐Implementierung und die Dauer der Aktionen unterliegt großer Varianz, allerdings ist eine Kommunikation mit dem Kad‐Netzwerk ausgehend von einem Windows PC problemlos möglich, sofern keine hohen zeitlichen Anforderungen gestellt werden. Bei höheren zeitlichen Anforderungen ist es allerdings möglich, durch die auch in Windows vorhandene Threadpriorisierung den Client in dieser Umgebung zu beschleunigen und die Varianz zu 59 verringern. Inwiefern die Ergebnisse Zedboard Clients auch unter Windows erreicht werden können, muss noch untersucht werden. 6 Zusammenfassung Das implementierte CoAP‐Protokoll kann zusammen mit der Reed Solomon Codierung zur Fehlerkorrektur auf zwei verschiedene Arten genutzt werden. Zum einen kann der CoAP‐Client bei der Übertragung direkt mit einem Server kommunizieren und somit eine Speicherung mit gezielter Adressierung erreicht werden. Die Daten werden auf nur einem Knoten gespeichert, wobei die Reed Solomon Codierung optional für Robustheit gegen Paketverluste genutzt werden kann. Die zweite Möglichkeit, das implementierte System zu nutzen, besteht darin, dass der CoAP‐Client über den Reverse Proxy kommuniziert und somit eine verteilte Speicherung der Daten in Form von Reed Solomon Chunks stattfindet. Diese Form der Speicherung ist sowohl robust gegen Paketverluste als auch gegen Knotenausfälle. Beide Kommunikationsformen sind zu harter Echtzeit fähig, da sowohl die im Rahmen dieser Arbeit implementierten Verfahren zur Übertragung und Codierung deterministisch arbeiten, als auch der modifizierte Kad‐Client, der als Grundlage dient. Die prinzipielle Anwendbarkeit in Automatisierungsumgebungen ist somit gegeben, wobei die eingesetzte Strategie bei der Speicherung (verteilt oder gezielt adressiert) passend zum spezifischen Anwendungsszenario gewählt werden kann. Das Problem der echtzeitfähigen Fabrikvernetzung inklusive einer möglichen Verbindung von Büro‐ und Fabriknetzwerk wird damit innovativ gelöst. Von bestehenden IE‐Systemen unterscheidet sich das vorgestellte Netzwerk durch eine besondere Netzwerkarchitektur und dem damit verbundenen geringen manuellen Konfigurationsaufwand. Die vorgestellten Messungen haben ergeben, dass das implementierte Übertragungsprotokoll ohne die Absicherung durch Reed Solomon bereits jetzt schnell genug ist, um Datenübertragungen auf allen Ebenen eines industriellen Automatisierungsnetzwerkes zu ermöglichen. Die durch Reed Solomon Codierung abgesicherte Übertragung ist ebenfalls bereits funktionsfähig und robust gegen Paketverluste und Knotenausfälle. Die Geschwindigkeit erlaubt derzeit jedoch nur einen Einsatz auf der Leitebene eines industriellen Netzwerkes, welche geringere zeitliche Anforderungen besitzt. Mit allgemeinen Performanceverbesserungen sowie auch mit gezielten Anpassungen für ein bestimmtes Anwendungsgebiet sind jedoch viele Einsatzbereiche des entwickelten Systems zur verteilten Datenspeicherung denkbar, so auch der Einsatz auf der Feldebene eines Automatisierungsnetzwerkes. Genauere Aussagen lassen sich erst mit Kenntnis eines genauen Anforderungsprofils treffen. Insgesamt wurden die Ziele der Arbeit erreicht und ein Konzept entwickelt, welches eine echtzeitfähige Datenübertragung großer Datenmengen aufgeteilt auf mehrere Ethernet Frames ermöglicht. Auch die angestrebte verteilte Datenspeicherung auf mehreren P2P‐Knoten mit hoher Zuverlässigkeit durch Datenredundanz konnte realisiert werden. Ein funktionsfähiger Prototyp des Systems konnte erfolgreich implementiert und getestet werden. Die Tests haben nachgewiesen, dass ein Einsatz eines solchen Systems im angestrebten Bereich der industriellen Automatisierungsumgebungen möglich ist. Schon als Prototyp genügt das implementierte System teilweise den typischen zeitlichen Anforderungen einer solchen Umgebung. Die Leistungsfähigkeit kann in Zukunft zudem auf verschiedenen Wegen gesteigert werden und das System an konkrete Anwendungsgebiete angepasst oder hierfür erweitert werden. 60 61 I. Abbildungsverzeichnis Abbildung 1: Beginn des DST‐Algorithmus' mit einer Suchtoleranz von . ................................ 9 Abbildung 2: Erste Halbierung: Knoten auf der linken Seite sind für die Hashwerte 1000 bis 1111 zuständig, Knoten auf der rechten Seite für die Hashwerte 0000 bis 0111. ........................................... 9 Abbildung 3: Zweite Halbierung: In jedem der vier Segmente des Kreises sind noch zwei Knoten enthalten, die jeweils für Hashwerte entsprechend der Kennzeichnung des Viertelkreises zuständig sind. Hier wird das Präfix‐Matching deutlich. Knoten sind jeweils für Hashwerte zuständig, die mit ihrem eigenen Hashwert eine Übereinstimmung der ersten beiden Bits aufweisen. .......................... 10 Abbildung 4: Letzter Schritt des DST‐Algorithmus: Präfix‐Matching mit Übereinstimmung der ersten drei Bits. Knoten auf dem Rand zwischen zwei Segmenten sind für Hashwerte des angrenzenden höherwertigen Segments zuständig. Ein weiterer Schritt ist nicht möglich, da einige Hashwerte dann nicht mehr abgedeckt wären. Die Suchtoleranz wird abschließend auf 2 eingestellt. ......................... 10 Abbildung 5: Kad‐Routingtabelle als binärer Baum [1] ......................................................................... 10 Abbildung 6: Zwei GET Requests mit "piggy‐backed" Response [8] [7] ................................................ 23 Abbildung 7: GET Request mit separater Antwort [8] [7] ..................................................................... 24 Abbildung 8: Aufbau des CoAP Protokolls [1] [3] .................................................................................. 24 Abbildung 9: CoAP Optionsfeld [8] ........................................................................................................ 26 Abbildung 10: Aufbau der Block Optionen [10] .................................................................................... 28 Abbildung 11: Kommunikationsbeispiel mit Block1 Option .................................................................. 29 Abbildung 12: Kommunikationsbeispiel mit Block2 Option und Größenanpassung ............................ 30 Abbildung 13: GET Request über NON‐Nachrichten [8] ....................................................................... 32 Abbildung 14: Funktionsablauf von ProcessPUT ................................................................................... 34 Abbildung 15: Funktionsablauf von ProcessGET ................................................................................... 35 Abbildung 16: Client PUT‐Aktion Hauptthread ..................................................................................... 37 Abbildung 17: Hauptthread der GET‐Aktion ......................................................................................... 39 Abbildung 18: CoAP Kommunikation im HaRTKad‐Netz ....................................................................... 40 Abbildung 19: Reed Solomon Encoding in Segmenten ......................................................................... 47 Abbildung 20: Codewort Interleaving ................................................................................................... 47 II. Tabellenverzeichnis Tabelle 1: Übersicht über einige bekannte IE‐Systeme [7] ................................................................... 18 Tabelle 2: Hauptbestandteile des entwickelten Systems zur Echtzeitdatenübertragung in Automatisierungsumgebungen ............................................................................................................. 19 Tabelle 3: Merkmale einer REST Architektur [9] ................................................................................... 21 Tabelle 4: CoAP Request Methoden ...................................................................................................... 22 Tabelle 5: Delta‐ und Längenfeld der CoAP‐Optionen .......................................................................... 26 Tabelle 6: Prinzip einer Map .................................................................................................................. 32 Tabelle 7: Definition von ...................................................................................................... 38 Tabelle 8: Reed Solomon Bezeichner .................................................................................................... 45 62 Tabelle 9: Anforderungen an das Datenübertragungsverfahren in einer Automatisierungsanlage..... 51 Tabelle 10: Zeitmessungen von PUT‐Aktionen des Windows Clients ohne Reed Solomon Encoding und bei direkter Kommunikation mit dem Server ........................................................................................ 52 Tabelle 11: Zeitmessungen von GET‐Aktionen des Windows Clients ohne Reed Solomon Decoding und bei direkter Kommunikation mit dem Server ................................................................................ 53 Tabelle 12: Zeitmessungen von PUT‐Aktionen des Windows Clients mit Reed Solomon Encoding und bei direkter Kommunikation mit dem Server ........................................................................................ 54 Tabelle 13: Zeitmessungen von GET‐Aktionen des Windows Clients mit Reed Solomon Decoding und bei direkter Kommunikation mit dem Server ........................................................................................ 55 Tabelle 14: Zeitmessungen von PUT‐Aktionen des Windows Clients mit Reed Solomon Encoding und bei Kommunikation über den Reverse Proxy ........................................................................................ 55 Tabelle 15: Zeitmessungen von GET‐Aktionen des Windows Clients mit Reed Solomon Decoding und bei Kommunikation über den Reverse Proxy ........................................................................................ 55 Tabelle 16: Berechnung der Verzögerung durch den Reverse Proxy .................................................... 55 Tabelle 17: Zeitmessungen von PUT‐Aktionen des Zedboard Clients ohne Reed Solomon Encoding und bei direkter Kommunikation mit dem Server ................................................................................ 56 Tabelle 18: Zeitmessungen von GET‐Aktionen des Zedboard Clients ohne Reed Solomon Decoding und bei direkter Kommunikation mit dem Server ................................................................................ 56 Tabelle 19: Zeitmessungen von PUT‐Aktionen des Zedboard Clients mit Reed Solomon Encoding und bei direkter Kommunikation mit dem Server ........................................................................................ 57 Tabelle 20: Zeitmessungen von GET‐Aktionen des Zedboard Clients mit Reed Solomon Decoding und bei direkter Kommunikation mit dem Server ........................................................................................ 57 Tabelle 21: Maximale Größe des Netzwerkes in Abhängigkeit der Anwendungsklasse bei direkter Client Server Kommunikation ............................................................................................................... 58 Tabelle 22: Maximale Größe des Netzwerkes in Abhängigkeit der Anwendungsklasse bei Kommunikation via Reverse Proxy und inklusive Kad‐Suche ................................................................ 59 63 III. Literaturverzeichnis [1] P. Danielis, „Peer‐to‐Peer‐Technologie in Teilnehmerzugangsnetzen,“ University of Rostock, Rostock, 2012. [2] R. Gubitz, „Entwurf eines echtzeitfähigen Peer‐to‐Peer Clients,“ University of Rostock, Rostock, 2013. [3] J. Skodzik, P. Danielis, V. Altmann und D. Timmermann, „Time Synchronization in the DHT‐based P2P Network Kad for Real‐Time Automation Scenarios,“ University of Rostock, Rostock, 2013. [4] J. Skodzik, P. Danielis, V. Altmann und D. Timmermann, „HaRTKad: A Hard Real‐Time Kadmelia Approach,“ University of Rostock, Rostock, 2013. [5] Real Time Engineers Ltd., „FreeRTOS,“ [Online]. Available: http://www.freertos.org. [Zugriff am 31 Juli 2013]. [6] F. Klasen, V. Oestreich und M. Volz, Industrielle Kommunikation mit Feldbus und Ethernet, Berlin: VDE Verlag GmbH, 2010. [7] E. Schweißguth, „Literaturarbeit Echtzeitdatenübertragung in Automatisierungsumgebungen,“ University of Rostock, Rostock, 2013. [8] IETF CoRE Working Group, „Constrained Application Protocol (CoAP),“ [Online]. Available: http://tools.ietf.org/html/draft‐ietf‐core‐coap‐17. [Zugriff am 17 Juli 2013]. [9] R. T. Fielding, „Representational State Transfer (REST),“ [Online]. Available: http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm. [Zugriff am 17 Juli 2013]. [10] IETF CoRE Working Group, „Blockwise transfers in CoAP,“ [Online]. Available: http://tools.ietf.org/html/draft‐ietf‐core‐block‐11. [Zugriff am 17 Juli 2013]. [11] J. Skodzik, P. Danielis, V. Altmann und D. Timmermann, „Extensive Analysis of a Kad‐based Distributed Storage System for Session Data,“ University of Rostock, Rostock. [12] M. Riley und I. Richardson, „An introduction to Reed‐Solomon codes: principles, architecture and implementation,“ [Online]. Available: http://www.cs.cmu.edu/afs/cs.cmu.edu/project/pscico‐ guyb/realworld/www/reedsolomon/reed_solomon_codes.html. [Zugriff am 2 Mai 2013]. [13] M. Gotzmann, „Untersuchung und Implementierung von Erasure Resilient Codes für eine P2P‐ basierte Speicherplattform,“ University of Rostock, Rostock, 2009. [14] A. Partow, „Schifra,“ [Online]. Available: http://www.schifra.com/. [Zugriff am 28 Juni 2013]. [15] M. Felser, „Real ‐ Time Ethernet ‐ Industry Prospective,“ [Online]. Available: 64 http://www.control.aau.dk/~ppm/P7/distsys/01435742.pdf. [Zugriff am 1 Mai 2013]. [16] B. Sklar, „Reed‐Solomon Codes,“ [Online]. Available: http://hscc.cs.nthu.edu.tw/~sheujp/lecture_note/rs.pdf. [Zugriff am 2 Mai 2013]. [17] G. C. Buttazzo, Hard Real‐Time Computing Systems, New York: Springer Science+Business Media, LLC, 2011. [18] Zedboard.org, „Zedboard,“ [Online]. Available: http://www.zedboard.org/. [Zugriff am 13 August 2013]. 65 IV. Selbstständigkeitserklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbstständig angefertigt habe und keine anderen als die angegebenen Hilfsmittel verwendet habe. Die aus Quellen direkt oder indirekt übernommenen Teile der Arbeit sind als solche kenntlich gemacht. Diese Arbeit wurde bisher nicht veröffentlich oder in gleicher oder ähnlicher Form einer anderen Prüfungsbehörde vorgelegt. Ort, Datum Unterschrift 66