Leistungshandbuch für Analysis Services Technischer Artikel zu
Werbung

Leistungshandbuch für Analysis Services
Technischer Artikel zu SQL Server
Autoren: Richard Tkachuk und Thomas Kejser
Beiträge und technische Lektoren:
T.K. Anand
Marius Dumitru
Greg Galloway
Siva Harinath
Denny Lee
Edward Melomed
Akshai Mirchandani
Mosha Pasumansky
Carl Rabeler
Elizabeth Vitt
Sedat Yogurtcuoglu
Anne Zorner
Veröffentlicht: Oktober 2008
Betrifft: SQL Server 2008
Zusammenfassung: In diesem Whitepaper wird beschrieben, wie Anwendungsentwickler Techniken
zur Optimierung der Abfrage- und Verarbeitungsleistung auf ihre OLAP-Lösungen für SQL Server 2008
Analysis Services anwenden können.
Copyright
Die Informationen in diesem Dokument stellen die zum Datum der Veröffentlichung aktuelle
Ansicht der Microsoft Corporation zu den erörterten Themen dar. Da Microsoft auf geänderte
Marktbedingungen reagieren muss, dürfen diese Informationen nicht als Verpflichtung von
Microsoft ausgelegt werden, und Microsoft kann nicht garantieren, dass alle Informationen in
dem Dokument nach dem Datum der Veröffentlichung noch genau zutreffen.
Dieses Whitepaper dient ausschließlich Informationszwecken. MICROSOFT ÜBERNIMMT FÜR
DIE INFORMATIONEN IN DIESEM DOKUMENT KEINE GEWÄHRLEISTUNG, WEDER
AUSDRÜCKLICH, KONKLUDENT NOCH GESETZLICH.
Die Benutzer/innen sind verpflichtet, sich an alle anwendbaren Urheberrechtsgesetze zu halten.
Unabhängig von der Anwendbarkeit der entsprechenden Urheberrechtsgesetze darf kein Teil
dieses Dokuments ohne ausdrückliche schriftliche Erlaubnis der Microsoft Corporation für
irgendwelche Zwecke vervielfältigt oder in einem Datenempfangssystem gespeichert oder darin
eingelesen werden, unabhängig davon, auf welche Art und Weise oder mit welchen Mitteln
(elektronisch, mechanisch, durch Fotokopieren, Aufzeichnen usw.) dies geschieht.
Es ist möglich, dass Microsoft Rechte an Patenten bzw. an angemeldeten Patenten, an Marken,
Urheberrechten oder sonstigem geistigen Eigentum besitzt, die sich auf den fachlichen Inhalt
dieses Dokuments beziehen. Die Bereitstellung dieses Dokuments gewährt Ihnen jedoch
keinerlei Lizenzrechte an diesen Patenten, Marken, Urheberrechten oder anderem geistigen
Eigentum, es sei denn, dies wurde ausdrücklich durch einen schriftlichen Lizenzvertrag mit der
Microsoft Corporation vereinbart.
© 2008 Microsoft Corporation. Alle Rechte vorbehalten.
Microsoft, Excel, SQL Server, Visual Basic, Windows und Windows Server sind Marken der
Microsoft-Unternehmensgruppe.
Alle anderen Marken sind Eigentum ihrer jeweiligen Inhaber.
2
Inhalt
1
Einführung ............................................................................................................................................. 6
2
Grundlegendes zur Architektur des Abfrageprozessors ....................................................................... 6
2.1
Sitzungsverwaltung ................................................................................................................... 7
2.2
Auftragsarchitektur ................................................................................................................... 8
2.3
Abfrageprozessor ...................................................................................................................... 9
2.3.1
Abfrageprozessorcache....................................................................................................... 10
2.3.2
Abfrageprozessorinterna .................................................................................................... 12
2.4
3
Verbessern der Abfrageleistung ......................................................................................................... 18
3.1
Basislinien für Abfragegeschwindigkeiten............................................................................... 18
3.2
Diagnostizieren von Abfrageleistungsproblemen ................................................................... 21
3.3
Optimieren von Dimensionen ................................................................................................. 23
3.3.1
Identifizieren von Attributbeziehungen .............................................................................. 23
3.3.2
Effektive Verwendung von Hierarchien .............................................................................. 25
3.4
Maximieren des Werts von Aggregationen............................................................................. 26
3.4.1
Ermitteln von Aggregationstreffern .................................................................................... 26
3.4.2
Interpretieren von Aggregationen ...................................................................................... 27
3.4.3
Erstellen von Aggregationen ............................................................................................... 28
3.5
Verbessern der Abfrageleistung mithilfe von Partitionen ...................................................... 32
3.5.1
Einführung ........................................................................................................................... 32
3.5.2
Aufteilen von Partitionen in Slices ...................................................................................... 33
3.5.3
Überlegungen zu Aggregationen für mehrere Partitionen ................................................. 33
3.5.4
Distinct Count-Partitionsentwurf ........................................................................................ 34
3.5.5
Ändern der Größe von Partitionen ..................................................................................... 34
3.6
3
Datenabruf .............................................................................................................................. 17
Optimieren von MDX............................................................................................................... 35
3.6.1
Diagnostizieren des Problems ............................................................................................. 35
3.6.2
Bewährte Methoden für Berechnungen ............................................................................. 35
3.7
Cachevorbereitung .................................................................................................................. 49
3.8
Verbessern der Mehrbenutzerleistung ................................................................................... 51
4
3.8.1
Erhöhen der Abfrageparallelität ......................................................................................... 51
3.8.2
Speicherheaptyp ................................................................................................................. 53
3.8.3
Blockieren von Abfragen mit langer Ausführungszeit ........................................................ 53
3.8.4
Netzwerklastenausgleich und schreibgeschützte Datenbanken ........................................ 54
Verstehen und Messen der Verarbeitung........................................................................................... 55
4.1
Verarbeitungsauftrag (Übersicht) ........................................................................................... 55
4.2
Verarbeiten von Basislinien ..................................................................................................... 56
4.2.1
Systemmonitor-Ablaufverfolgung....................................................................................... 56
4.2.2
Profiler-Ablaufverfolgung ................................................................................................... 57
4.3
5
Verbessern der Leistung der Dimensionsverarbeitung ...................................................................... 58
5.1
Grundlegendes zur Dimensionsverarbeitungsarchitektur ...................................................... 58
5.2
Dimensionsverarbeitungsbefehle ........................................................................................... 61
5.3
Flussdiagramm zur Optimierung der Dimensionsverarbeitung .............................................. 62
5.4
Bewährte Methoden für die Leistung der Dimensionsverarbeitung ...................................... 63
5.4.1
Verwenden von SQL-Sichten zum Implementieren der Abfragebindung für Dimensionen
63
5.4.2
Optimieren der Attributverarbeitung für mehrere Datenquellen ...................................... 63
5.4.3
Reduzieren des Aufwands für Attribute ............................................................................. 64
5.4.4
Effektive Verwendung der Eigenschaften KeyColumns, ValueColumn und NameColumn 64
5.4.5
Bitmapindizes entfernen ..................................................................................................... 65
5.4.6
Deaktivieren der Attributhierarchie und Verwenden von Elementeigenschaften ............. 65
5.5
6
Optimieren der relationalen Dimensionsverarbeitungsabfrage ............................................. 66
Verbessern der Leistung der Partitionsverarbeitung.......................................................................... 66
6.1
Grundlegendes zur Partitionsverarbeitungsarchitektur ......................................................... 67
6.2
Partitionsverarbeitungsbefehle............................................................................................... 67
6.3
Flussdiagramm zur Optimierung der Partitionsverarbeitung ................................................. 68
6.4
Bewährte Methoden für die Leistung der Partitionsverarbeitung ......................................... 70
6.4.1
Optimieren von Dateneinfügungen, Aktualisierungen und Löschungen............................ 71
6.4.2
Auswählen effizienter Datentypen in Faktentabellen ........................................................ 72
6.5
6.5.1
4
Ermitteln der Vorgänge, bei denen Verarbeitungszeit aufgewendet wird ............................. 57
Optimieren der relationalen Partitionsverarbeitungsabfrage ................................................ 72
Entfernen von Joins............................................................................................................. 73
7
8
5
6.5.2
Hinweise zur relationalen Partitionierung .......................................................................... 73
6.5.3
Hinweise zur relationalen Indizierung ................................................................................ 74
6.5.4
Verwenden von FILLFACTOR = 100 für den Index und der Datenkomprimierung ............. 76
6.6
Beseitigen des Datenbanksperrenaufwands ........................................................................... 76
6.7
Optimieren des Netzwerkdurchsatzes .................................................................................... 77
6.8
Verbessern des E/A-Subsystems ............................................................................................. 79
6.9
Erhöhen der Parallelität durch Hinzufügen weiterer Partitionen ........................................... 79
6.10
Anpassen der maximalen Anzahl von Verbindungen.............................................................. 80
6.11
Anpassen von ThreadPool und CoordinatorExecutionMode .................................................. 81
6.12
Anpassen von BufferMemoryLimit.......................................................................................... 81
6.13
Optimieren der ProcessIndex-Phase ....................................................................................... 82
6.13.1
Verhindern des Überlaufs temporärer Daten auf den Datenträger ................................... 82
6.13.2
Beseitigen von E/A-Engpässen ............................................................................................ 83
6.13.3
Hinzufügen von Partitionen zum Erhöhen der Parallelität ................................................. 83
6.13.4
Optimieren von Threads und AggregationMemory-Einstellungen..................................... 83
Optimieren von Serverressourcen ...................................................................................................... 85
7.1
Verwenden von PreAllocate .................................................................................................... 85
7.2
Deaktivieren von Flight Recorder ............................................................................................ 86
7.3
Überwachen und Anpassen des Serverarbeitsspeichers ........................................................ 86
Zusammenfassung .............................................................................................................................. 87
1 Einführung
Da die Optimierung der Abfrage- und Verarbeitungsleistung für Microsoft® SQL Server® Analysis Services
ein relativ umfassendes Thema ist, sind in diesem Whitepaper die Leistungsoptimierungstechniken in die
folgenden drei Segmente unterteilt.
Verbessern der Abfrageleistung – Die Abfrageleistung beeinflusst direkt die Qualität der
Endbenutzerumgebung. Daher ist sie der primäre Vergleichstest zum Bewerten des Erfolgs einer OLAPImplementierung (Online Analytical Processing, analytische Onlineverarbeitung). Analysis Services bietet
eine Reihe von Mechanismen zum Beschleunigen der Abfrageleistung, einschließlich Aggregationen,
Zwischenspeichern und indizierten Datenabruf. Darüber hinaus können Sie die Abfrageleistung durch
Optimieren des Entwurfs der Dimensionsattribute, Cubes und MDX-Abfragen (Multidimensional
Expressions) verbessern.
Verbessern der Verarbeitungsleistung – Die Verarbeitung ist der Vorgang, bei dem Daten in einer
Analysis Services-Datenbank aktualisiert werden. Je höher die Verarbeitungsleistung ist, desto schneller
können Benutzer auf aktualisierte Daten zugreifen. Analysis Services bietet eine Reihe von
Mechanismen zum Beeinflussen der Verarbeitungsleistung, einschließlich effizienter
Dimensionsentwurf, effektive Aggregationen, Partitionen und eine sparsame Verarbeitungsstrategie
(z. B. inkrementelle statt vollständige Aktualisierung und proaktives Zwischenspeichern).
Optimieren von Serverressourcen – Verschiedene Moduleinstellungen, die sich auf die Abfrage- und
Verarbeitungsleistung auswirken, können optimiert werden.
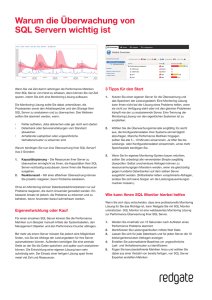
2 Grundlegendes zur Architektur des Abfrageprozessors
Zum möglichst schnellen Ausführen von Abfragen für Endbenutzer bietet die Analysis ServicesAbfragearchitektur mehrere Komponenten, die beim effizienten Abrufen und Auswerten von Daten
zusammenarbeiten. In Abbildung 1 werden die drei wichtigsten Vorgänge aufgeführt, die bei Abfragen
auftreten – Sitzungsverwaltung, Ausführung von MDX-Abfragen und Datenabruf –, sowie die
Serverkomponenten, die am jeweiligen Vorgang beteiligt sind.
6
Abbildung 1 Architektur des Abfrageprozessors in Analysis Services
2.1 Sitzungsverwaltung
Clientanwendungen kommunizieren mit Analysis Services mithilfe von XML for Analysis (XMLA) über TCP/IP
oder HTTP. Analysis Services stellt eine XMLA-Überwachungskomponente bereit, die alle XMLAKommunikationen zwischen Analysis Services und den Clients verarbeitet. Der Analysis Services-SitzungsManager steuert, wie Clients Verbindungen zu einer Analysis Services-Instanz herstellen. Benutzer, die durch
das Windows®-Betriebssystem authentifiziert wurden und Zugriff auf mindestens eine Datenbank haben,
können eine Verbindung zu Analysis Services herstellen. Nachdem ein Benutzer eine Verbindung mit Analysis
Services hergestellt hat, bestimmt der Sicherheits-Manager Benutzerberechtigungen basierend auf der
Kombination von Analysis Services-Rollen, die für den Benutzer gelten. Je nach Architektur der
Clientanwendung und der Sicherheitsberechtigungen der Verbindung erstellt der Client bei Anwendungsstart
eine Sitzung und verwendet dann die Sitzung erneut für alle Anforderungen des Benutzers. Die Sitzung stellt
den Kontext bereit, unter dem Clientabfragen vom Abfrageprozessor ausgeführt werden. Eine Sitzung
besteht, bis sie von der Clientanwendung oder vom Server geschlossen wird.
7
2.2 Auftragsarchitektur
Analysis Services verwendet eine zentralisierte Auftragsarchitektur zum Implementieren von Abfrageund Verarbeitungsvorgängen. Ein Auftrag ist eine generische Einheit der Verarbeitungs- oder
Abfragearbeit. Ein Auftrag kann je nach Komplexität der Anforderung mehrere Ebenen geschachtelter
untergeordneter Aufträge umfassen.
Bei Verarbeitungsvorgängen wird beispielsweise ein Auftrag für das zu verarbeitende Objekt wie z. B.
eine Dimension erstellt. Ein Dimensionsauftrag kann dann mehrere untergeordnete Aufträge erzeugen,
die die Attribute in der Dimension verarbeiten. Bei Abfragen werden Aufträge zum Abrufen von
Faktendaten und Aggregationen aus der Partition verwendet, um Abfrageanforderungen zu erfüllen. Bei
einer Abfrage, die auf mehrere Partitionen zugreift, wird z. B. ein untergeordneter oder
Koordinatorauftrag für die Abfrage selbst zusammen mit einem oder mehreren untergeordneten
Aufträgen pro Partition generiert.
Abbildung 2 Auftragsarchitektur
Im Allgemeinen wirkt sich die parallele Ausführung mehrerer Aufträge positiv auf die Leistung aus,
solange ausreichend Prozessorressourcen zur effektiven Verarbeitung der gleichzeitigen Vorgänge sowie
ausreichend Speicher- und Datenträgerressourcen vorhanden sind. Die maximale Anzahl von Aufträgen,
die für die aktuellen Vorgänge (einschließlich Verarbeitungs- und Abfragevorgänge) parallel ausgeführt
werden können, wird durch die CoordinatorExecutionMode-Eigenschaft bestimmt:
•
Ein negativer Wert gibt die maximale Anzahl von parallelen Vorgängen an, die pro Kern pro
Vorgang gestartet werden können.
•
Der Wert 0 signalisiert, dass keine Einschränkung besteht.
•
Ein positiver Wert gibt eine absolute Anzahl von parallelen Vorgängen an, die pro Server
gestartet werden können.
Der Standardwert für CoordinatorExecutionMode ist -4, wodurch angegeben wird, dass vier Aufträge
parallel pro Kern gestartet werden. Dieser Wert ist für die meisten Serverumgebungen ausreichend.
Zum Vergrößern des Grads der Parallelität auf dem Server können Sie den Wert dieser Eigenschaft
8
erhöhen, indem Sie entweder die Anzahl der Aufträge pro Prozessor erhöhen oder die Eigenschaft auf
einen absoluten Wert festlegen.
Damit wird global die Anzahl von Aufträgen erhöht, die parallel ausgeführt werden können. Allerdings ist
CoordinatorExecutionMode nicht die einzige Eigenschaft, die parallele Vorgänge beeinflusst. Sie müssen
auch die Auswirkungen weiterer globaler Einstellungen wie der MaxThreads-Servereigenschaften
berücksichtigen, die die maximale Anzahl von Abfrage- oder Verarbeitungsthreads ermitteln, die parallel
ausgeführt werden können (weitere Informationen zu Threadeinstellungen finden Sie unter Verbessern
der Mehrbenutzerleistung). Darüber hinaus können Sie mit feinerer Granularität für einen bestimmten
Verarbeitungsvorgang die maximale Anzahl von Verarbeitungstasks, die parallel ausgeführt werden
können, mit dem MaxParallel-Befehl angeben. Diese Einstellungen werden in den folgenden
Abschnitten ausführlicher erläutert.
2.3 Abfrageprozessor
Der Abfrageprozessor führt MDX-Abfragen aus und generiert ein entsprechendes Cellset oder Rowset.
Dieser Abschnitt enthält eine Übersicht darüber, wie der Abfrageprozessor Abfragen ausführt. Weitere
Informationen zum Optimieren von MDX finden Sie unter Optimieren von MDX.
Zum Abrufen der von einer Abfrage angeforderten Daten erstellt der Abfrageprozessor einen
Ausführungsplan, um die angeforderten Ergebnisse aus den Cubedaten und -berechnungen zu
generieren. Es gibt zwei unterschiedliche Typen von Abfrageausführungsplänen, und welcher Plan vom
Modul ausgewählt wird, kann sich in bedeutendem Maße auf die Leistung auswirken. Weitere
Informationen finden Sie unter Teilbereichberechnung.
Zur Kommunikation mit dem Speichermodul verwendet der Abfrageprozessor den Ausführungsplan zum
Übersetzen der Datenanforderung in eine oder mehrere für das Speichermodul verständliche
Teilcubeanforderungen. Ein Teilcube ist eine logische Einheit für Abfrage, Zwischenspeichern und
Datenabruf – er ist eine Teilmenge von durch den Kreuzjoin eines oder mehrerer Elemente aus einer
einzelnen Ebene jeder Attributhierarchie definierten Cubedaten. Ein oder mehrere Elemente aus einer
einzelnen Ebene werden manchmal auch als einzelne Auflösung oder einzelne Granularität bezeichnet.
Eine MDX-Abfrage kann je nach Attributgranularität und Berechnungskomplexität in mehrere
Teilcubeanforderungen aufgelöst werden. So würde z. B. eine Abfrage, die jedes Element der CountryAttributhierarchie enthält (sofern es sich nicht um eine Parent-Child-Hierarchie handelt) in zwei
Teilcubeanforderungen aufgeteilt werden: eine für das Alle-Element und eine weitere für die CountryElemente.
Beim Auswerten von Zellen verwendet der Abfrageprozessor den Abfrageprozessorcache zum Speichern
von Berechnungsergebnissen. Die entscheidenden Vorteile des Caches sind die Optimierung der
Auswertung von Berechnungen und die Unterstützung der Wiederverwendung von
Berechnungsergebnissen für mehrere Benutzer (mit denselben Sicherheitsrollen). Zur Optimierung der
Cachewiederverwendung verwaltet der Abfrageprozessor drei Cacheebenen, die die Ebene der
Cachewiederverwendbarkeit bestimmen: global, Sitzung und Abfrage.
9
2.3.1 Abfrageprozessorcache
Beim Ausführen einer MDX-Abfrage speichert der Abfrageprozessor Berechnungsergebnisse im
Abfrageprozessorcache. Die entscheidenden Vorteile des Caches sind die Optimierung der Auswertung
von Berechnungen und die Unterstützung der Wiederverwendung von Berechnungsergebnissen für
mehrere Benutzer. Ziehen Sie zur Verdeutlichung, wie der Abfrageprozessor das Zwischenspeichern bei
der Ausführung der Abfrage verwendet, das folgende Beispiel in Betracht. Sie verfügen über ein
berechnetes Element mit der Bezeichnung "Profit Margin". Wenn eine MDX-Abfrage "Profit Margin"
nach "Sales Territory" anfordert, speichert der Abfrageprozessor die "Profit Margin"-Werte ungleich
NULL für jedes Sales Territory zwischen. Zum Verwalten der Wiederverwendung der
zwischengespeicherten Ergebnisse für mehrere Benutzer unterscheidet der Abfrageprozessor zwischen
verschiedenen Kontexten im Cache:
Abfragekontext – enthält das Ergebnis von Berechnungen unter Verwendung des WITHSchlüsselworts innerhalb einer Abfrage. Der Abfragekontext wird nach Bedarf erstellt und nach
Abschluss der Abfrage beendet. Daher wird der Cache des Abfragekontexts nicht für mehrere
Abfragen in einer Sitzung freigegeben.
Sitzungskontext – enthält das Ergebnis von Berechnungen unter Verwendung des CREATESchlüsselworts innerhalb einer bestimmten Sitzung. Der Cache des Sitzungskontexts wird
zwischen Anforderungen in derselben Sitzung wiederverwendet, jedoch für mehrere Sitzungen
freigegeben.
Globaler Kontext – enthält das Ergebnis von für Benutzer freigegebenen Berechnungen. Der
Cache des globalen Kontexts kann für Sitzungen freigegeben werden, wenn für die Sitzungen
dieselben Sicherheitsrollen gelten.
Die Kontextebenen richten sich nach der jeweiligen Ebene der Wiederverwendung. Auf der obersten
Ebene kann der Abfragekontext nur innerhalb der Abfrage wiederverwendet werden. Auf der untersten
Ebene hat der globale Kontext das größte Potenzial zur Wiederverwendung für mehrere Sitzungen und
Benutzer.
Abbildung 3 Ebenen des Cachekontexts
Während der Ausführung muss jede MDX-Abfrage auf alle drei Kontexte verweisen, um alle potenziellen
Berechnungen und Sicherheitsbedingungen zu identifizieren, die die Auswertung der Abfrage
beeinflussen können. Zum Auflösen einer Abfrage, die ein von einer Abfrage berechnetes Element
10
enthält, erstellt der Abfrageprozessor z. B. einen Sitzungskontext zur Auswertung von
Sitzungsberechnungen und einen globalen Kontext zur Auswertung des MDX-Skripts und zum Abrufen
der Sicherheitsberechtigungen des Benutzers, der die Abfrage gesendet hat. Diese Kontexte werden nur
dann erstellt, wenn dies noch nicht geschehen ist. Nach dem Erstellen werden sie nach Möglichkeit
wiederverwendet.
Obwohl eine Abfrage auf alle drei Kontexte verweist, kann sie nur den Cache eines Kontexts verwenden.
Dies bedeutet, dass der Abfrageprozessor für jede Abfrage den zu verwendenden Cache auswählen
muss. Der Abfrageprozessor versucht immer, den umfassend anwendbaren Cache zu verwenden, je
nachdem, ob er das Vorhandensein von Berechnungen bei einem engeren Kontext erkennt.
Stellt der Abfrageprozessor zur Abfragezeit erstellte Berechnungen fest, verwendet er immer den
Abfragekontext, selbst wenn eine Abfrage auch auf Berechnungen aus dem globalen Kontext verweist
(die Ausnahme sind Abfragen mit von einer Abfrage berechneten Elementen in der Form
Aggregate(<set>), die den Sitzungscache gemeinsam nutzen). Sind keine Abfrageberechnungen, jedoch
Sitzungsberechnungen vorhanden, verwendet der Abfrageprozessor den Sitzungscache. Der
Abfrageprozessor wählt den Cache je nach Vorhandensein von Berechnungen im Bereich aus. Dieses
Verhalten ist besonders für Benutzer mit MDX-generierenden Front-End-Tools relevant. Erstellt das
Front-End-Tool Sitzungsberechnungen oder Abfrageberechnungen, wird der globale Cache nicht
verwendet, auch wenn die Sitzungs- oder Abfrageberechnungen nicht ausdrücklich verwendet werden.
Es gibt weitere Berechnungsszenarien, die beeinflussen, wie der Abfrageprozessor Berechnungen
zwischenspeichert. Beim Aufrufen einer gespeicherten Prozedur aus einer MDX-Berechnung verwendet
das Modul immer den Abfragecache. Der Grund dafür ist, dass gespeicherte Prozeduren nicht
deterministisch sind (dies bedeutet, dass nicht sichergestellt werden kann, was die gespeicherte
Prozedur zurückgibt). Folglich wird nichts global oder im Sitzungscache zwischengespeichert. Die
Berechnungen werden stattdessen im Abfragecache gespeichert. Darüber hinaus bestimmen die
folgenden Szenarien, wie der Abfrageprozessor Berechnungsergebnisse zwischenspeichert:
11
•
Die Verwendung von Zellensicherheit, eine der Funktionen UserName, StToSet oder
LookupCube im MDX-Skript oder in der Dimensions- oder Zellensicherheitsdefinition
deaktivieren den globalen Cache (dies bedeutet, dass bereits ein Ausdruck, der diese Funktionen
verwendet, das globale Zwischenspeichern für den gesamten Cube deaktiviert).
•
Falls sichtbare Gesamtwerte für die Sitzung durch Festlegen der standardmäßigen MDX Visual
Mode-Eigenschaft in der Analysis Services-Verbindungszeichenfolge auf 1 aktiviert sind,
verwendet der Abfrageprozessor den Abfragecache für alle in dieser Sitzung ausgegebenen
Abfragen.
•
Wenn Sie sichtbare Gesamtwerte für eine Abfrage durch die VisualTotals-Funktion in MDX
aktivieren, verwendet der Abfrageprozessor den Abfragecache.
•
Bei Abfragen, die die untergeordnete SELECT-Syntax (SELECT FROM SELECT) verwenden oder auf
einem Sitzungsteilcube (CREATE SUBCUBE) basieren, wird der Abfragecache bzw. Sitzungscache
verwendet.
•
Willkürliche Formen können den Abfragecache nur dann verwenden, wenn sie in einem
untergeordneten SELECT-Ausdruck, in der WHERE-Klausel oder in einem berechneten Element
verwendet werden. Eine willkürliche Form ist eine Menge, die nicht als Kreuzjoin von Elementen
von derselben Ebene einer Attributhierarchie ausgedrückt werden kann. So ist z. B. {(Food,
USA), (Drink, Canada)} eine willkürliche Menge, ebenso wie {customer.geography.USA,
customer.geography.[British Columbia]}. Eine willkürliche Form auf der Abfrageachse schränkt
die Verwendung eines Caches nicht ein.
Auf der Grundlage dieses Verhaltens wird, wenn die Abfragearbeitsauslastung von der
Wiederverwendung von Daten für mehrere Benutzer profitieren kann, das Definieren von
Berechnungen im globalen Bereich empfohlen. Ein Beispiel für dieses Szenario ist eine strukturierte
Berichtsarbeitsauslastung mit wenigen Sicherheitsrollen. Im Gegensatz dazu ist bei einer
Arbeitsauslastung, die einzelne Datasets für jeden Benutzer erfordert, wie in einem HR-Cube mit vielen
Sicherheitsrollen oder bei Verwendung dynamischer Sicherheit, die Gelegenheit zur Wiederverwendung
von Berechnungsergebnissen für mehrere Benutzer reduziert oder ausgeschlossen. Folglich sind die
Leistungsvorteile im Zusammenhang mit der Wiederverwendung des Abfrageprozessorcaches nicht so
hoch.
Teilausdrücke (d. h. Teile einer Berechnung, die mehrmals im Ausdruck verwendet werden können) und
Zelleigenschaften werden nicht zwischengespeichert. Erstellen Sie stattdessen ein separates
berechnetes Element, damit der Abfrageprozessor zuerst ausgewertete Ergebnisse zwischenspeichern
und die Ergebnisse für nachfolgende Verweise wiederverwenden kann. Weitere Informationen finden
Sie unter Zwischenspeichern von Teilausdrücken und Zelleigenschaften.
2.3.2 Abfrageprozessorinterna
Es gibt mehrere Änderungen an Abfrageprozessorinterna in SQL Server 2008 Analysis Services. In diesem
Abschnitt werden diese Änderungen vor der Einführung spezifischer Optimierungstechniken erläutert.
2.3.2.1 Teilbereichberechnung
Das Konzept der Teilbereichberechnung lässt sich am besten durch die Gegenüberstellung mit einer
naiven oder zellenweisen Auswertung einer Berechnung erklären. Nehmen wir eine RollingSum für eine
einfache Berechnung an, die den Umsatz für das Vorjahr und das laufende Jahr summiert, und eine
Abfrage, die die RollingSum für 2005 für alle Produkte anfordert.
RollingSum = (Year.PrevMember, Sales) + Sales
SELECT 2005 on columns, Product.Members on rows WHERE RollingSum
12
Eine zellenweise Auswertung dieser Berechnung würde dann wie in Abbildung 4 dargestellt erfolgen.
Abbildung 4 Zellenweise Auswertung
Dabei werden die 10 Zellen für [2005, All Products] jeweils der Reihe nach ausgewertet. Für jede Zelle
wird zum Vorjahr navigiert, der Umsatzwert abgerufen und zum Umsatz für das laufende Jahr
hinzugefügt. Bei diesem Ansatz gibt es zwei wesentliche Leistungsprobleme.
Zum einen werden, wenn die Daten eine geringe Dichte besitzen (d. h., wenn sie dünn gefüllt sind),
Zellen berechnet, obwohl sie einen NULL-Wert zurückgeben sollten. Im obigen Beispiel ist die
Berechnung der Zellen außer für Product 3 und Product 6 überflüssig. Die Auswirkungen dessen können
extrem sein – in einem dünn gefüllten Cube kann der Unterschied mehrere Größenordnungen bei der
Anzahl ausgewerteter Zellen betragen.
Zum anderen ergibt sich ein hoher Mehraufwand, selbst wenn die Daten absolut dicht sind, d. h. jede
Zelle einen Wert enthält und keine überflüssige Bearbeitung leerer Zellen stattfindet. Dieselben Schritte
(z. B. Abrufen des Elements für das Vorjahr, Einrichten des neuen Kontexts für die Zelle des Vorjahrs und
Prüfen auf Rekursion) werden für jedes Produkt neu ausgeführt. Es wäre viel effizienter, diese Schritte
aus der inneren Schleife für die Auswertung jeder Zelle auszulagern.
Nehmen wir jetzt an, dasselbe Beispiel wäre mit Teilbereichberechnung ausgeführt worden. Zuerst
nehmen wir an, dass in einer Ausführungsstruktur bestimmt wird, welche Stellen ausgefüllt werden
müssen. Bei der entsprechenden Abfrage muss die Stelle
[Product.*, 2005, RollingSum]
berechnet werden (wobei * jedes Element der Attributhierarchie bedeutet). Bei der entsprechenden
Berechnung bedeutet dies, dass zuerst die Stelle
13
[Product.*, 2004, Sales]
gefolgt von der Stelle
[Product.*, 2005, Sales]
berechnet werden und dann der +-Operator auf diese beiden Stellen angewendet werden muss.
Wenn "Sales" selbst von Berechnungen abgedeckt ist, werden die zum Berechnen von "Sales"
erforderlichen Stellen bestimmt, und die Struktur wird erweitert. In diesem Fall ist "Sales" ein BasisMeasure, sodass wir einfach die Speichermoduldaten zum Füllen der beiden Stellen auf den Blättern
abrufen und dann in der Struktur nach oben gehen. Dabei wird der Operator zum Füllen der Stelle am
Stamm angewendet. Daher werden die eine Zeile (Product3, 2004, 3) und die beiden Zeilen { (Product3,
2005, 20), (Product6, 2005, 5)} abgerufen, und der +-Operator wird auf sie angewendet, um die
Ergebnisse in Abbildung 5 zu erzielen.
Abbildung 5 Ausführungsplan
Der +-Operator wird für Stellen ausgeführt, nicht nur für Skalarwerte. Er ist für das Kombinieren der
beiden angegebenen Stellen verantwortlich, um eine Stelle mit jedem Produkt zu erstellen, das an einer
der beiden Stellen mit dem summierten Wert angezeigt wird. Dies ist der Abfrageausführungsplan. Wir
arbeiten dabei immer nur mit Daten, die einen Beitrag zum Ergebnis leisten können. Es geht nicht um
die theoretische Stelle, für die wir die Berechnung ausführen müssen.
Ein Abfrageausführungsplan kann sowohl Teilbereich- als auch zellenweise Knoten enthalten. Einige
Funktionen werden im Teilbereichmodus nicht unterstützt, und das Modul greift dann auf den
zellenweisen Modus zurück. Das Modul kann aber auch beim Auswerten eines Ausdrucks im
zellenweisen Modus in den Teilbereichmodus zurückkehren.
14
2.3.2.2 Aufwändige und nicht aufwändige Abfragepläne
Das Erstellen eines Abfrageplans kann aufwändig sein. Der Aufwand für das Erstellen eines Abfrageplans
kann sogar den Aufwand für die Abfrageausführung übersteigen. Das Analysis Services-Modul verfügt
über ein grobes Klassifizierungsschema – aufwändig im Vergleich zu nicht aufwändig. Ein Plan wird als
aufwändig angesehen, wenn der zellenweise Modus verwendet wird oder Cubedaten zum Erstellen des
Plans gelesen werden müssen. Andernfalls wird der Ausführungsplan als nicht aufwändig angesehen.
Cubedaten werden in Abfrageplänen in verschiedenen Szenarien verwendet. Einige Abfragepläne führen
auf Grund von MDX-Funktionen wie PrevMember und Parent zur gegenseitigen Zuordnung von
Elementen. Die Zuordnungen werden aus Cubedaten erstellt und während der Erstellung des
Abfrageplans materialisiert. Die IIf-, CASE- und IF-Funktionen können auch aufwändige Abfragepläne
generieren, falls Cubedaten zur Partitionierung von Cuberaum für die Auswertung einer Verzweigung
gelesen werden müssen. Weitere Informationen finden Sie unter IIf-Funktion in SQL Server 2008
Analysis Services.
2.3.2.3 Ausdrucksdichte
Die Dichte eines Ausdrucks bezieht sich auf die Anzahl von Zellen mit Werten ungleich NULL im Vergleich
zur Gesamtanzahl von Zellen. Wenn relativ wenige Werte ungleich NULL vorhanden sind, wird der
Ausdruck als Ausdruck mit geringer Dichte bezeichnet. Bei vielen Werten weist der Ausdruck eine hohe
Dichte auf. Wie wir weiter unten sehen, kann die Dichte eines Ausdrucks den Abfrageplan beeinflussen.
Wie lässt sich aber feststellen, ob ein Ausdruck eine hohe oder geringe Dichte aufweist? Nehmen wir ein
einfaches nicht berechnetes Measure – hat es eine hohe oder geringe Dichte? In OLAP weisen
Basisfakten-Measures eine geringe Dichte auf. Dies bedeutet, dass ein typisches Measure nicht über
Werte für jedes Attributelement verfügt. Beispielsweise kauft ein Kunde nicht an den meisten Tagen die
meisten Produkte von den meisten Geschäften. Vielmehr trifft das Gegenteil zu. Ein typischer Kunde
kauft an einigen Tagen einen kleinen Prozentsatz aller Produkte von einer kleinen Anzahl von
Geschäften. Weiter unten sind weitere einfache Regeln für häufig verwendete Ausdrücke aufgeführt.
Ausdruck
Reguläres Measure
Konstanter Wert
Skalarer Ausdruck, z. B. count,
.properties
<exp1>+<exp2>
<exp1>-<exp2>
<exp1>*<exp2>
<exp1> / <exp2>
Sum(<set>, <exp>)
15
Geringe/hohe Dichte
Geringe Dichte
Hohe Dichte (ausgenommen konstante NULL-Werte, Werte
TRUE/FALSE)
Hohe Dichte
Geringe Dichte, wenn sowohl exp1 als auch exp2 eine geringe Dichte
aufweisen; andernfalls hohe Dichte
Geringe Dichte, wenn entweder exp1 oder exp2 eine geringe Dichte
aufweisen; andernfalls hohe Dichte
Geringe Dichte, wenn <exp1> eine geringe Dichte aufweist;
andernfalls hohe Dichte
Von <exp> geerbt
Aggregate(<set>, <exp>)
IIf(<cond>, <exp1>, <exp2>)
Wird durch die Dichte der Standardverzweigung bestimmt (siehe IIf)
2.3.2.4 Standardwerte
Jeder Ausdruck besitzt einen Standardwert – den Wert, den der Ausdruck in den meisten Fällen
annimmt. Der Abfrageprozessor berechnet den Standardwert eines Ausdrucks und verwendet diesen an
den meisten Stellen wieder. In den meisten Fällen ist dies NULL (leer oder ohne Eintrag in der Microsoft
Excel®-Tabellenkalkulationssoftware), da häufig (jedoch nicht immer) das Ergebnis eines Ausdrucks mit
NULL-Eingabewerten NULL ist. Das Modul kann dann das NULL-Ergebnis einmal berechnen und muss nur
Werte für die stark reduzierte Stelle ungleich NULL berechnen.
Außerdem werden die Standardwerte in der Bedingung in der IIf-Funktion verwendet. Der
Ausführungsplan hängt häufig davon ab, welche Verzweigung ausgewertet wird. Die Standardwerte
häufig verwendeter Ausdrücke werden in der folgenden Tabelle aufgelistet.
Ausdruck
Reguläres Measure
IsEmpty(<regular measure>)
Standardwert
NULL
TRUE
<regular measure A> = <regular
measure B>
TRUE
<member A> IS <member B>
FALSE
Kommentar
Keine.
Die meisten theoretischen Stellen werden von
NULL-Werten belegt. Daher gibt IsEmpty meist
TRUE zurück.
Werte für beide Measures sind prinzipiell NULL,
dies wird somit in den meisten Fällen zu TRUE
ausgewertet.
Dies unterscheidet sich vom Vergleichen von
Werten – das Modul geht davon aus, dass in den
meisten Fällen unterschiedliche Elemente
verglichen werden.
2.3.2.5 Veränderliche Attribute
Zellenwerte hängen meistens von Attributkoordinaten ab. Bestimmte Berechnungen hängen jedoch
nicht von jedem Attribut ab. Beispielsweise hängt der Ausdruck
[Customer].[Customer Geography].properties("Postal Code")
nur vom Customer-Attribut in der Customer-Dimension ab. Wenn dieser Ausdruck über einem
Teilbereich mit anderen Attributen ausgewertet wird, können alle Attribute, von denen der Ausdruck
nicht abhängt, entfernt, der Ausdruck aufgelöst und über den ursprünglichen Teilbereich zurück
projiziert werden. Die Attribute, von denen ein Ausdruck abhängt, werden als seine veränderlichen
Attribute bezeichnet. Betrachten Sie beispielsweise die folgende Abfrage:
16
with member measures.Zip as
[Customer].[Customer Geography].currentmember.properties("Postal Code")
select measures.zip on 0,
[Product].[Category].members on 1
from [Adventure Works]
where [Customer].[Customer Geography].[Customer].&[25818]
Der Ausdruck hängt vom Customer-Attribut und nicht vom Category-Attribut ab, daher ist "Customer"
im Gegensatz zu "Category" ein veränderliches Attribut. In diesem Fall wird der Ausdruck nur einmal für
den Kunden ausgewertet und nicht entsprechend der Anzahl von Produktkategorien.
2.3.2.6 Zusammenfassung zu Abfrageprozessorinterna
Abfragepläne, Ausdrucksdichte, Standardwerte und veränderliche Attribute sind die wichtigsten
internen Konzepte für das Abfrageprozessorverhalten – wir kehren zu diesen Konzepten zurück, wenn
wir das Optimieren der Abfrageleistung erläutern.
2.4 Datenabruf
Bei der Abfrage eines Cubes zerlegt der Abfrageprozessor die Abfrage in Teilcubeanforderungen für das
Speichermodul. Für jede Teilcubeanforderung versucht das Speichermodul zuerst, Daten vom
Speichermodulcache abzurufen. Wenn im Cache keine Daten verfügbar sind, versucht das Modul, Daten
von einer Aggregation abzurufen. Falls keine Aggregation vorhanden ist, müssen die Daten von den
Faktendaten von Partitionen einer Measuregruppe abgerufen werden.
Jede Partition ist in Gruppen von Datensätzen mit 64 KB unterteilt, die als Segment bezeichnet werden.
Für jede Teilcubeanforderung wird ein Koordinatorauftrag erstellt. Die Anzahl der erstellten Aufträge
entspricht der Anzahl der Partitionen. (Dies gilt dann, wenn die Abfrage Daten innerhalb des
Partitionsslice anfordert. Weitere Informationen finden Sie unter Aufteilen von Partitionen in Slices.)
Jeder dieser Aufträge:
17
Nimmt einen weiteren Auftrag für das nächste Segment in die Warteschlange auf (wenn das
aktuelle Segment nicht das letzte Segment ist).
Verwendet die Bitmapindizes, um zu bestimmen, ob im Segment der Teilcubeanforderung
entsprechende Daten vorhanden sind.
Scannt das Segment, wenn Daten vorhanden sind.
Bei einer einzelnen Partition sieht die Auftragsstruktur wie folgt aus, nachdem jeder Segmentauftrag in
die Warteschlange aufgenommen wurde.
Abbildung 6 Auftragsstruktur beim Scannen der Partition
Unmittelbar nach dem Aufnehmen eines Segmentauftrags in die Warteschlange werden weitere
Segmentaufträge gestartet. Dabei entspricht die Anzahl der Aufträge der Anzahl der Segmente. Wenn
die Indizes anzeigen, dass im Segment keine dem Teilcube entsprechenden Daten enthalten sind, wird
der Auftrag beendet.
3 Verbessern der Abfrageleistung
Zum Verbessern der Abfrageleistung muss zuerst eine Diagnose der aktuellen Situation und des
Engpasses erstellt und dann eine der verschiedenen Techniken wie Optimieren des Dimensionsentwurfs,
Entwerfen und Erstellen von Aggregationen, Partitionierung und Anwenden bewährter Methoden
angewendet werden.
Dabei ist es wichtig, vor dem Anwenden bestimmter Techniken zuerst die Ursache des Problems zu
erkennen, um zielgerichtet vorzugehen.
3.1 Basislinien für Abfragegeschwindigkeiten
Vor dem Beginn der Optimierung ist eine reproduzierbare Basislinie erforderlich. Nehmen Sie eine
Messung für leere (nicht aufgefüllte) Speichermodul- und Abfrageprozessorcaches und einen
vorbereiteten Betriebssystemcache vor. Führen Sie dazu wie folgt die Abfrage aus, leeren Sie den
Formelcache und Speichermodulcache, und initialisieren Sie dann das Berechnungsskript durch
Ausführen einer Abfrage, die nichts zurückgibt und zwischenspeichert.
select {} on 0 from [Adventure Works]
Führen Sie die Abfrage ein zweites Mal aus. Verwenden Sie bei der erneuten Ausführung der Abfrage
SQL Server Profiler zur Ablaufverfolgung mit den aktivierten zusätzlichen Ereignissen:
18
Query Processing\Query Subcube Verbose
Query Processing\Get Data From Aggregation
Die Ablaufverfolgung enthält wichtige Informationen.
Abbildung 6 Beispielablaufverfolgung
Der Text für das Query Subcube Verbose-Ereignis verdient eine Erklärung. Er enthält Informationen für
jedes Attribut in jeder Dimension:
0: Zeigt an, dass das Attribut nicht in der Abfrage enthalten ist (das Alle-Element wird
getroffen).
*: Zeigt an, dass jedes Element des Attributs angefordert wurde.
+: Zeigt an, dass mindestens zwei Elemente des Attributs angefordert wurden.
<ganzzahliger Wert>: Zeigt an, dass ein einzelnes Element des Attributs getroffen wurde. Die
ganze Zahl stellt die Daten-ID des Elements dar (einen vom Modul generierten internen
Bezeichner).
Speichern Sie die Ablaufverfolgung, sie enthält wichtige Informationen zur zeitlichen Steuerung und
zeigt weiter unten erläuterte Ereignisse an.
Verwenden Sie den ClearCache-Befehl, um den Speicher- und Abfrageprozessorcache zu leeren.
<ClearCache xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID>Adventure Works DW</DatabaseID>
</Object>
19
</ClearCache>
Der Betriebssystemdateicache wird von allen anderen Hardwareaktivitäten beeinflusst. Versuchen Sie
daher, sonstige Aktivitäten zu reduzieren oder zu vermeiden. Dies kann besonders schwierig sein, wenn
der Cube auf einem von anderen Anwendungen verwendeten SAN (Storage Area Network) gespeichert
wird.
SQL Server Management Studio zeigt Abfragezeiten an, dabei ist jedoch einiges zu beachten. Diese Zeit
ist die Zeitdauer für das Abrufen und Anzeigen des Cellsets. Bei umfangreichen Ergebnissen kann die Zeit
zum Rendern des Cellsets der Zeit entsprechen, die der Server zum Generieren benötigt hat. Eine SQL
Server Profiler-Ablaufverfolgung informiert nicht nur darüber, für was die Zeit aufgewendet wird,
sondern auch über die genaue Moduldauer.
20
3.2 Diagnostizieren von Abfrageleistungsproblemen
Wenn die Leistung nicht Ihren Erwartungen entspricht, kann die Ursache in mehreren Bereichen liegen.
In Abbildung 8 wird veranschaulicht, wie die Ursache des Problems diagnostiziert werden kann.
storage engine
No
Optimize
Dimensions
No
Define
Aggregations
Query
Processor or
Storage
Engine
Dimensions
Optimized?
MDX
Optimized
No
Yes
Yes
Aggregations
Hit?
Yes
Partitions
Optimized
query processor
Yes
Optimize MDX
Fragmented
Query Space
Yes
No
Warm Cache
Memory Bound
No
No
Optimize
Partitions
CPU Bound
No
Yes
Preallocate or add
memory
Yes
Add CPU or Read
only database
I/O Bound
Yes
No
Improve I/O or
scale out (multiuser only)
Increase Query
Parallelism
Abbildung 7 Flussdiagramm zur Optimierung der Abfrageleistung
21
Im ersten Schritt wird bestimmt, ob das Problem im Abfrageprozessor oder im Speichermodul liegt.
Erstellen Sie mit SQL Server Profiler eine Ablaufverfolgung, um die Zeitdauer für das Scannen von Daten
durch das Modul zu bestimmen. Schränken Sie die Ereignisse auf nicht zwischengespeicherte
Abbildung 8 Bestimmen der zum Scannen von Partitionen aufgewendeten Zeit
Speichermodulabrufe durch ausschließliches Auswählen des Query Subcube Verbose-Ereignisses und
Filtern nach Ereignisunterklasse=22 ein. Das Ergebnis ähnelt Abbildung 9.
Wird der Großteil der Zeit im Speichermodul für Abfrageteilcubeereignisse mit langer Ausführungsdauer
aufgewendet, liegt wahrscheinlich ein Problem mit dem Speichermodul vor. Ziehen Sie Techniken wie
das Optimieren des Dimensionsentwurfs, das Entwerfen von Aggregationen oder die Verwendung von
Partitionen in Betracht, um die Abfrageleistung zu verbessern. Wenn der Großteil der Zeit nicht im
Speichermodul, sondern im Abfrageprozessor aufgewendet wird, konzentrieren Sie sich auf das
Optimieren von MDX.
Das Problem kann das Formelmodul und das Speichermodul betreffen. Fragmentierter Abfrageraum
kann dort mit Profiler diagnostiziert werden, wo viele Abfrageteilcubeereignisse generiert werden. Die
einzelnen Anforderungen dauert möglicherweise nicht lange, die Summe unter Umständen schon.
Ziehen Sie in diesem Fall das Vorbereiten des Caches in Betracht, um die eventuell auftretende E/AÜberlastung zu reduzieren.
Bestimmte Probleme mit der Mehrbenutzerleistung können durch Behandeln von
Einzelbenutzerabfragen gelöst werden, jedoch sicherlich nicht alle. Einige für
Mehrbenutzerumgebungen benutzerdefinierte Konfigurationseinstellungen sind im Abschnitt
Verbessern der Mehrbenutzerleistung beschrieben.
Wenn der Cube optimiert ist, kann die CPU- und Speicherressourcennutzung optimiert werden. Das
Erhöhen der Anzahl von Threads für Einzel- und Mehrbenutzerszenarien wird im Abschnitt Erhöhen der
Abfrageparallelität beschrieben. Dieselbe Technik kann zum Reservieren von Arbeitsspeicher für das
Verbessern der Abfrage- und Verarbeitungsleistung verwendet werden und ist im Abschnitt zur
Verarbeitung mit dem Titel Verwenden von PreAllocate enthalten.
Die Leistung kann im Allgemeinen durch Erweitern von CPU, Arbeitsspeicher oder E/A verbessert
werden. Derartige Empfehlungen werden in diesem Dokument nicht behandelt. Es gibt andere
verfügbare Techniken zum dezentralen Skalieren mit Clustern oder schreibgeschützten Datenbanken.
Diese werden in folgenden Abschnitten nur kurz erläutert, um ihre Eignung zu bestimmen.
Das Überwachen der Speicherauslastung wird in einem separaten Abschnitt mit dem Titel Überwachen
und Anpassen des Serverarbeitsspeichers erläutert.
22
3.3 Optimieren von Dimensionen
Ein optimierter Dimensionsentwurf ist einer der wichtigsten Erfolgsfaktoren für eine leistungsstarke
Analysis Services-Lösung. Einer der ersten Schritte zur Verbesserung der Cubeleistung ist das
schrittweise Durchlaufen der Dimensionen und Feststellen der Attributbeziehungen. Die beiden
wichtigsten Techniken zum Optimieren des Dimensionsentwurfs für die Abfrageleistung sind:
Identifizieren von Attributbeziehungen
Effektive Verwendung von Benutzerhierarchien
3.3.1 Identifizieren von Attributbeziehungen
Attributbeziehungen definieren funktionale Abhängigkeiten zwischen Attributen. Mit anderen Worten
heißt das, wenn A ein verknüpftes Attribut B hat, geschrieben: A B, dann gibt es ein Element in B für
jedes Element in A und viele Elemente in A für ein bestimmtes Element in B. Bei der Attributbeziehung
City State muss z. B., wenn die aktuelle Stadt Seattle ist, der "State" Washington sein.
Häufig bestehen Beziehungen zwischen Attributen, die nicht unbedingt in der ursprünglichen
Dimensionstabelle manifestiert sind, mit der das Analysis Services-Modul die Leistung optimieren kann.
Standardmäßig sind alle Attribute mit dem Schlüssel verbunden, und das Attributbeziehungsdiagramm
stellt einen "Busch" dar, in dem alle Beziehungen vom Schlüsselattribut abgehen und am jeweiligen
Attribut enden.
Abbildung 9 Attributbeziehungen als Busch
23
Die Leistung kann durch das Festlegen von durch die Daten unterstützten Beziehungen optimiert
werden. In diesem Fall identifiziert ein Modellname die Produktlinie und Unterkategorie, und die
Unterkategorie identifiziert ein Kategorie (ein einzelne Unterkategorie ist also in nicht mehr als einer
Kategorie vorhanden). Nach dem Neudefinieren der Beziehungen im Attributbeziehungs-Editor ergibt
sich Folgendes.
Abbildung 10 Neu definierte Attributbeziehungen
Durch Attributbeziehungen wird die Leistung in zwei wichtigen Punkten verbessert:
Indizes werden erstellt, und Kreuzprodukte müssen nicht das Schlüsselattribut durchlaufen.
Auf Attributen basierende Aggregationen können für Abfragen für verknüpfte Attribute
wiederverwendet werden.
Betrachten Sie das Kreuzprodukt zwischen Subcategory und Category in den beiden Abbildungen weiter
oben. In der ersten Abbildung, in der keine Attributbeziehungen explizit definiert wurden, muss das
Modul zuerst feststellen, welche Produkte in jeder Unterkategorie vorhanden sind, und dann
bestimmen, zu welchen Kategorien das jeweilige Produkt gehört. Für Dimensionen mit nicht trivialer
Größe kann dies zeitaufwändig sein. Bei definierter Attributbeziehung erkennt das Analysis ServicesModul über bei der Verarbeitung erstellte Indizes im Voraus, zu welcher Kategorie jede Unterkategorie
gehört.
Betrachten Sie beim Definieren der Attributbeziehung den Beziehungstyp als flexibel oder fest. Bei einer
flexiblen Attributbeziehung können die Elemente während Dimensionsaktualisierungen verschoben
werden. Bei einer festen Attributbeziehung wird sichergestellt, dass die Elementbeziehungen fest sind.
Beispielsweise ist die Beziehung zwischen "Month" und "Year" fest, da sich das Jahr für einen
bestimmten Monat bei der erneuten Verarbeitung der Dimension nicht ändert. Die Beziehung zwischen
"Customer" und "City" kann jedoch flexibel sein, da sich Kunden bewegen. (Dabei ist anzumerken, dass
sich das Definieren einer Aggregation als flexibel oder fest nicht auf die Abfrageleistung auswirkt.)
24
3.3.2 Effektive Verwendung von Hierarchien
Nur in Attributhierarchien verfügbar gemachte Attribute werden vom Aggregationsentwurfs-Assistenten
nicht automatisch für die Aggregation berücksichtigt. Abfragen, die diese Attribute enthalten, werden
durch das Zusammenfassen von Daten aus dem Primärschlüssel beantwortet. Ohne Aggregationen kann
sich die Abfrageleistung für diese Attributhierarchien verlangsamen.
Zur Verbesserung der Leistung kann ein Attribut mit der Aggregation Usage-Eigenschaft als
Aggregationskandidat markiert werden. Detailliertere Informationen zu dieser Technik finden Sie unter
Vorschlagen von Aggregationskandidaten. Sie sollten jedoch vor dem Ändern der Aggregation UsageEigenschaft überlegen, ob Sie Benutzerhierarchien nutzen können.
Mithilfe von Analysis Services können Sie zwei Typen von Benutzerhierarchien, natürliche und
unnatürliche Hierarchien, mit jeweils unterschiedlichem Entwurfs- und Leistungsmerkmalen erstellen.
In einer natürlichen Hierarchie verfügen alle als Ebenen an der Hierarchie beteiligten Attribute über
direkte oder indirekte Attributbeziehungen von der untersten bis zur obersten Ebene der Hierarchie.
In einer unnatürlichen Hierarchie besteht die Hierarchie aus mindesten zwei aufeinander folgenden
Ebenen ohne Attributbeziehungen. In der Regel werden mithilfe dieser Hierarchien Drilldownpfade
häufig angezeigter Attribute erstellt, die keiner natürlichen Hierarchie folgen. So können Benutzer z. B.
eine Hierarchie von "Gender" und "Education" anzeigen.
Abbildung 11 Natürliche und unnatürliche Hierarchien
In Bezug auf die Leistung verhalten sich natürliche Hierarchien ganz anders als unnatürliche Hierarchien.
In natürlichen Hierarchien wird die Hierarchiestruktur in Hierarchiespeichern auf dem Datenträger
materialisiert. Zudem werden alle an natürlichen Hierarchien beteiligten Attribute automatisch als
Aggregationskandidaten betrachtet.
Unnatürliche Hierarchien werden nicht auf dem Datenträger materialisiert, und die an unnatürlichen
Hierarchien beteiligten Attribute werden nicht automatisch als Aggregationskandidaten betrachtet.
Stattdessen bieten sie Benutzern einfach zu verwendende Drilldownpfade für häufig angezeigte
Attribute ohne natürliche Beziehungen. Durch das Zusammenstellen dieser Attribute in Hierarchien
können Sie auch eine Vielzahl von MDX-Navigationsfunktionen verwenden, um Berechnungen wie
Prozentsatz des übergeordneten Elements einfach auszuführen.
25
Definieren Sie für alle an der Hierarchie beteiligten Attribute kaskadierende Attributbeziehungen, um
natürliche Hierarchien zu nutzen.
3.4 Maximieren des Werts von Aggregationen
Eine Aggregation ist eine im Voraus berechnete Zusammenfassung von Daten, mit der Analysis Services
die Abfrageleistung verbessert.
Das Entwerfen von Aggregationen ist der Vorgang, bei dem die effektivsten Aggregationen für die
Abfragearbeitsauslastung ausgewählt werden. Beim Entwerfen von Aggregationen müssen Sie die
Abfragevorteile von Aggregationen im Vergleich zum Zeitaufwand für das Erstellen und Aktualisieren der
Aggregationen berücksichtigen. Durch das Hinzufügen nicht benötigter Aggregationen kann sich die
Abfrageleistung sogar verschlechtern, da die Aggregation durch die seltenen Treffer in den Dateicache
verschoben wird und gleichzeitig andere Elemente entfernt werden.
Während Aggregationen pro Measuregruppe-Partition physisch entworfen werden, gelten die
Optimierungstechniken zum Maximieren des Aggregationsentwurfs unabhängig von der Anzahl der
Partitionen. In diesem Abschnitt werden Aggregationen, wenn nicht anders angegeben, im
grundlegenden Konzept eines Cubes mit einer Measuregruppe und einer Partition erläutert. Weitere
Informationen dazu, wie die Abfrageleistung mithilfe mehrerer Partitionen verbessert werden kann,
finden Sie unter Verbessern der Abfrageleistung mithilfe von Partitionen.
3.4.1 Ermitteln von Aggregationstreffern
Zeigen Sie mithilfe von SQL Server Profiler an, wie und wann Aggregationen zum Beantworten von
Anfragen verwendet werden. In SQL Server Profiler gibt es mehrere Ereignisse, die das Erfüllen einer
Abfrage beschreiben. Das Ereignis, das sich speziell auf Aggregationstreffer bezieht, ist das Get Data
From Aggregation-Ereignis.
Abbildung 12 Szenario 1: SQL Server Profiler-Ablaufverfolgung für Cube mit
Aggregationstreffer
In Abbildung 13 wird eine SQL Server Profiler-Ablaufverfolgung der Auflösung der Abfrage für einen
Cube mit Aggregationen dargestellt. In der SQL Server Profiler-Ablaufverfolgung werden die vom
Speichermodul zum Produzieren des Resultsets ausgeführten Vorgänge angezeigt.
26
Das Speichermodul ruft Daten von Aggregation C 0000, 0001, 0000 ab, wie vom Get Data
From Aggregation-Ereignis angegeben. Zusätzlich zum Aggregationsnamen,
Aggregation C, wird in Abbildung 13 der Vektor 000, 0001, 0000 angezeigt, der den Inhalt
der Aggregation beschreibt. Weitere Informationen zur Bedeutung dieses Vektors finden Sie
im nächsten Abschnitt Interpretieren von Aggregationen.
Die Aggregationsdaten werden in den Measuregruppencache des Speichermoduls geladen,
wo sie vom Abfrageprozessor abgerufen werden, der das Resultset zum Client zurückgibt.
In Abbildung 14 wird eine SQL Server Profiler-Ablaufverfolgung derselben Abfrage für denselben Cube
dargestellt. Diesmal enthält der Cube jedoch keine Aggregationen, die die Abfrageanforderung erfüllen
können.
Abbildung 14 Szenario 2: SQL Server Profiler-Ablaufverfolgung für Cube ohne Aggregationstreffer
Nach dem Übermitteln der Abfrage ruft das Speichermodul keine Daten aus einer Aggregation ab,
sondern wechselt zu den Detaildaten in der Partition. Ab diesem Punkt ist der Vorgang gleich. Die Daten
werden in den Measuregruppencache des Speichermoduls geladen.
3.4.2 Interpretieren von Aggregationen
Beim Erstellen einer Aggregation durch Analysis Services wird jede Dimension nach einem Vektor
bekannt, der angibt, ob das Attribut auf die Attribut- oder auf die Alle-Ebene zeigt. Die Attributebene
wird durch 1 und die Alle-Ebene wird durch 0 dargestellt. Betrachten Sie z. B. die folgenden Beispiele
von Aggregationsvektoren für die Produktdimension:
Aggregation By ProductKey Attribute = [Product Key]:1 [Color]:0 [Subcategory]:0 [Category]:0
or 1000
Aggregation By Category Attribute = [Product Key]:0 [Color]:0 [Subcategory]:0 [Category]:1 or
0001
Aggregation By ProductKey.All and Color.All and Subcategory.All and Category.All = [Product
Key]:0 [Color]:0 [Subcategory]:0 [Category]:0 or 0000
Zum Identifizieren jeder Aggregation kombiniert Analysis Services die Dimensionsvektoren in einem
langen Vektorpfad, der auch als Teilcube bezeichnet wird, wobei die Dimensionsvektoren durch Kommas
getrennt werden.
27
Die Reihenfolge der Dimensionen im Vektor wird durch die Reihenfolge der Dimensionen im Cube
bestimmt. Verwenden Sie zum Feststellen der Reihenfolge der Dimensionen im Cube eine der beiden
folgenden Techniken. Wenn der Cube in SQL Server Business Intelligence Development Studio geöffnet
ist, können Sie auf der Registerkarte Cubestruktur die Reihenfolge von Dimensionen in einem Cube
überprüfen. Die Reihenfolge von Dimensionen im Cube wird im Bereich "Dimensionen" angezeigt.
Alternativ können Sie die Reihenfolge von in der XMLA-Definition des Cubes aufgeführten Dimensionen
überprüfen.
Die Reihenfolge von Attributen im Vektor für jede Dimension wird durch die Reihenfolge von Attributen
in der Dimension bestimmt. Die Reihenfolge von Attributen in jeder Dimension kann durch Überprüfen
der XML-Datei der Dimension festgestellt werden.
Die folgende Subcubedefinition (0000, 0001, 0001) beschreibt beispielsweise eine Aggregation für
Folgendes:
Product – All, All, All, All
Customer – All, All, All, State/Province
Order Date – All, All, All, Year
Beim Überprüfen von Aggregationstreffern in SQL Server Profiler ist es hilfreich, wenn Sie wissen, wie
diese Vektoren gelesen werden. In SQL Server Profiler können Sie anzeigen, wie der Vektor durch
Aktivieren des Query Subcube Verbose-Ereignisses bestimmten Dimensionsattributen zugeordnet wird.
3.4.3 Erstellen von Aggregationen
Um das erfolgreiche Anwenden des Aggregationsentwurfsalgorithmus durch Analysis Services zu
unterstützen, können Sie die folgenden Optimierungstechniken zum Beeinflussen und Verbessern des
Aggregationsentwurfs ausführen. (In den folgenden Abschnitten werden die jeweiligen Techniken
genauer beschrieben.)
Vorschlagen von Aggregationskandidaten – Beim Entwerfen von Aggregationen in Analysis Services
berücksichtigt der Aggregationsentwurfsalgorithmus nicht automatisch jedes Attribut für die
Aggregation. Überprüfen Sie daher im Cubeentwurf die für die Aggregation berücksichtigten Attribute,
und entscheiden Sie, ob zusätzliche Aggregationskandidaten vorgeschlagen werden müssen.
Angeben von Statistiken zu Cubedaten – Für sinnvolle Bewertungen von Aggregationskosten analysiert
der Entwurfsalgorithmus für jeden Aggregationskandidaten Statistiken zum Cube. Beispiele für diese
Metadaten sind die Anzahl von Elementen und Faktentabellen. Durch das Sicherstellen der Aktualität
der Metadaten kann die Effizienz des Aggregationsentwurfs verbessert werden.
Verwendungsbasierte Optimierung – Führen Sie die Abfragen aus, und starten Sie den Assistenten für
verwendungsbasierte Optimierung, um Aggregationen auf bestimmte Verwendungsmuster
auszurichten.
28
3.4.3.1 Vorschlagen von Aggregationskandidaten
Beim Entwerfen von Aggregationen in Analysis Services berücksichtigt der
Aggregationsentwurfsalgorithmus nicht automatisch jedes Attribut für die Aggregation. Zum Optimieren
dieses Prozesses verwendet Analysis Services die Aggregation Usage-Eigenschaft, um die zu
berücksichtigenden Attribute zu bestimmen. Überprüfen Sie für jede Measuregruppe die automatisch
für die Aggregation berücksichtigten Attribute, und entscheiden Sie dann, ob zusätzliche
Aggregationskandidaten vorgeschlagen werden müssen.
Aggregation Usage-Regeln
Ein Aggregationskandidat ist ein Attribut, das von Analysis Services für eine potenzielle Aggregation in
Betracht gezogen wird. Um zu ermitteln, ob ein bestimmtes Attribut ein Aggregationskandidat ist, greift
das Speichermodul auf den Wert der Aggregation Usage-Eigenschaft zurück. Der Aggregation UsageEigenschaft wird ein Attribut pro Cube zugewiesen, sie gilt daher global für alle Measuregruppen und
Partitionen im Cube. Für jedes Attribut in einem Cube kann die Aggregation Usage-Eigenschaft einen
von vier potenziellen Werten haben: Full, None, Unrestricted und Default.
Full – Jede Aggregation für den Cube muss dieses Attribut oder ein verknüpftes Attribut enthalten, das
sich weiter unten in der Attributkette befindet. Nehmen wir als Beispiel eine Produktdimension mit der
folgenden Kette verknüpfter Attribute an: Product, Product Subcategory und Product Category. Wenn
Sie als Aggregation Usage für Product Category Full angeben, erstellt Analysis Services unter Umständen
eine Aggregation, die Product Subcategory im Gegensatz zu Product Category enthält, falls Product
Subcategory mit Category verknüpft ist und damit Gesamtwerte für Category abgeleitet werden können.
None – Keine Aggregation für den Cube darf dieses Attribut enthalten.
Unrestricted – Für den Aggregations-Designer gelten keine Einschränkungen, das Attribut muss aber
dennoch ausgewertet werden, um festzustellen, ob es sich um einen wertvollen
Aggregationskandidaten handelt.
Default – Der Designer wendet eine Standardregel basierend auf dem Typ des Attributs und der
Dimension an. Dies ist der Standardwert der Aggregation Usage-Eigenschaft.
Die Standardregel legt fest, welche Attribute für die Aggregation berücksichtigt werden. Die
Standardregel ist in vier Einschränkungen unterteilt.
Default Constraint 1 – Unrestricted: Für das Granularitätsattribut der Measuregruppe einer Dimension
bedeutet der Standardwert Unrestricted. Das Granularitätsattribut entspricht dem Schlüsselattribut der
Dimension, solange die Measuregruppe über das Primärschlüsselattribut mit einer Dimension
verbunden ist.
Default Constraint 2 – None for Special Dimension Types: Für alle Attribute (außer Alle) in nicht
materialisierten m:n-Bezugsdimensionen und Data Mining-Dimensionen bedeutet der Standardwert
None.
29
Default Constraint 3 – Unrestricted for Natural Hierarchies: Eine natürliche Hierarchie ist eine
Benutzerhierarchie, in der alle an der Hierarchie beteiligten Attribute Attributbeziehungen zu dem
Attribut enthalten, das als Quelle für die nächste Ebene dient. Für solche Attribute bedeutet der
Standardwert Unrestricted, außer für nicht aggregierbare Attribute, die auf Full festgelegt werden
(selbst wenn sie sich nicht in einer Benutzerhierarchie befinden).
Default Constraint 4 – None For Everything Else. Für alle anderen Dimensionsattribute bedeutet der
Standardwert None.
3.4.3.2 Beeinflussen von Aggregationskandidaten
Beachten Sie angesichts des Verhaltens der Aggregation Usage-Eigenschaft die folgenden Richtlinien:
Nur als Attributhierarchien verfügbar gemachte Attribute – Wird ein bestimmtes Attribut nur als
Attributhierarchie wie Color verfügbar gemacht, sollte die entsprechende Aggregation UsageEigenschaft wie folgt geändert werden.
Ändern Sie zuerst den Wert der Aggregation Usage-Eigenschaft von Default in Unrestricted, wenn das
Attribute ein häufig verwendetes Attribut ist oder besondere Überlegungen zum Verbessern der
Leistung in einem bestimmten Pivotvorgang oder Drilldown vorliegen. Bei zusammengefassten
Berichten im Scorecardformat möchten Sie z. B. für Benutzer eine gute Antwortzeit für die erste Abfrage
vor dem Drill zu weiteren Details sicherstellen.
Das Festlegen der Aggregation Usage-Eigenschaft einer bestimmten Attributhierarchie auf Unrestricted
empfiehlt sich zwar in bestimmten Szenarien, allerdings sollten nicht alle Attributhierarchien auf
Unrestricted festgelegt werden. Durch das Erhöhen der Anzahl der zu berücksichtigenden Attribute
vergrößert sich auch der Problemraum, den der Aggregationsalgorithmus betrachten muss. Der
Assistent braucht mindestens eine Stunde zum Abschließen des Entwurfs und bedeutend mehr Zeit zur
Verarbeitung. Legen Sie die Eigenschaft nur für die am häufigsten abgefragten Attributhierarchien auf
Unrestricted fest. Die allgemeine Regel sind fünf bis zehn Unrestricted-Attribute pro Dimension.
Ändern Sie dann den Wert der Aggregation Usage-Eigenschaft von Default zu Full in dem
ungewöhnlichen Fall, dass sie in nahezu jeder Abfrage verwendet wird, die Sie optimieren möchten.
Dieser Fall kommt jedoch selten vor, und die Änderung sollte nur für Attribute mit relativ wenigen
Elementen vorgenommen werden.
Selten verwendete Attribute – Für an natürlichen Hierarchien beteiligten Attributen sollten Sie die
Aggregation Usage-Eigenschaft von Default zu None ändern, wenn sie nur selten von Benutzern
verwendet werden. Mit diesem Ansatz können Sie den Aggregationsspeicherplatz reduzieren und zu den
fünf bis zehn Unrestricted-Attributen pro Dimension gelangen. Ein Beispiel sind bestimmte Attribute,
die nur von einigen fortgeschrittenen Benutzer verwendet werden, die eine etwas verlangsamte
Leistung akzeptieren würden. In diesem Szenario zwingen Sie im Prinzip den
Aggregationsentwurfsalgorithmus dazu, nur Zeit für das Erstellen der Aggregationen aufzuwenden, die
der Mehrheit der Benutzer die meisten Vorteile bieten.
30
Der Aggregationsentwurfsalgorithmus analysiert das Kosten-Nutzen-Verhältnis jeder auf Aggregationen
basierten Anzahl von Elementen und von Faktentabellen-Datensätzen. Durch das Sicherstellen der
Aktualität der Metadaten kann die Effizienz des Aggregationsentwurfs verbessert werden. Die Anzahl
von Faktentabellen-Quelldatensätzen kann in der EstimatedRows-Eigenschaft jeder Measuregruppe und
die Anzahl von Attributelementen kann in der EstimatedCount-Eigenschaft jedes Attributs definiert
werden.
3.4.3.3 Verwendungsbasierte Optimierung
Der Assistent für verwendungsbasierte Optimierung prüft die Abfragen im Abfrageprotokoll (das vorher
eingerichtet werden muss) und entwirft Aggregationen, die die obersten 100 der langsamsten Abfragen
abdecken. Verwenden Sie den Assistenten für verwendungsbasierte Optimierung mit einem
Leistungsgewinn von 100 %, dadurch werden Aggregationen so entworfen, dass direkte Treffer der
Partition vermieden werden.
Nachdem die Aggregationen entworfen wurden, können sie dem vorhandenen Entwurf hinzugefügt
werden oder den Entwurf vollständig ersetzen. Achten Sie beim Hinzufügen zum vorhandenen Entwurf
darauf, dass die beiden Entwürfe Aggregationen enthalten können, die nahezu identischen Zwecken
dienen und beim Kombinieren miteinander redundant sind. Überprüfen Sie die neuen Aggregationen im
Vergleich zu den alten und stellen Sie sicher, dass keine nahezu doppelten Aggregationen vorhanden
sind. Der Aggregationsentwurf kann in SQL Server Management Studio oder Business Intelligence Design
Studio auf andere Partitionen kopiert werden.
Aggregationsentwürfe haben hinsichtlich des Aufwands Auswirkungen auf Metadaten. Vermeiden Sie
daher ein Übermaß an Entwürfen und versuchen Sie stattdessen, die Anzahl von Aggregationsentwürfen
pro Measuregruppe auf ein Minimum zu beschränken.
3.4.3.4 Aggregationen und Parent-Child-Hierarchien
In Parent-Child-Hierarchien werden Aggregationen nur für das Schlüsselattribut und das Attribut der
obersten Ebene, d. h. das Alle-Attribut, erstellt, außer wenn es deaktiviert ist. Verwenden Sie möglichst
keine Parent-Child-Hierarchien mit vielen Elementen. (Was sind viele Elemente? Es gibt keine bestimmte
Anzahl, da die Abfrageleistung auf Zwischenebenen der Parent-Child-Hierarchie mit der Anzahl der
Elemente linear abnimmt.) Schränken Sie darüber hinaus die Anzahl von Parent-Child-Hierarchien im
Cube ein.
In einem Entwurfsszenario mit einer großen Parent-Child-Hierarchie sollten Sie das Quellschema ändern,
um einen Teil oder die gesamte Hierarchie in eine reguläre Hierarchie mit einer festen Anzahl von
Ebenen neu zu organisieren. Nach der Neuorganisation der Daten in die Benutzerhierarchie können Sie
mit der Hide Member If-Eigenschaft jeder Ebene die redundanten oder fehlenden Elemente
ausblenden.
31
3.5 Verbessern der Abfrageleistung mithilfe von Partitionen
Partitionen unterteilen Measuregruppendaten in physische Einheiten. Durch die effiziente Verwendung
von Partitionen werden die Abfrage- und Verarbeitungsleistung verbessert und die Datenverwaltung
vereinfacht. In diesem Abschnitt wird speziell erläutert, wie die Abfrageleistung mithilfe der Partitionen
verbessert werden kann. Betrachten Sie die Vor- und Nachteile von Abfrage- und Verarbeitungsleistung,
bevor Sie die Partitionierungsstrategie festlegen.
3.5.1 Einführung
Mithilfe mehrerer Partitionen können Sie die Measuregruppe in separate physische Komponenten
aufteilen. Die Vorteile der Partitionierung für eine verbesserte Abfrageleistung sind:
Aufteilen von Partitionen in Slices: Partitionen ohne Daten im Teilcube werden nicht abgefragt,
wodurch die Kosten für das Lesen des Index vermieden werden (oder für das Scannen der
Tabelle im ROLAP-Modus, in dem keine MOLAP-Indizes vorhanden sind).
Aggregationsentwurf: Jede Partition kann über einen eigenen oder freigegebenen
Aggregationsentwurf verfügen. Folglich können häufiger oder unterschiedlich abgefragte
Partitionen über eigene Entwürfe verfügen.
Abbildung 15 Intelligentes Abfragen nach Partitionen
In Abbildung 15 wird die Profiler-Ablaufverfolgung der Abfrage angezeigt, die Reseller Sales Amount
nach Business Type von Adventure Works anfordert. Die Reseller Sales-Measuregruppe des Adventure
Works-Cubes enthält vier Partitionen, eine für jedes Jahr. Da die Abfrage zu 2003 in Slices aufgeteilt ist,
kann das Speichermodul direkt zur 2003 Reseller Sales-Partition wechseln und andere Partitionen
ignorieren.
32
3.5.2 Aufteilen von Partitionen in Slices
Partitionen sind an eine Quelltabelle, Sicht oder Quellabfrage gebunden. Bei MOLAP-Partitionen
identifiziert Analysis Services während der Verarbeitung intern den in jeder Partition enthaltenen
Datenbereich mithilfe der Min und Max DataIDs jedes Attributs, um den in der Partition enthaltenen
Datenbereich zu berechnen. Der Datenbereich für jedes Attribut wird dann kombiniert, um die
Slicedefinition für die Partition zu erstellen. Mithilfe dieser Informationen kann das Speichermodul
optimieren, welche Partitionen während der Abfrage gescannt werden, indem nur die für die Abfrage
relevanten Partitionen ausgewählt werden. Bei ROLAP-Partitionen und Partitionen zum proaktiven
Zwischenspeichern muss der Slice in den Eigenschaften der Partition manuell identifiziert werden.
Die Min und Max DataIDs können ein einzelnes Segment oder einen Bereich angeben. So ergibt z. B. die
Partitionierung nach Jahr denselben Min und Max DataID-Slice für das Year-Attribut, und Abfragen zu
einem bestimmten Zeitpunkt ergeben nur Partitionsabfragen an die Partition dieses Jahres.
Sie sollten stets bedenken, dass der Partitionsslice als Bereich von DataIDs beibehalten wird, den Sie
nicht explizit steuern können. DataIDs werden während der Dimensionsverarbeitung zugewiesen, wenn
neue Elemente gefunden werden. Bei einer falschen Reihenfolge in der Dimensionstabelle kann sich die
interne Sequenz von DataIDs von Attributschlüsseln unterscheiden. Dies kann zu unnötigen
Lesevorgängen in der Partition führen. Daher kann es ein Vorteil sein, den Slice für MOLAP-Partitionen
selbst zu definieren. Wenn Sie z. B. nach Jahr partitionieren und einige Partitionen einen Bereich von
Jahren enthalten, wird durch das Definieren des Slices das Problem überlappender DataIDs explizit
vermieden.
Stellen Sie beim Verwenden mehrerer Partitionen für eine bestimmte Measuregruppe immer sicher,
dass Sie die Datenstatistiken für jede Partition aktualisieren. Stellen Sie insbesondere sicher, dass die
Partitionsdaten und die Anzahl der Elemente die spezifischen Daten in der Partition genau wiedergeben
und nicht die Daten in der gesamten Measuregruppe.
Für Partitionen mit weniger Zeilen als IndexBuildThreshold (mit einem Standardwert von 4096) wird der
Slice nicht definiert, und es werden keine Indizes erstellt.
3.5.3 Überlegungen zu Aggregationen für mehrere Partitionen
Beachten Sie beim Definieren der Partitionen, dass diese keine einheitlichen Datasets oder
Aggregationsentwürfe enthalten müssen. Für eine bestimmte Measuregruppe verfügen Sie z. B. über
drei 3 Jahrespartitionen, 11 Monatspartitionen, 3 Wochenpartitionen und 1 bis 7 Tagespartitionen. Der
Vorteil heterogener Partitionen mit verschiedenen Detailebenen besteht darin, dass Sie das Laden neuer
Daten einfacher verwalten können, ohne vorhandene Partitionen zu beeinflussen (mehr dazu im
Abschnitt zur Verarbeitung), und Aggregationen für Gruppen von Partitionen entwerfen können, die
dieselbe Detailebene nutzen.
Für jede Partition kann ein unterschiedlicher Aggregationsentwurf verwendet werden. Mithilfe dieser
Flexibilität können Sie die Datasets bestimmen, die einen höheren Aggregationsentwurf erfordern.
33
Betrachten Sie das folgende Beispiel. In einem Cube mit mehreren Monatspartitionen fließen neue
Daten unter Umständen in eine einzelne Partition, die dem letzten Monat entspricht. Im Allgemeinen ist
das auch die am häufigsten abgefragte Partition. Eine gängige Aggregationsstrategie ist in diesem Fall
die Ausführung der verwendungsbasierten Optimierung für die aktuellste Partition, wobei ältere,
weniger häufig abgefragte Partitionen unverändert bleiben.
Außerdem kann der neueste Aggregationsentwurf zu einer Basispartition kopiert werden. Diese
Basispartition enthält keine Daten, sondern nur den aktuellen Aggregationsentwurf. Wenn eine neue
Partition hinzugefügt werden soll, z. B. am Beginn eines neuen Monats, kann die Basispartition zu einer
neuen Partition geklont werden. Wenn der Slice für die neue Partition festgelegt wurde, kann sie Daten
als die aktuelle Partition entgegennehmen. Nach der ersten vollständigen Verarbeitung kann die
aktuelle Partition für den restlichen Zeitraum inkrementell aktualisiert werden.
3.5.4 Distinct Count-Partitionsentwurf
Bei Distinct Count-Partitionen sind einige Besonderheiten zu beachten. Beim Abfragen von Distinct
Count-Partitionen müssen die Segmentaufträge jeder Partition miteinander koordiniert werden, um
Zählungsduplikate zu vermeiden. Beispielsweise müssen beim Zählen unterschiedlicher Kunden mit
Kunden-ID und gleicher Kunden-ID in mehreren Partitionen die Aufträge der Partitionen die
Übereinstimmung erkennen, um denselben Kunden nicht mehrmals zu zählen.
Enthält jede Partition einen nicht überlappenden Wertebereich, wird diese Koordination zwischen
Aufträgen vermieden, und die Abfrageleistung kann sich um 20 % bis 300 % verbessern!
Weitere Informationen zu Optimierungen für Distinct Count finden Sie im Whitepaper "Analysis Services
Distinct Count" unter folgendem Link:
http://www.microsoft.com/downloads/details.aspx?FamilyID=65df6ebf-9d1c-405f-84b108f492af52dd&displaylang=en
3.5.5 Ändern der Größe von Partitionen
Für Nicht-Distinct Count-Measuregruppen haben Tests mit Partitionsgrößen zwischen 200 MB und 3 GB
gezeigt, dass die Partitionsgröße alleine keine deutlichen Auswirkungen auf die Abfragegeschwindigkeit
hat. Die Partitionierungsstrategie sollte auf den folgenden Faktoren basieren:
34
Erhöhung von Verarbeitungsgeschwindigkeit und -flexibilität
Erweiterung der Verwaltbarkeit beim Einfügen neuer Daten
Verbesserung der Abfrageleistung durch das Löschen von Partitionen
Unterstützung für unterschiedliche Aggregationsentwürfe
3.6 Optimieren von MDX
Das Debuggen bei Problemen mit der Berechnungsleistung in einem Cube kann sich beim Vorliegen
vieler Berechnungen schwierig gestalten. Versuchen Sie zuerst, die Auswirkungen des Problems
einzugrenzen, und wenden Sie dann bewährte Methoden auf MDX an.
3.6.1 Diagnostizieren des Problems
Das Diagnostizieren des Problems kann relativ einfach sein, wenn eine einfache Abfrage eine bestimmte
Berechnung aufruft (in diesem Fall können Sie mit dem nächsten Abschnitt fortfahren). Bei
Ausdrucksketten oder einer komplexen Abfrage dagegen kann die Suche nach dem Problem
zeitaufwändig sein.
Versuchen Sie, die Abfrage auf den einfachsten Ausdruck zu reduzieren, der das Leistungsproblem
reproduziert. Bei einigen Clientanwendungen kann die Abfrage selbst das Problem sein, sollte sie große
Datenmengen verlangen, ein Pushdown zu unnötig niedrigen Granularitäten (unter Umgehung von
Aggregationen) durchführen oder Abfrageberechnungen enthalten, die den globalen Cache und den
Sitzungscache des Abfrageprozessors umgehen.
Wenn sich bestätigt, dass das Problem im Cube selbst vorliegt, müssen Sie alle Berechnungen aus dem
Cube entfernen oder auskommentieren. Dazu gehören:
Benutzerdefinierte Elementformeln
Unäre Operatoren
MDX-Skripts (außer der Berechnungsanweisung, die beibehalten werden sollte)
Führen Sie die Abfrage erneut aus. Unter Umständen muss sie wegen fehlender Elemente geändert
werden. Ändern Sie die Berechnungen, bis das Problem reproduziert wird.
3.6.2 Bewährte Methoden für Berechnungen
Dieser Abschnitt enthält eine Reihe bewährter Methoden, mit denen die beste Abfrageleistung für den
Cube erzielt werden kann.
3.6.2.1 Zellenweiser Modus im Vergleich zum Teilbereichmodus
Die mit dem Teilbereichmodus erzielte Leistung ist fast immer höher als die mit dem zellenweisen
Modus erzielte Leistung. Weitere Informationen, einschließlich einer Liste von im Teilbereichmodus
unterstützten Funktionen, finden Sie unter "Leistungsverbesserungen für MDX in SQL Server 2008
Analysis Services" in der SQL Server-Onlinedokumentation unter folgendem Link:
http://msdn.microsoft.com/de-de/library/bb934106(SQL.100).aspx
35
In der folgenden Tabelle werden die häufigsten Gründe für das Verlassen des Teilbereichmodus
aufgelistet.
Feature oder Funktion
Festlegen von Aliasen
Kommentar
Verwenden Sie zum Ersetzen einen Mengenausdruck statt eines Alias.
Beispielsweise wird diese Abfrage im Teilbereichmodus ausgeführt:
with
member measures.SubspaceMode as
sum(
[Product].[Category].[Category].members,
[Measures].[Internet Sales Amount]
)
select
{measures.SubspaceMode,[Measures].[Internet Sales
Amount]} on 0 ,
[Customer].[Customer Geography].[Country].members on 1
from [Adventure Works]
cell properties value
aber fast dieselbe Abfrage, in der der Mengenausdruck durch einen Alias
ersetzt wurde, wird im zellenweisen Modus ausgeführt:
with
set y as [Product].[Category].[Category].members
member measures.Naive as
sum(
y,
[Measures].[Internet Sales Amount]
)
select
{measures.Naive,[Measures].[Internet Sales Amount]} on 0
,
[Customer].[Customer Geography].[Country].members on 1
from [Adventure Works]
cell properties value
Spätes Binden in
Funktionen:
LinkMember, StrToSet,
StrToMember,
StrToValue
Funktionen zum spätem Binden sind Funktionen, die vom Abfragekontext
abhängig sind und nicht statisch ausgewertet werden können. Der folgende
Code ist z. B. statisch gebunden:
with member measures.x as
(strtomember("[Customer].[Customer
Geography].[Country].&[Australia]"),[Measures].[Internet
Sales Amount])
36
select
measures.x on 0,
[Customer].[Customer Geography].[Country].members on 1
from [Adventure Works]
cell properties value
Eine Abfrage ist spät gebunden, wenn ein Argument nur im Kontext
ausgewertet werden kann:
with member measures.x as
(strtomember([Customer].[Customer
Geography].currentmember.uniquename),[Measures].[Internet
Sales Amount])
select
measures.x on 0,
[Customer].[Customer Geography].[Country].members on 1
from [Adventure Works]
cell properties value
Benutzerdefinierte
gespeicherte Prozeduren
LookupCube
Häufig verwendete Microsoft Visual Basic® for Applications (VBA)- und
Excel-Funktionen werden in MDX vom System unterstützt.
Benutzerdefinierte gespeicherte Prozeduren werden im zellenweisen
Modus ausgewertet.
Häufig sind verknüpfte Measuregruppen eine geeignete Alternative.
3.6.2.2 IIf-Funktion in SQL Server 2008 Analysis Services
Die IIf-Funktion von MDX ist ein häufig verwendeter Ausdruck, dessen Auswertung aufwändig sein kann.
Das Modul optimiert die Leistung auf Grundlage einiger einfacher Kriterien. Die IIf-Funktion verwendet
drei Argumente:
iif(<condition>, <then branch>, <else branch>)
Wenn die Bedingung TRUE ergibt, dann wird der Wert aus der THEN-Verzweigung verwendet;
andernfalls wird der Ausdruck aus der ELSE-Verzweigung verwendet.
Beachten Sie den Begriff "verwendet" – eine oder beide Verzweigungen werden unter Umständen
ausgewertet, auch wenn ihr Wert nicht verwendet wird. Es kann für das Modul weniger aufwändig sein,
den Ausdruck im gesamten Bereich auszuwerten und bei Bedarf zu verwenden – dies wird als Eager-Plan
bezeichnet –, als den Bereich in eine möglicherweise große Anzahl von Fragmenten aufzuteilen und nur
bei Bedarf auszuwerten – dies wäre ein Strict-Plan.
Hinweis: Einer der häufigsten Fehler in MDX-Skripts ist die Verwendung von IIf, wenn die Bedingung von
Zellenkoordinaten statt von Werten abhängig ist. Verwenden Sie Bereiche und Zuweisungen, wenn die
Bedingung von Zellenkoordinaten abhängig ist. Danach wird die Bedingung nicht im gesamten Bereich
ausgewertet, und das Modul wertet eine oder beide Verzweigungen nicht im gesamten Bereich aus.
37
Zugegebenermaßen erzwingt die Verwendung von Zuweisungen in einigen Fällen eine schwer
verwaltbare Bereichsdefinierung und die Wiederholung von Zuweisungen, es lohnt sich jedoch immer,
die beiden Methoden zu vergleichen.
Die erste Überlegung ist, ob der Abfrageplan aufwändig oder nicht aufwändig ist. Die meisten
Abfragepläne mit IIf-Bedingung sind nicht aufwändig, bei komplexen geschachtelten Bedingungen mit
mehreren IIf-Funktionen kann jedoch ein Wechsel zum zellenweisen Modus erfolgen.
Als nächste Überlegung stellt das Modul fest, welchen Wert die Bedingung am meisten verwendet. Dies
hängt vom Standardwert der Bedingung ab. Wenn TRUE der Standardwert der Bedingung ist, dann ist
die THEN-Verzweigung die Standardverzweigung – die Verzweigung, die im überwiegenden Teil des
Teilbereichs ausgewertet wird. Mithilfe einiger einfacher Regeln zur Auswertung der Bedingung kann die
Standardverzweigung bestimmt werden:
In Ausdrücken mit geringer Dichte sind die meisten Zellen leer. Der Standardwert der IsEmptyFunktion für einen Ausdruck mit geringer Dichte ist TRUE.
Der Vergleich mit NULL für einen Ausdruck mit geringer Dichte ist TRUE.
Der Standardwert des IS-Operators ist FALSE.
Wenn die Bedingung nicht im Teilbereichmodus ausgewertet werden kann, ist keine
Standardverzweigung vorhanden.
Einer der häufigsten Verwendungszwecke der IIf-Funktion besteht darin, zu überprüfen, ob der Nenner
ungleich NULL ist:
iif([Measures].[Internet Sales Amount]=0, null, [Measures].[Internet Order
Quantity]/[Measures].[Internet Sales Amount])
Es gibt keine Berechnung für "Internet Sales Amount", die Dichte ist daher gering. Folglich ist TRUE der
Standardwert der Bedingung, und die Standardverzweigung ist die THEN-Verzweigung mit dem NULLAusdruck.
Die folgende Tabelle zeigt, wie jede Verzweigung einer IIf-Funktion ausgewertet wird.
Verzweigungs-Abfrageplan
Verzweigung ist
VerzweigungsStandardverzweigung Ausdrucksdichte
Auswertung
Aufwändig
Nicht zutreffend
Nicht zutreffend
Strict
Nicht aufwändig
TRUE
Nicht zutreffend
Eager
Nicht aufwändig
FALSE
Hohe Dichte
Strict
38
Nicht aufwändig
FALSE
Geringe Dichte
Eager
In SQL Server 2008 Analysis Services kann das Standardverhalten mit Abfragehinweisen außer Kraft
gesetzt werden.
iif(
[<condition>
, <then branch> [hint [Eager | Strict]]
, <else branch> [hint [Eager | Strict]]
)
Wann sollte das Standardverhalten überschrieben werden? Hier finden Sie die häufigsten Szenarien, in
denen Sie das Standardverhalten überschreiben sollten:
Das Modul ermittelt, dass der Abfrageplan für die Bedingung aufwändig ist, und wertet jede
Verzweigung im Strict-Modus aus.
Die Bedingung wird im zellenweisen Modus und jede Verzweigung im Eager-Modus
ausgewertet.
Der Verzweigungsausdruck weist eine hohe Dichte auf, wird jedoch problemlos ausgewertet.
Betrachten Sie z. B. den einfachen Ausdruck weiter unten, der den Umkehrwert eines Measures
verwendet.
with member
measures.x as
iif(
[Measures].[Internet Sales Amount]=0
, null
, (1/[Measures].[Internet Sales Amount]) )
select {[Measures].x} on 0,
[Customer].[Customer Geography].[Country].members *
[Product].[Product Categories].[Category].members on 1
from [Adventure Works]
cell properties value
39
Der Abfrageplan ist nicht aufwändig, die ELSE-Verzweigung ist nicht die Standardverzweigung und der
Ausdruck weist eine hohe Dichte auf, er wird also im Strict-Modus ausgewertet. Dadurch wird das
Modul gezwungen, den Raum zu materialisieren, in dem es ausgewertet wird. Dies wird in SQL Server
Profiler mit ausgewählten Query Subcube Verbose-Ereignissen veranschaulicht, wie in Abbildung 16
dargestellt.
Abbildung 16 Standardmäßige IIf-Abfrageablaufverfolgung
Beachten Sie die Teilcubedefinition für die Product- und Customer-Dimension (Dimension 7 bzw. 8) mit
dem '+'-Indikator für das Country-Attribut und das Category-Attribut. Dies bedeutet, dass mehrere,
jedoch nicht alle Elemente eingeschlossen werden – der Abfrageprozessor hat festgestellt, welche Tupel
die Bedingung erfüllen, den Speicherplatz partitioniert und wertet den Teil für diesen Speicherplatz aus.
Um die Partitionierung des Speicherplatzes durch den Abfrageplan zu verhindern, kann die Abfrage wie
folgt geändert werden (fett angezeigt).
with member
measures.x as
iif(
[Measures].[Internet Sales Amount]=0
, null
, (1/[Measures].[Internet Sales Amount]) hint eager)
select {[Measures].x} on 0,
40
[Customer].[Customer Geography].[Country].members *
[Product].[Product Categories].[Category].members on 1
from [Adventure Works]
cell properties value
Abbildung 17 IIf-Ablaufverfolgung mit MDX-Abfragehinweisen
Jetzt sind dieselben Attribute mit einem '*'-Indikator markiert. Dies bedeutet, dass der Ausdruck über
den gesamten Bereich statt über einen partitionierten Bereich ausgewertet wird.
3.6.2.3 Zwischenspeichern von Teilausdrücken und Zelleigenschaften
Teilausdrücke (Teile eines berechneten Elements oder einer Zuweisung) werden nicht
zwischengespeichert. Wenn ein aufwändiger untergeordneter Ausdruck mehrmals verwendet wird,
sollten Sie daher ein separates berechnetes Element erstellen, das der Abfrageprozessor
zwischenspeichern und wiederverwenden kann. Betrachten Sie das folgende Beispiel.
this = iif(<expensive expression >= 0, 1/<complex expression>, null);
Die wiederholten Teilausdrücke können extrahiert und wie folgt durch ein ausgeblendetes berechnetes
Element ersetzt werden.
create member currentcube.measures.MyPartialExpression as <expensive expression> ,
visible=0;
this = iif(measures.MyPartialExpression >= 0, 1/ measures.MyPartialExpression, null);
41
Nur die Wertzelleneigenschaft wird zwischengespeichert. Falls komplexe Zelleneigenschaften Elemente
wie Blasen-Ausnahmefarben unterstützen müssen, sollten Sie ein separates berechnetes Measure
erstellen; beispielsweise statt:
create member currentcube.measures.[Value] as <exp> , backgroundColor=<complex
expression>;
das folgende:
create member currentcube.measures.MyCellPrope as <complex expression> , visible=0;
create member currentcube.measures.[Value] as <exp> , backgroundColor=<complex
expression>;
3.6.2.4 Vermeiden des Imitierens von Modulfunktionen mit Ausdrücken
Mehrere systemeigene Funktionen können mit MDX imitiert werden:
Unäre Operatoren
Berechnete Spalten in der Datenquellensicht (Data Source View, DSV)
Measureausdrücke
Semiadditive Measures
Sie können alle diese Funktionen in MDX-Skript reproduzieren (in bestimmten Fällen ist dies sogar
erforderlich, da einige nur in der Enterprise-SKU unterstützt werden), dies beeinträchtigt jedoch häufig
die Leistung.
Beispielsweise versuchen distributive unäre Operatoren (Operatoren, deren Elementreihenfolge nicht
relevant ist, wie +, - und ~) im Allgemeinen doppelt so schnell, ihre Möglichkeiten mit Zuweisungen zu
imitieren.
Es gibt seltene Ausnahmen. Beispielsweise lässt sich die Leistung nicht distributiver unärer Operatoren
(Operatoren mit *, / oder numerischen Werten) mit MDX verbessern. Möglicherweise kennen Sie
darüber hinaus spezifische Merkmale Ihrer Daten, um mithilfe einer Abkürzung die Leistung zu
verbessern.
42
3.6.2.5 Entfernen veränderlicher Attribute in Mengenausdrücken
Mengenausdrücke unterstützen keine veränderlichen Attribute. Dies wirkt sich auf alle
Mengenfunktionen wie Filter, Aggregate, Avg und andere aus. Sie können dieses Problem umgehen,
indem Sie invariante Attribute für ein einzelnes Element explizit überschreiben.
In dieser Berechnung werden z. B. für den Verkaufsdurchschnitt nur die Verkäufe im Wert von mehr als
100 Dollar berücksichtigt.
with member measures.AvgSales as
avg(
filter(
descendants([Customer].[Customer Geography].[All Customers],,leaves)
, [Measures].[Internet Sales Amount]>100
)
,[Measures].[Internet Sales Amount]
)
select measures.AvgSales on 0,
[Customer].[Customer Geography].[City].members on 1
from [Adventure Works]
Diese Berechnung dauert auf einem Laptop immerhin 2:29. Der Verkaufsdurchschnitt für alle Kunden
überall hängt jedoch nicht von der aktuellen Stadt ab ("City" ist somit kein veränderliches Attribut). Wir
können "City" als veränderliches Attribut durch Überschreiben für das Alle-Element wie folgt explizit
entfernen.
with member measures.AvgSales as
avg(
filter(
descendants([Customer].[Customer Geography].[All Customers],,leaves)
, [Measures].[Internet Sales Amount]>100
)
43
,[Measures].[Internet Sales Amount]
)
member measures.AvgSalesWithOverWrite as (measures.AvgSales, root([Customer]))
select measures.AvgSalesWithOverWrite on 0,
[Customer].[Customer Geography].[City].members on 1
from [Adventure Works]
Dies dauert nicht einmal eine Sekunde – eine deutliche Änderung der Leistung.
3.6.2.6 Vermeiden der Zuweisung von Werten ungleich NULL zu andernfalls
nicht leeren Zellen
Das Analysis Services-Modul entfernt leere Zeilen sehr effizient. Werden Berechnungen mit Werten
ungleich NULL hinzugefügt, die NULL-Werte ersetzen, kann Analysis Services diese Zeilen nicht
entfernen. Beispielsweise ersetzt diese Abfrage NULL-Werte durch den Bindestrich, und das nicht leere
Schlüsselwort entfernt sie nicht.
with member measures.x as
iif( not isempty([Measures].[Internet Sales Amount]),[Measures].[Internet Sales
Amount],"-")
select descendants([Date].[Calendar].[Calendar Year].&[2004] ) on 0,
non empty [Customer].[Customer Geography].[Customer].members on 1
from [Adventure Works]
where measures.x
non empty bezieht sich auf Zellenwerte und nicht auf formatierte Werte. In seltenen Fällen können
NULL-Werte stattdessen mit der Formatzeichenfolge durch dasselbe Zeichen ersetzt werden, dabei
werden leere Zeilen und Spalten in ungefähr der Hälfte der Zeit entfernt.
with member measures.x as
[Measures].[Internet Sales Amount], FORMAT_STRING = "#.00;(#.00);#.00;-"
select descendants([Date].[Calendar].[Calendar Year].&[2004] ) on 0,
44
non empty [Customer].[Customer Geography].[Customer].members on 1
from [Adventure Works]
where measures.x
Dies kann nur in seltenen Fällen verwendet werden, weil die Abfrage nicht gleichwertig ist – bei der
zweiten Abfrage werden vollständig leere Zeilen entfernt. Wichtiger ist, dass weder Excel noch
Reporting Services das vierte Argument in format_string unterstützen. Weitere Informationen zum
Verwenden der format_string-Berechnungseigenschaft finden Sie unter "FORMAT_STRING Contents
(MDX)" in der SQL Server-Onlinedokumentation unter folgendem Link:
http://msdn.microsoft.com/de-de/library/ms146084.aspx
3.6.2.7 Vermeiden des Aufwands für das Berechnen formatierter Werte
Unter bestimmten Umständen wiegen die Kosten für das Bestimmen der Formatzeichenfolge für einen
Ausdruck die Kosten für den Wert selbst auf. Um festzustellen, ob dies für eine langsam ausgeführte
Abfrage gilt, vergleichen Sie die Ausführungszeit mit und ohne die FORMATTED_VALUEZelleneigenschaft wie in der folgenden Abfrage.
select [Measures].[Internet Average Sales Amount] on 0 from [Adventure Works] cell
properties value
Falls das Ergebnis ohne die Formatierung deutlich schneller ist, wenden Sie die Formatierung wie folgt
direkt im Skript an.
scope([Measures].[Internet Average Sales Amount]);
FORMAT_STRING(this) = "currency";
end scope;
Führen Sie außerdem die Abfrage (mit angewendeter Formatierung) aus, um den Umfang eines
Leistungsvorteils festzustellen.
3.6.2.8 Überlegungen zu geringer/hoher Dichte mit "expr1 * expr2"-Ausdrücken
Platzieren Sie beim Schreiben von Ausdrücken als Produkte von zwei anderen Ausdrücken den Ausdruck
mit der geringeren Dichte auf der linken Seite.
45
Betrachten Sie die folgenden beiden Abfragen, die über die Signatur einer Währungsumrechnung zum
Anwenden des Wechselkurses an Blättern der Date-Dimension in Adventure Works verfügen. Der
einzige Unterschied besteht im Austauschen der Reihenfolge der Ausdrücke im Produkt der
Zellenberechnung. Die Ergebnisse sind gleich, die Verwendung von Internet Sales Amount mit geringerer
Dichte führte jedoch zu Einsparungen von ungefähr 10 %. (Das ist in diesem Fall nicht viel, kann jedoch
in anderen Fällen erheblich mehr sein. Die Einsparungen hängen von der relativen Dichte zwischen den
beiden Ausdrücken ab, und die Leistungsvorteile können variieren).
Geringe Dichte zuerst
with cell CALCULATION x for '({[Measures].[Internet Sales Amount]},leaves([Date]))'
as
[Measures].[Internet Sales Amount] *
([Measures].[Average Rate],[Destination Currency].[Destination Currency].&[EURO])
select
non empty [Date].[Calendar].members on 0,
non empty [Product].[Product Categories].members on 1
from [Adventure Works]
where ([Measures].[Internet Sales Amount], [Customer].[Customer Geography].[StateProvince].&[BC]&[CA])
Hohe Dichte zuerst
with cell CALCULATION x for '({[Measures].[Internet Sales Amount]},leaves([Date]))'
as
([Measures].[Average Rate],[Destination Currency].[Destination Currency].&[EURO])*
[Measures].[Internet Sales Amount]
select
non empty [Date].[Calendar].members on 0,
non empty [Product].[Product Categories].members on 1
from [Adventure Works]
46
where ([Measures].[Internet Sales Amount], [Customer].[Customer Geography].[StateProvince].&[BC]&[CA])
3.6.2.9 Vergleichen von Objekten und Werten
Verwenden Sie IS, um zu bestimmen, ob das aktuelle Element oder Tupel ein bestimmtes Objekt ist.
Beispielsweise ist die folgende Abfrage nicht nur nicht leistungsfähig, sondern falsch. Sie erzwingt eine
unnötige Zellenauswertung und vergleicht Werte statt Elemente.
[Customer].[Customer Geography].[Country].&[Australia] = [Customer].[Customer
Geography].currentmember
Führen Sie darüber hinaus beim Ableiten, ob CurrentMember ein bestimmtes Element ist, keine
zusätzlichen Schritte aus, indem Sie Intersect und Counting einschließen.
intersect({[Customer].[Customer Geography].[Country].&[Australia]},
[Customer].[Customer Geography].currentmember).count > 0
Führen Sie diese Abfrage aus.
[Customer].[Customer Geography].[Country].&[Australia] is [Customer].[Customer
Geography].currentmember
3.6.2.10
Auswerten der Mengenmitgliedschaft
Mit Intersect kann am besten bestimmt werden, ob sich ein Element oder Tupel in einer Menge
befindet. Mit der Rank-Funktion wird der zusätzliche Vorgang zum Bestimmen der Position dieses
Objekts in der Menge ausgeführt. Verwenden Sie diese Funktion nicht, wenn Sie sie nicht benötigen.
Führen Sie beispielsweise statt
rank( [Customer].[Customer Geography].[Country].&[Australia],
<set expression> )>0
Folgendes aus
47
intersect({[Customer].[Customer Geography].[Country].&[Australia]}, <set> ).count > 0
3.6.2.11
Verschieben von Berechnungen zum relationalen Modul
In einigen Fällen können Berechnungen zum relationalen Modul verschoben und mit weitaus besserer
Leistung als einfache Aggregate verarbeitet werden. Hier gibt es keine einzelne Lösung. Wenn jedoch
Leistungsprobleme auftreten, sollten Sie überlegen, wie die Berechnung statt der Auswertung bei der
Abfrage in der Quelldatenbank oder DSV aufgelöst und vorab gefüllt werden kann.
Statt z. B. Ausdrücke wie Sum(Customer.City.Members,
cint(Customer.City.Currentmember.properties(“Population”))) zu schreiben, sollten Sie eine separate
Measuregruppe für die Tabelle "City" mit einem Summenmeasure für die Spalte "Population"
definieren.
Als zweites Beispiel können Sie das Produkt von revenue * Products Sold an Blättern berechnen und mit
Berechnungen aggregieren. Bei der Berechnung dieses Ergebnisses in der Quelldatenbank oder in der
DSV wird eine außerordentlich hohe Leistung erzielt.
3.6.2.12
NON_EMPTY_BEHAVIOR
In einigen Fällen ist die Berechnung des Ergebnisses eines Ausdrucks aufwändig, selbst wenn wir
basierend auf dem Wert eines Indikatortupels im Voraus wissen, dass es NULL ist. Die
NONEMPTY_BEHAVIOR-Eigenschaft war in einigen Fällen für diese Art von Berechnungen hilfreich.
Wenn die Auswertung dieser Eigenschaft NULL ergab, war der Ausdruck garantiert NULL und (in den
meisten Fällen) umgekehrt.
Diese Eigenschaft erbrachte in früheren Versionen häufig erhebliche Leistungsverbesserungen. In SQL
Server 2008 wird die Eigenschaft häufig ignoriert (da das Modul in vielen Fällen automatisch mit nicht
leeren Zellen umgeht) und kann in einigen Fällen zu einer verminderten Leistung führen. Entfernen Sie
sie aus dem MDX -Skript und fügen Sie sie wieder hinzu, nachdem der Leistungstest eine Verbesserung
ergibt.
Für Zuweisungen wird die Eigenschaft wie folgt verwendet.
this = <e1>;
Non_Empty_Behavior(this) = <e2>;
Für berechnete Elemente im MDX-Skript wird die Eigenschaft folgendermaßen verwendet.
create member currentcube.measures.x as <e1>, non_empty_behavior = <e2>
48
In SQL Server 2005 Analysis Services gab es komplexe Regeln für das Definieren der Eigenschaft, wenn
sie vom Modul verwendet oder ignoriert wurde, und für die Verwendung durch das Modul. In SQL
Server 2008 Analysis Services hat sich das Verhalten dieser Eigenschaft geändert:
Es ist weiterhin garantiert, dass, wenn NON_EMPTY_BEHAVIOR NULL ist, der Ausdruck auch
NULL sein muss. (Falls dies nicht zutrifft, können immer noch falsche Abfrageergebnisse
zurückgegeben werden.)
Der umgekehrte Fall gilt jedoch nicht unbedingt; d. h., der NON_EMPTY_BEHAVIOR-Ausdruck
kann ein Ergebnis ungleich NULL zurückgeben, wenn der ursprüngliche Ausdruck NULL ist.
Das Modul ignoriert diese Eigenschaft in den meisten Fällen und leitet das Verhalten für nicht
leere Elemente des Ausdrucks selbst ab.
Wird die Eigenschaft durch das Modul definiert und angewendet, dann ist sie semantisch gleichwertig
(jedoch nicht gleichwertig hinsichtlich der Leistung) mit dem folgenden Ausdruck.
this = <e1> * iif(isempty(<e2>), null, 1)
Die NON_EMPTY_BEHAVIOR-Eigenschaft wird verwendet, wenn <e2> eine geringe Dichte und <e1> eine
hohe Dichte aufweist oder <e1> im naiven zellenweisen Modus ausgewertet wird. Wenn diese
Bedingungen nicht erfüllt werden und sowohl <e1> als auch <e2> eine geringe Dichte aufweisen (z. B.
<e2> eine viel geringere Dichte als <e1> aufweist), kann eine verbesserte Leistung durch Erzwingen des
Verhaltens wie folgt erzielt werden.
this = iif(isempty(<e2>), null, <e1>);
Die NON_EMPTY_BEHAVIOR-Eigenschaft kann als einfacher Tupelausdruck mit einfachen
Elementnavigationsfunktionen wie .prevmember oder .parent oder als aufgelistete Menge ausgedrückt
werden. Eine aufgelistete Menge ist gleichwertig mit NON_EMPTY_BEHAVIOR der resultierenden
Summe.
3.7 Cachevorbereitung
Bei Abfragen wird der Arbeitsspeicher in erster Linie zum Speichern zwischengespeicherter Ergebnisse
im Speichermodul- und Abfrageprozessorcache verwendet. Zum Optimieren der Vorteile des
Zwischenspeicherns können Sie häufig die Antwortzeiten für Abfragen durch das Vorabladen von Daten
in einen oder beide Caches verbessern. Dies kann entweder durch vorheriges Ausführen einer oder
mehrerer Abfragen oder mit der CREATE CACHE-Anweisung erreicht werden. Dieser Prozess wird als
Cachevorbereitung bezeichnet.
Die beiden Mechanismen sind ähnlich, obwohl die CREATE CACHE-Anweisung den Vorteil hat, dass keine
Zellenwerte zurückgegeben werden und sie im Allgemeinen schneller ausgeführt wird, da der
Abfrageprozessor umgangen wird.
Die Ermittlung der Elemente für die Zwischenspeicherung kann schwierig sein. Ein Ansatz besteht darin,
eine Ablaufverfolgung bei der Ausführung der Abfrage und der Überprüfung von Teilcubeereignissen
auszuführen. Das Auffinden vieler Teilcubeanforderungen derselben Granularität zeigt an, dass der
49
Abfrageprozessor viele Anforderungen für leicht unterschiedliche Daten ausführt. Als Ergebnis führt das
Speichermodul viele kleine, aber zeitaufwändige E/A-Anforderungen aus, statt die Daten effizienter
massenhaft abzurufen und dann Ergebnisse aus dem Cache zurückzugeben.
Zur Vorabausführung von Abfragen können Sie eine Anwendung erstellen, die eine Menge
verallgemeinerter Abfragen ausführt, um typische Benutzeraktivitäten zur Beschleunigung des Prozesses
zum Auffüllen des Caches zu simulieren. Wenn Sie z. B. feststellen, dass Benutzer Abfragen nach Monat
und nach Produkt ausführen, können Sie eine Menge von Abfragen erstellen, die Daten nach Produkt
und nach Monat anfordern. Wenn Sie diese Abfrage beim Starten von Analysis Services bzw. beim
Verarbeiten der Measuregruppe oder einer ihrer Partitionen ausführen, wird der Abfrageergebniscache
vorab mit Daten zum Auflösen dieser Abfragen geladen, bevor Benutzer diese Typen von Abfragen
übermitteln. Durch diese Technik werden die Antwortzeiten von Analysis Services auf von dieser Menge
von Abfragen erwartete Benutzerabfragen deutlich verbessert.
Zum Feststellen einer Menge verallgemeinerter Abfragen können Sie mit dem Analysis ServicesAbfrageprotokoll die in der Regel durch Benutzerabfragen abgefragten Dimensionsattribute feststellen.
Mit einer Anwendung wie einem Microsoft Excel-Makro oder einer Skriptdatei können Sie den Cache
vorbereiten, wenn Sie einen Vorgang ausgeführt haben, der den Abfrageergebniscache leert. Diese
Anwendung könnte z. B. am Ende des Cubeverarbeitungsschritts automatisch ausgeführt werden.
Beim Testen der Effektivität verschiedener Cachevorbereitungsabfragen sollten Sie den
Abfrageergebniscache zwischen den einzelnen Tests leeren, um die Gültigkeit der Tests sicherzustellen.
Beachten Sie, dass die zwischengespeicherten Ergebnisse durch andere Abfrageergebnisse verschoben
werden können. Möglicherweise müssen die Ergebnisse im Cache nach einem bestimmten Zeitplan
aktualisiert werden. Beschränken Sie außerdem die Cachevorbereitung entsprechend der Kapazität im
Arbeitsspeicher, um weitere Abfragen zwischenspeichern zu können.
Aggressives Scannen von Daten
Möglicherweise werden bei der Auswertung eines Ausdrucks mehr Daten angefordert, als zum
Bestimmen des Ergebnisses erforderlich sind.
Wenn Sie vermuten, dass mehr Daten als erforderlich abgerufen werden, können Sie mithilfe von SQL
Server Profiler diagnostizieren, wie eine Abfrage für Teilcubeabfrageereignisse und Partitionsscans
verarbeitet wird. Überprüfen Sie für Teilcubescans das Subcube Verbose-Ereignis und ob mehr Elemente
als erforderlich vom Speichermodul abgerufen werden. Bei kleinen Cubes ist dies wahrscheinlich kein
Problem. Bei größeren Cubes mit mehreren Partitionen kann dies die Abfrageleistung deutlich
beeinträchtigen. Die folgende Abbildung veranschaulicht, wie ein einzelnes Abfrageteilcubeereignis zu
Scans von Partitionen führt.
50
Abbildung 18 Aggressives Scannen von Partitionen
Es gibt dazu zwei Lösungsmöglichkeiten. Enthält ein Berechnungsausdruck eine willkürliche Form (diese
wird im Abschnitt zum Abfrageprozessorcache definiert), kann der Abfrageprozessor unter Umständen
nicht feststellen, dass die Daten auf eine Partition beschränkt sind und Daten von allen Partitionen
anfordern. Versuchen Sie, die willkürliche Form zu vermeiden.
In anderen Fällen ist der Abfrageprozessor beim Anfordern von Daten einfach übermäßig aggressiv. Bei
kleinen Cubes spielt dies keine Rolle, bei sehr großen Cubes dagegen schon. Wenn Sie dieses Verhalten
beobachten, wenden Sie sich an den Kundenservice und -support von Microsoft, um weitere Hinweise
zu erhalten.
3.8 Verbessern der Mehrbenutzerleistung
In vielen Fällen lässt sich eine schlechte Mehrbenutzerleistung auf eine schlechte Einzelbenutzerleistung
zurückführen. Dies trifft jedoch nicht immer zu. In einigen Fällen nutzt Analysis Services beim Skalieren
der Anzahl von Benutzern nicht alle Ressourcen auf dem Computer. Es gibt einige Optionen zur
Steigerung der Leistung.
3.8.1 Erhöhen der Abfrageparallelität
Bei Abfragen verwendet Analysis Services zum Verwalten von Clientverbindungen einen
Überwachungsthread, um Anforderungen zu brokern und bei Bedarf neue Serververbindungen zu
erstellen. Zum Erfüllen von Abfrageanforderungen verwaltet der Überwachungsthread Arbeitsthreads
im Abfragethreadpool und Verarbeitungsthreadpool, weist bestimmten Anforderungen Arbeitsthreads
zu, initiiert neue Arbeitsthreads, wenn in einem bestimmten Pool nicht genügend aktive Arbeitsthreads
vorhanden sind, und beendet bei Bedarf im Leerlauf befindliche Arbeitsthreads.
Zum Erfüllen einer Abfrageanforderung werden die Threadpools wie folgt verwendet:
51
Arbeitsthreads vom Abfragepool überprüfen die Daten bzw. Berechnungscaches für alle zu einer
Clientanforderung gehörenden Daten und/oder Berechnungen.
Gegebenenfalls werden Arbeitsthreads vom Verarbeitungspool zugeordnet, um Daten vom
Datenträger abzurufen.
Nachdem Daten abgerufen wurden, speichern Arbeitsthreads vom Abfragepool die Ergebnisse
im Abfragecache, um zukünftige Abfragen aufzulösen.
Arbeitsthreads vom Abfragepool führen erforderliche Berechnungen aus und verwenden einen
Berechnungscache zum Speichern von Berechnungsergebnissen.
Je mehr Threads zum Beantworten von Anfragen verfügbar sind, desto mehr Abfragen können parallel
ausgeführt werden. Dies ist besonders wichtig in Szenarien mit einer großen Anzahl von Benutzern, die
Abfragen ausführen.
Threadpool\Query\MaxThreads legt die maximale Anzahl von Arbeitsthreads fest, die im
Abfragethreadpool verwaltet werden. Der Standardwert dieser Eigenschaft ist entweder 10 oder 2x die
Anzahl der Kerne (dies ist ein Unterschied zu SQL Server 2005, überprüfen Sie daher diesen Wert für
aktualisierte Instanzen). Durch das Erhöhen von Threadpool\Query\MaxThreads wird die Leistung einer
bestimmten Abfrage nicht erheblich gesteigert. Der Vorteil des Erhöhens dieser Eigenschaft besteht
vielmehr darin, dass die Anzahl gleichzeitig verarbeitbarer Abfragen erhöht werden kann.
Da Abfragen auch das Abrufen von Daten von Partitionen umfassen, müssen Sie außerdem die im
Verarbeitungspool verfügbare maximale Anzahl von Threads berücksichtigen, wie von der
Threadpool\Process\MaxThreads-Eigenschaft angegeben. Standardmäßig ist der Wert dieser
Eigenschaft 64 in SQL Server 2005. Dieser Wert hat sich in SQL Server 2008 in 64 oder 10x die Anzahl der
Kerne geändert, je nachdem, welcher Wert größer ist (dies ist auch der gegenwärtig empfohlene Wert).
Beachten Sie bei den Szenarien für das Ändern der Threadpool\Process\MaxThreads-Eigenschaft, dass
sich Änderungen dieser Einstellung auf den Verarbeitungsthreadpool für Abfragen und für die
Verarbeitung auswirken. Weitere Informationen dazu, wie sich diese Eigenschaft speziell auf
Verarbeitungsvorgänge auswirkt, finden Sie unter Anpassen von Threadeinstellungen.
Während Änderungen der Threadpool\Process\MaxThreads-Eigenschaft und der
Threadpool\Query\MaxThreads-Eigenschaft den Parallelitätseffekt bei Abfragen steigern kann, müssen
auch die zusätzlichen Auswirkungen von CoordinatorExecutionMode berücksichtigt werden. Betrachten
Sie das folgende Beispiel. Wenn Sie auf einem Server mit vier Prozessoren die Standardeinstellung von 4 für CoordinatorExecutionMode übernehmen, können für alle Servervorgänge insgesamt 16 Aufträge
gleichzeitig ausgeführt werden. Werden also zehn Abfragen parallel ausgeführt und insgesamt
20 Aufträge benötigt, können jeweils immer nur 16 Aufträge gestartet werden (vorausgesetzt, dass zu
dieser Zeit keine Verarbeitungsvorgänge ausgeführt werden). Beim Erreichen des
Auftragsschwellenwertes warten nachfolgende Aufträge in einer Warteschlange, bis ein neuer Auftrag
erstellt werden kann. Wenn die Anzahl der Aufträge der Engpass für den Vorgang ist, wird folglich durch
Erhöhen der Anzahl von Threads nicht unbedingt die Gesamtleistung verbessert.
In der Praxis kann der Ausgleich von Aufträgen und Threads schwierig sein. Wenn der Parallelitätseffekt
gesteigert werden soll, muss der größte Engpass für die Parallelität bewertet werden, z. B. die Anzahl
gleichzeitiger Aufträge und/oder die Anzahl gleichzeitiger Threads oder beides. Um dies zu bestimmen,
überprüfen Sie die folgenden Leistungsindikatoren:
52
Threads\Warteschlangenlänge für Aufträge im Abfragepool: Die Anzahl von Aufträgen in der
Warteschlange des Abfragethreadpools. Ein Wert ungleich NULL bedeutet, dass die Anzahl von
Abfrageaufträgen die Anzahl verfügbarer Abfragethreads überschritten hat. In diesem Szenario
sollten Sie die Anzahl von Abfragethreads erhöhen. Ist jedoch die CPU-Auslastung bereits sehr
hoch, führt eine erhöhte Anzahl von Threads nur zu Kontextwechseln und einer beeinträchtigten
Leistung.
Threads\Ausgelastete Threads im Abfragepool: Die Anzahl ausgelasteter Threads im
Abfragethreadpool.
Threads\Im Leerlauf befindliche Threads im Abfragepool: Die Anzahl im Leerlauf befindlicher
Threads im Abfragethreadpool.
Weitere Informationen finden Sie unter
http://www.microsoft.com/technet/prodtechnol/sql/bestpractice/ssasqptb.mspx.
3.8.2 Speicherheaptyp
Der Mehrbenutzerdurchsatz kann durch Verwendung des Windows-Heaps statt des Analysis ServicesHeaps verbessert werden. Diese Steigerung beim Durchsatz kann zu geringen, aber messbaren Kosten
bei Einzelbenutzerabfragen führen. Beim Mehrbenutzerdurchsatz wurden jedoch Verbesserungen um
bis zu 100 % gemessen (dies bedeutet die Verwaltung doppelt so vieler Abfragen im selben Zeitraum).
Die deutlichen Vorteile beim Mehrbenutzerdurchsatz wiegen in der Regel die Kosten bei der
Einzelbenutzerleistung auf. Ändern Sie die folgenden Parameter, um den NTLFH-Heap-Manager anstelle
des OLAP-Heap-Managers zu verwenden.
Einstellung
MemoryHeapType
HeapTypeForObjects
Standardwert
1
1
Mehrere Benutzer
2
0
3.8.3 Blockieren von Abfragen mit langer Ausführungszeit
In Mehrbenutzerszenarien können Abfragen mit langer Ausführungszeit andere Abfragen ausschließen –
sogar Abfragen mit kürzerer Ausführungszeit –, indem sie alle verfügbaren Threads beanspruchen.
Außerdem können sie die Ausführung anderer Abfragen blockieren, bis die Abfrage mit längerer
Ausführungszeit abgeschlossen wurde. Die Aggressivität, mit der jeder Koordinatorauftrag Abfragen
verwendet, kann durch Ändern der Methode für die Aufnahme jedes Segmentauftrags in die
Warteschlange reduziert werden. Wie unter Datenabruf erläutert, wird jeder Segmentauftrag sofort in
die Warteschlange aufgenommen, bevor der vorherige Segmentauftrag das Scannen von Daten startet.
Sie können dieses Verhalten ändern, um Segmentaufträge zu serialisieren, indem Sie die folgenden
Einstellungen verwenden.
Einstellung
Standardwert
CoordinatorQueryBalancingFactor
-1
CoordinatorQueryBoostPriorityLevel 3
53
Nicht blockierende
Einstellungen für mehrere
Benutzer
1
0
Beachten Sie dabei, dass diese Einstellungen zwar das Blockieren von Abfragen mit kürzerer
Ausführungszeit durch Abfragen mit längerer Ausführungszeit reduzieren oder beenden, jedoch auch
den Gesamtdurchsatz verringern. Wenden Sie sich an den Kundenservice und -support von Microsoft,
wenn nach dem Ändern dieser Einstellungen weiterhin blockierende Abfragen auftreten.
3.8.4 Netzwerklastenausgleich und schreibgeschützte Datenbanken
Obwohl sie über den Rahmen dieses Dokuments hinausgehen, können grundlegende
Entwurfsänderungen zum Behandeln von Abfrageproblemen genutzt werden und werden hier kurz
erläutert.
3.8.4.1 Netzwerklastenausgleich
Wenn die Prozessorauslastung in einem einzelnen System als Ergebnis einer MehrbenutzerabfrageArbeitsauslastung der Leistungsengpass ist, kann mit einem Cluster von Analysis Services-Servern zum
Verarbeiten von Abfrageanforderungen die Abfrageleistung verbessert werden. An Anforderungen kann
ein Lastenausgleich über zwei Analysis Services-Server oder über eine größere Anzahl von Analysis
Services-Servern vorgenommen werden, um eine große Anzahl gleichzeitiger Benutzer zu unterstützen
(dies wird als Serverfarm bezeichnet). Bei Lastenausgleichsclustern nimmt die Leistung in der Regel
linear zu. Sowohl Microsoft als auch Drittanbieter stellen Clusterlösungen bereit. Die
Lastenausgleichslösung von Microsoft ist Netzwerklastenausgleich (Network Load Balancing, NLB), eine
Funktion des Windows Server®-Betriebssystems. Mit NLB kann ein NLB-Cluster von Analysis ServicesServern erstellt werden, der im Mehrhostmodus ausgeführt wird. Wenn ein NLB-Cluster von Analysis
Services-Servern im Mehrhostmodus ausgeführt wird, wird an eingehenden Anforderungen ein
Lastenausgleich zwischen Analysis Services-Servern ausgeführt. Beachten Sie bei der Verwendung eines
Lastenausgleichsclusters, dass die Datencaches für jeden Server im Lastenausgleichscluster verschieden
sind, was bei Abfragen durch denselben Client zu unterschiedlichen Abfrageantwortzeiten führt.
Mit einem Lastenausgleichscluster kann außerdem die Verfügbarkeit für den Fall sichergestellt werden,
dass ein einzelner Analysis Services-Server ausfällt. Eine zusätzliche Optionen zum Steigern der Leistung
mit einem Lastenausgleichscluster ist die Verteilung von Verarbeitungstasks an einen Offlineserver.
Nach der Verarbeitung neuer Daten auf dem Offlineserver können die Analysis Services-Server im
Lastenausgleichscluster mithilfe der Analysis Services-Datenbanksynchronisierung aktualisiert werden.
Wenn die Benutzer viele Abfragen übermitteln, die Faktendatenscans erfordern, kann ein
Lastenausgleichscluster eine gute Lösung darstellen. Abfragen, die eine große Anzahl von
Faktendatenscans erfordern können, umfassen z. B. umfangreiche Abfragen (wie Anzahl erste Daten
oder Mediane) und Zufallsabfragen für sehr komplexe Cubes, bei denen die Wahrscheinlichkeit von
Aggregationstreffern sehr gering ist.
Im Allgemeinen ist ein Lastenausgleichscluster zum Steigern der Analysis Services-Leistung jedoch nicht
erforderlich, wenn die meisten Abfragen mit Aggregationen aufgelöst werden. Konzentrieren Sie sich
also zuerst auf einen guten Aggregations- und Partitionierungsentwurf. Außerdem wird das
Leistungsproblem nicht durch einen Lastenausgleichscluster gelöst, wenn die Verarbeitung den Engpass
darstellt oder wenn Sie versuchen, eine einzelne Abfrage von einem einzelnen Benutzer zu verbessern.
54
Eine Einschränkung bei der Nutzung eines Lastenausgleichsclusters ist die Nichtverwendbarkeit des
Rückschreibens, da für das Rückschreiben der Daten kein einzelner Server vorhanden ist.
3.8.4.2 Schreibgeschützte Datenbanken
Als Neuigkeit in SQL Server 2008 kann eine Datenbank als schreibgeschützt markiert und von mehreren
Instanzen von Analysis Services verwendet werden. Mehrere Instanzen von Analysis Services können
also ein einzelnes Datenverzeichnis gemeinsam nutzen (das sich in der Regel in einem SAN befindet).
Diese Option sollte berücksichtigt werden, wenn die Mehrbenutzerarbeitsauslastung für
Speichermodulanforderungen niedrig, für den Abfrageprozessor jedoch hoch ist. Analysis Services
unterstützt zwar mehrere Instanzen, die auf denselben Datenordner verweisen, die Verwaltung von
Benutzersitzungen für diese Instanzen liegt jedoch bei der Anwendung.
4 Verstehen und Messen der Verarbeitung
Die folgenden Abschnitte bieten eine Anleitung zum Optimieren der Verarbeitung von Cubes. Bei der
Verarbeitung werden Daten aus einer oder mehreren Datenquellen in ein oder mehrere Analysis
Services-Objekte geladen. Während OLAP-Systeme in der Regel nicht danach beurteilt werden, wie
schnell sie Daten verarbeiten, wirkt sich die Verarbeitungsleistung darauf aus, wie schnell neue Daten
für Abfragen verfügbar sind. Für jede Anwendung gelten zwar unterschiedliche Anforderungen für die
Datenaktualisierung von monatlichen Aktualisierungen bis hin zu Datenaktualisierungen nahezu in
Echtzeit, aber je höher die Verarbeitungsleistung ist, desto früher können Benutzer aktualisierte Daten
abfragen.
Analysis Services stellt mehrere Verarbeitungsbefehle bereit, die eine genaue Steuerung der
Datenladevorgänge und der Aktualisierungsfrequenz von Cubes ermöglichen.
4.1 Verarbeitungsauftrag (Übersicht)
Zur Verwaltung von Verarbeitungsvorgängen verwendet Analysis Services zentral gesteuerte Aufträge.
Ein Verarbeitungsauftrag ist eine von einer Verarbeitungsanforderung erzeugte generische
Arbeitseinheit.
In Bezug auf die Architektur kann ein Auftrag in übergeordnete und untergeordnete Aufträge unterteilt
werden. Für ein bestimmtes Objekt können je nach der Position des Objekts in der OLAPDatenbankhierarchie mehrere Ebenen geschachtelter Aufträge vorhanden sein. Anzahl und Typ
übergeordneter und untergeordneter Aufträge richten sich nach 1) dem zu verarbeitenden Objekt wie
Dimension, Cube, Measuregruppe oder Partition und 2) dem angeforderten Verarbeitungsvorgang wie
ProcessFull, ProcessUpdate oder ProcessIndexes.
Wenn Sie z. B. einen ProcessFull-Vorgang für eine Measuregruppe ausgeben, wird ein übergeordneter
Auftrag für die Measuregruppe mit untergeordneten Aufträgen für jede Partition erstellt. Für jede
Partition werden mehrere untergeordnete Aufträge erzeugt, um den ProcessFull-Vorgang für die
Faktendaten und Aggregationen auszuführen. Darüber hinaus implementiert Analysis Services
55
Abhängigkeiten zwischen Aufträgen. Beispielsweise sind Cubeaufträge von Dimensionsaufträgen
abhängig.
Die wichtigsten Gelegenheiten zum Optimieren der Leistung betreffen die Verarbeitungsaufträge für die
Kernverarbeitungsobjekte: Dimensionen und Partitionen. Beide haben einen eigenen Abschnitt in
diesem Handbuch.
Zusätzliche Hintergrundinformationen zur Verarbeitung finden Sie im technischen Hinweis Analysis
Services 2005 Processing Architecture.
4.2 Verarbeiten von Basislinien
Erstellen Sie zuerst eine Basislinie, um die Auswirkungen der Optimierungs- und Diagnoseprobleme zu
bestimmen. Mithilfe der Basislinie können Sie die Ursachen von Problemen analysieren und die
Optimierungsmaßnahmen entsprechend ausrichten.
In diesem Abschnitt wird beschrieben, wie die Basislinie eingerichtet wird.
4.2.1 Systemmonitor-Ablaufverfolgung
Windows-Leistungsindikatoren sind die wichtigsten Grundlagen der Leistungsoptimierung von Analysis
Services. Richten Sie mit dem Tool perfmon eine Ablaufverfolgung mit diesen Leistungsindikatoren ein:
56
MSOLAP: Verarbeitung
o Gelesene Zeilen/Sekunde
MSOLAP: Prozeduraggregationen
o Geschriebene Temp-Datei-Bytes/Sekunde
o Erstellte Zeilen/Sekunde
o Aktuelle Partitionen
MSOLAP: Threads
o Im Leerlauf befindliche Threads im Verarbeitungspool
o Warteschlangenlänge für Aufträge im Verarbeitungspool
o Ausgelastete Threads im Verarbeitungspool
MSSQL: Speicher-Manager
o Serverspeicher gesamt
o Zielserverspeicher
Prozess
o Virtuelle Bytes – msmdsrv.exe
o Arbeitsseiten – msmdsrv.exe
o Private Bytes – msmdsrv.exe
o % Prozessorzeit – msmdsrv.exe und sqlservr.exe
Logischer Datenträger:
o Mittlere Sek./Übertragung – Alle Instanzen
Prozessor:
o % Prozessorzeit – Gesamt
System:
o Kontextwechsel/Sekunde
Konfigurieren Sie die Ablaufverfolgung so, dass die Daten in einer Datei gespeichert werden. Beim
Optimieren der Verarbeitung reicht es aus, alle 15 Sekunden zu messen.
Messen Sie beim Optimieren diese Leistungsindikatoren nach jeder Änderung erneut, um festzustellen,
ob Sie sich Ihrem Leistungsziel nähern. Beachten Sie auch die für die Verarbeitung benötigte Gesamtzeit.
Die Verwendung und Interpretation der einzelnen Indikatoren werden in den nachfolgenden
Abschnitten erläutert.
4.2.2 Profiler-Ablaufverfolgung
Führen Sie zum Optimieren der SQL-Abfragen, die einen Teil der Verarbeitung bilden, auch eine
Ablaufverfolgung für die relationale Datenbank aus. Verwenden Sie dazu SQL Server Profiler, wenn SQL
Server die relationale Datenbank ist. Wenn Sie nicht SQL Server verwenden, wenden Sie sich an den
jeweiligen Datenbankhersteller, um Hilfe zum Optimieren der Datenbank zu erhalten. Nachfolgend wird
angenommen, dass SQL Server als relationale Datenbank für Analysis Services verwendet wird.
Erfassen Sie in der SQL Server Profiler-Ablaufverfolgung auch folgende Ereignisse:
Performance/Showplan XML Statistics Profile
TSQL/SQL:BatchCompleted
Schließen Sie die folgenden Ereignisspalten ein:
TextData
Reads
DatabaseName
SPID
Duration
Sie können die Vorlage Tuning verwenden und einfach die Spalte Reads und Showplan XML Statistics
Profiles hinzufügen. Konfigurieren Sie die Ablaufverfolgung ähnlich wie die perfmon-Ablaufverfolgung
so, dass sie zur späteren Analyse in einer Datei gespeichert wird.
Konfigurieren Sie die SQL Server Profiler-Ablaufverfolgung so, dass sie in einer Tabelle statt einer Datei
protokolliert wird. Dadurch können die Ablaufverfolgungen später einfacher korreliert werden.
Die von diesen Ablaufverfolgungen erfassten Leistungsdaten werden im folgenden Abschnitt zum
Optimieren der Verarbeitung verwendet.
4.3 Ermitteln der Vorgänge, bei denen Verarbeitungszeit aufgewendet wird
Zum korrekten Ausrichten der Verarbeitungsoptimierung sollten Sie zuerst ermitteln, wo die Zeit
aufgewendet wird: bei der Partitionsverarbeitung oder der Dimensionsverarbeitung. Da Dimensionen
57
vor Partitionen verarbeitet werden, lässt sich einfach messen, wie viel Zeit für Dimensionen
aufgewendet wird.
Unterscheiden Sie bei der Partitionsverarbeitung zwischen ProcessData und ProcessIndex – die
jeweiligen Optimierungstechniken sind sehr verschieden. Wenn Sie die von uns empfohlene bewährte
Methode befolgen, zuerst ProcessData gefolgt von ProcessIndex statt ProcessFull auszuführen, lässt
sich die aufgewendete Zeit einfach ablesen.
Wenn Sie ProcessFull verwenden, statt eine Aufteilung in ProcessData und ProcessIndex vorzunehmen,
erhalten Sie eine Vorstellung davon, wann jede Phase endet, indem Sie die folgenden PerfmonLeistungsindikatoren beobachten:
Während ProcessData ist der Leistungsindikator MSOLAP:Verarbeitung – Gelesene
Zeilen/Sekunde größer als NULL.
Während ProcessIndex ist der Leistungsindikator MSOLAP:Prozeduraggregationen – Erstellte
Zeilen/Sekunde größer als NULL.
ProcessData kann weiter in die durch den SQL Server-Prozess aufgewendete Zeit und die durch den
Analysis Services-Prozess aufgewendete Zeit aufgeteilt werden. Mithilfe der erfassten ProzessLeistungsindikatoren können Sie ermitteln, wo die meiste CPU-Zeit aufgewendet wird.
5 Verbessern der Leistung der Dimensionsverarbeitung
Das Leistungsziel der Dimensionsverarbeitung ist die Aktualisierung von Dimensionsdaten mit einer
effizienten Methode, die sich nicht negativ auf die Abfrageleistung abhängiger Partitionen auswirkt. Die
folgenden Techniken zum Erreichen dieses Ziels werden in diesem Abschnitt erläutert:
Optimieren von SQL-Quellenabfragen
Reduzieren des Aufwands für Attribute
Dieser Abschnitt enthält außerdem Informationen zur Dimensionsverarbeitungsarchitektur.
5.1 Grundlegendes zur Dimensionsverarbeitungsarchitektur
Bei der Verarbeitung von MOLAP-Dimensionen werden Aufträge zum Extrahieren, Indizieren und
permanenten Speichern von Daten in mehreren Dimensionsspeichern verwendet.
Zum Erstellen dieser Dimensionsspeicher verwendet das Speichermodul die in Abbildung 19
dargestellten Aufträge.
58
Abbildung 19 Aufträge zur Dimensionsverarbeitung
Erstellen von Attributspeichern
Für jedes Attribut in einer Dimension wird ein Auftrag instanziiert, um die Attributelemente zu
extrahieren und in einem Attributspeicher permanent zu speichern. Der Attributspeicher besteht aus
dem Schlüsselspeicher, Namensspeicher und Beziehungsspeicher.
Da der Beziehungsspeicher Informationen zu abhängigen Attributen enthält, ist das Sortieren der
Verarbeitungsaufträge erforderlich. Zum Bereitstellen des richtigen Workflows analysiert das
Speichermodul die Abhängigkeiten zwischen Attributen und erstellt dann eine Ausführungsstruktur mit
der richtigen Sortierung. Mithilfe der Ausführungsstruktur wird dann die beste parallele Ausführung der
Dimensionsverarbeitung festgelegt.
Abbildung 20 stellt eine Beispielausführungsstruktur für eine Time-Dimension dar. Die durchgezogenen
Pfeile stellen die Attributbeziehungen in der Dimension dar. Die gestrichelten Pfeile stellen die implizite
Beziehung jedes Attributs zum Alle-Attribut dar.
Hinweis: Die Dimension wurde mit kaskadierenden Attributbeziehungen konfiguriert, eine bewährte
Methode für alle Dimensionsentwürfe.
59
Abbildung 20 Beispiel einer Ausführungsstruktur
In diesem Beispiel wird das Alle-Attribut zuerst verarbeitet, falls keine Abhängigkeiten zu einem anderen
Attribut bestehen, gefolgt vom Fiscal Year-Attribut und Calendar Year-Attribut, die parallel verarbeitet
werden können. Die weiteren Attribute folgen entsprechend der Abhängigkeiten in der
Ausführungsstruktur. Dabei wird das Primärschlüsselattribut immer zuletzt verarbeitet, da es immer
über mindestens eine Attributbeziehung verfügt, außer wenn es das einzige Attribut in der Dimension
ist.
Die zur Verarbeitung eines Attributs aufgewendete Zeit hängt in der Regel von 1) der Anzahl von
Elementen und 2) der Anzahl von Attributbeziehungen ab. Die Anzahl von Elementen für ein bestimmtes
Attribut lässt sich zwar nicht steuern, allerdings kann die Verarbeitungsleistung durch die Verwendung
von kaskadierenden Attributbeziehungen verbessert werden. Dies ist besonders wichtig für das
Schlüsselattribut, da es die meisten Elemente enthält und alle anderen Aufträge (Hierarchie,
Decodieren, Bitmapindizes) auf seinen Abschluss warten. Attributbeziehungen senken die
Speicheranforderung während der Verarbeitung. Bei der Verarbeitung eines Attributs müssen alle
abhängigen Attribute im Arbeitsspeicher gespeichert werden. Ohne Attributbeziehungen müssten bei
der Verarbeitung des Schlüsselattributs alle Attribute im Arbeitsspeicher gespeichert werden. Dies kann
dazu führen, dass nicht genügend Speicherplatz vorhanden ist.
Weitere Informationen zur Bedeutung der Verwendung von kaskadierenden Attributbeziehungen finden
Sie unter Identifizieren von Attributbeziehungen.
Erstellen von Decodierungsspeichern
Decodierungsspeicher werden vom Speichermodul intensiv verwendet. Bei Abfragen werden damit
Daten von der Dimension abgerufen. Bei der Verarbeitung werden sie zum Erstellen der Bitmapindizes
der Dimension verwendet.
60
Erstellen von Hierarchiespeichern
Ein Hierarchiespeicher ist eine permanente Darstellung der Baumstruktur. Für jede natürliche Hierarchie
in der Dimension wird ein Auftrag zum Erstellen der Hierarchiespeicher instanziiert.
Erstellen von Bitmapindizes
Für die effiziente Suche nach Attributdaten im Beziehungsspeicher zur Abfragezeit erstellt das
Speichermodul zur Berichtsverarbeitungszeit Bitmapindizes. Bei Attributen mit einer sehr großen Anzahl
von Elementen kann die Verarbeitung der Bitmapindizes einige Zeit in Anspruch nehmen. In den meisten
Szenarien bieten die Bitmapindizes bedeutende Vorteile bei Abfragen. Bei Attributen mit hoher
Kardinalität wiegt dieser Vorteil jedoch unter Umständen den Verarbeitungsaufwand beim Erstellen des
Bitmapindex nicht auf.
5.2 Dimensionsverarbeitungsbefehle
Wenn Sie einen Verarbeitungsvorgang für eine Dimension ausführen müssen, geben Sie
Dimensionsverarbeitungsbefehle aus. Jeder Verarbeitungsbefehl erstellt einen oder mehrere Aufträge
zum Ausführen der erforderlichen Vorgänge.
In Bezug auf die Leistung sind die folgenden Dimensionsverarbeitungsbefehle die wichtigsten:
ProcessFull
ProcessData
ProcessIndexes
ProcessUpdate
ProcessAdd
Mit dem ProcessFull-Befehl wird der gesamte Speicherinhalt der Dimension gelöscht und neu erstellt.
ProcessFull führt im Hintergrund alle Aufträge zur Dimensionsverarbeitung und einen impliziten
ProcessClear-Auftrag für alle abhängigen Partitionen aus. Dies bedeutet, dass bei jeder Ausführung
eines ProcessFull-Vorgangs für eine Dimension ein ProcessFull-Vorgang für abhängige Partitionen
ausgeführt werden muss, um den Cube erneut online zu schalten.
Mit ProcessData wird der gesamte Speicherinhalt der Dimension gelöscht, und nur die Attribut- und
Hierarchiespeicher werden neu erstellt. Außerdem werden Partitionen gelöscht. ProcessData ist die
erste Komponente, die von einem ProcessFull-Vorgang ausgeführt wird.
ProcessIndexes erfordert, dass für eine Dimension bereits ein Attribut- und Hierarchiespeicher erstellt
wurden. Die Daten in diesen Speichern werden beibehalten, anschließend werden die Bitmapindizes
neu erstellt. ProcessIndexes ist die zweite Komponente des ProcessFull-Vorgangs.
Im Gegensatz zu ProcessFull löscht ProcessUpdate den Inhalt des Dimensionsspeichers nicht.
Stattdessen wendet es Aktualisierungen intelligent an, um abhängige Partitionen beizubehalten.
Insbesondere sendet ProcessUpdate SQL-Abfragen zum Lesen der vollständigen Dimensionstabelle und
wendet dann Änderungen auf die Dimensionsspeicher an. ProcessUpdate kann Einfüge-, Update- und
61
Löschvorgänge verarbeiten, abhängig vom Typ der Attributbeziehungen (fest oder flexibel) in der
Dimension. Beachten Sie, dass ProcessUpdate ungültige Aggregationen und Indizes löscht, sodass die
Aggregationen neu erstellt werden müssen, um die Abfrageleistung zu verwalten. Flexible
Aggregationen werden jedoch nur dann gelöscht, wenn eine Änderung festgestellt wird.
ProcessAdd optimiert ProcessUpdate in Szenarien, in denen nur neue Elemente eingefügt werden
müssen. ProcessAdd löscht oder aktualisiert keine vorhandenen Elemente. Der Leistungsvorteil von
ProcessAdd besteht darin, dass eine andere benannte Abfrage von Quelltabellen oder
Datenquellensichten verwendet kann. Diese beschränkt die Zeilen der Quelldimensionstabelle, sodass
nur die neuen Zeilen zurückgegeben werden. Dadurch ist es nicht notwendig, alle Quelldaten zu lesen.
Darüber hinaus behält ProcessAdd auch alle Indizes und Aggregationen (flexible und feste) bei.
Hinweis: ProcessAdd steht nur als XMLA-Befehl zur Verfügung.
5.3 Flussdiagramm zur Optimierung der Dimensionsverarbeitung
Relational or Analysis
Services problem?
AS
No
Apply dimension design
best practise
lower query
speed ok?
Use
<PreAllocate>
Analyse
Attribute
Usage
Replace attribute
hierarchy with member
properties
Remove bitmaps
Memory can
be reserved
for Analysis
Services?
No
Index tuning advisor
not used for
slice and dice?
Yes
Dim
fast enough
Yes
Done
62
Relational
Weitere Informationen zur SQL Server-Wartestatistik und zu ihrer Verfolgung finden Sie unter
sys.dm_os_wait_stats in der SQL Server-Onlinedokumentation.
5.4 Bewährte Methoden für die Leistung der Dimensionsverarbeitung
Es gibt einige allgemeine und gute Entwurfsmethoden, die einfach zu implementieren sind und schnell
Vorteile für die Leistung der Dimension bringen. Versuchen Sie, diese beim Entwerfen von Dimensionen
in die bewährten Methoden einzubinden.
In SQL Server 2008 Analysis Services werden die Analysis Management Objects (AMO)-Warnungen von
Business Intelligence Development Studio bereitgestellt, um das Entwerfen bewährter Methoden zu
unterstützen.
5.4.1 Verwenden von SQL-Sichten zum Implementieren der Abfragebindung für
Dimensionen
Die Abfragebindung für Dimensionen ist zwar in SQL Server 2008 Analysis Services nicht vorhanden,
kann jedoch durch die Verwendung einer Sicht (anstelle von Tabellen) für die zugrunde liegende
Dimensionsdatenquelle implementiert werden. Auf diese Weise können Sie Hinweise, indizierte Sichten
und andere Optimierungstechniken relationaler Datenbanken zum Optimieren der SQL-Anweisung
verwenden, die über die Sicht auf die Dimensionstabellen zugreift.
Es ist in der Regel sinnvoll, das Unified Dimensional Model (UDM) auf der Grundlage von
Datenbanksichten zu erstellen. Sie können somit nicht nur die relationale Optimierung anwenden,
sondern auch den NOLOCK-Hinweis in der Sichtdefinition verwenden. Dieser Hinweis entfernt den
Sperrenaufwand aus der Datenbank, wodurch sich noch weitere Vorteile für die Leistung ergeben
können.
Sichten erleichtern das Debuggen. SQL-Abfragen können direkt an Sichten ausgeführt werden, um die
relationalen Daten mit dem Cube zu vergleichen. Daher bieten Sichten eine gute Möglichkeit zum
Kapseln von Geschäftslogik, die Sie normalerweise als Abfragebindung in das UDM implementieren
würden. Obwohl die UDM-Syntax der SQL-Sichtsyntax ähnelt, können keine SQL-Anweisungen für das
UDM ausgegeben werden.
5.4.2 Optimieren der Attributverarbeitung für mehrere Datenquellen
Stammt eine Dimension aus mehreren Datenquellen, ermöglicht die Verwendung von kaskadierenden
Attributbeziehungen das Unterteilen von Attributen während der Verarbeitung entsprechend der
Datenquelle. Stammen die Schlüssel-, Namens- und Attributbeziehungen eines Attributs aus derselben
Datenbank, kann die SQL-Abfrage für dieses Attribut durch das Abfragen nur einer Datenbank optimiert
werden. Ohne kaskadierende Attributbeziehungen wird die OPENROWSET-Funktion von SQL Server, die
eine Methode für das Zugreifen auf Daten aus mehreren Quellen bereitstellt, zum Zusammenführen der
Datenstreams verwendet. In diesem Fall wird die Verarbeitung für das Schlüsselattribut wegen des
erforderlichen Zugriffs auf mehrere abgeleitete OPENROWSET-Tabellen extrem langsam ausgeführt.
63
Wenn möglich, führen Sie ETL aus, um alle für die Dimension erforderliche Daten in derselben SQL
Server-Datenbank zu speichern. Dies ermöglicht Ihnen, die Abfrage mit dem relationalen Modul zu
optimieren.
5.4.3 Reduzieren des Aufwands für Attribute
Jedes Attribut, das in eine Dimension eingebunden wirkt, beeinflusst die Cubegröße, die
Dimensionsgröße, den Aggregationsentwurf und die Verarbeitungsleistung. Wenn Sie feststellen, dass
ein Attribut nicht von Endbenutzern verwendet wird, sollten Sie dieses Attribut vollständig aus der
Dimension löschen. Nach dem Entfernen überflüssiger Attribute können Sie eine Reihe von Techniken
anwenden, um die Verarbeitung der übrigen Attribute zu optimieren.
5.4.4 Effektive Verwendung der Eigenschaften KeyColumns, ValueColumn und
NameColumn
Wenn Sie einer Dimension ein neues Attribut hinzufügen, wird das Attribut mithilfe von drei
Eigenschaften definiert. Die KeyColumns-Eigenschaft gibt ein oder mehrere Quellfelder an, die jede
Instanz des Attributs eindeutig identifizieren.
Die NameColumn-Eigenschaft gibt das Quellfeld an, das Endbenutzern angezeigt wird. Wird für die
NameColumn-Eigenschaft kein Wert angegeben, dann wird sie automatisch auf den Wert der
KeyColumns-Eigenschaft festgelegt.
ValueColumn ermöglicht das Übermitteln weiterer Informationen zum Attribut und wird in der Regel für
Berechnungen verwendet. Im Gegensatz zu Elementeigenschaften ist diese Eigenschaft eines Attributs
stark typisiert und bietet in Berechnungen eine verbesserte Leistung. Auf den Inhalt dieser Eigenschaft
kann über die MemberValue-Funktion von MDX zugegriffen werden.
Durch die Verwendung von ValueColumn und NameColumn sind keine überflüssigen Attribute mehr
erforderlich. Dadurch wird die Gesamtzahl an Attributen im Entwurf reduziert, und der Entwurf wird
effizienter.
Analysis Services ermöglicht das Abrufen der Eigenschaften KeyColumns, ValueColumn und
NameColumn von verschiedenen Quellspalten. Dies ist nützlich beim Vorliegen einer einzelnen Entität
wie eines Produkts, das durch zwei unterschiedliche Attribute identifiziert wird: einen Ersatzschlüssel
und einen beschreibenden Produktnamen. Wenn Benutzer Daten nach Produkten in Slices aufteilen
möchten, stellen sie möglicherweise fest, dass der Ersatzschlüssel nicht über Geschäftsrelevanz verfügt,
und entscheiden sich stattdessen für die Verwendung des Produktnamens.
Die bewährte Methode besteht darin, ein numerisches Quellfeld der KeyColumns-Eigenschaft statt einer
Zeichenfolgeneigenschaft zuzuweisen. Damit wird nicht nur die Verarbeitungszeit reduziert, sondern
auch die Größe der Dimension. Dies gilt besonders für Attribute mit vielen Elementen, d. h. mehr als
eine Million Elemente.
64
5.4.5 Bitmapindizes entfernen
Bei der Verarbeitung des Primärschlüsselattributs werden Bitmapindizes für jedes verknüpfte Attribut
erstellt. Das Erstellen der Bitmapindizes für den Primärschlüssel kann zeitaufwändig sein, wenn dieser
ein oder mehrere verknüpfte Attribute mit hoher Kardinalität enthält. Zur Abfragezeit sind die
Bitmapindizes für diese Attribute beim Beschleunigen des Abrufvorgangs nicht sinnvoll, da das
Speichermodul noch zahlreiche unterschiedliche Werte durchsuchen muss. Dies hat möglicherweise
negative Auswirkungen auf die Abfrageantwortzeiten.
Beispielsweise identifiziert der Primärschlüssel der Customer-Dimension jeden Kunden eindeutig nach
Kontonummer, Benutzer möchten für Daten jedoch möglicherweise auch eine Slice-and-Dice-Analyse
nach der Sozialversicherungsnummer des Kunden durchführen. Jede Kundenkontonummer weist eine
1:1-Beziehung mit der Sozialversicherungsnummer eines Kunden auf. Um zu verhindern, dass Zeit für
das Erstellen unnötiger Bitmapindizes für das Sozialversicherungsnummer-Attribut aufgewendet wird,
können die entsprechenden Bitmapindizes durch Festlegen der AttributeHierarchyOptimizedStateEigenschaft auf Not Optimized deaktiviert werden.
5.4.6 Deaktivieren der Attributhierarchie und Verwenden von
Elementeigenschaften
Als Alternative zu Attributhierarchien bieten Elementeigenschaften einen anderen Mechanismus zum
Verfügbarmachen von Dimensionsinformationen. Beim jeweiligen Attribut werden
Elementeigenschaften automatisch für jede Attributbeziehung erstellt. Für das Primärschlüsselattribut
bedeutet dies, dass jedes Attribut mit direkter Beziehung zum Primärschlüssel als Elementeigenschaft
des Primärschlüsselattributs verfügbar ist.
Falls Sie nur auf ein Attribut als Elementeigenschaft zugreifen möchten, können Sie nach der
Überprüfung der Gültigkeit der korrekten Beziehung die Hierarchie des Attributs deaktivieren, indem Sie
die AttributeHierarchyEnabled-Eigenschaft auf False festlegen. In Bezug auf die Verarbeitung können
durch Deaktivieren der Attributhierarchie die Leistung verbessert und die Cubegröße reduziert werden,
da das Attribut nicht mehr indiziert oder aggregiert wird. Dies kann sich besonders bei Attributen mit
hoher Kardinalität als hilfreich erweisen, die eine 1:1-Beziehung mit dem Primärschlüssel aufweisen. Für
Attribute mit hoher Kardinalität wie Telefonnummern und Adressen ist in der Regel keine Slice-andDice-Analyse erforderlich. Durch das Deaktivieren der Hierarchien für diese Attribute und den Zugriff
über Elementeigenschaften kann Verarbeitungszeit gespart und die Cubegröße reduziert werden.
Bei der Entscheidung über die Deaktivierung der Attributhierarchie müssen die Auswirkungen der
Verwendung von Elementeigenschaften auf Abfragen und die Verarbeitung berücksichtigt werden.
Elementeigenschaften können nicht auf die gleiche Weise wie Attributhierarchien und
Benutzerhierarchien auf einer Abfrageachse in Business Intelligence Design Studio platziert werden. Zum
Abfragen einer Elementeigenschaft müssen die Eigenschaften des Attributs abgefragt werden, das die
Elementeigenschaft enthält.
65
Wenn Sie die dienstliche Telefonnummer für einen Kunden benötigen, müssen Sie z. B. die
Eigenschaften des Kunden abfragen und dann die Telefonnummer-Eigenschaft anfordern. Aus Gründen
der Benutzerfreundlichkeit stellen die meisten Front-End-Tools Elementeigenschaften problemlos in der
Benutzeroberfläche dar.
Im Allgemeinen ist das Abfragen von Elementeigenschaften langsamer als das Abfragen von
Attributhierarchien, da Elementeigenschaften nicht indiziert und nicht an Aggregationen beteiligt sind.
Die tatsächlichen Auswirkungen auf die Abfrageleistung hängen von der Verwendungsweise des
Attributs ab.
Falls Benutzer z. B. für Daten auch eine Slice-and-Dice-Analyse nach Kontonummer und
Kontobeschreibung durchführen möchten, kann es in Bezug auf die Abfrage vorteilhafter sein, wenn bei
Problemen mit der Verarbeitungsleistung die Attributhierarchien vorhanden sind und die Bitmapindizes
entfernt werden.
5.5 Optimieren der relationalen Dimensionsverarbeitungsabfrage
Im Gegensatz zu Faktenpartitionen, die nur eine Abfrage an den Server senden, senden
Verarbeitungsvorgänge für Dimensionen mehrere Abfragen. Dimensionen sind in der Regel kleine,
komplexe Tabellen mit sehr wenigen Änderungen im Vergleich zu Fakten. Tabellen mit solchen
Merkmalen können häufig vielfach indiziert mit geringem Einfügungs/Aktualisierungsverwaltungsaufwand für das System sein. Sie können dies bei der Verarbeitung zu Ihrem
Vorteil nutzen und die relationalen Indizes großzügig verwenden.
Die einfachste Methode zum Optimieren der für die Dimensionsverarbeitung verwendeten relationalen
Abfragen ist die Verwendung des Datenbankoptimierungsratgebers für eine Profiler-Ablaufverfolgung
der Dimensionsverarbeitung. Bei den kleinen Dimensionstabellen müssen Sie möglicherweise nur jeden
vorgeschlagenen Index hinzufügen. Richten Sie bei den größeren Tabellen die Indizes auf die am
längsten ausgeführten Abfragen aus.
6 Verbessern der Leistung der Partitionsverarbeitung
Das Leistungsziel der Partitionsverarbeitung ist die Aktualisierung von Faktendaten und Aggregationen
mit einer effizienten Methode, die die allgemeinen Anforderungen für die Datenaktualisierung erfüllt.
Die folgenden Techniken zum Erreichen dieses Ziels werden in diesem Abschnitt erläutert: Optimieren
von SQL-Quellenabfragen, Verwenden von mehreren Partitionen, Abstimmung von E/A, Optimieren von
Netzwerkgeschwindigkeiten und Abstimmung von Thread- und Parallelitätseinstellungen.
66
6.1 Grundlegendes zur Partitionsverarbeitungsarchitektur
Während der Verarbeitung von Partitionen werden Quelldaten mit den in Abbildung 21 dargestellten
Aufträge extrahiert und auf einem Datenträger gespeichert.
Abbildung 21 Aufträge zur Partitionsverarbeitung
Verarbeiten von Faktendaten
Faktendaten werden mit drei gleichzeitigen Threads verarbeitet, die die folgenden Aufgaben ausführen:
Senden von SQL-Anweisungen zum Extrahieren von Daten aus Datenquellen
Suchen von Dimensionsschlüsseln in Dimensionsspeichern und Füllen des Verarbeitungspuffers
Schreiben des Puffers auf den Datenträger, wenn der Verarbeitungspuffer voll ist
Erstellen von Aggregationen und Bitmapindizes
Aggregationen werden bei der Verarbeitung im Arbeitsspeicher erstellt. Während zu wenige
Aggregationen kaum Einfluss auf die Abfrageleistung haben, kann sich bei übermäßig vielen
Aggregationen die Verarbeitungszeit ohne zusätzlichen Vorteil für die Abfrageleistung erhöhen.
Falls Aggregationen nicht in den Arbeitsspeicher passen, werden Segmente in temporäre Dateien
geschrieben und am Ende des Vorgangs zusammengeführt. Bitmapindizes werden ebenfalls in dieser
Phase erstellt und segmentweise auf den Datenträger geschrieben.
6.2 Partitionsverarbeitungsbefehle
Wenn Sie einen Verarbeitungsvorgang für eine Partition ausführen müssen, geben Sie
Partitionsverarbeitungsbefehle aus. Jeder Verarbeitungsbefehl erstellt einen oder mehrere Aufträge
zum Ausführen der erforderlichen Vorgänge.
Die folgenden Partitionsverarbeitungsbefehle sind verfügbar:
67
ProcessFull
ProcessData
ProcessIndexes
ProcessAdd
ProcessClear
ProcessClearIndex
ProcessFull löscht den Speicherinhalt der Partition und erstellt ihn neu. Im Hintergrund führt ProcessFull
ProcessData-Aufträge und ProcessIndexes-Aufträge aus.
ProcessData löscht den Speicherinhalt des Objekts und erstellt nur die Faktendaten neu.
Für ProcessIndexes ist eine Partition mit bereits erstellten Daten erforderlich. ProcessIndexes behält die
während ProcessData erstellten Daten bei und erstellt auf deren Grundlage neue Aggregationen und
Bitmapindizes.
ProcessAdd erstellt intern eine temporäre Partition, verarbeitet sie mit den Zielfaktendaten und führt
sie dann mit der vorhandenen Partition zusammen. Beachten Sie, dass ProcessAdd der Name des XMLABefehls ist, in Business Intelligence Development Studio und SQL Server Management Studio erfolgt die
Bereitstellung als ProcessIncremental.
ProcessClear entfernt alle Daten aus der Partition. Beachten Sie, dass ProcessClear der Name des XMLABefehls ist. In Business Intelligence Development Studio und SQL Server Management Studio erfolgt die
Bereitstellung als UnProcess.
ProcessClearIndexes entfernt alle Indizes und Aggregate aus der Partition. Damit werden die Partitionen
in denselben Zustand versetzt, als wäre ProcessClear gefolgt von ProcessData gerade ausgeführt
worden. Beachten Sie, dass ProcessClearIndexes der Name des XMLA-Befehls ist. Dieser Befehl steht in
Business Intelligence Development Studio und SQL Server Management Studio nicht zur Verfügung.
6.3 Flussdiagramm zur Optimierung der Partitionsverarbeitung
Im folgenden Flussdiagramm wird der Optimierungsprozess von ProcessData beschrieben.
68
Waiting for
PAGEIO_X
in SQL Server?
Source query fully
optimized?
Yes
How many
partitions does the
process query
touch?
No
>1
Repartition
cube or
relational
No
Add cluster
index to
support quey
Yes
Denormalize
and use star
schema
Yes
=1
No
Optimize data types
Use lock
elimination
No
Waiting for
LCK_X in SQL?
Yes
Query supported by
index?
Model
Apply Data
Compression
No
Yes
Yes
Using SQL
2008?
Waiting for
ASYNC_NETWORK_IO
in SQL Server?
Joins in
query?
No
Yes
Still waiting for
PAGEIO_X?
Enough
NIC Capacity
NIC
< # Cores in
Analysis
Services Adjust network packet
size
Still waits for
ASYNC_NETWORK_IO
?
NIC Near
capacity
Optimize
network
infrastructure
Tune I/O system or
upgrade hardware
NIC interrupt affinty
configured?
Yes
Afinitze network and
distribute load
No
Yes
CPU load on
Analysis Services?
=100
<100
CPU load on SQL
Server
Adjust
threadpool
=100
< #Cores
=0
Repartition
cube
>0
Max connections in
data source
< # Cores in
Analysis Services
Für ProcessIndexes gilt das nachfolgende Flussdiagramm.
69
= # Cores in
Analysis
Services
Done
<100
Idle threads
Increase max connection
to #cores in Analysis
Services
Try shared memory
connections if available
= # Cores
# Concurrent
processing
partitions
>0
Add memory
or
move tempdir
to faster drives
I/O bottleneck
Yes
Add more I/O
capacity
% Processor Time
<100%
No more
threads
Adjust ThreadPool
settings
<
requested
Adjust AggMemMin
Temp vytes
written
=0
=100%
Yes
<100%
Idle threads
Max speed achieved
# Processing
partitions
= requested
Possible to request
more partitions?
No
Possible
Design for more
partitions?
Not viable
Adjust
CoordinatorBuildMaxThreads
6.4 Bewährte Methoden für die Leistung der Partitionsverarbeitung
Verwenden Sie für den Entwurf der Faktentabellen die Anweisungen in den folgenden technischen
Hinweisen:
70
Die zehn wichtigsten bewährten Methoden zur Erstellung eines großen skalierbaren relationalen
Data Warehouse
Bewährte Methoden zur Verarbeitung in Analysis Services
6.4.1 Optimieren von Dateneinfügungen, Aktualisierungen und Löschungen
Dieser Abschnitt enthält Informationen zum effizienten Aktualisieren von Partitionsdaten für das
Verarbeiten von Einfügungen, Aktualisierungen und Löschungen.
Einfügungen
Wenn in einem durchsuchbaren, verarbeiteten Cube einer vorhandenen Measuregruppe-Partition neue
Daten hinzugefügt werden sollen, können Sie eine der folgenden Techniken anwenden:
ProcessFull – Führen Sie einen ProcessFull-Vorgang für die vorhandene Partition aus. Während
des ProcessFull-Vorgangs bleibt der Cube für das Durchsuchen mit den vorhandenen Daten
verfügbar, während eine separate Gruppe von Datendateien für die neuen Daten erstellt wird.
Wenn die Verarbeitung abgeschlossen ist, stehen die neuen Partitionsdaten zum Durchsuchen
zur Verfügung. Beachten Sie, dass ProcessFull technisch gesehen nicht erforderlich ist, falls Sie
nur Einfügungen vornehmen. Zum Optimieren der Verarbeitung für Einfügevorgänge können Sie
ProcessAdd verwenden.
ProcessAdd – Verwenden Sie diesen Vorgang zum Anhängen von Daten an die vorhandenen
Partitionsdateien. Beim häufigen Ausführen von ProcessAdd wird empfohlen, in regelmäßigen
Abständen ProcessFull auszuführen, um die Partitionsdatendateien neu zu erstellen und neu zu
komprimieren. ProcessAdd erstellt intern eine temporäre Partition und führt diese zusammen.
Dies führt im Laufe der Zeit zur Datenfragmentierung und zur Notwendigkeit, ProcessFull in
regelmäßigen Abständen auszuführen.
Enthält die Measuregruppe mehrere Partitionen, wie im vorherigen Abschnitt beschrieben, besteht ein
effektiverer Ansatz darin, eine neue Partition zu erstellen, die die neuen Daten enthält, und dann
ProcessFull für diese Partition auszuführen. Mit dieser Methode können neue Daten ohne
Auswirkungen auf die vorhandenen Partitionen hinzugefügt werden. Wenn die Verarbeitung für die
neue Partition abgeschlossen ist, steht sie für Abfragen zur Verfügung.
Aktualisierungen
Wenn Datenaktualisierungen ausgeführt werden müssen, können Sie ProcessFull ausführen. Dabei ist es
natürlich sinnvoll, die Aktualisierungen auf eine bestimmte Partition auszurichten, damit nur eine
einzelne Partition verarbeitet werden muss. Eine bessere Methode als die direkte Aktualisierung von
Faktendaten ist die Verwendung eines Journal-Mechanismus zum Implementieren von
Datenänderungen. In diesem Szenario wandeln Sie eine Aktualisierung in eine Einfügung um, die die
vorhandenen Daten korrigiert. Mit dieser Methode können Sie einfach fortfahren, der Partition neue
Daten mit ProcessAdd hinzuzufügen. Durch die Verwendung von Journalen verfügen Sie außerdem über
einen Überwachungspfad der Änderungen der Faktentabelle.
Löschungen
Für Löschungen bieten mehrere Partitionen einen hervorragenden Mechanismus zum Rollout
abgelaufener Daten. Betrachten Sie das folgende Beispiel. Sie verfügbar zurzeit über 13 Monate Daten in
einer Measuregruppe, 1 Monat pro Partition. Der älteste Monat soll aus dem Cube entfernt werden.
Dazu löschen Sie einfach die Partition ohne Auswirkungen auf eine der anderen Partitionen.
71
Falls bestimmte alte Dimensionselemente nur im abgelaufenen Monat vorhanden waren, können Sie
diese mit einem ProcessUpdate-Vorgang für die Dimension entfernen (jedoch nur, wenn sie flexible
Beziehungen enthält). Zum Löschen von Elementen aus dem Schlüssel-/Granularitätsattribut einer
Dimension muss die UnknownMember-Eigenschaft der Dimension auf Hidden festgelegt werden. Der
Grund dafür ist, dass der Server nicht weiß, ob ein dem gelöschten Element zugewiesener
Faktendatensatz vorhanden ist. Bei entsprechender Festlegung dieser Eigenschaft wird das Element bei
der Abfrage ausgeblendet. Eine weitere Möglichkeit besteht darin, die Daten aus der zugrunde
liegenden Tabelle zu entfernen und einen ProcessFull-Vorgang auszuführen. Dies kann jedoch mehr Zeit
in Anspruch nehmen als ProcessUpdate.
Wenn die Größe der Dimension zunimmt, sollten Sie einen ProcessFull-Vorgang für die Dimension
ausführen, um gelöschte Schlüssel vollständig zu entfernen. In diesem Fall müssen jedoch auch alle
verknüpften Partitionen erneut verarbeitet werden. Dies erfordert möglicherweise ein großes
Batchfenster und ist nicht für alle Szenarien geeignet.
6.4.2 Auswählen effizienter Datentypen in Faktentabellen
Während der Verarbeitung müssen Daten aus SQL Server in Analysis Services verschoben werden. Je
größer die Zeilen sind, desto mehr Bandbreite ist zum Verschieben der Zeilen erforderlich.
Bestimmte Datentypen können vom Charakter ihres Entwurfs her schneller verwendet werden als
andere. Verwenden Sie in Faktentabellen möglichst nur diese Datentypen, um die beste Leistung zu
erzielen.
Faktenspaltentyp
Ersatzschlüssel
Datumsschlüssel
Measures mit ganzen Zahlen
Numerische Measures
Distinct Count-Spalten
Schnellste SQL Server-Datentypen
tinyint, smallint, int, bigint
int im Format jjjjMMtt
tinyint, smallint, int, bigint
smallmoney, money, real, float
(Beachten Sie, dass zum Verarbeiten der Typen
decimal und vardecimal mehr CPU-Leistung
erforderlich ist als für die Typen money und float.)
tinyint, smallint, int, bigint
(Wenn die Count-Spalte char ist, sollten Sie
entweder Hashing oder das Ersetzen durch einen
Ersatzschlüssel in Betracht ziehen.)
6.5 Optimieren der relationalen Partitionsverarbeitungsabfrage
In der ProcessData-Phase werden Zeilen aus einer relationalen Quelle und in Analysis Services gelesen.
Analysis Services kann in dieser Phase Zeilen mit einer sehr hohen Rate verwenden. Zum Erreichen
dieser hohen Geschwindigkeiten muss die relationale Datenbank so optimiert werden, dass ein
geeigneter Durchsatz bereitgestellt wird.
72
Im nachfolgenden Unterabschnitt wird angenommen, dass SQL Server die relationale Quelle ist. Beim
Verwenden einer anderen relationalen Quelle sind einige Hinweise weiterhin gültig. Wenden Sie sich
jedoch an Ihren Datenbankexperten, um plattformspezifische Anweisungen zu erhalten.
Analysis Services verwendet die Partitionsinformationen zum Generieren der Abfrage. Falls Sie keine
Abfragebindungen im UDM vorgenommen haben, ist die Ausgabe der SELECT-Anweisung an die
relationale Quelle ganz einfach. Sie besteht aus:
SELECT für die zur Verarbeitung erforderlichen Spalten. Dies sind die Dimensionsspalten und die
Measures.
Optional einem WHERE-Kriterium bei der Verwendung von Partitionen. Sie können dieses
WHERE-Kriterium durch Ändern der Abfragebindung der Partition steuern.
6.5.1 Entfernen von Joins
Falls Sie eine Datenbanksicht oder eine benannte UDM-Abfrage als Basis von Partitionen verwenden,
sollten Sie Joins in dieser Abfrage entfernen. Denormalisieren Sie dazu die die verknüpften Spalten zur
Faktentabelle. Wenn Sie einen Sternschemaentwurf verwenden, sollten Sie diesen Schritt schon
durchgeführt haben.
Hintergrundinformation zu relationalen Sternschemas und zum Durchführen von Entwurf und
Denormalisierung für eine optimale Leistung finden Sie unter:
Ralph Kimball, The Data Warehouse Toolkit
6.5.2 Hinweise zur relationalen Partitionierung
Beim Verwenden der Partitionierung auf der relationalen Seite sollten Sie sicherstellen, dass jede
Cubepartition maximal eine relationale Partition berührt. Verwenden Sie zum Überprüfen das XML
Showplan-Ereignis aus der SQL Server Profiler-Ablaufverfolgung.
Nach dem Entfernen aller Joins sollte der Abfrageplan ähnlich wie in Abbildung 22 aussehen.
Abbildung 22 Optimale Partitionsverarbeitungsabfrage
73
Klicken Sie auf den Tabellenscan (in diesem Fall kann es auch ein Bereichsscan oder eine Indexsuche
sein), und zeigen Sie den Eigenschaftenbereich an.
Abbildung 23 Zugriff auf zu viele Partitionen
Es wird auf Partition 4 und Partition 5 zugegriffen. Der Wert für Tatsächliche Partitionsanzahl sollte 1
sein. Ist dies nicht der Fall (wie oben), sollten Sie die Partitionierung der relationalen Quelldaten erneut
ausführen, sodass jede Cubepartition maximal eine relationale Partition berührt.
6.5.2.1 Sonderfall: Distinct Count
Für Distinct Count-Measuregruppen gelten spezielle Anforderungen bei der Partitionierung. In der Regel
wird die Time-Dimension oder eine andere Dimension als Partitionierungsspalte verwendet. Bei der
Partitionierung einer Distinct Count-Measuregruppe muss die Partitionierung jedoch nach dem Wert der
Distinct Count-Measurespalte erfolgen.
Gruppieren Sie die Distinct Count-Measurespalte in separate, nicht überlappende Intervalle. Jedes
Intervall sollte ungefähr gleich viele Zeilen aus der Quelle enthalten. Diese Intervalle bilden dann die
Quelle der Analysis Services-Partitionen.
Da die Parallelität der ProcessData-Phase von der Menge der vorhandenen Partitionen beschränkt wird,
sollten Sie die Distinct Count-Measure in so viele gleich große, nicht überlappende Intervalle aufteilen,
wie CPU-Kerne auf dem Analysis Services-Computer vorhanden sind.
Ab Analysis Services 2005 ist es möglich, nicht ganzzahlige Spalten für Distinct Count-Measuregruppen
zu verwenden. Sie sollten dies jedoch aus Leistungsgründen vermeiden. Im unten angeführten
Whitepaper wird erläutert, wie mit Hashfunktionen nicht ganzzahlige Spalten für Distinct Count in ganze
Zahlen umgewandelt werden. Es enthält außerdem Beispiele für die Partitionierungsstrategie mit nicht
überlappenden Intervallen.
Analysis Services Distinct Count Optimization
6.5.3 Hinweise zur relationalen Indizierung
Während in der Regel angestrebt wird, dass jede Cubepartition maximal eine relationale Partition
berührt, gilt dies nicht für den umgekehrten Fall. Es ist absolut umsetzbar, dass mehrere
Cubepartitionen auf dieselbe relationale Partition zugreifen. Beispielsweise kann eine relationale Quelle,
die mit einem nach Monat partitionierten Cube nach Jahr partitioniert wird, weiterhin eine optimale
Verarbeitungsleistung bieten.
74
Wenn zwischen relationaler und Cubepartition keine 1:1-Beziehung besteht, sollte in der Regel ein Index
die Faktenverarbeitungsabfrage unterstützen. Für diesen Zweck ist ein gruppierter Index am besten
geeignet, wenn die Belastungsstrategie die Verwaltung eines solchen Index zulässt.
Wenn eine Verarbeitungsabfrage von einem Index unterstützt wird, sollte der Plan wie folgt aussehen.
Abbildung 24 Korrekt vom Index unterstützte Verarbeitung
Weitere Informationen zum Optimieren von Abfragen finden Sie unter:
Top 10 SQL Server 2005 Performance Issues for Data Warehouse and Reporting Applications
Itzik Ben-Gan und Lubor Kollar, Inside Microsoft SQL Server 2005: T-SQL Querying
6.5.3.1 Sonderfall: Distinct Count
Wie bei der Partitionierung ist Distinct Count auch beim Indizieren ein Sonderfall.
Den Distinct Count-Verarbeitungsabfragen wird durch Analysis Services eine ORDER BY-Klausel
hinzugefügt. Wenn Sie z. B. einen Distinct Count für CustomerPONumber in FactInternetSales erstellen,
erhalten Sie bei der Verarbeitung diese Abfrage:
SELECT … FROM FactInternetSales
ORDER BY [CustomerPONumber]
Wenn die Partition viele Zeilen enthält, kann das Sortieren der Daten einige Zeit in Anspruch nehmen.
Ohne unterstützende Indizes sieht der Abfrageplan etwa folgendermaßen aus.
Abbildung 25 Durch Distinct Count verursachte relationale Sortierung
Bemerken Sie die lange Zeitdauer, die der Sortiervorgang beansprucht? Durch Erstellen eines nach der
Distinct Count-Spalte sortierten gruppierten Index (in diesem Fall CustomerPONumber) können Sie
diesen Sortiervorgang löschen und erhalten einen Abfrageplan, der wie folgt aussieht.
75
Abbildung 26 Durch einen optimale Index unterstützte Distinct Count-Abfrage
Dieser Index muss natürlich verwaltet werden. Durch seine Platzierung werden die
Verarbeitungsabfragen auf jeden Fall beschleunigt.
6.5.4 Verwenden von FILLFACTOR = 100 für den Index und der
Datenkomprimierung
Die Seitenteilung in einem Index kann dazu führen, dass die Seiten des Index zu weniger als 100 % voll
sind. Der Effekt ist, dass SQL Server beim Scannen des Index mehr Datenbankseiten als nötig liest.
Sie können durch Abfragen der SQL Server-DMV sys.dm_db_index_physical_stats nach Indexseiten
suchen, die nicht voll sind. Liegt der Wert der Spalte avg_page_space_used_in_percent deutlich unter
100 %, muss eine Neuerstellung des Index mit FILLFACTOR 100 vorgenommen werden. Es ist nicht
immer möglich, den Index auf diese Weise neu zu erstellen, mit diesem Trick können jedoch E/AVorgänge reduziert werden. Bei veralteten Daten empfiehlt es sich, die Indizes in der Tabelle neu zu
erstellen, bevor die Daten als schreibgeschützt markiert werden.
In SQL Server 2008 können Sie entweder mit der Zeilen- oder der Seitenkomprimierung die Anzahl von
E/A-Vorgängen weiter reduzieren, die die relationale Datenbank zum Ausführen der
Faktenverarbeitungsabfrage benötigt. Bei der Komprimierung entsteht CPU-Verarbeitungsaufwand, die
Reduzierung von E/A-Vorgängen ist diesen Aufwand jedoch häufig wert.
6.6 Beseitigen des Datenbanksperrenaufwands
Wenn SQL Server einen Index oder eine Tabelle scannt, werden beim Lesen der Zeilen Seitensperren
eingerichtet. So wird sichergestellt, dass viele Benutzer gleichzeitig auf die Tabelle zugreifen können. Für
Data Warehouse-Arbeitsauslastungen ist dieses Sperren auf Seitenebene jedoch nicht immer die
optimale Strategie, besonders wenn große Datenabrufabfragen wie die Faktenverarbeitung auf die
Daten zugreifen.
Durch Messen des Perfmon-Leistungsindikators MSSQL:Sperren – Sperranforderungen/Sekunde und
die Suche nach LCK-Ereignissen in sys.dm_os_wait_stats können Sie sehen, wie groß der bei der
Verarbeitung verursachte Sperrenaufwand ist.
Zum Beseitigen dieses Sperrenaufwands stehen Ihnen drei Optionen zur Verfügung:
76
Option 1: Legen Sie die relationale Datenbank vor der Verarbeitung auf schreibgeschützten Modus
fest.
Option 2: Erstellen Sie die Faktenindizes mit ALLOW_PAGE_LOCKS = OFF und ALLOW_ROW_LOCKS
= OFF.
Option 3: Verarbeiten Sie über eine Ansicht, die den WITH (NOLOCK)-Abfragehinweis oder den
WITH (TABLOCK)-Abfragehinweis angibt.
Option 1 passt möglicherweise nicht immer in Ihr Szenario, da zum Festlegen der Datenbank auf
schreibgeschützten Modus exklusiver Zugriff auf die Datenbank erforderlich ist. Es ist jedoch eine
schnelle und einfache Möglichkeit, um eventuelle Wartevorgänge auf eine Sperre vollständig zu
entfernen.
Option 2 ist häufig ein sinnvoller Ansatz für Data Warehouses. Da SQL Server-Lesesperren (S-Sperren)
mit anderen S-Sperren kompatibel sind, können zwei Leser zwei Mal auf dieselbe Tabelle zugreifen,
ohne dass die feine Granularität von Seiten- oder Zeilensperren erforderlich ist. Wenn Einfügevorgänge
nur während der Batchausführung erfolgen, kann die Beschränkung auf Tabellensperren eine geeignete
Option sein. Erstellen Sie zum Deaktivieren von Zeilen-/Seitensperren für eine Tabelle und einen Index
ALL folgendermaßen neu.
ALTER INDEX ALL ON FactInternetSales REBUILD
WITH (ALLOW_PAGE_LOCKS = OFF, ALLOW_ROW_LOCKS = OFF)
Option 3 ist eine überaus nützliche Methode. Die Verarbeitung über eine Ansicht bietet Ihnen eine
zusätzliche Abstraktionsebene auf der Datenbank – eine gute Entwurfsstrategie. In der Sichtdefinition
können Sie einen NOLOCK- oder TABLOCK-Hinweis zum Entfernen des Datenbanksperrenaufwands
während der Verarbeitung hinzufügen. Dies hat den Vorteil, dass die Beseitigung der Sperren
unabhängig von der Erstellung und Verwaltung von Indizes ist.
CREATE VIEW vFactInternetSales
AS
SELECT [ProductKey], [OrderDateKey], [DueDateKey]
,[ShipDateKey], [CustomerKey], [PromotionKey]
,[CurrencyKey], [SalesTerritoryKey], [SalesOrderNumber]
,[SalesOrderLineNumber], [RevisionNumber], [OrderQuantity]
,[UnitPrice], [ExtendedAmount], [UnitPriceDiscountPct]
,[DiscountAmount], [ProductStandardCost], [TotalProductCost]
,[SalesAmount], [TaxAmt], [Freight]
,[CarrierTrackingNumber] ,[CustomerPONumber]
FROM [dbo].[FactInternetSales] WITH (NOLOCK)
Beachten Sie beim Verwenden des NOLOCK-Hinweises die möglicherweise auftretenden Dirty Reads.
Weitere Informationen zum Sperrverhalten finden Sie unter SET TRANSACTION ISOLATION LEVEL in der
SQL Server-Onlinedokumentation.
6.7 Optimieren des Netzwerkdurchsatzes
Während ProcessData müssen Zeilen zwischen SQL Server und Analysis Services übertragen werden.
Sind diese beiden Dienste auf verschiedenen Computern installiert, tritt TCP/IP-Netzwerkverkehr auf.
Alle Netzwerkkomponenten sollten so konfiguriert sind, dass sie den erforderlichen Durchsatz
unterstützen. Wenn der Ethernet-Durchsatz durchgängig bei 80 % der maximalen Kapazität liegt, wird
77
durch zusätzliche Netzwerkkapazität ProcessData. in der Regel beschleunigt. Außerdem werden Sie
Wartezeiten für ASYNC_NETWORK_IO in SQL Server feststellen, wenn das Netzwerk zu einem Engpass
wird.
Zusätzlich zum Erstellen eines Hochgeschwindigkeitsnetzwerks gibt es weitere Konfigurationen, die Sie
ändern können, um den Netzwerkverkehr weiter zu beschleunigen.
Unter den Eigenschaften der Datenquelle wird durch Vergrößern der Netzwerkpaketgröße für SQL
Server der zum Erstellen vieler kleiner Pakete erforderliche Protokollaufwand reduziert. Der
Standardwert für SQL Server 2008 ist 4096. Mit einer Data Warehouse-Auslastung kann eine Paketgröße
von 32K (in SQL Server entspricht dies dem Zuweisen des Wertes 32767) zu einer schnelleren
Verarbeitung beitragen. Ändern Sie nicht den Wert von SQL Server, sondern überschreiben Sie ihn in der
Datenquelle.
Abbildung 13 Optimieren der Netzwerkpaketgröße
Beachten Sie, dass der Aufwand für den Transport von Daten über das TCP/IP-Netzwerk beträchtlich ist.
Denken Sie daran, dass Analysis Services bei Installation auf demselben Computer wie SQL Server
Shared Memory-Verbindungen verwenden kann. Shared Memory-Verbindungen verursachen beim
Datenaustausch zwischen SQL Server und Analysis Services einen minimalen Aufwand. Je nach
Verarbeitungsauslastung können Sie daher die Verarbeitung durch Konsolidierung von SQL Server und
Analysis Services auf demselben Computer beschleunigen.
78
Sie können durch Ausführen der folgenden SELECT-Anweisung überprüfen, ob die Verbindung Shared
Memory verwendet.
SELECT session_id, net_transport, net_packet_size
FROM sys.dm_exec_connections
net_transport für die Analysis Services-SPID sollte Folgendes anzeigen: Shared memory.
Weitere Informationen zu Shared Memory-Verbindungen finden Sie unter:
Erstellen einer gültigen Verbindungszeichenfolge mithilfe des Shared Memory-Protokolls
6.8 Verbessern des E/A-Subsystems
Wenn Sie das relationale Quellsystem vollständig optimiert und Netzwerkengpässe beseitigt haben,
sollten Sie sich dem E/A-Subsystem zuwenden.
In Bezug auf SQL Server können Sie die E/A-Latenz aus sys.dm_os_wait_stats messen. Wenn Sie
durchgängig lange Wartezeiten für PAGELATCH_IO sehen, können Sie von einem schnelleren E/ASubsystem für SQL Server profitieren.
Falls Sie die Analysis Services-Dateien auf einem separate Laufwerkbuchstaben oder Bereitstellungspunkt
platziert haben (was empfohlen wird), können Sie mit dem perfmon-Leistungsindikator Physischer
Datenträger E/A-Wartezeiten messen. Liegen die Wartezeiten konsistent über 0,015 Sekunden, können
Sie auch von schnelleren I/O-Vorgängen auf den Analysis Services-Laufwerken profitieren.
Techniken zum Optimieren von E/A-Subsystemen gehen über den Rahmen dieses Dokuments hinaus.
Weitere Informationen finden Sie in den folgenden technischen Hinweisen und Whitepapers:
Storage Top 10 Best Practices
SQL Server 2000 I/O Basics
Predeployment I/O Best Practices
6.9 Erhöhen der Parallelität durch Hinzufügen weiterer Partitionen
Jetzt bestehen die Einschränkungen beim Optimieren nur noch in der verfügbaren CPU-Leistung und der
Fähigkeit, Vorgänge mit hoher Parallelität auszugeben. Entscheidend ist dabei der Prozessor:GesamtLeistungsindikator in der Basislinien-Ablaufverfolgung. Falls dieser Leistungsindikator nicht 100 %
beträgt, wird die CPU-Leistung nicht voll ausgenutzt. Vergleichen Sie im weiteren Verlauf der
Optimierung die Basislinien, um eine Verbesserung festzustellen, und achten Sie beim Senden von mehr
Daten durch das System auf das erneute Auftreten von Engpässen.
Durch die Verwendung mehrerer Partitionen kann die Verarbeitungsleistung verbessert werden.
Mithilfe von Partitionen können Sie parallel an vielen, kleineren Teilen der Faktentabelle arbeiten. Da
mit einer einzelnen Verbindung zu SQL Server nur die Übertragung einer begrenzten Anzahl von Zeilen
pro Sekunde möglich ist, kann durch das Hinzufügen von mehr Partitionen und damit mehr
Verbindungen der Durchsatz erhöht werden. Die Anzahl der Partitionen, die parallel verarbeitet werden
79
können, hängt von der CPU- und Computerarchitektur ab. Vergrößern Sie als Faustregel die Parallelität,
bis bei MSOLAP:Verarbeitung – Gelesene Zeilen/Sekunde keine Erhöhung mehr festzustellen ist. Die
Anzahl der parallel verarbeiteten Partitionen kann mithilfe des perfmon-Leistungsindikators MSOLAP:
Prozeduraggregationen – Aktuelle Partitionen gemessen werden.
Durch die parallele Verarbeitung mehrerer Partitionen ergeben sich Vorteile in verschiedenen Szenarien,
dabei sind jedoch einige Richtlinien zu beachten. Beachten Sie, dass bei der Verarbeitung einer
Measuregruppe ohne verarbeitete Partitionen Analysis Services die Cubestruktur für diese
Measuregruppe initialisieren muss. Dazu wird eine exklusive Sperre angewendet, die die parallele
Verarbeitung von Partitionen verhindert. Entfernen Sie diese Sperre, bevor Sie den vollständigen
parallelen Prozess auf dem System starten. Stellen Sie beim Entfernen der Initialisierungssperre sicher,
dass vor dem Beginn des parallelen Vorgangs mindestens eine verarbeitete Partition pro
Measuregruppe vorhanden ist. Falls keine verarbeitete Partition vorhanden ist, können Sie
ProcessStructure für den Cube ausführen, um seine Anfangsstruktur zu erstellen, und dann die
Measuregruppe-Partitionen parallel verarbeiten. Diese Beschränkung tritt nicht auf, wenn Sie
Partitionen in derselben Clientsitzung verarbeiten und mit dem MaxParallel-XMLA-Element den Grad
der Parallelität steuern.
6.10 Anpassen der maximalen Anzahl von Verbindungen
Wenn der Parallelitätseffekt der Verarbeitung auf mehr als 10 parallele Partitionen gesteigert wird,
muss die maximale Anzahl von Verbindungen angepasst werden, die Analysis Services für die Datenbank
geöffnet hält. Diese Anzahl kann in den Eigenschaften der Datenquelle geändert werden.
Abbildung 28 Hinzufügen weiterer Datenbankverbindungen
Legen Sie diese Anzahl mindestens auf die Anzahl von Partitionen fest, die parallel verarbeitet werden
sollen.
80
6.11 Anpassen von ThreadPool und CoordinatorExecutionMode
Diese serverweiten Eigenschaften erhöhen die Anzahl von Threads, mit denen parallele
Verarbeitungsvorgänge unterstützt werden können.
ThreadPool\Process\MaxThreads legt die maximale Anzahl der während der Verarbeitung für Analysis
Services verfügbaren Threads fest. Auf großen Computern mit mehreren CPUs ist der Standardwert
dieser Einstellung unter Umständen zu niedrig, um alle CPU-Kerne nutzen zu können. Beachten Sie beim
Erhöhen dieses Leistungsindikators jedoch, dass sich eine erhöhte Parallelität der Verarbeitung auch auf
Abfragen auswirkt, die auf dem System ausgeführt werden. Wenn Sie mehr CPU-Leistung und Threads
für die Verarbeitung reservieren, wird weniger CPU-Leistung für Abfrageantworten verwendet. Bei der
Verarbeitung der Cubes in einem Batchfenster ist dies unter Umständen kein Problem.
Überprüfen Sie zum Optimieren dieser Einstellungen für die ProcessData-Phase den perfmonLeistungsindikator für das Objekt MSOLAP: Threads, und beachten Sie die Anweisungen in der
nachfolgenden Tabelle.
Situation
Warteschlangenlänge für Aufträge im
Verarbeitungspool > 0 und
Im Leerlauf befindliche Threads im
Verarbeitungspool = 0
über eine längere Zeit während der Verarbeitung.
Warteschlangenlänge für Aufträge im
Verarbeitungspool > 0 und Im Leerlauf befindliche
Threads im Verarbeitungspool > 0 gleichzeitig
während der Verarbeitung.
Aktion
Erhöhen Sie Threadpool\Process\MaxThreads,
und testen Sie erneut.
Verringern Sie CoordinatorExecutionMode, und
testen Sie erneut.
Der Prozessor –% Prozessorzeit – Gesamt-Leistungsindikator kann als ungefähre Anzeige dafür
verwendet werden, in welchem Maße diese Einstellungen geändert werden sollten. Das Ziel sollte sein,
möglichst in die Nähe von 100 % CPU-Auslastung zu gelangen. Wenn z. B. die CPU-Last 50 % beträgt,
können Sie Threadpool\Process\MaxThreads verdoppeln, um zu sehen, ob sich damit auch die CPUAuslastung verdoppelt.
Weitere Informationen zum Anpassen von Threadpools finden Sie im folgenden Whitepaper:
SQL Server 2005 Analysis Services (SSAS) Server Properties
6.12 Anpassen von BufferMemoryLimit
OLAP\Process\BufferMemoryLimit legt die Größe der während der Partitionsverarbeitung verwendeten
Faktendatenpuffer fest. Der Standardwert von OLAP\Process\BufferMemoryLimit ist zwar für die
meisten Bereitstellungen ausreichend, im folgenden Szenario sollte die Eigenschaft jedoch geändert
werden.
81
Wenn die Granularität der Measuregruppe stärker zusammengefasst ist als die relationale
Quellfaktentabelle, sollte die Größe der Puffer erhöht werden, um die Datengruppierung zu
vereinfachen. Wenn z. B. die Quelldaten die Granularität Tag und die Measuregruppe die Granularität
Monat aufweist, muss Analysis Services die täglichen Daten vor dem Schreiben auf den Datenträger
nach Monat gruppieren. Diese Gruppierung erfolgt innerhalb eines einzelnen Puffers und wird in den
Datenträger geleert, nachdem sie voll ist. Durch das Erhöhen der Puffergröße wird die Häufigkeit
verringert, mit der die Puffer auf den Datenträger ausgelagert werden. Da dadurch ein höheres
Komprimierungsverhältnis möglich ist, verringert sich die Größe der Faktendaten auf dem Datenträger,
und die Leistung erhöht sich. Beachten Sie jedoch, dass bei hohen Werten für BufferMemoryLimit mehr
Arbeitsspeicher verwendet wird. Wenn nicht mehr genügend Arbeitsspeicher vorhanden ist, wird die
Parallelität verringert.
6.13 Optimieren der ProcessIndex-Phase
Während der ProcessIndex-Phase werden Aggregationen im Cube erstellt. Zu diesem Zeitpunkt werden
im relationalen Modul keine Aktivitäten mehr ausgeführt. Wenn Analysis Services und SQL Server
dasselbe Feld verwenden, können Sie alle CPU-Kerne für Analysis Services nutzen.
Die Kennzahl, die während ProcessIndex optimiert wird, ist der Leistungsindikator
MSOLAP:Prozeduraggregationen – Erstellte Zeilen/Sekunde. Mit zunehmendem Leistungsindikator
nimmt die ProcessIndex-Zeit ab. Mit diesem Leistungsindikator können Sie überprüfen, ob durch die
Optimierungsmaßnahmen die Geschwindigkeit erhöht wurde.
6.13.1
Verhindern des Überlaufs temporärer Daten auf den Datenträger
Während der Verarbeitung legt der Aggregationspuffer den Speicherplatz fest, der zum Erstellen von
Aggregationen für eine bestimmte Partition verfügbar ist. Ist der Aggregationspuffer zu klein, wird er
von Analysis Services mit temporären Dateien ergänzt. Temporäre Dateien werden im Ordner TempDir
erstellt, wenn der Arbeitsspeicher gefüllt ist und Daten sortiert und auf den Datenträger geschrieben
werden. Nachdem alle erforderlichen Dateien erstellt wurden, werden sie am endgültigen Ziel
zusammengeführt. Die Verwendung temporärer Dateien kann möglicherweise während der
Verarbeitung zu einer Leistungseinbuße führen. Überprüfen Sie zum Überwachen von während der
Verarbeitung verwendeten temporären Dateien den Indikator
MSOLAP:Prozeduraggregationen\Geschriebene Temp-Datei-Bytes/Sekunde.
Außerdem müssen Sie bei der parallelen Verarbeitung mehrerer Partitionen oder bei der Verarbeitung
eines gesamten Cubes in einer einzigen Transaktion sicherstellen, dass der erforderliche
Gesamtarbeitsspeicher den Wert der Memory\TotalMemoryLimit-Einstellung nicht überschreitet. Falls
Analysis Services Memory\TotalMemoryLimit während der Verarbeitung erreicht, wird die
Vergrößerung des Aggregationspuffers unterdrückt, und unter Umständen werden temporäre Dateien
während der Aggregationsverarbeitung verwendet. Außerdem ist möglicherweise bei unzureichendem
virtuellen Adressraum für diese gleichzeitig ausgeführten Vorgänge nicht genügend Arbeitsspeicher
verfügbar. Bei nicht ausreichendem physikalischen Arbeitsspeicher erfolgt die Speicherauslagerung.
Führen Sie bei beschränkten Ressourcen weniger Vorgänge parallel aus.
82
In der Standardkonfiguration löst Analysis Services eine Ausnahme wegen unzureichenden
Arbeitsspeichers aus, wenn während der Verarbeitung versucht wird, zu viel Arbeitsspeicher
anzufordern. Dieser Fehler kann unter Umständen durch Festlegen von MemoryLimitErrorEnabled auf
false in den Servereigenschaften deaktiviert werden. Dies kann jedoch zu einem Überlauf des
Datenträgers und zum Verlangsamen des Verarbeitungsvorgangs führen.
Sollte es nicht möglich sein, den Überlauf von Daten auf den Datenträgers zu verhindern, ist zumindest
sicherzustellen, dass sich der Ordner TempDir und die Seitendatei auf einem schnellen E/A-System
befinden.
6.13.2
Beseitigen von E/A-Engpässen
Während ProcessIndex ist die Datenträgeraktivität in der Regel niedriger als während ProcessData.
Wenn bei ProcessData kein E/A-Engpass auftritt, ist die E/A-Geschwindigkeit mit hoher
Wahrscheinlichkeit auch für ProcessIndex ausreichend. Überwachen Sie trotzdem den E/A-Vorgang
mithilfe der Richtlinien aus Verbessern des E/A-Subsystems.
6.13.3
Hinzufügen von Partitionen zum Erhöhen der Parallelität
Analog zu ProcessData kann durch die parallele Verarbeitung vom mehr Partitionen ProcessIndex
beschleunigt werden. Dabei gilt dieselbe Optimierungsstrategie: Erhöhen Sie die Anzahl der Partitionen,
bis sich keine höhere Verarbeitungsgeschwindigkeit mehr feststellen lässt.
6.13.4
Optimieren von Threads und AggregationMemory-Einstellungen
Während ProcessIndex scannt und aggregiert Analysis Services die während ProcessData erstellten
Partitionen. Dieser Vorgang lässt sich auf zwei Arten parallel ausführen:
Verwenden Sie mehrere Threads, um die Segmente einer Partition jeweils gleichzeitig zu
scannen und zu aggregieren.
Scannen und aggregieren Sie mehrere Partition gleichzeitig mit einer geringeren Anzahl von
Threads.
Beide Methoden können in den meisten Fällen gleichzeitig verwendet werden. Sie können die
Ausführung mithilfe von Servereigenschaften steuern. Darüber hinaus sind beide Einstellungen durch
die Threadeinstellungen auf dem Server beschränkt, wie in Anpassen von ThreadPool und
CoordinatorExecutionMode erläutert.
Falls Sie mehr Partitionen hinzufügen, um den Parallelitätseffekt zu steigern, müssen Sie eventuell die
AggregationMemory-Einstellungen ändern. Ermöglicht der Entwurf das Hinzufügen von mehr
Partitionen nicht, können Sie CoordinatorBuildMaxThreads ändern, um den Parallelitätseffekt weiter zu
steigern.
Wenn die mit dem Leistungsindikator Prozessor –% Prozessorzeit – Gesamt gemessene CPU-Auslastung
unter 100 % liegt und keine E/A-Engpässe bestehen, können Sie die Geschwindigkeit der ProcessIndexPhase mit den Techniken in diesem Abschnitt unter Umständen weiter steigern.
83
6.13.4.1
Anpassen von Threadeinstellungen
Analog zu ProcessData muss möglicherweise die Threadpooleinstellung angepasst werden, um eine
optimale Leistung zu erzielen. Halten Sie sich an die Richtlinien aus Anpassen von ThreadPool und
CoordinatorExecutionMode.
6.13.4.2
Anpassen der AggregationMemoryMin-Eigenschaft
Unter den Servereigenschaften finden Sie die folgenden Einstellungen:
OLAP\Process\AggregationMemoryLimitMin
OLAP\Process\AggregationMemoryLimitMax
Diese Einstellungen, ausgedrückt als Prozentsatz des Analysis Services-Arbeitsspeichers, bestimmen, wie
viel Arbeitsspeicher in jeder Partition für das Erstellen von Aggregationen zugeordnet wird. Wenn
Analysis Services die Partitionsverarbeitung startet, wird die Parallelität basierend auf der
AggregationMemoryMin-Einstellung gedrosselt. Wenn Sie z. B. fünf parallele
Partitionsverarbeitungsaufträge mit AggregationMemoryMin = 10 starten, werden ungefähr 50 % des
Arbeitsspeichers für die Verarbeitung zugeordnet. Wenn nicht mehr genügend Arbeitsspeicher
vorhanden ist, werden neue Partitionsverarbeitungsaufträge gesperrt, während sie auf verfügbaren
Arbeitsspeicher warten. Wenn viele Partitionen parallel verarbeitet werden, kann durch Reduzieren des
Werts für AggregationMemoryLimitMin die Geschwindigkeit von ProcessIndex erhöht werden. Durch
die Begrenzung des pro Partition zugeordneten Mindestarbeitsspeichers kann ein höherer Grad an
Parallelität in der ProcessIndex-Phase erzielt werden.
Analog zu den anderen Analysis Services-Leistungsindikatoren wird bei dieser Einstellung ein Wert von
über 100 als feste Anzahl von Kilobytes interpretiert. Bei Computer mit großem Arbeitsspeicher kann ein
absoluter Kilobyte-Wert eine bessere Kontrolle des Arbeitsspeichers als ein Prozentwert bieten.
6.13.4.3
Anpassen von CoordinatorBuildMaxThreads
Beim Scannen einer einzelnen Partition wird die Anzahl von Threads zum Scannen von Blöcken durch die
CoordinatorBuildMaxThreads-Einstellung eingeschränkt. Diese Einstellung legt die maximale Anzahl der
pro Partitionsverarbeitungsauftrag zugeordneten Threads fest. Ihr Verhalten entspricht
CoordinatorExecutionMode (weitere Informationen finden Sie im Abschnitt zur Auftragsarchitektur.)
Weist diese Einstellung einen negativen Wert auf, wird ihr absoluter Wert mit der Anzahl von Kernen im
Computer multipliziert, um die maximale Anzahl ausführbarer Threads zu bestimmen. Weist die
Einstellung einen positiven Wert auf, ist dies die absolute Anzahl ausführbarer Threads. Beachten Sie
dabei, dass bei der Verarbeitung die Einschränkung durch die Anzahl von Threads im
Verarbeitungsthreadpool weiterhin besteht. Eine Erhöhung dieses Werts kann also auch eine
Vergrößerung des Verarbeitungsthreadpools bedeuten.
84
Partition
Process Job
Thread n
Thread 1
Thread 0
n = CoordinatorBuilMaxThread
Segments
Segments
Segments
Abbildung 29 CoordinatorBuildMaxThreads
Falls durch die Verwendung von mehr Partitionen keine hohe Parallelität erzielt werden konnte, können
Sie den CoordinatorBuildMaxThreads-Wert ändern. Durch die Erhöhung dieses Werts können Sie mehr
Threads pro Partition verwenden.
Möglicherweise müssen Sie auch die AggregationMemoryMin-Einstellungen anpassen, um optimale
Ergebnisse zu erzielen.
7 Optimieren von Serverressourcen
Neben dem Optimieren der Anwendung müssen in bestimmten Fällen einfach nur mehr
Hardwareressourcen hinzugefügt werden, um den Server selbst zu optimieren. In diesem Abschnitt
werden serverweite Einstellungen erläutert, mit denen die Leistung verbessert werden kann.
7.1 Verwenden von PreAllocate
Mit der PreAllocate-Einstellung in msmdsrv.ini kann physischer Arbeitsspeicher für Analysis Services
reserviert werden. Wenn neben Analysis Services noch andere Dienste auf demselben Computer
installiert sind, kann durch das Festlegen von PreAllocate eine stabilere Speicherkonfiguration
bereitgestellt werden.
Verfügt das zum Ausführen von Analysis Services verwendete Dienstkonto auch über das Privileg
Sperren von Seiten im Speicher, dann bewirkt PreAllocate, dass Analysis Services große Speicherseiten
verwendet. Sperren von Seiten im Speicher wird mit gpedit.msc festgelegt. Beachten Sie, dass große
Speicherseiten nicht an die Auslagerungsdatei ausgelagert werden können. Dies kann in Bezug auf die
85
Leistung ein Vorteil sein, allerdings können viele zugeordnete große Seiten dazu führen, dass das System
nicht mehr reagiert.
Lassen Sie ungefähr 20 % des Systemarbeitsspeichers für das Betriebssystem frei, wenn PreAllocate mit
großen Seiten verwendet wird.
Wichtig: PreAllocate hat die größten Auswirkungen auf das Windows Server® 2003-Betriebssystem. Mit
der Einführung von Windows Server 2008 wurde die Arbeitsspeicherverwaltung deutlich verbessert. Wir
haben diese Einstellung unter Windows 2008 Server getestet, jedoch keine Vorteile durch die
Verwendung von PreAllocate auf dieser Plattform festgestellt. Angesichts der Nachteile von PreAllocate
bietet diese Einstellung unter Windows Server 2008 wahrscheinlich kaum Vorteile.
Weitere Informationen zu den Auswirkungen von PreAllocate finden Sie im folgenden technischen
Hinweis:
Running Microsoft SQL Server 2008 Analysis Services on Windows Server 2008 vs. Windows
Server 2003 and Memory Preallocation: Lessons Learned
7.2 Deaktivieren von Flight Recorder
Flight Recorder stellt einen Mechanismus zum Aufzeichnen der Analysis Services-Serveraktivität in
einem kurzfristigen Protokoll bereit. Flight Recorder bietet zwar viele Vorteile bei der
Problembehandlung bestimmter Abfrage- und Verarbeitungsprobleme, führt aber auch zu einem
gewissen E/A-Aufwand. Wenn Sie in einer Produktionsumgebung arbeiten und die Funktionen von Flight
Recorder nicht benötigen, können Sie diese Protokollierung deaktivieren und den E/A-Aufwand
entfernen. Mit der Servereigenschaft Log\Flight Recorder\Enabled wird gesteuert, ob Flight Recorder
aktiviert ist. Standardmäßig ist diese Eigenschaft auf true festgelegt.
7.3 Überwachen und Anpassen des Serverarbeitsspeichers
In der Regel ist ein möglichst großer Arbeitsspeicher optimal. Falls die Datendateien im
Betriebssystemcache gespeichert werden können, wird die Leistung des Speichermoduls nicht
beeinflusst. Wenn das Formelmodul eigene Ergebnisse zwischenspeichern kann, werden Zellenwerte
wiederverwendet statt neu berechnet. Während der Verarbeitung wird die Leistung auch verbessert,
wenn kein Überlauf von Ergebnisse auf den Datenträger erfolgt. Beachten Sie jedoch, dass Analysis
Services AWE-Arbeitsspeicher auf 32-Bit-Systemen nicht verwendet. Falls für den Cube ein großer
Arbeitsspeicher erforderlich ist, wird die Verwendung von 64-Bit-Hardware empfohlen.
Wichtige Arbeitsspeichereinstellungen sind Memory\TotalMemoryLimit und
Memory\LowMemoryLimit, ausgedrückt als Prozentsatz des verfügbaren Arbeitsspeichers. Der
Arbeitsspeicher kann mit dem Task-Manager oder mit den folgenden Leistungsindikatoren überwacht
werden:
86
MSAS2008:Speicher\Speicherauslastung KB
MSAS2008:Speicher\Speicheruntergrenze KB
MSAS2008:Speicher\Speicherobergrenze KB
Wenn PreAllocate nicht verwendet wird, gibt Analysis Services bei nicht vorhandener Auslastung
Speicher frei – andere Anwendungen (wie das SQL Server-Modul) können freigegebenen Speicher
beanspruchen. Daher ist es wichtig, nicht nur Analysis Services korrekt zu konfigurieren, sondern auch
andere Anwendungen auf dem Computer.
Führen Sie, bevor Sie entscheiden, dass zusätzlicher Arbeitsspeicher erforderlich ist, die in den
Abschnitten zu Abfragen und Verarbeitung beschriebenen Schritte aus, um die Cubeleistung zu
optimieren.
8 Zusammenfassung
Dieses Dokument bietet die Mittel zur Diagnose und zum Behandeln von Verarbeitungs- und
Abfrageleistungsproblemen mit SQL Server 2008 Analysis Services. Weitere Informationen
finden Sie unter den folgenden Themen:
http://sqlcat.com/: SQL Customer Advisory Team
http://www.microsoft.com/sqlserver/: SQL Server-Website
http://technet.microsoft.com/de-de/sqlserver/: SQL Server TechCenter
http://msdn.microsoft.com/de-de/sqlserver/: SQL Server DevCenter
Wenn Sie Vorschläge oder Anmerkungen haben, können Sie sich jederzeit an die Autoren
wenden. Sie erreichen Richard Tkachuk unter [email protected] oder Thomas Kejser unter
[email protected].
War dieses Whitepaper hilfreich? Senden Sie uns Ihr Feedback. Nennen Sie uns anhand einer
Skala von 1 (schlecht) bis 5 (sehr gut) die Bewertung dieses Whitepapers und die Gründe für
Ihre Bewertung. Beispiel:
Vergeben Sie eine gute Bewertung auf Grund der guten Beispiele, hervorragenden
Screenshots, klaren Formulierungen oder aus einem anderen Grund?
Vergeben Sie eine weniger gute Bewertung auf Grund schlechter Beispiele, ungenauer
Screenshots oder unklarer Formulierungen?
Dieses Feedback trägt zur Verbesserung der Qualität von uns veröffentlichter Whitepapers bei.
Feedback senden
87