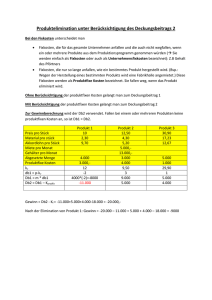
XML-Speicherstrukturen in DB2 for z/OS Version 9.1 und
Werbung

XML-Speicherstrukturen in DB2 for z/OS Version 9.1 und Überführungskonzepte für nicht-native XML-Speicherformen - Studienarbeit eingereicht von Christoph Koch [email protected] Betreuer Prof. Klaus Küspert, Friedrich-Schiller-Universität Jena Norbert Wolf, DATEV eG Friedrich-Schiller-Universität Jena Fakultät für Mathematik und Informatik Institut für Informatik Lehrstuhl für Datenbanken und Informationssysteme August 2011 Danksagung Die vorliegende Studienarbeit ist nur durch die breite Unterstützung zahlreicher Akteure ermöglicht worden. Ihnen möchte ich an dieser Stelle meinen Dank aussprechen: Prof. Klaus Küspert Prof. Küspert trug maßgeblich dazu bei, dass ich mit der DATEV eG in Kontakt getreten bin. Ein durch ihn vermitteltes Praktikum im Jahr 2010 legte den Grundstein für diese Studienarbeit, deren universitäre Betreuung ebenfalls Prof. Küspert selbst übernahm. Dabei scheute er keine Mühen und reiste neben diversen Besprechungsterminen in Jena auch mehrfach zur DATEV eG nach Nürnberg an. Norbert Wolf Herr Wolf übernahm als Fachberater Datenbanken die Betreuung der Studienarbeit in der DATEV eG. In engem Kontakt stand er mir stets für Fragen zur Verfügung und investierte viel Zeit darin, mich mit seinem Wissen fachlich zu unterstützen. Darüber hinaus gab er mir auch zahlreiche persönliche Ratschläge, so dass er für mich eine Funktion als Mentor einnahm. „Workflowgestütztes Antrags- und Genehmigungsverfahren (WAG)“-Team Das WAG-Team in der DATEV eG zeigte früh Interesse an der erbrachten Arbeit. In einzelnen Meetings schilderten die verantwortlichen Kollegen die hier untersuchte Problematik aus Anwendersicht und gaben dadurch Hinweise und Anregungen für die Zielsetzung dieser Studienarbeit. Weiterhin stellte das WAG-Team erste Testdaten zur Verfügung, anhand derer verschiedene Aspekte untersucht werden konnten. Diese wurden zusätzlich auch für die Testläufe des entwickelten Prototyps herangezogen. Dr. Henrik Loeser Dr. Loeser ist Mitarbeiter der IBM und hat dort intensiv zur Entwicklung der nativen XML-Speicherstrukturen im DB2 beigetragen. Er stellte sich zur Verfügung, spezielle Fragen auf diesem Gebiet zu beantworten. Mit sehr hilfreichen, umfangreichen Ausführungen trug er damit zu den detaillierten Betrachtungen dieser Arbeit bei. Dr. Ernst Lugert Als Leiter der Abteilung Datenbanken der DATEV eG hat mich Dr. Lugert ebenfalls weitreichend unterstützt. Er ermöglichte es mir, trotz meines parallel laufenden Studiums in Jena diese Arbeit anzufertigen. Zusätzlich erkundigte sich Dr. Lugert während regelmäßiger Besprechungstermine nach dem aktuellen Stand der Arbeit und zeigte bei auftretenden Problemen hilfreiche Gedankenansätze auf. Karin Arneth Frau Arneth hat durch ihre Position im Sekretariat der Abteilung Datenbanken einen großen Beitrag zu der Organisation dieser Arbeit geleistet. Dabei koordinierte sie unter anderem sämtliche Terminangelegenheiten. Weiterhin nahm sich Frau Arneth die Zeit, um die vorliegende Arbeit grammatikalisch zu prüfen und trug somit merklich zu deren Qualität bei. Uwe Heger Mit seinem breiten Wissensspektrum von Datenbanken bis hin zur Anwendungsentwicklung unterstützte mich Herr Heger aus der Gruppe Datenbankadministration der DATEV eG bei der Erstellung des Prototyps. Ebenfalls nahm er an vielen konzeptuellen Überlegungen teil und reicherte damit die Studienarbeit an. Eva Ising Frau Ising ist in der DATEV eG Mitarbeiterin der Gruppe Datenbanksysteme. Sie stellte meine Ansprechpartnerin bei schwerwiegenden Problemen im DB2 for z/OS dar und leitete diese mit großem Engagement zur schnellen Bearbeitung an die IBM weiter. Allen diesen Personen, sowie auch den nicht genannten Mitarbeitern der Gruppe Datenbankadministration der DATEV eG, die mich sehr herzlich in ihr Kollegium aufgenommen haben, gilt mein besonderer Dank. Kurzfassung Unter dem Thema „XML-Speicherstrukturen in DB2 for z/OS V9.1 und Überführungskonzepte für nicht-native XML-Speicherformen“ fokussiert diese Studienarbeit die strukturellen Aspekte der datenbankseitigen XML-Ablage in DB2 for z/OS. Darin eingeschlossen werden sowohl die in der DATEV eG vorhandenen nicht-nativen als auch die nativen XML-Speicherformen im Detail betrachtet und evaluierend gegenübergestellt. Darüber hinaus liegt ein weiterer Schwerpunkt dieser Arbeit in der Untersuchung von Möglichkeiten und daraus abgeleiteten Konzepten, die eine Überführung der konventionell gespeicherten XML-Dokumente in den nativen Datentyp XML realisieren können. Abschließend sollen die dabei gewonnenen Erkenntnisse in Form eines Prototyps zur XML-Überführung verifiziert werden. Inhaltsverzeichnis 1 Einleitung ..............................................................................................................................8 1.1 Motivation.........................................................................................................................8 1.2 Einstiegsbeispiel ...............................................................................................................9 1.3 Gliederung ......................................................................................................................11 2 Die DATEV eG...................................................................................................................13 2.1 Eingetragene Genossenschaft .........................................................................................13 2.2 Daten und Fakten ............................................................................................................13 2.3 Portfolio ..........................................................................................................................13 2.4 Hintergrund der XML-Untersuchung .............................................................................14 3 Grundlagen..........................................................................................................................15 3.1 XML................................................................................................................................15 3.2 DB2 for z/OS ..................................................................................................................17 3.3 IBM Data Studio.............................................................................................................18 3.4 Nativ vs. nicht-nativ........................................................................................................19 3.5 DATEV-Konventionen...................................................................................................20 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9............................................22 4.1 XML nicht-nativ als VARCHAR ...................................................................................24 4.1.1 Struktur.....................................................................................................................24 4.1.2 Inline-Datentyp.........................................................................................................25 4.1.3 Character-String .......................................................................................................25 4.1.4 Kompatibilität...........................................................................................................26 4.2 XML nicht-nativ als CLOB ............................................................................................26 4.2.1 Struktur (LOB-Spezifika).........................................................................................26 4.2.2 Struktur (DATEV-Spezifika) ...................................................................................28 4.2.3 Outline-Datentyp ......................................................................................................28 4.2.4 Character-String und Kompatibilität ........................................................................29 4.3 Besonderheit: Verteilung über mehrere Tupel................................................................29 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1..........................................32 5.1 Verwaltungskonzept für natives XML............................................................................33 5.2 Explizite XML-Verwaltungsobjekte...............................................................................33 5.3 Implizite XML-Verwaltungsobjekte...............................................................................34 5.4 DocID..............................................................................................................................35 5.5 XML-Tablespace ............................................................................................................36 5.6 XML-Auxiliary-Tabelle..................................................................................................37 5.6.1 DocID-Spalte............................................................................................................39 5.6.2 Min_NodeID-Spalte .................................................................................................39 5.6.3 XMLData-Spalte ......................................................................................................39 5.7 Indexe..............................................................................................................................42 5.7.1 NodeID-Index...........................................................................................................43 5.7.2 DocID-Index.............................................................................................................44 5.7.3 User-Defined-Indexe ................................................................................................45 5.8 Locking ...........................................................................................................................47 5.9 Logging...........................................................................................................................48 5.10 Kompression ...................................................................................................................49 6 Gegenüberstellung: native vs. nicht-native XML-Speicherstrukturen................................51 6.1 Evaluierender Vergleich .................................................................................................51 6.2 LOB-RowID und XML-DocID ......................................................................................52 7 Überführungskonzepte für nicht-native XML-Speicherformen..........................................55 7.1 Differenzierte Ansätze ....................................................................................................55 7.1.1 Möglichkeit zum Fallback........................................................................................55 7.1.2 „Fehlertoleranz“ .......................................................................................................57 7.1.3 Offline- vs. Online-Migration ..................................................................................58 7.1.4 Einzeilige vs. verteilte nicht-native XML-Dokumente ............................................59 7.1.5 Anwendungsseitiger vs. datenbankseitiger Migrationsprozess ................................61 7.2 Herausforderungen..........................................................................................................63 7.2.1 Vorangehende Leerzeichen im Quelldokument .......................................................63 7.2.2 Implizite Konvertierung: EBCDIC zu Unicode .......................................................64 7.2.3 Ungültige Zeichen im Quelldokument .....................................................................65 7.2.4 „Record Size“-Limit bei der Konkatenation von VARCHARs ...............................66 7.2.5 Entfallende laufende Nummer..................................................................................68 7.3 Fazit ................................................................................................................................69 8 Prototyp: XML-Migrator.....................................................................................................70 8.1 Architektur – modifiziertes MVC-Pattern ......................................................................70 8.2 Migrationsphasen............................................................................................................73 8.2.1 Input und Input-Handling.........................................................................................73 8.2.2 Preprocessing............................................................................................................75 8.2.3 Build Trigger ............................................................................................................77 8.2.4 Copy Data.................................................................................................................79 8.2.5 Switch View .............................................................................................................83 8.2.6 Postprocessing..........................................................................................................85 9 Schlussbetrachtung..............................................................................................................87 Abkürzungs- und Begriffsverzeichnis .........................................................................................88 Abbildungsverzeichnis.................................................................................................................97 Literaturverzeichnis .....................................................................................................................99 1 Einleitung 1 Einleitung Das aktuelle Kapitel dient einer Einführung in den Sachverhalt der vorliegenden Studienarbeit. Dabei schließt sich an eine einleitende Motivation ein Anwendungsbeispiel an, das den Einstieg in das Themengebiet erleichtern soll. Daran anknüpfend wird die Gliederung der Arbeit näher erläutert. 1.1 Motivation Mit der Verabschiedung der Spezifikation der Extensible Markup Language (XML) im Jahr 1998 existierte der neue De-facto-Standard für den Austausch von Daten in seiner ersten Version. Nachdem diese Auszeichnungssprache in den vergangenen Jahren immer mehr an Verbreitung gewann, nahm sie auch Einzug in den Datenbanksektor. Neben der Entwicklung dedizierter XML-Datenbankmanagmentsysteme wurden in diesem Zusammenhang auch relationale Datenbankmanagmentsysteme wie das von IBM [IBM11i] vertriebene DB2 for z/OS um XML-Strukturen erweitert. Die ersten Bestrebungen der IBM kamen dabei bereits im Jahr 2001 mit der Einführung des XML-Extenders auf. Dieser basierte auf verschiedenen nichtnativen XML-Speicherformen (siehe Kapitel 4). Mittlerweile ist die native XML-Speicherung durch die pureXML-Technologie [IBM11j] ein fest integrierter Bestandteil des DB2 for z/OS und weiterer DB2-Ausprägungen anderer Plattformen. [Mil11] Neben zusätzlichen datenbankseitigen Erweiterungen war und ist es weiterhin möglich, XML-Dokumente auch als einfache Textdokumente abzulegen. Dieser Ansatz wurde beispielsweise in der DATEV eG [DAT11e] bis zur Einführung der pureXML-Technologie und den damit verbundenen nativen Speichermöglichkeiten gewählt. Da diese Ablageform der nichtnativen XML-Speicherung weitgehend überlegen ist, existiert die Anforderung, bisher nichtnativ gespeicherte XML-Dokumente in die native Struktur zu überführen. Hier setzt auch diese Studienarbeit auf, die speziell die folgenden Ziele im DB2-Kontext verfolgt: Untersuchung der konventionellen nicht-nativen Strukturen für die Speicherung von XML Darstellung der neuen physischen Strukturen des Datentyps XML in DB2 for z/OS Version 9.1 8 1 Einleitung Entwicklung von Konzepten, um nicht-native XML-Dokumente in die native XMLSpeicherstruktur zu überführen Erprobung der Konzepte anhand eines selbstimplementierten Prototyps Da die Ausgangssituation in DB2 for z/OS bei der DATEV eG durch das Vorhandensein von nicht-nativ relational gespeicherten XML-Dokumenten gekennzeichnet ist, wird von einer relationalen Speicherung von XML-Inhalten weiterhin ausgegangen. Eine Gegenüberstellung von relationaler und XML-Speicherung erfolgt nicht. Auch Mischformen aus relationaler und XML-Speicherung sollen hier nicht diskutiert werden. Die gestellten Ziele beziehen sich in ihrem Umfang stets auf den direkten Vergleich von nicht-nativen und nativen XMLSpeicherformen innerhalb von DB2 for z/OS. 1.2 Einstiegsbeispiel Um einen leichteren Einstieg in die Thematik zu bekommen, soll der zusätzliche Nutzen, den die native XML-Speicherung gegenüber der nicht-nativen Ablage hat, an einem einfachen Beispiel demonstriert werden. Angenommen, eine Projektanwendung speichert Kundendaten in Form von XML-Dokumenten ab. Da diese Daten von der Anwendung ausschließlich als XML verarbeitet und in diesem Format sehr oft mit weiteren Anwendungen ausgetauscht werden, ist zu ihrer datenbankseitigen Ablage eine Tabelle „Kunde“ mit zwei Spalten „ID“ und „Kundendaten“ vorgesehen worden. Dabei enthält die erste Spalte „ID“ die eindeutige Kundennummer. Diese findet sich ebenfalls stets in den enthaltenen XML-Dokumenten der „Kundendaten“Spalte wieder, was aber für das folgende Szenario irrelevant ist. Da das Projekt bereits seit vielen Jahren Kundendaten speichert, basiert die XML-Speicherung auf der nicht-nativen Form einer einfachen Textablage. Seit kurzem ist die Projektanwendung um neue Funktionen erweitert worden. Nun ist es unter anderem möglich, ähnlich einem Telefonbuch, alle betrieblichen Telefonnummern der Kunden zusammen mit ihren Namen anzeigen zu lassen. Dazu muss die Anwendung (leider) stets die nicht-nativ gespeicherten XML-Dokumente der „Kundendaten“Spalte aller Kunden komplett laden, auch wenn deren Telefonnummer eventuell gar nicht bekannt oder nur die Privatnummer vorhanden ist. Dabei werden ebenfalls zwangsweise Informationen der Kunden abgefragt, die für die gegebene Aufgabe unnötig sind. Die insgesamt dazu notwendige Verarbeitung ist sehr aufwendig und zeitintensiv, da die Tabelle „Kunde“ 9 1 Einleitung mittlerweile über 100.000 Einträge umfasst. Abbildung 1 veranschaulicht die dabei entstehende Zugriffskette und die dazu nötige SQL-Anweisung. ID Kundendaten … … 1001 <customerinfo id="1001"> <name> Mustermann </name> <phone type="work"> 408-555-1358 </phone> </customerinfo> XML XML XML XML XML … ProjektProjektanwendungen SELECT ID, KUNDENDATEN FROM KUNDE … Abbildung 1: Anwendungsbeispiel mit nicht-nativer XML-Speicherung Unter Verwendung der nativen XML-Speicherstrukturen kann dieser Aufwand wesentlich reduziert werden. Mithilfe des XMLEXISTS-Prädikats1 [IBM11a] ließe sich datenbankseitig nach den Kunden suchen, deren betriebliche Telefonnummer bekannt ist. Zusätzlich könnten durch zwei weitere XMLQUERY-Funktionsaufrufe [IBM11a] deren Rufnummern gemeinsam mit dem Namen der Kunden ausgelesen werden. Dadurch wäre eine gezielte und vor allem effiziente Übermittlung der für die Anwendung relevanten Informationen möglich. Unnötiger Kommunikationsaufwand zwischen Datenbank und Anwendung würde entfallen. Um dies zu realisieren, genügt es, aus Anwendungssicht lediglich die SQL-Anfrage abzuändern und diese unter anderem um diverse XPath-Pfadausdrücke zu ergänzen. Abbildung 2 zeigt das veränderte SQL-Statement und die daraus resultierende Zugriffskette. [IBM11a] 1 weiteres Anwendungsbeispiel siehe Abschnitt 5.7.3 10 1 Einleitung ID Kundendaten … … <customerinfo id="1001"> <name> Mustermann </name> <phone type="work"> 408-555-1358 </phone> </customerinfo> 1001 … SELECT XMLQUERY('$doc/customerinfo/name/text()‘ PASSING XML AS "doc") AS NAME, XMLQUERY('$doc/customerinfo/phone/text()‘ PASSING XML AS "doc") AS PHONE FROM KUNDE WHERE XMLEXISTS( '$doc/customerinfo/phone[@type="work"] '‚ PASSING KUNDENDATEN AS "doc" ); Muste rman n, 40 8- … … 555-1 35 8 ProjektProjektanwendungen Abbildung 2: Anwendungsbeispiel mit nativer XML-Speicherung 1.3 Gliederung Die Strukturierung dieser Arbeit basiert auf den Ausführungen aus dem Abschnitt 1.1. Im Detail ergibt sich für die abzuhandelnden Aspekte jedoch eine feinere Granularität. An dieser Stelle sollen daher die inhaltlichen Schwerpunkte der weiteren Kapitel umrissen werden. Die DATEV eG (Kapitel 2) Die vorliegende Arbeit wurde im Rahmen einer Werkstudententätigkeit in der DATEV eG erstellt. In Kapitel 2 erfolgt daher eine kurze Vorstellung dieses Unternehmens. Dabei wird auch auf die Intentionen der dortigen Untersuchungen hinsichtlich der XML-Thematik Bezug genommen. Grundlagen (Kapitel 3) In diesem Kapitel 3 erfolgt die detaillierte Erklärung wesentlicher Begrifflichkeiten, die im Verlauf der Arbeit von größerer Bedeutung sind. Dabei wird unter anderem auf die Auszeichnungssprache XML, das in diesem Zusammenhang betrachtete Datenbankmanagementsystem DB2 for z/OS und das zur Untersuchung hauptsächlich verwendete Tool IBM Data 11 1 Einleitung Studio näher eingegangen. Weiterhin finden hier die verschiedenen XML-Speicherformen, nativ beziehungsweise nicht-nativ und auch die internen Konventionen der DATEV eG Erwähnung. XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 (Kapitel 4) Bereits vor Version 9 des DB2 for z/OS wurde XML datenbankseitig abgelegt. Die verschiedenen Möglichkeiten und die zugehörigen Strukturen einer solchen nicht-nativen XMLSpeicherung bilden den Kern von Kapitel 4. Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 (Kapitel 5) Mit der Einführung der pureXML-Technologie ist auch ein nativer XML-Datentyp in DB2 for z/OS integriert worden. Die ihm zugrunde liegenden Strukturen werden in Kapitel 5 detailliert betrachtet. Darin inbegriffen sind explizite und implizite Verwaltungsobjekte wie Tablespaces, Tabellen, zusätzliche Spalten und diverse Indexe. Weiterhin werden in diesem Kapitel die Aspekte Logging, Locking und Kompression des nativen XML-Datentyps aufgegriffen. Gegenüberstellung: native vs. nicht-native XML-Speicherstrukturen (Kapitel 6) In Kapitel 6 werden die unterschiedlichen XML-Speicherstrukturen evaluierend gegenübergestellt. Dabei liegt ein zusätzlicher Schwerpunkt auf dem Vergleich der Konzepte der LOB-RowID und der XML-DocID. Überführungskonzepte für nicht-native XML-Speicherformen (Kapitel 7) Um die nicht-nativen XML-Dokumente in die native Speicherform zu überführen, sind verschiedene Vorbetrachtungen notwendig. Diese werden in Kapitel 7 aufgezeigt und in Form von konkreten Überführungskonzepten gebündelt. Prototyp: XML-Migrator (Kapitel 8) In Kapitel 8 wird ein auf den entwickelten Überführungskonzepten aufbauender Prototyp vorgestellt. In dem Zusammenhang wird insbesondere auf dessen Architektur eingegangen und der Ablauf detailliert beschrieben, in dem er die Überführung realisiert. 12 2 Die DATEV eG 2 Die DATEV eG Die DATEV eG [DAT11e], fortan als DATEV bezeichnet, ist ein Softwarehaus und ITDienstleister für Steuerberater, Wirtschaftsprüfer und Rechtsanwälte sowie deren Mandanten. In dem folgenden Kapitel soll eine kurze Vorstellung des Unternehmens erfolgen. 2.1 Eingetragene Genossenschaft Bei der Organisationsform der DATEV handelt es sich um eine eingetragene Genossenschaft. Als solche ist sie nicht auf die Maximierung der eigenen Gewinne ausgerichtet. Vielmehr steht das Wohl der Genossenschaftsmitglieder im Vordergrund. Demnach zeichnet sich eine erfolgreiche Genossenschaft nicht durch ihren eigenen Erfolg aus, sondern durch den ihrer Mitglieder. Im Fall der DATEV sind dies Steuerberater, Wirtschaftsprüfer und Rechtsanwälte. [DAT11a] 2.2 Daten und Fakten Die DATEV wurde 1966 von 65 Steuerbevollmächtigten, darunter Heinz Sebiger2, in Nürnberg gegründet. Dort befindet sich auch heute noch der Hauptsitz der Genossenschaft. Bundesweit zählt die DATEV 25 Niederlassungen, mehr als 5.800 Mitarbeiter und über 39.000 Mitglieder. Seit 1996 wird sie von dem Vorstandsvorsitzenden Prof. Dieter Kempf [DAT11d] geleitet. [DAT11b] 2.3 Portfolio Das Leistungsspektrum der DATEV umfasst Software für verschiedene Bereiche wie Rechnungswesen, Personalwirtschaft, betriebswirtschaftliche Beratung, Steuerberechnung und Organisation von Unternehmen und Kanzleien. Zusätzlich bietet die Genossenschaft ihren 2 bis 1996 Vorstandsvorsitzender der DATEV eG 13 2 Die DATEV eG Mitgliedern noch weitere Leistungen. Darin eingeschlossen sind unter anderem Möglichkeiten des IT-Outsourcing [DAT11f] (beispielsweise in Form von DATEVasp [DAT11g]) oder die Nutzung des hauseigenen Druck- und Versandzentrums. Ebenso zählen vielfältige Fortbildungsund Informationsangebote zu Gesetzesänderungen, Programmhandling, Betriebswirtschaft oder Qualitätssicherung zum Portfolio der DATEV. Alle genannten Leistungen unterstehen den höchsten Datenschutz- und Datensicherheitsanforderungen. [DAT11c] 2.4 Hintergrund der XML-Untersuchung In der DATEV sind verschiedene Datenbankmanagementsysteme im Einsatz. Eine zentrale Rolle nimmt dabei DB2 for z/OS ein, das aktuell in Version 9.1 („new-function mode“) eingesetzt wird. DB2 for z/OS ist dabei auf zwei Mainframes der jüngsten z196-Generation [IBM11k] installiert, die als zentrale Daten- und Anwendungsserver dienen. [DAT10] Die Zuständigkeit für DB2 for z/OS liegt in der Abteilung Datenbanken. Die dortige Ausrichtung orientiert sich stets an den aktuellen Möglichkeiten im Datenbankmanagementsystem. Daher trat auch die XML-Thematik in der vergangenen Zeit vermehrt in den Fokus der Betrachtung. Vielmehr aber ergab sich der Grund für die in dieser Arbeit durchgeführten Untersuchungen durch einen anderen Aspekt. Bereits seit längerer Zeit befinden sich diverse nichtnativ gespeicherte XML-Daten von verschiedenen Projektanwendungen in DB2 for z/OS. Durch die mit DB2 for z/OS Version 9 eingeführten Möglichkeiten der pureXML-Technologie ergeben sich in diesem Zusammenhang verschiedene Fragestellungen. Im Mittelpunkt steht dabei die Frage nach dem Mehrwert einer möglichen nativen XML-Speicherung gegenüber den bisherigen nicht-nativen Ablageformen. Da vor allem die internen Strukturen dieser beiden Speichervarianten von Interesse sind, entschloss sich die DATEV im Rahmen einer intensiveren Untersuchung, die Strukturen detaillierter zu betrachten und mögliche Überführungskonzepte für nicht-native XML-Dokumente zu erarbeiten. 14 3 Grundlagen 3 Grundlagen Das folgende Kapitel dient der ausführlichen Beschreibung grundlegender Aspekte, die im weiteren Verlauf der Arbeit von Bedeutung sein werden. Zusätzlich zu den aufgeführten Erklärungen finden sich allgemeine Abhandlungen der relevanten Begrifflichkeiten ebenfalls im Abkürzungs- und Begriffsverzeichnis. 3.1 XML Die Extensible Markup Language (XML) wurde 1998 durch das World Wide Web Consortium (W3C) [W3C11] eingeführt. Dabei handelt es sich um eine Auszeichnungssprache (Markup Language) zur Beschreibung hierarchisch strukturierter Daten. Aktuell existieren zwei Versionen der XML-Spezifikation: XML 1.0 [W3C08] und XML 1.1 [W3C06]. Generell hat XML die Eigenschaft, ein flexibles und universell einsetzbares Datenaustauschformat darzustellen. Im Kern der XML-Spezifikation stehen die Konzepte XML-Dokument, XML-Schema und XMLNamespace. [Mül08] Ein XML-Dokument ist grundlegend ein Text-Dokument, das durch diverse Auszeichnungen (Markups) strukturiert ist. Diese werden auch als Tags bezeichnet, wobei auf jeden öffnenden genau ein schließender Tag folgen muss. Mit Hilfe jener Auszeichnungen lassen sich die einzelnen Bestandteile eines XML-Dokuments voneinander separieren. Aufgrund der hierarchischen (Baum-) Struktur der XML-Daten werden diese Bestandteile fortan auch als Knoten bezeichnet. Ein XML-Dokument kann aus einem bis beliebig vielen Knoten zusammengesetzt sein. Dabei ist zwischen Elementen, Attributen, Kommentaren und Verarbeitungsanweisungen zu unterscheiden. Zusätzlich können XML-Dokumente noch eine einleitende XML-Deklaration und eine Document-Type-Definition (DTD) [Von05] umfassen. Elemente und Attribute sind die wichtigsten Knotentypen. Ein Element wird durch die oben genannten Tags begrenzt. Dazwischen befindet sich der Elementinhalt, der mit einem Text oder weiteren Elementen gefüllt sein kann. Leere Elemente sind ebenfalls zulässig. Wichtig ist, dass jedes XML-Dokument genau aus einem Wurzelelement besteht, welches alle weiteren Elemente in sich trägt. Attribute sind stets an bestimmte Elemente gebunden. Dort werden sie innerhalb des öffnenden Element-Tags deklariert. Auf die Beschreibung der weiteren Knotentypen soll hier verzichtet und auf [Von05] verwiesen werden. [Hee02, Mül08] 15 3 Grundlagen Bei XML-Dokumenten ist zwischen wohlgeformten und gültigen Dokumenten zu unterscheiden. Während jedes XML-Dokument, das den in der XML-Spezifikation festgelegten Syntaxregeln entspricht, gleichzeitig auch ein wohlgeformtes Dokument darstellt, gilt dies bezüglich der Gültigkeit nicht. Damit ist jene Gültigkeit also „mehr“ als nur die Wohlgeformtheit. Eine ausführliche Abhandlung der Syntaxregeln ist in [W3C08] beziehungsweise in [W3C06] zu finden. Aufgrund der späteren Bedeutung (siehe Abschnitt 7.2.1) soll jedoch an dieser Stelle auf eine Einschränkung gezielter hingewiesen werden. Jedes XML-Dokument muss entweder mit einer XML-Deklaration oder dem Wurzelelement beginnen. Dementsprechend ist das erste Zeichen des Dokuments immer eine öffnende Tag-Klammer („<“). Sollte diese Eigenschaft verletzt sein, dann gilt das Dokument als nicht wohlgeformt. Mit Hilfe der DTD oder den später in die XML-Spezifikation aufgenommenen XMLSchemas kann die Struktur von XML-Dokumenten genauer beschrieben und damit auch eingeschränkt werden. Auf diese Weise können beispielsweise die einzelnen Elemente und Attribute, die Reihenfolge ihres Auftretens oder auch die möglichen Werte (Wertebereiche) vordefiniert werden. Ein XML-Dokument gilt nur dann als gültig, wenn es diesen Einschränkungen genügt. Das dazu notwendige Prüfen des Dokuments wird fortan auch als Validierung bezeichnet. Sollte weder eine DTD noch ein XML-Schema definiert sein, dann gilt ein wohlgeformt XMLDokument automatisch als gültig. Abbildung 3 zeigt ein Beispiel für ein solches wohlgeformtes Dokument. Da DTDs wie auch XML-Schemas für den weiteren Verlauf der Arbeit nebensächlich sind, wurde im Beispiel auf deren Angabe verzichtet. [Mül08] Element (öffnender Tag) Attribut <customerinfo id="1001"> <name> Mustermann </name> <phone type="work"> 408-555-1358 </phone> </customerinfo> Elementinhalt Element (schließender Tag) Abbildung 3: wohlgeformtes XML-Dokument XML-Namespaces sind Namensräume, die optional für Elemente und Attribute vergeben werden können. Sie dienen dazu, in unterschiedlichen Kontexten auftretende gleiche Elemente 16 3 Grundlagen und Attribute voneinander zu unterscheiden und mittels eines Uniform Resource Identifiers (URI) eindeutig zu identifizieren. Da XML-Namespaces analog zu den XML-Schemas für die hier erbrachte Arbeit nicht weiter relevant sind, wird von einer detaillierteren Betrachtung dieses Konzepts abgesehen und auf [Mül08] verwiesen. 3.2 DB2 for z/OS DB2 ist ein von IBM vertriebenes relationales Datenbankmanagementsystem, das für verschiedene Plattformen verfügbar ist. Die verbreitetsten Produktlinien sind dabei das in dieser Arbeit betrachtete DB2 for z/OS (aktuelle Version: 10) [IBM11n] und DB2 for Linux UNIX and Windows (DB2 for LUW, aktuelle Version: 9.7) [IBM11o]. In seinen Ursprüngen geht DB2 vor allem auf den in den 1970er Jahren entwickelten Prototypen „System R“ [Ley11] zurück, aus dem dann SQL/DS3 als erstes relationales Produkt der IBM entstand. DB2 ist erstmalig 1983 als Datenbankmanagementsystem für das Betriebssystem Multiple Virtual Storage (MVS) [IBM78] veröffentlicht worden. Aus diesem entwickelte sich das heutige z/OS-Betriebssystem [IBM11p] der modernen IBM-Mainframe-Architektur „System z“. [Mil11] Die umgangssprachlich auch als Dinosaurier betitelten Großrechner galten lange Zeit als vom „Aussterben“ bedroht. Aufgrund ihrer Eigenschaft, hohe Anforderungen an Skalierbarkeit, Verfügbarkeit und Sicherheit erfüllen zu können, nehmen sie jedoch auch heute noch eine wichtige Rolle in der IT-Landschaft zahlreicher Großunternehmen ein. In den vergangenen Jahren hat sich in der Industrie sogar eine steigende Tendenz gezeigt, den Mainframe wieder vermehrt einzusetzen. IBM hat diesen Trend gefördert und investiert daher fortwährend in die Weiterentwicklung der Plattform „System z“. DB2 for z/OS wurde und wird dabei ebenfalls permanent modernisiert und um neue Features wie beispielsweise die native Speicherung von XML-Daten erweitert. Diese bildet den Kern der hier erbrachten Ausarbeitung. Im weiteren Verlauf der Arbeit wird DB2 for z/OS verkürzt als DB2 bezeichnet. Verweise auf andere DB2Produktlinien sind dagegen speziell kenntlich gemacht. [Com07, Pic09] Wie bereits in Abschnitt 2.4 erwähnt, wird DB2 innerhalb der DATEV momentan in Version 9.1 („new-function mode“) eingesetzt. Sofern nicht anders kenntlich gemacht, beziehen sich alle weiteren Erwähnungen stets auf diese DB2-Version. [DAT10] 3 heute DB2 Server for VSE & VM [IBM11q] 17 3 Grundlagen 3.3 IBM Data Studio Das IBM Data Studio ist ein von IBM vertriebenes Datenbanktool, das auf der EclipsePlattform [Ecl11] aufbaut. Es soll Entwicklern und Administratoren bei der Arbeit mit IBMDatenbanksoftware, wie beispielsweise DB2, unterstützen. Die Funktionalitäten des IBM Data Studio lassen sich in vier Kernbereiche einteilen [IBM09b]: Design Entwicklung Administration Tuning Bislang wurden für die aufgeführten Aufgabenbereiche von IBM unter anderem die Tools DB2 Control Center [IBM11l], Optimization Service Center (OSC) [IBM09d] und Visual Explain [IBM11m] empfohlen. Mit dem Release des IBM Data Studio galten diese als veraltet („deprecated“). Speziell die Funktionalitäten des bislang eigenständigen Produkts Visual Explain sind nun offiziell Bestandteil des IBM Data Studio. Ein großer Vorteil des IBM Data Studio ist dessen Eigenschaft, innerhalb einer Eclipse-basierten Umgebung gleichzeitig Werkzeuge zur Anwendungsentwicklung und zur Umsetzung von Datenbankprojekten zur Verfügung zu stellen. So lassen sich zum Beispiel Java-Applikationen parallel zu den darin eingebetteten SQL-Anfragen verwalten, entwickeln und testen. [IBM09b] Das IBM Data Studio gibt es in einer „Integrated Development Environment (IDE)“und einer „Stand Alone“-Version. Beide Varianten sind in ihren Basisausführungen (ohne Upgrades4) kostenfrei verfügbar. Sie unterscheiden sich nur in dem Umfang der integrierten Datenmodellierungs- und Anwendungsentwicklungsmodule. Während die IDE-Version alle verfügbaren Basisfunktionalitäten umfasst, ist für die Stand-Alone-Version gezielt auf einzelne Module verzichtet worden. [IBM11g] In der DATEV wird momentan die aktuelle IDE-Version 2.2.1.0 des IBM Data Studio untersucht. Neben den verschiedenen Komponenten des Tools sind dabei auch grundlegende Aufgaben betrachtet worden, zu deren Unterstützung die Verwendung des IBM Data Studio denkbar wäre. Die folgende Aufzählung gibt eine Übersicht der einzelnen Anwendungsszenarien: Abfrage von Strukturen und Inhalten aus dem Datenbankkatalog 4 IBM Optim Query Tuner, Optim pureQuery Runtime, etc. 18 3 Grundlagen Datenänderungen (INSERT, UPDATE, DELETE) [IBM11a] DDL-Generierung für Datenbankobjekte SQL-Skripte erstellen und ausführen Schemaänderungen (CREATE, ALTER, DROP) [IBM11a] Statistiken erstellen oder aktualisieren Visual Explain Analyse von SQL-Anfragen und -Zugriffsplänen Abfrage und Analyse des Dynamic Statement Cache Abfrage und Analyse von Packages [IBM09e] Import/Export von Zugriffsplänen Service SQL/Query Environment Capture Abfrage von Subsystem-Parametern (zParms) Verarbeitung clientseitiger XML-Dokumente Der zuletzt aufgeführte Punkt dieser Auflistung lässt bereits darauf schließen, dass das IBM Data Studio XML-Daten verarbeiten kann. Als eines der (noch) wenigen Tools ist es in der Lage, mit dem nativen XML-Datentyp in DB2 umzugehen und aus dessen Strukturen abgefragte Daten darzustellen. Diese Eigenschaft ist der Hauptgrund, weshalb das IBM Data Studio für die Untersuchungen, die im Rahmen der hier erbrachten Arbeit stattfanden, verwendet wurde. 3.4 Nativ vs. nicht-nativ Im Verlauf dieser Arbeit wird die Unterscheidung zwischen nativer und nicht-nativer XMLSpeicherung eine wichtige Rolle einnehmen. Um ein grundlegendes Verständnis dieser Speicherformen zu bekommen, sollen an dieser Stelle zunächst die Begriffe „nativ“ und „nichtnativ“ unterschieden werden. Der Wortherkunft nach bedeutet „nativ“ unter anderem „natürlich“ oder „unverändert“. Das heißt, native XML-Daten sind natürlich und unverändert in einem hierarchischen Datenmodell abgelegte Daten. Dabei ist ein Speicherformat vorausgesetzt, das dem Verarbeitungsformat entspricht. Formen der einfachen Textablage von XML (beispielsweise als VARCHAR oder CLOB) sind davon ausgeschlossen und werden als nicht-native oder auch XML-enabled Speicherung betitelt. Im weiteren Verlauf findet dahingehend ausschließlich der Begriff „nichtnativ“ Verwendung. Auf diese Weise gespeicherte XML-Dokumente benötigen ein Mapping 19 3 Grundlagen von dem vorliegenden (relationalen) Speichermodell hin zu dem XML-Datenmodell. Da in dieser Arbeit weitgehend auf die Betrachtung der per Dekomposition realisierten XMLSpeicherung (siehe Kapitel 4) verzichtet wird, ergibt sich das erwähnte Mapping im Wesentlichen durch ein notwendiges Parsen der nicht-nativ gespeicherten Dokumente. [Päß07] Die native XML-Speicherung ist der nicht-nativen in vielerlei Hinsicht überlegen. Eine Betrachtung der einzelnen Vor- und Nachteile dieser Ablageformen erfolgt in den Kapiteln 4 und 5. Ein zusätzlicher Fokus liegt dabei stets auf den Strukturbesonderheiten der jeweiligen Speichermöglichkeiten. 3.5 DATEV-Konventionen Die Datenbankadministration der DATEV verwaltet in DB2 eine Vielzahl von Datenbankobjekten. Diese reichen von Tabellen (ca. 7.500) und Views (ca. 10.000) bis hin zu diversen anwendungsspezifischen Packages (ca. 20.000). Damit die Gesamtheit der Objekte einheitlich strukturiert und nach den bisherigen Erfahrungswerten optimal konstruiert ist, unterliegt ihre Erstellung in der DATEV verschiedenen Konventionen. Diese werden über die Zeit hinweg stetig weiterentwickelt und an neue Erkenntnisse und Technologien angepasst. Im Folgenden sollen einige Konventionen näher beschrieben werden, die im Rahmen der hier erbrachten Arbeit direkt oder indirekt von Relevanz sind. An erster Stelle soll dabei die Beziehung zwischen Tablespace und Tabelle betrachtet werden. Zwischen diesen Objekten besteht in der DATEV generell eine (n:1)-Beziehung. Das heißt jeder Tablespace umfasst nur genau eine Tabelle beziehungsweise eine Partition einer Tabelle. Umgekehrt gilt, dass sich eine Tabelle entweder genau in einem Tablespace befindet oder, sofern sie partitioniert ist, jede Partition einer Tabelle genau einer Tablespace-Partition zugeordnet ist. Der Grund für diese Struktur liegt vor allem in der Recoverability. In DB2 ist der Tablespace das kleinstmögliche Granulat für eine Recovery. Sollte dieser mehrere Tabellen enthalten, so wären sie von einem eventuell notwendigen Wiederherstellungsprozess stets alle betroffen. In der DATEV besteht jedoch die Anforderung, gezielt auf Tabellenebene beziehungsweise Partitionsebene eine Recovery durchführen zu können. Damit dies gewährleistet werden kann, darf ein Tablespace demnach nicht mehr als eine Partition oder im unpartitionierten Fall eine komplette Tabelle enthalten. [Sur03] Eine weitere relevante Konvention ergibt sich aus der Art und Weise, wie anwendungsseitige Tabellenzugriffe erfolgen. In der DATEV ist ein direkter Tabellenzugriff 20 3 Grundlagen durch Anwendungen nicht vorgesehen. Auf jeder Tabelle existiert eine beliebige Anzahl von Views, die diesem Zugriff dienen. Dabei ist eine Verschachtelung der Sichten ineinander zulässig, sodass auch Views auf anderen Views aufsetzen können. Da sämtliche Tabellenzugriffe stets über die einzelnen Sichten erfolgen, sind auch die dazu notwendigen Zugriffsberichtungen auf Ebene der Views definiert. Diese Konstruktion bietet den Vorteil, dass die Tabellen von den Zugriffen losgelöst sind (Datenunabhängigkeit). Auf diesem Weg können den Anwendungen datenbankseitig notwendige Änderungen durch das Umdefinieren von Views transparent gemacht werden. Jene Möglichkeit wird unter anderem auch von dem im Verlauf der Arbeit entwickelten Prototypen (siehe Kapitel 8) ausgenutzt. [Heg06] Zuletzt sollen noch die DATEV-internen Namenskonventionen für Datenbankobjekte näher beschrieben werden. Diese haben weniger funktionale Bedeutung, erleichtern aber die Wartung und Orientierung innerhalb des DB2. Abhängig von den im EntityRelationship-Diagramm [FSU10] modellierten Objekten und ihrem expliziten Namen wird beispielsweise jeder daraus abgeleiteten Tabelle ein „T“, jeder View ein „V“, jedem Primärschlüsselindex ein „P“, jedem Fremdschlüsselindex ein „F“ und jedem weiteren Index ein „I“ als Präfix im Namen vorangesetzt. Die konkrete Bezeichnung der Indexe und der Views leitet sich wie auch der Name jeder Tabelle somit von der zugehörigen Entität ab. Sofern mehrere gleichnamige Indexe oder Views vorhanden sind, wird der Bezeichnung als Suffix eine ab „2“ beginnende fortlaufende Nummer angefügt. Der Name einer Datenbank ist frei wählbar. Die Bezeichnung eines Tablespace leitet sich wiederum von den ersten fünf Zeichen des zugehörigen Datenbanknamens ab und wird um eine dreistellige Nummerierung beginnend ab „001“ ergänzt. Abbildung 4 fast die genannten Aspekte grafisch zusammen. [Heg06] Views VMeineTabelle VMeinTabelle2 Tabellen TMeineTabelle TAndereTabelle VMeineTabelle… PMeineTabelle 1:1 Indexe FMeineTabelle 1:1 IMeineTabelle Tablespaces Daten001 Daten002 Datenbank Datenbank Abbildung 4: DATEV-Konventionen 21 Daten… 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 Bis zur Einführung von Version 9 existierte in DB2 keine Möglichkeit, XML nativ zu speichern. Zwar erlaubt der bereits zuvor existierende XML-Extender die datenbankseitige Verarbeitung von XML-Dokumenten. Diese ist jedoch entweder an die definierte Dekomposition zu relationalen Daten („xml collection“) oder an die Deklaration als benutzerdefinierter Datentyp („xml column“) gebunden. Beide Varianten entsprechen einer nicht-nativen Speicherung [IBM04b]. Das Konzept der „xml collection“ definiert sich durch „Data Access Definition (DAD)“-Dateien. Diese enthalten genaue Informationen über die Zusammensetzung der einzelnen XML-Kollektionen. In DB2 Version 9 findet sich auf abgewandelte Art die Dekomposition in der XMLTABLE5 Funktion wieder. [IBM04b, IBM11a] Die als „xml column“ betitelte Speicherform des XML-Extenders legt XMLDokumente entweder datenbankseitig als Character-Strings oder in Form von Dateien im Dateisystem ab. Um effizient auf diesen Character-Strings abfragen beziehungsweise in ihnen suchen zu können, behilft sich der XML-Extender des Text-Extenders [IBM04c]. Die Verknüpfung der beiden Erweiterungen ermöglicht zum einen strukturierte Suche und zum anderen Volltextsuche auf den nicht-nativen XML-Dokumenten. [IBM04b] Trotz dieser vielseitigen Möglichkeiten betrachtete die DATEV den XML-Extender nicht näher. Grund dafür war unter anderem seine fehlende Data-Sharing-Fähigkeit [IBM06b]. Weiterhin ist bis zuletzt von einer datenbankseitigen XML-Verarbeitung abgesehen worden, so dass sich keine Vorteile für die Anwendung des XML-Extenders ergaben. Mit dem immer mehr aufkommenden Performance-orientierten Bestreben, XML-Funktionalitäten von der Anwendung in die Datenbank auszulagern, änderte sich dies. In diesem Zusammenhang existierte in DB2 aber bereits die pureXML-Technologie. Seit ihrer Einführung gilt sie gegenüber dem XML-Extender als zu bevorzugende Alternative. Neben der nativen XML-Ablage ist vor allem der Performance-Aspekt einer der Hauptargumente für diesen Wechsel. Aus den zuletzt genannten Gründen soll der XML-Extender in den weiteren Ausführungen keine erneute Beachtung finden. [NR06] 5 Syntax [IBM11a], Anwendungsbeispiele [NR07] 22 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 Um XML-Daten in DB2 vor Version 9 speichern zu können, mussten diese in einen relationalen, datenbankkompatiblen Datentyp überführt werden. Dafür bieten sich zwei Möglichkeiten6 an. Zum einen die Speicherung von XML als einfache Zeichenkette (Character-String) und zum anderen die Ablage als Binärstring (Binary-String). Die letztgenannte Variante der Binärstring-Ablage sei dabei nur der Vollständigkeit halber erwähnt. Eine solche Speicherung würde den Informationsgehalt des Dokuments seitens der Datenbank auf ein Minimum beschränken. Die zur Interpretation eines binär nicht-nativ gespeicherten XML-Dokuments notwendigen Informationen, wie beispielsweise der verwendete Zeichensatz, wären nur der Projektanwendung bekannt. Externe Anwendungen erwarten unter Umständen Daten eines anderen Formats und könnten die vorliegenden Binärdaten nicht als nicht-natives XML verarbeiten. Üblicher, und daher in den weiteren Untersuchungen näher betrachtet, ist die zuerst erwähnte Variante: die Ablage von XML-Dokumenten nicht-nativ als Zeichenkette. In diesem Fall ist das Dokument zwar nicht in seiner hierarchischen Form gespeichert, kann aber dennoch von Fremdanwendungen als solches erkannt werden. Grund dafür sind der datenbankseitig bekannte Zeichensatz und die selbstbeschreibende Struktur des XML-Dokuments. In Abbildung 5 werden die die erwähnten Varianten der nicht-nativen XMLSpeicherung veranschaulicht. Die Dekomposition als zusätzliche Möglichkeit zur nicht-nativen XML-Speicherung wird nicht berücksichtigt, da sie in DB2 vor Version 9 ausschließlich per XML-Extender realisierbar ist und dieser nicht weiter betrachtet werden soll. nicht-native XML-Speicherformen Binary-String Character-String CHAR VARCHAR CLOB Abbildung 5: nicht-native XML-Speicherformen Zur Ablage von Zeichenketten bieten sich in DB2 die Character-String-Datentypen an. Da der einfache, fixe Datentyp CHAR mit seiner maximalen Länge von 255 Zeichen eher ungeeignet ist, dienen zumeist die variabel langen Datentypen VARCHAR und CLOB zur nicht-nativen Ablage von XML. Diese beiden Speicherformen werden in den nächsten Abschnitten näher betrachtet. [IBM04a] 6 da XML-Extender-Betrachtung vernachlässigt 23 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 4.1 XML nicht-nativ als VARCHAR Die nicht-native Speicherung von XML als VARCHAR wird im Folgenden ausgeführt. Während im Abschnitt 4.1.1 die strukturellen Besonderheiten dieser Speicherform aufzeigt werden, erfolgen in den Abschnitten 4.1.2, 4.1.3 und 4.1.4 evaluierende Betrachtungen anhand ausgewählter Aspekte. Diese wurden entsprechend der Charakteristika des Datentyps ausgewählt. 4.1.1 Struktur Die nicht-native Speicherform von XML als VARCHAR wird häufig wegen ihrer einfachen Struktur verwendet. Der Anwender deklariert in der Tabelle wie in Abbildung 6 zu sehen lediglich eine Spalte als VARCHAR(x)7. Zusätzlicher DDL-Aufwand besteht nicht (vgl. Abschnitt 4.2). [IBM04a] Primärschlüssel … relationale Spalten … nnXML (VARCHAR) 1 … XML (1) 2 … XML (2) Abbildung 6: XML nicht-nativ als VARCHAR 7 x entspricht dabei einer ganzen Zahl und es gilt x < 32 K - Größe der übrigen Spalten der Tabelle - zusätzliche Kontrollinformationen (20 Byte Pageheader, eventuelle Overflow-Pointer, etc.) [IBM09c] 24 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 4.1.2 Inline-Datentyp Ein VARCHAR ist ein Inline-Datentyp und unterliegt der maximalen Record Size von 32 K. Somit kann er eine Länge von 1 bis maximal 32704 Zeichen haben. Sollte ein XML-Dokument größer als diese Limitierung sein, muss es durch eine zusätzliche Logik (in der Regel in der Anwendung) über mehrere Tupel der Tabelle verteilt werden. Das ist ein unerwünschter Nebeneffekt und erhöht die Komplexität der Speicherung und Verarbeitung. Nähere Details dazu finden sich im Abschnitt 4.3. Die Variante der nicht-nativen Speicherung als VARCHAR ist daher besonders für die Ablage kleiner XML-Dokumente eine einfache Lösung, da hier der Aufteilungsaufwand entfällt. [IBM04a] 4.1.3 Character-String Da es sich bei der Speicherung von XML als VARCHAR um eine nicht-native, Character-String basierte Variante handelt, ergibt sich der Nachteil, dass ein XML-Dokument nur im Ganzen sinnvoll verarbeitbar und extern zugreifbar ist. DB2 hat keine Informationen darüber, dass es sich bei dem Inhalt einer gespeicherten VARCHAR-Spalte um ein XML-Dokument handeln könnte. Demnach verarbeitet es dieses ebenso wie einen herkömmlichen Character-String. Möglichkeiten wie ein gezielter Knotenzugriff oder eine gezielte Änderung innerhalb des XMLDokuments entfallen zwangsweise und müssen anwendungsseitig realisiert werden. [IBM04a] Entsprechend verhält es sich mit der Validierung gegen XML-Schemas. Ein VARCHAR-Inhalt kann nicht datenbankseitig gegen ein Schema validiert werden. Somit existiert auch keine Möglichkeit, ein als VARCHAR nicht-nativ gespeichertes XML-Dokument datenbankseitig gegen ein XML-Schema zu validieren. Aus der Abbildung des XML-Dokuments als Character-String ergibt sich zudem, dass jedes auf diese Weise aus DB2 abgefragte Dokument stets komplett in der Anwendung in das XML-Format geparst werden muss. Vorher ist eine Verarbeitung der gewünschten Teile des Dokuments nicht möglich, weshalb anwendungsseitig für die nicht-native XML-Speicherung erneut ein erhöhter Aufwand resultiert. 25 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 4.1.4 Kompatibilität Trotz der zuletzt genannten Nachteile hat die nicht-native XML-Speicherung als VARCHAR in der DATEV aktuell dennoch ihre Berechtigung. Die in der Datenbankadministration verwendeten Tools sind (im Gegensatz zum DB2 selbst) zu großen Teilen keine IBM-Produkte. Da mit der Einführung des nativen Datentyps XML ab Version 9 tiefe Veränderungen in DB2 vorgenommen wurden, befinden sich externe Toolhersteller8 (teilweise) noch im Prozess, ihre Produkte an die neuen Anforderungen vollständig und effizient anzupassen. Auf der anderen Seite müssen die bereits vorhandenen Produktlösungen auch in der DATEV erst untersucht und eingeführt werden. In den weiteren Ausführungen wird der beschriebene Sachverhalt als Kompatibilitätsproblem der Tools bezeichnet. Die nicht-native Speicherung von XML als VARCHAR umgeht zu großen Teilen dieses Problem. 4.2 XML nicht-nativ als CLOB Die nicht-native Speicherung von XML als CLOB wird in den folgenden Abschnitten näher ausgeführt. Während Abschnitt 4.2.1 und Abschnitt 4.2.2 die strukturellen Besonderheiten dieser Speicherform aufzeigen, erfolgt in den Abschnitten 4.2.3 und 4.2.4 eine evaluierende Betrachtung anhand ausgewählter Aspekte. Diese wurden entsprechend der Charakteristika des Datentyps ausgewählt. 4.2.1 Struktur (LOB-Spezifika) Die Variante XML nicht-nativ als CLOB zu speichern ist verglichen mit der zuvor betrachteten Speicherform als VARCHAR komplexer bezüglich ihrer Struktur. Grund dafür ist unter anderem die datenbankseitige Klassifikation der LOBs als Outline-Datentypen. Diese werden nicht innerhalb der Basistabelle gemeinsam mit anderen Spalten9 abgelegt. Stattdessen sind sie in LOB-Auxiliary-Tabellen innerhalb spezieller LOB-Tablespaces ausgelagert. Ein 8 CA (www.ca.com) und BMC (www.bmc.com) 9 vom Datentyp INTEGER, DECIMAL, CHAR, etc. (fortan als relationale Spalten bezeichnet) 26 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 LOB-Indikator10 [IBM06a] wird anstelle des Werts der LOB-Spalte in die Basistabelle eingefügt. Die Zuordnung einer LOB-Spalte der Basistabelle zu ihrer LOB-Auxiliary-Tabelle wird durch die Katalogtabelle SYSIBM.SYSAUXRELS beschrieben. Um von der Basistabelle auf die einzelnen LOB-Inhalte der LOB-Auxiliary-Tabelle zugreifen zu können, dienen die RowID und ein spezieller Auxiliary-Index. Während die RowID eine eindeutige Identifizierung jedes LOB-Tupels ermöglicht, dient der Auxiliary-Index der Verbindung der einzelnen Tupel. Er verknüpft jede Ausprägung seiner zugehörigen LOB-Spalte der Basisstabelle mit einem konkreten LOB-Wert in der LOB-Auxiliary-Tabelle. Eine ähnliche Form der Auslagerung ist in der Struktur des nativen XML-Datentyps zu finden (siehe Abschnitt 5.3). [IBM06a] Abbildung 7 veranschaulicht die Struktur, die der LOB- und somit insbesondere der CLOB-Speicherung in DB2 zugrunde liegt. „nnXML“ bezeichnet die CLOB-Spalte, die zur nicht-nativen XML-Ablage genutzt wird. Basistabelle Primärrelationale … … schlüssel Spalten 2 … nnXML (CLOB) RowID LOBABC… Indikator LOB123… Indikator Auxiliary-Index 1 Auxiliary-Tabelle RowID LOB Value ABC… XML(1) 123… XML(2) Abbildung 7: Struktur des Outline-Datentyps LOB Die zur LOB-Verwaltung notwendigen Objekte (RowID-Spalte, LOB-Tablespace, LOBAuxiliary-Tabelle, Auxiliary-Index) müssen explizit vom Nutzer angelegt werden. Erst ab Version 9 bietet sich auch die Möglichkeit der impliziten Erstellung durch DB2. Der anwendungsseitige Zugriff auf LOBs gestaltet sich dagegen stets transparent, so dass die Inhalte direkt aus der Basistabelle abfragbar sind. Die notwendige Verknüpfung der Tupel aus Basis- und LOB-Auxiliary-Tabelle wird im Hintergrund automatisch durchgeführt. 10 enthält unter anderem Informationen über Nicht-Vorhandensein (null) oder Ungültigkeit eines LOB- Wertes 27 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 4.2.2 Struktur (DATEV-Spezifika) Eine weitere Besonderheit in der Struktur der LOB-Speicherung ergibt sich durch die DATEVinternen Spezifika. Die LOB-Datentypen gelten bezüglich Schemaänderungen11 als problematisch in ihrer Handhabung durch Tools der Datenbankadministration. Daher ist intern insbesondere auch für CLOBs ein Verwaltungskonzept gewählt worden, das dieses Problem isoliert. LOBs werden von den restlichen Spalten der Tabelle in jeweils einer eigenen Zusatztabelle pro LOB-Spalte separiert abgelegt. Lediglich der Primärschlüssel ist in allen Tabellen zu finden, um die eindeutige Tupelzuordnung gewährleisten zu können. In ihrer Bezeichnung sind die Zusatztabellen an die Basistabelle angelehnt und pro LOB-Spalte durch eine nummerierte Endung beginnend ab zwei ergänzt. Wie sich die gesamte DATEV-interne Struktur der nicht-nativen XML-Speicherung als CLOB darstellt zeigt Abbildung 8. „nnXML“ bezeichnet dabei eine CLOB-Spalte, die zur nicht-nativen Ablage von XML-Dokumenten genutzt wird. Basistabelle Primärrelationale … … schlüssel Spalten Basistabelle2 Auxiliary-Tabelle Primärschlüssel nnXML (CLOB) RowID RowID LOB Value 1 … 1 LOBIndikator ABC… ABC… XML(1) 2 … 2 LOBIndikator 123… 123… XML(2) Abbildung 8: XML nicht-nativ als CLOB inklusive DATEV-Spezifika 4.2.3 Outline-Datentyp Die Beschaffenheit des CLOBs als Outline-Datentyp erlaubt es, Dokumente bis zu 2 GB in einem Tupel abzulegen. Musste bei der nicht-nativen Speicherung von XML als VARCHAR eine zusätzliche Logik erstellt werden, die zu große XML-Dokumente auf mehrere Zeilen verteilt und später wieder zusammensetzt, ist dies bei der CLOB-Lösung nur selten der Fall. Gänzlich 11 beispielsweise Drop einer Spalte, etc. 28 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 auszuschließen ist es aber nicht, da unter anderem die maximale LOB-Größe nicht standardmäßig 2 GB beträgt und über die zParms LOBVALA12 und LOBVALS13 erheblich eingeschränkt sein kann. [IBM04a] 4.2.4 Character-String und Kompatibilität Trotz der differenzierten Struktur ist die nicht-native Speicherung von XML als CLOB der VARCHAR-Variante sehr ähnlich, da beide Formen auf einer Character-String-Ablage basieren. So ergibt sich für XML nicht-nativ als CLOB ebenfalls der bei jedem Zugriff notwendige Parse-Aufwand des gesamten Dokuments in der Anwendung und die fehlende Möglichkeit der datenbankseitigen XML-Schemavalidierung. Gezielte Knotenzugriffe sind ebenso wie gezielte Änderungen am XML-Dokument nicht durchführbar. Dafür besteht aber auch hier die Kompatibilität zu der in der DATEV-Datenbankadministration momentan eingesetzten Toollandschaft (siehe Abschnitt 4.1.4). 4.3 Besonderheit: Verteilung über mehrere Tupel Wie bereits im Abschnitt 4.1.2 beschrieben, handelt es sich bei dem Datentyp VARCHAR um einen Inline-Datentyp. Dieser charakterisiert sich durch die direkte Ablage von Daten in die explizit deklarierte Spalte innerhalb der Tabelle. Mit Ausnahme der LOB-Auxiliary-Tabelle existiert in DB2 für jede Tabelle eine Beschränkung der Größe ihrer Tupel von im Höchstfall 32 K. Diese ergibt sich durch die maximal zulässige Record Size und ist aufgrund des häufigen Vorhandenseins weiterer Spalten in der gleichen Tabelle noch geringer als der angegebene Wert. Aus Sicht der Modellierung ist es nur bedingt sinnvoll, eine Tabelle mit ausschließlich einer VARCHAR-Spalte zur nicht-nativen Speicherung von XML anzulegen. Grund dafür sind die gewünschte explizite Zusicherung/Gewährleistung der Eindeutigkeit und die zu garantierende performante Selektierbarkeit der abgelegten Tupel. Diese machen es ratsam, eine oder 12 spezifiziert die maximale Größe (in KB) eines LOBs (beim Bind-In und Bind-Out) [IBM11d, Zha08a] 13 spezifiziert den maximalen virtuellen Speicher (in MB) ,der zur Verarbeitung von LOBs im Subsystem genutzt werden kann [IBM11e, Zha08a] 29 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 mehrere separate Primärschlüsselspalten in der Tabelle mitzuführen, geben dies aber nicht zwingend vor. Denn zum einen ist es in DB2 zulässig, Tabellen ohne explizite Primärschlüsseldeklaration zu erstellen. Zum anderen könnten einzelne nicht-nativ gespeicherte XML-Tupel auch über Character-String-Funktionen – wenn auch nur sehr umständlich – differenziert und selektiert werden. Hier sei kurz erwähnt, dass nativ gespeicherte XML-Dokumente unter Verwendung des XMLEXISTS-Prädikats auf wesentlich einfachere Weise verglichen werden können. [IBM04a, IBM11a] Um XML-Dokumente, die größer als 32 K sind, nicht-nativ in Form eines VARCHARs speichern zu können, müssen diese Dokumente in Teilstücke zerlegt und über mehrere Tupel verteilt abgelegt werden. Im Fall der nicht-nativen Speicherung von XML als CLOB ist dies in seltenen Fällen ebenfalls notwendig. Zwar gilt für CLOBs eine Beschränkung von maximal 2 GB. Diese ist aber in der DATEV durch die Verwendung der LOB-spezifischen zParms auf nur 40 MB reduziert (siehe Abschnitt 4.2). [IBM04a] Die zur Aufteilung „zu großer“14 Dokumente notwendige Logik gestaltet sich unabhängig ob VARCHAR oder CLOB gleich. Bedingt durch die unterschiedlichen Ausgangssituationen unterscheidet sich die Struktur der Aufteilung leicht voneinander (VARCHAR: Inline-Datentyp (siehe Abschnitt 4.1), CLOB: Outline-Datentyp (siehe Abschnitt 4.2)). In beiden Fällen erfolgt ein anwendungsseitiges Aufteilen des Originaldokuments in Teilstücke mit der für den Zieldatentyp zulässigen Größe. Das Ergebnis sind abgeschnittene Zeichenketten, so dass selbst einzelne Knotenbezeichnungen über die Grenze von Teilstücken hinaus zertrennt sein können. Abbildung 9 veranschaulicht diese Aufteilung an einem Beispiel. Fortan wird in diesem Zusammenhang auch von „zerhacktem“ nicht-nativem XML gesprochen. nicht-natives XML („zerhackt“) <customerinfo id="1001"> <name> Mustermann </name> <phone type="work"> 408-555-1358 </phone> </customerinfo> Tupel 1 <customerinfo id="100 1"><name>Mustermann</ Tupel 2 name><phone type="wor k">408-555-1358</phon Tupel 3 e></customerinfo> Abbildung 9: Verteilung über mehrere Tupel 14 DATEV-intern 32 K für VARCHAR-Speicherung, 40 MB für CLOB-Speicherung (zParm LOBVALA) 30 4 XML-Speichermöglichkeiten in DB2 for z/OS vor Version 9 Damit sich während der Aufteilung kein Informationsverlust ergibt, muss die Position, die jedes Teilstück im Originaldokument hat, vermerkt werden. Hierfür dient eine zusätzliche Spalte eines ganzzahligen, numerischen Datentyps15, welche in der DATEV oft als laufende Nummer (LFDNR) bezeichnet wird. Die Konkatenation der Teilstücke in der aufsteigenden Sortierung der laufenden Nummer ergibt das Originaldokument. Durch das Mitführen der laufenden Nummer wird auf der Zusatztabelle die durch den bisherigen Primärschlüssel definierte Eindeutigkeit verletzt. Einzelne Schlüsselwerte können mehrfach für unterschiedliche laufende Nummern enthalten sein. Um dieser Eindeutigkeitsverletzung vorzubeugen, muss die LFDNR-Spalte im Zuge ihrer Erstellung in den Primärschlüssel der Zusatztabelle aufgenommen werden. Im Fall der VARCHAR-Speicherung ergibt sich zusätzlich ein Redundanzproblem aufgrund der übrigen relationalen Spalten. Damit diese nicht für jedes Teilstück repliziert und gewartet werden müssen, wird bereits für die Modellierung der Tabelle ein der nicht-nativen XML-Speicherung als CLOB sehr ähnlicher Ansatz gewählt (siehe Abschnitt 4.2.2). Dort sind die XML-Inhalte von den restlichen Spalten mit Ausnahme der Primärschlüsselspalten separiert. Die laufende Nummer findet nur in der Zusatztabelle Erwähnung und einer ungewollten Redundanz ist vorgebeugt. Abbildung 10 zeigt den unterschiedlichen Modellierungsansatz für nicht-nativ gespeicherte XML-Dokumente als VARCHAR mit verteilten Inhalten. Die beispielhaft angedeuteten Datensätze müssen dabei in der Zusatztabelle nicht zwingend sortiert abgelegt sein. Für den Fall der CLOB-Speicherung sei aus Gründen der Einfachheit und Analogie auf eine zusätzliche Abbildung verzichtet. einzeiliges verteiltes nicht-natives XML nicht-natives XML (Ausgangs-) Tabelle (Ausgangs-)Tabelle Primärrelationale nnXML … … schlüssel Spalten (VARCHAR) 1 2 … <…/> <…/> Primärrelationale … … schlüssel Spalten 1 Zusatztabelle Teilschlüssel LFDNR nnXML (VARCHAR) 1 1 <… 1 2 … 1 3 …/> … 2 … Abbildung 10: Modellierungsansätze für nicht-natives XML als VARCHAR 15 INT, SMALLINT oder BIGINT 31 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 DB2 erlaubt seit Version 9 die native Speicherung von XML-Dokumenten in dem gleichnamigen XML-Datentyp. Dieser setzt auf dem relationalen Schema auf, repräsentiert und speichert XML-Dokumente aber in einem spezifischen, wohldefinierten Modell. Bisher bestand ausschließlich die Möglichkeit, XML-Dokumente beispielsweise als VARCHARs (siehe Abschnitt 4.1) oder CLOBs (siehe Abschnitt 4.2) zu speichern. Eine Verarbeitung aus dieser Ablageform ist nur rechenintensiv durch vorangehendes Parsen des kompletten Dokuments möglich. [IBM10a] Mit dem neuen nativen Datentyp werden XML-Dokumente direkt in geparster hierarchischer Struktur gespeichert. Der Prozess des Parsens findet einmalig nur beim INSERT statt. Eine weitere serverseitige Verarbeitung der nativen Daten ist ohne zusätzlichen Aufwand effizient möglich. Bezüglich der Kommunikation zwischen Anwendung und Datenbank lässt sich ein zusätzlicher Vorteil ableiten. Zwar muss für einen externen XML-Zugriff noch immer ein anwendungsseitiges Parsen erfolgen. Jedoch lassen sich datenbankseitig bereits relevante Inhalte des XML-Dokuments mittels der Abfragesprache XPath herausfiltern, so dass nur diese noch in die Anwendung transportiert und dort gezielt geparst werden müssen. [IBM10a, NK09] An dieser Stelle sei erwähnt, dass es in DB2 Version 10 zudem möglich ist, natives XML binär16 zwischen Anwendung und Datenbank zu kommunizieren. Damit lassen sich die Kosten des Parsens auf beiden Seiten einsparen. [IBM11c] Ähnlich verhält es sich mit der XML-Schemavalidierung. XML-Dokumente, die nichtnativ gespeichert sind, können nur in einer externen Anwendung gegen XML-Schemas auf Gültigkeit geprüft werden (siehe Abschnitt 4.1 und Abschnitt 4.2). Im Gegensatz dazu ermöglicht DB2 für nativ abgelegte XML-Dokumente eine datenbankseitige XML- Schemavalidierung und sichert somit die Integrität der abgelegten XML-Dokumente im Datenbankmanagementsystem. Die dafür benötigten XML-Schemas werden aus dem XML-SchemaRepository17 bezogen und können dort hinterlegt werden. [NK09] Weitere vorteilhafte Aspekte der nativen XML-Struktur erklären sich anhand der Ausführungen in den folgenden Abschnitten. Dem gegenüber steht das Kompatibilitätsproblem, das die in der Datenbankadministration eingesetzten Tools des Unternehmens Computer Associates 16 Extensible Dynamic Binary XML [IBM10b] 17 Menge von Tabellen zur Ablage von XML-Schemas [IBM08a] 32 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 (CA) [CA11] (noch) mit dem nativen XML-Datentyp haben. Für eine genauere Ausführung dieses Aspekts sei auf Abschnitt 4.1.4 verwiesen. 5.1 Verwaltungskonzept für natives XML DB2 Version 9 übernimmt die Verwaltung von XML-Objekten komplett autonom und verhält sich dem Anwender gegenüber vollständig transparent. Dessen Sicht beschränkt sich dabei auf die in relationalen Tabellen enthaltenen Spalten vom Datentyp XML und die darin befindlichen XML-Dokumente. Ein ähnlicher Ansatz ist aus der Verwaltung von LOB-Objekten bekannt. Vergleicht man speziell die Datentypen XML und CLOB, dann wird deutlich, dass sich die ihnen zugrunde liegenden Strukturen sehr ähneln, die Ablageform von XML-Dokumenten aber erwartungsgemäß komplexerer Natur ist. Eine detaillierte Gegenüberstellung der einzelnen XMLSpeichermöglichkeiten erfolgt in Kapitel 6. 5.2 Explizite XML-Verwaltungsobjekte Wie bereits erwähnt, verwaltet DB2 natives XML selbst. Der Datenbankadministrator definiert in einer Tabelle eine oder mehrere Spalten vom Datentyp XML. Die den XML-Objekten zugehörigen Verwaltungsobjekte erstellt das Datenbankmanagementsystem implizit. [IBM08a] In den weiteren Betrachtungen wird aus Komplexitätsgründen weitestgehend von einem einfachen oder segmentierten Basis-Tablespace ausgegangen. DB2 kennt zusätzlich noch partitionierte18 Tablespaces. Durch diese ergeben sich bezüglich der nativen XML-Speicherung in einzelnen Fällen zusätzliche Besonderheiten, die in den weiteren Zusammenhängen nur kurz erwähnt werden sollen. [IBM08a] Zur Veranschaulichung zeigt Abbildung 11 die explizit zu erstellenden Objekte für eine beispielhafte Tabelle mit enthaltenen XML-Spalten. Dabei beschreibt „rel. Spalten“ eine beliebige Anzahl von (herkömmlichen) relationalen Spalten. „XML Spalte 1“ bis „XML Spalte n“ symbolisieren das Vorhandensein von n Spalten des Datentyps XML in der Basistabelle. 18 „Range-partitioned universal“- und „Partition-by-growth universal“-Tablespaces [Vil07] 33 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Alle weiteren Abbildungen dieses Kapitels bauen auf diesem Szenario auf und orientieren sich soweit wie möglich an den in Abschnitt 3.5 beschriebenen Konventionen. Basis-Tablespace „Daten001“ Basistabelle „TMeineTabelle“ rel. Spalten XML Spalte 1 … XML Spalte n Abbildung 11: explizit zu erstellende Objekte 5.3 Implizite XML-Verwaltungsobjekte Ausgehend von den Objekten, die explizit durch den Nutzer anzulegen sind, erzeugt DB2 für eine Tabelle mit enthaltenen XML-Spalten folgende zusätzliche Speicherstrukturen implizit: DocID in Basistabelle (inklusive zugehöriger Sequence) XML-Tablespace XML-Auxiliary-Tabelle DocID min_NodeID XMLData Indexe NodeID-Index DocID-Index Dabei ist anzumerken, dass für eine Tabelle mit enthaltenen XML-Spalten stets nur eine DocIDSpalte hinzugefügt und nur ein DocID-Index erstellt wird. Alle anderen impliziten Objekte befinden sich außerhalb der Basistabelle und werden pro XML-Spalte einmal erstellt. Abbildung 12 stellt sie in Zusammenhang dar. Für den Fall, dass es sich bei dem Basis-Tablespace um einen partitionierten Tablespace handelt, werden dementsprechend auch die XML-Tablespaces partitioniert. [IBM08a] 34 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 XMLTablespace (1:1) XMLAuxiliaryTabelle DocID min_NodeID XMLData Abbildung 12: implizite XML-Verwaltungsobjekte In den folgenden Unterabschnitten werden die aufgeführten Objekte detaillierter beschrieben. Die implizit erstellten Indexe sind zusammen mit den User-Defined-Indexen im Abschnitt 5.7 näher erläutert. 5.4 DocID Sobald eine Tabelle eine XML-Spalte enthält, wird ihr unabhängig von der Gesamtanzahl an enthaltenen XML-Spalten genau eine versteckte („hidden“) DocID-Spalte hinzugefügt (siehe Abbildung 13). Diese stellt einen eindeutigen (UNIQUE) Identifikator des Tupels dar und ist für dessen Lebenszeit unveränderbar konstant. Verglichen mit der RowID von LOBs zeigt sich bei der DocID ein etwas differenzierter Ansatz (siehe Abschnitt 6.2). [IBM11f] Basis-Tablespace „Daten001“ Basistabelle „TMeineTabelle“ rel. Spalten XML Spalte 1 … Abbildung 13: implizit erstellte DocID-Spalte 35 XML Spalte n DocID 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Funktional verknüpft die DocID die Einträge der Basistabelle mit den ihr zugehörigen XMLDokumenten in den XML-Auxiliary-Tabellen. Aus diesem Grund ist sie auch Bestandteil des NodeID- und des DocID-Index (siehe Abschnitt 5.7.1 und Abschnitt 5.7.2). [IBM10a] Die DocID wird in der Basistabelle „DB2_GENERATED_DOCID_FOR_XML“ unter als der 8-Byte vollständigen Datentyp Bezeichnung BIGINT gespeichert. [IBM10a] Um ihre Eindeutigkeit zu gewährleisten, wird die DocID anhand einer dedizierten Sequence vergeben. Diese ist ebenfalls vom Typ BIGINT und setzt sich namentlich aus einer zwölfstelligen Zeichenkette beginnend mit „SEQ“ zusammen. 5.5 XML-Tablespace Der pro XML-Spalte in der Basistabelle implizit erzeugte XML-Tablespace beinhaltet exakt eine XML-Auxiliary-Tabelle. Umgekehrt ist eine XML-Auxiliary-Tabelle nur in genau einem XMLTablespace enthalten. Somit existiert zwischen diesen Objekten jeweils eine (1:1)-Beziehung (siehe Abbildung 11). [IBM08a] Im Datenbankkatalog kennzeichnet sich ein XML-Tablespace stets durch den Type „P“ („Implicit table space created for XML columns”) und die Lock-Size „XML“. Er entspricht einem neu in DB2 Version 9 eingeführten „Universal Table Space (UTS)“-Typ mit maximaler Größe von 128 TB. Das bedeutet, dass es sich bei einem XML-Tablespace entweder um einen „Partition-by-growth universal“- oder einen „Range-partitioned universal“-Tablespace handelt. Die konkrete Organisationsform ist abhängig von der des Basis-Tablespaces. Ist dieser ein einfacher, segmentierter oder „Partition-by-growth universal“-Tablespace, dann wird auch der XML-Tablespace implizit als „Partition-by-growth universal“-Tablespace erzeugt. Handelt es sich bei dem Basis-Tablespace um einen herkömmlich partitionierten oder einen „Rangepartitioned universal“-Tablespace, dann gilt für den XML-Tablespace ebenfalls die Organisationsform des „Range-partitioned universal“-Tablespace. [IBM11a, IBM08a, Vil07] Der Name des XML-Tablespaces leitet sich von der Bezeichnung der Basistabelle ab. Er setzt sich aus maximal acht Zeichen der Form Xyyyzzzz zusammen. Dabei entspricht yyy den ersten drei Zeichen der Bezeichnung der Basistabelle und zzzz einer von null beginnenden fortlaufenden vierstelligen Nummerierung. [Mor10] 36 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Die vom XML-Tablespace verwendete Page Size beträgt wie auch die Seitengröße des ihm zugeordneten Bufferpools [IBM11f] immer 16 K. Letzterer ist frei definierbar und wird über den zParm TBSBPXML festgelegt. Sämtliche Anfragen auf den XML-Tablespace oder konkreter auf die in ihm befindliche XML-Auxiliary-Tabelle gehen zwangsweise über den definierten Bufferpool und werden somit „gecached“. [Zha08b, IBM11b] 5.6 XML-Auxiliary-Tabelle Wie bereits kurz in Abschnitt 5.3 erwähnt, wird pro XML-Spalte in der Basistabelle implizit eine XML-Auxiliary-Tabelle in einem ebenfalls implizit erstellten XML-Tablespace erzeugt. Diese Tabelle dient der eigentlichen Speicherung von XML-Dokumenten und setzt sich immer aus den drei Spalten DocID, min_NodeID und XMLData zusammen, welche in den folgenden Unterabschnitten näher beschrieben werden. [NK09] Eine direkte Ablagemöglichkeit von XML-Dokumenten in den Datensätzen der Basistabelle, wie es unter der Bezeichnung XML-Inlining zu verstehen ist, existiert in DB2 nicht. Sämtliche Dokumente werden stets in die XML-Auxiliary-Tabellen ausgelagert, weshalb die XML-Spalte in der Basistabelle nur im Sinne einer Indikatorspalte als VARCHAR(6) verwendet wird. Diese kann die Ausprägungen „null“, „invalid“ oder den Wert der „reserved bytes“ annehmen. [NK09] Die Zuordnung einer jeden XML-Spalte der Basistabelle zu ihrer speziellen XMLAuxiliary-Tabelle (siehe Abbildung 14) wird in der Katalogtabelle SYSIBM.SYSXMLRELS beschrieben. Dabei ist die Basistabelle über „TBNAME“, die XML-Spalte über „COLNAME“ und die zugehörige XML-Auxiliary-Tabelle über „XMLTBNAME“ namentlich referenziert. Der Name der Basistabelle und die Bezeichnung der XML-Spalte verweisen zusammen mit dem Tabellen-Owner per Fremdschlüssel19 auf die Katalogtabelle SYSIBM.SYSCOLUMNS. [IBM11a, NK09] 19 „on delete cascade“ 37 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Basis-Tablespace „Daten001“ Basistabelle „TMeineTabelle“ rel. Spalten XML Spalte 1 … XML Spalte n DocID SYSIBM.SYSXMLRELS DocID DocID XMLData XML-Aux-Tabelle(n) „XTMeineTabelle“ min_NodeID XML-Tablespace(s) „XTMe0000“ DocID XMLData „XTMeineTabelle000“ min_NodeID „XTMe0001“ DocID XMLData „XTMeineTabelle…“ min_NodeID „XTMe…“ XMLData „XTMeineTabelleXXX“ (XXX ≙ n-2) min_NodeID „XTMeXXXX“ (XXXX ≙ n-1) Abbildung 14: Zuordnung der XML-Strukturen Die Bezeichnung der XML-Auxiliary-Tabelle als solche ist nicht ganz exakt. Verglichen mit beispielsweise einer LOB-Auxiliary-Tabelle handelt es sich hier nicht um eine Auxiliary-Tabelle im herkömmlichen Sinn. Zum einen wird eine XML-Auxiliary-Tabelle datenbankseitig nicht als Auxiliary, sondern als normale Tabelle mit dem Type „P“ („Implicit table created for XML columns”) geführt. Zum anderen existiert für eine XML-Auxiliary-Tabelle kein Eintrag in der Katalogtabelle SYSIBM.SYSAUXRELS (vgl. Abschnitt 4.2.1). [IBM11a] Dennoch ist die Bezeichnung dieses Objekts als XML-Auxiliary-Tabelle zutreffend, da sie gemäß dem Wort „auxiliary“ sowohl „zusätzlich“ als auch „unterstützend“ für die interne Speicherung und Verarbeitung von XML-Dokumenten ist. Direkte Zugriffe auf diese Tabelle sind wie auch auf eine LOB-Auxiliary-Tabelle nicht möglich. In der Literatur findet sich für XML-Auxiliary-Tabelle teilweise synonym der Begriff „interne XML-Tabelle“. [Zha08b] Die Bezeichnung der XML-Auxiliary-Tabelle leitet sich von der Basistabelle ab. Sie setzt sich aus bis zu 22 Zeichen der Form Xyyyyyyyyyyyyyyyyyyzzz zusammen. Dabei entspricht yyyyyyyyyyyyyyyyyy den ersten 18 Zeichen der Bezeichnung der Basistabelle oder ihrem entsprechend kürzeren kompletten Namen. zzz entspricht einer von null beginnenden fortlaufenden dreistelligen Nummerierung und wird nur angefügt, wenn ein gleichnamiger Tabellenname bereits im Katalog vorhanden ist. [Mor10] 38 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 5.6.1 DocID-Spalte Die DocID-Spalte dient der Verknüpfung eines jeden Datensatzes der XML-Auxiliary-Tabellen mit seiner zugehörigen Zeile in der Basistabelle. Eine explizite Fremdschlüsselbeziehung zur DocID-Spalte der Basistabelle existiert nicht. Die Struktur dieser beiden Spalten ist jedoch identisch. [NK09, IBM11a] Zum besseren Verständnis sei an dieser Stelle bereits erwähnt, dass XML-Dokumente aufgrund ihrer Größe nicht immer in einer Zeile (eines XMLData-Records) gespeichert werden können. In solchen Fällen erfolgt datenbankseitig eine automatische Verteilung von Teilbäumen des XML-Dokuments auf mehrere Records (siehe Abschnitt 5.6.3). Somit können zu einer DocID innerhalb der Basistabelle mehrere Datensätze beziehungsweise DocIDs in der XMLAuxiliary-Tabelle gehören. [Zha08b, NK09] 5.6.2 Min_NodeID-Spalte Zusammen mit der DocID dient die min_NodeID vom Datentyp VARBINARY(128) ausschließlich zur Clusterung [IBM11f] der XML-Auxiliary-Tabelle. Auf diese Weise sind die Teile (Teilbäume) eines jeden XML-Dokuments in ihrer logischen Reihenfolge auch physisch benachbart gespeichert, was den Zugriff erleichtert und gleichsam Prefetching [IBM11f] ermöglicht. [Zha08b] Semantisch beschreibt die min_NodeID den Pfad von der Wurzel des XML-Dokuments zu dem ersten (minimalen) Knoten in einem Record. Formal ergibt sich dieser Pfad aus der Konkatenation der folgenden Node-IDs, deren konkrete Bedeutung im nächsten Abschnitt näher beschrieben wird [NK09]: Kontext Node-ID minimale Node-ID 5.6.3 XMLData-Spalte Wie bereits im Abschnitt 5.4 angedeutet, werden in der XMLData-Spalte vom Datentyp VARBINARY(15.850) die einzelnen XML-Dokumente, beziehungsweise bei entsprechender 39 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Größe auch nur Teilbäume der Dokumente, strukturiert abgelegt. Grund dafür ist die, für die Größe der Tupel der XML-Auxiliary-Tabellen, maximal zulässige Record Size (vgl. Abschnitt 4.3). Sollte die Aufteilung eines Dokuments auf mehrere Zeilen notwendig sein, wird für jeden ausgelagerten Teilbaum als Stellvertreter ein Proxy-Knoten im Elternbaum eingefügt (siehe Abbildung 15). [IBM10a] XMLData Record 1 Record 2 Record 3 Proxy-Node Kontext-Node Abbildung 15: Proxy-Node und Kontext-Node Die native Ablage von XML-Dokumenten unterliegt in DB2 keinen speziellen Speicherlimitierungen hinsichtlich ihrer Größe. Sie beschränkt sich lediglich durch die maximale Größe der XML-Tablespaces (siehe Abschnitt 5.5), in denen die Dokumente gespeichert werden. Dies gilt nicht für deren Verarbeitung. Insbesondere beim Bind-In und Bind-Out von XMLDokumenten wird der LOB-Manager genutzt. Dieser limitiert die verarbeitbare Größe auf höchstens 2 GB (siehe Abschnitt 4.2.3). Ein Nutzer kann dadurch nur XML-Dokumente von maximal diesem Ausmaß im virtuellen Speicher des DB2 verarbeiten. Weitere Einschränkungen sind durch die zParms XMLVALA20 und XMLVALS21 festgelegt. [Zha08a] Um die einzelnen Knoten (Nodes) eines XML-Dokuments innerhalb der XMLDataSpalte identifizieren zu können, unterscheidet DB2 zwischen verschiedenen Node-IDs, die nach 20 spezifiziert die maximale Größe (in KB) eines XML-Dokuments (beim Bind-In und Bind-Out) 21 spezifiziert den maximalen virtuellen Speicher (in MB), der zur Verarbeitung von XML-Dokumenten im Subsystem genutzt werden kann 40 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 der Dewey-Dezimalklassifikation22 vergeben werden. Auf eine detaillierte Darstellung dieses Konzepts sei hier verzichtet. Die für DB2 Version 9 relevanten Aspekte der Klassifikation sind für die verschiedenen Node-IDs stichpunktartig aufgeführt und zum Teil zusätzlich in Abbildung 16 und Abbildung 15 veranschaulicht [IBM10a, NK09]: 02 Node-IDs für gewählten Knoten: 04 02 lokale Node-ID 02 02 04 02 04 absolute Node-ID 02_04_04_02 02 04 06 Abbildung 16: XMLData - Document Tree lokale Node-ID Jeder Knoten besitzt eine lokale Node-ID (siehe Abbildung 16). Diese ist eindeutig innerhalb seines Elternknotens und wird abhängig von der Anzahl weiterer Kinderknoten des Parents fortlaufend um zwei inkrementiert. absolute Node-ID Die absolute Node-ID entspricht der Konkatenation aller lokalen Node-IDs auf dem Pfad von der Wurzel des XML-Dokuments zu dem aktuellen Knoten. Abbildung 16 veranschaulicht an einem Beispiel die Zusammensetzung einer absoluten Node-ID. Kontext-Node-ID Eine Kontext-Node-ID (siehe Abbildung 15) ergibt sich aus der Konkatenation aller lokalen Node-IDs auf dem Pfad von der Wurzel zu dem gemeinsamen Elternelement der Teilbäume eines Records. Vereinfacht formuliert lässt sie sich auch als die Konkatenation aller lokalen Node-IDs auf dem Pfad von der Wurzel zum Record beschreiben. 22 nähere Informationen siehe [Tat02] 41 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 maximale Node-ID Die Konkatenation aller lokalen Node-IDs eines Records auf dem Pfad von der Wurzel (Kontext-Knoten des Records) zu dem maximalen Blattelement wird als maximale Node-ID bezeichnet. minimale Node-ID Die minimale Node-ID entspricht der ersten Node-ID eines Records. Jeder XMLData-Record ist vom Datentyp VARBINARY und besteht aus einem Header und einem Body. Im Header sind allgemeine Informationen zum Record gespeichert [NK09]: Anzahl an Kindelementen Längen- und Kontextinformationen (Pfad und gegebenfalls Namespace) zu jedem Kind Kontext-Node-ID für alle nicht-Wurzel-Records23 Der Body umfasst den XML-Teilbaum/die XML-Teilbäume mit folgenden Informationen [NK09]: alle Knoten in verschachtelter Struktur, um die XML-Hierarchie zu repräsentieren jeder enthaltene Knoten enthält nur seine lokale Node-ID 5.7 Indexe Für die nativen XML-Strukturen existieren in DB2 drei verschiedene Indextypen: NodeID-Index DocID-Index User-Defined-Index In ihrer Kombination ermöglichen diese den gezielten effizienten Zugriff auf einzelne Knoten der gespeicherten XML-Dokumente. Eine gezielte Änderung der Dokumente ist erst ab Version 10 von DB2 möglich [NK09, IBM11c]. Um dies in Version 9 zu realisieren, muss stets das 23 Records, die nur Teilbäume des XML-Dokuments ohne den Wurzelknoten enthalten 42 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 komplette XML-Dokument aktualisiert werden, was zumeist einen enormen Mehraufwand darstellt. Die Indexe unterscheiden sich voneinander nicht nur bezüglich der indizierten Inhalte, sondern auch in ihren Eigenschaften. Strukturell weisen sie die folgenden Besonderheiten auf [IBM11a]: RANDOM-Order [Lyl07] Im Fall der RANDOM-Order werden die zu indexierenden Werte vor dem Einfügen in den Index verschlüsselt. Diese Kodierung ergibt eine quasi zufällige Ordnung der Indexwerte, woher auch der Name dieser neu in DB2 Version 9 eingeführten Indexform resultiert. UNIQUE WHERE NOT NULL Die Eigenschaft UNIQUE WHERE NOT NULL bedeutet, dass mehrfach auftretende Null-Werte innerhalb des UNIQUE-Index erlaubt sind. Dies gilt, obwohl in einem solchen Fall die Eindeutigkeit im eigentlichen Sinn nicht mehr gegeben ist. 5.7.1 NodeID-Index Der NodeID-Index ermöglicht den effizienten Zugriff von der Basistabelle zu den zugehörigen XML-Daten der jeweiligen XML-Auxiliary-Tabelle. Dieser Index wird immer dann benutzt, wenn kein User-Defined-Index existiert, über den die benötigten Inhalte (effizienter) abgegriffen werden können. Abhängig von der Anzahl der XML-Spalten in der Basistabelle existiert genau eine XML-Auxiliary-Tabelle, für die implizit exakt ein NodeID-Index erstellt ist. [IBM10a] Der NodeID-Index definiert sich als ein UNIQUE WHERE NOT NULL-Index, der sich per RANDOM-Order über den Spalten DocID und XMLData aufbaut (siehe Abbildung 17). 43 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 NodeID-Index (pro XML-Aux-Tabelle) „I_NODEID XTMeineTabelle…“ DocID DocID XMLData XML-Aux-Tabelle(n) „XTMeineTabelle“ min_NodeID DocID XMLData „XTMeineTabelle000“ min_NodeID DocID XMLData „XTMeineTabelle…“ min_NodeID XMLData „XTMeineTabelleXXX“ (XXX ≙ n-2) min_NodeID Abbildung 17: NodeID-Index Dabei benutzt er von der XMLData-Spalte nicht etwa das gesamte XML-Dokument, sondern nur gezielte Informationen. Diese beschränken sich auf die im Record enthaltenen ProxyNode-IDs und dessen maximaler Node-ID. Alle anderen Node-IDs werden als Null-Wert indexiert und stören wegen der verwendeten Indexcharakteristik die Uniqueness nicht. Mithilfe der Proxy-Node-ID lässt sich für einen gesuchten Knoten zwischen den benötigten (Teilbaum-)Records navigieren. Durch die maximale Node-ID kann identifiziert werden, ob es sich bei dem aktuellen Datensatz um denjenigen handelt, der den gesuchten Knoten in sich trägt. [NK09] Die Bezeichnung des NodeID-Index leitet sich von der XML-Auxiliary-Tabelle und damit indirekt von der Basistabelle ab. Sie setzt sich aus bis zu 29 Zeichen der Form I_NODEIDyyyyyyyyyyyyyyyyyyzzz zusammen. Dabei entspricht yyyyyyyyyyyyyyyyyy den ersten maximal 18 Zeichen des XML-Auxiliary-Tabellennamens und wird entsprechend dem vollen Tabellennamen verkürzt, sollte dieser weniger Zeichen lang sein. Die Zeichenkette zzz stellt eine von null beginnende dreistellige Nummerierung dar, die hinzugefügt wird, sobald ein Index gleichen Namens bereits in der Datenbank existiert. [Mor10] 5.7.2 DocID-Index Der DocID-Index ist ein normaler Index über der DocID-Spalte der Basistabelle. Unabhängig von der Anzahl an XML-Spalten erzeugt DB2 ab dem Vorhandensein der ersten XML-Spalte implizit genau einen solchen Index. [NK09] Seine Funktion hat der DocID-Index erst in Kombination mit den User-DefinedIndexen. Er ermöglicht die Rückabbildung für die in der XML-Auxiliary-Tabelle ermittelten DocIDs auf die zugehörigen Zeilen der Basistabelle. Abbildung 18 veranschaulicht diese 44 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Wirkungsweise. Eine detaillierte Betrachtung dieses Zusammenhangs erfolgt im Abschnitt 5.7.3 anhand einer beispielhaften Zugriffskette. [NK09] Basistabelle „TMeineTabelle“ rel. Spalten XML Spalte 1 … XML Spalte n DocID DocID-Index (pro Basistabelle) „I_DOCID TMeineTabelle“ User-Defined-Index (beliebig viele) „IMeineTabelle“ DocID DocID XMLData XML-Aux-Tabelle(n) „XTMeineTabelle“ min_NodeID DocID XMLData „XTMeineTabelle000“ min_NodeID DocID XMLData „XTMeineTabelle…“ min_NodeID XMLData „XTMeineTabelleXXX“ (XXX ≙ n-2) min_NodeID Abbildung 18: DocID-Index und User-Defined-Index Die Bezeichnung des DocID-Index entspricht den gleichen Vorgaben wie beim NodeID-Index (siehe Abschnitt 5.7.1). Lediglich das Präfix lautet in diesem Fall I_DOCID, weshalb sich auch die Gesamtlänge des Indexnamens um ein Zeichen verkürzt. [Mor10] 5.7.3 User-Defined-Indexe User-Defined-Indexe – oder genauer User-Defined-XML-Indexe – sind explizit vom Nutzer anzulegende Indexe. Es bestehen keinerlei Beschränkungen oder Vorgaben zur Anzahl an anzulegenden User-Defined-Indexen. Dennoch sollten sie genau wie auch herkömmliche Indexe nur dort eingesetzt werden, wo ihre Vergabe sinnvoll ist. Grund dafür ist der mit ihnen verbundene Speicherplatzbedarf und Wartungsaufwand. [NK09] Jeder User-Defined-Index basiert auf einem per XMLPATTERN [IBM11a] festgelegten XPath-Pfadausdruck und einem zugehörigen Datentyp, in den das Ziel des Ausdrucks gecastet wird. Über diesen definierten Pfad besteht somit eine direkte Verknüpfung mit dem beziehungsweise den indizierten Knoten des XML-Dokuments. Bezieht sich ein Statement in seinem Ausführungsplan beispielsweise innerhalb eines XMLEXIST-Prädikats24 auf einen 24 vgl. EXISTS-Prädikat [IBM11a] 45 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 solchen XPath-Ausdruck, so kann ein User-Defined-Index einen direkten und effizienten Zugriff auf dessen Ziel(e) ermöglichen. [NK09] Intern umfasst ein User-Defined-Index neben dem explizit definierten (gecasteten) Schlüsselwert stets noch die Spalten DocID und XMLData. Die DocID ist notwendig, um eine Rückabbildung per DocID-Index zu ermöglichen, und die XMLData enthält unter anderem die indizierten Zielknoten. [NK09] Inwieweit User-Defined-Indexe mit dem DocID-Index verknüpft sind zeigt Abbildung 18. Da die Benennung dieser Indexe wie auch deren Erstellung explizit erfolgt, ist sie hier an die DATEV-Namenskonventionen angepasst. Die tatsächliche Zusammenarbeit der beiden Indexstrukturen ist in Abbildung 19 schematisch dargestellt. Als Anwendungsbeispiel dient dabei eine SELECT-Abfrage mit enthaltenem XMLEXISTS-Prädikat in der WHERE-Klausel. Zum besseren Verständnis sei erwähnt, dass „xmlCol“ eine Spalte vom Datentyp XML in der Basistabelle „TMeineTabelle“ beschreibt. Ausgangssituation SELECT * FROM TMeineTabelle WHERE XMLEXISTS ('$doc/customerinfo[@id=1001]'‚ PASSING xmlCol AS "doc"); User-Defined-Index direkter Zugriff auf indizierte(n) Knoten des XMLData-Dokumentes (innerhalb XML (Auxiliary) Tabelle), liefert gezielte DocID(s) DocID-Index Rückabbildung auf Basistabelle anhand gesuchter DocID(s) weitere Verarbeitung Verarbeitung der selektierten Spalten (relationale Spalten + XML-Spalte) innerhalb des SELECT-Statements Abbildung 19: Zugriffskette mit User-Defined-Index 46 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 5.8 Locking Neben den bisher betrachteten Aspekten ergeben sich durch den nativen XML-Datentyp auch Besonderheiten für die Locking-Thematik. Sperren auf nativen XML-Dokumenten werden nicht knoten-, sondern dokumentweise vergeben. Das heißt, beispielsweise parallele Änderungen auf einem XML-Dokument sind nicht möglich. In diesem Zusammenhang ist zwischen Locks auf der Basistabelle, Locks auf der XML-Auxiliary-Tabelle und Locks auf dem XML-Tablespace zu unterscheiden. [IBM09a] Die Locks auf der Basistabelle verhalten sich analog zu den Locks auf einer LOBBasistabelle. Beide entsprechen gewöhnlichen Transaktionssperren und gestatten die Vergabe von „IS“-, „IX“-, „S“-, „U“-, „SIX“- und „X“-Locks. Für die Bedeutung der einzelnen Sperrmodi sei auf [IBM09a] verwiesen. Für die Sperren auf der XML-Auxiliary-Tabelle ist mit dem XML-Lock ein neuer Sperrtyp in DB2 eingeführt worden. Dieser sperrt tupelübergreifend alle Zeilen, die einem zu verarbeitenden XML-Dokument zugeordnet sind und somit dieselbe DocID besitzen (siehe Abschnitt 5.6.1). XML-Locks sperren also gesamte XML-Dokumente. Abhängig vom Zugriff werden sie nur als „S“ (Lesesperre) oder „X“ (Schreibsperre) vergeben. Auf eine detaillierte Darstellung der XML-Lock-Vergabe bei den verschiedenen SQL-Operationen sei an dieser Stelle verzichtet und auf [IBM09a] verwiesen. Es verbleibt die Betrachtung der Locks auf dem XML-Tablespace. Dort werden nur beim INSERT und UPDATE Sperren in Form von Page Latches und optional P-Locks (physische Sperren) gesetzt. Latches sind Kurzzeitsperren, die in DB2 zur physischen Konsistenzsicherung von Seiten genutzt werden. Nähere Informationen zu diesen beiden Sperrformen finden sich in [IBM09a]. Abbildung 20 zeigt am Beispiel eines „SELECT (with-RS25)“-Statements eine mögliche Sperrvergabe. Dabei ist in der Basistabelle das Tupel mit dem Primärschlüssel „1“ mit einer „S“-Lock versehen. Die zugehörigen Tupel in der XML-Auxiliary-Tabelle sind ebenfalls per „S“-Lock gesperrt. Auf dem XML-Tablespace befindet sich keine Sperre. 25 Isolation-Level „read stability“ [IBM09a] 47 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 XML-Tablespace Basistabelle XML-AuxiliaryTabelle PrimärDB2_GENERATED_ XML schlüssel DOCID_FOR_XML DocID min_NodeID XMLData „S“-Lock SELECT (with RS) 1 2 1 … … „S“-XML-Lock … … 1 … … 2 … … Abbildung 20: Sperrvergabe am Beispiel eines „SELECT (with RS)“-Statements 5.9 Logging Das Logging-Konzept für XML-Tablespaces funktioniert ähnlich wie das für LOB-Tablespaces. Der XML-Tablespace erbt das Logging-Attribut („LOGGED“ oder „NOT LOGGED“) des Basis-Tablespaces und passt sich bei dessen Änderung stets an den aktuellen Wert an. Eine explizite Deklaration dieser Option, wie sie für LOB-Tablespaces teilweise und für herkömmliche Tablespaces generell möglich ist, lässt DB2 für XML-Tablespaces nicht zu. [IBM07] Die Bezeichnung „NOT LOGGED“ bedeutet nicht, wie es namentlich suggeriert wird, dass gar keine Informationen zum XML-Tablespace im Log gespeichert werden. Kontrollinformationen26 loggt DB2 in jedem Fall. Tatsächlich ist unter „NOT LOGGED“ das Unterdrücken der Undo- und Redo-Logs zu verstehen. Alternativ zu dieser Option bezeichnet „LOGGED“ das vollständige Logging. Dabei werden ähnlich zum LOB-Logging für INSERTs und UPDATEs stets die unter Umständen sehr großen, kompletten Dokumente geloggt. Ein Delta-Logging, wie es für UPDATEs denkbar wäre, ist sowohl für LOB-, also auch für XMLDokumente nicht möglich. Grund dafür ist im Falle des XML-Loggings, dass diese Dokumente in DB2 Version 9 nur komplett geändert werden können. Selektive UPDATEs müssen in der Anwendung erfolgen und äußern sich datenbankseitig als DELETE und INSERT eines neuen XML-Dokuments. Mit Version 10 ist das Logging bei XML-Dokumenten optimiert worden. 26 beispielsweise das Öffnen und Schließen eines Page Sets [Wo10] 48 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Hier gibt es die Möglichkeit, datenbankseitig selektive UPDATEs auf XML-Dokumenten durchzuführen. Entsprechend wird dabei nicht das ganze XML-Dokument, sondern nur noch der Bereich geloggt, in dem die Änderung stattfand. [IBM07, IBM11a, Nic10, IBM06a] Auf den ersten Blick erscheint „NOT LOGGED“ vielleicht etwas unstimmig, da das Logging aus Recovery-Gründen explizit gewollt ist. Hierbei muss berücksichtigt werden, dass diese Option im Allgemeinen nicht als dauerhafte Lösung angedacht ist. Vielmehr soll sie dazu dienen, in gezielten Situationen Aufwandseinsparungen zu ermöglichen. Betrachtet man beispielsweise Batch-Abläufe [EIT11] mit massiven Änderungen auf XML-Daten, dann würde das parallel dazu notwendige Logging einen erheblichen Zusatzaufwand mit sich ziehen27. Anstatt des Loggens könnte man mit wesentlich weniger Aufwand vor und nach dem Batch-Ablauf ein Backup des Tablespace erstellen. Für den Batch-Ablauf selbst ließe sich dann mit „NOT LOGGED“ das Logging unterbinden, ohne dass die Recovery-Fähigkeit verloren geht. Dieses Vorgehen wird auch bei der Massendatenverarbeitung von Nicht-XML-Daten im Batch oft angewendet. [IBM07] 5.10 Kompression DB2 bietet die Möglichkeit, Daten über ein Dictionary komprimiert abzulegen. Um dies nutzen zu können, muss auf Tablespace-Ebene die COMPRESS-Option aktiviert sein. Eine Ausnahme stellen hierbei LOB-Tablespaces dar. Diese können nicht komprimiert werden. Für XMLDokumente in XML-Tablespaces dagegen besteht die Möglichkeit der Kompression. In Abhängigkeit zum Tablespace der Basistabelle wird die Eigenschaft „COMPRESS YES“ auf den XML-Tablespace vererbt. Diese kann aber jederzeit durch einen ALTER zu „COMPRESS NO“ deaktiviert werden. [IBM10a, IBM06a] Die Kompression von XML-Dokumenten erfolgt für enthaltene NamespaceAusprägungen, Attribut- und Elementnamen. Diese XML-Bestandteile werden zu Speicherplatz-sparenden Zahlenwerten codiert und ihre zugehörigen Decodierungsvorschriften in der Katalogtabelle SYSIBM.SYSXMLSTRINGS gesammelt. Für konkrete Ausprägungen von Attributen und Elementen beziehungsweise auch für den Namespacebezeichner „xmlns“ erfolgt keine Komprimierung mithilfe dieser Tabelle. [IBM10a] 27 auch bei Massendatenverarbeitung von nicht XML-Daten im Batch wird oft Logging abgeschaltet 49 5 Native XML-Speicherstrukturen in DB2 for z/OS Version 9.1 Bei der Abfrage eines XML-Dokuments durch den Anwender werden datenbankseitig alle komprimierten Teile durch ihre Originalstrings ersetzt. Aufgrund dieser Decodierung entsteht ein Zusatzaufwand, der geringfügig die Performance der Statementausführung beeinflusst. 50 6 Gegenüberstellung: native vs. nicht-native XML-Speicherstrukturen 6 Gegenüberstellung: native vs. nicht-native XMLSpeicherstrukturen XML-Dokumente können datenbankseitig in zwei unterschiedlichen Speicherformen abgelegt werden, der nativen und nicht-nativen XML-Speicherung. Im Kapitel 4 und im Kapitel 5 sind die einzelnen Ablagemöglichkeiten bereits detailliert beschrieben worden. Das folgende Kapitel dient einer vergleichenden Zusammenfassung. Darüber hinaus soll aufgrund der strukturellen Ähnlichkeit eine Gegenüberstellung des Konzepts der LOB-RowID mit der XML-DocID erfolgen. 6.1 Evaluierender Vergleich Im Rahmen des folgenden Abschnitts soll ein Überblick über die Vor- und Nachteile der nativen beziehungsweise der nicht-nativen XML-Speicherstrukturen gegeben werden. Abbildung 21 fasst die in dieser Arbeit betrachteten Aspekte zusammen. Für eine detaillierte Betrachtung sei auf Kapitel 4 und Kapitel 5 verwiesen. NichtNicht-natives XML NativesNatives-XML + einfach umsetzbar + einfach umsetzbar (Transparenz) - noch geringe Verbreitung und Nutzung + leicht portierbar + Kompatibilität zu vorhandenen Tools - erhöhter Aufwand bei Portierung - teilweise (noch) fehlende + kaum Beschränkungen hinsichtlich + kaum Beschränkungen hinsichtlich - keine gezielten Knotenzugriffe + gezielte Knotenzugriffe sind - ständiger anwendungsseitiger Parse- + mehr Funktionalität + einmaliger datenbankseitiger Parse- Kompatibilität zu vorhandenen Tools der Größe der Größe möglich performant möglich Aufwand des kompletten Dokumentes Aufwand beim Insert + gezielter Parse-Aufwand innerhalb der Anwendung - nur anwendungsseitiger XML- + datenbankseitige Schema-Validierung - nur physische Kompression auf + mögliche XML-Kompression Schemaabgleich möglich Tablespace-Ebene Abbildung 21: evaluierender Vergleich: natives XML - nicht-natives XML 51 6 Gegenüberstellung: native vs. nicht-native XML-Speicherstrukturen Zusätzlich sind in Abbildung 21 die Aspekte „Portierung“ und „mehr Funktionalität“ aufgegriffen, die bislang noch nicht weiter erwähnt wurden. Die Konzeption des nativen XMLDatentyps in DB2 ist sehr speziell und unterliegt keiner herstellerübergreifenden Normung. Beispielsweise äußert sich dies in der Namensgebung der impliziten Verwaltungsstrukturen oder in der Ausgestaltung der Indizierungsmöglichkeiten. Durch die dazu in DB2 verankerten Konzepte und Konventionen ergibt sich eine wachsende Komplexität der Datenablage. Sollte zukünftig eine Portierung zu einem anderen Datenbankmanagementsystem mit differenzierten XML-Speicherstrukturen notwendig sein, kann sich daraus ein nicht zu vernachlässigender Zusatzaufwand ergeben. Die Möglichkeiten, die sich hinter dem Stichpunkt „mehr Funktionalität“ verbergen, wurden teilweise bereits erwähnt. Damit soll vor allem auf die vielfältigen XMLDekompositions- und XML-Publishing-Funktionalitäten [NK09] des DB2 verwiesen werden. Mittels dieser lassen sich zum einen XML-Dokumente in relationale Strukturen zerlegen (Dekomposition). Umgekehrt ist es ebenfalls möglich, aus relationalen Strukturen XMLDokumente zu erzeugen (Publishing). Zwar bot DB2 unter anderem in Kombination mit dem XML-Extender bereits vor der Einführung von Version 9 ähnliche Funktionalitäten an. Diese setzen jedoch nicht auf dem nativen XML-Datentypen auf und sind in ihrem Umfang gegenüber den neuen Möglichkeiten wesentlich begrenzt. Performance-Nachteile sind dort ebenfalls anzunehmen. [Zha08b] 6.2 LOB-RowID und XML-DocID Viele Besonderheiten des LOB-Datentyps finden sich auch in der Struktur des nativen XMLDatentyps in DB2 wieder. Beide Datentypen sind als Outline-Datentyp realisiert und verwenden zu ihrer technischen Umsetzung Auxiliary-Tabellen und zugehörige Tablespaces (siehe Abschnitt 4.2 und Kapitel 5). Im Gegensatz dazu ist die datenbankseitige Klassifizierung der Tablespaces (siehe Abschnitt 5.5), das Logging (siehe Abschnitt 5.9) oder auch das Locking (siehe Abschnitt 5.8) für die hier diskutierten Datentypen unterschiedlich realisiert. In diesem Abschnitt sollen die Gemeinsamkeiten und Unterschiede der LOB-RowID und XML-DocID detaillierter betrachtet werden. Beide Objekte definieren sich als zusätzliche Spalte der Basistabelle und dienen deren Verknüpfung mit den jeweiligen Auxiliary-Tabellen. RowIDs lassen sich auch in anderen Kontexten zur eindeutigen Identifizierung verwenden. 52 6 Gegenüberstellung: native vs. nicht-native XML-Speicherstrukturen DocIDs dagegen werden nur im Zusammenspiel mit dem nativen XML-Datentyp in DB2 benutzt. Ebenfalls haben RowID-Spalten die Eigenschaft, dass sie explizit erstellt werden können beziehungsweise bis vor Version 9 des DB2 explizit erstellt werden mussten. Dies bringt den Vorteil mit sich, dass sie an vorhandene Namenskonventionen anpassbar sind, jedoch zusätzlichen Adminstrationsaufwand erfordern. DocID-Spalten werden generell, ohne Einflussnahme durch den Nutzer, implizit erstellt. [IBM06a, NK09] Weiterhin existieren sowohl für LOB-, als auch für XML-Dokumente zusätzliche zugriffsoptimierende Indexe, die auf der RowID- beziehungsweise der DocID-Spalte aufgebaut werden. Diese ermöglichen jeweils den gezielten Zugriff auf innerhalb der AuxiliaryTabellen gespeicherte komplette Dokumente. Im Kontext des nativen XML-Datentyps ist die Indizierung komplexerer Natur, da ebenfalls Strukturen zum selektiven Zugriff auf Knoten innerhalb der gespeicherten XML-Dokumente vorhanden sind. Näheres dazu findet sich in Abschnitt 5.7. [IBM06a, NK09] Als nächster Vergleichspunkt soll die Zusammensetzung der jeweiligen Objekte dienen. Dabei ist bei einer RowID zwischen interner und externer Repräsentation zu unterscheiden. Die interne Darstellung umfasst Angaben zu deren Länge sowie die nach dem Zufallsprinzip von DB2 automatisch generierte RowID selbst. Wird eine RowID aus der Datenbank abgefragt, so wird sie in eine externe Darstellung überführt. Diese erweitert die interne um den RecordIdentifier (RID) [CMS10]. Dieser Identifikator dient dem Auffinden eines einzelnen Records und setzt sich dementsprechend aus der Seitennummer und der Position des Records innerhalb der Seite zusammen. Er wird für alle Tupel in DB2 unsichtbar im Hintergrund mitgeführt. An dieser Stelle sei nochmals darauf hingewiesen, dass eine RowID und eine RID somit unterschiedliche Objekte bezeichnen. Während sich die externe Repräsentation der RowID über die Zeit hinweg beispielsweise durch einen REORG [IBM08b] ändern kann, ist dies für die interne nicht der Fall. Grund dafür ist die in der externen Darstellung enthaltene RID, die am Ende eines Umorganisierungsvorgangs in der Regel auf eine andere Seite als zuvor zeigt und somit währenddessen angepasst wurde. Die DocID der nativen XML-Struktur verhält sich in diesem Zusammenhang wie die intern repräsentierte RowID und bleibt für die Lebensdauer ihres Dokuments konstant. Allgemein unterscheidet sie sich jedoch in ihrer Zusammensetzung von der RowID, da sie unter anderem nicht zufällig sondern über eine separate Sequence vergeben wird. [IBM06a, CMS10, NK09] 53 6 Gegenüberstellung: native vs. nicht-native XML-Speicherstrukturen Gemeinsam ist beiden, dass sie dem Anwender gegenüber stets transparent bleiben. Aus dessen Sicht lässt sich direkt auf die Daten in den Basistabellen zugreifen. Von der im Hintergrund verborgenen Struktur der Datentypen merkt er nichts. Da beide Spalten ab Version 9 des DB2 implizit als versteckte („hidden“) Objekte angelegt werden können, ist es möglich, die RowID beziehungsweise die DocID für den Anwender komplett unsichtbar zu machen. [IBM06a, NK09] 54 7 Überführungskonzepte für nicht-native XML-Speicherformen 7 Überführungskonzepte für nicht-native XMLSpeicherformen Durch die native XML-Speicherung ergeben sich in DB2 für die datenbankseitige Ablage von XML-Dokumenten zahlreiche Vorteile. Diese sind zusammen mit den Strukturbesonderheiten des zugrunde liegenden XML-Datentyps in Kapitel 5 aufgezeigt. Neue Projektanwendungen können auf einfache Weise von der nativen XML-Ablage profitieren. Damit auch bereits vorhandene Anwendungen die daraus resultierenden Vorteile nutzen können, müssen vorher deren datenbankseitige nicht-native XML-Strukturen zu nativen überführt werden. Im Rahmen einer dazu notwendigen Migration sind verschiedene Ansätze und Herausforderungen zu berücksichtigen. Deren detaillierte Betrachtung erfolgt in den weiteren Abschnitten. Anknüpfend daran werden die dabei gewonnenen Ergebnisse am Ende des Kapitels in Form konkreter Überführungskonzepte zusammengetragen. 7.1 Differenzierte Ansätze Für die Gestaltung des Überführungsprozesses für nicht-native XML-Speicherformen sind einige Vorüberlegungen zu tätigen. Wie bei einer herkömmlichen Migration beeinflussen die Aspekte Fallbackmöglichkeit, „Fehlertoleranz“, Online-Durchführung und Lokation den Ablauf und die Performance des Prozesses. Im speziellen Rahmen der XML-Überführung kommt ein weiterer Einflussfaktor hinzu – die einzeilige oder verteilte Beschaffenheit der nicht-nativen XML-Ablage (siehe Abschnitt 4.3). In den folgenden Abschnitten dieses Kapitels werden neben der Darstellung der einzelnen Aspekte stets auch daraus abgeleitete Präferenzen angeführt. Diese bilden das konzeptuelle Fundament des in Kapitel 8 beschriebenen Prototypen. 7.1.1 Möglichkeit zum Fallback Der Begriff Fallback bedeutet in die deutsche Sprache übersetzt „Zurückfallen“. Im Zuge der Überführungskonzepte bezeichnet er die Möglichkeit, im Fehlerfall oder aus anderen Gründen auf den Ausgangszustand mit möglichst geringem Aufwand „zurückfallen“ zu können. 55 7 Überführungskonzepte für nicht-native XML-Speicherformen Datenbankseitig besteht auch unabhängig von dem im Folgenden beschriebenen Vorgehen die Möglichkeit des Fallbacks. Da in der Regel beispielsweise alle Datenmanipulationen in DB2 geloggt werden, ließe sich auch mit Hilfe der einzelnen Log-Records ein Fallback realisieren. Dies wäre jedoch sehr aufwändig. Für den Fall der XML-Überführung wird eine effiziente Möglichkeit zum Fallback benötigt. Voraussetzung dafür ist, dass die Struktur und die Daten der zu migrierenden Tabelle in ihrer Ursprungsform erhalten bleiben und durch den Migrationsprozess nicht verändert werden. Dies lässt sich beispielsweise mit Hilfe einer zusätzlichen (Ziel-)Tabelle gewährleisten. Sie enthält in der Regel neben der nativen XML-Spalte (anstatt der nicht-nativen XML-Spalte) auch alle weiteren Spalten und Strukturen der Ausgangstabelle. Abweichungen sind dabei allerdings je nach Anforderung möglich. Der Überführungsprozess kann nun so gestaltet werden, dass er die Daten aus der Ausgangstabelle nur liest und das Ergebnis der Migration in die zusätzliche Zieltabelle schreibt (siehe Abbildung 22). Die ursprünglichen Daten bleiben unverändert, sodass beispielsweise bei fehlschlagender oder falscher Migration effizient auf den Ausgangszustand „zurückgefallen“ werden kann. Fallback nicht effizient möglich Fallback möglich Ausgangstabelle MigrationsMigrationsprozess MigrationsMigrationsprozess Ausgangstabelle Zieltabelle ✓ Abbildung 22: Möglichkeit zum Fallback Diese Überführungsform findet sich auch in anderen Migrationskontexten wieder. Dort sind jedoch vorrangig Gründe wie Fragmentierung beziehungsweise Clusterung ausschlaggebend. Auf jene soll nicht näher eingegangen werden, da sie im Rahmen der XML-Überführung von untergeordneter Bedeutung sind. In Zusammenhang mit dem in Abschnitt 7.1.3 betrachteten Aspekt sei bereits erwähnt, dass im Fall einer Online-Migration die Ausgangstabelle nicht vollständig unangetastet bleiben kann. Damit es möglich ist, auf parallel zum Migrationsprozess stattfindende Änderungen zu 56 7 Überführungskonzepte für nicht-native XML-Speicherformen reagieren, können auf dieser Tabelle beispielsweise Trigger erstellt werden. Die Struktur der Ausgangstabelle sowie auch ihre Datensätze bleiben davon separiert. Lediglich die angesprochenen Änderungen selbst sind betroffen. Sie werden nur dann umgesetzt, wenn die durch sie aktivierten Trigger ihre Ausführung ebenfalls erfolgreich beenden. Ist dies nicht möglich, wird sowohl die Aktion des Triggers als auch das ihn aktivierende Statement zurückgerollt. Ähnlich verhält es sich auch mit dem Sperrgranulat des Tablespace der Ausgangstabelle. Dieses muss unter Umständen für den Prozess der Online-Migration angepasst werden. Auf die Daten der Ausgangstabelle wird dadurch jedoch kein Einfluss genommen. Alle in diesem Zusammenhang vorgenommenen Änderungen werden im Anschluss an die Migration stets auf ihren Ausgangszustand zurückgesetzt. [IBM11a] 7.1.2 „Fehlertoleranz“ Fehlertoleranz bezeichnet die Fähigkeit eines Systems, auch bei einer begrenzten Zahl fehlerhafter Subsysteme eine spezifische Funktion zu erfüllen. In dem Zusammenhang der XMLMigration definiert sich dieser Begriff auf eine abgewandelte Art. Unter Fehlertoleranz sei daher im Folgenden das fehlertolerante Verhalten bei ungültigen Quelldaten bezeichnet. Diese sollen erkannt und als nicht-verarbeitbar gekennzeichnet werden, sodass der Migrationsprozess ähnlich fehlertolerant abläuft, wie beispielsweise auch LOAD-Utilities [IBM08b]. Der weitere Überführungsprozess darf dabei nicht stoppen, sondern muss seine Arbeit ab dem nächsten Tupel fortsetzen. Ähnlich zur Fallbackmöglichkeit (siehe Abschnitt 7.1.1) lässt sich im Rahmen der XML-Migration Fehlertoleranz mit Hilfe einer zusätzlichen Fehlertabelle herstellen. Durch vorher definierte und geeignet berücksichtigte Fehlerfälle erkennt die Migrationsanwendung ungültige Tupel. Anstatt bei ihrem Auftreten abzubrechen, fügt sie diese in die Fehlertabelle ein. Der weitere Überführungsprozess kann die dadurch kenntlich gemachten Tupel ignorieren und die Migration bis zum Ende (oder einem unerwarteten Fehlerfall) fortführen. Abbildung 23 visualisiert die dabei stattfindende Abarbeitung. [Küs85] Fehlertabelle X Quelltabelle ✓ Zieltabelle Abbildung 23: "fehlertolerante" Überführung von Dokumenten 57 7 Überführungskonzepte für nicht-native XML-Speicherformen 7.1.3 Offline- vs. Online-Migration Rückt man die Projektanwendungen, die auf der Ausgangstabelle arbeiten, in den Fokus, dann ergeben sich aus deren Sichtweise zwei verschiedene Formen der Durchführung des Überführungsprozesses. Die einfachere Variante ist die Offline-Migration. Sie bedeutet für die Dauer des Prozesses den Stillstand der Kommunikation zwischen Projektanwendungen und Datenbank. Dies muss aber nicht zwingend hinderlich sein. Migrationsprozesse sind in der Regel in größere Batch-Jobs eingebunden, die in definierten Wartungsfenstern (zumeist nachts) abgearbeitet werden. Die Überführung der nicht-nativen XML-Dokumente ließe sich auf gleiche Weise in eine solche Batch-Abarbeitung integrieren. In diesem Fall ist die Offline-Migration die geeignetste Variante. Das Pendant der Offline-Migration ist die Online-Migration. Ähnlich wie es im Datenbankumfeld auch in modernen Online-Backup-Lösungen gehandhabt wird, gestaltet die OnlineMigration den Überführungsprozess transparent zu den Projektanwendungen. Infolgedessen bleibt eine Behinderung dieser Anwendungen durch den Migrationsvorgang aus. Um jene Transparenz im Fall der Online-Migration sicherzustellen, ist eine – verglichen mit der OfflineVariante – komplexere Ablauflogik des Prozesses notwendig. In dem Zusammenhang muss beispielsweise darauf geachtet werden, dass der lesende Zugriff auf der Ausgangstabelle (siehe Abschnitt 7.1.1) mit einem kleinen Sperrgranulat und nur für kurze Dauer durchgeführt wird. Zu lang gehaltene Sperren auf großen Blöcken oder gar eine Sperreskalation würden den parallelen Zugriff durch die Projektanwendungen unmöglich machen. [IBM11a] Eine weitere Besonderheit der Online-Migration ist bereits in Abschnitt 7.1.1 erwähnt worden. Da im allgemeinen Fall der Migrationsprozess außerhalb der Projektanwendungen stattfindet, ist es nicht möglich, Rücksicht auf die migrierten Daten zu nehmen. Das bedeutet, dass Tupel, die bereits in die Zieltabelle migriert wurden, während des Überführungsprozesses in der Ausgangstabelle geändert oder gelöscht werden können. Um einen aufwendigen, unter Umständen mehrfach erforderlichen Abgleichprozess nach der Migration zu vermeiden, können etwa Trigger verwendet werden. Mit deren Hilfe lassen sich parallel zum Migrationsprozess anfallende Änderungen selektiv in die Zieltabelle einpflegen („Nachfahren“). Die Verwendung von Triggern hat jedoch nicht nur Vorteile, sondern ist mit einem zusätzlichen DDL-Aufwand für deren Erstellung und geringfügigen Performancekosten für deren Ausführung auch negativ behaftet. Hierbei ist jedoch anzumerken, dass der entwickelte Prototyp die benötigten Trigger automatisch erstellt (siehe Kapitel 8), sodass der DDL-Aufwand für den Administrator an dieser Stelle wieder entfällt. Die Online-Migration sollte dennoch nur verwendet werden, wenn 58 7 Überführungskonzepte für nicht-native XML-Speicherformen der parallele Zugriff durch die Projektanwendungen (beispielsweise in Testumgebungen) sicherzustellen ist. [IBM11a] 7.1.4 Einzeilige vs. verteilte nicht-native XML-Dokumente Bezogen auf die Beschaffenheit der nicht-nativ gespeicherten XML-Dokumente ist zwischen einzeiligen und verteilten nicht-nativen XML-Dokumenten zu unterscheiden. Da eine detaillierte Darstellung dieser verschiedenen Formen bereits in Abschnitt 4.3 erfolgte, sollen an dieser Stelle nur die Konsequenzen betrachtet werden, die sich für den Überführungsprozess der abgelegten Dokumente ergeben. Abbildung 24 veranschaulicht die verschiedenen Ausgangssituationen. einzeilig verteilt nicht-natives XML Tupel 1 nicht-natives XML <customerinfo id="1001"> <name> Mustermann </name><phone type="work"> 408-555-1358 </phone> </customerinfo> Tupel 1 <customerinfo id="100 1"><name>Mustermann</ Tupel 2 name><phone type="wor k">408-555-1358</phon Tupel 3 e></customerinfo> Abbildung 24: einzeilige vs. verteilte nicht-native XML-Dokumente Während sich die Migration von einzeilig gespeicherten nicht-nativen XML-Dokumenten einfach gestaltet, ist dies für verteilte nicht-native XML-Dokumente nicht der Fall. Hier müssen vor dem eigentlichen Überführungsprozess erst durch eine zusätzliche Logik alle Teilstücke eines Dokuments zu einem Ganzen konkateniert (materialisiert) werden. Das Ergebnis kann daraufhin wie ein einzeilig gespeichertes nicht-natives XML-Dokument migriert werden. 59 7 Überführungskonzepte für nicht-native XML-Speicherformen Ein weiteres Problem ergibt sich in Zusammenhang mit der in Abschnitt 7.1.3 beschriebenen Online-Variante der Migration. Die dazu datenbankseitig auf der Ausgangstabelle notwendigen Trigger stoßen bezüglich paralleler Änderungen auf verteilten nicht-nativen XML-Dokumenten an ihre Grenzen. In den Projektanwendungen erfolgen Einfügungen, Änderungen und Löschungen stets dokumentweise. Dies gilt auch, wenn die Dokumente über mehrere Tupel verteilt gespeichert sind. Die Trigger reagieren jedoch entweder auf jedes Tupel oder jedes Statement, das auf den ihnen zugehörigen Tabellen ausgeführt wird. Da deren Aktivierung standardmäßig somit unmittelbar auf die Manipulation an einem einzelnen Teilstück erfolgt, ergibt sich für die in den Triggern zum Teil notwendigen Parse-Prozesse der XML-Daten ein Problem. Im Allgemeinen stellen XML-Teilstücke keine wohlgeformten XML-Dokumente dar. Daher schlagen in einem solchen Fall etwaige durch den Trigger initiierte Parse-Prozesse fehl und damit auch das den Trigger aktivierende Statement selbst. Um dies zu verhindern, wäre eine zusätzliche Logik nötig, die einen Trigger nur XML-dokumentweise aktiv werden lässt. Dazu müsste das letzte Teilstück eines verteilten XML-Dokuments als solches identifiziert werden können. Dies ist jedoch auf effiziente Weise nicht möglich, da nur anhand des Inhalts28 des zuletzt eingefügten Teilstücks erkennbar ist, ob ein weiteres folgen muss. [IBM11a] Im Folgenden sollen die einzelnen Trigger bezüglich der zuletzt beschriebenen Problematik näher betrachtet werden. Für DELETE-Trigger ist diese irrelevant, da sie in ihrem Body keine Überführung anstoßen, sondern nur anhand von Schlüsselinformationen gezielt ganze XML-Dokumente (wieder) aus der Zieltabelle entfernen. Bezüglich einer Mehrfachaktivierung aufgrund von verteilten Dokumenten würde bereits die erstmalige Ausführung eines DELETETriggers das gesamte native XML-Dokument aus der Zieltabelle entfernen. Erneute Aktivierungen für weitere Teilstücke desselben Dokuments würden das zu diesem Zeitpunkt nicht (mehr) vorhandene zugehörige XML-Dokument ebenfalls versuchen aus der Zieltabelle zu entfernen. Dabei tritt jedoch kein Fehler, sondern nur eine Warnung auf. Die Verwendung des DELETETriggers ist somit unkritisch. UPDATE-Trigger haben die Aufgabe, bei einem UPDATE von bereits migrierten nicht-nativen XML-Dokumenten die zugehörigen Tupel der Zieltabelle zu ersetzen. Dabei ist zur Überführung ähnlich wie bei dem weiter unten betrachteten INSERT-Trigger ebenfalls ein XML-Parse-Prozess nötig. Da UPDATEs in den Projektanwendungen jedoch ausschließlich für einzeilige XML-Dokumente verwendet werden (sonst DELETE und anschließender INSERT), sind sie von der oben geschilderten Problematik nicht betroffen. Dabei ist anzumerken, dass in 28 Das aktuelle Teilstück ist das letzte Teilstück, wenn es den schließenden Tag des Wurzelelements enthält. 60 7 Überführungskonzepte für nicht-native XML-Speicherformen diesem Zusammenhang auch verteilte nicht-nativ gespeicherte XML-Dokumente als einzeilig bezeichnet sind, wenn sie aus genau einem Teilstück bestehen. Es verbleibt die Betrachtung von INSERT-Triggern. Diese haben die Aufgabe, während des Überführungsprozesses neu in die Ausgangstabelle eingefügte, noch nicht berücksichtigte Tupel in die Zieltabelle zu migrieren. Dabei muss zwingend ein Parse-Prozess stattfinden. Dieser ist jedoch, wie bereits weiter oben beschrieben, aufgrund der Aktivierung des Triggers für jedes einzelne XML-Teilstück nicht durchführbar. INSERT-Trigger können somit nicht zur Überführung von parallel zur Migration eingefügten verteilten XML-Dokumenten genutzt werden. Damit durch das Einfügen dieser Dokumente dennoch keine Inkonsistenzen zwischen Ausgangs- und Zieltabelle entstehen, muss eine anwendungsseitige Logik die Aufgabe der INSERT-Trigger übernehmen. Näheres dazu findet sich im Abschnitt 8.2.3. Da der XML-Überführungsprozess keinen Einfluss auf die Beschaffenheit der nichtnativ gespeicherten XML-Dokumente hat, muss er sich methodisch der jeweiligen Ausgangssituation anpassen. 7.1.5 Anwendungsseitiger vs. datenbankseitiger Migrationsprozess Es gibt zwei Möglichkeiten, den Migrationsprozess zu gestalten: anwendungsseitig oder datenbankseitig. Unabhängig davon erfolgt die Steuerung dieses Prozesses stets in einer externen Anwendung, über welche auch die Nutzereingaben GUI-basiert realisiert werden. Abbildung 25 stellt die unterschiedlichen Migrationsvarianten schematisch dar. Erläuterungen dazu finden sich im Folgenden. 61 7 Überführungskonzepte für nicht-native XML-Speicherformen anwendungsseitig datenbankseitig AblaufAblaufsteuerung AblaufAblaufsteuerung MigrationsMigrationsprozess MigrationsMigrationsanwendung MigrationsMigrationsanwendung MigrationsMigrationsprozess DBMS DBMS DB DB Abbildung 25: anwendungsseitiger vs. datenbankseitiger Migrationsprozess Abhängig von der Gestaltung des Migrationsprozesses ergeben sich verschiedene Vor- und Nachteile. Die anwendungsseitige Migration hat ihre Stärke vor allem in der Mächtigkeit der Programmiersprache29. Mit deren Hilfe lassen sich zentrale Aufgaben, wie beispielsweise die Konkatenation von verteilten nicht-nativen XML-Dokumenten, auf einfache Weise realisieren. Anwendungsseitig bedeutet aber auch, dass die zu migrierenden Daten in die Anwendung transportiert werden müssen. Die dazu notwendige Kommunikation zwischen Datenbank und Anwendung kann somit die Gesamtperformance der Migration wesentlich beeinflussen. Jedes XML-Dokument muss (gegebenfalls in Teilstücken) aus der Datenbank gelesen und nach der anwendungsseitigen Verarbeitung wieder in diese geschrieben werden. Anzumerken ist hierbei, dass XML-Dokumente in der Regel ein größeres Datenvolumen besitzen, weshalb ihr Transportaufwand zu Lasten der Performance geht. Ein weiteres Problem der anwendungsseitigen Migration ergibt sich in Zusammenhang mit der Online-Migration (siehe Abschnitt 7.1.2). Diese benötigt zur Konsistenzsicherung beispielsweise Trigger. Mit deren Hilfe werden parallele Datenmanipulationen von der Ausgangs- auf die Zieltabelle übertragen. Da der Migrationsprozess im aktuell betrachteten Fall aber ausschließlich in der Migrationsanwendung erfolgen soll, müsste ein Trigger eine Funktion innerhalb jener Anwendung ausführen können. Dies jedoch ist nicht realisierbar. Zwar ist es möglich, die notwendige Anwendungslogik beispielsweise als externe Java-Prozedur durch den Trigger initiieren zu lassen. Dennoch müsste diese Logik dazu auch außerhalb der 29 Prototyp in Java realisiert 62 7 Überführungskonzepte für nicht-native XML-Speicherformen Migrationsanwendung definiert werden. Das widerspricht aber der Idee der anwendungsseitigen Migration, bei der der Überführungsprozess zentral in der Migrationsanwendung stattfinden soll. In dem betrachteten Kontext kann somit auf eine zusätzliche Überführungslogik in den Triggern nicht verzichtet werden. [IBM11a] Die Alternative zum anwendungsseitigen ist der datenbankseitige Migrationsprozess. Dieser sieht die zur Überführung notwendige Datenverarbeitung innerhalb des DB2 vor. Auf diese Weise bleibt die zuvor betrachtete Kommunikation der zu migrierenden Daten zwischen Datenbank und Anwendung aus. Stattdessen wird erheblich an Aufwand eingespart und somit die Möglichkeit einer effizienten XML-Überführung gegeben. Damit der gesamte Migrationsprozess innerhalb der Datenbank realisiert werden kann, muss dort aber unter anderem auch die Konkatenation von verteilten XML-Dokumenten erfolgen. Hierfür werden etwa Stored Procedures oder Recursive SQL benötigt. Insgesamt bleibt aber der datenbankseitige Migrationsprozess aufgrund seiner erheblichen Performancevorteile die effizientere Variante, sodass diese auch in dem entwickelten Prototypen (siehe Kapitel 8) Anwendung fand. [IBM11a] 7.2 Herausforderungen Unabhängig von den in den vorherigen Abschnitten diskutierten Ansätzen ergeben sich bei der Überführung von nicht-nativen zu nativen XML-Dokumenten diverse zusätzliche Herausforderungen. Diese lassen sich hauptsächlich auf Probleme beim datenbankseitigen Parsen der nicht-nativen XML-Dokumente zurückführen. In den weiteren Abschnitten werden die identifizierten Herausforderungen beschrieben und Möglichkeiten aufgezeigt, sie zu umgehen. 7.2.1 Vorangehende Leerzeichen im Quelldokument In DB2 lassen sich nicht-native XML-Dokumente nur dann parsen, wenn sie eine wohlgeformte Struktur besitzen (siehe Abschnitt 3.1). Daraus ergibt sich unter anderem die Bedingung, dass ein XML-Dokument stets mit einer öffnenden Tag-Klammer („<“) beginnt. Davor dürfen keine anderen Zeichen im Dokument enthalten sein. Dies wird durch die XML-Parser in den Projektanwendungen ebenso gehandhabt. Da aber die XML-Dokumente bei der nicht-nativen Speicherung dort zu Character-Strings konvertiert werden, sind speziell dem ersten Tag 63 7 Überführungskonzepte für nicht-native XML-Speicherformen vorangestellte Leerzeichen nicht generell auszuschließen. Der XML-Parser des DB2 erlaubt das Parsen solcher Dokumente nicht. Daher sind diese so vorzuverarbeiten, dass führende Leerzeichen abgeschnitten werden. Um dies zu gewährleisten, lässt sich beispielsweise eine UserDefined Function implementieren, die bis zum Beginn des ersten Tags alle Zeichen des XMLDokuments abschneidet. Abbildung 26 veranschaulicht diesen Prozess. „____“ symbolisiert dabei eine beliebige Kette vorangehender Leerzeichen. ____<customerinfo… <customerinfo… Abbildung 26: Abschneiden von vorangehenden Leerzeichen 7.2.2 Implizite Konvertierung: EBCDIC zu Unicode DB2 legt native XML-Dokumente intern stets in dem Encoding-Schema UTF-8 [Uni11b] ab. Hierbei handelt es sich um eine Unicode-Kodierung mit variabler Länge von maximal vier Bytes. Im Vergleich zu den älteren EBCDIC-Codepages, die pro Zeichen eine feste Länge von einem Byte verwenden, ist die Unicode-Zeichenkodierung in ihrem Umfang wesentlich mächtiger und erlaubt weitaus vielfältigere Zeichendarstellungen. Anforderungen wie die datenbankseitige Ablage von Sonderzeichen (beispielsweise „€“), können in EBCDIC-27330 nicht umgesetzt werden. Unter Verwendung einer Unicode-Codepage wäre dies jedoch möglich. Eine einfache Überführung der EBCDIC-Daten in den Unicode-Zeichensatz ist nur in Einzelfällen realisierbar. Aus der unterschiedlichen Zeichenlänge der beiden Kodierungen können sich im Rahmen einer Konvertierung für Projektanwendungen31 Probleme beim Verarbeiten der Daten ergeben. Ist ein Programm beispielsweise auf den EBCDIC-Zeichensatz ausgelegt, behandelt es nacheinander jedes Byte als ein separates Zeichen. Sollten die Daten einer solchen Anwendung in die Unicode-Zeichenkodierung überführt werden, muss auch die dortige Verarbeitung an die beispielsweise für UTF-8 variable Zeichenlänge angepasst werden. Dazu ist zum Teil ein erheblicher Eingriff in die Programmlogik erforderlich. Weitere Probleme, die aus der Konvertierung resultieren, sollen an dieser Stelle nicht betrachtet werden. [IBM01, Uni11a] 30 in der DATEV eG verwendete EBCDIC-Codepage 31 mit DB-Anbindung über Static-Embedded-SQL (beispielsweise Anwendungen in C++, Cobol oder Assembler) 64 7 Überführungskonzepte für nicht-native XML-Speicherformen Die Problematik, die sich in diesem Zusammenhang für die XML-Migration ergibt, ist bereits angedeutet worden. Da DB2 native XML-Dokumente stets im Encoding-Schema UTF-8 abspeichert, konvertiert es implizit alle nicht-nativen XML-Dokumente in diesen Zeichensatz. Dies gilt speziell auch für EBCDIC-Dokumente. In diesem Fall ist vor der Überführung zwingend die Kompatibilität der Projektanwendungen zu prüfen. Nur wenn dabei keine Probleme festgestellt werden, kann eine Migration der nicht-nativen XML-Dokumente stattfinden. Ansonsten müssen die Projektanwendungen vor oder parallel zum XML-Überführungsprozess an die Verarbeitung von Unicode-Daten angepasst werden. 7.2.3 Ungültige Zeichen im Quelldokument In Anlehnung an die im vorangehenden Abschnitt diskutierte Herausforderung ergibt sich durch die implizite Konvertierung des Encoding-Schemas eine weitere Schwierigkeit. Da der EBCDIC-Zeichensatz nur sehr wenige Sonderzeichen umfasst, interpretiert er alle darüber hinausgehenden Zeichen als ungültig. Sollte ein einzufügendes Dokument solche Zeichen enthalten, werden sie durch den Substitution-Character32 ersetzt, wobei die eigentlich kodierten Informationen verloren gehen. Dies kann insbesondere auch für nicht-native XML-Dokumente der Fall sein und wurde in der DATEV vereinzelt innerhalb der nicht-nativen XML-Daten des Testsystems festgestellt. Aus dem Vorhandensein dieser Substitution-Character ergibt sich für das während des XML-Überführungsprozesses notwendige Parsen ein Problem. Der XMLParser des DB2 akzeptiert Substitution-Character im Quelldokument nicht. Damit davon betroffene nicht-native XML-Dokumente von der Migration nicht ausgeschlossen sind, müssen die darin enthaltenen nicht verarbeitbaren Zeichen durch gültige Ausdrücke ersetzt werden. DB2 sieht dazu aktuell noch keine Möglichkeiten vor. Das Problem wurde jedoch bereits an das zuständige IBM-Labor übermittelt. Dort ist eine Lösung in Planung, die ungültige Zeichen während des XML-Parse-Prozesses durch einen per zParm definierten Character ersetzt. Für diesen Parameter wäre beispielsweise ein Leerzeichen oder ein Unterstrich (siehe Abbildung 27) denkbar. 32 EBCDIC Substitution-Character „3F“ (Hexadezimal-Darstellung) beziehungsweise „□“ (Zeichen) 65 7 Überführungskonzepte für nicht-native XML-Speicherformen <Preis Währung="Euro" Symbol="□">388</Preis> <Preis Währung="Euro" Symbol="_">388</Preis> Abbildung 27: Ersetzung ungültiger Zeichen 7.2.4 „Record Size“-Limit bei der Konkatenation von VARCHARs In Abschnitt 4.1.2 und Abschnitt 4.3 wurde bereits erwähnt, dass jedes Tupel einer Tabelle beziehungsweise die Ausprägung einer einzelnen Spalte eines Inline-Datentyps die maximal zulässige Record Size nicht überschreiten kann. Dies gilt insbesondere auch für Tabellen, die innerhalb von SQL-Abarbeitungen als Zwischenergebnisse erzeugt werden. Für die Migration von verteilten nicht-nativen XML-Dokumenten sind zusätzliche Logiken zu deren Konkatenation notwendig (siehe Abschnitt 7.1.4). Eine effiziente Variante dies zu realisieren liegt in der Verwendung von Recursive SQL. Die Rekursion muss dabei so gestaltet sein, dass in mehreren Schritten das bisherige Resultat der Konkatenation um jeweils ein XMLTeilstück erweitert wird. Dieser Prozess endet, sobald das gesamte Dokument zusammengefügt ist. Die Zwischenergebnisse der Rekursion sind dabei stets Tabellen, die den oben beschriebenen Einschränkungen unterliegen. Im Fall der Überführung von nicht-nativen XML-Dokumenten in Form von VARCHARs ergibt sich für den rekursiven Ansatz ein Problem. Aufgrund der InlineBeschaffenheit der VARCHAR-Datentypen wachsen die Tupel der Zwischenergebnisse immer weiter an. Wird dabei die maximale Record Size überschritten, bricht der Vorgang ab. Das ist jedoch allgemein der Fall, da sich die Verteilung der XML-Dokumente aus eben diesem Zusammenhang ergibt (siehe Abschnitt 4.3). Verteilte nicht-nativ als VARCHAR abgelegte XML-Dokumente lassen sich rekursiv somit nicht zusammenführen. Abbildung 28 veranschaulicht die Problematik. [IBM11a] 66 7 Überführungskonzepte für nicht-native XML-Speicherformen Zwischenergebnis Rekursionsschritt Teilschlüssel LFDNR … 1 … 1 … <customerinfo id="100 1"><name>Mustermann</ 2 … 2 … <customerinfo id="1001"><name>Mustermann</ name><phone type="work">408-555-1358</phon nnXML Abbildung 28: „Record Size“-Limit bei der Konkatenation von VARCHARs Eine Alternative zu dem zuvor beschriebenen Vorgehen liegt in der Konkatenation per Stored Procedure. Mit deren Hilfe ist es möglich, über eine Schleife alle Teilstücke der Dokumente innerhalb einer 2 GB großen CLOB-Variable zu verknüpfen und anschließend den weiteren Überführungsprozess durchzuführen. Näheres zur konkreten Umsetzung einer solchen Prozedur ist in Abschnitt 8.2.4 zu finden. Im Fall der nicht-nativen XML-Ablage als CLOB tritt das beschriebene Konkatenationsproblem des rekursiven Ansatzes nicht auf. Da ein CLOB ein Outline-Datentyp ist (siehe Abschnitt 4.2.3), wird er stets außerhalb der Ausgangstabelle verwaltet. Bei einer rekursiven CLOB-Konkatenation bleibt somit die tatsächliche (Inline-) Größe eines jeden Tupels der Zwischenergebnistabelle stets konstant innerhalb der maximal zulässigen Record Size (siehe Abbildung 29). Zwischenergebnis Rekursionsschritt 1 2 3 TeilLFDNR schlüssel … … … 1 2 3 … nnXML … <customerinfo id="100 1"><name>Mustermann</ … <customerinfo id="100 1"><name>Mustermann</ name><phone type="wor k">408-555-1358</phon … <customerinfo id="100 1"><name>Mustermann</ name><phone type="wor k">408-555-1358</phon e></customerinfo> Abbildung 29: Konkatenation von CLOBs An dieser Stelle liegt der Ansatz nahe, verteilte nicht-nativ als VARCHAR gespeicherte XMLDokumente über vorangehende CLOB-Casts dennoch rekursiv verknüpfen zu können. Die 67 7 Überführungskonzepte für nicht-native XML-Speicherformen Abarbeitung würde aber auch in einem solchen Fall weiterhin inline stattfinden, weshalb eine auf Stored Procedure basierende Lösung notwendig bleibt. 7.2.5 Entfallende laufende Nummer Damit verteilte nicht-native XML-Dokumente wieder in der korrekten Reihenfolge zusammengefügt werden können, muss die Position der einzelnen Teile im Originaldokument bekannt sein. Diese wird in Form einer zusätzlichen Spalte LFDNR in der Ausgangstabelle mitgeführt (siehe Abschnitt 4.3). Nachdem verteilte XML-Dokumente durch den Migrationsprozess zusammengefügt und in den nativen XML-Datentyp migriert wurden, ist die Positionsinformation der einzelnen Teile überflüssig. Die laufende Nummer entfällt somit als Spalte der Zieltabelle. Abbildung 30 veranschaulicht dieses Szenario. Teilschlüssel LFDNR … nnXML Primärschlüssel … XML … … … … … … … Abbildung 30: entfallende laufende Nummer Der Wegfall der LFDNR-Spalte ist jedoch nicht transparent gegenüber den Projektanwendungen. Ohne dass eine dortige Anpassung erfolgt, würde weiterhin versucht werden, alle einem XML-Dokument zugehörigen Teile in Abhängigkeit der laufenden Nummer zusammenzufügen. Wenn die Spalte LFDNR aber nicht mehr existiert, schlägt dieses Vorgehen stets fehl. Um das zu vermeiden, bieten sich verschiedene Möglichkeiten an. Im Normalfall sollte es möglich sein, die Projektanwendungen im Zuge einer XML-Migration so anzupassen, dass die dortige Konkatenationslogik entfernt wird. Dieses Vorgehen sieht auch der in Kapitel 8 beschriebene Prototyp vor. Sollte die Transparenz zur Anwendung jedoch absolute Priorität haben, muss die LFDNR-Spalte in der Zieltabelle weiterhin mitgeführt und für alle Tupel mit „1“ gefüllt werden. Als dritte Variante wäre auch eine weitere Möglichkeit denkbar. Sämtliche Views über der Zieltabelle könnten so definiert werden, dass sie diese um die LFDNR-Spalte mit dem fixen Wert „1“ ergänzen. Die Zugriffe durch die Projektanwendungen würden dann weiterhin eine laufende Nummer vorfinden und alle Teile – in diesem Fall stets genau ein Teil – des XML-Dokuments miteinander konkatenieren. 68 7 Überführungskonzepte für nicht-native XML-Speicherformen 7.3 Fazit An dieser Stelle sollen die Ergebnisse der zuvor betrachteten Abschnitte zusammengefasst werden. Für die differenzierten Ansätze ist dabei ein kurzes Fazit zu dem jeweils zu wählenden Vorgehen gegeben. Die identifizierten Herausforderungen sind bezüglich ihrer Lösbarkeit beurteilt. Differenzierte Ansätze: Möglichkeit zum Fallback muss gegeben sein Fehlertoleranz bezüglich ungültiger Quelldokumente ist erforderlich Offline-Migration vs. Online-Migration Offline für Produktionsdaten Online innerhalb Testumgebung einzeilige vs. verteilte nicht-native XML-Dokumente „It depends“ anwendungsseitige vs. datenbankseitige Migrationsprozesse datenbankseitige Migrationprozesse: Performance! Herausforderungen: vorangehende Leerzeichen im Quelldokument implizite Konvertierung: EBCDIC zu Unicode ungültige Zeichen im Quelldokument „Record Size“-Limit bei der Konkatenation von VARCHARs entfallende laufende Nummer gelöst zu beachten (noch) fehlende Lösung Aus den Ergebnissen der untersuchten Ansätze lassen sich zwei grundlegende Konzepte ableiten: zum einen die Offline-Migration und zum anderen die Online-Migration. Für alle weiteren Aspekte existiert, sofern ein Einfluss darauf möglich ist, stets eine zu präferenzierende Variante. 69 8 Prototyp: XML-Migrator 8 Prototyp: XML-Migrator Der XML-Migrator ist ein Prototyp, der die Überführung von nicht-nativen zu nativen XMLDokumenten anhand der zuvor in Kapitel 7 erarbeiteten Überführungskonzepte in DB2 realisiert. Dabei handelt es sich um eine Java-Anwendung, die im IBM Data Studio entwickelt wurde. Weitere Informationen zu diesem Tool sind in Abschnitt 3.3 zu finden. Der XMLMigrator benutzt eine per JDBC-Treiber Type 4 bereitgestellte Schnittstelle zu DB2. In seiner Architektur setzt der Prototyp aus Gründen der leichteren Verständlichkeit und einfacheren Wartbarkeit auf einem modifizierten Model-View-Controller (MVC)-Pattern [Eck07] auf. Dieses wird zusammen mit einer detaillierten Beschreibung der einzelnen Migrationphasen des Prototyps im weiteren Verlauf des Kapitels näher ausgeführt. 8.1 Architektur – modifiziertes MVC-Pattern Wie bereits erwähnt, basiert die Architektur des XML-Migrators auf einem modifizierten MVCPattern. Bevor eine ausführlichere Betrachtung dieses konkreten Musters erfolgt, sollen die voneinander entkoppelten Komponenten der Architektur stichpunktartig erklärt werden. [Eck07] Model „Datenmodell“ repräsentiert Daten und Regeln Regeln dienen der Steuerung des Datenzugriffs und der Datenänderungen View „Darstellung“ rendert und präsentiert die Daten aus dem Model reagiert auf Änderungen am Model Controller „Steuerung“ verknüpft Model(s) und View(s) übersetzt Benutzerinteraktionen an der View stößt entsprechende Model-Funktionen an 70 8 Prototyp: XML-Migrator Projiziert man die Interaktionen der einzelnen Komponenten untereinander auf einen Graphen, dann existiert für die ursprüngliche Form des MVC-Patterns stets mindestens eine Kante zwischen je zwei Komponentenknoten. Die modifizierte Variante dieses Architekturmusters weicht davon ab. Hier besteht keine direkte Verbindung zwischen Model und View. Stattdessen ist der Controller für die Verknüpfung dieser zwei Komponenten zuständig. Sämtliche Interaktionen zwischen Model und View müssen durch den Controller hindurch kommuniziert werden. Daraus ergibt sich der Vorteil, dass sowohl das Model, als auch die View sehr einfach austauschbar sind. In beiden Fällen müsste lediglich der Controller an die veränderten Komponenten angepasst werden. Abbildung 31 zeigt das Design des modifizierten MVC-Patterns. [Eck07] Abbildung 31: modifiziertes MVC-Pattern [Eck07] Für den XML-Migrator wurde diese modifizierte Variante nochmals leicht abgewandelt. Der Prototyp steuert sich komplett über Zustände, die über den Controller zwischen Model und View ausgetauscht werden. Die Abfolgelogik, in der die einzelnen Zustände erreicht werden können, ist im Model verankert. Eine Ausnahme stellen dabei Verzweigungen dar, die durch Nutzereingaben realisiert werden. In dem Fall muss auch die View beziehungsweise der Controller Informationen über die möglichen anzustoßenden Folgeprozesse enthalten. Eine weitere Besonderheit in der Architektur des XML-Migrators liegt in den unterschiedlichen Kommunikationsrichtungen. Änderungen am Model, wie beispielsweise das Setzen der möglichen nicht-nativen XML-Spalten der Ausgangstabelle, gelangen in Form von Events direkt durch den Controller hindurch in die View. Für den umgekehrten Weg ist dies 71 8 Prototyp: XML-Migrator nicht der Fall. Nutzerinteraktionen an der View (beispielsweise das Bestätigen der Eingabe der zur Ausgangs- und Zieltabelle erforderlichen Daten) werden nur dann bis zum Model durchgeleitet, wenn eine entsprechende Funktionalität im Controller vorhanden ist. Damit soll verhindert werden, dass sich fehlerhafte View-Implementierungen auf die Daten im Model auswirken können. Die Datenbankanbindung ist im XML-Migrator vom Model entkoppelt. Dieses instanziiert lediglich einen DB2-Executer, der die zentrale Ausführung und Fehlerbehandlung von SQL-Anfragen übernimmt. Daraus ergibt sich der Vorteil, dass das Model auf die Daten und die zur Migration notwendigen Datenbankanfragen beschränkt ist und zusätzliche Prozesse von diesem separiert werden können. Im Detail übernimmt der DB2-Executer folgende Aufgaben: Bereitstellen der Datenbankverbindung zentrale Behandlung von Fehlern und Warnungen Ausführung von SQL-Statements direkte Rückgabe der Ergebniswerte von SELECT-Statements als String eindimensionales Array zweidimensionales Array Abbildung 32 liefert eine Übersicht zur Architektur des Prototyps. View Property or State Controller Property or State (Call) (Event) DB2 Executer Model DBMS DB Abbildung 32: XML-Migrator-Architektur 72 8 Prototyp: XML-Migrator 8.2 Migrationsphasen Die Migration durch den XML-Migrator erfolgt in einer seriellen Abarbeitungsfolge. Diese ergibt sich in verallgemeinerter Form aus Nutzereingaben, Vorverarbeitung, Überführung und Nachverarbeitung. Im Detail existiert jedoch eine umfangreichere Kette von einzelnen Migrationsphasen. Diese werden in den weiteren Abschnitten ausführlicher beschrieben. In Abhängigkeit von den umzusetzenden Überführungskonzepten ergeben sich in den verschiedenen Phasen zum Teil Unterschiede zwischen der Online- und der Offline-Migration (siehe Abschnitt 7.1.3). Im Rahmen der Online-Variante werden die Migrationsvorgänge direkt ausgeführt. Für die Offline-Migration ist dies nicht der Fall. Hier werden die einzelnen SQLStatements zu einem Skript gebündelt, das anstelle der direkten Ausführung dem Migrationsanwender präsentiert wird, um beispielsweise in größere Batch-Jobs eingebunden werden zu können. Zusätzlich müssen in den jeweiligen Migrationsphasen stets die beiden Ausgangssituationen (einzeilige beziehungsweise verteilte nicht-native XML-Dokumente) berücksichtigt werden (siehe Abschnitt 7.1.4). Auf die sich daraus ergebenen Besonderheiten wird ebenfalls eingegangen. 8.2.1 Input und Input-Handling In der ersten Phase des XML-Migrators erfolgen die Eingaben des Anwenders und deren Verarbeitung. In einer Dialogsteuerung wird der Nutzer aufgefordert, die folgenden Informationen anzugeben: Ausgangstabelle (inklusive Schemaname) Zieltabelle (inklusive Schemaname) nicht-native XML-Spalte der Ausgangstabelle native XML-Spalte der Zieltabelle eventuell vorhandene laufende Nummer (bei verteilten nicht-nativen XMLDokumenten) Die Strukturen der Zieltabelle werden dabei vom XML-Migrator nicht selbst erzeugt. Diese Aufgabe ist im Vorfeld der Migration durch den Datenbankadministrator durchzuführen. 73 8 Prototyp: XML-Migrator Der Grund dafür liegt in der Flexibilität33 der Modellierung, die in vollem Umfang nur durch die manuelle Erstellung der Zieltabelle gewährleistet werden kann. Eine Restriktion ist dabei jedoch vom Datenbankadministrator einzuhalten. Mit Ausnahme der XML-Spalte müssen alle weiteren Spalten der Zieltabelle, die ihr Pendant in der Ausgangstabelle haben, in ihren Schemainformationen unverändert übernommen werden. In diesem Zusammenhang ist es aber nicht erforderlich, alle Spalten der Ausgangstabelle in die Zieltabelle zu überführen. Sofern der Primärschlüssel davon nicht betroffen ist, können auch einzelne Spalten von der Migration in die Zieltabelle ausgeschlossen werden. Bei der LFDNR-Spalte ist dies auch unabhängig von der Primärschlüsseldefinition zulässig. Abhängig von dem gewählten Vorgehen (siehe Abschnitt 7.2.5) wird sie aufgrund der stattfindenden Konkatenation in der Zieltabelle nicht mehr mitgeführt. Denkbar wäre auch ein Szenario, in dem nicht-native XML-Dokumente aus verschiedenen Tabellen in eine gemeinsame Zieltabelle mit nativen XML-Spalten überführt werden. Dies wird jedoch in der aktuellen Version des Prototyps nicht unterstützt. Nachdem die Eingaben vom Benutzer bestätigt wurden, erfolgt im XML-Migrator ihre Validierung. Dabei werden unter anderem die folgenden Aspekte geprüft: Bezeichnung der Objekte (Tabellen, Spalten) Ausgangs- und Zieltabelle müssen verschiedene Tabellen sein Existenz der Tabellen Existenz eines Primärschlüssels Datentyp der nicht-nativen und der nativen XML-Spalte Datentyp der laufenden Nummer (LFDNR) Bei erfolgreicher Gültigkeitsprüfung erfolgt die Bestimmung des Primärschlüssels. Wie bereits angedeutet, ist dieser für die Ausgangs- und Zieltabelle identisch. Für den XML-Migrator genügt es daher, den Primärschlüssel der Ausgangstabelle zu ermitteln. Dazu dient eine gezielte Abfrage auf den Katalogtabellen SYSIBM.SYSTABCONST und SYSIBM.SYSKEYCOLUSE. [IBM11a] 33 Benennung der Zieltabelle, zugeordneter Tablespace, etc. 74 8 Prototyp: XML-Migrator 8.2.2 Preprocessing Im Anschluss an die Verarbeitung der Nutzereingaben erfolgt eine Reihe von Vorverarbeitungsprozessen. Darunter fallen im Wesentlichen die folgenden Aktionen: User-Defined Function LTRIMNNXML erstellen Lock Size ändern Fehlertabelle erstellen Trigger erstellen Während die Trigger aufgrund ihres Umfangs und ihrer Geschlossenheit erst im nächsten Abschnitt betrachtet werden, erfolgt an dieser Stelle die Abhandlung der übrigen Aktionen. Die LTRIMNNXML-Funktion dient dem Abschneiden von vorangehenden Leerzeichen im XML-Dokument. Da die Notwendigkeit des Vorgehens bereits in Abschnitt 7.2.1 aufgezeigt wurde, liegt der Fokus hier auf der Implementierung der User-Defined Function. Diese erwartet als INPUT ein CLOB-Dokument mit maximal möglicher Größe von 2 GB (siehe Abschnitt 4.2.3). VARCHARs können aber durch implizit stattfindende Casts ebenfalls als Eingabewerte benutzt werden. Das durch die User-Defined Function realisierte Abschneiden basiert auf zwei skalaren Funktionen des DB2: SUBSTR [IBM11a] und POSSTR [IBM11a]. Zuerst wird mit Hilfe der POSSTR-Funktion die Position der ersten Tag-Klammer („<“) des XMLDokuments ermittelt. Unter der Verwendung der SUBSTR-Funktion können anschließend alle vorangehenden Zeichen, insbesondere auch Leerzeichen, bis zu dieser Position entfernt werden. Das Resultat ist ein nicht-natives XML-Dokument, das nach der Definition der Wohlgeformtheit (siehe Abschnitt 3.1) stets mit einer öffnenden Tag-Klammer beginnt. Abbildung 33 zeigt die DDL-Anweisung zur Erstellung der LTRIMNNXML-Funktion. [IBM11a] CREATE FUNCTION ZielTabellenSchema.LTRIMNNXML(DOC CLOB(2G)) RETURNS CLOB(2G) RETURN SUBSTR(DOC, POSSTR(DOC, '<')); Abbildung 33: DDL-Anweisung der LTRIMNNXML-Funktion Die Änderung der Lock Size ist nur für die Variante der Online-Migration notwendig. Hierbei ist es wichtig, den Überführungsprozess so durchzuführen, dass parallel dazu stattfindende Zugriffe auf die Ausgangstabelle durch die Projektanwendungen möglich sind. In diesem Zusammenhang wurde in Abschnitt 7.1.3 bereits diskutiert, dass es sinnvoll ist, ein kleines 75 8 Prototyp: XML-Migrator Sperrgranulat für den Tablespace der Ausgangstabelle zu verwenden. In DB2 stellt die Lock Size „ROW“ das kleinstmögliche Sperrgranulat dar. Um dieses für den Tablespace der Ausgangstabelle zu definieren, genügt ein ALTER-TABLESPACE-Statement (siehe Abbildung 34). Zuvor müssen der Tablespace und die ihm übergeordnete Datenbank jedoch erst über den Katalog bestimmt werden. Um nach der Migration die ursprüngliche Lock Size wieder herstellen zu können, ist sie vor der Anpassung aus dem Datenbankkatalog auszulesen und in einer Variablen zwischenzuspeichern. Erst danach kann die Änderung erfolgen. Ist diese getätigt, muss fortan nur noch sichergestellt werden, dass keine Sperreskalation stattfindet. Diese würde ebenfalls den parallelen Zugriff auf die Ausgangstabelle unmöglich machen. Da der Migrationsprozess der Online-Variante aber so konzipiert ist, dass er die nicht-nativen XMLDokumente in einzelnen kurzen Transaktionen entweder dokumentweise oder in kleinen Blöcken in die Zieltabelle überführt (siehe Abschnitt 8.2.4), ist auch dies berücksichtigt. Hier sei jedoch angemerkt, dass sich die vorübergehende Änderung der Lock Size auf die Performance der Projektanwendungen auswirken kann. Um eventuell dahingehend aufkommende Problemen zu vermeiden, sollten im Vorfeld der Migration die Auswirkungen einer solchen Anpassung überprüft werden. In bestimmten Fällen kann es daher sinnvoll sein, im Rahmen der XML-Überführung von einer Änderung der Lock Size abzusehen. [IBM11a] ALTER TABLESPACE BasisDatenbank.BasisTablespace LOCKSIZE ROW; Abbildung 34: DDL-Anweisung der „Lock Size“-Anpassung Ein weiterer Vorverarbeitungsschritt, der nur für die Online-Migration durchzuführen ist, besteht in dem Erstellen der Fehlertabelle. Diese dient dem in Abschnitt 7.1.2 beschriebenen Vorgehen, fehlerhafte, nicht migrierbare Tupel kenntlich zu machen. Strukturell setzt sie sich aus der Primärschlüsselspalte/den Primärschlüsselspalten (siehe Abschnitt 8.2.1) und einer weiteren Spalte zusammen, die genutzt wird, um mögliche SQL-Fehler während der Migration auf Satzebene zu protokollieren (siehe Abbildung 35). Die Überführungsprozesse im XMLMigrator sind so gestaltet, dass sie nur XML-Dokumente aus der Ausgangstabelle migrieren, die nicht in der Fehlertabelle enthalten sind. Hierbei ist anzumerken, dass weder als fehlerhaft erkannte, noch erfolgreich überführte XML-Dokumente aus der Ausgangstabelle entfernt werden. Wegen der sicherzustellenden Fallbackmöglichkeit (siehe Abschnitt 7.1.1) bleiben diese dort stets in ihrer ursprünglichen Form enthalten. Nähere Details zur Einbettung der Fehlertabelle in den Migrationsprozess finden sich in Abschnitt 8.2.4. 76 8 Prototyp: XML-Migrator ZielTabelleERROR Identifikator-Spalten … SQLCODE Abbildung 35: Struktur der Fehlertabelle Die Variante der Offline-Migration verzichtet auf die Erstellung einer Fehlertabelle, da hier eine direkte Ausführung der Migration nicht vorgesehen ist. Der XML-Migrator erzeugt in diesem Fall nur ein Skript, das beispielsweise in spätere Batch-Prozesse eingebunden wird. Solche Batch-Abläufe werden durch separate Tools gesteuert, die eigene Fehlererkennungs- und Fehlerbehandlungsmaßnahmen vorweisen. Für die Offline-Migration ist eine zusätzliche Logik der „Fehlertoleranz“ daher nicht notwendig. 8.2.3 Build Trigger Um im Rahmen der Online-Migration (siehe Abschnitt 7.1.3) parallel zum Überführungsprozess stattfindende Datenmanipulationen an der Ausgangstabelle auf die Zieltabelle zu übertragen, verwendet der XML-Migrator Trigger. Diese werden vor der Datenmigration von dem Prototypen selbst erzeugt und in Abhängigkeit zur Ausgangstabelle benannt. Im Fall der OfflineMigration sind parallele Zugriffe auf die Ausgangstabelle ausgeschlossen, Trigger werden nicht benötigt. Die Ausführungen dieses Abschnitts gelten daher nur für die Variante der OnlineMigration. Da durch die Projektanwendungen in der Regel parallel sowohl INSERTs, UPDATEs als auch DELETEs ausgeführt werden können, müssen auch die Trigger für diese Fälle ausgelegt sein. In Abschnitt 7.1.4 wurde bereits darauf hingewiesen, dass für die Migration von verteilten nicht-nativen XML-Dokumenten kein INSERT-Trigger definierbar ist. In dem XMLMigrator ersetzt daher ein anwendungsseitiger Timer Task [Sun05], der durch einen zugehörigen Timer [Sun05] gesteuert wird, dessen Logik. Die nachfolgende Auflistung zeigt für die verschiedenen Ausgangssituationen die jeweils benötigten Objekte. 77 8 Prototyp: XML-Migrator einzeilige nicht-native XML- verteilte nicht-native XML- Dokumente Dokumente INSERT-Trigger Timer Task (+ Timer) UPDATE-Trigger (UPDATE-Trigger) DELETE-Trigger DELETE-Trigger In den weiteren Ausführungen werden die Besonderheiten der einzelnen Trigger beziehungsweise des Timer Task detailliert beschrieben. Für den UPDATE- und den DELETE-Trigger ergeben sich dabei keine neuen Aspekte. Diese agieren entsprechend ihrer Spezifika und setzen entweder UPDATEs oder DELETEs an den Dokumenten der Ausgangstabelle auf deren Gegenstücke in der Zieltabelle um. Die Besonderheiten, die sich dabei für die Verarbeitung von verteilten nicht-nativen XML-Dokumenten ergeben, sind bereits in Abschnitt 7.1.4 beschrieben worden. Der wesentlichste Unterschied in den gegenübergestellten Situationen ergibt sich für die Behandlung von parallel durchgeführten INSERTs durch die Projektanwendungen. Für einzeilige nicht-native XML-Dokumente ist eine per INSERT-Trigger gesteuerte Überführungslogik realisierbar. Bei verteilten Dokumenten ist dies nicht möglich (siehe Abschnitt 7.1.4). Damit sichergestellt wird, dass parallel eingefügte, verteilte Dokumente trotzdem migriert werden, dient im XML-Migrator ein Timer Task. Dieser wird periodisch durch einen Timer in einem zuvor definierten Abstand ausgeführt. Dabei prüft er die Ausgangstabelle auf neu eingefügte Dokumente, die noch nicht in die Zieltabelle überführt wurden. Um diese zu finden, erfolgt anhand der Primärschlüssel ein Abgleich der Tupel der Ausgangs- mit denen der Zieltabelle. Sollte sich dabei herausstellen, dass parallele INSERTs stattgefunden haben, werden die davon betroffenen Tupel in die Zieltabelle überführt. Auf damit verbundene Prozesse wie beispielsweise die Konkatenation der einzelnen Teilstücke wird an dieser Stelle nicht weiter eingegangen. Stattdessen soll der Vorgang des gewählten Abgleichs ausführlicher betrachtet werden. Im aktuellen Prototyp ist dieser Prozess analog zum Kopiervorgang (siehe Abschnitt 8.2.4) so ausgelegt, dass er bei entsprechend großer Anzahl von Tupeln enorm aufwendig werden kann. Zwar findet pro Aktivierung des Timer Task nur ein einzelner Abgleich statt, dennoch müssen dazu sämtliche Tupel34 der Ausgangs- und Zieltabelle miteinander in Beziehung gesetzt werden, damit noch nicht überführte Dokumente gefunden werden können. Um diesen Vorgang effizienter zu gestalten, wäre es für eine zukünftige Umsetzung des XML-Migrators denkbar, 34 Der Vergleich findet allerdings auf der Ebene von Indexeinträgen statt. 78 8 Prototyp: XML-Migrator die parallel eingefügten Tupel automatisiert zwischenzuspeichern. Dies könnte beispielsweise durch einen einfachen INSERT-Trigger in einer separaten Tabelle erfolgen, sodass sich durch den Timer Task ohne aufwendige Abgleichsprozesse gezielt die fehlenden Dokumente überführen ließen. [Sun05] 8.2.4 Copy Data In dieser zentralen Phase wird der tatsächliche Migrationsvorgang der Daten realisiert. Er findet im Rahmen der Online-Migration durch den Prototyp selbst statt. Für die Offline-Variante der Migration erzeugt der XML-Migrator lediglich ein SQL-Skript, das beispielsweise in BatchAbläufe eingebunden werden kann. Dieses umfasst nur einen Teil der vorgestellten Logik, da viele Aspekte – beispielsweise die Verwendung von Triggern (siehe Abschnitt 8.2.3) – nur im Rahmen der Online-Migration von Relevanz sind. Folgende Vorgänge werden in angegebener Reihenfolge in das vom XML-Migrator erzeugte Skript einbezogen: User-Defined-Function LTRIMNNXML erstellen Überführung der (noch nicht migrierten) Daten inklusive Konkatenation (bei verteilten nicht-nativen XML-Dokumenten) Abschneiden etwaiger vorangehender Leerzeichen (mit LTRIMNNXMLFunktion) Parsen der Dokumente mit der XMLPARSE-Funktion [IBM11a] User-Defined-Function LTRIMNNXML entfernen Das Grundprinzip der Überführung der nicht-nativen XML-Dokumente in die native Speicherform ist für die Online- und Offline-Migration gleich. Es sieht vor, dass die Daten von der Ausgangstabelle nicht in die Zieltabelle verschoben, sondern stets Kopien der Dokumente verarbeitet werden. Die Daten der Ausgangstabelle bleiben zum Erhalt der Fallbackmöglichkeit (siehe Abschnitt 7.1.1) unverändert. Im weiteren Verlauf wird der Überführungsprozess daher auch als Kopiervorgang bezeichnet. Dieser folgt einem festen Muster. Nur Tupel, die in der Ausgangs-, aber nicht in der Ziel- und nicht in der Fehlertabelle sind, werden in die Zieltabelle überführt. Kommt es dabei zu einem Fehler, dann wird der Primärschlüssel (siehe Abschnitt 8.2.2) des davon betroffenen Tupels zusammen mit dem auftretenden SQLCODE [IBM08c] in die Fehlertabelle kopiert. Stößt der Prozess auf eine Warnung, dass keine Tupel mehr zu überführen sind, dann endet der Kopiervorgang. Die erwähnte Abhandlung der Fehlerfälle ist nur 79 8 Prototyp: XML-Migrator Teil der Online-Migration (siehe Abschnitt 8.2.2). Die folgenden aufeinander aufbauenden Beispielfälle veranschaulichen das geschilderte Vorgehen. Abbildung 36 zeigt die Ausgangssituation der Beispielsequenz. In der Ausgangstabelle befindet sich ein gültiges und ein ungültiges nicht-natives XML-Dokument. Die Fehler- und die Zieltabelle beinhalten keine Elemente. Ausgangssituation Fehlertabelle nnXML nnXML Quelltabelle Zieltabelle Abbildung 36: Ausgangssituation Im ersten Schritt erfolgt die Migration des gültigen Dokuments. Dieser Prozess wird erfolgreich ausgeführt, sodass sich in dessen Ergebnis (siehe Abbildung 37) das gültige XML-Dokument sowohl in der Ausgangstabelle als auch in migrierter nativer Form in der Zieltabelle befindet. Es wird somit von dem weiteren Überführungsprozess nicht mehr berücksichtigt. Schritt 1 Fehlertabelle nnXML nnXML nnXML ✓ Quelltabelle Zieltabelle Abbildung 37: erfolgreicher Kopiervorgang Als nächstes wird in Schritt 2 versucht das ungültige XML-Dokument zu migrieren. Dabei kommt es aber beispielsweise während des stattfindenden Parse-Prozesses zu einem Fehler (siehe Abbildung 38). Aus diesem Grund wird der Primärschlüssel des Dokuments zusammen mit dem auftretenden SQLCODE in die Fehlertabelle kopiert. 80 8 Prototyp: XML-Migrator Schritt 2 nnXML Fehlertabelle nnXML nnXML nnXML X Quelltabelle Zieltabelle Abbildung 38: fehlerhafter Kopiervorgang Im Anschluss an Schritt 2 befinden sich alle Dokumente der Ausgangstabelle vereinfacht gesprochen entweder in der Ziel- oder in der Fehlertabelle. Der Migrationsprozess erhält daher eine Warnung, dass keine weiteren Tupel zu überführen sind und beendet dementsprechend den Kopiervorgang in Schritt 3 (siehe Abbildung 39). Schritt 3 nnXML Fehlertabelle nnXML nnXML Quelltabelle nnXML Kopiervorgang endet Zieltabelle Abbildung 39: Abschluss des Kopiervorgangs Bei diesem Migrationsvorgehen müssen stets die Tupel, die in der Ausgangs- aber nicht in der Ziel- und nicht in der Fehlertabelle enthalten sind, identifiziert werden. Dazu dient in dem aktuellen Prototypen, ähnlich wie bei dem im vorangehenden Abschnitt betrachteten Timer Task, ein Abgleich der Tupel aus den betroffenen Tabellen anhand ihres Primärschlüssels. Dieser wird speziell im Fall der Online-Migration mehrfach verwendet und kann daher bei einer entsprechenden Vielzahl von Dokumenten sehr aufwendig sein. Um sich daraus ergebende Performance-Einbußen zu vermeiden, müssten separat Informationen zu den noch zu migrierenden Tupeln gepflegt werden. Anhand dieser Daten wäre dann ein gezielter Überführungsprozess ohne erforderliche Tabellenabgleiche möglich. Da die durch den Prototyp realisierte Online-Migration in ihrer aktuellen Form aber den Anforderungen an diese Migrationsvariante genügt, ist von einer tiefergehenden Betrachtung der Problematik abgesehen worden. 81 8 Prototyp: XML-Migrator Im Detail ergeben sich aber nicht nur aus der Migrationsform Unterschiede für den Kopiervorgang. Die Beschaffenheit der nicht-nativen XML-Dokumente hat ebenfalls einen erheblichen Einfluss auf dessen Gestaltung. Der XML-Migrator unterscheidet daher zwischen den in Abbildung 40 dargestellten Fällen, die in den weiteren Ausführungen näher beschrieben werden. nicht-native XML-Dokumente einzeilig als VARCHAR oder CLOB verteilt als VARCHAR als CLOB Abbildung 40: Fallunterscheidung für den Kopiervorgang Der einfachste Fall der Migration besteht in der Überführung von einzeiligen nicht-nativen XML-Dokumenten. Dabei ist innerhalb des Kopiervorganges keine Konkatenationslogik erforderlich. Ein mittels der LTRIMNNXML-Funktion realisiertes Abschneiden etwaiger vorangehender Leerzeichen und ein anschließendes Parsen genügen dem Überführungsprozess. Auch der Unterschied zwischen nicht-nativen XML-Dokumenten als VARCHAR oder CLOB ist hierbei irrelevant. Während die Offline-Variante der Migration für die gesamte Überführung von einzeiligen XML-Dokumenten genau eine Transaktion vorsieht, ist dies für die OnlineMigration aus Gründen der zu gewährleistenden Parallelität nicht der Fall. Hier überführt der XML-Migrator in einzelnen Transaktionen blockweise alle einzeiligen nicht-nativen XMLDokumente in die native Struktur. Das heißt, mehrere Dokumente werden zu kleinen Blöcken gebündelt und diese innerhalb einer gemeinsamen kurzen Transaktion in die Zieltabelle migriert. Das Risiko einer möglichen Sperreskalation wird dadurch verhindert (siehe Abschnitt 8.2.2). Die Behandlung von verteilten nicht-nativen XML-Dokumenten ist komplexer. Als CLOB verteilt abgelegte XML-Dokumente werden durch Recursive SQL konkateniert und anschließend wie einzeilige Dokumente überführt. Um in DB2 rekursive Statements nutzen zu können, wird zwingend eine Common Table Expression [IBM04d] benötigt. Diese ermöglicht es, ähnlich zu einer View, eine bestimmte SELECT-Anfrage oder die Vereinigung (UNION) von verschiedenen SELECT-Anfragen vorzudefinieren. Das Ergebnis lässt sich anschließend innerhalb des weiteren Statements wie eine Tabelle referenzieren. Eine Common Table Expression kann dabei auch auf sich selbst verweisen, wodurch ein rekursives Vorgehen 82 8 Prototyp: XML-Migrator ermöglicht wird. Auf zusätzliche Details zur Funktionsweise von rekursivem SQL sei an dieser Stelle verzichtet und auf [IBM04d] verwiesen. Während der Rekursion wird pro Schritt stets ein Teilstück zu dem bisherigen Zwischenresultat hinzugefügt und als neues Tupel in das Ergebnis der Common Table Expression aufgenommen (siehe Abbildung 29). Wenn kein weiteres Teilstück gefunden wird, endet die Rekursion mit dem dann komplett zusammengefügten nichtnativen XML-Dokument. Daraufhin erfolgt die weitere Verarbeitung wie für einzeilige Dokumente. Auf diese Weise lässt sich der gesamte Migrationsprozess für die Offline-Variante auf ein Statement reduzieren, das innerhalb einer einzigen Transaktion ausgeführt wird. Bei der Online-Migration ist aufgrund der möglichen Vielzahl an Teilstücken für jedes verteilte, als CLOB abgelegte XML-Dokument eine separate Transaktion vorgesehen. Für die Überführung von verteilten nicht-nativ als VARCHAR gespeicherten XMLDokumenten kann rekursives SQL nicht zur Migration verwendet werden (siehe Abschnitt 7.2.4). Der XML-Migrator führt den Kopiervorgang in einem solchen Fall mit Hilfe von vorher zu erstellenden Stored Procedures durch. Diese unterscheiden sich nur bezüglich des Konkatenationsprozesses von dem rekursiven Ansatz. Über eine Schleife werden alle Teilstücke eines Dokuments innerhalb einer CLOB-Variable mit maximal zulässiger Größe von 2 GB zusammen konkateniert. Hierbei ist darauf zu achten, dass die Variable mit der gleichen CCSID deklariert wird, mit der auch die Daten der Ausgangstabelle gespeichert sind. Grund dafür ist, dass bei unterschiedlichen zu verarbeitenden Zeichensätzen zahlreiche implizite Konvertierungsprozesse stattfinden würden. Diese benötigen Speicherplatz und können dazu führen, dass das Zusammenfügen der Teilstücke aus Ressourcenmangel abgebrochen wird. Nach der Konkatenation findet die weitere Überführung analog zur Migration von einzeiligen nichtnativen XML-Dokumenten statt. Im Fall der Offline-Migration sorgt eine zusätzliche Stored Procedure dafür, dass die Migrationsprozedur für jedes einzelne nicht-nativ gespeicherte XMLDokument der Ausgangstabelle ausgeführt wird. Die Offline-Migration findet somit innerhalb einer Transaktion statt. Bezüglich der Online-Migration wird durch den XML-Migrator für jedes verteilte Dokument ein separater Aufruf (CALL) der Migrationsprozedur ausgeführt. Jeder dieser Aufrufe erfolgt innerhalb einer eigenen, kurzen Transaktion. 8.2.5 Switch View Die Überführung der nicht-nativen XML-Dokumente wird nicht innerhalb der Ausgangstabelle sondern durch das Migrieren in eine separate (Ziel-)Tabelle realisiert (siehe Abschnitt 7.1.1). Daher arbeiten vorerst auch nach Abschluss des Kopiervorgangs sämtliche Projektanwendungen 83 8 Prototyp: XML-Migrator auf den nicht-nativen Daten. Bereits in Abschnitt 3.5 wurde aufgezeigt, dass in der DATEV keine direkten Tabellenzugriffe erfolgen. Stattdessen ist auf jeder Tabelle eine beliebige Anzahl von Views definiert, über die die Zugriffe auf die Daten realisiert werden. Um die Projektanwendungen auf die Verwendung der Zieltabellen umzustellen, genügt somit eine Anpassung dieser Sichten. DB2 erlaubt die Änderung (quasi „Umsetzung“) bestehender Views nicht. Diese müssen daher zuerst entfernt und anschließend auf modifizierte Art neu erstellt werden. Der XMLMigrator ist aus Komplexitätsgründen nicht dazu ausgelegt, diese Aktionen selbst auszuführen. Da die Sichten zwischenzeitlich zu entfernen sind, müssten sämtliche Rechte, die sich auf ihnen befinden, ausgelesen und nach dem Neuerstellen wieder vergeben werden. Dieser Aufwand erhöht sich nochmals durch den Fakt, dass auf den Views auch andere Views aufgesetzt sein können. Da in der Datenbankadministration der DATEV Tools vorhanden sind, die diesen Anforderungen gerecht werden, verweist der XML-Migrator für die Online-Migration lediglich auf die durchzuführenden Aktionen. Bezüglich der Offline-Migration ist es die Aufgabe des Datenbankadministrators, die Umsetzung der Views in das resultierende Skript einzupflegen. [IBM11a] In Abhängigkeit der vorhandenen Trigger-Objekte (siehe Abschnitt 8.2.3) muss die Umsetzung der Views unterschiedlich erfolgen. Für die Überführung von einzeiligen nichtnativen XML-Dokumenten lassen sich datenbankseitig sowohl INSERT-, UPDATE- als auch DELETE-Trigger definieren. Solange diese auf der Ausgangstabelle vorhanden sind, werden alle parallelen Änderungen in die Zieltabelle übertragen. Sollte der Kopiervorgang (siehe Abschnitt 8.2.4) abgeschlossen sein, erfolgt durch den XML-Migrator eine Meldung, die auf die vorzunehmende Umsetzung der Views von der Ausgangs- auf die Zieltabelle hinweist. Das damit verbundene Entfernen und Neuerzeugen kann vom Datenbankadministrator direkt nacheinander ausgeführt werden. Bis er dies erledigt hat, arbeiten weiterhin die Trigger und beugen somit möglichen Inkonsistenzen zwischen Ausgangs- und Zieltabelle vor. In Abschnitt 8.2.3 wurde aufgezeigt, dass für verteilte nicht-native XML-Dokumente kein INSERT-Trigger definierbar ist. Ein anwendungsseitiger Timer Task, gekoppelt an einen zugehörigen Timer, übernimmt dessen Aufgabe. Dieser ist jedoch nicht in der Lage, parallele Einfügungen direkt in die Zieltabelle zu übertragen. Stattdessen wird der Prozess erst nach der darauffolgenden Ausführung des Timer Task initiiert. Diese erfolgt durch den Timer in einem vordefinierten, periodischen Abstand, was in Bezug zur Umsetzung der View berücksichtigt werden muss. Sie darf nur dann durchgeführt werden, wenn die Ausgangs- und Zieltabelle konsistent zueinander sind. Damit dies im Fall der parallelen Einfügungen gewährleistet werden kann, muss zwischen dem Entfernen und dem Neuerstellen der Views eine abschließende 84 8 Prototyp: XML-Migrator Ausführung des Timer Task stattfinden. Hierbei werden letztmalig alle Tupel, die neu in die Ausgangstabelle eingefügt wurden, nachträglich in die Zieltabelle migriert. Da zu diesem Zeitpunkt keine Views mehr auf der Tabelle existieren, können keine weiteren parallelen Manipulationen an der Ausgangstabelle durch die Projektanwendungen ausgeführt werden. Die damit zusätzlich verbundene Nicht-Verfügbarkeit der Daten kann aufgrund der Kürze des Zeitraums toleriert werden. Entsprechend dieses Vorgehens wird der Datenbankadministrator eingangs aufgefordert, die Views der Ausgangstabelle lediglich zu entfernen. Erst nach der Abarbeitung des Timer Task sind diese von ihm modifiziert wieder zu erstellen. [Sun05] An dieser Stelle sei nochmals auf die Problematik der entfallenden laufenden Nummer hingewiesen (siehe Abschnitt 7.2.5). Je nach Erforderlichkeit einer Anpassung der Anwendung stellt die Phase der View-Umsetzung dafür eine geeignete Gelegenheit dar. 8.2.6 Postprocessing Die letzte Phase der Migration dient ausschließlich der Nachbereitung. Alle an der Ausgangstabelle vorgenommenen Anpassungen sind im Sinn der Fallbackmöglichkeiten (siehe Abschnitt 7.1.1) auf ihren Ursprungszustand zurückzusetzen. Im Einzelnen werden dabei für die Form der Online-Migration folgende Aktionen durchgeführt: Trigger entfernen INSERT-Trigger (sofern existent, siehe Abschnitt 8.2.3) UPDATE-Trigger DELETE-Trigger Lock Size zurücksetzen User-Defined Function LTRIMNNXML entfernen Da für die Offline-Migration keine Trigger benötigt werden und auch die Lock Size nicht anzupassen ist, muss lediglich das Entfernen der LTRIMNNXML-Funktion in das zu generierende Offline-Skript aufgenommen werden (siehe Abschnitt 8.2.4). Zusätzlich zu den aufgeführten Nachverarbeitungen ist in dieser Phase unabhängig von der Migrationsvariante noch eine Reorganisation (REORG) und eine anschließende Aktualisierung der Statistiken (RUNSTATS [IBM08b]) durchzuführen. Für die Offline-Migration existieren im Zusammenhang mit dem Steuerungssystem der Batch-Jobs eigene Mechanismen zur Ausführung dieser Prozesse, sodass der XML-Migrator an der entsprechenden Stelle auf deren 85 8 Prototyp: XML-Migrator Ausführung verweist. Im Fall der Online-Variante wird sowohl der REORG, als auch der RUNSTATS durch einen entsprechenden Aufruf (CALL) der Stored Procedure DSNUTILS initiiert. Dazu werden als Parameter eine selbst zu wählende Utility-ID, das auszuführende Utility-Statement, der Utility-Name, eine Variable, in die der RETURN CODE gespeichert wird, und im Fall des REORGs auch der Name eines Data-Sets benötigt, das dem Zwischenspeichern der zu reorganisierenden Daten dient. Die DSNUTILS-Prozedur umfasst noch zusätzliche (Input-)Parameter, die hier nicht weiter betrachtet werden sollen. Ein Stored-ProcedureAufruf muss stets voll-parametrisiert erfolgen. Daher sind alle nicht benötigten Parameter entsprechend des erwarteten Typs als Leerstring ('') oder „0“ zu setzen. [IBM11h] Um den Aufruf der DSNUTILS-Prozedur mit Übergabe der nötigen Parameter per JDBC-Treiber zu ermöglichen, lässt sich dieser beispielsweise innerhalb einer weiteren Prozedur verschachteln. Die zusätzliche Prozedur übernimmt dabei die Aufruffunktion mit fixen, zuvor definierten Parametern, die nicht weiter vorverarbeitet werden müssen. Dieser Ansatz wird aufgrund seiner Kompaktheit von dem XML-Migrator verfolgt, sodass er für die CALLs des REORG- und des RUNSTATS-Prozesses separate Stored-Procedures erzeugt. Abbildung 41 zeigt am Beispiel der REORG-Prozedur die dazu notwendige DDL-Anweisung. CREATE PROCEDURE ZielTabelleREORG() LANGUAGE SQL BEGIN DECLARE RC INT; CALL DSNUTILS( 'myReorgUtility', '', 'REORG TABLESPACE ZielDatenbank.ZielTablespace', RC, 'REORG TABLESPACE', 'myDataSet', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0, '', '', 0 ); END; Abbildung 41: DDL-Anweisung der REORG-Prozedur 86 9 Schlussbetrachtung 9 Schlussbetrachtung Bevor die native XML-Speicherung durch die pureXML-Technologie eingeführt wurde, existierten in DB2 zahlreiche Wege, XML-Dokumente abzulegen. Keiner davon entsprach jedoch einer optimalen Lösung, sodass sich über die Zeit hinweg dort eine heterogene nicht-native XMLLandschaft entwickelte. In der DATEV reduzieren sich die Ablageformen auf eine VARCHARund eine CLOB-basierte Speicherung mit einer möglichen Verteilung der Dokumente über mehrere Tupel. Diese Speicherformen wurden in der vorliegenden Ausarbeitung detailliert untersucht und den neuen nativen XML-Strukturen in DB2 gegenübergestellt. Die sich aus der nativen Speicherstruktur ergebenden Vorteile sind vielfältig. Sofern bestehende, XMLverarbeitende Projektanwendungen von den neuen, in DB2 integrierten XML-Funktionalitäten profitieren können, ist es daher ratsam deren Daten an den nativen Datentyp anzupassen. Anhand diverser relevanter Aspekte sind in dieser Arbeit Konzepte aufgezeigt worden, mit deren Hilfe eine Überführung von nicht-nativen XML-Dokumenten zu nativen in DB2 realisiert werden kann. Der beschriebene XML-Migrator zeigt prototypisch die Durchführbarkeit dieses Prozesses, wenngleich er noch Optimierungspotential bietet. Dahingehend ließe sich die Performance durch weiterführendes Tuning der verwendeten SQL-Statements verbessern. Im speziellen Fall der Online-Migration ergibt sich durch mehrfach notwendige Tabellenabgleiche eine, abhängig zur Menge von zu migrierenden Daten, wachsende Ineffizienz (siehe Abschnitt 8.2.4). Auch die Kommunikation zwischen Datenbank und Anwendung könnte durch die Bündelung von DDL-Statements zu kleinen Batch-Ausführungen optimiert werden. Funktional ist eine bereits in Abschnitt 8.2.1 angedeutete Erweiterung denkbar, die es ermöglicht, nicht-native XML-Dokumente verschiedener Tabellen in eine Zieltabelle zu migrieren. Den nächsten Schritt im Rahmen der Untersuchung der nativen XML-Speicherung sollte jedoch vorrangig eine andere Betrachtung darstellen. Die aus den theoretischen Ausführungen aufgezeigten Effizienzgewinne des nativen Datentyps müssen in praktischen Kontexten validiert werden. Diese Thematik soll im Rahmen der vorgesehenen Diplomarbeit des Autors [Koc11] im Laufe des Jahres 2011 weiter untersucht werden. Erst wenn sich die Vorteile dabei verifizieren lassen, kann eine allgemeingültige Migrationsempfehlung ausgesprochen werden. Für neue Projektanwendungen, die intern XML-Daten verarbeiten, ist es bereits jetzt sinnvoll, die Vorteile der nativen XML-Ablage in die Realisierungsplanung einzubeziehen. Finden sich die Projektanforderungen darin wieder, sodass sich Szenarien wie das zu Beginn der Arbeit angeführte Beispiel ergeben, so kann die native XML-Ablage weitreichende Performancevorteile mit sich bringen. 87 Abkürzungs- und Begriffsverzeichnis Auxiliary-Index Der Auxiliary-Index ist ein auf der LOB-Auxiliary-Tabelle aufbauender spezieller UNIQUE-Index. Er wird benutzt, um von der Basistabelle gezielt auf die LOB-Tupel der Auxiliary-Tabelle zugreifen zu können. Basistabelle Als Basistabelle werden in dieser Arbeit stets Tabellen bezeichnet, für die explizit vom Nutzer eine Spalte von einem LOB- oder XML-Datentyp definiert wurde. Im Rahmen der nativen XML-Strukturen werden abhängig von dieser Tabelle sämtliche impliziten Verwaltungsobjekte, wie beispielsweise die XML-Auxiliary-Tabelle oder der XML-Tablespace, erzeugt. Basis-Tablespace Die Bezeichnung Basis-Tablespace ist stets im Zusammenhang mit den Verwaltungsstrukturen von LOB- beziehungsweise XML-Daten gewählt. Dabei bezieht sie sich auf den Tablespace, der die Basistabelle enthält und somit explizit vom Nutzer anzulegen ist. BIGINT BIG INTeger Der BIGINT-Datentyp ist ein binärer Integer mit einer Genauigkeit von 63 Bits. Er deckt somit die komplette Spanne von -9223372036854775808 bis +9223372036854775807 ab. Binary-String Binary-Strings sind Folgen von Bytes. Verglichen mit Character-Strings sind sie nicht mit einer CCSID verknüpft. DB2 unterscheidet zwischen den Binary-String-Datentypen BINARY, VARBINARY und BLOB (der maximalen Länge nach geordnet). Bind-In Das Bind-In ist der Prozess des Einbindens oder auch Ladens von Daten in DB2. Der umgekehrte Vorgang bezeichnet sich als Bind-Out. Bind-Out Bei dem Bind-Out findet das Ausbinden oder auch Entladen von Daten aus DB2 statt. Der umgekehrte Vorgang bezeichnet sich als Bind-In. CCSID Coded Character Set Identifier Die CCSID ist eine 16-Bit lange Nummer. Sie identifiziert eine Vorschrift, mit der enkodierte Character-Strings zu interpretieren sind. 88 CHAR CHARacter Der Datentyp Character dient neben anderen Datentypen des DB2 der Speicherung von Character-Strings. Im Gegensatz zu dem VARCHARDatentyp lassen sich in einem CHAR-Record nur Character-Strings einer fest definierten Länge ablegen. Diese kann zwischen 1 und 255 Zeichen betragen. Character-String Ein Character-String ist eine Folge von Bytes zur Speicherung einzelner Zeichen. Die dazu nötige Umsetzung erfolgt anhand eines Enkodierschemas („encoding scheme“). Damit dieses bekannt ist, wird jedem Character-String eine CCSID zugeordnet. Enkodierschemas für Character-Strings sind beispielsweise EBCDIC oder Unicode. CLOB Character Large OBject Ein CLOB ist eine Form des LOBs. Speziell handelt es sich um einen variabel langen Character-String. Ein CLOB hat maximal eine Länge von 2147483647 Bytes (2 GB – 1 Byte). Somit dient er der Speicherung großer Zeichenketten. Im Rahmen dieser Arbeit wird der CLOB-Datentyp besonders im Zusammenhang mit der nicht-nativen XML-Speicherung betrachtet. (siehe Abschnitt 4.2) DATEV eG Die DATEV eG ist ein Unternehmen, das IT-Dienstleistungen für Steuerberater, Wirtschaftsprüfer und Rechtsanwälte erbringt. (siehe Kapitel 1) DB2 for z/OS DB2 ist eine Familie von relationalen Datenbankmanagementsystemen, die durch IBM entwickelt und vertrieben wird. Die z/OS Version des DB2 ist für den Einsatz auf dem Mainframe und dessen z/OS-Betriebssystem konzipiert worden. (siehe Abschnitt 3.2) DDL Data Definition Language Unter DDL verstehen sich SQL-Anweisungen zur Definition (Erstellen, Strukturändern und Löschen) von Datenbankobjekten, wie beispielsweise Tabellen, Indexe oder anderen Strukturen. 89 Dekomposition Dekomposition bezeichnet das Zerlegen von XML-Dokumenten in relationale Strukturen. Die „xml collection“-Variante des XML-Extenders baut beispielsweise auf der Dekomposition auf. In der pureXML-Technologie findet dieses Prinzip bei Bedarf durch die XMLTABLE-Funktion ebenfalls Verwendung. DocID Document IDentifier Die DocID ist ähnlich zu der LOB-RowID ein eindeutiger Identifikator für jedes einzelne XML-Dokument. Sie wird über eine dedizierte Sequence vergeben. Die DocID findet sich sowohl in der Basistabelle als auch in der XML-Auxiliary-Tabelle als Spalte wieder. Zu deren Verknüpfung ist sie zusätzlich zentraler Bestandteil aller XML-Indexe. (siehe Abschnitt 5.4) DocID-Index DocumentID-Index Dieser Index ist Teil der implizit für die native XML-Speicherung erzeugten Strukturen. Er umfasst die DocID-Spalte und dient in Kombination mit den User-Defined-Indexen der Rückabbildung auf die Basistabelle. (siehe Abschnitt 5.7.2) EBCDIC Extended Binary Coded Decimals Interchange Code EBCDIC ist ein Encoding-Schema, das unter anderem auf dem z/OS-System genutzt wird, um Character-Daten zu repräsentieren. Dieser Zeichensatz existiert in verschiedenen, teils länderspezifischen Ausführungen. Im Rahmen der vorliegenden Arbeit wird stets der Zeichensatz EBCDIC 273 betrachtet. GUI Graphical User Interface Eine GUI ist eine grafische Benutzeroberfläche. Sie ermöglicht es dem Benutzer, über grafische Elemente mit dem jeweiligen Programm zu interagieren. IBM Data Studio Das IBM Data Studio ist ein von IBM entwickeltes und vertriebenes Datenbanktool. Es bietet seinen Anwendern verschiedene Funktionalitäten in den Bereichen Design, Entwicklung, Administration und Tuning. In seiner Basisversion ist es kostenfrei einsetzbar. (siehe Abschnitt 3.3) 90 Inline-Datentyp Als Inline-Datentyp werden Datentypen bezeichnet, die ihre Datensätze ausschließlich in der Basistabelle ablegen. Damit wird die Größe eines InlineDatentyps durch die maximale Record Size beschränkt. In dieser Arbeit wird die Bezeichnung zumeist im Zusammenhang mit dem VARCHAR-Datentyp genannt. JDBC Java DataBase Connectivity JDBC stellt eine einheitliche Datenbankschnittstelle – Call Level Interface (CLI) – auf der Java-Plattform dar. Sie ist speziell auf relationale Datenbankmanagementsysteme ausgerichtet. Um die Verbindung mit einem solchen System herzustellen, wird ein von diesem abhängiger, spezieller JDBC-Treiber benötigt. LFDNR LauFenDe NummeR Für verteilte nicht-nativ gespeicherte XML-Dokumente muss zur späteren Zusammensetzbarkeit in einer zusätzlichen Spalte die Information über die Position jedes Teilstücks gespeichert werden. Diese Spalte wird DATEVintern in der Regel als laufende Nummer bezeichnet. Im Rahmen dieser Arbeit wird die Bezeichnung ebenfalls in diesem Kontext verwendet. LOB Large OBject LOBs sind, wie der Name schon sagt, große Objekte. Diese werden als Outline-Datentyp außerhalb der Basistabelle gespeichert. DB2 unterscheidet speziell zwischen CLOB, DBCLOB und BLOB, wobei vorwiegend der erstgenannte Datentyp in dieser Arbeit Erwähnung findet. LOB-Auxiliary- Eine LOB-Auxiliary-Tabelle ist eine Tabelle, die von DB2 genutzt wird, um Tabelle LOB-Daten außerhalb der Basistabelle abzulegen. Dazu muss sie in einem dedizierten LOB-Tablespace angelegt werden. Weiterhin ist es notwendig, auf der LOB-Auxiliary-Tabelle einen speziellen Auxiliary-Index zu erstellen, der den effizienten Zugriff auf deren Inhalte ermöglicht. LOB-Tablespace Ein LOB-Tablespace ist ein spezieller Tablespace in DB2. Er wird zur Verwaltung von LOB-Daten benutzt. Dazu enthält ein LOB-Tablespace genau eine LOB-Auxiliary-Tabelle mit einem darauf erstellten AuxiliaryIndex. Erst wenn diese Objekte vollständig erstellt sind, können im LOBTablespace Daten abgelegt werden. 91 Lock Size Unter der Lock Size ist das Granulat zu verstehen, mit dem einzelne Objekte gesperrt werden. Dabei ist in DB2 beispielsweise zwischen Row-, Page-, Table-, Tablespace- oder auch LOB-Level-Locking zu unterscheiden. Unabhängig vom Granulat wird die Lock Size in DB2 stets auf Tablespaces-Ebene definiert. nativ Die native XML-Speicherung entspricht einer „natürlichen“ Ablage. Dabei werden XML-Dokumente so gespeichert, dass sie direkt aus dem abgelegten Format ohne zusätzlich notwendiges Parsen verarbeitet werden können. DB2 stellt dafür den nativen XML-Datentyp zur Verfügung. (siehe Kapitel 5) nicht-nativ Im Gegensatz zur nativen XML-Speicherung handelt es sich bei der nichtnativen XML-Ablage um eine „unnatürliche“, abgewandelte Speicherform. Auf diese Weise abgelegte Dokumente müssen vor ihrer typspezifischen Verarbeitung stets in das XML-Format geparst werden. In der vorliegenden Arbeit werden hauptsächlich die Varianten der nicht-nativen XMLSpeicherung als CLOB und VARCHAR betrachtet. (siehe Kapitel 4) NodeID-Index Der NodeID-Index ist ein im Rahmen der nativen XML-Speicherung implizit von DB2 erzeugter Index. Er umfasst die DocID- und die XMLData-Spalte. Funktional realisiert der NodeID-Index die effiziente Verknüpfung der Tupel aus der Basistabelle mit den zugehörigen Tupeln der XML-Auxiliary-Tabelle. (siehe Abschnitt 5.7.1) Outline-Datentyp Ein Outline-Datentyp ist ein Datentyp, der seine Datensätze außerhalb der Basistabelle ablegt. Dazu benötigt er zusätzliche Objekte, die entweder explizit oder implizit erstellt werden müssen. Die LOB-Datentypen und auch der native XML-Datentyp sind Vertreter der Outline-Datentypen. Parse-Prozess Der Parse-Prozess dient im Rahmen der XML-Thematik zur Wandlung eines nicht-nativen XML-Dokuments in ein weiterverarbeitbares Format oder dem gezielten Zugriff durch das sukzessive Einlesen der Knoten des Dokuments. Dabei kann abhängig von dem verwendeten XML-Parser beispielsweise auch ein Validierungsvorgang erfolgen. 92 Record Ein Record bezeichnet eine physische Zeile innerhalb einer Tabelle oder einen anderen Datensatz (beispielsweise einen Index Record). In DB2 identifiziert sich ein Record durch eine RID. Jeder Record ist in seinem Volumen durch die maximal zulässige Record Size beschränkt, die sich selbst wiederum durch die Page Size bestimmt. Record Size Die Record Size beschreibt die Größe eines Datensatzes. Sie ist in DB2 durch die Page Size des jeweiligen Tablespace beschränkt. Die Summe aller Spaltenlängen eines Tupels muss zusammen mit einem geringfügigen Overhead in eine Page passen. Eine davon abweichende Konstellation, wie beispielsweise „spanned records“, ist nicht möglich. Recursive SQL Unter rekursivem SQL sind SQL-Statements zu verstehen, die über den UNION-Operator in einem rekursiven Ablauf verschiedene Ergebnismengen miteinander verknüpfen. Dieser Prozess erfolgt bis zum Eintreten einer definierten Bedingung, bei der der Vorgang abbricht. (siehe Abschnitt 8.2.4) RowID Row IDentifier Die RowID ist ein binärer Datentyp. Sie dient der eindeutigen Identifizierung einer Zeile in dem Tablespace ihrer zugehörigen Tabelle. Dazu enthält sie Informationen über die physische Lokation einer Zeile. Wird diese beispielsweise durch einen REORG (auf Tablespace-Ebene) verschoben, so wird auch die RowID entsprechend der neuen Adresse der Zeile angepasst. In dieser Arbeit wird die RowID besonders im Zusammenhang mit der DB2-internen LOB-Verwaltung betrachtet. Sequence Eine Sequence ist ein in der Datenbank gespeichertes Objekt. Sie wird genutzt, um eine fortlaufende Sequenz von Zahlen in einer monoton steigenden oder monoton fallenden Reihenfolge bereitzustellen. Sequences werden bevorzugt zur Generierung eindeutiger Primärschlüsselwerte verwendet, sofern diese ganzzahligen numerischen Datentypen entsprechen. Stored Procedure Eine Stored Procedure ist ein datenbankseitig definierbares Anwendungsprogramm, das über ein CALL-Statement ausgeführt werden kann. DB2 unterscheidet dabei zwischen folgenden Prozeduren: externen, SQL (externen) und SQL (nativen) [IBM11a]. 93 Trigger Bei einem Trigger handelt es sich um ein aktives Objekt, das bei bestimmten Nutzeraktionen (INSERT, UPDATE oder DELETE) automatisch eine im Trigger-Body definierte Reaktion ausführt. In DB2 ist dabei zusätzlich zwischen den Trigger-Formen BEFORE, AFTER und INSTEAD OF zu unterscheiden, die stets pro Aktion auf einer Zeile oder pro Statement definierbar sind. Unicode Unicode bezeichnet einen internationalen Standard für die Darstellung von Schriftzeichen. Dieser umfasst unter anderem die in DB2 verfügbare Zeichenkodierung UTF-8, welche für die native Ablage von XMLDokumenten genutzt wird. Aufgrund des verglichen mit dem EBCDICZeichensatz erweiterten Zeichenumfangs gewinnt der Unicode-Standard in DB2 zunehmend an Bedeutung. User-Defined User-Defined Functions sind in DB2 definierte Funktionen, die innerhalb von Function SQL-Statements verwendet werden können. Dabei ist zwischen externen, „sourced“ und SQL-skalaren Funktionen [IBM11a] zu unterscheiden. User-Defined-Index Unter User-Defined-Indexen sind im Rahmen dieser Arbeit vom Nutzer explizit anzulegende XML-Indexe bezeichnet. Diese basieren auf einem definierten XPath-Pfadausdruck und ermöglichen in Kombination mit dem DocID-Index den effizienten Zugriff auf spezifizierte Teilbäume eines XMLDokuments. (siehe Abschnitt 5.7.3) VARBINARY VARying-length BINARY Ein VARBINARY ist ein variabel langer Binary-String. Da es sich bei ihm um einen Inline-Datentyp handelt, ist er in seinem Ausmaß unter anderem durch die maximale Record Size beschränkt. Laut Definition darf er daher eine Länge von 1 - 32704 Bytes haben. VARCHAR VARying-length CHARacter Ein VARCHAR ist ein variabel langer Character-String. Da er ein InlineDatentyp ist, unterliegt er in seinem Ausmaß unter anderem der maximalen Record Size. Somit hat VARCHAR eine Länge von 1 - 32704 Bytes. Im Rahmen dieser Arbeit wird der VARCHAR-Datentyp besonders im Zusammenhang mit der nicht-nativen XML-Speicherung betrachtet. (siehe Abschnitt 4.1) 94 XML EXtensible Markup Language XML ist eine erweiterbare Auszeichnungssprache zur Repräsentation von hierarchischen Daten. Besondere Verbreitung hat es durch seinen Charakter als universelles Datenaustauschformat erlangt. (siehe Abschnitt 3.1) XML-Auxiliary- Die XML-Auxiliary-Tabelle ist ein implizit erstelltes Verwaltungsobjekt des Tabelle nativen XML-Datentyps. Sie dient der Ablage von XML-Dokumenten. In der XML-Auxiliary-Tabelle befinden sich die Spalten DocID, min_NodeID und XMLData. (siehe Abschnitt 5.6) XML-Extender Der XML-Extender ist eine Erweiterung des DB2. Er ermöglicht es über zwei verschiedene Ansätze („xml collection“ und „xml column“), XML-Daten zu verarbeiten. Bei beiden Varianten handelt es sich um nicht-native XMLSpeicherformen. XML-Inlining Unter XML-Inlining ist das Einlagern von XML-Datensätzen in die Basistabelle zu verstehen. In der aktuellen Version des DB2 for z/OS ist der native XML-Datentyp ein reiner Outline-Datentyp. DB2 for LUW beispielsweise kennt zur nativen Ablage von XML-Daten zusätzlich auch die Möglichkeit des XML-Inlining. XML-Lock Ein XML-Lock ist ein in DB2 neu eingeführter Sperrtyp. Er sorgt per „S“oder „X“-Sperre für das Locking von ganzen nativ gespeicherten XMLDokumenten. XML-Locks werden ausschließlich auf XML-AuxiliaryTabellen gesetzt. XML-Schema XML-Schemas dienen der Strukturbeschreibung von XML-Dokumenten. Sie stellen eine Alternative zu den mittlerweile als veraltet geltenden Document Type Definitions (DTD) dar. XML-Schemas werden in Form eigener XSDDokumente definiert. In DB2 sind sie im XML-Schema-Repository abgelegt. Von dort aus werden sie zur Validierung von XML-Dokumenten herangezogen. XML-Tablespace Ein XML-Tablespace ist ein implizit erstellter Tablespace. Er dient der Verwaltung von nativ gespeicherten XML-Daten. Pro nativer XML-Spalte wird genau ein XML-Tablespace erzeugt, welcher wiederum genau eine XML-Auxiliary-Tabelle in sich trägt. (siehe Abschnitt 5.5) 95 XPath XML Path Language XPath ist eine Abfragesprache für XML-Dokumente und dient der Adressierung von hierarchisch repräsentierten Inhalten. Aktuell existieren zwei Versionen der XPath-Sprachklassifikation: XPath 1.0 [W3C99] und XPath 2.0 [W3C10]. zParm Subsystem-Parameter zParms dienen der Konfiguration eines einzelnen Subsystems. Sie werden genutzt, um beispielsweise Default-Angaben festzulegen oder auch Limitierungen wie die maximale Größe eines XML-Dokuments im virtuellen Speicher zentral zu definieren. 96 Abbildungsverzeichnis Abbildung 1: Anwendungsbeispiel mit nicht-nativer XML-Speicherung ......................10 Abbildung 2: Anwendungsbeispiel mit nativer XML-Speicherung ...............................11 Abbildung 3: wohlgeformtes XML-Dokument ..............................................................16 Abbildung 4: DATEV-Konventionen .............................................................................21 Abbildung 5: nicht-native XML-Speicherformen...........................................................23 Abbildung 6: XML nicht-nativ als VARCHAR .............................................................24 Abbildung 7: Struktur des Outline-Datentyps LOB .......................................................27 Abbildung 8: XML nicht-nativ als CLOB inklusive DATEV-Spezifika........................28 Abbildung 9: Verteilung über mehrere Tupel.................................................................30 Abbildung 10: Modellierungsansätze für nicht-natives XML als VARCHAR ..............31 Abbildung 11: explizit zu erstellende Objekte................................................................34 Abbildung 12: implizite XML-Verwaltungsobjekte.......................................................35 Abbildung 13: implizit erstellte DocID-Spalte ...............................................................35 Abbildung 14: Zuordnung der XML-Strukturen.............................................................38 Abbildung 15: Proxy-Node und Kontext-Node ..............................................................40 Abbildung 16: XMLData - Document Tree....................................................................41 Abbildung 17: NodeID-Index .........................................................................................44 Abbildung 18: DocID-Index und User-Defined-Index ...................................................45 Abbildung 19: Zugriffskette mit User-Defined-Index ....................................................46 Abbildung 20: Sperrvergabe am Beispiel eines „SELECT (with RS)“-Statements .......48 Abbildung 21: evaluierender Vergleich: natives XML - nicht-natives XML.................51 Abbildung 22: Möglichkeit zum Fallback ......................................................................56 Abbildung 23: "fehlertolerante" Überführung von Dokumenten....................................57 Abbildung 24: einzeilige vs. verteilte nicht-native XML-Dokumente ...........................59 Abbildung 25: anwendungsseitiger vs. datenbankseitiger Migrationsprozess ...............62 Abbildung 26: Abschneiden von vorangehenden Leerzeichen.......................................64 Abbildung 27: Ersetzung ungültiger Zeichen .................................................................66 Abbildung 28: „Record Size“-Limit bei der Konkatenation von VARCHARs..............67 Abbildung 29: Konkatenation von CLOBs.....................................................................67 97 Abbildung 30: entfallende laufende Nummer.................................................................68 Abbildung 31: modifiziertes MVC-Pattern [Eck07].......................................................71 Abbildung 32: XML-Migrator-Architektur ....................................................................72 Abbildung 33: DDL-Anweisung der LTRIMNNXML-Funktion...................................75 Abbildung 34: DDL-Anweisung der „Lock Size“-Anpassung.......................................76 Abbildung 35: Struktur der Fehlertabelle .......................................................................77 Abbildung 36: Ausgangssituation ...................................................................................80 Abbildung 37: erfolgreicher Kopiervorgang...................................................................80 Abbildung 38: fehlerhafter Kopiervorgang.....................................................................81 Abbildung 39: Abschluss des Kopiervorgangs ...............................................................81 Abbildung 40: Fallunterscheidung für den Kopiervorgang ............................................82 Abbildung 41: DDL-Anweisung der REORG-Prozedur ................................................86 98 Literaturverzeichnis [CA11] CA Technologies. 2011. http://www.ca.com/de/default.aspx [CMS10] CENTERS for MEDICARE AND MEDICAID SERVICES (CMS). 03.04.2010. „DATABASE ADMINISTRATION DB2 STANDARDS“ http://www.cms.gov/dbadmin/downloads/db2standardsandguidelines.pdf [Com07] Computerwoche. 30.08.2007. „Das Herz der Weltwirtschaft“ http://www.computerwoche.de/heftarchiv/2007/35/1220473/ [DAT10] DATEV Portal. 22.12.2010. „Mehr Rechenleistung für Cloud-Dienste“ http://www.datev.de/portal/ShowPage.do?pid=dpi&nid=109742 [DAT11a] DATEV Portal. 2011. „Sicherung der Wohlfahrt“ http://www.datev.de/portal/ShowPage.do?pid=dpi&nid=120356 [DAT11b] DATEV Portal. 2011. „… was Sie über DATEV wissen sollten“ http://www.datev.de/portal/ShowPage.do?pid=dpi&nid=2155 [DAT11c] DATEV Portal. 2011. „Neu bei DATEV?“ http://www.datev.de/portal/ShowPage.do?pid=dpi&nid=81681 [DAT11d] DATEV Portal. 2011. „Vorstandsvorsitzender – Professor Dieter Kempf “ http://www.datev.de/portal/ShowPage.do?pid=dpi&nid=97649 [DAT11e] DATEV Portal. 2011. http://www.datev.de [DAT11f] DATEV Portal. 2011. „Alles aus einer Hand!“ http://www.datev.de/portal/ShowPage.do?pid=dpi&nid=104852 [DAT11g] DATEV Portal. 2011. „DATEVasp“ http://www.datev.de/asp 99 [Eck07] Eckstein, Robert. 03.2007. „Java SE Application Design With MVC“ http://www.oracle.com/technetwork/articles/javase/mvc-136693.html [Ecl11] Eclipse Foundation. 2011. „Eclipse“ http://www.eclipse.org [EIT11] evodion information technologies. 2011. „Glossar – Batch-Job” http://www.evodion.de/opencms/export/evodionIT/General/Glossar/b40.html [FSU10] Friedrich-Schiller-Universität. 2010. „Datenmodellierung mit dem EntityRelationship-Modell (E/R-Modell, ERM)” http://www.informatik.uni-jena.de/dbis/lehre/ws2010/dbs1/Folien/DBS1-WS1011-53110.pdf [Hee02] Heeskens, Hanno. 04.02.2002. „Was ist XML?“ http://mata.gia.rwth-aachen.de/Vortraege/Hanno_Heeskens/XML/script/node4.html [Heg06] Heger, Uwe. 20.12.2006. „DB-Schema und Namenskonvention“ DATEV eG, internes Dokument [IBM01] IBM Corporation. 2001. „Code Page 00273“ http://www-03.ibm.com/systems/resources/systems_i_software_globalization_pdf_ cp00273z.pdf [IBM04a] IBM Corporation. 03.2004. „DB2 Universal Database for z/OS Version 8 – SQL Reference“ http://publibfp.dhe.ibm.com/epubs/pdf/dsnsqj10.pdf [IBM04b] IBM Corporation. 10.2004. „DB2 for OS/390 and z/OS library – XML Extender Administration and Programming“ http://publibfp.dhe.ibm.com/epubs/pdf/dxxxa811.pdf [IBM04c] IBM Corporation. 03.2004. „DB2 for OS/390 and z/OS library – Text Extender Administration and Programming“ http://publib.boulder.ibm.com/epubs/pdf/desu1a02.pdf 100 [IBM04d] IBM Corporation. 05.2004. „IBM Redbook – DB2 UDB for z/OS Version 8: Everything You Ever Wanted to Know, ... and More“ http://www.redbooks.ibm.com/redbooks/pdfs/sg246079.pdf [IBM06a] IBM Corporation. 11.2006. „IBM Redbook – LOBs with DB2 for z/OS: Stronger and Faster“ http://www.redbooks.ibm.com/redbooks/pdfs/sg247270.pdf [IBM06b] IBM Corporation. 10.2006. „IBM Redbook – DB2 for z/OS: Data Sharing in a Nutshell“ http://www.redbooks.ibm.com/redbooks/pdfs/sg247322.pdf [IBM07] IBM Corporation. 06.2007. „IBM Redbook – DB2 9 for z/OS Technical Overview“ http://www.redbooks.ibm.com/redbooks/pdfs/sg247330.pdf [IBM08a] IBM Corporation. 02.2008. „DB2 Version 9.1 for z/OS – XML Guide“ http://publibfp.dhe.ibm.com/epubs/pdf/dsnxgk14.pdf [IBM08b] IBM Corporation. 12.2008. „ DB2 Version 9.1 for z/OS – Utility Guide and Reference“ http://www.sk-consulting.de/db2manuals/DB2%20V9%20Utility_Guide_dsnugk13.pdf [IBM08c] IBM Corporation. 12.2008. „ DB2 Version 9.1 for z/OS – Codes“ http://www.sk-consulting.de/db2manuals/DB2%20V9%20Codes_dsnc1k13.pdf [IBM09a] IBM Corporation. 12.2009. „IBM Redbook – DB2 9 for z/OS: Resource Serialization and Concurrency Control“ http://www.redbooks.ibm.com/redbooks/pdfs/sg244725.pdf [IBM09b] IBM Corporation. 2009. „Einstieg in IBM Data Studio für DB2“ http://public.dhe.ibm.com/software/dw/db2/express-c/wiki/Getting_Started_with_IBM_ Data_Studio_for_DB2_DE.pdf 101 [IBM09c] IBM Corporation. 10.2009. „ DB2 Version 9.1 for z/OS – Diagnosis Guide and Reference“ DB2 Version 9.1 for z/OS Licensed PDF Library. Publikation: LK5T-7336-03 [IBM09d] IBM Corporation. 11.12.2009. „Optimization Service Center for DB2 for z/OS” https://www-304.ibm.com/support/docview.wss?uid=swg27017059 [IBM09e] IBM Corporation. 03.2009. „IBM Redbook – DB2 9 for z/OS: Packages Revisited” http://www.redbooks.ibm.com/redbooks/pdfs/sg247688.pdf [IBM10a] IBM Corporation. 03.2010. „Manage XML Data with DB2 9 for z/OS“ Schulungsunterlagen (Kursnummer CV260) [IBM10b] IBM Corporation. 14.07.2010. „Extensible Dynamic Binary XML, Client/ Server Binary XML Format (XDBX)“ http://www-01.ibm.com/support/docview.wss?uid=swg27019354&aid=1 [IBM11a] IBM Corporation. 03.2011. „DB2 Version 9.1 for z/OS – SQL Reference“ http://publib.boulder.ibm.com/epubs/pdf/dsnsqk1a.pdf [IBM11b] IBM Corporation. 03.2011. „DB2 Version 9.1 for z/OS – DEFAULT BUFFER POOL FOR USER XML DATA field (TBSBPXML subsystem parameter)“ http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/index.jsp?topic=/com.ibm.db2z9. doc.inst/src/tpc/db2z_ipf_tbsbpxml.htm [IBM11c] IBM Corporation. 01.2011. „IBM Redbook – Extremely pureXML in DB2 10 for z/OS“ http://www.redbooks.ibm.com/redpieces/pdfs/sg247915.pdf [IBM11d] IBM Corporation. 03.2011. „DB2 Version 9.1 for z/OS – USER LOB VALUE STG field (LOBVALA subsystem parameter)“ http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/index.jsp?topic=/com.ibm.db2z9. doc.inst/src/tpc/db2z_ipf_lobvala.htm 102 [IBM11e] IBM Corporation. 03.2011. „DB2 Version 9.1 for z/OS – SYSTEM LOB VAL STG field (LOBVALS subsystem parameter)“ http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/index.jsp?topic=/com.ibm.db2z9. doc.inst/src/tpc/db2z_ipf_lobvals.htm [IBM11f] IBM Corporation. 03.2011. „DB2 Version 9.1 for z/OS – Introduction to DB2 for z/OS“ http://publib.boulder.ibm.com/epubs/pdf/dsnitk17.pdf [IBM11g] IBM Corporation. 04.02.2011. „Features in IBM Data Studio V2.2.1 (stand-alone versus IDE)“ https://www-304.ibm.com/support/docview.wss?uid=swg27020627&wv=1 [IBM11h] IBM Corporation. 03.2011. „DB2 Version 9.1 for z/OS – DSNUTILS stored procedure“ http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/index.jsp?topic=/com.ibm.db2z9. doc.ugref/src/tpc/db2z_sp_dsnutils.htm [IBM11i] IBM Corporation. 2011. http://www.ibm.com [IBM11j] IBM Corporation. 2011. „DB2 pureXML – Intelligent XML database management“ http://www-01.ibm.com/software/data/db2/xml/ [IBM11k] IBM Corporation. 03.2011. „IBM zEnterprise System” http://www-03.ibm.com/systems/de/z/hardware/zenterprise/z196.html [IBM11l] IBM Corporation. 2011 „Control Center overview” http://publib.boulder.ibm.com/infocenter/db2help/topic/com.ibm.db2.udb.cc.doc/db2_ud b/intro.htm [IBM11m] IBM Corporation. 24.06.2011. „Visual Explain for DB2 for z/OS” https://www-304.ibm.com/support/docview.wss?uid=swg27011680 [IBM11n] IBM Corporation. 2011. „DB2 for z/OS” http://www-01.ibm.com/software/data/db2/zos/ 103 [IBM11o] IBM Corporation. 2011. „DB2 for Linux, UNIX and Windows” http://www-01.ibm.com/software/data/db2/linux-unix-windows/ [IBM11p] IBM Corporation. „IBM System z – Operating System – z/OS” http://www-03.ibm.com/systems/z/os/zos/ [IBM11q] IBM Corporation. 2011. „DB2 Server for VSE & VM” http://www-01.ibm.com/software/data/db2/vse-vm/ [IBM78] IBM Corporation. 06.1978. „OS/VS2 MVS Overview” http://www.prycroft6.com.au/misc/download/GC28-0984-0_MVSoverview_ Jun78OCR2009.pdf [Koc11] Koch, Christoph. 2011. „Der Datentyp XML in DB2 for z/OS aus Performance-Perspektive“ [Küs85] Küspert, Klaus. 1985. „Fehlererkennung und Fehlerbehandlung in Speicherungsstrukturen von Datenbanksystemen“ Springer. ISBN: 3-540-15238-5 [Ley11] Ley, Michael. 13.07.2011. „System R” http://www.informatik.uni-trier.de/~ley/db/systems/r.html [Lyl07] Lyle, Bob. 09.05.2007. „DB2 9 Index Manager Enhancements“ http://www.idugdb2-l.org/conferences/NA2007/data/NA07C11.pdf [Mil11] Miller, Roger. 25.04.2011. „DB2 History“ http://www.dbisoftware.com/db2nightshow/20110425-Z01-roger-miller.pdf [Mor10] Morelli, Elaine. 15.07.2010. „Getting back to basics: LOBs and XML objects for DB2 for z/OS“ http://www.ibm.com/developerworks/data/library/techarticle/dm-1007db2lobsxml/ index.html [Mül08] Müller, Thomas. 02.04.2008. „Verfahren zur Verarbeitung von XMLWerten in SQL-Anfrageergebnissen“ http://deposit.ddb.de/cgi-bin/dokserv?idn=990512835&dok_var=d1&dok_ext=pdf& filename=990512835.pdf 104 [Nic10] Nicola, Matthias. 30.11.2010. „Node-level XML Updates in DB2 10 for z/OS“ http://nativexmldatabase.com/2010/11/30/node-level-xml-updates-in-db2-10-for-zos/ [NK09] Nicola, Matthias und Kumar-Chatterjee, Pav. 08.2009. „DB2 pureXML Cookbook“ IBM Press. ISBN-13: 978-0-13-815047-1 [NR06] Nicola, Matthias und Rodrigues, Vitor. 07.12.2006. „A performance comparison of DB2 9 pureXML and CLOB or shredded XML storage“ http://www.ibm.com/developerworks/data/library/techarticle/dm-0612nicola/ [NR07] Nicola, Matthias und Rodrigues, Vitor. 30.08.2007. „XMLTABLE by example, Part 1: Retrieving XML data in relational format“ http://www.ibm.com/developerworks/data/library/techarticle/dm-0708nicola/index.html [Päß07] Päßler, Manfred. 04.07.2007. „Datenbanken und XML – Passt das?“ http://inka.htw-berlin.de/datenverwaltung/docs/Paessler.pdf [Pic09] Picht, Hans-Joachim. 06.10.2009. „Wie ein Pinguin und ein Dinosaurier helfen können, Platz, Wartungskosten und Strom zu sparen“ http://www-05.ibm.com/at/symposium/pdf/11_Wie_ein_Pinguin_und_ein_Dinosaurier. pdf [Sun05] Sun Microsystems. 2005. „Using the Timer and TimerTask Classes“ http://enos.itcollege.ee/~jpoial/docs/tutorial/essential/threads/timer.html [Sur03] Surber, James. 08.10.2003. „Designing Tables and Structures for 24x7 “ http://www.widama.us/Designing_Tables_And_Structures_For_24x7.pdf [Tat02] Tatarinov, Igor et al. 2002. „Storing and querying ordered XML using a relational database system“ http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.2.5927&rep=rep1&type=pdf [Uni11a] Unicode Consortium. 2011. „About the Unicode Standard“ http://unicode.org/standard/standard.html 105 [Uni11b] Unicode Consortium. 02.2011. „The Unicode Standard Version 6.0 – Core Specification“ http://www.unicode.org/versions/Unicode6.0.0/ch02.pdf [Vil07] Villafuerte, Frances. 25.07.2007. „Universal Table Space and LOB Enhancements DB2 9 for z/OS“ http://www-07.ibm.com/tw/imc/seminar/download/07d3_5.pdf [Von05] Vonhoegen, Helmut. 03.2005. „Einstieg in XML“ Galileo Computing, ISBN: 3-89842-630-0 [W3C06] World Wide Web Consortium (W3C). 16.08.2006. „Extensible Markup Language (XML) 1.1 (Second Edition)“ http://www.w3.org/TR/2006/REC-xml11-20060816/ [W3C08] World Wide Web Consortium (W3C). 26.11.2008. „Extensible Markup Language (XML) 1.0 (Fifth Edition)“ http://www.w3.org/TR/2008/REC-xml-20081126/ [W3C10] World Wide Web Consortium (W3C). 14.12.2010. „XML Path Language (XPath) 2.0 (Second Edition)“ http://www.w3.org/TR/xpath20/ [W3C11] World Wide Web Consortium (W3C). 2011 http://www.w3.org [W3C99] World Wide Web Consortium (W3C). 16.11.1999. „XML Path Language (XPath) Version 1.0“ http://www.w3.org/TR/xpath/ [Wo10] Wolfson, Rich. 15.09.2010. „Harnessing the Power of the DB2 Logs“ http://www.bwdb2ug.org/PDF/Harnessing_the_Power_of_the_DB2_Logs.pdf [Zha08a] Zhang, Guogen. 2008. „DB2 pureXML® Podcast Series © IBM 2008: Part 2. Getting Started with pureXML in DB2 9 for z/OS“ http://www.ibm.com/developerworks/wikis/download/attachments/97321405/pureXML_ Podcast2_Getting_Started.pdf 106 [Zha08b] Zhang, Guogen. 08.2008. „Leveraging DB2 9 for z/OS pureXML Technology“ http://www.ibm.com/developerworks/wikis/download/attachments/1824/Leveraging_DB 29_for_zOS_whitepaper_v2.pdf Sämtliche Verweise auf Webseiten und online verfügbare Dokumentationen beziehen sich auf den Stand vom 17.08.2011 und wurden zu diesem Zeitpunkt letztmalig geprüft. 107 Selbstständigkeitserklärung Ich erkläre, dass ich die vorliegende Arbeit selbstständig und nur unter Verwendung der angegebenen Quellen und Hilfsmittel angefertigt habe. Jena, 19.08.2011, Christoph Koch