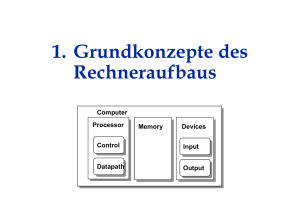
Technische Grundlage..
Werbung

F A C H H O C H S C H U L E F Ü R D I E W I R T S C H A F T F H D W , H A N N O V E R H A R DWA R E AUFBAU VON C OMPUTERSYSTEMEN Michael Löwe Abstract: Diese Einführung stellt die grundlegenden Konzepte moderner Computer Hardware dar. Vom Transistor bis zu den aktuellen Bussystemen werden alle Grundlagen im Überblick dargestellt: Schaltprinzip des Transistors, einfache Gatter, integrierte Schaltkreise, arithmetisch-logische Zentraleinheiten(ALU), Speicherelemente und -aufbau, Hardware-Automaten, Prozessoren, Speicherhierarchie aus Cache-, Hauptund Plattenspeicher sowie Speicher- und Peripheriebusse. Lernziele: Die Vermittlung eines grundlegenden Verständnisses der Hardware-Bausteine moderner Rechnersysteme steht im Vordergrund dieses Skripts. Dabei geht es weniger um Fakten über die aktuelle Rechnergeneration, sondern um das Verstehen grundsätzlicher Architekturen und Arbeitsweisen von Hardware. Nur wenige Mechanismen sind Grundlage aller derzeitigen Systeme, aber auch der meisten älteren und wahrscheinlich noch der nächsten und übernächsten Computergeneration. Wir achten auch nicht auf „enzyklopädische“ Vollständigkeit z. B. bei der Darstellung sämtlicher aktueller Peripherie. Vielmehr fokussieren wir auf Vollständigkeit bei den Interaktionsprinzipien verschiedener Hardwarebauteile, z. B. Prinzipien von Bussystemen, „Interrupts“ und „Direct Memory Access (DMA)“, wenn es um den Anschluss von Computerperipherie geht. Literatur und Vertiefung: Der Aufbau dieses Skripts folgt dem Lehrbuch: A. S. Tanenbaum, J. Goodman: Computerarchitektur. Prentice Hall, 1999. Zur Vertiefung des Stoffs wird dringend die Lektüre dieses Lehrbuchs empfohlen. G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Inhalt VOM TRANSISTOR ZUM HARDWARE-AUTOMATEN ............................................................................. 3 TRANSISTOREN .................................................................................................................................................... 3 GATTER ............................................................................................................................................................... 4 BIT-SPEICHER UND REGISTER ............................................................................................................................. 5 ABLAUFSTEUERUNGEN ........................................................................................................................................ 6 VOM HARDWARE-AUTOMATEN ZUM PROZESSOR ............................................................................... 8 MASCHINENBEFEHLE UND –PROGRAMME ........................................................................................................... 8 SPEICHERORGANISATION ................................................................................................................................... 10 SPEICHERARTEN ................................................................................................................................................ 11 PROZESSOR UND SPEICHER ................................................................................................................................ 11 PROZESSOROPERATIONEN UND -ZUSTÄNDE: DER DATENWEG .......................................................................... 12 ABLAUFSTEUERUNG IM PROZESSOR: MICRO-INSTRUKTIONEN .......................................................................... 14 REALISIERUNG VON MASCHINENBEFEHLEN DURCH MICRO-PROGRAMME ........................................................ 16 VOM PROZESSOR ZUM COMPUTER-SYSTEM ........................................................................................ 19 MEMORY-MAPPED INPUT/OUTPUT.................................................................................................................... 19 INTERRUPT-STEUERUNG .................................................................................................................................... 20 DIRECT MEMORY ACCESS (DMA) .................................................................................................................... 22 PERIPHERIE-BUSSE ............................................................................................................................................ 23 Busbreite und Bustakt ................................................................................................................................... 23 Synchrone und asynchrone Busse ................................................................................................................ 23 Auflösen von Konkurrenz ............................................................................................................................. 23 SPEICHERHIERARCHIE ....................................................................................................................................... 23 ANHANG A: ABBILDUNGEN ......................................................................................................................... 24 2 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR VO M T R A N S I S TO R Z U M H A R DW A R E - AU TOM A T E N Jedes Computersystem ist ein endlicher Automat, vgl. Skript „Grundlagen der Informatik – Theoretische Grundlagen“. Natürlich ist die Menge der unterschiedlichen Zustände, die ein moderner Computer annehmen kann, sehr groß. Denn sie besteht aus jeder Kombination der Inhalte jeder Festplatte, des Hauptspeichers, der Zustände der angeschlossenen Peripherie (z.B. Graphikkarte) und, wenn der Computer am Netz ist, auch der Zustände aller anderen Rechner, zu denen eine Verbindung besteht. Dennoch ist diese Menge endlich und jeder einzelne Rechenschritt eines Computersystems ein (einziger) Zustandswechsel. Aus diesem Grund wollen wir in diesem Abschnitt darstellen, wie man einen beliebigen vorgegebenen endlichen Automaten1 „in Hardware“ in Form einer Ablaufsteuerung realisieren kann. Dieses Prinzip der Ablaufsteuerungen oder des Hardware-Automaten ist Grundlage jedes Prozessors2. Prozessoren sind nur spezielle Formen solcher Automaten, die auf die Interpretation und Abarbeitung von Maschinenprogrammen spezialisiert und optimiert sind, siehe unten.3 TRANSISTOREN Die elementaren Bausteine eines modernen digitalen Computers sind „elektronische Schalter“, die Transistoren. Sämtliche elektronische Hardware eines Rechners kann durch Zusammenschalten von Transistoren aufgebaut werden. Wir werden das schrittweise in diesem Skript durchführen. Wir verwenden Transistoren nur als elektronische Schalter, da wir sie nur in digitale Geräte einbauen wollen.4 Das Schaltprinzip eines Transistors ist in Abbildung 1 dargestellt. Ein Transistor hat drei Anschlüsse: den Kollektor, den Emitter und die Basis. Diese drei Anschlüsse werden durch das Schaltbild für einen Transistor eindeutig identifiziert, siehe Abbildung 1 links. Ein Transistor schaltet die Kollektor-Emitter-Strecke in Abhängigkeit von der Basisspannung. Die Kollektor-Emitter-Strecke ist entweder geschlossen, das heißt, der Kollektor-Emitter-Widerstand ist 0, oder sie ist offen, das heißt, der Kollektor-Emitter-Widerstand ist sehr groß, für die verwendeten Betriebsspannungen sogar unendlich groß. Der „Transistorschalter“ ist geschlossen, wenn die Betriebsspannung zwischen Basis und Emitter anliegt, der „Transistorschalter“ ist offen, wenn keine Spannung anliegt, i. e. die Spannung zwischen Basis und Emitter gleich 0 ist. Eine Spannung zwischen der Basis und dem Emitter schaltet den Transistor also durch, die Abwesenheit einer Basis-Emitter-Spannung öffnet den Transistor. Daraus ergibt sich eine erste Verwendung eines Transistors zum Aufbau logischer Schaltungen, wie sie in Abbildung 2 wiedergegeben ist. Sämtliche Spannungen sind dabei Spannungen gegenüber Erde (0 Volt). Der Emitter wird geerdet (Das bedeutet die Emitter-Spannung ist gleich 0 Volt), der Kollektor wird über einen Widerstand R1 an die Betriebsspannung VCC5 angeschlossen, die Basis wird als Eingangssignal Vin benutzt und am Kollektor wird das Ausgangssignal Vout abgegriffen. Lassen wir jetzt nur die beiden Möglichkeiten 0 Volt oder VCC für die Basis, also für das Eingangssignal Vin zu, erhalten wir am Ausgang Vout das invertierte Signal, vgl. Abbildung 2 oben rechts. Denn ist die Basisspannung 0 Volt, dann ist auch die Basis-Emitter-Spannung 0. Das bedeutet aber, dass der Transistor geschlossen ist, sein Widerstand also unendlich groß ist. Die Spannung V CC fällt dann aber nach dem Ohm‘schen Gesetzt im Verhältnis der Widerstände R1 und des Transistorwiderstands ab. Der Transistorwiderstand ist jedoch unendlich, also fällt die gesamte Spannung zwischen Kollektor und EmitVergleiche auch Skript „Grundlagen der Informatik – Theoretische Grundlagen“! Das war immer schon so, auch als die Computer noch aus Röhren oder Relais aufgebaut waren, und das wird auf absehbare Zeit auch so bleiben. 3 Da sie Maschinenprogramme interpretieren, realisieren sie die universelle Funktion des zugrunde liegenden Programmiermodells, vgl. Skript: „Grundlagen der Informatik – Theoretische Grundlagen“. 4 Transistoren können auch zur Verstärkung von analogen Signalen eingesetzt werden, z. B. in Verstärkern für Audiosignale. Diese Verwendung ist für dieses Skript unerheblich und deswegen nicht beschrieben. 5 Üblicher Weise eine Niederspannung zwischen 3 und 24 Volt (natürlich gegenüber Erde), von der aber im folgenden „getrost“ abstrahiert werden kann. 1 2 3 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR ter ab. Das heißt Vout ist gleich VCC. Ist die Basisspannung VCC, i. e. ist Vin = VCC, dann bricht der Transistorwiderstand zusammen und das Ausgangssignal Vout wird auf 0 Volt gezogen. In diesem Fall fällt VCC vollständig an R1 ab. Mit dieser einfachen Schaltung haben wir einen logischen Inverter (oder Negierer) geschaffen. Dazu müssen wir nur die beiden Spannungen 0 und VCC als logisch „falsch“ bzw. logisch „wahr“ interpretieren.6 Das werden wir ab jetzt für den Rest dieses Skripts tun. Mit dieser Abstraktion werden wir die „lästigen Spannungen“ los und können die Wirkungsweise der Schaltung aus Abbildung 2 nach ausschließlich logischen Gesichtpunkten beschreiben. Diese Abstraktion wird in Stromlaufplänen dadurch nachvollzogen, dass für einen Inverter das Schaltsymbol in Abbildung 2 unten rechts gezeichnet wird. (Die Beschriftung mit „Not“ wird dabei üblicher Weise weggelassen.) GATTER Oben haben wir ein erstes logisches Schaltelement und seine „elektrische“ Realisierung kennen gelernt, den Inverter. Durch Hintereinander- und Parallelschaltung von Transistoren entstehen die Äquivalente zum logische „Und“ bzw. logischen „Oder“. Diese beiden Schaltungen sind in Abbildung 3 bzw. Abbildung 4 dargestellt. Jeweils rechts oben in den Abbildungen sind die Tabellen angegeben, die die Werte des Ausgangssignals in Abhängigkeit von den beiden Eingangssignalen darstellen. Das Schaltsymbol für diese Schaltungen, das in Stromlaufplänen verwendet wird, ist jeweils rechts unten in den Abbildungen dargestellt. Die Schaltungen ergeben kein reines „Und“ und kein reines „Oder“, sondern die jeweils negierten Versionen. Wenn wir aber einen Inverter hinter den Ausgang des „NAND“ oder des „NOR“ schalten, erhalten wir durch die doppelte Negation ein perfektes „Und“ bzw. „Oder“. Das Schaltsymbol dieser Schaltungen stimmt mit den negierten Versionen überein, nur der Negationskreis am Ausgang fehlt. Damit haben wir die Gatter, so nennt man diese elementaren Schaltungen, für das logische „Nicht“, „Und“, „Oder“, „negiertes Und“ und „negiertes Oder“ hergestellt.7 Durch Zusammenschalten dieser Gatter, i. e. Verbinden des Ausgangs eines Gatters mit dem Eingang eines weiteren Gatters, kann man nun kompliziertere logische Funktionen darstellen. In Abbildung 5 sind vier solche Schaltungen dargestellt. Zunächst einmal ist es möglich, jedes Gatter zu kaskadieren. Das sieht man für das Oder in Abbildung 5(A). Dadurch sind Oder-, Und-, invertierende Und- und invertierende Oder-Verknüpfungen von beliebig vielen Eingangssignalen möglich. Abbildung 5 (B) zeigt die Realisierung des Exklusiv-Oder. Diese Schaltung liefert genau dann den logischen Wert 1, wenn sich die beiden Eingaben unterscheiden. Das entsprechende Schaltsymbol ist grau unterlegt ebenfalls in der Abbildung angegeben. Die Abbildung 5 (C) und (D) zeigt zwei Schaltungen, die zwei Signale arithmetisch addieren. Der sogenannte Halbaddierer (C) erzeugt die Summe S und den Überlauf C für zwei einstellige Binärzahlen In1 und In2. Der Volladdierer (D) berücksichtigt einen etwaigen Überlauf einer vorangegangenen Addition CIn. Häufig stellt man die logisch Funktion, die durch eine Schaltung von Gattern realisiert wird, in Form von Wahrheitstabellen dar. Diese Wahrheitstabellen zeigen für alle Kombinationen der Eingangssignale den logischen Wert der Ausgangssignale. Die Wahrheitstabellen für die beiden Addierer aus Abbildung 5 sind in Abbildung 6 dargestellt. Bei dem Volladdierer sehen wir auch, dass ein Ausgang eines Gatters i. d. R. mehrere Eingänge anderer Gatter treiben kann. Ein Ausgang kann also mit mehreren Eingängen verknüpft werden. Im allgemeinen ist es aber nicht möglich mehrere Ausgänge zusammenzuschalten. Dazu sind spezielle Schaltungen nötig, wie wir unten sehen werden. Häufig findet man auch die Interpretation 0 für 0 Volt und 1 für V CC. Das sind dann aber nur einfachere und kürzere Namen für denselben Sachverhalt: 1 = „wahr“ und 0 = „falsch“. 7 Wir halten dabei fest, dass die negierten Versionen einfachere Schaltungen sind als die nicht negierten. Deswegen gibt es in der Elektronik eine Tendenz, alles und jedes aus den negierenden Gattern aufzubauen. 6 4 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Den Abstraktionsprozess vom Transistor über einfache logische Gatter (und, oder etc.), über zusammengesetzte Gatter (exklusiv oder), über einfache logische Funktionen (addieren) bis hin zu komplexen logischen Funktionen lässt sich beliebig fortsetzen. Wir wollen ihn hier soweit verfolgen, bis eine einfache arithmetisch/logische Einheit dargestellt werden kann, die wir als Basis allen Operierens in jedem Computer finden. Dazu benötigen wir noch einige wenige Grundbausteine. Abbildung 7 zeigt zum Beispiel einen 4-fachMultiplexer. Dieses Bauteil ermöglicht es, dadurch dass man eine binäre Zahl an den Signalen S0 und S1 anlegt, den Eingang aus den Eingangsleitungen D0 bis D3 auf den Ausgang zu schalten, der die entsprechende Nummer hat. Aus dem Multiplexer ergibt sich auf einfache Weise ein 2-auf-4-Dekodierer, wenn die D-Eingäng weggelassen werden und die Signale hinter den Und-Gattern direkt als Ausgaben genommen werden. Diese Schaltung zeigt Abbildung 8. Der Dekodierer hat immer eine Ausgangsleitung gesetzt (= logisch 1) und alle anderen sind unten (= logisch 0). Und zwar ist die Ausgangsleitung mit der Nummer gesetzt, die binär an den beiden Eingangsleitungen angelegt wurde. Es ist klar, dass man durch Fortsetzen dieser Schaltprinzipien ganz einfach 8-fach oder 16-fach Multiplexer bzw. 3-auf-8 oder 4-auf-16 Dekodierer aufbauen kann. Aus diesem Grund werden wir diese Bauteile im folgenden als elementar ansehen und von ihrem konkreten Aufbau aus Gattern abstrahieren. Die nächste Abstraktionsstufe erreichen wir, wenn wir eine arithmetisch/logische Einheit (ALU)8 aufbauen. Das ist eine logische Schaltung, die es erlaubt dieselben, Eingangssignale unterschiedlich zu verknüpfen, z. B. durch logisches Und oder durch logisches Oder oder durch Addition. Über Steuereingänge soll dabei die gewünschte Operation auswählbar sein. Ein einfache solche Einheit ist in Abbildung 9 dargestellt. Hier können wir vier verschiedene Operationen wählen: (i) logisches Oder, (ii) logisches Und, (iii) logisches exklusiv Oder und (iv) Addition. Die Operation wird immer mit den beiden 1-Bit Eingabesignalen In1 und In2 durchgeführt. Durch die Steuerleitungen F0 und F1 wird das Ergebnis, das am Ausgang der ALU erzeugt wird ausgewählt. Eine binäre 0 wählt z. B. das „Oder“ und eine binäre 3 die Addition. Es ist klar, dass für die Addition dann noch ein Überlauf als Eingabe benötigt und zusätzlich ein neuer Überlauf als Ausgabe erzeugt wird. Dieses Ausgangssignal ist bei allen anderen Operationen bedeutungslos. Es ist einfach, durch Parallelschalten aus solch einer 1-Bit-ALU eine Einheit zu konstruieren, die breitere Eingaben verknüpfen kann. Abbildung 10 zeigt eine ALU für 4-Bit breite Worte. BIT-SPEICHER UND REGISTER Bisher haben wir nur mehr oder weniger komplizierte logische Funktionen in Hardware gebaut. Bei allen Bauteilen, die wir bisher eingeführt haben, hängen die Ausgabesignale eindeutig von den Eingabesignalen ab. Das Bauteil selbst stellt also eine Funktion da. Um Hardware-Automaten bauen zu können, fehlt uns eine wichtige Zutat nämlich die Möglichkeit, Information speichern zu können. Nur dann können wir Zustände in Hardware nachbilden. Ein Informationsspeicher behält seinen Zustand (eines oder mehrerer Ausgangssignale), auch wenn sich bestimmte Eingabesignale ändern. Der einfachste Informationsspeicher ist ein SR-Latch, wie es in Abbildung 11 wiedergegeben ist. Sind die Eingabesignale S und R logisch auf 0, dann hat dieses Bauteil genau 2 stabile Zustände, nämlich (1) Q = 1 und Q = 0 sowie (2) Q= 0 und Q = 1. Denn im ersten Fall zwingt Q = 1 und S = 0 das NOr-Gatter in der Abbildung oben am Ausgang auf 0. Das ist Q. Und Q = 0 und R = 0 zwingt das NOr-Gatter in der Abbildung unten am Ausgang auf 1. Das ist aber Q. Im zweiten Fall ist die Konstellation genau umgekehrt. Die beiden anderen Möglichkeiten (3) Q = Q = 1 und (4) Q = Q = 0 sind instabil. Denn Q = 1 und S = 0 erzeugt Q = 0 und Q = 1 und R = 0 erzeugt Q = 0. Also folgt aus Q = Q = 1, dass Q = Q = 8 ALU = arithmetic/logical unit. 5 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR 0. Ebenso lässt sich für den vierten fall zeigen, dass Q = Q = 0 unmittelbar Q = Q = 1 erzwingt. Die Ausgangskonstellationen (3) und (4) werden also zufallsbedingt in einen der beiden stabilen Zustände zurückfallen. Jetzt betrachten wir, was passiert, wenn das Latch in einem stabilen Zustand ist und die Eingangssignale gesetzt werden. Nehmen wir zunächst an Q = 0 und Q = 1. Geht nun das Eingangssignal S auf 1, dann ist ein Eingang des Gatters oben in der Abbildung auf 1 und damit der Ausgang Q = 0. Dadurch sind beide Eingänge des Gatters unten in der Abbildung auf 0. Das bedeutet für den Ausgang Q = 1. Q = S = 1 ändert nichts an der Ausgabe des oberen Gatters. Also ändert sich die Ausgangskonstellation in den anderen stabilen Zustand, wenn S gesetzt wird und Q = 0 ist. Geht dann S wieder auf 0, bleibt dieser geänderte Zustand erhalten. Wird R gesetzt, wenn Q = 0 ist, ändert sich nichts an dem Zustand der Ausgänge. Nehmen wir nun an Q = 1 und Q = 0. Setzen wir nun R = 1, dann wechseln Q und Q ihren Wert. Geht R dann wieder auf 0, dann behält das Latch den geänderten Zustand. Setzen wir S in diesem stabilen Zustand, passiert nichts. Das bedeutet unter dem Strich: (1) Q = 1, wenn das Signal S (S von englich „set“) das letzte Eingangssignal war, das auf 1 gesetzt wurde, und (2) Q = 0, wenn das Signal R (R von englisch „reset“) das letzte Eingangssignal war, das auf 1 gesetzt wurde. Das Latch merkt sich also, was als letztes geschehen ist, S oder R. Und zwar merkt es sich das solange, bis wieder ein Ereignis S = 1 oder R = 1 eintritt. Damit haben wir unseren ersten digitalen Informationsspeicher für eine binäre Information. Das SR-Latch hat bloß einen Fehler: Sein Gedächtniszustand ist unbestimmt oder zufällig, wenn beide Eingänge S und R auf 1 gesetzt wurden. Denn S = R = 1 sorgt dafür, dass Q = Q = 0 ist. Das ist auch stabil, solange S und R auf 1 bleiben. Gehen sie aber beide auf 0 zurück, entsteht ein instabiler Zustand, siehe oben. Es bleibt dann dem Zufall überlassen, welcher stabile Zustand schließlich eingenommen wird. Dieses Schaltverhalten ist nicht wünschenswert. Aus diesem Grund ändern wir unsere Schaltung so ab, dass niemals gleichzeitig S und R auf 1 sein können. Das erreichen wir dadurch, dass wir R stets aus S durch Invertierung gewinnen. Dadurch geht uns aber der Gedächtniseffekt des Bauteils verloren. Denn Q ist dann immer (mit einer kurzen Verzögerung, die durch die Latenzzeit der Schaltung bedingt ist) gleich S. Wir erhalten einen Speichereffekt zurück, wenn wir S nicht permanent durchschalten, sondern nur in einem festen Taktrhythmus. Das Ergebnis dieser Überlegungen sehen wir in Abbildung 12, ein sogenanntes D-Latch. Bei diesem Bauteil wird das Signal S nur dann in das Latch übernommen, wenn das Eingangssignal Clk auf 1 ist. Für den Zeitraum, in dem Clk auf 0 ist, behält das Latch die Information vom letzten Mal. Ist der Takt von Clk asymmetrisch, das heißt ist Clk nur kurz auf 1 und lange auf 0, dann merkt sich das D-Latch die Information des Signals D, die beim letzten Clk = 1 anlag, entsprechend lange und konstant. Mit diesem Speicherbaustein haben wir die Schwächen des SR-Latches überwunden: Das D-Latch befindet sich immer in einem von zwei stabilen Zuständen Q = 1 oder Q = 0. Das Ausgangssignal Q stellt immer das invertierte Q dar. Das D-Latch merkt sich den Zustand, den D hatte, als das letzte Mal das ClkSignal auf 1 war. Wenn wir uns mehr als eine 1-Bit-Information merken müssen, lassen sich D-Latches problemlos parallel schalten. Solche Anordnungen von Speicherelementen nennt man auch Register. Abbildung 13 zeigt ein Register, das in der Lage ist, ein binäres Wort aus 4 Bit zu speichern. Mit jedem neuen Ereignis „Clk = 1“ speichert dieses Register die vier Eingangssignale D0 bis D3. ABLAUFSTEUERUNGEN Jetzt haben wir alle Voraussetzungen geschaffen, um einen endlichen Automaten in Hardware, eine sogenannte Ablaufsteuerung, bauen zu können: Wir können (logische) Funktionen in Hardware abbilden und wir können Zustände in Registern darstellen. 6 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Ist also eine endliche Maschine M=(E, A, Z, T: E Z Z, F: E Z A, z0)9 gegeben, analysieren wir zunächst die Mengen E (Eingabealphabet), A (Ausgabealphabet) und Z (Zustandsmenge). Alle diese Mengen sind endlich.10 Deswegen können wir die Elemente aller drei Mengen durchnummerieren. Wir nummerieren die Elemente in E mit e0, e1, ..., em; die Elemente in A mit a0, a1, ... an und die Elemente in Z mit z0, z1, ..., zp.11 Wir sorgen dabei dafür, dass der Anfangszustand z0 die Nummer 0 bekommt. Die Elemente aus dem Eingabe- und Ausgabealphabet und die Zustände müssen wir geeignet kodieren, denn Hardware-Ablaufsteuerungen können nur mit Binärsignalen umgehen. Also ordnen wir jedem Eingabezeichen ei die Binärzahldarstellung von i zu. Ebenso kodieren wir jedes Ausgabezeichen ai durch die Binärzahldarstellung von i. Und jedem Zustand zi ordnen wir die Binärzahl von i als Zustandsbezeichnung zu. Die m Eingabezeichen können wir dann mit 2log m Binärziffern darstellen. 12 Wir nennen diese Ziffern im Folgenden eb0, eb1, ..., ebe. Die n Ausgabezeichen können wir mit 2log n Binärziffern realisieren. Wir nennen diese Ziffern im Folgenden ab0, ab1, ..., aba Und für die p Zustände benötigen wir 2log p Binärziffern. Wir nennen diese Ziffern im Folgenden zb0, zb1, ..., zbz. Jetzt werden die beiden Funktionen T und F zu einer Wahrheitstabelle für die Ablaufsteuerung umgebaut. Dazu tragen wir als Eingänge die Signale eb0, eb1, ..., ebe, zb0, ..., zbz ein und als Ausgänge die Signale ab0, ab1, ..., aba zb0, zb1, ..., zbz. Jetzt können wir die Zeilen der Wahrheitstabelle füllen, indem wir für jede Kombination von Eingängen, in denen die Eingabebits eine Kodierung eines gültigen Eingabezeichens und die Zustandsbits eine Kodierung eines gültigen Zustands13 sind, die Kodierung des Folgezustands (T) und die Kodierung des Ausgabezeichens (F) eintragen. Diese Wahrheitstabelle muss dann als logische Funktion durch eine Schaltung von Gattern korrekt realisiert werden. Mit diesen Zutaten bauen wir die Ablaufsteuerung so wie in Abbildung 14 dargestellt auf. Wir benötigen ein Register, das den Kode für einen Zustand aufnehmen kann, und ein Register, das den Kode für das aktuelle Ausgabezeichen hält. Die Ausgänge des Zustandsregisters werden als die Eingangssignale zb0, ..., zbq in die logische Funktion, die T und F realisiert, gespeist. Die Ausgänge zb0, ..., zbq der logischen Funktion werden mit den entsprechenden Eingängen des Zustandsregisters verbunden. Die Ausgabesignale ab0, ab1, ..., aba werden auf die Eingänge des Ausgaberegisters geschaltet. Das Ergebnis ist eine Ablaufsteuerung, die im Rhythmus des Taktes (Clock) die Kodierung eines Eingabezeichens als Eingangssignal und den momentanen Zustand, zu einem neuen Zustand im Zustandsregister und einer neuen Belegung der Ausgabesignale im Ausgaberegister verarbeitet. Die Ausgabesignale (i. e. die Kodierung eines Ausgabezeichens) liegen dann in jedem Zustand an den Ausgängen des Ausgaberegisters an. Wir verzichten hier auf die Ausgabe von mehr als einem Zeichen in einem Schritt der Ablaufsteuerung: In jedem Schritt muss ein Zeichen ausgegeben werden. Um gar nichts auszugeben, muss ein Zeichen benutzt werden, dass dieses „Nichts“ repräsentiert. 10 Vgl. Skrip „Grundlagen der Informatik – Theoretische Grundlagen“. 11 Wir nehmen hier an, dass ein Zeichen für das „Nichts“ schon in E und A enthalten ist, wenn es im Maschinenmodell benötigt wird. 12 Dabei meint x die nach oben zur nächsten ganzen Zahl aufgerundete reelle Zahl x. 13 Da wir die Zustände als Binärzahlen kodieren, erhalten wir nur dann, wenn die Mächtigkeit der Zustandsmenge genau eine Zweierpotenz ist, die Eigenschaft, dass jede Binärzahl auch wirklich die Kodierung eines Zustands ist. 9 7 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR VO M H A R DW A R E - AU TO M A T E N Z U M P R OZ E S S OR Jeder moderne Mikroprozessor ist zusammen mit dem Hauptspeicher eine – zugegeben recht komplizierte – Ablaufsteuerung. In diesem Abschnitt wollen wir die wesentlichen Strukturen herausarbeiten, die die „logische Funktion“ und das „Zustandsregister“ in der Ablaufsteuerung Mikroprozessor besitzen. Die Bereiche Eingabe und Ausgabe vertagen wir auf das nächste Kapitel. Grob gesprochen entspricht der Hauptspeicher dem Zustandsregister und der eigentliche Prozessor der logischen Funktion einer Ablaufsteuerung. Das stimmt aber nur grob gesprochen: In derzeitigen Hauptspeichern kann so viel Information gespeichert werden, dass unmöglich jedes Bit bei jedem Prozessorschritt (Taktzyklus bei der Ablaufsteuerung) in die logische Funktion eingehen kann. Vielmehr werden in jedem Schritt nur bestimmte Teile des Hauptspeichers benutzt und verändert. Der Prozessor verändert also sein „Zustandsregister“ in jedem Schritt nur lokal. Globale Veränderungen benötigen viele einzelne lokale Zustandsänderungen. Die dazu nötige Speicherorganisation diskutieren wir unten im Abschnitt „Speicherorganisation“. Die Zustandsübergänge sind nicht wie in einer kleineren Ablaufsteuerung fest verdrahtet, sondern programmgesteuert. Das bedeutet, das ein Teil des Hauptspeichers ein Maschinenprogramm enthält, das vom Prozessor interpretiert wird. Ein Teil des Zustands eines Mikroprozessors enthält also die Information, wie der Zustand insgesamt zu transformieren ist. Mikroprozessoren (oder auch allgemein sämtliche Prozessoren in Computersystemen) sind darauf hin optimiert, diese Maschinenprogramme Anweisung für Anweisung aus dem Hauptspeicher zu lesen, zu verstehen und auszuführen. (Sie führen den sogenannten Fetch-and-Execute-Zyklus immer und immer wieder durch.) Wie solche Maschinenbefehle aussehen, beschreiben wir unten im Abschnitt „Maschinenbefehle und –Programme“. Wie wir unten sehen werden, ist die Interpretation der meisten Maschinenbefehle wiederum eine komplizierte Angelegenheit. I. d. R. kann das nicht direkt durch logische Schaltungen erfolgen. Aus diesem Grund ist der Prozessor selbst keine einfache „logische Funktion“, wie der Multiplexer oder der Dekodierer, die wir oben kennen gelernt haben. Er ist vielmehr selbst eine kleine „innere“ Ablaufsteuerung zum Interpretieren und Ausführen einzelner Maschinenbefehle. Auch diese Ablaufsteuerung ist heute meist programmgesteuert, gesteuert durch den Mikrokode“. Dieser Kode ist aber nicht mehr variable, wenn der Prozessor arbeitet. Insofern kann man den Mikrokode auch als fest verdrahtete logische Funktion für die innere Ablaufsteuerung eines Prozessors auffassen. Wir beschreiben die Aufgabe und die Struktur des Mikrokodes im Abschnitt „Ablaufsteuerung im Prozessor: Micro-“. Halten wir fest: Jeder moderne Prozessor ist eine (innere) Ablaufsteuerung zur Interpretation von einzelnen Maschinenbefehlen. Dazu verfügt jeder Prozessor über einen (inneren) Zustand, der durch eine Reihe von Registern auf dem Prozessor-Chip selbst realisiert ist. Die logische Funktion zur Veränderung dieses inneren Zustands bildet das Mikroprogramm auf dem Prozessor-Chip. Die Maschinenbefehle stehen im Hauptspeicher. Eine Reihe von Maschinenbefehlen heißt Maschinenprogramm. Prozessor und Hauptspeicher zusammen genommen stellen eine äußere Ablaufsteuerung dar: Durch Interpretation und Ausführung der einzelnen Anweisungen des Maschinenprogramms verändert der Prozessor den Zustand des Hauptspeichers. Diese Situation ist im Überblick in Abbildung 15 dargestellt. MASCHINENBEFEHLE UND –PROGRAMME Maschinenprogramme bilden die Schnittstelle zwischen Software und Hardware in einem Computersystem: 14 Sie sind selbst Software. Denn Maschinenprogramme sind „Texte“. Sie können von anderen Programmen erzeugt werden, z. B. von Compilern14 für höhere Programmiersprachen, vgl. Abbildung 15. Das heißt Maschinenprogramme sind spezielle Daten. Erst wenn sie sich an der richtigen Stelle im HauptCompiler übersetzen Programmtexte in einer Quellsprache in Programmtexte einer Zielsprache. 8 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR speicher befinden und der Prozessor beginnt, sie zu interpretieren, dann entfalten sie ihren funktionalen Charakter. Das bedeutet, dass Maschinenprogramme genau so Software sind wie Programme in irgendeiner höheren Programmiersprache.15 Sie sind selbst fast Hardware. Denn Maschinenprogramme bestehen aus Maschinenbefehlen. Diese Befehle spiegeln genau das wider, was der Prozessor kann, nicht mehr und nicht weniger. Das bedeutet, dass die Maschinenbefehle für jeden Prozessor anders aussehen und damit natürlich auch die Maschinenprogramme. Höhere Programmiersprachen sind darauf hin optimiert, Anwendungsprobleme gut lösen zu können. Maschinensprachen sind darauf optimiert, guten und direkten Zugriff auf die Leistungsmerkmale des vorhandenen Prozessors zu bekommen. Wie sehen nun solche Maschinensprachen aus? I. d. R. gibt es die folgende Klassen von Befehlen (in natürlich soviel leicht unterschiedlichen Varianten, wie es unterschiedliche Maschinensprachen gibt). Dabei sind A, B und C Platzhalter für Variablen (heute meist 32 oder 64 Bit breit), n steht für eine Konstante (heute meist 16 Bit) und L, S und D sind Label, das heißt Markierungen im Programm, wo sich bestimmte Maschinenbefehle, Unterroutinen oder Datenbereiche befinden. 1. Arithmetische und logische Verknüpfung, z. B. ADD A, B, C #addiere A und B und speichere das Ergebnis unter C ADD A, B #addiere B zu A (das Ergebnis ist in A) ADD #addiere auf einem Stapelspeicher die beiden obersten Elemente und lege das Ergebnis oben auf den Stapel INCR A #erhöhe den Wert von A um 1 DCR A #verringere den Wert von A um 1 SHIFT A, n #nimm A mit 2n mal. OR A, B #errechne A als logisches Oder von A und B etc. 2. Befehle zum Laden und Speichern von Daten, z. B. MOVE A, B #setze A auf den Wert von B MOVE A, n #setze A auf den Wert der Konstanten n LOAD A #lege den Wert von A oben auf einen Operandenstapel STORE A #speichere den obersten Wert eines Operandenstapels unter A etc. 3. Sprünge oder Programmverzweigungen, z. B. JUMP L #springe zu der Anweisung, vor der das Label „L:“ steht JUMPC L #springe zu L:, wenn das Ergebnis der letzten Verknüpfung kleiner oder gleich 0 war etc. 4. Einsprung in und Rücksprung aus Prozeduren, z. B. CALL S #springe in die Subroutine mit dem Label S:, merke dir den nächsten Maschinenbefehl als Rücksprungpunkt auf einem Stapelspeicher RETURN #springe zurück zum letzten gemerkten Rücksprungpunkt 5. Eingabe und Ausgabe, z. B. IN D, B, Dev #Eingabe über Gerät Dev16 von soviel Daten, wie der Wert von B angibt, beginnend im Speicher ab D: OUT D, B, Dev #Ausgabe über Gerät Dev von soviel Daten, wie der Wert von B angibt, beginnend im Speicher ab D: Unten sehen Sie links ein einfaches VB6-Programm, das die Zahlen von 1 bis n addiert. Rechts davon ist ein typisches Maschinenprogramm widergegeben, das dieselbe Aufgabe erledigt.17 Wir wollen dieses Programm zum besseren Verständnis kurz durchgehen. Zunächst werden die Werte der Variablen M und I auf die Konstanten 0 bzw. 1 gesetzt. Dann wird in X die Subtraktion von N und I durchgeführt. Ist das Vergleiche die Diskussion über den dualen Charakter von Programmen (Programme als Text und Programme als Funktion) im Skript „Grundlagen der Informatik: Theoretische Grundlagen“. 16 Dev ist genauer gesagt eine Geräteadresse, mehr davon unten. 17 Die Maschinensprache ist dabei fiktiv. Hier geht es nur darum ein Gefühl dafür zu bekommen, wie Programme in Maschinensprache im Gegensatz zu einer Hochsprache aussehen. 15 9 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Ergebnis kleiner oder gleich 0 wird zum Ende des Programms gesprungen. Sonst wird I auf M addiert und der Wert von I um 1 erhöht. Danach wird an der Programmstelle, die mit Next gekennzeichnet ist, weitergemacht. Programm in VB6 Äquivalentes Maschinenprogramm m = 0 For i = 1 To n Step 1 MOVE MOVE Next: MOVE SUB JUMPC ADD INC JUMP Exit: m = m + i next M, 0 I, 1 X, N X, I Exit M, I I Next Die Maschinenprogramme und –Befehle haben wir hier in einer symbolischen Form dargestellt. Sie werden so noch nicht direkt vom Prozessor verarbeitet. Zuvor werden sie von einem speziellen Übersetzer, dem sogenannten Assembler, bearbeitet und in einen Binärkode18 überführt. Dazu wird z. B. jeder Befehl wie etwa MOVE eindeutig durch z. B. 8 Bits kodiert, jedes Label hinter einem Sprung wird in einen 16-Bit Offset von der aktuellen Stelle umgesetzt und jede Variable wird in einen 16-Bit Offset bzgl. einer Basisadresse für alle Variablen übersetzt. Mehr dazu und dem speziellen Sinn, der darin liegt, später. Zunächst halten wir fest, dass die Maschinensprache die niedrigste Ebene für Software ist: Maschinenprogramme sind an der Struktur des zugrunde liegenden Prozessors orientiert, aber schon Daten und nicht mehr „fest in Hardware verdrahtete“ Ablaufsteuerungen. Damit wir verstehen können, wie ein Prozessor ein Maschinenprogramm in seinem Hauptspeicher lesen, verstehen und ausführen kann, müssen wir uns zunächst mit dem Aufbau des Speichers beschäftigen. SPEICHERORGANISATION Oben hatten wir bereits erläutert, wie man Register durch Parallelschalten (der Datenleitungen) von 1-BitSpeichern bauen kann, vgl. Abschnitt „Bit-Speicher Und Register“ und Abbildung 13. Register stellen immer sämtlich in ihnen gespeicherte Information gleichzeitig zur Verfügung und alle Bits können nur zusammen und gleichzeitig in einen neuen Zustand gebracht werden. Eine weitere wichtige Möglichkeit, einen Speicher zu strukturieren, ist die Zusammenschaltung der Datenleitungen. Alle Speicherbausteine liefern ihren Inhalt auf derselben Datenleitung ab. Das kann aber nicht gut gehen, wenn das alle Speicher gleichzeitig tun. Denn dann sind viele Ausgänge miteinander verbunden. Aus diesem Grund muss man bei dieser Schaltung eine zusätzliche Logik zur Adressierung der Speichereinheit vorsehen, deren Inhalt man abfragen möchte oder die man mit einer neuen Information füllen möchte. Das Prinzip einer solchen Schaltung ist für vier 1-Bit-Speicher in Abbildung 16 dargestellt. Es gibt nur eine Eingabeleitung für Daten „IN“, die auf den Eingang aller Speicherbausteine geschaltet ist. Es gibt nur eine Ausgabeleitung für Daten „OUT“, auf die die vier Ausgabesignale der Speicherbausteine über einen Multiplexer geschaltet werden. Zur eindeutigen Selektion eines dieser 4 Speicherelemente benötigt man zwei Adressleitungen – sowohl beim Lesen der gespeicherten Information als auch zum Schreiben einer neuen Information.19 Diese Adressleitungen werden sowohl dekodiert und auf den Takteingang der Speicherbausteine geschaltet, als auch als Steuerleitungen für den Multiplexer zur Auswahl der Ausgabe verwendet. Die Entscheidung, ob ein Bit gelesen oder geschrieben werden soll, wird mit Hilfe des Signals „WR“ getroffen.20 Ist es gesetzt (WR = 1), wird geschrieben, ist es nicht gesetzt (WR = 0), wird gelesen. Das Signal Folge von Bits (0 oder 1), meist in Gruppen von 8-Bits (= 1 Byte) angeordnet. n Adressleitungen macht 2n verschiedene Adressen. 20 WR kurz für englisch „write“. 18 19 10 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR „CS“ steuert, ob überhaupt einer dieser 4 Speicher „dran“ ist.21 Denn ist „CS“ nicht gesetzt, dann sind alle „CLK“-Eingänge auf 0 und die Steuerleitung zu dem Tri-State-Ausgang ist 0 und schaltet den Ausgang ab. (Zu dem Tri-State-Bauteil mehr weiter unten.) Betrachten wir die Lese- und Schreibvorgänge etwas genauer. Der Ablauf beim Schreiben sieht so aus: Zunächst wird die Adresse auf die Adressleitungen geschaltet und „CS“ gesetzt, dann wird das Signal, das geschrieben werden soll, auf die Leitung „IN“ geschaltet und zum Schluss das WR-Signal auf 1 gesetzt. In diesem Moment übernimmt das adressierte Latch die Information von „IN“. Zum Abschluss wird zunächst „WR“ zurückgenommen und dann „CS“. Der Speicherbaustein behält dann die geschriebene Information bis zum nächsten Schreibvorgang. Der Ablauf beim Lesen sieht so aus: Zunächst wird die Adresse auf die Adressleitungen geschaltet und „CS“ gesetzt (WR bleibt auf 0, Signal an IN ist unerheblich). Dadurch wird der Ausgang des adressierten Latches auf OUT geschaltet. Dort kann dann die gespeicherte Information „abgeholt“ werden. Wichtig dabei ist, dass die Signalkombination CS = 1 und WR = 0, die Steuerleitung des Tri-State-Bauteils in der Abbildung 16 ganz unten aktiviert. Nur bei aktivierter Steuerleitung (Steuerleitung = 1) schaltet solch ein Bauteil das Eingabesignal (egal ob 0 oder 1) durch. Ist die Steuerleitung = 0 trennt das Tri-StateElement den Eingang elektrisch vom Ausgang. Das bedeutet, dass solch ein Schaltelement am Ausgang drei verschiedene Zustände kennt: (1) logisch falsch oder 0, (2) logisch wahr oder 1 und (3) offen. Durch den dritten Zustand ist es möglich, mehrere dieser Bauteile mit ihren Ausgängen zu verbinden. Es entsteht immer ein definiertes Signal, wenn dafür Sorge getragen wird, dass immer nur eine Steuerleitung der so geschalteten Tri-State-Elemente aktiviert ist. Diese Technik ist die Grundlage sämtlicher elektrischer Bussysteme, die wir unten noch kennen lernen werden. Insbesondere wird es mit diesen Schaltelementen möglich, die IN- und die OUT-Signalleitung in Abbildung 16 physisch als dieselbe Leitung darzustellen. Dazu ist es nur erforderlich, dass sämtliche Bauteile, die Signale auf die IN-Leitung zum Schreiben in den Speicher aufschalten können, das ebenfalls über TriState-Ausgänge tun, die bei jedem Lesevorgang deaktiviert sein müssen. Kombiniert man diese beiden Möglichkeiten, 1-Bit-Speicher zu verbinden, können Speicherelemente mit im Prinzip beliebig breiten Daten- und Adressbussen hergestellt werden. Abbildung 17 zeigt drei Beispiele. Solche Speicherelemente lassen sich nun ihrerseits parallel- und zusammenschalten zu immer größeren Speichern. Abbildung 18 und Abbildung 19 zeigen wie das Zusammenschalten, also die Verdoppelung der adressierbaren Menge von Speicherinhalten, bzw. das Parallelschalten, also die Verdoppelung der Bitbreite, die bei einem Schreib- oder Lesevorgang gleichzeitig verarbeitet werden kann, funktioniert. Aktuell sind mehrere Megabits pro integriertem Schaltkreis zu kaufen. Die Organisation kann dabei sehr unterschiedlich sein. So kann z. B. ein 1Mbit-Chip als 1.048.576 1 Bit oder als 131.072 8 Bit organisiert sein. Im ersten Fall verfügt er über 20 Adressleitungen und nur eine Datenleitung, im zweiten Fall über 17 Adressleitungen und 8 Datenleitungen. Nimmt die Breite des Datenbusses zu, geht die Breite des Adressbusses entsprechend zurück. SPEICHERARTEN Wird in einer späteren Version des Skripts ergänzt. PROZESSOR UND SPEICHER Moderne Prozessoren sind ohne dazu gehörenden Hauptspeicher undenkbar. Beide treten immer paarweise auf. Das hat seinen guten Grund, wie wir oben dargestellt haben: Der Prozessor „ist“ die logische Funktion und der Hauptspeicher „ist“ das Zustandsregister der Ablaufsteuerung Mikroprozessor. Wie wir oben beschrieben haben, findet die Kommunikation zwischen dem Prozessor und dem Speicher über zwei Busse statt, nämlich den Adressbus, über den der Prozessor bestimmte Stellen im Speicher ansprechen kann, und den Datenbus, über den die Daten, die gelesen oder geschrieben werden sollen, vom 21 CS kurz für englisch „chip select“. 11 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Speicher zum Prozessor bzw. umgekehrt transportiert werden. Dieser Zusammenhang ist in Abbildung 20 dargestellt. Die Abbildung zeigt auch, dass der Hauptspeicher i. d. R. in unterschiedliche Bereiche strukturiert ist. Erst einmal ist da der Bereich, in dem das Programm steht. Aus diesem Bereich wird ausschließlich gelesen, wenn das Programm ausgeführt wird. Ein Maschinenprogramm besteht i. d. R. aus einer Folge von Befehlen (in der jeweiligen Maschinensprache), die alle in 8 Bits = 1 Byte kodiert sind. Aus diesem Grund wird auf diesen Speicherbereich i. d. R. so zugegriffen, dass immer 1 Byte gleichzeitig gelesen wird. Der Rest des Hauptspeichers ist den Daten, die das Programm bearbeitet, vorbehalten. Hier wird i. d. R. der Bereich globaler Konstanten (die bei der Programminterpretation auch nur gelesen werden) vom Rest der veränderbaren Variablen unterschieden. Der Variablenbereich besitzt weitere Struktur. Zum einen ist hier ein Stapel22 der lokalen Variablenbereiche für jede aktive Prozedur (inklusive der Rücksprungadressen) zu finden und zum anderen der Bereich für Zwischenergebnisse bei der Berechnung umfangreicher Ausdrücke. Dieser Bereich ist selbst wieder ein Stapel. Die Daten sind im Hauptspeicher in Form von Speicherworten abgelegt. Aktuell besteht ein Speicherwort bei den meisten Mikroprozessorsystemen aus 4 bis 8 Byte. Der Zugriff auf den Datenteil des Hauptspeichers erfolgt deswegen auch Wort-weise. Das bedeutet, dass bei jedem Lese- und Schreibvorgang in diesem Bereich die Anzahl von Bytes gleichzeitig gelesen zw. geschrieben wird, die ein Speicherwort ausmacht (z. B. 4 oder 8 Bytes gleichzeitig). Ein Speicher von 4 GByte enthält also 4.294.967.296 Bytes, aber bei einer Wortbreite von 4 Bytes nur 1.073.741.824 Worte. Dementsprechend benötigt man eine Adressbreite von 32, um jedes Byte adressieren zu können, aber nur eine Breite von 30, um jedes Wort adressieren zu können. Wir werden im Folgenden nicht explizit zwischen Wort- und Byteadressen unterscheiden, wenn aus dem Kontext klar ist, ob auf Daten oder auf Programmbefehle zugegriffen wird. Schon die oben dargestellte Speicheraufteilung macht deutlich, dass die Architektur des Prozessors Auswirkungen auf den Aufbau und die Struktur des Speichers hat und umgekehrt. Im Folgenden werden wir eine Beispielarchitektur für einen Mikroprozessor darstellen, die alle wichtigen Eigenschaften und Eigenarten der meisten derzeit verfügbarer Architekturen besitzt. Es geht uns aber nur darum, die wichtigen Prinzipien deutlich zu machen, ohne eine tatsächliche kommerzielle Prozessorarchitektur realitätsnah nachzubilden. PROZESSOROPERATIONEN UND -ZUSTÄNDE: DER DATENWEG Sämtliche Operationen, die ein Prozessor ausführen kann, müssen letztlich durch logische Funktionen in Hardware realisiert werden. Aus diesem Grund verfügt jeder Prozessor über eine Arithmetisch/Logische Einheit ALU23, wie wir sie in einer sehr einfachen Version schon oben dargestellt haben, vgl. Abbildung 9. Natürlich ist in einem realen Prozessor die Breite von Eingabe- und Ausgabeworten größer, aktuell 32, 64 oder 128 Bit. Und jede konkrete ALU realisiert deutlich mehr verschiedene Operationen als unser kleines Beispiel oben. Abbildung 21 zeigt eine ALU als Kern unseres Beispielprozessors. Sie erhält zwei Eingabeworte von je 32 Bit Breite über die Eingabebusse A und B. Ihre Ergebnisse sind ebenfalls 32 Bit breite Worte, die auf den Ausgabebus C aufgeschaltet sind. Zur Auswahl der Operation stehen 7 Steuerleitungen zur Verfügung, die durch den zusätzlichen Eingangsbus F unten rechts in Abbildung 21 angedeutet sind. Dadurch ist unser Prozessor in der Lage, insgesamt 27=128 verschiedene Operationen mit Hilfe seiner ALU auszuführen. In Abbildung 21 sind typische Operationen dargestellt, die eine reale ALU ausführen kann. Neben dem Ergebnis einer Operation liefert jede ALU zusätzliche Informationen über den Verlauf der letzten Operation, z. B. ob das Ergebnis 0 war oder ob ein Überlauf bei einer arithmetischen Operation aufgetreten ist. Diese zusätzlichen Informationen werden in unserer schematischen Abbildung über den zweiten Ausgangsbus der ALU, der mit Z beschriftet ist, dargestellt. In unserer Beispielarchitektur wird wir hier nur Das Funktionsprinzip eines Stapelspeichers wird in den Lehrveranstaltungen Softwaretechnik und Programmierung erläutert. 23 ALU kurz für englisch: „Arithmetic Logic Unit“ 22 12 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR eine einzige Information (1 Bit), im Fachjargon nur ein Flag24, nämlich ein Zero-Flag verwenden, das anzeigt, ob das Ergebnis auf dem C-Bus gleich 0 ist oder nicht. Damit eine ALU ihre Arbeit verrichten kann, müssen ihr Eingabeworte zugeführt und die Ergebnisse abgeholt werden. Welche Möglichkeiten ein Prozessor dazu anbietet, wird über seinen „Datenweg“ bestimmt. Der Datenweg ist ein Bündel von Datenbussen und Registern. Die Register sind prozessorinterne Speicherorte für die Eingaben und Ausgaben der ALU. Unser Datenweg aus Abbildung 21 hat 9 Register. Davon sind 8 Register 32 Bit breit und ein Register, das MBRRegister, nur 8 Bit breit. Die Register in unserem Beispiel haben folgende Bedeutung: MAR: Das „Memory Address Register“ wird genutzt, wenn der Prozessor Daten aus dem Speicher lesen oder in den Speicher schreiben will. In beiden Fällen enthält es die Adresse des Datenworts, das gelesen bzw. geschrieben werden soll. Bei einer Speicheroperation wird also das MAR auf den Adressbus geschaltet. Werden Daten gelesen oder geschrieben, handelt es sich immer um 32 Bit. Das bedeutet, dass das MAR Wortadressen entält.25 MDR: Das „Memory Data Register“ wird ebenfalls für Speicheroperationen von Daten benutzt. Beim Schreiben in den Speicher wird immer das Datenwort aus dem MDR geschrieben. Beim Lesen wird das aus dem Speicher gelesene Wort immer in das MDR geladen. Damit wird bei Speicherleseoperationen der Inhalt des MDR mit Speicherinhalt überschrieben. PC und MBR: Der „Programm Counter“ und das „Memory Byte Register“ sind ein Paar, die ähnlich zusammenspielen wie das MAR und das MDR. Sollen aus dem Speicher keine Daten sondern Instruktionen aus dem Maschinenprogramm beschafft werden, so enthält der PC die Adresse der zu beschaffenden Instruktion und MBR nimmt das Byte, das aus dem Speicher gelesen wurde, auf. Da Instruktionen i. d. R. in nur 8 Bit kodiert sind, muss das MBR nur 8 Bit breit sein. Über dieses Paar laufen ausschließlich Lesevorgänge. LV, CPP und SP: Das „Local Variables“-, das „Constant Pool Pointer“- und das „Stack Pointer“-Register enthalten bestimmte Adressen aus dem Speicher, die mit der oben beschriebenen Aufteilung des Speichers in verschiedene Bereiche korrelieren. LV enthält immer die Basisadresse des Bereiches, in dem die lokalen Variablen des gerade aktiven Maschinenunterprogramms enthalten sind, CPP zeigt auf die Basis des Konstanten-Pools und SP enthält die Adresse des Datenworts, das oben auf dem Operandenstapel liegt. Die Bedeutung der Register PC, LV, CPP und SP als Zeiger in den Speicher wird im Überblich in Abbildung 22 dargestellt. TOS: Enthält SP immer die Adresse des obersten Datenwortes auf dem Operandenstapel, so befindet sich in „Top of Stack“ immer das durch SP adressierte Datenwort selbst. TOS ist nur zur Effizienzsteigerung gedacht, da viele Operationen, insbesondere die arithmetischen Operationen, in unserer Prozessorarchitektur, das Datenwort vom „Top of Stack“ als Argument benötigen und i. d. R. auch ein neues Wort für den „Top of Stack“ berechnen. H: Das „Halt“-Register wird verwendet um Zwischenergebnisse zu speichern und für die nächsten ALUOperationen bereitzuhalten. Die prozessorinternen Busse des Datenwegs regeln, von wo die Eingaben für die ALU kommen können und wohin die Ergebnisse der ALU geschafft werden können. In unserem Beispiel umfasst der Datenweg 3 Busse, den A-, den B- und den C-Bus. Über den A-Bus erhält die ALU das erste Eingabewort. Hier ist in unserer Architektur nur ein Register, das H-Register, angeschlossen, siehe Abbildung 21. Der B-Bus führt der ALU das zweite Eingabewort zu. An den B-Bus sind 7 Register angeschlossen, nämlich alle Register außer dem H- und dem MAR-Register. H ist hier ausgeschlossen, da es immer das andere Eingabewort liefert. MAR kann keine Eingabe sein, da es sich mit seinem Inhalt immer an den Speicher wendet. 24 25 Flag englisch für Flagge, Zeichen Damit müsste es eigentlich nur 30 Bit breit sein, da die untersten 2 Bit bei Wortadressen immer 0 sind. 13 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Über den C-Bus werden die Ergebnisse der ALU zu ihren Speicherorten transportiert. An den C-Bus sind alle Register außer dem MBR-Register angeschlossen. Denn MBR wird ausschließlich durch Leseoperationen im Maschinenprogramm, sogenannte „Fetch“-Operationen, gefüllt. Der Datenweg eines Prozessors stellt die möglichen logischen Operationen (ALU) und die möglichen Kombinationen von Ein- und Ausgaberegistern dar. Welche Operation wann konkret mit welchen Eingaben und mit welchem Speicherort für die Ausgabe ausgeführt wird, regelt der eigentliche HardwareAutomat im Prozessor, der Micro-Controller. ABLAUFSTEUERUNG IM PROZESSOR: MICRO-INSTRUKTIONEN Die Ablaufsteuerung in einem Prozessor regelt, welche Operation die ALU ausführen soll, welche Eingaben sie aus welchen Registern erhält und welche Register die Ergebnisse der ausgewählten ALUOperation übernehmen sollen. In unserer Beispielarchitektur heißt das, dass bestimmt werden muss, welches Register auf den B-Bus gelegt wird, welches Signal zur Auswahl der Operation an die ALU gegeben wird und welche Register das Ergebnis vom C-Bus speichern sollen. Abbildung 23 zeigt diese beispielhafte Ablaufsteuerung, die wir im Folgenden erläutern. Die Ablaufsteuerung oder Micro Controller ist ein Hardware-Automat. Sein Zustand und seine Ausgaben werden durch das „Micro Instruction Register“ MIR gespeichert. Der Zustand des Automaten besteht dabei aus den Anteilen Addr und J des MIR, also aus 11 Bit; die aktuellen Ausgaben des Micro-Controllers stellen die Anteile ALU, C, M und B des MIR dar, also insgesamt 21 Bit oder Signale. Das Eingabezeichen für jeden Zustandübergang des Controllers besteht aus nur 9 Bit, die 8 Bit vom MBR und 1 Bit von der ALU, nämlich das Z-Flag. Die logische Funktion des Controllers wird durch das Register MPC („Micro Program Counter“) und den Steuerspeicher, der die eigentliche Wahrheitstafel für die logische Funktion erhält, realisiert. Der Zustandübergang erfolgt so: (1) die Eingabesignale Z und MBR werden im MPC26 mit dem aktuellen Zustand, i. e. Addr und Z, zu einer 9 Bit breiten Adresse für den Steuerspeicher verknüpft, (2) das an dieser Adresse gespeicherte Wort (die dort gespeicherte Micro Instruction) wird aus dem Steuerspeicher beschafft und (3) im MIR gespeichert. Danach ist der nächste Zustand ermittelt und die Ausgaben für diesen Zyklus stehen in ALU, C, M und B des MIR zur Verfügung. Diese Ausgaben steuern den Datenweg und die Verbindung zum Speicher. Im Folgenden verfolgen wir einen Zyklus oder Zustandsübergang des Micro Controllers genauer. Die Ausgangsposition dafür wird durch die 32 Bit im MIR bestimmt, die am Ende des Zyklus aktualisiert werden. 1. Ausbreitung der Ausgabesignale zu den Registern und der ALU: Die drei Ausgabebits B im MIR werden dekodiert. Das ergibt 8 Steuersignale, die mit 7 Registern des Datenwegs verbunden sind. Durch die Dekodierung ist immer genau eines dieser Signale asseriert27. Dieses Signal bestimmt, welches Register seinen Inhalt als Eingabe für die ALU über den B-Bus zur Verfügung stellt. Zwei Signale sind mit dem MBR verbunden. Über sie werden zwei unterschiedliche Arten gesteuert, wie der Inhalt des MBR auf den B-Bus geschaltet wird: (1) als die niederwertigsten 8 Bits eines 32-Bit-Wortes, dessen oberen 24 Bit allesamt „0“ sind oder (2) als Vorzeichen-behaftete Ganzzahl, so dass die oberen 24 Bit das Vorzeichen im höchsten der 8 Bit übernehmen. Der Name Micro Program Counter für die Komponente MPC ist also irreführend. Es handelt sich hier nicht um ein Register, wie etwa beim PC. Es ist vielmehr eine Komponente der Logischen Funktion, die aus den Eingaben und dem Zustand die nächste Instruktion ermittelt. Richtig ist die Bezeichnung nur insofern, dass die durch MPC ermittelte Adresse die nächste auszuführende Micro Instruction im Steuerspeicher angibt. 27 Der Terminus technicus „asseriert“ bedeutet, dass ein Signal anliegt. Dabei ist es unerheblich, ob das Signal positiv oder negativ kodiert ist. Positiv kodierte Signale liegen an, wenn sie logisch „1“ sind, negativ kodierte, wenn sie logisch „0“ sind. Im positiven Fall bedeutet asseriert, dass das Signal „high“ oder logisch „1“ ist, im negativen Fall, dass es „low“ oder logisch „0“ ist. 26 14 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Die 7 Bits ALU des MIR sind mit den Funktionsauswahlsignalen der ALU verbunden. Sie bestimmen also, welche Operation ausgeführt werden soll. 2. Ausbreitung der Signale auf dem B-Bus und durch die ALU zum C-Bus: Wenn die dekodierten B-Signale die Register erreicht haben, schaltet das ausgewählte Register seinen Inhalt auf den B-Bus. Alle anderen Register schalten ihre Tri-State-Ausgänge zum B-Bus auf „offen“. Über den B-Bus breiten sich diese Signale zur ALU aus, die bereits die Signale zur Funktionsauswahl erhalten hat. Dadurch können sich die Signale durch die ALU bis zum C-Bus, auf den nur die ALU Daten schreiben kann, ausbreiten. Diese Signale, auf dem C-Bus angekommen, stellen das Ergebnis der ALUOperation mit den ausgewählten Operanden dar. 3. Übernahme der C-Bus-Daten in die Empfängerregister und Übernahme der gelesenen Daten vom Speicher aus dem letzten Zyklus: Wenn die Daten auf dem C-Bus anliegen, haben sich bereits die 8 C-Signale des MIR bis zu den Registern ausgebreitet. Diese C-Signale bestimmen, welche Register das durch die ALU berechneten Ergebnisse speichern sollen. Die C-Signale sind nicht kodiert. Dadurch ist es möglich, dass mehr als ein Register das Ergebnis der ALU-Operation gleichzeitig aufnimmt. Außerdem werden die Daten, deren Lesen ggf. im letzten Zyklus eingeleitet wurde, ins MDR und/oder MBR übernommen, Details siehe nächster Punkt. Hier sind durch die richtige Programmierung Konflikte zwischen Übernahme aus dem Speicher und vom C-Bus in dasselbe Register zu vermeiden 4. Aufschalten der Adresse und Daten auf den Bus zum Speicher und Einleiten einer Speicheroperation: Die drei Signale M des MIR steuern den Adress- und Datenbus zum Speicher. Die einzelnen Signale stehen für Read (Lesen von Daten), Write (Schreiben von Daten) und Fetch (Lesen von Maschinenbefehlen). Ist eines der ersten beiden Signale asseriert, wird MAR als Adresse auf dem Adressbus verwendet, ist das dritte asseriert, stellt PC die Adresse dar. Wir nehmen an, das der Daten- und der Programmspeicher soweit getrennt sind, dass in einem Zyklus sowohl eine Speicheroperation in den Datenbereich als auch (gleichzeitig) eine Fetch-Operation im Programmbereich stattfinden kann. Da diese Steuersignale erst jetzt den Bus zum Speicher steuern, werden die in diesem Zyklus ermittelten Inhalte von MAR und PC zum Adressieren verwendet und im Falle einer Schreiboperation der Inhalt von MDR als Daten. Werden Daten gelesen, stehen sie nicht zu Beginn des nächsten Zyklus zur Verfügung sondern erst am Ende. Das bedeutet, dass sich der aus dem Speicher geholte Inhalt von MDR und/oder MBR nicht auf die Abarbeitung des nächsten Zyklus sondern erst auf die Abläufe im übernächsten Zyklus auswirkt. Der nächste Zyklus kann noch die alten Werte von MDR bzw. MBR für den B-Bus voraussetzen. 5. Errechnen der Adresse für die nächste Micro-Instruktion: Die ggf. neuen Inhalte des MBR breiten sich jetzt zum MPC aus, an dem sowohl die Addr- und J-Signale als auch das Z-Signal der ALU für diesen Zyklus anliegen. Aus diesen Signalen ergibt sich die nächste Steuerspeicheradresse wie folgt. J umfasst zwei Signal JamZ und Jam. Ist Jam gesetzt, errechnet sich die nächste Adresse aus dem logischen Oder von MBR und Addr. Das oberste, neunte Bit von MBR wird bei dieser Operation mit „0“ aufgefüllt. Die unteren 8 Bit von Addr sind hier i. d. R. gleich 0. Über diesen Weg ist es möglich, die nächste Maschineninstruktion als Adresse für die nächste Micro-Instruktion auszuwählen. An dieser Adresse sollte dann der Micro-Kode für diese Instruktion beginnen. Ist JamZ gesetzt, errechnet sich die nächste Adresse als logisches Oder aus Addr und Z. Dabei werden die unteren 8 Bit für Z mit 0 ergänzt und das neunte oberste Bit von Addr ist i. d. R. gleich 0. Hiermit ist eine Micro-Programmverzweigung in Abhängigkeit vom Ergebnis der letzten Operation möglich. 6. Laden des MIR für den nächsten Zyklus: Die jetzt feststehende Adresse für die nächste Micro-Instruktion selektiert ein Wort im Steuerspeicher, das zum Schluss des Zyklus ins MIR selbst übernommen und mit dem der nächste Zyklus gesteuert wird. Diese Abfolge der Schritte 1. – 6. wird immer und immer wieder ausgeführt, führt dazu, dass die Befehle in Maschinensprache, die in der Programmabteilung des Speichers stehen, interpretiert und ausgeführt werden und schließlich der Datenbereich des Hauptspeichers entsprechend der Semantik des Maschinen- 15 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR programms transformiert wird. Dazu ist natürlich nötig, dass an der richtigen Stelle im Steuerspeicher die richtigen Micro-Instruktionen stehen, die die einzelnen Maschinenbefehle realisieren. Wie das geschieht beschreibt der nächste Abschnitt. REALISIERUNG VON MASCHINENBEFEHLEN DURCH MICRO-PROGRAMME Die oben dargestellte Architektur ist ein ausgefeilter Aufbau zur Interpretation von typischen Maschinenbefehlen wie sie z. B. in der Java Virtual Maschine definiert werden. Jeder Maschinenbefehl wird durch eine Folge von Micro-Instruktionen, sogenannten Micro-Programmen, realisiert. Für diese Art der Realisierung wollen wir hier 3 typische Beispiele angeben. Bei den Maschinenbefehlen handelt es sich um: 1. add Addiert die beiden obersten Worte auf dem Operandenstapel, nimmt sie vom Stapel und schmeißt das Ergebnis auf den Stapel. 2. load index Schmeißt die lokale Variable mit dem Offset index von der Basisadresse in LV auf den Stapel. Dabei ist index eine natürliche Zahl von 1 Byte Größe. Es können also auf diese Weise 256 verschiedene Speicherzellen angesprochen und auf den Stapel geschmissen werden. 3. Goto offset Führt eine Programmsprung aus und zwar zu der Programmstelle, die sich von der aktuellen um offset unterscheidet. Dabei ist offset eine Ganzzahl in 16 Bit. Der Sprung kann also bis zu 215 Speicherzellen nach vorne oder 215+1 Speicherzellen nach hinten erfolgen. Man benutzt in den meisten Maschinensprachen heute keine absoluten Adressen mehr, sondern arbeitet mit Indices und Offsets. Damit hat in unseren Beispielen (1) jede lokale Variable in jeder Inkarnation 28 einer Prozedur immer dieselbe Position (relativ zur Basisadresse des Variablenbereichs der Inkarnation) und (2) kann jedes Programm an eine beliebige Stellen in den Programmspeicher gepackt werden, denn die Sprünge stimmen immer, da sie relativ zur Absprungstelle formuliert sind. Wie können nun solche Maschinenbefehle in unserer Micro-Architektur durch eine Sequenz von MicroInstruktionen erledigt werden. Dazu wollen wir uns erst einmal eine etwas abstraktere Notation für die Micro-Instruktionen verschaffen. Wie wir oben gesehen haben, kann man mit jeder Micro-Instruktion zwei Register verknüpfen, die Art der Verknüpfung auswählen und das Ergebnis in eine Reihe von Registern übernehmen. Zusätzlich kann man dann noch einen Datenschreib- oder –Lesevorgang und einen Programm-Fetch-Vorgang einleiten. Als letztes kann man bestimmen, wo im Micro-Kode fortgefahren werden soll. Also sieht eine allgemeine Micro-Instruktion so aus (Teilausdrücke in spitzen Klammern stellen Optionen dar.): Label: R1<= R2....> = R<op><R‘><;(rd|wr)><;fetch><;goto label|(MBR)<;label‘>> Jede Operation hat eine Adresse, die symbolisch durch „Label“ dargestellt wird. Das Ergebnis aus der ALU kann einem (R1) oder mehereren Registern (R1 = R2 =...) zugewiesen werden. Man kann jedes einzelne Register durch die ALU führen und anderen Registern zuweisen (R1 = R) oder man kann eine bestimmte ALU-operation (op) auswählen und ggf. ein weiteres Eingaberegister (R‘) bestimmen. Die Optionen <;(rd|wr)> und <;fetch> stehen für die mögliche Ergänzung einer Instruktion um Speicheroperationen. Der letzte optionale Teil der Instruktion behandelt den Fortgang im Micro-Programm. Steht hier nichts, soll mit genau der nächsten Micro-Instruktion für den aktuell interpretierten Maschinenbefehl fortgefahren werden. Dieser Befehl steht symbolisch genau hinter dem aktuellen Befehl.29 Ist beim „goto“ Zur Begrifflichkeit bei der Abarbeitung (insbesonders von rekursiven) Prozeduren siehe Lehrveranstaltung Programmierung. 29 Im Steuerregister ist das nicht nötig, da jeder Befehl seinen Nachfolger explizit benennen kann. 28 16 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR nur ein Label angegeben, verzweigt das Micro-Programm zu dieser Stelle30, sind zwei Label angegeben soll in Abhängigkeit vom Z-Flag der ALU verzweigt werden. Beispiele für diese symbolische Notation sind: 1. H = MDR 2. H = H + SP 3. H = MBR1 << 8 4. LV = MAR = H or MDR; rd 5. TOS = MDR; goto Main (1) setzt den Wert des Registers H auf den Wert des Registers MDR. (2) addiert zum Inhalt von H den Inhalt von SP und speichert das Ergebnis in H. (3) schiebt den Inhalt von MBR interpretiert als Byte um 8 Bit nach links und speichert das Ergebnis in H.31 (4) verknüpft den Inhalt von H und MDR durch logisches Oder, speichert das Ergebnis sowohl in MAR als auch in LV und leitet mit dem neuen Adresswert in MAR eine Datenleseoperation ein. (5) weist den Inhalt von MDR dem Register TOS zu und verzeigt danach zu der Micro-Instruktion mit dem Label „Main“. Bei dieser kleinen Programmiersprache muss man natürlich die vielen kleinen Eigenarten unserer MicroArchitektur beachten. Dazu gehört z. B., dass bei der Verknüpfung von zwei Argumenten das erste immer H sein muss und das zweite niemals H sein kann, dass es nicht möglich ist, in einer Instruktion ein „rd“ einzuleiten und in der nächsten an MDR zuzuweisen, oder dass gelesene Daten und Maschinenbefehle nicht in der nächsten Instruktion verwendet werden können. Beachtet man alle diese Randbedingungen können die Micro-Programme für unsere drei Beispielmaschinenbefehle so aussehen: Main: PC = PC + 1; fetch; goto (MBR) Add1: MAR = SP = SP - 1; rd Add2: H = TOS Add3: MDR = TOS = MDR + H; wr; goto Main Load1: Load2: Load3: Load4: Load5: H = LV MAR = MBR + H; rd MAR = SP = SP + 1 PC = PC + 1; fetch; wr TOS = MDR; goto Main Goto1: Goto2: Goto3: Goto4: Goto5: Goto6: MDR = PC - 1 PC = PC + 1; fetch H = MBR2 << 8 H = MBR or H PC = MDR + H; fetch wait; goto Main Jedes Micro-Programm für jeden Maschinenbefehl soll am Ende zum Label „Main“ verzweigen. Es soll zudem dafür sorgen, dass bei der Instruktion am Label „Main“ die nächste Instruktion bereits im MBR zur Verfügung steht. Die Main-Schleife erhöht dann den Programmzähler und veranlasst die Beschaffung des Inhalts der Speicherzelle mit der Adresse dieses neuen Programmzählers ins MBR. Gleichzeit verzeigt die Instruktion zu der Micro-Instruktion, die im Steuerspeicher unter der Adresse steht, die dem alten Inhalt von MBR ent- Hier ist auch die Verzweigung zum Start der nächsten Micro-Instruktion möglich, angedeutet durch (MBR). Diese Symbolik spiegelt den Effekt des Jam-Bits wieder. 31 Die hochgestellte 1 zeigt an, dass MBR als Byte interpretiert werden soll und nicht als ganze Zahl. Dafür verwenden wir eine hochgestellte 2. Siehe auch oben die zwei verschiedenen Auswahlmöglichkeiten von MBR auf dem B.Bus. 30 17 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR spricht. Das bedeutet also das die Byte-Kodes der Maschinenbefehle mit den Startadressen ihrer MicroProgramme im Steuerspeicher übereinstimmen.32 Betrachten wir nun den Kode für das „add“ etwas genauer: Der Einsprung in dieses Programm erfolgt aus „Main“ dadurch, dass der Maschinenbefehlskode für „add“ ins MBR gelangt war. Die Ausgangssituation ist, dass der PC bereits auf die nächste Instruktion zeigt und die Beschaffung dieser Instruktion ins MBR bereits von Main veranlasst wurde. Das ist so, weil der „add“-Befehl nur ein Byte lang ist und keine weiteren Bytes aus dem Maschinenprogramm für die Interpretation des „add“ beschafft werden müssen. Schon bei „Add2“ steht der nächste Maschinenbefehl in MBR bereit, so dass die Voraussetzungen zum Rücksprung nach „Main“ bereits dann gegeben sind. Der erste Operand für die Addition befindet sich bereits in TOS, das immer den obersten Eintrag des Stapels redundant speichert. „Add1“ leitet die Beschaffung des zweiten Operanden ein. Dazu wird der Operanden-Stapelzeiger „SP“ dekrementiert, ins MAR geladen und die Datenleseoperation eingeleitet. Gleichzeitig wird SP – 1 auch „SP“ zugewiesen, da das die Adresse des obersten Eintrags auf dem Stapel nach der Operation sein wird und hier das Ergebnis der Addition zu speichern ist. „Add2“ bringt das erste Argument der Addition nach H. Am Ende von „Add2“ steht im MDR das zweite Argument zur Verfügung. „Add3“ führt die eigentliche Addition durch, speichert das neue oberste Element des Stapel in TOS und in MDR und veranlasst das Speichern auf dem Stapel. Beachte, dass MAR immer noch die richtige Stapeladresse beinhaltet. Zum Schluss kehrt „Add3“ zu „Main“ zurück. Während der Ausführung der Instruktion in „Main“ wird der eigentliche Speichervorgang, den „Add3“ veranlasst hat, durchgeführt. Das Programm für „load“ ist etwas komplizierter, da hier aus dem Maschinenprogramm noch der index beschafft werden muss. Durch die Vorarbeit von „Main“ steht dieser Index bei „Load2“ im MBR zur Verfügung. „Load1“ und „Load2“ berechnen im MAR die Adresse der Variablen, die auf den Stapel geschmissen werden soll, und veranlassen ihre Beschaffung im MDR. Sie steht aber erst ab „Load4“ zur Verfrügung. „Load3“ erhöht den Stapelzeiger in den Operandenstapel und weist ihn auch MAR zu, weil „Load4“ an dieser Adresse schreiben will, und zwar den gerade beschafften Inhalt von MDR. Gleichzeitig erhöht „Load4“ den Programmzähler und beschafft den nächsten Maschinenbefehl für die Rückkehr ins „Main“. „Load5“ aktualisiert den TOS und verbringt somit die Zeit sinnvoll, die nötig ist, damit MBR mit dem neuen Maschinenbefehl gefüllt wird. Der Sprungbefehl „goto“ ist noch etwas komplizierter, da hier zwei weitere Bytes aus dem Maschinenprogramm zur Bestimmung des offset beschafft werden müssen. Das Nachvollziehen der Korrektheit dieses Micro-Programms lassen wir als Übung für den Leser. Es sei nur angemerkt, dass der Operator „<<8“ ein Verschieben um 8 Bit nach links bedeutet und die Operation „wait“ sehr einfach durch „SP=SP“ realisiert werden kann. Mit solchen oder ähnlichen Micro-Programmen lassen sich vielfältige Maschinenbefehle realisieren, insbesondere alle die der „Java Virtual Maschine“. Damit steht uns eine Hardware-Infrastruktur zur Interpretation moderner objektorientierter IT-Systeme zur Verfügung und wir haben die wesentlichen Eigenschaften und Merkmale der aktuellen Prozessortechnologien kennen gelernt, die dafür nötig sind. Mit Hilfe der Jam-Bit-Verknüpfung kann man also eine Sprungtabelle mit 256 Einträgen realisieren. Demnach sind maximal 256 verschiedene Maschinenbefehle möglich, deren Micro-Programm aber nur höchstens zwei Instruktionen lang sein kann. Meist werden alle Möglichkeiten für Befehlskodes nicht ausgenutzt. 32 18 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR VO M P RO Z E S S O R Z U M C O M P U T E R - S Y S T E M Den modernen Mikro-Prozessor haben wir bisher als Hierarchie von Hardware-Automaten kennen gelernt. Im innersten Kern liegt der Micro-Controller. Sein Zustand- und Ausgaberegister ist das MIR, sein Eingabestrom besteht aus den Maschinenbefehlen und den Flags der ALU und seine Ausgaben sind allesamt Steuerleitungen, die die Arbeitsweise des Datenwegs kontrollieren. Die logische Funktion, die sowohl Zustandstransformation als auch Ausgabeerzeugung regelt, ist durch den Steuerspeicher und einige Peripherie-Logik, wie den Decoder für den B-Bus oder den MPC, gegeben. Der Prozessor selbst, i. e. der Micro-Kontroller zusammen mit dem Datenweg, ist ebenfalls ein HardwareAutomat. Das „Zustands- und Ausgaberegister“ besteht hier aus dem MIR zusammen mit allen anderen Registern des Datenwegs. Ein- und Ausgaben sind hier alle Verbindungen zum Speicher, also das MAR, MDR, PC und die drei Steuerleitungen „Read“, „Write“ und Fetch“ als Ausgaben und MDR und MBR als Eingaben. Die logische Funktion dieses Automaten umfasst die des Micro-Controllers und die Ablaufsteuerung, die die Schritte 1 bis 6 des Micro-Instruktion-Zyklus kontrolliert (siehe oben). Nehmen wir zum Prozessor auch den Hauptspeicher hinzu, entsteht der Hardware-Automat auf der nächsten Ebene. Er ist schematisch in Abbildung 20 dargestellt. Sein Zustandsregister ist der Hauptspeicher, die logische Funktion scheint durch den Prozessor gegeben. Das trifft aber nicht die ganze Wahrheit. Denn, was ein Prozessor tut, ist programmgesteuert. Die logische Funktion hängt also vom Zustand ab. Die Analogie zum Hardware-Automaten, wie wir ihn im Abschnitt „Ablaufsteuerungen“ vorgestellt haben, wird besser, wenn wir den Teil des Hauptspeichers, der das Programm enthält, der logischen Funktion zuschlagen, siehe Abbildung 24. Ein Computersystem aus den Komponenten Prozessor und Speicher hat also einen Zustand, den Datenanteil des Hauptspeichers, und eine logische Funktion, teilweise realisiert in Hardware (eigentlicher MikroProzessor) und teilweise realisiert in Software (ein Maschinenprogramm). Ein- und Ausgabe ist hier aber noch nicht vorhanden. Bisher sind unsere Computer nur damit beschäftigt ihren eigenen Zustand zu transformieren. Wie die Umwelt darauf Einfluss nehmen kann und von den Ergebnissen erfährt, wie also Ein- und Ausgabe in Computer-Systemen organisiert ist, beschreiben wir in diesem Kapitel. MEMORY-MAPPED INPUT/OUTPUT Im Datenspeicher lesen und schreiben, ist für die Prozessoren, die wir oben vorgestellt haben, eine leichte Übung. Aus diesem Grund ist es naheliegend, Ein- und Ausgabe auch über diesen Mechanismus zu realisieren. Dazu verwendet man folgenden Trick: Ein Ein-/Ausgabegerät, wie zum Beispiel die Graphikkarte zur Erzeugung der Bildschirmausgabe, verhält sich zum Prozessor wie Hauptspeicher, stellt aber mit seinem Teil des Hauptspeichers noch etwas zusätzliches an, nämlich produziert im Falle der Graphikkarte ein Bild mit Hilfe einer Bildröhre. Diese Art der Eingabe und Ausgabe nennt „Memory-mapped Input/Output“. Der Name ist treffend. Denn der Speicher ist aufgeteilt wie eine politische Landkarte in viele Regionen, die manchmal nur Speicher darstellen, manchmal aber auch Speicher von Ein-/Ausgabegeräten. Alle Ein-/Ausgabegeräte müssen sich zum Prozessor wie einfacher Speicher verhalten. Das heißt Lesen und Schreiben von Datenworten muss hier für den Prozessor genauso möglich sein wie im reinen Speicher. Der Prozessor nutzt dazu den Adress- und Datenbus und dasselbe normale Protokoll zum Lesen und Schreiben (siehe oben). Zusätzlich nutzen die Ein-/Ausgabegeräte die Information in ihrem Speicherbereich zu weiteren Zwecken (Ausgabegeräte, Aktoren) oder machen Informationen aus der Umwelt in ihrem Speicherbereich für den Prozessor erkennbar (Eingabegeräte, Sensoren). Ein einfacher Ein-/Ausgabebaustein dieses Typs, der fast in jedem PC als zu finden ist, ist der parallel Port 8255 von Intel, vgl. Abbildung 25. Dieser Baustein verfügt über insgesamt 24 Ein/Ausgabeleitungen, die in drei Gruppen zu je acht Signalen, den Ports A, B und C, organisiert sind. Über diese Leitungen können entweder Ausgaben gemacht werden, z. B. Leuchtdioden oder verstärkende Tran- 19 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR sistoren ein- und ausgeschaltet werden. Oder es können Signale der Umwelt (Eingaben) über diese Ports in den 8255 gespeist werden, z. B. Zustände offen und geschlossen von Tasten etc. Neben den drei Ports verfügt der Baustein über ein 8-Bit breites Steuer- und Statusregister. Dieses Register kann der Prozessor beschreiben (genauso wie ein Byte im Speicher), um z. B. festzulegen, welche Ports Ausgaben und welche Ports Eingaben darstellen sollen. Ebenfalls kann über das Steuerregister festgelegt werden, welches Protokoll die Peripherie einhalten soll, wenn sie mit dem 8255 kommuniziert. Aus Sicht des Prozessors benimmt sich ein 8255-Baustein wie Speicher (linke Seite in Abbildung 25). Er kann über zwei Adressleitungen mit dem Adressbus verbunden werden. Daraus ergeben sich 22=4 Speicherzellen, nämlich die drei Ports und das Steuer-/Statusregister. Er hat 8 Leitungen, mit denen er auf den Datenbus geschaltet wird und verfügt über Steuersignale, wie CS oder WR, die regeln, ob der Baustein in einer Speicheroperation, die der Prozessor ausführt, „gemeint“ ist bzw. ob gelesen oder geschrieben werden soll. Natürlich hat der Baustein, wie normaler Speicher auch Tri-State-Verbindungen zum Datenbus, damit er nicht stört, wenn er gar nicht dran ist, i. e. wenn sein „Chip Select“ (CS) nicht asseriert ist. Der Prozessor kann mit dem 8255 Ausgaben ganz einfach dadurch erreichen, dass er in die Ports schreibt. Dadurch sind die entsprechenden Signale gesetzt und ggf. angeschlossene Leuchtdioden beginnen zu leuchten. Zur Realisierung von Eingaben liest der Prozessor die Port-Register regelmäßig aus und erfährt so z. B., ob eine Taste gedrückt ist oder nicht. Welche Ports Eingaben und welche Ausgaben sein sollen, bestimmt der Prozessor während der Baustein-Initialisierung. Die besteht aus dem Beschreiben des Steuerregisters, denn der Inhalt des Steuerregisters konfiguriert u. a. die Ports des 8255 als Ausgabe- oder Eingabeleitungen. Stellen wir uns einen einfachen Prozessor vor, der einen 16 Bit breiten Adressbus und einen 8 Bit breiten Datenbus zum Speicher hat, dann könnte für ein kleines eingebettetes System, wie etwa eine Waschmaschinensteuerung, die Speicheraufteilung (Memory Map) so aussehen: (1) Der Programmspeicher von 8 KByte EPROM liegt zwischen den Adressen 0 und 213 = 8192. (2) Der Datenspeicher von 8 KByte RAM liegt zwischen den Adressen 215= 32.768 und 215+213= 40.960. (3) Die Ein-/Ausgabe über einen einzigen 8255 liegt an den Adressen 215+214=49.152 bis 49.155. Die Schaltung der Adress- und CS-Leitungen, die diese Memory Map realisiert, ist in Abbildung 26 dargestellt. Die jeweils 13 Adressleitung von EPROM und RAM werden mit den Adressleitungen A0 bis A12 verbunden. Die beiden Adressleitungen des 8255 werden mit A0 und A1 beschaltet. Meistens versucht man Programm-, Daten- und Gerätespeicher möglichst weit von einander entfernt in der Memory Map unterzubringen. Denn dann sind alle Bereiche einzeln leicht erweiterbar, ohne andere Bereiche umkonfigurieren zu müssen. In unserem kleinen System lässt sich z. B. der Programmspeicher oder der Datenspeicher leicht verdoppeln oder verdreifachen, ohne die Adressen des anderen Speichers oder des 8255 ändern zu müssen. INTERRUPT-STEUERUNG Die Ausgabe über Memory Maps funktioniert prima. Die Eingabe ist nicht so elegant. Denn bei der Eingabe ist der Prozessor gefordert, immer und immer wieder und sehr regelmäßig die Speicherzellen auszulesen, wenn er keine (vielleicht sehr kurze) Eingabe verpassen will. Hat der Prozessor neben dem Warten auf Eingabe nichts weiteres zu tun, so kann man dieses „hektische Warten“ (englisch: Busy Waiting) in Form von stetigen Abfragen der Eingaberegister noch akzeptieren. Doch wenn der Prozessor gerade dabei ist, die letzte Eingabe ggf. durch komplizierte Berechnung der entsprechenden Ausgaben zu verarbeiten, ist die gleichzeitige Überwachung der Eingaberegister durch Busy Waiting ineffizient. Denn (1) verzögert sich dadurch die Erzeugung der Ausgabe und (2) können Eingabesignale verloren gehen, wenn die Überwachungsfrequenz nicht hoch genug ist. Die Situation ist besonders schlimm, wenn Eingaben selten sind. Dann sind die meisten Überwachungsvorgänge der Eingaberegister nutzlos, da immer und immer wieder unter großer Hektik festgestellt wird, dass keine Eingabe vorliegt, man also nicht so hektisch sein müsste. 20 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Hier sind komfortablere und Ressourcen schonende Mechanismen zur Eingabe gefragt. Die Eingabegeräte müssten in der Lage sein, dem Prozessor zu signalisieren, wann es lohnt, nach Eingaben zu schauen. Solange der Prozessor solche Signale nicht empfängt, kann er sicher sein, keine Eingabe zu verpassen. Erst, wenn er ein Signal des Eingabegeräts empfängt, schaut er in den entsprechenden Eingaberegistern nach, holt die Eingaben ab und beschäftigt sich danach bis zum nächsten Signal ausschließlich mit sinnvollen Sachen, z. B. dem Erzeugen der Ausgaben für die letzte Eingabe. Solche Eingabeverfahren nennt man Interrupt-gesteuerte Eingabe, die Signale der Eingabegeräte an den Prozessor Interrupts. Alle modernen Mikroprozessoren verfügen über Interrupt-Signale und einen Mechanismus zur Interrupt-gesteuerten Eingabe. Das Schema dieses Mechanismus ist immer gleich und in Abbildung 27 dargestellt. Der Bus zwischen Prozessor einerseits und Speicher und Ein/Ausgabegeräten andererseits wird um zusätzliche zwei Leitungen INT und INTA erweitert. Das Erzeugen und Behandeln eines solchen Interrupts läuft dann so ab: (1) Das Eingabegerät stellt neue Eingaben in seinen Eingaberegistern bereit. (2) Das Vorhandensein neuer Eingaben wird dem Prozessor durch Asserieren des Interrupt-Signals INT vom Eingabegerät angezeigt. (3) Der Prozessor kann den Interrupt bestätigen oder ablehnen, je nachdem ob er zur Zeit unterbrochen werden kann oder nicht. Bestätigt er, asseriert er INTA (Interrupt Acknowledge). (4) Ist der Interupt bestätigt, wird vom Eingabegerät in einem speziellen Interrupt-Zyklus des Busses ein Datum (z. B. ein Byte) über den Datenbus zum Prozessor übertragen, der sogenannte Interupt Vector. Der Interrupt Vector zeigt dem Prozessor an, um welchen Interrupt es sich handelt. Das ist dann wichtig, wenn mehrere Geräte Interrupt-gesteuert betrieben werden. (5) Der Prozessor nutzt den Interrupt Vector, um in ein Unterprogramm zu verzeigen, das diesen Interrupt behandeln soll. Dazu schaut der Prozessor in einer speziellen Tabelle im Hauptspeicher, der Interrupt-Sprung-Tabelle, nach. Sie enthält für jeden Interrupt Vector die Einsprungadresse des Unterprogramms, das diesen Interrupt behandeln soll. Dieses Programm wird dann angesprungen. (6) Dieses Unterprogramm holt nun die bereitgestellten Eingaben durch normale Speicherleseoperationen ab. (7) Der Abschluss der Behandlung eines Interrupts wird i. d. R. durch einen speziellen Maschinenbefehl „Return from Interrupt“ angezeigt. Führt der Prozessor diesen Befehl aus, nimmt er sein INTASignal zurück. (8) Das signalisiert dem Eingabegerät, dass seine Eingaben abgeholt wurden. Es nimmt also auch sein INT-Signal zurück. Jetzt kann der nächste Interrupt desselben oder eines anderen Gerätes verarbeitet werden. Wollen mehrer Geräte mit einem Prozessor Interupt-gesteuert Eingabedaten austauschen, enstehen sofort zwei Probleme: (1) Wie wird entschieden, welches Gerät drankommt, wenn zwei Geräte um die Aufmerksamkeit des Prozessors konkurrieren und (2) Was macht man mit Interrupts während der Behandlung eines anderen Interrupts. Um solche Probleme möglichst programmgesteuert zu lösen, wird in allen modernen Computersystemen ein Interrupt Controller eingesetzt, der die Koordination von mehreren Interrupt-fähigen Geräten übernimmt. Ein Baustein dieser Art ist der Intel 8259 in Abbildung 28. Dieser Baustein wird „zwischen“ den Prozessor und die Eingabegeräte geschaltet. Sämtliche Interrupt-Leitungen der Eingabegeräte werden mit den IR-Leitungen33 des 8259 verbunden (bis zu 8 Stück, bei mehr Geräten kann der 8259 kaskadiert werden, sodass höchstens 256 Eingabegeräte angeschlossen werden können) . 33 IR kurz für „Interrupt Request“. 21 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Der Interrupt Controller ist in solch einer Architektur der einzige Baustein, der direkt einen Interrupt beim Prozessor auslösen kann. Für den Prozessor ist der Controller ein normales Ein-/Ausgabegerät, das sich auch irgendwo in der Memory Map befindet. Durch Schreiben in die Steuerregister des 8259 kann der Prozessor Prioritäten für die Interrupts festlegen und Interrupts in Interrupts erlauben oder unterdrücken. Der Controller ist dann in der Lage, entsprechend dieser Steueranweisungen selbständig die Interrupt Requests der Geräte zu „schedulen“. Die beiden Bausteine 8255 und 8259, die wir oben zur Ein-/Ausgabe in Computersystemen vorgestellt haben, können gut zusammenarbeiten. Denn der 8255 verfügt auch über Eingabemodi, die bei Vorhandensein neuer Eingaben einen Interrupt erzeugen. Ja das physische Gerät selbst, das an eine Eingabeleitung eines der 8255-Ports angeschlossen ist, kann indirekt den Interrupt auslösen. Hier ein Beispiel: Den 8255 kann man so konfigurieren34, dass Port A und B Eingaben werden und der Port C je zur Hälfte (4 Bit) Steuersignale zum physischen Gerät darstellt. Eines dieser Signale ist ein Input Strobe STB für das Gerät, ein anderes ein Interrupt-Signal INTR für den Interrupt Controller. Verbindet man eine Taste (als mögliche Eingabesignalquelle) jetzt nicht nur mit einer Eingabeleitung z. B. auf Port A sondern auch mit dem Strobe-Signal von Port A, wird das Signal der Taste im Port A gespeichert und danach ein INTR asseriert. Interrupt Controller und Prozessor sind nun an der Reihe, das Abholen der Daten aus Port A zu koordinieren. Tun sie das durch Lesen aus Port A, nimmt der 8255 das Signal INTR am Ende der Leseoperation zurück. DIRECT MEMORY ACCESS (DMA) Die bisher vorgestellten Verfahren zur Ein- und Ausgabe sind vernünftig, wenn es sich um geringe Mengen von Daten handelt, die zwischen Prozessor und Gerät ausgetauscht werden müssen. Die Situation ändert sich, wenn größere Mengen ins Spiel kommen, z. B. wenn Datenblöcke von einer Festplatte oder einer DVD gelesen werden müssen. Werden diese Daten von dem Ein-/Ausgabegerät immer an einer festen Stelle im Speicher zur Verfügung gestellt, 1. muss der Prozessor sie dort abholen und selbst an den Platz schaffen, wo er sie benötigt, und 2. der (relativ große) Speicherbereich kann nur für dieses Gerät genutzt werden (feste Memory Map). Beide Probleme werden durch ein Ein-/Ausgabeverfahren gelöst, das „Direct Memory Access (DMA)“ heißt und in diesem Abschnitt vorgestellt wird. Fassen wir aber das bisher Erreichte nochmals zusammen. Die Zusammenarbeit von Prozessor und Geräten äußert sich bisher auf dem Bus, den sie teilen, so: (a) Nur der Prozessor schreibt Adressen. Die Geräte reagieren nur auf diese Adressen. (b) Der Speicher legt Daten nur dann auf den Bus, wenn zuvor der Prozessor eine Leseoperation „befohlen“ hat. (c) Geräte legen nur dann Daten (Interrupt Vector) auf den Bus, wenn zuvor der Prozessor einen entsprechenden Interrupt gutgeheißen hat. Das bedeutet, dass unsere Systeme bisher eine klare Master/Slaves-Struktur haben. Der Master, i. e. der Prozessor, hat die vollständige Kontrolle über das Gesamtsystem, und alle Slaves, i. e. alle Geräte und der Speicher, werden durch ihn koordiniert. Das bedeutet aber, wie immer in diesen Strukturen, dass alles und jedes – hier jeder Datenaustausch – über den Master laufen muss. Das kann schnell ineffizient werden, wenn der Prozessor nur noch mit dem Hin- und Herschaufeln von Daten beschäftigt ist und zu seiner eigentlichen Arbeit nicht mehr kommt. Will man den Prozessor von solchen Verwaltungsarbeiten (nämlich Daten an den richtigen Platz im Speicher zu schaffen) entlasten, muss man von der Master/Slaves-Struktur abweichen. Geräte müssen selbständig in der Lage sein, Daten in den Speicher zu schaffen, das heißt aus ihren Eingaberegistern an die richtige Stelle im Speicher zu schaufeln. Sie übernehmen selbst das Abholen ihrer Daten und zurVerfügung-stellen im Speicher. Das bedeutet, Daten werden nicht mehr abgeholt sondern gebracht. 34 Durch Schreiben in das Steuerregister. 22 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Den Ablauf eines solchen Datenaustausch per DMA zeigt Abbildung 29, am Beispiel einer Leseoperation von einer Festplatte: 1. Der gesamte Prozess wird durch den Prozessor initiiert. Er teilt dem Festplatten Controller mit, welche Daten (Spur und Sektor) er lesen möchte und wo (Startadresse) in den Speicher sie geschrieben werden sollen. Das geschieht auf die bekannte Weise durch Schreiben in Steuerregister des Festplatten Controllers. Dann gibt der Prozessor den Bus frei. 2. Sobald der Festplatten Controller die Daten von der Platte beschafft hat, bemächtigt er sich des Busses und schaufelt sie an die gewünschte Stelle im Speicher. Dazu führt er sich gegenüber dem Speicher wie ein Prozessor auf, denn er schreibt Adressen und Daten auf dem Bus. 3. Sind alle Daten im Speicher, zeigt das der Controller über einen Interrupt dem Prozessor an und gibt den Bus frei. DMA führt zu einer Slave/Masters-Struktur. Es gibt nur noch einen Slave, den Speicher. Alle DMAGeräte können Master sein, sich also genau so wie der Prozessor auf dem Bus und dem Speicher gegenüber verhalten. In konkreten Systemen wird diese Situation etwas dadurch entschärft, das sämtlicher DMA-Transfer durch einen DMA-Controller ausgeführt wird. Der Prozessor teilt nicht dem Gerät selbst seine Datenwünsche mit, sondern dem DMA-Controller. Ihm muss er natürlich auch sagen, von oder zu welchem Gerät der Transfer gehen soll. Der DMA-Controller übernimmt dann die Arbeit des Byte-Schaufelns. Er ist dabei in der Lage mehrere Transfers gleichzeitig zu bearbeiten. Ein DMA-Controller führt zu einer Master2/Slaves-Struktur. Nur der Prozessor und der Controller können die Masterrolle spielen und um den Bus und den Speicher konkurrieren, alle anderen Geräte und der Speicher bleiben Sklaven. Blocktransfer wird in einer späteren Version des Skripts ergänzt. PERIPHERIE-BUSSE Wird in einer späteren Version des Skripts ergänzt. BUSBREITE UND BUSTAKT Wird in einer späteren Version des Skripts ergänzt. SYNCHRONE UND ASYNCHRONE BUSSE Wird in einer späteren Version des Skripts ergänzt. AUFLÖSEN VON KONKURRENZ Wird in einer späteren Version des Skripts ergänzt. SPEICHERHIERARCHIE Wird in einer späteren Version des Skripts ergänzt. 23 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR ANHANG A: ABBILDUNGEN Kollektor Basis-Emitter Kollektor-Emitter Spannung Widerstand 0 +Vcc Basis Emitter Abbildung 1: Schaltprinzip eines Transistors 24 0 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR VCC R1 Vout Vin 0 +Vcc Vout +Vcc 0 Vin In NOT Abbildung 2: Transistorschaltung für einen Inverter 25 Out G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR VCC V In 1 0 0 + V cc + V cc R1 VIn1 Vout V In 2 0 + V cc 0 + V cc V ou t + V cc + V cc + V cc 0 VIn2 In1 In2 NAND Out Abbildung 3: Transistorschaltung für ein logisch invertiertes “Und” 26 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR VIn1 R1 VIn2 VCC VIn1 0 0 +Vcc +Vcc VIn2 0 +Vcc 0 +Vcc In1 In2 NOR Vout +Vcc 0 0 0 Vout Abbildung 4: Transistorschaltung für ein logisch invertiertes “Oder” 27 Out G RUNDLAGEN DER I NFORMATIK (A) H ARDWARE -A RCHITEKTUR (B) In1 Out In2 XOr (C) (D) CIn In1 In1 S In2 S In2 C COut Abbildung 5: (A) Oder von drei Eingängen, (B) Exklusiv-Oder, (C) Halb- und (D) Volladdierer Halbaddierer IN 1 IN 2 Volladdierer IN 1 S C (A+B) (Überlauf) IN 2 C In S C O ut ( Ü b e r la u f ) (A + B ) ( Ü b e r la u f ) 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 0 1 0 1 0 0 1 0 1 0 1 1 0 1 0 1 1 0 1 1 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 Abbildung 6: Wahrheitstabellen für den Halb- und den Volladdierer 28 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR D0 D1 D2 D3 S1 S0 Abbildung 7: Multiplexer 29 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR O0 O1 O2 O3 S1 S0 Abbildung 8: 2-auf-4-Dekodierer 30 G RUNDLAGEN DER I NFORMATIK D0 In1 D1 In2 D2 CIn D3 In1 Out In2 Addierer CIn COut 4-fach-Multiplexer H ARDWARE -A RCHITEKTUR 1-Bit ALU O Out S 0 S1 COut F0 F1 Abbildung 9: Zentraleinheit zur arithmetisch logischen Verknüpfung 31 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR In10 In11 In12 In13 In20 In21 In22 In23 In1 In2 Out In1 In2 Out In1 In2 Out In1 In2 Out CIn CIn CIn CIn COut F0 F1 COut F0 F1 COut F0 F1 COut COut F0 F1 Out0 Out1 Out2 Out3 F0 F1 Abbildung 10: ALU für 4 Bit breite Worte 32 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR S ¬Q R Q Abbildung 11: SR-Latch 33 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR D ¬Q Clk Q Abbildung 12: Getaktetes D-Latch 34 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR D0 D D1 Q D Clk Clk D2 Q D Clk Q0 D3 Q D Clk Q1 Clk Q2 Abbildung 13: Register aus 4 D-Latches 35 Q Q3 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Clock ee1, ,..., e 1 ..., emm Input Input 22 Zustandsregister Zustandsregister((log logp pBit) Bit) ((2log 2logm mBit) Bit) Next State ( 2log p Bit) Last Last State State 2 2 2 2 Logische 2logm 2logp 2logn 2logp LogischeFunktion Funktion((log m++log pBit Bit log n++log pBit) Bit) Output Output ((2log 2logn nBit) Bit) aa1, ,..., a 1 ..., ann Ausgaberegister Ausgaberegister(( loglognnBit) Bit) 2 2 Abbildung 14: Funktionsprinzip eines Automaten in Hardware 36 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Pascal Pascal Programm Programm VB6 VB6 Programm Programm C++ C++Compiler Compiler Pascal PascalCompiler Compiler VB6 VB6Compiler Compiler interpretiert C++ C++ Programm Programm Maschinenprogramm Maschinenprogramm steuert Prozessor Prozessor SW HW MikroMikroprogramm programm Speicherzustand Speicherzustand Abbildung 15: Maschinenprogramme – Schnittstelle zwischen Hardware und Software 37 G RUNDLAGEN DER I NFORMATIK IN WR CS H ARDWARE -A RCHITEKTUR D Q Clk A0 A1 D Q Clk O0 O1 O2 O3 Dekodierer/ Multiplexer Out ( Tri-State ) Abbildung 16: Adressierbarer Speicher 38 D Clk Q D Clk Q G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR A0 A1 D A0 A1 A2 A3 D A0 A1 A2 A3 D0 D1 D2 D3 41 Bit 161 Bit 164 Bit WR CS OE WR CS OE WR CS OE Abbildung 17: Speicherbausteine 39 G RUNDLAGEN DER I NFORMATIK DatenBus H ARDWARE -A RCHITEKTUR D0 D1 D2 D3 A0 A1 A2 A3 A0 A1 A2 A3 D0 D1 D2 D3 D0 D1 D2 D3 164 Bit 164 Bit WR CS OE WR CS OE Schaltung für 32 4 Bit WR OE A0 A1 A2 A3 A4 AdressBus Abbildung 18: Parallelschalten von Adressen 40 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR DatenBus D0 D1 D2 D3 D4 D5 D6 D7 A0 A1 A2 A3 WR CS OE A0 A1 A2 A3 D0 D1 D2 D3 D0 D1 D2 D3 164 Bit 164 Bit WR CS OE WR CS OE A0 A1 A2 A3 Schaltung für 16 8 Bit AdressBus Abbildung 19: Parallelschalten von Daten 41 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Speicher Adressbus Variablen-Stapel Konstanten Datenbus Operanden-Stapel Prozessor Prozessor Programm Abbildung 20:Zusammenspiel Prozessor - Speicher 42 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR MAR MAR MDR MDR Zum und vom Speicher MBR MBR PC PC LV LV C B CPP CPP SP SP Typische ALU-Funktionen: C=A+B C=AB C=A C=B C=B+1 C = ShiftLeft(A, 8 Bit) C = -A ... TOS TOS HH Z A ALU ALU Abbildung 21: Beispiel eines Datenwegs 43 F G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Speicher Adr 65.123..... Operanden-Stack Adressbus Variablen-Stack Konstanten Adr 0 Maschinen Programm Datenbus SP (top) LV (bottom of top) Prozessor Prozessor CPP (bottom) PC (random) Abbildung 22: „Register-Zeiger“ in den Hauptspeicher 44 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR read, write, fetch MPC MAR MAR MDR MDR 512 51232 32Bit Bit Steuerspeicher Steuerspeicher MBR MBR PC PC LV LV C 9 B 2 7 8 3 3 Addr Addr JJ ALU ALU CC M MBB MIR CPP CPP SP SP 2* Decode TOS TOS HH A 1 ZZ ALU ALU Abbildung 23: Beispiel einer Mikroarchitektur 45 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Bus Datenspeicher Datenspeicher (Zustand (Zustanddes des Systems) Systems) Ein- und und Ausgabe Ausgabe Geräte Ein(memory-mapped) (memory-mapped) Prozessor + Prozessor Prozessor Programm = Logische ProgrammProgrammspeicher speicher Funktion Abbildung 24: Prozessor und Speicher als Hardware-Automat 46 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR CS* A0 A1 WR* Reset D0 – D 7 Port A (8 Bit) Intel 8255A Status (8 Bit) Port B (8 Bit) Port C (8 Bit) } LEDs, Schalter, Digital-Analog-Wandler... verstärkende Transisoren... Servos, Relais, Schütze... Abbildung 25: Einfacher Beispielbaustein für "Memory-mapped Input/Output" 47 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Abbildung 26: Beispiel für eine "Memory Map" und die zugehörige Adressdekodierung A0 A15 CS 8K 8 EPROM CS D0 - D7 48 8K 8 RAM CS 8255 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Datenspeicher Datenspeicher 1. Interrupt Datenbus 256 Interrupt-Handler Adressbus Programmspeicher Programmspeicher Prozessor Prozessor 3. Au Memory-mapped Ein/Ausgabegeräte 2. Interrupt-Vektor (8 Bit = 256 Arten) fruf d es „in Abbildung 27: Behandlung von Interrupts 49 terrup t hand ler“ G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR INT INTA Prozessor Prozessor RD/WR/CS Adresse D0 - D7 Intel Intel 8259A 8259A Interrupt Interrupt Controller Controller Abbildung 28: Interrupt Controller 50 IR0 .. IR1 IR7 Gerät1: Gerät1:Uhr Uhr Gerät2: Gerät2:Tastatur Tastatur Gerät7: Gerät7:Festplatte Festplatte G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Speicher Prozessor Speicher Prozessor (2) (1) Interrupt Interrupt Controller Controller (3) VideoVideoController Controller DiskettenDisketten- FestplattenFestplattenController Controller Controller Controller BUS BUS Abbildung 29: Ablauf bei direktem Speicherzugriff (DMA) 51 G RUNDLAGEN DER I NFORMATIK Prozessor Prozessor H ARDWARE -A RCHITEKTUR LAN Speicher Speicher Speicherbus PCI-Bus PCI-Bus Brücke Brücke Netzwerk Netzwerk PCI-Bus SCSI-Bus Festplatte Festplatte ISA-Bus ISA-Bus Brücke Brücke USBUSBController Controller Universal Serial Bus SCSISCSIController Controller Audio Audio Video Video ISA-Bus Maus Maus Modem Modem Tastatur Tastatur Abbildung 30: Bussysteme in einem aktuellen PC 52 Drucker Drucker G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR t1 t2 t3 Mastertakt Adresse Daten MREQ RD WAIT Abbildung 31: Signalverlauf bei synchronem Bus 53 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Adresse Daten MREQ RD MasterSyn SlaveSyn Abbildung 32: Signalverlauf bei asynchronem Bus 54 G RUNDLAGEN DER I NFORMATIK H ARDWARE -A RCHITEKTUR Busanfrage Zentraler Zentraler Arbiter Arbiter Busgewährung Gerät Gerät11 Gerät Gerät22 Abbildung 33: Daisy Chain Arbiter 55 Gerät Gerät33