1.2 Das Papyrus-Portal als virtuelle Zusammenführung der
Werbung

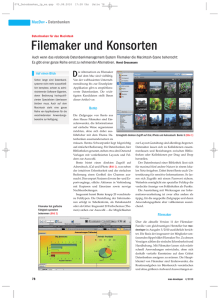
Papyrus-Portal Umsetzung einer Portallösung für alle Papyrus-Sammlungen in Deutschland von Prof. Reinhold Scholl (Uni Leipzig) Jens Kupferschmidt (Uni Leipzig) u. a. Leipzig, 15/05/2016 Version 1.0.1 Abstrakt Diese Dokumentation beschreibt die Umsetzung des DFG Papyrus-Portal-Projektes der Papyrussammlungen in Deutschland auf informationstechnischem Gebiet. Das aktuelle Release des Projektes ist 1.0. Als Grundlage der Datenhaltung wird eine Applikation verwendet, die auf dem MyCoReProjekt (http://www.mycore.de), Release 2.0 basiert. MyCoRe ist eine Arbeitsgruppe verschiedener deutscher Universitäten, die einen Open Source Kern und darauf aufbauende Anwendungen zur Lösung von Aufgaben aus den Bereichen digitale Bibliotheken und Sammlungen anbietet. Diese Komponenten bieten für das Papyrus-Portal-Projekt unserer Ansicht nach hinsichtlich ihrer Funktionalität sowohl eine gute Ausgangsbasis als auch langfristig die erforderliche Sicherheit bezüglich Soft- und Hardware-Anpassung. Die Anwendung unterliegt der GNU GENERAL PUBLIC LICENSE Version 2. Die vorliegende Dokumentation gliedert sich in folgende Teile: Allgemeine Projektbeschreibung Beschreibung der informationstechnischen Umsetzung mit MyCoRe in Verbindung zu anderen Datenbanken Anleitung zur Benutzung des Systems Installations- und Konfigurationsanleitung Änderungen Version 1.0.0 1.0.1 Datum 09.08.2007 20.11.2007 Autor Jens Kupferschmidt, URZ der Uni Leipzig Jens Kupferschmidt, URZ der Uni Leipzig Abkürzungen Kürzel Erläuterung ACL Access Control List – eine Technologie für die Zugriffskontrolle auf Daten. API Application Programming Interface – eine allgemeine Bezeichnung der Programmierschnittstellen in einem Projekt. HSQLDB Dies ist eine zu 100% in Java geschriebene SQL-Datenbank. ID Identifikator, eine eindeutige Marke JAVA Eine objektorientierte, weit verbreitete Programmiersprache. JDBC Java Database Connectivity – eine Schnittstelle zum einheitlichen Zugriff auf relationale Datenbanken. Jetty Ein Servlet-Engine-Produkt. SQL Structured Query Language – eine vereinheitlichte Abfragesprache für relationale Datenbanken. UBL Universitätsbibliothek Leipzig URZ Universitätsrechenzentrum der Universität Leipzig XML Extensible Markup Language – ein Standard zur Notation von Daten. XPath Ein Standard zum Zugriff auf XML-Daten. XSLT Extensible Stylesheet Language for Transformation Beschreibungssprache zur Transformation von XML Daten. – eine Inhaltsverzeichnis 1 Projektbeschreibung ................................................................................................................ 6 1.1 Allgemeiner Stand der digitalen Papyrus-Sammlungen in Deutschland .......................... 6 1.2 Das Papyrus-Portal als virtuelle Zusammenführung der Sammlungen ............................ 6 Version 1.0.1 2 1.3 Felder der Suche und der Trefferliste im Portal ................................................................ 7 1.4 Mapping der Metadaten .................................................................................................... 8 2 Technische Umsetzung ........................................................................................................... 9 2.1 Allgemeines zu MyCoRe .................................................................................................. 9 2.2 Zugriff auf die Datenbanken ............................................................................................. 9 3 Glossar ................................................................................................................................... 10 4 Anhang .................................................................................................................................. 11 1 Projektbeschreibung 1.1 Allgemeiner Stand der digitalen Papyrus-Sammlungen in Deutschland [ToDo] 1.2 Das Papyrus-Portal als virtuelle Zusammenführung der Sammlungen Die nachfolgende Tabelle beschreibt die konkreten Stadien der einzelnen digitalen Präsentationen der Papyrussammlungen, die bereits jetzt am Portal teilnehmen werden. Um die Entwicklung zu vereinfachen und ein Optimum an Aktualität zu erreichen, werden die veralteten Filemaker-Versionen einheitlich auf das aktuelle Release 9 migriert. So kann der Zugriff auf drei Arten von Systemen reduziert werden. Lokation Systemtyp Bemerkung Heidelberg Filemaker (Version 7) Migration auf Filemaker 9 Trier Filemaker (Version 5) Migration auf Filemaker 9 Köln Filemaker (Version 5) Migration auf Filemaker 9 Bonn Filemaker (Version 8.5) Migration auf Filemaker 9 Gießen Allegro HANS Halle-Jena-Leipzig MyCoRe (Version 2) Würzburg MyCoRe (Version 2) Tabelle 1: Beteiligte Lokationen Die Zusammenführung der Sammlungen erfolgt nur virtuell. Die Projektbeteiligten hatten sich im Vorfeld der Projektkonzeption gegen ein Harvesting der Daten durch eine zentrale Instanz ausgesprochen. Somit werden zum Zeitpunkt einer Anfrage alle beteiligten Systeme direkt abgefragt. Die Systeme in den Lokationen arbeiten völlig autonom. Es ist keine Synchronisation zwischen der Portal-Software und den Datenbanken in den Lokationen erforderlich. Das nachfolgende Bild zeigt den allgemeinen Ablauf der Arbeit des Portals. Dabei geht es vorrangig darum, was innerhalb der Portalanwendung abläuft. Funktionalitäten in den einzelnen Lokationen werden dabei nicht berücksichtigt. Diese obliegen auch weiterhin der Verantwortlichkeit und Gestaltung der jeweiligen Einrichtung. Version 1.0.1 3 Am Beispiel des MyCoRe-Papyrus-Projektes soll die verteilte Suche demonstriert werden. Hier geht es zwar um die Navigation innerhalb einer homogenen Programmlandschaft, durch andere Connectoren lässt sich das System auch auf andere Datenbanken ausbauen. Das Bild unten zeigt eine Trefferliste mit Daten aus zwei MyCoRe-Papyrus-Servern: Leipzig und Würzburg. Abbildung 2: Trefferliste einer Remote-Abfrage mehrerer MyCoRe-Papyrus-Server Abbildung 1: Allgemeiner Ablauf der Suche 1.3 Felder der Suche und der Trefferliste im Portal In der nachfolgenden Tabelle sind alle für das Portal festgelegten Felder für die Suche und Trefferlistenanzeige notiert. Diese Felder erhalten zur besseren Orientierung Nummern, die sie eindeutig im Portal-Projekt identifizieren. Nr. Suche Anzeige Bemerkung Port01 Inventarnummer Inventarnummer Text oder Textteile mit * Port02 Sammlung Sammlung Auswahlliste Port03 Sprache Sprache Auswahlliste Port04 Textart Textart Auswahlliste Port05 Titel Titel Text oder Textteile mit * Port06 Datum Datum Version 1.0.1 4 Nr. Suche Anzeige Bemerkung Port07 Herkunft Herkunft Text oder Textteile mit * Port08 Material Material Auswahlliste Port09 Inhalt Inhalt Text oder Textteile mit * Port10 Publikationsnummer Port11 statischer Link Verweis zum Originaldatensatz Port12 weitere Links z. B. zum HGV usw. Tabelle 2: Such- und Anzeigefelder für das Portal 1.4 Mapping der Metadaten Die zu vereinenden Datenbanken enthalten ganz unterschiedliche Arten von Feldern (Metadaten). Es muss also eine Zuweisung (Mapping) zwischen den Datenfeldern des portals und denen der einzelnen Datenbank-Instanzen erfolgen. In Vorfeld des Projektes wurden daher folgende Aspekte betrachtet: Auswahl der Felder, in denen eine allgemeingültige Suche stattfindet. Zuordnung dieser Felder zu einer allgemeinen Suchmaske. Zuordnung von Bezeichnungen (z. B. Ortsnamen) zu feststehenden einheitlichen Bezeichnungen. Festlegung und Zuordnung der in der Trefferliste anzuzeigenden Felder. 2 Technische Umsetzung 2.1 Allgemeines zu MyCoRe MyCoRe1 ist eigentlich als Repository für Dokumente und Sammlungen gedacht und implementiert worden. Da eine Vielzahl von Funktionalitäten wie ein Remote-Suchsystem, Verarbeitung mehrsprachiger statischer Web-Seiten und ein einfaches WCMS (Web Content Management System) integraler Bestandteil sind, wurde von den Teilnehmern beschlossen, das Papyrus-Portal-Projekt mit dieser Software zu realisieren. Hinzu kommt, dass diese Software durch ihre Open-Source-Lizensierung (GPL) frei verfügbar ist. 2.2 Zugriff auf die Datenbanken Der Zugriff des Portals auf die Datenbanken erfolgt mittels Connectoren. Diese implementieren ein Interface zwischen der MyCoRe-Suche und den Datenbanken. Bedingt durch die unterschiedliche Struktur der Datenbanken sind hier verschiedene Techniken anzuwenden. Zugriff über eine WebService-Schnittstelle zu allen MyCoRe-Papyrus-Projekten Zugriff mittels JDBC Treiber auf die FileMaker 9 Datenbanken Zugriff über eine WebService-Schnittstelle auf allegro/HANS 1 siehe http://www.mycore.de/ Version 1.0.1 5 Abbildung 3: Schema des verteilten Zugriffes 3 Innerhalb der Connectoren werden auch alle sammlungsspezifischen Mappings durchgeführt. Jedes Mapping soll über eine Konfigurationsdatei erfolgen. Weiterhin sind die Connectoren für die Umsetzung spezieller Thesauri zuständig. Das Resultat wird einheitlich entsprechend der Vorgabe für das Portal zurückgegeben. Glossar Harvesting Als Harvesting, also eine Ernte, bezeichnet man ein Verfahren bei dem Daten durch ein Leseverfahren von räumlich entfernten Servern eingesammelt werden. Die so gewonnenen Daten werden nun als Dienst Clients zur Verfügung gestellt. Bekanntester Vertreter ist das OAI-Projekt. Metadaten Unter Metadaten sind alle zum eigentlichen Objekt (in diesem Falle Papyri oder Dokumente) gehörenden beschreibenden Daten zu physikalischen und inhaltlichen Angaben zu verstehen. Servlet-Engine Servlets sind Programmteile, welche mit einen Web-Browser kommunizieren können und dynamische Web-Inhalte erzeugen. Die Servlet-Engine steuert den Zugriff auf die darin konfigurierten Servlets. Typische Vertreter sind die Projekte Tomcat und Jetty. 4 Anhang Tabellenverzeichnis Tabelle 1: Beteiligte Lokationen ............................................................................................................................. 6 Version 1.0.1 6 Tabelle 2: Such- und Anzeigefelder für das Portal .................................................................................................8 Abbildungsverzeichnis Abbildung 1: Allgemeiner Ablauf der Suche ..........................................................................................................7 Abbildung 2: Trefferliste einer Remote-Abfrage mehrerer MyCoRe-Papyrus-Server ...........................................7 Abbildung 3: Schema des verteilten Zugriffes ........................................................................................................9 Version 1.0.1 7